2025-03-28 機械学習勉強会
今週のTOPIC[blog] GPT-4oとGemini-2.0の画像生成能力はいかにして作られているのか[blog] LLMにJSONやソースコードを出力させるStructured Generationの技術[blog] RAGの検索性能を90%も低下させるテキストの落とし穴[blog] Foundation Model for Personalized Recommendation[oss] Memray[blog] FP8 trainingを支える技術 1メインTOPICIn Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agentsサマリー1. Introduction2. Related Work3. Problem Formulation4. Framework Overview5. Prospective Reflection: Topic-Based Memory Organization6. Retrospective Reflection: Retrieval Refinement via LLM Attribution7. Experimental Setup8. Experimental Results
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] GPT-4oとGemini-2.0の画像生成能力はいかにして作られているのか
- ChatGPTの画像生成とかを試してみると再帰的に生成されてるように見えたので、最近の画像生成AI界隈が自分の知ってる時代と変わってそうということでPick
- これは長崎のyu-ya4, yossy, giwa
- 異世界転生させたり


- 自分の理解は拡散モデルで止まっていたけど、その先のAny-to-Anyという分野に世界は進んでいた
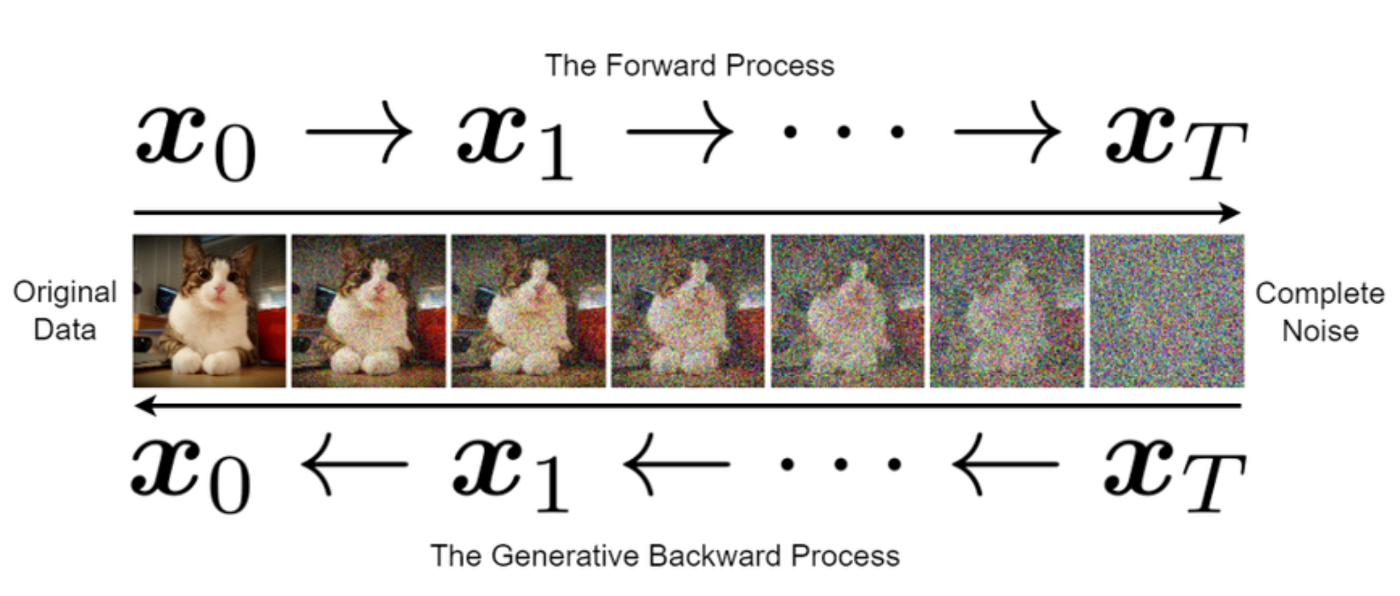
- 2022年にParti というGoogleのモデルで自己回帰型のモデルが出た。
- テキスト → 画像を配列から配列(画像トークン)への変換問題として扱う
- 画像トークンはVQGANで作成
- この時点でGoogleの拡散モデルのスコアを超えるレベルになっていたし、スケーリング即を持っていることも確認されていたが、一般に公開されることはなかった
- Any-to-Anyの画像生成AI
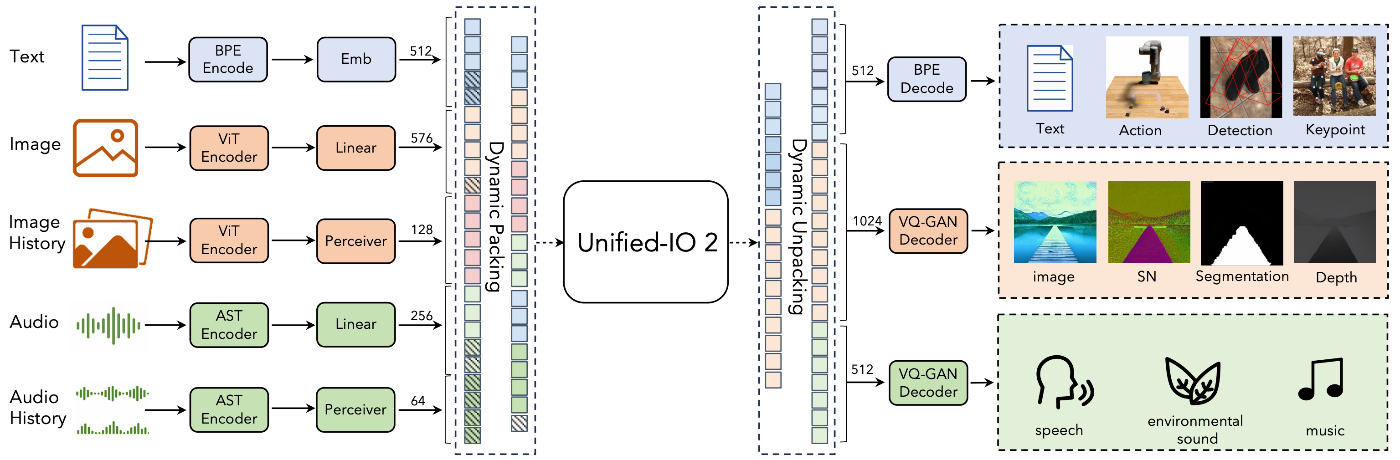
- テキスト、画像、音声など全てを離散トークンとして統一的に入力し、同時に多様なモダリティで出力できるモデルが出てきた (2023年末 ~ 2024年)
- AnyGPT
- Unified-IO2
- さらにこれらもスケーリング則が確認されていた
- Gemini-2.0
- Geminiは多様なモダリティを受け取って、Text DecoderとImage Decoderで出力するAny-to-Anyモデル
- Gemini論文では、Vision EncoderはPartiの研究を元に作られていると書かれてるので、少なくとも画像トークンを出力していると書かれている。
- GPT-4o
- 挙動を観察するとまず低解像度で画像トークンを生成 → 細部を徐々に追加していくというように見える
- 詳細は謎でみんな様々な予想をしている
[blog] LLMにJSONやソースコードを出力させるStructured Generationの技術
- よくJSONモードとか使ってるけど、実際技術的にどうやってやっているのかについての記事
- トークンの候補をそもそもコントロールするという手法がよく使われるらしい。
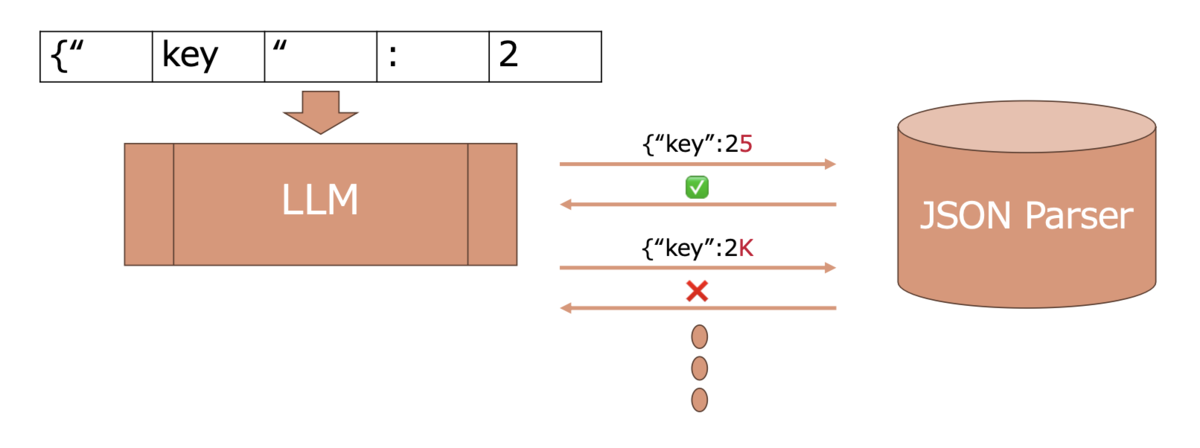
- Parserを用いた制約手法
- イメージは適宜Parserと連絡を取り合い、Parserが失敗したところでその単語を除外したりする
- 1単語生成あたりで数万のLLMの語彙を走査する必要があるのでめちゃくちゃ重たいので、効率化する研究がある。
- 正則言語
- 正則言語は後方参照を用いない正規表現で表現可能な言語
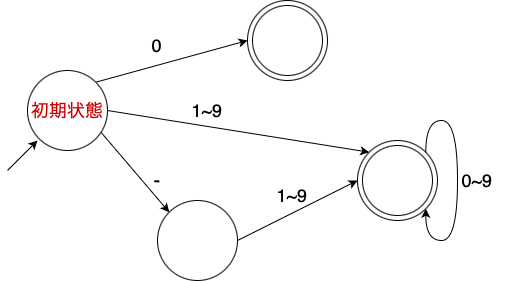
- 正則言語のParserは決定性有限オートマトンで表現できる。
- ある状態次に行く状態が一つだけに決まっているようなもの。整数とか。
- あるノードにいる間は文法的に正しいという状態が有限であることを利用して上手く判定を効率化する。
- 文脈自由言語
- 文脈自由言語は正則言語よりも表現力の高い言語
- この辺りはややこしいんで、元記事を参照
- 構文木で表現ですることができる
- 字句解析
- ある程度のまとまった文字列に対して文脈自由言語の終端記号列に変換する
- JSONの場合はSTRING, NUMBER, LBRACK( ), RBRACK (), COMMA, LBRACE (), RBRACE (), COLON, TRUE, FALSE, NULLなど。
- 正則言語+文脈自由言語のStructured Generation
- LLMの中間出力を字句解析
- 確定した終端記号を文法解析
- 次に続くことができる終端記号を列挙 (DFA)
- 終端記号を判定するDFAから前計算しておいた語彙マスクを取り出す
- 語彙マスクの和集合を取り、次に続くことができるLLMの単語を列挙
- 終端記号の種類数はPythonでも94種らしい
@Shun Ito
[blog] RAGの検索性能を90%も低下させるテキストの落とし穴
- RAGの性能悪化をもたらすバイアスを紹介
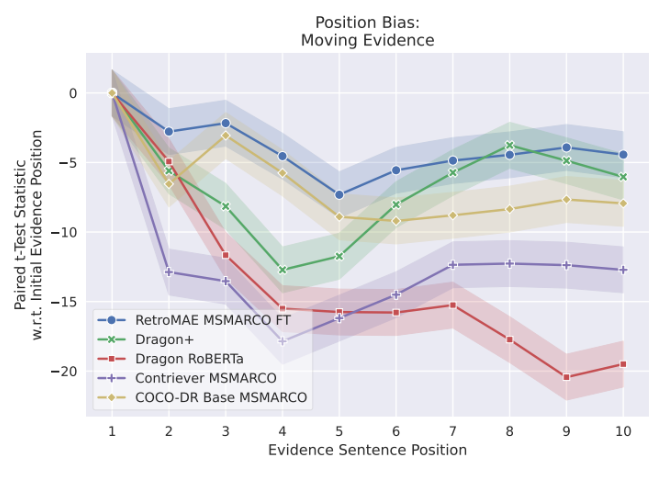
- 位置バイアス
- 回答となるべき情報が文章の先頭にあるほど類似度が高く出る
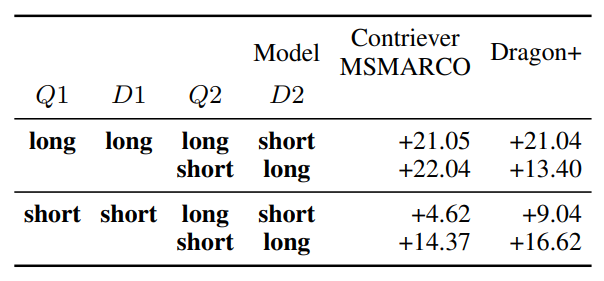
- 単語バイアス
- 表記揺れ(US ↔ United States)で類似度が大きく異なる(スコアはt-統計量)
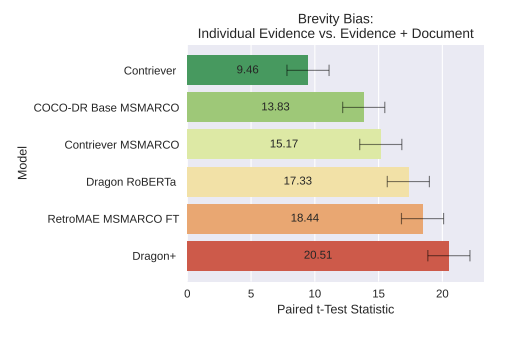
- 文章量バイアス
- 文中に正解となる情報以外の情報が混ざっている場合(値はt-統計量)
@qluto (Ryosuke Fukazawa)
[blog] Foundation Model for Personalized Recommendation
Netflixの推薦の最近。
Netflixではさまざまなシチュエーションにおける推薦機能を作って運用しているが、メンテナンスコストがやや気になったり、ひとつのモデルに対する改善を他のモデルへと活かすといったところに課題を感じており、それに応えるために推薦のための基盤モデルを作ったという話。
推薦問題をGPTのような next token prediction の問題と捉える。the autoregressive next-token prediction objective, similar to GPT とされているが、実際のモデルアーキテクチャがどのようなものなのかまでは言及していない。(他段階のデコーディングが〜と語られていたりはするので、少なくともdecoderの形はしているのだろう)
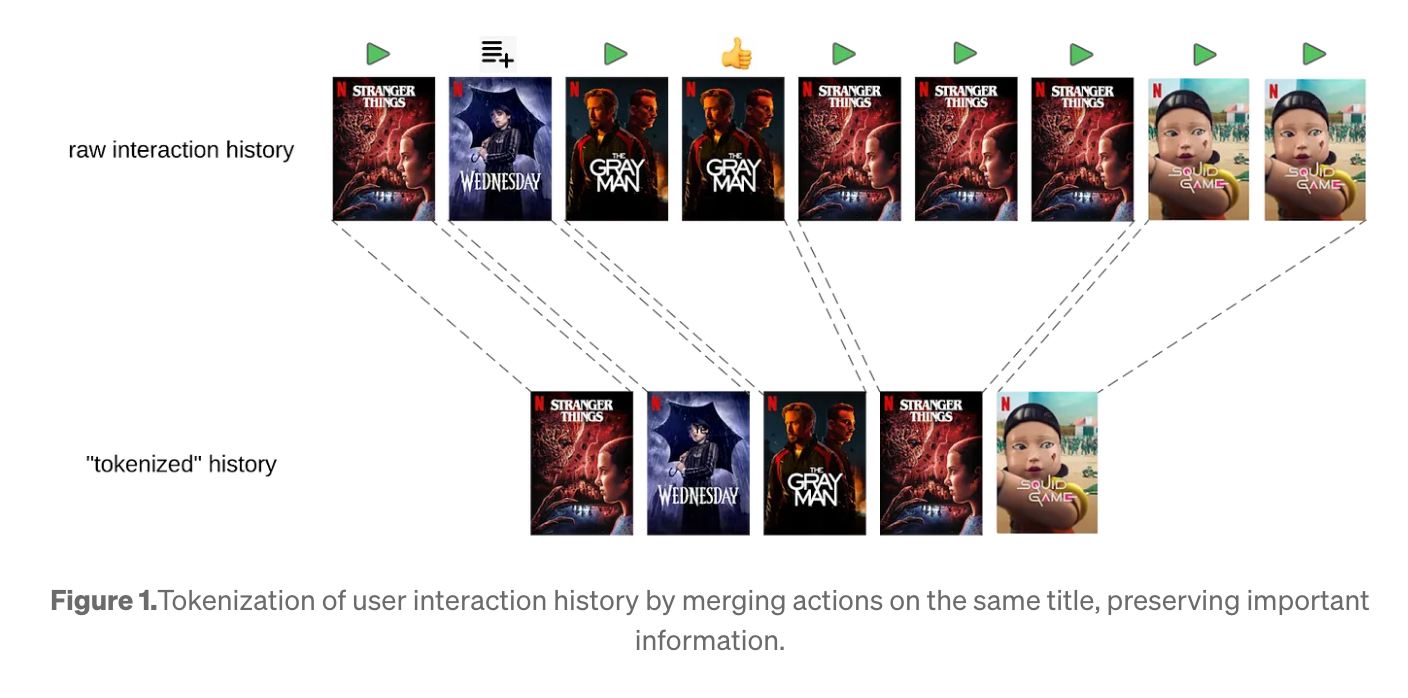
「トークン」はどのように扱われているか?
- ユーザーの1つひとつの行動(例えば「この映画を30分観た」「このゲームを一瞬開いた」など)を「トークン」として扱う
- 言語モデルのように単語ベースではなく、行動には多様な情報が含まれているので、それをどう表現するかが工夫ポイント
- トークンに含まれる情報の例:
- 行動の属性:
- ロケール(地域設定)
- 再生時間
- 再生したデバイス(TV, スマホなど)
- 実行時間(何時に再生したか)
- コンテンツ自体の情報:
- アイテムID(タイトルの識別子)
- ジャンル
- 国、言語 などのメタデータ
- 絶対時間(いつ見たか)と相対時間(前回の視聴からどれくらい経ってるか)を別々に扱って、時間に敏感な行動(たとえば、夜にホラーを好むユーザーなど)も捉えられるようにしている
@Yosuke Yoshida
[oss] Memray
- Bloombergが開発したPythonのメモリプロファイラ
- 特徴
- サンプリングせずにすべての関数呼び出しを追跡
- C/C++ライブラリ内もプロファイル可能
- 高速
- 収集したメモリ使用データをもとに、さまざまなレポートを生成
- usage
- CLI
- フレームグラフ
- live mode
- withブロックでコードを部分的にプロファイル
@Takumi Iida (frkake)
[blog] FP8 trainingを支える技術 1
- 所感
- 読んだ理由
- 建前:量子化を手段の一つとして考慮できれば、大規模モデルも色々検討できるようになる
- 本音:面白そうだったから
- pytorch/aoを元にした実装解説がありイメージが具体的に湧く
- FP8
- FP8には指数部、仮数部のビット数によって複数種類ある ↓E4M3で最大値を取る設定 →
- 使い分け
- Forward:アクティベーション、重み→E4M3
- Backward:勾配→E5M2

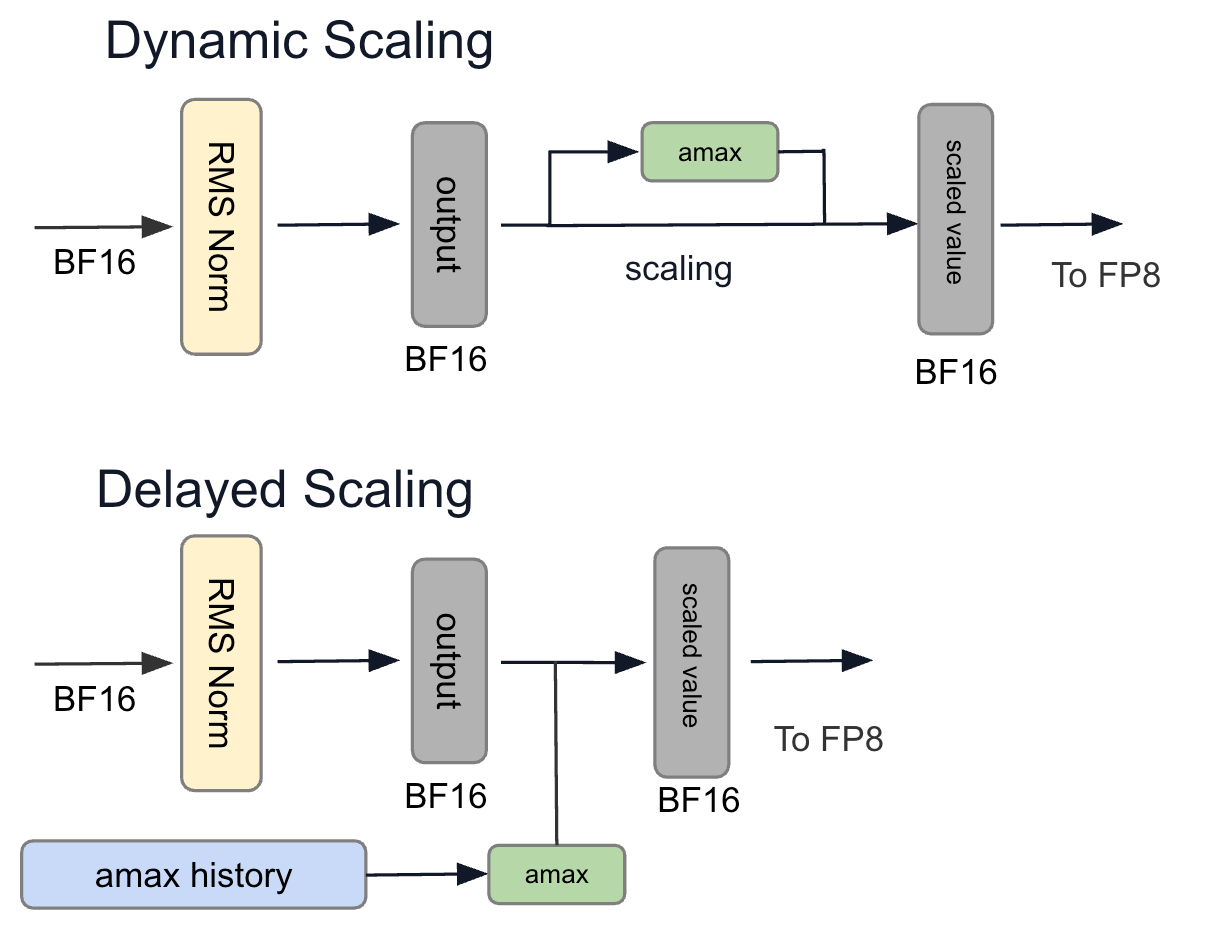
- スケーリングの設定
色々ある


- 量子化パラメータの推定タイミング
メインTOPIC
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long T. Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Iyer, Tianlong Chen, Huan Liu, Chen-Yu Lee, Tomas Pfister
Agent の長期記憶手法に関するGoogleらの論文
サマリー
1. Introduction
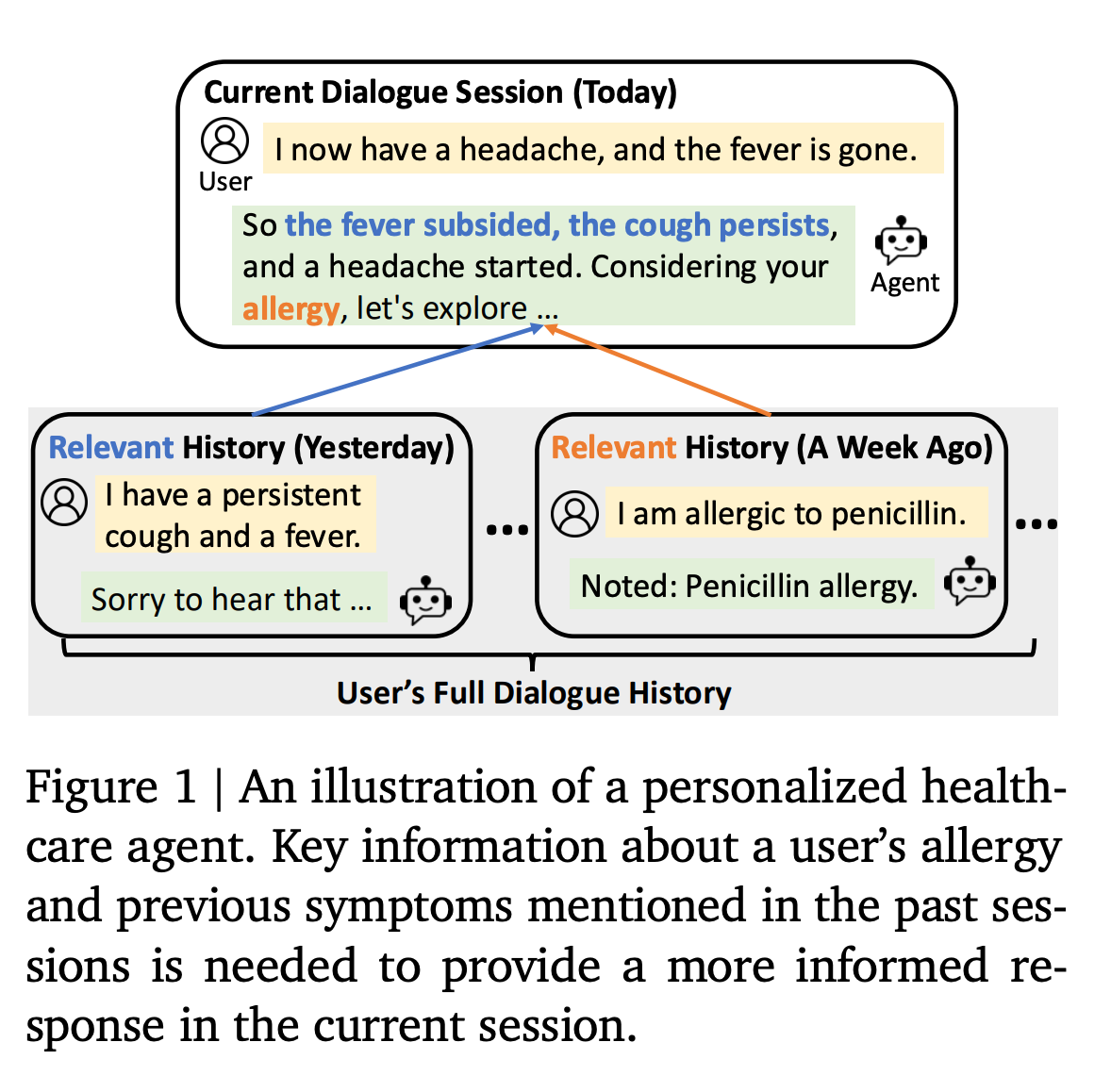
LLMはオープンエンドな対話において高い性能を発揮するが、対話の長期的なパーソナライゼーションに関しては依然として課題が残る。LLMは状態を保持しないため、過去の対話履歴から有用な情報を抽出し、継続的にパーソナライゼーションした対話に活用することが難しい。
従来手法の問題点
- 従来の外部メモリ機構は、固定的な粒度(ターンやセッション単位など)で情報を扱うため、実際の会話における意味的な区切りと一致せず、情報が断片化または不完全な形で保存される。
- 固定のリトリーバル手法は多様な対話コンテキストやユーザーの相互作用パターンに柔軟に対応できず、不要なノイズを含む検索結果となる可能性がある。
提案手法
Reflective Memory Management (RMM) という新たなメモリ管理機構を提案。RMMは以下の2つの反省的アプローチを統合する。
- Prospective Reflection(先行反省)
- 対話セッション終了時に、発話、ターン、セッションといった従来の境界を超え、会話の意味的なトピックごとに情報を要約・整理し、今後の検索に最適化された個人用メモリバンクを動的に構築する。
- Retrospective Reflection(後追い反省)
- 対話生成時にLLMが出力する引用(どのメモリが参照されたかの信号)を用いて、軽量なリランカーをオンライン強化学習により更新し、リトリーバル精度の向上を図る。
2. Related Work
Long-term Conversations for LLMs
- 長期対話においては、対話の一貫性および個人化の実現のために、過去の対話履歴の有効な活用が不可欠
- 従来のアプローチとしては、モデル内部のアーキテクチャ変更(注意機構の改良、KVキャッシュの最適化など)や対話履歴の要約を用いた直接条件付け手法(RAGなど)が提案
Memory-based Personalized Dialogue Agents
- MemoryBankやLD-Agentなどのシステムは、対話履歴を固定的なデータベースとして管理し、ヒューリスティックに基づいた検索を行うが、固定粒度に依存するため柔軟性に欠け、最新の情報反映が困難
本研究の位置づけ
RMMは、既存の手法が抱える「固定粒度」と「固定リトリーバル機構」の問題に対し、トピックベースの動的なメモリ整理と、LLM引用信号を用いたオンラインリトリーバルの最適化という新たな解決策を提示
3. Problem Formulation
複数の対話セッションにまたがるユーザーとの対話において、過去の対話履歴から有用な情報をメモリバンクに蓄積し、現在の対話においてその情報を適切に検索・活用することで、個人化された応答を生成する
主要な課題
- 記憶の保存
- 各セッション内で重要な情報を抽出し、後の対話で必要とされる際に効果的に活用できる形で保存する必要がある。
- 情報の検索
- 必要な情報のみを正確に検索し、不必要なノイズを排除することで、応答生成の品質を維持する必要がある。
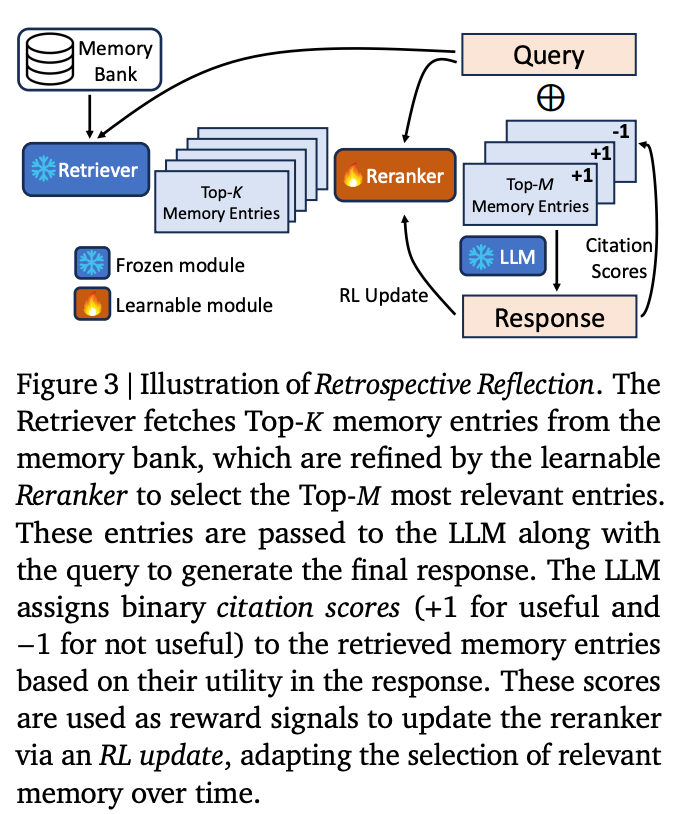
4. Framework Overview
システム構成
- メモリバンク
- 過去の対話履歴を「トピック要約」と「生の対話テキスト」のペアとして保持する。
- リトリーバー
- 現在のユーザークエリに対して、メモリバンクから候補となるメモリを抽出する。
- リランカー
- 初期に取得した候補(Top-K)の中から、より関連性の高いものを再選択(Top-M)する軽量モジュール
- LLM生成モジュール
- リランカーで選定されたメモリと現在の対話コンテキストを統合し、応答を生成する。
- 反省的更新
- LLMが生成する引用情報を基に、リランカーをREINFORCEアルゴリズムによりオンライン更新し、次回以降のリトリーバルの精度を向上させる仕組みを持つ。
アルゴリズムの流れ
クエリに対し、メモリバンクから候補を取得し、リランカーで精査する。その後、LLMが応答生成と共に引用を出力し、この引用情報を用いてリランカーのパラメータを更新する。この一連の流れにより、システムは動的かつ個人化された対話応答を実現する。

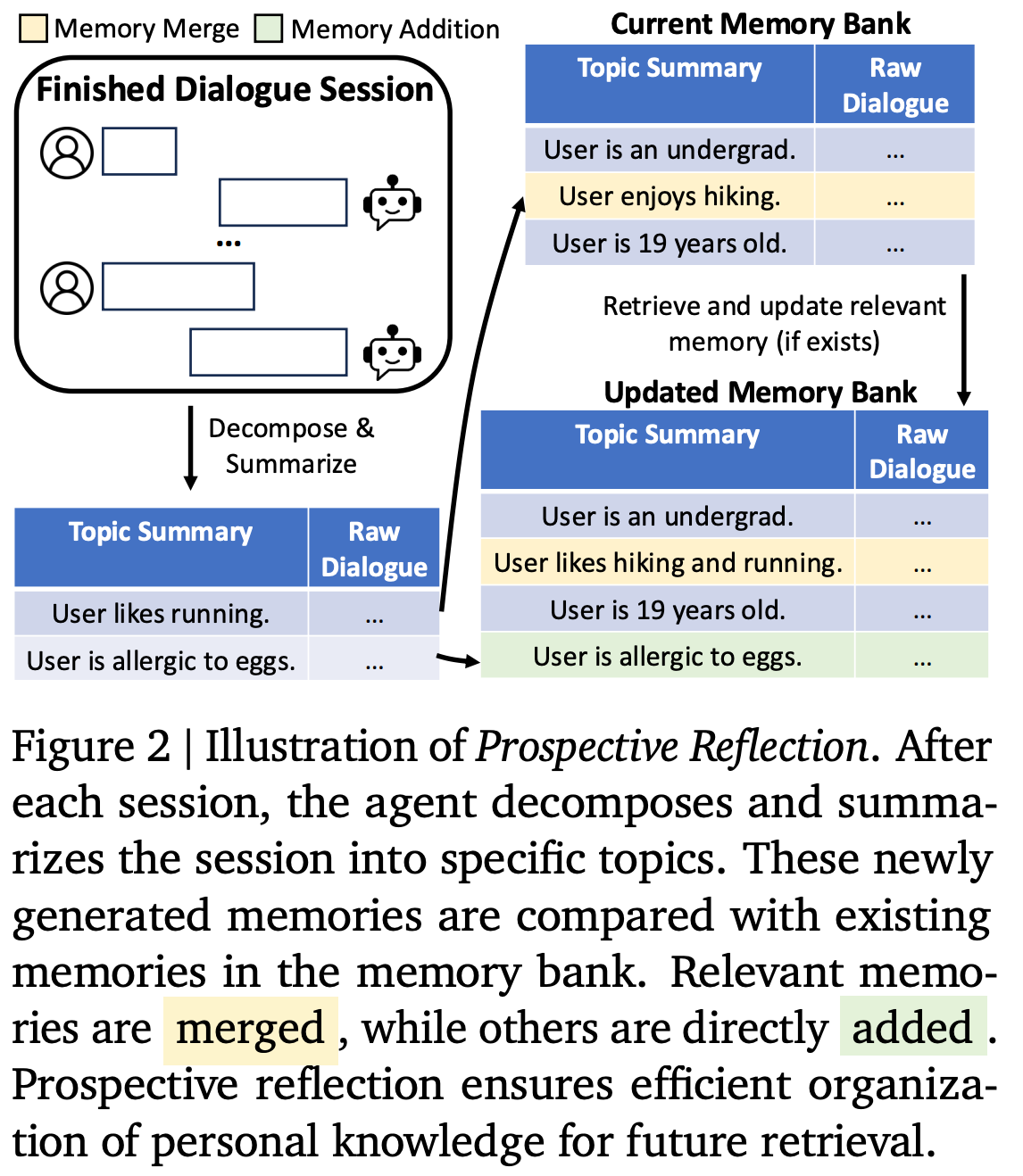
5. Prospective Reflection: Topic-Based Memory Organization
従来の固定的なターンやセッションの区切りでは、会話の意味的な単位を正確に捉えられず、情報が断片化する問題があった。そこで、本手法では対話セッション終了時に、会話内容を意味単位(トピック)ごとに分解・要約する。
プロセス
- メモリ抽出
LLMを用いて、セッション内の対話から複数のトピックに関連する情報を抽出し、簡潔な要約を生成する。
- メモリ更新
抽出した新たなメモリを、既存のメモリバンク内のエントリーと類似度計算を行い、既存の情報と重複していればマージし、そうでなければ新規エントリーとして追加する。
効果
この手法により、メモリは意味的にまとまった単位で整理され、将来的な検索時に必要な情報を正確かつ効率的に抽出できるようになる。
6. Retrospective Reflection: Retrieval Refinement via LLM Attribution
目的
初期のリトリーバル手法は固定的であり、対話の多様性に柔軟に対応できないため、動的な最適化が求められる。本手法は、LLMが生成する引用信号を利用して、リランカーをオンライン更新し、適切なメモリを選択する仕組みを提供する。
リランカーの設計
- 埋め込みの適応
- クエリおよび各メモリの埋め込みに対し、線形変換と残差接続を用いて改良を加える
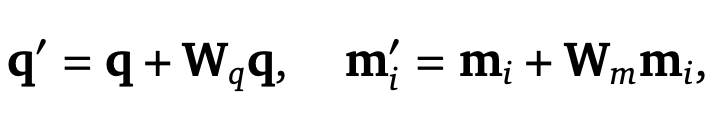
- 確率的サンプリング
- Gumbelトリックを用い、各メモリ候補に対して確率的にサンプリングし、Top-Mを選定
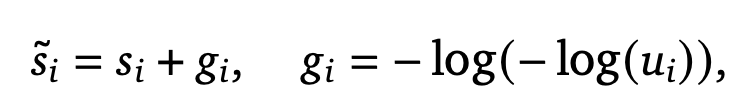
これにより、固定リトリーバルモデルを変更することなく、動的な適応が可能に
LLM Attributionと報酬設計
- LLMは応答生成時に、どのメモリが実際に利用されたかの引用を出力する。
- 引用されたメモリには正の報酬(+1)、引用されなかったものには負の報酬(−1)を割り当て、これを基にリランカーのパラメータをREINFORCEアルゴリズムにより更新する。
- この仕組みにより、リトリーバル精度が向上する。
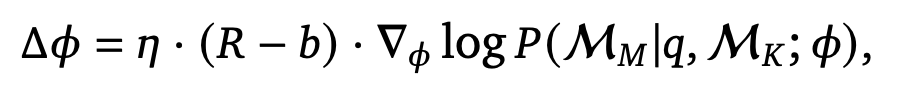
7. Experimental Setup
実験環境と使用モデル
- 生成モデル:Gemini-1.5-FlashおよびGemini-1.5-Pro
- リトリーバルモデル:Contriever、Stella、GTEなど、各種モデルを採用し、トップKおよびトップMの設定についても詳細な調整
- Contrieverがデフォルトとして利用されるほか、各手法間の比較実験が実施
使用データセットと評価指標
- MSC:複数セッションの対話データを用い、METEORやBERTScoreによる評価
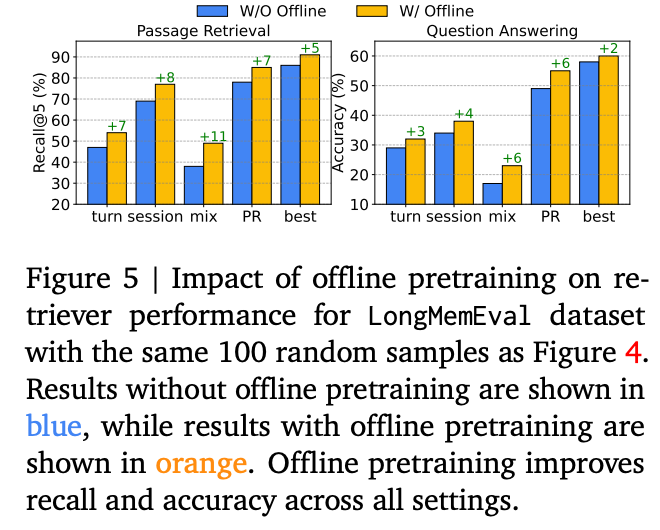
- LongMemEval:長期的な対話履歴からの情報検索能力を評価するためのデータセットであり、Recall@Kおよび応答正確性(Accuracy)を評価指標として採用
- また、LLM-as-a-Judgeにより人手アノテーションに近い評価も実施
比較対象手法
履歴を一切利用しない「No History」、長いコンテキストをそのまま与える「Long Context」、RAG、MemoryBank、LD-Agentなどとの比較実験を行い、各手法の有効性が検証されている。
8. Experimental Results
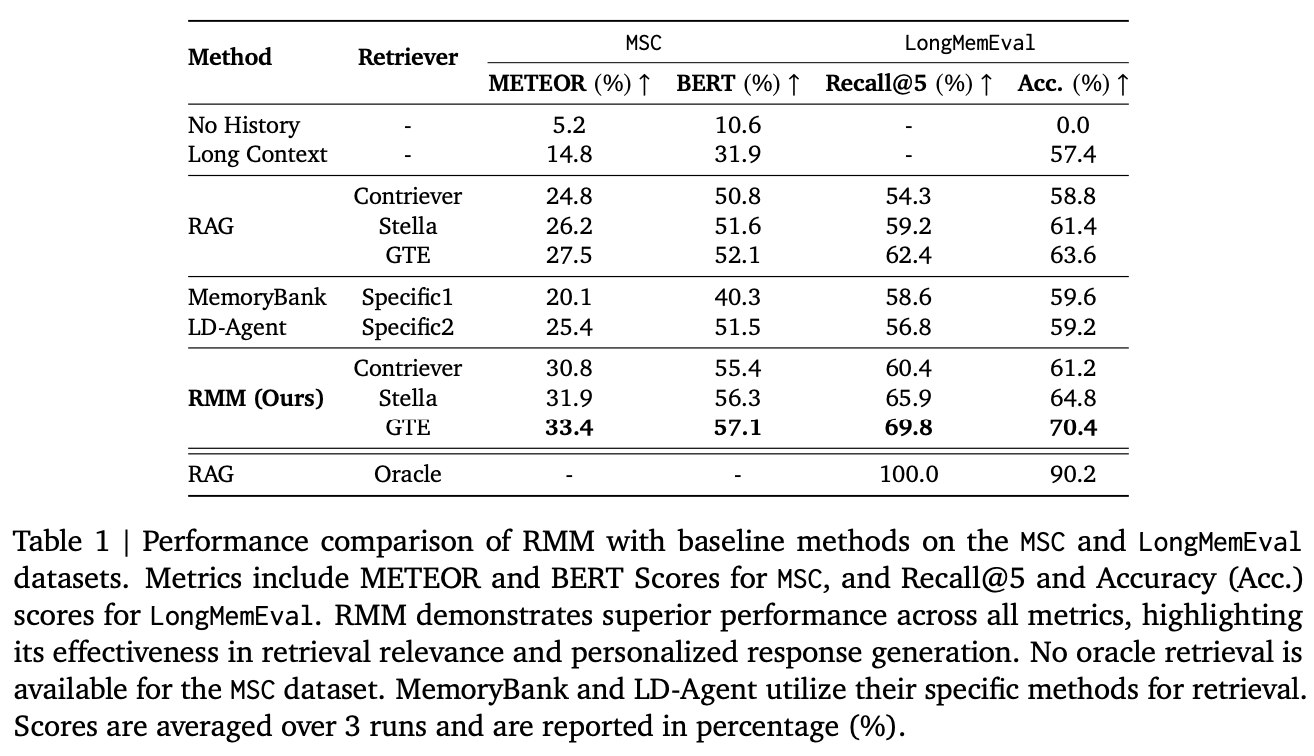
Main Results
- RMMは、MSCおよびLongMemEvalの各評価指標において、従来手法(Long Context、RAG、MemoryBank、LD-Agent)を上回る性能を示した。
- 特に、個人化された応答生成および適切なメモリ検索の面で顕著な改善が確認された。
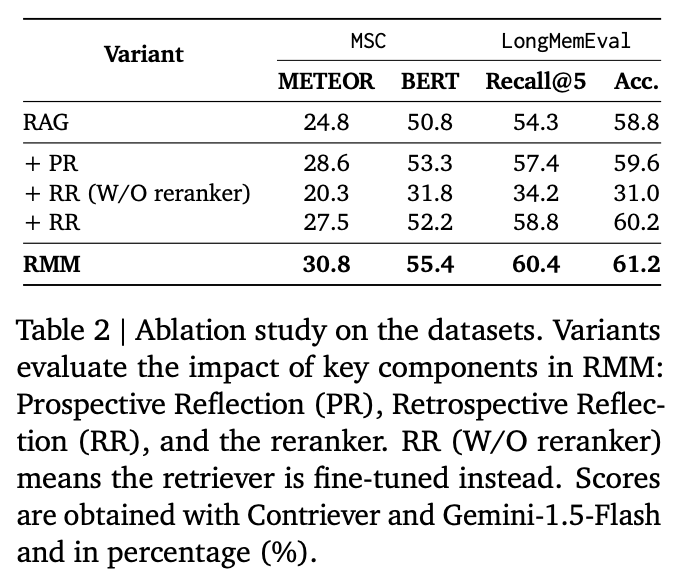
Ablation Study
- Prospective Reflectionの導入により、情報の整理および統合が向上し、性能が改善されたことが示される。
- 一方、Retrospective Reflection単体では十分な効果が得られず、リランカーとの組み合わせが必須であることが明らかとなった。
- 最終的に、完全なRMMフレームワークの統合により、最も高い評価が得られた。
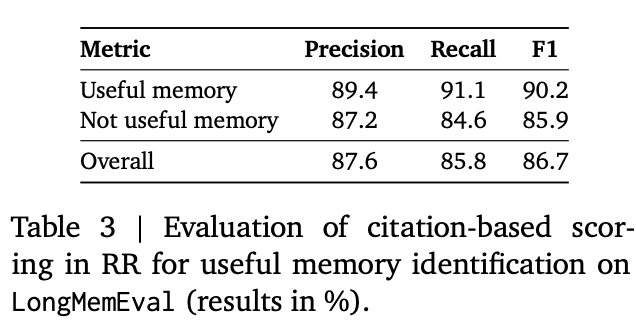
Validation of Citation Scores
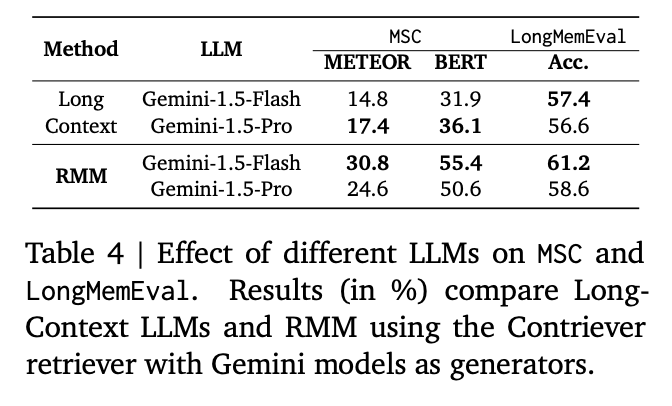
Effect of Different LLMs
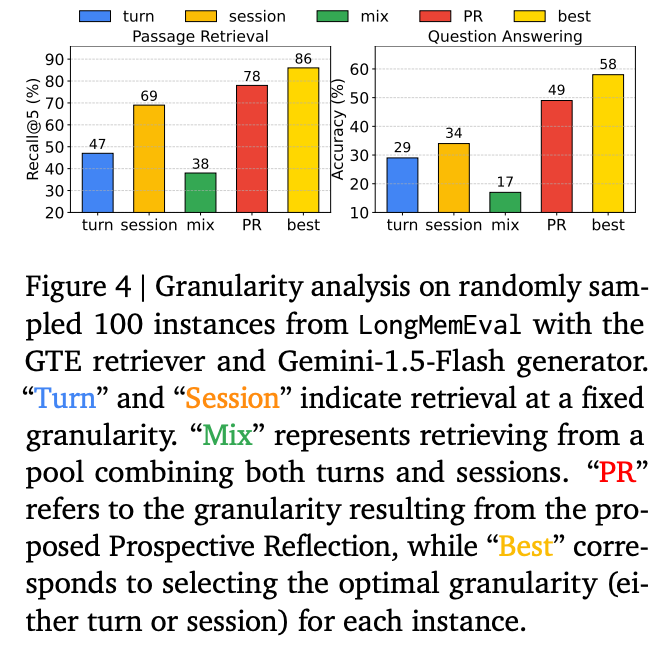
Effect of Different Granularities
Offline Supervised Training