2025-08-06 機械学習勉強会
今週のTOPIC[blog] GPT-OSS[blog] AIによる開発の前提知識を学ぶため「LLMのプロンプトエンジニアリング」を読んだ[論文] PixNerd: Pixel Neural Field Diffusion[blog]AIエージェントのおかげでdbt開発の大部分を自動化した話[blog]Qwen-Image: Crafting with Native Text Rendering[論文] Transmission With Machine Language Tokens: A
Paradigm for Task-Oriented Agent CommunicationメインTOPICMagistral3行まとめ導入手法インフラストラクチャデータ実験分析うまくいかなかったこと
今週のTOPIC
@Naoto Shimakoshi
[blog] GPT-OSS
- OSSのOpenAIモデルが公開
- GPT-OSS 120B: https://huggingface.co/openai/gpt-oss-120b
- GPT-OSS 20B: https://huggingface.co/openai/gpt-oss-20b
- 推論系のモデルで120Bがo4-mini、20Bでo3-mini程度の精度とのこと
- 学習方法
- 強化学習と o3 その他のフロンティアシステムを含む OpenAI の最先端の内部モデルに基づく手法を組み合わせて学習
- モデル
- MoEを採用

- Prompt
- Harmony形式というやつ
- チャンネルという概念があり、思考の過程などがanalysisに表示される。これはユーザへの送信を意図していない。(が見る分には楽しい)
- 学習時
- thinking keyにChain of Thought部分の内容を入れ込む
- 最後のターン以外はのthinkingキーは無視されるらしい。GPT-OSS自体もそのように学習している。そうしなければ、最後のターン以外の会話でも学習する必要が出てくるため、思考がないパターンの内容も学習してブレてしまうため。
例
- systemプロンプトとdeveloperプロンプトが内部的に分かれている。systemに現在の日付、モデルのID、Reasoning Effortなどを入れて、deloperが普通のsystemプロンプトという使い分けらしい。
- Hugging Face的には両方ともでdeveloperに落としてこんでる。
- は引数で指定
- Tool
- ブラウザとPythonとカスタムツールをサポート
- こんな感じで使える
@Yosuke Yoshida
[blog] AIによる開発の前提知識を学ぶため「LLMのプロンプトエンジニアリング」を読んだ
- オライリーのLLMのプロンプトエンジニアリング本を読んでの読書ノート
- 適切に構築されたプロンプト構造の話
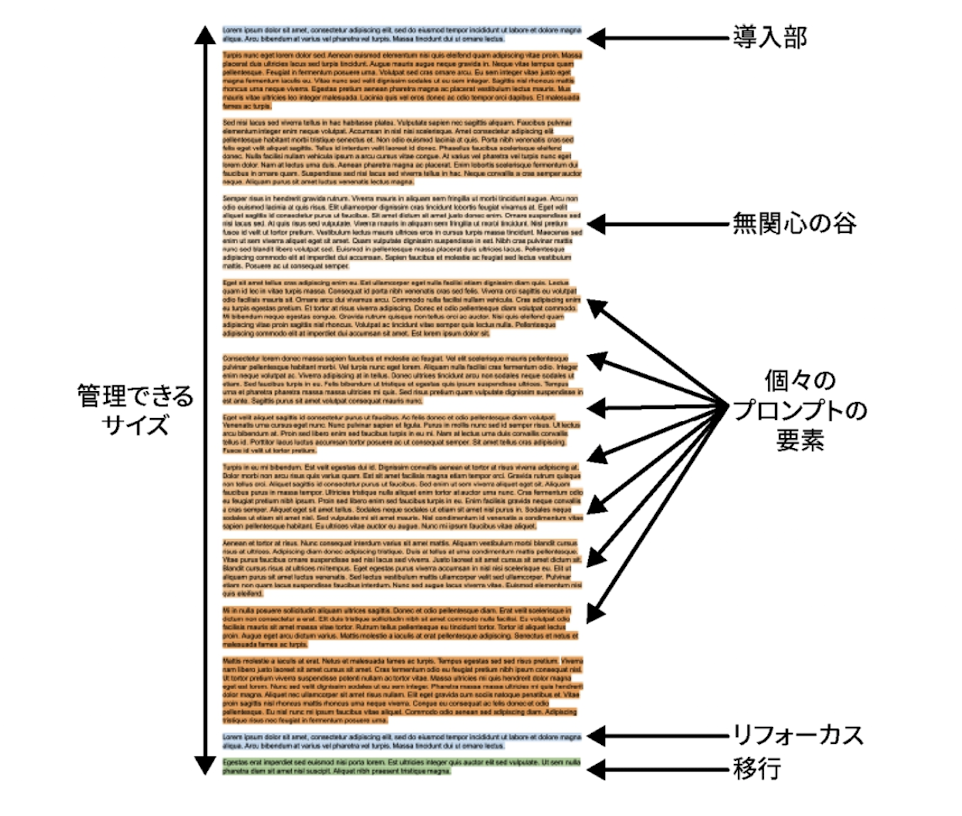
- 構造は、導入 => コンテンツ => リフォーカス => 移行の順
- 導入部: 生成するドキュメントの種類を明確にし、残りのコンテンツに正しくアプローチ。後に続く全ての内容のコンテキストを設定して、モデルに問題を最初から考えさせる役割。早い段階で焦点を絞る
- リフォーカス: すべてのコンテキスト要素を入れ終わったら、最後にもう一度、本題の質問をリマインド。導入部とサンドイッチにする
- 移行: 問題の説明から問題の解決へ移ったことを示す
@Takumi Iida (frkake)
[論文] PixNerd: Pixel Neural Field Diffusion
HuggingFace: huggingface.co
ニューラルフィールドを使って、ピクセル空間で直接拡散モデルで画像を生成するアプローチ。
潜在空間を使った拡散モデル(Latent Diffusion Models)は、VAEで圧縮して、それを元に戻す(復元する)が、VAEによる欠損などが生じるため、それを解決したい。
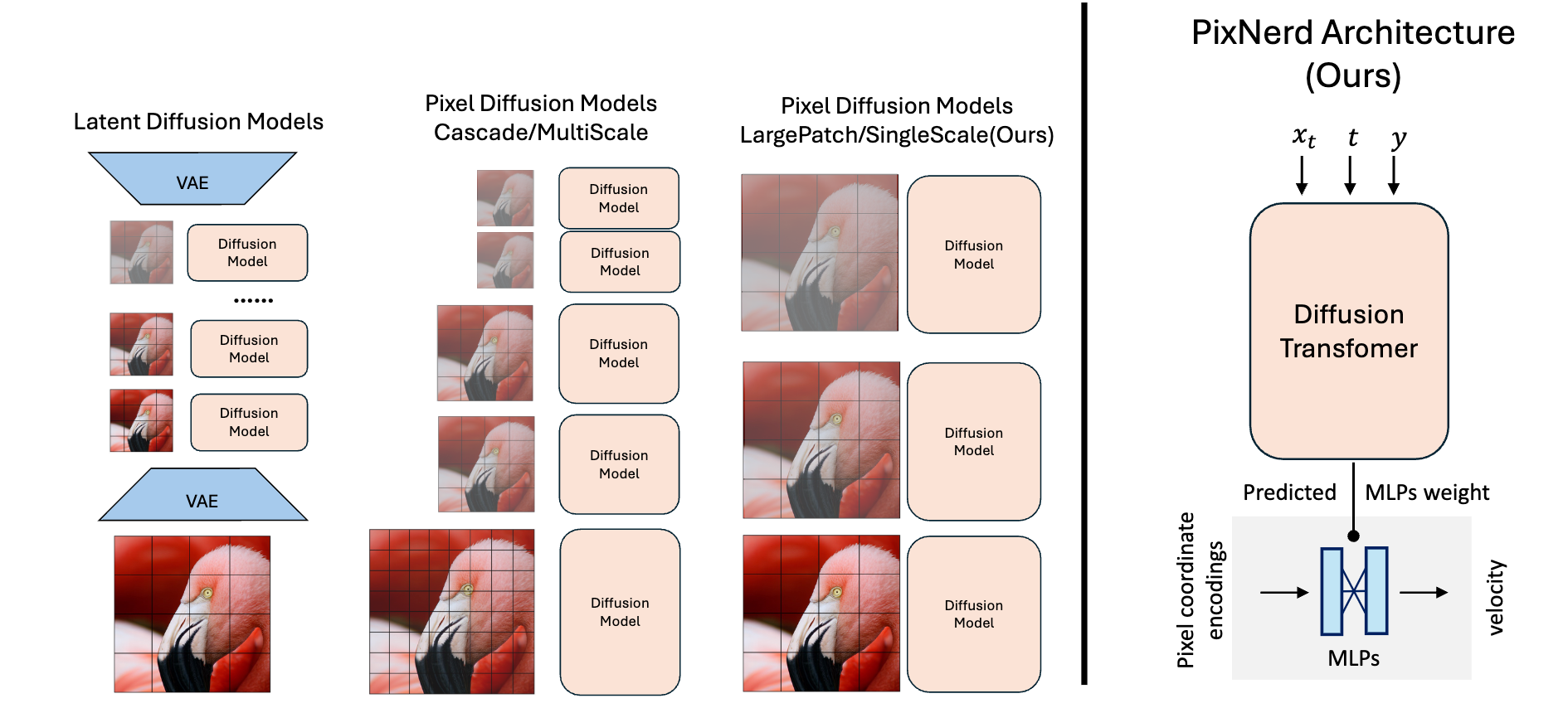
アプローチ
- 画像を大きなパッチに分割
- Diffusion Transformerで各パッチの情報から、そのパッチ内のノイズを予測
- Diffusion Transformerの出力を使って最終的なノイズを予測。ニューラルフィールド
Diffusion Transformer
従来のUNet → Diffusion Transformer
入力:パッチ内を1次元にしたもの。各時刻、各パッチ、(テキスト)条件が入る。
出力:パッチごとのノイズの予測値
ニューラルフィールド
NeRFと同じ仕組みを使って、最終的なノイズの予測を行う。
通常のNeRFではRGB値と密度を予測するが、ノイズを予測している。
Diffusion Transformerの予測値を使って、2層MLPの重みを推定させている。
入力:ピクセル座標の位置エンコーディング
PixNerdの良い点
VAEを排除したことで、1段のシンプルなモデルになり、高速化かつVAE非依存(VAEの性能が影響しない)
さらに、カスケードになっていたパイプラインを除去しており、高速化している。
結果
(参考)PixelFlowはカスケード構造になっているので遅い
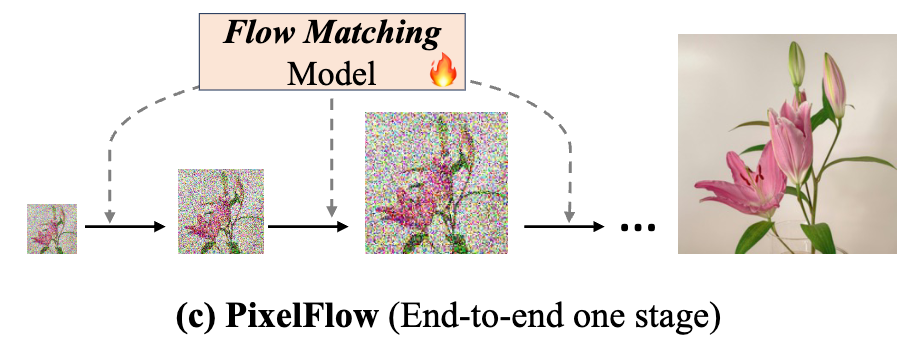

PixNerdの生成結果。キレイな画像が生成出来ている。

@Hiromu Nakamura (pon)
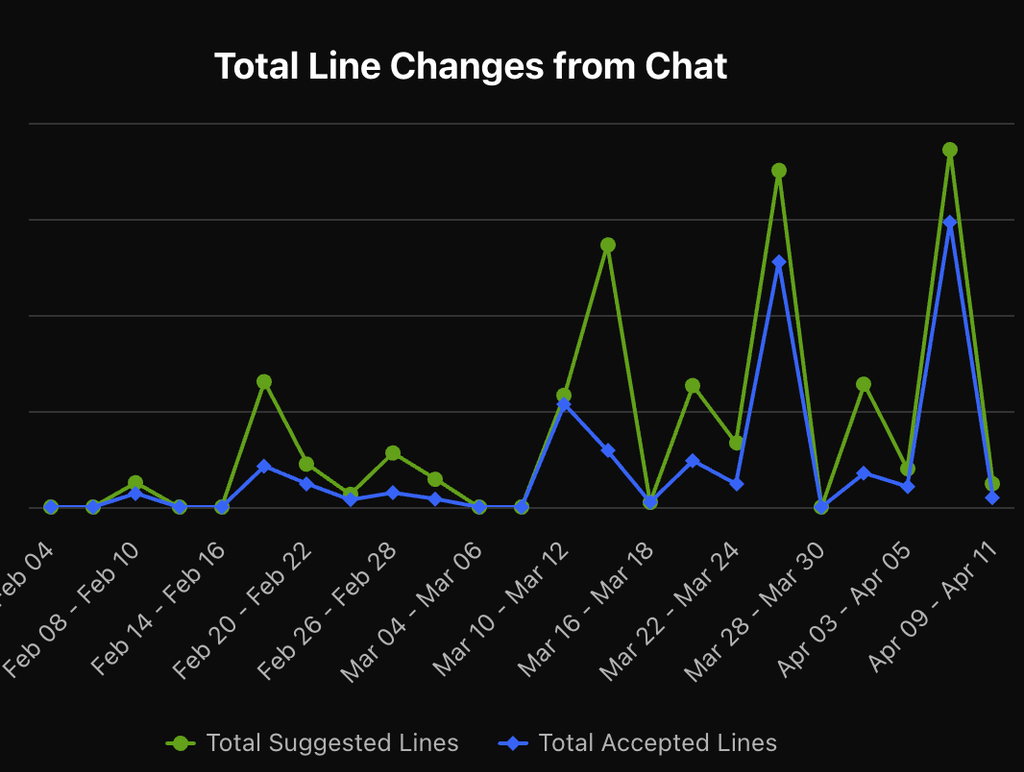
[blog]AIエージェントのおかげでdbt開発の大部分を自動化した話
AIでdbt model開発の速度向上。アノテーションバッチdbt移行プロジェクトの参考になるかもと思って読んだ。
すごい↓
Project Rules
- 共通的な部分(あらゆるdbt model開発で必要となる共通ルール。基本的にコンテキストとして渡します)
- , , ,
- ドメイン固有の部分(特定の事業・プロダクトのドメインや機能を説明するルール。コンテキストとして手動で渡します)
- , , ...
- トラブルシューティングや確認用(リファクタリング後のデータ比較など、dbt modelのリリース後に数値確認などに利用するルール。コンテキストとして手動で渡します)
- (社内のBigQuery MCPサーバーと合わせて利用します)
結果
- Step1. 社内独自で開発している を使ってdbt modelファイル群のテンプレートを作成する(🤖が✅)
- Step2. SQLを更新(🧑💻の修正)
- Step3. ローカルでを実行してエラーなくモデルが作成されるか確認(🤖が✅)
- Step4. を実行してschema.ymlを更新(🤖が✅)
- Step5. 必要に応じてdata_testsの追加・column descriptionの修正・Lightdash metadataを追加し、schema.ymlを更新(🤖がほぼ✅。一部🧑💻が修正)
- Step6. ローカルでを実行してdata_testsがパスすることを確認(🤖が✅)
- Step7. dbt modelの説明を記述するdocs.mdを更新(🤖が✅)
- Step8. PRを作成しレビューを依頼する(🤖が✅)
- pre-commit でリンターの実行・SQLフォーマットも修正される
- PR作成後、自動的に複数のCIが実行される
[pon] workflowもうまくやればAIがやってくれる。複雑で抽象化した自動化よりも、理解しやすくてドキュメントにもなるから良いんよな。
[blog]Qwen-Image: Crafting with Native Text Rendering
200億のMMDiT画像基盤モデルであるQwen-Imageをリリース
- 優れたテキストレンダリング
:Qwen-Imageは、複数行レイアウト、段落レベルのセマンティクス、きめ細かなディテールなど、複雑なテキストレンダリングに優れています。アルファベット言語(例:英語)と表語言語(例:中国語)の両方を高い忠実度でサポートします。
- 一貫した画像編集
: 強化されたマルチタスク トレーニング パラダイムにより、Qwen-Image は編集操作中に意味と視覚的なリアリズムの両方を保持する優れたパフォーマンスを実現します。
- 強力なクロスベンチマーク パフォーマンス
: 複数の公開ベンチマークで評価された Qwen-Image は、さまざまな生成および編集タスクにわたって一貫して既存のモデルを上回り、画像生成のための強力な基盤モデルを確立します。
データセット作れるかやってみた。日本語弱そう。。。

@ShibuiYusuke
[論文] Transmission With Machine Language Tokens: A
Paradigm for Task-Oriented Agent Communication
- LLMを使用したタスク指向型エージェントのワイヤレス通信システムに関する論文。
- エージェントの活用が広まることで、エージェント間の通信に特化したAIネイティブな新しい通信システムの必要性。
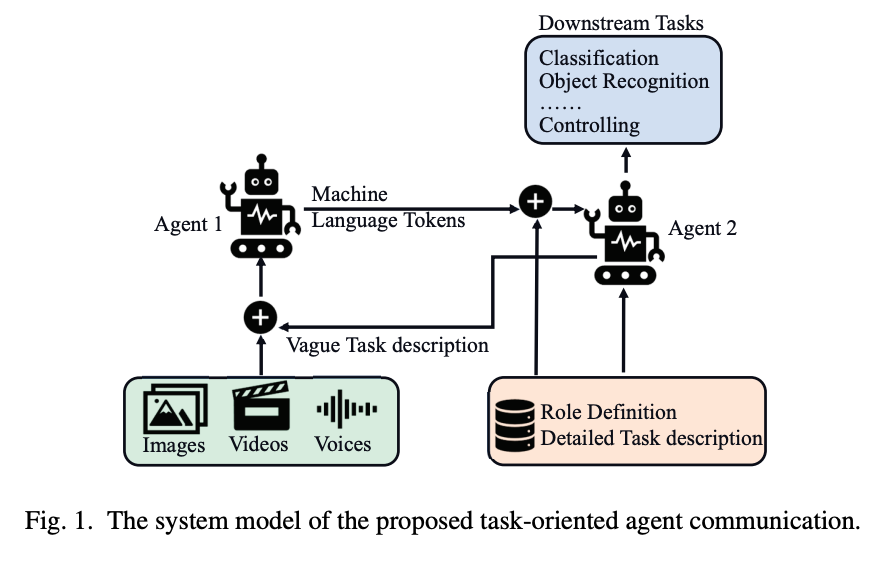
- 課題
- 自然言語やRGB画像のような既存のモダリティは人間が解釈するために最適化されているが、機械間の通信には伝送効率とセマンティック精度の両面で最適ではない。
- エージェントが特定の垂直ドメイン内で動作するように設計されているため、機械言語トークン表現には固有のスパース性が見られる。さらなる圧縮の可能性。
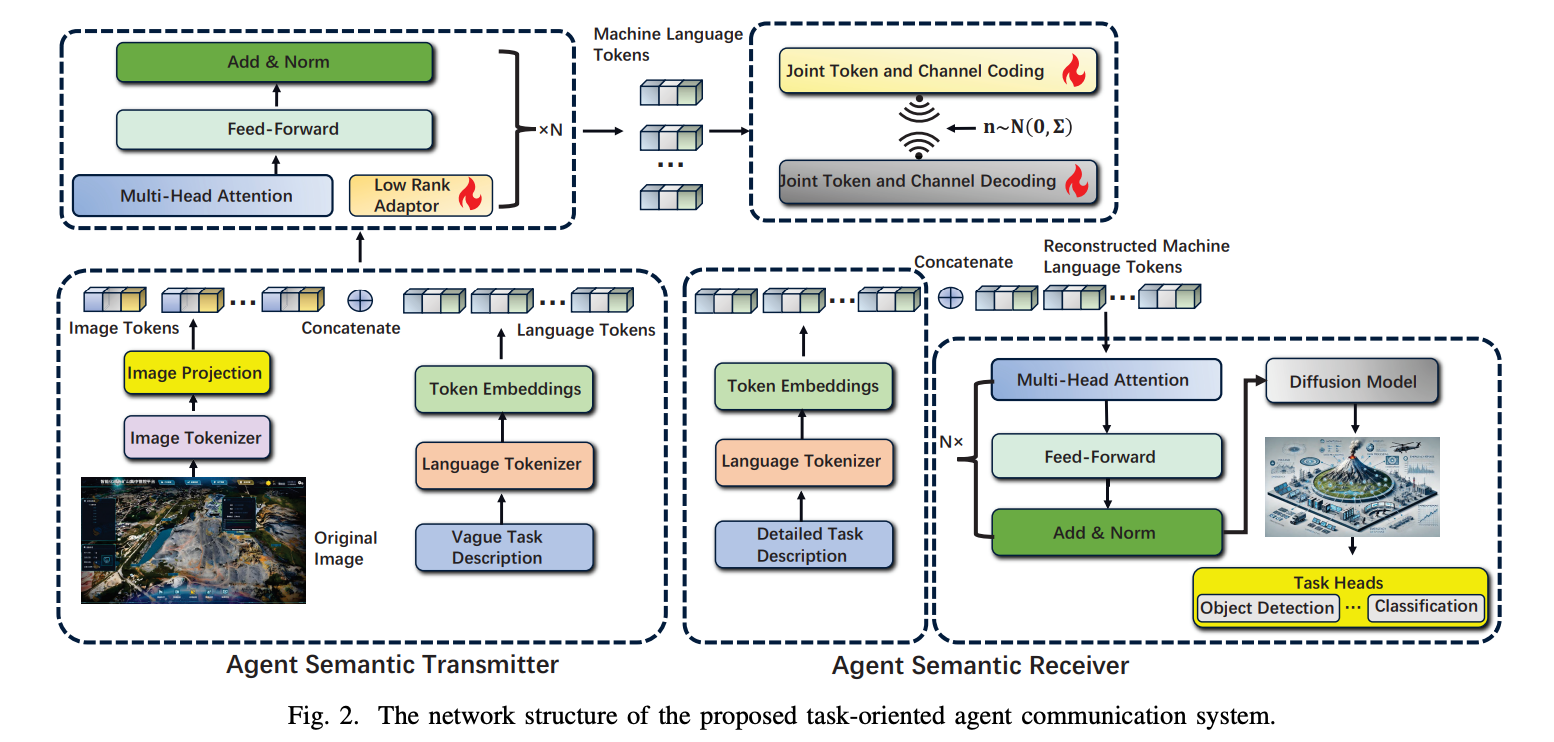
- タスク指向のエージェント通信システム
- 大規模言語モデル(LLM)を活用して、トークン埋め込みによって表現される特殊な「機械言語」を学習。機械言語トークンは、LLMによってタスクに特化して学習され、最適化されるため、高い意味的表現力と精度を提供
- マルチモーダルLLMを訓練し、マルチモーダルな入力からタスクを理解し、重要な情報を抽出して機械言語トークンで表現
- 無線通信における伝送効率が大幅に向上
- 伝送オーバーヘッドを削減するため、トークン系列のスパース性を利用してデータを圧縮し、通信路のノイズに対する耐性を高める「共同トークン・チャネル符号化(Joint Token and Channel Coding, JTCC)」スキームを導入
- 以下評価
- BenchMark2,3,4と比較したJPGの圧縮率
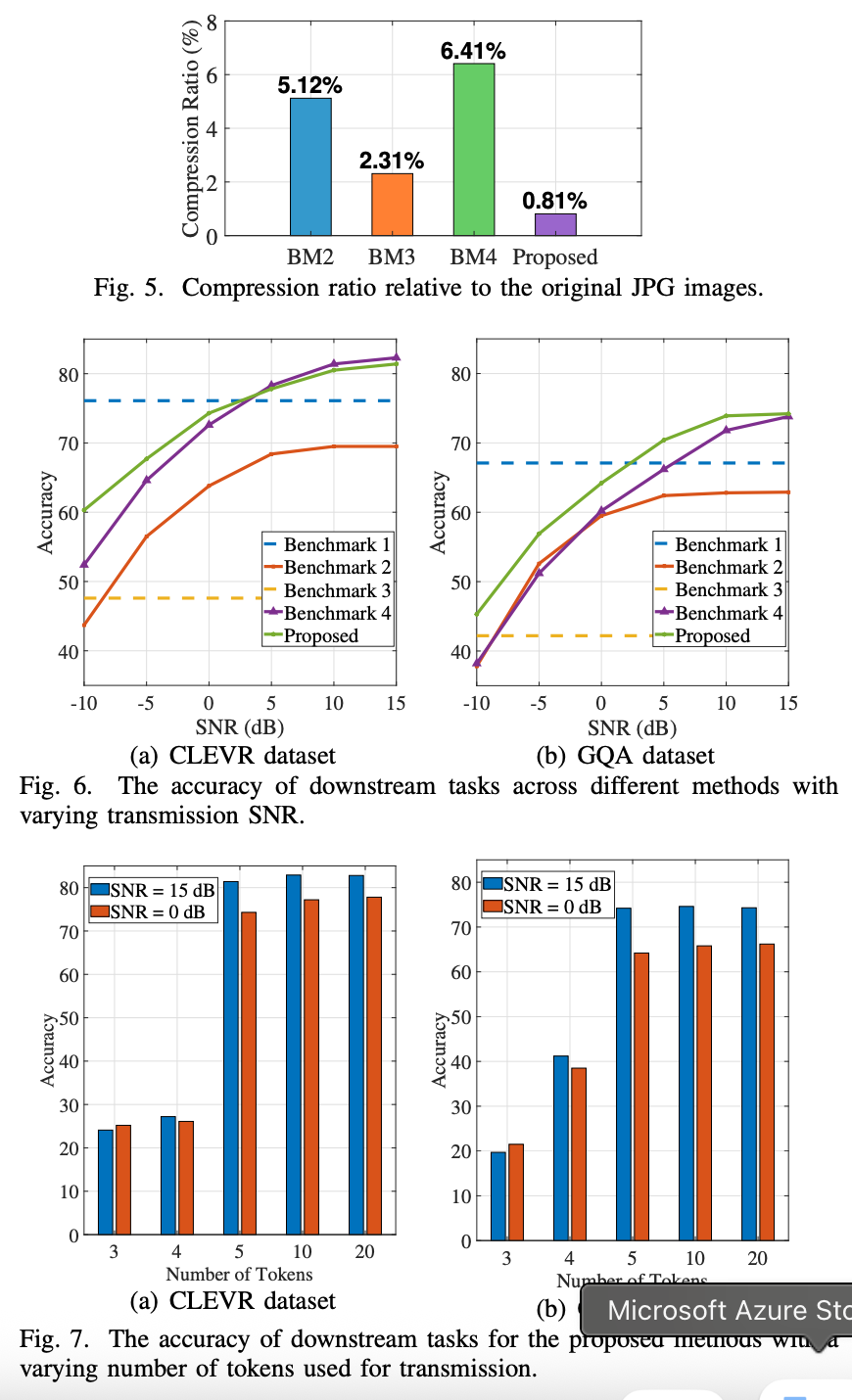
メインTOPIC
Magistral
| タイトル | Magistral |
|---|---|
| 著者 | Mistral AI |
| リンク | https://arxiv.org/abs/2506.10910 |
| 関連ページ | https://mistral.ai/news/magistral |
3行まとめ
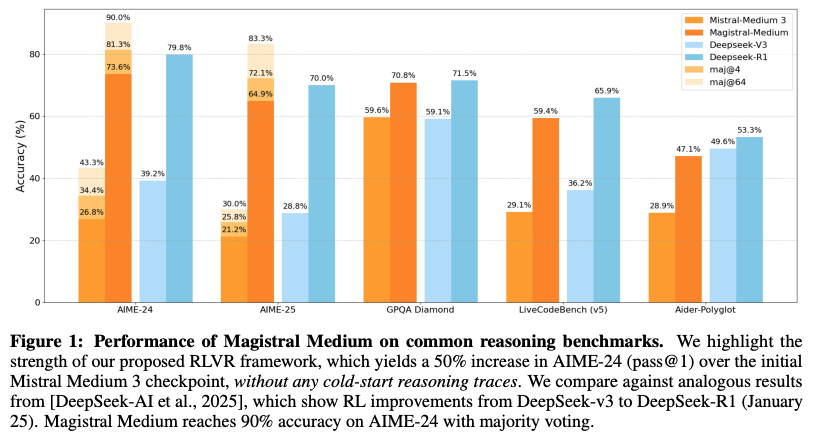
- MagistralはMistral Medium 3をベースに、既存の推論モデルの知見やトレースを一切使わず、独自設計のオンラインRLVR(Reinforcement Learning from Verifiable Rewards)パイプラインで「純粋な」強化学習のみを行い、推論能力を大幅に向上させた。
- この手法により、AIME-24でパス@1が26.8→73.6(約50%増)、LiveCodeBenchでも29.1→59.4と著しい改善を達成しつつ、マルチモーダル理解や命令従属性、関数呼び出し機能も維持・向上させている。
- さらに、同じアプローチで得られた推論トレースを活用した24Bパラメータの小型モデル「Magistral Small」も開発・公開し、学術・実用両面で再現可能なオープンソースとしてApache 2.0ライセンスで提供している。
導入
- MistralベースのReasoningモデル Magistral を作成
- Mistral Small 3 → Magistral Small (Apache 2.0)
- Mistral Medium 3 → Magistral Medium
- 貢献ポイント
- 既存reasoningモデルからの蒸留はせず、強化学習のみで訓練
- 大規模かつ高速なRL trainingのための構成
- CoT, 最終的な回答の両方をユーザーの言語に合わせて出力する多言語モデル
- Reinforcement Learning from Verifiable Rewards (RLVR) に対する知見の提供
手法
強化学習アルゴリズム
- Group Relative Policy Optimization (GRPO) を利用
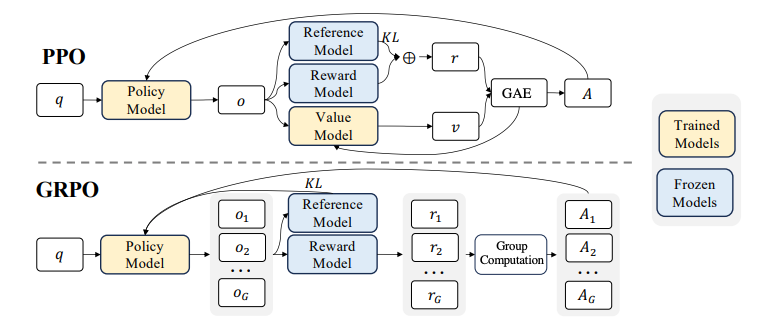
- 元々のGRPOの目的関数から変更
- before
- after
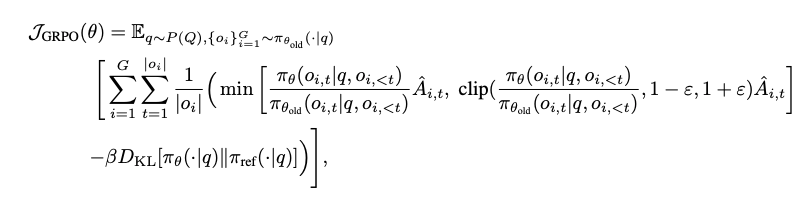
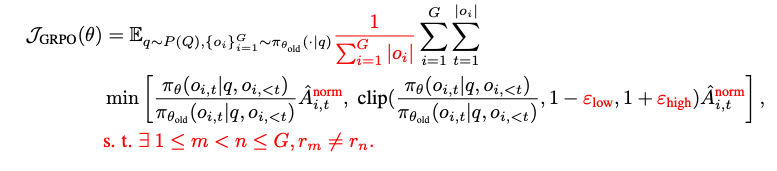
- 変更点
- KL-divergence項を削除: GRPOにおいて、policyのdivergeは大きく作用しないため、計算コスト削減のため削除
- lossの正規化: グループごとに生成されたトークン長の違いによるバイアスを緩和するため、グループ単位での正規化から、グループ全体での正規化に拡大
- Advantageの正規化: advantage(ある出力が平均よりどれだけ良いか) パラメータ A の正規化方法を変更(minibatch内でAを正規化)
- clip幅の調整
- before: 元の対数尤度の小さいtokenの上昇幅を抑えている
- after: low, highそれぞれの下限・上限を広げるように調整し、学習の余地を増やす
- non-diverge groupsの削除: すべて正解 or 間違いのtokenで構成されたグループは、Advantageが0になり、lossに影響を与えない。それらを除外してから正規化などの後続の計算をおこない、lossが過剰に小さくならないようにする。
報酬設計
- フォーマットに対する報酬
- 従うべきフォーマット
- 生成する回答は <think> タグから開始し、その後 </think> で終わっている。またそれらは1度だけ使われる。
- 数学の最終回答は、</think> の後に \boxed{} で囲む
- コードの回答は、マークダウン形式のコードブロックを含める
- フォーマットに1つでも違反すれば報酬は0、全て従っていれば0.1の報酬を加算する
- 正確さに対する報酬
- 数学: \boxed{} から回答を抜き出し、SymPyなどで整形した後、正解と比較し、同じであれば正解。
- コード: 最初のマークダウン形式のコードブロックから回答を抜き出し、C++で書かれていれば10sを上限にコンパイル(C++20)。利用可能なテストをランダムに20個選び、4sタイムアウト・300MBメモリでテストを実行する。テストが全て通れば正解。
- いずれも正解していれば0.9の報酬を与え、合計1.0の報酬となる。
- 長さに対するペナルティ
- 生成して良い最大の長さに近づいた場合、最大 -0.1 のペナルティを加算し、最大長に近づきすぎるのを防ぐ
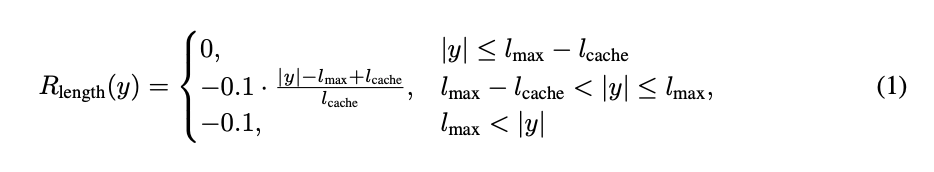
- 言語一貫性に対する報酬
- 特に言語制約なく強化学習すると、数学やコーディングの生成結果が複数言語の混ざったものになりがちな傾向にある。
- クエリデータの10%について、英語からフランス語・スペイン語・イタリア語・ドイツ語・中国語・ロシア語に翻訳。出力結果をfastText classifierにかけ、同じ言語だと判定されれば0.1の報酬を与える。
- これだけの制約で、任意の(事前に翻訳をかけた以外も含めた)言語について言語一貫性が改善
system prompt
- Be as casual and as long as you want の部分がexplorationを増やすのに有効(らしい)
インフラストラクチャ
オンライン強化学習を構成するワーカー
- Trainers: 勾配更新。モデルのメインコピーを保持
- Generators: 対数尤度付きで回答を生成。
- Verifiers: 出力を受け取り報酬を算出
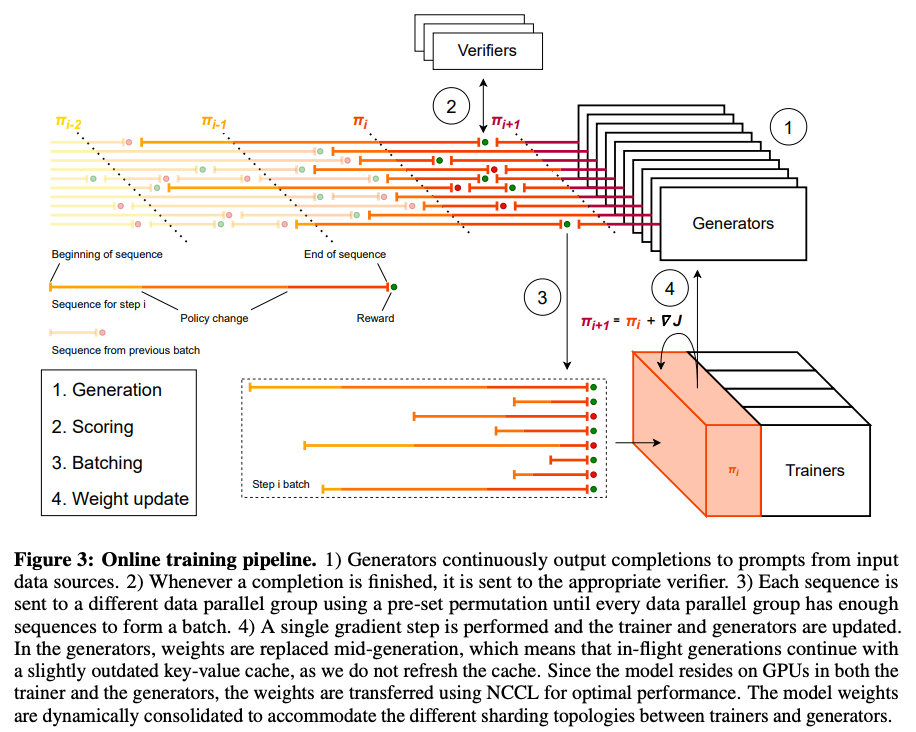
Challenges with distributed RL: クエリによってインプット・アウトプットする長さ(トークン列・時間)が大きく異なる
- 非同期生成
- 生成・検証が終わったsequenceをbatchに追加していく
- batchに必要な分が揃ったら、Trainerに流して新しいパラメータを得る
- 生成途中のものはKVキャッシュを使って元のパラメータのまま生成し続け、次の生成から新しいパラメータを反映
- Trainer Optimization
- Greedy Collation Algorithm: minibatchに含まれる系列長を揃えてpaddingを抑えるため、系列を長い順にsortした上でmicrobatchに分配していく。
データ
数学
- 元データ70万問から、問題が欠けておらず、「数値や式で正解を検証できる」ものを抽出
- Mistral Large 2で問題ごとに16回答を生成。極端な難易度(全く解けない or ほぼ必ず解ける)の問題を除外
- 得られたデータで24Bモデルを強化学習し、学習後に再度16回答を生成。極端な難易度の問題を再び除外し、「過半数の回答が同じ & 不正解」な問題を除外(正解が間違っている可能性が高い)。結果として3万8000問に。
コーディング
- 競技プログラミングデータ(問題・正解コード・テストケース)を収集
- テストのフィルタリング
- 出力結果が複数の正解コードで揃わないテストケースを除外
- 出力が揃っても間違っている場合は、テストの方を修正
- テストケースが少ない場合は、新しいテストを追加
- 結果として3万5000問に。
実験
Overview
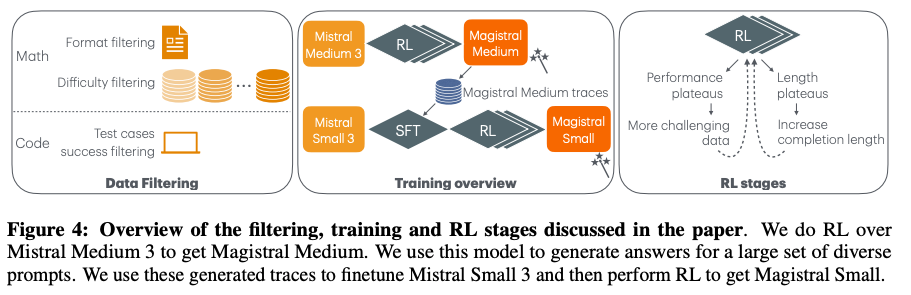
2種類のモデルを作成
- Mistral Medium 3 → RL → Magistral Medium
- 学習中モデルパフォーマンスが高まるにつれてデータの難易度を上げていく
- 生成する列の長さが短いままにならないよう、length penaltyを受けない長さを少しずつ長くしていく(16k → 24k → 32k)
- 生成する列の長さを伸ばすにつれて、バッチサイズを落としてメモリを抑える
- DeepSeek-v3 → R1よりも大きな改善幅に
- Mistral Small 3 → SFT (w/ Magistral Medium) → RL → Magistral Small
- SFT: Magistral Mediumの訓練中に得られた、正しく短すぎないCoT+最終回答のトレースと、外部ソースの問題をMagistral Mediumに解かせて得られた回答を利用
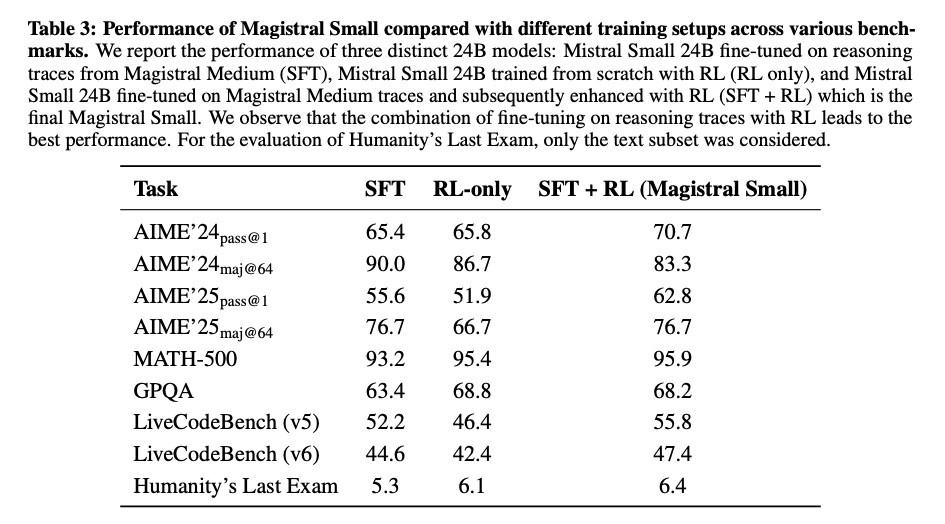
- SFT, RL単体よりも、SFT + RLが高性能
言語ごとの性能

分析
学習の進み方
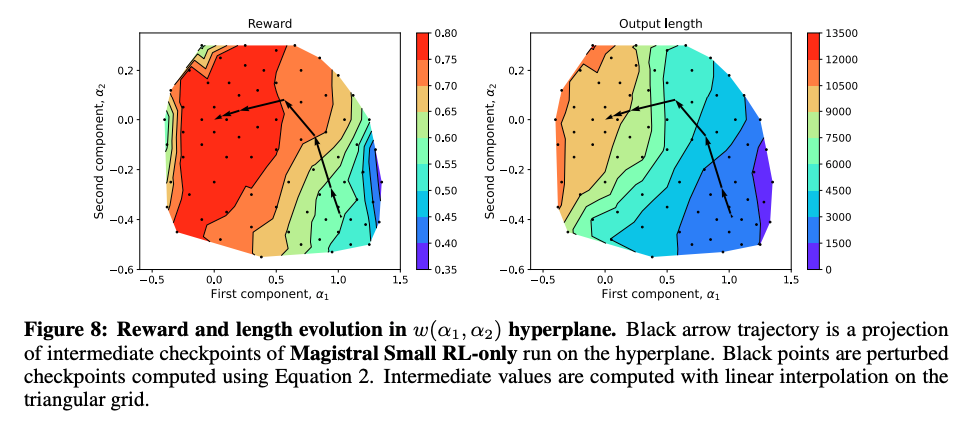
- チェックポイントごとに、重みをPCAで二次元化 & 回帰分析
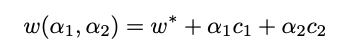
- 学習が進むにつれて、Reward, Output Lengthの大きくなる方向に進んでいる。Lengthは最大許容長まで増加。
マルチモーダル性能
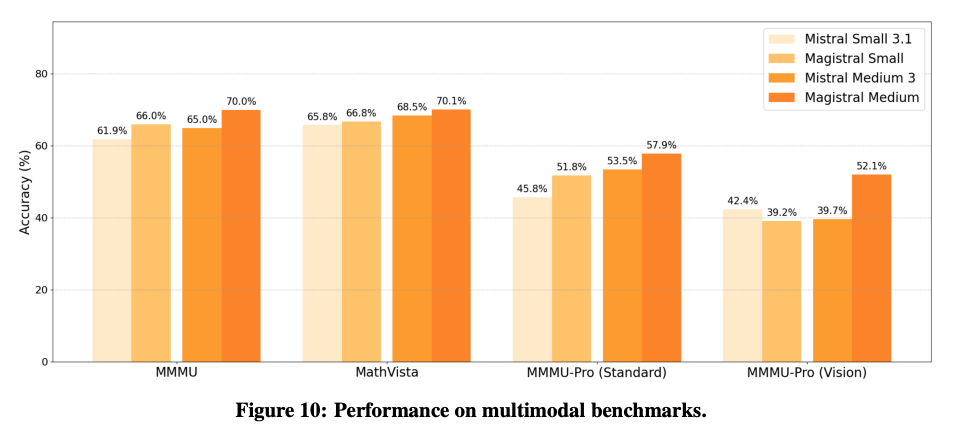
- 学習にはテキストデータしか利用していないが、マルチモーダルベンチマークで精度改善を確認
ツール利用・Agent性能
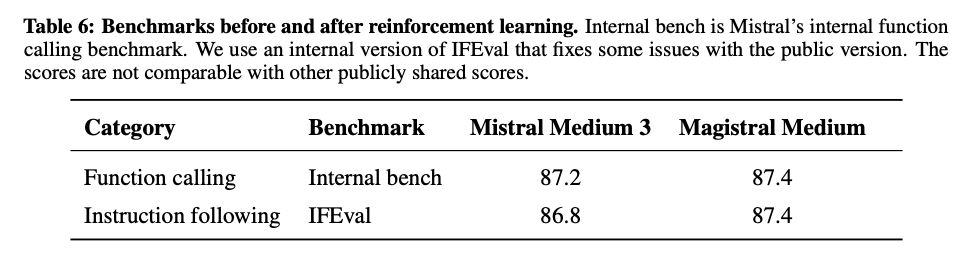
- Function calling, Instruction followingの改善も確認
うまくいかなかったこと
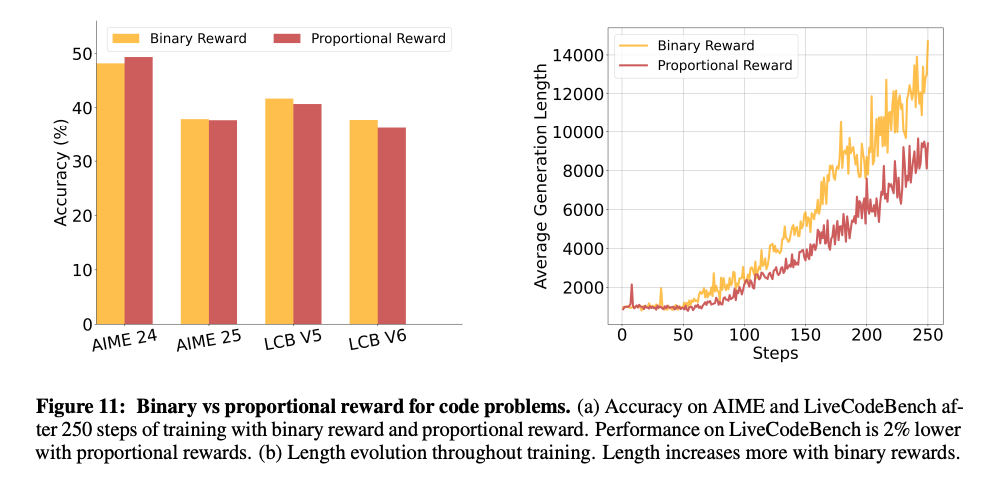
コーディングに対して、正解/不正解ではなく、テスト合格率に応じた報酬を与える
- 報酬の情報量は増えるが、間違った回答に関するsignalが入ることがノイズになり、性能がやや低下し、生成長も短くなる結果に。
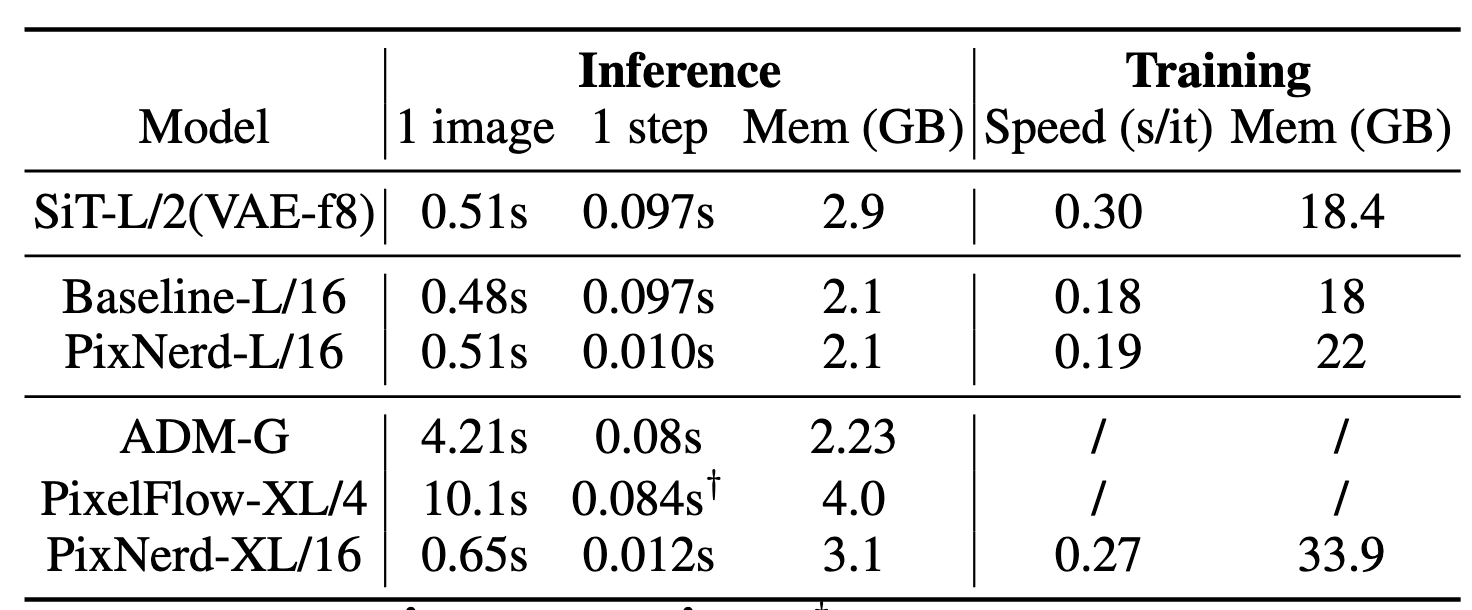
エントロピーターゲティング
- PPOで利用されているentropy bonus(現在のポリシーと状態とのエントロピー)は、データセットによって作用の仕方が大きく異なる
- 左のmathデータセットでは、clip幅の上限を制御する を上げた方がよりエントロピーを増やせている
- 右のmath+codeデータセットでは、entropy bonusを使った時のエントロピーが大きくなりすぎている
- entropy bonus termよりも を使った方がコントロールしやすい