
2025-08-14 機械学習勉強会
今週のTOPIC[論文] A Comprehensive Survey of Self-Evolving AI Agents -A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems-[report] Introducing Gemma 3 270M: The compact model for hyper-efficient AI[blog] オープンウェイトモデルで広がる生成AI活用: LLM API活用の課題と自社運用[blog]Microsoft Just Solved AI’s Biggest Problem: Why Magentic-UI Changes Everything[論文] TURA: Tool-Augmented Unified Retrieval Agent for AI SearchメインTOPICGPT-5 prompting guideサマリーAgentic workflow predictabilityControlling agentic eagerness(エージェントの自律性・積極性を制御する)Tool preamblesReasoning effortReusing reasoning context with the Responses APIMaximizing coding performance, from planning to execution Frontend app developmentCollaborative coding in production: Cursor’s GPT-5 prompt tuning Optimizing intelligence and instruction-followingSteeringInstruction followingMinimal reasoningMarkdown formattingMetaprompting
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] A Comprehensive Survey of Self-Evolving AI Agents -A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems-
- 自己進化するAI Agentについてのサーベイ論文。長いのでかいつまんで。
- Self-Evolving AI Agentsの構成要素は以下
- システム入力 (I): 最適化を導くタスク記述、コンテキスト情報、または入出力ペア
- エージェントシステム (A): 最適化の対象となるコアシステムで、さまざまなコンポーネントを持つ単一または複数のエージェントで構成される
- 環境 (E): 評価指標またはLLMベースの評価器を通じてフィードバック信号を提供する外部コンテキスト
- オプティマイザ (P): エージェントシステムを洗練させる役割を担うメカニズムで、その探索空間 (S) と最適化アルゴリズム (H) によって定義される
- Single Agentの最適化、MultiAgentの最適化、ドメイン最適化の3つがある
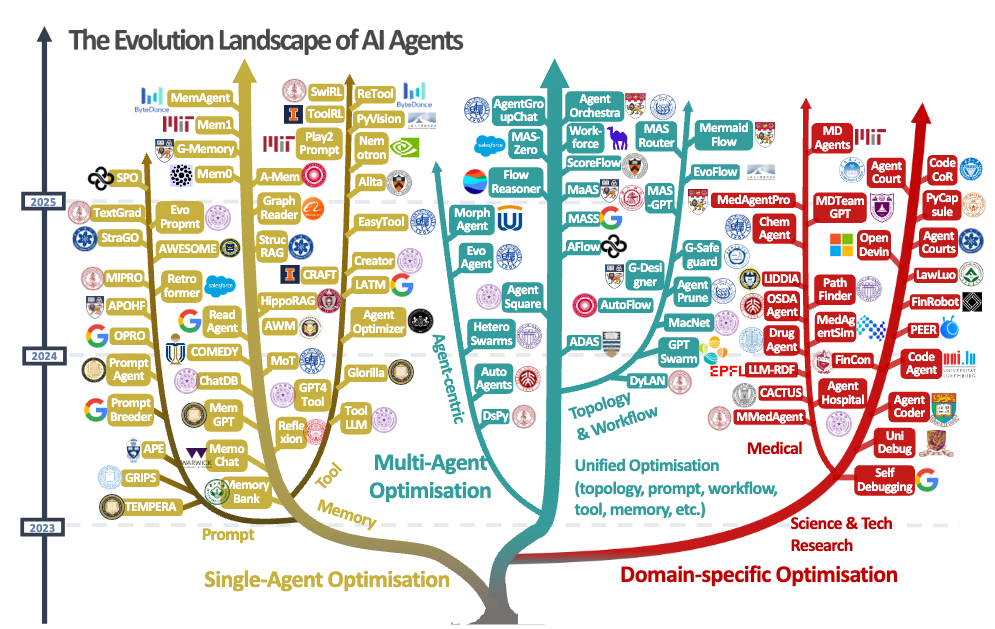
- 例えばSingleAgentの最適化は以下の4つの分野に分類される
- LLM動作最適化
- トレーニングベースの手法 (例:STaR(Self-Taught Reasoner))のような教師ありファインチューニング技術や、自己報酬メカニズムなどの強化学習アプローチ
- 推論ベースの手法(例:Baldur)推論ステップを検証するための検証モジュールを使用するフィードバックベースの手法や、複数の推論パスを探索するTree-of-Thoughtsのような検索ベースのアプローチ
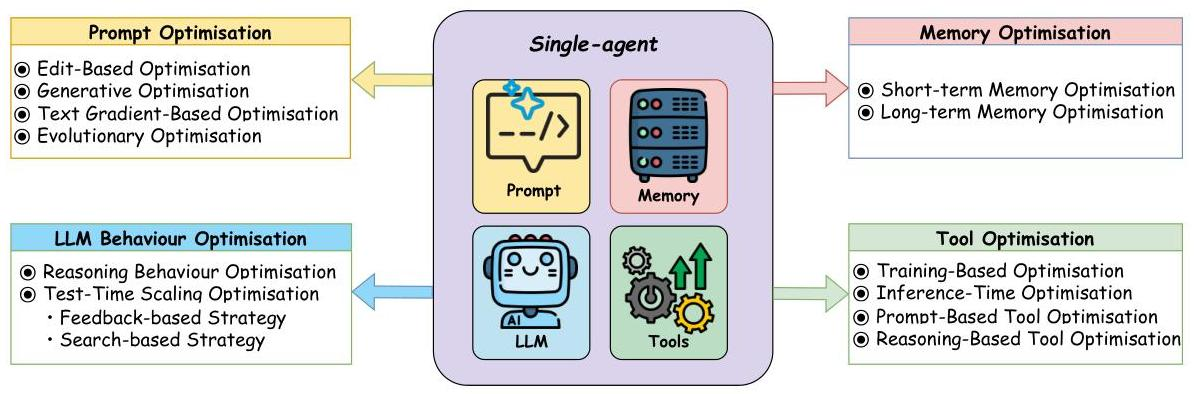
- プロンプト最適化
- 編集ベースの手法(例:GRIPS、TEMPERA):既存のプロンプトを反復的に洗練する
- 生成アプローチ(例:OPRO、PromptAgent):全く新しいプロンプトを作成する
- テキスト勾配ベースの手法(例:TextGrad):テキストに勾配のような最適化を適用する
- 進化的手法(例:EvoPrompt、Promptbreeder):生物学的着想を得たアルゴリズムを使用する
- メモリ最適
- MemoChatやReflexionのような技術を用いた短期記憶最適化で、最近の対話を管理する
- A-MEMやGraphReaderのような検索拡張生成(RAG)アプローチを含む長期記憶システムで、永続的な知識を保存する
- ツール最適化
- モデルをツール使用のためにファインチューニングする学習ベースの方法(例:ToolLLM、ReTool)
- 実行時にツール選択と使用を最適化する推論時戦略(例:EASYTOOL)
- エージェントが自律的に新しいツールを開発できるようにするツール作成アプローチ(例:CREATOR、CRAFT)
- 課題
- Endure - 安全適応に関する課題
- task metricsが優先され安全性が軽視されている
- Excel - 性能保持に関する課題
- ドメイン特化タスクにおいて良質なラベルがない
- マルチエージェント化すると性能と速度のトレードオフが発生
- 同じ最適化手法が違うモデルでも有効とは限らない
- Evolve - 自律最適化に関する課題
- マルチモーダルはまだ難しい
- ツールセットが固定化されてることによる限界
- 将来の方向性
- MOP(Model Offline Pretraining) → MOA (Model Online Adaptation) → MAO (Multi-Agent Orchestration) → MASE (Multi-Agent Self Evolving)と進化していく
- その他
- EvoAgentXといったフレームワークも登場していて気になる
- Agent as a Judgeという技術が最近注目
- 既存のLLM as a Judgeが最終結果でしか評価できなかったところを中間生成物も含めて評価できる枠組み
@Shun Ito
[report] Introducing Gemma 3 270M: The compact model for hyper-efficient AI
- Gemma3 270Mがリリース
- instruction-followingに強み
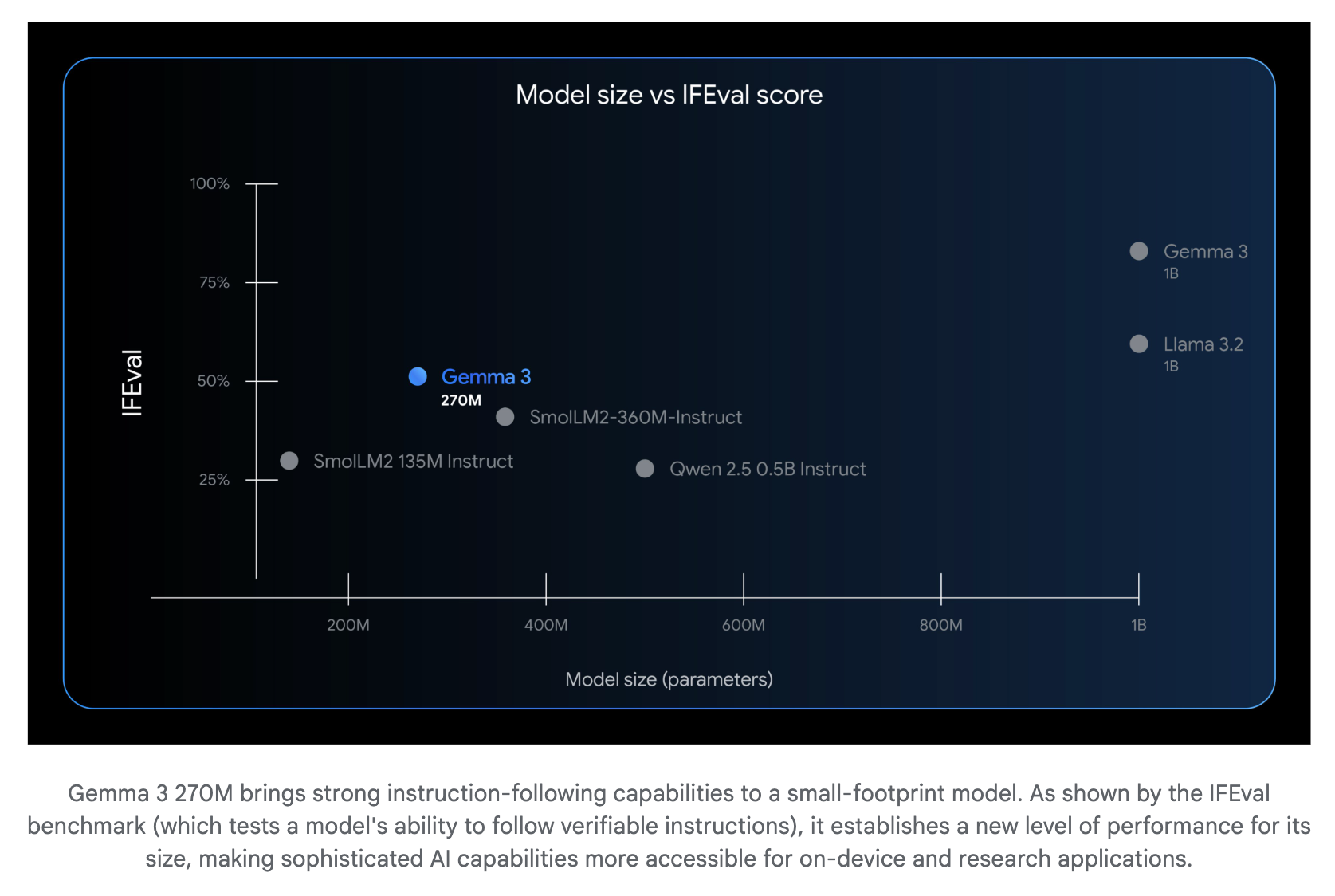
- ollamaで使える(ファインチューニングなし)
- 回答はとても速い
- サイズは小さいが、他言語が混ざらないのはすごい
参考: gpt-oss:20b(三目並べ)
@Yosuke Yoshida
[blog] オープンウェイトモデルで広がる生成AI活用: LLM API活用の課題と自社運用
- LLMのAPI活用における課題
- コスト面、速度面、安全面
- 解決策としてのオープンウェイトモデルの自社活用
- すべてのタスクを一度に移行するのは現実的ではない場合もある
- 完全な自社運用モデル移行が困難な場合でも、クローズドモデル(API)とオープンウェイトモデルを効果的に組み合わせることで、コスト削減とセキュリティ向上を実現
- 処理を複数のステップに分解し、自社運用モデルで前処理や定型作業を実行後、その結果をAPIに渡して後続の処理を実行
- CoGenesis(Zhang et al., 2024)では、端末上のSLMが個人のコンテキストを読み取って整形し、クラウド上のLLMがタスクを実行
- 入力内容の複雑度や機密性に応じて、自社運用モデルとAPIを動的に使い分けます。簡単なタスクは自社運用モデルで素早く回答し、難しいタスクはAPIを通じて実施
- CITER(Zheng et al., 2025)では、定型的な部分や平易な部分はSLMが生成し、重要度が高く正確さが必要な部分はLLMが担当
- このルーティングは強化学習で最適化
- APIをメインとしつつ、自社運用モデルが前処理や情報抽出で支援します。例えば自社運用モデルが社内文書から関連情報を検索・構造化し、その結果をコンテキストとしてクローズドモデルに提供
- Collab-RAG(Xu et al., 2025)では、SLMが複雑な質問を複数のサブクエリに分解することで検索精度を向上させ、LLMが最終的な回答を作成
- クローズドモデルの出力を教師データとして、自社運用モデルを改善
- 全体の出力のN(0 < N < 100)%をAPIで処理し、データを収集することで自社運用モデルを継続的に訓練
1. Pipeline(パイプライン)
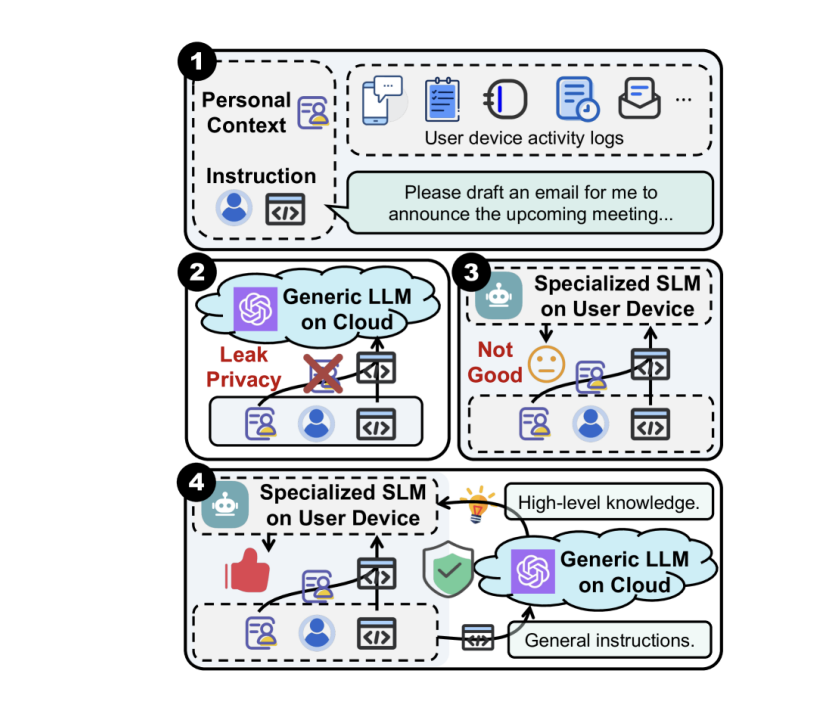
2. Routing(ルーティング)
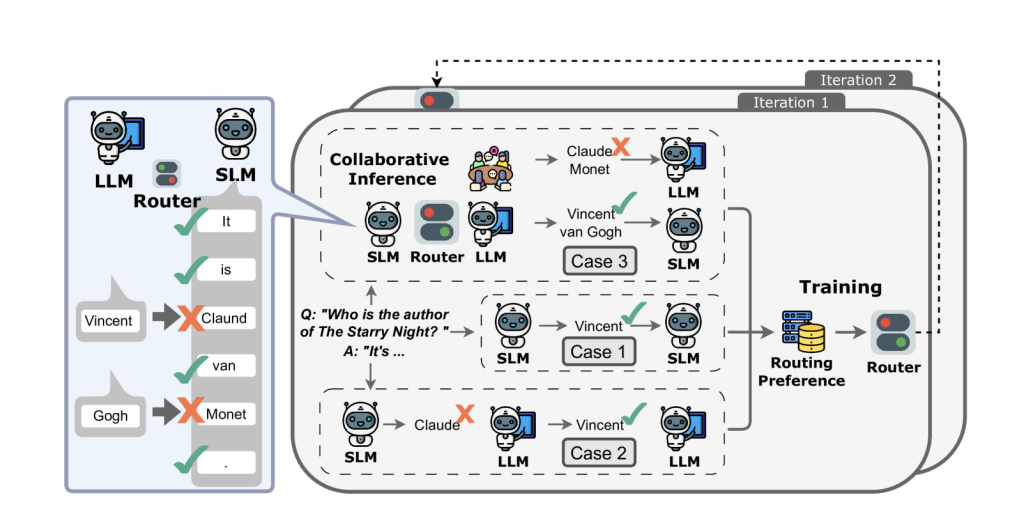
3. Auxiliary(補助/強化)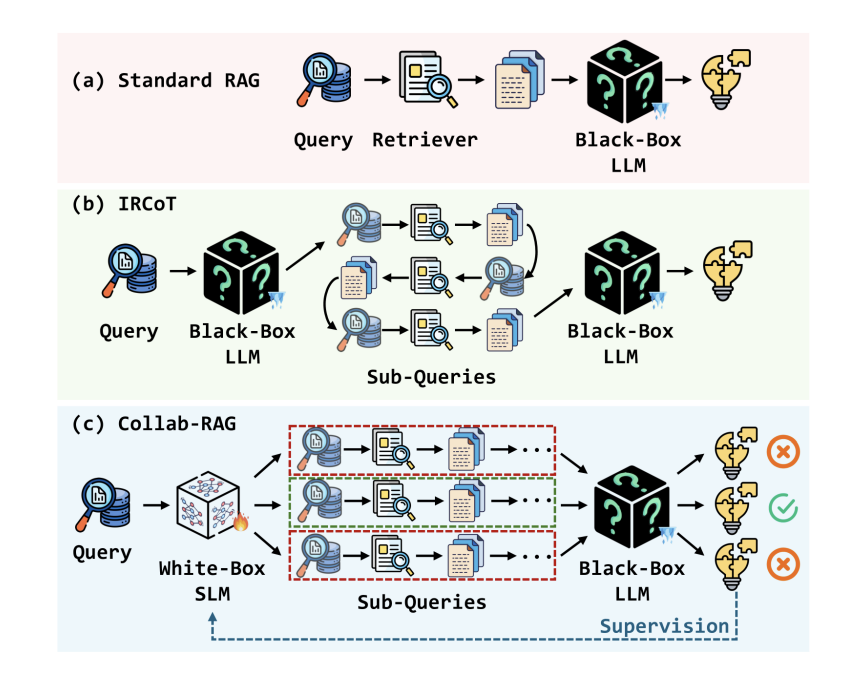
4. Knowledge Distillation(知識蒸留)
@Hiromu Nakamura (pon)
[blog]Microsoft Just Solved AI’s Biggest Problem: Why Magentic-UI Changes Everything
Human-AI collaborationなUI/UX体験を提供するMagentic-UIの紹介
[pon]AI-UI/UXのベストプラクティスが決まってないからこそ。こういう研究も大事
Six Collaboration Mechanisms: Co-planning, co-tasking, action approval, answer verification, memory, and multi-tasking
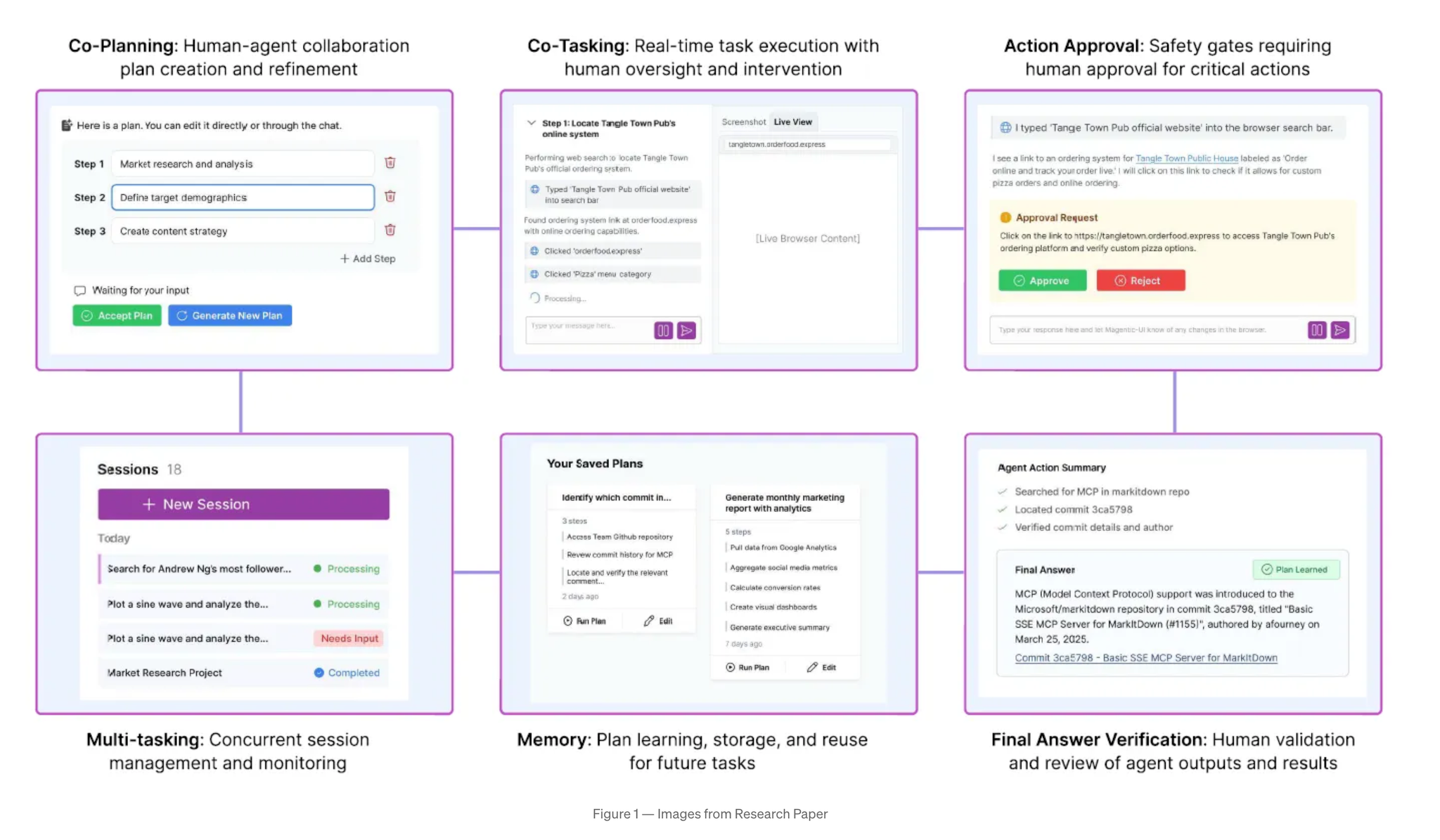
- Co-Planning
- 計画フェーズで、AIが出してきた計画を直接編集可能 ← [pon]良い!!!
- 曖昧な計画の修正
- ユーザーの知識を統合できる
- Co-Tasking
- エージェントに割り込む
- 進行中のアクションを一時停止
- 問題が発生している場合はガイダンスを提供
- エージェントが支援を求める
- システムは障害に遭遇すると説明や支援を求める。
- 最終検証
- 完了した作業を確認し、完了と判断する前にフォローアップの質問。
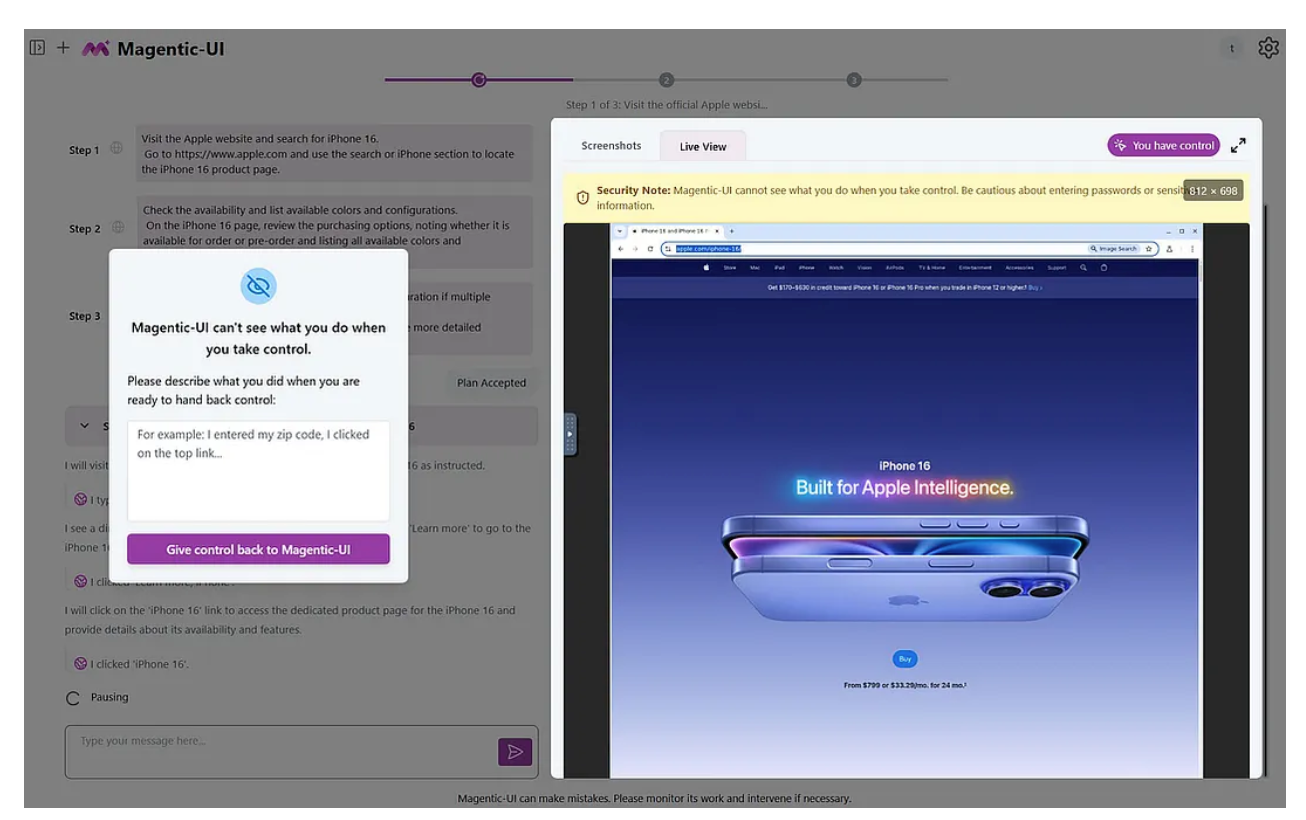
- リアルタイム制御ツール
- ライブプレビュー
- ウェブブラウザでエージェントのアニメーションインタラクションをリアルタイムで視聴
- 折りたたみ可能なインターフェース
- 計画ステップを展開して詳細なアクションを表示
- シームレスなハンドオフ
- 一時停止、リダイレクト、または手動制御を即座に実行
- 直接ブラウザアクセス
- 必要に応じて埋め込みブラウザにジャンプします
- → 複数のエージェント間のインタラクションを効率的に管理できるため、個々のエージェントのパフォーマンスが人間のレベルを下回った場合でも、価値を引き出すことができる。
- Memory
- ユーザーの介入を含むすべての履歴を処理し、再利用可能なプランを作成
- 直接再実行
- スマート提案
- 手動添付
- 自動検索
: 保存したプランを見つけて「プランを実行」をクリックします
: システムが新しいタスクに関連する計画を提案します
: 「プランを添付」を使用して特定のプランを添付します
: Vectorデータベースクエリにより、関連するプランが自動的に検索されます。
- セキュリティ
- 有害な行為からユーザーを保護する 2 段階のセキュリティ システムを示しています。
- アクション分類 ← [pon]どうやって作る?
- LLM セキュリティジャッジ
- 人間による承認
: 事前定義されたリスク レベル (常に安全、危険の可能性あり、決して安全ではない)
: 曖昧なアクションのカスタム評価
: リスクのある操作に対して明確な「はい/いいえ」プロンプトを表示
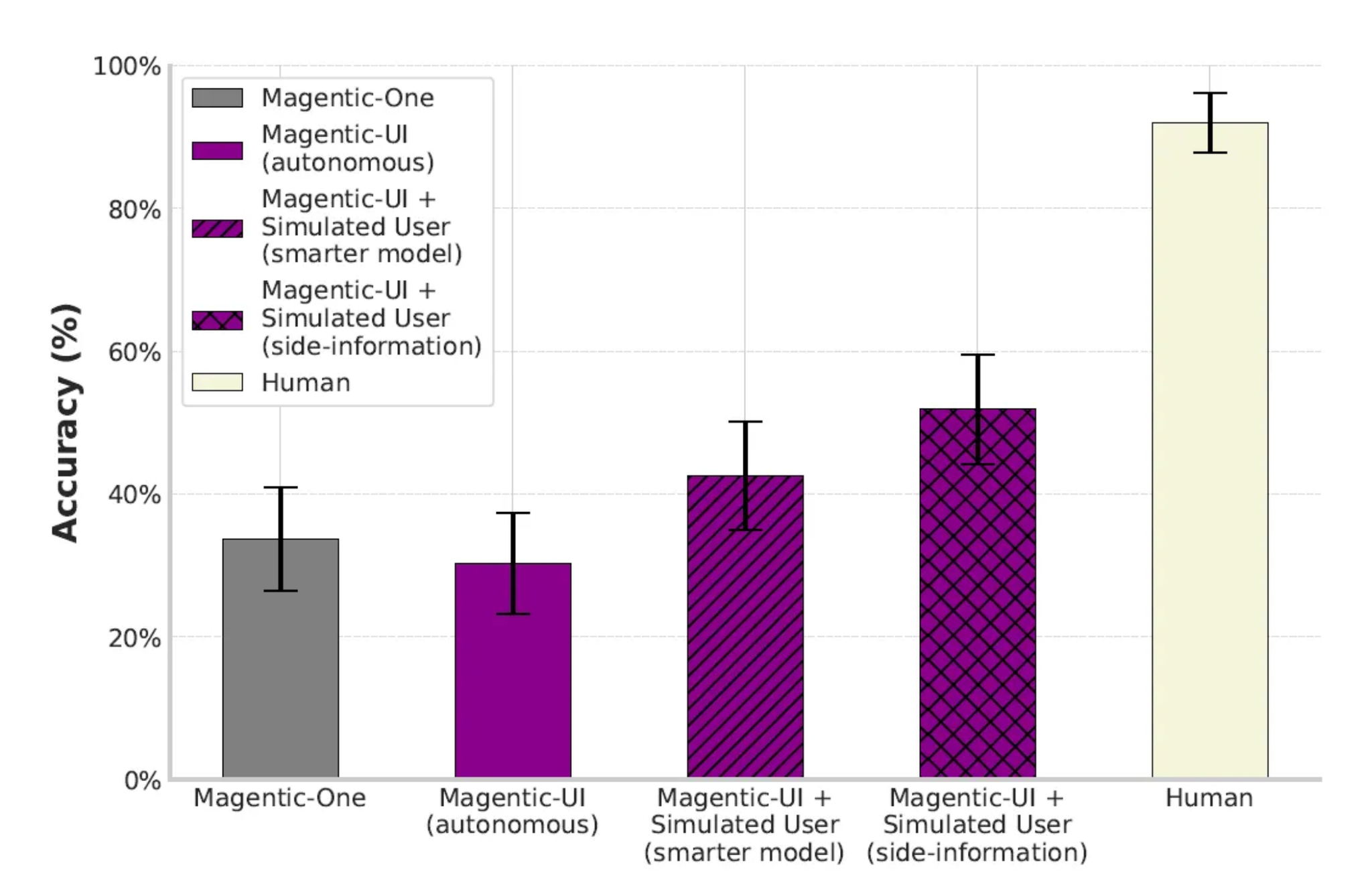
ユーザーとの協調を強化するにつれ、成功率が上がっている。
@ShibuiYusuke
[論文] TURA: Tool-Augmented Unified Retrieval Agent for AI Search
Abstract
- TURA(Tool-Augmented Unified Retrieval Agent) は、従来のRAGシステムの静的情報検索の限界を克服し、リアルタイムなAPI呼び出しや動的データベースアクセスを可能にする3段階のAI検索フレームワークを提案
- 3つのコアモジュール(意図理解に基づく検索、DAGベースのタスク計画、軽量化されたエージェント実行器)により、複雑な多段階クエリを並列処理し、低レイテンシーを実現
- Baiduの本格的な商用環境で数千万ユーザーに展開され、従来のRAGベースラインと比較して回答精度87.5%(vs 65.3%)、信頼性96.2%(vs 72.4%)という大幅な性能向上を実証
1. Introduction(序論)
- 従来の検索エンジンは静的な「10個の青いリンク」パラダイムに限定され、リアルタイムデータや動的情報にアクセスできない
- LLMによるRAGシステムも同様に静的なWebページからの情報検索に制限され、航空券予約やリアルタイム在庫確認などの動的クエリに対応不可
- TURAは静的RAGと動的情報源の間のギャップを埋めるAgentic architectureとして提案
- 2025年5月から数千万ユーザーに展開され、従来のRAGでは対応困難だった動的・トランザクショナルクエリに対して正確なリアルタイム回答を提供

2. Related Work(関連研究)
- RAGシステムは「検索してから生成」のパラダイムで発展してきたが、事前定義されたワークフローに依存し柔軟性に欠ける
- ツール拡張エージェント(Tool Augmented Agent)はReActフレームワークに基づき計画・行動・反省の3段階プロセスで外部リソースにアクセス
- 既存システムは静的ワークフロー、異種ツールの意味的統合の困難、RAGとツール使用の非効率な協調という課題を抱えるが、TURAは動的な検索決定、ツール選択、応答生成を統合した統一アーキテクチャでこれらの問題に対処
3. Problem Definition(問題定義)
- ユーザーの自然言語クエリqと多様なMCPサーバー集合M={M1, M2, ..., MN}が与えられる
- 回答品質Q(A)を最大化しつつ、レイテンシー制約L(π) ≤ τmaxを満たす最適実行戦略π*を見つける制約付き最適化問題として定式化
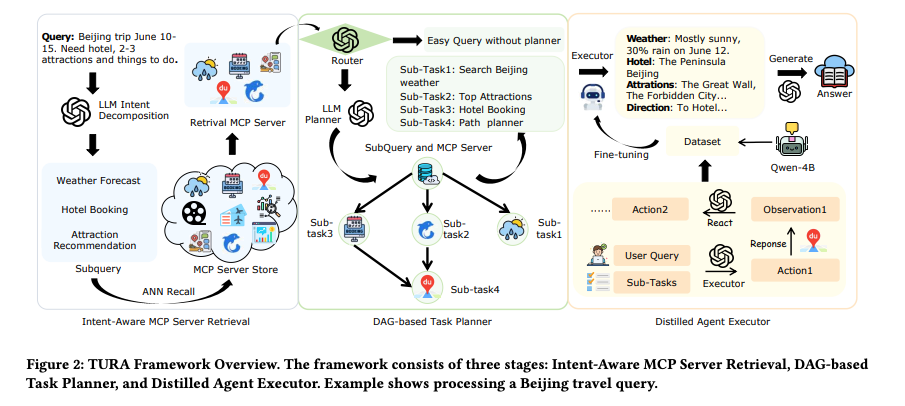
4. Method(手法)
- 意図理解に基づくMCPサーバー検索:LLMによるMulti-intentクエリ分解、サーバーレベルの意味インデックス拡張、密ベクトル検索によりRelevancyの高いMCPツールを効率的に特定
- DAGベースタスクプランナー:サブタスク間のデータ依存関係を有向非環グラフ(DAG)でモデル化し、独立タスクの並列実行により最適化されたレイテンシーを実現
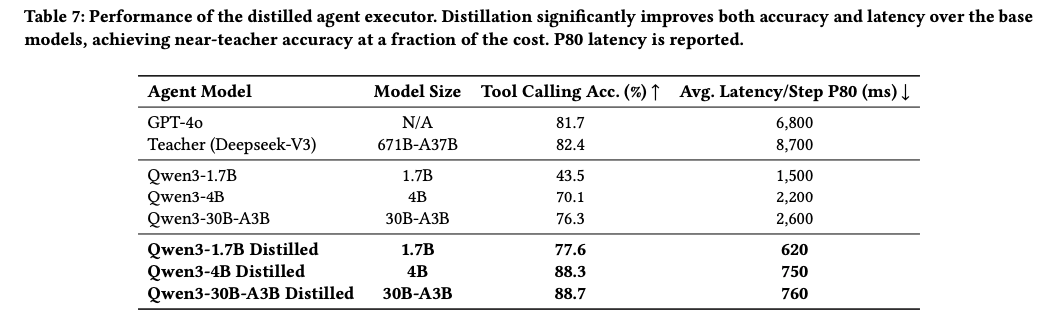
- 蒸留エージェント実行器:Deepseek-V3を教師モデルとしてQwen3シリーズをStudent modelに蒸留、「思考ありで訓練、思考なしで推論」パラダイムで高品質な判断を低コストで実現
- 思考ありで訓練、思考なしで推論
5. Experiments(実験)
- MCP-Bench:Baiduの匿名化された本番ログから構築した包括的ベンチマークで自然なクエリ分布を捕捉
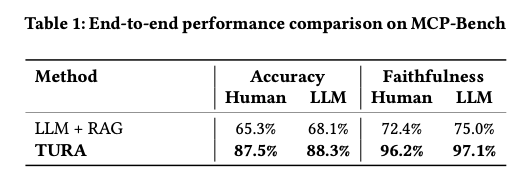
- エンドツーエンド評価:TURAは回答精度87.5% vs RAGベースライン65.3%、信頼性96.2% vs 72.4%という大幅な性能向上を達成
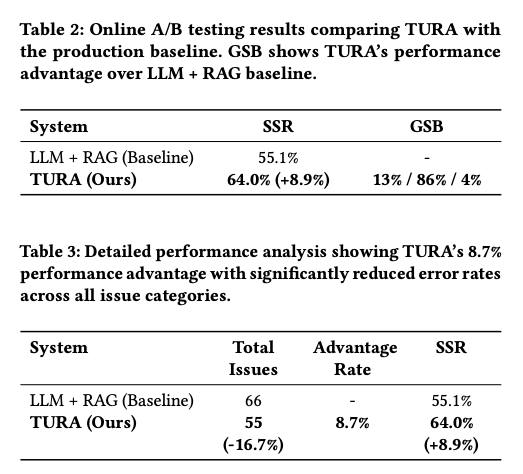
- オンラインA/Bテスト:セッション成功率を8.9%向上させ、総問題数を16.7%削減(66→55)し、全カテゴリで一貫した改善を実証
- アブレーション研究:クエリ分解とインデックス拡張が不可欠、DAGプランナーが44.2%のレイテンシー削減、蒸留により教師モデルを上回る性能(88.3% vs 82.4%)を66%低レイテンシーで実現
所感
- Towards AI Search ParadigmもBaiduの論文で、動的にTool Searchするのは同じスタンス(方法は異なる)。検索で多様な情報を収集する必要性を考えると、各情報源に対するMCPが増えて、情報源MCPの検索、選択が課題になってくる。
メインTOPIC
GPT-5 prompting guide
Anoop Kotha(OpenAI), Julian Lee(OpenAI), Eric Zakariasson, et al.

‣
サマリー
- OpenAIの最新のフラグシップモデルであるGPT-5のプロンプトエンジニアリングガイドブック
We’ve seen significant gains from applying these best practices and adopting our canonical tools whenever possible
Agentic workflow predictability
- GPT-5は開発者を念頭に置いてトレーニングされた。
- ツールの呼び出し、指示の遵ー守、長文文脈の理解の向上に焦点を当て、エージェント型アプリケーション向けの最良の基盤モデルとして機能するように設計されている。
- エージェント型アプリケーションやツールの呼び出しフローにGPT-5を採用する場合、ツールの呼び出し間で推論が保持されるため、より効率的で知的な出力を実現すResponses APIへのアップグレードを推奨。
Controlling agentic eagerness(エージェントの自律性・積極性を制御する)
エージェントにどんどん自律的に考えて行動して欲しいユースケースもあれば、決定的に動くように制御したいユースケースも存在する。どんなユースケースでも対応できるように訓練されており、その自律性・積極性を制御することが大切。
Prompting for less eagerness
デフォルトではGPT-5は正確な答えを出すために、エージェント環境で徹底的・包括的にコンテキストを収集しようと試みる。GPT-5のエージェント行動の範囲を縮小するには以下のようなアプローチが。
- reasoning_effortを低く設定する: これにより探索の深さが減り、効率とレイテンシが向上します。多くのワークフローは、中または低ので一貫した結果を達成できます。
- 問題空間の探索方法に関する明確な基準をプロンプトで定義する: これにより、モデルが多くのアイデアを探求し、推論する必要性が減ります。
- [yuya] コンテキスト収集だけでこんな詳細なプロンプトを開発者が書くべきなのか、、!?
- 固定のツール呼び出し予算を設定する(例:最大2回のツール呼び出し)。
- 不確実な状況でも進行を許可する「エスケープハッチ / 逃げ道」を明示的に提供する(例:「even if it might not be fully correct / 完全に正確でなくても)
Prompting for more eagerness
モデルの自律性を促進し、ツール呼び出しの持続性を高め、不明瞭な質問やユーザーへの引き渡しを減らしたい場合は以下のようなアプローチが。
- reasoning_effortを上げる
- タスクが完全に解決されるまで続行するよう促すプロンプトを使用する
- [yuya] パワハラ
一般的に、エージェント型タスクの停止条件を明確に定義し、安全な行動と危険な行動を区別し、モデルがユーザーに制御を戻すことが許容される場合を定義することは役立つ。
たとえば、ショッピング用のツールセットでは、チェックアウトと支払いツールはユーザーの確認を要求する際に低い不確実性閾値を明示的に設定すべきであり、検索ツールは極めて高い閾値を設定すべきです。同様に、コーディング環境では、ファイル削除ツールはgrep検索ツールよりもはるかに低い閾値を設定すべきです。
Tool preambles
GPT-5は、ユーザーにツール呼び出しの内容とその理由に関する中間的な更新を提供するためにトレーニングされており、ユーザーエクスペリエンスの向上を目指す。
プロンプトでツールプリアンブルの頻度、スタイル、コンテンツを制御できます(例:ユーザーの目標の言い換え、構造化された計画の概説、各ファイル編集ステップの簡潔な説明、完了した作業の要約)
以下は出力例
Reasoning effort
- モデルの思考の強度とツールを呼び出す意欲を制御するための「reasoning_effort」パラメーターを提供
- デフォルトは「medium」ですが、タスクの難易度に応じて調整する必要があります。複雑な多段階タスクの場合、最適な出力を確保するため、より高い思考強度を設定することを推奨します。さらに、異なるタスクを複数のエージェントのターンに分割し、各タスクに1ターンずつ割り当てることで、最高のパフォーマンスが得られることを確認しています。
Reusing reasoning context with the Responses API
- とにかくResponses APIを使え。
- Responses APIを使用した場合、Chat Completionsと比較して統計的に有意な改善が確認されている。
- 例えば、Responses APIに切り替えてprevious_response_idを指定し、以前の推論項目を以降のリクエストに返すようにしただけで、Tau-Bench Retailスコアが73.9%から78.2%に上昇しました。これにより、モデルは以前の推論トレースを参照できるようになり、CoTトークンの消費を削減し、各ツール呼び出し後に計画を再構築する必要を排除することで、遅延とパフォーマンスの両方を改善します。
Maximizing coding performance, from planning to execution
GPT-5は、コーディング能力においてすべての最先端モデルをリードしています。大規模なコードベースでバグの修正、大規模な差分処理、複数ファイルのリファクタリングや大規模な新機能の実装などに対応可能です。また、フロントエンドとバックエンドの両方をカバーする新しいアプリケーションを完全に一から実装する点でも優れています。
[yu]fm
Frontend app development
GPT-5は、優れた美的センスと厳密な実装能力を持っています。推奨は以下。
- Frameworks: Next.js (TypeScript), React, HTML
- Styling / UI: Tailwind CSS, shadcn/ui, Radix Themes
- Icons: Material Symbols, Heroicons, Lucide
- Animation: Motion
- Fonts: San Serif, Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
Zero-to-one app generation
- GPT-5は、一度でアプリケーションを構築する能力に優れています。
- モデル初期の実験において、ユーザーは以下のようなプロンプト(モデルに自己構築した評価基準に基づいて反復的に実行させる的なやつ)を使用することで、GPT-5の徹底した計画立案と自己反省の能力を活用し、出力品質を向上させることが判明しています。
Matching codebase design standards
- 既存のアプリでの変更やリファクタリングを実装する場合、モデルが作成したコードは既存のスタイルや設計基準に準拠し、コードベースにできるだけきれいに溶け込む必要があります
- プロンプトで、エンジニアリング原則、ディレクトリ構造、ベストプラクティスなど、コードベースの主要な側面を要約する指示を加えることで、この動作をさらに強化できます。
Collaborative coding in production: Cursor’s GPT-5 prompt tuning
私たちは、AIコードエディターCursorをGPT-5の信頼できるアルファテスターとして迎えることができたことを誇りに思っています。以下では、Cursorがプロンプトを調整し、モデルの機能を最大限に引き出すための方法を紹介します。詳細は https://cursor.com/blog/gpt-5
System prompt and parameter tuning
- Cursorのシステムプロンプトは、信頼性の高いツール呼び出しと、冗長性と自律的な動作のバランスに焦点を当てています
- モデルが冗長な出力を生成する傾向がある一方で、コード出力は高品質だが簡潔すぎるといった問題に直面しました。これを解決するため、APIのverbosityパラメータを「低」に設定し、プロンプトでコーディングツール内でのみ詳細な出力を強く推奨するように変更しました。
- モデルがユーザーに確認や次のステップを過剰に求めることがあり、長時間のタスクのフローを妨げていました。これを解決するため、利用可能なツールやコンテキストだけでなく、製品の動作に関する詳細な情報を含めることで、モデルが中断を最小限に抑え、より大きな自律性を持ってタスクを実行するよう促しました
- 以前のモデルでは効果的だったプロンプトの一部が、GPT-5では逆効果になることが判明しました(以下のような過度なコンテキスト収集を促すプロンプト)。
- これを解決するため、プロンプトを洗練し、徹底性に関する表現を和らげることで、GPT-5が内部知識に依存すべきか、外部ツールを使用すべきかについて、より良い判断を下すようになりました
- また、構造化されたXML仕様(例:<[instruction]_spec>)の使用が指示順守を向上させることを見出しました
Optimizing intelligence and instruction-following
Steering
GPT-5は非常に操縦性の高いモデルであり、冗長性、トーン、ツール呼び出しの動作に関するプロンプト指示に非常に敏感です
Verbosity
新しいAPIパラメータ「」が導入され、これはモデルの最終的な回答の長さに影響を与えます。プロンプトで自然言語による冗長性の上書きを指定することで、モデルがグローバルデフォルトから逸脱する特定のコンテキストで振る舞いを変更できます(例:Cursorのコーディングツールでの詳細な出力)
Instruction following
プロンプトの指示に外科的な精度で従うため、矛盾したまたは曖昧な指示を含む不適切に構築されたプロンプトは、他のモデルよりもGPT-5に悪影響を及ぼす可能性があります。これは、モデルが矛盾を解決する方法を探すために推論トークンを費やしてしまうためです
Minimal reasoning
GPT-5では「最小推論」が初めて導入され、これは推論モデルパラダイムの利点を享受しつつ、最速のオプションです。レイテンシに敏感なユーザーやGPT-4.1の現行ユーザーにとって最適なアップグレードとされています。
最小推論レベルでは、プロンプトに強く依存するため、以下の点が重要です:
- 最終回答の開始時に、思考プロセスを要約した短い説明をモデルに与えるよう促す。
- エージェント型ワークフローにおいてはタスクの進行状況をユーザーに継続的に更新する、徹底的で記述的なツール呼び出しプリアンブルを要求する。
- ツール指示を可能限り明確にし、エージェントの持続性に関するリマインダーを挿入する。
- プロンプトによる計画がより重要になります。なぜなら、モデルが内部計画のために利用できる推論トークンが少ないためです。
- 以下が例。2行目とはかエージェントがタスクとすべてのサブタスクを完全に完了するまでユーザーに制御を返さないように保証している
Markdown formatting
デフォルトでは、APIのGPT-5は最終回答をMarkdownでフォーマットしませんが、特定のプロンプト(例:セマンティックに正しい場合にのみMarkdownを使用するよう指示)は、階層的なMarkdownフォーマットを誘導するのに成功しています
Metaprompting
GPT-5をそれ自体のメタプロンプターとして使用することに大きな成功が見出されています。
GPT-5に、望ましい動作を引き出すため、または望ましくない動作を防ぐために、失敗したプロンプトにどのような要素を追加または削除できるかを尋ねるだけで、プロンプトの修正が生成され、本番環境に展開されています