
2025-08-19 機械学習勉強会
今週のTOPIC[論文] A personal health large language model for sleep and fitness coaching[blog]Four places where you can put LLM monitoring[論文] BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining[blog] gpt-ossモデルのサービングにおけるリクエスト処理性能評価 ― NVIDIA H100・A100・L4の比較[blog]Amazon Bedrock AgentCore Memory: Building context-aware agents[Deck] Distributed Inference Serving - vLLM, LMCache, NIXL and llm-d
[blog] LLM分散推論サービス入門ガイド ~分散LLM推論基盤を構築・理解するためのステップ~メインTOPIC:VertexRegen: Mesh Generation with Continuous Level of Detailひとことでいうとイントロ関連研究3Dメッシュの生成詳細度制御 (Level of Detail, LoD)前提知識:プログレッシブメッシュとはVertexRegen(提案手法)実験データセットモデル結果感想
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] A personal health large language model for sleep and fitness coaching
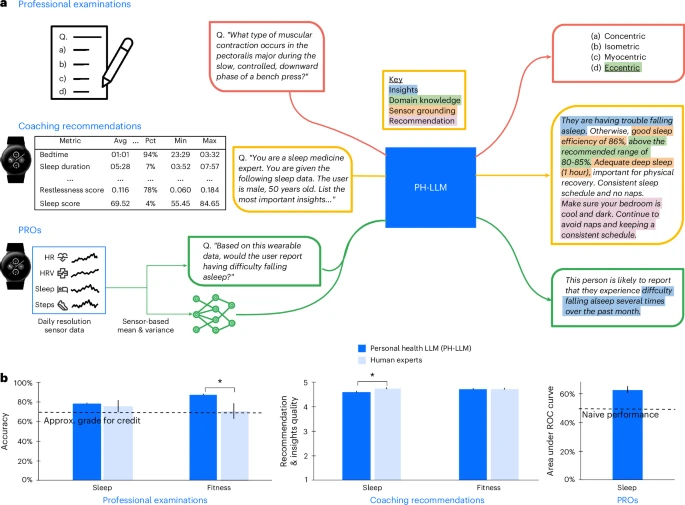
- DeepMindのウェアラブルデバイスを用いてパーソナライズされたヘルスケアのモニタリングを行うことができるPH(Personal Health)-LLMというモデルの研究。Nature論文。
- 睡眠系とフィットネス系の多肢選択問題において人間より高い性能を達成。
- モデル
- Gemini Ultra 1.0
- 実際の睡眠系とフィットネス系の長文のケーススタディを回答するタスクで学習。
- 2段階目で毎日の睡眠と活動メトリックスを含むセンサーデータから、睡眠障害と睡眠障害予測のためにマルチモーダルアダプターを微調整。
- Patient-reported outcomes (PRO)と多肢選択問題とコーチンング文章の3つを学習
- アダプターは3層のMLPでメトリクスに集計したセンサーデータを入力
@Yuya Matsumura
[blog]Four places where you can put LLM monitoring
- LLM / Agent プロダクトにおいて監視を入れるべき4つのポイント(青い箱)について述べた記事。
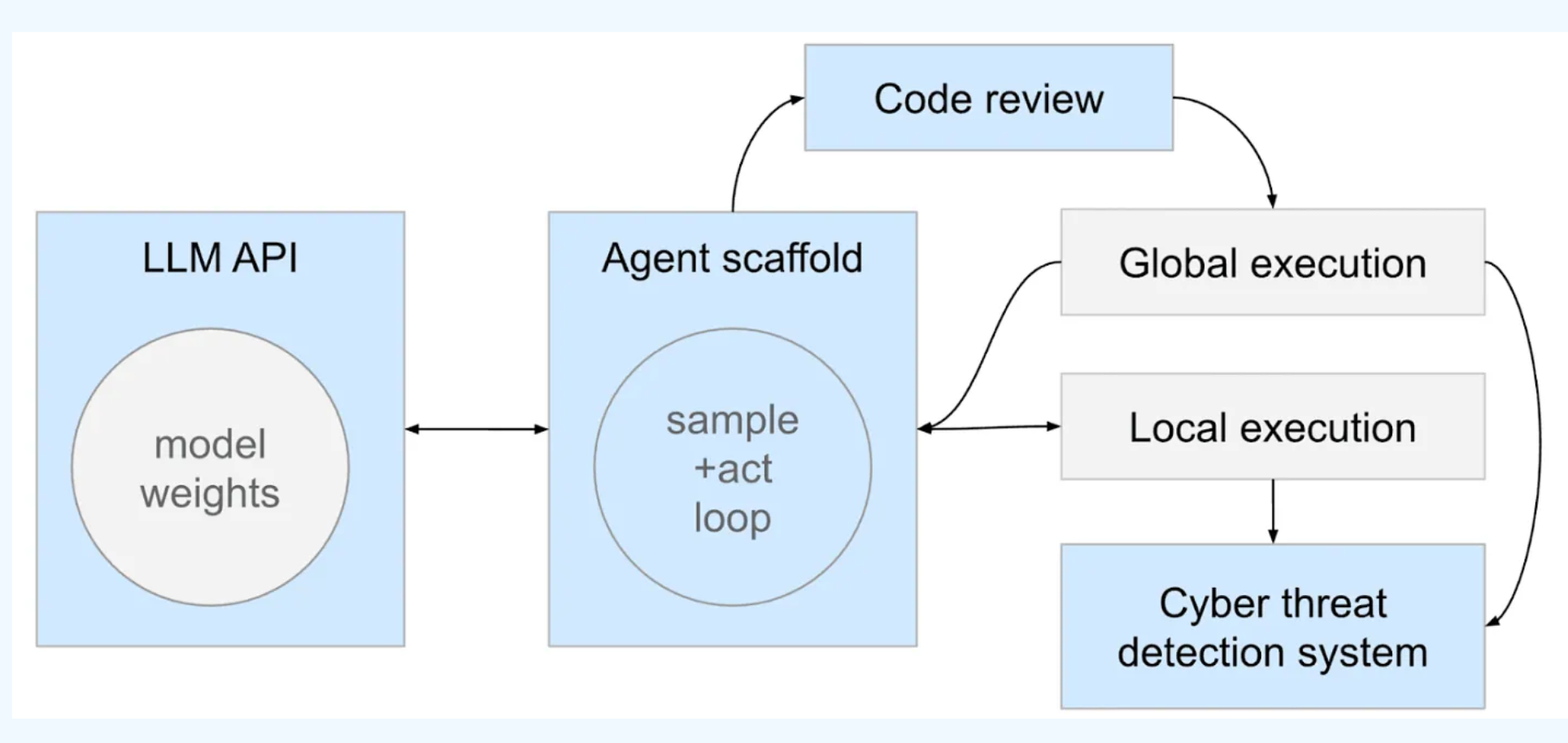
- Monitors in agent scaffolds
- LLMを呼び出すSDKやフレームワークなど、LLM API と実行環境をつなぐ部分に監視をいれよう。エージェントの権限を管理した上で、いつAPIを呼び出すのか、いつアクション・Toolを実行するのかを司る部分。 Claude Code and Cursor agentsを想像してね。
- pros
- シンプルさ: エージェントの権限に関するシステムが既に存在しており、エンドユーザーが権限に関する設定を記述できるため、それに乗っかることで考えることを少なくできる。最もシンプルな選択肢であり、変更も容易
- 柔軟性: LLM監視に対応する権限システムを適応させ、高度な戦略を実装できます。
- コンテキスト: LLMコンテキストと実行環境の両方のコンテキストを持つ
- cons
- 頻繁な更新: エージェントスキャフォールドは頻繁に更新され、新しいものが作成されるため、監視がセキュリティインフラの重要な要素となる場合には理想的ではありません
- 新規性: エージェントスキャフォールド内の監視は比較的新しく、他の種類の監視が持つ慣性や業界経験の恩恵を受けていません。
- 文化的な違い: エージェントを構築するチームは、歴史的に敵対的な脅威の検出や、ノイズの多いリスク信号をトリアージするシステムの構築にあまり焦点を当てていませんでした。
- (時に) 脆弱な環境: エージェントスキャフォールドロジックがエージェントまたはユーザーが制御するマシンで実行される場合があり、エージェントやユーザーによる監視の無効化といった攻撃の可能性が生じます。
- Monitors in cyber threat detection-and-response systems
- 大きい組織には “detection and response” チームが存在して、もろもろの監視してるよね!従来のシステムとLLM/エージェントシステムはいろいろと違う部分も多いけど、従来のアプローチも十分有効だよ!
- pros
- 成熟度: 既存のインフラストラクチャは比較的成熟しており(非LLMベースの監視に関しては)、関連する組織的な困難(他チームからの機密情報へのアクセス、専門家による反復作業など)に対処する体制が既に整っています。
- 実行コンテキスト: アクションが実行される場所に関する豊富なコンテキストを持っており、アクションの結果に比較的直接アクセスできるため、正当化やコードの難読化に対して敏感ではありません。
- 共謀に対する自動的な堅牢性: AIがインシデント対応を行う際に、監視対象のエージェントが実際に攻撃を試みている場面を指摘しないように、限られた情報フローの結果として共謀することが困難になる可能性があります
- cons
- LLMコンテキストの欠如: LLMエージェントがアクションを実行した理由に関するコンテキストがありません。
- 情報過多: これらのシステムが処理しなければならない膨大な情報量により、一連のアクションを組み立てたり、コストのかかるLLMベースの監視を使用したりすることが困難になる場合があります。
- 非サイバー脅威への不適用: サイバー攻撃に見えない脅威(例:説得、後続AIのデータポイズニング、サボタージュなど)にはあまり適用できません。
- 介入が鈍く、遅延がある: 何かを検知した場合でも、微妙な方法で介入することは難しく、手遅れになることもあります。これはオフライン監視に最適であることを意味します
- Monitors in LLM APIs
- LLMの生成が実行される前に処理をはさめる!
- LLM API自体が安全に設計、しっかりと監視されており、データセンター内で実行されるどのコードからでも使用しても問題ないほどのものもあれば、外部で堅牢な安全対策を実装しているスキャフォールド内でしか使うべきでないようなものまで存在する。
- pros
- 堅牢性: エージェントスキャフォールドでの監視を誤って使用しなかったり、AIが研究過程で直接LLM APIを使用することに起因する問題が発生したりするのを防ぎやすくなります。
- LLMコンテキスト: APIはLLMが持つすべてのコンテキストを持っており、原則として特定のアクションがもたらすリスクを評価するために必要なコンテキストの大部分を持っています。
- ある程度の成熟度: LLM APIでLLM監視が既に展開され始めています
- cons
- 実行コンテキストの欠如: LLM APIは、アクションがどこで実行されるかデフォルトでは知りません。セキュアなサンドボックスで実行されるのか、全く実行されないのか、あるいは非常に機密性の高い環境で実行されるのかが不明です。
- エージェントスキャフォールドとの非連携: 「モニターが疑わしい場合、エージェントスキャフォールドにユーザーに尋ねるよう指示する」といったことを行いたい場合、APIとエージェントスキャフォールドの両方を更新する必要があり、この連携は非効率で反復速度を低下させる可能性があります。
このセクションでは、安全なLLM APIと安全でないLLM APIの両方を持つ戦略が提案されています。
- Monitors in code reviews
- すでに人間がチェックしている部分に監視を入れるのは自然なアプローチ。コードがAIにより多量に生成されるようになってくるならば、レビュー自体にもAIを入れていく。
- pros
- 成熟度: コードレビューは昔から行われています。
- 実行コンテキスト: コードがマージされた際にどこで実行されるかを知ることができます(特にインフラストラクチャ・アズ・コードの場合)。
- LLMコンテキスト: LLMの完全なトランスクリプトは得られないかもしれませんが、変更を実装する理由を知ることができます。
- 柔軟性: これはコアエージェントスキャフォールドとは独立したシステムであるため、生産性を大きく損なうことなく変更を加えることができ、エージェントスキャフォールドの場合よりも人間にフォールバックすることが自然です
- cons
- レビュー対象外の脅威には不適用: 悪意のあるコードがコードレビューを通過する脅威にのみ機能します。
- pro/con まとめると
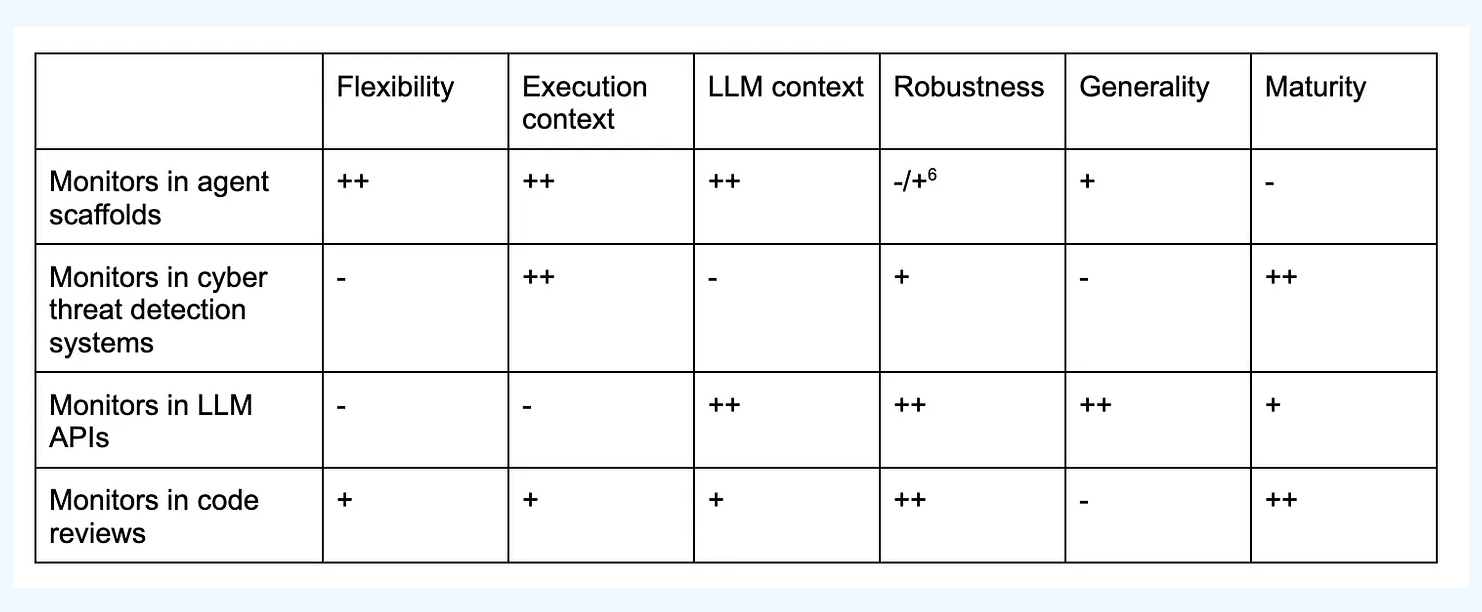
- 基本pro-conの世界だし、全部やるのが理想ではあるが、以下の優先度でやるといいよ(自信ないらしいけど)
- 基本的なサイバー脅威検出システムが欠けていないことを確認(AI企業であれば、これは元々行うべきことですよね?ニッコリ)
- 簡単に導入できるであろう、エージェントスキャフォールドにモニターを構築
- より堅牢にするためにAPIに機能を追加
- AIが大量のコードを生成し、人間によるコードレビューが形骸化し始めた場合、自動化されたモニターをコードレビューに追加
- 上記を継続的に維持・改善
@Shun Ito
[論文] BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining
- by DatologyAI (arxiv, 2025/08)
- LLM学習のための合成データセット作成手法「BeyondWeb」を提案
- 良質なWebデータは飽和気味なので、合成データセットを作りたい
- 提案手法
- Webデータのリフレージング(要約、スタイルやフォーマットの変更)
- 提案手法のデータセットを使うと、より良質な学習が可能
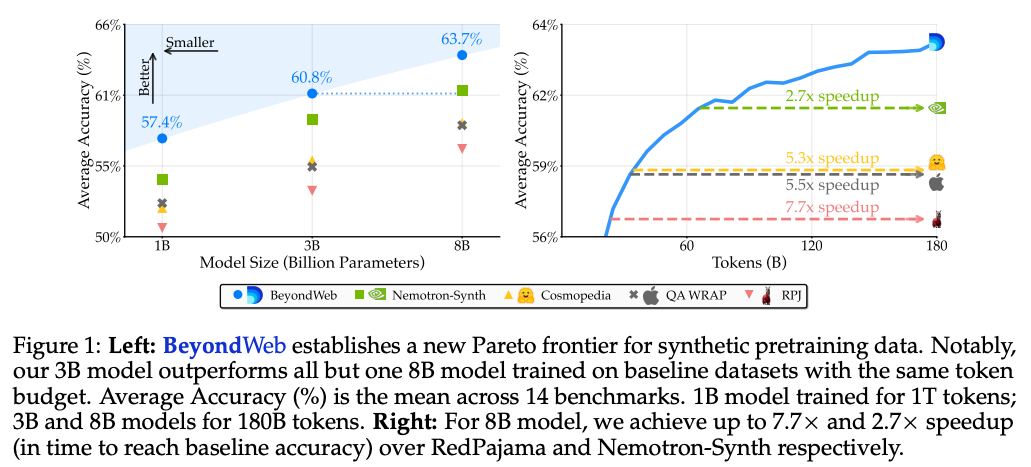
- 得られた知見
- 単なる要約だけでなく、スタイルやフォーマットの変更を加えることが有効
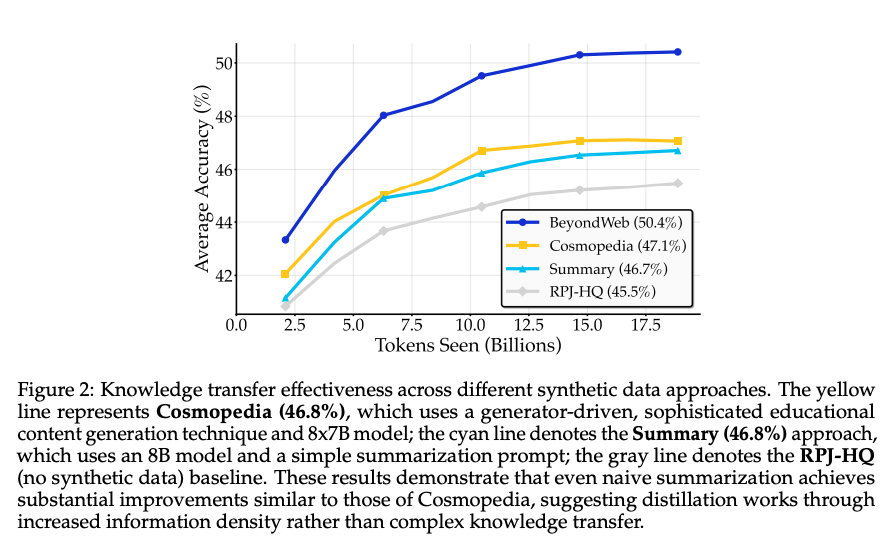
- Summary(要約だけ)の手法で、既存手法のCosmopedia(軽量LLMで教科書風の文章を合成する)と同等の精度
- スタイルやフォーマットの変更を加えたBeyondWebがそれらを大きく上回っている
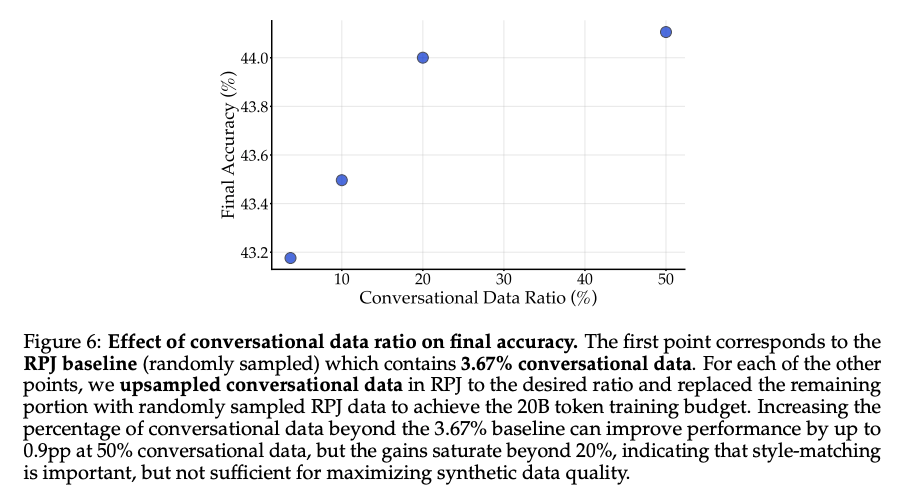
- Webデータに少ない会話フォーマットを増やして精度改善
- 元々は全体の2.7%ほど
- 20%までは改善が見られるが、それ以降は頭打ちになってしまう傾向
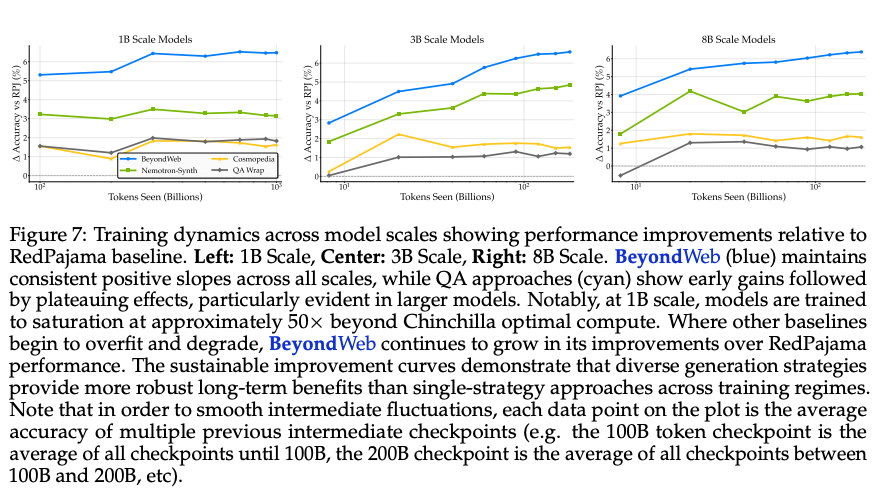
- より多いトークン数で学習させるなら、フォーマットは多様な方が有効
- Token Seenが増えるほど、多様性のあるBeyondWebは一貫して右肩上がりだが、既存の単一フォーマットのデータでは伸びが小さい
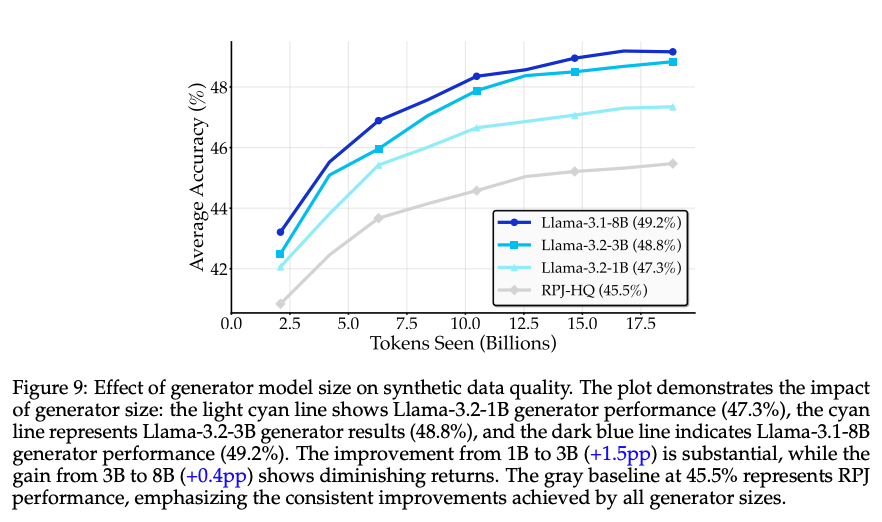
- リフレージングに使うLLMは3B程度で良い
- 1B, 3B, 8Bで実験。3B以降は伸び幅が小さくなっている。
- LLMのアーキテクチャによる違いはあまりなかった
@Yosuke Yoshida
[blog] gpt-ossモデルのサービングにおけるリクエスト処理性能評価 ― NVIDIA H100・A100・L4の比較
- 利用したインスタンスタイプ
- a3-highgpu-1g(26 vCPU, 234 GB メモリ, 1 × NVIDIA H100 80GB)
- a2-ultragpu-1g(12 vCPU, 170 GB メモリ, 1 × NVIDIA A100 80GB)
- g2-standard-4(4 vCPU, 16 GB メモリ, 1 × NVIDIA L4 24GB)
- GPU種別、モデル種別、プロンプトのトークン数、Reasoning effort の設定値(low, medium, high)、並列リクエスト数(1, 2, 4, 8, 16)の組み合わせで実験
- プロンプトについては、自社の想定ユースケースに近い内容をもとに、約2,000、4,000、8,000トークン程度となるよう調整
- これらはテンプレートから動的に生成し、それぞれ5,000パターンを用意しています。実験時には、この中からランダムに選択
- vLLMで推論
- 負荷試験には、オープンソースの負荷試験ツールLocustを使用
- 各条件の組み合わせごとに120秒間の試験を行い、Locustの出力値のRequests/sとMedian Response Timeを採用
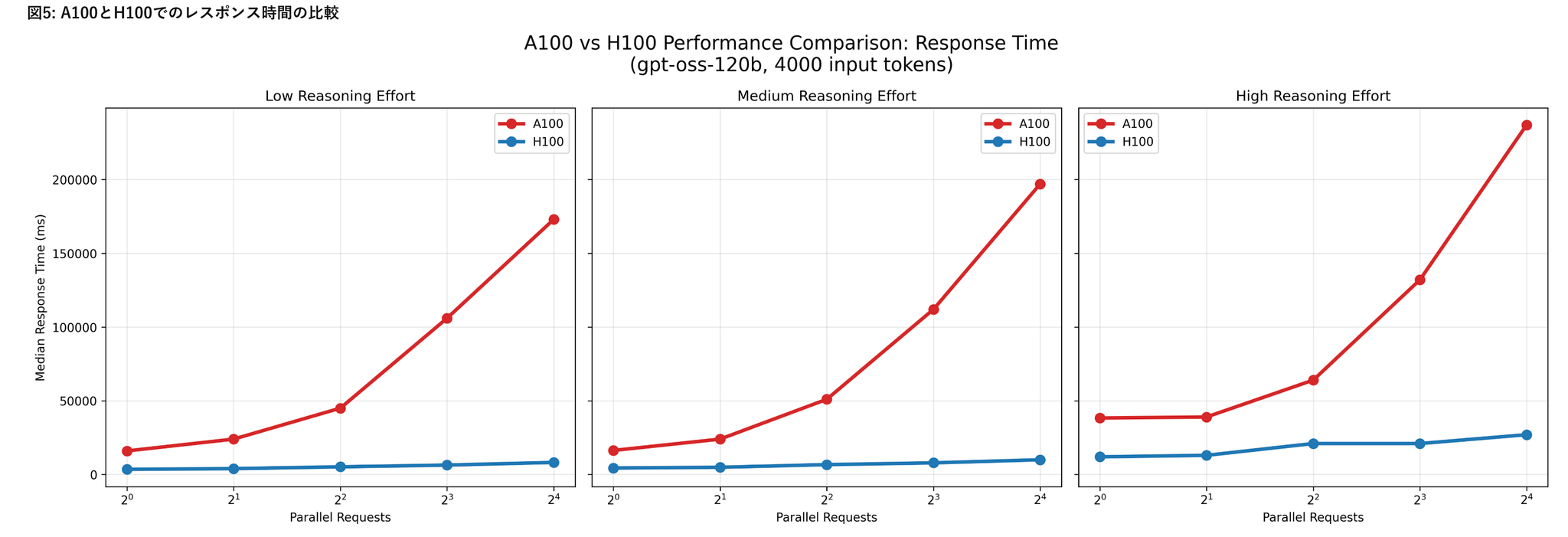
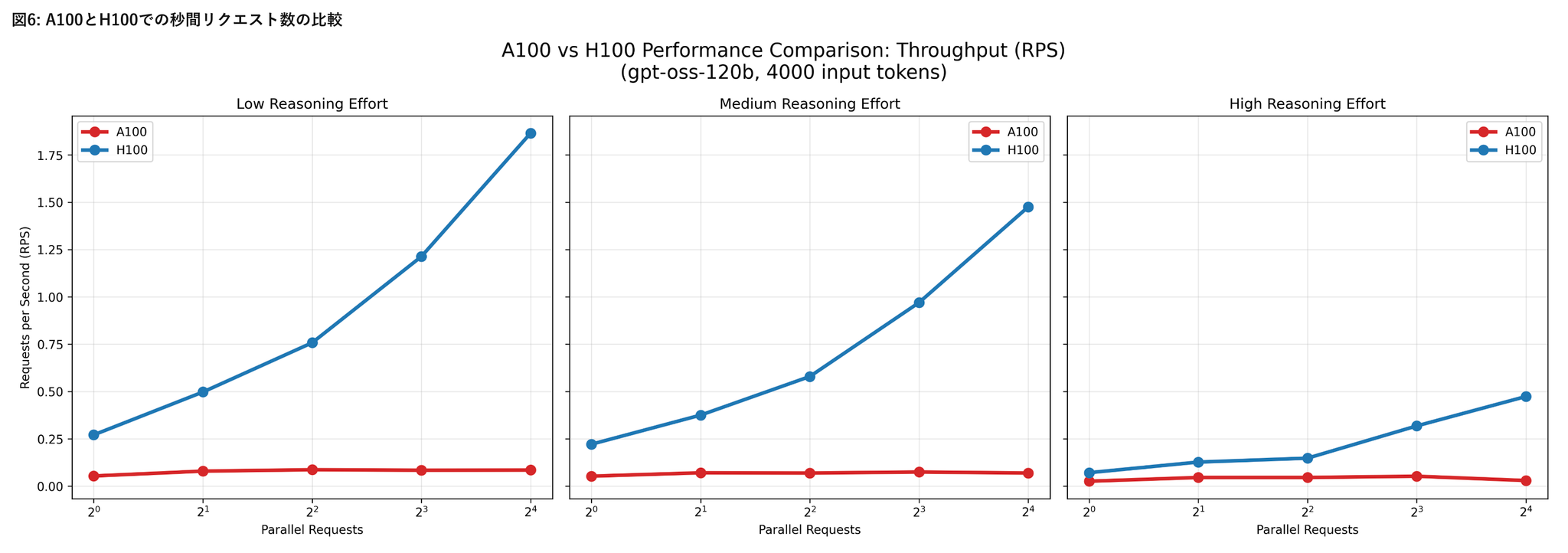
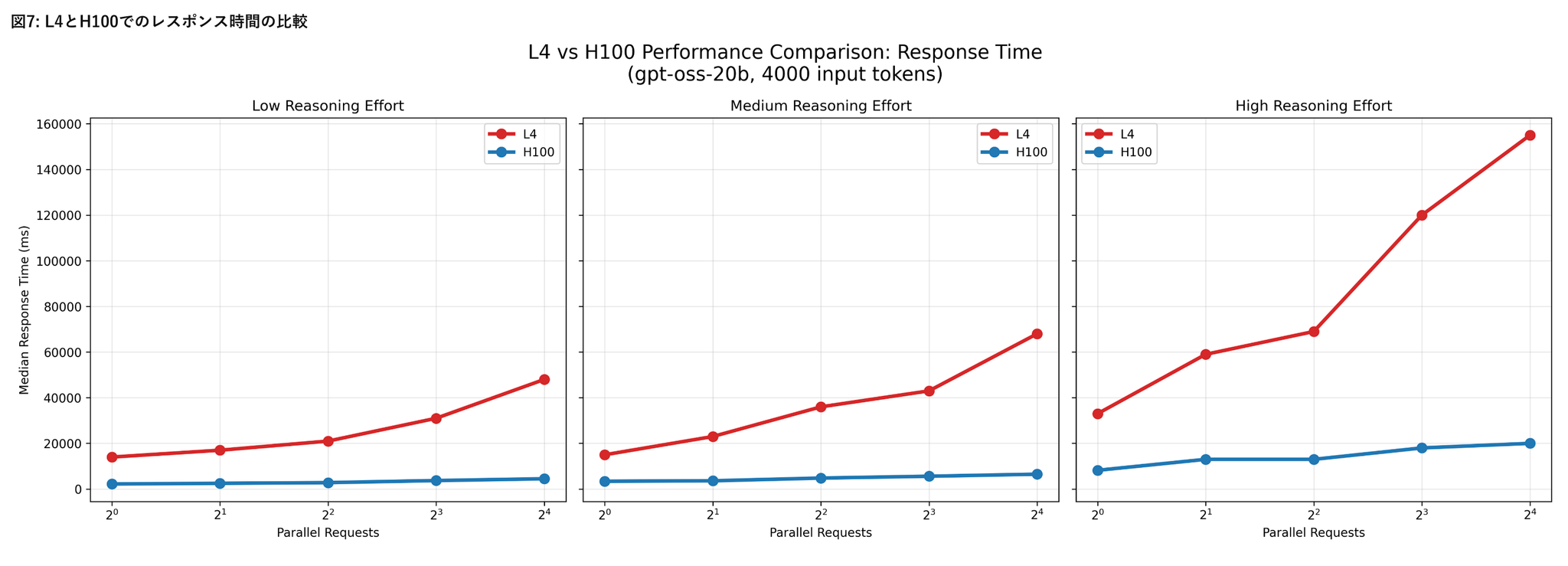
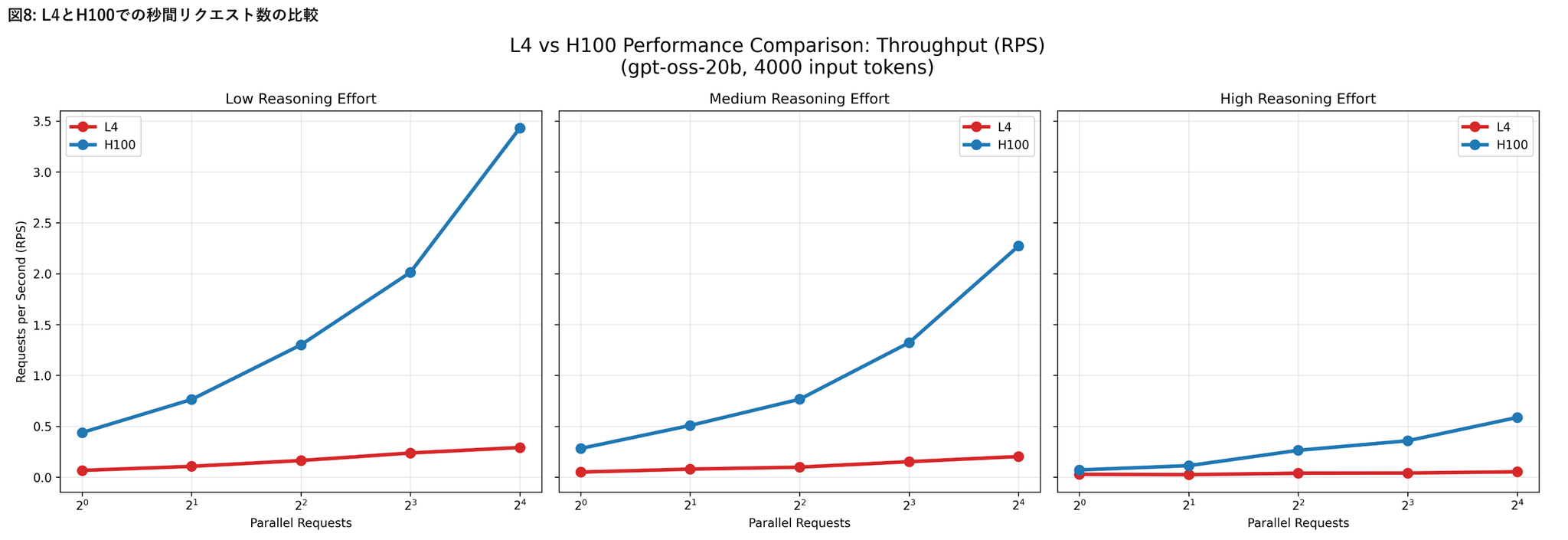
H100環境におけるリクエスト処理性能
- H100上でgpt-oss-20bおよびgpt-oss-120bを実行
- リクエスト並列数、入力トークン数、Reasoning effort の組み合わせによるレイテンシとスループット
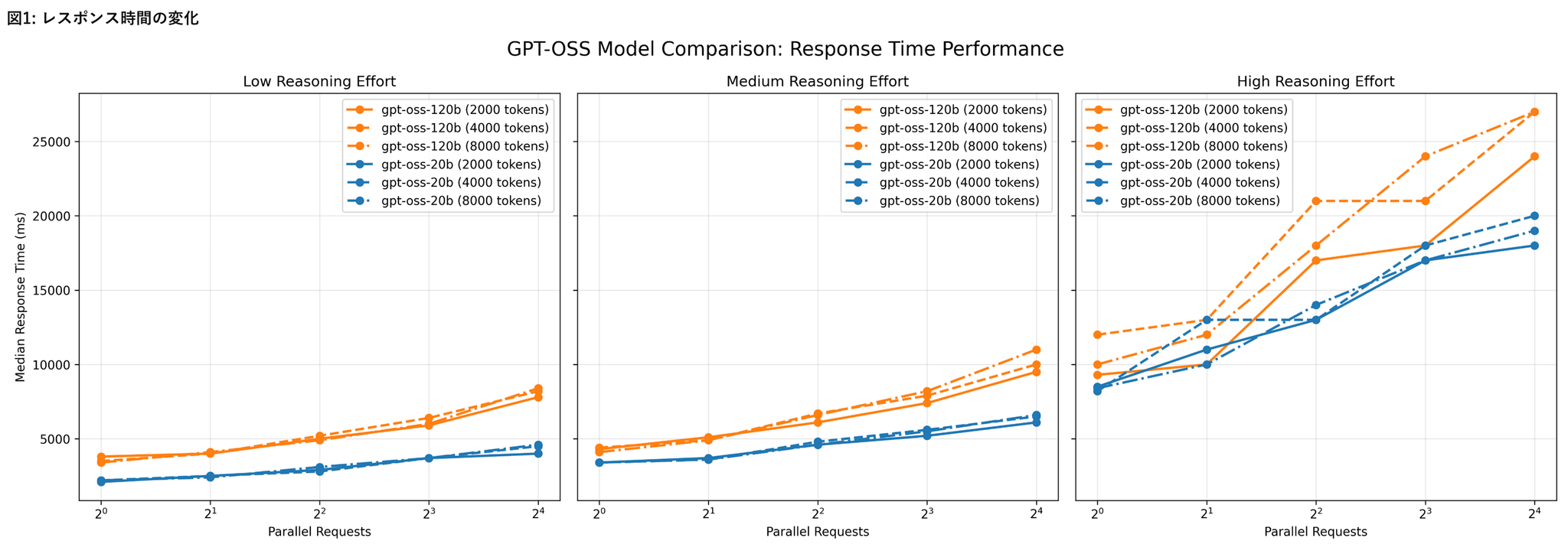
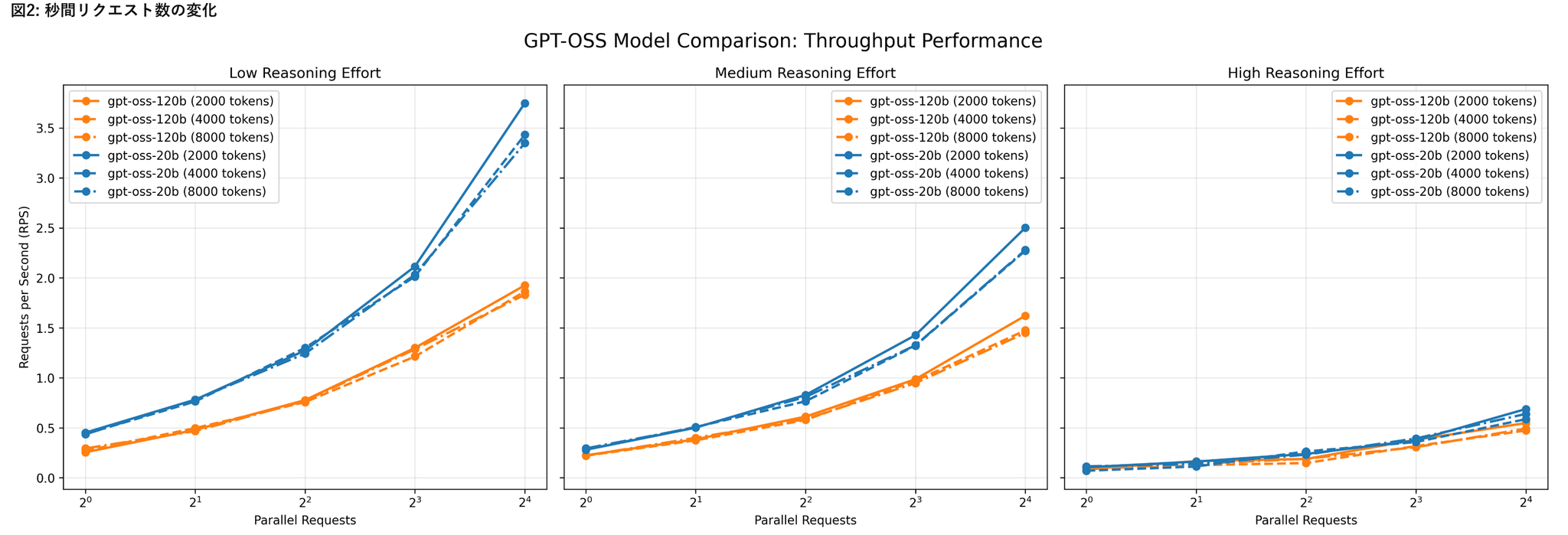
- リクエスト並列数の増加による影響
- 低~中程度の負荷条件(Reasoning effort が low〜medium、かつ20bモデル)では、vLLMの並列処理機構が有効に機能している様子が見られた
- Reasoning effortの影響
- Reasoning effortの設定値をlowからhighに上げると、レスポンス時間が顕著に増加し、RPSは低下
- モデル内部の推論負荷が増すことで、並列化による効果が打ち消される
- モデルサイズの影響
- gpt-oss-120bはgpt-oss-20bに比べ、全体的にレスポンス時間が長く、RPSが低い傾向
- ただしその差は2倍以上にはならず、モデル規模の拡大に比して処理性能の低下は比較的緩やか
- 入力トークン数の影響
- 入力トークン数を増加させても、処理性能への影響は相対的に小さい
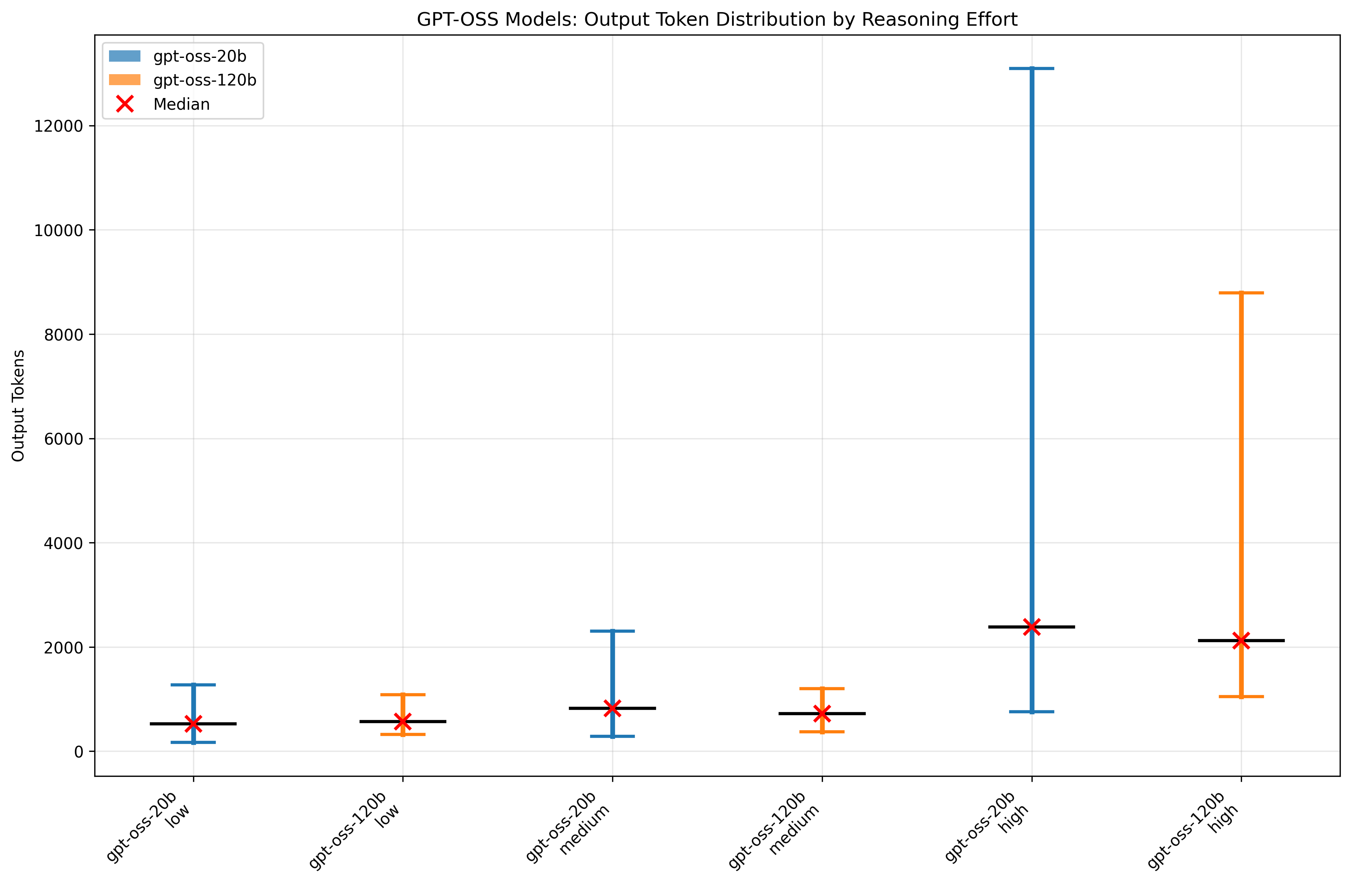
出力トークン数の影響分析
- 平均値の観点では、両モデルともReasoning effortがlowおよびmediumの場合に大きな差はなく、highの場合に出力量が増加
- モデル同士を比較すると、各Reasoning effortにおいてほぼ同程度の出力量が得られ、必ずしも120b が多いわけではなく、場合によっては 20b が上回ることもありました
- 一方で、大きな出力量への上振れは20bの方が顕著でした。
- すなわち、本評価条件においては、モデル間のレスポンス時間差は出力量そのものではなく、トークンあたりの推論時間に起因すると考えて良さそうです。
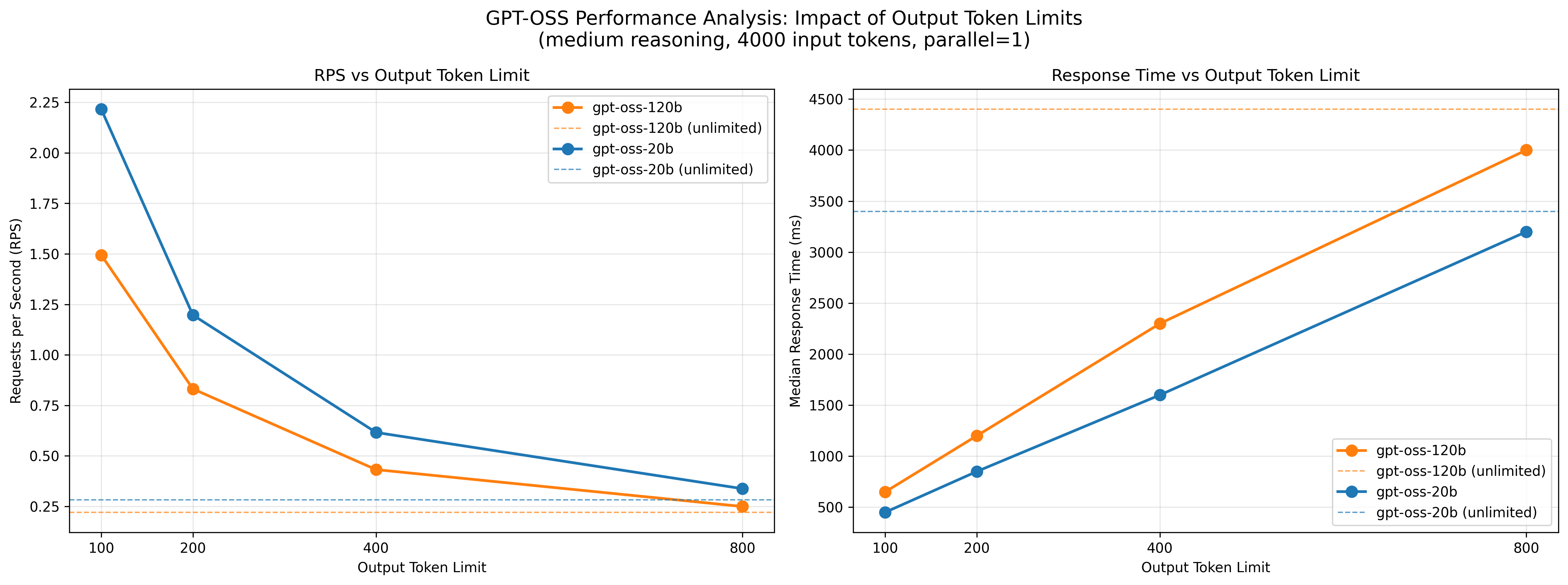
- 出力トークン数とレスポンス時間の関係を分析するため、出力トークン数を 100, 200, 400, 800 に制限して同一条件下でベンチマークを行いました(並列数 1、Reasoning effort medium、入力トークン数 4000)
- リクエスト処理性能は出力トークン数に強く依存することが明らかとなり、レスポンス時間の抑制には出力トークン数の制御が有効
- リクエスト処理性能と推論精度を両立する観点からは、小さいモデルでReasoning effortをhighにするよりも、大きいモデルでmediumを用いたり、最大出力長を適切に制御する方が応答性能の安定化に寄与
A100およびL4環境におけるリクエスト処理性能
- A100上でgpt-oss-120bを、L4上でgpt-oss-20bをそれぞれ実行した結果
- 本評価では入力トークン数を4000に固定
- A100およびL4環境はいずれもモデルの推論実行は可能でしたが、H100と比較して応答時間が大幅に長く、並列数を増加させてもスループットはほとんど改善しませんでした。
- これらの環境は少数リクエストの処理には利用可能である一方、大規模な並列処理やサービス用途でのgpt-ossの安定運用には適さない
@Hiromu Nakamura (pon)
[blog]Amazon Bedrock AgentCore Memory: Building context-aware agents
短期記憶、長期記憶を自動でやってくれるよーとのことでどうやってるの?を調査
汎用的なAgent用ミドルウェア設計として勉強になる
AgentCore Memoryの内部実装
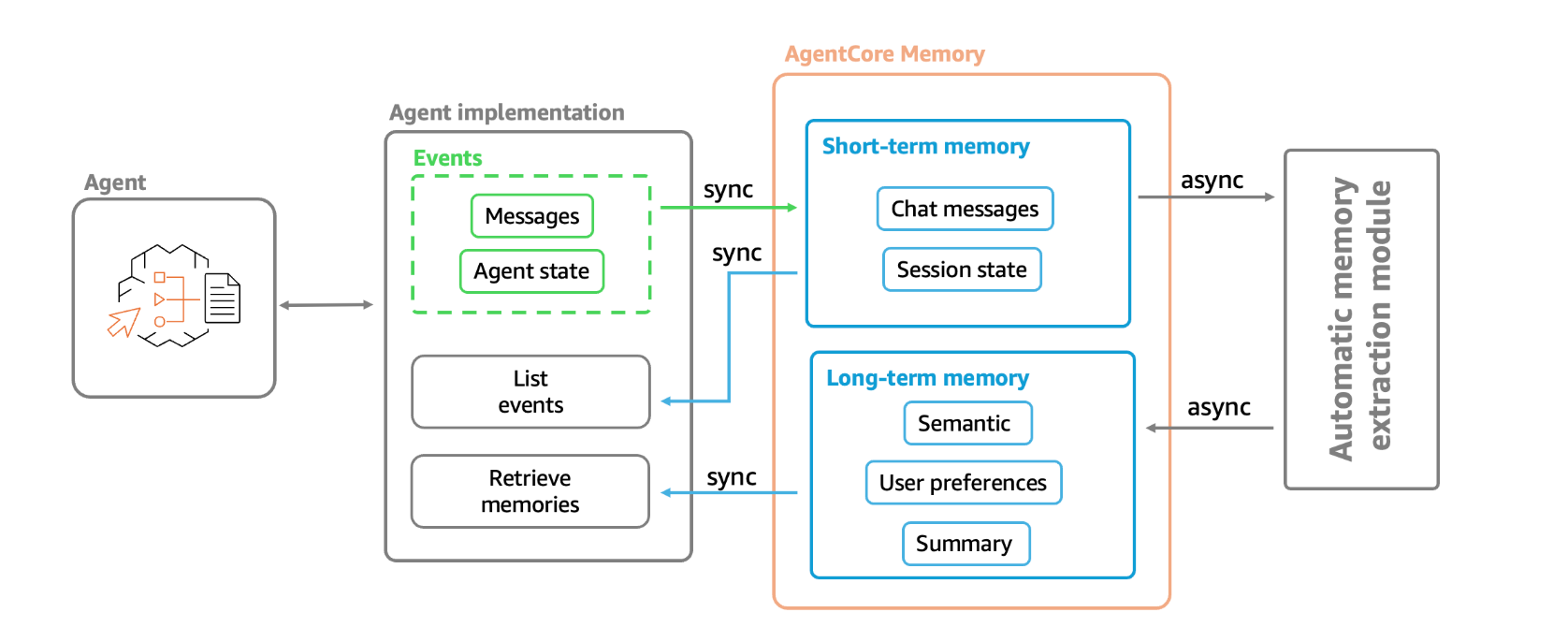
短期記憶
- 短期メモリは、生のインタラクションデータを不変のイベントとしてキャプチャ
- ユーザーとエージェント間の会話、システムイベント、状態変化、その他のインタラクションデータを構造化して保存するのをサポート。イベントは、AgentCoreメモリリソースに同期的に保存される
長期記憶
- 長期記憶には、生の出来事から抽出された洞察、好み、知識が含まれます。逐語的なデータを保存する短期記憶とは異なり、長期記憶は、ユーザーの好み、会話の要約、重要な洞察など、セッションを超えて持続する意味のある情報を捉える。
短期 → 長期
- 裏で勝手にやってくれる!!
- 柔軟性を高めるため、Bedrock AgentCore はカスタムメモリ戦略も提供。
- 特定の LLM を選択し、特定のドメインまたはユースケースに合わせて抽出と統合のプロンプトをオーバーライドできます。例えば、セマンティックメモリプロンプトに追加することで、特定の種類のファクトやメモリのみを抽出するように設定できます。
- [pon]ここはマジで素晴らしい。ユーザーでプロンプト保有できる設計が良い
- ‣
[pon]こういうプロンプトカスタム可能な、メモリレイヤーは増えていきそうだなー。裏側の非同期な処理をうまく抽象化してくれる設計のやつ。
@ShibuiYusuke
[Deck] Distributed Inference Serving - vLLM, LMCache, NIXL and llm-d
[blog] LLM分散推論サービス入門ガイド ~分散LLM推論基盤を構築・理解するためのステップ~
[blog] LLM分散推論サービス入門ガイド ~分散LLM推論基盤を構築・理解するためのステップ~
- LLMの推論はリクエスト多様化・GPUメモリ(KV-Cache)制約・需要増から分散推論が必須。
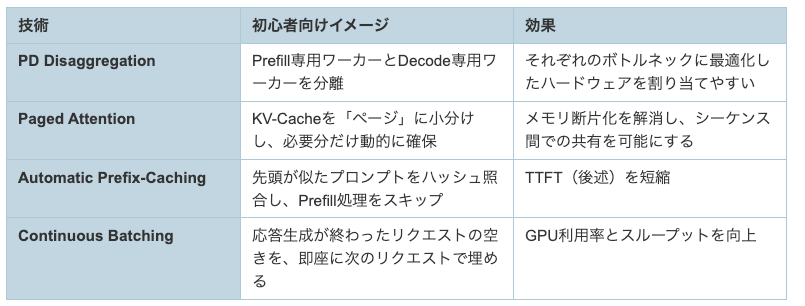
- 推論はPrefill(計算律速)とDecode(メモリ帯域律速)の2フェーズに分かれ、両者を分離するPD Disaggregationが有効
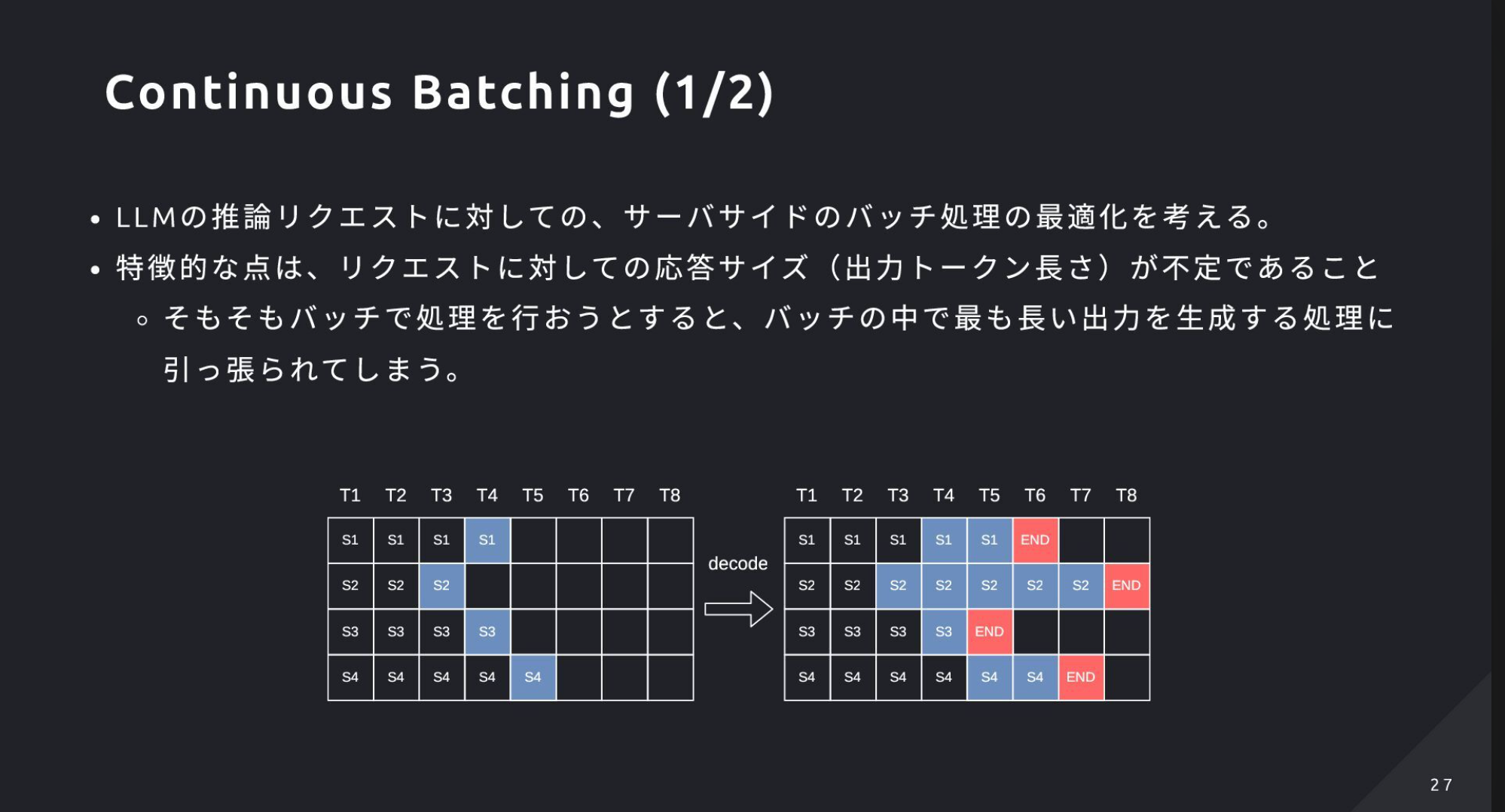
- vLLMの主要最適化は、Paged Attention(KV-Cacheのページ管理)、Automatic Prefix-Caching(先頭一致の再利用)、Continuous Batching(逐次入替バッチ)などで、高スループットとTTFT短縮を狙う
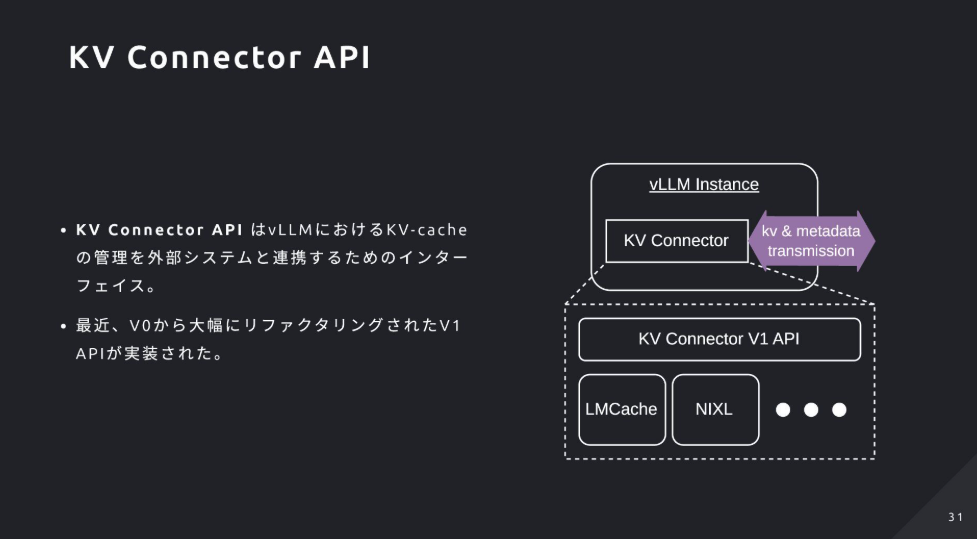
- KV-Cache共有はKV Connector API+LMCache(Storage/Transport、中央集約とP2P、Redisで位置管理)+NIXLで実現し、PD分離やノード間転送を高速化
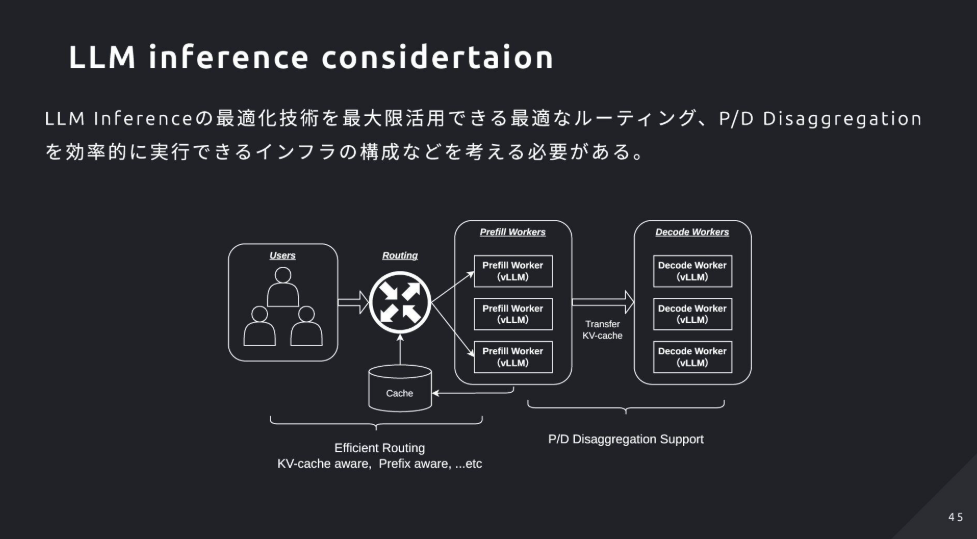
- Kubernetes上の分散推論スタック「llm-d」は、GIEによるセッション/負荷/Prefix/KVCache-awareなルーティングとkv-cache-managerでの最適転送を提供。評価指標はTTFT・TPOT(ITL)・Pass@1で、理論→単一ノード最適化→キャッシュ共有→オーケストレーション→計測の順で構築を勧める。
3. 基本概念をおさらい
3.1 Transformer と Attention
- 自己注意(Self-Attention)で系列内の関連性を計算し、QKV行列を用いる
- 自己回帰型LLMでは、各トークン生成のたびに過去トークンへのAttention再計算が必要で計算量が増える
3.2 KV-Cache とは
- 一度計算したKey/ValueをGPUメモリに保持し、以降の生成で再利用して無駄な再計算を省く仕組み
- 新規トークン分のK/Vだけを計算し、過去分はキャッシュから読み出すことで特にDecode処理を高速化
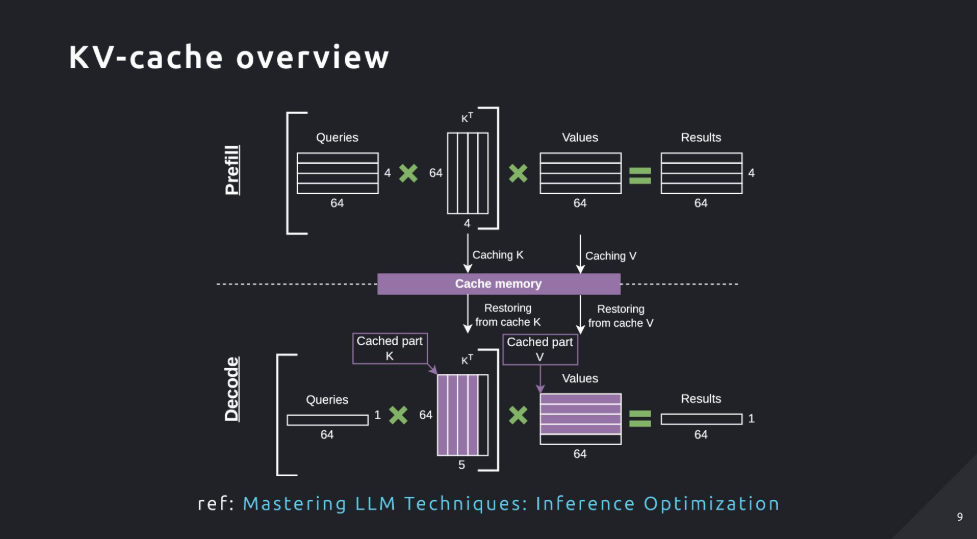
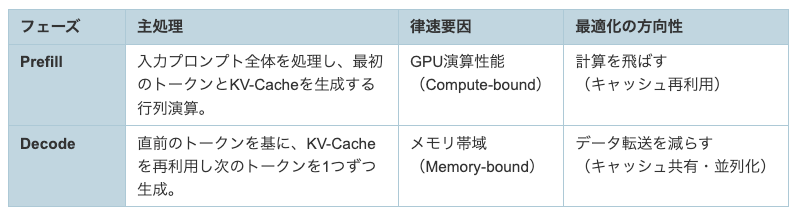
3.3 Prefill フェーズと Decode フェーズ

- Prefill:入力全体を処理して最初のトークンとKV-Cacheを生成する段階。計算律速(Compute-bound)
- Decode:直前トークンとKV-Cacheを使い1トークンずつ生成。メモリ帯域律速(Memory-bound)
- フェーズのボトルネックが異なるため、Prefill/Decodeを別ワーカーに分離するPD Disaggregationが有効(ただしKV共有やルーティングが課題)
4. vLLMが実装する主な最適化
- PD Disaggregation:Prefill用とDecode用のワーカーを分離して、それぞれのボトルネックに合わせて最適化・スケールしやすくする
- Paged Attention:KV-Cacheを固定サイズのブロックに分割して動的割り当てし、断片化を防ぎつつ共有(参照カウント+Copy-on-Write)を可能にする

- Automatic Prefix-Caching:プロンプトの先頭一致をハッシュで検出し、既存のKV-Cacheを再利用してPrefill計算をスキップ(TTFT短縮)
- Continuous Batching:生成完了したシーケンスの空きを直ちに新規リクエストで埋め、GPU利用率とスループットを最大化
5. KV-Cacheを”みんなで”使い回す仕組み
- PD Disaggregationを実現するには、分離されたワーカー間でKV-Cacheを高速に共有する仕組みが必須
- KV Connector API:vLLM本体と外部キャッシュ基盤を疎結合にするプラグインIFで、様々な共有方式を差し替え可能にする
- LMCache:①StorageでKV-CacheをCPU/NVMeへ退避・永続化、②Transportで別ノードへP2P転送を提供。共有戦略はCentralizedとP2Pの両対応
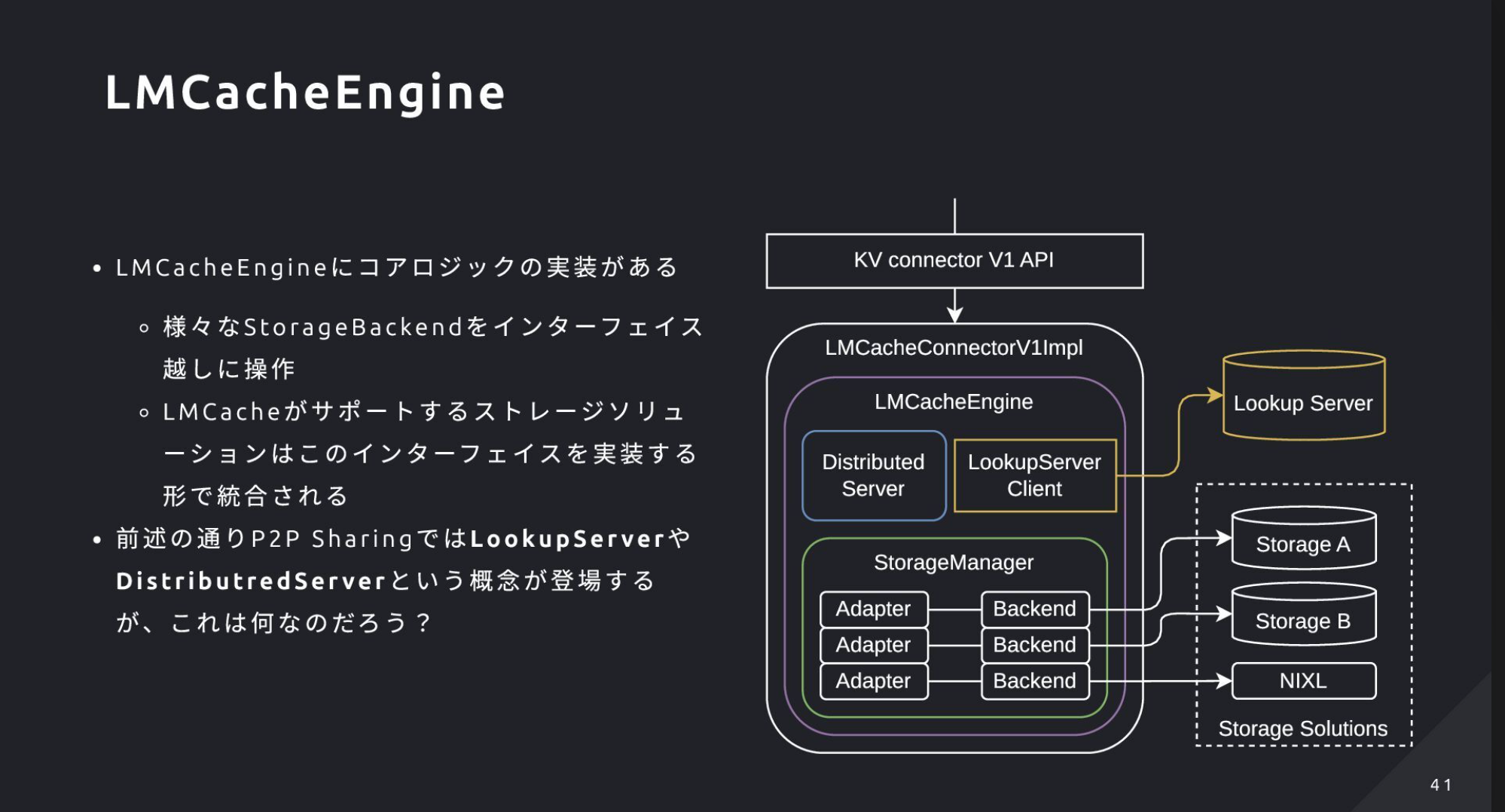
- P2P共有の流れ:RedisをLookup ServerとしてどのノードがKVを持つか管理し、Distributed Serverが送受信を担当。問い合わせ→該当ノードから直接受け取る
- NIXL:GPU/ストレージ間転送を抽象化・高速化するNVIDIAライブラリ。LMCacheはこれを使い最適経路でKV-Cacheを転送

6. Kubernetes上の分散推論スタック - llm-d
- llm-dの概要:vLLM・LMCache・NIXLをKubernetesネイティブに統合し、スケール可能で最適な分散LLM推論基盤を目指すオープンソースプロジェクト
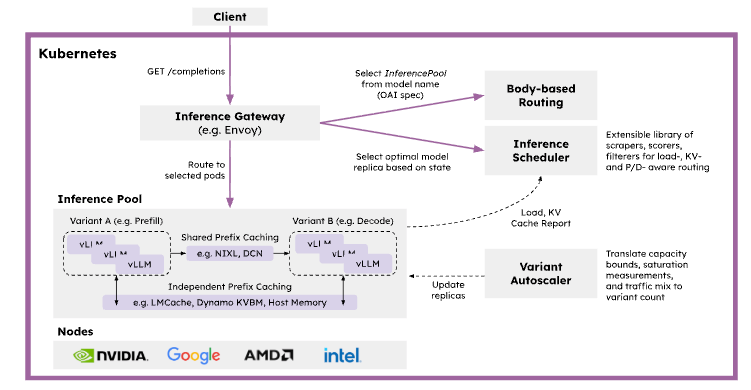
- 主な機能:
- Prefill/Decode Podの自動デプロイ&オートスケール
- GIE(Gateway API Inference Extension)によるLLM特化のインテリジェントルーティング
- vLLM/LMCache最適化を最大限活用できる環境提供
- GIEとルーティング:Kubernetes公式拡張のGIEを採用し、EnvoyのExternal Processingで最適Podを選択。セッション継続(x-session-token)・負荷・Prefix一致・KV再利用量の各スコアでルーティングを決定
- スコアリング指標:Session-aware/Load-aware/Prefix-aware/KVCache-awareの各Scorerを組み合わせ、最もスコアが高いPodに転送
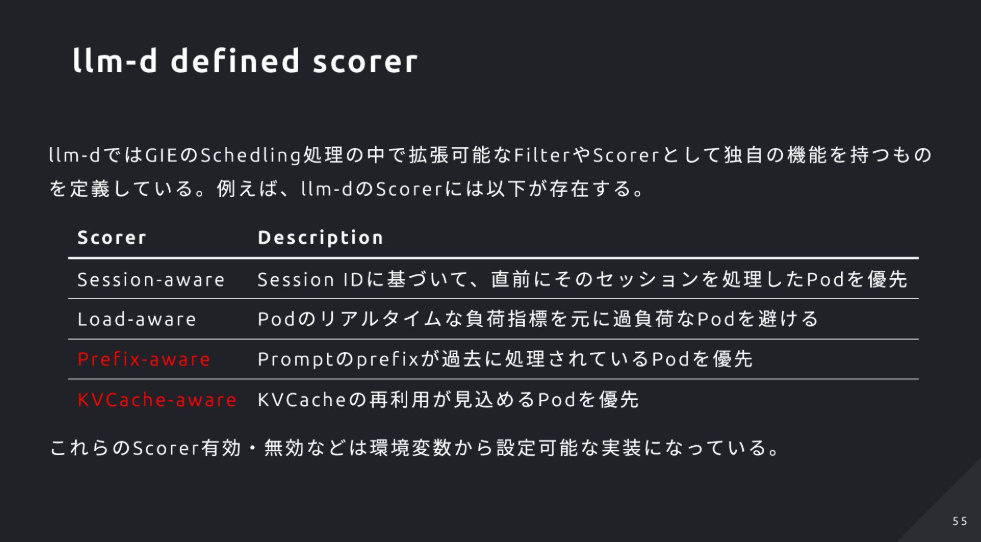
- kv-cache-manager:LMCacheが使うRedisのKV所有情報をインデックス化し、最長PrefixでキャッシュヒットするPodを高速特定してKVCache-awareルーティングを実現
7. LLM推論の性能評価指標

メインTOPIC:VertexRegen: Mesh Generation with Continuous Level of Detail
| タイトル | VertexRegen: Mesh Generation with Continuous Level of Detail |
|---|---|
| 著者 | Xiang Zhang, Yawar Siddiqui, Armen Avetisyan, Chris Xie, Jakob Engel, Henry Howard-Jenkins |
| 所属 | UC San Diego, Meta Reality Labs Research |
| 論文リンク | https://arxiv.org/abs/2508.09062 |
| プロジェクトページ | https://vertexregen.github.io/ |
| 備考 | ICCV2025採択 |
ひとことでいうと
彫刻を削るようなイメージでメッシュデータを生成するVertexRegenを提案。
一般にLevel of Detailでは、メッシュの詳細度を頂点の集約・分割を実行して制御するが、それを学習できるようにしている。
[partial-to-complete]
既存手法では部分的にポリゴンを作っていき、全体を生成していくが、完成するまで全体がわからない欠点がある=途中で止められないし、詳細度の制御もできない。
[coarse-to-fine]
VertexRegenでは、途中で止めてもオブジェクトの全体感がわかるし、詳細度の途中経過を見ることができる。計算量に応じた出来栄えになる。
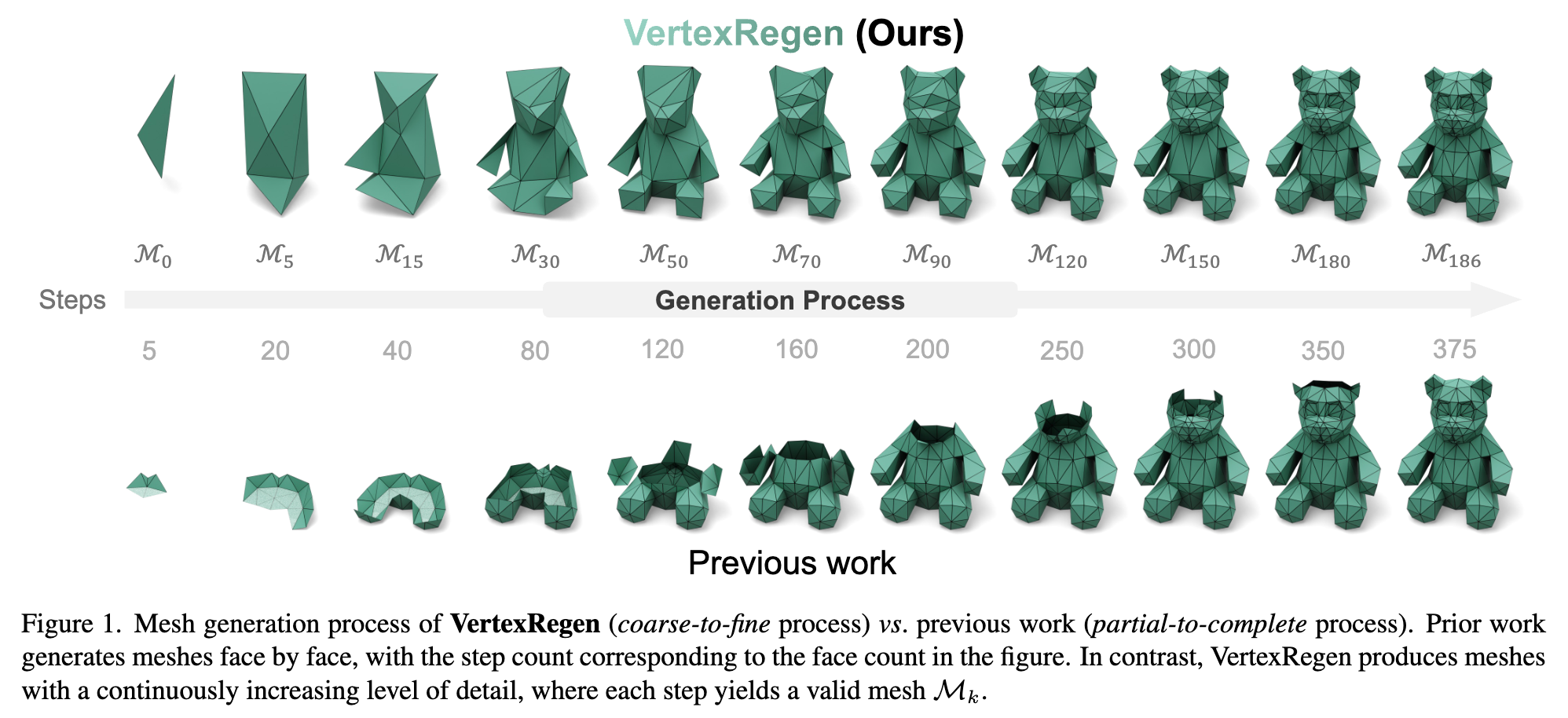
プロジェクトページに生成過程の動画があるので見る
イントロ
メッシュは映画製作やデザイン、ゲーム業界で便利。データ量だったり、扱いやすさだったりで利点がある。
ボリュームレンダリング(NeRFやGaussian Splatting)が流行ってるが、表面がわからなかったりするので、後処理でメッシュにする研究も盛んに行われている。
ただ、ボリュームレンダリング→メッシュに変換する過程で、トポロジーが崩れたり、面が荒かったりする問題がある。
参考:NeRFの図
メッシュを直接生成する研究もあるが、Transformerベースの自己回帰モデルでメッシュを生成するアプローチでは、有効なメッシュを得るために必ずシーケンスを最後まで生成しきる必要がある。
→ 生成途中で詳細度の制御が不可能
本論文では、
- プログレッシブメッシュ
- エッジを減らす操作(=Edge Collapse)とエッジを増やす操作(=Vertex Split)を使って、詳細度を連続的に生成できるようにする。Vertex Splitの方が生成タスク。
- 粗いメッシュから始めて、細かくしていく
関連研究
3Dメッシュの生成
メッシュへの変換
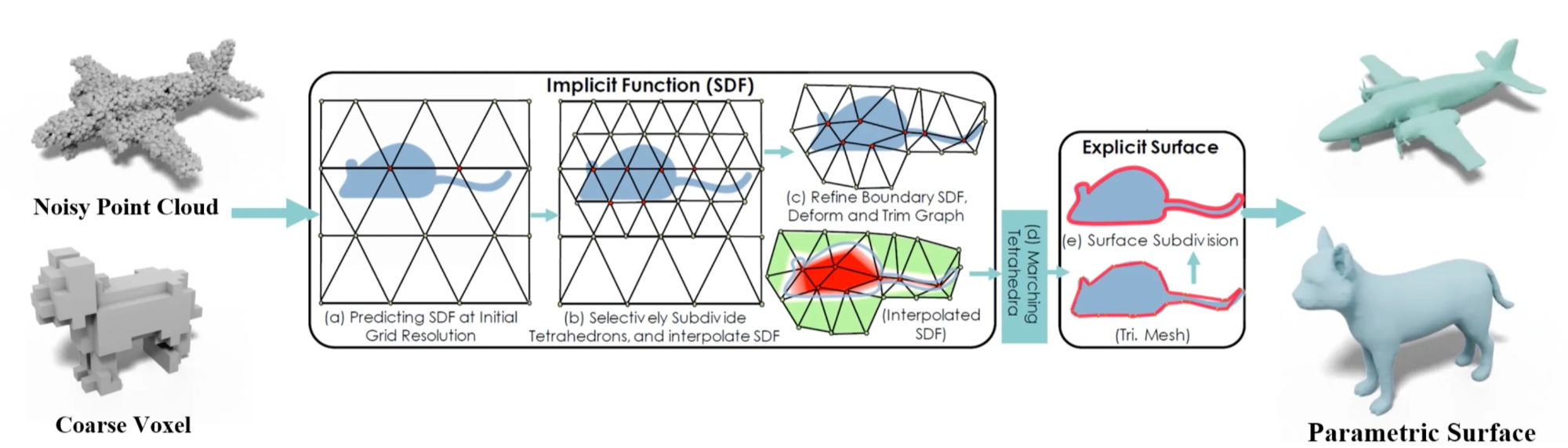
点群やボクセル、符号付き距離関数(SDFs)、ニューラルフィールド、Gaussian Splattingなどの様々な表現からメッシュを抽出する研究が行われている。
変換過程で、表面抽出技術が必要になるが、ポリゴンが過剰になってしまう(=テッセレーションが悪い)
メッシュの直接生成
色々な条件入力を使って、メッシュの生成を行う手法がある。
- PolyGen:2つのネットワークで、面と頂点を自己回帰的に予測。画像を入力している模様。
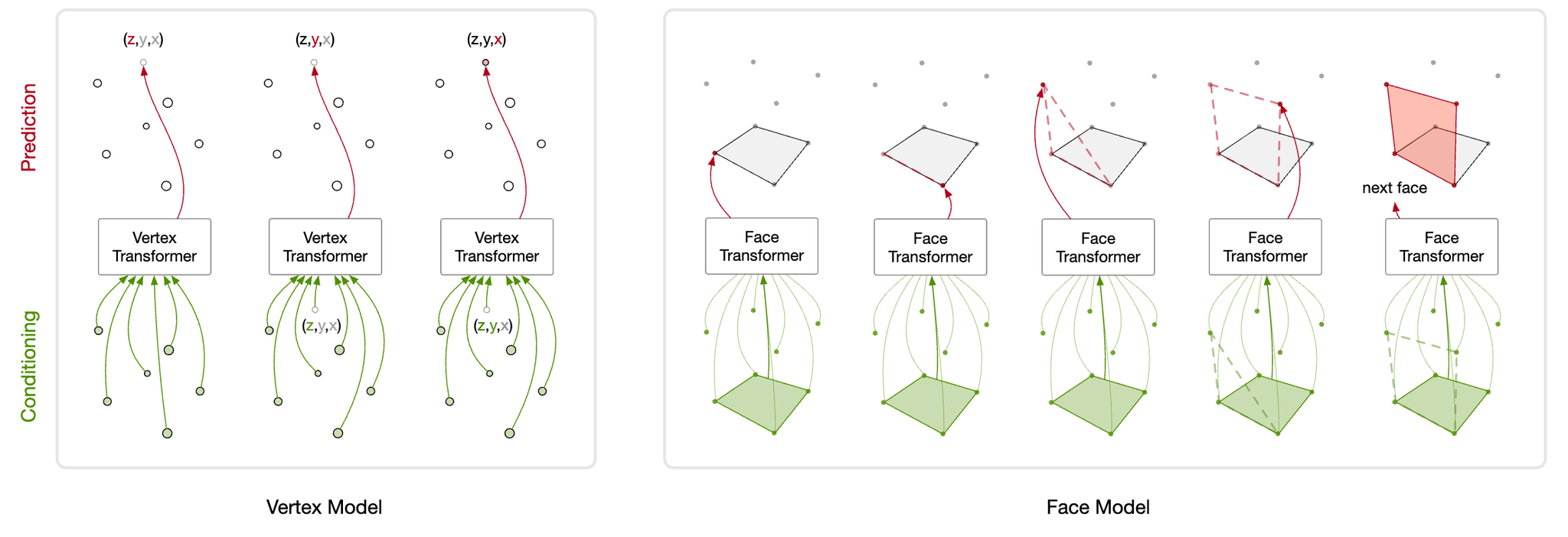
- MeshAnything:点群で形状の条件付を行う

- PivotMesh:ピボット頂点を生成することで階層的に生成できるようにした
→ いずれも部分的に作成して、全体を完成させる(partial-to-complete)パラダイム
詳細度制御 (Level of Detail, LoD)
コンピュータグラフィックスでレンダリングの高速化の一つとして利用されている技術。
カメラからの深度などを使って、メッシュの細かさ(詳細度)を増減させることでレンダリングの複雑さを低減する。

前提知識:プログレッシブメッシュとは
[Hoppe, 1996]で提案されている方法
任意の三角形のメッシュに対して、可逆な連続表現を作成する。
以下のような性質がある。
- Edge Collapseが単純化に十分である(頂点数を削減しても構造が維持される)
- 2つの操作が可逆であること
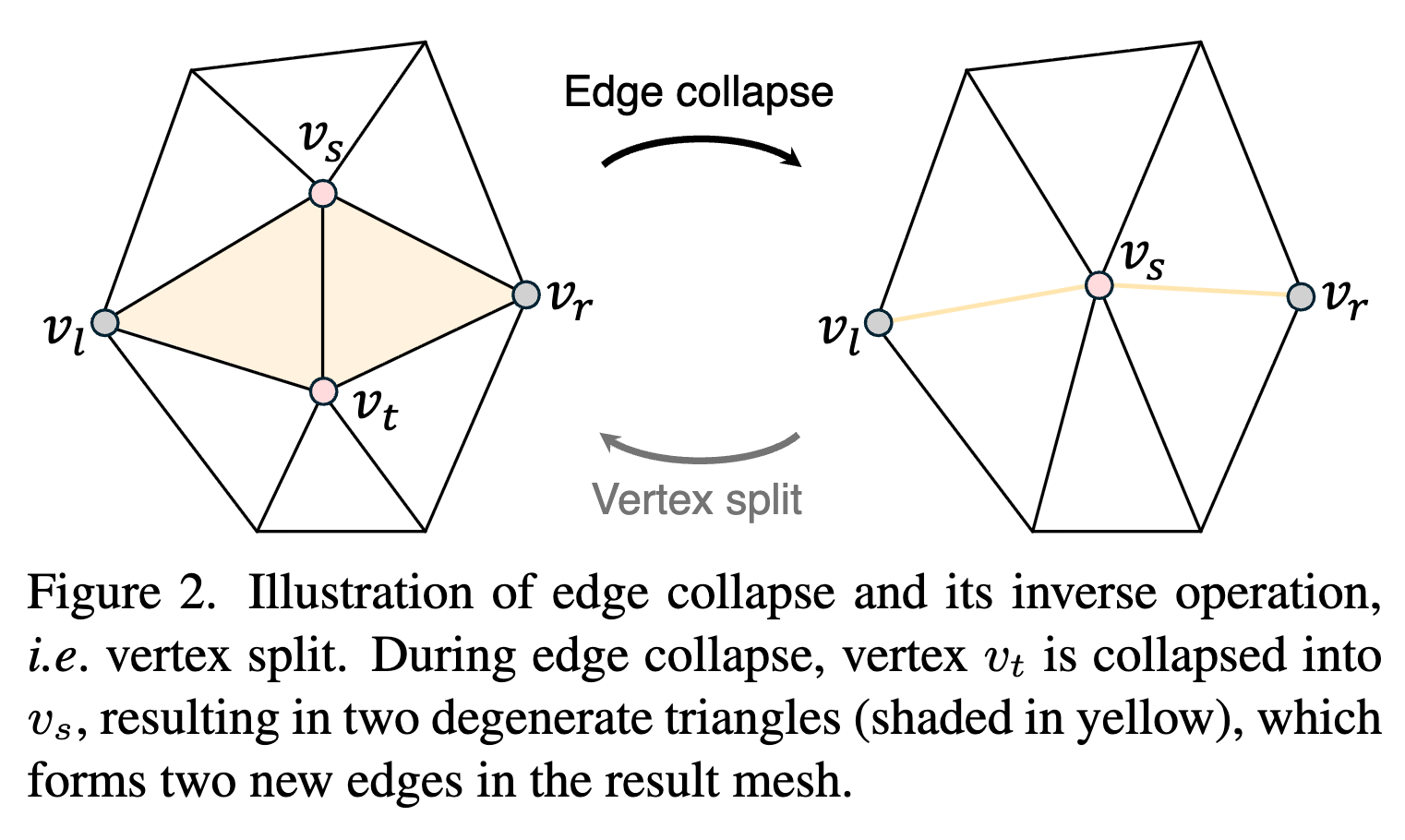
初期のメッシュ
次のようにEdge Collapseを適用(単純化)していき、粗いメッシュを作成していく。
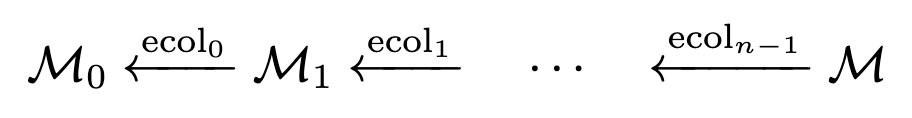
Vertex Split
Edge Collapseと逆の操作
初期のメッシュ とEdge Collapseを使うことで、逆方向のシーケンスを得られる。
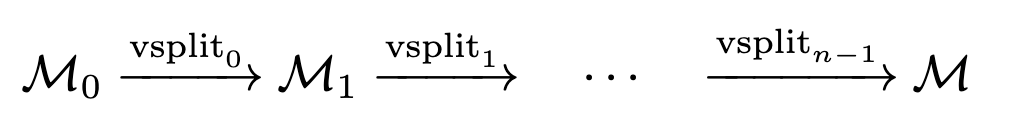
※
VertexRegen(提案手法)
プログレッシブメッシュのフローを拡散モデルでいう、拡散過程と生成過程に見立てて生成してみる。
VertexRegenでは、初期のメッシュ の推論から始まり、その後の分割頂点を自己回帰的に順番に予測していく。

初期メッシュのトークン化するとこのようになる。
頂点はxyz必要で、ポリゴンの三角形1個は3頂点。メッシュはそれらの集まり。

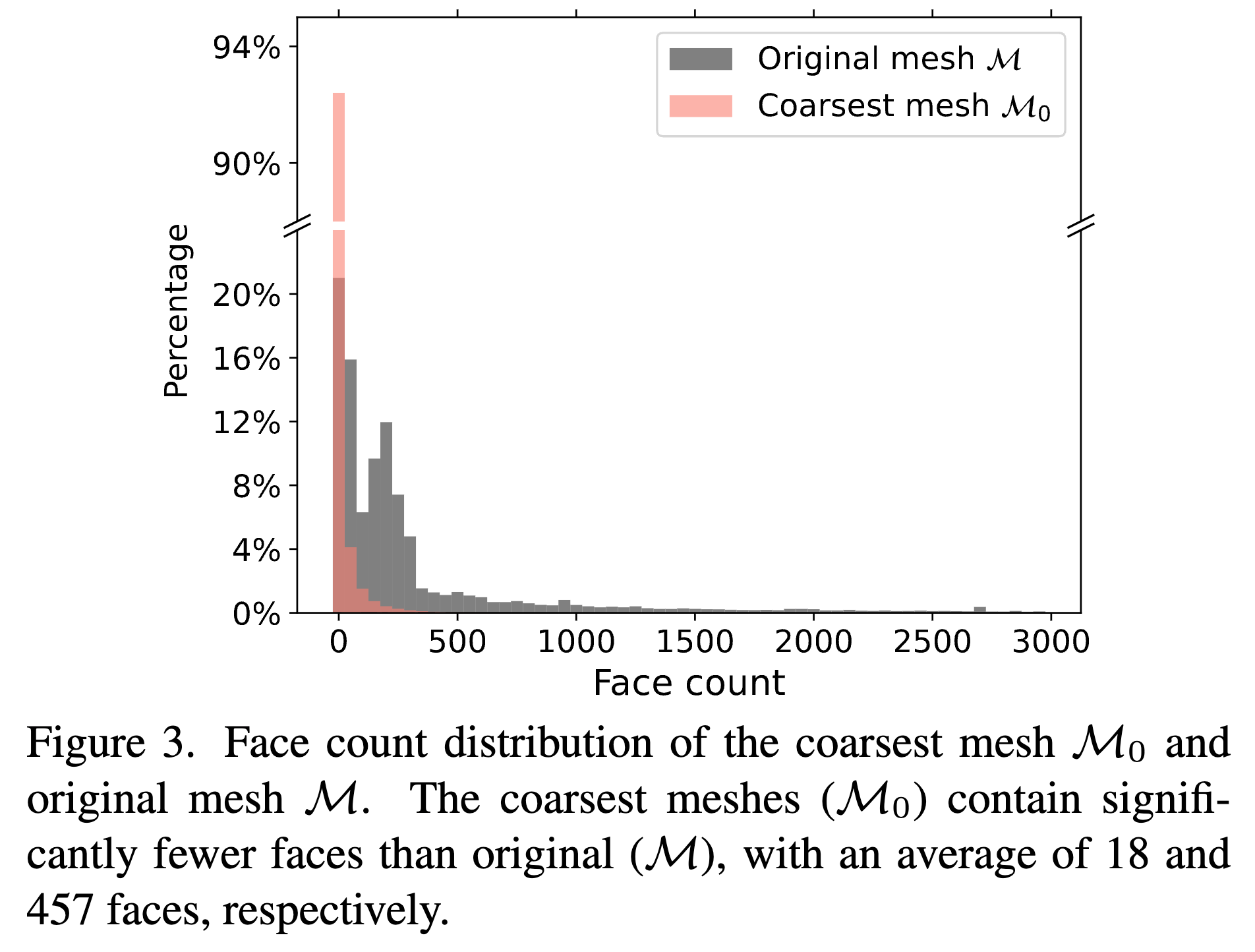
メッシュを単純化していくと、次のようなポリゴンの分布になる。
オリジナルのポリゴン数の平均が457個に対して、初期メッシュは平均18個なので、めっちゃ削減できている。
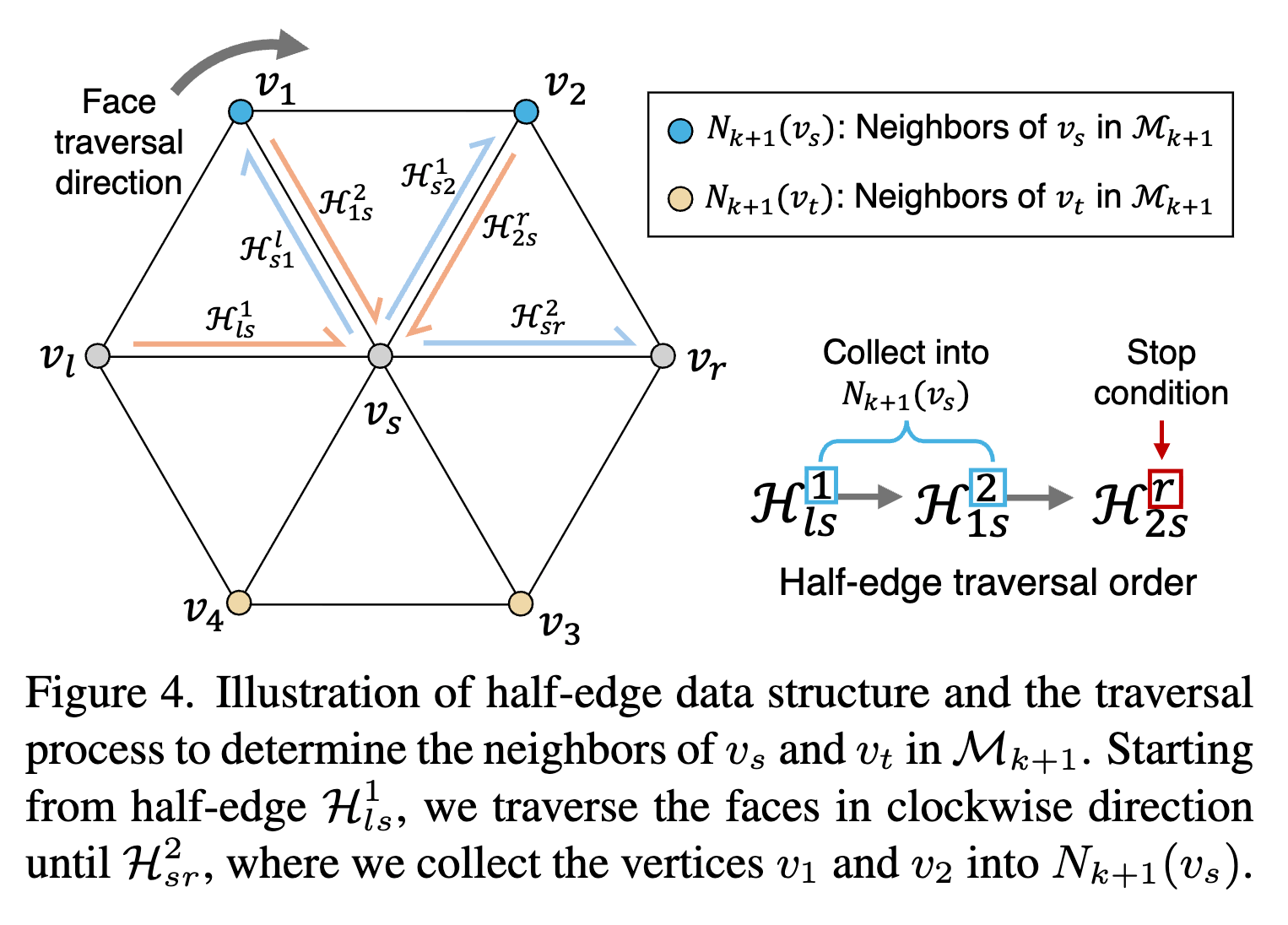
頂点分割後の接続をどうするか
頂点分割するときに、分割対象にした点( の頂点 )と新たに追加した点(の新頂点 )の隣接点を新たに接続し直すのは結構たいへんで、全探索するのは不可能。
→ ハーフエッジを使って、隣接点を探せば十分
ハーフエッジ=一辺に対して、2つの方向を持つ単方向エッジ。どの面に属しているかなどがわかりやすくなり、頂点の増減による影響範囲が把握しやすくなる。
新たなvsの隣接点は から、新たなvtの隣接点は から探していく。
モデルの予測では、最初に初期メッシュM0を予測した後、頂点分割( )を順々に予測していく。
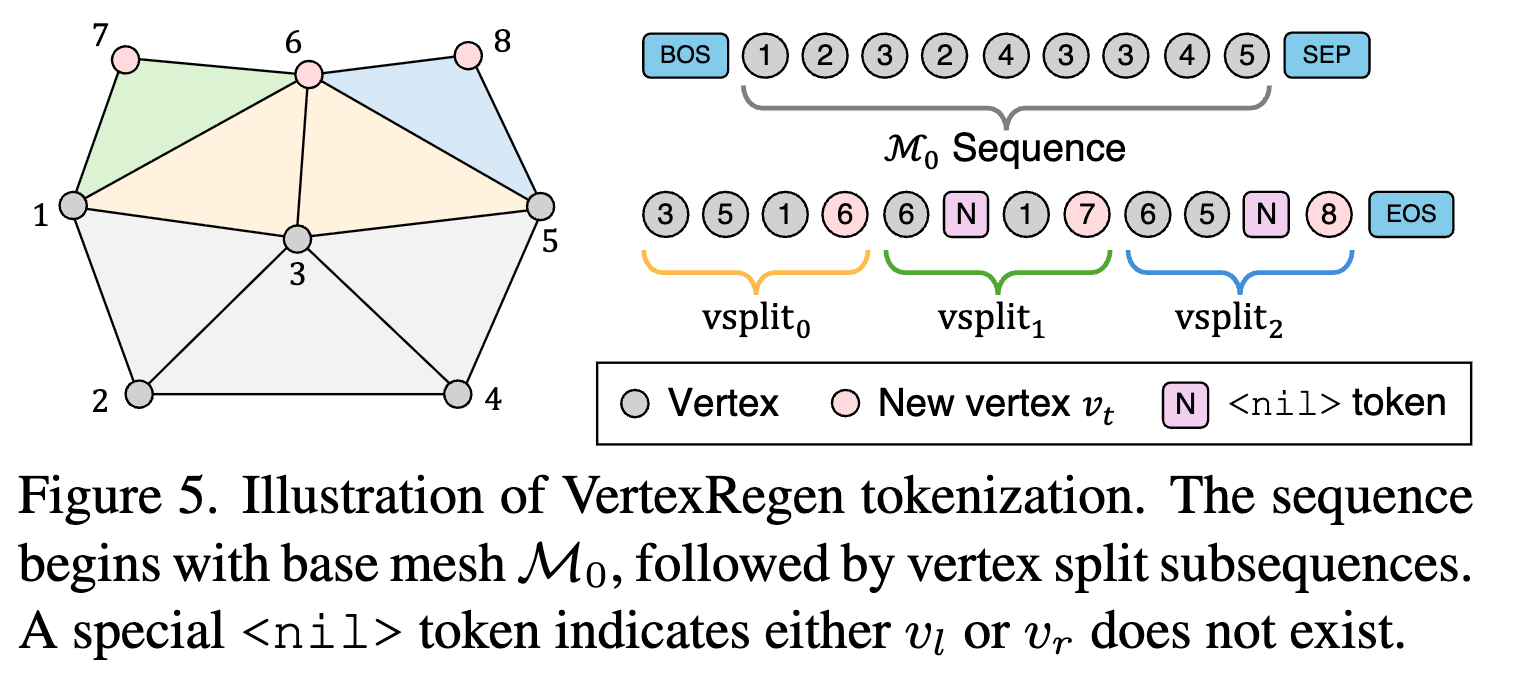
初期メッシュM0は頂点順序はいい加減に出している感じ?
他の分割頂点は基本的に4点を出力するが、頂点 vsと頂点vtのときは、nilトークンを出力するようにする。
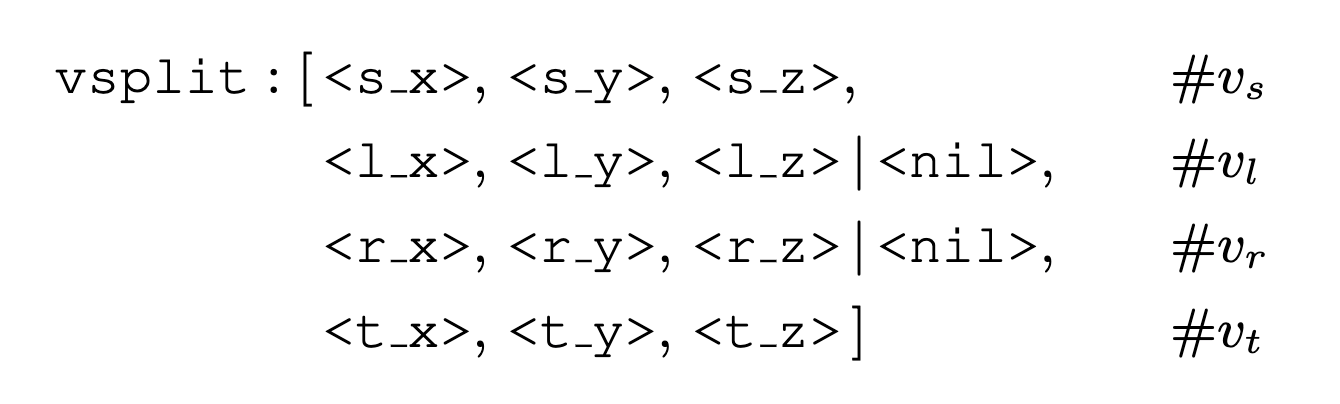
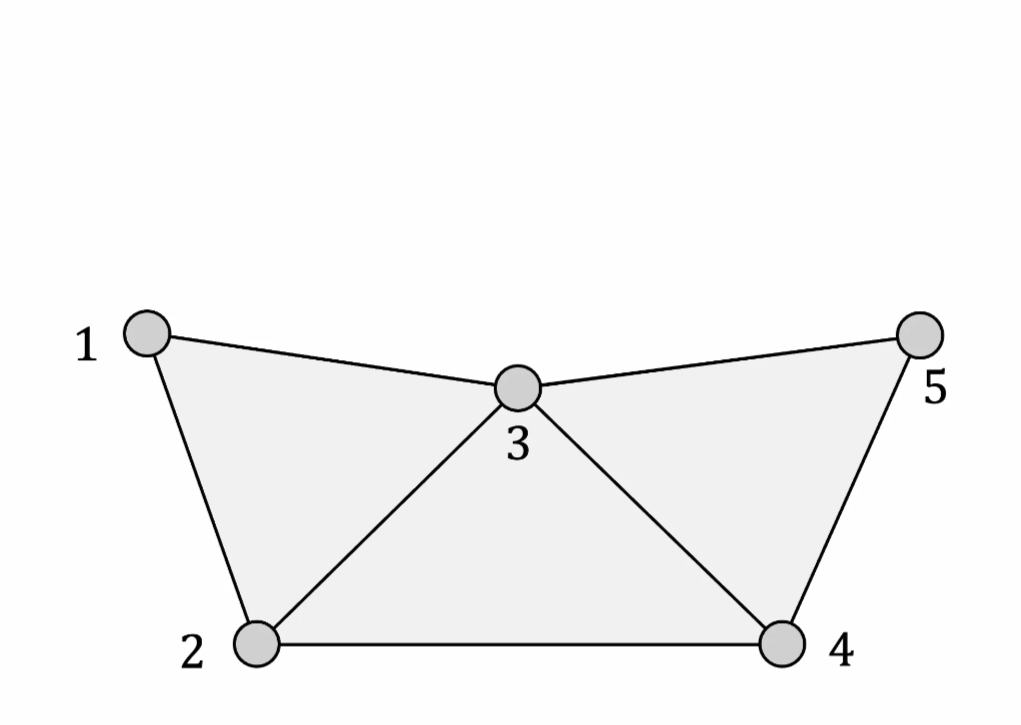
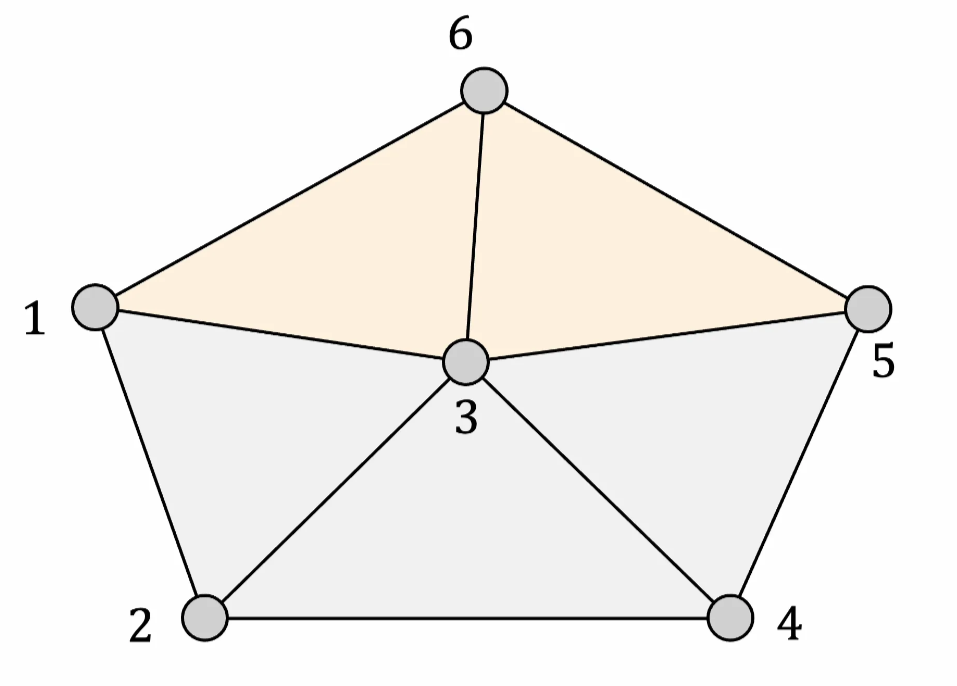
頂点6→頂点7→頂点8というように頂点追加(分割)した結果。7と8は外周辺に対して追加しているので、
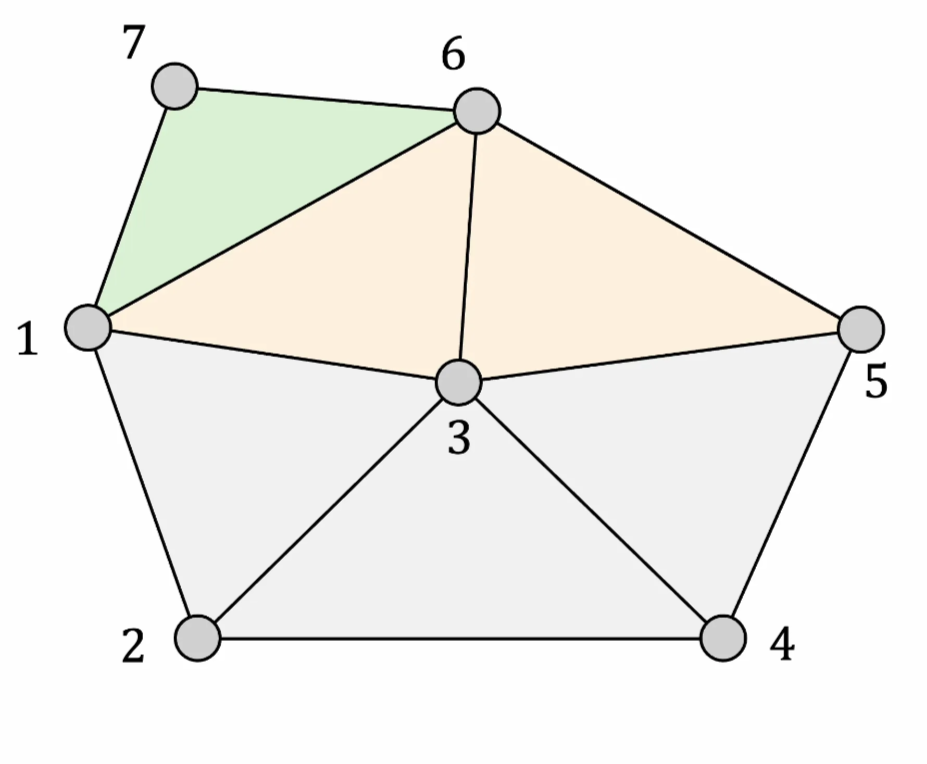
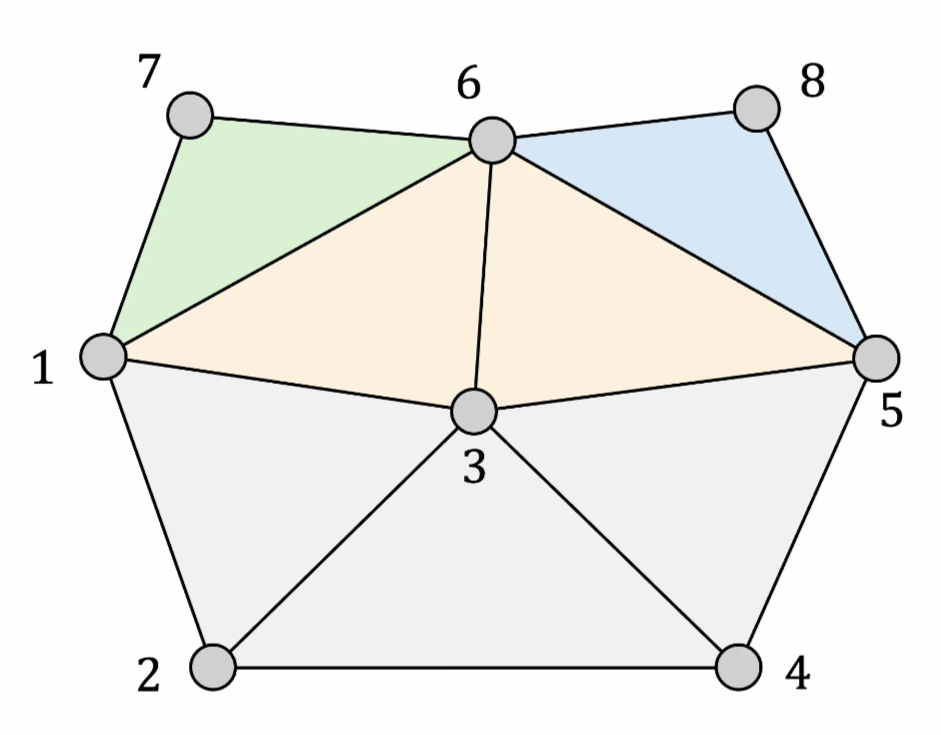
実験
データセット
Objaverse-XLから収集した約150万の3Dメッシュ
これらの頂点を単純化(Edge Collapse)して、平均457面の約150万のメッシュデータセットを作成。
モデル
事前学習済みのOPT-350Mを学習。これ専用というわけではなく、割と汎用的なオープンな言語モデルな模様。
結果
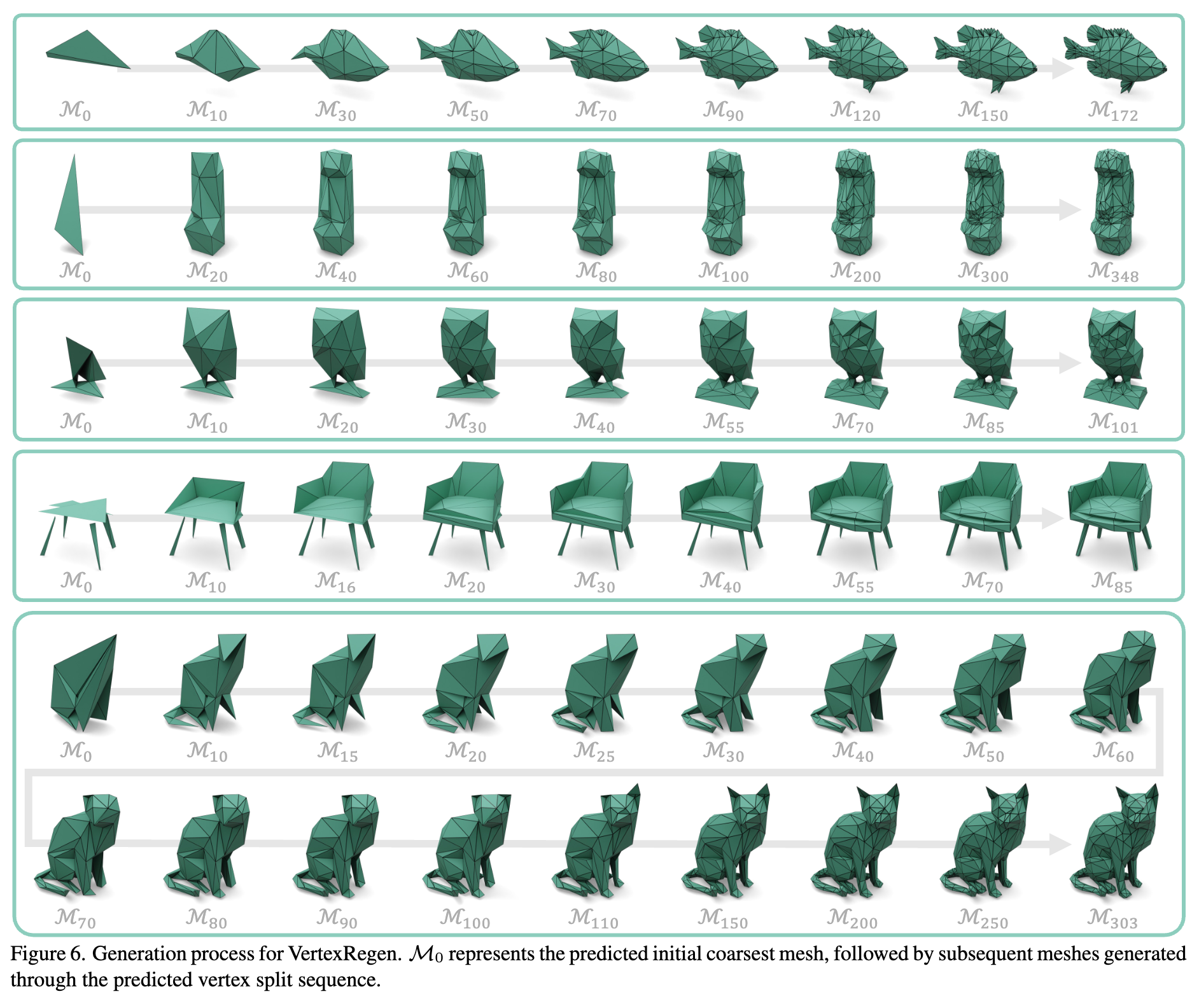
生成結果
ポリゴン数が徐々に増えていくような、意図した生成が出来ている。
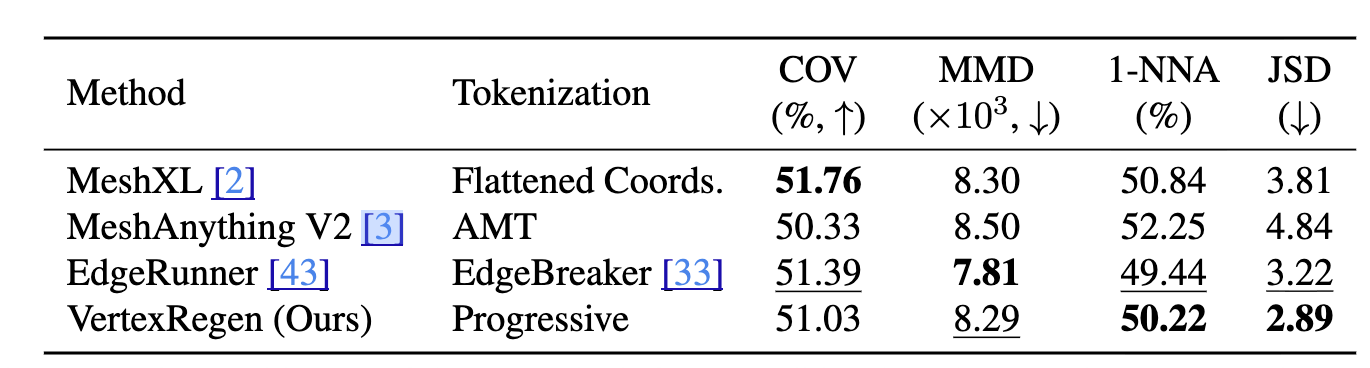
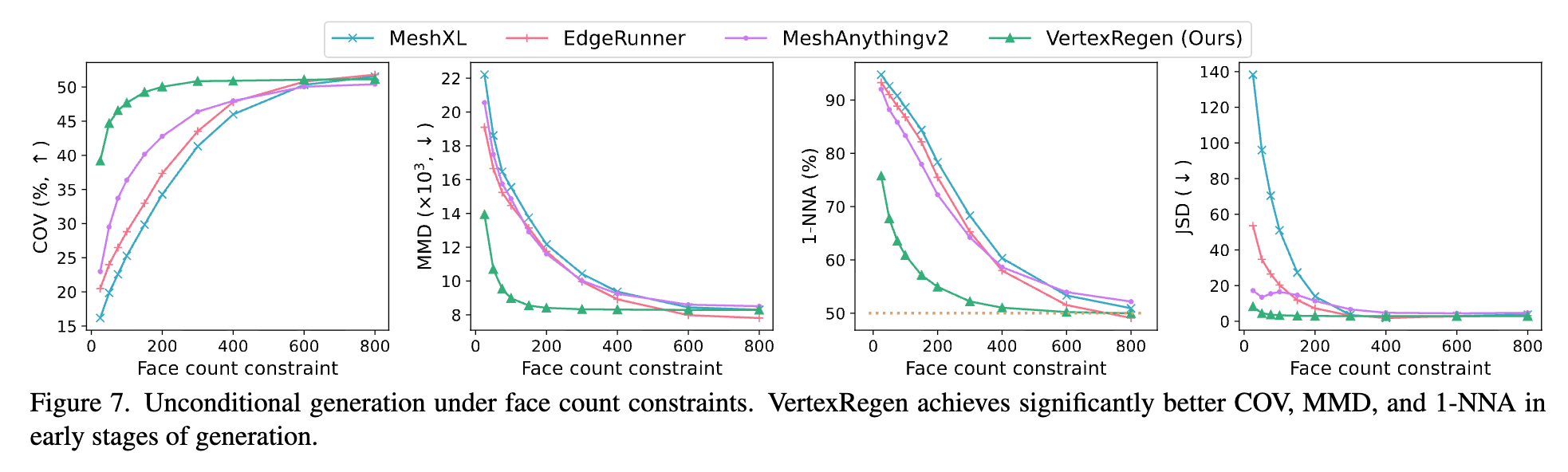
先行研究との比較
先行研究に倣って、点群ベースの評価指標(COV, MMD, 1-NNA, JSD)で評価。
- Converage (COV) measures: 多様性を測る指標
- Minimum Matching Distance (MMD): 品質(忠実度)
- 1-Nearest Neighbor Accuracy (1-NNA): 品質と多様性の両方。それらのバランス感
- Jensen Shannon Divergence (JSD): 分布がどれだけ似ているか
数値的には先行研究と大差ない
ビジュアル的にも他の手法と遜色ない

横軸を面の数としたときの各指標を測ったグラフ。
VertexRegenが面の数が少ないときに用スコアを達成している。

感想
こういうそもそも生成方法が違う手法は面白い。
「生成時間に応じて次第に細かくなる」というのは、レンダリングを単純化するために利用されるLoDと同じような思想を共有しているように感じた。細かくレンダリングする必要がないのであれば、計算時間は短いほうがいいよねと思う。