2025-08-26 機械学習勉強会
今週のTOPIC[論文] AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs[論文] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification[blog] Claude Code の学習モードで自分の手でコードを書く練習をしよう[blog] DINOv3: Self-supervised learning for vision at unprecedented scale[blog] Ragas / Testset Generation for RAG [blog] Turbocharging Denodo AI SDK: How Semantic Caching Makes Text-to-SQL 9X FasterメインTOPICINTERN-S1: A SCIENTIFIC MULTIMODAL FOUNDATION MODELTLDR1 Introduction2 Model Architecture2.1 VISION ENCODER2.2 DYNAMIC TOKENIZER2.3 TIME SERIES ENCODER3 Infrastructure3.1 PRE-TRAINING AND SFT INFRASTRUCTURE3.2 RL INFRASTRUCTURE4 Continue Pre-training4.1 SCIENTIFIC DATA4.1.1 テキストデータ4.1.2 MULTI-MODAL DATA4.2 TRAINING STRATEGY5 Post-training5.1 OFFLINE REINFORCEMENT LEARNING5.1.1 INSTRUCTION DATA CURATION5.1.2 DATA MIXTURE EXPERIMENTS5.2 ONLINE REINFORCEMENT LEARNING5.2.1 Mixture-of-Rewards (MoR) フレームワーク5.2.2 TASKS AND VERIFIERS5.2.3 POLICY OPTIMIZATION5.2.4 EXPERIMENTS6 Evaluation6.1 EVALUATION CONFIGURATION6.2 BENCHMARKS6.2.1 一般推論ベンチマーク6.2.2 科学推論ベンチマーク
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs
- AgentをLLMのファインチューニングなしにファインチューニングするという手法
- 我々的にはコスパが良さそうな雰囲気で気になった
- 課題
- 新しいドメインに適応できない手作業で作成されたワークフローに依存している
- 新しいドメインごとに計算コストの高いファインチューニングを必要とする
- ⇒ メモリベースでファインチューニングなしでの適応手法(Case-based Learning)を提案
- Memory-based Markov Decision Process (M-MDP)
- ケースバンクに過去にどのような状況でどのようなアクションをとり、どのような報酬が得られていたかを保存しそれを参照する
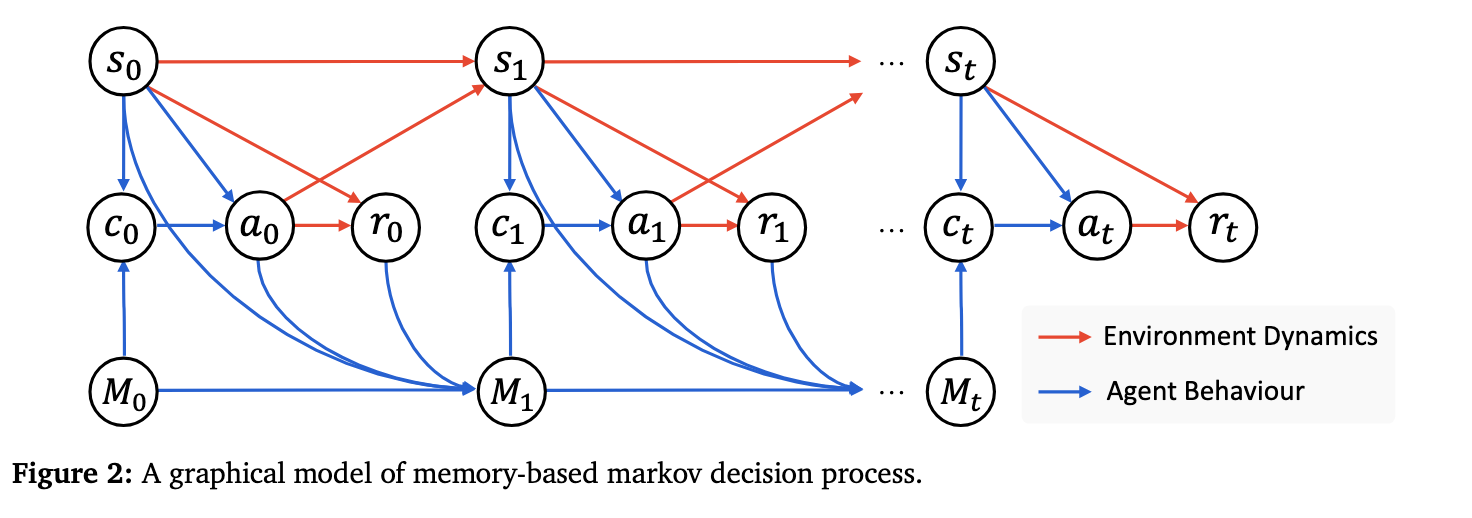
- Case-Based Reasoning Agent
- 以下の確率を最大化することが目標
- Retrieve
- 現在の状況とメモリから特定の過去の経験を思い出す確率
- Reuse & Revise
- 現在の状況と過去の経験から特定の行動をする確率
- Evaluation
- 行動した結果として期待した報酬が得られているか
- Retain
- 現在の状況から特定の行動をしたときに得られた報酬を保存
- Transition
- 行動の結果次の状況になる確率
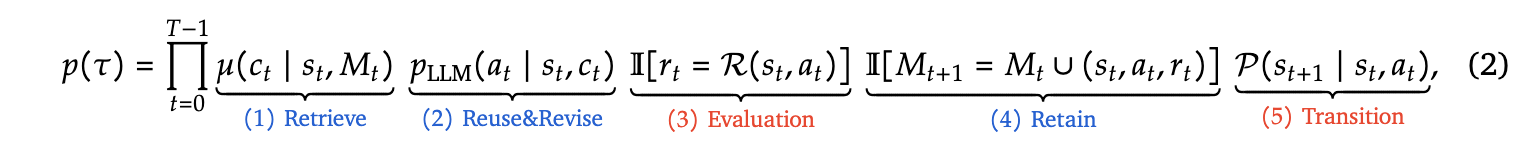
- ソフトQ学習
- Q値の求め方
- カーネル法による近似
- あるケース(c)を選んだ時の全ての経験(s, r)を呼び出し、その状況が現在の状況(s)にどれくらい似てるかを計算して、その類似度で過去のQ値を重みづけする
- 直接的に確率を予測
- 状態(s)でケース(c)を参照したときにタスクが成功する確率をニューラルネットワークで学習させる
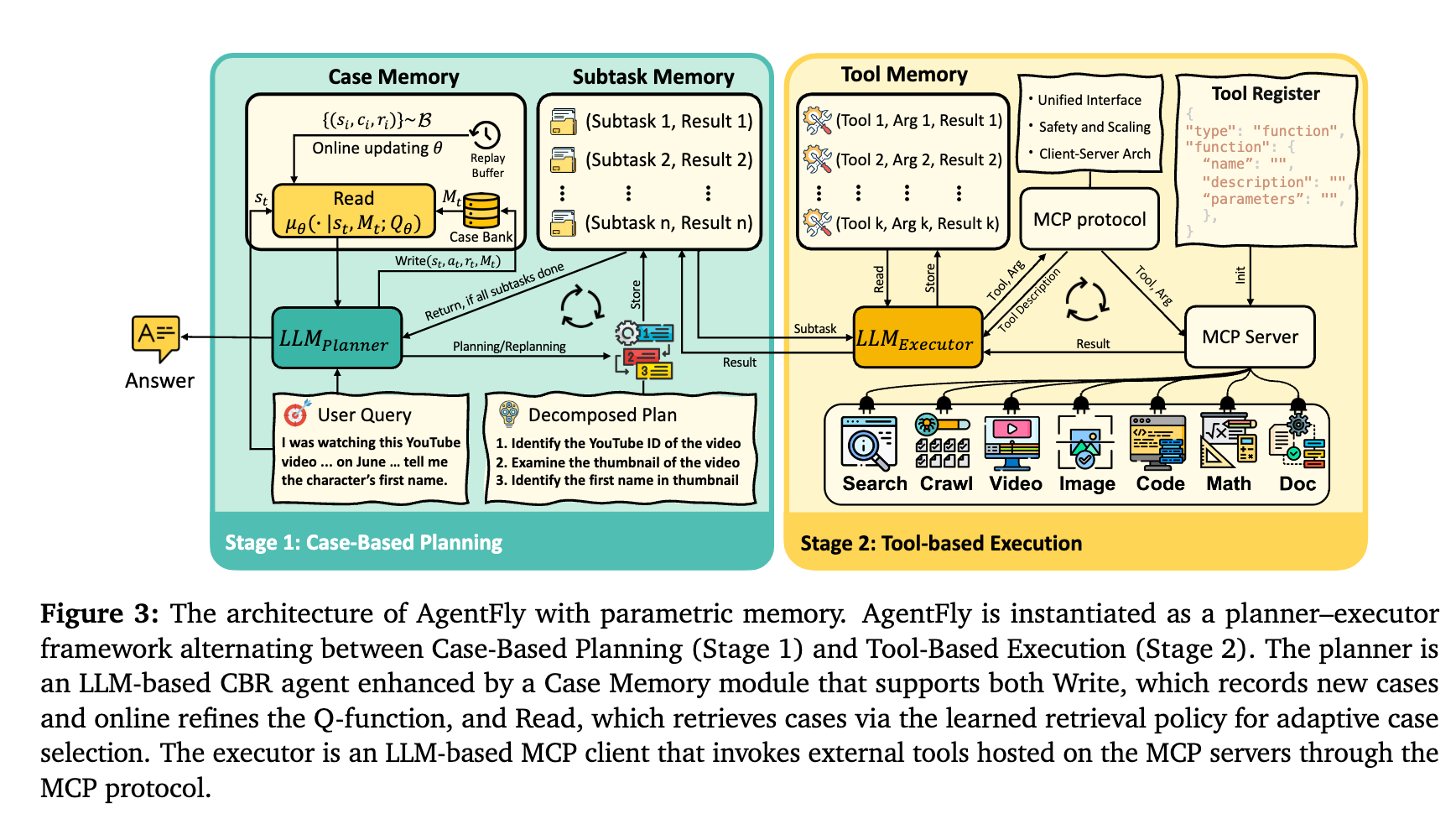
- 全体のイメージ
- Toolの実行順序を保存しておいて、全てが完了した後にCase MemoryのQ値を更新する
- (Plannerにo3よりGPT 4.1を使った方がいいという話があってへえとなった)
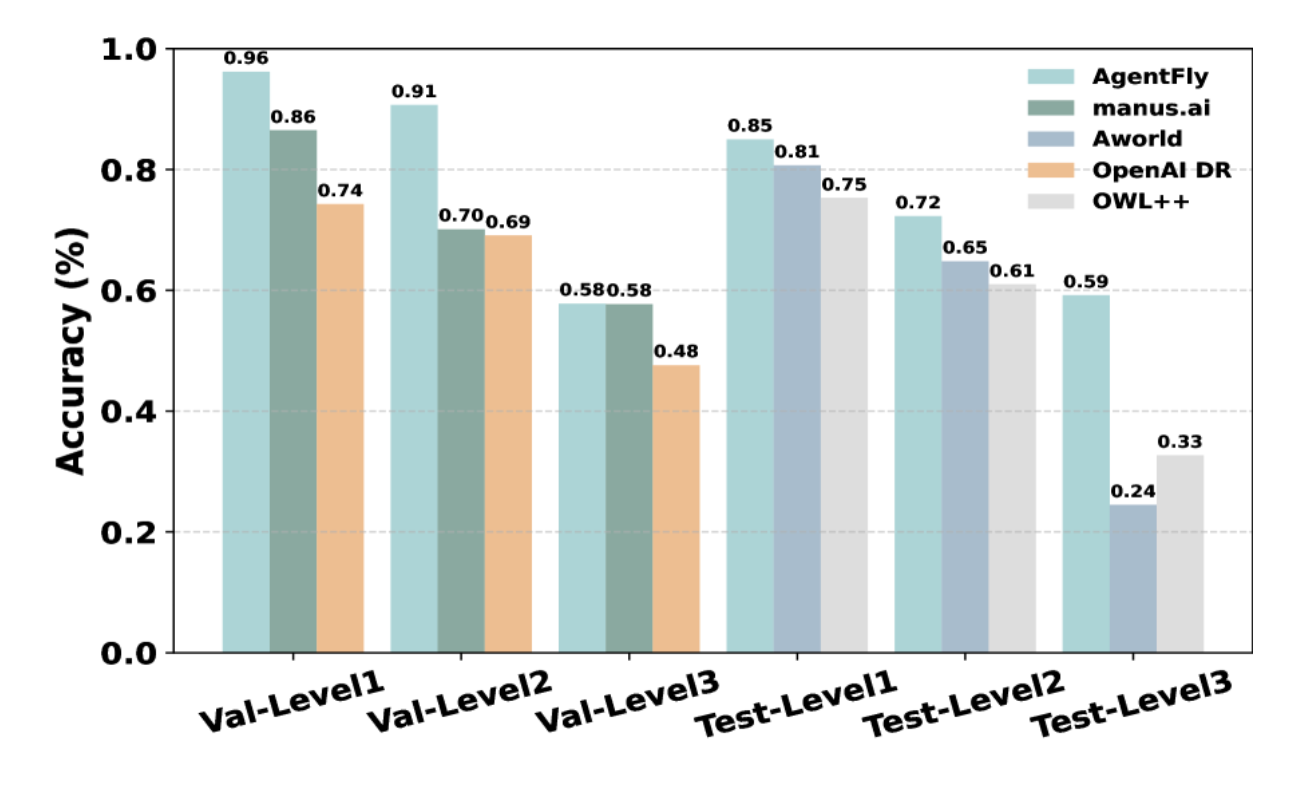
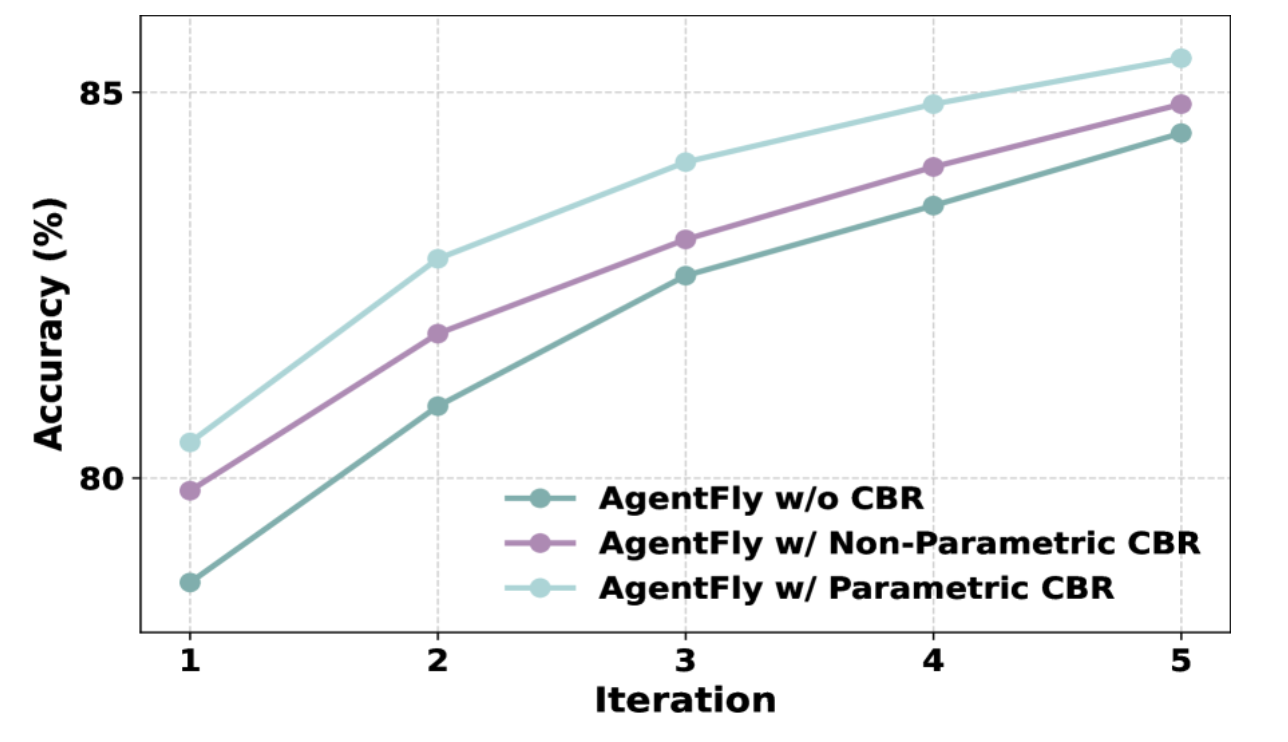
- OSSフレームワークと比較してGAIAデータセットで高い精度を達成
- 学習を重ねることでも賢くなっている
- (w/o CBRでも精度が上がってるのはどういうこと?パッと読んだだけだと分からず)
@Yuya Matsumura
[論文] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
- LLMにおいて強化学習が注目されてる、成果が出ている理由のひとつは(一般的なSFTに対する)その汎化能力だと理解しているのですが、本論文で提案している Dynamic Fine-Tuning (DFT) によってSFTの枠組みで汎化性能が引き上げられるよという内容。
- 実装としても従来のSFTに一行を加える(損失にstopgradientしたモデルの予測確率をかけておく)だけというシンプルなもの。
- 観測されているデータ分布の歪みによる影響モデル分布でうまいこと補正すると理解した。蒸留とかは実質同様のことをやっている。
@Takumi Iida (frkake)
[blog] Claude Code の学習モードで自分の手でコードを書く練習をしよう
Claude Codeの でLearningにするとInsightとしてどのような考えでその実装をしようとしているのかがわかるようになる。
あと、人に実装を手伝ってもらう(逆だとは思うが)ようなTODOを組んでくることもある。
筆者はあえて間違った実装をしているが、Claude Codeはその間違いを指摘して修正してくれる。
[blog] DINOv3: Self-supervised learning for vision at unprecedented scale
DINOv3のMetaによる公式ブログ。一部論文からも抜粋。
DINOv2の時点でだいぶ強かったので、注目されている。
CVPR2025でも「DINOv2が強いから達成できた」というような論文が結構ある。
Gram Anchoring
何に対処したか:
大規模学習をすると、クラス分類タスク(IN1k)は上がっていくが、学習をしていくと特長の局所性が失われて、密なタスク(セグメンテーションタスク)の性能が下がっていく課題があった。
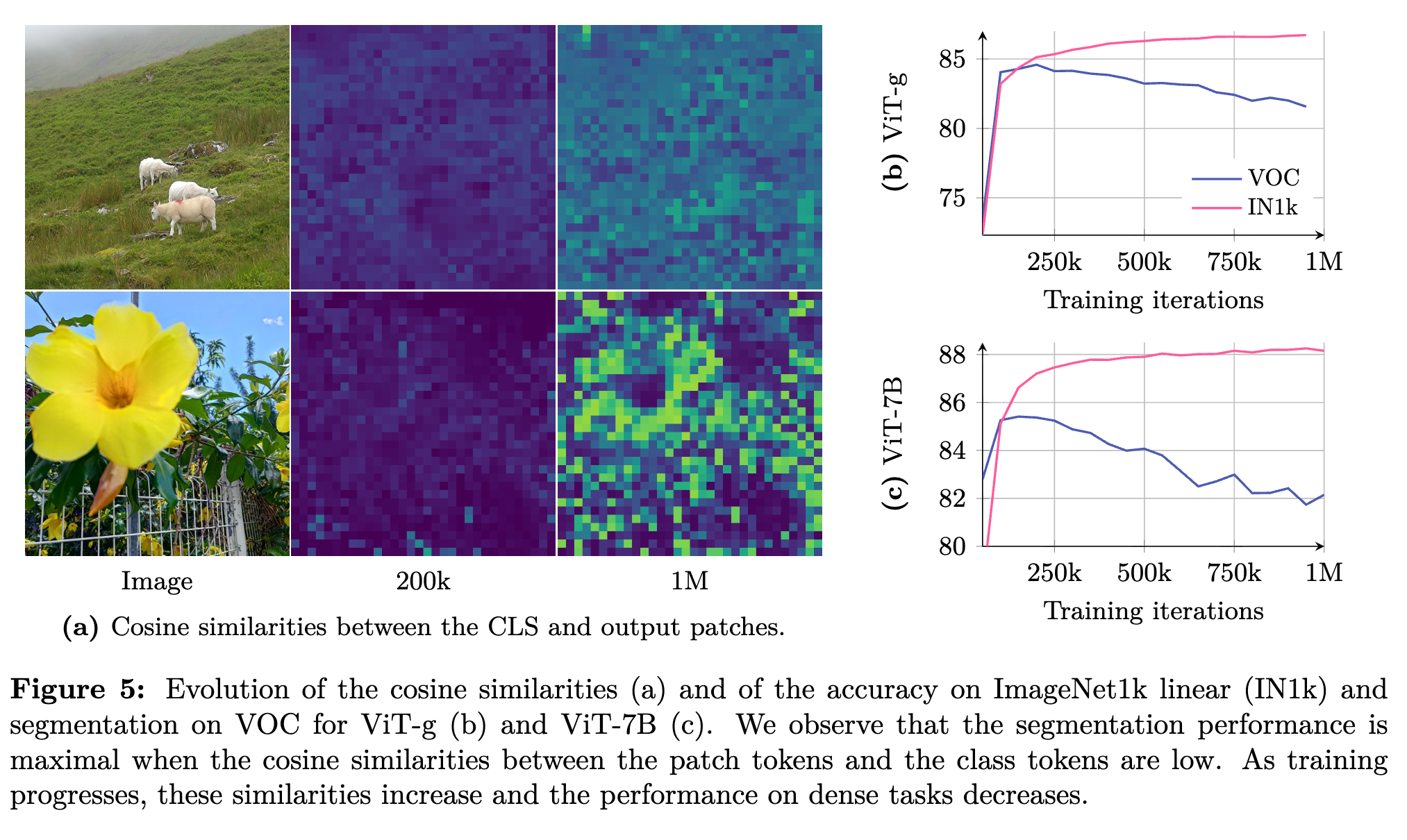
この論文は、学習が進むにつれて、特徴マップがノイジーになってしまう(局所特徴が失われる)ことが原因だと考えている。
どう解決したか
グラム行列(=画像内のすべてのパッチ特徴の内積)に基づく目的関数を提案
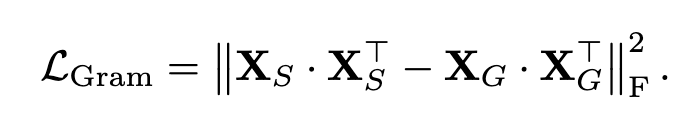
上のグラフで見たように、初期のモデルのほうが密なタスクが強い。その早期モデルを教師モデルとして活用する。教師モデルから得られるグラム行列(Gram Teacher)との損失を計算している。
パッチ間でどれくらい似ているかを測ることができ、局所特徴を維持できる。
成果物
データセット
LVD-1689Mというインスタグラムから収集したデータセットを構築している。Metaによって有害なデータなどがフィルタリングされているらしい。DINOv2だと142M(LVD-142M)だったので、12倍近いサイズになっている。
DINOv3は他のDINOと同じく自己教師あり学習(SSL)モデルのため、特定の正解ラベルが不要。アノテーションはされていない。
モデル
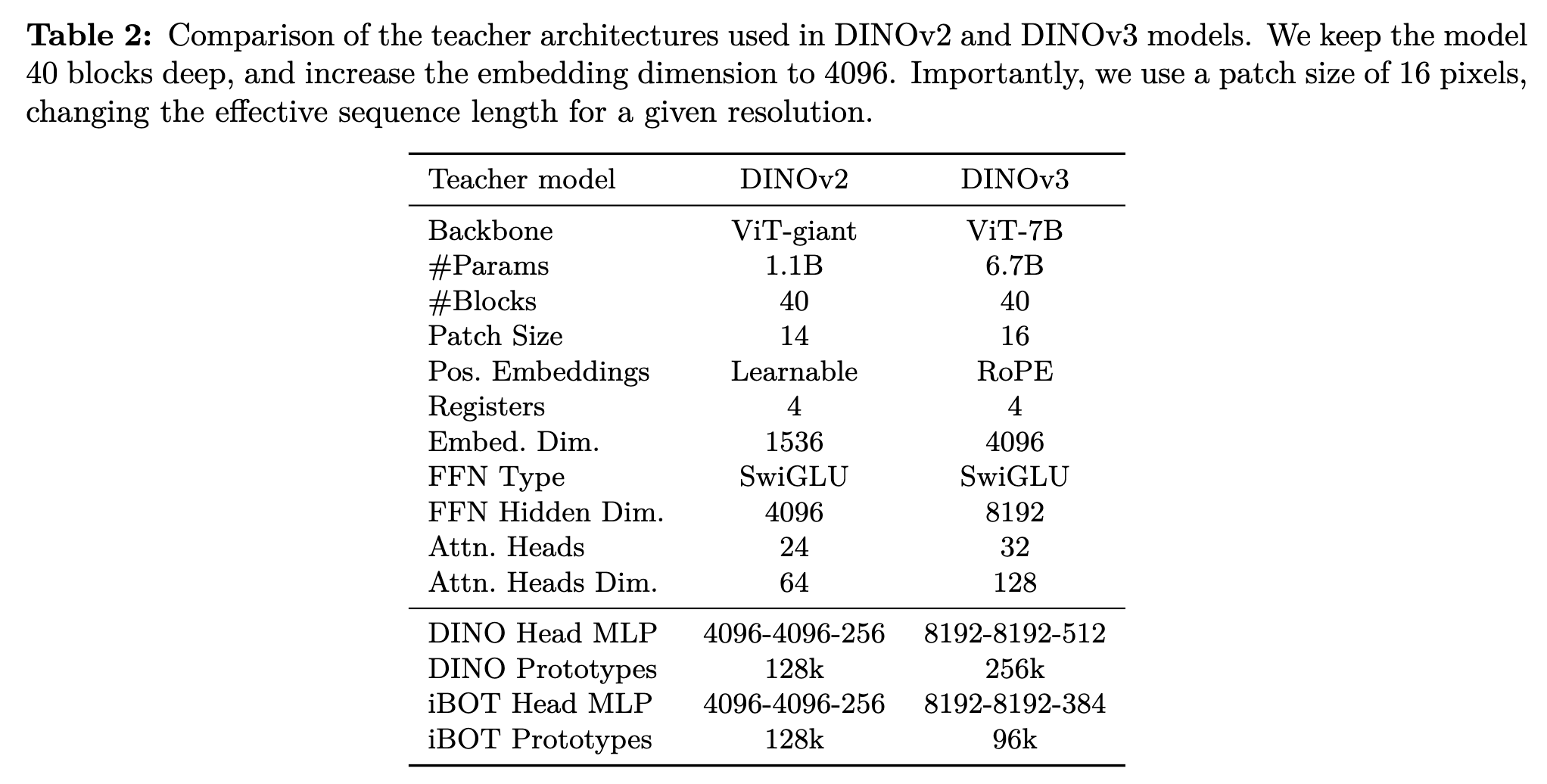
モデルサイズはDINOv2に比べるとかなり大きい。
定量&定性結果
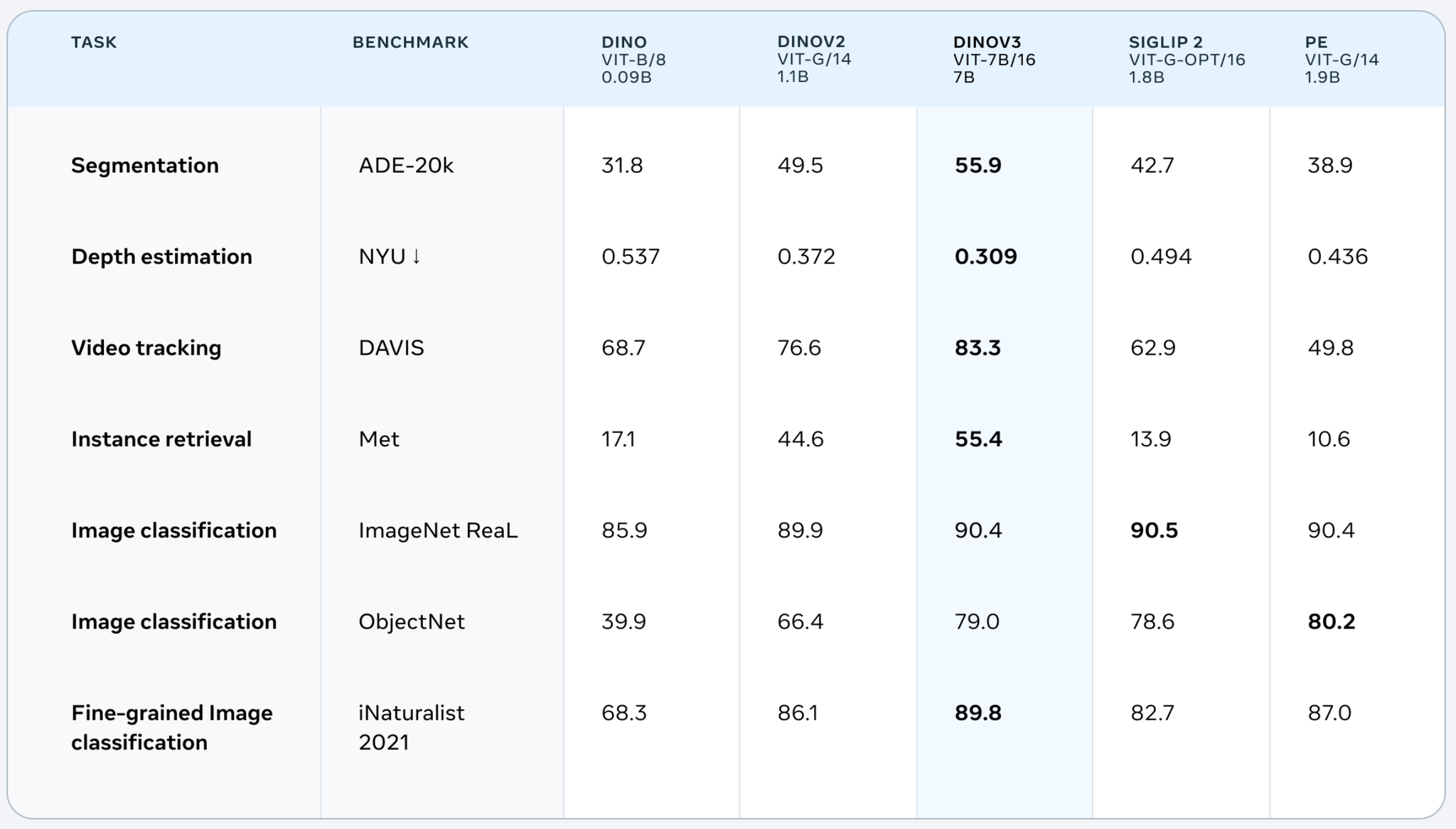
さまざまなタスクのベンチマークでかなり良いスコア。
赤十字部分のパッチ特徴と他の部分とのコサイン類似度を可視化してみると、同じ果物に対して強く反応するようなヒートマップを獲得できる。

@Hiromu Nakamura (pon)
[blog] Ragas / Testset Generation for RAG
RagasがRAGを評価するためのテストセット生成をサポートしていたので、その内部について。別チャンクを跨いで階層化されたドキュメントや複雑な関係を持つデータからマルチホップが必要なクエリを生成できる。
与えられた文書セットから様々な種類のクエリを生成する場合、LLMがクエリを作成できるように適切なチャンクまたは文書セットを特定することが大きな課題。この問題を解決するために、Ragasはテストセット生成に知識グラフベースのアプローチを採用している。
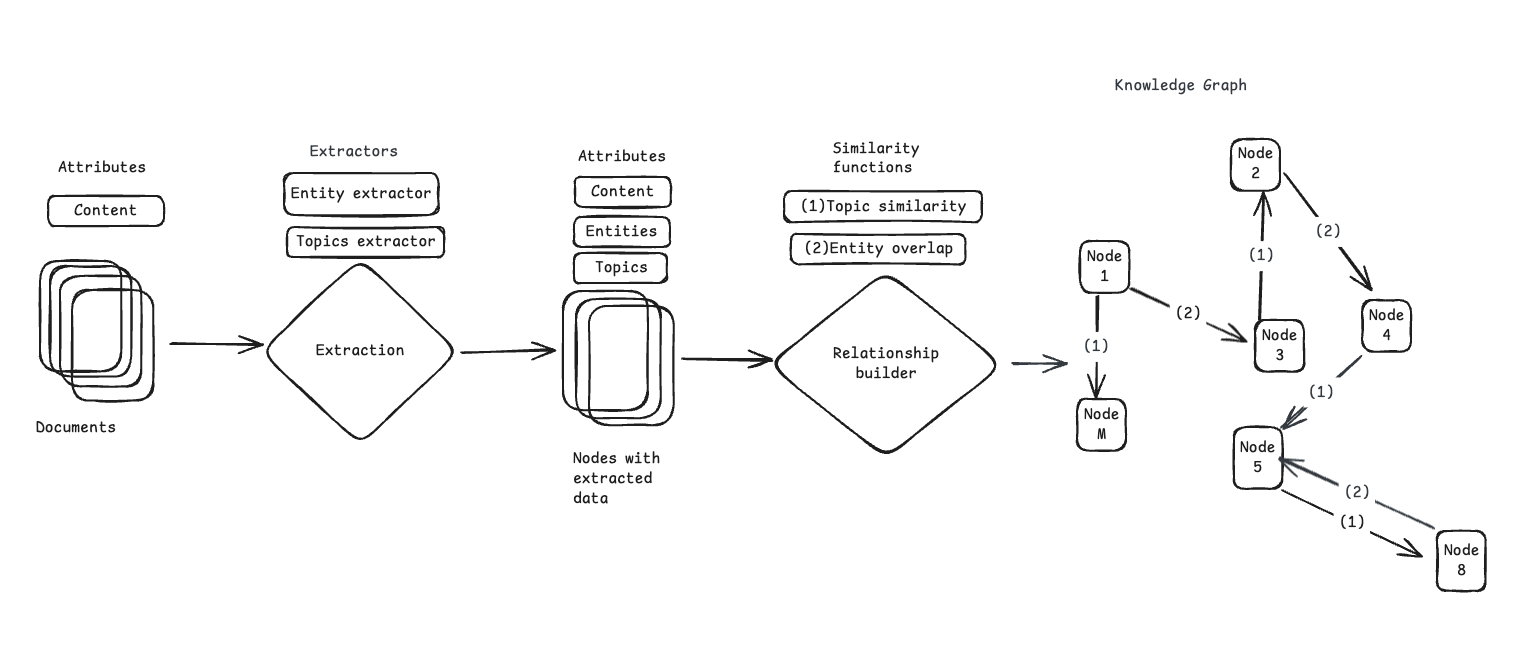
ナレッジグラフに対してクエリを生成しするための各項目は、次のパラメータの組み合わせ。
- ノード: クエリを生成するために使用されるノード
- クエリの長さ: 希望するクエリの長さ。短い、中くらいの長さ、長いなどです。
- クエリ スタイル: クエリのスタイル。Web 検索、チャットなどになります。
[blog] Turbocharging Denodo AI SDK: How Semantic Caching Makes Text-to-SQL 9X Faster
txtsqlのパフォーマンスとコストをセマンティックキャッシュ + 軽量LLMで突破する話。結果がすごいというよりは「あー確かにそういうこともできるか」系
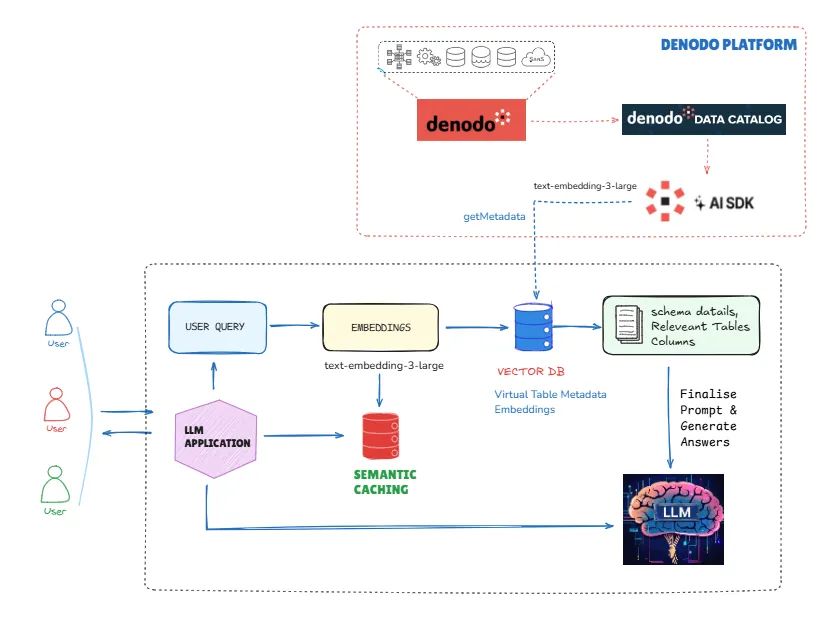
- txt2sqlの結果をベクトルにしてキャッシュしておく。
- ユーザーからのリクエストが来たらキャッシュに問い合わせ、似たクエリを取得
- その後LLMで質問との意味検証を実施。
- LLMでキャッシュでとってきたクエリを微修正
結果
18のリクエストで実験。30~40個のデータをキャッシュにプリロードしている。少ない気はするが
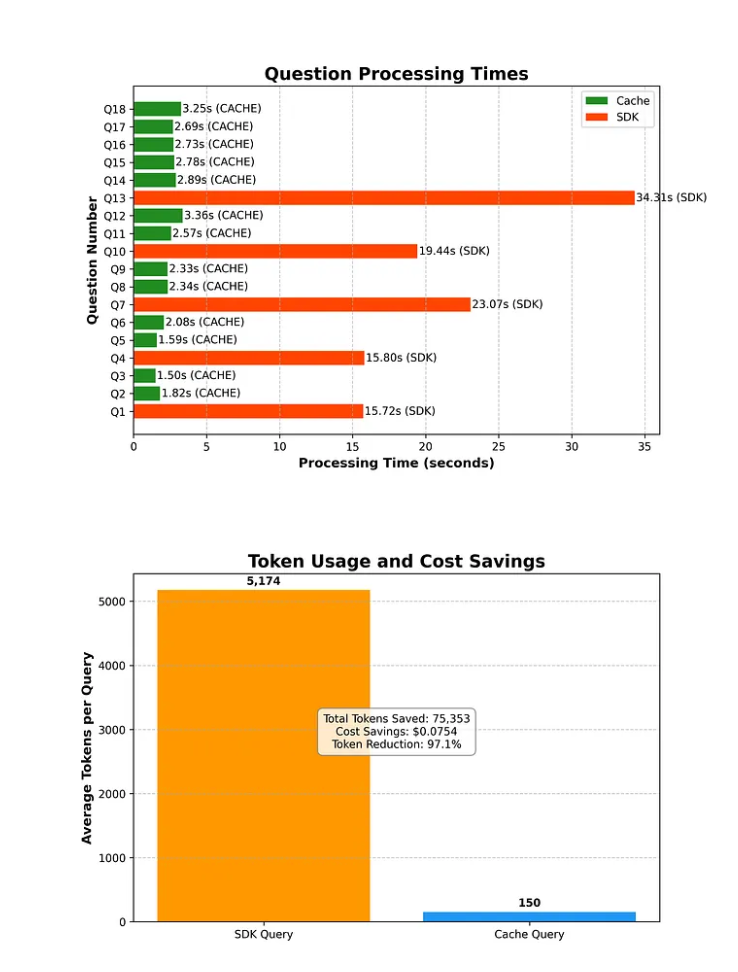
- トークン効率
97.1%のトークン削減、合計71,353トークン節約
- 速度の向上
応答時間が8.9倍高速化(2.45秒対21.47秒)
- キャッシュの有効性
ヒット率 83.3% (18 件中 15 件の質問がキャッシュから提供されました)
- コスト削減
大規模なAPIコストの大幅な削減
- 意味認識
異なる言い回しにもかかわらず、質問のバリエーションを正常に識別
所感
- ヒット率高すぎる。テストセット、プリロードセットが恣意的に選択されている感じはある。
- ヒットしなかった時のパフォーマンスへの影響大きそう
- 相当ロングテールじゃないと難しそう
- ただ、以前のデータと軽量LLMで大きな処理をうまくskipするというアーキテクチャは面白かった。数秒かかるキャッシュという概念は新鮮。
@ShibuiYusuke
メインTOPIC
INTERN-S1: A SCIENTIFIC MULTIMODAL FOUNDATION MODEL

- Intern-S1 Team, Shanghai AI Laboratory
- Shanghai AI Laboratoryが提供しているInternLMシリーズのmultimodal reasoning model for scientific task.

TLDR
- Intern-S1は科学分野に特化した専門性と汎用的な理解・推論能力を兼ね備えた、マルチモーダル基盤モデル
- アーキテクチャはMixture-of-Experts (MoE) を採用しており、総パラメータ数2410億のうち、280億が活性化パラメータ
- 学習データは5兆トークンに及び、そのうち2.5兆トークン以上が科学分野のデータ
- 事後学習段階では、1000以上の多様なタスクの強化学習(RL)を同時に行うための新しいフレームワーク「Mixture-of-Rewards (MoR)」を導入
- 評価では、一般的な推論タスクにおいてオープンソースモデルの中でトップクラスの性能を示し、特に専門的な科学タスクではクローズドソースの最先端モデルを上回る結果を達成
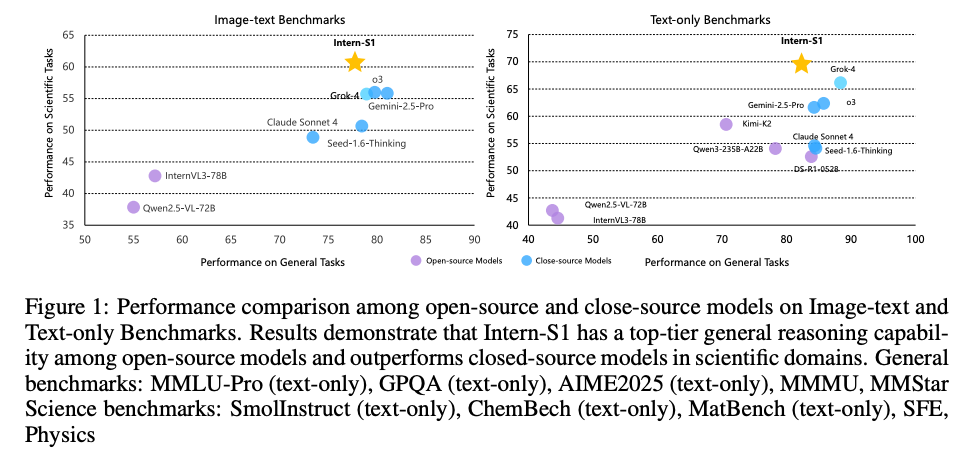
1 Introduction
- 科学研究はAGI開発の究極的な目標の一つであり、AIに極めて高い能力が必要
- 既存のオープンソースモデルは一般的な分野で大きな進歩を遂げたものの、専門性が高く価値のある科学分野ではクローズドソースモデルとの間に大きな性能差あり
- この性能差を埋めるため、Intern-S1は画像、テキスト、分子構造や時系列信号といった多様な科学データを処理できるマルチモーダルモデルとして開発
- How can we enhance a model’s capability to tackle low-resource tasks in a scalable way?
- 事前学習
- recall and filtering pipeline: ウェブデータマイニングのAgent workflow → データのpurityを2~50%改善
- page-level PDF document parsing pipeline: 2.5 trillion tokens
- 事後学習
- Mixture of Reward (MoR): RLにおける多様なタスクの報酬を共通の報酬スカラーに集約し、効率化
2 Model Architecture
- Intern-S1のアーキテクチャは多様な科学データを効率的に処理するために、専門化された複数のエンコーダを統合した設計
- 具体的には、視覚情報、構造化された科学データ(分子構造など)、時系列信号という3つの異なるモダリティに対応するため、それぞれに最適化されたアプローチを採用
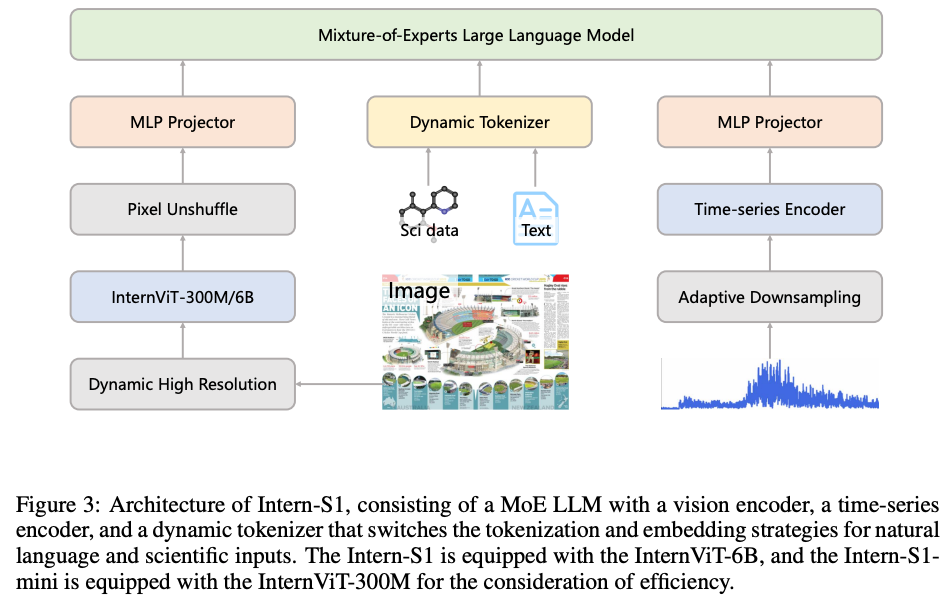
2.1 VISION ENCODER
視覚情報を処理するため、Intern-S1はInternViTシリーズのVision Transformer(ViT)を採用。モデルの規模に応じて、2種類のエンコーダを使い分ける
- Intern-S1 (フルモデル): InternViT-6B を使用。60億パラメータを持つ大規模エンコーダで、高解像度で詳細な視覚表現を生成する能力に優れている
- Intern-S1-mini (軽量モデル): 計算効率を考慮し、InternViT-300M を採用。InternViT-6Bから蒸留されたコンパクトなモデル
両エンコーダとも固定の入力サイズ(448x448ピクセル)だけでなく、動的な解像度にも対応可能で、高解像度のコンテンツをより効果的に処理可能。エンコーダから出力された視覚トークンは、 という技術でトークン数を4分の1に削減
2.2 DYNAMIC TOKENIZER
静的トークナイザー(Static Tokenizer)の問題がありました。静的トークナイザーでは自然言語と分子式のような専門的な科学データを同じ戦略で分割して埋め込むため、特に科学データに対して非効率という課題
動的トークナイザー(Dynamic Tokenizer)を提案
- モダリティの識別: 入力された文字列の中から、のような特別なタグや、RDKitのようなドメイン固有のツールを用いて、自然言語、分子構造(SMILES形式)、タンパク質配列(FASTA形式)などの異なるモダリティを識別
- はSMILES形式で分子を表現
- RDKit等のツールを用いて分子やタンパク質の文字列を判定
- 分割と埋め込み: 識別された各部に対して、それぞれに最適化された異なる分割戦略を適用。各モダリティの埋め込み空間をConcat。
- 例えば「C」という文字がDNA配列で使われる場合と分子式で使われる場合で、異なる意味表現を持つことを可能にする。「C」がDNA配列、分子式、選択問題の選択肢で登場してバイアスがかかる課題に対処

この動的トークナイザーにより、Intern-S1は科学データ(SMILES形式)において、OpenAIやDeepseekなどの他のモデルと比較して圧縮率(1トークンあたりの文字数)を最大70%向上させることに成功
2.3 TIME SERIES ENCODER
地震波、重力波、天文光度曲線など、時間経過と共に記録される連続的な数値データを扱うために、時系列エンコーダを統合
これらのデータは長大で連続的で明確な意味構造を持たないため、LLMが直接扱うには不向き
時系列エンコーダ
- 適応的ダウンサンプリング: 生の時系列信号を直接受け取り、専用の適応的ダウンサンプリングモジュールで情報を圧縮
- Transformerベースの処理: ダウンサンプリングされた後、Transformerベースのブロックで処理され、時間的な依存関係を捉えた表現に変換
これにより、サンプリングレートや期間が大きく異なる多様な科学的時系列信号を統一的に表現し、LLMが理解・推論しやすい形式に変換。画像モダリティを補完し、モデルが多様な科学データを理解する能力をさらに強化する
3 Infrastructure
Intern-S1の事前学習、事後学習を支えるインフラは、LLMの効率と安定性を最大化するために並列化技術、低精度計算、カスタム最適化を組み合わせて構築
「事前学習・SFT」と「強化学習(RL)」の異なるパラダイムに最適化
3.1 PRE-TRAINING AND SFT INFRASTRUCTURE
事前学習やSFTのような、Next token predictionをベースとするタスクでは以下の技術を活用
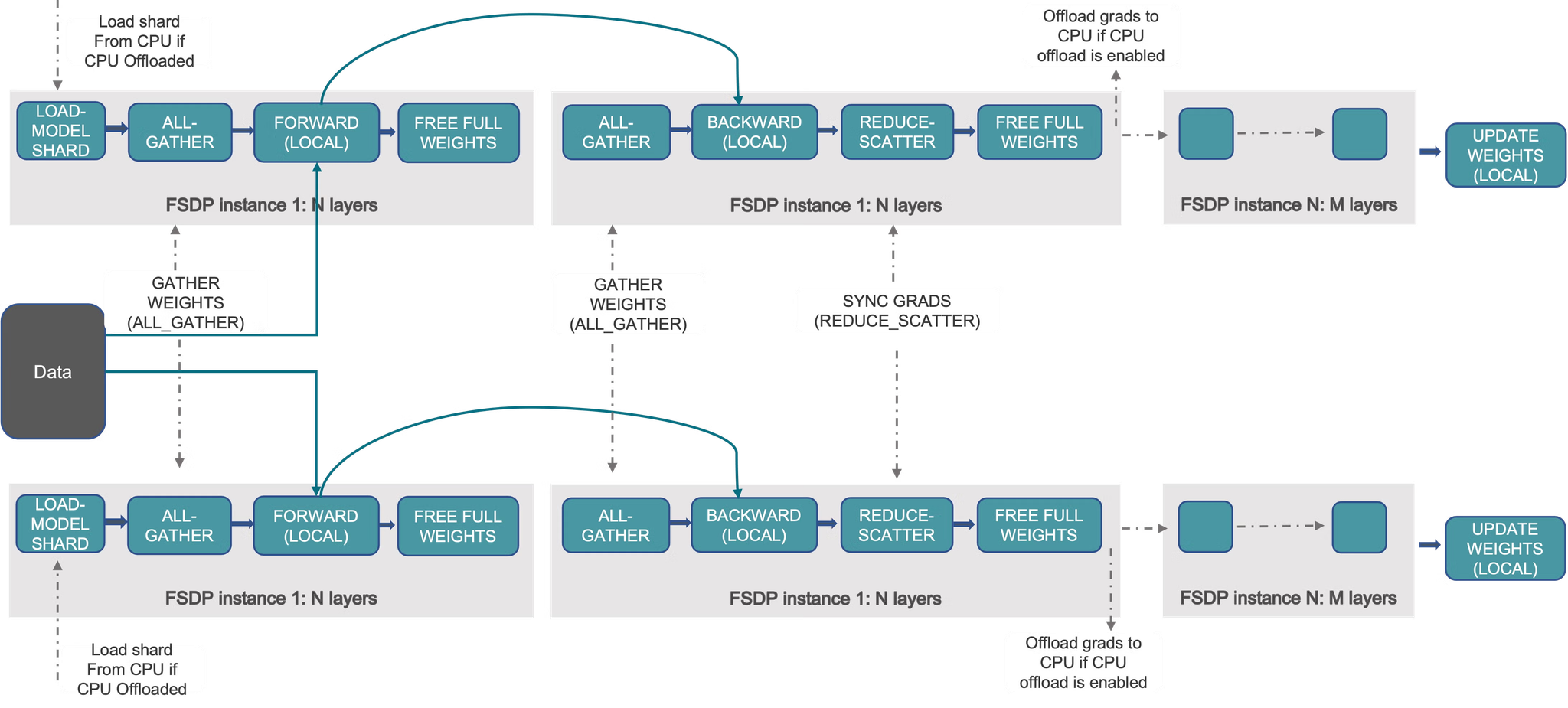
- 並列化: モデルのパラメータを複数のGPUに分散させるために、FSDP(Fully Sharded Data Parallelism)を採用
- FSDP is a type of data-parallel training, but unlike traditional data-parallel, which maintains a per-GPU copy of a model’s parameters, gradients and optimizer states, it shards all of these states across data-parallel workers and can optionally offload the sharded model parameters to CPUs. Usually, model layers are wrapped with FSDP in a nested way, so that only layers in a single FSDP instance need to gather the full parameters to a single device during forward or backward computations. The gathered full parameters will be freed immediately after computation, and the freed memory can be used for the next layer’s computation. In this way, peak GPU memory could be saved and thus training can be scaled to use a larger model size or larger batch size. To further maximize memory efficiency, FSDP can offload the parameters, gradients and optimizer states to CPUs when the instance is not active in the computation.
- FP8トレーニング: 計算効率を向上させるため、行列積(GEMM)にFP8(8ビット浮動小数点数)精度での計算を導入
- ただし学習の安定化のため、Vision tower(ViT)はBF16精度を維持
- 高速化カーネル: 複数のカスタムカーネルを導入し、計算をさらに効率化
- Grouped GEMMカーネル: MoEアーキテクチャで発生する動的なグループサイズに対応し、メモリと計算のオーバーヘッドを削減
- Liger-kernel: 線形層とクロスエントロピー層の計算を融合させ、処理を高速化
- Flash Attention-3: 可変長のシーケンスに対応したFlash Attentionを利用
- 可変長バランシング戦略 (Variable-Length Balanced Strategy, VLBS): FSDPで可変長のシーケンスデータを学習させると、GPU間の計算負荷に著しい不均衡が生じる問題がある。この課題を解決するため以下3ステップを実行。全GPUの計算負荷が均等になり、学習フレームワークにおいて平均2倍の高速化を実現
- ドキュメントをランダムにバケットに詰める
- スライディングウィンドウを適用し、バケットをグループ化する
- 各ウィンドウ内で、シーケンスの最大長に基づいてソートする
3.2 RL INFRASTRUCTURE
強化学習フェーズでは、データ生成(ロールアウト)とポリシー更新を高速に繰り返すため、専用のインフラを構築
- 並列化: FSDPと1-way Expert Parallelismを組み合わせて使用。この構成は、エキスパート間の通信を不要にし、長いシーケンスを学習する際にMoEモデルで発生しがちなメモリの爆発的な増加を防ぐ
- FP8トレーニングと推論: ロールアウトのスループットを最大化するため、学習と推論(データ生成)の両方でFP8精度を利用。メモリ帯域幅への圧力が大幅に軽減され、計算スループットが向上
- コロケーション設計: 学習エンジンと推論エンジンを同じデバイスセット上に配置する設計
- ロールアウト: データ生成(推論)は、LMDeployというサービングフレームワークを用いて、8-way Expert Parallelismで実行。重みはFP8形式で保存され、メモリフットプリントを最小限に抑制。CPUオフロードと継続的バッチングの両方を有効にしてスループットを最大化
4 Continue Pre-training

継続事前学習は高品質な科学データを大規模に活用し、独自の学習戦略を適用することで、モデルの専門性と汎用性を両立させることを目指す。
「科学データの準備」と「学習戦略」
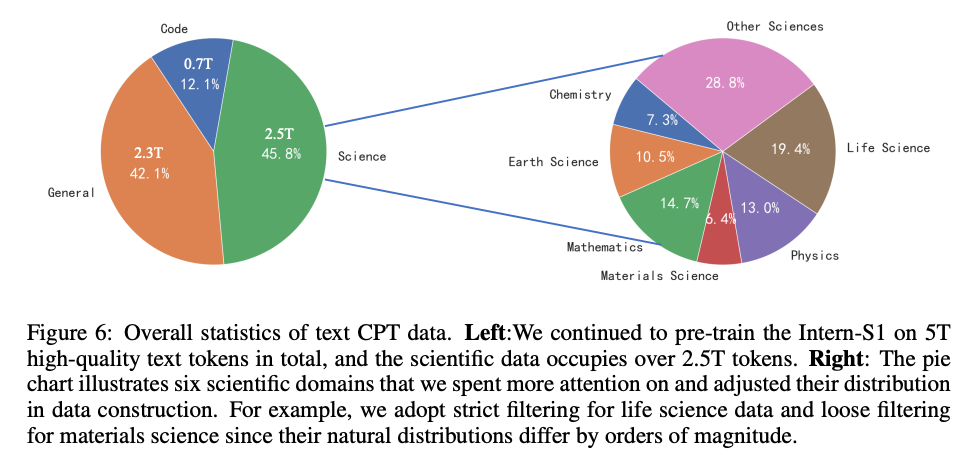
4.1 SCIENTIFIC DATA
合計5兆トークンに及ぶ継続事前学習データのうち、半分近い2.5兆トークン以上が科学分野のデータ
4.1.1 テキストデータ
高品質な科学テキストデータを大規模に収集するため、以下の3つの独自パイプラインを用意
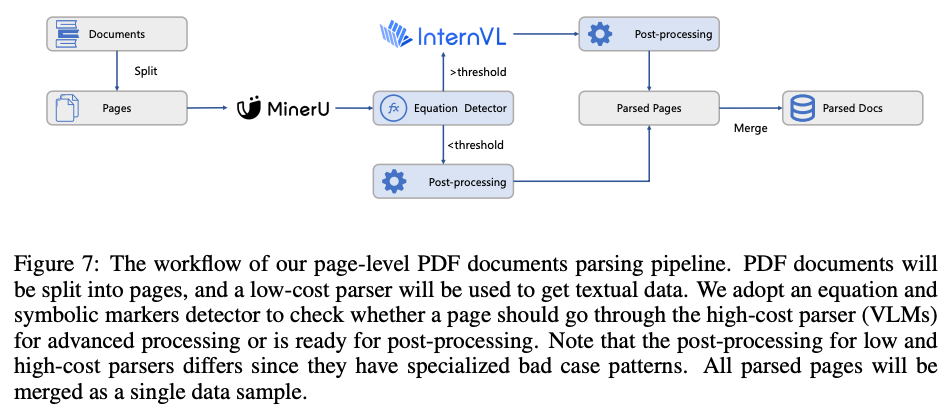
- Page-level PDF documents parsing Webやアーカイブから収集したPDF文書は科学知識の宝庫だが、その解析品質がモデル性能に直結。特に数式や記号が多い文書は解析が困難
- 全てのページを低コストのパーサー(MinerU)で処理
- 次に、数式や記号の数を検出し、解析が不十分である可能性が高いページのみを、高コストなVLM(InternVLやQwen-VL)で再処理
そこで、コストと品質のバランスを取るため、ハイブリッドな解析パイプラインを構築。アーカイブ文書の5%、Web収集PDFの3%のページを高コストパーサーで処理するだけで、全体の品質を担保
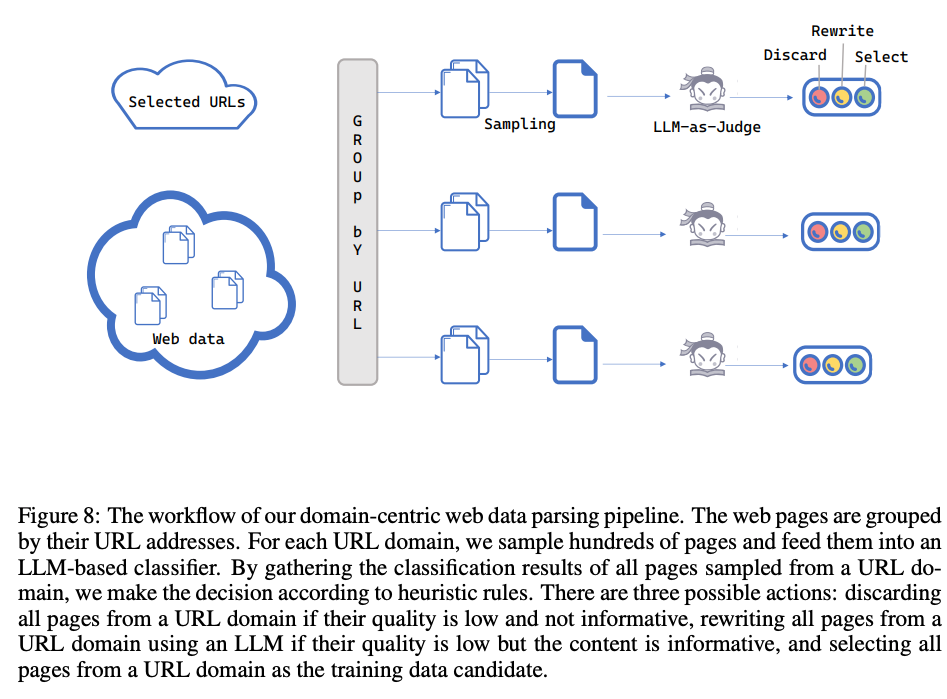
- Domain-centric web data parsing Webページはドメイン(URL)ごとに特性が大きく異なるため、画一的な処理では品質を保つことが困難。
- この問題に対し、URLドメイン単位でページをグループ化し、各ドメインから数百ページをサンプリングしてLLMベースのエージェントに評価させる手法を導入
- エージェントはそのドメイン全体の品質を判断し、「破棄」「LLMによる書き直し」「選択」のいずれかのアクションを決定。低コストな分類器では見逃してしまうような構造的な問題を効率的に特定し、対処することが可能
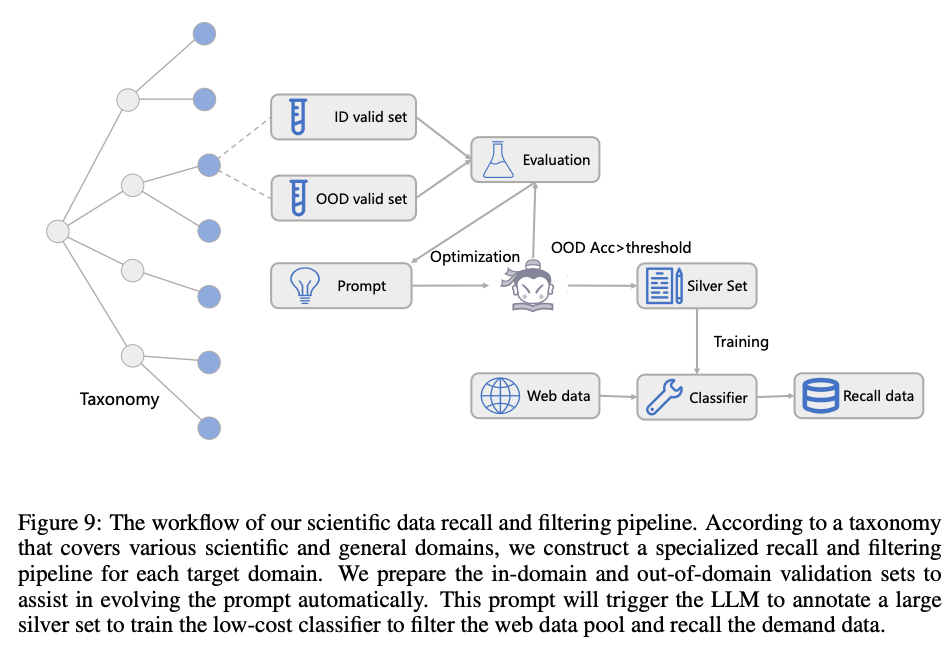
- Scientific data recall and filtering 一般的なWebデータに含まれる科学関連のテキストはわずか2%程度。
- モデルの科学的能力を強化するため、この中から関連データを効率的に「リコール(抽出し)」「フィルタリング」する必要あり
- 6つの主要な科学ドメイン(Mathematics, Physics, Chemistry, Life Science, Earth Science, and Materials Science)を設定し、LLMを用いてアノテーションしたデータで軽量な分類器(fastTextモデルや小規模LLM)を学習
- この分類器を用いて大規模なWebデータをフィルタリングした結果、対象ドメインのデータ比率を2%から50%まで引き上げる
4.1.2 MULTI-MODAL DATA
テキストのみの学習後、画像とテキストを組み合わせたマルチモーダル学習に移行
- 学習データは合計で約2500億トークン
- 言語データが700億
- 画像-テキストデータが1800億(うち300億が科学データ)
- データ品質を確保するため、図や数式、表などの科学的構造を保持し、視覚情報と周囲のテキストを正しく関連付けることを目的としたパイプラインを構築
- VLMで設問と選択肢の整合性チェックや、数式が正しくレンダリングされるかの検証
4.2 TRAINING STRATEGY
高品質なデータを最大限に活かすため、以下の学習戦略が採用
- バッチサイズウォームアップ 学習の初期段階では、小さいバッチサイズの方がモデル性能が向上しやすい一方、大きいバッチサイズの方がインフラ効率は高まるというジレンマ
この問題に対し、Intern-S1では学習初期に小さいバッチサイズ(4Mトークン)を使用し、学習が進んだ段階で大きいバッチサイズ(10Mトークン)に切り替える戦略を採用
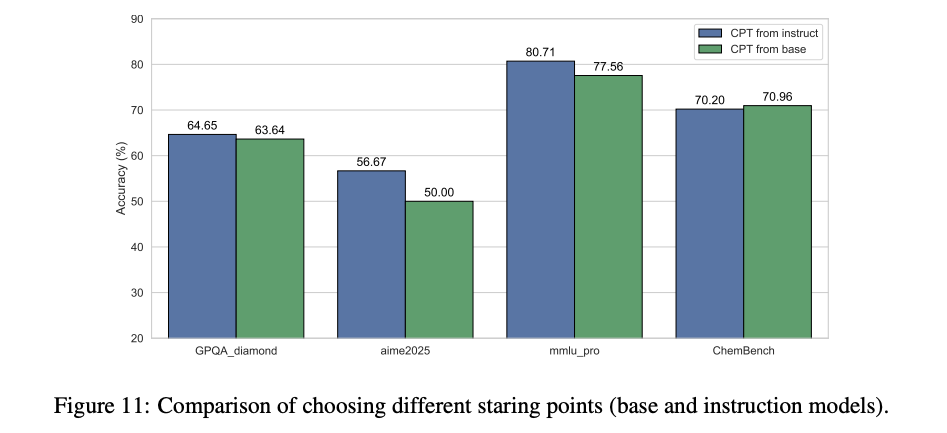
- 開始点の選択 継続事前学習を「ベースモデル」から始めるか、「インストラクションモデル(対話用に微調整されたモデル)」から始めるか
実験の結果、インストラクションモデルから開始する方が、最終的により良い性能に繋がる。特に、ポストトレーニングによって特定の能力(例:コーディング)が新たに獲得・強化されるドメインでその傾向が顕著
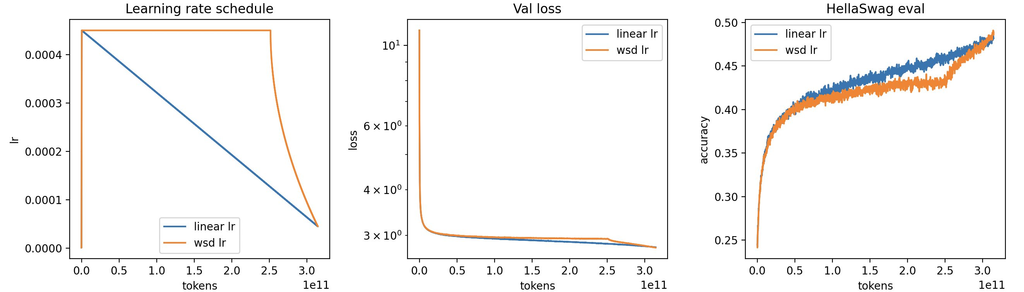
- ハイパーパラメータ Xtuner: ‣ を活用 学習率やバッチサイズといったハイパーパラメータはスケーリング則に基づいて科学的に決定
- WSD(Warmup-Stable-Decay)学習率スケジューラと、勾配ノイズとバッチサイズの関係式に基づき、学習の進行に合わせてバッチサイズを66Mから132Mトークンへと増加
- 学習プロセスで、各ステップにおける学習損失と学習率の関係性を計測し、最適な学習率を算出
- 学習プロセスは安定しており、損失スパイクなし
- 最終的な学習損失は、スケーリング則による予測値1.16に対し、実績値が1.17~1.18となり、極めて高い精度で学習品質をコントロール
- マルチモーダル学習
- マルチモーダル学習の段階では、LLMの一部を凍結する一般的なアプローチとは異なり、ビジョンエンコーダを含む全てのモデルパラメータを同時に更新
5 Post-training
2段階のポストトレーニング: 高品質なデータを用いた「オフライン強化学習(SFT)」、多様な報酬を統合する「オンライン強化学習」
5.1 OFFLINE REINFORCEMENT LEARNING
一般的にSFTと呼ばれるが、本研究では使用するデータがBoN(Best-of-N)サンプリング(複数の応答候補から最良のものを選ぶ報酬ベースの手法)のため、「オフライン強化学習」と位置づけ
5.1.1 INSTRUCTION DATA CURATION
- テキストのみのデータ 多様なカテゴリのデータを補強:Agent, Code, General Dialogue, Instruction Following, Mathematics, Reasoning, Long Text, Safety, Chemistry, Life Sciences, and Physics データの品質と多様性を確保するため、「フィルタリング」「ラベリング」「エンハンスメント」のコンポーネントからなるパイプラインを開発
- フィルタリング: ルールベースとモデルベースの手法を組み合わせ、繰り返し表現や不完全なデータ、ハルシネーションを含むコンテンツなどを排除
- ラベリング: データは「カテゴリ」(最低3段階で定義。例:数学→応用数学→線形代数)と「難易度」の2軸で分類。難易度は、正解がある場合は小規模モデルの正答率で、ない場合はドメイン固有の基準で決定
- エンハンスメント: データが不足している or 品質が低いドメインについては、応答を再構築したり、合成データを生成したりしてデータセットを補強
- マルチモーダルデータ
視覚-言語推論データを追加し、モデルの思考能力を強化。科学分野における専門能力を高めるため、科学ドメインに特化したvision language instruction dataを補強
5.1.2 DATA MIXTURE EXPERIMENTS
キュレーションしたデータを用いて、最適な性能を引き出すためのデータ混合比率を決定
- Atomic Capability Validation: コアとなるデータセットに各ドメインのデータを個別に追加学習させ、それぞれのデータセットが対応するベンチマークの性能向上に寄与するかを検証
- Compositional Capability Validation: 効果が確認された全てのデータセットを統合し、ドメイン間のデータ競合を解消しながら、最終的な混合比率とハイパーパラメータを決定
5.2 ONLINE REINFORCEMENT LEARNING
5.2.1 Mixture-of-Rewards (MoR) フレームワーク
事後学習の第2段階では1000以上のタスクを同時に強化学習する
MoRは、論理推論、学術問題、指示追従、対話など、性質が全く異なる複数のタスクからの多様な報酬シグナルを一つの最適化プロセスに統合するフレームワーク。個別の能力を単独で伸ばすのではなく、専門的能力と汎用的な対話能力をバランスよく獲得させる
- 課題: 複数のタスクを同時に学習させると、タスクごとの難易度や収束速度が異なるため、一部のタスクに過学習したり、他のタスクの学習が不十分になったりする
- 解決策: この問題を解決するため、「オフライン」と「オンライン」を組み合わせたハイブリッドなデータフィルタリング戦略を導入
- オフライン戦略: 事前に各タスクの難易度と収束速度を個別に評価し 、その結果に基づいて最終的な学習データの混合比率を決定
- オンライン戦略: 学習中に、必要量より多くのデータを生成し 、その中から精度や品質などの基準で優れたデータだけをリアルタイムで選別
- 効果: この組み合わせにより、タスク間の性能バランスを保ち、過学習や学習不足を防ぎながら、全体の学習効率を高める
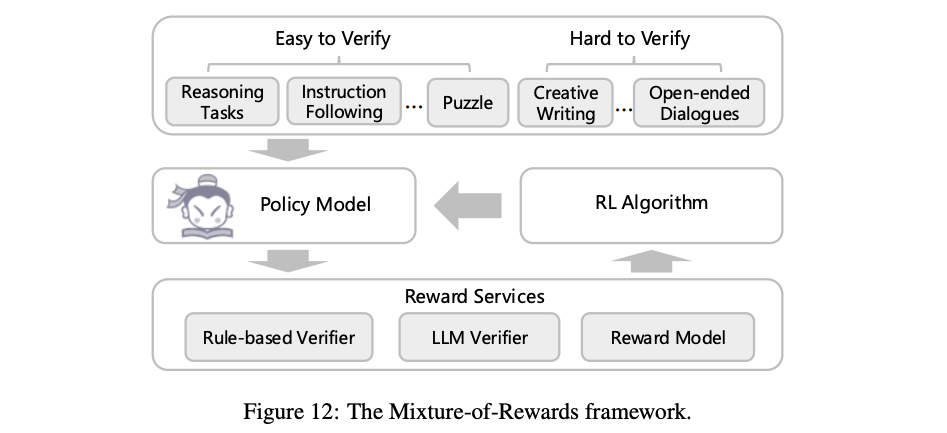
5.2.2 TASKS AND VERIFIERS
- Large scale sandboxes: InternBootcampという環境を利用し、アルゴリズム、暗号解読、物理方程式など、正解がプログラムで検証可能な1000種類以上の合成タスクを生成
- Multi-modality reasoning tasks: 数学や科学VQAなど、明確な正解が存在するタスクでは、Compass Verifierという軽量な生成モデル型検証機とルールベースの検証機を組み合わせる
- Human preference alignment: クリエイティブライティングや自由対話など、正解が一つに定まらないタスクでは、POLAR-7Bという報酬モデルを使用。応答の絶対的な良し悪しではなく、2つの応答の相対的な優劣を評価することで、よりスケーラブルで汎用的な報酬を提供
5.2.3 POLICY OPTIMIZATION
MoEモデルにGRPOのような強化学習を適用すると、推論時と学習時で活性化されるエキスパートが微妙に異なるため、学習が不安定になる深刻な課題がある
The fundamental issue arises from the computational discrepancy between the inference engine and the training engine. In our training framework, the kernels used in these two engines are different, which leads to slight numerical differences. In large-scale MoE models, the use of dynamic expert routing and FP8 quantization significantly amplifies this discrepancy, causing a mismatch between the experts activated during inference and training. As a result, the policies used during inference and training diverge significantly, making the process more off-policy than intended. … token-level clipping based on the ratio of new and old policy logprobabilities is unreliable for MoE models due to the differences in expert routing.
- この問題に対処するためOREALアルゴリズムを採用
- 良いサンプル(ポジティブ)にはSFT(教師ありファインチューニング)を、悪いサンプル(ネガティブ)には方策勾配法を適用
- 高速化: オリジナルのOREALは、トークン単位で報酬を計算するモデルが必要で計算コストが高すぎたため、高速化のためにこのトークンレベルの報酬モデルを削除
- エントロピー崩壊の防止: 報酬モデルを削除した副作用で、モデルが多様な出力を生成する能力(探索能力)を失ってしまう「エントロピー崩壊」が発生
- これを防ぐため、損失関数にKLダイバージェンス制約項(KL-Cov)を追加し、モデルの探索能力を維持
5.2.4 EXPERIMENTS
- Hybrid data filtering strategy: オフラインで簡単すぎる問題やノイズの多い問題を除外し、オンラインで学習に不向きなデータ(全て正解または全て不正解のデータ)を除外する戦略により、学習効率を大幅に向上
- Entropy control: KL-Cov戦略により、学習を通じてモデルのエントロピーが約0.2に維持され、探索能力を失うことなく継続的に正答率が向上
- DAPOと比較
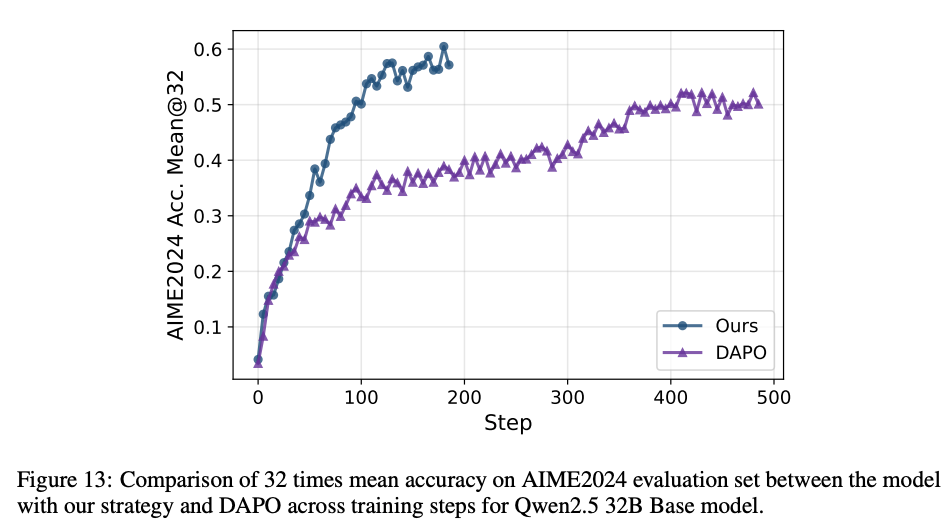
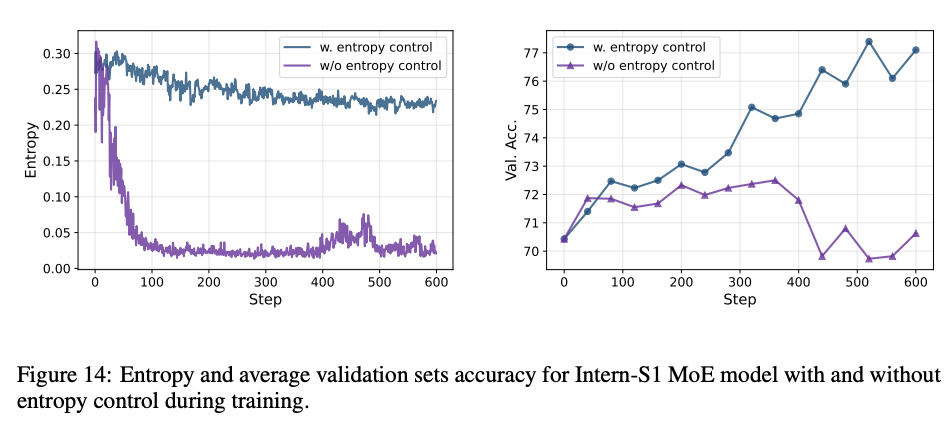
6 Evaluation
「一般推論能力(general reasoning)」と「科学推論能力(scientific reasoning)」の領域にわたって、テキストのみおよびマルチモーダルのベンチマークで評価
6.1 EVALUATION CONFIGURATION
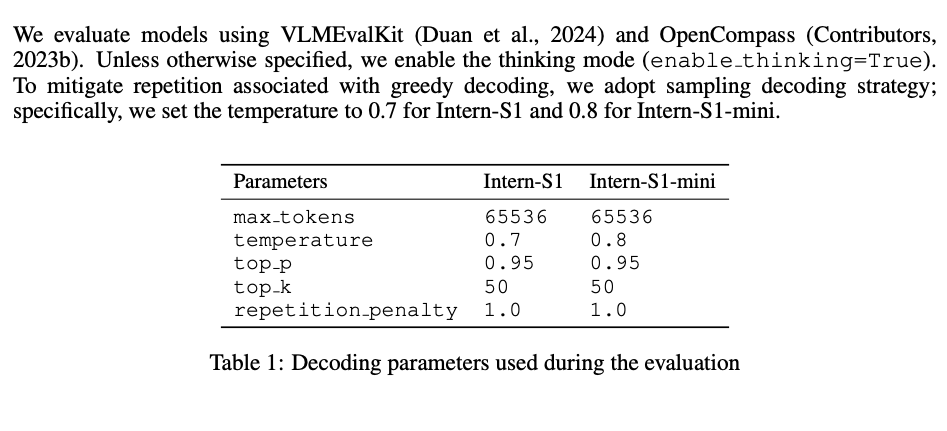
- 評価ツールキット: VLMEvalKitとOpenCompass
- デコーディング戦略: モデルが性急な回答を生成するのを防ぎ、より深い思考を促すため、thinking modeを有効化。greedy decoding(最も確率の高いトークンを選ぶ)に伴う繰り返しを避けるため、サンプリングデコーディング戦略を採用
6.2 BENCHMARKS
評価には、モデルの能力を様々な側面から測るため、影響力と代表性の高いベンチマークが選定されました 。
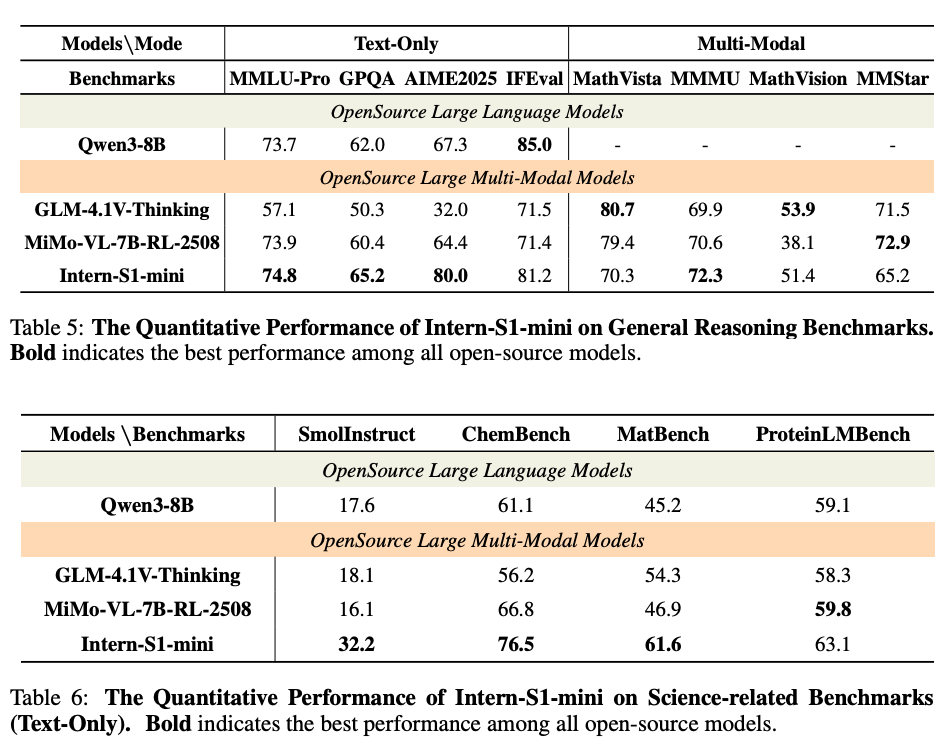
6.2.1 一般推論ベンチマーク
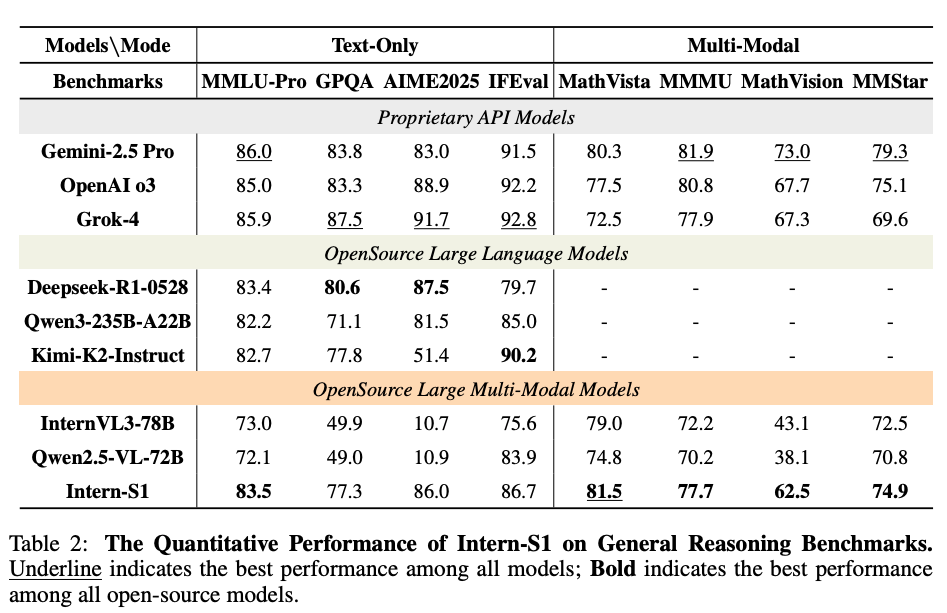
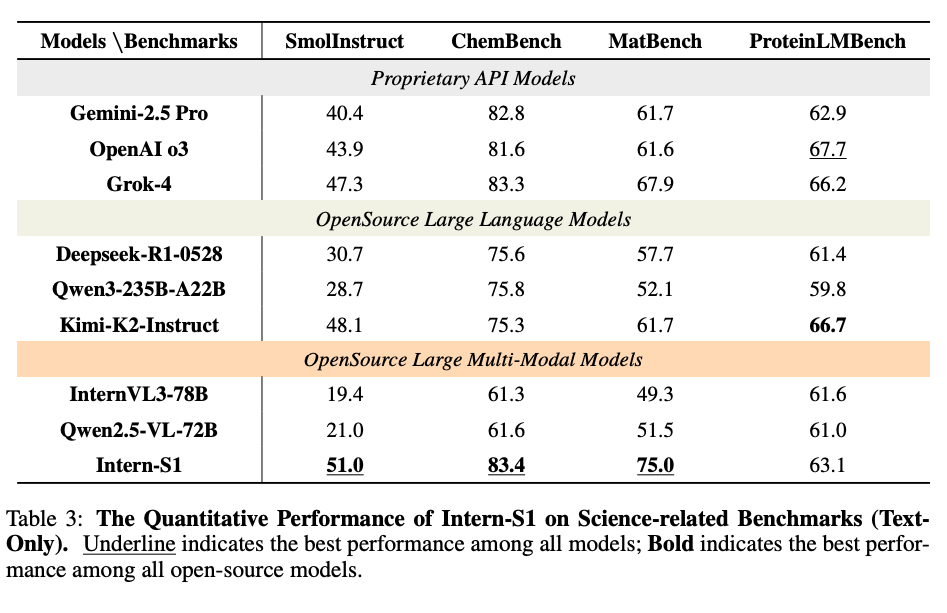
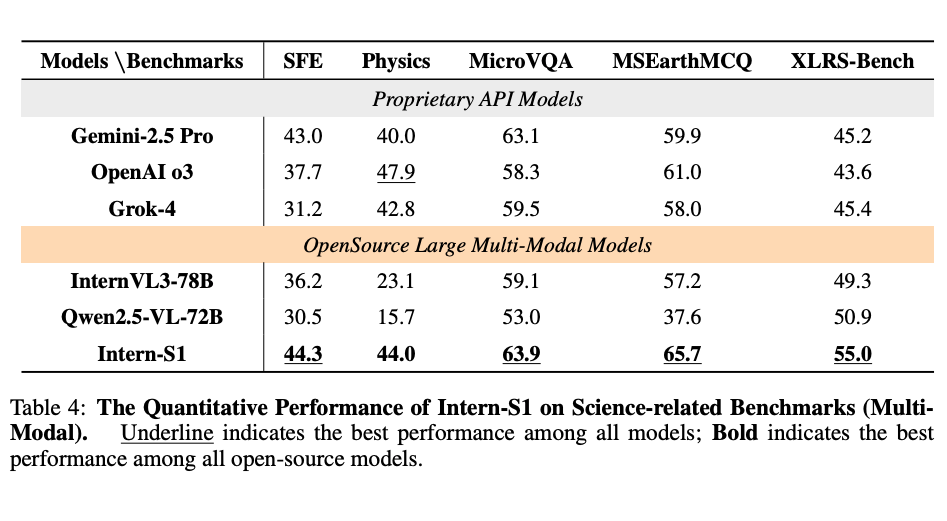
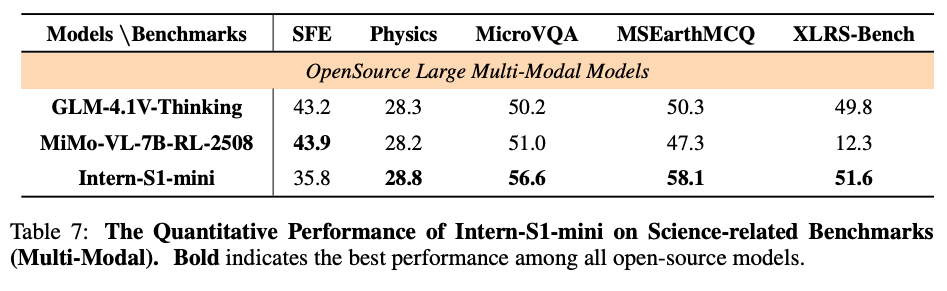
6.2.2 科学推論ベンチマーク