
2025-09-02 機械学習勉強会
今週のTOPIC[論文] On the Theoretical Limitations of Embedding-Based Retrieval[blog] How we built Agent Fill[論文] Efficient Code Embeddings from Code Generation Models[blog] Uber が社内で運用している会計部門向けのAIエージェント『Finch』[slide] AIグラフィックデザインの進化:断片から統合(One Piece)へ / From Fragment to One Piece: A Survey on AI-Driven Graphic Design[論文] Vision-Guided Chunking Is All You Need: Enhancing RAG with Multimodal Document UnderstandingメインTOPICT-GRAG: A Dynamic GraphRAG Framework for Resolving
Temporal Conflicts and Redundancy in Knowledge RetrievalAbstractIntroductionTemporal GraphRAGTemporal Knowledge Graph GeneratorTemporal Query DecompositionThree-layer Interactive RetrieverLLM Augmented GeneratorTime-LongQA Dataset実験Overall PerformanceTemporal Query Decomposition: TQDの効果。Impact of Retrieved Unit Count. まとめAppendix(面白かったとこだけDocBenchプロトコルナレッジグラフ構築プロンプトデータセット生成プロンプトponの感想
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] On the Theoretical Limitations of Embedding-Based Retrieval
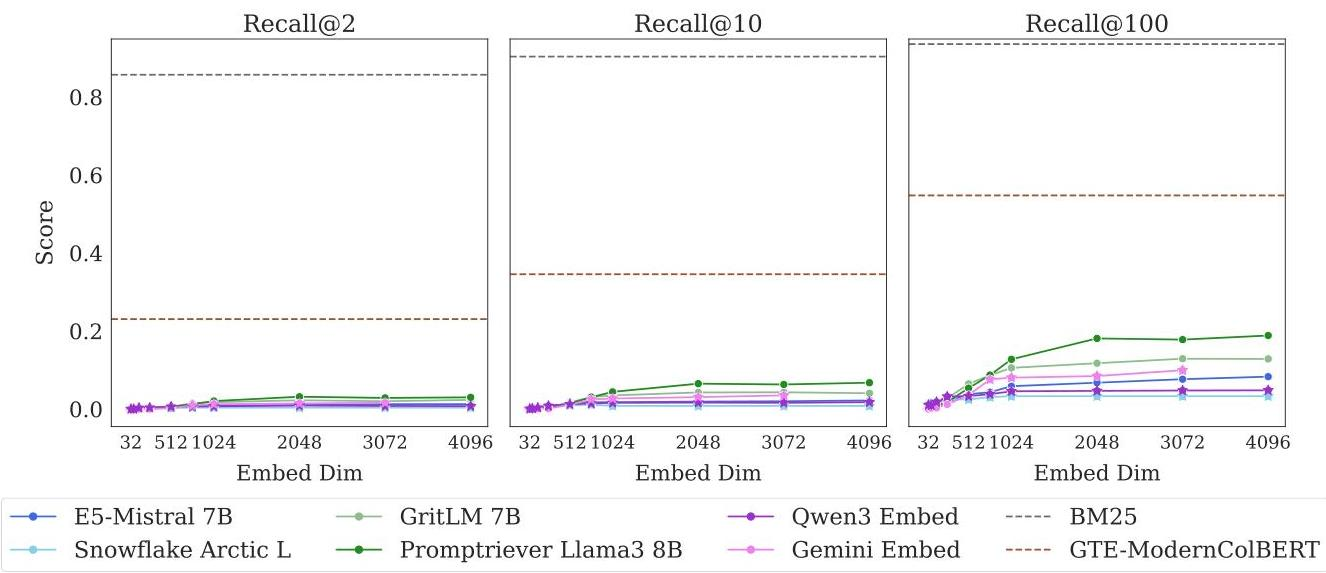
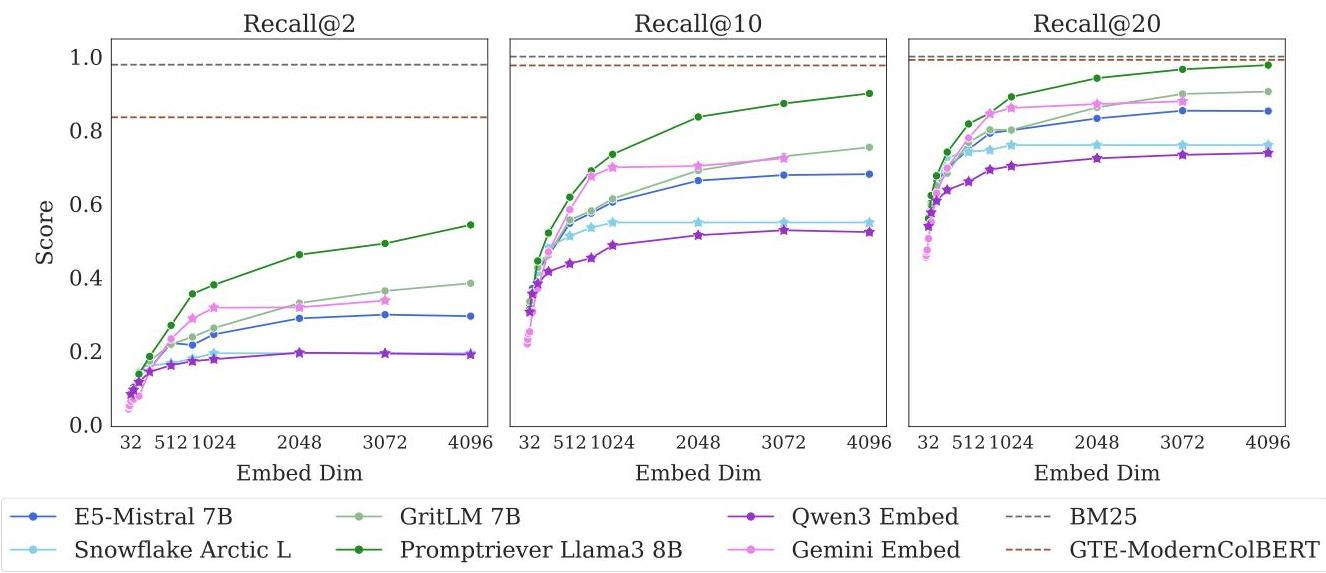
- ベクトル検索は世の中で主要な検索方法になっているが、数学的な限界はなんなのか?という論文
- クアッカワラビー好きなのは誰?のような単純な自然言語を用いたクエリデータセットのLIMITを提案し、世の中でよく使われているEmbeddingが上手くいかないよっていうのを数理的にも証明
- 左の図のようにqとdを組み合わせて右のデータセットを作成する
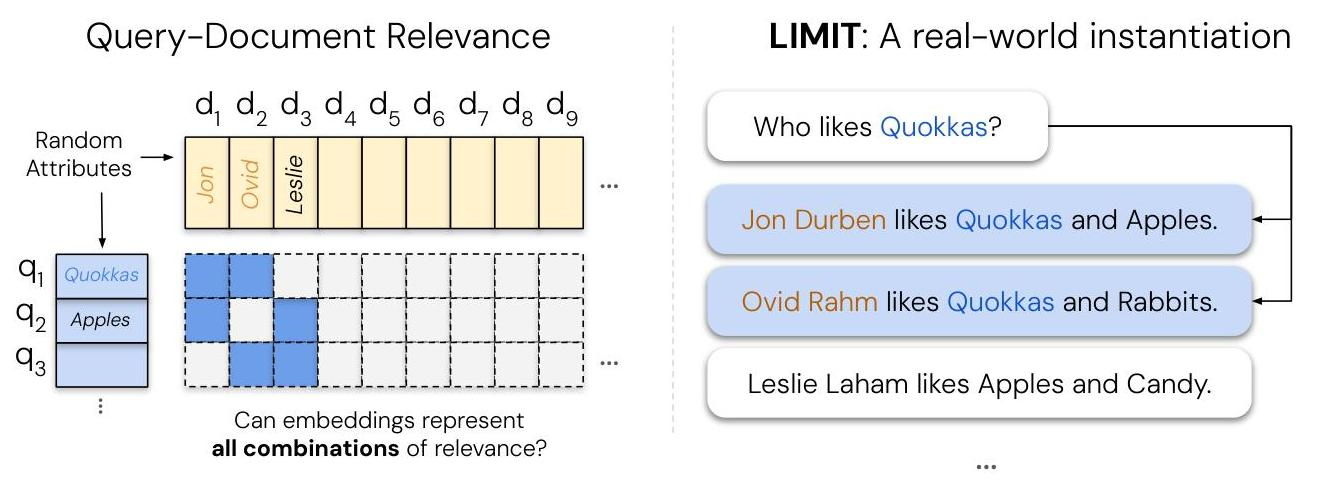
- Query Embedding とDocument Embedding を用いて上の図の左側の行列を再現するのが目標
- のrankは の次元 になる
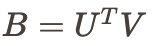
- この を再現する難しさをAのrankを用いて表現できる。
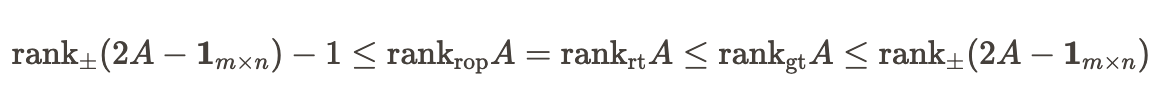
- つまり、 を超えるrankのAを作ってしまえば、どんな高次元のベクトルを持ってきたとしても を再現することができなくなってしまうということ
- B ⇒ Aに近づけるように学習させていくLeakyな実験を実際に実行
- dを増やせばドキュメントの組み合わせが増えても再現できるようになるが、3次元関数的に必要次元数が増えている
- Webレベルで50万文書に対しては4096次元でも対処できないことがわかった
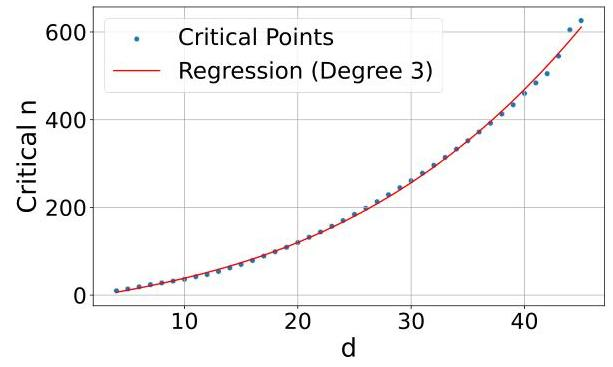
- LIMITで実験
- rankの話から色々な組み合わせが要求される質問が一番難しいと仮定
- Xが好きなのは誰? ⇒ Xは、[好きなもの1], [好きなもの2], ... が好きです というデータセットを作成
- BM25のような古典的なキーワード検索モデルや、ColBERTのようなマルチベクトルモデルは、単一ベクトルの埋め込みモデルよりはるかに良い性能
- 文書が46くらいのサイズでも全然ダメ
@Yuya Matsumura
[blog] How we built Agent Fill
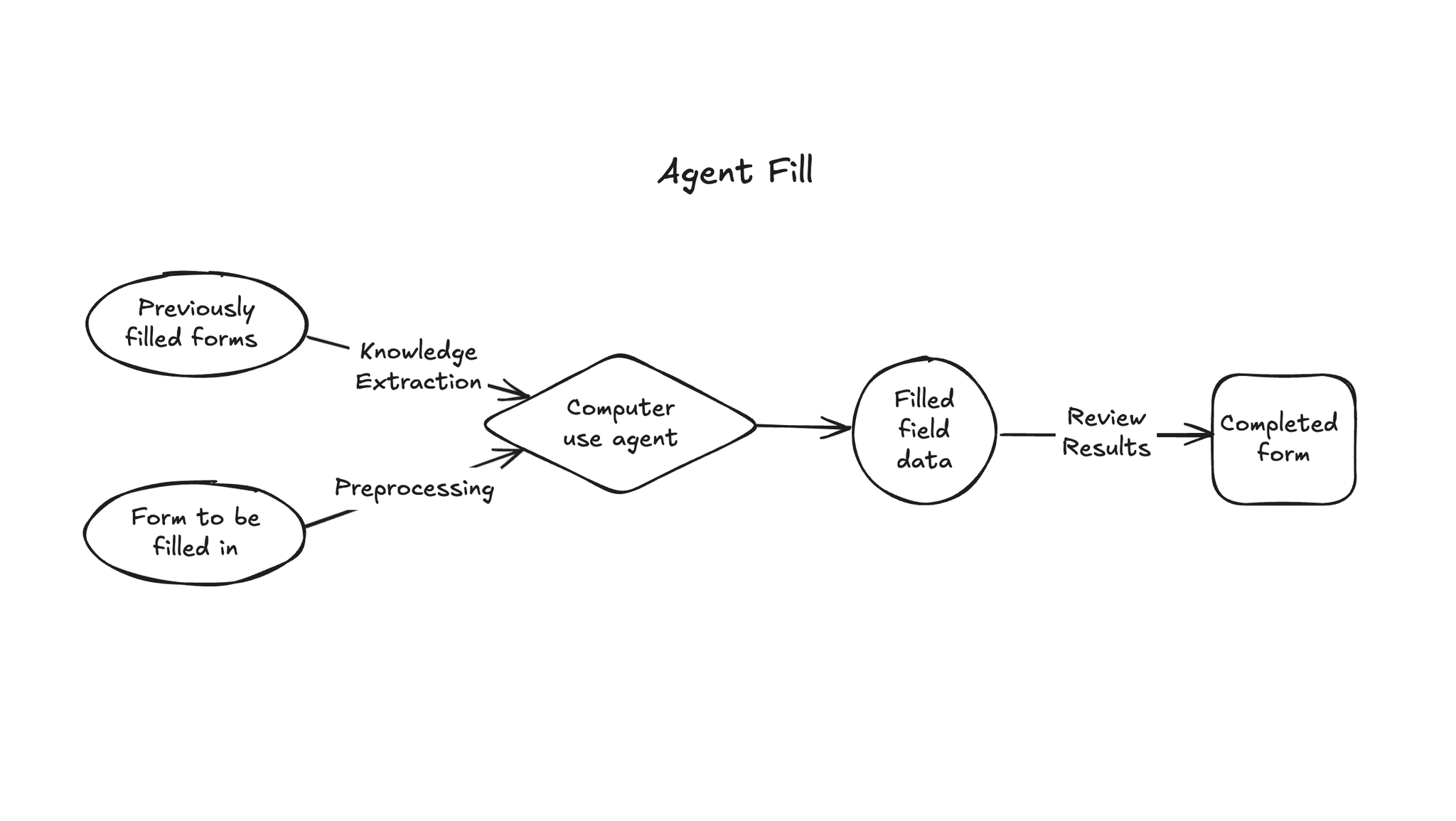
- ramp社のエージェント型PDFフォーム入力ツール “Agent Fill”
- みんな大嫌いなPDFへの情報入力をやってくれるAI Agent プロダクト。
- https://labs.ramp.com/agent-fill
- 過去に記入されたフォームからの知識抽出による必要コンテキストの収集は生のPDFをGemini 2.5 Proに突っ込む。Geminiのマルチモーダル力への期待。
- 記入対象のフォームの構造理解は、OCRしたテキストと、pymupdfで得たPDFウィジェットをClaude Sonnet 4に突っ込んで獲得。Claudeのスキーマ忠実性に期待。
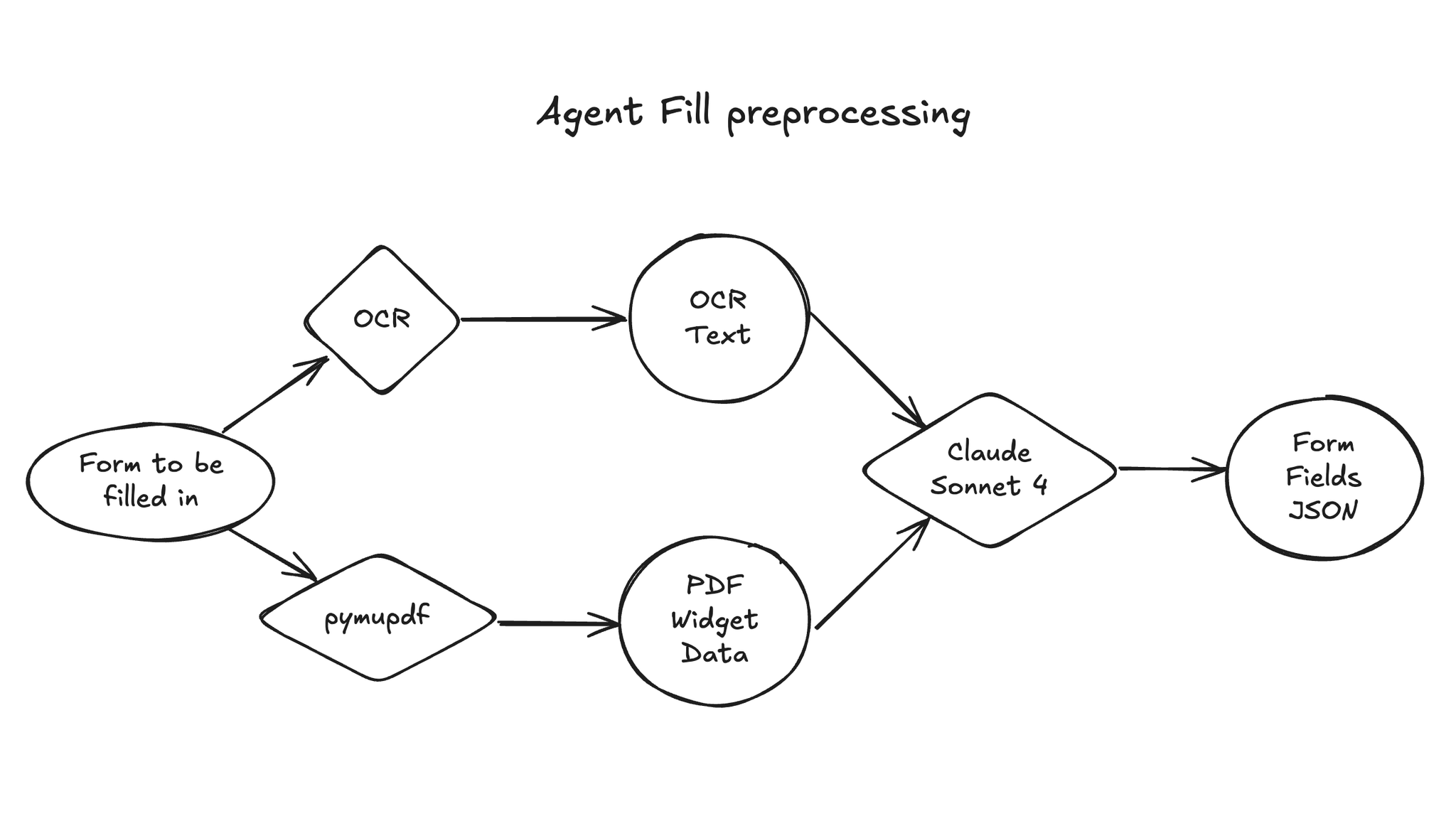
- 以上を組み合わせて Computer use で入力
- もちろん間違うこともあるのでHITLを体験よく行うためにPDFエディタを開発!
- JSAIの企業展示のPDF(2024年分を参考データとして、空の2025年分のPDFを埋めさせてみた)で実験
- なんか壊れた(たぶん元が日本語エクセルなのが悪いか)けどなんか入力できているイキフン
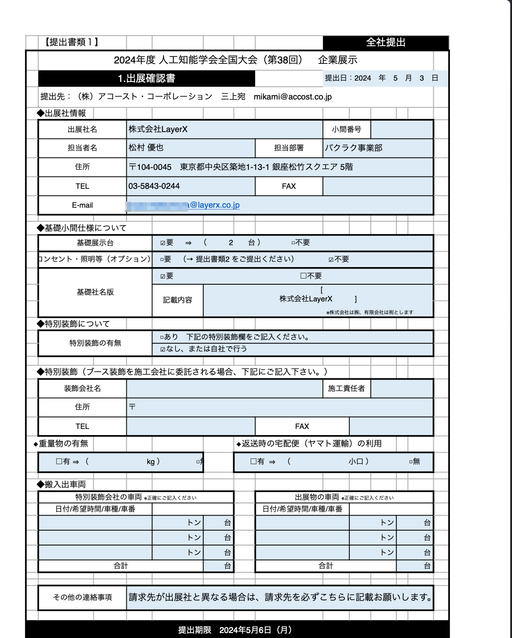

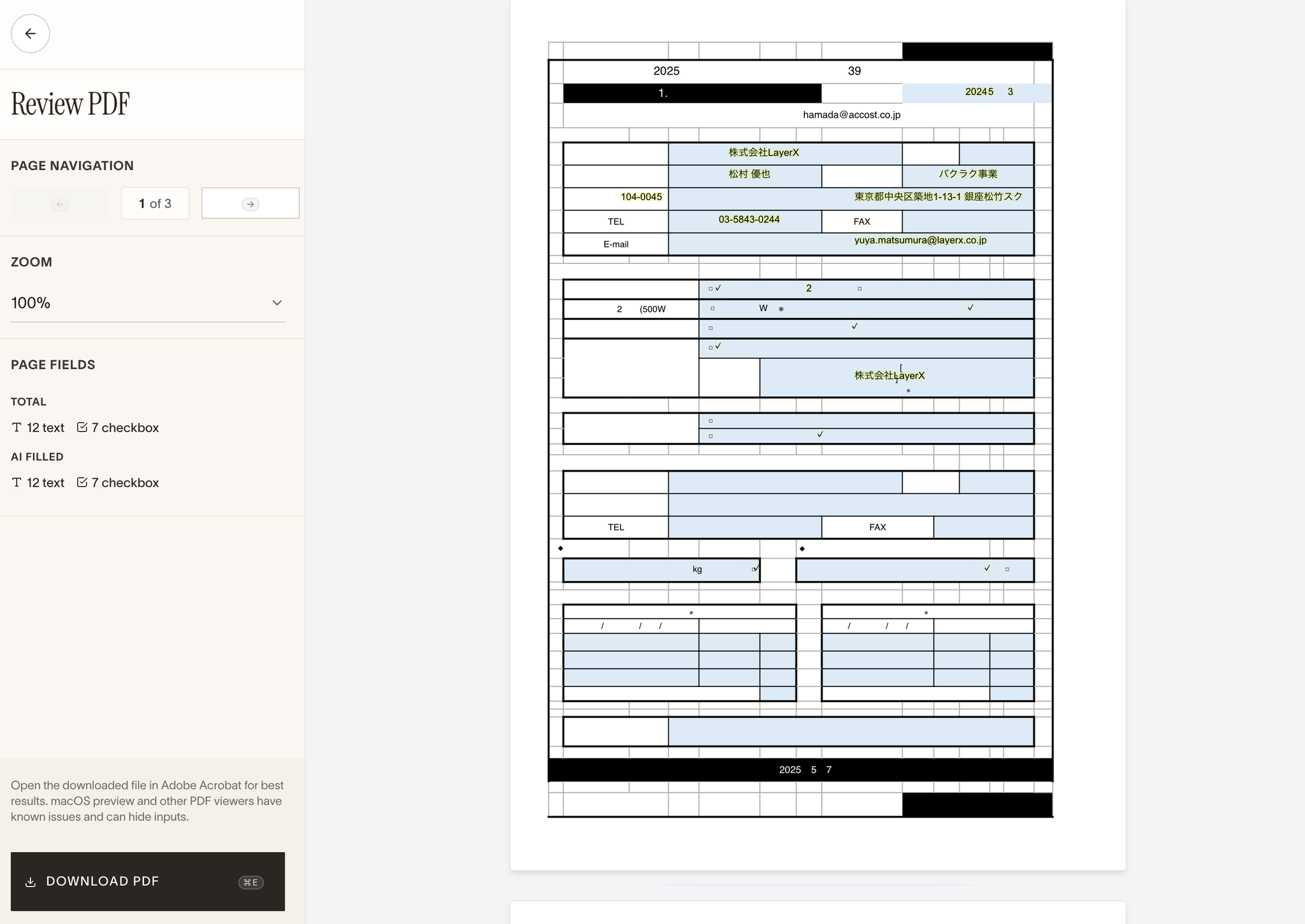
- Learnings
- マルチモーダルな文脈の力。AIエージェントに複数のモダリティ(例:フォームのスクリーンショット、OCRテキスト、PDFウィジェットデータ)で部分的に冗長な文脈を提供すると、複雑なタスクの実行や推論におけるその有効性が大幅に向上した。
- 柔軟なエージェントアーキテクチャにより、エージェントのワークフローの各ステップを最適化することができた。ツールを迅速に試行・交換することで、結果の精度向上を実現。→ 詳細はなかった。
- AIエージェントの効果性にもかかわらず、重要な金融ワークフローにおいては、エンドツーエンドの体験のために人間の関与が依然として必要。人間がエージェントの結果を確認するためのPDFエディターを構築しました。 → AIエージェント w/HITL のいい例だなと感じた。
@Shun Ito
[論文] Efficient Code Embeddings from Code Generation Models
- 2種類のcode embedding modelをデコーダベースで構築
- jina-code-embedding-0.5b
- jina-code-embedding-1.5b
- 提案
- backbone: Qwen2.5-Coder-0.5b / 1.5b(コード生成LLM)
- embedding: last-token pooling(最終トークンの隠れ状態)
- 入力するQuery, Documentそれぞれに、タスクに応じたprefixを付与
- 同じコードでもタスクに応じて異なる埋め込みが得られる
- Matryoshka representation learning を利用
- Contrastive Learning (InfoNCE) で事前学習済み Qwen2.5-Coder をさらに学習
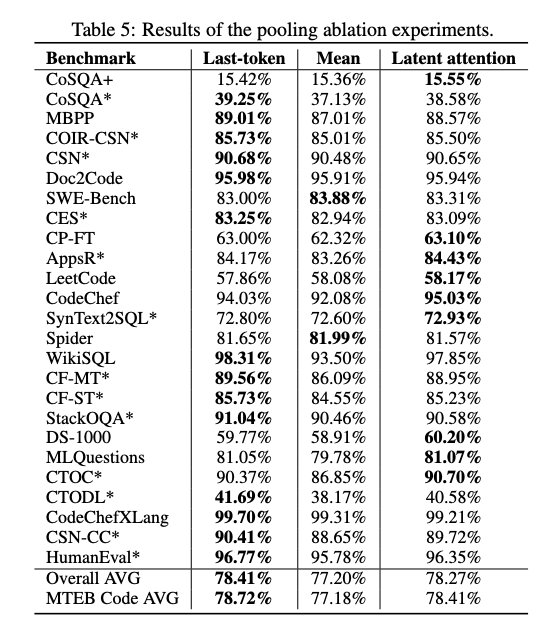

- 結果
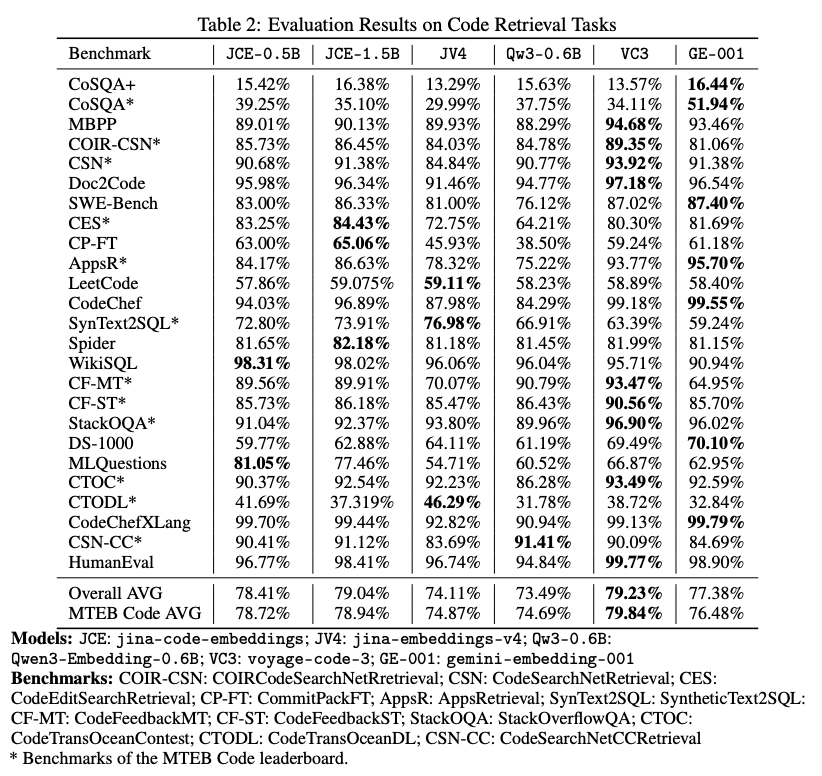
- retrievalタスクの様々なベンチマークで、同程度のサイズのモデル(Qw3-0.6B)や、少し大きいモデル(JV4, GE-001)にoutperform
@Yosuke Yoshida
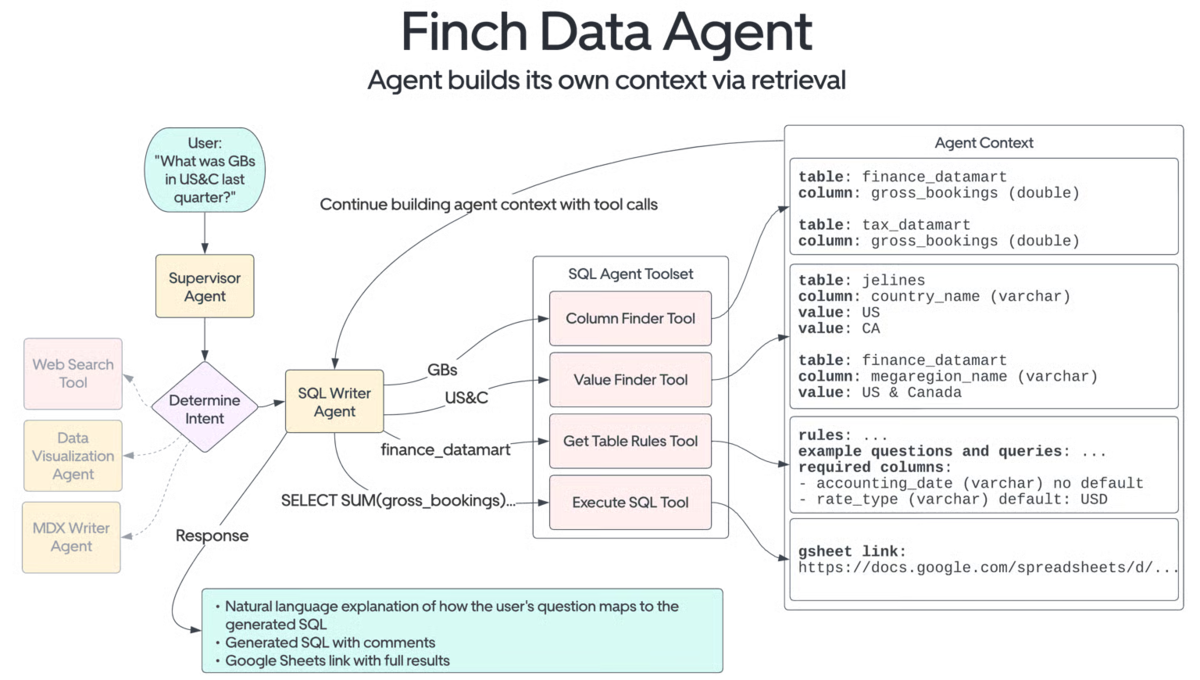
[blog] Uber が社内で運用している会計部門向けのAIエージェント『Finch』
- Uber社のテックブログで公開されていた『Finch』についての記事をまとめてくれているブログ
- 財務部門は重要な判断をデータを活用して行わなければならない一方で、財務部門のメンバーがデータにアクセスするには複数のボトルネック
- 最新の正確なデータを探すために、幾つものシステム (Presto, IBM Planning Analytics, Oracle EPM, Google Docs) に個別にアクセスして調べなければならないので手間がかかる。
- 必要な情報を取得するために複雑な SQL クエリを記述しなければならず、スキーマやドキュメントを確認しつつ、場合によってはデバッグも行いつつクエリ構築してもなお、バグを含んだクエリを記述してしまうリスクがある。
- クエリが複雑すぎる場合や、必要なデータへのアクセス権を持たない場合、データサイエンスチームの人にデータ取得を依頼しなければならず、数時間から数日のリードタイムが発生してしまう。
- Finch が提供する価値
- Slack を通じて自然言語で会話できる AI: 例えば、「What was GB value in US&C in Q4 2024?」と質問すれば正しいデータを自律的に取得して応答してくれる。
- Uber の社内用語に精通: 前述の質問にあるような社内特有の用語を適切な一般用語に変換してくれる。 (例: 「US&C」 → US and Canada region、 「GBs」 → gross bookings)
- 自律的にクエリを実行: アクセスができるすべてのテーブルのメタデータから、ユーザーのリクエストに最も関連性のあるテーブルを選択して、正確な SQL クエリを実行してくれる。
- 適切なアクセス制御とセキュリティの確保: RBAC が実行時に組み込まれることにより機密性の高い財務情報にアクセスできるユーザーを適切に制限。
- Google Sheets へのクエリ結果の出力: 大規模なテーブルのクエリ結果は自動的に Google Sheets に出力することによって、後続のワークフローをユーザーが自分の好むツールを利用して処理できるように工夫。
- Finch のアーキテクチャ
- 大規模言語モデルにアクセスするには社内の生成 AI ゲートウェイを経由
- 各社が提供する大規模言語モデルのインターフェイスを統一して開発工数を低減
- 大規模言語モデルの課金を一元管理
- 外部への情報流出を防ぐためにセキュリティ観点のチェックを行い、個人情報等のセンシティブな文言は検閲
- Finch の AI エージェントは LangGraph を利用して実装
- データ取得エージェント (Data Retrieval Agent) や統括エージェント (Supervisor Agent) といったエージェント間でやり取りが行われ、各タスクが適切な順序で実行されるように制御
- データソースとなる SQL テーブルのカラムとその値、また対応する自然言語の別名といったメタデータを OpenSearch のインデックスに保存
- OpenSearch のファジーマッチング により、LLM 単体でクエリを生成させた場合に比べて正確な WHERE 句フィルターを生成させることができるようになった
- ユーザーとのやり取りでは Slack SDK を用いて API 経由で Slack と連携
- でエージェントの進捗状況を、 LangGraph のコールバックハンドラを使って、逐一 Slack のステータスメッセージをリアルタイム更新
- 待たされている感を低減させたり、正しい情報を取得できているかをユーザーに見せてユーザービリティを向上
- Slack AI Assistant API を活用し、ユーザーと Finch が新しいやり取りを始めた時におすすめ質問の提示、Slack アプリ内で Finch のピン留めや、Finch と常時やり取りできる分割ペインの常時表示を実現
- Finch 内のデータ処理の流れ
- パフォーマンスと精度の担保
- AI エージェントの精度評価
- 各サブエージェント (SQL Writer、Document Reader) を事前に用意した「期待される応答」の一覧に対して評価
- 特にデータ取得系のサブエージェント(例: SQL Writer Agent)では、生成したクエリの結果を「正解クエリ (ゴールデンクエリ) 」の結果と (おそらく構文解析を行なって) 比較
- 統括エージェント (Supervisor Agent) のサブエージェント選択精度
- 元のブログ記事では言及はありませんが、恐らく一般的な単体テストのようにテストケースとなる質問と想定される選択ツールを用意しているのだと推測
- エンドツーエンド検証
- 実運用に近いクエリをシミュレーションし、システム全体の信頼性を検証
- 回帰テスト
- 過去に実行されたクエリを再実行し、システムプロンプトやモデル変更をデプロイする前に精度ドリフトを検知

@Takumi Iida (frkake)
[slide] AIグラフィックデザインの進化:断片から統合(One Piece)へ / From Fragment to One Piece: A Survey on AI-Driven Graphic Design
AI駆動型グラフィックデザインの技術調査論文に対するまとめ。基本的なところから解説してあり、ありがたい。
認識系と生成系タスクを組み合わせてAI駆動型グラフィックデザインを行う流れ
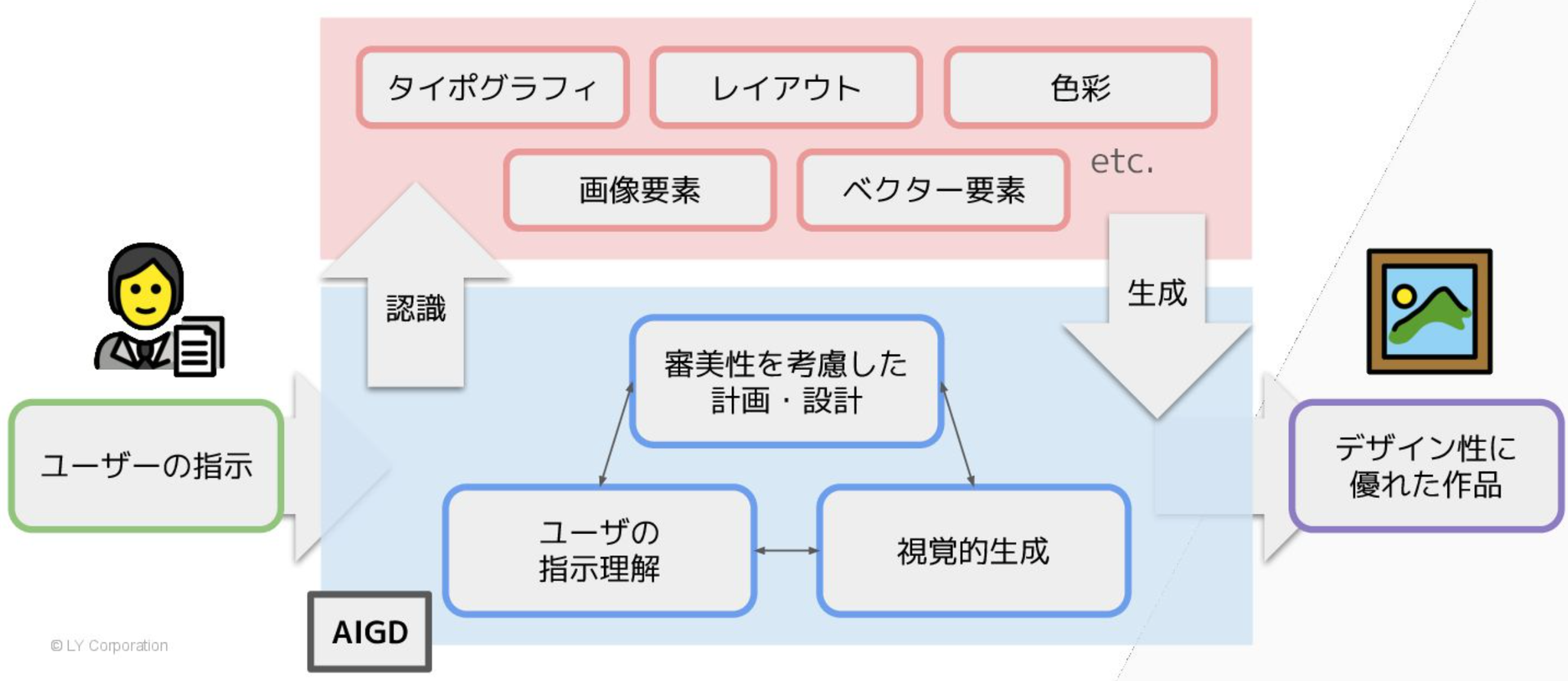
このスライドわかりやすい

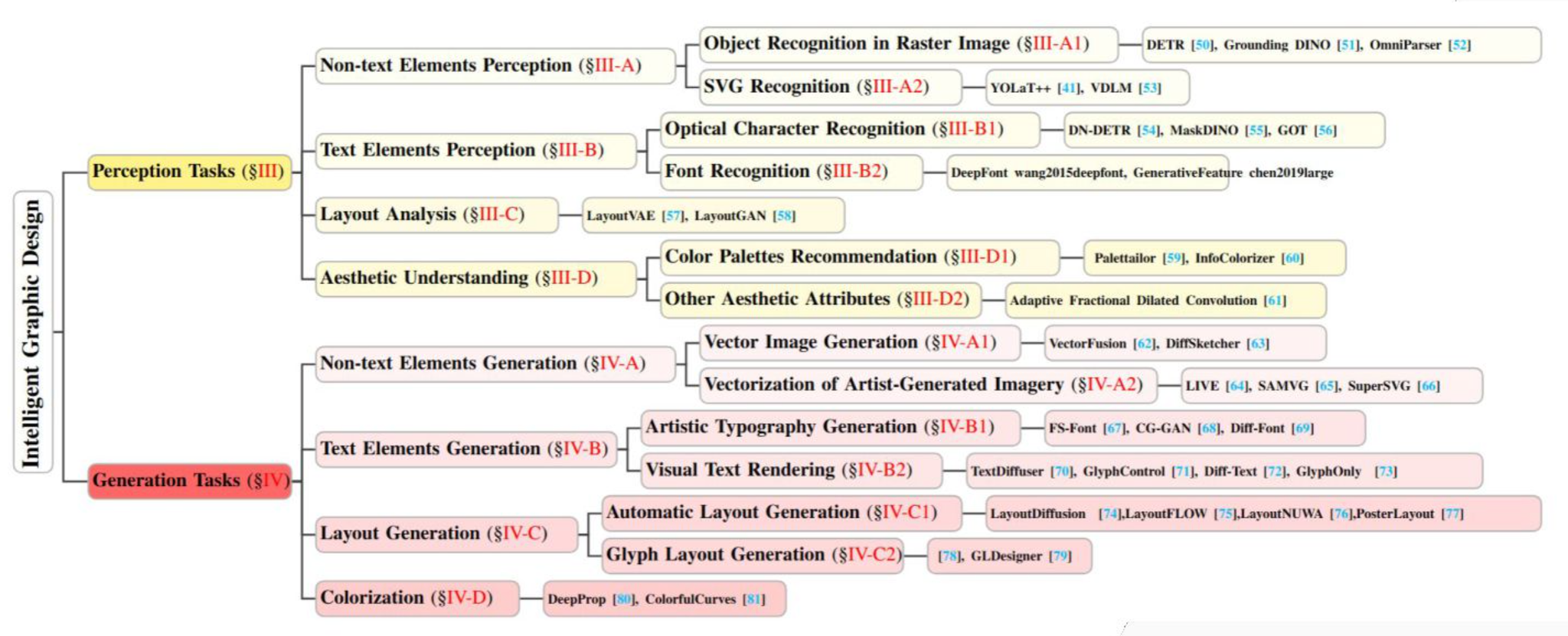
認識タスク
テキスト要素の認識
グラフィックデザインとなるとフォントも重要になってくるのかと思った(そりゃそう)
- OCR:文字検出して、文字認識
- フォント認識:文字の太さや、アスペクト比、イタリック形式など判別
- その他:SVG(最近はLLMで流行りつつある)
レイアウト認識
- 初期:要素の位置や間隔、フォントスタイルなどを特徴量に
- 近年:低次元ベクトルへ変換し、要素間の関係を理解できるように ここらへんは文書レイアウト解析と似てる部分がある
審美性理解
- 初期:人手による配色指標やルールベースの評価
- 近年:構成要素間の審美的整合性を考慮したDNN
- 審美的属性
- カラーパレット推薦
- コントラスト配列のバランス
- ユーザごとの審美的嗜好
とはいえ絶対的な正解がなくむずい
デザイン生成タスク
非テキスト要素の生成
- SVG生成
- ラスタ画像からベクタ化 前紹介した: メインTOPIC:OmniSVG
- 画像のベクタ化
- 輪郭検出やセグメンテーションを通じてピクセルをグループ化。曲線などへ変換
- 輪郭ベース
- レイヤー構造 (これも OmniSVGのときに軽く紹介したLIVEとか)
テキスト要素の生成
- 装飾フォント(筆跡)
- フォントのスタイル変換
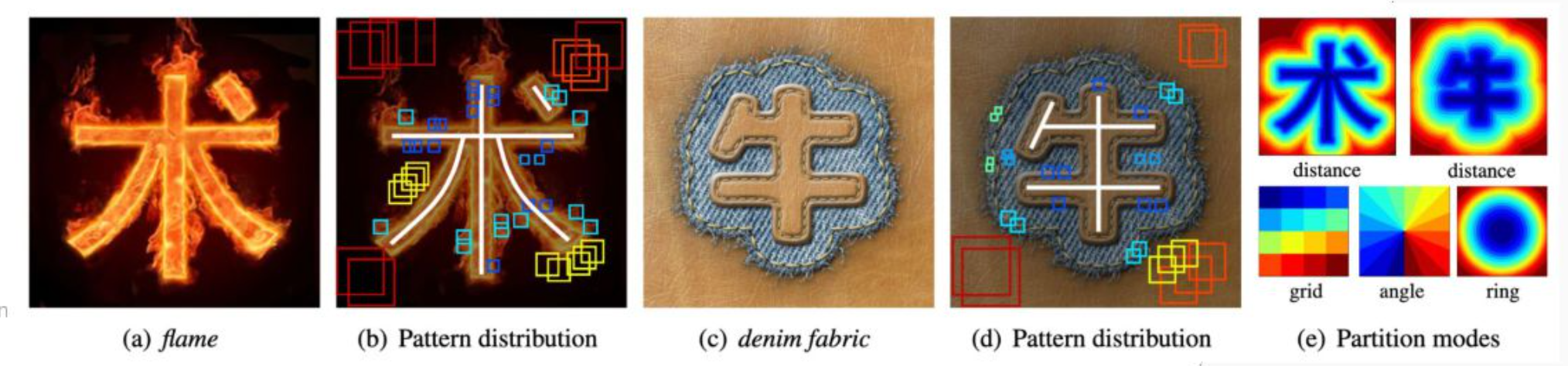
- セマンティックタイポグラフィ:文字に意味性と可読性を両立される “calligram” こういうのらしい。GreeeeNみたいなのあるな。GreeeeNはGRe4N BOYZに名称変更してる。
レイアウト生成
テンプレートを選択してレイアウトを自動生成することが多いらしい。
コンテンツにあった形でレイアウトを生成するかどうかといった、コンテンツ依存か非依存かなどの方向性がある。
現在と将来の展望
- マルチモーダルLLMの活用(割愛)
- 現在の課題
- ユーザの意図の理解不足
- 解釈性の欠如
- レイヤ制御むずい
- 複数の媒体にまたがってデザインを一貫させるのが困難
@ShibuiYusuke
[論文] Vision-Guided Chunking Is All You Need: Enhancing RAG with Multimodal Document Understanding
- 大規模マルチモーダルモデルを活用して、PDFのような複雑な文書の構造と意味を理解し、Retrieval-Augmented Generation(RAG)システムの性能を向上させる新しい文書チャンキング手法を提案
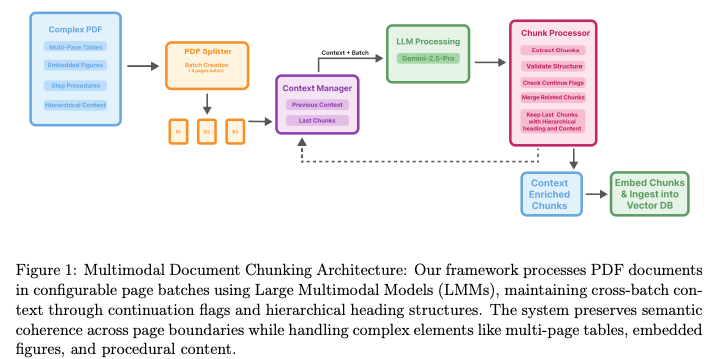
- マルチモーダルなアプローチ: テキストだけでなく、文書のレイアウト、図、表などの視覚的要素も理解するために、大規模マルチモーダルモデルを利用
- バッチ処理と文脈維持:
- PDF文書を設定可能なページ数(例:4ページ)のバッチに分割して処理
- バッチ間の文脈を維持するメカニズムを導入し、複数ページにまたがるコンテンツ(表や手順など)の連続性を保持
- 階層的な見出し構造:
- 文書全体で一貫した3レベルの見出し階層(文書タイトル > セクション見出し > サブトピック)を適用
- これにより、各チャンクが文書全体のどの部分に位置するかの文脈が保持
- コンテンツの整合性維持:
- 手順や箇条書き、表の行などを一つのチャンクにまとめるルールを適用し、情報の分断を防ぐ
- 特に、複数ページにわたる表は、ヘッダー情報を各行のチャンクに含めることで、文脈が失われないようにする
- 継続フラグ: 各チャンクに、前のチャンクからの続きであるかを示すフラグ()を付与し、後処理で関連コンテンツを結合しやすくする
従来手法の課題
- 従来のテキストベースのチャンキング手法(固定サイズ、スライディングウィンドウなど)は、複雑な文書構造、複数ページにわたる表、埋め込まれた図などをうまく扱えず、意味的な一貫性が失われがち
- テキストのみを抽出するため、文書の理解に不可欠な視覚的要素やレイアウト構造が無視される
実験と結果
- 評価: 技術マニュアル、財務報告書、研究論文など、多様な文書を含む独自のデータセットで評価
- チャンキングモデルにはを、RAGシステムの応答生成にはを使用
- 性能向上:
- 提案手法を用いたRAGシステムは、従来の固定サイズチャンキングを用いたシステムと比較して、精度が0.78から0.89に向上
- 生成されたチャンクの質的分析では、複数ページにわたる表の整合性や手順の連続性が維持されるなど、意味的・構造的な一貫性が大幅に改善されていることが確認

- チャンクの粒度: 提案手法は、従来の手法に比べて約5倍多くの、より体系的で文脈に適したチャンクを生成。これにより、より正確な情報検索が可能に
課題と今後の展望
- 課題: 8〜9ページ以上にわたる非常に複雑な表や、入り組んだ図の正確な処理には依然として課題が残る。また、計算コストと処理時間も課題
メインTOPIC
T-GRAG: A Dynamic GraphRAG Framework for Resolving Temporal Conflicts and Redundancy in Knowledge Retrieval
[pon]ちょっと前に紹介したzep(Graphiti)の論文では会話データセットの評価であり、ナレッジや知識検索に焦点を当てていなかった。今回は「知識検索における時間的矛盾を解決するためのGraphRAGフレームワーク」を提案する論文を読んだ。Graphitiとはまた違ったTKGで面白かった。
Abstract
- 大規模言語モデル(LLM)は、自然言語生成において優れた性能を発揮していますが、内部知識が古くなっていたり不完全であったりするため、知識集約的なタスクでは依然として限界があります。
- GraphRAGは構造化された知識グラフとマルチホップ推論を通じて性能をさらに向上させます。
- しかし、既存のGraphRAG手法は、知識の時間的ダイナミクスをほとんど考慮しておらず、時間的な曖昧さ、時間非依存な検索、意味的な冗長性などの問題を引き起こしています。
これらの制約を克服するために、我々はTemporal GraphRAG(T-GRAG)を提案。これは、知識の時間的進化をモデル化する、動的な時間認識RAGフレームワークです。
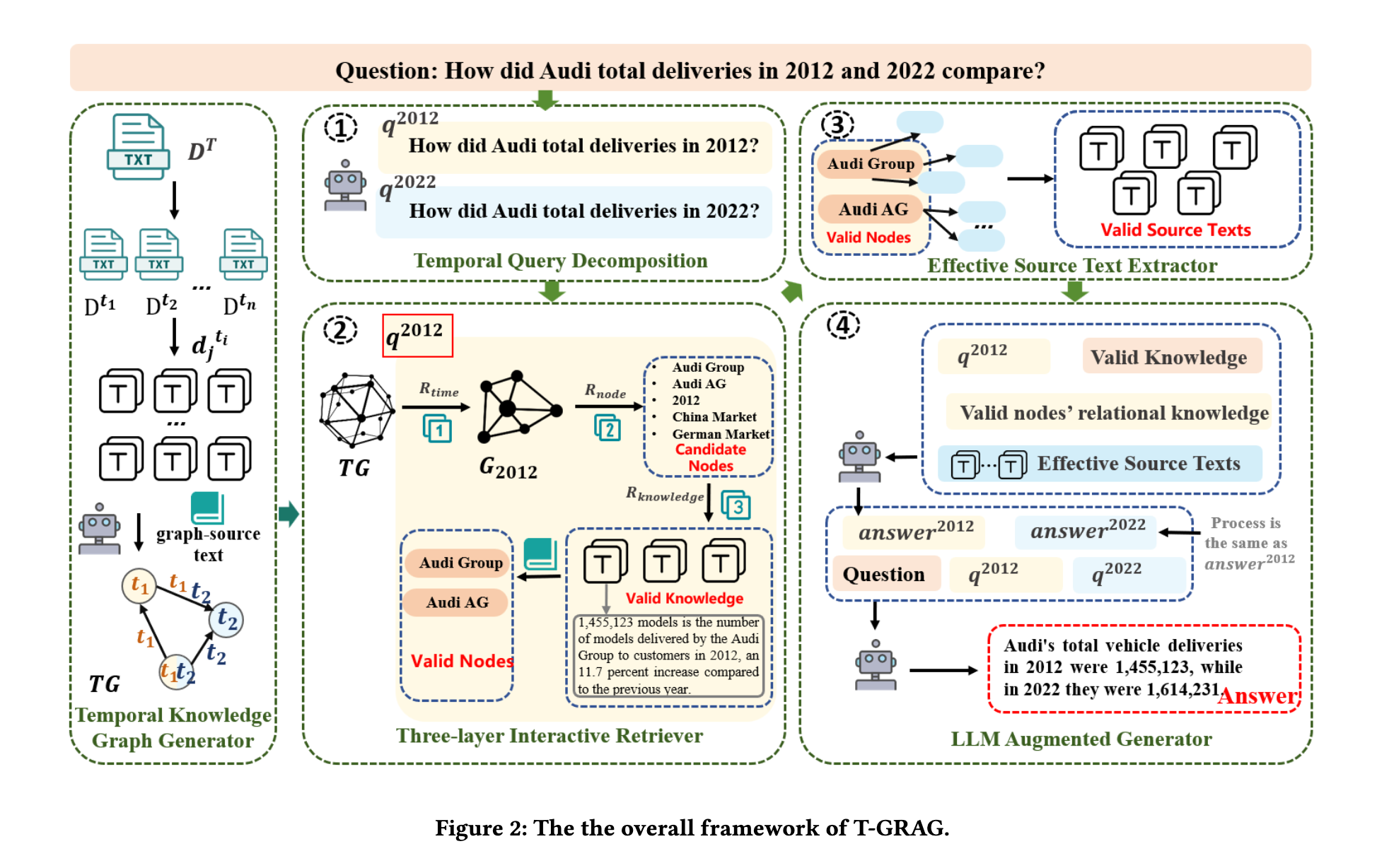
- T-GRAGは、5つの主要なコンポーネントで構成されています。
- (1)タイムスタンプ付きの進化するグラフ構造を作成するTemporal Knowledge Graph Generator
- (2)複雑な時間的クエリを管理可能なサブクエリに分解するTemporal Query Decompositionメカニズム
- (3)時間的サブグラフ全体で検索を段階的にフィルタリングおよび改良するThree-layer Interactive Retriever
- (4)ノイズを軽減するSource Text Extractor
- (5)文脈的および時間的に正確な応答を合成するLLMベースのGeneratorです。
また、進化する知識にわたる時間的推論をテストするために設計された、実際の企業の年次報告書に基づく新しいベンチマークデータセットであるTime-LongQAを紹介。
[pon]GitHubにコードはあるみたところ、グラフDBはneo4j メモリ上での処理にnetworkxを使ってる。ベクトル検索はhnsw
T-GRAG
Arvin0313 • Updated Nov 24, 2025
Introduction
- GraphRAGはマルチホップ推論や長文質問応答タスクにおいて優れた性能を発揮し、広く注目を集めています。
- しかし、実際のアプリケーションでは、知識は静的なものではなく、時間とともに継続的に進化します
- 既存のGraphRAGの増分更新メカニズムは、グラフの時間的進化特性を考慮せず、単にグラフ情報を積み重ねているだけです。
- 知識ベースが拡大し続けると、GraphRAGは3つの主要な課題に直面します。
- 課題1:知識モデリングにおける時間的な曖昧さがインデックス作成エラーを引き起こします。
- 現実世界では、知識は時間とともに進化します。エンティティは、時期によって異なる属性を持つことがあります。例えば、企業の純現金収支、製品出荷量、組織構造。
- しかし、既存のGraphRAG手法は、知識グラフやインデックス可能な埋め込みを構築する際に、こうした時間的特性を無視します。
- このモデリング上の欠陥により、GraphRAGは意味的には類似していても時間的に異なる事実を区別できません。
- 課題2:時間非依存な検索は、無関係な結果をもたらします。
- [pon]これ大事
- 知識グラフに時間情報が存在する場合でも、現在のGraphRAGの検索メカニズムは、検索プロセス中にそれを効果的に活用することができません。
- その結果、トピック的には関連性があるものの、時間的に一致しない情報が検索される可能性があります。
- 課題1とは異なり、この問題は検索段階で発生し、システムは検索結果をクエリの時間的な意図に合わせることができません。
- 課題3:同じ時点での冗長な情報は、検索における意味的関連性を阻害します。
- [pon]ここも大事
- 知識が特定の時点と正しく整合している場合でも、個々のノード内の意味的冗長性により課題が残ります。
- たとえば、図1に示すように、2022年のAudi Groupを表すノードには、車両納入統計、財務実績、組織変更など、複数の種類の事実が含まれている場合があります。
- この情報はすべて同じ時間枠に属していますが、そのすべてが特定のクエリに関連するわけではありません。
- ユーザーが2022年のAudiの車両納入台数のみに関心があるとします。
- ノードの表現が無関係な財務情報によって支配または歪められている場合、結果として得られる埋め込みはクエリとの類似性が低く見える可能性があります。
- その結果、ノードのランクが低くなったり、検索から除外されたりする可能性があります。
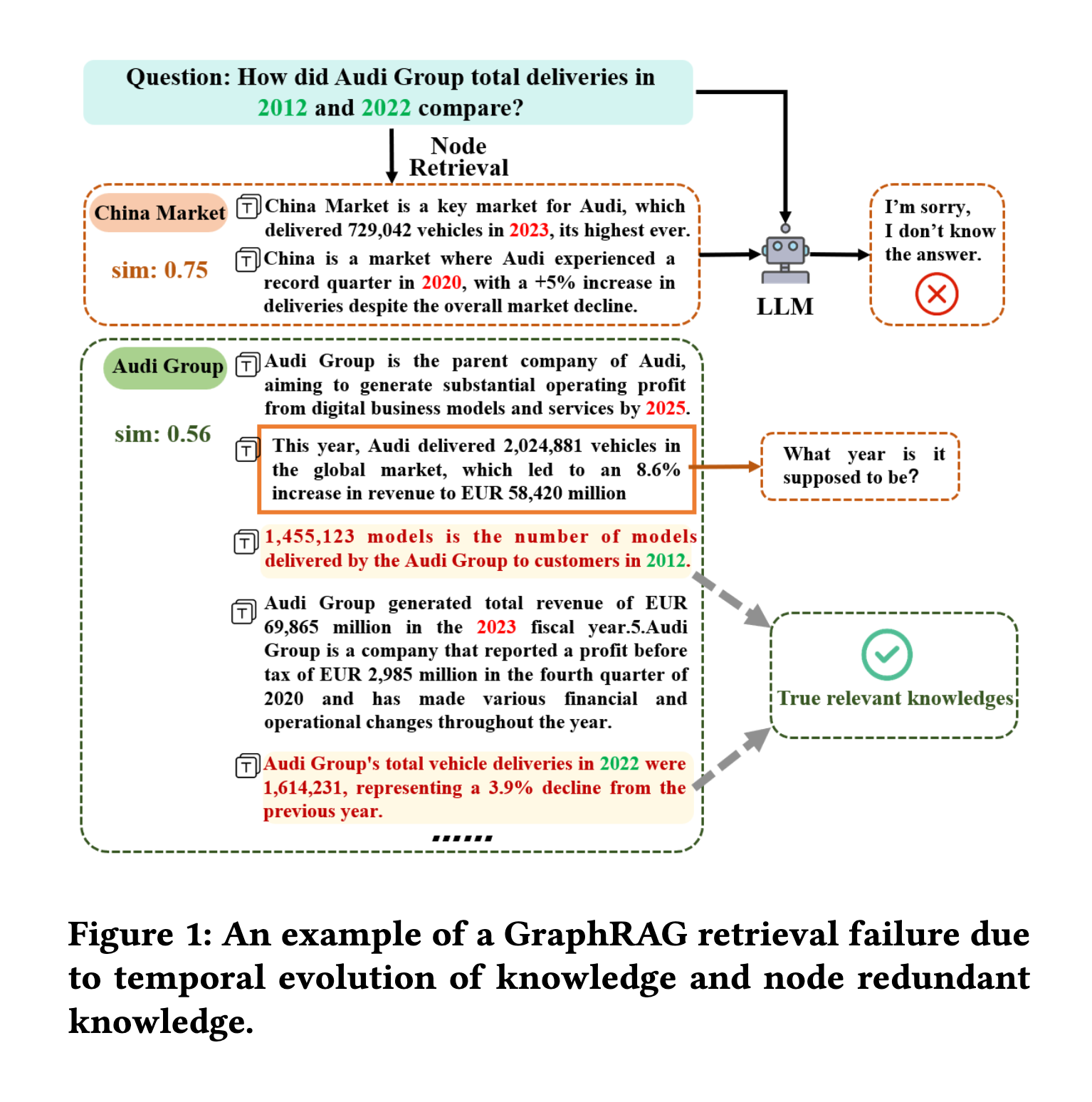
本論文ではT-GRAGの提案とTime-LongQA Datasetと呼ばれるデータセットを構築
Temporal GraphRAG
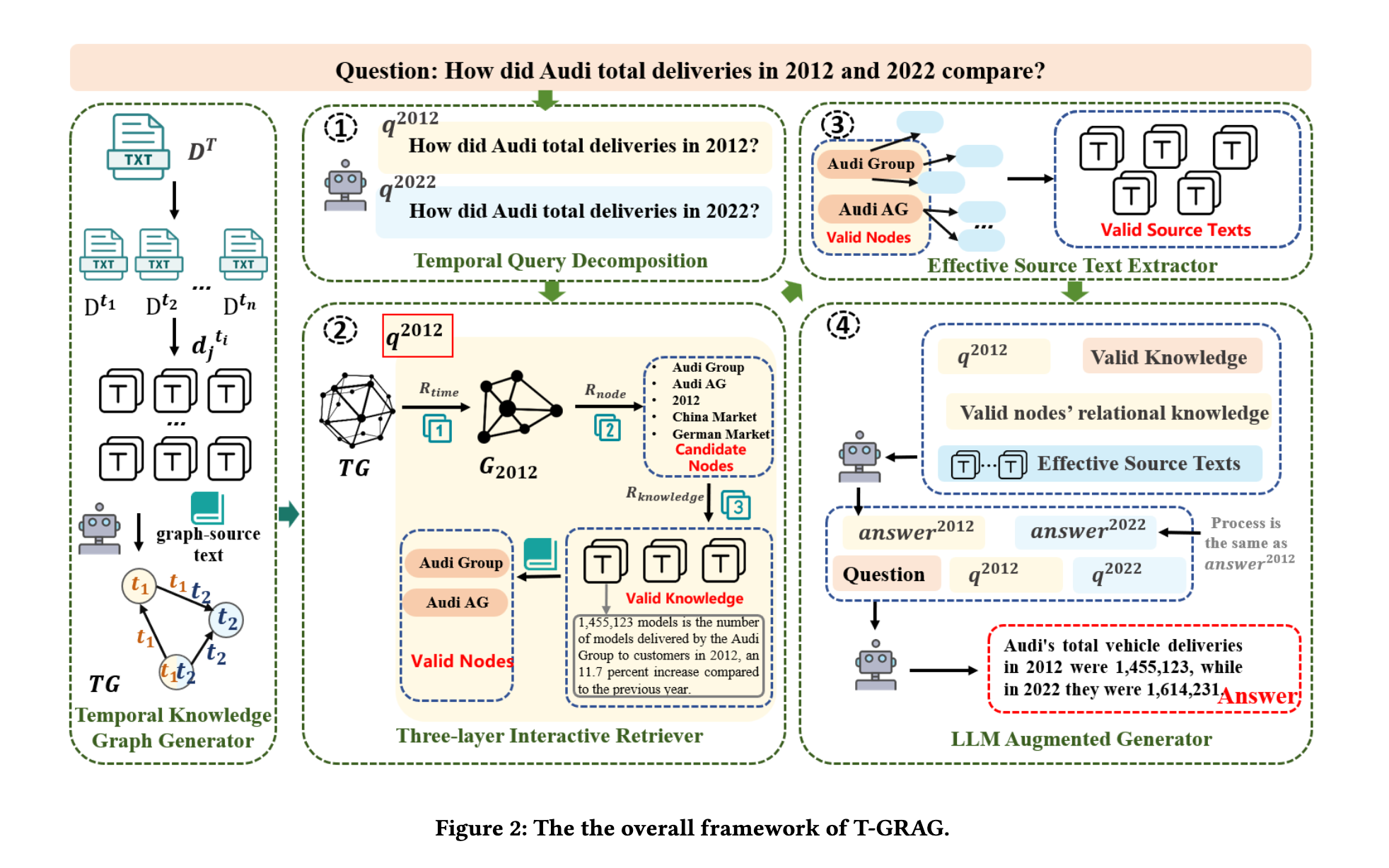
T-GRAGは主に5つのモジュールで構成される
- Temporal Knowledge Graph Generator
- Temporal Query Decomposition
- Three-layer Interactive Retriever
- Valid Source Text Extractor
- LLM Augmented Generator
Temporal Knowledge Graph Generator

step1
- 時間的ソーステキスト知識ベース を複数の時間帯に分割し、時間的進化のモデリングを容易にする。次に、各時間帯 のテキストを、処理単位として機能する固定サイズのテキストブロック に分割する。
step2
- LLM を使用してグラフ情報を抽出する。(Appendix B参照)
- テキストブロック内のすべてのエンティティを、エンティティの名前、タイプ、および説明を含めて識別する。
- 次に、関連するエンティティ間の関係を識別し、ソースエンティティとターゲットエンティティ間の関係タイプと説明を明確にする。
- エンティティと関係に時間属性を導入し、対応するタイムスタンプ を知識 に関連付けて、異なる時点での同じエンティティの知識を区別する。
- グラフの更新プロセス中、最新のタイムスタンプを持つ知識がエンティティと関係に継続的に追加され、過去の知識との混同を回避する。
step3
- 時間的動的グラフ知識ベースを構築する。 各エンティティは、として定義される。ここで、はエンティティ の時間属性を示し、 は時間 に発生する の知識を示す。
Temporal Query Decomposition
LLM の強力な時間的意味認識を活用して、クエリの時間制約を分析、推論、および分解する Temporal Query Decomposer (TQD) を導入する。
- 元のクエリQが与えられた場合、TQD は最初に LLM を利用して、その時間制約を識別して解析する。プロンプトはfew-shotベース(appendix B)
- クエリに時間制約が含まれていない場合、元のクエリは変更されず、質問がすべての期間にわたる知識を必要とすることを示す。
Three-layer Interactive Retriever
- [pon]提案手法の最重要ポイント。3段階構成のretriever
- temporal subgraph retriever:
- タイムスタンプを持つサブ時間クエリに対して、時間的知識グラフから時間的サブグラフを検索します。ここで、内のノードと関係は、時点からの知識のみを含みます。
- 時点の知識のみを含む各エンティティは、として定義されます。
- さらに、事前学習済みの埋め込みモデルを使用して、のノード埋め込みを生成します。 具体的には、ノード内のすべての知識をエンコードして、のノード埋め込みを生成します。 ここで、は出力ベクトルの次元を表します。
- coarse-grained node retriever:
- クエリとサブグラフ内のノードの両方をエンコードし、それらの意味的類似性を計算し、上位n個の最も関連性の高いノードを候補として選択します
- テキスト情報の整合性のある処理を保証するために、サブクエリに同じ埋め込み戦略を適用します。
次に、クエリに関連する候補ノードを特定するために、最近傍探索法を使用します。ここで、コサイン類似度を使用して、クエリ埋め込みとノード埋め込みの間の類似度を測定します。
上位n個の最も関連性の高いノードが、検索の候補ノードとして選択されます。
- fine-grained knowledge retriever:
- 候補ノード内の知識の各要素について、同じ埋め込み戦略を用いて個別に埋め込みを生成します。 その後、コサイン類似度を用いてクエリと知識の埋め込み間の距離を測定し、上位k個の最も類似した知識ブロックを有効な知識として選択します。 最終的に、を含むノードを有効なノードとみなします。
LLM Augmented Generator
- 有効なグラフ情報は、3層のインタラクティブな知識検索器から抽出された上位k個の関連知識と、有効なノードに関連付けられた関係知識で構成されます。
- 同時に、有効なテキスト情報には、有効なソーステキスト検索器によって抽出された上位個の関連ソーステキストが含まれており、LLMが完全な意味的コンテキストにアクセスできるようになっています。
- これらを使い、クエリに対する正確な回答を生成します。
最終的に、元のクエリと、すべてのサブ時間クエリおよびそれに対応する回答がLLMに入力され、包括的な最終回答が生成されます。
Time-LongQA Dataset
- 時間的進化がある、長いテキストのデータセットを構築するために、2012年から2023年までの公開されているAudiの年次報告書をベースコーパスとして選択しました。
- MinerUを使用して、ソーステキストをPDF形式からMarkdown形式に変換し、テキストコンテンツのみを保持しました。
- その後、1,538個の単一時間制約付き質問 、524個の二重時間制約付き質問 、113個の多重時間制約付き質問(3つ以上の時間点)、および117個の時間制約なし質問を含む、自動化された時間的質問応答(QA)ペア構築プロセスを設計しました。
- データセット構築のためのプロンプトの詳細は、後述
QAペアの生成と検証
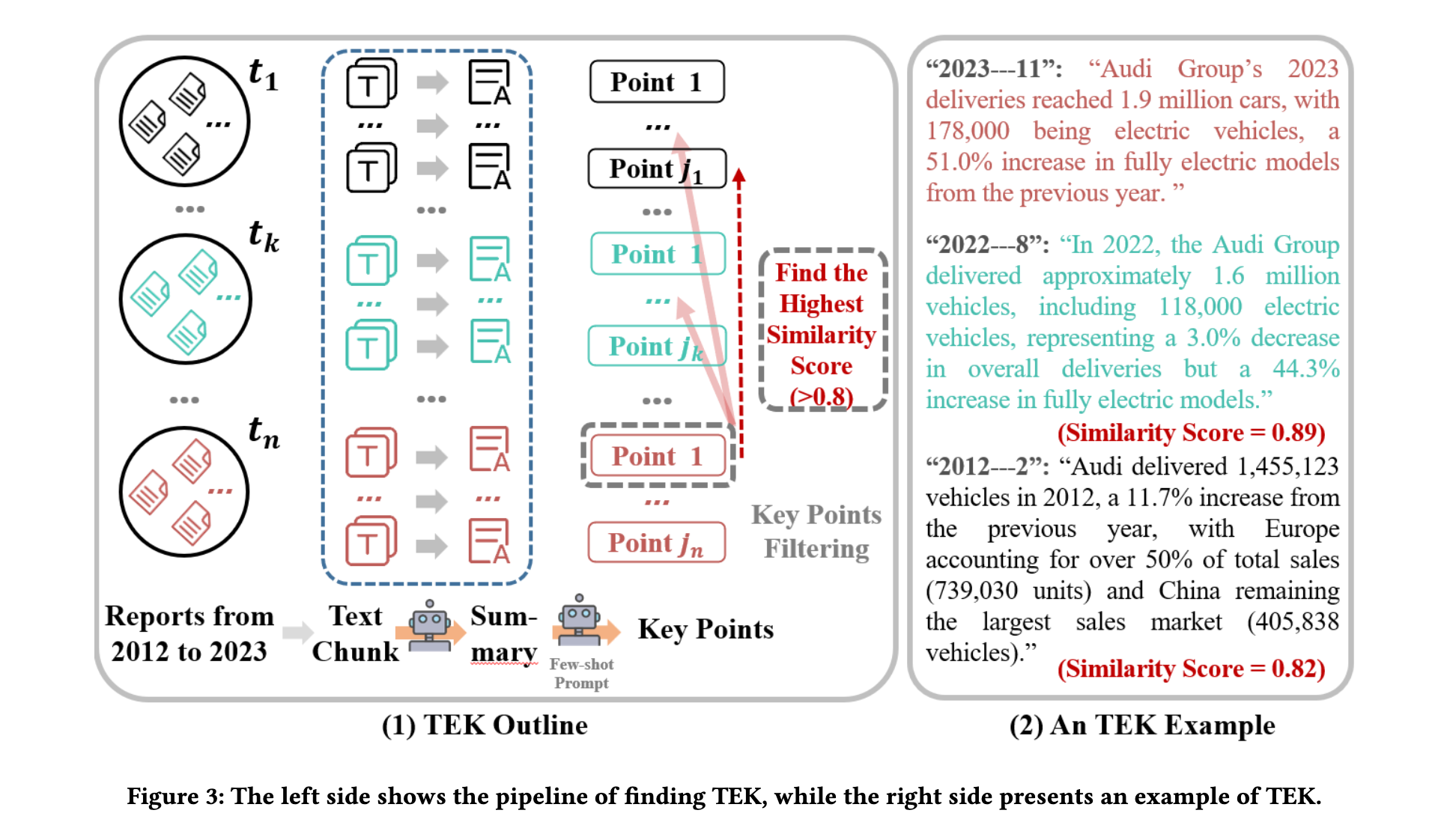
- まず、各年次報告書を2,000トークンごとのテキストブロックに分割。
- 時間的な長文テキスト内の時間的進化知識(TEK)を特定し、抽出されたTEKに基づいて2つ以上の時点を含む質問を生成する。
- TEKの見つけ方 TCELongBench [24]に触発され、LLMに基づくTEK抽出プロセスを提案する。
- プロセスは以下の通りである。
- まず、各タイムスタンプにおけるすべてのテキストブロックに対して要約表現を生成します
- 次に、few-shotプロンプトを使用して、各テキストブロックの要約からキーポイントを導出する。
- 続いて、最新のタイムスタンプのキーポイントから始めて、コサイン類似度検索を使用して、各過去のタイムスタンプで最も類似したキーポイントを、閾値を超える類似度スコアで検索する。
- 最後に、多数の年次報告書から複数のTEKを発見した。
- と については、GPT-4を利用して対応するQAペアを生成した。
- 最後に、生成されたすべてのQAペアに対して手動による検証を実施し、特にを扱う場合(例えば、AudiのCEOの交代など)、潜在的な時間的矛盾を避けるように注意を払った。
実験
実験設定 ベースライン。
提案するT-GRAGを、3つのタイプのベースラインメソッドと比較する。
- Standard LLMs (Base LLM)
- この設定では、言語モデルが外部データにアクセスせずに、その内部知識のみに基づいて質問に回答できるかどうかを評価する。
- Text RetrievalAugmented LLMs (Vanilla RAG)
- 元のテキストコーパスを知識源として使用し、dense retrieverを用いて関連するテキストパッセージを検索する。
- Graph Retrieval-Augmented LLMs (GraphRAG)
- nano-GraphRAGパイプラインをGraphRAGのベースラインとして採用する。 この設定では、グラフ構造化された知識ベースが最初に元のテキストから構築される。 次に、このグラフ上で検索を実行して、意味的に関連するサブグラフまたはノードを取得する。
- すべてのベースラインについて、3つのLLMを比較
- LLaMA-3.1-70B-Chat
- Qwen2.5-72B-Instruct
- LLaMA3.1-Nemotron-70B-Instruct-HF
評価指標。
Qwen2.5-72Bを使用して、それらが正解とどの程度一致するかを評価する。
- 各サンプルはモデルによって独立して3回評価され、多数決戦略が適用される。3回の評価のうち少なくとも2回が正しいと判断された場合、その回答は正しいと見なされる。
- 最終的なLLMscoreは、回答の精度によって測定される。
- LLMベースの評価に使用されるプロンプトは、DocBenchプロトコルに従う(後述
- パラメータ設定。 すべてのRAGベースの手法について、dense retrievalのための埋め込みモデルとしてstella-en-1.5B-v5 を採用する。
- ソーステキストに対する検索戦略は、チャンクサイズを1000、top-𝑡を5に設定する。 GraphRAGとT-GRAGの場合、検索されるコンテキストトークンの総数は1600トークンに制限される。 T-GRAGに特化して、候補ノード数を30に設定し、グラフ検索スコアに基づいて、上位個の最も関連性の高い知識ユニットを選択する。ここで、である。
Overall Performance
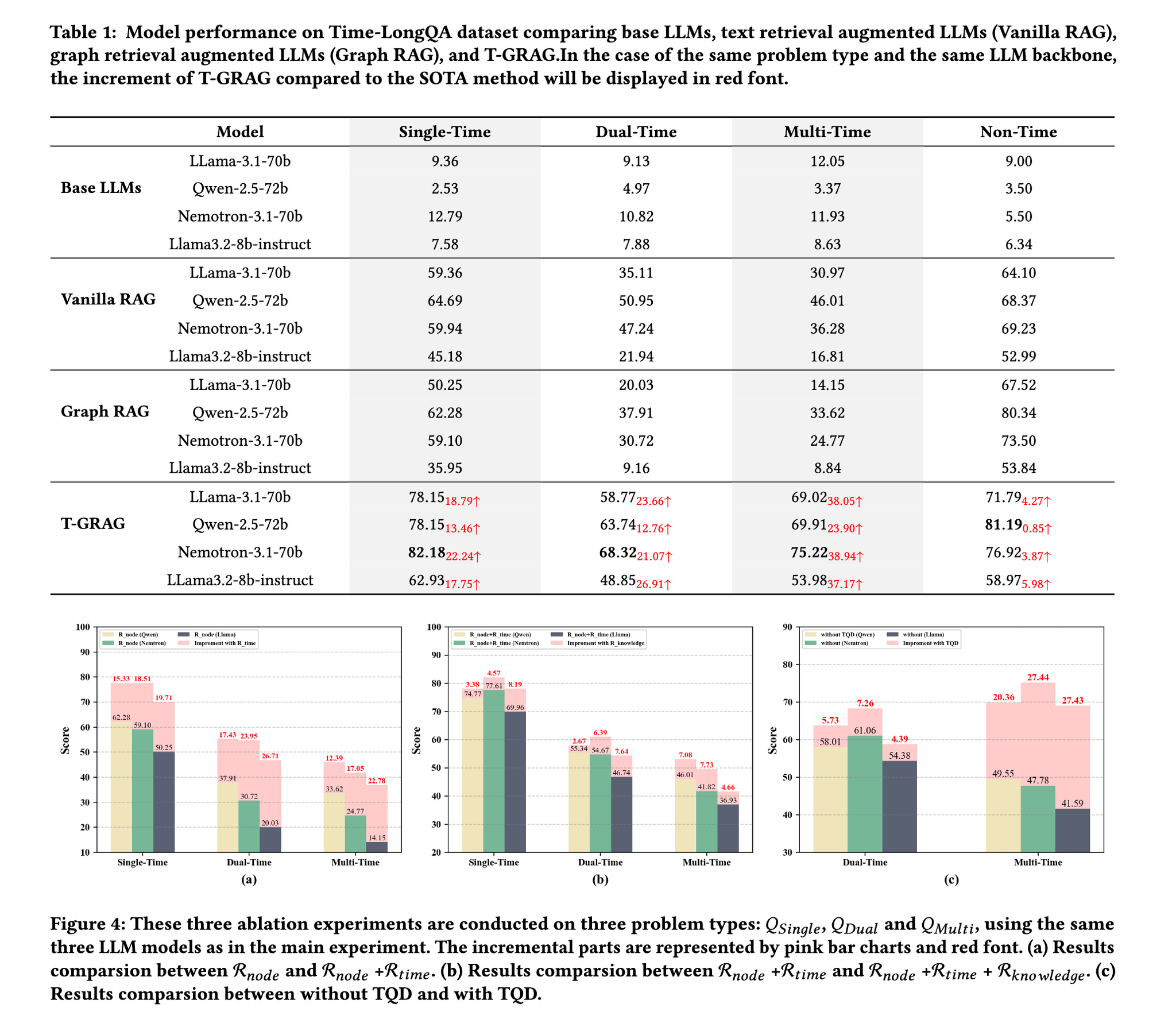
- [pon]実験結果の中で特に重要であろう場所をピックアップ
- 複雑な時間的制約におけるT-GRAGの改善はより顕著
- ソーステキストから直接検索するVanilla RAGと比較して、GraphRAGはより複雑なパイプラインを備えており、より高い計算コストがかかる。
- しかし、調査結果は、場合によっては、Graph RAGのパフォーマンスがVanilla RAGよりも低いことを示している。
- 主な理由は、ノード知識の過剰な冗長性にあり、それがリトリーバーが関連するローカル情報を正確に抽出する能力を損なうことにある。
- T-GRAGの検索フレームワークがこの問題を効果的に軽減することをさらに示している。
Temporal Query Decomposition: TQDの効果。
複数時間制約の質問に対処するTemporal Query Decomposition (TQD)の有効性を評価するために、TQDを有効にしたものと無効にしたものの2つのバリアントのT-GRAGを比較する。
- 2つの設定の唯一の違いは、TQDモジュールが含まれているかどうかである。
- この改善(図4(c))は、TQDが質問を時間的範囲が単純化されたサブクエリに分解する能力によるものと考えられる。これにより、時間的推論の複雑さが軽減されるだけでなく、矛盾する時点によって引き起こされる検索の衝突も回避される。
- さらに、TQDは時間的サブグラフのサイズを縮小し、その結果、後続のノードおよび知識検索の関連性と精度が向上する。
Impact of Retrieved Unit Count.
モデルの性能が検索されたユニット数(top-kのこと)にどの程度影響を受けるかを調査するために、検索設定を5(デフォルト)3および1に変更する。
- 対応する結果を図5に示す。
- 検索されるユニット数が減少するにつれて、すべての手法でモデルの性能が低下する。
- 具体的には、T-GRAGは平均20.66%、GraphRAGは26.65%の精度低下を示し、Vanilla RAGは54.55%の低下と最も大きな影響を受けている。
- 特に、T-GRAGとGraphRAGは、削減された検索コンテキストに対してより高いロバスト性を示し、特にやのような時間的に要求の厳しい質問において顕著である。
- このことは、グラフベースの検索戦略が、制約された検索条件下でより優れた回復力を持つことを示唆している。
- この利点は、検索の粒度の細かさに起因すると考えられる。GraphRAGがノードレベルで検索するのに対し、T-GRAGはノード内の知識レベルの粒度まで範囲を絞り込むことで、検索されるセグメントが少なくても重要な情報が保持されるようにする。

まとめ
動的知識ベース向けに調整された、新しい検索拡張生成フレームワークであるTemporal GraphRAG (T-GRAG)を提案
- T-GRAGは、時間的ドリフトや知識の冗長性など、進化するコーパスにおける検索エラーにつながる主要な課題に対処する。
- 時間的進化を伴う長文の企業レポートで構成される、新しく構築したTemporal-Datasetでの実験により、T-GRAGが長文テキストの時間的QAタスクにおいて、GraphRAGおよびVanilla RAGを一貫して上回ることが示された。
- 特に、我々のThree-layer Interactive Retrieverは冗長な知識を効果的にフィルタリングし、時間的クエリ分解モジュールは正確なクロス時間検索を保証する。
- これらの結果は、T-GRAGが検索精度と回答精度の両方を大幅に向上させ、適応的な時間認識型RAGシステムの強力な基盤を築くことを示している。
Appendix(面白かったとこだけ
DocBenchプロトコル
DocBenchはLLMベースの文書読み取りシステム+質問([pon]NotebookLM的な)を評価するために設計された新しいベンチマーク
 allenai_org
allenai_orgその中の評価用プロンプトを利用している質問タイプによって指標を分ける

ナレッジグラフ構築プロンプト
プロンプトは、以下のステップでエンティティと関係性を抽出するようにLLMに指示します。
- すべてのエンティティの識別(Identify all entities)
- 入力テキストからすべてのエンティティを特定します。 特定された各エンティティについて、以下の情報を抽出します。
- entity_name:エンティティの名前(大文字で始まる)。
- entity_type:定義されたエンティティタイプリスト({entity_types})の中から該当するタイプ。
- entity_description:エンティティの属性と活動に関する包括的な説明。
- 関連するエンティティペア間の関係の識別(Identify all pairs of (source_entity, target_entity) that are clearly related to each other)
- ステップ1で識別されたエンティティの中から、互いに「明確に関連している」すべてのペア(source_entity, target_entity)を特定します。
- 各関連エンティティペアについて、以下の情報を抽出します。
- source_entity:関係の出発点となるエンティティの名前。
- target_entity:関係の終点となるエンティティの名前。
- relationship_description:なぜこれらのエンティティが関連していると判断したかの説明。
- relationship_strength:関係の強さを示す数値スコア。
データセット生成プロンプト
具体的には、以下の3種類のプロンプトが設計され、データセットの生成と検証に利用されました。
- Prompt for Generating Summary (要約生成用プロンプト)
- 目的: 長文のソーステキスト(企業の年次報告書)から、その中心的な内容を純粋なテキスト形式で要約させるために使用されます。
- 要件:
- 元のテキストの大部分の詳細を網羅すること。
- 代名詞の使用を最小限に抑え、エンティティ名を明確に特定すること。
- 時間関連データやその他の重要な詳細を省略せず、包括的かつ正確な要約を作成すること。
- 引用符や特殊記号を避け、標準的な段落形式でプレーンテキストとして出力すること。
- Prompt for Generating Key Points (キーポイント生成用プロンプト)
- 目的: 生成された要約から、さらに重要なキーポイント(主要な事柄)を抽出させるために使用されます。
- 要件:
- キーポイントが互いに独立しており、内容が重複しないようにすること。
- 数字、名前、日付などを含む、簡潔で正確かつ完全なキーポイントであること。
- 複雑な書式や改行を避け、1〜2文で記述すること。
- 特定の年に発生したイベントに関わるキーポイントのみを抽出し、それ以外のものは無視すること(非常に重要)。
- 代名詞を避け、参照するエンティティを明確にすること。
- 特定の導入フレーズ(例:「記事では議論されている」)を使用しないこと。
- このキーポイントを利用して、後続のQAペア生成が行われます。
- Prompt for Creating QA pairs (QAペア作成用プロンプト)
- 目的: 上記のキーポイントや要約されたテキストを基に、実際の質問(Q)と回答(A)のペアを生成させるために使用されます。
- 要件(Single-Time QA pairsの場合):
- 質問は多様で、人物、数字、場所など様々な側面をカバーすること。
- 質問の情報は豊富かつ明確で、回答の曖昧さを避けること。
- 単純な文字列一致を避ける、挑戦的な質問を3つ設計すること。
- 各質問の回答は簡潔で、質問の情報の冗長性や繰り返しを避けること。
- 質問に含まれるイベントは、元のテキストで指定された明確な時間属性を持つこと。時間属性が特定できない場合は、その質問を破棄し、別のイベントで質問を作成すること(非常に重要)。
- 各質問には時間属性を含めること。
- 要件(Dual-Time QA pairsの場合):
- 2つの異なるタイムスタンプに対応するオリジナルテキストを使用して質問に答える必要があり、これらのテキスト間には時間的な比較可能性がなければならないこと。
- 質問はクローズドエンドであること。
- 質問は具体的なエンティティ、数字、または時間に関するものであり、抽象的な概念(例:Audiの戦略)に関するものではないこと。
- 質問の情報は十分かつ明確であり、曖昧な回答を避けること。
- 問題に複数のサブ質問を含めず、明確かつ具体的にすること。
- 問題には2つのタイムスタンプ(year1とyear2)を含めること。
- 回答は簡潔で明確であり、長すぎたり繰り返したりしないこと。
ponの感想
- Graphitiはセマンティックレイヤーを導入して3段階ナレッジグラフにしていたが、こっちはノードを見つけてきてから埋め込むのが面白い。絶対に特定の時間サブグラフに絞って回答を作るぞという気概を感じる
- さらにノードを引っ張ってきた後、さらに不要な知識を削るために類似スコア取ってる。不要なナレッジは消し飛ばすという気概
- データセット作成がナレッジグラフ作りを意識しており、自分に有利に作ってる感はある
- データセット生成プロンプトはナレッジグラフを作る際にデータを整形するのに良さそう。