
2025-09-09 機械学習勉強会
今週のTOPIC[blog] Best Practices for Building Agentic AI Systems: What Actually Works in Production[論文] Memp: Exploring Agent Procedural Memory[blog] Don’t Build Multi-Agents[論文]Arctic-Text2SQL-R1: Simple Rewards, Strong Reasoning in Text-to-SQL[Blog] Agentic Workflows Towards Natural-Language Programming for GitHub Actions[論文]Large Language Models Sensitivity to The Order of Options in Multiple-Choice QuestionsメインTOPICUniversal Deep Research: Bring Your Own Model and Strategy概要IntroductionResearch MechanismInputs(入力)Operation(動作)Outputs(出力)User Interface主要コンポーネント振る舞いと設計意図LimitationsConclusions & Recommendationsコード感想
今週のTOPIC
@Yuya Matsumura
[blog] Best Practices for Building Agentic AI Systems: What Actually Works in Production
- UserJot のAIエージェント機能開発における試行錯誤をまとめたブログ。後半が実践的で面白い。
- UserJot は、プロダクトへの要望を一元管理するプラットフォームで、顧客向けに voting や discussion などのコミュニティ機能も提供しており、それらをもとに取り組む ticket の優先度づけなども行える。
- 学び
- サブエージェントのステートレスは絶対条件:「今回だけ」と状態を追加するたびに、数日でシステムが壊れた。
- 二段階構造で十分:複雑な階層構造を試してみたが、価値を付加せずに複雑さだけを増した。
- ほとんどのタスクに必要なのはシンプルなエージェント:エージェント呼び出しの90%は、最もシンプルで最速のモデルを使用
- → 適切なタスク分解をして構築したエージェントシステムのいきつく先はファインチューニングしたSLMだってやつ思い出した。
- 明示は暗黙に勝る:明確なタスク定義と構造化された応答が必要。魔法は存在しない。
- 並列実行はすべてを変える:10のエージェントを同時に実行することで、5分かかるタスクが30秒で完了するように。
@Shun Ito
[論文] Memp: Exploring Agent Procedural Memory
- 与えられたタスクをメモリを参照しつつ遂行する仕組みを提案
- 過去の類似タスクに関するログ(メモリ)を検索
- ログをContextに加えてタスクを実行
- 結果を元に検索されたログ(メモリ)を更新
- 類似タスクのメモリを使うことで、タスクの理解や試行錯誤を短縮できる

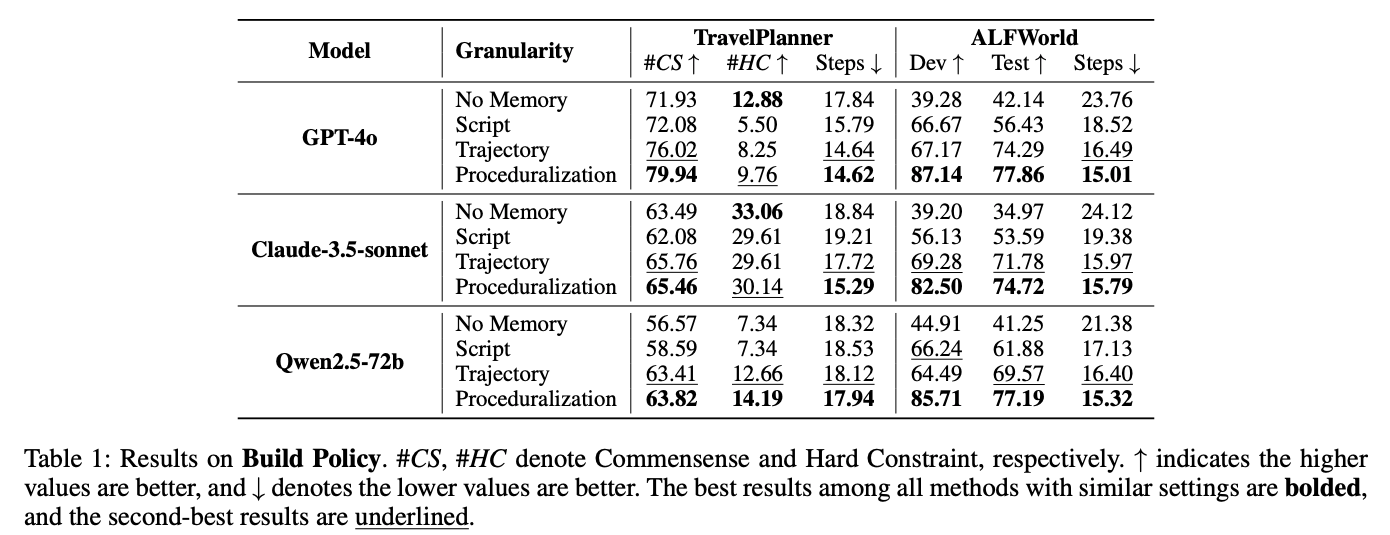
- Memory Storage & Retrieval
- 保存形式
- Trajectory: 訓練データからタスクが解かれた手順(文章?)を抽出しそのまま記録
- Script: trajectoryをLLMでサマライズした上で記録
- Proceduralization: Trajectory + Script
- 実験的にはProceduralizationが最良
- retrievalはベクトル検索(コサイン類似度)。タスクそのままではなく、キーワードを抽出してから検索した方が高精度
- 下限の閾値を決めているかがわからなかった
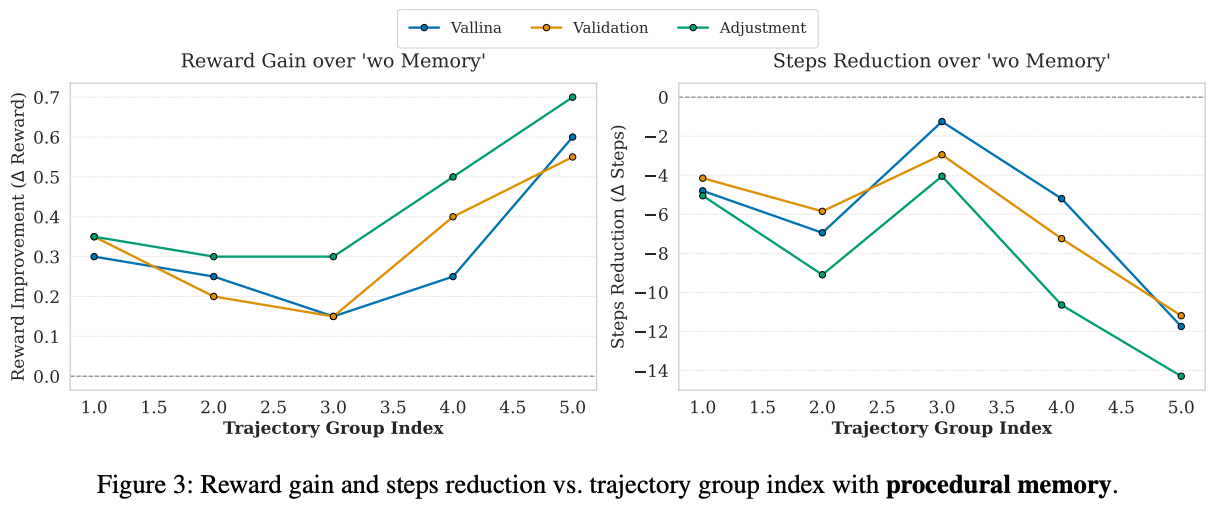
- Memory Update
- 更新方法
- Vanilla Memory Update: 新しいタスクの軌跡を全て追加していく
- Validation: 成功したタスクのみ軌跡を追加
- Adjustment: 失敗した場合は既存のメモリを修正
- Adjustmentが、精度改善・ステップ数削減に最も効果的
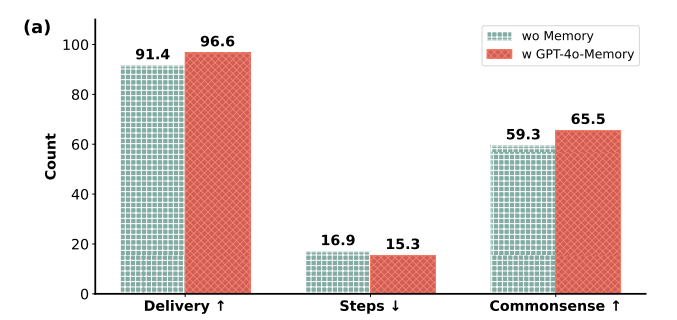
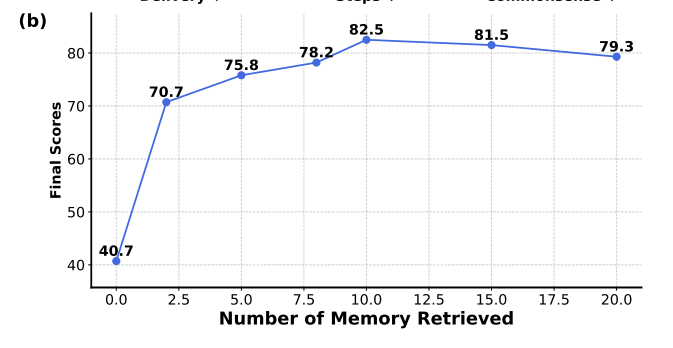
- その他知見
- 強いモデルで構築されたメモリを弱いモデルで使っても精度向上
- retrievalされるメモリを増やすと精度が上がるが、多すぎるとノイズになって悪化する
@Takumi Iida (frkake)
[blog] Don’t Build Multi-Agents
Cognition AIの記事。この記事で言いたいことは2つ
- コンテクストを与えよう
- エージェントは暗黙知・暗黙的な決定を行いながらタスクをこなしていくので、マルチエージェント化するとそれらが共有できない
- 最初にタスクを受け取るエージェントがおり、サブタスクに分けてサブエージェントに分配していくアーキテクチャ(タスクを分けて分配するだけしかしない)
- 欠点:サブエージェントは各々のしごとをするが、コンテキストが共有されておらず、実は別々のものを目指して作っていたということがあり得る。
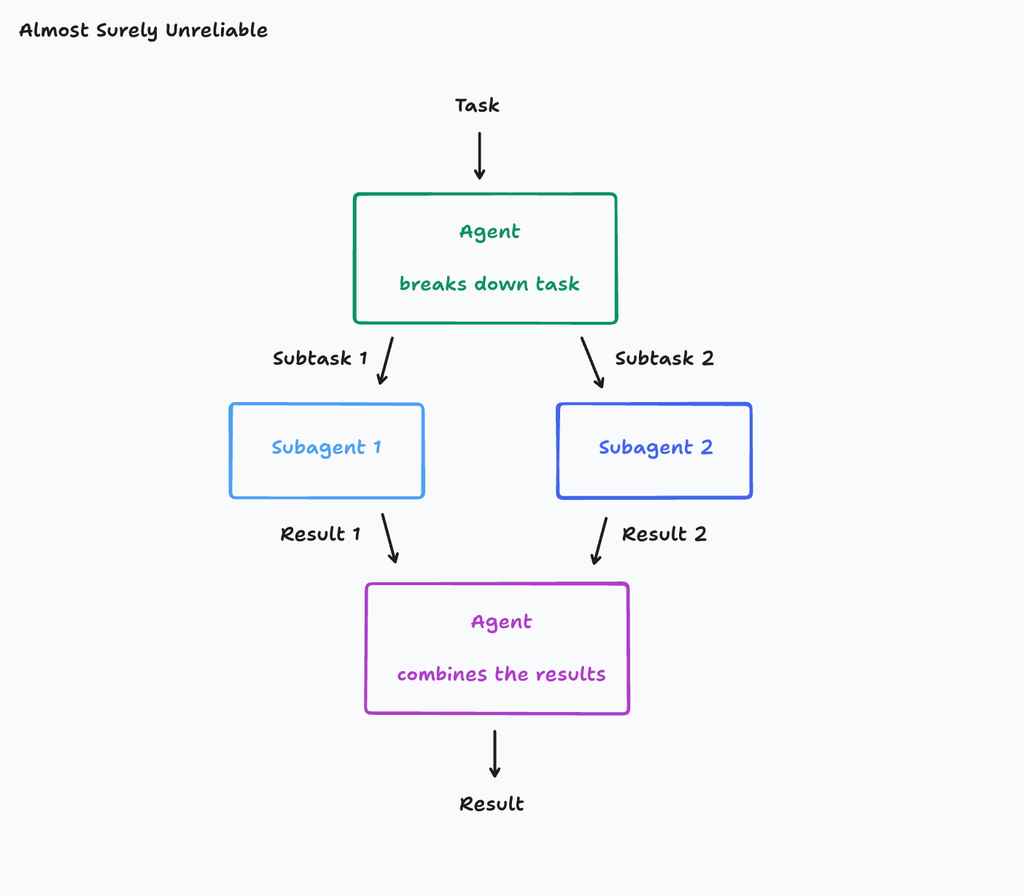
- コンテキスト(会話など)も共有してあげる
- 欠点:サブエージェント同士のコンテクストが共有されていないので、調和の取れたものが生成できない。そのため、サブエージェント同士の一貫性がなくなる。
- 著者の主張:サブエージェント1とサブエージェント2は明示的にはかかれていないを元に動作しており、(各々が判断するので)互いの行動がズレてしまう
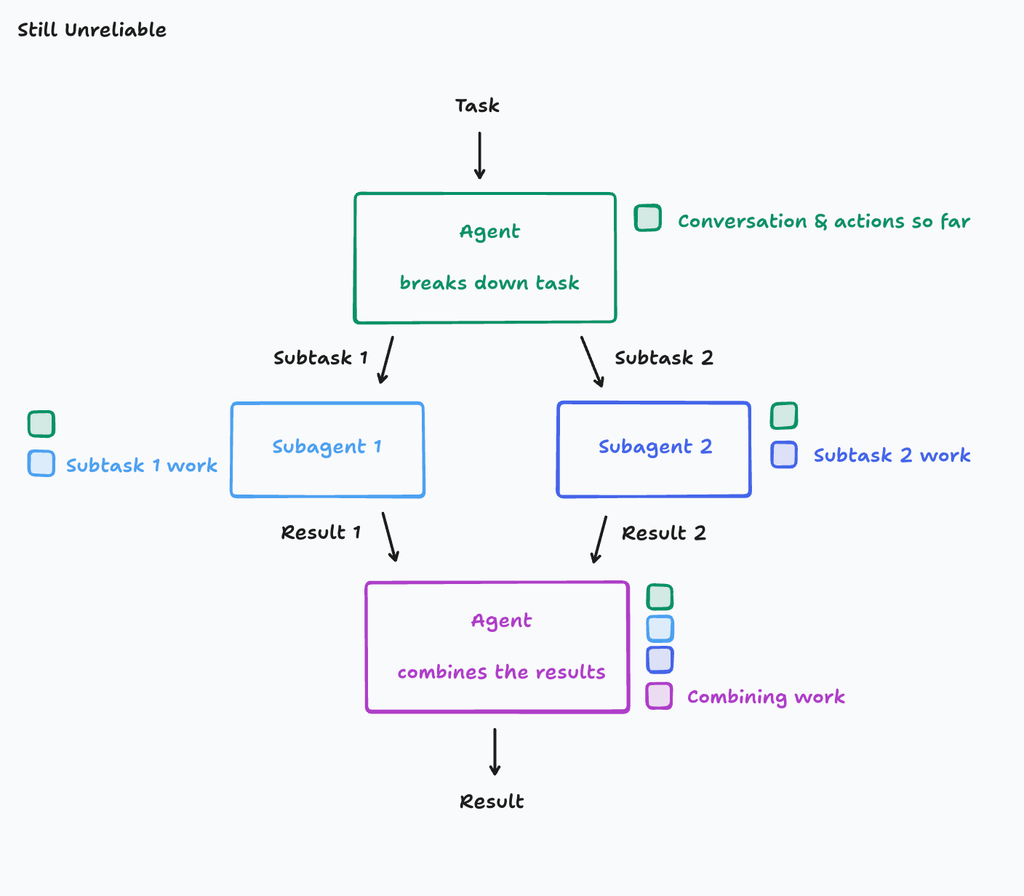
著者がいいたいこと
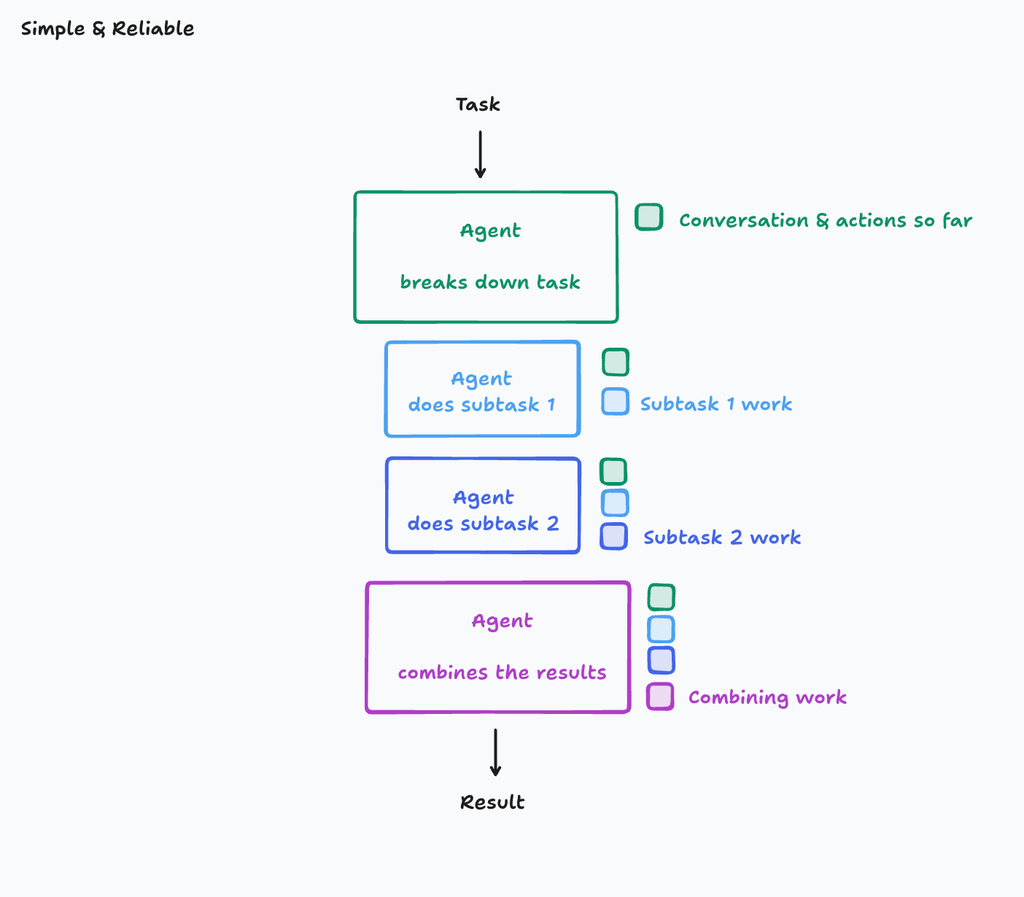
マルチエージェント化すると、暗黙的な決定が共有できないので、シングルスレッドで線形にエージェントを作るのが良い。
ただし、非常に大きなタスクで、サブタスクが多いとコンテクストウィンドウを超えてしまう可能性がある。
解放の一つとして、行動と会話の履歴を重要なところ(詳細、イベント、意思決定)だけ圧縮して次に伝えていく方法がある。Context Compression LLMは投資が必要で、難しいところではあるらしい。Cognition AIではこういった解決を試みている。
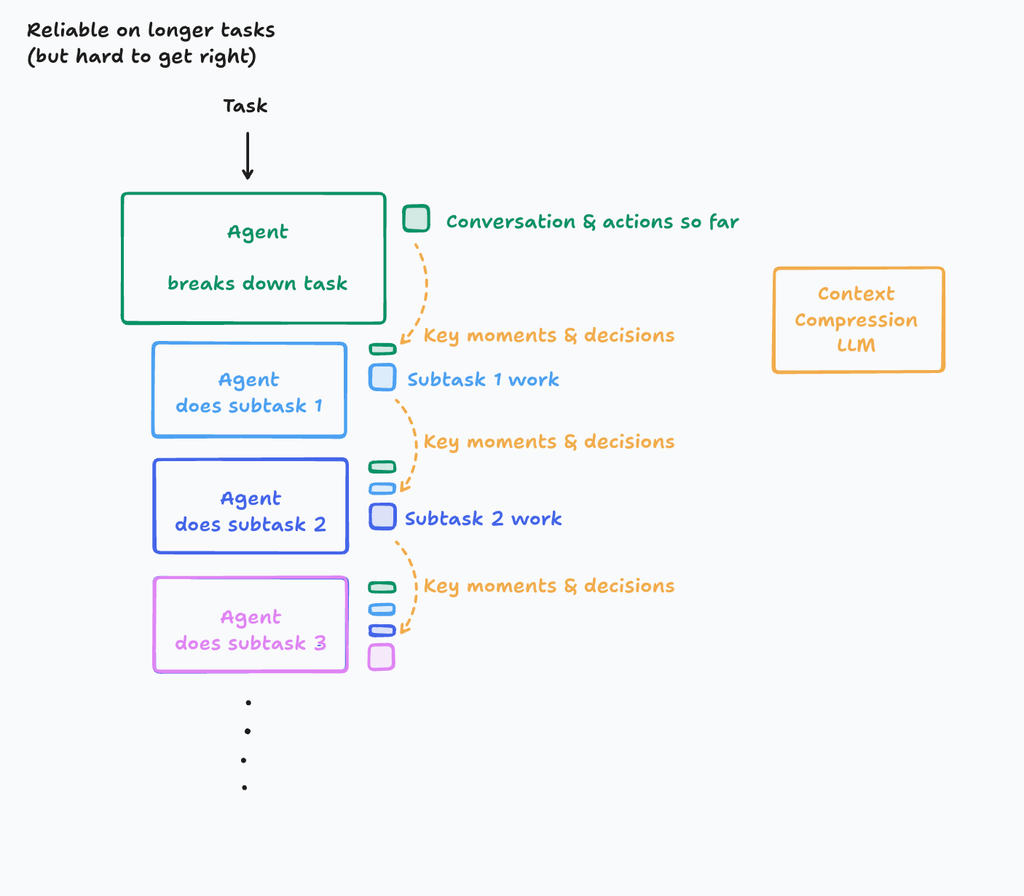
Claude Codeもサブタスクを生成するエージェント。ただ、並行して動作することはない。
コードを書くだけのエージェントと質問に答えるだけタスクをやるエージェントがいる。
@Hiromu Nakamura (pon)
[論文]Arctic-Text2SQL-R1: Simple Rewards, Strong Reasoning in Text-to-SQL
- [pon] 最近LLMによるText2SQLをやるので読んだ。Data-Centric AI感ある。
- [pon] PPOとかGRPOとかで脳が止まるので、いいかげんちゃんと調べた。
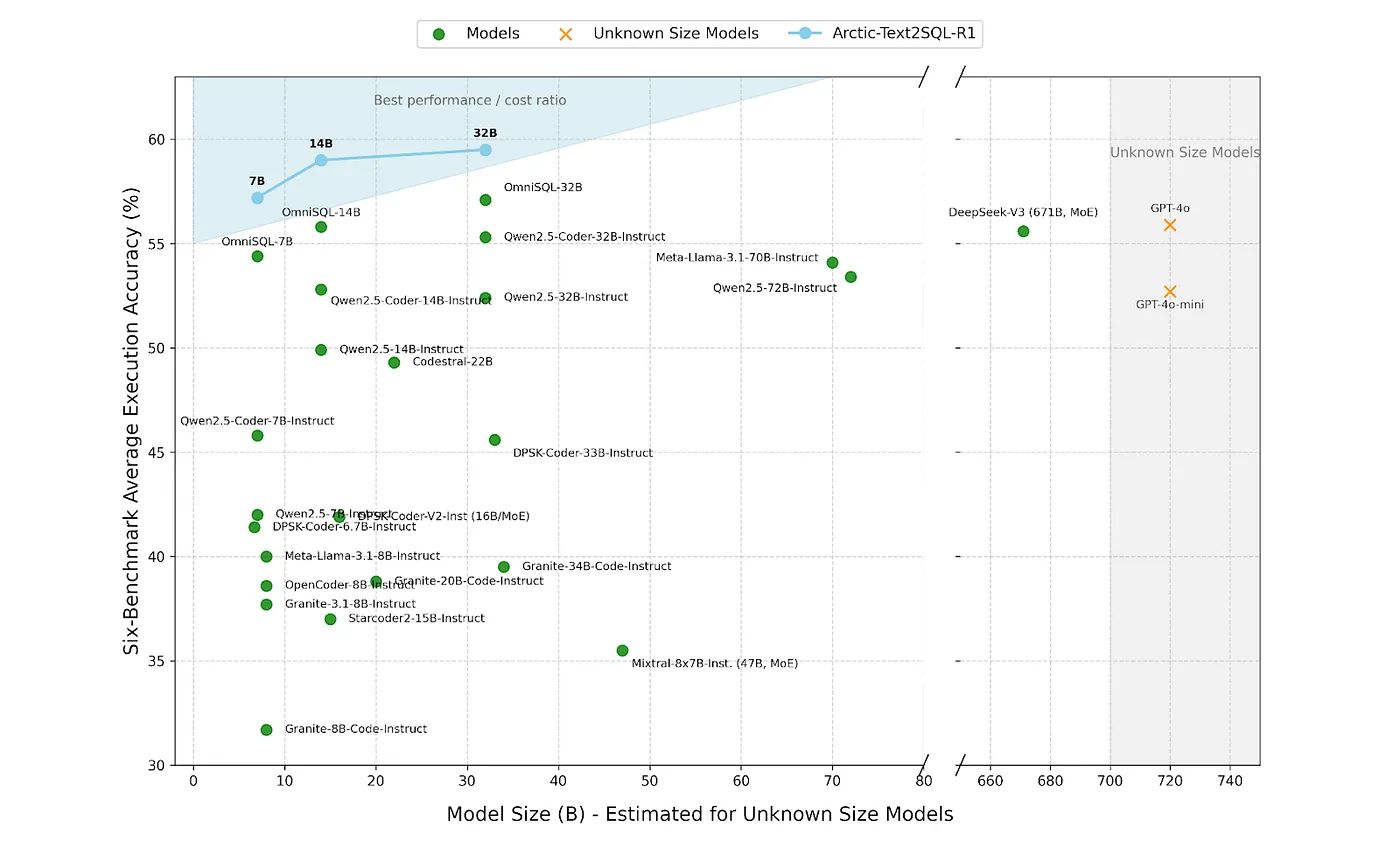
- モデルサイズに対してAccuracyが高いローカルLLM。オープンソース。
図はブログの方が見やすい
BIRD-dev, Spider-test, Spider2.0-SQLite, Spider-DK, Science Benchmark, and EHRSQLも含めた比較。7BでGPT-4o超え
手法
- ポリシー最適化手法はGRPO
- 強化学習素人すぎるのでGRPOを軽く調べたメモ。
- 状態価値関数を使用せず、そのかわりにグループ相対優位性 (Group Relative Advantage)という考え方を導入。同じ質問に対し複数の出力(回答)を生成させ、それらの報酬を比較することで、方策モデルの学習を効率化するもの。
- これがわかりやすかった
- 今までは状態価値関数も学習する必要があった。

- 超シンプルな報酬モデル設計
- 今までは文字列のオーバーラップ、スキーマの適合性、部分一致などを集約した、非常に手の込んだ報酬シグナルを使ったりしてたらしい
- 真の目的(SQLの実行結果の正確性)に集中して学習することを可能にし、複雑な中間目標によって学習プロセスが歪められるのを防ぐ。これにより、学習の安定性が向上し、結果としてより高い実行精度と優れた汎化能力を持つText-to-SQLモデルが実現された。
- 初期モデルはQwen2.5-Coderを利用
- データの品質を目的としたフィルタリング、拡張を適用
- BIRDおよびSPIDERトレーニングデータセットのの多くのSQLクエリが、実行時に空の結果を返すことを発見して除外。
- スキーマはあるもののデータが投入されていないGretel-Synth [27]を用いて、トレーニングデータを拡張する。
- GPT-4oを使用して、テーブルごとにINSERT文を生成し(詳細はAppendix Aを参照)、参照SQLが空でない結果を取得するまで繰り返しサンプリングする。
- 関連ドメインからの妨害テーブルをランダムに追加してスキーマの複雑さを増し、SQLの長さが160文字を超え、実行が成功したクエリのみをフィルタリングされていないプールに保持する。
- しかし、上で単純にトレーニングデータセットに追加すると、パフォーマンスが低下した。
- この問題を解決するために、モデルベースのフィルタリングを採用した。具体的には、Qwen2.5-Coder-32B-Instを使用して、10回の生成(tempearture=1.0)のうち少なくとも1回が正しかったクエリのみを保持した。
- この厳選されたGretel-Synth-Filteredセットは、結果を著しく改善する。
[pon] 学習データセット生成に涙ぐましい試行錯誤を感じる
[pon] シンプルな報酬モデル設計の有無を直接比較する実験は、論文中に明示的には報告されてないので、これがどのくらい起因したのかはわからんなー
@ShibuiYusuke
[Blog] Agentic Workflows Towards Natural-Language Programming for GitHub Actions
- コマンドに オプションが追加
- 自然言語でのワークフロー記述: 専門的なスクリプト言語の代わりに、自然言語(Markdown)を使ってAIエージェントのタスクを定義
- GitHub Actionsとの連携: 作成したワークフローは、GitHub Actionsを通じて安全に実行
- 反復的なタスクの自動化: ドキュメントの更新や問題の管理など、繰り返しの多い作業をAIによって自動化
- 共同作業の強化: チームのワークフローを改善し、ソフトウェア開発プロセス全体の効率を高める
- 透明性と監査可能性: AIによるタスクの実行状況を監視・管理できるため、透明性と説明責任が確保
- 研究プロトタイプ: このプロジェクトはまだ初期段階の研究プロトタイプ
@Yuito Ebihara
[論文]Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions
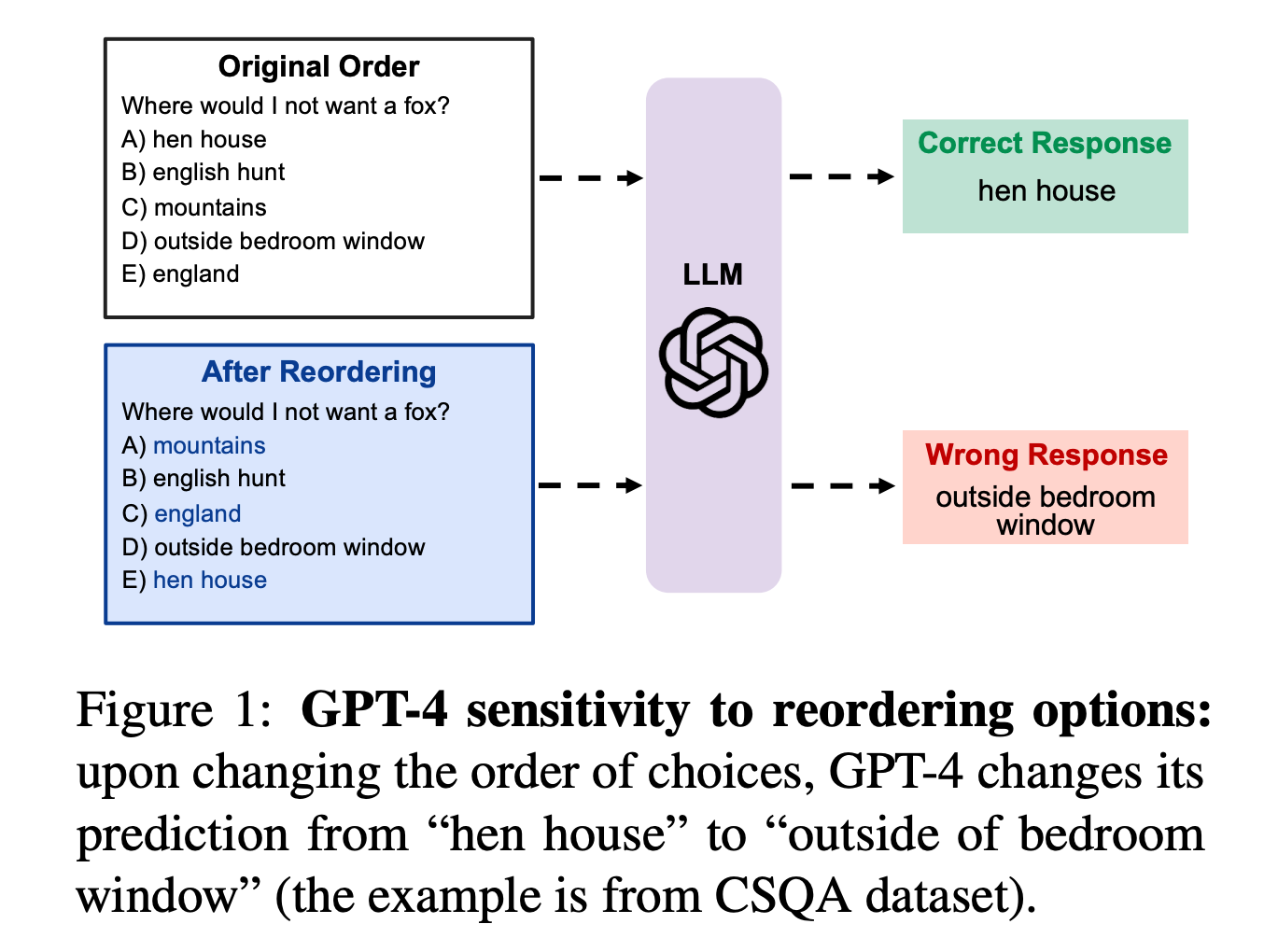
- ACL 2024 (findings)
- 多肢選択問題において、選択肢の順序がLLMの正答率に影響を及ぼす
- 正解の可能性が高い(とモデルが考えている)選択肢が複数ある場合に、順序の影響が大きくなる
- 1番目と2番目の選択肢を入れ替えて、正解率の変化を計測
- 可能性の高い2つの選択肢の位置が
- 近い→バイアス軽減、遠い→バイアス増幅
- ランダムに選択肢を入れ替えて多数決させたり(Majority)、先に回答の根拠を説明させる (MEC) ことで較正できるが、MECは逆効果になる場合がある
- 無理に説明しようとしてハルシネーションを起こしている?
- 学び
- reasoningモデルだとどうなるか気になるが、少なくとも古いモデルの回答ポン出しはバイアスがかかるらしい
- バイアスは他にもありそうなので、雑にStructured Outputs 使う時などは注意
- descriptionフィールドを最初に置くのはMECっぽい
- オカルトだが、Structured OutputsをLLM as a judgeに組み込むと(S, A, B, Cしか出力していなくても)分布が変わる気がする
メインTOPIC
Universal Deep Research: Bring Your Own Model and Strategy
| タイトル | Universal Deep Research: Bring Your Own Model and Strategy |
|---|---|
| 著者 | Peter Belcak, Pavlo Molchanov |
| 所属 | NVIDIA Research |
| リンク | https://arxiv.org/abs/2506.02153 |
| 関連ページ | https://github.com/NVlabs/UniversalDeepResearch |
- 前に紹介したSmall Language Models are the Future of Agentic AIと同じ第一著者の方
- 論文としては短いので、コードリーディングする時間を取ります
概要
- 既存のDeep Research Tool (DRT)は、特定のモデルと固定化された戦略に縛られている。
- そのため、ユーザが情報源の優先度づけやコストの制御ができない
- Universal Deep Resarch (UDR)は、任意の言語モデルをWrapする形で使用する汎用的なAgentシステムで、ユーザーが自然言語で記述した戦略を実行可能なコードへ変換し、そのコードが同期ツール呼び出しと進捗通知を制御しながら検索・要約・レポート生成を進めることができる。
- 実際のユーザインタフェースのプロトタイプまで作成し、汎用的なリサーチシステムの提案を行った。
Introduction
- Deep Research Tool (DRT)とは
- Research Promptを受け取り、Researchの進捗状況について継続的にユーザーに対して更新し、最終的にReportを表示するように設計されたシンプルなユーザーインターフェース。
- Agentのロジックは、Code Agencyを通じてLLMとToolをコードオーケストレーションとして利用したり、LLM Agencyを通じて推論やモデルのTool Callを利用して実装される
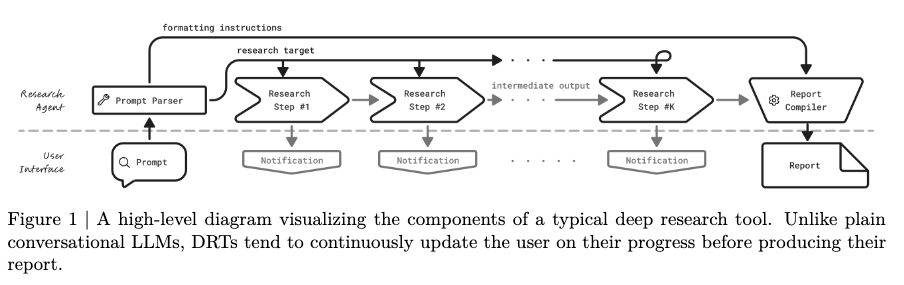
- 一般的なDeep Research System
- Gemini・Perplexity・OpenAI Deep ResearchはユーザーのpromptをResearch計画に変換し、反復的に検索を行い、十分なデータを収集したと判断するまで続けられる。
- Grok3 DeepSearchは、二層構成の探索 + LLMによる検証・要約という形で動く。
- 一つは常時稼働のクローラーとしてWebを巡回して、ひたすらIndexを作り続ける。
- ユーザが問い合わせをすると、オンデマンドの検索エージェントが起動し、必要なページをリアルタイムに取りに行く。リアルタイムに取りに行ったページは、LLMによって要点抽出や信頼性評価などを行って情報を集めて、十分になったらレポートを作成する。
- エンタープライズ領域での検索
- コーパスが限定されるので、定型的なパイプラインが主流。
- NVIDIA AI-Q Research Assistantの場合
- PromptからReport Planを作成
- 回答のためのデータソースを検索
- レポートを作成
- 必要に応じて更なるクエリのために、レポートのギャップを振り返る
- 出典の包括的なリストを提供
- そのほかにもSambaNova Deep ResearchやERP AI Deep Research
- 既存のDeep Research Systemの問題点
- 情報源の優先度、クロスバリデーション、コストの制御などをユーザーが戦略レベルで指定できない
- 産業別に必要な特化戦略を柔軟に設計・実装できず、高価な専用エージェントに頼っている
- 基盤モデルが交換できない
- これらの課題を解決することで、toC向けとtoB向けの機能のギャップを解消し、Deep Researchのような特化システムとモデルを分離して、システムに依存しないモデルの競争を可能にする
- UDRの要点は以下
- 追加のFine Tuningを必要とせず、ユーザが独自の完全カスタムなDeepResearchシステムを作ることができる
- システムの肝は、ユーザのResearch Promptを許容される制御フローと利用可能なツールの範囲内で、実行可能なコードスニペットに変換すること
Research Mechanism
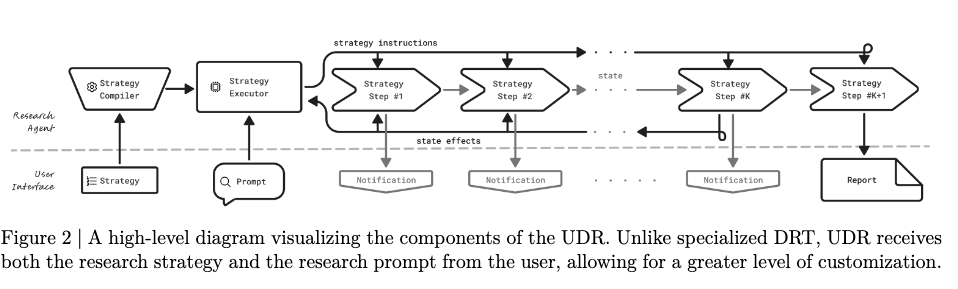
Inputs(入力)
- Research Strategy:UDRインスタンスの挙動を完全に規定する仕様で、手順を箇条書きや番号付きリストで明確に記述することが推奨されます。これにより、戦略コンパイラが手順の境界を正確に把握し、各ステップに対応するコードを生成しやすくなります。
- ⇒ Appendix Aに例
- Research Prompt:調査対象のテーマや出力フォーマットを含む一般的なリクエスト。暗黙の制約は存在せず、必要な条件確認や抽出は戦略側で明示的に行います。戦略は、プロンプトから自身に必要な情報(例:出力様式、対象範囲)を取り出して用います。
- ⇒ Appendix Bに例
Operation(動作)
フェーズ1:Strategy processing(戦略のコード化)
- 戦略テキストは、利用可能な関数や許可された制御構造の制約とともにLLMへ渡され、単一の「呼び出し可能関数」に変換されます。この関数は研究プロンプトを引数にとり、進捗通知を継続的に返すジェネレーターとして実装されます。
- 絶対に通知の辞書をyieldで返すように実装
- モデルが手順を飛ばしたり独自の制約を勝手に導入したりする逸脱を抑えるため、生成コードの各ブロックの先頭に「このコードが対応する戦略ステップ」をコメントで明記させます。利用可能ツール(例:search関数)の仕様は、ユーザーメッセージ内のDocstringでモデルに与えられます。
フェーズ2:Strategy execution(戦略の実行)
- State modifications
- LLMのコンテキスト外で行われ、テキスト片や中間成果は名前付きのコード変数に保存されます。これにより、長いワークフローでも小さなコンテキスト長で動作でき、実験では8kトークン程度で十分に処理可能だった。
- Tool use
- 同期的な関数呼び出しとして実装され、決定的で透明な挙動を保証。状態がコード側に永続するため、早い段階で得た情報にも正確に再参照できる。将来的には性能向上のため非同期化に拡張可能な設計です。
- LM reasoning
- 要約・ランキング・抽出など局所的処理に限定され、全体のオーケストレーションは生成コードが担います。これにより、LMの自由推論に依存した気まぐれな制御を避け、ステップに忠実な進行を保つ。
- Notifications(通知)
- 実行者が明示的に定義し、ジェネレーターのyieldで構造化辞書として逐次送出されます。通知はtype・timestamp・descriptionなどの緩いスキーマを持ち、UIはこれをリアルタイム表示する。
- Reliability(信頼性)
- 戦略全体を一括でコード化する方式が、ステップごとの分割生成や戦略をそのまま思考指示として与える方式よりも、手順の欠落や同期不整合が少なく堅牢だった。コメントでステップ対応を強制することが逸脱防止に効く。
- Efficiency(効率)
- 制御フローはCPU実行のコード、LLMが局所タスクという二層化で分離
- 必要な箇所にだけ小さな文脈でLLMを呼ぶため、GPUコストやレイテンシが抑えられ、全体の計算資源消費を最小化できる。
- Security(安全性)
- 生成コードの実行はサンドボックスで隔離され、ホスト環境へのアクセスを遮断
- この隔離はデフォルトで必須であり、プロンプトインジェクションやコード実行リスクに対する必須の防御策。
Outputs(出力)
- Notifications
- 実行中に時系列で放出される構造化イベントで、UIが低レイテンシに可視化します。
- 通知内容の粒度や文言は戦略側で完全に制御され、必要に応じて追加ペイロード(例:中間統計)を含められる。
- Research Report
- 変数に蓄積された状態から戦略ロジックに従って合成され、最後の通知として明確なタイプ(例:"final_report")で返される。
- レポートはMarkdownや表、参考文献など、戦略で規定されたフォーマットに従い、トレース可能性と再現性がある。
User Interface
UIとしては既存のDRT向けのUIと互換性のあるもの。

主要コンポーネント
- Search bar
- Research Promptを入力する入口
- トピック・質問・望ましい出力形式などをまとめて指定します。深い探索はここでの指示を起点に開始されます。
- Strategy selection list
- 過去に作成・保存した研究戦略を一覧表示し、即座に適用できる
- これにより、ユーザーはプロンプトごとに戦略を作り直す必要がない
- Edit strategy button
- 研究フローの粒度や検証手順、通知内容などをユーザーが直接調整できる
- Strategy editing text area
- 編集ボタンで展開され、現在の戦略が自動で差し込まれる
- 自然言語で手順を書き換えるとUDR側で実行可能コードに変換される
- Research progress notifications
- 実行中のステップがアイコン・説明・タイムスタンプ付きで時系列に表示される
- 戦略で定義した通知粒度がそのままUIに可視化され、ブラックボックスになりがちな中間処理を透過化
- Stop research button
- 任意の時点で探索を中断できます。不要なリソース消費や望ましくない方向性を早期に止める運用上の安全弁として機能します。
- Generate report button
- ユーザーが手動停止した場合にのみ表示
- 少なくとも1件の結果処理後で、最終レポート候補が生成される前という条件付きで、収集済み情報に基づく暫定レポートを作成できる
- Report viewer
- 最終(または暫定)レポートをMarkdownで整形表示します。
- 見出しや表などの構造化要素を正しくレンダリングし、レビューや共有を容易にします。
振る舞いと設計意図
- 実行中は戦略が明示した通知のみが逐次表示され、必要な場合にのみ内部状態を開示する方針です。これにより、低レイテンシな可観測性と情報過多の回避を両立します。
- 途中停止からの暫定レポート生成をサポートすることで、長い探索でも早期の意思決定や方向修正が可能になります。
- 全体として、UIは「戦略の選択・編集→実行→監視→レポート化」という一連の体験を一画面で完結させ、UDRの“ユーザーが戦略を主導する”設計思想を体感的に支える構造になっています。
Limitations
- 言語モデルのコード生成への依存
- UDRの挙動が戦略に忠実であるかは生成コードの品質に左右されます。コメントでステップ対応を強制しても、戦略が曖昧・過少指定な場合には意味的なずれやロジックのハルシネーションが残り得る
- ユーザー定義戦略の信頼性
- UDRは戦略が論理的に健全で安全かつ目的適合であることを前提にしている
- システム側は構文的・実行時の基本的な検査以上は行わないため、粗悪な戦略は非効率・不完全な出力やレポート未生成といった結果を招き得る
- 実行時のリアルタイム相互作用の制約
- UDRは進捗通知をライブ表示できるが、実行途中の介入やユーザーの即時フィードバックに基づく動的分岐はサポートしていない
- 意思決定ロジックは事前に戦略にする必要があり、長時間・探索的なワークフローでの適応性は限定される
Conclusions & Recommendations
- UDRは「ほぼ任意の汎用LLMの外側に深層リサーチ機能を付与し、Fine Tuningなしで動作させつつ、戦略レベルの主導権をユーザーに与えられる」ことを実証した
- 技術的には、制御ロジックをCPU実行のコードに分離し、LLMを局所タスクに限定する設計は、コストとレイテンシを抑えつつ、長いワークフローでも安定して運用できる基盤になり、戦略を直接編集することで、領域特化タスクに適合しやすい。
- 一方で、実務上では、ユーザが「十分に洗練された戦略を一から作ること」は想像以上に骨が折れる。そのため、戦略作成・改良の負担を下げる仕組みは必要。
- これらから以下3つを提案
- 展開する際は「戦略をユーザーに持参させる」のではなく、編集可能な戦略ライブラリを同梱することを推奨します。既製のテンプレート群を起点に小さな改変から始められるようにすることで、導入障壁と運用負荷を大きく下げられる。
- LMの推論(thinking)に対するユーザー側の制御手段をさらに探求するべき。思考の深さ・幅・検証強度・予算などを、戦略やUIから明示的に指定できるようにする研究開発の必要性がある
- 多数のユーザープロンプトを自動的に「決定的に制御されたエージェント」に変換するパイプラインの研究をするべき。プロンプトから手順化・ツール連携・停止条件設定までを自動合成し、複雑タスクを安定遂行できるエージェント化の一般手法を目指す。
コード
(メモ代わり)
- 実装
- 外部ファイルにsession_keyを使ってログを格納
- グローバルなインメモリを所有
実際の流れ (、ハードコードバージョン)
- 検索開始
- でプロンプトが有効なクエリか確認
- prompt(ユーザの入力)をタスク実行部とレポート作成部に分割
- taskのpromptをtopicに分解
- topic単位で
- topic単位で
- 普通にコードでTavilySearchを実行してるだけ
- 検索結果から でTOPICに関連する段落を抽出
- 最終的にレポート作成
- ソースのindexからURLをコードで紐付け
- 実際の流れ (、動的実行バージョン)
- クラス群
- : 8192 # コンテキスト長の制限
- : False # 長いコンテキストの強制使用
- : 1024 # 最大反復回数
- : "none" # インタラクションレベル
- LLMが生成したPython関数を管理
- のような検索機能などを「スキル」として登録
- 各スキルは名前、ドキュメント、実際のコードを持つ
- : 利用可能な関数のディクショナリ
- : 変数や中間結果を保存
- : 実行環境のグローバル変数
- : LLMクライアント設定
- : タスク実行プロファイル
- を事前定義済み関数として読み込み
- 必ず使うような関数はskillとして定義しておく
- まずでルーチンタスクを作成して順次実行
- 既存スキルと現在の変数 (tidings)とメッセージ内容からコードを生成
- astでparseして関数名、引数、docstring、codeを取得
(harness4.py:26-46)
(harness4.py:49-89)
(harness4.py:91-550)
コード生成プロンプト
感想
- 大層な名前がついてるが、ただのCoding Agentレベルのことしかできていない気がする。
- 単純に戦略を書いてくれたらそれをコードとして表現してあげるよ、ってだけ?
- 状態(Tidings)も結局Contextに渡しているので、コンテキストの節約に繋がらないのでは?必要なコンテキストのみに絞る工夫があるのかと思った。
- プロトタイプも論文内に書かれているが実装されていなかったり、code実行環境も隔離されていなかったりと論文の主張と食い違っている。
- だとLLMに入力するpromptなども生成させてるので、要約・ランキング・抽出など局所的処理に限定させるという処理も未実装ぽかった?SKILLSに入れるようにすればいい気がする