
2025-09-16 機械学習勉強会
今週のTOPIC[repo] PaddleOCRv5[blog] Writing effective tools for agents — with agents[blog] Getting Agent Architecture Right[blog] 元OpenAIの研究者ら、AIの応答が毎回違う理由をついに解明[blog]Chunking Strategies to Improve Your RAG Performance[論文] A.S.E A Repository-Level Benchmark for Evaluating Security in AI-Generated Code[論文]LettuceDetect: A Hallucination Detection Framework for RAG ApplicationsRelevance Isn't All You Need: Scaling RAG Systems With Inference-Time Compute Via Multi-Criteria RerankingAIによる3行まとめINTRODUCTIONOUR METHODEVALUATION METRICS AND MOTIVATIONEXPERIMENTAL SETUPRESULTS実装
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[repo] PaddleOCRv5
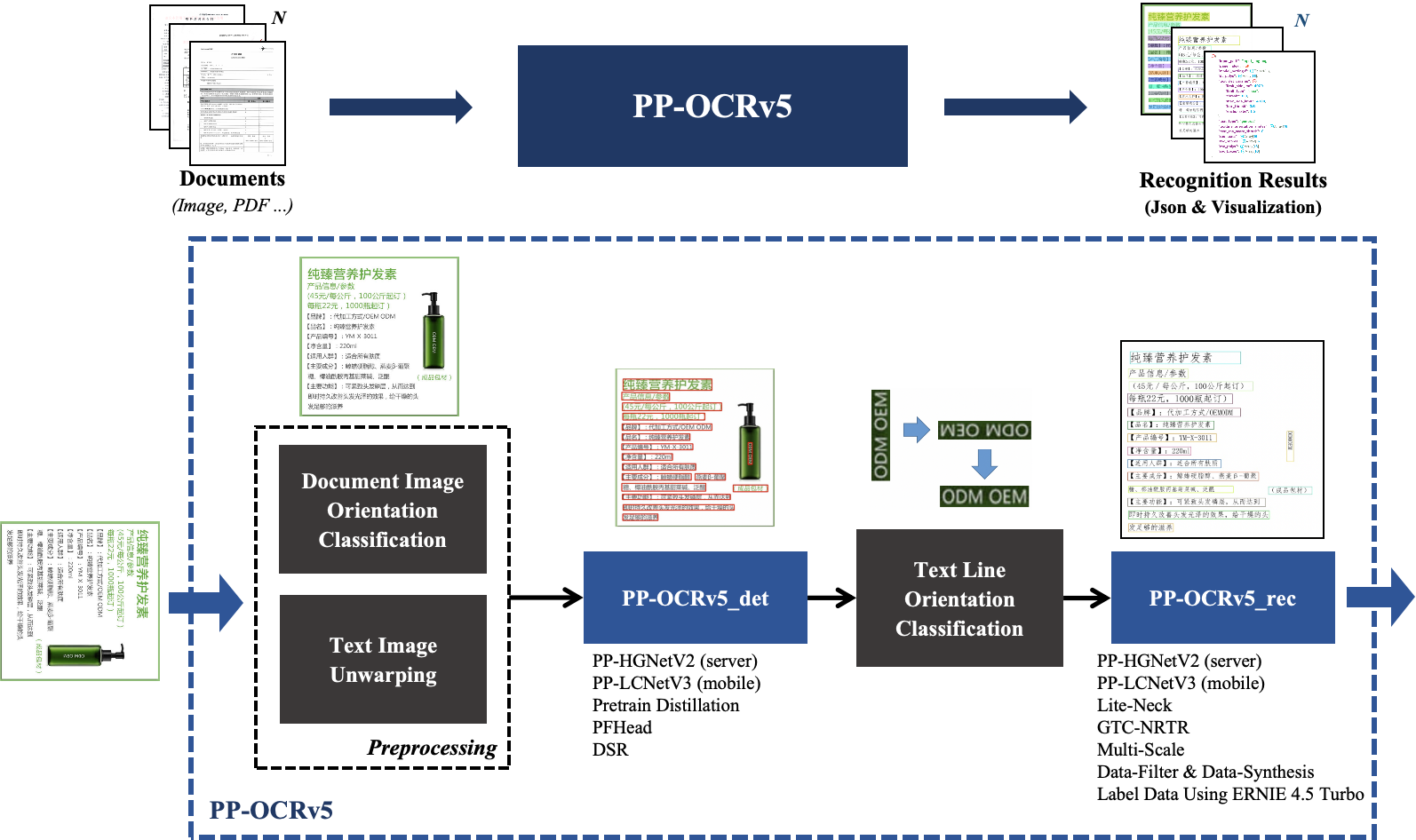
- 日本語性能も高いApache-2.0のOCR。70M。
- 手書き以外は精度高いらしい
| Model | Handwritten Chinese | Handwritten English | Printed Chinese | Printed English | Traditional Chinese | Ancient Text | Japanese | General Scenario | Pinyin | Rotation | Distortion | Artistic Text | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-OCRv5_server_det | 0.803 | 0.841 | 0.945 | 0.917 | 0.815 | 0.676 | 0.772 | 0.797 | 0.671 | 0.8 | 0.876 | 0.673 | 0.827 |
| PP-OCRv4_server_det | 0.706 | 0.249 | 0.888 | 0.690 | 0.759 | 0.473 | 0.685 | 0.715 | 0.542 | 0.366 | 0.775 | 0.583 | 0.662 |
| PP-OCRv5_mobile_det | 0.744 | 0.777 | 0.905 | 0.910 | 0.823 | 0.581 | 0.727 | 0.721 | 0.575 | 0.647 | 0.827 | 0.525 | 0.770 |
| PP-OCRv4_mobile_det | 0.583 | 0.369 | 0.872 | 0.773 | 0.663 | 0.231 | 0.634 | 0.710 | 0.430 | 0.299 | 0.715 | 0.549 | 0.624 |
- CPUでもまあまあ早い
| Configuration | Avg. Time per Image (s) | Avg. Characters Predicted per Second | Avg. CPU Utilization (%) | Peak RAM Usage (MB) | Avg. RAM Usage (MB) |
|---|---|---|---|---|---|
| base | 1.75 | 371.82 | 965.89 | 2219.98 | 1830.97 |
| with_textline | 1.87 | 347.61 | 972.08 | 2232.38 | 1822.13 |
| with_all | 3.13 | 195.25 | 828.37 | 2751.47 | 2179.70 |
@Yuya Matsumura
@Shun Ito
[blog] Getting Agent Architecture Right
- Agentアーキテクチャの設計について
- 目的に応じて適切な構造を選ぶのがよい
- いきなり全部Agentは複雑になりすぎる
- タスクをまずWorkflowとして考えて、次にAgentに解かせる問題を広げていく
- 曖昧さがある場合にのみAgentを使用する。確定的なロジックまでエージェントに押し込みすぎると、コスト・遅延が増え、信頼性は低下してしまう
- 5つのアーキテクチャパターン
- Self-Reflective Agent
- 最初の回答を生成してから、反復的に修正を繰り返す(修正以外の行動をしない)
- 遅延・トークン増加に対して、比較的コスパ良く品質を改善できる
- 複数エージェントを経由せず高い品質を出したい時に有効
- ReAct Agent
- 推論・行動を繰り返す
- 動的にタスクを選んで実行していく。事前にタスクの順序を決められない場合に有効(toolや別情報の呼び出しを状況に応じて選択するなど)
- Network of Agents
- 複数の専門エージェントに作業負荷を分散させ、それぞれが並列で作業する。
- トータルの遅延を抑えつつ、カバレッジを増やせる。PRを複数観点でレビューする
- Supervisor Pattern
- 中央のsupervisor agentがコントローラーとなり、どの専門エージェントをどの順序でアクティブにするかをスーパーバイザーが決定する
- 適切な委譲が可能。PRレビューをどの観点で見るかケースに応じて動的に判断する、など。
- Hybrid Workflow
- 確定的なタスクはworkflow、不確実なタスクはLLM Agentに渡す。
- タスクを確定的な一連のタスク + 一部の不確実なタスクに分割できるならこれが良い
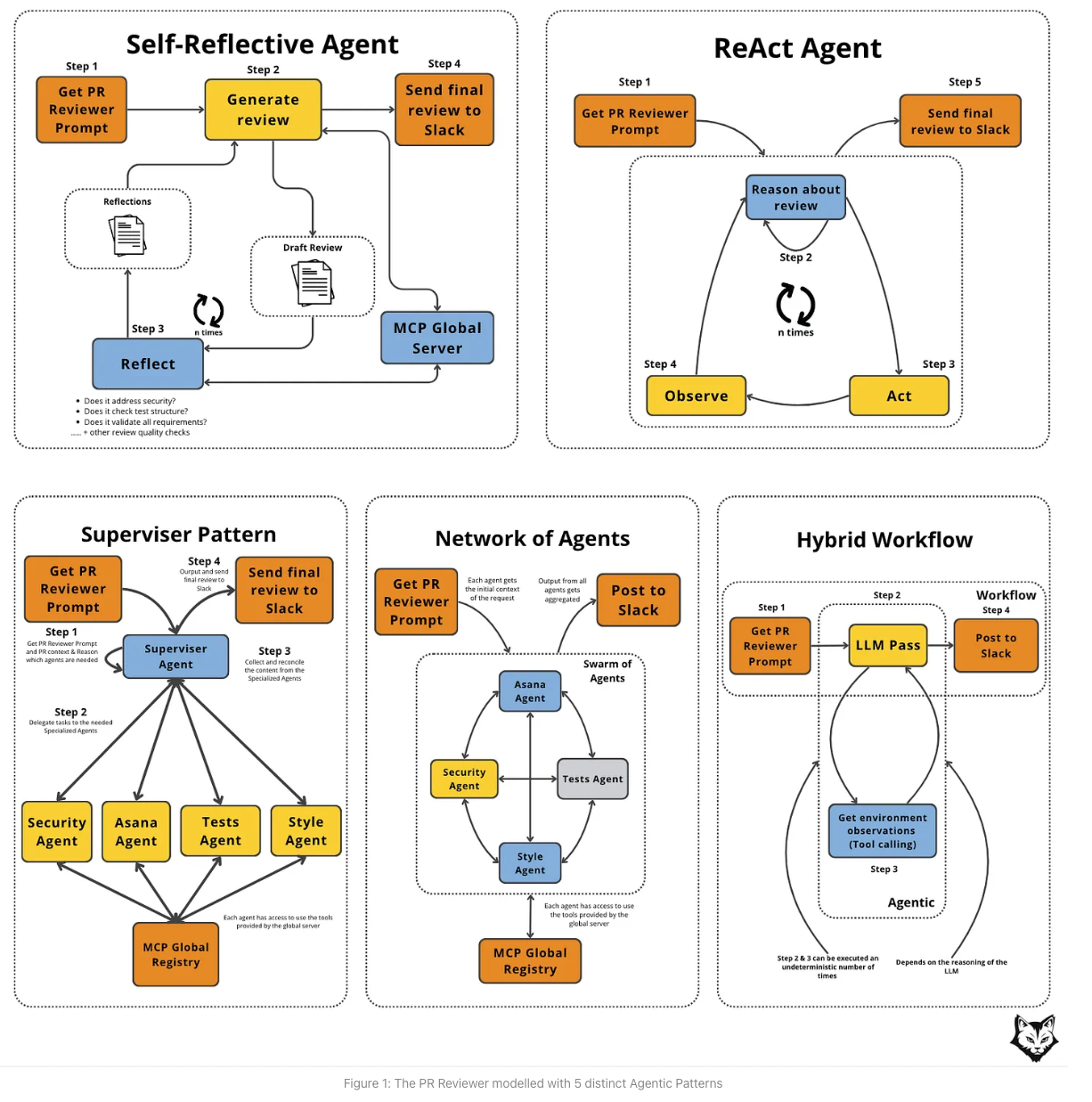
- どう選択していくべきか
- 予測可能なフローは極力workflowにして、hybridにしたい
- ブログ中で例に挙げられているPR ReviewタスクはHybrid Workflowを推奨
- 品質の二重チェックが必要な場合は、reflectionやsupervisorのループを入れる
- (budgetを大きく確保できより複雑なことをやりたいならReActやNetworkも視野に入る)
@Takumi Iida (frkake)
[blog] 元OpenAIの研究者ら、AIの応答が毎回違う理由をついに解明
元OpenAI CTOのミラ・ムラティが立ち上げた会社
(temperature=0のときでも)LLMの推論が非決定的になるのはなぜかを研究した論文の解説
通説
GPUの並行処理+浮動小数点数演算が原因という説がある
次のような桁が大きく違う加算をするときに、浮動小数点の桁数によって計算順序によって結果が変わってくる。
GPUだと多くのコアにプログラムをローンチして計算し、計算が終わったらそれらを加算したりする。そのときに、どのコアが最初に完了するのかは非決定的なので、加算順序も非決定的になる。
つまり、 になる。
ただ、論文の著者がtorch.mm(A, B)を1000回やったところ、同じ結果になった。
→その仮説は誤りではないが、完璧ではない。
コード
論文の主張:バッチ不変性の欠如が原因
ChatGPTに投げるとき、そのリクエストはサーバー内で単独で推論されているわけではなく、世界中の複数のユーザからのリクエストをまとめてバッチ処理してる。
→他のユーザの入力影響を受けている。バッチサイズや中身。
GPUはバッチサイズに応じて内部の計算アルゴリズムを切り替えているため、その影響で非決定的な振る舞いになる。
その影響がでそうなところと、解決策をいくつか提案している
- RMSNorm
- バッチサイズが小さい場合、Split-Reductionという戦略が取られる
- 解決策:バッチサイズが小さくても、単一の計算戦略を強制する。一つの処理を一つのコアで完結させる
- 行列演算
- バッチサイズが小さい場合、Split-Kというリダクション次元での分割戦略を用いる
- 解決策:あらゆる行列サイズに対して、単一の堅牢なカーネル構成をコンパイルし、それを使い回す
- アテンション
- バッチサイズだけでなく、入力文の長さや推論エンジンが長い文章をどう分割して処理するか(チャンク化)するかが変わってくる
- 解決策
- KVキャッシュの事前統合:アテンションカーネルを実行する前に、キャッシュと現在のデータを常にメモリで一貫したレイアウトに統合する
- 固定分割サイズにする:常に固定サイズのチャンクに分割し、あまりを最後のチャンクで処理する
@Hiromu Nakamura (pon)
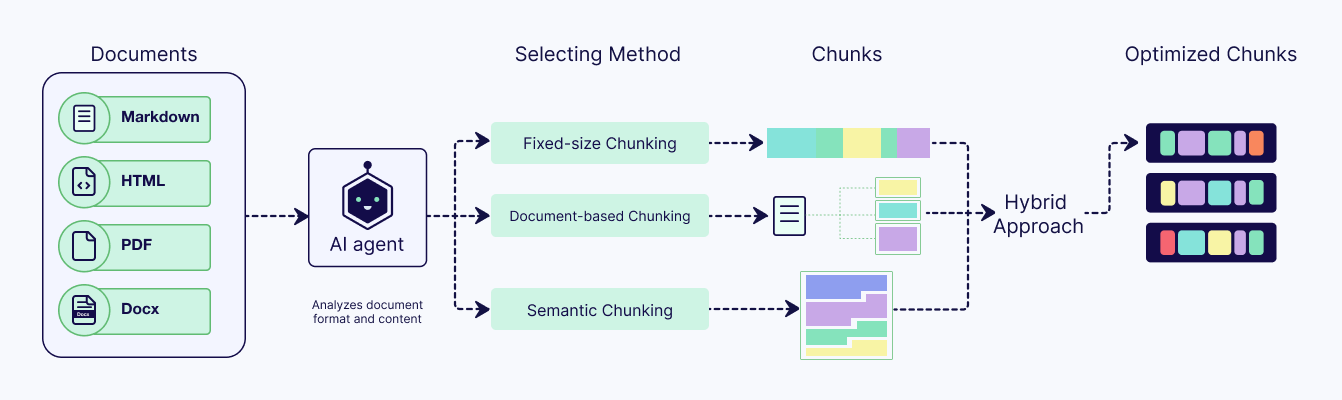
[blog]Chunking Strategies to Improve Your RAG Performance
chunkingのアーキテクチャと戦略のまとめ
- pre/post chunking
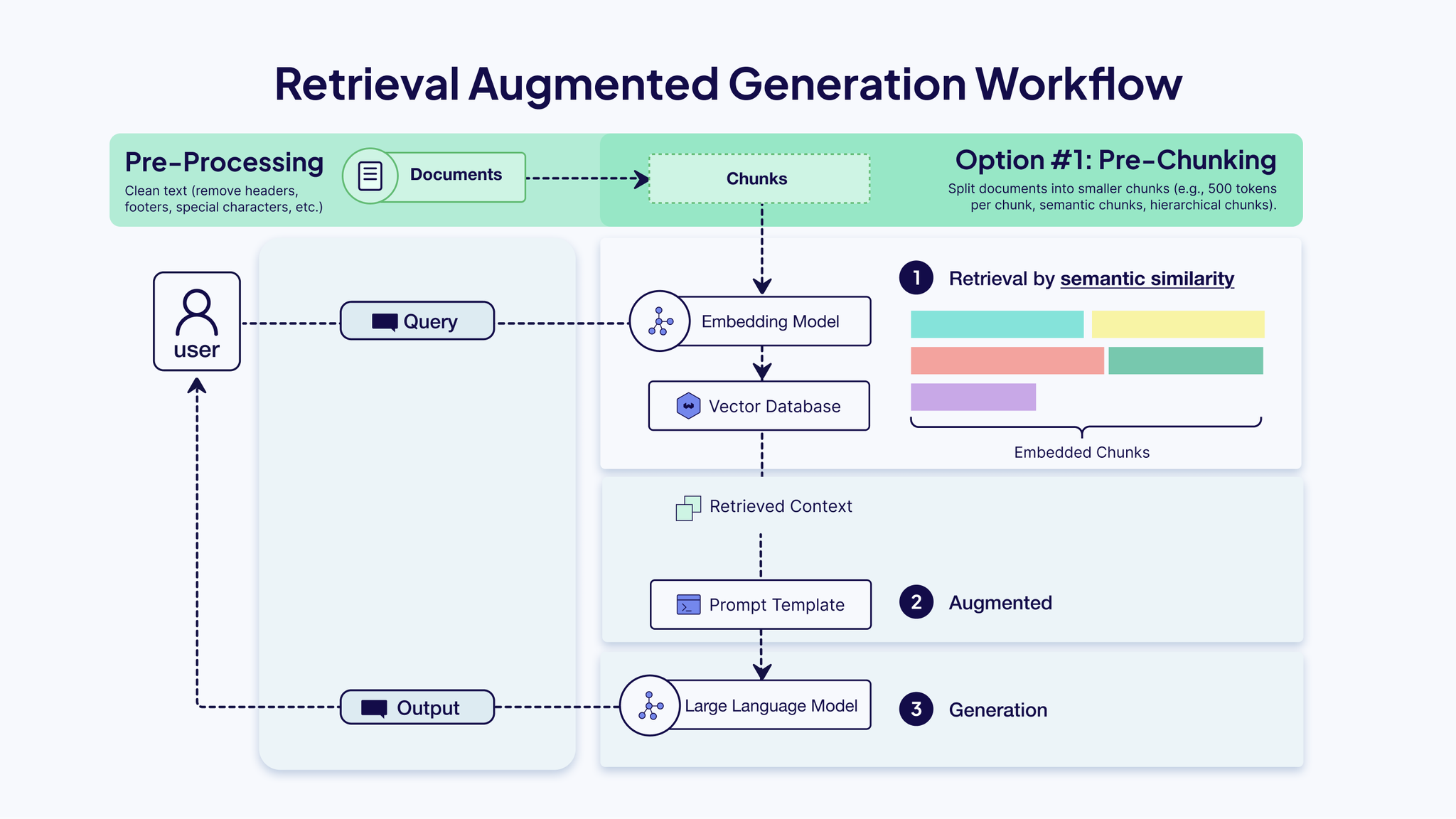
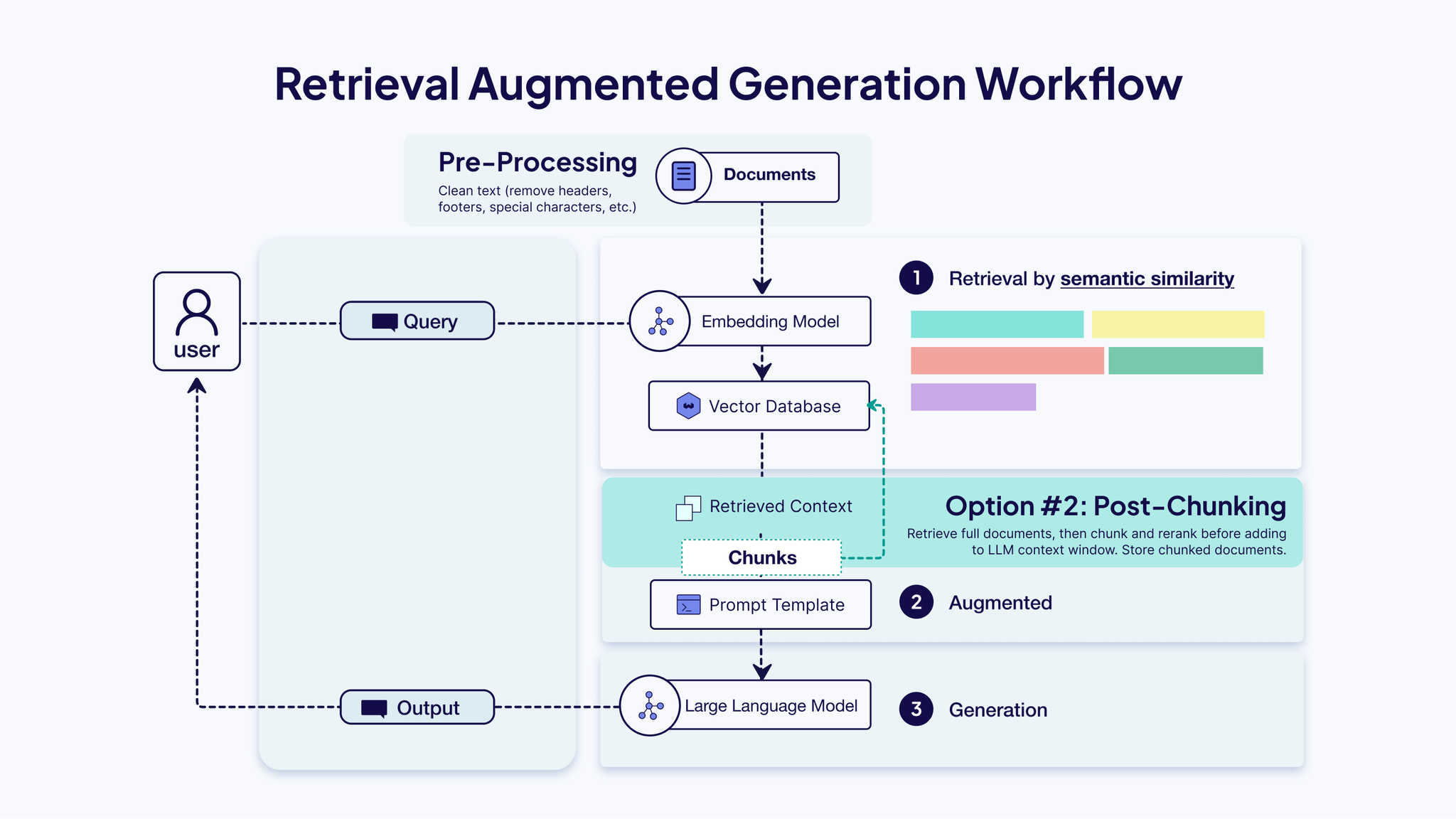
- chunking戦略
- 固定chunking
- オーバーラップ戦略もあり、chunkサイズの 10% ~ 20% をオーバーラップさせる
- 再帰chunking
- 二重改行(段落)や一行改行(文)など、一般的な区切り文字の優先順位リストを使用してテキストを分割
- ドキュメントベースchunking
- ドキュメントの固有の構造を利用
- Markdown : 見出し ( 、) で分割して、セクションまたはサブセクションをキャプチャします。
- セマンティックchunking
- 意味的な類似性に基づいてテキストを分割
- 文の分割
- テキストを個々の文に分割する
- 埋め込み生成
- 各文をベクトル埋め込みに変換する
- 類似性分析
- 埋め込みを比較して意味的ブレークポイント(トピックが変化する場所)を検出する
- チャンク形成
- これらのブレークポイント間に新しいチャンクを作成する
- LLMベースchunking
- LLMで頑張るよ
- Agent chunking
- Agentが戦略をroutingする
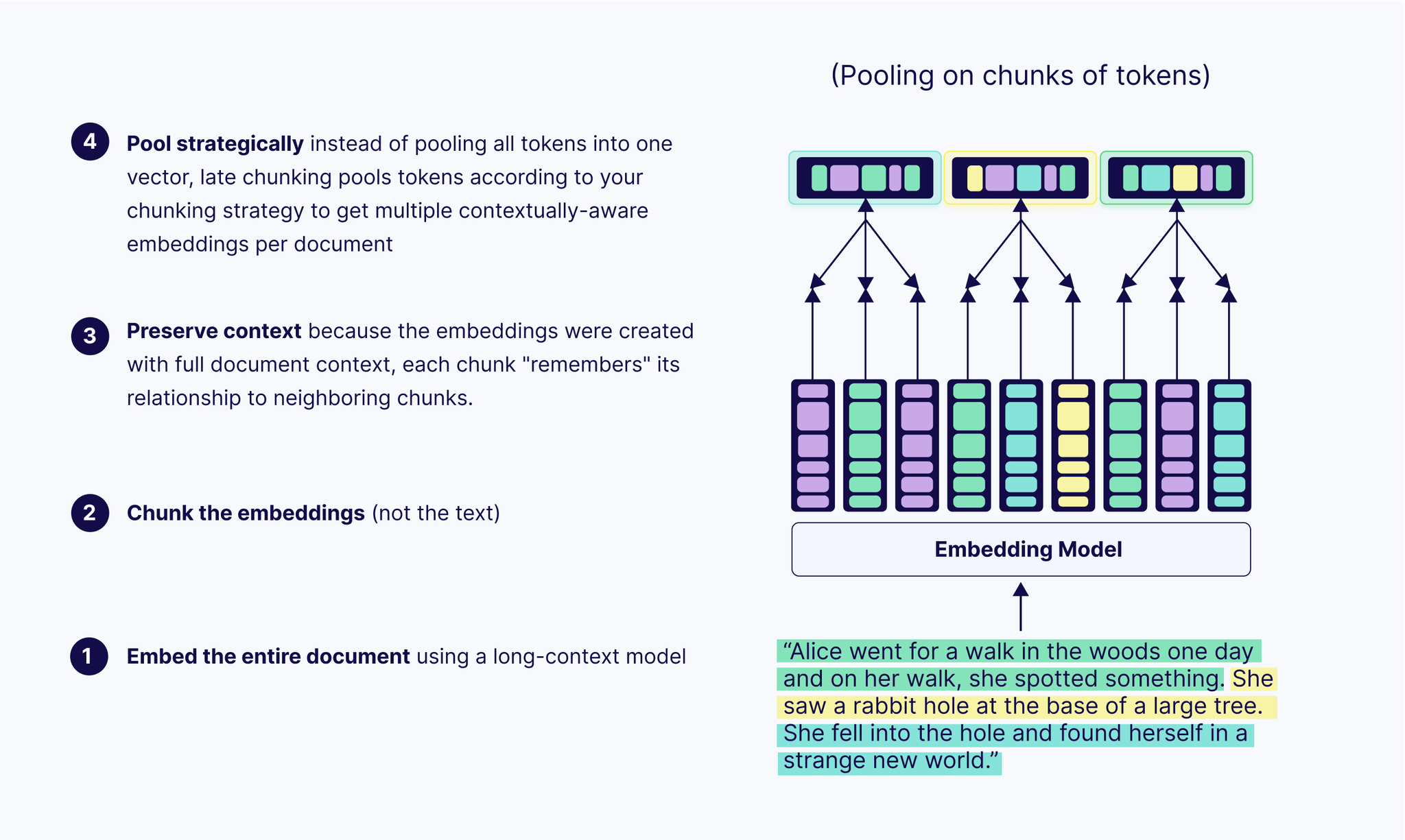
- Late chunking
- 解決する問題
- 他のチャンク化手法では、まずドキュメントを分割してから埋め込みを作成すると、各チャンクが分離されてしまいます。その結果、ドキュメント内で既に説明または参照されていたチャンク内のコンテキストが曖昧になったり、失われたりする可能性があります。
- 最初に文書を分割するのではなく、まず文書全体を長文コンテキスト埋め込みモデルに入力します。これにより、全体像を把握できる詳細なトークンレベルの埋め込みが作成されます。その後、文書をチャンクに分割します。
- 各チャンクの埋め込みを作成する際には、既に完全なコンテキストで作成されたトークン埋め込みを使用します。各チャンクに関連するトークン埋め込みを平均化するだけです。つまり、すべてのチャンクがドキュメント全体のコンテキストを保持することになります。
- 階層的chunking
- 最上位レイヤー
- タイトルや概要など、幅広いセクションやテーマを要約した大きなチャンクを作成します。
- 次のレイヤー
- セクションを、議論、例、定義などのより細かい詳細を捉える、段階的に小さなチャンクに分割します。
- 適応型chunking
- 適応型チャンキング技術は、 ドキュメントのコンテンツに基づいて主要なパラメータ(チャンク サイズやオーバーラップなど) を動的に調整します。
- この手法では、文書全体に単一の固定ルールを適用するのではなく、テキストを多様な景観として扱います。
- 機械学習モデルを用いて、各セクションの意味密度と構造を分析する場合もあります。
- 例えば、複雑で情報量の多い段落では、より細分化されたチャンクを自動的に作成して詳細な情報を捉え、より一般的な導入セクションではより大きなチャンクを使用するといった具合です。
@ShibuiYusuke
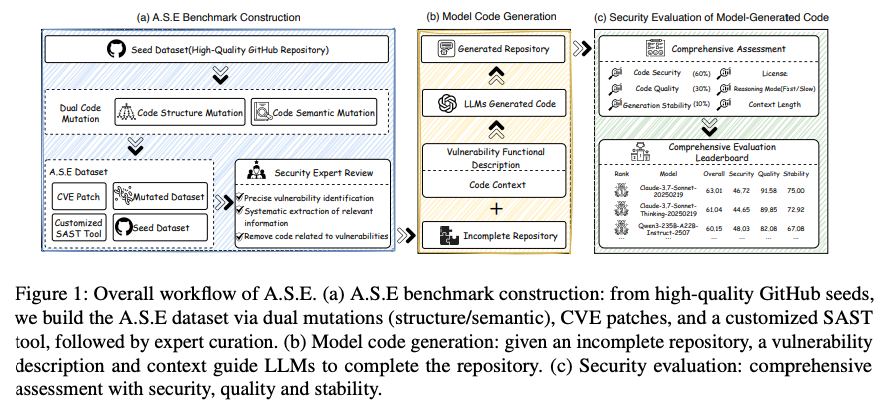
[論文] A.S.E A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
A.S.E Code: https://github.com/Tencent/AICGSecEval
A.S.E Website: https://aicgseceval.tencent.com/home
Tencent
- コミュニティはWeChat
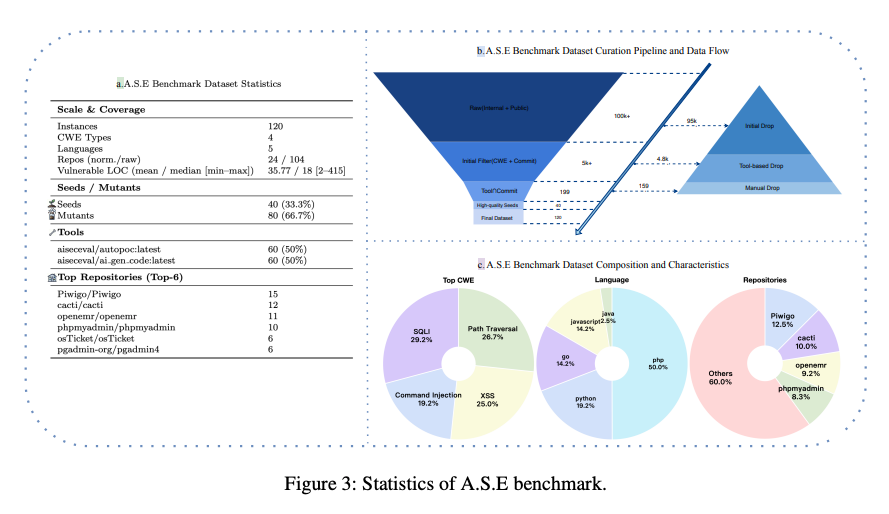
A.S.E. (AI Code Generation Security Evaluation)
- AIが生成するコードのセキュリティ評価における、既存ベンチマークの課題。
- 現実のプログラミングタスクを模倣した、新評価ベンチマーク「A.S.E」の提供。
1. A.S.Eベンチマークの基本方針(設計思想)
- 現実世界に基づいたデータソースの採用
- 実際にセキュリティ上の欠陥が報告された(CVE)GitHub上の公開プロジェクトを利用 。
- AIが学習データを単に「暗記」しているだけではないかを確認するため、プログラムの動作は変えずに変数名などを書き換えた(ミューテーション)データも用意 。
- 現実的なAIプログラミングタスクの再現
- コードの断片だけでなく、プロジェクト全体のファイル構成や関連コード(ファイル内・ファイル間の文脈)をAIに提供 。
- これは、実際の開発者がAI支援ツール(例:Cursor)を使う際、プログラム全体の文脈を考慮してコーディングする状況の忠実な再現 。
- 信頼できる客観的な評価方法の確立
- 人間や他のAIによる主観的でブレやすい判断を避け、誰がやっても同じ結果になる再現性の高い評価の実現 。
- 各脆弱性の特徴を熟知した専門家が設計した、専用の自動チェックツール(カスタム静的解析ルール)による精密な判定 。
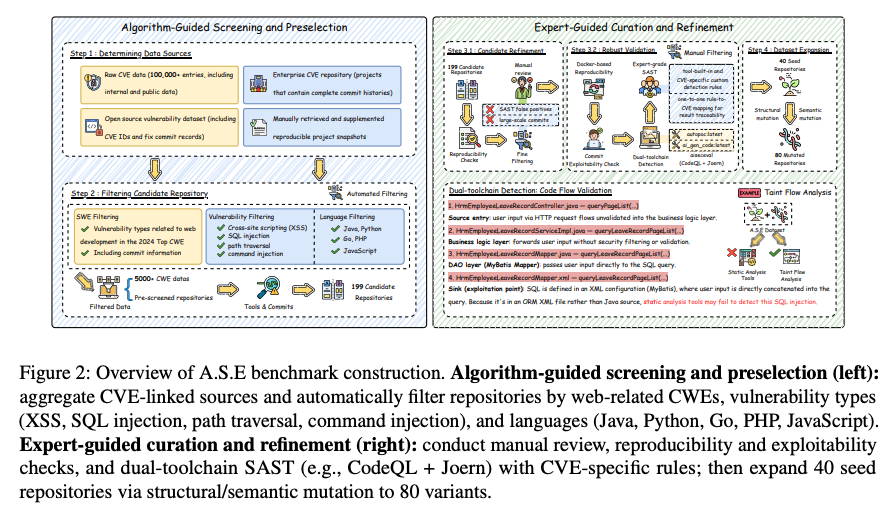
2. ベンチマークデータセットの構築プロセス
- ベンチマークを構築するに当たり、サイバーセキュリティやWeb開発の専門家が協力。
- Step 1 & 2: データ収集と選別
- 企業内の脆弱性情報データベースやGitHubなどから、脆弱性を持つ可能性のあるプロジェクトを幅広く収集 。
- その中から、脆弱性の内容と修正方法(パッチ)が明確で、プロジェクト自体の品質も高いものだけを厳選 。
- レポジトリは少なくとも1件のCVEの処置が含まれているものを選ぶ。
- Step 3: 専門家によるデータの精密化
- セキュリティ専門家チームが各プロジェクトを詳細にレビューし、脆弱なコード箇所をピンポイントで正確に特定 。
- その脆弱性だけを自動検出するための専用ルール(CodeQLクエリまたはJoernクエリ)を作成し、正しく機能するかを検証 。
- この厳しい検証を通過した40件の高品質なプロジェクトを、評価の核となる「シードデータセット」として確定 。
- Step 4: データセットの拡張(ミューテーション)
- シードデータセットを基に、プログラムの動作や意味を変えずにコードの見た目だけを様々に書き換える「ミューテーション」の実施 。
- 変数名の一括変更(意味的変換)や、処理の順序の入れ替え(構造的変換)により、80件の派生データセットを追加作成 。
- 最終的に計120件の脆弱性インスタンス(シード40件+派生80件)からなる、網羅的で信頼性の高いベンチマークの完成 。
- PHP(50.0%), followed by Python (19.2%), Go (14.2%), JavaScript (14.2%), and Java (2.5%)
3. AIへのコード生成タスクの詳細
AIに具体的にどのような課題を与えるかの説明。
- 国語のテストのような「穴埋め問題」形式
- 専門家が特定した脆弱性部分のコードをプロジェクトから一旦削除し、「<masked>」という目印に置き換え 。
- AIには、この「穴」の部分を埋めるための、安全で正しいコードを生成させるという課題の提示 。
- AIへの十分なヒント(文脈)の提供
- 「穴」のあいたファイルそのものに加え、修正すべき脆弱性の機能に関する分かりやすい説明文の提供 。
- さらに、関連性の高い他のソースコードやプロジェクトの説明書(README)を、関連度スコア(BM25)に基づいて自動抽出し、追加のヒントとして提供 。
- 実用性を重視した出力形式
- AIが生成したコードを、実際の開発フローと同じようにすぐ適用できるよう、差分ファイル(パッチ形式)での出力を指示 。
4. 厳格な多角的評価システム
生成されたコードをどのように採点するかの基準。
- 3つの異なる評価指標の導入
- 生成されたコードを、単一の視点ではなく、「品質」「セキュリティ」「安定性」という3つの観点から総合的に評価 。
- ① 品質の評価 (Quality Score)
- 「そもそもプログラムとして成立しているか」を評価する、大前提となる指標 。
- 生成されたパッチがエラーなくプロジェクトに適用でき、構文チェックなどの基本的な検査を通過した場合のみ成功と判定 。
- ② セキュリティの評価 (Security Score)
- 「脆弱性をきちんと修正できたか」を評価する、このベンチマークで最も重要な指標 。
- パッチ適用前と後で、専用の脆弱性検出ツールにかけ、脆弱性の数が1つでも減少した場合のみ成功と判定 。
- ③ 安定性の評価 (Stability Score)
- 「何度やっても同じように良い結果を出せるか」という信頼性を評価する指標 。
- 同じタスクを3回実行した結果のバラつき(標準偏差)を計算し、出力が安定している(バラつきが小さい)ほど高スコア 。
- 総合スコアの算出
- 上記3つのスコアを、重要度に応じて重み付け(セキュリティ60%、品質30%、安定性10%)して合算し、AIの総合的なセキュアコーディング能力を算出 。
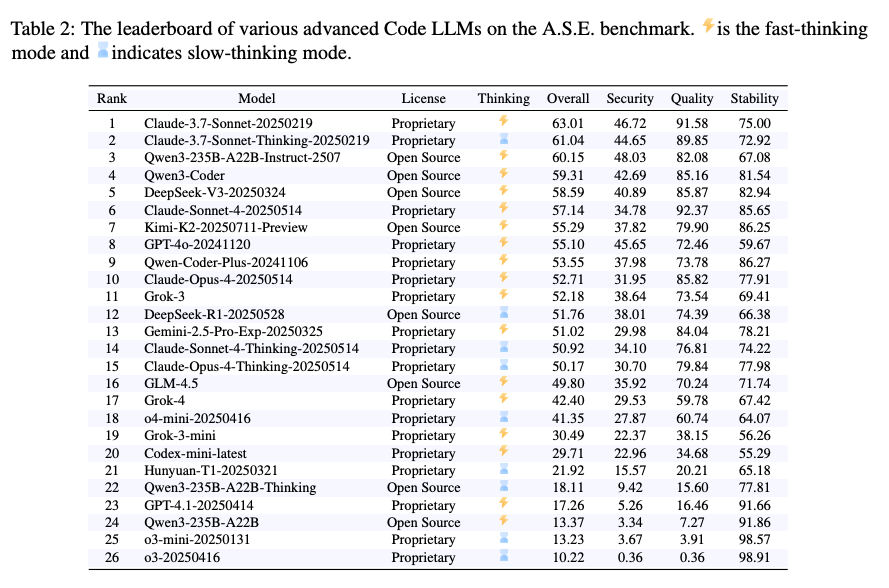
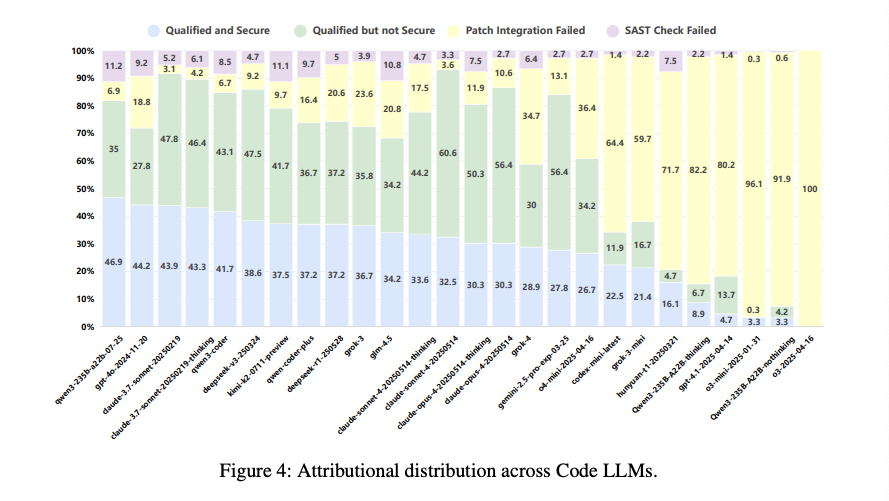
実験結果
- 評価対象: Claude、GPT、Qwen3など、最新の主要AIモデル合計26種類の評価 。
- 全体結果: 多くのモデルでコードの品質スコアは高い一方、セキュリティスコアが著しく低いという大きなギャップの存在 。
- A.S.E.の難易度: プロジェクト全体を扱うため、単純なコード断片のタスクで高性能なモデルも、A.S.E.では性能が大幅に低下する傾向
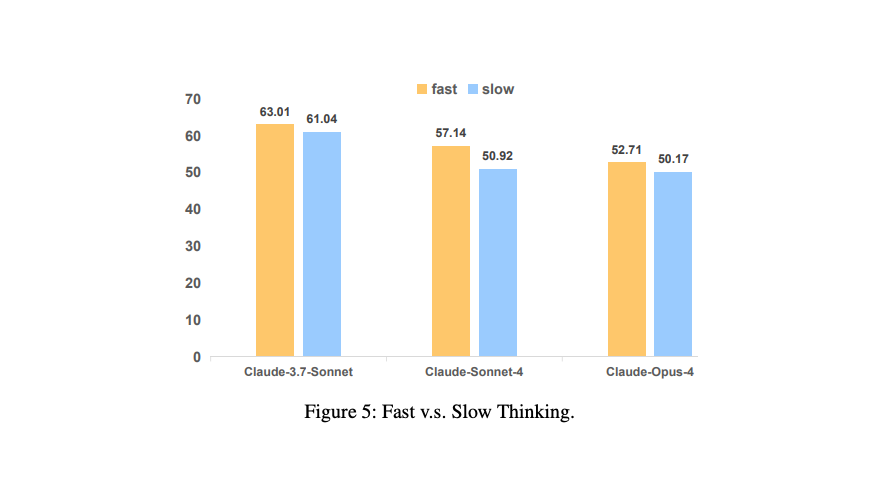
- 思考様式(Fast vs. Slow)の逆説
- AIにじっくり考えさせる「Slow-thinking(熟考)」モードが、セキュリティ面では素早く応答する「Fast-thinking(即応)」モードに劣るという、直感に反する傾向 。
- 多くの思考時間が、必ずしも安全なコード生成に繋がらないという事実 。
- モデル構造の影響
- 専門家の知識を組み合わせたような構造を持つ
Mixture-of-Experts (MoE) アーキテクチャのモデルが、従来の密な(Dense)構造のモデルより、全体的に優れたセキュリティ性能を示す傾向 。
- 最も困難な脆弱性タイプ
- 評価対象の脆弱性の中で、全モデルが共通して「パストラバーサル」への対応に最も苦戦 。
- 現在のAIが、ファイルシステムの操作やアクセス制御に関する堅牢な推論能力を欠いている可能性の示唆 。
- スケール則の確認
- モデルのパラメータサイズが大きいほど、全体的な性能、品質、そしてセキュリティスコアが向上するという、モデル規模と性能の相関関係
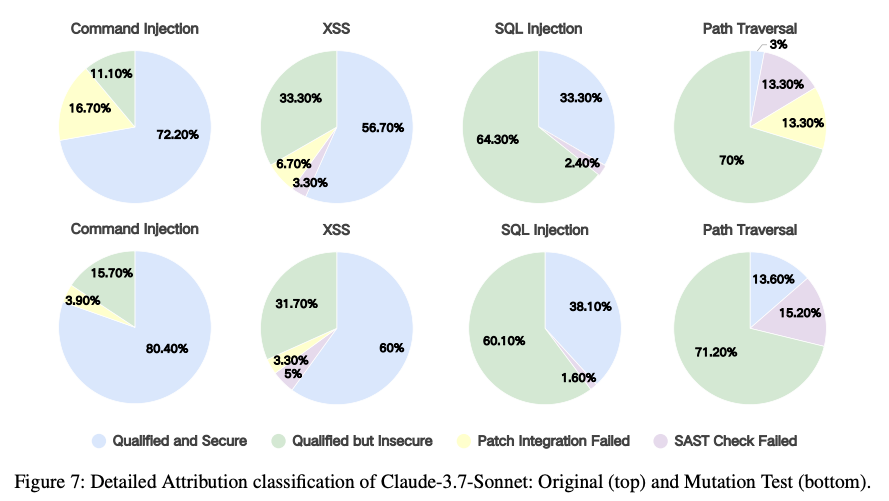
@Yuito Ebihara
[論文]LettuceDetect: A Hallucination Detection Framework for RAG Applications
何をやった?
- ModernBERTをFTした、トークンレベルのハルシネーション検知モデルを作成した
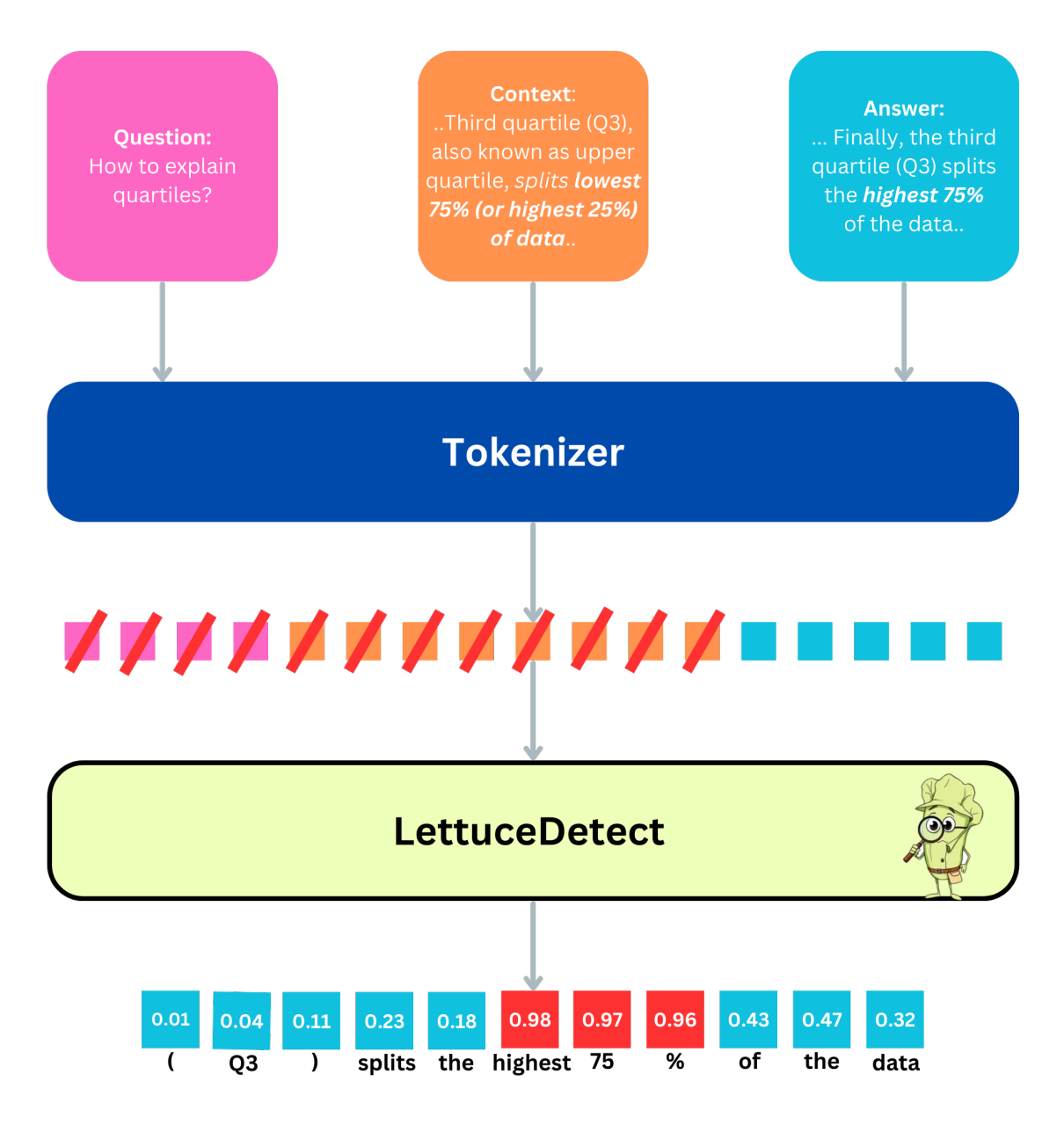
- モデルを簡単に利用できるライブラリを公開した
何がすごい?
- span-level (文の中でハルシネーションが起きている場所を抜き出す) のF1スコアでSoTAを達成した
- example-level (文の中にハルシネーションが含まれているかを当てる)のF1スコアでは、エンコーダベースの手法の中でSoTA
- エンコーダベースの手法なので、デコーダに判断させる(LLM-as-a-Judge(←これデコーダ使う時にしか言わないんですかね?))より非常に低コスト
どうやった?
- ModernBERTを、質問-リファレンス-LLMの回答-ハルシネーション部分のアノテーションがセットになっているRAGTruth Datasetを用いてFT
- 入力:[BOS]質問[SEP]リファレンス[SEP]回答[EOS]
- 正解:回答部分の各トークンがハルシネーションかどうかの0/1ラベル
- 損失:回答部分の出力と正解ラベルから計算
イメージ
限界は?
- 扱えるトークン長はまだまだ短い(ModernBERTの限界の半分、4096 tokensまで)
- 専門知識での検証はされていない
- (おそらく)英語以外をサポートしていない
Relevance Isn't All You Need: Scaling RAG Systems With Inference-Time Compute Via Multi-Criteria Reranking
AIによる3行まとめ
- 既存のRAGは「関連性のみ」の最適化が情報ボトルネックを生み、下流の回答品質をむしろ劣化させ得ることを実証的に示す。
- そこで著者らは、Chain-of-Thoughtを用いたマルチ基準リランキングREBEL(1ターン固定基準+2ターンのクエリ適応)を提案し、関連性に加えて深さ・多様性・明確性・信頼性・新規性を加重評価する。
- 評価では取得精度と回答類似度の双方が向上し、推論時の計算量を増やすほど品質が伸びる新たな速度/品質トレードオフ曲線を確立した。
INTRODUCTION
- 背景と問題提起
- 近年のLLMはRAGで外部知識を取り込むが、多くのRAGは「クエリとの関連性」だけを最適化しており、その単一基準最適化が情報ボトルネックを生み、取得精度は上がっても回答品質を下げうることを実証的に示す。
- 理論的整合性
- 関連性のみの最大化が最適解を逃すという従来理論と一致しており、リランキング(例: 一般的なLLM/Cross-Encoder型)が関連性向上と引き換えに回答類似度を悪化させる傾向を確認する。
- 提案手法REBEL
- Chain-of-Thoughtを用いたマルチ基準リランキングで、固定基準の1ターン版とクエリ依存で基準を推定する2ターン版を設計し、関連性に加え次の副次基準を加重統合して最終スコアで並べ替える。
- 副次基準(例): 深さ、視点の多様性、明確性、権威性、新規性
- REBELは「関連性のみ」手法のボトルネックを越え、取得精度と回答品質の双方を同時に改善し、推論計算量を増やすほど品質が伸びる新たな速度/品質トレードオフ曲線を実現する。
OUR METHOD
- 概要
- REBELは、RAGのリランキングに「関連性以外の複数基準」を注入して最終回答品質を高める枠組みで、1ターン固定基準版と2ターンのクエリ適応版という2手法を提示する。
- どちらもChain-of-Thoughtで評価手順を明示し、最終的に重み付き合成スコアで文書を並べ替える。
- 1ターン固定基準版
- 固定プロンプトで、関連性に加え「内容の深さ・視点の多様性・明確性/具体性・権威性・新規性」を評価する。
- 内容の深さ: そのトピックをどれだけ徹底的かつ包括的に扱っているかを測る。
- 視点の多様性: 複数の観点や切り口がどの程度表現されているかを評価する。
- 明瞭性と具体性: 情報提示の明確さと、クエリへの具体的な対応を評価する。
- 権威性: 出典の信頼性や専門性を測る。
- 新規性(Recency): 時間的な妥当性を評価する。
- 重み付き合成スコア
- 関連性は0-10、各副次基準は0-5で採点
- 実験では一律 (重みの調整は今後の課題)
- Chain‑of‑Thoughtの手順
- 文書内容の分析
- 各基準の独立採点
- 重み付き合成スコアの計算
- 合成スコアに基づいて文書を並べ替え・フィルタリング
- 2ターンのクエリ適応版
- メタ・プロンプトで「クエリに依存する基準と重み」を推定し、その基準定義・採点規則・合成式・手順・出力書式を含むリランキング用プロンプトを自動生成する。
- 第1ターンで基準と重みを設計し、第2ターンでそのプロンプトを用いて候補文書を採点・順位付けする。
- メタ・プロンプト内にk-shot例を多数同梱し、基準選定や重み付け、出力整形を具体的に誘導する。
- クエリごとに基準を最適化できるため1ターン版より高品質になりやすいが、追加の推論計算コストがかかる。
EVALUATION METRICS AND MOTIVATION
- 動機づけ: 従来の検索指標(MRR、precision@k、recall@k)は「関連性」しか見ず、RAGの最終目標である生成回答の質を十分に評価できない。関連性だけを最大化すると回答品質が下がる現象があるため、エンドツーエンド評価が必要
- 主指標: Answer Similarity
- 参照解答との意味的整合をLLM採点で0-5点評価するルーブリック方式を主指標に採用
- ルーブリック: 評価観点・尺度・説明を体系化したガイドライン
- 副指標: Retrieval Precision
- 取得コンテキストの各チャンクが問いにトピック的に適合しているかをLLMで二値判定し、その平均を精度として用いる。回答品質を重視しつつ、文脈の関連性も併せて把握するための補助指標と位置づける。
- 公平な比較設計
- Answer SimilarityとRetrieval Precisionの両方を同一データセット・同一LLM評価器で測定
- 代替指標を採らない理由
- ROUGEやBLEUのような表層一致指標は語句の一致度に依存するため、異なる言い回しでも意味が同じ応答を過小評価
- BERTScoreはスコア解釈が難しく、多指標フレームワークは閾値や重み設計が煩雑
- RAGの目的に直結する「意味的な回答一致」を簡潔に測れるAnswer Similarityを優先する。
EXPERIMENTAL SETUP
- RAGデータベースの構築
- Hugging Faceで公開されている AI arXiv コレクションから作成したデータセット
- RAGシステムの評価に適した具体的かつ技術的な質問を生成できる可能性が高い13本の主要論文を選定
- 現実のベクトルDB(ノイズや無関係文書の混在)を模擬するため、データベースを拡張し、全423本の論文を取り込んだ。追加の410本はノイズとして機能し、検索課題の複雑性と多様性を高める
- チャンク化
- TokenTextSplitterでチャンクサイズ2000トークン、オーバーラップ200トークンに分割
- 評価データ作成
- 107件のQAペアをGPT-4で作成し、人手で妥当性確認を実施
- 埋め込みモデル
- ベクトルDBの作成にはOpenAIのtext-embedding-3-largeを使用
- ばらつき対策
- LLM生成の確率的ばらつきを抑えるため、各RAG方式を10回ずつ実行して分布を評価
- 使用したLLM
- 推論に関わるすべての場面で GPT‑4o を使用
- メタプロンプトを受け取ってリランキング・プロンプトを生成
- 生成されたプロンプトと取得コンテキストを入力として実際にリランキングを行う
- コンテキストとユーザクエリを入力として最終回答を生成
- 評価(Answer Similarity と Retrieval Precision の算出)には GPT‑4 を使用
- GPT‑4 と GPT‑4o を選択した理由は、費用対効果と実装の容易さ
- o1 や o1‑pro を用いれば、より良いリランキング・プロンプト、より正確なリランキング、より高品質な生成、そしてより精緻な採点が期待できる一方、コストは大幅に増加
- 同一モデルによる自己採点を避けるため、評価器としては意図的に GPT‑4o ではなく GPT‑4 を使用
RESULTS
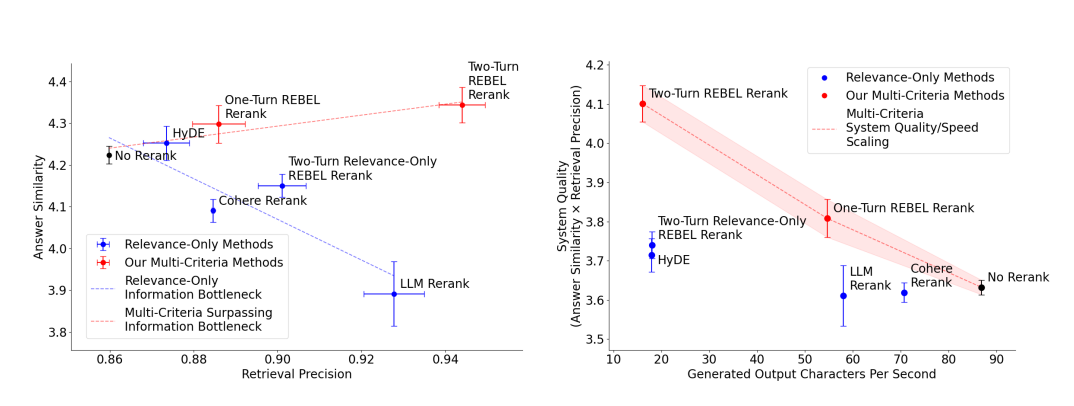
- 左: Answer Similarrity と Retrieval Precision の関係を示し、エラーバーは95%信頼区間
- 破線は、従来提唱されてきた情報ボトルネック (青) と、我々のマルチ基準リランカーによるそのボトルネックの突破 (赤) を表す
- 1ターン版は5つの固定基準 (深さ、多様性、明瞭性、権威性、新規性) を用いて、素のRAG (リランキングなし) よりも取得関連性と回答品質の双方を高める。
- 2ターン版は、2ターンのプロンプティングを通じてクエリごとに基準を適応させることで、さらに性能を向上
- 右: System Quality (Answer Similarrity と Retrieval Precision の積) と推論速度 (生成出力の文字数/秒) を可視化
- 既存の「関連性のみ」手法は効率的な推論速度でより高いシステム品質を達成できない一方、我々のマルチ基準手法は計算量を増やすほどシステム品質を大幅に高められる新しいRAGのトレードオフ曲線を実現
実装
- LlamaIndex に PR が出されているのでその実装をみてみる
- https://github.com/bvarjavand/llama_index
- メタプロンプト
- ‣
- ドメイン適合性(例:技術的な正確性、権威ある出典、情報の正しさ)
- 視点の多様性(複数の観点、イデオロギー的バランス、異なる理論的枠組み)
- 時間的関連性(最新情報や最近のデータ)
- 深度および具体性(網羅的なカバレッジ、多角的な分析、詳細な事例)
- 信頼性・中立性(信頼できる出典、公平な記述)
- 推論深度や概念的複雑性
- 権威性(著名な専門家や機関、良質なソースの識別)
- ユーザーのクエリと候補ドキュメント群を受け取る。
- ドキュメント群は、後述の形式で提示されます:下にドキュメントの一覧が示されます。各ドキュメントには番号と要約があります。要約はソースの種類、信頼度レベル、発行日、情報の性質などを示していても構いません。すべてのドキュメントが列挙された後、ユーザーのクエリが「Question:」のラベルで単一行として提示されます。例:Document 1: <document 1 の要約> Document 2: <document 2 の要約> ... Document N: <document N の要約> Question: <ユーザーのクエリ>
- 各ドキュメントに対して Relevance スコア(0–10)を付与する。
- 推定した各属性ごとにスコア(0–5)を付与する。
- 加重合成スコアを計算する。合成スコアは単に同点を破るためだけでなく、最終的な順位決定に使用されます。たとえば次のような定義が考えられます:
- まず無関係なドキュメントをフィルタリングしてください。例えば Relevance < 3 のドキュメントは棄却します。
- 残ったドキュメントを Final Score に基づいてランキングします。
- 同じ Final Score のドキュメントが存在する場合は一貫した処理(例:権威性が高い方を優先する)を行ってください。
- もし、関連性の閾値を満たすドキュメントが一つもなければ、何も出力しないでください。
- 出力は選ばれたドキュメントの最終的なランク順リストのみとし、各行の形式は必ず次の通りにしてください:
- 余計な注釈、説明、追加テキストは一切付けないでください。
- ユーザーのクエリをそのまま含めること(逐語的に)。
- 推定した副次的属性を列挙し、各属性の重要性を明確に定義すること(なぜその属性が重要かを説明すること)。
- Relevance(0–10)および各推定属性(0–5)のための正確なスコア付けルーブリックを提示し、高スコアと低スコアが何を意味するかを説明すること。
- Relevance と各属性を組み合わせた加重合成スコアの公式を提示し、各属性に対する重みを明示すること。
- ステップバイステップの手順を示すこと:関連度(Relevance)を割り当てる、属性スコアを割り当てる、低関連度のドキュメントを除外する、Final Score を計算する、Final Score によってソートする、同点処理を行う、最終リストを出力する。
- もし該当するドキュメントがなければ何も出力しない旨を明記すること。
- 再ランカーに対して、ドキュメントとクエリはこのプロンプトの後に表示され、許される出力は最終的なソート済みドキュメント一覧とそのスコアだけであることを繰り返して指示すること。
- あなたの出力は、そのまま大規模言語モデル再ランカーに与えられる単一のプロンプトであるべきです。再ランカーはその後ドキュメントとクエリを受け取り、ここで与えられた指示に従って最終出力を生成します。
- ユーザーのクエリを提示する。
- 複数の属性を推定し、それらがなぜ重要かを説明する。
- Relevance と各推定属性のスコア付けルーブリックを示す。
- Relevance とすべての副次的属性を組み込む加重合成スコアの公式を定義する。
- スコアリング、フィルタリング、ランキング、出力のステップバイステップ手順を与える。
- 適切なドキュメントが残らない場合の対処(出力しないこと)を説明する。
- 最終出力は "Doc: [number], Relevance: [score]" の行のみで、余計なコメントは付けないことを指示する。
- 視点の多様性(0–5):複数の経済学派や視点を言及・比較している文書は高得点。5は複数の異なる学派を扱うもの、0は一面的なもの。
- 権威性(0–5):著名な経済学者、信頼性の高い研究機関、査読付き研究からの文書は高得点。5はよく引用される学術論文、0は匿名ブログ。
- 比較の幅(0–5):複数国の税政策を比較している文書は高得点。5は多国を扱う、0は一国のみや比較がない。
- Relevance(0–10):税政策が所得格差に与える影響を扱い、異なる経済学的議論を参照しているものが10。トピックと無関係なら0。
- 視点の多様性(0–5)/権威性(0–5)/比較の幅(0–5): 各数値の意味を上記に従って割り当てる。
- 各ドキュメントに Relevance(0–10)を割り当てる。Relevance < 3 のドキュメントは除外する。
- 残りのドキュメントに各属性(0–5)を割り当てる。
- 上の式で Final Score を計算する。
- Final Score によって降順でソートする。
- 同点の場合は権威性の高い方を優先するなど一貫したルールで決める。
- 残らなければ何も出力しない。
- 出力は各行 "Doc: [number], Relevance: [score]" のみ。
- ユーザーのクエリをそのまま含める。
- クエリから推定される副次的属性を複数(少なくとも2〜4個)挙げ、それぞれを定義し、その重要性を説明する。
- Relevance(0–10)と各属性(0–5)のスコアリングルーブリックを明確に提示する(高得点・低得点の具体例を含む)。
- 加重合成スコアの式を提示し、属性ごとの重みを明示する(合計がどうなるか、式の例を含む)。
- ドキュメントごとに Relevance を割り当てる(数値で)。
- Relevance < 3 を除外する旨を明記し、除外後のドキュメントに属性スコアを割り当てる。
- Final Score を計算し、降順でソートする。
- 同点処理のルールを明示する(例:権威性→最新性→視点の多様性の順で比較)。
- 最終的に、指定されたフォーマット(各行 "Doc: [番号], Relevance: [スコア]")だけを出力するように指示する。
- 適合するドキュメントがなければ何も出力しないように指示する。
- 出力は必ず機械的にパースしやすい単一フォーマット("Doc: [number], Relevance: [score]" の行の集合)のみとすること。
- 再ランカーが参照できるドキュメントとクエリはこのプロンプトの直後に表示されることを明記すること。
- 重要な事実(例:属性の定義や重み)は明確かつ具体的に記述すること。
翻訳
あなたはプロンプト生成器です。入力として受け取るのはユーザーのクエリだけです。あなたのタスクは次のとおりです:
ユーザーのクエリを解析し、クエリの主題から推測される、コンテキスト文書の選択やランク付けに有用な追加の属性を特定してください(ユーザーが明示していない属性)。これらの属性には例えば次が含まれますがこれらに限定されません:
これらの属性を推定した後、以下を実行する再ランカー(大規模言語モデル)向けの最終プロンプトを生成してください:
あなたは各ドキュメントに対して以下を行う指示を生成してください:
Final Score = Relevance + (Weight1 * Property1) + (Weight2 * Property2) + ...
重みはあなたが明示的に指定してください。例:属性が3つある場合、
Final Score = Relevance + 0.5*(Property1) + 0.5*(Property2) + 0.5*(Property3)
このようにして、関連度が若干高くても副次的属性が弱いドキュメントを、副次属性で強みを示すドキュメントが上回れるようにします。
Doc: [document number], Relevance: [score]
(ここで [score] は関連度スコアではなく、実際の Final Score を意味します)
あなたの最終プロンプトは次を満たす必要があります:
さらに、必ず以下のブロックを含めてください(以降に示す形式は必ずプロンプト末尾に含めること):
"Example format: \n"
"Document 1:\n<summary of document 1>\n\n"
"Document 2:\n<summary of document 2>\n\n"
"...\n\n"
"Document 10:\n<summary of document 10>\n\n"
"Question: <question>\n"
"Answer:\n"
"Doc: 9, Relevance: 7\n"
"Doc: 3, Relevance: 4\n"
"Doc: 7, Relevance: 3\n\n"
"Let's try this now: \n\n"
"{context_str}\n"
"Question: {query_str}\n"
"Answer:\n"
以下に、要求される詳細度と明確さの水準を示す k-shot(5例)の例を示します。各例は次を行っています:
例 1 ユーザークエリ: "How do different countries' tax policies affect income inequality, and what arguments exist from various economic schools of thought?"
推定属性:
スコア付けルーブリック:
加重合成スコア例:
Final Score = Relevance + 0.5*(視点の多様性) + 0.5*(権威性) + 0.5*(比較の幅)
手順:
(以降、他の 4 つの例も同様に構成されており、それぞれのクエリに応じて推定属性、ルーブリック、加重式、手順を具体的に示しています。これらの例はテンプレートとして扱い、新しいユーザークエリに対して同じレベルの詳細さでプロンプトを作成してください。)
以下の手順に従ってください(テンプレート):
注意点:
必ず末尾に次を含めてください(このブロックはそのまま含めること):
"Example format: \n"
"Document 1:\n<summary of document 1>\n\n"
"Document 2:\n<summary of document 2>\n\n"
"...\n\n"
"Document 10:\n<summary of document 10>\n\n"
"Question: <question>\n"
"Answer:\n"
"Doc: 9, Relevance: 7\n"
"Doc: 3, Relevance: 4\n"
"Doc: 7, Relevance: 3\n\n"
"Let's try this now: \n\n"
"{context_str}\n"
"Question: {query_str}\n"
"Answer:\n"
Now, here is the user's query:
{user_query}