2025-09-24 機械学習勉強会
今週のTOPIC[blog] LoRAの進化:基礎から最新のLoRA-Proまで[blog] Diffusion Beats Autoregressive in Data-Constrained Settings[論文] Is the Watermarking of LLM-Generated Code Robust?メインTOPICImproving Context Fidelity via Native Retrieval-Augmented Reasoning背景提案実験
今週のTOPIC
@Shun Ito
[blog] LoRAの進化:基礎から最新のLoRA-Proまで
- LoRAの派生系をまとめて紹介している記事
- 分類
- スケーリング・学習率調整型
- LoRAのアダプター行列に適用されるスケーリングファクターや学習率を調整し、学習の安定性と速度を改善
- 構造変更型
- LoRAの基本構造そのものを改良し、性能向上
- 勾配最適化・初期化型
- LoRAの最適化プロセスやアダプター行列の初期化を改良することで、フルファインチューニングの学習を模倣
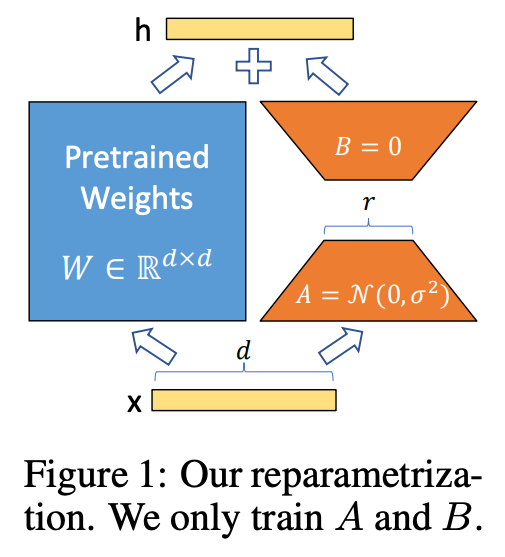
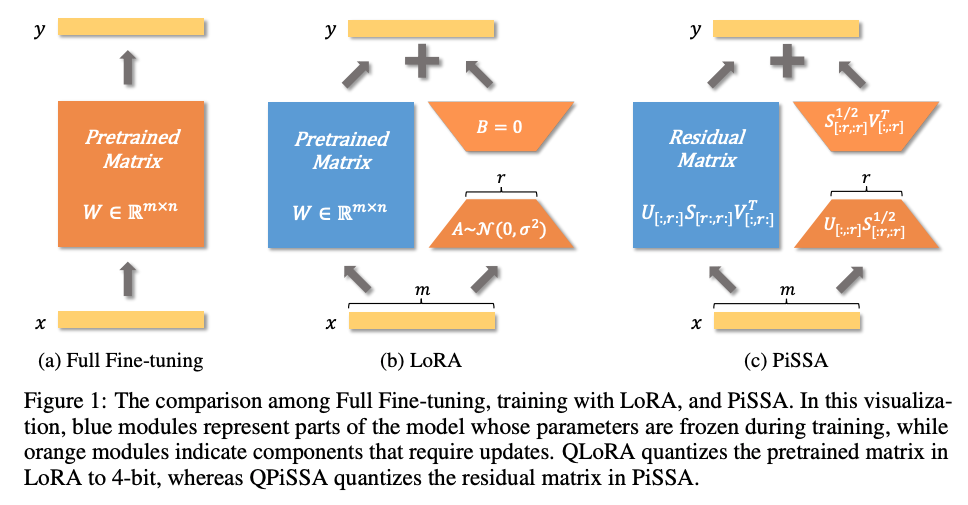
- LoRA
- 低ランク行列A, Bだけを学習する
- スケーリング・学習率調整型
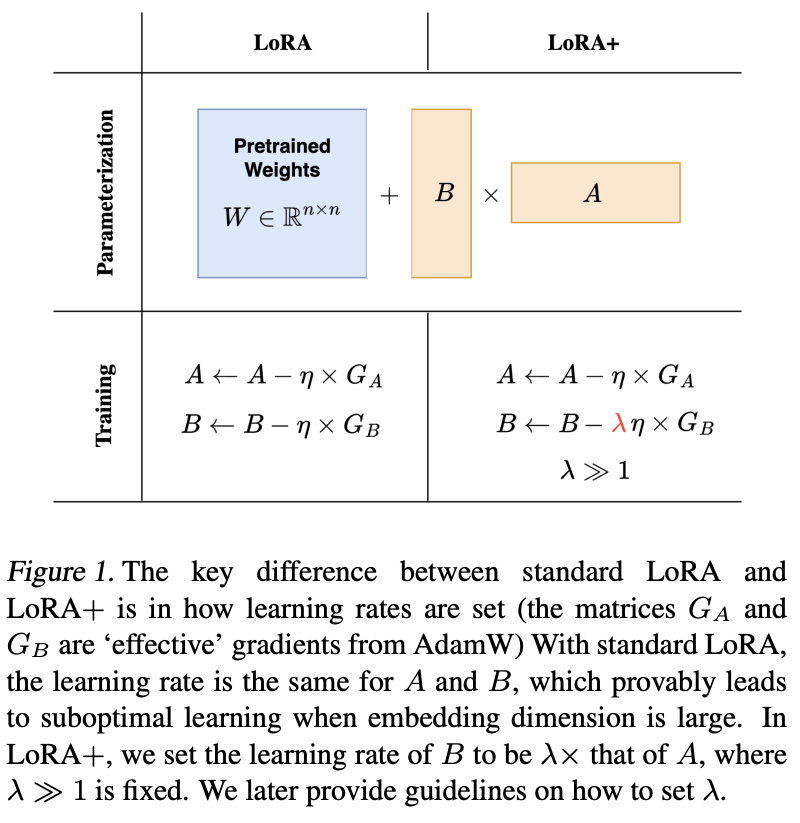
- LoRA+ (2024)
 arXiv.orgLoRA+: Efficient Low Rank Adaptation of Large Models
arXiv.orgLoRA+: Efficient Low Rank Adaptation of Large Models - アダプター行列AとBに、それぞれ異なる学習率を適用させて、収束速度と最終的な性能を改善
- 構造変更型
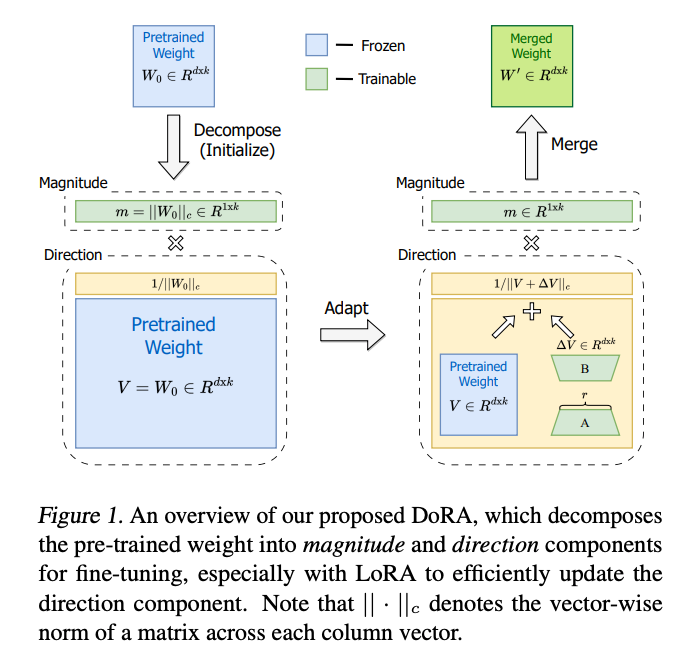
- DoRA (2024) arXiv.orgDoRA: Weight-Decomposed Low-Rank Adaptation
- 学習済みの元の重みをマグニチュード m と方向行列 v に分解し、方向成分だけLoRAで学習。
- 勾配最適化・初期化型
- PiSSA (2024) arXiv.orgPiSSA: Principal Singular Values and Singular Vectors Adaptation...
- 重み行列に特異値分解を適用し、「主要な低ランク行列」と「残差行列」に分解し、その結果と特異ベクトルを使ってA, Bを初期化
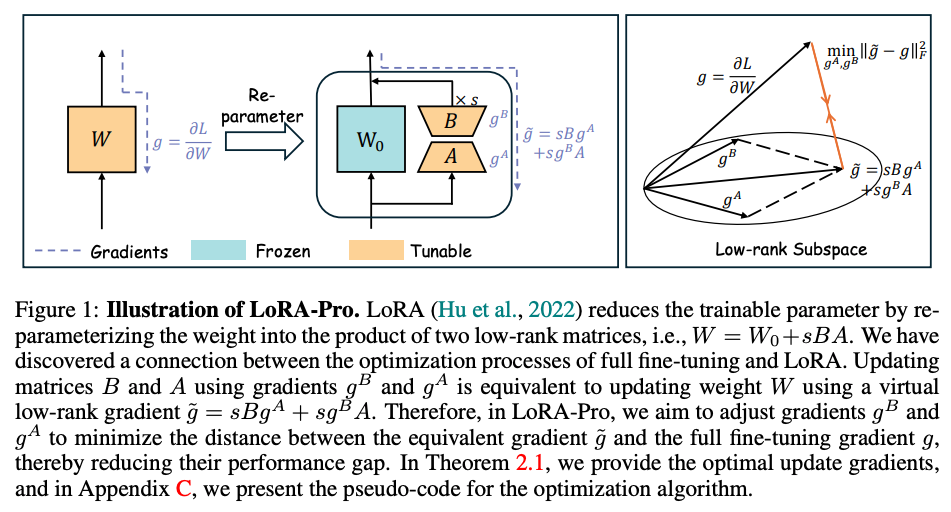
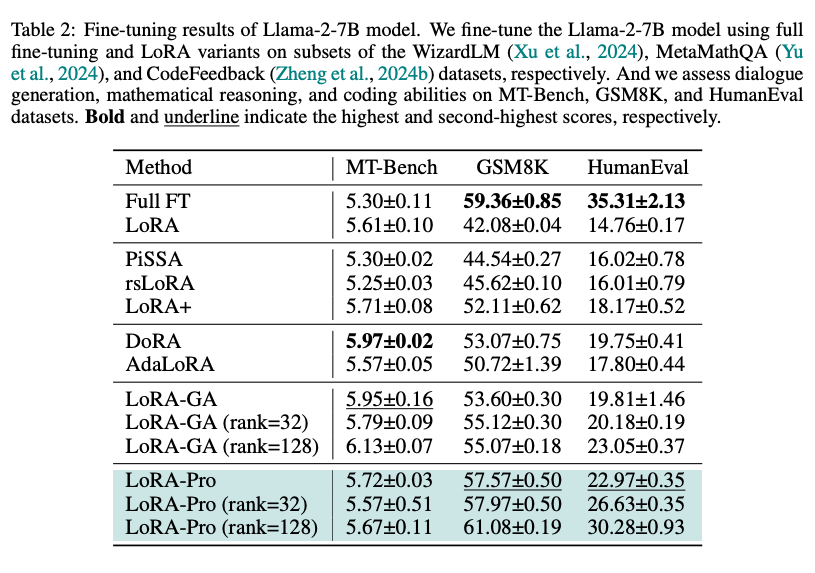
- LoRA-pro (2025)
- LoRAのA, Bに対する勾配(の組み合わせ)が、フルファインチューニングにおける真の勾配に近づくよう調整しながら学習する
- 既存手法と比べ、最終的な性能の改善を実験的に確認
@Takumi Iida (frkake)
[blog] Diffusion Beats Autoregressive in Data-Constrained Settings
CMUが発表した論文の公式ブログ
論文のプロジェクトリンク:https://diffusion-scaling.github.io/
データが制限されているときだと、拡散モデルと自己回帰モデルどっちがいいの?という疑問に対する研究
モチベーション
“Compute is growing—better algorithms, better hardware, bigger clusters—but data is not growing. We have just one internet, the fossil fuel of AI.” — Ilya Sutskever
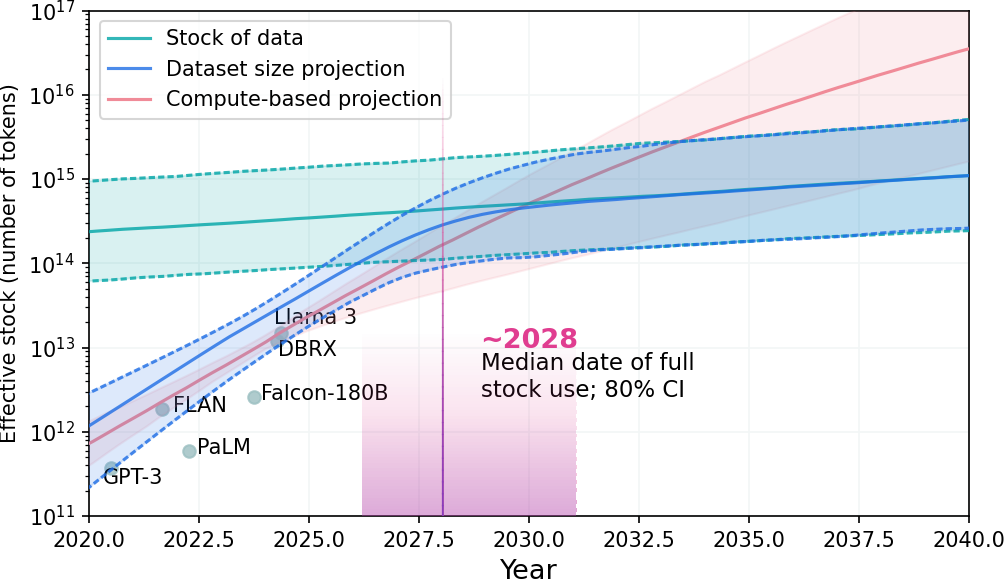
計算能力やアルゴリズムが良くなっていく一方で、今後データセットがボトルネックになってくる。
Epoch AIが公開した図によると2028年ごろそうなるだろうと予想されている。
そういったデータ量が制限されている中で、各分野で成功している拡散モデル(ビジョン)と自己回帰モデル(テキスト)のどちらが良いのかを議論するのは有意義。
離散拡散モデルでテキストを処理するなど他分野へ活用しようとする動きもあり、どちらを使ったらいいのか迷うよね。というところのヒントになればという気持ちが入っている。
Nieらの研究だと離散拡散LLMは自己回帰LLMの16倍の計算量がいると報告しているが、筆者はこの実験結果に懐疑的。
自己回帰モデルは離散拡散モデルのマスキングの一部であるとみなせる。
逆に、離散拡散モデルは自己回帰モデルのデータ拡張とみなせる。
→ 本研究の主張=データ量が違うときに差が出てくるのでは?
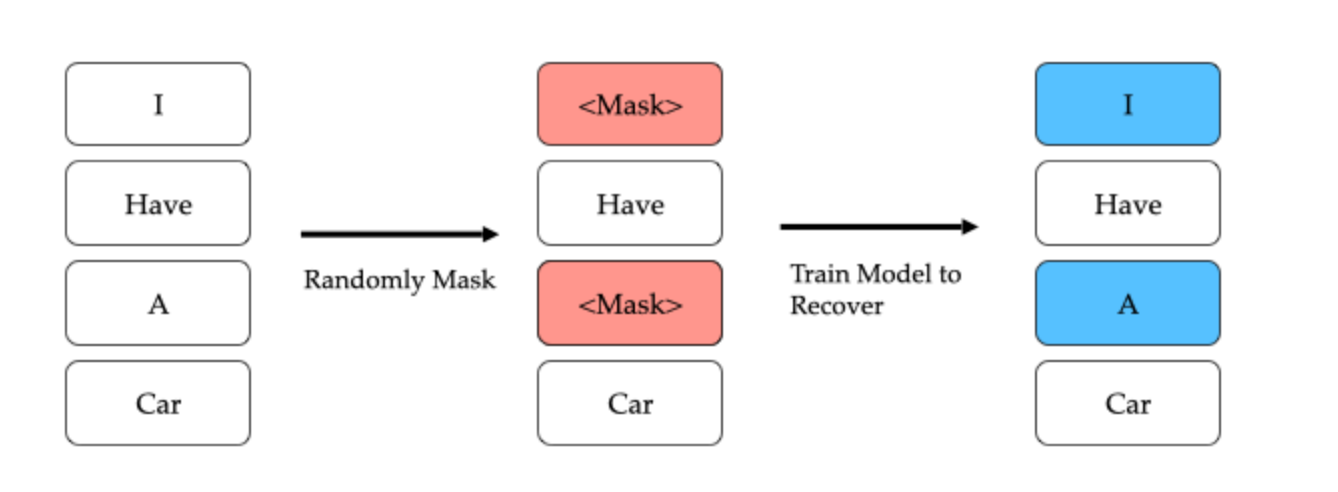
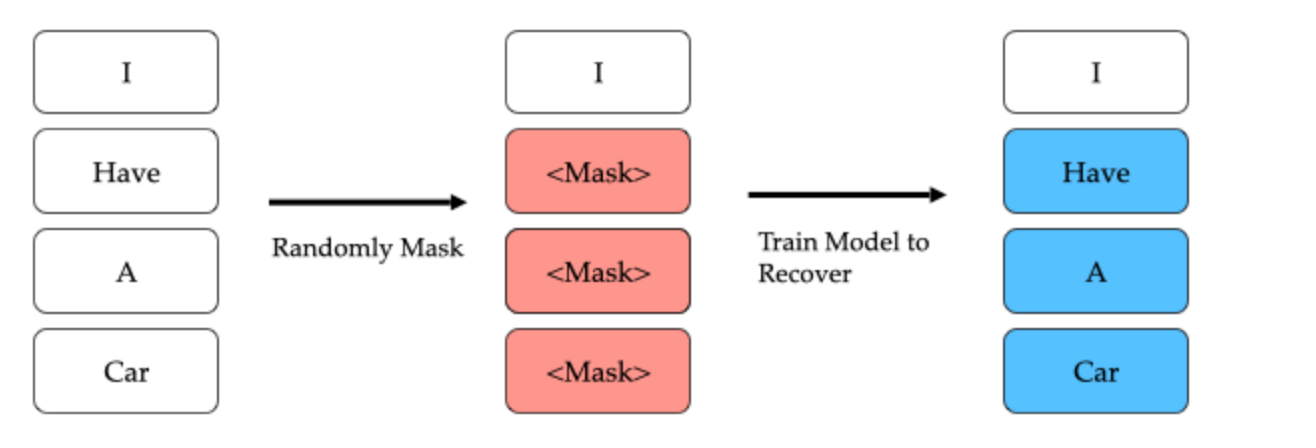
色々な実験の結果
似たような主張も多いが記事中では8つの発見として紹介している
- 十分な計算量で学習した場合、拡散モデルは自己回帰モデルよりも良い性能
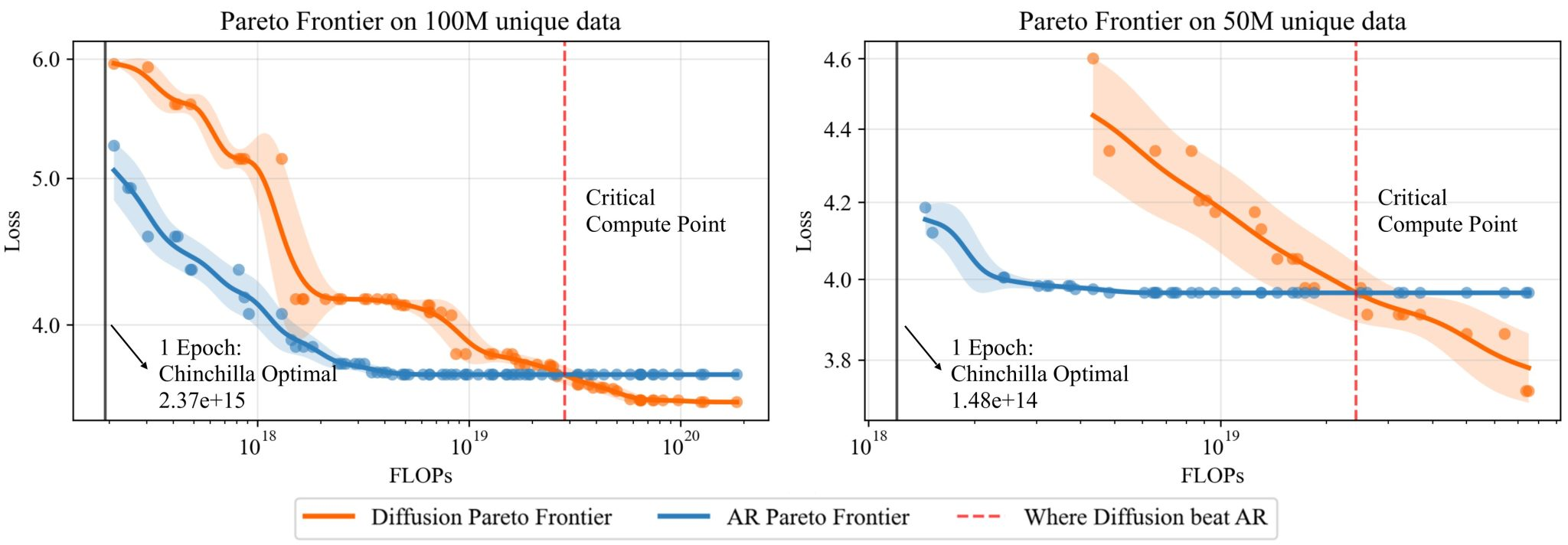
- 拡散モデルは過学習しにくい。エポック数を10倍にしても過学習しなかった。 実験では、モデルサイズとエポック数を増減させている。 → 拡散モデルは学習(≒ 計算量増加)の恩恵を受けやすい
- 拡散モデルはデータの繰り返しても過学習しにくい(=エポック数を増やしたときの恩恵大きい) ↑と似たような内容だが、学習トークン数で計測
- 拡散モデルはデータ再利用の半減期が長い
- 自己回帰モデルでは最大4エポックまでの繰り返しなら、新たなデータを追加するのと同じような効果がある。 拡散モデルの場合は最大100エポックくらいまで繰り返しても効果が高い。
- 拡散モデルが自己回帰モデルを超えるのに必要な計算量は下式である程度予測できる。 詳しくは読めてないが、拡散モデルと自己回帰モデルの損失差から求めてるっぽい。
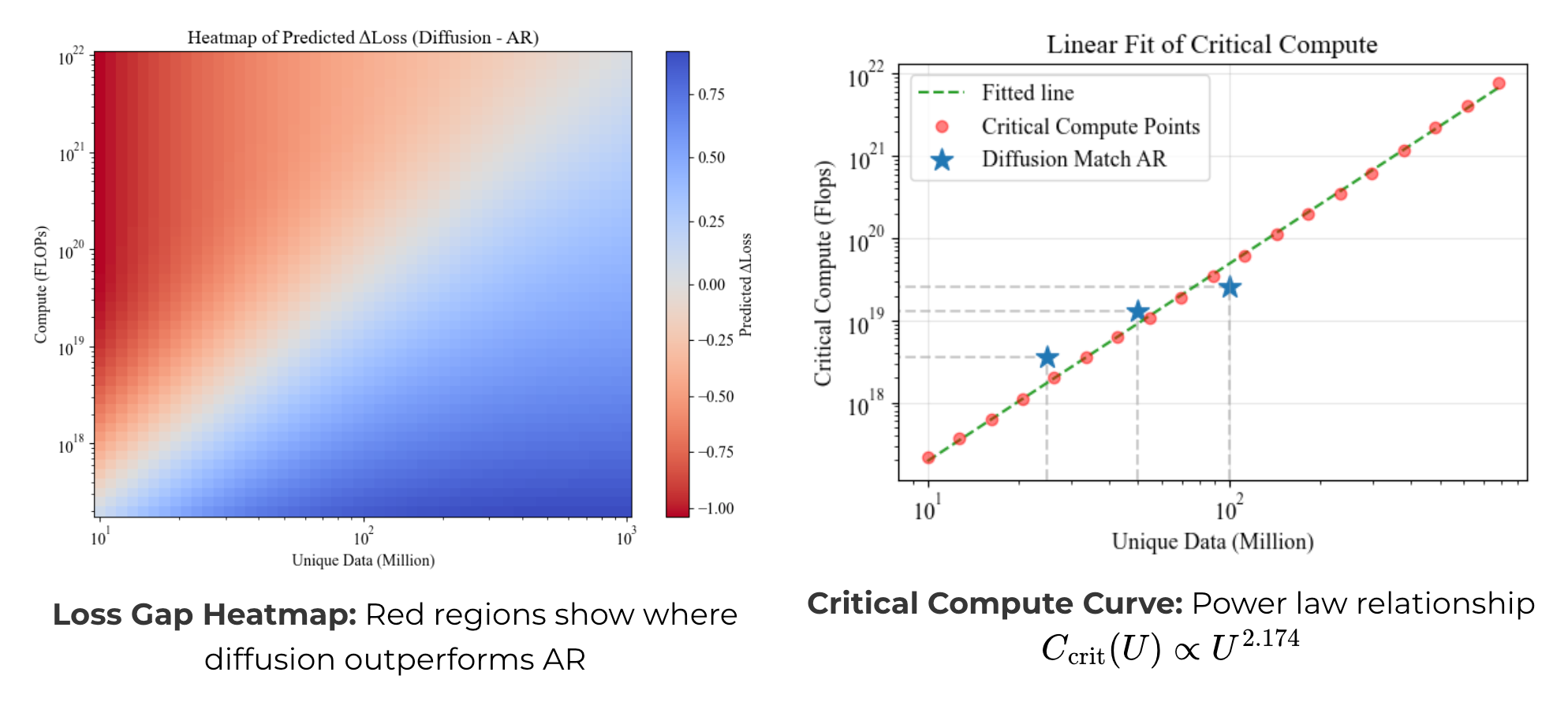
- 拡散モデルのデータ効率性は下流タスクの性能向上にも寄与する
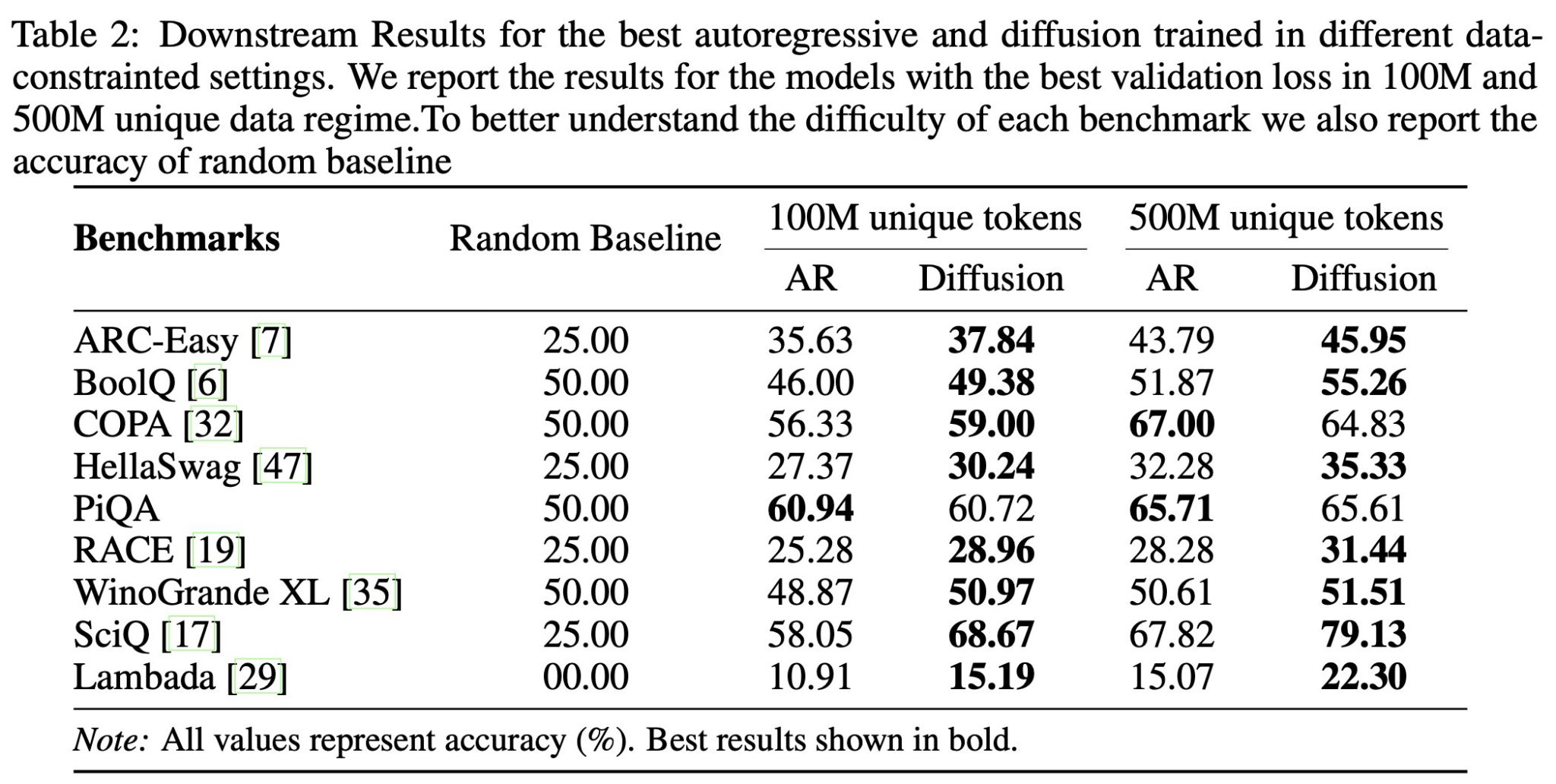
- 拡散モデルの多様なトークン順序がデータ効率性を高めている
感想と結論
拡散モデル推しっぽい
次のように使い分け
- 計算能力に制約がある場合→自己回帰モデル
- データに制約がある場合→拡散モデル
@Ryoma Nakai
[論文] Is the Watermarking of LLM-Generated Code Robust?
ICLR2024
背景
- LLM(大規模言語モデル)テキスト生成に広く使われているが、盗用検出や悪用防止のために「ウォーターマーク(透かし)」を入れる技術が注目されている。
- ウォーターマーク: 生成モデルが何かを生成した時に、それが生成モデルから生成されたことを確かめるために埋め込む情報
- 一方で、そのようなウォーターマークを回避し、検知を逃れるために少し生成テキストを書き換える攻撃手法がある
- コード生成の文脈でウォーターマーク手法の攻撃に対するロバスト性を論じた研究はない
- また自然言語に比べ、コードは意味を保った編集が行いやすい
目的
- 本研究の目的は、既存のウォーターマーク手法がコード生成においてどれだけ堅牢かを体系的に評価すること。
- つまり、コード生成後の編集によりウォーターマークの効果が薄まらないかを検証すること
実験方法
- UMD, Unigramという手法でWatermarkが埋め込まれたPython codeを生成
- どちらもGreen List, Red Listに基づいた手法
- 語彙集合の一定割合をGreen, それ以外をRedに割り振る
- LLMはtokenを生成する際にGreenの生成が行われやすくなるようバイアスをかけて生成を行う
- 生成された文の各トークンがGreenにはいるか、Redにはいるかは独立に二項分布に従うと仮定し仮説検定を行う
- 帰無仮説H0: 文はGreen, Redの分割関係なしに生成された
- z値が3.0を超えればH0を棄却し文はLLMで生成されたとみなす。
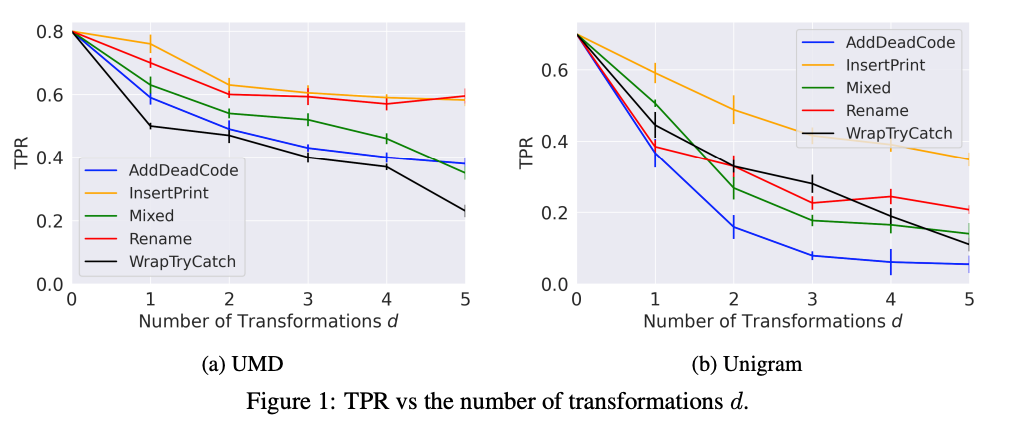
- Python codeに以下のような意味を保つ変換を行う
- AddDeadCode: dead-codeの挿入
- a=rand() if(a != a) b = 0 を挿入
- Rename: 識別子のRename
- InsertPrint: print文の挿入
- WrapTryCatch: try-catchで囲む
- Mixed: 上記の変換をランダムに組み合わせd回行う
- HumanEvalデータセットでコードの生成を行い、LLM製コードが変換のちに検知できるかをTPR, FPRの観点で調査
結果
- 機械的な編集で大幅に検知性能が低下した
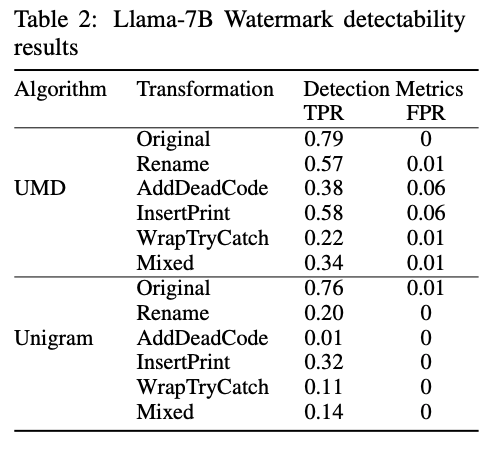
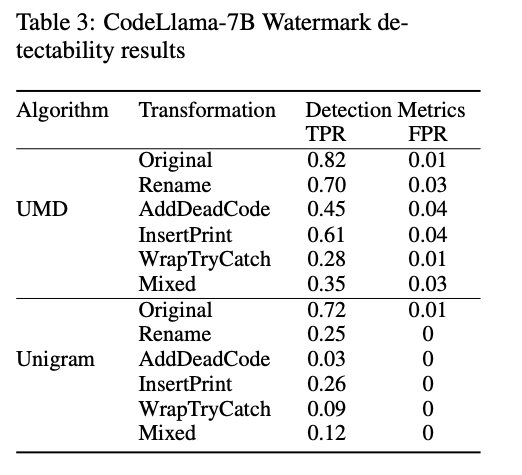
(CodeLlama-7B)
結論
- コード生成タスクにおいては簡単な編集でウォーターマーク効果を消すことができる
- コード生成においても堅牢なウォーターマーク手法の開発が必要
メインTOPIC
Improving Context Fidelity via Native Retrieval-Augmented Reasoning
| Title | Improving Context Fidelity via Native Retrieval-Augmented Reasoning |
|---|---|
| Authors | Suyuchen Wang, Jinlin Wang, Xinyu Wang, Shiqi Li, Xiangru Tang, Sirui Hong, Xiao-Wen Chang, Chenglin Wu, Bang Liu |
| Venue | EMNLP2025 |
背景
- LLMに、質問で与えられたコンテキストにきちんと沿った回答をさせたい
- 解決したい課題: Context hallucination problem
- 間違った回答
- 一般的に間違ってはいないが、与えられた情報に従った回答になっていない
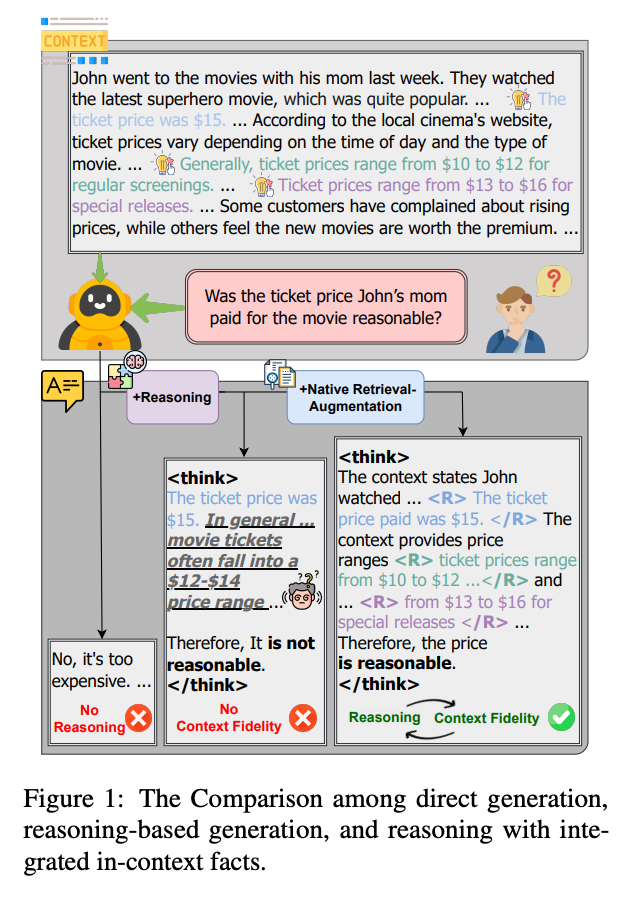
- 既存手法
- RAG: 与えられたevidence群を並び替えて上位のものを使う。学習データの作成が高コストで、推論コストも高い。
- モデルによる外部検索: 最新の情報にアクセスできるが、ユーザーに与えられたコンテキストとはズレる可能性がある。
提案
Overview
- CARE (Context-Aware Retrieval-Enhanced reasoning)
- Reasoningの過程で、入力された情報を明示的にRetrievalし、その上で回答する
- 提案手法のため、SFT + RL でLLMを学習
- Retrieval部分は専用トークン で囲む
- RLを組み合わせてラベル付きデータの収集コストを減らす
Supervised Fine-Tuning Phase
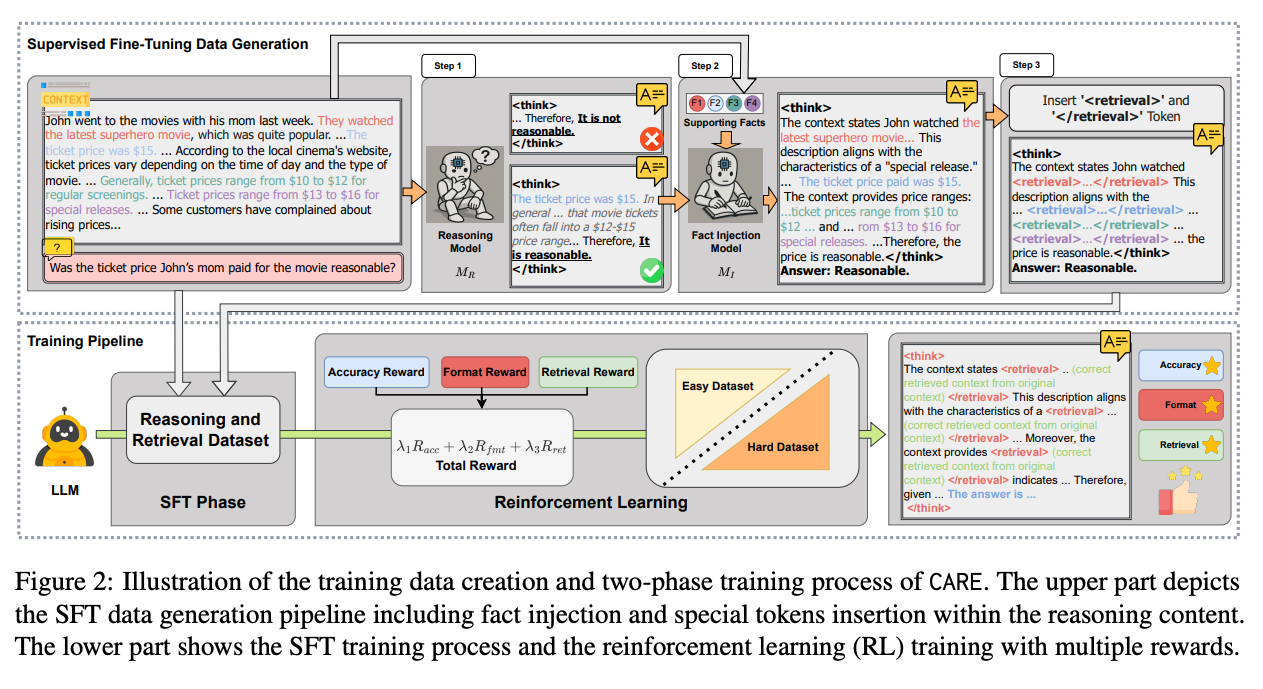
- 既存のQAデータセットにラベル付けしたものを作成し、それを使ってSFTを行う
- データ生成
- Reasoning Step Generation
- 推論モデルで回答を生成する。SFTでは整合性が取れるものだけを使って学習させるため、最終回答が正解しているものだけを採用。
- ここでは途中の推論がコンテキストを考慮できているかどうかは不問なので、回答は合っていてもコンテキストが使えていない可能性がある。
- 採用された回答の推論部分が次のステップに使われる
- Evidence Integration
- Fact Injection Modelで、採用された推論テキストに正解の論拠(supporting fact)を差し込む形で修正する
- 必ず全ての論拠を差し込むわけではなく、推論テキストに準じたものだけを使う
- 結果的に全ての論拠を差し込めた修正済み推論テキストだけを採用する
- Retrieval Token Insertion
- 差し込まれた論拠を専用トークン で囲み、SFT用のデータセットとして利用する
Reinforcement Learning Phase
- 学習アルゴリズム → GRPO
- 報酬設計 → 3種類の重み付け和
- Accuracy Reward: 生成された最終回答が正解しているかどうか
- Format Reward: 出力が指定フォーマット(推論部分を示すトークン , 抜き出された論拠を示すトークン )に従っているかどうか
- Retrieval Reward: タグ内の内容が実際に入力Contextに存在している場合
- 一致の判断は完全一致?
- Curriculum Learning
- 最初は短いコンテキスト・単純なQAを使って学習し、徐々に長文やマルチホップなQAを混ぜ込んでいく。難しいデータの割合は学習ステップに対して線形に増やす(線形スケジューリング)
- short-context → short-answer QA to long-context → multihop long-answer QA
- 単純なQAの精度が低下してしまう Catastrophic Forgetting という現象を回避できる
実験
データセット
- SFT
- Supporting Factsのラベルがある HotpotQA を利用
- 推論モデル: DeepSeek-R1
- Fact Injection Model: DeepSeek-V3
- 生成されたSFTデータセット: 7739サンプル
- RL
- DROP(短文・単純QA)
- MS MARCO(長文・複雑QA)
- 評価
- LongBenchのQAベンチマーク
- MultiFieldQA-En
- HotpotQA
- 2WikiMQA
- MuSiQue
- コンテキスト史実性評価
- CofCA(Counterfactual QA)
- Wikipediaを改変した反事実情報を含む。
- モデルが事前知識ではなく入力文脈に忠実でいられるかを評価。
モデル
- 使用モデル
- LLaMA-3.1 8B
- Qwen2.5 7B / 14B
比較手法
- Original Model: ベースLLMそのまま。
- ReSearch(RLベースのオンライン検索、Qwen2.5 7Bで利用可能)
- R1-Searcher(RLベースの検索、LLaMA-3.1 8B と Qwen2.5 7B)
- CRAG(Corrective RAG、Qwen2.5 7B/14B)
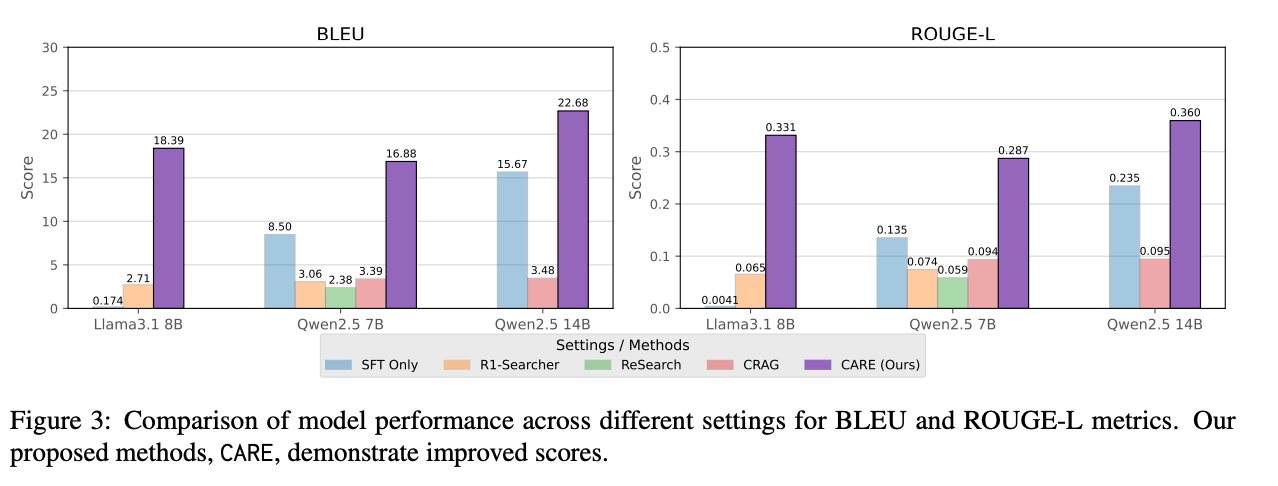
結果
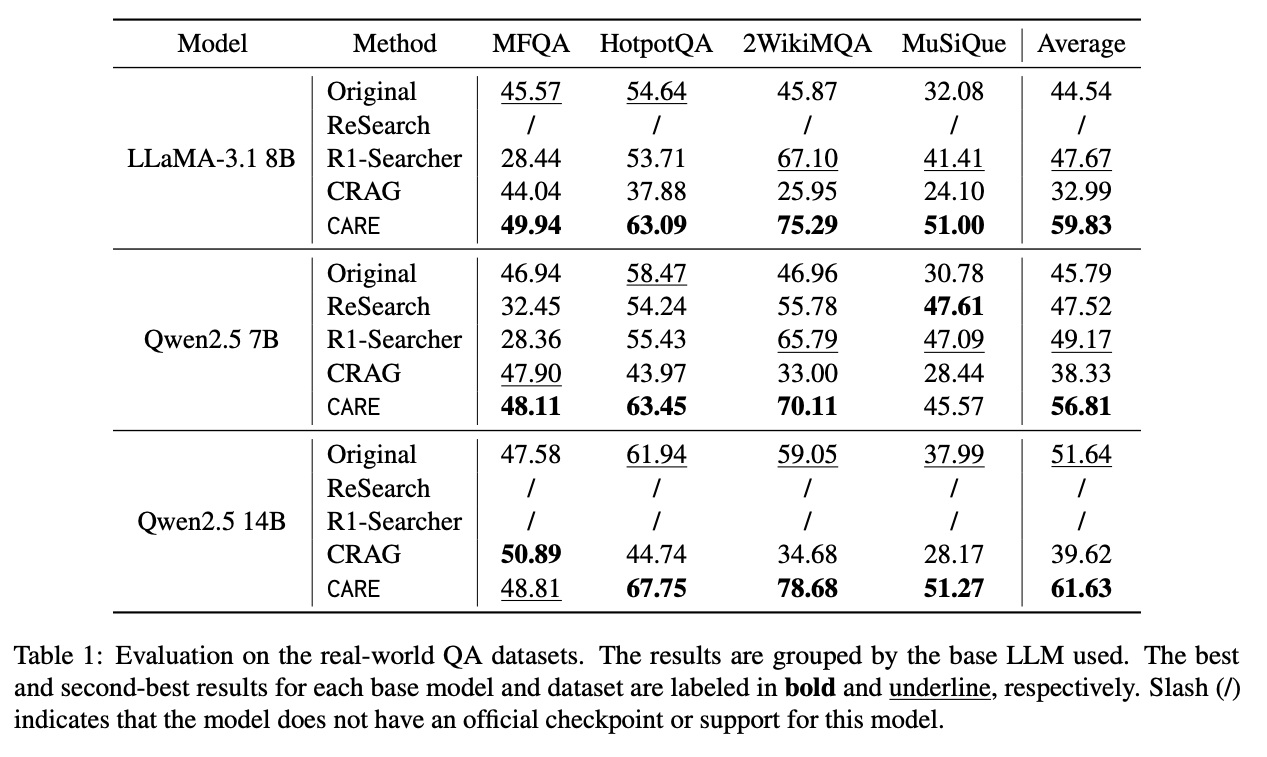
- Question-Answering Performance
- すべてのモデルサイズ・データセットでベースモデルや既存手法より高いF1スコアを達成
- 特に Multi-Hop QA (2WikiMQA, MuSiQue) での改善が大きい
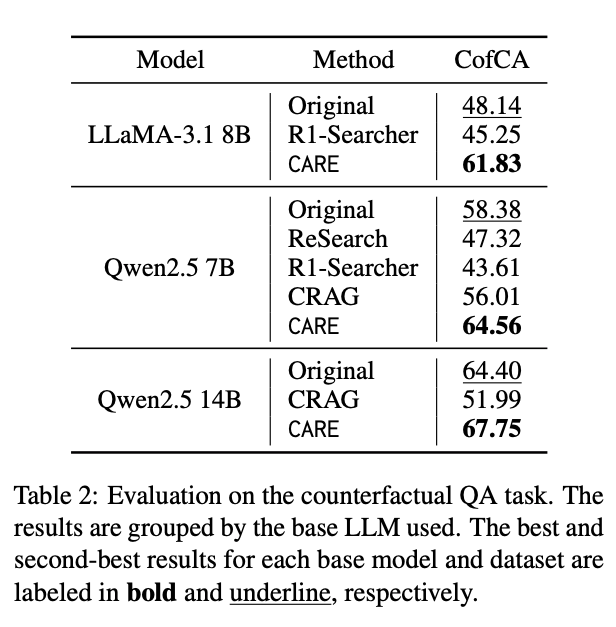
- Counterfactual QA Performance
- すべてのモデルで良い性能
- 外部検索を利用する手法はコンテキストと矛盾する知識に引っ張られて性能が悪化する
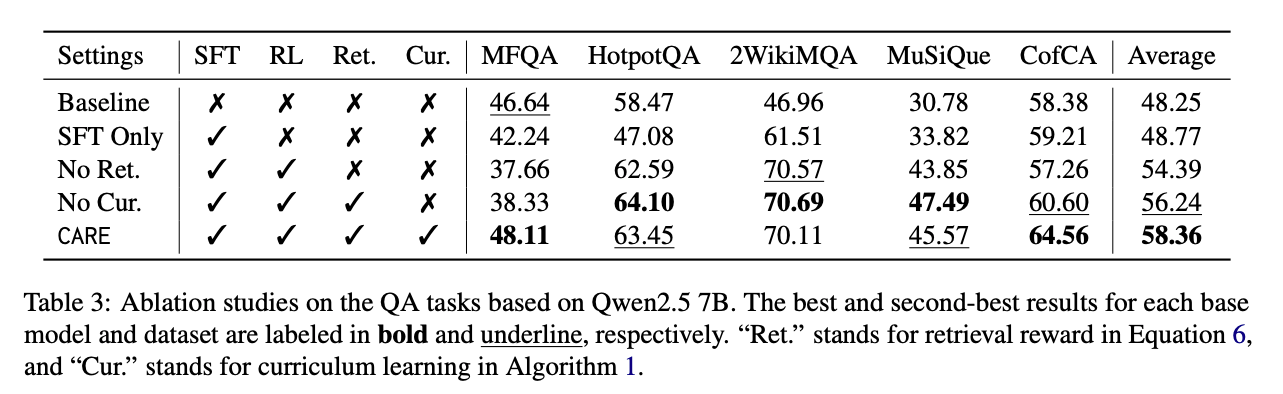
- Ablation Study(学習方法)
- Qwen2.5 7Bで4パターン検証
- SFT Only
- No Retrieval Reward: 「 タグ内の内容が実際に入力Contextに存在している」ことへの報酬を除く
- No Curriculum Learning: 最初に利用する簡単なデータセットだけで学習
- CARE: 提案手法そのまま
- Retrieval Rewardは文脈への参照品質に関係するので、取り除くと性能悪化が大きい
- Curriculum Learningは、Multi-Hop QAではむしろ除いた方が良い場合もある。長文QAや反事実QAでは不安定。
- AverageはCAREがベスト。
- Evidence Retrieval Evaluation
- モデルサイズに関わらず性能改善