
2025-09-30 機械学習勉強会
今週のTOPIC[論文] ShinkaEvolve: Evolving New Algorithms with LLMs, Orders of Magnitude More Efficiently[blog] 決定論的システムと非決定論的AI Agentの接合点:OSSフレームワークEmbabelが拓く新しいソフトウェア開発の可能性[論文] EmbeddingGemma: Powerful and Lightweight Text Representations[blog] Effective context engineering for AI agents[論文]ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization[論文] GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS[論文] 大規模言語モデルに対するサンプリングを活用したメンバーシップ推論攻撃 (言語処理学会2024)メインTOPIC:
Agentic Any Image to 4K Super-Resolution一言でいうと選定理由イントロ手法システムの全体像知覚エージェント修復エージェント顔修復パイプラインプロファイリングモジュールモデルカードプロンプト計算資源実験(抜粋):自然画像の超解像Ablation StudiesQ-MoEポリシー顔修復モジュールの有無実行時間感想
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] ShinkaEvolve: Evolving New Algorithms with LLMs, Orders of Magnitude More Efficiently
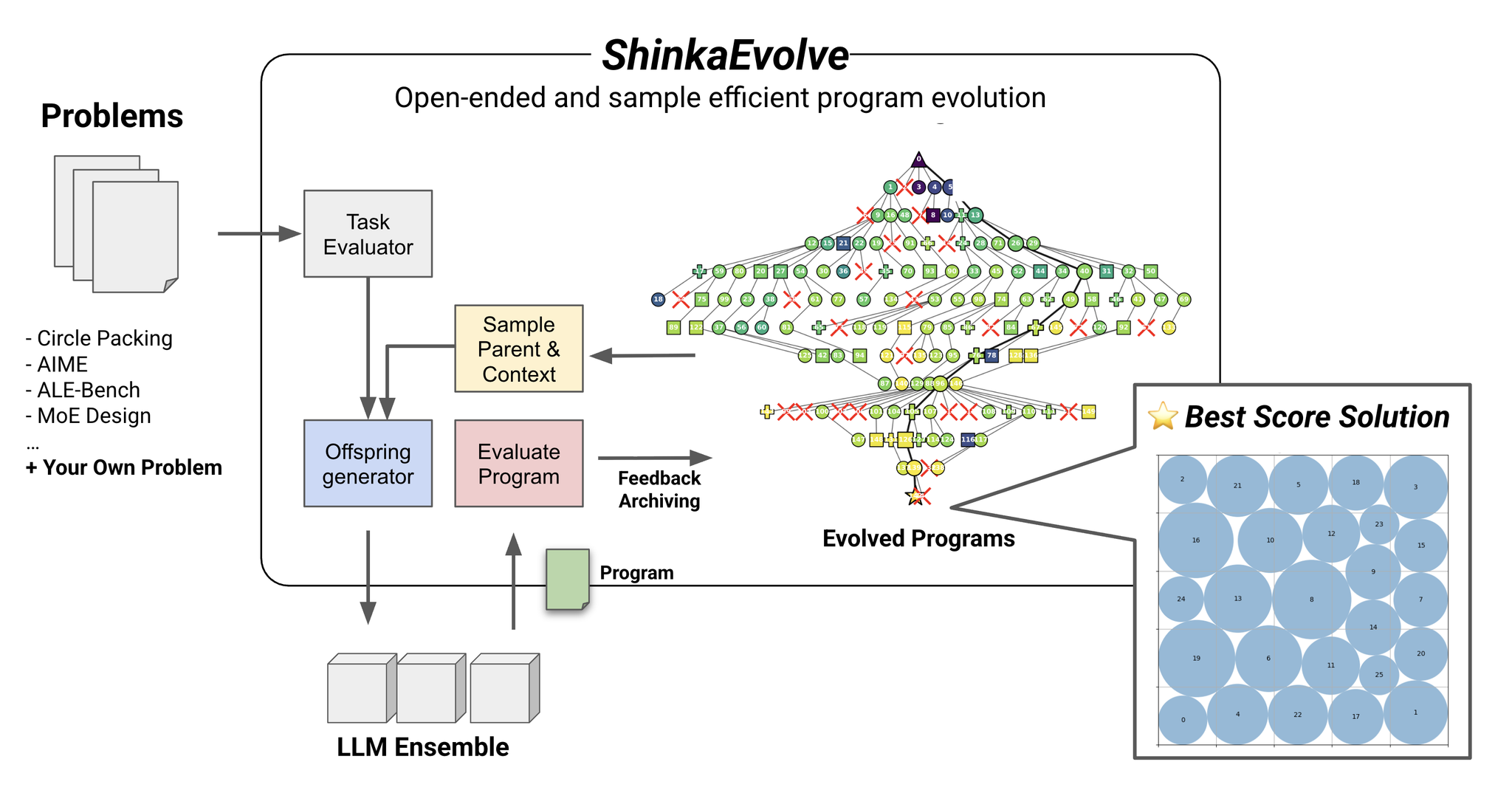
- 先行研究
- 既存のアプローチはサンプル効率が悪いかつ手法が公開されていない
- OSSでサンプル効率の高いShinkaEvolveを提案
- 手法
- 一般的に進化的アルゴリズムは効率が良くない
- サンプル効率を上げるために3つの段階的制御フローを作成した
- Parent Selection Strategy
- 一様サンプリングや貪欲な山登り法ではなく、重み付きサンプリング
- fitnessはタスク毎に異なる性能を表す指標
- Circle Packing: 縁の半径の合計
- AIME: 正答率
- ALE -Bench: 平均スコア
- novelty_factorは子孫の少なさで評価
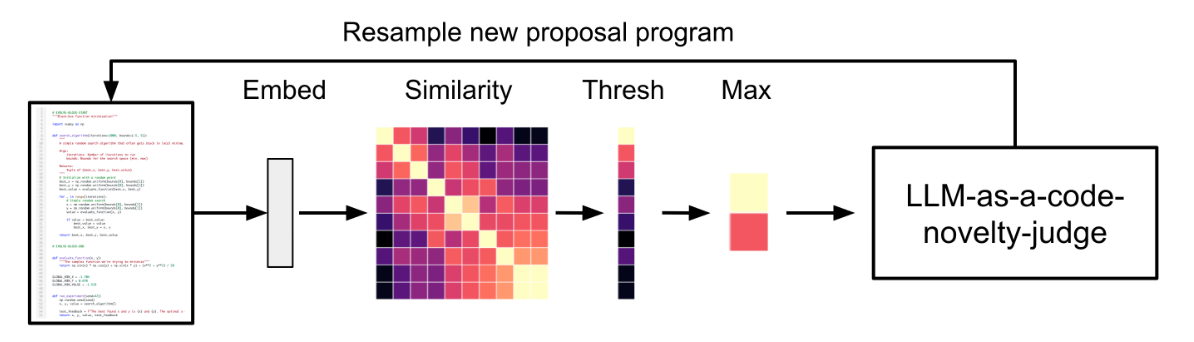
- Code Novelty Rejection Sampling
- 似たようなコードであれば再度計算しないための工夫
- すでに実行されたコード群と新しいコードのコサイン類似度を計算し、その最大値が0.95を超えた場合は受け入れない
- 二段階目としてLLM as a judge的に本当にその二つのコードは本当に同じなのかを判定。
- LLMをかますと時間はかかるがサンプル効率は上がる。
- 重複評価を50%削減できた
- Adaptive LLM Ensemble Selection
- 異なるLLM (GPT、Gemini、Claude、DeepSeek)の相対的なパフォーマンスに基づいて、それらのサンプリング確率を動的に適応。
- Multi-Armed Banditの一つであるUCB1を改良して使用
- どのモデルを使うかを決めるための手法
- これらの手法を通じて「プログラム」を最適化するのがやりたいこと。promptを最適化するのではない。
- Full Edit, Diff Edit, Cross Over(二つの組み合わせ)のどれかを使う
- 以下にプロンプト一覧
- 結果
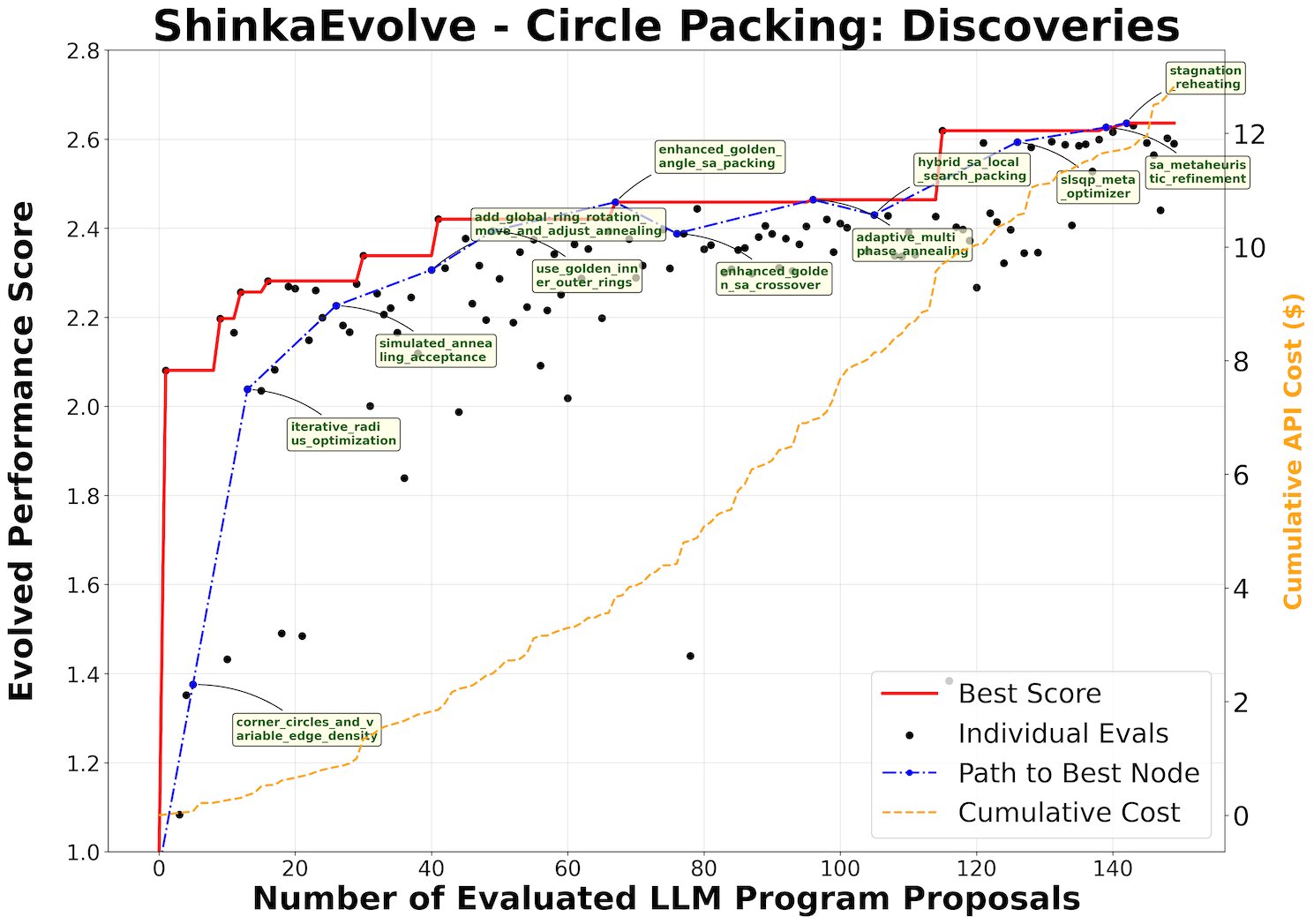
- Circle Packing
- たった150サンプルでAlphaEvolveの解を上回った
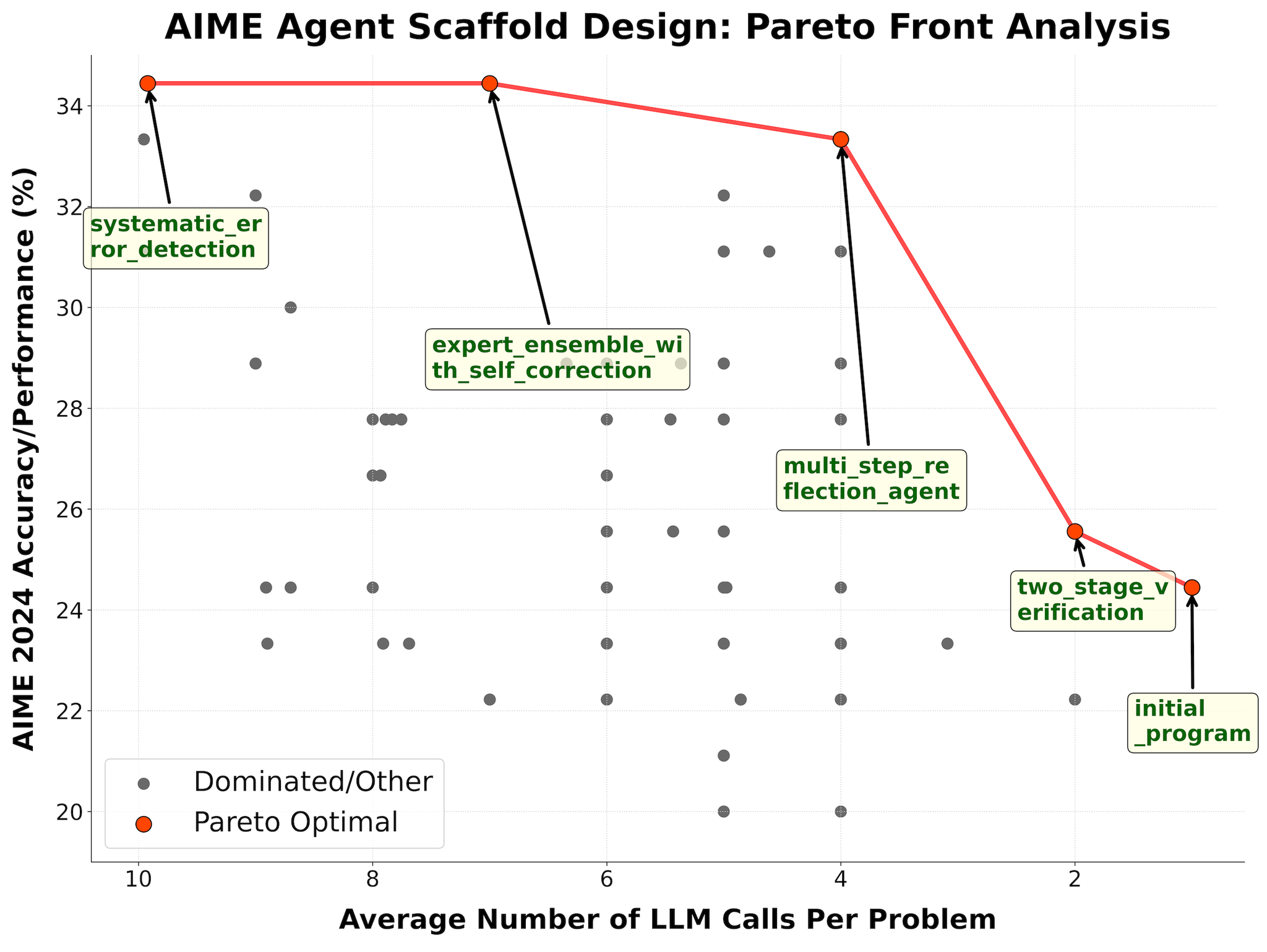
- AIME
- 10回までの呼び出しという制限の中で高い性能を発揮
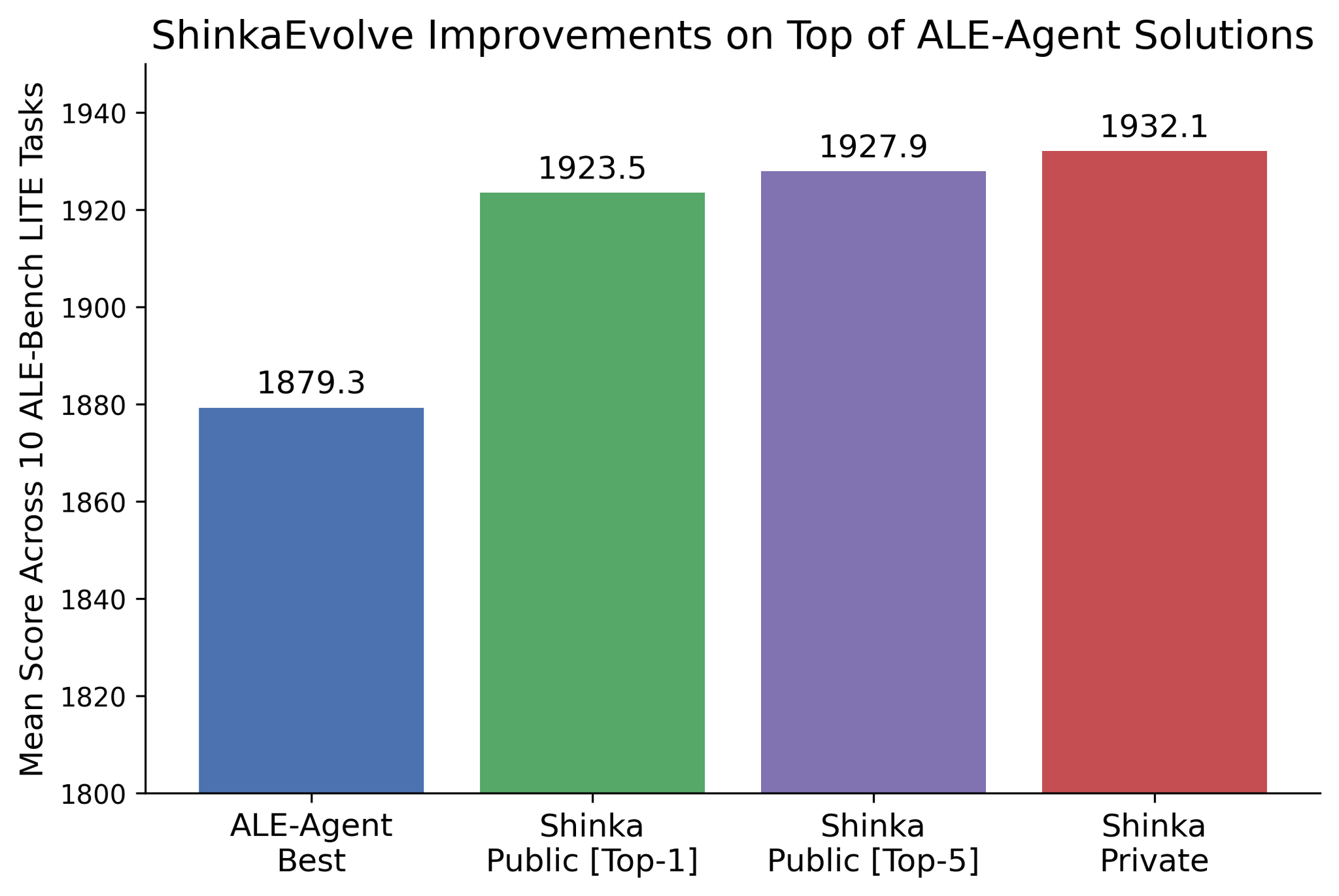
- ALE-Bench
- NP困難問題の最適化
- そもそも優秀だったALE-Agentに対して更に改良。コンテストに参加していれば2位の性能だった。
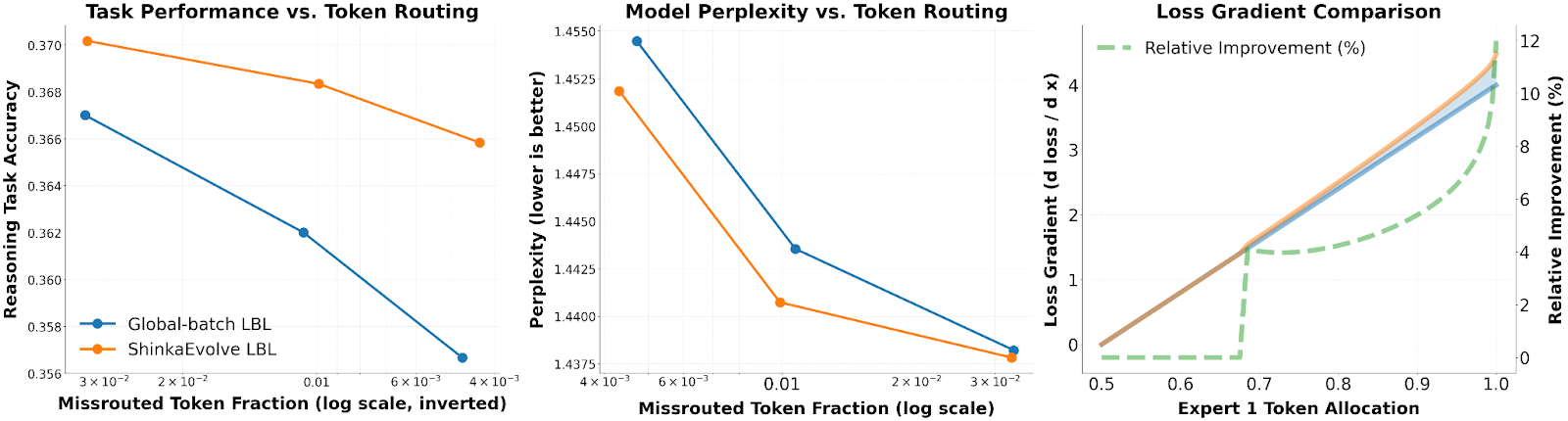
- LLM Training
- MoEを作成するときのLoad Balancing Loss (LBL)を最適化させて、DeepSeekチームが発見したLBLよりも優れた性能を見せた
@Yuya Matsumura
[blog] 決定論的システムと非決定論的AI Agentの接合点:OSSフレームワークEmbabelが拓く新しいソフトウェア開発の可能性
- プロダクトにAIエージェントを組み込むにあたって、AIならではの非決定性が難しいよね。特に、決定的な部分と非決定的な部分が入り混じるようなタスクの扱いが難しいよね、という課題の解決を目指したAIエージェントフレームワーク Embabel というフレームワーク紹介
- 紹介されている特徴
- 多くのエージェントフレームワークがLLMにすべて任せるのに対し、Embabellはタスク実行前にGOAP (Goal Oriented Action Planning) というLLMに依存しないアルゴリズムを用いて計画を策定する。
- LLMの入出力の定義に、KotlinのデータクラスやJavaのレコードといった厳格な型を持つドメインモデルを利用
embabel-agent
embabel • Updated Dec 23, 2025
- 後者はPydantic AIやzodの利用、あるいはStructured Outputsなど同等のものあるくない?と思ったが、1のGOAPとの組み合わせがユニークで強いと理解した。
- GOAPでは記載の通りLLMを利用せずに、定義されたドメインモデル・型を組み合わせることでGoalを達成できるようなPlanを決定的に組み上げる仕組み。
- それぞれのActionの入出力の型が厳格に決まっているので、Condition を Goal に繋げるようなパズルをしているよう。
- Actionごとに型に加えて前提条件(preconditions)と結果条件(postconditions)ももち、これもヒント。
- Planを実行中に不都合が生じたらPlanを作り直す。
- ワークフロー生成のヒントになりそうだなと感じた。とはいえ、Actionや状態が複雑だとどこまでいけるんだろう。
- あと、Java / Spring との親和性が高いのはそうで、既存のエンタープライズシステムにエージェントを導入する際には有効な手段となりそう。
@Shun Ito
[論文] EmbeddingGemma: Powerful and Lightweight Text Representations
- EmbeddedGemma
- パラメータ数: 308M
- 大規模モデルに匹敵する精度
- 多言語に対応

- 学習方法
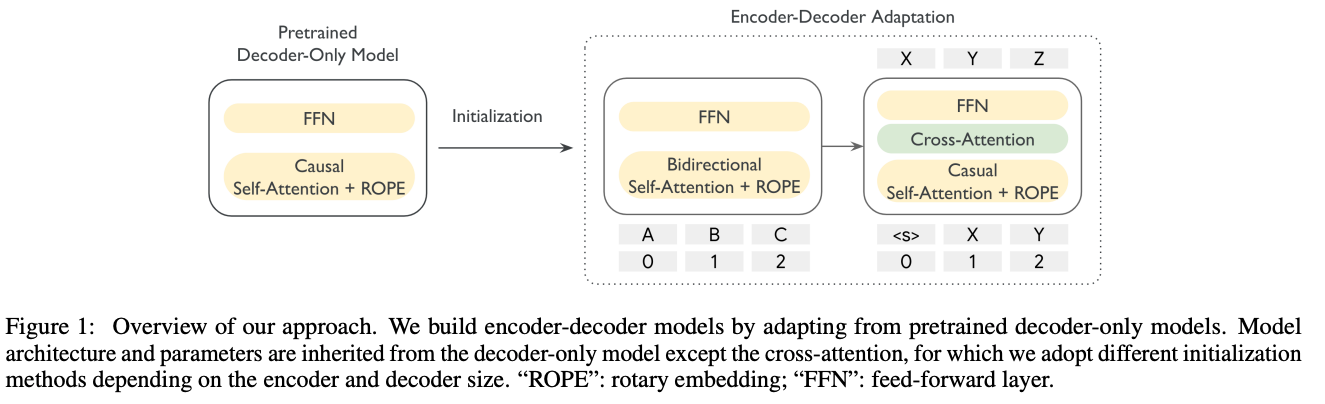
- Gemma 3 (decoder-only, 300M) をベースにし、Encoder-Decoderモデルに変換しpretrain → encoder部分だけ取り出す
- decoder-only checkpointを使ってencoder, decoderを初期化
- EncoderがBidrectional Self-Attentionに変わるので文脈表現の質が向上する
- Decoderの値で初期化することで、知識を受け継ぎ学習がより安定化する
- Pre-finetuning
- 大規模で様々なタスク・コーパスの入った query-target ペアデータを使い学習
- Finetuning
- より品質の高いタスク特化データを使った学習
- ベイズ最適化でタスクの混合比率を調整し、得意領域の異なる何パターンかのモデルを得る
- Model Souping
- finetuningで得られたモデルのパラメータの平均をとって1つに統合する
- 評価
- より大きなモデルに対して同等以上の性能

@Yosuke Yoshida
[blog] Effective context engineering for AI agents
- コンテキスト設計の変化
- 推論前に埋め込み検索を使う → ジャストインタイム型コンテキスト
- ジャストインタイム型コンテキスト
- すべてを事前処理せず、識別子(ファイルパス、クエリ、リンクなど)を保持
- 実行時に必要情報を動的に読み込む
- 完全記憶ではなく外部の索引システムを利用して必要時に検索
- 人間の認知との類似
- メタデータの活用
- ファイル名・フォルダ構造・タイムスタンプが行動指針や関連性判断に役立つ
- 探索を通じて段階的に文脈を発見し、必要情報のみを作業メモリに保持
- エージェントは網羅的ではあるが必ずしも関連しない情報に埋もれることなく、適切なサブセットに集中
- トレードオフ
- ランタイム探索は速度が遅くなる
- 適切なツール設計がないと誤用や情報見落としのリスク
- ハイブリッド戦略
- 一部データは事前取得し、残りは動的探索
- Claude CodeではCLAUDE.mdを初期挿入しつつ、globやgrepで補完
- インデックスの陳腐化や構文木の複雑化を回避
- 変化の少ない法務・財務分析に有効
@Hiromu Nakamura (pon)
[論文]ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
[pon]途中でサマライズするだけと見せかけて、パラダイムの強化学習 + 蒸留要約ツールと結構楽しい。
定期的な文脈要約を通じて無期限の探索を可能にする新しいパラダイムであるReSumを提案。ReSumは、増大するインタラクション履歴をコンパクトな推論状態に変換し、文脈の制約を回避しながらtaskの解決を目指す
要約ツール
- LLMを要約ツールとして利用するが、汎用的なLLM、特に小規模なモデルは、ウェブ検索のコンテキストで効果的に会話を要約するのに苦労することが多い。
- gpt-oss-120bなどのLLMから収集された⟨Conversation , Summary⟩ペアを使用して、Qwen3-30B-A3B-Thinkingをファインチューニングすることにより、要約機能を特化させ、ReSumTool-30Bを作成。
ReSumパラダイム学習
- エージェントがReSumパラダイムを習得できるようにするために、調整されたReSum-GRPOアルゴリズムを通じて強化学習(RL)を採用。
- エージェントはReSumTool-30Bを呼び出して会話を圧縮し、要約状態から続行し、完全な軌跡を複数の部分に自然に分割する。
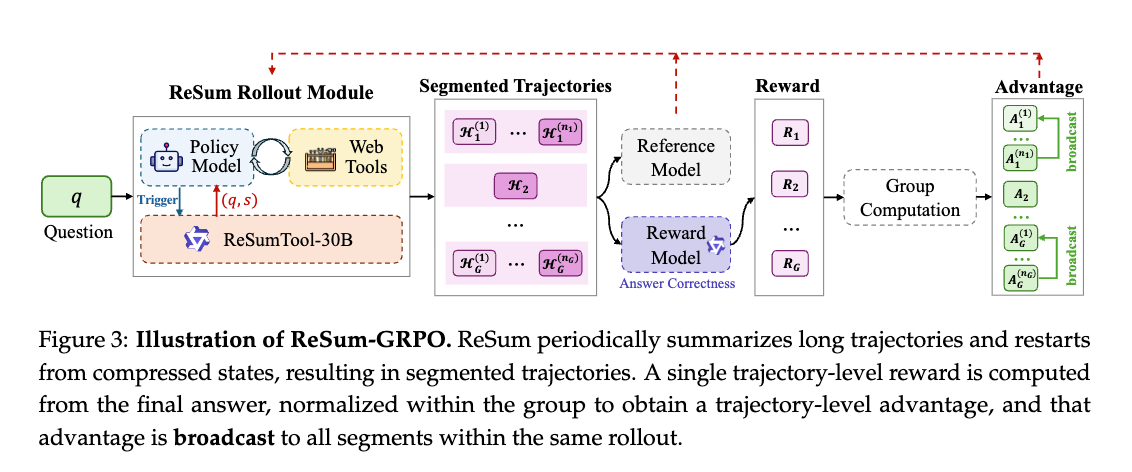
- 軌跡レベルの報酬 R_1の計算:
- ロールアウト H_1 が終了し、このロールアウト全体に対する単一の報酬 R_1を計算します。
- 軌跡レベルのAdvantage の計算:
- グループ内の他のロールアウトの報酬と比較して正規化
- Advantageブロードキャスト:
- のブロードキャスト: この計算された単一のAdvantage は、そのロールアウトを構成するすべてのセグメント に、同じ値として分配(ブロードキャスト)されます。
実験
- 実験には、エージェントが広範な探索を必要とする3つの挑戦的なベンチマーク(GAIA、BrowseComp-en、BrowseComp-zh)を使用。(問題解決に必要な探索ステップが非常に長い「父親が心臓病で亡くなり、妻との間に5人の子供をもうけた後、姉がいた画家。後に夫婦関係が破綻し、さらに3つの関係を持った。この人物を題材にした文学作品は何という名前か?」)
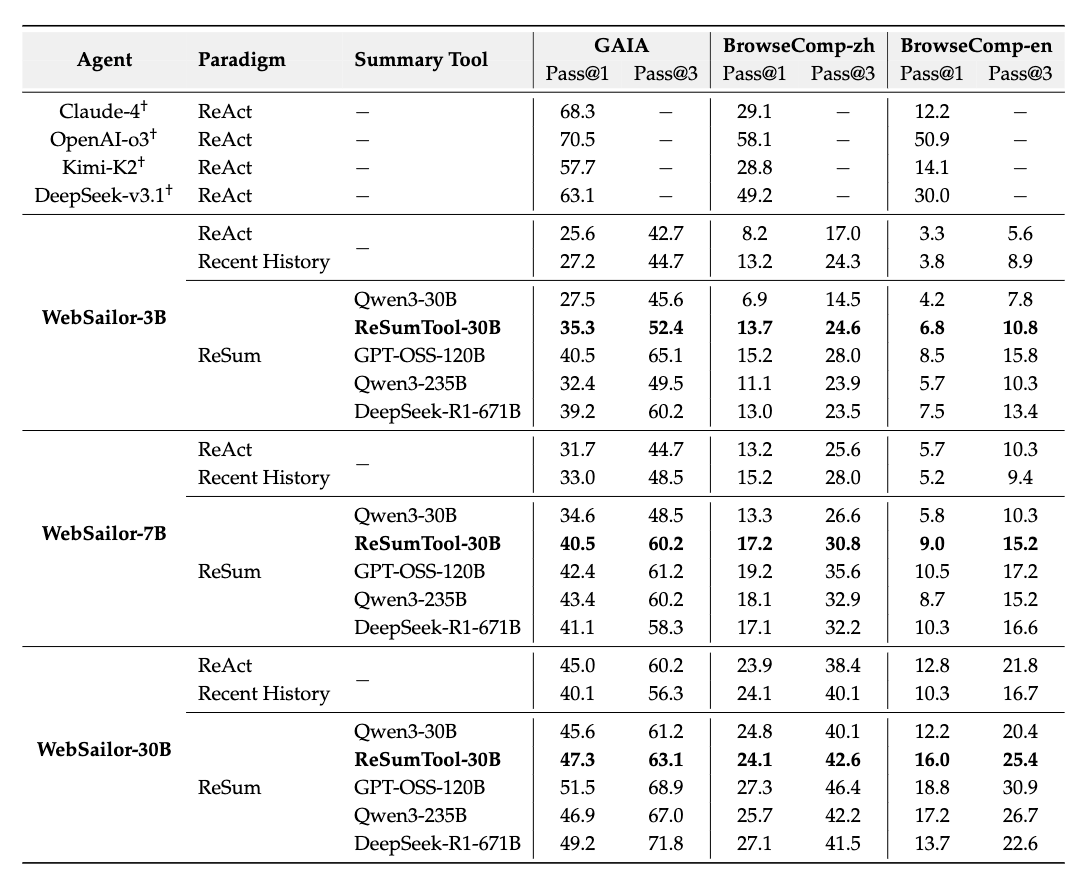
- LLM AS toolを蒸留で作るのかーおもしろー
- サマライズなどユーザーとのやり取りを分割して強化学習ってこうやるのねー
@ShibuiYusuke
[論文] GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS
TL;DR
- 研究の背景と目的:
- 高性能なAIモデルが労働市場に与える影響(タスクの自動化、雇用の代替など)についての議論が活発化
- AIの経済的影響を測る従来の方法(AI導入率やGDP成長率など)は、技術が普及した後にしか評価できない「遅行指標」であるという課題
- AIの能力そのものを直接測定することで、AIが経済に与える潜在的な影響を、社会に広く普及する前に評価するアプローチを提案
- GDPvalベンチマークの概要:
- GDPvalは、AIモデルの性能を現実世界の経済的に価値のあるタスクで評価するために作られたベンチマーク
- 米国のGDP(国内総生産)に貢献する上位9セクター、44職種の業務をカバー
- タスクは実際の業務成果物に基づいており、評価は主に人間の専門家による直接比較

- GDPvalの利点:
- 現実性 (Realism): 学術的なテストとは異なり、タスクは業界の専門家が実際に行った業務に基づいて作成
- 代表的な網羅性 (Representative breadth): ソフトウェア工学など特定の分野に偏らず、44職種にわたる1,320のタスクをカバー
- コンピュータ使用とマルチモーダル性: CADファイル、ビデオ、スプレッドシートなど、多様なファイル形式の操作を要求
- 主観性 (Subjectivity): 正確さだけでなく、構造、スタイル、美しさといった主観的な要素も評価対象
- 上限のない評価 (No "upper limit"): 満点が決まっているテストと異なり、比較対象(ベースライン)をより高性能なモデルに更新し続けることで、継続的な評価が可能
- 長期的な難易度 (Long-horizon difficulty): タスクの完了には、専門家でも平均7時間、長いものでは数週間かかる

内容
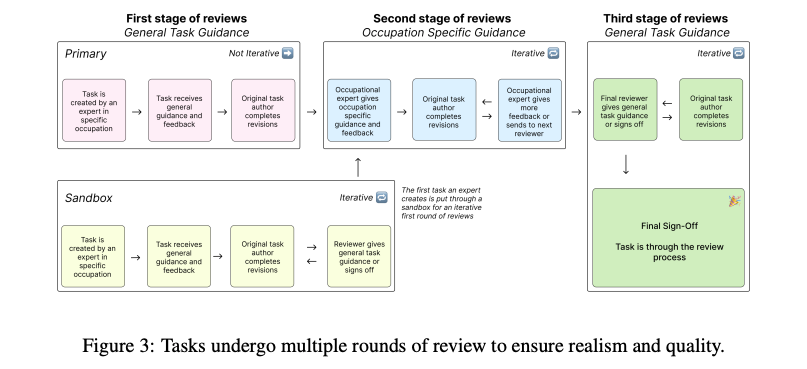
- タスクの作成 (Task Creation)
- タスクの基本構成
- リクエスト (Request): 実際の業務依頼を模した指示書。多くの場合、作業に必要な背景情報やデータを含む参照ファイルが添付される
- デリバラブル (Deliverable): リクエストに応じて作成されるべき成果物。人間の専門家が実際に作成した「お手本」
- 網羅性の確保: タスクを作成した専門家は、自分たちが作ったタスクがどの業務に該当するかを、米国労働省の職業情報データベース「O*NET」のタスクリストと照合。ベンチマークが特定の業務に偏らず、その職種の代表的な活動を広くカバー
- 品質評価: 作成されたタスクの質を評価するため、別の専門家が各タスクを複数の観点から評価
- 難易度 (Difficulty): タスクを遂行する上で求められる専門性や複雑さ
- 代表性 (Representativeness): そのタスクが、その職種の典型的な業務内容をどれだけ反映しているか
- 完了時間 (Time to complete): 専門家がそのタスクを完了するのに要する平均的な時間
- 全体的な品質 (Overall quality): 現実世界の業務基準に照らした総合的な質
- タスクの金銭的価値の推定: 各タスクの経済的な価値を概算するために、専門家が報告した平均完了時間に、米国労働省の職業雇用賃金統計(OEWS)から得た該当職種の中央時給を掛け合わせて算出
- 人間の専門家による評価と自動評価 (Human Expert Grading and Automated Grading)
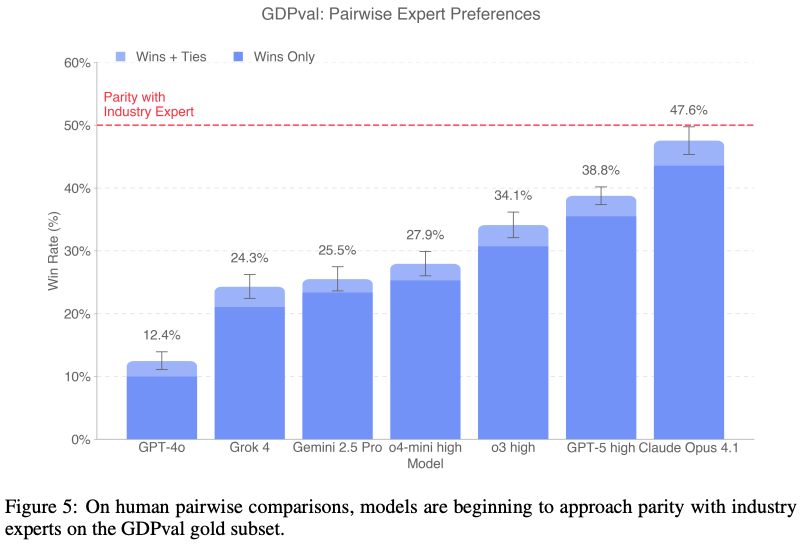
- 人間による評価 (Human Expert Grading):
- ブラインド・ペアワイズ比較: GDPvalの主要な評価方法は、専門家によるブラインド(誰が作ったか分からない状態)でのペアワイズ(一対一の)比較
- 評価プロセス: 評価者はまずタスクのリクエストと参照ファイルを受け取る。その後、ラベルが伏せられた2つ以上の成果物(例:人間の専門家が作ったもの vs. AIが作ったもの)を提示され、どちらが優れているかを客観的および主観的な基準で判断し、順位付け
- 時間と労力: この評価作業は非常に手間がかかり、ゴールドサブセットのタスク1件を比較評価するのに、専門家は平均で1時間以上を費やす。評価者は、なぜその順位にしたのか、詳細な根拠も記述
- 自動評価 (Automated Grading):
- 開発目的: 人間による評価は高コストで時間もかかるため、より迅速かつ安価な代替手段として、実験的な自動評価モデルを開発
- 性能: この自動評価モデルは、人間の専門家が行うのと同様のスタイルでペアワイズ比較を行うように訓練。人間の評価者との一致率が65.7%。人間同士の評価者間の一致率(70.8%)と比較してもわずか5%の差であり、高い精度を持っていることを示唆
- 役割: あくまで専門家による評価を補完する「代理(proxy)」であり、完全に代替するものではないと位置づけ
- 実験と評価
- モデル比較
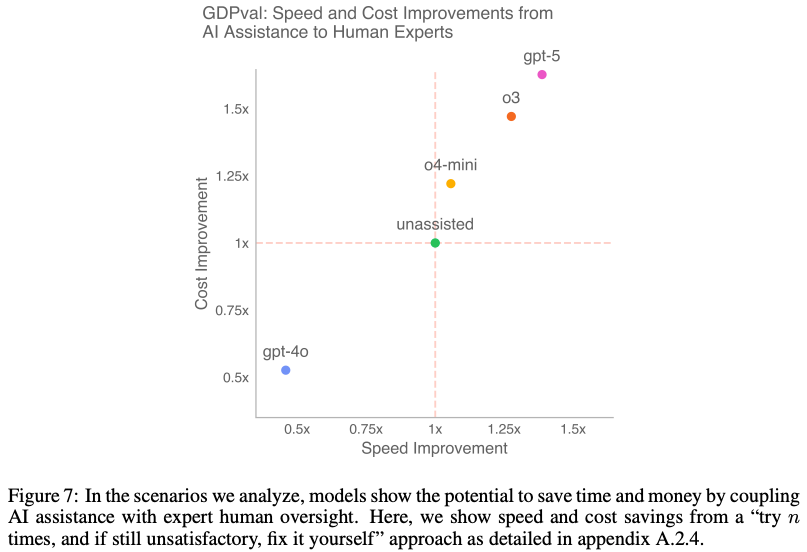
- 速度とコストの比較 (Speed and Cost Comparison):
- AIを専門家の業務フローに組み込むシナリオ(例:「まずAIにやらせてみて、満足できなければ自分で修正する」)を分析
- その結果、AIの支援と人間の専門家による監督を組み合わせることで、業務の速度とコストを改善できる可能性があることが示唆
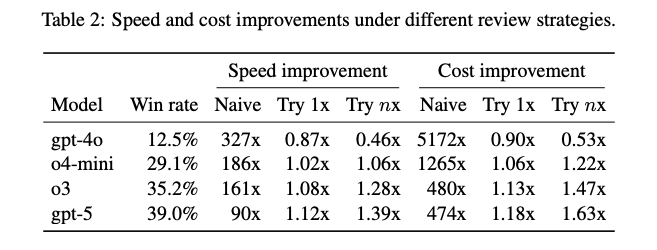
- 限界 (Limitations)
- データセットサイズ: カバーしている職種は44で限定的
- タスクの焦点: PC上で完結する知識労働に焦点が当てられており、手作業、物理的なタスク、暗黙知や対人コミュニケーションが重要な業務は含まれていない
- タスクの形式: 現実の業務と異なり、必要な情報がすべて最初に与えられる「ワンショット」形式であり、対話的に要件を明確にしていくプロセスは含まれていない
- 評価コスト: 専門家による評価は高品質だが非常に高コスト。自動評価はそれを補うものだがまだ限界あり
データセット例:指示(プロンプト)と添付ファイルで構成。以下には指示プロンプトのみ例示
@Ryoma Nakai
[論文] 大規模言語モデルに対するサンプリングを活用したメンバーシップ推論攻撃 (言語処理学会2024)
- ACL 2025に採択
背景
- LLMの学習データは秘匿されがち
- 多くのLLMで学習に利用されたデータは公開されない
- メンバーシップ推論攻撃(Membership Inference Attacks; MIA)
- 一般にメンバーシップ推論攻撃は、AIモデルの学習データとしてあるデータが利用されたか否かを判定するタスク
- LLMにおいては、メンバーシップ推論攻撃により権利的に保護された著作物がLLMの学習に利用されたか否かを知ることができる
- 既存のMIA手法はLLMの尤度を利用できることを前提しているが、尤度が必ずしも手に入るとは限らない
- 尤度が高い生成ができているなら学習データにあったと考えられる
本研究が取り組む課題
- LLMの学習データセットに対象テキストxが含まれるか否かのbinary classificationを行うこと
- ただし、既存手法の設定とは異なりLLMの尤度等は利用できず出力テキストのみを利用可能とする
提案手法 SaMIA(Sampling-based MIA)
基本的なアイデア
学習データに入っているデータであれば、正確に生成できるはず
詳細
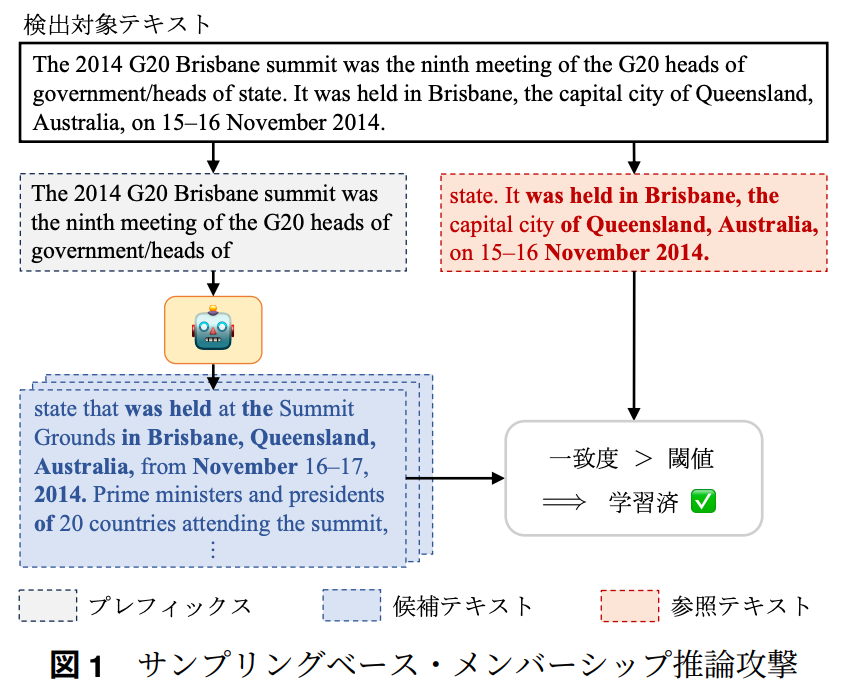
- 検出対象テキストxをx = concat(x_prefix,x_ref)のように分割
- LLMにx_prefixを複数回入力し、出力x_cand_1, …, x_cand_mをサンプリング
- 出力とx_refの類似度(ROUGE)の平均を学習データに存在したっぽさとして利用
実験設定
データセット
- 既存研究に倣ってWikiMIAを利用
- MIAの性能はテキスト長さに依存するので異なる単語数(32,64,128,256)で検出性能を評価
- テキスト長が長い方が性能はいい傾向にある
- 判断材料増えると考えればこの傾向は自然だと思う
- 2023年以降のデータを未学習、2017年以前のデータを学習済とみなす
- 未学習か学習済かをデータのカットオフに応じて設定
対象LLM
- GPTJ-6B, OPT-6.7B,Pythia-6.9B,LLaMA2-7B
- いずれもカットオフ日は2022年以前
比較手法
尤度やLOSSを利用した手法群
結果
- AUC-ROCによる評価
- 尤度にアクセスできないという制限を課してなお既存法とcompetitiveな性能

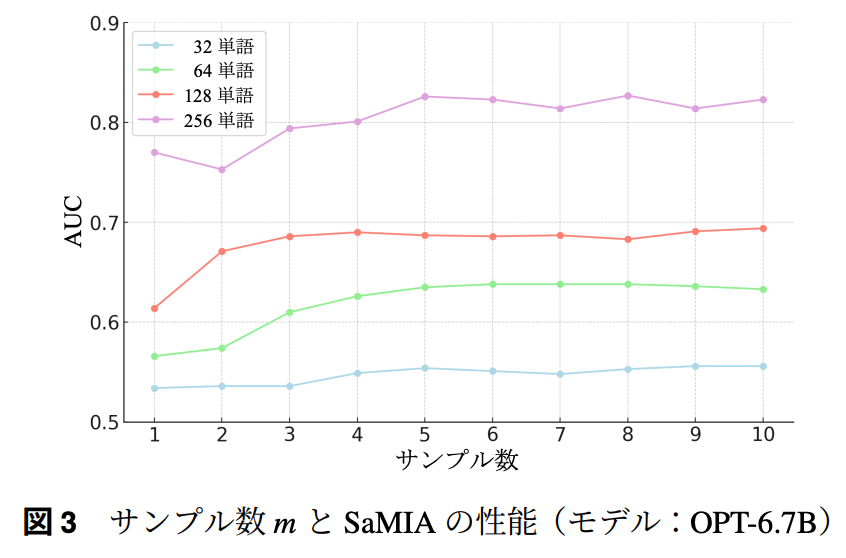
- サンプリング回数とSaMIAの性能
- 4,5回程度のサンプリングで十分そうに見える
- 単語数ごとのスコア分布
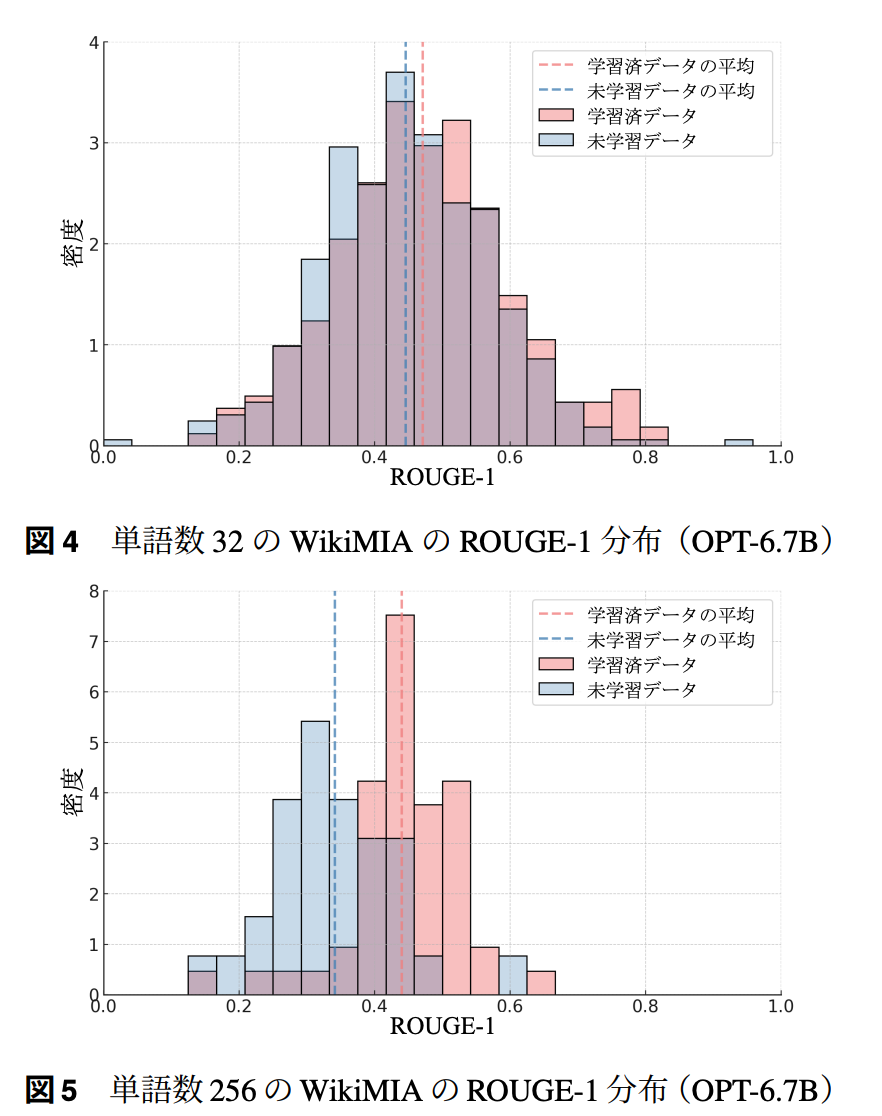
結論
- 尤度を提供しないようなLLMでもテキストが学習データに入っているかを判断すること(=メンバーシップ推論攻撃)は尤度を提供するLLMと同程度以上にできる
メインTOPIC: Agentic Any Image to 4K Super-Resolution
| タイトル | Agentic Any Image to 4K Super-Resolution |
|---|---|
| 著者 | Yushen Zuo1, Qi Zheng1+, Mingyang Wu1+, Xinrui Jiang2+, Renjie Li1,Jian Wang3, Yide Zhang4, Gengchen Mai5, Lihong V. Wang6, James Zou2,Xiaoyu Wang7, Ming-Hsuan Yang8, Zhengzhong Tu1* |
| 所属 | Texas A&M University, Stanford University, Snap Inc. , CU Boulder, UT Austin, California Institute of Technology, Topaz Labs, UC Merced |
| プロジェクトページ | https://4kagent.github.io/ |
| 論文リンク | https://arxiv.org/abs/2507.07105 |
| コード | https://github.com/taco-group/4KAgent |
| 備考 | NeurIPS 2025採択 |
一言でいうと
様々な画像を4Kの解像度にアップスケールさせる超解像用エージェントシステム 4KAgentを作成した。
エージェントシステムの大まかな流れ
- プロファイリング:特定のユースケースに基づいてパイプラインをカスタマイズ
- 知覚エージェント(Perception):VLMと画質評価エージェントを使って、入力画像を分析し、修復計画を立てる
- 修復エージェント(Restortion):品質駆動型の混合エキスパートポリシー(Quality-Driven Mixture-of-Expert, Q-MoE)に基づいて、計画を実施
結果
26個の多様なベンチマークで評価し、広範なドメインでSoTA。
- 自然画像、ポートレート写真、AI生成コンテンツ、衛星画像、医用画像(顕微鏡、眼底画像、超音波、X線画像)など
- NICやMUSIQ、PSNRなどで定量評価

選定理由
画像系でエージェントって言うのをあまり聞いたことがなく、気になった。
イントロ
超解像=低解像度から高解像度にアップスケールするタスク
超解像が活躍するシーン
- ブレ除去(ディブラー)
- モヤ除去(ディヘイズ)
- 雨滴除去
- 暗所補正
- リモートセンシング
- 監視カメラ(科捜研ででてきそうなやつ)
最近だと、合成画像(劣化をシミュレーション)に対してだけではなく、写真やビデオ撮影で自然に生じる劣化に対しても超解像できるRealSRというタスクに興味が移ってきている。
→より実用的なタスク設定、モデルを作る必要あるよねという話
LLMを使ったエージェンティックな修復フレームワークはこれまでも出てきている。
- RestoreAgent, NeurIPS, 2024
- AgenticIR, ICLR, 2025
しかし、利用できる状況が限られている。
- x4にしかアップスケールできない
- ドメインシフトに弱い
- 多様なユーザの要求に答えられない
- ノイズ除去だけやりたい
- 忠実度と知覚品質のバランス
- 具体的なワークフローがほしい
提案手法の4KAgentでは
- あらゆる画像を4Kに超解像可能。ドメインシフトに強い
- 解釈可能
本論文の貢献をまとめると
- 4KAgent:汎用的なあらゆる画像を4Kにアップスケール可能。古典的な劣化もリアリスティックな劣化も対応可能で、リモートセンシングや顕微鏡画像、生物画像なども対応できる。
- Q-MoEと顔修復パイプライン
- プロファイルモジュール:様々な修正タスクに合わせてシステムをカスタマイズできるようにするモジュール
手法
システムの全体像
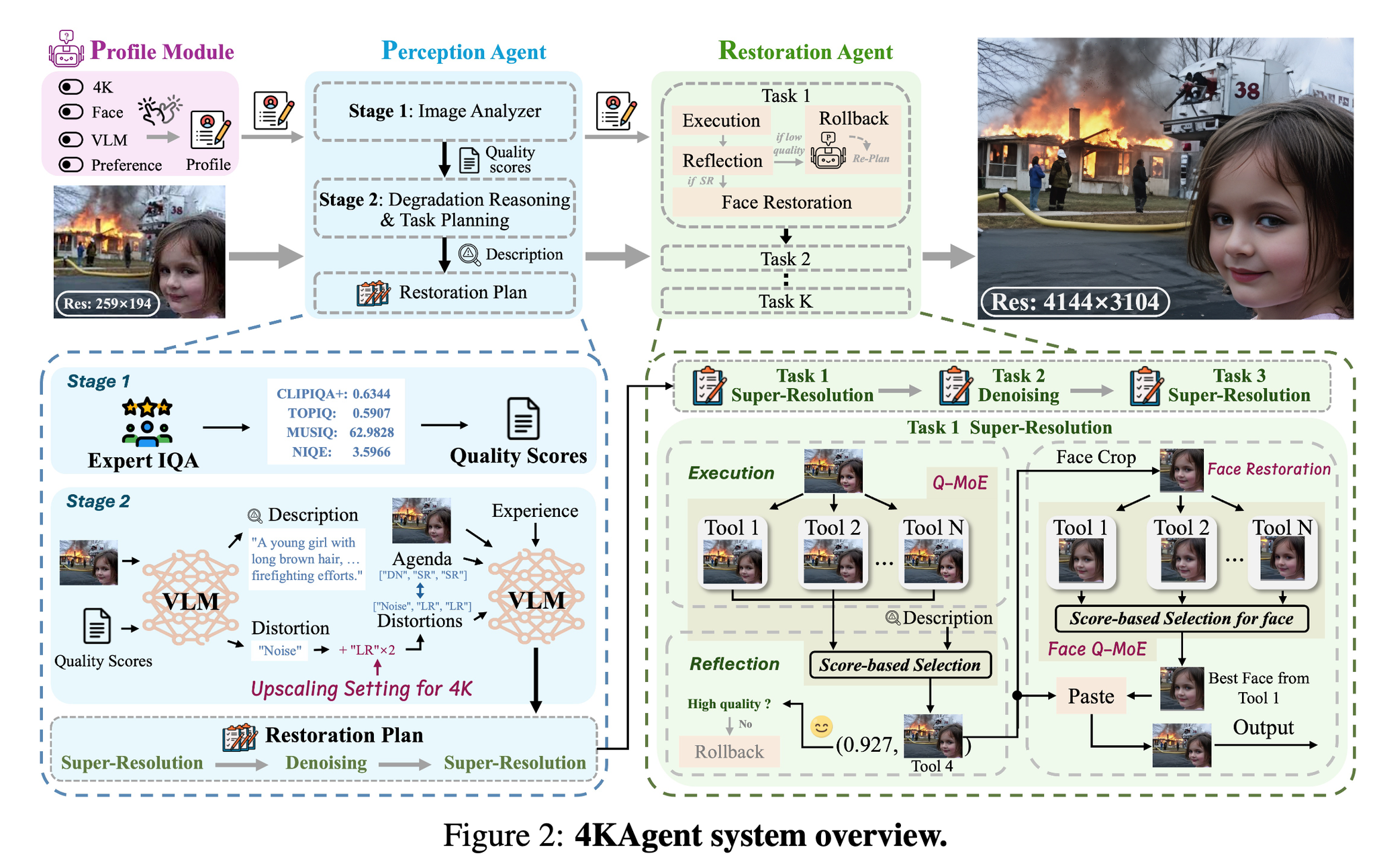
知覚エージェント
劣化(ノイズやブレなど)を分析、意味的・構造的な特徴を抽出し、修正計画を立てる。
修正計画=ノイズ除去やデブラーや超解像などのシーケンス
以下4つのモジュールがある
- Image Analyzer
- Image Quality Assessment(画像の品質評価)のツールを呼び出す
- 具体的にはCLIPIQA, TOPIQ, MUSIQ, NIQEを採用
- 劣化推論 (Degradation Reasoning)
- IQAの評価に基づいてリーズニングするためにVLM を活用
- このVLMが入力画像 とIQA評価 を元に以下を出力
- 劣化リスト (どんな損傷があるのかというリストだと思われ)
- 最初の修正アジェンダ (それらをどういう順番で修正していくのかというものだと思う)
- 説明文 を作る
- アップスケーリング係数の設定
- 4K解像度に到達するために必要な超解像スケールを自動的に決定する こんな数式で決めるらしい。どちらかが4000ピクセルを超えるようなスケールにするということかな
- タスクプランニング
- 劣化リストと修正するためのアジェンダを取得したらLLM/VLMを使って、修正計画 を立てる
E=経験, Mp=LLM/VLM。画像が利用できる場合にはVLMを使うらしい。
(全体的にふわっとしている)
修復エージェント
品質駆動型MoE(Q-MoE)を使って修復計画にしたがって、複数の修正ツールから最適な出力を選択する。
修正された画像品質がしきい値以下だったらロールバック
以下の3つのステップを密に組み合わせて復元していく
- 実行ステップ
- タスク計画 PIに基づいて復元ステップを順次実行
- 画像をすべてのツールボックスを通過するように入力 明るさ調整、デフォーカスデブラーリング、モーションデブラーリング、デヘイジング、ノイズ除去、デレーニング、JPEG 圧縮アーティファクト除去、超解像度、顔復元
- Reflectionステップ
- 各ツールの出力を評価して、最適な画像を選択する
- 選好モデルと無参照のIQAを行って画質のスコアリングを行う。スコアリングはそれらの加重平均。これをQuality-driven Mixture-of-expert (Q-MoE) と読んでいる。
- 選好モデル:‣
- 無参照IQA:NIQE, MANIQA, MUSIQ, CLIPIQA
- ロールバックステップ
- 修正計画のk番目の画像品質スコアがしきい値以下だった場合、後続の修正計画を作り直す。(もう一度知覚エージェントのタスクプランナー に投げる)
顔修復パイプライン
人の顔部分は視覚的に敏感で意味的に重要な場合が多い。自然な肌の質感や同一性の保持などが難しい。
→専用の顔修復パイプラインを構築
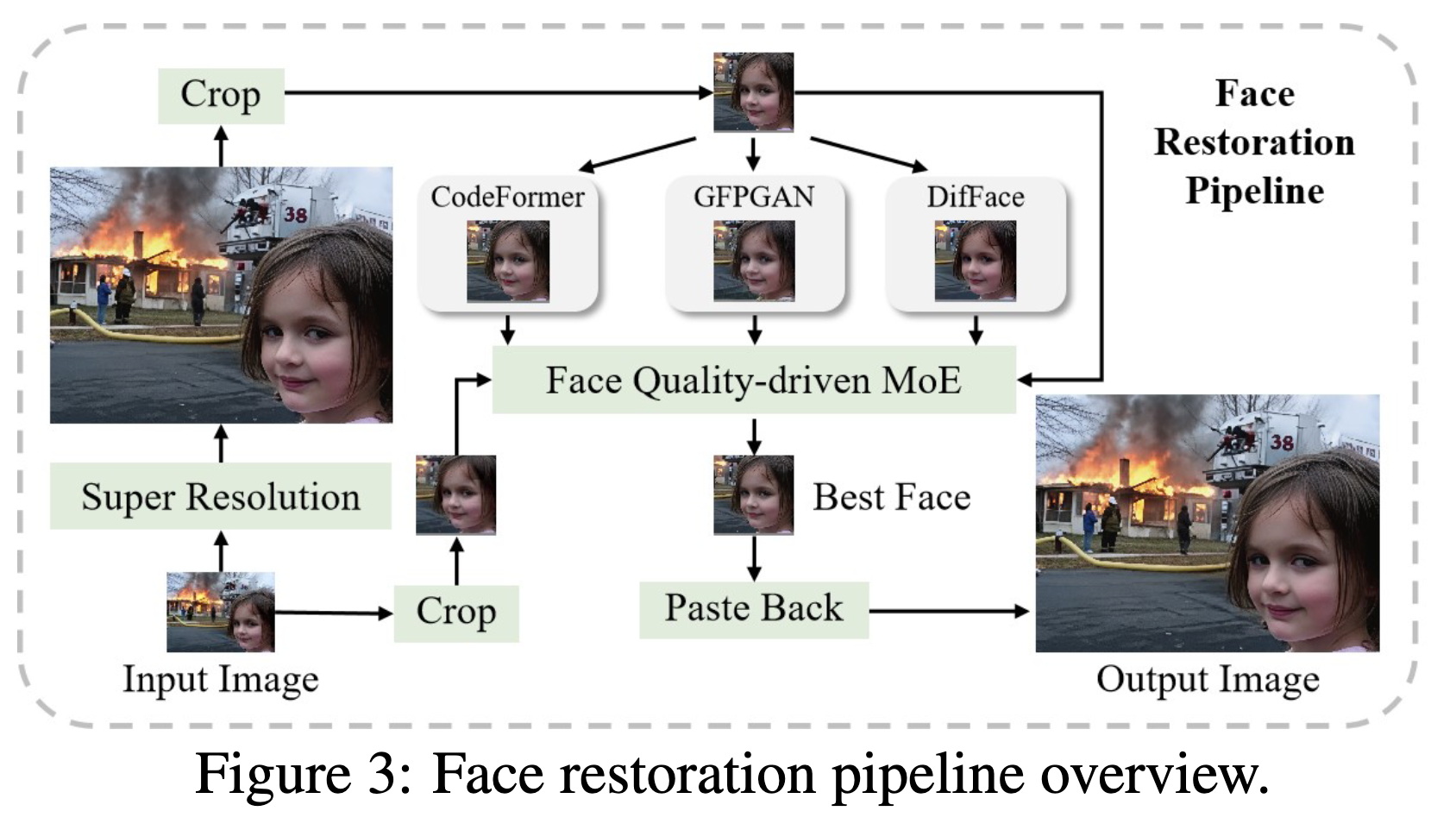
超解像前の画像と超解像後の画像、それぞれに対して顔検出してクロップ&貼り付け
ここでも修復フェーズと同様に、複数の顔修復ツールがあり、それぞれで品質評価からのベストな画像選択を行っている。
品質評価要素としては、以下の組み合わせ
- ArcFace:顔特徴のコサイン類似度を取って、同一性を確保しようとしてる
- CLIB-FIQA:顔専用のIQA指標
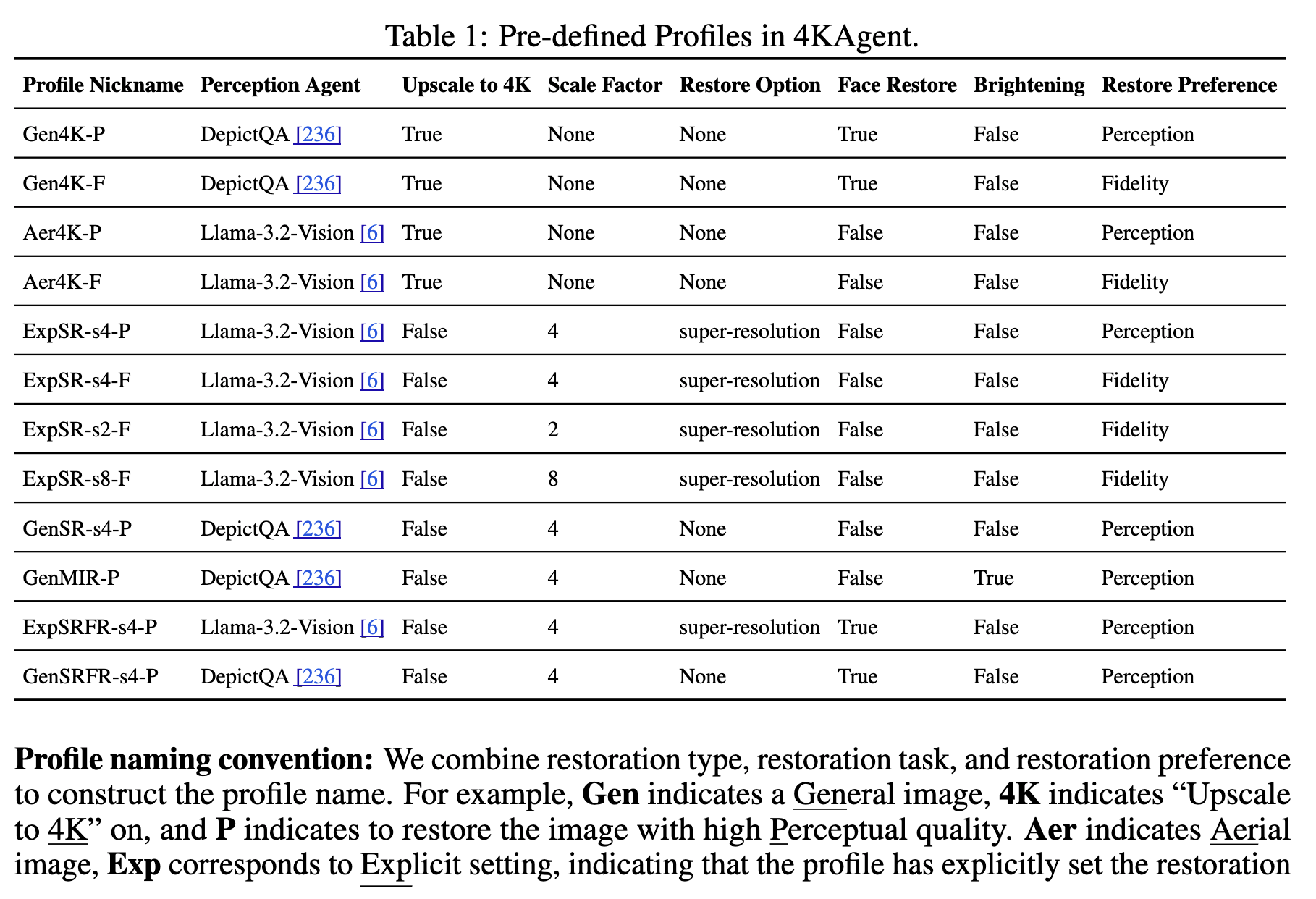
プロファイリングモジュール
ユーザがシステムをカスタマイズするためのモジュール
例「忠実度と知覚的な品質のどちらを優先するか」
カスタイマイズ可能な要素
- Perception Agent:どのLLM/VLMを使うか(デフォはLlama-vision)
- Upscale to 4K:4Kにアップスケールするかどうか
- スケールファクタ:デフォルトx4にアップスケールだが、x2,x4,x8,x16が選択可能
- 修復オプション:デフォルトだとPerception Agentが選択修復手法を選択するが、自分で選べる
- 顔の修復:顔専用モジュール使うかどうか
- 明るさ調整
- 修復嗜好:忠実度と知覚品質どちらを優先するか
モデルカード
4KAgentシステムは柔軟なので、色々モデルやら切り替えられるし、ある程度実験するための組み合わせを作っといたよ。という一覧
プロファイル
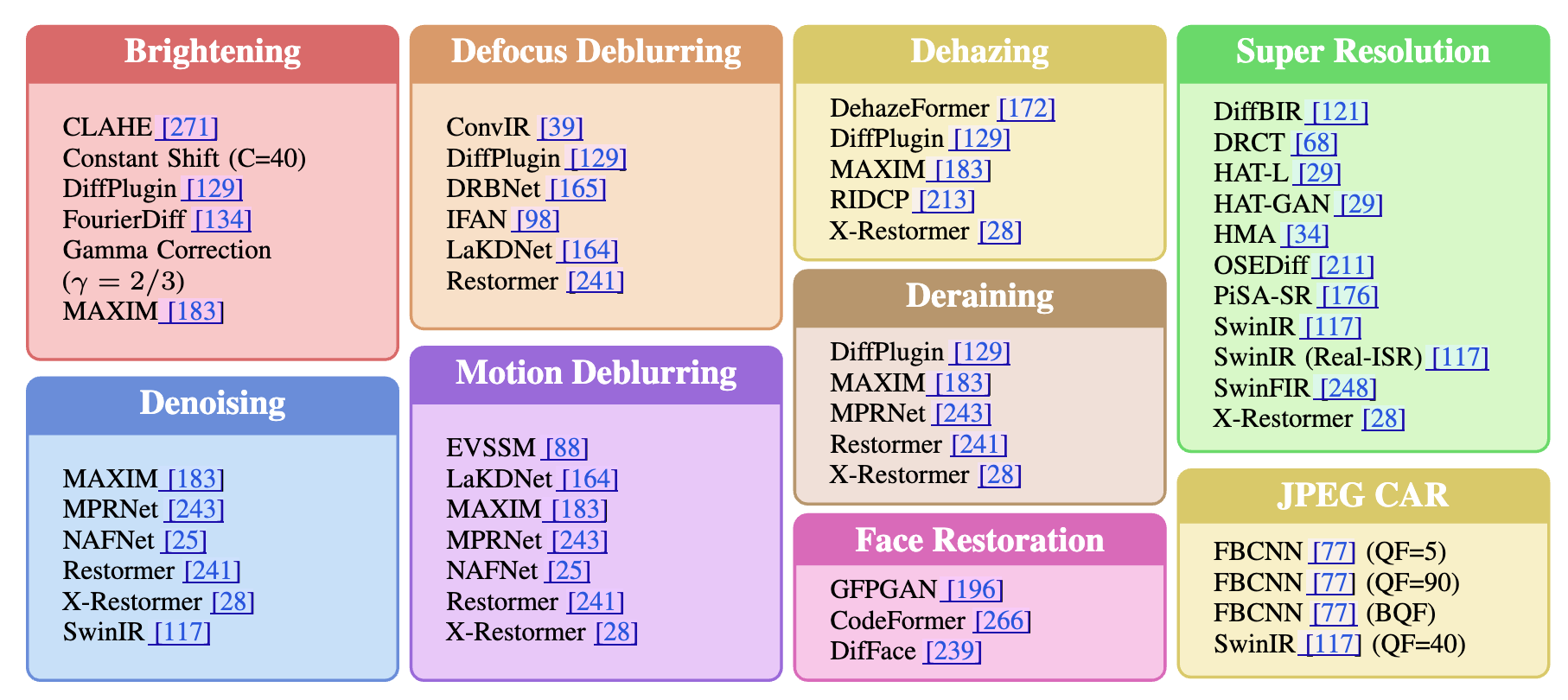
Model Zoo 9つのタスクがあり、それぞれのタスクの中に色々なモデル(ツール)がある。
プロンプト
劣化リスト推論(Degradation Reasoning)のためのLlama-Vision用プロンプト
原文
日本語訳
ロールバック用のプロンプト(これをもとに再計画を立ててもらう)
原文
日本語訳
計算資源
基本的に2枚のNVIDIA RTX 4090を使って実験しているらしい
異なるエージェントを異なるGPUに割り当ててメモリを節約できる
実験(抜粋):自然画像の超解像
めちゃくちゃ実験が長いので一つ紹介
以下の自然画像の超解像データセットを使って実験(枚数的に超多い訳では無いが、これだけでも多いな…)
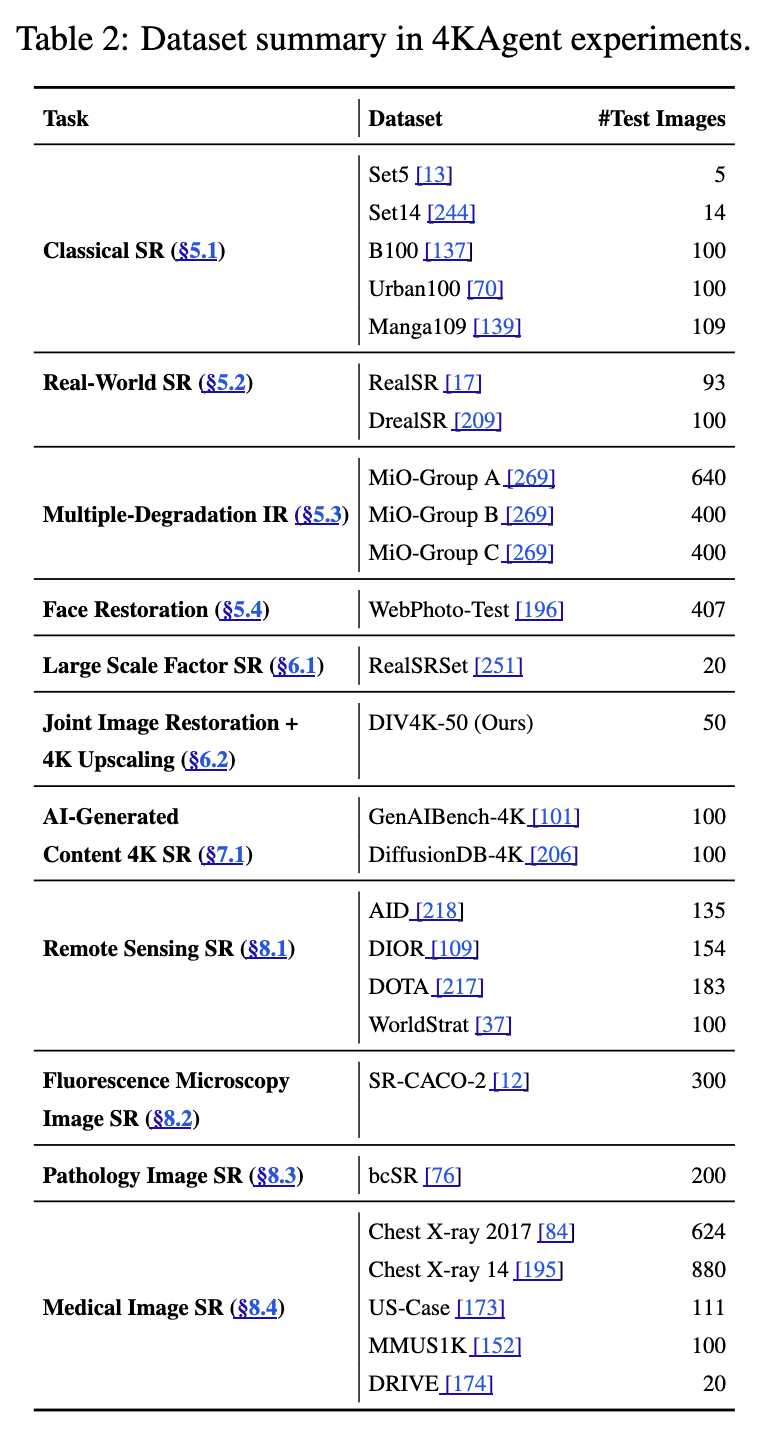
既存研究との比較

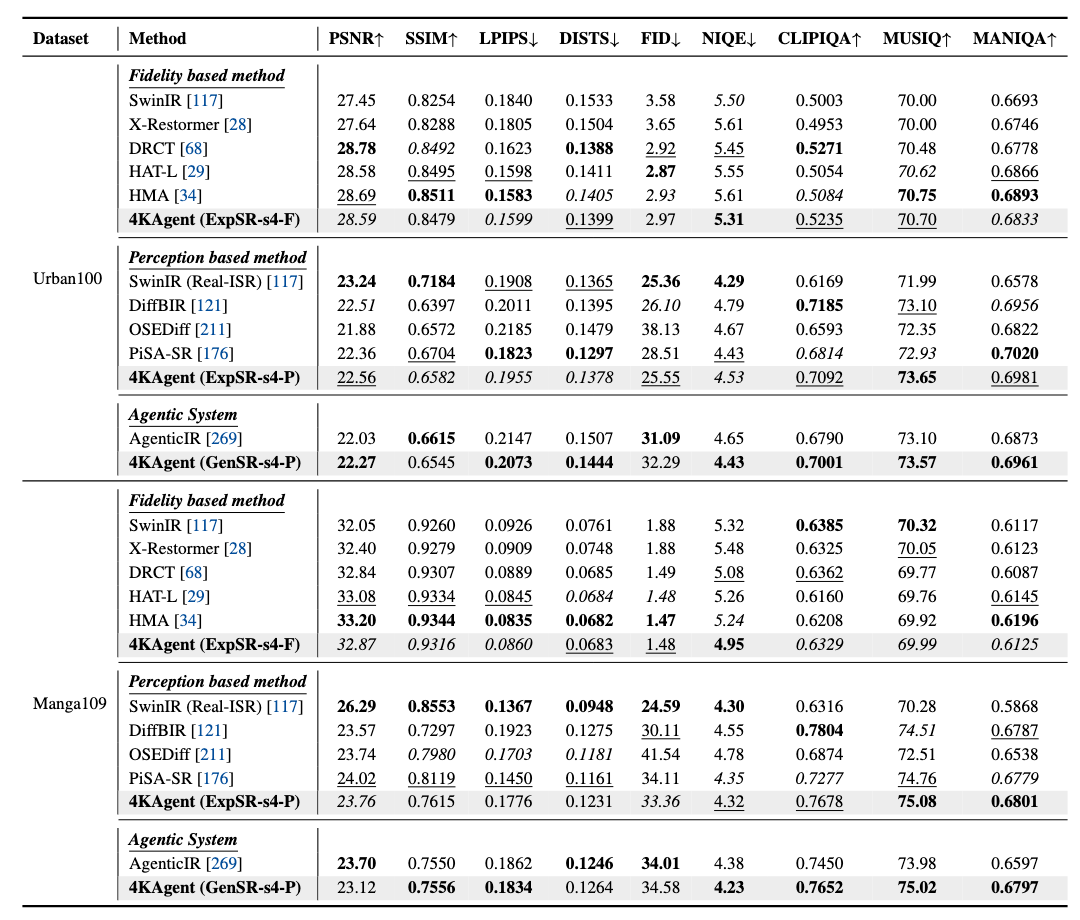
忠実度を測れるPSNR, SSIMでは、Set5, B100, Urban100, Manga109データセットでトップ3にランクイン。
知覚ベースの指標であるNIQE, CLIPIQA, MUSIQ, MANIQAでは、ほとんどのケースでトップ2に入っている。

SwinIR:のっぺりとしてしまう
DiffBIR:立地だが、忠実度が低い
AgenticIR:シャープだが、視覚的な妥当性を損なう色ズレやアーティファクトが生じる
4KAgent:忠実度や知覚的な美しさを制御できる(ちなみにGenSR-s4-Pは知覚的な美しさを重視してるモデルっぽい)
Ablation Studies
Q-MoEポリシー
AgenticIRではDFS(幅優先探索)を使って使用するエキスパートを選択している。
それと比べたときQ-MoEは効果があるか検証

参考:AgenticIRのDFS (読めてないけど)順番に成功するまで試すアプローチっぽい雰囲気

顔修復モジュールの有無
顔専用の修復モジュールを使ったほうがきれいに生成できる。
こういうときは超解像オプションを外したほうが、一般的な画像のIQA指標と顔のIQA指標の2つを活用できてきれいになるらしい。(この辺は実験設定のオプションぽい)

実行時間
求める画像の品質によって実行時間は変わってくる。
4090を使った推論時間が下表。
一番早かったのはExpSR-s4-Fのプロファイル(実験セット)で4倍したときで、逆に遅い場合はGen4K-Pのとき。
x20してるので、かなーり実行時間が違ってる。

並列実行することで高速化できると書かれている。
個人的には、かなり遅いんじゃないかという所感。
感想
画像生成をエージェンティックにやっていくのは面白いと思った。(この論文初ではないが)
結構計算パワーで戦ってる印象を受けるが、なんだかんだでこういう論文はなかなか倒せないと思ってる。