
2025-10-07 機械学習勉強会
今週のTOPIC[論文] Extract-0: A Specialized Language Model for Document Information Extraction[論文] Rethinking Thinking Tokens: LLMs as Improvement Operators[blog] 物体検出モデルの推論高速化入門[blog] Why Multi-Agent Systems Need Memory EngineeringOpenAI Agent BuilderメインTOPICYou Don’t Bring Me Flowers: Mitigating Unwanted
Recommendations Through Conformal Risk Controlサマリー1. Introduction2. Related Work3. Case Study: A Video-Sharing Platform3.1 Sparsity of Negative Feedback3.2 Analysis of the Watch Time3.3 Trend of Video Reporting Patterns3.4 Unwanted, Disliked and Harmful Content4. Recommender Systems With Risk Control4.1 Measuring Unwanted Content4.2 Conformal Risk Control5. Risk Control via Item Replacement5.1 A Property for Safe Alternatives6. A Simple Post-Hoc Pipeline7. Experiments With Real Data(RQ1&RQ2) Replacing unwanted items ensures risk control and mitigates performance degradation.(RQ3) The choice of score function impacts the number of previously seen items in the recommendation set.(RQ4) There exists a trade-off between ensuring the safety of replacement items and the recommendation set size.(RQ5) Risk control is biased toward high-reporting users.8. Discussion and Limitations9. Conclusions
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] Extract-0: A Specialized Language Model for Document Information Extraction
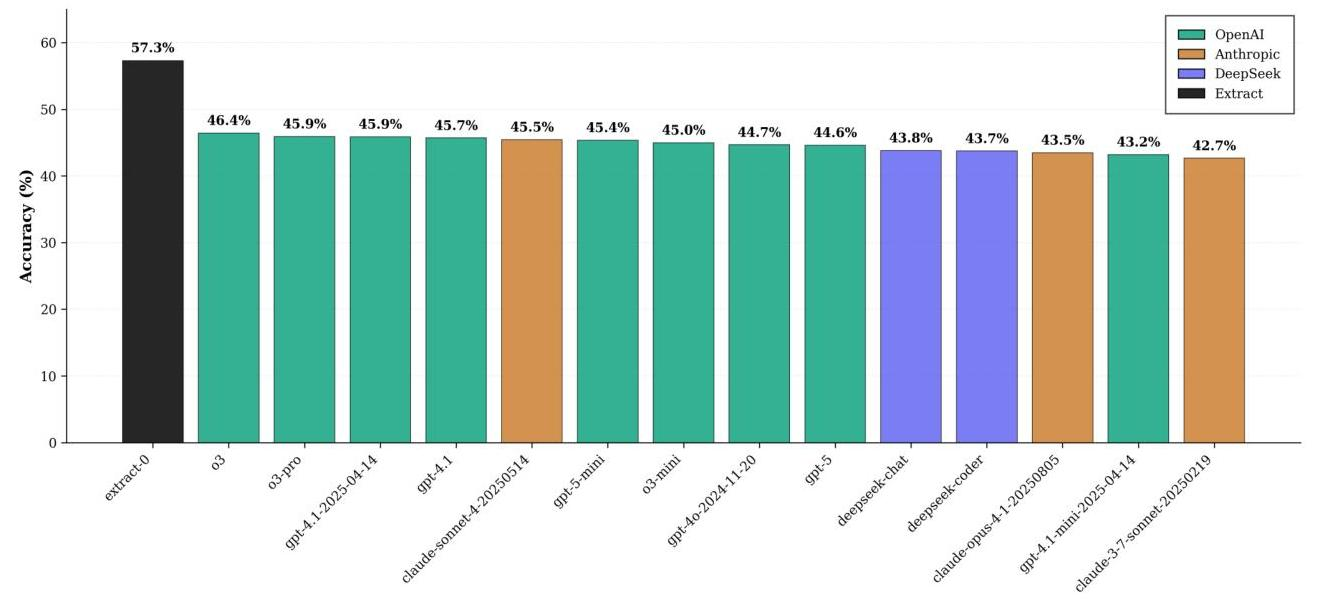
- DIE (Document Information Extraction)のために設計された7BパラメータのExtract-0モデル。
- 既存のフロンティアモデルである汎用的なモデルを大幅に上回る性能
- 単一のH100GPUでのトレーニングコストはわずか196ドル
- コード:https://github.com/herniqeu/extract0
- モデル:https://huggingface.co/datasets/HenriqueGodoy/extract-0
- 手法
- ベースモデル:
- 訓練
- 合成データ生成
- 教師ありファインチューニング(SFT)
- Group Relative Policy Optimization(GRPO)
- 合成データ生成
- arXiv論文、PubMed Central記事、Wikipediaエントリ、FDAデータベースなど多様なソース
- 2000文字ずつのチャンクにし、コンテキストメモリを保持することで一貫性を保つアーキテクチャ。(c: チャンク, M: メモリ)
- 各ステップで抽出された情報を保持
- 文章チャンクを色々組み合わせることでデータ拡張
- SFT
- Rank = 16, スケーリングファクター= 32でLoRAファインチューニング
- GRPO
- 従来の厳密な一致判定基準は、情報抽出の評価においては不十分。
- 意味的類似性に伴う類似度を導入
- 型を考慮して以下のように設計
- リストフィールド: 文の埋め込みのコサイン類似度(しきい値=0.35)を用いた二部マッチングを使用
- スカラーフィールド: 数値は相対差で比較、日付は時間的距離で比較
- 文字列フィールド: 埋め込みベースの意味的類似度を用いて評価
- 結果
- 自分で設計した報酬で比較してるので、トレーニング無しのフロンティアモデルよりは報酬レベルでは高くなりやすいバイアスはかかりそう

@Shun Ito
[論文] Rethinking Thinking Tokens: LLMs as Improvement Operators
- 長いCoTで精度は改善するものの、コンテキスト長が膨大になり、計算コスト・レイテンシの増加も重い。
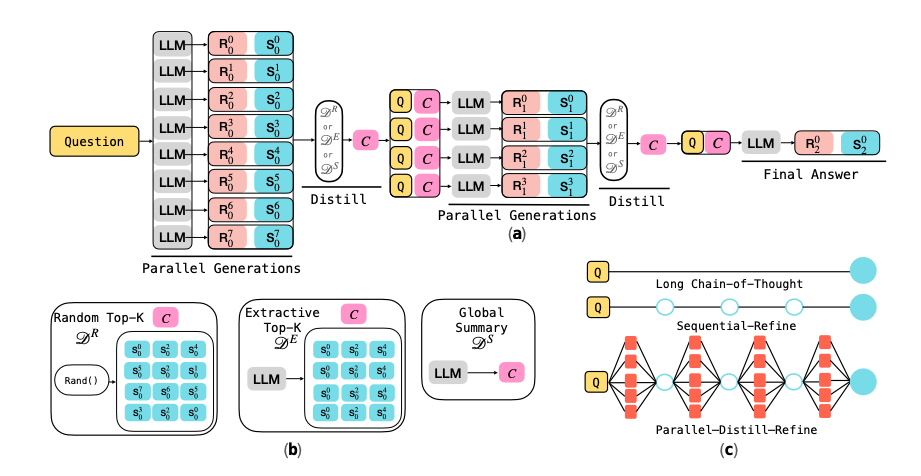
- 提案: LLMを、自分の出力を段階的に改善していくシステムとして扱う
- Sequential Refinement
- あるラウンドのinput: 元々のタスク(質問)+ 前ラウンドの回答
- 前回の回答から、直接新しい回答を生成し、次のラウンドに進む
- Parallel-Distill-Refine
- あるラウンドのinput: 元々のタスク(質問)+ 前ラウンドの回答
- 複数のdraftを並列生成し、それらを短い要約に蒸留する
- 元々のタスク(質問)+ 要約から回答を生成し、次のラウンドに進む
- 実験
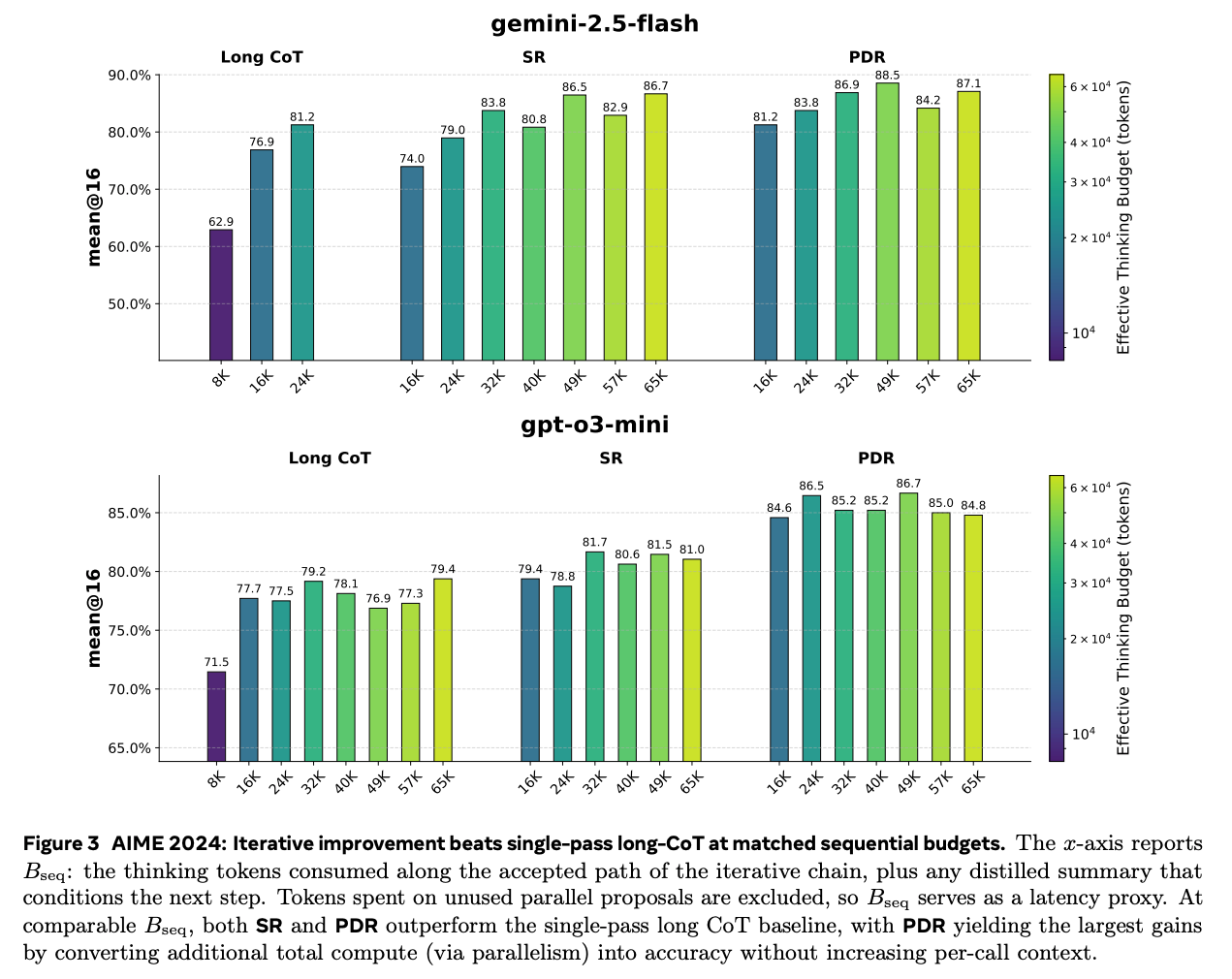
- 横軸は出力までの直列のトークン数(=レイテンシ)。
- 同じレイテンシで比較すると、1つのCoTよりもイテレーションを回すSR, PDRが性能が良い。特に要約を挟んでいるPDRが最も性能が良い
- 1ラウンドあたりで扱うコンテキストサイズも小さくなるので、SR, PDRが嬉しい
@Takumi Iida (frkake)
[blog] 物体検出モデルの推論高速化入門
物体検出モデルの推論高速化方法をまとめた記事
アプローチ
- モデル構造や入出力設計の変更(ハードル高め)
- 数値精度の削減・量子化
- プルーニング(ハードル高め)
- 小規模モデルへの知識蒸留(ハードル高め)
- 計算処理の最適化
プルーニングや蒸留はアルゴリズムやモデルの構築フローで大きな変更を伴うためハードル高め。
一方、計算処理の最適化は同じ計算を効率的に実行することで推論を高速化→導入優しめ
PyTorchモデルのまま高速化
- torch.compile
- PyTorchコードを最適化されたカーネルにJITコンパイルして高速化
- 学習と推論に利用可能
- inductorバックエンドだと以下のようにカーネル生成
- NVIDIA GPU環境→Tritonベースのカーネル
- CPU環境→C++/OpenMPベースのカーネル
- ONNXやTensorRTなどにも変換できるが、ネイティブランタイム使ったほうが速いらしい+バックエンドなどの各種設定で速度変わってくるので注意
この辺の情報ありがたい。最近改善してきているので、導入メリット上がってる。
2022年10月時点ではtimmモデルの幾何平均推論速度の改善が1.03倍だったのに対して、2025年9月時点のPyTorch 2.10.0a0では1.96倍と大きく改善していることが分かります。
- メモリレイアウトの変更
- NCHWからNHWCに変える NHWC形式のほうが空間的に隣接するピクセルがメモリ上でも近い位置に配置されるので、畳み込み効率が良い
- 半精度推論
- fp32→fp16, bf16
- bf16は対応デバイスに影響あるので注意。性能も変わってきたりする。 AVX-512命令サポートしてるかなど
(物体検出の高速化という文脈でいえば)NMSでしっかりとSuppressionするのも重要。特にscore_thr
推論エンジンの利用
ONNX Runtime
クロスプラットフォームの推論エンジン。ONNX形式のモデルを最適化して、ハードウェアに応じて高速に実行。
[fr] とりあえず(まずは)これだろというイメージ
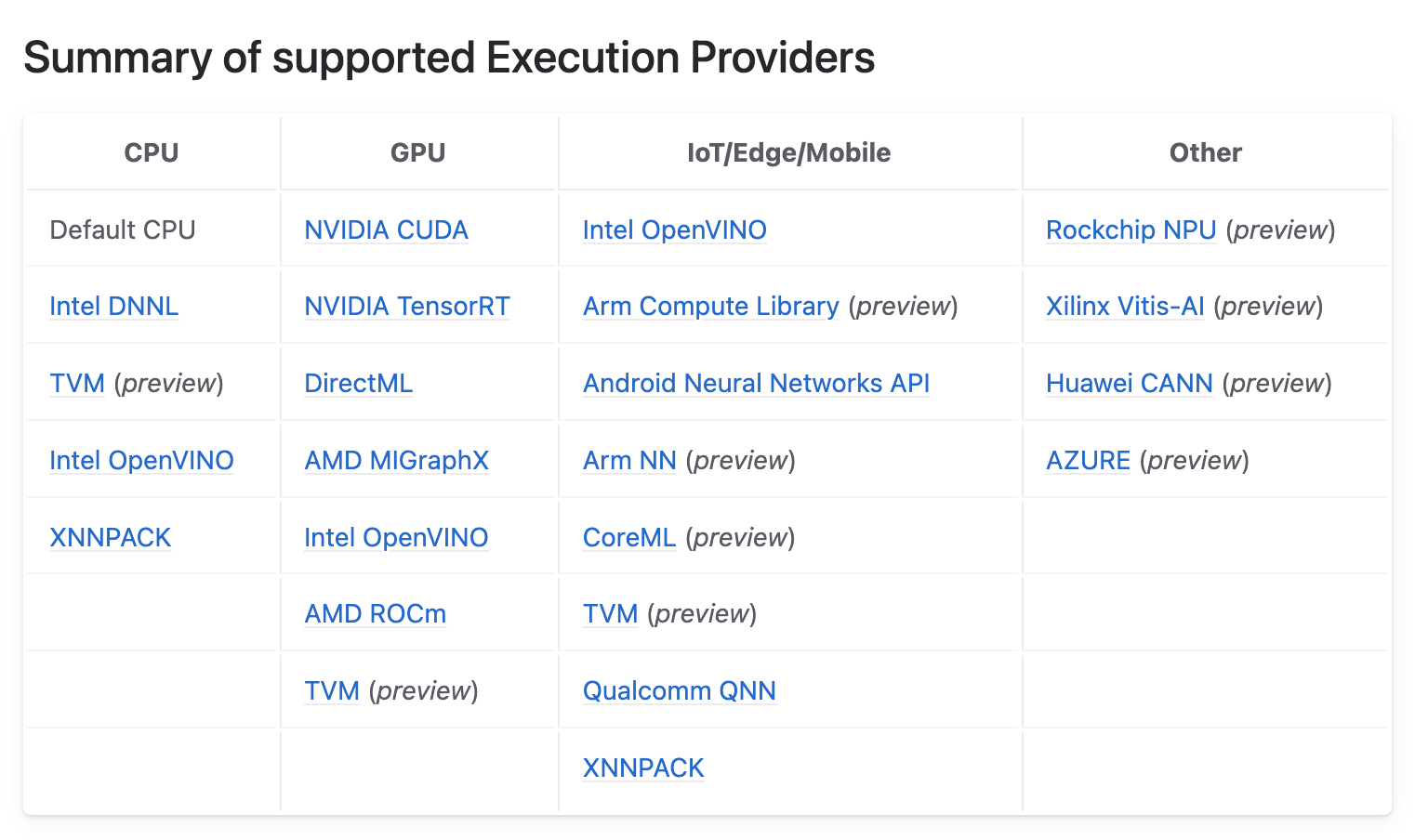
Execution Provider(EP)という仕組みで動作
様々なProvider (OpenVINOやCUDA、TensorRT)が提供されており、同じONNXモデルを様々な実行環境で効率的に動作可能。
OpenVINO
Intelが開発する推論最適化ツールキット。Intel製のCPU、GPU、NPUに対応。
OpenVINOのモデル変換APIを通じてOpenVINO IR形式にエクスポート。
このIR形式を使用することで、ストレージ消費量や初回推論のレイテンシを削減可能
NNCF(Neural Network Compression Framework)という量子化やプルーニング、LLMの重み圧縮などの最適化が可能。第2世代Xeon以降でINT8の行列計算を効率的に行えるVNNI命令がサポートされている。
MMDeploy Inference SDK
OpenMMLab製ライブラリのPyTorchモデルを各種プラットフォームにデプロイするためのツール
ONNX、TensorRT、OpenVINO IRなどに変換可能
モデルをCLIで変換すると変換されたモデルに加え、そのモデルが推論時に利用するファイル群(deploy.jsonやpipeline.jsonなど)が生成される
- deploy.json:変換されたモデルの情報。ビット精度やシェイプなど。
- pipeline.json:(モデルの外側にある)前処理や後処理の情報
ベンチマーク結果
ベースライン=mmdetectionのAPIを使ってPyTorch (FP32)で推論したレイテンシ
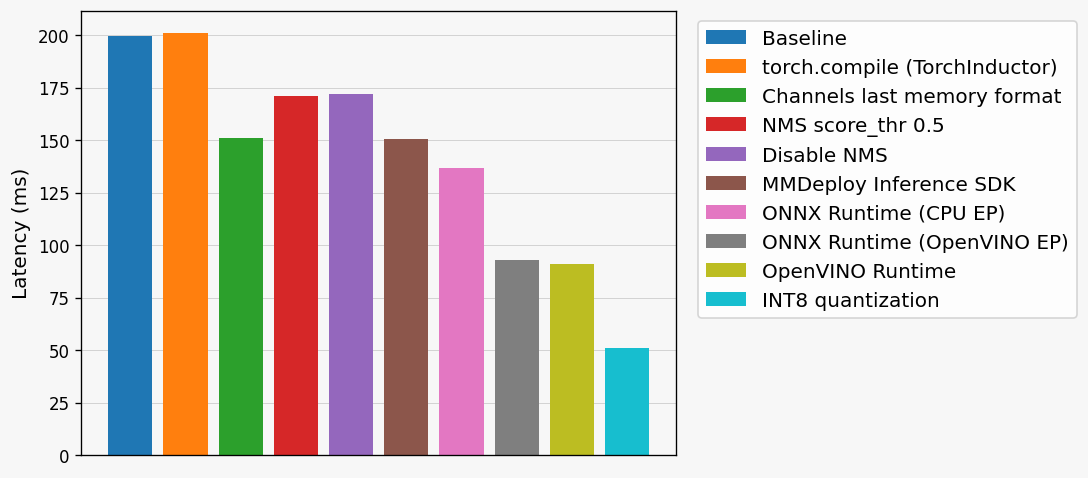
ONNXRuntimeは計算環境によってProviderを切り替えると、結構パフォーマンスが変わってくる
@Hiromu Nakamura (pon)
[blog] Why Multi-Agent Systems Need Memory Engineering
[pon]分散システム?となること請け合い
マルチエージェントの課題
- 作業の重複が頻繁に発生し、エージェントは他のエージェントがすでに完了していることを知らずにタスクを繰り返します。
- 一貫性のない状態とは、異なるエージェントが異なる現実のバージョンに基づいて動作し、矛盾する決定や推奨事項につながることを意味します。
これにより
- エージェントが互いにコンテキストと過去の決定を絶えず再説明しなければならない
- カスケード障害によって、あるエージェントのコンテキスト汚染が共有インタラクションを通じて他のエージェントに伝播してしまう。
マルチエージェントメモリ
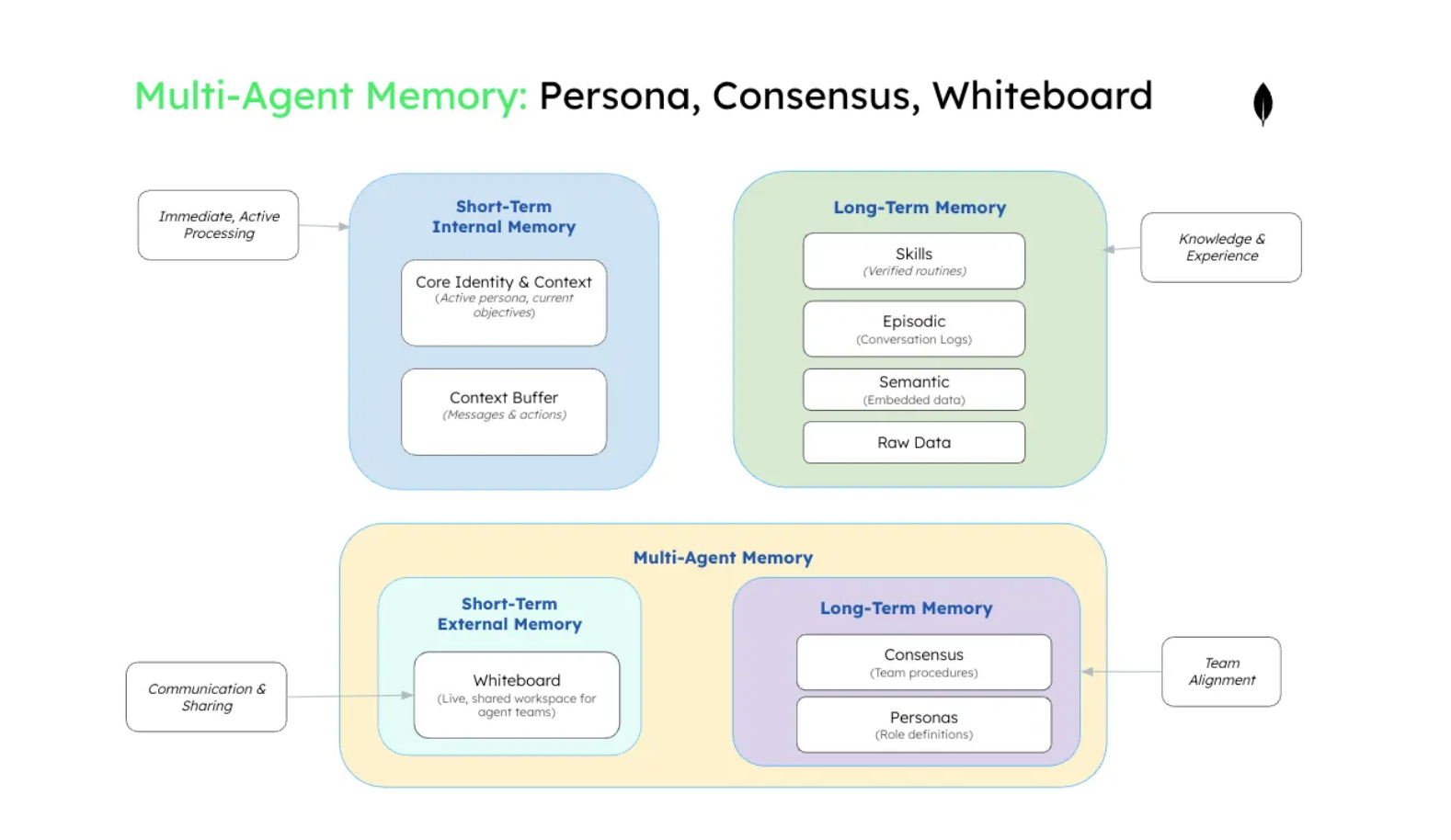
- メモリエンジニアリング技術のほとんどは、マルチエージェントシステムではなく、個々のエージェントの最適化に重点を置いています。
- しかし、協調には、シングルエージェントシステムでは決して必要とされなかった根本的に新しいメモリ構造とパターンが必要です。
- マルチエージェントシステムには、検証済みのチーム手順のためのコンセンサスメモリ(手続き型メモリの特殊な形態)、役割ベースの協調のためのペルソナライブラリ(意味記憶のペルソナメモリの拡張)、そしてホワイトボードメソッド(短期的なコラボレーション向けに構成された共有メモリの実装)といった革新的な技術が必要です。
特にこれ
競合解決(同時更新の処理)
- アトミック操作
- メモリユニットを更新するための重要なメモリ操作が完全に実行されるか、まったく実行されないことを保証します。複数のエージェントが共有メモリユニットに対して同時にメモリ操作を実行する必要がある場合、アトミック操作は、システムの不整合状態を引き起こす可能性のある部分的な更新を防止します。
- バージョン管理パターン
- 共有メモリへの変更を時間の経過とともに追跡し、エージェントが情報がどのように進化したかを理解し、時間的な優先順位またはエージェントの権限レベルに基づいて競合を解決できるようにします。
- コンセンサスメカニズム
- エージェントが同じトピックについて矛盾する情報を持つ状況に対処します。システムは、どの情報が信頼できるかを判断し、古い知識に基づいて動作するエージェントに修正情報をどのように伝達するかを決定する必要があります。
- 優先度ベースの解決
- エージェントの役割、情報の最新性、または信頼度に基づいて競合を解決します。専門技術エージェントの評価は、技術的な問題に関する汎用エージェントの結論を覆す場合があります。
- ロールバックとリカバリ
- 競合によって不整合な状態が発生した場合でも、システムは問題のある変更を元に戻すことができます。メモリ更新によって下流の調整に障害が発生した場合、システムは既知の正常な状態にロールバックし、より適切な競合解決方法で再試行することができます。
[pon]絶対むずい!!
@ShibuiYusuke
OpenAI Agent Builder
TLDR
- OpenAI製、AI Agentワークフローを作るためのGUI
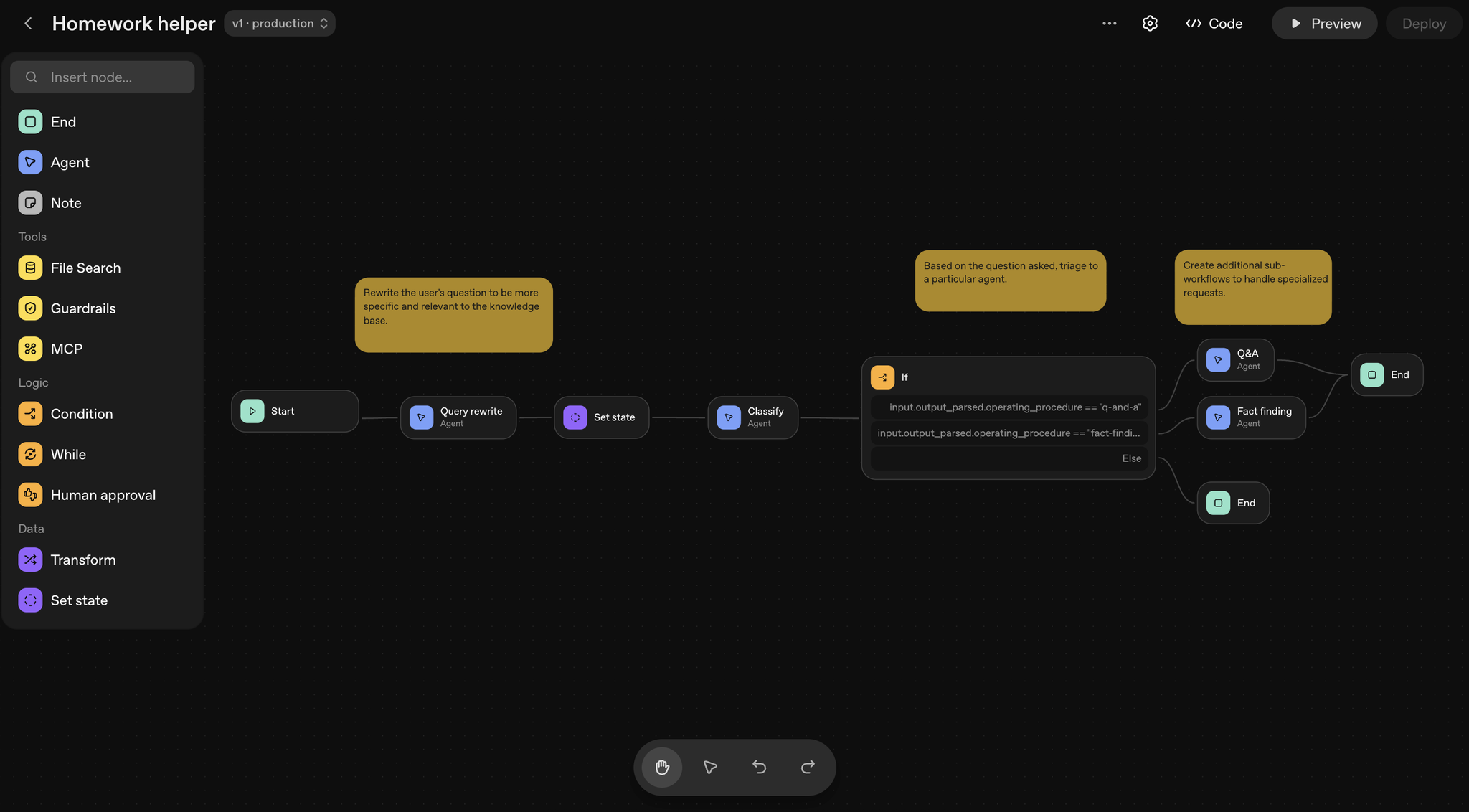
開発
- 各種ノードを提供:
 OpenAI Platform
OpenAI Platform

| カテゴリ | ノード名 | 説明 |
| コアノード | Start | ワークフローへの入力を定義します。ユーザーの入力を会話履歴に追加し、そのテキストを後続のノードで利用できるようにします 。 |
| Agent | モデルへの指示、ツール、設定を定義します 。ユーザーのクエリを書き換えたり 、質問を分類したり と、特定の役割を持たせることができます。 | |
| Note | プロンプトに注釈を付けたり、コンテキストを共有したりするためのコメント機能です 。フローの動作には影響しません 。 | |
| ツールノード | File Search | 作成済みのベクトルストアからデータを検索します 。 |
| Guardrails | 個人情報(PII)やジェイルブレイクといった、不適切な入力や誤用を監視するための入力モニターを設定します 。 | |
| MCP | GmailやZapierなどのサードパーティ製ツールや外部サービスを呼び出します 。 | |
| ロジックノード | If/else | Common Expression Language (CEL) を用いて、条件に応じた処理の分岐ロジックを追加します 。 |
| While | Common Expression Language (CEL) を用いて、特定のカスタム条件に基づいたループ処理を定義します 。 | |
| Human approval | ワークフローの途中で、エンドユーザーに承認を求めるステップを設けます 。例えば、エージェントが作成したメールを送信する前に確認を求める場合などに使用します 。 | |
| データノード | Transform | 出力のデータ形式を再形成します(例: オブジェクトを配列に変換)。 |
| Set state | ワークフロー全体で利用可能なグローバル変数を定義します 。あるエージェントの出力を、後の複数のステップで利用したい場合に便利です 。 |
Agent BuilderのSafety
- プロンプトインジェクション: 信頼できないテキストデータがAIシステムに注入され、その中に含まれる悪意のある内容がAIへの指示を上書きしようとする、一般的で危険な攻撃。最終的な目的はプライベートデータの抜き取り、意図しないアクションの実行、モデルの動作変更など多岐にわたる
- プライベートデータ漏洩: 攻撃者の意図がなくても、エージェントが誤ってプライベートなデータを共有してしまうリスク。
- 例:ユーザーが意図した以上のデータをMCPに送信してしまう等
- リスクを軽減するためのベストプラクティス
- 信頼できない入力の扱いに注意する: 信頼できない入力(ユーザーからのテキストなど)は、影響を限定するためユーザーメッセージ経由で渡す。デベロッパーメッセージに直接注入すると、攻撃者に高いレベルの制御権を与えてしまう
- 構造化出力でデータフローを制約する: ノード間でenumや固定スキーマといった構造化出力を定義することで、攻撃者が悪意のある命令やデータを紛れ込ませるための自由形式のチャネルを排除
- 明確な指示と例を与える: ハルシネーションや誤解による意図しない動作(例:許可されていない返金)を防ぐため、プロンプトで明確なポリシーと具体例を示し、エージェントを正しく導くことが最も効果的
- 最新モデルを使用する: GPT-5またはGPT-5-miniは、開発者の指示に従う能力が高く、プロンプトインジェクションなどに対する堅牢性あり
- ツールの承認を有効にする: MCPツールを使用する際は、必ずツールの承認を有効にし、エンドユーザーが全ての操作を確認・承認。Agent Builderでは ノードを使用
- ガードレールを活用する: 組み込みのガードレール機能を使って、個人情報(PII)の編集やジェイルブレイクの試みを検出し入力をサニタイズする
- 評価とトレースを行う: を使ってパフォーマンスを評価・改善し、トレースグレーディングによってエージェントの意思決定やツール呼び出しのどの部分に間違いがあったかを特定
リリース
- Chatkitにリリース可能
所感
メインTOPIC
You Don’t Bring Me Flowers: Mitigating Unwanted Recommendations Through Conformal Risk Control
Giovanni De Toni, Erasmo Purificato, Emilia Gomez, Andrea Passerini, Bruno Lepri, Cristian Consonni (Best Full Paper)
- RecSys2025 Best Full Paper
サマリー
- コンフォーマル・リスク・コントロール(CRC)を用い、モデルやデータ分布に依存せずに、パーソナライズされたレコメンデーションにおける望まれないコンテンツの割合を理論的に証明された形で制限する手法を提案。
- アイテムに関する単純なバイナリフィードバック(例:「レコメンドしない」ボタンなど)を活用。
- 従来のCRCアプローチの限界(レコメンドするアイテムセットのサイズが小さくなること)に対処するため、以前に消費されたアイテムからの暗黙的なフィードバックを活用し、レコメンデーションセットを拡張しながら、ロバストなリスク軽減を保証する。
- このアプローチは、人気オンライン動画共有プラットフォームのデータを用いた実験的評価により、最小限の労力で、望まれないレコメンデーションの効果的かつ制御可能な削減を保証することが実証されている。
1. Introduction
レコメンダーシステムが広く使用されることで、ユーザーがコンテンツと関わる方法は大きく変化した。これらのシステムは、eコマース、ソーシャルメディア、コンテンツストリーミング といったドメイン全体で、パーソナライズされた体験を提供する。
レコメンデーションアルゴリズムを効果的にする基本的な概念は、意図せず望まれないコンテンツの拡散に寄与する可能性がある。そのため、プラットフォームは、既存の信念を強化するフィルターバブルや、潜在的に危険または有害なコンテンツを拡散していることについて批判を受けることがある。
YouTubeの「Not Interested」ボタンのような機能は、ユーザーの認知度の低さ、使用の複雑さ、または限定的な効果といった問題に悩まされている。
望まれないコンテンツやバイアスを軽減する方法は研究されてきたが、システムのリスクに対してユーザーに正確かつ透明な制御をどのように付与するかは不明なままである。
本論文では、コンフォーマル予測(Conformal Prediction)に基づいた、事後的なアプローチを提案し、期待値において望まれないレコメンデーションへの露出を理論的に保証された形で軽減する。
本手法ではコンフォーマル・リスク・コントロール(CRC) を適用し、潜在的に安全でないアイテムを予測後・事後的にフィルタリングし、それらを以前に消費された安全なコンテンツに置き換えることによってレコメンデーションセットを構築する。
Contributions
- 望まれないコンテンツに関連する報告パターン(reporting patterns)と視聴時間の行動を理解するための、実データに関する包括的な分析。
- 繰り返し消費されたコンテンツ(repeated content)を活用することで、理論的な保証のもと、レコメンデーションにおける望まれないコンテンツを制限するコンフォーマルリスク制御に基づく手法の提案
- パーソナライゼーションの必要性と望まれないレコメンデーションの最小化のバランスを取る、安全な代替コンテンツを選択するための実用的なヒューリスティック手法の提案
- 実世界のデータセットを用いた実験と除去処理により、不要なコンテンツを大幅に削減する本手法の有効性を実証
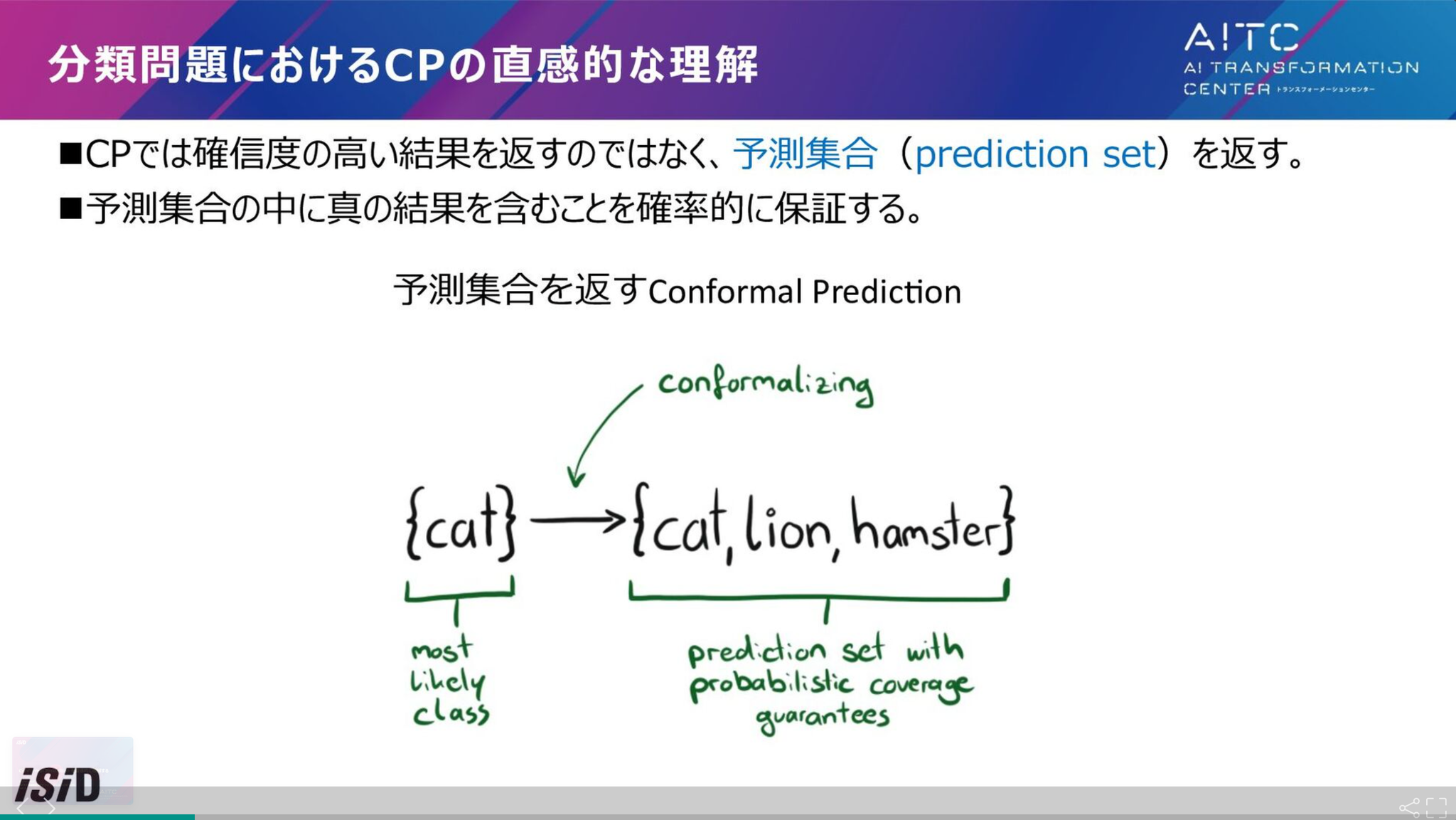
補足:コンフォーマル予測(Conformal Prediction)
予測区間・予測集合のに真の結果を含むことを確率的に保証する手法
指定した再現率を保証して推論(その分適合率は落ちる)みたいなイメージで理解。📝
自信があるときは狭めに・決定的に推論し、自信がないときは広めに推論する。
以下の資料で完全理解しました。画像は以下のスライドからの引用。
2. Related Work
レコメンダーシステムは、誤情報、ヘイトスピーチ、および不快または無関係なアイテムのような望まれないコンテンツを助長しているとして、批判に直面している。
フィードバックツールのようなユーザーがレコメンダーシステムに影響力を与えられるような工夫もあるが、低い視認性と不明確なシステム応答によってうまく機能していないことが多い。
先行研究によるコンテンツモデレーションや公平性制約、多様性の促進などは、有害コンテンツの制限に対して一定の効果はあるものの、理論的な保証を欠くことが多く、きめ細かなユーザー行動を取り入れることはめったにない。
本論文のアプローチは、グループレベルの保証 を超えて、望まれないコンテンツへの露出に対するアイテムレベルの制御を提供している。
コンフォーマル・メソッドはレコメンダーシステムにも導入されているが、レコメンデーションにおける望まれないコンテンツの割合を制御するためにコンフォーマル技術を使用した先行方法はない。
本論文では、プラットフォーム全体で確立された行動である繰り返されたコンテンツ消費 を利用し、パフォーマンスを維持しながらリスク制御に関する理論的に保証された手法を提案する。
3. Case Study: A Video-Sharing Platform
人気のある中国のショート動画共有プラットフォームKuaishou (快手)からのデータ(KuaiRandデータセット)を利用して分析。daily active ユーザーは3億人を超える。データセットは27,000人の快手ユーザーをサンプリングして収集されたもので、対象ユーザーは2022年4月8日から5月8日までの1か月間に合計約3,200万本の動画を視聴。
データセットには、動画の試聴時間やユーザーが「Do not recommend」または「Report」ボタンをクリックしたときのようなネガティブフィードバックデータが含まれる。約29%のユーザーが少なくとも1本の動画に対してネガティブフィードバックを提供している。
いろいろフィルタリングした結果、7601人のユーザー、5600万回のインタラクション、1000万本のユニーク動画が残った。ユーザー1人あたり平均7,417本の動画(中央値:4,623本)を視聴し、標準偏差は9,223本と大きい。
3.1 Sparsity of Negative Feedback
ネガティブフィードバックは非常に疎である。60%のユーザーは動画を1000本視聴しても多くて1本に対してしか報告しない。全体で95%超のユーザーは、レコメンドされた動画100本あたり多くても1本しか報告しない。
:ユーザーに視聴された動画の数のうち、報告された動画の数の割合
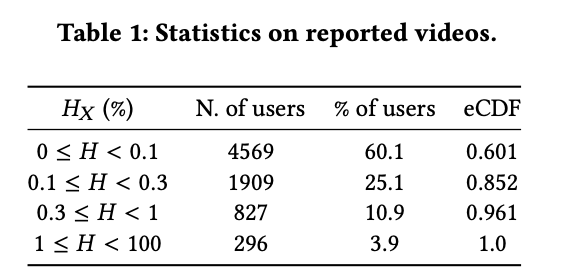
データの疎性は、望まれないコンテンツのレコメンデーションを最小限に抑えるためにこの情報を活用したいシステムにとって課題となる。
3.2 Analysis of the Watch Time
ユーザーと動画のインタラクションは、ユーザーが動画をどれほどの時間視聴したのかで定義する。0なら全くみていなくて、0.5なら半分、1なら全部視聴。
未報告の動画(a左)と報告された動画(a右)の の分布は類似しており、両方ともゼロ付近でピークに達している。これは、多くの動画がスキップされるか、非常に短時間だけ視聴されることを示している。インタラクションの21%が視聴時間ゼロに終わっている。
また、強調されているように1付近にもピークがある。特に、報告された動画にもこの傾向があるのはなぜか?
さらに、一部のユーザーと動画のインタラクションは動画の本来の再生時間を超えている(1を超えている)ことから、ユーザーが時折動画に長居することが示唆される。
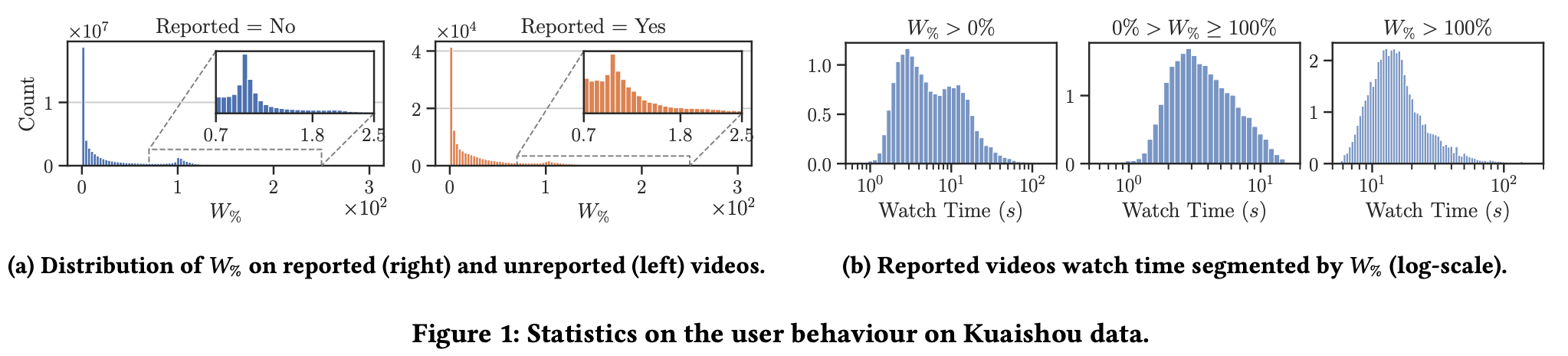
報告された動画に焦点を当て、その再生時間に基づいてグループ分けする。本分析では、最も一般的な7秒から12秒の長さの動画を対象とし、視聴時間の分布を集計したのが(b)。0s と10s あたりにピーク。(0sのピーク??)
(あんまりこちらの分析の意図が理解できなかった)
したがって、我々は以下の2つのシナリオをモデル化する:(a) 動画が最大でも全編視聴されるインタラクション(0% < 𝑊% ≤ 100%)、および (b) 動画が再生時間を超えて視聴されるインタラクション(𝑊% > 100%)。
図1bの中央および右端のプロットは、両分布がそれぞれ左側尾と右側尾を持つほぼ正規分布形状を示している。このような挙動は、ページビューにおける滞在時間などの記述に一般的に用いられる対数正規分布またはワイブル分布を考慮することでモデル化できる。
3.3 Trend of Video Reporting Patterns
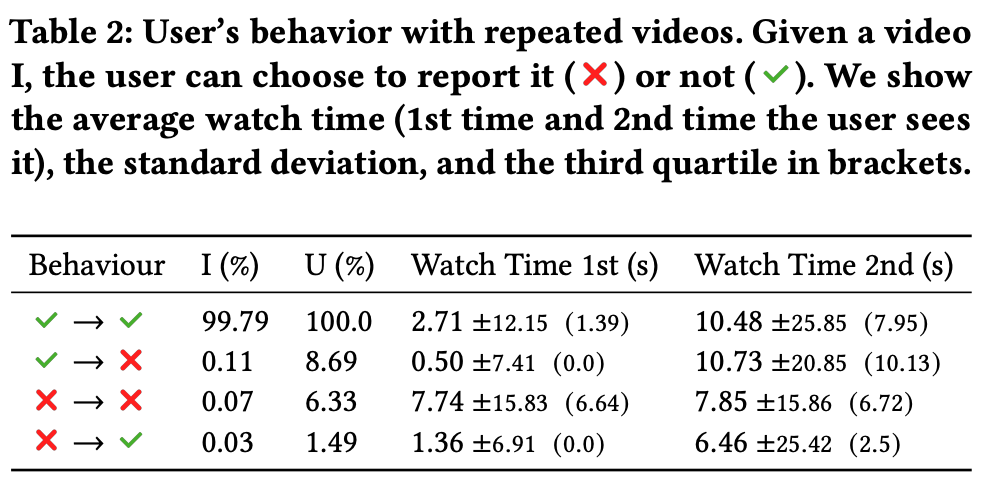
ユーザが一度視聴した動画を再視聴する際の行動を分析。平均して、ユーザーが視聴した動画の2.6%は以前に見たものだった。
表2の通り、ユーザーの8%には以前に報告した動画が表示され(3+4行目)、別の8%は当初報告していなかった視聴済み動画を報告している(2行目)。
後者の行動は、ユーザーが最初に動画に出会った際にスキップしたか(視聴時間が短い)、報告プロセスが煩雑(例:複数回のクリックが必要)だと感じた可能性があることを示唆している。以前に視聴した動画を新たに報告した場合の視聴時間の75パーセンタイル(2行目)が、最初に報告された動画の75パーセンタイル(4行目)と類似していることも根拠のひとつと考えられる。(なるほど?即skipする人と、即報告する人が同じくらいいるということかな?)
2度連続で報告された動画は、非常に類似した視聴時間を示す(3行目)。これはユーザーが強く不要と判断したコンテンツを示す、より強力なフィードバックであると推測される。これらの知見は、プラットフォームの絶え間ない新規コンテンツ供給の影響を受けている可能性がある。これにより、ユーザーが同一動画を複数回視聴する可能性は低減される。しかしながら、ユーザーの16%は、過去に視聴した動画を少なくとも1本、再度視聴または報告している。
最後に、2回目に見られた動画の平均視聴時間がより長くなることを示している。2回目(2行目)に新たに報告された動画では視聴時間が大幅に増加しており、ユーザーが不適切なコンテンツを報告する前に意図的に詳細に再確認している可能性を示唆している。
分析の要約:
- 動画のエンゲージメントと有害性の認識は完全には相関していない。図1aが示すように、報告された動画は報告されていない動画と同じ𝑊%分布を示している。したがって、エンゲージメントを最大化することは、ユーザーに有害性の低い動画を提供することを意味しない。
- 快手では、明示的なユーザーフィードバックにもかかわらず、システムが望ましくないコンテンツを提案する(表2参照)。
- ユーザーの95%以上が視聴する動画の1%未満しか評価しないことを踏まえると、レコメンダーシステムはこのわずかな明示的な否定的フィードバックの有用性を最大化すべきである。
- インタラクションの21%が視聴時間ゼロで終了し、視聴時間分布がゼロ付近で強いピークを示すことから(3.2節参照)、極めて短いエンゲージメントは有害または望ましくないコンテンツの早期指標となり得る。
3.4 Unwanted, Disliked and Harmful Content
オンラインプラットフォームは、ユーザーが複数のチャネルを通じてフィードバックを表現するための様々なメカニズムを提供している。
現実的な設定で軽減技術を効果的に評価するためには、望まれないアイテムや有害なアイテムと、単にユーザーの期待を満たさないアイテムとを区別するフィードバック信号を考慮することが不可欠である。
KuaiRandデータセットの分析は、高い視聴時間を持つ動画が、それでもなお明示的に望まれないものとしてフラグを立てられる可能性があることを明らかにしている(Table 2を参照)。
アイテムの評価やスキップを代理指標として用いる研究が多くあるが、これらの代理指標は不十分である可能性がある。
本論文の知る限りでは、KuaiRandデータセット のみが、そのような明示的で非集計なフィードバックを提供している。
4. Recommender Systems With Risk Control
レコメンダーシステムは、ランク付け器 によって推定された関連性スコアに基づき、アイテムセット S(U) を出力する。事後処理ステップとして、スコア s(U, I) が特定の閾値 λ 以上のアイテムのみを保持する。
最適なランク付け器 によって誘導されるセット のリスク を、ユーザー定義の値 未満に理論的に保証しつつ制限することが目標である。
コストのかかる操作(ランク付け器 の再トレーニング)を避けるため、事後処理ステップで、リスクが 未満であることを保証する最適な 閾値を見つけることで目的を達成する。
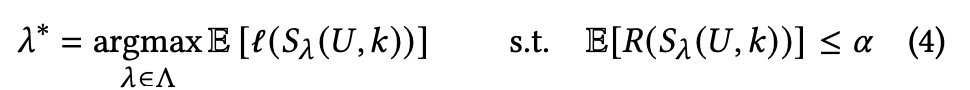
4.1 Measuring Unwanted Content
本設定では、レコメンデーション内で一度見られたアイテムについて、ユーザーが嫌悪感を表明した場合に、そのアイテムはユーザーにとって望まれないものと見なされる。
アイテムがユーザー によってフラグが立てられたかどうかを示すバイナリ確率変数 を用いて、全体のリスク を、フラグが立てられたアイテムの割合として定義する。
シンプルにレコメンドされたうち報告される割合です。
4.2 Conformal Risk Control
ホールドアウトされたキャリブレーションセットを使用して、コンフォーマル・リスク・コントロール を介して最適な閾値 を見つけることができる。
Theorem 4.1: リスク関数が に関して非増加であるなど特定の条件を満たす場合、特定の を選択するならば….が成り立つ。
閾値を増加させるとアイテムが削除されるため、 内で有害なアイテムを選択する可能性は単調に減少する。ので成立する!これは、モデルに依存せず、分布に依存しない。
5. Risk Control via Item Replacement
従来の単純なフィルタリング(除去)アプローチは、結果として得られるセット のサイズの制御を失うという代償を伴う。
Proposition 5.1: 除去戦略では、リスク を達成するために、レコメンデーションプールからあまりにも多くのアイテムを削除しなければならないかもしれない結果、ユーザーに 個のアイテムを返すことができない可能性がある。
… 証明したら成立…
よって、この戦略は最適ではない。例えば、動画ストリーミングプラットフォームの場合、アイテムを「無駄にして」おり、潜在的にエンゲージメントを低下させている。
5.1 A Property for Safe Alternatives
本論文では、代替アプローチとして、潜在的に望まれないアイテムをより安全なアイテムに置き換えることから成る戦略を採用し、Proposition 5.1の影響を回避する。具体的には、ユーザーが以前に見たアイテムを再び消費するという事実を利用する。
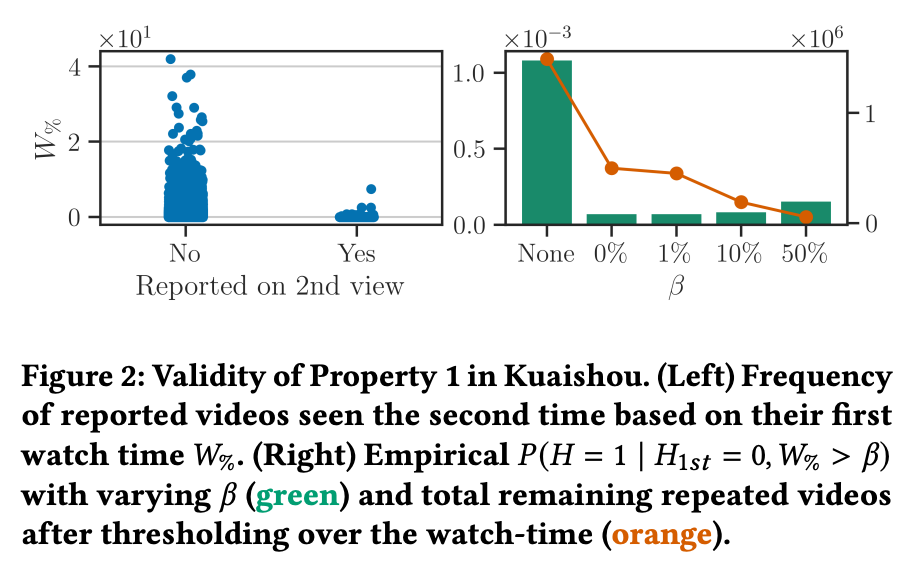
Property 1(安全性の形式化): ユーザーがアイテムを最初に見たとき報告しなかった ()、かつ、特定の変数 (例:視聴時間)が閾値 を超えている場合、アイテムが2回目にフラグが立てられる確率 がゼロである、と仮定する。
図 2より、2回目の視聴で報告される動画は、初回視聴時の視聴時間がはるかに短いことが示されている。視聴時間に基づいて でフィルタリングすることで、有害な動画を選択する可能性を全体的にほぼゼロに減らすことができる。
安全な代替アイテムのプール は、以前に見て、有害であるとフラグを立てておらず(報告しておらず)、Property 1を満たすアイテムで構成される。
新しいアイテムのプール は、フィルタリングされたセットに安全なアイテムを追加することで構築される。
特性 1が成り立つ場合、この置き換え戦略によって構築されたセットは、コンフォーマル・リスク・コントロールの単調性要件を満たす(Theorem 4.1)。
6. A Simple Post-Hoc Pipeline
Algorithm 1は、任意の事前学習済みレコメンダーシステムに適用可能な、単純な事後処理アルゴリズムである。ユーザー定義のリスクレベル が与えられたとき、最終的なレコメンデーションリストにおける望まれないコンテンツの割合を理論的保証つきの状態で制御できる。
このアルゴリズムは、リスク制御の閾値 でアイテムをフィルタリングし、以前に見た、非フラグ付け、視聴時間が を超える動画を特定して代替案として追加した後、ランク付け器を使用してトップ アイテムを選択する。

もし代替案が利用できない場合、最終的なレコメンデーションセットは $k$ 個未満のアイテムしか含まない可能性がある。
計算量はリランク計算が支配的なので、このアルゴリズムに変更しても計算量観点での懸念はない。
7. Experiments With Real Data
KuaiRandデータセットを使用し、除去戦略(Remove)と置き換え戦略(Replace)を比較した。
(RQ1&RQ2) Replacing unwanted items ensures risk control and mitigates performance degradation.
リスク制御の有効性 (図 3c)
望ましい削減レベル (横軸)は、すべての戦略とランキングモデルで厳密に制御されている。経験的削減(実際の効果)は望ましいターゲットと等しいかそれよりも優れており、Algorithm 1がリスク制御を確実に実施することを確認している。
効用の維持 (図 3a, 3b):
アイテムの除去戦略はnDCGを急激に低下させる。対照的に、置き換え戦略は、より高いnDCGを維持する。(x はアイテムを削除するとガクンとnDCGが落ちているが、○はそうでもないよね)
データセットサイズ (図 3d)
望まれないコンテンツの完全な除去()が必要な場合、唯一の選択肢は、レコメンデーションセット内のすべてのアイテムを削除または置き換えることである。remove だと推薦アイテムが0になる。removeでも期待するアイテム数 k より小さくなることも。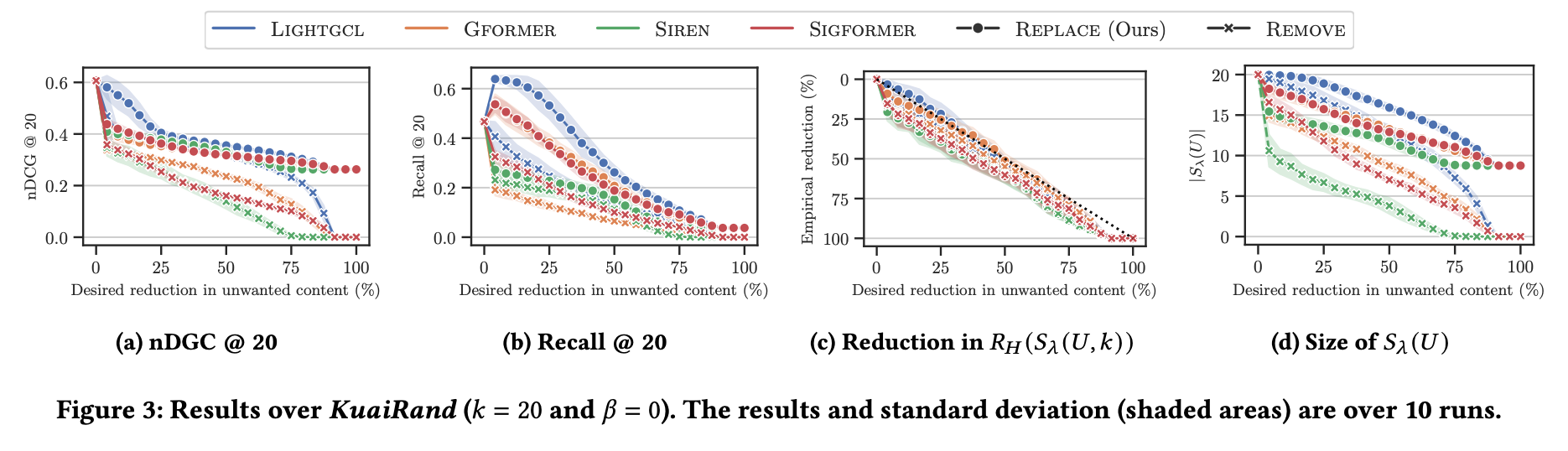
(RQ3) The choice of score function impacts the number of previously seen items in the recommendation set.
ネガティブフィードバックを学習に利用する符号認識型モデル(SiReN、SIGformer)は、符号非認識型モデル(LightGCL、GFormer)と比較して、同等のリスク制御レベルに対して置き換えられたアイテムが多くなる。
これは、Kuaishouデータセットにおけるネガティブフィードバックの比率が低いため、符号認識型モデルがより高い不確実性を示し、より多くのアイテムを置き換えるか削除する必要があるためだと考察されている。
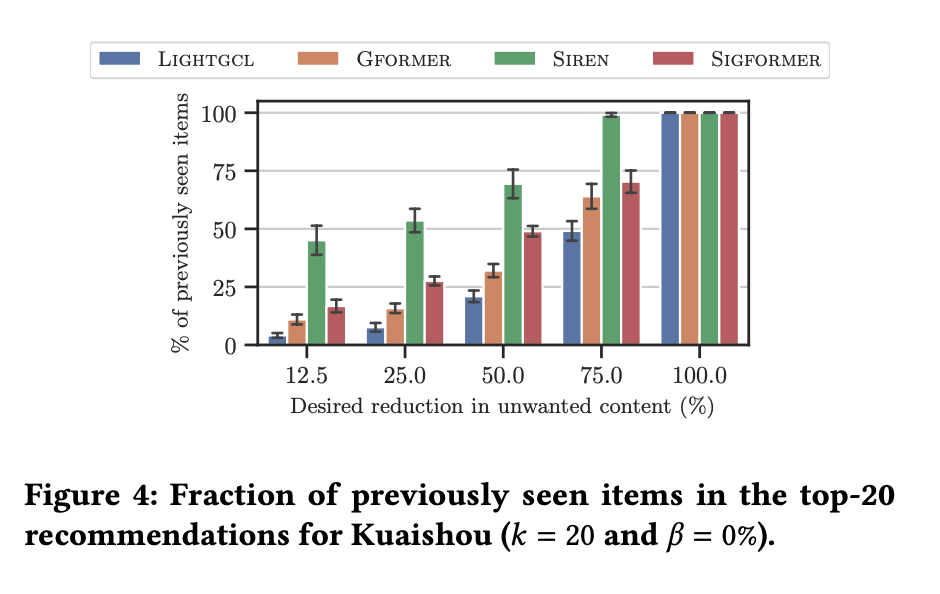
(RQ4) There exists a trade-off between ensuring the safety of replacement items and the recommendation set size.
代替アイテムの安全性を高めるためにフィルタリング閾値 を増加させる影響を調査した(図 5)。
フィルタリングがない場合 () (図 5a)、リスク制御が失敗している。つまり、以前に見たアイテムが、再びレコメンドされたときに望まれないものと判明し、報告されている。
より厳格なフィルタリング(たとえば全部視聴)にすれば、リスクは減るが、性能や候補・レコメンドアイテム数が減っている。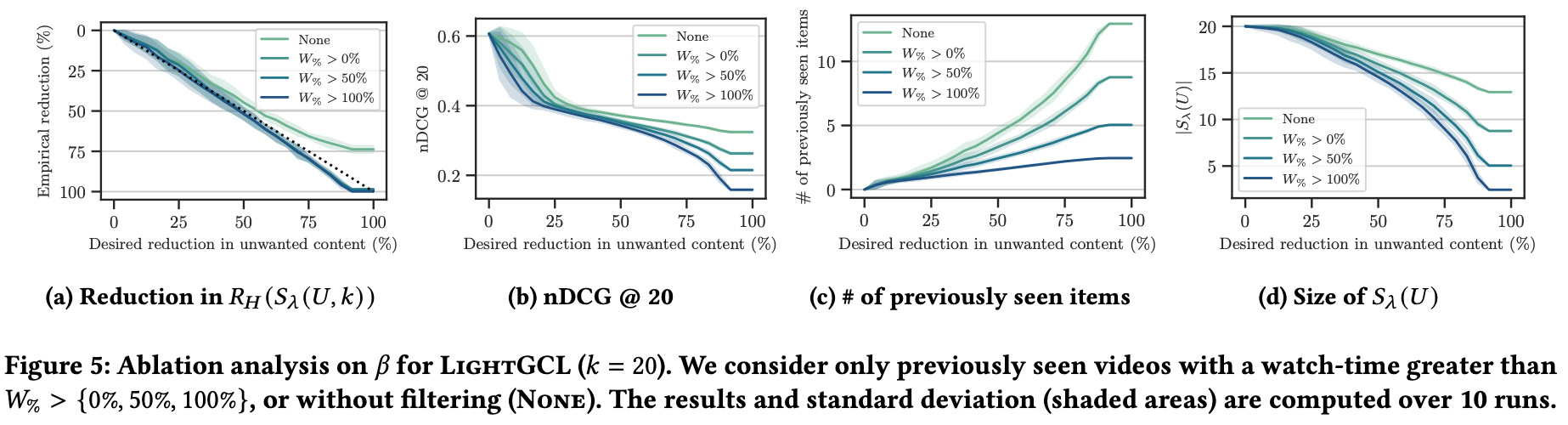
(RQ5) Risk control is biased toward high-reporting users.
ユーザーを低報告ユーザーと高報告ユーザー()に分類して分析
低報告ユーザーは期待よりも大きく望まないアイテムが除かれている。つまり、高報告ユーザーがリスク閾値 のキャリブレーションに不釣り合いに影響を与え、潜在的にすべての人にとって過度に保守的な行動につながる可能性が示唆される。低報告ユーザーに対する同等のリスク保証は、より少ないアイテムの変更または削除によって達成できる可能性がある。
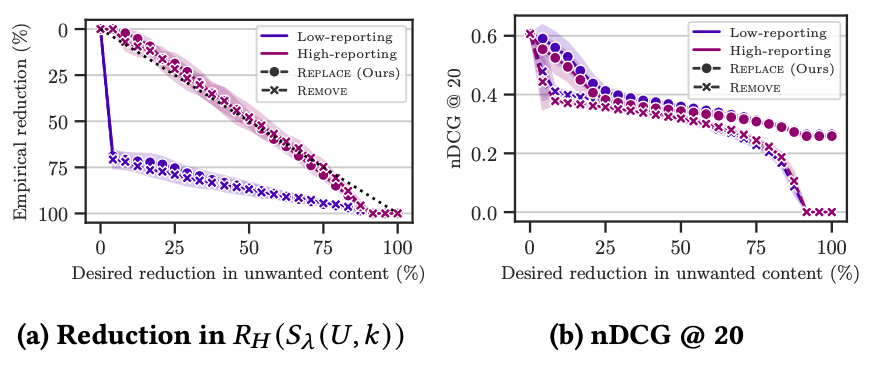
8. Discussion and Limitations
Methodology
リスク制御手順(Algorithm 1)は、ユーザー全体で期待されるリスクを最小限に抑えるグローバルな閾値 を計算する。実際には、十分なインタラクションが利用可能であれば、単一ユーザーからのデータを使用して をキャリブレーションするなど、閾値をパーソナライズすることが好ましいかもしれない。
現在のリスク関数(Eq. (5))は、ランキングにおけるアイテムの位置を考慮しておらず、各アイテムがリスクに等しく貢献するものとして扱っている。
Evaluation
本分析と実験は、単一のデータセット(KuaiRand)に依存しており、これは現在、この現象を研究するための唯一の現実的な基盤を提供している。この依存性は、発見の外部妥当性を制限する可能性がある。
欧州デジタルサービス法(Digital Services Act)の第40条 は、検証された研究者に大規模なオンラインプラットフォームからのデータアクセスを許可しており、本アプローチの検証を可能にするかもしれない。
User experience
特定のアイテムを以前に見たコンテンツに置き換えることは、アンバランスなレコメンデーションにつながり、ユーザーを同じコンテンツに繰り返し露出させる可能性がある。これは、分極化の増加 のような意図しない負の影響をもたらす可能性がある。
代替アプローチとして、コミュニティからのキュレーションされたアイテムリストや、ユーザー提供のポジティブFBに基づく代替案(例:いいねされた動画)も考えられる。
システム的な視点として、動画共有プラットフォームはユーザーフィードバックを集約してコンテンツをダウンランクし、限定的なフィードバック活動しか持たないユーザーが集合的な判断を選択できるようにすることで、コールドスタート問題 に対処できるかもしれない。
9. Conclusions
本研究は、コンフォーマル・リスク・コントロールに根ざした、単純だが効果的なユーザー中心の手順(Algorithm 1を参照)を導入し、任意のレコメンダーシステムが提案する望まれないコンテンツの割合を軽減する。
本手法は、モデルに依存せず、既存のシステムとの統合が容易であり、分布に依存しない理論的保証によって裏付けられている。
ユーザーフィードバックとレコメンダーの行動の変化との間の接続を確保することにより、望まれないコンテンツの存在をプロアクティブに制限する。
本フレームワークが、レコメンデーションセットのサイズと効用との間のトレードオフを提供することで、望まれないレコメンデーションへの露出を制御可能に削減できることが示された。
これらの発見は、より安全でユーザー中心のレコメンダーシステムの開発に向けた方向性を示している。