
2025-10-14 機械学習勉強会
今週のTOPIC[論文] Less is More: Recursive Reasoning with Tiny Networks[OSS] GraphQA: Natural Language Graph Analysis Framework[blog] AI エージェントにとって難しいタスクとは何か? SWE-bench から考える[blog] AI OCRの検証記録 ~ ニーリーでの検証結果はこうでした ~[論文] Paper2VideoAutomatic Video Generation from Scientific Papers[blog]I Ran an 80-Billion-Parameter AI Model on My 8GB GPU -My Experience with oLLMメインTOPICIn-the-Flow Agentic System Optimization for Effective Planning and Tool UseINTRODUCTIONLLM推論能力の進歩と既存アプローチの課題AGENTFLOWの提案関連研究の進展に繋がる示唆:PRELIMINARYIN-THE-FLOW AGENTIC SYSTEM OPTIMIZATION3.1 AGENTFLOW:インフロー型エージェントシステム3.2 IN-THE-FLOW REINFORCEMENT LEARNING OPTIMIZATIONEXPERIMENTSTraining評価MAIN RESULTSFlow-GRPOはツール利用を最適化する。Flow-GRPOは新しいソリューションの自律的な発見を促進する。
Flow-GRPOでトレーニングされたAGENTFLOWが、タスクプランニングとツール利用において強化された能力を開発することを示している。PLANNERの訓練戦略報酬の増加と応答の凝縮による最適化されたプランニング。ツール統合された推論強化学習に対するFlow-GRPOの効率。 関連研究結論おまけ[pon]所感
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] Less is More: Recursive Reasoning with Tiny Networks
- Samsungの論文
- わずか7MパラメータのTiny Recursive Model(TRM)によって、複雑な推論タスクにおいて、より大規模な特殊モデルと最先端のLarge Language Models(LLM)の両方を大幅に上回る性能を発揮。
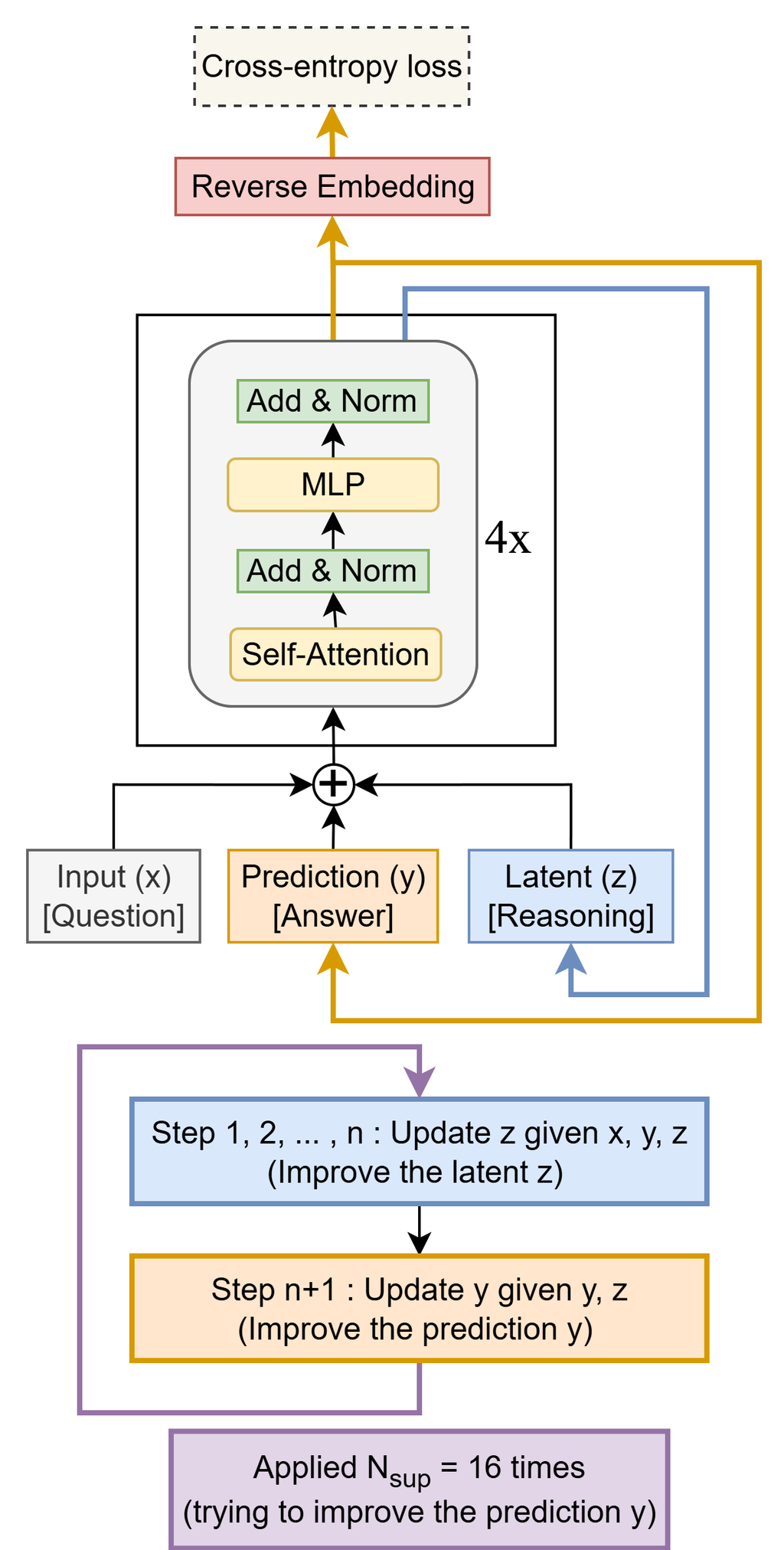
- HRM(Hierarchical Reasoning Model)と言われる研究を発展させ単純化したもの
- 構造
- Input (x): 解決すべき問題または質問
- Predictoin (y): 現在の解答または解決策
- Latent (z): 問題の文脈と推論チェーンを維持する推論特徴
- 単純なTransformer. + MLP
- 学習の疑似コード
- n回潜在変数zを更新した後に、潜在変数とyを使ってyを洗練する
- 洗練させるステップ自体もT回行われるが、ここには勾配を発生させない
- (めっちゃ勾配消失とかが起きそうだが、なぜ上手くいく?)
- 論文では、単に改善方向の残差成分を学習するだけだから?と書いてあった。HRMの論文では固定点に収束する的なことが書いてあったが、そんなことはなく、収束しないらしい。

- 学習データは実際にタスクに合わせて1000サンプル程度を拡張したものを使用
- 文字列を出力させるようなタスクでは学習させず、数独とか迷路、パズルのような数値出力のデータだけで検証。
- (出力空間が狭いから小さいネットワークで学習できるという話な気がする)
- 結果
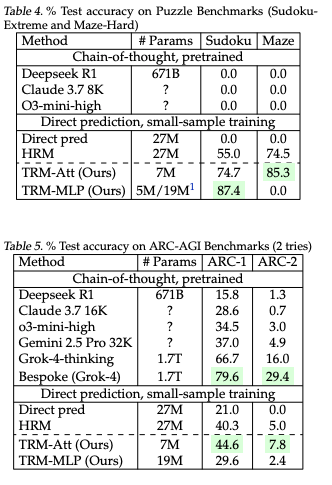
@Yuya Matsumura
[OSS] GraphQA: Natural Language Graph Analysis Framework
自然言語でグラフについて質問できるOSS GraphQA
自然言語の入力を受け取ったAI Agentが、グラフの性質に応じた最適なグラフアルゴリズムを選択した上で NetworkX のAPIに変換し実行して分析してくれるので、グラフやNetworkX などグラフ処理系のライブラリに精通していなくとも、グラフの分析ができる。
たとえば以下のようなコードを書かなくとも
こんな感じで分析できる。
@Shun Ito
[blog] AI エージェントにとって難しいタスクとは何か? SWE-bench から考える
- SWE-bench-verified
- Pythonの12のリポジトリに提出された500件のissueについて、正しく解けるかどうかを単体テストで確認するベンチマーク
- 現状の傾向
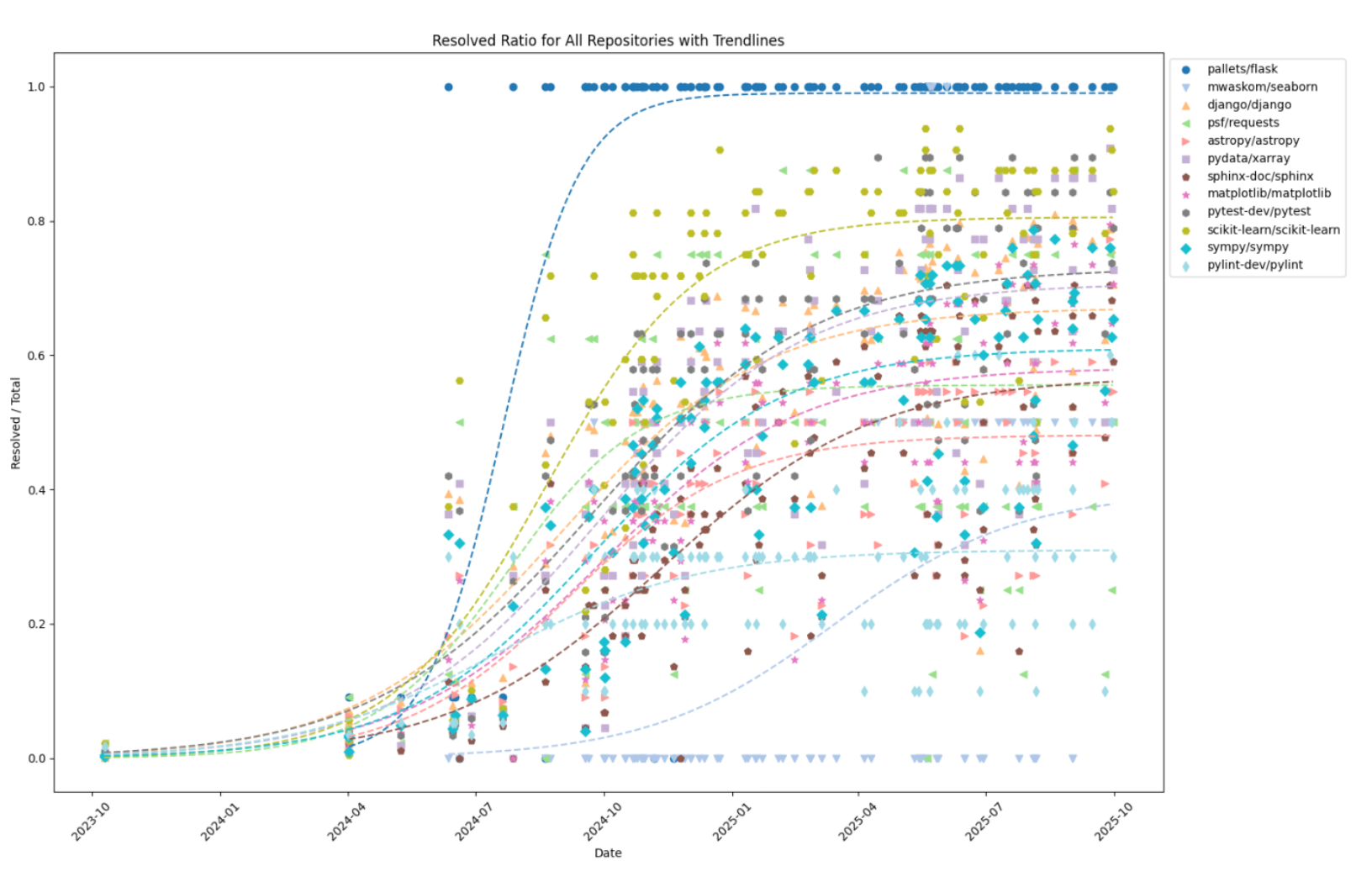
- リポジトリごとの解かれている割合
- flaskはほぼ100%
- seabornやpylintはほとんど解けていない
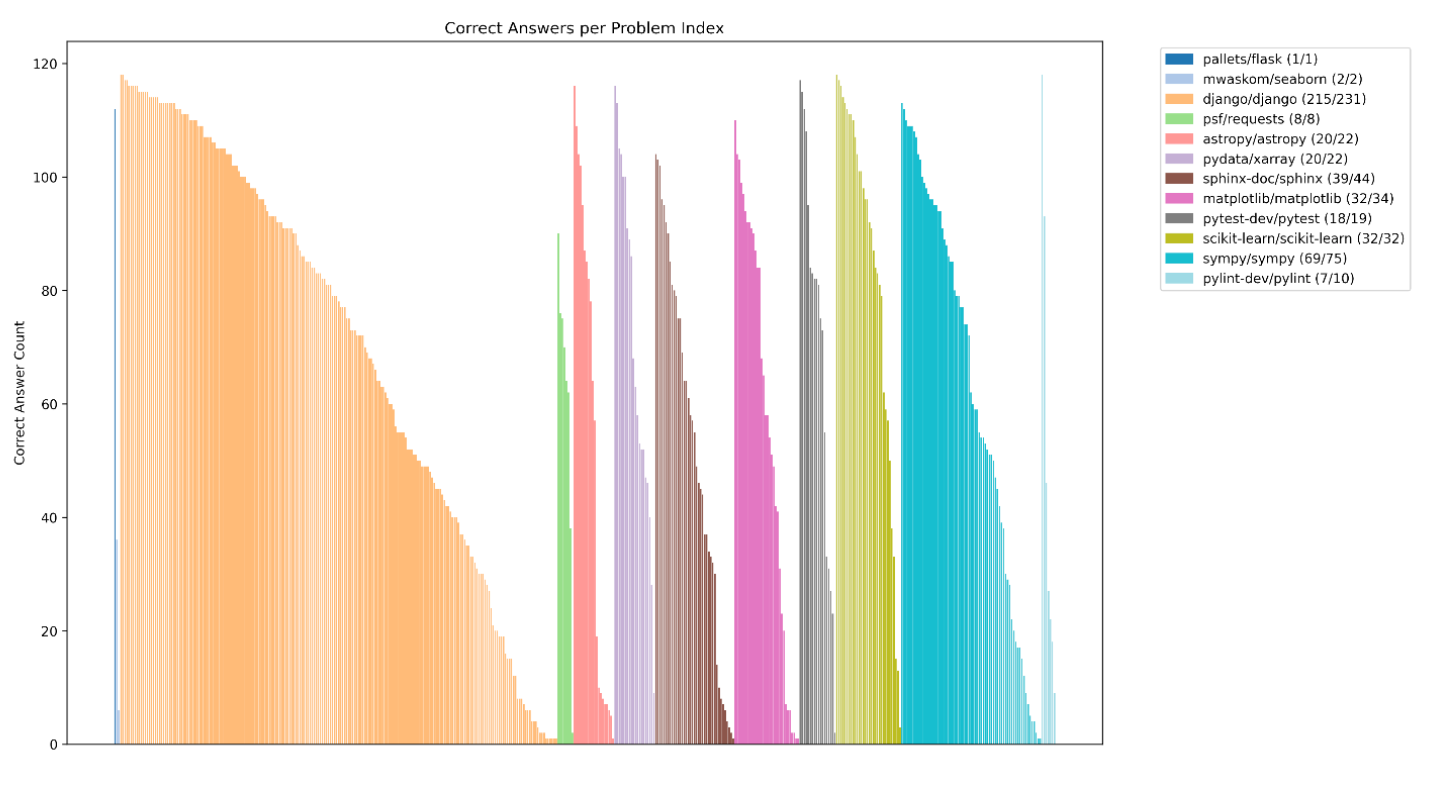
- リポジトリ・タスクごとの正答したエージェント数
- タスクによって正答率ほぼゼロ〜ほぼ100%まで存在
- 問題文の長さと想定難易度
- 問題文の長さと正答率にあまり相関はない
- 人間的な難しさとAIの正答率に、ざっくりとした相関はあるが異なる部分もある
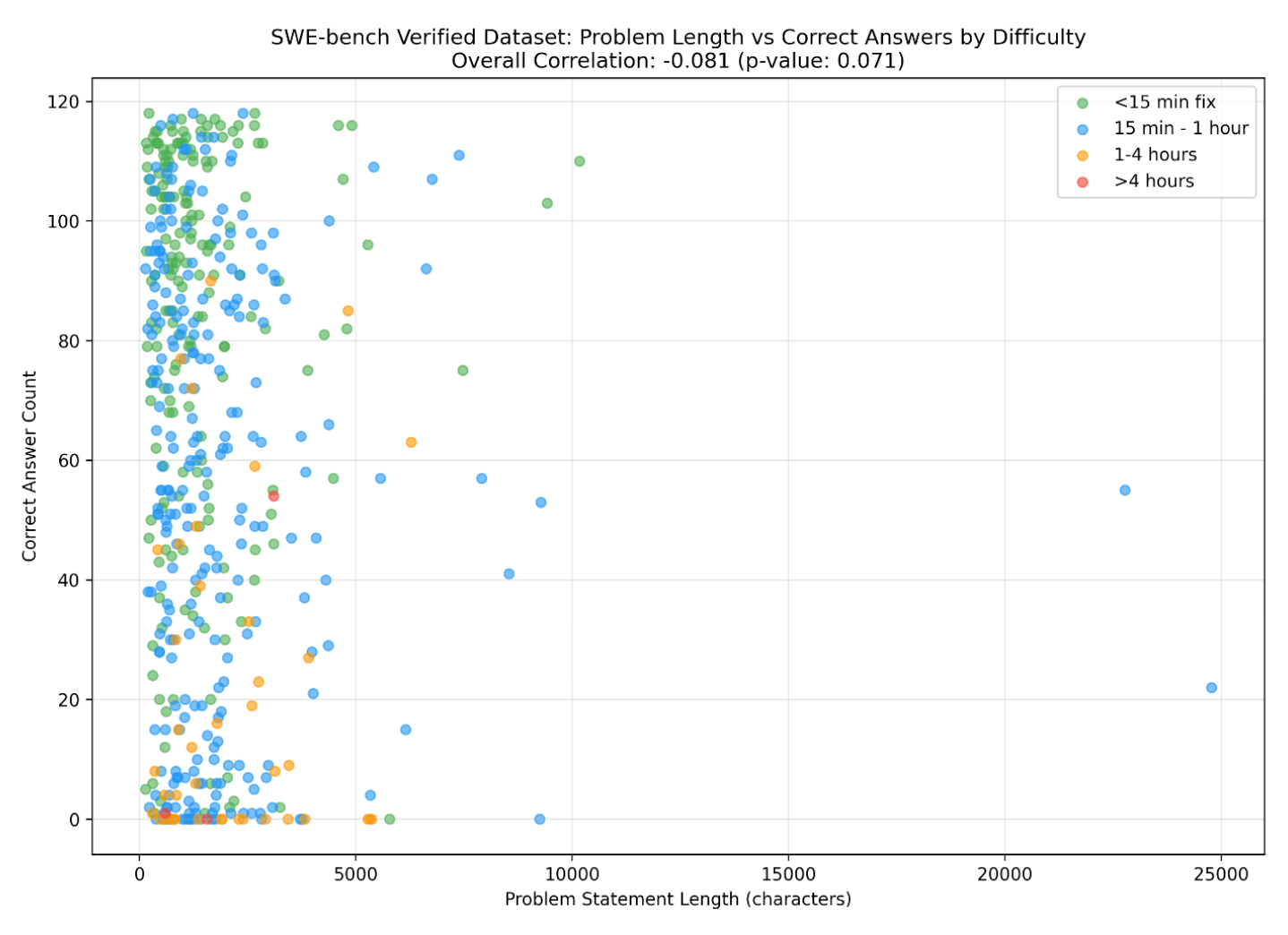
- 具体的なタスク
- 人間には難しいが、AIには簡単
- ‣
- sympyの累積分布関数(CDF)の実装(>4 hours)
- 人間的には、それぞれの確率分布を調べつつ実装するので時間がかかる
- 実装上は他の部分への依存関係が少なく、知識があれば解ける
- ‣
- djangoの実行時importの修正(1-4 hoursで最多の90エージェントに解かれている)
- Pythonのドキュメントの内容を理解できていれば解ける
- 人間には簡単だが、AIには難しい
- ‣
- djangoの負の時刻を表す正規表現の修正(<15 min fix)
- のようなパターン
- Claude Sonnet 4.5でも失敗しているらしい。
- ‣
- matplotlibのオリジナルなcmapを使う際の挙動修正(<15 min fix)
- 内部的に持っている値を書き換えるような修正で、それでいいんだ感がややある & こういう特殊そうな対応はAIは書きづらい?
- 知識問題や依存が少ない実装はAIエージェントでも解きやすいが、特殊な事情が入ってくるとまだ苦手な傾向
@Yosuke Yoshida
[blog] AI OCRの検証記録 ~ ニーリーでの検証結果はこうでした ~
- 検証対象PDFファイルについて
- 一般的によくある契約書などの「印字された文字」と「手書き文字」が混在した書類
- 検証指標について
- 381件のPDFに対して、1 PDFあたり12項目を読み込み、項目ごとの正解率を算出
- モデルの違いによる検証
- Geminiシリーズが他モデルと比較して頭一つ抜けた正解率

- 前処理の違いによる検証
- グレー化を適用することで、多少の精度改善
- ノイズ除去と回転を適用しても精度に変化は見られない

- 対象項目を絞ることによる違いの検証
- 項目の絞り込みよる精度の違いは特段見られない

- 正立判定(番外編)

@Takumi Iida (frkake)
[論文] Paper2VideoAutomatic Video Generation from Scientific Papers
論文の解説をするプレゼン動画を生成する研究。話者のアイデンティティを保ったままプレゼン動画を作成できる。そのためのベンチマークPaper2Videoも作成。

Paper2Video:
101の研究論文(論文、プレゼン動画、スライド、話者メタデータ)を使ったベンチマーク
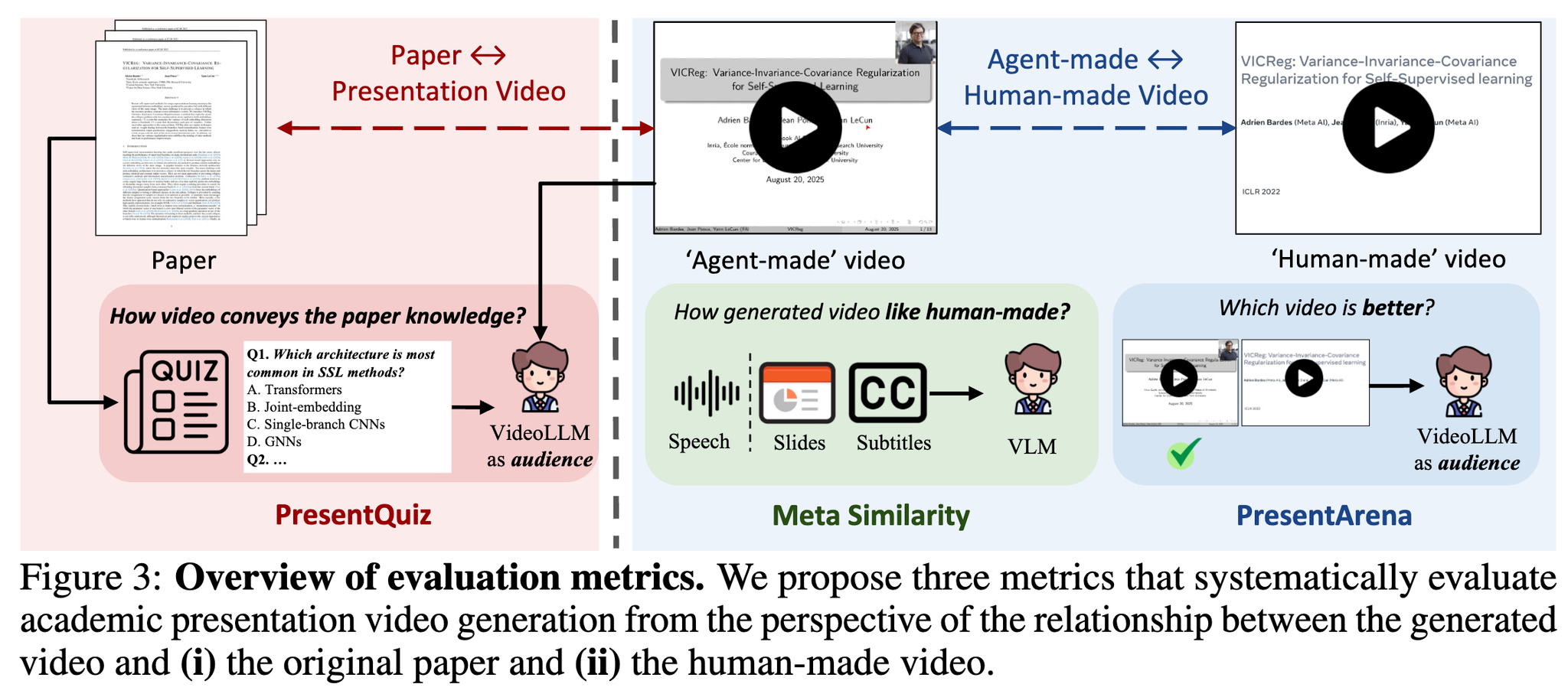
- Meta Similarity:人間が作成したようなプレゼン動画か 中間の生成物(スピーチ、スライド、字幕)がちゃんと著者にアラインされてるか
- スライド画像と字幕をペアにして、生成物のペア・人が作成したペアの両方をVLMで5段階評価
- 音声:著者の音声ベクトルのコサイン類似度
- PresentArean:どちらの動画が良いか VideoLLMで2つのプレゼン動画を比較。(A, B), (B, A)で2回クエリして順序バイアスを軽減
- PresentQuiz:プレゼン動画でちゃんと論文の知識を伝えられているか VideoLLMにプレゼン動画を見せて、質問に答えられるか [frkake] 見た人が答えられるかって視点がいいなと思った
- IP Memory:そのプレゼン動画を見たときに、(どれだけインパクトがあって結果として)記憶に残っているか (これは実装むずいよねってことを言ってる)

PaperTalker:プレゼン動画を生成するマルチエージェントフレームワーク

Beamerでスライド化できるようにLaTeXからコンパイルエラーがでないようにガッとスライドを作って、微調整。その後字幕やらを作っていく。
- Tree Search Visual Choice ルールベースで図とテキストのパラメータを調整して、VLMでどれがいいかを評価。それを繰り返す。 例)フォントサイズを1.25→0.75→0.5→0.25のようにスイープ
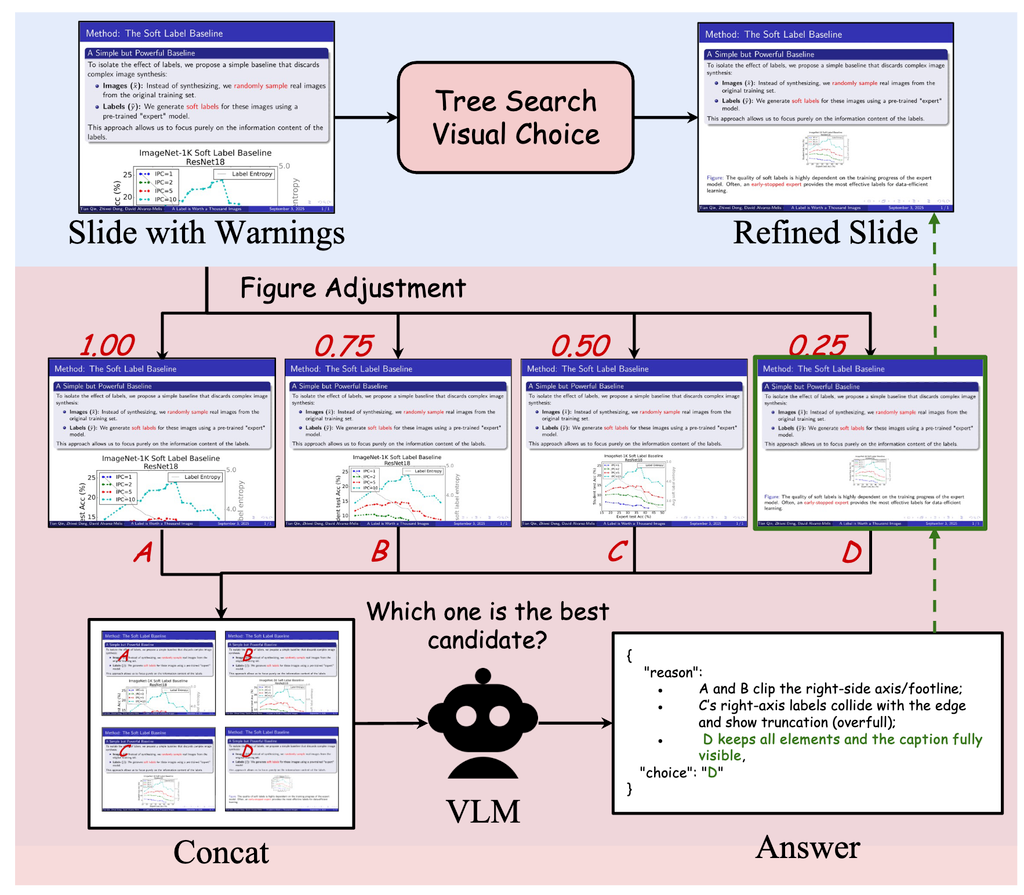
- Cursor Grounding
- Audio Synthesis
- Talking Head Rendering
細かいけど
生成された動画を見てみたが、カーソルがあんまり動かない(話してるところにカーソルを当てたら動かない)のは、もっといい感じになるといいなと思った。直線的に動くのも気になり。
雑感だけど、聞きやすくて見やすくていいなと思った。タイムスケジュールとかもやりやすくなるので、時間の制約がある場合なので有用だなと感じた。
あと、普通に長時間生成できてていい
@Hiromu Nakamura (pon)
[blog]I Ran an 80-Billion-Parameter AI Model on My 8GB GPU -My Experience with oLLM
リポジトリ
モデル全体を GPU VRAM に詰め込む代わりに、oLLM はモデルの重みとアテンション キャッシュを SSD から GPU にリアルタイムで直接ストリーミング。
結果80Bが7.5GB VRAMに乗ったと。量子化なしで、また精度を失わずに動作。ただ2sで1tokenと遅い(泣

メインTOPIC
In-the-Flow Agentic System Optimization for Effective Planning and Tool Use
訓練可能なインフロー型エージェントフレームワークであるAGENTFLOWを導入する。これは、進化するメモリを通じて4つのモジュール(planner、executor、verifier、generator)を連携させ、複数ターンのループ内でplannerを直接最適化する。
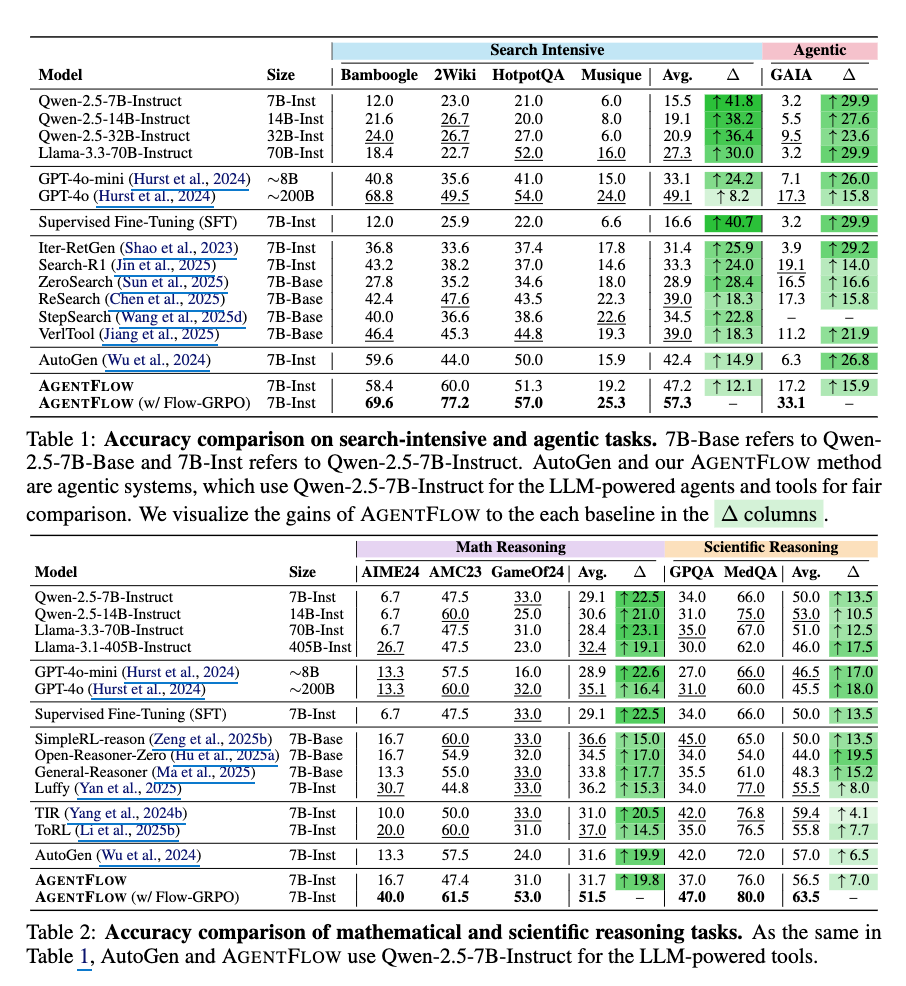
10個のベンチマークにおいて、7Bスケールのバックボーンを持つAGENTFLOWは、検索で14.9%、エージェントで14.0%、数学で14.5%、科学タスクで4.1%の平均精度向上を達成し、GPT-4oのような大規模なプロプライエタリモデルをも凌駕する、トップパフォーマンスのベースラインを上回る。
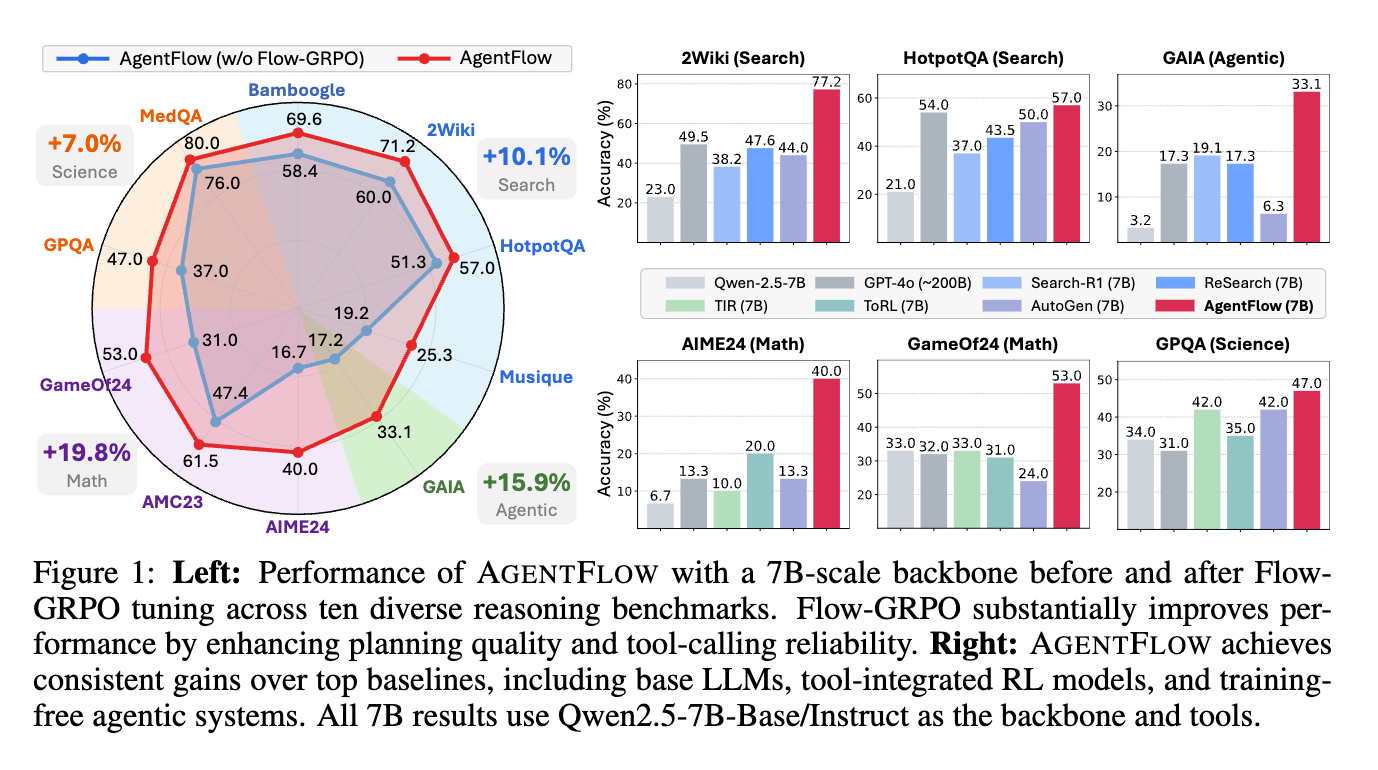
[pon]GPT-5との比較も気になる。Agenticタスク、数学系の伸びが強い。
INTRODUCTION
LLM推論能力の進歩と既存アプローチの課題
- 強化学習(RL)の進歩により、LLMの推論能力が向上。
- ツールを組み込んだ既存のLLMアプローチは、単一の「モノリシックなポリシー(monolithic policy)」で思考とツール呼び出しを統合。
- しかし、このアプローチには以下のような課題がある。
- スケーリングの難しさ: 長い推論ステップ(long horizons)、多様なツール、ツールからのフィードバックによって変化する環境において、学習が不安定。 汎化能力の弱さ: 未知のタスクやツールに対する推論時の汎化能力が脆いという問題がある。
- エージェントシステムの可能性と現在の課題
- 「エージェントシステム(Agentic systems)」は、問題を専門モジュール(例: プランナー、実行者)に分解することで、モノリシックなモデルに代わる有望な選択肢として登場。
- これらのシステムは、共有メモリとモジュール間のコミュニケーションを通じて協調動作する。
- しかし、ほとんどのエージェントシステムは、以下の課題を抱えています。
- トレーニングフリー: 手動で作成されたロジックやプロンプティングに依存しており、実際のマルチターンインタラクションの動的な挙動から切り離されている。 学習の限界: ライブ環境での成功や失敗から十分に学習できず、「疎な報酬(sparse rewards)」や「脆い適応(brittle adaptation)」、非効率な「オーケストレーション(orchestration)」といった問題に直面。
AGENTFLOWの提案
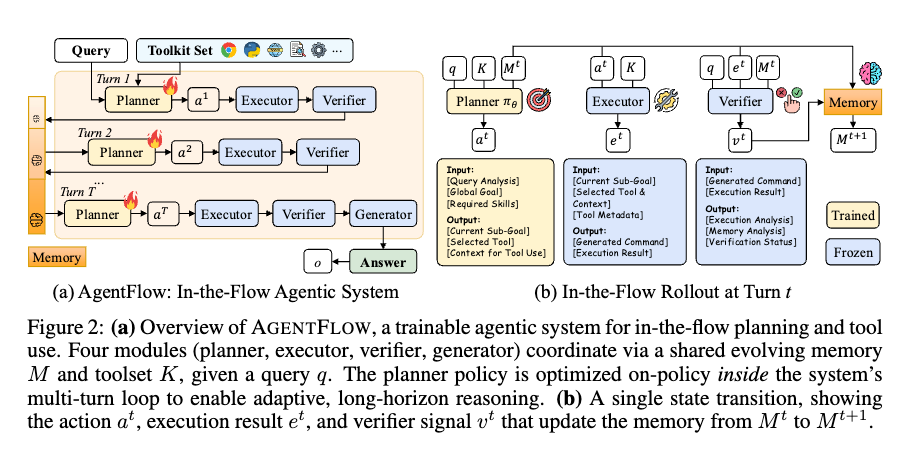
- これらの課題を解決するために「AGENTFLOW」という学習可能な「in-the-flowエージェントフレームワーク」を提案。
- AGENTFLOWは、プランナー、実行者、検証者、生成者の4つの専門モジュールが、進化するメモリを通じて連携。
- 特徴: マルチターンループ内で直接プランナーを「in-the-flow」で最適化し、ツール呼び出し、検証者からのシグナル、メモリ更新によって形成される軌跡に動的に適応する。
- Flow-GRPO: 長期間で疎な報酬のクレジット割り当て問題に対処するため、「Flow-based Group Refined Policy Optimization (Flow-GRPO)」というオンポリシーアルゴリズムを導入。
- これにより、マルチターンの強化学習問題を、検証可能な単一の「trajectory-level outcome(軌跡レベルの成果)」報酬を各ターンにブロードキャストすることで、一連の扱いやすいシングルターンポリシー更新に変換。 学習を安定させるために、「group-normalized advantages」を使用。
関連研究の進展に繋がる示唆:
- 従来のモノリシックなLLMやトレーニングフリーのエージェントシステムが抱えるスケーリングと汎化の課題に対し、AGENTFLOWは「in-the-flow」かつ「モジュール化」された学習フレームワークという新たなアプローチを提示。
- この方向性は、複雑なリアルワールドタスクにおけるLLMエージェントの適用範囲を大きく広げる可能性を秘める。
- Flow-GRPOによって、長期間・疎な報酬という強化学習の難題に対し、マルチターンRLをシングルターン更新のシーケンスに変換するという手法は、今後のエージェント学習の効率性と安定性を高めるための重要な一歩となるでしょう。
- 特に、軌跡レベルの報酬を各ターンにブロードキャストし、グループ正規化アドバンテージを用いる方法は、同様の課題を持つ他の多段階意思決定システムにも応用できるかもしれません。
- [pon]この軌跡レベルの報酬を各ターンにブロードキャストするのは最近よく見るな
- 前回紹介したReSUM GRPOとかも
PRELIMINARY
- このセクションでは、本論文の主要な貢献であるAGENTFLOWを理解するために必要な予備知識として、大規模言語モデル(LLM)における強化学習、ツール統合型推論モデル、およびエージェントシステムについて説明している。
- 推論LLMのための強化学習 (Reinforcement learning for reasoning LLMs)
- GRPO (Group Relative Policy Optimization)
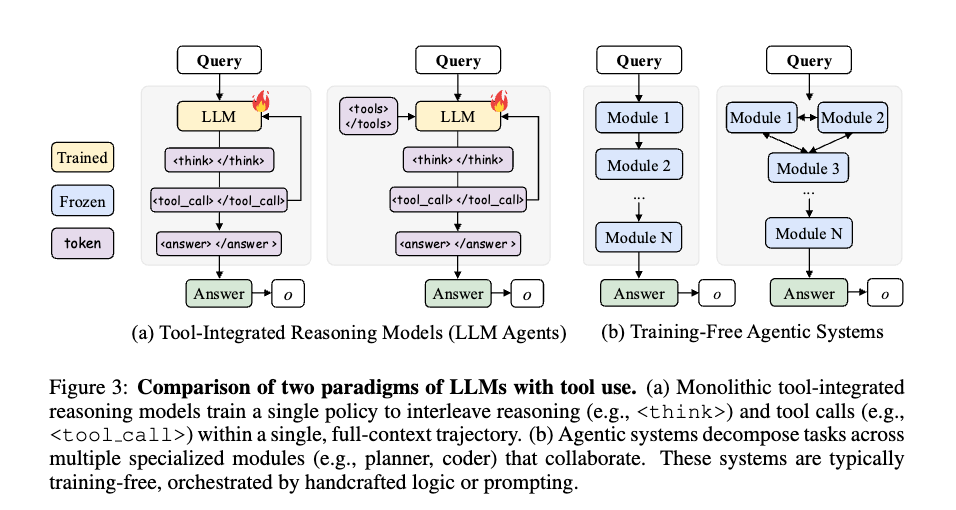
- ツール統合型推論モデル (Tool-integrated reasoning models (LLM agents))
- 概念: LLMにウェブ検索やコード実行などの外部ツールを連携させ、知識検索や正確な計算能力を向上させるアプローチ。
- 動作: LLMは<think>(思考)と<tool call>(ツール呼び出し)といったトークンを交互に生成し、推論プロセスとツール呼び出しを連携させる。
- 軌跡: この過程で生成される一連のモデルの生成とツールによる観測は、軌跡(trajectory)として表現される。 : ターン におけるコンテキスト(状態)。 : 生成されたアクション(思考とツール呼び出し)。 : ツールの実行結果。
- 課題: 従来のツール統合型アプローチは、単一のモノリシックなポリシーをフルコンテキストの推論で訓練するため、長期間のタスクや多様なツールにおいてスケーリングが困難であり、新たなシナリオへの汎化能力も弱いという課題があった。
- ツール使用を伴うエージェントシステム (Agentic systems with tool usage)
- 概念: モノリシックなモデルの代替案として、複数のモジュール(プランナー、クリティックなど、それぞれが役割やツールを持つ)に作業を分解し、共有メモリとモジュール間通信を通じて連携するシステム。
- 利点: 問題をサブゴールに分解し、複数ターンにわたって反復することで、多様なツールを必要とするタスク、長期的なタスク、または多段階推論を要する複雑な問題に対処できる。
- 課題: 多くのエージェントシステムは「トレーニング不要(training-free)」であり、手作業のロジックやプロンプトのヒューリスティックに依存している。このため、モジュールがいつどのように連携すべきか、変化するツールの出力に適応するか、初期の誤りから回復するかといった点でロバストな調整が難しいという課題がある。また、トレーニングを行う場合でも、オフラインでの学習は実際のマルチターンインタラクションの動的な状況から切り離されてしまう問題がある。
- [pon]麻雀点数計算生成タスクはこの辺結構大変だったのでわかる
本論文のAGENTFLOWは、これらの既存アプローチの課題(モノリシックなポリシーのスケーリング性と汎化性の問題、トレーニング不要なエージェントシステムのロバスト性の欠如)を克服するために、「in-the-flow」での強化学習最適化を導入します。これにより、マルチターンループ内でプランナーを直接最適化し、動的な環境に適応できる。
IN-THE-FLOW AGENTIC SYSTEM OPTIMIZATION
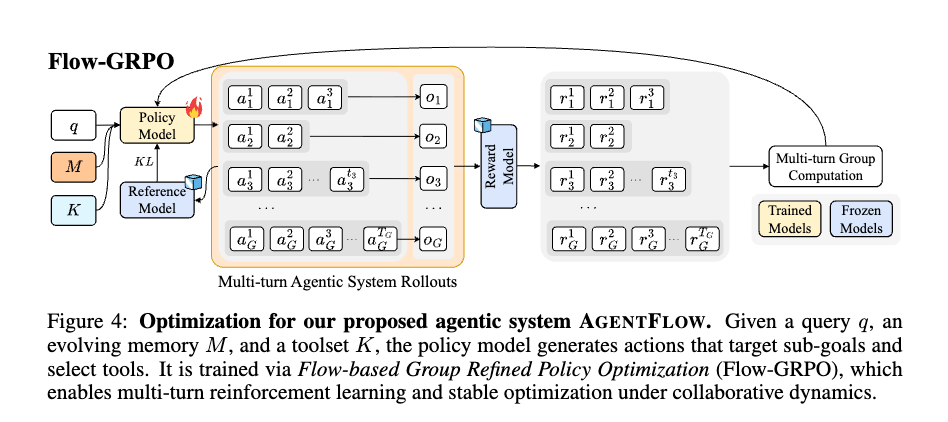
訓練可能だがモノリシックな推論モデルと、柔軟だが静的なエージェントシステムとの間のギャップを埋めることを目指す。
AGENTFLOWは、エージェントシステムのマルチターンループ内でプランナーを直接最適化する
3.1 AGENTFLOW:インフロー型エージェントシステム
上図に示すように、このフレームワークは、共有の進化するメモリとツールセットによって調整された、4つのモジュールで構成される
- Action Planner
- Tool Executor
- Execution Verifier
- Solution Generator
これらのモジュールは、アクションプランニング、ツール実行、コンテキスト検証、およびソリューション生成を実行するために、順番に反復的に相互作用し、それによって複数ターンにわたるツール統合された推論を可能にする。
ここで、AGENTFLOWの問題解決プロセスを、マルチターンMarkov Decision Process (MDP)として形式化する。
- クエリとツールセットが与えられた場合、システムは可変のターン数で進行する。をターンの前のメモリ状態とする(はから初期化される)。
- ターンtにおいて、Action Planner (訓練可能なポリシー)は、サブゴールを策定し、適切なツールを選択し、メモリから関連するコンテキストを取得して、アクションを生成する:。
- Tool Executor は、コンテキストとともに選択されたツールを呼び出し、実行観測を生成する。
- Execution Verifier は、が有効であるかどうか、および蓄積されたメモリがクエリを解決するのに十分であるかどうかを評価し、二値検証信号を生成する。
- もしの場合、メモリは新しい証拠を取り込むために決定論的に更新される:。ここで、は、エージェントプロセス情報(時間、ターンインデックス、エラー信号などのコンテキストの詳細とともに)を簡潔で構造化された形式で記録するメモリ更新関数を示す。
- このプロセスは、(終了)になるか、あらかじめ定義された最大ターン数に達するまで繰り返される。
- ターンで終了すると、ソリューション生成器は、クエリと累積されたメモリを条件として、最終的なソリューションを生成する:。
まとめると次のように形式化できる。
各項の詳しい説明は以下の通りです。
- 最終的な解答が生成される結合確率
- Action Plannerの確率分布です。ターンにおいて、現在のクエリ、利用可能なツールセット、および現在の記憶(メモリ)を条件として、プランナーが特定のアクションを選択する確率を表します。このが、Flow-GRPOによって最適化される、学習可能なポリシーです。
- Tool Executorの確率分布。実行結果を生成する確率を表す。
- Execution Verifierの確率分布です。検証シグナルを生成する確率を表す。このシグナルは、メモリが十分であるか、またはさらなるツールが必要かを示す。
- Solution Generatorの確率分布です。ジェネレータが最終的な回答を生成する確率を表す。
この式は、AGENTFLOWが複数の専門モジュールを協調させ、進化する記憶とツールセットを通じて、多段階の意思決定と推論を行う「in-the-flow」エージェントシステムの動作を数学的にモデル化したものである。特に、プランナーのポリシーがこのシステム内で直接最適化されることで、適応的で長期間にわたる推論が可能になる。
3.2 IN-THE-FLOW REINFORCEMENT LEARNING OPTIMIZATION
このセクションでは、AGENTFLOWの主要な訓練アプローチである「IN-THE-FLOW強化学習最適化(In-the-Flow Reinforcement Learning Optimization)」について説明。これは、従来の訓練方法が抱える課題を解決し、エージェントシステムが動的な環境で効果的に学習できるようにするためのもの。
主なポイントは以下の通り。
解決すべき課題:
- ツール連携型エージェントシステムは、長期間のタスクとスパースな報酬(sparse rewards)の下で動作します。スパースな報酬とは、エージェントがタスクを完了したときにのみ報酬が得られ、途中のステップでは具体的な報酬がない状況を指す。「アクションプランナー(Action Planner)」は相互依存する一連のアクションを選択し、その間、ツール実行結果や検証フィードバックによって状態()が変化する。
従来のオフライン訓練の限界:
- 従来のオフライン訓練(例:教師ありファインチューニングや選好ファインチューニング)は、キュレーションされたデータセットを用いてプランナーを訓練するが、これは実際の実行ループとは切り離される。 この分離により、実行者(Executor)、検証者(Verifier)、解答生成者(Solution Generator)とのリアルタイムな連携が妨げられる。
- 訓練時と展開時の間で分布シフト(distribution shift)が発生し、中間的な決定の重要性に関するガイダンスが不足する。
- 結果として、プランナーはマルチターン(複数回のやり取り)のダイナミクスにうまく適応できず、初期のエラーが連鎖し、後からの修正も困難になる。
IN-THE-FLOW :
これらの問題を解決するために、AGENTFLOWは実行の「流れの中で(in the flow)」プランナーを最適化します。
- 現在のポリシーの下でAGENTFLOWシステム全体をロールアウトし、実際に生成された状態、アクション、ツールイベントの軌跡(trajectory)を収集。
- この軌跡を利用して、システム内でポリシーを更新。
- このアプローチは、マルチターンの「クレジットアサインメント問題(credit-assignment problem)」に直接対処し、プランナーを推論時に直面する正確な状態に基づいて訓練する。 本論文で提案されているFlow-GRPOは、このスパースで軌跡レベルの報酬の下での学習を安定させるように設計されている。
ポリシー最適化の目的関数:
- プランナーポリシーは、オンポリシーのロールアウトにおける期待報酬を最大化するように訓練。
- 目的関数は以下。
- パラメータを持つポリシーのパフォーマンス(期待される報酬)。
- ポリシーによって生成された軌跡に対する期待値。
- 完了した軌跡に対する報酬。
- 目的関数を最大化する最適なポリシーパラメータ。
- ロールアウトは、によってオンポリシーで生成された決定()のシーケンス。
最終結果に基づく報酬(Final-outcome reward):
- 各中間アクションは最終的な解答に間接的にしか影響せず、その価値は数ターン後にしか現れない可能性があるため、個々のアクションに報酬を割り当てることは困難。
- この問題に対処するため、ロールアウト内のすべてのアクションに単一のグローバル報酬シグナルが与えられる。これは最終解答の正確性に基づいて決定される。
- 報酬は以下の式で表されます。
- : 各アクションに割り当てられる報酬。
- : アクションの報酬関数。
- : 最終解答がクエリと正解に対して正しいかどうかを示す報酬(のバイナリ値)。
- この設計により、軌跡全体の成功シグナルが推論チェーンの各ターンに伝播され、個々のアクション()の決定がグローバルな正しさと整合するようになる。
- この単一の軌道レベルの成功信号が、その軌道内のすべてのターン におけるプランナーのアクション に「ブロードキャスト」される。つまり、その軌道内にあるすべての行動が、同じ最終結果の報酬を受け取る。
この新しいアルゴリズムは
- (i) エージェントシステムにおけるマルチターンの強化学習問題を、扱いやすい一連のシングルターンのポリシー更新として定式化し、
- (ii) ローカルなプランナーの決定をグローバルな成功と整合させるために、単一の軌跡レベルの結果をすべてのターンにブロードキャストする。
訓練では、検証可能な最終結果の報酬を割り当てるために、LLMベースのルーブリックを使用し、グループ正規化されたアドバンテージ、KL正則化、および学習を安定させるためのクリッピングを使用する。
EXPERIMENTS
主な実験では、Action Planner、Tool Executor、Executive Verifier、Solution Generatorのすべてのモジュールは、Qwen2.5-7B-Instructモデル(Yang et al., 2024a)でインスタンス化される。
これらのうち、Action Plannerのみが訓練可能である。
このシステムは5つのインタラクティブなツールで動作する。
- Base GeneratorはQwen2.5-7B-Instructのインスタンスであり、プランナーが外部ツールを使用しない場合にデフォルトの推論エンジンとして機能する。
- Python Coderは、クエリを与えられてPythonコードを生成・実行し、実行結果を返す
- Google Searchはウェブを検索し、上位K件の検索結果の要約を返す。
- Wikipedia Searchは、与えられたクエリに一致する記事を検索し、要約を返す。
- Web Searchは、与えられたウェブページから要約された情報を返す。
強化学習(RL)のファインチューニング段階では、Search-R1 (Jin et al., 2025) とDeepMath (He et al., 2025) のデータを訓練データとして混合し、検索と数学の領域にわたる質問と回答のペアの例を提供する。
Training
- の学習率を使用する。
- Action Plannerは、探索と利用のバランスを取るために、サンプリング温度0.5でアクションを生成する。
- ポリシーの崩壊を防ぎ、訓練を安定させるために、係数β = 0.001で参照ポリシーに対するKLダイバージェンスペナルティを組み込む。
- プランナーの最大出力長は、ロールアウト中の完全な探索を保証するために、2048トークンに設定されている。
- バッチサイズは32を使用し、サンプルごとに8回のロールアウトを行う。
- トレーニングの1回の更新ステップ(イテレーション)において、合計で32個の「クエリ-正解ペア」(Query-Label Pair)を処理する
- 8回のロールアウトは、同じクエリに対して、現在のプランナーポリシーの異なる確率的な行動パスを探索するために行われます。プランナーはサンプリング温度0.5でアクションを生成するため、同じクエリでも異なるアクションシーケンスやツール利用が生じる可能性があります。
- 訓練速度を加速するために、ロールアウトあたりの最大ターン数を3に制限する。
- 最終結果の報酬信号は、LLM-as-judgeによって提供され、これにはGPT-4oを使用する。
- すべてのツール呼び出しは、外部サービスの遅延をロバストに処理するために、500秒のタイムアウトで同期的に実行される。
- ツール内のLLMエンジンは、確定的で安定した出力を保証するために、温度0.0に設定されている。
- 完全な訓練プロセスは、8つのNVIDIA A100 GPU上で実施された。
評価
AGENTFLOWのツール使用能力を包括的に評価するために、以下の4種類の推論タスクに関する実験を行う。
- (1) Bamboogle、 2Wiki、 HotpotQA 、Musique を含む知識集約型検索
- (2) GAIA などのエージェント的推論
- (3) AIME2024、AMC23、 GameOf24 を含む論理密度の高い数学的推論、
- (4) GPQA、MedQAを含む科学的推論
ランダム性を軽減するため、すべての実験において3回の試行の平均精度を報告する。
MAIN RESULTS
Flow-GRPOはツール利用を最適化する。
Flow-GRPOによる強化学習(Reinforcement Learning: RL)トレーニングの前後で、ツール利用の分布を比較する。
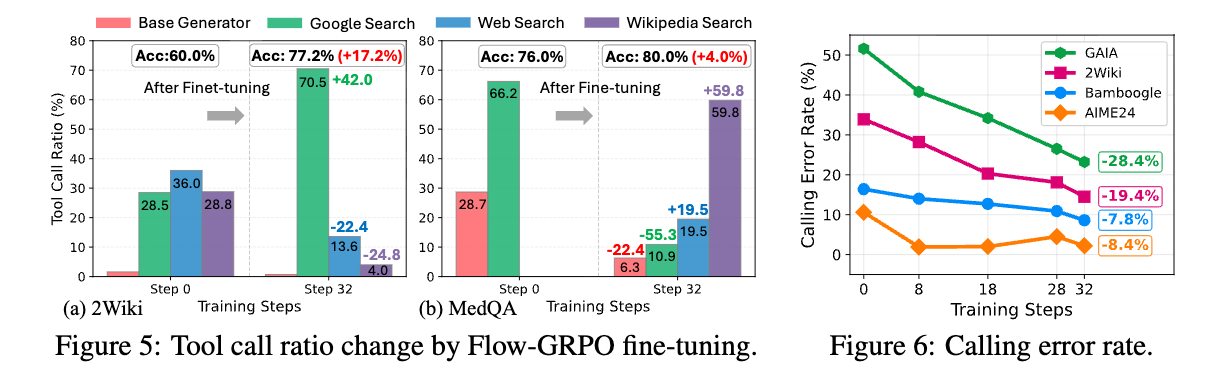
- 知識集約型のタスクである2WikiとMedQAの結果を示しており、タスク精度が向上するとともに、明確な最適化パターンを示している。
- 広範な事実知識を必要とする2Wikiでは、Flow-GRPOはプランナーを最適化し、Google Searchの利用を42.0%増加させている。
- 対照的に、高度なドメイン固有の情報検索を必要とする専門的なMedQAベンチマークでは、ファインチューニングにより、プランナーは一般的なツールから離れ、Google Searchの呼び出しを減らし(66.2→10.9%)、代わりにドキュメント内Web検索(0→19.5%)と専門的なWikipedia検索(0→59.8%)を優先する。
- これは、プランナーがタスクに適したツールを選択することを学習していることを示している。
- この傾向は、トレーニングプロセスがモデルにどのツールを使用するかだけでなく、適切な引数と形式で正しく呼び出す方法も教えていることを示しており、より堅牢で効果的なツール統合につながっている。
- [pon]結果的にtool利用も最適化できるの良い
Flow-GRPOは新しいソリューションの自律的な発見を促進する。 Flow-GRPOでトレーニングされたAGENTFLOWが、タスクプランニングとツール利用において強化された能力を開発することを示している。

プランナーは、適応的な効率、より強力な自己修正、およびステップごとの問題解決におけるツールの自発的な新しい統合を示し、効果的なソリューション経路を自律的に発見する。
上図の例では
- ステップ1-2(検索ツール): ファインチューニング前と同様に、Wikipedia Searchでは結果が見つからず、Google SearchでTropicos ID「100370510」を正常に取得。
- ステップ3(Python Coder): Python Coderツールを使用するが、ファインチューニング前とは異なり、クエリの内容を「tropicos_id のISBN-10チェックデジットを計算するPythonスクリプトを書き、実行せよ」と、変数を直接参照する形式で指示。しかし、「name 'tropicos_id' is not defined」というエラーが発生し、まだ失敗します。これは、変数名がPython環境内で定義されていないため。
- ステップ4(Python Coder): AGENTFLOWは前のステップのエラーから学習し、クエリを修正して「100370510 のISBN-10チェックデジットを計算するPythonスクリプトを書き、実行せよ」と、数値を直接渡すように変更。 さらに、提供されたPythonコードは、ISBN-10チェックデジットを計算するための正しいロジック(各桁に重みを付けて合計し、11で割った余りを計算)を実装。
PLANNERの訓練戦略
AGENTFLOWにおけるAction Plannerモジュールの様々な訓練戦略の影響を分析するためにアブレーション研究を実施した。

- より高性能なplannerは有益であるが、限界がある。固定されたQwen2.5-7B-Instructのベースラインを、より強力なプロプライエタリモデルであるGPT-4oに置き換えても、平均でわずか5.8%の向上しか得られない。
- これは、より強力なモデルがプランニングを改善する一方で、その静的な性質がAGENTFLOWのライブなダイナミクスとの共同適応を妨げるという、主要なボトルネックを示している。
- オフラインの教師あり微調整(SFT: Supervised Fine-Tuning)は性能の崩壊につながり、フロー内の強化学習(RL: Reinforcement Learning)が重要となる。
- 静的なplannerの限界は、AGENTFLOWにおけるAction Plannerとして、GPT-4oの行動をオフラインのSFTによって蒸留する際に、さらに露呈する。
- これにより、壊滅的な性能の崩壊が発生し、平均精度は固定されたベースラインと比較して19.0%低下する。
- この失敗は、SFTのトークンレベルの模倣目的から生じるものであり、これは軌跡レベルのタスク成功とは整合せず、plannerが動的なツールのフィードバックに適応したり、複合的なエラーから回復したりすることを妨げる。
- 対照的に、我々のオンポリシーのFlow-GRPO法でplannerを訓練することは非常に効果的であることが証明された。最終的な結果を最適化することにより、plannerは長期的なワークフローを処理することを学習し、固定されたベースラインと比較して平均17.2%の向上を達成する。
報酬の増加と応答の凝縮による最適化されたプランニング。
- 訓練セットにおける平均報酬と応答長を追跡することにより、AGENTFLOW plannerの訓練ダイナミクスを分析する
- 訓練報酬は着実に増加しており、Flow-GRPOによる効果的なポリシー改善を示している。 一方、応答長は、初期の探索的な上昇の後、徐々に短くなり安定する。
- 一方、応答の長さは、最初の探索的な増加の後、徐々に短くなり安定する。 これは、プランナーが簡潔さと情報量のバランスを取り、不必要に長い出力を避けることを学習していることを示している。
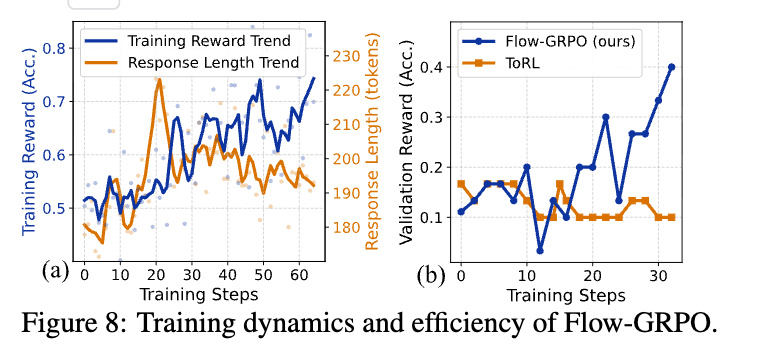
ツール統合された推論強化学習に対するFlow-GRPOの効率。
- AIME24において、AGENTFLOW(Flow-GRPOで学習)を、モノリシックなツール統合された推論ベースライン(ToRL)と比較する。 上図に示すように、AGENTFLOWは持続的な性能向上を達成し、検証精度は着実に向上している。 対照的に、ToRLの性能はすぐに停滞し、下降傾向にあり、分解と安定したクレジット割り当てを使用して不安定性を回避する、我々のアジェント的な学習アプローチの優れた効率を強調している。
関連研究
- エージェントシステムは、タスクを専門化されたモジュールに分解することで、モノリシックなモデルに代わる選択肢を提供する。
- そのようなシステムの多くは学習を必要とせず、事前学習済みのLLMを、手作りのロジックとプロンプトによって調整する。これは、AutoGen (Wu et al., 2024)、MetaGPT (Hong et al., 2024)、OctoTools (Lu et al., 2025)などのフレームワークに見られる。
- しかし、この静的なアプローチでは、経験から協調戦略を学習し、適応する能力が制限される。
- この点を認識し、最近の研究では、これらのシステムを訓練して協調性を向上させる試みがなされている (Deng et al., 2025; Liao et al., 2025)。
- しかし、ほとんどの訓練パラダイムはオフラインであり、教師ありファインチューニングや、静的なデータセットに対するpreference optimizationに依存している (Motwani et al., 2024; Park et al., 2025)。
- これらの手法は、システムのライブな、複数ターンのダイナミクスから切り離されており、モジュールが進化するツールの出力に適応したり、初期のミスから回復したりすることを妨げている。
結論
- 進化するメモリを介して4つの専門化されたモジュールを調整し、複数ターンのループ内でプランナーを直接最適化する、訓練可能なインザフローのエージェントシステムであるAGENTFLOWを提案した。
- 長期にわたる、報酬が疎な設定下で安定したオンポリシー学習を可能にするために、FlowGRPOを導入した。これは、単一の検証可能な軌道レベルの結果をすべてのターンにブロードキャストし、グループ正規化されたアドバンテージでクレジット割り当てを安定させることによって、複数ターンのRLを扱いやすい単一ターンのポリシー更新のシーケンスに変換する。
- 包括的な実験により、AGENTFLOWが強力なクロスドメイン性能を達成し、専門化されたベースラインや、より大規模なプロプライエタリモデルさえも凌駕することが示された。
おまけ
Instruction for Tool Executorのプロンプトも面白い
- 単なるAPI呼び出しだけでなく、ツールから返された結果に対して後処理が必要な場合や、複数のツール呼び出しを複雑なロジックで連携させたい場合がある。コード生成を介することで、このような高度なデータ処理や制御フロー(例:条件分岐、繰り返し)も理論的にはエグゼキューターの能力として実現しやすくなる。例えば、検索結果から特定の情報を抽出してPythonスクリプトの入力として使う、といったシナリオが考えられる。
[pon]所感
- AFlowやMaaSみたいなWorkflow自動生成と比較して、対応できる汎用性は高そう。ただ、決定論的なフローで生成し、コントローラブルにしたい場合は、Workflow自動生成に軍杯かなー。
- 最終ターンで失敗すると各軌跡の報酬がゼロになるの厳しいが、タスク成功だけに焦点を当てるとこうなるのか。
- 狭いポイントであってもプランニングが必要なマルチターン+tool利用最適化が必要な場合は試してみても良いかもしれない。
- ちなみにすぐ触れる。
- 内部ではverlっていうRLライブラリ使ってるらしい