2025-10-21 機械学習勉強会
今週のTOPIC[slide] はじめてのDSPy - 言語モデルを『プロンプト』ではなく『プログラミング』するための仕組み[blog] Equipping agents for the real world with Agent Skills[論文] LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings[論文] DeepSeek-OCR: Contexts Optical Compression[blog]Benchmarking AI Agents: The Challenge of Real-World Evaluation[論文]Enabling Personalized Long-term Interactions in LLM-based
Agents through Persistent Memory and User ProfilesメインTOPICMulti-agent Architecture Search via Agentic SupernetTLDR1. Introduction2. Related Work3. Methodology3.1. Preliminary3.2. Agentic Architecture Sampling3.3. Cost-constrained Supernet Optimization4. Experiments4.1. Experiment Setup4.2. Performance Analysis4.3. Cost Analysis4.4. Case Study4.5. Framework AnalysisAppendix
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[slide] はじめてのDSPy - 言語モデルを『プロンプト』ではなく『プログラミング』するための仕組み
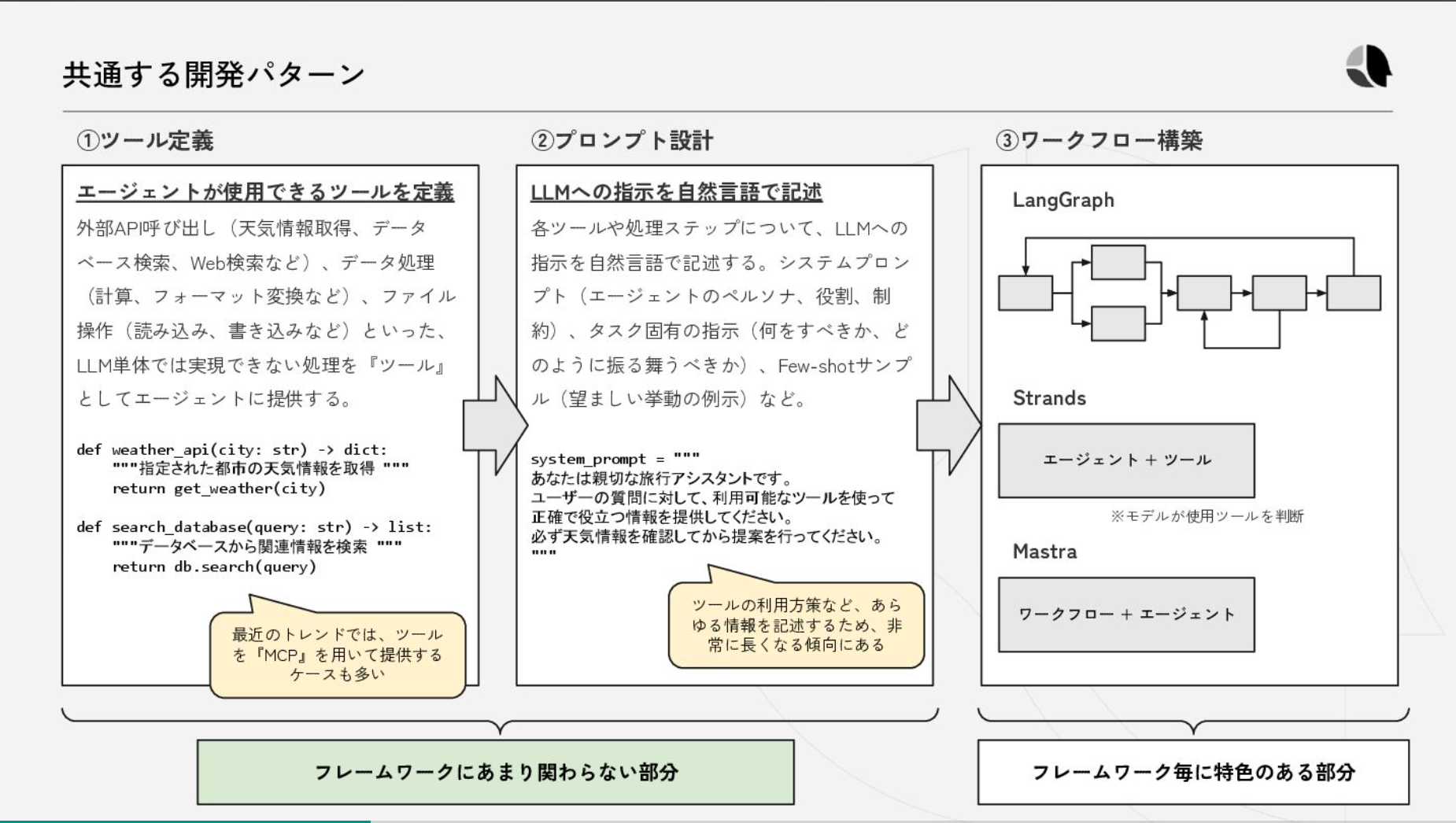
- 最近DSPyというのが流行ってる
- どんなフレームワークを使おうとツール定義やプロンプト設計は変わらない
- 評価の仕組みを作ったとしてもアップデートを人手で行うのはメンテコストが高い
- DSPyの思想
- プロンプトを手書きするのではなく、データと評価関数によって自動生成する
- 元々は論文がある:https://arxiv.org/abs/2310.03714
- 基本構造
- シグネチャ
- formatやデフォルト値なども設定できる
- モジュール
- Pytorch likeな書き方
- コードで生成させたりCoTだったりReActだったり色々ある
- https://dspy.ai/api/modules/ReAct/
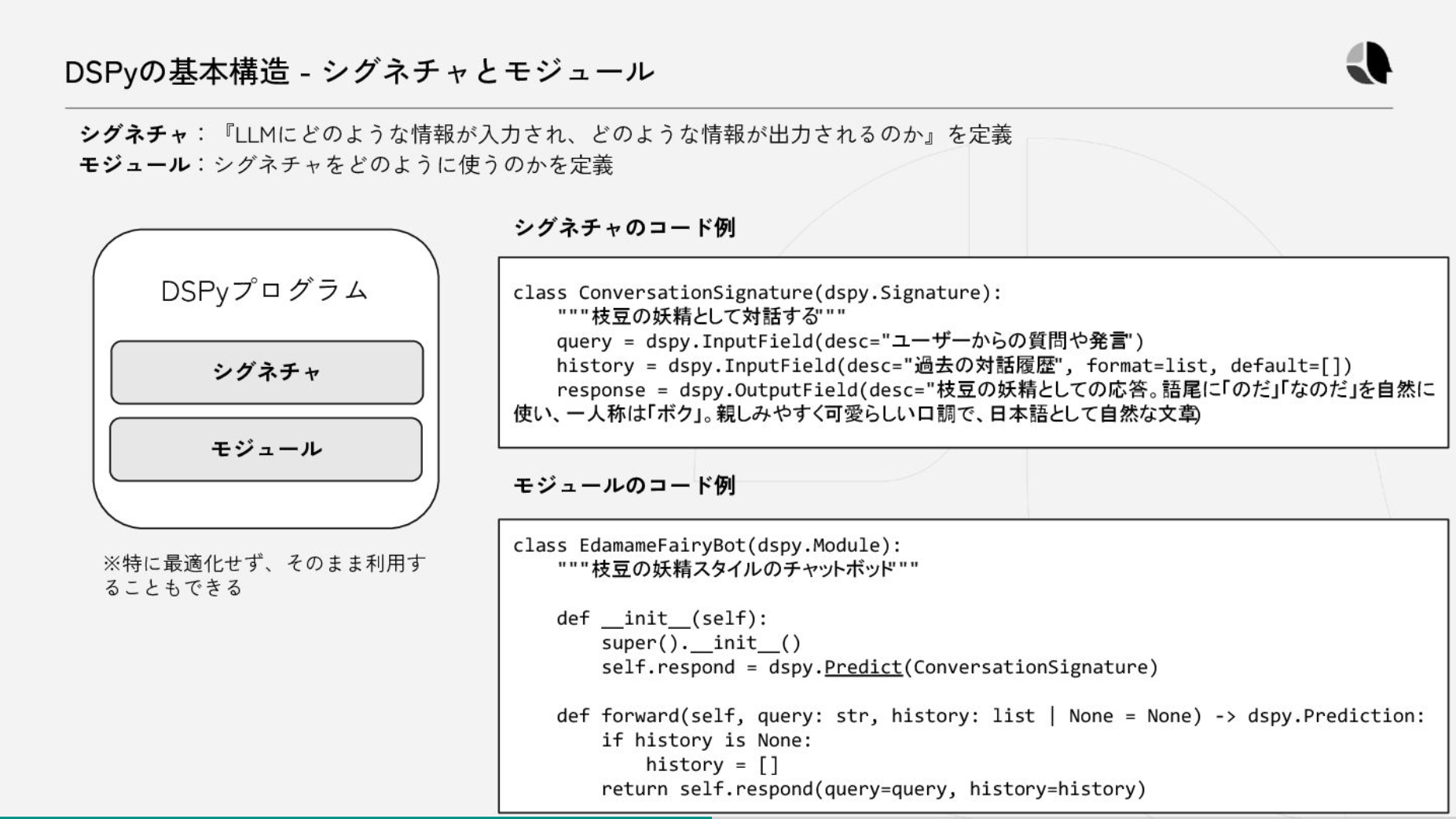
- プロンプトを意識せずに実行できる。内部的にはプロンプトが生成されている。

- データセットと評価関数を渡せば最適化をしてくれる
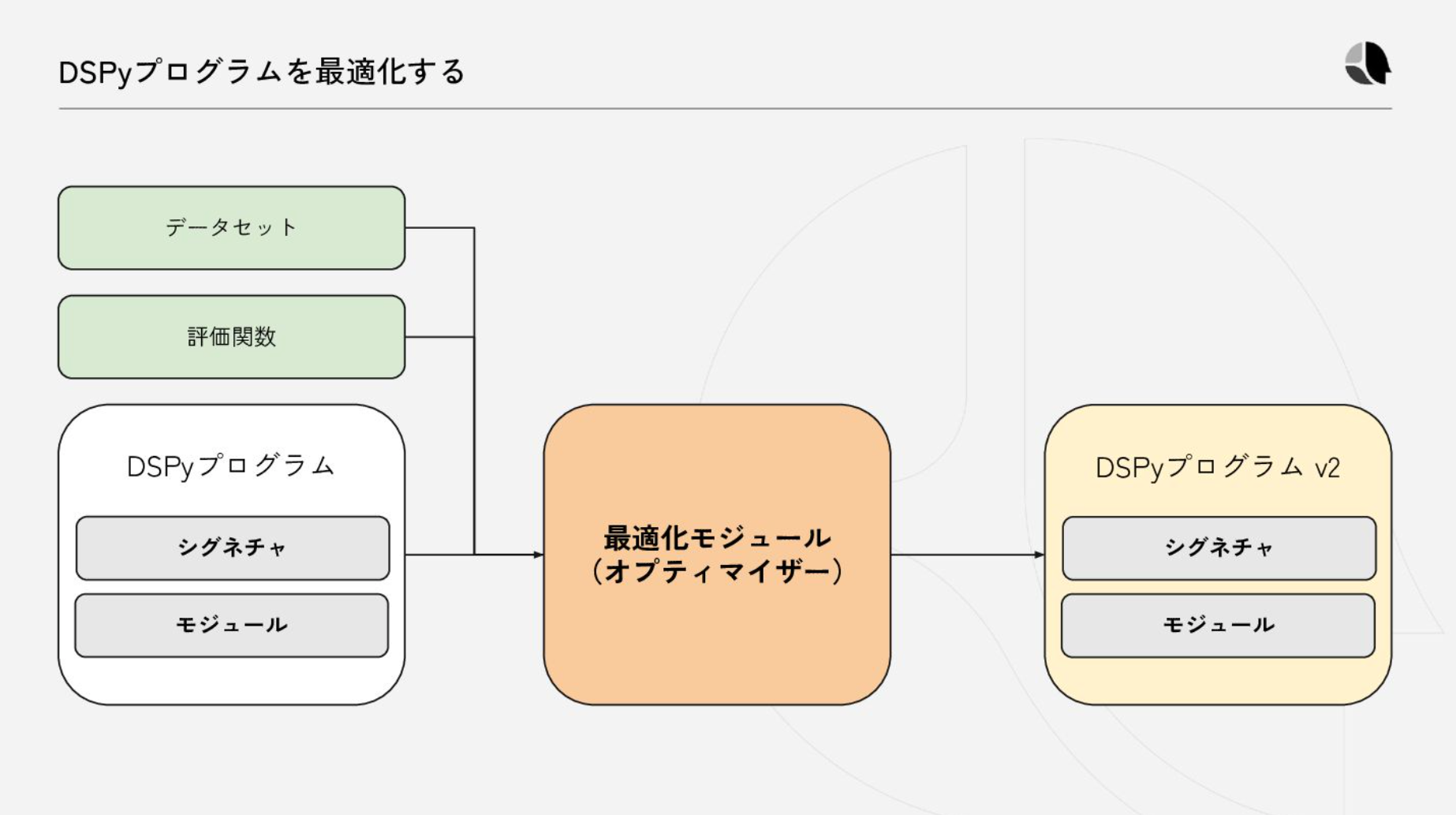
- 色々なOptimizer
- https://dspy.ai/api/optimizers
- 最適化に2000件で数時間かかったりするらしい
- としたら保存もloadもできる

- 最近はマルチモーダルに対応したり、モデルのファインチューニング機能も強化され強化学習に対応したりしている
@Yuya Matsumura
[blog] Equipping agents for the real world with Agent Skills
Anthropic から発表された Agent Skills は、従来のMCPサーバー / tool 登録においてすべての情報を最初にコンテキストに含めないとならなかったコンテキスト肥大の問題を解消。
必要なときに必要な情報だけ読んでコンテキストに追加する(progressive disclosure)ことができるような構造を提供。

スキルごとに用意される (PDF処理に関するものは など)にはyamlフォーマットで name と description が定義される。このスキルをいつ実行すべきかを判断するための情報をここに含める。Agent は起動時にこの name と description しか読まない。なのでコンテキストが大きく節約される。
実行が必要だと判断した際に初めてマークダウンで記述された の本体を読んでコンテキストに含めてスキルを獲得する。

単一のスキルが複雑化してきて が大きくなりすぎたり、特定ケースのみで実行したい処理が出てきた場合は、スキルディレクトリ内にファイルを追加して切り出す。 内にそれぞれのファイルをいつ利用するべきかを記述することで、必要な場合のみ追加のファイルをコンテキストに読み込むようにする。
文書ファイルだけではなく、Pythonのスクリプトファイルも追加・参照可能。決定的な動作ができる。


@Shun Ito
[論文] LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings
- 市場調査の効率化のため、人間の購買意欲をLLMでシミュレートしたい
- 1~5のLikert Scaleの回答を想定し、人間の回答と同じような回答分布をLLMで生成する
- Direct Likert Rating (DLR)
- そのまま5段階の回答を生成させる
- 回答が3に偏り、分布が狭くなる。結果人間の回答との相関が低くなる。
- Follow-up Likert Rating (FLR)
- まず短いテキストで回答を生成し、別のプロンプトで5段階に変換
- Semantic Similarity Rating (SSR)
- 生成した短いテキストと、あらかじめ5段階それぞれに定義されている文章とのコサイン類似度を計算し、一番近いものに割り当てる
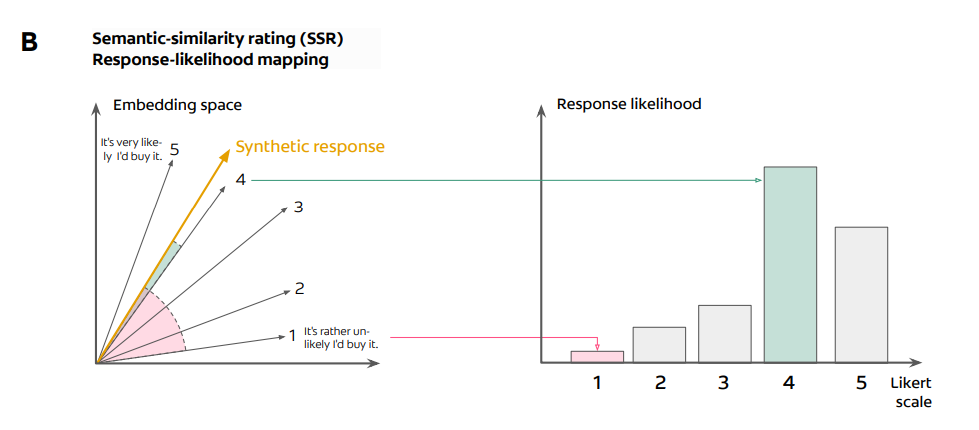
- LLMにさまざまなデモグラパターンを与えて、回答の分布を生成させる
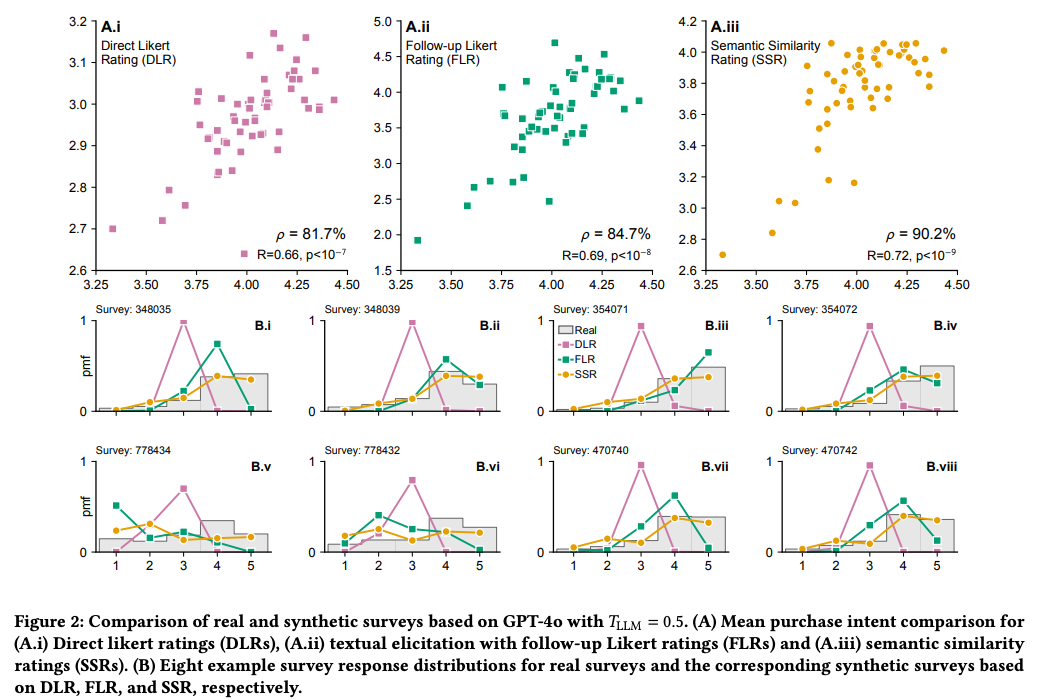
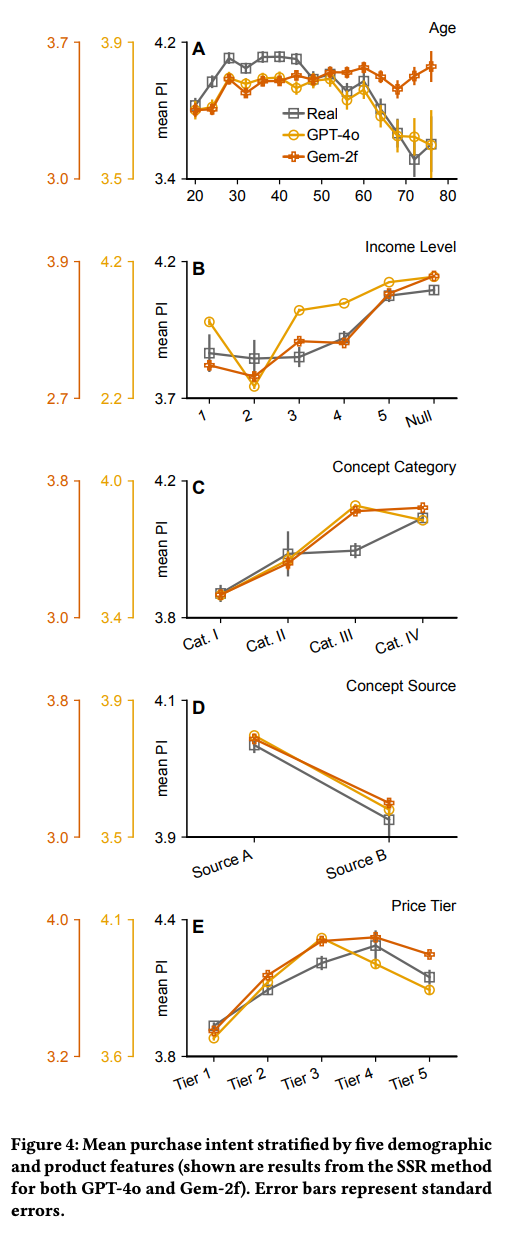
- 結果
- SSRにすることで、相関係数や段階ごとの割合が、人間の回答と近くなる
- 属性に分けた回答分布も人間と概ね近い回答を出せている
- GeminiのAgeや、GPT-4oのIncomeなど、一部乖離の大きいものはある
@Takumi Iida (frkake)
[論文] DeepSeek-OCR: Contexts Optical Compression
概要
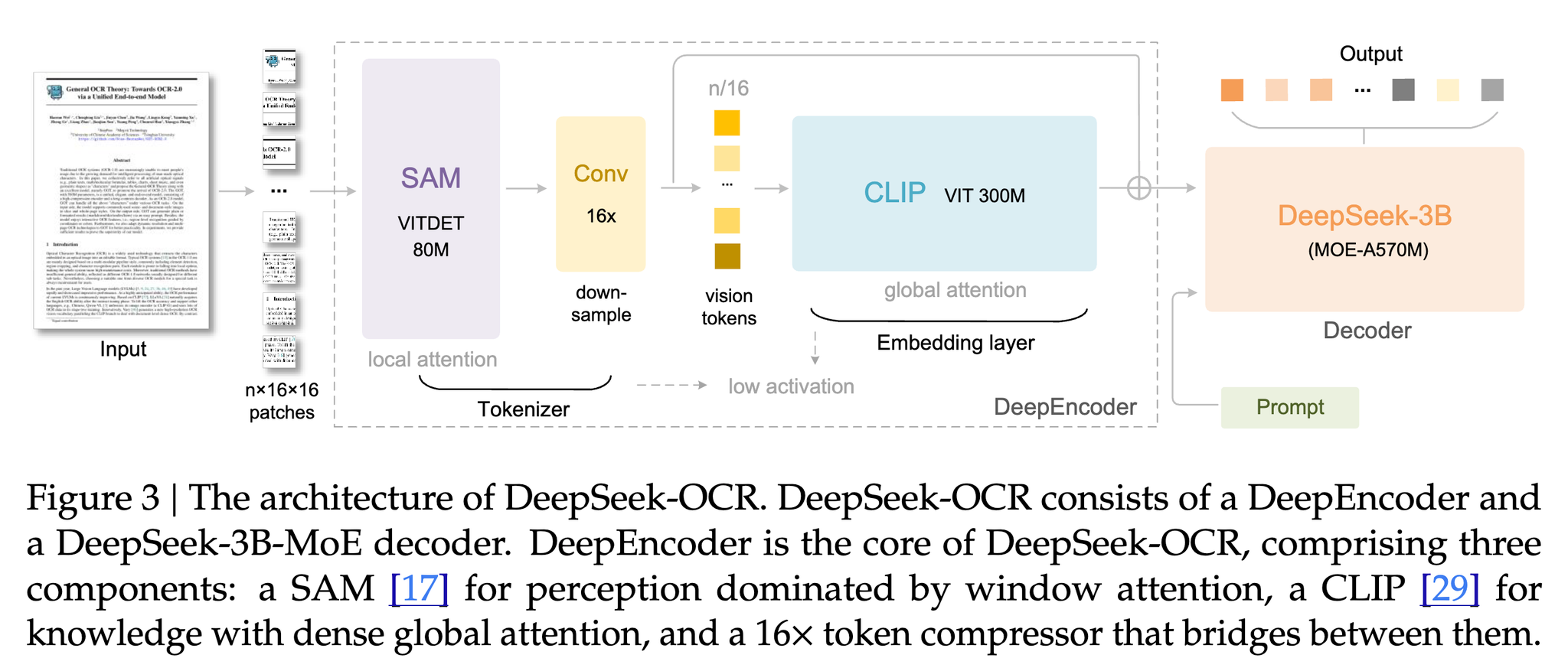
大量のテキスト情報を、より少ないVision Tokenを使って画像として圧縮することで効率的に処理できるようにする
従来
- 左(Vary/DeepSeekVL):VITDetとViTが並列→LLM
- 中(InternVL/DeepSeekVL2):画像をタイルに分割→ViT入力→LLM
- タイルに分割して、並列計算
- 右(Qwen2VL):画像をパッチに分割→ViT入力→LLM
- パッチベースのセグメンテーションを行い、画像全体を直接処理
以下のようなデメリットがある

DeepSeek-OCRのアーキテクチャ
エンコーダ
画像の特徴抽出&視覚表現のトークン化&圧縮をやる
以下のことができるエンコーダを構築したい
- 高解像度を処理できる
- 高解像度で低いアクティベーション(メモリ消費量が少ない)
- ビジョントークンが少ない
- 複数解像度の入力ができる
- 適度なパラメータ数
そのため、SAM + CLIPのエンコーダを作成
- SAM: window-attentionが主体
- CLIP: 密なグローバルアテンションを持つ
複数解像度のサポート
「デコードにいくつのビジョントークンが必要か」というのに対処する必要があるため、複数解像度の入力をサポートする必要がある。
DeepEncoderは2つの主要な入力モードをサポート
- ネイティブ解像度(以下は解像度とトークン数)
- Tiny: 512x512 (64)
- Small: 640x640 (100)
- Base: 1024x1024 (256)
- Large: 1280x1280 (400)
- 動的解像度:2つのネイティブ解像度で構成
- Gundamモード:n x640x640のタイル(ローカルビュー)と1024x1024のグローバルビュー
- Gundam Masterモード:1024x1024(ローカルビュー)と1280x1280のグローバルビュー
それぞれ、リサイズしたりパディングしたりなど処理が違う。

デコーダ
DeepSeek-3B-MoEを使用
推論時、64のルーティングされたエキスパートのうち6つと2つの共有エキスパートを使用する
DeepEncoderから得られた潜在視覚トークン(latent vision token)からオリジナルのテキスト表現を再構成する
データ
OCR 1.0
インターネットから収集した、約100言語・30Mページの多様なPDF
中国語+英語が約25Mでその他が5Mページ
二種類のアノテーションを実施
- 荒いアノテーション:fitzから得られる情報
- 光学的なテキスト、特に少数言語に対して
- 細かいアノテーション(中国語と英語の2Mページ)
- 高度なレイアウトモデル(PP-DocLayout)とOCRモデル(MinerUやGOT-OCR2.0)を使用してアノテーション

OCR 2.0
チャートや化学式、平面幾何学の解析データをOCR 2.0と呼ぶ
- チャート
- pyechartsとmatplotlibを使用して10M画像をレンダリング
- 線グラフ、棒グラフ、円グラフ、複合グラフをカバー
- 化学式:PubChemのSMILES形式からRDKitで画像化
- 平面幾何学画像:Sloe Perceptionで生成
一般的なビジョンデータ
DeepSeek-VL2に倣って、キャプション、検出、グラウンディングなどのタスクに関連するデータを生成
テキストのみデータ
社内のテキストのみの事前学習データを10%導入
学習方法
- DeepEncoderを独立して学習
OCR1.0, OCR2.0, LAIONで学習
- DeepSeek-OCRを学習
上記のデータで学習
結果
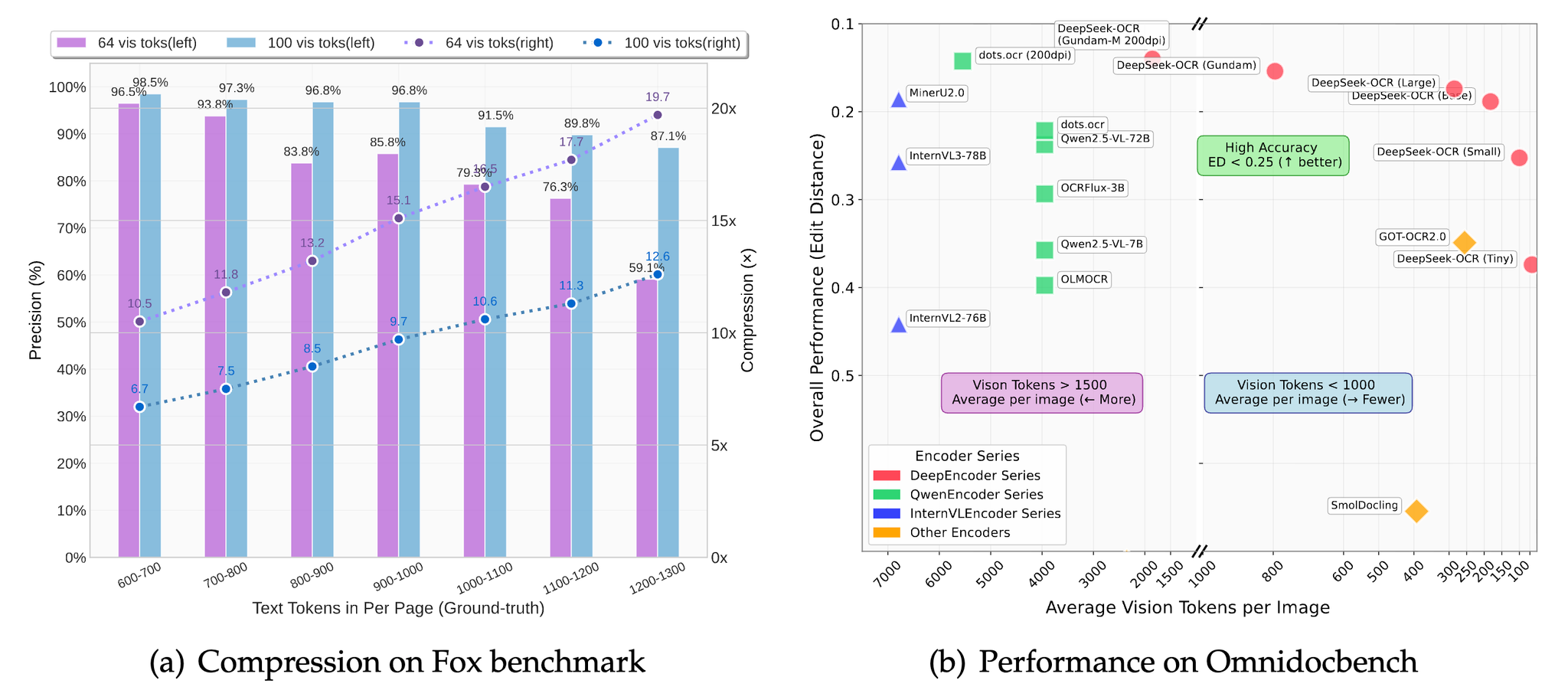
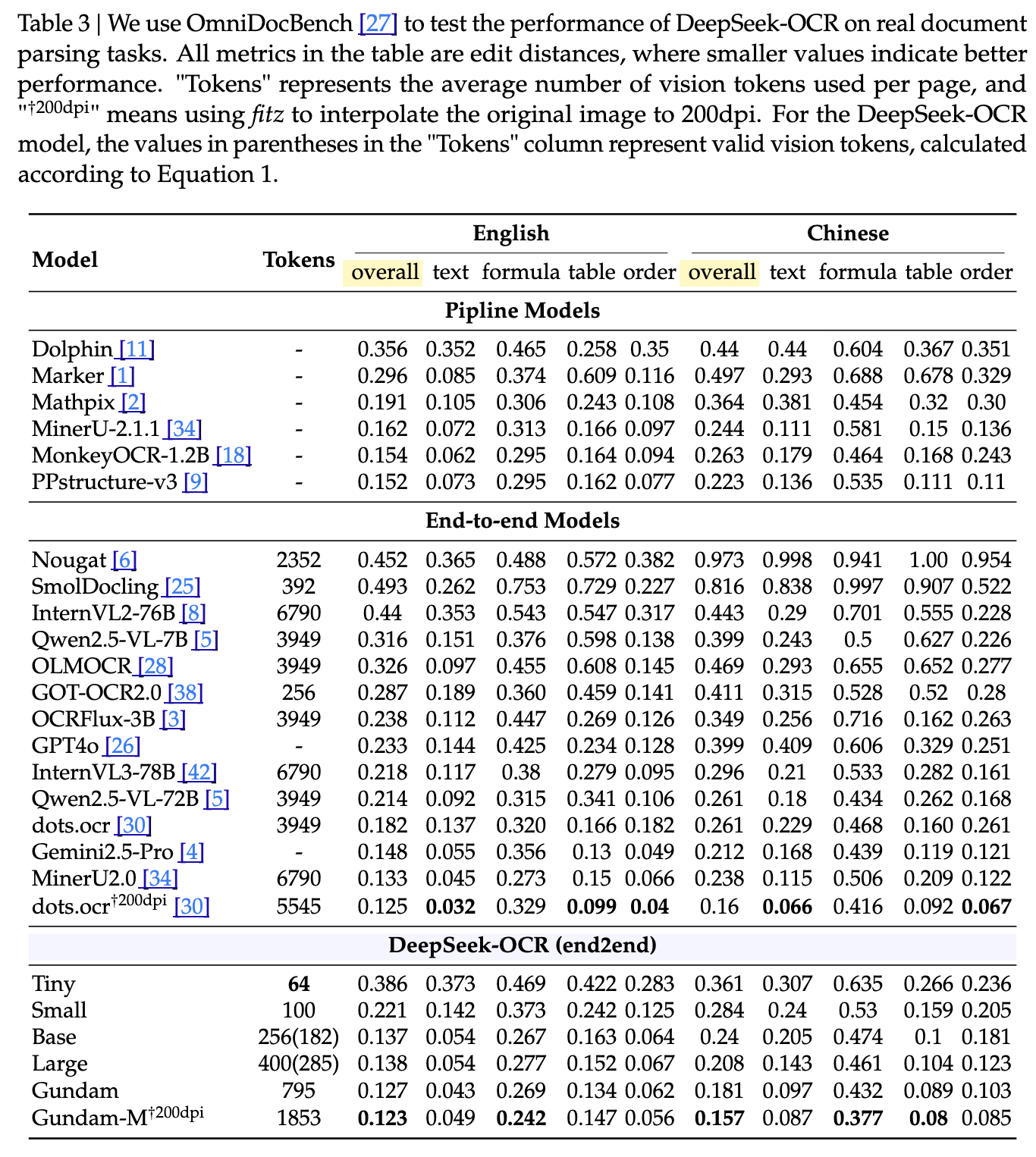
↓画像中の文字やグラフの数値が抽出できてる

@Hiromu Nakamura (pon)
[blog]Benchmarking AI Agents: The Challenge of Real-World Evaluation

論文より引用
概要
- 既存のベンチマークはビジネスにとって最も困難な部分、つまり複雑な内部データベースとのやり取りを回避している。
- Tau-benchとTau2-bench は、ローカルJSONファイルとして保存された模擬データベースを使用して、カスタマーサポートの会話をシミュレート。
- エージェントはツールを介して読み書きでき、評価では最終的な回答と結果のデータベース状態の両方がチェックされる。
- ローカルJSONファイルでデータベースをモック化し、会話出力とデータベース状態の変化の両方を検証する
- 重要なのは、ユーザーとユーザーエージェントのインタラクションもシミュレートし、現実世界のやり取りを模倣している点。
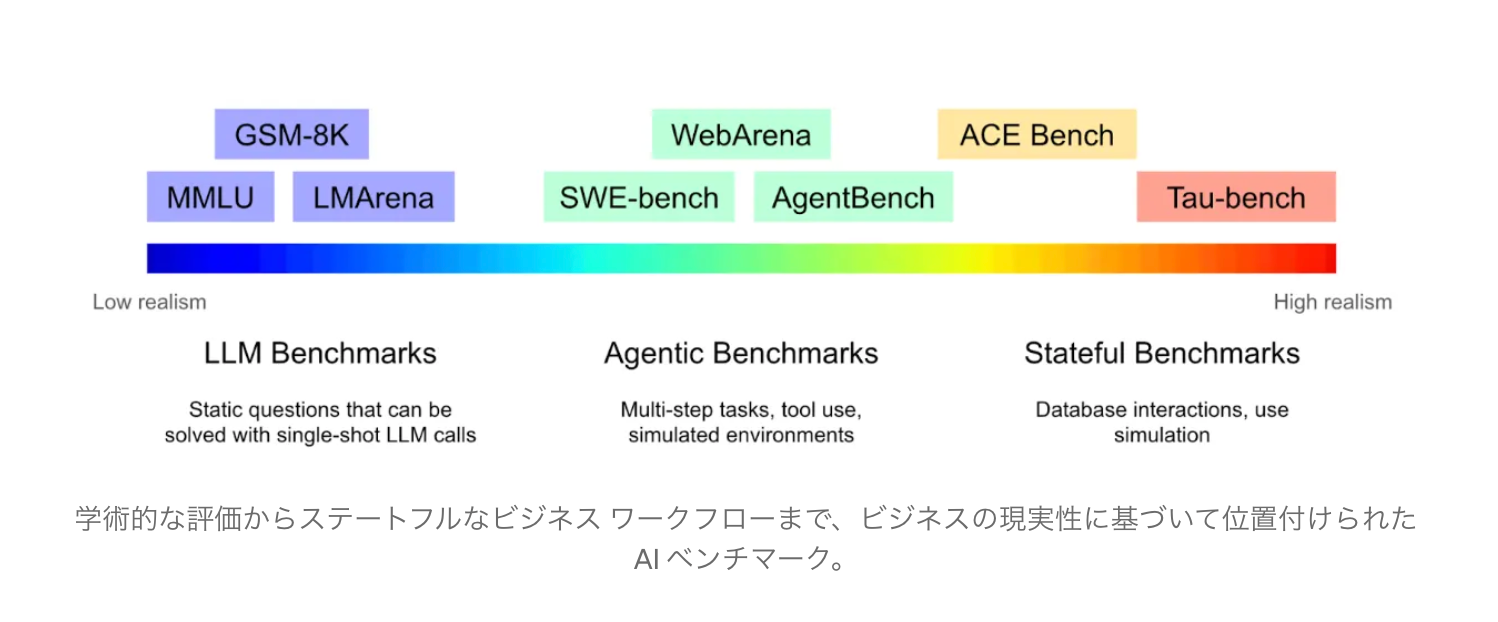
実際のビジネスワークフローにステートフルベンチマークを適応させる
- 制御された状態ライブラリの構築は最も難しい部分
- 実際のツールとデータベースの使用を検討しますが、ユーザー (および関連するすべてのデータ) を本番環境からベンチマーク環境にコピーすると、次のような課題が生じます。
- データモデルは複雑で進化し続けており、それを複製し、コピーとオリジナルとの整合性を維持するのは容易ではありません。
- テスト実行は冪等にする必要があります。例えば、エージェントが1回のテスト実行でデータベースに書き込みを行った場合、次のテスト実行ではデータベースに影響を与えないようにする必要があります。
- 匿名化も容易ではない。データの一貫性を保つ必要がある。
- [pon]確かに、pre-prodあっても書き込みが発生するテストの場合、それのcleanupがいるのか。。。きついな。。。
[pon]ステートフルエージェントの評価…。確かにかなりソフトウェアエンジニアリング力問われる
@Akira Manda(zunda)
[論文]Enabling Personalized Long-term Interactions in LLM-based
Agents through Persistent Memory and User Profiles
サマリー
何を解決したか
現在のLLMエージェントはパーソナライズが不十分 → 過去の対話を活かせず、ユーザー個別対応ができない
どう解決したか
3つの統合アプローチで実現:
- マルチエージェント協調(動的な適応)
- 3層メモリシステム(長期的一貫性)
- 進化するユーザープロファイル(個別対応)
成果
- 従来RAGより検索精度+20%向上
- ユーザーがパーソナライゼーションを実感(5日間スタディ)
- パーソナライゼーションの技術要件を体系化
問題設定と研究アプローチ
システム全体像
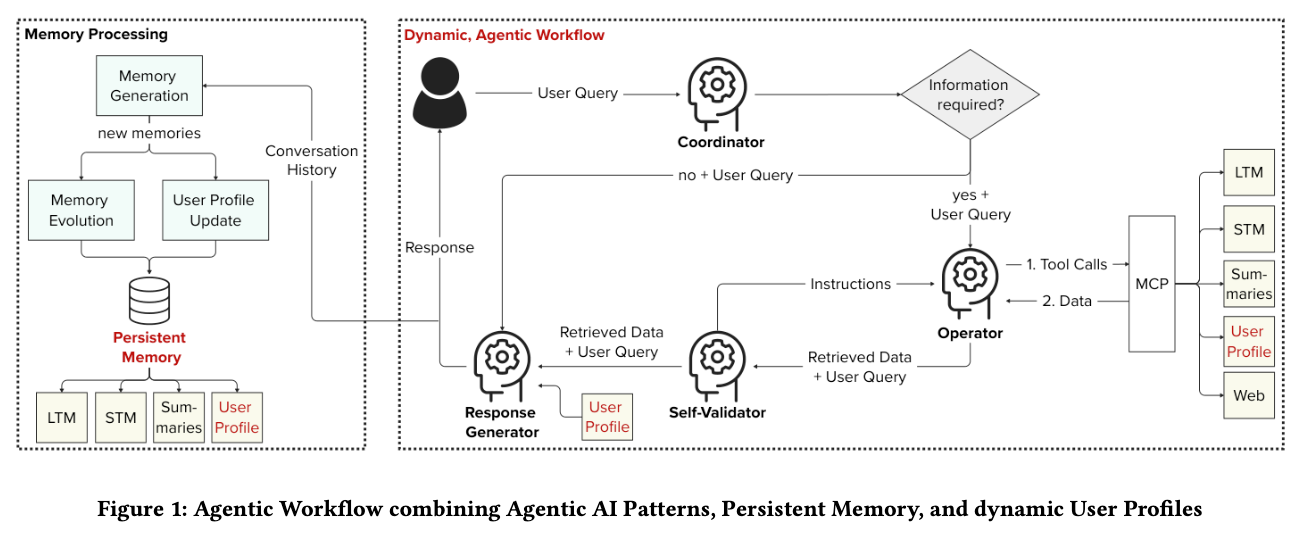
メモリ更新
3層のメモリ構造
STM (短期) → 最新の会話をそのまま保存
↓
Summaries → 主要トピックを要約
↓
LTM (長期) → 重要な情報のみ保存(埋め込みベクトル化)
LTMへの保存内容
| 要素 | 内容 |
|---|---|
| 埋め込み | 会話の要約をベクトル化 |
| タグ | LLMが生成した意味タグ(例:"料理", "レシピ") |
| 時刻 | いつの会話か |
| 関連メモリTop-5 | 意味的に関連する他のメモリへのリンク |
更新の流れ
会話終了
↓
LLMが要約を生成
↓
タグを自動生成
↓
LTMに保存 + 関連メモリTop-5を計算
↓
関連メモリ側のリンクも自動更新
検索での活用
ユーザー: "最近料理について何した?"
↓
タグで拡張検索: ["最近", "料理", "活動"]
↓
User Profileで絞り込み: 興味="料理" → 関連度UP
↓
ヒットしたメモリの関連Top-5も取得
↓
より正確な情報を返答
評価と結果
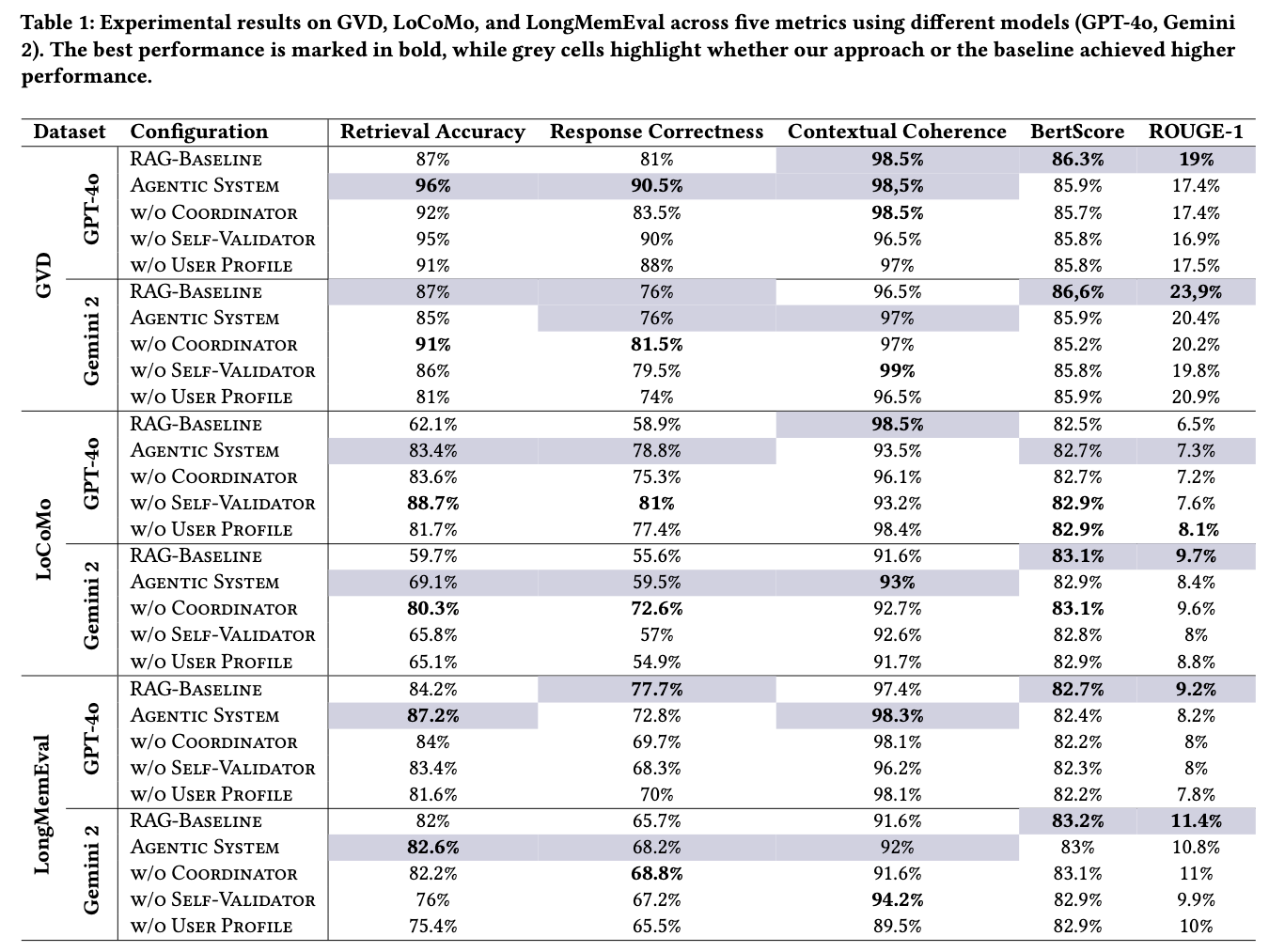
検索精度(Retrieval Accuracy)
LoCoMo: 62% → 83% (+21%) ★
GVD: 87% → 96% (+9%)
LongMemEval: 84% → 87% (+3%)
| 除去 | 結果 | 結論 |
|---|---|---|
| User Profile | 検索-5.6%、応答-2.8% | 必須コンポーネント |
| Coordinator | GPT-4o: 悪化 / Gemini 2: 改善 | △ モデル依存 |
| Self-Validator | 軽微な影響 | △ ノイズ対応で有用 |
実ユーザー評価(5日間スタディ)
参加者の声
肯定的評価
- 「過去の会話を覚えている」
- 「人間らしい対話」
- 「日を追うごとに理解が深まる」
改善点
- 応答が長い・一般的
- 曖昧な質問への対応不足
- プロアクティブ性の欠如:システムから質問してほしい
メインTOPIC
@ShibuiYusuke
Multi-agent Architecture Search via Agentic Supernet
- GitHub: ‣
TLDR
- 「単一の最適なシステムを探す」という考え方から、「アーキテクチャの確率的・連続的な分布を最適化する」という新しいパラダイムへと転換
- Agentic Supernet: 様々なエージェントの操作(オペレータ:CoT, ReAct, Debateなど)を多数内包する、確率的で連続的なアーキテクチャの巨大なネットワーク
- 動的なサンプリング: MaASはユーザーからのクエリ(質問)を受け取ると、その内容(難易度やドメイン)に応じて、Agentic Supernetから最適なエージェント構成(サブネットワーク)を動的にサンプリング
- コストを考慮した最適化: トレーニング中、MaASは環境からのフィードバック(生成された回答の質やコスト)に基づき、スーパーネットの分布と各オペレータを共同で最適化。これにより、高品質な解を低コストで生成するアーキテクチャが優先されるようになる
- 高いパフォーマンス: 既存の手法(手動・自動)と比較して、性能が0.54%~16.89%向上
1. Introduction
背景と動向
- 単一AIエージェントの成功。複数のエージェントを協調または競合させるマルチエージェントシステム(MAS)が個々のエージェントの認知能力や知的ポテンシャルを超えることが示唆
- しかし初期のMAS(例: CAMEL, AutoGen, MetaGPT)は、プロンプトエンジニアリングやエージェント間の通信パイプラインなど、手作業による設定に大きく依存したため、多様なドメインへの迅速な適応が制限
既存の自動化手法とその課題
- 近年の研究はMAS設計の自動化へと移行。プロンプトの最適化 、エージェント間通信の最適化 、エージェントプロファイルの自己進化等々。特定側面を自動化する手法が登場。
- ADAS、AgentSquare、AFlowといった最新の手法は、探索空間を広げ、単一で複雑なエージェントワークフローを最適化することで、手動設計のシステムを上回る性能を達成
- しかし、これらの「one-size-fits-all(画一的)」なシステムを探索するアプローチには2つの大きな課題がある
- リソース効率の悪さ: 簡単な問題(例: 小学生レベルの算数)にも、複雑でリソースを大量に消費するシステムを適用してしまい、トークンコストやLLMの呼び出し回数が不必要に増大
- 複数ドメインへの対応困難: ファイル読解やWeb検索など、性質の異なるタスクが混在するベンチマークでは、全てのタスクに最適な単一のシステムは存在しない
本研究の提案:MaASとAgentic Supernet
- これらの課題に対し、本研究は「単一の最適なシステム」を探すのではなく、「マルチエージェントシステムの分布」を生成・最適化するという新しいパラダイムを提案
- 「Agentic Supernet」という概念を導入。膨大な数の候補となるMASを内包する、確率的で連続的なアーキテクチャの分布
- このスーパーネットを基盤とする自動化フレームワーク「MaAS (Multi-agent Architecture Search)」を提案。MaASは、与えられたクエリ(質問)に応じて、スーパーネットから適切なMASをサンプリングし、高品質な解と最適なリソース配分を実現

2. Related Work
- LLMエージェントとエージェントシステム: AutoGenやLLM-Debateなどの初期のMASは、手作業による設計に大きく依存しており、未知の課題への適応性に制約あり
- エージェントシステムの自動化: 既存の自動化研究は、(1)プロンプト最適化、(2)エージェント間通信、(3)エージェントプロファイリングの3つに大別。
- AFlowなどの最新手法は、MCTS(モンテカルロ木探索)などを用いてMASのワークフロー自動化を実現したが、依然として単一の最終システムを探索するパラダイムに従う
- AutoMLとの関連: エージェントシステムの自動化の歴史は、AutoML、特にNAS(ニューラルアーキテクチャ探索)の進展と類似。
- NASで用いられた強化学習、進化的アルゴリズム、MCTSといった技術が、エージェント自動化にも応用。
- NASの分野では、これらのブラックボックス的な手法は、最終的に効率的な「スーパーネット」を用いた手法に取って代わられた。
- 本研究は、この着想に基づき、初めてAgentic Supernetを活用したMAS探索フレームワークを提案
3. Methodology
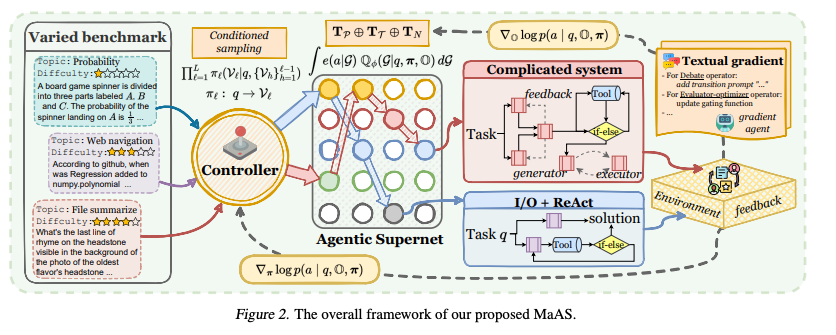
- MaASはクエリを入力として受け取り、コントローラーを活用して、クエリごとにagentic supernetからサブネットワーク(カスタマイズされたマルチエージェントシステム)をサンプリング
- サンプリングされたシステムでクエリを実行後、MaASはフィードバックを受け取り、スーパーネットのパラメータ化された分布とagentic operatorを共同で最適化
3.1. Preliminary
- MaASの探索空間と最適化の目的を形式的に定義
- Agentic Operator
- MaASの基本的な構成要素(ビルディングブロック)
- 単なるLLMの呼び出しではなく、複数のLLM呼び出しやツール利用を含む複合的なプロセス。single/multi-agent workflow含む
- 例:「CoT(Chain-of-Thought)」、「Multi-agent Debate」、「ReAct(推論と行動の相乗効果)」等が、それぞれ一つのオペレータとして定義される

- Multi-agent System, MAS
- 選択された複数の「エージェントオペレータ」の集合(グラフのノード)と、それらの接続関係(グラフのエッジ)で構成される有向非巡回グラフ(DAG)
- どのオペレータをどの順番で実行するかというワークフロー全体が一つのMAS
- Agentic Supernet
- 本研究の中核となる概念
- 考えられる全てのMASを内包する、確率的かつ連続的なアーキテクチャの巨大な分布(ネットワーク)。探索空間
- 具体的には、L層の階層構造を持ち、各層でどのオペレータが選択されるかの確率分布を持つ。無数のMASの組み合わせの中から、最適なものを確率的に探索することが可能

- 問題の定式化
- 従来の手法が「単一の最適なMASを見つける」ことを目的としていたのに対し、MaASでは与えられたクエリに対して、システムの性能を最大化し、コストを最小化するようなMASを生成する条件付き確率分布を最適化することを目指す

3.2. Agentic Architecture Sampling
- クエリが与えられた際に、スーパーネットからどのようにして具体的なMASを一つ選び出す(サンプリングする)か
- コントローラーネットワーク ( )
- クエリ 、スーパーネットの確率分布 、利用可能なオペレータ を入力として受け取る
- クエリの内容と、前の層で選択されたオペレータの情報を考慮して、現在の層でどのオペレータを選択するかを決定
- 下記のプログラムのとおり、pytorchで書かれたネットワーク
‣
- 早期終了オペレータ ( )
- 簡単なクエリは複雑なワークフローを必要としないため、「早期終了オペレータ」を導入。サンプリング中にこのオペレータが選択されると、その時点でアーキテクチャの構築を打ち切り、不要なリソース消費を防ぐ
- サンプリングプロセス
- Mixture-of-Expert (MoE) スタイル のネットワークを利用
- 1層に複数のオペレータが入る、多層ネットワーク
- クエリと過去の層の情報を基に、各オペレータの「活性化スコア」を計算
- スコアが最も高いオペレータから順に有効化していき、有効化されたオペレータのスコアの累積値が閾値を超えるまでこのプロセスを繰り返し
- クエリの複雑さに応じて、各層で選択されるオペレータの数が動的に変わる仕組み

3.3. Cost-constrained Supernet Optimization
- サンプリングしたMASを実行し、その結果(フィードバック)を用いてスーパーネット自体をより良く更新(最適化)する方法
‣
‣
- 最適化の目的関数
- MASが正しい答え を生成する確率 を最大化し、同時にそのMASの実行コスト を最小化することを目指す

- 分布 の勾配推定
- MASの実行は外部APIの呼び出しなどを含むため、微分不可能
- empirical Bayes Monte Carloを用いて、分布 に関する勾配を近似的に計算
- 複数のMASをサンプリングし、それぞれの「コストを考慮した重要度重み」を計算
- 高品質な解を低コストで生成したMASほど重みが大きくなり、分布 がそのようなMASをより生成しやすくなるように更新
- ステップ1:Sampling
- まず、現在の確率分布に従って、複数の異なるMASの候補 () をランダムにサンプリング。これが「モンテカルロ法」の核。 exactな計算ができない代わりに、試行(サンプリング)を重ねて全体の傾向を掴もうというアプローチ
- ステップ2:評価と重み計算
- 次に、サンプリングした各MAS () を実際にクエリで実行し、その性能とコストを評価。それぞれのMASに対して「コストを考慮した重要度重み (cost-aware importance weights) 」を計算
- Gk正規化された性能:
- 今回サンプリングした他の全てのMAS候補と比較して、がどれだけ優れた解を生成したかを示す。あるMASが単に良い解を出しただけでなく、他の候補よりも「相対的に」優れているほど、この値は大きくなる(empirical Bayes)。観測されたデータ(他のサンプルの性能)を使って、あるサンプルの良さを事後的に評価
- Gk正規化されたコスト:
- 他のMAS候補と比較して、がどれだけ低コストだったかを示す
- λ: 性能とコストのどちらを重視するかを調整するトレードオフパラメータ
- 結果として、 は「他の候補と比べて、性能が高く、かつコストが低いMAS」ほど大きな正の値を取る
- ステップ3:勾配の推定と更新
- 最後に、ステップ2で計算した重要度重みを使って、全体の勾配を推定
- 各サンプルが持つ「本来の勾配の方向 」に対して、その重要度で重み付けをして足し合わせる
- が大きな正の値の場合、そのMAS () がサンプリングされやすくなる方向へ、確率分布を強く更新
- が負の値(性能が悪くコストが高い)の場合、そのMASがサンプリングされにくくなる方向へ更新
- このプロセスを繰り返すことで、スーパーネットの分布は、徐々に高性能かつ低コストなMASを生成するように進化していくことを期待
- オペレータ の勾配推定 (テキスト勾配)
- オペレータ自体(プロンプトやツール利用のロジック)も微分不可能
- この問題を解決する「テキスト勾配 (Textual Gradient)」
- 性能が悪かったオペレータを分析し、改善案をテキスト形式で生成する
- 生成される改善案には、プロンプトの更新、モデルの温度設定の変更、オペレータの構造変更(分割、統合など)が含まれる
- スーパーネットの接続確率だけでなく、構成要素であるオペレータ自体も自己進化していくことが可能
- テキスト勾配は、数値的な勾配ベクトルを計算する代わりに、勾配エージェントが、オペレータの改善案をテキスト形式で生成する
- サンプリングされたMASがクエリを実行し、その結果(フィードバック)が悪かった場合に、勾配エージェントが「どうすればこのオペレータはもっと良くなるか」を分析し、以下の3種類の「勾配」をテキストで出力
- プロンプト勾配 ():
- オペレータ内のプロンプトを改善
- 例:Refine(洗練)プロセスに few-shot の例を追加する
- 温度勾配 ():
- LLMの出力の多様性を制御するパラメータを調整
- 例:Ensemble(アンサンブル)で使うLLMのを下げて、出力を安定させる
- ノード構造勾配 ():
- オペレータの構造自体を変更
- 例:オペレータを分割、統合、あるいは内部ロジックを変更。「Debate(討論)オペレータに、討論者役のLLMを1体追加する」
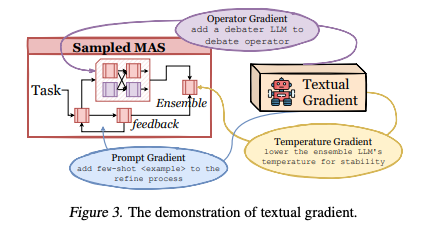

Text gradientのプロンプト
4. Experiments
4.1. Experiment Setup
- タスクとベンチマーク: 数学(GSM8K, MATH)、コード生成(HumanEval, MBPP)、ツール利用(GAIA)の3ドメイン、6つの公開ベンチマークで評価
- ベースライン: 比較対象として、(1)単一エージェント実行手法、(2)手動設計のMAS、(3)(部分的または完全な)自律型MASの3種類、計14以上の手法と比較
- 実装詳細: LLMにはgpt-4o-miniやQwen-2.5-72b-instructなどを使用し、API経由でアクセス。スーパーネットの層数は4と設定
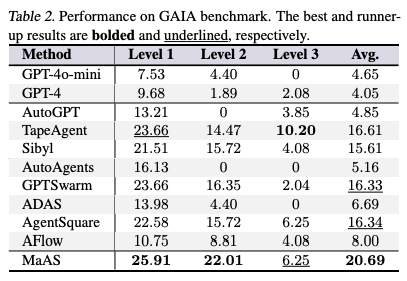
4.2. Performance Analysis
- MaASは全てのタスクドメインで最高のパフォーマンスを達成
- 手動設計の手法より平均3.90%~6.40%、既存の自動化手法より平均2.07%~8.26%高い性能

- 特に、多様なドメインのタスクを含むGAIAベンチマークにおいて、MaASはクエリに応じて適応的にシステムをサンプリングできるため、他の手法が性能向上に苦戦する中で、大幅な改善(Level 1で18.38%、Level 2で17.61%)を達成
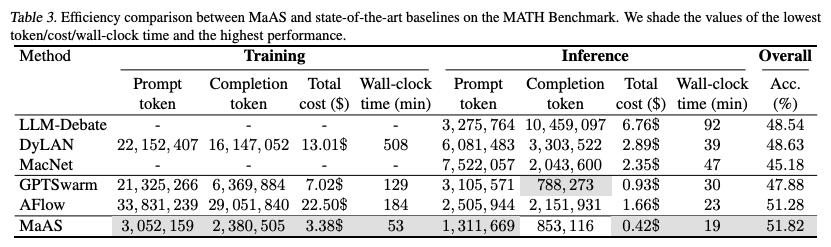
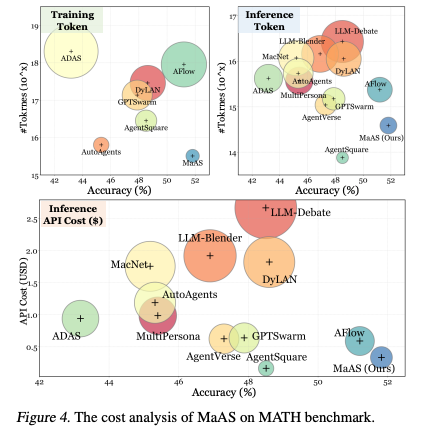
4.3. Cost Analysis
- トレーニングコスト: MaASは他の最適化指向のワークフローの中で、最も少ないトレーニングトークン消費で最高の精度を達成
- 例:AFlowはMaASと同等の精度で、トレーニングのAPIコストはMaASの6.8倍(22.50ドル vs 3.38ドル)
- 推論コスト: MaASは最高の精度を達成しながら、推論時のAPIコストは0.42ドルと非常に低コスト。クエリの難易度に応じて動的にリソースを割り当てるAgentic Supernetの能力によるもの
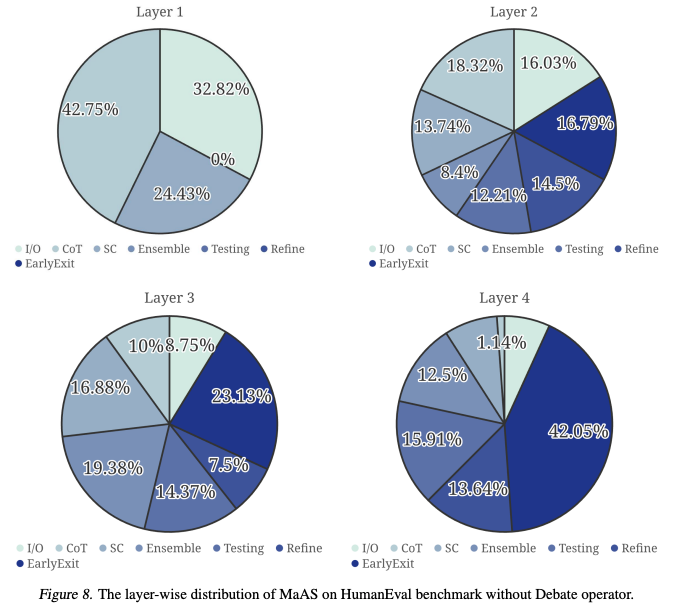
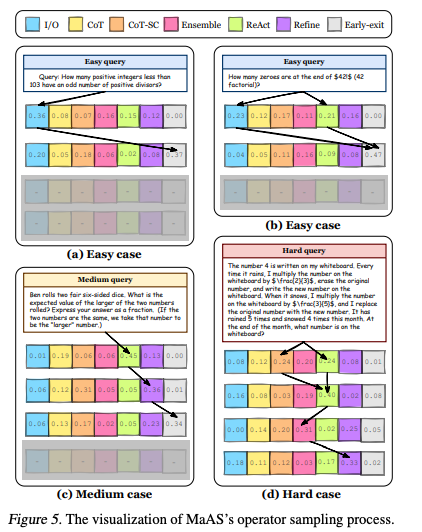
4.4. Case Study
- 簡単なクエリに対して、MaASは2層目で「早期終了オペレータ」を選択し、確率0.37や0.47でサンプリングを打ち切ることを学習
- 一方、より難しいクエリに対しては、追加の層をサンプリングし、クエリの難易度に応じてMASをカスタマイズする能力を示す
4.5. Framework Analysis
- 感度分析: スーパーネットの層数は4、サンプリング回数は4が性能とコストのバランスが良い
- アブレーションスタディ: 「テキスト勾配」を取り除くと性能低下が最も大きく、MaASの自己進化能力の重要性が確認。
- また、「早期終了」や「コスト制約」を取り除くと性能への影響は小さいものの、推論コストが不必要に増加
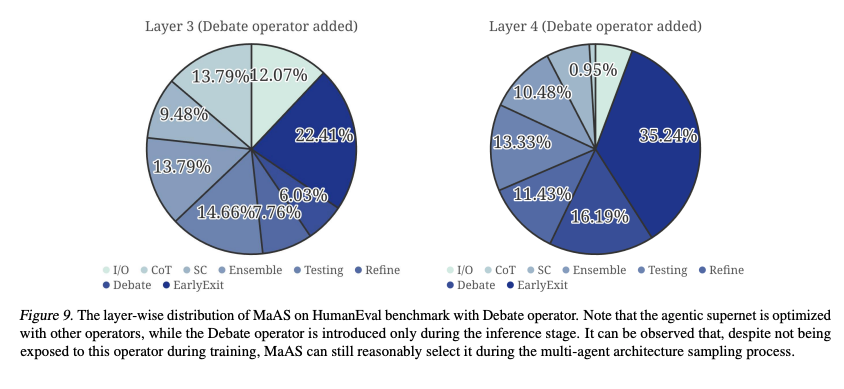
- 転移可能性分析: gpt-4o-miniで最適化されたスーパーネットは、Qwen-2.5-70bなどの他のモデルや、異なるデータセットに対しても良好な性能を示し、高い転移性を持つことが確認
- 帰納的分析: トレーニング時に使用しなかった「Debate」オペレータを推論時に追加した場合でも、MaASはそれを適切な割合で合理的に選択・活用できることが示され、未知のオペレータへの汎化能力(帰納的能力)を持つことが実証