
2025-10-28 機械学習勉強会
今週のTOPIC[論文]Scaling Laws for Differentially Private Language Models[論文] Human-in-the-loop or AI-in-the-loop? Automate or Collaborate?[oss] johannschopplich/toon[blog] LLMのキモい算術[blog]How to Make LLMs Shut Up[論文] Thought Communication in Multiagent Collaboration[論文]Deep Self-Evolving ReasoningメインTOPICTraining-Free Group Relative Policy Optimization概要IntroductionTraining-Free GRPO MethodologyRL AlgorithmGroup Advantage ComputationOptimization報酬設計プロンプト実験結果Cross domain transfer analysis計算コスト結論感想
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Yuya Matsumura
[論文]Scaling Laws for Differentially Private Language Models
- LLMに生のデータを食わせて学習するのはリスクあるよね。学習時に入力データにノイズを食わせて匿名化して学習しよう!差分プライバシー!
- DP適用時は通常のLLMとは異なるスケーリング則。それを明らかにしたよ。
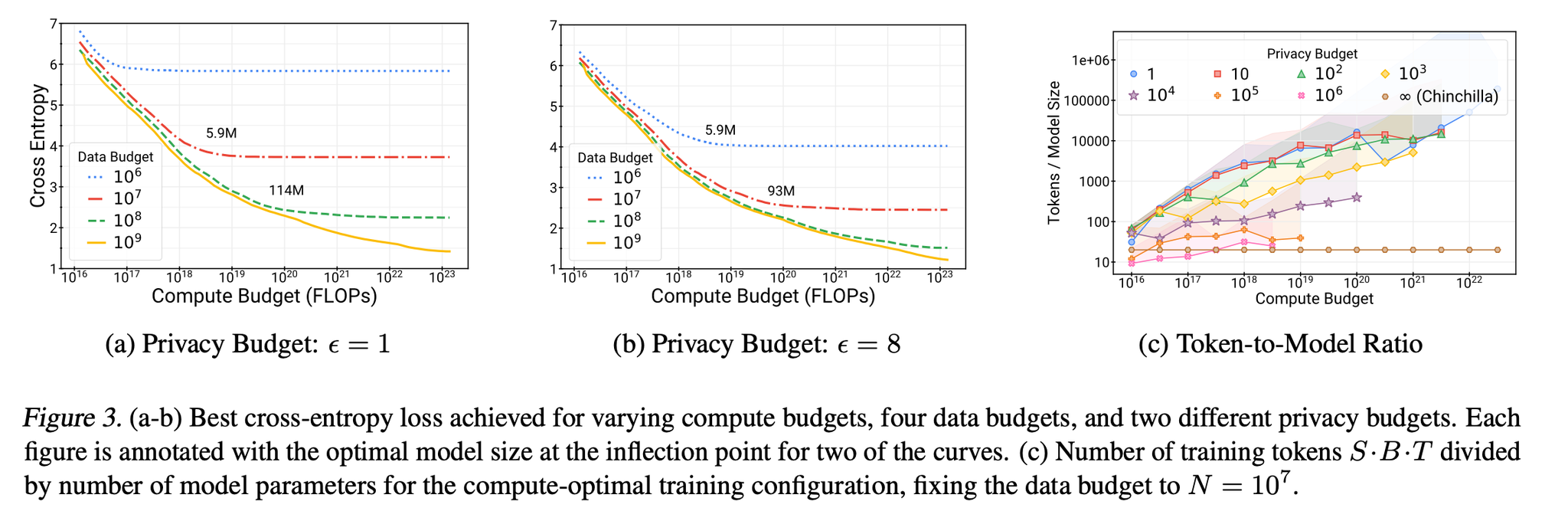
- 同じデータ量・計算リソースの場合、DPの最適なモデルサイズは通常の10-100分の1。つまり大きいモデルの学習が大変。
- VaultGemma というDP適用モデルを作って公開したよ。
- 同じモデルサイズで比較すると性能は5年前のモデル同等くらいだよ。プライバシーを守った状態でのLLMの進化が待たれるね。
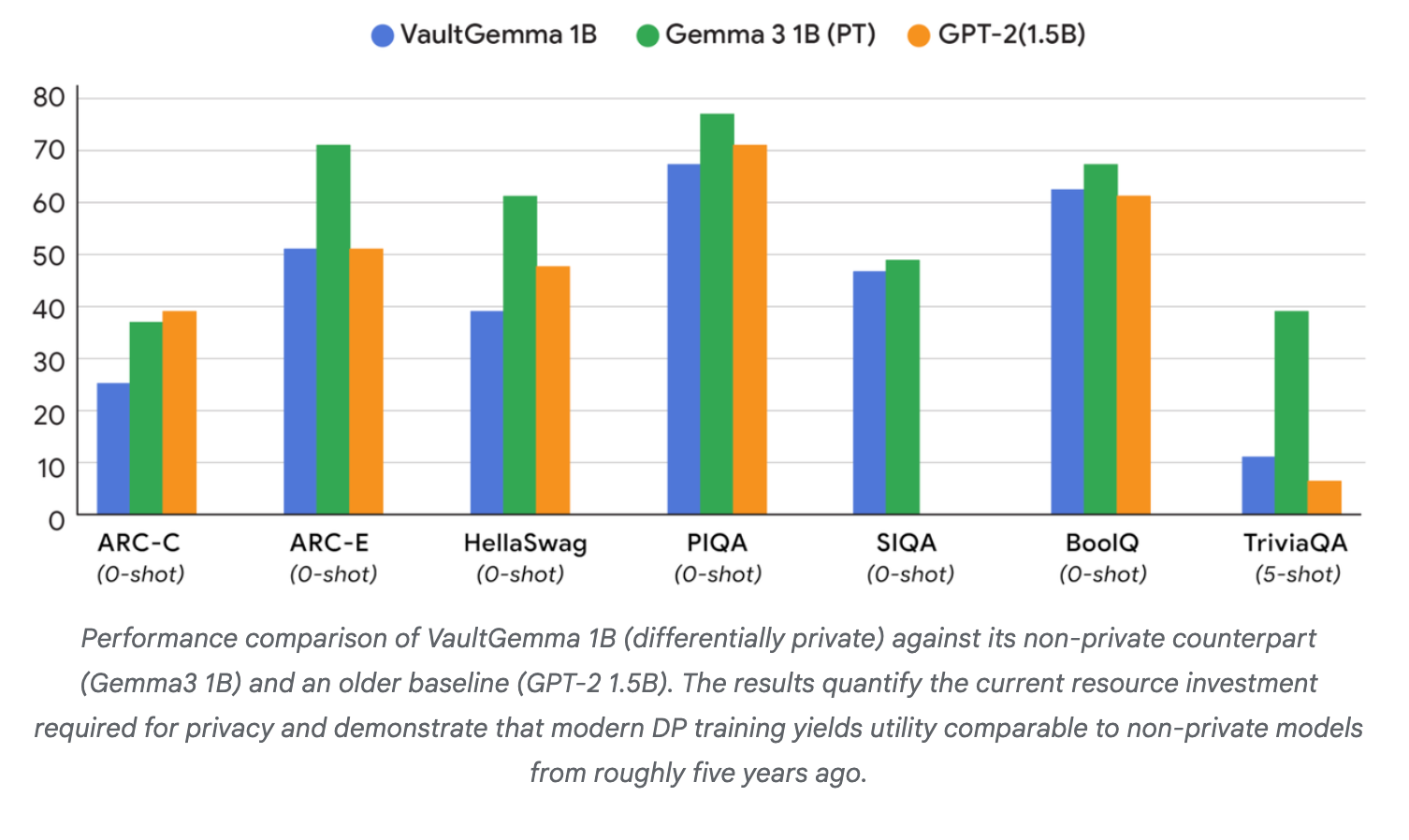
@Shun Ito
[論文] Human-in-the-loop or AI-in-the-loop? Automate or Collaborate?
- AAAI2025
- Human-in-the-Loop (HIL) に対して AI-in-the-Loop (AI2L) という概念を提唱
- HIL: AI/MLが主体で人間が補助的に組み込まれている
- 精度を上げるために人間の知識・フィードバックを使う
- Active Learning
- Weakly Supervised
- あくまで目的はAI/MLがより正しい結果を出せるようにすること
- AI2L: 人間が主体でAIシステムが補助的に組み込まれている
- あくまで人間が意思決定するためのサポートとしてAIが使われる
- AIが示した情報を元に人間が最終判断を下す
- 人間とAIが同じループの中にあるもの全般がHILと呼ばれているものの、人間が主体的な意思決定者であるものはAI2Lと呼んだ方がいいのでは? という主張
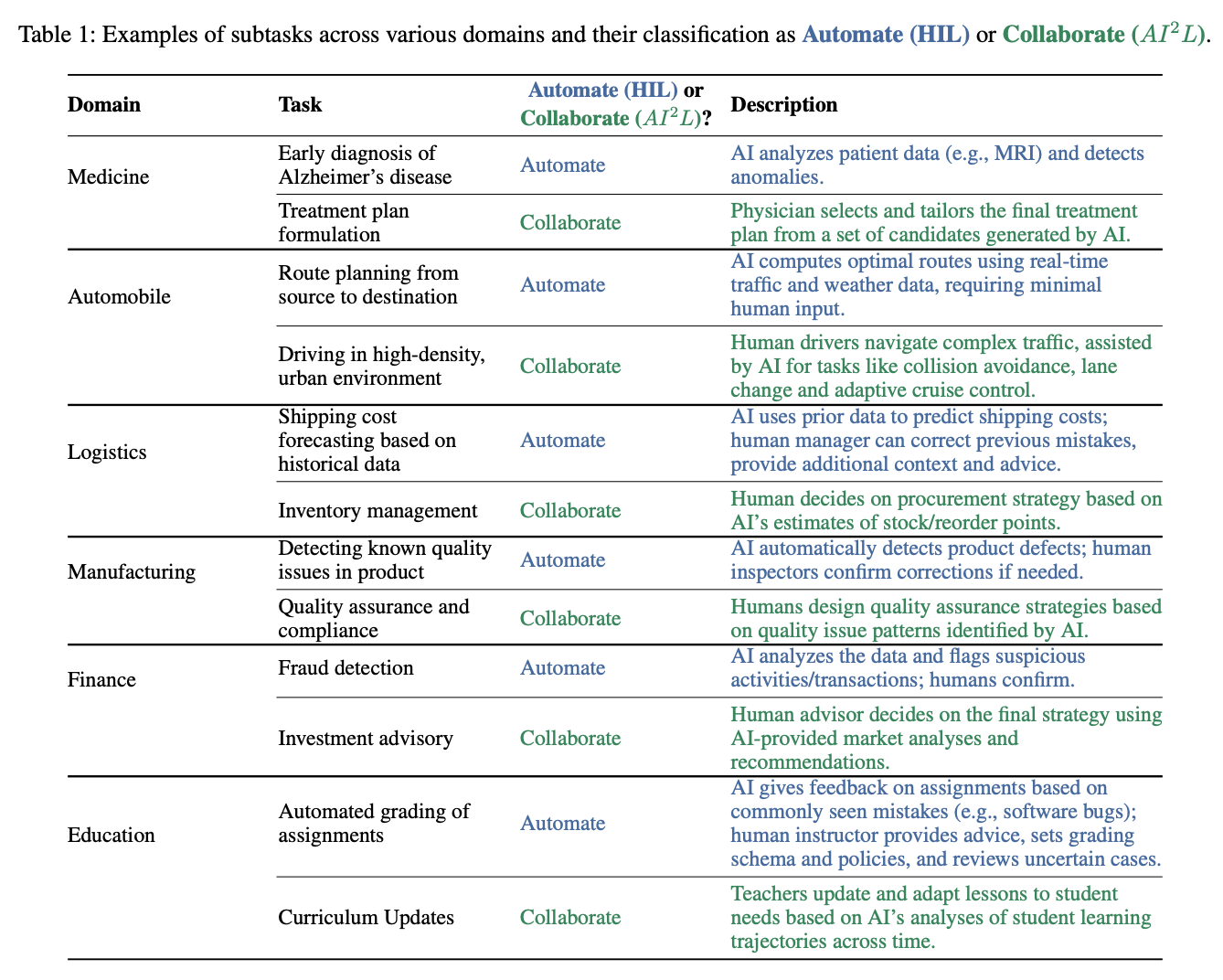
- タスクの例
- 医療
- HIL: MRIから異常検知
- AI2L: AIが出した情報を元に医師が治療方針を決定
- 運転
- HIL: 目的地への最適ルートの推定
- AI2L: AIが衝突しないように補助しつつ、人間が混雑した都会の道路を運転
- AI2Lにおける評価指標
- AIの精度も大事ではあるが、人間中心のメトリクスも重要
- 説明・解釈可能性、インタラクティブ性、一般化能力、信頼性・透明性
- 人間にとってAIの提案内容や根拠が理解できるものかどうか、対話・協調がしやすい(効率的)か、人間がAIを信頼できるかどうか
- Ablation Studyが重要
- 組み込まれている様々な要素が、AIが人間の判断をどう変えたかを分析する必要がある。
- AIがどういう情報を提供したか、説明の内容や出し方、対話の仕方など…

その他
@Yosuke Yoshida
[oss] johannschopplich/toon

- 標準的なJSON形式は冗長でトークン消費量が多い
- TOONは同じ情報を少ないトークン数で表現できます
- 主な特徴
- 💸 トークン効率性: JSONと比較して通常30~60%少ないトークン数で表現可能
- 🤿 LLM向けのガードレール機能:明示的な長さ制限とフィールドリストにより、モデルが出力内容を容易に検証可能
- 🍱 最小限の構文:冗長な句読点(中括弧、角括弧、ほとんどの引用符)を削除
- 📐 インデントベースの構造: 読みやすさを向上させるため、中括弧の代わりにスペースを使用します
- 🧺 タブ形式の配列: キーを一度宣言すれば、繰り返しなく行データをストリーム形式で追加できます
- ベンチマーク
- 検索精度
- 3種類のLLMを対象に、データ検索タスクで性能を評価
- TOONは86.6%の精度を達成し(JSONの83.2%と比較して)、同時にトークン使用量を46.3%削減
@Takumi Iida (frkake)
[blog] LLMのキモい算術
LLMが内部的にどうやって計算をやっているかを解説した記事。
真面目に計算してるわけじゃなくて、何が一番っぽいかというのを推論してる。
この論文では、{op1} - {op2}のプロンプトテンプレートを用意して、ガッと計算(推論)させてみると、第何層の何番目のニューロンがどういうときに発火するのかというのをはじめに観測してる。すると、
- 第24層の12439番目のニューロンは結果が150から180の間にあるときに発火する
- 第30層の1582番目のニューロンは結果の一の位が8のときに発火する
というようなことが観測できたらしい。
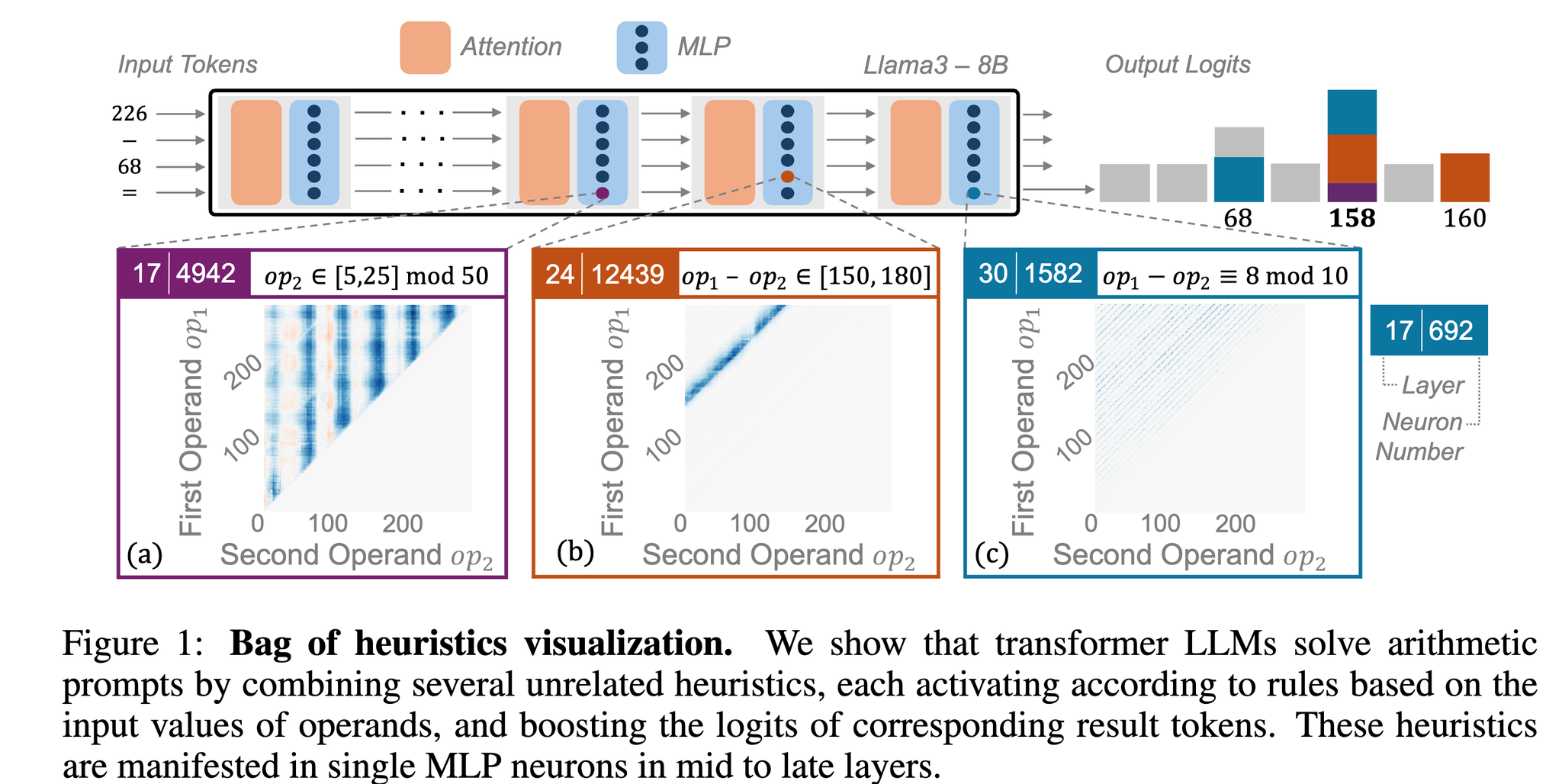
このとき、演算結果が158だったときには、それぞれのニューロンの発火が積み重なって、結果的に158が最も答えらしいぞ、ということになってLLMの推論結果としてでてくる。らしい。
{op1}や{op2}、あるいは評価結果が特定のパターンに当てはまるときのみ発火するニューロンのことをヒューリスティックニューロンと呼び、著者らはこういった粗い条件が無数に積み重なって答えにたどり着くのをヒューリスティックの束(bag of heuristics)と呼んでいる。
で、各層のヒューリスティックニューロンがどれくらい結果に寄与しているかはロジットレンズという方法で算出できる。
ざっくり言えば、各層の出力を最線形層に通せば、その時点でのトークンロジットや、その層のトークンロジットへの寄与がわかるというもの。
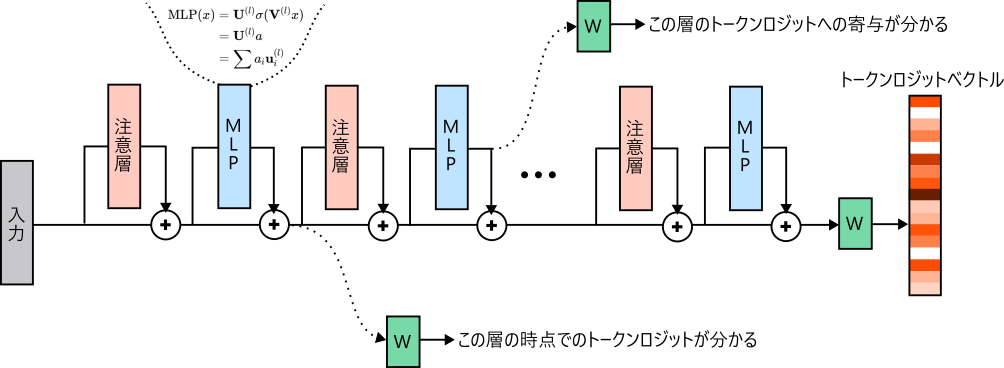
ヒューリスティックニューロン+ロジットレンズを使えば、LLMがどうして間違えているのかの分析に使える。
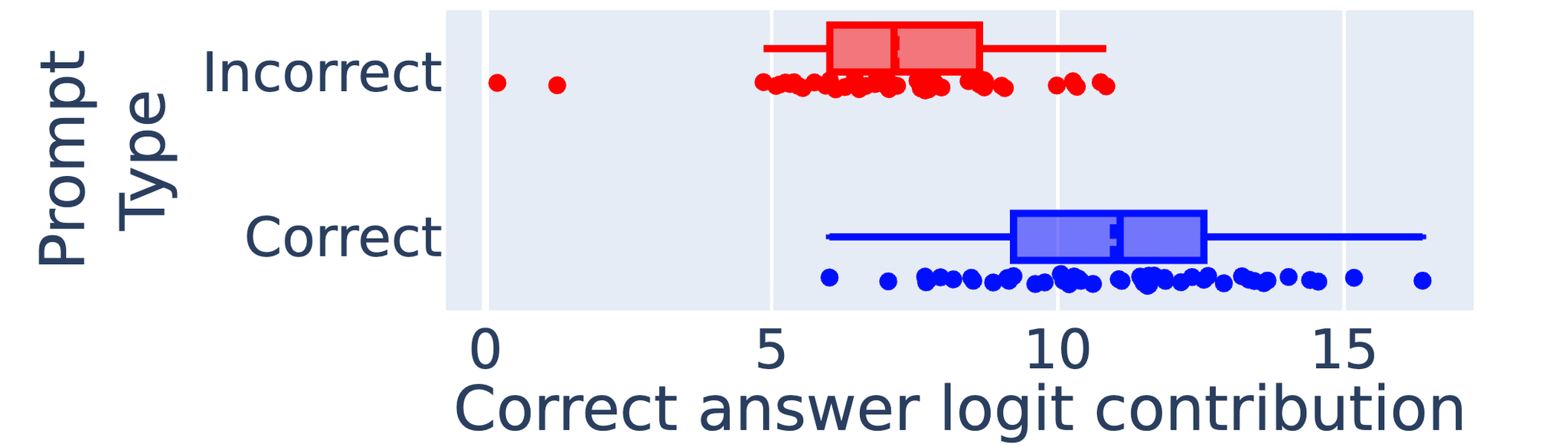
下図は、正しく推論できるプロンプト(Correct)と間違った結果を出すプロンプト(Incorrect)をそれぞれ50サンプル入力したときの、ヒューリスティックニューロンの寄与度を測った図。
Incorrectプロンプトの方は、正しいヒューリスティックニューロンの寄与度が平均して低くなることが確認できる。
→本来反応してほしいヒューリスティックニューロンが反応できなかった。
例えば、結果が158のときには一の位が8のときに反応するはずが、反応できなかったみたい
感想:
単純な四則演算ではなく、どれが一番答えらしいかというのを確率的に解いていて面白いとおもた
@Hiromu Nakamura (pon)
[blog]How to Make LLMs Shut Up
お世話になっているGreptileの記事。
課題
最も多く寄せられた苦情は、ボットがコメントをあまりにも多く残してしまうというものでした。
次のことが必要だった:
- Greptileが生成したコメントの数を減らす方法を見つけ出す
- つまり、どのコメントを削除するかを決めることが必要だった。
- つまり、各コメントの品質を評価する方法を見つける必要があった。
既存の Greptile のコメントを分析したところ、約 19% は適切、2% はまったく間違っており、79% は nits (技術的には正しいが開発者が気にしないコメント) であることがわかった。

数々の取り組みは失敗
- プロンプトでNITSを弾く
- LLM-as-a-Judge
- LLM に nit コメントの生成を止めさせることができなかったため、LLM がコメント + diff ペアの重大度を 1 から 10 のスケールで評価し、7 未満の評価を受けたコメントを単純に削除できるフィルタリング ステップを追加した。
- LLM自身の出力に対する判断はほぼランダムだった。ワークフローに全く新しい推論呼び出しが追加されたため、ボットの動作は著しく遅くなる。
ここまでの学び
- プロンプトは機能しません
- LLMは重症度評価が下手
- Nitsは主観的なものであり、定義や基準はチームによって異なります。
最後の試み:クラスタリング
最後の試みとして、開発者が対応/賛成/反対した過去のコメントをチームレベルで埋め込みベクトル化し、ベクトルデータベースに保存することにしました。その目的は、反対されたコメントの最小数と非常に類似したコメントを除外することです。
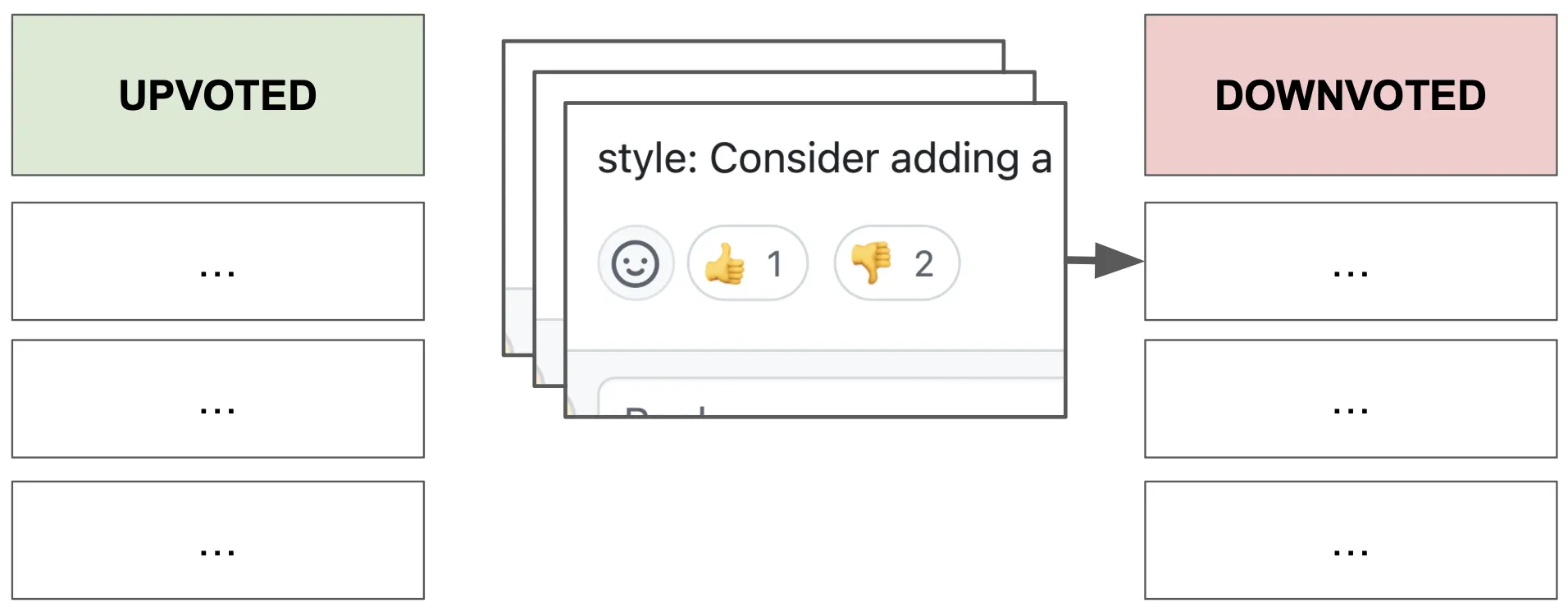
Greptile がコメントを生成すると、そのベクトル埋め込みを生成し、単純なフィルターに通しました。
- コメントのコサイン類似度が特定のしきい値を超え、固有の低評価コメントが少なくとも 3 件ある場合、そのコメントはブロックされます。
- 状況は同じですが、3 つの賛成
コメントがあれば、承認されます。
- どちらもない場合、または両方ともない場合、合格となります。
これはうまくった。ほとんどの「nits」は少数のクラスターに分類できることがわかった。
- ユーザーは「nits」コメントに低評価を付け、同じ種類のコメントに十分な数の低評価がされると、ボットはその種類の新しいコメントをフィルタリングできるようになる。
- この機能の導入から2週間以内に、既存ユーザーの対応率(Greptileのコメントのうち、開発者がマージ前に対応した割合)は19%から55%以上に上昇。
@ShibuiYusuke
[論文] Thought Communication in Multiagent Collaboration
TLDR
複数のAIエージェントが協調してタスクを解決する際に、従来の自然言語(テキスト)によるコミュニケーションの限界を克服するための新しいパラダイム「思考コミュニケーション(Thought Communication)」を提案
エージェントが生成するテキストの背後にある「潜在的な思考」を直接抽出し、共有することで、より効率的で誤解のない協調を実現する
論文では、この「思考」を理論的に回復可能であること(識別可能性)を数学的に証明し 、それを実現するための具体的なフレームワーク「THOUGHTCOMM」を開発
1. Introduction
- 言語は本質的に曖昧で情報が失われやすい(lossy)という制約
- LLMを用いたマルチエージェントシステムも同じ制約を引き継いでおり、テキストやその埋め込み表現を交換することでコミュニケーションしており、エージェント間の認識のズレや非効率な協調を引き起こす原因となる
- 本研究では、言語の限界を超えるために、人間でいう「テレパシー」のように、エージェントの心(mind)と心(mind)が直接対話する「思考コミュニケーション」という新しいパラダイムを提唱
- エージェントの行動や応答は、その背後にある目標、信念、推論プロセスといった「潜在的な思考」に基づいていると考えられる
2. Problem Formulation
Data-generating process
- エージェントの応答の元となる潜在的な概念を「思考 」と定義
- 例えば「荷物の多さ」「速さ」「時間厳守」といった複数の要素からなるベクトル
- エージェントがコミュニケーション直前に内部に持っている表現を「モデル状態 」と定義
- LLMの隠れ層の表現などに相当
- 「思考」から「モデル状態」が、未知の生成関数 によって生成されるというモデルを立てる
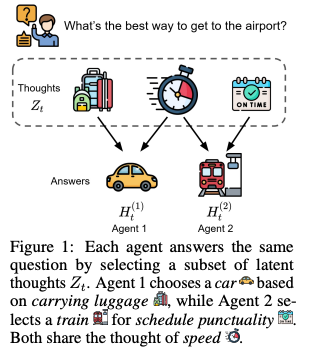
- 具体例
- 質問: 「空港へ行くのに最適な方法は?」
- 潜在的な思考 ( ): {荷物がある, 速さ, 時間通り}
- エージェント1: 「荷物」と「速さ」を重視 → モデル状態 を形成 → 「車」と応答
- エージェント2: 「速さ」と「時間通り」を重視 → モデル状態 を形成 → 「電車」と応答
- この例では、「速さ」が共有された思考、「荷物」や「時間通り」が各エージェント固有の(プライベートな)思考となる
The structure of thoughts
- 単に思考の内容を明らかにするだけでなく、「どのエージェントがどの思考を持っているか」という構造を理解することが重要
- この構造は、生成関数のヤコビアン行列(各思考がモデル状態の各要素にどれだけ影響を与えるかを示す行列)の非ゼロパターンによって表現できると定義
3. Identifiability Theory
- 観測されたモデル状態 から、本当に元の潜在的な思考 を正しく復元できるのか?
- 下記定理の証明は論文のAppendix参照
- 定理1:共有思考の識別可能性:
- 任意の2エージェント間で共有されている思考は、他の思考(プライベートな思考など)と混ざることなく、正しく分離して復元できる
- エージェント間のコミュニケーションの土台となる「共通認識」を正確に捉えることを保証
- 定理2:プライベートな思考の識別可能性:
- あるエージェントだけが持つプライベートな思考もまた、他のエージェントが持つ思考と混ざることなく、分離して復元できる
- 個々のエージェントが持つ独自の視点や知識を失うことなく活用でき、多様性に基づいた高度な問題解決が可能
- 定理3:思考の構造の識別可能性:
- 個々の思考だけでなく、「どの思考がどのエージェントに属しているか」という関係性の構造全体も(順序の入れ替えを除いて)一意に復元できる
- エージェントは他者が何を考えているかだけでなく、自分とどの程度思考が似ているか・異なっているかを構造的に把握
4. THOUGHTCOMM

Uncovering the Latent Thoughts
- 目的:各エージェントが生成した表面的な応答(テキスト)の背後にある、内的な「思考」をデータとして取り出す
- 入力データの収集:
- コミュニケーションを行う直前の各エージェント ( ) から、それぞれの「モデル状態 ( )」を収集
- 具体的には、エージェントが自身の応答文を生成した際の、最後のトークンの隠れ層表現(内部的なベクトル表現)に相当
- 集められた全エージェントのモデル状態は、一つの大きなベクトルに連結
- 潜在思考へのエンコード:
- この連結されたモデル状態ベクトルを、「スパース正則化オートエンコーダ」(ニューラルネットワーク)に入力
- オートエンコーダのエンコーダ部分 ( ) が、高次元のモデル状態から、より低次元で本質的な情報を持つ「潜在的な思考 ( )」のベクトルを抽出(エンコード)
- オートエンコーダの学習:
- オートエンコーダは、「入力されたモデル状態 を、一度、潜在思考 に圧縮し、その後デコーダ部分 ( ) で元の にできるだけ忠実に復元する」ように学習
- 正則化制約(スパース性)をヤコビアン行列に課す。これにより、各思考がどのモデル状態に影響を与えるかが明確になり、「思考の識別可能性」を担保
Leveraging the Structure of Thoughts
- 目的:抽出された思考を分析し、どの思考が「共有」されていて、どの思考が「プライベート」なのかを判断し、各エージェントに最適な形で情報を届けること
- 思考の関連性分析:
- Uncovering the Latent Thoughtsで学習したオートエンコーダの内部構造(ヤコビアン行列の非ゼロパターン)を利用して、抽出された思考ベクトルの各次元(各思考要素)が、どのエージェントのモデル状態に影響を与えているかを特定
- 合意度による重み付け:
- 各思考要素に対して、「エージェント合意度 ( )」というスコアを計算。その思考がいくつのエージェントに共通して影響を与えているか
- 例:3エージェント全員に影響する思考は合意度3、1エージェントのみに影響する思考は合意度1
- 個人化された思考ベクトルの構築:
- エージェントごとに、関連する思考を合意度別にグループ分け
- 各グループに異なる重み ( ) を与えて結合し、エージェントごとに個人化された思考ベクトル ( ) を構築。単に情報を並べるだけでなく、「これは全員の共通認識」「これは特定のエージェントのユニークな視点」といった情報の種類を区別して伝える
Latent Injection via Prefix Adaptation
- 目的:個人化された思考ベクトルを、実際に各エージェントの次の応答生成に反映させる
- プレフィックスベクトルへの変換:
- 個人化された思考ベクトル ( ) を、「アダプタ ( )」と呼ばれる小さなニューラルネットワークに入力
- アダプタは、この思考ベクトルを「プレフィックスベクトル ( )」と呼ばれる特殊なベクトルに変換。このベクトルは、LLMが普段扱うトークンの埋め込みベクトルと同じ次元を持つ
- LLMへの注入:
- エージェントが次の応答を生成する際、通常の入力(対話履歴など)のトークン埋め込み列の先頭に、このプレフィックスベクトルを付加(prepend)
- LLMは、この付加されたプレフィックスベクトルを文脈の一部として解釈し、応答を生成。これにより、エージェントは「この思考を考慮して話しなさい」という、テキストではない「潜在的な指示」を受け取ったかのように振る舞う
- アダプタの学習:
- アダプタは、思考を注入した結果、意味的におかしくなったり、不自然な文章が生成されたりするのを防ぐように学習。あくまで言語的な一貫性を保つことが目的であり、タスクそのものを解くための学習ではない
5. Experiment
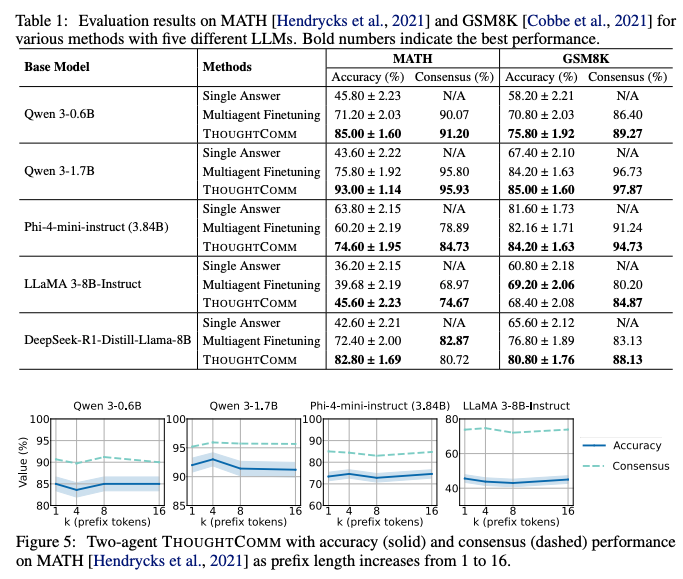
- 軽量な学習: 既存手法がLLMモデル全体を再学習(ファインチューニング)する必要があるのに対し、THOUGHTCOMMが学習するのは軽量なオートエンコーダとアダプタのみ
- モデル規模に依存しないコスト: この学習コストは、LLM本体のパラメータ数ではなく、その埋め込み次元数にのみ依存。例えばLlama 3の70Bモデルと405Bモデルでは埋め込み次元が同じであるため、THOUGHTCOMMの学習コストは変わらないことを意味する。将来さらに巨大なモデルが登場しても、効率的に適用できる高いスケーラビリティ
- 議論ラウンド数が増えても性能が向上: 2エージェントによる議論のラウンド数を2回から6回に増やしていく実験では、ベースライン手法の正解率が低下したのに対し、THOUGHTCOMMは正解率と合意形成率の両方が向上し続ける
所感
- LLMの内部状態ベクトルを使って各AI Agentの思考を共有する論文。
- LLMの内部状態を抽出できる必要があるため、OpenAI GPTのようなAPIで提供されるLLMでは使えなさそう。実際に論文ではオープンモデルで実験している。
@Akira Manda(zunda)
[論文]Deep Self-Evolving Reasoning
ざっくり
自己検証が弱い小型LLMでも、反復を深く・並列に回せば正解に寄る。鍵は“検証精度”ではなく「改善確率>劣化確率」。
Deep Self-Evolving Resoning(DSER)全体像とマルコフ連鎖

- 解く→検証→修正を1ステップの遷移として、状態を「正解/不正解」に潰したマルコフ連鎖で捉える。
- 直感:なら長期に正解が優勢(検証の逐次精度は仮定しない)。
DSERの性能(AIME2024/2025)

- 青線: Avg@64(64本の独立DSERプロセスの平均精度=単一DSERプロセスのPass@1推定)
- 橙線: Cons@64(64本の最終解の多数決精度)
- 立ち上がり:多数決(橙)は少反復で高止まりしやすい/平均(青)はゆっくり右肩上がり
- Pass@1(Avgで推定)の改善幅
- AIME 2024: +6.5%(82.8→89.3)
- AIME 2025: +9.0%(74.4→83.4)
- 備考:単発では解けなかった9問中5問をDSERで解決。8B+多数決が600B単発(Pass@1)を部分的に上回る場面あり。

- 速く高精度に達するタイプ:改善確率が十分大きく、劣化確率が小さい。
- 速立ち上がりだが誤答質量が残るタイプ:正答側の定常が0.5強で、Avgは頭打ちでもConsは早期高止まり。
- 非常にゆっくり改善するタイプ:Avgは漸増、Consは後半でようやく正答優位を確立。
ざっくりまとめ
- 反復推論を「正答/誤答」の二状態マルコフ連鎖で捉え、なら長期に正答優位へ収束。
- 小型モデル+DSER+多数決で、大型モデル単発を部分的に凌駕し得る。
- 並列数K・反復数Tを調整できるので、難易度に応じてK/Tを配分し、早期停止を入れるとコスト効率がよい(易問は浅く、難問だけ深く+広く)
メインTOPIC
Training-Free Group Relative Policy Optimization
| タイトル | Training-Free Group Relative Policy Optimization |
|---|---|
| 著者 | Youtu-Agent Team |
| 所属 | Tencent Youtu Lab |
| リンク | https://arxiv.org/abs/2510.08191 |
| 関連ページ | https://github.com/TencentCloudADP/youtu-agent/tree/training_free_GRPO |
概要
LLMエージェントの性能をパラメータ更新なしで向上させる強化学習フレームワーク「Training-Free GRPO」の提案 。最終結果のシグナル(報酬)から「意味的優位性(semantic advantage)」を言語的に抽出し、それを「経験ライブラリ」としてコンテキストに組み込むことで、モデルの振る舞いを最適化する 。これにより、従来のファインチューニング手法が抱える高コストや過剰適合のリスクを回避しつつ、高い性能向上を実現する 。
Introduction
既存のLLMは高い汎用能力を持つが、専門領域(数学的推論、Web探索など)では性能が低下する課題がある 。これは、外部ツールの利用や特定のプロンプト戦略が求められるためである。
この課題に対し、従来は以下の手法が用いられてきた。
- 教師ありファインチューニング (SFT)
- 高品質なラベル付きデータセットを用いてモデルのパラメータを微調整する手法 。
- データセットの作成に莫大なコストと時間が必要であり、スケーラビリティに欠ける。
- 強化学習 (RL/RLHF)
- PPOやGRPOといったアルゴリズムを用い、望ましい振る舞いを学習させる 。
- モデルのパラメータを直接更新するため、計算コストが高く、訓練データへの過剰適合や、元々の汎用能力を失うリスクがある 。
これらの手法は、高品質なデータや大規模な計算リソースを必要とし、パラメータを恒久的に変更してしまう。 Training-Free GRPOは、モデルのパラメータを一切変更せず(凍結し)、コンテキスト空間で最適化を行うことでこれらの課題を解決する 。
これは、LLMがすでに新しいシナリオに適応するための基本的な能力を持っており、強力な性能を達成するためには、限られたサンプルによる最小限の練習しか必要としないというインサイトに基づいている。
Training-Free GRPO
Training-Free GRPOは、最適化の対象をモデル内部のパラメータ空間から、モデルへの入力であるコンテキスト空間へと移す 。
- 経験的知識 (experiential knowledge) と呼ばれる自然言語の集合を学習し、それをプロンプトの一部として与えることでモデルの振る舞いを誘導する 。
- この外部知識は「学習されたトークンプライア (learned token prior)」として機能し、出力確率分布に影響を与える 。
- パラメータ更新を伴う勾配計算を完全に排除し、LLMの推論APIコールのみで学習サイクルを完結させる 。

| 特徴 | 従来型GRPO (Conventional GRPO) | Training-Free GRPO (本手法) |
|---|---|---|
| 最適化の対象空間 | パラメータ空間 | コンテキスト空間 |
| モデル更新手法 | 勾配降下によるパラメータ更新 | LLMによる推論のみの経験ライブラリ更新 |
| 優位性(Advantage)の形式 | 数値的優位性 | 意味的優位性 (自然言語での成功/失敗理由) |
| 計算コスト | 高 | 低 |
| データ要件 | 中〜高 | 極小 (数十サンプルで有効) |
| ベースモデルの状態 | 更新される | 凍結 |
Methodology
Training-Free GRPOは、従来型GRPOの枠組みを維持しつつ、パラメータ更新を不要にするための工夫が施されている。
RL Algorithm
学習は、従来型GRPOのプロセスを模倣しつつ、パラメータ更新をコンテキスト更新に置き換えることで進行する。
- Vanilla GRPO
- 従来型GRPOは、価値モデル(Critic)を不要にした強化学習アルゴリズムである 。
- 1つのクエリに対し、複数の出力(ロールアウト)を生成する 。
- 各出力を報酬モデルでスコアリングする 。
- グループ内の報酬の平均と標準偏差から、各出力の数値的優位性 を計算する 。
- この優位性を用いて、勾配降下法によりモデルのパラメータを更新する 。
- Training-Free GRPO
- Rollout and Reward: 従来型GRPOと同様に、現在の経験ライブラリ を条件として複数の出力を生成し、報酬モデルでスコアリングする 。
- Group Advantage Computation: ここが本手法の核心。数値的優位性を計算する代わりに、LLM自身にロールアウト群を比較・分析させ、成功と失敗の要因を自然言語で抽出させる。これにより、意味的優位性 (semantic advantage) を生成する。
- Distilling and Updating Experiential Knowledge: 抽出された意味的優位性 を基に、外部の経験ライブラリ を更新する。この更新もLLMにプロンプトを通じて実行させ、「追加」「削除」「修正」「維持」のいずれかの操作を行わせる 。
- Guiding Future Generations: 更新された経験ライブラリ を次のロールアウト時のコンテキストとして与えることで、モデルの振る舞いを改善していく 。
Group Advantage Computation
- Vanilla GRPOと同様にG個のtrajectoryを生成し、評価
- その後、プロンプトテンプレートを用いてQuestionと結果から要約を生成
- 要約結果と経験ライブラリ、Questionを用いて自然言語でAdvantageを生成する。
Optimization
を用いて、以下の操作を経験ライブラリに行う
- Add: に書かれた内容をそのまま経験ライブラリに追加。
- Delete: に基づいて、品質の低い経験ライブラリを削除。
- Modify: に基づいて、経験ライブラリの内容を洗練、改善する
- Keep: 経験ライブラリを変更しない

報酬設計
報酬モデルは単純なスカラ値(良し悪しのスコア)を出力するのみ。
複雑な報酬関数を設計するのではなく、そのスカラ値の差が生まれる理由をLLMに言語化させる(意味的優位性の抽出)ことで、リッチなフィードバック信号を生成する。
プロンプト
- 必要なPromptは4つ (https://github.com/TencentCloudADP/youtu-agent/blob/training_free_GRPO/training_free_grpo/math/prompts.py)
- 問題解決のためのPrompt
- 要約するためのPrompt
- Group Advantageを計算するためのPrompt
- OptimizeするためのPrompt
実験
- Dataset
- 数学的推論: AIME 2024 (AIME24), AIME 2025 (AIME25)
- 訓練データとして、DAPO-Math-17Kデータセットから100サンプルを選択 (DAPO-100)
- Web探索: WebWalkerQA
- 訓練データとして、AFM (Chain-of-Agents) web interaction RL datasetから100サンプルを選択 (AFM-100)
- 評価指標: 正解率 (Accuracy)
- 実装
- モデル: DeepSeek-V3.1-Terminusのような実世界でファインチューニングができないモデルを対象
- 学習: 数十の訓練サンプルのみを使用
結果
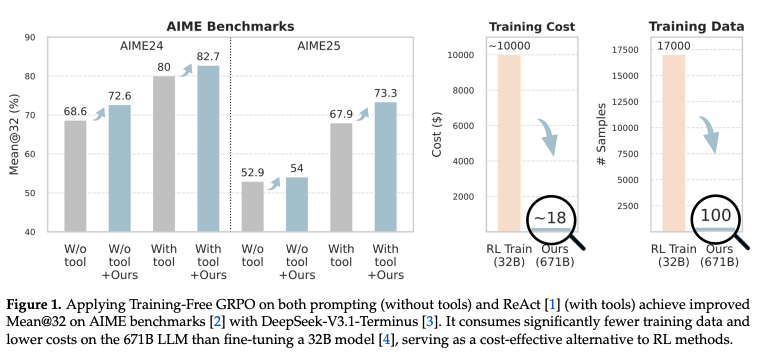
数学的推論
- Toolを使ったモデルでも使わないモデルでも性能の向上を確認できた
- 訓練エポックを増やすことで性能の向上とToolの利用数も少なくなることを確認
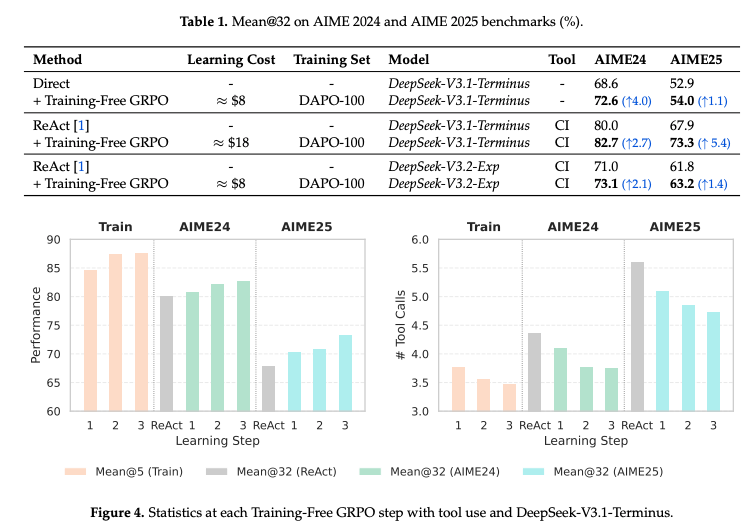
- 既存の現実的にファインチューニング可能なモデルに適用した時にも一貫して改善はする
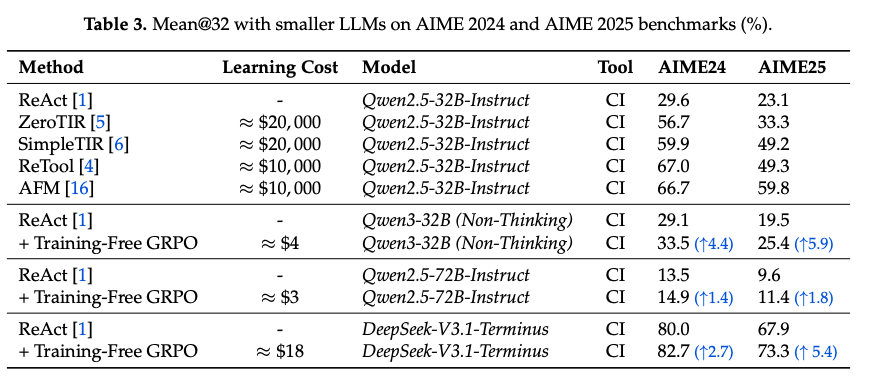
- 単純にDeepSeek-V3.1-Terminusで経験 (コンテキスト)を生成させるだけでは性能向上が確認できなかった
- また、正解を渡さないことによって暗黙的な多数決などによって学習させても改善が見えるので、正解を作りにくい領域にも使えることが示唆される。
- グループを複数ロールアウトすることで性能が伸びている

Web探索
- 同様の改善
- QwQ-32Bに適用した場合は改善が見られず、pass@1が逆に悪化
- 複雑なツール使用シナリオだと、baseモデルの推論能力とツール使用能力に依存することを示唆
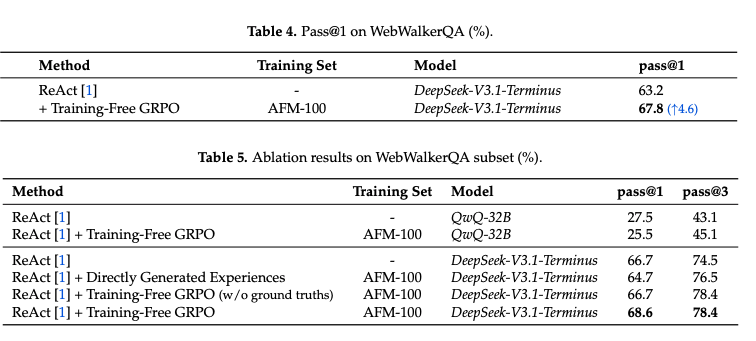
Cross domain transfer analysis
- ReToolの場合は、AIMEの場合は劇的な改善を見せているが、WebWalkerの場合は悪化してしまっている
- またMiroThinkerはWebWalkerで改善が見れるが、AIMEではReToolより改善幅が小さい
- 一方で、Training-Free GRPOは同じフレームワークで一貫して多様なドメインで改善される

計算コスト
- ReToolの場合は20,000GPU時間が必要なため10,000ドルほどお金がかかる
- 一方で、Training-Free GRPOは6時間ほどで18ドルで学習が完了する
結論
エージェント推論において、パラメータ空間ではなくコンテキスト空間で強化学習を行うという、新しいフレームワーク「Training-Free GRPO」を紹介した。
- outcomeベースの報酬からLLM自身の推論能力で「意味的優位性」を抽出し、それを経験ライブラリとして蓄積することで、パラメータ更新なしにエージェントの振る舞いを改善できることを示した 。
- これにより、従来手法の課題であった計算コストとデータ要件を劇的に削減し、エージェント開発の民主化を促進する可能性がある 。
- 今後の展望として、高品質な「経験ライブラリ」自体が資産として流通する「経験エコノミー」の到来も示唆される。
感想
- ブログでも書いたが、これ系の狭い範囲でのPrompt最適化が今後流行る気がする。論文中で書いてある通り、小さいモデルで強化学習を行なっても限定的にしか賢くならない。
- ベースの知識はフロンティアモデルの方が圧倒的にもちろん賢い。少しアラインメントするだけで解けるようになることがほとんどなので、最適化する範囲を狭めてあげてAPIモデルを賢くしてあげるのが進むべき方向性か?