2025-11-04 機械学習勉強会
今週のTOPIC[slide] 戦えるAIエージェントの作り方[論文] Every Activation Boosted: Scaling General Reasoner to 1 Trillion Open Language Foundation[論文]AGENT DATA PROTOCOL: UNIFYING DATASETS FOR
DIVERSE, EFFECTIVE FINE-TUNING OF LLM AGENTSContext Engineering 2.0: The Context of Context Engineering[論文]Federation of Agents: A Semantics-Aware Communication Fabric for Large-Scale Agentic AIメインTOPICKnowledge Compression via Question Generation: Enhancing Multihop Document Retrieval without Fine-tuningAbstract1. Introduction2. Literature Review3. Motivations4. Task definition5. Methodology5.1 Main approach5.2 構文的アルゴリズムの説明 (Retrieval Processのstep3)5.3 Data6. Experiments6.1 Evaluation Methodology
7. Results7.1 Task 17.2 Task28. Discussions10. Limitations参考
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[slide] 戦えるAIエージェントの作り方
- 秋葉さんのW&B Fully Connectedの登壇資料。実践的で有用なためシェア。
- AI ScientistやALE-Agentのような専門家にも勝てるAI Agentを作るためにはどうしたらいいか
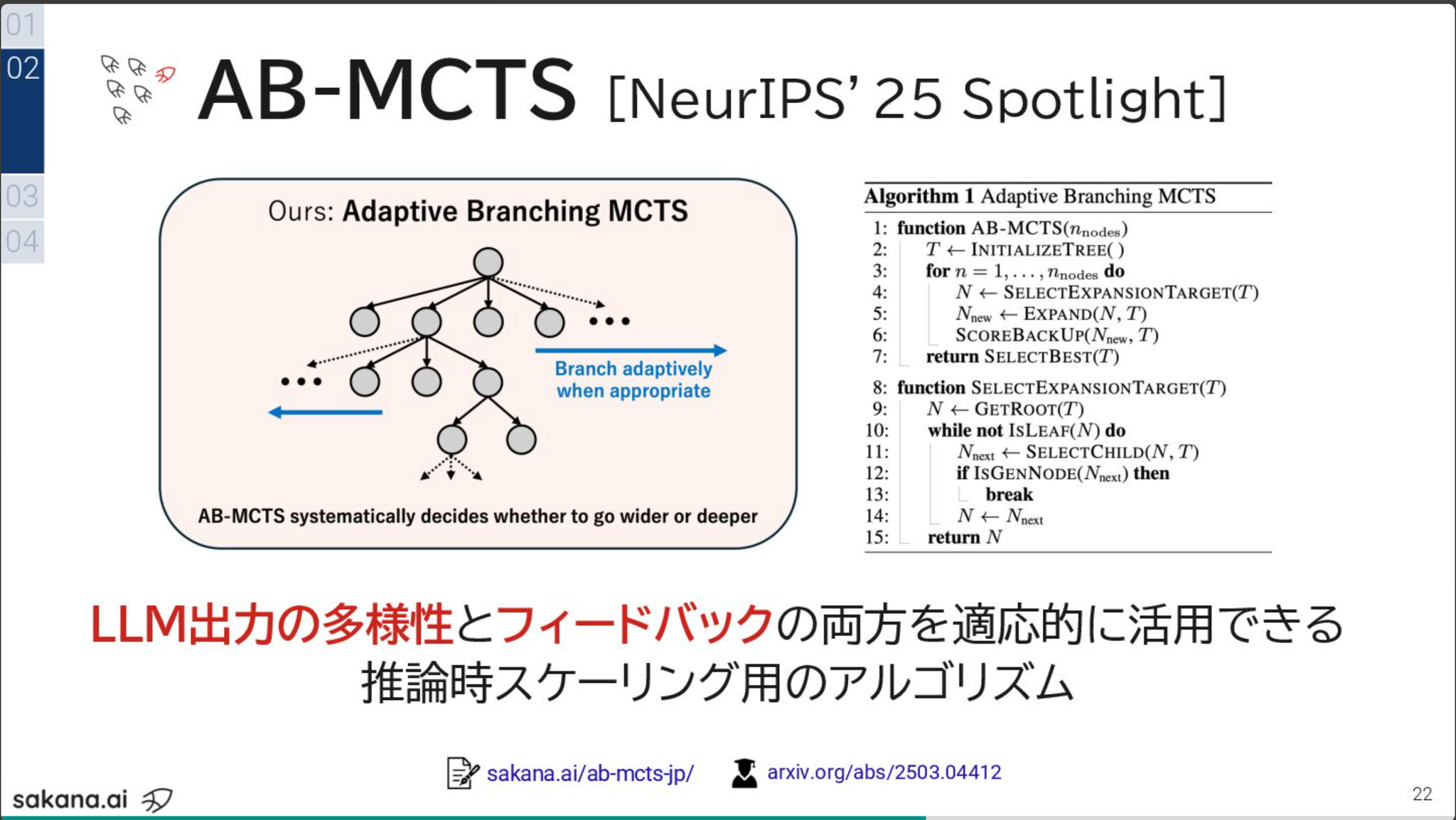
推論時スケーリング
- 学習時だけでなく、推論時に計算量を投入する

- 今すぐ出来る手法としてアプローチ3がめちゃくちゃ重要
- SWE-Bench LiteでDeepSeek-Coder-V2で試した場合、1回だと16%の正答率が250回呼び出したら56%になる (Pass@k)
- 単純にやるだけだと効率が悪いよねってところでの工夫が重要
- Go wide (Repeated Sampling) とGo deep (Sequential Refinement) を組み合わせたAB-MCTS
- 複数の実案件で利用中らしい
ドメイン知識の活用
- プロンプト
- 知識や方法論のようなドメイン知識をPromptにどう入れるか。特徴量エンジニアリングと通ずるものがある。(Bet AI Dayでも話した話)
- ワークフロー
- 正しい取り組み方をコードで教えてるというドメイン知識注入。
- ルーブリック
- 評価基準をちゃんと定めてLLM as a Judgeすることで、推論時スケーリングが可能
@Shun Ito
[論文] Every Activation Boosted: Scaling General Reasoner to 1 Trillion Open Language Foundation
- by Inclusion AI
- 1Tパラメータ級のMoE(Mixture-of-Experts)モデル Ling 2.0シリーズ を構築
- MoEの設計指針の知見を実験的に整理
- 課題: MoEは様々な要因が含まれており、かつ相互依存もあるので、大規模モデルにおける知見が整備されていなかった
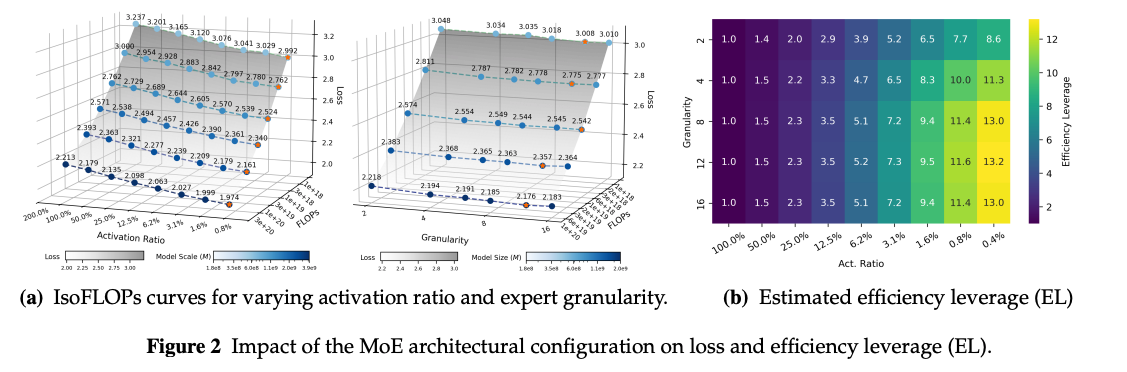
- Efficiency Leverages (EL) = Denseモデルが必要とするFLOPs(計算量) ÷ MoEモデルが必要とするFLOPs を指標として、様々な設定で実験的に検証
- Activation Ratio(Expertsの活性化率)が最も大きな要因(小さいほど良い)
- Granularityは大きいほど良いわけではなく、8-12が最適
- Computer Budgetを増やすと精度にも寄与する
- その他の要因はあまり重要ではない(上の3つを考慮すればよい)
- 定式化もしてくれている(Activation rate, Granularity, Computer budget)
- この式に則って、Ling 2.0 のアーキテクチャを決定
- granularity = 8 + 1 shared, activation ratio = 3.5%
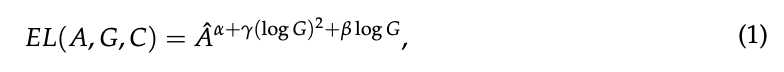
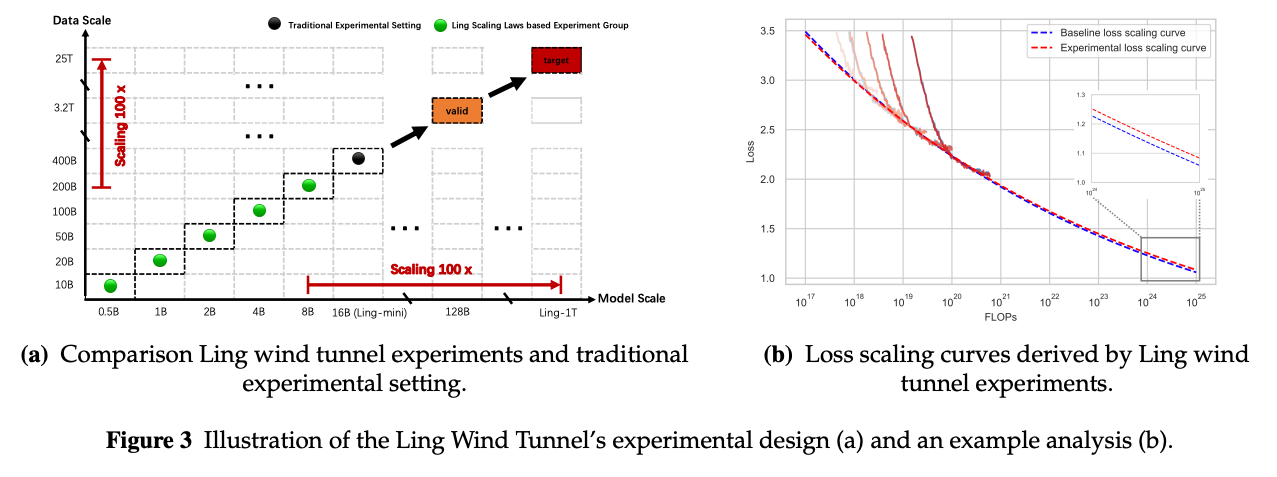
- 小規模モデルの訓練で大規模モデルの性能を予測し実験効率化
- 1Tオーダーの大規模モデルを設定を変えて実験するのは効率が悪い
- スケール即のオーダーに従って、0.5B, 1B, 2B, 4B, 8B のモデルとそれぞれ 10B, 20B, 50B, 100B, 200B tokens データセットを用意
- それぞれをある (A, G, C) の設定で学習し、1Tモデルでの性能を予測する
- 結果として誤差0.01で予測でき、従来の方法(16Bを400Btokensで学習して見積もり)よりも35%の計算量削減
- その他訓練時の工夫ポイント(列挙のみ)
- 総計20Tトークン規模の学習データを使用し、一般知識データに加え、数学・コードデータ比率を段階的に増加(32%→46%)。
- 中間訓練段階でのCoT(Chain-of-Thought)導入により推論能力を事前活性化。
- WSM(Warmup-Stable-Merge)スケジューラにより、従来の学習率減衰をチェックポイント統合へ代替し、1〜2ポイントの安定的性能向上を実証。
- Decoupled Fine-Tuning(DFT)により、即応型・深層推論型の二種出力モードを確立。
- Evo-CoT(進化的CoT)とLinguistic-unit Policy Optimizationを用いた微粒度RL最適化により、高難度推論性能を強化。
- Group Arena Rewardにより、人間評価との整合性を細粒度に調整。
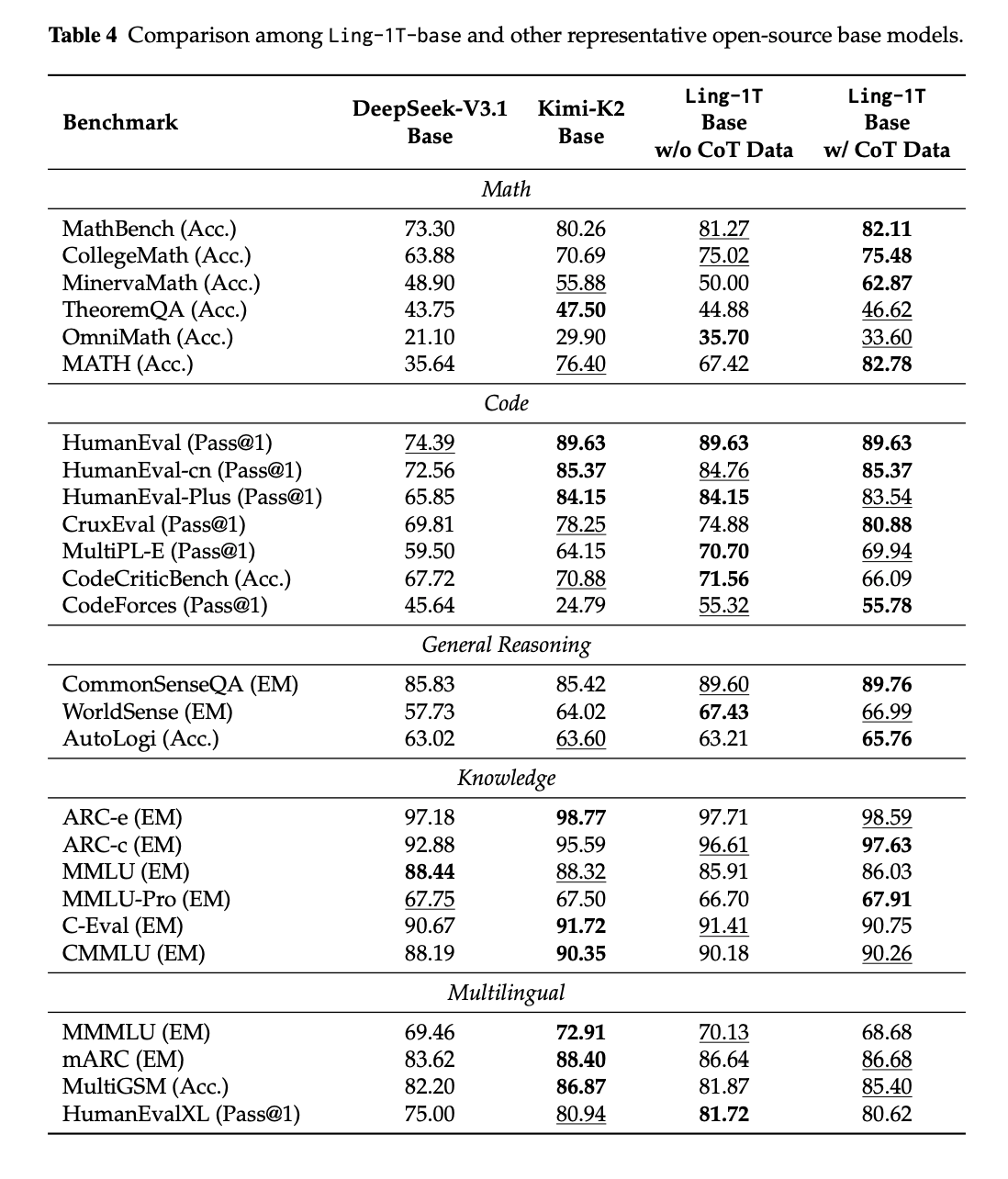
- Baseモデルの性能面はCode, Mathに強み
@Hiromu Nakamura (pon)
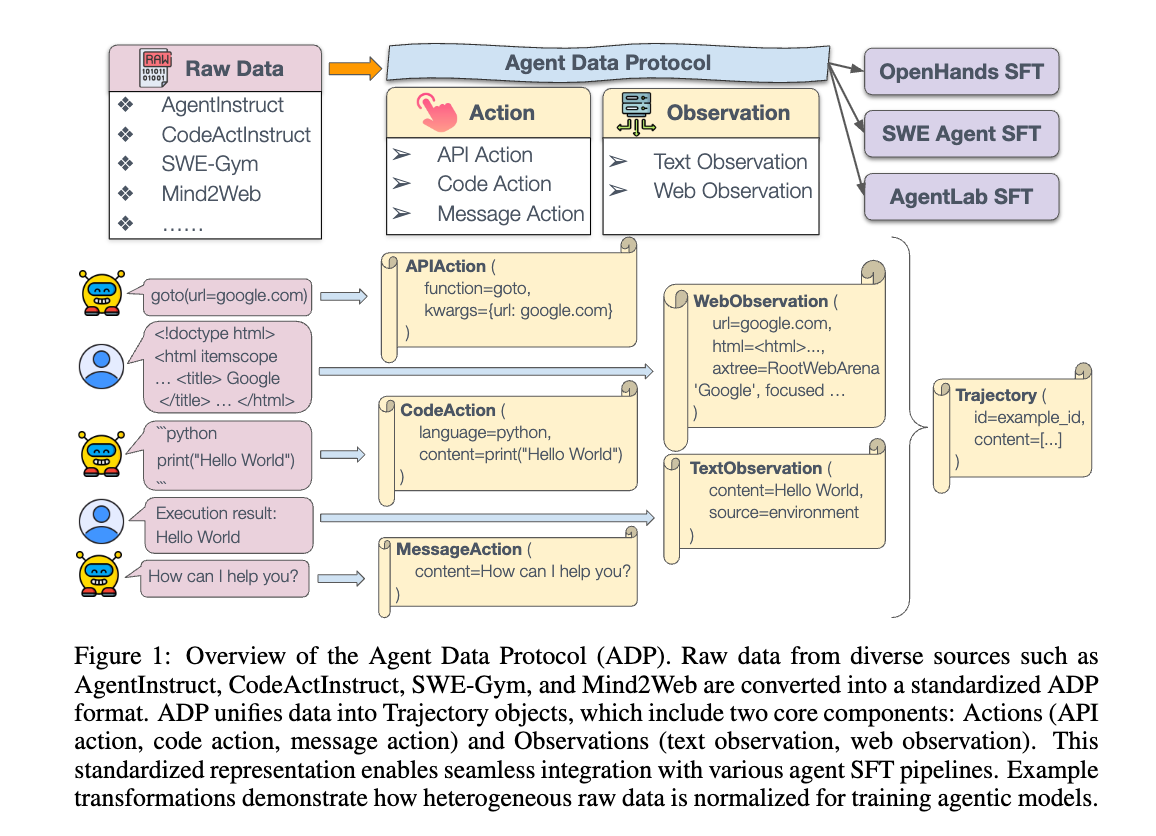
[論文]AGENT DATA PROTOCOL: UNIFYING DATASETS FOR
DIVERSE, EFFECTIVE FINE-TUNING OF LLM AGENTS
LLMのためのデータ変換でお困りなので読んだ
概要
- 本研究では、ボトルネックは基礎となるデータソースの不足ではなく、多様なデータが異質なフォーマット、ツール、インターフェースに分散していることであると主張する。
- agent data protocol (ADP)を導入。これは、多様なフォーマットのエージェントデータセットと、下流の統合されたエージェントトレーニングパイプラインとの間の「共通言語」として機能する軽量な表現言語である。
- ADP を使用してエージェントをトレーニングすると、コーディング(SWE-Bench Verified)、ウェブブラウジング(WebArena)、研究(GAIA)、およびエージェントのツール使用(AgentBench)を含む、多様なドメインでパフォーマンスが大幅に向上することが示されている
- (ADP の実用性を示すための最初のステップとして、既存の13個のデータセットから ADP へのコンバーターと、ADP から3つの異なるエージェントアーキテクチャへのコンバーターを実装。これに基づいて、我々は ADP Dataset V1 と呼ばれる、130万のトレーニング軌跡からなる、エージェントトレーニング用の最大規模の公開データセットを作成しリリース)
課題と制約
既存のエージェント訓練データセットが豊富にあるにもかかわらず、これらのリソースの効果的な大規模利用を妨げるいくつかの根本的な課題がある。
- データキュレーションの複雑さ:高品質のエージェント訓練データの作成には、多大なリソースと専門知識が必要となる。
- 手動キュレーションはコストがかかり、ドメイン知識が必要となる。合成生成はデータ品質の検証において課題に直面する。記録されたエージェントのロールアウトは、既存のベースラインエージェントの能力によって根本的に制約され、軌跡の多様性と複雑さが制限される。
- データセット形式の異質性:既存のagent訓練用データセットはそれぞれ独自の表現形式、行動空間、観測構造を採用しています。
- 例えば、一部のウェブデータセットはHTMLを使用し、一部はアクセシビリティツリー構造を使用しています。
- 既存の研究では、データの標準化が指摘され、取り組みも始まっていますが、それらは主にタスク固有またはagent固有の統一に焦点を当てており、データ表現のコミュニティ全体の標準化には至っていません。そのため、他のデータセットやagentとのプラグアンドプレイが制限され、複数のデータセットをまとめて利用するには依然として多大なエンジニアリング努力が必要となり、異なるデータソース間の統合を妨げています。
- 分析と比較の困難さ:既存のデータセットの多様な構造は、異なるデータソース間での体系的な比較や定量的な分析を困難にし、異なるデータセットの相対的な有用性、網羅性、品質を理解する研究者の能力を制限し、データ駆動型の選択や改善を妨げている。
AGENT DATA PROTOCOL
- ADPは、既存の異質なagent訓練用データセットと大規模な教師ありagentのファインチューニングとの間のギャップを埋める統一されたスキーマを確立します。
- 設計原則
- 単純性:ADPは、シンプルで直感的な構造を維持します。
- これにより、データセットごとの特殊なエンジニアリングの必要性を排除する簡単なフレームワークを提供することで、データキュレーションの複雑さという課題に直接対処し、大規模なagentデータの利用を、大規模な適応作業なしに研究者が利用できるようにします。
- 標準化:ADPは、さまざまな形式の既存のagent訓練用データセットを標準化された形式に統一する統一された表現を提供するように設計
- データセット形式の異質性という課題に対処します。
- 表現力:ADPは、複雑なagentの軌跡を重要な情報を失うことなく正確に表現できるように設計されています。
- ADPは、さまざまなドメインにわたる既存のagentデータセットの幅広い多様性をカバーするのに十分な表現力を持っているため、研究者はこれらの多様なデータセットを同じ条件とコンテキストに置くことができ、分析と比較の困難さという課題に直接対処します。
- Trajectory
- (1) id: 軌跡ID
- (2) content: agentとユーザー/環境とのインタラクションを表すactionとobservationの交互のシーケンス(actionとobservationは後述)
- (3) details: データセット固有の情報(データセットソースのURLなど)のための柔軟なメタデータ辞書で構成されます。
- Actions
- agentの意思決定と行動を表します。
- 各種Action (AP Actions、Code Actions、 Message Actions)で定義
- Observation
- 環境からのエージェントの認識を表し、2つのタイプに分類される: • Text Observations: ユーザーの指示や環境からのフィードバックなど、さまざまなソースからのテキスト情報をキャプチャする。
- source: observation の発生源 ("user" または "environment")
- content: 観察されたテキスト。
agentデータの利用における根本的な課題に対処することで、ADPはagent訓練の進歩を促進し、大規模なagentのSFTをより広範な研究コミュニティが利用できるようにすることを目指しています。
アーキテクチャ
ADPスキーマはPydanticスキーマとして実装されており、設計はシンプルでありながら表現力豊かです。各ADP標準化agent軌跡は、Trajectoryオブジェクトとして表されます。
変換パイプライン
- Raw to Standardized
- 元のデータセット形式を ADP の標準化されたスキーマに統合する。各データセットは生の形式で抽出され、各データセット固有のアクションと observations を ADP の標準化されたアクションおよび observation 空間にマッピングすることにより、ADP スキーマに変換される。
- 例えば、HTML 表現を使用したウェブブラウジングタスクは APIAction と WebObservation のペアに変換され、実行出力を使用したコーディングタスクは CodeAction と TextObservation のペアにマッピングされる。
- Standardized to SFT
- この段階では、ADP の標準化された軌跡を、言語モデルのトレーニングに適した教師ありファインチューニング (SFT) 形式に変換する。
- 異なるエージェントフレームワークは、異なるアクション空間、observation 形式などで動作する。例えば、OpenHands はウェブブラウジング機能を備えた IPython 実行を使用し、SWE-Agent は構造化された bash コマンドとファイル操作を使用し、AgentLab は DOM ベースのウェブインタラクションに焦点を当てている。
- 各エージェントハーネスについて、変換プロセスは、エージェントのフレームワークに基づいて、各タイプのアクションと observation をターゲットエージェントのアクションおよび observation 空間に変換する、エージェント固有のスクリプトを1つ使用する。
- この段階では、コンテキスト管理、システムプロンプトの指定、および特定の Agent アーキテクチャに最適化された SFT 対応の命令-応答ペアを作成するための会話のフォーマットを処理する。
- Quality Assurance
- この段階では、自動検証を通じて、エージェント形式、ツールの使用、および会話構造との整合性におけるデータの正確性と一貫性を保証する。
- 品質チェックの例としては、ツール呼び出し形式の検証、ほとんどのツール呼び出しが英語の思考とペアになっていることの確認、会話が適切に終了しているかどうかの確認などが含まれる。
エージェント訓練研究に対するADPの実践的な影響
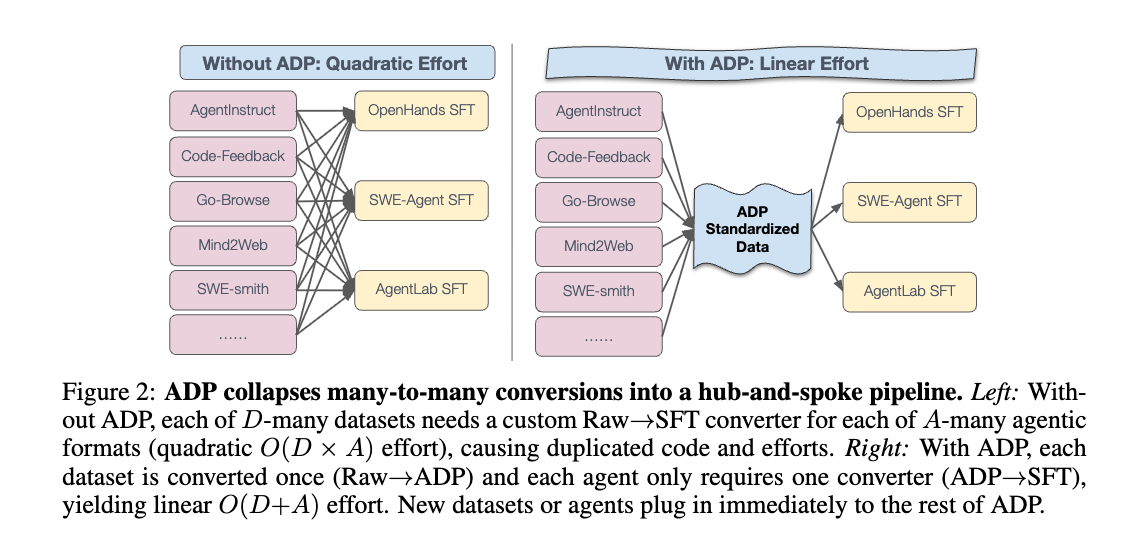
- データセット変換(データセットごとに1回)。 comitterは、各rawデータセットをADPスキーマに正確に1回変換します。 それ以降、そのデータセットは、任意のエージェントハーネスで使用できる標準化されたリソースとなります。
- エージェント固有の変換(エージェントごとに1回)。 各エージェントは、ADP→SFT用の単一のスクリプトを保持します。データセットごとのエンジニアリングは不要です。新しいデータセットを追加しても、エージェント側のスクリプトを変更する必要はありません。
- ADPがない場合。 研究者は、データセットとエージェントのペアごとにRaw→SFTコンバーターを作成する必要があり、グループ間で労力が重複し、大規模なデータ統合が脆弱で遅くなります。
実験
- 選択されたデータセットは、Mind2Webのような小規模なものから、Orca AgentInstructのような大規模なものまで、全体で130万を超えるインスタンスを含んでいる。複数の、多様な既存のデータセットをADP形式に統一し、それらを混ぜ合わせて作成された学習データセットとした。
- LLaMA-Factory (Zheng et al., 2024b)の同じSFTパイプラインを使用して、すべてのモデルをファインチューニングした。
- 評価ベンチマーク これらのエージェントを、異なるドメインにまたがる4つのベンチマーク(ベンチマーク評価コードの可用性とエージェントの専門性に基づく)にわたって評価した。この包括的な評価は、多様なタスクにわたって重要な情報を保持するADPの表現力を示している。
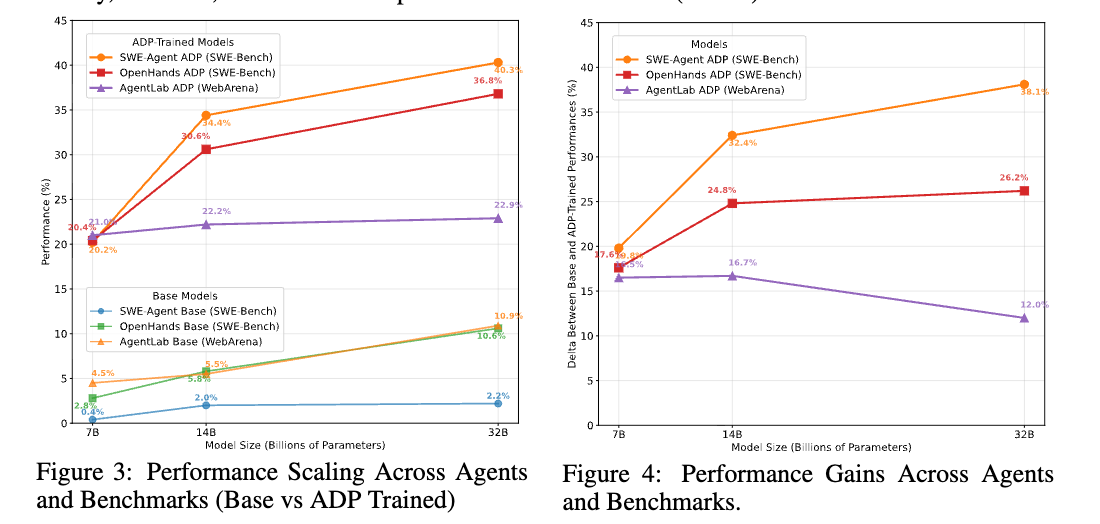
「ADPがファインチューニングなしのモデルに対してどれだけ効果があるか」
これらの向上は、コーディングとブラウジングの両方の設定に及び、統一されたクロスドメインのADPトレーニングコーパスが、ドメイン固有の調整なしにSOTAまたはニアSOTAのパフォーマンスを提供でき、モデル、アクション空間、およびエージェントハーネス全体で効果的であることを示している。
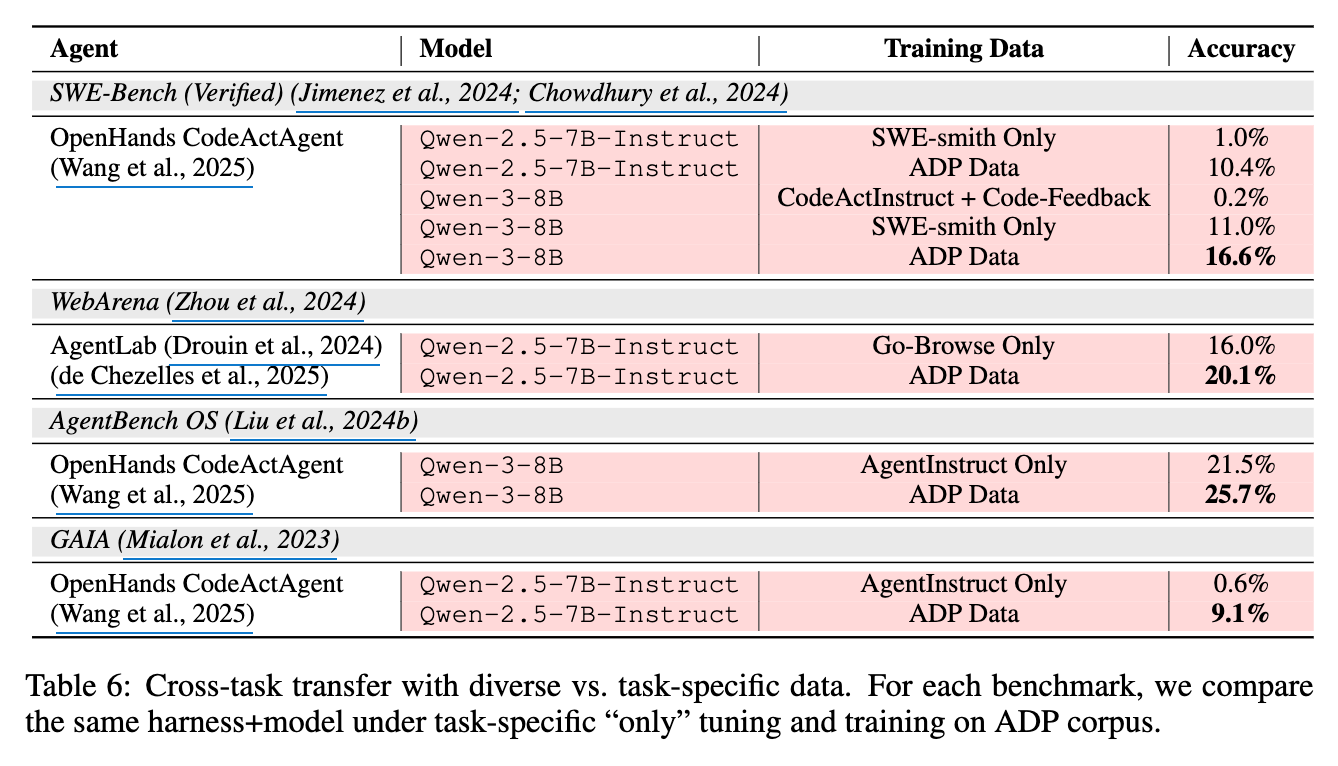
「単一のデータセットでファインチューニングされたモデルと比較してどうだった」
各ベンチマークについて、タスク固有の「only」チューニングとADPコーパスでの学習において、同一のハーネスとモデルを比較する。
データ多様性が、エージェントのタスク間での汎化に役立つかどうかを調査する。
エージェントのセットアップと評価を固定したまま、異なるデータ混合で学習した場合を比較する。(i) Base (チューニングなし)、(ii) タスク固有のfine-tuning (例: SWE-smith Onlyなど)、(iii) ADP Data (§ 5で詳述)という混合されたクロスドメインコーパス。
Table 6に示すように、ADPはターゲットタスクにおいてタスク固有のチューニングを一貫して上回り、さらに重要なことに、シングルドメインチューニングが他のタスクにしばしば引き起こす負の転移を回避する
[pon]
- ADRによる標準化により、エンジニアリング工数削減、だけでなく、モデルの汎化能力を飛躍的に向上させるというのが面白かった。特に最近データをいじいじしてるので。
- ADR生成はPydanticを提供してくれてるので、こちらで生成もしやすい
@ShibuiYusuke
Context Engineering 2.0: The Context of Context Engineering
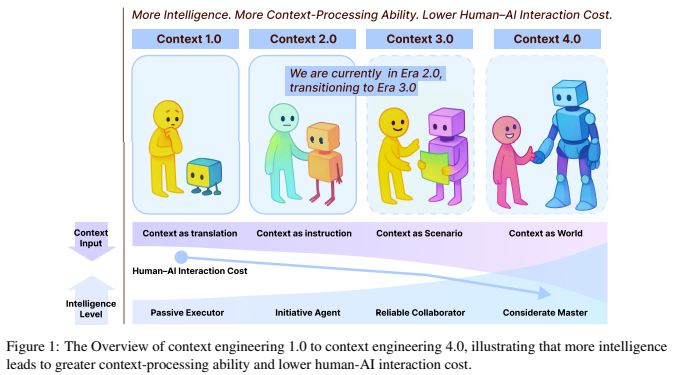
5. Context Management
5.1 Textual Context Processing
生テキストをどう処理するかの設計パターン
- タイムスタンプの付与:
最も単純な方法。生成順序を保持できるが、意味的な構造を持たず、検索効率も悪化
- 機能的・意味的属性によるタグ付け:
「目標」「決定」「行動」といった機能的な役割タグを付与
意味は明確だが、柔軟性に欠ける場合あり
- QAペアによる圧縮:
コンテキストを質疑応答のペアに変換
検索エンジンやFAQシステムには有効だが、文脈の自然な流れが失われ、要約や推論には不向き
- 階層的ノートによる圧縮:
情報をツリー構造で整理
アイデアのグループ化には明確だが、因果関係などの論理的なつながりや、時間の経過に伴う理解の進化を表現するのは困難
5.2 Multi-Modal Context Processing
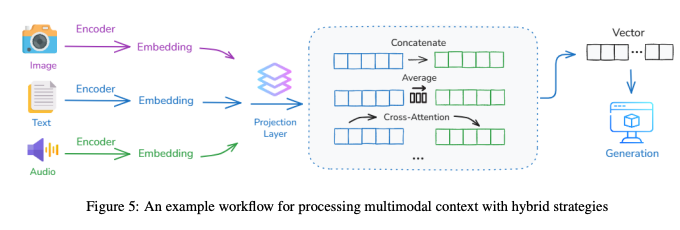
テキスト、画像、音声、センサーデータなど、構造も情報密度も時間的ダイナミクスも異なる情報をどう統合するかが課題
- 比較可能なベクトル空間へのマッピング:
- 異なるモダリティ(例:画像とテキスト)を、まずそれぞれ専用のエンコーダで処理
- 次に「プロジェクション層」を通して、すべてのベクトルを共通の埋め込み空間にマッピング
- 異なるモダリティ間でも意味的な類似性を比較できるようになる
- 自己注意(Self-Attention)のための結合:
- 現代のマルチモーダルLLM(GPT-4やClaudeなど)で採用されているアプローチ
- 共通空間にマッピングされたテキストトークンと視覚トークンを、単一のTransformerアーキテクチャで一緒に処理
- 「テキストのどのフレーズが画像のどの領域を指しているか」といった対応関係を学習
- 交差注意(Cross-Attention)による片方から他方への注目:
- 一方のモダリティ(例:テキスト)を「クエリ」として使い、もう一方(例:画像)の特定部分(キー/バリュー)に直接注目させる方法
- 関連情報をターゲットを絞って柔軟に取得
5.3 Context Organization
5.3.1 Layered Architecture of Memory
- 有名なアナロジーとして、「LLMはCPU、コンテキストウィンドウはRAM(高速だが容量制限あり)」
コンテキストエンジニアリングは、OSがどのデータをRAMにロードするか決定するプロセスに類似
- OSと同様に、AIも時間的な関連性や重要性に基づいてメモリを階層化(分離)することが有効
- 短期記憶:時間的関連性が高いコンテキストのサブセット
- 長期記憶:処理・抽象化された、重要性が高いコンテキストのサブセット
- 記憶転送:短期記憶から長期記憶への転送プロセス。頻繁なアクセスや重要性に基づいて情報が「定着」するプロセス
5.3.2 Context Isolation
- 「コンテキスト汚染」(不要な情報が混ざること)を防ぐための戦略
- サブエージェント (Subagent):
- 各サブエージェントは、独自の隔離されたコンテキストウィンドウ、カスタムプロンプト、制限されたツールを持つ特化型AIアシスタント
- 特定のタスクをサブエージェントに委任すると、メインの会話コンテキストを汚染せずに独立して動作
この原則の好例が、Claude Codeのサブエージェントシステム
- 軽量な参照 (Lightweight References):
- ファイルやログのような重い情報は外部ストレージに保存
- モデルのコンテキストウィンドウには、その情報への簡潔な参照(ポインタや要約)のみを配置
- トークンのオーバーヘッドを削減しつつ、必要に応じて全コンテキストにアクセス
5.4 Context Abstraction
- 対話履歴やツール出力などの生コンテキストは急速に蓄積
- これらを処理せずに放置すると、システムが重要な情報を見失う可能性あり
自己ベーキング (Self-Baking)
- この課題の解決策が「コンテキストの抽象化」、すなわち生コンテキストをよりコンパクトで構造化された表現に変換
- 「自己ベーキング」:エージェントが自身のコンテキストを消化し、永続的な知識構造に変換するプロセス
- これが「想起」と「学習」を分ける要素。自己ベーキングがなければ思い出すだけだが、それがあれば知識を蓄積可能
自己ベーキングの代表的な設計パターン

- (A) 生コンテキスト + 自然言語(NL)要約:
- 元の生コンテキスト全体を保存し、それに加えて定期的に自然言語の要約を生成
- シンプルで柔軟ですが、要約自体は非構造化テキストであるため、要約間の関連性理解や深い推論が困難
- (B) 生コンテキスト + 固定スキーマ:
- 生コンテキストを保存するだけでなく、キーとなる情報を定義済みの構造(スキーマ)に抽出
- スキーマには、エンティティマップ(人・場所・モノの関係性)、イベントレコード、タスクツリー(タスクの階層構造)など
- 具体例:
- 生要約よりも効果的な推論が可能だが、信頼性の高い抽出器(Extractor)の設計が困難
CodeRabbitはコードレビュー前に、ファイル間の依存関係や過去のPR履歴をエンコードした構造化された「ケースファイル」を構築
- (C) ベクトルへの逐次的圧縮:
- 情報を意味を反映した高密度ベクトル(埋め込み)としてエンコード
- 古い埋め込みは定期的に要約(プーリングなど)されたり、既存の長期状態と融合されたりして、より抽象的で安定した意味記憶へと「自己ベーキング」される
- コンパクトで柔軟、意味検索に適しているが、生成されたベクトルは人間が読めず、特定の記憶の編集や調査が困難
6. Context Usage
6.1 Intra-System Context Sharing
- 最新のLLMアプリケーションは、多くの場合、より大きなワークフローの一部を担当する複数のエージェントで構成
- 複数のエージェントがうまく機能する理由の一つは、単一エージェントよりもシステム全体で多くのトークンを扱えること
- 課題は、エージェント間でいかにコンテキストを共有し、一貫して協調動作させるか
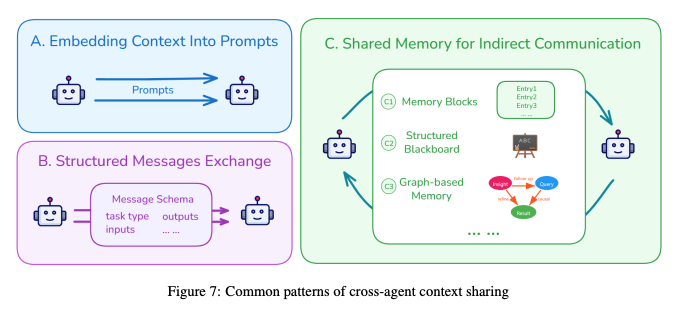
(A) プロンプトへのコンテキスト埋め込み
- 前のエージェントのコンテキスト(多くの場合、平易なテキストに再フォーマットされたもの)を、次のエージェントの入力プロンプトに直接含める方法
- AutoGPTやChatDevのような、エージェントがシーケンシャルに動作するシステムで一般的
(B) 構造化メッセージの交換
- エージェントは固定フォーマット(スキーマ)を使用して構造化されたメッセージを交換
- メッセージには通常、「タスクタイプ」「入力データ」「出力結果」「推論ステップ」などが含まれる
- LettaやMemOSなどのシステムがこのアプローチを採用
(C) 共有メモリによる間接的コミュニケーション
- エージェントが直接メッセージを送受信する代わりに、共有メモリ空間(中央集権的外部ストレージなど)に読み書き
- メモリブロック: MemGPTやA-MEMなどで採用される一般的なプール方式
- 構造化ブラックボード: 共有スペースをトピックやタスク単位で分割する方式
- グラフベースメモリ: 推論プロセスをグラフとして表現
- 具体例: Task Memory Engine (TME) は推論プロセスをタスクグラフとして表現し、各ノードがステップ(入力・出力・状態)を、エッジがステップ間の依存関係を表現
6.2 Cross-System Context Sharing
- これは、CursorとChatGPTのように、異なるシステム間(プラットフォームやアプリ間)でコンテキストを共有する方法
- 各システムが独自フォーマットを持つため、システム内共有よりも困難
アダプタによる変換
- 各システムは独自フォーマットを維持しつつ、他システムが読めるように変換器(アダプタ)を追加
- 柔軟だが、接続システムごとに個別のアダプタが必要
システム間での共通表現の使用
- すべてのシステムが共通表現(フォーマット)を使うことに合意
- 共通のデータフォーマット: JSONスキーマやAPI仕様
- 人間が読める要約: 構造化データの代わりに自然言語の短い説明を交換
- セマンティック・ベクトル: コンテキストを意味的に表現したベクトル形式
6.3 Context Selection for Understanding
- コンテキストウィンドウが拡大しても、入力トークンの「質」がボトルネック
- 課題は、利用可能なすべてのコンテキスト(メモリ、ツール定義、RAG結果など)の中から、最も有用なサブセットを選ぶこと
- これは「アテンションの前のアテンション(選択)」と呼べるプロセス
- 経験則として、AIの性能はコンテキストウィンドウが約50%を超えると低下
選択時に考慮すべき要素:
- 意味的関連性: 現在のクエリに最も類似したメモリを選択(ベクトル検索など)
- 論理的依存性: 現在のタスクが過去の出力や決定に依存している場合
- 新しさと頻度: 最近・頻繁に使われた情報を優先
- 重複情報: 同義情報が複数ある場合、古いものを除外
- ユーザーの好み: ユーザーが重視する情報傾向を学習
RAGにおける戦略:
RAGパイプラインでは通常
- ソースを管理可能なチャンクに分割(固定長または意味境界)
- 検索を実行(ベクトル検索・grep・知識グラフ)
- 検索結果をLLMでリランキング(並べ替え)して精度を向上
6.4 Proactive User Need Inference
- 現在のコンテキスト利用の多くは「受動的」だが、ユーザーはニーズを明示的に言語化できないことが多い
- コンテキストエンジニアリングは、エージェントが潜在的なニーズ・好み・目標を能動的に推論し、支援できるようにすべき
能動的推論の形態
- ユーザーの好みの学習と適応:
会話履歴や文書からパターンを抽出し、ユーザープロファイルを構築・更新
- 関連する質問からの隠れた目標の推論:
- 具体例:
一連のクエリを分析し、潜在的な意図を抽出
ユーザーが「Pythonのデコレータ」→「パフォーマンスチューニング」と質問した場合、背後には「ソフトウェア設計の効率改善」という広い目標がある可能性
- ユーザーの苦戦に基づく支援:
試行錯誤や停滞を検出し、視覚化ツール・チェックリストなどを提案
6.5 Lifelong Context Preservation and Update
- コンテキストが長期的に蓄積されると、その管理が課題
主な課題:
- ストレージのボトルネック:
高圧縮・高精度・低遅延を同時に満たす保存方式は存在しない
- 処理能力の低下:
Transformerの 計算量がボトルネックとなり、入力が長くなると注意が拡散
- システムの不安定性:
累積誤差が時間と共に増幅し、予期せぬ動作を招く可能性あり
- 評価の困難性:
長期メモリチェーンの妥当性を評価することが困難
解決策の方向性 — セマンティック・オペレーティング・システム:
- 単なるウィンドウ拡張や検索精度向上では不十分
人間のように時間と共に成長する知的OSの構築が必要
- 知識の追加・修正・忘却を行う動的メモリ管理、推論ステップの追跡・修正機構を備える
6.6 Emerging Engineering Practices
KVキャッシング
- 過去のトークンのアテンション状態(Key・Value)をキャッシュし、再計算を省く技術
- キャッシュヒット率がレイテンシとコストに直結
- ヒット率向上策:
- システムプロンプトを安定化(小さな変更でキャッシュ無効化を防ぐ)
- 追記専用で決定的な更新
- ウォームアップ(予測的ローディング)
ツール設計
- 説明: 明確かつ正確でなければならず、曖昧さは失敗の原因となる
- 規模: ツールが多すぎると信頼性が低下
- 具体例: DeepSeek-v3ではツールが30個を超えると性能が低下、100個以上でほぼ失敗
コンテキストの内容
- エージェントの「間違い」を隠してはいけない。失敗を記録することで自己修正が可能
- 従来のFew-shotプロンプティングは、エージェント設定では逆効果になることがある
- 対策: 過去の行動記録に小さな構造的変化(異なる言い回しや形式)を加えることで反復パターンを防ぎ、ロバスト性を向上
マルチエージェントシステム(Claudeの経験)
- 「リード」エージェントは、サブタスクに明確な目標を設定すべき
- 検索戦略は「広範な探索」から「焦点化された分析」へ段階的に移行するのが最適
実践的な小技 (Tricks)
- ファイルでサブゴールを管理するのは一般的だが、長期タスクでは初期目標を見失うことがある
- 解決策:
更新時に目標を自然言語で復唱することで、モデルが焦点を維持しやすくなる
@Akira Manda(zunda)
[論文]Federation of Agents: A Semantics-Aware Communication Fabric for Large-Scale Agentic AI
ざっくり
- 固定ロールや手作業で頑張るの多エージェントから卒業
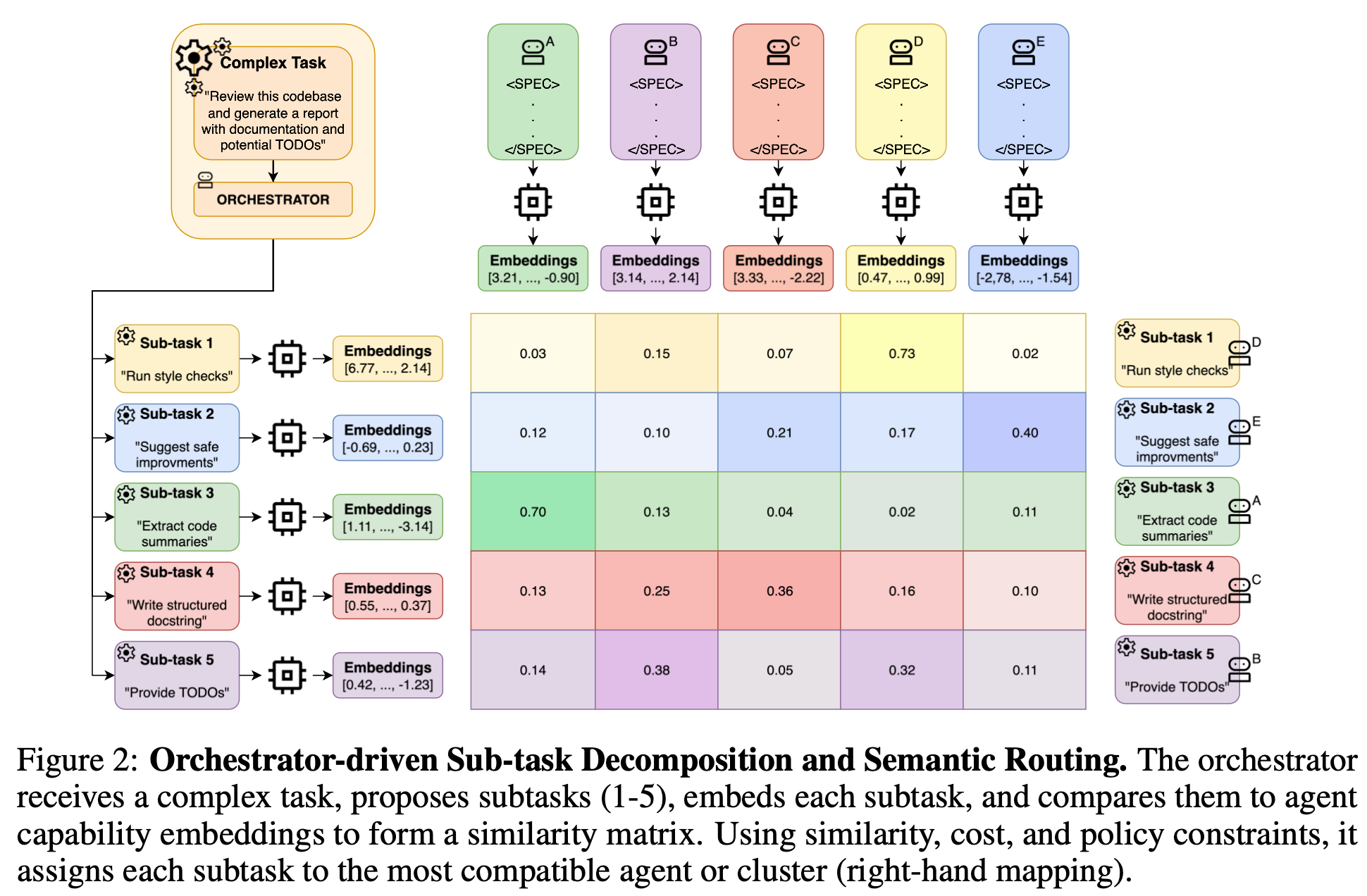
- 機械可読な「能力プロフィール(VCV)」を検索して最適なエージェントを選別
- 意味ルーティング→合意DAG→クラスタ協調(MQTT上)で大規模かつ制約順守の協調を実現
何が新しいの?
- 能力レジストリの作り方
- VCVという機械可読なプロフィールで、意味的な近さ・ポリシー順守・リソース適合を同時に見る
- 単なる多数決ではなく、分解→割当→小さなチームでの数ラウンドの擦り合わせ→合成という“段取り”をきちんと設計
- 通信をHTTPではなくMQTTに寄せ、スケールと運用を最初から考えた作りにしている
Spec is 何?
- 各エージェントが記憶し行動に反映する仕様書(自然言語)
- 役割や禁止事項、安全規範を含む自然言語の行動規範を想定
- 埋め込み化して能力選抜にも使えるようにする
VCV is 何?
- はエージェント
- は能力の意味埋め込み(学習済み言語モデルによって生成)
- は離散スキルのビット表現
- はレイテンシや帯域・メモリ・エネルギーなどのリソース指標
- は規制・セキュリティなどのポリシーフラグ
- はそのエージェントの仕様書(Spec)の埋め込み
- はバージョン番号
タスク実行時
- Agent-0(Orchestrator)がタスク文をベクトル化し、類似のVCVを取得する。
- 類似VCVのうちのいく人かのエージェントにタスク分解案を聞き、まとめ、DAGにする。
- “意味の近さ×ポリシーOK×リソース合う×Spec相性”でスコアを出し、最適な担当を決める。
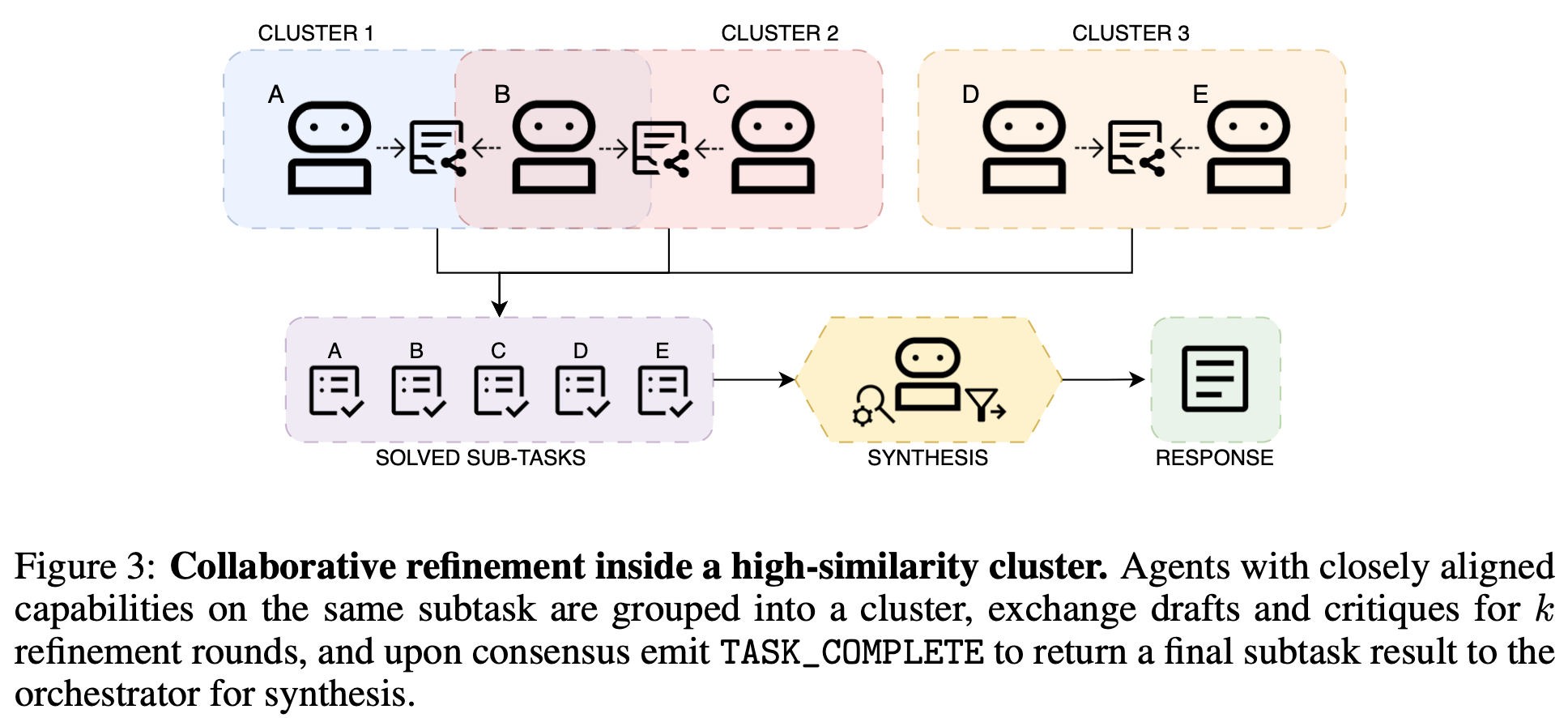
- 同じサブタスク組は似た者同士で小クラスタにして、専用チャンネルを作る。
- タスクを受け取ったAgent-1側は初稿を出す。クラスタ内で互いに読み合い・直し合いを数ラウンド回して、合意できたらTASK_COMPLETEを返します。危ない内容はSpec準拠で拒否・保留する。
- 仕上げ(Agent‑0側): 返ってきた結果でDAGを前に進め、最後にうまく合成する。終わったら結果を公開し、評判やVCVを更新して次に備える。
実験&結果
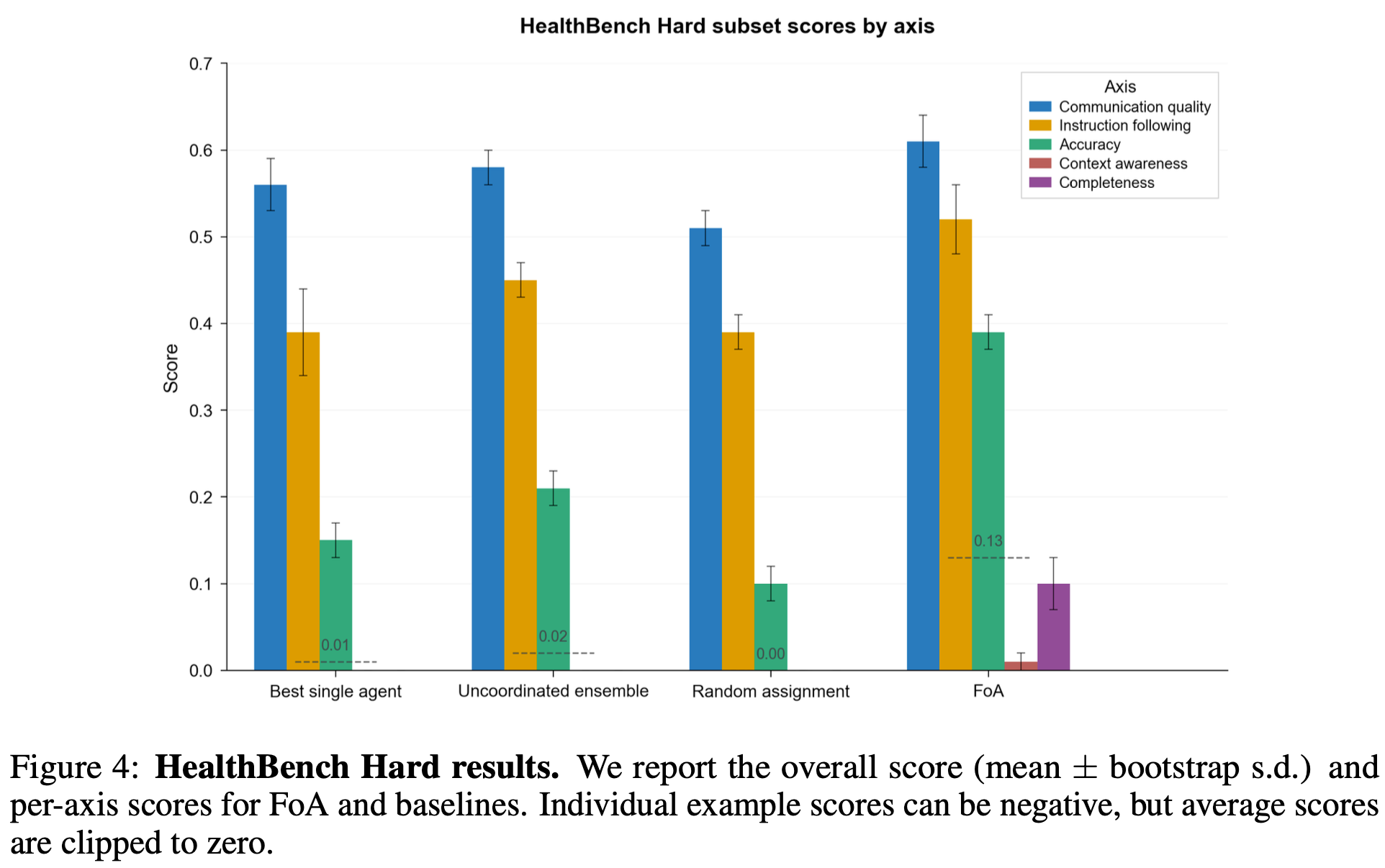
- ベンチマークはHealthBench Hard(医療系1,000マルチターン、0〜1にクリップした平均スコア)を採用。オープンエンド評価で現実的な対話品質を測る設計。
- 比較は単独エージェント、分解・協調なしの単純アンサンブル、ランダム割当を用意。FoAは能力駆動ルーティング+クラスタ協調を有効化。
- 総合スコアはFoAが約0.13を記録。単独エージェント比で約13×、単純アンサンブル比で約6.5×の相対改善を達成。
- Fig.4の軸別比較では、正確性・網羅性・文脈理解・コミュニケーション品質・指示遵守の各軸でFoAが一貫して上回る。特に高リスクで多視点が効く問いで伸びが顕著。
- ランダム割当は大幅に劣後し、能力・ポリシー・リソース適合を見た意味ルーティングの効果が明確。クラスタ内の数ラウンド精錬とDAG分解の相乗効果が有効に働く構図。
所感
- 飼っているエージェントの繋ぎ合わせとか複雑になっていくだろうし、動的配置は夢がありそう(界隈では普通なんです?)
- 今回の実験でレスポンスが537秒らしいが、速さを求めていくとマルチエージェントはつらい、、、ってことになりそう?
メインTOPIC
Knowledge Compression via Question Generation: Enhancing Multihop Document Retrieval without Fine-tuning
Abstract
- 本研究は、質問ベース知識エンコーディング (question-based knowledge encoding) を提案し、RAGにおける検索精度をファインチューニングや従来のチャンク分割なしで向上
- 単一ホップ検索タスク
- Recall@3が0.84に到達
- 従来のチャンク分割 0.23
- 300文字以内の paper-card (簡潔な要約) を導入し、BM25の性能を大幅に改善
- 簡易な技術系クエリでMRR@3を0.56 → 0.85
- マルチホップ検索タスク
- LongBench QA v1の2WikiMultihopQAでLLaMA2-Chat-7Bに構文リランキングを適用しF1-score 0.52を達成
- チャンク分割ベース (0.328) やファインチューニング済み手法 (0.412) を上回る
- 本手法はファインチューニングの要件を不要にし、検索レイテンシを低減し、直感的な質問駆動型の知識アクセスを可能にし、さらにベクトル格納量を80%削減
- RAGに対するスケーラブルで効率的な代替手段として位置づけられる
1. Introduction
- RAGは文書コーパスの規模が大きくなるにつれ、関連情報を効率よく検索することが難しくなり、全体的な性能や応答品質に悪影響を及ぼしがちである
- この問題に対処するため、既存研究は主に意味理解を高めるアーキテクチャ上の革新やドメイン特化のファインチューニング戦略に注目してきた
- これらは重要である一方で、しばしば過小評価されてきた重要な要素がチャンク分割
- たとえ高度な意味理解を備えたモデルであっても、入力コンテキストが不適切に分割されていたり、クエリの意図とずれていたりすれば、性能は低下
- 本研究では、質問およびクエリ生成を知識圧縮として活用し、単一文書および複数文書のより効果的な検索を可能にする新しいアプローチを提案する
- 実験は次の問いに答えることを目的とする
- 質問ベースの知識エンコーディングは、従来のチャンク分割法と比べて、RAG システムの検索性能をどのように向上させることができるか
- 構文的リランキングおよび paper-card は、科学文書における情報検索の正確性と効率にどのような影響を与えるか
- 質問生成は、スケーラブルでファインチューニング不要の RAG アーキテクチャにおいて、有効な知識圧縮手法となり得るか
2. Literature Review
- RAGの鍵は「どう分割して検索に載せるか」であり、固定長、構造(再帰)、意味(埋め込みクラスタ)、ハイブリッドなど多様なチャンク戦略がある。
- 固定長チャンク
- 文書を等しい長さのスパンに分割。セグメント間の文脈を保つためにオーバーラップを持たせるのが一般的
- 適切に実装された場合、この方法は堅牢かつ信頼性が高く、計算効率の観点から依然として有力な選択肢
- 構造ベース
- 見出し、節、表といった文書の階層構造を活用して自然な境界でセグメント化
- 金融レポートQAの評価では、128~512 語の幅広いチャンク長にわたって固定長を一貫して上回る結果が示された
- 制約: 多くのオンライン文書は統一的な構造を持たず、埋め込みメディア、動的コンテンツ、非標準的な HTML/CSS が混在することが多く、自動構造解析は不安定
- 意味ベース
- 埋め込みを計算し、意味的類似度に基づいてテキストをクラスタリング
- 単純な意味ベース分割は検索性能の向上が限定的である一方、計算負荷が大きくなる
- RAG におけるチャンク分割の改善を狙ったさまざまな戦略
- LLM を対話的に用いて文書内の自然な内容遷移を検出し、適切な境界を見つける方法
- RAG に組み込むと、固定長や簡易なチャンク分割より高い QA 精度を示し、場合によっては最先端モデルに匹敵
- 事前にチャンクを定義せず、文書全体をエンコードしてコンテキスト内で根拠抽出
- 文境界に整合するよう制約付きデコーディングで根拠スパンを得る
- オンラインで複数のクエリを生成、リランキングする RAG-Fusion
- クエリ生成をオンラインで行うためレイテンシの悪化、また関連性の低いクエリが混入する可能性があるという欠点も指摘されている
- 課題
- 計算コストの高さ
- 多くの高度なチャンク分割は大規模言語モデルやtransformer encoderに依存し、特にファインチューニングや推論で相当の計算資源を要する
- ドメイン特化のファインチューニングの必要性
- ミクスチャ手法やチャンク不要手法などは、ルータ等の補助コンポーネントの学習やモデルの微調整を伴い、実装の複雑さを増し、低リソース環境での利用可能性を下げる。
- レイテンシとスケーラビリティ
- 対話的・動的なチャンク分割は精度面で有利な一方、リアルタイム検索や大規模展開では遅延の増大につながりやすい
- これらを踏まえ、本論文は質問・クエリ生成を「知識圧縮」として用い、構文リランキングやpaper-cardsで、微調整なし・低遅延・省ストレージな検索を目指す立場をとる
3. Motivations
- 本研究のアプローチは、質問生成を質問応答よりも重視し、質問を「知識圧縮」の単位として用いることで、文書を読み切らずとも焦点や論点を露出させられると仮定する。
- 文書内に question cues (質問の手掛かり) を配置して意味的境界を作ることで、関連内容を結び、検索精度と理解の深さを同時に高められると考える。
- この知識圧縮はRAGにおいてメモリ使用削減にも寄与し、従来のチャンク最適化やファインチューニングに頼らずにスケール可能性を向上させる。
- 本研究は、機械が高品質な質問を生成して科学的発見を促進できるかを探る一連の取り組みの一部であり、質問生成・クエリ生成がRAGの検索能力を間接的に押し上げるかを検証する。
- 併せて、提案の利点と限界(冗長生成や長文での焦点欠如など)も観察し、実運用の妥当性を評価する姿勢をとる。
4. Task definition
単一ホップ文書検索
- ユーザのクエリに対して単一の文書を検索
- 生成ではなく、純粋な文書検索の性能
マルチホップ文書検索
- 入力クエリに対して、単一の文書内の最大4つのパッセージをまたいで回答
5. Methodology
5.1 Main approach
- 本手法は大きく二つの要素から成る
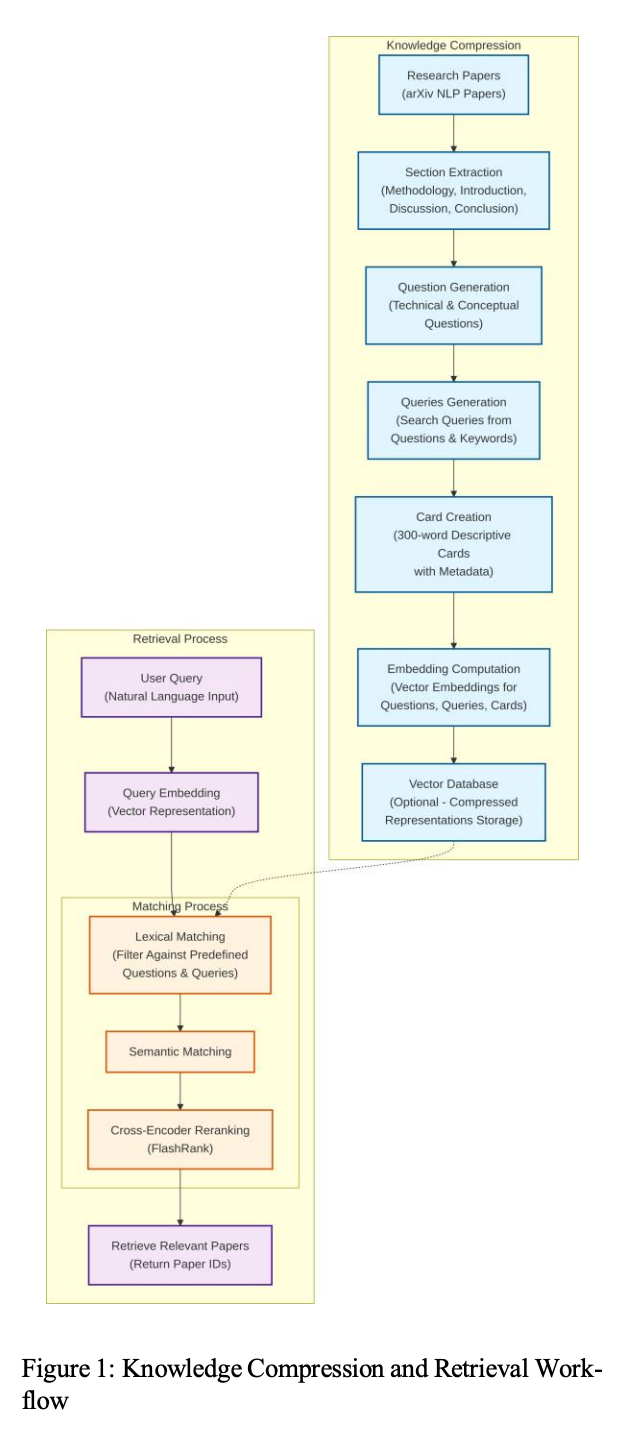
Knowledge Compression Pipeline
- セクション抽出:arXiv の自然言語処理分野の論文から、情報量の多い節(方法、序論、考察、結論)を体系的に抽出する。
- 質問生成:各節について、論文の中核的貢献を捉える技術的質問と概念的質問を生成する。
- クエリ生成:生成した質問と抽出したキーワードから、各論文に紐づく複数の検索クエリを構築する。
- カード作成:論文の主題、主要な知見、メタデータ(掲載プラットフォーム、著者、公開日、IDまたはDOI)を含む、300語以内の簡潔な記述カードを合成する。
- 埋め込み計算:すべての質問、クエリ、カードについてベクトル埋め込みを計算する。
- ベクタデータベース:これらの圧縮表現はベクタDBに保存でき、全文書を保持する必要がなくなる。
Retrieval Process
- ユーザクエリ:自然言語のクエリを受け取る。
- クエリ埋め込み:クエリをベクトル表現に変換する。
- 照合:
- 語彙的照合:あらかじめ用意した質問と語彙レベルで一致させるためのフィルタリングを行う。
- 意味的照合:語彙的照合で上位となった質問について、その質問が圧縮している元セクションの内容を用いて意味的照合とリランキングを行い、関連する論文IDを特定する。
- 返却:関連論文のIDをユーザに返す。
Figure 1
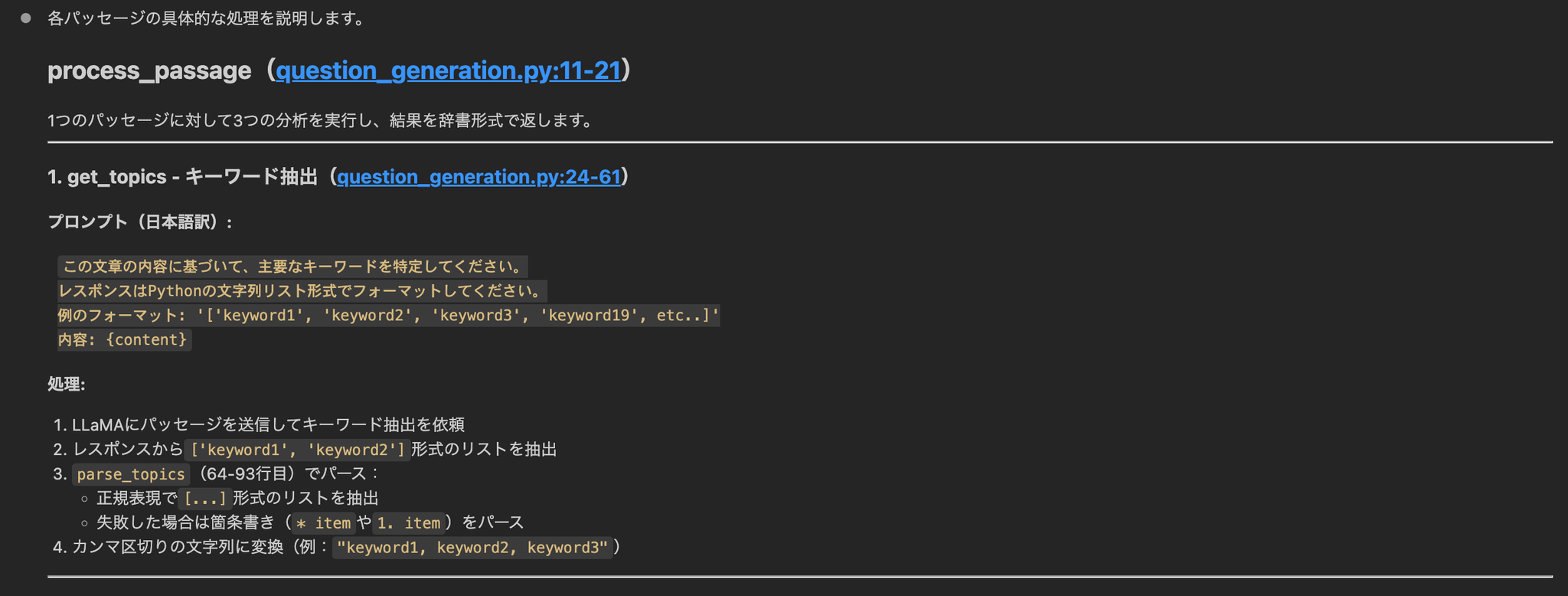
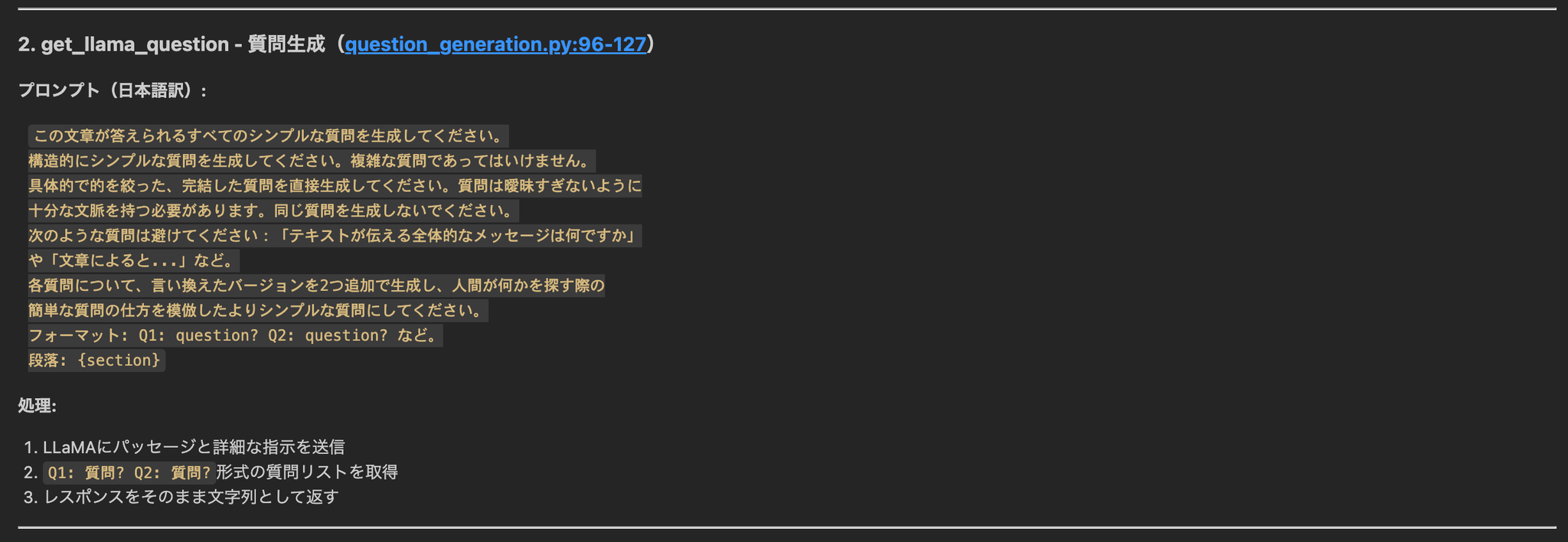
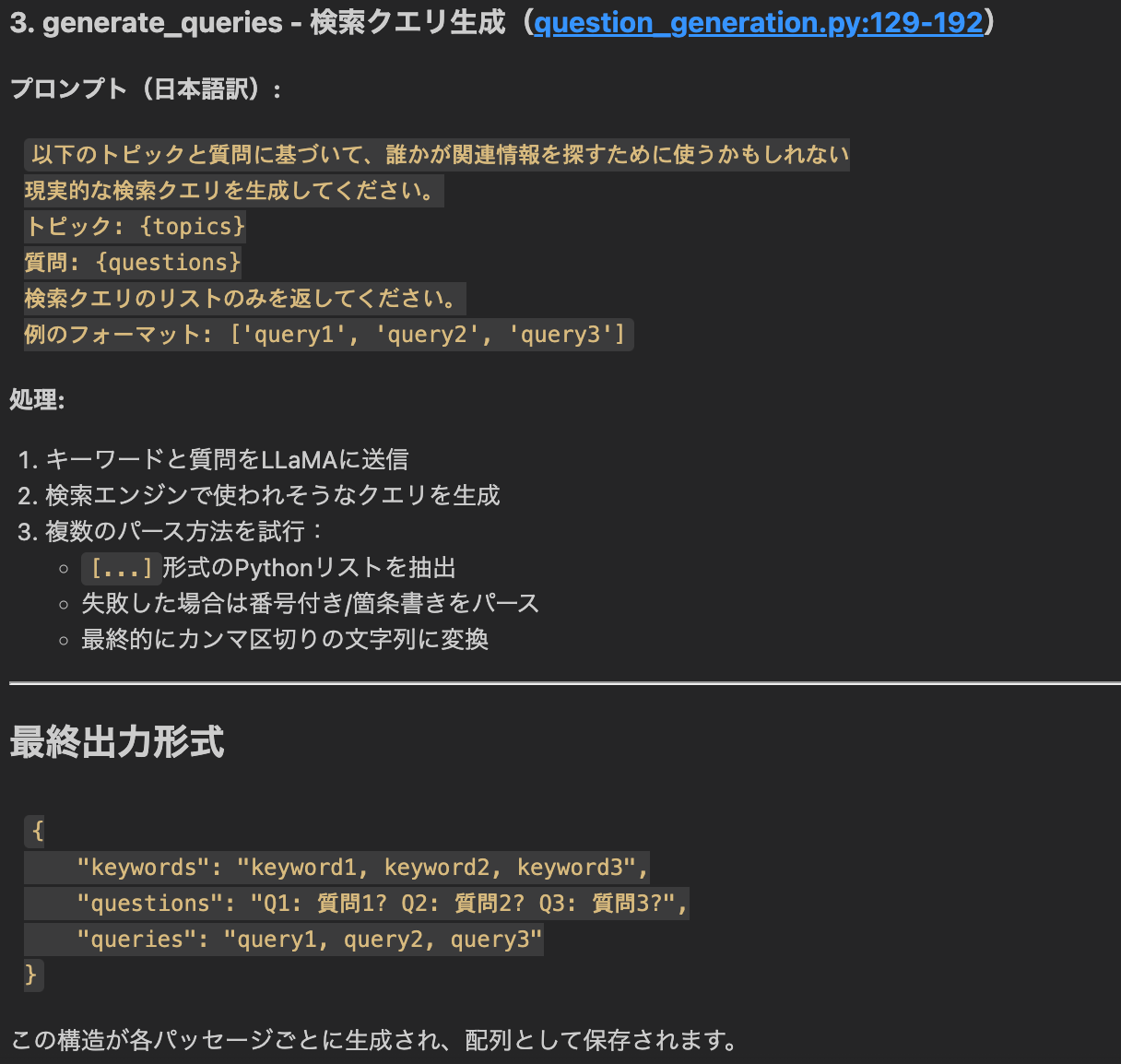
5.2 構文的アルゴリズムの説明 (Retrieval Processのstep3)
- キーワード抽出:品詞タグ付けでクエリを処理し、前置詞などの関係詞と等位接続詞、特定の句読記号を優先的に除外して意味のあるキーワードを抽出する。
- 出現頻度スコアリング:各パッセージに対し、その中に現れるクエリ・キーワードの総出現回数をスコアとして与える。これによりキーワード被覆と反復の重要度を共に捉える。
- しきい値フィルタリング:スコアがパラメータ k 以上のパッセージのみを残す。これによりクエリ関連性の最低水準を保証する。
- 順序保持:頻度スコアで単純に並べ替えるのではなく、フィルタ後のパッセージを元の出現順に再整列する。これにより文書集合の意味的・論理的な流れを維持し、首尾一貫した情報検索を可能にする。
- Top-k 選択:最終的に、順序保持した候補から先頭の6パッセージを返す。関連性と出力の扱いやすさのバランスを取るためである。
5.3 Data
単一ホップ文書検索
- 入力クエリに基づく直接的な文書検索に焦点を当て、109 本の科学論文からなるデータセットを用いた
- これらは arXiv の自然言語処理分野から無作為に抽出されたもので、すべての検索手法を同一データセット上で評価した
マルチホップ文書検索
- LongBench QA v1 データセットを用い、その中の 2WikiMultihopQA と 2WikiMultihopQA_e のサブセットを選択
- モデル評価に用いたサンプル数は、両サブセット200件ずつ
- 平均すると、2WikiMultihopQA_e は約 6,146 語、2WikiMultihopQA は約 4,887 語を含む
6. Experiments
6.1 Evaluation Methodology
- 第1タスクでは、Accuracy@k または Recall@k を主要評価指標として用いる。
- Accuracy@k と Recall@k は、このシナリオでは同値となり、正解文書が上位k件に含まれているかという二値的な成功・失敗を適切に捉える
- また補助的な指標として、正解の順位に重みづけを行う MRR(Mean Reciprocal Rank)も併用する。
評価設計
- 本タスクでは二つの評価を実施
- 第一に、提案手法を構造ベース、固定長、BM25 といった従来のチャンク分割・検索手法と比較し、さらに、従来のアブストラクトを用いた BM25 と、提案手法で生成したpaper-cardを用いた BM25 とを比較
- 第二に、LongBenchQA v1 で用いられているのと同一のデータセットにおいて、最先端手法との比較ベンチマークを行った
- 使用モデル
- 提案手法の構築と、BM25・再帰チャンク分割・固定長チャンク分割との比較評価には Llama 3.2 3B Instruct を用いた
- 第二の評価(モデル比較)では次の生成モデルを使用
- Llama2-7B-chat-4k
- Vicuna-7B(16K コンテキスト)
- Llama3-8B(8K コンテキスト)
実験設定
単一ホップ文書検索
- 提案手法を固定長チャンク分割、再帰チャンク分割、BM25 と比較
- 評価は二つのクエリ様式で実施
- V2: 技術的で構文が明確なクエリ
- V3: 概念的・広義なクエリ
- クエリは各論文から抽出した既定の質問・クエリパターンに基づき、Claude 4 を用いたゼロショットプロンプトで生成
- 従来のアブストラクトと、提案手法で生成したpaper-cardの双方で BM25 の性能を比較
- 検索に用いる生成モデルは Llama 3.2 3B Instruct で、選択した論文セクションを扱えるようコンテキスト長のみ 6000 トークンに拡張
マルチホップ文書検索
- LongBenchQA v1 の評価方針に従い、主要指標として F1 を採用
- 使用モデルは前述の三つで、推論設定は共通とし、プロンプトテンプレートは LongBenchQA v1 と整合、温度は 0.5 に固定
- さらに、構文的リランカーについて、主要パラメータ L の値を 2 と 3 で比較した。
- L は、各パッセージ内に位置とは独立に同時出現すべきクエリ語の最小数
7. Results
7.1 Task 1
Global performances
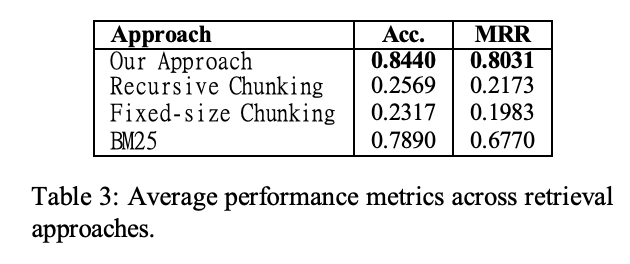
- Table3: 提案手法と各従来手法の平均性能を示す
- 提案手法は Accuracy 0.8440、MRR 0.8031 を達成し、再帰チャンク分割(Accuracy 0.2569、MRR 0.2173)、固定長チャンク分割(Accuracy 0.2317、MRR 0.1983)を大きく上回った
- BM25 は Accuracy 0.7890、MRR 0.6770 で、提案手法に次ぐ結果となった
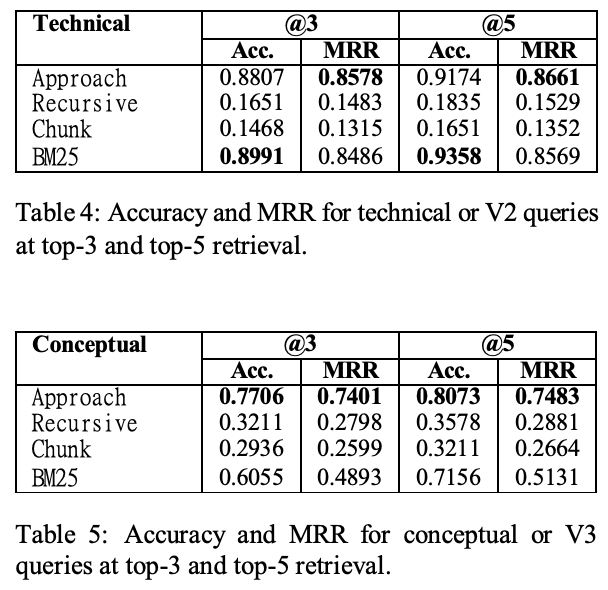
- Table4, 5: さらに、クエリの性質に基づく二つの側面(技術的/概念的)での詳細評価
- 技術的クエリ(V2)
- Accuracy (@3, @5)
- BM25 > Approach > Recursive > Chunk
- MRR (@3, @5)
- Approach > BM25 > Recursive > Chunk
- 概念的クエリ(V3)
- Accuracy (@3, @5)
- Approach > BM25 > Recursive > Chunk
- MRR (@3, @5)
- Approach > BM25 > Recursive > Chunk
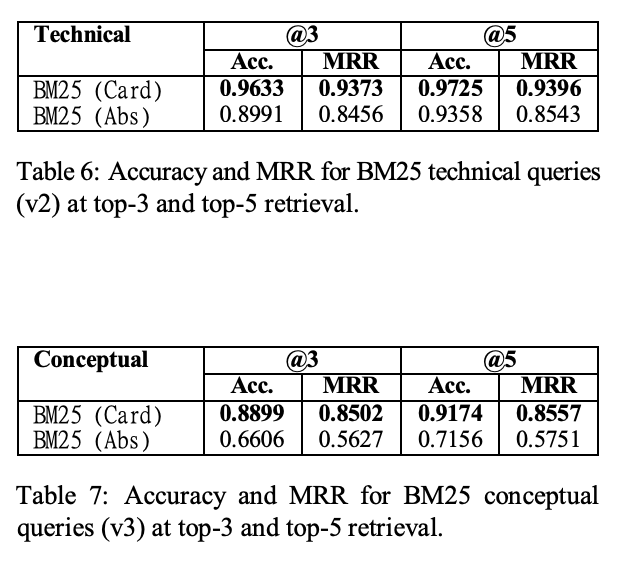
BM25 Boosted
- 従来のアブストラクトと、本手法で生成したpaper-cardを用いた場合の BM25 の性能を比較
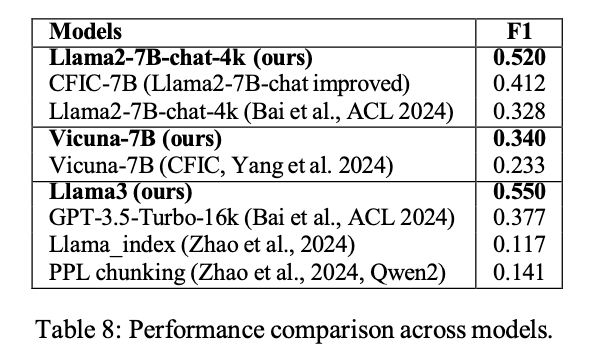
7.2 Task2
- Table8: マルチホップ検索における各モデルの F1 を示す
- 提案手法を適用したモデルはいずれも従来実装を上回った
- Table9: さらに 2WikiMultihopQA_e において、コンテキスト長 0–4K と 4K–8K の範囲別に、構文的リランカーのパラメータ L(2 または 3)を変えて詳細評価

8. Discussions
- 提案手法は、NLP系の学術論文に対する単一ホップ検索で従来のチャンク分割法を明確に上回りました。特に概念的クエリでの安定性が高く、技術的クエリに強いBM25と比べてもMRRの低下が小さいことが示されました。
- BM25は技術的クエリでは高精度ですが、概念的クエリでは性能と安定性が大きく落ちます。これに対し、paper-cardを併用するとBM25の精度とMRRが大幅に改善し、両クエリ種で安定性も高まりました。
- 再帰・固定長チャンク分割は対象が学術論文のため難易度が高く、Accuracyが伸び悩みました。一方、提案手法はカードと質問を核にするため、長文でも要点に素早く到達しやすい構造になっています。
- ストレージ・計算効率の面で提案手法は大きな利点があります。全文チャンクを大量に保持する代わりに、カードと主要質問の少数埋め込みだけを索引すればよく、カード自体も数KB程度で軽量です。
- マルチホップでは、構文的リランカー(キーワード共起と原順保持)により候補パッセージを高品質に絞り込めました。Lという共起しきい値は重要で、L=3は長い文脈で強く、L=2は短い文脈で当てやすい一方で長文ではノイズが増える傾向があります。
- 提案手法を組み合わせたモデルは、既存の素の実装やチャンク系のベースラインを上回りました。特に、従来構成のモデルと比べてF1が大幅に向上し、差分の多くは構文的理解を高める再ランクの効果に起因すると示唆されます。
- 総合的な利点として、ファインチューニング不要、低レイテンシ、ストレージ節約、意味情報の保全、そして質問駆動で直観的にアクセスできる点が挙げられます。これらにより、RAGに対するスケーラブルで実運用しやすい代替案として位置づけられます。
10. Limitations
- 長大なコンテキストでは、簡潔で焦点の定まった質問やクエリを安定して生成するのが難しく、キーワードが冗長化しやすい傾向がありました。とくに1万語級のマルチホップ設定で深みのある質問生成が崩れやすいです。
- 構文的リランカーは関連パッセージの選別に有効でしたが、固定パラメータ L に依存するため柔軟性に欠けます。文脈に応じて最適な L を自動調整できる仕組みが今後の改善点です。
- 現行のモデルは、複雑かつ長大なテキストから質の高い質問を幅広い難易度で生成する訓練が不十分と示唆されました。意味理解だけでなく、語間関係を安定に捉える構文理解が不足しています。
- 生成した質問は論文単位で紐づくものの、コーパス拡大時に有効な上位構造の設計が不十分です。質問と出典をグラフ構造で組織化することで、可搬性・検索効率・スケール性が向上すると考えられます。
- 微調整を行わない前提は汎用性の利点がある一方で、性能上の上限として作用しました。とりわけ構文的側面へ特化した微調整は、ドメインバイアスを強める純粋な意味的微調整より汎用性を保った改善が見込めます。
- 総じて、質問生成品質の向上、質問群のスケーラブルな構造化、リランカーの適応化(動的 L)の3点が主要な改善課題です。これらは長文・多段推論下での安定性と精度向上に直結します。
参考
- 質問生成の実装
‣