
2025-11-11 機械学習勉強会
今週のTOPIC[論文] MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming[oss] confident-ai/deepeval[論文] Reasoning with Sampling: Your Base Model is Smarter Than You Think[論文] Arctic Inference with Shift Parallelism: Fast and Efficient
Open Source Inference System for Enterprise AI[論文] VIR-Bench: Evaluating Geospatial and Temporal Understanding of MLLMs via Travel Video Itinerary Reconstruction[論文] Scaling Agent Learning via Experience Synthesis[論文] No-Human in the Loop: Agentic Evaluation at Scale for RecommendationメインTOPICThinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction概要背景問題設定Scaling Test-Time InteractionTTI: Curriculum-Based Online RL for Scaling Interaction実験コメント
今週のTOPIC
@Naoto Shimakoshi
[論文] MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming
- ICML 2025 Workshop on Multi-Agent Systems
- 従来のワークフロー生成は、Planが脆弱なために実行不可能なワークフローを作りがち。
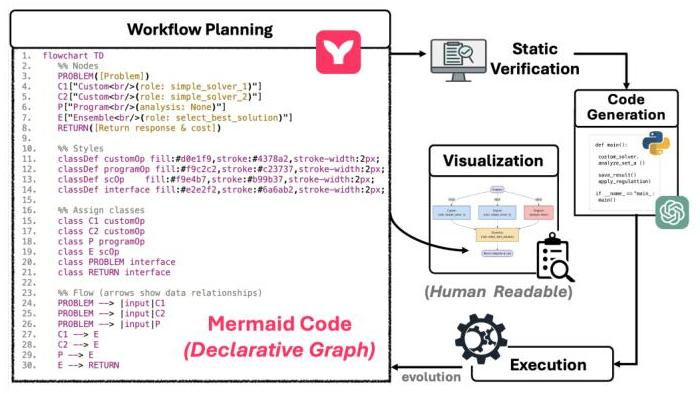
- Mermaidでグラフを表現することで静的解析、可視化、コード生成までを一貫して行えるようにした。
- 最適化として進化的プログラミングを採用した。
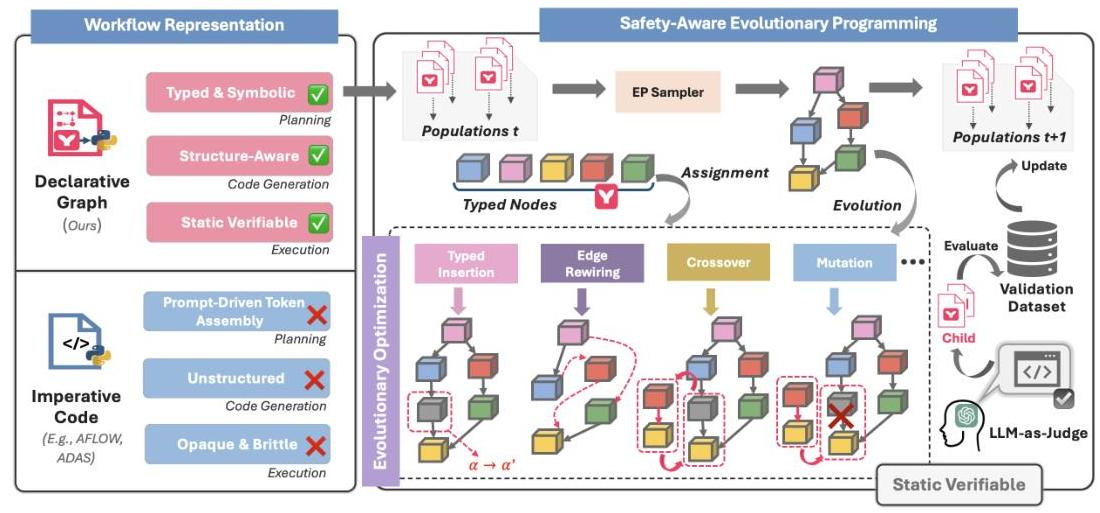
- 既存研究
- AFlow、MaAS、MetaGPTなどのシステムは通常、ワークフローをPythonスクリプトやJSONツリーを使用して表現
- 計画の決定が実装の詳細と密結合している
- 問題
- 実行時のみのエラーしか検知できず、失敗が高コスト
- 小さな変更でもワークフロー全体を無効にしてしまい、再検証コストがでかい
- 解釈可能性が低い。構造が暗黙的で、人間にも機械にも読み解きにくい。
- 再利用性が限られる
- GPTSwarmのインタラクショングラフやMetaGPTのSOPスタイルのテンプレート
- 静的解析がしにくい、形式の自由度が高い
- DebFlowやEvoFlowのような進化的アプローチ
- 制約が弱く計算リソースが無駄になる
- 手法
- 宣言的グラフ
- まず何をしたいか (ノードの役割や入出力、エッジ)を明示し、実装と切り離す
- これにより、構造と意味が人間にも機械にも明快に見え、静的検証が可能になる。これが共通インターフェースになる。
- ノードは をもち、 は入出力の型変換、 はPromptや分析方針など、コード生成時に必要な情報が入る。エッジにはラベルをつけて、情報の種類や流れを明示しつつ、ノードの を使って型整合を取る。
- ノードに型をもたせているので、 と で機械的にPromptと入出力フォーマットを一意に定めることで、Mermaid → Pythonへの変換が規則的で安定する。
- ノードの編集はMermaidの静的な制約の中での局所的な編集に閉じることができる。
- 静的検証とカスタムチェック Mermaidの文法レベルの検証に加え、ワークフロー特有のルール(PROBLEMとRETURNの存在、全ノードが入力から出力までつながっているか、Ensembleノードには複数入力があるか、など)を独自のチェッカーで確認。
- - 特殊な推論戦略に使用され、定義された役割を通じて特定のタスクを実行する。 例:K["Custom<br/>(role: validate_1)"]
- - ワークフローのエントリーノードと終了ノードであり、問題の入力点と出力点の両方を含む。 例:PROBLEM([Problem])
- - コード生成と計算を実行するノードであり、特に数学的な問題に適している。 例:P["Programmer<br/>(analysis: ’Calculate step by step’)"] 数学の問題のみがこのノードタイプを使用する。
- - 複数のソリューションを1つの結果に結合するノードであり、適切に機能するには複数の入力を必要とする。 例:ENSEMBLE["ScEnsemble<br/>"]
- - ソリューションをValidationするためのノードであり、コードが定義済みのテストケースに合格するかどうかを確認するために使用。 例:T["Test<br/>" コードの問題のみがこのノードタイプを使用する。
- - 問題の説明に基づいてコードを生成するために特別に設計されたノード。 例:CODE_GEN["CustomCodeGenerate<br/>(instruction: xxx)"] コードの問題のみがこのノードタイプを使用する。
- 進化的プログラミング
- 以下の操作を行う
- Node置換
- Node追加
- Edgeの再配線
- Node削除
- サブグラフの変異
- 交叉
- 二つの親グラフが共有するインターフェース節点(型・インターフェース整合が保たれる点) を境にサブグラフを入れ替え。
- ハードチェック:MermaidCLIによる構文コンパイル
- ソフトチェック:Mermaidコードから正規表現などでコンポーネント情報を引っ張ってきてチェック
- 以下のValidationを実装
- W1 - 必須のPROBLEMおよびRETURNインターフェースノードの存在を確認
- W2 - 各ノードがPROBLEMからRETURNへのパスを持つワークフロー内で適切に接続されていることを確認
- W3 - PROBLEMおよびRETURNノードがインターフェース型として正しく分類されていることを検証
- W4 - すべてのノードが構成に従って有効な型を持っていることを確認
- W5 - ScEnsembleOpノードが少なくとも2つの入力接続を持つことを確認
- 各世代の探索で、履歴バッファに「過去の有効ワークフローとスコア」蓄積。スコアを元に親を二つサンプリングしてから、LLM-as-a-Judgeで「タスク適合性・構造品質・一貫性」などを評価し、最有望の子だけを選んで本評価に回す。
- (ponさんのblogで言うところのVerifier的な)
LayerX エンジニアブログRepeated Samplingを使ったLLM推論時スケーリングで麻雀点数計算問題生成タスクを解くぞ! - LayerX エンジニアブログ
- 全体のサイクル
- 初期化: 既知の良質なMermaidワークフローを用意し、履歴バッファに格納。
- 親選択: 履歴バッファからスコアと多様性を考慮して親を二つ選ぶ。
- 生成: N個の候補グラフをLLMで生成。
- 静的検証: ハード+ソフトチェックで不適合を排除。
- 予備評価: LLM-as-a-Judgeで有望度をスコアリングし、トップの子を選抜。
- 実行評価: 選抜子をコード生成して実行し、解答精度やpass@1等のメトリクスでスコア化。
- 更新: 子とスコアを履歴バッファに追加し、次ラウンドへ。 このループで、壊れにくく、かつ改善が積み上がる探索が実現します。
(Appendix ) Node タイプ
(Appendix) Validation
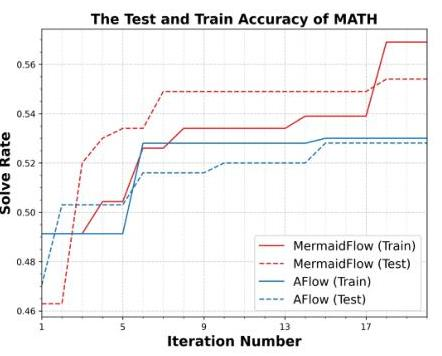
- 結果
- MATHとCode系のベンチマークでSoTAより全体的に改善
- AFlowより効率も良い

@Yosuke Yoshida
[oss] confident-ai/deepeval
- LLM Evaluation Framework
- LLM as a Judge の実装が豊富で、自前で実装するときの参考によさそう
 GitHub
GitHub- e.g. conversation_completeness ‣
- extract_user_intentions
- generate_verdicts
- generate_reason
会話からユーザーの「意図(目的)」を抽出し、JSONで返す。
その意図が会話の中で満たされたかを判断し、 の形で返す。
全体の「完成度スコア(0〜1)」に対して、なぜその点数なのかを簡潔に説明する理由文をJSONで返す。
@Takumi Iida (frkake)
[論文] Reasoning with Sampling: Your Base Model is Smarter Than You Think
推論時に追加の訓練を必要としない純粋なサンプリングを使って、ベースモデルの性能を(追加学習時と)同等の性能まで引き上げる
貢献
- Reasoningタスクに有効なべき分布によるサンプリング
- ベースモデルの尤度に従ってトークンサブシーケンスを反復的にリサンプリングするMCMCを提案。これにより、べき分布の近似サンプリングができる。
発想の仕方
仮説として、RL事後学習はベースモデルの分布をシャープにしてるだけなのでは?という研究がいくつかある。なので、ベースモデルからサンプリングするだけでいいのでは?
↓
具体的には、RL事後学習がシャープ化してるだけなら、同じような効果を得られるターゲットサンプリング分布を獲得できれば良さそう。
提案手法:べき分布からのMCMCサンプリング
MCMC的に分布のシャープ化を行う。
具体的には、「次にくるトークン」っぽいの確度をさらに上げて、そうじゃないやつの確度は下げる。
確率に温度αをつけて推論すると、シャープになる。
※べき分布からのサンプリングと一緒じゃないかという誤解が生まれそうだが、それとは違うらしいことが証明にかかれてる。ただの分布に関する数学的な証明。
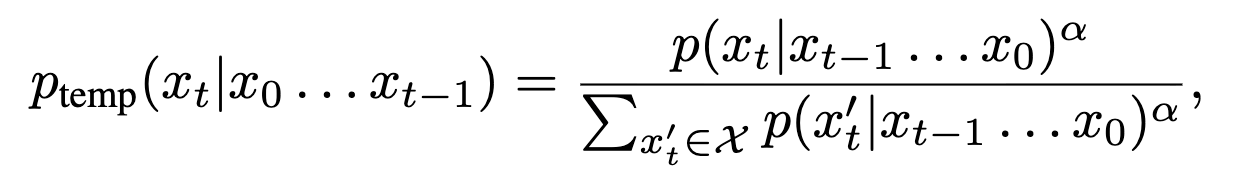
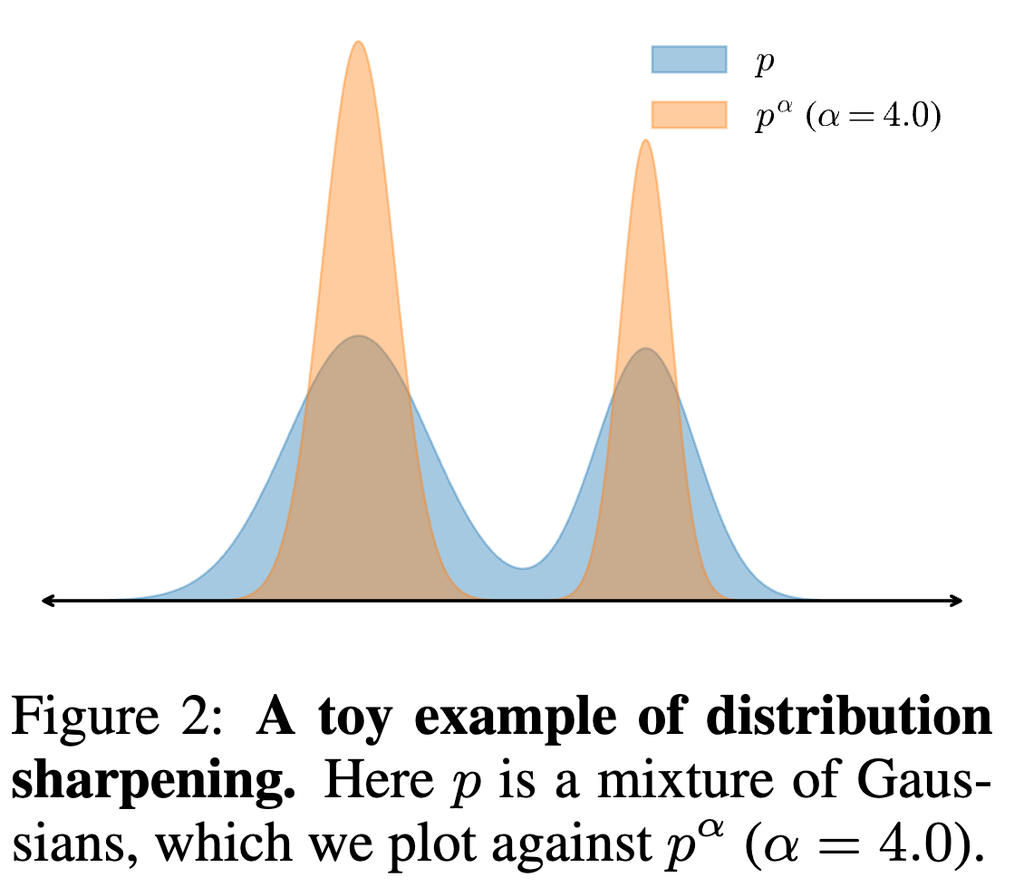
メトロポリスヘイスティング法
理想的には、↑のようなべき統計のシャープ化を直接やりたいが、計算量的に無理がある。
そのため、MCMC法の一つであるメトロポリスヘイスティング法(MH法)を使って近似する。
ざっくり言えば、新たな候補を生成し、それを受理するか否かを繰り返すことで、目標の分布(今回だとべき分布)に収束するようなサンプリングを構築できる手法らしい。
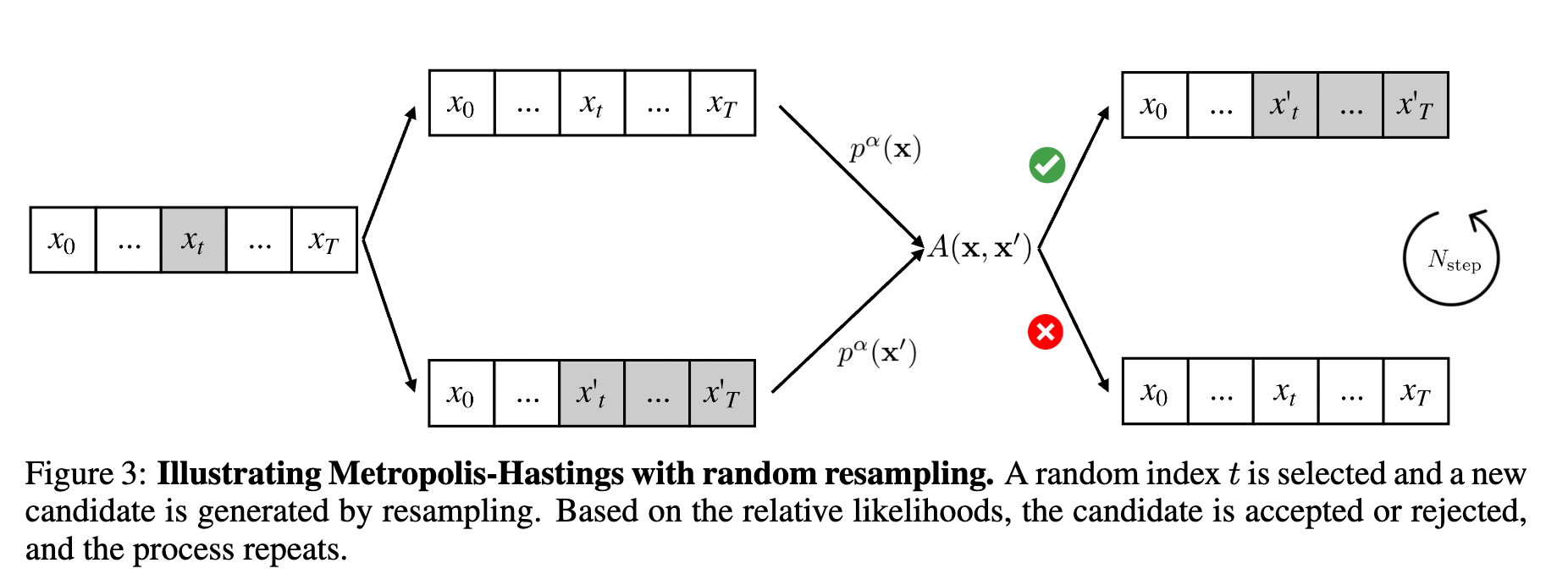
この論文では、LLMを使ってランダムな位置tから始まるシーケンスを生成することで、MH法を使うための制約を超えているらしい。
ただし、LLMを使って(べき分布を近似するために)推論しまくるのは、これもまたコストがかかるので次の工夫をしてる。
自己回帰MCMCによるべき分布サンプリング
目標とするべき分布 に収束するまで、その中間の分布からサンプリングされた結果を次のMCMCプロセスの初期値に利用する。これにより、悪い初期化をしてしまうことを避けて高速化を図っている。
アルゴリズム
ブロックごとに処理する+MCMCステップが確定したらそのブロックを確定させて、次のブロックにすすむ(10行目の処理っぽい)

結果
たしかに強い様に感じる
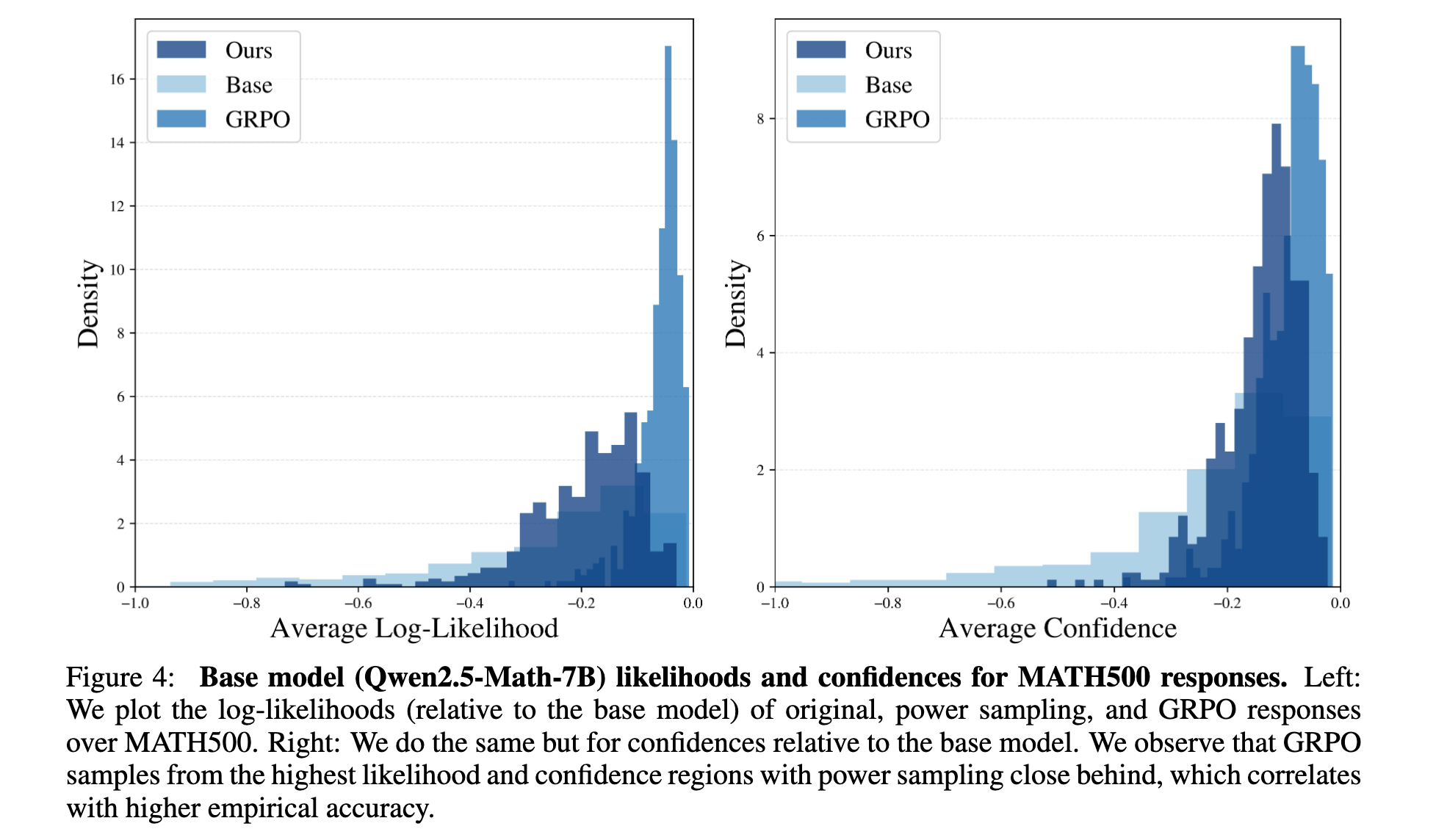
各モデルの対数尤度や確度をヒストグラムでプロットしてみた
提案手法はベースモデルよりも高い尤度領域からサンプリングしてるけど、広がりは維持したままにできてる。(色味が同じでちょっとわかりにくい…)
計算時間について具体的な結果はかかれてないが、推論時に多くのLLM推論を必要とするのでかなり計算時間はかかりそう。
RL事後学習をするのとどっちがコストかかるかトレードオフを考えたほうがいいと主張。
@Hiromu Nakamura (pon)
[論文] Arctic Inference with Shift Parallelism: Fast and Efficient
Open Source Inference System for Enterprise AI
LLM推論はレイテンシ、スループット、コストの間でトレードオフが生じている。Snowflake AI ResearchのオープンソースvLLMプラグインであるArctic Inferenceは、Shift Parallelismという動的な並列化戦略を導入し、実際のトラフィックに適応しながら、リクエスト完了時間が最大3.4倍、生成時間が1.75倍高速化
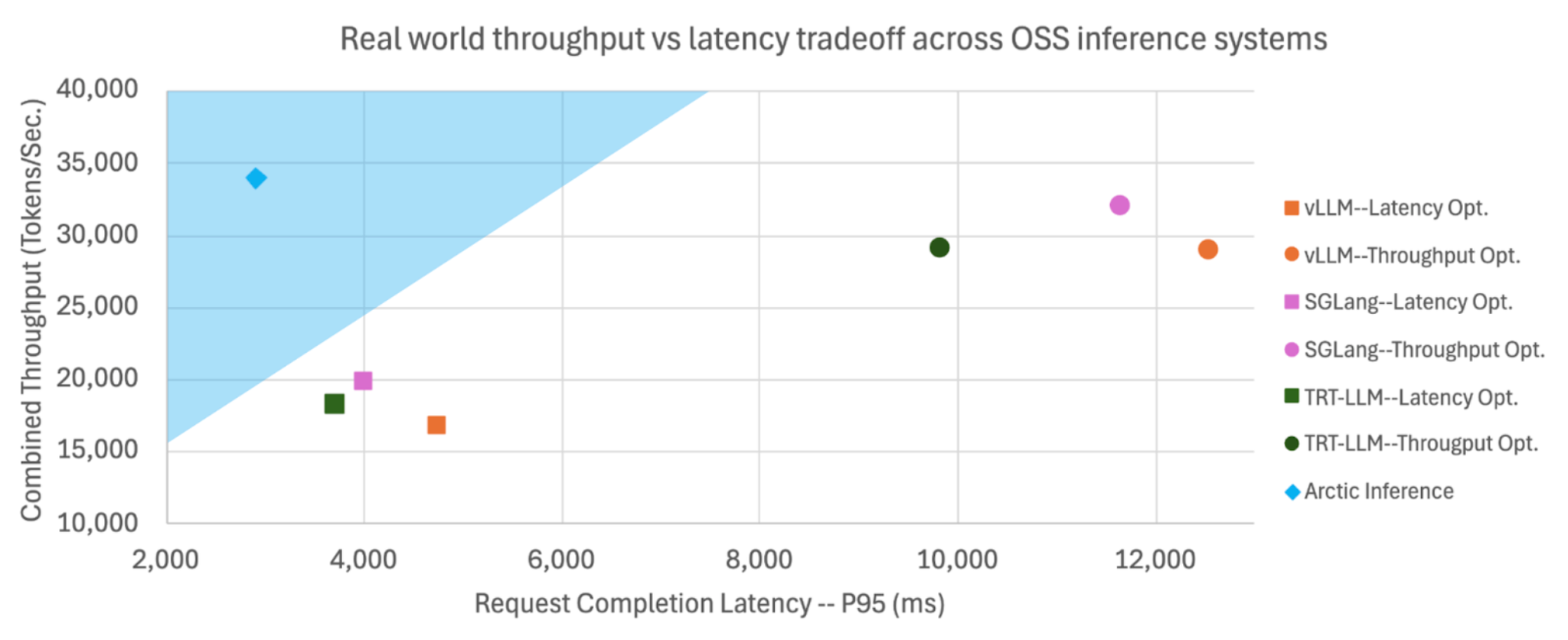
Shift Parallelism
リアルタイムで変化する予測不可能なトラフィックパターンに動的に適応するように設計されています。(バッチサイズもよって切り替わるき課
既存課題
- 従来の並列化アプローチ(例:TP(Tensor Parallelism)、DP(Data Parallelism))が特定の指標(低レイテンシまたは高スループット)のために静的に最適化されていた
- これはKVキャッシュのメモリレイアウトがTPとSP間で違うため、データ変換/転送コストが高くなるため
手法
- Shift Parallelismは動的に以下の2つのモードを切り替えることで、これらすべての指標を単一のデプロイメントで達成します
- Tensor Parallelism (TP):小規模なバッチ向けで、TPOT(Time Per Output Token)を最大化します
- Sequence Parallelism (SP) :大規模なバッチ向けで、TTFT(Time To First Token)を最小化し、ほぼ最適なスループットを実現します。
- つまりSPはDPをTPとKVキャッシュメモリレイアウトが不変になるように設計されたもの
- これらをバッチサイズによって切り替える!
三方よしを実現
Arctic Inferenceがコミュニティ向けに公開。vLLM Pluginとして入れることができる。
ArcticInference
snowflakedb • Updated Apr 14, 2026
@ShibuiYusuke
[論文] VIR-Bench: Evaluating Geospatial and Temporal Understanding of MLLMs via Travel Video Itinerary Reconstruction
- ‣
- 評価スクリプト
- データセット: soya.infini-cloud.net
- 入手するためには登録が必要。
- 早稲田大学、CyberAgent、AI Shiftの論文
- 感想
- 動画と旅行と地理情報という自分の興味ど真ん中なテーマ
- Appendixが豊富で面白い
1. はじめに (Introduction)
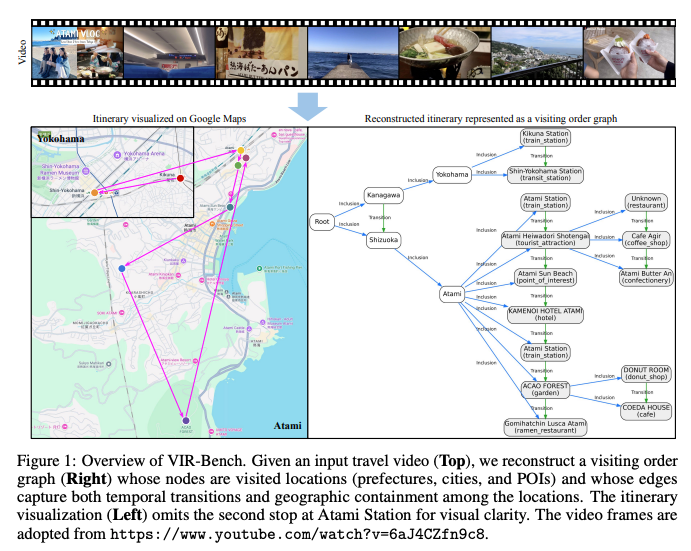
マルチモーダル大規模言語モデル(MLLM)の動画理解能力、特に「長期間の地理空間的・時間的推論」能力を評価するための新しいベンチマーク「VIR-Bench」を提案
- 背景と課題:
- 近年のMLLMは動画理解において顕著な進歩
- 既存のベンチマークは主に屋内シーンや短時間の屋外活動に焦点を当てており、複数都市にまたがる数日間の旅行のようなマクロなスケールのシナリオが未検討
- VIR-Benchの提案: このギャップを埋めるため、旅行Vlog動画から旅程を再構築するタスクを設計。再構築された旅程は「訪問順序グラフ(Visiting Order Graph)」として表現され、場所(ノード)と、それらの地理的包含関係および時間的遷移関係(エッジ)から成る
- 主な発見: 最先端のプロプライエタリ(クローズド)モデルであっても、特にPOI(地点)の特定や遷移関係の予測において苦戦しており、長時間の空間的・時間的スケールを扱う難しさが浮き彫りに
- 応用: 本ベンチマークの知見を活用した旅行計画エージェントのプロトタイプを開発し、実際のアプリケーションにおける有効性を検証
2. 関連研究 (Related Work)
2.1 動画ベンチマーク (Video Benchmarks)
既存の動画理解ベンチマーク(Ego4D, HourVideo, VSI-Benchなど)は、主に屋内シナリオや短距離の移動に焦点を当てており、都市間移動のような長距離移動を含まず。VIR-Benchは、広範囲な空間(例:東京から大阪)と長時間(数日間)にわたる動画理解能力を包括的に評価することで、この不足を補う
2.2 旅程抽出 (Itinerary Extraction)
テキストからの旅程抽出は自然言語処理分野で研究されてきたが、動画から直接旅程を抽出・再構築する体系的な研究はこれが初。本研究は、動画中心の地理空間的・時間的理解のための新たなベンチマークを確立
2.3 旅程生成 (Itinerary Generation)
自動旅程生成は、古典的な最適化問題からLLMを用いた手法へと進化。既存の研究は主にテキストデータ(ユーザーの好みや旅行記)を入力とするが、本研究は動画を入力として旅程を再構築する点で異る
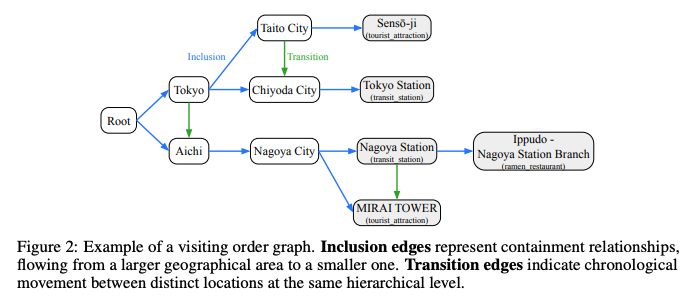
3. データセット構築 (Dataset Construction)
VIR-Benchは、日本全国で撮影された200本の旅行動画と、それに対応する訪問順序グラフで構成
3.1 訪問順序グラフ (Visiting Order Graph)
旅程は、以下の4種類のノードと2種類のエッジを持つ階層的な有向グラフで表現
- ノード(場所):
- Root: グラフの開始ノード
- Prefecture(都道府県): 最上位の行政区画(例:東京、大阪)
- City(市区町村): 都道府県内の自治体(例:千代田区、名古屋市)
- POI(Point of Interest): 具体的な施設名(例:東京駅、MIRAI TOWER、特定のレストラン)
- エッジ(関係性):
- Inclusion(包含): 地理的な包含関係(大きいエリアから小さいエリアへ。例:愛知 → 名古屋市 → 名古屋駅)
- Transition(遷移): 同一階層レベルの異なる場所間の時間的な移動(例:東京 → 愛知、名古屋駅 → MIRAI TOWER)
3.2 データアノテーション (Data Annotation)
10名のアノテーターが、日本で撮影されたYouTubeの旅行動画を各20本収集。動画内で訪問が確認できるすべてのPOIについて、開始・終了時間とGoogleマップのURLを記録。特定できない場所は「UNKNOWN」プレースホルダーで対応。最終的に、日本の47都道府県中43都道府県にまたがる3,689のPOIが特定
4. 実験 (Experiments)
4.1 タスク定義 (Task Definition)
エンドツーエンドの生成は困難であるため、タスクを2つに分解
- ノード予測: 動画から訪問したすべての場所(都道府県、市区町村、POI)をリストアップする、GeoGuessrのようなタスク
- エッジ予測: 動画と訪問場所の正解リストが与えられた状態で、場所間の包含関係(地理的知識)と遷移関係(時間的理解)を予測
4.2 ベンチマークモデル (Benchmark Models)
オープンウェイトモデル(VideoLLaMA3, LLaVA-Video, InternVL3, Qwen2.5-VL)とプロプライエタリモデル(GPT-4o, o1-mini, Gemini-1.5 Pro/Flash)をゼロショットで評価
4.3 評価指標 (Evaluation Metrics)
ノード予測とエッジ予測のそれぞれについて、適合率(Precision)、再現率(Recall)、F1スコアのマクロ平均で評価。POIノードは、類似度スコアが0.7以上、または0.5以上かつカテゴリが一致する場合に正解とみなす

4.4 主な結果 (Main Results)
- 全体性能: プロプライエタリモデルがオープンモデルを一貫して上回りました 。Gemini-1.5 Proが最も高性能だが、それでも都市/POIノード予測や遷移エッジ予測のF1スコアは約60にとどまる
- 遷移エッジ予測の困難さ: 最も難しいタスクであり、多くのモデルがF1スコア1桁台。失敗原因として、タスクの誤解釈や、階層レベルの制約(例:異なる都市のPOI間を直接遷移させてしまう)を無視する傾向が見られる
- 思考モデルの効果: o1-miniやGemini-1.5 Proのように、推論(Thinking)時間を設けることで、特にエッジ予測の性能が大幅に向上
4.5 アブレーション研究 (Ablation Study)
- フレーム数: 入力フレーム数を増やす(例:64から128以上)と、特に時間的推論が必要なタスクで性能が向上
- 音声: Gemini-1.5 Flashで音声入力を除外すると、遷移エッジ予測の性能が約50%低下し、時間的理解における音声の重要性が確認
5. 旅行計画エージェント (Travel-planning Agent)
5.1 タスク定義 (Task Definition)
POIリスト、動画、計画の制約(人数、期間、予算)を入力とし、詳細な旅行計画(旅程、交通手段、推奨レストラン・宿泊施設など)をMarkdown形式で出力
5.2 エージェントシステムの実装 (Implementation of the Agent System)
Gemini-1.5 Proをバックボーンとし、全体を調整するオーケストレーターと、5つの専門エージェント(計画、Googleマップ検索、ルート検索、宿泊施設検索、サマリー作成)で構成されるマルチエージェントシステムを実装
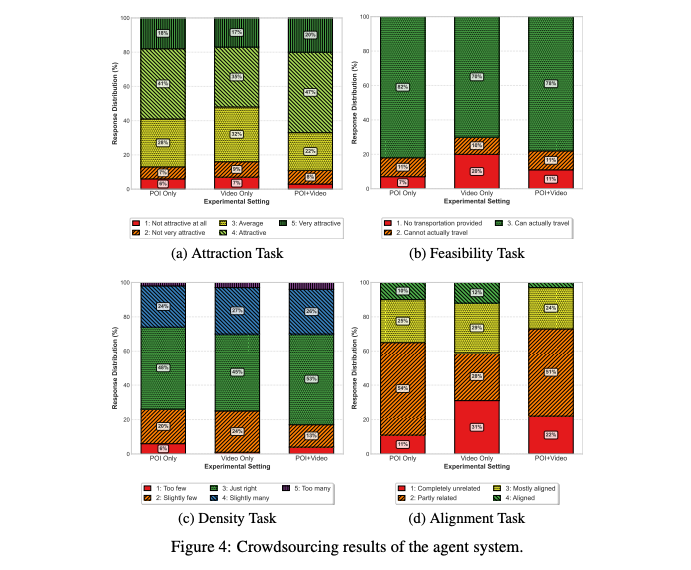
5.3 実験設定 (Experimental Setup)
「POIリストのみ」「動画のみ」「POIリスト+動画(P+V)」の3つの入力設定で生成された計画を、クラウドソーシングによって4つの観点(魅力、実現可能性、密度、動画との整合性)で評価
5.4 結果と考察 (Results and Discussion)
- P+Vの優位性: 「POIリスト+動画」の設定が最も魅力的な計画を生成。動画は現地の雰囲気や具体的な活動といった豊かな文脈を提供し、計画の魅力を高める
- 動画のみの不安定さ: 「動画のみ」の設定では、最初のPOI特定に失敗すると、動画内容と「完全に無関係」な計画が生成される割合が最も高い(31%) 。
- POI選択戦略: エージェントは、動画内での滞在時間が長く、Googleマップでの評価が高いPOIを優先的に計画に組み込む傾向
@Akira Manda(zunda)
[論文] Scaling Agent Learning via Experience Synthesis
この論文 is ?
- 現実の環境でAIエージェントを訓練するのは、お金も時間もかかり、しかも不安定。
- DreamGymは「現実で試す前に、学びに必要な経験だけをうまく作って与える」仕組み。
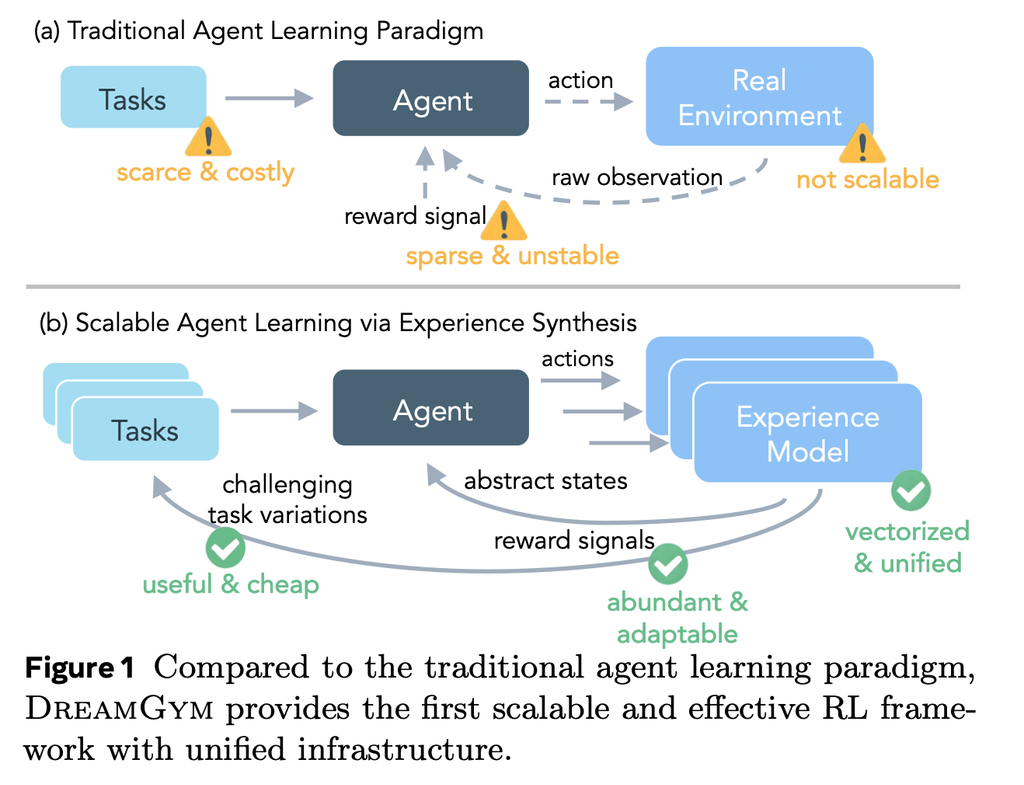
背景と課題
- 実環境は遅いし壊れやすい。長い操作やサーバ管理が必要。
- 与えられる課題が少なく単調で、すぐにパターン学習になってしまう。
- 成功・失敗の判定(報酬)が間違っていたり遅かったりする。

DreamGymのコア発想
- 現実そっくりを再現しない。代わりに「テキストで表した簡潔な世界」で、次に何が起きるかと成否をAIが筋道立てて作る。
- 過去の似た体験も参照して、作る内容の「現実味」を保つ。
- ちょうど良い難しさの課題を自動で増やしていく。

3つのコンポーネント
- 経験モデル: 今の状態と行動から「次に起きること」と「評価」を説明付きで作る。
- リプレイ(思い出帳): 本物の少量データ+過去の合成データを貯めて、参照して間違いを減らす。
- 課題ジェネレーター: 今の実力でギリ解ける課題を自動で作り続ける。
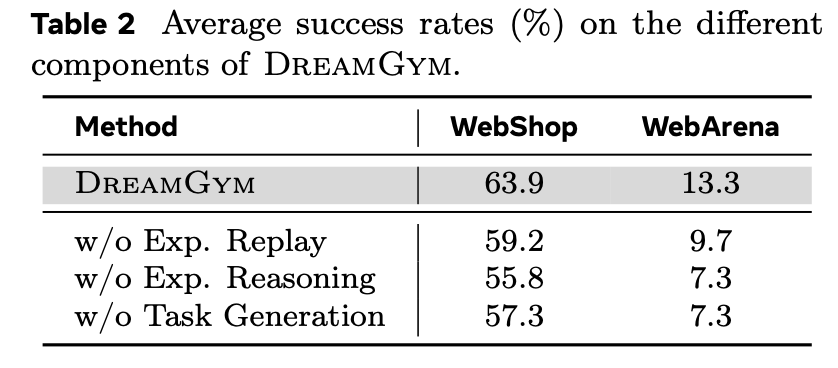
実験結果
- WebのようにRLが難しい環境でも、成功率が大きく上がった(+30%超)。
- 本物の環境で8万回試すのと同じレベルに、合成だけで到達。
- 現実に移す時は、必要な実データが10分の1で、性能は+40%。
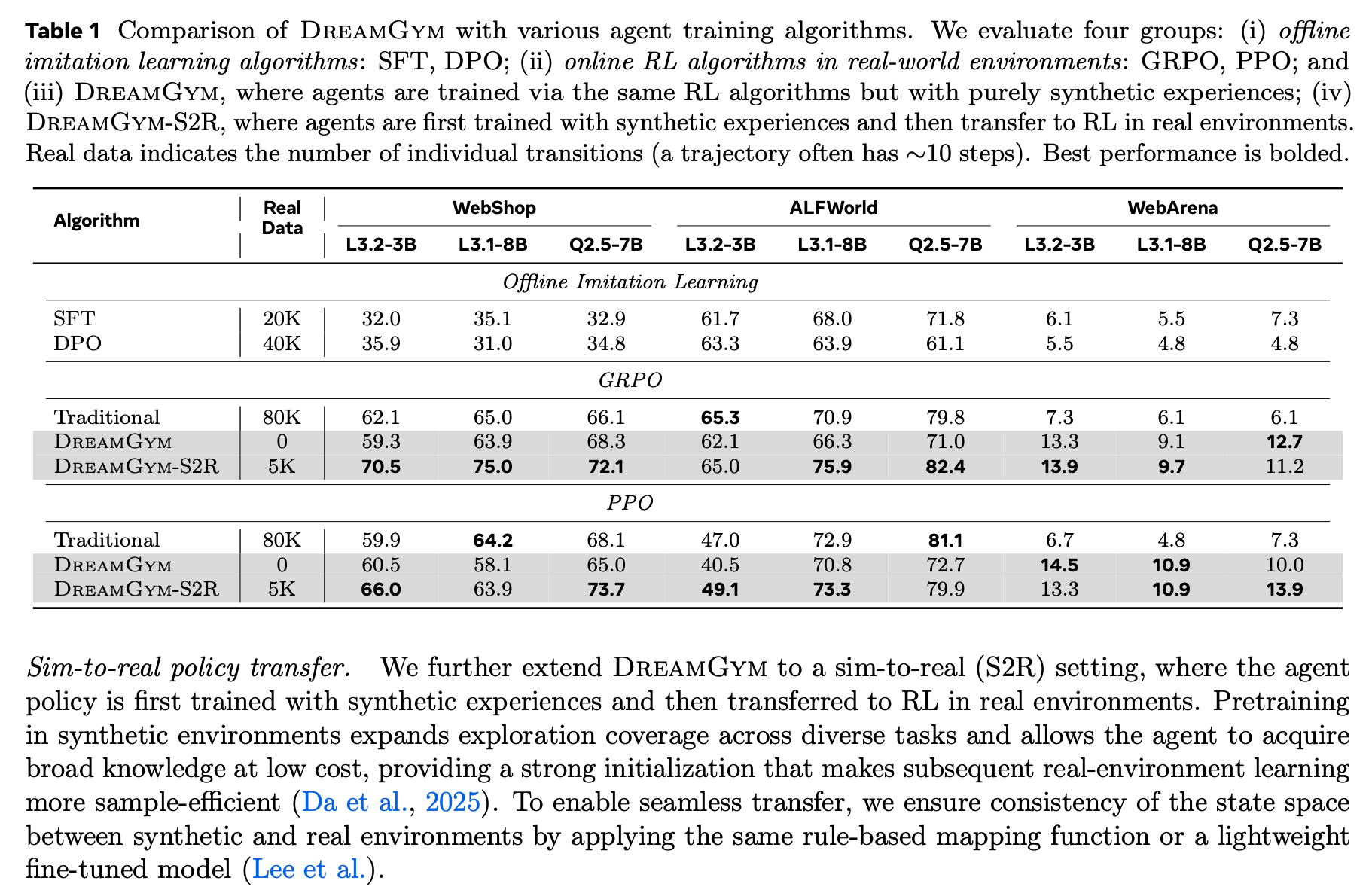
なぜ効くのか
- 余計な見た目情報を捨て、学習に必要な筋だけを濃く与えるから。
- 「なぜそうなるか」を説明しながら作るので、ブレにくい学習信号になる。
- 常に中くらいの難しさを出し続けるので、成長が止まらない。
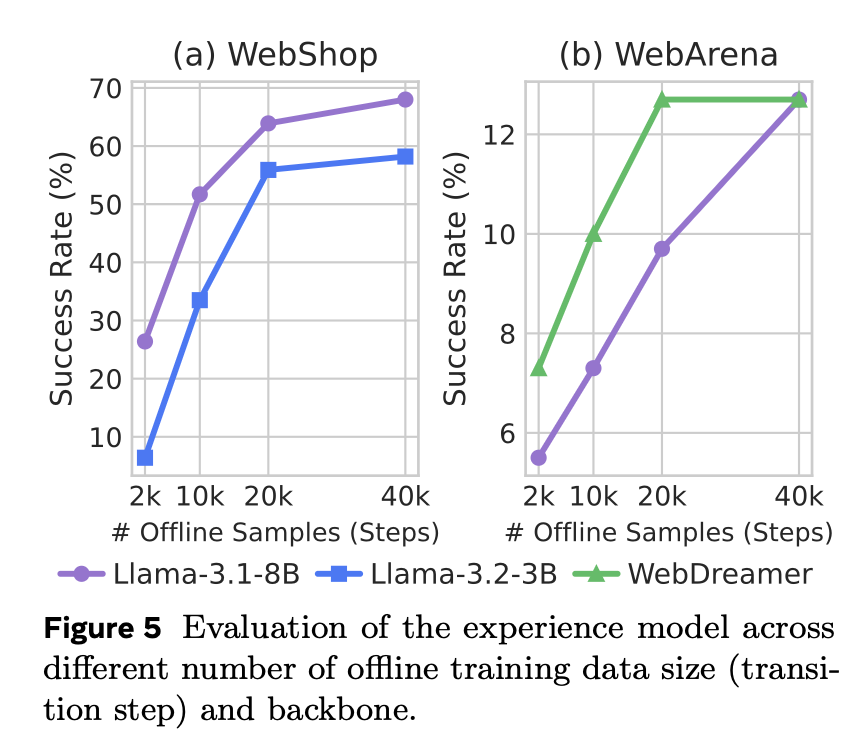
アブレーションと分析
- リプレイなし→現実味が下がり、間違いが増える。
- 説明なし→内容が浅くなり、評価の間違いが増える。
- 課題生成なし→すぐ頭打ちになる。

まとめ
- 問題は「どれだけ試すか」ではなく「どんな経験を与えるか」。
- 正しい経験を合成できれば、現実に出る前に強いエージェントを作れる。
@Shuhei Nakano(nanay)
[論文] No-Human in the Loop: Agentic Evaluation at Scale for Recommendation
- NeurIPS 2025 ワークショップに採択された研究
- Walmart の研究
対象問題
LLM as a judge:スケーラブルで信頼できる評価パイプラインの構築
- 大量のアイテムペアに対して単一のLLMを単純に適用するのは難しい
- モデルファミリー、サイズ、設定によって判定がどのように変化するかについてほとんど知られていない
Complementary-Item Recommendation:追加商品を推薦する

研究の貢献
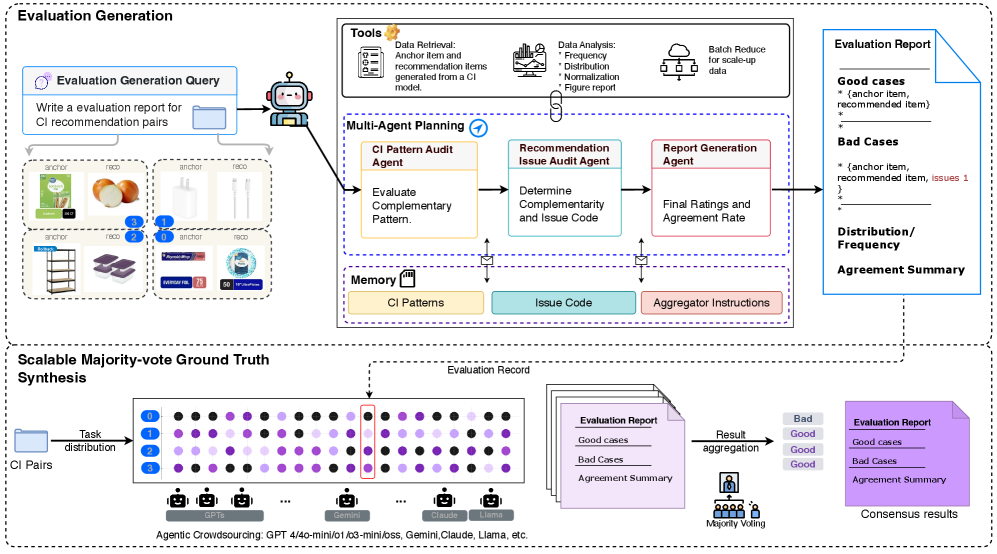
- ScalingEvalの提案
36種類のLLM(GPT、Gemini、Claude、Llamaを含む)を、コンセンサス駆動型評価プロトコルを使用して複数の製品カテゴリーにわたって体系的に比較する大規模ベンチマーク
- 人間のアノテーションなしの評価
パターン監査と問題コードをスケーラブルな多数決投票によって正解ラベルに集約し、人間のアノテーションなしにLLM評価者の再現可能な比較を可能
キモは?
基本的なアイデア:36種類のAIに同じ商品の組み合わせを評価させて、多数決で正解を決める
2段階のプロセス
Step1:各AIが評価レポートを作成
- パターンチェック
- 「この2つの商品は補完関係にあるか?」を判定
- 例: スマホ + スマホケース → ✓補完関係
- 問題点チェック
- ダメな理由を特定
- 例: 「サイズが合わない」「全く無関係」など
- レポート作成
- 良い組み合わせと悪い組み合わせをまとめる
Step2:多数決で最終判断
- 36個のAIがそれぞれ独立に評価
- 各商品ペアについて投票
- 過半数の意見を「正解」とする
- 意見が割れた場合 → 「却下」を優先(保守的判断)
有効性の検証方法
- 大規模ベンチマーク: 36種類のLLM(GPT、Gemini、Claude、Llamaを含む)を複数の製品カテゴリーにわたって体系的に比較
- カテゴリー別分析: 構造化されたドメイン(電子機器、スポーツ)では一致しやすい。ライフスタイルカテゴリー(衣類、食品)では不一致しやすい傾向
メインTOPIC
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
| Authors | Junhong Shen, Hao Bai, Lunjun Zhang, Yifei Zhou, Amrith Setlur, Shengbang Tong, Diego Caples, Nan Jiang, Tong Zhang, Ameet Talwalkar, Aviral Kumar |
|---|---|
| Venue | NeurIPS 2025 Workshop on Multi-Turn Interactions in Large Language Models |
概要
- Agentの性能向上のため、Reasoningの長さではなくInteractionの回数を増やす手法を提案
- Interactionの回数を増やすための学習方法を提案
- WebVoyagerやWebArenaでの実験で、既存手法を上回る性能を確認
背景
- ブラウザやTerminal、物理世界などDynamicな環境で複数ステップのタスクをこなすAgentの性能向上を考える
- 既存手法は、各ステップの精度を高めるため、より長く考えるように促すものが多い = Scaling Test-Time Compute(CoTなど)
- ただ、長く考えたとしても与えられた情報の中で洗練されていくに過ぎず、新しい情報をそこで得られているわけではない。
- より長く考えるのではなく、AgentのInteraction回数を増やすことで性能向上を目指したい = Scaling Test-Time Interaction
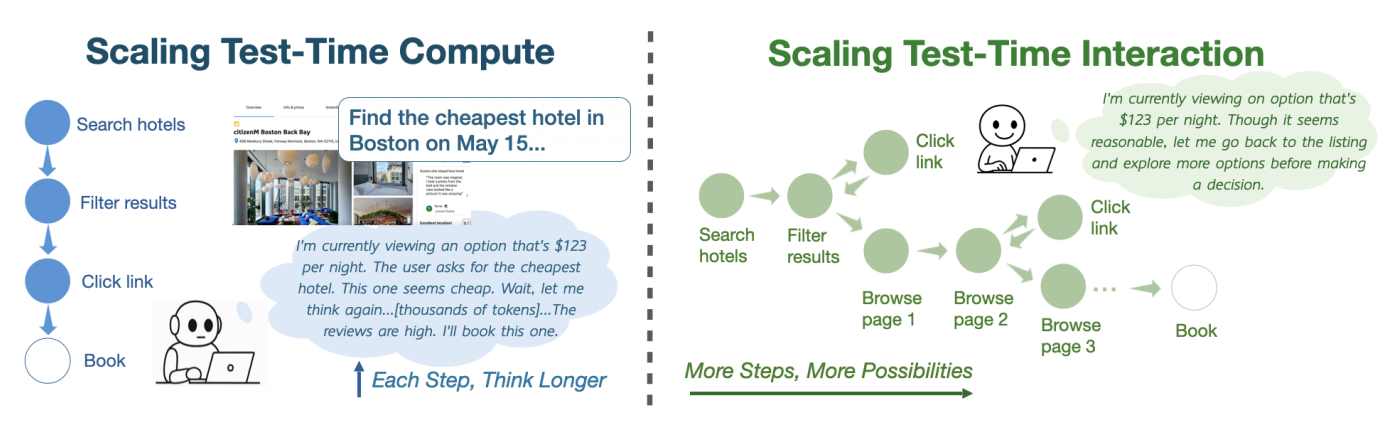
問題設定
- Webブラウザ上のタスクを考える。
- 各ステップで環境が観測 を返し、エージェントは行動 を選択。
- 最大ステップ数に達するか「stop」すると終了。
- 報酬は成功=1 or 失敗=0。
Scaling Test-Time Interaction
まず Test-Time Interaction が有効そうかどうかを、簡易的な実験で確かめる
- WebArenaデータセットで、Gemma 3 12B を使って実験
- Agentがタスク完了を出力したら、”You just signaled task completion. Let’s pause and think again…” といったプロンプトで強制的にタスクの見直しを実行させる
詳細なプロンプト
結果: 複数回の re-check で、性能 (Success Rate) の向上を確認
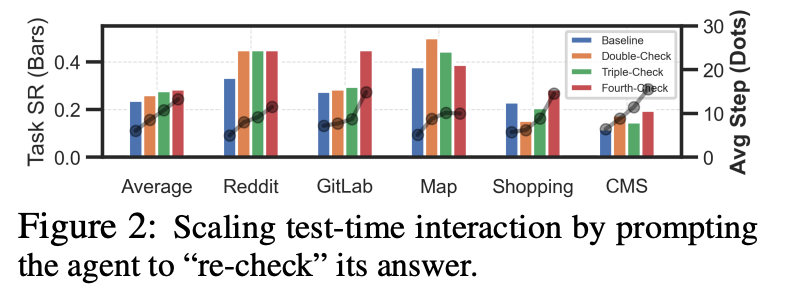
- re-check時の出力例
- 確信パターン: I previously stated the driving time was approximately 30 minutes....30 minutes seems plausible with typical traffic conditions. I’ll stick with my previous answer.
- 修正パターン: My apologies. I jumped to a conclusion prematurely. Although the address book displays the desired address, the task requires me to change it....I should click button [24] to modify the address.
- 最大25%程度のアクションが修正された
- より多くのActionを求めたときに、Agentが別の選択肢を検討したり間違いを修正でき、性能を上げられる可能性がある。
- re-checkを繰り返すと良くなり続けるわけではなく、正しい回答を間違いに修正してしまうことも発生する
Test-Time Interaction と Per-Step Test-Time Compute とで比較実験
- Test-Time Interaction: 前述のプロンプトによるre-check
- Per-Step Test-Time Compute
- budget forcing: CoTの最後で “wait and think again” を挿入し、思考を続けさせる
- best-of-n: stepごとに n = 3, 5, 7 の回答を生成し、多数決で決める
- 結果1: total compute (tokens per trajectory) に対する success rate の比較
- Interaction Scaling: tokens増加に伴う性能向上が比較的大きい
- Budget Forcing: tokens増加に伴って性能向上するが、伸び幅はやや控え目
- Best-of-N: コストがかかる割にあまり伸びない
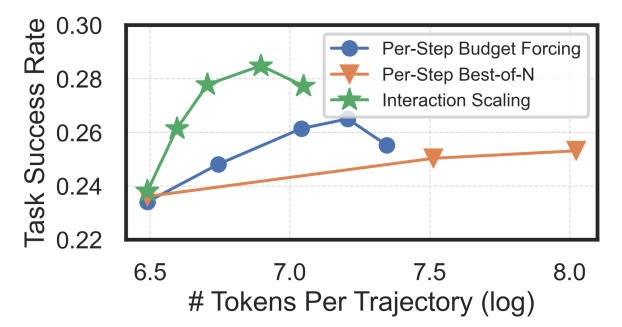
- 結果2: total compute (stepごとのtokens) と step数 のトレードオフ
- WebArenaにおいては、across stepsのscalingの方が、within stepsのscalingよりも効果的
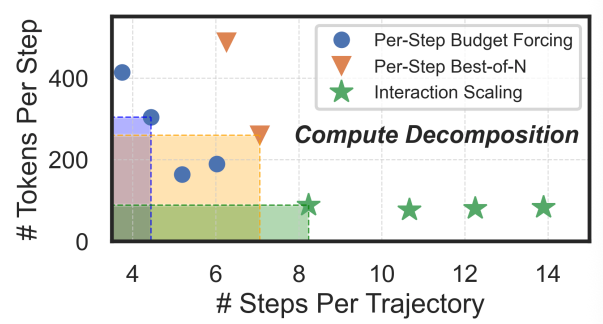
※ ここでの実験はプロンプトによる簡易的なものだが、実際には一連の行動における探索・活用の切り替えといった複雑な行動をさせたい。
TTI: Curriculum-Based Online RL for Scaling Interaction
Agentがより多くの行動を生み出すような訓練を考える
方針: 最大ステップ数(h; horizon)を大きくして学習
- h = 5, 10, 20で実験
- h = 5: 学習が速く、序盤で性能が高くなるが、overfittingしており次第に悪化する。評価時にも、interactionの回数制限に到達する前に早々と打ち切ってしまう傾向にある。
- h = 20: 学習はゆっくりで着実に性能を上げていく。個々の挙動を見ると、序盤に “going back” や “trying random links” など探索的な行動を高く評価しており、遅い学習の要因になっている。
- hが大きいほどinteractionは多くなっていくが、最終的な性能はデータ(ドメイン)次第
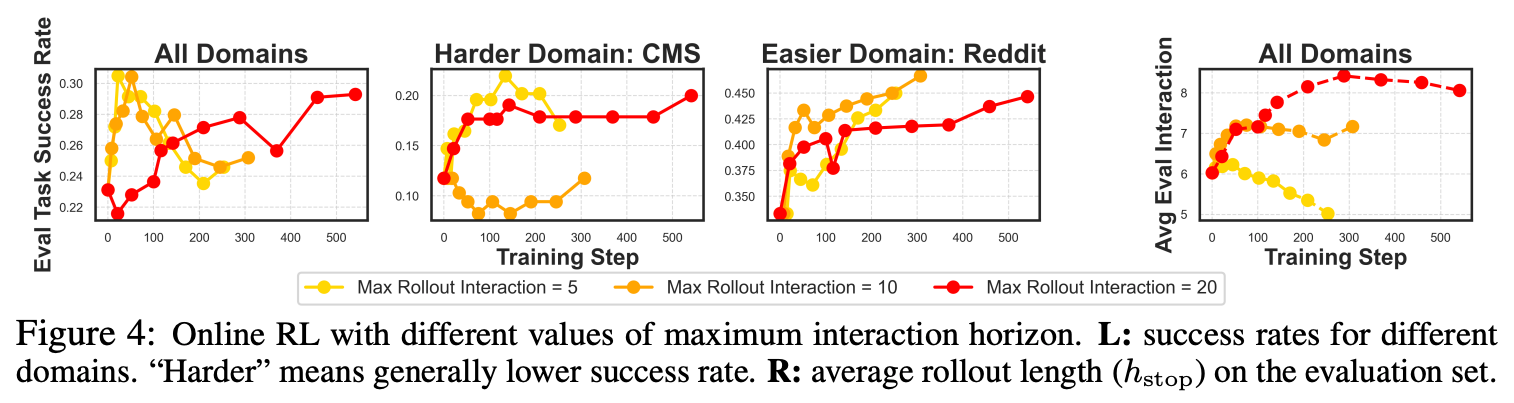
提案: h を次第に大きくしていく curriculum-based online RL
- 一般的な curriculum learning はデータの難易度を次第に高くしていくが、提案手法は最大ステップ数を次第に多くしていく
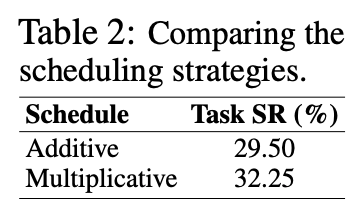
- ステップ数の増やし方

- Additive vs. Multiplicative
- WebArenaの一部のデータを使った実験で高性能だったMultiplicativeを採用
実験
実験設定
- データ: 427 tasks across 13 domains from WebVoyager, 812 (full) tasks from WebArena
- Prompting-based verifier based on Gemma 3 27Bを使った合成データを作成
- 学習: Gemma 3 12B を 10 iterations、multiplicative schedule ,
- Baseline: Gemma 3 12B をh = 10, 30で固定して学習
WebVoyagerでの結果
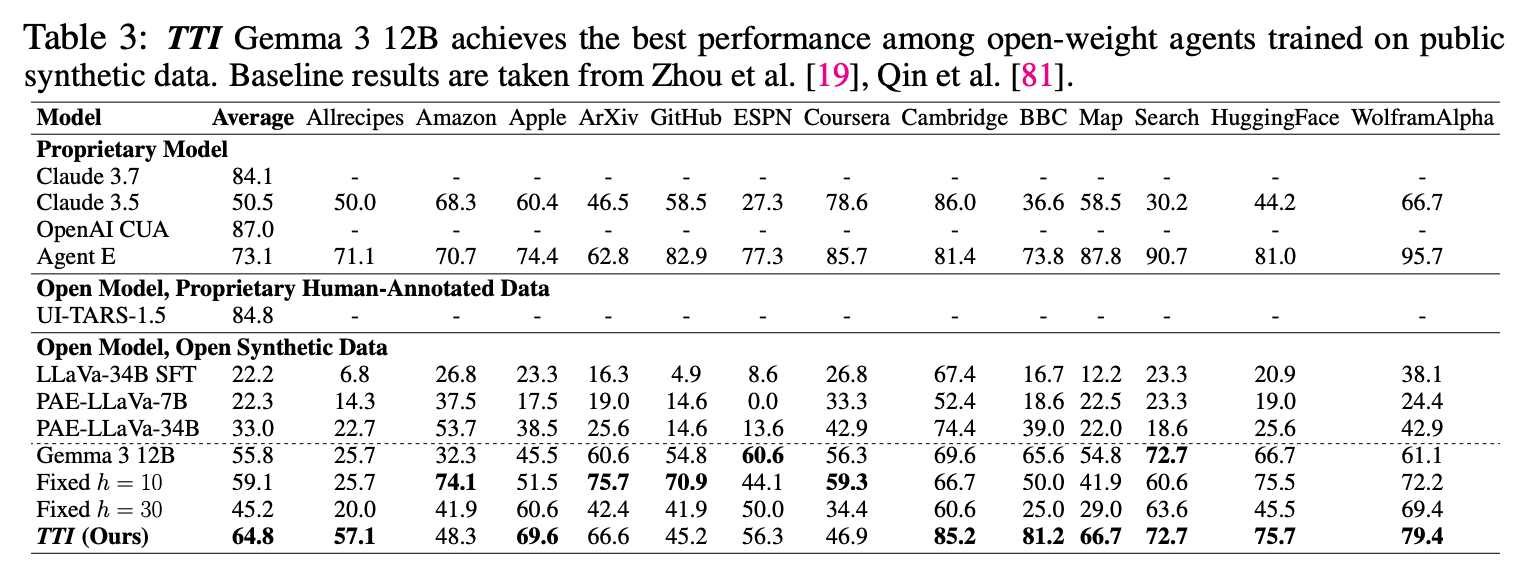
- Open Modelの中では提案手法の TTI が平均的に良い結果。
- 非公開の人間アノテーションデータを使ったUI-TARSには劣る
- hを固定したものよりも比較的良い結果に。
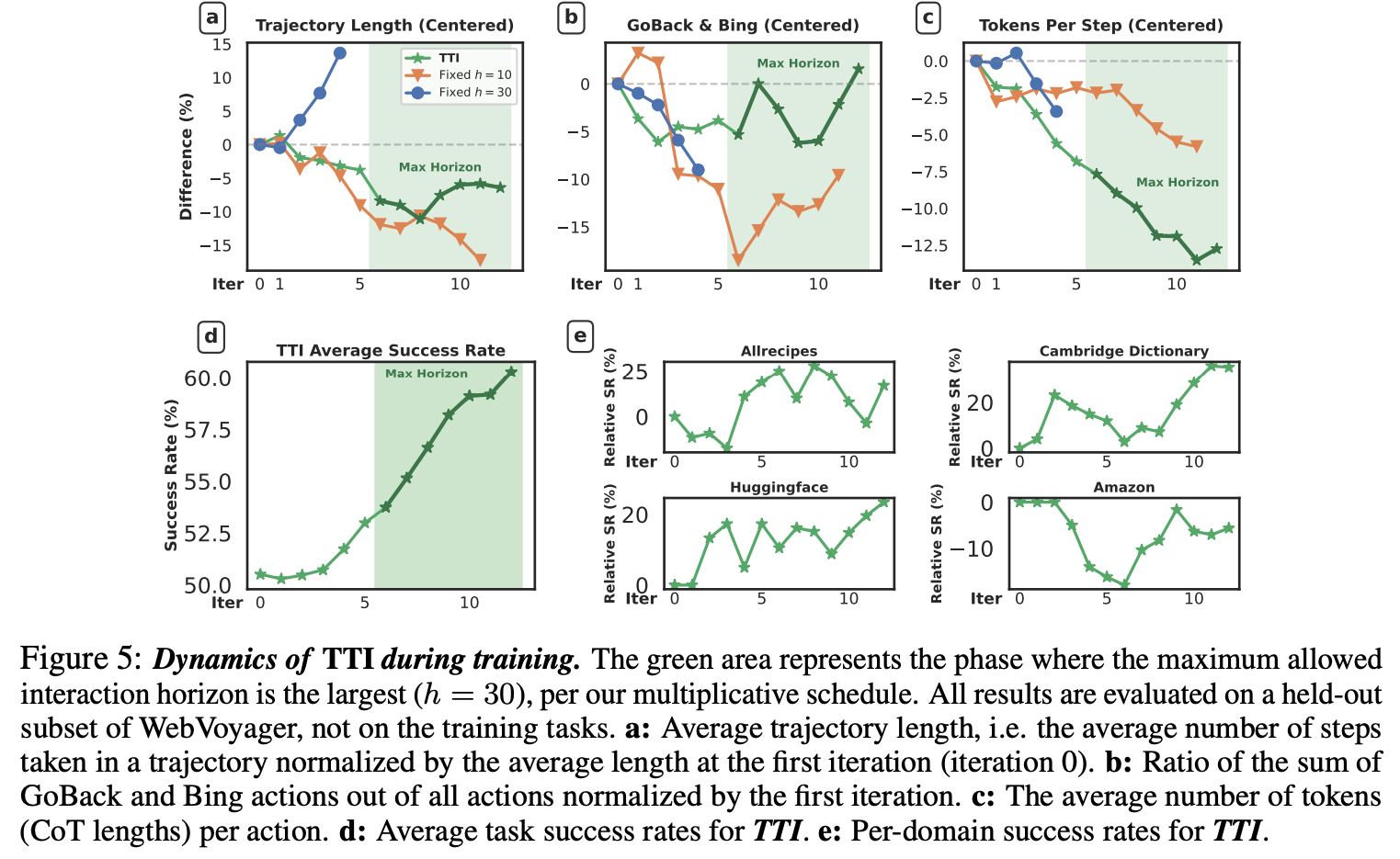
- 学習の様子
- Trajectory Lengthが一度下がってから上がるのはcurriculumの影響。h=10はstep数がどんどん減り、h=30は逆に増えていくが、その間くらいの遷移になっている。stepあたりのtoken数は減少
- GoBackやBing(検索)は学習が進んでもほどほどに残っている
- Success Rateは順調に上昇
WebArenaでの結果
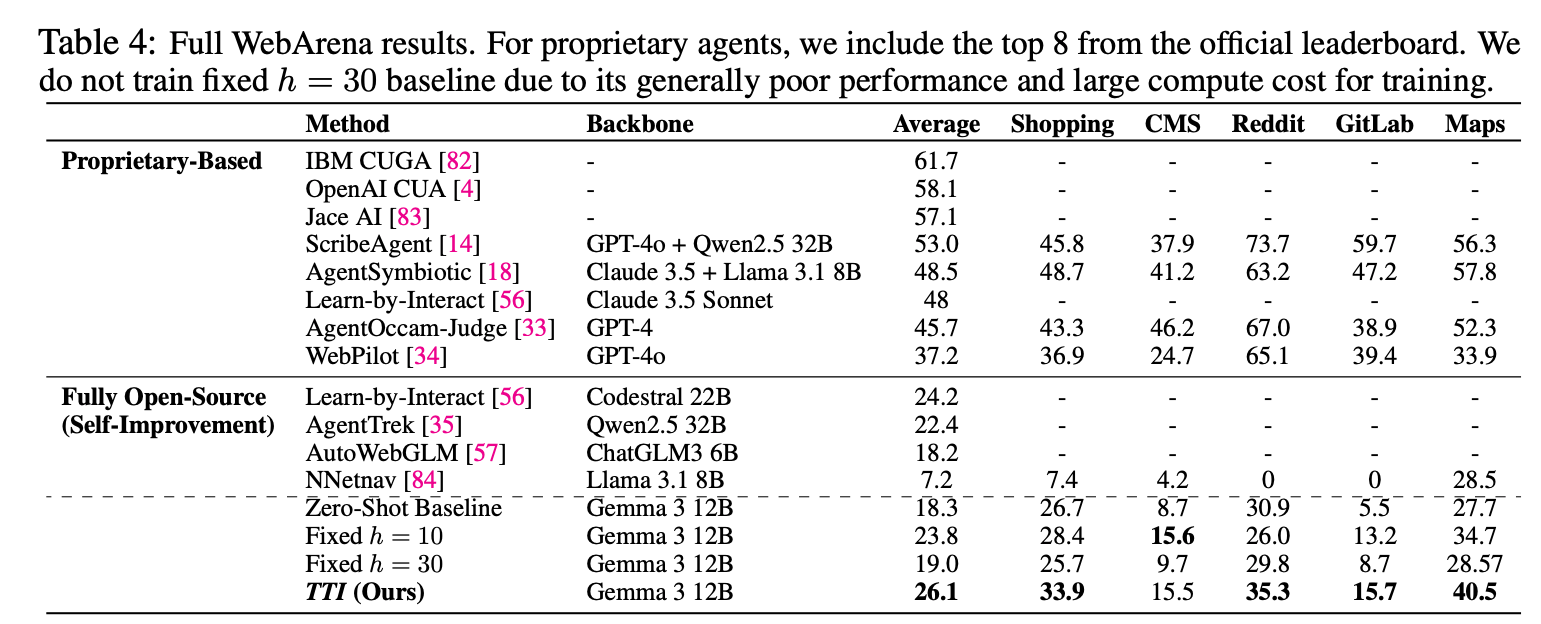
- Open Modelの中では提案手法の TTI が平均的に良い結果。
- Baselineからの伸び幅はWebVoyagerよりも小さい
- WebArenaの方がタスクとして難しい
- WebArenaの操作上の制約で失敗するパターンがある
コメント
- ブラウジングのように、探索を多めにしても悪影響が少ない環境だと有効そう。
- HITLのように途中で人間が介入するタスクだと、無限に質問が飛んできてしまうので注意が必要そう。質問する前の段階で色々試して、程よく情報を集めた上で質問してくれるような調整ができるとよい?