
2025-11-25 機械学習勉強会
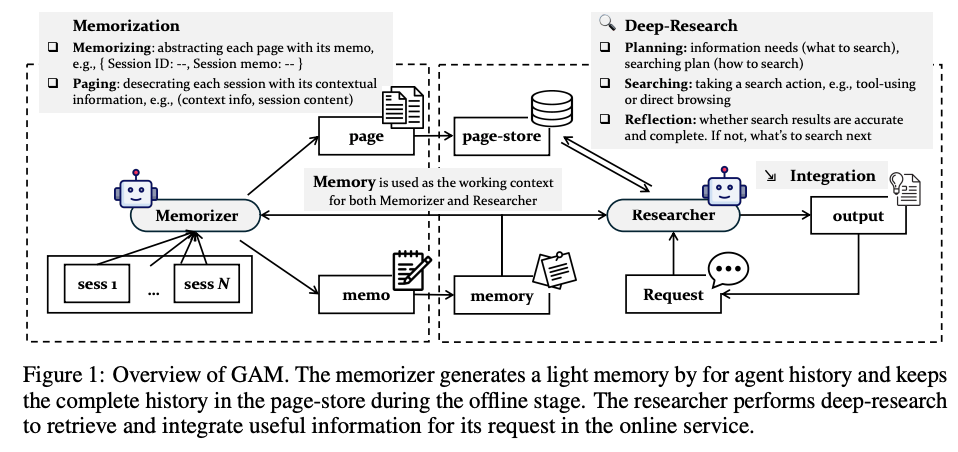
今週のTOPIC[blog] NVIDIA NeMoを利用したGPT-OSSの学習[論文] General Agentic Memory Via Deep Research[blog] Introducing advanced tool use on the Claude Developer PlatformSAM3系が色々でた[論文]Guidelines for Human-AI Interaction[blog] Spec-Driven Development: The Waterfall Strikes BackLyftLearn Evolution: Rethinking ML Platform ArchitectureメインTOPICVideo models are zero-shot learners and reasonersサマリー1. Introduction2. Methods3. Qualitative results: Sparks of visual intelligence? / 定性的な実験結果集4. Quantitative results / 定量的な評価実験5. Discussion
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] NVIDIA NeMoを利用したGPT-OSSの学習
- GPT-OSSを学習させるときに読む記事。関係ないけどところどころCallOutで教育的要素があって教科書っぽい。
- Unslothなどとの違いは、大規模クラスターなどで学習させたいかどうか。小規模であればUnslothで大丈夫 (なはず)
- LoRA Finetuningは対応してるが、Continual Pre-Trainingなどを本格的にやるにはハードルがある。
- 普通ならContext 8,192に制限されるのが、Context Parallelismで増やすことができる
- gpt-ossはアーキテクチャが特殊
- bias項が存在
- QK Normの欠如
- self-attention sink(learnable softmax)の存在
- これらのせいで元のCUDAやC++コードを修正する必要がある
- (途中はスパコンの話で何もわからん)
- HF形式からNemo形式に変換するための公式スクリプトが分かりにくいから独自実装(NVIDIA製あるある。。)
- gpt-ossの学習をNeMoで行うには、HuggingFace形式で公開されているcheckpointをNeMoで読み込めるようにNeMo形式のcheckpointに変換する必要がある。これが大変
- TransformerEngineのupdate
- cuDNNのupdate
- cuDNNをupdateしてもPyTorchなどは再buildしなくても良いので、cuDNNのみをアップデートすれば良い。(共有ライブラリなのでpathを貼りなおしたら大丈夫)
@Shun Ito
[論文] General Agentic Memory Via Deep Research
- AgentのメモリのretrievalにDeep Researchの仕組みを使おうという論文
- 既存のAgentic Memory手法
- 要約した情報を蓄積しておき、都度参照する方式が多い
- 参照はembeddingやkeyによる検索など
- 課題: 圧縮した情報は一部の情報が欠落してしまう。圧縮方法も手法ごとに独自の工夫が盛り込まれており、一般化しづらい。
- 提案: General Agentic Memory (GAM)
- あるセッションに関する要約情報のmemo・フル情報のpageを用意し、Deep Researchによって必要な情報だけを参照・抽出する仕組み
- Memorizer
- memo: 各セッション(会話・作業履歴)から重要情報だけを抽出し、既存のmemoryと整合性を持たせながら情報を追加
- page: その時点での過去のtrajectory + セッション情報をすべてまとめてpageとし、page-storeに追加
- Researcher
- Requestに対して、memoryに基づいてretrieveする情報とその手段を決定し、検索を実行
- 手段: vector or keyword-based or ID-based search
- 集まった情報が十分かを判断し、不十分なら再度検索に戻り、十分なら最終結果を返す
- 要約だけでは欠落してしまう情報もpage-store + DeepSearchでリクエストに応じて参照できる点が強み
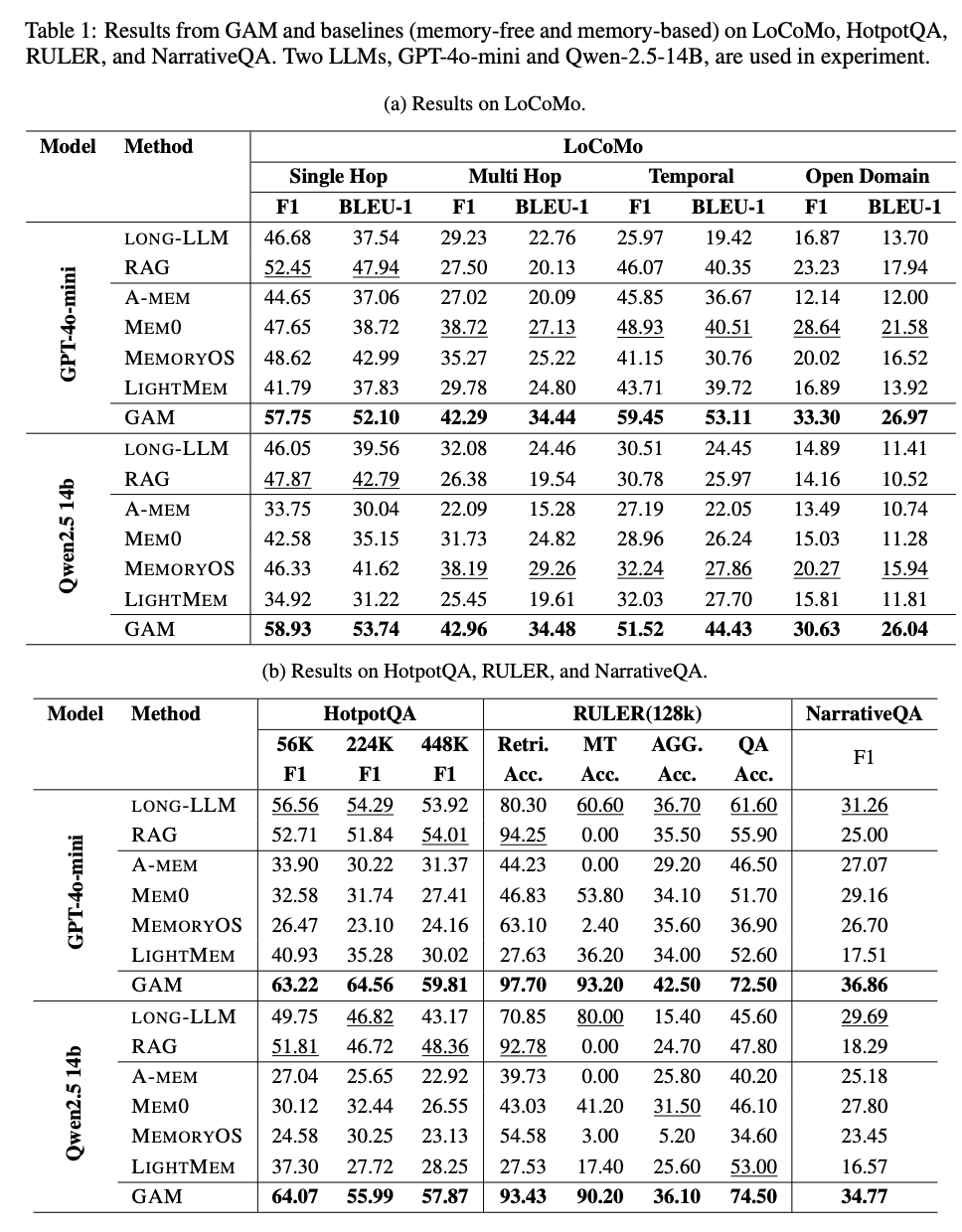
- 結果
- 精度
- ベンチマーク上は、既存のメモリ手法より完全に良くなっている
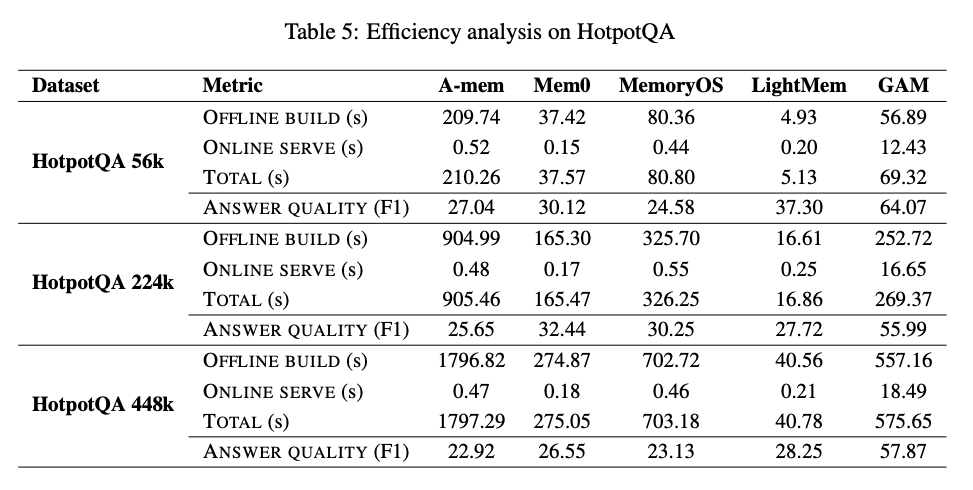
- 速度
- offline build(memoryの構築)はやや時間がかかるものの、A-memやMemoryOSと同等以上程度に収まっている
- A-memは個々の要約にタグ付けをしたり、別の要約との関連性を整理したりするので時間がかかる
- さすがにonline serveは時間がかかってしまう
- トータルで見たらA-memやMemoryOSと同等以上 & 精度既存手法より上回っているので、Efficiencyは悪くないという主張
@Yosuke Yoshida
[blog] Introducing advanced tool use on the Claude Developer Platform
- モデルが数百~数千ものツールをシームレスに連携させるには、すべてのツール定義を最初にコンテキストに詰め込むことなく、無制限のツールライブラリを利用できる必要がある
- Claudeに3つの新しいベータ機能を追加
Tool Search Tool
- Tool Search Toolでは必要なツールを必要な時に動的に発見
- 正規表現ベースおよびBM25ベースの検索ツールが標準で利用可能
- 埋め込み表現やその他の手法を用いたカスタム検索ツールも実装可能
Programmatic Tool Calling
- Claudeは複数のツールを呼び出してそれらの出力を処理し、実際にコンテキストに取り込む情報を制御するコードを生成
Tool Use Examples
- ツール定義に直接サンプル呼び出し例を記載できる
例
@Takumi Iida (frkake)
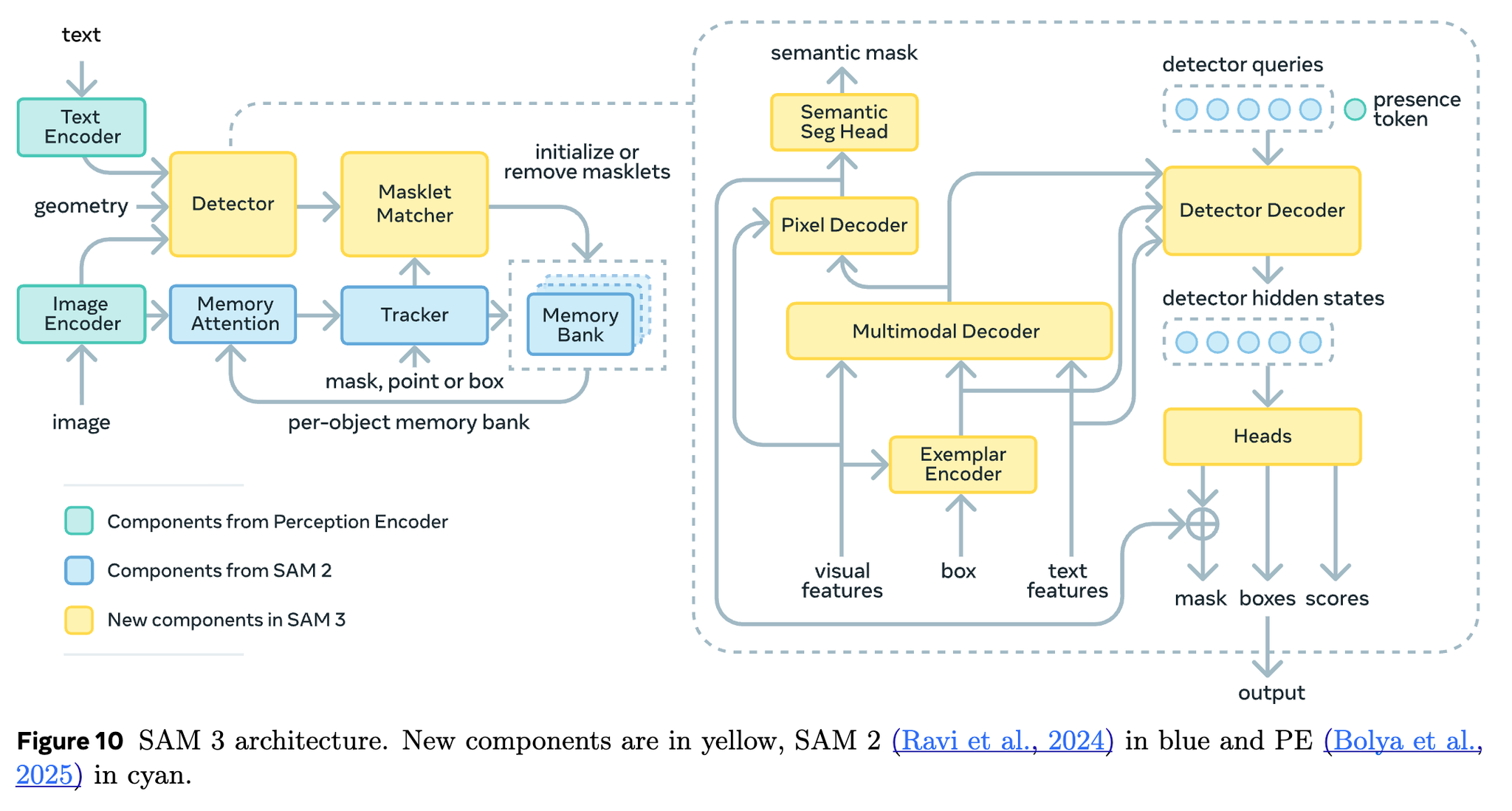
SAM3系が色々でた
SAM3系が発表された。全部同日11/19にでている。
SAM 3: Segment Anything with Concepts
SAM 3はタイトルにwith Conceptと書いてるように、検出対象のコンセプトを使ったプロンプトを使って検出できる。
具体的には、「名詞」や「画像の例(Image Exemplars)」を使ってセグメンテーションできる。

- 画像と(もしあれば)Image Examplerを別々にImage Encoderに入れる
- 動画の場合はDetectorとTrackerの結果を組み合わせてトラッキング
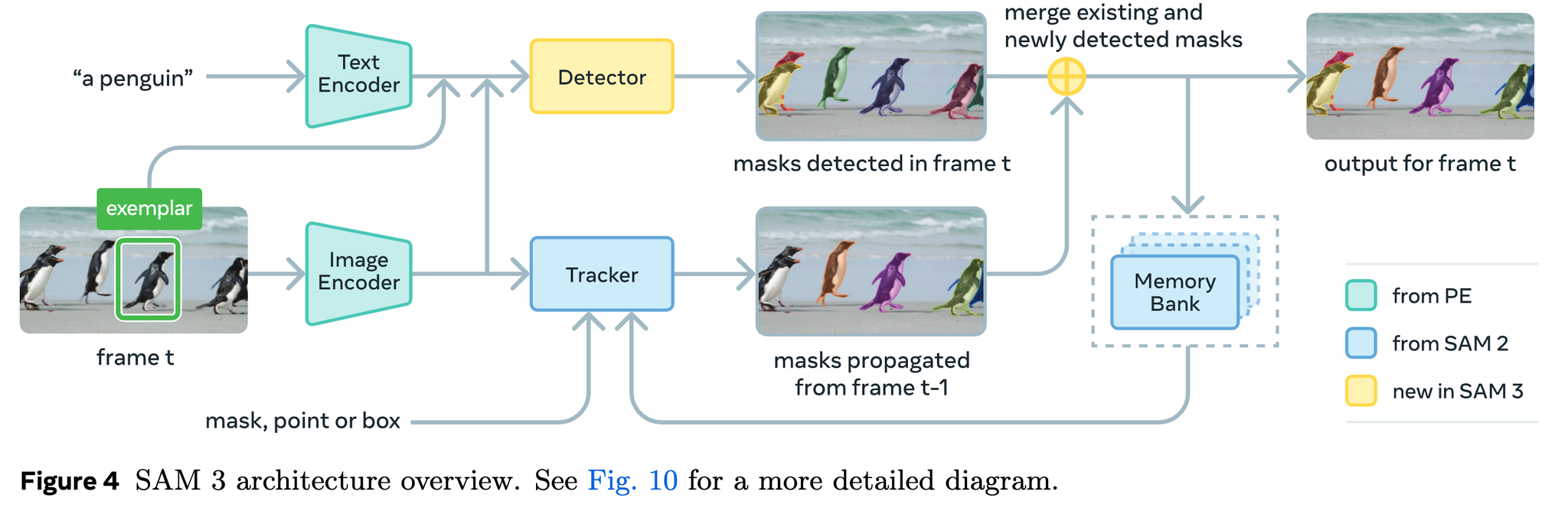
SAM 3の工夫点=Presence Head
Detector Decoderに、画像中に対象物体があるかどうかを判定するPresence Tokenを導入
→物体認識(Presence Token)と物体の位置推定(Detector Queries)を分離できる
SAM3 Agentとしても使えるよと言ってる

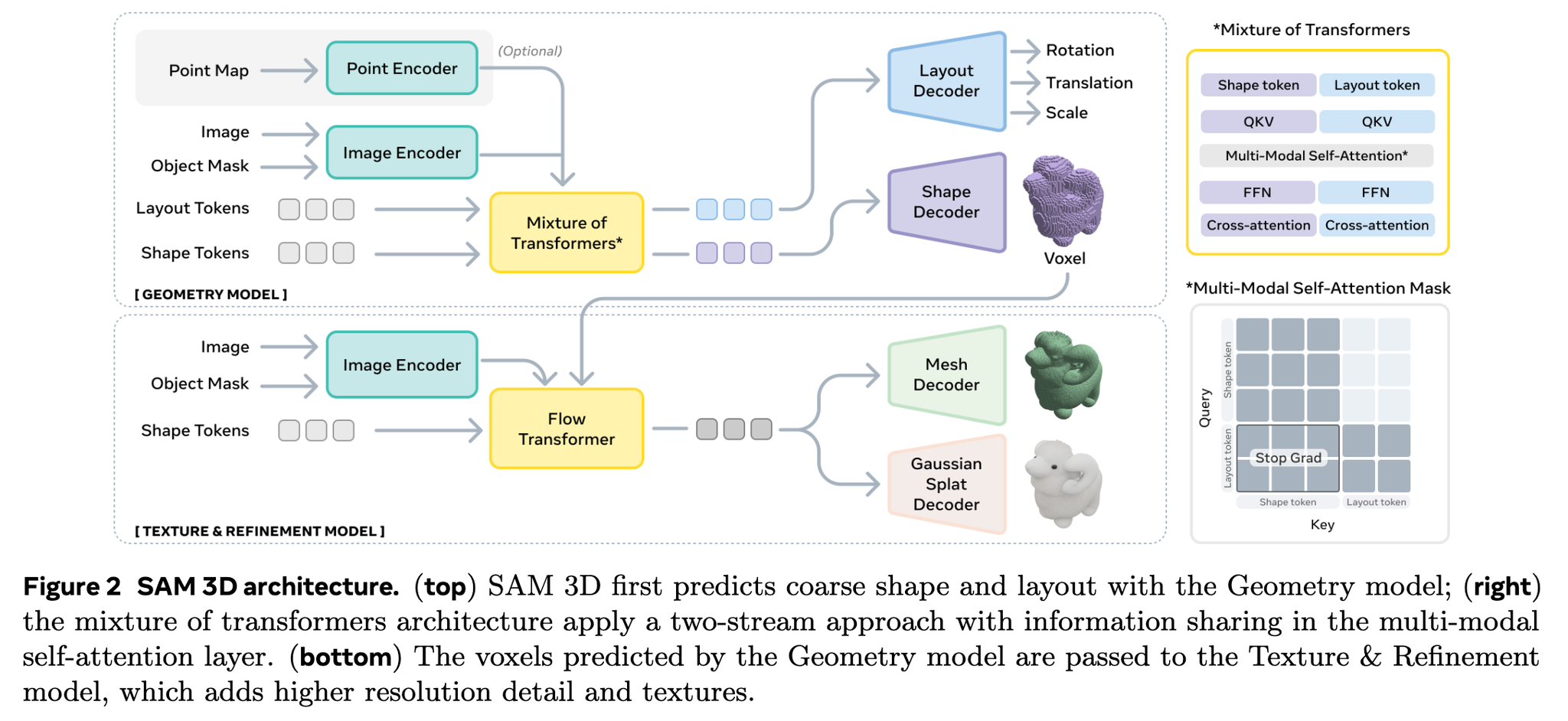
SAM 3D関連
物体を3D化するのと全身を3D化するSAMがでてる
3D物体の方

図を眺めることしかできてないけど、ボクセル化した後にメッシュ化したり、ボリュームレンダリングしているっぽい
3D全身の方

- 全身と手の検出は別にやる
- MHRに加えてカメラパラメータも推定してる
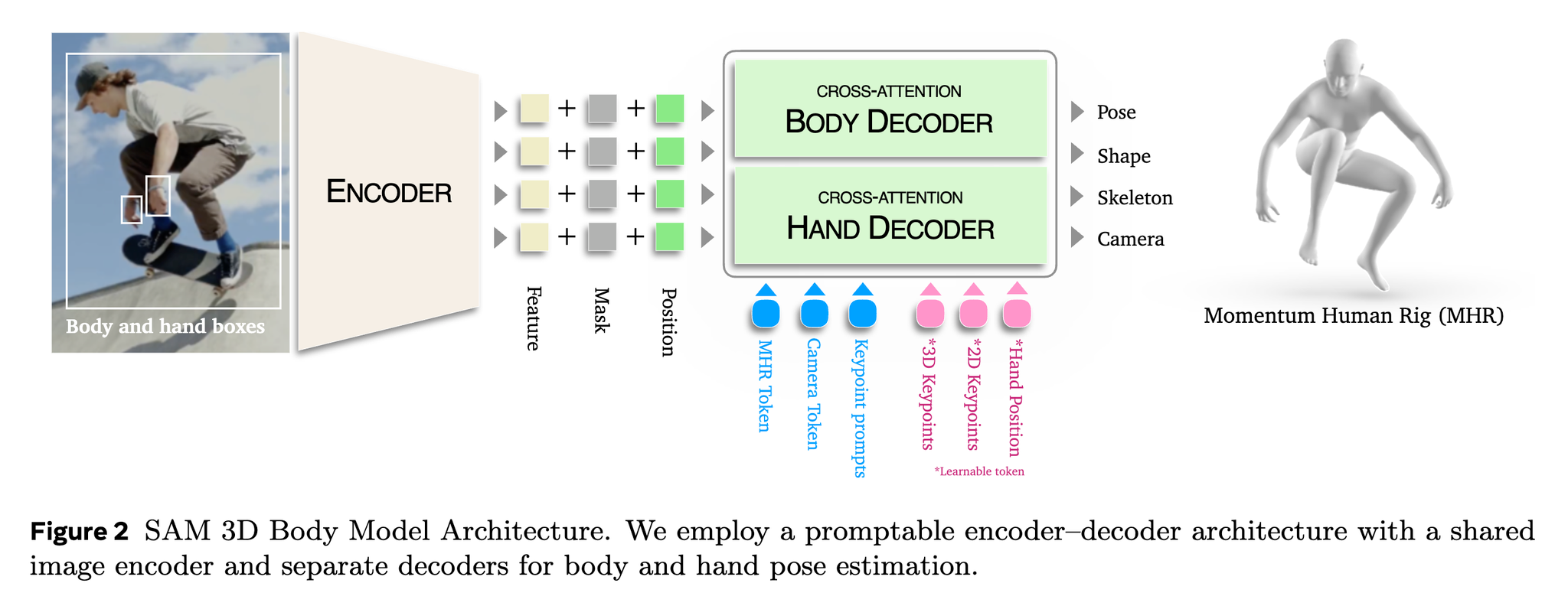
MHRは骨格と表面の分離ができている+異なる詳細レベル(LOD)を持っているらしい
骨格と表現が分離できてないと、体型を変えたときに関節点も変わってしまう問題があった
MHR (Momentum Human Rig)のLOD

@Hiromu Nakamura (pon)
[論文]Guidelines for Human-AI Interaction

[pon] 2019年と古いけど、LLMで改めて注目されている。
Microsoftが人間とAIのインタラクションにおける18の設計ガイドラインをまとめたもの。ユーザーがAIシステムとどのように関わるかという時間軸に基づいて、「初期段階」「インタラクション中」「誤動作時」「長期的な利用」の4つのカテゴリに分類。各ガイドラインには、ユーザーがAIシステムをより効果的かつ快適に利用するための具体的な指針が示されている。
[pon]サービスにAIを入れる時のチェック項目としても良さそう。
Initially(初期段階)
AIシステムを使い始める前の最初の段階で、ユーザーに明確に伝えるべきガイドラインです。
[pon] Defensive UXとしてもこの概念はよく出てくる。
- G1: Make clear what the system can do. (AIシステムができることを明確にする) 説明: AIシステムがどのような機能や能力を持っているのかを、ユーザーが明確に理解できるように設計するべきです。これにより、ユーザーはシステムの限界や可能性を把握し、適切に利用できます。
- G2: Make clear how well the system can do what it can do. (AIシステムがどの程度うまくできるかを明確にする) 説明: AIシステムがどれくらいの精度で動作し、どのくらいの頻度で間違いを犯す可能性があるのかを、ユーザーが把握できるように設計するべきです。期待値を適切に設定することで、ユーザーの不満を減らし、システムへの信頼を築きます。 例: 音楽推薦システムが「お客様がお気に召すと思います」といった控えめな表現を使用し、推薦の確実性が100%ではないことを示唆する。
During interaction(インタラクション中)
ユーザーがAIシステムと積極的にやり取りしている間に適用されるガイドラインです。
- G3: Time services based on context. (コンテキストに基づいてサービスを提供するタイミングを計る) 説明: AIシステムは、ユーザーの現在のタスクや環境に合わせて、サービスを提供したり、中断したりするタイミングを適切に判断すべきです。これにより、ユーザーの邪魔にならず、必要な時に役立つ情報を提供できます。 例: ナビゲーションアプリが、地図の更新と実際の位置情報に基づいて、タイムリーな経路案内を提供する。
- G4: Show contextually relevant information. (文脈に関連する情報を表示する) 説明: ユーザーの現在のタスクや環境に最も関連性の高い情報を表示すべきです。これにより、ユーザーは必要な情報を素早く見つけ、より効率的に作業を進められます。 例: 映画のタイトルを検索すると、現在地に近い上映館と本日の上映時刻が表示される。
- G5: Match relevant social norms. (関連する社会的規範に合わせる) 説明: AIシステムが提供する体験は、ユーザーの社会的・文化的背景を考慮し、期待される方法で届けられるべきです。不適切だと感じられるインタラクションは、ユーザーの不信感や不快感につながります。
- G6: Mitigate social biases. (社会的偏見を軽減する) 説明: AIシステムの言語や行動が、望ましくない不公平なステレオタイプや偏見を強化しないように配慮すべきです。公平で包括的な体験を提供することが重要です。
When wrong(誤動作時)
AIシステムが間違いを犯したり、ユーザーの期待に沿わない動作をした場合に適用されるガイドラインです。
- G7: Support efficient invocation. (効率的な起動をサポートする) 説明: ユーザーが必要なときにAIシステムのサービスを簡単に呼び出したり、リクエストしたりできるようにすべきです。これにより、システムの活用が促進されます。 例: 音声アシスタントが特定のウェイクコマンド(例:「Hey Siri」)を言うだけで起動できる。
- [pon]これだけカテゴリズレてないか?
- G8: Support efficient dismissal. (効率的な却下をサポートする) 説明: ユーザーが不要なAIシステムのサービスを簡単に無視したり、却下したりできるようにすべきです。これにより、ユーザーはシステムをコントロールしている感覚を保てます。 例: Eコマースサイトの推薦機能が、画面の下の方に表示され、簡単にスクロールして無視できる。
- G9: Support efficient correction. (効率的な修正をサポートする) 説明: AIシステムが間違った場合でも、ユーザーが簡単に編集、修正、または回復できるようにすべきです。これにより、ユーザーは間違いから迅速に復旧し、システムを継続して利用できます。 例: リマインダー設定後、UI上に「タップして編集」という表示があり、設定内容を簡単に修正できる。
- [pon]今日朝会で話したやつ。workflow生成系を修正可能はむずい。
- G10: Scope services when in doubt. (不明な場合はサービス範囲を限定する) 説明: AIシステムがユーザーの意図について不確かな場合、曖昧さを解消するための対話を行ったり、サービスの提供範囲を穏やかに制限したりすべきです。これにより、誤った推測による不利益を避けます。 例: オートコンプリート機能が、直接自動補完するのではなく、通常3〜4つの候補を提示する。
- [pon]Alex Mentor(社内のナレッジシステム)でやられてた。
- G11: Make clear why the system did what it did. (システムがなぜそのように動作したのかを明確にする) 説明: AIシステムがなぜ特定の行動をとったのか、その理由をユーザーが理解できるように説明を提供すべきです。これにより、ユーザーはシステムの動作を信頼しやすくなります。 例: ナビゲーションアプリが、選択された経路が「最速ルート」であるという理由をサブテキストで表示する。
Over time(長期的な利用)
ユーザーがAIシステムを継続的に利用する中で、システムがどのように学習し、変化し、ユーザーにフィードバックを提供すべきかに関するガイドラインです。
- G12: Remember recent interactions. (最近のインタラクションを記憶する) 説明: 短期的な記憶を保持し、ユーザーがその記憶を効率的に参照できるようにすべきです。これにより、連続するタスクや対話がスムーズになります。 例: 検索エンジンが、以前の検索クエリの文脈(例:「彼が結婚しているのは誰?」)を記憶し、会話の流れを継続した検索を可能にする。
- G13: Learn from user behavior. (ユーザーの行動から学習する) 説明: ユーザーの行動から時間をかけて学習し、ユーザーエクスペリエンスをパーソナライズすべきです。これにより、システムは個々のユーザーにとってより有用になります。 例: 音楽推薦システムが、曲をプレイリストに追加するたびに新しい推薦を生成する。
- G14: Update and adapt cautiously. (慎重に更新・適応する) 説明: AIシステムの動作を更新したり適応させたりする際、ユーザーエクスペリエンスに破壊的な変更が生じないよう制限すべきです。一貫性と予測可能性を保つことが重要です。 例: 音楽推薦システムが、ユーザーが曲を選択した際に直下の曲リストは更新するが、上部のリストは固定したままにする。
- G15: Encourage granular feedback. (きめ細かいフィードバックを促す) 説明: ユーザーがAIシステムとの通常のインタラクション中に、自分の好みを示すフィードバックを提供できるようにすべきです。これにより、システムはより的確に学習できます。 例: メールアプリで、AIが重要でないと判断したメールをユーザーが直接「重要」とマークできる。
- G16: Convey the consequences of user actions. (ユーザーの行動の結果を伝える)
説明: ユーザーの行動がAIシステムの将来の挙動にどのように影響するかを、即座に更新したり伝えたりすべきです。これにより、ユーザーは自分の行動がシステムに与える影響を理解し、より意図的にシステムを操作できます。 例: ソーシャルネットワークで、広告を非表示にすると将来表示される広告の関連性が調整されることを伝える。
- G17: Provide global controls. (全体的なコントロールを提供する) 説明: ユーザーが、AIシステムが何を監視し、どのように動作するかを全体的にカスタマイズできるようにすべきです。これにより、プライバシーの管理やシステム動作の調整が可能になります。 例: 写真整理アプリが、ユーザーが位置情報履歴をオンにすることを許可し、AIが訪問した場所に基づいて写真をグループ化できるようにする。
- G18: Notify users about changes. (変更についてユーザーに通知する) 説明: AIシステムが新しい機能を追加したり、既存の機能を更新したりした際に、ユーザーに通知すべきです。これにより、ユーザーはシステムの進化を把握し、新しい機能を活用できます。 例: ナビゲーションアプリが、重要な新機能についてアプリ内で簡単な説明(コールアウト)を表示し、特に注意が必要な新機能はポップアップで通知する。
@Akira Manda(zunda)
[blog] Spec-Driven Development: The Waterfall Strikes Back
ざっくり筆者の主張
SDDはWaterfall時代の「Big Design Up Front」の焼き直しであり、Markdownを大量に読む作業に時間を奪われるだけである。コーディングエージェントの真価は、仕様書で縛ることではなく、自然言語で小さく反復開発すること(Natural Language Development)にある。
Spec-Driven Development (SDD)
コーディングエージェント(Claude Code、Cursor等)を「正しく」導かせるために、事前にLLMで以下を自動生成するアプローチ:
- 製品仕様書(Requirements)
- 実装設計(Design)
- タスクリスト(Tasks)
代表的なツール: GitHub Spec-Kit、AWS Kiro、Tessl、BMad Method

SDDの問題点(著者の主張)
| 問題 | 内容 |
| Context見落とし | 既存コードの文脈を見落とす。結局、専門家のレビューが必要 |
| Markdown地獄 | 大量のMarkdownに埋もれたミスのチェッ |
| 官僚主義 | 3段階のプロセスが過剰なケースが多い。重複や過剰な設計が見られる |
| 偽アジャイル | ユーザーストーリー」と称する文書を生成するが、その定義が誤用されているケースが多い |
| 二重コードレビュー | 設計書のコード+実装コードの両方をレビュー |
| 偽りの安心感 | エージェントは仕様に従わないこともある(テスト未実装でも「完了」扱い等) |
| リターンの先細り | 新規プロジェクトには有効だが、徐々に仕様と実要件が乖離していくとつらい。既存の大規模コードベースでは使えないケースが多い |
だいたいのコーディングエージェントがplan / task listを持っているから、SDDでの上積みはあんまりメリットがないかも?
SDDへの批判(著者の主張)
SDDは「開発者をソフトウェア開発から排除する」という誤った問いを解こうとしている
- Waterfallモデルの再来(Big Design Up Front)
- ソフトウェア開発は本質的に非決定的。計画では不確実性を排除できない("No Silver Bullet")
- 結局、仕様書のエラーを見つけるにはビジネスアナリストと開発者の両方のスキルが必要 → 「開発者不要」の約束は果たせない
代替案(Natural Language Development)
アプローチ: 複雑な要件を単純な要件に分割し、小さく反復する
Lean Startup的サイクル:
- 最もリスクの高い仮説を特定
- それを検証する最小限の実験を設計
- 実装 → 失敗なら2へ、成功なら1へ戻る
結論
アジャイルが殺した仕様書を、なぜ今さら復活させるのか?
- SDDは「開発者排除」を夢見るCS卒の発想
- コーディングエージェントは「機関車」に閉じ込めず、「車や飛行機」として活用すべき
- 必要なのは仕様書ではなく、よりリッチなビジュアルインタラクション
[zunda] 結構過激なアンチSDDな著者。SDDは仕様の明確化やドキュメント化だったり、チームの共通認識を揃えるあたりに効果はありそうだけど、それだけであればSDDというフレーム自体の採用はいらないのかも?
@Shuhei Nakano(nanay)
LyftLearn Evolution: Rethinking ML Platform Architecture
まとめ:
LyftのMLプラットフォームの移行戦略の話。
当初は全てKubernetesで運用していたが、規模拡大に伴い運用負荷が増大。
そこでオフライン処理(学習・開発)はAWS SageMakerへ移行し、オンライン処理(予測サービス)はKubernetesを維持するハイブリッド戦略を採用した。
学び:
- 「全部変える」より「必要な部分だけ変える」
- 学習部分(オフライン)は問題が多かったのでSageMakerへ
- オンライン → Kubernetesのまま
- ユーザーに負担をかけない設計
- エンジニアにコード書き換えを強制しない
- 段階的な移行の重要性
- 一気に変えず、リポジトリごとに少しずつ移行
- 問題があればすぐに戻せる仕組み
課題1:環境の完全な再現
KubernetesとSageMakerは別の技術なので、ユーザーのコードを一切変更せずに動かすために、環境を完全に再現する必要があった。
解決策:
- 認証情報の自動注入の仕組みを再現
- メトリクス収集の仕組みを作り直し
- ハイパーパラメータの受け渡し方法を工夫(SageMakerの制限を回避するためS3経由に)
課題2:起動時間の改善
Kubernetesでは常にサーバーが待機していたので30-45秒で起動できた。SageMakerは使った分だけ課金なので経済的だが、サーバーを起動する時間がかかる。
解決策:
- SOCIを使用して、Dockerイメージ全体をダウンロードせず、必要な部分だけを読み込む(40-50%高速化)
SageMaker fetches only the filesystem layers needed immediately rather than pulling entire multi-gigabyte images.
- 頻繁に使うジョブにはウォームプール(待機状態のサーバー)を用意
課題3:Sparkの通信問題
データ分析によく使われるSparkは、「ドライバー」と「実行者(Executor)」が通信する必要がある。移行後はドライバーがSageMaker Studio、実行者がKubernetesクラスターという構成になり、2つの異なる環境間の双方向通信が最初はブロックされていた。
解決策:
- AWSチームと協力して、SageMaker Studioのネットワーク設定を変更し、Kubernetesクラスターからの接続を許可
メインTOPIC
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, Robert Geirhos
サマリー
Google DeepMind による論文。大量の文書で学習したLLMが汎用的なNLPタスクを解く能力を獲得したように、動画/ビデオ生成モデル(Veo3)が汎用的なCVタスク(エッジ検出やセグメンテーション等々)を解く能力を獲得できるのかという問いに答える論文。
大規模ビデオ生成モデルの様々なCVタスクにおける高いゼロショット推論性能(汎用性)や複雑なタスクに対応する能力(推論能力)を示した。
Nano Banana Pro が賢すぎる - 画像生成モデルであるにもかかわらず、言語タスクに関しても賢くて汎用性が高すぎるのに衝撃を受けており、モーダルを超えた知性の獲得への興味が高まったので選んだ。
1. Introduction
著者らは、LLMがNLP領域の基盤モデルになったのと同様に、ビデオモデルがCV領域のための統一された汎用基盤モデルになるだろうと信じている。
NLPはタスク固有のモデル(翻訳、質問応答、要約などなど)から、汎用的な言語理解が可能なLLMへと根本的に進化した。LLMの能力は、ウェブスケールデータセットで大規模な生成モデルを訓練するという単純なプリミティブから出現し、few-shot の in-context learning や zero-shot learning を通じて新しいタスクを解決可能となった。ここでの zero-shot 学習とは、タスク固有のファインチューニングや推論ヘッドの追加なく、タスクの指示を含むプロンプトをモデルに与えることでタスクを解くことを意味する。
昨今のCVは、数年前のNLPの状態に似ており、セグメンテーションのための “Segment Anything」” やオブジェクト検出のためのYOLOシリーズのような、優れたタスク固有のモデルが存在する。一部のCVタスクを統一しようとする試みは存在するが、プロンプトを与えるだけであらゆる問題を解決できる既存のモデルは存在しない。
そこで、NLPでゼロショット学習を可能にしたのと全く同じプリミティブを、ビデオ生成モデルにも適用する。
本研究では、「LLMが汎用言語理解を発展させたのと同様に、ビデオモデルは汎用ビジョン理解を発展させるのか?」という問いに答える。
本研究の主な報告
- 62の定性タスクと7つの定量タスクにわたる18,384本の生成動画を分析し、Veo 3が訓練も適応もされていない幅広いタスクを解決できること(汎用性)を示す。
- Veo 3は、視覚世界を知覚、モデル化、操作する能力に基づいて、迷路解決や対称性解決のような初期の「Chain-of-Frames (CoF)」視覚的推論の能力を示す。
- タスク固有の特化モデルは依然としてビデオ生成モデルのzaro-shot推論を上回るが、Veo 2からVeo 3への大幅かつ一貫した性能向上が観察され、動画モデルの能力が急速に進歩していることをを示す。
2. Methods
Approach and motivation
本研究ではシンプルに、「Veoにプロンプトを与える」というミニマリストな戦略を採用し、LLMの進化をなぞることで、汎用CVモデルとしての Veo 3 の能力を探求する。

つまり、プロンプトがタスク固有の学習やアダプテーションに取って代わる事象がCV領域においてもビデオモデルによって引き起こされることを示したい。
Video generation
各タスクについて、Google CloudのVertex AI APIを介して、公開されているVeo 2またはVeo 3モデルにクエリを発行する。
モデルには、初期入力画像(モデルが生成する動画の最初のフレームとして使用する)とテキスト指示のプロンプトを与える。モデルはその後、8秒間、16:9のアスペクト比で720p解像度、24 FPSのビデオを生成する。使用したモデルIDは、Veo 3が、Veo 2がである。
Vertexのドキュメントによると、APIはLLMベースのプロンプトリライターを使用しているため、一部のタスクではLLMからソリューションが来ている可能性が高いが(例:数独)、本研究ではこのシステム全体を単一のブラックボックスエンティティとして扱う。ただし、スタンドアロンのLLM(Gemini 2.5 Pro)が、入力画像のみから主要なタスク(例:ロボットナビゲーション、迷路解決、視覚的対称性)を解決できないことを確認し、ビデオモデルの推論能力を分離した。
Why Veo?
本論文の核となる主張(ビデオモデルはゼロショット学習器であり推論器である)は、十分な能力を持つ任意のモデルで成功を実証することで裏付けられる。Veoはテキストからビデオへ、および画像からビデオへのリーダーボードで常に上位にランク付けされているため、選択された。
後述の定量分析では、約半年以内にリリースされたVeo 3(2025年5月発表、2025年7月リリース)とVeo 2(2024年12月発表、2025年4月リリース)を比較し、性能の急速な向上を示した。
3. Qualitative results: Sparks of visual intelligence? / 定性的な実験結果集
ビデオモデルのビジョン基盤モデルとしての可能性を評価するため、ビジョンタスク全体にわたる包括的な定性調査から開始。
観測された能力を以下の4つの階層的能力に分類。各能力は前段階の能力を基盤として構築される。
- 知覚 (Perception):視覚情報を理解するための基礎能力
- 超解像(superresolution)
- 結合探索/バインディング問題(conjunctive search / binding problem):「青い」「球」を、「赤い」「球」や「青い」「立方体」と区別した上で探している
- モデル化 (Modeling):オブジェクトの知覚に基づいて、視覚世界のモデルを形成
- 浮力(buoyancy):水面に落としたボトルのキャップが浮いている
- 世界の状態の記憶(memory of world states):一度近づいた後に引いても同じ街並み
- 操作 (Manipulation):知覚されモデル化された世界を有意義に変更
- 3D対応のポーズ変更(3D-aware reposing )
- 瓶の開閉(jar opening)
- 推論 (Reasoning):一連の操作ステップを通じて、空間と時間全体で推論
- ロボットナビゲーション
- 規則的な外挿(rule extrapolation):右下のグリッドを他のグリッドが定めたルールに準拠するよう修正させる。セルを埋める、クリアする、またはセルの色を変更することができる。

これらの能力の境界はしばしば重複するが、この階層はビデオモデルの創発的な能力を理解するための枠組みとなる。たとえば、迷路を解く際には、迷路を知覚し、その状態をモデル化(壁と床など)し、オブジェクトを操作(ネズミ)して開始から終了まで移動させる必要がある。

この定性的な実験を示すセクションにおいては各タスクについて、Veo 3に12回プロンプトを提示し、キャプションに成功率を報告する。成功率は、生成された動画のうちタスクを解決した動画の割合(著者らによる判定)として定義される。成功率が0より大きい場合、モデルがタスクを解決する能力を有することを示唆し、成功率が1に近いほど、ランダムシードに関係なくタスクが確実に解決されることを示す。第4節で行う体系的な定量化に代わるものではないが、これはモデル能力の大まかな見積もりを提供する(結果の概要は以下)。
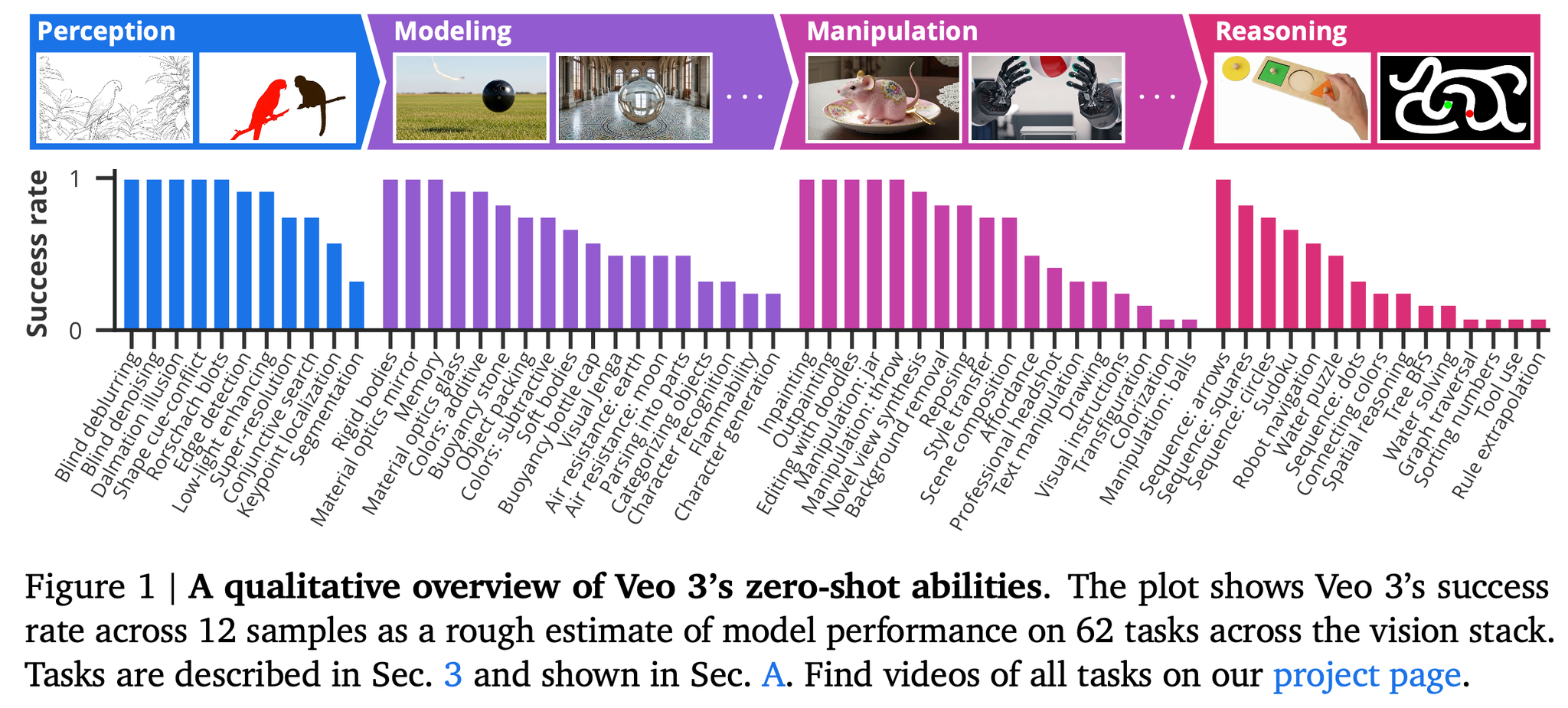
知覚 (Perception)
タスク固有の訓練を一切行わずに、Veo 3は以下のような一連の古典的なコンピュータビジョンタスクを実行できた。デノイジングを除いてこれらのタスクはいずれも明示的には訓練されていない。
- エッジ検出(成功率: 0.92)。
- セグメンテーション(成功率: 0.33)
- キーポイント局所化(成功率: 0.58)
- 超解像度(成功率: 0.75)
- ブラインドデブラーリング (成功率: 1.0)
- ブラインドデノイジング(成功率: 1.0)
- 低照度強調(成功率: 0.92)
他の知覚タスクもええ感じ
- Shape cue-conflict understanding:形状と他の視覚的手がかり(たとえばテクスチャ/質感)が矛盾する際に、モデルが何を信頼するかを評価

- Rorschach blot interpretation:曖昧なインクのしみを見て、そこに何が見えるのかを答えさせる。


Veo 3は、訓練タスクをはるかに超えた創発的なゼロショット知覚能力を示す。LLMがタスク固有のNLPモデルを置き換えたのと同様に、ビデオモデルも、十分に安価で信頼性が高くなれば、コンピュータビジョンにおけるほとんどの特注モデルを置き換える可能性が高い。
Modeling: intuitive physics & world models
世界の物理法則などの原理を理解することは、視覚世界における予測・行動の性能を上げるための重要な要素である。可燃性や、剛体・軟体のダイナミクスおよびその相互採用、落下時の空気抵抗、浮力などを理解していることが観察された。


その他も諸々
Manipulation: editing&imagination
めっちゃいろいろ
落書きの指示で画像を編集したり

nano banana pro でもできた
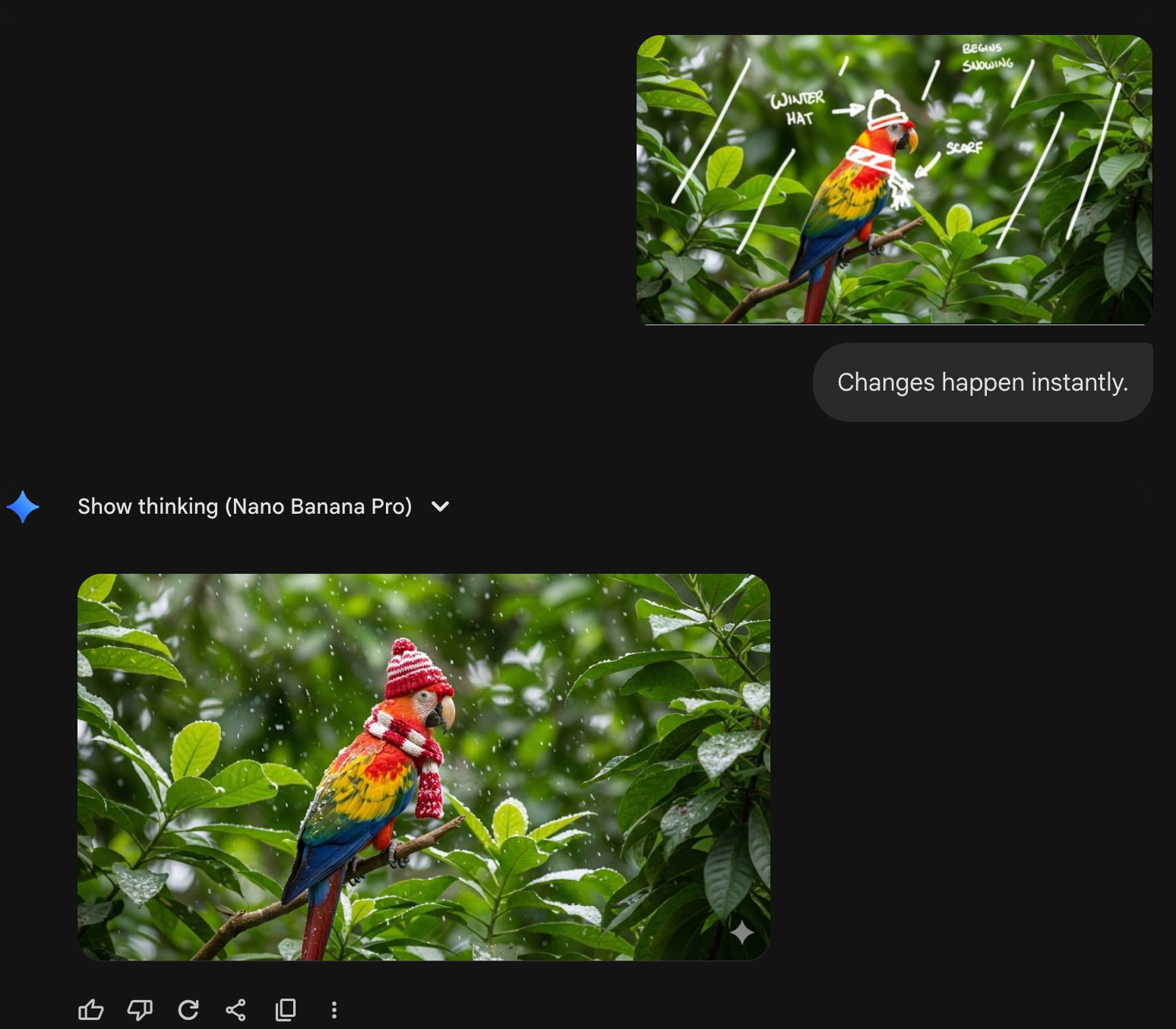
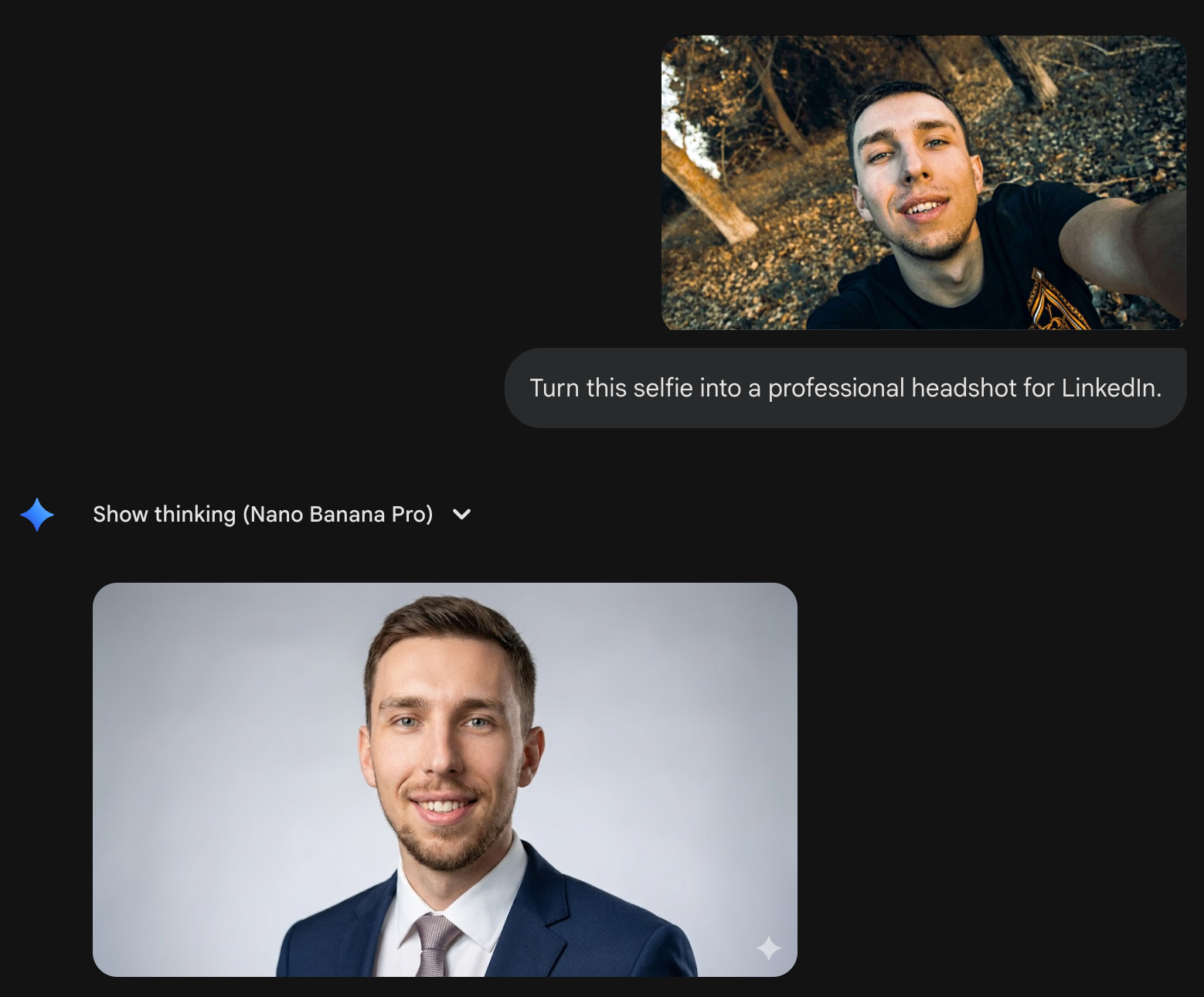
自撮りからポートレート写真を生成したい

nano banana pro でもできた
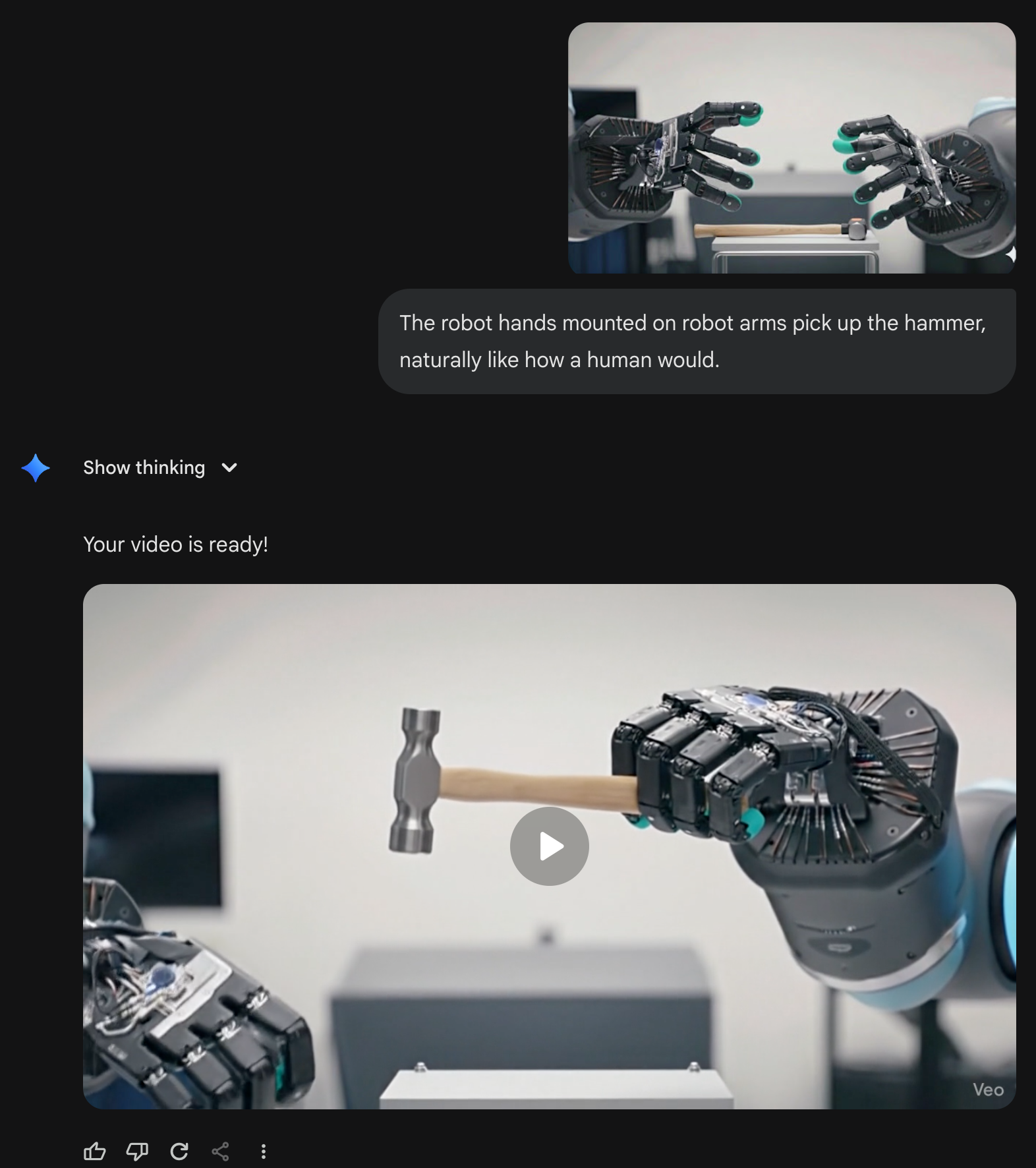
画像中の物体の使い方を理解したり(これは言語情報として持ってる気がするな?)

nano banana pro でやろうとしたら Veo が動いた
推論 (Reasoning)
知覚、モデル化、および操作をすべて統合して視覚的推論に取り組む。言語モデルが人間が考案した記号を操作するのに対し、ビデオモデルは現実世界の次元である時間と空間全体にわたって変化を及ぼせる・画像を生成できる。
これらの変化は生成されたビデオでフレームごとに適用されるため、これはLLMにおける連鎖的思考(Chain-of-Thought)に類似しており、Chain-of-Frames(CoF)と呼ぶことができるかもしれない。
言語ドメインでは、連鎖的思考によりモデルは推論問題に取り組むことが可能になった。同様に、Chain-of-Frames(別名:ビデオ生成)は、時間と空間にわたる段階的な推論を必要とする困難な視覚問題をビデオモデルが解決することを可能にするかもしれない。
広告によく出てくるタイプのミニゲームが解けている感じ。
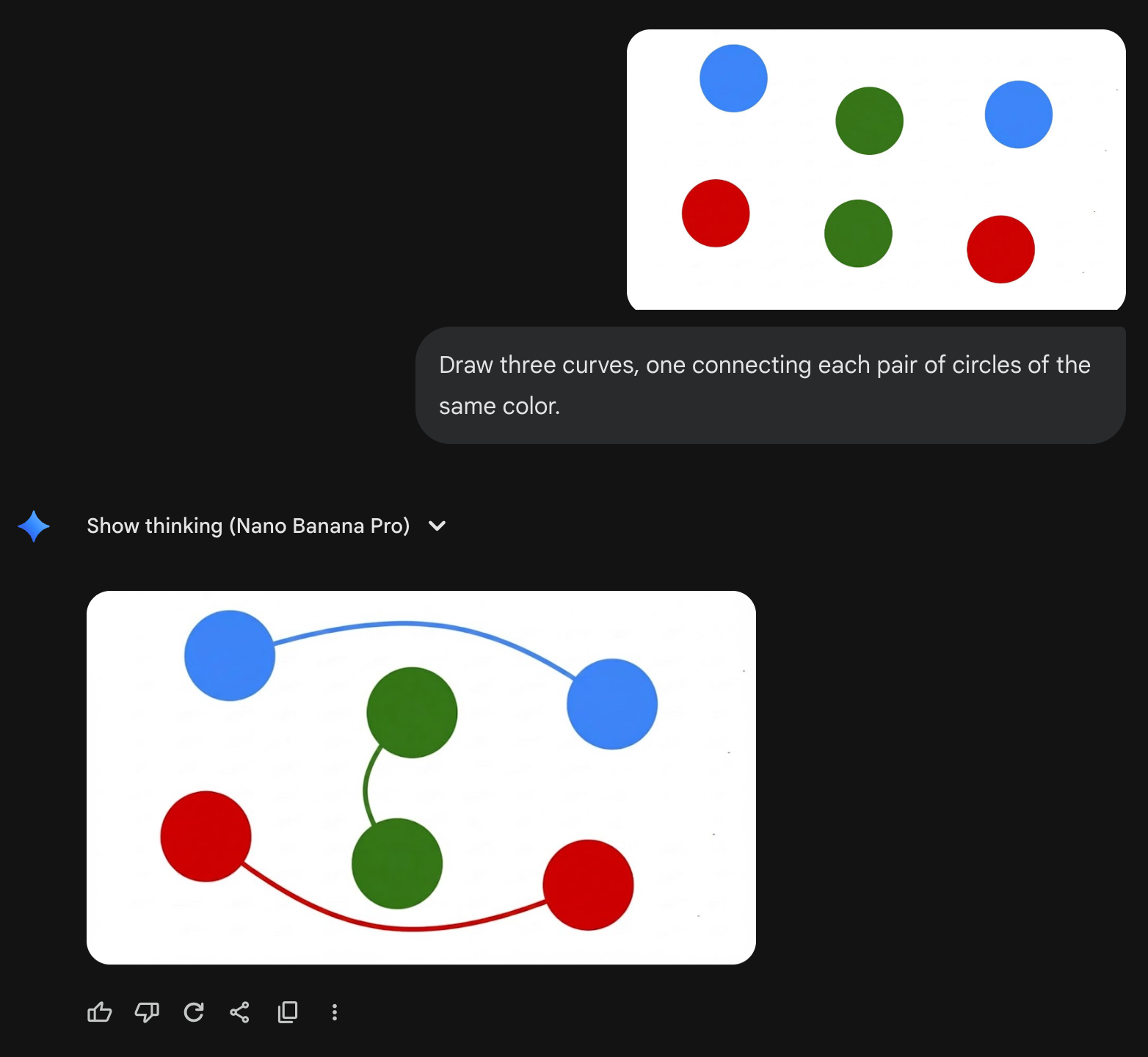
同じ色を結ぶ
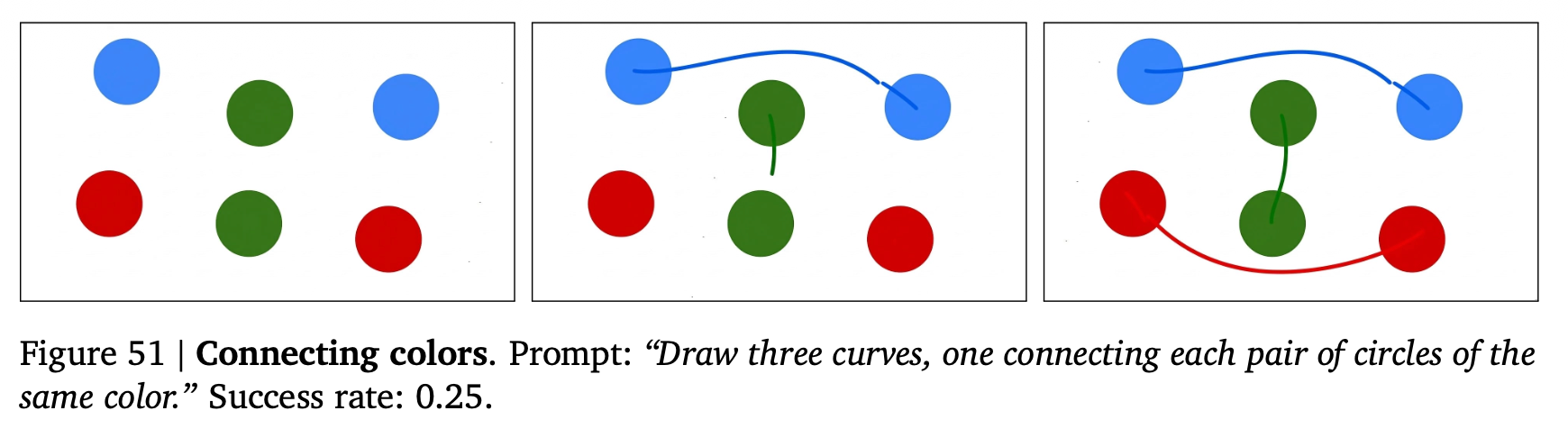
nano banana pro でもできた
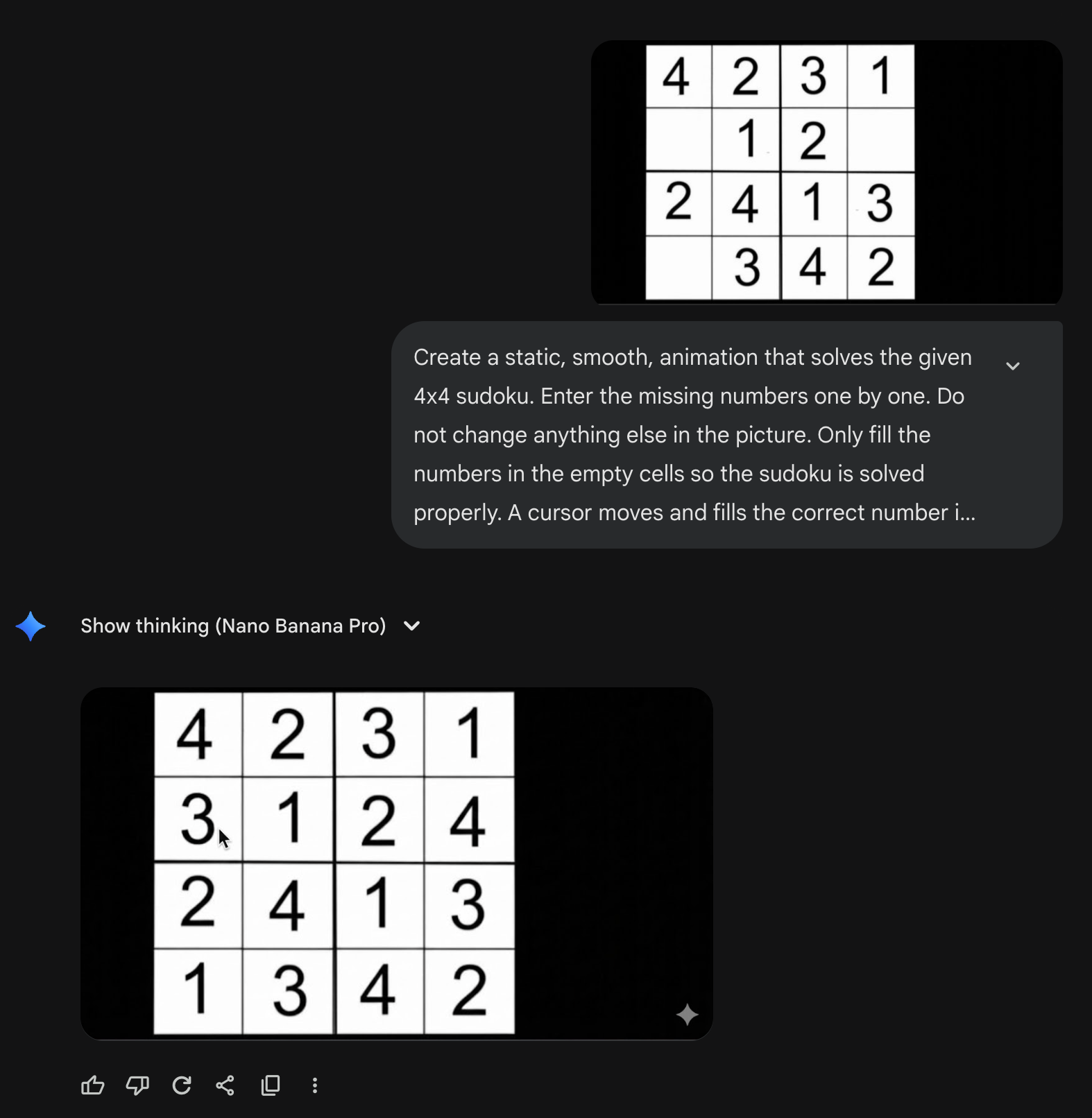
シンプルな数独

nano banana pro でもできた

フレームごとのビデオ生成は、言語モデルにおける連鎖的思考に類似している。連鎖的思考(CoT)が言語モデルに記号による推論を可能にするのと同様に、「Chain-of-Frames」(CoF)はビデオモデルに時間と空間にわたる推論を可能にする。
4. Quantitative results / 定量的な評価実験
7つのタスクを抜粋して定量評価を実施(modeling は公開ベンチがあるからここには含めない)。
生成された動画のうち(該当するものが存在する場合)ベストフレームとラストフレームで性能を個別に評価する。みんな大好き Nano Banana と比較。
全体的な傾向として、Veo 2からVeo 3への大きな性能向上が観察された。これは Nano Banana の性能に匹敵するか上回る。
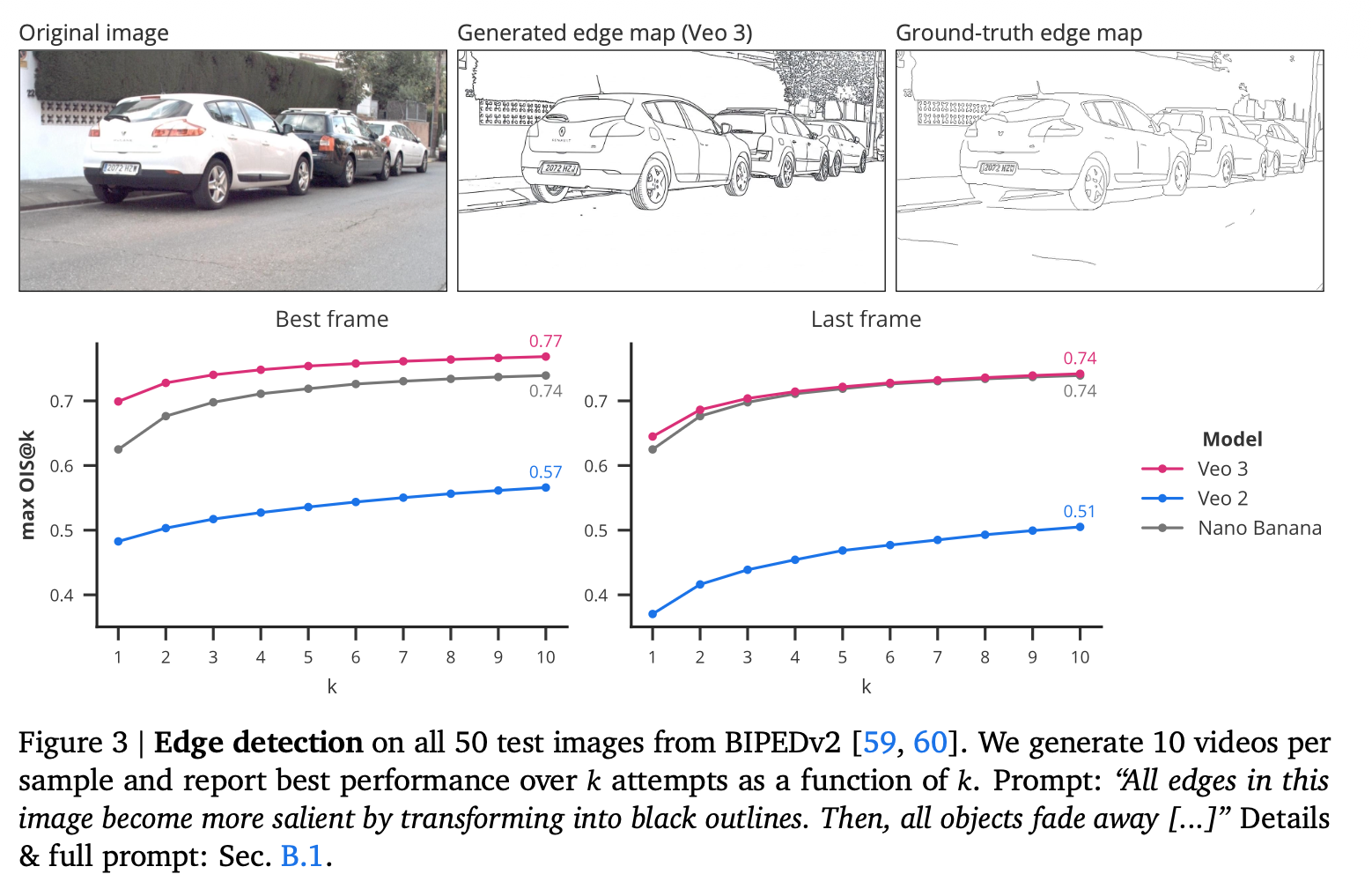
エッジ検出の性能比較図と画像例
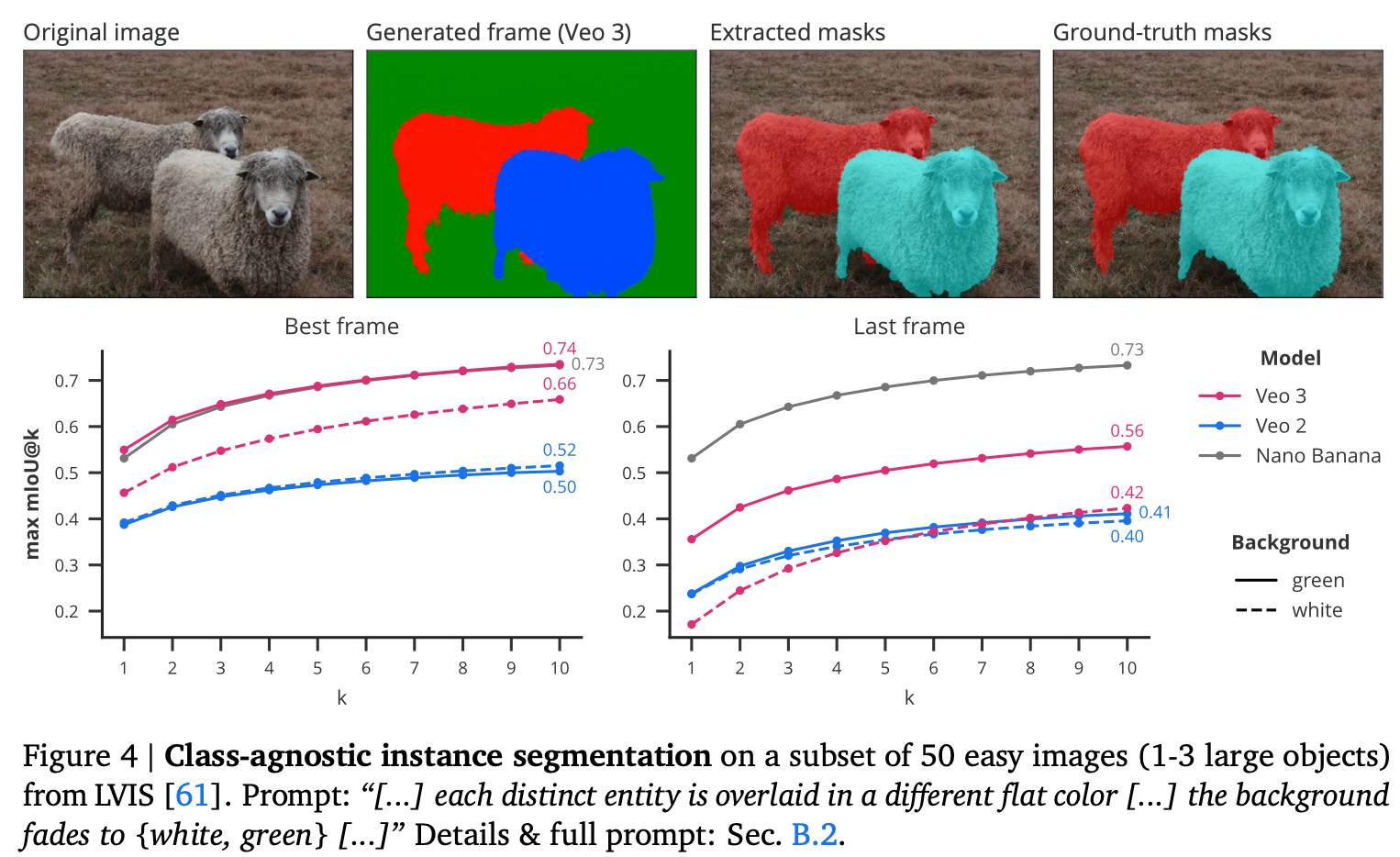
セグメンテーションタスクにおけるの性能比較図と画像例
画像編集の性能比較図と画像例

迷路解決の性能比較図と迷路の例
複雑なパターンではVeo3が強い
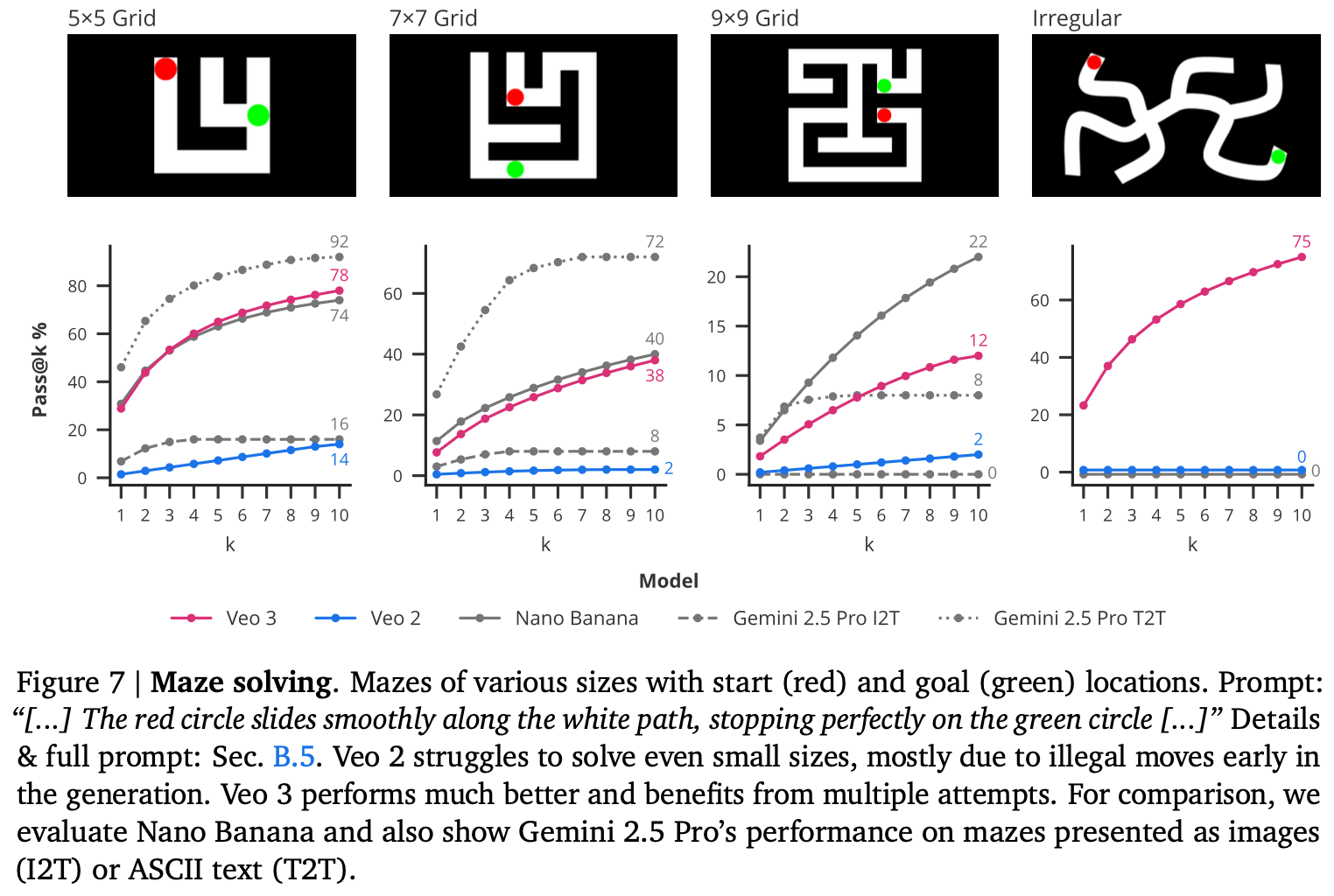
複雑なやつは nano banana pro でも解けなかった!(gemini はこの論文を知っているので、正解の画像が論文中に含まれていないことが大きいかもしれない)
視覚的対称性解決の性能比較図と画像例
nano bananaさん苦手らしい
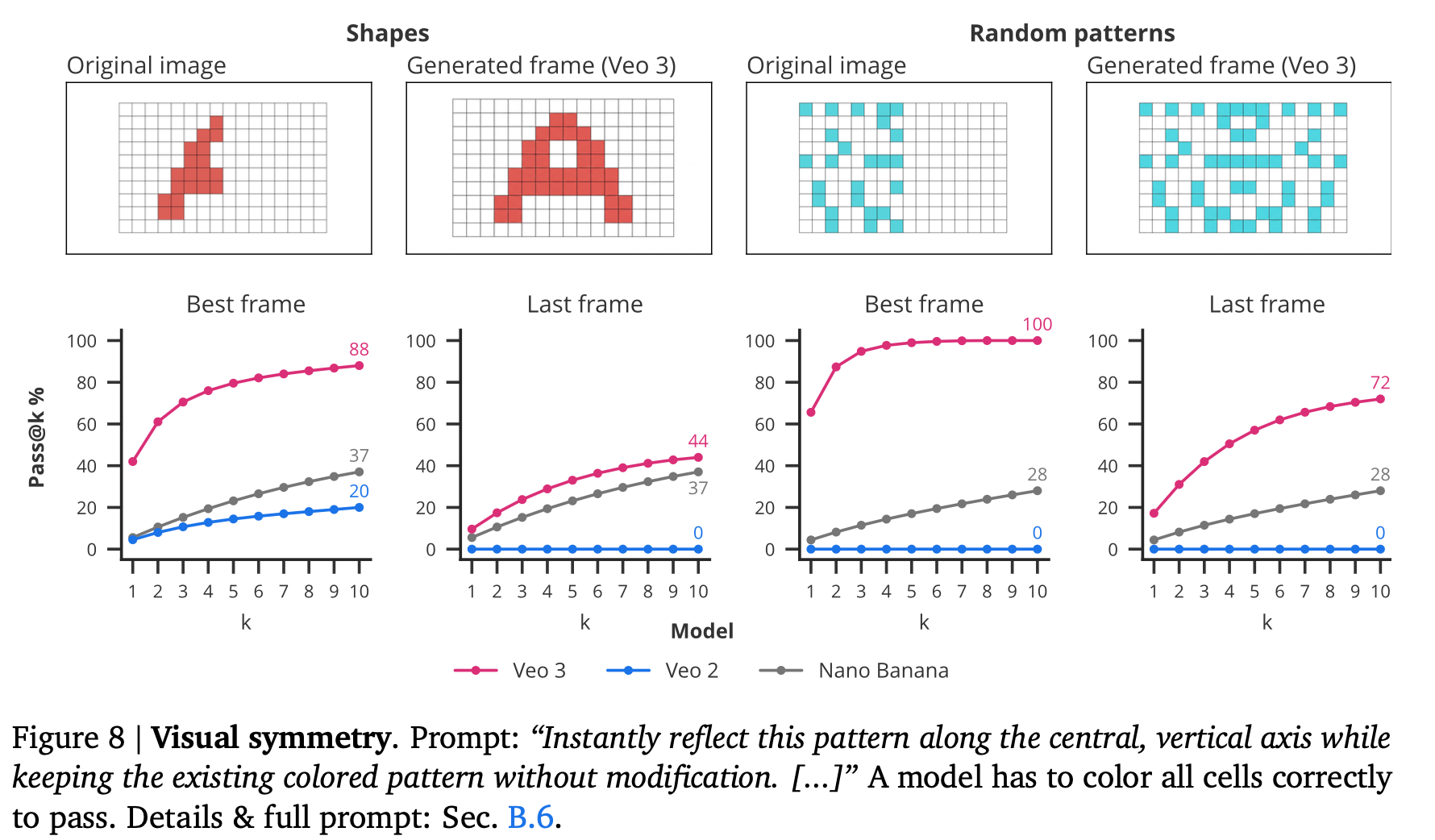
nano banana pro でできなかった(惜しい!)
視覚的類推解決の性能比較図と画像例
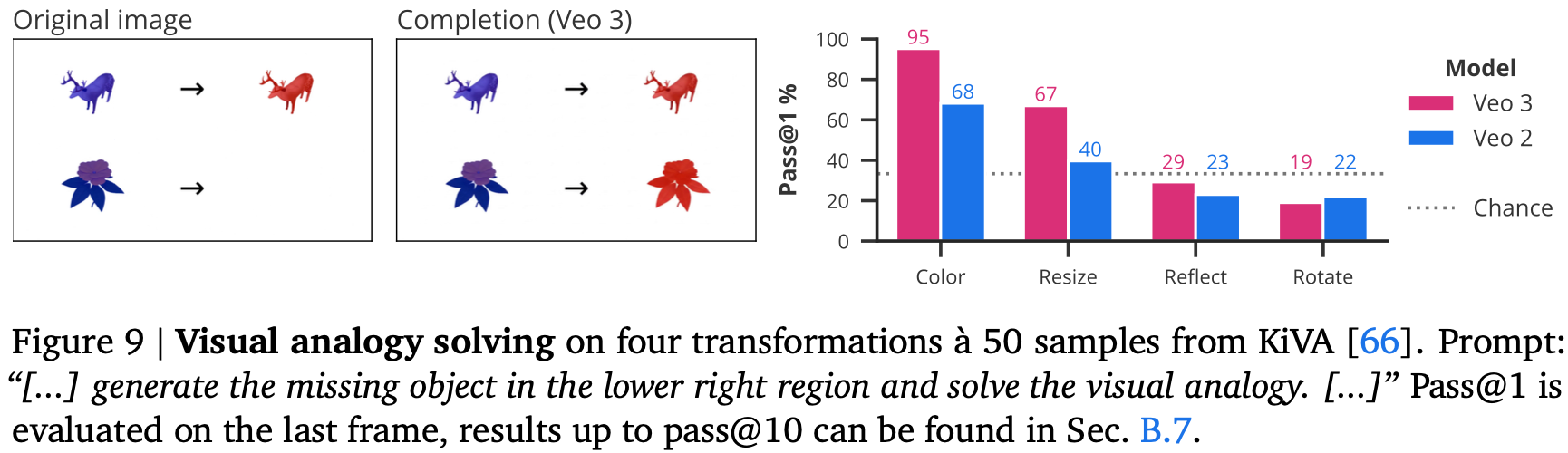

完璧からは程遠いが、オブジェクトを知覚し、モデル化し、操作する能力に基づいて構築されたVeo 3は、創発的な視覚的推論能力を示す
5. Discussion
サマリー
大規模言語モデルにおいて起きたのと同様のパラダイムが、大規模ビデオモデルの創発的な能力によってコンピュータビジョンでも起こりつつあると主張する。本研究の核となる発見は、Veo 3が、知覚からモデル化、操作、さらには初期の視覚的推論に至るまで、ビジョンスタック全体にわたる幅広いタスクをゼロショット方式で解決できることである。そのパフォーマンスはまだ完璧ではないが、Veo 2からVeo 3への大規模で一貫した改善は、LLMが言語に対してそうであったように、ビデオモデルがビジョンの汎用基盤モデルになることを示している。
パフォーマンスは下限である
タスクは無数の方法で表現できる。例えば、迷路は白黒グリッド、ビデオゲーム、またはフォトリアリスティックなシーンとして提示でき、プロンプトは線、移動するオブジェクト、または光る経路の形で解決を要求できる。さらに、視覚的には、迷路は白黒グリッド、パックマンゲーム、またはアパートのフォトリアリスティックな俯瞰図として表現できる。
これには3つの意味がある。第一に、プロンプトエンジニアリング—別名、開始フレームとしての視覚的プロンプトを含む—は、LLMにとってと同様に視覚タスクにとっても重要である。
第二に、モデルのタスクパフォーマンスと、そのタスクを解決するための根底にある能力(すなわち、コンピタンス)を区別しなければならない。
第三に、結果として、ここで報告された特定の視覚的およびテキストプロンプトでのモデルパフォーマンスは、モデルの真の能力の下限と見なされるべきである。(プロンプトなどもナイーブで改善の余地あり)
ビデオ生成は高価だが、コストは下がる傾向にある
ビデオの生成は現在、特注のタスク固有モデルを実行するよりも高価であるが、汎用モデルの経済性は予測可能な軌道に乗っている。Epoch AI は、LLMの推論コストが、特定の性能レベルで年間9倍から900倍の速さで低下していると推定している。NLPでは、初期の汎用モデルも法外に高価であると考えられていた。それにもかかわらず、急速に低下する推論コストと、汎用モデルの魅力が相まって、ほとんどのタスク固有の言語モデルが置き換えられた。NLPがガイドであるならば、ビジョンにおいても同じ傾向が展開されるだろう。
多芸は無芸か?
多くのタスクで、Veo 3のパフォーマンスは専門化されたモデルの最先端を下回っている。これは、LLMの初期の時代を反映している。GPT-3は、多くのタスクでファインチューニングされたモデルよりもはるかに低いパフォーマンスを報告していた。これは言語モデルが基盤モデルになるのを止めなかった。そして、我々は、これがビデオモデルがビジョン基盤モデルになるのを止めるとは考えていない。
これには2つの理由がある。第一に、Veo 2からVeo 3へのパフォーマンスの大幅な変化は、時間とともに急速な進歩があったことの証拠である。
第二に、セクション4のスケール結果は、pass@10がpass@1よりも一貫して高く、まださちる兆候がないことを示している。したがって、自動検証機能による後訓練のような標準的な最適化ツールキットと組み合わせた推論時間スケーリング方法 は、パフォーマンスを向上させる可能性が高い。我々がここでテストするタスクについて、Veo 3は、命令チューニングやRLHF をまだ受けていない事前訓練された言語モデルに似ている。
展望
これはビジョンにとってエキサイティングな時代である。NLPが最近、タスク固有のモデルから汎用モデルへと変革したのを見て、知覚から視覚的推論まで、幅広いタスクをゼロショット方式で実行する創発的な能力によって可能になる、同じ変革がビデオモデルを通じてコンピュータービジョンでも起こる(ビジョンにとっての「GPT-3モーメント」)ことが考えられる。