
2025-12-02 機械学習勉強会
今週のTOPIC[論文] Qwen3-VL Technical Report[blog] Transformers v5: Simple model definitions powering the AI ecosystem[blog] Sarashina2.2-Vision-3B: コンパクトかつ性能が高いVLMの公開[論文] Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens[blog]Your Company’s AI Server Bill Can Now Be Zero: Save a Ton Of MoneyEvolution and Scale of Uber’s Delivery Search PlatformメインTOPICAgent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated ReasoningAgent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language ReasoningサマリーAgent0/Agent0-VL サマリー1. Agent0 (LLM版: 垂直方向の進化)2. Agent0-VL (VLM版: 品質の深化)Agent01. Introduction2. Preliminaries3. The Agent 0 Framework3.1. Framework Overview3.2. Curriculum Agent Training3.3. Executor Agent Training4. Experiments4.1. Experimental Setup4.2. Main Results4.3. AnalysisAgent0-VL1. Introduction2. Preliminaries3. Methodology3.1 Unified Solver-Verifier Architecture3.2 Tool-Grounded Verification and Self-Repair3.3 Self-Evolving Reasoning Cycle(SERC: 自己進化推論サイクル)4. Experiments4.1 Experimental Setup4.2 Main Results4.3 Ablation Studies4.4 Performance as a Process Reward Model4.5 Case Study比較1. 関係性の概要:2. アーキテクチャとメカニズムの比較Agent0のメカニズム:出題と解答の競争Agent0-VLのメカニズム:推論と検証の協調3. 技術的な詳細比較最適化手法 (Optimization)データの扱い
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
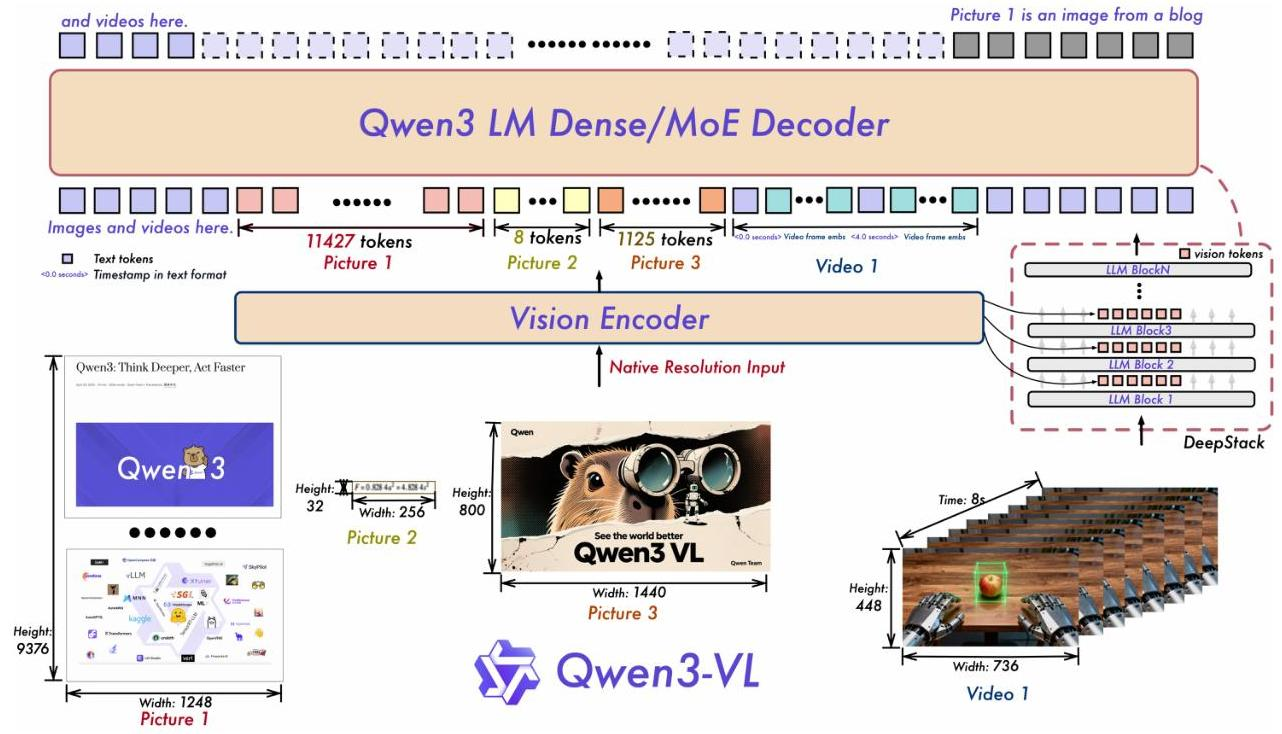
@Yuya Matsumura
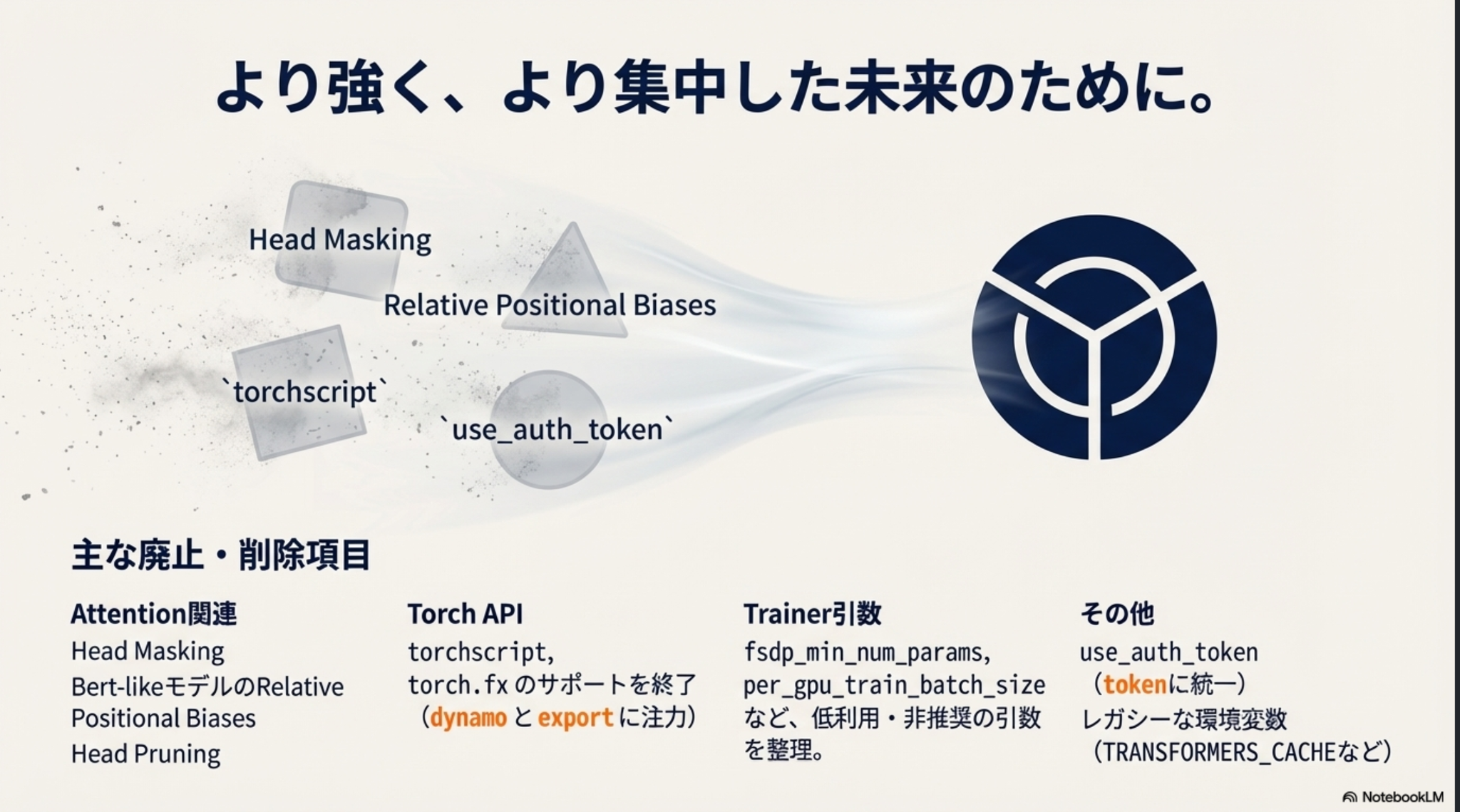
[blog] Transformers v5: Simple model definitions powering the AI ecosystem
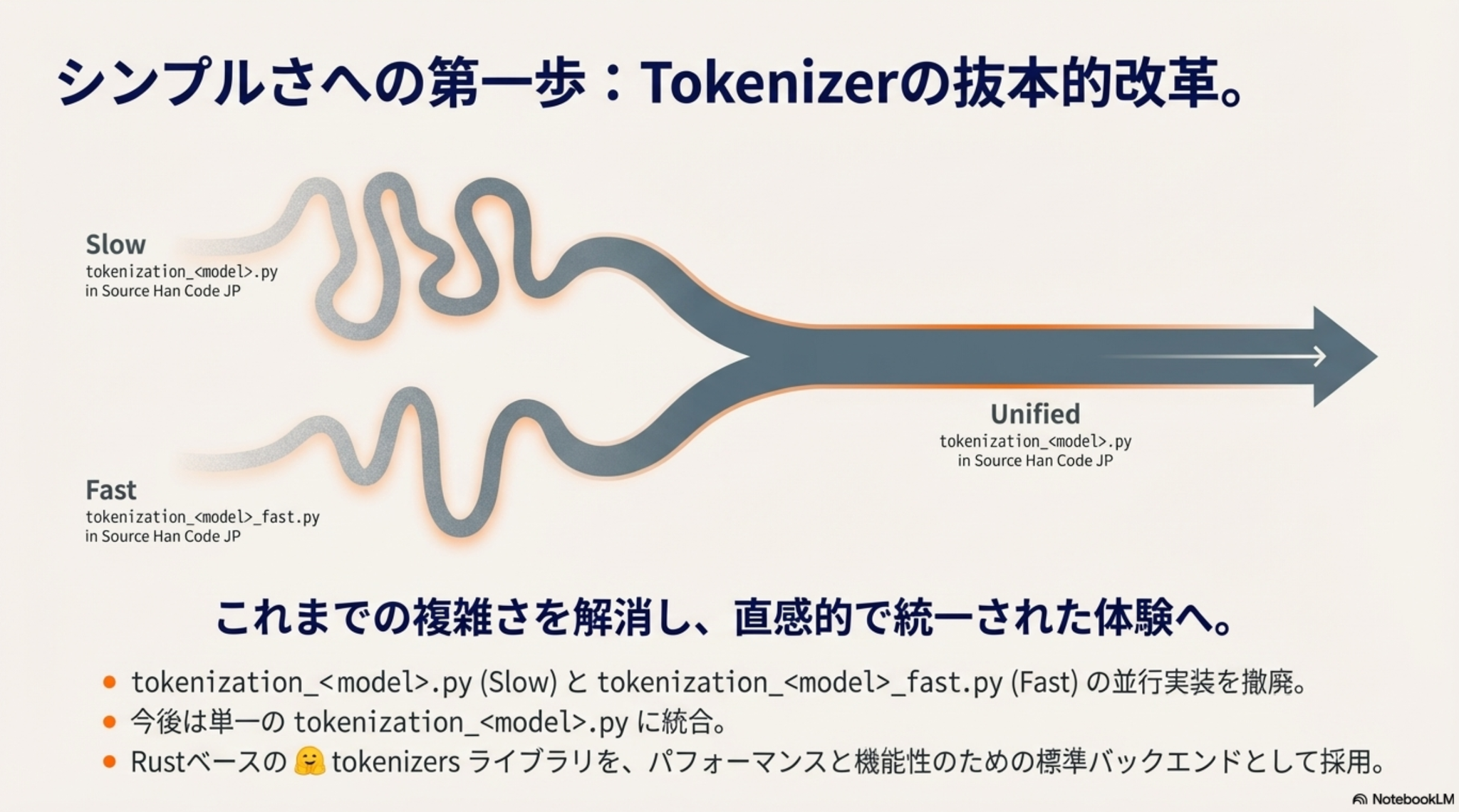
みんな大好き transformers が5年ぶりのメジャーアップデート(まだ予定)
リリースノートはこちら
ざっくりと以下のような感じ
- tokenizerのバックエンド統一による取り扱いやすさ向上
- TensorFlow/Flaxサポートを縮小し、 PyTorchフォーカス

- 本番利用(特に大規模データ)を想定した推論機能強化
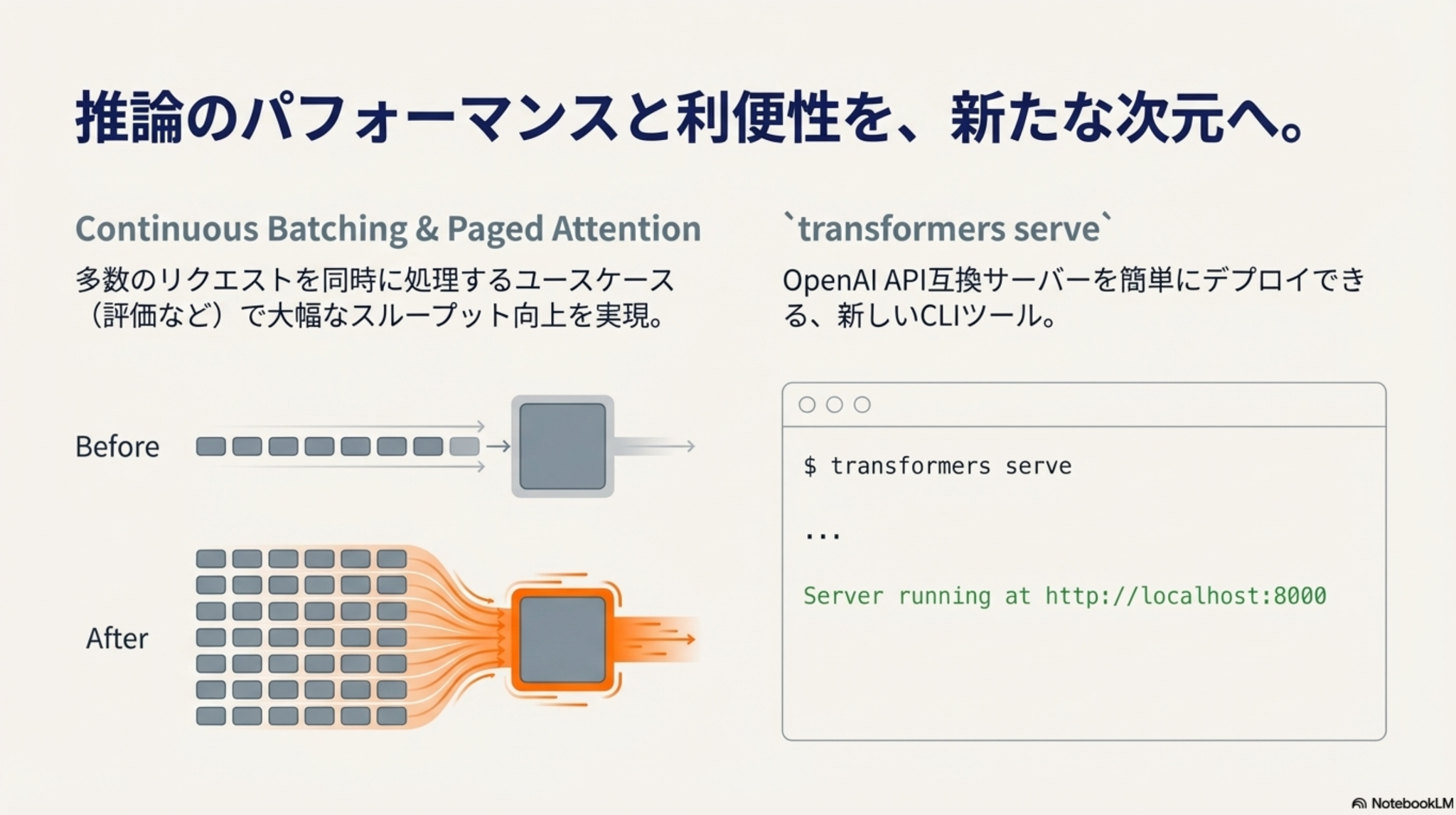
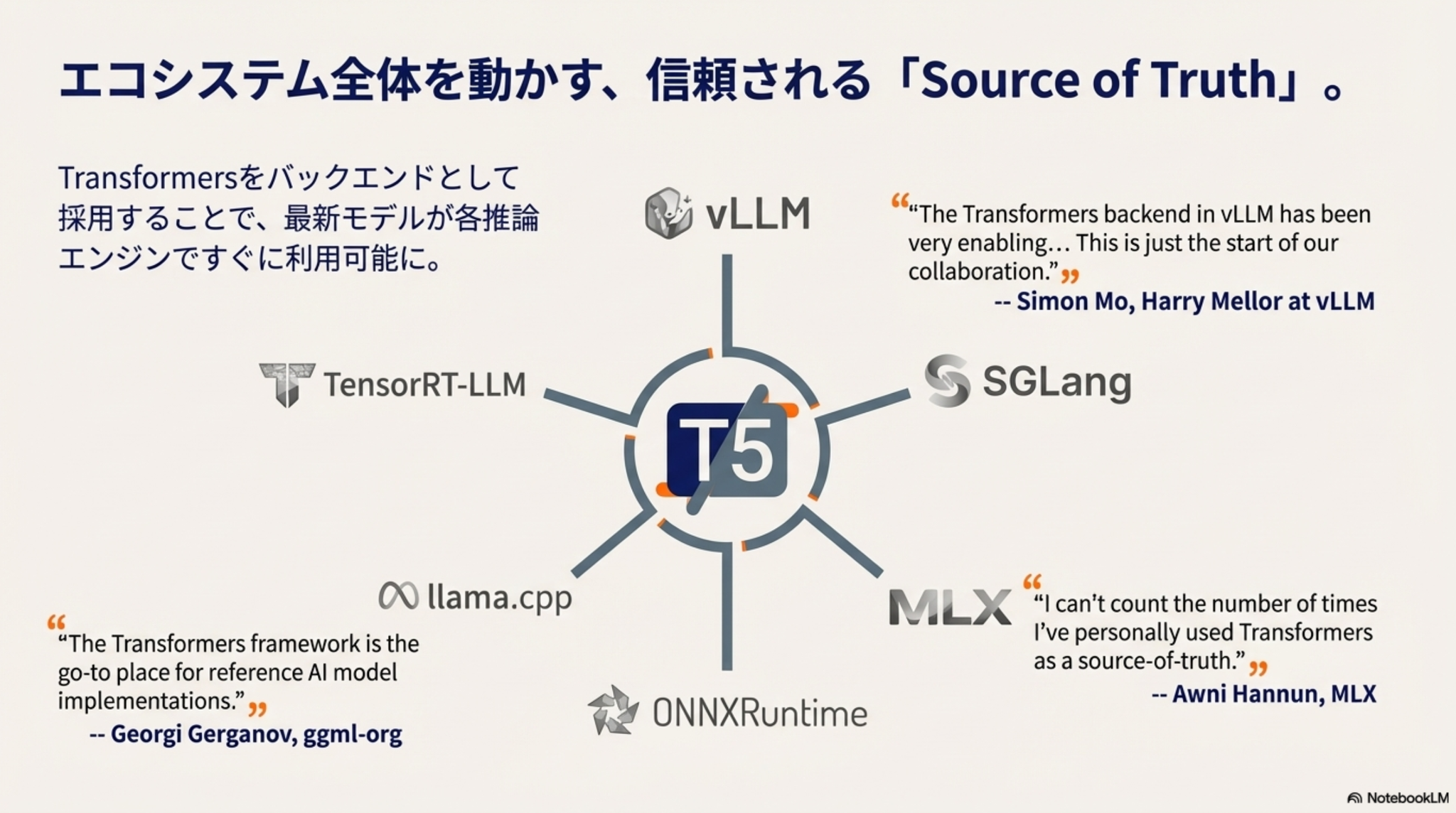
- 量子化への対応強化

- 他リファクタリング多数
@Shun Ito
[blog] Sarashina2.2-Vision-3B: コンパクトかつ性能が高いVLMの公開
- 日本の地理や文化・文書理解に強みのあるVLM: Sarashina2.2-Vision-3B
写真から場所を当てる例(blogから引用)

ユーザー:
Sarashina2.2-Vision:
ポスターの日本語を理解する例(blogから引用)

ユーザー:
Sarashina2.2-Vision:
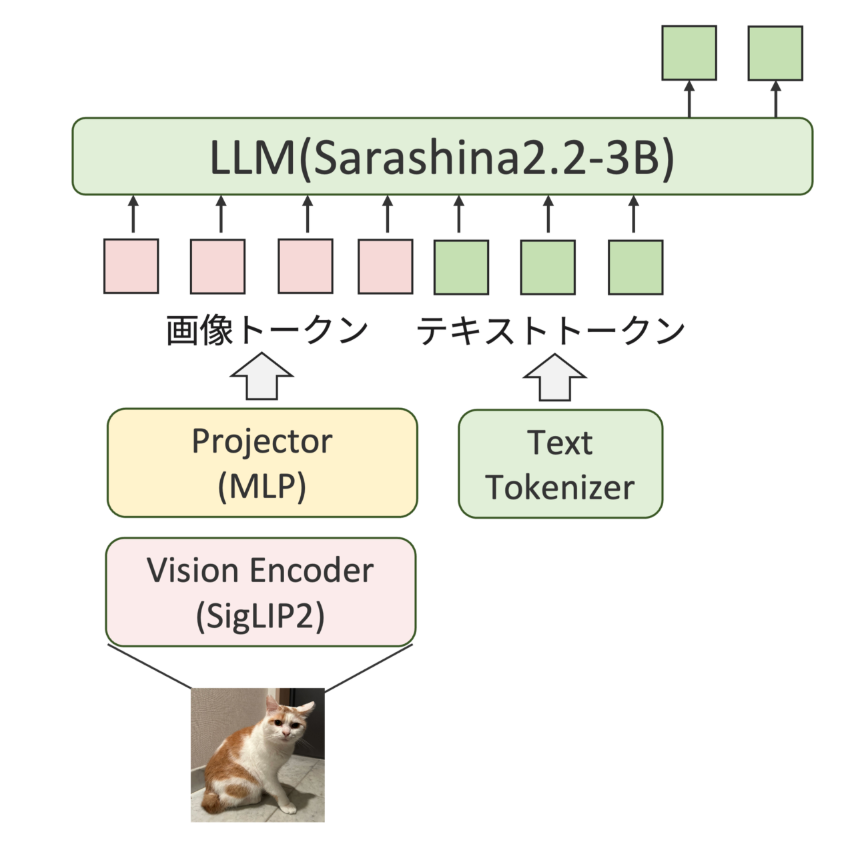
- アーキテクチャ
- LLM, Vision Encoderは学習済みモデルのパラメータを初期値として利用
- Projectorは2層の線形層をランダム初期化
- 学習プロセス
- Projector Warmup: 埋め込み空間を合わせる
- 画像Encoderの埋め込み空間をLLMの埋め込み空間と合わせるためProjectorを用意
- 英語の画像キャプションデータで学習
- Vision Encoder Pretraining: 画像理解能力の引き上げ
- LLMのパラメータを固定し、Vision Encoder + Projectorを学習
- 日本語を含む図表やOCRデータを利用
- Full Model Pretraining: 画像と言語を統一的に理解する能力を上げる
- LLM + Vision Encoder + Projectorを学習
- 日本語を含む図表やOCRデータに加えて、画像とテキストが混在するinterleavedデータも利用
- Instruction Tuning: 指示追従能力のチューニング
- Projector + LLMを学習
- 画像キャプションデータやVQAデータ・テキストデータを利用
- Post-training: Mixed Preference Optimization: 推論能力を高めつつ人間好みの回答を出力させる
- Projector + LLMを学習
- 3つの損失関数を組み合わせたPreference Optimization
- Preference Loss: ChosenとRejectedのペアの相対的な好みを学習
- Quality Loss: 回答がどれだけ高品質か学習
- Generation Loss: 回答を生成するためのプロセスを学習
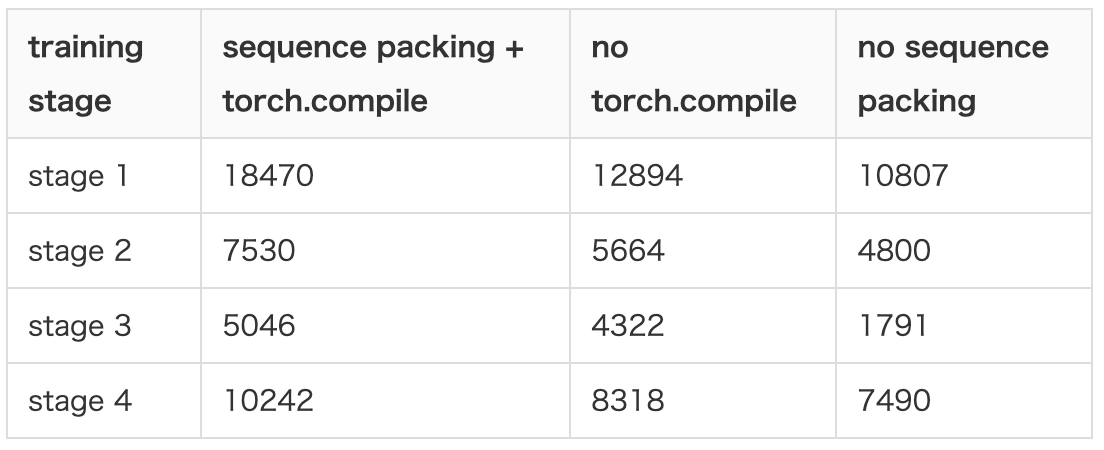
- 学習高速化のための工夫
- Sequence Packing
- 最大シーケンス長に合わせてパディングするのではなく、最大シーケンス長に達するまで複数のサンプルを1つのサンプルとして連結する
- torch.compileのサポート
- 両方を含めることでスループット(token数 / (秒*GPU数))は1.2~1.5倍程度に
- 評価結果
- 画像に関する質問に答えるタスク
- LLM-as-a-Judge with gpt-oss-120bで評価
- 評価データセットの品質を上げるため、多肢選択形式と自由記述形式が混ざっているものを多肢選択形式に統一したり、「本文中に記載がありません」が答えのサンプルを除外したりしている
- このような取り組みは継続的にやっているようですごい
- 日本語ベンチマークでの結果
- 英語ベンチマークでの結果
- パラメータ数は小さめなものの、ベンチマークに対する性能は比較的良い結果に
| モデル | パラメータ数(B) | BusinessSlideVQA | JDocQA | Heron-Bench | JMMMU |
|---|---|---|---|---|---|
| karakuri-vl-32b-instruct-2507 | 32.7 | 4.087 | 3.669 | 2.718 | 0.595 |
| Qwen3-VL-4B-Instruct | 4.4 | 4.105 | 3.596 | 0.276 | 0.491 |
| Sarashina2.2-Vision-3B | 3.8 | 3.932 | 3.327 | 3.214 | 0.484 |
| Stockmark-2-VL-100B-beta | 95.5 | 3.973 | 3.168 | 2.563 | - |
| Qwen2.5-VL-3B-Instruct | 3.8 | 3.516 | 3.019 | 2.000 | 0.450 |
| Qwen3-VL-2B-Instruct | 2.1 | 3.612 | 3.051 | 2.155 | 0.368 |
| InternVL3_5-4B | 4.7 | 3.311 | 2.626 | 1.893 | 0.437 |
| Sarashina2-Vision-14B | 14.4 | 3.110 | - | 2.184 | 0.432 |
| InternVL3_5-2B | 2.3 | 2.795 | 2.393 | 1.864 | 0.384 |
| Sarashina2-Vision-8B | 8.0 | 2.913 | - | 2.214 | 0.376 |
| Heron-NVILA-Lite-2B | 2.0 | 1.694 | 2.083 | 2.214 | 0.380 |
| Heron-NVILA-Lite-1B | 0.9 | 1.416 | 1.741 | 1.903 | 0.286 |
| モデル | パラメータ数(B) | ChartQA | DocVQA | InfoVQA | MMMU | MMStar | RealWorldQA |
|---|---|---|---|---|---|---|---|
| karakuri-vl-32b-instruct-2507 | 32.7 | 0.799 | 0.919 | 0.795 | 0.622 | 0.665 | 0.697 |
| Qwen3-VL-4B-Instruct | 4.4 | 0.684 | 0.948 | 0.798 | 0.570 | 0.560 | 0.712 |
| Sarashina2.2-Vision-3B | 3.8 | 0.630 | 0.831 | 0.567 | 0.410 | 0.447 | 0.625 |
| Stockmark-2-VL-100B-beta | 95.5 | 0.141 | 0.023 | - | - | 0.000 | 0.026 |
| Qwen2.5-VL-3B-Instruct | 3.8 | 0.76 | 0.924 | 0.75 | 0.485 | 0.549 | 0.586 |
| Qwen3-VL-2B-Instruct | 2.1 | 0.629 | 0.927 | 0.725 | 0.443 | 0.425 | 0.641 |
| InternVL3_5-4B | 4.7 | - | 0.823 | 0.541 | 0.600 | 0.273 | 0.553 |
| Sarashina2-Vision-14B | 14.4 | 0.356 | 0.729 | 0.49 | 0.376 | 0.359 | 0.519 |
| InternVL3_5-2B | 2.3 | - | 0.710 | 0.381 | 0.504 | 0.188 | 0.473 |
| Sarashina2-Vision-8B | 8.0 | 0.325 | 0.682 | 0.469 | 0.308 | 0.342 | 0.511 |
| Heron-NVILA-Lite-2B | 2.0 | 0.238 | 0.479 | 0.293 | 0.367 | 0.393 | 0.314 |
| Heron-NVILA-Lite-1B | 0.9 | 0.181 | 0.346 | 0.209 | 0.245 | 0.263 | 0.268 |
@Takumi Iida (frkake)
[論文] Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens
一般的にVLMでは画像エンコーダ→テキストで特徴を渡しているが、空間理解を伴う密なタスクをするにはテキストトークンだと不十分
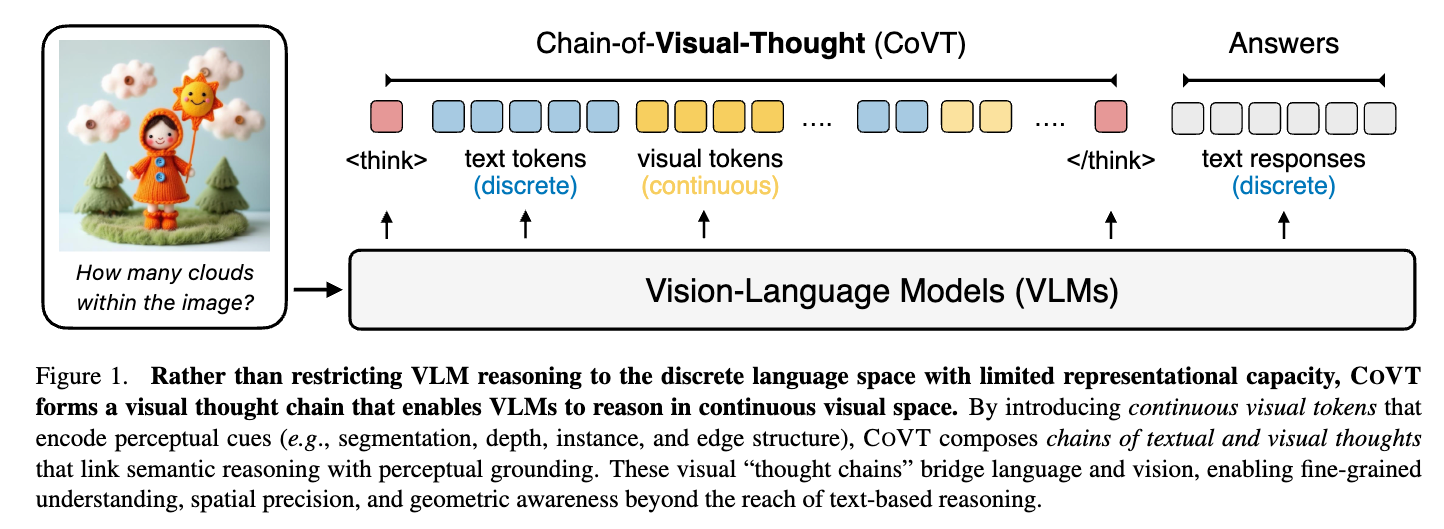
そこで、筆者たちはChain-of-Visual-Thought (CoVT)を提案。連続的な視覚トークンを利用。
概念図
思考過程に視覚トークンを使って考えさせる
学習パイプライン
VLMが視覚トークンを出力できるように学習。学習するのはVLMと投影レイヤ(projection)部分。各画像のデコードは推論時は基本行わないが、必要ならやる。
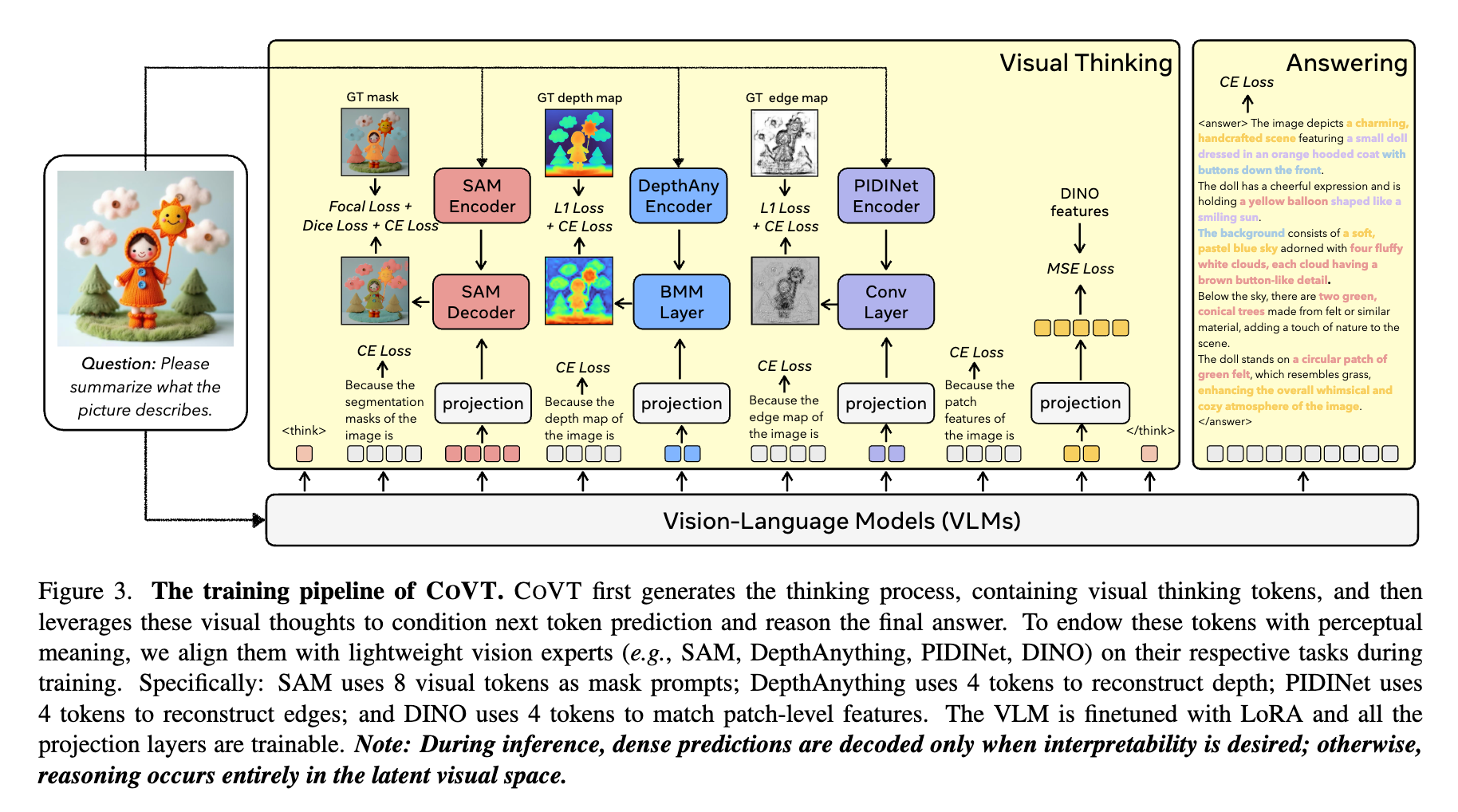
学習に使う視覚トークン
| トークン名 | 役割 (Role) | 教師モデル (Expert) | トークン数 |
|---|---|---|---|
| Segmentation | 物体の特定、2D位置情報の把握 | SAM (Segment Anything Model) | 8 |
| Depth | 奥行き、3D空間関係の理解 | Depth Anything v2 | 4 |
| Edge | 構造、境界線の検出 | PIDINet | 4 |
| DINO | 意味的な特徴、全体的な文脈 | DINOv2 | 4 |
例えば、i番目のセグメンテーショントークンからi番目のセグメンテーションマスクを作る方法は次式。fはSAMエンコーダの埋め込みベクトル。
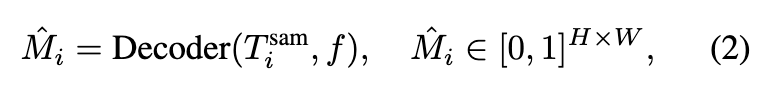
学習方法は下図のように
- 理解ステージ:画像+視覚トークンを学習して、視覚トークンの意味を学習
- 生成ステージ:画像+質問に対する答えとして、視覚トークンを生成。画像から必要な情報を取ってくる学習
- 推論ステージ:画像+質問を入力して、 という形式で思考プロセスの中に視覚トークンを入れて推論できるようにする
- 効率化ステージ:ランダムにトークンの一部をドロップアウトしてロバスト化

結果

Visual Tokenを使ったほうがベースライン(Qwen2.5-VL-7B)よりも良い
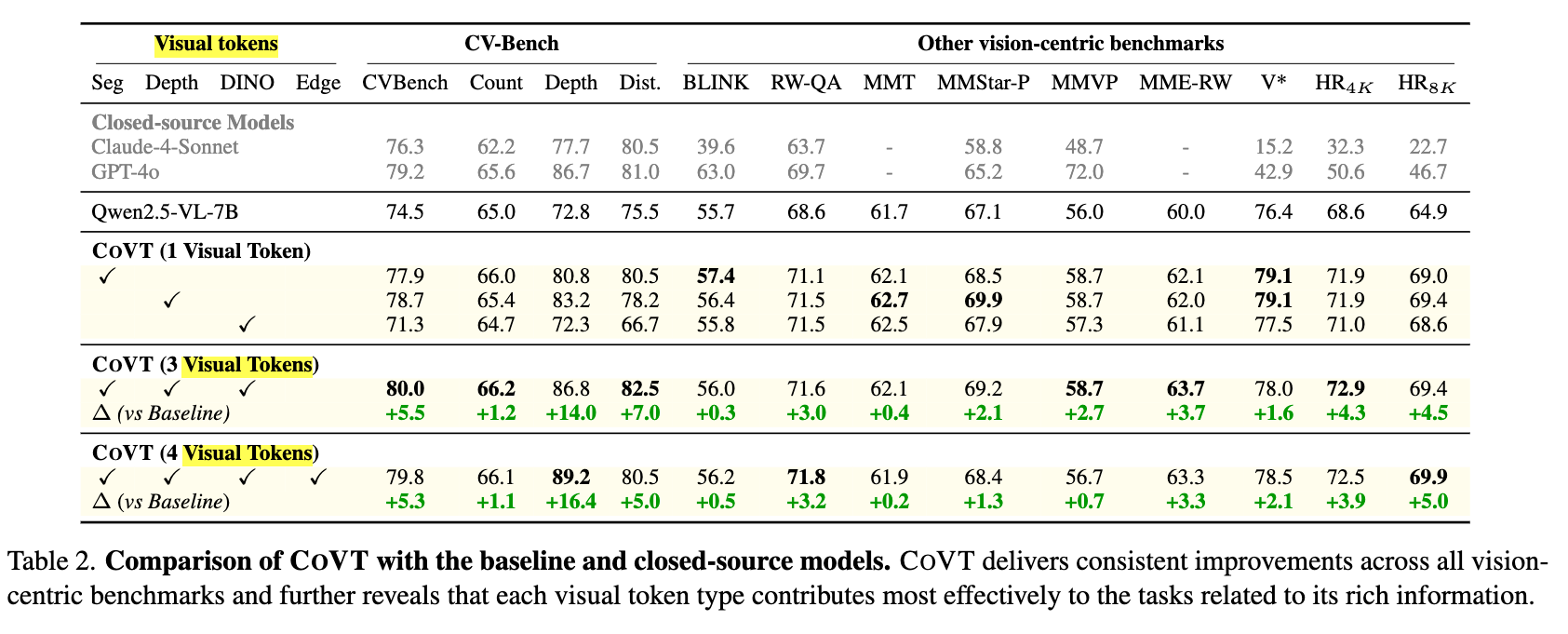
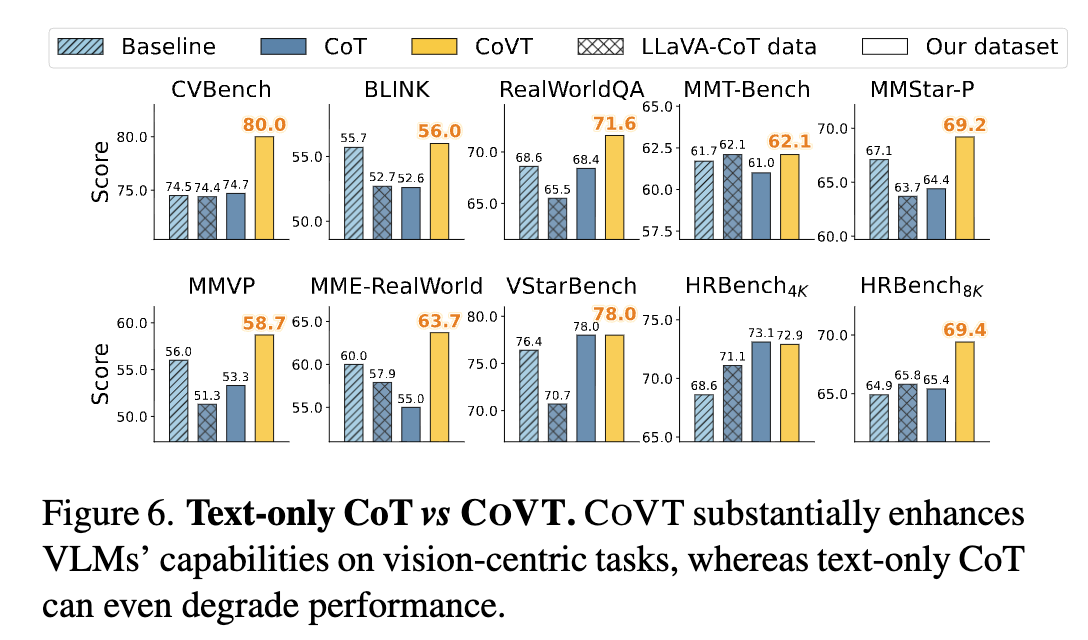
視覚能力を問うベンチマークを使ってるのもありそうだが、テキストのみでCoTをするよりも視覚トークンも使ってCoT (=CoVT) したほうが良い結果
@Hiromu Nakamura (pon)
[blog]Your Company’s AI Server Bill Can Now Be Zero: Save a Ton Of Money
下は先週web.devからでた記事。WebGPUが主要ブラウザで人権を得てきた
 web.dev
web.devONNX Runtime と Transformers.js はどちらも、WebGPU を使用して高速なローカルモデルの推論と計算をブラウザで実行できるようにしています。この進歩により、高性能なウェブベースの AI アプリケーションを開発する新たな可能性が開かれます。
そこでLLM機能をSLMをゼロコストにセキュアに提供する方法
を紹介していたのが今回の記事
- ChromeやSafariなどのブラウザで 数十億パラメータのLLMが動く
- GPUをブラウザから直接使える(WebGPU)
- C++/Rustの推論エンジンがブラウザで動く(WASM)
- transformers.js がそれを簡単に扱えるAPIとして提供
実践例
- Phi-3-mini(3.8Bパラメータ)の4bit量子化モデルを使用。
- 初回だけ ~1.9GB のモデルをダウンロード → 以降はブラウザキャッシュ。
- サンプルコードでは ブラウザ内チャットボット を構築可能。
企業・開発者にとって最大のメリット
- サーバー費ゼロ
- API使用料ゼロ
- 低レイテンシ
- 完全オフラインで動く
[pon]
LLMだけでなく、MLの軽いモデルならWebGPUで動かすとかもありなのか。
ただしロード時間をどうするかなんだよな(Llama-3.1-8B-Instruct-q4f32_1-MLCで試して、ロードに10s)。あとユーザー影響の調査が難しい
あとOpenAI仕様互換のinterfaceを提供する君もあった。モデルのPartial Loadも対応。
web-llm
mlc-ai • Updated Feb 24, 2026
@Shuhei Nakano(nanay)
Evolution and Scale of Uber’s Delivery Search Platform
課題
- 検索精度の問題 レキシカル検索では同義語、タイポ、略語などが処理できない
- スケールとコストのトレードオフ
セマンティック検索するとお金が…
- 本番運用
本番のトラフィックを止めずに安全にデプロイ・ロールバックしたい
モデルとインデックスの更新
解決策
- Two-Tower structure + LLMベースのセマンティック検索
- Qwen LLMをバックボーンにしたTwo-Tower Structureを採用
- 多言語対応・商用利用のため選択されたと思われる
- クエリ埋め込みはリアルタイム、文書埋め込みはバッチ処理で分離
- Matryoshka Representation Learningにより、1つのモデルで複数次元の埋め込みを出力可能に。推論時に次元を選択でき、速度と精度のトレードオフを再訓練なしで調整できる。
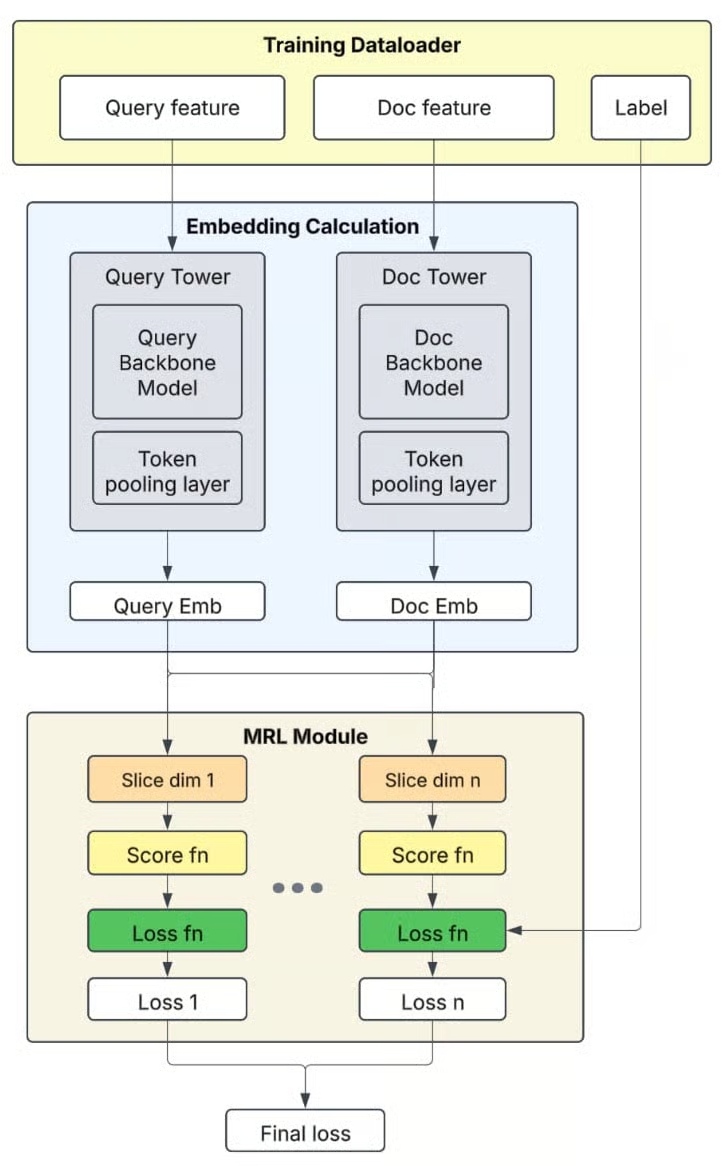
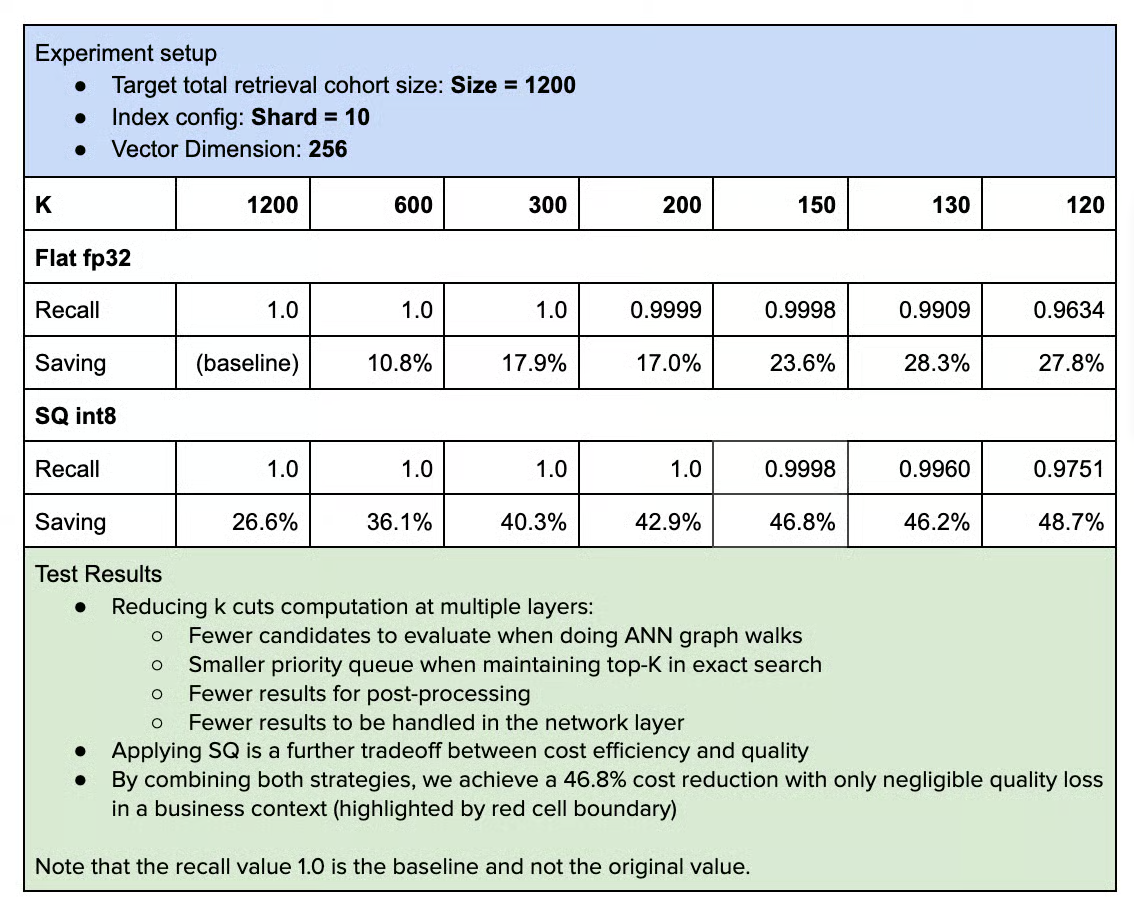
- 多層的なコスト最適化
- シャードレベルのk削減
- 全シャードから均等に取る必要はない
- データ分布を分析し、必要最小限のkを算出
- スカラー量子化
- 通常埋め込みはfloat32で保存
- int8にするだけで追加25%以上のコスト削減、しかもrecallは同等以上
- MRL次元削減
- 1536次元 → 256次元 = ストレージ約83%削減
- プリフィルター
- ANN検索の前に、明らかに不要な候補を除外
- ベクトル計算の前に、単純な条件比較で候補を減らせる
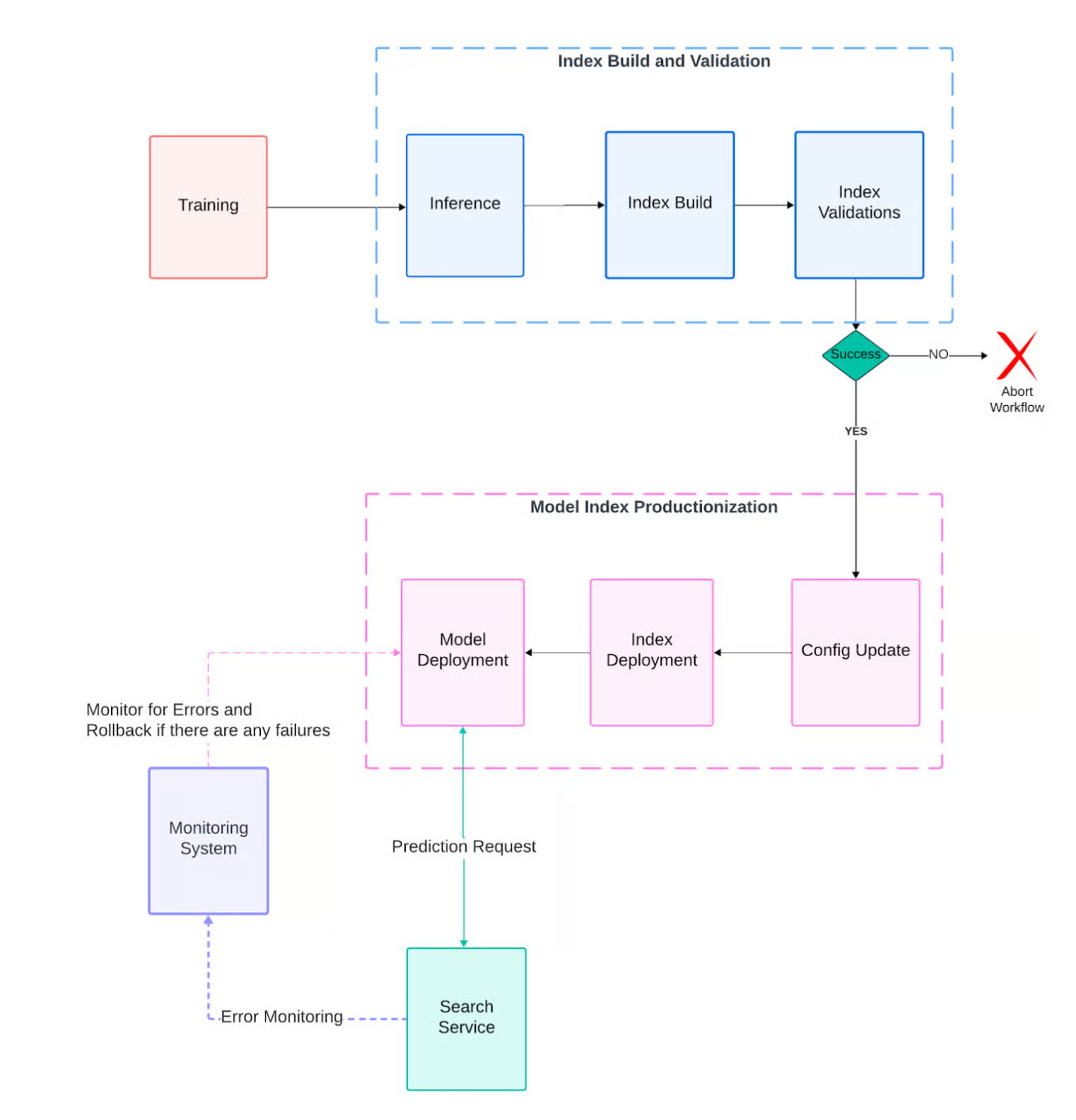
- Blue/Greenデプロイ + 3層の検証ゲート
- インデックス内にembedding_blueとembedding_greenの2カラムを持ち、切り替え可能に
- デプロイ前に3つのチェック
- Completeness: 文書数がソーステーブルと一致するか
- Backward-compatibility:本番稼働中カラムがバイト単位で同一か
- Correctness: 非本番環境でリアルクエリを流してrecallを比較
- サービング時にもモデルIDの整合性をサンプリング検証し、不一致があれば自動ロールバック
学べそうなこと
- アーキテクチャ設計
- Two-Tower structureはクエリと文書の処理を分離でき、スケーラビリティに優れる
- MRLは「1モデルで複数ユースケース」を実現する実践的なテクニック
- コスト最適化の考え方
- 単一の最適化ではなく、k削減×量子化×次元削減×プリフィルターを組み合わせて効果を積み上げる
- オフライン評価で定量的にrecall vs コストを測定してから本番適用
- MLOpsの実践パターン
- Blue/Greenデプロイをインデックスカラムレベルで実装するアイデア(ストレージ節約)
- ビルド時・デプロイ時・サービング時の3層で検証を入れる多重防御
- 2週間サイクルでの自動更新パイプライン
- トレードオフの判断
- 2つの独立したインデックス(より安全)vs 1インデックス2カラム(よりコスト効率)の選択と、後者を選んだ上でのリスク軽減策
メインTOPIC
担当: @ShibuiYusuke
Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
Peng Xia (1), Kaide Zeng (1), Jiaqi Liu (1), Can Qin (2), Fang Wu (3), Yiyang Zhou (1), Caiming Xiong (2), Huaxiu Yao (1)
(1) UNC-Chapel Hill, (2) Salesforce Research, (3) Stanford University
Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning
Jiaqi Liu (1), Kaiwen Xiong (1), Peng Xia (1), Yiyang Zhou (1), Haonian Ji (1), Lu Feng (1), Siwei Han (1), Mingyu Ding (1)
(1) UNC-Chapel Hill
サマリー
Agent0/Agent0-VL サマリー
- 共通のテーマ:人間のデータに頼らない「自律的な進化」
- 両モデルは高コストな人間によるラベル付きデータ(教師データ)を使用せず、「ツール(プログラム実行など)」を学習プロセスに組み込むことで、AIが自分自身でデータを生成・評価し、限界なく賢くなることを目指したフレームワーク。
1. Agent0 (LLM版: 垂直方向の進化)
「より難しい問題」を自分で作り解くことで能力を向上。
- 対象: テキスト、数学、一般推論(LLM)。
- 仕組み: 「出題者(カリキュラムエージェント)」と「回答者(エグゼキュータ)」の2者が競い合う。出題者は「相手がツールを使わないと解けないギリギリの難問」を作ることで報酬を得るため、問題の難易度が無限にインフレ。
- 最適化: ADPO(自信がないデータの学習重みを下げ、難問の学習リミッターを外す技術)により、ノイズの多い自己生成データからでも効率的に学習。
2. Agent0-VL (VLM版: 品質の深化)
「自分の見間違い」をツールで検算・修正し、信頼性を高める。
- 対象: 画像理解、視覚的推論(VLM)。
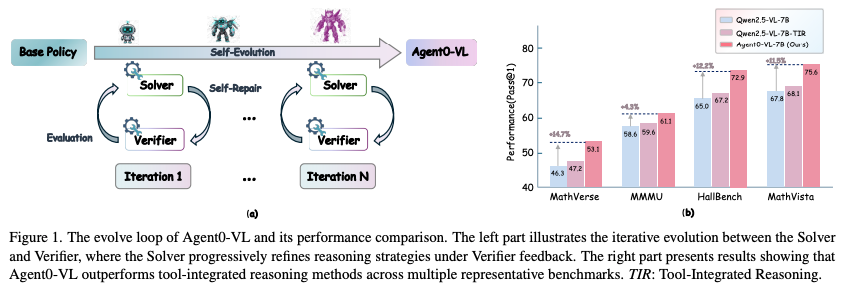
- 仕組み: 単一モデルの中で「解決者(Solver)」と「検証者(Verifier)」の2つの役割を切り替える。解決者が画像を見て解いた答えを、検証者が「ツールを使って事実確認(Grounding)」し、間違っていれば「自己修正(Self-Repair)」。
- 最適化: SERCサイクル(推論→検証→修正のループ)により、VLM特有の「幻覚(ハルシネーション)」を減らし、正解率を向上。
Agent0
1. Introduction
- 現状の課題:
- データ依存: 既存の高性能なLLMエージェントは人間が作成した大量かつ高品質なデータセットに依存。スケーラビリティのボトルネックとなり、AIの能力を人間の知識の範囲内に留める。
- 既存の自己進化の限界: データ依存を脱却するために「自己進化(Self-Evolution)」が研究されているが、モデル自身の知識の範囲内でしか問題を生成できず学習の停滞、また多くの手法が単一ターン(Single-round)の対話に限定されているため、複雑な推論能力が育ちにくいという欠点。
- Agent 0のアプローチ:
- 完全自律型: 外部データや人間の注釈を一切使用せず(Zero Data)、ベースモデルから出発してエージェントを進化。
- 共生的競争: 「カリキュラムエージェント(出題者)」と「エグゼキュータエージェント(回答者)」の2者が競い合うように進化。
- ツール統合: エグゼキュータエージェントにPythonコード実行などのツールを使わせることで、モデル内部の知識限界を突破し、より複雑な問題解決を可能にする。
2. Preliminaries
Agent0の基礎となる強化学習アルゴリズムについて定義。
- GRPO (Group Relative Policy Optimization):
- Agent0はDeepSeekMathなどで採用されているGRPOをベースにしている。
- 特徴: 従来のPPOのように「Critic(価値関数モデル)」を学習させる必要なし。その代わり、同じプロンプト に対して複数の回答 をサンプリングし、そのグループ内での相対的な報酬差(平均からの乖離)を用いて利得(Advantage)を計算。
3. The Agent 0 Framework
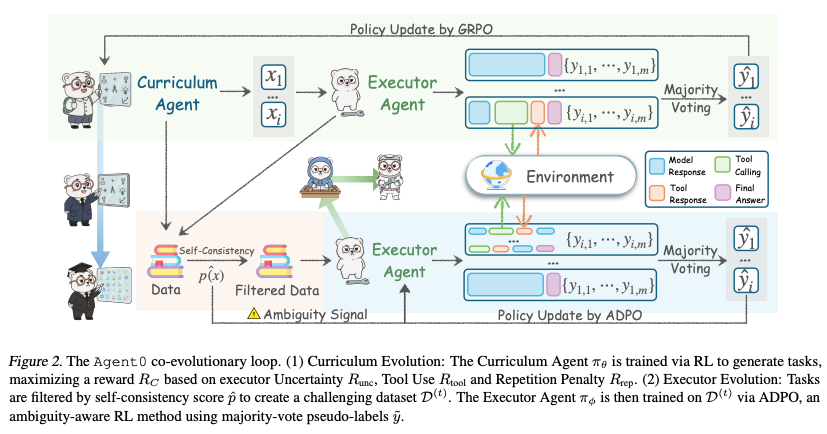
3.1. Framework Overview
- 構成: 同じベースモデル( )から初期化された2つのエージェントで構成。
- カリキュラムエージェント ( ): エグゼキュータにとって「最適な難易度」のフロンティアタスクを生成。
- エグゼキュータエージェント ( ): 提供されたタスクを解決。
- サイクル:
- カリキュラムの進化: エグゼキュータを苦戦させるタスクを生成するように学習。
- エグゼキュータの進化: 生成されたタスクを解くように学習。
これらを反復することで能力向上。
3.2. Curriculum Agent Training

カリキュラムエージェントは、以下の3つの要素から成る複合報酬 を最大化するようにGRPOで訓練。
- 不確実性報酬 ( - Uncertainty Reward):
- エグゼキュータが「確信を持てない」問題を生成することを奨励。
- エグゼキュータに複数回回答させ、その回答の一貫性(Self-consistency: )を計測。
- が0.5(最も迷っている状態)に近いほど報酬が高くなるよう設計( )。簡単すぎる問題や難しすぎる問題を排除。
- ツール使用報酬 ( - Tool Use Reward):
- エグゼキュータが回答プロセスで「ツール(コード実行)」を使用した場合に報酬。
- カリキュラムエージェントは「暗算や知識だけでは解けず、ツールを使わざるを得ないような複雑な問題」を作成するよう圧力を受ける。
- 反復ペナルティ ( - Repetition Penalty):
- 生成される問題の多様性を保つため、バッチ内で似たような問題(BLEUスコアで判定)が多い場合、ペナルティを与える。
3.3. Executor Agent Training
エグゼキュータは、カリキュラムエージェントが生成した問題を解くことで能力を向上。
3.3.1. Dataset Curation and Trajectory Generation
- マルチターン・ロールアウト:
- 単なる回答生成ではなく、思考テキスト生成 → ツール呼び出し(コード) → サンドボックスでの実行 → 実行結果のフィードバック → さらなる思考... という「マルチターン」のプロセスを実行。
- エラーが発生しても自己修正(Self-correction)する機会が生まれる。
- 疑似ラベル(Pseudo-Label): 正解データがないため、自身の多数決回答(Majority Voting)を「正解」とみなして学習。
- タスクフィルタリング: カリキュラムエージェントが生成した大量のタスクから、エグゼキュータの正答率(一貫性 )が特定の範囲内(例: 0.3〜0.8)にある「学習効果の高いタスク」のみを抽出。
3.3.2. Ambiguity-Dynamic Policy Optimization (ADPO)
「疑似ラベルのノイズ」と「難問における探索不足」という課題があるため、新たにADPOアルゴリズムを導入。
- GRPO:全てのデータを平等に信用して学習
- ADPO:データの自信(曖昧さ)を見て、怪しいデータは疑い、難しい正解は学習
- Ambiguity-Aware Advantage Scaling:
- 一貫性が低い( が低い)タスクは、多数決で決めた正解ラベル自体が間違っている可能性あり。一貫性が低いタスクの学習への寄与度(Advantage)を割り引くことで、誤った学習を防ぐ。
- Ambiguity-Modulated Trust Regions:
- 通常のPPO/GRPOでは、学習の安定化のために更新幅をクリッピング(制限)するが、難問の解決を阻害。難問の正解トークンは初期段階では確率が非常に低いため、クリッピングされるといつまでも確率が上がらない。
- ADPOでは、一貫性が低い(難しい)タスクに対してはクリッピングの上限を緩和し、更新(探索)の許容範囲を上げる。変化率。

| タスクの状態 | フィルタリング | 重み (信頼度) | クリッピング (自由度) | エージェントの挙動 |
| 簡単すぎ | 除外 | - | - | 学習しない(時間の無駄) |
| 中くらい | 学習対象 | 高 (信頼する) | 低 (慎重に) | 「正解はこれだ」と確信を持って、着実に微調整する。 |
| 難問 | 学習対象 | 低 (疑う) | 高 (大胆に) | 「正解か怪しいけど、もし当たりなら大きく化ける可能性があるから、大胆に試してみよう」 |
| 無理ゲー | 除外 | - | - | 学習しない(ノイズ除去) |
4. Experiments
4.1. Experimental Setup
- モデル: Qwen3-Base (4Bおよび8B) を使用。
- 比較対象: ベースモデル、ツールありベースモデル、および最先端の自己進化手法(R-Zero, Absolute Zero, SPIRALなど)。
- ベンチマーク: 数学(MATH, GSM8K等)および一般的推論(MMLU-Pro, SuperGPQA等)。
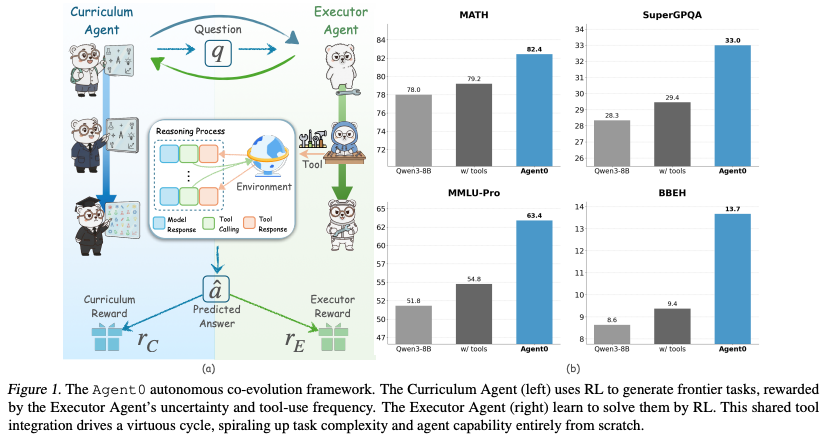
4.2. Main Results
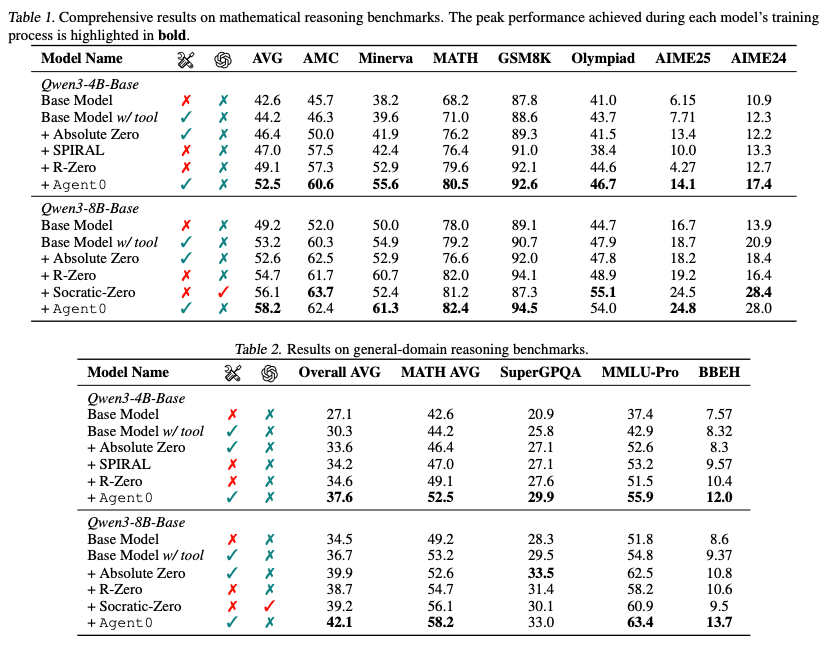
- 性能向上: Agent0は数学および一般的推論の両方で、比較対象のすべての手法を上回る。特にQwen3-8Bでは数学で18%、一般推論で24%の向上を達成。
- 汎用性: 数学に特化した訓練をしているにもかかわらず、MMLU-Proのような一般的な推論タスクでも高いスコアを出しており、獲得した「ツールを使った論理的推論能力」が汎用的であることを示す。
- AMCで唯一Agent0より良い結果を出しているSocratic-ZeroはOpenAI APIを利用。
4.3. Analysis
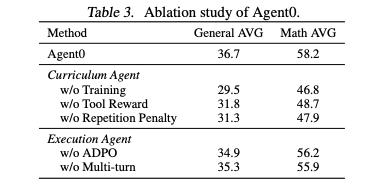
- Ablation Study:
- 「ツール報酬 ( )」を削除すると性能が大きく低下。カリキュラムエージェントにツール使用を強制させることの重要性が証明。
- ADPOを通常のGRPOに戻すと性能が低下。ノイズ対策と探索促進の効果を確認。
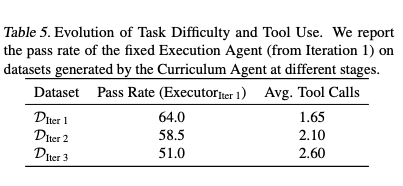
- 難易度の進化:
- イテレーションが進むにつれて、カリキュラムエージェントが生成する問題は「単純な計算」から「条件が複雑な応用問題」へと進化し、回答に必要なツール呼び出し回数も増加していることを確認。
- 具体的な生成問題の例では、Iter 1の幾何学問題から、Iter 3の複雑な制約付き最適化問題へと変化。

感想
- データ量や難易度をコントロールしてLLMエージェントを強化学習するにあたりLLMで学習データ生成。
- 特定ドメインのタスク(例:日本の請求書処理等)だと学習データは確実に少数(または存在しない)ため、ドメイン特化LLMエージェントの開発で良いアイデアになりそう。
- Figureで使われているアイコンがかわいい。

Agent0-VL
1. Introduction
- 背景と課題:
- データの壁: 既存のVLMエージェントの多くは、人間が作成した選好データ(Preference Data)や外部報酬に依存して学習しているが、これにはスケーラビリティ(拡張性)の限界があり、エージェントの能力の上限を決めてしまっている。
- 自己評価の限界: データ不足を補うため、モデル自身が批評家(Critic)となる「自己報酬学習」が研究されているが、テキストベースの自己評価だけでは複雑な視覚的推論(幾何学計算や図表分析など)を正確に検証できず「評価ハルシネーション(もっともらしいが間違った評価)」を起こしやすいという問題。
- Agent0-VLの提案:
- ツール統合型評価: ツール(プログラム実行など)を「推論」だけでなく、「自己評価」と「自己修正」のプロセスにも導入。外部報酬ゼロで、客観的な証拠に基づいた自己改善が可能。
- 統一アーキテクチャ: 単一のモデル内に「Solver(解決者)」と「Verifier(検証者)」という2つの役割を統合し、これらが相互作用する「自己進化推論サイクル(SERC)」を提案。
2. Preliminaries
- POMDP(Partially Observable Markov Decision Process)としての定式化:
- マルチモーダル推論のプロセスを部分観測マルコフ決定過程(POMDP)と定義。
- マルチモーダルな推論環境ではエージェントが環境全体を把握できるわけではない。
- ツール利用を含めた複数ステップの推論行動で環境を観測。
- 構成要素:
- 状態空間 ( ): テキストの文脈、画像特徴量、過去のツール入出力を含む潜在的な推論状態。
- 行動空間 ( ): 「テキストによる推論ステップ」または「構造化されたツール呼び出し(Pythonコードなど)」のいずれか。
- 観測空間 ( ): ツールや環境からのフィードバック(計算結果や検索結果など)。
- これらが連なって推論の軌跡(Trajectory) を形成。
3. Methodology
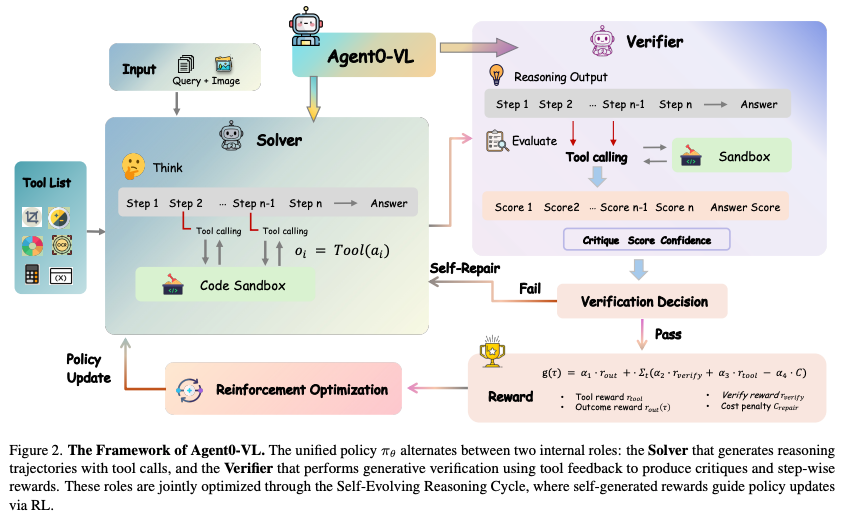

3.1 Unified Solver-Verifier Architecture
単一のVLM(パラメータ を共有)が役割指示トークン に応じて2つのモードを切り替え。
- Solver ( ):
- マルチターンの推論を行い、必要に応じてツールを呼び出し、その実行結果(観測 )を取り込んで推論を進める。
System prompt

- Verifier ( ):
- 生成的検証モード。Solverの推論ステップ を入力とし、以下の検証タプル を出力。
- : 事実としての正確さ(-1〜1)。
- : 認識論的な確信度(0〜1)。
- : 推論の欠陥を説明する自然言語の批評。
- Verifier自身もツールを再呼び出しして事実確認(クロスチェック)を行うことが可能。
System prompt

3.2 Tool-Grounded Verification and Self-Repair
- 検証プロセス
- Solverが推論ステップ(行動 と観測 )を生成すると、Verifierはそれを入力として、以下の 検証タプル を生成。
- Verifierは単にテキストを読むだけでなく、必要に応じて外部ツールを呼び出し、事実確認(Cross-check)を実施。
- プロセス報酬 ( ):
- Verifierの評価に基づき、各ステップの報酬を計算。これは「ツールの正しさ」「意味的な信頼性」を組み合わせたもの。
- 自己修正ゲート ( ):
- 修正を行うかどうかは、確信度 と閾値 に基づくゲート関数 で決定
- (確信度が低い)場合、 となり、修正がトリガー。
- (自信がある)場合、 となり、修正なし。
- Verifierの確信度 がしきい値 を下回った場合(自信がない場合)、修正ゲートが開き、自己修正プロセスが始まる。
- 修正指示 に基づき、Solverは該当部分を再生成(修正)。
- 無駄な修正を防ぐため、修正コスト がペナルティとして報酬から引かれる。
3.3 Self-Evolving Reasoning Cycle(SERC: 自己進化推論サイクル)
準備段階:コールドスタート (Cold-Start Initialization)
いきなり強化学習を始めてもモデルはツールの使い方も自己評価のフォーマットも知らないため、学習が機能しない。最初に教師あり学習(SFT)を実行。
- 目的: ツール使用の構文や、自己評価のフォーマットをモデルに教え込むこと 。
- 方法: 構築したデータセット(SFTステージ用)を用いて、Solverとしての振る舞いとVerifierとしての振る舞いの基礎を学習。
強化学習は「内部ループ」と「外部ループ」の二重構造で行われる。
- 内部ループ(経験生成):
- Solverが推論軌跡を生成し、Verifierがそれを即座に評価・検証・修正。最終的な報酬 を算出。
- 推論の実行 (Solver): 与えられたマルチモーダルタスクx(画像+質問) に対して、Solverがツールを使いながら推論を行い、軌跡 を生成。
- 検証とプロセス報酬 (Verifier): 生成された軌跡の各ステップtに対して、Verifierが再評価を行い、検証タプル とプロセス報酬 を算出。
- 条件付き自己修正 (Self-Repair): もしVerifierの確信度が閾値 を下回った場合、推論の軌跡を修正。修正が行われた場合、修正コスト(ペナルティ) が適用。
- 総リターン の計算: その軌跡全体の価値(スコア)を決定。「最終的な正解/不正解の報酬 ( )」と「途中のプロセス報酬の合計」を組み合わせたもの。
- 外部ループ(ポリシー更新):
- 収集された軌跡データを用いて、GRPO (Group Relative Policy Optimization)でモデルを更新。
- モデルは「平均的な生成結果よりも優れた軌跡(正の利得を持つ軌跡)」の確率を高めるように学習し、推論能力と検証能力が同時に向上。
- グループサンプリング: 1つのタスクに対して、G個(例: 8個等)の異なる軌跡 をサンプリング。
- 相対的利得 (Relative Advantage) の計算: それぞれの軌跡が「グループの中でどれくらい優れているか」を計算。
- 平均よりスコアが高ければプラス、低ければマイナス。Criticモデル(価値関数)を別途学習させる必要がなくなる。
- ポリシーの更新 (Optimization): 以下の目的関数を最大化するようにモデル を更新。
- 目的: 「相対的利得 が高い(優秀な)軌跡」を生成する確率を高めること。
- 制約: KLダイバージェンス( )を用いて、元のモデルから急激に変化しすぎないように制御。
4. Experiments
4.1 Experimental Setup
- ベンチマーク: MathVerse, MathVista, WeMath(数学・科学)、ChartQA, HallusionBench(視覚的幻覚・図表)など、計7つのベンチマークを使用。
- ベースライン: クローズドソース(GPT-4o, Claude-3.7など)、オープンソース(Qwen2.5-VL, InternVLなど)、および他の自己進化手法(Vision-Zeroなど)と比較。
- 学習データ: SFT段階用に20万件、RL段階用に4万件のツール統合型推論データを構築。
4.2 Main Results
- 全体性能: Agent0-VL(7Bモデル)は、ベースモデルであるQwen2.5-VL-7Bと比較して12.5%の性能向上を達成。また、Qwen3-VL-8Bを用いた場合でもベースを6.1%上回る。
- ドメイン別: 特に数学的推論(MathVistaなど)で大きな向上(+18.1%)が見られた。これはツールによる正確な計算が寄与。
- 反復進化: SERCのイテレーションを重ねるごとに(Iter 1 → 2 → 3)、性能が単調増加し、自己進化が安定して機能していることが証明。
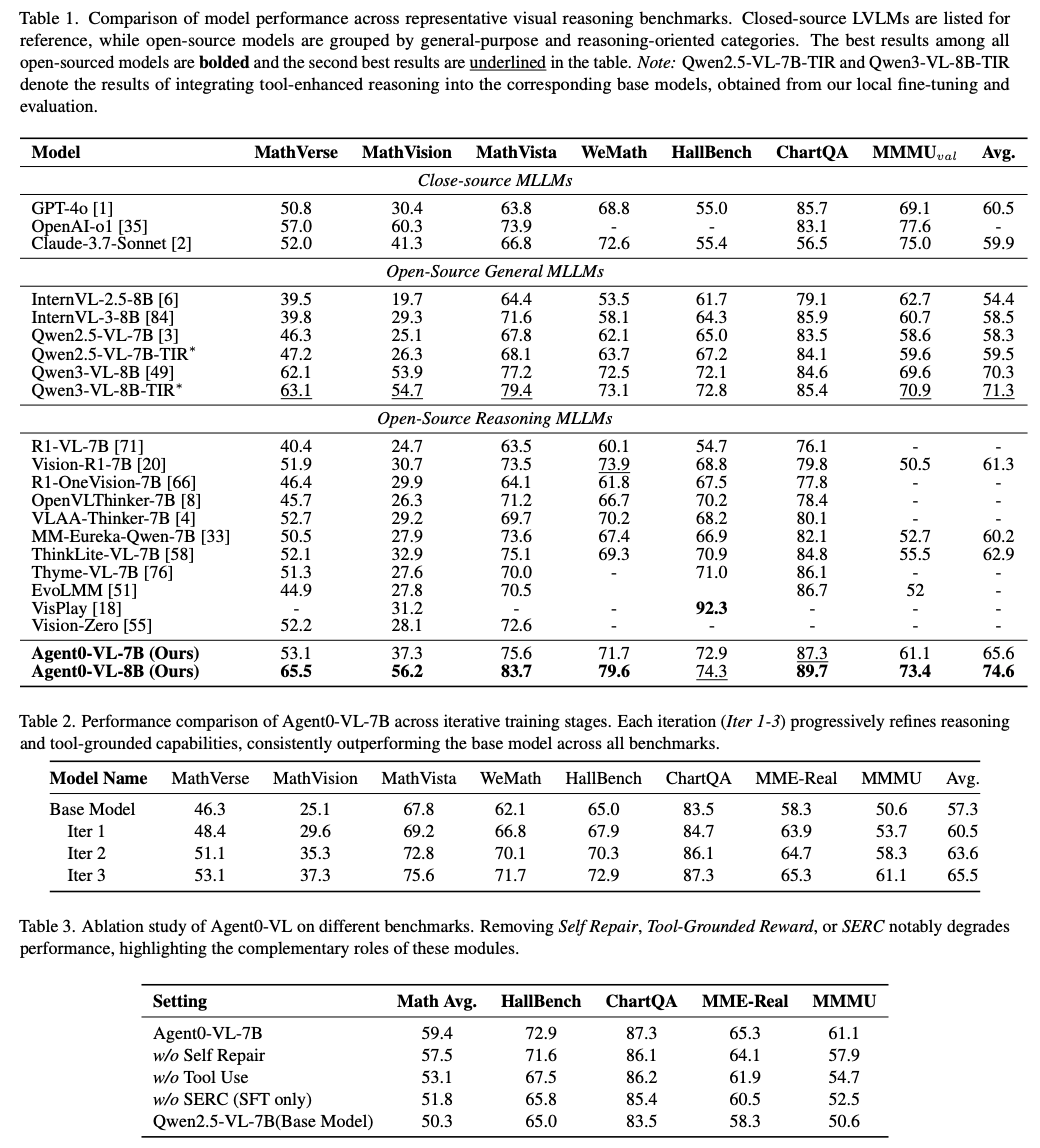
4.3 Ablation Studies
- SERCなし(SFTのみ): 最も性能が低下(-8.7%)。強化学習ループの重要性が示された。
- ツール使用なし: 性能が低下(-6.5%)。テキストだけの推論では限界。
- 自己修正なし: 性能が低下(-2.5%)。エラーを直す機会を与えることの効果。
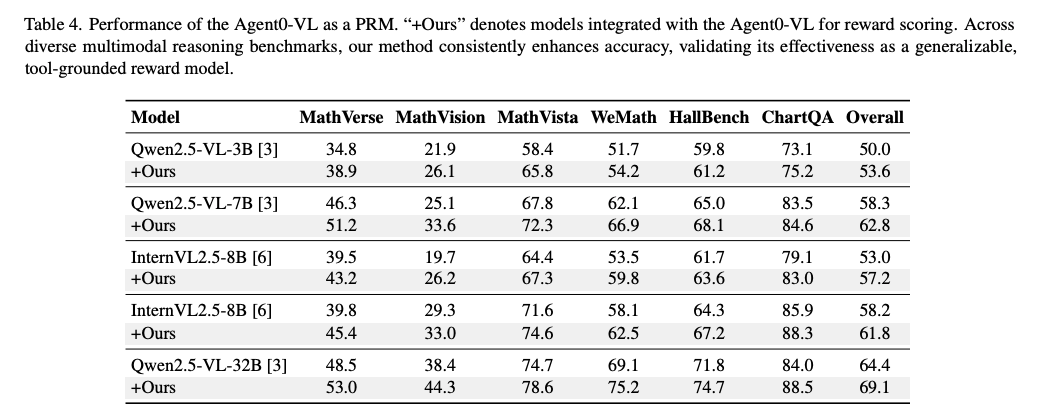
4.4 Performance as a Process Reward Model
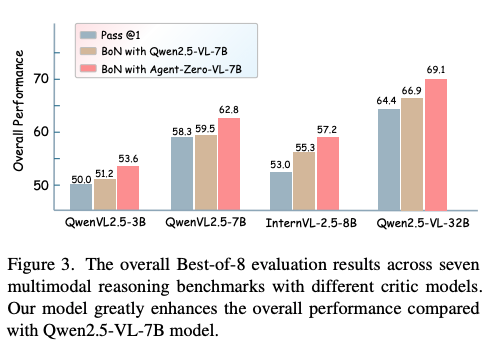
- Agent0-VLを「推論」させず、単に「他モデルの回答を評価する採点者(PRM)」として使った場合でも、他のVLM(Qwen2.5-VL-32Bなど)の推論精度を平均7.3%向上。Verifierの汎用性が高いことを示す。
4.5 Case Study
- 事例: 「沿岸警備隊の監視塔の死角(Blind Spot)」を計算する幾何学問題において、Solverが初期推論で論理エラー。
- 修正プロセス: Verifierがツールを用いて定義を確認し、誤りを指摘(Critique)。その後、自己修正モジュールが修正パッチを生成し、Solverが正しい推論を再実行して正解に到達。

比較
1. 関係性の概要:
- Agent 0:
- ドメイン: 数学、一般推論(テキスト・コードベース)。
- 「より難しい問題」を自分で作り出すことで、能力の天井を突き破る(垂直方向の進化)。
- Agent 0-VL:
- ドメイン: 視覚言語(Vision-Language)。
- 「幻覚(Hallucination)」を防ぐために、ツールを使って自分を厳密に検証・修正する(品質方向の深化)。
2. アーキテクチャとメカニズムの比較
| 特徴 | Agent 0 | Agent 0-VL |
| 構成 | 2つの独立したLLMエージェント (Curriculum Agent vs Executor Agent) | 単一モデル内の2つの役割 (Solver vs Verifier) |
| 関係性 | 教師が生徒を困らせる問題を作る。 | 自助努力で修正する。 |
| 進化の原動力 | タスクの難易度上昇 簡単な問題 → 複雑な問題へ。 | 推論プロセスの純化 誤った推論 → 修正された推論へ。 |
| アルゴリズム | GRPO + ADPO (ADPOでノイズ耐性を強化) | GRPO (SERCサイクル) (プロセス報酬の最適化に特化) |
Agent0のメカニズム:出題と解答の競争
Agent 0は、「カリキュラムエージェント」が「エグゼキュータエージェント」に対して、ギリギリ解けるかどうかの難問(フロンティアタスク)を投げ続けることで進化。
- 狙い: モデルの知識限界(天井)を突破すること。
- 図式: 教師「これなら解けないだろう(ツールを使わせる問題作成)」→ 生徒「ツールを使って解いてやる」→ 教師「ぐぬぬ、次はもっと難しい問題を…」
Agent0-VLのメカニズム:推論と検証の協調
Agent 0-VLは、VLM特有の「画像を見間違える(幻覚)」問題に対処するため、同一モデルが「Solver(解く人)」と「Verifier(検算する人)」を行き来。
- 狙い: 推論の信頼性と事実整合性(Grounding)を高めること。
- 図式: Solver「画像から数値を読み取って計算したよ」→ Verifier「本当に?ツールで画像認識し直して計算検算してみるね…間違ってるから直して」→ Solver「修正しました」
3. 技術的な詳細比較
最適化手法 (Optimization)
- Agent0 (ADPO): 自己生成した正解データ(疑似ラベル)にはノイズが含まれるため、ADPOを導入。これは、自信がないデータの重みを下げ、難問の学習率(クリッピング上限)を上げる手法。
- Agent0-VL (Process Reward): 推論の「途中経過」を重視。Verifierが出す に基づくプロセス報酬を設計し、GRPOで全体を最適化。ここでは「修正ゲート(Repair Gate)」による自己修正の有無も報酬に関わる。
データの扱い
- Agent0: 完全なZero Data(ベースモデルのみから開始)。
- Agent0-VL: 視覚的推論は初期のハードルが高いため、最初に教師あり学習(SFT)でツール使用の作法を学ばせ(Cold Start)、その後に外部報酬なしの自己進化(RL)へ移行。