
2025-12-09 機械学習勉強会
今週のTOPIC[論文] OpenCUA: Open Foundations for Computer-Use Agents[論文] 1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities[論文] MemLoRA: Distilling Expert Adapters for On-Device Memory Systems[blog] Saga パターンを理解する[論文] BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents[論文] Continuous Autoregressive Language Models[論文] Measuring Agents in ProductionメインTOPICLLM Reasoning for Cold-Start Item Recommendation論文情報1. どんなもの?一言でいうと背景:コールドスタート問題とは本研究のアプローチ提案する2つの推論戦略2. 先行研究と比べてどこがすごい?既存研究の限界本研究の新規性① コールドスタートへの特化② Fine-tuning手法の体系的比較③ 本番環境での評価3. 技術や手法のキモはどこ?タスク設定Re-rankingタスク提案手法A:Structural ReasoningStep 1: 推論パス構築Step 2: マッチスコア計算Step 3: 重み付け集約提案手法B:Soft Self-Consistency従来のSelf-Consistencyとの違い2つの手法の関係Fine-tuning戦略SFT(Supervised Fine-Tuning)GRPO(Reinforcement Learning)SFT + GRPO4. どうやって有効だと検証した?実験設定評価指標の説明実験結果①:推論戦略の比較(Fine-tuningなし)Table 1より💡 Key Insight実験結果②:Fine-tuningの効果Base-Reasonの場合Soft Self-Consistencyの場合💡 Key Insight実験結果③:Warm-start での比較🎉 重要な発見5. 議論はある?トレードオフの存在推論戦略の選び方Fine-tuning手法の選び方早見表:目的別の推奨組み合わせ限界と今後の課題なぜSFT+GRPOはCold-startで苦戦するか?まとめTake Home Message1. LLM推論はCold-start推薦に有効2. シンプルな手法が意外と強い3. Fine-tuning手法は目的に応じて選択4. 少量データでも本番モデルを超える可能性おまけ:OCRへの応用イメージStructural Reasoning的アプローチSoft Self-Consistency的アプローチ
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] OpenCUA: Open Foundations for Computer-Use Agents
- NeurIPS 2025 spotlight
- 既存のCUA (Computer Use Agent)は、訓練データやアーキテクチャ、開発プロセスの詳細が非公開。
- 主な貢献
- 訓練データセット作成のアノテーション基盤作成
- 訓練データからClaude sonnetを使ったReflectionでデータを増強する戦略を提案。
- 実際にQwen2.5-VL-70Bベースで訓練させて主要ベンチマークで、Claude Sonnet 4に匹敵する結果を獲得。(OSSでは最高)
- 効率的な評価ベンチマーク作成
- 残りは以下
@Yuya Matsumura
[論文] 1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
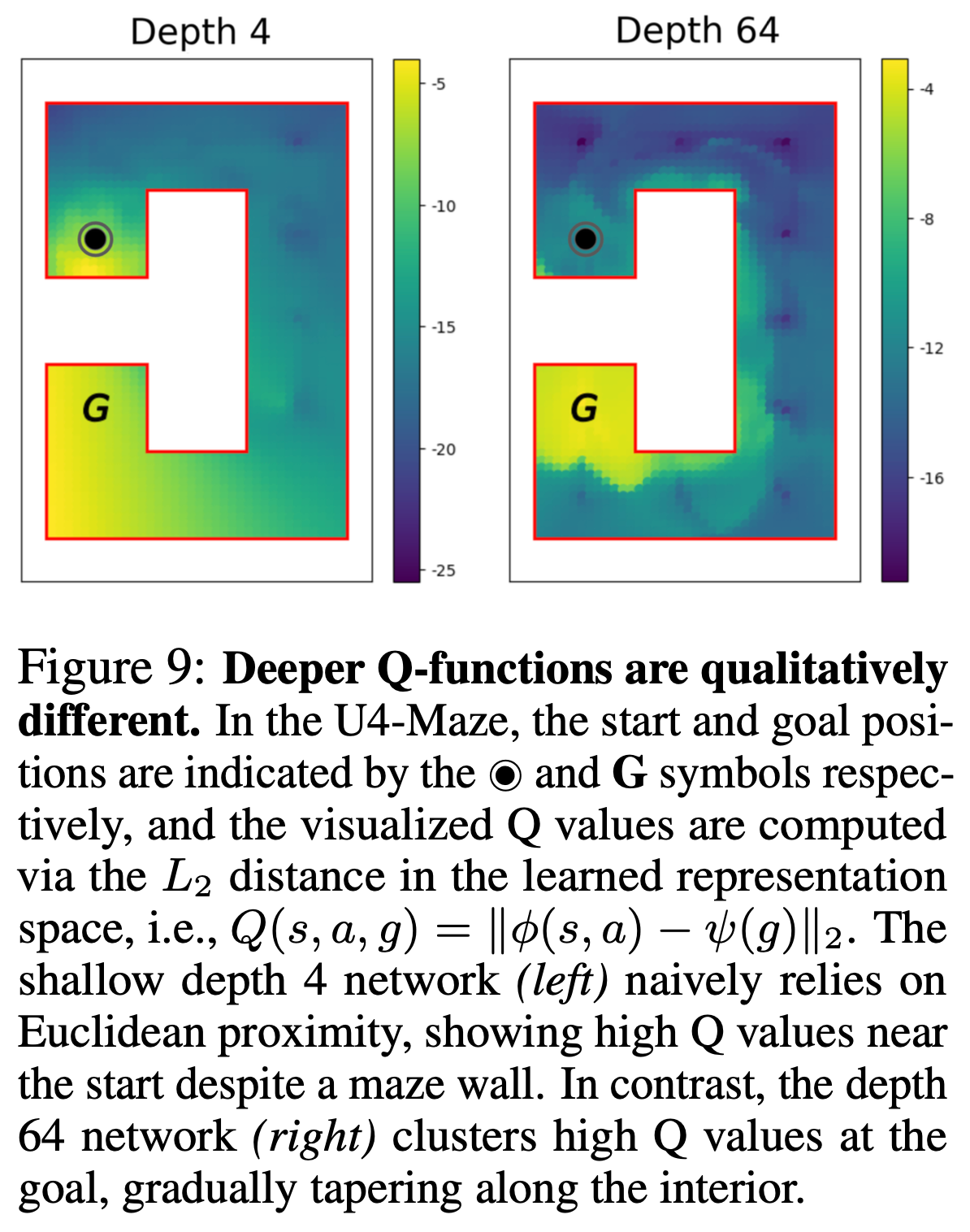
強化学習においても深いネットワークにスケールさせることによる大きな性能向上、創発性が見られたという報告。NeurIPSのベストのひとつ。

層を増やすほど大きな進化・創発性が獲得される
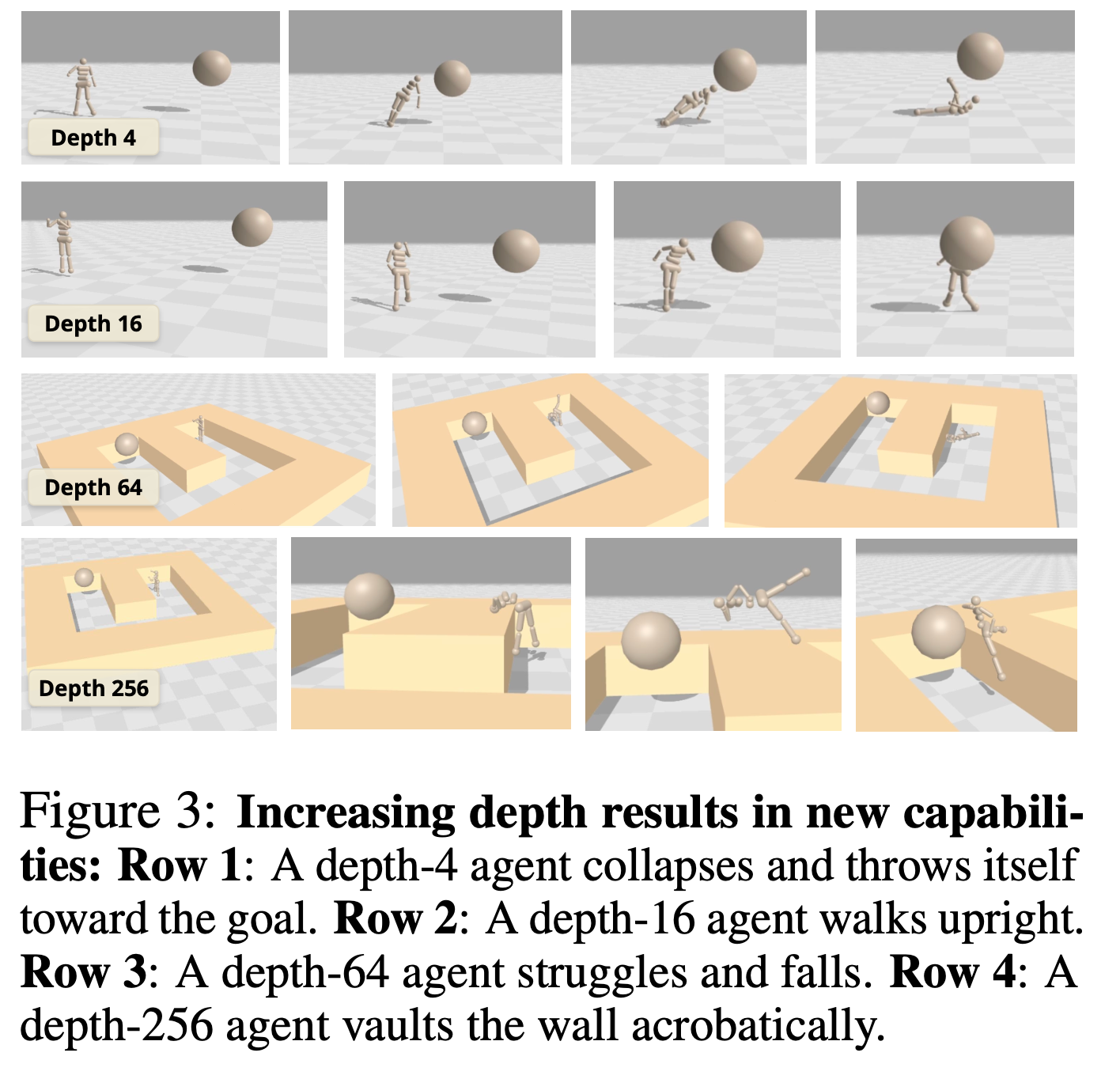
環境の構造を理解した豊かな表現を学習
浅いネットワークでは壁を無視したゴールとの単純な距離で価値を判断している様子が見える。

@Shun Ito
[論文] MemLoRA: Distilling Expert Adapters for On-Device Memory Systems
- デバイスで動かすような小型の言語モデル(SLM)にメモリ能力を持たせたい
- 既存のメモリシステムはLLMが前提となっているものが多い
- Mem0は会話履歴からの情報抽出・メモリの更新をそれぞれ別の(Tool Call能力のある)LLMに実行させ、長大なプロンプトを使って制御している。これはSLMには厳しい。
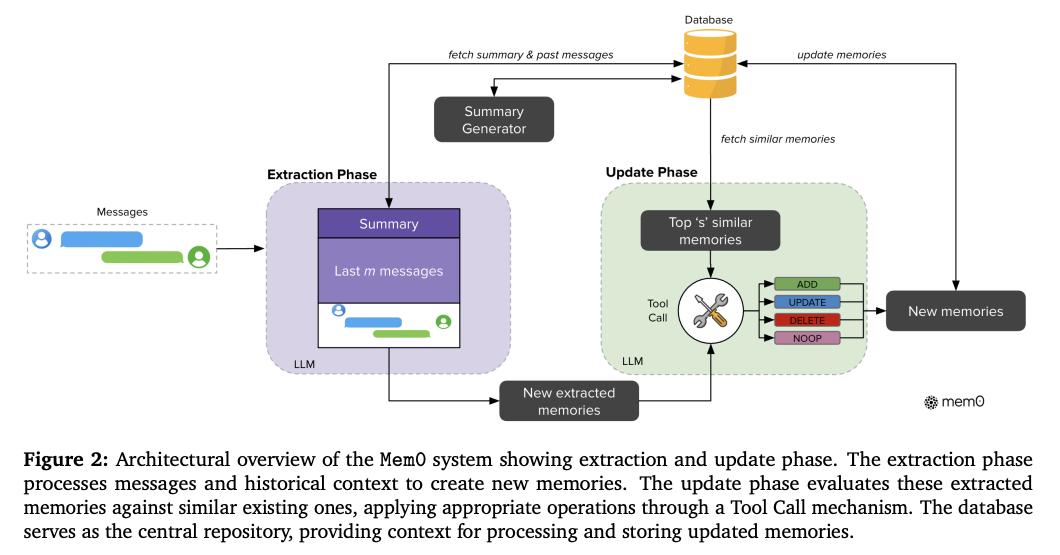
Mem0のプロンプト例(情報抽出)
- 提案: LoRAベースの専門アダプタを付与して、単一のSLMが短いプロンプトで複数の役割をこなせるようにする
- LoRAアダプタは3種類
- 情報抽出(会話履歴などから保存すべき情報を抽出)
- メモリ更新(抽出されたデータを元にメモリを更新)
- 回答生成(メモリを使いつつ質問に回答)
- VQAタスクで使うアダプタも別途用意
- 長大なプロンプトが必要だったものは、SLMに求める動きをLoRA学習時に組み込むことで、実行時は一行程度のプロンプトでも適切に動くようになり、コンテキストウインドウを節約できる。
- 情報抽出:
- メモリ更新:
- 学習は教師モデル(Gemma2-27B, gpt-oss-120B)からの蒸留
- 結果: 推論に必要なリソースを押さえた上で、LLMと同程度以上の結果に
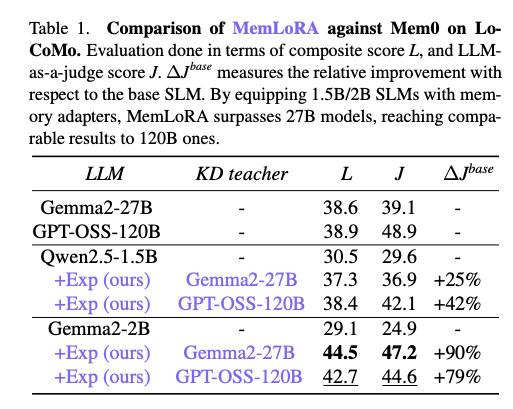
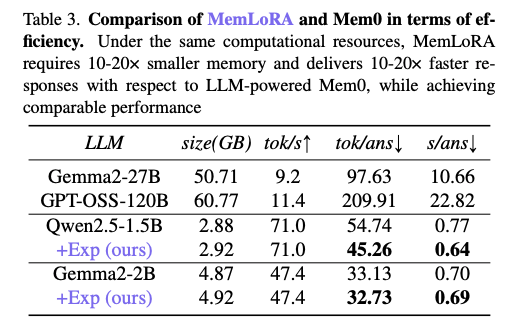
@Yosuke Yoshida
[blog] Saga パターンを理解する
- Saga パターンは、1987 年に Hector Garcia-Molina と Kenneth Salem によって発表された論文「Sagas」で初めて提唱された概念
- 複数のサービスにまたがるビジネス処理を、一連のローカルトランザクションの連鎖として実装する設計パターン
オンライン注文システムの例
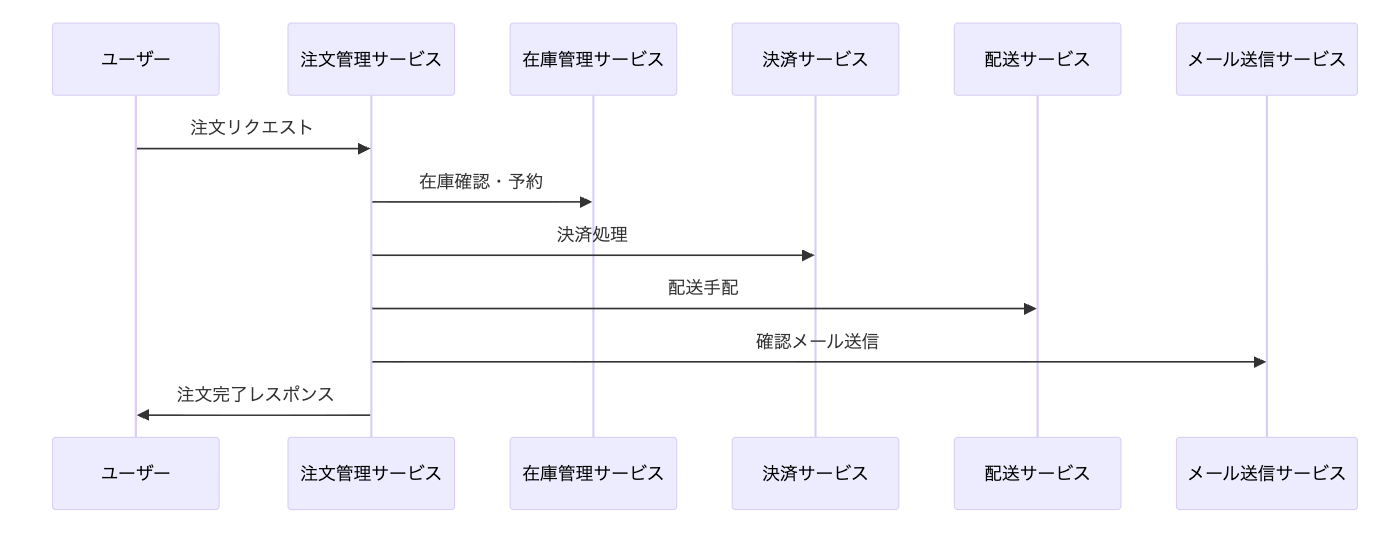
- 補償トランザクション
- 失敗時のデータ整合性を保つための仕組み
- 途中で失敗した場合、それまでに実行された全てのトランザクションに対応する補償トランザクションが、逆順で実行される
- e.g. 在庫を 1 個減らしたトランザクションの補償は、在庫を 1 個増やすトランザクション
- トランザクション種類の分類
- 補償可能トランザクション(Compensatable Transaction)
- 後続のステップで失敗が発生した場合に、対応する補償トランザクションによって取り消すことができるトランザクション
- これらのトランザクションは、Saga の前半部分に配置され、ビジネスルールの検証や外部システムとの連携など、失敗の可能性があるステップの前に実行されます。
- ピボットトランザクション(Pivot Transaction)
- Saga における 決定点(Go/No-Go Point) として機能する特別なトランザクション
- ピボットトランザクションが成功すると、Saga は最後まで実行されることが保証されます。逆に、ピボットトランザクションが失敗した場合は、それまでに実行された補償可能トランザクションの補償処理が実行されます。
- 再試行可能トランザクション(Retriable Transaction)
- ピボットトランザクション成功後に実行され、必ず最終的に成功することが保証されているトランザクション
- これらのトランザクションは失敗しても補償処理を行わず、代わりに成功するまで再試行を続けます。
- フェーズ構造による最適化
- フェーズ 1(検証・確認) : 赤色
- 補償可能トランザクションを集約し、失敗時は即座に処理を終了できます。外部在庫確認などのリスクの高い処理をここで実行します。
- フェーズ 2(決定) : 黄色
- ピボットトランザクションである決済処理を実行します。この段階の成功により、以降の処理完了が保証されます。
- フェーズ 3(実行・確定) : 緑色
- 再試行可能トランザクションを順次実行し、データの確定と関係者への通知を行います。
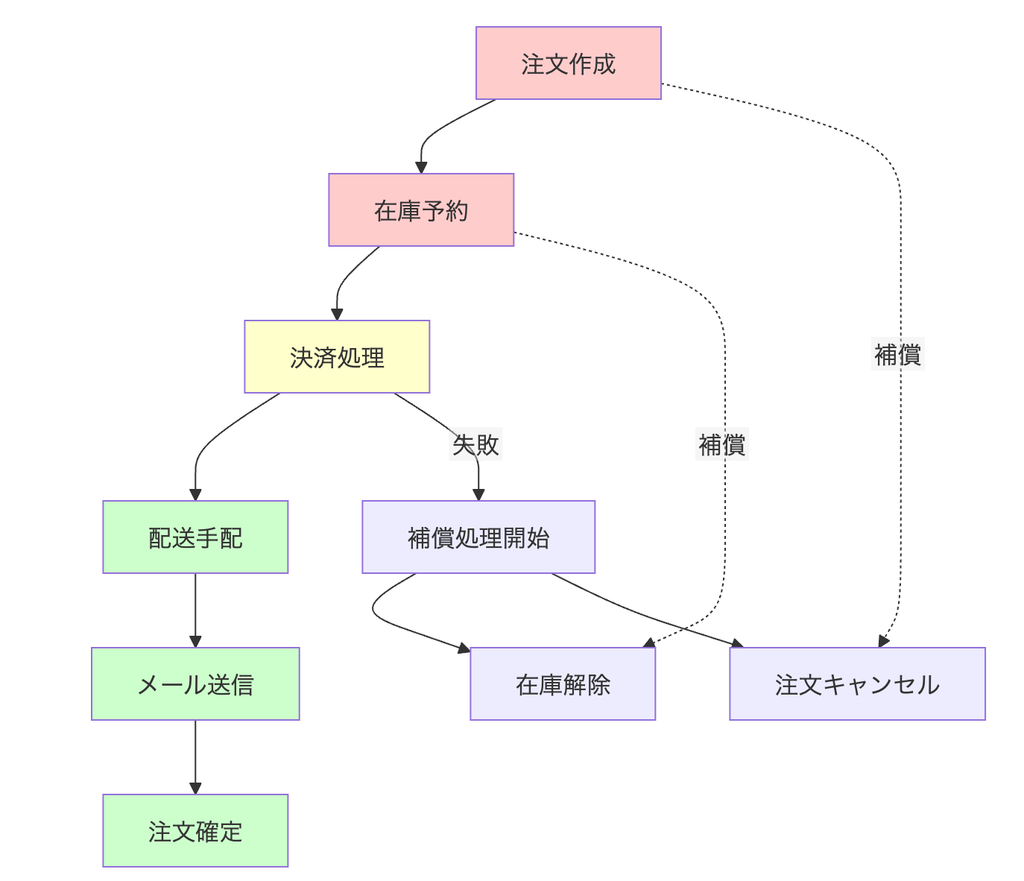
@Takumi Iida (frkake)
[論文] BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents
ツリー構造とナレッジグラフを組み合わせて、RAGの精度を向上させた
背景
階層構造や複雑なレイアウトを持つドキュメントのRAGには以下の課題があった
- 構造や意味の欠落
- テキストベースの手法:ドキュメントのレイアウトを無視してしまう
- レイアウト解析:ブロック間の繋がりが捉えられない
- 検索フローの静的性
- シンプルな質問と複雑な質問の検索プロセスが同じなので、非効率
これらを解決しようというのがBookRAG
手法
データの作り方
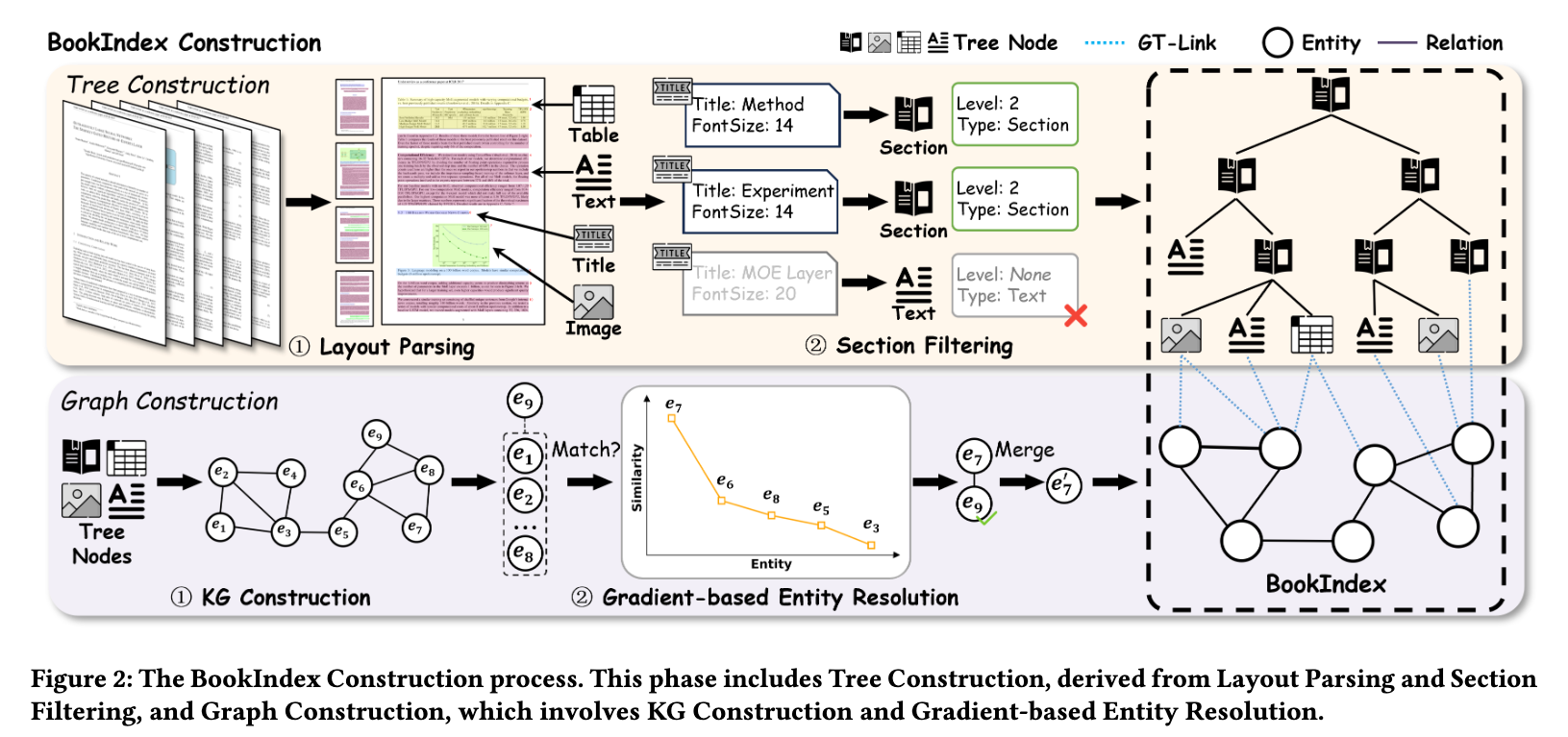
BookRAGでは、ドキュメントをツリー構造とナレッジグラフの組み合わせで管理する。
以下のような構造を抽出して、それらをGT-Link (Graph-Tree Link)という方法でつなげる。
- 階層ツリー:ドキュメントの目次構造(章、節、パラグラフ…)をそのままツリーにする
- ナレッジグラフ:ドキュメント内の詳細なエンティティ(用語、概念)とそれらの関係性を抽出してグラフ化
GT-Linkでは、グラフ上のエンティティがツリー状のどのノードに出現するのかを明示的にリンクさせる。グラフ(意味)とツリー(場所)を結びつける役割。
違う単語だけど、同じ意味のものは同一のものとして扱えるようにする必要がある。(LLMとLarge Language Modelは同じだとか)
紐づけ方は、勾配ベース(Gradient-based Entity Resolution)で行っており、類似度スコアの急激な勾配を検知。
よくわからなかったので、例示させてみた powered by Gemini
| 順位 | 候補の単語 | 類似度スコア | 状況 |
|---|---|---|---|
| 1位 | Qwen (本人) | 0.99 | ほぼ完全一致 |
| 2位 | Qwen-7B (表記ゆれ) | 0.95 | 非常に高い(同じ仲間) |
| 3位 | Tongyi Qianwen (別名) | 0.92 | 非常に高い(同じ仲間) |
| --- ここに「崖」がある --- | ここが境界線! | ||
| 4位 | LLM (上位概念) | 0.65 | ガクッと下がる |
| 5位 | Llama 2 (競合モデル) | 0.60 | さらに下がる |
| 6位 | AI (一般用語) | 0.40 | 全然違う |
top-kでベクトル検索をかけて↑のような一覧を持ってきて、類似度が急激に下がるところから上を同一のものとして扱おうというもの

検索方法
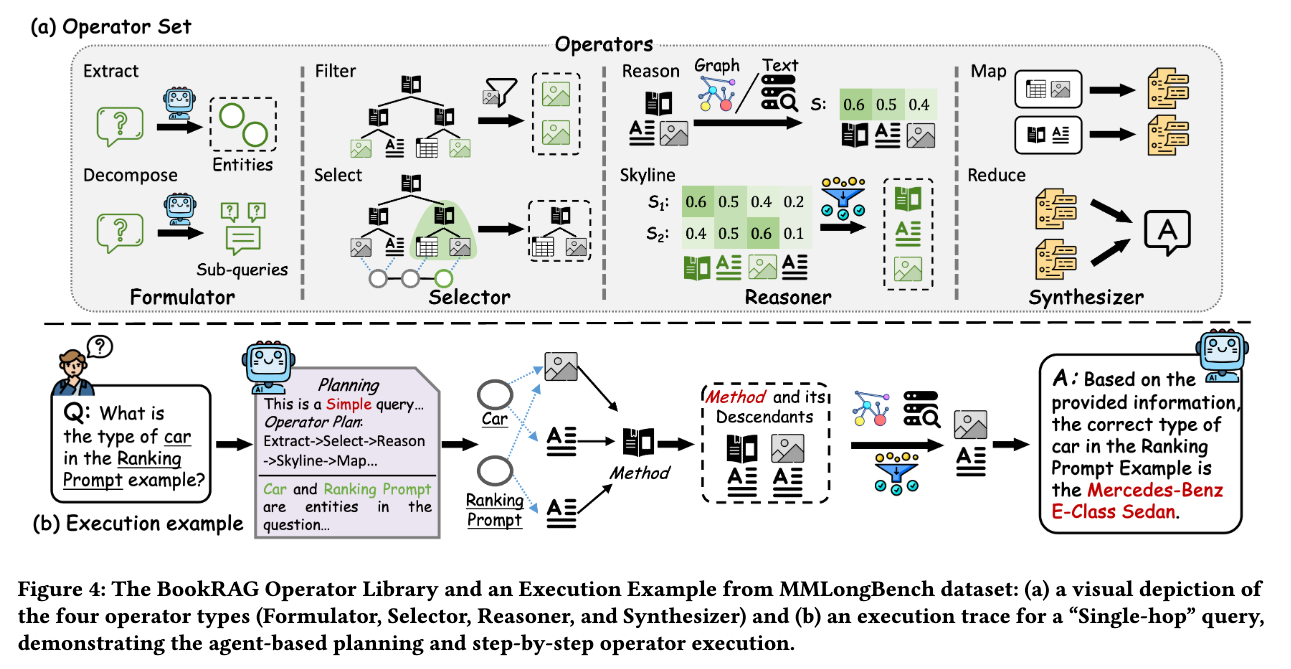
ユーザのクエリに応じて検索方法を変える。
- Formulator:入力されたクエリをエンティティやサブクエリに分解
- Selector:重要単語との関係性や構造的な条件を元に参照するデータを選択
- Reasoner:関連するドキュメントの関連度を評価
- Synthesizer:回答を生成
具体的にはこういうことをやっている↓
日本語訳
| オペレーター | タイプ (Type) | 説明 (Description) | パラメータ (Parameters) |
| Decompose | Formulator | 複雑なクエリを、より単純で実行可能なサブクエリに分解する。 | (自己完結) |
| Extract | Formulator | クエリから主要なエンティティを識別して抽出する(ナレッジグラフ $G$ へのリンク)。 | (自己完結) |
| Filter_Modal | Selector | 検索されたノードをモーダルタイプ(例:表、図)によってフィルタリングする。 | : 文字列 |
| Filter_Range | Selector | 指定された範囲(例:ページ、セクション)に基づいてノードをフィルタリングする。 | : (開始, 終了) |
| Select_by_Entity | Selector | 指定されたエンティティ ($V$) にリンクされたセクション内のすべてのツリーノード ($N$) を選択する。 | : 文字列 |
| Select_by_Section | Selector | LLMを使用して関連するセクションを選択し、その中のすべてのツリーノード ($N$) を選択する。 | : 文字列, : リスト[文字列] |
| Graph_Reasoning | Reasoner | サブグラフ ($G'$) 上でマルチホップ推論を実行し、グラフの重要度とGT-Linkを使用してツリーノード ($N$) をスコアリングする。 | : 文字列, : $G'$ |
| Text_Reasoning | Reasoner | 関連性に基づいて、検索されたツリーノード ($N$) を再ランク付け(Rerank)する。 | : 文字列 |
| Skyline_Ranker | Reasoner | 複数の基準に基づいてノードを再ランク付けする。 | : リスト[文字列] |
| Map | Synthesizer | 部分的に検索された情報を使用して、部分的な回答を生成する。 | (入力: リスト[文字列]) |
| Reduce | Synthesizer | 部分的な情報やすべてのサブ問題の回答から、最終的な回答を合成する。 | (入力: リスト[文字列]) |

結果
ベンチマークではBookRAG最強。かなりスコア上がっている。
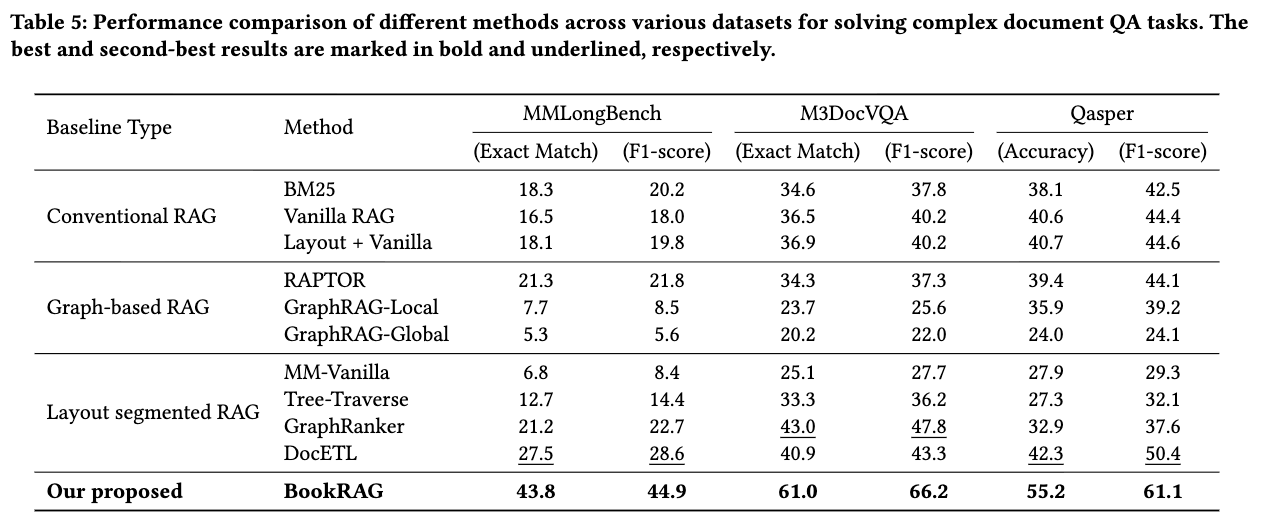
クエリの効率性:実行時間とトークンのコストは既存の手法よりも多い。(y軸注意)
同等の仕組みをもつDocETLよりは効率が良い。
@Hiromu Nakamura (pon)
[論文] Continuous Autoregressive Language Models
現行のLLM(GPT・Llama・Claude など)は、すべて 「1トークンずつ生成する仕組み」 を採用している。しかしトークンは約 15ビット程度の低情報量 であり、それを1回の前向き計算(forward pass)で扱うため、長い文の生成では計算量が指数的に増大する。
CALMのアプローチは「次のトークンを予測する」のではなく、「次の連続ベクトル(連続空間上の潜在表現)を予測する」 という設計。
● ステップ1:複数トークンを1つのベクトルに圧縮
CALMは自動エンコーダ(VAE)を使い、Kトークンを1つの潜在ベクトルに圧縮する。
例:
K=4の場合、4トークン → 1ベクトル に集約される。
● ステップ2:モデルはベクトル列を自己回帰的に予測
通常LLM:
CALM:
トークン列ではなく、ベクトル列を予測する。
● ステップ3:ベクトル z からトークン群を復元
予測された z はデコーダによりトークン列に戻される。
再構築精度は 99.9%以上 とされる。
効果:推論ステップ数の劇的減少
K=4 なら、
- トークン1000個生成 → 1000ステップ
- CALM → 250ステップ
となり、計算量は理論上 1/4 となる。
Attention計算も同様に短縮されるため 高速化・省コスト化 が同時に成立する。
エンコーダの工夫
CALMのエンコーダは以下の特徴を持つ。
- Variational Autoencoder (VAE) を採用
- 「圧縮された latent は点ではなく 分布 として表現」
- decoder は latent の揺らぎに耐えられるよう学習する
- latent が多少ズレても意味的に同じトークン群を復元
VAE は latent を 確率分布(平均 μ と分散 σ²) として扱う。
つまり、
これにより、
その他の工夫
- KL-clipping
- ランダムマスキング・ドロップアウト
これにより「エラー耐性のある圧縮器」を構築している。
Likelihood-free 学習方式
連続ベクトルには 語彙(vocabulary) が存在しないため、softmax による確率分布が定義できない。
そのためCALMは Energy Scoreに基づく損失関数 を採用する。
Energy Scoreは尤度を必要とせず、サンプル間の距離に基づいてスコアを計算する。要するに、Likelihood-free学習方式とは、明示的な確率分布(尤度)を計算・最大化することなく、モデルから直接サンプルを生成し、そのサンプルを用いて学習を行う方式である。
概念的には、
- 正解ベクトルに近づく
- 同時に多様性を失わない(collapseしない)
という性質をもつ「strictly proper scoring rule」を用いる。
評価指標
CALMは確率を直接扱わないため、従来の perplexity が使えない。
代わりに開発されたのが BrierLM 。
Perplexityがモデルの「驚き度」を測るのに対し、BrierLMはモデルの「予測精度」と「不確実性(多様性)」のバランスを評価する。その最大の特長は、明示的な尤度を必要としない点です。モデルからサンプルを生成するだけで評価が可能。
- ベクトルからサンプリングして
- 復元された n-gram (多分 SentencePiece / BPE ベース)がどれだけ正解に一致するか
BrierLMが従来のPerplexityなどの尤度ベースの評価指標が適用できないモデル(CALMなど)においても、モデルの性能を正確に評価できる有効な手段であることを主張
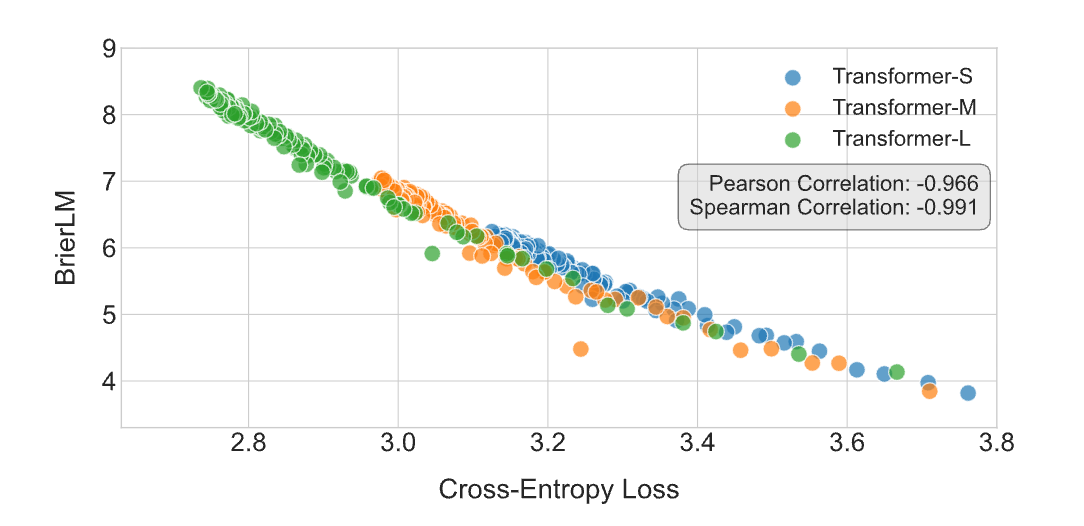
実験結果:高速かつ高性能
論文では以下の結果が報告されている。
- CALM-M(371M) が
- 通常の Transformer(281M)を 精度で上回る
- 訓練計算量 44%削減
- 推論計算量 34%削減
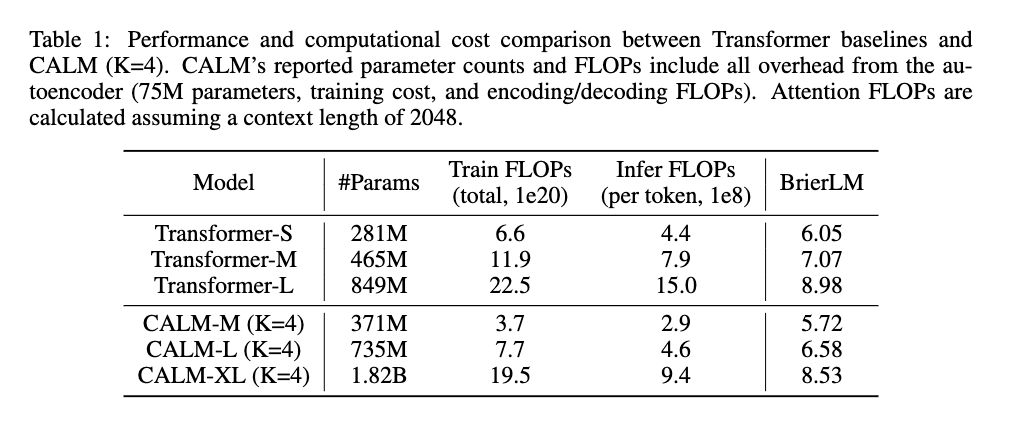
また、モデル規模を増やすと性能も素直に向上し、スケーリング性に問題はないとされる。K を大きくしすぎると精度低下のリスクが出る。K=4なら同等または上回る性能を達成
まとめ
従来は以下がスケーリング軸だった。
- パラメータ数
- データ量
- 訓練ステップ数
- コンテキスト長
CALMはこれに 意味帯域幅(K)」という新たな軸 を追加する。
- K=1(従来のトークン生成)
- K=4(4トークンまとめて生成)
- Kを大きくするほど高速化・効率化が進む
という、新しい次元のスケーリング戦略である。
@ShibuiYusuke
[論文] Measuring Agents in Production
Melissa Z. Pan 1 *, Negar Arabzadeh 1 *, Riccardo Cogo 2, Yuxuan Zhu 3, Alexander Xiong 1, Lakshya A Agrawal 1, Huanzhi Mao 1, Emma Shen 1, Sid Pallerla 1, Liana Patel 4, Shu Liu 1, Tianneng Shi 1, Xiaoyuan Liu 1, Jared Quincy Davis 4, Emmanuele Lacavalla 2, Alessandro Basile 2, Shuyi Yang 2, Paul Castro 5, Daniel Kang 3, Joseph E. Gonzalez 1, Koushik Sen 1, Dawn Song 1, Ion Stoica 1, Matei Zaharia 1 *, Marquita Ellis 5 *
1 UC Berkeley, 2 Intesa Sanpaolo, 3 UIUC, 4 Stanford University, 5 IBM Research, *Project Co-Leads.
1. イントロダクション (Introduction)
AIエージェントへの期待と現実のギャップ、そして本研究の目的の提示。
- 背景: 大規模言語モデル(LLM)の進化により、自律的にタスクをこなす「AIエージェント」への注目。コーディングだけでなく、金融、保険、教育など多様な分野での導入の進展。
- 課題: しかし、エージェントの導入成功率は低く(ある研究では95%が失敗)、成功と失敗を分ける要因についての技術的知見の不足。
- 研究の独自性: 本研究は、研究室のプロトタイプではなく、「実際にユーザーに使われているデプロイ済みエージェント」に焦点を当てた初の大規模調査という位置づけ。
2. 関連研究 (Related Work)
既存研究との相違点の明確化。
- これまでの調査は、「将来の市場予測」や「経営幹部の意識調査」、あるいは「学術的分類(Taxonomy)」が中心。
- 本研究は、現場のエンジニアから直接収集した技術的データ(アーキテクチャ、ツール、評価手法など)に基づく点が特徴。
3. 方法論 (Methodology)
データ収集方法の記述。
- アンケート調査: 306件の有効回答の取得。そのうち86件が「本番運用中」または「パイロット運用中」のシステムに関する回答。
- 詳細インタビュー: 20のチームに対する詳細ヒアリングの実施。いずれも実ユーザーを持つシステムであり、スタートアップから大企業まで多様な組織が対象。
- 定義: 「プロダクション(本番)」とは、ターゲットエンドユーザーが実業務環境で実際に利用している状態の指示。
4. RQ1: アプリケーション、ユーザー、要件 (Applications, Users, Requirements)
What are the applications, users, and requirements of agents?
「なぜエージェントを作り、誰が使い、どのような要件があるのか」の分析。
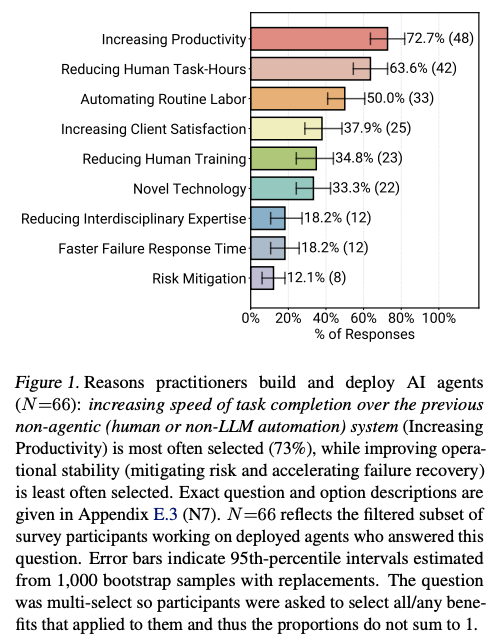
4.1 エージェント導入の動機
- 生産性が最優先: 導入理由の圧倒的1位は「生産性向上と効率化(72.7%)」、次点は「人的作業時間の削減(63.6%)」という傾向。
- リスク回避は二の次: 「リスク軽減」や「障害対応迅速化」を理由とするケースは少なく(10〜20%台)、効果測定の難しさが要因と推測。
4.2 適用ドメイン
- 多様な業界: コーディング支援に加え、金融・銀行(39.1%)、テクノロジー(24.6%)、企業サービス(23.2%)など、26以上の多様ドメインでの稼働。
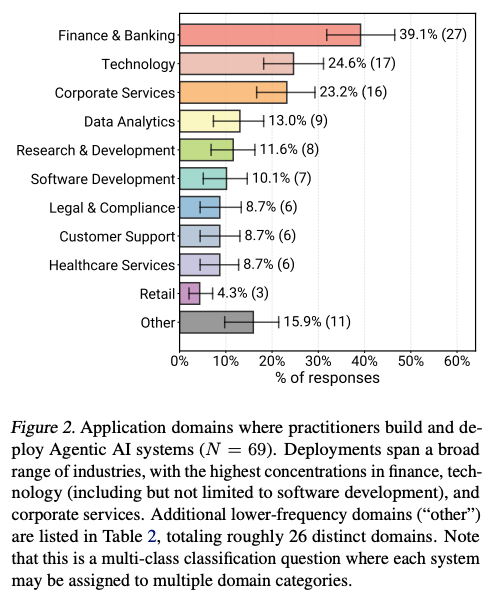
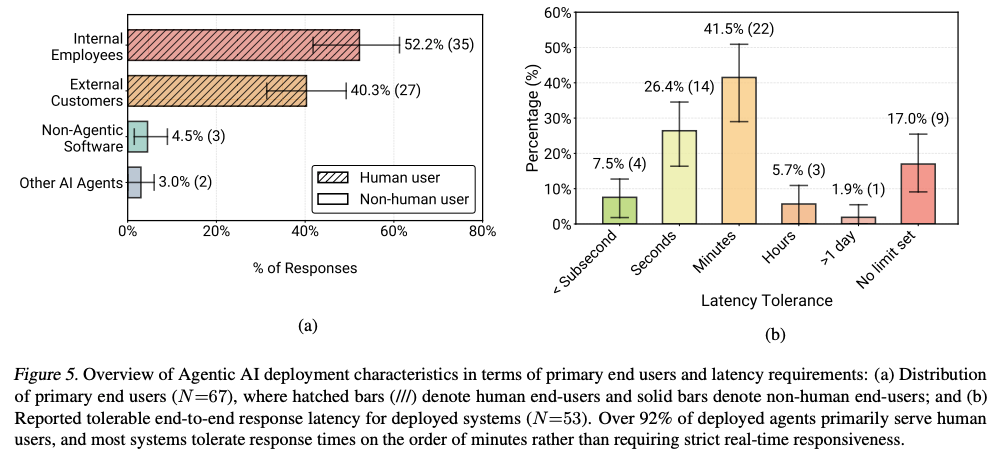
4.3 ユーザー層
- 対人間: 92.5%のシステムが、他のAIではなく「人間」へのサービス提供。
- 社内利用が中心: ユーザーの過半数(52.2%)が社内従業員という構成。社内利用であればエージェントのミスによるリスクが低く、人間監督(Human-in-the-loop)の容易さが背景。
4.4 レイテンシ(応答速度)の要件
- 遅くても許容: 応答に「数分」を許容するシステムが最多で、即時応答(サブ秒)を求めるケースは少数。
- 理由: エージェントが代替するタスクは、人間なら数時間〜数日かかるケース(例:保険審査、障害ログ調査)が多く、数分の思考時間でも「十分高速」とみなされる状況。
- 例外: 音声対話のようなインタラクティブシステムではレイテンシが深刻課題。
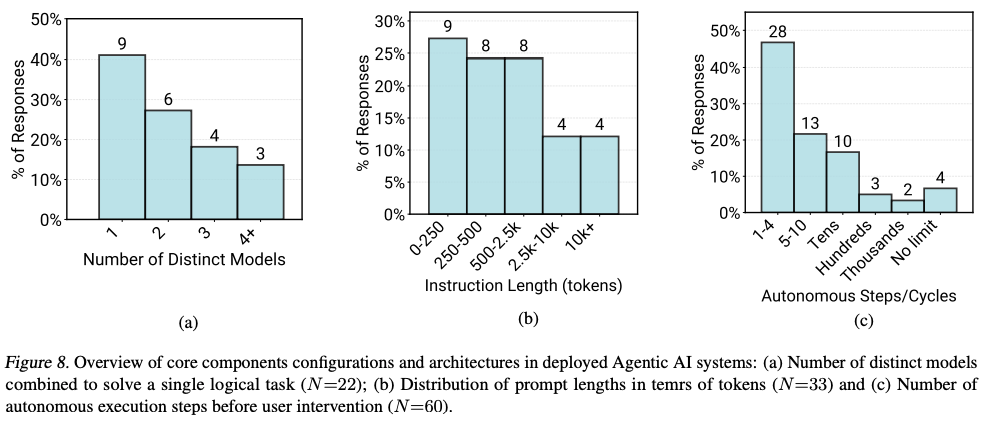
5. RQ2: モデル、アーキテクチャ、技術 (Models, Architectures, Techniques)
What models, architectures, and techniques are used to build deployed agents?
現場での技術選択の分析。「シンプルさ」と「制御性」が主要概念。
5.1 モデルの選択
- プロプライエタリ(商用)モデルの優勢: 20件のインタビュー中17件がOpenAI (GPT-4) や Anthropic (Claude) などのクローズドソースモデルを採用。
- オープンソースの役割: コスト削減やデータの社外持ち出し禁止(規制)など制約下での利用が中心。
- 複数モデルの利用: 半数のチームが複数モデルを使い分け。理由は推論能力よりも、コスト最適化やモデル更新時の挙動変化(ドリフト)管理。
5.2 重み調整(ファインチューニング)
- ほぼ未実施: 70%のケースで追加学習(ファインチューニングや強化学習)の非実施。
- プロンプトで十分: 高性能モデルへの適切プロンプト付与のみで多くのユースケースに対応可能という状況。ファインチューニングはメンテ負荷の高さやアップデート脆弱性が理由で敬遠。
5.3 プロンプティング戦略
- 手動作成が基本: プロンプトは人手による作成・修正が中心。DSPyのような自動最適化ツールは約5%とレアケース。
- 長大プロンプト: 多量のコンテキスト保持のため、1万トークン超のプロンプトが12%存在。
5.4 エージェントアーキテクチャ
- 自律性の制限: エージェントの連続実行ステップ数を10ステップ以下に制限するシステムが全体の68%。
- 静的ワークフロー: 自律プランニングより、定義済手順(RAGパイプラインなど)に従う静的ワークフローの選好。
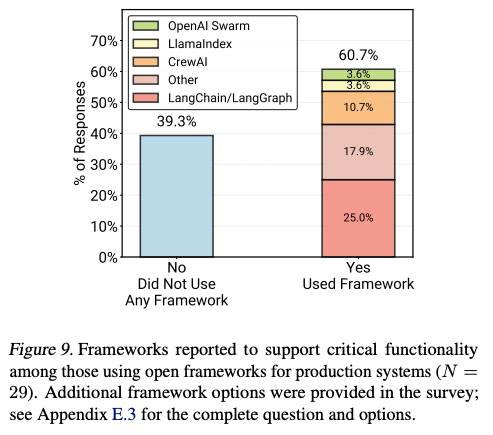
5.5 開発フレームワーク
- アンケートと実態の乖離: アンケートでは6割がLangChainなどの利用と回答する一方、成功インタビュー事例(20件)の85%がフレームワーク非使用(自社製スクラッチ実装)。
- 理由: 抽象化過多によるデバッグ難、依存関係の複雑化などを懸念し、自前APIコールの方が制御しやすいという判断。
6. RQ3: 評価手法 (Evaluation)
How are agents evaluated for deployment?
エージェント品質保証の手法の分析。
6.1 ベースラインとベンチマーク
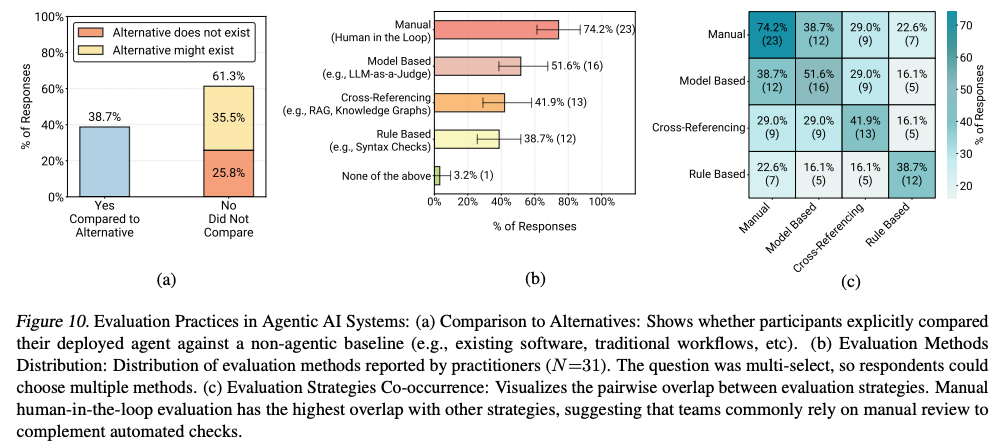
- 比較対象の不在: 多くのシステム(61.3%)が既存非エージェントシステムとの厳密比較を未実施。
- 独自ベンチマーク: 汎用ベンチマークの実業務非適合により、25%が独自テストセット(ゴールデンセット)を作成。残り75%は正式ベンチマーク不保持でA/Bテストやユーザーフィードバックによる評価。
6.2 評価方法
- 人間評価が中心: 74.2%のチームがHuman-in-the-loop(人間確認)を実施。開発時のみならず実行時にも人間が最終チェックを担当。
- LLM-as-a-judge: LLMによる評価手法も51.6%で採用。ただし単独利用はなく、必ず人間検証との併用(信頼度スコア確認など)。
7. RQ4: 開発の課題 (Challenges)
What are the top challenges in building deployed agents?
開発者が直面する主要課題の分析。
7.1 信頼性と評価の難しさ
- 最大課題: 全ステージで「信頼性(Reliability)」が最大課題。
- 正解不明問題: エージェント出力の正否を自動判定する検証メカニズムの不在(例:生成文の質)による評価困難。
7.2 レイテンシの課題
- ブロッカーではない: レイテンシは課題として挙がるものの、導入断念レベルの決定的問題となるのは15%程度。
- 非同期処理: 多くのシステムがバックグラウンドでの非同期処理により、ユーザー体験を損なわず時間をかけた処理を実現。
7.3 セキュリティとプライバシー
- 優先度中程度: セキュリティは重要ながら、出力品質や正しさ(信頼性)に比べると優先度は低下。
- 対策: サンドボックス環境での実行、データベースへの書き込み権限不付与(Read-only)によるリスク管理。
8. ディスカッション (Discussion)
調査結果から見えてくる3つの主要トレンドの議論。
8.1 制約による信頼性の確保
信頼性が未解決課題であるにもかかわらず、エージェントが本番導入可能である理由は、「環境と自律性の厳格制限」による信頼性確保。
完全自由エージェントではなく、定義された枠内でのみ動作するツールとしての設計による実用化の実現。
8.2 豊富な応用機会
現行モデル能力(プロンプトエンジニアリングのみ)でも、多様ドメインでの価値創出の実現。特に、人間向けインターフェース(チャットなど)だけでなく、ソフトウェア運用保守などへの応用余地の存在。
8.3 未解決の研究課題
- 失敗検知: エージェントの失敗を実行時に検知するツール・手法の必要性。
- 事後学習: ファインチューニングをより手軽かつモデルアップデート耐性の高いものとする研究の必要性。
- 推論時探索: 複数モデルを用いた推論時探索(inference-time search)手法の実用化への期待。
9. 結論 (Conclusion)
成功エージェントは、魔法のような自律AIではなく、「生産性向上のために、シンプルな技術と厳格管理下で運用される自動化ツール」という結論。
感想
- 脱フレームワークや少ないステップ数でのエージェント開発が主流。自律性よりもコントローラビリティとシンプルさ、手軽さ優先。
- 遅くて信頼(人間の介入有り)>早くて不安(完全自動)。
- 評価セットは自作する。汎用ベンチマークは業務を反映していない。
メインTOPIC
LLM Reasoning for Cold-Start Item Recommendation
論文情報
| 項目 | 内容 |
|---|---|
| 著者 | Shijun Li (UT Austin), Yu Wang, Jin Wang, Ying Li, Joydeep Ghosh, Anne Cocos (Netflix) |
| 所属 | Netflix × University of Texas at Austin |
1. どんなもの?
一言でいうと
LLMの推論能力を活用して、新規アイテム(コールドスタート)の推薦精度を向上させる手法
背景:コールドスタート問題とは
新作映画が公開される
↓
ユーザーの視聴データがない
↓
協調フィルタリングが機能しない
↓
適切な推薦ができない😇
本研究のアプローチ
新作映画が公開される
↓
LLMが持つ世界知識を活用
↓
タイトル・ジャンル・俳優などから推論
↓
ユーザーの好みにマッチするか判断
提案する2つの推論戦略
| 戦略 | 特徴 |
|---|---|
| Structural Reasoning | 履歴を構造化し、複数パスで推論 |
| Soft Self-Consistency | 複数推論を柔軟に統合 |
2. 先行研究と比べてどこがすごい?
既存研究の限界
| 課題 | 詳細 |
|---|---|
| 対象シナリオ | Warm-start(十分なデータあり)のみ |
| Fine-tuning | SFTのみ、または直接推論 |
| 評価 | 公開データセットでの評価が中心 |
本研究の新規性
① コールドスタートへの特化
- 学習データに 一度も出現しない アイテムが対象
- LLMの学習時点より 後に公開 されたアイテム
- → 真に「未知」のアイテムへの推薦
② Fine-tuning手法の体系的比較
- SFT(教師あり学習)
- GRPO(強化学習)
- SFT + GRPO(ハイブリッド)
③ 本番環境での評価
- Netflix本番ランキングモデルとの比較
- Discovery指標で 8%の改善 を達成
3. 技術や手法のキモはどこ?
タスク設定
Re-rankingタスク
入力:50候補
- Netflix本番モデルのTop 40
- コールドスタート 10件(ターゲット含む)
出力:再ランキングされた推薦リスト
提案手法A:Structural Reasoning
Step 1: 推論パス構築
ユーザー履歴を 3つの軸 で分解:
人間が明示的に定義している
| 軸 | 例 |
|---|---|
| 俳優 | 「Annaの出演作を5本視聴」 |
| ジャンル | 「アクション映画を頻繁に視聴」 |
| 監督 | 「Tom監督作品を3本視聴」 |
Step 2: マッチスコア計算
候補アイテム:アクション映画、主演Anna、監督Tom
俳優パス → マッチスコア: 0.9
ジャンルパス → マッチスコア: 0.7
監督パス → マッチスコア: 0.6
Step 3: 重み付け集約
考慮する要素:
- Prominence(顕著性):どれだけ強い嗜好か
- Recency(最新性):最近の視聴ほど重視
- Action type(行動タイプ):視聴完了 vs 途中離脱
最終スコア = Σ (マッチスコア × 重要度重み)
提案手法B:Soft Self-Consistency
従来のSelf-Consistencyとの違い
| 項目 | 従来手法 | Soft Self-Consistency |
|---|---|---|
| 統合方法 | 厳密な多数決 | 柔軟な要約 |
| LLMの自律性 | 低い | 高い |
| 複雑さ | 高い | シンプル |
2つの手法の関係
Structural Reasoning
- 明示的なパス構築指示
- スコア計算の指示
- 重み付けの指示
Soft Self-Consistency
- LLMに全て委任
Fine-tuning戦略
SFT(Supervised Fine-Tuning)
学習データ
成功した推論パス 7252件
- Base-Reasonから抽出
- Soft Self-Consistencyから抽出
目的
推論パターンの模倣学習
GRPO(Reinforcement Learning)
報酬設計
正解予測 → +1.0
不正解予測 → -0.1
パース失敗 → -1.0
特徴
- PPOより計算効率が良い
- Criticモデル不要
SFT + GRPO
Step 1: SFTで基礎学習
↓
Step 2: GRPOで探索的改善
↓
両方の利点を統合
4. どうやって有効だと検証した?
実験設定
| 項目 | 設定 |
|---|---|
| ベースモデル | Qwen-2.5-32B-Instruct |
| SFT手法 | QLoRA(4-bit量子化) |
| 評価指標 | Recall@1 (AnyPlay), Recall@1 (Discovery) |
評価指標の説明
| 指標 | 意味 |
|---|---|
| AnyPlay | 任意の再生行動を捉える |
| Discovery | 新規・未視聴コンテンツの発見を捉える |
Discovery refers to plays involving novel or previously unseen content, while AnyPlay captures any type of user playback behavior.
実験結果①:推論戦略の比較(Fine-tuningなし)Table 1より
| 手法 | AnyPlay | Discovery |
|---|---|---|
| Fast-Reason(ベースライン) | 0% | 0% |
| Direct-Rec | +83.33% | -34.04% |
| Base-Reason | +104.17% | -29.15% |
| Structural Reasoning | +16.67% | -6.36% |
| Soft Self-Consistency | +4.38% | +6.38% |
💡 Key Insight
複雑な推論 ≠ 常に良い結果
- Base-Reason:AnyPlayに強い
- Soft Self-Consistency:Discoveryに強い&バランス良好
実験結果②:Fine-tuningの効果
Base-Reasonの場合
| 手法 | AnyPlay | Discovery |
|---|---|---|
| Fine-tuningなし | 0% | 0% |
| +SFT | +8.16% | +2.63% |
| +GRPO | +5.10% | +18.42% |
| +SFT+GRPO | +7.14% | +7.89% |
Soft Self-Consistencyの場合
| 手法 | AnyPlay | Discovery |
|---|---|---|
| Fine-tuningなし | 0% | 0% |
| +SFT | +22.45% | +0.21% |
| +GRPO | +12.24% | +6.00% |
| +SFT+GRPO | +8.16% | +0.34% |
💡 Key Insight
SFTとGRPOは異なる指標を最適化する傾向
- SFT → AnyPlay向上
- GRPO → Discovery向上
実験結果③:Warm-start での比較
| 手法 | AnyPlay | Discovery |
|---|---|---|
| Fine-tuningなし | 0% | 0% |
| +SFT | +17.31% | +15.22% |
| +GRPO | +11.54% | +17.39% |
| +SFT+GRPO | +25.00% | +32.61% |
| Netflix本番モデル | +96.15% | +23.91% |
🎉 重要な発見
SFT+GRPOが でNetflix本番モデルを8%上回る
- 本番モデル:数億サンプルで学習
- 提案手法:数千サンプルで学習
- → 少量データでも本番を超える可能性
5. 議論はある?
トレードオフの存在
推論戦略の選び方
| 戦略 | AnyPlay | Discovery | 推奨ケース |
|---|---|---|---|
| Structural Reasoning | ◎ | △ | 一般的な再生率を重視 |
| Soft Self-Consistency | ○ | ◎ | 新規コンテンツ発見を重視 |
Fine-tuning手法の選び方
| 手法 | AnyPlay | Discovery | Cold-start | Warm-start | 推奨ケース |
|---|---|---|---|---|---|
| SFT | ◎ | △ | ○ | ○ | AnyPlay重視 |
| GRPO | ○ | ◎ | ◎ | ○ | Discovery重視・Cold-start |
| SFT+GRPO | ○ | ○ | △ | ◎ | Warm-startで最高性能 |
早見表:目的別の推奨組み合わせ
| 目的 | 推論戦略 | Fine-tuning |
|---|---|---|
| AnyPlay最大化 | Structural Reasoning | SFT |
| Discovery最大化 | Soft Self-Consistency | GRPO |
| Warm-startで総合性能 | どちらでも | SFT+GRPO |
| Cold-startでバランス | Soft Self-Consistency | GRPO |
限界と今後の課題
| 限界 | 詳細 |
|---|---|
| Cold-start vs Warm-start | SFT+GRPOはWarm-startでいい結果だがCold-startでは苦戦 |
| 学習データの影響 | Cold-startアイテムが学習データに含まれないことが原因 |
| 指標間のトレードオフ | AnyPlayとDiscoveryの同時最適化は困難 |
なぜSFT+GRPOはCold-startで苦戦するか?
学習データ = Warm-startアイテムのみ
↓
モデルは「見たことあるアイテム」の推薦が得意になる
↓
Cold-start(未知のアイテム)には汎化しにくい
まとめ
Take Home Message
1. LLM推論はCold-start推薦に有効
従来の協調フィルタリングが苦手な領域で、LLMの世界知識と推論能力が活きる
2. シンプルな手法が意外と強い
Soft Self-Consistency(シンプル版)がStructural Reasoning(複雑版)よりバランス良好
3. Fine-tuning手法は目的に応じて選択
- AnyPlay重視 → SFT
- Discovery重視 → GRPO
- Warm-start → SFT+GRPO
4. 少量データでも本番モデルを超える可能性
数千サンプルの学習で、数億サンプルで学習した本番モデルをDiscoveryで8%上回った