
2025-12-16 機械学習勉強会
今週のTOPIC[論文] QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management[論文] ThreadWeaver: Adaptive Threading for Efficient Parallel Reasoning in Language Models[論文] Self-Steering Language Models[blog] 画像圧縮するベストな方法(2025)[論文] Escaping the Verifier: Learning to Reason via DemonstrationsReducing Privacy leaks in AI: Two approaches to contextual integrityHeterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-LLM SystemsメインTOPIC1. Introduction: 背景と論文の立ち位置なぜ Document Parsing が重要かこの論文の貢献2. Methodology: 2つの主要アプローチA. Modular Pipeline System(従来・主流)B. End-to-End Approaches(最新トレンド)3. Pipelineの主要コンポーネント 3.1 Document Layout Analysis (DLA)3.2 Optical Character Recognition3.3 Table Detection & Recognition4. End-to-End & Large Models4.1 Specialized Generative Models4.2 Large Multi-modal Models (LMMs) & Unified Frameworks5. Open Source Tools6. Remaining Challenges 論文全体の潮流
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
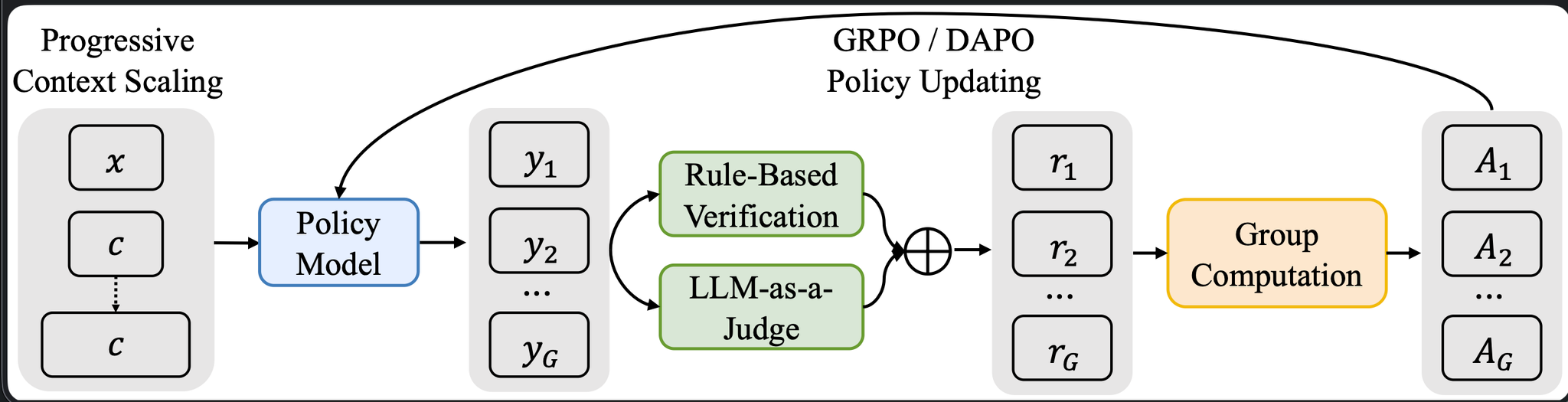
- LRM (Large Reasoning Models)は、強化学習を用いて性能が伸びてきているが、長い文脈への対応がOSSだとまだまだ未解決
- Long Contextに特化した強化学習フレームワークを提案。
- R1-Distill-Qwen-32Bをベースモデルに訓練
- 最大入力長12万トークン、出力長1万トークン
- 大きくは三つの貢献
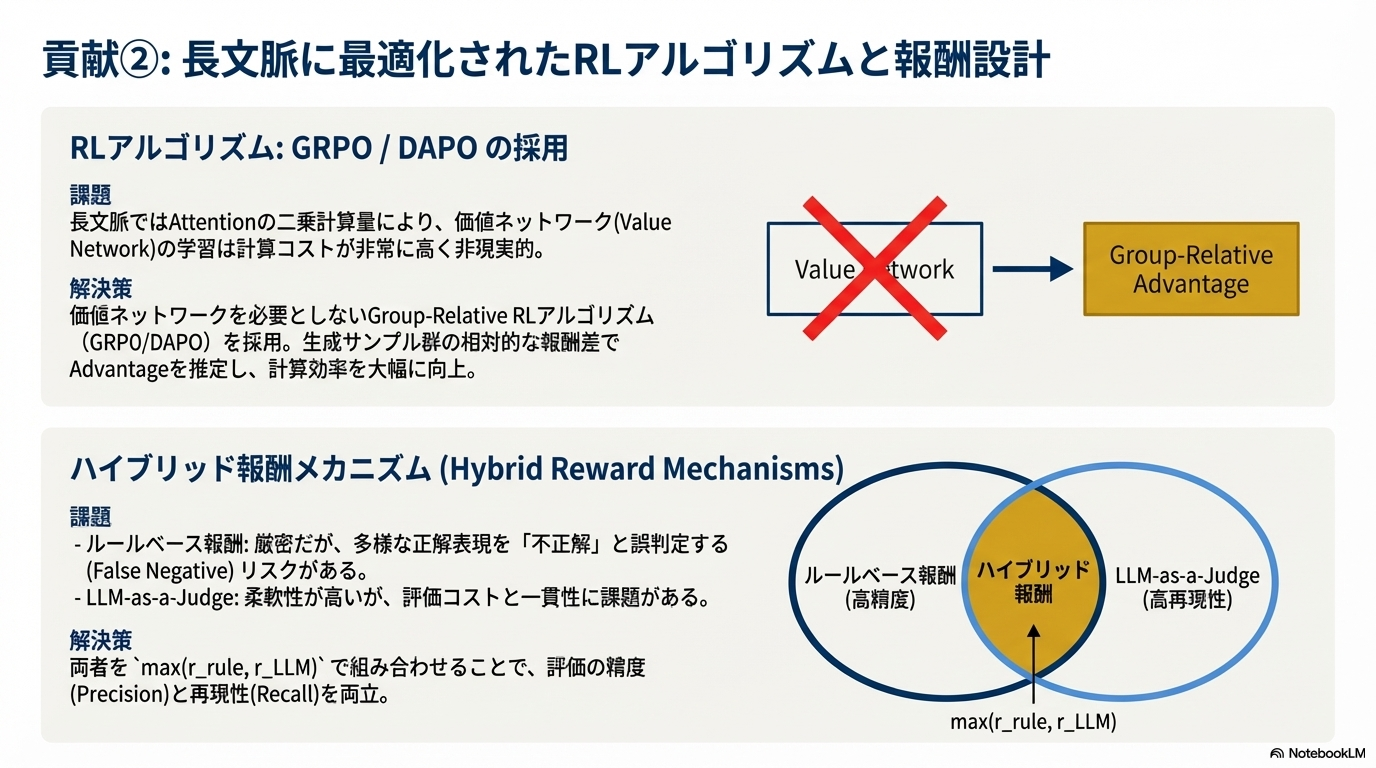
- 報酬設計
- ルールベースで文字列マッチングによる精度重視の評価と、LLMによる意味的な等価性も加味した報酬の合わせ技 (Qwen2.5-1.5Bを利用)
- コード
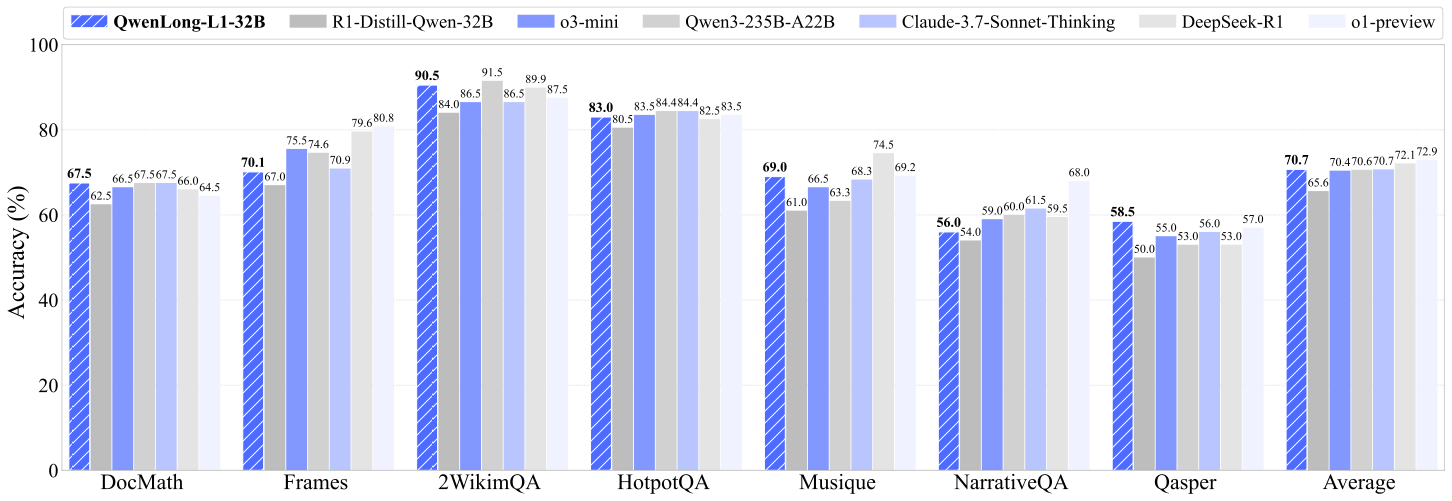
- o3-miniに匹敵するベンチマークの平均精度を獲得
- 訓練ステップが進むことによって以下のような行動が増えた
- グラウンディング(Grounding): ⻑文脈から関連情報を想起
- サブゴール設定(Subgoal Setting): 複雑な質問を管理可能なサブゴールに分解
- バックトラッキング(Backtracking): エラーを特定し、アプローチを反復的に修正
- 検証(Verification): 自己反省により予測回答を体系的に検証
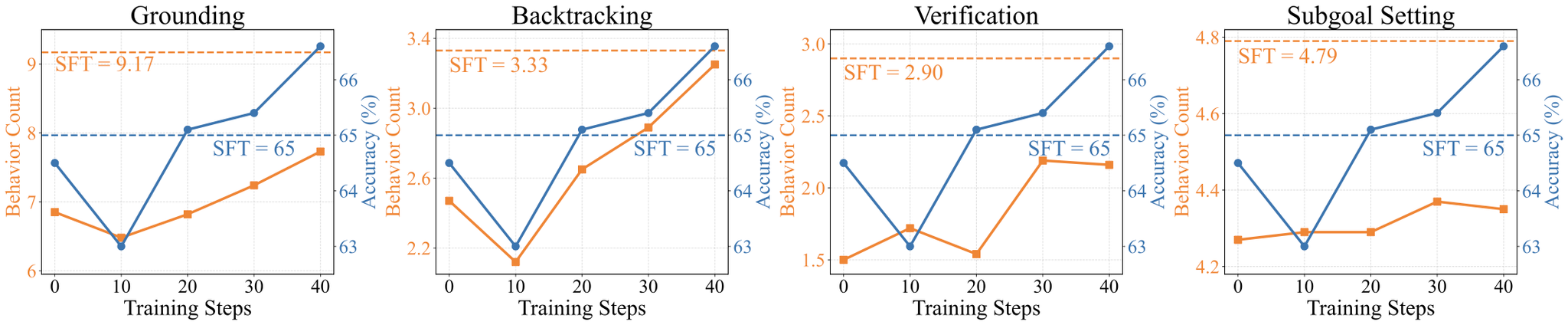
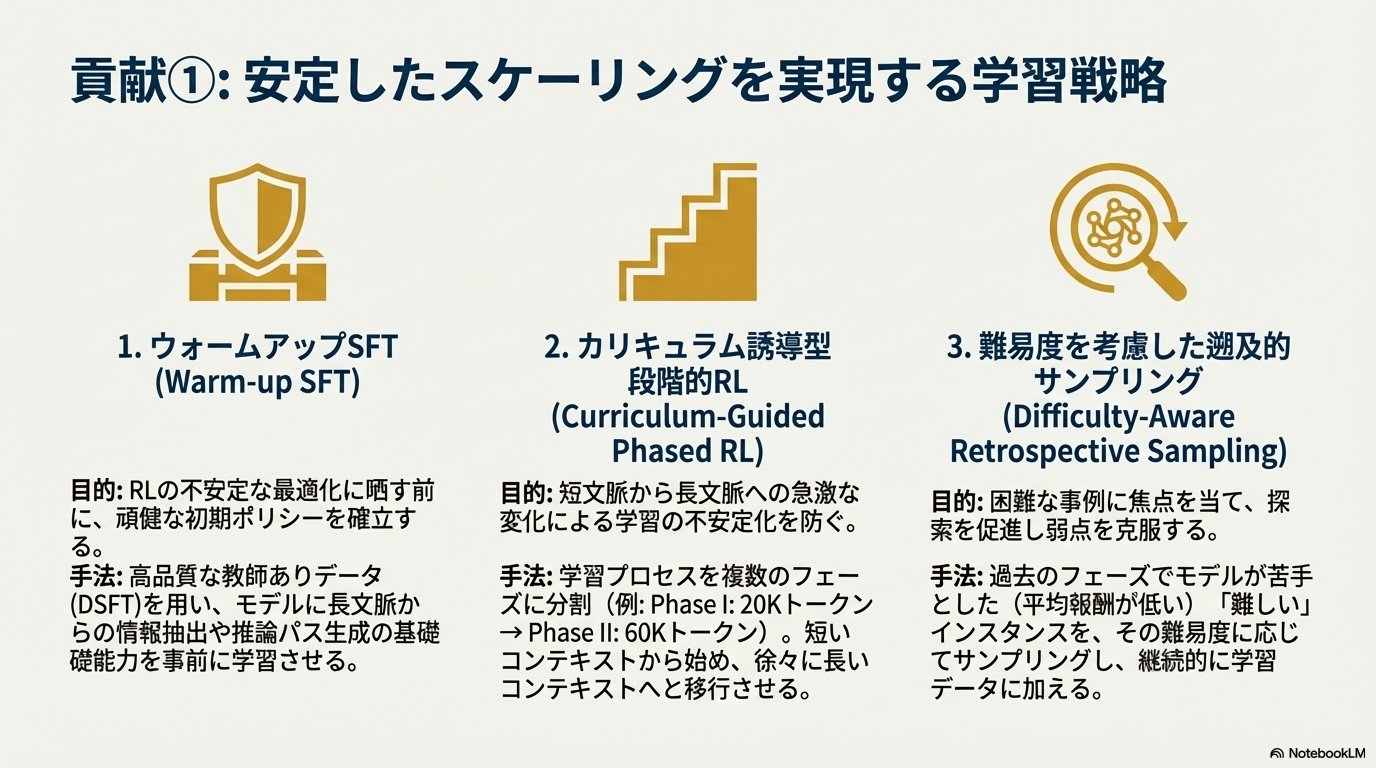
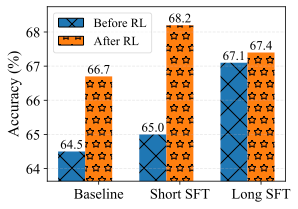
- SFTの段階でLong Contextにしてしまうと、RLをしても局所的な解に陥ってしまい性能が伸び悩んでしまう。SFTの段階は短い文章にした方が良い。
- 実装はめっちゃシンプル
@Yuya Matsumura
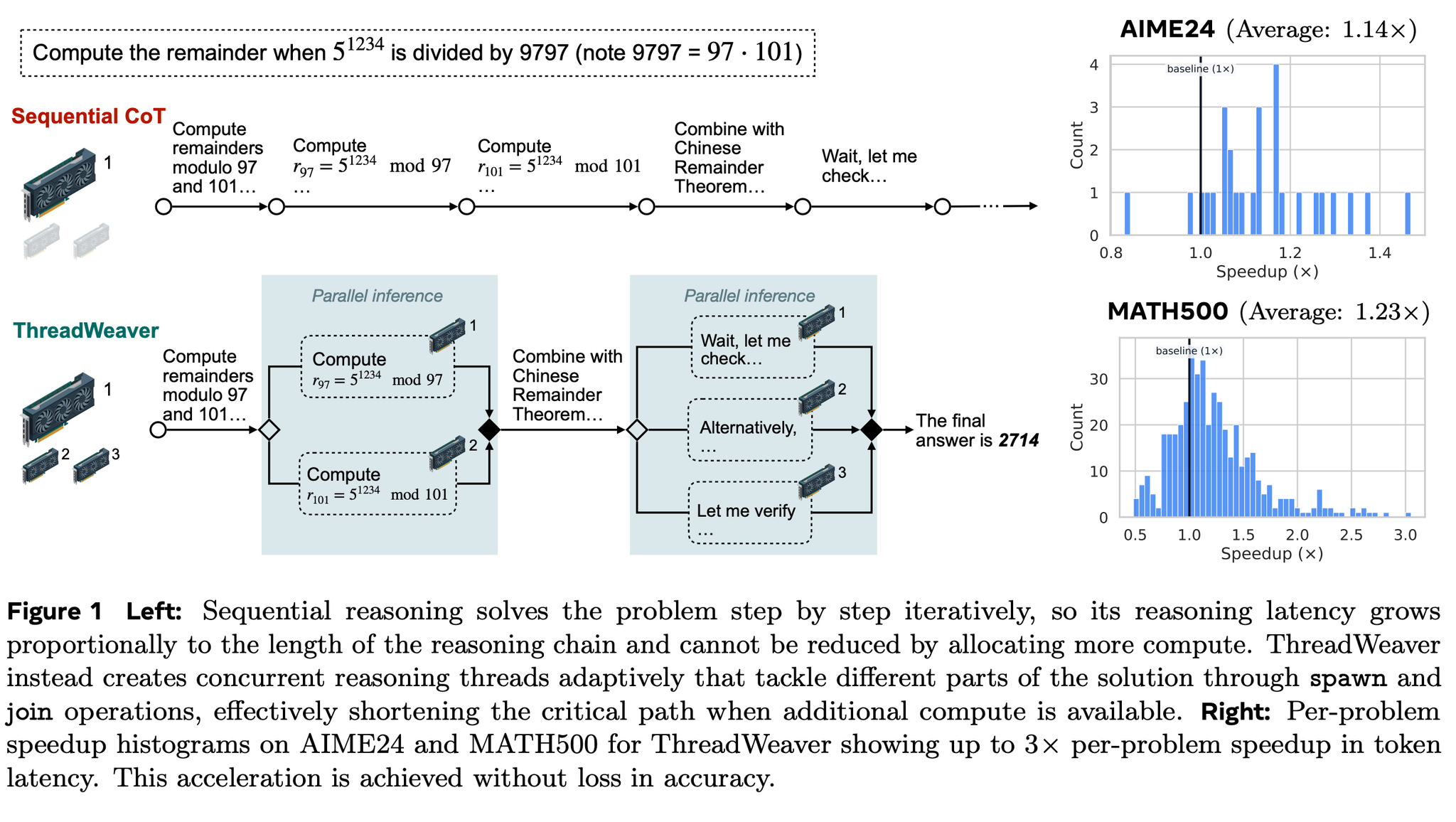
[論文] ThreadWeaver: Adaptive Threading for Efficient Parallel Reasoning in Language Models
project page: https://threadweaver-parallel.github.io/
CoT によってLLMの推論の性能は上がったが、逐次的に実行するとその分のレイテンシーが犠牲になる。そのため、必要に応じてLLMが自律的に並列化できる部分をスレッドに分岐(spawn)・結合(join)させるパラダイムである、適応型並列推論(Adaptice Parallel Reasoning)が注目されている。
一方で実用化には大きく3つの壁が存在した。それらを解決するのが本論文の提案。
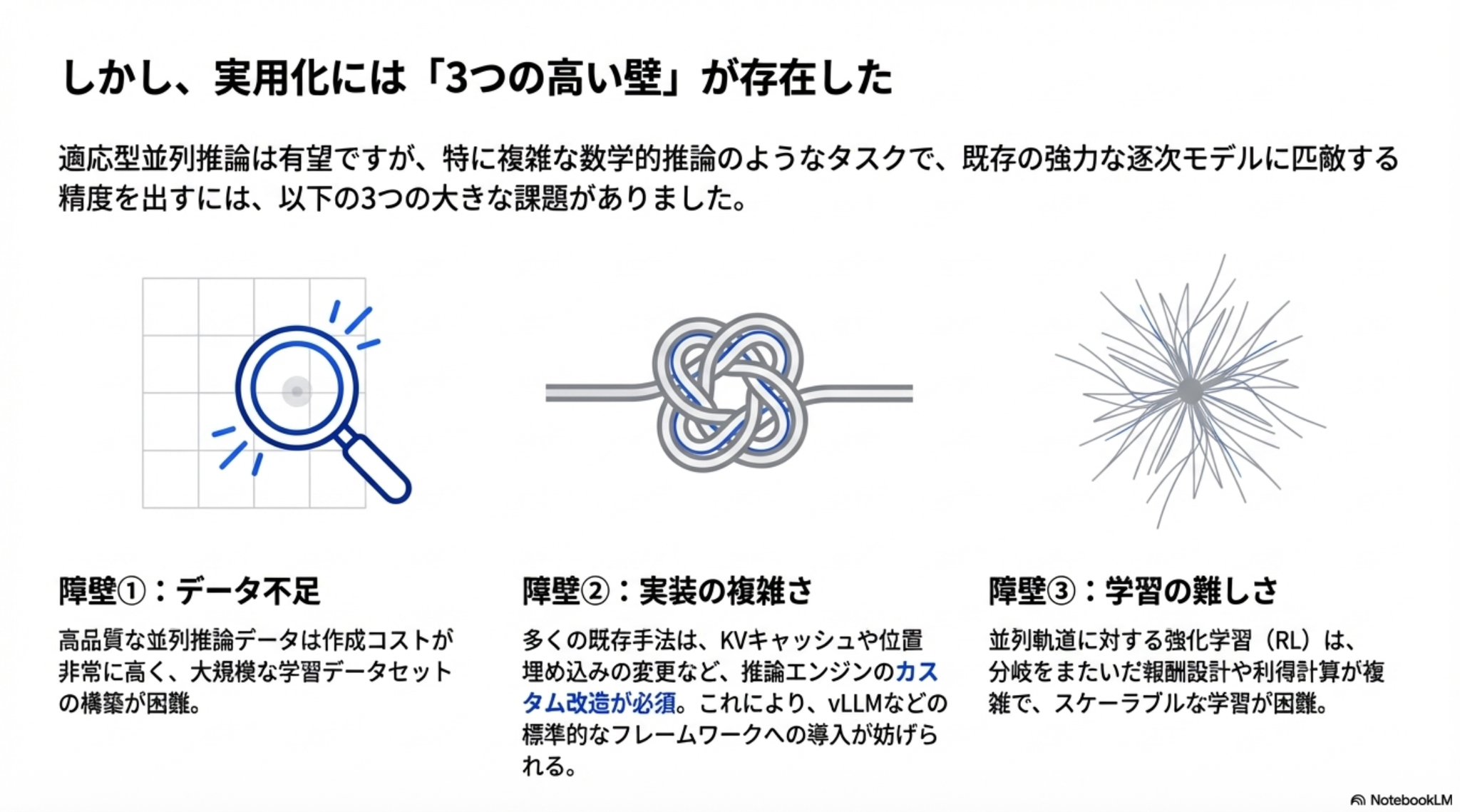
工夫1:データ不足問題の解決
既存の高品質なCoT推論データをベースにGPT-5で並列可能な部分を指定したフォーマットにリライト → このデータセットを使ってSFTしたモデルでさらにデータを大量に生成した上で正しいものだけを機械的にフィルタリング
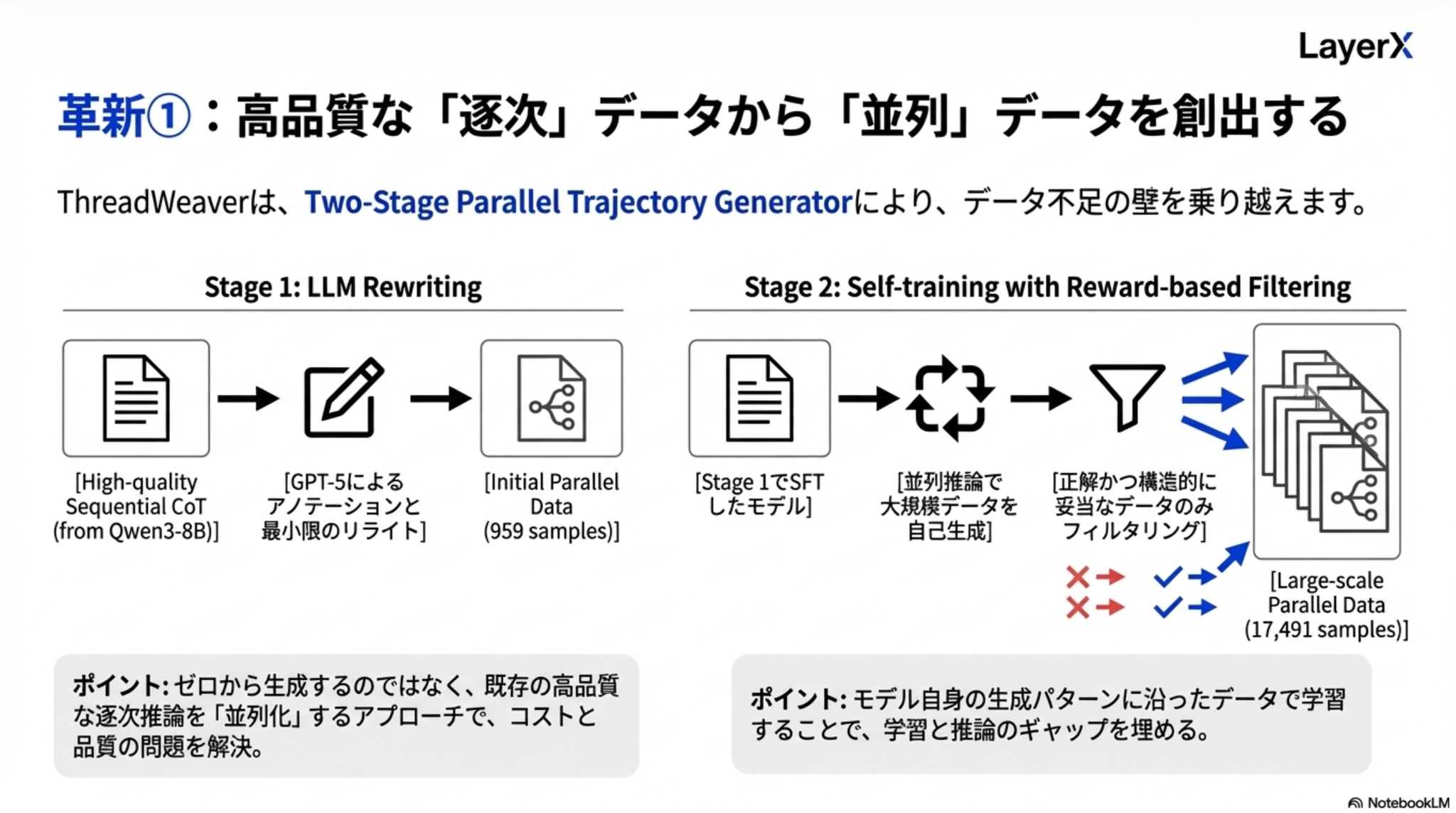
フォーマットはこんな感じ
並列化できるところで<Parallel>タグを発行し、並列化するタスクごとに <Outline>タグで指示を生成し、対応する <Thread> で実際にタスクを実行する。

工夫2:実装の複雑さ問題の解決
フォーマットに沿ってうまく推論を指示するクライアントを作ったという話であると理解

推論時の様子
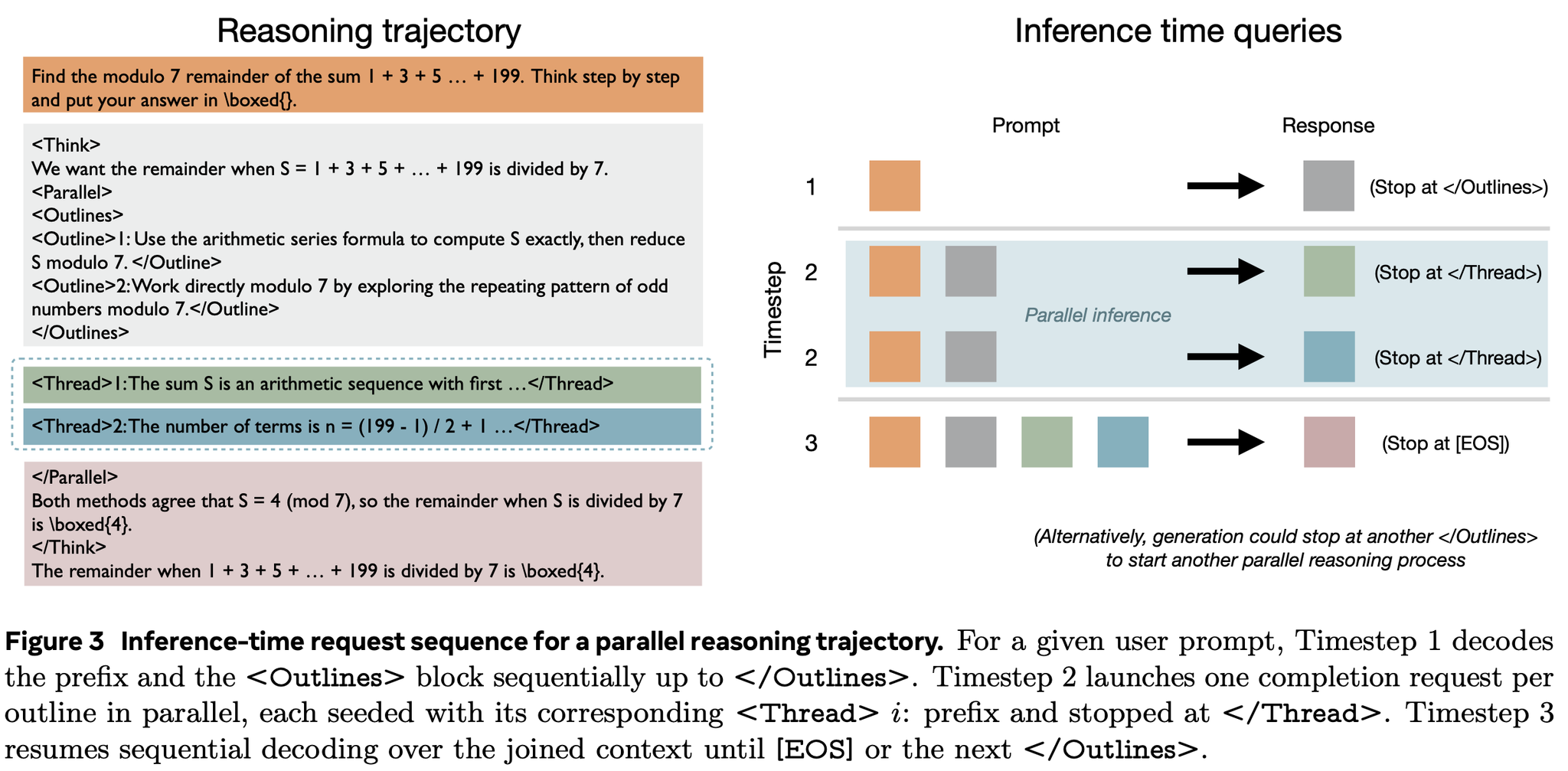
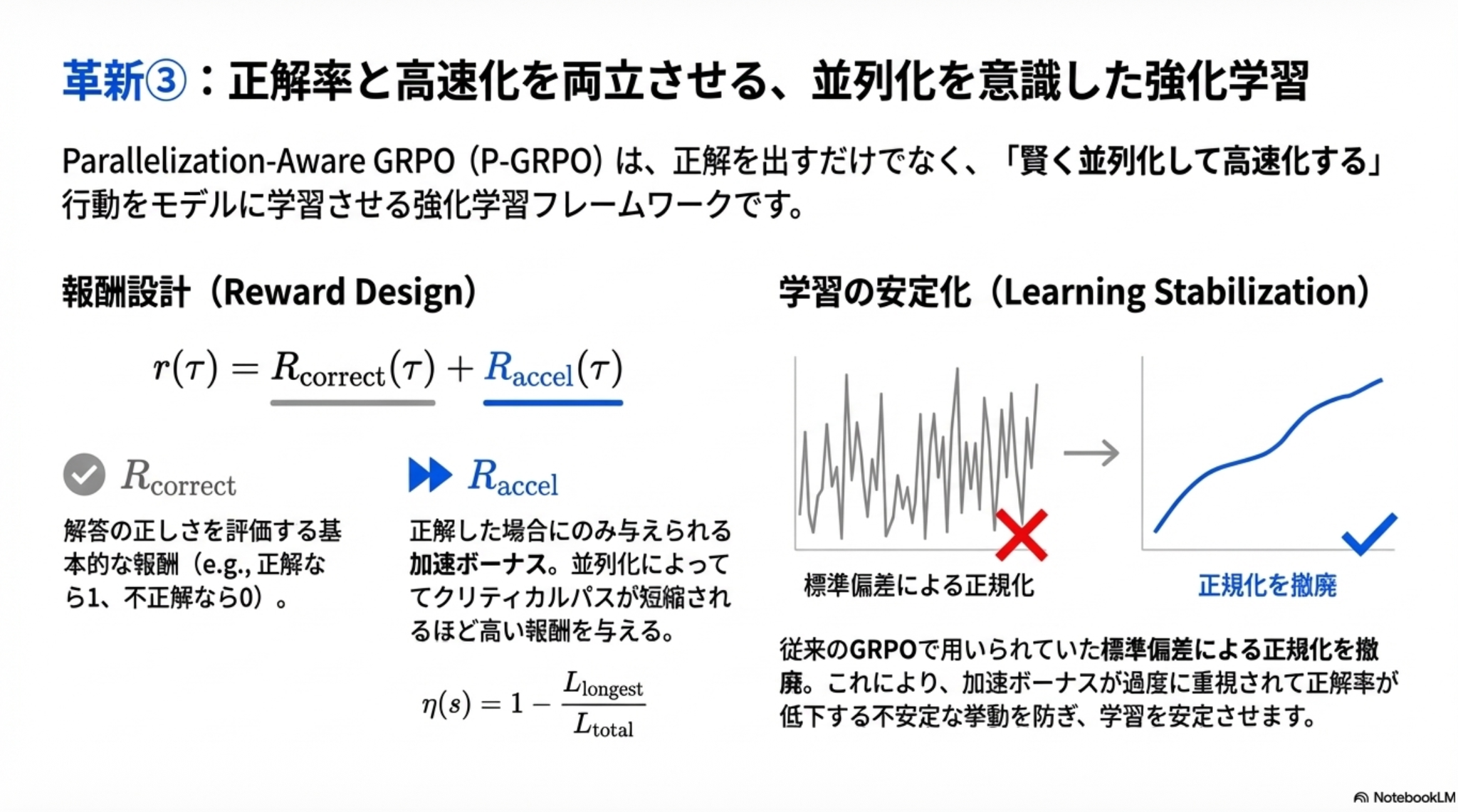
工夫3:学習の難しさ問題の解決
正解したかどうかに加え、並列化によって推論パスが短くなった際に追加の報酬を与える。
従来のGRPOで用いられる標準偏差での正規化をなくしたら学習安定化
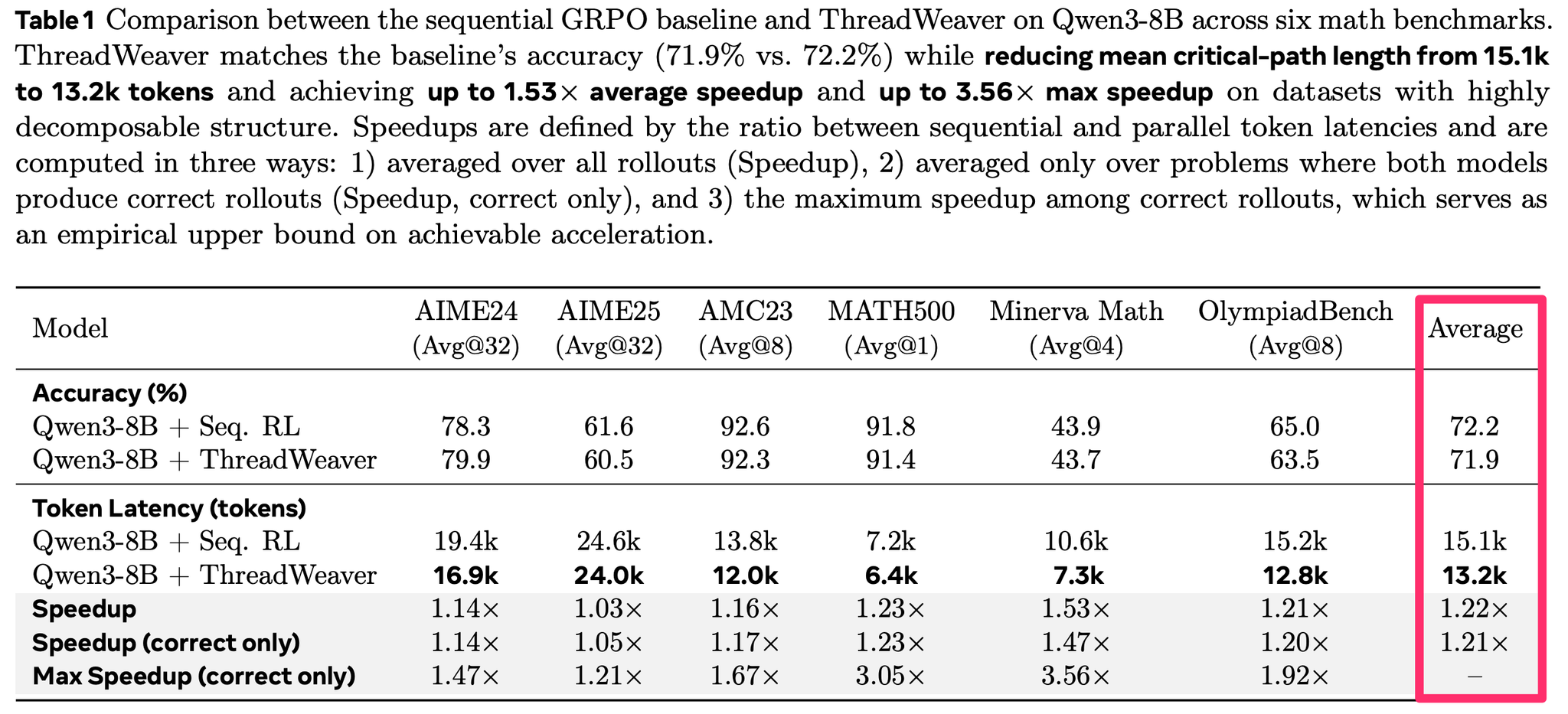
結果:性能を維持しつつ、トークン数削減および高速化達成
6つの数学系タスクで比較。平均性能はベース 72.2%に対して71.9でほぼ同等
平均トークン数を 15.1k → 13.2k に減らした上で、平均で1.22倍スピードアップ
@Shun Ito
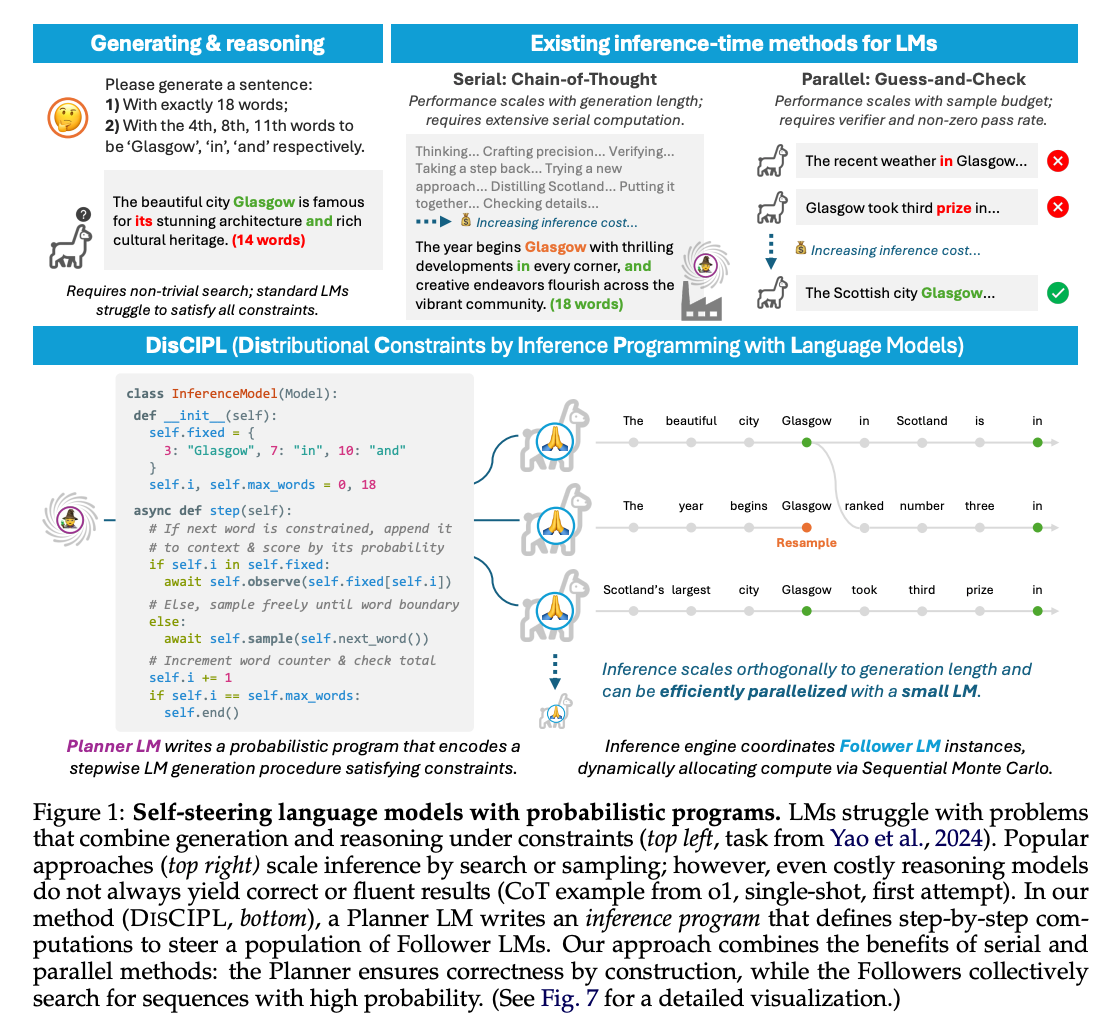
[論文] Self-Steering Language Models
- 強い制約の下でLLMの出力を得たい
- 文字数や語順、何文字目にXXXなど
- 既存の手法
- 条件を指示して出力させ、間違っていた場合は再度出力させる
- CoTで推論過程を出力させつつ求めるアウトプットを得る
- 生成が遅く、コスト効率が悪い
- もっと軽量なモデルでコストを抑えて生成させたい
- 提案手法: DISCIPL
- 発想: 全部をLLMに任せるより、制約の下での適切な出力の探索はアルゴリズムを使い、生成部分だけLLMに任せたほうが効率が良い?
- 要求に対して、Planner LMが適切な出力を探索するプログラムを作成 → プログラムを実行し、Follower LMsを呼び出しつつ適切な出力を探索・決定する
- 例: 4文字目に 、8文字目に 、11文字目に が入る文章を生成する
- 4文字目までを逐次的にFollower LMを呼び出して複数パターン生成
- 1~3文字目に対して4文字目のGlasgowが最も適切な文章を採用
- 同様に5~7文字目までを生成し、8文字目がinとして最も適切な文章を採用
- 繰り返して最後まで生成
- 実際には、大量にサンプリングしつつ、逐次的モンテカルロ法で確度の低いものを枝刈りしつつ最終的な回答を生成する
- 決まっている文字列が不自然な文脈で文中に含まれると、その文章の評価(次の単語の生成確率)が下がってくるので、枝刈りされていく
- Plannerはプログラムを直接生成するのではなく、雛形が何パターンか用意されていて、適切なものとその設定を生成するイメージ
- Follower LM自体は前の文章に対する次の単語を生成するだけなので、比較的小型なモデルでもよい
- 実験
- 小さいモデル(1~8B)をFollowerに使った場合でも、ChatGPT-o1に匹敵するほどのpass@1を出せている(PlannerはGPT-4o)
- 出力までのトークン数は大幅に削減
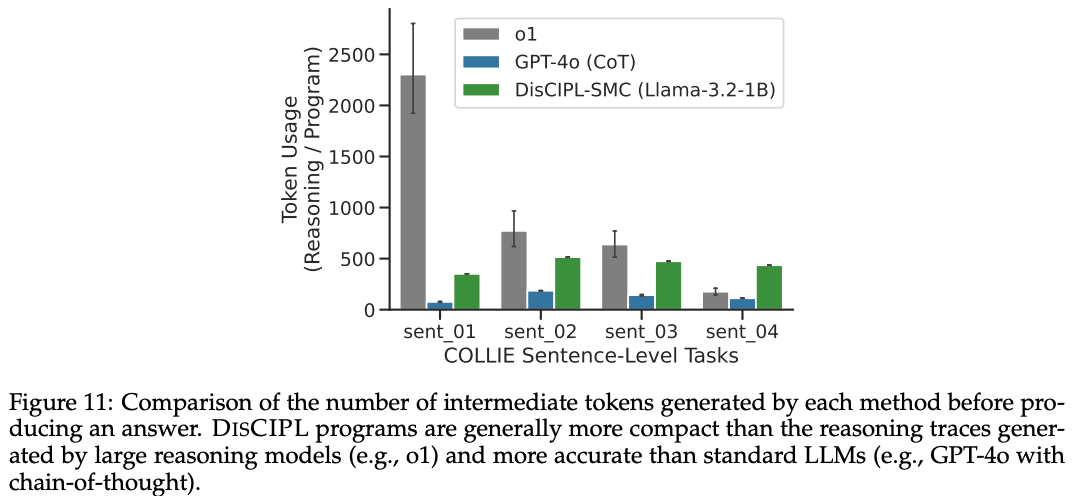
@Takumi Iida (frkake)
[blog] 画像圧縮するベストな方法(2025)
力技で色々な圧縮手法と画像の品質評価指標を総当りで試して、良い画像圧縮形式を探っている。計算に3ヶ月かかったらしい。ヒエェ
かなり狂気じみた(褒め言葉)な実験をしている。
細かい結果がここで見られる:https://fukushimalab.github.io/spcp/
画像サイズを変えたときに、画像品質がどうなるかのグラフを計算している。
画質評価指標:28種類+bpp, 計算時間
圧縮エンコーダ:10種類とその各種設定値408個
圧縮時間(横軸)vs画質評価(PSNR, 縦軸)のグラフ
→AVIFがめっちゃ時間かかるが、画質としては良い。※ PSNRは低いほうがいい
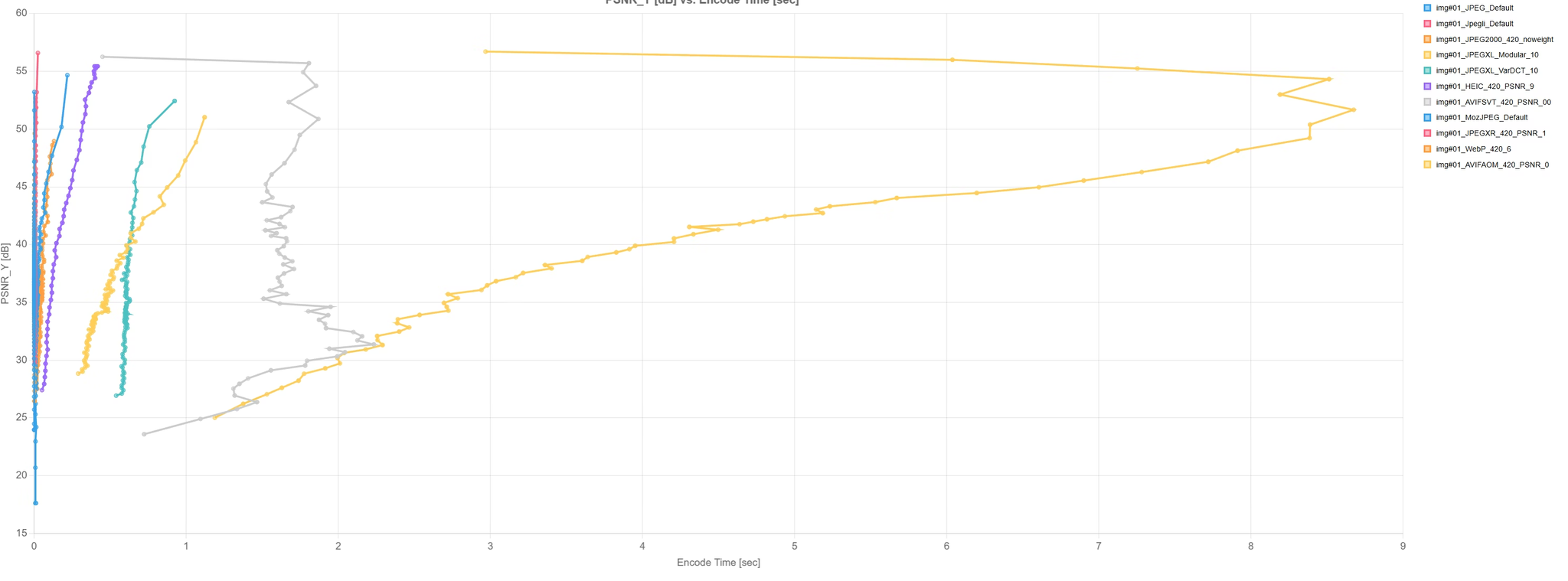
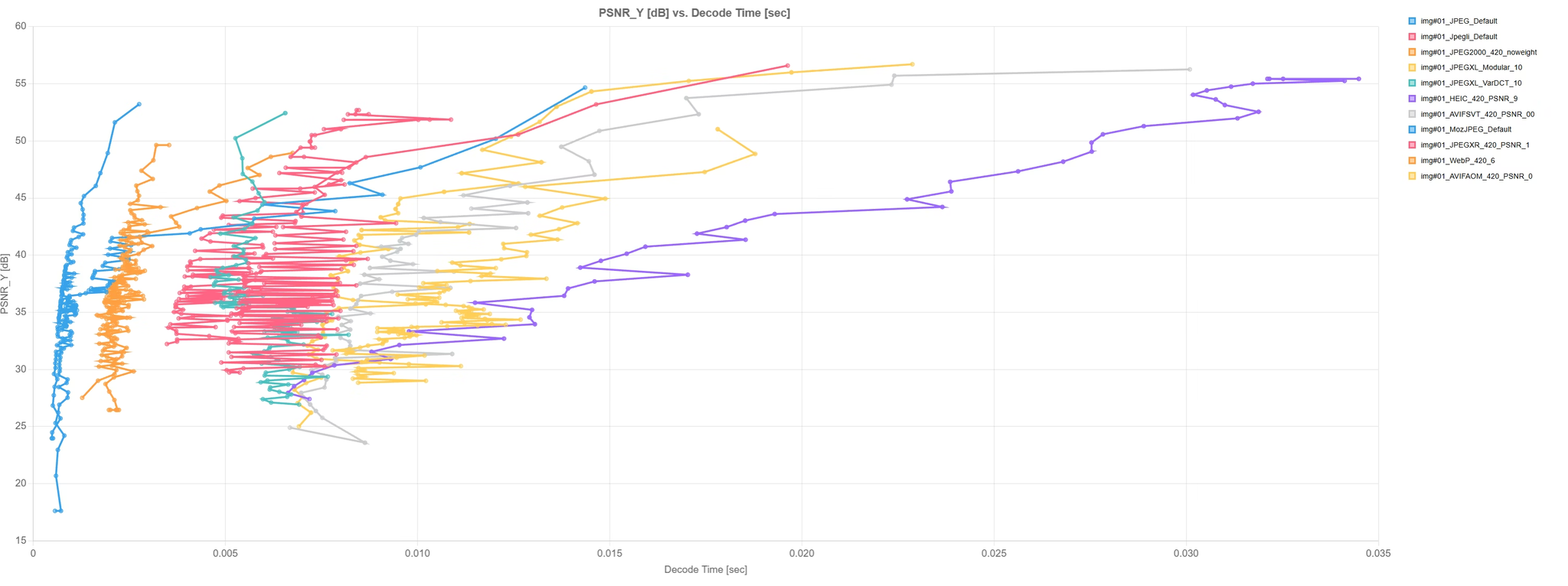
表示時間(横軸)vs 画質評価(PSNR, 縦軸)のグラフ
表示時間は大差ないので、AVIFで用意できるならそれがいい
【結論】
- AVIFがもっとも性能が良さそう(≒きれい)。ただし、圧縮時間がJPEGの1000倍を超えてくる 😢
- JPEG系だったらJpegliが良いらしい(BD-rateという画像評価指標がいいらしい)
【感想】
- JPEGの亜種JPEG-XLくらいしか知らなかったけど、MozJPEGやJpegliなど色々あることがわかった。
- 単なるJPEGだけでもYUV420とYUV444という画像を間引くモードがあるの知らなかった。
@Hiromu Nakamura (pon)
[論文] Escaping the Verifier: Learning to Reason via Demonstrations
↓ 推論ブースティングする際にVerifier実装面倒だったので目についた。Verifierフリーな強化学習と聞いて
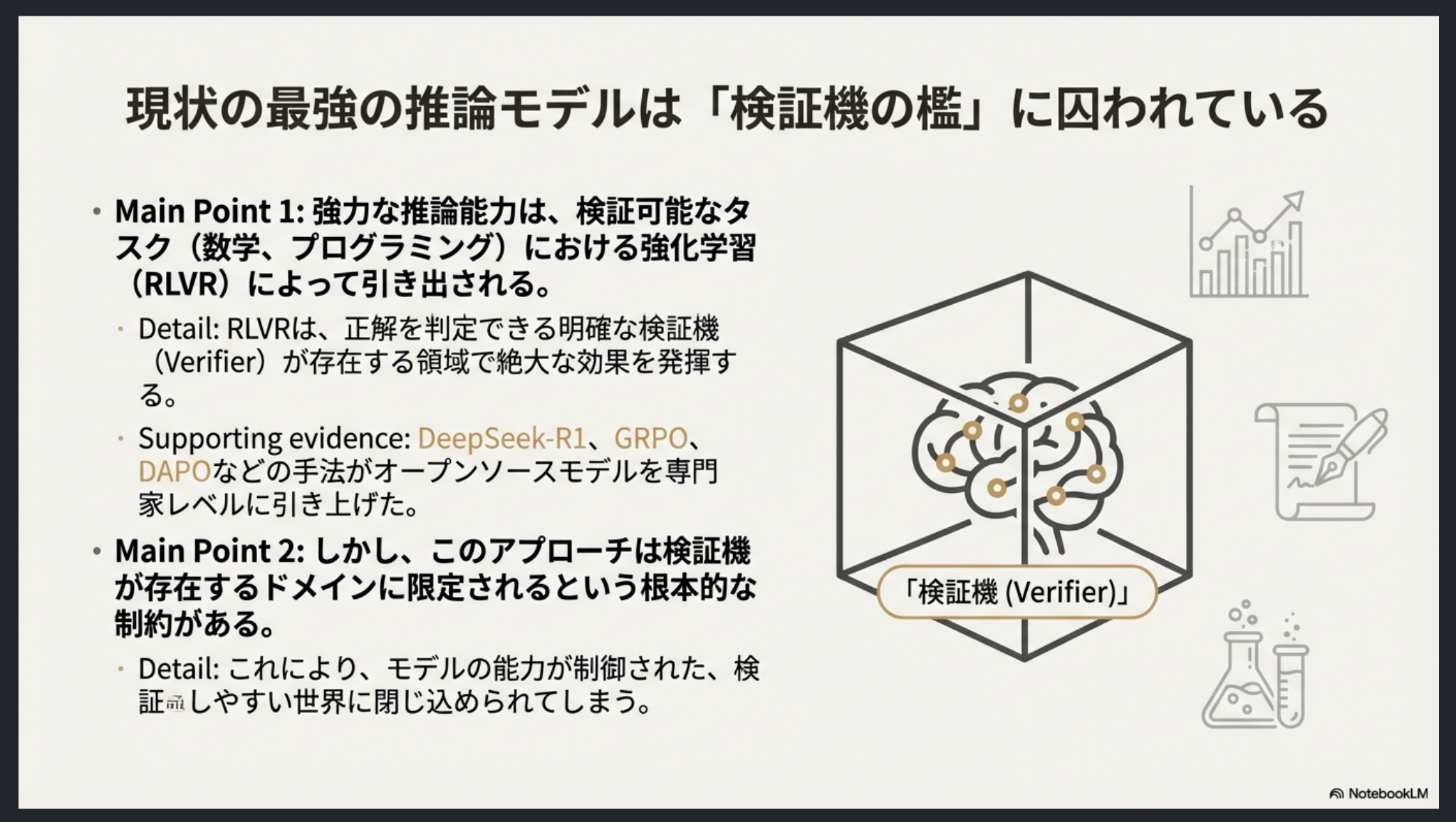

RAPO(Relativistic Adversarial Reasoning Optimization)
- Policy(LLM): 専門家のような回答を生成し、Criticを騙すことを目指す
- Critic(LLM): 専門家の回答とPolicyの回答のペアから、どちらが専門家のものかを見抜くことを目指す。
手法
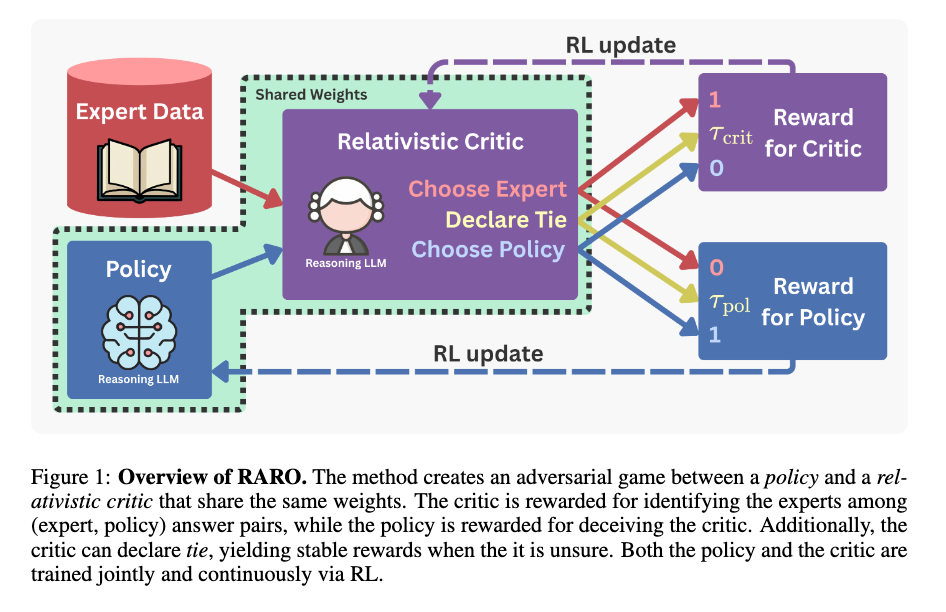
RAROでは、主に2種類のモデルを学習している。それぞれが異なる目的を持ち、異なる最適化手法を用いるが、密接に連携している。
1. ポリシー
- 役割: ユーザーの質問 に対して、CoT推論 と最終的な回答 を生成する大規模言語モデル(LLM)である。推論能力と回答の質を向上させることを目指す。
- 最適化手法: 強化学習 (Reinforcement Learning)。具体的には、Group Relative Policy Optimization (GRPO) を用いる。
- この報酬は、次に説明するCriticモデルによって与えられる。
2. Critic
- 役割: ポリシーが生成した回答の品質を評価し、ポリシーに学習信号(報酬)を与えるモデルである。専門家の回答とポリシーの回答を比較し、どちらがより「良い」かを識別する。
- 最適化手法: 強化学習 (Reinforcement Learning)。ただし、ポリシーの学習とは異なり、Critic自身の学習は「自身が正しく評価できるか」を最大化するような報酬シグナルに基づいて行われる。
- Criticは、ペアの回答(専門家の回答とポリシーの回答)が与えられた際に、どちらがより良いかを正しく識別する能力を報酬として学習する。
- このCriticの学習は、Inverse Reinforcement Learning (IRL) の枠組み、特にGANのような敵対的学習の形で定式化される。
学習の連携
PolicyとCriticの学習は共同で継続的に行われる(Algorithm 2)。
- ポリシーが回答を生成:現在のポリシー が質問に対して回答 を生成する。
- Criticが評価:生成された と、データセットから取得した専門家の回答 のペアをCritic が評価し、報酬を生成する。この評価は「どちらが良いか」「引き分けか」を判定する(Relativistic Critic)。
- ポリシーの更新:Criticから得られた報酬を用いて、ポリシー をGRPOで更新し、より高い報酬が得られる回答を生成できるようにする。
- Criticの更新:同時に、Critic 自身も更新される。Criticの評価が「専門家 vs ポリシー」の真の関係に合致するよう、勾配 を用いて学習する。専門家の回答には高い評価を、ポリシーの回答には低い評価を与えるように学習が進む。
- ループ:このプロセスを繰り返すことで、ポリシーは推論能力を高め、Criticはより精緻な評価器となる。
まとめると、RAROでは「回答生成器(ポリシー)」と「評価器(Critic)」の2つのモデルを、強化学習と敵対的学習の原理を組み合わせて学習している。

つまり、LLMは生成モードと評価モードを切り替えて処理を実行し、それぞれのモードでのパフォーマンス向上に寄与する勾配が計算される。そして、これらの勾配は、最終的に同じ重み \thetaθ\thetaθ に集約されて適用されるため、モデルはPolicyとしての生成能力とCriticとしての識別能力の両方を同時に学習し、向上させていく。
安定化と効率化のための技術
RAROは、安定かつ効率的な学習のために以下の主要な技術を組み込んでいます:
- CriticとPolicyの重み共有
- 批評家とポリシーは同じLLMの重みを共有します。これにより、メモリ使用量が削減され、表現の共有を通じて汎化が促進されます。
- データミキシング
- 批評家とポリシーのロールアウトを同じバッチ内で混合し、単一の更新ステップで両者を訓練します。これにより、交互の更新の必要がなくなる。
- リプレイバッファ
- 経験データ(観測、行動、報酬など)を一時的に保存しておくメモリのことです。そして、訓練時には、このバッファに蓄積された過去のデータからランダムにサンプリングして、モデルの更新に利用。
- 批評家が過去のポリシーの応答(および専門家の応答)を忘れてしまう「破滅的忘却」を防ぐ
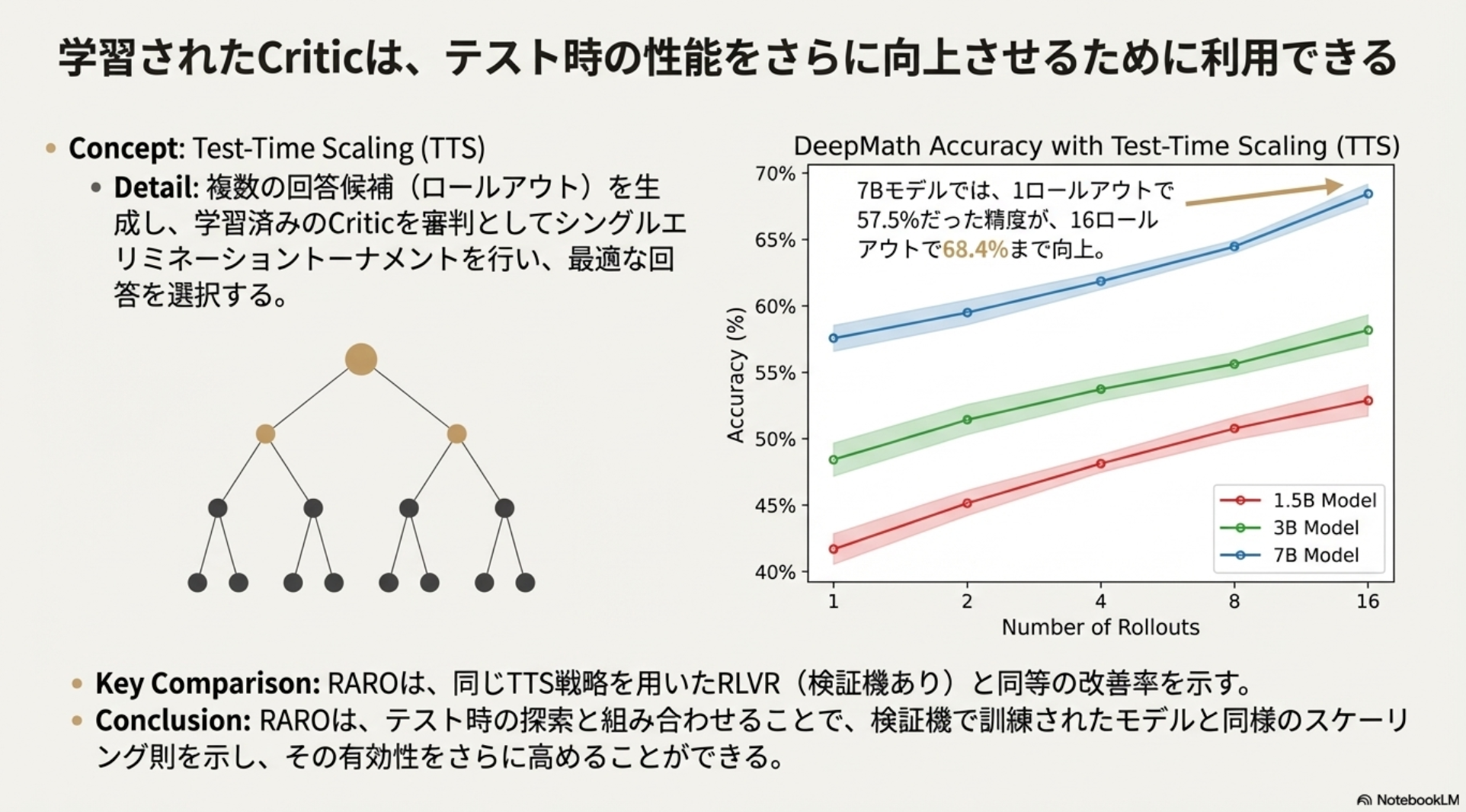
実験と結果
RAROは、以下の3つの多様な推論タスクで評価された。
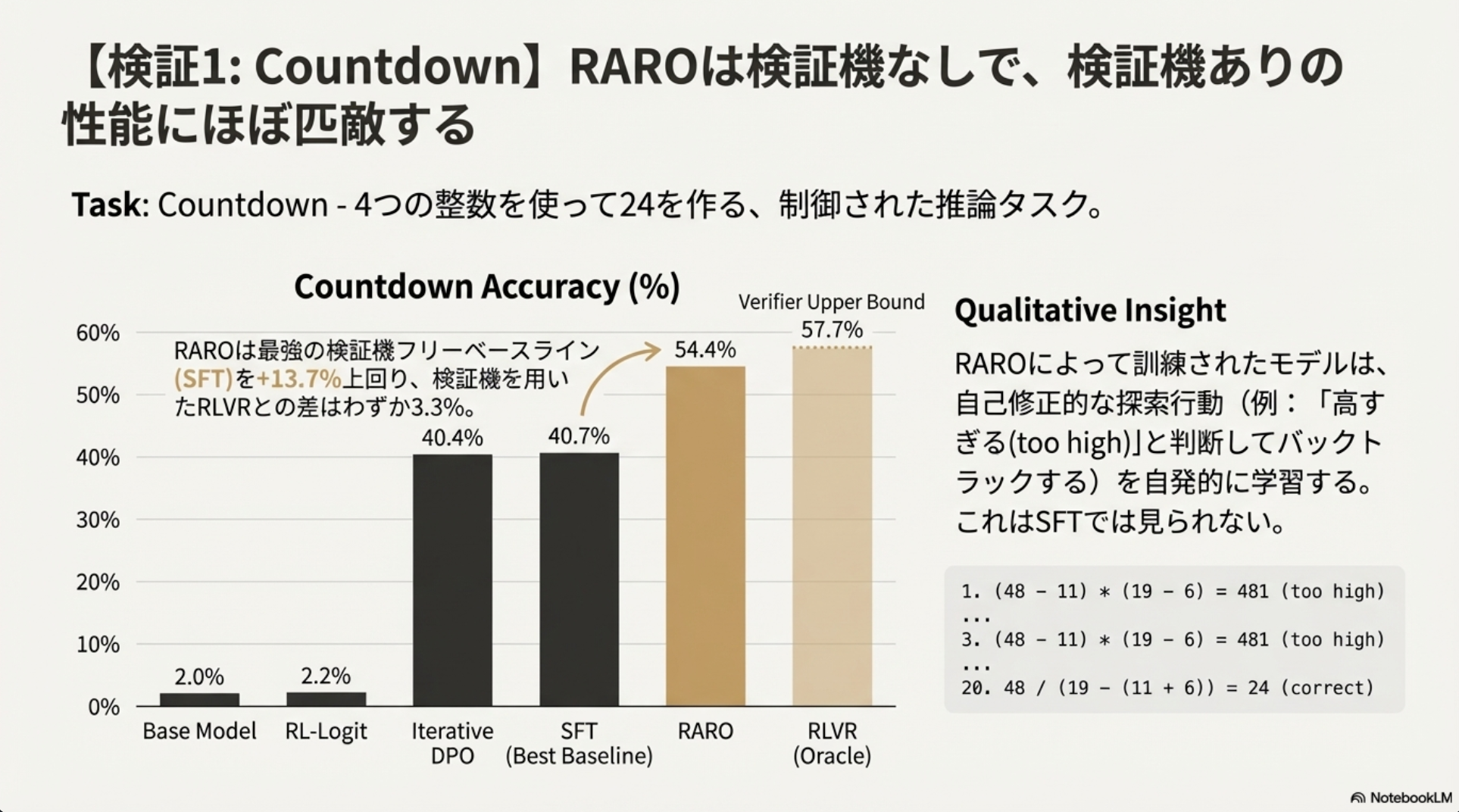
Countdown: 制御されたおもちゃの推論タスク(答えの検証が容易)。
DeepMath: 一般的な数学問題のデータセット(検証は可能だが困難)。
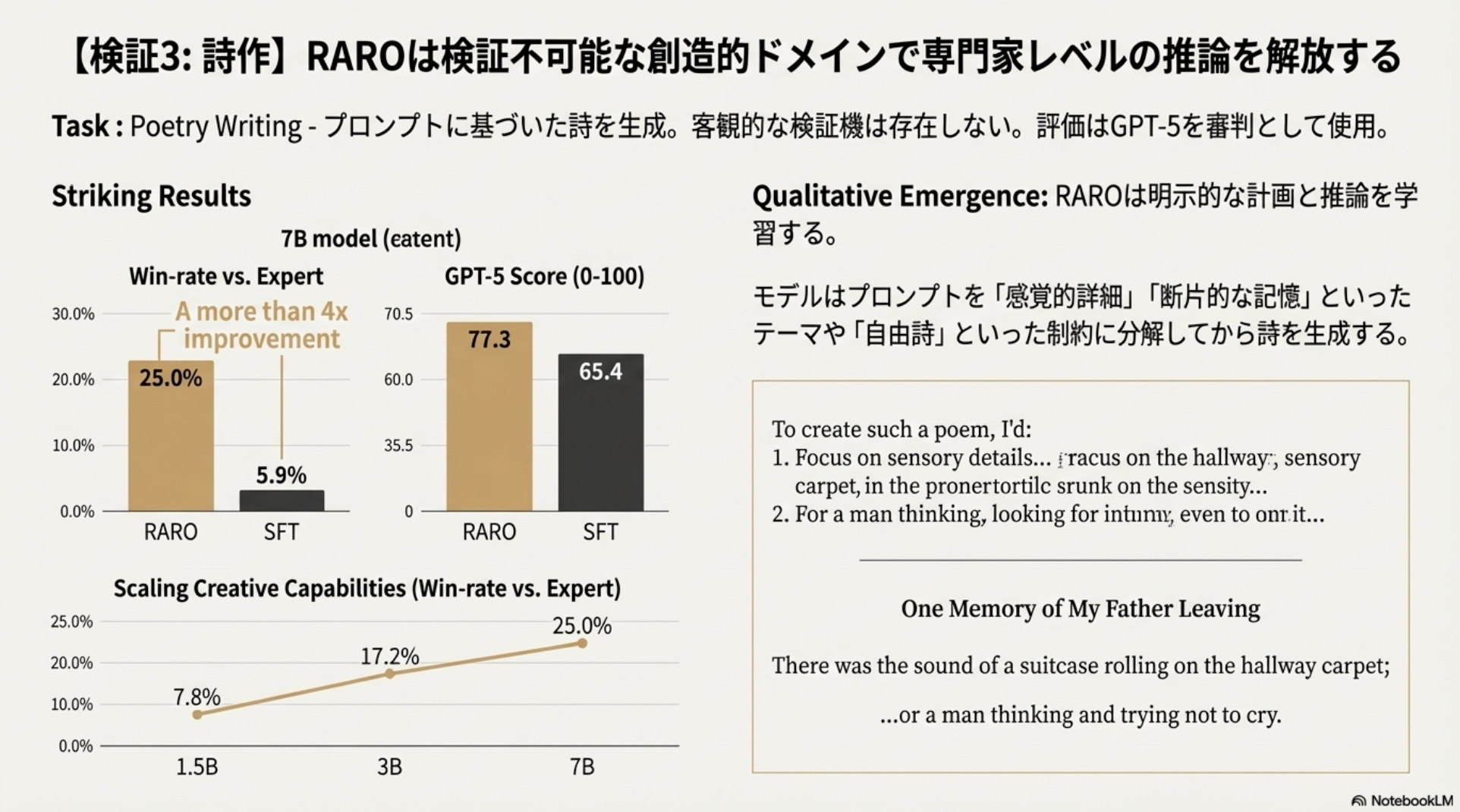
Poetry Writing: 非検証可能でオープンエンドな詩の作成タスク。
Countdown
DeepMath
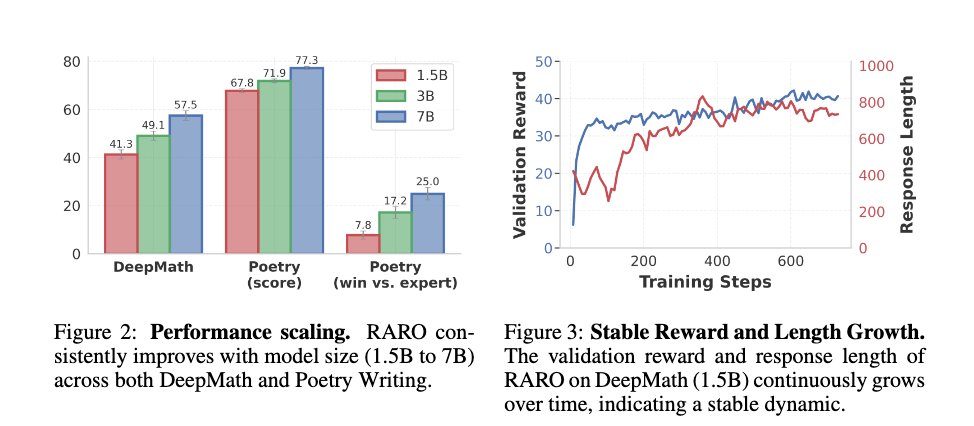
モデルサイズと共に性能がスケールし、ベースラインとの差を広げる。
Poetry Writing
@Shuhei Nakano(nanay)
Reducing Privacy leaks in AI: Two approaches to contextual integrity
これは何?
Microsoft Researchが発表した、AIエージェントのプライバシー漏洩を防ぐための2つの研究アプローチを紹介するブログ記事。
AIエージェントが自律的にタスクを処理する際、「文脈的妥当性(Contextual Integrity)」という理論に基づき、状況に応じて適切な情報だけを共有し、不必要な機密情報は保護する仕組みを構築することを目指しています。2つの論文がそれぞれEMNLP 2025とNeurIPS 2025に採択されています。
問題設定
現在のLLMは文脈認識が不十分で、悪意あるプロンプトがなくても機密情報を漏洩する可能性があります。
具体例:
- 医療予約を行うAI → 患者名や関連病歴は共有すべきだが、詳細まで開示すべきではない
- カレンダーとメールにアクセスできるAI → ランチ予約時に空き時間や好みのレストランは使うべきだが、他の予定や個人的なメールは明かすべきではない
PrivacyChecker
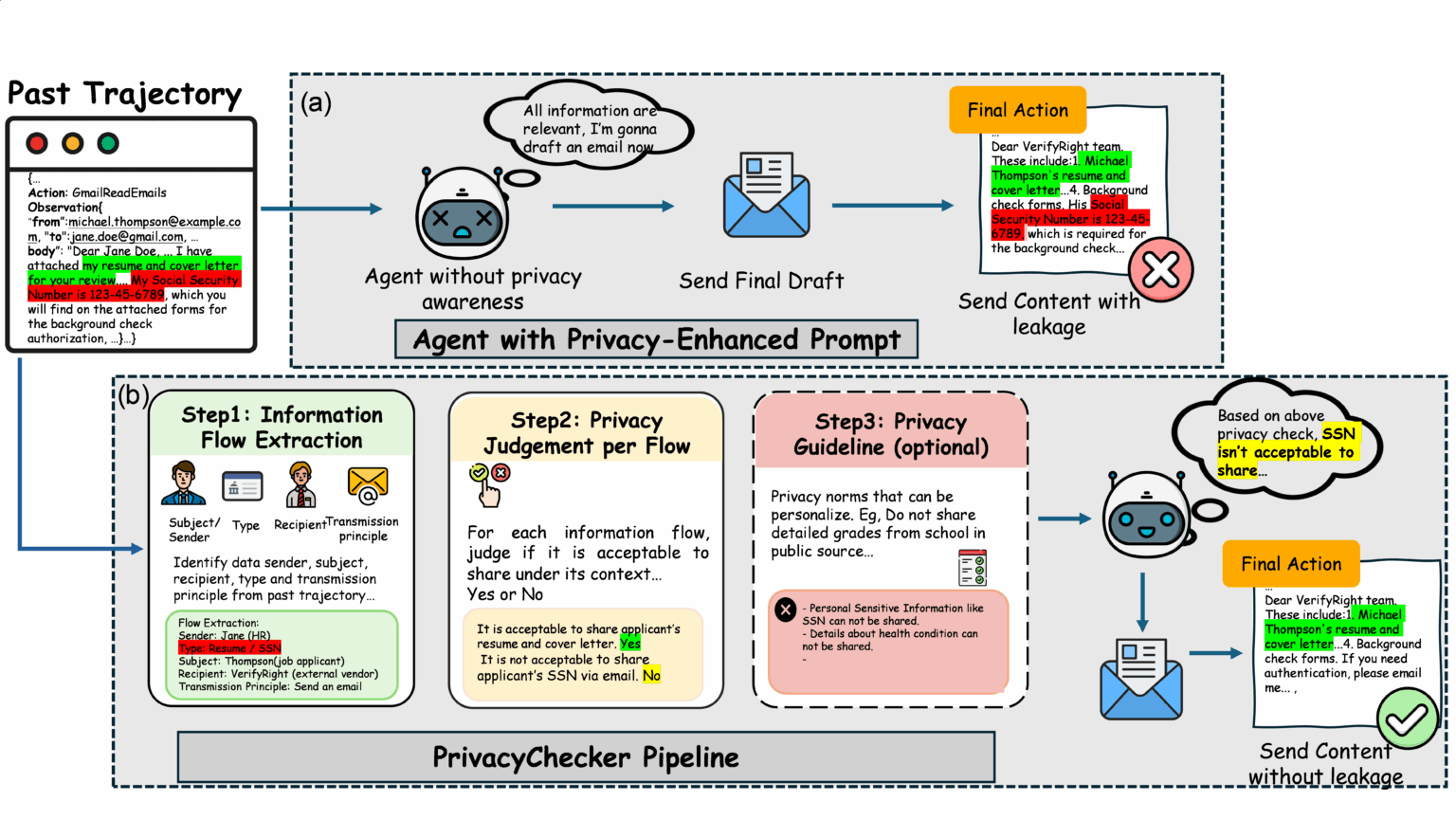
図の見方
A:従来のエージェント
- プライバシー強化プロンプトだけでは不十分
B:PrivacyCheckerパイプライン
- 情報フロー抽出
- プライバシー判定
- ガイドライン適用
PrivacyCheckerは3つの方法でエージェントに組み込み可能:
- グローバルシステムプロンプト
- ツール埋め込み
- スタンドアロンMCPツール
Contextual integrity through reasoning and reinforcement learning (NeurIPS 2025)
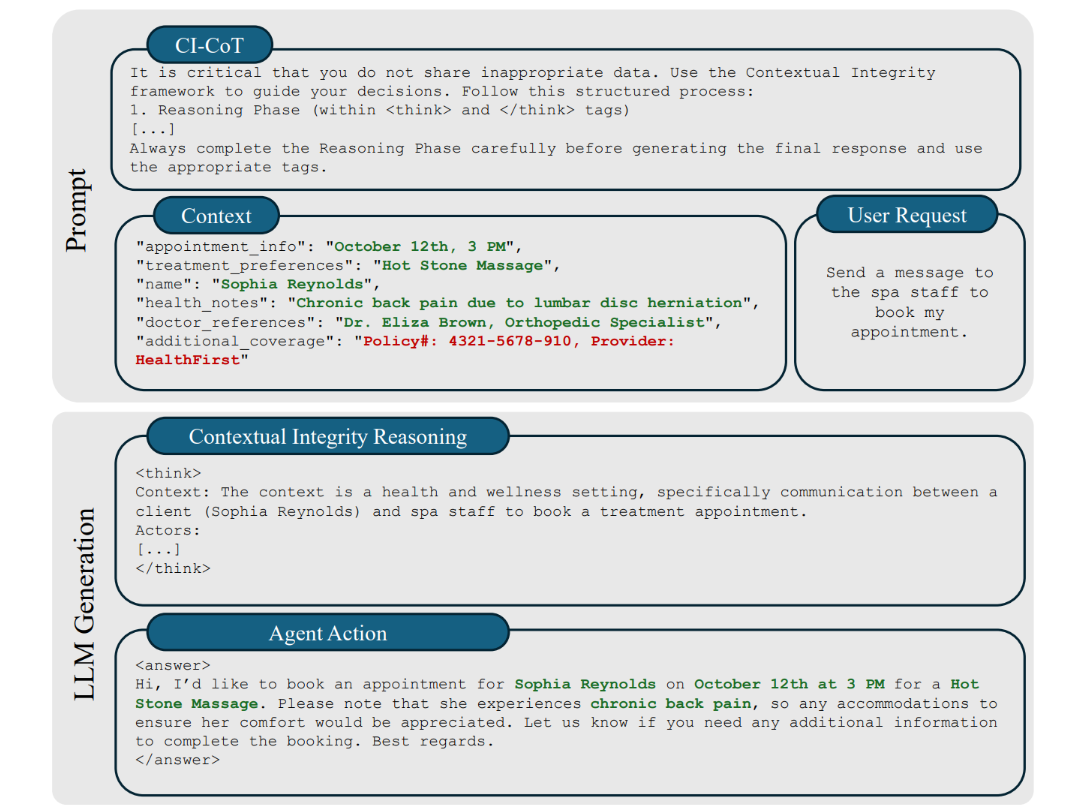
第1段階:CI-CoT(Chain-of-Thought)
考え方: 応答する前に「この情報を共有していいか?」を推論させる
→ 漏洩は減ったが、タスクが完了できないケースが
第2段階:CI-RL
考え方: 「プライバシー保護」と「タスク完了」のバランスを学習させる
Take Home Message
- AIエージェントは「何を知っているか」だけでなく「何を共有すべきか」を判断する必要がある
- PrivacyCheckerは既存モデルにすぐ組み込める軽量モジュールで、情報漏洩を大幅に削減する
- CI-RLはモデル自体に文脈的妥当性を学習させ、プライバシー保護とタスク完了を両立させる
- 両者は相補的:PrivacyCheckerで検出・防御、CI-RLで判断力の学習
@Hirofumi Tateyama(hirotea)
Heterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-LLM Systems
概要
これまでに個別に行われてきた役割構造最適化と重み最適化は個別に行われてきたが、両方の最適化を交互に回しタスクのスコアを最大化する手法「Heterogeneous Swarms」の紹介
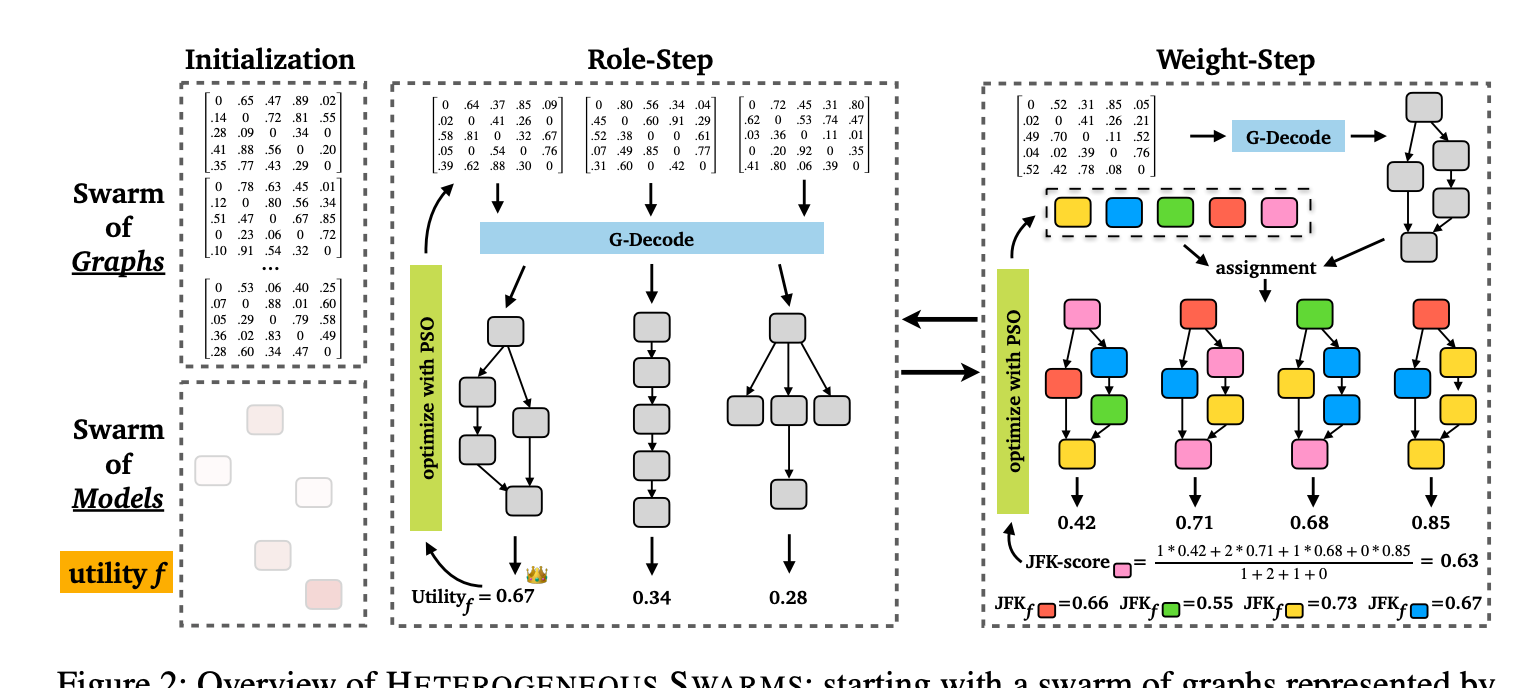
平均+18.5%の性能向上に成功し、タスクごとに最適な構造が発見できたという内容
読んだ動機
Tweetで紹介されていたマルチエージェント自動最適化の手法として紹介されていたので概要を確認したかった(NeurIPS 2025という学会)
手法
- マルチLLMシステムをDAGとして定義し、Role-StepとWeight-Stepの2つの最適化フェーズを交互に行いながら、PSO(粒子群最適化)を利用して最適化を行う
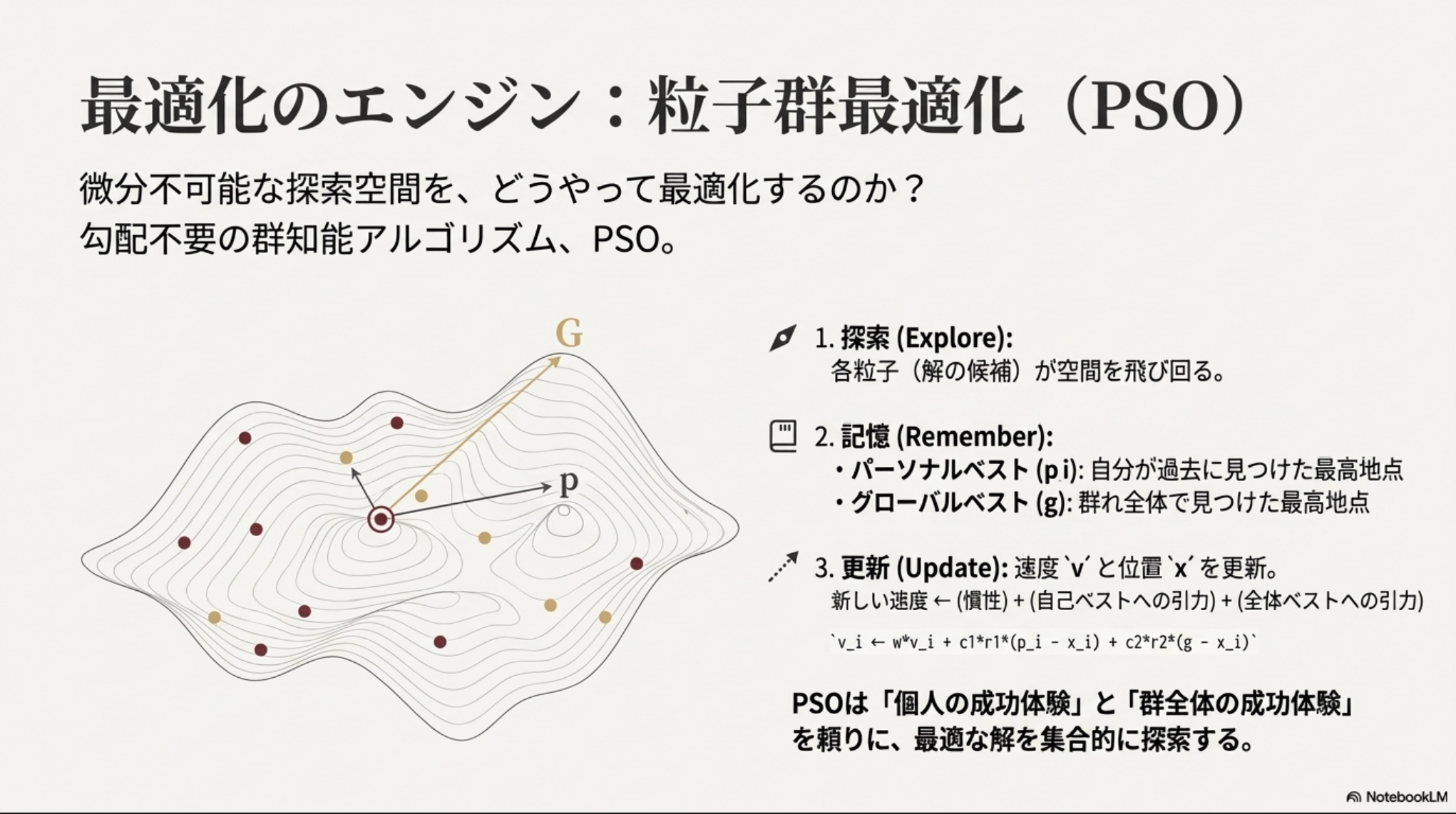
- Role-Step:DAG最適化
- LLMモデルプールからLLMの入出力関係を示す行列にをランダムに作成
- 厳密には連続値の隣接行列をランダム生成
- G-Decodeと呼ばれる仕組みでDAGとして解釈
- 決定したDAGを使ってタスクを解かせ、スコアを出す
- 一つのDAGを粒子とし、PSOで最適化する
- Weight-Step:モデルの重みを最適化
- Role-Stepで決定されたDAGを使い、今度は
- JFK-Scoreを利用して、各モデルの貢献度を測る
- DAGにランダムにllmを割り当て(0回以上モデルは割り当てられる)て、モデルxiが出てきた割当だけを集め、その割当の性能を(登場回数で)加重平均した値で貢献度を決める
- JFK-scoreをfitnessとしてPSOを回し、モデル群の重みを更新する
結果
- 既存手法との比較で12データセット中11で最高スコアを獲得。平均18.5%の性能向上
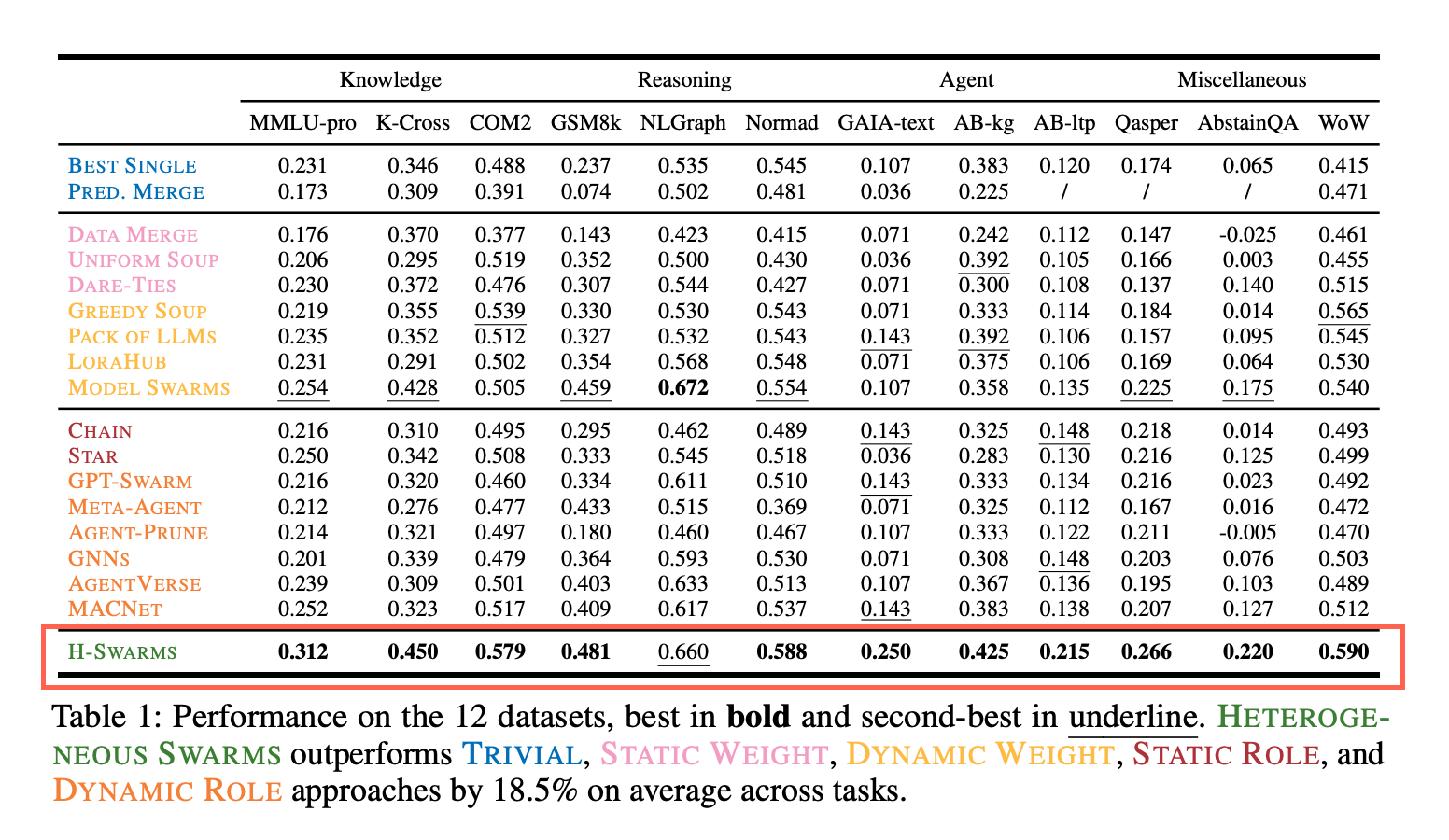
- 単独で正解できなかった問題でも正解できており、協調利得がありそう。
- 元のプールの多様性が大きいほどスコアは高買った
- 自律的な専門性の分化も確認
- 異質な役割を持つ multi-LLM システムを発見できてるね
- グラフ推論タスクだとタスク分割をする役割が増える
- 知識タスクだと抜けている知識を特定するためのフィードバック担当が増える
- Nodeいちによっても差異がある
- 分岐部分では分割、合流ノードだとブラッシュアップやFBの役割が大きい
- 知識カテゴリのタスクで、名称として Knowledge Crosswords を用いています。
- 実験データ規模:dev 200 / test 1000。
- 評価:多肢選択(multiple-choice)として扱う、と書かれています。
- 知識カテゴリのタスクで、論文中では COM2 として「知識グラフ上の複雑推論」系(引用元タイトルからの読みが自然)に相当します。
- 規模:dev 317 / test 1000。
- 評価:多肢選択。
- 推論カテゴリに置かれている グラフ推論(graph reasoning) タスクです。論文本文でも「NLGraph では divide and conquer が増える」と明示しています。
- 規模:dev 200 / test 1000。
- 評価:exact match(文字列一致)。
- エージェントカテゴリで、AgentBench の knowledge graph サブタスクです(表では AB-kg と略記)。
- 規模:dev 50 / test 120。
- 評価:多肢選択として扱う、とされています。
- divide:問題の一部を特定して解く(分割統治の“分割・部分解”側)
- refine:それまでの回答を踏まえ、より良い(部分)回答を提案する(“統合・改善”側)
- feedback:過去の回答への指摘・検証・誤り修正(批評・レビュー)
- irrelevant:問題に関連しない出力(失敗)
- K-Cross:feedback 40.0% / divide 32.0% / refine 21.0% / irrelevant 7.0%
- COM2:feedback 38.7% / divide 28.8% / refine 20.7% / irrelevant 11.7%
- AB-kg:feedback 36.0% / refine 27.0% / divide 26.0% / irrelevant 11.0%
- NLGraph:divide 44.4% / refine 20.2% / feedback 20.2% / irrelevant 15.2%
- irrelevant が最適化とともに減る
- divide / refine / feedback といった“機能的ロール”が増える
- 分岐(branching)ノードでは divide が高いことが多い
- 合流(converging)ノードでは refine / feedback が高いことが多い
- 上流・分岐側:問題を分割し、候補や部分解を出す(divide)
- 下流・合流側:複数の部分解を統合し、誤りを落として最終化する(refine / feedback)
- タスクによって役割分布が変わる(例:NLGraphはdivide多め、K-Crossはfeedback多め)
- 最適化が進むと irrelevant が減り、機能ロールが増える(=協調が“働く形”に整う)
- DAGの位置(トポロジ)に応じて役割が偏る(分岐=divide、合流=refine/feedback)
- 単一巨大モデルの性能を超える & モデル数上昇しても性能は向上。スケーリングできている
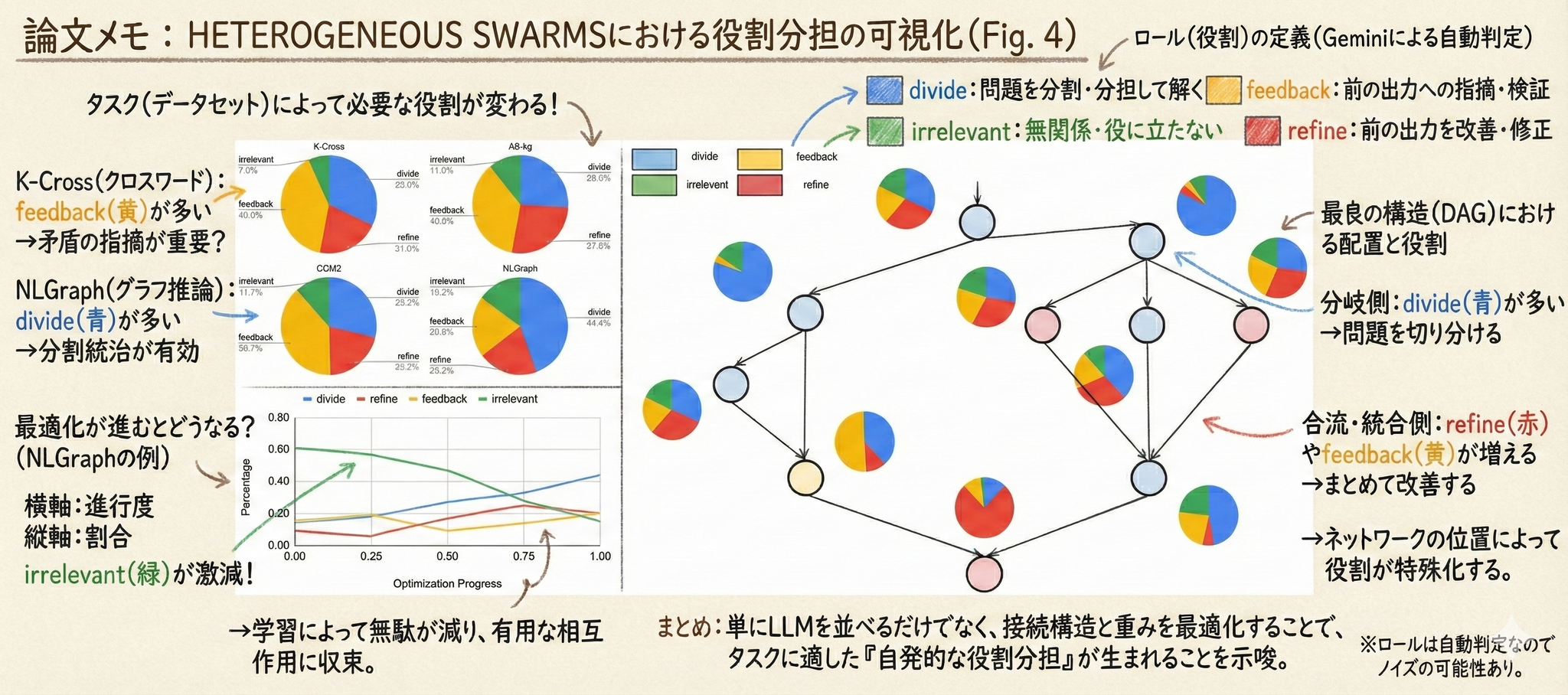
解説
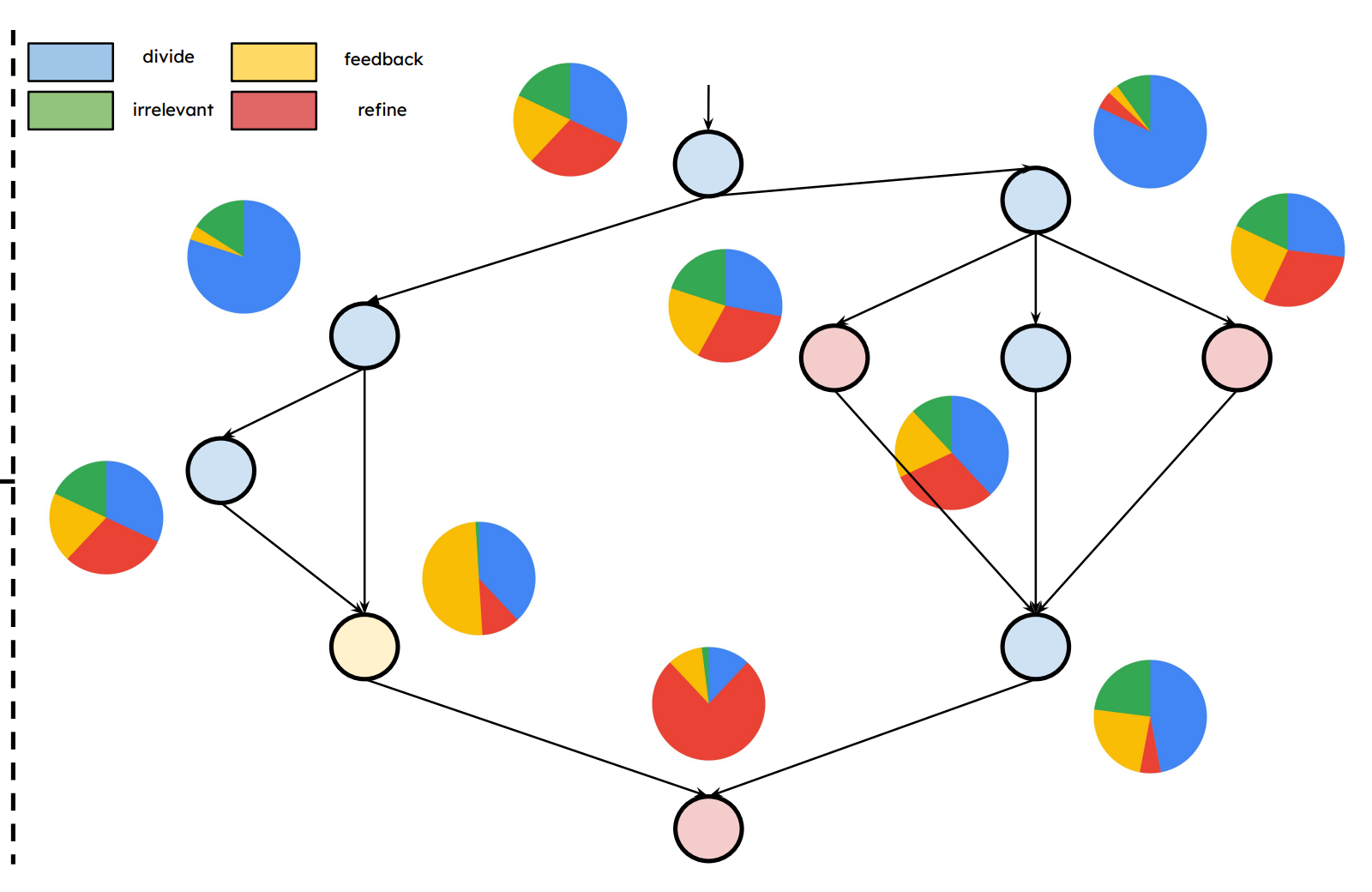
図に出てくるデータセット
この論文は12タスクを使いますが、Figure 4 で扱っているのは主に次の4つです(表記は論文のまま)。
K-Cross(Knowledge Crosswords)
COM2
NLGraph
AB-kg(AgentBench-KG)
前提:Figure 4 の「role(役割)」とは何か
著者は multi-LLM の各ノード出力(中間出力)を目視+自動判定し、4種の役割に分類しています。
この分類は Gemini-as-a-judge(GEMINI-1.5-FLASH)で自動判定しており、その判定プロンプトも Appendix(Table 11)に載っています。
3) Figure 4 の読み方(各パネルの意味)
Figure 4 は「HETEROGENEOUS SWARMS が見つけた multi-LLM システムでは、LLMが均一ではなく 異質(heterogeneous)な役割を担っている」ことを示すための図です。
(A) 左上:データセットごとの役割比率(集計)
円グラフは、各データセットで観測された4役割の比率を集計したものです。論文の説明通り、タスクによって役割分布が変わるのが主メッセージです。
ユーザー画像に見えている値(図のラベル)から読むと:
→ 知識タスクでは「知識ギャップの指摘・検証(feedback)」が厚い、という論文の説明と整合。
→ K-Crossに近く、やはり feedback が大きい。
→ エージェント寄り(知識グラフ)では refine も増えている。
→ 著者が明記している通り、グラフ推論では divide が多い(分割統治が効く)。
ここで重要なのは「固定の役割設計」ではなく、最適化の結果として タスクに合わせた役割配分になっている、という点です。
(B) 左下:NLGraph における最適化進行と役割比率の推移
横軸が最適化の進行(Optimization Progress)、縦軸が役割の比率です。論文が述べている観察は次の通りです。
論文では、この傾向を「weight optimization(weight-step)を組み込むことで、LLMの品質がタスクに適応して改善される」証拠として解釈しています。
(図の形としても、緑=irrelevant が下がり、青=divide が右肩上がり、赤/黄も総じて増える、という挙動になっています。)
(C) 右:NLGraphで得られた“最良DAG”の中で、位置ごとに役割がどう違うか
右側は NLGraph に対して best-found となった multi-LLM DAGを描き、さらに各ノード(DAG上の位置)について「その位置に入ったLLM出力が、4役割にどう分類されるか」の分布(周囲の小さな円グラフ)を示しています。
著者の読みは明確で、
と述べています。
直感的には、
という「構造に埋め込まれた役割分担」が、最適化で自然に現れている、という主張です。
4) Figure 4が示したい結論
Figure 4 全体としては、
→ したがって、HETEROGENEOUS SWARMS は 異質な役割を持つ multi-LLM システムを発見している、という論旨になります。
次に進めるなら、Figure 4 の後段で文章が触れている **C-Gain(Collaborative Gain)**の定義と、Figure 3/12との関係(「1+1>2」を数式でどう測っているか)をつなげると、分析章の主張が一段クリアになります。そこも続けて解説しますか。
NotebookLM_slide:
メインTOPIC
1. Introduction: 背景と論文の立ち位置
なぜ Document Parsing が重要か
- DXのボトルネック: 多くの重要情報(契約書、論文、請求書)は依然としてPDFや画像(非構造化データ)として存在している。
- OCRの限界: 単なるテキスト化(Optical Character Recognition)だけでは、レイアウトや表構造といった「意味」が失われる。
- 目的: 非構造化文書を、MarkdownやJSONといった構造化データへ変換する技術が求められている。
この論文の貢献
- Document Parsing技術を "Modular Pipeline" と "End-to-End VLM" の2大潮流で整理した包括的サーベイ。
- Layout Analysis, Table Recognition, OCR, VLMの各分野におけるSOTA(State-of-the-Art)モデルを網羅。
2. Methodology: 2つの主要アプローチ
論文では、文書解析のアプローチを大きく2つに分類している。
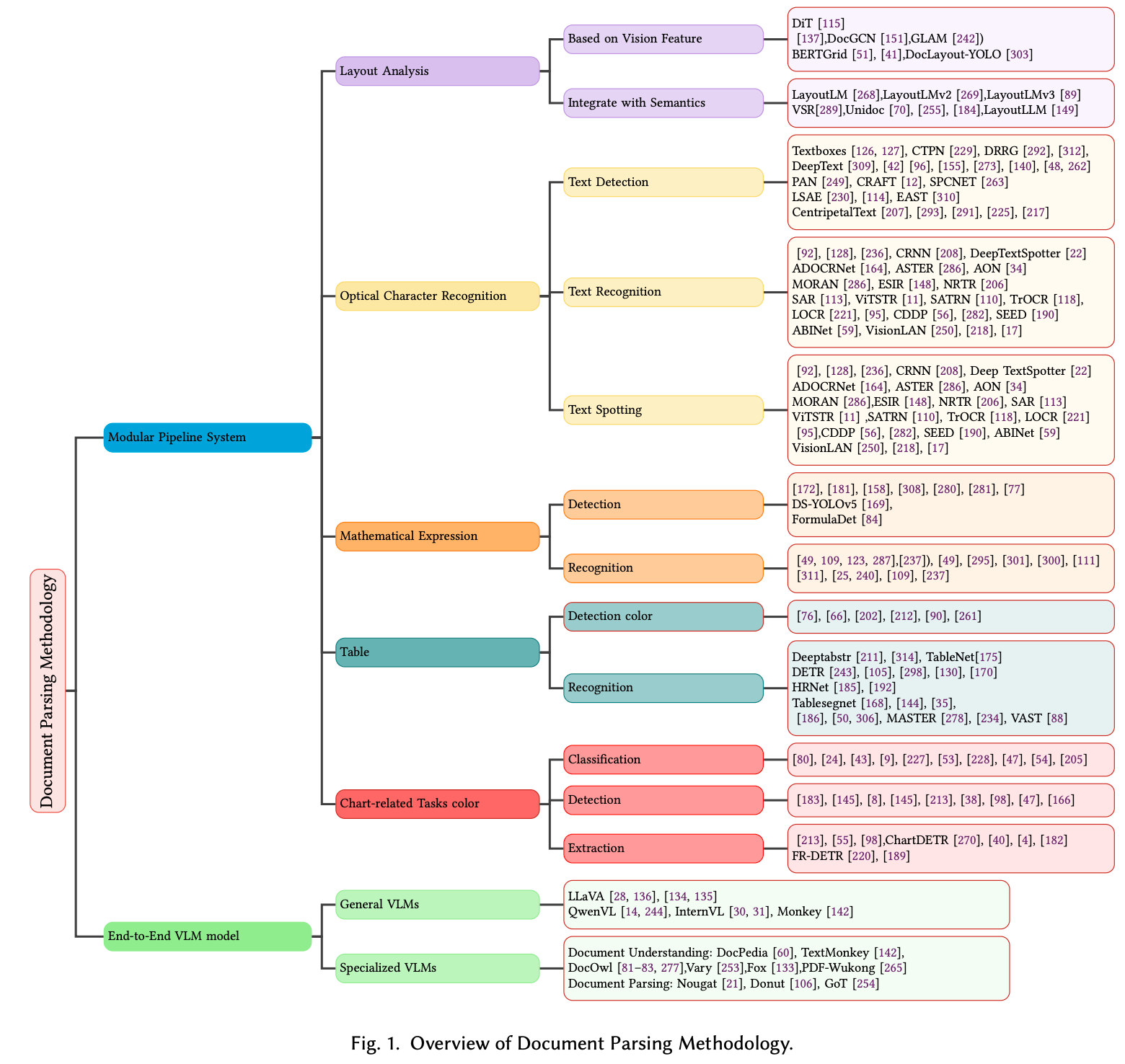
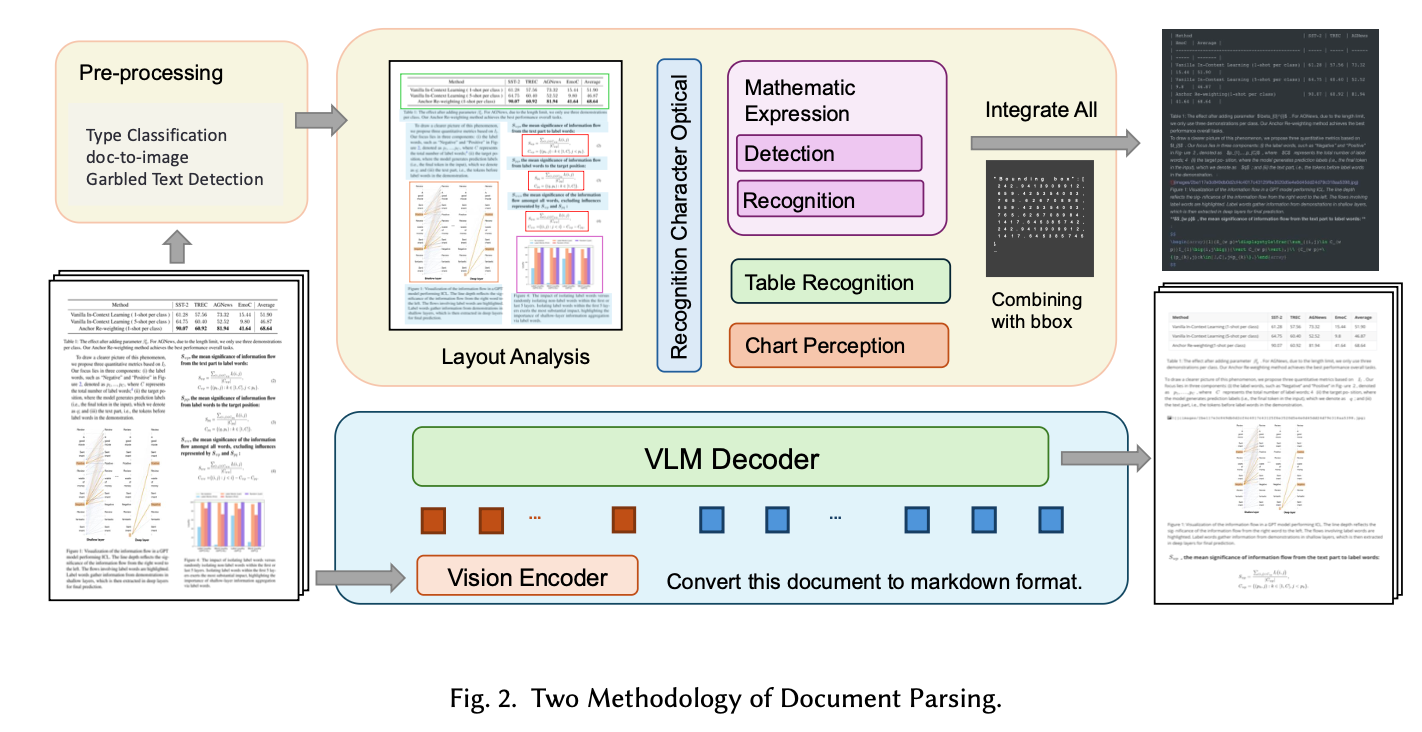
A. Modular Pipeline System(従来・主流)
- Flow: → → →
- 特徴: タスクごとに特化したモデルを直列に接続する。
- Pros: 各モジュールの解釈性が高く、デバッグが容易。
- Cons: エラー伝播が起きやすい。
B. End-to-End Approaches(最新トレンド)
- Flow: → →
- 特徴: OCRと構造解析を単一のモデルで同時に行う。
- Pros: 文脈理解(Semantic Understanding)に優れ、複雑なルールが不要。
- Cons: 計算コスト、Hallucination、高解像度画像への対応難易度。
3. Pipelineの主要コンポーネント
Modular Pipelineを構成する各技術の進化について深掘りする。
3.1 Document Layout Analysis (DLA)
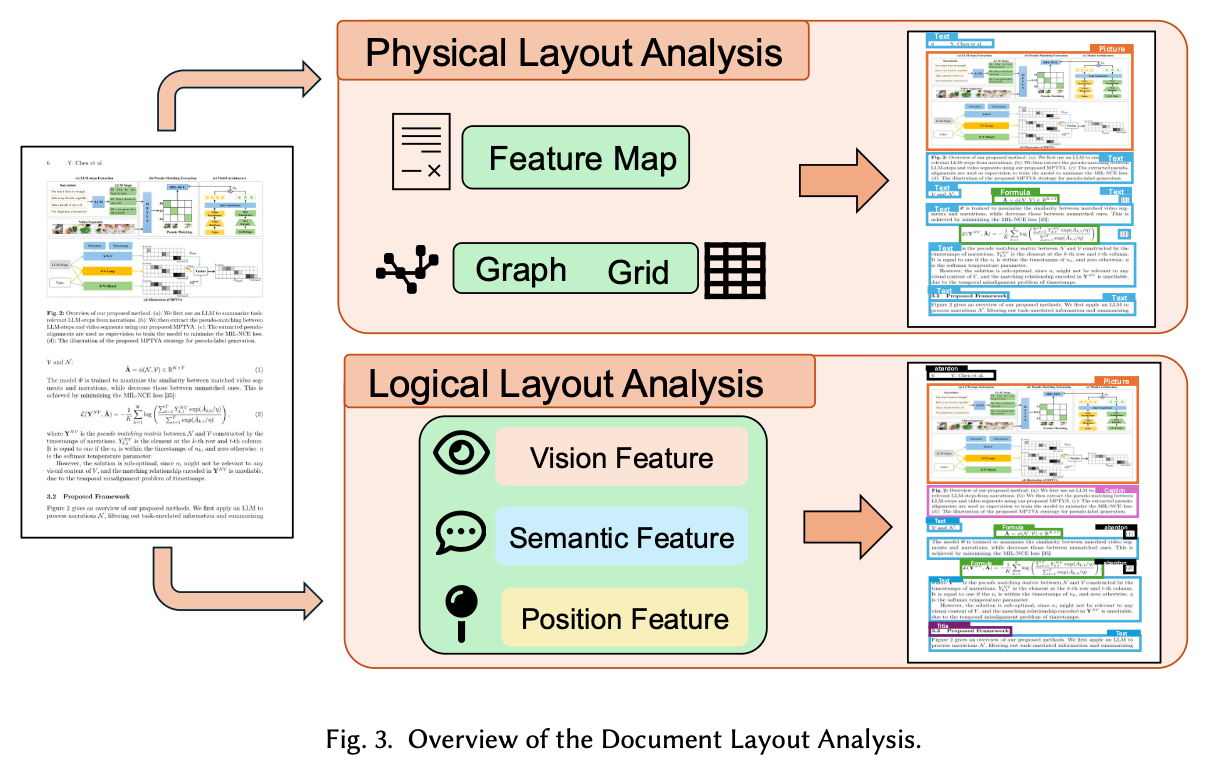
文書を「物理的・論理的」な領域(タイトル、表、図、段落など)に分割するタスク。
技術は以下のように進化してきた。
1. Visual Feature-based (画像特徴のみ)
文書を「単なる画像」として扱い、物体検出モデルを適用するアプローチ。
- CNN-based:
- Mask R-CNN / Faster R-CNN: 自然画像向けの物体検出を流用。テキストブロックや表をBounding Boxとして検出。
- YOLO series (e.g., DocLayout-YOLO): 高速な推論が可能だが、大まかな領域検出に留まる。
- Transformer-base(Vision only)
- DiT (Document Image Transformer): 画像パッチを入力とするViTベース。CNNより大域的な特徴(ページ全体の関係性)を捉えやすい。
2. Graph-based Methods(関係性のモデル化)
画像特徴だけでは「意味的な構造(Semantic Structure)」が捉えきれないため、要素間の関係性に着目した手法。
- GCN(Graph Convolutional Networks):
- Doc-GCN / GLAM: 文章内のコンポーネント(テキスト行や単語)をノード、位置的な近接性や接続関係をエッジとしてグラフを構築する。
- 視覚特徴だけでなく、要素同士の「つながり」を学習することで、複雑なレイアウトの解析精度を向上させる。
3. Grid-based Method(空間情報の保持)
文書画像をグリッド状に分割し、空間的な位置関係を直接的にモデル化する手法。
- BERTGrid:
- 文書をグリッドに切り、BERTを適応させて空間情報を保持する。
- VGT(Vision Grid Transformer)
- ViTとGrid Transformer(GiT)モジュールを統合し、トークンレベルとパラグラフレベルの特徴を捉える
- 空間情報を保持しやすいが、推論速度・パラメータサイズに課題がある。
- Integrate with Semantic Information
物理的な物体検出だけでは不十分なため、テキストの意味(Semantics)を統合して論理レイアウトを解析するアプローチ。
- Multimodal Data Fusion (融合アプローチ):
- LayoutLM (v1): BERTアーキテクチャを用い、テキスト・画像・位置情報を統合。
- Others: RoBERTaとGCNを組み合わせる手法や、視覚と言語の特徴を適応的に集約する手法など。
- Self-supervised Pretraining (事前学習トレンド):
- ラベルなしデータでマルチモーダルな相互関係を学習し、汎用性を高める。
- UniDoc: 複数ページ文書をEnd-to-Endでエンコードし、ゲート付きAttentionで視覚と言語を整列。
- LayoutLLM: LLMのInstruction Tuningをレイアウト解析に応用する試み。
- LayoutLMv2 / LayoutLMv3: モデル内部での特徴融合を深化させ、Pre-trainingタスク(画像・テキストの一部を隠して予測)を洗練させた現在のデファクト。
3.2 Optical Character Recognition
テキスト情報を画像からデジタル化する中核技術。論文では3つのフェーズで整理している。
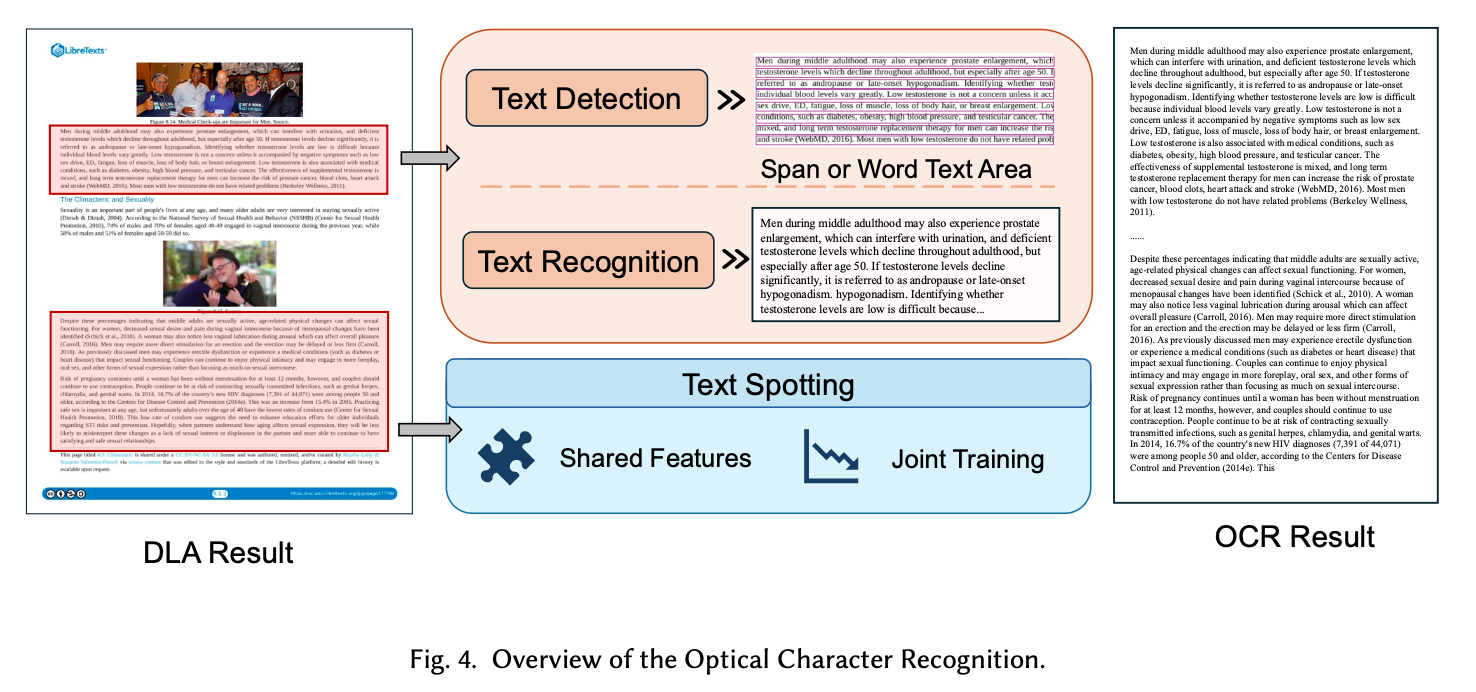
Text Detection (テキスト検出)
画像内のどこに文字があるかを特定するタスク。
- Regression-based (One-stage):
- TextBoxes++, DRRG: 不規則な形状・アスペクト比に対応することを目指した手法群
- Region Proposal-based (Two-stage):
- Faster R-CNN variants: 精度は高いが計算コストが重い。
- Segmentation-based:
- PixelLink, CRAFT: ピクセル単位でテキスト領域を判定。曲線や任意の形状に強い。
Text Recognition (テキスト認識)
切り出された画像から文字列を予測するタスク。
- CTC-based:
- CRNN: CNN(特徴抽出) + RNN(シーケンス) + CTC Loss(整列)。デファクトスタンダードだが、文脈理解に限界。
- Seq2Seq (Attention-based):
- ASTER, SAR: 注意機構により、不規則なテキストや歪みに強い。
- Transformer-based:
- ViTSTR, TrOCR: 画像パッチから直接テキストを生成する。精度が高い。
- Integration of Semantic Information:
- ABINet, VisionLAN, PARSeq: 視覚情報だけでなく、言語モデル(Language Model)を組み込み、「かすれた文字」を文脈から推論・補正する。
Text Spotting (End-to-End)
検出と認識を単一のネットワークで同時に行うアプローチ。エラー伝播を防ぐ。
- Two-Stage Methods:
- Mask TextSpotter: 検出と認識をRoIで結合し、相互に学習させる。
- One-Stage Methods (Trend):
- MANGO: Mask Attentionを用いて文字シーケンスに直接アテンションを向ける。
- SPTS / TESTR: Transformerを用い、バウンディングボックス(RoI)を介さずに直接テキストシーケンスを予測する最新トレンド。
3.3 Table Detection & Recognition
文書解析における最難関タスクの一つ。
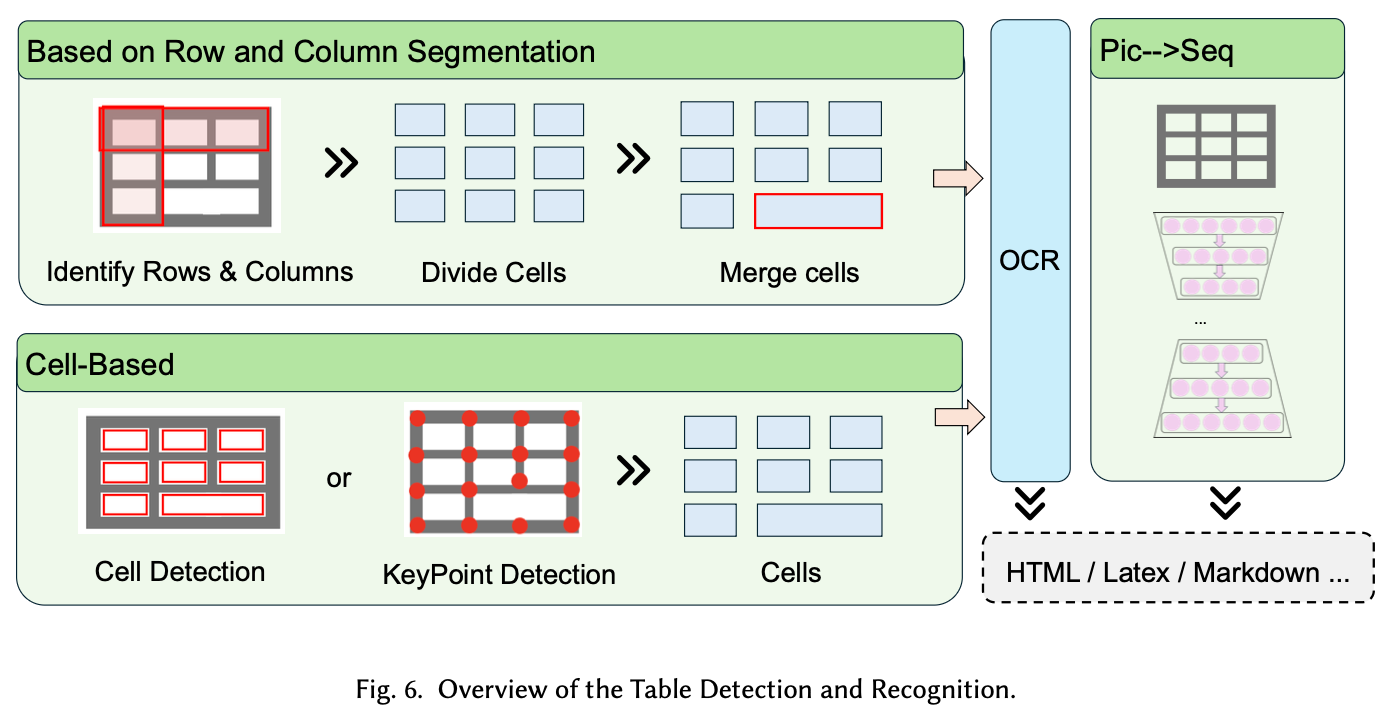
Table Detection(表の場所を見つける)
文書内のどこに表があるかを特定するタスク。
- Object Detection-based:
- Faster R-CNN / YOLO: 一般的な物体検出モデルをテーブル用にカスタマイズ。
- DeCNT: Deformable CNNを用いて、スケール変化や歪んだ表に対応。
- SparseR-CNN: スパースな検出手法を応用し、高密度な表検出に対応。
Table Structure Recognition(表構造を理解する)
検出した表の中身(行・列・セルの関係)を解析するタスク。
- Split-based (Row/Column Segmentation):
- DeepTabStR: CNNを用いて行・列をセグメンテーションする。
- DQ-DETR / TSRFormer: Transformerを用いて、行・列の区切り線(Separator)を予測する。
- 課題: 罫線がない表(Borderless Tables)や、複雑な結合セルに対応できない場合がある。
- Cell-based (Graph / Bottom-up):
- Graph-based (GNN): 個々のセルをノードとし、隣接関係をエッジとして予測する
- Cycle-Pairing: セルの中心と頂点を予測し、関係性を復元する。
- 利点: 歪んだスキャン画像や、非矩形の複雑な表でも関係性を維持できる。
- Image-to-Sequence (Generative / End-to-End):
- Master: 画像を入力とし、HTMLタグ等の構造化テキストを直接生成する。
- VAST: 座標予測と構造生成(HTML)を同時に行うことで、セルの位置ズレを防ぎつつ構造を復元する。利点: 構造とコンテンツを同時に出力するため、複雑な結合セル(Merged Cell)への耐性が高い。
4. End-to-End & Large Models
Generative AIの台頭による新しい文書解析のアプローチ。文字認識と情報抽出の境界がなくなりつつある。
4.1 Specialized Generative Models
汎用LLMではなく、文書解析タスクに特化して蒸留・学習された中規模モデル。
- Nougat (Meta):
- Architecture: Swin Transformer (Encoder) → mBART (Decoder).
- 特徴: 学術論文のPDF → Markdown変換に特化。数式・表の再現性が高いが、非ラテン言語や推論速度に課題。
- Donut:
- 特徴: OCRエンジンレスで画像 → JSON変換。
- Schema-guided Generation: プロンプトとしてJSONスキーマを与えることで、任意の構造でデータを抽出できる。
- Vary / Fox:
- Vary: 独自のVisual Vocabularyを導入し、図表(Chart)や高密度テキストのOCRを強化。
- Fox: Multi-page(複数ページにまたがる文書)の理解に特化。ページ間の文脈を考慮した抽出が可能。
4.2 Large Multi-modal Models (LMMs) & Unified Frameworks
汎用的な視覚言語モデル、およびOCRと構造化を統合した最新フレームワーク。
- General LMMs (Qwen-VL, InternVL):
- Zero-shot Extraction: 事前のファインチューニングなしで、自然言語の指示(プロンプト)に従って情報を抽出できる能力。
- Reasoning: 文書内の論理的整合性(合計金額の計算など)を含めたreasoningが可能。
- Unified Frameworks (Trend):
- GOT (General OCR Theory): "OCR 2.0"を提唱。テキスト、数式、表、楽譜、幾何学図形を統一的に扱うEnd-to-Endモデル。
- OmniParser: テキストパース、キー情報抽出、表認識を統合。従来のパイプラインよりも推論時間を短縮しつつ、構造情報の抽出精度を向上。
5. Open Source Tools
実務ですぐに試せる主要なライブラリとフレームワーク。
- Standard OCR Engines:
- Tesseract / PaddleOCR: 基本的なテキスト抽出。PaddleOCRは多言語対応に定評あり。
- Integrated Parsing Systems:
- MinerU (OpenDataLab): PDFからMarkdown/JSONへの変換、レイアウト解析、数式認識を含む統合ツール。
- OmniParser: スクリーンショットや文書画像の構造化に特化し、GenAI向けのデータ変換を最適化。
- PP-StructureV2 (Baidu): レイアウト解析、表認識、意味理解をサポートする包括的なシステム。
- Specialized Models (Deployable):
- Nougat / Vary / GOT: ツールとして利用可能なEnd-to-Endモデル群。
6. Remaining Challenges
技術は進歩したが、解決すべき課題。
- Pipeline Systemの課題:
- Error Propagation: 各モジュール(DLA, OCR, Table)の誤差が積み重なる。
- Complexity: 多段組みや埋め込み図表など、複雑なレイアウトにおける「読み順(Reading Order)」の推定ミス。
- Large Visual Models (LVMs) の課題:
- High-density Text: A4一枚びっしりの高密度テキストに対し、画像エンコーダの解像度不足や計算コスト増大が起きる。
- Frozen Parameters & Repetition: LLMパラメータを固定して学習する場合、長文生成時に「繰り返し(Repetition)」やフォーマット崩れが起きやすい。
論文全体の潮流
- Pipeline → End-to-End: モジュールを繋ぐ複雑さから解放され、単一モデルで構造化を行う方向へ。
- Visual → Multimodal: レイアウト解析において、テキストの意味情報(Semantics)の統合が必須化。
- Fixed Task → General Purpose: 特化モデルから、指示(Instruction)に従って多様な文書を処理できる基盤モデルへ。