
2026-01-06 機械学習勉強会
今週のTOPIC[論文]LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm
[論文] Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling[blog] Understanding Manifold Constrained Hyper Connections[論文] How to Auto-optimize Prompts for Domain Tasks? Adaptive Prompting and Reasoning through Evolutionary Domain Knowledge Adaptation[report]Uni-Parser Technical Report[blog]Raising the Bar on ML Model Deployment Safety[論文]Adaptation of Agentic AIメインTOPICRecursive Language Models概要先行研究長文脈処理における課題既存の長文脈管理手法主要な貢献1. Recursive Language Models (RLM) の提案2. 推論時スケーリングによるコンテキスト拡張3. タスク非依存の汎用手法実験結果評価タスク評価手法とベースライン主要な実験結果主要な観察結果RLM軌跡における創発パターンパターン1: モデルの事前知識に基づくコード実行による入力情報のフィルタリングコード実装の詳細RLMシステムプロンプト(GPT-5版)主要な機能状態管理Qwen3-Coder版との違いサマリーエージェントベースラインCodeActベースライン関連研究との比較長文脈LMシステムRLMの独自性制限事項と今後の課題1. 最適な実装メカニズムの探索不足2. 再帰の深さの制限3. 既存のフロンティアモデルのみでの評価4. 小規模入力でのわずかな性能低下5. 高い分散とランタイムコスト結論主要な成果実装の核心今後の展望Appendixまとめ
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Yuya Matsumura
[論文]LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm
Baidu による、新しい進化型エージェント LoongFlow の提案。AlphaEvolve の進化版。進化的アルゴリズムを活用して、与えられた問題を解くアルゴリズムを改善していく。
進化的アルゴリズムに最近のAIエージェントの知見を組み合わせていったという印象を持ちました。
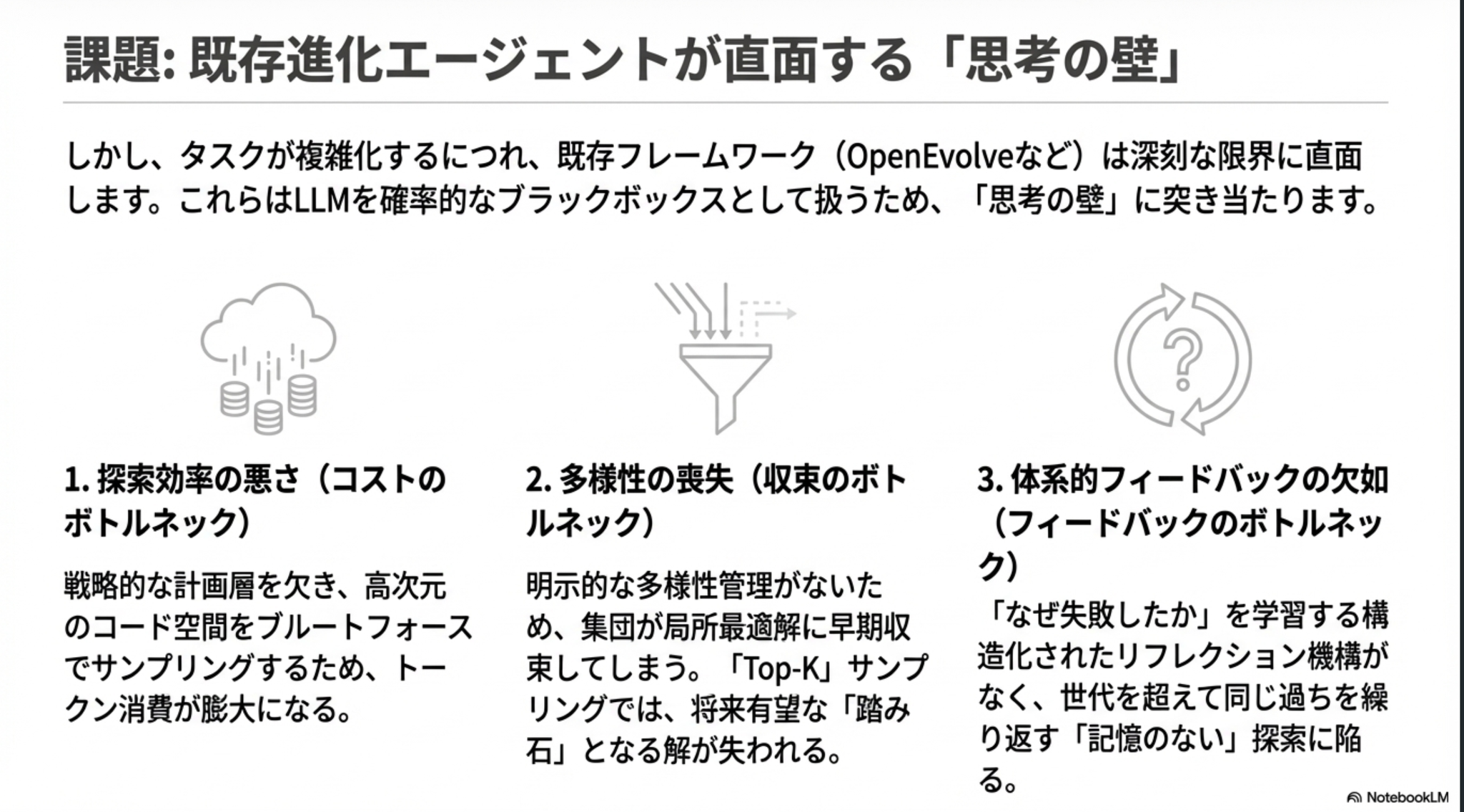
AlphaEvolveってそんな探索効率悪いんだ。
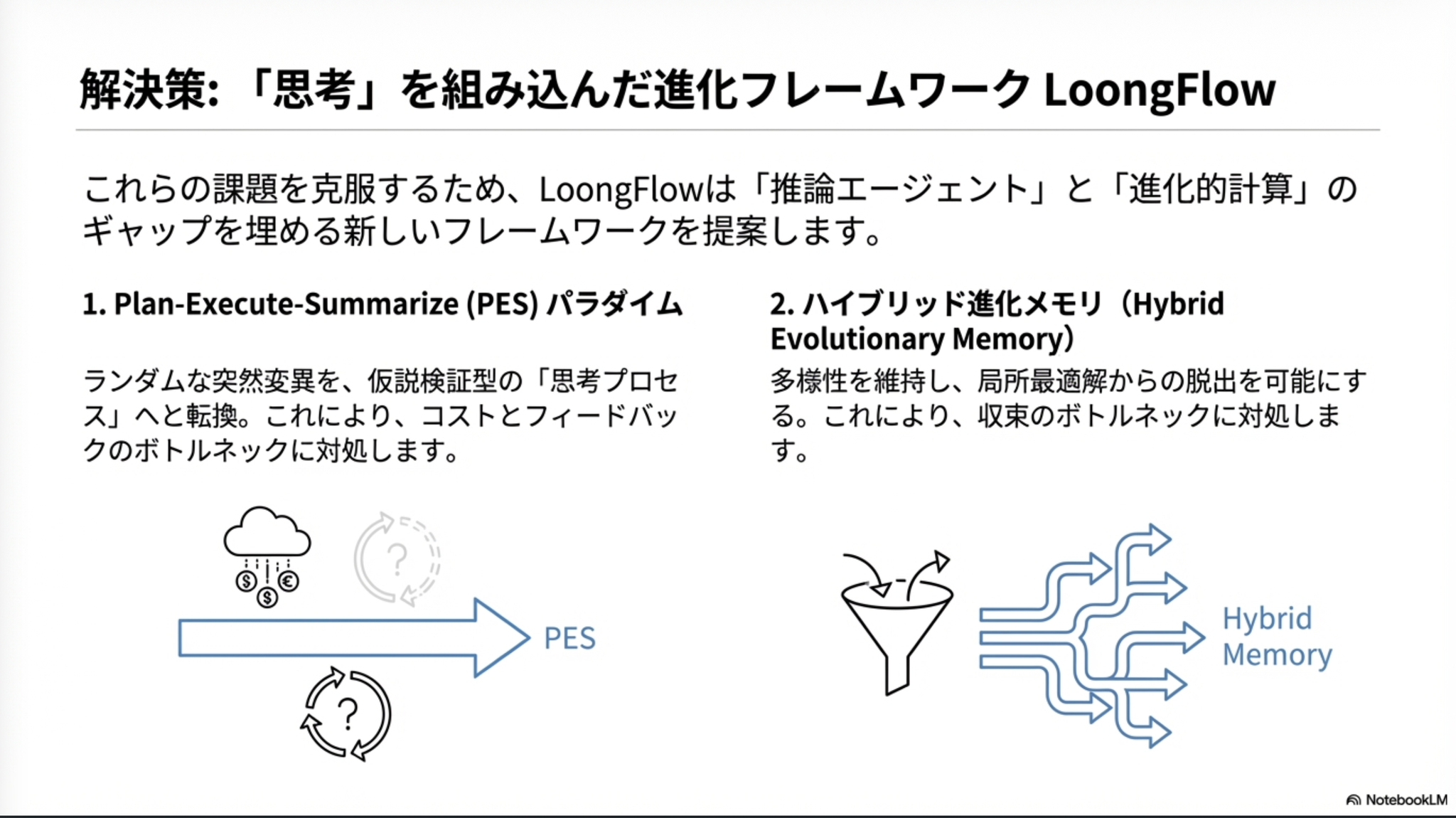
PESパラダイムのほうはいわゆるエージェントのReflection的な話か。ハイブリッド進化メモリも、その名の通りメモリ管理の話。多様性の部分はマルチエージェントの話。
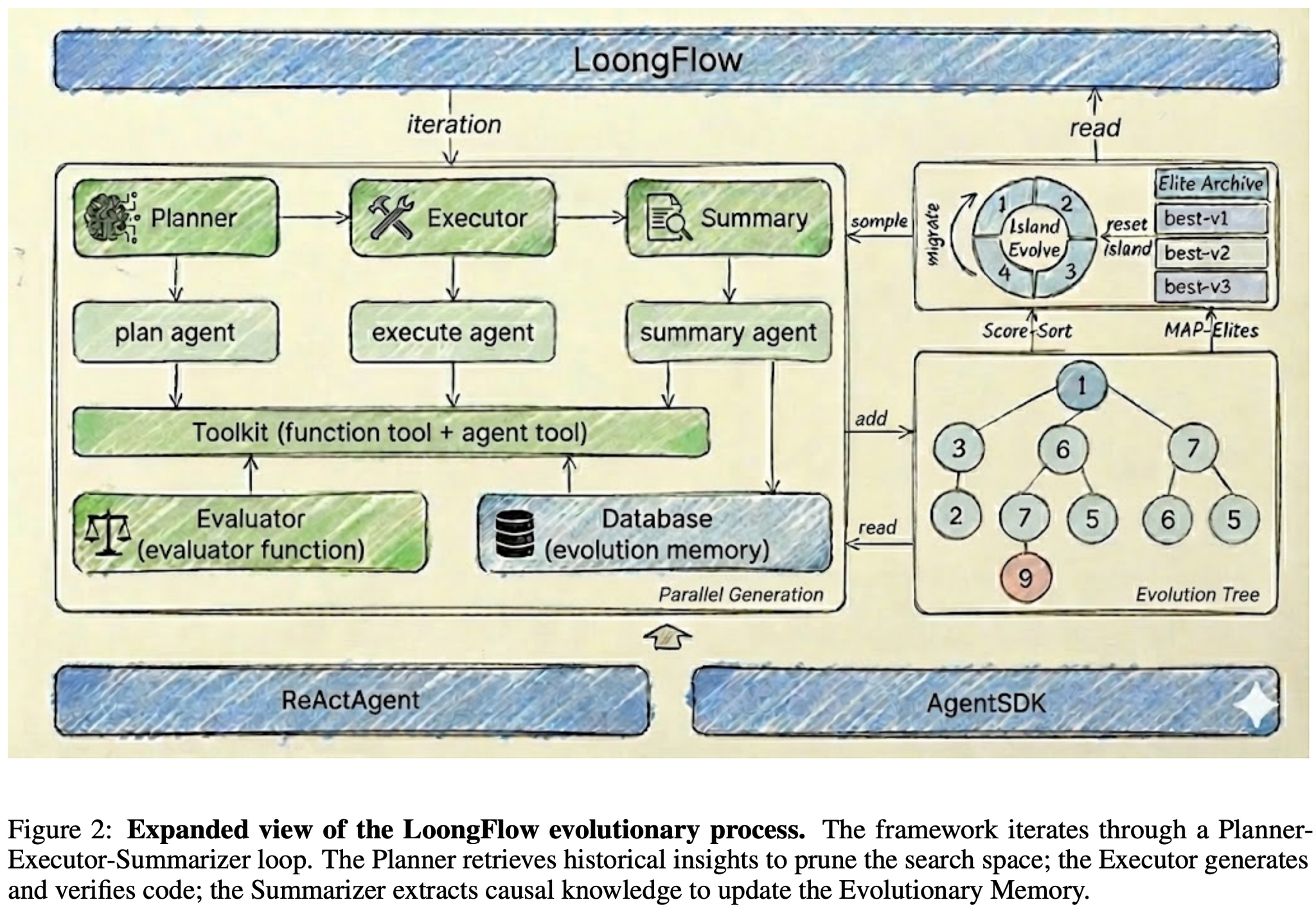
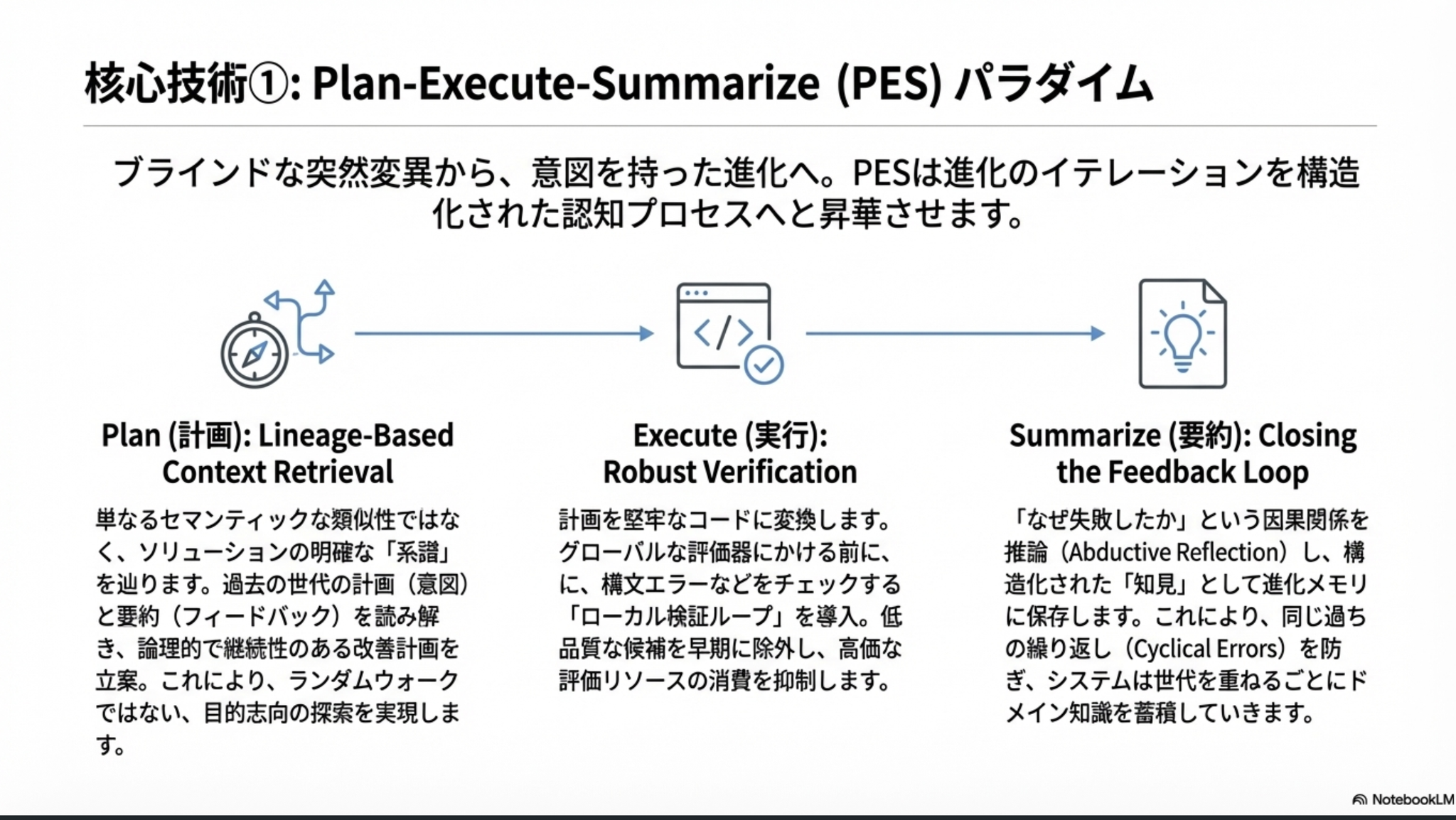
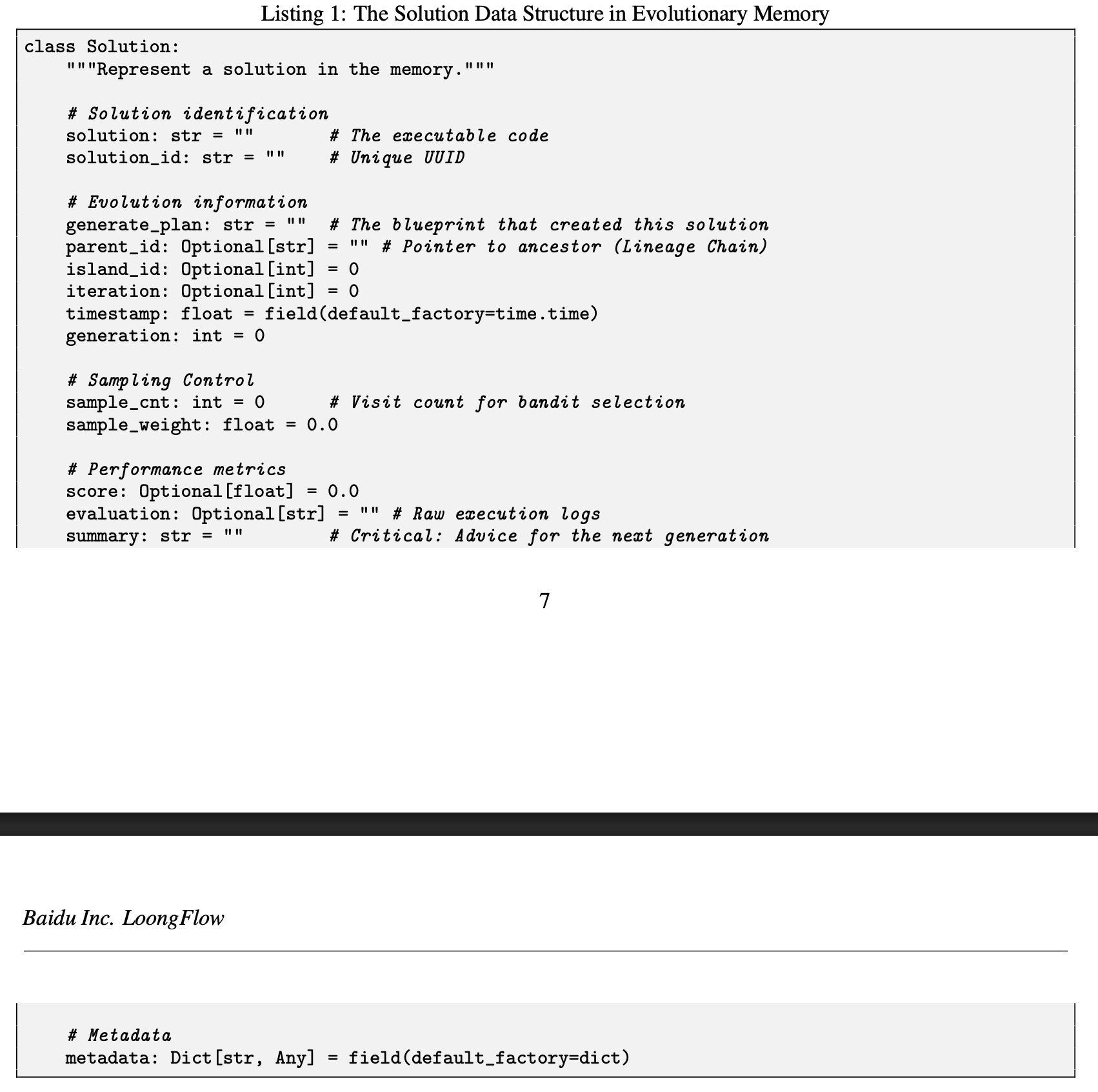
Summary を構造化して残し、次世代以降で活用しやすいように。
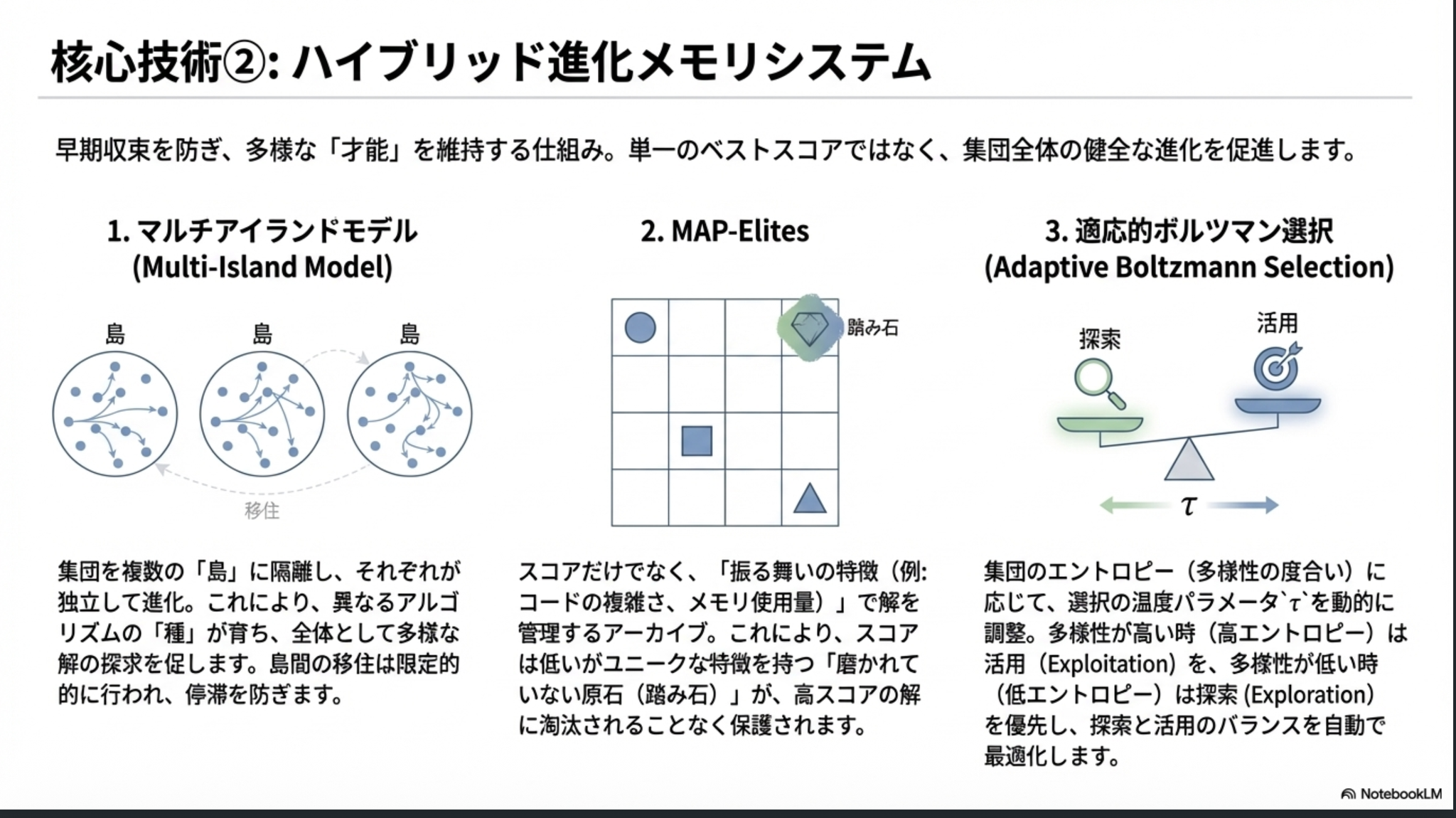
マルチエージェントだなと思った。基本的に独立して動くサブエージェント群をうまいこと組み合わせることでより良い多様なアウトプットを目指す。


@Shun Ito
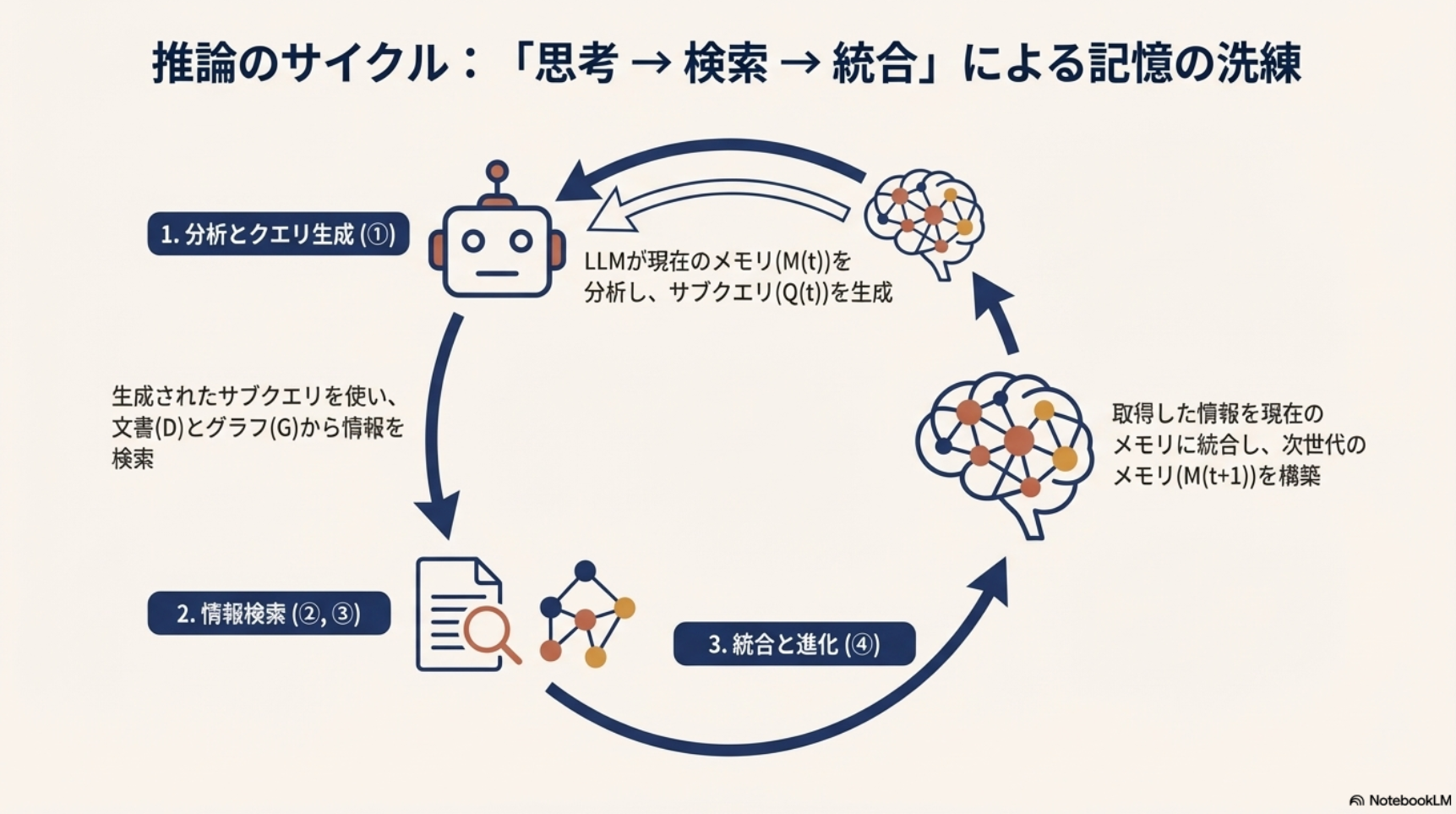
[論文] Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
- RAGの推論時にHyper-Graphのメモリを利用し、長いテキストに含まれる複雑な関係性を正しく捉えて回答生成したい
- 通常のRAG: 文書チャンク
- GraphRAG: 文書チャンク + 文書の構造化グラフ
- 提案: 文書チャンク + 文書の構造化グラフ + Hyper-Graph構造のメモリ
- 提案手法: HGMEM
- おおまかな流れ
- ユーザーからの入力クエリに対して、すでに用意されているチャンク・グラフそれぞれから関連する情報を抽出
- 抽出情報をHyper-Graphとしてメモリに記録
- 情報が十分なら回答を生成、不十分ならさらにクエリを作成して情報を追加し、メモリのHyper-Graphを更新する
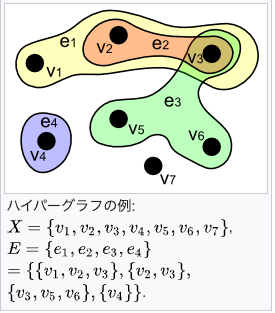
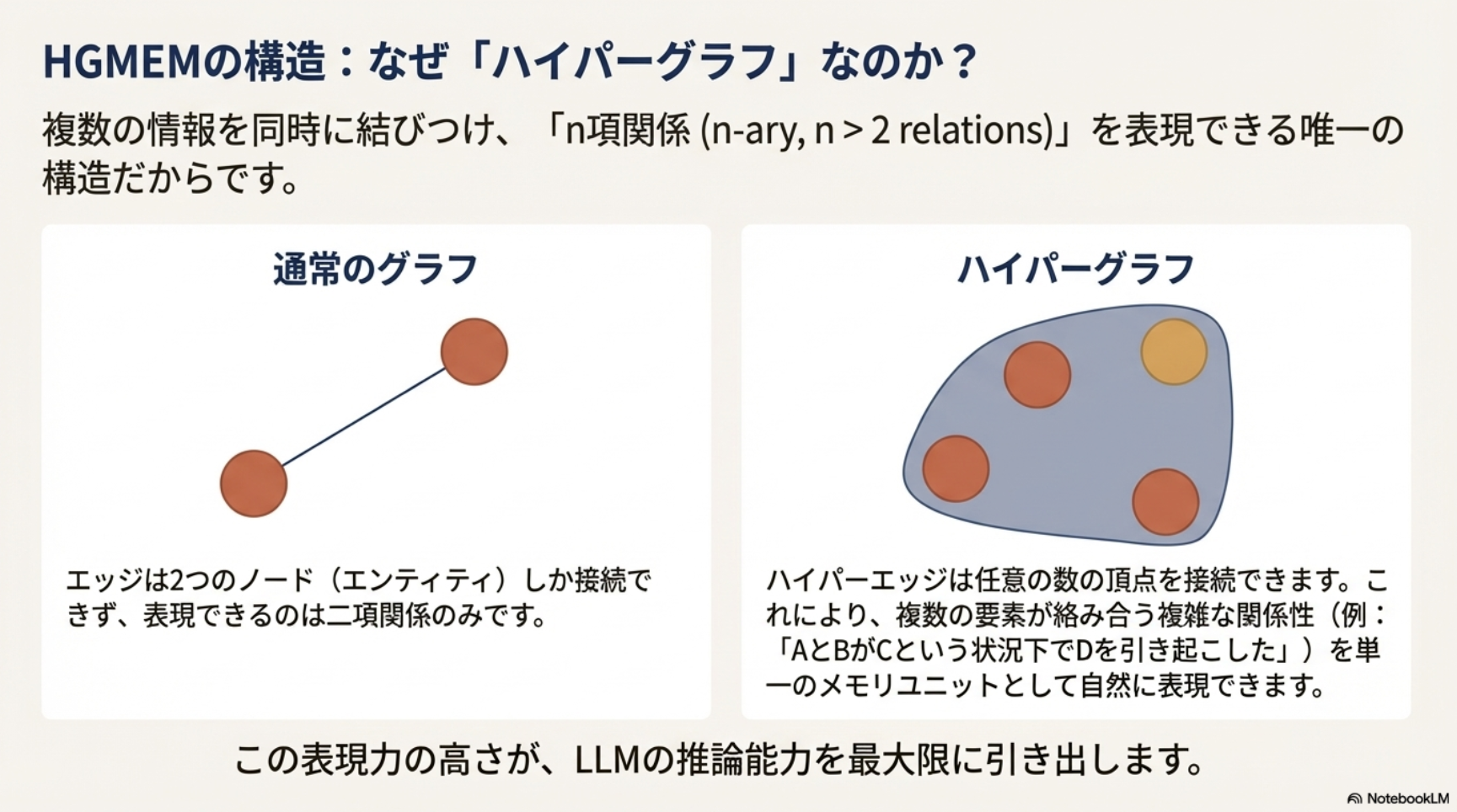
- Hyper-Graphについて
- 複数のノード・エッジをより高次な集合(ハイパーエッジ)としてまとめられる
- 通常のグラフだと2つのノード間の関係性は同列に扱われるが、ハイパーエッジでまとめることで情報のまとまりを明示的に表現した上でLLMに渡せる
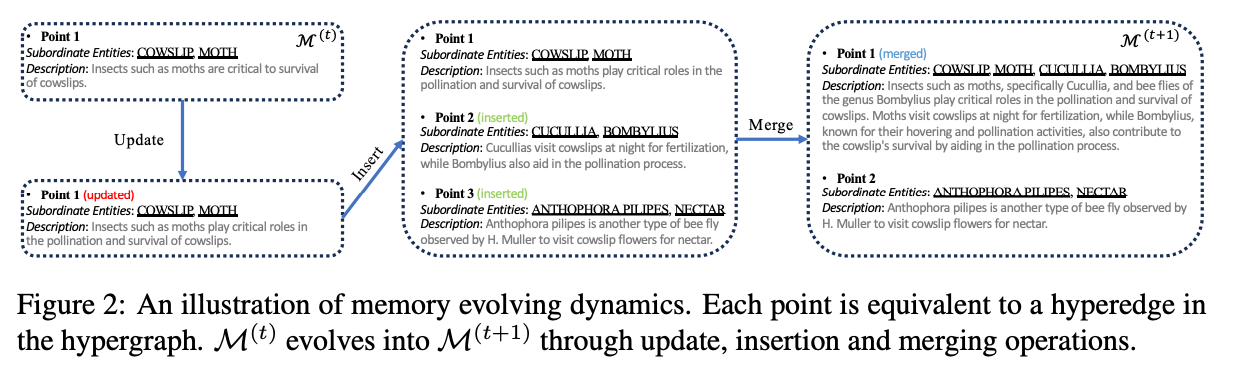
- どういう情報を追加し、それをどう更新(Insert, Update, Merge)するかはLLM with prompt で判断
- 更新例
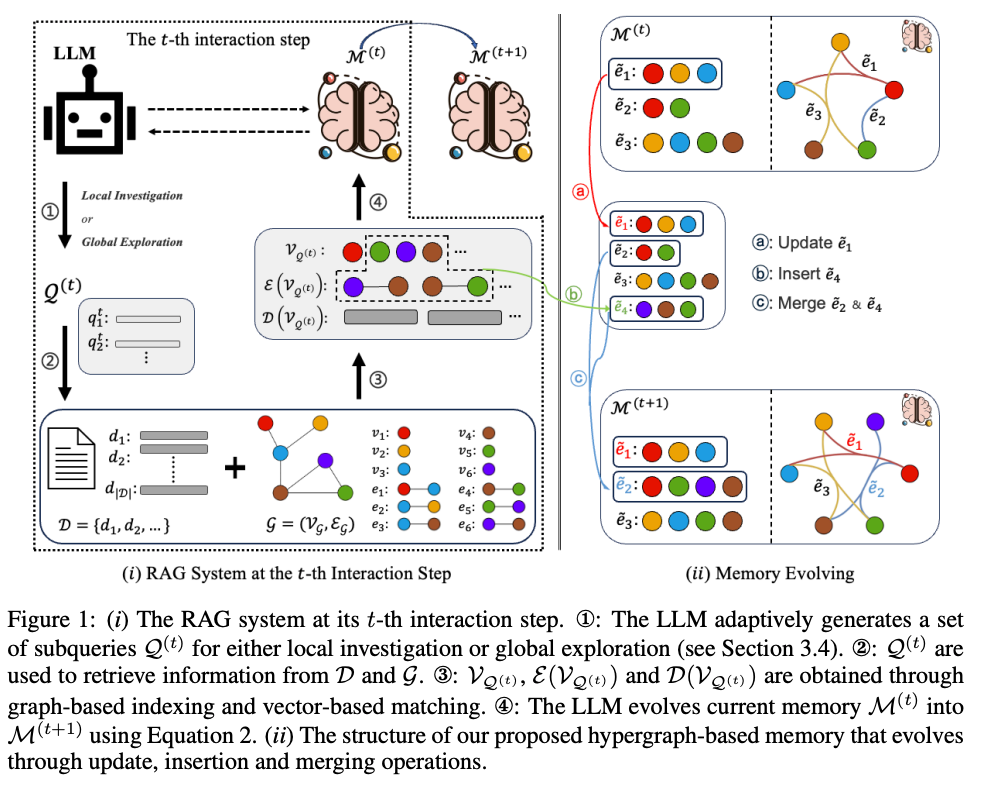
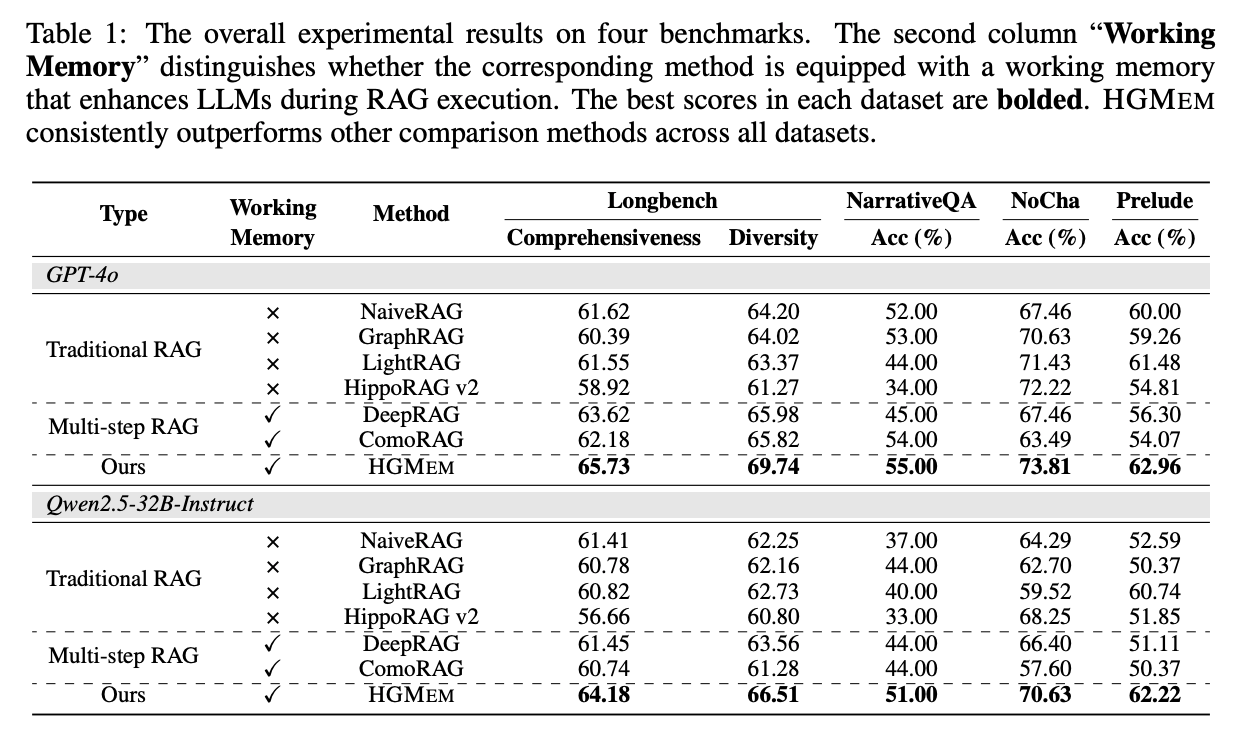
- 結果
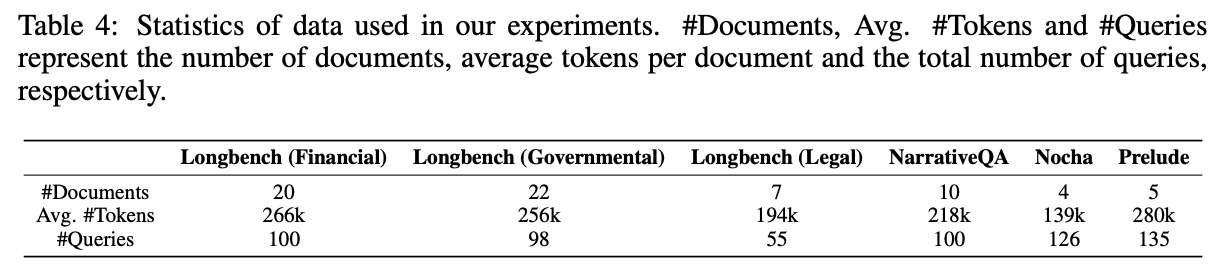
- ドキュメントあたりのトークン数が多いベンチマークで実験
- 既存のRAG、マルチステップRAGよりも良い精度
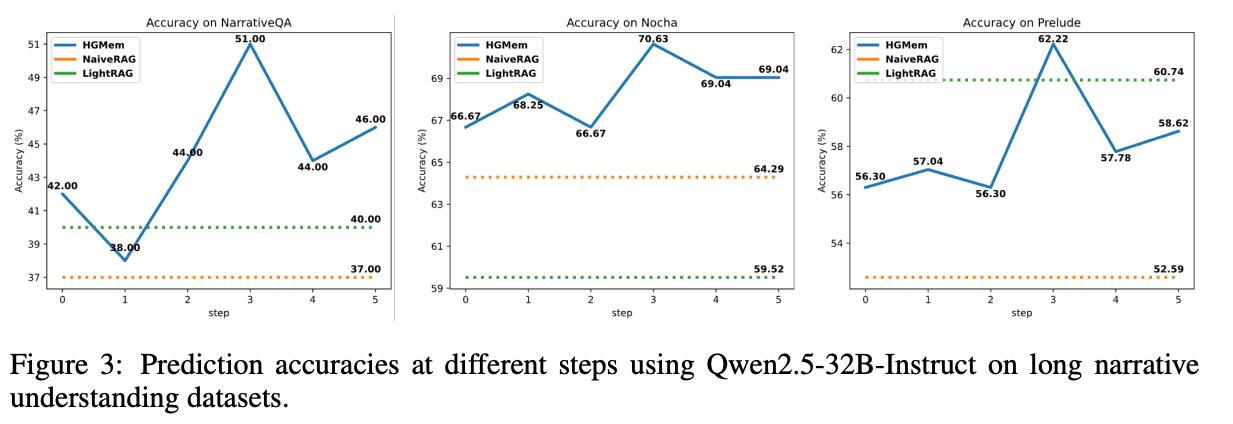
- 実験した中では、3step程度で一番良い精度になるらしい
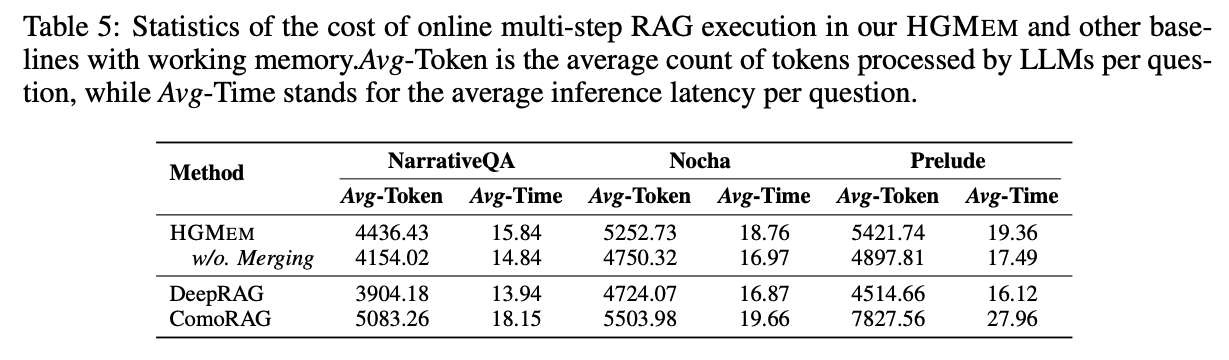
- 実行時間は、既存のマルチステップRAGと同等程度
@Takumi Iida (frkake)
[blog] Understanding Manifold Constrained Hyper Connections
DeepSeek-AIがクリスマス🎄 に出したmHC (Manifold-Constrained Hyper-Connection) の解説記事。ざっくり理解ではResNetの進化版と捉えて良さそう。
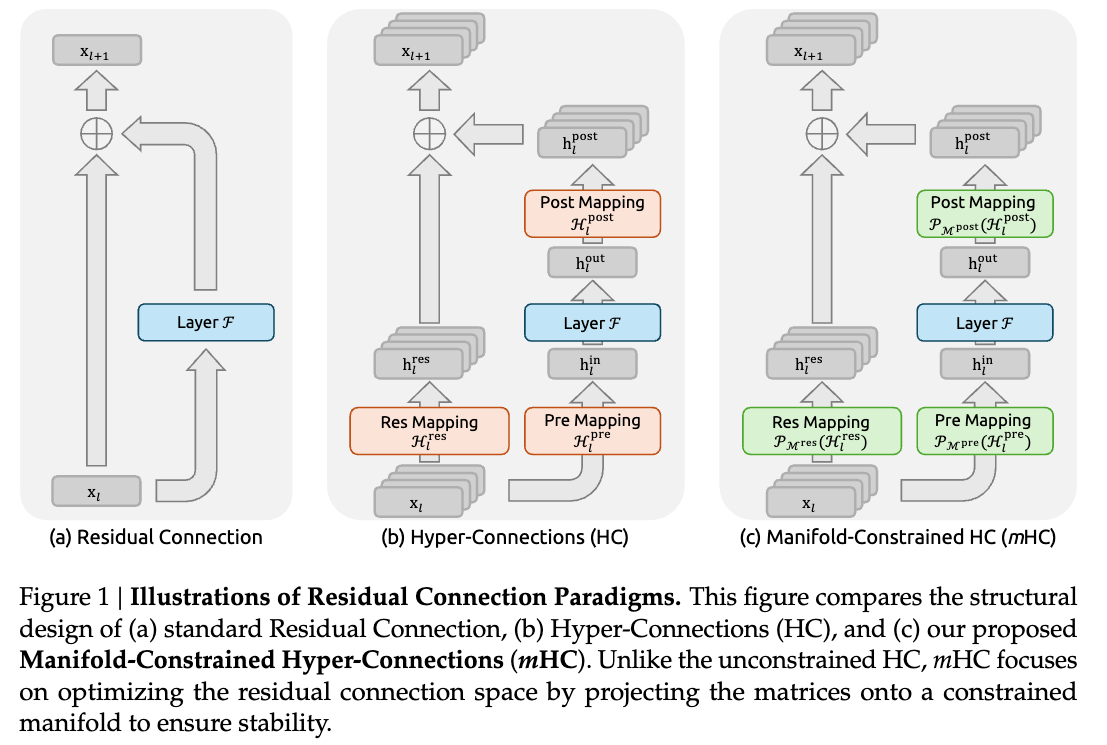
ResNet
ResNetでは、恒等写像を横からくっつける。これによって、深いネットワークの学習安定化につなげている。
ただし、DeepSeekの27Bパラメータとかになってくると、接続パターンが多様化して対応できなくなっていた。
Hyper Connections (HC)
3つのマッピング機構を使って、線形に次元数を調整している。
(重み)行列に制約がないので、信号の増幅や減衰を引き起こし、大規模な学習で不安定になる可能性がある。
Manifold-Constrained HC (mHC)
二重確率行列のバーコフ多面体 (Birkoff polytope of doubly stochastic matrices)を使ってHCの安定化を図っている。ざっくりいうと行列の行と列の合計が1になるように制約している。
二重確率行列
- 非負性: 行列内のすべての要素が 0 以上である
- 行の和が1: どの行(横一列)の要素を足しても合計が 1 になる。
- 列の和が1: どの列(縦一列)の要素を足しても合計が 1 になる。
二重確率行列の利点として以下のことがあるらしい。
- 信号の安定化(Norm Preservation)二重確率行列のスペクトルノルム(最大特異値)は 1 以下になります。これにより、信号が層を通過する際に過度に増幅(爆発)したり減衰(消失)したりするのを防ぎ、学習を安定させます 。
- 層を重ねても性質が保たれる(Compositional Closure)「二重確率行列同士の積もまた二重確率行列になる」という数学的な性質があります。これにより、深い層まで重ねていっても信号の総量や性質が保存され、安定した情報の伝播が可能になります 。
- 凸結合としての解釈幾何学的には、入力特徴量の「凸結合(Convex Combination)」として機能します。つまり、情報を混ぜ合わせる(Mixする)役割を果たしますが、信号の総エネルギー量は変えないため、恒等写像(Identity Mapping)に近い安定性を保つことができます 。
これによって、複数レイヤに渡って恒等写像の特性が復元されて、信号の消失や爆発を防ぎながら拡張残差ストリームのパフォーマンス上の利点を維持できる。
HCのフォワードパスはこのようになっているが
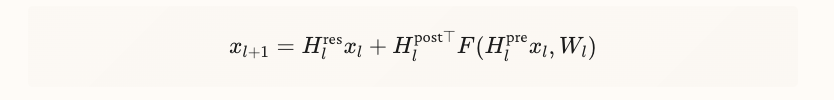
レイヤを重ねるとこのようになって、 が発散してしまう(第一項)。この を二重確率行列 (doubly stochastic matrix) というらしい。
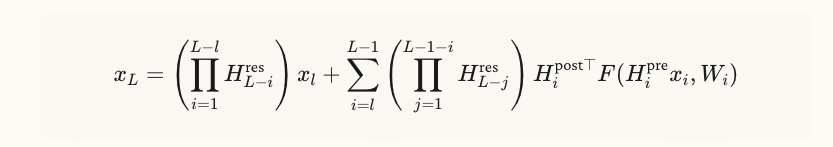
mHCでは、 に次の制約を加えて発散を防ぐ。Sinkhornアルゴリズムを使って、列と行を繰り返し正規化することで二重確率行列にしているらしい。
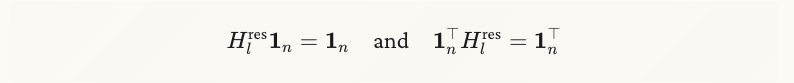
ひとことまとめ
HCと同じ構成だが、Res Mapping行列 に制約を加えることで信号の発散を防いでいる。
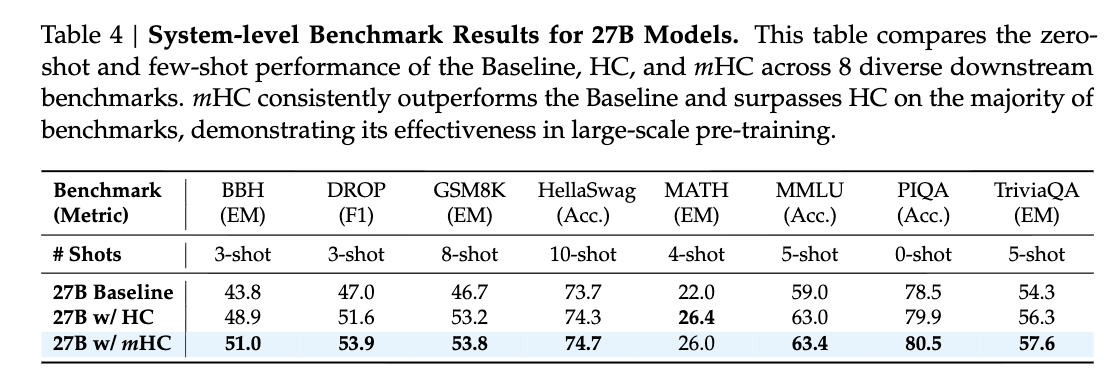
結果
mHCは安定的に学習できている。勾配も跳ねてない。
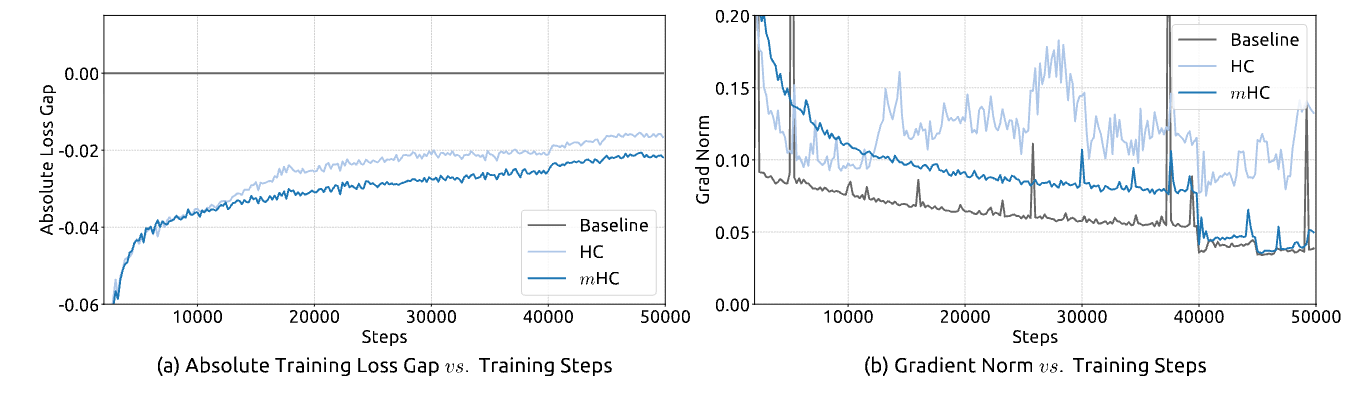
性能も良い
@Hiromu Nakamura (pon)
[論文] How to Auto-optimize Prompts for Domain Tasks? Adaptive Prompting and Reasoning through Evolutionary Domain Knowledge Adaptation
目的と課題
理想的には、適切に構築されたセマンティック因果グラフ(SCG: Semantic Causal Graph)と効果的なシステムプロンプトは、LLMの推論プロセスと予測性能を大幅に向上させる。しかし、現実には以下の2つの問題により性能が変動する可能性がある。
- SCGが不完全または不正確である
- システムプロンプトがLLMを効果的にガイドできない
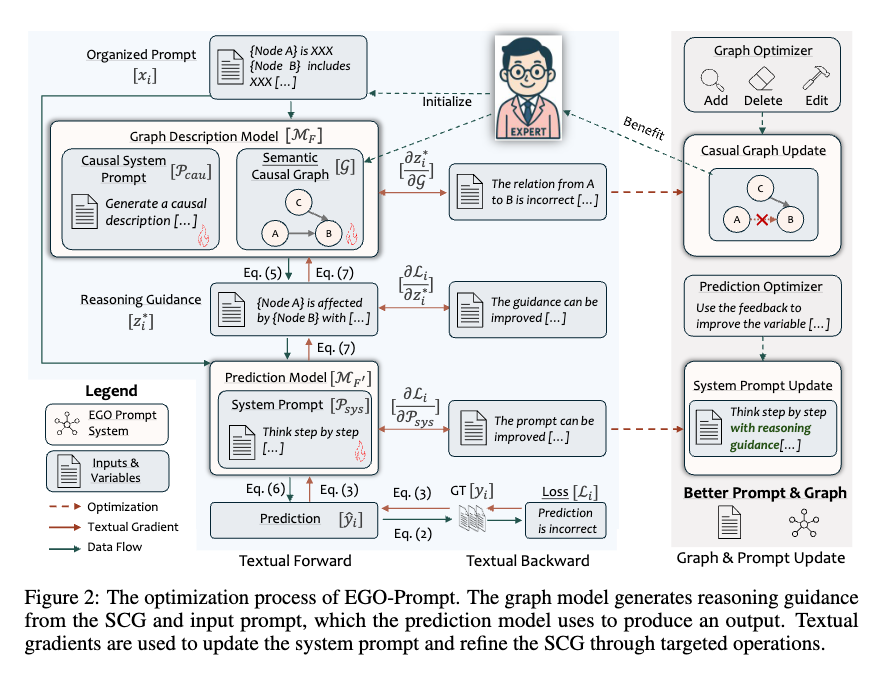
EGO-Promptは、これらの課題に対処するため、テキスト勾配手法をSCGおよびプロンプトの最適化に応用する。
Iterative Optimization
テキスト勾配を利用して、システムプロンプト、SCG 、および因果システムプロンプトを更新する。SCGの修正は、以下の3つの操作に限定される。
- 候補ノードセットからのノードとその因果記述・リンクの追加
- ノードとその関連記述の削除
- 不正確または不必要な既存記述の編集
これらの仕組みにより、EGO-Promptは人間の専門家が作成した不完全な初期SCGとプロンプトを、グラウンドトゥルースデータからのテキスト勾配に基づいて自動的に洗練し、LLMのドメイン固有タスクにおける推論精度と解釈性を向上させている。
[pon]node数 edge数が10程度の小さなグラフ(実験より)を想定してるし、groundtruth必要だったりとちょっと使いにくさはある
@Akira Manda(zunda)
[report]Uni-Parser Technical Report
概要
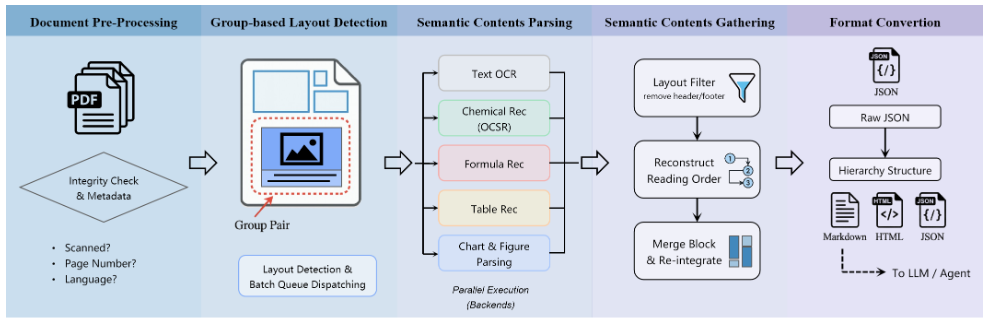
科学文献や特許などのPDFドキュメントを、構造化データへ変換するために設計された解析エンジン。
VLM(視覚言語モデル)によるEnd-to-End解析ではなく、特化型モデルを組み合わせたパイプライン方式を採用。
さらに、それを支える非同期マイクロサービスアーキテクチャにより、単一ページの処理速度だけでなく、システム全体のスループット(単位時間あたりの処理枚数)を最大化し、20ページ/秒という性能を実現している。
背景と課題
科学文献や特許には、テキスト以外に「数式」「化学構造式」「表」「グラフ」が混在しており、既存手法には以下の課題が存在した。
- VLMベースの手法: 汎用性は高いが、計算効率が低くコストが高い。また、非テキスト領域(化学式等)で幻覚を起こすリスクがある。
- 従来のパイプライン手法: 直列処理のため遅延が発生しやすく、レイアウト解析のミスが文脈分断を招いていた。
技術的アプローチ:速度と精度の両立
Uni-Parserは、「賢いモデル」と「待たせないシステム」を融合させた設計となっている。
1. システムインフラ(速度の源泉)
単一ページのレイテンシ短縮以上に、「待ち時間の隠蔽(Latency Masking)」によるスループット向上に主眼が置かれている。
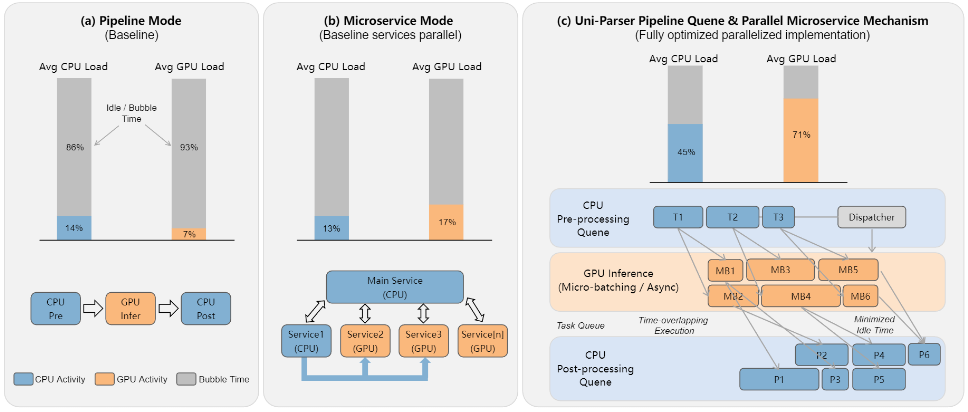
- 非同期マイクロサービス: レイアウト解析モデルが完了したバッチから即座にタスクキューへ投入される。後続の各エキスパート(OCR、化学式認識など)は、前のページの全処理完了を待たずに並列に稼働する。
- パイプライン並列化 (Pipeline Parallelism): CPU(前処理・後処理・データ転送)とGPU(推論)の処理を時間的にオーバーラップさせ、GPUのアイドル時間(Bubble time)を極小化している。
- 動的負荷分散: ドキュメントの内容(化学式が多い等)に応じて、各マイクロサービスのインスタンス割り当てを動的に調整し、ボトルネックを解消する。
2. アルゴリズムとモデル(精度の源泉)
- グループベースのレイアウト検出:
- 物体検出モデル(DETRベース)を使用。「図とキャプション」などを意味的なペアとして認識し、文脈の維持を実現する。
- 学習には50万ページ規模の独自データセット(人間によるアノテーション含む)を使用。
- 情報の統合と順序復元:
- 非同期でバラバラに処理された結果は、保持されたページ情報・座標情報・グループ情報をキーとして再統合(Gathering)される。
- ページをまたぐ段落や表についても、言語的な連続性やレイアウトの手がかりを用いてマージ処理を行い、正しい文書構造を復元する。
- 特化型エキスパートモデル:
- 既存モデルをそのまま使うのではなく、科学・特許ドメインの実データを用いた大規模なファインチューニングを行っている。
- 化学構造: MolParser 1.5。1000万枚の実データ学習を追加し、キラル/マーカッシュ構造に対応。
- 図表・キャプション: Qwen-2.5-VL-3B をベースに、数十万〜数百万件の科学図版データセットでファインチューニング(SciParser等)。
- 表構造: SLANet をベースに、化学式や数式を含む複雑な表データセットで再学習。
- その他: 数式(PP-Formulaベース)、テキスト(PP-OCRv5ベース)もそれぞれチューニング済み。
評価結果
パフォーマンス
- スループット: 8 x NVIDIA RTX 4090D GPU環境において、最大 20ページ/秒 の処理速度を報告。
- 大規模処理: 240 GPU(NVIDIA L40)クラスタ構成において、1600万件以上のドキュメントを6日未満で処理した実績がある。
化学構造認識精度
論文内のベンチマーク(Uni-Parser Benchmark)において、既存ツールと比較して高い精度を示している。
| Model | All | Chiral (キラル) | Markush (省略記法) |
|---|---|---|---|
| MolParser 1.5 (Uni-Parser) | 0.886 | 0.809 | 0.805 |
| MolParser 1.0 | 0.800 | 0.676 | 0.664 |
| MolScribe | 0.417 | 0.274 | 0.168 |
考察と展望
- データ抽出への応用:
- 化学構造や反応式を高精度に構造化データとして抽出できる点は、大規模な化学・生物医学データベースの構築(AI4Science)や、RAGにおける検索精度の向上に寄与すると期待される。
- ツールキットの公開:
- としての公開が計画されている。
@Shuhei Nakano(nanay)
[blog]Raising the Bar on ML Model Deployment Safety
1. これは何?
UberのML基盤プラットフォーム「Michelangelo」における、2025年にロールアウトされたMLモデルの安全なデプロイメント戦略についての解説記事。
2. 問題設定
2.1 MLモデル固有のリスク
従来のソフトウェアと比較し、MLモデルには以下の特性がある。
| 観点 | 従来のコード | MLモデル |
|---|---|---|
| 動作特性 | 決定論的 | 確率的 |
| 検証方法 | 静的テストで検証可能 | データと密結合しており、静的テストのみでは不十分 |
| 障害モード | 予測可能 | オフライン評価では良好でも、本番環境で失敗する可能性がある |
Uberスケールにおける課題
- データドリフトや統合時のエッジケースにより、本番環境で予期せぬ障害が発生する
- 軽微な性能劣化であっても、数分以内に大規模な影響を及ぼす可能性がある
- 数千のモデルが本番稼働しており、その多くが日次または週次で再学習される
- 一貫した安全基準の維持と、開発チームの速度維持を両立する必要がある
3. 解決策
3.1 ハイブリッド安全フレームワークの採用
Uberは以下の二層構造で安全性を担保している。
| 層 | 説明 |
|---|---|
| 集中型(プラットフォーム強制) | すべてのデプロイに自動適用されるベースライン保護 |
| 分散型(チーム主導) | ドメイン固有の検証をツール・フレームワークでサポート |
3.2 MLライフサイクル全体を通じた安全策
各フェーズにおける主要な施策は以下の通りである。
| フェーズ | 主な施策 |
|---|---|
| データ・特徴量エンジニアリング | 欠損値の明示的処理の強制、スキーマ自動検証、分布シフト検出 |
| モデル訓練 | 分布統計の記録、レイテンシ予算に対する評価、標準化されたモデルレポートの生成 |
| 本番前検証 | バックテスト、シャドウテスト(重要ユースケースの75%以上で実施) |
| ロールアウト | 段階的なトラフィック増加、閾値ベースの自動ロールバック |
| 本番監視 | Hueによるリアルタイム監視(可用性、レイテンシ、スコア分布、特徴量ヘルス) |
3.3 安全性スコアリングシステム
デプロイ準備度を定量的に評価するため、以下4指標を追跡している。
| 指標 | 内容 |
|---|---|
| オフライン評価カバレッジ | 過去30日間に評価された本番モデルの割合 |
| シャドウデプロイメントカバレッジ | ライブシャドウトラフィックで検証されたデプロイの割合 |
| ユニットテストカバレッジ | MLモノレポにおけるテストカバレッジ(全体および新規行) |
| パフォーマンス監視カバレッジ | アクティブな監視パイプラインを持つ本番モデルの割合 |
3.4 今後の方向性
| 領域 | 取り組み内容 |
|---|---|
| GenAI活用 | 監視パイプラインの自動生成、デプロイ前コードレビューの自動化 |
| GenAIアプリ・エージェント対応 | ポリシー準拠、出力関連性、ハルシネーション率等の行動シグナル監視 |
| セマンティックドリフト検出 | 埋め込みベースモデルにおける意味的変化の検出 |
| 大規模モデル対応 | シャーディング戦略、大規模モデル向けロールバック機構の整備 |
4. Take Home Message
- MLモデルは確率的かつデータ依存であり、従来の静的テストだけでは品質担保が困難である
- 「集中型の自動保護」と「分散型のチーム主導検証」を組み合わせたハイブリッドアプローチが有効である
- 目指すべきは「Safety by Default」—すべてのデプロイがデフォルトで安全な状態
@Hirofumi Tateyama(hirotea)
[論文]Adaptation of Agentic AI
About
AI Agentとツールをタスク・環境最適化する手法を4パターンに分けて整理したサーベイ論文。
最適化対象と手法で4パターンに分けている
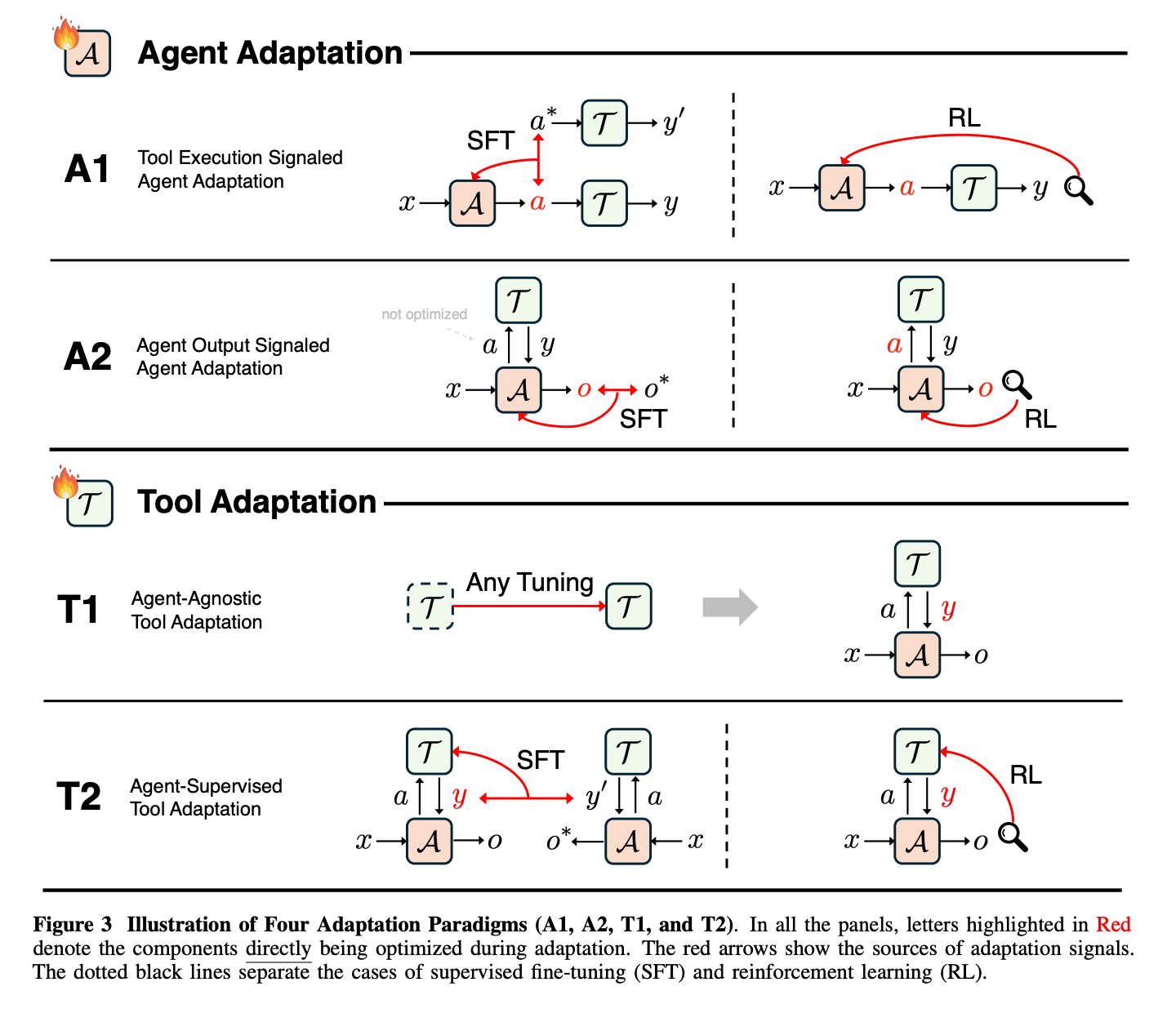
パターン
A1:Tool Execution Result as Signal
- ツール実行結果を教師信号としてエージェントを最適化する
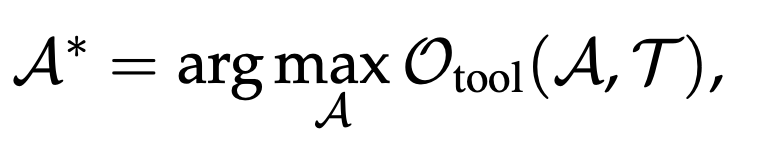
- SFT→近年ではRLVRを軸に、PPO/GRPOでツール操作精度をあげる方向が人気に
- RLVR:自動計算可能な報酬をもとにRLする手法
A2:Agent Output as Signal
- Tool利用有無を問わず、最終的な出力を教師信号としてエージェントを最適化する
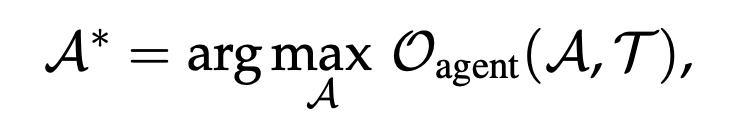
- ショートカット学習や評価ハックに脆い
T1:Agent-Agnostic Tool Adaptation
- LLMは固定し、Toolを最適化する
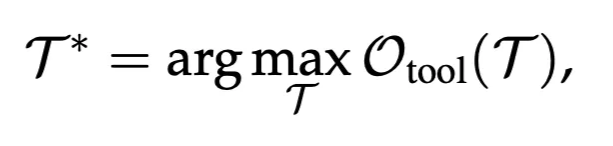
- RetriverやReranker, Plannerなどの出力結果を評価し、精度改善を行う
T2:Agent-Supervised Tool Adaptation
- LLMは固定するがLLMの出力評価をもとにツールを最適化する
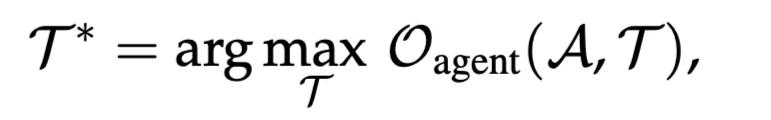
- LLMが使いやすいように、どのようにツールを最適化させられるか?というAとは逆のアプローチ
- 専門特化した小型Subagentをトレーニングする方向へシフトできる
- この論文の推しポイントはここ
- 強いClosedなモデルのツールとして小型LLMをタスク特化させてトレーニングする方がA2と比べて学習コストも格段に小さく済むよね
- タスク特化のLLMをスキルや知識のモジュールとして分離し、個別に学習できるようになり、柔軟性が上がる
Memo
- LLMのRLについては商用LLMのリリースノート中心に頻繁にみかけるので理解をふかめたく読んだ
- モデルによってツールの使い分けが上手い/下手のようなモデル特性の差はA1/A2の差分から生まれていそうと考えた
- 各所で述べられている「大型モノリシックvs小型専門家モジュールアーキテクチャ」構図を、エージェント適応とツール適応という学習手法の設計空間観点から評価していて学びになる
- 学習手法が公開されているモデルを手法ごとに整理してくれているのも深掘りに向いている(知らないモデルばかり)
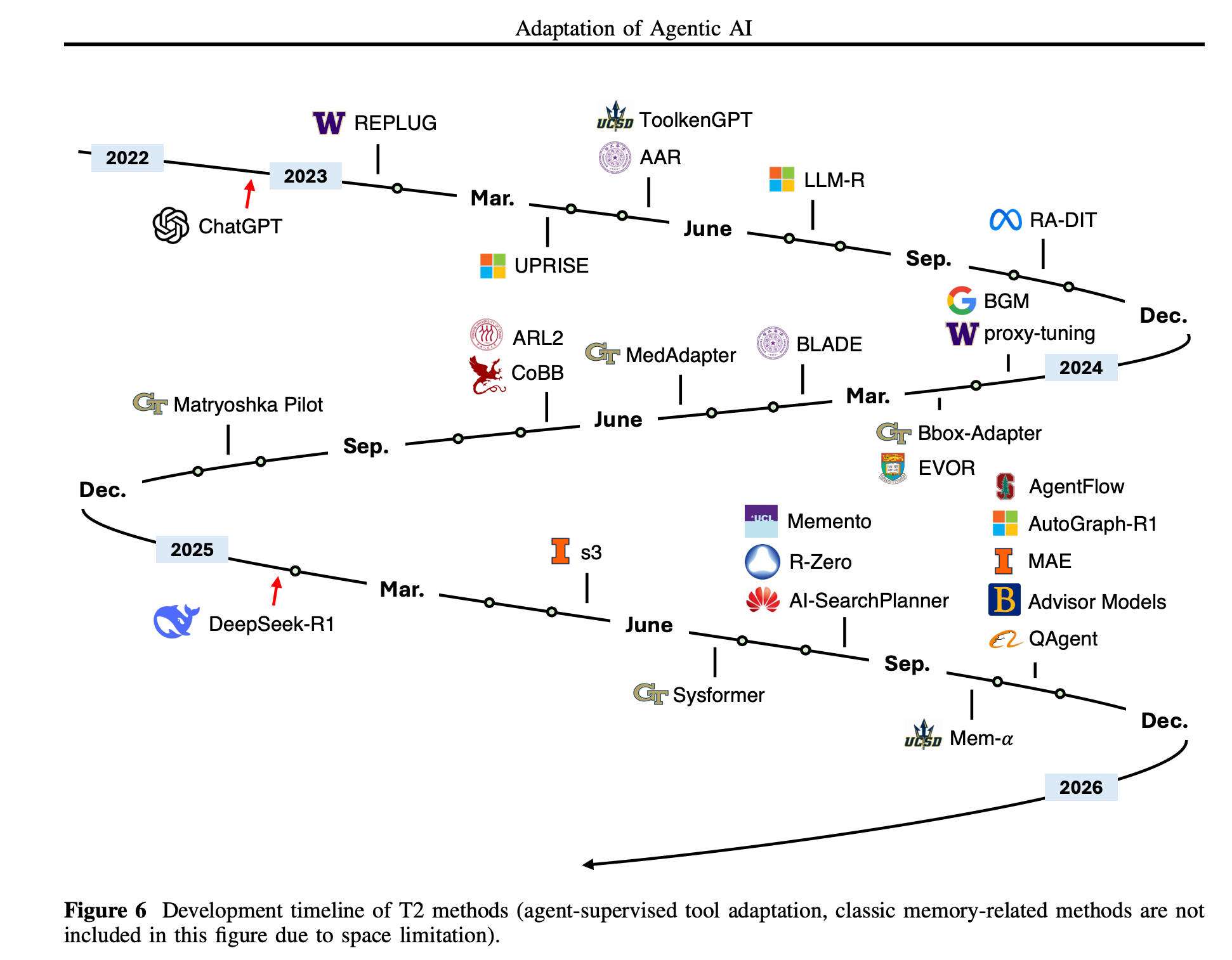
- チューニング手法や応用例をガッと学べて良いサマリーだった
- 理解に役立ったもの
- kuto-sanのブログ
- TRPO/PPO/GRPO
メインTOPIC
Recursive Language Models
論文情報
| タイトル | Recursive Language Models |
|---|---|
| 著者 | Alex L. Zhang (MIT CSAIL), Tim Kraska (MIT CSAIL), Omar Khattab (MIT CSAIL) |
| arXiv ID | 2512.24601v1 |
| 投稿日 | 2025年12月31日 |
| カテゴリ | Artificial Intelligence (cs.AI), Computation and Language (cs.CL) |
| 公式実装 | github.com/alexzhang13/rlm(MIT License) |
概要
本論文は、大規模言語モデル(LLM)が任意の長さのプロンプトを処理する新しい推論時スケーリング手法として、Recursive Language Models (RLM) を提案。RLMは、長いプロンプトを外部環境の一部として扱い、LLMがプログラム的にプロンプトを検査・分解し、その断片に対して自身を再帰的に呼び出すことを可能にする。評価実験では、モデルのコンテキストウィンドウの2桁(100倍)を超える入力を成功裏に処理し、短いプロンプトでも基本LLMや一般的な長文脈手法を大幅に上回る性能を示した。GPT-5やQwen3-Coder-480Bといった最先端モデルを用いた4つの多様な長文脈タスクにおいて、クエリあたりのコストを同等またはより低く抑えながら、劇的な性能向上を達成。
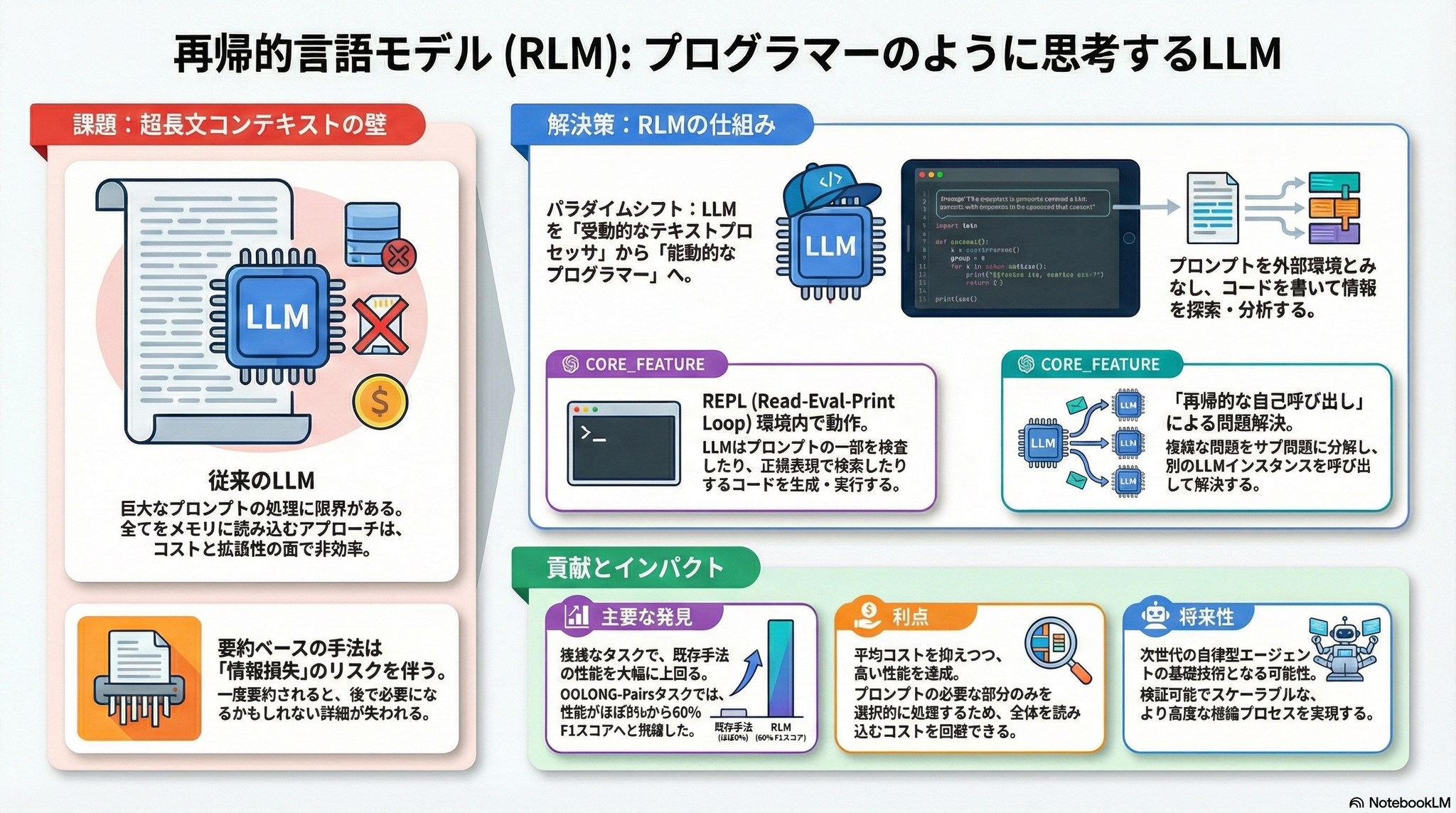
先行研究
長文脈処理における課題
近年の研究では、LLMの実効的なコンテキストウィンドウは、物理的な最大トークン数よりもはるかに短いことが指摘されている。特にcontext rot(文脈劣化)という現象が知られており、GPT-5のような最先端モデルでさえ、コンテキストが長くなると品質が急速に低下。
本論文は、この実効的なコンテキストウィンドウをタスクの複雑さと独立して理解することはできないという仮説を立てている。より「複雑な」問題は、シンプルな問題よりもさらに短い長さで劣化することを示す。
既存の長文脈管理手法
長文脈管理には主に2つのアプローチ:
- アーキテクチャの変更と再訓練: より長いコンテキストを扱えるようにモデル自体を変更する方法
- LM周辺のスキャフォールド構築: LMの周囲にコンテキストを暗黙的に処理する仕組みを構築する方法(RLMはこちら)
既存の手法:
- コンテキスト圧縮・要約: コンテキストが閾値を超えたら繰り返し要約する手法(Baleen、OpenHands Context Condensation、ReSum等)。プロンプトの多くの部分への密なアクセスを必要とするタスクには十分な表現力がない。
- 明示的メモリ階層: MemWalker、MemGPT、mem0、gMemoryなどのように、ツリー構造やメモリ階層を構築する手法
- タスク分解とサブLM呼び出し: ViperGPT、THREAD、DisCIPL、ReDel、Context Folding、AgentFoldなどの手法。タスクの再帰的分解に焦点を当てているが、基本LMのコンテキストウィンドウを超える入力を処理できない。
RLMは、これらの先行研究と異なり、プロンプトを外部環境に配置するというシンプルな直感により、任意の長さの文字列をシンボリックに操作し、永続的なREPL環境からの実行フィードバックを通じて再帰を反復的に改善可能。
主要な貢献
1. Recursive Language Models (RLM) の提案
RLMは、長いプロンプトをニューラルネットワーク(Transformerなど)に直接入力するのではなく、LMがシンボリック的に相互作用できる環境の一部として扱う。
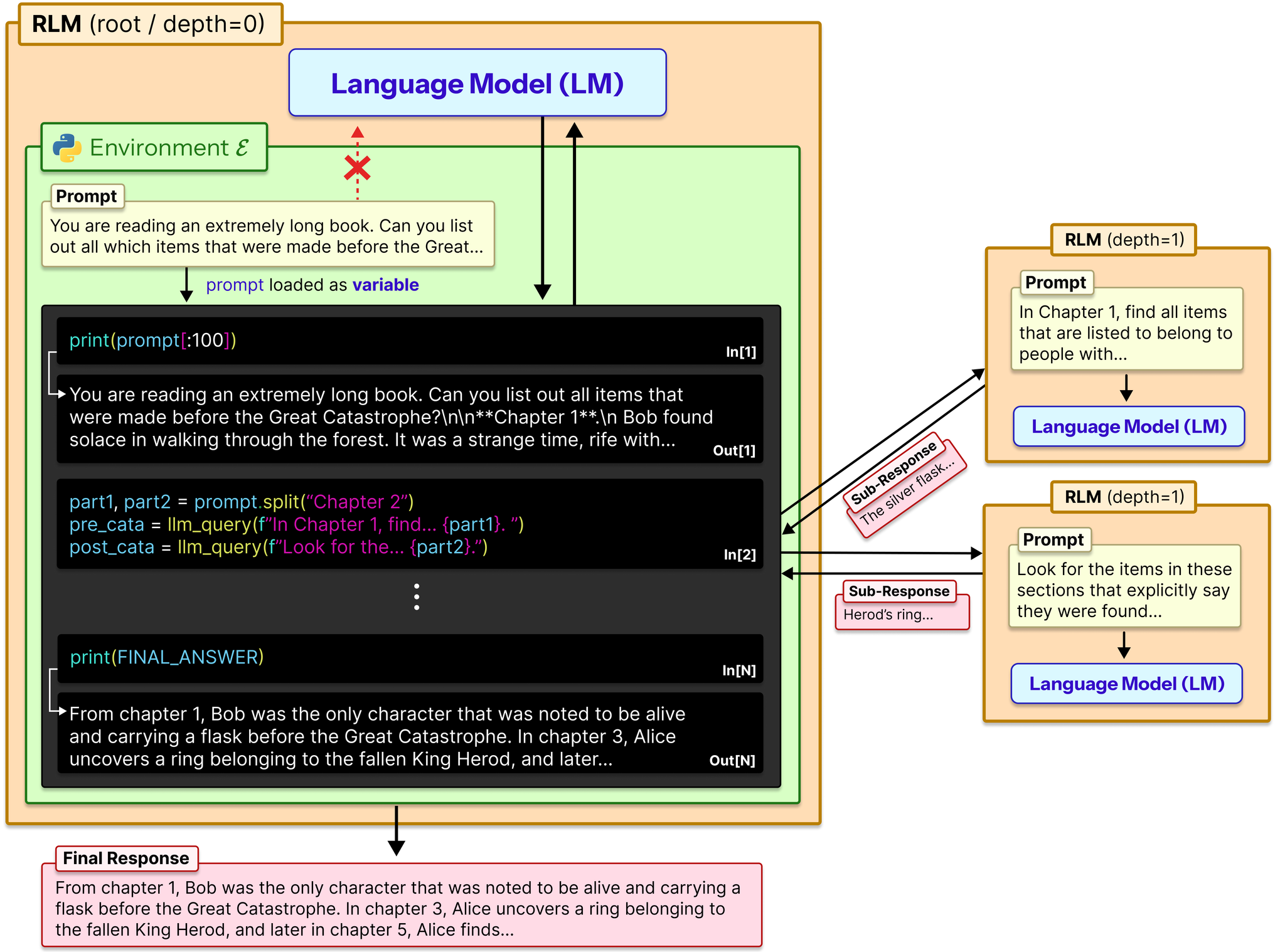
RLMの動作メカニズム:
- プロンプト が与えられると、RLMはRead-Eval-Print Loop (REPL)プログラミング環境を初期化し、 を変数の値として設定
- LMに環境の一般的な情報(例:文字列の長さ)を提供し、を覗き込んで分解するコードを書くことを許可
- 実行による副作用を反復的に観察可能
- 重要: RLMは、LMが生成するコード内で、プログラム的にサブタスクを構築し、自身を再帰的に呼び出すことを推奨
この設計により、RLMはプロンプトをオブジェクトとして外部環境に配置することで、多くの先行手法の根本的な制限に対処。
実装: rlm/core/rlm.py のRLMクラスが上記のメカニズムを実装。completion()メソッドが反復ループを制御し、_completion_turn()で各ステップのLM呼び出し→コード抽出→REPL実行を処理。
2. 推論時スケーリングによるコンテキスト拡張
RLMは、訓練やアーキテクチャの変更なしに、推論時の計算のみでコンテキストを劇的に拡張。この手法は、out-of-core アルゴリズム(小さいが高速なメインメモリで、データの取得方法を巧妙に管理することで、はるかに大きなデータセットを処理できるシステム)からインスピレーションを得ている。
3. タスク非依存の汎用手法
RLMは特定のタスクに特化した手法ではなく、様々な長文脈タスクに対して単一の固定プロンプトで対応できる汎用的な推論パラダイム。
実験結果
評価タスク
論文では、情報密度(処理が必要な情報量)とその入力サイズに対するスケーリングパターンが異なる4つのタスクで評価:
1. S-NIAH (Single Needle-in-a-Haystack)
- 概要: 大量の無関係なテキストから特定のフレーズや数値を見つけるタスク
- 複雑性: 入力サイズに関わらず一定の処理コスト(定数オーダー)
- タスク数: 50タスク
- 評価指標: Accuracy (正しいフレーズを見つけられたタスクの割合)
2. BrowseComp-Plus (1K documents)
- 概要: DeepResearchのための多段階質問応答ベンチマーク。複数の文書にわたる推論が必要
- 複雑性: 複数の文書から情報を組み合わせる必要があり、S-NIAHより複雑
- データ: 10万文書のオフラインコーパスから1000文書を提供
- タスク数: 150タスク(ランダムサンプリング)
- 評価指標: Accuracy
3. OOLONG (trec_coarse split)
- 概要: 入力のチャンクを意味的に検査・変換し、集約して最終回答を形成する長時間推論ベンチマーク
- 複雑性: データセットのほぼすべてのエントリを使用する必要があり、入力長に対して線形にスケール。(該当するエントリを全て抜き出せ、のようなタスク)
- タスク数: 50タスク(質問の意味ラベル付きデータセット)
- 評価指標: 数値回答は 、その他は完全一致
4. OOLONG-Pairs
- 概要: OOLONGのtrec_coarse splitを手動で修正し、チャンクのペアを集約する必要がある20の新しいクエリを追加
- 複雑性: データセットのエントリのほぼすべてのペアを使用する必要があり、入力長に対して二次にスケール。(該当するペアを全て抜き出せ、のようなタスク)
- 評価指標: F1スコア
5. LongBench-v2 CodeQA
- 概要: コードリポジトリ理解のための多肢選択タスク
- 複雑性: コードベース内の固定数のファイルにわたる推論が必要
- 評価指標: 正解率
評価手法とベースライン
使用モデル:
- GPT-5 with medium reasoning(商用最先端モデル)
- Qwen3-Coder-480B-A35B(オープン最先端モデル)
比較手法:
- Base Model: LMを直接使用
- RLM with REPL: Python REPL環境にコンテキストを文字列としてロード。サブLMへのクエリが可能
- GPT-5実験では、再帰呼び出しにGPT-5-miniを使用、ルートLMにGPT-5を使用
- RLM with REPL, no sub-calls: サブLM呼び出しなしのアブレーション版
- Summary agent: コンテキストが閾値を超えると要約を繰り返すエージェント
- GPT-5では、コスト削減のため圧縮にGPT-5-nanoを使用
- CodeAct (+ BM25): ReActループ内でコードを実行できるエージェント。BrowseComp+ではBM25レトリーバーを装備
主要な実験結果
表1: 長文脈ベンチマークにおける性能・コスト比較
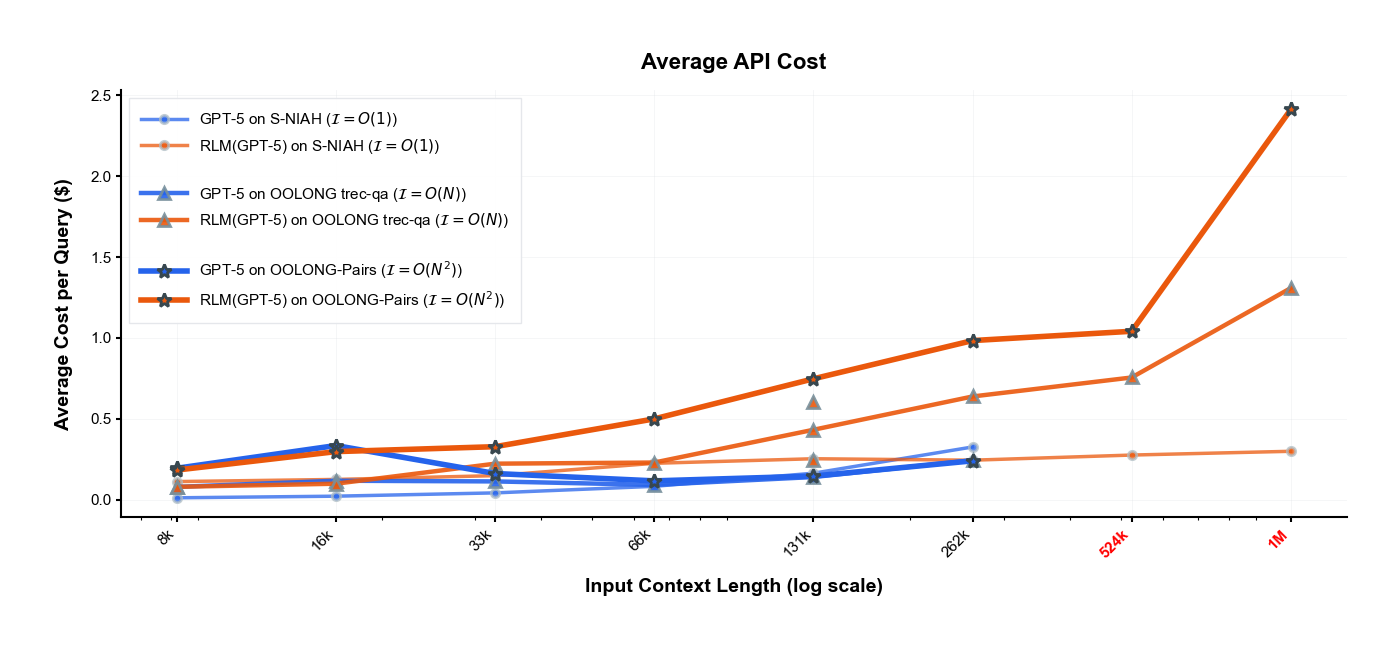
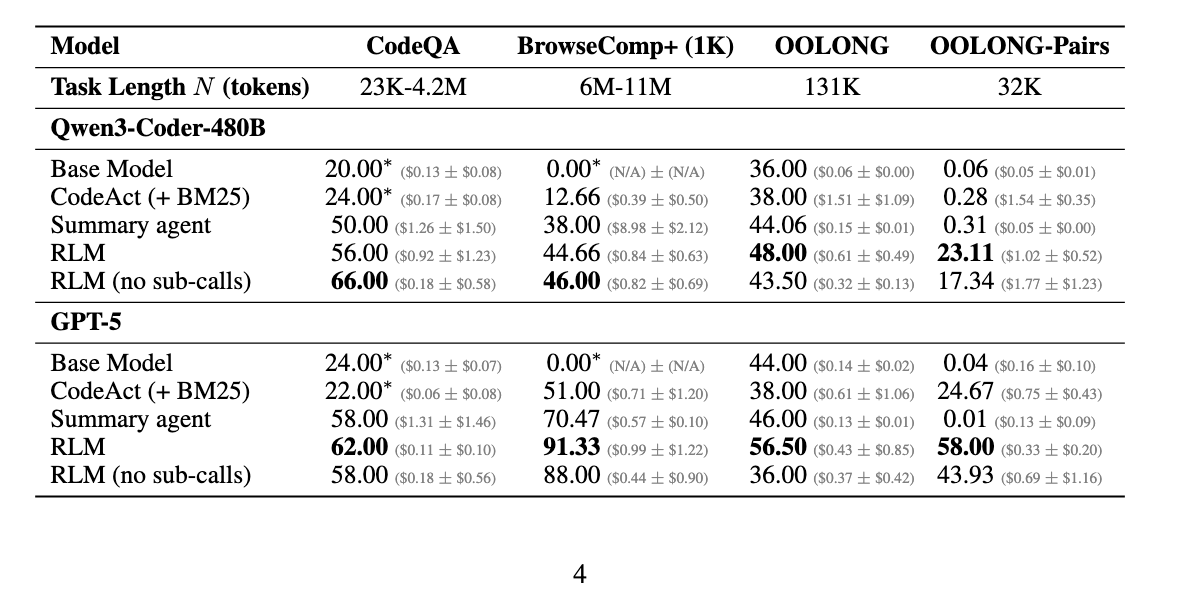
グレーの括弧内は平均APIコスト±標準偏差。 *は入力コンテキスト制限に達したことを示す。
no sub-callsは他のLMを呼ばずにメインのLMだけで全てを処理する、という理解
主要な観察結果
1. RLMは10M+トークン領域にスケール可能で、既存手法を大幅に上回る
- すべてのタスクで、RLMはフロンティアLMの実効的コンテキストウィンドウをはるかに超える入力タスクで強力な性能を実証
- 基本モデルや一般的な長文脈手法を最大2倍の性能で上回りながら、同等またはより安価な平均トークンコストを維持
- BrowseComp-Plus (1K)の例:
- GPT-5-miniが6-11M入力トークンを取り込むコストは$1.50-$2.75
- RLM(GPT-5)の平均コストは**$0.99で、要約およびレトリーバルベースラインを29%以上上回る
- OOLONG:
- RLM(GPT-5)は基本モデルを28.4%上回る
- RLM(Qwen3-Coder)は基本モデルを33.3%上回る
- OOLONG-Pairs:
- GPT-5とQwen3-Coderの基本モデルは両方ともF1スコア<0.1%とほとんど進展なし
- RLM(GPT-5): 58.00%のF1スコア
- RLM(Qwen3-Coder): 23.11%のF1スコア
- 極めて情報密度の高いタスクを処理するRLMの創発的能力を強調
2. REPL環境は長い入力処理に必要、再帰的サブ呼び出しは情報密度の高い入力に強力な利点を提供
RLMの重要な特性は、コンテキストを環境 の変数としてオフロードし、モデルが相互作用できるようにすること。
- サブ呼び出し機能なしでも、RLMのアブレーションはモデルのコンテキスト制限を超えてスケール可能
- CodeQAとBrowseComp+(Qwen3-Coder)では、アブレーション版がRLMを17.9%と3%上回る
しかし、OOLONGやOOLONG-Pairsのような情報密度の高いタスクでは、再帰的LMサブ呼び出しが必要:
- すべての情報密度の高いタスクで、RLMはサブ呼び出しなしのアブレーション版を10%-59%上回る
3. LM性能は入力長と問題複雑性の関数として劣化、RLM性能はより良くスケール
S-NIAH、OOLONG、OOLONG-Pairsのベンチマークは、 から トークンまでの範囲のコンテキスト長を持つ固定数のタスクを含む。各ベンチマークは、入力コンテキストの処理コスト(それぞれおおよそ定数、線形、二次)によって大まかに分類可能。
それぞれでのplotでは、inputのContext長の範囲で解けるタスクのみを渡して判断。
主要な発見:
- GPT-5の性能は、より複雑なタスクで著しく速く劣化
- RLM性能も劣化するが、はるかに遅い速度で劣化
- コンテキスト長が を超えると、RLMは一貫してGPT-5を上回る
- RLMコストはタスクの複雑性に比例してスケールするが、GPT-5と同じオーダーのコスト内に留まる
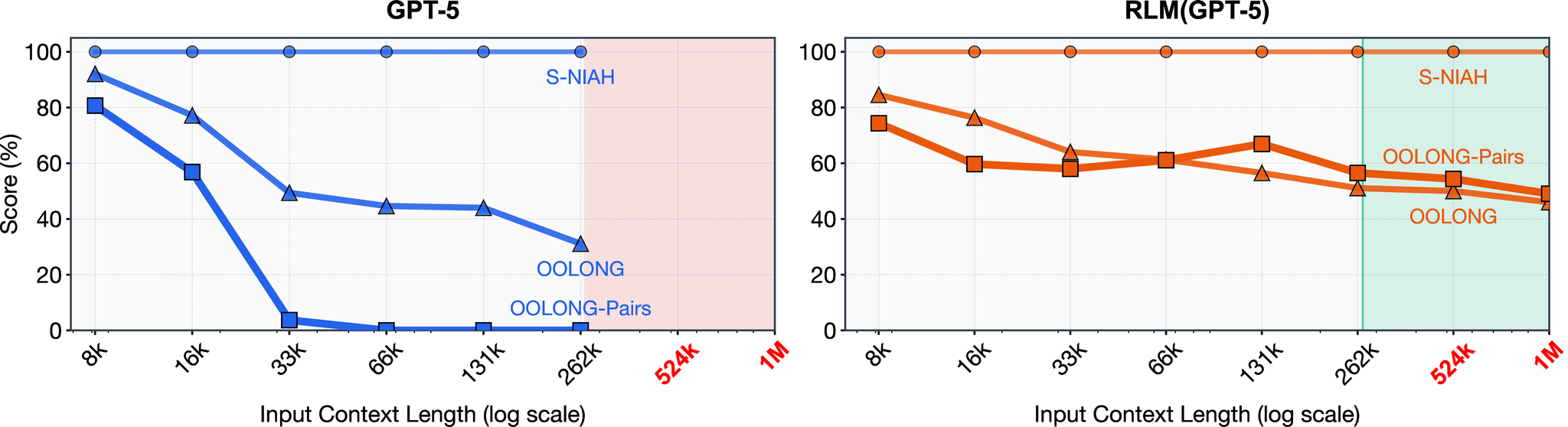
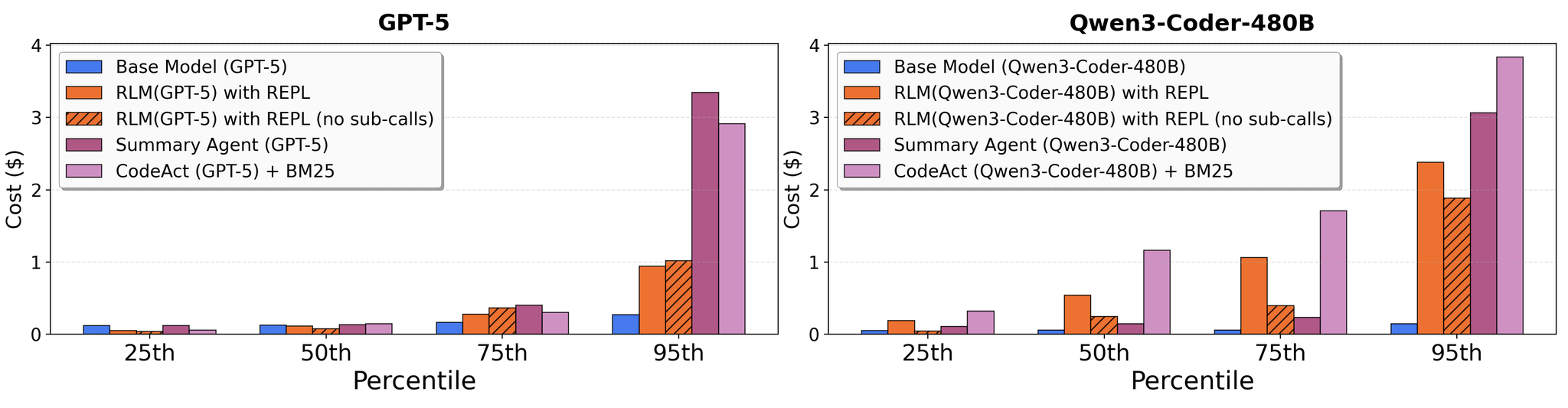
4. RLMの推論コストは基本モデル呼び出しと同等だが、軌跡の長さの違いにより高い分散
- GPT-5の場合、中央値のRLM実行は中央値の基本モデル実行より安価
- しかし、多くの外れ値RLM実行は基本モデルクエリよりも著しく高価
- 要約ベースライン(全入力コンテキストを取り込む)と比較して、RLMはすべてのタスクで強力な性能を維持しながら最大3倍安価
5. RLMはモデル非依存の推論戦略だが、異なるモデルは異なる決定を示す
GPT-5とQwen3-Coder-480Bは両方とも基本モデルや他のベースラインと比較してRLMとして強力な性能を示すが、すべてのタスクで異なる性能と動作を示す。
- BrowseComp-Plusでは、RLM(GPT-5)がほぼすべてのタスクを解決する一方、RLM(Qwen3-Coder)は半分しか解決できない
- RLMシステムプロンプトは各モデルですべての実験で固定され、特定のベンチマークに調整されていない
- GPT-5とQwen3-Coderの唯一の違いは、Qwen3-Coderに対してサブ呼び出しの使いすぎを警告する追加の行のみ
RLM軌跡における創発パターン
明示的な訓練なしでも、RLMは興味深いコンテキスト管理と問題分解動作を示す。
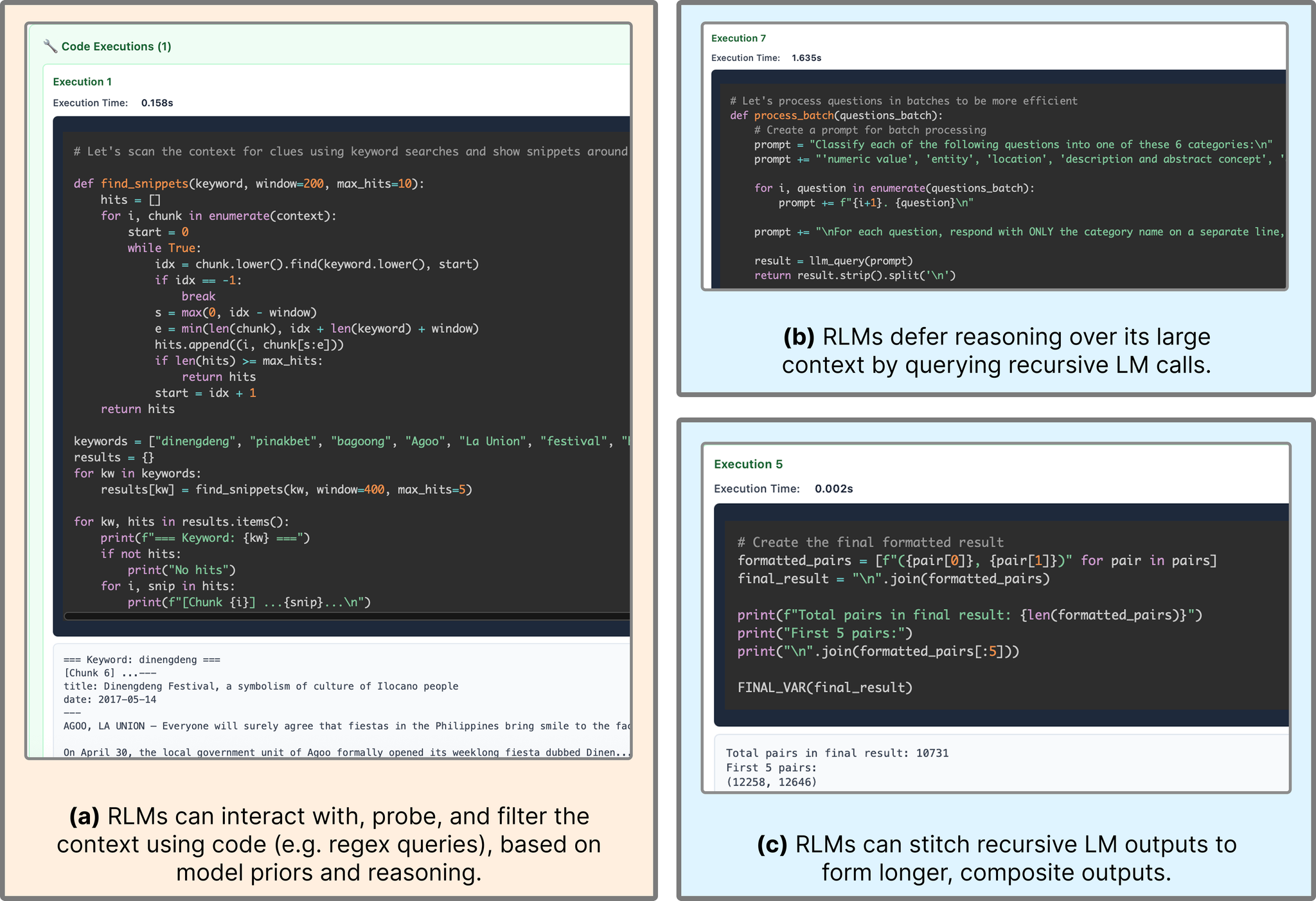
パターン1: モデルの事前知識に基づくコード実行による入力情報のフィルタリング
RLMが膨大な入力でコストを爆発させずに強力な性能を維持できる重要な直感は、LMが明示的に見ることなく入力コンテキストをフィルタリングできる能力。
例: RLM(GPT-5)がクエリを使用して、元のプロンプト内のキーワード(例:「festival」)や事前知識を持つフレーズ(例:「La Union」)を含むチャンクを検索。
一般的な戦略:
- コンテキストをルートLMに数行印刷してプローブ
- その観察に基づいてフィルタリング
パターン2: チャンク化と再帰的サブLM呼び出し
RLMは、本質的に無制限の長さの推論チェーンをサブ(R)LM呼び出しに委譲。分解の選択は、特に情報密度の高い問題において、タスクの性能に大きく影響。
観察: 実験では、均一なチャンク化やキーワード検索を超えた複雑なパーティショニング戦略は観察されなかった。
例: RLM(Qwen3-Coder)がOOLONGの1000行以上のコンテキストで改行によってチャンク化。
パターン3: 小さいコンテキストでのサブLM呼び出しによる回答検証
サブLM呼び出しを通じた回答検証のいくつかの戦略を観察:
- サブLMを使用して検証を実行することで、暗黙的にcontext rotを回避
- コード実行のみを使用してプログラム的に回答の正しさを検証
しかし、一部のケースでは、回答検証が冗長でタスクごとのコストを著しく増加。
パターン4: 長い出力タスクのために変数を通じて再帰的LM出力を渡す
RLMは、REPLで変数を返すことにより、基本LMの制限をはるかに超えた本質的に無制限のトークンを生成可能。REPLを通じて、RLMはプログラム的およびサブ(R)LM出力呼び出しの混合として、これらの変数を反復的に構築可能。
例: OOLONG-Pairs軌跡で、RLMが入力に対するサブLM呼び出しの出力を変数に保存し、それらをつなぎ合わせて最終回答を形成。
コード実装の詳細
RLMシステムプロンプト(GPT-5版)
RLMの実装は、システムプロンプトひとつでシンプル。以下は、GPT-5用のRLM with REPLのシステムプロンプトの主要部分:
日本語訳
主要な機能
- 変数: クエリに関する極めて重要な情報を含む変数
- 以下のようにしてまずcontextを読み込むコードを実行して、変数に格納
- 関数: REPL環境内でLLMをクエリする関数(約500K文字を扱える)
- 文: REPLコードの出力を表示し、推論を継続する能力
実装: rlm/environments/local_repl.py でとが実装。ソケット通信経由でのLMHandlerにリクエストを送信し、サブLM呼び出しを実現。
RLMは2つの方法で最終回答を提供:
- : 回答を直接提供
- : REPL環境で作成した変数を最終出力として返す
状態管理
- Local実行は辞書に格納
- Docker環境は.ファイルに格納
- (知らなかったけど、pklの上位互換で関数なども保存できる形式らしい)
Qwen3-Coder版との違い
Qwen3-Coder-480B-A35B用のプロンプトには、サブLM呼び出しの過剰使用を防ぐための追加の警告行:
この警告がないと、Qwen3-Coderはすべてに対してサブ呼び出しを試み、基本的なタスクで数千のLMサブ呼び出しにつながることが実験で判明した。
サマリーエージェントベースライン
要約エージェントベースラインは、以下の流れに従う:
- コンテキストが満杯になるまで反復的に入力を与える
- 満杯になった時点で、すべての関連情報を要約するようクエリ
- 要約後、継続
- 単一ステップでモデルのコンテキストウィンドウより大きいコンテキストが与えられた場合、このコンテキストをチャンク化し、これらのチャンクに対して要約プロセスを実行
GPT-5ベースラインでは、コストの爆発を避けるためGPT-5-nanoを使用して要約を実行。これにより、BrowseComp+でGPT-5とQwen3-Coderの間でコストに大きな差が発生(Qwen3-Coderを使用する要約エージェントは平均で約20倍高価)。
CodeActベースライン
CodeActエージェントは、ReActループ内でPythonコードを実行可能。RLMとは異なり、プロンプトをコード環境にオフロードせず、代わりにLMに直接提供。
BrowseComp+のような適切なタスクでは、入力コンテキストをインデックス化するBM25レトリーバーを装備。
関連研究との比較
長文脈LMシステム
| 手法カテゴリ | 代表的手法 | RLMとの違い |
|---|---|---|
| アーキテクチャ変更 | Train Short Test Long, Efficiently Modeling Long Sequences, Leave Context Behind | RLMは推論時のみで対応、訓練不要 |
| 非可逆的コンテキスト管理 | MemWalker, ReSum, MemGPT, mem0, gMemory | RLMはLM自身がコンテキスト管理を暗黙的に処理 |
| タスク分解 | ViperGPT, THREAD, DisCIPL, ReDel, Context Folding, AgentFold | これらはタスク分解に焦点、RLMはプロンプト自体を環境に配置してシンボリック操作可能に |
RLMの独自性
- シンボリック操作: プロンプトを外部環境に配置することで、任意の長さの文字列をシンボリック的に操作可能
- 実行フィードバック: 永続的なREPL環境からの実行フィードバックを通じて再帰を反復的に改善
- 情報損失なし: 要約のような非可逆的圧縮を行わず、必要に応じてコンテキストのすべての部分にアクセス可能
制限事項と今後の課題
1. 最適な実装メカニズムの探索不足
現在の実装では、Python REPL環境内での同期サブ呼び出しに焦点を当てているが、代替戦略も考えられる:
- 非同期サブ呼び出し: ランタイムと推論コストを大幅に削減できる可能性
- サンドボックス化されたREPL: セキュリティとパフォーマンスの向上
実装: 公式実装では複数の実行環境をサポート(rlm/environments/):
- : ホストプロセスで直接実行(Python 使用)
- : Docker隔離環境
- : Modalクラウドサンドボックス
バッチ処理による並列サブLM呼び出しもで実装済み。
2. 再帰の深さの制限
最大再帰深度を1(サブ呼び出しはLM)に設定したが、既存の長文脈ベンチマークで強力な性能を示したものの、より深い再帰層の調査が必要。
実装: RLMクラスのmax_depthパラメータで制御。深度上限に達すると通常のLM呼び出しにフォールバック。
3. 既存のフロンティアモデルのみでの評価
実験は既存のフロンティアモデルを使用したRLMの評価に焦点。RLMとして使用するために明示的にモデルを訓練すること(ルートまたはサブLMとして)により、追加の性能向上が得られる可能性。
観察された非効率性: 現在のモデルはコンテキストに対する非効率な意思決定を行う。
仮説: RLM軌跡は推論の一形態と見なすことができ、既存のフロンティアモデルをブートストラップすることで訓練可能(STaR、Quiet-STaRなど)。
実装: 公式実装では多様なバックエンドをサポート(rlm/clients/): OpenAI, Anthropic, OpenRouter, Portkey, LiteLLM, ローカルモデル(vLLM経由)
4. 小規模入力でのわずかな性能低下
構造上、RLMは基本LMよりも厳密に多くの表現能力を持つ(ルートLMを呼び出す環境の選択は基本LMと同等)。しかし実際には、より小さい入力長でRLM性能がわずかに悪いことが観察され、基本LMとRLMを使用する間のトレードオフポイントの存在を示唆。
5. 高い分散とランタイムコスト
RLMはタスクの複雑性に応じて反復的にコンテキストと相互作用するため、軌跡の長さに大きな違いが発生。これにより:
- 中央値は基本モデルより安価
- しかし外れ値は著しく高価
- 現在の実装ではすべてのLM呼び出しがブロッキング/シーケンシャル
実装: max_iterationsパラメータ(デフォルト30)で反復上限を制御。rlm/logger/で実行時間とトークン使用量を記録し、コスト分析が可能。
結論
本論文は、入力コンテキストをオフロードし、言語モデルが出力を提供する前に言語モデルを再帰的にサブクエリできる汎用推論フレームワーク、Recursive Language Models (RLM) を導入。
主要な成果
- 劇的なスケーラビリティ: モデルのコンテキストウィンドウの100倍を超える入力を処理可能
- タスク非依存: 単一の固定プロンプトで多様なタスクに対応
- コスト効率: 同等またはより低いコストで大幅な性能向上
- 推論時のみ: 訓練やアーキテクチャ変更が不要
実装の核心
- Python REPL環境に変数としてコンテキストをオフロード
- LMがコードと再帰的LM呼び出しでコンテキストを推論可能
- 純粋にトークン空間ではなく、プログラム的な操作を可能に
今後の展望
複数の設定とモデルにわたる結果は、RLMが長文脈問題と一般的な推論の両方に対して効果的なタスク非依存パラダイムであることを示した。
期待される方向性:
- RLMとして推論するようにモデルを明示的に訓練する今後の研究
- これにより、次世代の言語モデルシステムのための別のスケール軸が生まれる可能性
RLMは、推論時スケーリングという新しいパラダイムを通じて、言語モデルの能力を劇的に拡張する可能性を示す。
Appendix
タスク複雑性とスケーリングパターンの新しい視点
論文は、長文脈処理を考える上で重要な視点を提供。
仮説: LMの実効的コンテキストウィンドウは、タスクと独立して理解できない
これは、従来の「モデルXのコンテキストウィンドウはYトークン」という単純な理解を超える。
タスクの複雑性の分類:
- 定数オーダー (S-NIAH): 入力サイズに関わらず一定の処理
- 線形オーダー (OOLONG): 入力のほぼすべてのエントリを処理
- 二次オーダー (OOLONG-Pairs): 入力のほぼすべてのペアを処理
この分類により、タスクの本質的な難しさを定量化でき、どの手法が適切かを判断可能。
コスト分析の詳細
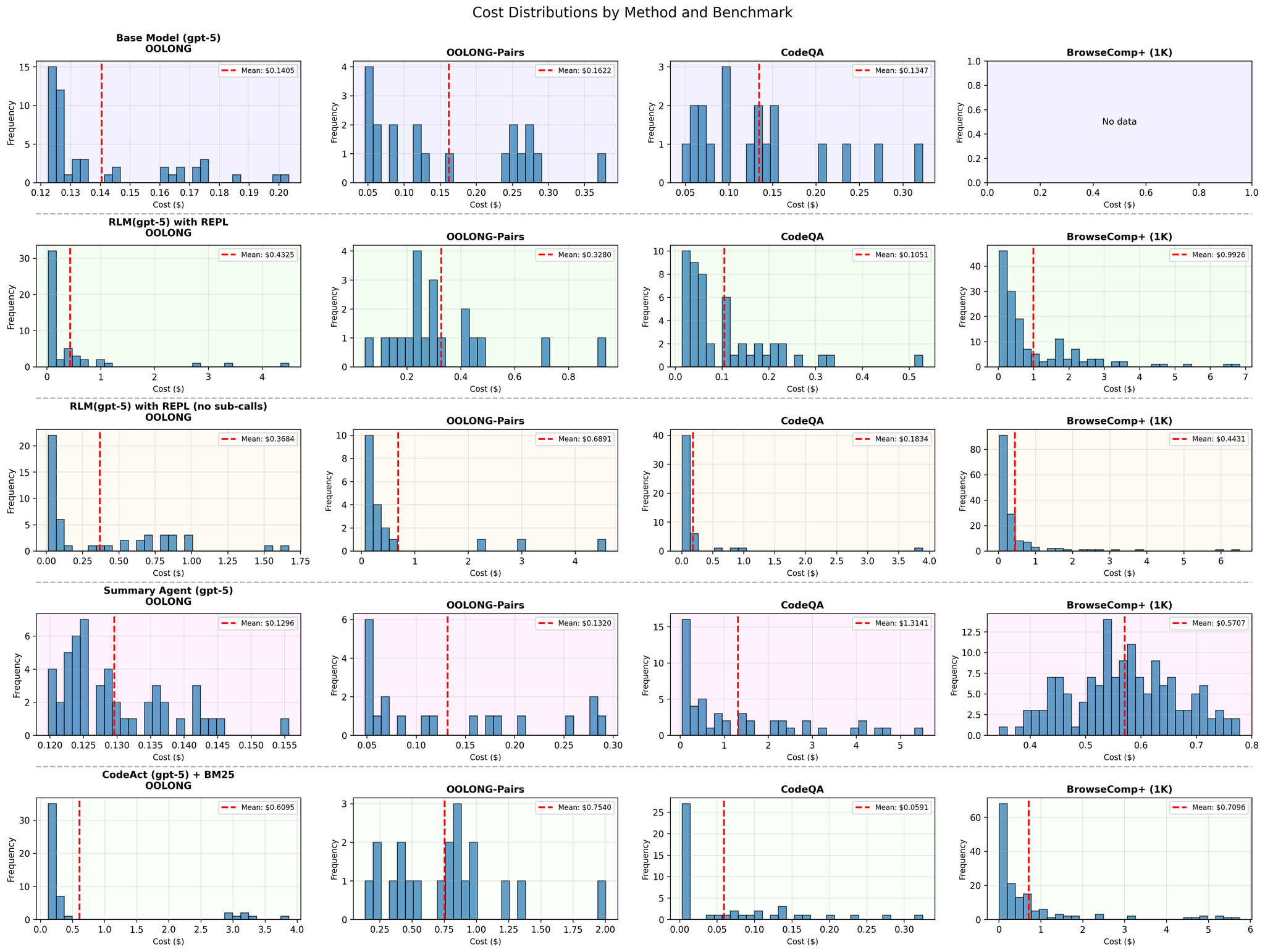
論文は、平均コストだけでなく、四分位点やコスト分布も詳細に報告:
- 25パーセンタイル、50パーセンタイル(中央値)、75パーセンタイル、95パーセンタイル
- これにより、外れ値の影響を理解可能
GPT-5の場合、RLMの中央値コストは基本モデルより安価だが、95パーセンタイルでは著しく高くなる。一部のタスクで非常に長い軌跡が生成されることを示す。
実用的な示唆
- いつRLMを使うべきか:
- 入力がモデルのコンテキストウィンドウを超える場合
- 情報密度が高いタスク(プロンプトの多くの部分への密なアクセスが必要)
- 複雑な推論が必要なタスク
- いつ基本LMで十分か:
- 入力が短く、モデルのコンテキストウィンドウに収まる場合
- シンプルなタスク(例:S-NIAHのような定数オーダーの複雑性)
- コスト管理:
- 中央値コストは基本モデルと同等またはより低い
- しかし、一部のクエリで高コストの外れ値が発生する可能性
- 非同期実装により、ランタイムとコストをさらに削減できる可能性
まとめ
Recursive Language Models (RLM)は、長文脈処理における根本的なパラダイムシフトを提案。プロンプトを外部環境に配置し、LM自身がプログラム的に相互作用できるようにすることで、訓練やアーキテクチャ変更なしに、推論時のみでコンテキストを劇的に拡張可能。
実験結果は、RLMが最先端のLMと既存の長文脈手法を大幅に上回ることを示しており、特に情報密度の高いタスクで顕著な改善が見られた。今後、RLMとして推論するようにモデルを明示的に訓練することで、さらなる性能向上が期待される。