
2026-01-13 機械学習勉強会
今週のTOPIC[論文] Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents[論文] RelayLLM: Efficient Reasoning via Collaborative Decoding[blog] Deep Delta Learning[paper]S-LORA: SERVING THOUSANDS OF CONCURRENT LORA ADAPTERS[blog] Demystifying evals for AI agents[paper] MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic MemoryMixLM: High-Throughput and Effective LLM Ranking via Text-Embedding Mix-Interaction概要データセット1. ラベル生成 (Label Generation)2. Stage 2:ランキング教師モデル用プロンプト (Teacher Training Prompts)3. Stage 3:混合入力ランキング用プロンプト (Mixed Input Ranking Training Prompts)補足:データセットの規模Three-stage TrainingStage 1: ドメイン推論ファインチューニング (Domain Reasoning Fine-Tuning)Stage 2: ランキング教師モデルの学習 (Ranking Teacher Training)Stage 3: エンコーダとランカーのジョイント学習 (Joint Encoder-Ranking Training)自己アライメント損失 (Self-Alignment Loss)1. 2通りの入力を用意する2. 2つの値を比較・計算する① 隠れ層のアライメント ( L_{hidden-align} )② 予測分布のアライメント ( L_{pred-align} )3. 合計する
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
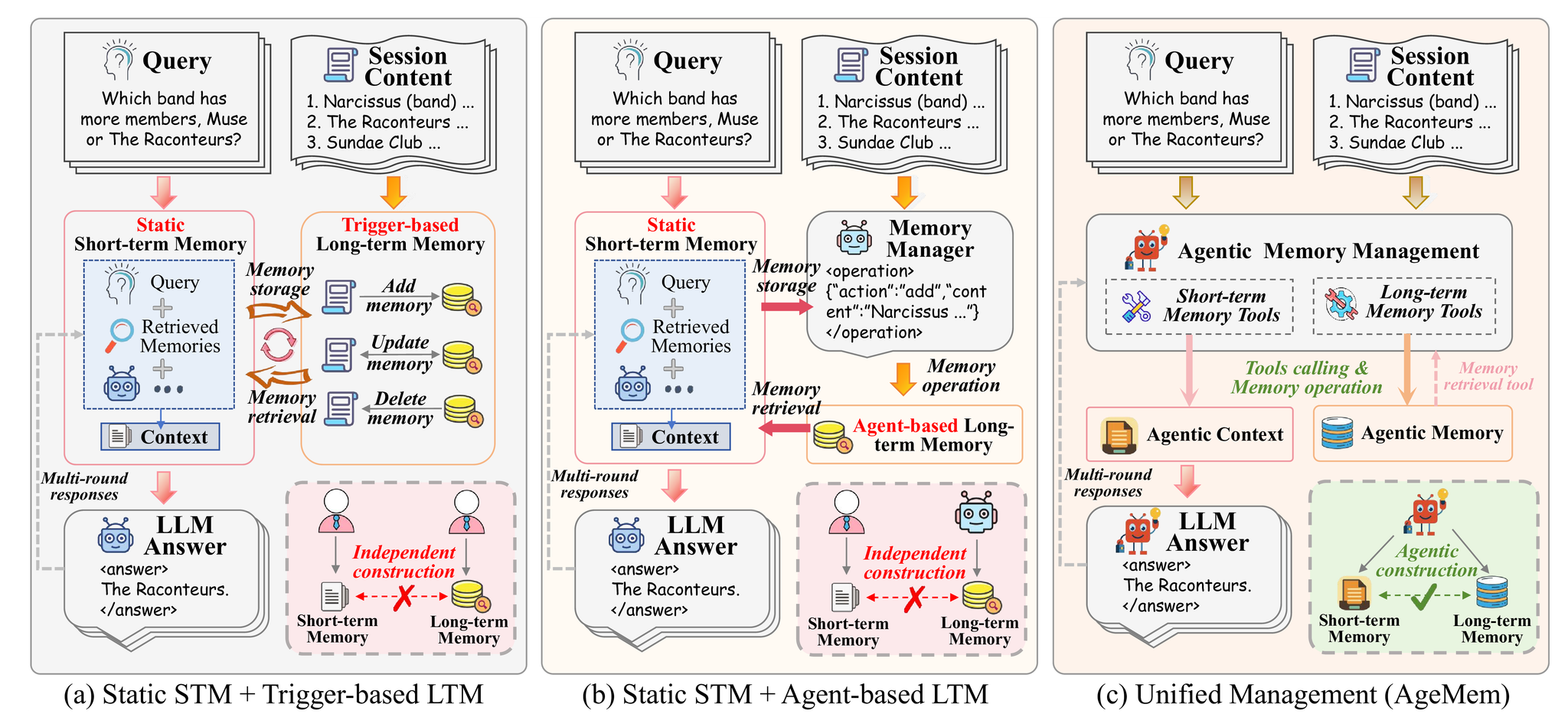
[論文] Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents
- 既存の研究はヒューリスティックに長期記憶(Long-Term Memory: LTM)と短期記憶(Short-Term Memory: STM)を独立したコンポーネントとして扱い解決してきていた。それらToolのアクションとしてAgentに統合して強化学習で解くという論文。
- ツールインターフェースを用いたメモリ管理。これらをアクション空間に組み込む。
| ツール | 対象 | 機能 |
|---|---|---|
| Add | LTM | 長期メモリ に新しい知識を追加 |
| Update | LTM | 長期メモリ のエントリを修正 |
| Delete | LTM | 長期メモリ からエントリを削除 |
| Retrieve | STM | 長期メモリから コンテキスト へエントリを取得 |
| Summary | STM | コンテキスト のセグメントを要約 |
| Filter | STM | コンテキスト から無関係なセグメントをフィルタリング |
- 訓練方法 (3ステップ):3ステップと書いてるが1ロールアウトで以下を順番に行うということっぽい?
- LTM構築:カジュアルな会話設定で重要な情報を長期メモリに保存することが目的
- STM制御:1のLTMは保持された上で、Agentに意味的に関連しているが無関係なクエリを提示する (Hard Negative的な)。ノイズを抑制するのが目的。
- 統合:正確な推論と効果的なメモリ取得の両方を必要とする正式なクエリを受け取る。
- GRPOのVariantはStepごとに計算する
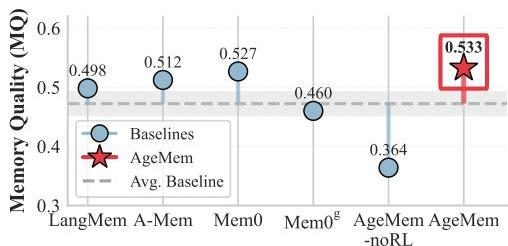
- 実験結果
- メモリ品質 (どれくらい使用したLTMが実際にタスク解決に必要な情報と類似してるかをQwen-Maxで評価)
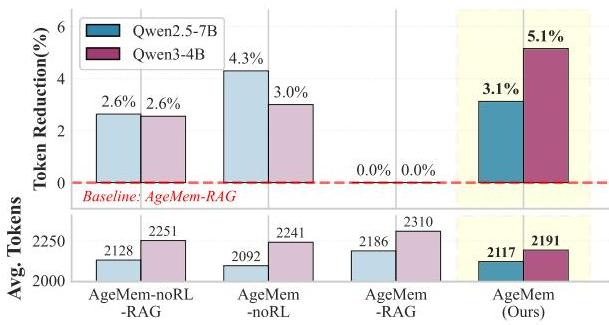
- コンテキスト管理効率。RAGより3.1%、5.1%削減
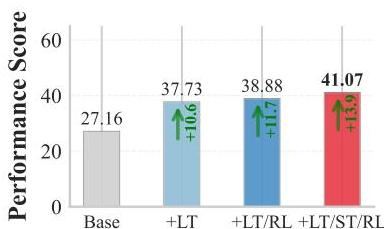
- アブレーションスタディ
- あんま強化学習の貢献でかくない?
@Shun Ito
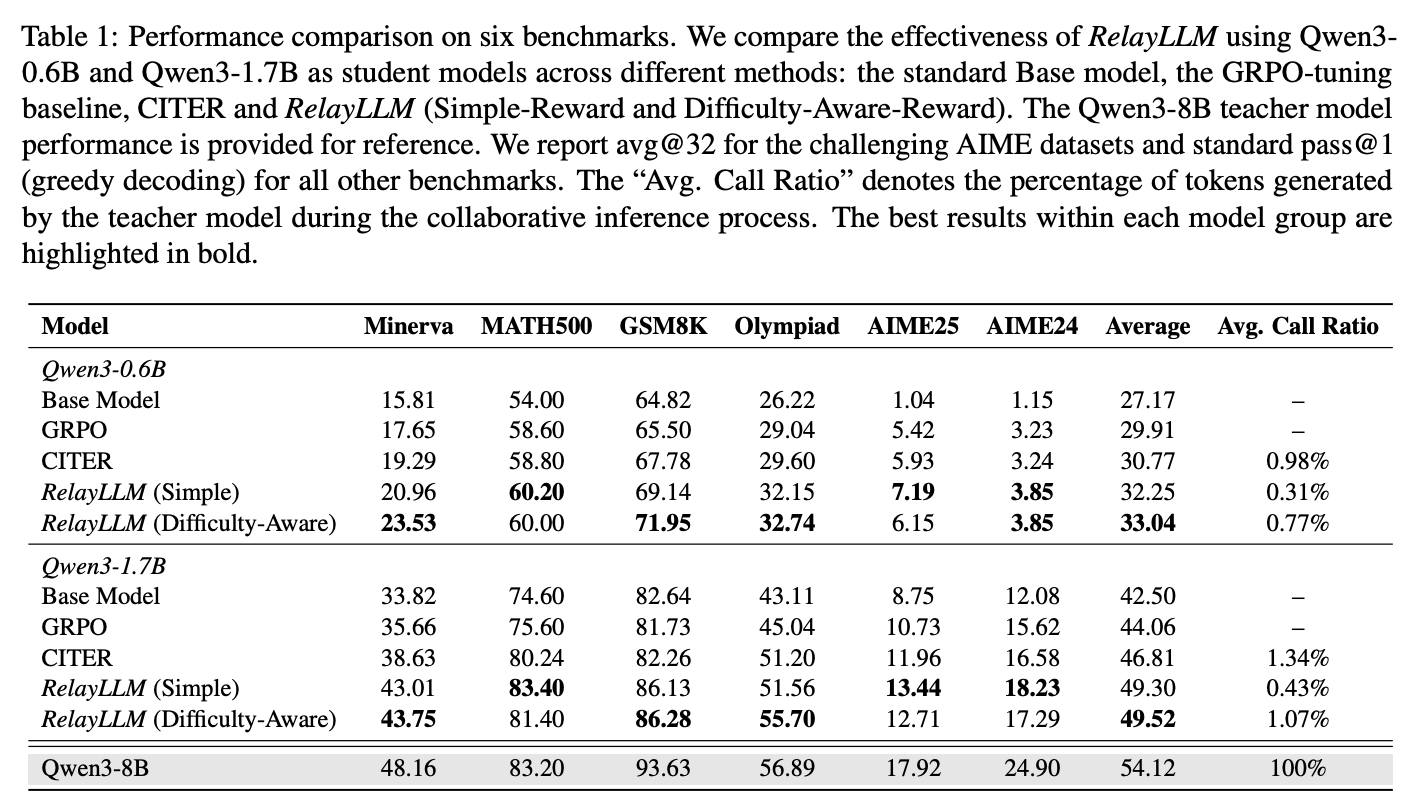
[論文] RelayLLM: Efficient Reasoning via Collaborative Decoding
- LLMの推論を高速化させたい。
- LLMは遅いが精度が高い。
- SLMは速いが精度がイマイチなことがある。
- 提案: SLMとLLMの推論をリレー形式で接続する
- 基本的にはSLMが回答を生成する
- LLMに生成させた方がよいと判断したタイミングで Command Pattern を生成。nトークンだけLLMが生成し、その後はまたSLMが生成する。
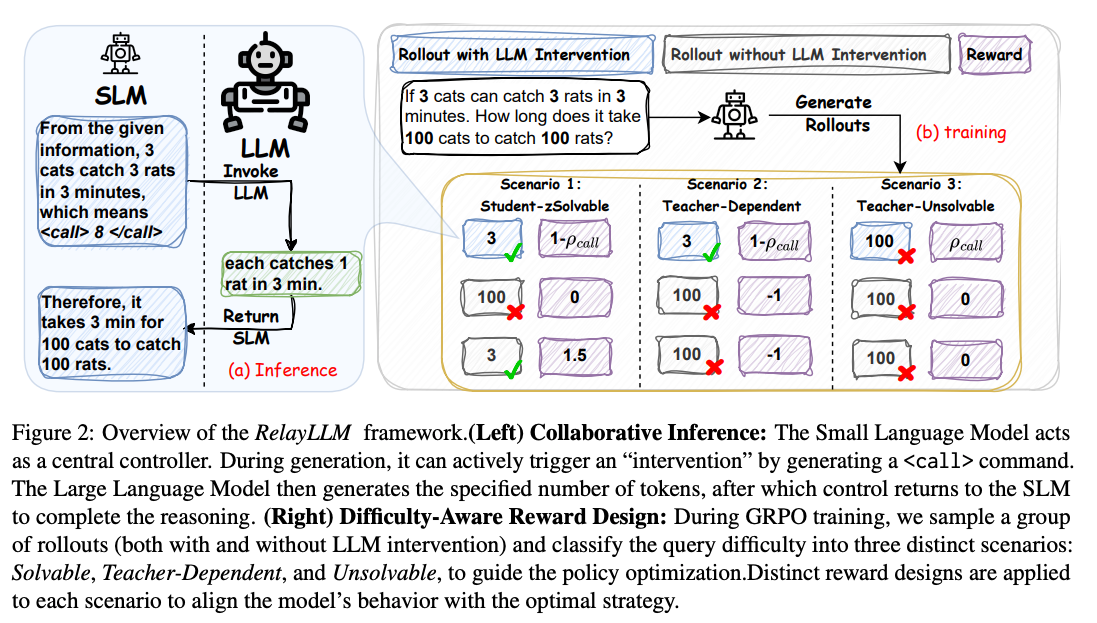
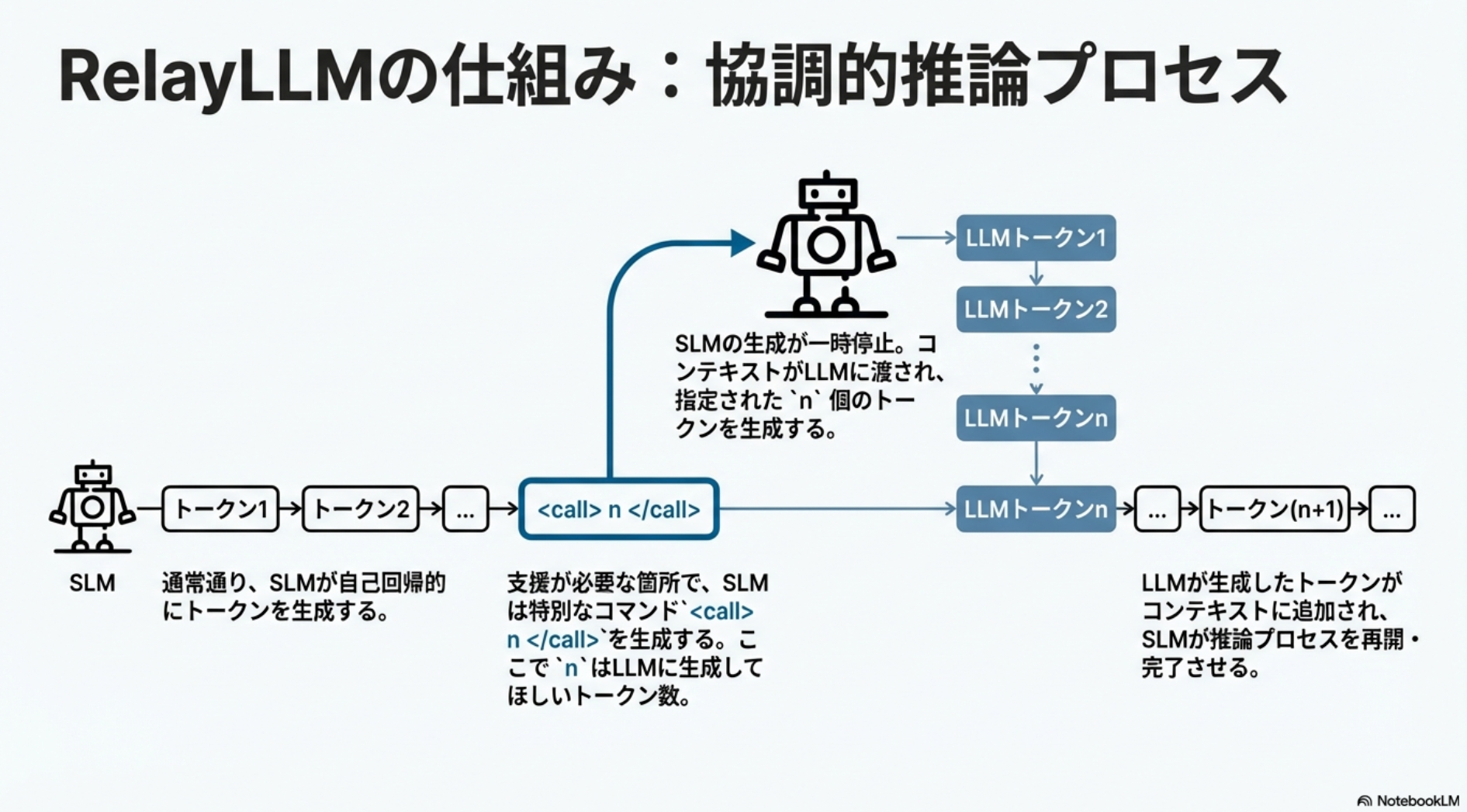
- Command Pattern を生成させるための学習
- supervised warm-up
- 学習させる文章にランダムな位置に Command Pattern を差し込んでfine-tune。n もランダムに決定。
- まず Command Pattern を生成できるようにする
- RL with GRPO
- 2種類の報酬を用意
- Simple Reward: accuracy と efficiency のバランス
- Difficulty-Aware Reward: GRPOのgroupの回答から難易度を推定して報酬を切り替え
- Student-Solvable: groupの中にLLMの呼び出し無しで正解したものがあるパターン。LLMを呼び出さずに正解したものに r = 1.5 の報酬(正解してもLLMを呼んでいる場合は冗長なコストを使っているため報酬なし)
- Teacher-Dependent: LLMを呼び出したグループにだけ正解があるパターン。LLMを呼ばなかった場合に r= -1.0 のペナルティ
- Teacher-Unsolvable: LLMを呼んでも正解がなかったパターン。LLMを呼び出したものに小さめの報酬。
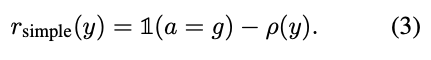
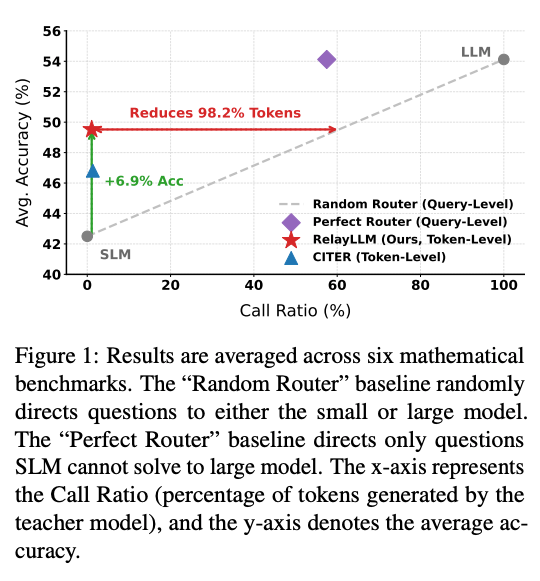
- 結果: 既存のrouterよりも精度・コストのトレードオフがより良い位置にある
@Takumi Iida (frkake)
[blog] Deep Delta Learning
Deep Delta Learningの解説記事。
残差接続(Residual Connection)は特徴を加算する方法なので、ネットワークが学習できる変換の種類が制限される。
Deep Delta Learningは標準的な残差接続を一般化するデータ依存の幾何学的変換を導入して、この制約に対処。
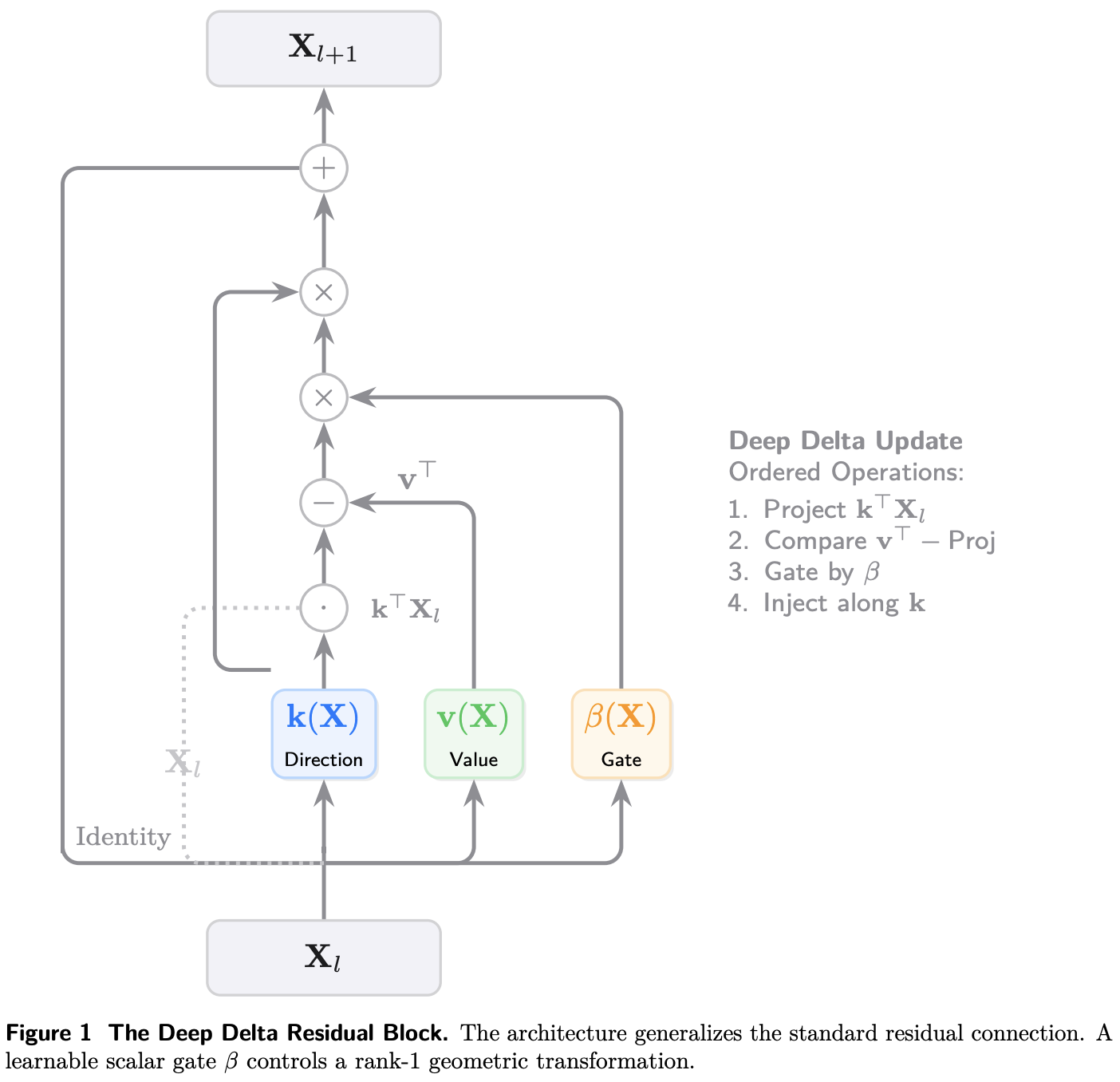
残差接続では、符号を反転したり、完全に忘れたりすることができない。
Deep Delta Learningのアーキテクチャを数式化すると下記になる。
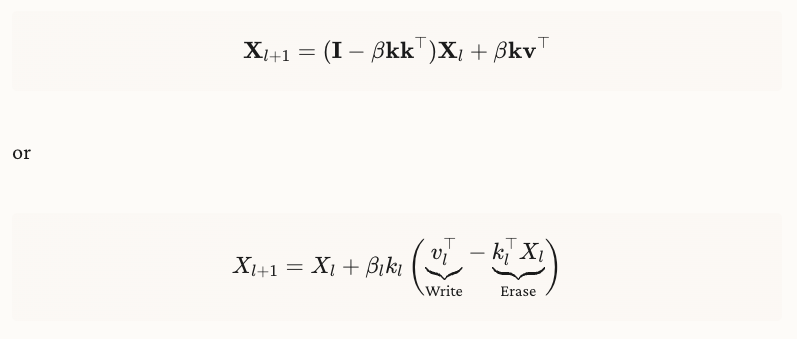
- k : 方向ベクトル(正規化されている、学習される)
- v : 値ベクトル(何を書き込むか、学習される)
- : ゲートの役割を持つスカラー値。これも学習される。
具体例:k = [1, 0], β = 1 のときDelta Operator は以下のようになる。
1つ目の要素(左上)は消去され、2つ目の要素(右下)の要素はそのまま残る(恒等写像)。
kに並行な成分が消去される。
βの値によって、次のような振る舞いになるらしい。
| モード | β値 | スペクトル | 動作 | 解釈 |
|---|---|---|---|---|
| 恒等写像 | β→0 | 1 | Xl+1≈Xl | スキップ接続: 深い伝播のための信号保存 |
| 射影 | β→1 | 0,1 | det(A)→0 | 忘却: 超平面k⊥への直交射影、kに平行な成分を消去 |
| 反射 | β→2 | −1,1 | det(A)→−1 | ハウスホルダー反射: k方向に沿って状態を反転、負の固有値を導入して振動的/対立的なダイナミクスをモデル化 |
使い方
実験結果がなかったで実際どうなんだろうか
先週紹介したmHCとDeep Delta Learningの発表タイミングが近いのもあって、古典的な接続モジュールの再考が行われてきた感ある。
@Hiromu Nakamura (pon)
[paper]S-LORA: SERVING THOUSANDS OF CONCURRENT LORA ADAPTERS
単一LLMに対する動的にLoRa Adapterを切り替えるのって具体的にどうやるんだっけ?と思ったので読んだ。テナントごとにLoRa Adapterを学習して、単一のベースモデルに対して使い分けたりなど。
1. 概要と背景
S-LoRAは、単一または複数のGPUで数千ものLoRAアダプタを効率的に提供するために設計されたシステムである。
2. LoRAサービングの課題
既存の手法には主に二つのアプローチがあるが、いずれもマルチアダプタ環境には適さない。
- 重みのマージ:アダプタをベースモデルに統合すると推論の遅延はゼロになるが、アダプタごとにモデル全体のコピーを保持する必要があり、メモリ効率が極めて悪い。
- 動的な入れ替え:実行時にアダプタをベースモデルに追加・削除する方法は、同時実行(バッチ化)ができず、スループットが大幅に低下する。
3. S-LoRAの主要技術
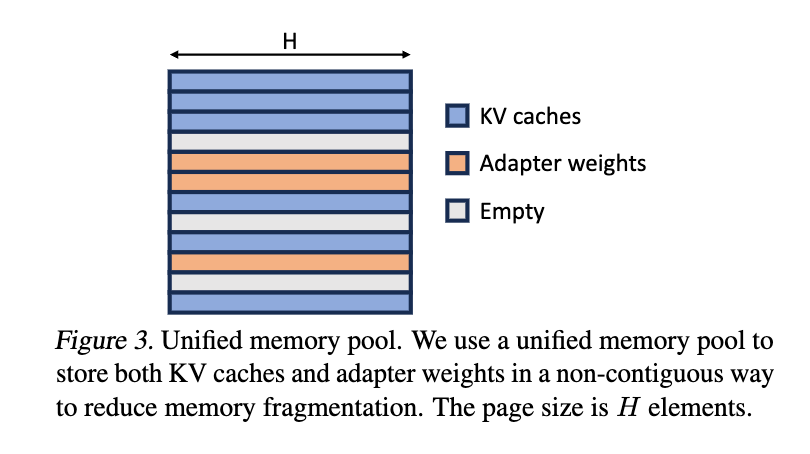
3.1 統合ページング(Unified Paging)
S-LoRAは、動的に変化するKVキャッシュ(推論時の中間データ)とアダプタの重みを、一つの共通メモリプールで管理する。
- フラグメンテーションの抑制:KVキャッシュ(形状:シーケンス長×隠れ層サイズ)とLoRAの重み(形状:ランク×隠れ層サイズ)は、共に「隠れ層サイズ」という共通の次元を持つ。これに着目し、ページ単位で管理する。
- LLMの計算において、隠れ層の次元数(Hidden Dimension, H)はモデル全体で固定された定数である。
- KVキャッシュの形状: (SH)。つまり「トークン数 S」×「隠れ層 H」。
- LoRA重みの形状: (RH)。つまり「ランク r」×「隠れ層 H」。
- ここで重要なのは、「1トークン分のキャッシュ」も「LoRAのランク1つ分の重み」も、どちらもメモリ上では「長さ H のベクトル」として表現されるという点。S-LoRAはこの「長さ H」を1ページ(最小単位)として定義。
- 効率的なメモリ利用:アダプタのランクやリクエストの長さが異なっていても、メモリプール内で非連続的に配置することで、メモリの断片化を防ぎ、より大きなバッチサイズを可能にする。
3.2 Heterogeneous Batchinとカスタムカーネル
計算面では、ベースモデルの計算(xW)とLoRAの計算(xAB)を分離する。
- 計算の分離:全リクエストで共通のベースモデル計算をバッチ化して行い、その後で個別のLoRA計算を実行する。
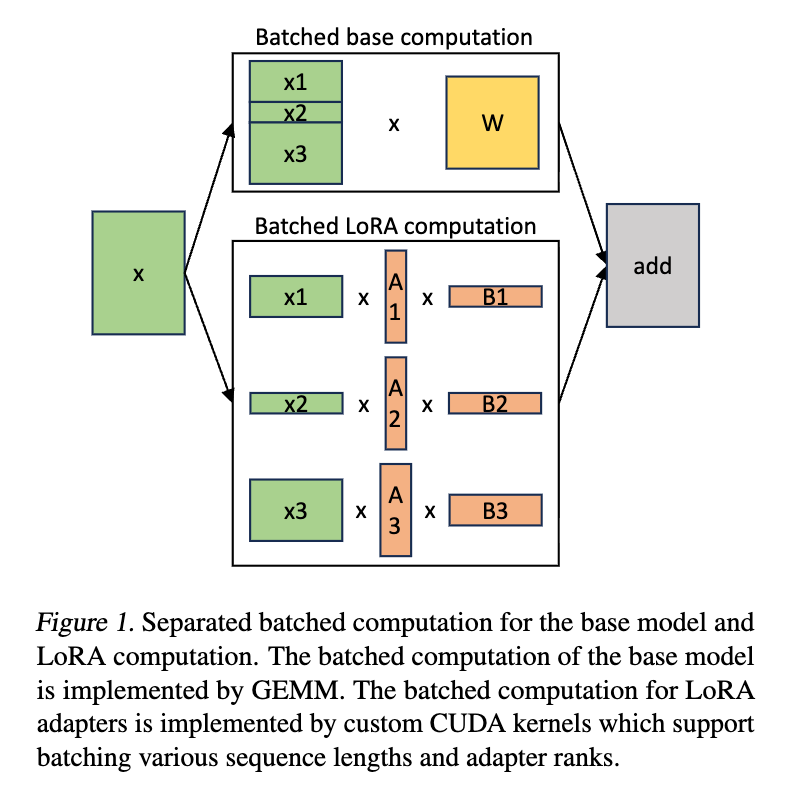
- カスタムCUDAカーネル:異なるランクやシーケンス長を持つアダプタが非連続なメモリ上にある状態でも、効率よく計算できる専用カーネル(MBGMMやMBGMV)を実装している。これにより、パディングによる無駄を排除し、高いハードウェア利用率を実現している。
3.3 S-LoRA TP(新しいテンソル並列戦略)
大規模モデルを複数のGPUで動かす際、LoRAの追加計算による通信オーバーヘッドが問題となる。
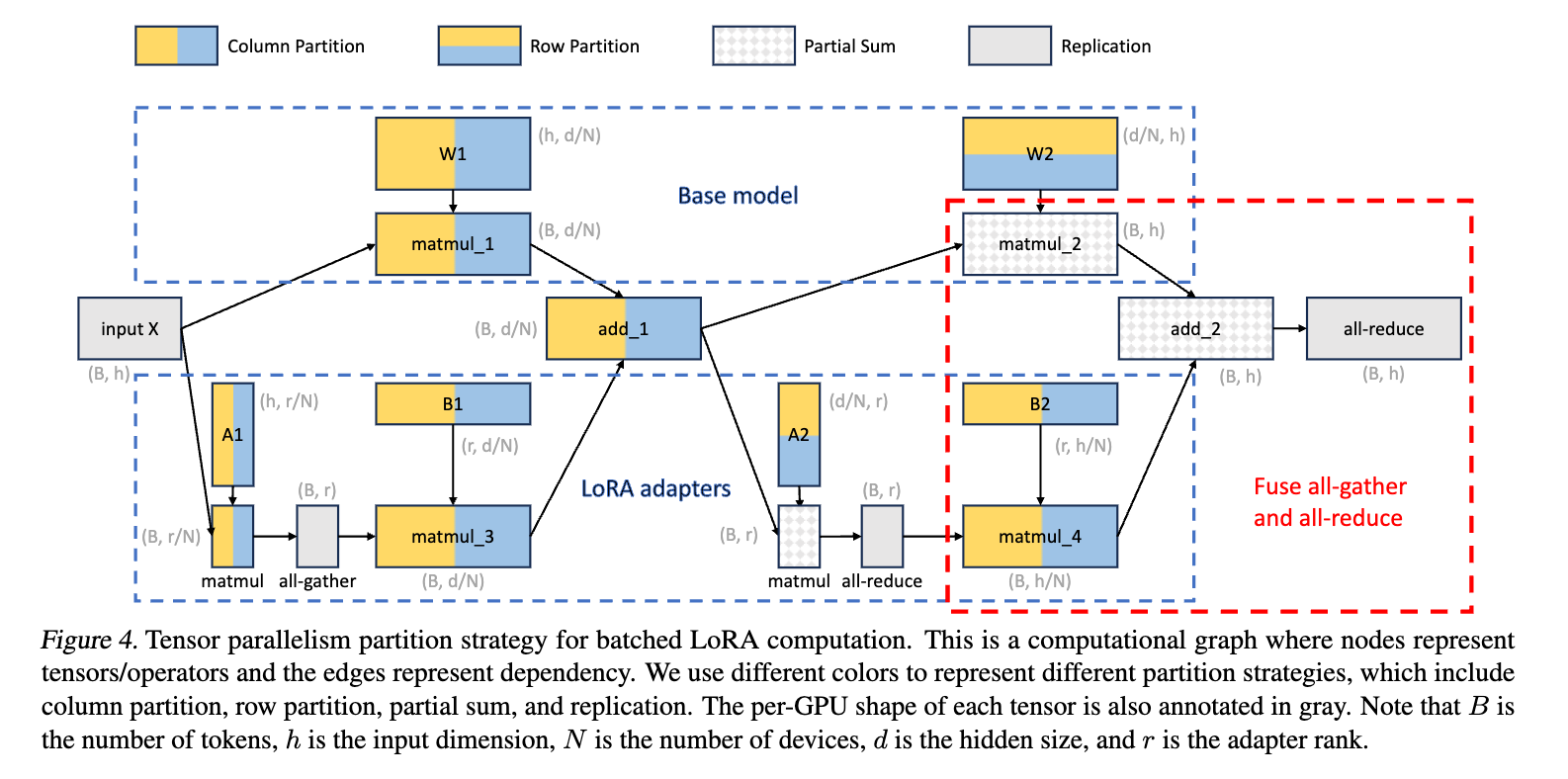
- 通信の最小化:LoRAのランクrは隠れ層のサイズhよりも遥かに小さい(r≪h)ため、中間テンソルの通信コストはベースモデルの通信に比べて無視できるほど小さい。
- 通信の融合:LoRAの計算結果をベースモデルの計算結果と合算する際、通信(All-reduceなど)をベースモデルの通信と統合することで、余計な同期コストを抑えている。
- 2層のMLPを例にとる
- ベースモデル(上段):
- LoRAアダプタ(下段):
◦ 最初の重み行列 (W1) は列分割(column-partitioned)され、2番目の重み行列 (W2) は行分割(row-partitioned)**される。
◦ 分散されたデバイスから部分和を蓄積するために、All-reduce通信が必要となる。
◦ 1つ目の重みのアダプタ行列 A1 と B1 は列分割される。中間結果を収集するためにAll-gather操作が使用される。
◦ 2つ目の重みのアダプタ行列 A2 は行分割、 B2 は列分割される。中間結果を合算するためにAll-reduce操作が使用される。
◦ 最終的に、LoRAの計算結果がベースモデルの結果(add 2)に加算される。この際、matmulのためのAll-gather操作を最終的なAll-reduceに融合させているのが特徴。
この戦略は、セルフアテンション層にも適用可能である。QKV(クエリ・キー・バリュー)投影行列を W1 と見なし、出力投影行列を W2 と見なすことで、ヘッドの次元を分割して並列化する。
4. スケジューリングと最適化
- アダプタ・クラスタリング: 同じアダプタを使用するリクエストを優先的にバッチに含めることで、GPUメモリへのアダプタ読み込み回数を減らし、スループットを向上させる。
- 早期中断(Early Abort): システムのキャパシティを超える負荷がかかった際、サービスレベル目標(SLO)を満たせない可能性が高いリクエストを早期に特定して処理を中止し、システム全体の満足度を維持する。
- プリフェッチ: 現在のバッチを計算している間に、待機キューにある次のアダプタを予測してメインメモリからGPUメモリへ転送し、I/Oの遅延を隠蔽する。
5. 評価結果
セットアップ
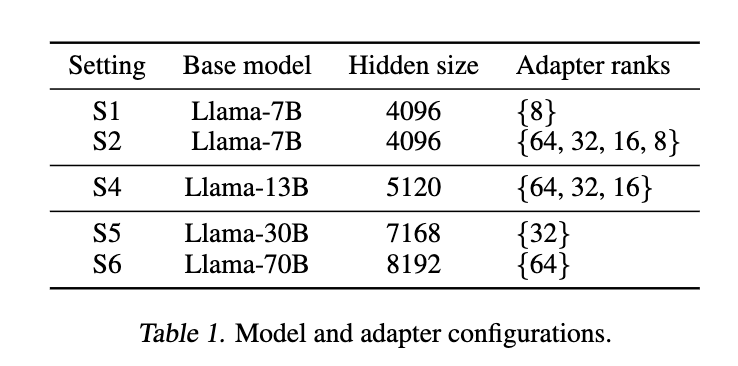
Baseline
- HuggingFace PEFT
- vLLM m-packed
- 高スループットなサービングシステムであるvLLMを用いた、「素朴な(ナイーブな)」マルチモデル提供の解決策である。
- 構成: vLLM自体はLoRAをネイティブにサポートしていないため、LoRAの重みをあらかじめベースモデルに統合(マージ)したモデルを複数用意し、別々のプロセスとして実行する。
- 特徴: モデル全体のコピーを複数保持するため、GPUメモリの制約により少数のアダプタ(5個未満)しか扱えず、それ以上ではメモリ不足(OOM)となる。
- S-LoRA(提案手法)
- S-LoRA-no-unify-mem:
◦ 統合ページング(Unified Paging)を除外したS-LoRA
- S-LoRA-bmm:
◦ 統合ページングとカスタムカーネルの両方を除外したS-LoRA
結果
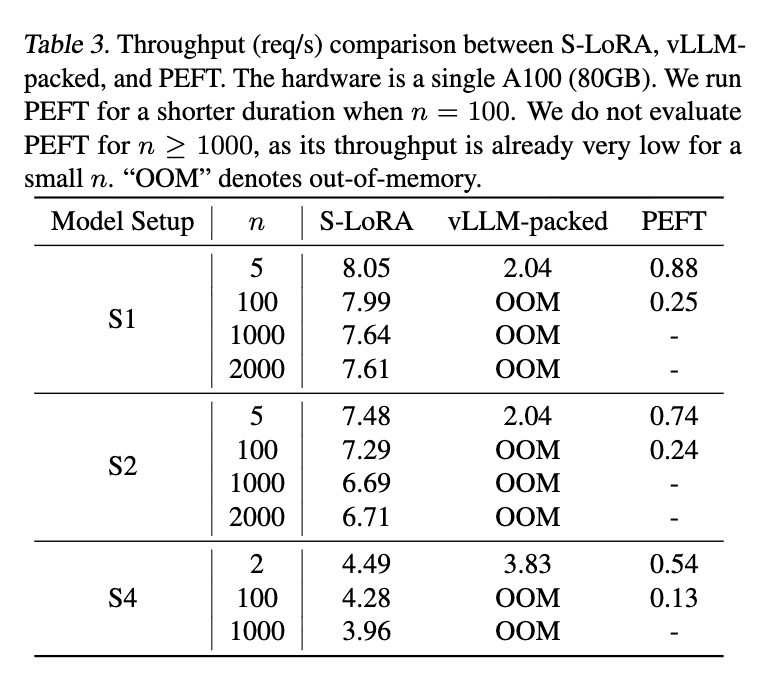
S-LoRAは、単一のA100(80GB)GPUで最大2,000個のアダプタを同時にサービング可能である。
◦ vLLM-packedは、アダプタごとにモデルのコピーを作成するため、メモリ制限により5個未満のアダプタしか扱えず、それ以上ではメモリ不足(OOM)となる。
◦ HuggingFace PEFTは、バッチ間でのアダプタ入れ替え(スワップ)により多数のアダプタを扱えるが、高度なメモリ管理やバッチングがないため、スループットはS-LoRAの30分の1程度と極めて低い。
◦ S-LoRAは、vLLM-packedに対しても最大4倍のスループット向上を達成している。
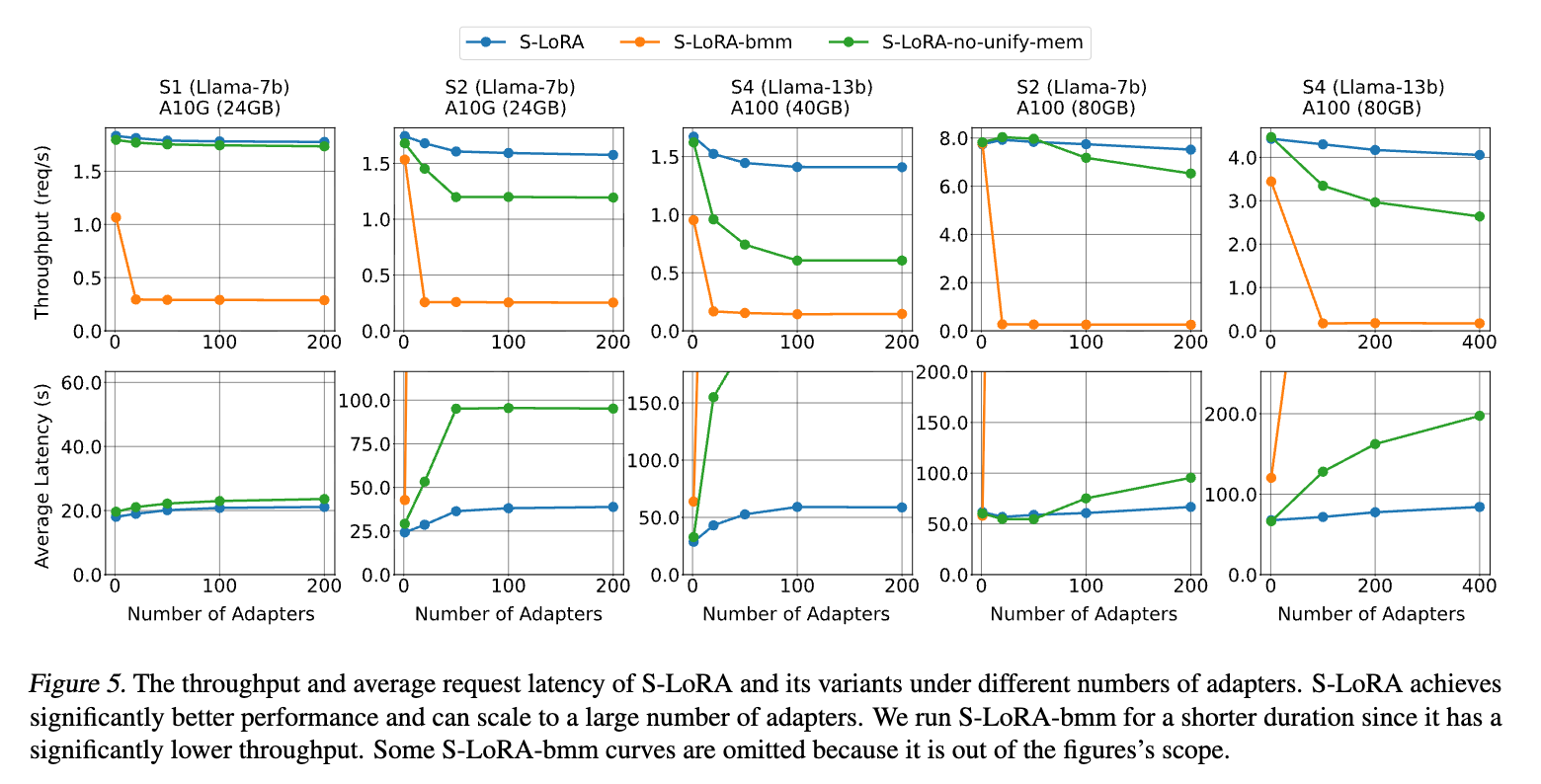
◦ S-LoRAは、アダプタの数が増えてもスループットがほとんど低下しない。
◦ これは、アダプタ数が増えても、現在実行中のバッチに含まれる「アクティブなアダプタ数」は一定であるため、追加のオーバーヘッドが限定的だからである。
◦ 統合メモリなしのやカスタムカーネルなしのよりも常に高い性能を示しており、提案手法の有効性が裏付けられている。
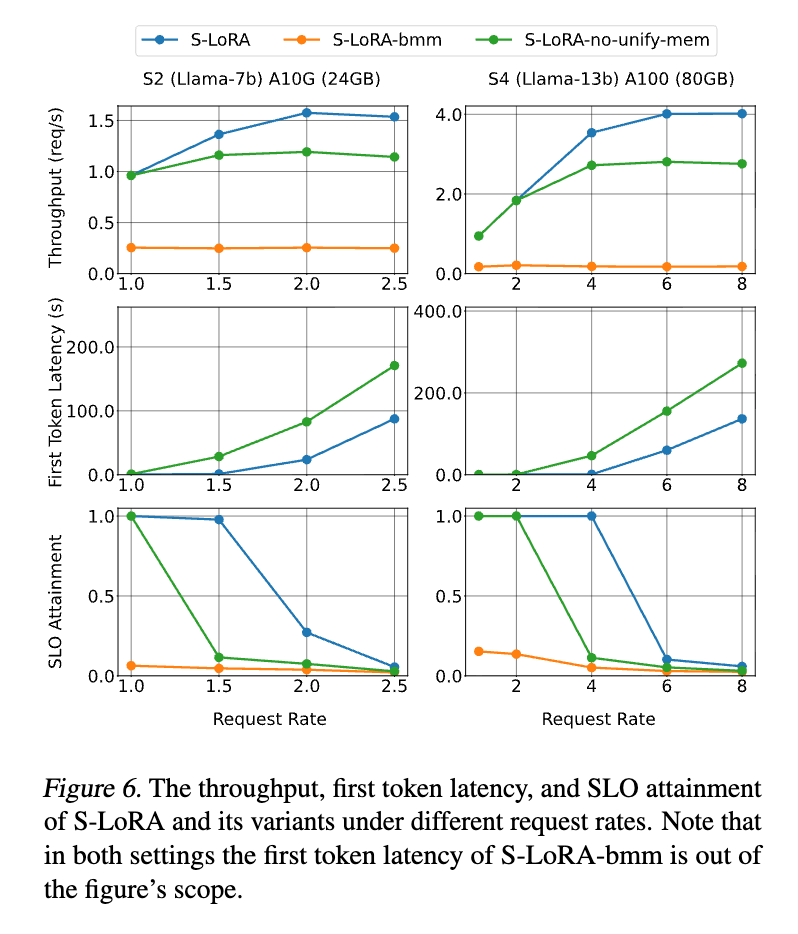
リクエストが到着する頻度(Request Rate)を変化させた際の性能を示している。
- 主張: リクエストレートが高まっても、S-LoRAはバリアントに比べて高いSLO達成率(SLO Attainment)と低い第1トークン遅延を維持できる。
- (パディングを用いた標準的なバッチ行列演算)は、非効率な計算により遅延がグラフ外に飛び出すほど悪化している。
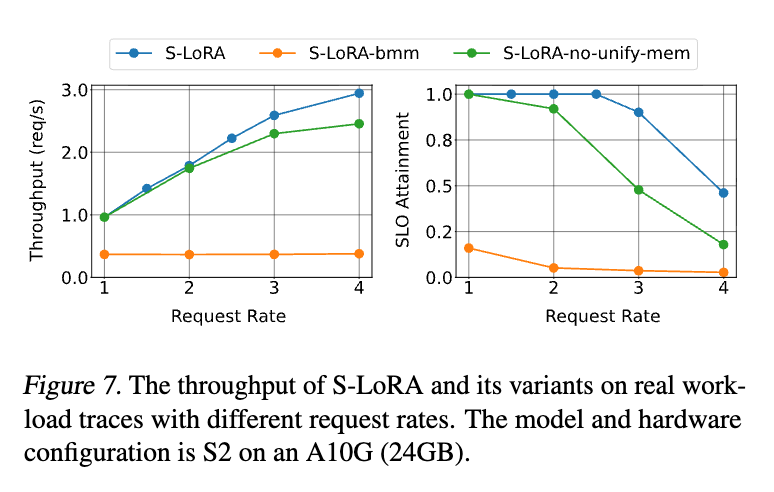
LMSYS Chatbot Arenaの実データを用いたテスト結果である。
- 主張: 合成データ(Synthetic Workload)だけでなく、実際の利用環境においても、S-LoRAは高いスループットとSLO達成率を維持できることが証明された。
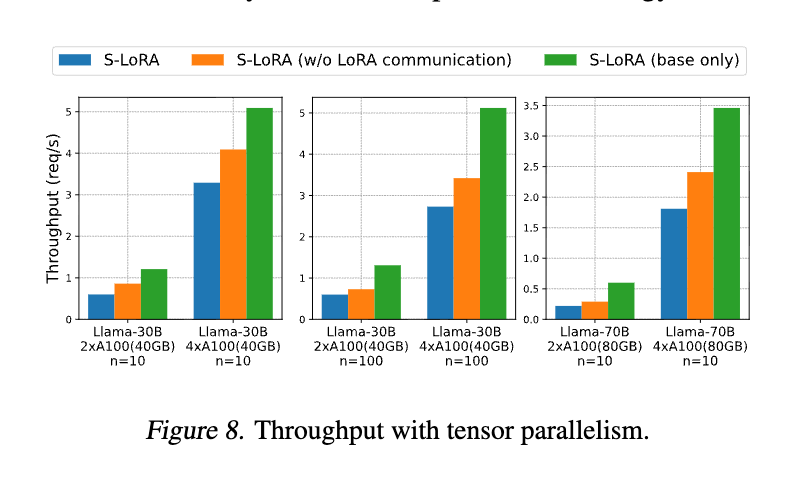
Llama-30Bや70Bを複数のGPUで実行した際の結果を示している。
- 低オーバーヘッド: 「LoRA通信あり」と「なし」の差が極めて小さいことから、S-LoRAのテンソル並列戦略におけるLoRA追加計算の通信コストは無視できるほど小さいことがわかる。
- 超線形スケーリング: GPUを2枚から4枚に増やすと、スループットが2倍以上に向上する。これは、GPUが増えることでメモリ制約が緩和され、より大きなバッチサイズが可能になるためである。
[pon]vLLMではすでにmulti LoRAは(当然ながら)サポートされており、この研究成果がベースになっているっぽい
@Shuhei Nakano(nanay)
[blog] Demystifying evals for AI agents
これは何?
AnthropicによるAIエージェントの評価システム構築に関する実践ガイド。コーディング、会話、リサーチ、コンピュータ操作など様々なタイプのエージェントを体系的にテストする方法を、実際の導入事例とともに解説した技術文書です。
問題設定
AIエージェントは複数ターンにわたってツールを使い、状態を変更し、適応します。この自律性と柔軟性が評価を困難にしています。従来の単一ターン評価では不十分で、エラーが伝播・複合化します。
評価なしでは、チームは本番環境でしか問題を発見できず、「悪化した」という報告を検証する手段がなく、修正が他の問題を引き起こす悪循環に陥ります。Claude Codeも 、開発を加速させました。
評価システムの基礎
基本構造
- タスク: 定義された入力と成功基準を持つテスト
- トライアル: タスクへの各試行(モデル出力は変動するため複数回実行)
- グレーダー: パフォーマンスを評価するロジック
- トランスクリプト: 試行の完全な記録
- アウトカム: 環境の最終状態(例:予約エージェントが「完了」と言うだけでなく、実際にDBに予約が存在するか)
なぜ必要か
- 問題をユーザーに影響する前に可視化
- ベースラインと退行テストを自動取得
- 新モデルへの迅速な移行(評価なしは数週間、ありなら数日)
- プロダクトと研究チーム間の最も効率的なコミュニケーションチャネル
3種類のグレーダー
1. コードベース
文字列マッチ、テスト実行、静的解析など。高速・客観的・再現可能だが、有効なバリエーションに脆弱。
2. モデルベース
LLMによるルーブリック評価、ペアワイズ比較など。柔軟でニュアンスを捉えるが、非決定的で人間とのキャリブレーションが必要。
3. 人間
専門家レビュー、A/Bテスト。ゴールドスタンダード品質だが、高コスト・遅い。
重要なのは各タスクに適したグレーダーの組合わせを選ぶこと
エージェントタイプ別の評価戦略
コーディングエージェント
評価方法: ユニットテストによる決定論的評価が自然
- SWE-bench Verified: GitHubのissueを与え、テストスイートで評価
- Terminal-Bench: Linuxカーネルのビルドなどエンドツーエンドのタスク
実装例: 認証バイパス脆弱性の修正
- 決定論的テスト(空/nullパスワード拒否)
- LLMルーブリック(コード品質)
- 静的解析(ruff, mypy, bandit)
- 状態チェック(セキュリティログ確認)
重要ポイント: 特定のステップを厳密にチェックせず、「何を生成したか」を評価。エージェントは予期しない有効なアプローチを見つけることが多い。
会話エージェント
評価方法: エンドステートのアウトカムとルーブリックの組み合わせ
- τ-Bench/τ²-Bench: 小売サポートや航空券予約での複数ターン対話をシミュレート
成功の多次元性:
- チケットは解決されたか(状態チェック)
- 10ターン未満で完了したか(トランスクリプト制約)
- トーンは適切だったか(LLMルーブリック)
リサーチエージェント
評価の課題: 「包括的」「適切に出典付け」の定義がコンテキスト依存で、正解が変動する
評価戦略:
- 根拠性チェック: 主張がソースでサポートされているか
- 網羅性チェック: 重要な事実を含んでいるか
- ソース品質チェック: 権威ある情報源を参照しているか
- LLMベースのルーブリックを専門家の人間判断と頻繁にキャリブレーション
コンピュータ使用エージェント
評価方法: 実際/サンドボックス環境でエージェントを実行し、意図したアウトカムを確認
- WebArena: ブラウザタスクでURL・ページ状態・バックエンド状態を検証
- OSWorld: OS全体の制御をテスト(ファイルシステム、DB、UI要素を検査)
非決定性への対処
エージェントの動作は実行間で変動します。
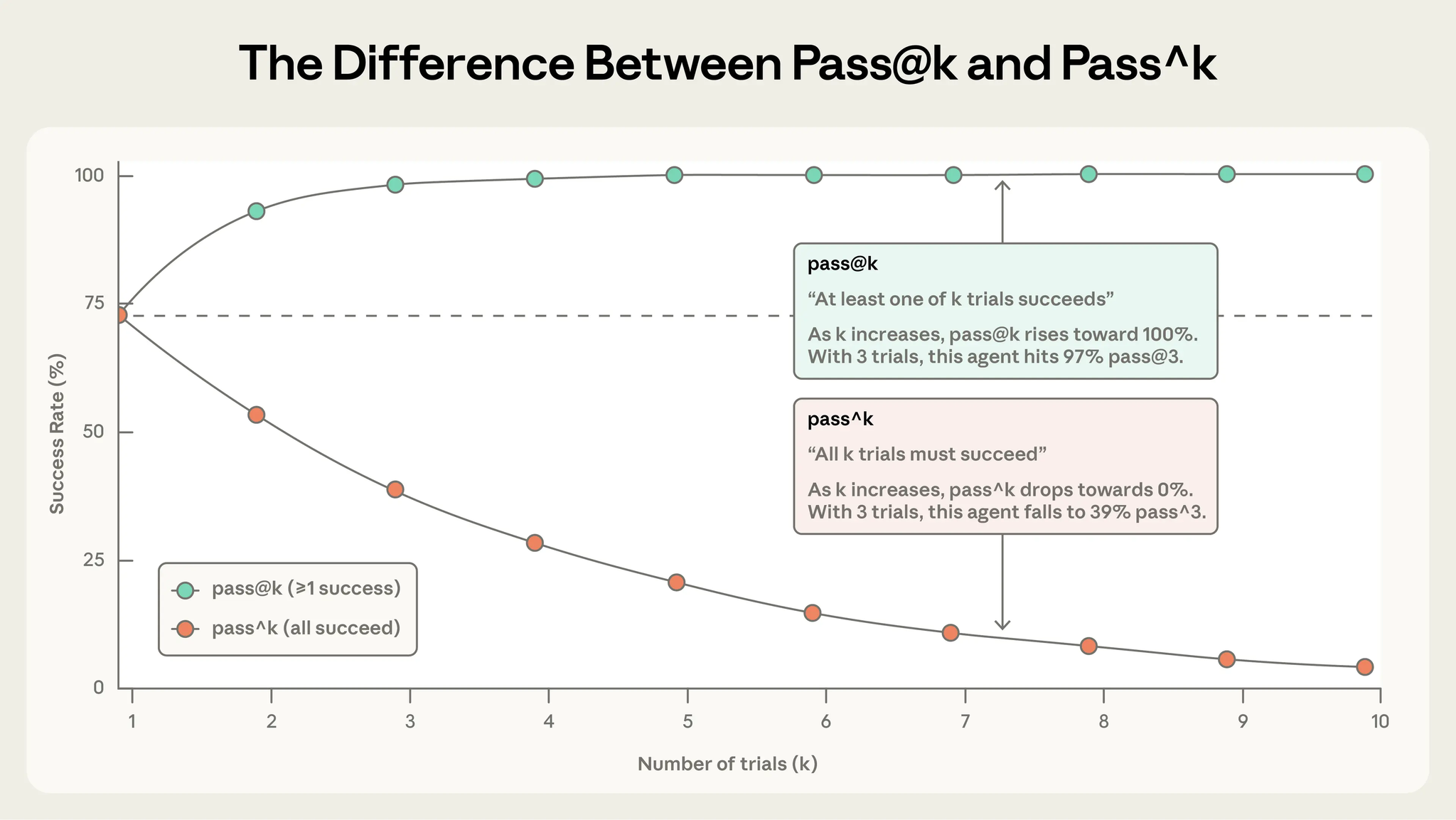
pass@k: k回の試行で少なくとも1回成功する確率(kが増えるほど上昇)
pass^k: k回すべてが成功する確率(kが増えるほど低下)
使い分け: pass@kは1回の成功が重要な場合、pass^kは一貫性が不可欠な場合に使用。
ゼロから始める実践ロードマップ
ステップ1-3: タスク収集
- 早期に開始: 20-50の実際の失敗事例から始める(数百必要だという思い込みを捨てる)
- 手動テストから: 既に検証している動作、バグトラッカー、サポートキューから
- 明確なタスク: 2人の専門家が同じ判定に達するように。参照解を作成してタスクが解決可能であることを証明
- バランス: 動作が発生すべきケースと発生すべきでないケースの両方をテスト(一方的な評価は一方的な最適化を生む)
ステップ4-5: ハーネスとグレーダー設計
- 安定した環境: 各トライアルをクリーン環境から開始し、共有状態を避ける
- 慎重なグレーダー設計:
- 決定論的グレーダーを優先、必要に応じてLLM、検証に人間を使用
- 複数コンポーネントのタスクには部分クレジットを導入
- LLMグレーダーは人間専門家とキャリブレーション
- バイパスやハックに耐性を持たせる
ステップ6-8: 長期メンテナンス
- トランスクリプトを読む: グレーダーが正しく機能しているか検証する最重要習慣。失敗が公平に見えるか確認
- 飽和を監視: 100%の評価は退行追跡のみで改善シグナルなし。SWE-bench Verifiedは30%→80%以上へ
- 継続的メンテナンス: 専任チームがインフラを所有、ドメイン専門家とプロダクトチームがタスクを貢献
- 評価駆動開発: 能力を定義する評価を先に構築し、エージェントがそれを満たすまで反復
他の評価手法との組み合わせ
単一の手法ですべてを捉えられません。スイスチーズモデルのように複数レイヤーで補完:
- 自動評価: ローンチ前・CI/CDで。高速・再現可能だが事前投資必要
- 本番監視: ローンチ後。実際のユーザー行動を捉えるが事後対応的
- A/Bテスト: 実際のアウトカムを測定するが遅い
- ユーザーフィードバック: 予期しない問題を発見するがまばら
- 手動レビュー: 微妙な問題を捉えるが時間集約的
- 人間研究: ゴールドスタンダードだが高コスト
最も効果的なチームはこれらを組み合わせます。
Take Home Message
評価は早期に、継続的に構築すべきコア機能
評価なしのチームは事後対応ループに陥り、実際の退行とノイズを区別できません。早期投資するチームは開発が加速し、失敗がテストケースになり、メトリクスが推測に取って代わります。
実践の鍵:
- 20-50タスクから始める。完璧を待たない
- 3種類のグレーダーを適切に組み合わせる
- エージェントタイプに応じた戦略を採用
- トランスクリプトを読む習慣が最重要
- 複数の評価手法を組み合わせる(自動評価、本番監視、A/B、フィードバック、人間評価)
- 評価をプロダクトチームが所有し、評価駆動開発を実践
パターンはエージェントタイプで異なりますが、基本は一定です。価値は複利的に増大しますが、評価をアフターソートではなくコアコンポーネントとして扱う場合にのみです。
@Kyohei Uto(kuto)
[paper] MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
1. どんなもの?
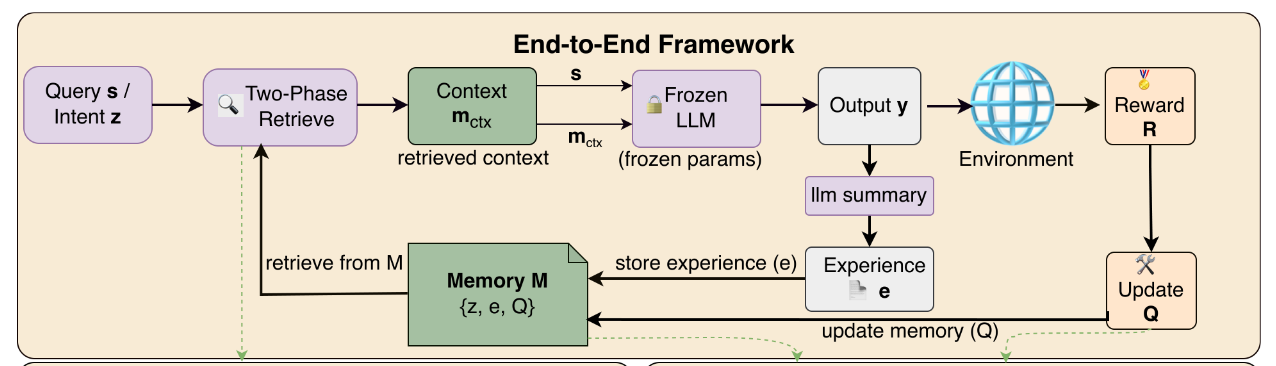
- AIエージェントがメモリを参照しながら行動するタスクにおいて、メモリをRL的に更新することで、モデルの再学習なしにタスクの遂行能力を継続的に向上させる「MEMRL」を提案
2. 先行研究と比べてどこがすごいの?
過去タスクの情報を記憶して現在のタスクの精度を改善したい場合以下のような方法がある
- RAG
- 過去の経験情報をメモリに記録しておき、タスク実行時に検索してfew shot exampleとして利用する
- 従来の類似度ベースの検索では「似ているが結果には寄与しない経験」を取得する問題がある
- MemP
- 類似研究。過去の経験をテキストとして記録しておき、タスクの実行結果(成功/失敗)に基づいて逐次テキストを更新する手法
 arXiv.orgMemp: Exploring Agent Procedural Memory
arXiv.orgMemp: Exploring Agent Procedural Memory ZennAIエージェントに「過去の失敗」を教えて、精度を上げる
ZennAIエージェントに「過去の失敗」を教えて、精度を上げる
MEMRLはFTなしにRAGやMemP以上の性能を達成している
3. 技術や手法の"キモ"はどこにある?
重要なポイントは3つ
- メモリベースMDPによる定式化
- policyの分解
- Q値のランタイム更新
メモリベースMDP
Mementoという論文で定義されたメモリベースMDPとして定式化する
- 状態 : ユーザークエリの埋め込みベクトル
- 行動 : メモリバンクからどのメモリを選択するか
- 価値関数 : クエリに対してメモリを適用したときの期待される有用性(Utility)
なお、本論文でのメモリは(ユーザクエリ埋め込み, 経験, 有用性)の3つのペアで構造化されたもの。経験はAIエージェントの一連の軌跡を指す。
policyの分解
メモリバンクがありクエリを受け取った場合のLLMの方策は以下2つに分解できる。
- 検索ポリシー(Retrieval Policy)
- クエリに対してメモリバンク から特定のメモリコンテキストを選択する確率
- これが最適化対象。ただしNNのような方策パラメータを持つわけではなくメモリのQ値をアップデートすることで検索ポリシーが変わるイメージ。
- 推論ポリシー(Inference Policy)
- クエリと検索されたコンテキストを条件として出力 を生成する確率
- LLMによる方策。学習しないため凍結
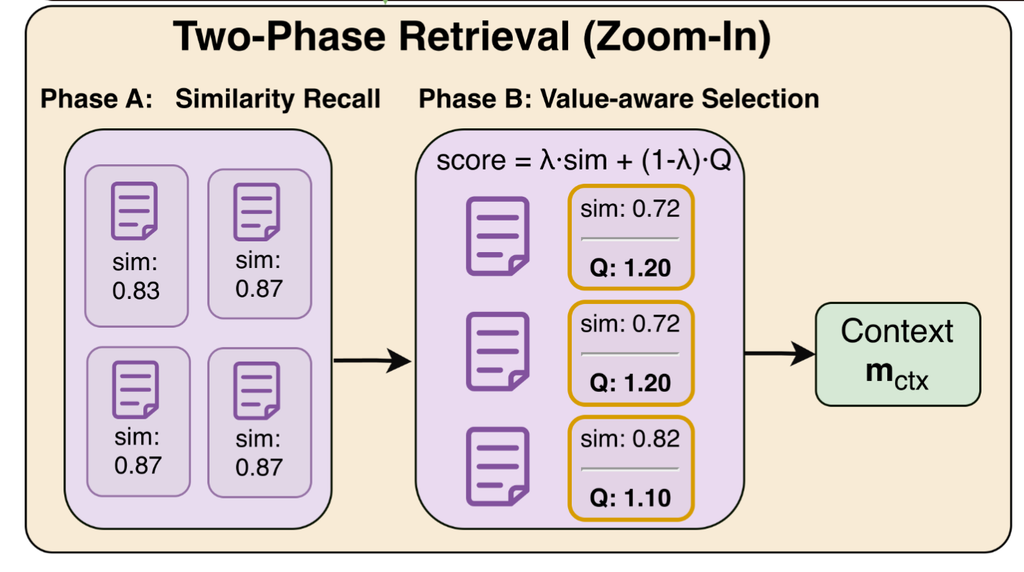
検索ポリシーの補足
もう少し補足すると検索ポリシーは以下のような2段階の検索で表現される
- クエリとの類似度に基づいてメモリ候補を粗く絞り込む
- 類似度とQ値の重み付けで決定されるスコア関数に基づいてrerankingしてメモリを抽出しLLMのコンテキストとする
つまりLLMのFTは不要でQ値の更新=検索ポリシーの更新
ランタイム有用性更新
タスク実行後のタスク成功報酬 (0,1)に基づき、使用したメモリのQ値を以下の式で更新
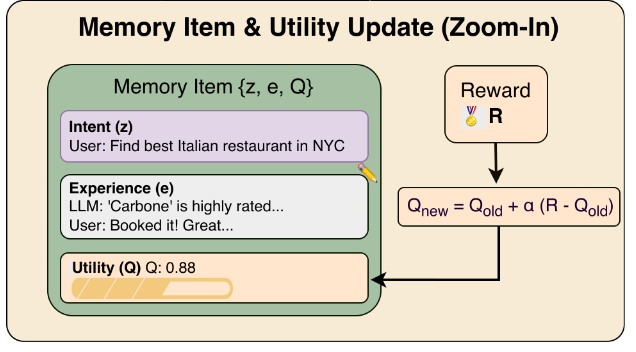
単純な更新式のため報酬が得られれば即時にQ値を更新可能
[kuto]古典的なQ学習と似たようなものという理解。タスクを実際に最後まで行うモンテカルロ法によってQ値を更新する方式なので、タスクの試行回数が十分にないケースや新しく追加されたメモリの場合はQ値が不安定となり得る
4. どうやって有効だと検証した?
4つのベンチマークを用いて、既存のメモリベース手法(MemP, Mem0)やRAG手法(Standard RAG, Self-RAG)と比較検証を実施。
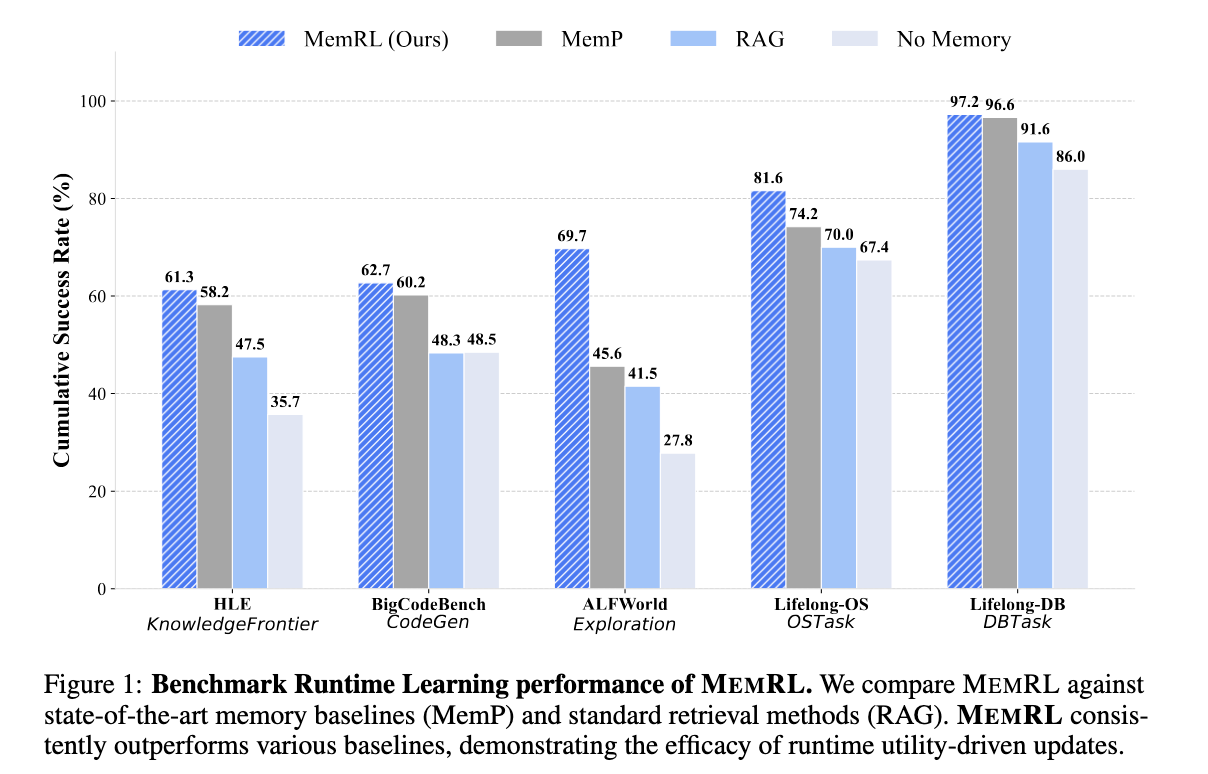
- すべてのベンチマークにおいて、MEMRLはベースラインを一貫して上回る
- 特に探索が重要なALFWorldでは従来手法であるMemPと比較して24.1ptの精度改善
[kuto] 累積成功率(継続的な学習過程において1回でもタスクが成功した割合)指標をメインで利用してるが探索を行う提案手法に有利な点がやや気になる
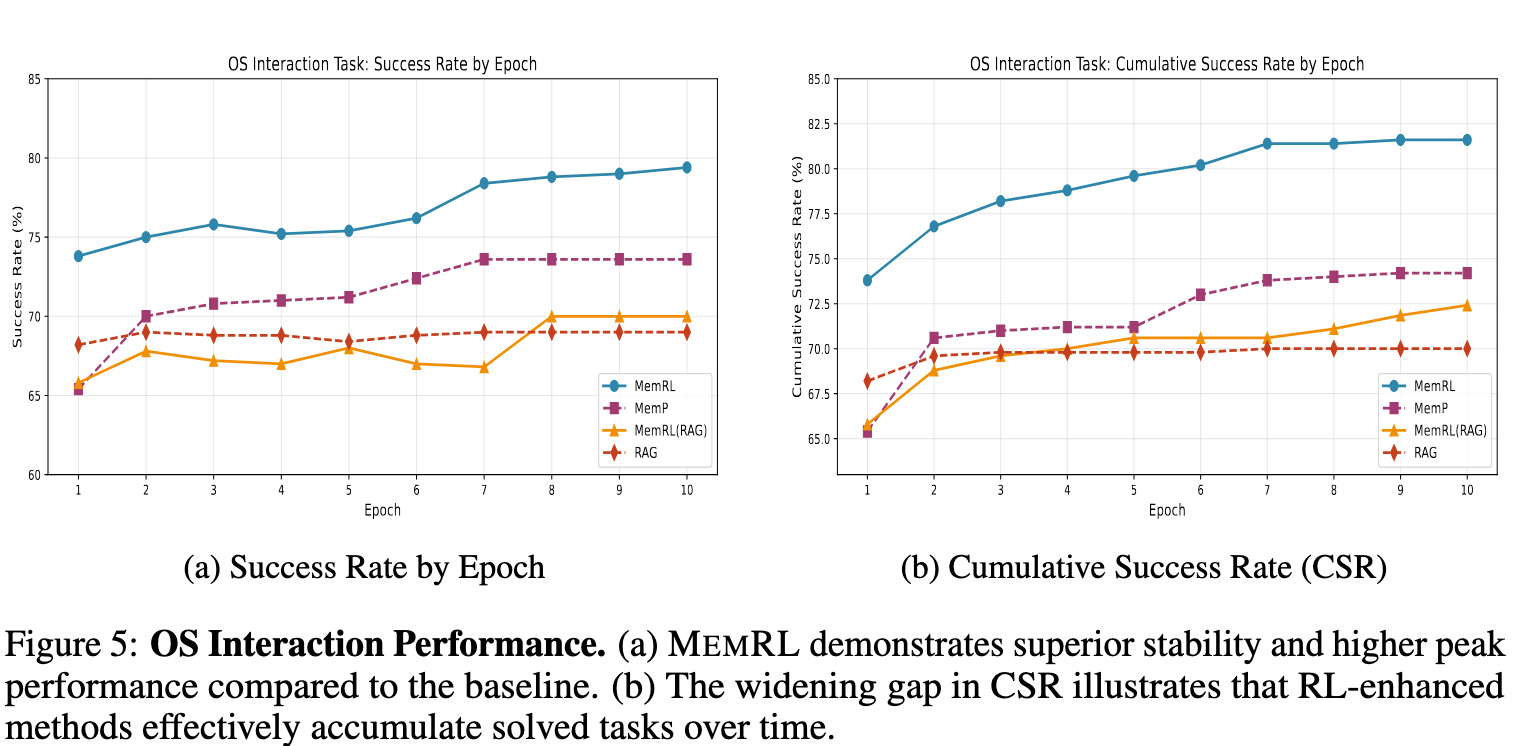
- MEMRLでは継続的な学習(epochの増加)に応じて成功率が増加している
- MemPも緩やかに増加, RAGは学習しないので変化なし
[kuto] Epoch=1でMemPとの差がこれだけ大きい理由がよく分からない
感想
- 学習コストはほぼなく、逐次更新ができる点や継続学習ができる点は魅力的
- メモリのテキストそのものを更新するMemPのような手法と比べて、メモリに紐づいた数値を更新する点が性能に寄与しているという理解
- この論文だととりあえず履歴は全保存する前提だがメモリバンクがどんどん大きくなるのは問題としてありそう
- メモリに紐づくQ値を更新してrerankingするだけなので複雑なコンテキストエンジニアリングはまだ難しそう
MixLM: High-Throughput and Effective LLM Ranking via Text-Embedding Mix-Interaction
概要
データセット
1. ラベル生成 (Label Generation)
学習データの正解ラベルは、人手ではなく、社内の7BパラメータLLM(Relevance Judge)によって生成されます。
- データソース: 実際のユーザーログからサンプリングされたクエリとアイテムのペアを使用します。
- 7Bモデルへの指示: ガイドライン(CRITERIA)と例(EXAMPLES)を与えた上で、クエリとアイテムのペアを分析させます。
- 入力:
- 出力: 「詳細な理由付け(CoT)」と共に、「0〜4の5段階評価スコア」を出力させます。
- Ground Truthの作成: 生成された整数スコア(0-4)を正規化し、 の範囲の連続確率値( )に変換したものを、Stage 2およびStage 3の正解ラベル(Ground Truth Labels)として使用します。
2. Stage 2:ランキング教師モデル用プロンプト (Teacher Training Prompts)
Stage 2では、テキスト全文を入力とする「教師モデル(Ranker LLM)」を学習させます。
- プロンプト形式:
- システム指示: (余計なテキストは含めず、適合度に基づいてYesかNoだけで答えよ)。
- 構成: の後に、 としてアイテムの全文がそのまま入力されます。
- 役割: このモデルは、Stage 3でMixLMが蒸留(Distillation)するための「Teacher Score」を生成する役割を担います。
3. Stage 3:混合入力ランキング用プロンプト (Mixed Input Ranking Training Prompts)
Stage 3では、エンコーダとランカーを同時に学習(Co-training)させるため、プロンプトが特殊な形状になります。
- Encoder LLMへの入力:
- という形式で、アイテムのテキスト情報のみを入力し、埋め込み(Embeddings)を生成させます。
- Ranker LLMへの入力:
- Stage 2と同様に「YesかNoだけで答えよ」という指示を与えますが、 の部分はテキストではなく、エンコーダが出力した に置き換えられます。
- プロンプト構成:
- これにより、Stage 2の全文プロンプトと比較して、入力シーケンス長が大幅に短縮されます。
補足:データセットの規模
セクション4.3のTable 1と併せて確認すると、各データの規模は以下の通りです。
- 推論学習用(Stage 1): 18万件(180k)。7BモデルのCoT(思考の連鎖)も学習データに含まれます。
- ランキング学習用(Stage 2 & 3): 1,090万件(10.9M)。ここではCoTは使用せず、正規化された確率ラベルを使用します。
Three-stage Training
Stage 1: ドメイン推論ファインチューニング (Domain Reasoning Fine-Tuning)
この段階の目的は、ベースとなるLLMに対し、クエリとアイテム(求人など)の適合性を判断するための論理的な推論能力と文脈理解力を強化することです。
- モデル: 0.6Bパラメータの事前学習済みLLMを使用します。
- 教師データ: 実際のユーザーログからサンプリングされた18万件(180k)のクエリとアイテムのペアを使用します。
- 学習手法: 社内の7Bパラメータ「関連性判定モデル(Relevance Judge)」から知識を蒸留します。具体的には、7Bモデルが生成した「思考の連鎖(Chain-of-Thought)」を含む推論プロセスと判定スコアを、ロジット間のKLダイバージェンスを用いて学習します。
- 役割: ここで学習されたモデルは、以降のStage 2およびStage 3におけるRanker LLMの初期モデルとして機能します。
Stage 2: ランキング教師モデルの学習 (Ranking Teacher Training)
この段階では、本番環境では計算コストが高すぎて使用できないものの、非常に精度の高い「テキスト全文入力型」のランキングモデル(教師モデル)を作成します。
- モデル: Stage 1で学習したモデルを初期値として使用します。
- データセット: 約1,090万件(10.9M)の大規模なサンプルを使用します。
- 入力形式: アイテム情報の圧縮を行わず、クエリとアイテム説明文の全文テキストを入力します
- 学習手法: 7B判定モデルによる5段階評価スコアを正規化した「正解確率分布(ground truth probabilities)」をターゲットとし、KLダイバージェンス損失を用いた教師ありファインチューニング(SFT)を行います。
- 役割: このモデルは、Stage 3でMixLM(生徒モデル)が模倣すべき「理想的な挙動」を示す教師(Ranking Teacher)となります。
Stage 3: エンコーダとランカーのジョイント学習 (Joint Encoder-Ranking Training)
これがMixLMの核心となる工程で、アイテムを圧縮する「Encoder LLM」と、混合入力を処理する「Ranker LLM」を同時に学習(Co-training)させます。
- モデル構成:
- Ranker LLM: Stage 1のモデルで初期化します。
- Encoder LLM: 対照学習で訓練された0.6BのGTE(General Text Embedding)モデルで初期化します。
- 入力形式: クエリは「テキスト」、アイテムはエンコーダが出力する「埋め込みトークン」として混合入力します。
- 学習目的と3つの損失関数: 以下の3つの損失関数を組み合わせて最適化します。
- SFT損失: 7B判定モデルが生成した正規化された正解ラベル(確率分布)との誤差(KLダイバージェンス)を最小化します。
- ランキング蒸留損失 (Ranking Distillation Loss): Stage 2で作成した「全文教師モデル」が出力する確率分布と、MixLMの出力分布を一致させるように学習します。これにより、全文から得られる豊富な情報を、圧縮された入力でも再現できるようにします。
- 自己アライメント損失 (Self-Alignment Loss): Rankerモデル自身に「全文」を入力した時の挙動(隠れ層の状態および出力確率)と、「埋め込み」を入力した時の挙動を近づけるための正則化項です。
- カリキュラム学習: 学習を効果的に進めるため、2つのフェーズに分けます。
- フェーズ1: 「自己アライメント」の重みを大きくし、埋め込み空間とテキスト空間の整合性を高めることに集中します。
- フェーズ2: 「蒸留」の重みを大きくし、ランキング精度の向上に集中します。
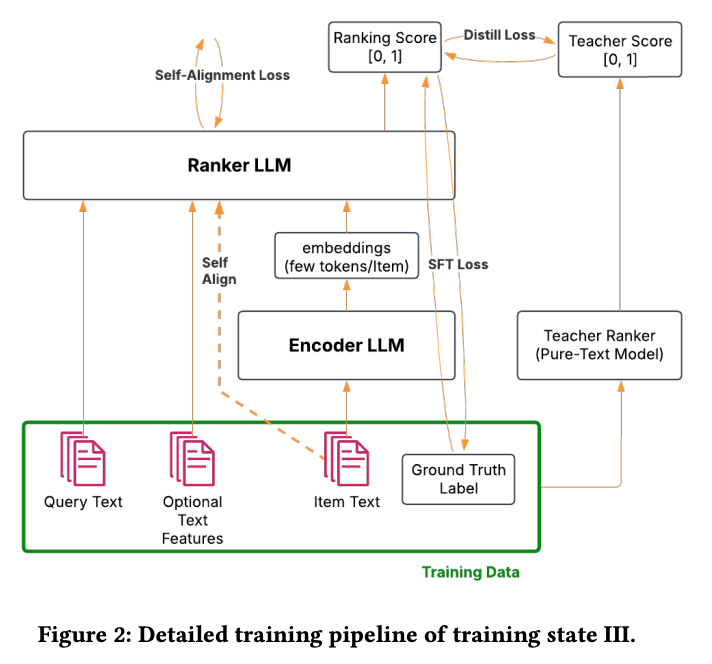
自己アライメント損失 (Self-Alignment Loss)
1. 2通りの入力を用意する
まず、学習中のMixLM(Rankerモジュール)に対して、同じクエリとアイテムのペアを2つの異なる形式で入力します。
- A. 全文入力(Full Text Prompt):
- 従来のモデルのように、アイテムをすべてテキストとして入力します。
- この時のRankerモデルのパラメータを とします。
- B. 混合入力(Mixed Input Prompt):
- MixLMの本領である、エンコーダ( )が作った「埋め込み」を入力します。
- この時の全体のパラメータを とします。
2. 2つの値を比較・計算する
「A(全文)」を正解(ターゲット)と見なし、「B(埋め込み)」が「A」と同じ振る舞いをするように、以下の2つの損失を計算します。
① 隠れ層のアライメント ( )
モデル内部の「考え方」を合わせるための計算です。
- 取得するもの: 最後のトークンに対応する、出力層直前の隠れ層ベクトル(Hidden States)。
- 全文入力時:
- 混合入力時:
- 計算式: 2つのベクトルの コサイン類似度(Cosine Similarity) を計算し、1から引きます。
- これが0に近いほど、埋め込み入力時でもテキスト入力時と同じような「内部表現」ができていることを意味します。
② 予測分布のアライメント ( )
モデルの「最終結論」を合わせるための計算です。
- 取得するもの: 最終的なYes/Noの確率分布。
- 全文入力時:
- 混合入力時:
- 計算式: 2つの確率分布間のKLダイバージェンスを計算します。
- これにより、確信度まで含めて出力結果を一致させます。
3. 合計する
最後に、これら2つをハイパーパラメータ で重み付けして足し合わせます。