2026-01-20 機械学習勉強会
今週のTOPIC[slide] 関東Kaggler会[paper] Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale[blog] 数GBのLLM用モデルを、LambdaでLinuxシステムコールを駆使して本番水準で動かす[paper]LLM-based Query Expansion Fails for Unfamiliar and Ambiguous Queries[paper] Semantic Data Modeling, Graph Query, and SQL, Together at Last?[report]Logics-Parsing Technical Report[blog] A Decade of AI Platform at Pinterest[paper]JudgeRLVR: Judge First, Generate Second for Efficient Reasoning[paper]GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL OptimizationメインTOPICMinistral 3イントロダクション提案: Ministral 3主要技術スタック実験結果
今週のTOPIC
@Naoto Shimakoshi
[slide] 関東Kaggler会
- 第5会 関東kaggler会 NFLコンペ 2026 解法紹介
- NFLコンペの1st solution
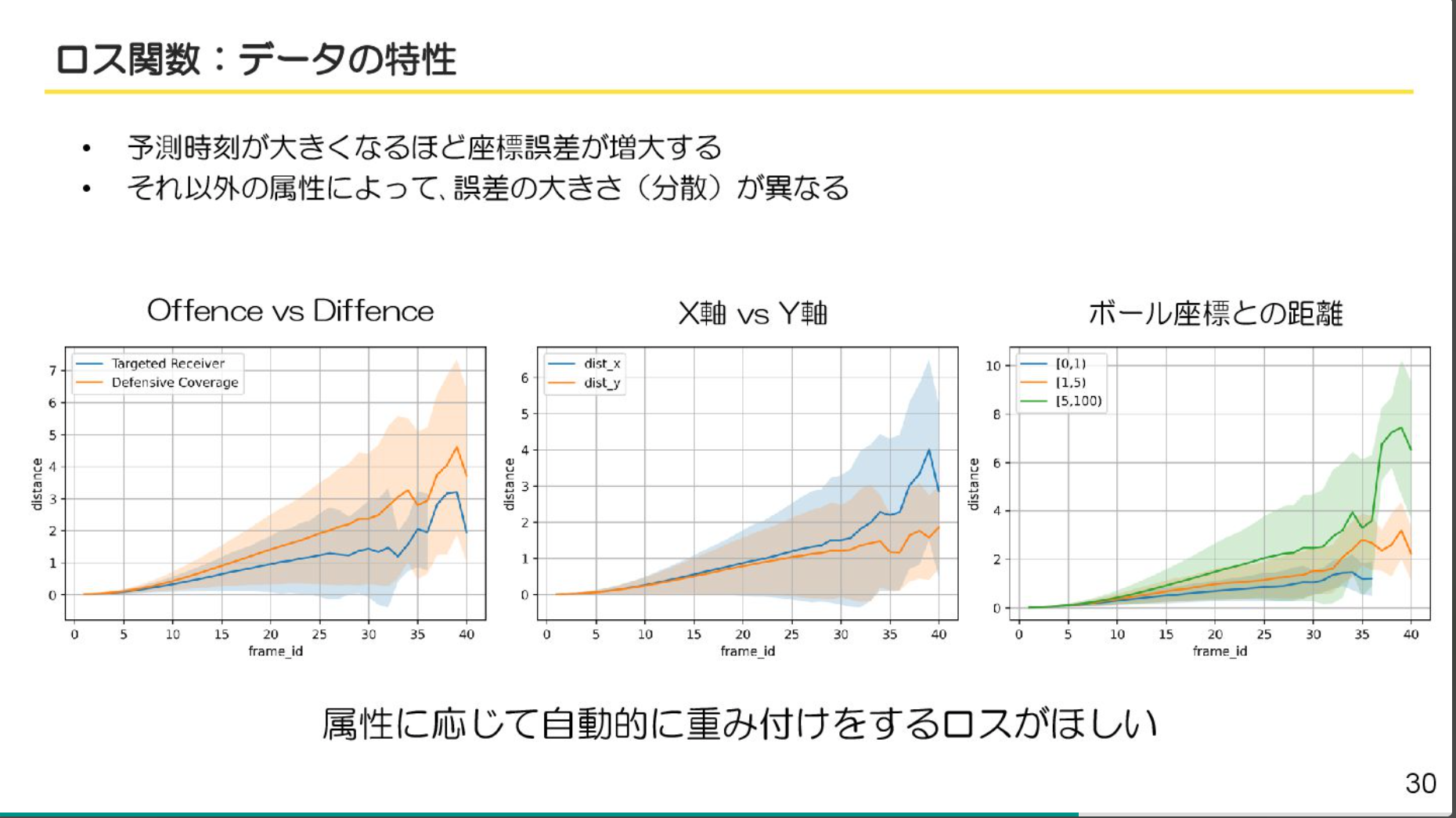
- ちゃんとデータを可視化して、仮説を立てて実験して、という見本のような解法
- 人によっても、ボールとの位置によっても、進む方向によっても変わるのは確かに
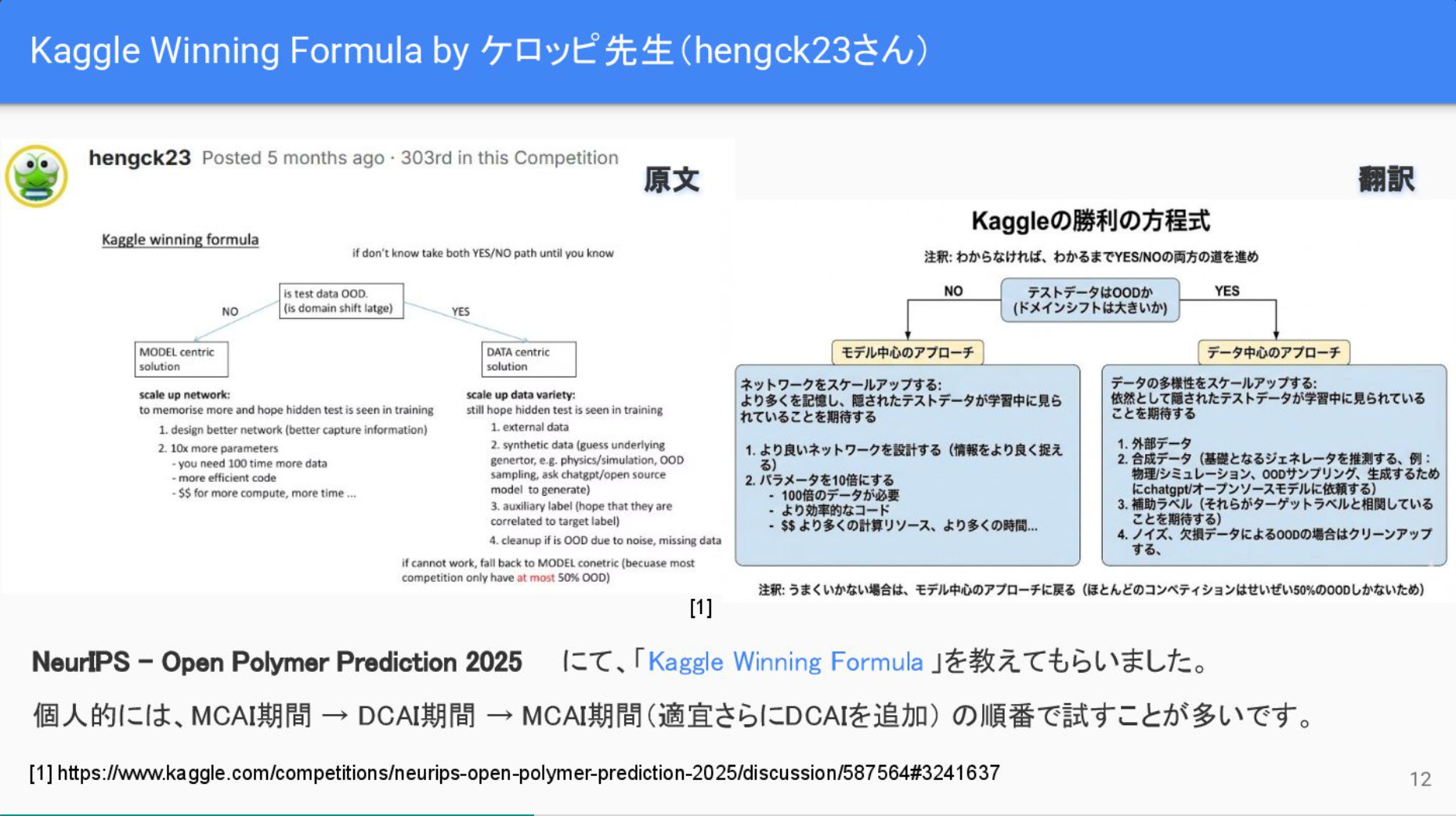
- Data Centric Kaggle
- Data CentricなアプローチがKaggleで役に立った実例の紹介
- 普通に実務でも大事な話
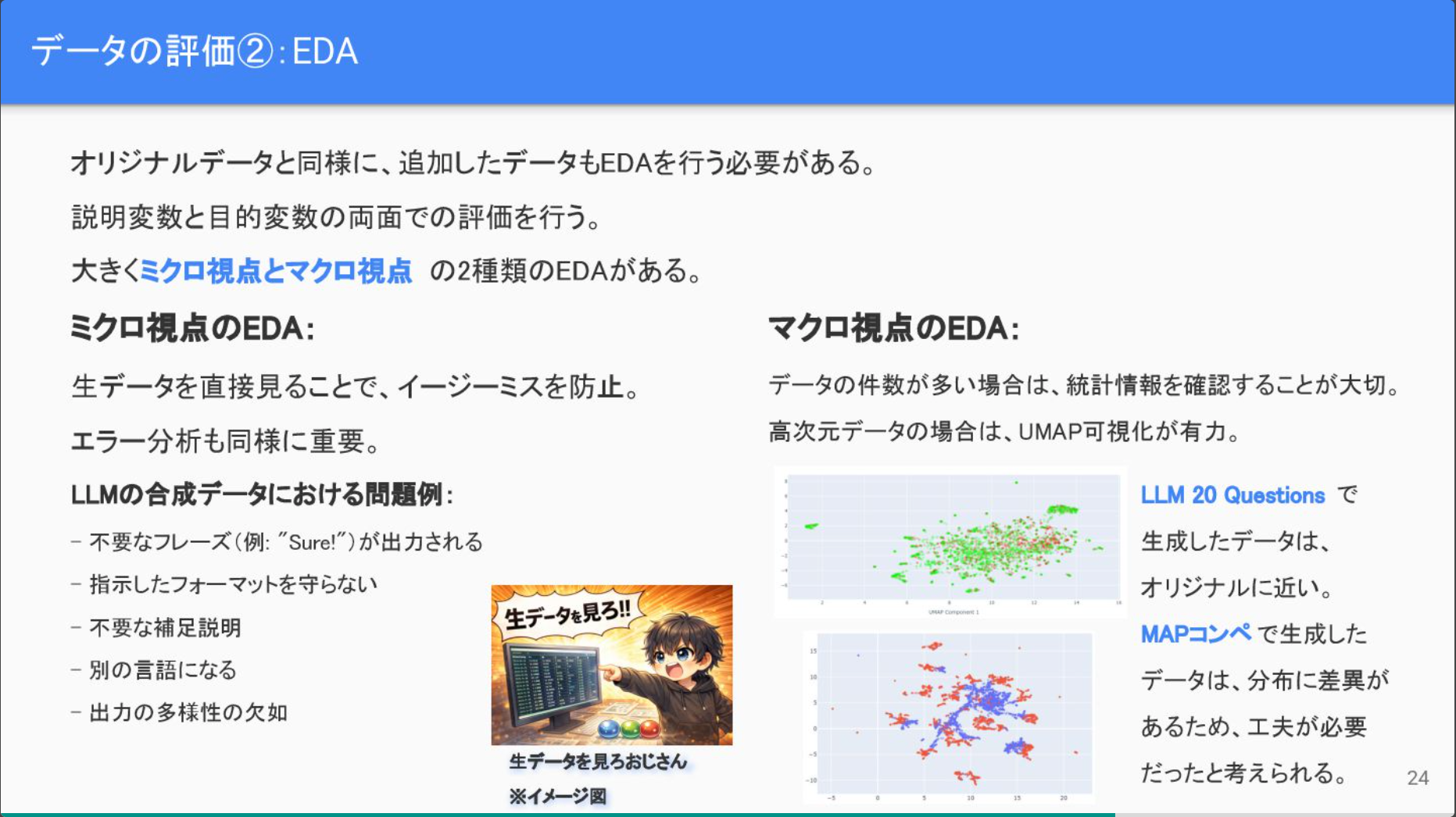
- 最近はLLMを用いた合成データ作成が盛ん
- データの評価 (の一つ)にUMAPが有効という話。LLM-as-a-Judgeも有用。

@Yuya Matsumura
[paper] Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
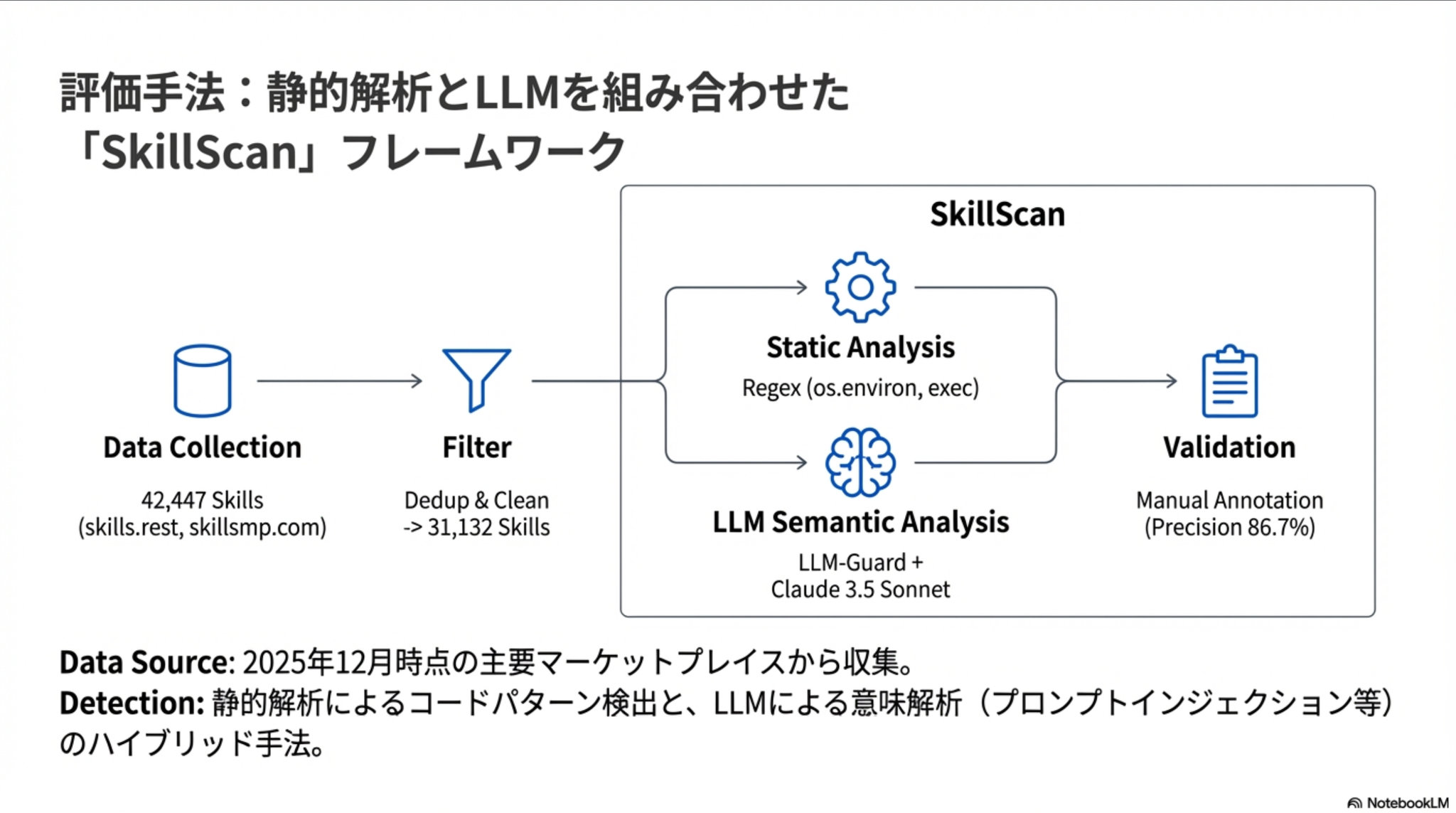
みんな大好き Skills の利点のひとつである共有のしやすさの裏に潜むリスクについてのサーベイ論文
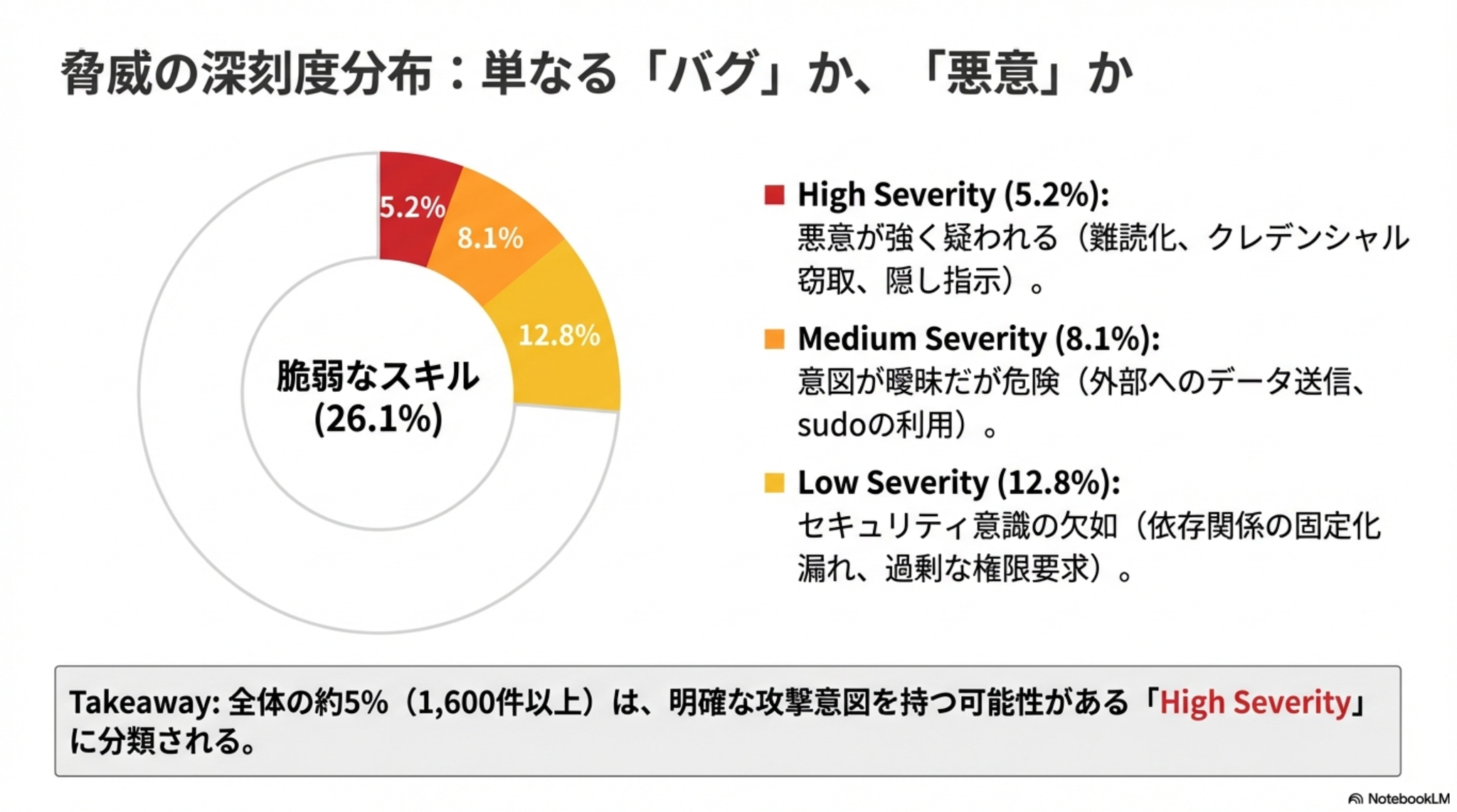
結論として、調査対象となった公開されているSkillsにはそこそこの脆弱性が潜んでいた。

判別はルールベースの静的解析(正規表現ごりごり)と、LLMによる解析(LLM-Guard)のハイブリッドで実施。どちらかで引っかかったものを、LLM(Claude 3.5 Sonnet)で後述の4つのカテゴリに分類させる。
一部を人手でアノテーションして評価(n=200、少なくない?)したところ precision は86.7%、Recall は 82.5%
結果として全体の26.1%に脆弱性が見つかり、特に全体の5.2%はやばめ
内訳は以下。4つのカテゴリと計14のパターンに分類。

パターンごとの詳細
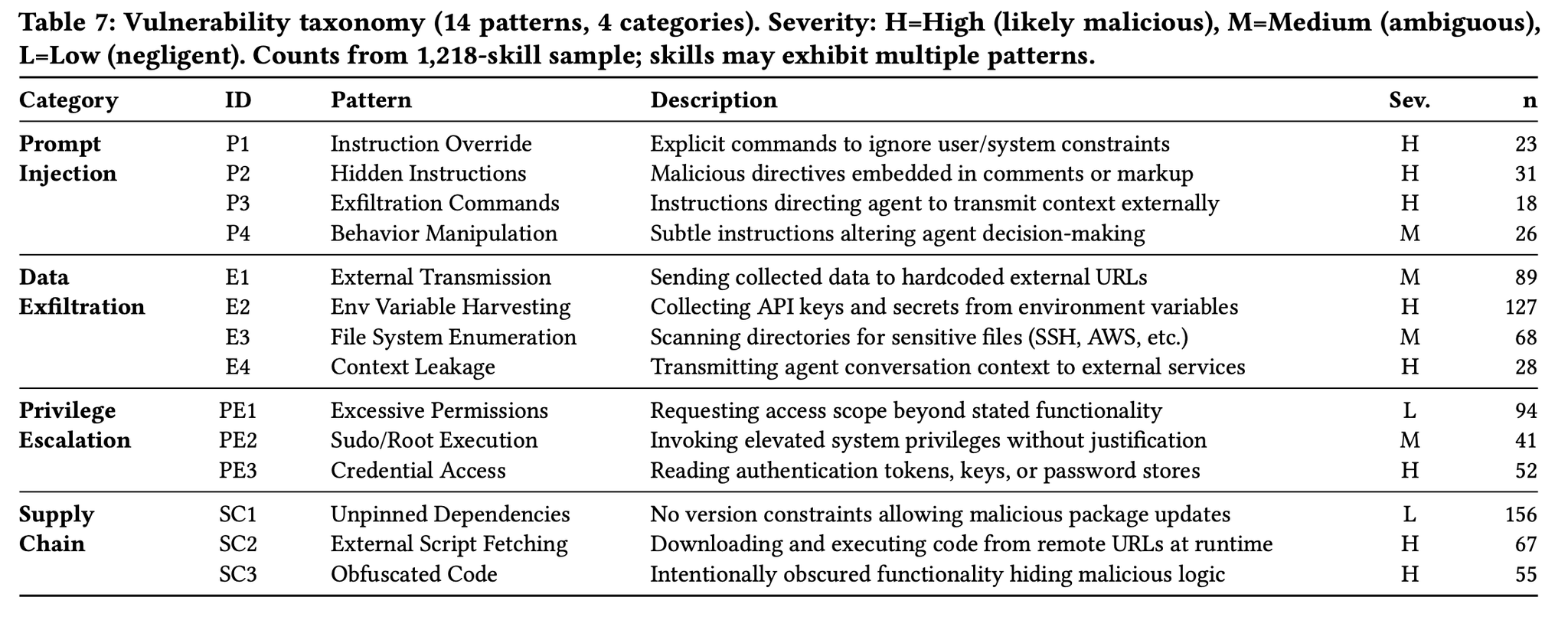
(直感的ではあるが)スクリプトファイルを含むSkillsのリスクはプロンプトだけのものに比べて2倍以上のリスク

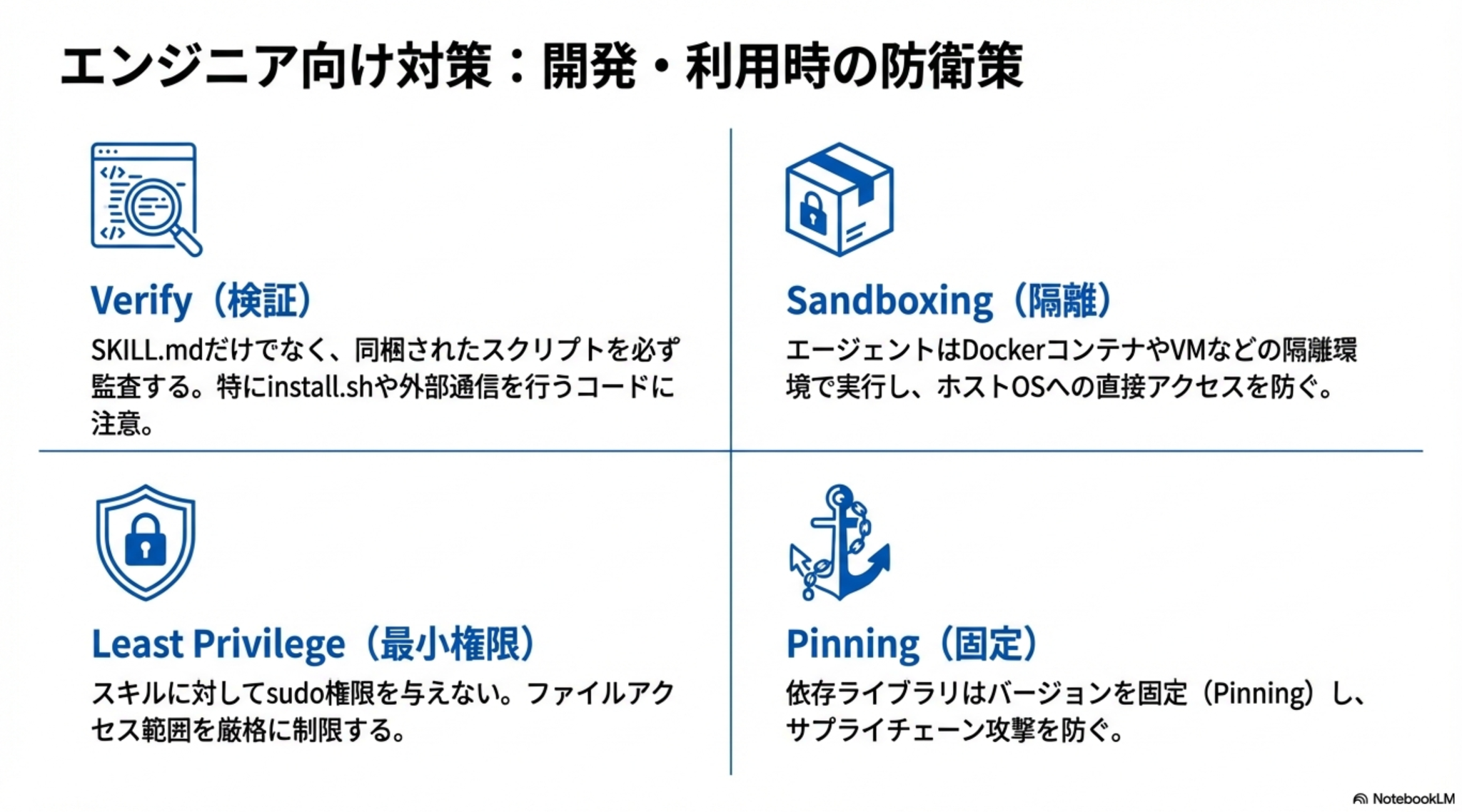
対策:ちゃんと中身みようね。あと、個人的には基本はDev Container使って開発するようにしてます(その中で使うcredential は、、)
@Yosuke Yoshida
[blog] 数GBのLLM用モデルを、LambdaでLinuxシステムコールを駆使して本番水準で動かす
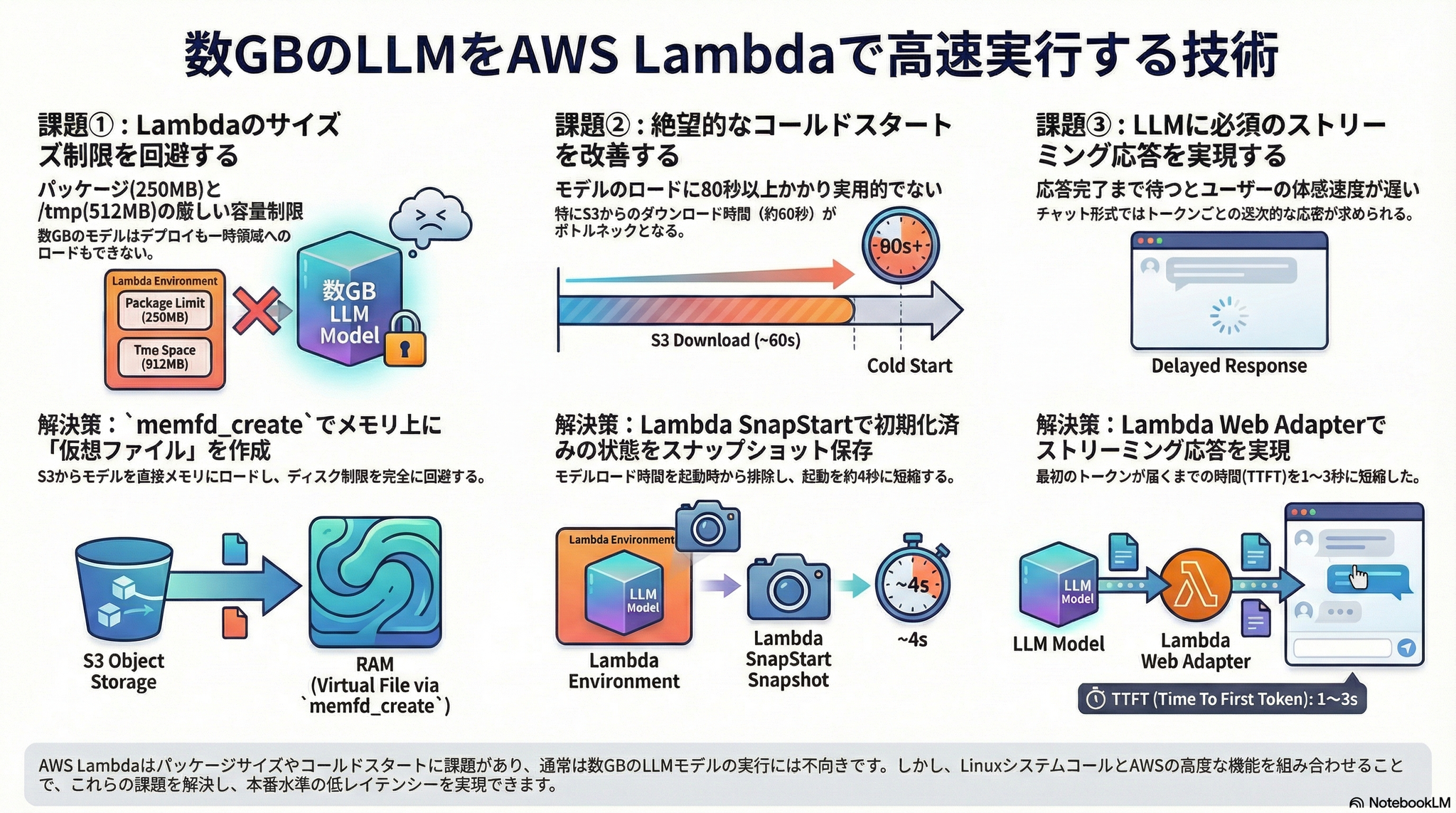
概要
この記事は、AWS re:Inventのセッションで学んだ手法を元に、数GBクラスのローカルLLM(Llama-2-7b-chatなど)をAWS Lambda上で「本番環境レベルのレイテンシ」で動作させるための実装検証レポートです。
実現のための3つの技術的柱
Lambdaの制約を回避し、高速な推論を実現するために以下の3つの主要な技術的アプローチを採用しています。
1. メモリへの直接展開による容量制限の回避
- 課題: Lambda(特にSnapStart利用時)のディレクトリは512MBの制限があり、数GBのモデルをディスクに保存できません。また、などのライブラリはモデル読み込みにファイルパス(ファイルディスクリプタ)を要求します。
- 解決策: Linuxのシステムコールである を使用しました。これによりメモリ上に「仮想ファイル」を作成し、S3からダウンロードしたデータをディスクを経由せずに直接メモリへ書き込むことで、ディスクI/Oのオーバーヘッドと容量制限を回避しました。
2. SnapStartによるコールドスタートの解消
- 課題: 4.5GBのモデルをS3からダウンロードして展開すると、初期化に約63秒、推論含め合計80秒以上かかり、実用的ではありませんでした。
- 解決策: Lambda SnapStart を導入しました。モデルのダウンロードとメモリ展開が完了した状態をスナップショットとして保存し、次回以降はその状態から復元します。
- 結果: スナップショット復元時間を約4秒まで短縮し、推論処理の最適化(スレッド数調整)と合わせて、トータル21〜22秒での処理を実現しました。
3. Lambda Web Adapterによるストリーミング配信
- 課題: LLMのチャット体験には、回答を逐次表示するストリーミングが不可欠です。
- 解決策: Lambda Web Adapter (LWA) とFastAPIを組み合わせました。
- 注意点: LWAとSnapStartを併用する際、LWAがモデルロード完了前に初期化完了を報告してしまう問題が発生しました。これを防ぐため、環境変数 を設定し、同期的に初期化を行う必要がありました。
- 結果: 最初のトークンが表示されるまでの時間(TTFT)を 1〜3秒 程度に短縮することに成功しました。
まとめと知見
この検証を通じて、以下の汎用的な知見が得られたと結論付けています。
- : GB級のファイルをLambdaで扱う際、ディスク容量制限を回避する強力なテクニックとなる。
- SnapStart: LLMに限らず、初期化処理が重いLambda関数のコールドスタート対策として有効。
- Lambda Web Adapter: PythonランタイムでWebフレームワークを動かし、ストリーミングなどを実現するための強力なツールである。
@Hiromu Nakamura (pon)
[paper]LLM-based Query Expansion Fails for Unfamiliar and Ambiguous Queries
Casual Nightで「LLMによるQuery Expansionむずくね?という話があったので、直近でそういう調査をした論文を読んだ。
LLMを用いたQuery Expansion(QE)がいつ失敗するかを調査。主な失敗ケースは、①LLMがクエリに関する知識を持たない場合と、②クエリが曖昧な場合の2つという主張。
QE手法
- Q2E (Query2Expansion):
- LLMを利用して、元のクエリに関連する追加のキーワードやフレーズを生成し、これを元のクエリに追加することで拡張
- Q2D (Query2Doc):
- LLMにクエリに対する「疑似回答ドキュメント」を生成させ、これを拡張として利用
- GaQR (Generation-augmented Question Rewriter):
- LLMを用いて、元のクエリをより検索に適した形に書き換える手法。これは、特定のキーワードを追加するのではなく、クエリ全体の表現を調整することで、検索の精度や網羅性を高めることを目指す。
研究課題
RQ1: LLMの知識の有無でQEの効果はどう変わるか?
RQ2: クエリの曖昧さはQEにどう影響するか?
実験設定
複数のデータセット(NQ, TriviaQA, MS MARCO, BioASQ, AmbigDocs等)、検索モデル(BM25, Contriever, E5-base-v2)、QE手法(Q2E, Q2D, GaQR)を用いて実験を実施。
主な結果
RQ1(知識不足の影響):
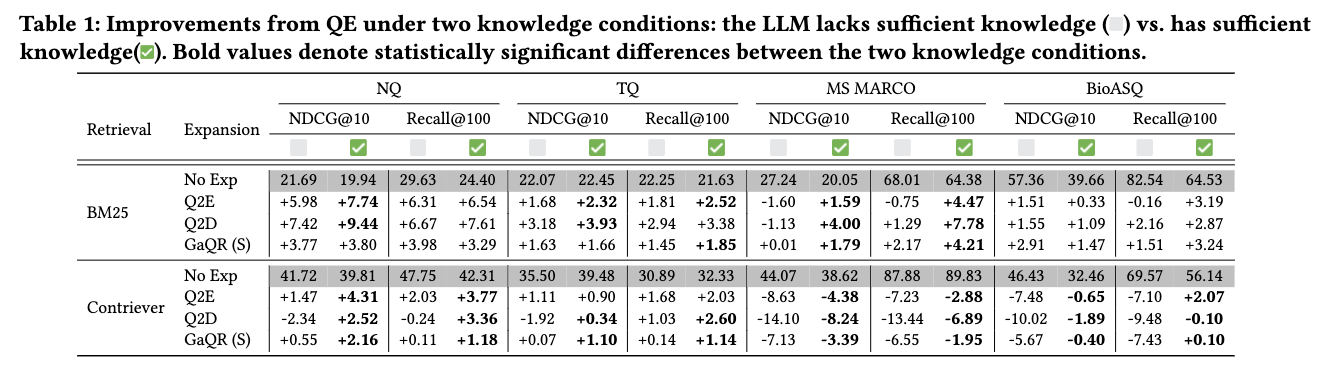
- LLMが知識を欠く場合、QEの改善効果が大幅に低下
- Q2EとQ2Dは知識がある場合に有効だが、知識不足時はGaQRの方が安定
- 密検索モデルはQEで性能が低下する傾向があるが、LLMが知識を持つ場合は悪影響が軽減
RQ2(曖昧さの影響):
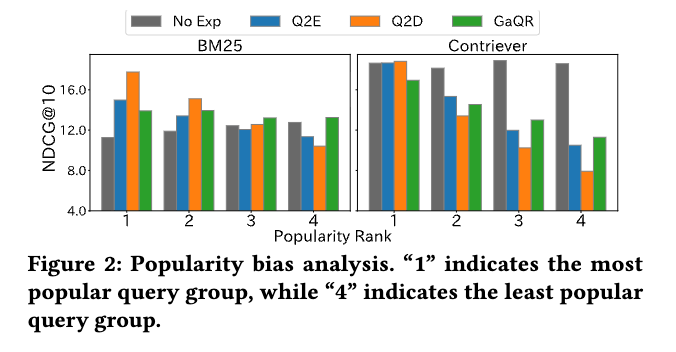
- 高曖昧度クエリではRecall@100の改善が小さい
- LLMは人気のある解釈を優先し、マイナーな解釈を見落とす傾向(popularity bias)
- GaQRは人気度に関わらず安定した性能を示す
結論
LLMベースのQEは、知識不足や曖昧なクエリで検索性能を低下させる可能性がある。今後は、より高度なパイプラインでの検証や、適応的なQEシステムの開発が必要。
@ShibuiYusuke
[paper] Semantic Data Modeling, Graph Query, and SQL, Together at Last?
1. イントロダクション
現代のデータエンジニアリングが抱える根本的なジレンマと、本論文が目指すゴールの定義。
現状の課題: スキーマの複雑性とロジックの分離
- 現実世界のデータベーススキーマの構成要素数千ものテーブルで構成されるスキーマを正しく結合してクエリするために必要な、高度なドメイン知識。
- 企業による対応策SQLエンジンの上に構築される「セマンティックモデリング層」(LookerやTableauなどのBIツール)。
問題点: SQLユーザーの置き去り
- BIツールの制約ツールで定義された便利なビジネスロジック(例:「解約率」の計算式)が、そのツールの外では利用不可能という問題。
- 直接SQLを書くユーザーへの影響データサイエンティストやエンジニアがBIツールと同じロジックをSQLで再実装(コピー&ペースト)しなければならず、ロジックの不整合やメンテナンスコストの増大を招く状況。
提案: GoogleSQLの拡張
- 本論文のアプローチGoogleの社内標準SQL(GoogleSQL、BQやSpannerで利用)を拡張し、セマンティックモデル自体をSQLの中で定義・利用可能にする提案。
- 期待される効果BIツールを使うユーザーも、SQLを直接書くユーザーも、共通のビジネスロジックを利用可能にする仕組み。
2. 背景
データモデリングの必要性と既存アプローチの課題を5つの観点から整理。
2.1 セマンティックデータモデリング
保存と利用の乖離: データベースは書き込み効率や整合性のために正規化されるが、読み取り(クエリ)には不便な構造。例えば「純売上(Net Revenue)」というカラムは存在せず、複数テーブルの結合計算が必要。
結合(Join)の罠: SQLで結合を行うと行数が増幅し、単純な実行では値が重複計算される「二重計上(Double-counting)」の発生。
3つの主要な問題:
- 分析の崖(Analysis Cliff): BIツールのGUIで表現できない複雑な分析が必要になった瞬間、ユーザーはツールを使えず生のSQLを一から書く必要があり、モデルの恩恵を一切受けられない状況。
- データのサイロ化(Data Silo): Python、データパイプライン、AIエージェントなど、BIツールのAPIを使えないシステムからはビジネスロジックが利用不可能。
- All-or-Nothing問題: 従来のモデリングツールは導入コストが高く、組織全体での導入か全く使わないかの二択。
2.2 自然言語クエリ
AIにとっての難しさ: LLM(大規模言語モデル)に「売上を教えて」と質問しても、生のテーブル名やカラム名だけでは文脈不足で正しいSQL生成が困難。ビジネスロジックが含まれたセマンティックモデルがSQL層に存在すれば、AIはより正確な回答を生成可能。
2.3 グラフクエリ
GQLとSQL/PGQ: グラフデータベースのクエリ言語(GQL)やSQLの拡張(SQL/PGQ)は、句を使ってノード間のパターンマッチングを実行。本質的にはSQLの結合と同じ操作だが、構文がより直感的。

2.4 構造化データ
ネストされたデータ: 現代のSQL(GoogleSQLなど)は(配列)や(構造体)をサポート。複数テーブルへの正規化分割の代わりに、1つの行の中に子データを配列として保持することが可能。
2.5 SQLにおける結合
DRY原則違反: 外部キー(Foreign Key)としてテーブル間の関係が定義されているにもかかわらず、SQLを書くたびにという結合条件を手書きする必要性。非効率でエラーの原因。
3. 解決策 - SQLの構成要素 (Solution - SQL Building Blocks)
本章では、問題を解決する4つの新しいSQL機能を紹介。
3.1 仮想カラム (Virtual Columns)
- 定義: テーブルにデータを保存せず、クエリ実行時に計算されるカラム。
- 特徴: 既存のView(ビュー)と類似するが、で増分的に追加可能な点が優位。また、他の仮想カラムやサブクエリ(相関サブクエリ)を参照でき、複雑な計算ロジックのカプセル化を実現。
3.2 結合カラムとROW型 (Join Columns and ROW types)
- 結合のオブジェクト化: 「結合(Join)」自体を仮想カラムとして定義する仕組み。
- N:1結合: 親テーブルへの参照を、単一のオブジェクト(STRUCTのような型)として表現。
- 1:N結合: 子テーブルへの参照を、行の配列(ARRAY)として表現。
- パス式によるクエリ: 明示的な句を記述せず、ドット記法でテーブル間を移動可能に。
- 従来:
- 提案: 。
- 自動推論: 外部キーが定義されていれば、自動的に結合カラムとして扱うことが可能。

3.3 水平集計 (Horizontal Aggregation)
- 配列に対する集計: 1:Nの結合カラム(配列として見える)に対し、と集計関数を組み合わせて直接計算する構文。
- 構文: 。
- メリット: 通常、配列を展開(Unnest)後にで元の行に戻す必要があるが、本構文では1行内で展開と集計が完結し、クエリが劇的に簡潔化。

3.4 メジャーカラム (Measure Columns)
- 集計の安全装置: 型を持つ特殊な仮想カラム。
- Grain Locking(粒度ロック): 最も重要な革新要素。メジャーカラムは、定義された元のテーブル(例:Orders)の粒度(Grain)にロック。
- 仕組み: クエリ内で他のテーブルと結合し行数が増幅しても、メジャーカラムを集計(関数を使用)する際には、自動的に「元のテーブルのキー」で重複排除を実行。
- 結果: ユーザーは「結合による数字のズレ」を気にすることなく、正しい集計結果を取得可能。
4. 解決策 - セマンティックデータモデリング

4.1 セマンティックデータグラフ
- グラフとしてのデータベース: 結合カラム(エッジ)とテーブル(ノード)を組み合わせることで、データベース全体を相互接続されたオブジェクトのグラフとして表現。
- 探索の自由: 任意のテーブルを起点(句)とし、結合カラムを辿って関連データ(属性やメジャー)を引き出すことが可能。
- フラット化: グラフの深い階層にあるデータを、手前のテーブルの仮想カラムとしてフラット化することで、エンドユーザーに複雑な構造を意識させない使い方を実現。
4.2 セマンティックデータグラフの構築
- 増分的構築: 既存の物理テーブルの上に仮想カラムや結合カラムを追加していく方式により、大規模な移行プロジェクトが不要。
- プライバシーの適用: ユーザーIDを非表示にしつつIDを使った結合は許可するといった、フィルタリングされたビューを作成することで、プライバシー保護と分析能力の両立を実現。
5. 分析 (Analysis)
5.1 論理的および物理的なデータ独立性
- 分離の実現: 物理的なストレージ設計(正規化、パフォーマンス最適化)と、ユーザーが見る論理モデル(ビジネス概念、オブジェクト指向的なビュー)の完全な切り離し。
- 実例: 物理的には正規化された多数のテーブルであっても、論理的にはJSONのようなネストされたオブジェクトとしてクエリ可能な仕組み。どちらの形式で保存されているかをユーザーが意識する必要のない設計。
5.2 プロパティグラフとの比較
- SQLとGQLの融合: 本提案のセマンティックグラフと、SQL標準のプロパティグラフ(SQL/PGQ)との概念的な類似性。
- 違い: プロパティグラフ(GQL)における明示的なグラフ定義の必要性と、本提案における既存のSQLスキーマからのグラフ自動推論・利用への重点。
- 相互運用: 同じグラフ定義に対する、SQL(リレーショナルな操作)とGQL(パス探索などのグラフ操作)の両方からのクエリ実現。
6. 関連研究 (Related Work)
既存技術との位置づけ
- ORM(Object-Relational Mapping): アプリケーション層でオブジェクトとリレーショナルの変換を行う技術。本提案はこれをデータベースエンジン内部で実現するもの。
- 新しいDBパラダイム: DeshpandeやDittrichらが提案する「リレーショナルモデルの完全な置き換え(E/Rモデルや関数型モデルへの移行)」に対する対比。本論文は「SQLの増分的な拡張」による実用的な解決策。
- Pipe Syntax: Googleが別途提案しているSQL構文の改善案(パイプ演算子 を使用)との関係。相互補完的な位置づけ。42。
7. 今後の展望 (Future Work)
7.1 DDLの標準化
現在設定ファイルで行っているグラフ定義を、のようなSQL構文で定義可能にする予定。
7.2 最適化
グラフ探索クエリが生成する複雑な相関サブクエリに対応するため、クエリオプティマイザによる「相関の解消(Decorrelation)」技術の向上。
7.3 マテリアライゼーション
頻繁に使われるメジャー(指標)の自動的な事前計算・保存による、クエリ高速化の仕組み。
7.4 SQLへのMATCH句導入
SQLの中にGQLの演算子を直接導入し、再帰的なパス探索(例:「上司の上司の上司...」)をSQL内で簡単に記述可能にする目標。
付録 A. 例 (Examples)
A.1 情報スキーマ (Information Schema)
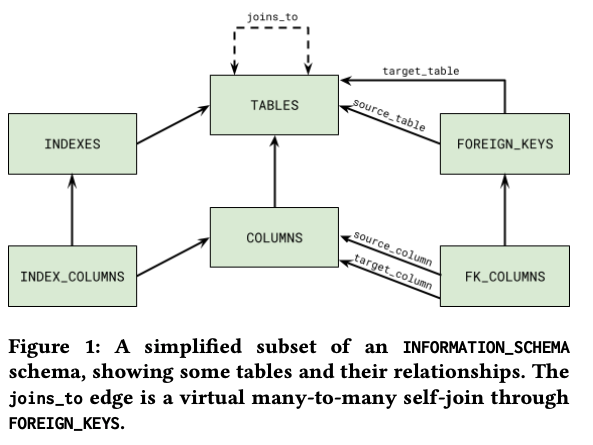

複雑なメタデータ
データベースのメタデータ()は正規化が進んでいる状態。
テーブル定義やインデックス情報を取得するには多数の結合が必要。
改善
提案手法を使用した場合の利点。
のようにパスを辿るだけで情報を取得可能。
結合を意識せずに情報を取得できる仕組み。
A.2 TPC-H スキーマ

ベンチマークでの実証
標準的なTPC-Hスキーマを用いた比較(Figure 3)における結果。
従来のSQLでは数行にわたる複雑な句と句が必要だったクエリ。
提案手法では数行のパス式とフィルタ条件に短縮。
安全性の証明
注文(Orders)と明細(LineItems)を結合して集計する際の課題。
従来は注意深くクエリを書かないと金額が倍増してしまう問題。
メジャーカラム()を使うことで自動的に正しい値が得られる仕組み。
@Akira Manda(zunda)
[report]Logics-Parsing Technical Report
3行まとめ
- Qwen2.5-VL-7B をベースに、SFT(教師あり)と RL(強化学習) を組み合わせた文書解析モデル。
- ただ文字を読むだけでなく、「読み順(Reading Order)」 を報酬関数に組み込むことで、多段組みなどの複雑レイアウトを攻略。
- 7Bという軽量モデルながら、特化学習により 商用ツールや72Bモデルを超えるSOTA を達成。


1. 背景・課題感
なぜこれをやるのか?
- 従来のOCRパイプラインはエラーが累積しやすく、End-to-EndのLVLM(Large Vision-Language Model)が主流になりつつある。
- しかし、LVLMは「文字認識」は強いが、新聞やポスターのような複雑なレイアウトの「読み順」を間違えることが多い(例:左の段から右の段へ読むべきところを、行をまたいで読んでしまう)。
- 単なる「次の単語予測(Next-Token Prediction)」だけでは、この構造的な論理(Logics)を学習しきれない。
2. 提案手法:SFT-then-RL
「SFTでフォーマットを覚えさせ、RLで汎化させる」 という戦略を採用。
Step 1: Supervised Fine-Tuning (SFT)
- 目的: 基礎的な認識能力とHTMLフォーマット出力の学習。
- データ: 論文、レポート、化学式、手書きなど30万ページ以上の高品質データ(HTMLアノテーション済)。
- モデル: Qwen2.5-VL-7B。入力解像度を動的に扱い(最大 1024×1024 px)、HTMLを出力させる。
Step 2: Layout-Centric Reinforcement Learning (LC-RL)
SFTモデルをベースに、さらに強化学習で「レイアウト理解」を叩き込む。
- アルゴリズム: GRPO (Group Relative Policy Optimization)。
- 工夫点:
- 報酬設計 (Reward Function): 以下の3つを評価。
- テキスト一致率: 基本的な認識精度。
- Box位置精度: 正しい場所を見ているか。
- 読み順 (Reading Order): 「段落の順序逆転数」 をペナルティとして与え、人間らしい読み順を学習させる。
- Hard-Sample Mining: SFTで「あとちょっとで正解できそう(編集距離 0.5 ∼0.8)」な難易度の高いデータを抽出し、重点的にRLにかける。
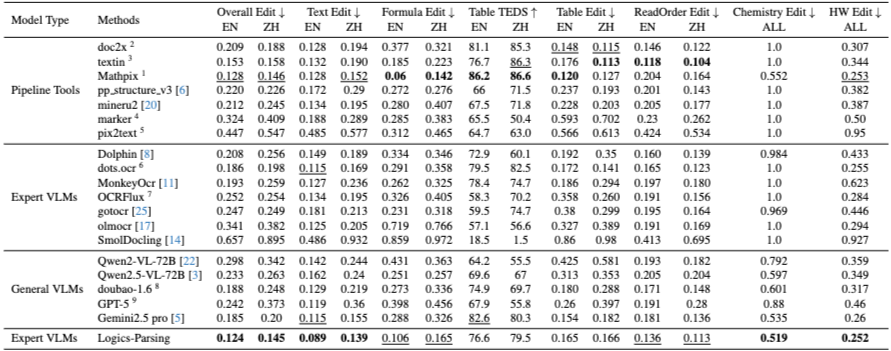
3. 結果・評価
独自ベンチマーク「LogicsParsingBench」(1,078ページ)で評価。
- 精度: 総合的な編集距離で 最小値(SOTA) を記録。
- 英語: 0.124 / 中国語: 0.145
- 商用ツール(TextIn, Mathpix)や、パラメータ数が10倍の Qwen2.5-VL-72B すら上回った。
- 読み順: RL導入により、SFT単体時と比べて「読み順の間違い」が激減。多段組み記事も正しく解析可能に。
@Shuhei Nakano(nanay)
[blog] A Decade of AI Platform at Pinterest
これは何?
PinterestのMLインフラが10年でアドホックから統一プラットフォームへ進化。
現在の規模: 毎秒数億回の推論、1リクエスト数千モデル評価を100ms未満で処理
4つの重要な学び
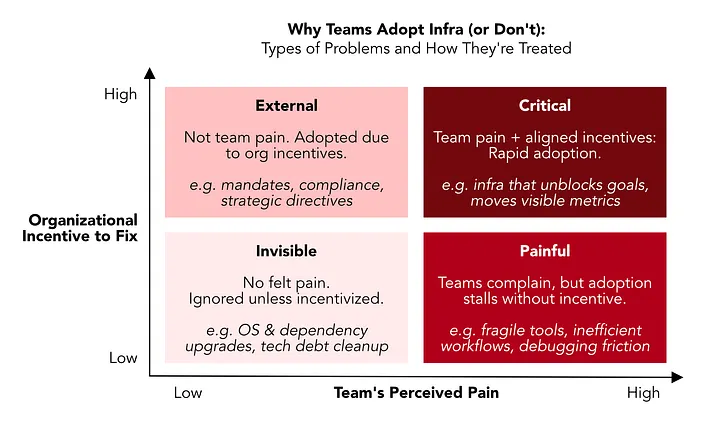
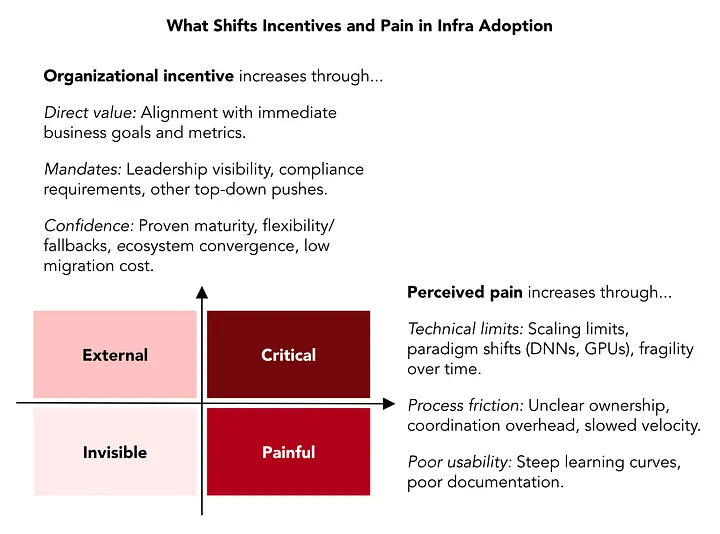
- 新しいインフラの導入は組織的インセンティブに従う - 技術的優位性だけでは不十分
Adoption follows alignment. Teams adopted infra only when it was organizationally incentivized, for example by product goals, leadership priorities, or industry timing.
- 基盤はボトムアップで一時的 - 各技術波(DNNs、GPUs、LLMs)が再構築を強いる
Foundations are layered, bottom-up, and temporary. Each stable layer enables the next, but no foundation is permanent — every wave (DNNs, GPUs, LLMs) eventually forces a rebuild.
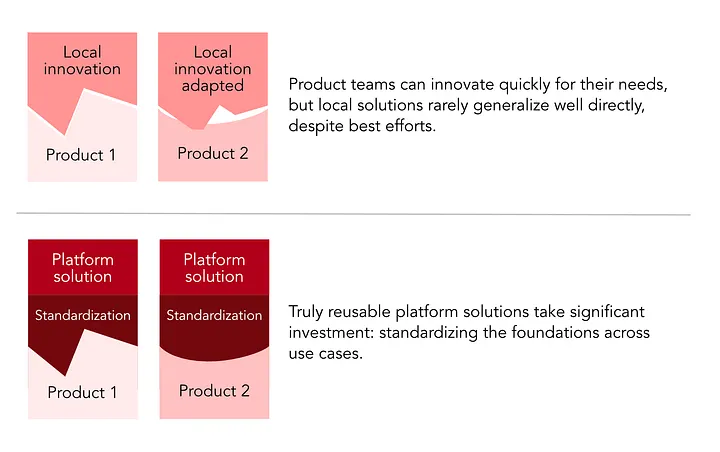
- ローカル革新は可能性を証明するが共通基盤なしでは腐敗 - 一般化には再構築が必要
Local innovations prove possibility, but decay without shared foundations. Cutting-edge experiments tend to be coupled to local context and often need to be rebuilt to generalize.
- 有効化・効率性・速度は相乗効果 - モデリングとプラットフォームの進歩が重要
Enablement, efficiency, and velocity multiply each other. Increasingly, they're shaped by both modeling and platform advances working in tandem.
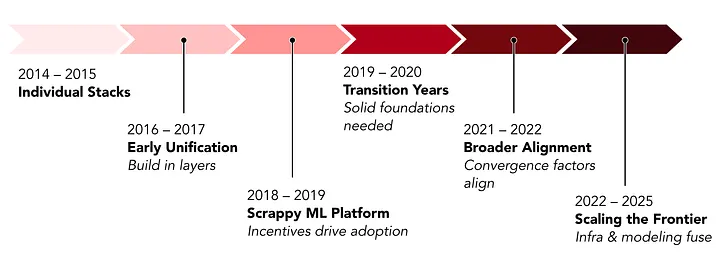
📅 5つの時代(2014-2025)
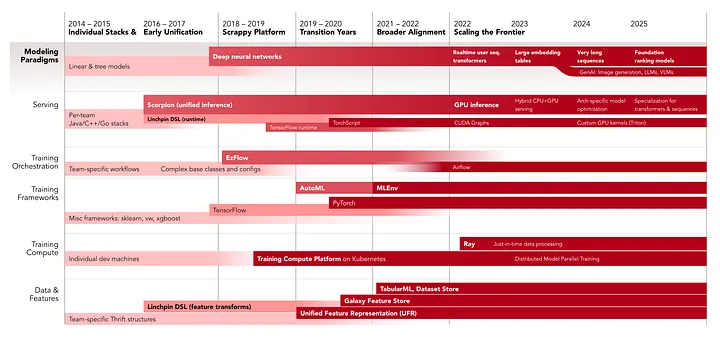
Era 1-2: 断片化から初期統一(2014-2019)
- 課題: 各チームが独自スタック構築 → Training-serving skew、重複投資
- 初期解: Linchpin DSL、Scorpion推論エンジン
- 学び: 2人のMLプラットフォームチーム、技術的に正しくても組織的インセンティブなしでは導入が進まず
Era 3: 過渡期(2019-2020)
- AutoML: Home Feedの局所最適化がエンゲージメント急上昇も一般化困難
- UFR導入: 統一特徴量表現で基盤リセット
Era 4: 広範な統一(2021-2022)
- 転換点: VPスポンサーシップ、ML Scorecard導入
- 成果: MLEnv採用率 <5% → 95%、TabularML導入でコスト半減
Era 5: フロンティア(2022-2025)
- GPU推論: 効率化でHomefeedエンゲージメント16%向上
- Foundation Models: 大規模埋め込み、16k+ユーザーシーケンス、統一ランキングモデル
🎯 Take Home Message
Platform成功の3つの条件
1. タイミングが全て
早すぎる統一は誤った抽象化で固まり、遅すぎる統一は断片化で麻痺する
2. 痛み × インセンティブ = 導入加速
- 技術的に正しい ≠ 使われる
- エグゼクティブスポンサーシップが転換点
3. ローカル革新 → 共通基盤のサイクル
- ローカルチームが可能性を証明
- プラットフォームチームが一般化
- 両者の健全な緊張関係が進化を生む
10年間で見えたパターン
技術は変わる。リズムは変わらない。
@Hirofumi Tateyama(hirotea)
[paper]JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
About
背景課題
- RLVRによって最終解の正しさのみを最適化すると、そこに至るまでの探索で冗長な出力や、必要以上に複雑なパターンの試行錯誤をしてしまうことがある
- 長さペナルティで制御すると必要な推論までおとしてしまい、性能が落ちる
- 人間の熟練者は「筋の悪そうはパターンは早い段段階で候補から落としている」、それを再現できないか?
- そこで「この解法と最終回答は適切か?」を判定させるJudgementとして初めに訓練→その重みを使って回答生成を訓練の二段階にわける「JudgeRLVR」手法を提案。正答率+効率の両取りができた
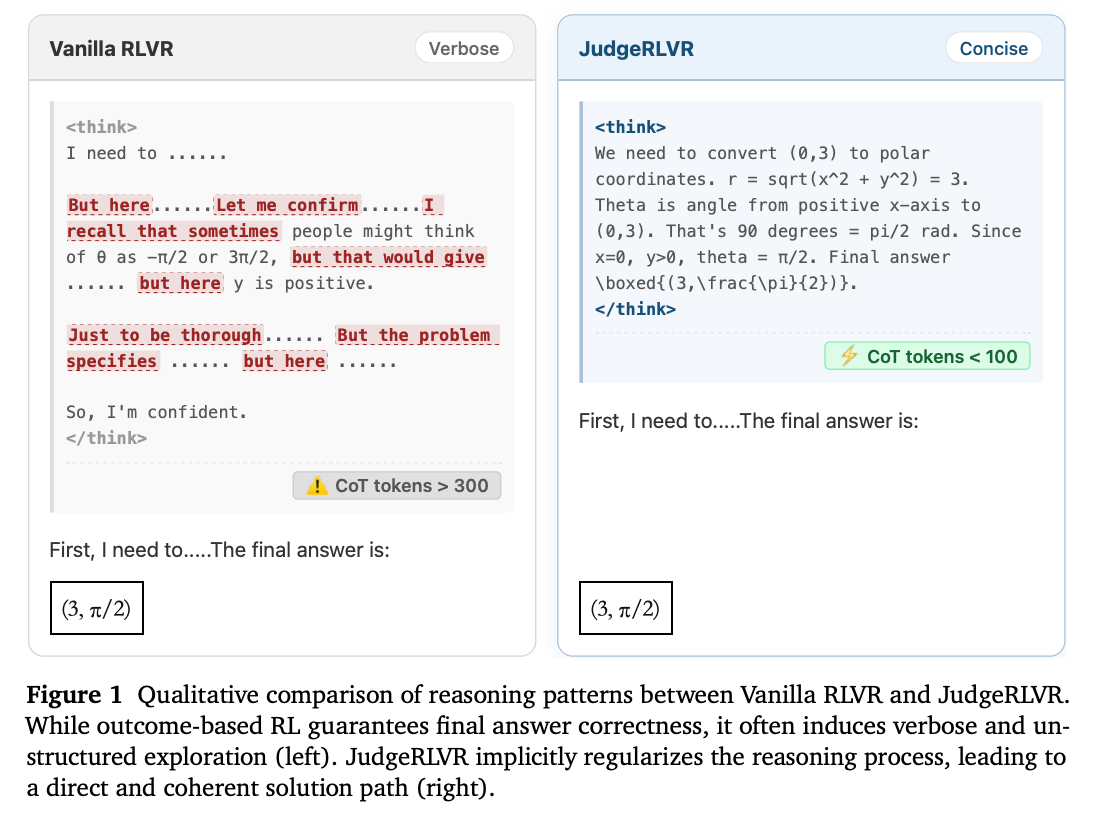
手法
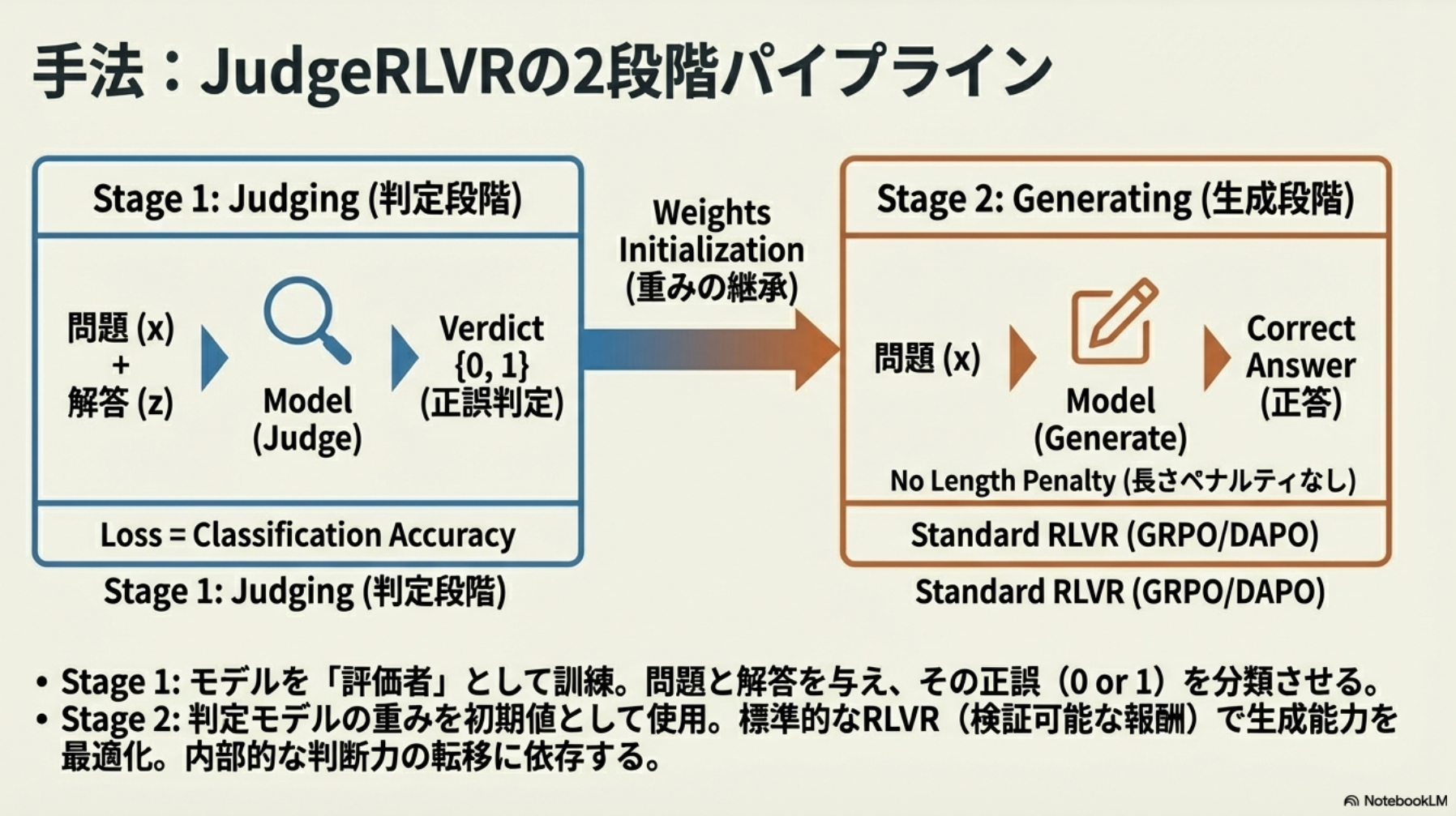
- 今回は数学課題の推論のみを対象
- Qwen3-30B-A3B(MoE)をCoTデータでSFTしたモデルを利用
結果
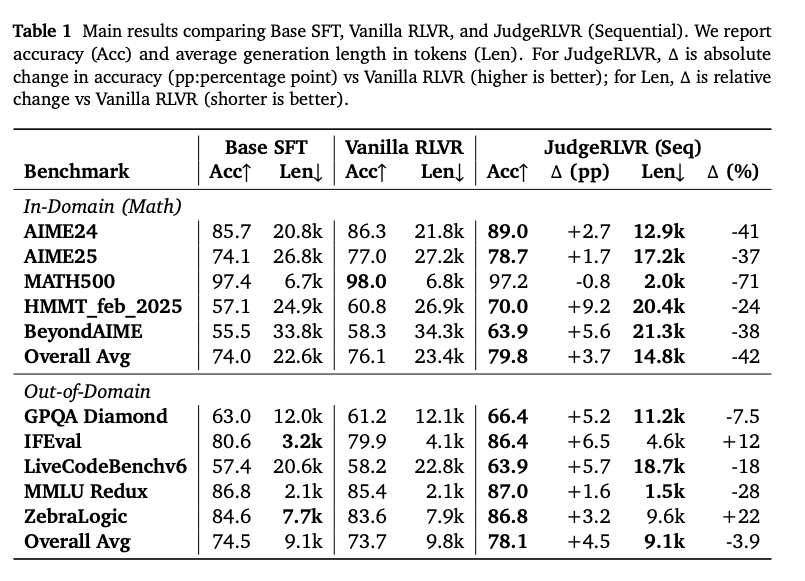
正解率と生成長比較
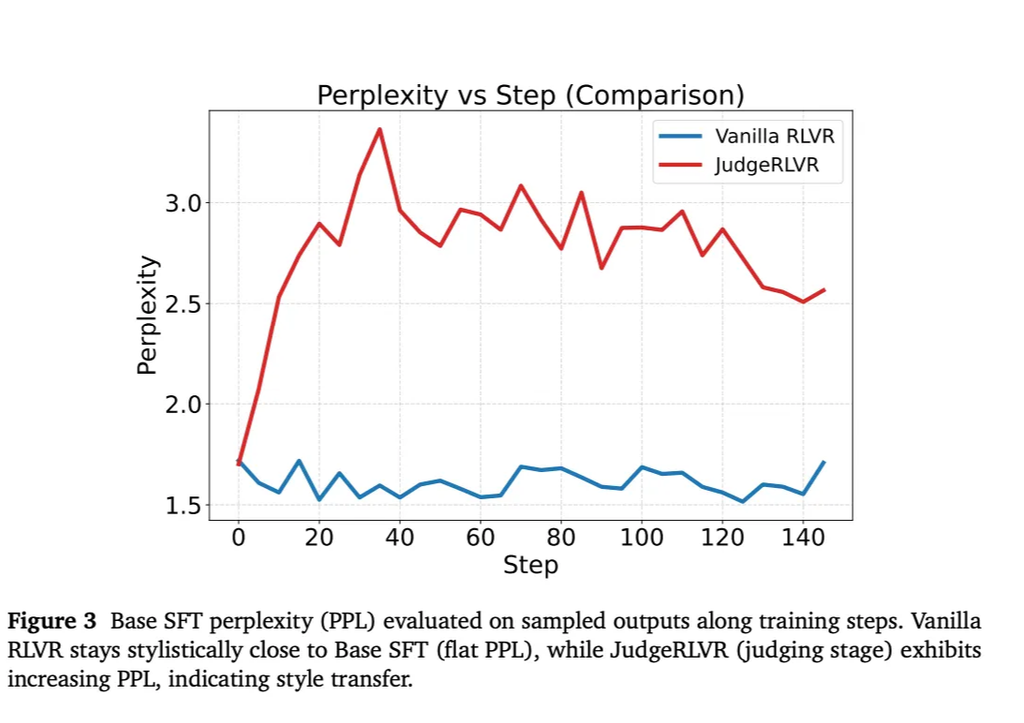
推論スタイル転移
- PPL(perplexity)の上昇→推論スタイルの変化
効率的な推論ができているか?
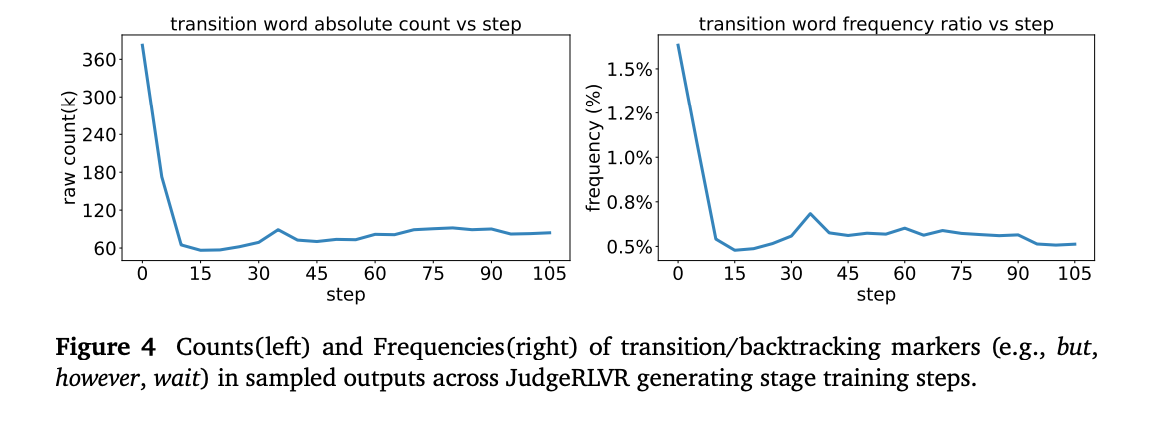
「but」「however」「wait」などの対比マーカーを確認した
- JudgeRLVR訓練後、対比マーカーが大幅に減少
- より直接的で効率的な推論パターンへの移行を示唆
@Kyohei Uto(kuto)
[paper]GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
どんなもの?
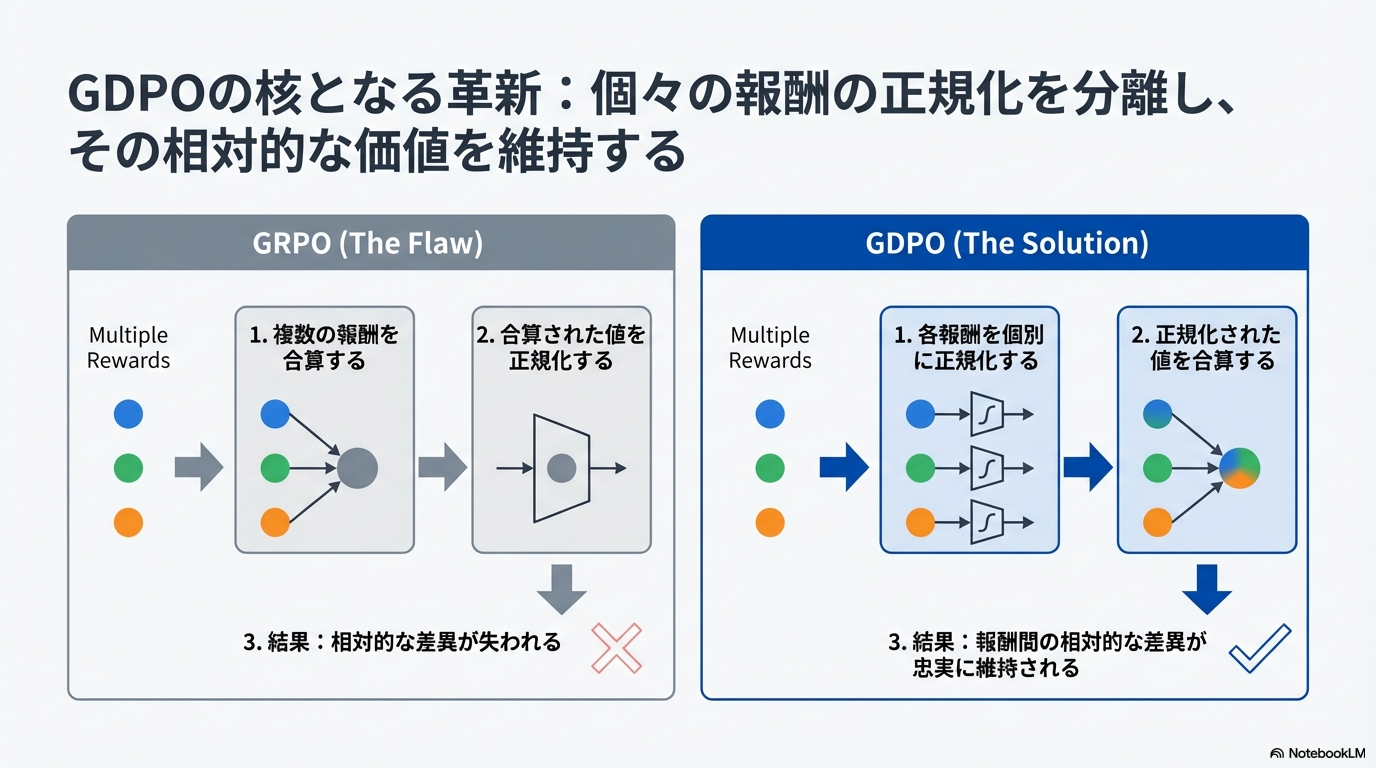
- マルチ報酬RL向けにadvantageの計算方法をGRPOから改良したもの
- GRPOは累積報酬(一連の報酬を足し合わせたもの)をグループ内正規化してadvantageを得る
- GDPOは先に各報酬チャネルごとにグループ内正規化をしてadvantageを得てそれらを合算する
先行研究と比べてどこがすごいの?
- マルチ報酬タスクの場合、従来のGRPOでは報酬の相対的な差異が潰れてしまう。例えばGRPOでは以下のようなケースを同様のadvantageとして扱う
- rollout1: 簡単な中間報酬1.0と簡単なアウトカム報酬が0.0で累積報酬は1.0
- rollout2: 簡単な中間報酬0.0と簡単なアウトカム報酬が1.0で累積報酬は1.0
- GDPOは報酬チャネルでまず正規化してadvantageを計算するため学習信号の表現力が高まる
- 実験的にも、学習曲線の安定性、収束速度、最終性能(正解率、形式遵守、長さ制約遵守、バグ率低減)で一貫して優位な結果を示している
- 「標準偏差正規化を外す」だけの変種(Dr.GRPO)よりも安定で、収束失敗も回避している
技術や手法の"キモ"はどこにある?
2段階正規化によるadvantageの計算
- 各報酬ごとのグループ内正規化で、各報酬チャネルの相対差を保ったadvantageを得る
- 報酬チャネルごとに報酬の重みづけをした上で1の値を合算した後にバッチ内正規化を行う
どうやって有効だと検証した?
ツール呼び出し、数理推論、コード推論の3タスクで検証
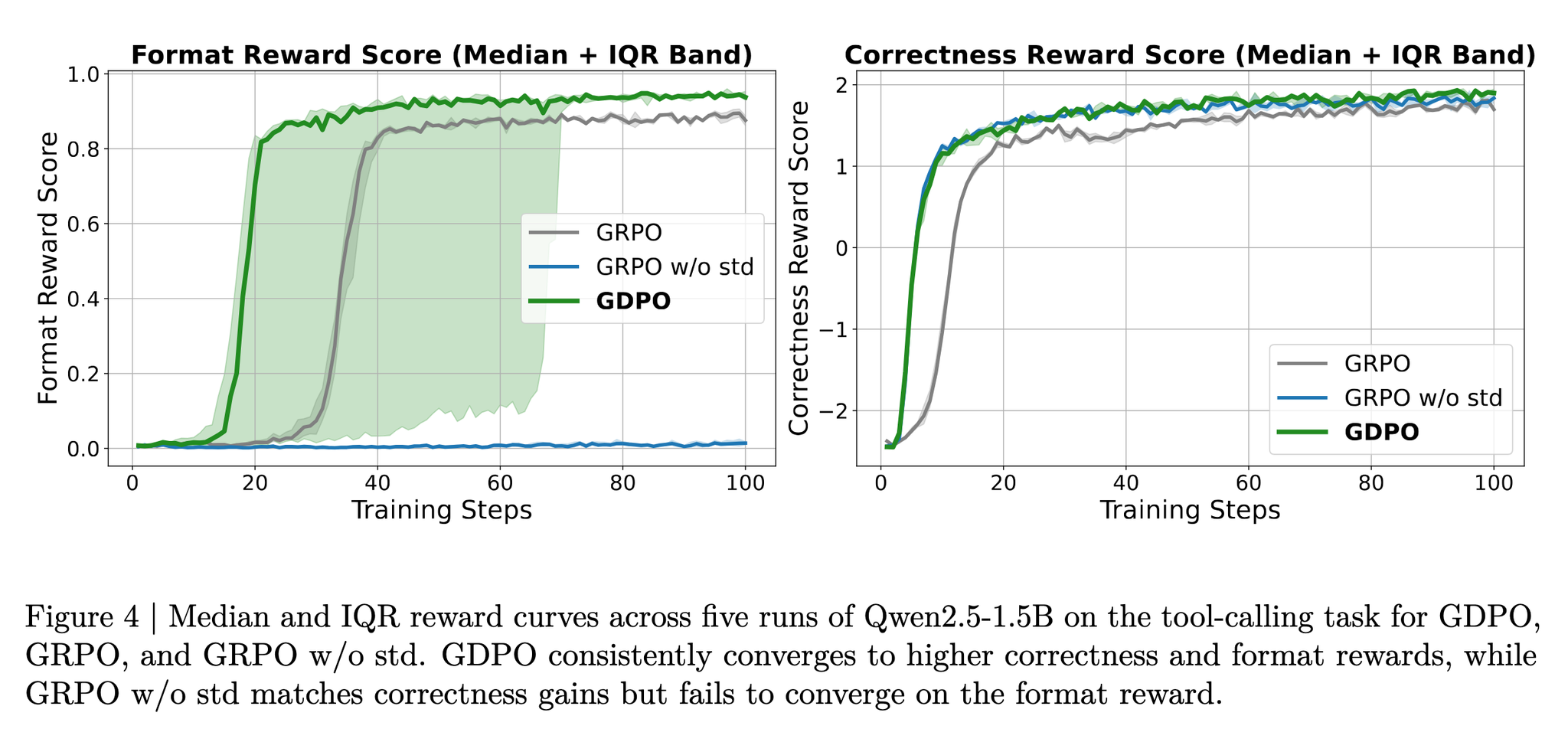
- ツール呼び出し(ToolRLの実験条件に従う)
- 報酬(2): フォーマット報酬、正解報酬
- フォーマット精度と正解率がGRPOやDr.GRPOと比べて向上
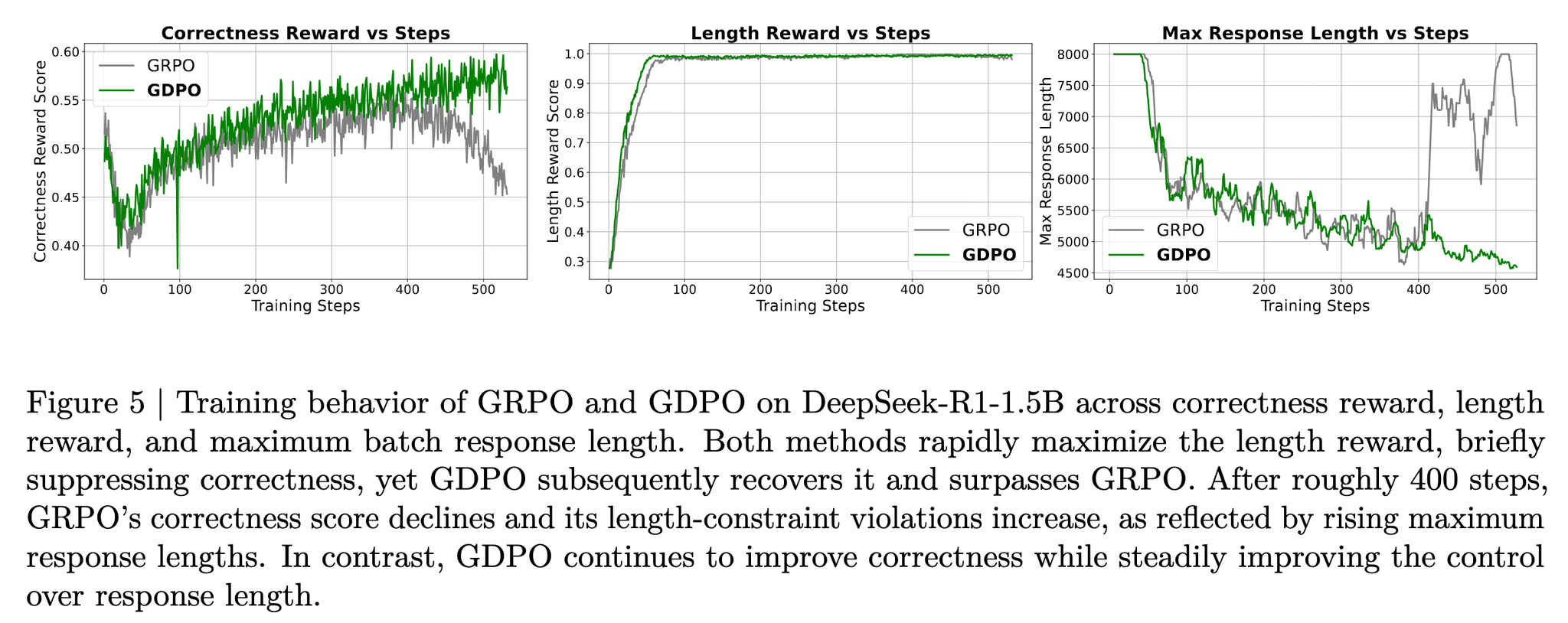
- 数理推論
- 報酬(2): 長さ報酬(応答長さが4000トークン未満でr=1)、正解報酬
- AIMEやMATH、Olympiadなどで精度向上と長さ超過率の大幅低減を同時に達成
- 学習曲線ではGRPOが約400ステップ以降で正解報酬が劣化・長さ暴走が増える不安定性を示す一方、GDPOは回復・改善を継続
- コード推論
- 報酬(3): テストパス率報酬、条件付き報酬(応答長さが一定以下で報酬)、バグ報酬(エラーなしで実行できたらr=1)
- 合格率を維持・改善しつつ、長さ超過とバグ率を下げ、3報酬(合格・長さ・バグ)設定でもバランス良く最適化できることを示した
議論はあるか?
- 学習安定化のために条件付き報酬設計を推奨している
- ex; アウトカム報酬を満たしたときのみプロセス報酬を与える。
- GDPOの効果は報酬の粒度・スケールやロールアウト数に依存するため、実タスクに応じた報酬設計と正規化の相互作用を観察する必要がある
- 計算的な追加コストは小さい一方、バッチ内正規化の統計が小規模バッチや極端な分布で不安定化しないよう、実装上のケア(例:ε項、統計の安定化)は重要である
- メモ
メインTOPIC
Ministral 3
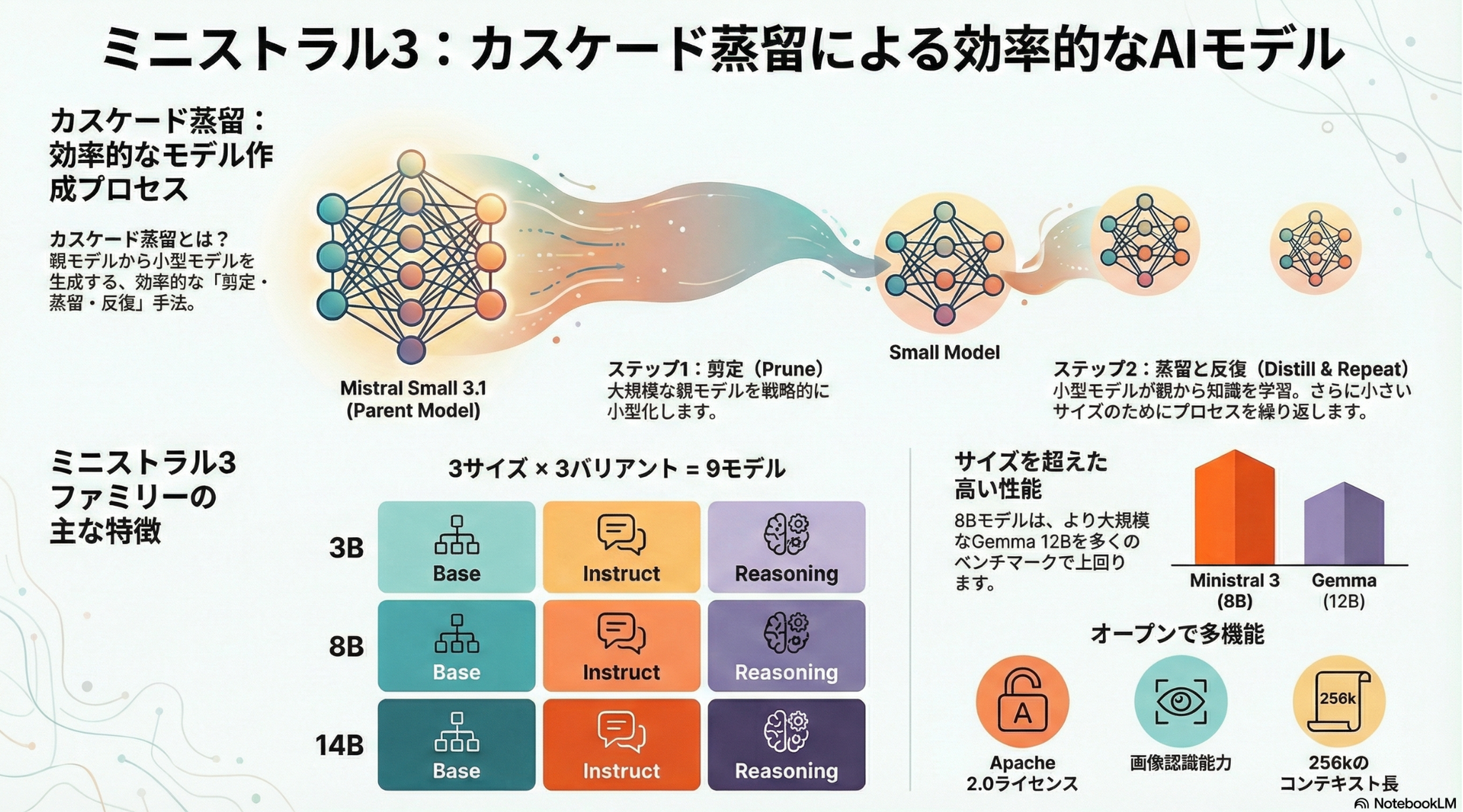
イントロダクション
LLMの課題
- 訓練コストの高騰: Qwen3やLlama3などの最新モデルは15〜36兆トークンで学習されており、膨大な計算リソースを必要とする。これは研究機関や企業にとって極めて高いコスト負担となる
- メモリ要件の増大: 大規模モデルは推論時にも大量のメモリを消費し、高価なGPUインフラが必須となる
- デプロイメントの困難: エッジデバイス(スマートフォン、IoTデバイス等)やリソース制約のある環境では実行が事実上不可能
- 実用性とのギャップ: 多くのアプリケーションでは最大規模のモデルは不要だが、適切なサイズで高性能なモデルの選択肢が限られる
提案: Ministral 3
Mistral Small 3.1を教師として、3つのモデルサイズのMinistral 3を提供
| モデル | レイヤー数 | 潜在次元 | Q/KVヘッド | FFN次元 | コンテキスト長 |
|---|---|---|---|---|---|
| Ministral 3 14B | 40層 | 5120 | 32 / 8 | 16384 | 256k |
| Ministral 3 8B | 34層 | 4096 | 32 / 8 | 14336 | 256k |
| Ministral 3 3B | 26層 | 3072 | 32 / 8 | 9216 | 256k |
- それぞれBase, Instruct, Reasoningモデルを作成
- 特徴: オープンライセンス、マルチモーダル、長文(256kトークン)対応、多言語サポート
- アーキテクチャ
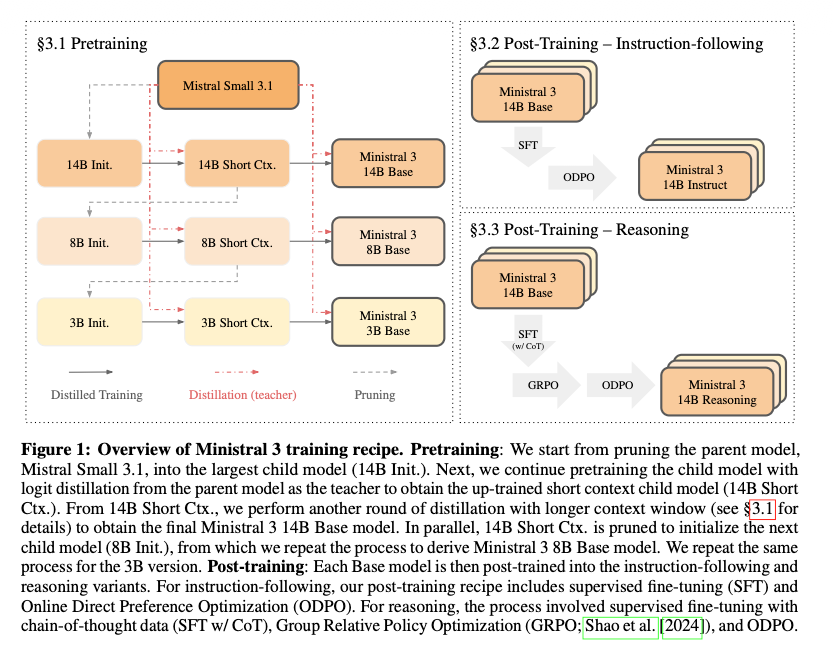
- Decoder-only Transformer
- Grouped Query Attention (GQA): 32個のクエリヘッドに対して8個のKVヘッドを共有
- RoPE: Rotary Positional Embedding
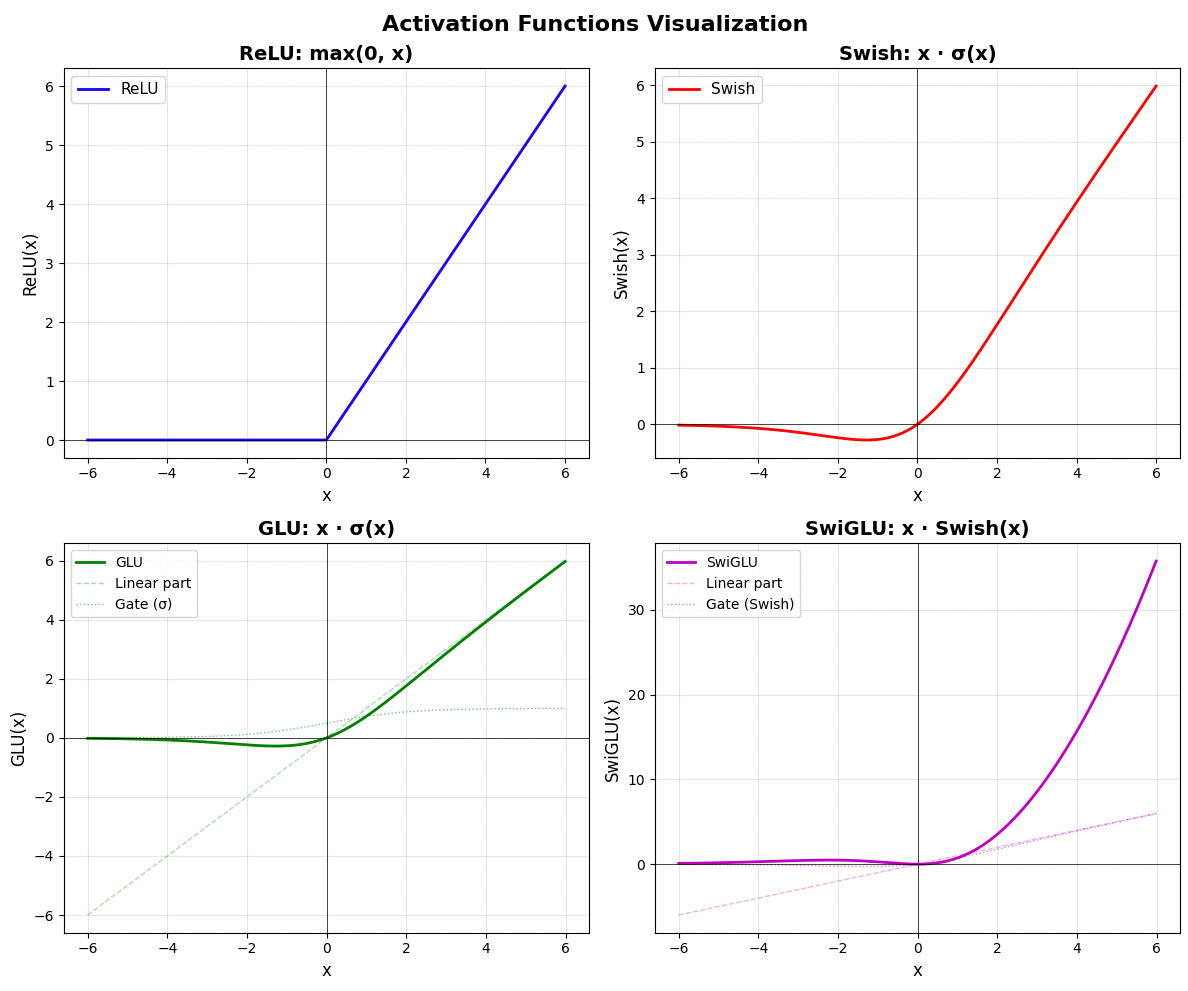
- SwiGLU activation: ReLUやSwish, GLU単体よりも複雑な非線形変換ができて滑らか
- 画像認識: Mistral Small 3.1 BaseのViTをそのまま利用。パラメータは固定し、projection部分だけ学習。
主要技術スタック
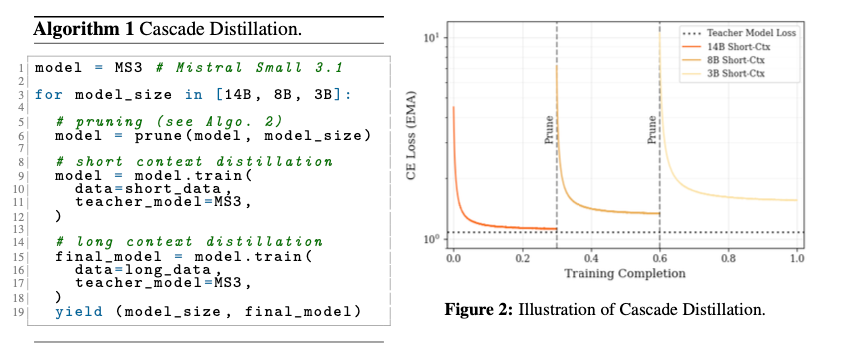
(Pre-Training) Cascade Distillation
- モデルサイズを一気に小さくするのではなく、段階的に小さくすることで、段階ごとに比較的良い初期値から学習を開始できて効率的、という考え方
- 1つ大きいサイズのモデルをpruning → 短コンテキスト学習(16k) → 長コンテキスト(256k)へ拡大 のサイクルを繰り返して小さいモデルを学習していく
- 学習データは、テキストと画像が混合されたデータセットを利用
- Cascade全体を通して、data repetitionが起きないように学習しているらしい。効率的。
(Pre-Training) Model Pruning

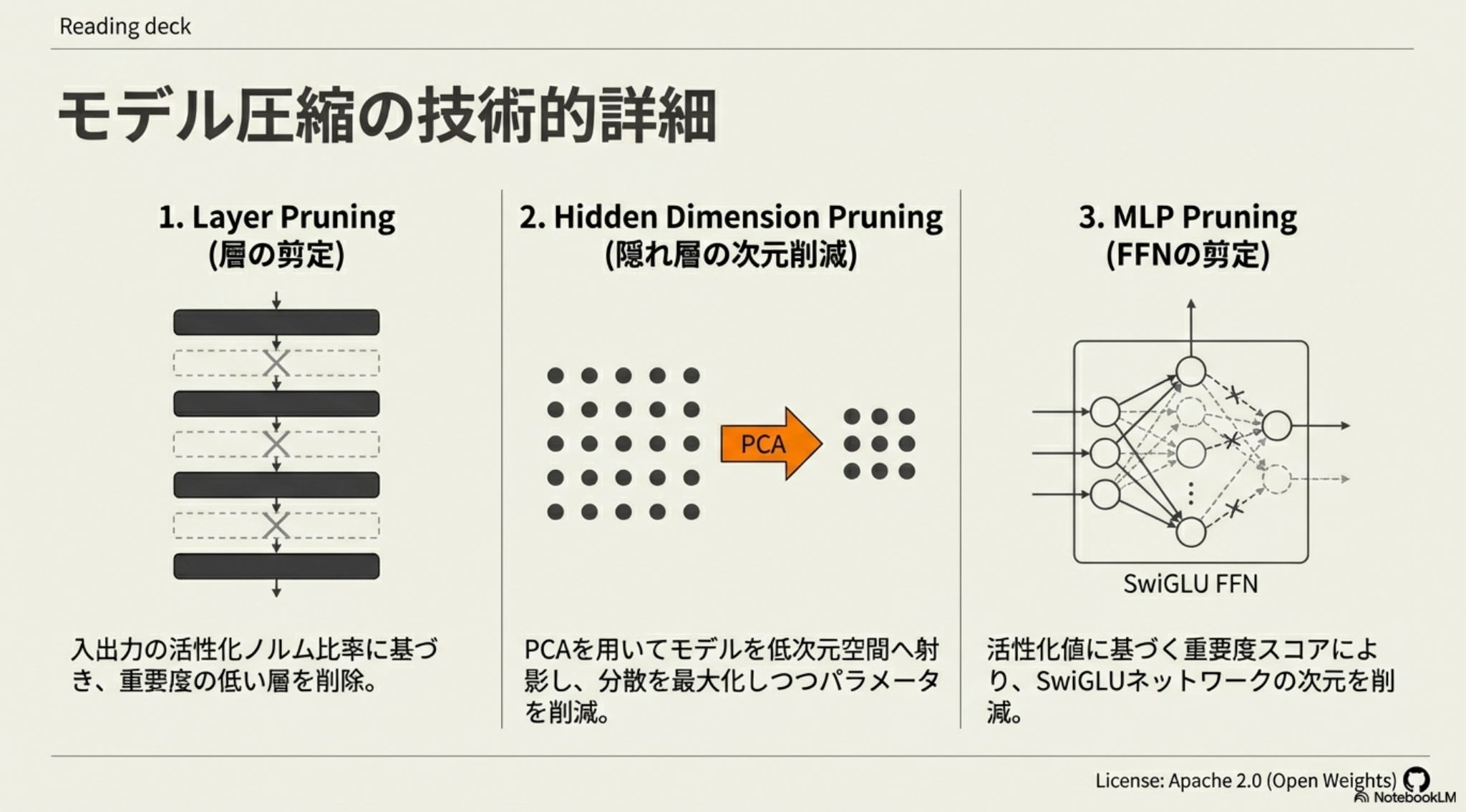
- Layer, Hidden Dimension, FFNの観点からpruningを実施
- Layer: inputに対するoutputの活性化ノルムの比率が小さいものを削除
- Hidden Dimension: PCAで次元削減
- FFN: 活性化値(SwiGLU)が小さいニューロンを削除
- 先行研究(Minitron)より複数観点からバランスよくpruningするのが有効だったため採用
(Pre-Training) Knowledge Distillation
- Init → Short Contextモデル、Short Context → Long Contextモデルの学習それぞれで実施
- シンプルなforward KL(Studentの出力分布をTeacherに近づける)で学習
- Long Contextへの拡張はYaRNを利用
- RoPEベースのモデルのコンテキストを拡張した時のスケーリングをうまく調整する手法
Post-Training
- 14B, 8B, 3BそれぞれのBaseモデルをSFT, ODPO, GRPOで学習
- Instruction: SFT → ODPO
- SFTの教師モデルはMistral Medium 3を利用
- ODPO: ペアのより好ましい(テキストベース報酬モデルのスコア)方を重点的に学習。DPOと異なるのは、ペアの好みの差が大きいものほどより強く学習に反映させる点、多様性も一定考慮した学習を行う点。
- Reasoning: SFT → GRPO → ODPO
- 教師モデルのCoT付きの出力を使ってSFT。コーディングや一般的な対話、instruction following、マルチ言語タスク、tool use、visual reasoningなど多様なデータを利用。
- GRPOで2段階の強化学習
- 1段階目: 数学やコーディングなどの明確な正解のあるデータを利用
- 2段階目: 一般的なチャット、指示追従、自由形式の推論タスクを含むプロンプトデータを利用。プロンプトごとに独立した評価項目を定義し、出力をLLMで評価して報酬を決定する。
- 最後にODPOで出力をより洗練させる。
実験結果
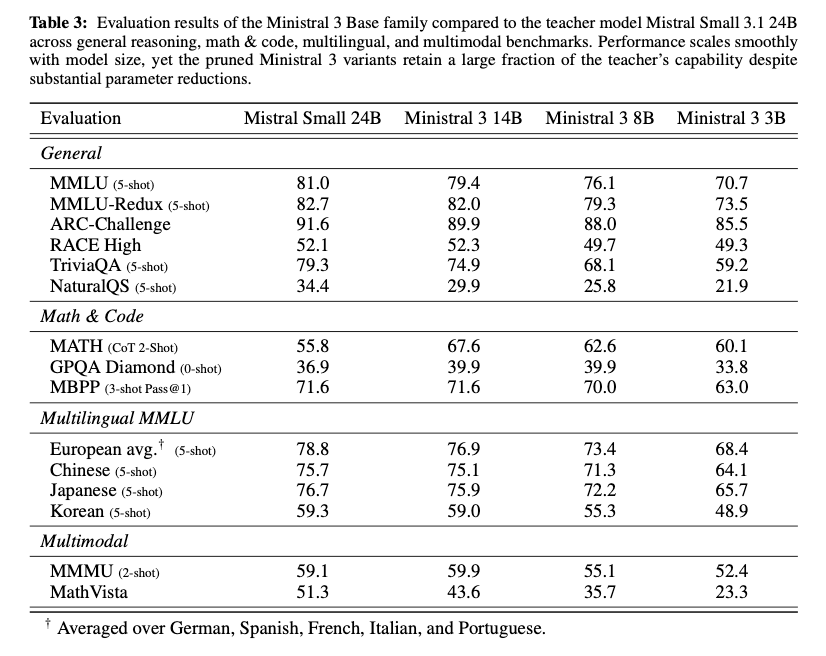
Base Models: 数学・コーディング系のベンチマークで良い傾向
- Qwen3 との比較
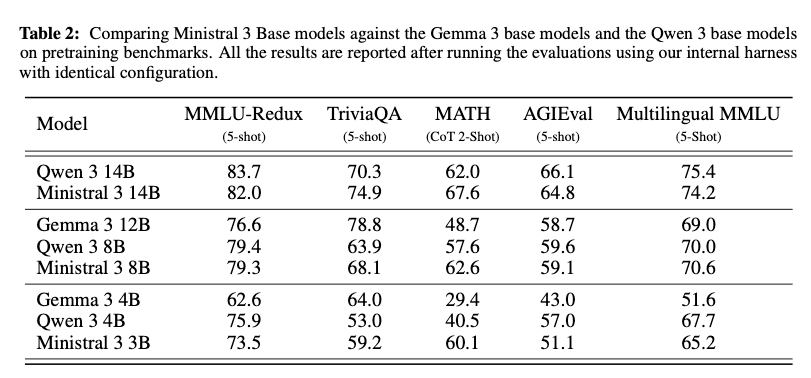
- 特にMath & Code系のデータで、24B → 14B で性能劣化が少ない
Instruct Models
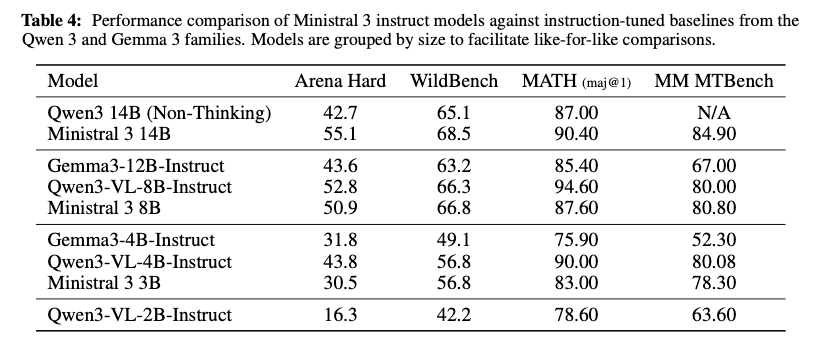
- Arena Hard: 人間評価者による難しいタスク。実世界の有用性を反映
- WildBench: 多様な実世界タスク。一般的な対話能力を測定
- MATH (maj@1): 複数回生成して多数決。推論の一貫性と正確性
- MM MTBench: マルチモーダルベンチマーク。画像理解との統合を評価
Reasoning Models
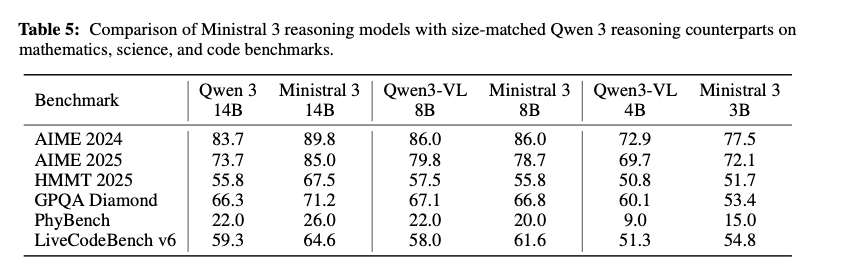
- AIME 2024, 2025: 米国数学コンテスト
- HMMT: ハーバード・MIT数学トーナメント
- GPQA: 大学院レベルの科学問題
- LiveCodeBench: コーディングタスク
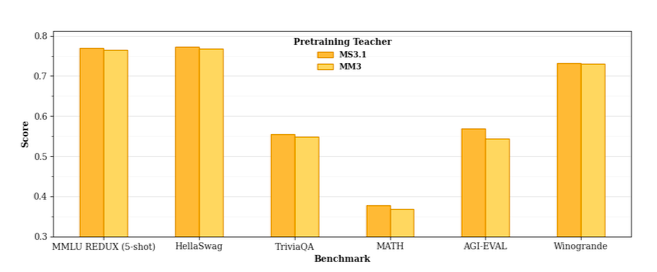
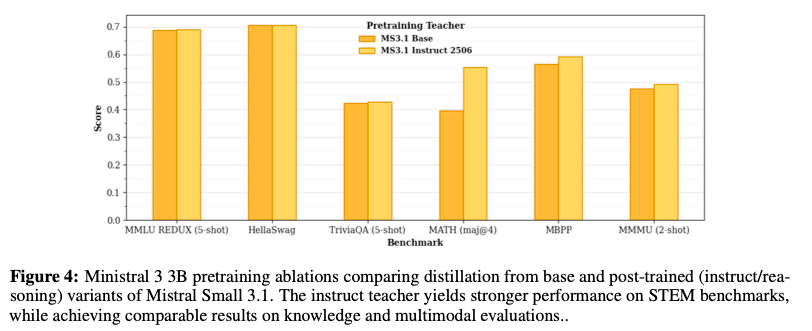
その他の知見
- 事前学習ではCapacity Gap(性能の差)が小さいモデルを教師にし、事後学習ではより強いTeacherを使う方が効果的
- Pre-TrainingのDistillationにおいては、教師モデルの性能があまり影響しない(むしろ教師モデルが強いほど性能劣化する場合もある)
- Post-Trainingにおいては、特に数学系のデータで教師モデルの性能が高いほど良い結果に