2026-01-27 機械学習勉強会
今週のTOPIC[paper] Reasoning Models Generate Societies of Thought[論文] Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space[paper] Diva: Dynamic Range Filter for Var-Length Keys and Queries[Paper] Deep Research: A Systematic Survey[paper]Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research[blog] The AI Evolution of Graph Search at Netflix: From Structured Queries to Natural Language[paper]τ 2-Bench: Evaluating Conversational Agents in a Dual-Control EnvironmentメインTOPIC:TRivia: Self-supervised Fine-tuning of Vision-Language Models for Table Recognition概要背景提案手法:TRivia全体Table QA-driven自己教師ありファインチューニングTable QA-driven GRPO学習データの生成TRivia-3B結果定量評価Ablation Study補足
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Yuya Matsumura
[paper] Reasoning Models Generate Societies of Thought
Reasoning モデルの高度な推論能力のメカニズムを解明するGoogle の論文。高度な推論能力は、単なる計算量・思考量の増加(Chain of Thought)ではなく、AIが内部において「思考の社会 / Society of Thought」と呼ばれる、異なる視点を持つ多人数での議論のようなプロセスをシミュレーションすることで生まれているという主張。
特徴の分析
DeepSeek-R1 や QwQ-32B の推論トレースを分析した結果、従来のモデルと比較して以下のような会話的特徴が顕著に見られた。
- 自問自答(Question–answering): 自ら問いを立てて答える
- 視点の転換(Perspective shifts): 代替案や異なる見方を探る
- 対立意見の調整(Conflicts of perspectives): 矛盾などへの鋭い指摘
- 和解(Reconciliation): 対立する見解を統合
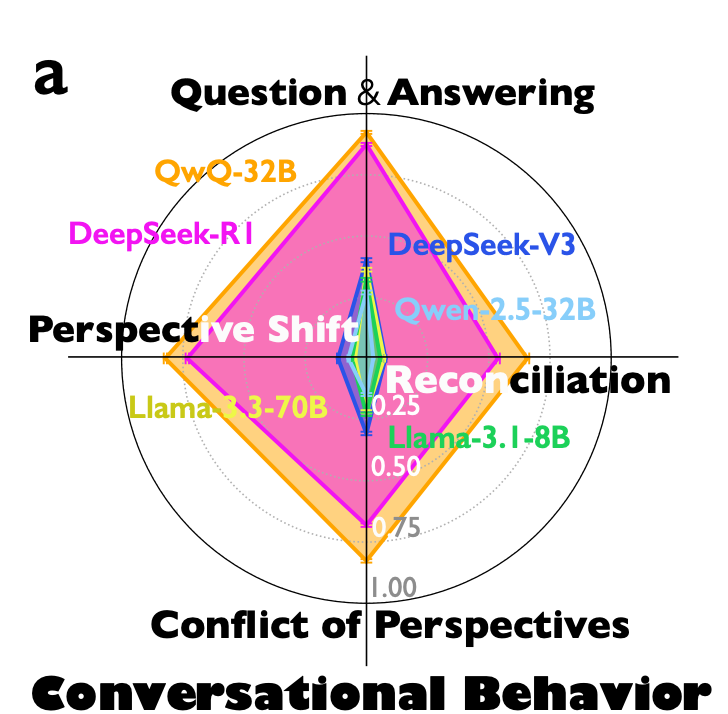
Fig.1 - a: reasoning model(DeepSeek-R1, QwQ-32B) においてそれぞれの特徴を持つ会話量が顕著
役割も様々なものが観測される。単に情報を出すだけではなく、意見を求めたり、同意する・反対するといった双方向の役割。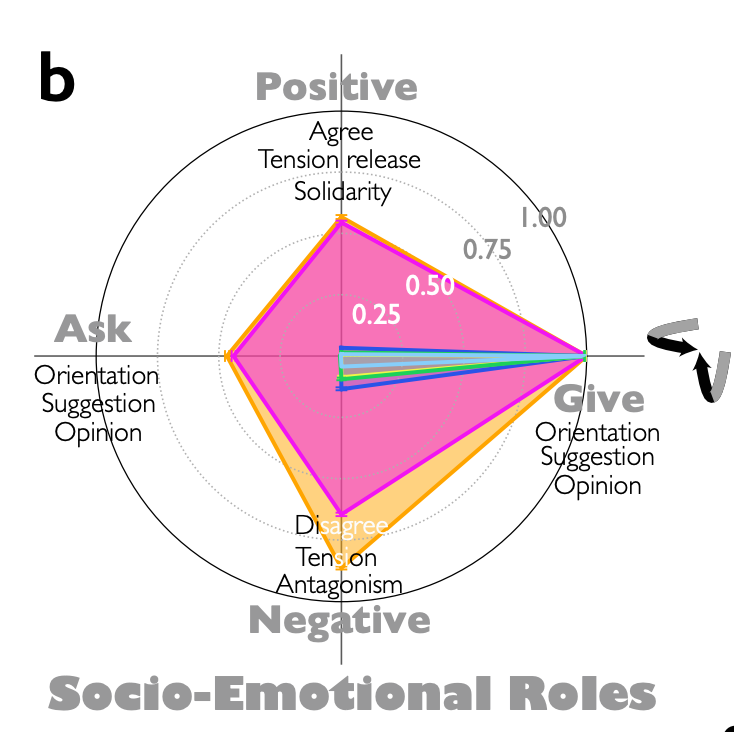
Fig.1 - b: reasoning model(DeepSeek-R1, QwQ-32B) においてそれぞれの特徴を持つ会話量が顕著
これらの特徴は、タスクの難易度が上がるほど顕著にもなる。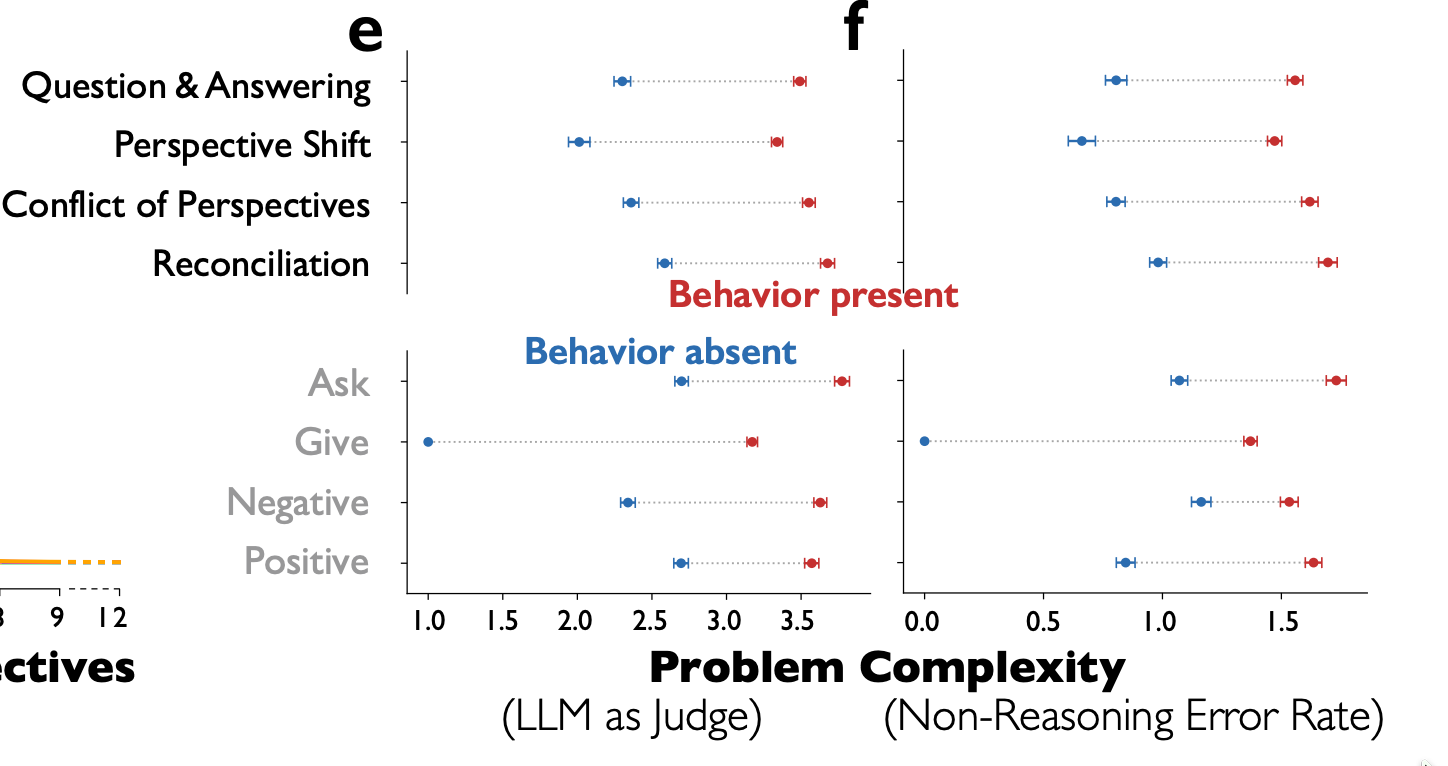
Fig.1 - e, f:
メカニズムの検証
前述のような会話特徴に関連するニューロンの特定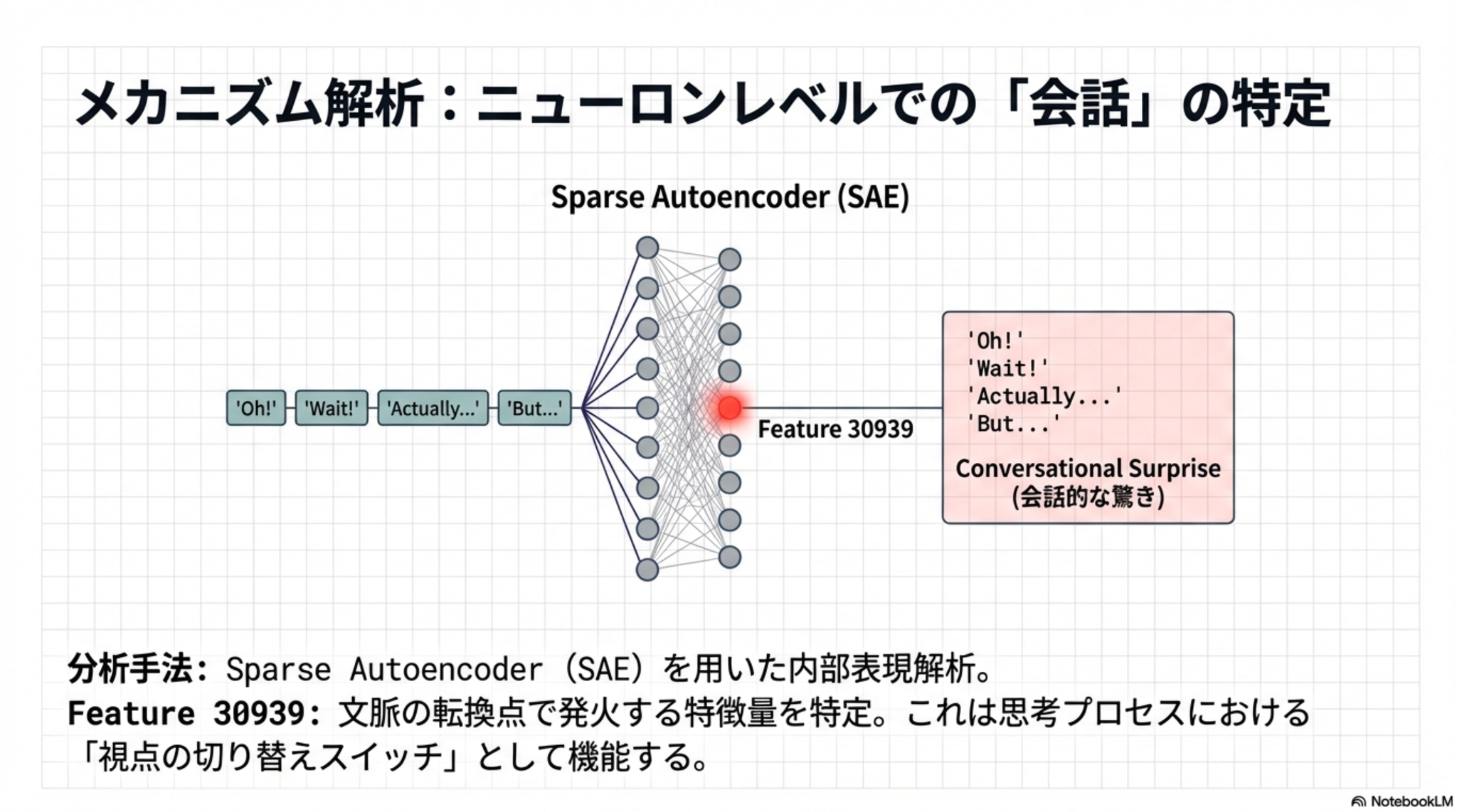
そのようなニューロンによる影響度を変化/steering させることにより、推論性能がどう変わるかの介入実験を実施。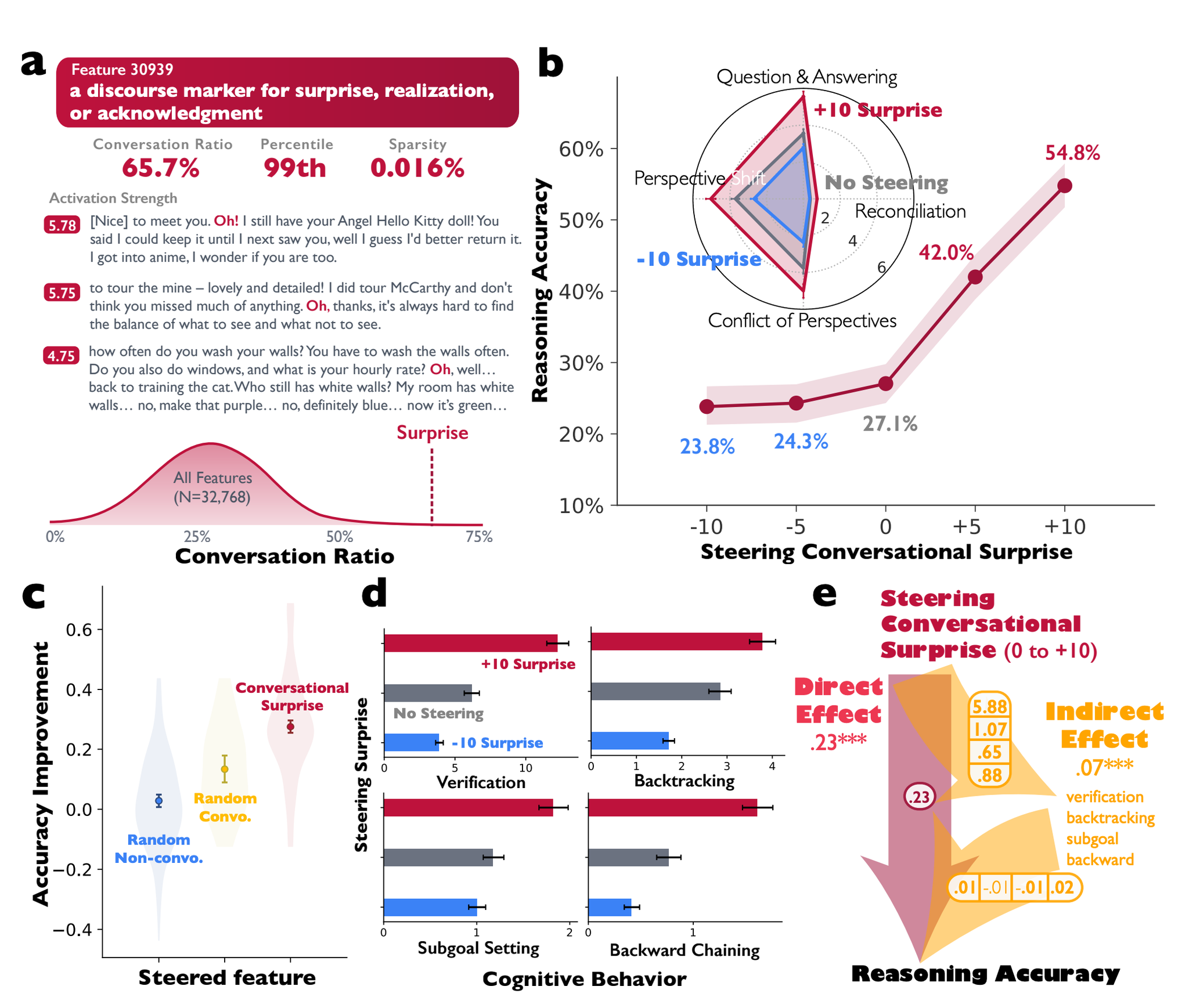
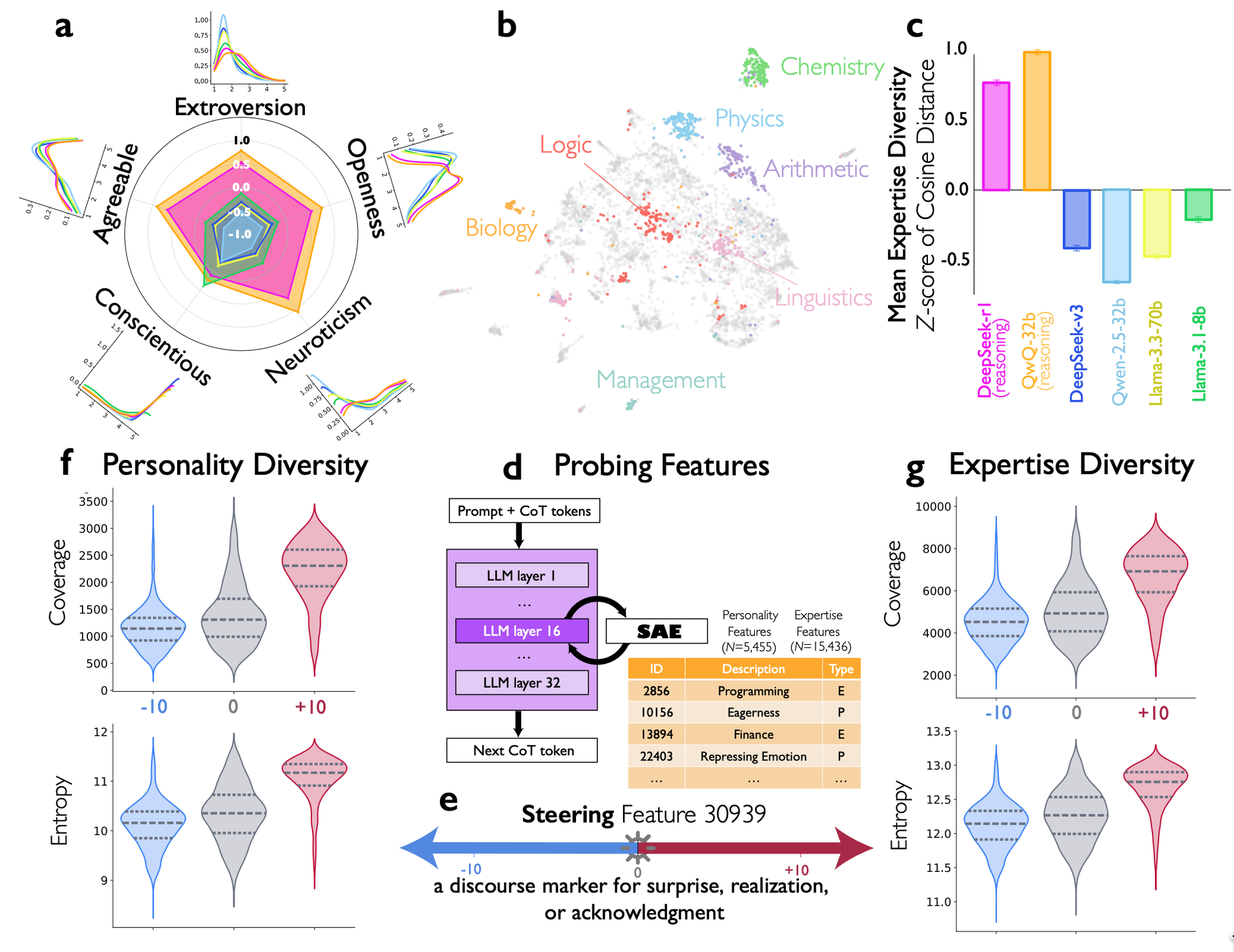
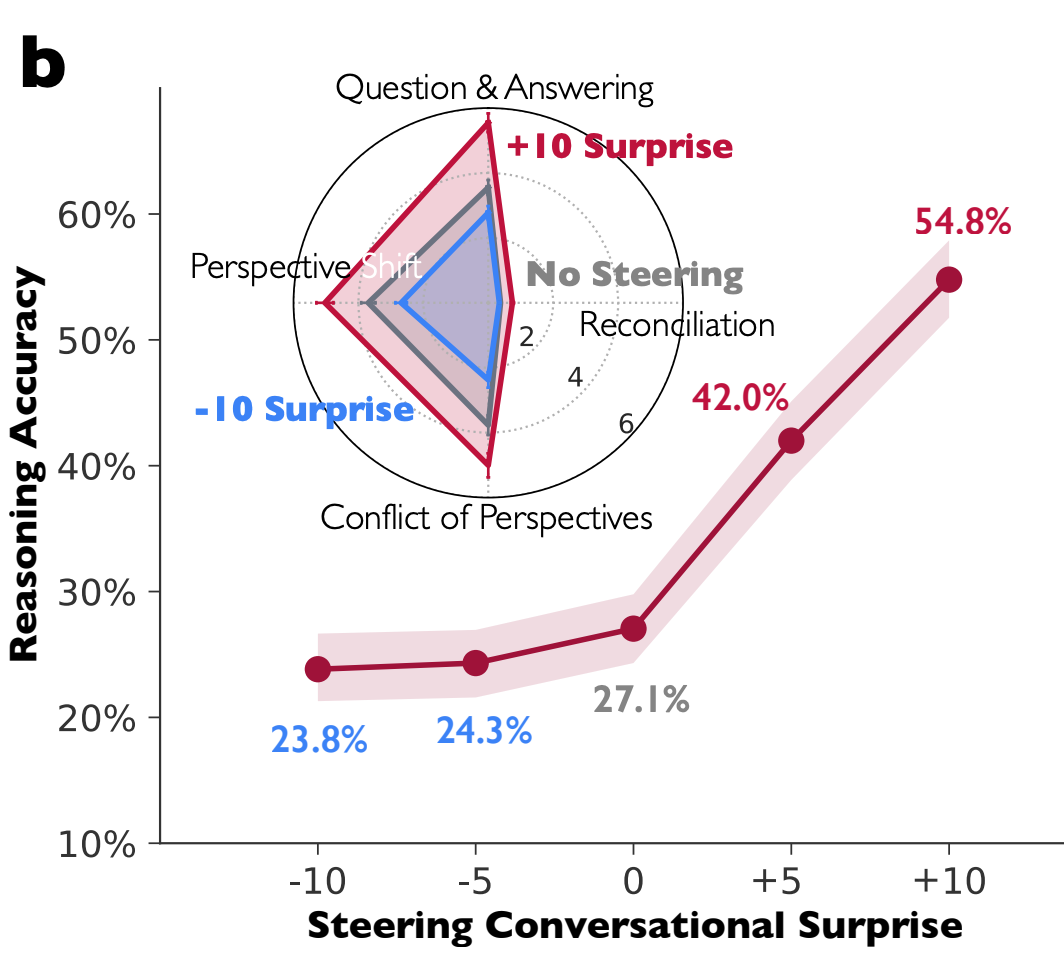
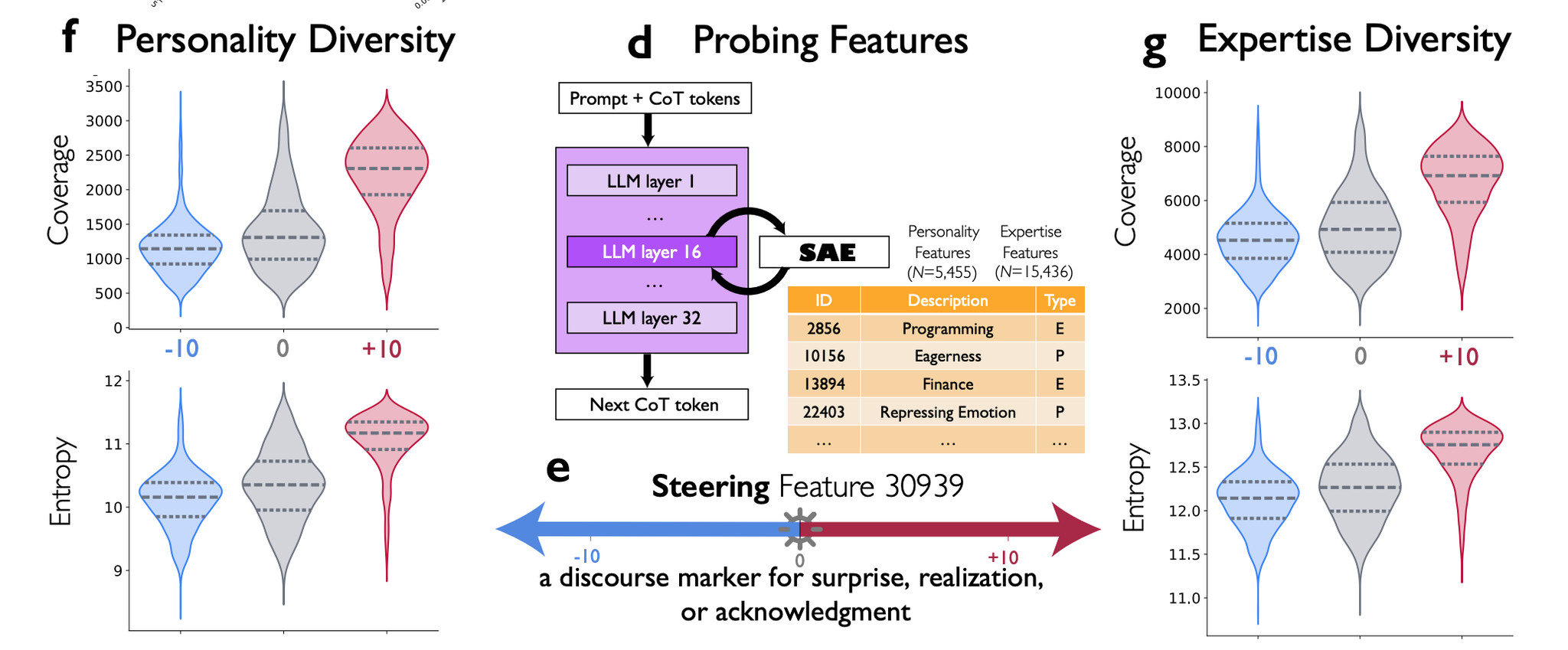
[参考]元の実験結果 Fig. 2, 3
上記の「会話的な驚き」に関する特徴を活性化させることで、計算問題の正答率が倍増。g逆に、非活性化させると性能低下。
「検証(Verification)」や「後戻り(Backtracking)」といった重要な認知戦略が誘発されることも確認された。
「会話的な驚き」に関する特徴を活性化させることで、AIの人格や専門性の多様性が増大。
人格:外交的、神経質、開放的…etc.
専門性:論理学者、直感的な問題解決者、プログラミング、ファイナンス…etc.
能力獲得のプロセス調査
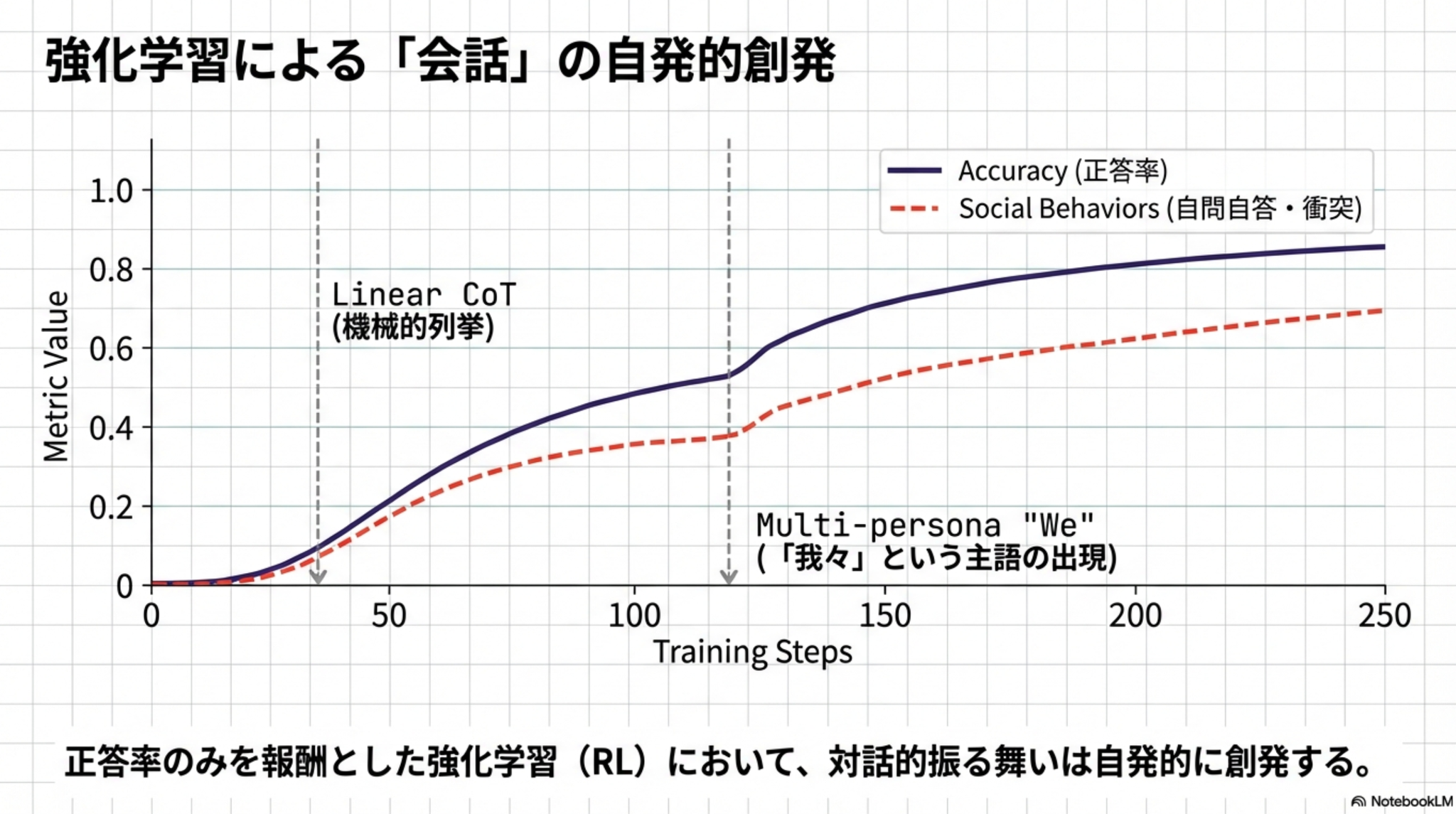
Qwen-2.5 3B を用いた強化学習の実験を実施
「最終的に正解すること」のみを報酬として会話の仕方を教えずとも、自発的に「自問自答」や「視点の対立」といった会話的振る舞いを獲得した。
最初は機械的な計算だけであったのが、次第に主語が”We”になり、複数の視点での議論が見られた。
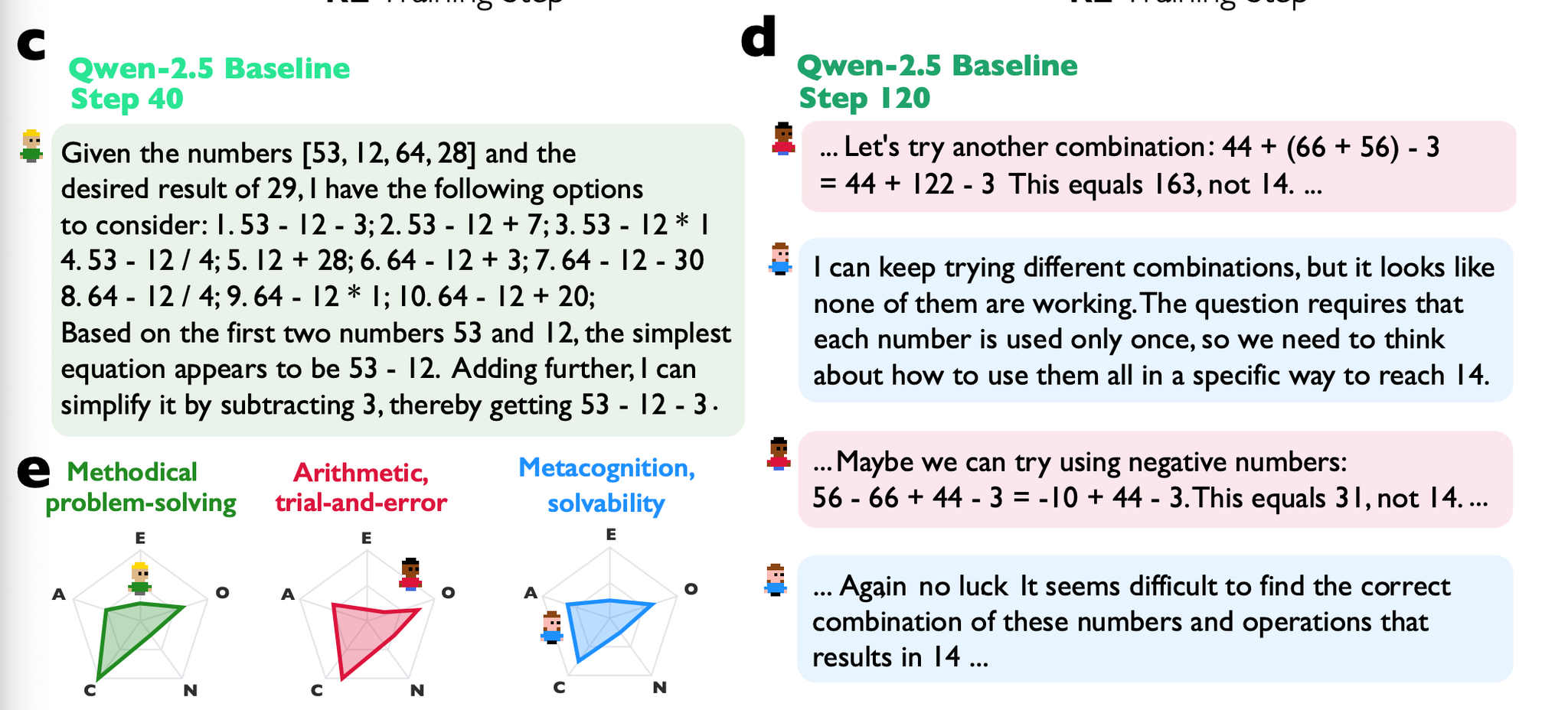
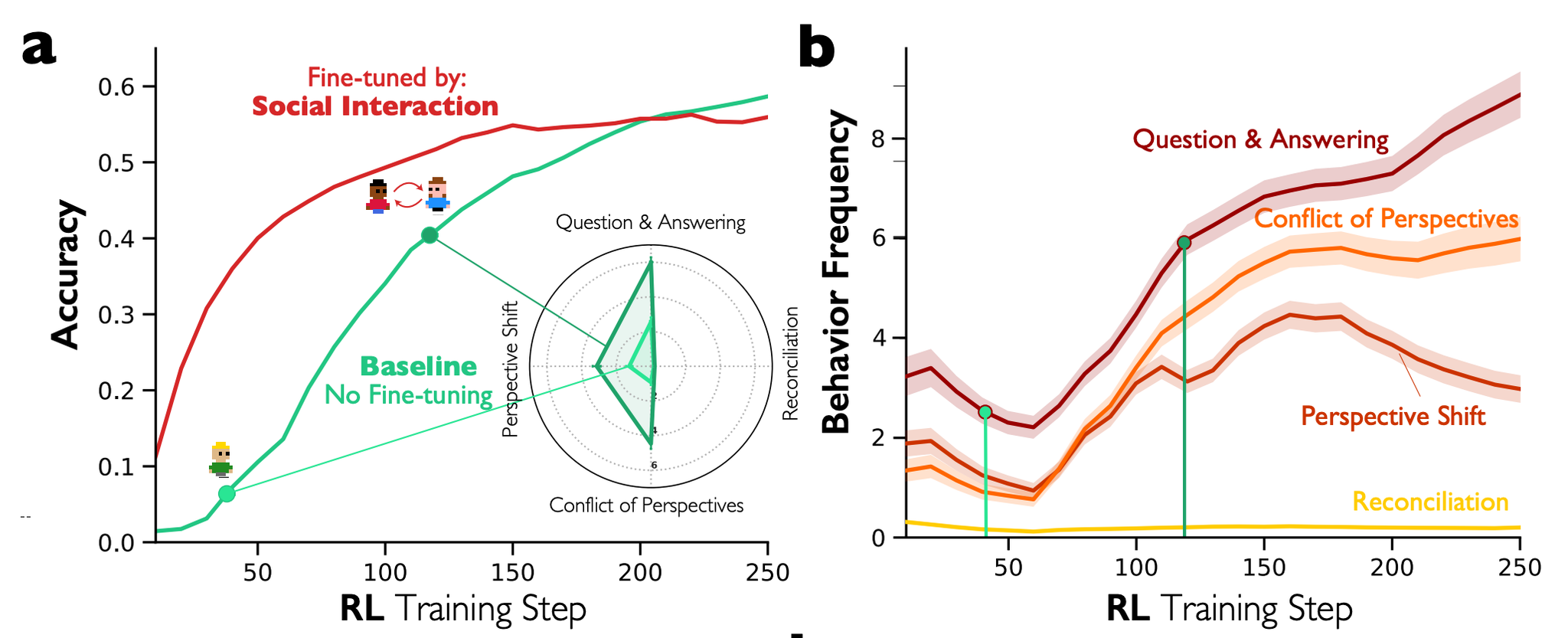
さらに、事前に複数人での議論形式のデータでSFTしたモデルは、学習初期における推論性能向上のスピードが圧倒的であった(学習が進むと追いつかれてる)。
@Shun Ito
[論文] Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
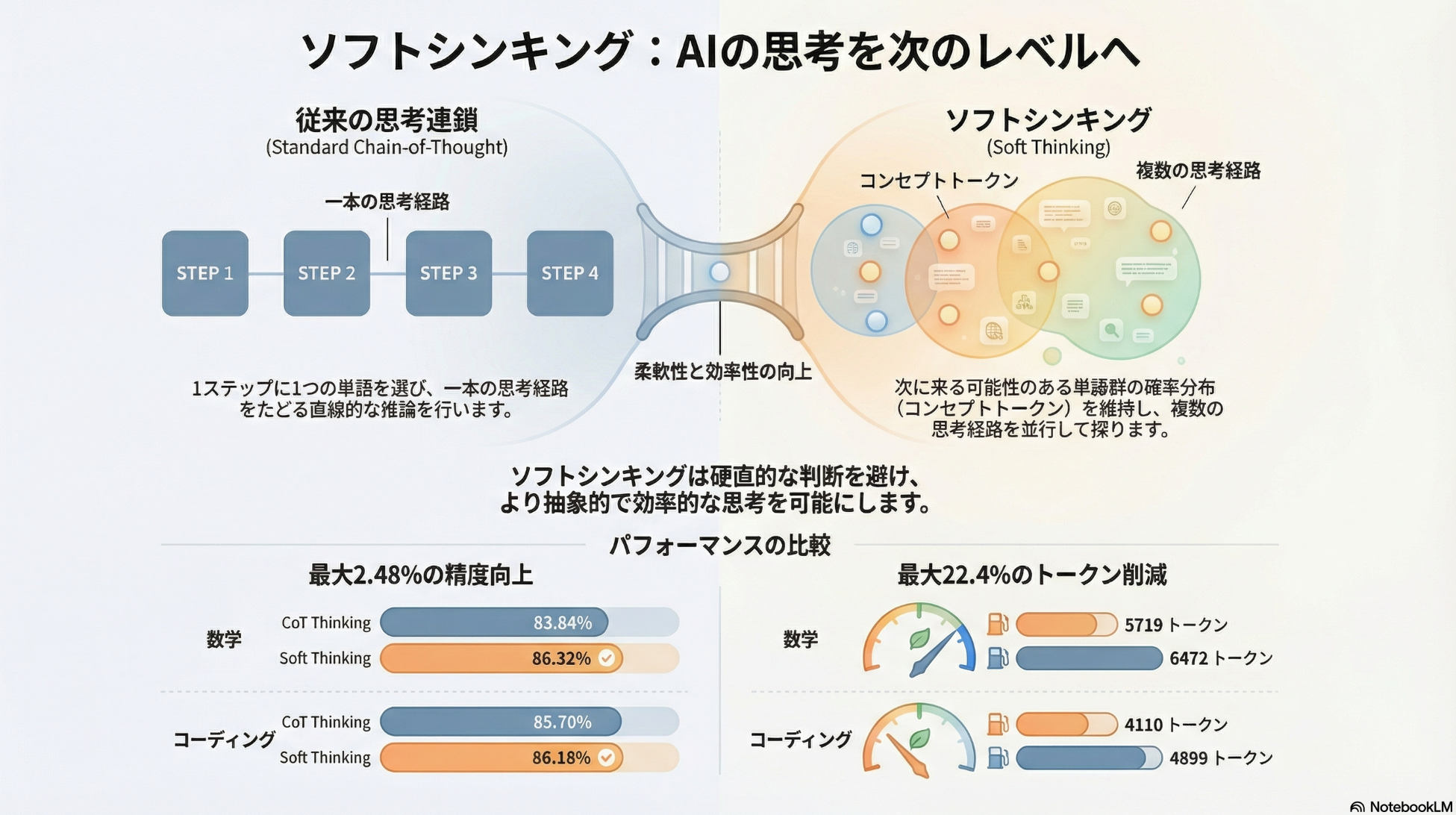
- 従来のCoTは、推論ステップごとに離散トークンを1つサンプリングして推論を進める
- 推論が離散的・逐次的のため、各ステップで単一の分岐に確定してしまう
- 不確実性の高い局面でも、確率分布を即座に一点に潰すため、誤った経路に早期収束しやすい
- 人間のような「複数候補を並行的に保持したまま思考する」振る舞いを表現できない
- 提案: Soft Thinking
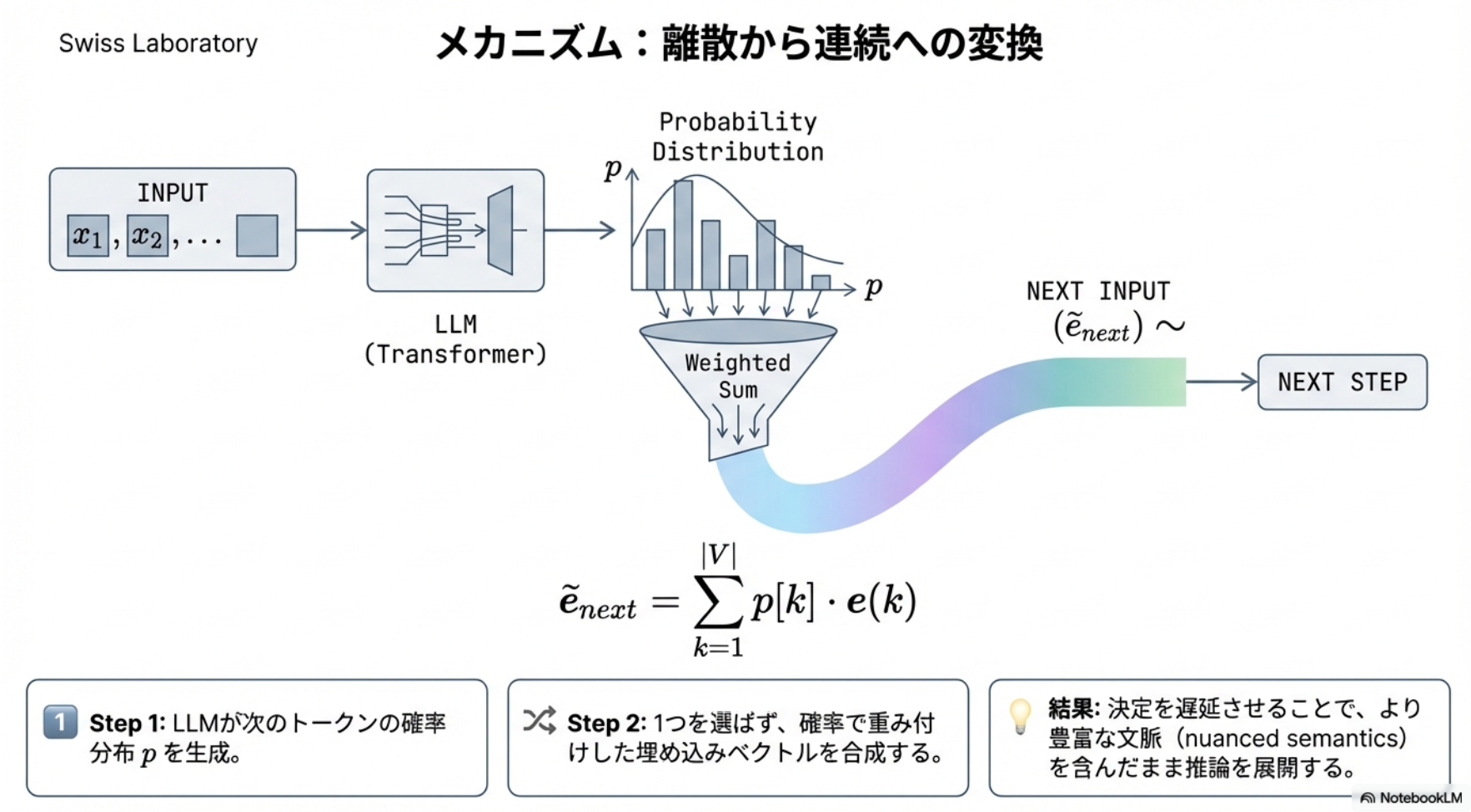
- Thinking中は、サンプリングしたトークンを次の入力とするのではなく、確率分布を単一の埋め込みベクトルに圧縮したものを入力とする
- 従来のサンプリング時点のトークンごとの生成確率とそれぞれの埋め込み表現の重み付け和を計算し、次のステップの入力ベクトルにする
- 単語を1つに決めるサンプリングを経由しないので、より多くの情報を使ったThinkingができる。
- 確率分布のエントロピーの低い状態がkステップ続いた時点でThinkingを終了する。
- 最終的な回答の生成は、通常通りトークンを生成していく。
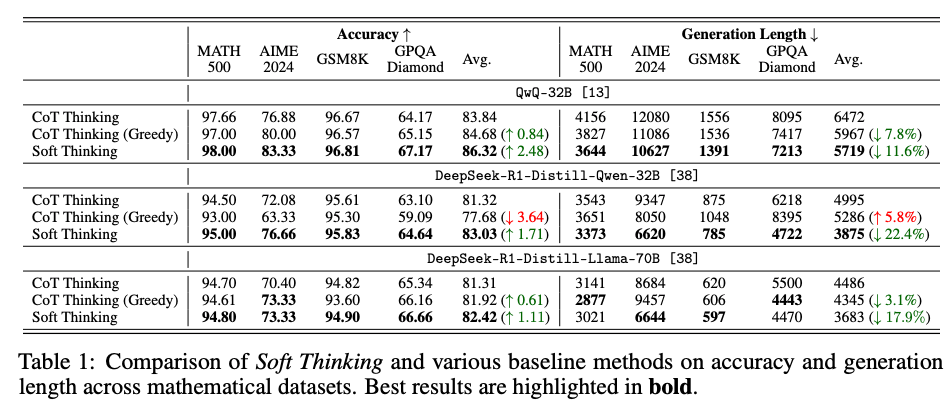
- 結果
- Generation Lengthを抑えつつ、精度向上
- Thinking自体もより質の高いものに(ステップごとの生成確率top1を表示)

@Hiromu Nakamura (pon)
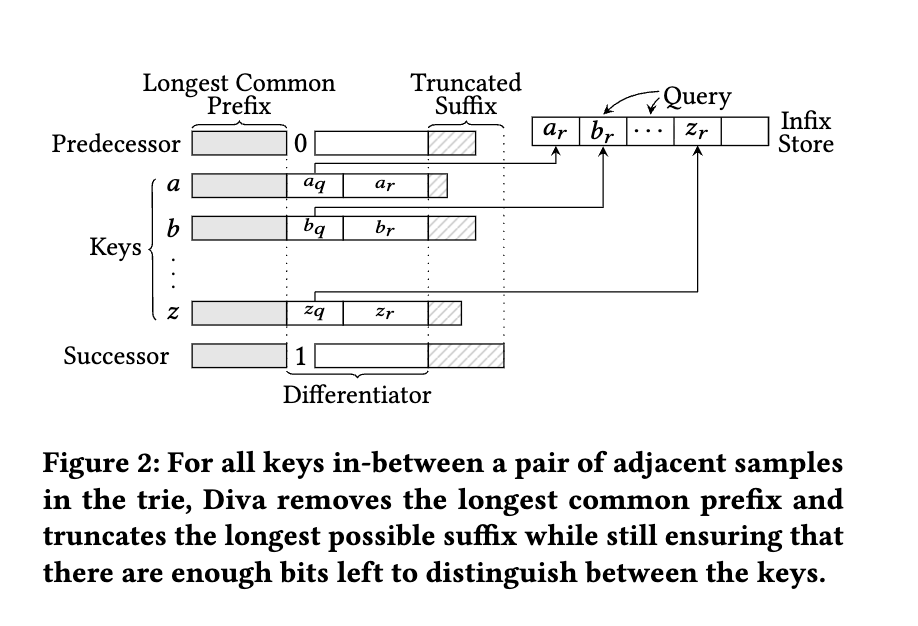
[paper] Diva: Dynamic Range Filter for Var-Length Keys and Queries
- Divaは、可変長キーとクエリ、動的更新、そして高いパフォーマンスを同時にサポートする初のレンジフィルター(特定の範囲にデータが存在するかどうかを近似的に回答する範囲フィルター)
- Divaは、既存のフィルターと比較して、FPRとクエリレイテンシーのバランスに優れ、特に可変長データと動的ワークロードにおいて、最高の性能と低いメモリフットプリントを実現。
これまでのレンジフィルタはトレードオフに直面してきた。例えば、高いメモリ効率を追求すると動的な更新が難しくなったり、固定長キーを前提としないとFPRやパフォーマンスが不安定になったりしていた。Divaは、以下の要素を組み合わせることで、この困難な「同時達成」を実現している。
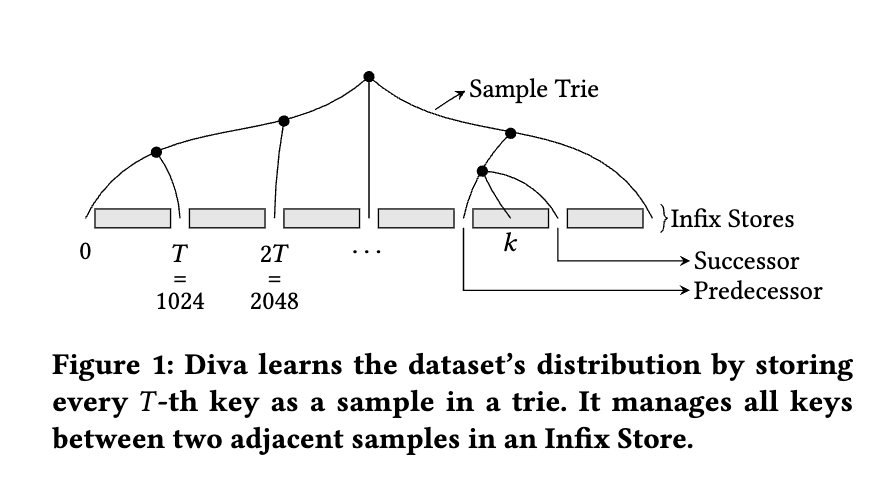
- データ分布の学習とトライへの格納(累積分布関数(CDF)を近似)
- Divaは、ソートされたデータセットから一定間隔(例えば1024個ごと)でキーを抽出(サンプリング)し、それをトライ構造に格納。
- データをサンプリングし、キャッシュ効率の良いトライに格納することで、キーの分布を学習し、密な領域と疎な領域を効率的に分離します。これにより、可変長クエリと可変長キーに対応しつつ、FPRを堅牢に保つ。
- y-Fast trieの活用: サンプルを格納するトライとしてy-Fast trieを利用することで、検索を効率的に行い、クエリパフォーマンスを大幅に向上させている。
- [pon]predecessor・successor検索特化のTRIEらしい。また調べる。
- infixの概念と効率的な圧縮: サンプル間のキーについて、最長共通プレフィックスを除去し、さらにサフィックスを切り詰めることで、キーの中央部分(infix)を抽出します。
- このinfixは、キーを識別するのに十分なビット数を持ちながらも、大幅なデータ圧縮を可能にし、メモリ効率に貢献します。また、冗長ビットの除去により、infixの識別能力を高めている。
- infixの長さは目標とする偽陽性率(ϵ)と、サンプリングされたキーの間にあるキーの数(T)の2つの要素によって数学的に決定される。
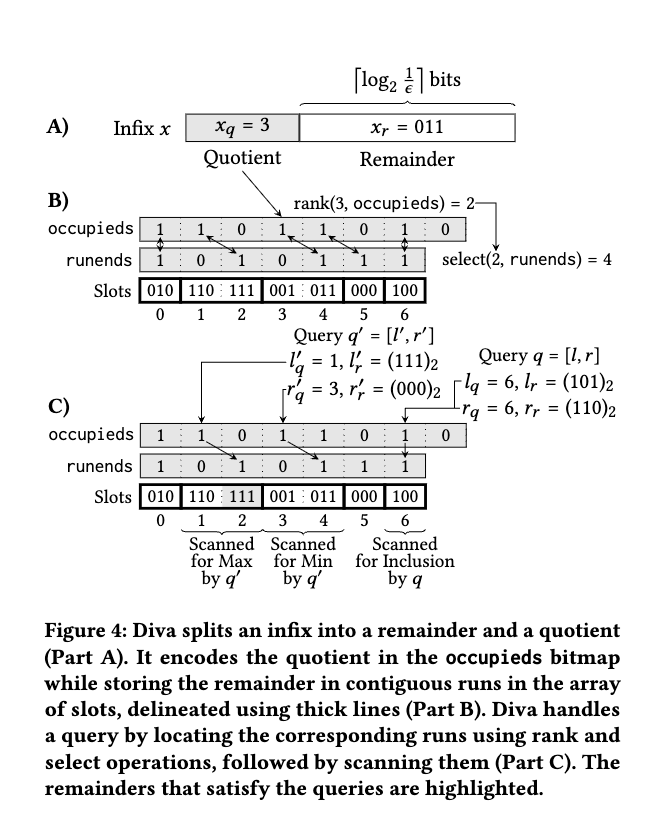
- Infix Store: 抽出されたインフィックスは、定数時間で操作可能な「Infix Store」という動的なデータブロックに格納されます。ここでは、Knuthの商(多倍長除算)を用いて、データを商と余りに分割して効率的に管理し、ビットマップとrank/select操作を駆使して高速な検索を実現する。
- Infixの分割
- Quotient (x_qxqx_qxq): Infixの上位ビット部分。Infixがどの「区画」に属するかを示す。
- Remainder (x_rxrx_rxr): Infixの下位ビット部分。同じQuotientを持つInfix内でさらに詳細な区別を行う。
- 各ビットマップと配列
- 各ビットは特定のQuotientの存在を示す。ビットが1の場合、そのQuotientを持つInfixが少なくとも1つ存在する。
- 図の例では、Quotient 0, 1, 3, 4, 6が存在するため、対応する位置が1になっている。
- Slots配列内の各スロットに対応するビットマップ。 ビットが1の場合、そのスロットがRunの終わりを示す。Runとは、同じQuotientを持つInfixのRemainderが連続して格納されている部分を指す。
- InfixのRemainderが格納される。同じQuotientを持つRemainderは連続したスロットに配置される。
- 図の太線で囲まれた部分が各Runを示している。例えば、Quotient 0のRunはSlots[0]に010を、Quotient 1のRunはSlots[1]に110を、Quotient 3のRunはSlots[3]に001、Slots[4]に011を格納している。
- これらの操作は、occupiedsビットマップとrunendsビットマップを使って、InfixのRunの位置を効率的に特定する。
- 復習
- rank(3, occupieds) = 2:
- occupiedsビットマップのインデックス3までに1が2つ(インデックス0と1の位置)存在することを示す。これは、Quotient 3がoccupiedsビットマップの
- 中で2番目に現れる存在しているQuotientであることを意味する(0-indexed)。
- select(2, runends) = 4: runendsビットマップの2番目の1がインデックス4に存在することを示す。これは、Quotient 3に対応するRunがSlots配列のインデックス4で終わることを意味する。
ちょい長いので時間あればで[toggle]
occupiedsビットマップ:
runendsビットマップ:
Slots配列:
rankとselect操作:
例: Infix xのQuotientが3である場合、
これにより、特定のQuotientを持つInfixのRemainderがSlots配列のどこに格納されているかを高速に特定できる。
実験
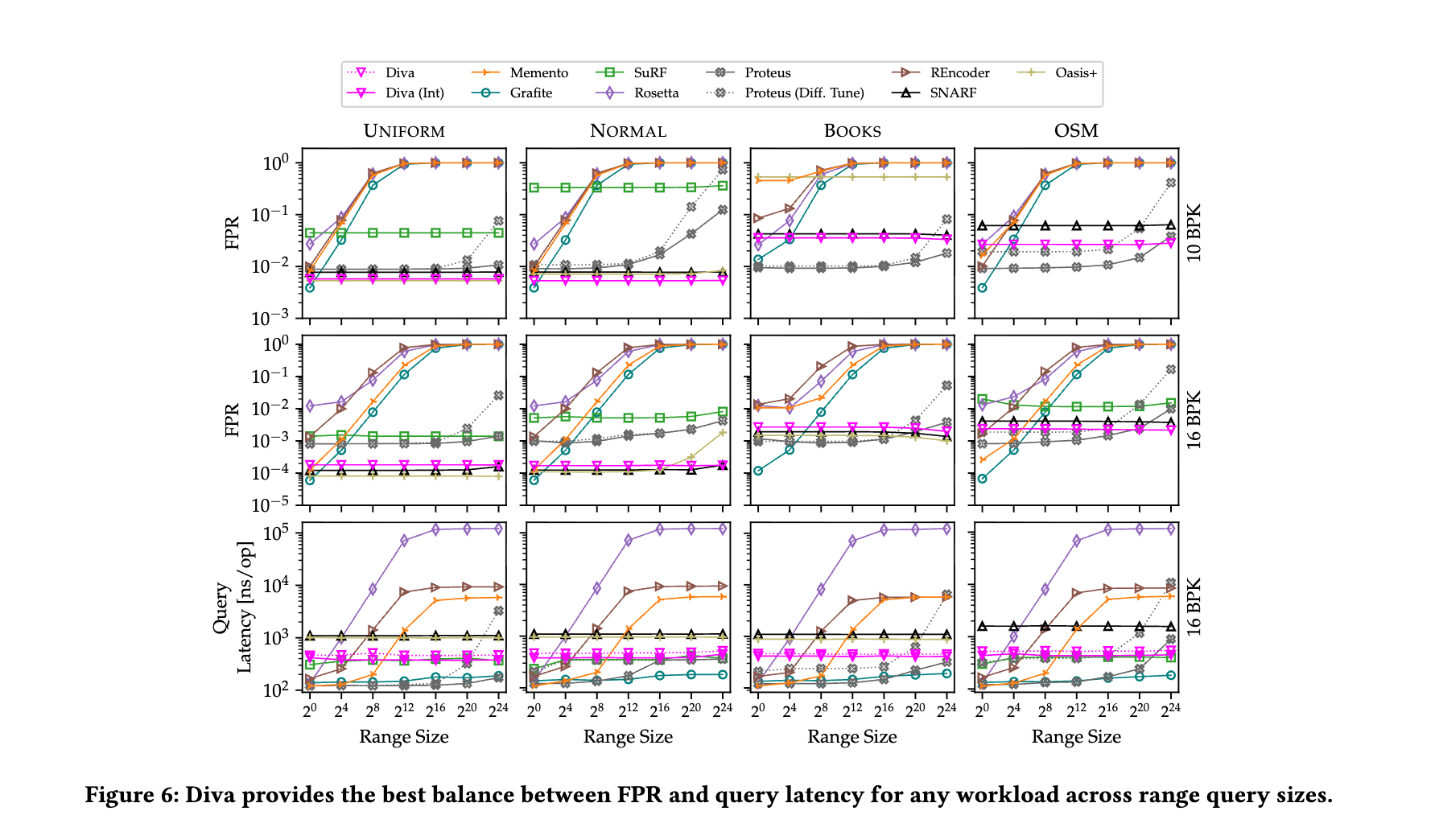
Divaは、可変長キーとクエリをサポートしながら、様々なワークロードとレンジサイズにおいて、低いFPRと高速なクエリレイテンシの両方をバランス良く提供できることをこの図は示している。これは、多くの既存フィルタが一部の目標のみを達成している中で、Divaが「汎用性のある」レンジフィルタとしての優れたバランスを持つことを裏付けている。
そのほか論文では動的操作のサポートなども論じている。
@ShibuiYusuke
[Paper] Deep Research: A Systematic Survey
- Deep Researchに関するSurvey論文。
- 3. Key Components in Deep Research Systemのみピックアップして紹介。
3. Key Components in Deep Research System
Deep Research (DR) システムの概要。
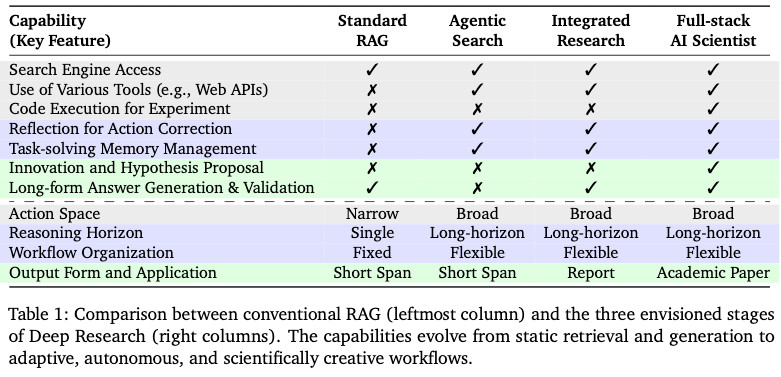
- 複雑なリサーチ課題を入力とし、構造化された回答(長文レポート等)を出力する閉ループのワークフロー。
- 以下の4つの主要コンポーネントが相互に連携して機能。
主要コンポーネント:
- クエリ計画 (Query Planning): 複雑な問題をサブクエリに分解すること。
- 情報収集 (Information Acquisition): 外部知識を検索・フィルタリングすること。
- メモリ管理 (Memory Management): 長期的な文脈を維持・更新すること。
- 回答生成 (Answer Generation): 証拠を統合し、検証可能な回答を作成すること。
3.1 クエリ計画 (Query Planning)
複雑で論理的に入り組んだ質問を、段階的に解決可能な一連のサブクエリ(サブタスク)に変換するプロセス。推論の信頼性と正確性を向上させる効果。
3.1.1 並列計画 (Parallel Planning)
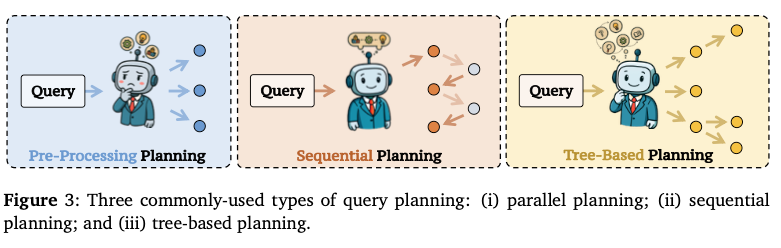
概要
- 元のクエリを一度のパスで複数の独立したサブクエリに分解。
- 下流コンポーネントとの反復的な相互作用は通常なし。
利点
- サブクエリの並列処理による高効率性。
代表的な手法
- Least-to-Most Prompting: 複雑なタスクを単純なサブクエリの順序付きリストに分解する手法。
- COVE: 複数の独立したサブ質問を生成し、並列に証拠を収集・検証する手法。
- Rewrite-Retrieve-Read: 強化学習で最終回答の正確性を最大化するようクエリリライターを訓練する手法。
欠点
- ワンショット実行のため、途中で得られた証拠のフィードバック不可。
- サブクエリ間の依存関係(条件付き独立性の仮定)を無視する傾向。
- 文脈不足により回答不能なサブクエリが生じる可能性。
3.1.2 順次計画 (Sequential Planning)
概要
- クエリを複数の反復ステップで分解。
- 各分解ステップは前ステップの結果に基づく構造。
利点
- 中間結果の取り込みと動的な推論軌道の修正が可能。
- ステップごとの推論や曖昧性解消が必要な複雑タスクに適合。
代表的な手法
- LLatrieval: 取得ドキュメントの検証失敗時に欠落知識を特定し新クエリを生成する反復プロセス。
- Search-R1 / R1-Searcher: LLMの内部推論を活用し、エンドツーエンドの強化学習で順次検索を実行する手法。
欠点
- 推論ターン数増加による計算コストとレイテンシの増大。
- ターン数増加に伴うノイズ蓄積とエラー伝播のリスク。
3.1.3 ツリーベース計画 (Tree-based Planning)
概要
- サブクエリを探索空間内のノードとして扱う方式。
- 木構造や有向非巡回グラフ(DAG)として表現。
- 並列計画と順次計画の特徴を統合したアプローチ。
利点
- モンテカルロ木探索(MCTS)などによる有望な推論パスの探索・剪定。
- 依存関係のあるサブクエリ分解と局所的な並列実行の両立。
代表的な手法
- RAG-Star: MCTSとUCT(Upper Confidence Bound for Trees)による有望ノードの選択・展開とクエリ分解。
- DeepRAG: 二分木探索によるクエリの反復的分解と、パラメータ知識・検索知識の選択決定。
課題
- 堅牢なモジュール訓練の難易度。
- 速度と質のトレードオフ。
- 強化学習における信用割当問題(Credit Assignment)への対処の必要性。
3.2 情報収集 (Information Acquisition)
LLMの内部知識を補強するための外部情報取得。
3.2.1 検索ツール (Retrieval Tools)
テキスト検索
- 字句検索 (Lexical): TF-IDFやBM25など、単語の一致に基づく手法。
- 意味検索 (Semantic): クエリと文書をベクトル化し、意味的な類似度でマッチングする手法(Dense Retrieval)。
- 商用Web検索: GoogleやBingなどのAPIを利用した、リアルタイムでの権威ある情報へのアクセス。WebGPTなどが代表例。
マルチモーダル検索
テキストだけでなく、図、表、チャートなどの視覚情報も検索対象。
- レイアウト解析(LayoutLM等)、画像-テキスト類似度(CLIP等)、構造化データ検索(テーブル解析)の組み合わせ。
- 特定のデータポイント(表のセルやチャートの座標)に基づいた、検証可能な引用(Grounded Citation)の実現。
3.2.2 検索タイミング (Retrieval Timing)
検索実行タイミングの決定(Adaptive Retrieval)。不必要な検索はコスト増やノイズ混入の原因となるため、モデルが「何を知らないか」を認識することが重要。
- 確率ベース戦略: 生成するトークンの確率(自信)が低い場合の検索トリガー。
- 一貫性ベース戦略: 複数の回答を生成し、意味的な整合性が低い場合の検索実行。
- 内部状態プロービング: モデルの隠れ状態(Internal States)を分析し、生成された回答の事実性を予測して検索を判断。
- 言語化戦略: のようなスペシャルトークンを生成するようモデルを訓練し、自律的に検索を要求(例:Self-RAG, Search-R1)。
3.2.3 情報フィルタリング (Information Filtering)
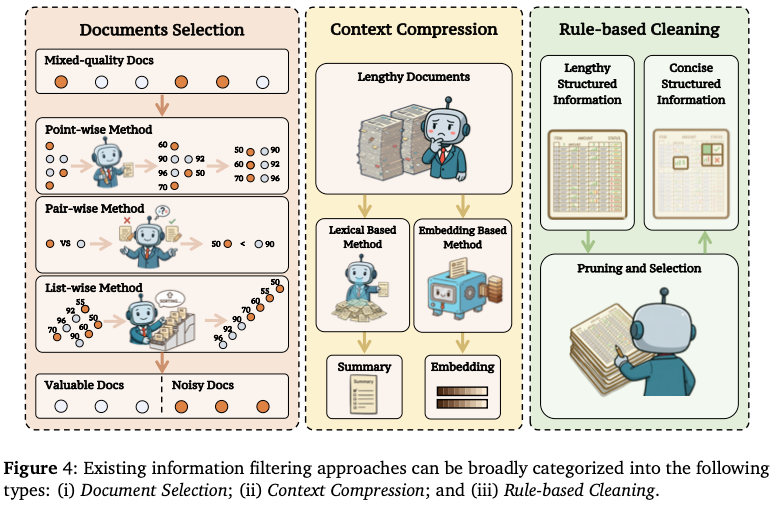
検索された情報からのノイズ除去と、有用な情報のみの選別。
ドキュメント選択
- Point-wise: 各文書を個別にスコアリング(Relevance Score)。
- Pair-wise: 2つの文書を比較してランク付け。
- List-wise: 文書リスト全体を入力し、LLMにランキングを生成(RankGPTなど)。
コンテンツ圧縮
- 字句ベース: LLMを用いた要約生成と、重要なポイントのみの保持。
- 埋め込みベース: 文脈を固定長のベクトル列に圧縮(ICAEなど)。
- ルールベース: HTMLタグやスクリプトなどの構造的ノイズの除去。
3.3 メモリ管理 (Memory Management)
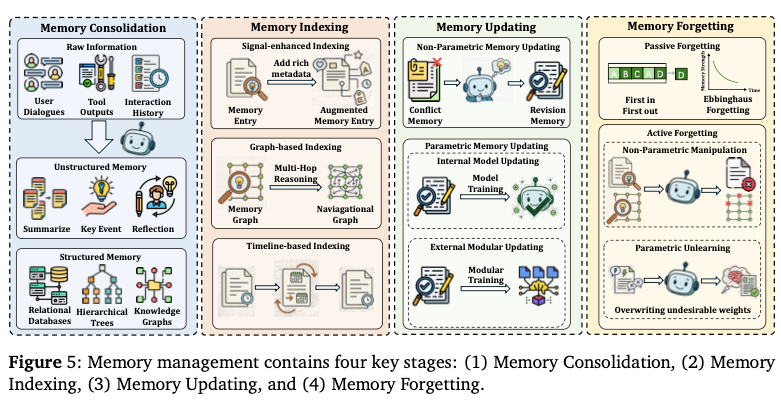
長期的なタスク解決において、首尾一貫したコンテキストを維持するためのライフサイクル管理。
3.3.1 メモリ統合 (Memory Consolidation)
短期的な経験(対話やツール出力)を長期的な表現に変換する手法。
- 非構造化: 長い対話を要約やイベントログとして蒸留する方式(例:MemoryBank, MemoChat)。
- 構造化: 情報をデータベース、グラフ、木構造などに変換し、エンティティ間の複雑な関係を捉える方式(例:HippoRAG, ChatDB)。
3.3.2 メモリインデックス (Memory Indexing)
統合されたメモリに対して、効率的な検索のためのナビゲーションマップ(インデックス)を構築する手法。
- シグナル強化: 感情やトピックなどのメタデータを付与する方式。
- グラフベース: メモリをノード、関係をエッジとして表現し、マルチホップ推論を可能にする方式。
- タイムラインベース: 時系列や因果関係に沿ってメモリを配置し、文脈の進行を理解しやすくする方式。
3.3.3 メモリ更新 (Memory Updating)
新しい情報に基づいて既存の知識を修正する手法。
- 非パラメトリック更新: 外部データベースに対して、矛盾の解消(Conflict Updating)や自己反省による修正(Self-Reflection Updating)などの操作を行う方式(ADD, UPDATE, MERGEコマンド等)。
- パラメトリック更新: モデルの重み自体を更新する方式。再学習(Global Updating)や特定知識の編集(Localized Updating)、あるいは専用の軽量モジュールを追加する手法(Modular Updating)。
3.3.4 メモリ忘却 (Memory Forgetting)
古くなったり無関係になった情報を削除する手法。
- 受動的忘却: FIFO(先入れ先出し)キューや、エビングハウスの忘却曲線のような減衰モデルを使用する方式。
- 能動的忘却: 矛盾や誤りを検知した際に、明示的なDELETEコマンドやパラメータのアンラーニング(Unlearning)を実行する方式。
3.4 回答生成 (Answer Generation)
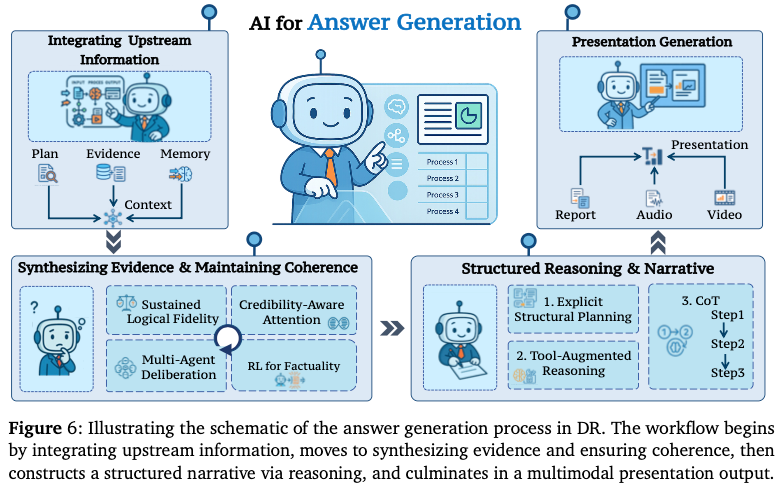
上流コンポーネントからの情報統合と最終的な回答生成。
3.4.1 上流情報の統合
- 基本的な統合: クエリ計画、検索された証拠、メモリ状態の統合。
- Stateful Query Planning: 計画とメモリを密結合させ、自己修正を行いながら生成を進める手法。
3.4.2 証拠の合成と一貫性の維持
矛盾する証拠の解決:
- 信頼度認識アテンション: 情報源の信頼性に基づく重み付け。
- マルチエージェント討議: 複数のエージェントによる異なる視点からの証拠分析と合意形成。
- 事実性のための強化学習: 証拠に裏付けられた発言への報酬付与とハルシネーション抑制。
長文の一貫性:
- SFTや適応的な報酬関数を用いた情報密度と一貫性の管理により、長いレポートでも論理的な流れを維持。
3.4.3 推論と物語の構造化
回答の背後にある推論プロセスの明示。
- Chain-of-Thought (CoT): 中間的な推論ステップ生成後の最終回答出力。
- 明示的な構造計画: アウトライン作成後の執筆、または計画に基づく非線形な議論展開。
3.4.4 プレゼンテーション生成 (Presentation Generation)
テキスト生成を超えたマルチモーダル出力への進化。
- マルチモーダル統合: 視覚データ(チャート、表)の統合や音声ナレーションの生成。
- スライド生成: 論文やレポートからテキスト・図・レイアウトを含むプレゼンテーションスライド(PPT)の自動生成システム(PPTAgentなど)。
@Akira Manda(zunda)
[paper]Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
1. 背景・課題感
なぜ本研究が必要なのか
近年のDeep ResearchエージェントはWeb上のテキスト情報処理には長けているが、科学論文、技術レポート、金融資料といった専門的なマルチモーダル文書(PDF等)の処理には課題がある
既存のシステム(MDocAgentやM3DocRAGなど)には、主に以下の3つの制約が存在している
- 解析(Parsing)の精度不足: 単純なOCRではレイアウト構造が失われ、図表と本文の関連性が断絶する。一方で、文書を単なる画像(スクリーンショット)として扱う手法では、細粒度な情報の特定や抽出が困難
- 検索戦略の柔軟性欠如: 多くのシステムは「チャンク」や「ページ」といった固定された粒度でしか検索を行えない。人間のように「まずは要約で全体像を把握し、その後に特定の図表を詳細に調べる」といった柔軟な戦略が取れなかった。
- 反復的な調査プロセスの不在: 既存のRAGシステムの多くは、1回の検索と生成で完結するシングルターン形式。複雑な問いに対して証拠を段階的に積み上げ、論理を構築する「Deep Research」のワークフローが確立されていなかった。
2. 本研究の貢献
本研究が達成したこと
本研究は、Web検索に限られていたDeep Researchの概念を拡張し、ローカルのマルチモーダル文書コレクションに対して適用可能な統合システムを提案。主な貢献は以下の通り。
- Deep Multimodal Parsingの確立: 文書をテキストや画像単体としてではなく、レイアウト構造と視覚的意味を保持した「マルチ粒度表現」として解析・保存するフレームワークを構築
- 適応的な検索アーキテクチャの実装: クエリの性質に応じて、検索対象とするモダリティ(テキスト/画像/ハイブリッド)や粒度(要約/全文/ページ/チャンク)を動的に選択する仕組みを導入
- エージェントによる反復ワークフロー: 計画、検索、評価、再検索というサイクルを回すことで、既存の最先端モデルと比較して3.4倍の精度向上を実現
- 評価基盤(M4DocBench)の構築: マルチモーダル、マルチホップ、マルチドキュメント、マルチターンという4つの要素を兼ね備えた、実用的なリサーチタスク評価のためのベンチマークを公開
3. 提案手法:Doc-Researcherの詳細
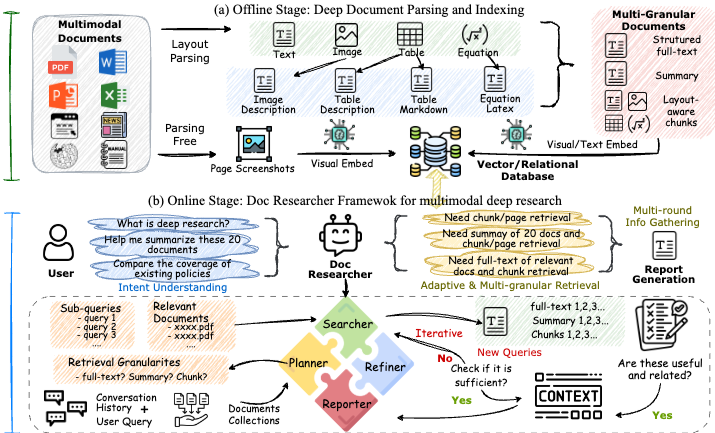
システム構成
本システムは、「オフラインでの解析・インデックス構築」と「オンラインでのDeep Research実行」の2段階で構成される。
Phase 1: Deep Multimodal Parsing & Indexing(解析・インデックス化)
文書の構造と意味を保持するため、以下の処理を行う。
- Layout-Aware Parsing: 解析ツール「MinerU」を使用し、テキストだけでなく、図、表、数式のバウンディングボックス(位置情報)と種別を特定する。
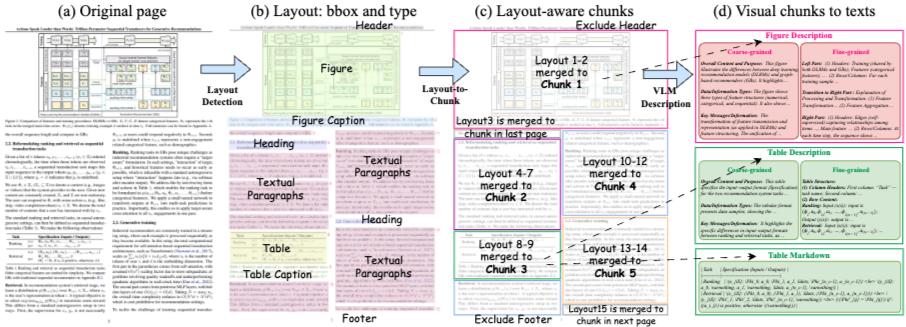
- マルチモーダル要素の変換: 検索性を高めるため、視覚要素をテキスト情報へ変換する。
- 図・表: VLM (Qwen2.5-VL) を用いて、文脈理解用の「要約」と詳細な「記述」を生成
- 数式: 画像からLaTeX形式へ変換
- マルチ粒度チャンキング (Multi-granular Chunking): 検索エージェントが状況に応じて使い分けられるよう、以下の4つのレベルで文書を表現・保存する。
- Chunk: レイアウト解析に基づき、意味的に結合されたテキストおよび画像ブロック
- Page: ページ全体のスクリーンショットおよびテキスト(視覚的文脈の保持用)
- Full-text: 構造化された文書全文
- Summary: LLMによって生成された文書全体の要約
Phase 2: Multimodal Deep Research(リサーチ実行)
LangGraphを用いたマルチエージェントワークフローにより、回答を生成する。
Agent 1: Planner(計画立案)
クエリと対話履歴を分析し、計算効率と検索精度を最適化する。
- Document Filtering: クエリと「文書要約」を照合し、無関係な文書を検索対象から除外(検索空間を60-80%削減)
- Granularity Selection: 質問のタイプに基づき、最適な検索粒度(Summary/Chunk等)を決定
- Sub-query Decomposition: 複雑な質問を、具体的な検索実行用のサブクエリ群に分解
Agent 2: Iterative Search-Refine Loop(反復検索・精緻化)
情報の十分性を満たすまで、以下のループを実行する。
- Hybrid Retrieval: テキスト埋め込みと視覚埋め込み(画像チャンクのベクトル化)を組み合わせたハイブリッド検索を実行し、候補を取得
- Refine: 取得した候補から、LLMが関連性の低い情報をフィルタリング・重複排除
- Evaluate: 現在の証拠で質問に回答可能か(十分性)を評価
- 不十分な場合:新たなサブクエリを生成し、次回の検索ループへ移行
- 十分な場合:ループを終了し、レポーターへ情報を渡す
Agent 3: Reporter(回答生成)
- 収集された証拠(テキストおよび視覚情報)を統合し、回答を生成する。
- 回答中の根拠部分には、文書のページIDやバウンディングボックスに基づいた引用(multimodal citations)を付与し、検証可能性を担保する。
4. 実験結果・評価
新たに構築されたM4DocBench(158の質問、304の文書で構成)を用いた評価結果
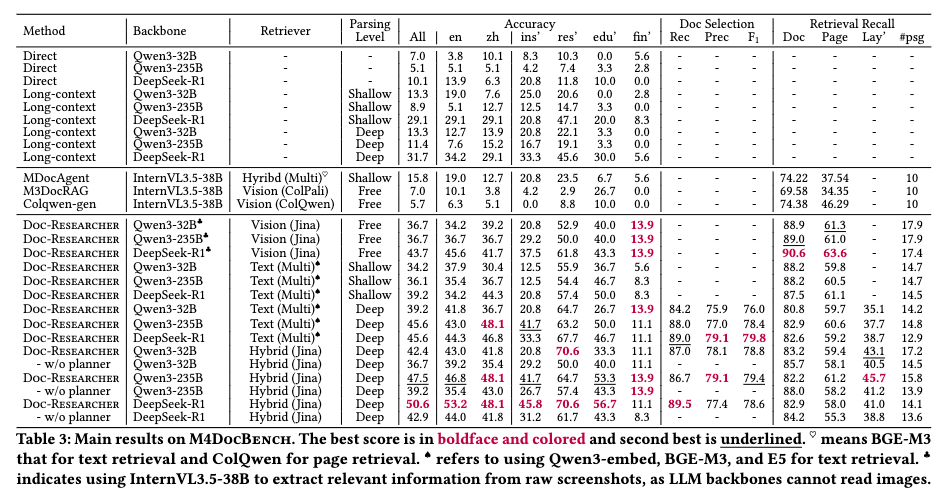
- 総合精度の向上: Doc-Researcherは**50.6%**の正解率を達成しました。これは、既存のSOTAモデルであるMDocAgent(15.8%)や、単純なLong-context入力(9〜31%程度)を大きく上回る結果
- Parsing手法の比較: Deep Parsing(提案手法:レイアウト構造保持)を用いた場合、Shallow Parsing(単純なOCR)と比較して精度が11.4%向上しました。また、Parsing-free(画像のみ処理)の手法と比較しても高い精度を示した。
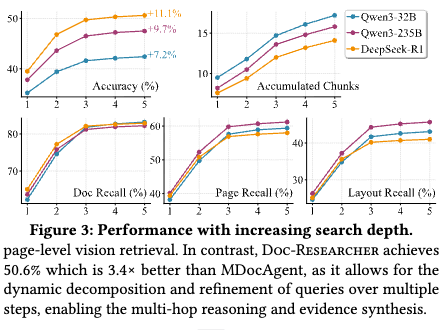
- 反復検索(Iterative Loop)の効果: 検索ループを1回(ターン1)から5回(ターン5)まで増やす過程で、回答精度が7.2%〜11.1%向上することが確認されました(使用するLLMにより変動)。特に最初の3ターンでの精度向上が顕著であり、反復的な証拠収集の有効性が実証された。
- ハイブリッド検索の優位性: テキスト検索のみ、あるいは画像検索のみの構成と比較し、両者を組み合わせたハイブリッド検索が最も高いリコール(再現率)と回答精度を記録した。
@Shuhei Nakano(nanay)
[blog] The AI Evolution of Graph Search at Netflix: From Structured Queries to Natural Language
これは何?
NetflixのGraph Search プラットフォームに自然言語検索機能を追加。LLMを活用してユーザーの日常言語をGraph Search Filter DSLに変換。
課題: ユーザーは「90年代のロボット映画でアメリカ製のもの」と自然言語で検索したいが、既存システムは複雑なDSL(Domain Specific Language)を必要としていた。
3つの主要課題
1. ユーザー体験の断片化
各アプリケーションが独自のUI部品を持ち、ユーザー体験が異なる。DSLのサポートも一貫性がない。ユーザーは各アプリの使い方を「学習」する必要がある。
2. SMEのボトルネック
専門家は何をしたいか正確にわかっているのに、大規模なUIフォームの記入と質問の翻訳という非効率なプロセスがボトルネックになる。
3. コンテキストスイッチングの摩擦
ユーザーは自然言語で考え行動する。クエリビルダーやDSLのような技術的構造物ではない。コンテキストスイッチを強いることで摩擦が生じ、進捗が遅くなる、または妨げられる。
Text-to-Query アーキテクチャ
正確性の3つの次元
1. 構文的正確性(Syntactic Correctness)
- パースできるか?
- DSLの文法に従っているか?
2. 意味的正確性(Semantic Correctness)
- フィールドタイプを尊重しているか?
- 実際に存在するフィールドのみ使用しているか?
- 制約された値のみを使用しているか?
3. 実用的正確性(Pragmatic Correctness)
- ユーザーの意図を本当に捉えているか?
- 最も困難な課題
コンテキストエンジニアリング(RAGパターン)
Field RAG
課題: 一部のインデックスには数百のフィールドがあるが、ユーザーの質問は通常数個のフィールドしか参照しない。すべてを含めるとレイテンシ増加と正確性低下。
解決策:
- インデックスフィールドとメタデータの埋め込みをベクトルストアに作成
- ユーザーの質問をチャンキング
- ベクトル検索で上位K個の関連フィールドを特定
- 重複排除してコンテキストに提供
Controlled Vocabularies RAG
課題: 一部のフィールドは制御された語彙(国名など)に制限される。数千の値を持つ場合もあり、すべてを提供するとコンテキストが爆発。提供しないとLLMが存在しない値を幻覚する。
解決策:
- 制御語彙の値とメタデータの埋め込みを作成
- ユーザーの質問に対してベクトル検索
- 関連する上位K個の値を特定
- 制御語彙タイプごとに重複排除
すべてのメタデータをコンテキストとして提供するナイーブな方法は単純なケースでは機能したがスケールしなかった。一部のインデックスには数百のフィールド、一部の制御語彙には数千の有効値がある。
バリデーションと信頼構築
構文バリデーション
- AST(抽象構文木)パーサーで検証
- パース失敗 = クエリが不正
意味バリデーション
- LLMがハルシネーションしたフィールドや値を検出
- インデックスメタデータと照合
- エラー返却 or フィードバックループで自己修正
実用的正確性への対応
1. Show Our Work
生成されたフィルターをユーザーフレンドリーな方法でUIに可視化。返している答えが探しているものか明確に見えるようにして、結果を信頼できるようにする。
- 生成されたDSLをASTに変換
- ASTを既存のUI部品(Chips、Facets)にマッピング
- ユーザーはハルシネーションフィードバックを即座に得られる
2. @mentions による明示的エンティティ選択
ユーザーに「@mentions」を使って既知のエンティティを参照する能力を提供。Slackと同様、@を入力すると直接エンティティを検索できる。
- 曖昧性を除去
- RAG推論ステップをバイパス
- 実用的正確性を大幅に向上
エンドツーエンド アーキテクチャ
プロセス
- 前処理: ユーザーの質問と@mentionsを入力
- RAGパターン: フィールドと値でコンテキストをスコープ
- LLM生成: 構文的・意味的に正確なフィルター文を生成
- 検証: DSLを検証し幻覚をチェック
- 出力: ASTを含む最終レスポンス
Take Home Message
アプローチの本質
バランスの取れた設計
LLMの関与と決定論的戦略を戦略的にバランス。RAGパターンでコンテキストを最適化し、バリデーションで正確性を保証。
3つの正確性次元
- 構文的正確性: パーサーで検証可能
- 意味的正確性: メタデータ検証で対応
- 実用的正確性: 可視化と明示的選択で信頼構築
@Kyohei Uto(kuto)
[paper]τ 2-Bench: Evaluating Conversational Agents in a Dual-Control Environment
エージェントのシミュレーション環境に興味があり読んだ
初回投稿日: 2025年6月9日
1. どんなもの?
- 会話型AIエージェントを評価するためのベンチマーク「 -bench」を提案
- エージェントとユーザーの双方がツールを使用する「デュアルコントロール」環境
- Telecom(通信)、Airline(航空)、Retail(小売)3つのドメインタスクがあるがTelecomメインで紹介
- Telecomはスマホの技術サポートなどの課題を解決するタスク。エージェントには効果的な推論に加え、ユーザーの行動を適切に導き、連携や調整を行う能力が求められる
- なおここでいうユーザはLLMによるシミュレータを指す
- ↓のようにユーザもエージェントの指示に従って「スマホのステータスバー情報を確認する」といったツールアクションを行うのが特徴
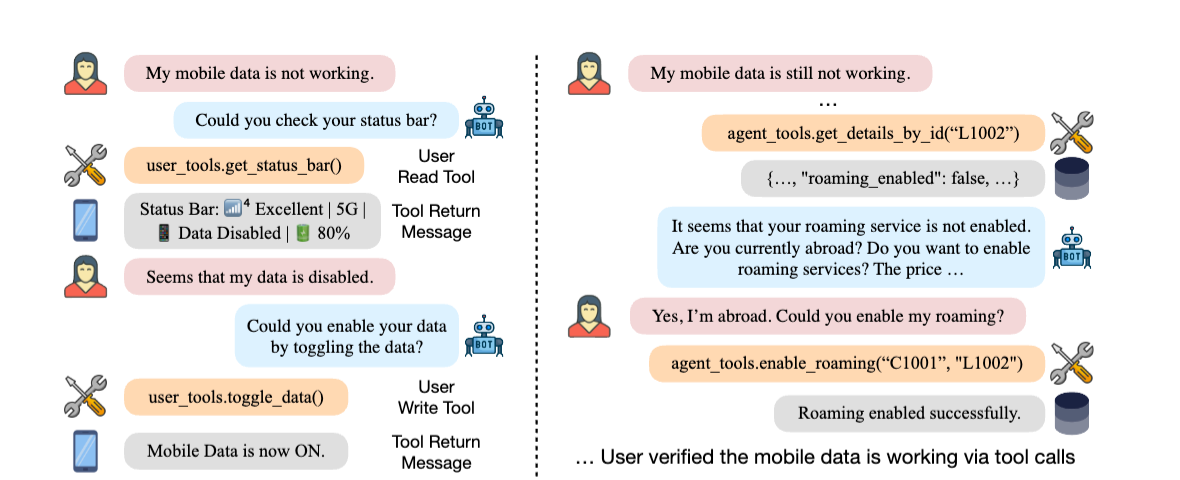
2. 先行研究と比べてどこがすごいの?
- 既存のベンチマーク(tau-benchなど)はユーザは情報提供のみでエージェントのみが行動(ツール利用)を行う「シングルコントロール」環境である
- 現実のタスクはユーザーとの双方向のアクションや連携が必要であることが多くより実践的なエージェントのベンチマーク設計となってる
3. 技術や手法の"キモ"はどこにある?
Dec-POMDP(分散部分観測マルコフ決定過程)による定式化
- 部分観測→エージェントはすべての情報にアクセスできず、ユーザに適切に指示して情報をもらう必要がある
- 分散制御→エージェントとユーザ、双方のアクションが環境を変化させる(ex; エージェントがユーザに指示して電源をOFFにする)
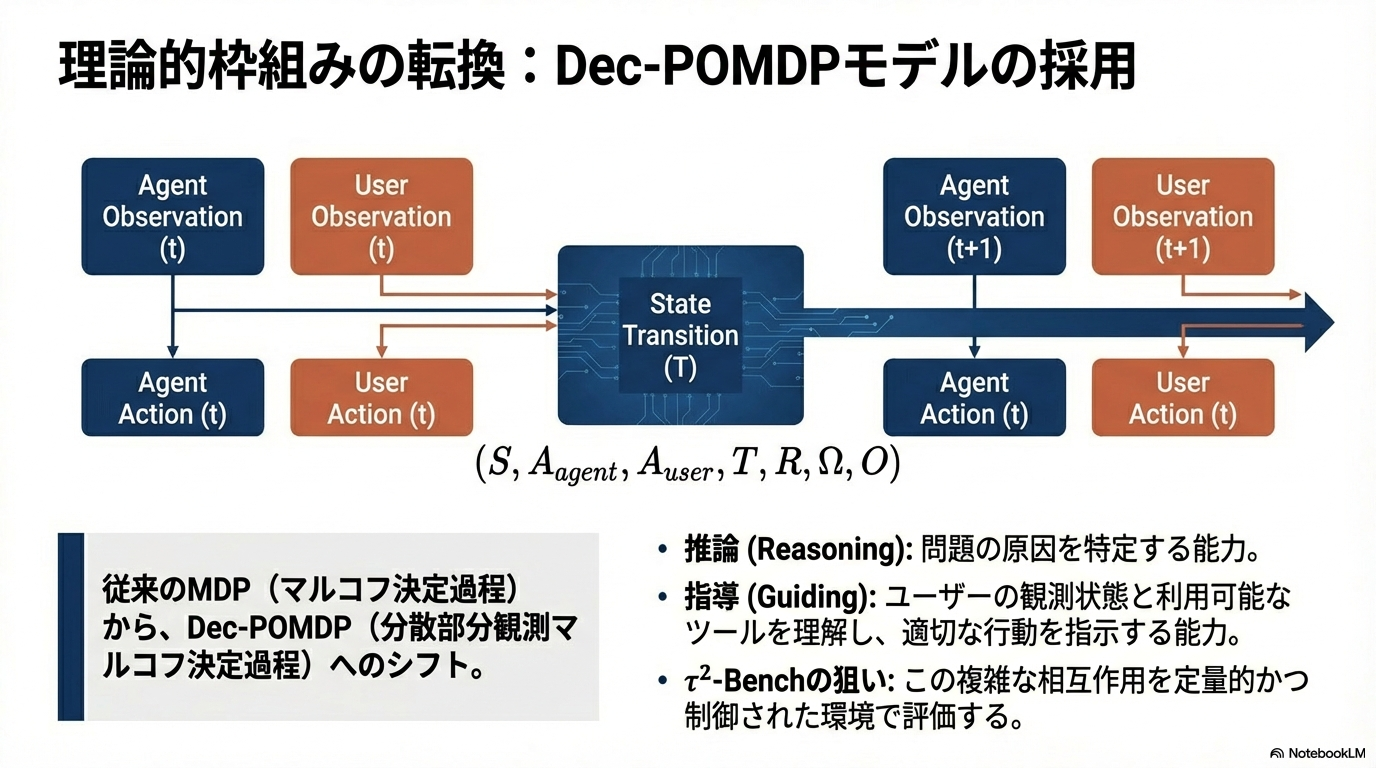
プログラムによるタスク生成と検証
- ドメイン内でのタスクは「初期化関数」「解決関数(ツール呼び出し)」「アサーション関数(成功判定)」の3つの組み合わせで生成される
- これにより、タスクの正当性が保証され、複雑さを制御しながら大量のシナリオを作成可能
LLMをユーザシミュレータとして利用
- プロンプトを与えてLLMをユーザとして振る舞わせる
- ただし自由な行動ではなくエージェントのようにツール実行能力を持たせることで行動を制限してる
- これによりユーザーが不可能な操作を行ったり矛盾する情報を話したりすることを防ぎ、プロンプトエンジニアリングへの依存を減らしている
4. どうやって有効だと検証した?
- 論文中ではGPT-4.1, o4-mini, Claude 3.7 Sonnetなどの当時のSOTAモデルを用いて評価を実施
- エージェントのみ行動する場合と、エージェントとユーザーが相互に行動する場合とでタスク成功率(pass^1)が約20%低下することが判明
- 現在のモデルにとって「推論」そのものよりも「コミュニケーションと調整」が大きなボトルネックであることを示唆している
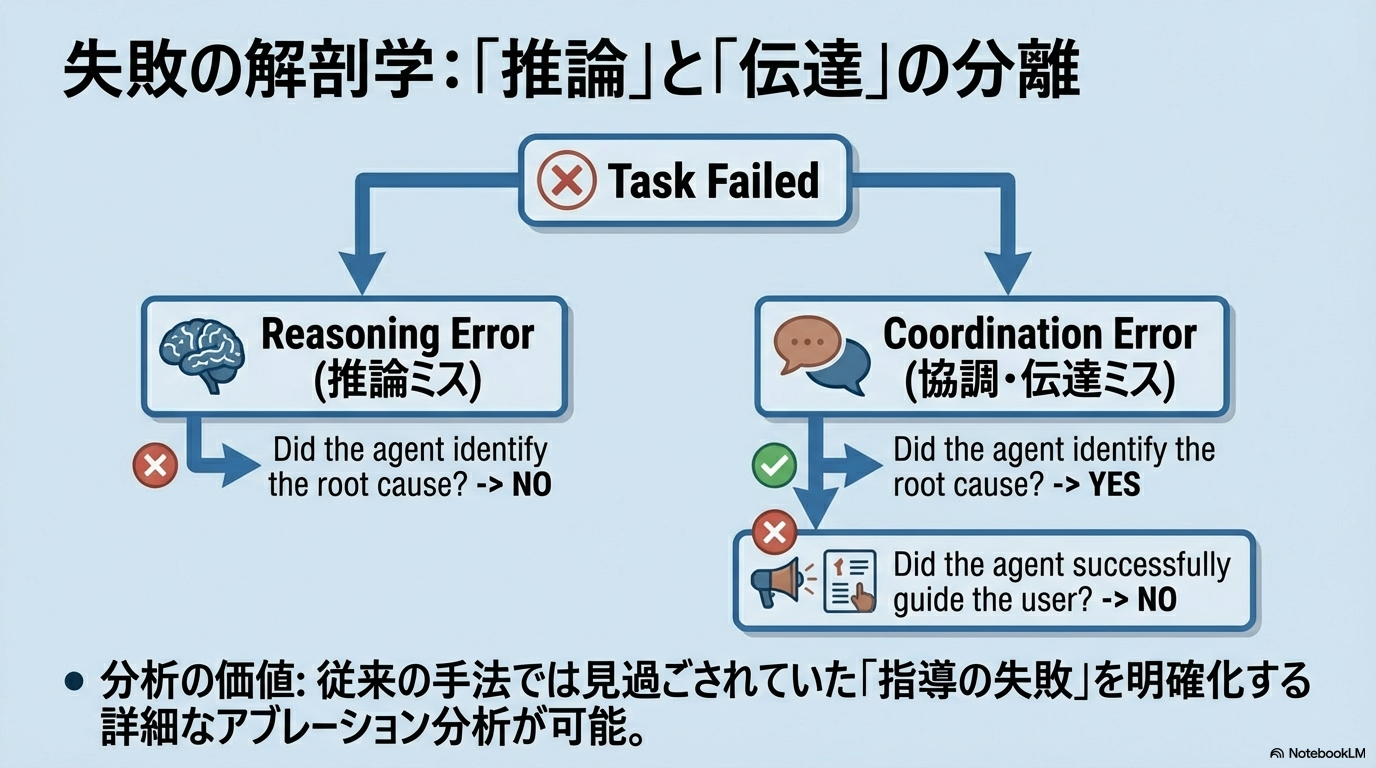
補足
- 2026/01現時点でも最新のモデルのエージェントベンチマークとして利用されている
- Gymnasium(従来のRLで環境に利用されているライブラリ)互換の環境であり、カスタム環境を作ることも可能
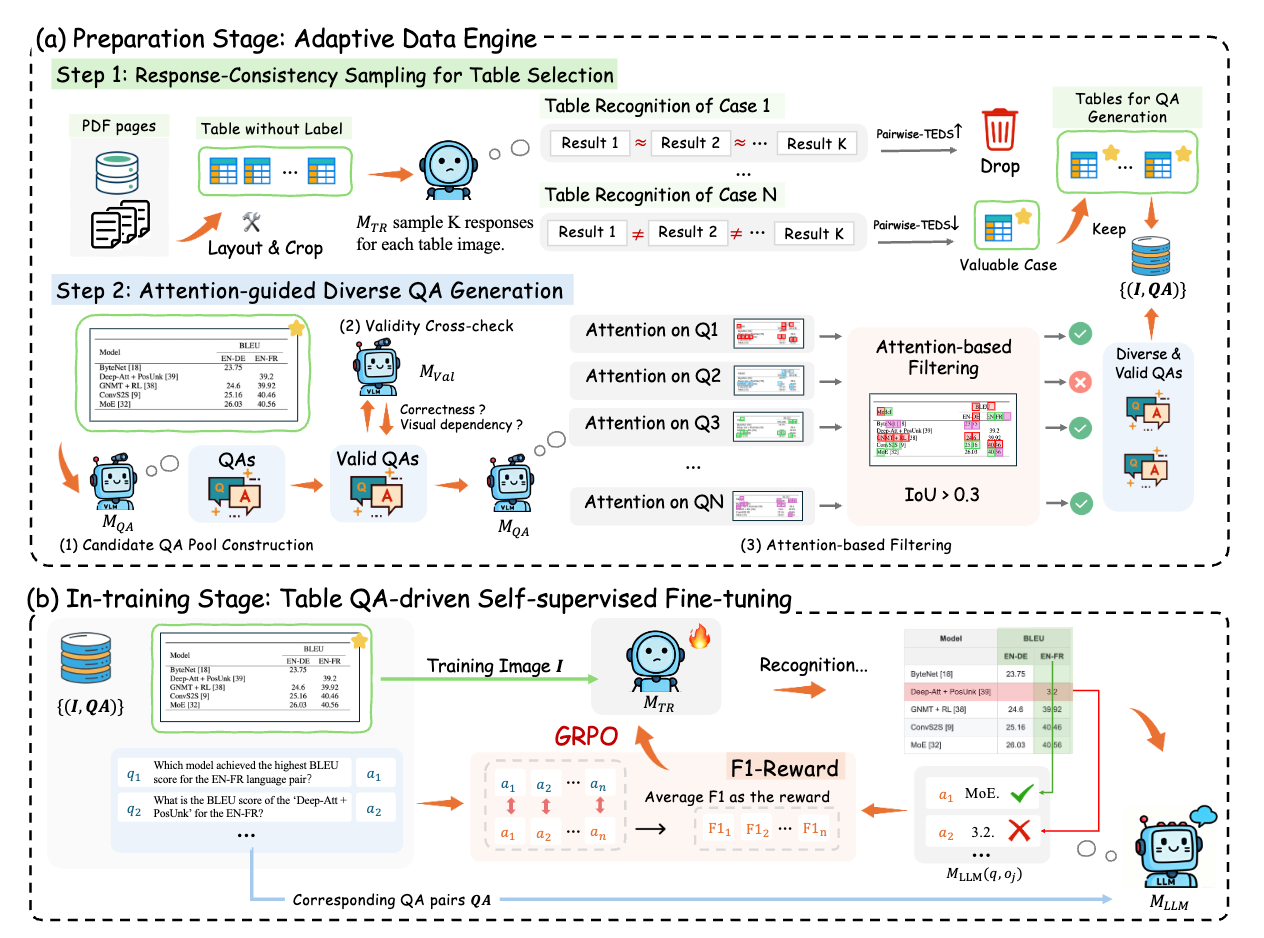
メインTOPIC:TRivia: Self-supervised Fine-tuning of Vision-Language Models for Table Recognition
| タイトル | TRivia: Self-supervised Fine-tuning of Vision-Language Models for Table Recognition |
|---|---|
| 著者 | Junyuan Zhang, Bin Wang, Qintong Zhang, Fan Wu, Zichen Wen, Jialin Lu, Junjie Shan, Ziqi Zhao, Shuya Yang, Ziling Wang, Ziyang Miao, Huaping Zhong, Yuhang Zang, Xiaoyi Dong, Ka-Ho Chow, Conghui He |
| 所属 | The University of Hong Kong, Shanghai AI Laboratory, Peking University, Shanghai Jiaotong University, Sensetime |
| arXiv | 2512.01248 |
| GitHub | opendatalab/TRivia |
概要
ラベルなしの表画像を使って学習できる自己教師ありFine-tuning(FT)フレームワークTRiviaを提案。
質疑応答ベースの報酬メカニズムとGRPOを組み合わせたVLMのFTを行う。
背景
- クローズドモデル(Geminiなど)
- 多くのデータを使って学習されているが、非公開
- オープンモデル
- 透明性は高いが、大量のデータで学習できていない(既存のデータセットのリソースが限られている)
→オープンモデルのデータ拡充が求められる
データを増やす既存アプローチとその課題
| アプローチ | 課題 |
|---|---|
| 合成データ | 視覚的多様性に欠け、実世界分布との乖離がある |
| 手動アノテーション | 高コストで時間がかかる |
| クローズドモデル(Geminiなど)からの蒸留 | 教師モデルの性能上限に制約される |
| クローズドモデルのAPI | プライバシー懸念、オフライン利用不可 |
提案手法:TRivia
TRiviaでは、テーブルのQAタスクを行うことで自己教師あり学習を可能にしている
全体
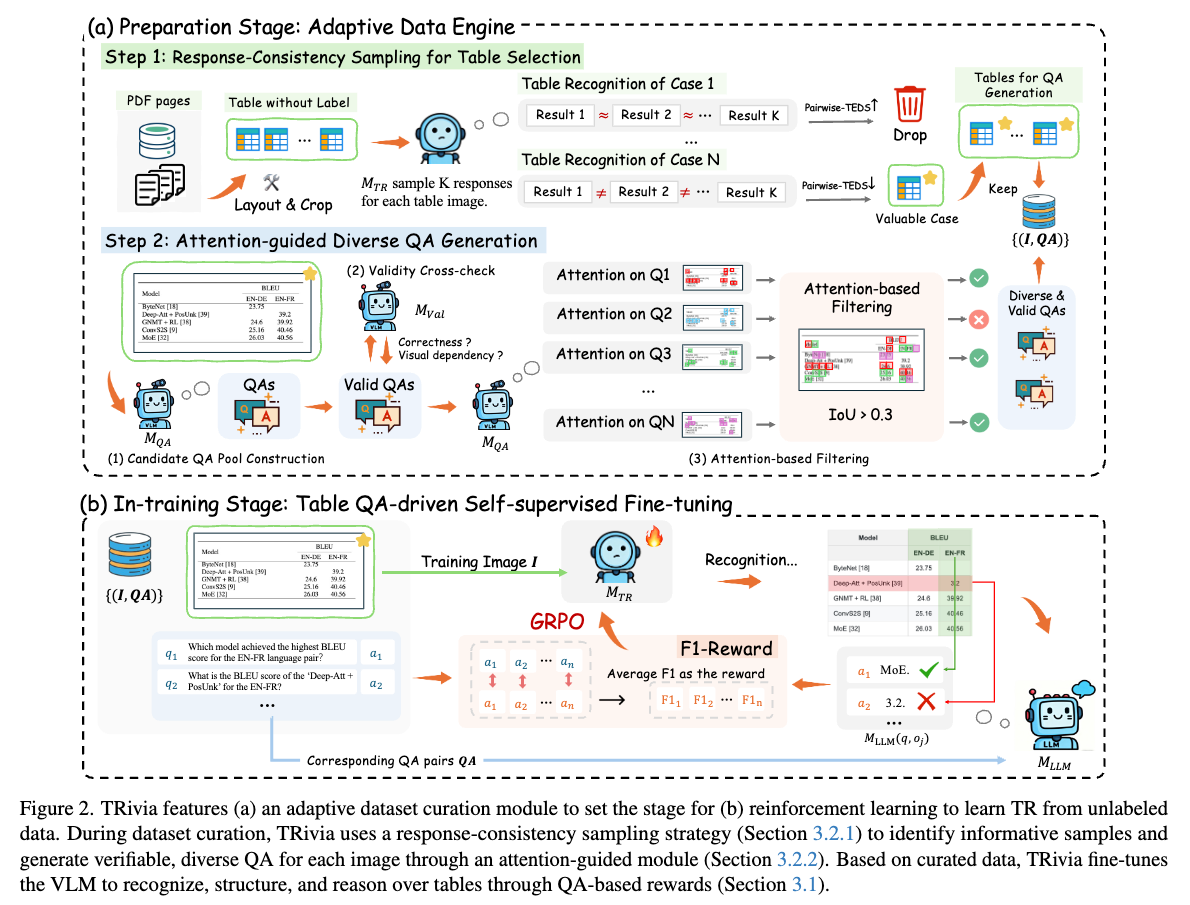
全体上は上図。以下の2段階で学習
- ラベルなし表画像からGTを準備する
- 半教師あり学習
Table QA-driven自己教師ありファインチューニング
強化学習(GRPO)を利用して、自己教師あり学習を行う。
表のQAタスク(Table QA)をアノテーション不要の報酬を提供するための代替タスクとして行う。
つまり、表に関しての質問に正しく答えられるように学習する。
モチベーション
- 完全なHTMLマークアップを予測するよりも、有効なQAタスクを生成するほうがはるかに簡単
- モデルは列や行の結合(colspanやrowspan)を予測しなくても良い
- QAタスクの正当性は追加のモデルを使ってクロスチェックできる
- 一方で、HTMLを使う場合には不可能
Table QA-driven GRPO
各トレーニングサンプルは として表す( )。
※ からQAを生成するのは後述
- TRモデルがポリシーとして機能し、各画像 に対してR個の認識応答グループ を生成する。
- [fr] oは表画像から認識できた要素ということっぽい
- 認識された表に基づいて回答するが、それらの質問qと出力された応答oを受け取り、回答を生成
- 予測された回答と正解とのF1スコアを計算し、 に対する全体的な報酬はこれの平均になる。
また、無効な認識結果(構文エラー、繰り返し出力など)を除外している。
学習データの生成
学習に有効なデータのサンプリング
多様なモデル応答を引き出すサンプルを生成するために、各表画像に対して複数の認識結果をサンプリング。
それをTEDS(TEDS=Tree Edit Distance-based Similarity)を使って、構造的な類似性を計算。
下記はK個の認識結果がある時、各認識結果の要素同士をペアごとに計算している式。
このスコアが低い→認識結果の多様性が高く、モデルの不確実性が高い→GRPOにとってより価値のあるサンプル
アテンションに基づく多様なQA生成
↓のような良いQAセットを作りたい
- 各画像のQAセットは、異なる表領域をカバーしている
- その正当性が検証可能である
VLMにQAペアを生成させるプロンプトを与える(=ナイーブなアプローチ)では、表の一部しかカバーされないことが多い(下図の左2つ)。
TRiviaでは、アテンションに基づいてQAを生成することで、この問題を解決。
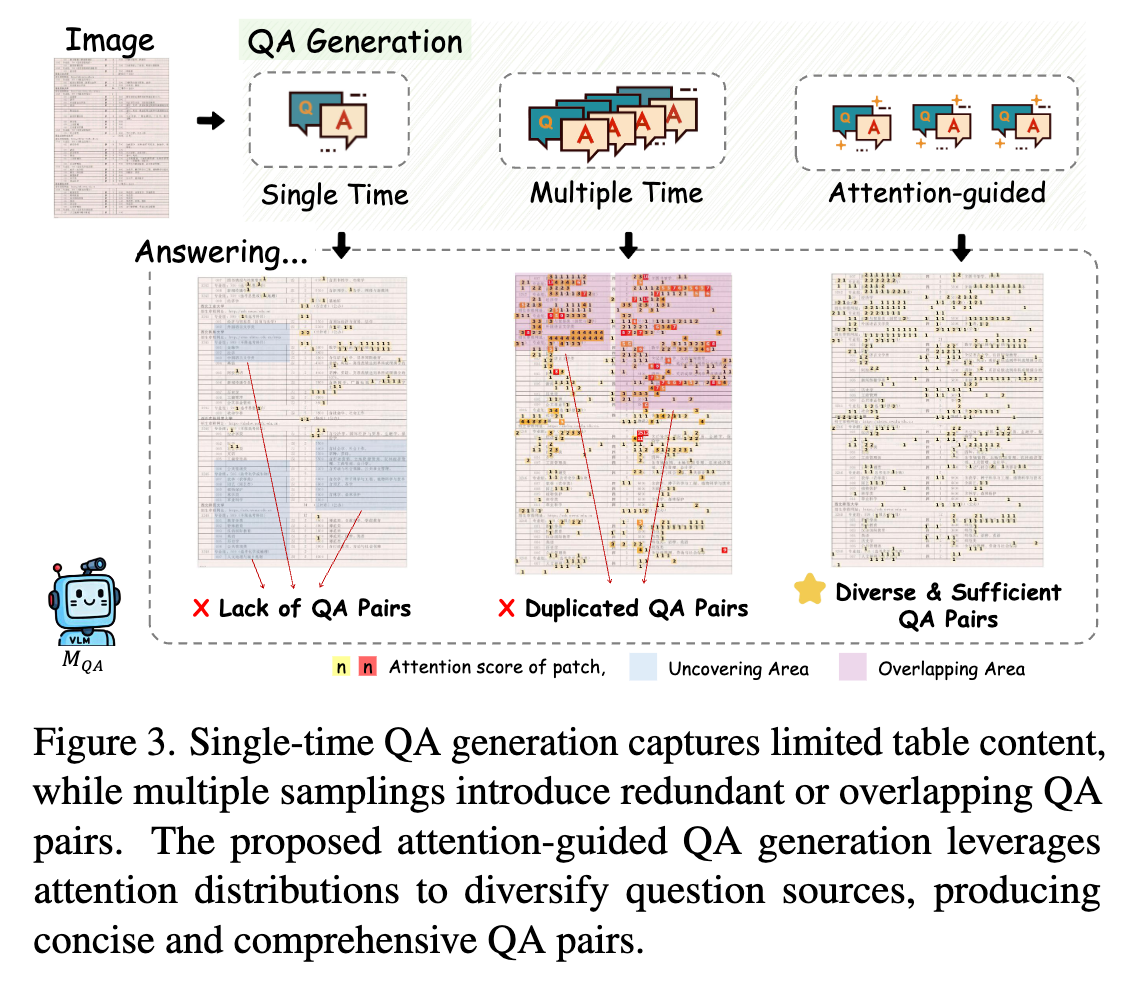
やっていることは、QA生成モデル によって生成されたQAペアについて、その視覚的なソース(Visual Source)を視覚トークンのセットとして抽出する。
式の説明=あるしきい値 以上のアテンションスコアを持つ視覚トークンのセット
貪欲(greedy)に選んでいくらしい。
データの生成プロセスのまとめ
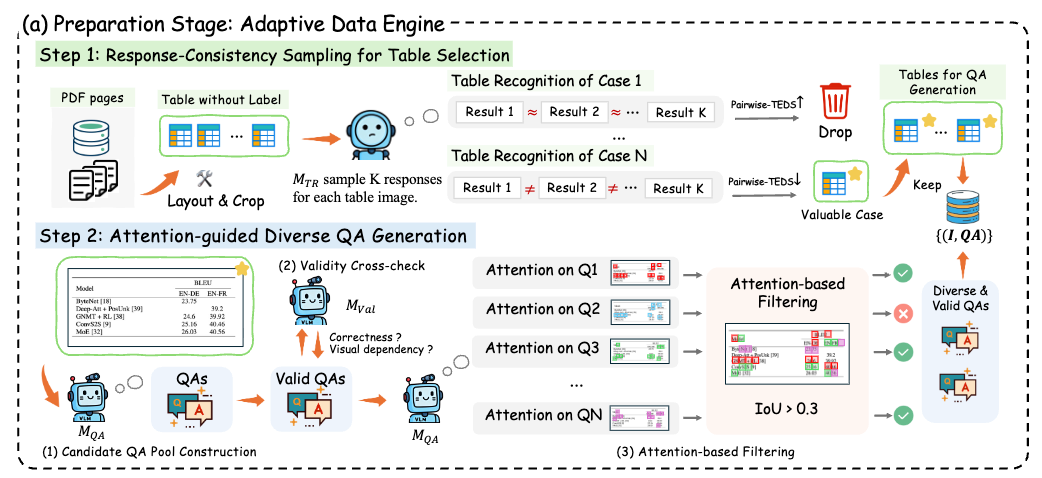
- 候補QAプールを構築 画像 が与えられると、QA生成(教師)モデル が複数回プロンプトされ、候補QAペアのプール を生成
- 正当性のクロスチェック(説明なかったけど) 各候補ペアは、外部 VLM によって視覚的依存性と正しさをクロスチェックされます。具体的には、画像があれば正しく回答できるが、画像なしでは回答できないペアのみを保持
- アテンションガイド付きのQA選択 広範な表のカバレッジを確保するために、視覚的ソースの重複が最小限である有効なペアを貪欲法(greedy)で選択
TRivia-3B
Qwen2.5-VL-3B-Instructをファインチューニングして、TRivia-3Bを作成。
3段階で学習
| Stage | やること | データ規模 | データセット | 特徴 |
|---|---|---|---|---|
| Stage 1 | OTSL Warm-up (OTSLへの順応) | 70万サンプル | PubTabNet, SynthTabNet, MMTab | 視覚エンコーダとアライメントモジュールは凍結 |
| Stage 2 | Supervised Fine-tuning (実画像で学習) | 5万サンプル | * WTW-Dataset * A large-scale dataset for end-to-end table recognition in the wild * SEMv2 * Webからキュレーション | 全パラメータ更新 |
| Stage 3 | TRiviaの提案部分 | 10万サンプル(ラベルなし) | WebからPDFを収集 | QAベース自己教師あり |
Stage 3の設定
- Doclayout-YOLOを利用してレイアウト検出を行い、表をクロップして10万サンプルの表画像を抽出している
- Qwen2.5-VL-72B-InstructでQAペアを生成
- QAの正当性チェックにはInternVL3-78Bを使用
- 画像あたり30のQAペア
表をコンパクトに表せるフォーマット(MarkdownやHTMLと比べて良い)
| タグ | 意味 |
|---|---|
| コンテンツを持つセル | |
| 空セル | |
| 水平スパン(左からの継続) | |
| 垂直スパン(上からの継続) | |
| 2Dスパン(両方向) | |
| 改行(新しい行) |
例:
↓HTML
結果
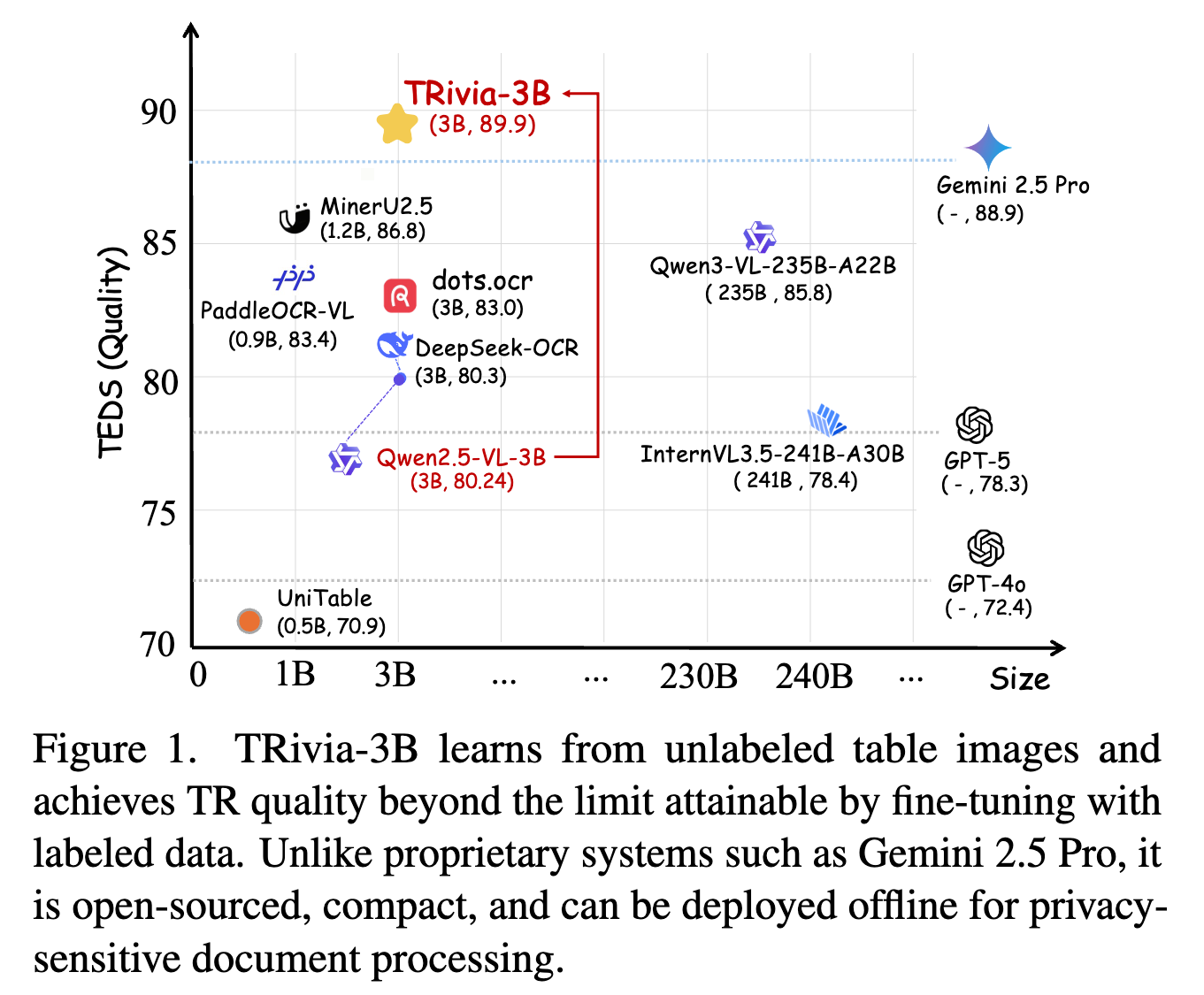
定量評価
4つのベンチマークで高いTEDSとS-TEDSを達成。
- Expert TR modelsがPubNetで高いS-TEDSなのは過学習しているかららしい。(このデータセットで学習されているため)
- 他のVLM(72Bや235Bなど)と比べるとずっと少ないパラメータ数(3B)だが、スコアで勝っている
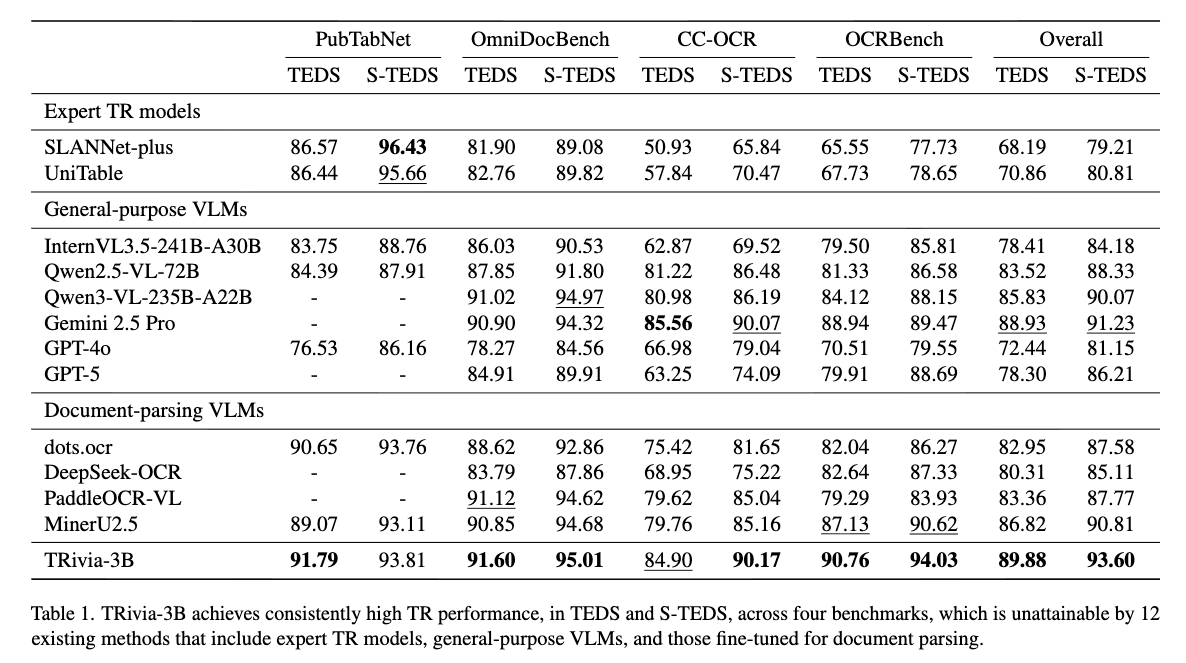
| ベンチマーク | 説明 | サンプル数 | 特徴 |
|---|---|---|---|
| OmniDocBench v1.5 | デジタルPDFの多様なテーブルタイプ | 512 | 学術論文、ビジネス文書など高品質データ |
| CC-OCR | スキャン・撮影テーブル画像 | 300 | 長テーブル、複雑構造、手書き含む実世界データ |
| OCRBench v2 | 多様な実世界テーブル画像 | 700 | 広範な視覚条件とテーブル形式 |
評価指標
- TEDS (Tree Edit Distance-based Similarity): テーブル構造とコンテンツの両方を評価(0-100、高いほど良い)
- S-TEDS (Structure-only TEDS): テーブル構造のみを評価(セル内容を無視)
Ablation Study
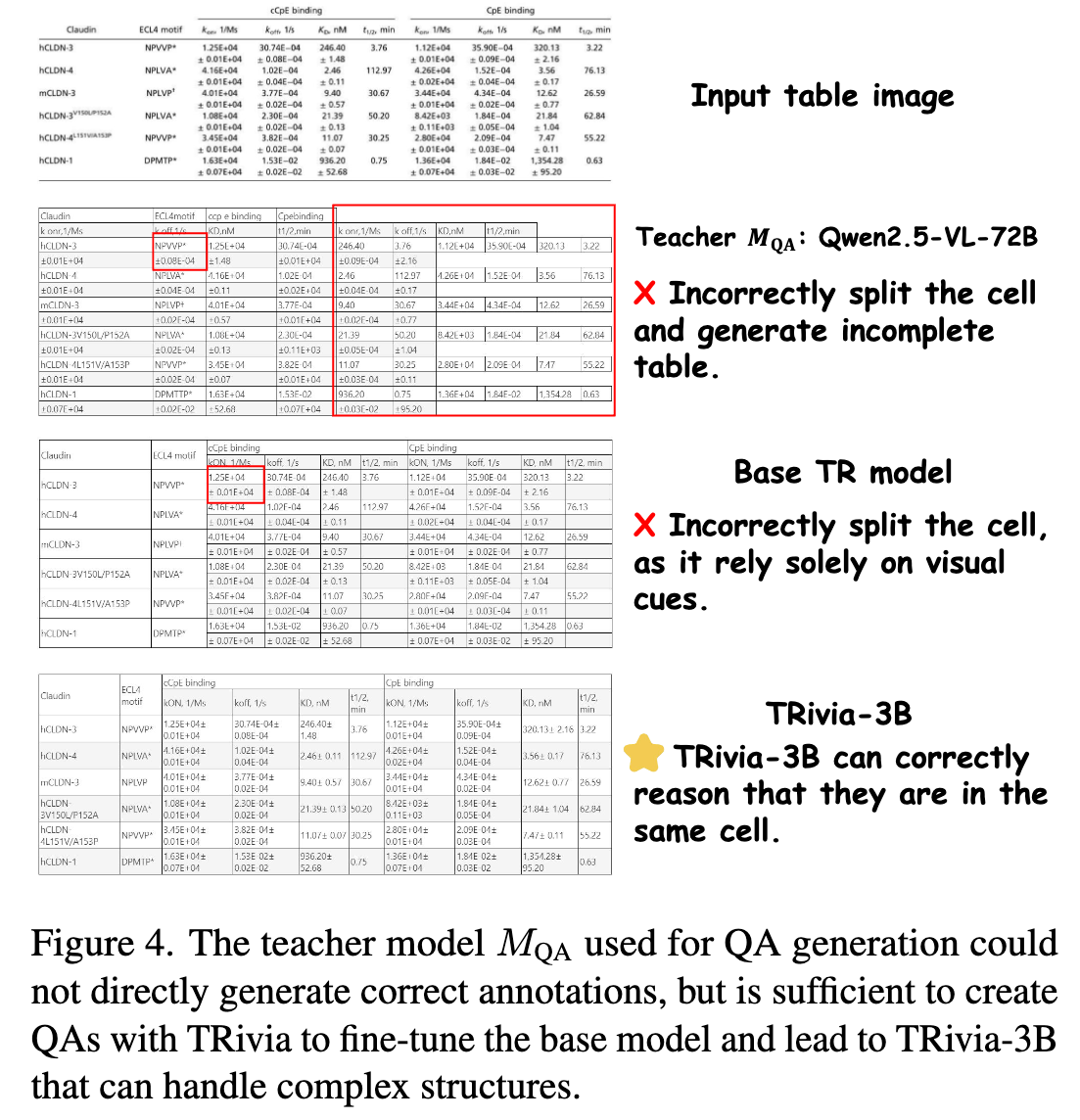
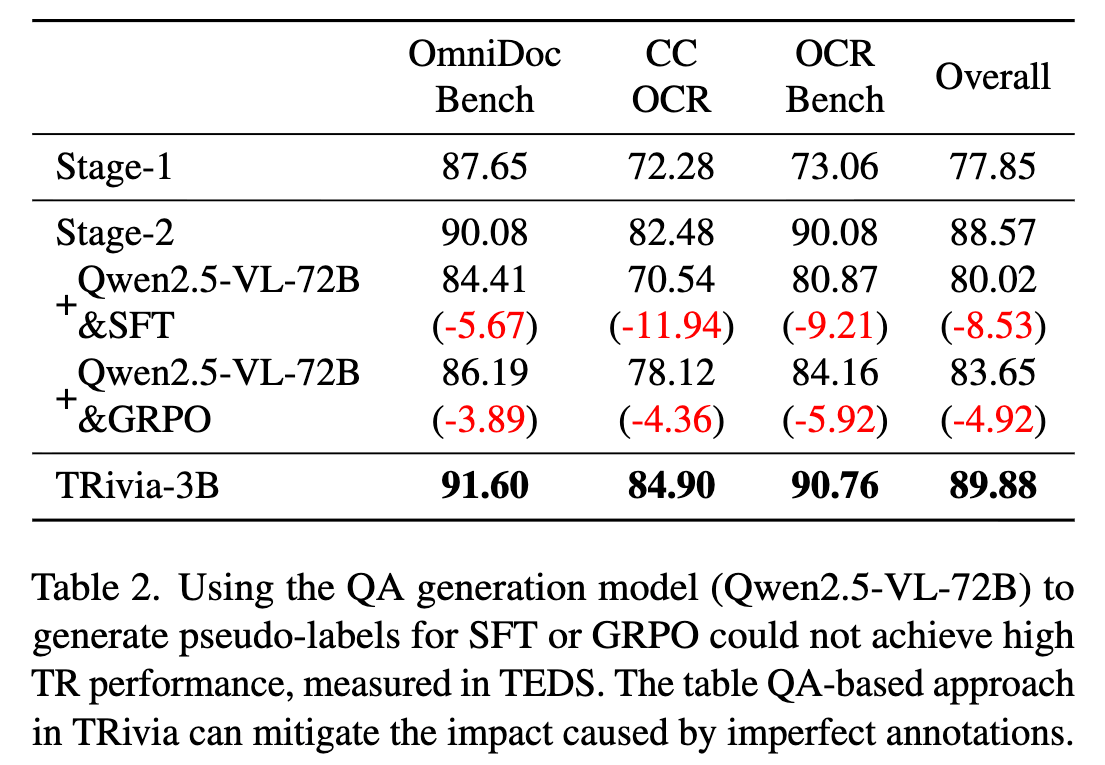
Qwen2.5-VL-72BでHTMLを生成して、学習してみるのはどうか
TRiviaではQAを生成して、それで学習している。完全なHTMLを生成させるのではどうか
Qwen2.5-VL-72Bでは良いHTMLを生成できずに失敗→表認識モデル(TR Model)も失敗(左図)
不完全なラベルで学習すると精度が低下する(右表)。
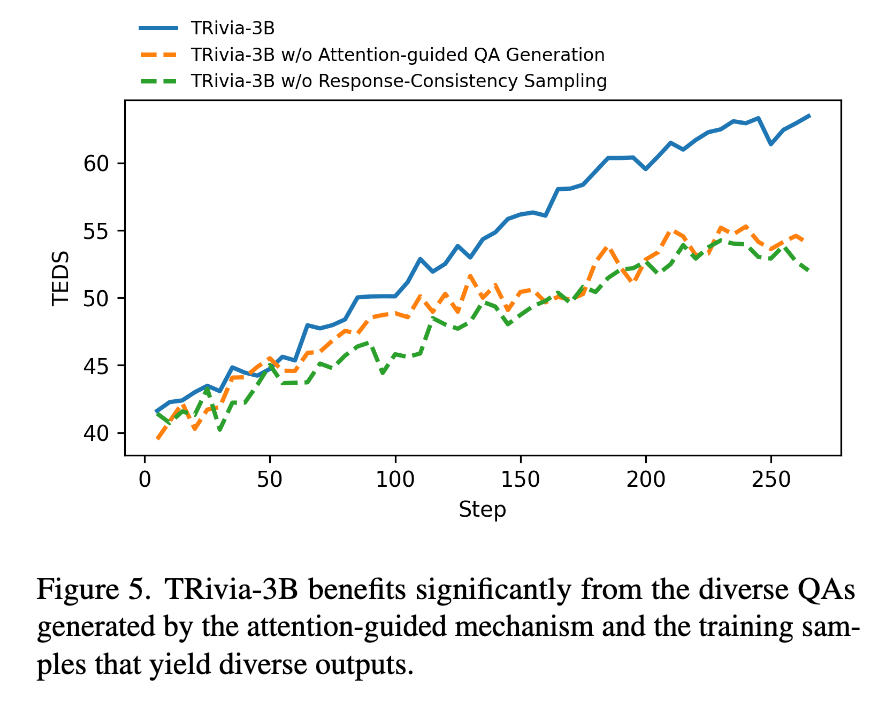
QAの多様性を上げる施策がうまくいっているか
- アテンションに基づいた質問を生成した効果(オレンジ) アテンションを使わなかった場合
- 一貫性サンプリングの効果(緑) 学習データを準備するときに、(認識)結果がばらつくサンプルで学習。そのサンプリングを行わなかった場合
補足
QA生成をするプロンプト

回答をするプロンプト

回答が合っているかクロスチェックをするプロンプト

テーブル認識をするプロンプト