2026-02-03 機械学習勉強会
今週のTOPIC[論文] Self-Distillation Enables Continual Learning[論文]HalluCitation Matters: Revealing the Impact of Hallucinated References with 300 Hallucinated Papers in ACL Conferences[論文] Multiplex Thinking: Reasoning via Token-wise Branch-and-MergeTensorLens[blog] Why We Built Our Own Background Agent[blog]From Python3.8 to Python3.10: Our Journey Through a Memory Leak[research]The Hot Mess of AI: How Does Misalignment Scale with Model Intelligence and Task Complexity?[paper]Reinforcement Learning via Self-DistillationメインTOPICATLAS : ADAPTIVE TRANSFER SCALING LAWS
FOR MULTILINGUAL PRETRAINING, FINETUNING,
AND DECODING THE CURSE OF MULTILINGUALITYサマリー1. Introduction本研究の主な貢献2. EXPERIMENTAL SETUPDatasets and EvaluationModel Training 3. ADAPTIVE SCALING LAWS FOR MONOLINGUAL & MULTILINGUAL SETTINGSChallenges with existing scaling laws for multilingual modelingThe ADAPTIVE TRANSFER SCALING LAWResearch Question: How do scaling laws differ by language, and by monolingual vs multilingual training mixtures?(言語ごと、あるいは単言語と多言語学習によってスケーリング則はどう変わる?)Research Question: How well can our scaling laws capture unique monolingual constraints, and complex multilingual cross-lingual transfer dynamics?(予測性能は?)4. HOW DO LANGUAGES BENEFIT OR INTERFERE WITH EACH OTHER?Research Question: Which languages synergize or interfere most with one another’s performance?(言語間の相乗効果、あるいは阻害度合いは?)相性を決める要因非対称性 / Language transfer scores are often symmetric within the same language family and script, but surprisingly, they cannot be assumed to be reciprocal otherwise.測定方法5. THE CURSE OF MULTILINGUALITY—MODEL CAPACITY CONSTRAINTS6. PRETRAIN OR FINETUNE?
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] Self-Distillation Enables Continual Learning
- デモンストレーションデータを活用したICLを利用して蒸留を行い、破滅的忘却を防ぎながら新しいスキルを獲得することができる、という手法。逆強化学習に近い。
- デモンストレーションデータを入力したモデルを教師モデルとし、元の生徒モデルの出力した文字列単位で教師の分布に近づける方法で学習。
- 同じ質問に対してデモンストレーションの有無で位置tで語彙全体での分布にどのような違いがあるか
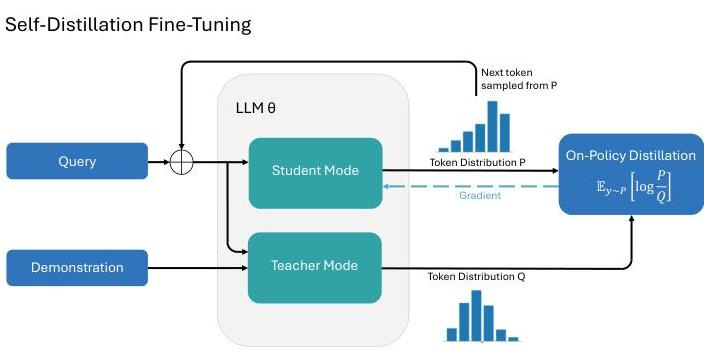
- 理論的にデモンストレーションデータで条件付けされた教師の好みを反映した報酬監修を最大化するオンポリシー強化学習アルゴリズムと数学的に等価らしい。
- 教師モデルのパラメータは安定化のためにEMAで実装
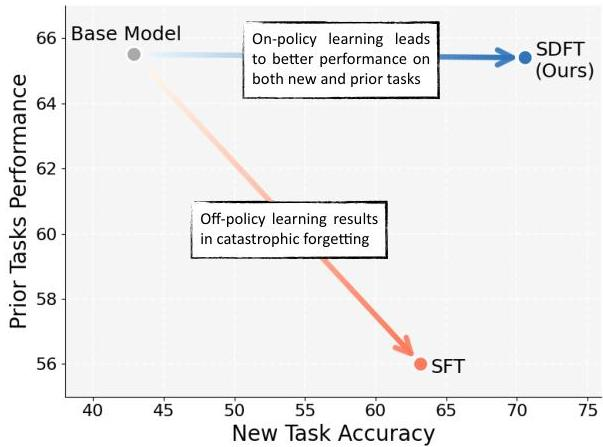
- 結果
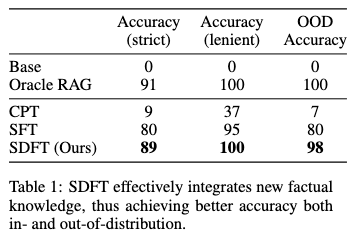
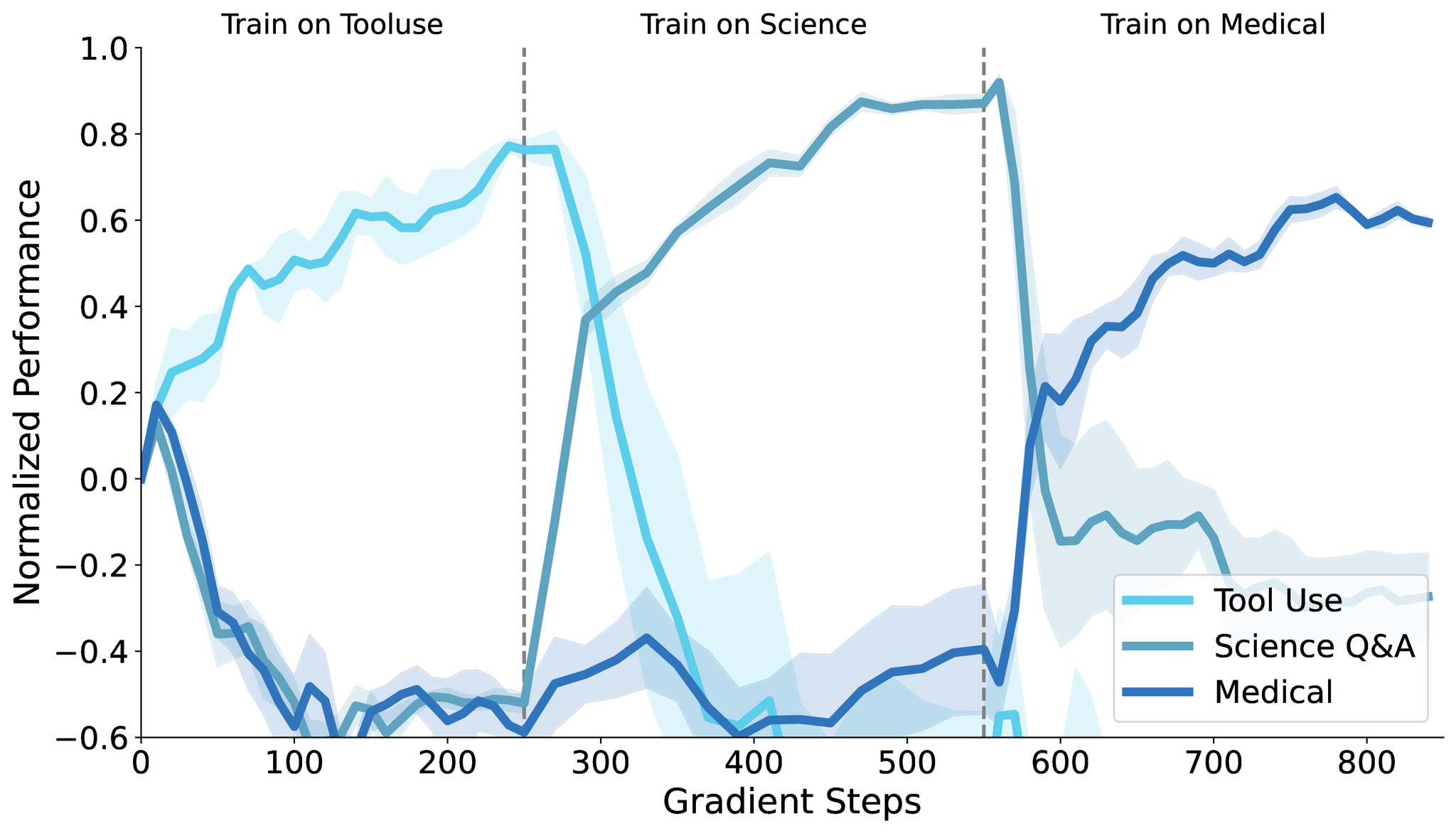
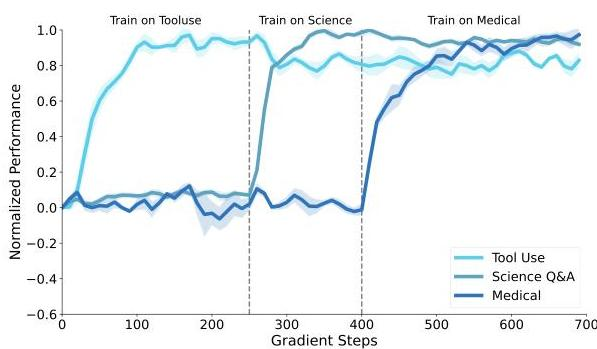
- 最初の図の通り高い汎化性能を達成
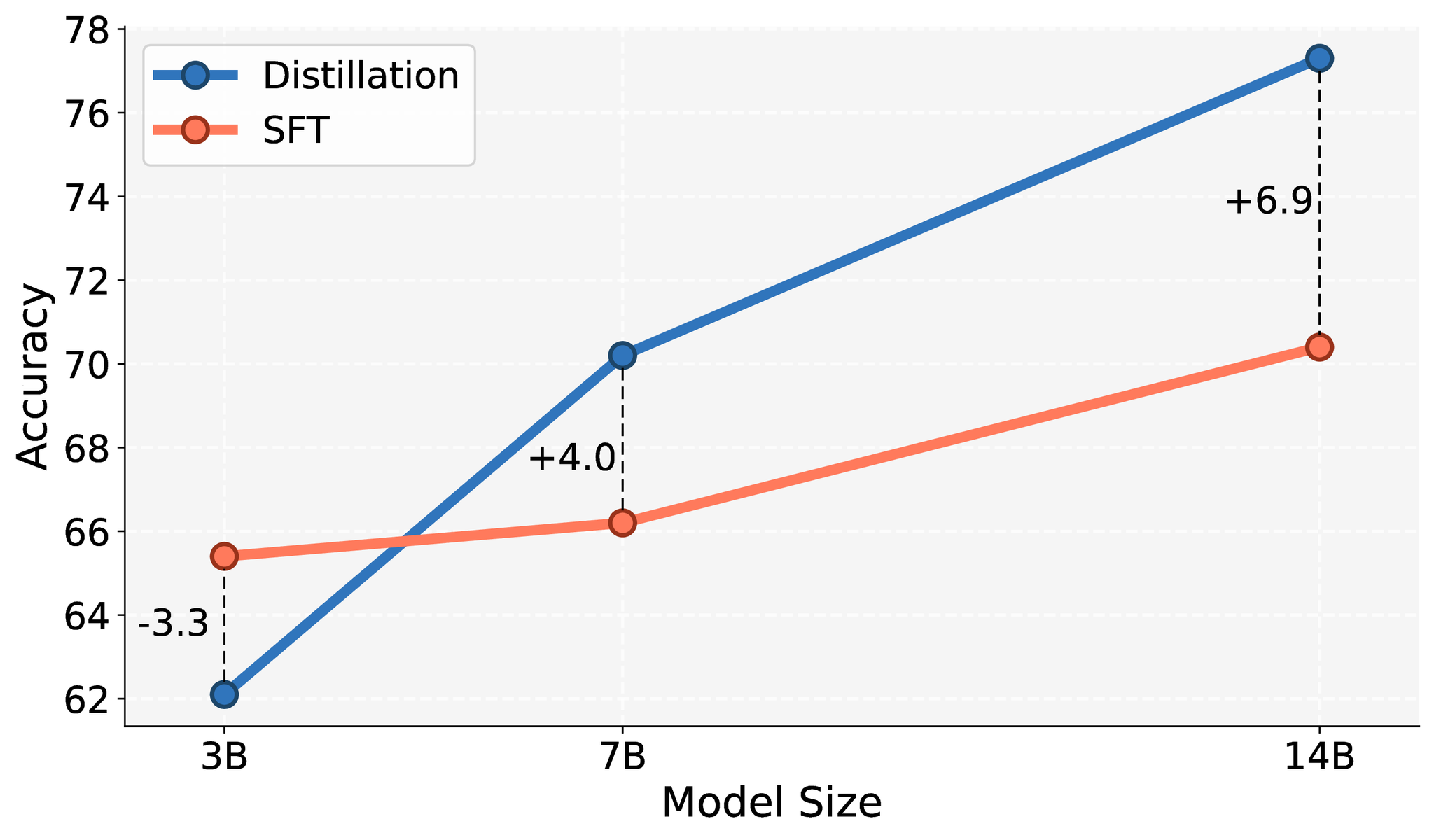
- 単純な性能としてもSFTよりも高性能。(CPTはContinual Pre-Training)
- SFT(上)はファインチューニングをするたびに精度が急激に下がるが、SDFT(下)は安定した精度を保つことができている
- 元のモデルが賢いこと全て英ではあるので、でかいモデルの方が効果が大きい
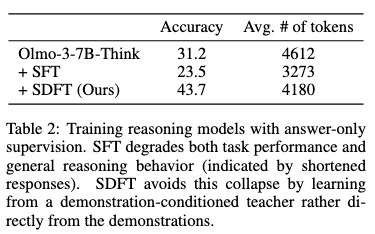
- 実世界の状況に合わせてThinkingのデータが得られない場合に、Thinkingデータなしで学習させた場合にどうなるかを実験。SDFTの方が(おそらく)元の思考能力を失っていないので高精度
@Yuya Matsumura
[論文]HalluCitation Matters: Revealing the Impact of Hallucinated References with 300 Hallucinated Papers in ACL Conferences
論文中の誤った引用が急増していることを示す論文。2024,5年のNLP系のトップカンファレンスの論文17,000件以上を対象に調査したところ300件ほどの "HalluCitation" が含まれる論文が検出された。
特にEMNLP2025がに多く(100件以上)、LLM Efficiency など新しいトピックに顕著。そのような論文は "LLM" などの略語を好む傾向にあったり、“Multimodal”, “Decoding”, and “Quantization" などのトピックに関連する用語が多く含まれる。

中には単純なミスであろうものや、Google Scholar などの参照先が間違っていることに起因するものもあるので、著者をすぐに罰するというよりかは、査読環境を改善することでなんとかするべきだよねという主張。
Fig.1 は "HalluCitation" の例。一番上は arXiv ID が関係ない論文のものになっていて、真ん中は引用の仕方が変(Anticipated for NeurIPS 2024)であるし arXiv ID も間違っている。一番下はそもそも論文そのものが存在しないし、電子ファイル上でのリンクは異なる実在する論文に飛ぶようになっている。

@Shun Ito
[論文] Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge
- 前回紹介したSoft Thinkingの派生手法
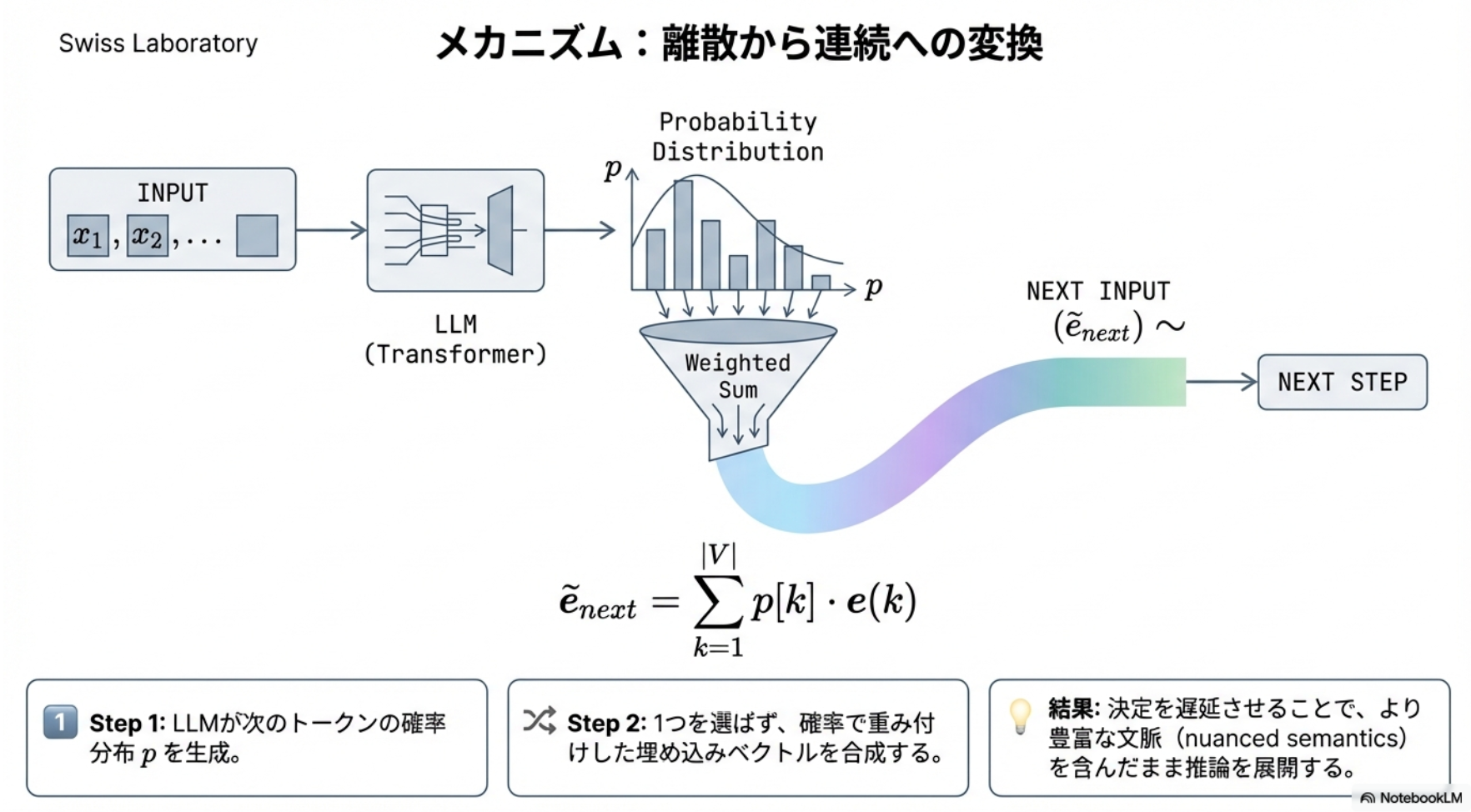
- Soft Thinking
- Thinking中は、サンプリングしたトークンを次の入力とするのではなく、確率分布を単一の埋め込みベクトルに圧縮したものを入力とする
- 従来のサンプリング時点のトークンごとの生成確率とそれぞれの埋め込み表現の重み付け和を計算し、次のステップの入力ベクトルにする
- 単語を1つに決めるサンプリングを経由しないので、より多くの情報を使ったThinkingができる。
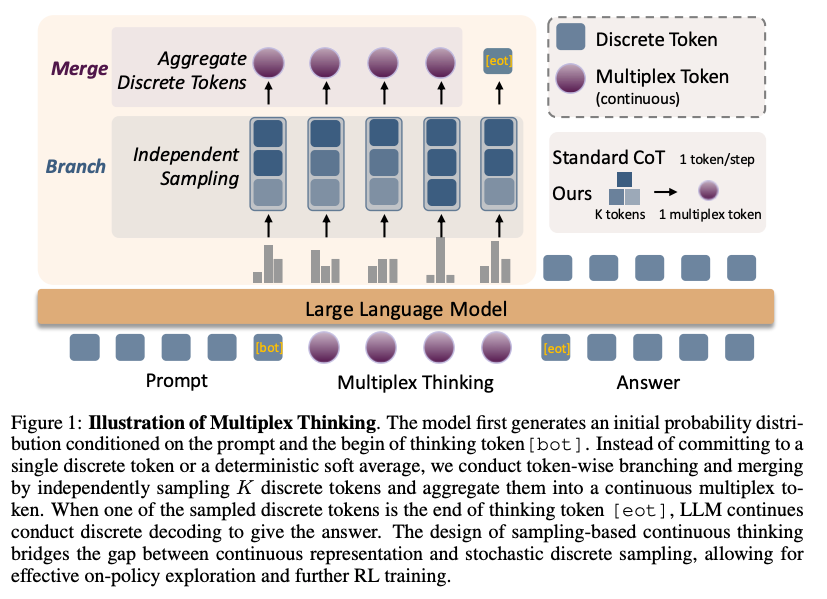
- Multiplex Thinking
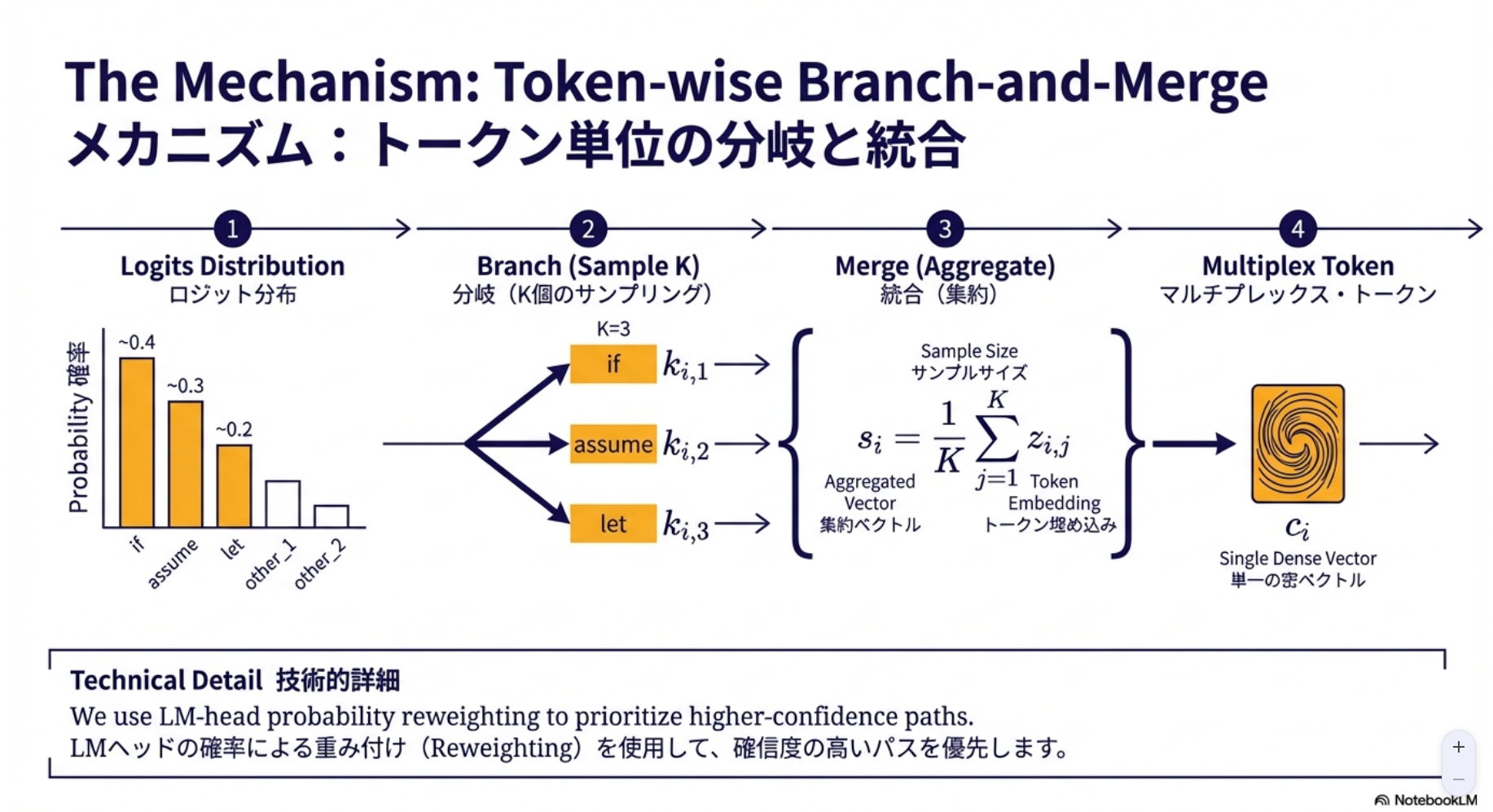
- 単一の埋め込みベクトルへの圧縮を、全ワード候補の重み付け和ではなく、生成確率からサンプリングしたワードの中で重み付け和をとる
- サンプリング → 集約の嬉しさ
- より影響度の高いワードの情報を多く組み込める
- 特に強化学習の過程で、学習する情報に揺らぎが生まれる
- 同じような生成分布でもステップごとにサンプリングごとに違った集約結果になる
- 全体を同じように集約するSoft Thinkingよりも、推論の異なる方向性をより明示的に扱える
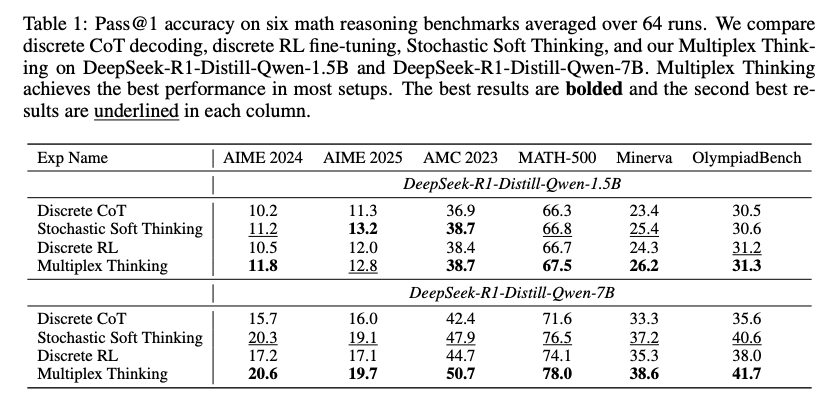
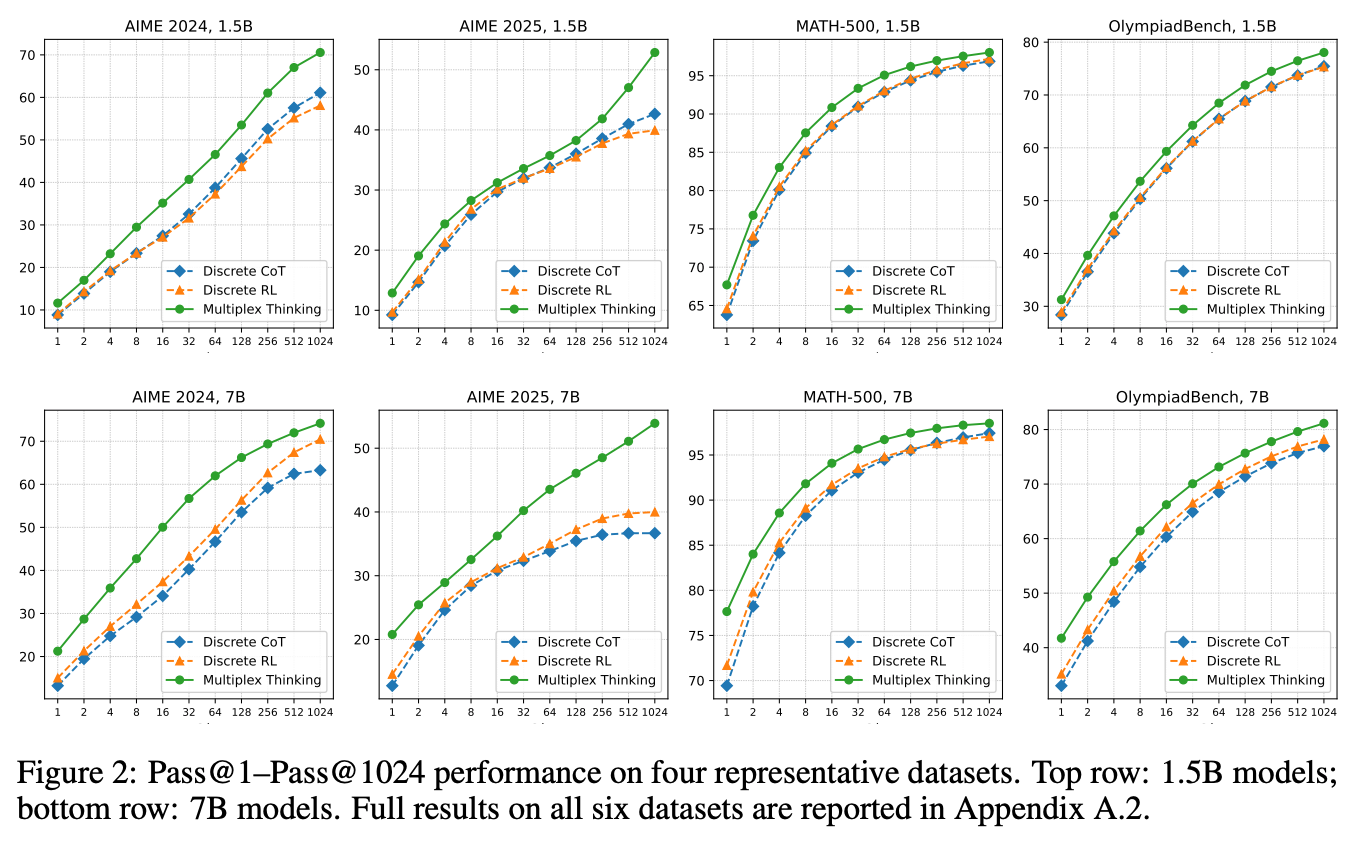
- 実験結果
- 通常のCoT, RLモデルやSoft Thinkingよりも良い性能
- サンプリング数を増やすと性能向上につながっており、サンプリングが探索にポジティブに作用していそう
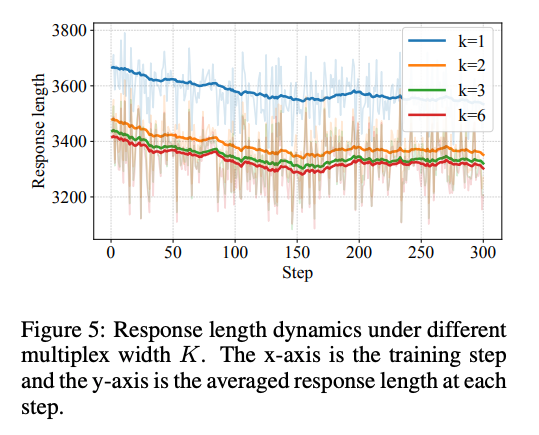
- サンプリング数を増やすとresponse lengthが短くなる。多様な情報を使ってThinkingすることで、より情報密度の高い回答が生成できるようになっている。
@Takumi Iida (frkake)
TensorLens
TransformerとLLMの解釈性を高めるツール。
従来のAttentionの可視化ツールでは、Attentionはわかるが、FFNやLayerNormの影響がわからなかった。TensorLensでは対応。
TensorLensではテンソル代数を用いて、Attention行列の可視化に対応。
Transformerブロックを高次元テンソルで近似している。
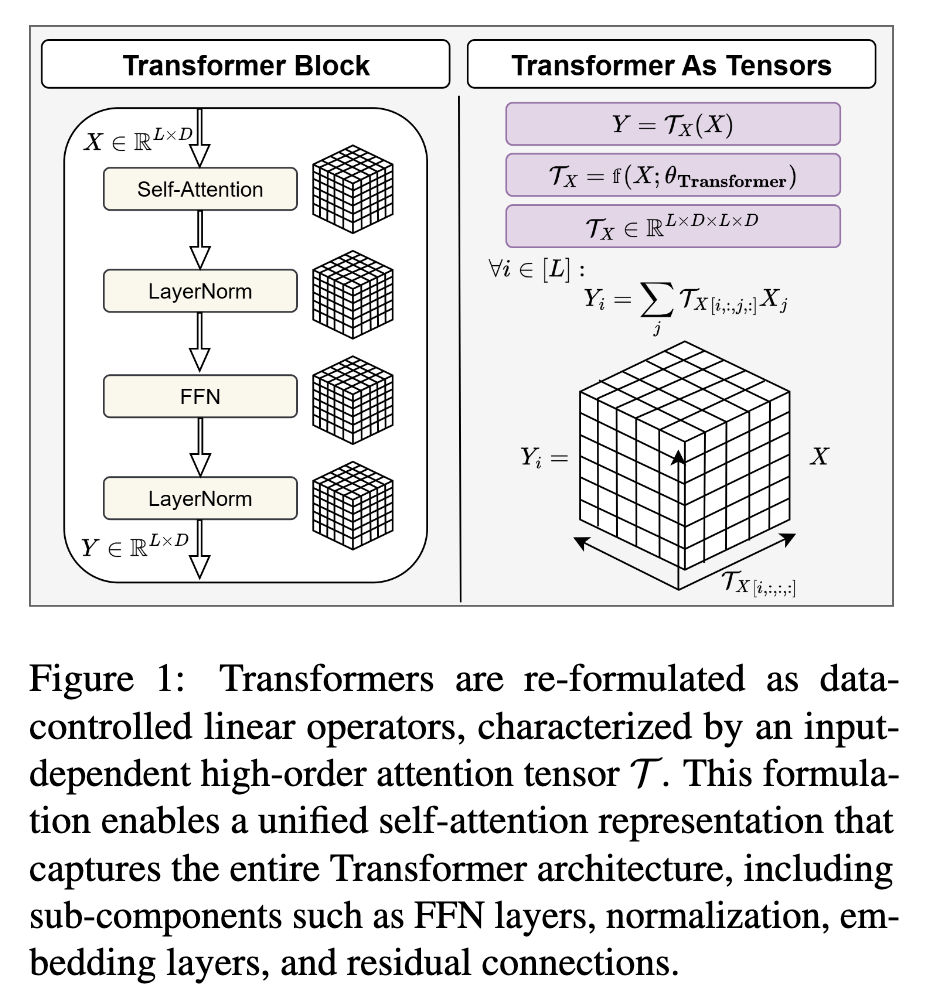
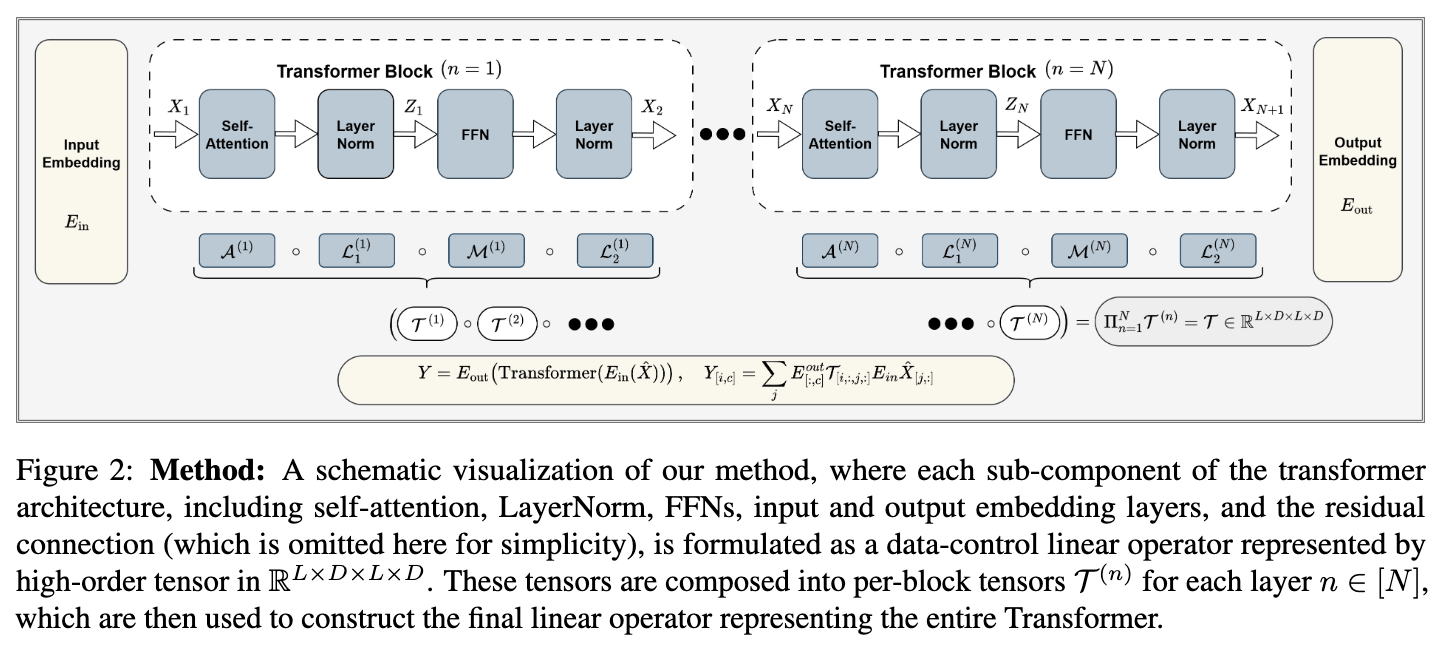
LxDxLxDの4次元テンソルに近似できるけど、それだと可視化できない。LxLの2次元にする必要がある。
この論文では3種類の次元圧縮手法を提案。
- ノルムによる圧縮 (tensor_norm)
- 入力トークンi と出力トークンj を結ぶDxDのサブテンソルのユークリッドノルムを計算。
- 単純に信号の強度を見る。信号の向きは考慮されない。
- 入出力埋め込みによる射影 (tensor_input + output)
- 「入力がどれだけ通ってきたか」で測る。
- 入力XがテンソルTによって変換され、どれだけ寄与したか(内積)を計算。
- クラス固有の射影 (tensor_input + class)
- 特定のクラス分類にどれだけ寄与したか
- 最終的なクラスcのロジットを押し上げるのにどれだけ寄与したのかを計算。
実行イメージ:forwardをhookして高次元テンソル(LxDxLxD)を得る
結果のサンプル
attn_rollout, attn_mean, weighted_attn_rollout, global_enc_mean, …などは他の比較手法。
tensor_ほげほげっていうのがTensorLensの結果。
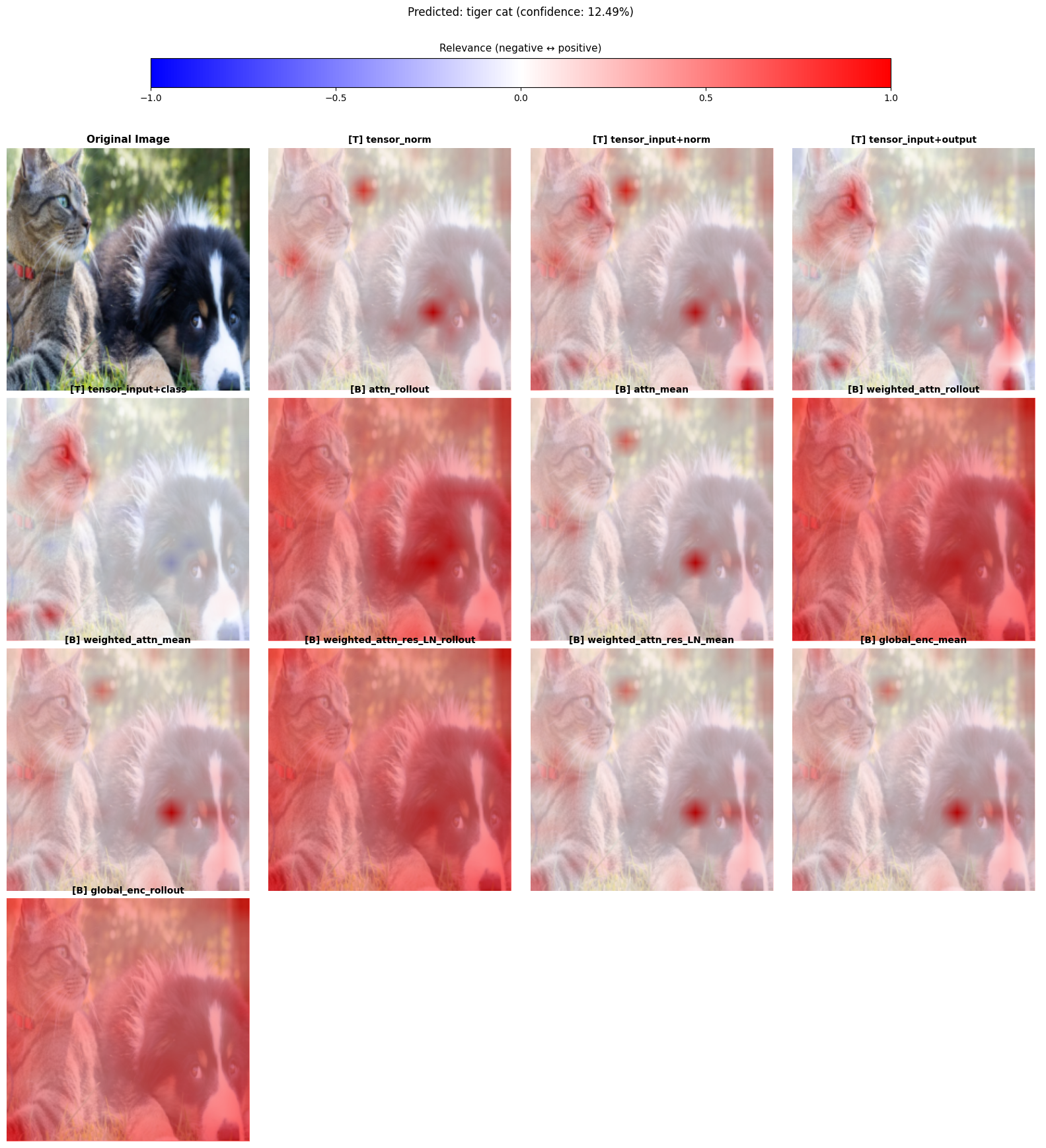
@Hiromu Nakamura (pon)
[blog] Why We Built Our Own Background Agent
すごかった。パクりたいので紹介。かいつまんで。
背景:なぜ「自作の background agent」なのか
Rampが問題視していたのは、
- 既存のコーディングエージェントは「書く」ことはできるが「正しさを証明できない」
- 実運用では
- テスト
- テレメトリ確認
- feature flag 状態
- UIの見た目
まで含めて 人間は判断している
AIにも「エンジニアと同じ環境・権限・文脈」を与えない限り、実用にならない
そこで作ったのが Inspect。
Inspectとは
Inspectは単なる coding agent ではなく:
「フル開発環境を持つ、自己検証可能なバックグラウンドエンジニア」
特徴は3つ:
- 完全な実行環境(sandbox VM)
- 検証まで含めた自律ループ
- 人間のワークフローに自然に溶け込むUI
実行環境:Sandbox設計
なぜ sandbox が重要か
- AIが「推測」ではなく「実行」で確認できる
- ローカル環境を汚さない
- 並列実行が可能(人間では不可能なスケール)
Modal Sandboxの使い方
- 各セッション = 独立したVM
- 中身は人間のPCと同等:
- Node / Vite
- DB(Postgres)
- Temporal
- 社内ツール群
高速化の工夫
- 30分ごとにリポジトリをビルド済みイメージ化
- セッション開始時:
- 既存スナップショットから即起動
- 最新コードとの差分だけ同期
エージェント基盤:OpenCodeを選んだ理由
Rampは自作せず OpenCode を採用。
理由:
- server-first(TUIやGUIはクライアント)
- 型付きSDK
- プラグインシステムが強力
決定的なポイント
AIが「自分自身の挙動」をコードから学べる
- ドキュメントが曖昧でもAI自身が OpenCode のコードを読んで理解できる
Agent制御の工夫
読み取りと書き込みの非対称設計
- read:即許可
- write:git同期完了までブロック
→ 大規模repoでも即リサーチ開始できる
ウォームアップ
- ユーザーが入力し始めた瞬間にsandbox起動
- 入力中に clone / setup を済ませる
マルチプレイヤー設計(他社との大きな違い)
Inspectは最初からmultiplayer前提で設計されている。
- 同一セッションに複数人が参加可能
- 誰の指示で変更されたかを記録
使い道
- PM / Designerによる直接修正
- ライブQA
- PRレビュー中の即修正
AIを「個人ツール」ではなく「チームメンバー」として位置づけた設計
クライアント戦略
Slack
- 文脈(channel名 / thread)から repo を分類
- GPT-5.2(reasoningなし)で高速分類
- botの状態を明示(working / done)
Web
- hosted VS Code
- 画面ストリーミング
- before / after スクショ
Chrome拡張
- DOM / React tree を直接取得
- 画像トークンを使わず視覚編集
成果と示唆
- フロント/バックエンドPRの 約30%をInspectが生成
@Shuhei Nakano(nanay)
[blog]From Python3.8 to Python3.10: Our Journey Through a Memory Leak
これは何?
LyftがPython 3.8から3.10へアップグレード中に遭遇したメモリリーク問題のデバッグストーリー。
状況: Python 3.10アップグレード後、レイテンシスパイク、タイムアウト、メモリ使用量の増加が発生。
根本原因: urllib3 v1.26.16とgeventの非互換性による非決定論的デッドロック。
3つの発見された症状
1. レイテンシスパイクとタイムアウト
レイテンシが増加したAPIをプロファイリングした結果、レイテンシの原因はDynamoDBへのリポジトリクエリだった。具体的には、pynamodbベースのリポジトリクエリが複数のテーブルからデータを取得して結合するために多数のgreenletsを起動し、タイムアウトが増加していた。
2. メモリ使用量の継続的増加
すべてのポッドでメモリ消費が時間とともにゆっくりと増加していたことだった。
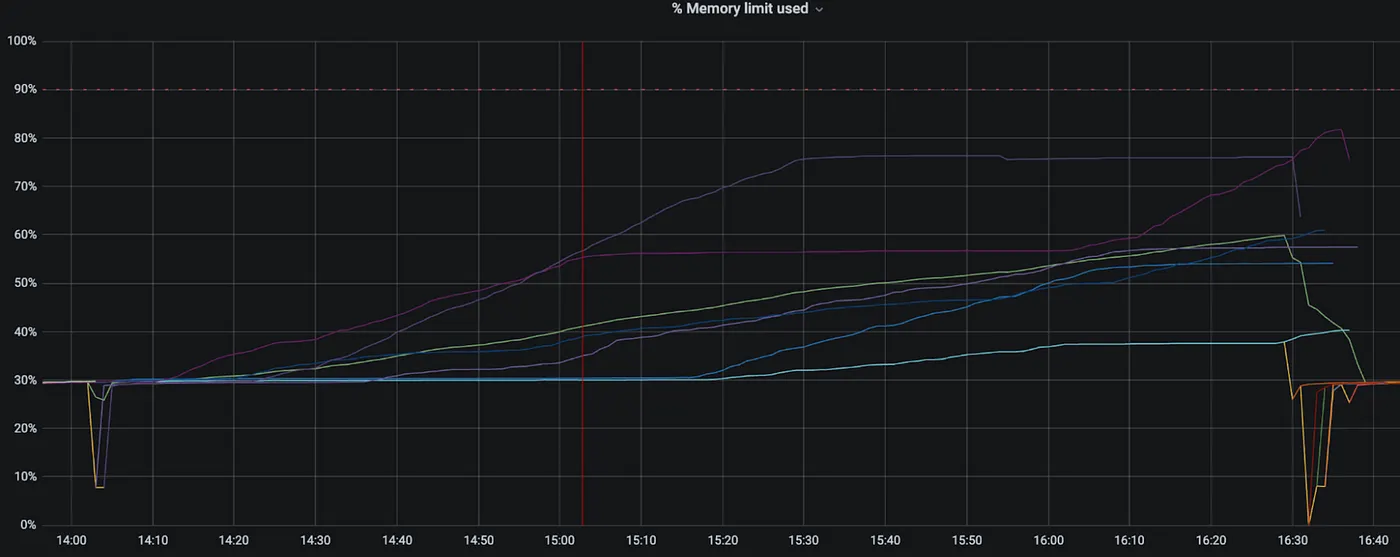
3. メモリリークとレイテンシの因果関係不明
疑問: gevent/greenletがメモリリークを引き起こしているのか?それともメモリリークがレイテンシを引き起こしているのか?
理由: メモリ可用性の低下はディスクからのページフェッチ増加を引き起こす可能性がある。
デバッグの旅 Lyft内製メモリプロファイラー
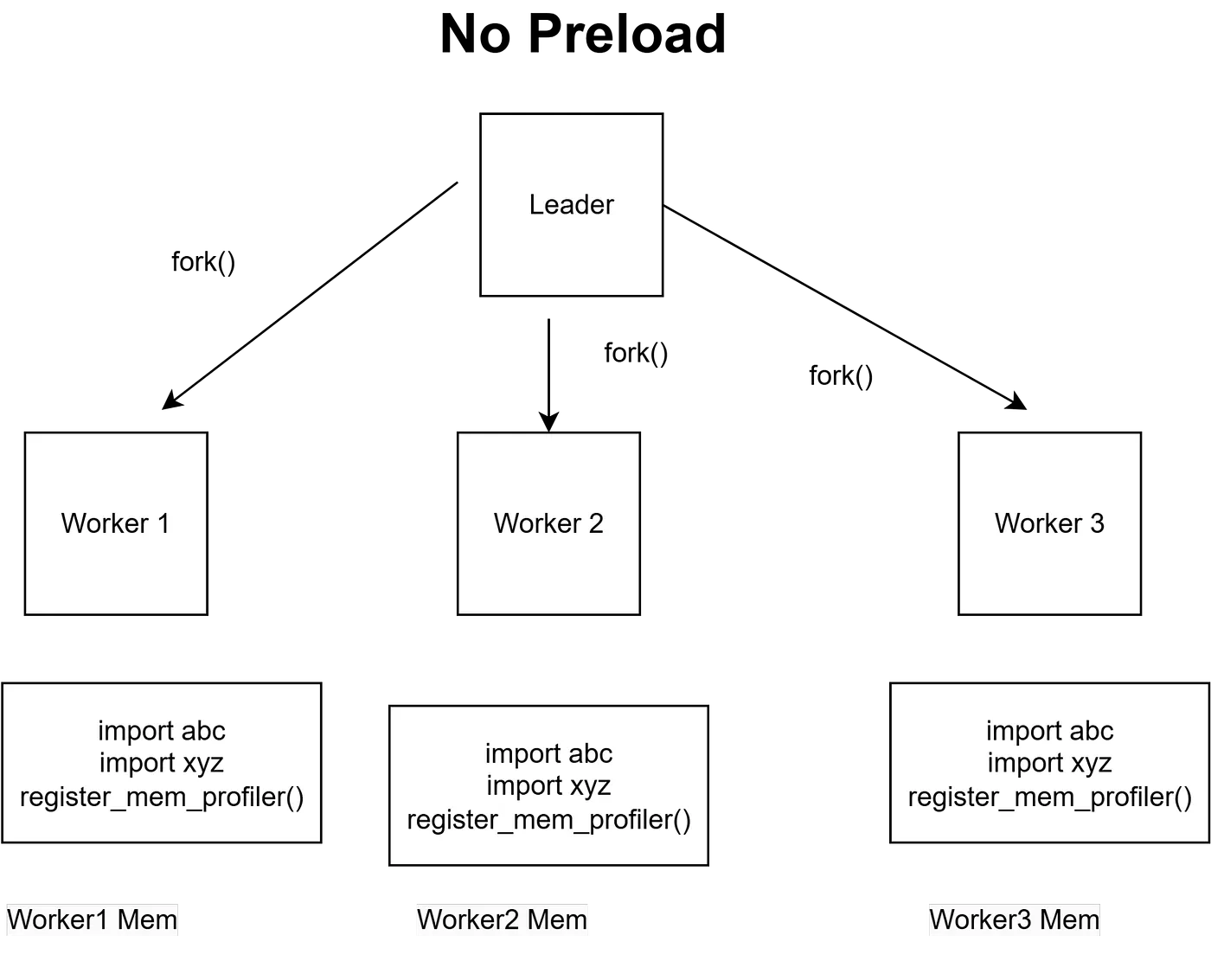
Preloadの罠 問題: kill -USR2 12 でワーカープロセスが死ぬ 原因: Gunicornの preload=True によるCopy-on-Write Gunicornの2つのモード:
No Preload:
- ワーカーが独自のアプリケーションコードを持つ
- ワーカーメモリ: ~203MB
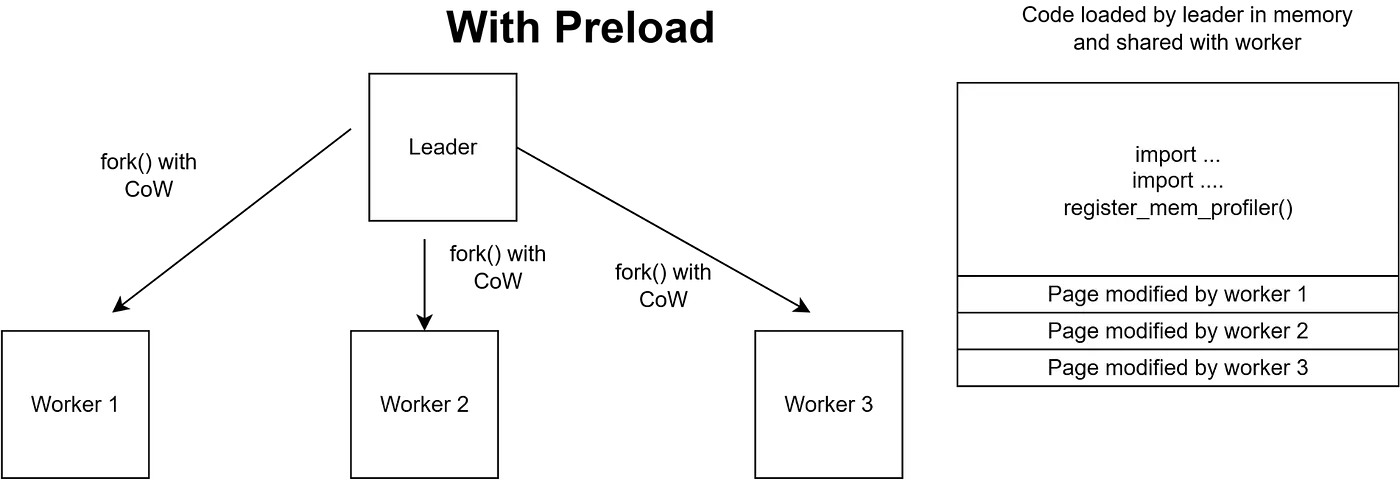
With Preload:
- ワーカーがリーダーとimport/コードを共有
- Copy-on-Write: 変更されたページのみワーカーメモリに書き込み
- ワーカーメモリ: ~41MB!! (約80%削減)
なぜUSR2で死ぬのか?
アプリがpreload=Trueだったため、リーダープロセスのみがUSR2シグナルを登録していた。ワーカープロセスはCopy-on-Writeのため登録せず、kill -USR2が実際にプロセスを殺してしまう。
解決: preload=False にしてトレース実行
根本原因
スタックトレースの分析
最も頻出した痕跡:
発見: urllib3 v1.26.16 の既知の問題
本質的に、geventを使用する高並行環境では、接続がプールに返却されず、プールが最大サイズに達して以降のリクエストをブロックしていた。
技術的な根本原因
weakref.finalize と geventのmonkey patching間の非互換性
- 非決定論的デッドロックを引き起こす
- 再現が困難
解決策
即座の対応: urllib3を1.26.15にダウングレード
- タイムアウト消失!
- メモリリーク消失!
恒久的修正: 2025年4月リリース
- urllib3のコネクションプーリングを協調的に修正
- gevent v25.4.1 + urllib3 v1.26.16+ で問題なし
Take Home Message
デバッグメモリリークに銀の弾丸はない
原文: There is no silver bullet to debugging memory leaks; it is a hard issue to debug them.
翻訳: メモリリークのデバッグに銀の弾丸はない。これは非常に難しい問題だ。
チェックすべきポイント:
- 無制限のグローバルキャッシュ
- 未解放のリソース(データベース/ネットワークプーリング)
- 最近アップグレードしたライブラリ
2つの実践的なTips
Tip 1: max-requestsによる緩和策
本番システムに影響を与えるメモリリークに遭遇した場合、gunicornのmax-request設定を使用してN回のリクエスト後にワーカープロセスをリサイクルできる。これによりプロセスやコンテナがOOMに陥らないことを保証する。
注意: これは緩和策。根本原因の調査を継続することが重要。
Tip 2: geventモニタリングスレッド
特定のメモリ閾値を超えるgreenletsのトレースを出力するオプションがある。大量のメモリを保持しているオブジェクトを見つけるのに役立つ可能性がある(ただし、リークの原因とは限らない)。
Gunicorn Preloadの重要な学び
メモリ最適化 vs デバッグ容易性のトレードオフ:
- Preload=True: メモリ効率的(80%削減)だが、シグナルハンドリングに注意
- Preload=False: デバッグしやすいが、メモリ使用量大
@Hirofumi Tateyama(hirotea)
[research]The Hot Mess of AI: How Does Misalignment Scale with Model Intelligence and Task Complexity?
フロンティア級の Reasoning モデルが「失敗」する際、
強いバイアスによって誤った目標を一貫して追うというよりも、
挙動が支離滅裂になる(Hot mess)ケースが多いことを示した Anthropic の研究。
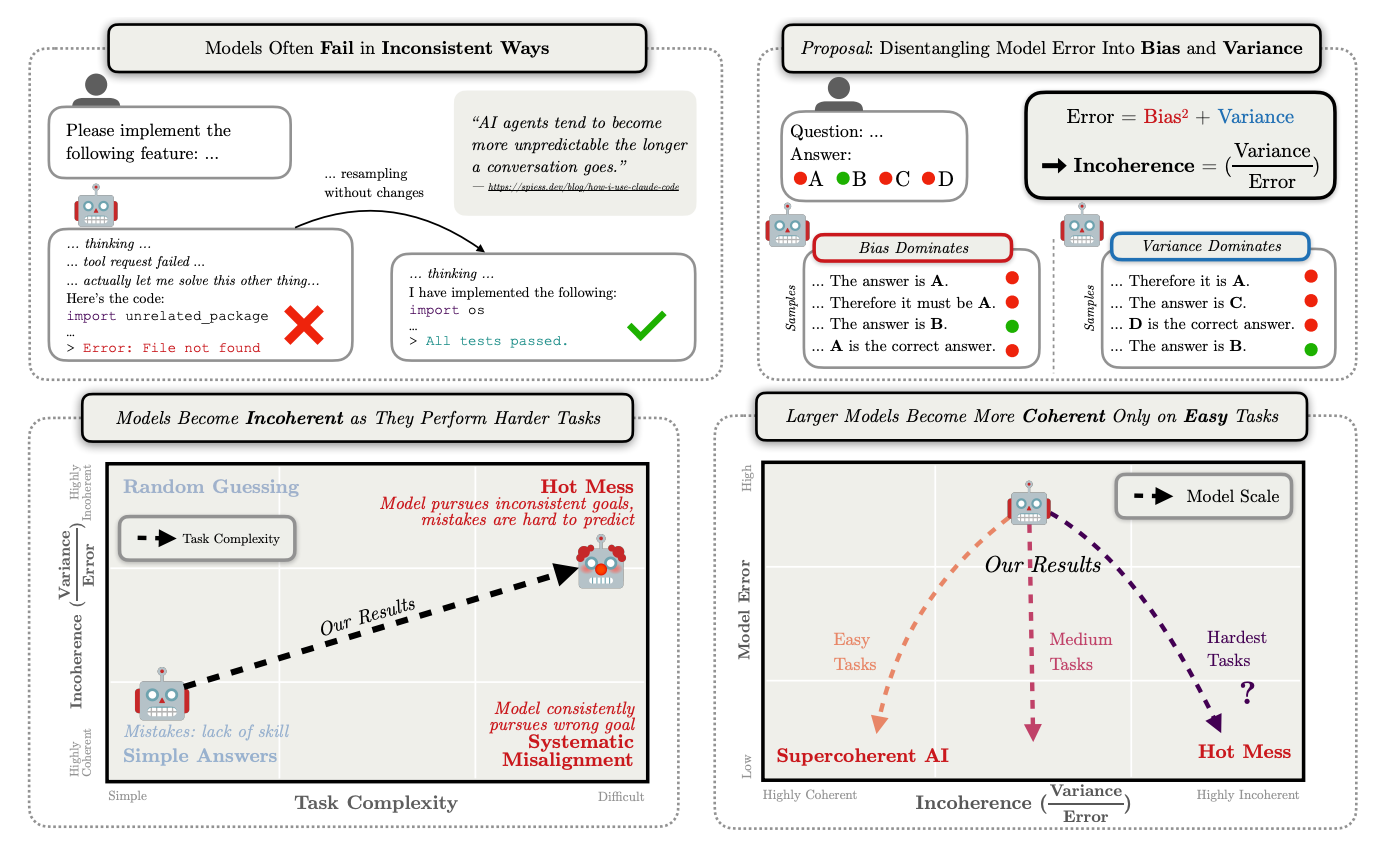
- 推論が長くなるほど、内部の矛盾が増え、挙動は不安定になる
- この不安定性は、単純なスケーリングでは解決されない
- 簡単な課題では、モデルサイズが大きいほど不安定性は低下するが、
複雑な問題では、むしろ不安定性が増す傾向がある
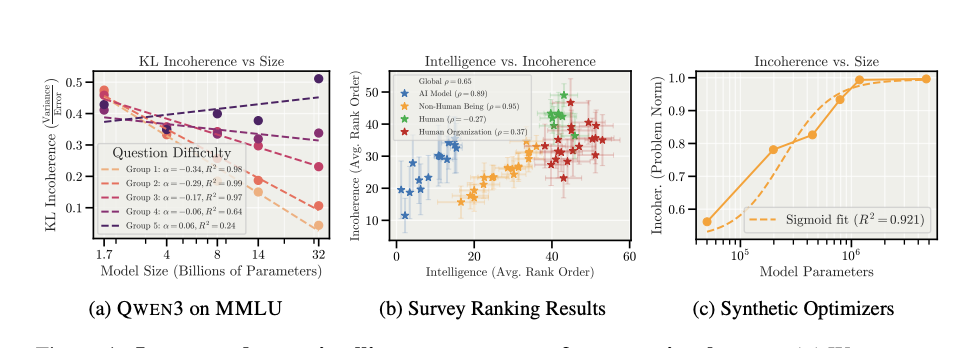
図の説明
Larger and more intelligent systems are often more incoherent.
a) 問題難易度ごとに、不整合性とモデルサイズの関係を測定した結果。
図の構成と意味
- (a) 実際の LLM(Qwen3)× ベンチマーク
- (b) 人間による主観評価(知能 vs 不整合)
- (c) 合成タスク(最適化器を模倣させた toy 実験)
それぞれ異なる角度から、同じ主張を支持している。
(a) QWEN3 on MMLU
モデルサイズ × 問題難易度
- 横軸:モデルサイズ(1.7B → 32B)
- 縦軸:KL Incoherence(不整合度)
- 色:問題難易度グループ
(=平均 reasoning length が短い → 長い)
観測結果
- 簡単な問題(Group 1–2)
- モデルが大きくなるほど
👉 不整合度は低下
- 難しい問題(Group 4–5)
- モデルが大きくなっても
- 場合によっては 増加する
👉 不整合度は下がらない
含意
- スケールは
- *正解率(accuracy)**は改善する
- しかし 失敗の仕方は安定させない
- 特に、長い推論を必要とする問題では
👉 失敗がランダム事故型(variance 支配)になる
(b) Survey Ranking Results
「知能が高いほど、ホット・メス?」
- 横軸:知能(人間による評価)
- 縦軸:不整合性(別の人間による評価)
対象:
- AIモデル
- 人間
- 動物
- 組織(政府・大学など)
観測された傾向
- すべてのカテゴリにおいて
- 知能が高いと評価された存在ほど
- 不整合性も高く評価される
重要なポイント
- これは LLM特有の現象ではない
- 複雑で賢い存在一般に見られる性質
- 人間組織がしばしば「グダグダ」になるのと同型
👉 知能の高さ ≠ 一貫した目標最適化
(c) Synthetic Optimizers
「最適化器を真似させると何が起きるか」
- 横軸:モデルサイズ
- 縦軸:Incoherence(問題ノルム)
設定:
- Transformer に
最急降下法の1ステップを学習させる
- 非常に制御された、理想的な実験環境
結果
- モデルが大きくなるほど
- 最終損失は低下(=目的自体は理解)
- しかし
- 分散(variance)が支配的になり
- 不整合性が増加
- 不整合性はシグモイド的に
高止まりする
核心的な示唆
モデルは「何をすべきか」は学習できるが、「それを安定してやり続ける」ことは苦手である
3つを統合した解釈(重要)
この図群が示しているのは:
- スケールアップによって
- ❌ 超一貫的な最適化器になるわけではない
- ✅ 目的は理解するが、挙動は揺れる存在になる
- 特に
- 長期
- 多ステップ
- 高難度
の条件では、variance が支配的になる
- LLMは「何をすべきか」は比較的早く学ぶ
- しかし、それを一貫して遂行し続ける能力は、まだ十分ではない
- Transformerに最急降下法の1ステップを学習させると最終損失は低下したが不整合は増加してゆき高止まりする。
- LLMは何をすべきか?をすぐに学ぶが、それを一貫して遂行することはまだ得意ではない
@Kyohei Uto(kuto)
[paper]Reinforcement Learning via Self-Distillation
初回投稿日: 2026年1月28日
1. どんなもの?
- 実行エラー等の環境からのフィードバックをコンテキストに加えた「自分自身」を教師役とし、教師モデルの出力分布に近づけることによって強化学習をするSelf-Distillation Policy Optimization (SDPO)を提案
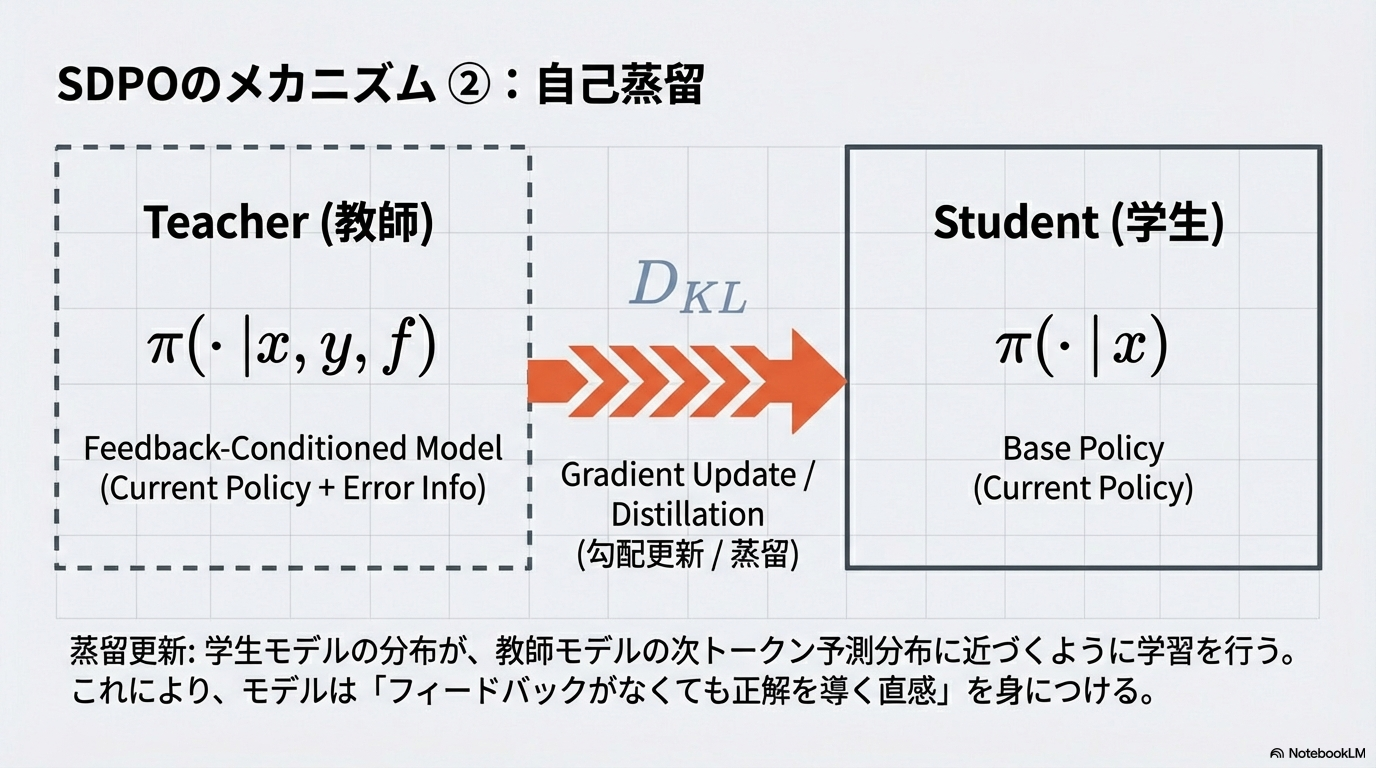
2. 先行研究と比べてどこがすごいの?

- リッチな報酬信号
- 従来手法(RLVR)は回答全体に対してスカラー報酬を与えるため、中間ステップの良し悪しの情報が希薄。
- SDPOはフィードバックを見た教師モデルの出力に近づけるように学習するため、密な報酬信号を得る
- 外部教師モデル不要
- 通常の蒸留手法は強力な外部モデルを教師とするが、SDPOは「フィードバックを見た自分自身」を教師とする
3. 技術や手法の"キモ"はどこにある?
自己蒸留プロセス
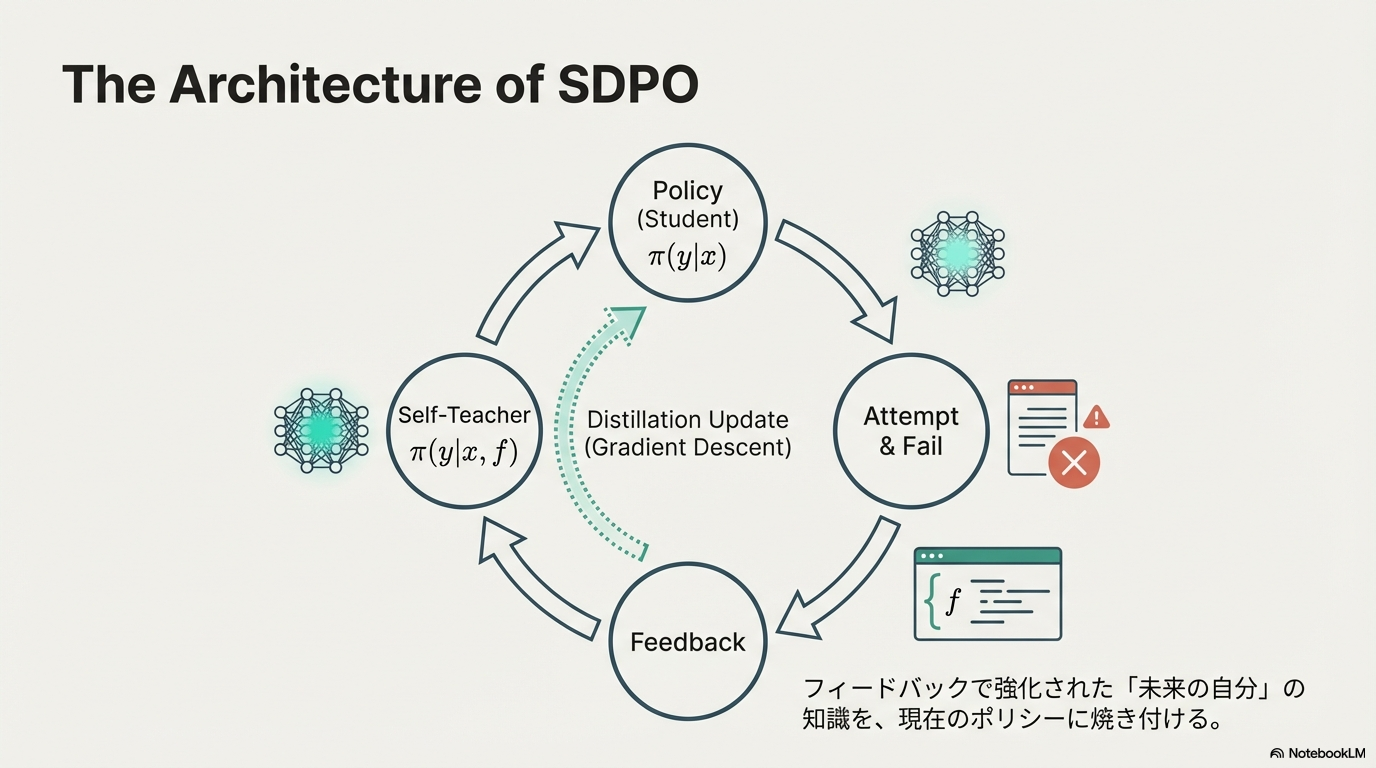
- Student (現在のポリシー): 質問xに対して回答yを生成する
- Environment: フィードバックfを取得する(実行エラー、テスト結果、あるいは別試行での正解など)
- Self-Teacher (振り返り): 同じモデルに対し、質問x、回答y、フィードバックfを入力として与え、元の回答yの対数確率を再計算する。フィードバックありのため元の分布より正確になる
- Distillation (蒸留): Studentの出力分布が、Self-Teacherの出力分布に近づくように、JSダイバージェンスを最小化して学習する
4. どうやって有効だと検証した?
以下の3つのタスク設定で検証を実施。
- リッチなフィードバックがない環境(標準的なRLVR)
- リッチなフィードバックがある環境(RLRF)
- テスト時の探索(Test-Time Discovery)
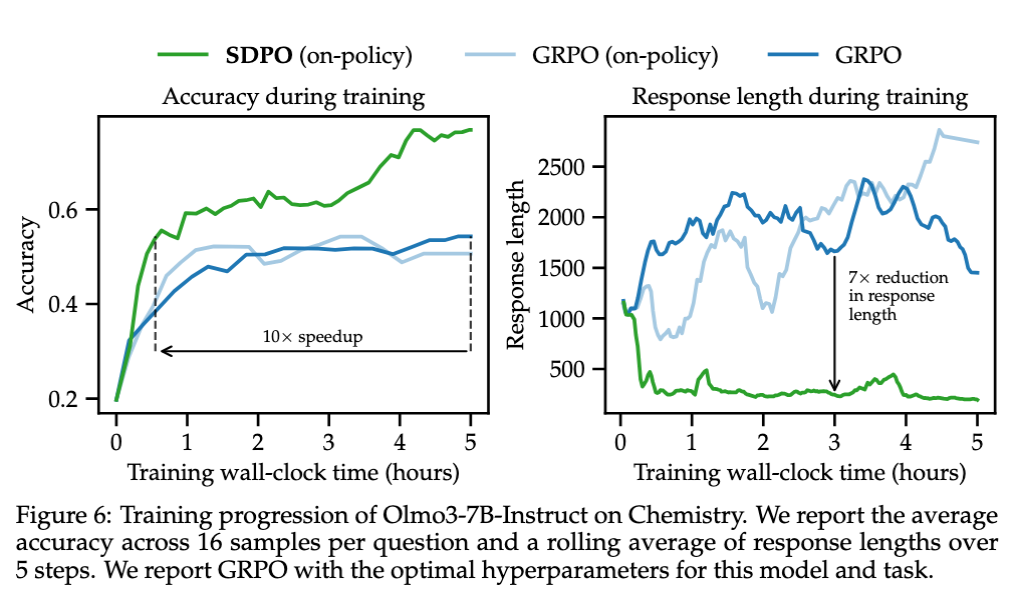
ベースラインのGRPOと比較して、出力の長さを抑えつつ精度を大幅に改善
5. 議論はあるか?
- モデルサイズへの依存 SDPOの効果はベースモデルの「In-context Learning能力」に依存する。Qwen3シリーズでの実験では、モデルサイズが大きくなるほどGRPOに対する優位性が高まることが確認された。
- フィードバックがリッチでないケース
リッチなフィードバックが得られないスカラー報酬しかない問題設定でも、バッチ内の他のrolloutで成功した回答を「フィードバック」として失敗した試行のコンテキストに含めることで、GRPOを上回る性能を示した。

感想
- 環境からのフィードバックをプロセス報酬として与えるのではなくコンテキストに含めて自己蒸留するアイデア面白い
- スカラー報酬だと情報が薄いというのはその通りなので、リッチなフィードバックは重要かもという気持ちになってきた。プログラムのようにコンパイルエラーが得られる環境はレアなので正しいフィードバックができるverifierがあればプロセス報酬や今回のself distilationに使える
メインTOPIC
ATLAS : ADAPTIVE TRANSFER SCALING LAWS FOR MULTILINGUAL PRETRAINING, FINETUNING, AND DECODING THE CURSE OF MULTILINGUALITY
Shayne Longpre, Sneha Kudugunta, Niklas Muennighoff, I-Hung Hsu, Isaac Caswell, Alex Pentland, Sercan Arik, Chen-Yu Lee, Sayna Ebrahimi
サマリー
Google DeepMind らによる論文。スケーリング則(Scaling laws)の研究は主に英語に焦点を当てこられたが、主要なAIモデルは数十億人の世界中のユーザーにサービスを提供している。AIモデルの利用者の半分以上が英語以外の言語を話すのだが、それでいいんだっけ?という問いに答えるために、10M〜8Bのパラメータ、400以上の学習言語、48の評価言語にまたがる774の多言語学習実験を行い、過去最大規模の多言語スケーリング則の研究を実施。
モノリンガル(単言語)およびマルチリンガル(多言語)事前学習の両方に対応する適応型転移スケーリング則(ATLAS: ADAPTIVE TRANSFER SCALING LAW)を導入し、多言語モデルにおける言語間の関係性を分析、以下の事実を明らかにした。
- CROSS-LINGUAL TRANSFER MATRIX(言語間転移行列):38×38(1444ペア)の言語間における学習に及ぼす影響の大きさを測定
- A scaling law for the curse of multilinguality(言語に依存しないスケーリング則):新しく言語を追加する際に、性能を犠牲にすることなくモデルサイズとデータを最適にスケーリングする方法を導出
- A general pretrain vs finetune formula:ゼロから事前学習する場合と、多言語チェックポイントからファインチューニングする場合のどちらが効率的かの分岐点を特定
1. Introduction
これまでのスケーリング則の研究は主に英語に集中していたが、現代の主要モデル(OpenAI, Anthropic, Google DeepMind等)は大規模な多言語利用者をターゲットとしています。しかし、publicな多言語スケーリング則の研究は限られています。そこで本研究では、以下のRQに取り組む。
- 異なる言語のスケーリング則の特性はどう違うのか?
- 38言語間の言語間転移の利益はどの程度か?
- 「多言語化の呪い(curse of multilinguality)」(学習言語を増やすとモデル容量の制限により各言語の損失が悪化する現象)をモデル化できるか?
- ゼロから事前学習すべきか、多言語チェックポイントからファインチューニングすべきか?
本研究の主な貢献
- ATLAS(The ADAPTIVE TRANSFER SCALING LAW):従来の研究よりも、未知のモデルサイズ(N)、データ(D)、計算量(C)、学習混合比(M)に対して優れた汎化性能を持つスケーリング則の提案
- CROSS-LINGUAL TRANSFER MATRIX(言語間転移行列):38×38(1444ペア)の言語間における学習に及ぼす影響の大きさを測定
- A scaling law for the curse of multilinguality(言語に依存しないスケーリング則):新しく言語を追加する際に、性能を犠牲にすることなくモデルサイズとデータを最適にスケーリングする方法を導出
- A general pretrain vs finetune formula:ゼロから事前学習する場合と、多言語チェックポイントからファインチューニングする場合のどちらが効率的かの分岐点を特定
2. EXPERIMENTAL SETUP
Datasets and Evaluation
語彙に依存しない損失(vocabulary-insensitive loss)で評価。通常のCE-Lossでは、語彙サイズやtokenizerの違いに敏感なので、言語間で評価がブレる(同じ意味を表すのに英語だと1トークンなのに、日本語だと数トークン必要など)。やっているのは、トークン単位の損失をトークンあたりのバイト数で正規化(同じ情報量・バイト数で細かくトークン分割される方が損失が小さくなるのをならす)。
Model Training
3. ADAPTIVE SCALING LAWS FOR MONOLINGUAL & MULTILINGUAL SETTINGS
Challenges with existing scaling laws for multilingual modeling
データの繰り返し(Repetition)を考慮していない
英語のような高リソース言語はデータが無限にある前提で計算されるが、ヒンディー語やスワヒリ語のような低リソース言語はデータが少なく、学習中に同じデータを何度も繰り返す必要がある。既存の法則は、繰り返すことによる「収穫逓減(やればやるほど効果が薄れる現象)」をうまくモデル化できていない。
言語間の「助け合い」を区別できない
多言語モデルでは「スペイン語の学習がポルトガル語の性能を上げる」といった転移(Transfer)が起きるはず。しかし、既存の法則はすべてのデータをひとまとめにするか、ターゲット言語しか見ないため、「どの言語がどれくらいターゲット言語の役に立ったか」をうまくモデリングできていない。
The ADAPTIVE TRANSFER SCALING LAW
上記課題を解決するため、ATLASという新しいスケーリング則を提案。 最大の特徴は、「実効データ量( )」という概念を導入し、学習データを3つに分けて計算する点。
ベースは以下の式(1)であり、モデルサイズ(N)が増えると損失が小さくなり、データサイズ(D)が大きくなると損失が小さくなる。
は3つのパートに別れている。
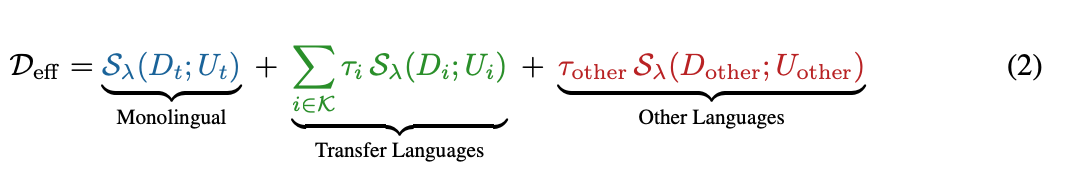
- Monolingual
- ターゲット言語そのもののデータ
- Transfer Languages
- ターゲット言語にとって「有益な」上位の言語データ
- 転移係数 τ(どれくらい役立つかの重み)が掛けられる
- Other Languages
- 残りのすべての言語データ。これらはターゲット言語にとってノイズになるか、わずかな助けにしかならないため、別の重みで計算される。
飽和関数(Saturation Function)の導入: データの繰り返し利用による学習効果の減衰のモデリング
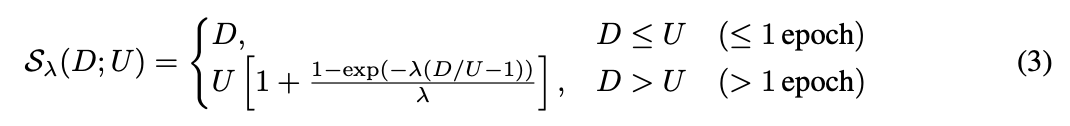
はじめてデータが使われる場合はそのままだが、2epoch目以降はデータ量が割り引かれる。
Research Question: How do scaling laws differ by language, and by monolingual vs multilingual training mixtures?(言語ごと、あるいは単言語と多言語学習によってスケーリング則はどう変わる?)

多言語語彙(Multilingual vocab, 今回は Sentence Piece)で特定の言語を学習させると、その言語だけを専門に学習させる場合(Monolingual)に比べて、同じ性能を出すためにより多くの計算リソースが必要になる(同じデータサイズにおいて、必要なモデルサイズは点線、波線、実践の順に大きい)
これを計算効率税(compute-efficiency tax)と呼んでいるが、英語で特に顕著であり、他の言語と混ぜることで英語単体の性能効率は減少している。逆に、低リソース言語は他の言語から恩恵を受けていそう。
Research Question: How well can our scaling laws capture unique monolingual constraints, and complex multilingual cross-lingual transfer dynamics?(予測性能は?)
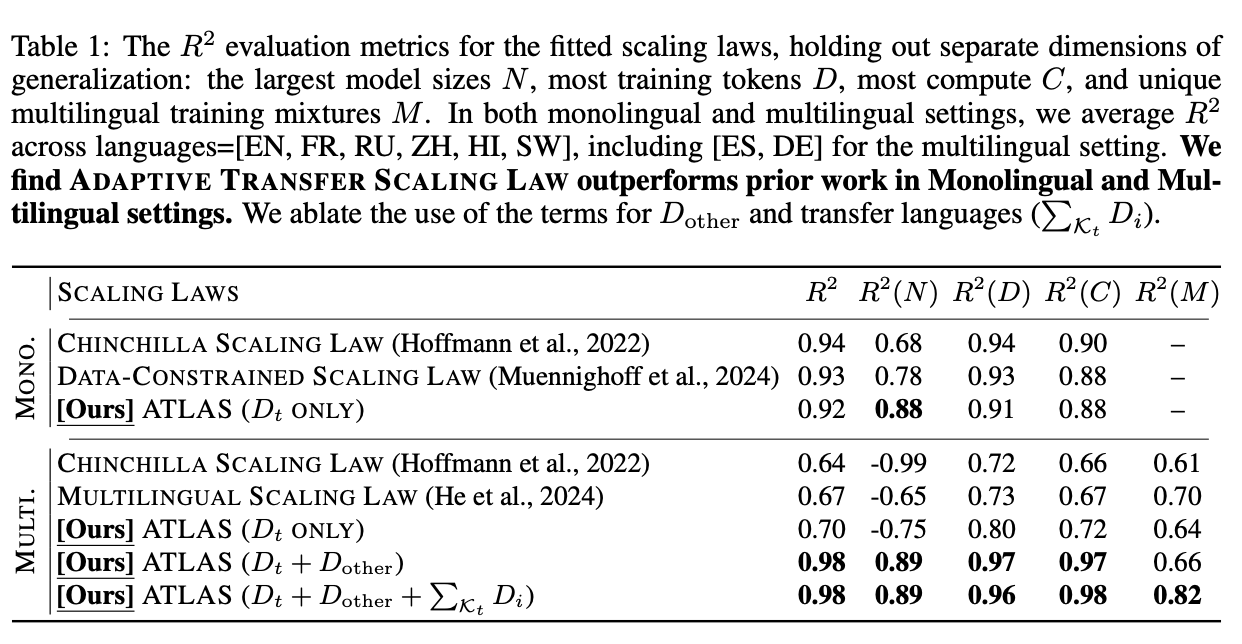
高いね。
4. HOW DO LANGUAGES BENEFIT OR INTERFERE WITH EACH OTHER?
Research Question: Which languages synergize or interfere most with one another’s performance?(言語間の相乗効果、あるいは阻害度合いは?)
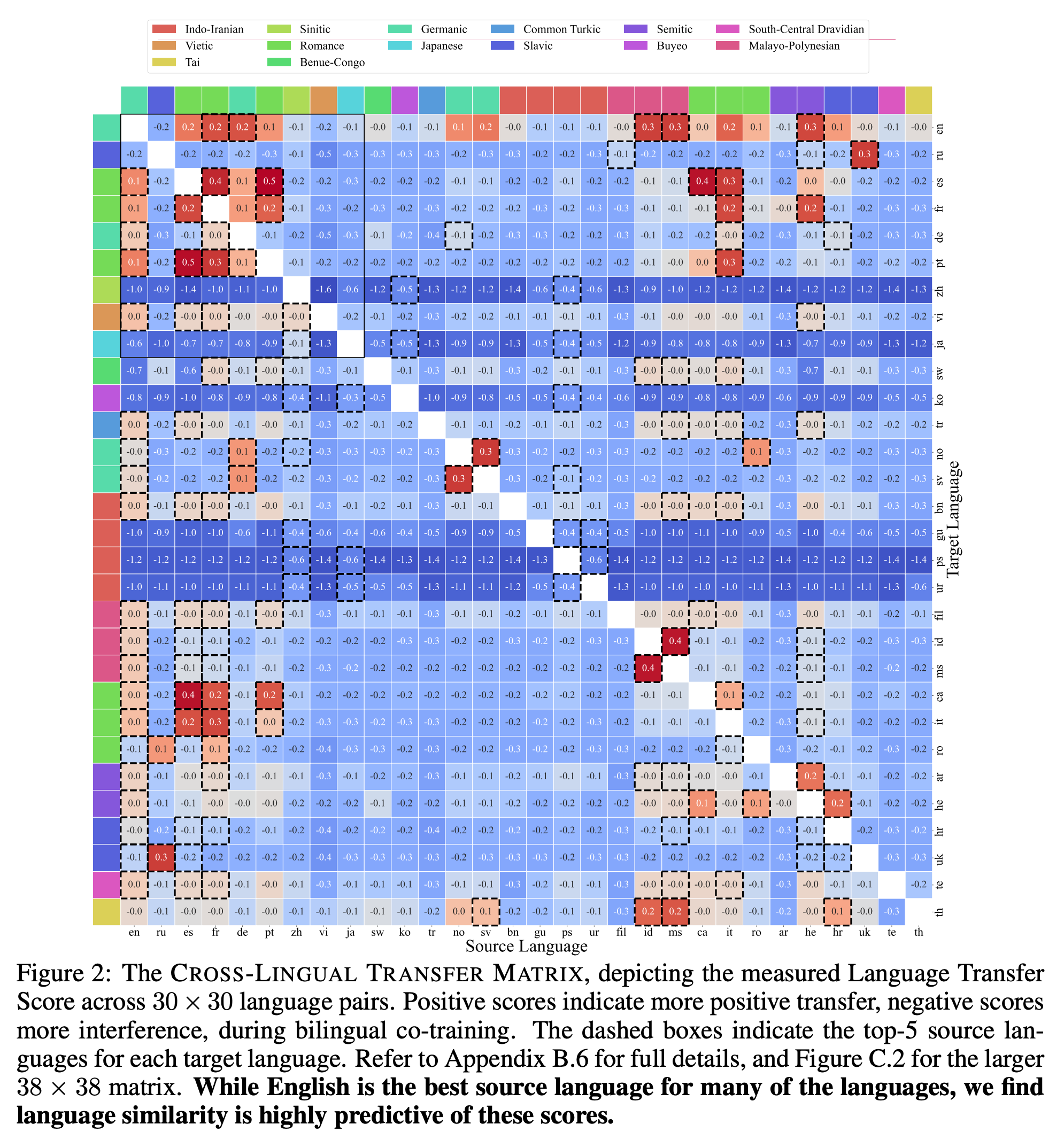
Source Language が Target Language の学習にどのような影響を与えるかをmatrixで表現
相性を決める要因
A. 文字体系(Script)と語族(Family)の共有
「同じ文字体系(スクリプト)を使っているか」が、語族が同じであること以上に強いプラスの効果を生む。
Script: ラテン文字、キリル文字、漢字など
Language Family: 同じ祖先言語からの派生で文法などが似ている。ゲルマン語派、ロマンス語派、など
「同じ語族」かつ「同じ文字体系」の言語(例:スペイン語とポルトガル語、ノルウェー語とスウェーデン語)。これらは強い相乗効果を生みます。
文字体系の壁: 語彙や文法が似ていても、文字が異なると(例:ラテン文字とキリル文字)、相乗効果は大幅に薄れるか、干渉し合う傾向がある。これは、モデルが表面的な文字表現(サブワード)を共有できるかどうかが、知識転移の主なメカニズムであることが示唆される。
B. 英語は万能
多くの言語にとって、Englishと一緒に学習することはプラスの効果をもたらる。30言語中19のケースで、英語が最も役立つソース言語となっている(セルが破線で囲まれている)。これは英語のデータ量が豊富で品質が高いためと考えられる。
C. 低リソース言語の孤立
ウルドゥー語やパシュトー語のような一部の低リソース言語は、他のほぼすべての言語に対して「負の転移(干渉)」を示す。これらは他の言語と混ぜると性能が落ちやすく、扱いが難しいことを示す。
非対称性 / Language transfer scores are often symmetric within the same language family and script, but surprisingly, they cannot be assumed to be reciprocal otherwise.
英語は多くの言語を助けますが、逆に他の言語が英語の性能を上げる効果は薄い(あるいは邪魔をする)ことが多い
ただし、「同じ語族かつ同じ文字体系」のグループ(フランス語とスペイン語など)の間では、お互いに助け合う対称的な関係が見られた
測定方法
Bilingual Transfer Score (BTS) という独自の指標
- ターゲット言語だけを学習したモデル(モノリンガル)を作る。
- ターゲット言語とソース言語を50:50で混ぜて学習したモデル(バイリンガル)を作る。
- 両者が「同じ到達点(損失値)」に達するのにかかった学習ステップ数を比較
混ぜた方が早く到達できた → プラス(助けになった)
混ぜた方が時間がかかった → マイナス(邪魔になった)
5. THE CURSE OF MULTILINGUALITY—MODEL CAPACITY CONSTRAINTS
“多言語の呪い” : モデル容量が限られているため、モデルサイズが一定のまま学習させる言語数を増やすとパフォーマンスが低下する。
多言語の呪いに対して、言語数をrKにスケールアップする場合にモデル性能を維持するためにはモデルサイズまたはデータサイズをどれほど増やす必要があるのかを表す。
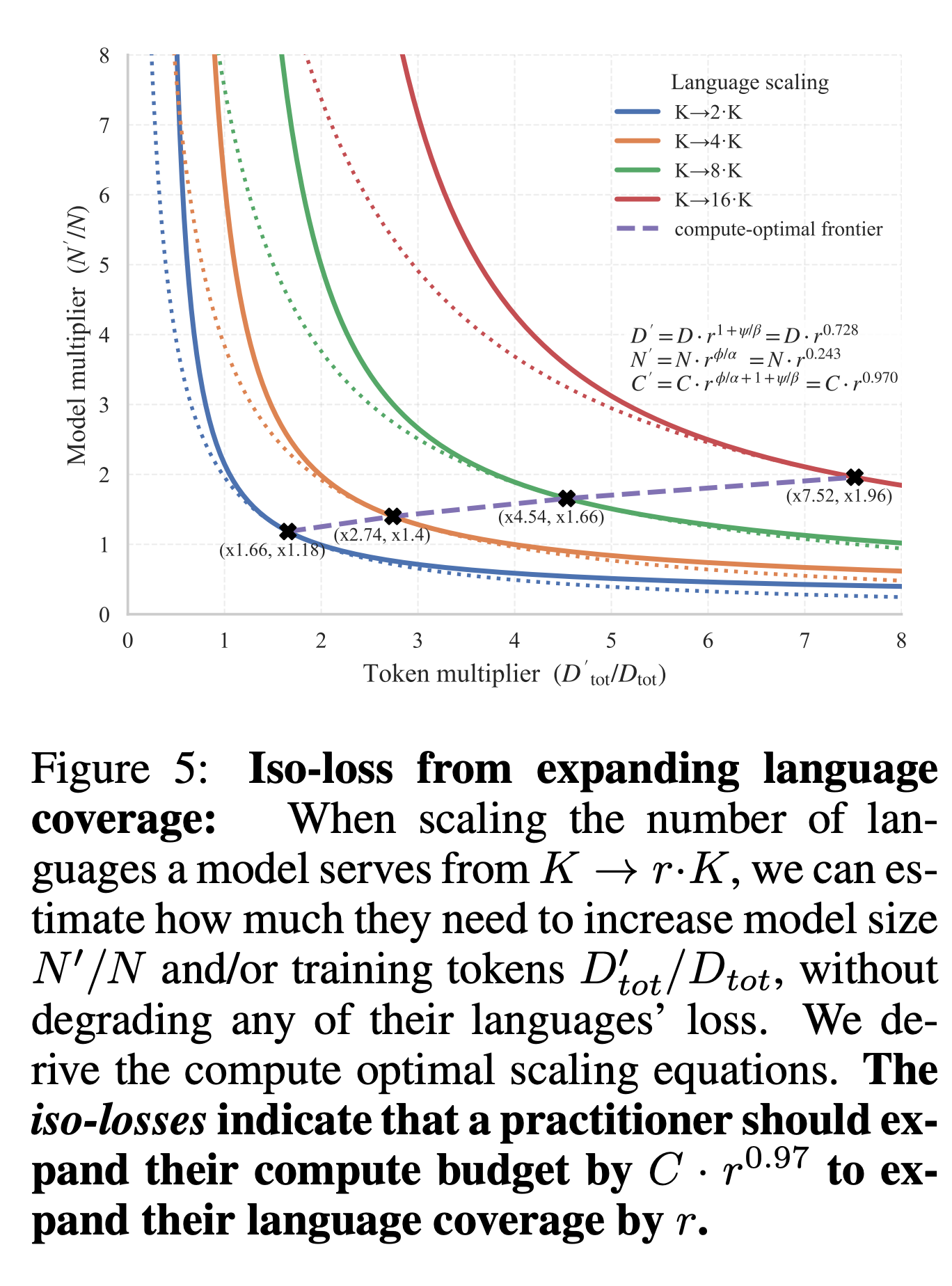
たとえば言語数を2倍にする場合、同等の性能を維持するためにはモデルサイズを1.18倍、データの合計を1.66倍にする必要がある。確かにコストは大きくなるのだが、言語数を2倍にしているのにもかかわらず、データ量を2倍にせずとも済んでいる。これは、言語間でtransferが発生しているからであろう。
また、データサイズよりもモデルサイズを大きくするほうが言語数が増えた際のペナルティ解消に効いている(データサイズは1.66倍にするが、モデルサイズは1.18倍で済んでいる)。
※ compute-optimal frontier:計算最適フロンティア):「性能(損失)を維持したまま言語数を増やす際、総計算量(C≈6ND)が最小になるようなモデルサイズ(N)とデータ量(D)の組み合わせ」**を、ラグランジュの未定乗数法を用いて算出したものです。
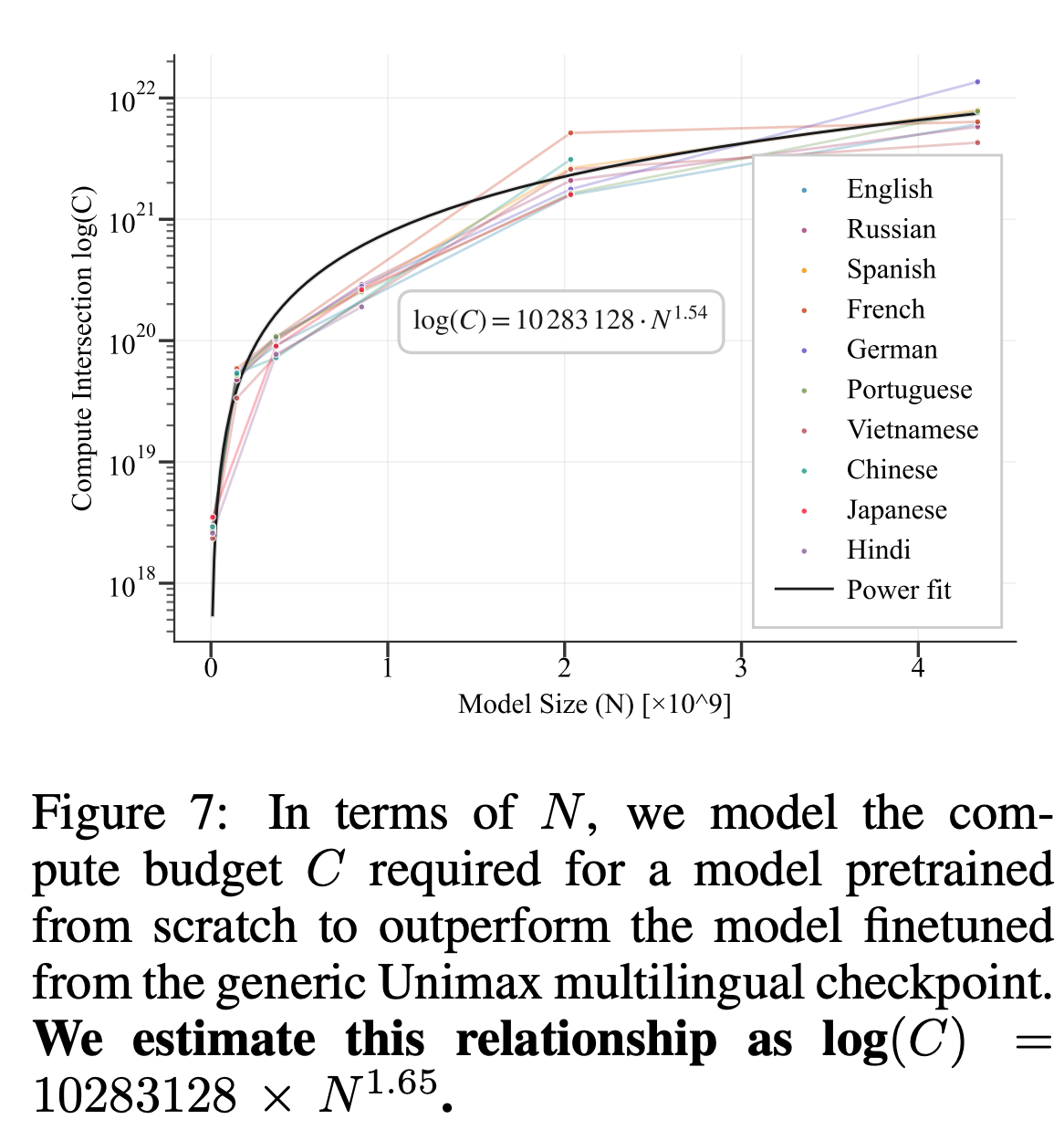
6. PRETRAIN OR FINETUNE?
基本的にfinetuningのほうが高い性能を出しやすいが、ゼロから事前学習の場合でも十分なデータ量で十分に学習を進めれば同等の性能に追いつく。言語ごとにデータ量を増やした際のゼロからの事前学習(点線)と事前学習済みモデルからのfintune(破線)のロスを比較したのが以下。実線はロスの差を表しており、0(右縦軸)になったところ(・)ではゼロからの事前学習がfintuningに追いついたことを示す。これをクロスオーバーポイントと呼ぶ。

言語によってぶれるが、144B-283Bトークンの間にクロスオーバーポイントは存在するので、このデータ量を目安にして、ゼロからの事前学習を行うのか、finetuningにするのか決めれば良いであろう。
以下はモデルサイズと事前学習における計算予算の関係を表したもの。モデルサイズが大きくなるほど必要な計算予算は増える。学習の目安に。