2026-02-10 機械学習勉強会
今週のTOPIC[論文] Kimi K2.5: Visual Agentic Intelligence[論文] F-GRPO: Don't Let Your Policy Learn the Obvious and Forget the Rare[blog] Claude Opus4.6はどのようにPPTXを生成しているか[paper] Learning to Reason in 13 ParametersメインTOPICClosing the Loop: Universal Repository Representation with RPG-Encoder1. Introduction1.1 背景:リポジトリレベルAIエージェントの課題二極化した情報表現の問題1.2 提案:逆プロセスとしての統合とRPG-Encoder提案の視点RPG-Encoderの提案RPG: ‣1.3 本研究の主な貢献2. Related Work2.1 Repository Generation(リポジトリ生成)2.2 Repository Understanding(リポジトリ理解)3. Method3.1 RPG Encoding: Extracting RPG from CodebasesPhase 1: Semantic LiftingPhase 2: Semantic Structure ReorganizationPhase 3: Artifact Grounding3.2 RPG Evolution: Incremental Maintenance更新の流れ3つの更新プロトコル3.3 RPG Operation: Unified Reasoning Substrate4. Experiments Setup4.1 Repository Understanding(リポジトリ理解タスク)4.2 Repository Reconstruction(リポジトリ再構築タスク)Main Result & Analysisリポジトリ理解リポジトリ再構築と忠実度アブレーション研究(要素除去テスト)コスト効率:95.7%の削減
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] Kimi K2.5: Visual Agentic Intelligence
- めちゃくちゃ精度が高いと噂のKIMI K2.5のテクニカルレポート
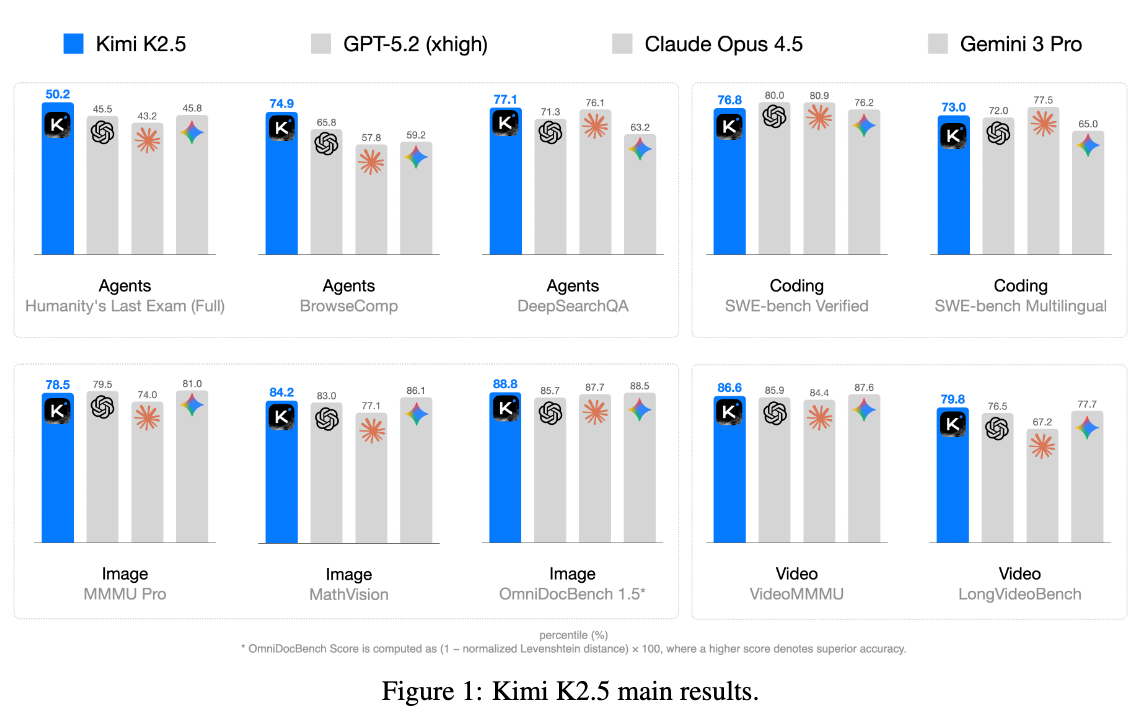
- 主要な貢献

- Joint Optimization
- 従来のマルチモーダル学習はトレードオフに悩まされることが多かった。
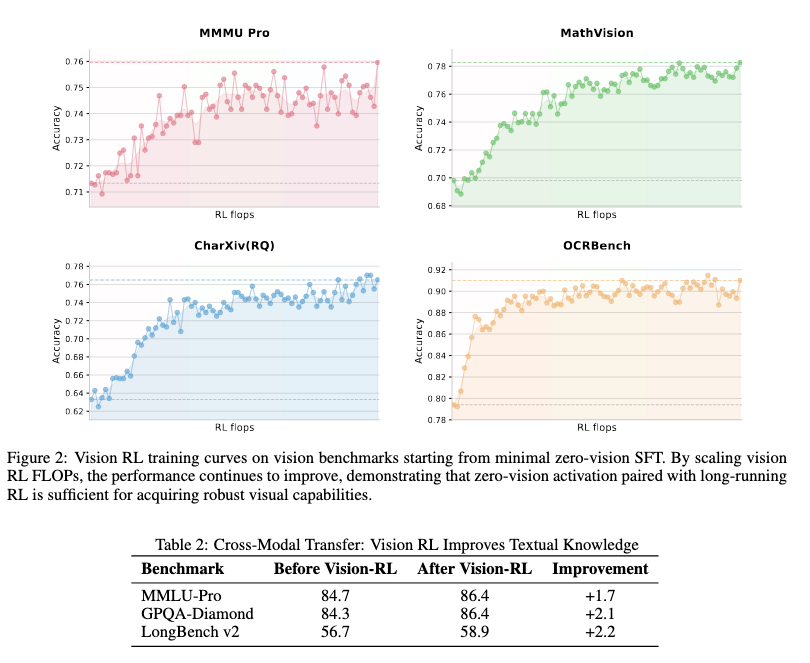
- 従来のpre trainingは学習終盤にVisionを結合させていたが、pre trainingの初期段階から低い比率でVisionを少しだけ統合することで安定したマルチモーダルパフォーマンスが得られた
- 具体的にはテキストだけで学習させることもあれば、Visionをたまに混ぜるといった予算の管理を行う
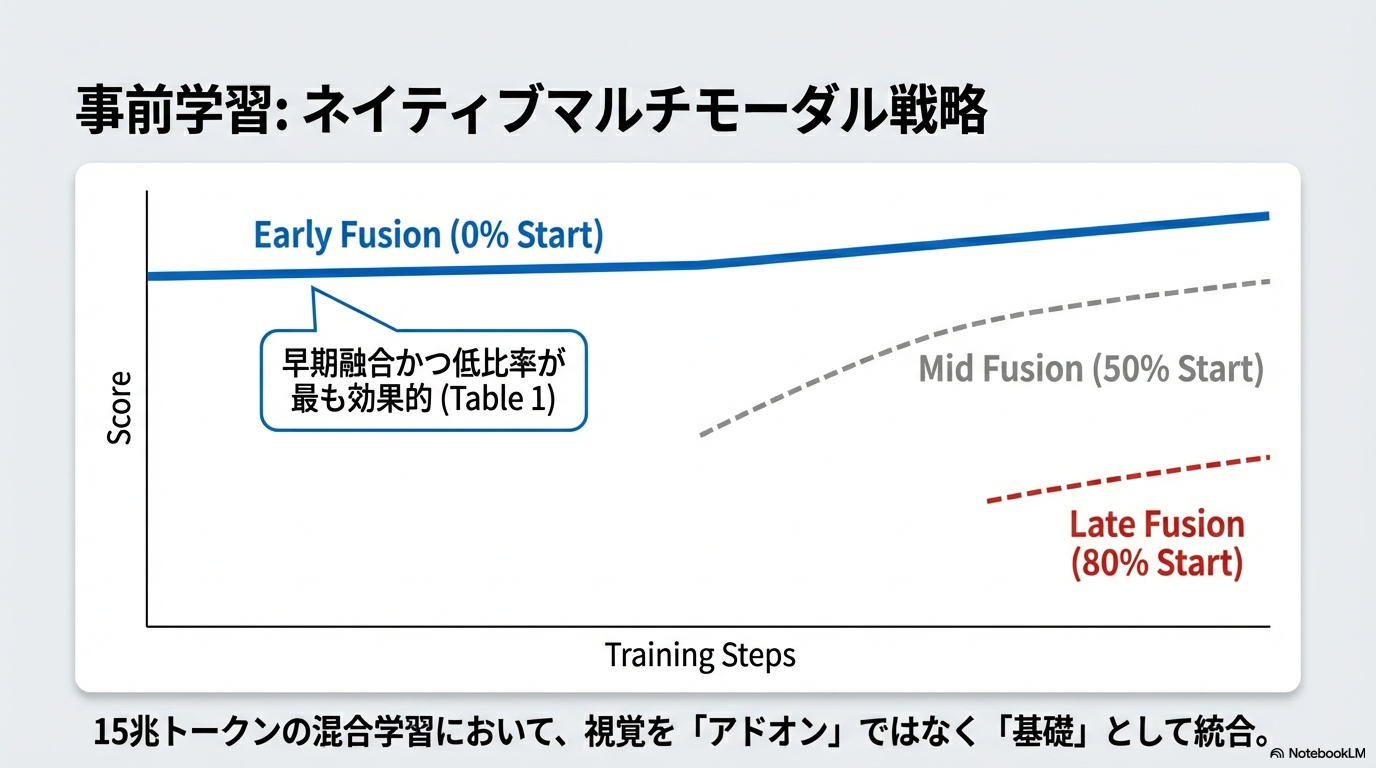
- Zero-Vision SFT
- 画像操作を全てIPythonのプログラム実行で置き換え、テキストのみでSFTを行う。
- 従来の「まず画像内の座標 $(x,y)$ を注視し、次にその部分をクロップして詳細を確認し、最後に物体を検出する」といった操作を学習させると、特定のTool Callの呼び出しの形式に従って学習することとなり、汎化性能が失われる。プログラムの方が一貫した表現で、論理的に記述できるため、汎化性能を失いにくい。
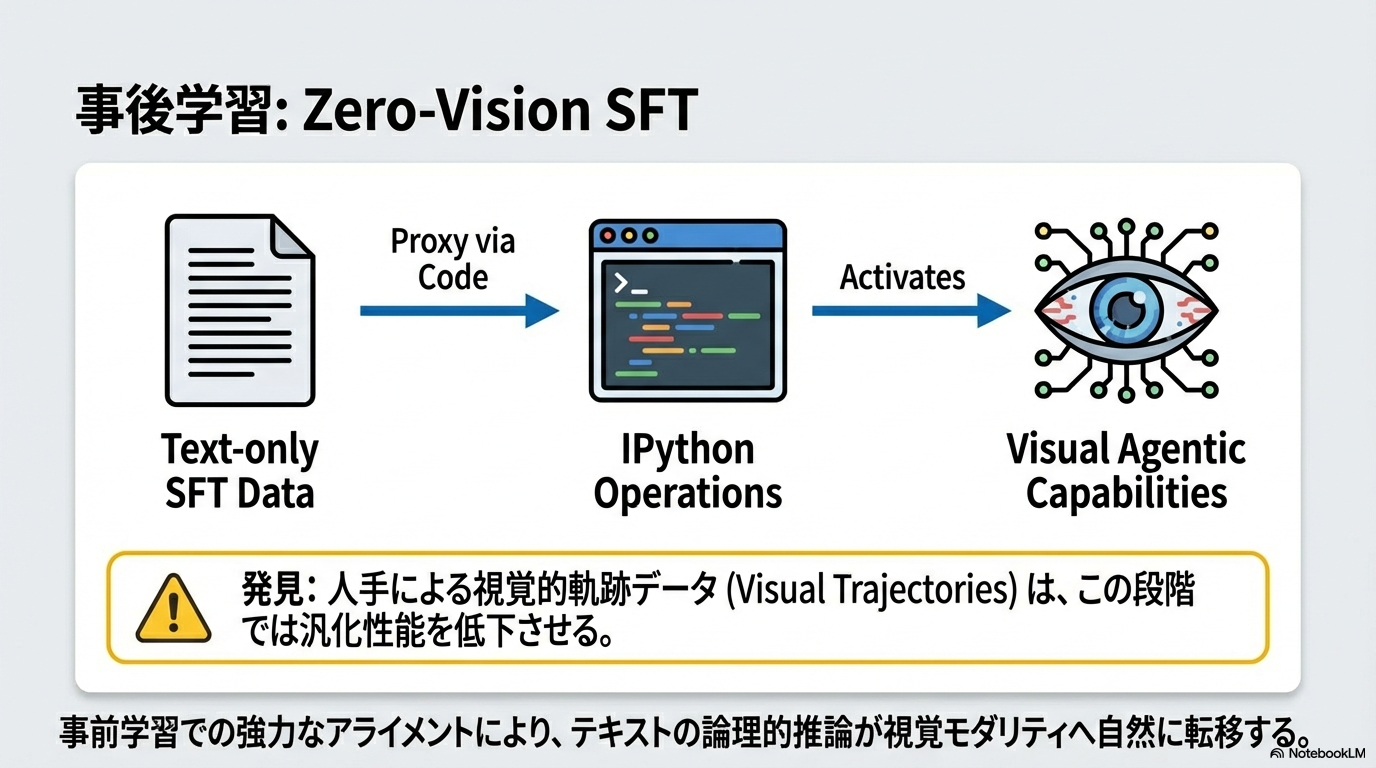
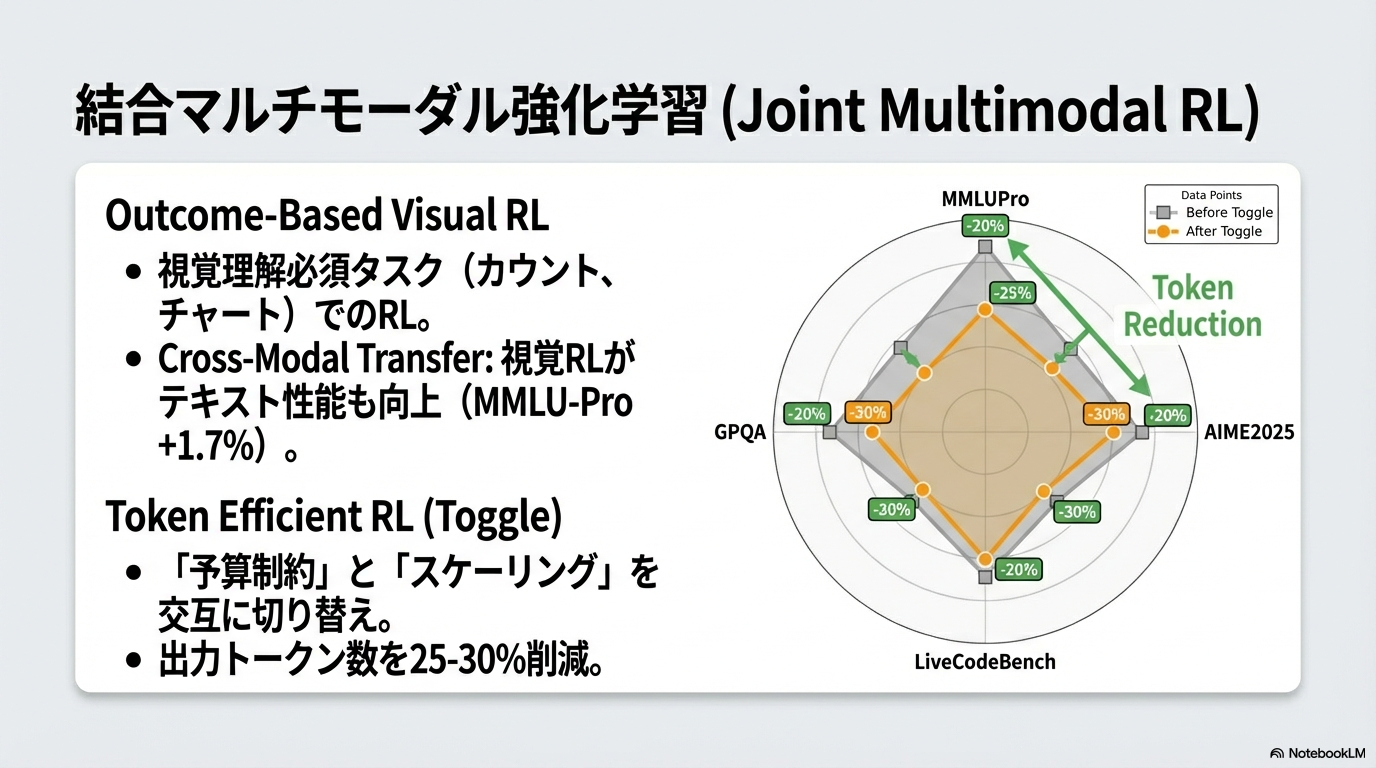
- Joint Multimodal RL
- Zero-Vision SFTの後に、アウトカムベースで視覚系のタスクを強化学習
- 実際の視覚入力に基づいて正確に推論・実行できるようにRefinementすることが目的。
- Zero-Vision SFTでコードを記述できるようになったものを、ちゃんと使いこなせるようにするイメージ
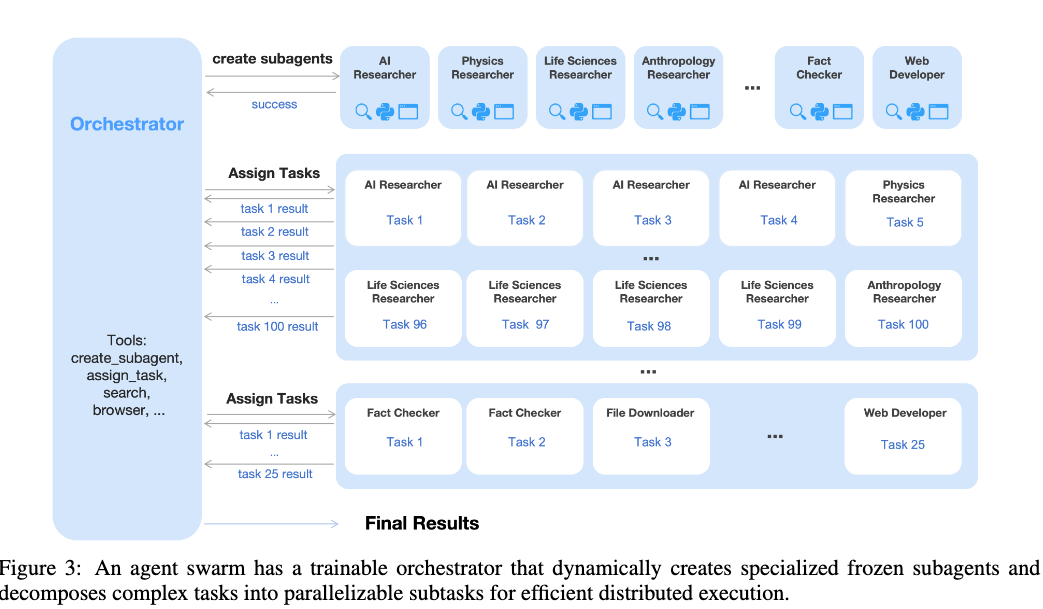
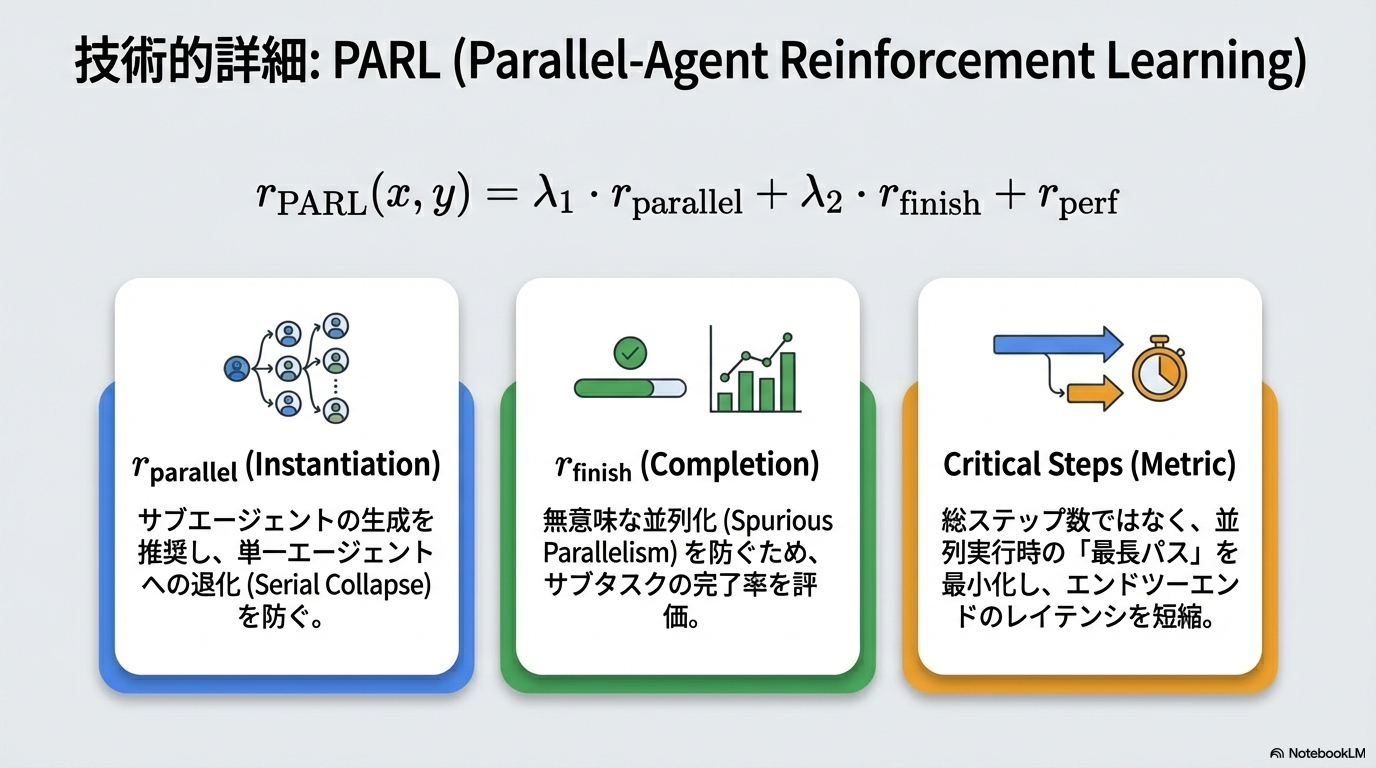
- Agent SwarmとParallel-Agent Reinforcement Learning (PARL)
- 訓練可能なオーケストレータと、固定された中間ポリシーチェックポイントから実体化された凍結されたサブエージェントからなる分離アーキテクチャ。
- サブエージェントは凍結して環境観測として扱うことで、高レベルの調整ロジックを低レベルの実行習熟度から切り離し、より堅牢な収束を実現。
- オーケストレーターとサブエージェントは同じKimi K2.5
- 普通のタスク完了の報酬に加えて早期完了を目標とするRLを行う
- 精度向上、かつレイテンシ改善
Toolはweb search, code interpreter, web browsingに加えたcreate_subagenとassign_taskのみ
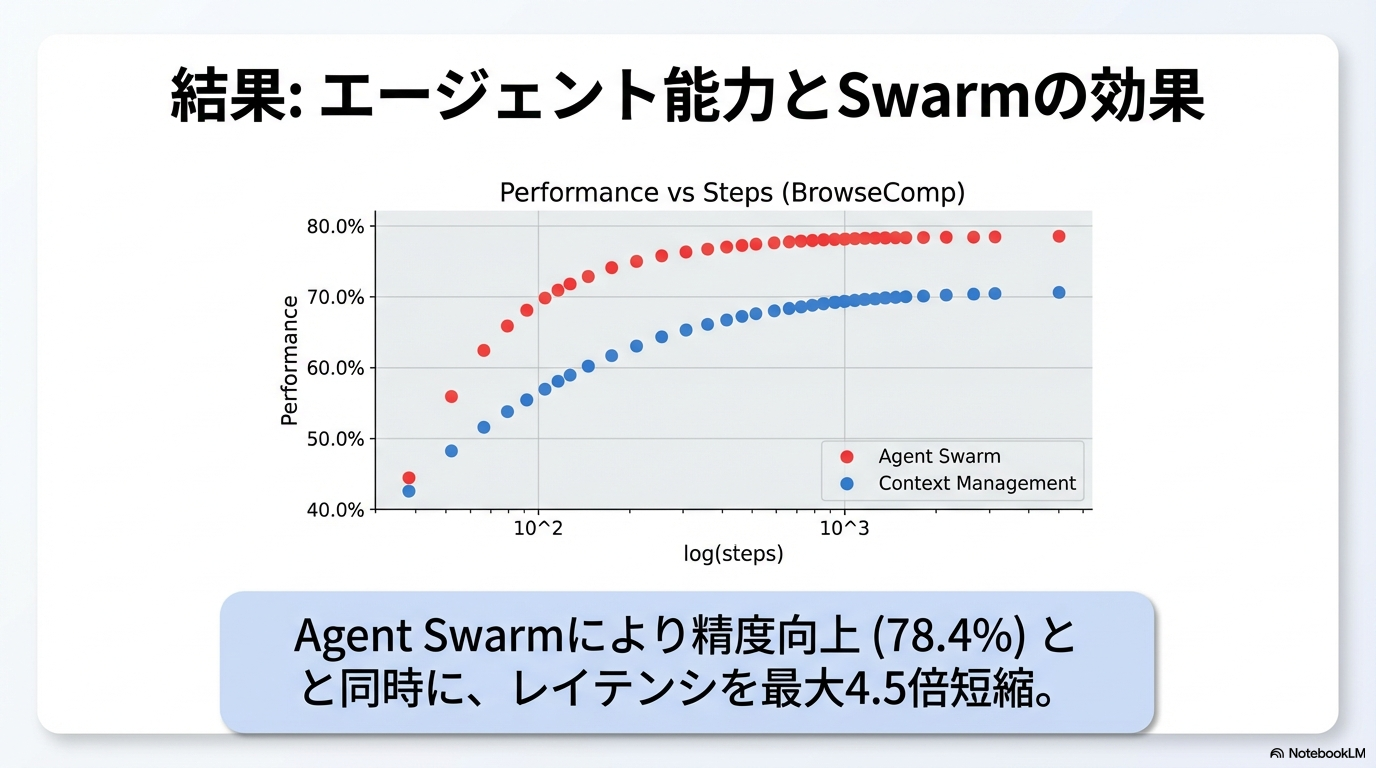
- インフラとかも工夫してるらしい (ちゃんと読めておらず)
@Shun Ito
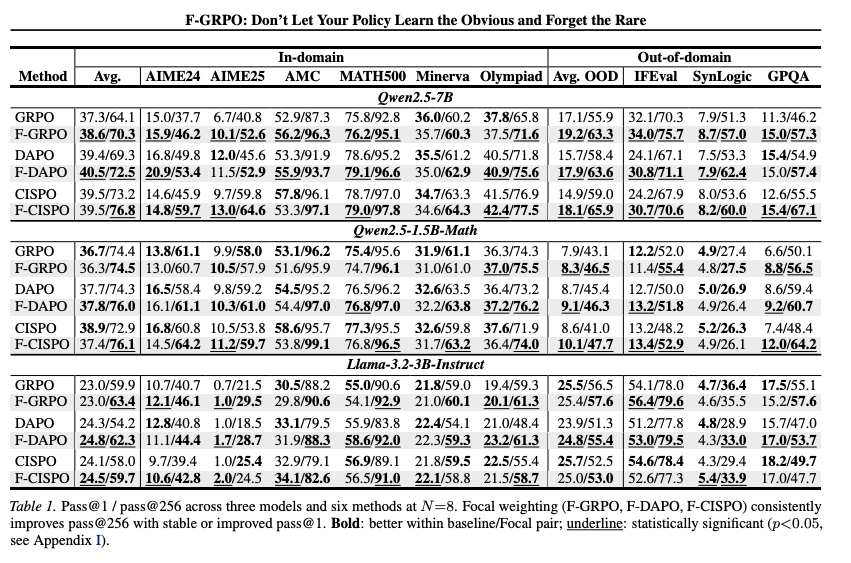
[論文] F-GRPO: Don't Let Your Policy Learn the Obvious and Forget the Rare
- GRPOの改良版の提案
- 課題
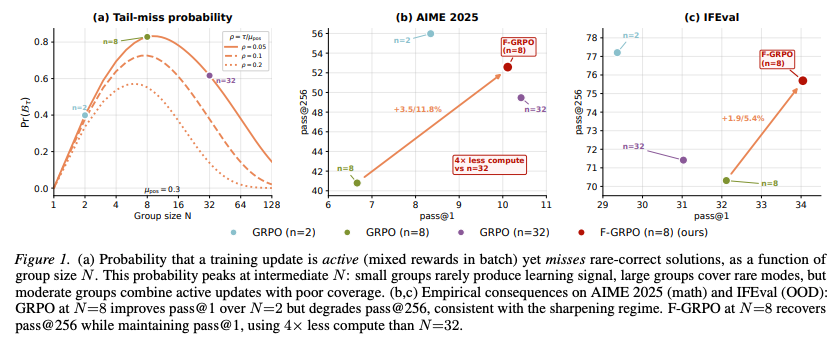
- 通常のGRPOでは、計算量を抑えるため、group size をあまり大きくできない
- そのため「レアだが正しい解」をサンプルしづらく、簡単なタスクのありふれた正解にフィードバックが偏る
- ありふれた正解しか生成されないようになり、多様な正解候補が失われる
- pass@1 はよくなるが、pass@256 は落ちる
- 手法
- 元々のGRPO
- inputの難易度(正解したrolloutの割合)が多いほどadvantageを抑える
- 正解率:
- 正解率に応じた重み付け
- いわゆる Focal Loss と同じようなアプローチ
- 成功率が高いinputに関する更新を弱めることで、多様性が維持される狙い
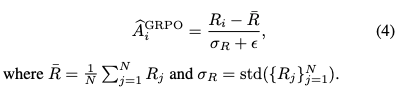
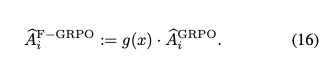
- 実験
- group sizeを大きくするほど「レアな正解」をフィードバックできる確率は高まるので、group sizeが大きいほど精度は上がりやすい
- 提案手法は、固定のgroup size (N=8) で N=32 相当の性能に
- GRPO以外の手法にも適用可能で有効
@Takumi Iida (frkake)
[blog] Claude Opus4.6はどのようにPPTXを生成しているか
パワポで使ってみたけどめちゃくちゃ便利だった。
生成後に自分で編集できるのが強いし、文字が崩れない。
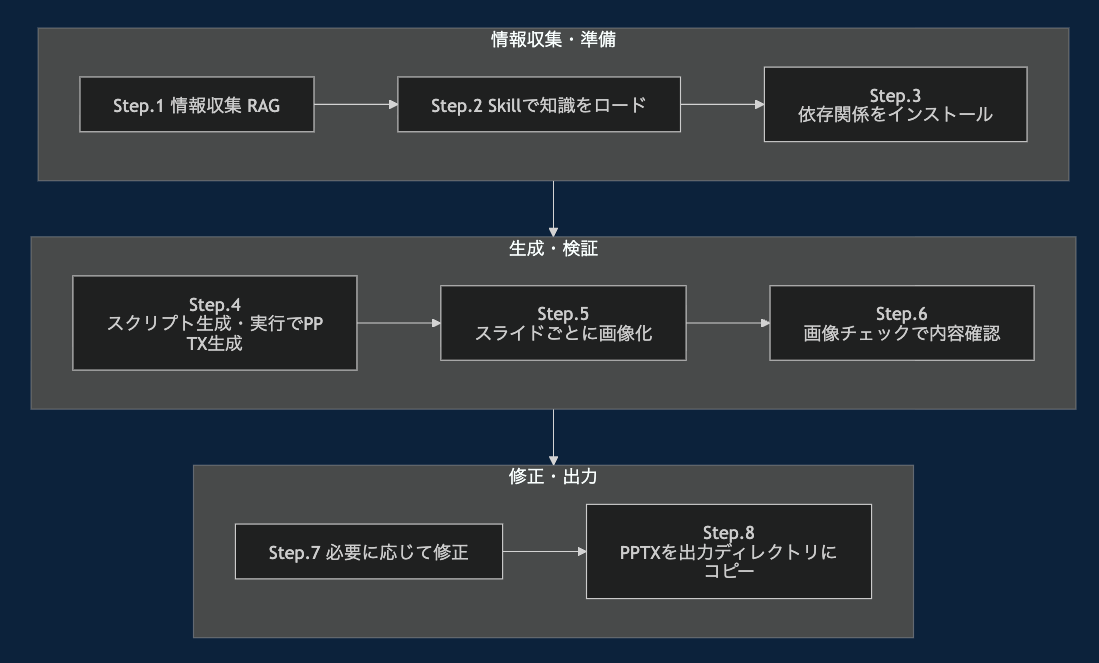
SKILLSで基本的に生成してる
Claude SKILLSで必要なライブラリをインスコ、その後PPTX生成用のNode.jsスクリプトを生成&実行
PPTX生成スクリプト
出来栄えはPPTXファイルを画像化して評価
Claudeが画像をチェックして品質評価
汚かったらその都度修正
感想
パワポアドオンからじゃないとできないかなと感じてたけど、パワポ使えなくてもClaude Codeで作れそうな雰囲気を感じたので共有してみた
Claude Codeでやってみた↓
もともと紹介しようと思ってた論文
- 論文中の図表がめっちゃ長いとスライド中に入らずに崩れる
- ひょっとしたら必要なライブラリが入ってなくて、ちょっとレイアウト崩れてるかも
- パワポに統合されたClaudeの方がいまのところ使いやすくて綺麗かも。論文解説のタスクを任せたのが悪かったのかもしれないが
@Hiromu Nakamura (pon)
[paper] Learning to Reason in 13 Parameters
LoRAの更新サイズを1パラメータまで縮小できる「TinyLoRA」を提案し、8BモデルのQwen2.5をわずか13パラメータでGSM8Kにおいて91%の精度を達成。
この図(@akshay_pachaarさん作)がわかりやすかった
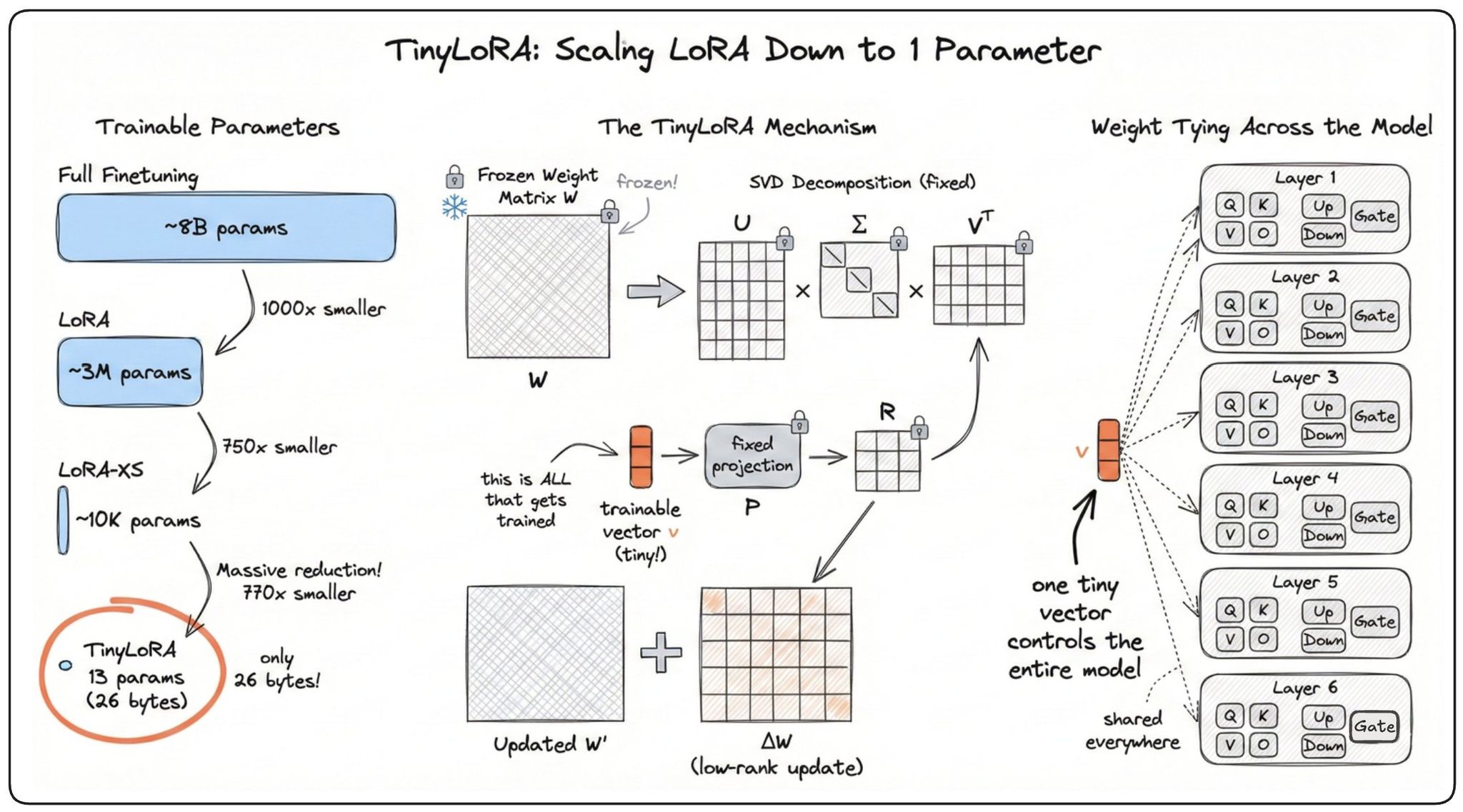
- SFTと比較して、RLは少ない情報で高パフォーマンスを達成できるという観察に基づき、TinyLoRAはRLと組み合わせることで極めて低いパラメータ数で高い性能を達成
- 例えば、Qwen2.5-7B-InstructモデルをGSM8Kでファインチューニングする際、TinyLoRAとGRPOを組み合わせることで、わずか13個のパラメータ(bf16で26バイト)で91%の精度を達成しています。これは、同じパフォーマンスレベルに達するためにSFTが必要とする更新サイズよりも100〜1000倍小さいもの。
関連研究
先行研究では、VeRA、VB-LoRA、LoRA-XSなど、さまざまなLoRAの拡張が提案されているが、これらは主に10K〜10Mパラメータスケールで機能する。本研究は、これを10Kパラメータ未満の超低パラメータスケールに拡張。
SFTとRLの更新能力
本研究は、SFTとRLがモデルを良好なパフォーマンスに訓練するために必要なキャパシティの差を分析。
SFTは、次トークン予測の損失関数で訓練されます:
一方、RLのポリシー勾配法は以下の目的関数に基づいて訓練される:
RLは各エポックで新しい継続を複数サンプリングするため、SFTよりも多くのデータを提供するように見えますが、その情報のほとんどはノイズです。有用なシグナルは報酬にのみ存在し、このシグナルはクリーンかつスパースです。SFTでは、報酬アノテーションがないため、モデルは実演に含まれるすべてのトークンを等しく情報を持つものとして扱ってしまいます。このため、SFTは多くのビットの情報を吸収する必要があり、そのうちタスクに関連するのはごく一部です。対照的に、RLはよりスパースでクリーンなシグナルを受け取るため、より少ないキャパシティでも効果的に学習できるという仮説を立てています。
TinyLoRA
TinyLoRAは、LoRAおよびLoRA-XSをさらに拡張し、わずか1パラメータにまでスケーリング可能にする手法です。
LoRA
- 線形層 W ∈ ℝ^(d×k) を W' = W + AB で適応。ここで A ∈ ℝ^(d×r)、B ∈ ℝ^(r×k) は訓練可能で、訓練可能なパラメータ数はモジュールあたり O(dr)。
LoRA-XS
- W' = W + UΣRV^⊤ を使用し、R ∈ ℝ^(r×r) のみが訓練可能。モジュールあたりのパラメータ数は O(r²)。
TinyLoRA
- LoRA-XSの r×r 行列 R を、低次元の訓練可能なベクトル v ∈ ℝ^u を固定のランダムテンソル P ∈ ℝ^(u×r×r) を介して射影することで置き換える。更新ルールは以下の通り:
ここで P_i ∈ ℝ^(r×r) は固定のランダム行列。これにより、各モジュールはわずか u 個のパラメータのみを訓練。
パラメータ共有
- 訓練可能なベクトル v を複数のモジュール間で共有する (weight tying factor)を導入することで、パラメータ数をさらに削減。全モジュールで共有()すると、総パラメータ数を 個にまで減らすことができ、最小で1パラメータでの訓練が可能になる。
実験
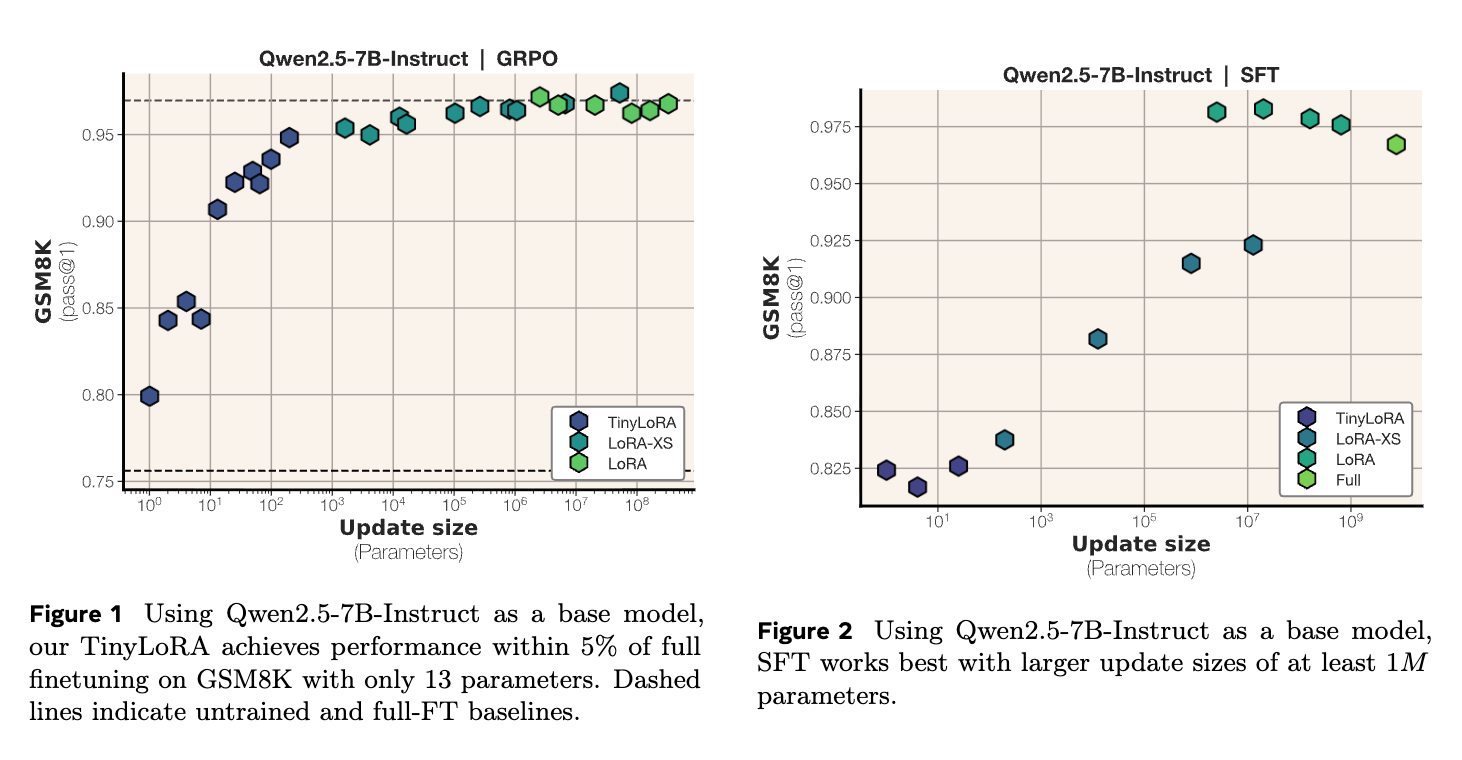
GRPO
- パラメータ数と性能の関係: 全体として、更新するパラメータの数が増えるにつれて、GSM8Kにおけるモデルの性能が向上している。
- TinyLoRAが非常に少ないパラメータ数で高い性能を達成している。例えば、わずか13のパラメータ(X軸で10¹と10²の間にある青い点)で91%もの精度を達成している。これはベースモデルの76%から大幅な改善。
- 1パラメータという極めて少ない更新(X軸の10⁰の点)でも、ベースラインの76%から約80%へと5%程度の性能向上を見せている。
SFT
- Supervised Fine-Tuningが低パラメータ領域では効果が限定的であり、高精度を達成するためには多くのパラメータを更新する必要がある
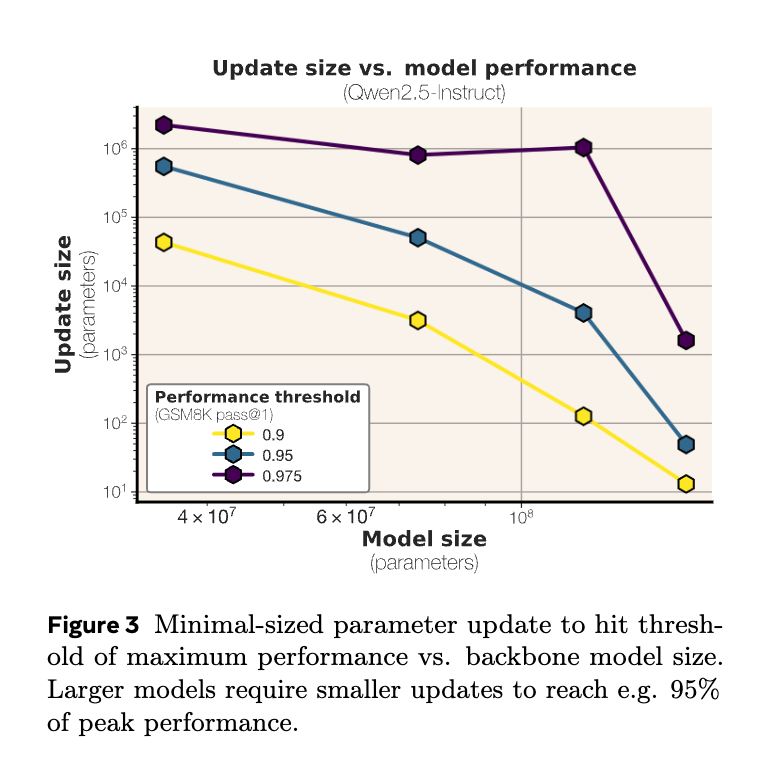
論文が主張する「モデルサイズが大きくなるにつれて、フルファインチューニングの95%のピーク性能に達するための絶対パラメータが少なくなる」という傾向を裏付けている(P8, Section 6.4)。これは、極めて大規模な(兆規模の)モデルが、ほんの一握りのパラメータで多くのタスクに対して簡単に学習可能である可能性を示す。
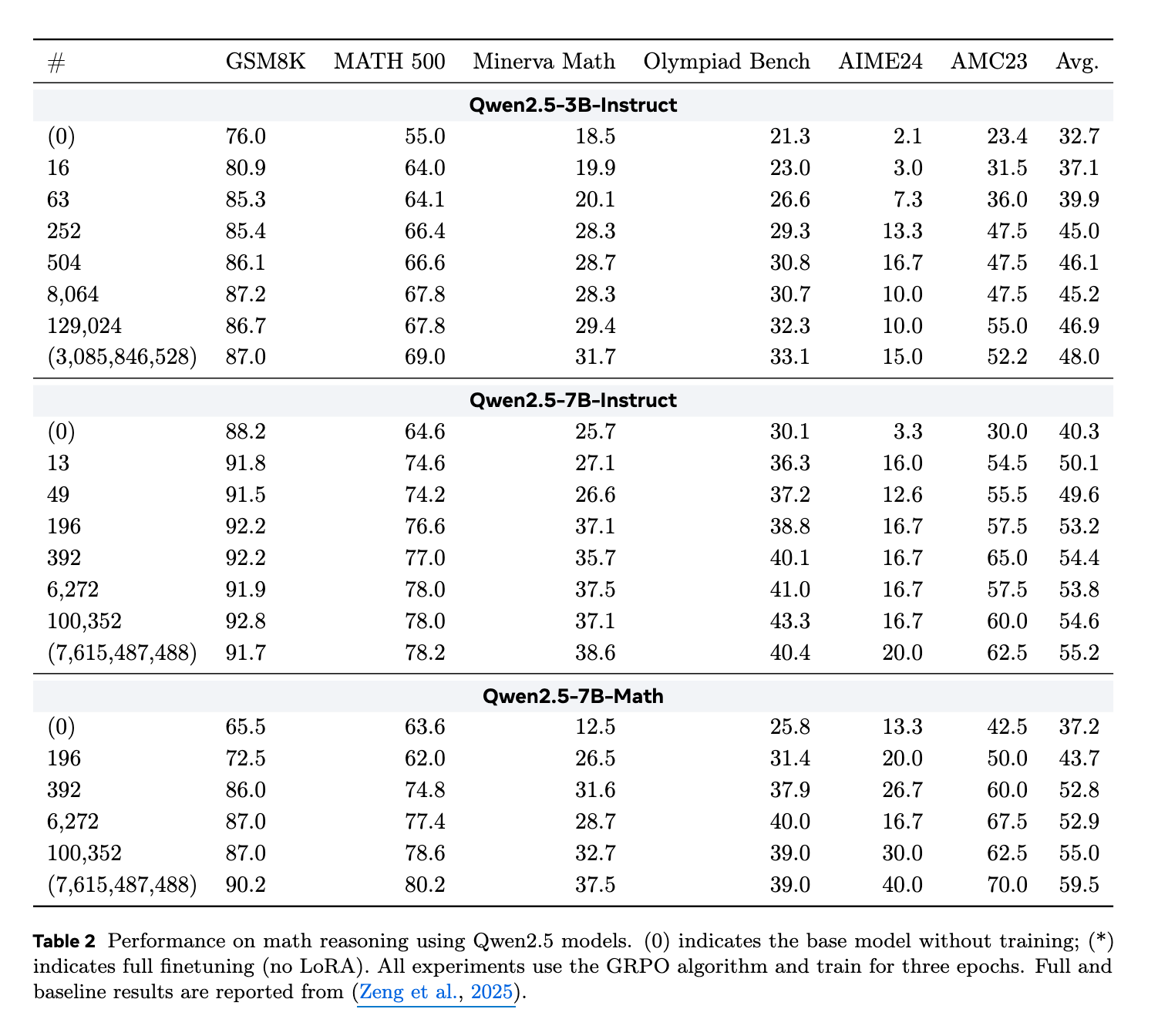
TinyLoRAは、より複雑な数学推論ベンチマークスイートにおいても、極めて少ないパラメータ数で強力なパフォーマンスを発揮。例えば、Qwen2.5-7B-Instructをわずか196パラメータでファインチューニングすることで、6つの困難な数学ベンチマーク全体で絶対性能向上分の87%を維持
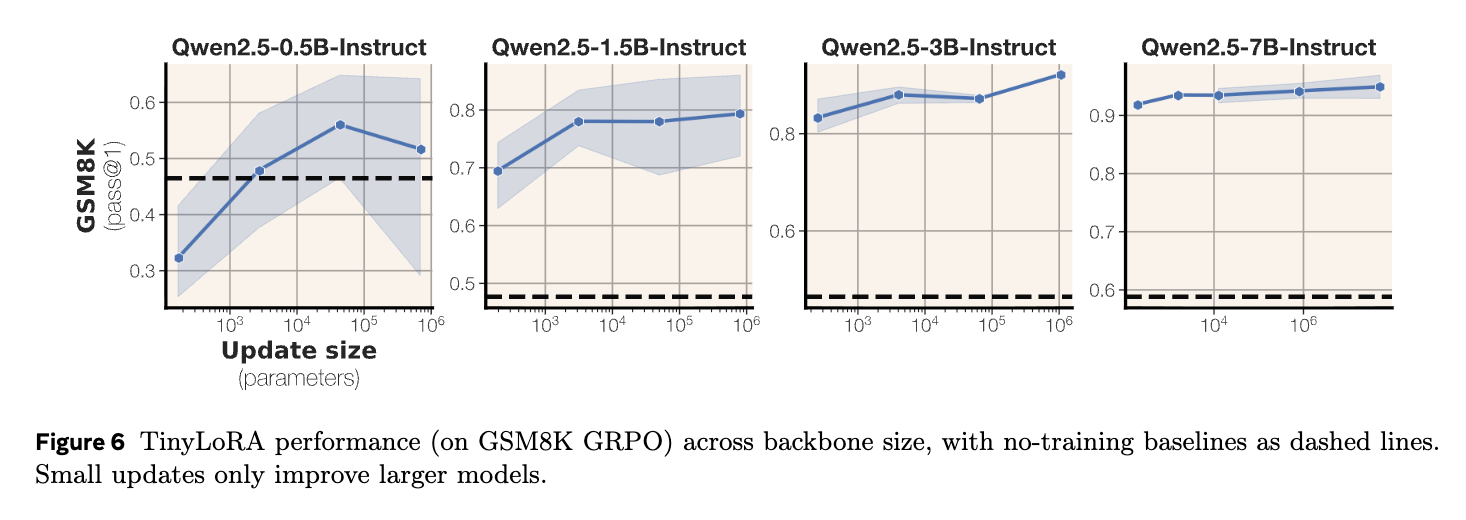
低パラメータ適応は、大規模なバックボーンモデルでより効果を発揮します。つまり、モデルサイズが大きくなるほど、同じ数の更新パラメータで得られる性能改善が大きくなる。
結論として、TinyLoRAは、以前考えられていたよりもはるかに少ないパラメータでモデルを効果的にチューニングできることを示しました。特にRLと組み合わせることで、更新ファイルサイズを1KB未満に抑えつつ、フルファインチューニングに近いパフォーマンスを達成できることを実証。
メインTOPIC
Closing the Loop: Universal Repository Representation with RPG-Encoder
Paper: arxiv.org

Jane Luo¹*, Chengyu Yin¹*, Xin Zhang¹*†, Qingtao Li¹, Steven Liu¹, Yiming Huang², Jie Wu³, Hao Liu¹, Yangyu Huang¹, Yu Kang¹, Fangkai Yang¹, Ying Xin¹, Scarlett Li¹
¹Microsoft Research Asia, ²UCSD, ³Tsinghua University
*Equal contribution, †Corresponding author
1. Introduction
1.1 背景:リポジトリレベルAIエージェントの課題
現在のソフトウェアエンジニアリングエージェントは、大規模なコードベースを扱う際に「推論の分断 (Reasoning Disconnect)」に直面する。エージェントが利用できる情報の表現形式が、以下の二つに二極化してしまっていることに起因。
二極化した情報表現の問題
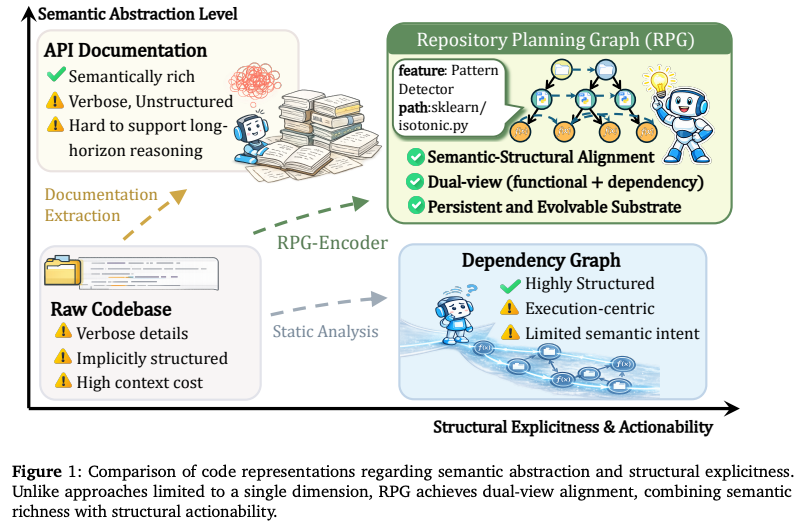
- APIドキュメント(意味的だが構造欠如)。
- 関数の目的や意図(Semantics)は自然言語で豊富に記述。
- しかし、「この関数がシステム全体のどこに位置し、どのモジュールから呼ばれているか」という構造的なナビゲーション情報が欠如。
- 依存関係グラフ(構造的だが意味欠如)。
- ファイル間のimportや関数呼び出し(Call Graph)といった構造的な論理は正確。
- しかし、「なぜそのコードが存在するのか」という意味的な深さ(意図)が欠落。
- 例:「認証モジュール」という概念的なまとまりはグラフ上には現れず、単なるファイルノードの集合としてしか見えない状態。
既存の手法(RAGや単純なグラフ探索)はこのどちらか一方に偏っており、エージェントは「機能の意図」と「実装の場所」を結びつけるのに膨大な試行錯誤が必要。
1.2 提案:逆プロセスとしての統合とRPG-Encoder
提案の視点
ソフトウェア開発における「理解」と「生成」を、互いに逆方向のプロセスとして捉える新しい視点。
- 生成 (Generation): 抽象的な「意図」を具体的な「実装」へと展開するプロセス(Intent → Implementation)。
- 理解 (Comprehension): 具体的な「実装」を抽象的な「意図」へと圧縮するプロセス(Implementation → Intent)。
RPG-Encoderの提案
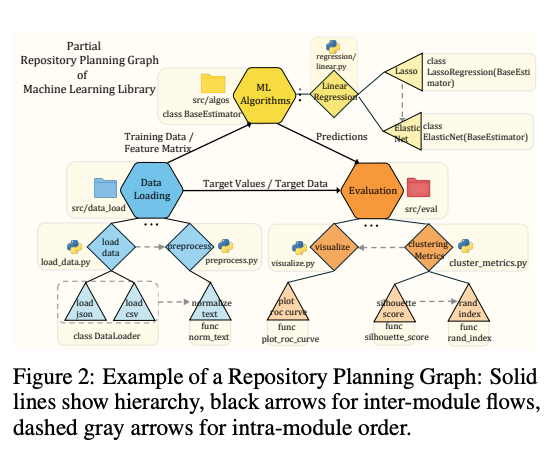
このループを閉じる(Closing the Loop)ために、先行研究で生成タスクの「青写真」として使われていた RPG (Repository Planning Graph) を、リポジトリ理解にも適用可能な普遍的な中間表現(Universal Representation)へと拡張するフレームワーク。
RPG:  huggingfacePaper page - RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
huggingfacePaper page - RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Jane Luo¹*‡, Xin Zhang¹*†, Steven Liu¹‡, Jie Wu¹²‡, Jianfeng Liu¹, Yiming Huang³, Yangyu Huang¹, Chengyu Yin¹, Ying Xin¹, Yuefeng Zhan¹, Hao Sun¹, Qi Chen¹, Scarlett Li¹, Mao Yang¹
¹Microsoft, ²Tsinghua University, ³University of California, San Diego
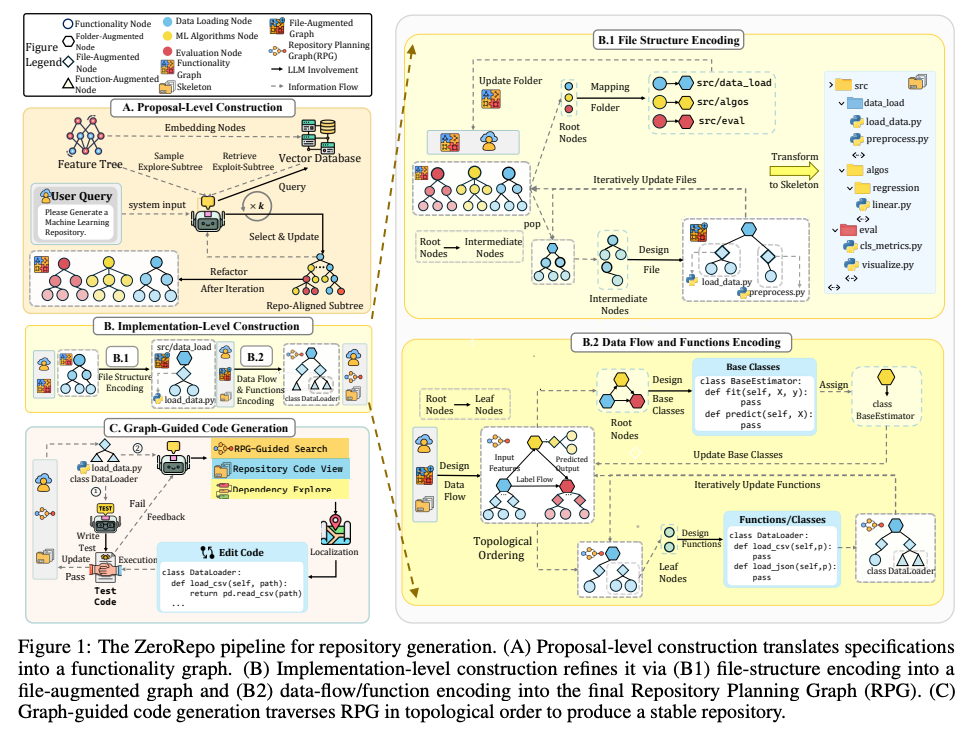
1.3 本研究の主な貢献
- RPG Encoding (構築): 生のソースコードから、「意味的特徴(意図)」と「依存関係(構造)」を融合させたRPGを自動抽出する技術を確立。
- RPG Evolution (進化): リポジトリの変更(コミット)に対し、グラフ全体を再構築するのではなく、差分のみを更新する「増分更新(Incremental Update)」メカニズムを導入。これによりメンテナンスコストを95.7%削減。
- RPG Operation (運用): エージェントが構造認識型のナビゲーションを行うための統一インターフェースを提供。
- SOTAの達成:
- SWE-bench Verified: 関数レベルの特定精度(Acc@5)で93.7%を達成し、既存最高モデル(OrcaLoca)を大きく上回る。
- RepoCraft: リポジトリ復元タスクにおいて98.5%のカバレッジを達成し、高い忠実度(Fidelity)を証明。
2. Related Work
2.1 Repository Generation(リポジトリ生成)
- トレンド
- 単一ファイルの補完(Copilot等)から、リポジトリ全体の一貫性を重視するアーキテクチャ生成(MetaGPT, Commit)へ移行。
- RPGの位置付け
- 先行研究では、RPGは生成時の「静的な設計図」として使用。
- 本研究は、これを動的かつ双方向(読み書き可能)な表現へと昇華させた点が新規性。
2.2 Repository Understanding(リポジトリ理解)
- トレンド
- 受動的な情報検索(RAG: コード断片のベクトル検索)から、能動的な構造探索(LocAgent, KGCompass: グラフやツリーの探索)へシフト。
- 既存の限界
- 従来の依存関係グラフは、ノード名(関数名など)のみに頼って検索を行うため、名前が曖昧な場合(例: , )に検索精度が低下。
- RPG-Encoderは、ノードにリッチな意味記述(要約)を付与することでこれを解決。
3. Method
RPG-Encoderは「Encoding(抽出)」「Evolution(保守)」「Operation(利用)」の3つの柱で構成。
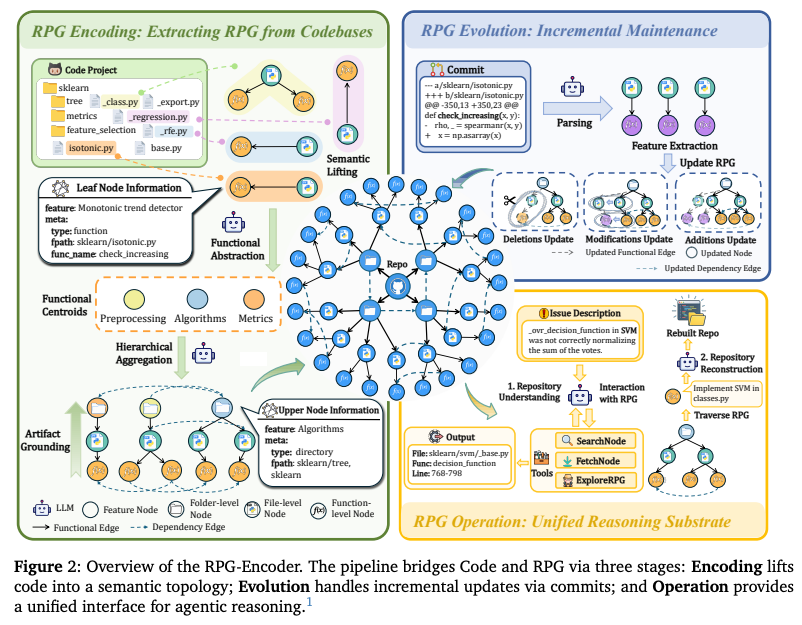
3.1 RPG Encoding: Extracting RPG from Codebases
生のコードベースをエージェントが解釈可能なグラフに変換するプロセス。以下の3フェーズで実行。
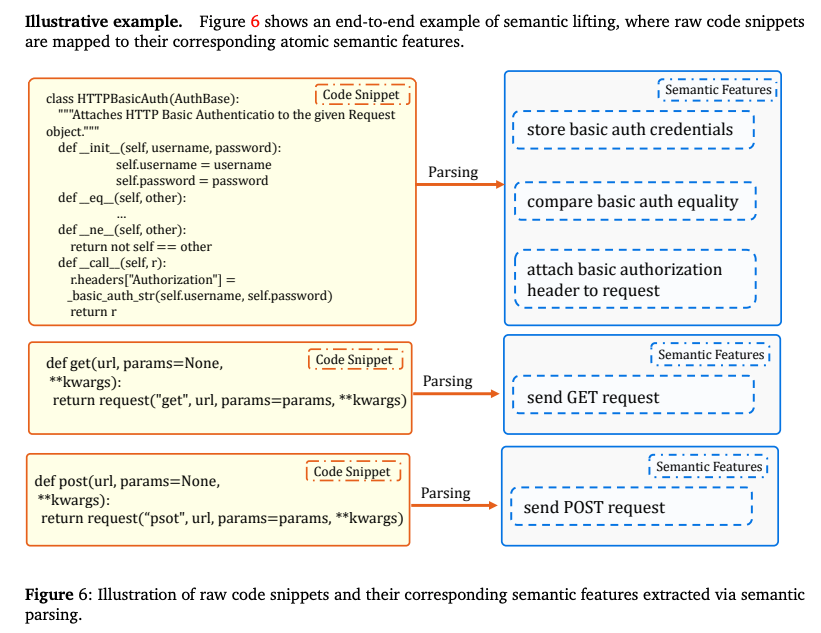
Phase 1: Semantic Lifting
コードの「実装の詳細」と「機能的な意図」の粒度のギャップを埋める処理。
- 処理内容
- 各ファイル内の関数・クラスに対し、LLMを用いて意味的特徴(f:機能説明)と構造メタデータ(m:シグネチャ、行数)を抽出。
- 要約の集約
- 関数レベルの特徴をボトムアップに集約し、ファイル全体の機能を表現する要約を生成。
- これにより、低レベルノードのレジストリが作成される。
Phase 2: Semantic Structure Reorganization
物理的なディレクトリ構造に縛られず、機能的な意味に基づく階層構造を構築。
- 問題点
- 物理フォルダ構造は開発の都合(ビルド設定など)で決まることが多く、必ずしも「機能のまとまり」を表さない。
- 機能的トポロジーの構築
- 抽出された全特徴をLLMが分析し、リポジトリ全体の主要な機能(例: 「データ前処理」「認証」)を特定して重心(Centroids)を定義。
- これに基づき、抽象的な高レベルノード( )による階層ツリーを構築。
Phase 3: Artifact Grounding
抽象的な「機能ツリー」を、現実の「物理ファイル」および「実行パス」と結合。
- LCA (Lowest Common Ancestor) マッピング
- 抽象的な機能ノードが、物理ディレクトリのどこに対応するかを特定。
- その機能に属するファイル群が共有する最小のディレクトリ範囲を計算し、そこにノードを「接地(Grounding)」。
- 依存関係の注入
- AST(抽象構文木)解析を行い、物理ファイル間の や関数呼び出し関係を抽出。
- これを依存関係エッジ( )としてグラフに追加。
- 結果
- RPGは「機能的な階層(Is-a/Has-a関係)」と「実行時の依存関係(Calls/Imports関係)」の両方を持つハイブリッドなグラフ。
詳細
このプロセスは、コードの「実装の詳細」を剥ぎ取り、「機能的な意図」だけを抽出して再構築する作業であり、RPG-Encoderの根幹を成す。
A.1.1 Semantic Lifting via Prompted Semantic Parsing
生のコードは変数名や制御構文(for文、if文)などの「実装ノイズ」が多く、そのままではエージェントにとって情報過多。「Semantic Lifting(意味的持ち上げ)」とは、コードから本質的な「機能(Intent)」だけを抽出する作業。
特徴抽出のプロセス
LLM(GPT-4など)を使用し、各コードファイルから以下の2種類の情報を抽出。
意味的特徴(f: Semantic Features)
- そのコードが「何をするものか」という自然言語による要約。
構造メタデータ(m: Structural Metadata)
- ファイルパス、関数シグネチャ(引数・戻り値)、行数、親クラスなどの静的な情報。
厳格な命名規則(Feature Naming Rules)
抽出の際、LLMが勝手な解釈をしないよう、非常に厳格なルールを課す。
Verb-Object形式の強制
- 機能説明は必ず「動詞 + 目的語」の形にする。
- 悪い例: (実装っぽい)。
- 良い例: (意図が明確)。
- 効果: 表記ゆれを防ぎ、ベクトル検索時の精度を高める。
単一責任の原則(Single Responsibility)
- 「データを読み込んで前処理する」といった複合機能は、 と に分割して記述させる。
ノイズの除去(Filtering)
すべてのコードが重要わけではない。
- 除外対象: ゲッター/セッター、単純なデータクラス、ボイラープレート(定型文)コード。
- 抽出対象: アルゴリズム、ビジネスロジック、主要な制御フローを持つ部分。
ボトムアップ集約(Bottom-up Aggregation)
- まず「関数/クラスレベル」で特徴を抽出。
- 次に、それらを集約して「ファイルレベル」の要約(File Summary)を生成。
- これにより、詳細度(粒度)の異なる情報の階層が生まれる。
A.1.2 Latent Architecture Recovery for Hierarchical Encoding
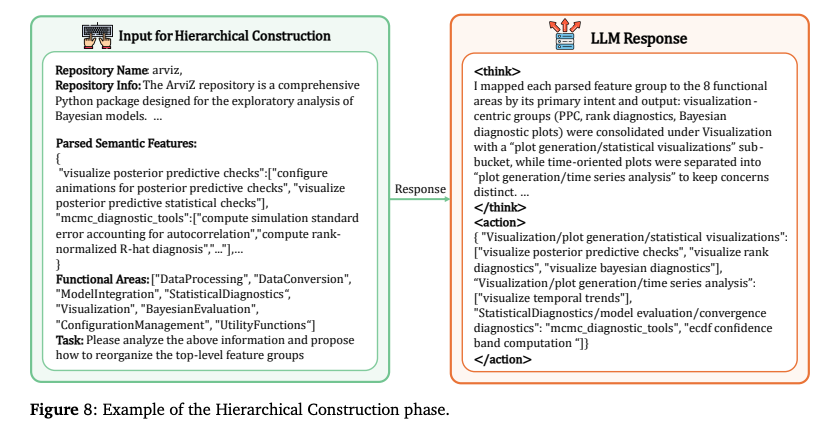
A.1.1で抽出された「機能のリスト」はフラット(平坦)な状態。これを整理棚に入れるように階層化するのがこのステップ。重要なのは、「物理フォルダ構造」ではなく「機能的な意味」で整理するという点。
物理構造 vs 機能構造
- 物理構造の限界: 開発者はしばしば、便宜上 や といったフォルダに無関係な機能を放り込む。これをそのまま学習すると、エージェントは「には何でもある」と混乱。
- 解決策: 物理配置を無視し、機能の意味に基づいた「理想的な階層構造(Functional Topology)」をゼロから作り直す。
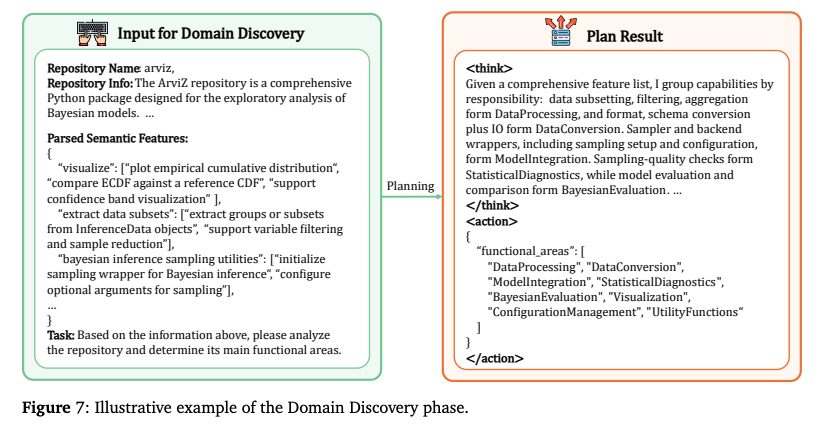
ドメイン発見
- A.1.1で抽出したリポジトリ全体の「意味的特徴(全リスト)」をLLMに入力。
- LLMはそれらを分析し、このリポジトリを構成する主要な「機能領域(Functional Areas)」を発見。
- 例(機械学習リポジトリの場合): , , , 。
階層構築
- 発見された領域(トップレベル)の下に、個々の特徴(ボトムレベル)を分類。
- 通常、3階層程度の深さを持つツリー構造()が構築される。
- Level 1: (領域)。
- Level 2: (サブモジュール)。
- Level 3: (具体的な機能)。
重心(Centroids)の計算
- 各カテゴリ(ノード)には、そこに属する機能の特徴ベクトルを平均化した「重心ベクトル」を保持。
- これは後の「増分更新(新規ファイルの自動分類)」や「検索(類似度判定)」で使われる重要な指標。
A.1.3 Artifact Grounding: Anchoring Abstract Subtrees to Directory Scopes
最後のステップは、A.1.2で作った「理想の地図(機能ツリー)」を、「現実の住所(ファイルシステム)」にピン留めし、さらに「道路(依存関係)」を通す作業。
接地 (Grounding) の必要性
機能ツリー上の「認証機能」ノードは、概念としては存在するが、物理的にどのフォルダにあるかはまだ未定義。これを定義しないと、エージェントはコードを見に行けない状態。
LCA (Lowest Common Ancestor) メカニズム
- ある機能ノード(親)に属するすべての「葉ノード(具体的な関数)」のファイルパスを収集。
- それら全てのパスに共通する「最も深いディレクトリ」を計算(LCAアルゴリズム)。
- そのディレクトリを、その機能ノードの「物理的スコープ(Scope)」として設定。
- 技術的補足: 大規模リポジトリでも高速に計算できるよう、Trie木(トライ木)を用いて の計算量で処理。
依存関係の注入 (Dependency Injection)
最後に、コードとしての「つながり」をグラフに追加。
- AST解析: 全ファイルの抽象構文木を解析し、、関数呼び出し、クラス継承の関係を抽出。
- エッジ追加: これらを「依存関係エッジ(Caller/Callee)」としてグラフに組み込み。
3.2 RPG Evolution: Incremental Maintenance
リポジトリは常に変化。毎回グラフをゼロから作り直すコストを回避するため、増分更新(Incremental Update)を採用。
更新の流れ
- コミットレベル解析: 変更されたファイル(Diff)のみを解析対象。
3つの更新プロトコル
- Deletions (削除)
- 削除されたエンティティに対応するノードを除去。
- 構造的衛生 (Structural Hygiene): 子ノードが消えて空になった親カテゴリ(抽象ノード)も再帰的に削除し、グラフ内に「幽霊ノード」が残らないよう処理。
- Modifications (修正)
- 意味的ドリフト (Semantic Drift) の判定: 変更が単なるリファクタリングか、機能変更かを判定。
- 機能が変わっていない場合、ノードの説明文(f)のみを更新し、グラフ上の位置は維持。これにより構造変更コストを抑制。
- Additions (追加)
- Semantic Routing (意味的ルーティング): 新しいファイルや関数をどこに配置すべきか決定。新規ノードの特徴ベクトルと、既存の機能重心との類似度を計算し、最適な親ノードの下に自動的にルーティング。
詳細
リポジトリは日々更新されるが、そのたびにグラフ全体を再構築(Re-encoding)していては、コストも時間もかかりすぎる。Gitのコミット差分(Diff)のみを解析し、グラフを局所的に「手術」する手法を開発。メンテナンスコストを削減。
具体的なアルゴリズム
全体像:イベント駆動型の更新サイクル
システムは、コミットによって発生する変更を以下の3つの「イベント」に分類し、それぞれ専用のプロトコルで処理。
- 削除 (): ファイルや関数が消えた。
- 変更 (): 内容が書き換わった。
- 追加 (): 新しいファイルや関数が生まれた。
A.2.2 ノード削除:構造的衛生の維持
単にノードを消すだけでなく、グラフの整合性を保つための「掃除(Hygiene)」が重要。
- 基本動作。削除されたコードに対応する葉ノード()をグラフから除去。
- Structural Hygiene(構造的衛生)。葉ノードを削除した結果、親の「機能ノード(抽象ノード)」が空っぽになる(子がゼロになる)場合への対応。
- 再帰的削除。空になった親ノードを即座に削除。さらにその親も確認し、ルートに向かって再帰的に不要な枝を剪定。
- 目的。グラフ内に中身のない「幽霊ノード(Ghost Nodes)」が残るのを防止。エージェントが探索中に「空のフォルダ」を開いて無駄足を踏むのを回避。
A.2.3 差分変更(変更プロセス:意味的ドリフトの判定)。
既存のコードが書き換えられた場合のグラフ更新手法。著者は「怠惰な更新(Lazy Update)」戦略を採用。
課題
コードが変わったからといって、必ずしもグラフ上の「位置(カテゴリ)」を変える必要はない。例えば、変数のリネームやバグ修正程度なら、その関数は依然として「認証機能」の一部。
意味的ドリフト(Semantic Drift)の判定
システムは、変更前後のコードから特徴ベクトル()を抽出し、比較。cosine similarityで閾値以上であればDrift。
- 軽微な変更(Driftなし)
- 意味的な役割が変わっていないと判定された場合(類似度が高い場合)、グラフの構造(エッジ)は維持。
- 更新するのはノードの「説明文(要約)」のみ。
- メリット。トポロジー再計算のコストをゼロに。
- 重大な変更(Driftあり)
- 機能が根本的に変わった場合(例:「ログイン関数」が「データ削除関数」に書き換えられた)、そのノードを一度削除し、新しいノードとして再挿入(A.2.4へ移行)。
A.2.4 ノード追加:意味的ルーティング
新しいファイルや関数が追加されたとき、それをグラフの「どこ」にぶら下げるかを決定するアルゴリズム。これをSemantic Routing(意味的ルーティング)と呼ぶ。
- 課題。新規ファイル は、既存の「データ処理」の下に入れるべきか、「ネットワーク」の下に入れるべきか。
- アルゴリズム
- 重心(Centroids)の利用
- 類似度マッチング
- ルーティング(Routing)
- 閾値判定
既存の各機能カテゴリ(抽象ノード)は、その配下のノード群の特徴ベクトルを平均した「重心ベクトル」を保持。
新規ノードの特徴ベクトル()と、すべての候補親ノードの重心とのコサイン類似度を計算。
最も類似度が高い親ノード(Top-1)を選択し、そこにエッジを張る。
もしどの親とも類似度が低い場合(全く新しい機能群が追加された場合)、新しい「抽象ノード」を新規作成し、そこにぶら下げる。
3.3 RPG Operation: Unified Reasoning Substrate
エージェントがRPGを「脳」として活用するための3つの主要ツール。
- 自然言語クエリ(例: "JWTトークンの検証ロジック")を受け取り、意味的特徴(f)との類似度検索を行って、探索の起点(エントリーポイント)となる候補ノードを返す仕組み。
- 特定のノードIDを指定し、その詳細情報(完全なソースコード、子ノードリスト、メタデータ)を取得する機能。
- Semantic Traversal: 機能階層を上下に移動(親「認証機能」⇔子「ログイン」)する機能。
- Dependency Traversal: 依存関係を移動(呼び出し元⇔呼び出し先)する機能。
- この「二重の視点(Dual-View)」により、エージェントはコードの「役割」と「動作」を多角的に理解できる仕組み。
詳細
- 前提。優れた地図であっても、それを読むための「コンパス(ツール)」と「歩き方(戦略)」がなければ目的地(バグ箇所など)には到達不可能。
- 本セクションの内容。具体的な仕組みの詳述。
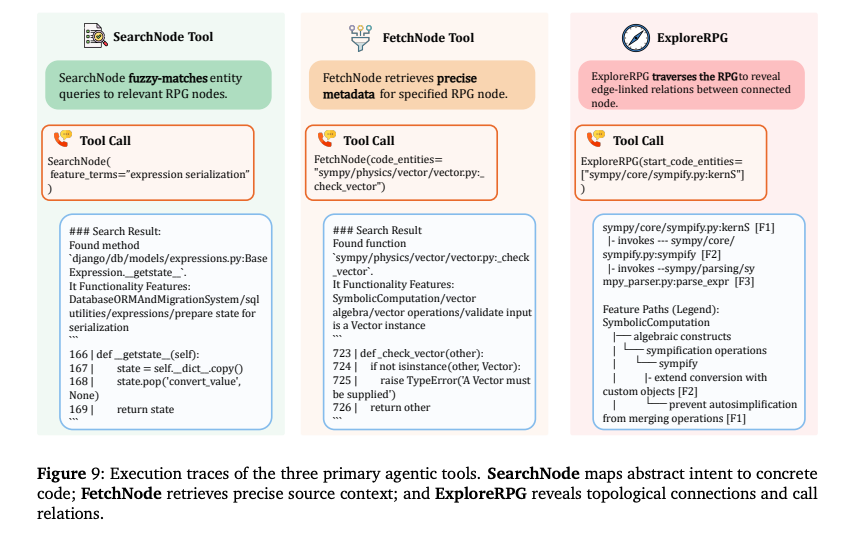
A.3.1. Tool Interfaces and Prompt Specifications
エージェントには、リポジトリ全体を一度に読み込ませるのではなく(トークン制限のため不可能)、以下の3つの専用ツールを通じてRPGを探索させる仕組み。
:エントリーポイントの特定
- 機能。自然言語クエリを受け取り、グラフ全体から関連性の高いノードを検索。
- 仕組み。
- クエリと、各ノードの「意味的特徴(f: 要約)」とのベクトル類似度(Embedding Similarity)を計算。
- 上位k個の候補ノードIDを返却。
- 用途。「JWT認証のロジックはどこ?」といった、探索の最初の足がかり(Initial Grounding)を発見。
:詳細情報の取得
- 機能。特定のノードIDを指定し、その「中身」を取得。
- 返却データ。
- コード/要約。葉ノードならソースコード全文、中間ノードなら機能要約。
- メタデータ。ファイルパス、行数、最終更新者など。
- 子ノードリスト。そのノードに含まれる下位の関数やクラス。
- 用途。検索で当たりをつけたノードが、本当に探しているものかどうかの検証(Verification)。
:構造的・論理的移動
- 機能。現在のノードから、指定したタイプのエッジを辿って隣接ノードに移動。これがRPG最大の特徴。
- 2つの移動モード(Dual-View Traversal)。
- Semantic Navigation(意味的ナビゲーション)。
- または を指定。
- 機能の階層を上下。(例:「認証モジュール」⇔「ログイン関数」)。
- Dependency Navigation(依存関係ナビゲーション)。
- (誰から呼ばれているか) または (誰を呼んでいるか)を指定。
- 実行フローを追跡。(例:「関数」→「関数」)。
- 用途。バグの原因追及や、修正の影響範囲の特定など、文脈の拡大(Expansion)。
A.3.2. Tool-use Policy for Repository Understanding
エージェントが効率的に探索を行うための戦略設計。
戦略 1: Search-then-Zoom Pattern
エージェントの行動ログ分析から導出された、最も成功率の高い基本動作パターン。
- Global Search(広域検索):
- を使用し、リポジトリ全体から候補エリアを絞り込む処理。
- 詳細確認前に、大まかな「機能ブロック」を特定する手法。
- Zoom-in Verification(局所的検証):
- 特定エリアに対しを実行し、詳細を確認する段階。
- 正解発見時は終了、未発見時は次ステップへ移行。
- Context Expansion(文脈拡大):
- を用いた、周辺ノードや依存先の調査プロセス。
戦略 2: Dual-View Navigation
「機能」と「依存関係」の視点を切り替えながら探索することで、探索失敗を防ぐ手法。
- シナリオ例: 「データベース接続エラー」の修正タスク。
- Step (Semantic):
- で「Database」機能カテゴリを探索。
- への到達。
- Step (Dependency):
- コード確認でもエラー原因が不明な状態。
- 「この関数の呼び出し元は?」という視点でを実行。
- 呼び出し元のに移動し、誤った引数渡しを発見。
「静的な分類(Is-a)」と「動的な実行(Calls)」を行き来できる点が、RPG操作の最大の強み。
4. Experiments Setup
4.1 Repository Understanding(リポジトリ理解タスク)
- 目的: バグ修正タスクにおいて、修正すべきファイルや関数をどれだけ正確に特定(Localization)できるか。
- データセット:
- SWE-bench Verified: 人間による検証済みの高品質な500件の問題。
- SWE-bench Live Lite: 最新のリポジトリを含む300件の問題(データ汚染のリスクを排除)。
- 比較手法: Agentless(単純検索)、LocAgent、OrcaLoca(これまでのSOTA)、CoSILなど。
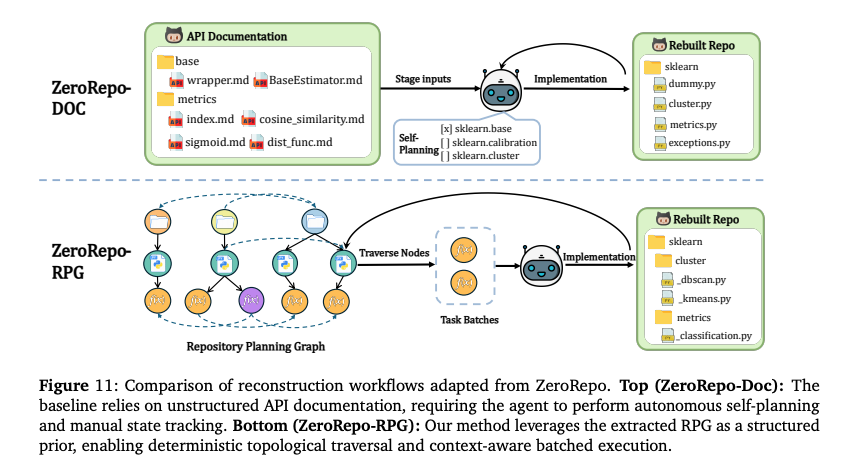
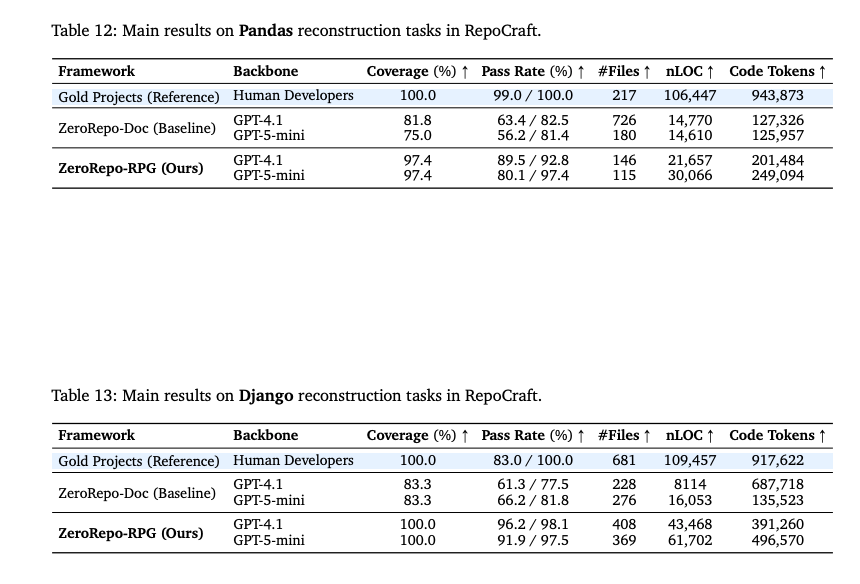
4.2 Repository Reconstruction(リポジトリ再構築タスク)
- 目的: RPGがどれだけ元のリポジトリの情報を保持しているか(Fidelity)の検証。既存ライブラリ(Scikit-LearnやDjango等)をゼロから再実装。
- 比較:
- ZeroRepo-Doc: APIドキュメントのみを与えて実装させる(構造情報なし)。
- ZeroRepo-RPG: RPGを与えて実装させる(構造情報あり)。
Main Result & Analysis
リポジトリ理解
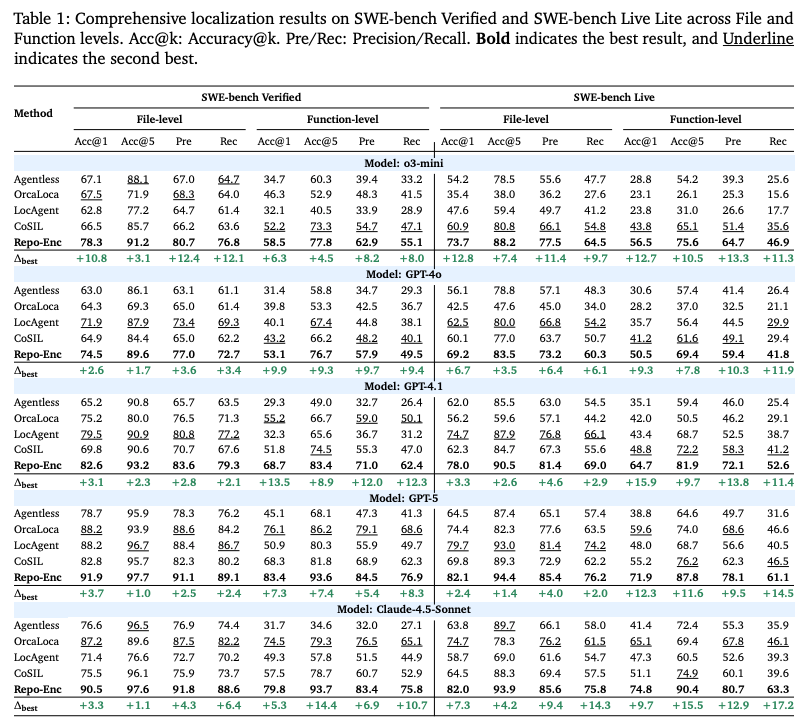
- 結果
- SWE-bench Verifiedにおいて、RPG-Encoderは関数レベルのAcc@5で93.7%を達成。
- 比較
- 以前の最高精度を持つOrcaLoca(79.3%)を14.4ポイント上回る結果。
- ファイルレベルでも97.3%というほぼ完璧な特定率を記録。
- 要因
- 意味的検索(SearchNode)で当たりをつけ、依存関係探索(ExploreRPG)で確信度を高めるというプロセスが功を奏したこと。
リポジトリ再構築と忠実度
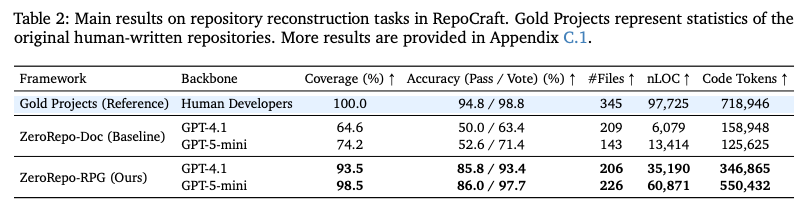
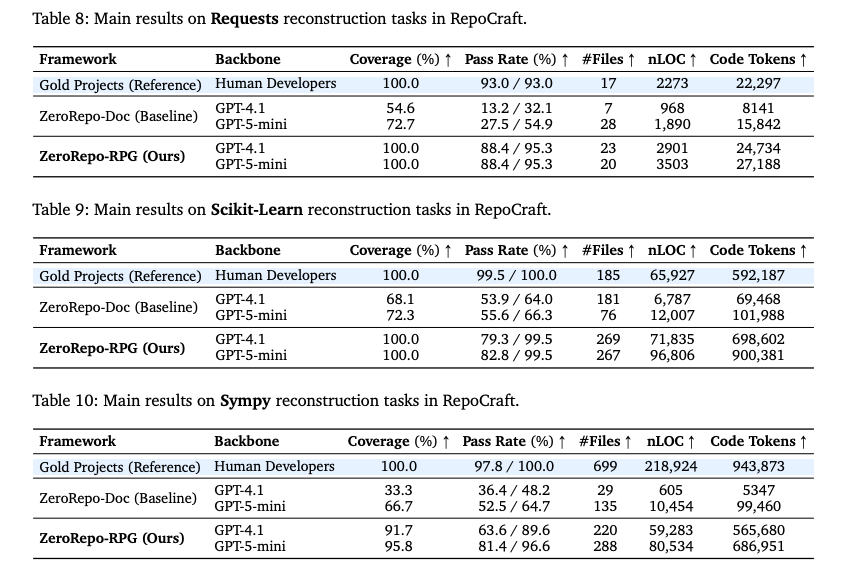
- 結果
- カバレッジ: 元のリポジトリに存在する公開API(クラス、関数、メソッド)のうち、生成されたリポジトリに正しく実装されたものの割合。RepoCraftベンチマークにおいて、RPGを用いた再構築は98.5%を達成。
- テスト通過率: 元レポジトリのテストスイートを実行した通過率。86.0%を達成。
- Pass: テストスイートの通過率
- Vote: 意図された機能が実装されている率
- Stats
- #File: ファイル数。
- nLOC: Normalized Line Of Codes。意味のあるコード行数。
- Code Token Count: コードのトークン数。
アブレーション研究(要素除去テスト)
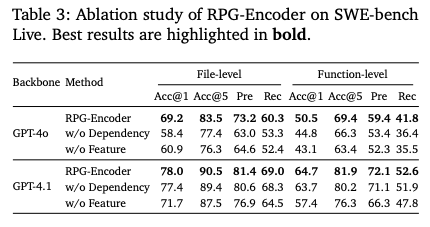
- 意味的特徴なし (w/o Features)
- 現象: ノードの要約説明を削除すると、探索ステップ数が増加し、検索精度が低下。
- 原因: エージェントはファイル名だけで中身を推測しなければならず、何度もで中身を確認する「試行錯誤ループ」に陥る状態。
- 依存関係なし (w/o Dependency)
- 現象: 依存関係エッジを削除すると、トークンコストが増加。
- 原因: で「呼び出し元」を辿れないため、エージェントは手動でgrep検索のような非効率な探索を行う必要が生じる状態。
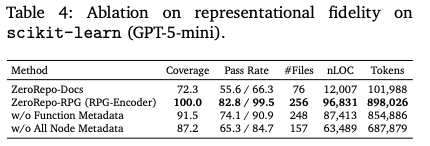
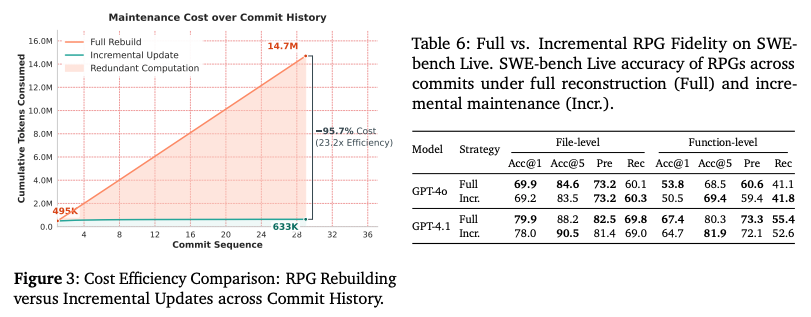
コスト効率:95.7%の削減
- コスト効率の分析結果
- 比較対象:リポジトリ更新時にRPG全体を再生成する場合と、増分更新(Incremental Maintenance)を行う場合。
- 削減率:提案手法により、トークンコストを95.7%削減。
- 実用的意義:巨大なリポジトリでもリアルタイムにRPGを維持・運用することが経済的に可能。