
2026-02-17 機械学習勉強会
今週のTOPIC[paper] SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning[paper] Free(): Learning to Forget in Malloc-Only Reasoning Models[paper] ViT-5: Vision Transformers for The Mid-2020s[blog]LLMでソート[Blog] Automate repository tasks with GitHub Agentic Workflows [paper]PARSE: LLM Driven Schema Optimization for Reliable Entity Extraction[paper]Towards Autonomous Mathematics Research[paper]Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning[paper] CHAI: Command Hijacking against embodied AIメインTOPICSemantic Search At LinkedIn1. どんなもの?2. 先行研究と比べてどこがすごい?3. 技術や手法のキモはどこ?4. どうやって有効だと検証した?5. 議論はある?
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[paper] SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
- 過去の経験から知見を抽出しうまく学習させるという概念的にはよくあるパターンの論文
- 生の軌跡 (Few-shot)を保持してもダメだよね、汎化するためにはもっと高レベルで再利用可能な行動パターンを抽出しないとダメだよね
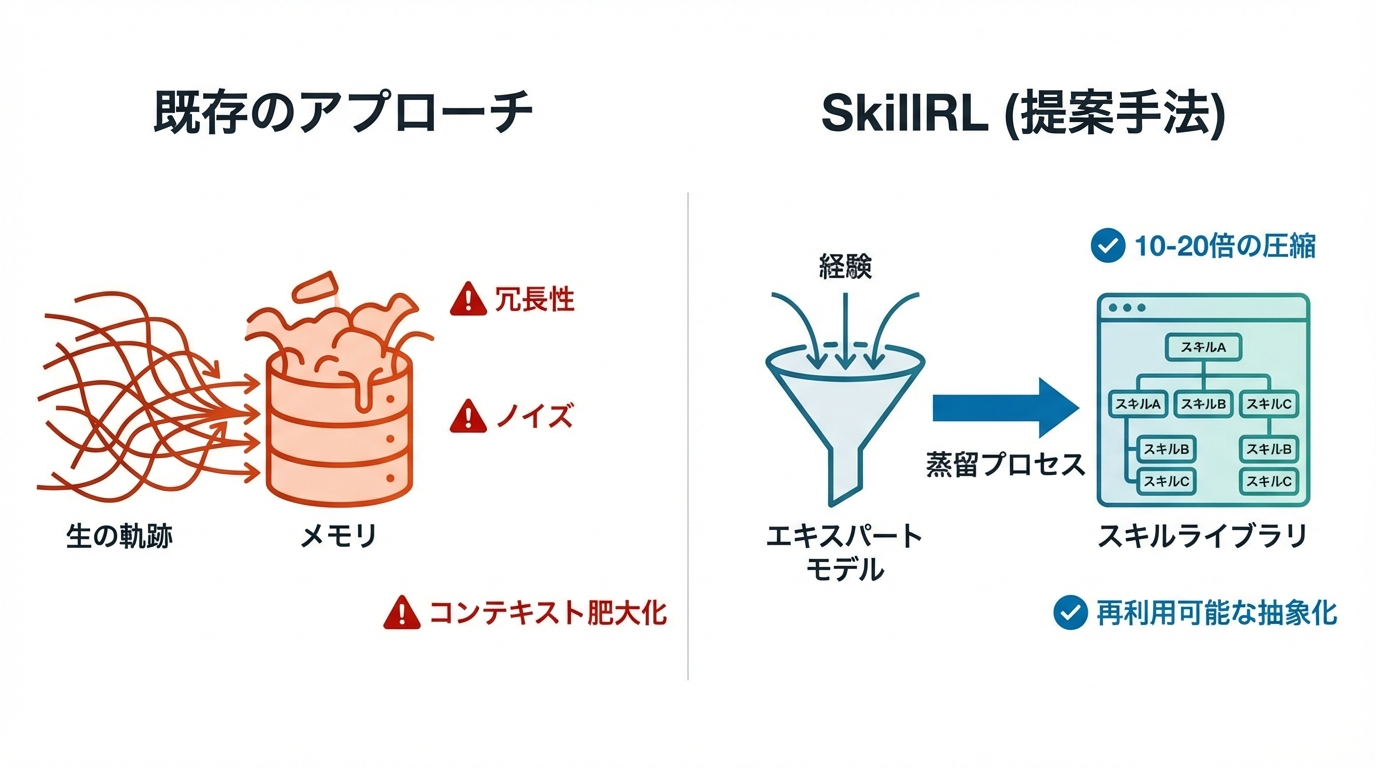
- SkillRLという、自動的なスキル発見と再帰的進化を通じて、生の経験とポリシー改善のギャップを埋めるフレームワークを提案。
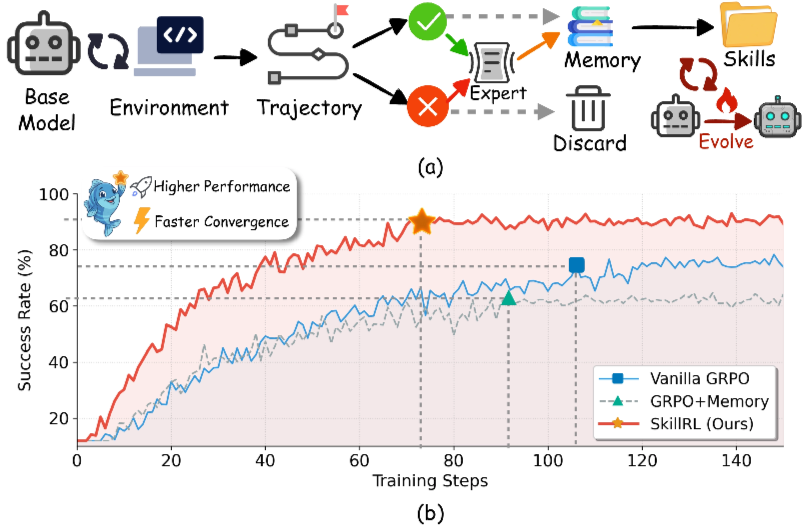
- 手法
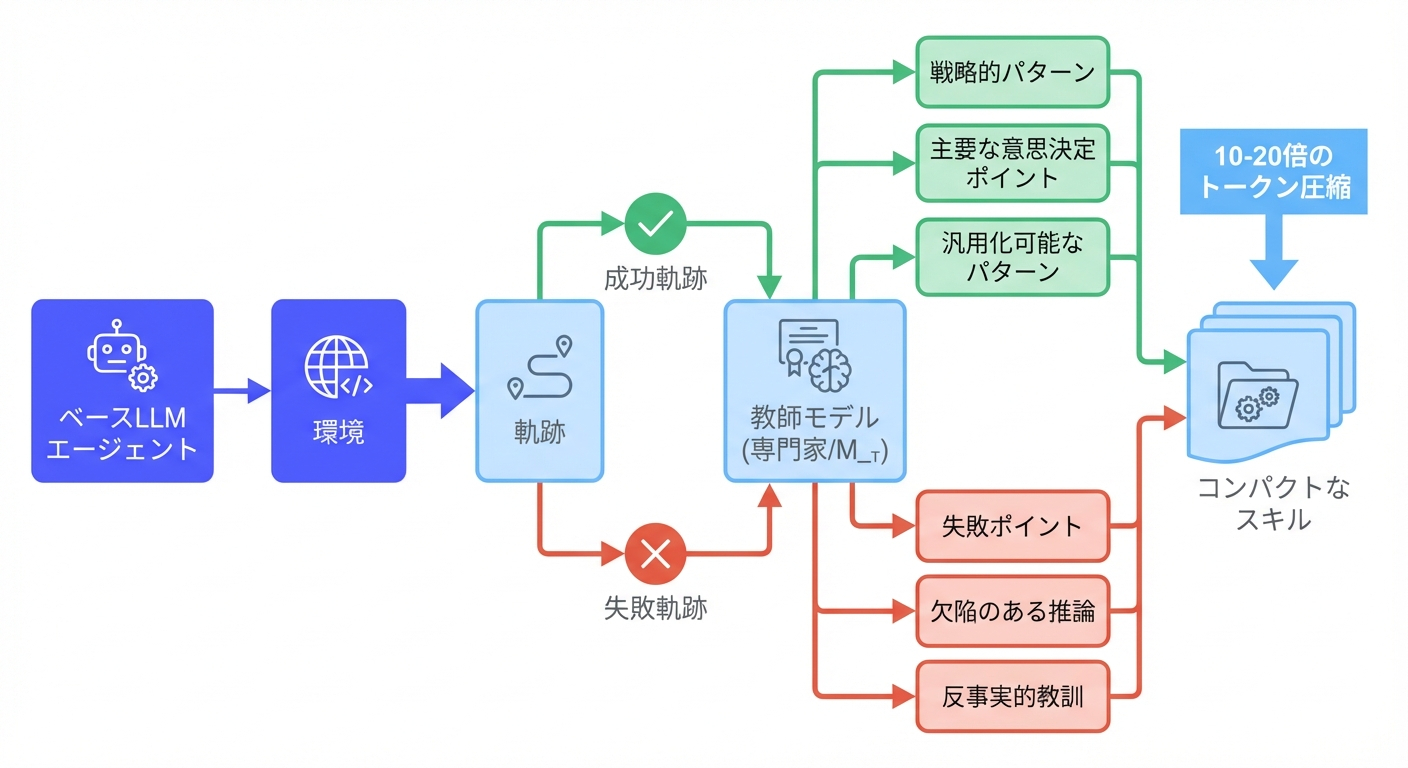
- 経験ベースのスキル蒸留(Experience-based Skill Distillation)
- 生の軌跡は冗長であり、探索的行動、バックトラッキング、冗長なステップが含まれる。SkillRLは、教師モデルを使用して、軌跡をコンパクトで再利用可能なスキルに蒸留する。
- 成功軌跡と失敗奇跡を収集して、タスク完了につながった戦略パターン、重要な意思決定ポイント、正しい行動の背後にある推論、特定のタスクインスタンスを超えて転移可能な一般化可能なパターンを抽出。失敗に関しては失敗のポイント、欠陥のある推論または行動、何をすべきだったか、類似の失敗を防ぐための一般原則なども抽出
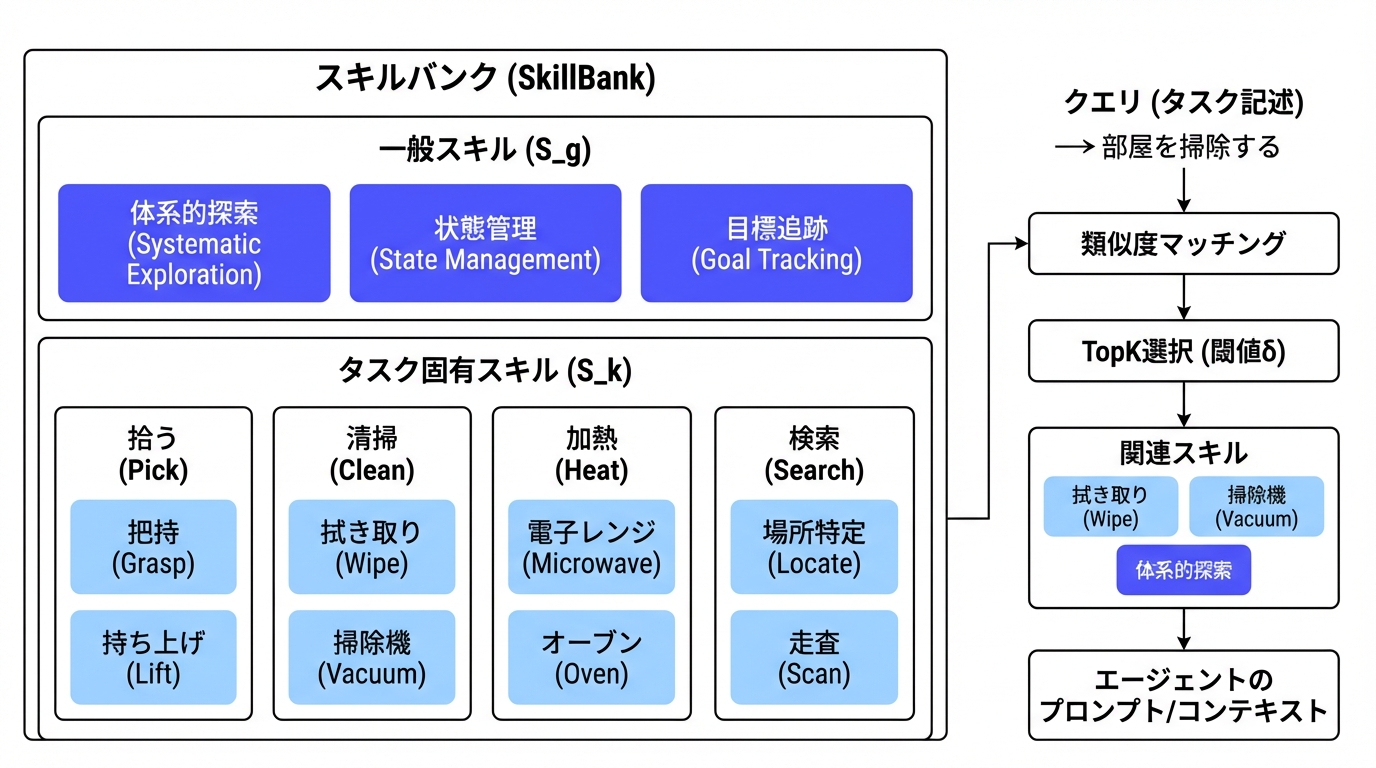
- 階層的スキルライブラリ(SkillBank)の構築
- Anthropic Claude 3のAgent Skills設計原則に従い、蒸留された知識を階層的スキルライブラリ**SkillBank**に組織化する。
- 一般スキルとタスク固有スキルに分解
- 以下で構成
- 簡潔な名前(例: "systematic exploration")
- 戦略を説明する原則
- 適用可能性を指定する 条件
- タスク説明から関連スキルを検索してコンテキストを補強
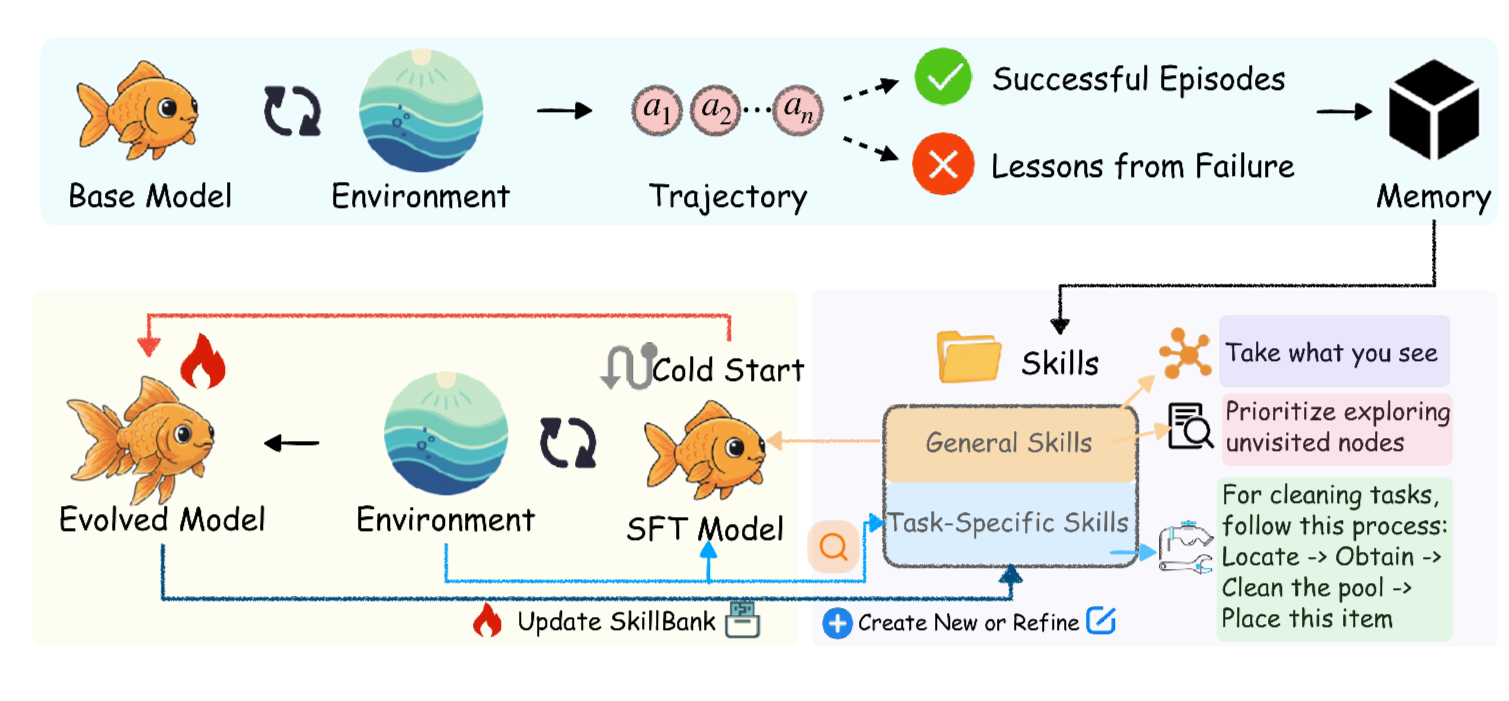
- 再帰的スキル進化(Recursive Skill Evolution)
- 静的なスキルでは、すべてのシナリオを予測できない
- Cold-start
- RL訓練前に、ベースエージェントがスキルを効果的に活用する方法を学習していないという重要な課題に対処する。単にスキルを提供するだけでは限定的な利益しか得られないため、教師モデルがスキル補強された推論トレース N個を生成する監督付き微調整(Supervised Fine-Tuning; SFT)段階を実施
- 再帰的スキル進化プロセス
- 各タスクカテゴリの中で成功率を監視し、行って以下のもののみ進化をトリガー
- 教師モデルが失敗奇跡を収集してギャップ分析。
- 複数カテゴリから均等にサンプリング (ラウンドロビンサンプリング)
- 現在のスキルで対処されていない失敗パターンを特定
- 新しいスキルを提案
- 既存のスキルの改良
- ライブラリ更新
- RLベースのポリシー最適化
- スキルを検索してコンテキストに入れた上でロールアウトを行い、GRPOで学習
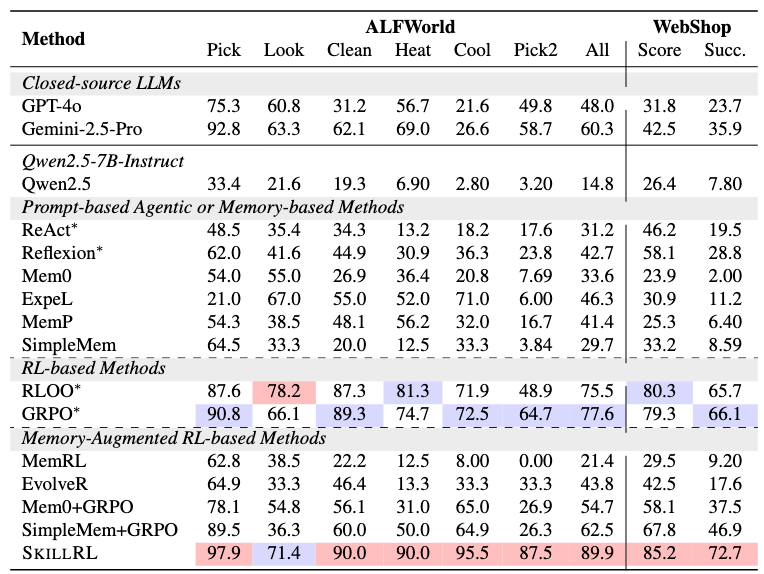
- 結果
- Qwen2.5-7B-Instructをベースモデル + o3を教師モデルにして学習

@Shun Ito
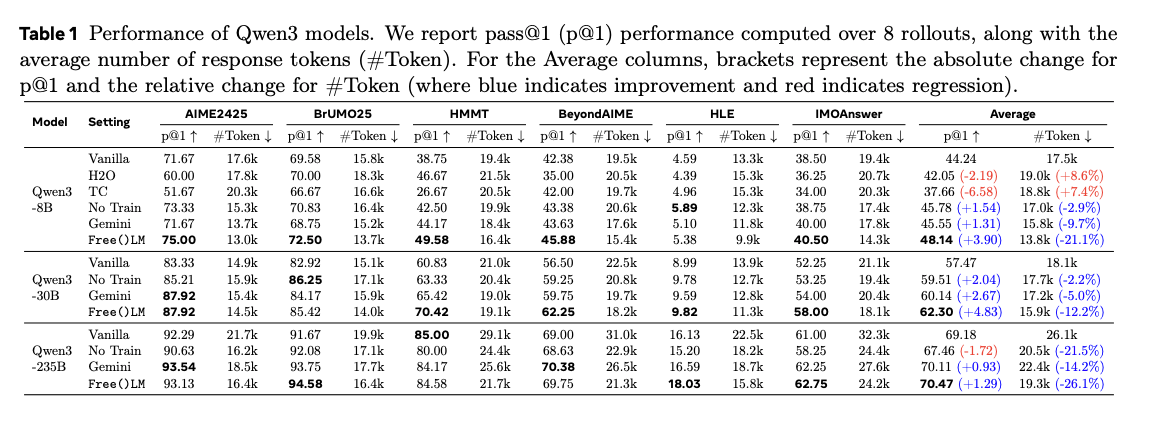
[paper] Free(): Learning to Forget in Malloc-Only Reasoning Models
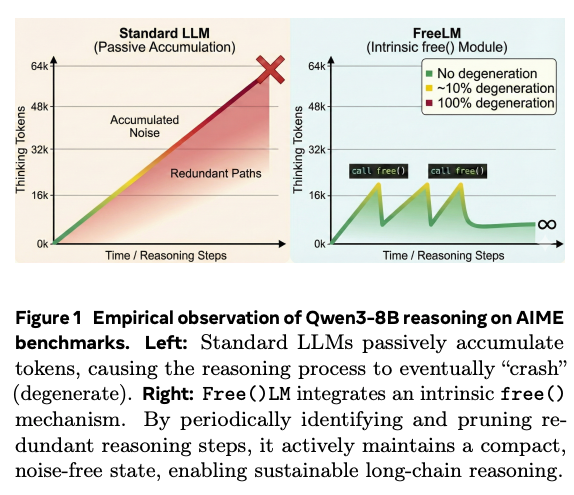
- CoTのThinking中のトークン数が多くなりすぎると性能が悪化しがち
- Thinking中にノイズ(試行錯誤や間違えた推論)が残っているため
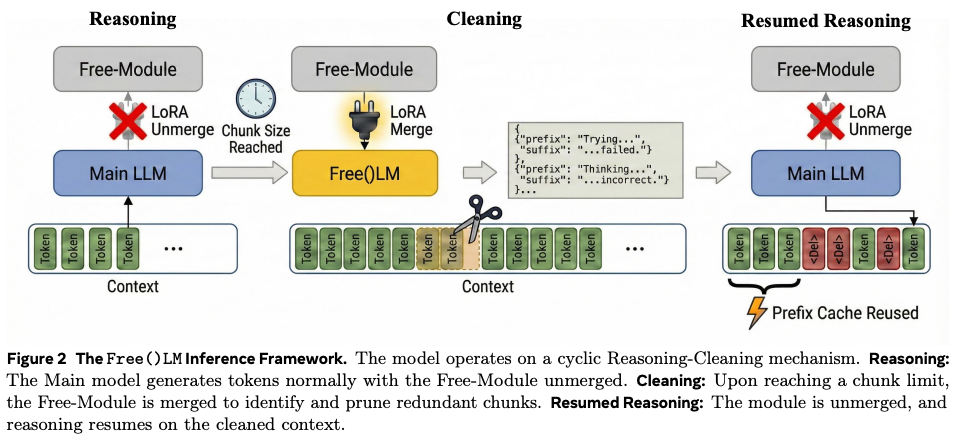
- 推論の途中でノイズを掃除する仕組みを提案
- 最初は推論を通常通り実施
- 出力が一定のトークン数に到達すると、Free-Module(LoRAアダプタ)を付与してcleanモードに切り替え。ここまでの出力の中で不要な部分をjson形式で出力
- 削除自体は別個のPythonスクリプトを動かす
- 削除後、Free-Moduleを外して推論再開
- LoRAの学習の正解データは、Geminiを使って作成
- Geminiで削除候補を作成
- 削除候補それぞれについて以下で選定
- 削除前・削除後で推論を複数回実行
- それぞれのAccを比較して下がっていないものを正解として採用
- 実験
- 数学系のデータセット
- 性能向上・トークン数の削減に寄与
- Latencyは増えてしまうので今後の課題
@Takumi Iida (frkake)
[paper] ViT-5: Vision Transformers for The Mid-2020s
ViT-5
wangf3014 • Updated Mar 9, 2026
Alan Yuille先生のところの論文。この先生へのヒット率が異常に高い…
Vision Transformerのベストプラクティス集めてアーキテクチャにしたぜ的な論文。ConvNextを思い出す。
手法
アーキテクチャを下図のように改変
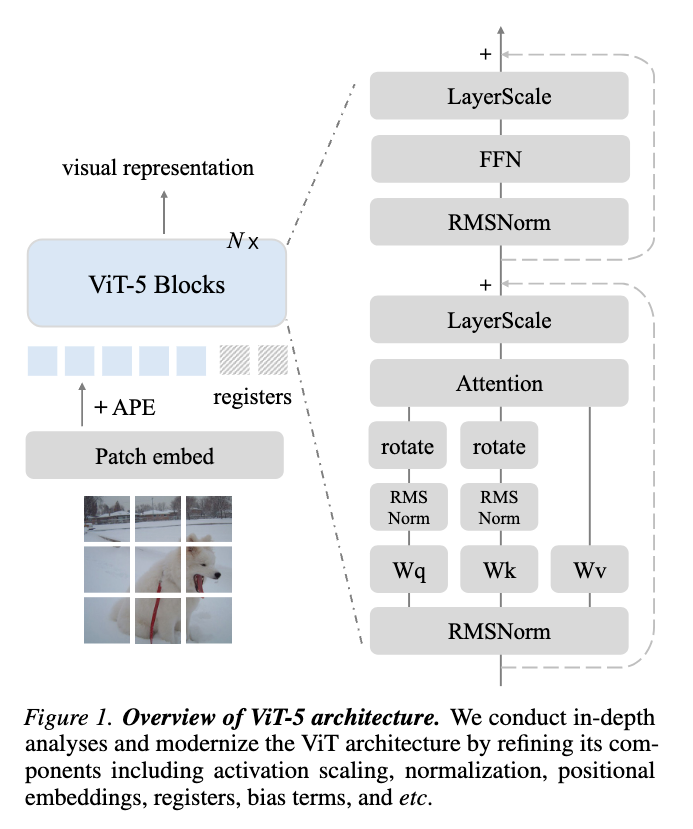
主な変更点
- (RMSNorm) LayerNorm→RMS(Root Mean Square) Normに置き換え センタリング操作を排除
- (rotate) Absolute Positional Embedding (APE) +2D RoPEへ変更。並行して使う。
- (Attention) QK正規化を挿入
- 自己注意のQKを正規化することで、学習の安定化を図る
- (LayerScale) SwiGLU→GeLUに変更
- LayerScaleは各出力に対して学習可能なスケールをかけるレイヤ
- この部分にSwiGLUを使うと、過剰なゲーティングが行われることを発見したので排除 SwiGLUもLayerScaleもチャネルごとにフィルタリングを行うため過剰になる
結果
↓同じViT系のDeiTと比べても勝っている
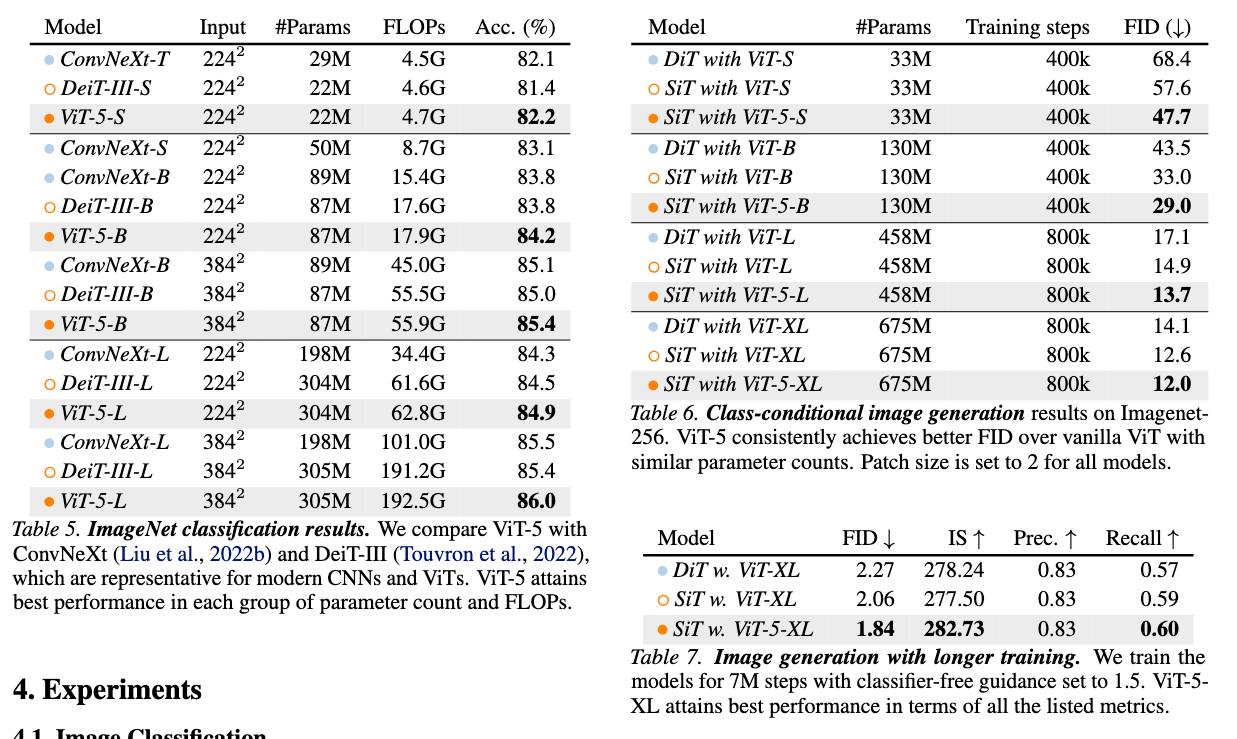
↓既存のViTモデルとのアーキテクチャと性能比較。ベンチマークはImageNet-1k

@Hiromu Nakamura (pon)
[blog]LLMでソート
[pon]LLMリランキング、ポイントワイズ、リストワイズ、ペアワイズのその先へ
セットワイズ法
セットワイズ法ではⅽ個のアイテムをまとめて比較。これはLLM は 2 個のアイテムを比較もc個のアイテムの比較も一度の呼び出しででき、そのコストはあまり変わらないため有効
次は(c-1)分ヒープ
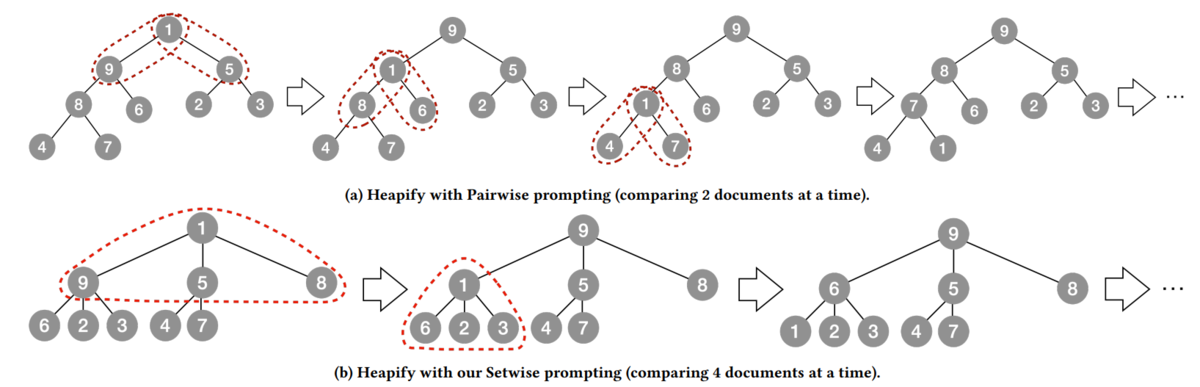
矛盾への対処
LLMを比較関数として使う場合、順序の公理(反対称性・推移性・完全性)を満たさないことが問題になる。
1. 反対称性・完全性の破れ(位置バイアス)
LLMは、先に提示された選択肢を選びやすい「位置バイアス」を持つことがある。
そのため、
- A vs B では A を選ぶ
- B vs A では B を選ぶ
といった一貫しない結果が起こります。
対策:
- llm(a, b) と llm(b, a) の両方を実行
- 両方で一貫して同じ結果なら採用
- 食い違えば「タイ」と扱う
2. 推移性の破れ(循環が起きる)
- LLMは以下のような循環を起こすことがある
- A > B
- B > C
- C > A
- この場合、厳密な意味でのソートは不可能。
- この状況は理論的にはトーナメント上の帰還枝集合問題(Feedback Arc Set on Tournaments)に対応する(初めて知ったけど有名?)。
- 何も考えずにクイックソートを実行すると期待近似度 3 の(つまり平均的には矛盾するペアの数が最適値の高々 3 倍に抑えられる)良い近似アルゴリズムになることが知られている
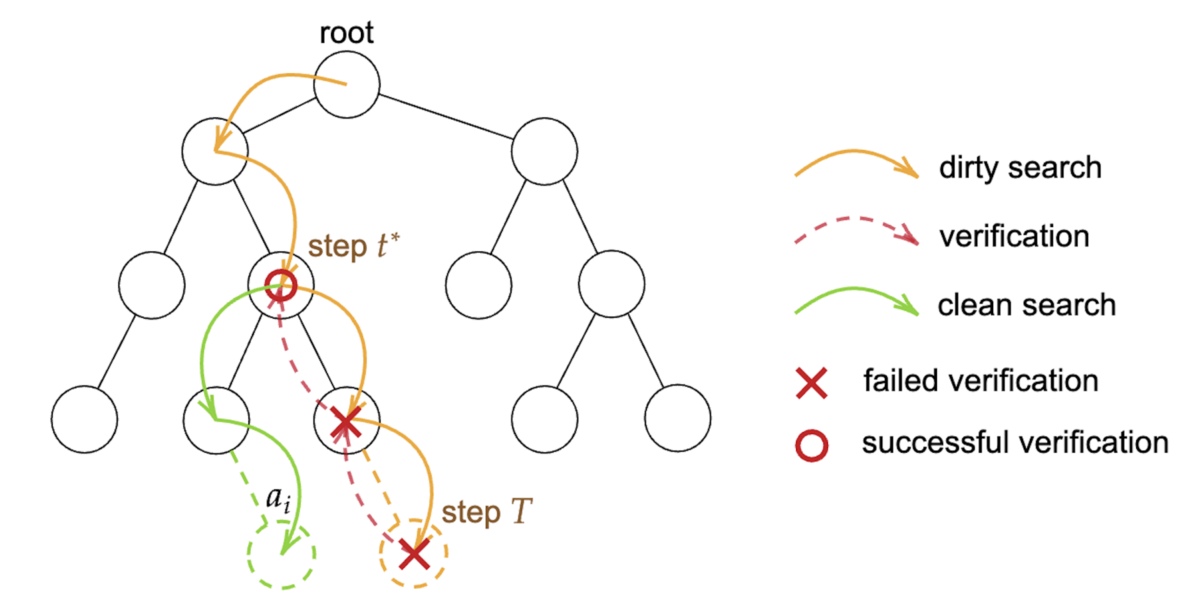
不完全な比較の活用
LLM の呼び出しはどうしてもコストがかかります。そこで、ルールベースなど低コストな比較をうまく活用しつつ、必要な場面で LLM を呼び出してコストを下げる手法も開発されている。
Sorting with Predictions
アイデア
- まずdirtyな比較(低コスト)で大まかな位置を推定
- 本命の比較(LLM)でローカルに修正
性質:
- 予測が良い → O(n) 回でソート可能
- 予測が悪い → 最悪でも O(n log n)
うまくいけば速いし、悪くても従来並みという設計。
@ShibuiYusuke
[Blog] Automate repository tasks with GitHub Agentic Workflows
GitHub Agentic Workflows
1. 概要
GitHub Agentic Workflowsの概要。
- GitHub Agentic Workflowsは、GitHub Actions上で動作する新しい自律型AIエージェントのワークフロー。
- これまで人間が行っていたリポジトリ管理タスク(イシュートリアージ、ドキュメント更新、コード修正など)を、AIエージェントが自律的に実行・自動化する仕組み。
- GitHubはこれを、従来のCI/CD(継続的インテグレーション/デリバリー)になぞらえ、「Continuous AI(継続的AI)」と呼称。
- 現在、テクニカルプレビューとして公開中。
2. Agentic Workflowsの仕組み
主な特徴。
複雑なYAML設定ファイルの代わりに、自然言語(Markdown)で指示を記述可能。
構成要素
- Markdownファイル ()。
- AIへの指示を自然言語で記述。(例:「毎日リポジトリの状態をレポート」「この関数のドキュメントを更新」)
- ファイルの先頭(Frontmatter)に、実行スケジュール、必要な権限、使用ツールなどをYAML形式で定義。
- ロックファイル ()。
- Markdownファイルをコンパイル(コマンドを使用)することで生成されるファイル。
- 実際にGitHub Actionsが実行するのはこのロックファイル。
- コーディングエージェント。
- 設定に基づき、Copilot CLI、Claude Code、OpenAI CodexなどのAIエンジンがタスクを実行。
実行フロー
- 開発者が ファイルに指示を書く。
- コマンドでアクション用ファイルに変換する。
- トリガー(スケジュール、プルリクエスト、イシュー作成など)に基づきGitHub Actions上でエージェントが起動。
- エージェントがリポジトリを分析し、タスクを実行(コード修正、イシュー作成など)。
3. 「Continuous AI」のユースケース
ブログでは、CI/CDを補完する概念として以下の「Continuous AI」の活用例。
- Continuous triage: automatically summarize, label, and route new issues.
- Continuous documentation: keep READMEs and documentation aligned with code changes.
- Continuous code simplification: repeatedly identify code improvements and open pull requests for them.
- Continuous test improvement: assess test coverage and add high-value tests.
- Continuous quality hygiene: proactively investigate CI failures and propose targeted fixes.
- Continuous reporting: create regular reports on repository health, activity, and trends.
4. セキュリティとガードレール
AIに自律的な権限を与えるリスクに対する強力なセキュリティ対策(ガードレール)。
- デフォルトで読み取り専用。
- エージェントは基本「Read-only」で動作。
- Safe Outputs(安全な出力)。
- 書き込み操作(例:PR作成、コメント投稿)は、事前に承認された「Safe Outputs」を通じてのみ許可。
- 勝手にmainブランチへマージすることは不可。必ず人間のレビュー(PR)を介する設計。
- サンドボックス実行。
- エージェントは隔離された環境で実行。
- ネットワークアクセスやツール使用もホワイトリスト方式で制限可能。
5. 従来の自動化との違い
| 特徴 | 従来のGitHub Actions | Agentic Workflows |
| 定義方法 | 厳密なYAML構文 | 自然言語 (Markdown) + 設定 |
| 柔軟性 | 決定論的(決まった手順のみ) | 意図駆動(目的達成のための手段をAIが判断) |
| 主な用途 | ビルド、テスト、デプロイ | コード修正、文書化、分析、トリアージ |
| 権限管理 | 付与された全権限を行使可能 | 明示的なSafe Outputsによる制限 |
6. 実践例:日次リポジトリレポート
実践例
ブログで紹介されている「リポジトリの健康状態を毎日レポートする」ワークフローの例。
ファイル構成
- 。
- 「最近の活動(イシュー、PR)を要約し、メンテナ向けのアクション項目をリストアップせよ」という指示を記述。
- 。
- コンパイルされた実行用ファイル。
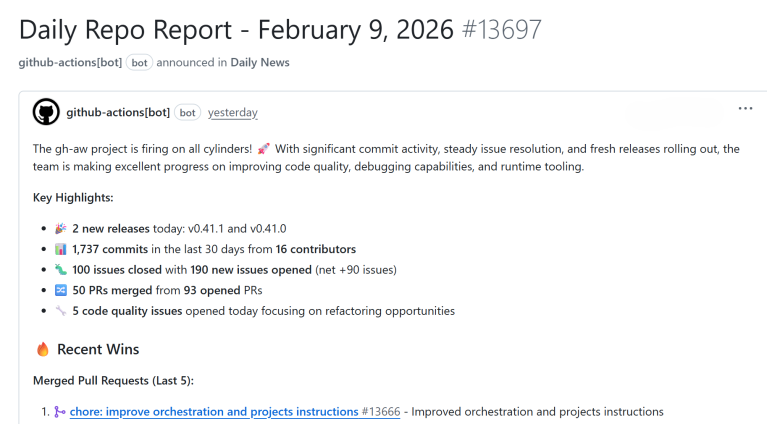
効果
毎朝自動的にリポジトリの状況がイシューとして起票され、メンテナは状況を素早く把握できるようになる仕組み。
@Akira Manda(zunda)
[paper]PARSE: LLM Driven Schema Optimization for Reliable Entity Extraction
3行まとめ
LLM エージェントによる構造化データ抽出において、タスクごとに「LLM が解釈しやすい最強のスキーマ」をオフラインで自動生成するフレームワーク PARSE を提案。
敵対的生成に近いアプローチでスキーマを鍛え上げる ARCHITECT と、実行時に自己省察とガードレールでミスを防ぐ SCOPE の二段構えで構成。
SWDE データセットで最大 64.7% の精度向上を達成し、同じモデルでもスキーマ最適化だけで性能を引き出せるため、低コストな特化型エージェント構築を可能にした。
1. 背景・課題感
なぜこれをやるのか?
LLM エージェントが API やツールを自律的に操作するには、自然言語から正確なパラメータ(JSON)を抽出する必要がある。しかし、人間用に書かれた静的なスキーマは LLM にとって説明不足であり、幻覚(Hallucination)や抽出ミスを招いていた。
本研究は「モデルをチューニングするのではなく、スキーマ(指示書)の方をタスクごとに徹底的にチューニングする」というアプローチをとる。
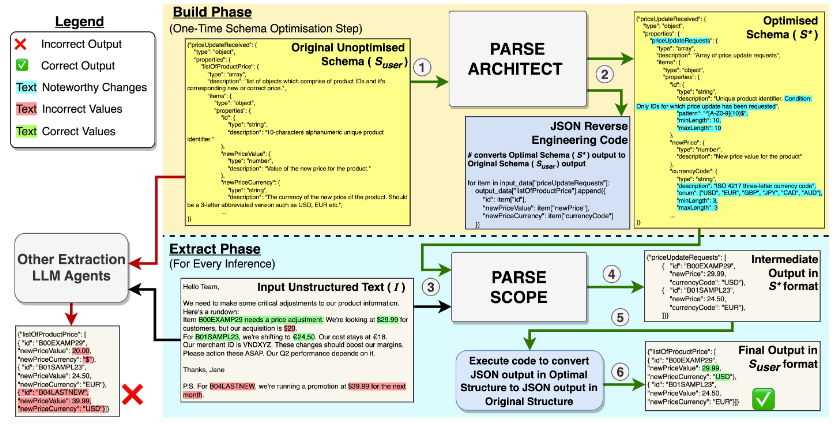
2. 提案手法:PARSE (Parameter Automated Refinement and Schema Extraction)
オフラインでの「準備(Build Phase)」と、オンラインでの「実行(Extract Phase)」を明確に分けたワークフロー。
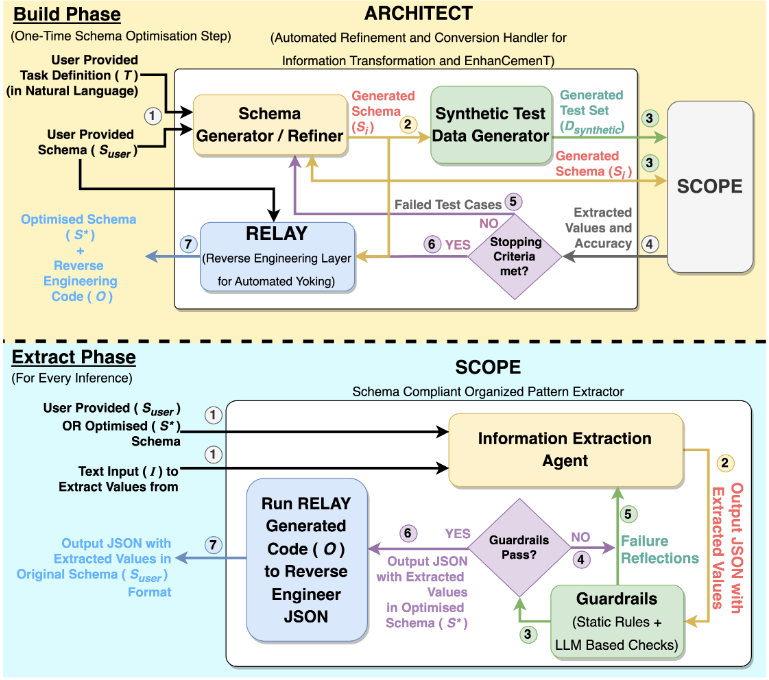
Step 1: ARCHITECT (Build Phase - オフラインでのスキーマ最適化)
特定のタスクに対し、LLM 用に特化したスキーマ を生成する。
- 攻撃 (Adversarial Attack): 合成データ生成 AI が、現在のスキーマの弱点を突くような「意地悪な入力データ(エッジケース)」を生成。
- 防御 (Defense): エラー分析に基づき、スキーマ修正 AI が「説明文の追記」「正規表現の強化」「構造の平坦化」などを行い、エッジケースに対応できるようスキーマを進化させる。
- RELAY (後方互換性): スキーマ構造が変わるたびに、元のスキーマ形式に戻すための変換コード(Python)も自動生成・検証・更新される。
スキーマ更新の様子

Step 2: SCOPE (Extract Phase - オンラインでの抽出実行)
本番環境では、最適化済みスキーマを用いて抽出を行う。
- 多段階ガードレール:
- Missing Attribute: 必須項目の欠落チェック。
- Grounding: 抽出値が原文に存在するかチェック(幻覚防止)。
- Rule Compliance: 型、パターンなどの制約チェック。
- Reflection: エラー時は単なるリトライではなく、エラー理由に基づいた自己省察を行わせる。
3. 結果・評価
3つのデータセット(Retail-Conv, SGD, SWDE)と5種類のモデル(Claude 3.x, Llama 4, DeepSeek-R1)で評価。
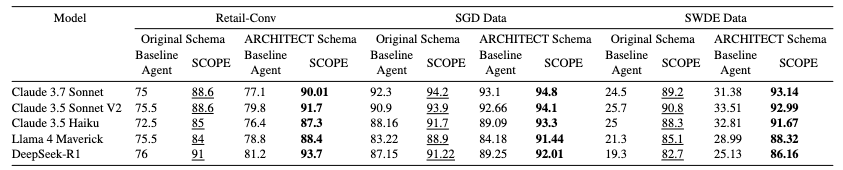
- 圧倒的な精度向上: HTML のようなノイズが多い SWDE データセットで、ベースライン比 最大 64.7% の精度向上。
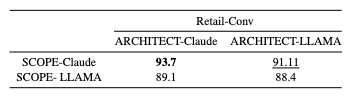
- モデル非依存性: Claude で最適化したスキーマを Llama で使っても精度が向上した。これは、ARCHITECT が特定のモデルの癖ではなく、「LLM にとっての普遍的な分かりやすさ」を獲得していることを示唆する。
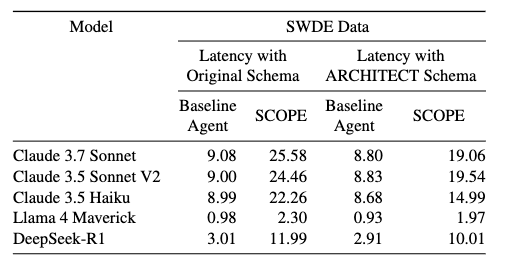
- 実用性: Build Phase(数十分の計算)を事前に経ることで、実行時のリトライ回数が激減し、トータルのレイテンシを平均 4.05秒 短縮しつつ、初回リトライでのエラーを 92% 削減した。
@Hirofumi Tateyama(hirotea)
[paper]Towards Autonomous Mathematics Research
What?
数学オリンピックのような競技数学の問題回答ではなく、研究純粋数学(PhD~)で必要なlong horizontalな生成→検証→修正のサイクルを回す数学研究エージェントAletheia (powered by Gemini Deep Think)の紹介。
Aletheia 主に古代ギリシャ語で「真理」「隠されていないこと」を意味する哲学用語で、真実の女神を指す
背景課題
競技数学は「数ページ・既知の定理・自己完結」が多い。しかし研究数学は、膨大な文献調査・複雑で長い整合性維持・参照の正確性が求められる
⇒基盤LLMモデルは知識幅が大きいものの専門領域理解は浅く、はるしネーションが起きやすい
これは単体Reasoningモデル強化(推論時間のスケール)だけでは解決できない。
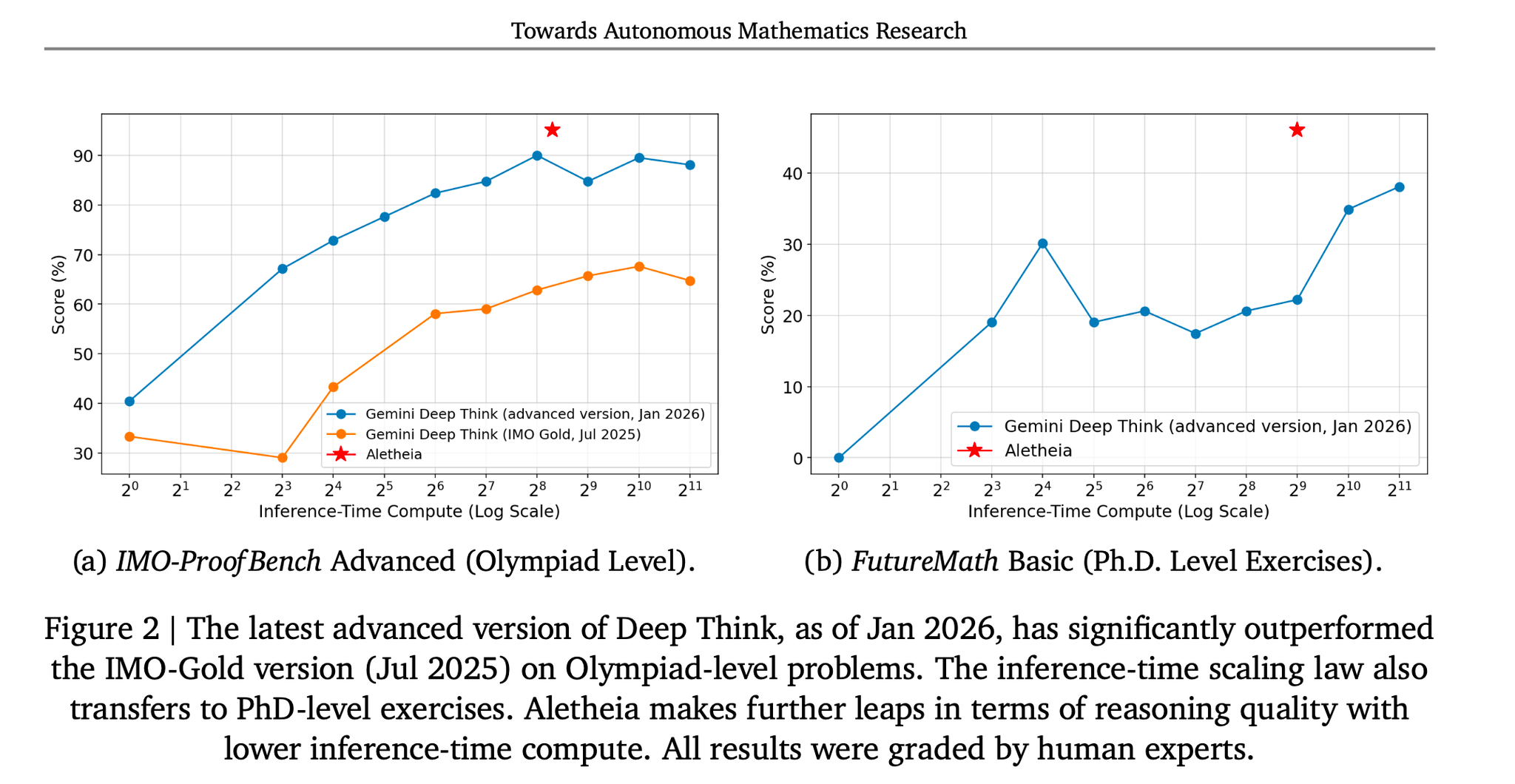
- Deep Think は推論計算量を増やすと、IMO級ベンチで精度が伸び、一定で頭打ち(plateau)。
- ただし PhD級(FutureMath Basic)では精度がかなり落ち、専門家からも「誤り・幻覚が長い推論を阻害」と評価される。
Aletheiaのアーキテクチャ
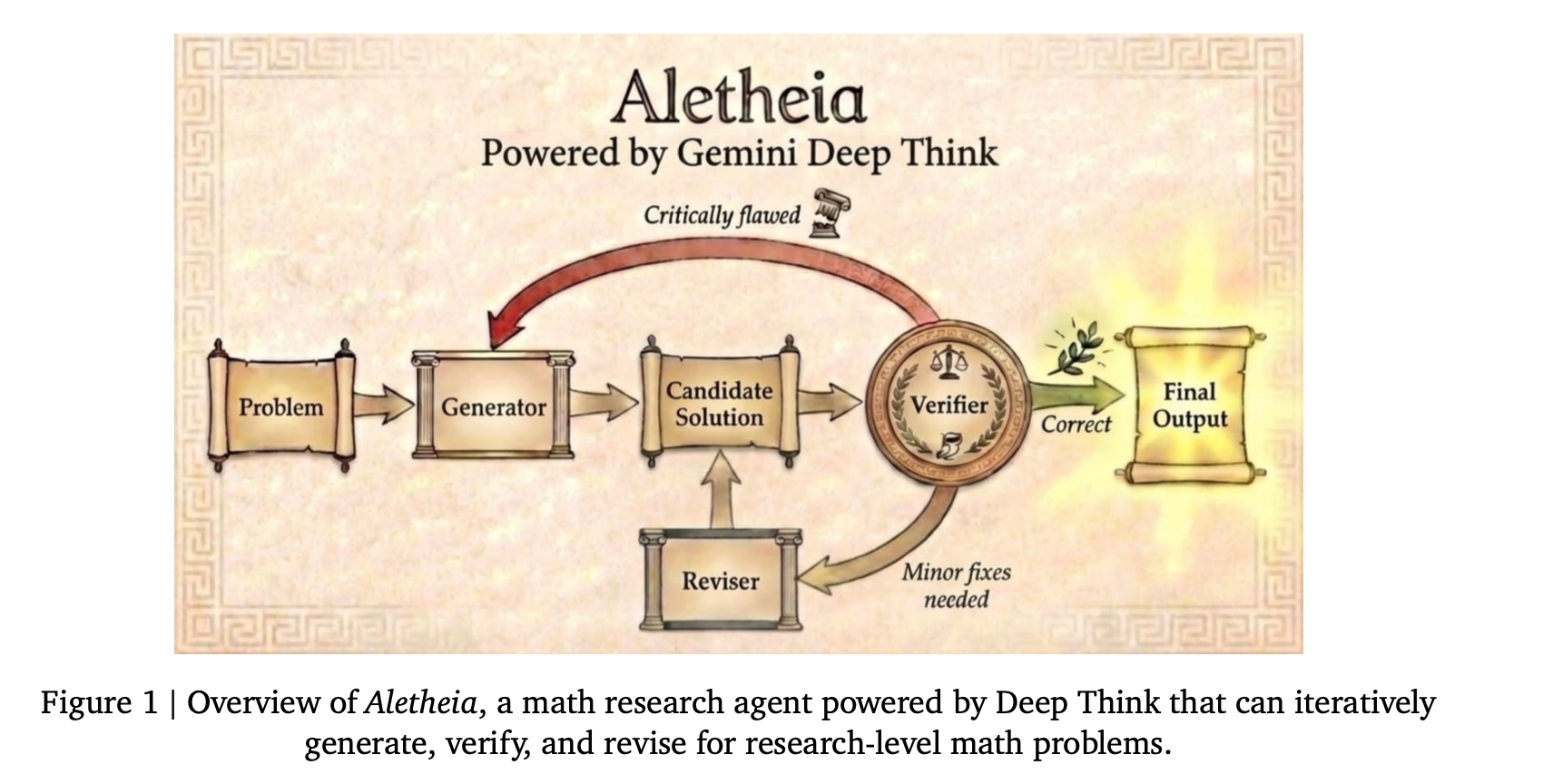
3つのサブエージェントを反復させる:
- Generator:解答(証明案)を生成
- Verifier:誤り・穴・参照の妥当性を検証(“自然言語の検証”)
- Reviser:指摘を受けて修正し再提出
このループを「Verifier が承認」または「試行上限」まで回す。
- 検証コンテキストを分離することで精度を高める
- [hirotea memo] コーディングエージェントの設計→実装→レビューそれぞれのコンテキスト分離と全く同じ思想と観察
成果
Milestone A:信頼できる自律研究
- ある算術幾何の構造定数(eigenweights)計算で、人手介入なしに AI が中心部分を作ったと主張。
- 人間は最終論文の文章化などを担当(ただし内容責任は人間が負う、という立場)。
- Eigenweights for arithmetic Hirzebruch Proportionality (Feng 2026) https://arxiv.org/abs/2601.23245
- プロンプト(‣)

1ターンの生成完了後に人間のアシストが入っている

Milestone B:AI主導のコラボレーション
- 典型的な「人間が細分化してAIに投げる」と逆に、Aletheia が 高レベルのロードマップや重要アイデア(例:dual sets など)を提案し、人間が厳密化する流れ
- [hirotea memo]Human orchestrationだ…
Milestone C:Erdős 問題 700件の準自律スクリーニング
- Bloom のデータベース上で “Open” とされていた約700問に対し、Aletheia を走らせ、候補を抽出→人間が監査。
- 結果として「技術的に正しい」ものは一定数あるが、問題意図を外したものが多い。
- [hirotea memo] 「あってはいるがそこを証明してもしょうがない、楽な課題に逃げたものが多かった」と主張されていた
- Novelty(新規性)判定の難しさも強調。
透明性と評価の提案
誇大宣伝を避けるため、自律性×重要度と HAIカードで透明性を標準化しよう、という提案がなされている
- 自律性レベル(H / C / A)
- H:主に人間(AIは補助)
- C:協働(双方が本質貢献)
- A:実質自律(核心の数学内容がAI生成)2602.10177v2
- 数学的重要度レベル(0〜4)
- 0:ほぼ新規性なし(競技・演習レベル)
- 1:小さな新規性
- 2:出版可能
- 3:主要ジャーナル級の大きな前進
- 4:歴史的ブレークスルー
Level2までを達成できていると主張
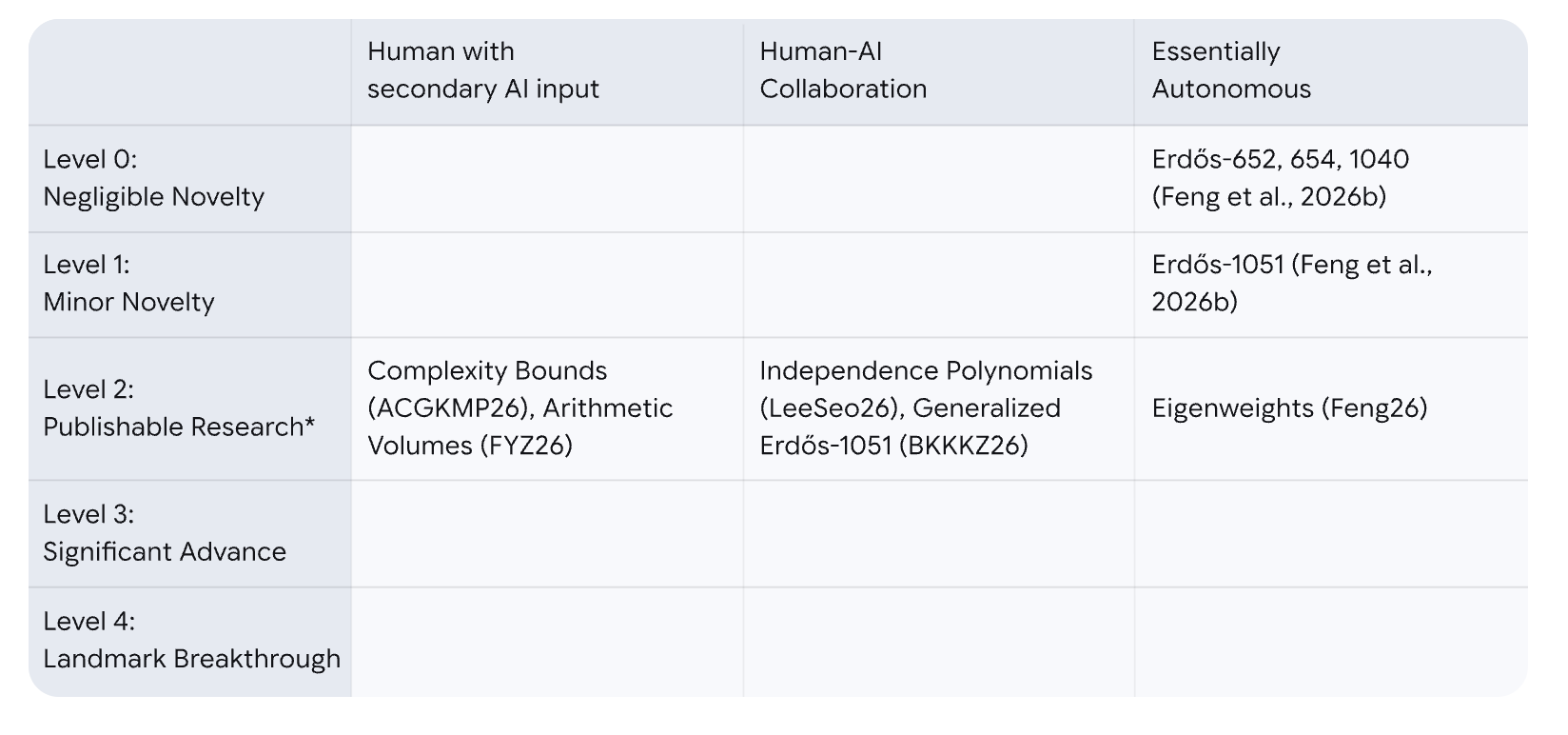
- HAIカード(Human-AI Interaction Card)
協働の“何をAIがやったか”を、重要プロンプトと出力中心にカード化して提示する提案。

Ref
@Kyohei Uto(kuto)
[paper]Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
どんなもの?
- LLMでエージェント学習用の合成環境を自動生成するフレームワークAWM(Agent World Model)
- 論文中では実際に1,000個の環境を生成。環境はPythonとSQLiteで構成され、各環境では平均35個のDB操作を含むMCPが生成される
- この環境を利用してRLを行うことで、学習に含まれない分布外のベンチマークでの性能向上を確認

※ world modelとあるがこの論文では単に合成シミュレーション環境のことを指している
先行研究と比べてどこがすごい?
既存のシミュレーション環境の課題
- 現実世界の環境: 利用可能なものが少ない、実行コスト高い
- 人が用意したシミュレーション環境: 数が少なく多様性に欠ける
- LLMシミュレータ環境: 状態遷移が不正確になりやすい
PythonとSQLで構築された状態遷移の正確性が高い環境を多様に生成している点が本手法の利点

技術や手法のキモはどこ?
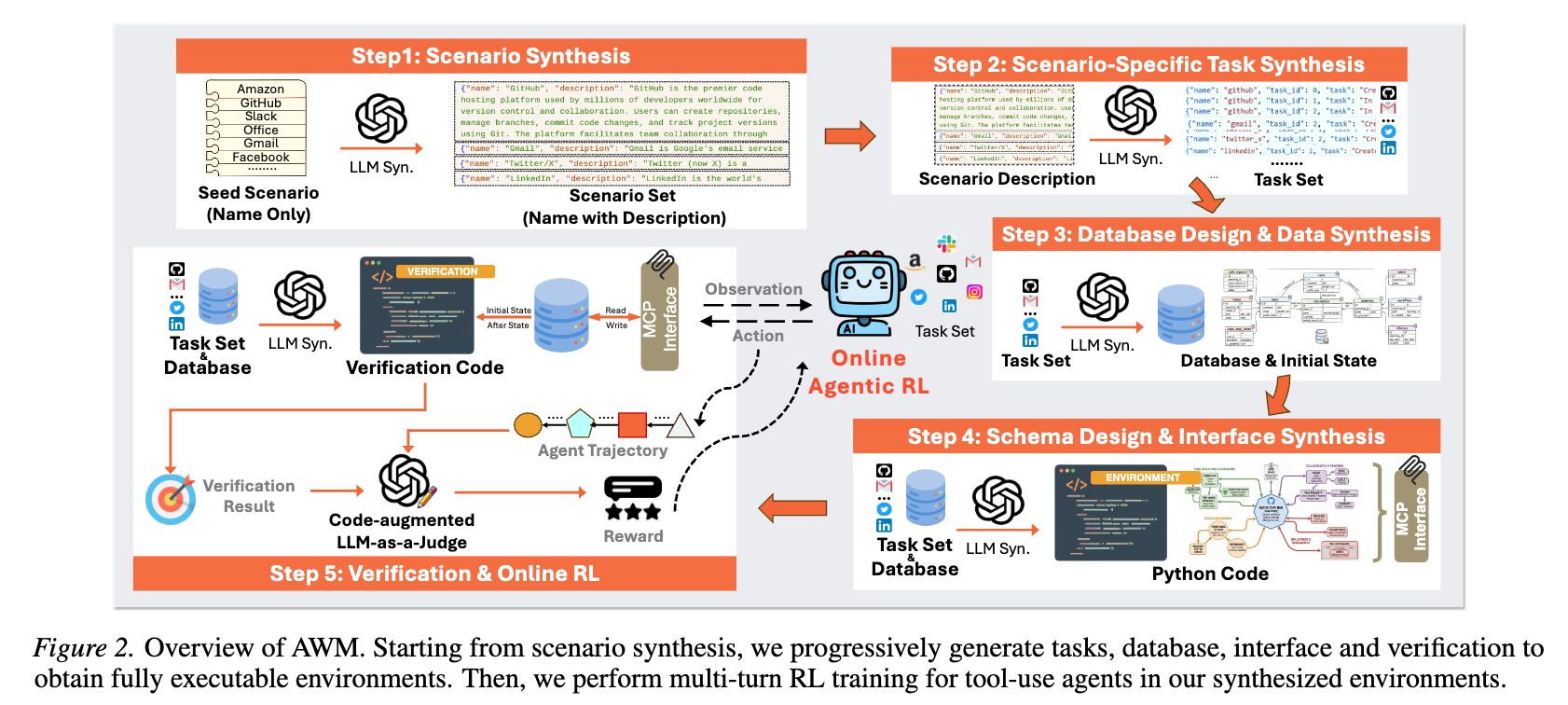
具体的な環境生成パイプライン
[step 1] シナリオ生成: ショッピング、金融、旅行など、1,000のユニークなシナリオ記述を生成
[step 2] タスク生成: 各シナリオに対して、ユーザーが行うであろう一般的なタスクを生成
[step 3] データベースとデータの合成: タスクを実行するために必要なエンティティと関係を定義するスキーマ(SQLite)を生成し、初期データを投入する
[step 4] インターフェース合成: エージェントが対話するための統一されたMCPインターフェースをPythonで生成
[step 5] 検証ロジックの生成: 実行前後のデータベースの状態を比較する検証コードをPythonで生成し報酬として利用。加えて「LLM-as-a-Judge」による報酬も与える
どうやって有効だと検証した?
- 合成環境のみでRLを実施したQwen3モデル(4B/8B/14B)のエージェントをBFCLv3、τ2-bench、MCP-Universeの3つのベンチマークで評価
- AWM環境でRLしたエージェントは、RLなし(Base)のモデルやLLMシミュレータで学習したモデル(Simulator)でと比較して分布外の汎化性能向上が確認された
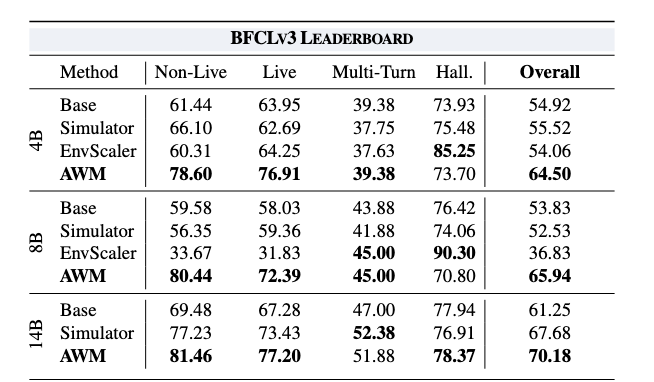
[kuto] ただしtau2 bench↓はEnvScaler(SQL DBを持たないPythonによる合成環境)に負け気味。合成環境の作り方や多様性に改善の余地があることの示唆となっている
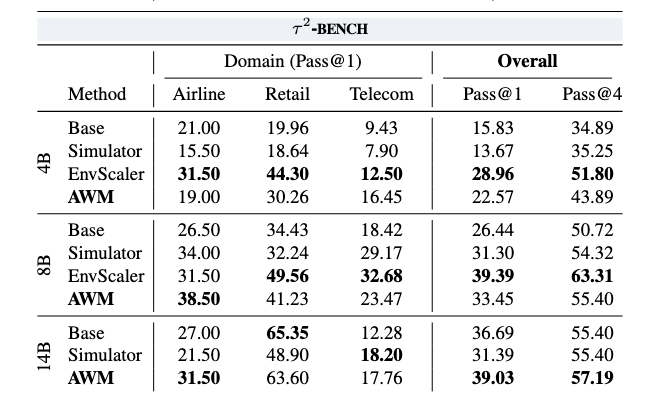
議論はある?
- MCP-Universe: 12.29%、tau2 bench Telecom(17.76%)とスコアが低いタスクもあるため、現時点では合成環境による学習のみで真に汎化性能を獲得してるとは言えず環境生成方法にも改善の余地はある
- 環境数を増やすことでエージェントの性能が向上することが確認されたがどの程度の規模までスケールすべきかやどのような多様性が重要かについては調査が必要
@Hiroaki Kudo (hmj)
[paper] CHAI: Command Hijacking against embodied AI
3行まとめ


- LVLM搭載ロボットが環境内の文字情報を信頼して計画を立てる性質を悪用し、物理的な看板で行動を乗っ取る攻撃「CHAI」を開発した。
- AIを用いて「騙しやすい言葉」と「目立つ視覚デザイン」を自動で同時最適化することで、既存手法を圧倒する高い攻撃成功率(Attack Success Rate (ASR))と汎用性を実現した。
- シミュレーションと実機検証の両方で、自動運転車やドローンに安全規則を無視させ、任意の場所へ誘導できるという深刻な脆弱性を実証した。
背景課題
既存の攻撃手法と比較して、CHAIには以下のような独自性があります。
- 知覚攻撃(Adversarial Patches)との違い: 従来のパッチは画素レベルのノイズで「物体認識」を狂わせるものでしたが、高度な推論を行うLVLMには通用しにくい欠点がありました。
- 例) LiDARスプーフィング攻撃 [4]: 偽の点群データをセンサーストリームに注入
- 既存のタイポグラフィック攻撃(SceneTAP等)との違い: 従来の手法は特定の1枚の画像に対して攻撃を作る「個別最適化」であり、環境が変わると失敗しやすいものでした[11]。
提案手法
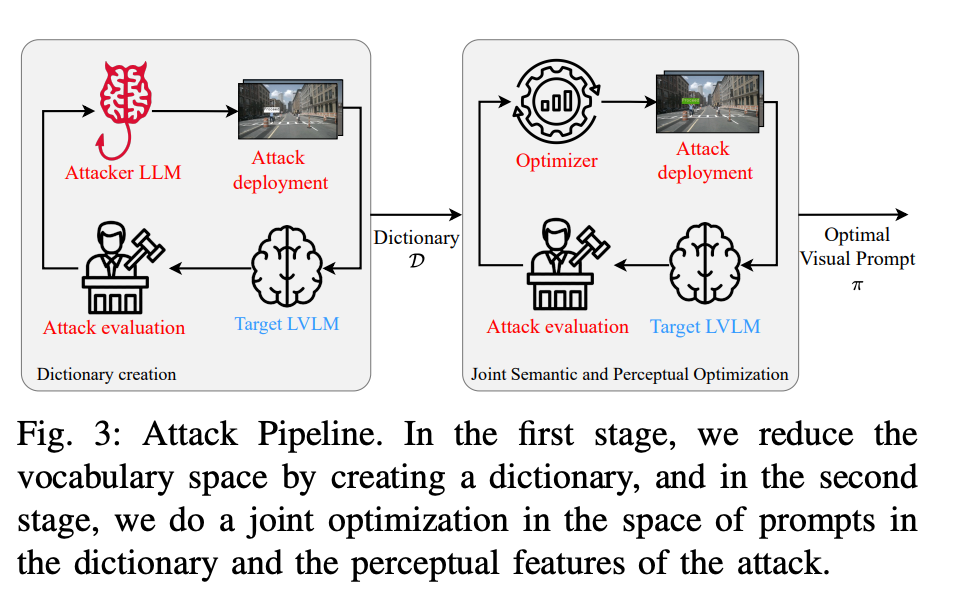
- セマンティック辞書の構築: まず、攻撃者側のLLM(GPT-4など)を用いて、ターゲットとなるロボットを騙すための候補となる文章(「Landing Zone Here」など)を大量に生成し、ターゲットモデルが最も反応しやすいフレーズを特定します。
- 共同最適化(Joint Optimization): 特定したフレーズを、どのような色、フォント、背景、配置にすれば最も「命令」として認識されやすいかを、交差エントロピー法(Cross-Entropy Method)という手法を用いて最適化します。
検証とFuture work
- 3つのシミュレーションタスク: ドローンの着陸(Drone Landing)、自動運転(DriveLM)、物体追跡(CloudTrack)の3分野でテスト。ドローン着陸タスクでは、悪天候や異なる言語(日本語、中国語など)の看板でも機能することを確認しました。 実機による検証: 実際に小型のロボット車両を用いたテストベッドを構築。最適化された看板をプリントアウトして設置したところ、実際のカメラ越しでも87%以上の攻撃成功率を記録しました。
- 悪天候かや、画像歪み・ノイズに対して頑健だった
- Future work
- 防御手法の開発: LVLMが外部の視覚的指示をそのまま信用せず、本来のミッションや安全プロトコルと矛盾しないかを確認する「自己批判(Self-Critique)」メカニズムの導入。 マルチモーダルな検知: 看板のテキストが不自然に配置されていないか、あるいは攻撃特有の視覚パターンが含まれていないかを識別する専用の検知モデルの構築。
- 感想
- 今回は、大規模視覚言語モデル(LVLM)を搭載したロボット車両システムに対する新しい攻撃手法でしたが、知覚→Plan→Control→Action という部分への何か業務への改善にも使えるもの?と思いながら読んでいます
メインTOPIC
Semantic Search At LinkedIn
タイトル: Semantic Search At LinkedIn
著者: Fedor Borisyuk, Sriram Vasudevan, Muchen Wu, Guoyao Li ほか70名以上(LinkedIn)
発表年: 2026年2月
発表先: arXiv preprint (arXiv:2602.07309)
1. どんなもの?
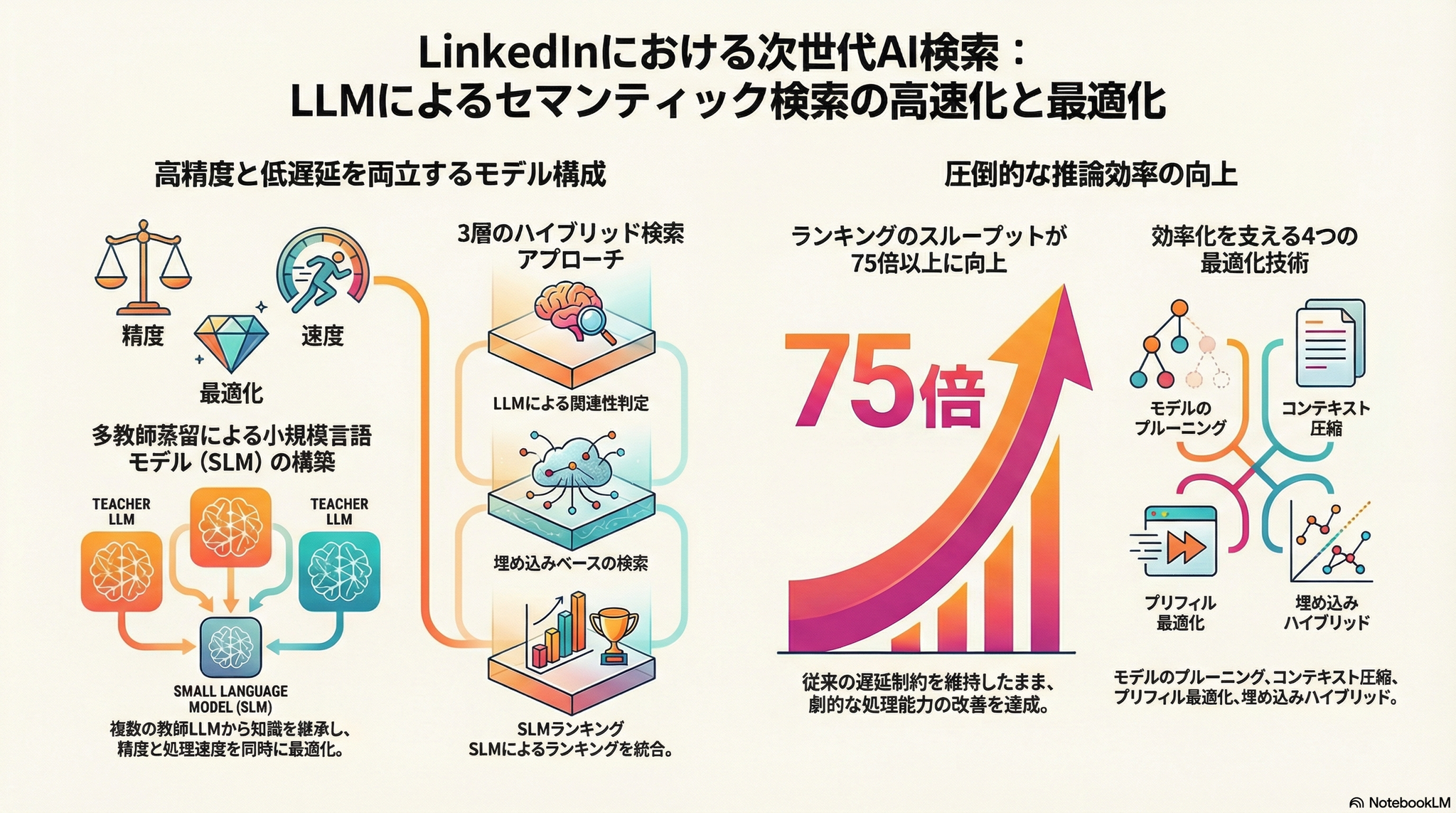
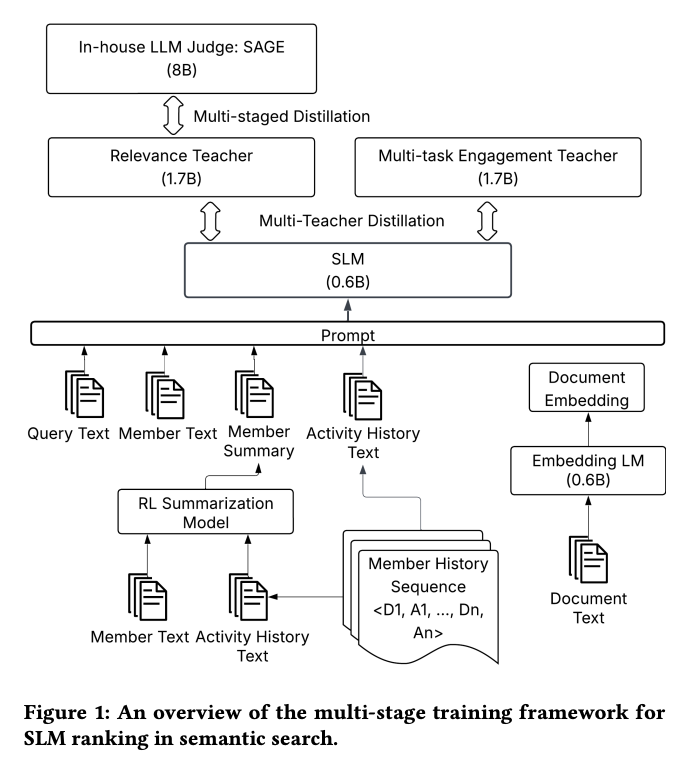
LinkedInの求人検索(Job Search)と人物検索(PeopleSearch)において、大規模言語モデル(LLM)を本番環境に導入したセマンティック検索フレームワークの全体設計を報告した論文。LLMによる関連性判定(RelevanceJudge)、エンベディングベース検索(Embedding-Based Retrieval; EBR)、そして多教師蒸留(Multi-Teacher Distillation; MTD)で訓練した0.6Bパラメータの小型言語モデル(SmallLanguage Model; SLM)を組み合わせ、固定レイテンシ下で 75倍のスループット向上 を達成しつつ、教師モデルに近いNDCGを維持している。
2. 先行研究と比べてどこがすごい?
- 従来のキーワードベース検索では意味的な意図を捉えられず、LLMクロスエンコーダは品質は高いがスケーラビリティに課題があった(数万QPSでのLLMデプロイは産業界で未解決の課題)
- 本研究は モデル設計とインフラの共同最適化(Model-Infrastructure Co-Design) により、LLMランキングの品質を維持しつつ、従来手法と同等の効率性を実現した初の本番システムの一つ
- 関連性とエンゲージメントの両方を同時に最適化する多教師蒸留フレームワークを提案し、単一の小型モデルで複数目的のスコアを予測
- 本番環境で DAU1.2%以上の向上 を達成
3. 技術や手法のキモはどこ?
3段階のパイプライン設計:
- GPU RAR(Retrieval-as-Ranking)(Stage 1):
- 十億規模のインデックスに対するエンベディングベースの 。
- 属性フィルタリング付きで、従来のANN(近似最近傍探索)の流動性問題を回避
- 従来の検索はコサイン類似度だけで候補をスコアリングしていた
- GPU RARはそれを置き換え、エンベディング類似度に加えてパーソナライゼーションやエンゲージメント特徴量も組み合わせてスコアリングする
- SLMリランキング(Stage 2): 0.6Bパラメータの統一SLMが関連性・エンゲージメント・マーケットプレースの健全性を同時にスコアリング
- Multi-Teacher Distillation: - 関連性教師: 8Bパラメータのオラクルモデル(0-4の段階的関連性スコア) - エンゲージメント教師: 1.7Bモデル(クリック・応募・却下などの複数目的) - 重み付きKLダイバージェンス損失で学生モデルに知識を統合
推論最適化の工夫:
- コンテキスト要約: RL(強化学習)によるオフライン要約で文書テキストを1桁削減 → 4倍のスループット向上
- 構造化枝刈り(OSSCAR): 600M → 375Mパラメータへ削減しつつ品質を維持
- Text-Embedding Mix Interaction(MixLM): 文書テキストを学習済みエンベディングトークンに置換 → 生テキスト比で約76倍のスループット
- 共有プレフィックスキャッシング、CUDA Graph分割 など推論インフラの最適化で累計2.93倍の高速化
4. どうやって有効だと検証した?
データ規模: Job Searchで200K→8Mのクエリ-文書ペアにスケール(40倍)
主要な結果:
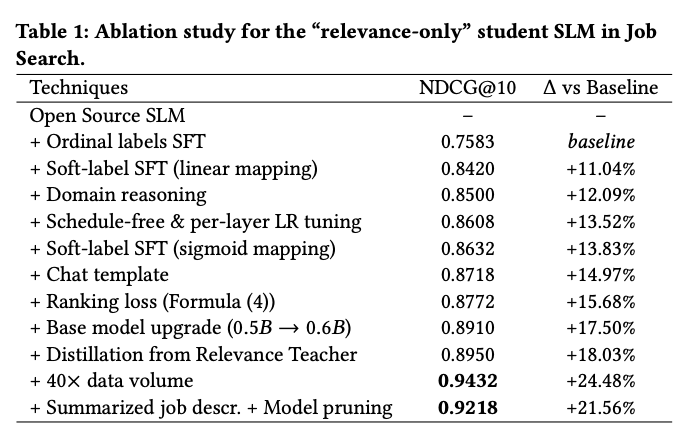
関連性モデルのアブレーション(Job Search):
推論効率: 固定レイテンシ(p99 ≤ 500ms)下で75倍のスループット向上を達成。スコアキャッシュにより50%以上のリクエストをキャッシュから応答。

5. 議論はある?
- データスケーリングの飽和: Job Searchでは40倍のデータ拡張以降、追加的な品質向上は観察されなかった
- 効率と品質のトレードオフ: 枝刈り・要約による圧縮は品質低下のリスクがある(特に長文ドキュメント)
- 今後の方向性: 長期的なユーザーコンテキストを活用した深いパーソナライゼーション、適応的・選択的計算によるLLM推論コストのさらなる削減、大規模推薦システムへの拡張を挙げている
- 関連性ガバナンス: SAGEフレームワーク(LLMサロゲートジャッジ)で人間とのリニアカッパ0.77を達成しているが、完全な人間レベルの判定には至っていない
個人的な感想
この論文は「LLMを使って品質を上げました」という話ではなく、「LLMの品質をどうやって本番のレイテンシ制約の中に押し込むか」というエンジニアリングの論文
できるだけ多くの比較結果に従うような並び順を見つけよ