
2026-02-24 機械学習勉強会
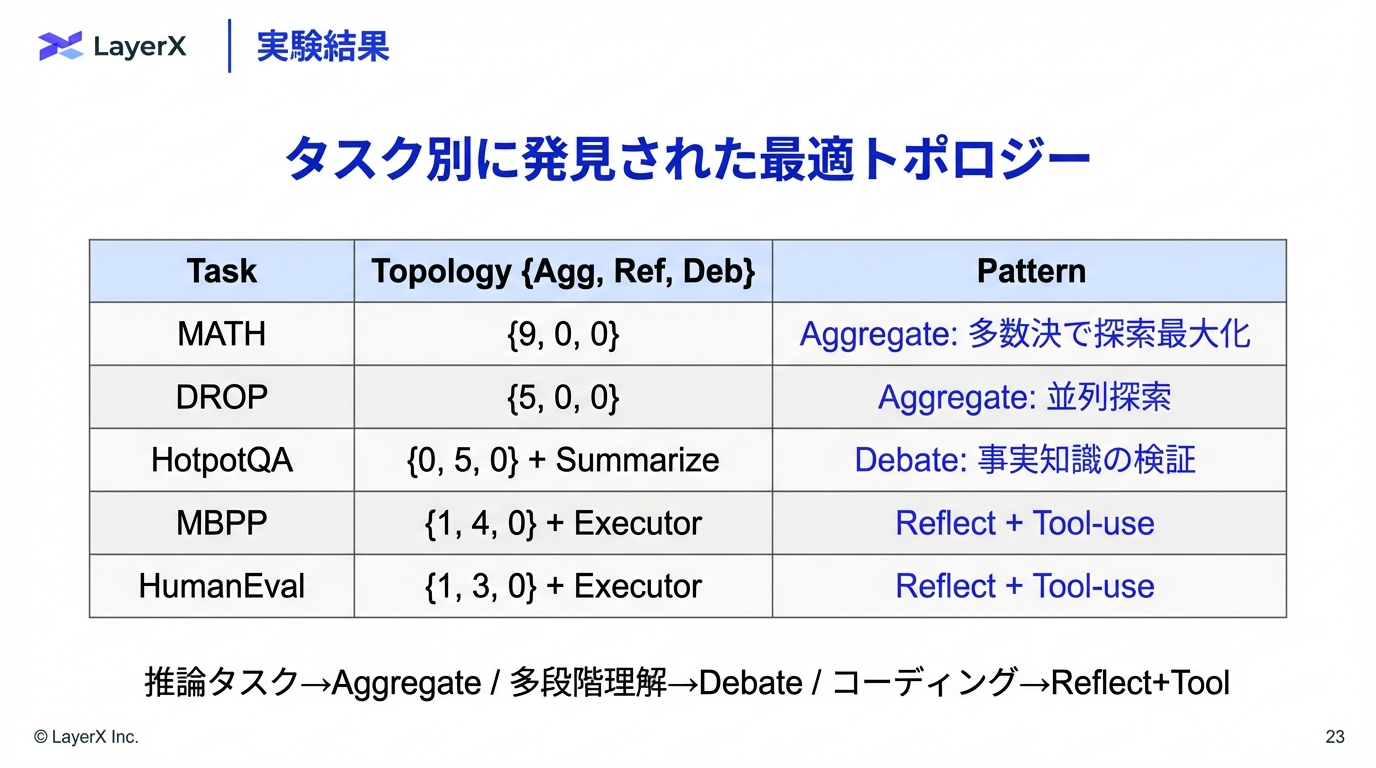
今週のTOPIC[paper] Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies[paper] Modeling Distinct Human Interaction in Web Agents[論文] SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes[blog]Cog-RAG: Giving RAG a Brain That Thinks Before It Retrieves[blog] Scaling LLM Post-Training at Netflix[Blog]Measuring AI Agent Autonomy in Practice (Anthropic)[paper]KLong: Training LLM Agent for Extremely Long-horizon TasksメインTOPICSTRUCTSENSE: A TASK-AGNOSTIC AGENTIC
FRAMEWORK FOR STRUCTURED INFORMATION
EXTRACTION WITH HUMAN-IN-THE-LOOP
EVALUATION AND BENCHMARKINGIntroduction背景と課題StructSenseの提案Architecture & ImplementationSystem Components"Task-Agnostic" Configuration4 Specialized AgentsCase Study: Task DefinitionsTask 1: 心理評価尺度のスキーマ抽出 (Schema-based)Task 2: リソース情報の抽出 (Resource Extraction)Task 3: NER(固有表現抽出) (NER Term Extraction)Experimental Setup & Evaluation CriteriaModelsEvaluation SettingsMetricsResults & Critical AnalysisTask 1 (Schema) & Task 2 (Resource)Task 3 (NER Term Extraction)考察1: Judge Agentの実効性考察2: オントロジー評価の限界 (Semantic Fidelity)考察3: コストとパフォーマンスのトレードオフDiscussion & Future WorkTask Type and HIL Impact制限事項: オントロジー不在の領域
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi






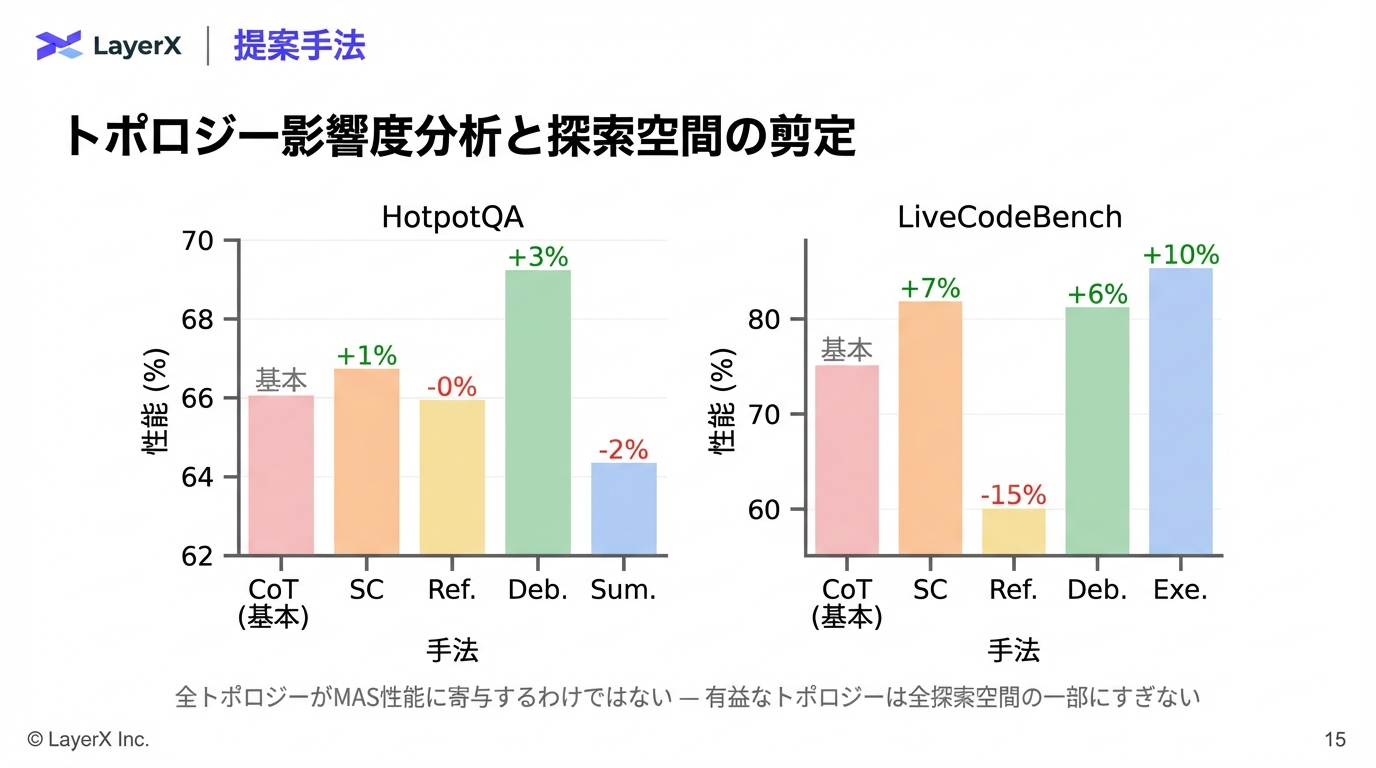



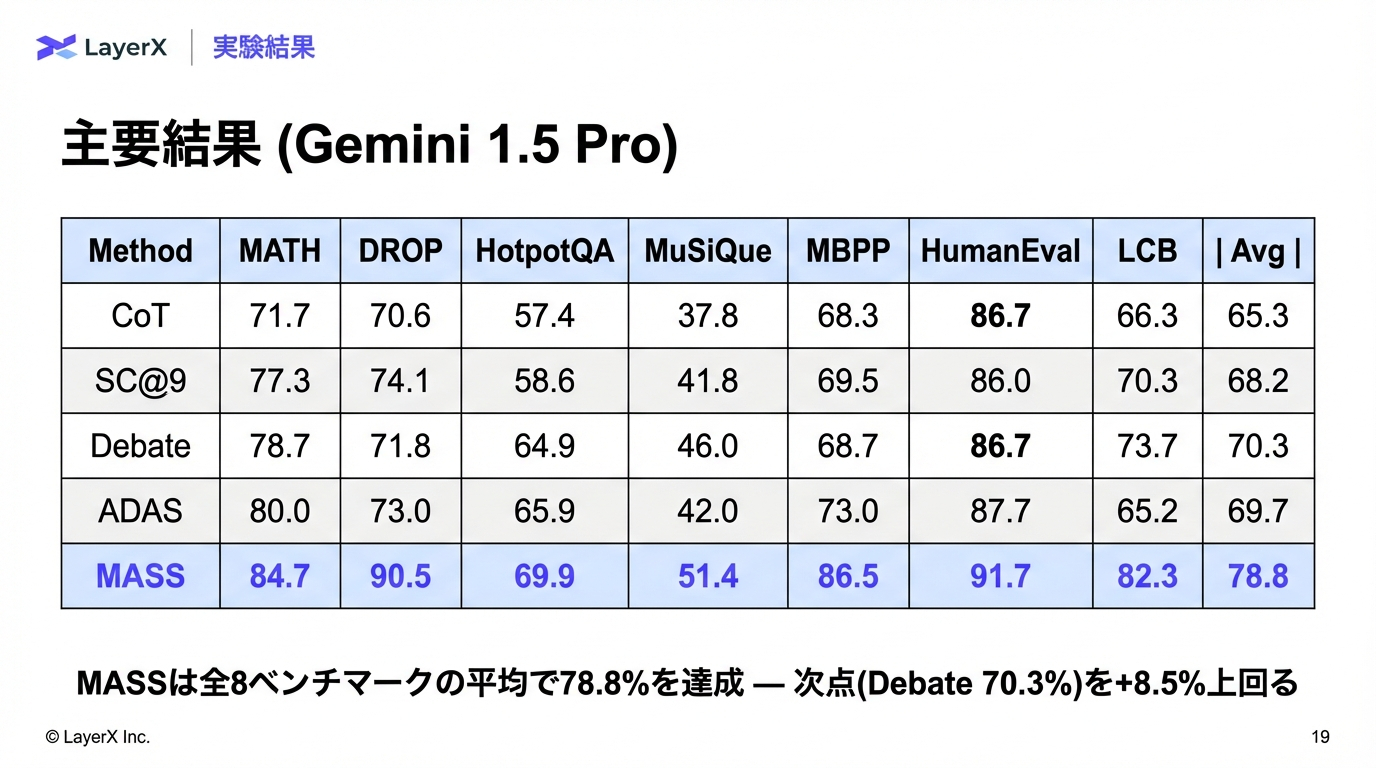
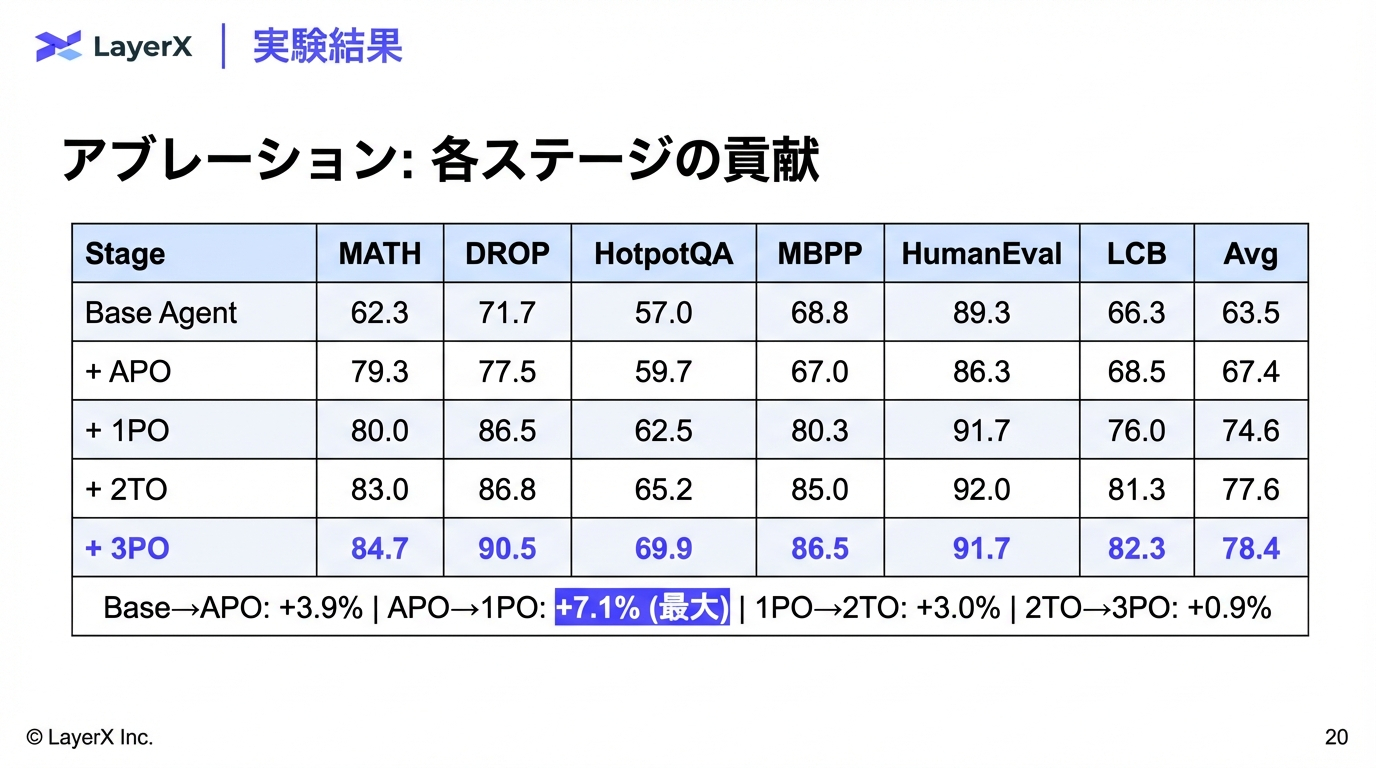
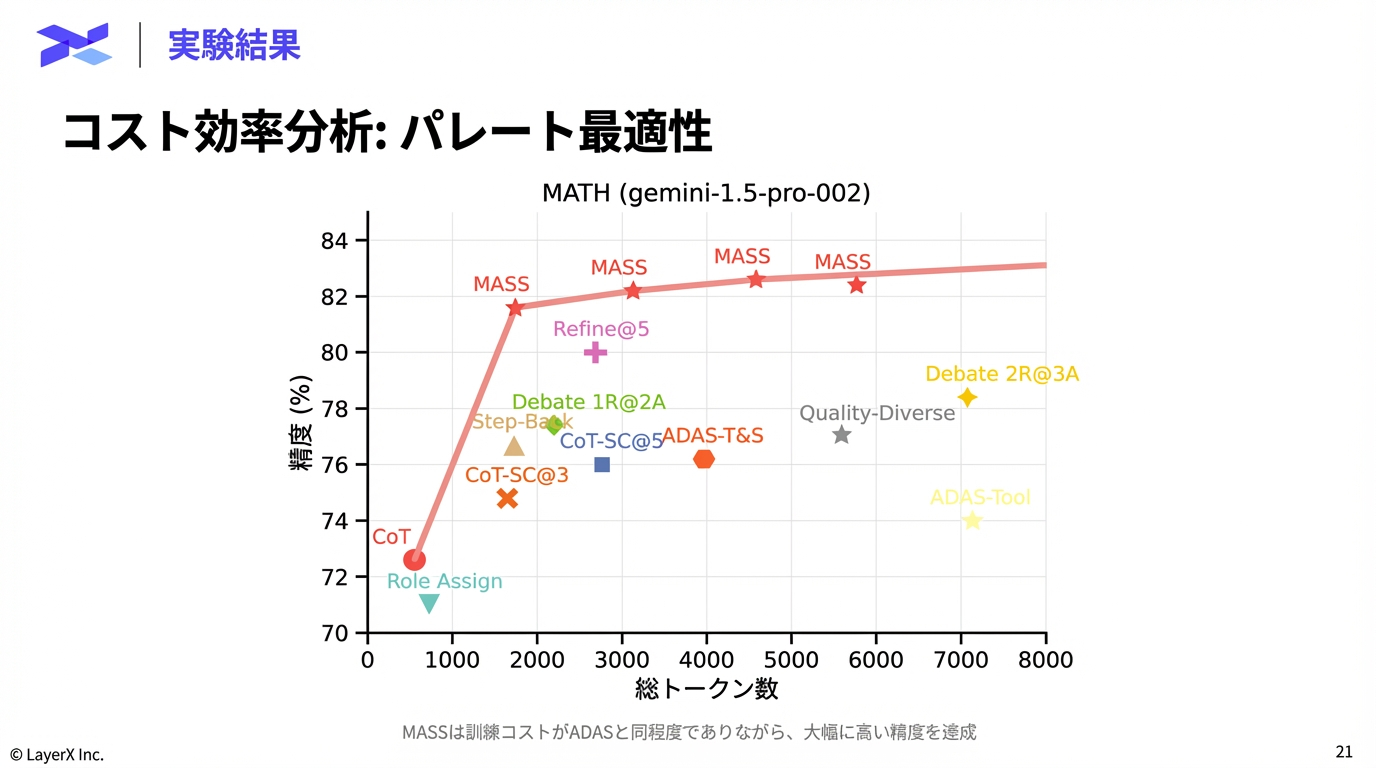




@Shun Ito
[paper] Modeling Distinct Human Interaction in Web Agents
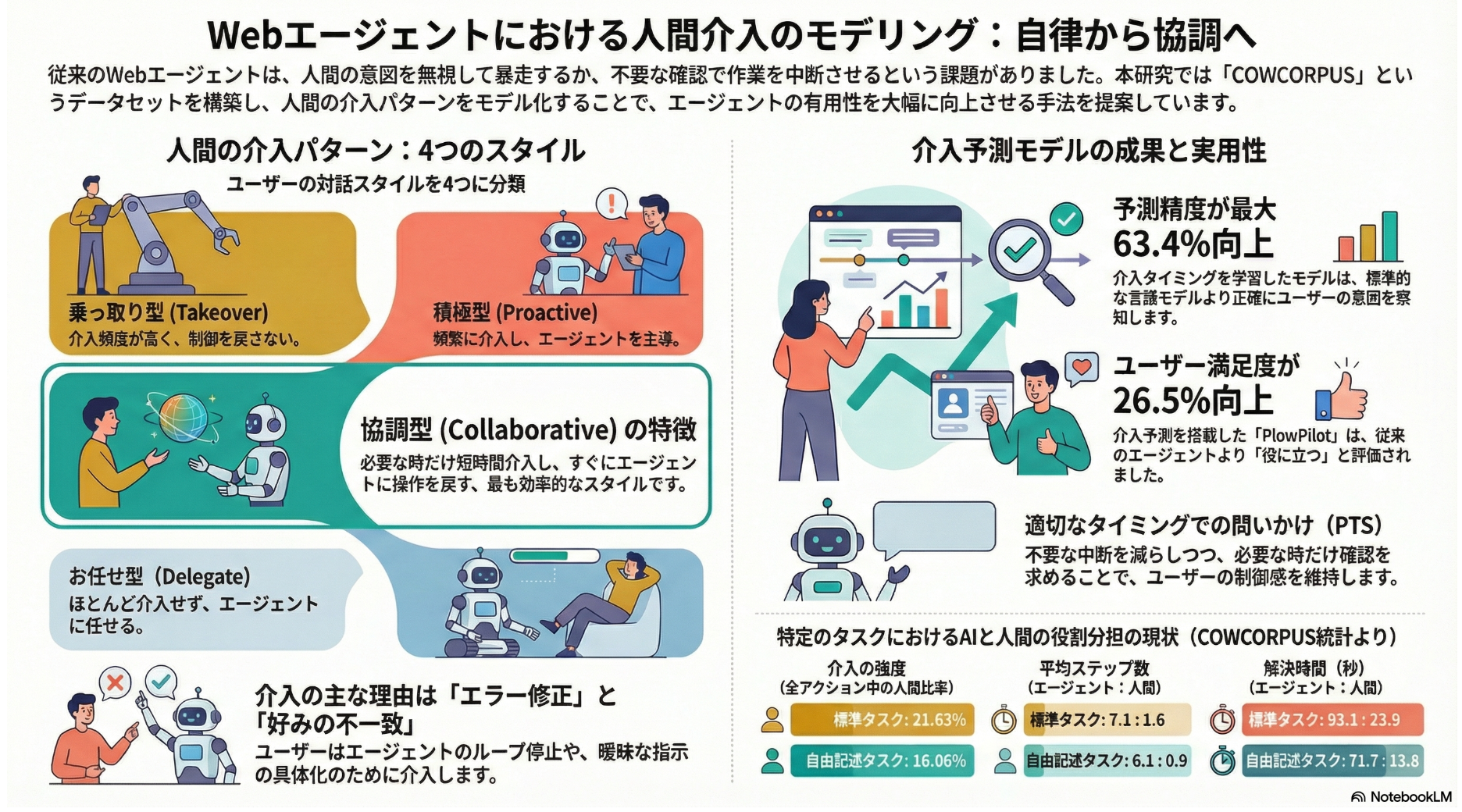
- Web操作自動化のAIエージェントで、人間の介入(途中で止めて修正、引き継ぎなど)を適切に入れられるようにしたい
- NG: 人が止めるべきところで確認せず進んでしまう
- NG: 過剰に確認してしまう
- 提案: 人間の介入が発生するタイミングを予測する
- データセット COWCORPUS を作成
- 20人 x 20タスク = 400軌跡の実行履歴
- タスク: 条件に見合う航空券の検索や、仕事の検索、ショッピングなど
- 人間の介入パターンを4分類し、それぞれで予測モデルを作成(データセットから集計した介入頻度や介入タイミングなどの特徴量をクラスタリング)
- Hands-off(手放し):ほぼ介入しない(最初から最後まで任せる)
- ※ 介入がないので予測対象外
- Hands-on(手を動かす監督):介入が多く、エージェントと交互に操作しがち
- Collaborative(協調):必要な時だけ短く介入し、すぐエージェントに戻す(handbackが高い)
- Takeover(乗っ取り):普段はあまり介入しないが、終盤などで人が引き継いだら 戻さず 自分で完了
- 問題設定: 2値分類
- In: 過去の操作履歴と現在の画面のスクショ
- Out: ask_user(介入あり) or agent_continue(介入なし)
- 予測モデル: マルチモーダルな言語モデル
- few-shot: Claude-4-Sonnet、GPT-4o、Gemini-2.5-pro
- 学習あり: Gemma-27B、LLaVA-8B
- 評価指標: 正解タイミングとの距離に基づく評価
- 推論は、ユーザーの過去ログから該当する介入パターンを決定し対応するモデルを利用

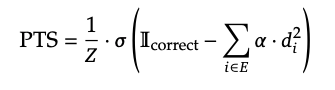
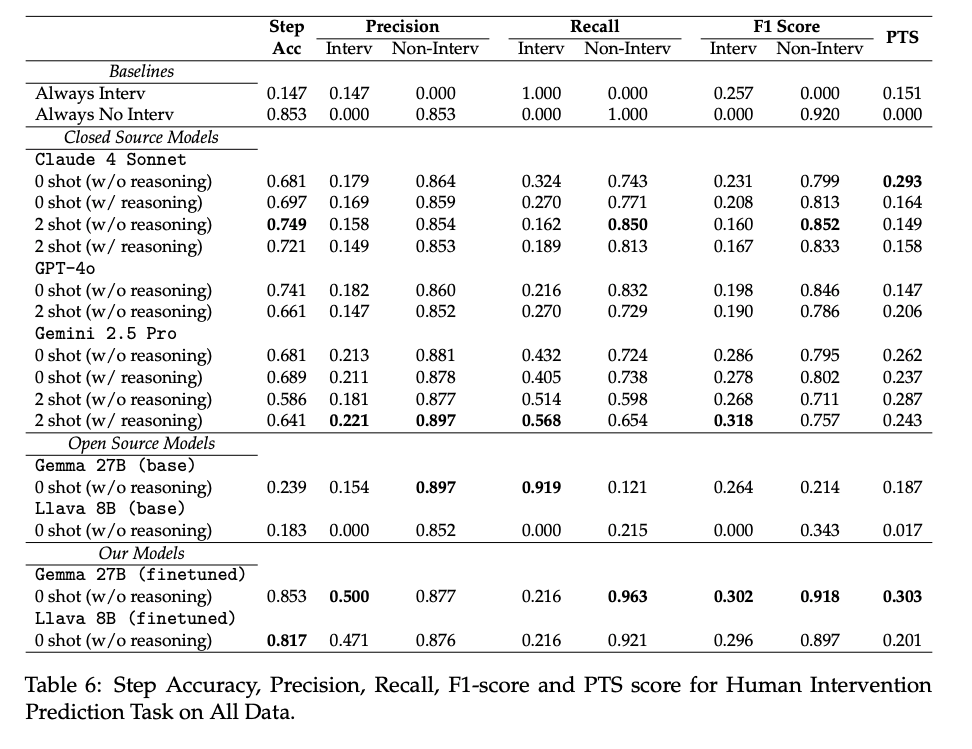
- 結果
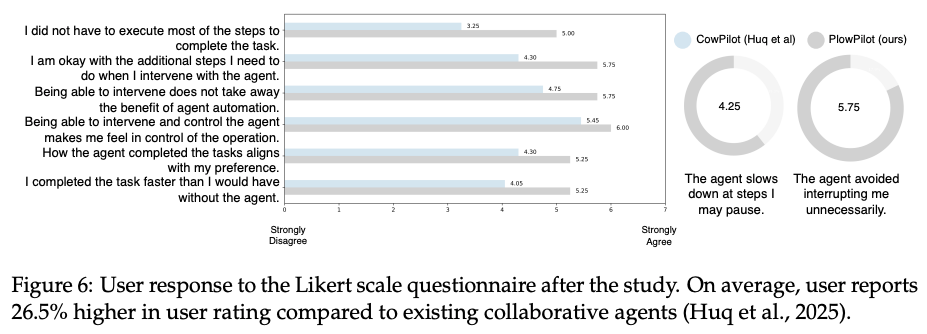
- few-shotよりも学習モデルが全体的に良い傾向(LMではない予測モデルも見たかった)
- ツール化して実験: 既存ツールよりも満足度の高い結果
@Takumi Iida (frkake)
[論文] SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes
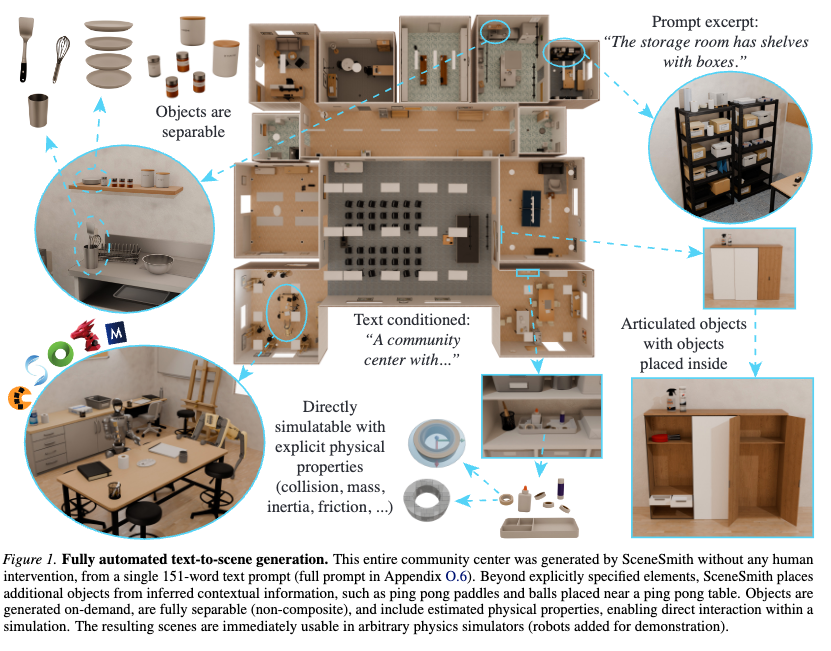
VLMのエージェントを使って、3Dシーンを生成する論文。
生成した仮想世界を使ってロボット操作ができる。
3Dシーンの生成パイプライン
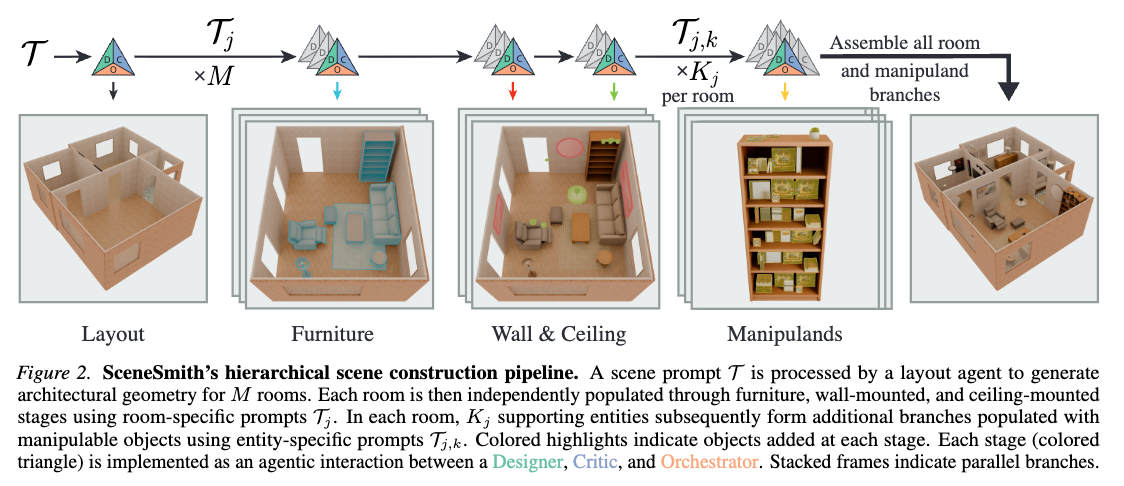
ハコを作って、中に詰めていくイメージで生成していく。
3つのエージェント(下図のトライアングル部分)
- D=Designer:シーンの状態変更を提案。Structured Toolsを使って、実際に配置変更などができる
- C=Critic:もっともらしさや物理的な現実性などを評価
- O=Orchestrator:上2エージェントの交流促進
で生成
生成順序:
- Layout M部屋生成される。複数部屋で1シーン(レイアウト)という解釈。
- Furniture(床に置く家具) M部屋別々に生成していく
- Wall&Ceiling(壁や天井にかけるもの)
- 操作可能なオブジェクト
3Dオブジェクトの生成パイプライン
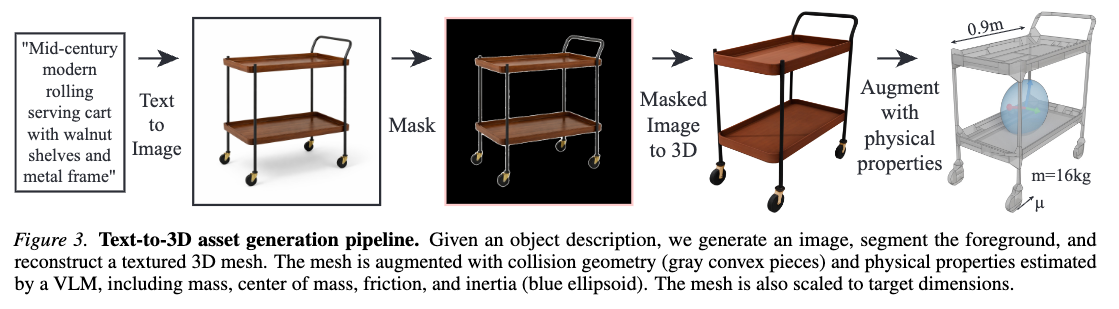
テキストから2D画像生成をして、その後3D化していく。
[frkake] 苦手なオブジェクトでないのかな。例えば、このカートの柱が白色になるだけでセグメンテーションが厳しい気がする。生成時のアテンションかなにかを取れば、行けたりするのかな
評価方法
下図はロボット操作の評価パイプライン。
- タスク(果物を一つてにとって、皿の上に置く)が与えられると、シーンの制約情報(何があるのかなど)のテキストを生成
- 生成されたテキストから3Dシーンを生成して、ロボットがタスクをできるかどうかを評価
[frkake] 下流タスクが解けるかで評価するのいいね
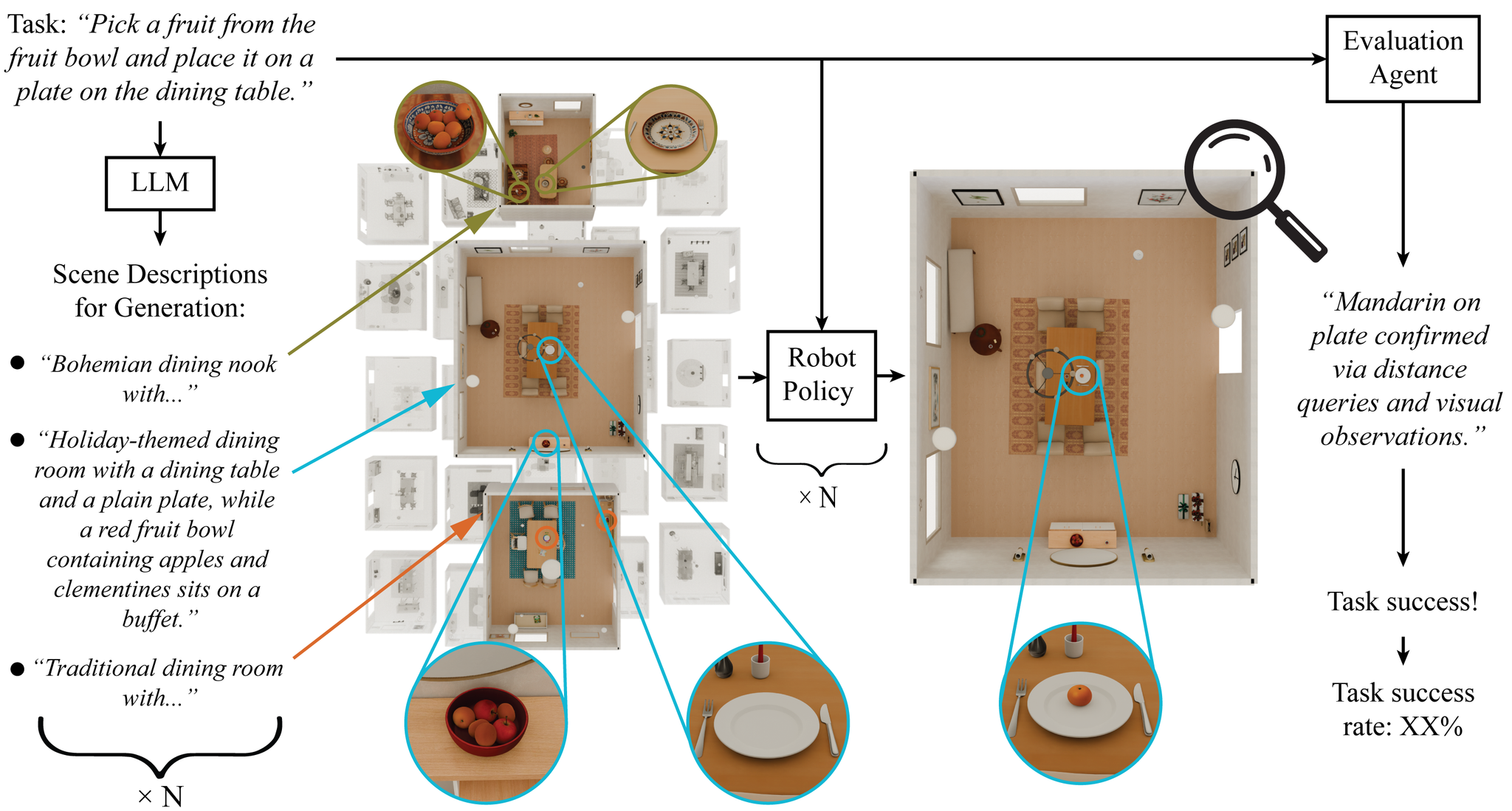
結果
比較手法と比べて密なシーンが生成できる。
定性的な結果はプロジェクトページのデモを見てもらうのが一番いい。

[frkake]
エージェントによる分散的な生成と評価がうまく組み合わされていると感じた。
各部屋手分けして生成したり、数をたくさん生成して、最終タスク(ロボット操作)がうまくいくかで評価する方法は、計算リソースを無視すればとても理にかなっていると感じた。
数を打って妥当な配置にするのを狙ってできるようになれば、更に発展しそう。
@Hiromu Nakamura (pon)
[blog]Cog-RAG: Giving RAG a Brain That Thinks Before It Retrieves
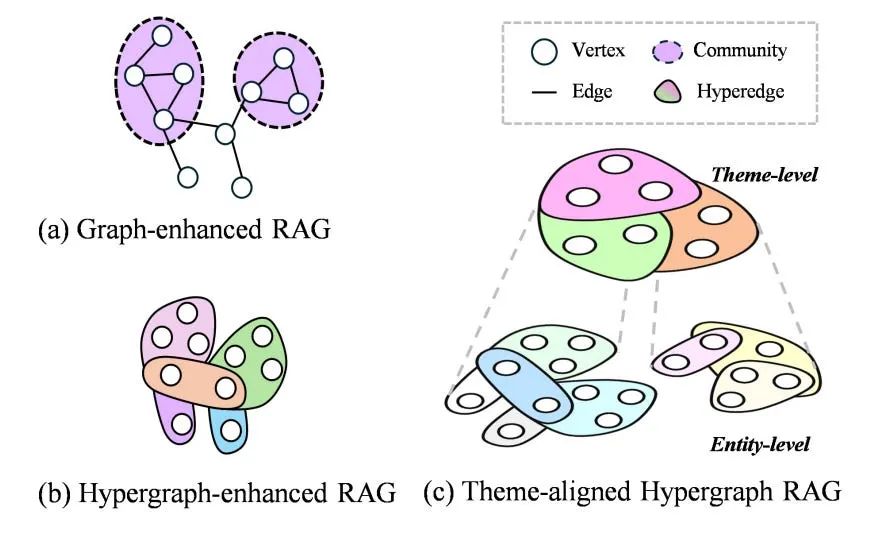
Cog-RAGは、人間が複雑なタスクを処理する際の「トップダウン型」の認知プロセス(まず全体のテーマを把握し、そこから詳細情報を思い出す)に着想を得た、新しい検索拡張生成(RAG)のフレームワーク。
従来の課題
これまでのグラフ構造を取り入れたRAG手法は、主に2つのエンティティ間の関係(低次の関係)を捉えることに留まっていた。そのため、複数のエンティティ間の複雑な関係(高次の関係)や、文書全体を貫くテーマの構造を統一的に整理することが困難。
Hypergraph
1. 従来のグラフの限界(1対1の関係しか表せない)
- 従来の知識グラフは、2つのノードを1つのエッジで結ぶ「2項関係(1対1の関係)」しか表現できません。そのため、複数の要素が絡み合う複雑なグループの関連性を表現するのに限界があった。
2. ハイパーエッジによる「高次な関係性」の表現
- 単なる1対1の関係にとどまらず、複数の人物・イベント・概念が同時に関与するような「高次(beyond pairwise)の依存関係」を自然に捉えることができる。
3. 情報損失の回避と意味の保持
- 既存のグラフRAG(GraphRAGなど)では、複数のエンティティ間の関係を捉えるために「クラスタリング」を用いてコミュニティに分割していたが、この手法は離散的な分類に依存するため、情報の断片化や欠落(情報損失)を招いていた。ハイパーグラフを用いれば、テキストからグラフへ変換する際の意味情報の保持を最大化できる。
Cog-RAGの2つのコア技術
Cog-RAGは、大局的なテーマと局所的な詳細情報を結びつけるため、以下の主要なアプローチを導入している。
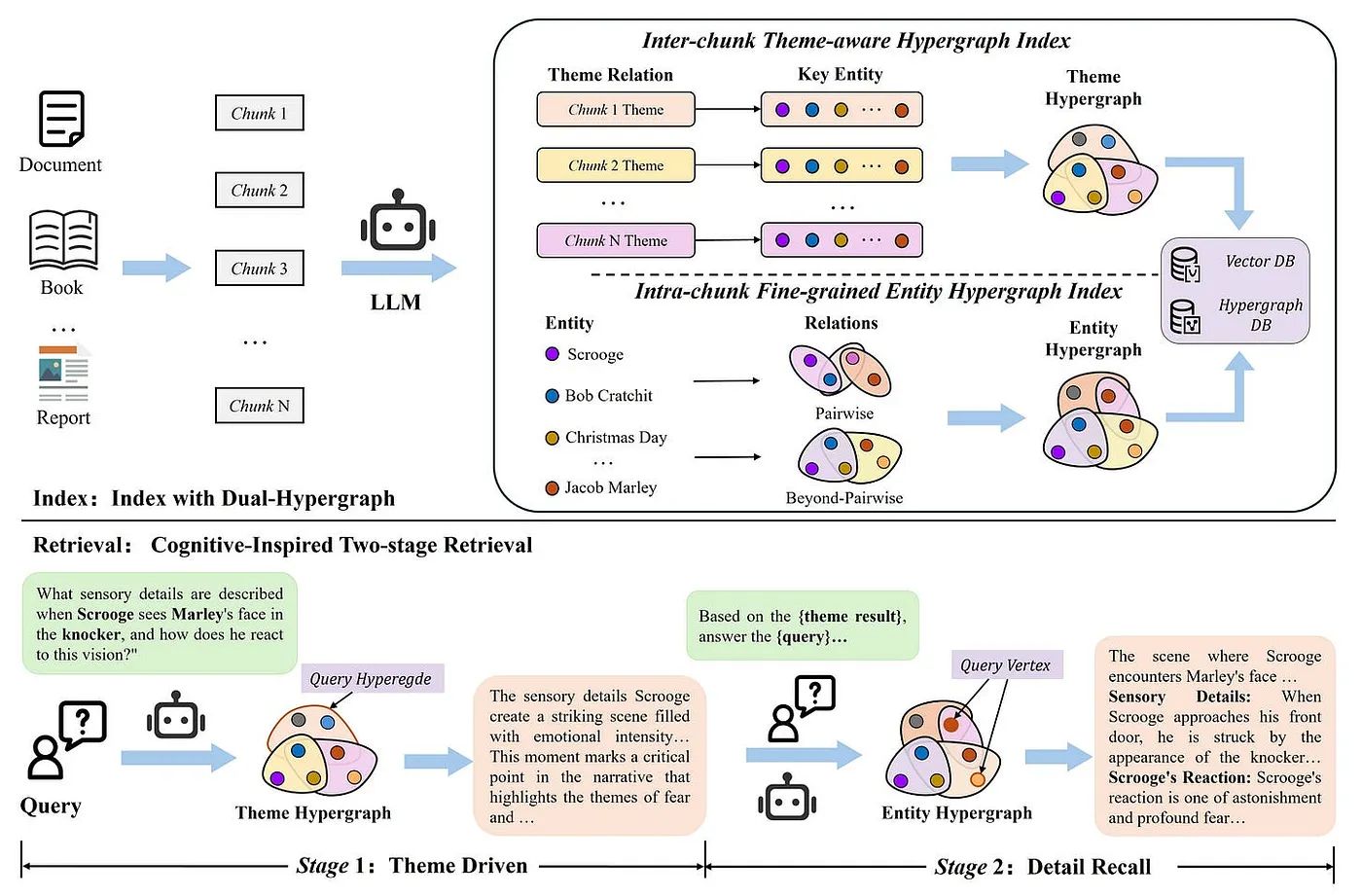
1. デュアルハイパーグラフ・インデックス
複雑な関係性をモデリングできる「ハイパーグラフ」を用いて、異なる2つの粒度で知識を構造化。
- テーマハイパーグラフ: 文書のチャンク(まとまり)間における「テーマ」の繋がり(ストーリーラインや概要など)を捉え、情報の大局的な意味構造(マクロ)を構築。
- エンティティハイパーグラフ: チャンク内に存在する人物・イベント・概念などのエンティティ間の、複雑で高次な関係性をきめ細かく(ミクロ)モデル化。
2. 認知に着想を得た2段階検索
人間の推論パターンを模倣し、以下の2段階で検索と生成。
- 第1段階(テーマ主導): まず、ユーザーのクエリに関連するテーマを「テーマハイパーグラフ」から検索し、全体的な文脈の拠り所(アンカー)として機能。
- 第2段階(詳細想起): 第1段階で得たテーマをガイドとして、「エンティティハイパーグラフ」から関連する詳細なエンティティ情報を検索。これにより、マクロなテーマとミクロな詳細情報の一貫性を保ちながら回答を生成。
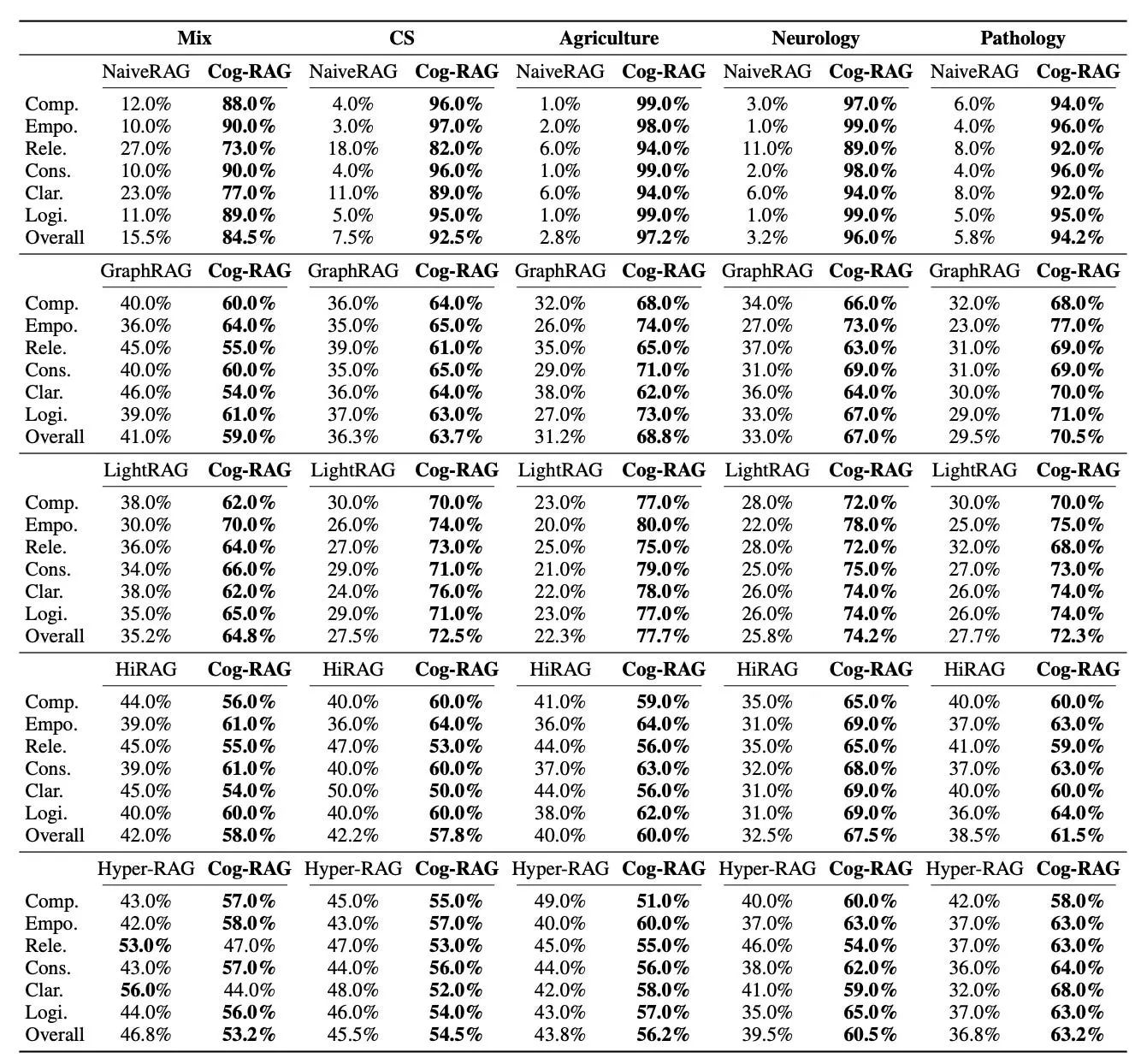
評価結果
Cog-RAGは、GraphRAGやLightRAG、Hyper-RAGといった既存の最先端手法と比較して、多様なデータセット(医療、コンピュータサイエンス、農業など)や複数のLLMにおいて、包括性・関連性・論理性などのあらゆる評価基準で大幅に優れたパフォーマンスを達成。
[pon]
- 多階層は珍しくはないが、個人的にハイパーグラフが面白かった。マクロをどう正しく構築するかが重要だよね?は最近の流れな気がする。
- ただこれ更新削除に関する話がない。PageIndexみたいに静的で長い文章対象なら使えそう。
@Shuhei Nakano(nanay)
[blog] Scaling LLM Post-Training at Netflix
- タイトル: Scaling LLM Post-Training at Netflix
- 著者 / 組織: Netflix Technology Blog(AI Platform Team)
- 公開日: 2026年2月
1. どんな記事?
NetflixのAI Platformチームが、LLMのPost-Trainingを大規模に運用するための社内フレームワークを構築した事例紹介。推薦・パーソナライゼーション・検索にLLMを活用する中で、SFTからオンポリシー強化学習まで統一的に扱えるインフラを整備し、研究者がインフラではなくモデル改善に集中できる環境を実現した。
2. 何が課題だったのか?
- ポストトレーニングがアドホックなスクリプトベースで運用されており、分散学習・データパイプライン・チェックポイント管理が研究者個人の負担になっていた
- 可変長シーケンスのパディングによるGPU計算の無駄と、FSDP(Fully Sharded Data Parallelism)ワーカー間の形状不一致による同期オーバーヘッド
- DeepSeek-R1やGRPO(Group Relative Policy Optimization)の登場でSFTだけでは不十分になり、SFTからRLへのワークフロー移行を統一的に扱う仕組みが必要に
- Netflix固有のデータ(メンバーのインタラクションイベント列など非自然言語データ)やビジネス指標の最適化に、汎用フレームワークでは対応しきれなかった
3. アーキテクチャ・技術的アプローチ
フレームワークは4つの柱で構成される。
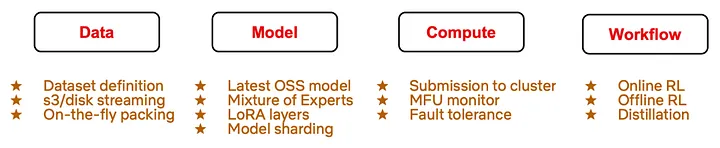
Data(データ管理)
- 損失マスキング(Loss Masking): アシスタントトークンのみに損失を適用し、プロンプト部分を学習対象から除外
- 非同期パッキング(Asynchronous Packing): 可変長シーケンスを固定長に詰め込み、CPUパッキングとGPU計算をオーバーラップ
- ドキュメントマスク: パッキングされたサンプル間のクロスアテンションを防止
Model(モデル構成)
- Qwen3、Gemma3、MoE(Mixture-of-Experts)等のモダンアーキテクチャ対応
- LoRA(Low-Rank Adaptation)統合、テンソル並列(Tensor Parallelism)とFSDPの高レベルシャーディングAPI
- 語彙サイズを64の倍数にパディングし、最適化されたcuBLASカーネルを利用
Compute(計算基盤)
- 単一ノードから数百GPU規模まで統一的なジョブ投入インターフェース
- MFU(Model FLOPS Utilization)モニタリング
- パラメータ・オプティマイザ状態・データローダー・データミキサーの包括的チェックポイント
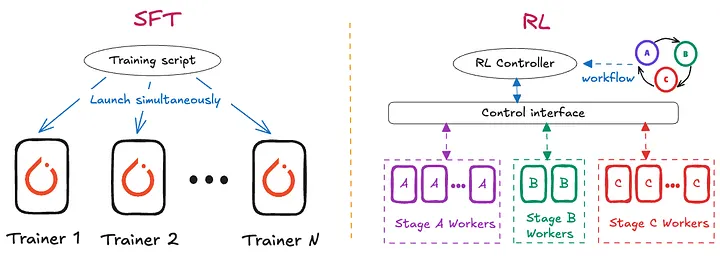
Workflow(ワークフロー)
- SFT: SPMD(Single Program, Multiple Data)モデル。薄いドライバーが同一のRayアクターを起動
- RL: アクティブコントローラーがPolicy / Rollout Workers / Reward Model / Reference Modelの専門化されたロールをオーケストレーション
- OSSライブラリVerlを統合し、Rayアクターのライフサイクル管理とGPU割り当てを実現
4. 設計上のこだわり・工夫
- Hugging Face完全互換: チェックポイントはHF形式で保存/読込し、Walled Gardenを回避。AutoTokenizerを唯一の正として学習-推論間のトークナイゼーション乖離を防止
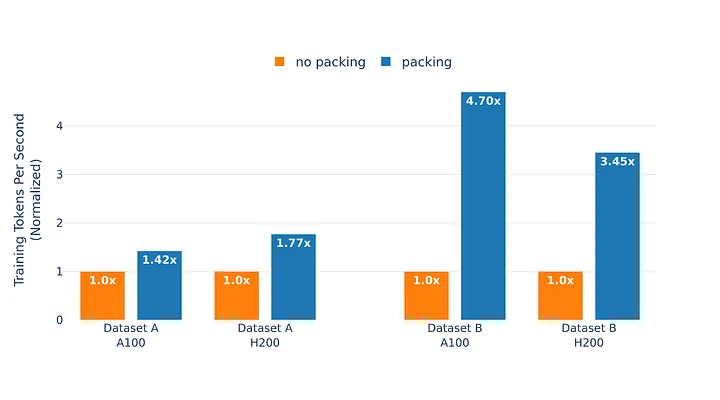
- 非同期パッキング: CPU側のパッキング処理とGPU計算をオーバーラップさせ、偏りのあるデータセットで最大4.7倍のスループット向上
- 語彙パディング: 語彙サイズを64の倍数に揃えることで最適化カーネルを利用可能にし、未対応時の約3倍の性能劣化を回避
- Logit Verifier: 新規アーキテクチャをAIコーディングエージェントで自動変換し、ロジット一致で機械的正確性を検証するゲート機構
- 内部最適化とオープン性の両立: FlexAttention、Chunked Cross-Entropy等の内部最適化を適用しつつ、HF Hubからの素早いモデル取り込みを維持
5. 現時点の制約と今後の展望
- 新規モデルアーキテクチャには明示的なサポート追加が必要(vLLM、SGLang、torchtitan等と同様の設計上の制約)
- フレームワーク最適化を犠牲にしつつ迅速なアーキテクチャ探索を可能にするHugging Faceバックエンドのフォールバックモードを計画中
- RL手法の急速な進化(SFTが「テーブルステークス」化)にフレームワークが追従し続ける必要がある
6. Take Home Message
- ポストトレーニングはモデリングだけでなくエンジニアリングの問題。データパイプライン・分散計算・ワークフロー管理を統一的に抽象化することで、研究者の生産性が劇的に変わる
- SFTはもはやゴールではなく出発点。オンポリシーRL(GRPO等)への対応がポストトレーニング基盤の必須要件になりつつある
- オープンエコシステムとの互換性を保ちつつ内部最適化する設計思想は、社内MLプラットフォームを構築する際の重要な指針。Walled Gardenを作らないことで、OSSの進化を素早く取り込める
- 非同期パッキングや語彙パディングなど、地味だが定量的インパクトの大きい最適化の積み重ねが、大規模運用では効いてくる
@Hirofumi Tateyama(hirotea)
[Blog]Measuring AI Agent Autonomy in Practice (Anthropic)
Summary
- エージェントの自律稼働時間は3ヶ月で約2倍(99.9パーセンタイルで25分→45分超)に伸びている
- 熟練ユーザーほど自動承認率が2倍(20%→40%超)に上がるが、介入頻度も約2倍(5%→9%)に増える——監視戦略が「逐一承認」から「放任+異常時介入」へシフトする
- APIでのエージェント利用の約50%はソフトウェア工学に集中、高リスク×高自律の象限はまだスカスカだが、医療・金融・サイバーセキュリティでの利用が出始めている
What?
Anthropicが Claude Code と 公開API の数百万件の人間-エージェント間インタラクションを、プライバシー保護ツール Clio で分析し、「実世界でエージェントにどれだけ自律性が与えられているか」を定量的に明らかにしたレポート。
本稿における エージェント の定義: ツール(コード実行、外部API呼び出し、他エージェントへのメッセージ送信など)を通じて 行動 を取れるAIシステム
概要
この文書は、AnthropicがパブリックAPI上のツールコール(エージェントの行動)を分析するための手法とプロンプトをまとめたものです。
概要: 2026年1月19日〜2月2日の間に約99.8万件のツールコールをサンプリングし、Claude Sonnet 4.5(temperature 0.2)を使って多次元の分類を行っています。
分類の次元(ディメンション):
- Action(行動):エージェントが具体的に何をしたか(例:検索した、返金を発行した)
- Goal(目標):エージェントが追求している高レベルの目的
- Goal Complexity(目標の複雑さ):Minimal〜Unboundedの6段階で、目標構造の複雑さを評価
- Environment(環境):エージェントがやり取りした外部システム
- Environment Type(環境タイプ):エージェント内部のスクラッチパッド、サンドボックス、個人の仮想環境、共有仮想環境、物理世界などに分類
- Environmental Impact(環境への影響):観察のみ〜包括的な影響まで5段階
- Human in the Loop:人間のオペレーターが関与しているかどうか
- Autonomy(自律性):1〜10のスコアで、人間の監視の度合いを評価
- Reversibility(可逆性):アクションの取り消しやすさ(簡単に元に戻せる〜不可逆)
- Risk(リスク):1〜10のスコアで、潜在的なリスクの大きさを評価
- Safeguards(安全策):エージェントの行動を制約する保護措置の有無と内容
- Agentic Architecture(エージェントアーキテクチャ):単一/マルチエージェント × スコープ付き/汎用ツールの組み合わせ
- NIST Activity Category:NIST AI 200-1に基づく活動分類(コンテンツ生成、意思決定、情報検索など)
- Goal Domain Category:業界/ドメイン分類(ソフトウェア工学、医療、金融など)
- Environment Category:システム種別(ローカルファイル、CLI、Web API、データベースなど)
- Safeguards Category:サンドボックス、権限制限、人間の承認など具体的な保護メカニズムの分類
- Confidence(確信度):分類全体に対する確信度(1〜10)
- Reflection(振り返り):分類の曖昧さや問題点についてのコメント
目的: AIエージェントの実世界での展開状況(採用度、自律性、影響力、リスク)を体系的に把握し、トレンドを追跡することです。
背景課題
- エージェントはすでにメールトリアージからサイバー攻撃検知まで幅広く使われている
- しかし「人がエージェントにどのくらい自律性を与えているか」「どの領域で使われているか」「リスクの高い行動はどれくらいか」についての実証データがほとんどない
- 事前評価(ベンチマーク)だけでは実運用の姿は見えない
⇒ ポスト・デプロイメントの実測 が不可欠だが、インフラがまだ未整備
分析手法
2つのデータソースを補完的に使用:
| ソース | 強み | 弱み |
|---|---|---|
| 公開API | 数千顧客の多様なエージェントを横断的に分析可能 | 個々のtool callしか見えず、セッション全体の再構成が不可能 |
| Claude Code | セッション全体を追跡でき、自律性・介入・信頼形成を直接観察可能 | 単一プロダクト(ほぼSWE用途)のみ |
Finding 1:自律稼働時間の伸長
- Claude Codeの 中央値ターン長は約45秒 で、ここ数ヶ月ほぼ安定
- 一方で 99.9パーセンタイル は2025年10月〜2026年1月で 25分未満 → 45分超 にほぼ倍増
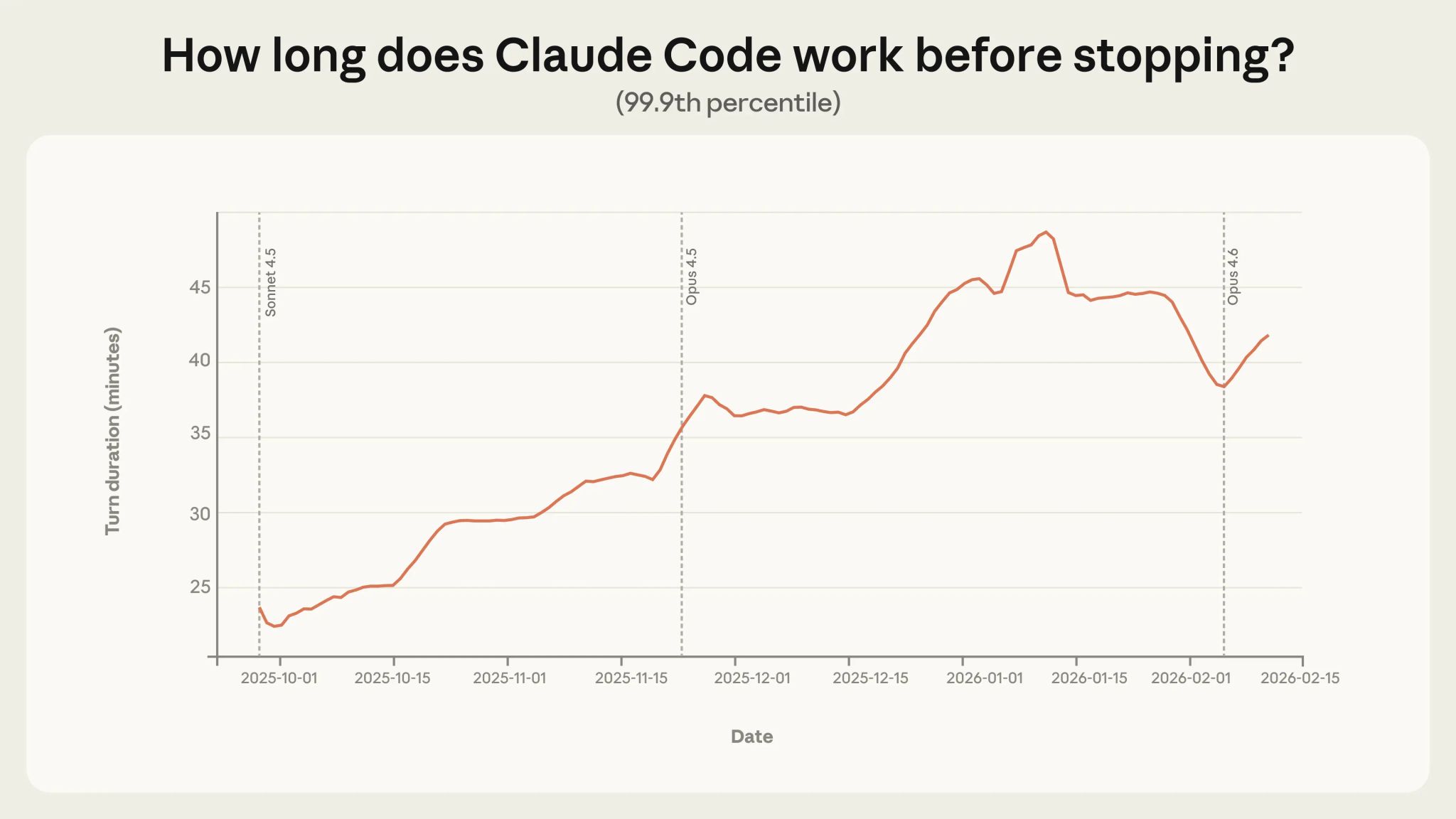
- この伸びはモデルリリースのタイミングと無関係にスムーズ → 能力向上だけでなく、ユーザーの信頼蓄積 + タスクの野心化 + プロダクト改善 が複合的に寄与
- Anthropic社内データでは、最難関タスクの成功率が2倍になる一方、人間の介入回数は 5.4回→3.3回 に減少
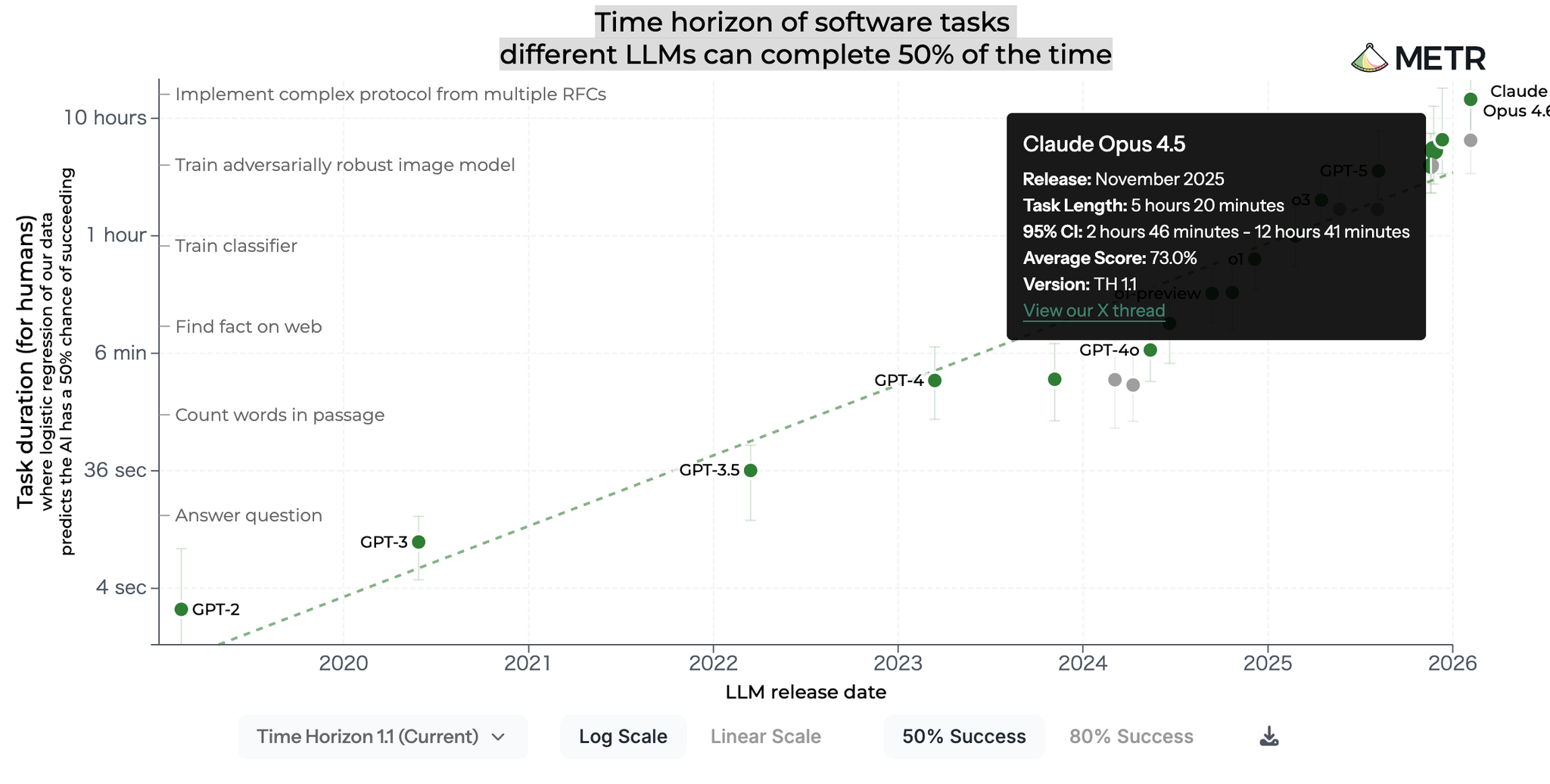
METRの評価では Claude Opus 4.5 は「人間5時間相当」のタスクを50%成功率でこなせるとされるが、実運用の99.9パーセンタイルは約42分。「実際にAgentが5時間稼働し続ける」ことを示しているわけではない。能力と実運用のギャップ=デプロイメント・オーバーハング が存在する
Finding 2:熟練ユーザーの行動変容
- 新規ユーザー(<50セッション)の自動承認率:約20%
- 750セッション超のユーザー:40%超
- しかし同時に、割り込み率も5%→9%に上昇
⇒ 矛盾に見えるが、監視戦略が変わっている:
| 新規ユーザー | 熟練ユーザー |
|---|---|
| 1アクションごとに承認 → 割り込みの必要が少ない | 自動承認で走らせ、問題時に介入 → 割り込みが増える |
- 公開APIでも同傾向:単純タスクの87%にヒューマン関与、高複雑タスクでは67%に低下
- 効果的な監視 ≠ 全アクション承認。必要なときに介入できる位置にいること
Finding 3:Claudeの自発的停止
- タスク複雑度が上がると、Claude自身が確認のために停止する頻度が、人間の割り込み頻度の2倍以上 になる
- Claudeが止まる理由トップ:
- アプローチの選択肢を提示(35%)
- 診断情報・テスト結果の収集(21%)
- 曖昧な要求の明確化(13%)
- 人間が割り込む理由トップ:
- 不足している技術コンテキストの提供(32%)
- Claudeが遅い・暴走している(17%)
⇒ エージェント自身の不確実性認識 → 自発的停止 は、外部セーフガード(権限制御・人間承認)を補完する重要な安全特性
Finding 4:リスクと自律性の分布
- 公開API上の tool call を、Claudeがリスク(1-10)と自律度(1-10)でスコアリング
- 大多数は低リスク。80%のtool callに何らかのセーフガードが存在、73%にヒューマンインザループ、不可逆的操作はわずか0.8%
- ただし「高リスク×高自律」象限はゼロではない:
- APIキー窃取バックドアの実装(リスク6.0, 自律度8.0)
- 暗号通貨の自律取引(自律度7.7, リスク2.2)
- 患者医療記録の取得・表示(リスク4.4, 自律度3.2)
- ※高リスククラスタの多くはレッドチーム評価と推定される
Finding 5:ドメイン分布
- SWEが 全tool callの約50% を占有
- BI、カスタマーサービス、営業、金融、ECなどが数%ずつ
- SWEが先行するのは「コードは実行して検証できる」ため信頼を築きやすいから
- 法律・医療・金融では出力検証に専門知識が必要なため、信頼構築が遅い可能性
提言
| 対象 | 提言 |
|---|---|
| モデル開発者 | ポストデプロイメント監視インフラへの投資、モデルに自己不確実性認識を訓練させること |
| プロダクト開発者 | 「全アクション承認」ではなく、ユーザーが信頼できる可視性+簡便な介入手段を設計すること |
| 政策立案者 | 特定のインタラクションパターン(例:全行動への人間承認)を義務化するのは時期尚早。「介入可能なポジションにいるか」に焦点を |
エージェントの自律性は、モデル・ユーザー・プロダクトの3者が共同構築(co-construct)するものであり、事前評価だけでは捉えられない。実世界での測定インフラの整備が急務。
すべての行動を人間に承認させるなど、特定のインタラクションパターンを規定する監視要件は、必ずしも安全上のメリットをもたらすものではなく、摩擦を生み出すだけである。エージェントとエージェント測定の科学が成熟するにつれて、特定の形態の関与を求めることではなく、人間が効果的に監視と介入を行える立場にあるかどうかに焦点が当てられるべき。
Ref
余談: Agentベンチマークについて
気になったのでメジャーなのBench Markについて調べた。METRにわかりやすくまとめられている
ベンチマーク比較
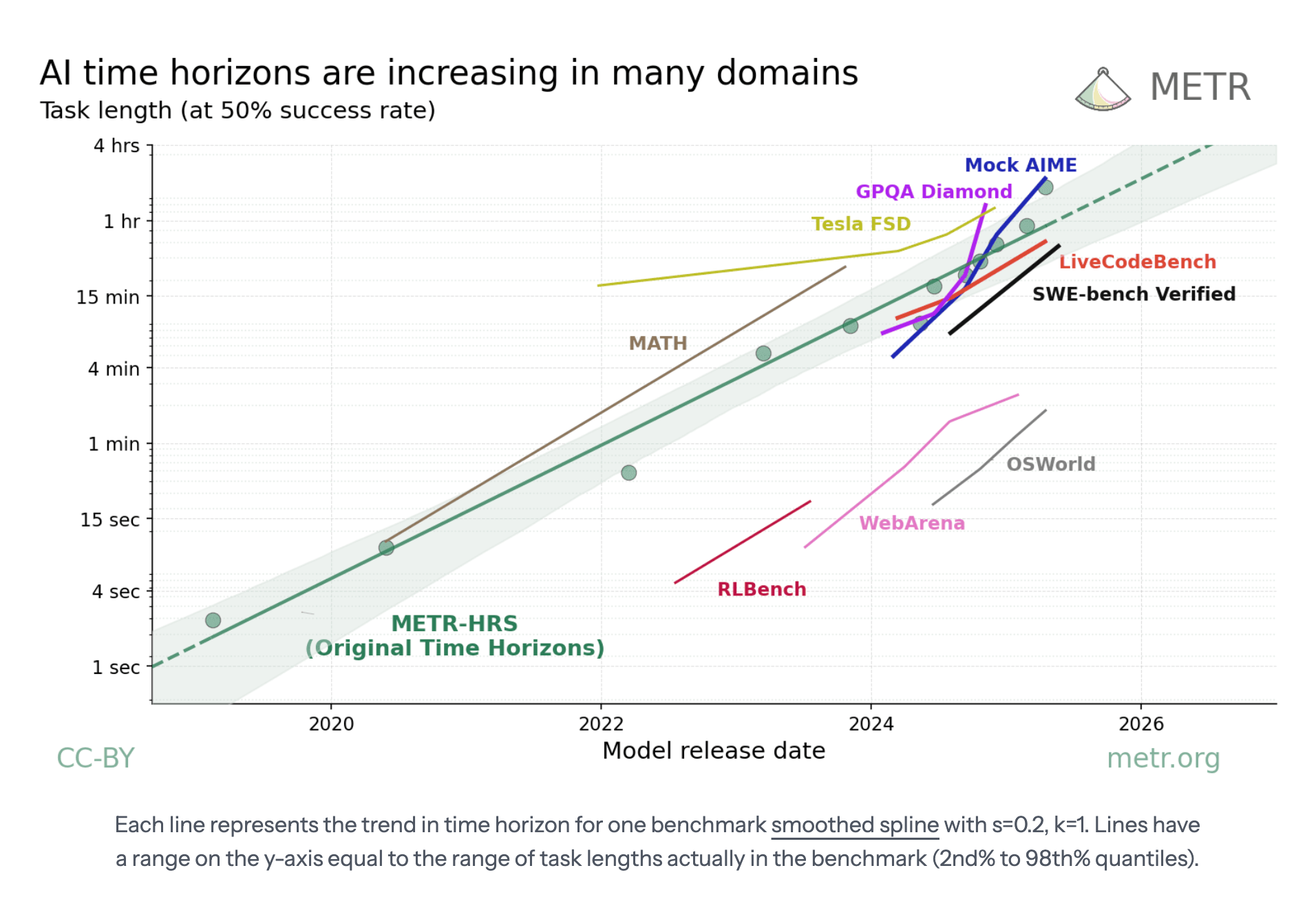
| Domain | Benchmark | Task length range | Baselines | Agent data (can we estimate β?) | Description | Source |
|---|---|---|---|---|---|---|
| Software dev | METR-HRS | 1s-16h | ✅ | ✅ Individual tasks | Semi-realistic software tasks | METR |
| SWE-bench Verified | 7m-2h | 🟨 | ✅ Individual tasks | PRs extracted from Github | Epoch AI | |
| Agentic computer use | OSWorld | 8s-45s | ✅ | ❌ Overall | GUI application tasks | Leaderboard |
| WebArena | 5s-9m | ✅ | ❌ Overall | DOM-based web tasks | Leaderboard | |
| Math contests | Mock AIME | 5m-4h | ❌ | ✅ Individual tasks | US high school contest for top 5% | Epoch AI |
| MATH | 2s-30m | 🟨 | ❌ Overall | Easier math contest problems | Various | |
| Competitive programming | LiveCode-Bench[9] | 4m-1.5h | ❌ | ✅ 3 difficulty buckets | LeetCode & similar problems | Leaderboard |
| Scientific QA | GPQA Diamond | 5m-3h | ✅ | ✅ Individual tasks | Difficult scientific MCQs | Epoch AI / various |
| Video QA | Video-MME | 1s-1h | ❌ | ✅ 3 time buckets | Questions about long videos | Leaderboard |
| Autonomous driving | Tesla FSD Tracker | N/A | N/A | ❌ (Mean time to disengagement) * ln(2) | Composite data from Tesla tracking apps | Website |
| Simulated robotics | RLBench | 4s-20s | 🟨 | ❌ Overall | Vision-guided manipulation | Leaderboard |
Baselines の凡例:
- ✅ = 人間がすべてのタスクに取り組んだ
- 🟨 = おおよそのアノテーション、またはタスクのランダムサンプルに対する人間のデータ
- ❌ = ベースラインなし(推定所要時間のみ)
スコア頭打ちが近い・データ汚染の可能性も指摘
- Why SWE-bench Verified no longer measures frontier coding capabilities 欠陥テストや訓練露出がスコア解釈を壊しうる、という指摘。Hackが起きてきている可能性が指摘
hirotea memo
Metrのスコアが注目集めている中でClaudeCodeの実自律作業時間についてのレポートが出ていたのでざっと読みました。ClaudeCodeの自律稼働率は概ね体感と一致。一方さらにロングランタスクでも任せられる可能性をCCからも強く感じている(2~3時間くらいは任せられる)
人間が8時間かけて完了する仕事を50%の確率で成功させる可能性を持ったAIを手にしているのであれば、パワーをどう引き出すか?を考えていく必要があると感じた
@Kyohei Uto(kuto)
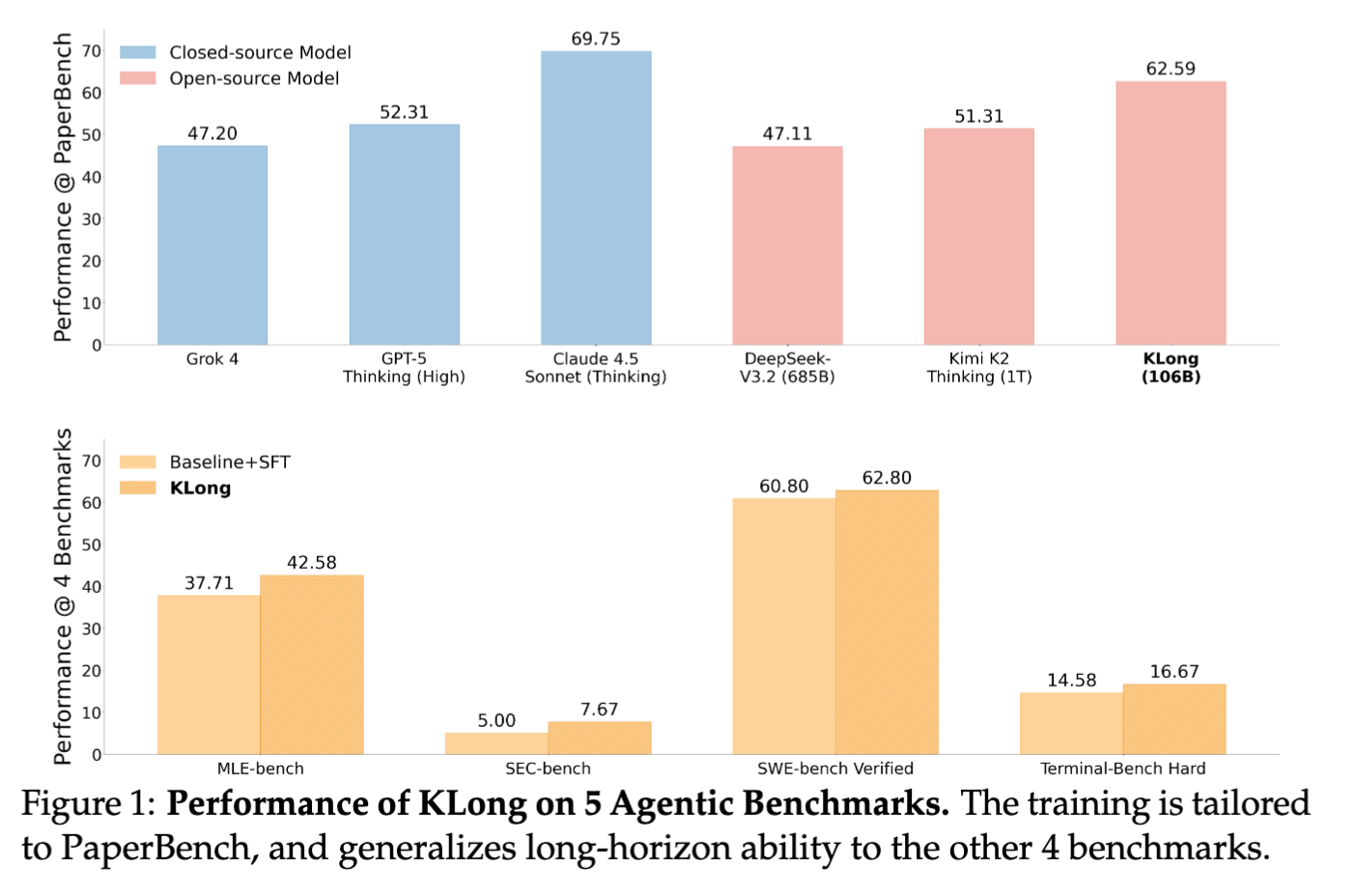
[paper]KLong: Training LLM Agent for Extremely Long-horizon Tasks
どんなもの?
- コンテキストウィンドウの制限や報酬の希薄さにより既存のLLMエージェントが苦手としてきた「極めて長期的なタスク(Extremely Long-horizon Tasks)」を解決するためのLLMエージェント「KLong」を提案
- PaperBench(研究論文の再現実装タスク)を対象に学習を実施し、その結果、106Bパラメータのモデルでありながら、1TパラメータのKimi K2 Thinkingを上回る性能を達成した
技術や手法の"キモ"はどこにある?
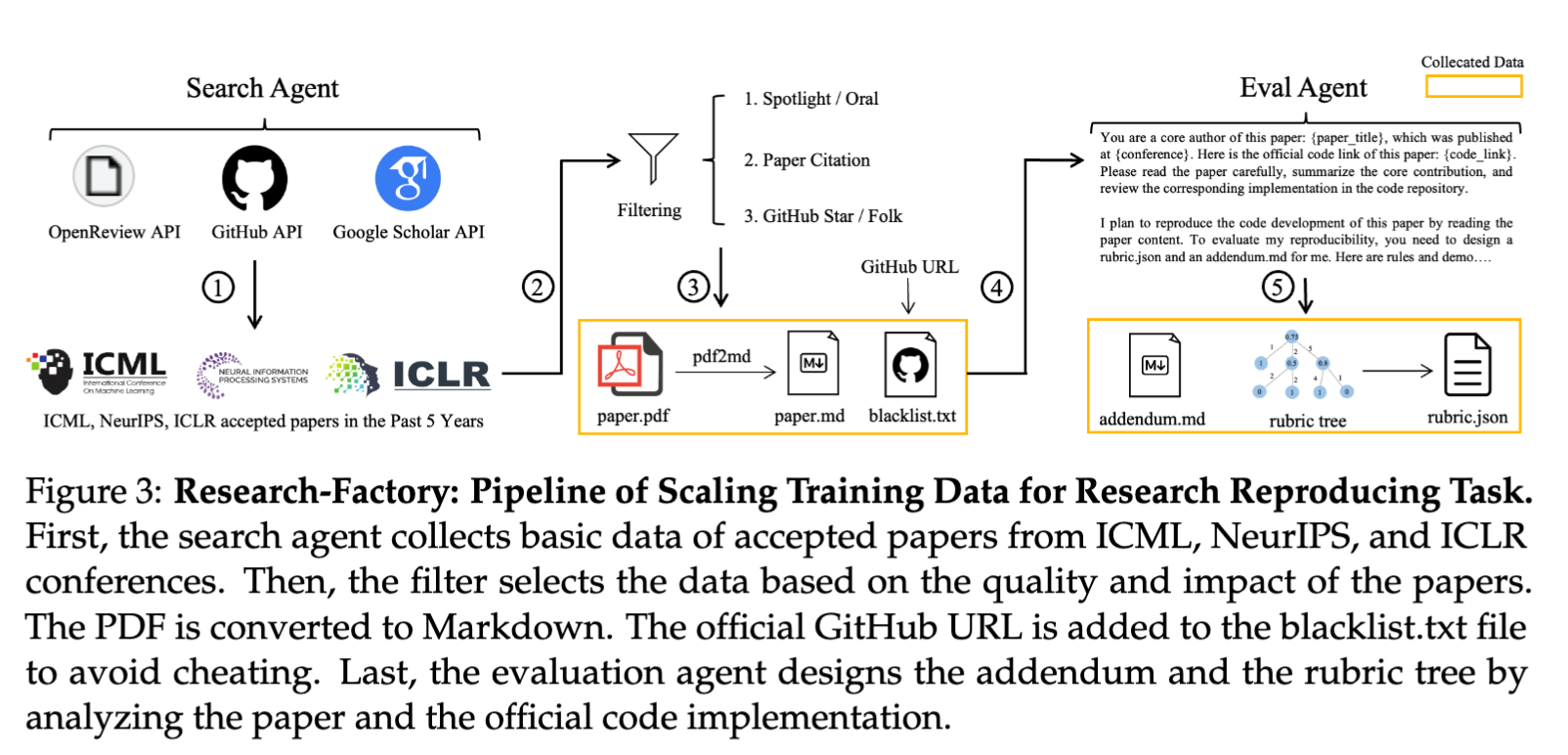
Research-Factory(自動データ生成)
以下のパイプラインによって数千の高品質な再現実装の軌跡(教師データ用途)と評価用ルーブリック(報酬用途)をSonnet 4.5で生成する
Trajectory-splitting SFT(軌跡分割SFT)
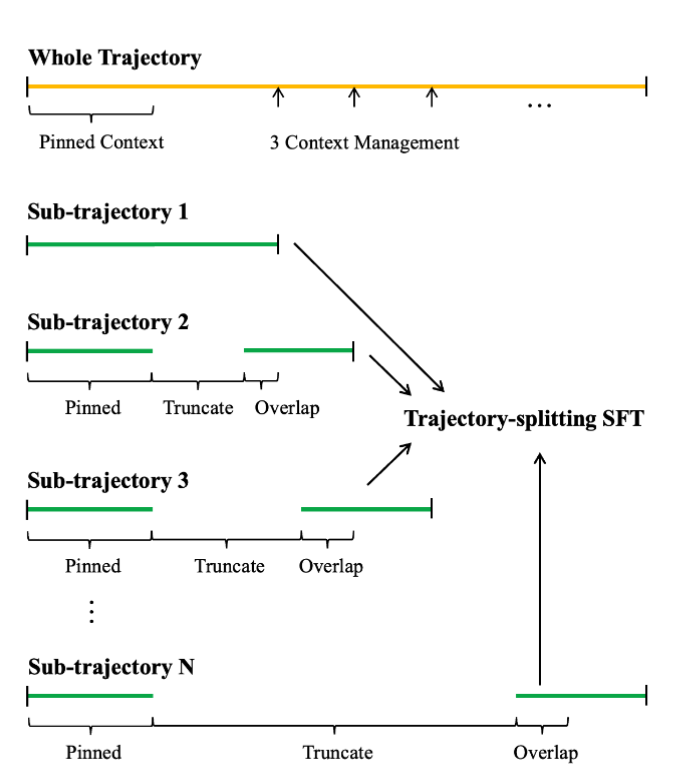
- コンテキストウィンドウを超える超長文の履歴を学習するために、軌跡を複数のサブ軌跡に分割する
- この際、論文読み込みパートを常に先頭に固定(pinning)し、前後のサブ軌跡をオーバーラップさせることで文脈の連続性を保つ
[kuto]中間コンテキストをまるっと落として問題ないの?という疑問を持ったが生成物である論文再現実装コードは環境から常に参照できる。落としているのはあくまで会話や変更履歴
Progressive RL(段階的強化学習)
いきなり長時間タスクでRLを行うと報酬が希薄で学習が安定しないため、タイムアウト時間を段階的に延ばしていく手法を採用
- 学習を複数のステージmに分割し各ステージのタイムアウト時間をT1 < T2 < …Tmと設定する
- 長い軌跡をサブ軌跡に分割(Trajectory-splitting)し、サブ軌跡単位で学習
[kuto]ルーブリックとLLMによるdense報酬なので分割して学習でも問題ない
どうやって有効だと検証した?
- PaperBenchにおいてKLongは平均スコア62.59を記録し、オープンソースモデルの中で最高性能を達成した
- PaperBenchで学習後、MLE-benchなどの異なるドメインのタスクでも評価を行い、ベースラインからの改善を確認することで汎化性能を実証した
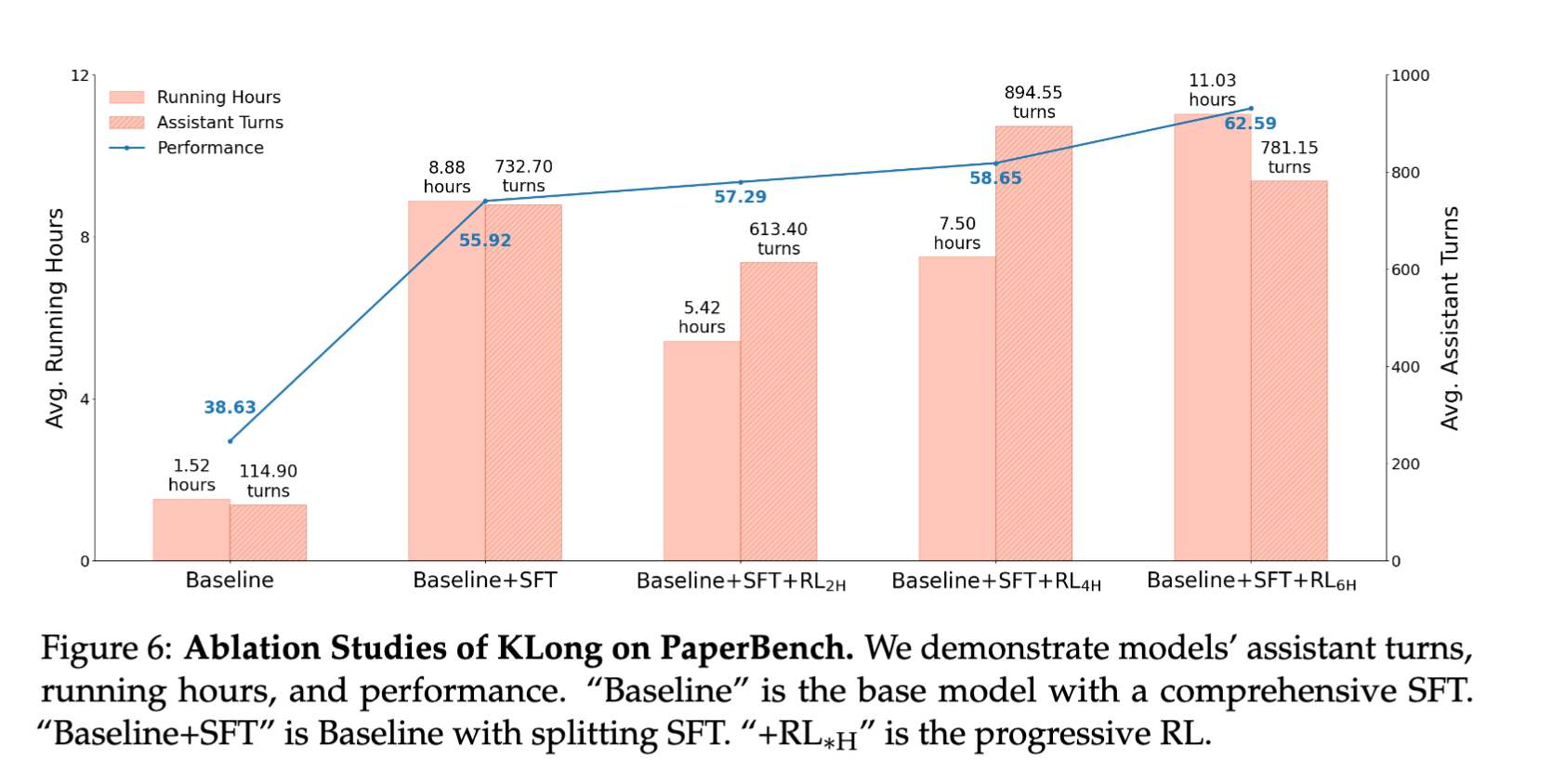
- Progressive RLによる段階的なスコア改善を確認
[kuto] ただRLによる伸び幅は小さくSFTによる伸びのほうが大きい
議論はあるか?
- 軌跡分割(Trajectory decomposition)は完全な軌跡最適化の近似に過ぎず、分割されたサブ軌跡をまたぐような長期的な依存関係を完全には捉えきれない可能性がある
- 報酬シグナルを自動評価モデル(Judge)に依存しているため、Judgeのバイアスが影響する可能性がある
メインTOPIC
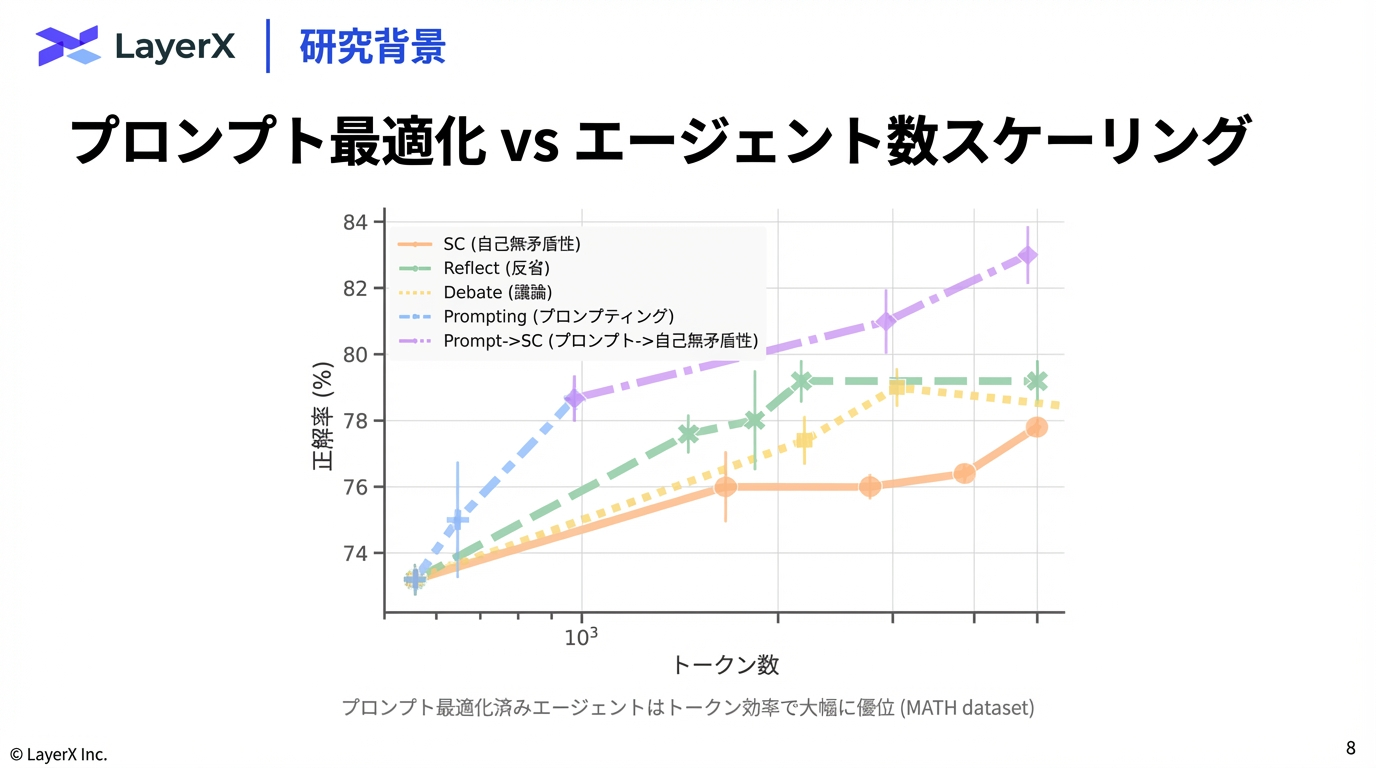
STRUCTSENSE: A TASK-AGNOSTIC AGENTIC FRAMEWORK FOR STRUCTURED INFORMATION EXTRACTION WITH HUMAN-IN-THE-LOOP EVALUATION AND BENCHMARKING
Introduction
背景と課題
科学論文は年間数百万本単位(2022年実績:330万本)で出版されており、研究者が最新の知見を追跡・統合することは不可能に近い状態にある。この解決策として、非構造化テキスト(論文PDFなど)からの構造化情報抽出(SIE: Structured Information Extraction)が重要視されているが、既存手法には以下の課題がある。
- 従来のPipeline手法: NER(固有表現抽出)や関係抽出を多段で行うため、エラーが伝播しやすく柔軟性に欠ける。
- LLMベースの手法: 柔軟性は高いが、専門領域(神経科学など)における幻覚(Hallucination)や、用語の多義性(Polysemy)に対応できない。また、FAIR原則(Findable, Accessible, Interoperable, Reusable)に準拠した形式での出力が困難である。
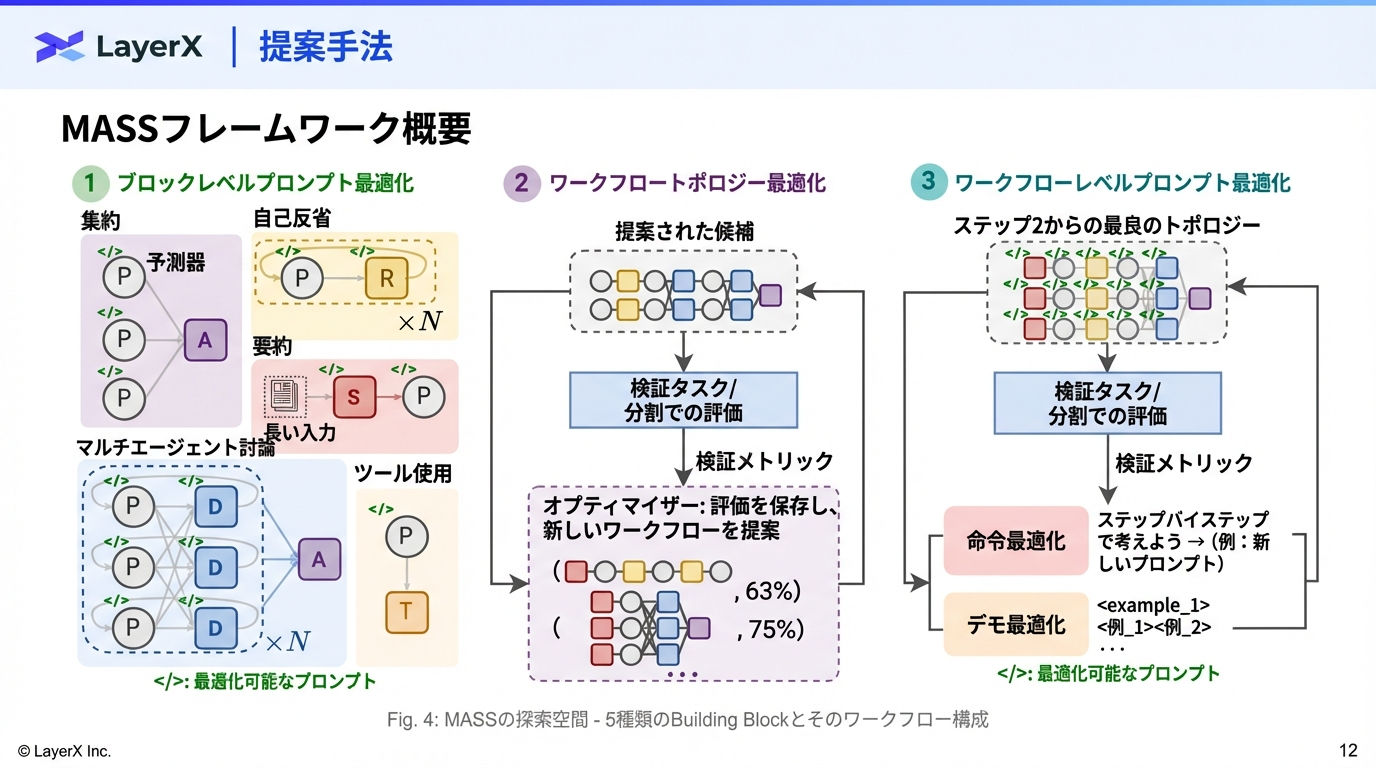
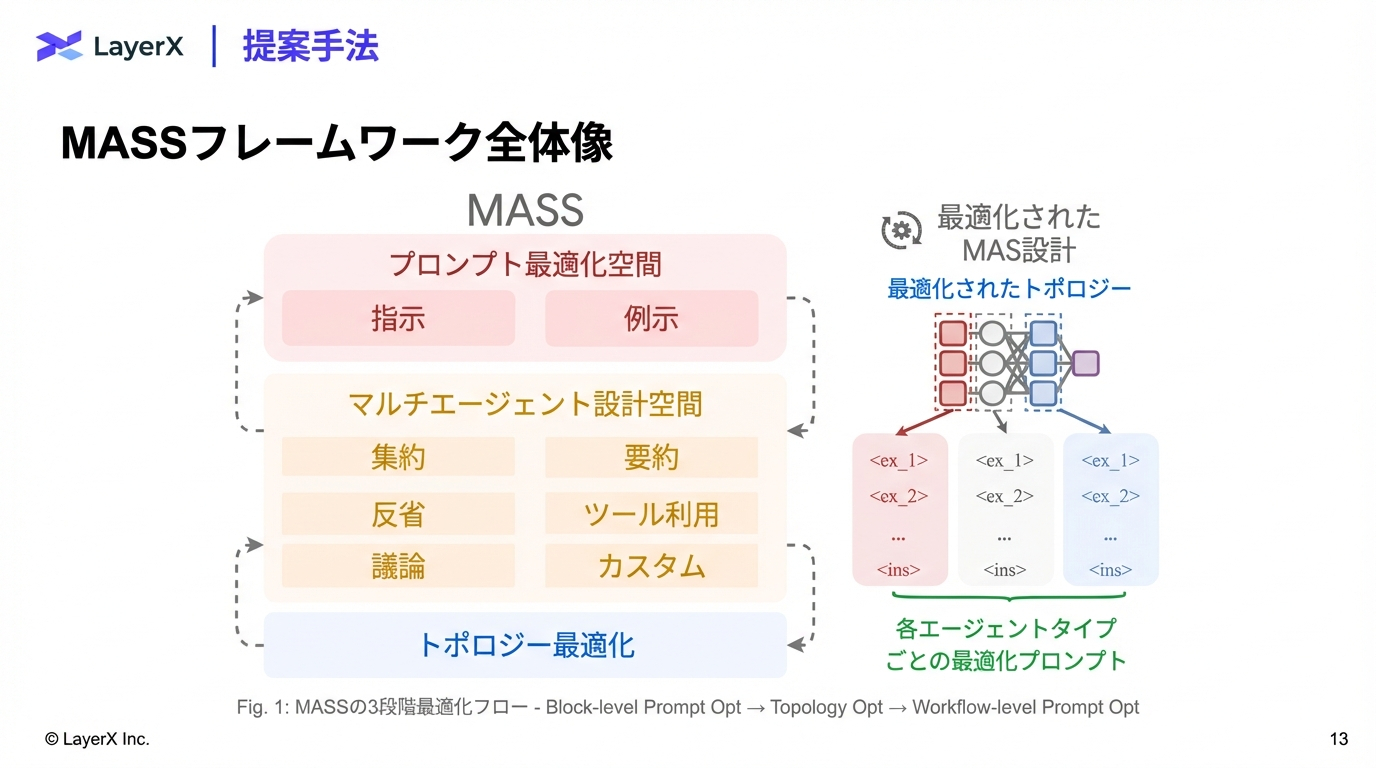
StructSenseの提案
本論文では、LLMを基盤としつつ、以下の要素を統合したタスク非依存型のマルチエージェントフレームワーク「StructSense」を提案する。
- Ontology-Guided: 外部のオントロジーデータベースを参照し、用語を正規化IDにマッピング(Grounding)することで幻覚を抑制。
- Agentic Capabilities: 自己評価(Judge)やツール利用による反復的な改善プロセス。
- Human-in-the-Loop (HIL): 人間のフィードバックループをシステムに組み込み、信頼性を担保。
Architecture & Implementation
StructSenseは CrewAI フレームワーク上で実装され、4つの専門エージェントがメモリ(Short/Long-term)を共有しながら協調動作するアーキテクチャを採用している。
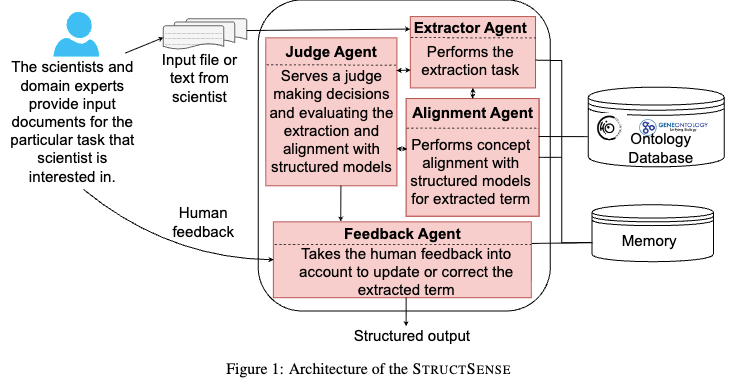
System Components
- Input Parsing:
- 論文PDFを GROBID (Fylo API経由) でパースし、XML/JSON構造化テキストに変換して入力する。
🧐 Deep Dive: なぜ今更GROBIDなのか? (Legacy vs Modern)
特徴 GROBID (本論文採用) Modern OCR / VLM (GPT-4o Vision等) コスト 低 (CPUベース) 高 (GPU/API Token) 構造理解 得意 (セクション構造) 苦手 (視覚的レイアウト依存) 長文耐性 高い (ページ単位で処理可) 低い (コンテキスト長制限) 数式・図表 苦手 得意 学術論文特有の「論理構造(Title, Abstract, Introduction...)」を正確に切り出し、後続のエージェントに「ここはMethodセクションだ」と伝えるためには、視覚情報よりも構造情報に強いGROBIDが依然として最適解であるという判断です。
- Ontology Database:
- Weaviate (Vector Database) を使用。
- 格納データ: Uberon (解剖学), Cell Ontology, NeuroBehavior Ontology, Biolink Model 等。
- 検索方式: キーワード検索(完全一致)とベクトル検索(意味類似)のハイブリッド。
オントロジーとは何か? (Why needed?) 単なる「辞書」ではありません。概念(Class)と関係性(Relation)が定義された「知識の設計図」です。多義性の解消: "Cortex" が「脳(UBERON:0000956)」か「植物(PO:0005708)」かをIDで区別できる。推論の基盤: 「海馬は脳の一部」という知識があれば、「アルツハイマーは海馬に影響する→つまり脳に影響する」という推論が可能になる。 StructSenseでは、LLMのふわっとした生成テキストを、この「IDで管理された世界」に杭打ち(Grounding)することで幻覚を防いでいます。

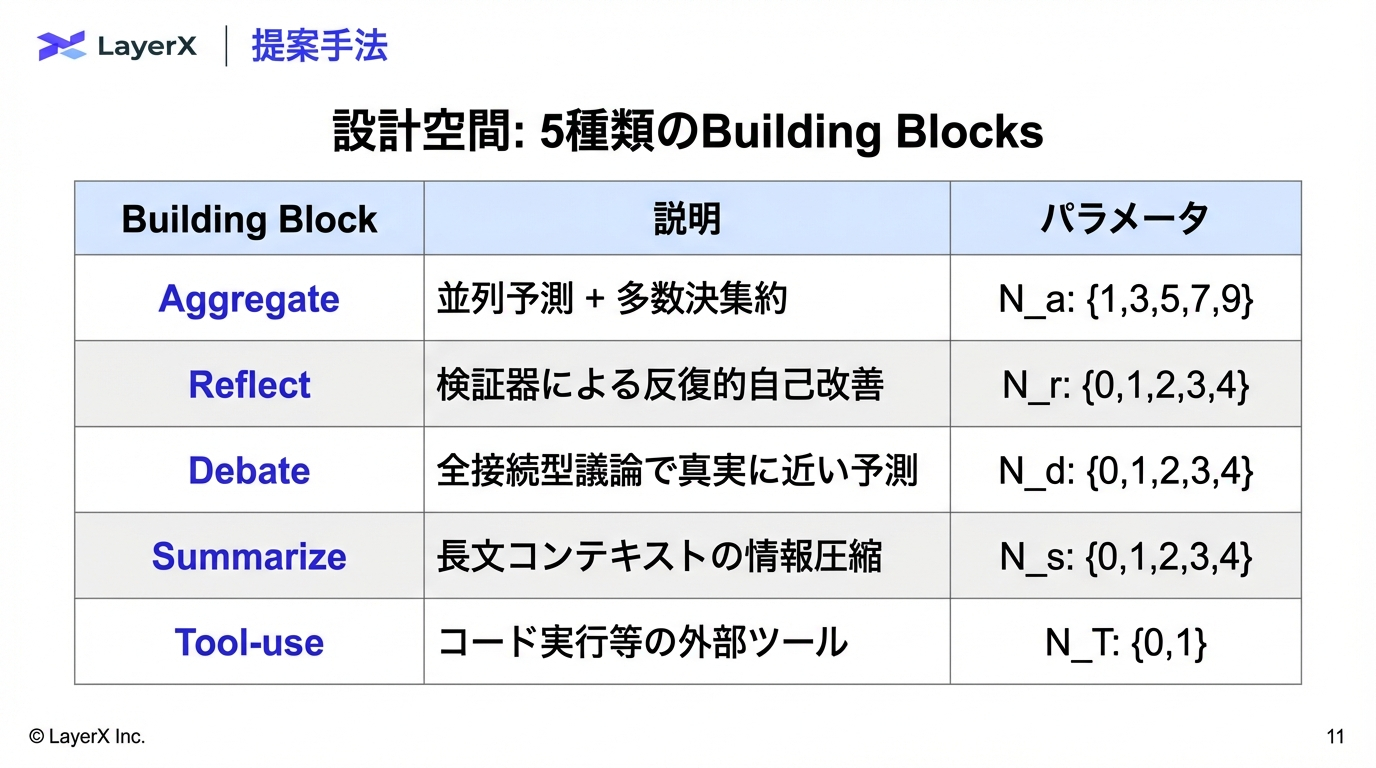
"Task-Agnostic" Configuration
各エージェントは以下の3つの入力を受け取ることで、タスク非依存(Task-Agnostic)な動作を実現している。
- Input Data: 前段の出力(テキストやJSON)。
- Task Configuration: 「何を抽出するか」の定義(例: Extract Brain Region with Ontology ID)と出力スキーマ(JSON Schema)。
- Agent Configuration: 使用モデル(LLM)、パラメータ(Temperature等)、使用ツール(Weaviate API等)の設定。
設計意図: 汎用性の確保 エージェントのロジック(Pythonコード)は共通化されており、設定ファイル(YAML等)を差し替えるだけで、「心理尺度の抽出(Task 1)」から「神経科学NER(Task 3)」まで、全く異なるドメイン・タスクに対応できる設計となっている。これがタイトルの "Task-Agnostic" の意味するところである。
4 Specialized Agents
各エージェントは役割分担を行い、前のエージェントの出力を参照して処理を進める。
| Agent | 役割 | 動作詳細 |
|---|---|---|
| 1. Extractor Agent | 抽出 | パース済みのテキストセクションから、タスク定義(JSON Schema)に基づきエンティティ候補を抽出する。この段階ではオントロジーIDは付与されない。 |
| 2. Alignment Agent | 照合 | Extractorの出力を受け取り、Weaviateを検索してオントロジーマッピングを行う。<br>例: テキスト中の "cortex" が「脳の大脳皮質 (UBERON:0000956)」か「植物の皮層」かを文脈から判断し、IDを付与する。本システムの核となる機能。 |
| 3. Judge Agent | 評価 | LLM-as-a-Judgeとして機能。抽出とアライメントの品質に対し、自信度スコア(0.0-1.0)を付与する。 |
| 4. Feedback Agent | 介入 | 人間からの修正指示(HIL)を受け取り、メモリを更新してExtractor/Alignmentエージェントへ再実行を指示する。 |
Case Study: Task Definitions
神経科学(Neuroscience)ドメインにおいて、構造化の難易度と性質が異なる3つのタスクで評価を行っている。
Task 1: 心理評価尺度のスキーマ抽出 (Schema-based)
- Input: 心理評価尺度(アンケート用紙)のPDF(例: Mood and Feelings Questionnaire)。
- Output: ReproSchema 形式のJSON(質問文、選択肢、スコアリングロジック)。
- 特性: Structured (定型)。正解がPDF内に明記されており、構造が決定的であるため、Instruction Following能力が問われる。
Task 2: リソース情報の抽出 (Resource Extraction)
- Input: 論文全文。
- Output: 使用された「モデル」「データセット」「ツール」の名前、URL、カテゴリ。
- 特性: Semi-structured (半定型)。カテゴリ分類やオントロジー紐付けにはドメイン知識が必要となる。
Task 3: NER(固有表現抽出) (NER Term Extraction)
- Input: 論文全文。
- Output: 脳領域、細胞タイプ、実験手法などのエンティティとオントロジーID。
- 特性: Unstructured (非定型 / Open-ended)。最も難易度が高い。
- 多義性(例: "Nucleus"は細胞核か神経核か?)の判断が必要。
- 抽出粒度(MouseかRodentか)の判断が必要。
Experimental Setup & Evaluation Criteria
Models
比較対象として以下の3モデルを採用(OpenRouter API経由)。
- Claude 3.7 Sonnet (Anthropic) - High-end
- GPT-4o-mini (OpenAI) - Efficient / Mid-range
- DeepSeek V3 (DeepSeek) - Open Source
実験設定の意図: モデル選定
GPT-4o (無印) ではなく mini や DeepSeek を選定しているのは、「安価なモデル + 人間介入」 という構成が、高価なSOTAモデル単独と比較してコストパフォーマンスや実用性でどこまで対抗できるかを検証する意図がある。
Evaluation Settings
- Autonomous (Non-HIL): LLMエージェントのみで完結。
- Human-in-the-Loop (HIL): 著者らが開発したツール AIProofBuddy を介して人間が修正指示を出す。
Metrics
- Standard: Precision, Recall, F1 Score
- Ontology Alignment Rate: オントロジーIDまで正しく紐付けられた割合。
- Shannon Diversity Index (\(H\)): (Task 3のみ)
単に数を多く抽出するだけでなく、多様なカテゴリ(脳、遺伝子、行動など)をバランスよく網羅できているかを測る指標。
Results & Critical Analysis
Task 1 (Schema) & Task 2 (Resource)
- Claude 3.7 Sonnet: Task 1で F1=1.00 を達成。HILなしでも完璧に動作。
- DeepSeek V3:
- Task 1では複雑なJSON生成に失敗しF1=0.38と低迷。
- Task 2(リソース抽出)ではHILの介入により F1 0.68 → 0.76 へ大幅に改善。
- 分析: 構造が決まっているタスクでは上位モデルの自律動作で十分だが、曖昧さを含むタスクではHILによる補正効果が大きい。
Task 3 (NER Term Extraction)
最も難易度の高いタスクにおける各モデルの挙動比較。
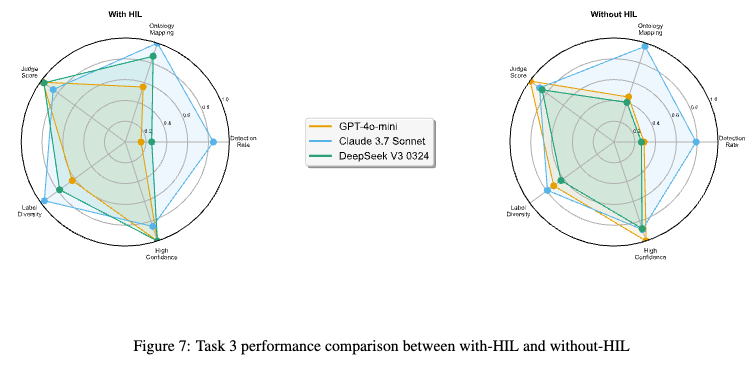
考察1: Judge Agentの実効性
GPT-4o-miniの結果に注目すると、Alignment Rate(精度)が45.5%と低いにも関わらず、Judge Score(自己評価)は 0.995 (ほぼ満点) を記録している。これは典型的な Overconfidence (自信過剰) である。
軽量モデルに自己評価を行わせても、自身の幻覚を肯定するだけで機能しない可能性が高い。一方、ClaudeやDeepSeek (HILあり) ではスコアと精度が相関しており、Judge機能の信頼性はベースモデルの性能に依存する。
考察2: オントロジー評価の限界 (Semantic Fidelity)
現状の評価指標は「完全一致(Exact Match)」だが、Claude 3.7などは正解IDと異なっていても、オントロジー階層上で意味的に正しい上位概念(例:特定の魚種ではなく「条鰭類」)を回答しているケースが見られた。実運用上は有用な回答であり、単純な正解率以上の実力が上位モデルにはあると推測される。
考察3: コストとパフォーマンスのトレードオフ
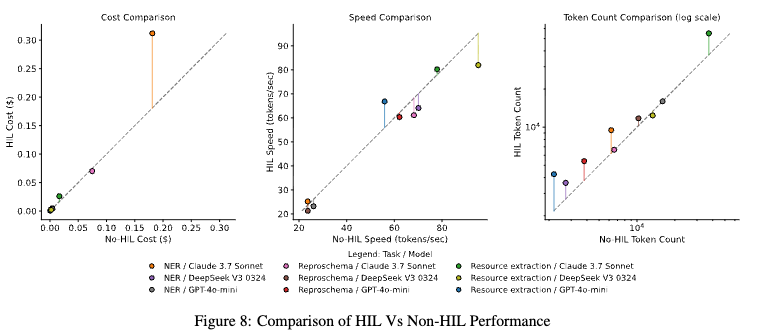
- Cost: HILを導入すると、フィードバックループの分だけトークン消費が増えるため、コストは上昇する(Claude 3.7のNERタスクで 約1.7倍)。
- Speed: Claude 3.7が最速(78 tps)、DeepSeek V3が最も遅い(23 tps)。
- 結論: 科学論文のメタ分析のように、誤ったデータが許されない(High-Stakesな)タスクでは、コスト増は精度担保のための保険として正当化される。一方、大量データ処理には向かない。
Discussion & Future Work
Task Type and HIL Impact
- Structured Task: モデルの基本性能で勝負が決まるため、HILの出番は少ない。
- Open-ended Task: モデル間の能力差が顕著に出る。ここでHILを導入すると、特に下位モデル(DeepSeek)の性能を「実用不可」から「実用可能」レベルまで引き上げることができる
制限事項: オントロジー不在の領域
StructSenseは「オントロジーによる知識グラウンディング」を前提としている。社内ドキュメントなどオントロジーが整備されていない領域では、Alignment Agentが機能せず、単なるLLM抽出となるため、本論文で示された多義性解消や幻覚抑制の効果は期待できない。
今後の展望として、LLMにオントロジー自体を生成させる(Ontology Learning)アプローチとの統合が挙げられている。