
2026-03-03 機械学習勉強会
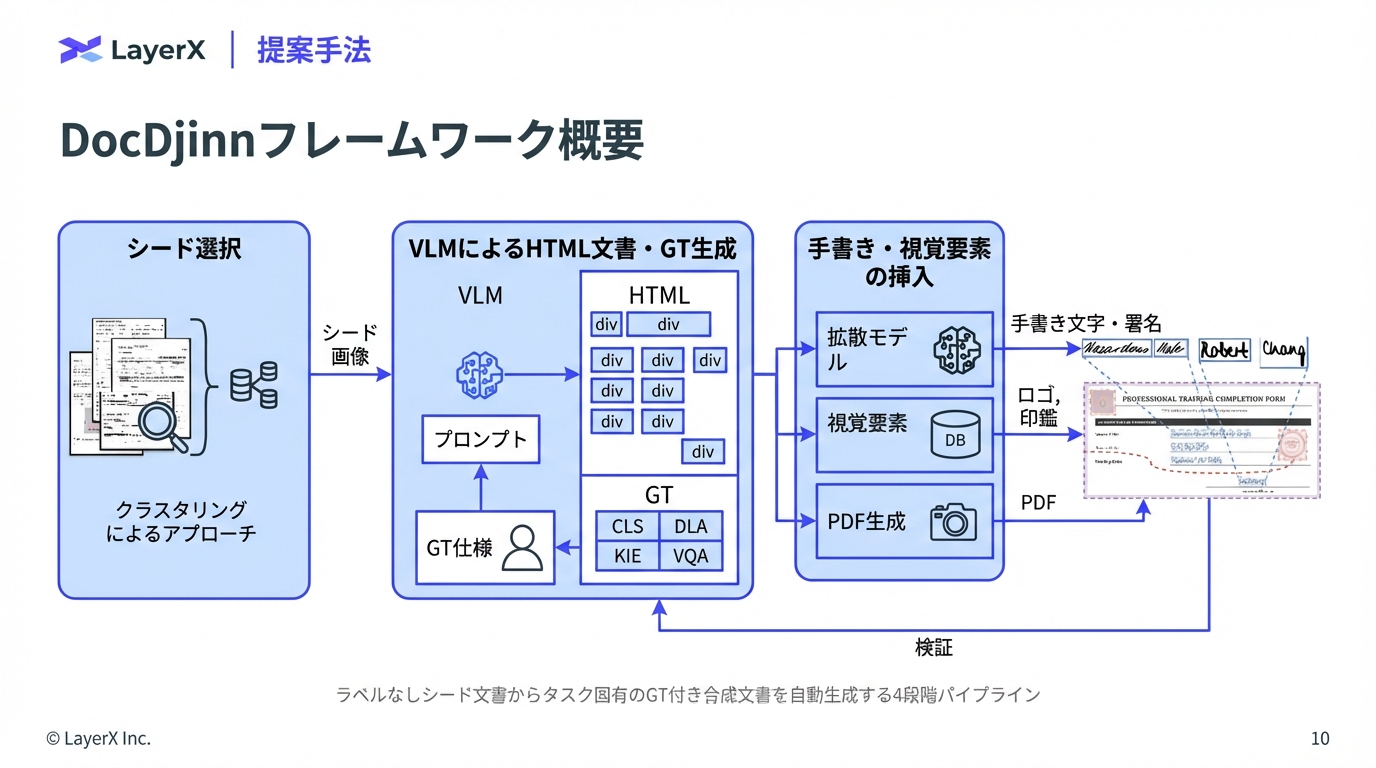
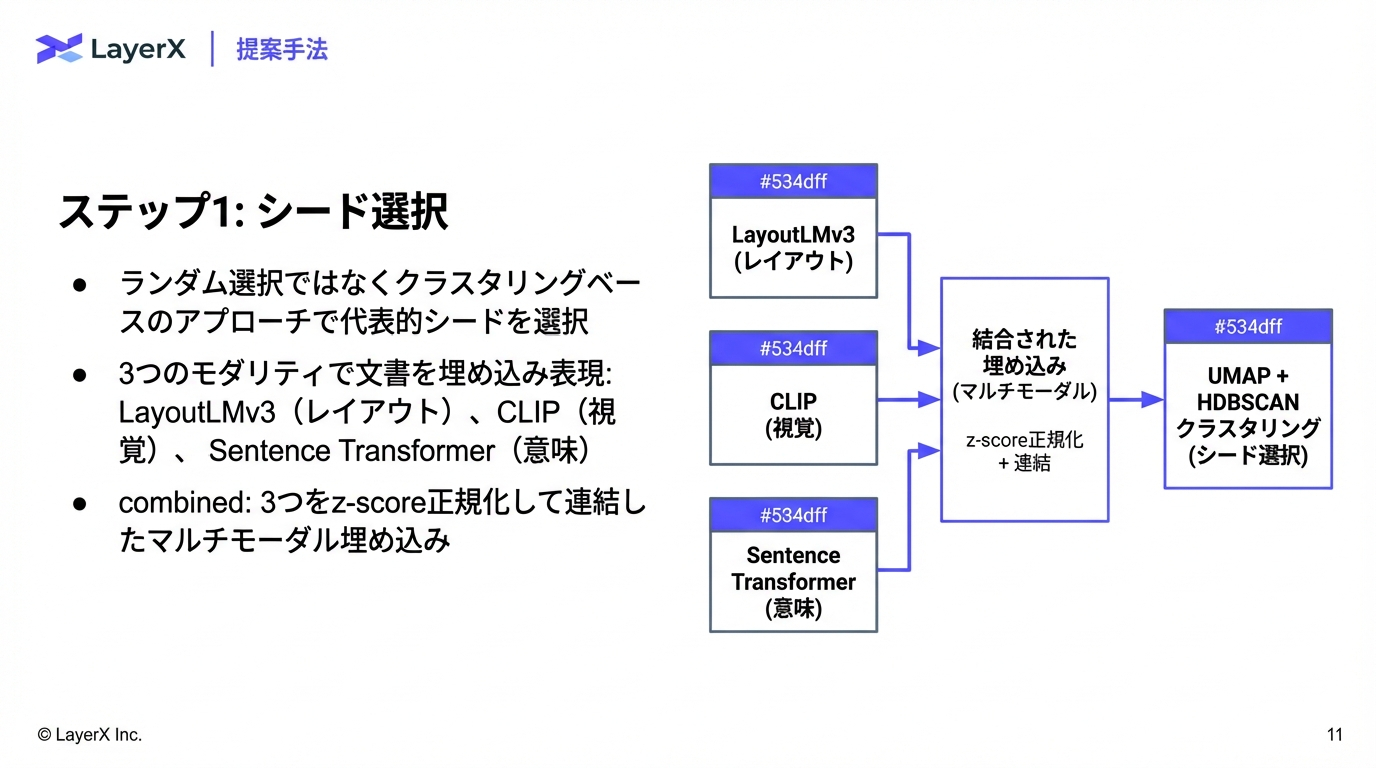
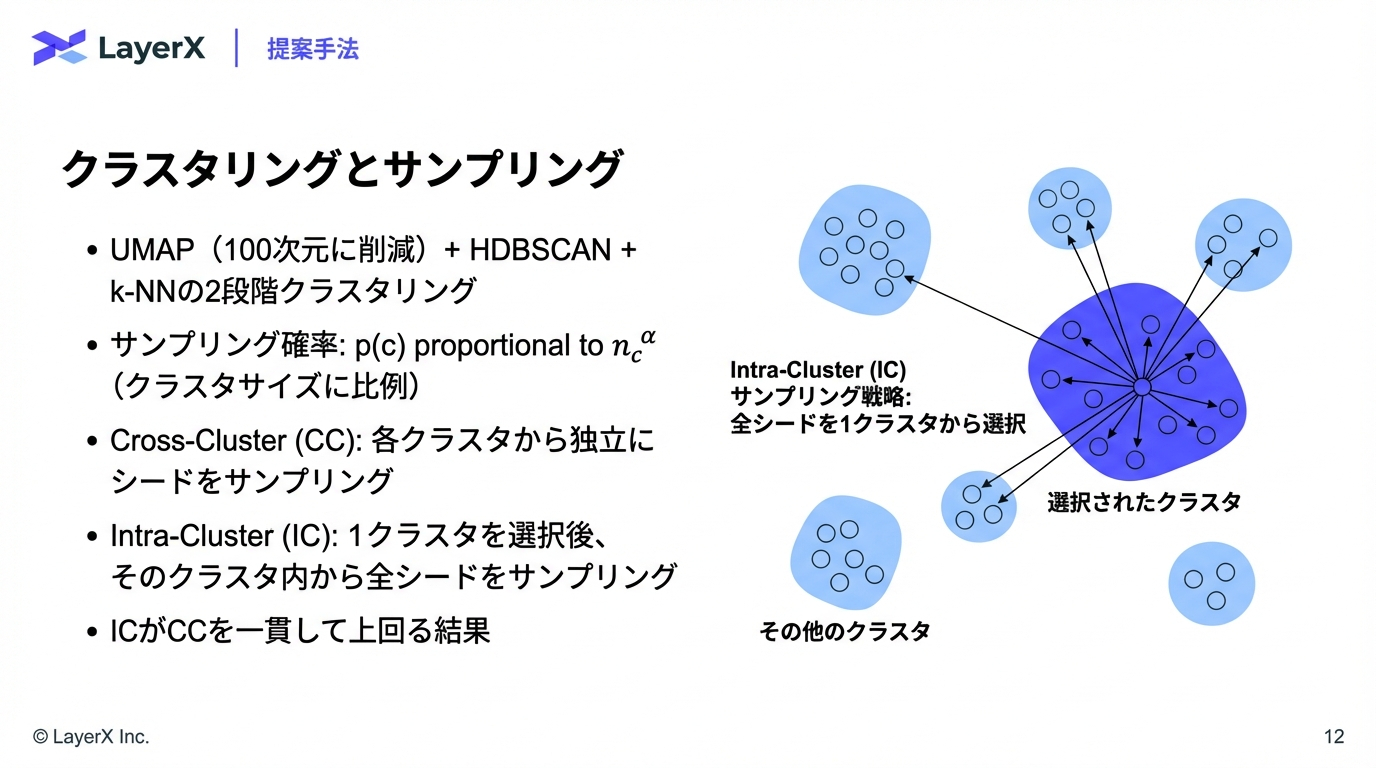
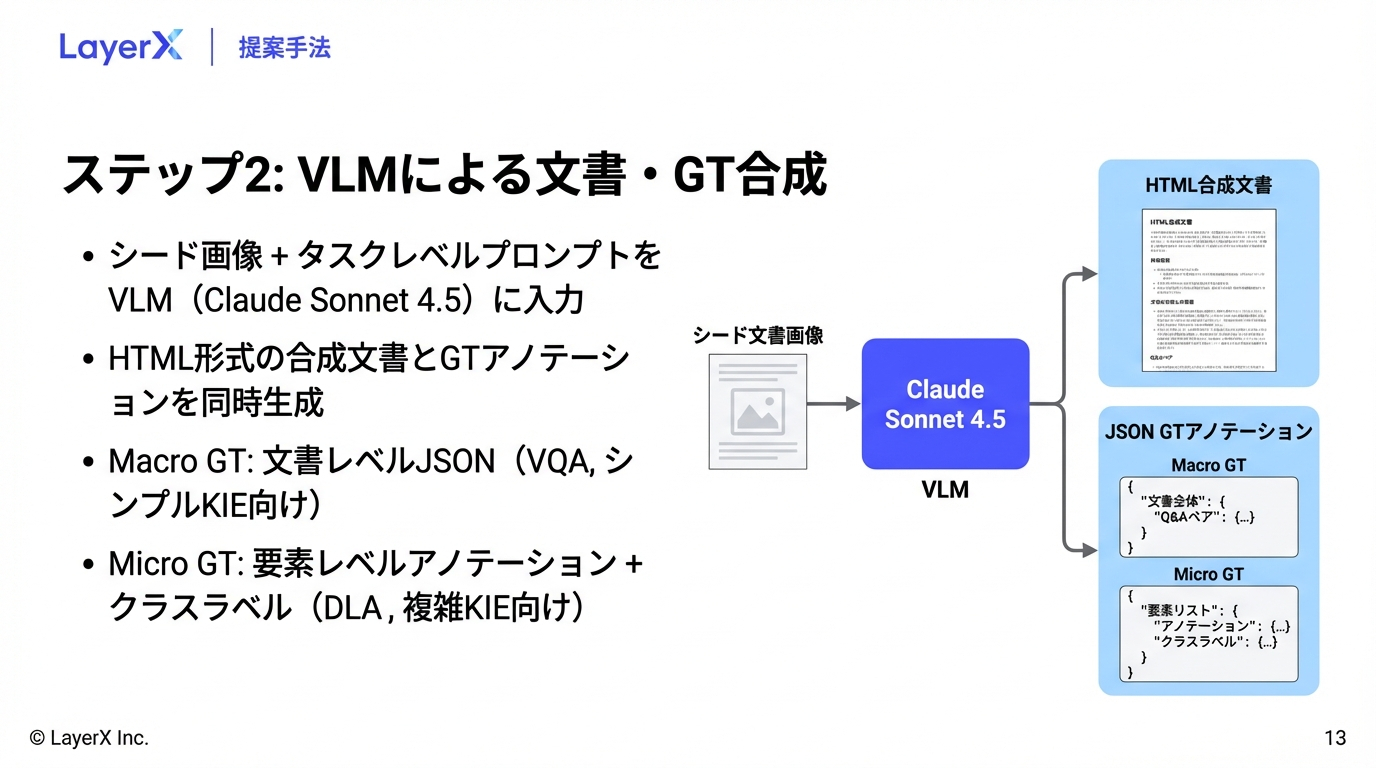
今週のTOPIC[paper] DocDjinn: Controllable Synthetic Document Generation with VLMs and Handwriting Diffusion[paper] LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding[paper] OCR-Agent: Agentic OCR with Capability and Memory Reflection[blog] MediaFM: The Multimodal AI Foundation for Media Understanding at Netflix[論文]ExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction[blog] The Emerging "Harness Engineering" Playbook[blog]Unlocking Agentic RL Training for GPT-OSS: A Practical RetrospectiveメインTOPICDoc-to-LoRA: Learning to Instantly Internalize ContextsIntroductionPreliminariesMeta-Learning Context DistillationImplanting Synthetic Needle-in-a-Haystack InformationExperimentsRelates Work
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi












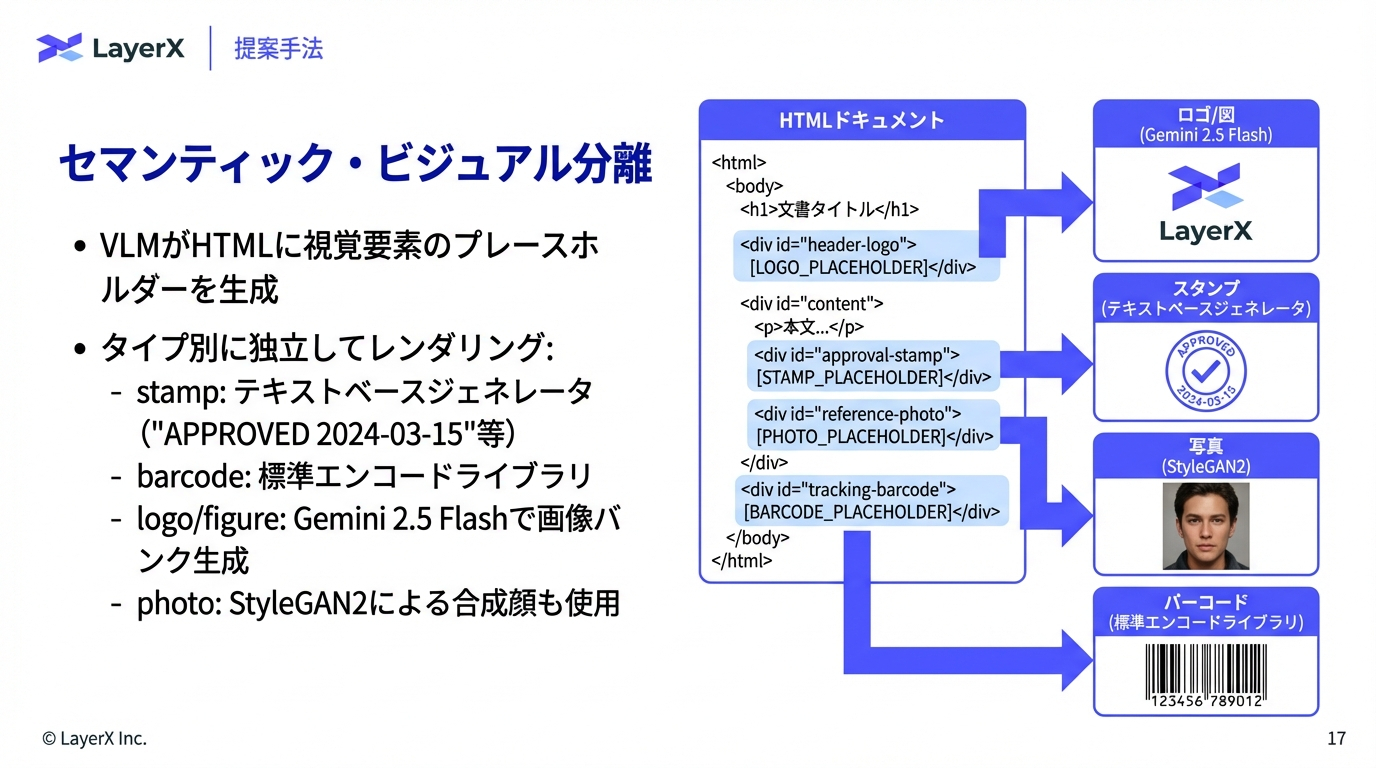



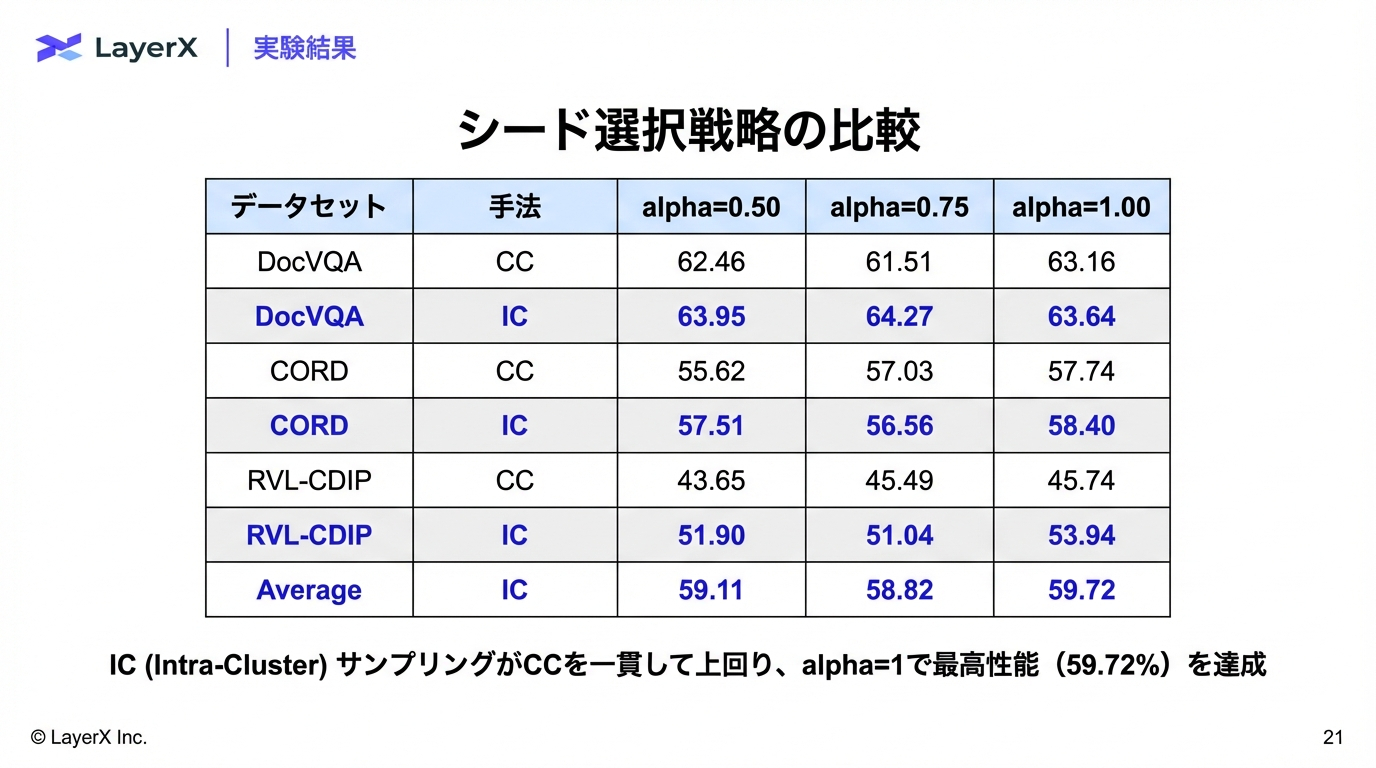
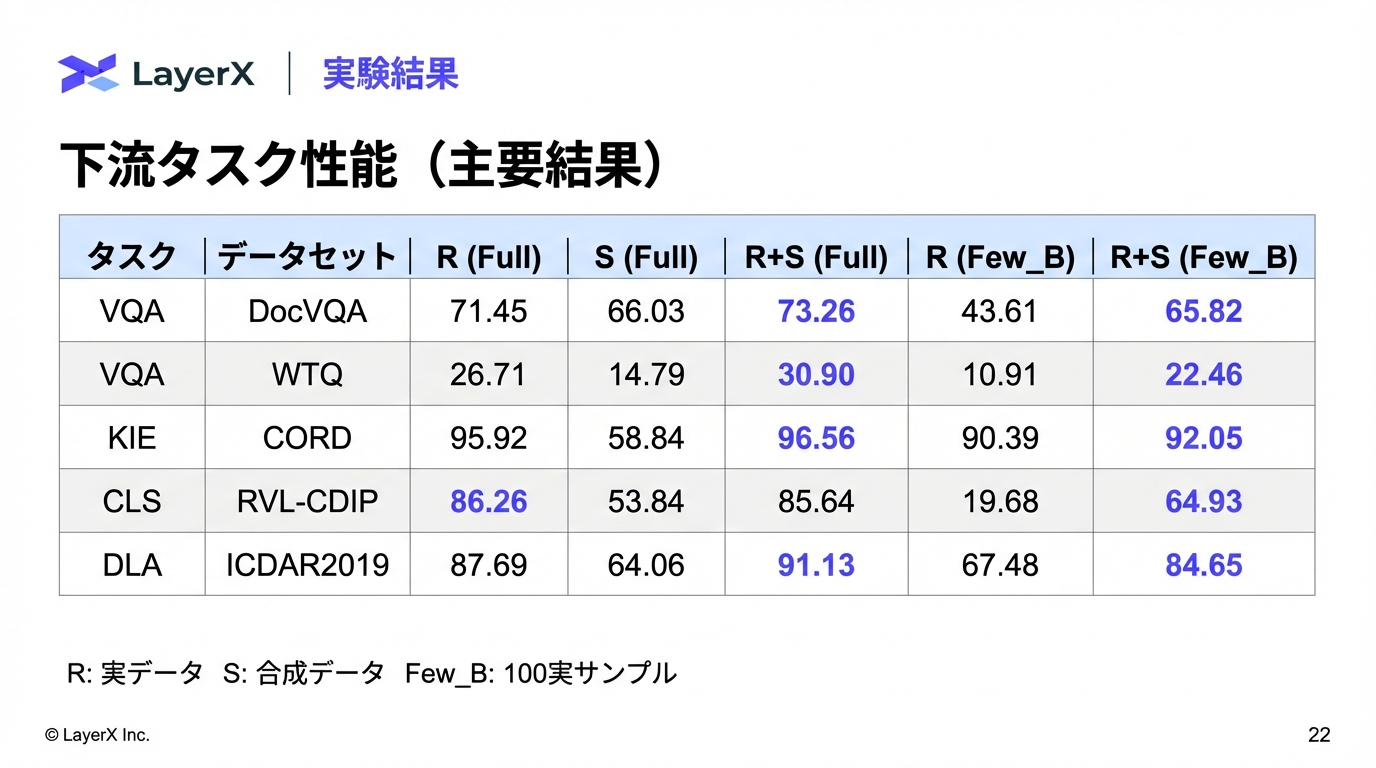

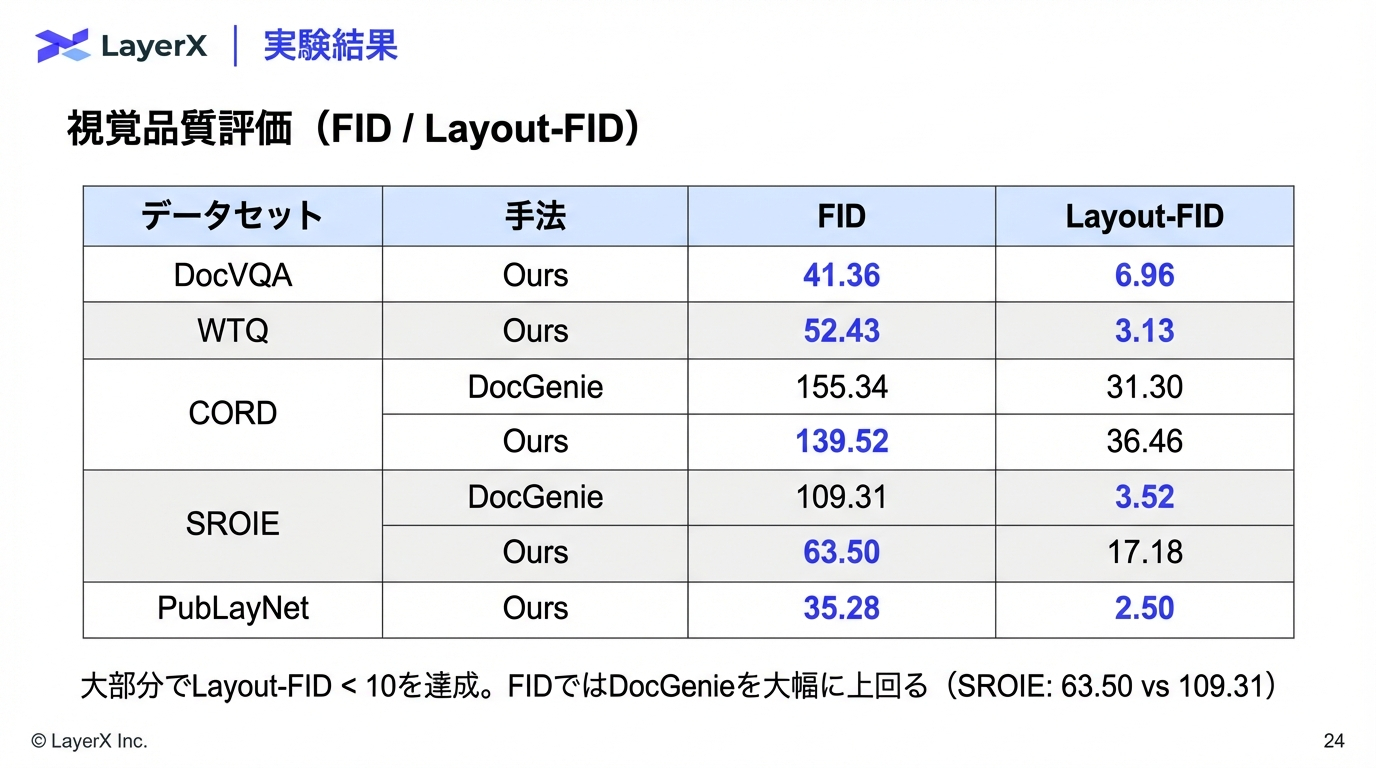




@Shun Ito
[paper] LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding
- 投機的デコーディング(Speculative Decoding)を高速化したい
- 投機的デコーディングの手続き
- 「ドラフトモデル」が複数トークンを予測
- 大きな「ターゲットモデル」で検証
- 採用確率に基づいて採用
- p: ターゲットモデル
- q: ドラフトモデル
- p ≥ q なら採用
- q > p ならp/q の確率で採用
- → 受理率を上げることで高速化できる
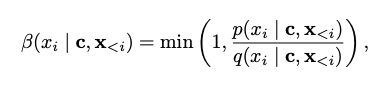
- 提案: 受理率が上がるようにドラフトモデルを学習する
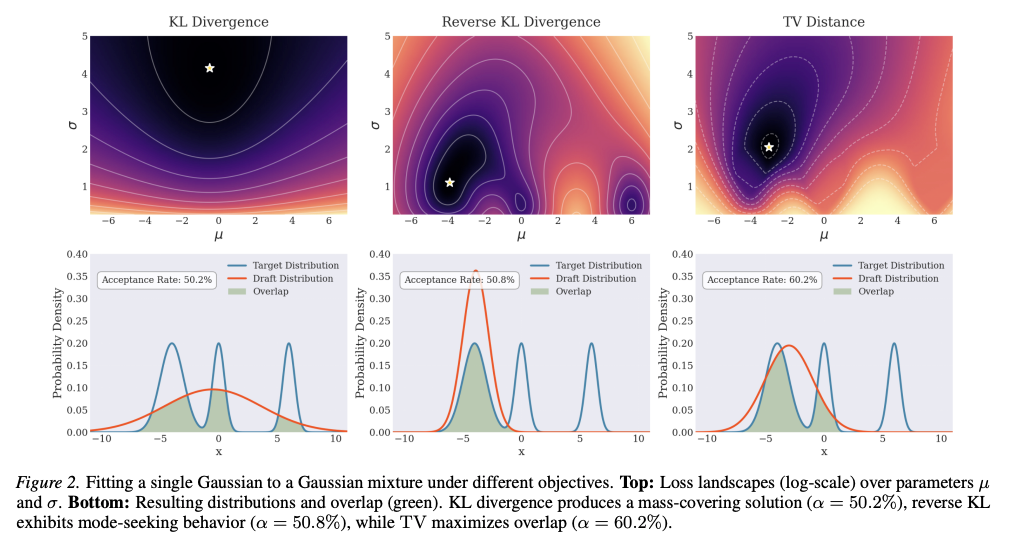
- 従来はターゲット・ドラフトのKL-Loss
- KLで分布として近い距離に近づくような学習はできるが、モデルサイズのギャップによる限界はある。
- 例えば、ターゲットで確率の低い領域でもドラフトで確率が高めになっている場合、その領域では採択率の低いトークンが生成される。
- 分布の重なりを最大化するTotal Variation距離もある
- 重なり方が近づくことで、受領率の向上が見込める
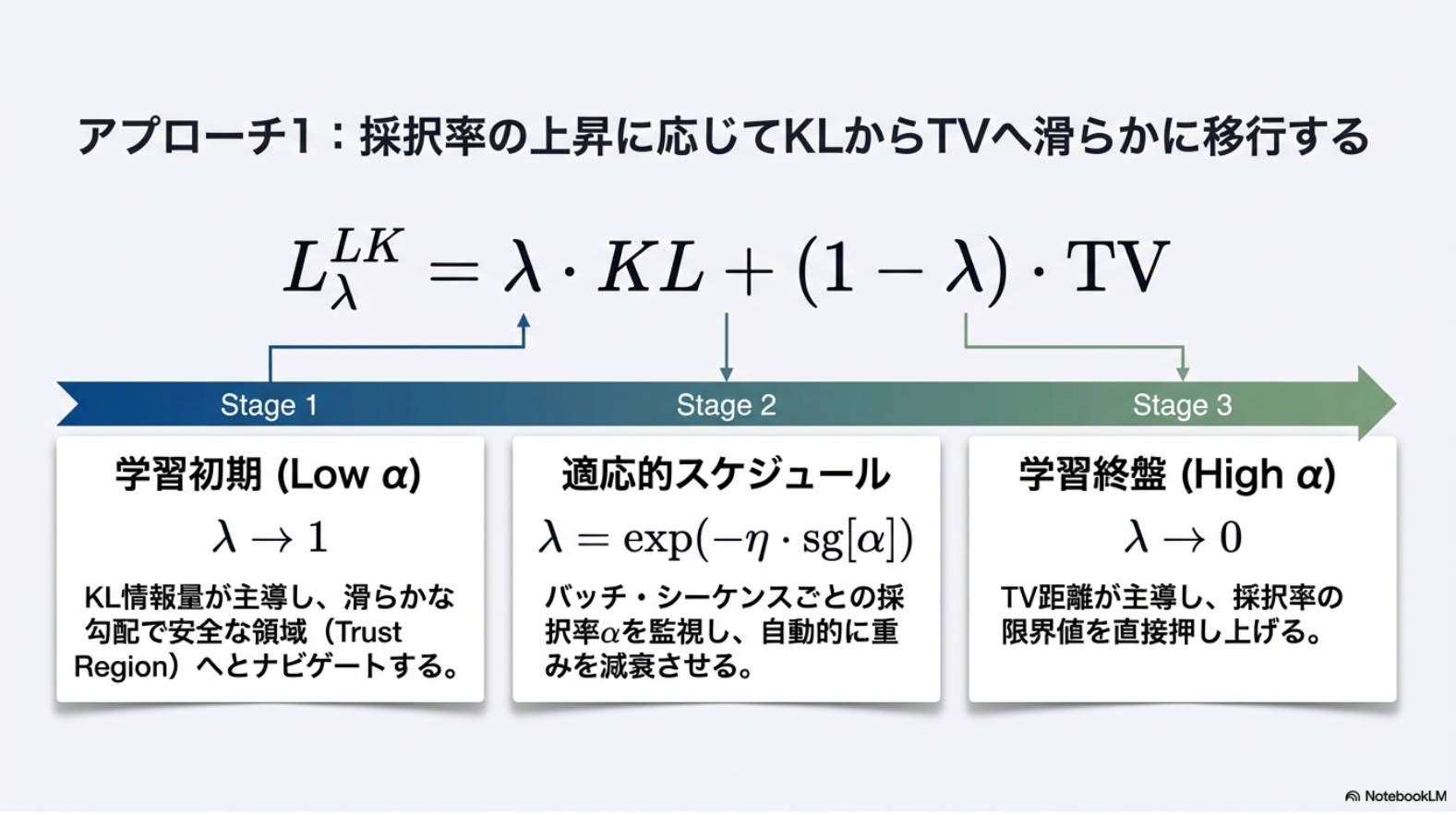
- アプローチ1: KLで全体的な最適化を行いつつ、TVの最適化も含める
- アプローチ2: 対数TVの最適化
- LK Loss は KL をひっくり返した命名
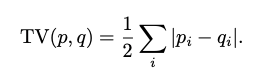

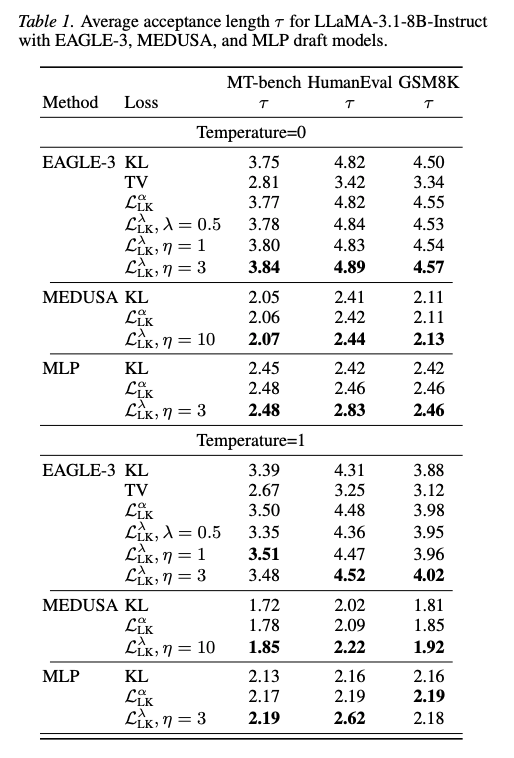
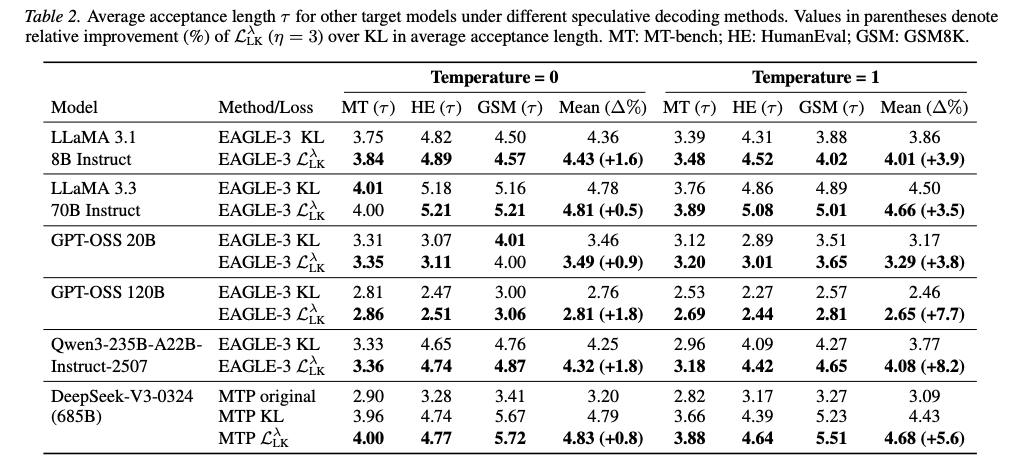
- 結果
- ドラフトモデルの複数アーキテクチャで実験。提案手法でより長く採用される傾向。アプローチ1がやや良し
- 様々なターゲットモデルでも良い性能
@Takumi Iida (frkake)
[paper] OCR-Agent: Agentic OCR with Capability and Memory Reflection
OCRの結果を修正して、良い結果にするエージェントを作った
背景
VLMによるOCRは高い性能になってきているけど、自己修正むずい
理由:
- VLMの能力を超えたアクションが提案されてしまう(Capability Hullucination)
- 例:画像の解像度をあげる
- 効果的ではない修正ループに陥る(Refinement Stagnation)
これらに対して、OCR-Agentでは以下の2つの方法で結果の修正を行っている
- Capability Reflection
- 実行可能なアクションをフィルタリングし、現実的な修正計画のみを抽出
- Memory Reflection
- 過去の反省の履歴を維持して、同じ間違い(無意味な修正)の反復を防ぐ
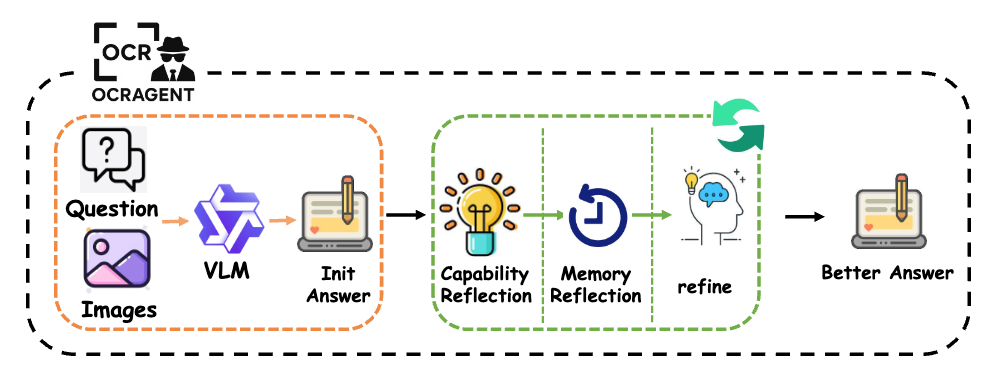
処理の流れ
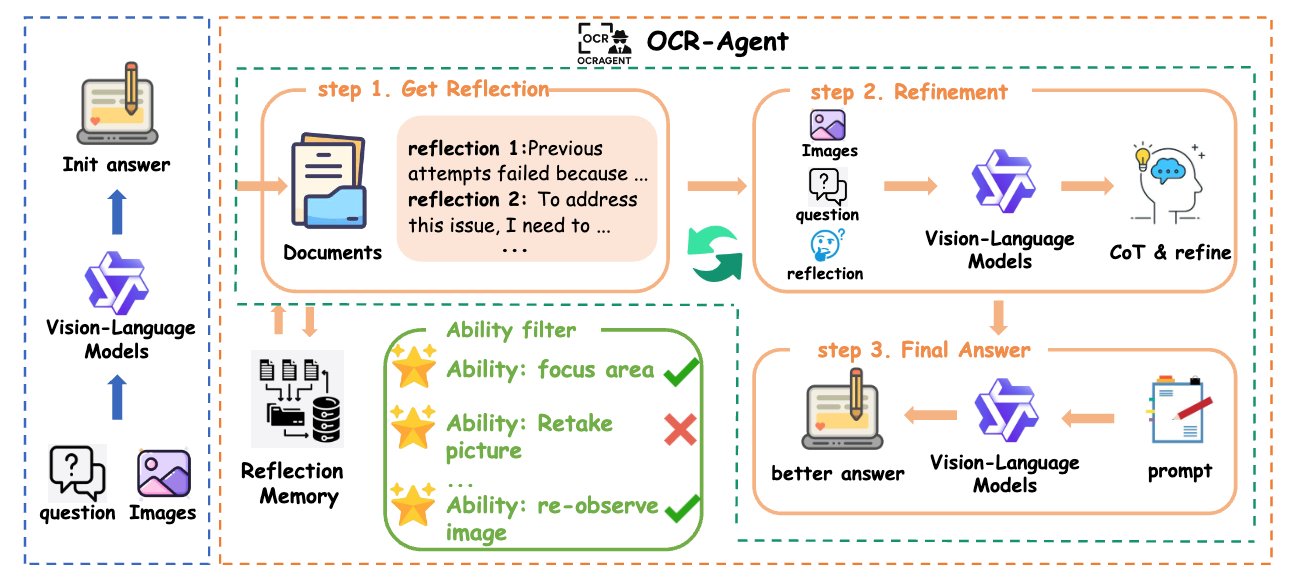
LLMが図中にいないけど、ReflectionとRefinement, Ability FilterはLLMがやっている。
- 初期の結果を生成
- (Reflection)リフレクション生成
- (Memory)メモリに追加。もし、過去のリフレクションがあれば、それも利用。
- リフレクションを生成
- (Ability Filter)実行可能なアクションをフィルタリング
入力は画像(I)、クエリ(質問, Q)、アクション(A)、メモリ(M)
- (Refinement)リフレクション結果を追加して、VLM再実行
結果
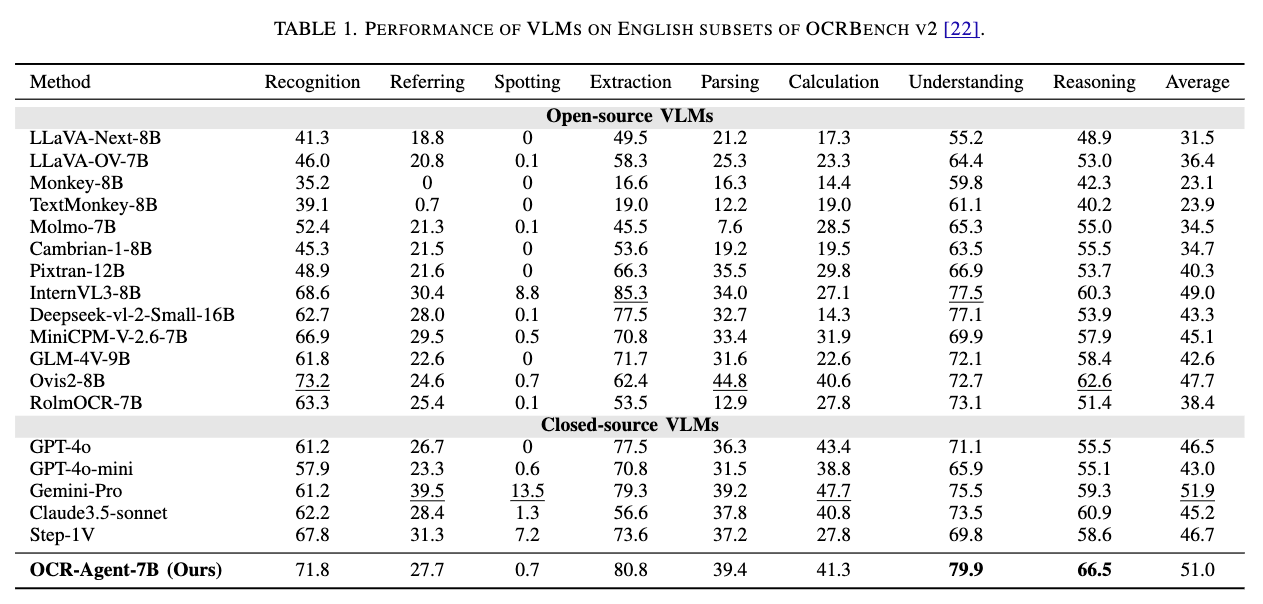
定量評価
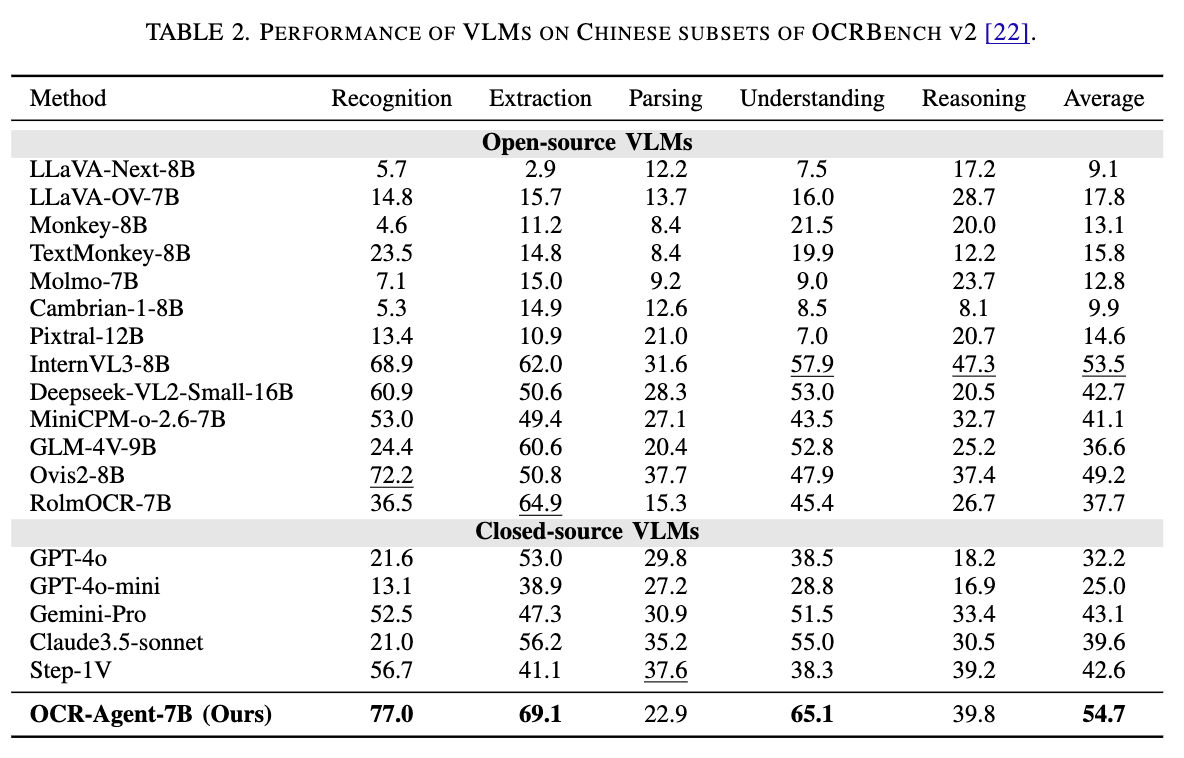
Englishについては特にいうことなし。そこそこいい。Chineseは、SoTA達成。
English
Chinese
定性評価
OCR-Agent (Ours)では、⊿BCDが間違えていると気付いたときに、どこが間違っているのかの情報を記憶(Memoryのおかげ)。また、Capability Reflectionにより、「交差する線と三角形の性質」を正しく再評価できている。 のところ

@ShibuiYusuke
[blog] MediaFM: The Multimodal AI Foundation for Media Understanding at Netflix
Netflixが独自に開発したマルチモーダルAI基盤モデル「MediaFM」のアーキテクチャ、学習方法、およびその応用成果について解説。
1. 開発の背景と目的(導入)
Netflixが世界中のメンバーに最適なストーリーを届けるために必要なこと。
- コンテンツの深い理解: 大作映画からニッチなドキュメンタリー、ライブイベント、ポッドキャストまで、あらゆる形式のコンテンツニュアンスを機械レベルで深く理解すること。
- 長編動画理解の難しさ: 映画やドラマのエピソード全体にまたがる物語の依存関係や感情の起伏を把握するには、非常に高度な長編動画理解技術。
- マルチモーダルの重要性: コンテンツの本質理解には、視覚(ビデオ)だけでなく、シーンの切り替わりやトーンを把握するための音声(オーディオ)などの非視覚的モダリティ。
- MediaFMの誕生: これらの課題解決のため、Netflixの膨大なカタログ(数千万のショットデータ)を活用し、音声・映像・テキスト(字幕)を統合して文脈を学習する社内基盤モデル「MediaFM」。
MediaFMの概要
定義: Netflixのカタログの一部を使用して事前学習された、初のトライモーダル(音声・映像・テキストの要素)コンテンツ埋め込み(Embedding)モデル。
アーキテクチャ: Transformerベースのエンコーダを中核とし、視覚・音声・テキストの情報を統合して、ショット間の時間的関係を学習。これにより、コンテンツのより深くニュアンスに富んだ「ショットレベルの埋め込み(ベクトル表現)」を生成。
主な用途: 新規タイトルのコールドスタート時のレコメンデーション、プロモーション素材(アートワークや予告編)の最適化、社内のコンテンツ分析ツールのバックボーン。
設計思想: テキスト生成(生成AI)ではなく「埋め込み(ベクトル表現)」を出力に選んだ理由は、モジュール性を重視したため。表現を一度生成すれば社内の全サービスで再利用でき、アーキテクチャの変更にも柔軟に対応可能。
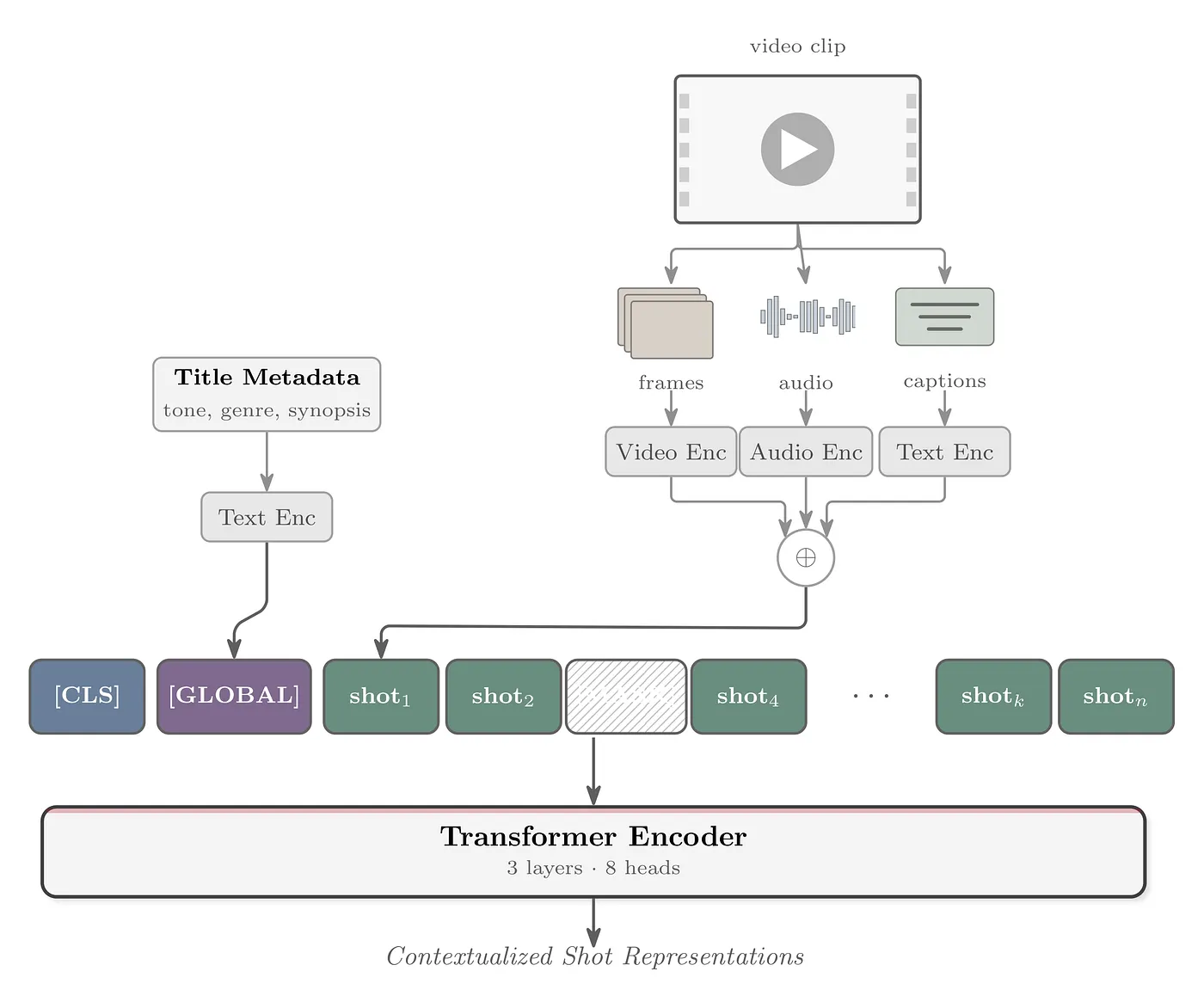
入力データの表現と前処理
最小単位: 動画をアルゴリズムで分割した「ショット(Shot)」。
3つのモダリティ(要素)の埋め込み生成:
- 映像 (Video): Shot detectionした可変長のショットを利用。 という社内モデル(動画検索データセットでファインチューニングされたCLIPスタイルのモデル)を使用し、ショットから均等間隔で抽出したフレームをベクトル化。
- 音声 (Audio): Meta FAIRのを使用して音声サンプルをベクトル化。
- テキスト (Timed Text): OpenAIのを使用して、字幕や音声解説などのタイムドテキストをベクトル化。(テキストがない場合はゼロパディングで補完)
統合(フュージョン):
- これら3つの埋め込みは結合(Concatenate)され、正規化されて2304次元の単一の埋め込みベクトルになる。
- 学習時は、同じ映画やエピソードから抽出された「時系列順に並んだショットのシーケンス(最大512ショット)」としてモデルに入力。
モデルアーキテクチャと学習目的
コアアーキテクチャ:BERTに似たTransformerエンコーダ。
処理のステップ
- 入力の投影:2304次元の統合ベクトルを線形レイヤーでモデルの隠れ次元に圧縮。
- シーケンス構築と特殊トークン:
- 先頭に学習可能なトークンを追加。
- タイトル全体(あらすじやタグなどのメタデータ)をテキストモデルでベクトル化したものをトークンとしての直後に追加。これにより、全ショットに作品全体の文脈(グローバルコンテキスト)を付与。
- 文脈化 (Contextualization):位置情報(Positional Embeddings)を付与し、Transformerスタックに通すことで、「前後のショットの文脈」を踏まえた表現を獲得。
- 出力の投影:Transformerの出力を再び2304次元の空間に戻す処理。
学習手法:Masked Shot Modeling (MSM)
自己教師あり学習の一種である「MSM」を採用。
- 入力シーケンス内のショットの20%をランダムにトークンに置き換え。
- モデルは、前後の文脈から「マスクされたショットの元のベクトル表現」を予測(コサイン距離を最小化するように最適化)。
- オプティマイザにはMuon(隠れ層パラメーター)とAdamWを使用。
5. 応用タスクと評価
MediaFMの埋め込みの評価対象と有効性。
- 評価レベル: クリップ(数秒〜1分程度の短い動画)レベルのタスクで評価。
- 応用範囲: 社内のさまざまなアプリケーションで価値を提供。
- 重要な知見: 単独のクリップではなく、エピソード全体など「より大きな文脈(コンテキスト)の中で埋め込みを抽出する」アプローチが非常に有効。
主なタスクは以下の通り:
- 広告の関連性 (Ad Relevancy): 広告配置に最適なNetflixクリップを分類するタスク。
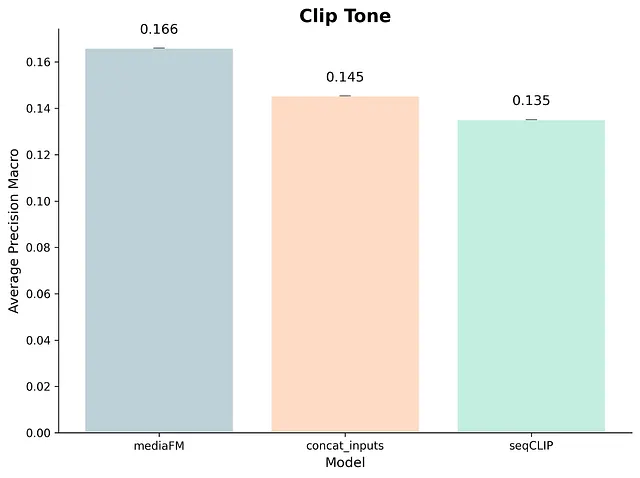
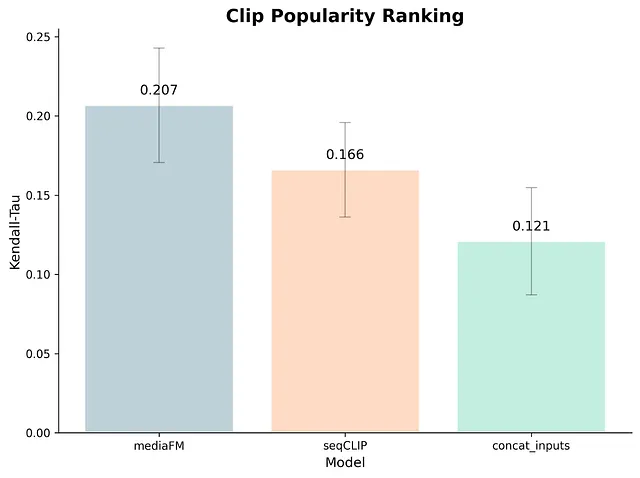
- クリップの人気度ランキング (Clip Popularity Ranking): 同じ作品内の他のクリップと比較して、クリック率(CTR)がどれくらい高くなるかを予測。
- クリップのトーン分類 (Clip Tone): 内部チームが定義した100種類のトーン(不気味、面白いなど)にクリップをマルチラベル分類。
- クリップのジャンル分類 (Clip Genre): アクション、アニメ、コメディなど11のコアジャンルに分類。
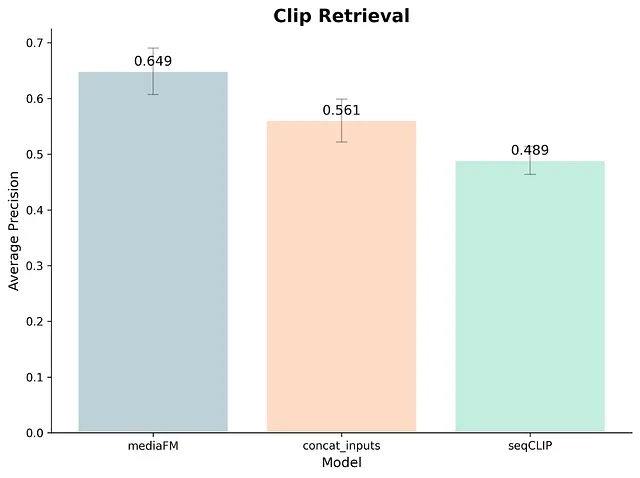
- クリップの抽出・評価 (Clip Retrieval): 作品を宣伝するための「魅力的なクリップ」かどうかを人間による正解データをもとに二値分類。
6. 成果とアブレーション(要素ごとの効果測定)
比較結果と有効性の検証。
ベースラインとの比較。
- MediaFMは、内部モデル(SeqCLIP)や外部の強力なベースライン(Google VertexAIのマルチモーダル埋め込み、TwelveLabsのMarengo)と比較して、すべてのタスクで優れたパフォーマンス(精度)を発揮。
- 特に、広告の関連性など「深い物語の理解」が求められるタスクで大きな改善。
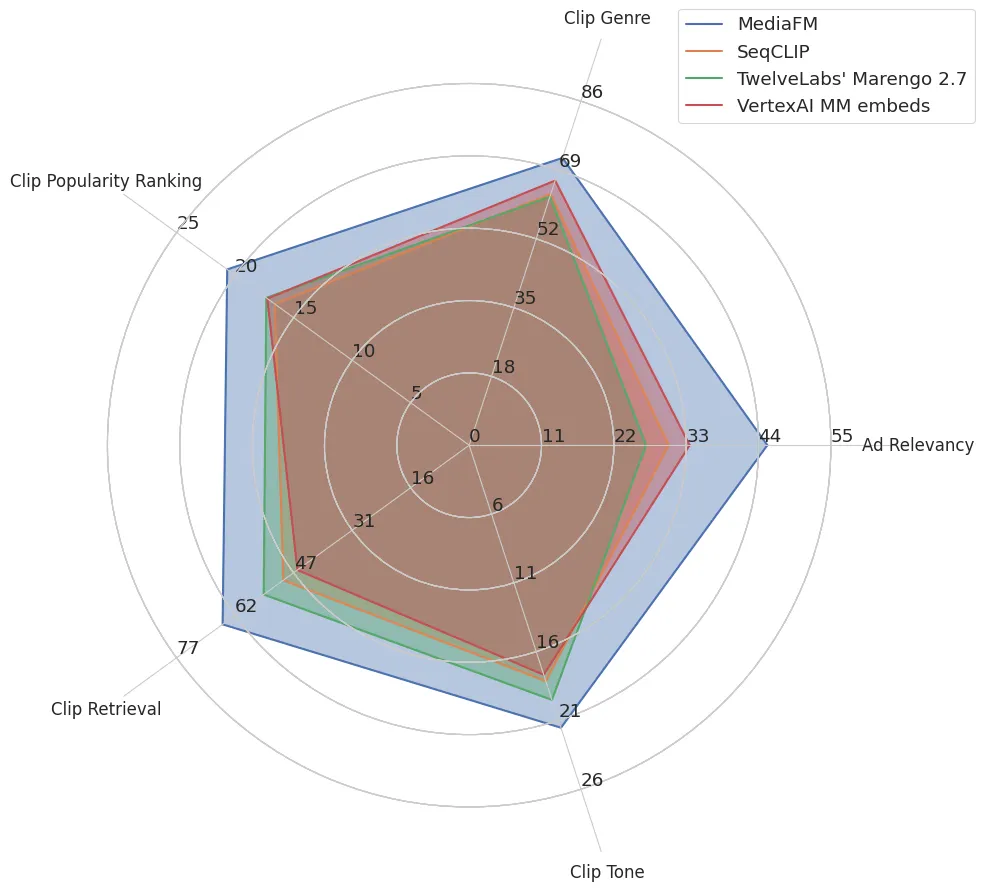
アブレーション(どの要素が効いているか)の分析。
MediaFMの成功の要因は「複数モダリティの統合」と「文脈化(Contextualization)」の2点。これらを切り分けて分析した結果、以下のことが判明。
- 文脈化の絶大な効果。 例えば「人気度ランキング」において、ただのモダリティを単純に結合しただけ(文脈化なし)では精度が落ちるケースがあったが、Transformerによる前後のショットの文脈化(Contextualization)を追加したことで、パフォーマンスが飛躍的に向上。
- 「クリップの抽出」タスクでは、要素を追加するごとに約%ずつ段階的な精度向上。
今後の展望
現在の取り組み:
- カタログデータを用いた自己教師あり学習の知見を活用し、さらなる発展を模索中。
- モダリティの統合を学習済みの事前学習済みマルチモーダルLLM(Qwen-Omniなど)を、次世代モデル開発の「より強力な出発点」として活用するための調査を実施中。
まとめ:
MediaFMの特徴と成果。
- マルチモーダル統合: 動画を構成する「映像・音声・テキスト(字幕)」を融合。
- 時間的文脈の学習: Transformerで「時間的な文脈」を学習。
- 深い理解の実現: Netflixのコンテンツを単なる映像データではなく「物語」としてAIに深く理解させることに成功。
- 位置づけ: 画期的な基盤モデル。
@Akira Manda(zunda)
[論文]ExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction
1. 背景・課題感
LLMによる構造化情報抽出(PDF-to-JSON)の需要と現実のギャップ
エンタープライズ領域では、契約書や財務報告書などの非構造化文書(PDF)から、システムで利用可能な構造化データ(JSON)を自動抽出することが強く求められている。しかし、実運用におけるJSON Schemaは非常に巨大かつ複雑であり、現在のLLM開発には以下の2つの大きなボトルネック(Gap)が存在する。
- Gap 1(ベンチマークの不在): 既存の文書理解ベンチマークは数十項目程度の小さなスキーマに限定されており、エンタープライズ規模(数百項目)の広範なスキーマを用いて、PDFからのエンドツーエンドの抽出性能を測るベンチマークが存在しない。
- Gap 2(評価手法の欠如): 既存の評価フレームワークは、すべてのフィールドを「完全一致」などで一律に評価してしまう。しかし実際には、IDには「厳密一致」、金額には「許容誤差」、企業名には「意味的等価性」が求められ、さらに「情報の欠落(omission)」と「幻覚(hallucination)」を明確に区別する必要がある。
2. 本研究の貢献
本研究は、上記の課題を解決するために「ExtractBench」をオープンソースとして公開した。
- ExtractBench Datasetの構築
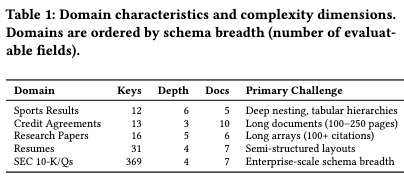
- 経済的価値の高い5つのドメイン(SEC 10-K/Q、与信契約、論文、履歴書、スポーツ結果)からなる35のPDF文書。
- 人間による高品質なアノテーション(約68時間)を経た、12,867の評価可能フィールドを含む。
- Schema-Driven Evaluation(スキーマ駆動型評価)の提案
- JSON Schemaを単なる構造定義ではなく、「実行可能な評価仕様」として扱う新しい評価インフラ。
3. 提案手法:Schema-Driven Evaluationの詳細
従来のグローバルな単一指標(単純なテキスト比較など)による評価を廃止し、AST(抽象構文木)ベースのdual-traversal(二重トラバーサル)アーキテクチャを採用している。これにより、JSON Schemaを「何を出力すべきか」だけでなく「どう評価すべきか」の実行可能な仕様として扱う。
ASTベースのdual-traversal(同時探索)の仕組み:
単純な「JSONの文字列・辞書比較」では、複雑な (外部参照)やネストに対応できません。そこで本フレームワークはコンパイラ的なアプローチをとる。
- スキーマのAST化: JSON Schemaを解析し、構造と「各フィールドの評価ルール」が紐づいた木構造(AST)の「評価ガイド」を生成する(等も解決済み)。
- 同時トラバース(dual-traversal): この「評価ガイド」の木構造をなぞりながら、人間が作成した「正解JSON」とLLMが生成した「予測JSON」の2つの木を同時に降りていく。
- ローカル評価(Visitorパターン): 木の末端(各フィールド)に到達するたびに、「評価ガイド」に書かれたルール(例:許容誤差0.1%)を読み取り、その場で正解と予測の値をスコアリングする。
この設計により、369フィールドのような巨大で複雑なスキーマでも、各フィールドの評価を独立して並列計算することが可能になり、スケーラビリティを担保しています。
【具体例:スキーマ内に評価ルールを直接埋め込む(Appendix Cより)】
従来のJSON Schemaを拡張し、各フィールドの定義に という項目を追加しているのが最大の特徴です。これにより、評価スクリプトが自動で最適な採点を行います。
- 厳密一致(IDやコード)
- ファジーマッチ(企業名などのタイポ許容)
- 意味的等価性(フリーテキスト、LLMが判定)
- 許容誤差付きの数値(財務データなど、0.1%の誤差を許容)
主要なアプローチ:
- 並列かつ独立した評価: トラバーサル・ロジックとメトリクス計算が分離されているため、369フィールドのような巨大なスキーマでも各フィールドを独立して高速に評価できる(プラグイン形式で新しいメトリクスの追加も容易)。
- Missing Valueの厳密な区別: 正解データと予測データ間で、「Present(値あり)」「Null(明示的な空)」「MISSING(出力自体が存在しない)」の3状態をポリシーベースで区別し、単純な間違いとOmission(情報欠落)、Hallucination(幻覚)を切り分ける。
- 配列のセマンティックアライメント: 順序の入れ替わりや欠損があるオブジェクト配列に対しては、位置ベースの比較ではなく、LLMを用いてアイテム間の意味的なマッチングを行う。マッチしたペア・見逃した正解アイテム(False Negative)・誤って予測されたアイテム(False Positive)を特定し、配列レベルでPrecision・Recall・F1を計算する。さらにマッチしたペアに対しては、アイテムスキーマのフィールドレベルのメトリクスを用いて再帰的に内容を評価する。
4. 実験結果・評価
最先端のフロンティアモデル(Gemini 3 Pro/Flash, GPT-5/5.2, Claude 4.5 Opus/Sonnet)を対象にゼロショット評価を実施した結果、現在のLLMはエンタープライズ規模のスキーマに対して信頼性がないことが浮き彫りになった。

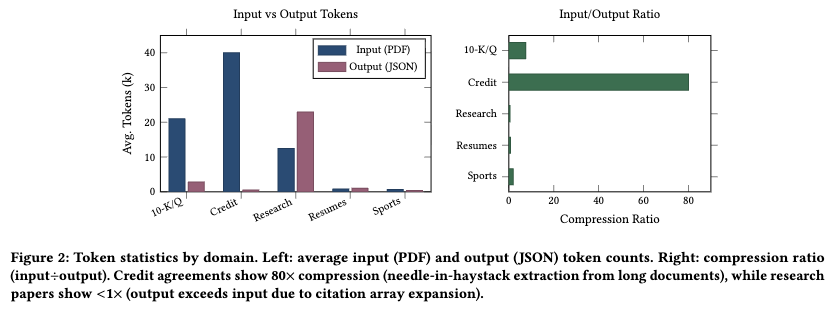
なぜ失敗するのか?(分析と追加実験)
- 最大の要因は「スキーマの幅(Breadth)」: ネストの深さよりも、出力すべき構造のボリューム(フィールド数や配列の長さ)がLLMの出力を破綻させる。
- Structured Output(制約付きデコーディング)の罠: OpenAI等のStructured Outputs APIを使用した場合の実験結果も報告されている。
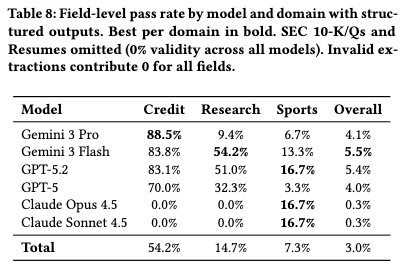
構造化出力モードでの結果。プロンプトベースでのパス率4.6%に対し、構造化モードでは3.0%へと逆に精度が低下した。(※注: Table 8の表上では「SEC 10-K/Q」と「Resumes」が省略されているが、これらは全モデルでパス率0%であった。特に全フィールドの84%を占める巨大な「SEC 10-K/Q」が0%であるため、Overallが3.0%に引き下げられている)
論文では失敗要因として以下の2点を挙げている。
- Grammar complexity scaling: 巨大なスキーマを文法制約としてコンパイルすると、APIの内部制限に抵触したり、トークンごとの制約チェックのオーバーヘッドによりモデルがコンテンツ推論に使えるキャパシティが減少する。
- Rigid structural enforcement(硬直した構造強制): プロンプトモードではモデルが困難なセクションをスキップしたりNullを出力するなど部分的な正解を保持できる(graceful degradation)が、制約付きデコーディングではスキーマの全構造を強制されるため、出力バジェットが枯渇した場合に破綻状態に陥りやすい。
@Shuhei Nakano(nanay)
[blog] The Emerging "Harness Engineering" Playbook
- タイトル: The Emerging "Harness Engineering" Playbook
- 著者 / 組織: Charlie Guo / Artificial Ignorance (Substack)
- 公開日: 2026年2月23日
1. どんな記事?
AIコーディングエージェントを本番運用で効果的に活用するための新たな専門領域「ハーネスエンジニアリング(Harness Engineering)」の形成を論じた記事。OpenAI、Stripe、OSSプロジェクトなど複数の先進事例から収束的なプラクティスを抽出し、エージェント時代のエンジニアの役割変化と具体的な運用手法を体系化している。
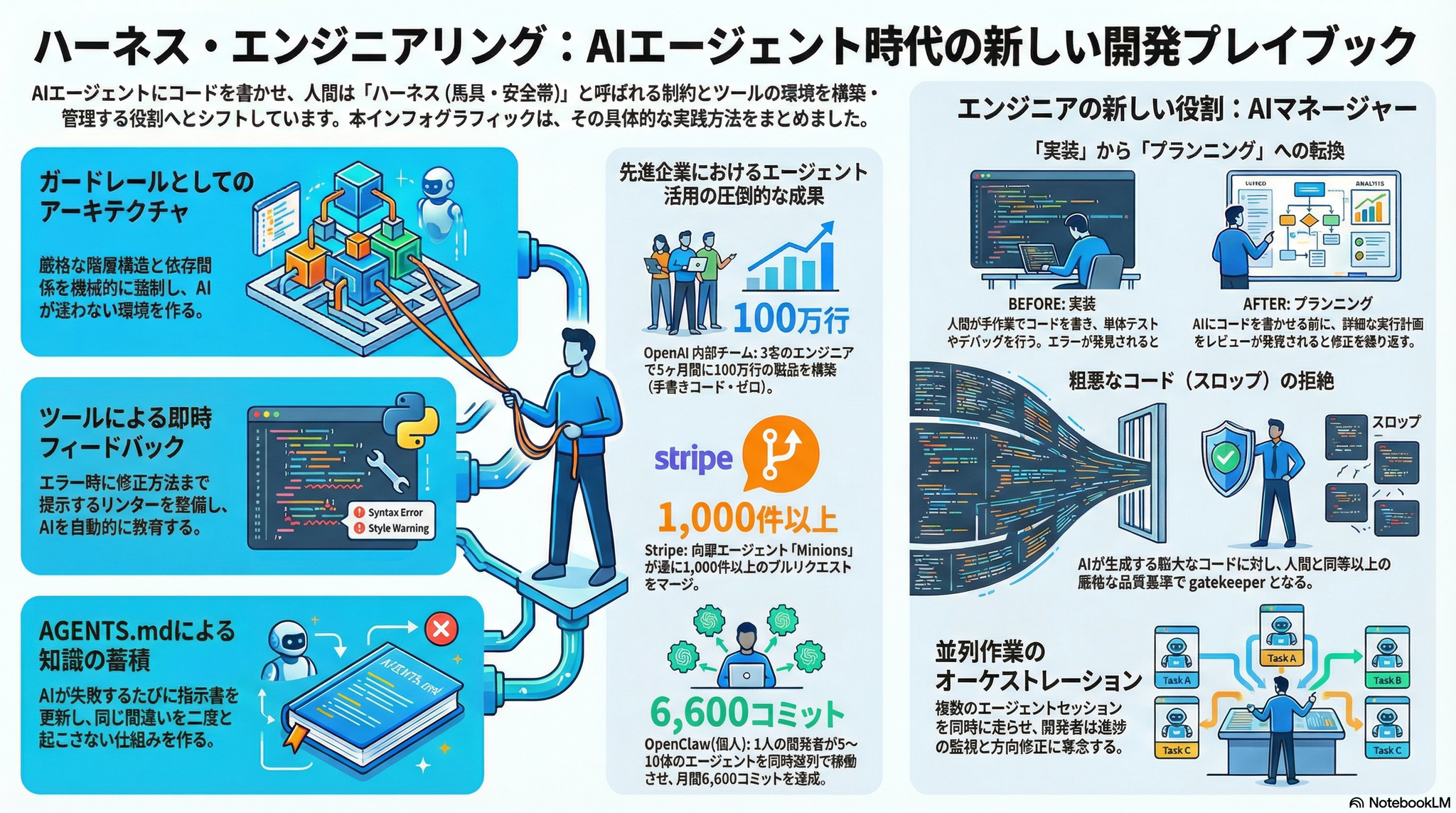
2. 何が課題だったのか?
- AIエージェントがコードを書く能力自体はボトルネックではなく、構造化された環境の欠如がエージェントの生産性を制約していた(OpenAIチームの知見)
- エージェントが生成するコードにはエントロピーが蓄積しやすく、品質維持が困難
- レガシーコードベースへのエージェント適用は依然として複雑
- エンドツーエンドテストの網羅性にギャップがあり、ビジョン制限やツールアクセスの制約からバグが検証をすり抜ける
3. アーキテクチャ・技術的アプローチ
記事では4つのコアプラクティスを「ハーネスエンジニアリング」として整理している。
a) ガードレールとしてのアーキテクチャ
- OpenAIは厳密なレイヤードアーキテクチャ(依存方向のバリデーション、許可されたエッジの制限)を採用
- AIが自ら生成したカスタムリンターで制約を機械的に強制
- Stripeはプレウォーム済みのサンドボックス「devbox」を用意し、MCPサーバー(Model Context Protocol)経由で400以上の社内ツールへのアクセスを提供
b) フィードバック基盤としてのツール
- CLI/MCPサーバーによるツールのエージェントアクセシブル化
- リンターのエラーメッセージをリメディエーション(修正指示)として設計し、ツール自体がエージェントを教育する仕組み
c) 記録体系としてのドキュメント
- AGENTS.md がオープン規約として定着:リポジトリルートに配置し、エージェントがセッション開始時に自動読み込み
- 過去のエージェントの失敗をAGENTS.mdに反映し、同じ間違いの再発を防ぐ生きたフィードバックループ
- Anthropicは構造化された進捗ファイルとJSON形式のフィーチャートラッキングを使用
d) エージェントによるドキュメント保守
- OpenAIはバックグラウンドエージェントが陳腐化したドキュメントをスキャンし、クリーンアップPRを自動作成する仕組みを構築
4. 設計上のこだわり・工夫
- 「制約を増やす」逆説的アプローチ: エージェントの信頼性を高めるために、解空間を広げるのではなく狭めることが有効という反直感的な知見
- 計画先行の徹底: コード実行前に必ずレビュー済みの計画書を作成。Anthropicの「イニシャライザーエージェント」はWebアプリで200以上のフィーチャーリストとテスト手順を事前生成
- 並列化の2モード:
- Attended(有人): エンジニアが3〜4セッションを同時管理
- Unattended(無人): タスク投入→CI/テスト→PRレビューのみ人間が介入(Stripeモデル)。より成熟したハーネスが必要だがスケール性に優れる
- 定量的成果:
- OpenAIは3人のエンジニアで5ヶ月間に100万行の社内プロダクトを手書きコードゼロで構築
- Stripeは週1,000以上のマージPRをエージェントで生成
- Peter Steinbergerは月6,600以上のコミットを5〜10エージェント同時運用で実現
5. 現時点の制約と今後の展望
- コードエントロピー: エージェント生成コードの「ガベージコレクション」エージェントはまだ実験段階
- スケールでの検証: E2Eテストのカバレッジギャップは未解決
- Brownfield問題: 成功事例はグリーンフィールド(新規開発)またはハーネスをゼロから構築したチームに偏り、レガシーコードベースへの適用は依然として複雑
- 文化的適応: 組織的な意図的投資が必要で「偶然には起きない」。アルゴリズム的パズルを好むエンジニアはエージェントネイティブなワークフローへの適応が遅く、プロダクト志向の開発者の方が素早く適応する傾向がある
6. Take Home Message
- エージェント活用のボトルネックはAIの能力ではなく「環境設計」にある。 制約・ツール・ドキュメント・フィードバックループの整備(=ハーネス)こそが生産性を決定する
- AGENTS.mdのような「生きたドキュメント」はエージェント運用の基盤となる。 エージェントの失敗を即座に反映し、二度と同じ間違いをさせない仕組みが品質を担保する
- エンジニアの役割は「実装者」から「環境構築者+品質管理者」へ二分化している。 アーキテクチャ設計とワークフロー管理が新たなコアコンピタンスになる
- Unattended並列化はスケールのカギだが、成熟したハーネスが前提条件。 まずAttendedモードで運用を安定させ、段階的にUnattendedへ移行するアプローチが現実的
@Kyohei Uto(kuto)
[blog]Unlocking Agentic RL Training for GPT-OSS: A Practical Retrospective
概要
LinkedInチームがgpt-ossを利用したAgentic RLに取り組んだ際に学習をうまくワークさせるための試行錯誤のプロセスを紹介したブログ。
論文とかではあまり語られない苦労があって面白い
前提
- ByteDance SeedチームがOSSで開発しているverlというRLフレームワークを利用
- verl内に実装レシピがあるReTool(ツール統合型推論で数学タスクのRL)で実験
- Qwen2.5(赤)とgpt-oss(青)で学習するとgpt-ossは獲得報酬が増加しない問題が確認された
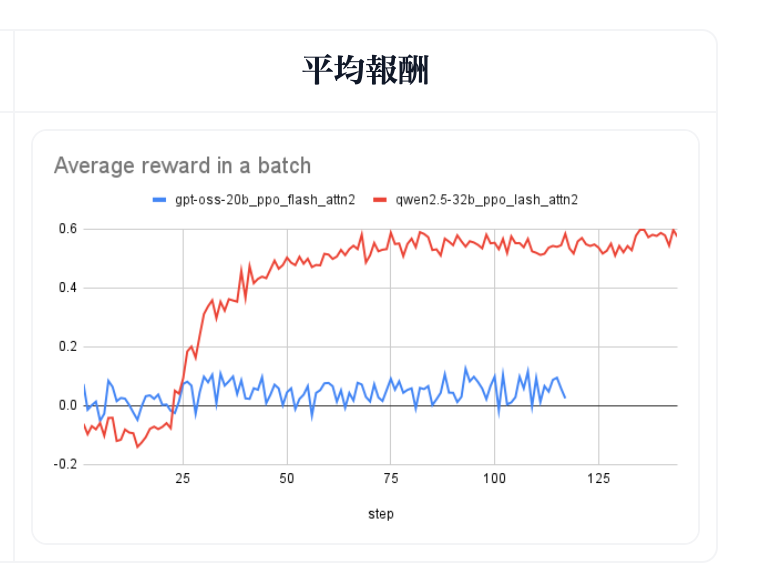
gpt-ossでRLをやる際に発生した問題
多いため抜粋して3つ紹介
問題1. 重点サンプリングのclip率が高い
観測事象
- PPOでは挙動方策と学習方策にズレがある場合重点サンプリングをして期待値を補正している
- 重点サンプリングが大きな値をとると学習が不安定になるので一定以上の場合clipしている
- オンポリシーPPOの場合、データ収集用方策が学習対象方策と同一となるためclip率は常に0になることを期待するが↓ではそうなっていない
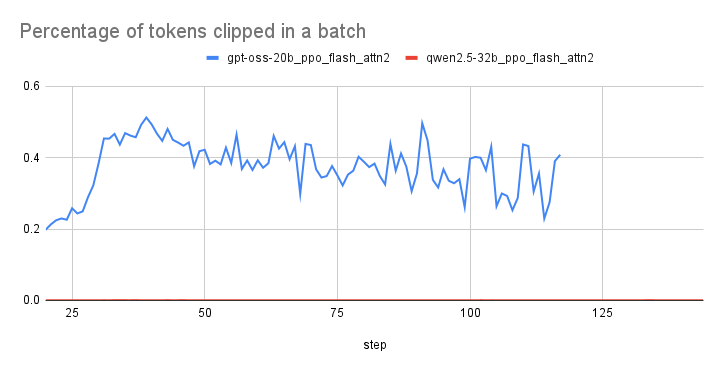
原因
- gpt-ossはMoEであり、入力が同じでも実行のたびに異なる専門家ルーティングになる可能性がある。その場合当然出力(方策)も変わる
- verlの旧実装では挙動方策を得るためにrollout時と学習時で2度実行する仕組みになっていた
解決策
- 2度実行する実装を1度だけに修正する
結果
- clip率が高い問題は解消
- ただし報酬値は改善せず
問題2. 学習と推論の環境ミスマッチ
- 観測された事象
- 勾配ノルムが問題1を解決してもgpt-oss(青)では爆発している
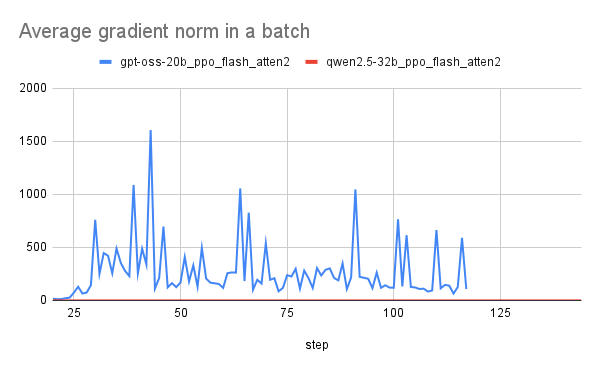
原因
- 下記実行環境の違い
- 学習: 数値精度と安定性を重視するFSDP (Fully Sharded Data Parallel)環境
- 推論: スループットを最優先に最適化するvLLMやSGLang環境
- これによって本来オンポリシーでは方策が一致すべきところに差異が生じている
解決策
- ロールアウト補正(今回はシーケンスレベルの重点サンプリング)を有効化する
結果
- 勾配ノルムの爆発は解消
- ただし報酬の伸びがイマイチ
問題3. アテンションシンク機能
観測された事象
- 試しにattentionを凍結して学習させると報酬推移が似ている(赤)
- アテンションの学習がうまくいっていないのでは?
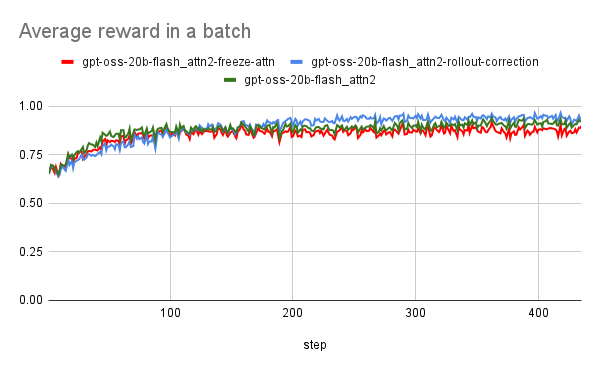
原因
- gpt-ossでは学習安定化のためにsoftmax計算内に学習可能なスカラーパラメータを持つアテンションシンク機能がある
アテンションシンク
- FSDPはflash attention v2でありアテンションシンクをサポートしていない
- アテンションシンクの逆伝播処理はv2もv3もサポートしていない
解決策
- アテンションシンクの勾配を計算するためのforward/backword処理を実装
結果
- すべての設定において学習が安定し、報酬が着実に向上していく様子が確認された(赤)
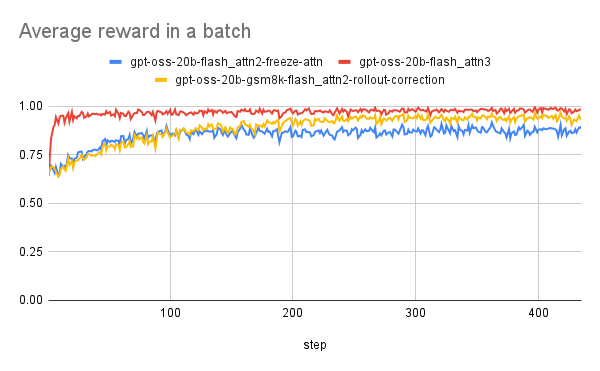
- 学び
- 問題1,2で指摘された方策が想定と異なるという事象は結構起こり得そう
- 結果に違和感を持ったら、指標から仮説を立てる、問題を簡単にする、ライブラリ実装や実行環境も含めて疑う
メインTOPIC
Doc-to-LoRA: Learning to Instantly Internalize Contexts
LLM(大規模言語モデル)が長い入力コンテキストからの情報を、極めて効率的かつ即座に「内蔵化 (internalize)」することを可能にする新しい手法である「Doc-to-LoRA (D2L)」を提案する。

Introduction
課題
- LLMは、コンテキストウィンドウに情報を配置する「in-context learning (ICL)」(またはプロンプティング)を通じて、文書理解や多段階推論を行うが、これは効率的ではない。
- ICLは「transient」(一時的)であり、推論時にメモリを大量に消費する。Transformerの二次注意力コストにより、長いプロンプトはレイテンシを増加させ、KV-cacheの肥大化を招く。また、文脈長が長くなると生成品質が低下する傾向がある (Lost in the Middle)。
- 既存の解決策として「supervised finetuning (SFT)」(教師ありファインチューニング)があるが、これにはタスク固有のデータセット収集が必要であり、過学習のリスクや情報変更ごとの再訓練コストが高いという問題がある。
- 「Context Distillation (CD)」は情報をモデルのパラメータに内部化する有望な代替手段であり、一度内部化されれば推論は速くなるが、その訓練プロセスは依然として遅く、メモリ集約的であり、情報が常に変化する場合には実用的ではない。
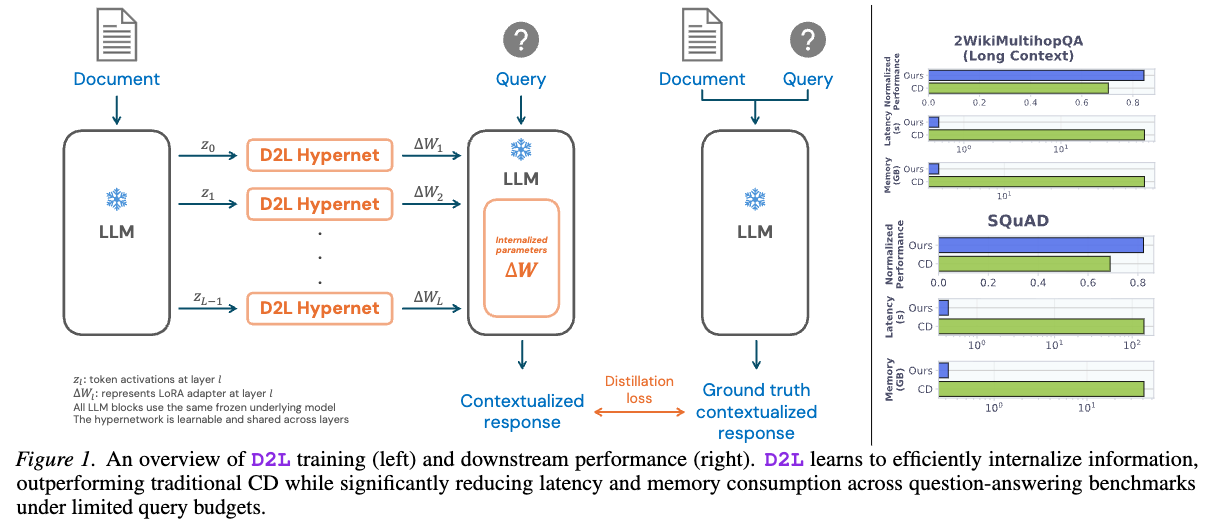
Doc-to-LoRA (D2L) の提案:
- D2Lは、ICLの利便性とCDの効率的な内部化を組み合わせることを目指している。 これは、ハイパーネットワーク (Hypernetworks) を用いてCDプロセスをメタ学習する手法である。
- 具体的には、ハイパーネットワークが、与えられた文脈から、対象LLMのための軽量なLoRAアダプター (LoRA: Low-rank adaptation of large language models) を生成する。
- 一度アダプターが生成されれば、LLMは元の文脈を再消費することなく後続のクエリに応答でき、推論時のレイテンシとKV-cacheのメモリ消費を削減する。
- 訓練が完了すれば、ハイパーネットワークはどのような新しい文脈に対しても再利用でき、学習されたCDプロセスを単一の安価なフォワードパスで実行できるようになる。
D2Lの主な貢献:
- CDプロセスをハイパーネットワークに蒸留し、単一のフォワードパスで内部化オーバーヘッドを償却するメタ学習目的を導入。
- 入力長の変動に強く、長文脈をチャンク化することで高ランクLoRAを生成できる設計されたアーキテクチャ。これにより、対象LLMのネイティブコンテキストウィンドウの4倍を超える文脈長で、ほぼ完璧なゼロショット精度を達成。
- 限られた計算予算の下で、従来のCDを上回り、内部化の効率を大幅に改善し、更新レイテンシとメモリ使用量を削減することを示した実証的検証。
- 長文QAタスクにおいて、訓練長を超える文書へのゼロショット汎化を実証。
- Visual-Language Model (VLM) からテキストベースのLLMへの視覚情報の効果的なゼロショット転送を実証。
これにより、D2LはLLMの迅速な適応を促進し、頻繁な知識更新やパーソナライズされたチャット行動の可能性を開くとされている。
Preliminaries
- Context Distillation (CD) の定義
- CDは「自己蒸留(self-distillation)」メソッドであり、in-context prompt によって誘導される振る舞いや知識を、大規模言語モデル(LLM)のパラメータ内に「内部化」することを目指す。 従来の知識蒸留 (Distilling the Knowledge in a Neural Network) とは異なり、CDでは同じLLMを教師モデルと生徒モデルの両方に用いる点が特徴である。
- 教師モデル: コンテキスト にアクセスできる。
- 生徒モデル: コンテキスト にアクセスできない。
CDの目的は、教師モデルがコンテキストとクエリに基づいて生成する応答を、生徒モデルがコンテキストなしで模倣するように学習させることである。
- Query-Dependent Distillation
- CDの基本的な目的は、与えられたコンテキストとクエリのペア に対し、教師モデル が生成する応答 を生徒モデル が模倣するように学習することである。これは以下の目的関数によって表される:
- ここで はカルバック・ライブラー情報量(Kullback–Leibler divergence)を示す。 は教師モデル(オリジナルのLLM)のパラメータ、 はコンテキストに特化して内部化された生徒モデルのパラメータである。
- この形式は単一の トリプレットに焦点を当てており、「query-dependent distillation」と呼ばれる。しかし、この方法は過学習のリスクがある。
- Internalization の定義: Query-Independent Distillation
- より堅牢な内部化を実現するため、「query-independent distillation」が提案される。
- これは、コンテキスト に対して複数のクエリ と、教師モデルが生成した対応する応答 を利用して、小さなデータセット を作成する。
- このデータセット を用いて、生徒モデルは以下の目的関数を最適化する:
- この最適化プロセスが、本論文における「内部化(internalization)」の具体的な定義である。内部化が成功すると、モデルは内部化されたパラメータ を通じてコンテキスト の情報にアクセスできるようになり、あたかも がコンテキストとして与えられているかのように振る舞うことができる。
- これにより、安全ガイドラインやユーザーの好みなど、特定の情報をモデルのパラメータに永続的に埋め込むことが可能になり、リアルワールドのアプリケーションに大きな影響を与える。
- D2LとContext Distillation
- D2Lは、このquery-independent CDプロセスをメタ学習するハイパーネットワークとして機能する。
- つまり、ハイパーネットワークは与えられたコンテキストから、そのコンテキストの知識を内部化したLoRAアダプターを生成する方法を学習する。これにより、従来のCDのような高コストな学習プロセスを単一の順方向パスに償却することを目指している。
Meta-Learning Context Distillation
- D2Lは、クエリに依存しないCDをメタ学習することに焦点を当てている。これは、一度モデルのパラメータに内部化された知識が、まだ見たことのない新しいダウンストリームのクエリに対しても汎用的に機能することを意味する。
- ハイパーネットワークの役割
- D2LはハイパーネットワークHϕを利用する。このハイパーネットワークは、与えられたコンテキストを入力として受け取り、フリーズされたベースモデルを変更するためのLoRAアダプターパラメータのセットを生成する。
- 生成されたは、元のモデルパラメータに加算され、コンテキストが内部化されたモデルを形成する。ここで、と表される。
- (実験の設定ではハイパーネットワークのパラメータ数は309M)
- メタトレーニングプロセスと目的関数
- 従来のCDは、各コンテキストに対して個別のパラメータ更新()を最適化する必要があった。これに対し、D2Lは単一のハイパーネットワークをメタトレーニングし、多様なコンテキスト(タスク)にわたって汎化することを目指す。
- その目的は、コンテキスト条件付きの教師モデル()と、ハイパーネットワークによってコンテキストが内部化された生徒モデル()との間のKullback–Leibler divergence (KLダイバージェンス)を最小化することである。
- この目的関数は、以下のように数式で表現される:
- ここで、は多様なコンテキスト、クエリ、応答を含むメタトレーニングデータセットである。
- : ハイパーネットワークのパラメータ。
- : メタトレーニングデータセットからサンプリングされたコンテキストと、それに関連するクエリ・応答ペアのデータセットについての期待値。
- : からサンプリングされたクエリと応答についての期待値。
- : コンテキストにアクセスできる教師LLMが、クエリに対して応答を生成する確率分布。
- : ハイパーネットワークによって生成されたLoRAアダプターが適用されたLLMが、クエリに対して応答を生成する確率分布。このモデルはコンテキストに直接アクセスせず、内部化された知識に依存する。
- 訓練後の利点:
- 訓練されたハイパーネットワークは、任意の新しいコンテキストが与えられた際に、単一の順方向パスで対応する内部化されたパラメータを生成できる。
- これにより、従来のCDが必要とする高コストなクエリ生成プロセスや逆伝播の計算オーバーヘッドを大幅に償却し、低レイテンシーでの知識内部化を実現する。
Implanting Synthetic Needle-in-a-Haystack Information
このセクションの目的は以下の3点である。
- 知識の内在化: D2Lが、元のコンテキストを直接読み込むことなく、LLMが埋め込まれた情報を想起できるように、知識の内在化を成功させること。
- コンテキスト長の克服: LLMが本来持つコンテキスト長の制限を効果的に回避すること。 推論コストの削減: 特に長い入力において、推論に必要な計算リソースを削減すること。
- この目的を達成するために、本論文では「Needle-in-a-Haystack(NIAH)」と呼ばれる合成情報検索タスクを用いてD2Lを評価している。
NIAHタスクの詳細は以下の通りである。
- タスクの定義: NIAHタスクは、長い邪魔な文書(haystack)の中から特定の情報(needle)を見つけ出すことをモデルに要求する。例えば、「魔法の数字は0042です」といった特定の4桁の数字を定義する文が、多くの無関係なテキストの中にランダムに挿入される。モデルの目標は、プロンプトが与えられたときにその数字を正確に取得することである。
- ベースモデル: すべての実験で、コンテキスト長8Kトークンのgemma-2-2b-itがベースLLMとして使用される。
- D2Lのメタトレーニングには、32から256トークン長の入力コンテキストが使用された。 トレーニング入力は、1から8のチャンクにランダムに分割され、最小チャンクサイズは25トークンである。
評価時の設定
- ベースラインモデル: haystackとクエリの両方に直接アクセスする。
- D2L: ベースLLMは元のコンテキストのどの部分にも直接アクセスせず、「魔法の数字は何ですか?数字だけを答えてください。」というクエリプロンプトのみが与えられる。
- D2Lがこのタスクで良いパフォーマンスを出すためには、コンテキスト情報をNeedleの値を格納するLoRAアダプターにマッピングすることを学習する必要がある。これにより、適応されたベースモデルはLoRAアダプターに含まれる知識のみに基づいて正しい応答を返すことができる。
- D2Lは、入力が1024トークンよりも長い場合、1024トークンを最大チャンクサイズとして等しいサイズのチャンクに分割して処理する。これは、トレーニング中に見た最大シーケンス長256トークンの4倍である。
NIAH実験の主な結果は以下の通りである。
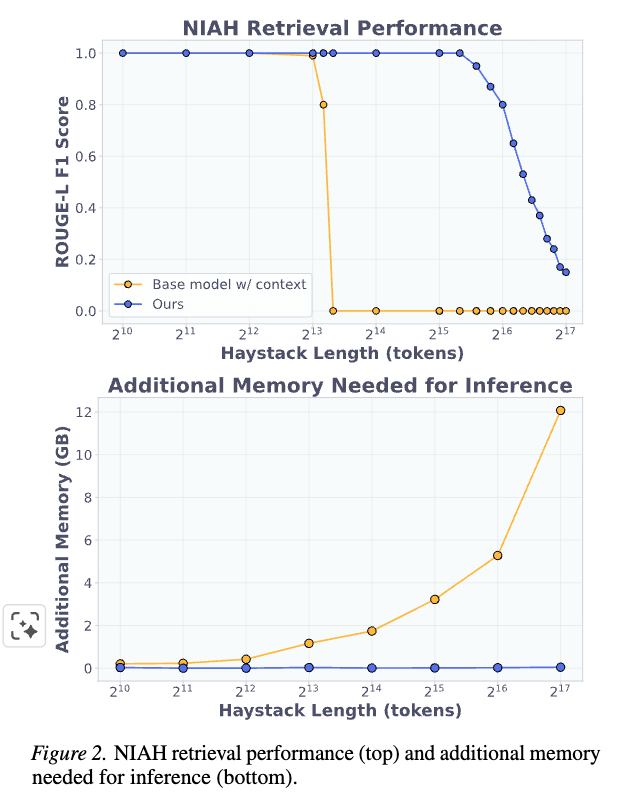
- 知識の内在化とコンテキスト長一般化(Figure 2上部):
- D2LはNeedle情報を成功裏に内部化し、8Kトークンまでのhaystackにおいて、インコンテキスト情報を持つベースモデルと同様に完璧に近い精度を達成した。
- haystackが8Kトークンを超えると、ベースモデルのパフォーマンスはコンテキスト長制限により急激に低下するが、D2Lはこれらのより長いシーケンス全体で高い情報検索精度を維持した。
- 特に、モデルがトレーニングフェーズで曝露されたチャンク数の5倍にあたる40チャンク(40Kトークン)まで、パフォーマンスはほぼ完璧なままであった。この結果は、D2Lがチャンクサイズとチャンク総数の両方で強い一般化能力を示すことを実証している。
- 推論コストの削減(Figure 2下部):
- D2Lは高い精度を達成するだけでなく、特に拡張されたコンテキスト長において、ベースモデルよりも少ないメモリを必要とし、顕著な効率改善を示した。
- 128Kトークンのhaystackに対して応答を生成するために、ベースモデルは12GB以上の追加メモリを使用するが、内部化された知識を持つモデルは、haystackの長さに関わらず一貫して大幅に少ないメモリ(50MB未満)を使用する。
- この結果は、ユーザーが長いプライベート文書を最初に内部化することで、推論時のメモリを大量に消費するKVキャッシュを回避できるという、実世界の潜在的な応用を強調している。
Experiments
本セクションでは、D2Lの性能評価を、これまでの人工的なNeedle-in-a-Haystack (NIAH)タスクから、より現実世界に近い質疑応答(QA)タスクへと移行する。D2Lが様々なQAベンチマークにおいて、文脈を内部化する能力を評価することが目的である。
5.1.1. リーディングコンプレヘンションタスクにおける効率的かつ効果的な内部化
3つの標準的なリーディングコンプレヘンションベンチマークでパフォーマンスを評価します:
- SQuAD(スパン抽出、Rajpurkar et al., 2016)
- DROP(パッセージに対する離散推論、Dua et al., 2019)
- ROPES(背景知識を用いた推論、Lin et al., 2019)。
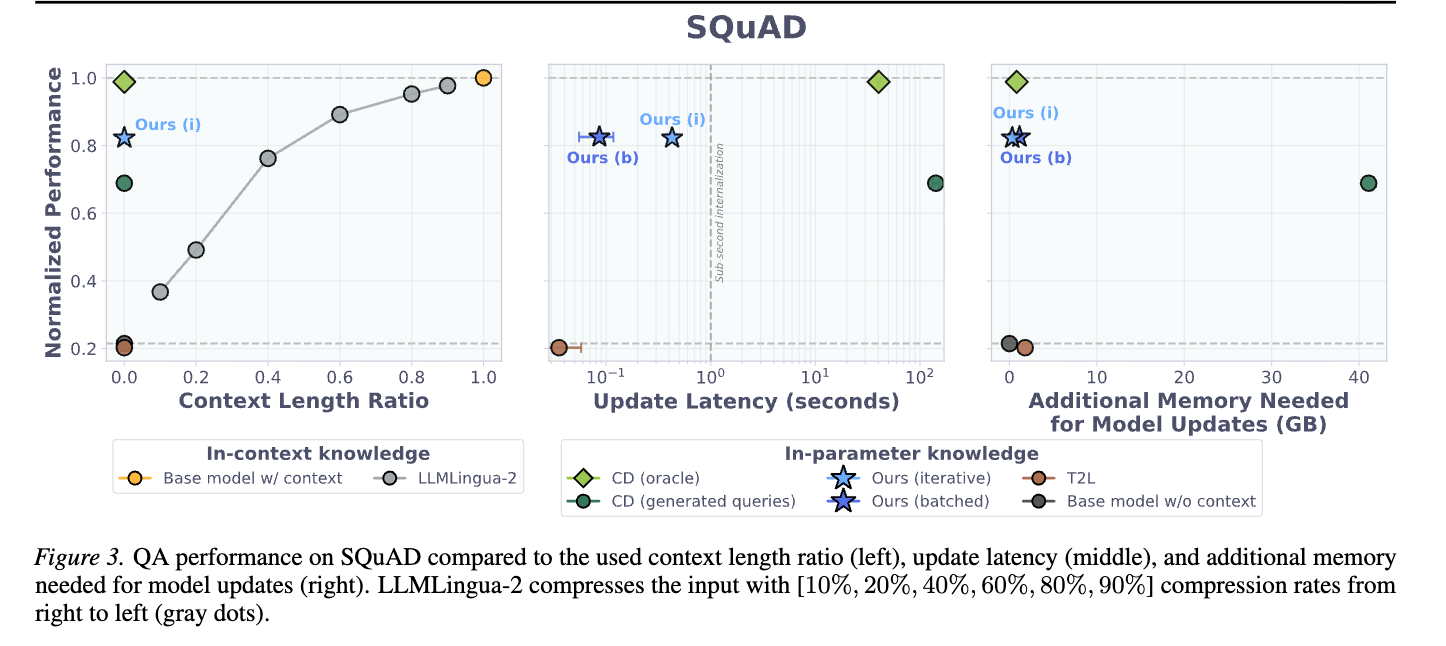
この図は3つのグラフで構成され、それぞれ異なる評価指標と正規化された性能(Normalized Performance)を比較している。
左のグラフ:正規化された性能 vs. 文脈の長さの比率
横軸はContext Length Ratio(文脈の長さの比率)を示す。これはLLMLingua-2などのプロンプト圧縮手法で、元の文脈をどれだけ圧縮したかを表す(比率が低いほど圧縮率が高い)。D2Lなどの内部化手法は推論時に文脈を消費しないため、この比率は0.0となる。
縦軸はNormalized Performance(正規化された性能)で、Base model w/ context(文脈ありのベースモデル)の性能を1.0とした場合の相対的な性能を示す。
主な結果:
- Base model w/ context(オレンジ色の丸):推論時に文脈を直接利用するため、最高の性能(1.0)を示す
- LLMLingua-2(灰色の丸):文脈を圧縮するにつれて性能が低下
- Ours (i)(青い星、D2Lのイテレーションモード):文脈を必要としないにもかかわらず、Base model w/ contextに近い高い性能(約0.82)を達成
- CD (oracle)(緑の菱形):理想的な文脈蒸留の性能(約0.98)で、最も高い内部化性能を示す
- CD (generated queries)(緑の丸):生成されたクエリを用いた文脈蒸留の性能で、Ours (i)よりも低い(約0.7)
- T2L(茶色の丸)とBase model w/o context(黒い丸):性能が低い
中央のグラフ:正規化された性能 vs. 更新レイテンシ(秒)
横軸はUpdate Latency (seconds)(モデル更新にかかる時間)を対数スケールで示す。縦軸は左のグラフと同様にNormalized Performanceである。
垂直の破線はSub-second internalization(1秒未満での内部化)の目安を示し、D2Lの目標達成を示唆している。
主な結果:
- CD (oracle)とCD (generated queries):高い性能(または中程度の性能)を示すが、更新に数十秒から百秒以上かかる。これは従来の文脈蒸留が計算コストの高いプロセスであることを示す
- Ours (i)とOurs (b)(D2Lのバッチモード):性能はCD (oracle)よりやや低いが、更新時間は0.1秒から1秒未満と非常に高速で、「Sub-second internalization」を達成。D2Lがリアルタイムまたはインタラクティブなアプリケーションで大きな利点を持つことを示す
右のグラフ:正規化された性能 vs. モデル更新に必要な追加メモリ(GB)
横軸はAdditional Memory Needed for Model Updates (GB)(モデル更新に必要な追加メモリ量)を示す。縦軸は同様にNormalized Performanceである。
主な結果:
- CD (generated queries):モデル更新に40GB以上の追加メモリが必要
- CD (oracle):約8GBの追加メモリを使用
- Ours (i)とOurs (b):性能を維持しつつ、追加メモリ消費が大幅に少ない。Ours (i)は2GB未満、Ours (b)は約10GBと、CD (generated queries)よりはるかに効率的。D2Lがリソース制約のある環境でも実用的であることを示す
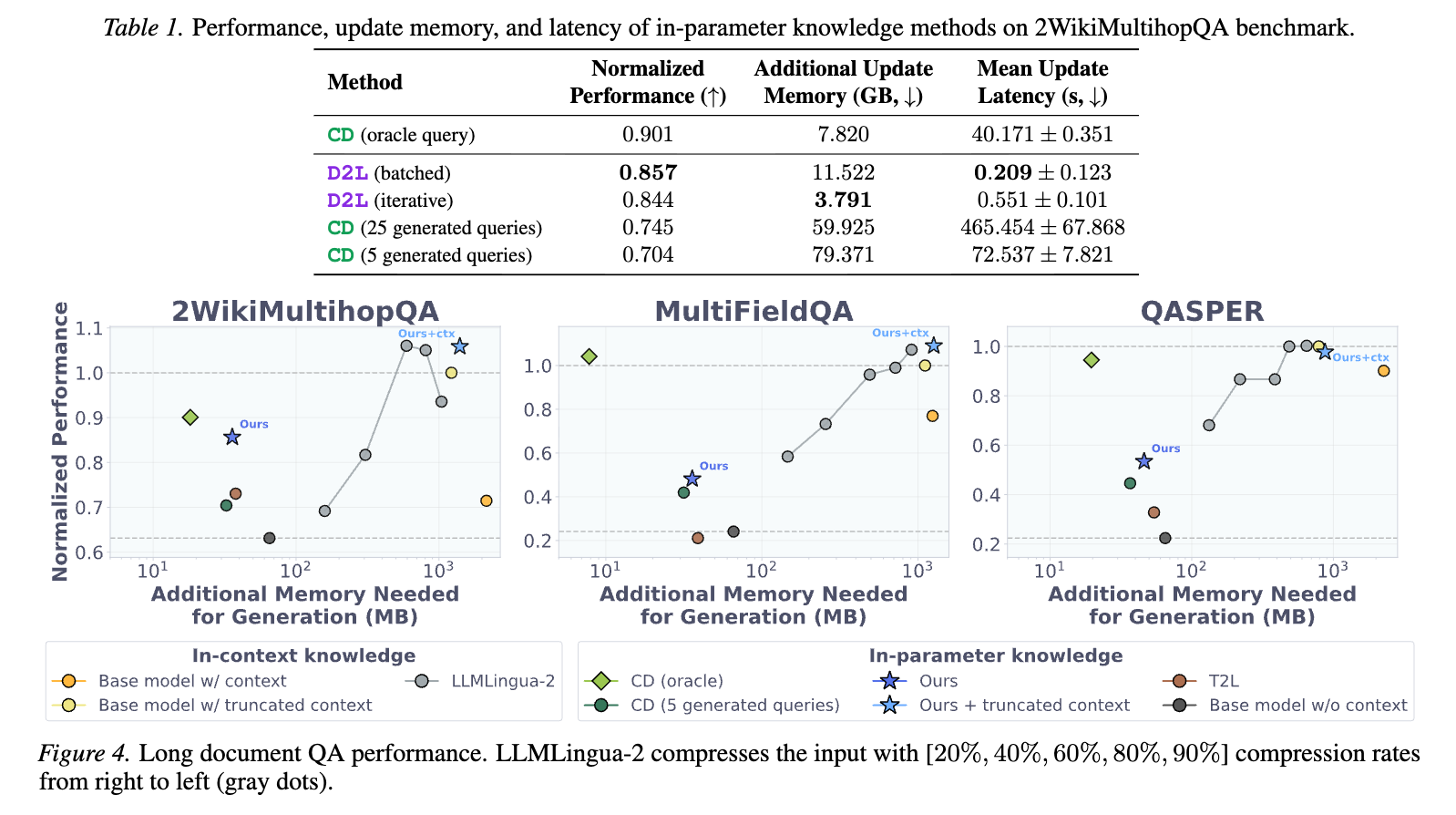
上部のテーブルは、各手法の性能、更新時の追加メモリ消費、および更新にかかる平均レイテンシを示している。
主な観察:
D2Lの性能と効率:
D2L (青い星)は、推論時の追加メモリが非常に少ない(100MB未満)にもかかわらず、CD (5 generated queries)やT2Lといった他のパラメータ内知識手法よりも高い性能を示す。
Base model w/ contextが最も高い性能を示すが、推論時のメモリ消費も最も大きい(約1GB)。D2Lは、このメモリ消費を大幅に削減しつつ、比較的近い性能を達成している。
長文コンテキストへのゼロショット汎化:
D2Lは、トレーニングで見たことのない長いコンテキスト(最大32Kトークン)に対しても高い性能を発揮し、ゼロショットでの汎化能力を示している。
Ours + truncated contextの興味深い挙動:
2WikiMultihopQAとMultiFieldQAのデータセットでは、D2Lで内部化されたモデルに切り詰められたコンテキストが与えられた場合(水色の星)、その性能はBase model w/ contextやCD (oracle)と同等か、QASPERにおいてはそれらをわずかに上回ることもある。
これは、LLMが長いコンテキストで直面する「lost-in-the-middle」問題や注意ノイズによって情報が失われる場合に、D2Lによって内部化された知識がLLMの性能を補強し、堅牢性を高める可能性を示唆している。LLMが外部コンテキストから情報を十分に引き出せない際、内部化された知識にフォールバックすることで、より正確な応答を生成できると考えられる。
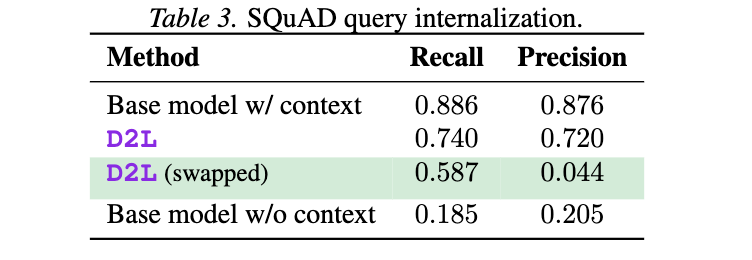
この表は、SQuADデータセットにおけるクエリの内在化能力を評価した実験結果を示している。ここでは、Doc-to-LoRA(D2L)が通常のコンテキスト(文書)ではなく、クエリ(質問)をモデルのパラメーターに内在化させる「極端な汎化テスト」を行った場合のパフォーマンスを評価している。評価指標はRecallとPrecisionである。各行の詳細は以下の通り。
Base model w/ context:
ベースモデルがコンテキスト(関連文書)とクエリの両方に直接アクセスできる場合の性能を示す。Recall: 0.886、Precision: 0.876と最も高い性能を発揮している。これは、モデルが質問に答えるために必要な情報に全てアクセスできるため、性能の上限に近い値と見なせる。
D2L:
通常のD2Lの設定、つまり文書をモデルのパラメーターに内在化させ、クエリのみを与えられた場合の性能を示す。Recall: 0.740、Precision: 0.720と、コンテキスト付きベースモデルには及ばないものの、文書情報を効率的に内在化できている。
D2L (swapped):
この行が今回の実験の主な焦点である。D2Lが文書ではなくクエリを内在化するように学習された場合の性能を示している。評価時には、モデルは文書に直接アクセスできるが、クエリにはアクセスできない状態である。Recall: 0.587と、コンテキスト付きベースモデルや通常のD2Lに比べて低いものの、何らかの関連情報を引き出せていることが示唆される。一方、Precision: 0.044と極めて低い値を示している。これは、モデルが正しい回答を生成する能力に乏しいことを意味する。論文では、クエリを内在化したモデルは時折正しい答えを生成するものの、その出力が「非常に冗長」であるため、Precisionが急激に低下すると説明されている。この結果は、D2Lが本来の目的(文書知識の内在化)から外れた「極端な汎化テスト」でも一定のRecallを示し、そのポテンシャルを示している。
Base model w/o context:
ベースモデルがコンテキスト(関連文書)もクエリも与えられない場合の性能を示す。Recall: 0.185、Precision: 0.205と性能が非常に低い。これは、モデルが質問に答えるための情報を持たないため、ほとんど推測に頼っている状態を表しており、性能の下限と見なせる。
結論: D2Lは文書知識の内在化において高い性能を発揮するが、クエリの内在化という「極端な汎化テスト」においては、特に精密性において大きな課題を抱えることが明らかになった。しかし、それでもコンテキストなしのベースモデルよりはRecallが高く、D2Lが事実情報以外の様々な種類の情報も内在化できる可能性を示唆している。
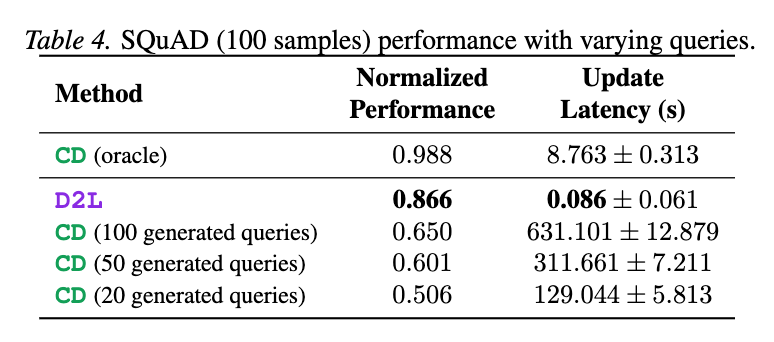
この図は、コンテキスト情報を大規模言語モデル(LLM)に内部化する各手法の性能と処理時間を比較したものである。
Method(手法): コンテキスト内部化に使われた方法を示す。
- CD (oracle): Context Distillation(CD)の理想的なケースで、特定のクエリに対して直接最適化を行った場合の理論上の性能上限を示す。実際のシステムでは実現が難しい。
- D2L: 本論文で提案されているDoc-to-LoRA手法。ハイパーネットワークを使ってコンテキストをLoRAアダプターに変換し、LLMに即座に内部化させる。
- CD (X generated queries): 実際のCD手法で、X個の生成クエリを使って内部化を行う。クエリ数が多いほど学習信号が増え、性能が向上する可能性がある。
Normalized Performance(正規化された性能): 内部化された知識を使って質問応答タスクを解くモデルの性能を正規化した値。値が高いほど性能が良い。CD (oracle) の性能が基準(0.988)となっており、他の手法がどれだけそれに近いかを示している。
Update Latency (s)(更新遅延(秒)): コンテキスト情報をLLMに内部化するのにかかる時間(秒)。値が小さいほど内部化が速い。
分析:
性能:
CD (oracle)が最高の性能(0.988)を達成しているが、これは理想的なケースであり、実用的な比較対象とはならない。
D2Lはその次に高い性能(0.866)を達成しており、CD (oracle) にかなり近い値である。
従来のCD手法(生成クエリを使用)は、クエリ数を増やせば性能は向上する(20クエリで0.506、100クエリで0.650)が、D2Lの性能には及ばない。これは、D2Lがハイパーネットワークを介して「多くのクエリにわたる蒸留の効果」を償却しているため、少ないクエリ数で訓練された従来のCDよりも、多様なクエリに対して堅牢な内部化を学習しているからだと考えられる。
更新遅延:
D2Lは極めて低い更新遅延(0.086秒)を達成している。これは、コンテキストを読み込んだ後、ほぼ瞬時にLLMを更新できることを意味する。
CD (oracle) は8.763秒かかる。
従来のCD手法は、クエリ数が増えるほど遅延が大幅に増加し、100クエリでは631.101秒(約10分)もかかる。これはユーザー体験の観点から現実的ではない。
結論:
D2Lは、従来のCD手法(特に実用的なクエリ数に制限された場合)と比較して、はるかに高速なコンテキスト内部化を実現しつつ、高い性能を維持できる。これは、リアルタイムで変化する情報やユーザーの好みに合わせてLLMを迅速に適応させる必要がある場面で、D2Lが非常に実用的であることを示している。
Relates Work
このセクションでは、Doc-to-LoRA (D2L) が既存の関連研究、特にハイパーネットワークやコンテキスト蒸留 (CD) とどのように異なり、それらをどう基盤としているかを説明する。
ハイパーネットワークの活用:
ハイパーネットワークとは、別のネットワークの重みを生成するネットワークである(Hypernetworks)。タスク適応を償却するメタ学習器として長年利用されてきた。
LLMでは、ハイパーネットワークはタスク固有のパラメータを動的に生成し、オンザフライでの適応を可能にする (Ivison & Peters, 2022; Ivison et al., 2023; Phang et al., 2023; Lv et al., 2024)。
D2Lもこの原理を採用している。ハイパーネットワークがコンテキスト情報から直接LoRAパラメータを生成することで、従来のCDに伴うオーバーヘッドを回避する。
コンテキスト蒸留 (CD) との関連:
CDは、インコンテキストプロンプトによって誘発される振る舞いをモデルのパラメータに内部化する自己蒸留手法である。
D2Lは、このCDプロセスをメタ学習によって近似する。高コストなクエリ生成や逆伝播のプロセスをメタトレーニング段階に償却することで、単一の順伝播で即座かつ低コストで知識を内部化できる。
先行研究には、CDを目的としてハイパーネットワークを訓練するMEND (Li et al., 2024)、タスク命令を圧縮するGisting (Mu et al., 2024)、prefix-tuningに基づくCartridges (Eyuboglu et al., 2025) などがある。
D2Lの独自性: D2Lは、これらの先行研究とは異なり、コンテキストとして提示される任意の情報に適用できる汎用的なCDプロセスを捉えることを目指している。時間的・メモリ的に効率的である点も特徴だ。
Generative Adapter (GA) との比較:
GA (Chen et al., 2025) は、教師データトークンに対する次トークン予測損失を用いてハイパーネットワークを最適化する。事前学習コーパスで訓練された後、SFTデータセットでファインチューニングされる。
D2Lの独自性: D2LはCD目的を用いてハイパーネットワークをメタ訓練する。主に生成されたクエリと自己応答を使用し、コンテキスト固有のLoRAアダプタを出力する。
実験結果は、頑健な汎化のためにCD目的を用いることが重要であることを示している。GAはSFT損失による訓練のため高いF1スコアを達成する可能性があるが、D2Lはより高いリコール(事実に即した回答の網羅性)を示す。これは、GAがより短い応答を生成するものの、事実の正確性が低い可能性があることを示唆している。
D2Lが生成クエリと自己応答を使用することで、ファインチューニングデータセットが利用できないドメインへの拡張が可能となる。
プロンプト圧縮との比較:
プロンプト圧縮の先行研究 (Mu et al., 2024; Pan et al., 2024; Chevalier et al., 2023; Zhang et al., 2025a) は、トークン空間で動作し、トークン数を削減する。
D2Lは、重みデルタを予測するハイパーネットワークを介してパラメータ空間で動作する。永続的で再利用可能な適応を可能にする点で異なる。
[pon] 毎回投げる長いコンテキストどうするの問題の一つの解かも。ただメタトレーニングのパワーはいる(gemma-2-2b-itの場合でさえ8基のH200 GPUで約5日間、あとデータセット作成)。我々の実践ではまだここにコストを投下するほどは困ってないが研究として面白い。