
2026-03-10 機械学習勉強会
今週のTOPIC[paper] Perch 2.0 transfers 'whale' to underwater tasks[blog] Claude Code が RAG を捨てた理由 -「Agentic Search」という選択肢[blog] Quantization-Aware Training in TorchAO (II)[paper]DeepRead: Document Structure-Aware Reasoning to Enhance
Agentic Search[blog] Improving Deep Agents with Harness EngineeringメインTOPICGLM-5: from Vibe Coding to Agentic Engineering概要背景と動機既存手法の課題GLM-5の解決策モデルアーキテクチャ1. DSA(DeepSeek Sparse Attention)2. MLA(Multi-Latent Attention)3. Muon Split4. MTP(Multi-Token Prediction)学習パイプライン事前学習データ(総28.5Tトークン)中間学習(Mid-Training)事後学習(Post-Training)5段階Step 1: Supervised Fine-Tuning(SFT)Step 2: Reasoning RLStep 3: Agentic RLStep 4: General RLStep 5: On-Policy Cross-Stage Distillation実験結果主要ベンチマーク結果(GLM-5 vs 主要モデル)CC-Bench-V2結果考察と限界感想
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Yuya Matsumura
[paper] Perch 2.0 transfers 'whale' to underwater tasks
Google DeepMind / Research の論文。ドメイン跨いだ転移学習に興味があるので選んだ。
- Perch 2.0 という鳥類、哺乳類、両生類、昆虫を含む14,597種で事前学習された教師あり生物音響基盤モデルおよびPerch2.0を利用した生物音響分類手法の提案
- 課題感
- 海洋生物の音響データは収集コストが高いので、データがたくさんある鳥類などの陸上生物で学習した基盤モデルでなんとかしたいよね。
- Perch 2.0
- Xeno-Canto、iNaturalist、Tierstimmenarchiv、FSD50Kといったデータベースから収集された、150万件以上のラベル付き録音データを使用
- モデル構造は EfficientNet-B3
- ラベルを当てる分類タスク(教師あり学習 )+ 元データの予測による自己教師あり学習で学習
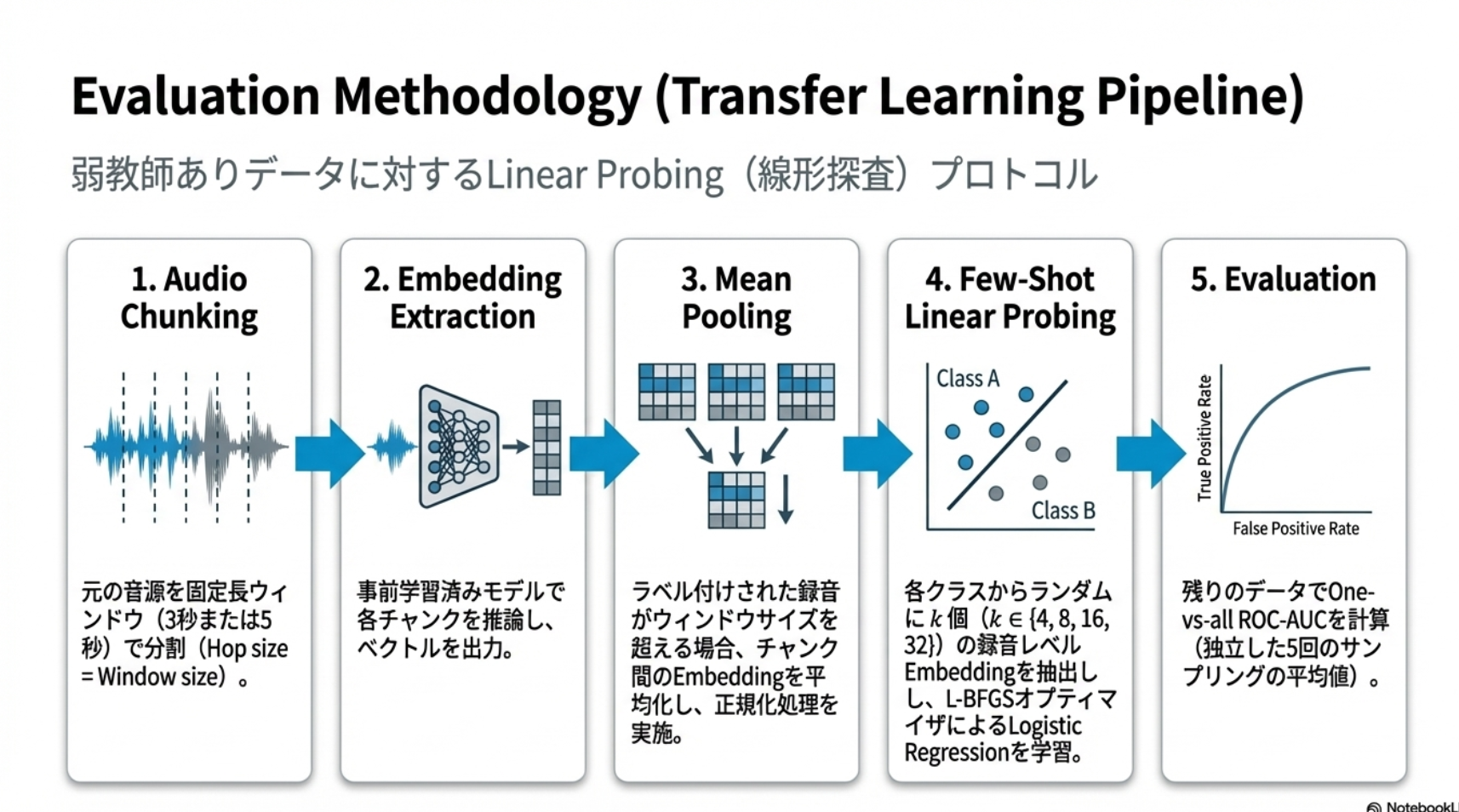
- 推論・評価
- Perch 2.0 に音声データを入力した得られた(windowごとに分割、平均を取る) embedding を利用する。
- クラスごとにk個ずつサンプリングし、分類モデル(ロジスティック回帰)を学習する。
- サンプリングして学習に利用しなかったサンプルで評価する。
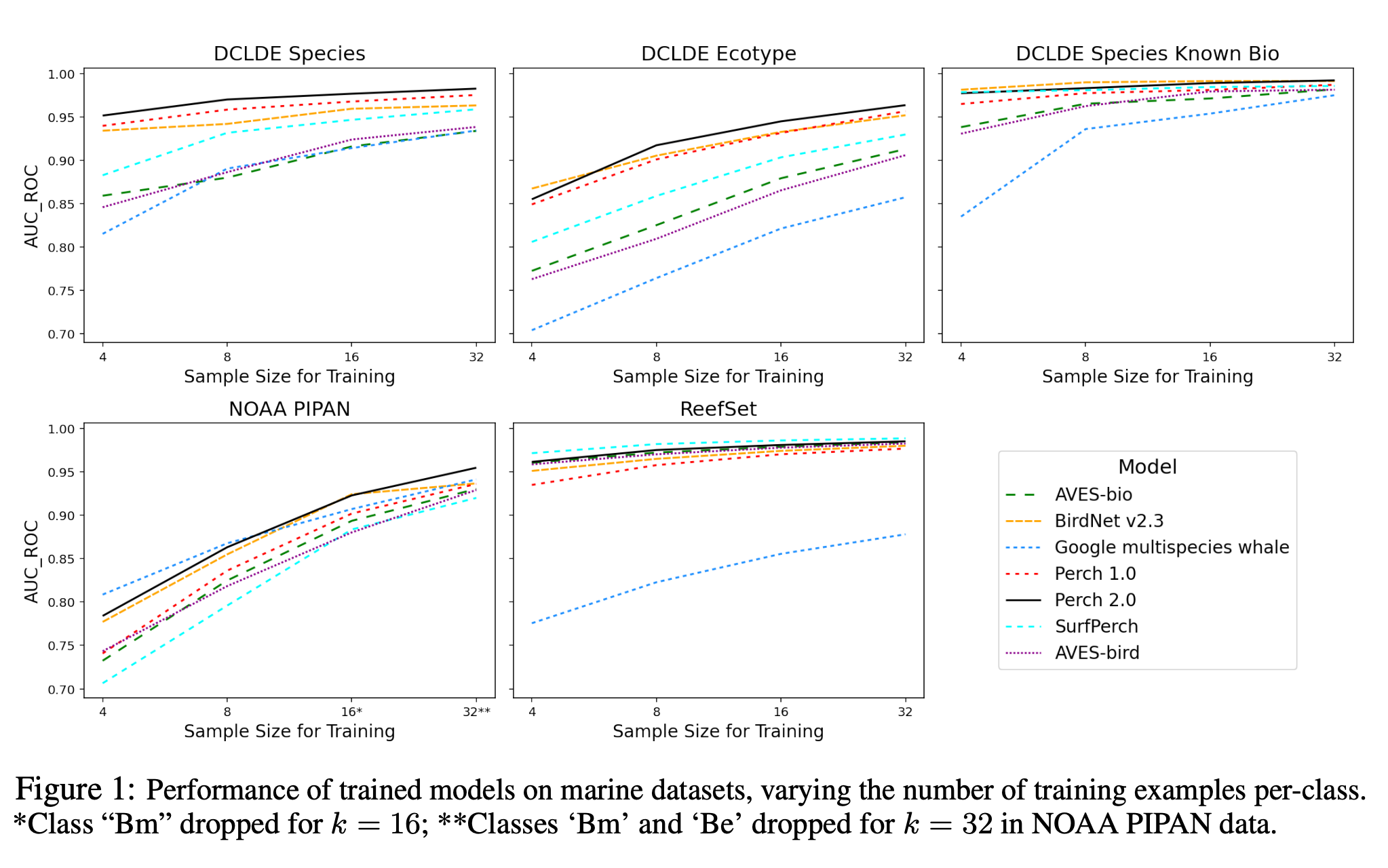
- 評価データセット(こんなんあるんですね、面白い。)

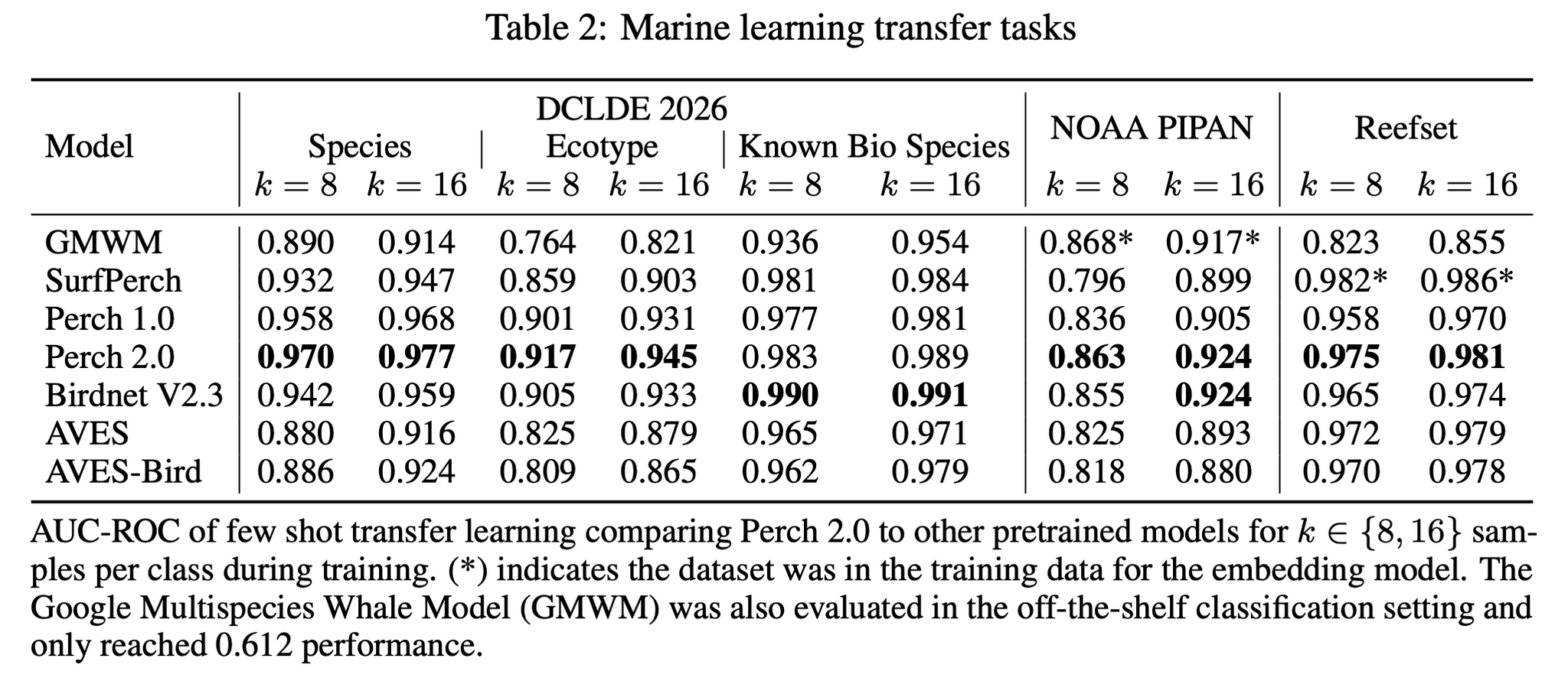
- 評価結果
- 黒実線(提案手法)が全体的に強い。特に、海洋生物系のデータセットで強いのが素晴らしい。
- くじら特化の Google multispecies whale model(GMWM) とくじらデータセットの NAAA PIPAN の組み合わせや、サンゴ + 鳥類データで学習した SurfPerch とサンゴデータセットのReefSetの組み合わせなどでいい勝負(しかもこれら特化モデルはリークしている)
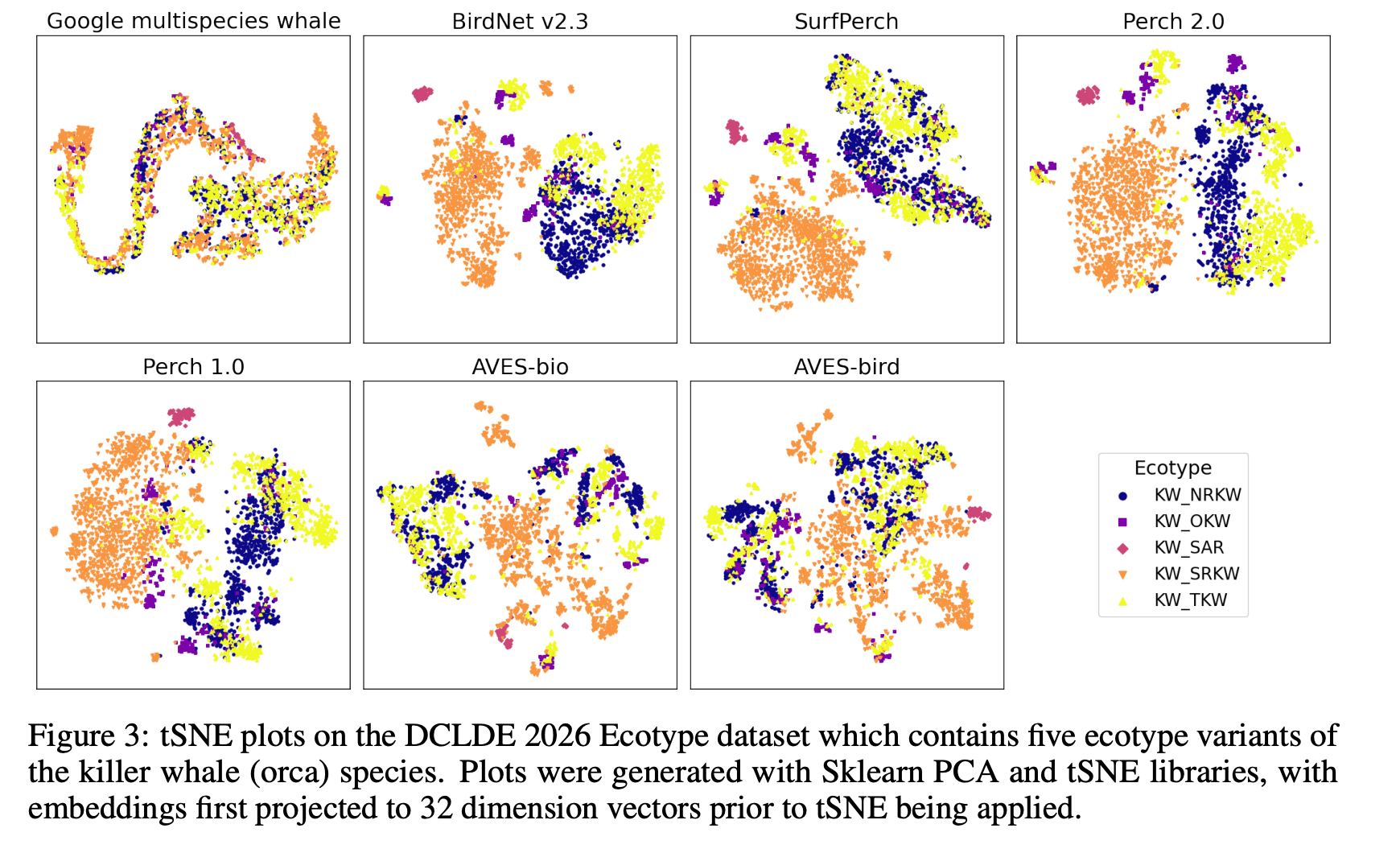
- みんだ大好き tSNE で embedding をマッピングしたら、なんかうまく分類できている気がする。
- 考察:なんで少数サンプルクラスもうまいこと分類できる?
- スケーリング即の話。
- 鳥類の音響分類タスクが十分に難しいため、それができるならくじらとかも当てれるようになるのでは?
- 生物学的な観点として、鳥類も海洋哺乳類は全く異なる進化をしてきているが、発声の物理的メカニズムには共通する部分があるのでは?
@Yosuke Yoshida
[blog] Claude Code が RAG を捨てた理由 -「Agentic Search」という選択肢
1. 概要・背景
- Claude Codeの中心的な開発者であるBoris Cherny氏が、インタビューで「コード検索においてRAG(検索拡張生成)の採用をやめ、Agentic Searchを選んだ」と語った
2. なぜRAGを捨てたのか?(実運用での課題)
Claude Codeチームも最初はRAG(ベクトルデータベース)を試しましたが、以下の致命的な問題に直面しました。
- リアルタイム性の欠如(同期ずれ): 開発中のコードは絶えず変化するため、ローカルでコードを書いてもインデックスへの反映が遅れ、最新情報が検索できない。
- 権限管理の壁: 誰がどのインデックス(他人のデータなど)にアクセスできるかの制御が非常に困難だった。
3. Agentic Searchとは何か?なぜRAGの代わりになるのか?
- Agentic Searchの正体は、AIエージェント自身にとを使わせるという極めてシンプルな手法です。
- 従来のRAGは「人間は適切な検索キーワードを思いつけない」という前提のもと、システム側でベクトル化して「意味検索」をサポートしていました。
- しかし、現在のLLMエージェントは賢いため、自ら曖昧な意図を具体的なキーワード(例:)に変換し、ディレクトリ構造を読み解きながら、情報が見つかるまで検索を何度も試行錯誤(反復)できます。
- つまり、検索システム(パイプライン)を賢くするのではなく、「エージェント自身の知性」に検索を委ねたのが最大の違いです。
4. Agentic Searchを機能させる「3つの前提条件」
- 人間の手による構造化: ファイルの命名規則やディレクトリ構成を人間が整理しておくこと。
- 検索ガイドの整備: プロジェクト内にのようなファイルを用意し、エージェント向けに構造や規約を自然言語で案内すること。
- エージェントの検索能力: LLMがツールを使いこなす十分な推論能力を持つこと。
5. 結論と学び
- 人間向けの検索システムでは依然としてRAGは有効
- しかし、AIエージェントにコードや文書を探させる場合は、複雑なRAGシステムを構築・維持するよりも、人間がドキュメントを整理してガイドを書き、あとはAgentと単純な検索ツール(grep等)に任せる分業スタイルの方が理にかなっています。
@Takumi Iida (frkake)
[blog] Quantization-Aware Training in TorchAO (II)
TorchAOがUnslothやAxolotlに組み込まれてLLMのQATがやりやすくなったよ。
PARQという高度なQATも取り入れたよ。
QATの仕組み
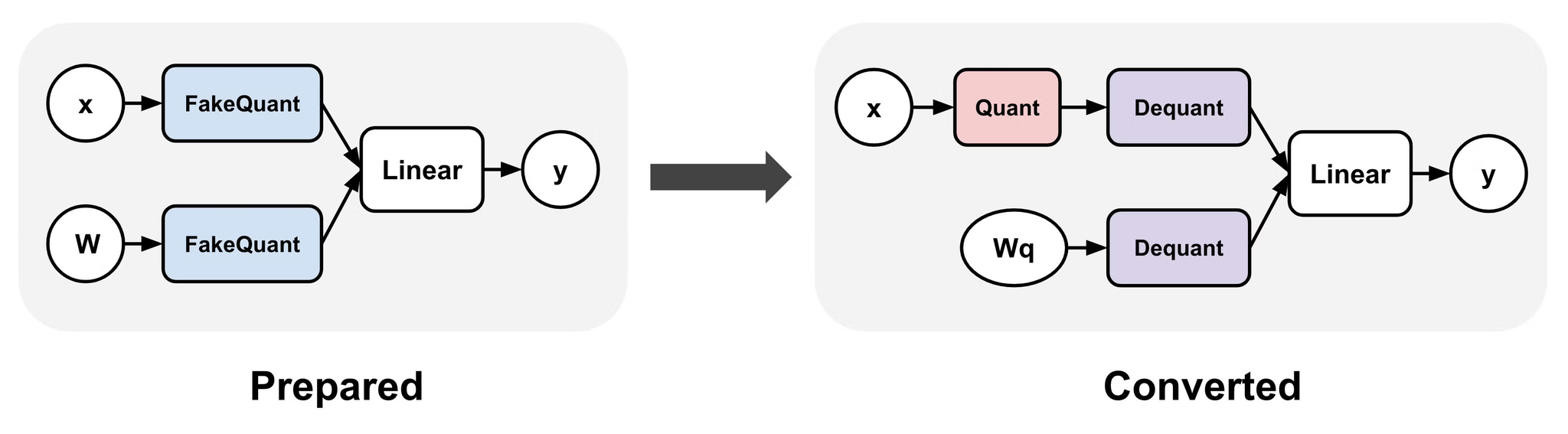
fake quantレイヤーを入れることで、量子化されたあとのアクティベーション(中間出力)を模倣できるようになる。
それにより、推論時にアクティベーションを量子化しても精度劣化を低減できる。
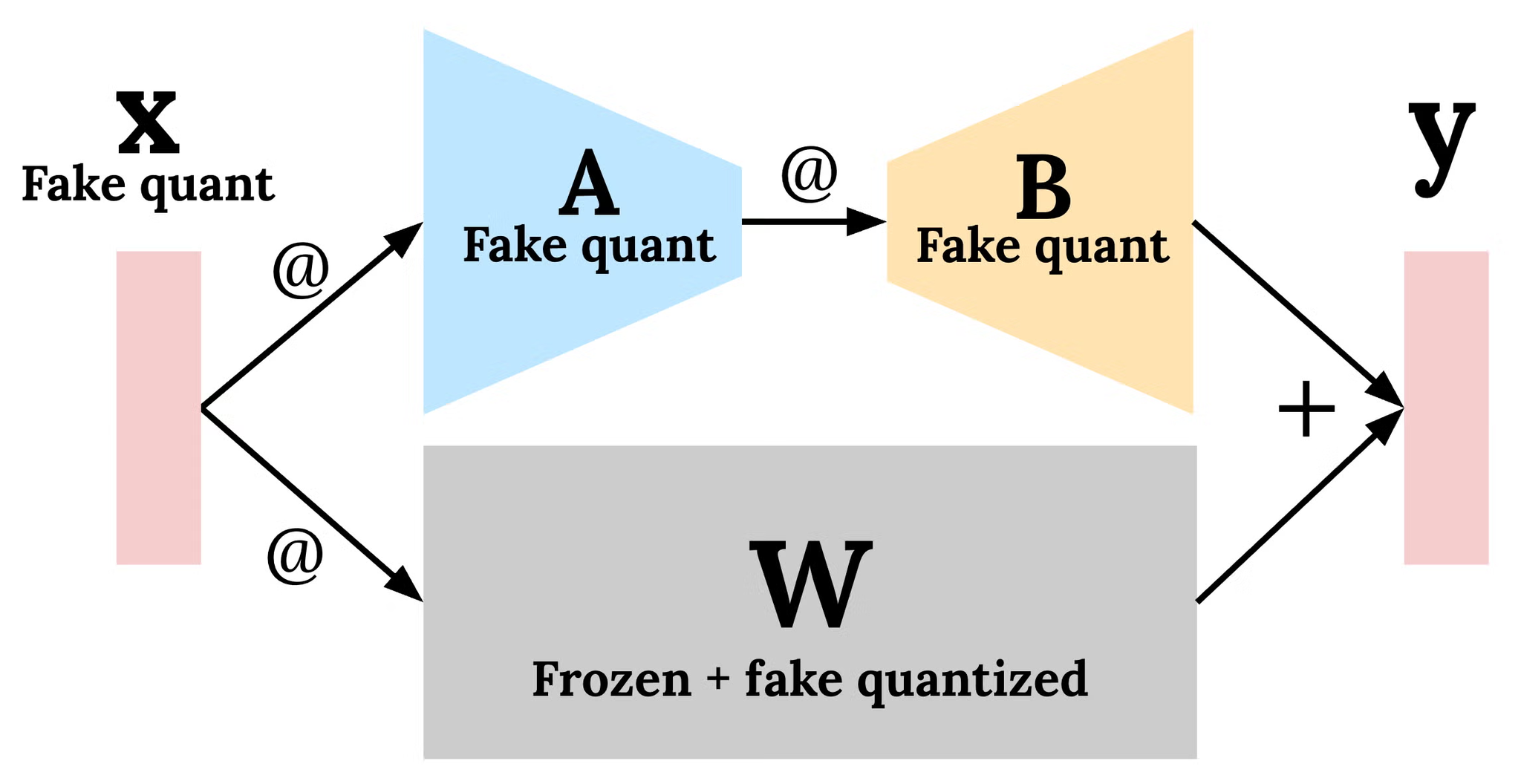
LLMの学習をするときはLoRA部分にQAT取り込むことで、学習の高速化+メモリ削減ができる。
生PyTorchでやる場合は次のコードで実験できる。簡単!
Unslothに統合されており、
(QAT+LoRAの学習)qat_schemeで指定してあげる
学習し終わったら変換&保存
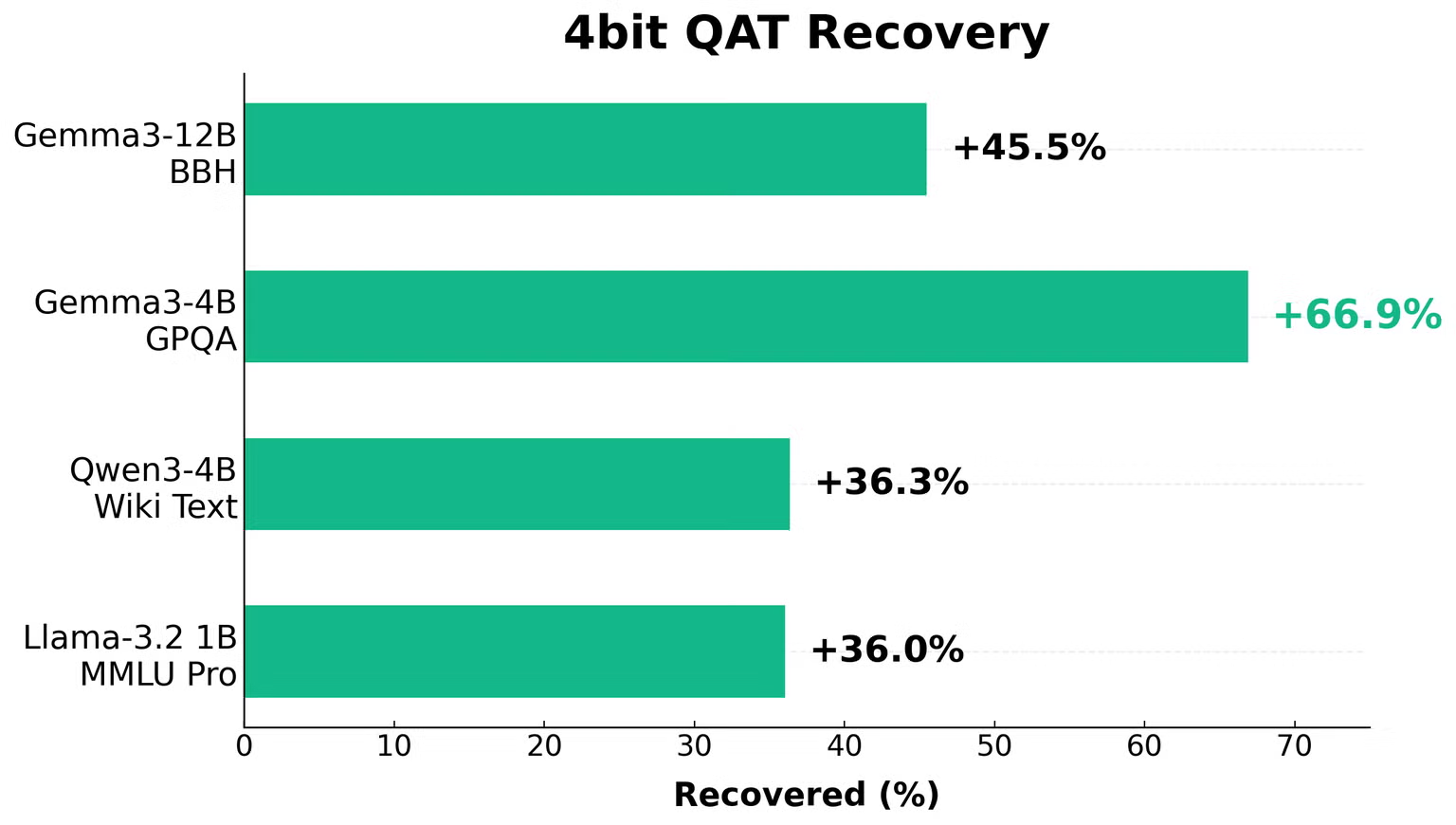
Gemma3-4Bで性能劣化少なかったよ(INT4 QAT + LoRA)
(さわりだけ)PARQは量子化対象のモジュールを入れ替えなくていいっぽく、prepare以外で実装を綺麗に保てそう
| stage | PARQ | torchao |
|---|---|---|
| prepare | ||
| convert |
@Hiromu Nakamura (pon)
[paper]DeepRead: Document Structure-Aware Reasoning to Enhance
Agentic Search
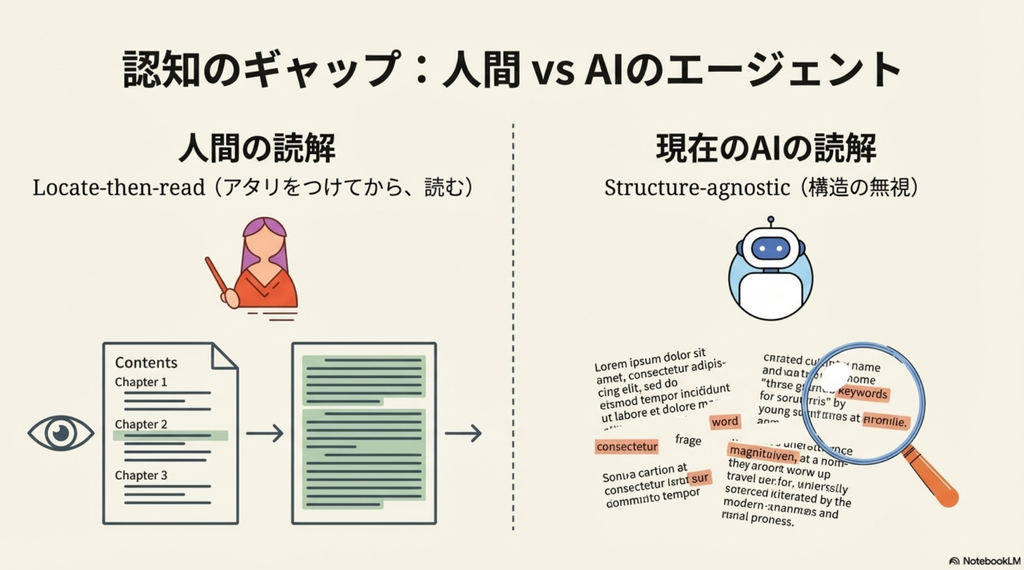
[pon]長文データの構造を利用するPageIndexが面白かったので、同じ方向性のやつを読んでみた
DeepReadは、大規模言語モデル(LLM)のエージェント的検索能力を強化するための、構造認識型文書推論エージェントである。既存のエージェント的検索フレームワークが、長文文書を「構造化されていないチャンクのフラットな集合」として扱い、人間が情報を理解する上で不可欠なネイティブな階層的組織や順次的な論理を無視しているという課題に対処するため、本研究は文書ネイティブの構造的先験知識を操作可能な推論能力へと変換することを提案する。
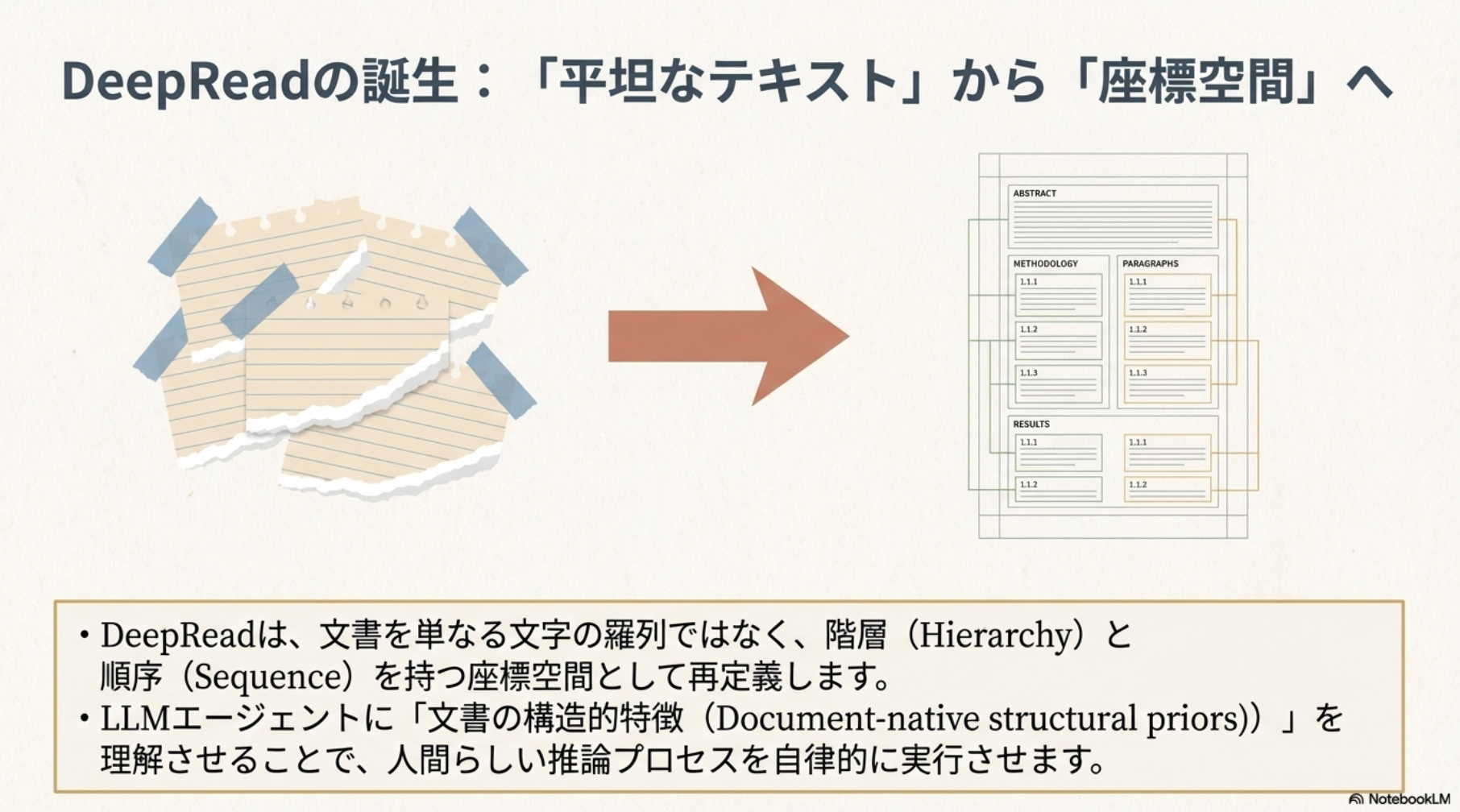
文書構造モデリングと協調的ツール利用
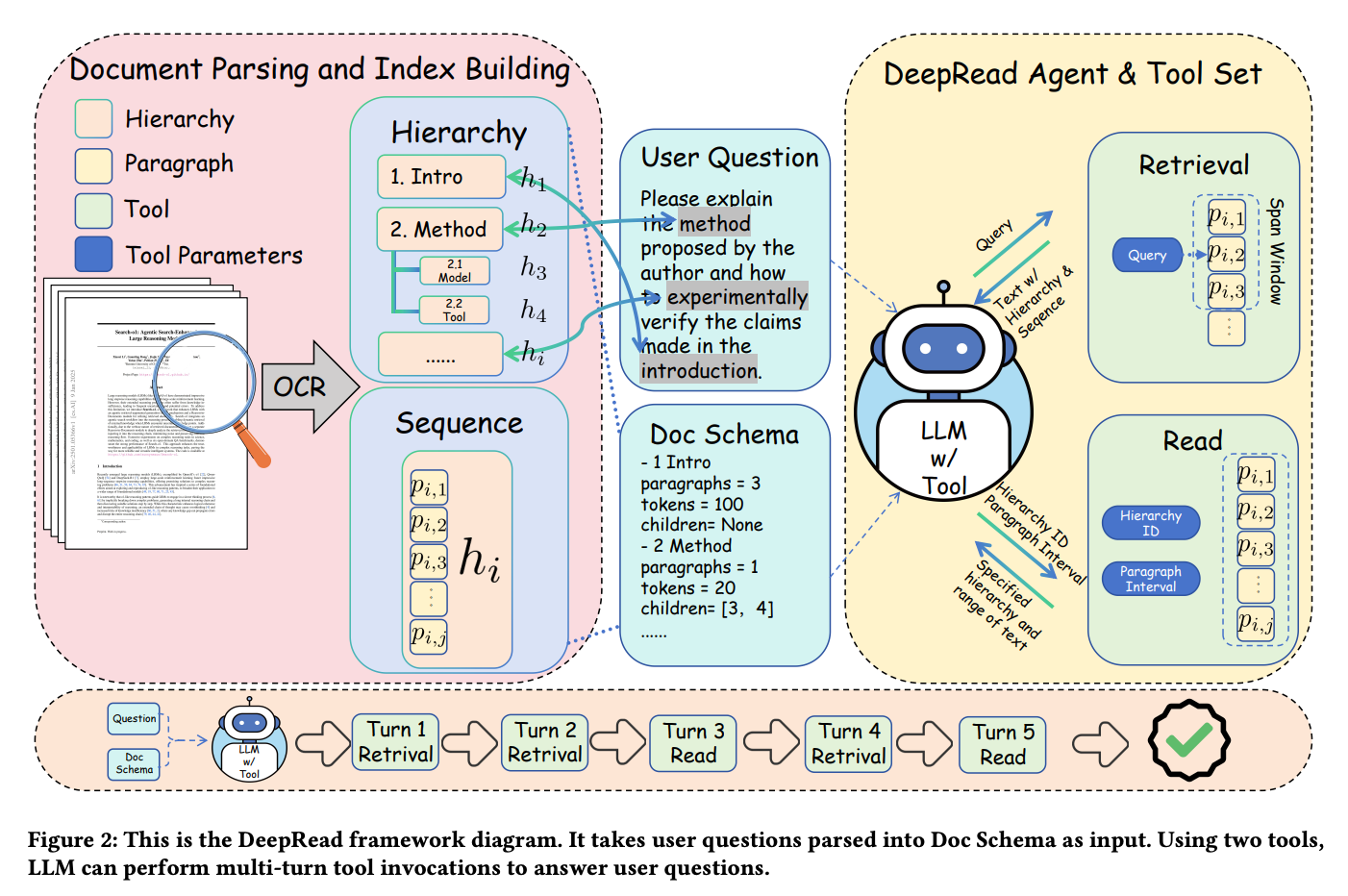
Document Parsing and Index Building (文書解析とインデックス構築)
- DeepReadが想定する現代のOCRは、文字だけでなく、文書の持つ「構造」を正確に抽出します。Sequence (連続性): 段落の並び順やテキストの流れを認識します。
- Hierarchy (階層性)
- 章、節、小見出しといった文書の階層構造。
- Doc Schema (文書スキーマ)
- OCRによって抽出された構造情報は、「Doc Schema」として整理されます。図の左中央にあるツリー構造は、文書の目次(Table of Contents: TOC)のメタデータを示しています。
- 例えば「1. Intro」「2. Method」「2.1 Model」「2.2 Tool」といった階層的な見出しがあり、それぞれの見出しには、その下にどれくらいの段落があるか(paragraphs=Num)、どれくらいのトークン数か(tokens=Num)、そして子ノード(サブセクション)があるか(children=[ID list])といった情報が付与されています。また、各段落には「Hierarchy ID」や「Paragraph Interval」といった具体的な「座標」が割り当てられます。
- これをプロンプトに入れる。これにより次が可能に
- グローバルなプランニングと初期探索の方向付け
- より絞ったクエリ生成が可能に
- 読解コストの見積もりとツール選択の最適化
- 効率的な局所的文脈の拡大
- 探索履歴の活用と無駄な重複回避
DeepRead Agent & Tool Set (DeepReadエージェントとツールセット)
- ツールを装備した大規模言語モデル
- 質問に対する回答を生成するために、自律的に思考し、適切なツールを選択して使用します。
- Tool (ツール)
- LLMは、人間のように賢く文書を読み解くために、2つの異なる種類のツールを使用します。
- Retrieve (検索):
- 入力: QueryText w/ Hierarchy & Sequence (LLMが生成した検索クエリ)
- 機能: 文書全体の中から、セマンティック(意味的)に最も関連性の高い「情報断片」(通常は段落)を素早く見つけ出し、そのテキストと「座標」を返します。
- Span Window: 図に示されているように、このツールは単一の関連段落だけでなく、その前後の段落(設定されたウィンドウサイズW=(w↑, w↓)の範囲)も一緒に取得します。これは、人間が関連する文を見つけた際に、その周辺の文脈も一緒に目を通す「スキャニング」の動作を模倣しています。
- ReadSection (セクション読み込み):入力
- 機能: 特定の文書の、特定のセクション内にある、指定された範囲の段落を連続的に、かつ正しい順序で読み込み、そのテキストと座標を返します
- 「context fragmentation (コンテキストの断片化)」を軽減する上で非常に重要なツールです。
- Tool Parameters (ツールパラメータ): LLMは、これらのツールを呼び出す際に、適切な引数(検索クエリ、読み込みたい範囲の座標など)を渡します。
処理フロー

このシーケンスは、LLMがどのように自律的にツールを使い、情報を収集していくかという**「思考の連鎖」を示しています。これがDeepReadの提唱する「locate-then-read」パターンです。
- Turn 1 (Retrival): まず、ユーザーの質問に対し、LLMは関連しそうな情報を広範囲に検索(Retrieve)しようとします。
- Turn 2 (Retrival): 最初の検索結果から、さらに別の検索クエリを生成し、情報を絞り込んだり、別の側面を探したりするために、再度検索(Retrieve)を行います。
- Turn 3 (Read): 検索結果から、あるセクションに重要な情報がまとまっていると判断すると、LLMはRetrieveツールで得た座標を元に、そのセクションをじっくりと連続的に読み込む(ReadSection)ツールを呼び出します。これにより、文脈を損なわずにまとまった情報を取得します。
- Turn 4 (Retrival): 読み込み結果から、まだ情報が不足していると判断した場合、あるいは別の情報源が必要な場合、再度検索(Retrieve)に戻ります。
- Turn 5 (Read): 最終的な回答に必要な情報が特定のセクションにあると判断すれば、そのセクションを再度じっくりと読み込む(ReadSection)**ことで、回答を完成させます。
[pon]DeepReadはセマンティック検索 + 構造的連続読み込み(ハイブリッド型)。PageIndexは構造のみのナビゲーション(純粋な構造ベース、かつ「vectorless」)という感じ
実験
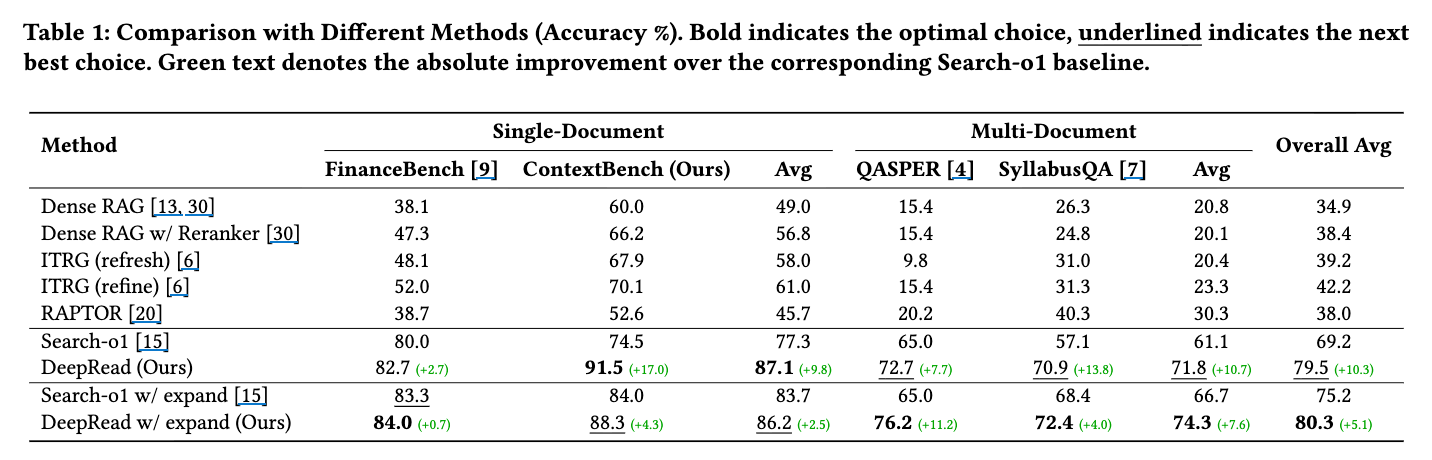
「expand」オプションは、検索でヒットした段落の周囲の段落も「受動的に」含める(コンテキストを広げる)機能。セマンティック検索のためのDense Retriever としては、Qwen3-embedding-8b を使用。Reranker としては、Qwen3-reranker-8b が使用。LLM-as-a-Judge としては、主にDeepSeek V3.2 を使用
DeepReadはSearch-o1を 10.3ポイント 上回った。
DeepReadの論文では、特にReadSectionツールの貢献が強調されている。
- 従来のSearch-o1は、文書を「平坦で構造のないチャンクの集合」として扱う。このため、情報を断片的にしか捉えられず、本来連続しているはずの文脈が途切れてしまう(「コンテキストの断片化」)問題があった。
- DeepReadのReadSectionツールは、Retrieveツールで特定した座標に基づいて、関連するセクション内の段落を連続的に、かつ正しい順序で読み込むことができる。これにより、人間が自然に行うような「文脈を理解しながら読む」ことが可能になり、情報の断片化が大幅に軽減され、特にContextBenchのような複雑な長文タスクで大きな性能向上に繋がった。
ただ、プロンプトにTOCを入れるのでtoken数は増える。
Appendix
プロンプトはこんな感じ
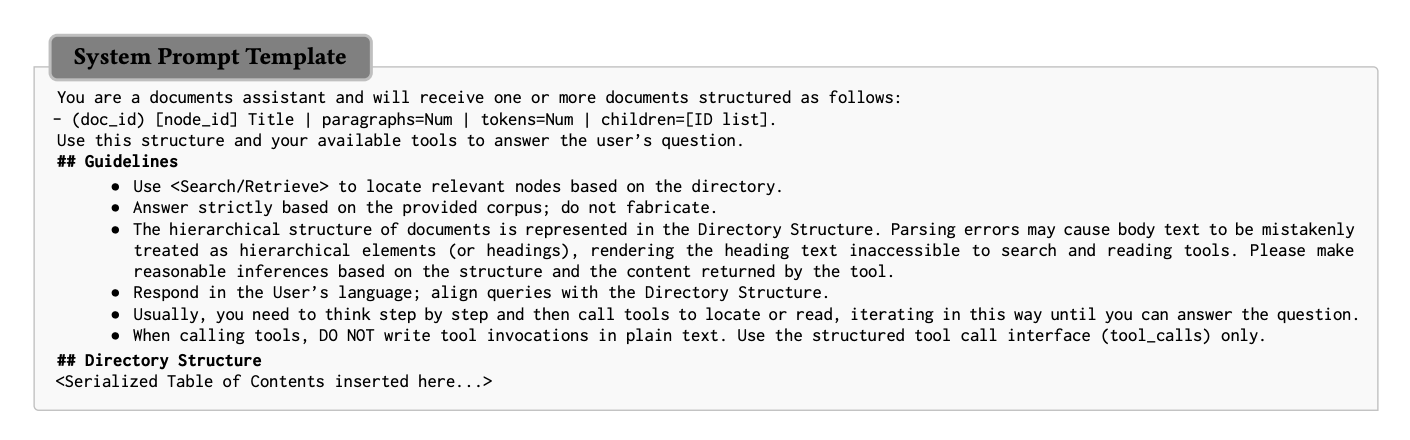
[pon]TOC全てぶちこむってマルチドキュメントの数が少ないからできることな気はしているが。。。QASPERで1,585本の論文データなので、これくらいなら耐えれるのか。。。
@Shuhei Nakano(nanay)
[blog] Improving Deep Agents with Harness Engineering
- タイトル: Improving Deep Agents with Harness Engineering
- 著者 / 組織: LangChain Team
- 公開日: 2026年2月17日
1. どんな記事?
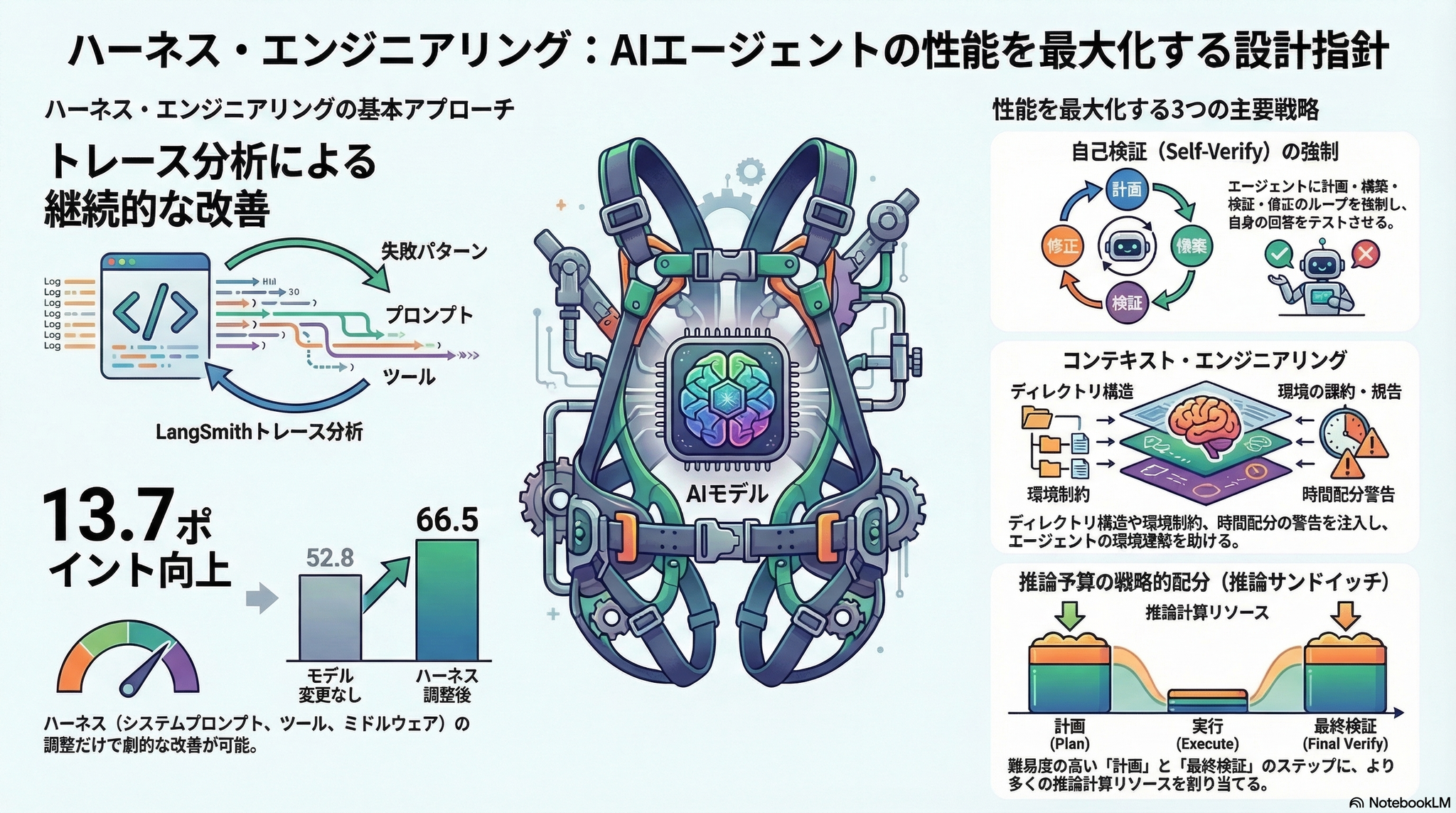
LangChainチームが、コーディングエージェントの基盤モデル(GPT-5.2-Codex)を一切変更せず、モデルの外側にある「ハーネス(Harness)」——システムプロンプト・ツール・ミドルウェア——の設計改善だけで、Terminal Bench 2.0 ベンチマークのスコアを 52.8% → 66.5%(+13.7pt)、ランキングを 30位 → 5位 に押し上げた実践記録。エージェントの性能はモデルだけでなく、その周辺設計で大きく変わることを定量的に示した。
2. 何が課題だったのか?
- エージェントが同じファイルを何度も編集し続ける「ドゥームループ(Doom Loop)」に陥り、トークンと時間を浪費する問題
- 推論トークンを常に最大で使うとタイムアウトが頻発し、逆にスコアが低下する(extra-high固定で 53.9% にとどまる)
- エージェントが実行環境(ディレクトリ構造・利用可能ツール)を自力で探索するコストが大きく、本質的な問題解決に集中できない
- タスク完了前の自己検証が不十分で、誤った回答をそのまま提出してしまう
- 失敗原因の分析が手作業に依存しており、改善サイクルが遅い
3. アーキテクチャ・技術的アプローチ
| コンポーネント | 役割 |
|---|---|
| GPT-5.2-Codex | 基盤LLM(4段階の推論モードを持つ) |
| Harbor | 実験オーケストレーション基盤 |
| Daytona サンドボックス | エージェント実行用の隔離環境 |
| LangSmith | 全エージェントアクションのトレース・観測プラットフォーム |
| Trace Analyzer Skill | トレースを取得→並列分析エージェントを生成→改善提案を統合する自動分析ツール |
ハーネスの3つの最適化軸:
- システムプロンプト — タスクの構造化、行動指針の注入
- ツール — エージェントが利用できる外部機能群
- ミドルウェア — モデルの入出力に介入する制御レイヤー
4. 設計上のこだわり・工夫
Build & Self-Verify Loop
- 「計画→実装→検証→修正」の4フェーズに構造化
- で、タスク完了前に必ず検証パスを通過させる設計
- テストを「正しさの担保」かつ「エージェントへのフィードバック信号」として活用
Environmental Context Injection
- がディレクトリ構造・利用可能ツールを事前マッピングしてエージェントに注入
- 「プログラム的テストで評価される」ことを明示的に伝達し、行動バイアスを調整
- 時間予算の警告を組み込み、期限内完了を促進
Loop Detection
- がファイルごとの編集回数をツールフックで追跡
- N回超過時にアプローチの再考を促すプロンプトを自動挿入
Reasoning Sandwich 戦略
- 計画・検証フェーズ → extra-high 推論 / 実装フェーズ → high 推論
- フルextra-highでは53.9%(タイムアウト多発)だが、このハイブリッド方式で 63.6〜66.5% を達成
- トークン効率と精度のトレードオフを、フェーズごとの推論予算配分で解決
トレース分析のブースティング的アプローチ
- 機械学習のブースティング(Boosting)に着想を得て、前回の失敗モードに集中して次の改善を行う反復サイクルを構築
5. 現時点の制約と今後の展望
制約
- ハーネスの最適設計はモデルアーキテクチャごとに異なるため、モデル変更時に再チューニングが必要
- ループ検出等のガードレールは現行モデルの制約に対する一時的な対策であり、モデル進化に伴い不要になる可能性
今後の展望
- マルチモデルハーネス — 大型モデルで計画、小型モデルで実装を分担するオーケストレーション
- RLM(Reinforcement Learning from Model outputs) — モデル出力からの強化学習による自律的改善
- メモリシステム — エージェントが過去の経験を蓄積し、継続的に自律改善するアーキテクチャ
6. Take Home Message
- モデルを変えなくてもハーネス設計で性能は大幅に変わる — 同一モデルで+13.7ptの改善は、プロンプトやツール設計への投資対効果が極めて高いことを示す
- エージェントに環境を自力探索させるな、事前に与えよ — コンテキスト注入により、エージェントは本質的な問題解決に集中できる
- トレース分析による反復改善が鍵 — 失敗モードを体系的に分析→対策する「ブースティング的サイクル」が継続的な性能向上を可能にする
- 推論予算はフェーズごとに最適配分せよ — 常に最大推論では逆効果。計画・検証に厚く、実装に薄く配分する「サンドイッチ戦略」が有効
7. 関連リソース
- Terminal Bench 2.0 — エージェントコーディングベンチマーク。ML・デバッグ・生物学分野の89タスクで構成。本記事の評価基盤。
- Deep Agents(LangChain OSS) — 本記事の成果物として公開されたPython/JavaScript実装。ハーネス設計の具体的なリファレンス。
- LangSmith — エージェントのトレース・観測・分析プラットフォーム。トレースベースの反復改善サイクルを実現する基盤ツール。
メインTOPIC
GLM-5: from Vibe Coding to Agentic Engineering
概要
GLM-5は前作GLM-4.5のARC(Agentic, Reasoning, Coding)統合MoEアーキテクチャを継承しつつ、モデルのスケールアップとそれに伴う訓練の計算コスト削減の工夫やRLインフラ変更による訓練効率化を実現
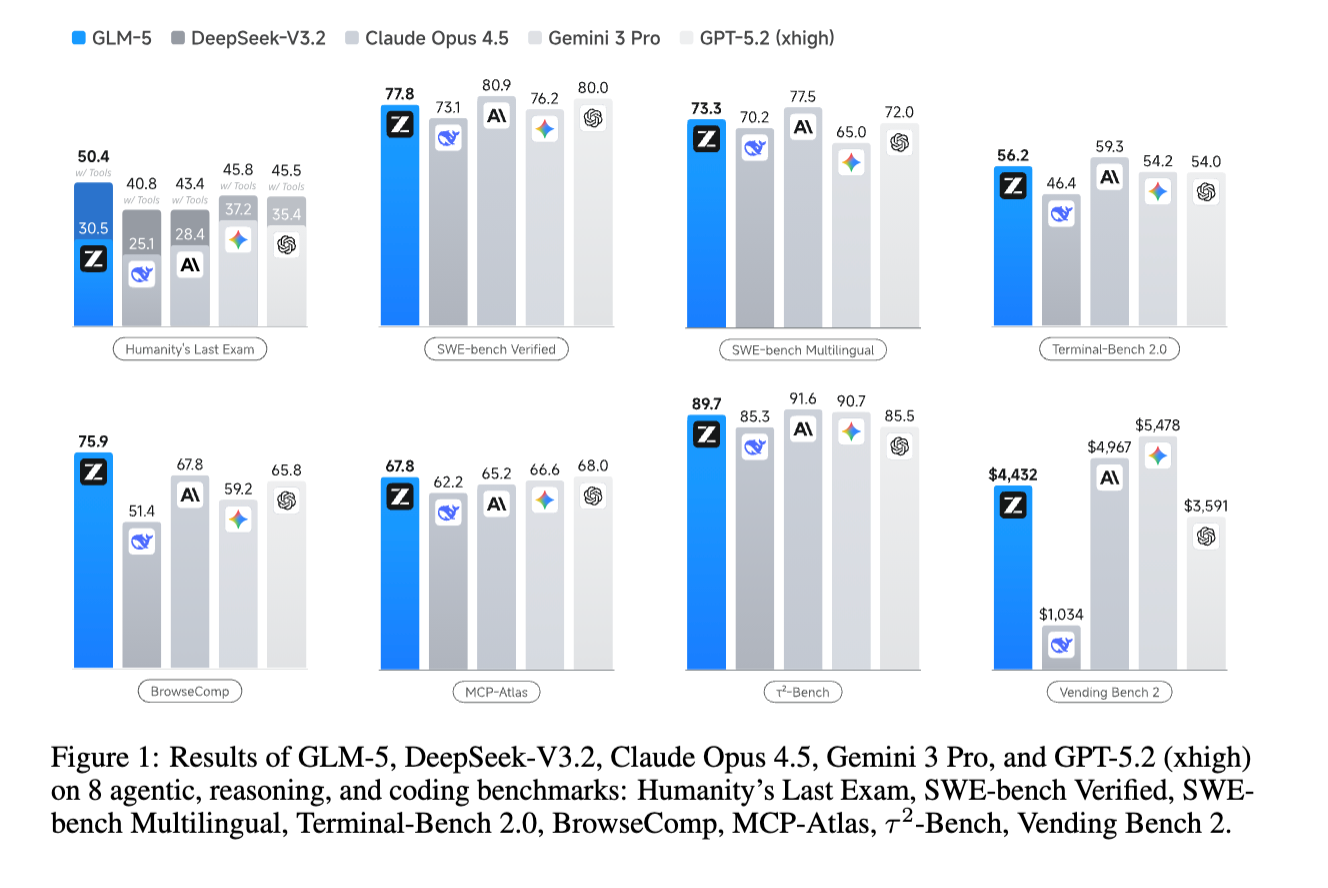
オープンウェイトモデルとして初めてArtificial Analysis Intelligence Index v4.0でスコア50を突破し、BrowseCompでオープン・クローズド全フロンティアモデル中1位を記録した
背景と動機
前世代のGLM-4.5は、ARC(Agentic, Reasoning, Coding)能力をMoEアーキテクチャに統合し、主要ベンチマークでSOTAを達成した。しかし、LLMが「受動的な知識リポジトリ」から「能動的な問題解決エージェント」へと進化する中で、いくつかのボトルネックが表面化した。
既存手法の課題
- アーキテクチャの限界: 従来の密なアテンション( )や既存のMoEアーキテクチャのままGLM-4.5(355B)からスケールアップすると、特に128Kなどの長文脈において計算量が非現実的なレベルに増大する。
- RL(強化学習)の非効率性: 従来の同期型RLでは、軌道生成(Rollout)と学習(Training)が結合しているため、長期間のタスク生成時に待機時間が発生し、GPU利用率が著しく低下する。
- 評価指標のギャップ: 静的なコード評価だけでは、リポジトリ探索や継続的な機能実装といった、実世界の開発プロセスの正確な評価ができない。
GLM-5の解決策
これらの課題に対し、GLM-5はアーキテクチャ・学習インフラ・評価の3方面から以下の解決策を導入した。
- アーキテクチャの刷新と推論コスト削減
- DSA(DeepSeek Sparse Attention)を採用し128K文脈での計算量を半減し、総パラメータ数744B(アクティブ40B)へのスケールアップを実現した
- さらに追加の効率化手法を導入し、推論コストを押し下げた
- 「MLA-256」によるデコード計算量の削減
- 「Muon Split」による最適化の安定化
- 「3層共有のMTP(Multi-token Prediction)」でコスト維持しつつ投機的デコーディングの承認率を向上
- 非同期RLインフラの構築
- 推論生成エンジンと学習エンジンを完全に分離した非同期RLインフラ(slimeフレームワーク)を構築
- 非同期処理によってGPU利用率を最大化し、大規模なエージェント軌道の探索・学習を可能にした
- 実世界向け統合評価スイートの構築
- 静的ベンチマークの限界を補うため、新規の内部評価スイート「CC-Bench-V2」を構築
- 「Agent-as-a-Judge(エージェントによる自動評価)」を活用し、フロントエンド・バックエンド・長期タスク(Long-horizon)におけるエンドツーエンドの開発能力を包括的に評価可能にした
モデルアーキテクチャ
GLM-5は744Bの総パラメータ(40Bのアクティブパラメータ)を持つMoEモデル。旧モデルであるGLM-4.5からモデルサイズが倍以上に増えている。
モデルパラメータ
| パラメータ | GLM-4.5 | GLM-5 |
|---|---|---|
| 総パラメータ数 | 355B | 744B |
| アクティブパラメータ数 | 32B | 40B |
| エキスパート総数 | 160 | 256 |
| アクティブなエキスパート | 9 (8 routed + 1 shared) | 9 (8 routed + 1 shared) |
| 全体のレイヤー数 (Total Layers) | 92(推定※) | 80 |
| MoEレイヤー数 | 89 | 75 |
| Denseレイヤー数 | 3 | 3 |
| Hidden Dim | 5,120 | 6,144 |
| MoE Intermediate Dim | 1,536 | 2,048 |
| 語彙サイズ (Vocabulary Size) | 151,552 | 154,880 |
4つの計算効率化手法を導入
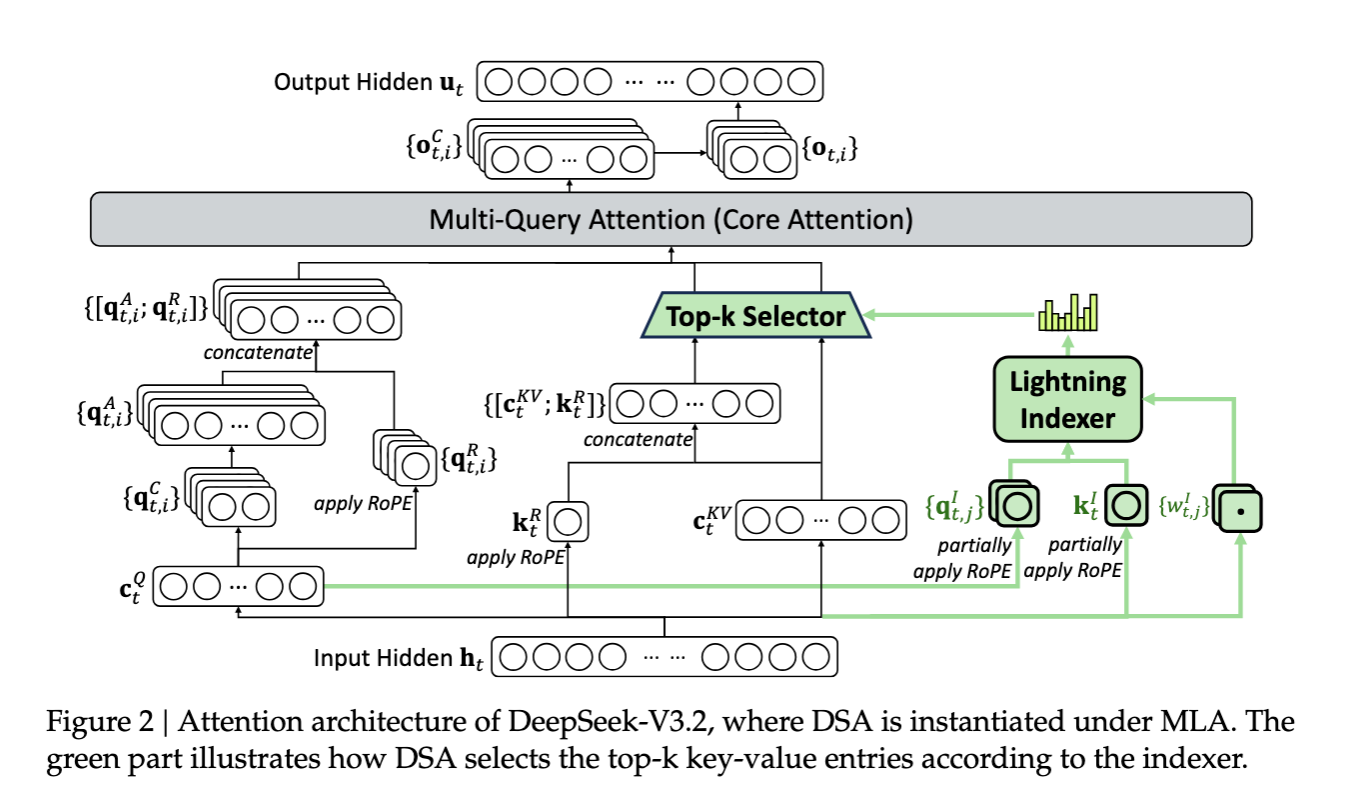
1. DSA(DeepSeek Sparse Attention)
- アテンションの計算コスト削減のためDeepSeek V3.2で提案されたDSAを導入
- コンテキスト長が伸びる中間学習後(後述)にDSAを導入することによりアテンションの計算量を1.5~2倍程度削減する
DSA補足
DSAは軽量な学習済みIndexerによって過去トークンを重要度順に並び替え、上位k個(本論文ではk=2048)のトークンに限定してスパースにアテンションを計算する機構
2. MLA(Multi-Latent Attention)
- GPUメモリ効率と長文脈処理速度を向上させるため、KV-cacheを潜在次元(今回はd=576)に圧縮するMLAを導入
MLA補足
以下の例だと10トークンで1トークンあたり7168次元のものを576次元の潜在次元に圧縮(中央下)してKVキャッシュする
クエリも同様に潜在空間に圧縮(中央上)して10トークンのアテンションを計算する(左上)
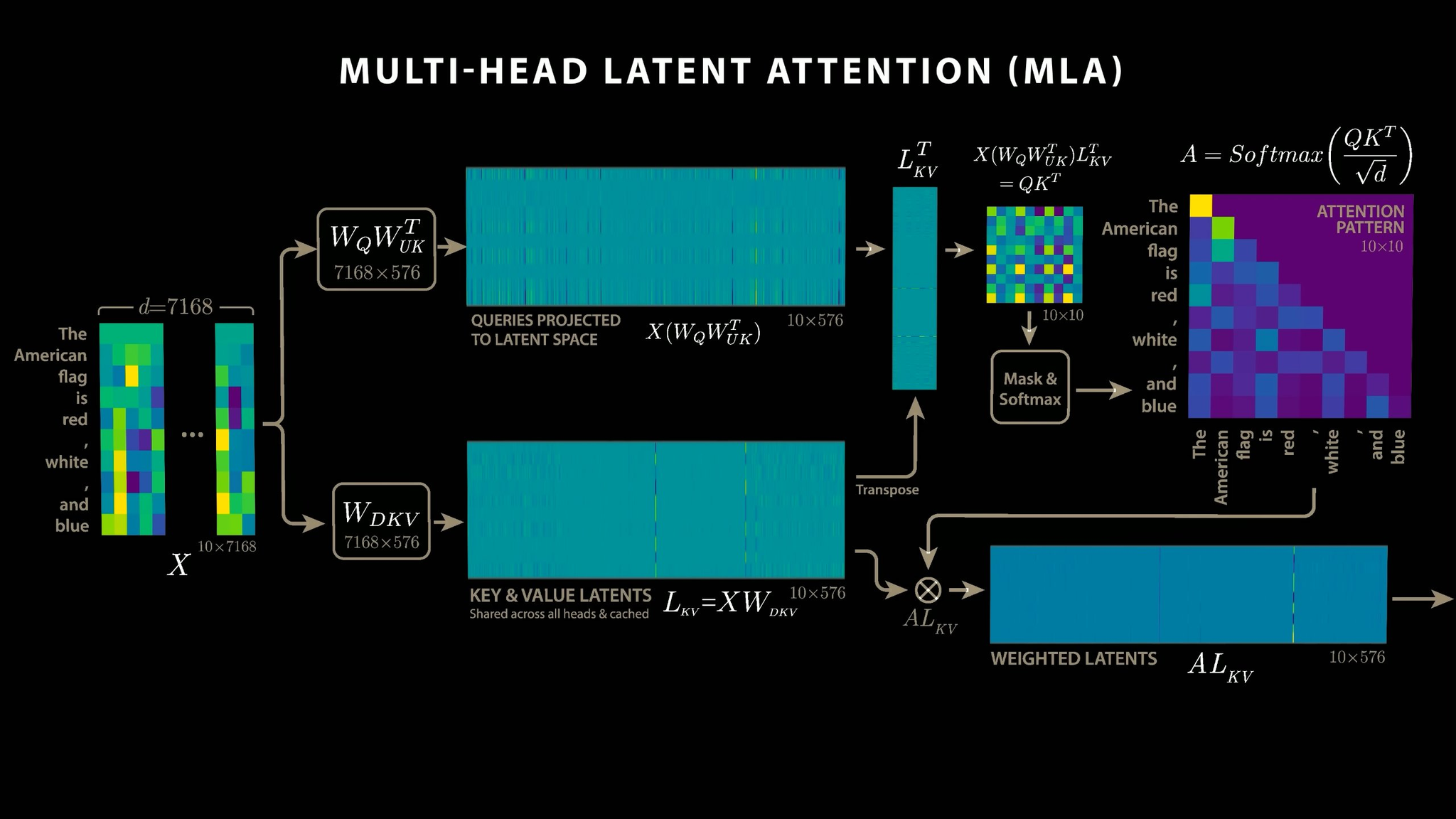
 TwitterSkalskiP on Twitter / X
TwitterSkalskiP on Twitter / X- さらにデコード時の計算効率化のためアテンションヘッド数を1/3に削減しヘッド次元をDeepSeekの128から256に増加させる改良(MLA-256)を実施
3. Muon Split
- 旧モデルであるGLM-4.5ではMuon Optimizerを利用していた
Muon Optimizer補足
- SGD with Nesterovモメンタムで勾配を計算した後、Newton-Schulz法でその勾配行列を直交化(orthogonalize)してからパラメータ更新する
- 2次モーメント不要のためAdamWよりメモリが少ない
- AdamWが勾配行列内の各パラメータごとにスケールを調整するのに対し、Muonは行列全体の幾何学的構造を考慮するため性能が上がりやすい
- しかしGLM5で導入したMLAをMuonと一緒に利用すると全ヘッドが同じスケールで更新されてしまい性能が低下する問題が確認された
- これを解決するために各アテンションヘッドの射影行列を独立に行列直交化する手法(Muon Split)を導入し改善
4. MTP(Multi-Token Prediction)
- 通常のLLMはnext token predictionだがGLM5は3つのMTPレイヤーを追加し+3token予測
- MTPをもとに投機的デコーディングによって計算時間を短縮している
- 単純にMTPレイヤーを3つ追加するとメモリコストが増えるので、3つのMTPレイヤーで共通のパラメータを利用するようにした
- これによりDeepSeek-V3と同じメモリコストを維持しつつ投機的デコーディングの承認率を向上(Accept Length: DeepSeek-V3.2の2.55に対し2.76で8%改善)
学習パイプライン
- 事前学習 (→コード、推論)
- 中間学習 (コンテキスト長拡大)
- 事後学習 (SFT → RL(x3) → オンポリシー蒸留)
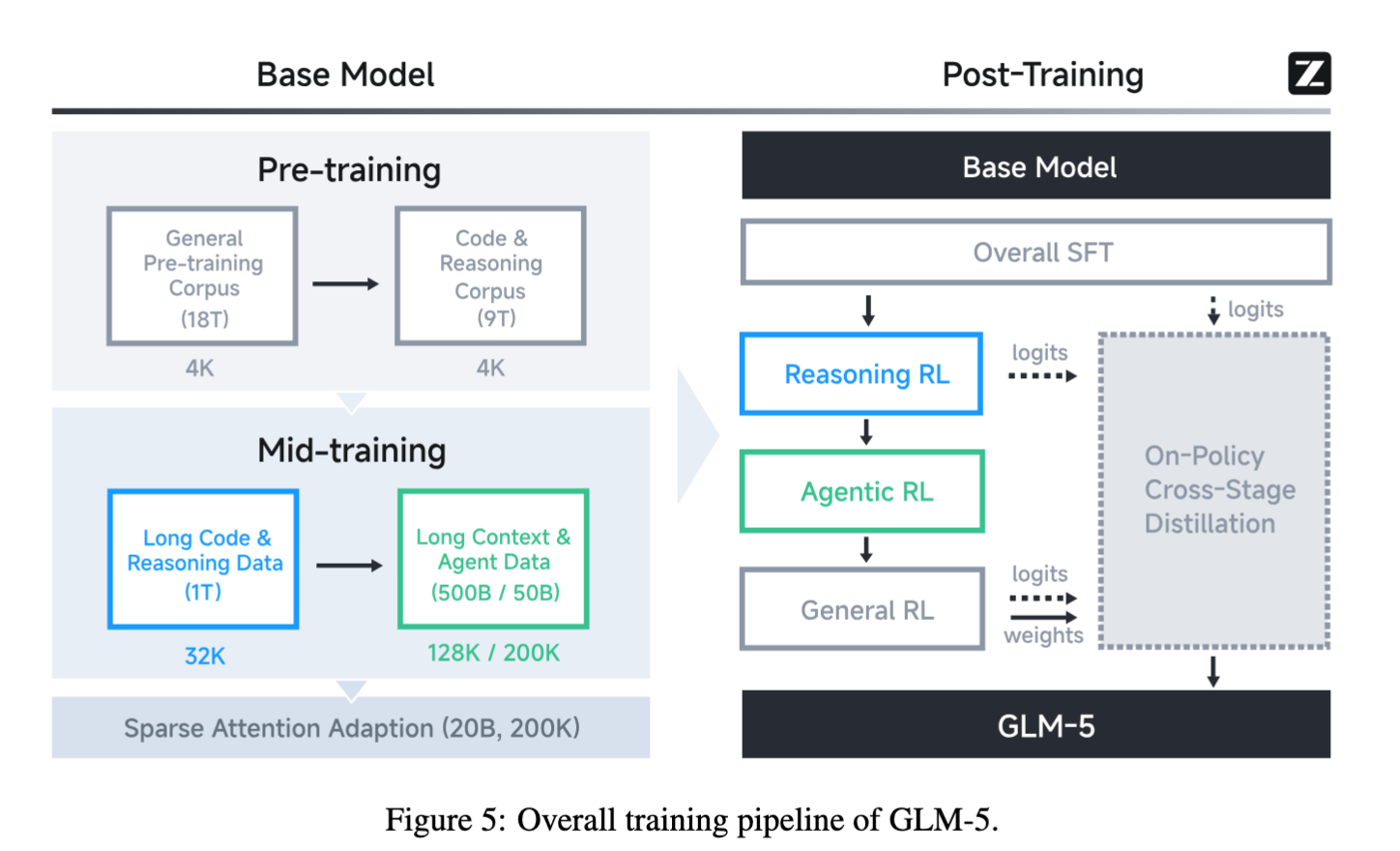
事前学習データ(総28.5Tトークン)
- Webデータ: 文埋め込みベースのDCLM分類器と世界知識分類器(Wikipediaエントリとのマッチ)で高品質データを抽出
- コードデータ: ファジー重複排除後に一意トークンを28%増加、9言語(Python, Java, Go, C, C++, JavaScript, TypeScript, PHP, Ruby)をカバー
- 数学・科学データ: LLMスコアリングとチャンク集約スコアリングアルゴリズムで高品質データを選択
- 合成・AI生成・テンプレートデータは厳格に排除
中間学習(Mid-Training)
- 3段階で文脈長を段階的に拡張
- 32K(1Tトークン)→ 128K(500Bトークン)→ 200K(50Bトークン)
- SWEデータとして約1000万のIssue-PRペア(計約160Bトークン)を収集
- 長文脈データではMRCR系データを200Kステージに追加して超長マルチターン対話の再現性を強化した。
事後学習(Post-Training)5段階
RLフェーズでは非同期設計にアップデートしたRLフレームワークであるslimeを利用(Agentic RLで触れる)
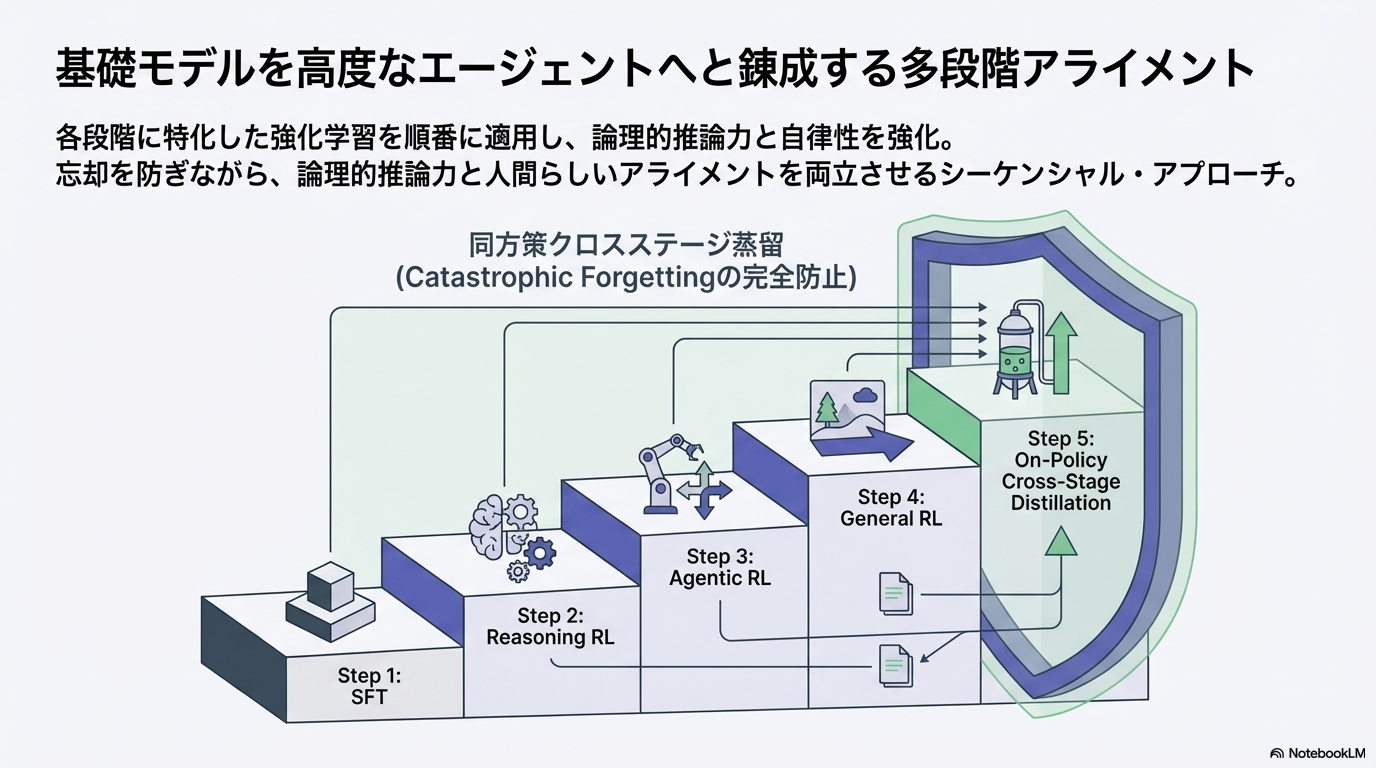
Step 1: Supervised Fine-Tuning(SFT)
- 旧モデルとの違い
- GLM-4.5より論理的・簡潔なスタイルに調整
- 多言語・多ロール構成のデータを拡充
- GLM-4.7が苦手とする難問のみを残すフィルタリング
- 軌跡内の誤ったセグメントは「ロスをマスク」して保持 → 誤りを補強せずに、エラー修正の挙動を学習させる
- 思考モードの導入(3種類)
- (おそらくGLM-4.7で)複数の検証可能な環境上で、下記の思考を実施するようにプロンプトを設定して成功事例の軌跡を収集している
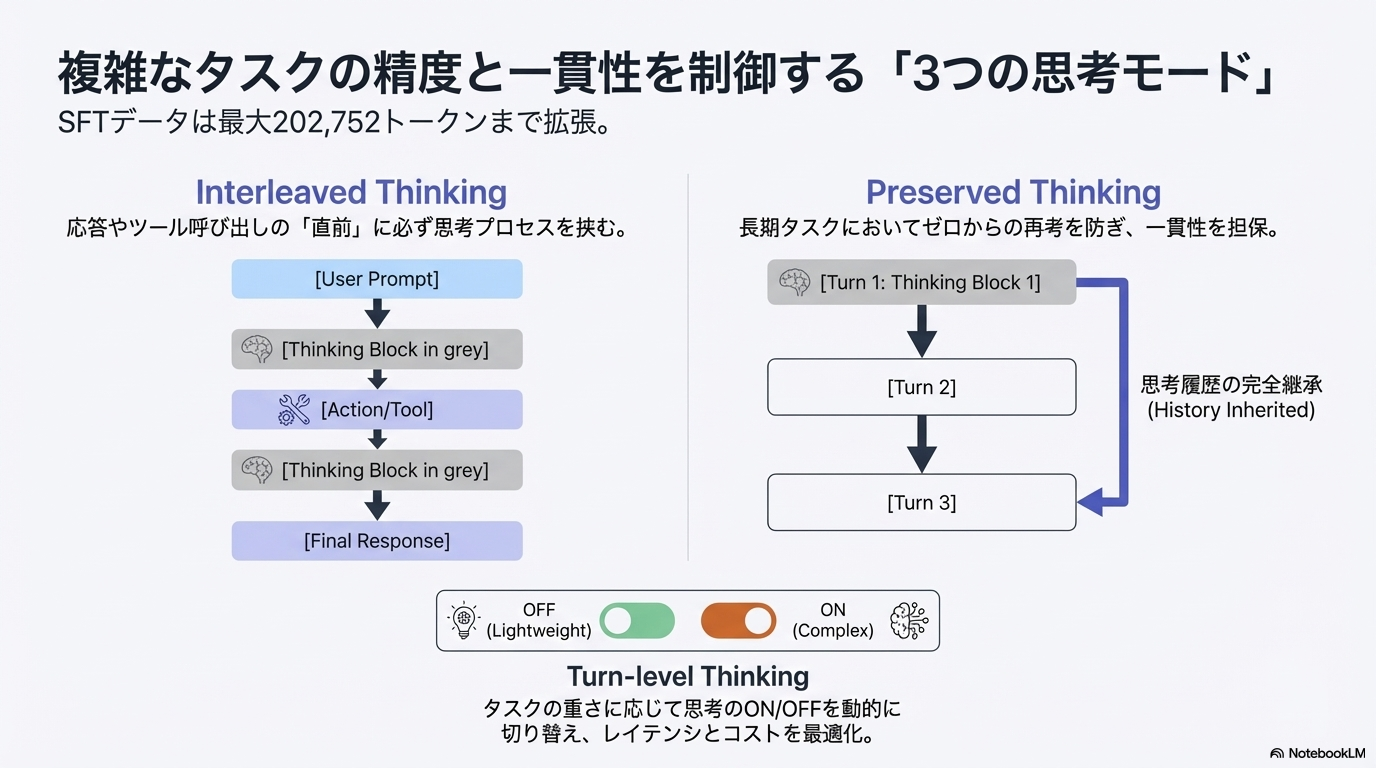
Step 2: Reasoning RL
- 数学、科学、競技プログラミング、ツール統合推論を同時にGRPOでRLVR
- 推論モデルと学習モデルの方策のズレを補正し、学習を安定させる手法であるIcePopを利用
- 2025/8に技術レポートとして公開されたテクニック
- https://ringtech.notion.site/icepop
最適化の損失関数
ポイント
- :学習ポリシーと推論ポリシーの比率(mismatch ratio)
- :mismatch比が を外れたサンプルは勾配0にして学習しない
- KL正則化項はあえて削除し、RL収束を加速
DSA特有の実装上の工夫
- DSAアーキテクチャではインデクサー(重要なKVエントリを選択するモジュール) のTop-k選択が非決定論的だとRL学習が不安定になることを発見
- CUDA実装のTop-kは非決定論的であるため決定論的な挙動をするを利用し安定した学習を実現
- インデクサーのパラメータはRL中には凍結(学習不安定化を防止 + 高速化)
Step 3: Agentic RL
- エージェントのロールアウトは非常に長く、同期型RL(学習エンジンとロールアウトエンジンを同期)ではGPUがアイドル状態になりやすい
- slimeというRLフレームワークを利用した非同期分離アーキテクチャを採用
slime
昨年THUKEGが公開されたRLフレームワーク
GLM系のRLは以前からslimeが使われている
 GitHub
GitHub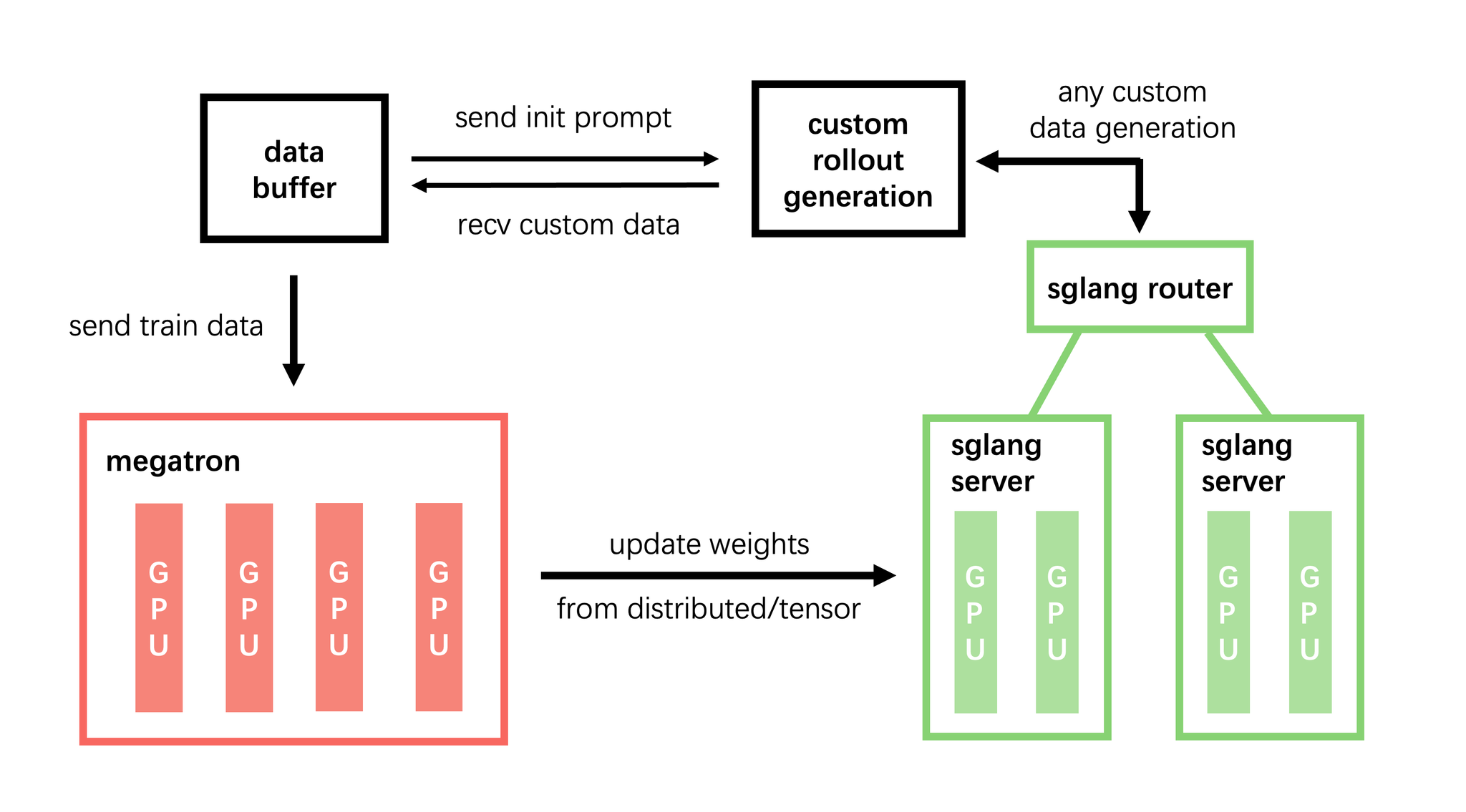
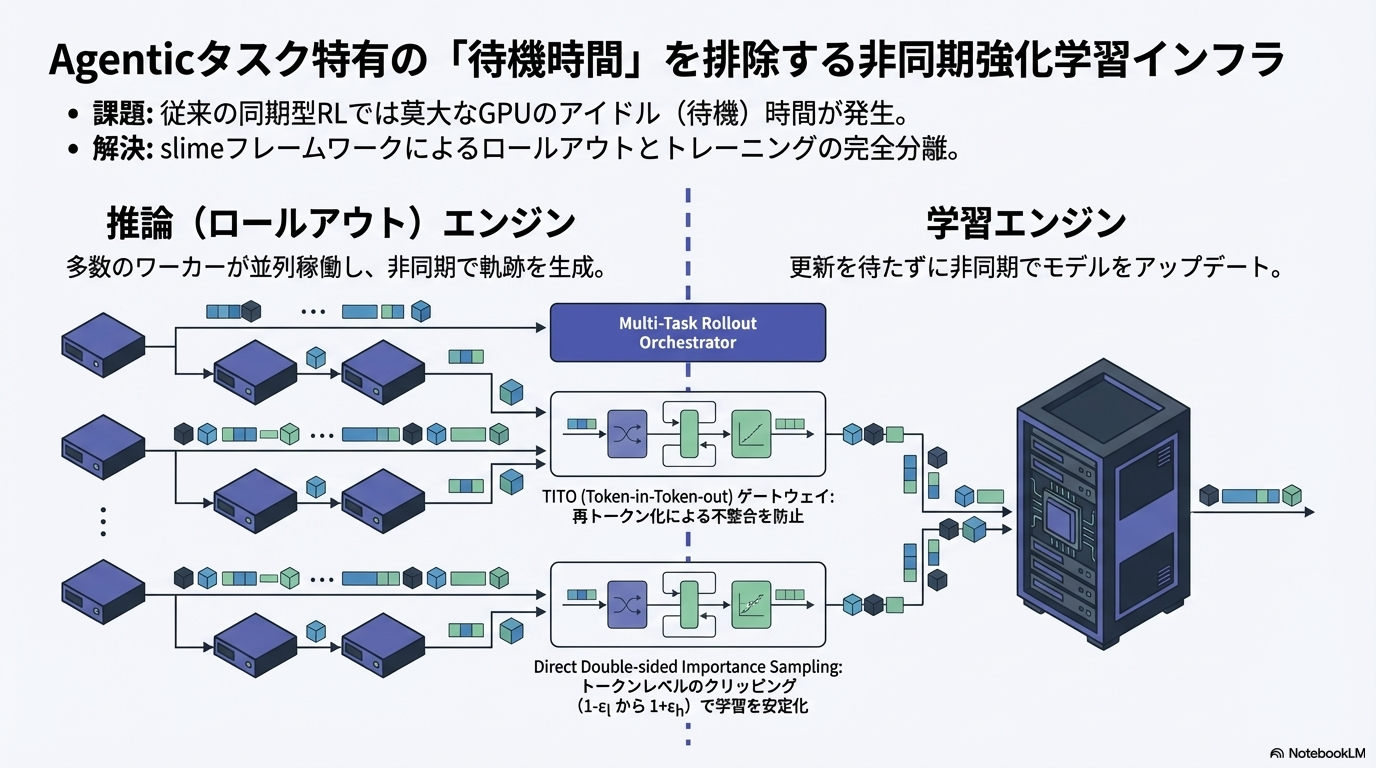
設計のポイント
- 各タスクが独立マイクロサービスとして登録 → SWE、ターミナル、検索等を統一的に扱える
- 1000以上の同時ロールアウトをサポート
- タスクサンプリング比率を動的に調整
- オフポリシー問題への対処として、モデル重みを周期的に同期
学習安定化の2つの仕組み
① Token-in-Token-out(TITO)ゲートウェイ
- 問題:テキストに変換してから再トークナイズすると、トークン境界のズレが発生する
- 解決:推論エンジンのトークンID+メタデータをそのまま学習エンジンに渡す
- 効果:Action(行動)と報酬・アドバンテージの対応が正確に保たれる
② Direct Double-sided Importance Sampling
非同期RLでは複数バージョンのモデルが軌跡生成に関与するため、従来の 追跡は不可能。代わりに を保存して利用
- 区間外のトークンは勾配を0にマスク(クリッピングではなく完全除外)
- の追跡が不要 → 実装がシンプル
ノイズサンプルの除去:
- 古すぎる軌跡(ポリシーバージョンの差が閾値$\tau$超)は破棄
- 環境クラッシュによる失敗サンプルも除去(モデルの問題ではないため)
- GRPOのグループで有効サンプルが半数未満 → グループごと破棄
Step 4: General RL
AI特有の「冗長で定型的なテキスト」になるのを防ぐため、人間の専門家の回答をアンカーとして混ぜ込み、自然なスタイルを担保する。以下の3軸で
- 基礎的正確性: 指示無視、事実誤り、幻覚(ハルシネーション)の排除(すべての前提条件)
- 感情知性: 共感的で自然な、人間らしいコミュニケーションの実現
- タスク特化品質: ライティング、Q&A、翻訳など、個別タスクにおける応答の質向上
ハイブリッド報酬システム(3種類を組み合わせ)
| 報酬タイプ | 長所 | 短所 |
|---|---|---|
| Rule-based | 精度高い・解釈しやすい | ルールで表現できる範囲のみ |
| ORM(Outcome Reward Model) | 分散低い・学習効率高い | 報酬ハッキングに弱い |
| GRM(Generative Reward Model) | 報酬ハッキングに強い | 分散高い |
Step 5: On-Policy Cross-Stage Distillation
- Reasoning RL → Agentic RL → General RLと段階的に学習すると、以前のステージで獲得した能力が劣化(Catastrophic Forgetting) してしまう
- そこで事後学習の一番最後に過去フェーズの最終checkpointモデルを教師モデルとして蒸留することで性能の劣化を防ぐ
- そこで各ステージの最終checkpointを教師モデルとして使い、オンポリシー蒸留する
オンポリシー蒸留とは
- 生徒モデルが生成したトークン列に対して教師モデルの確率分布を教師信号として分布を近づけるようにして蒸留する手法。
- 逆にオフポリシーの場合は固定トークンor教師モデルが生成したトークン列に対して生徒モデルの確率分布を近づけるように蒸留する。
- オンポリシーの方が実際に生徒がサンプリングしたトークンに対して学習が行われるため分布シフトが起こりにくい
- 最近は生徒モデル=教師モデルで教師モデルの方のみにプラスの情報を渡して蒸留する自己蒸留も流行ってきてる
- 通常の蒸留は教師モデルと生徒モデルの分布を近づけるようにKLダイバージェンスを損失関数に利用するが、この論文では(おそらく実装簡略化のために)GRPOベースで学習している
- 現在のポリシーが教師より「良い」トークンを予測できているかでアドバンテージを計算する
- 上記のように教師モデルとの比較でAdvantageが計算できるためGRPOのグループサイズは1として扱う(通常のGRPOより軽量)
実験結果
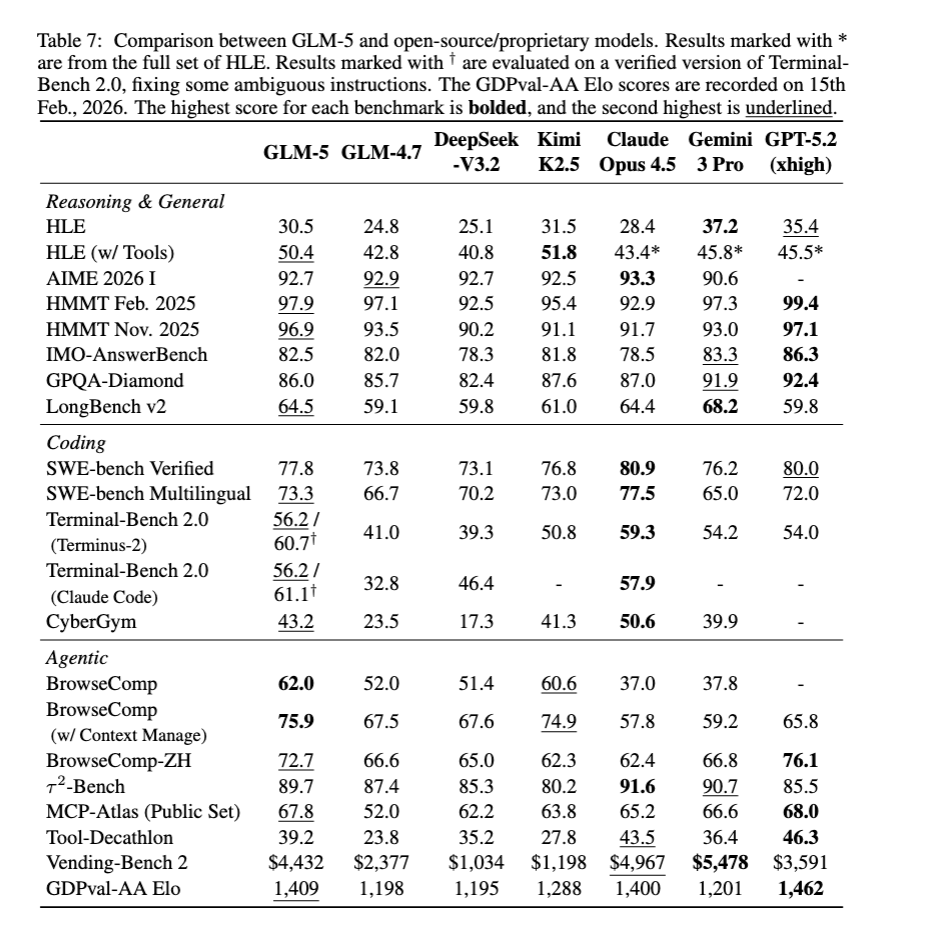
主要ベンチマーク結果(GLM-5 vs 主要モデル)
CC-Bench-V2結果
CC-Bench-V2とは
- 本論文で提案されたベンチマーク
- 単なる知識の有無を問うのではなく、Agentic Engineering、Long-horizon tasksの遂行能力を測定することに特化している
- 以下の3つの主要なカテゴリーでモデルの性能を評価
- フロントエンド(Frontend): ユーザーインターフェースやウェブ開発に関連する実装能力
- バックエンド(Backend): サーバーサイドのロジックやシステム設計能力
- 長期タスク(Long-horizon tasks): 複雑な依存関係や多数のステップを必要とする、長時間の推論・実行を伴うタスク
- Agent as a Judgeを採用。LLM as a JudgeよりAgenticに検証する点に違いがある
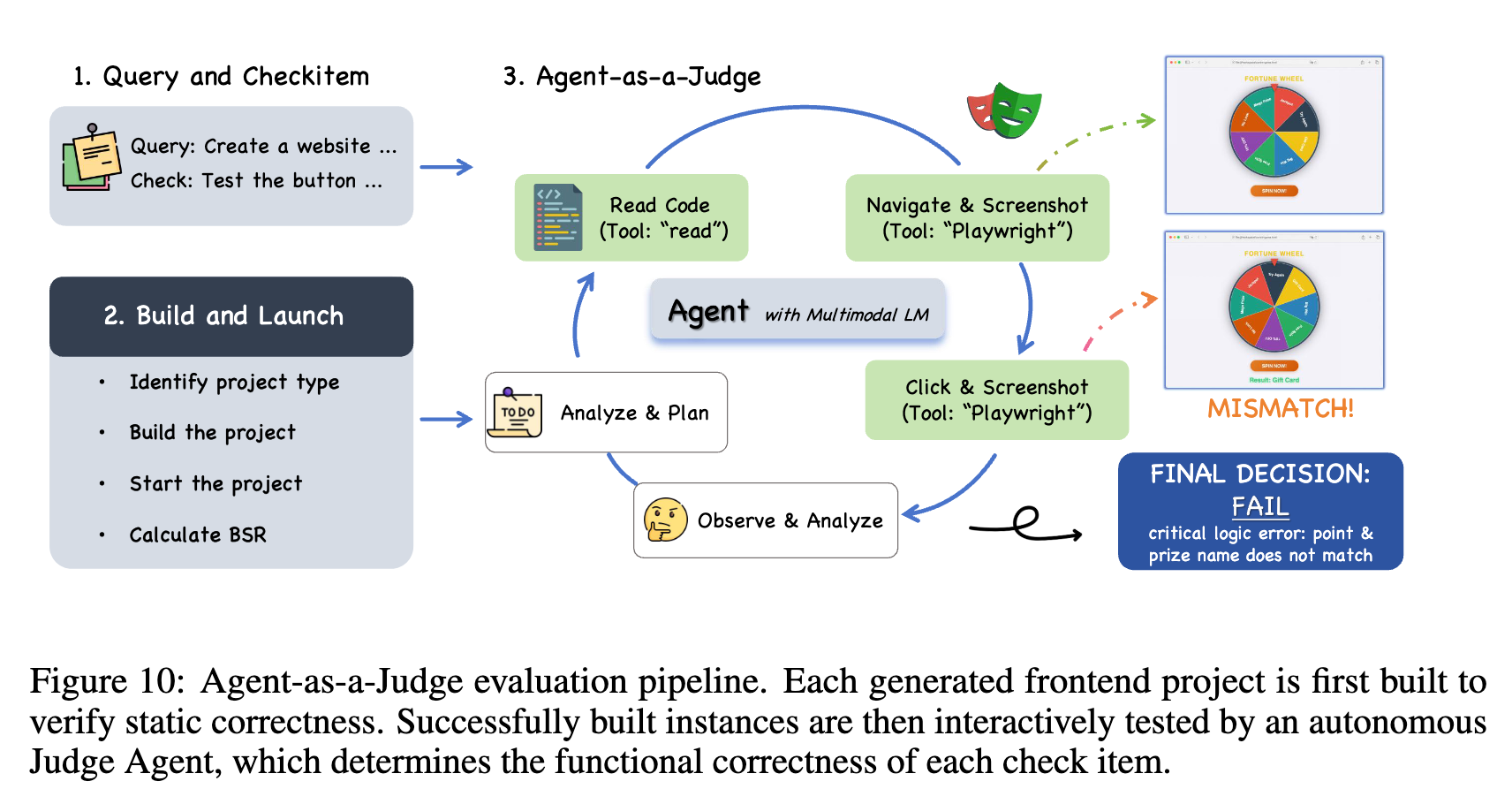
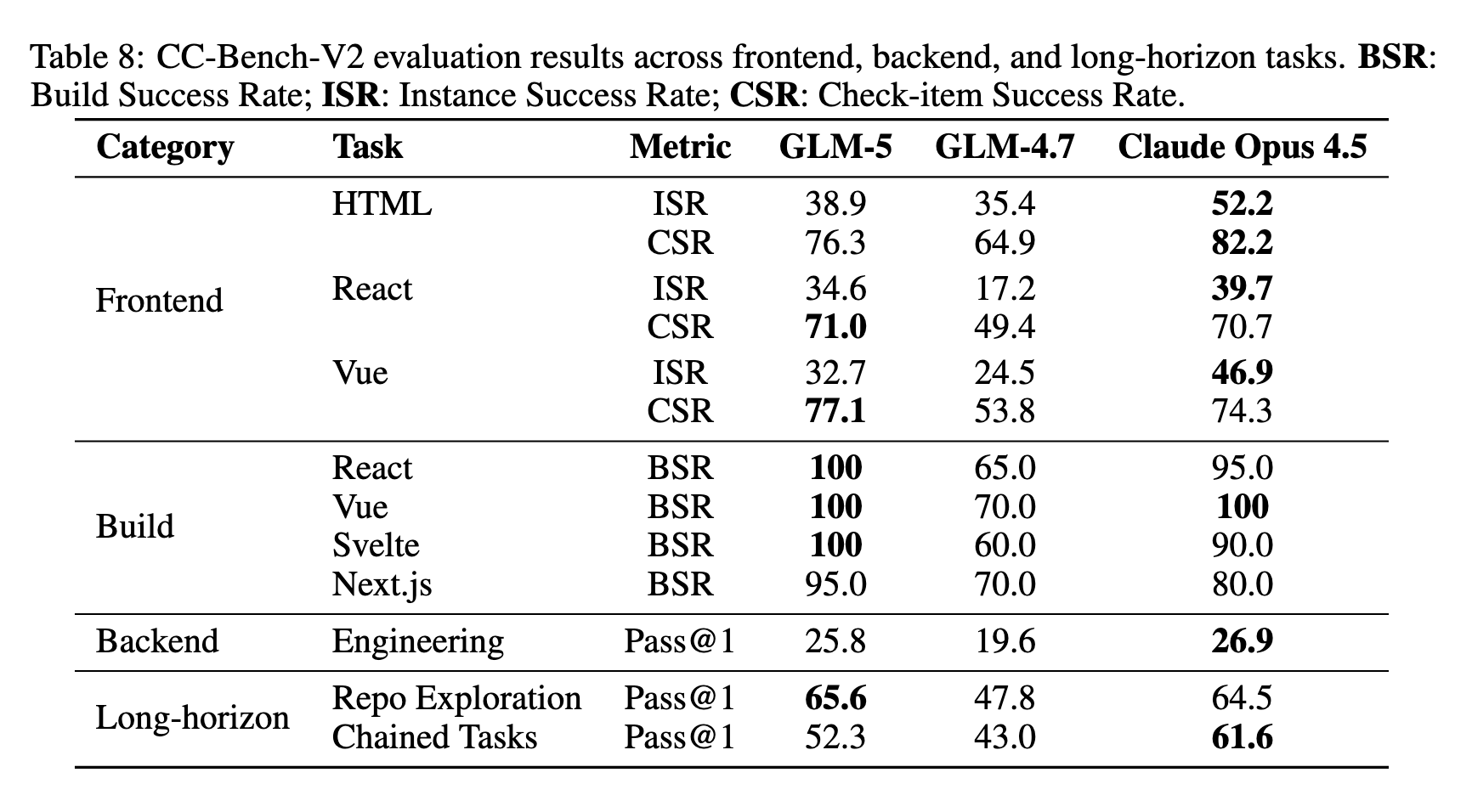
考察と限界
強み:
- BrowseComp(コンテキスト管理あり75.9)では全フロンティアモデル中1位を記録。Hierarchical Context Managementが特に効果的
- CC-Bench-V2のRepo Exploration(65.6)ではClaude Opus 4.5(64.5)を上回り、リポジトリ探索能力が優秀
- オープンウェイトモデルとして初めてAI Intelligence Index v4.0でスコア50を突破
- 匿名モデル「Pony Alpha」でOpenRouterに公開した実験で、ユーザーの25%がClaude Sonnet 5、20%がDeepSeekと推測(中国LLMのフロンティア競争力を実証)
弱み・限界:
- SWE-rebench(動的に更新される実際のGitHubイシュー)では42.1%にとどまり、Claude Opus 4.6(52.9%)、GPT-5.2(51.7%)に対して有意な差が残る
- Chained Tasks(52.3 vs Claude Opus 4.5の61.6)では長期チェーンでのエラー累積が問題
- Frontend ISR(HTML 38.9、React 34.6、Vue 32.7)ではClaude Opus 4.5に対して有意な差が残存
- GPQA-Diamond(86.0 vs GPT-5.2の92.4):科学的専門知識の深さでトップモデルとの差がある
今後の課題:
- On-Policy Cross-Stage DistillationのMLA統一によるMQA(Multi-Query Attention)モードへの移行
- 長期一貫性と長期自己訂正の改善(Chained Tasksの課題解決)
- 中国チップ生態系との継続的な深化と適応範囲の拡大
感想
- 計算量削減手法の工夫が詰まった集大成という感じで、知らない手法も多く勉強になった
- 大規模かつ高速に学習したいなら非同期処理は必須な気もするのでその選択肢としてslimeは良さそう
- Swallowの学習でも使われている
 ZennQwen3-Swallow & GPT-OSS-Swallow
ZennQwen3-Swallow & GPT-OSS-Swallow