2026-03-17 機械学習勉強会
以下について
今週のTOPIC[paper] Multimodal OCR: Parse Anything from Documents[slide] Synthetic Data Powering Pretraining[paper] LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation[paper] Flash-KMeans: Fast and Memory-Efficient Exact K-Means[paper] HiSem-RAG: A Hierarchical Semantic-Driven Retrieval-Augmented Generation Method[Blog/Paper] Systematic debugging for AI agents: Introducing the AgentRx framework[paper]UP TO 36X SPEEDUP: MASK-BASED PARALLEL INFERENCE PARADIGM FOR KEY INFORMATION EXTRACTION IN MLLMS[blog] Optimizing Recommendation Systems with JDK’s Vector API[paper]OpenClaw-RL: Train Any Agent Simply by TalkingHogeメインTOPICCUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation概要背景と動機GPU最適化はLLMには難しい課題torch.compileをベースラインとするKernelBench?既存手法の課題RLの対象?手法Data Synthesis(訓練問題の合成)Agent Loop(SKILL.md+Harness)OpenHands + ReAct + Agent Skills でAgenticループを回すSKILL.mdHarness(compile / verification / profiling)探索空間の制約(reward hacking対策)Stable RLの設計そのままRLをすると17ターンで崩壊する対策(3段階 warm-start + PPO)2) なぜ必要か3) Step 0: Single-turn PPO warm-up4) Step 1: Actor 初期化 = RFT5) Step 2: Critic 初期化 = Value pretraining6) Step 3: Full Multi-Turn PPOまとめ実験結果(KernelBench)Main Results: Table 1Table 2:各手法ごとの性能Training Dynamics: Figure 4 & 5Case StudyLevel2に強い理由?考察と限界強み限界感想参考資料Seed1.6について
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi








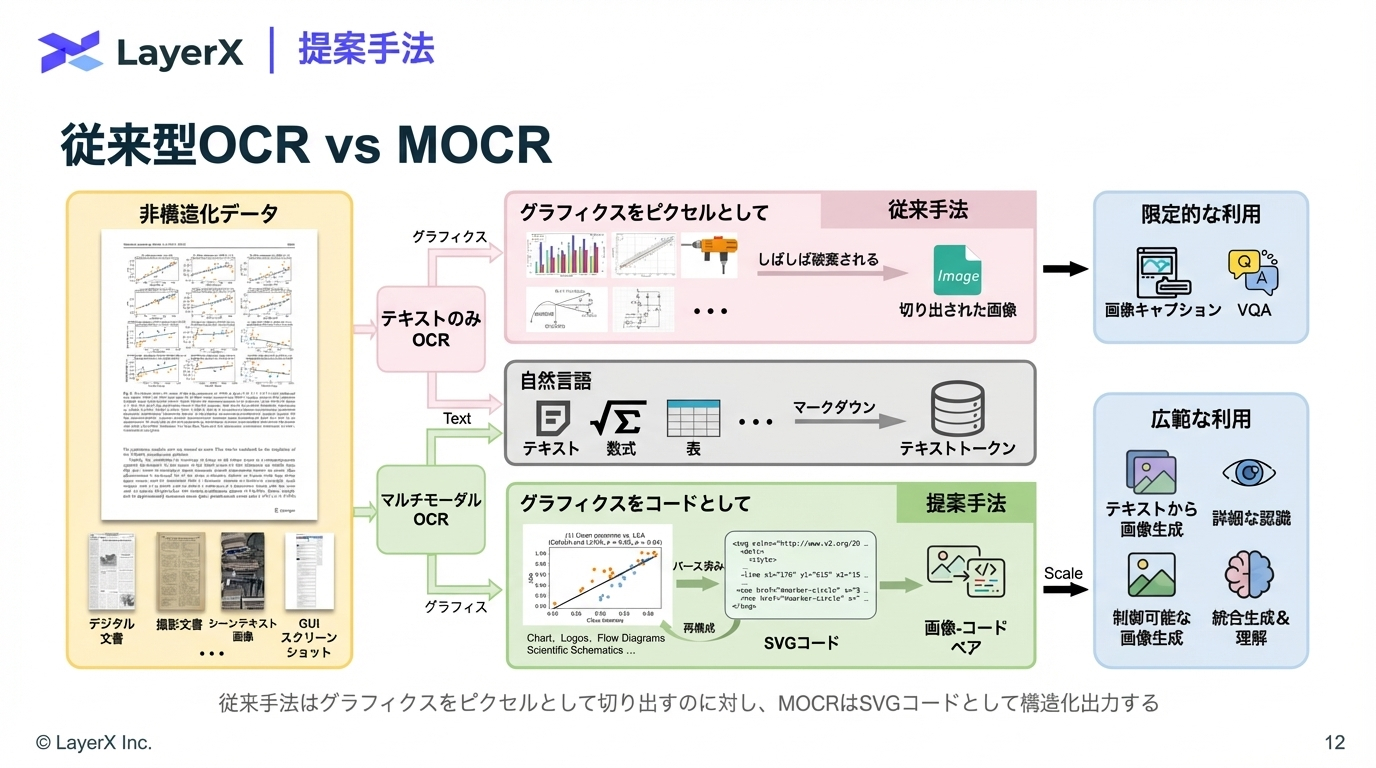

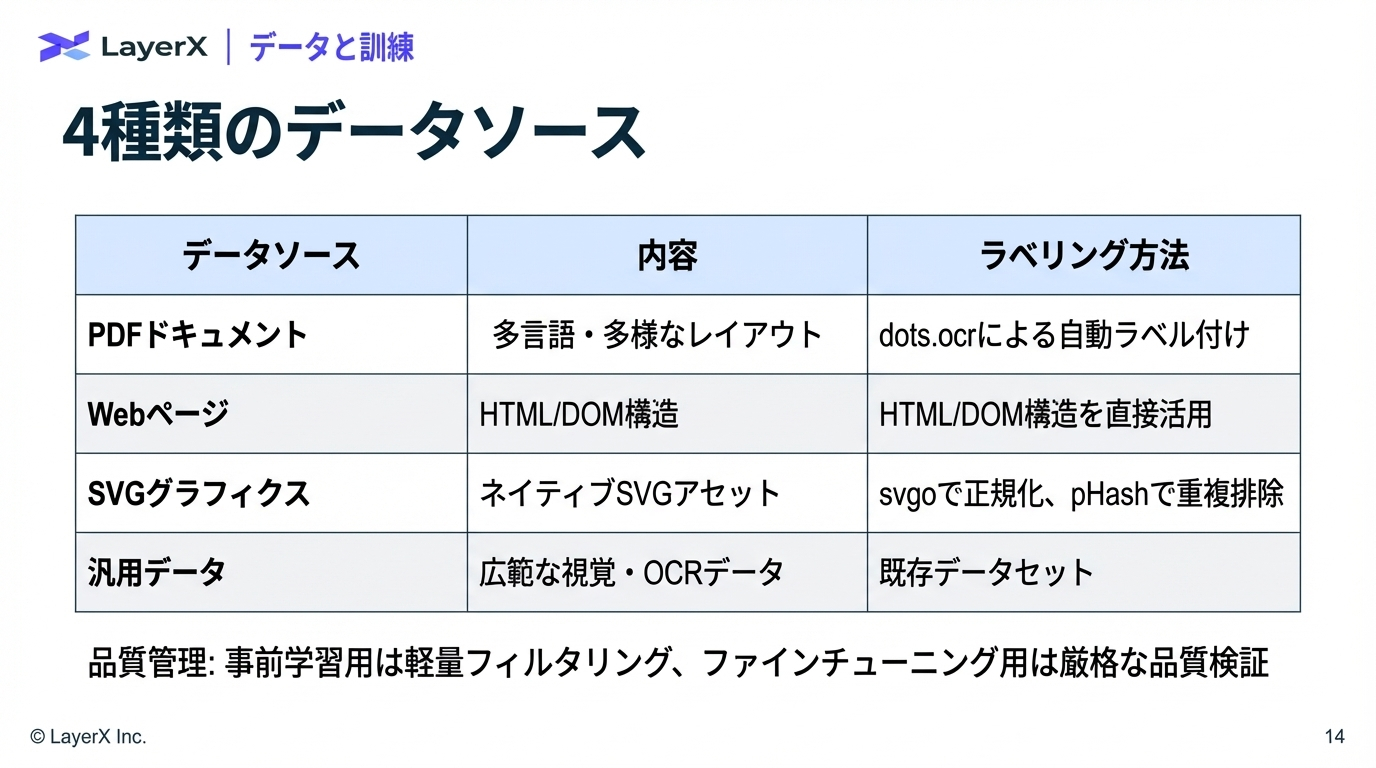
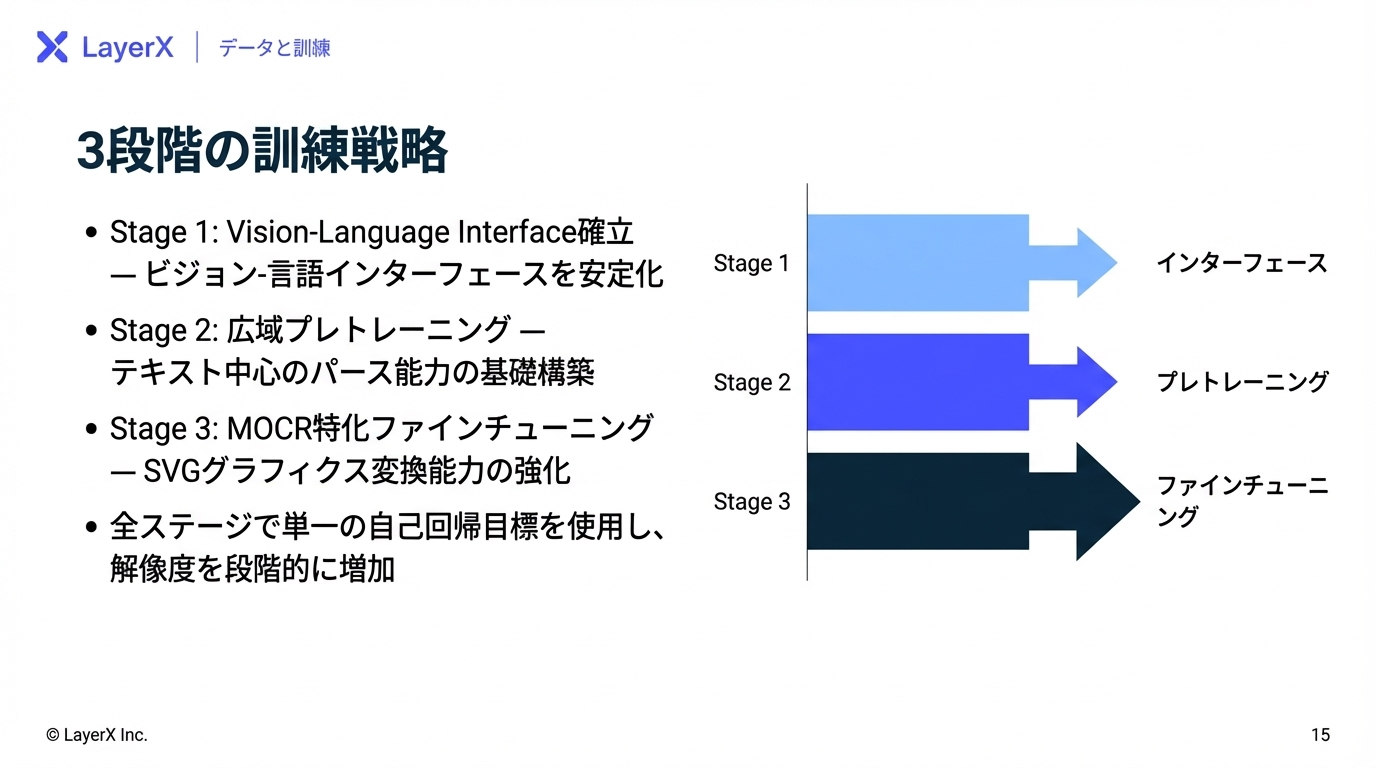

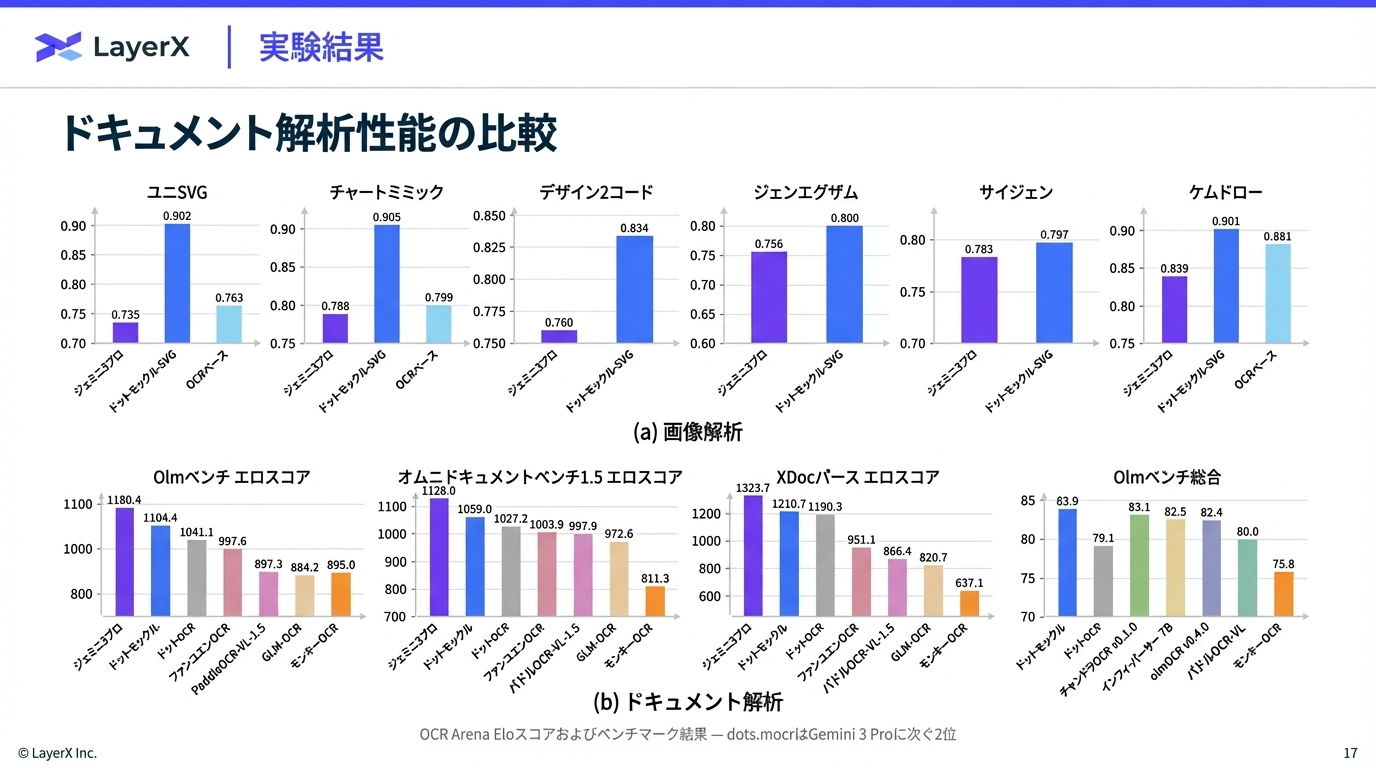
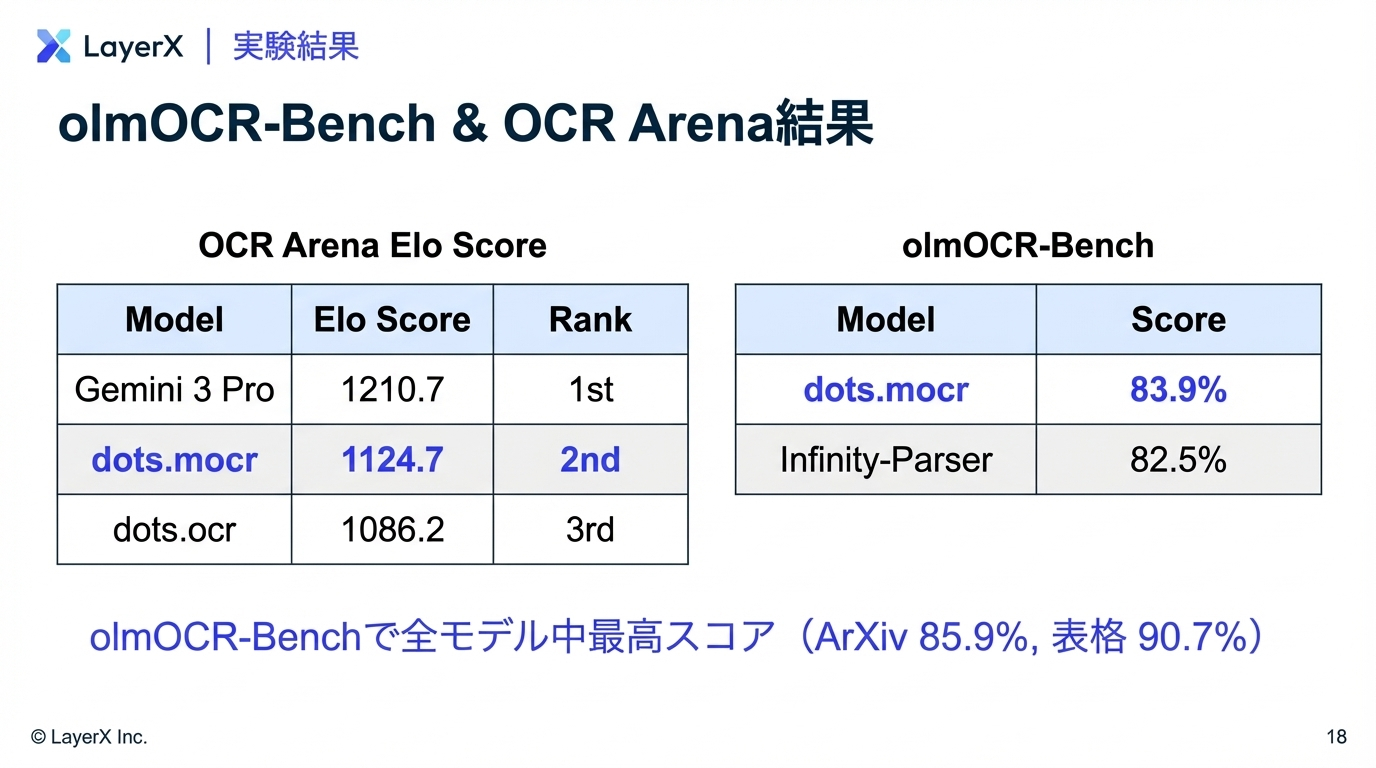
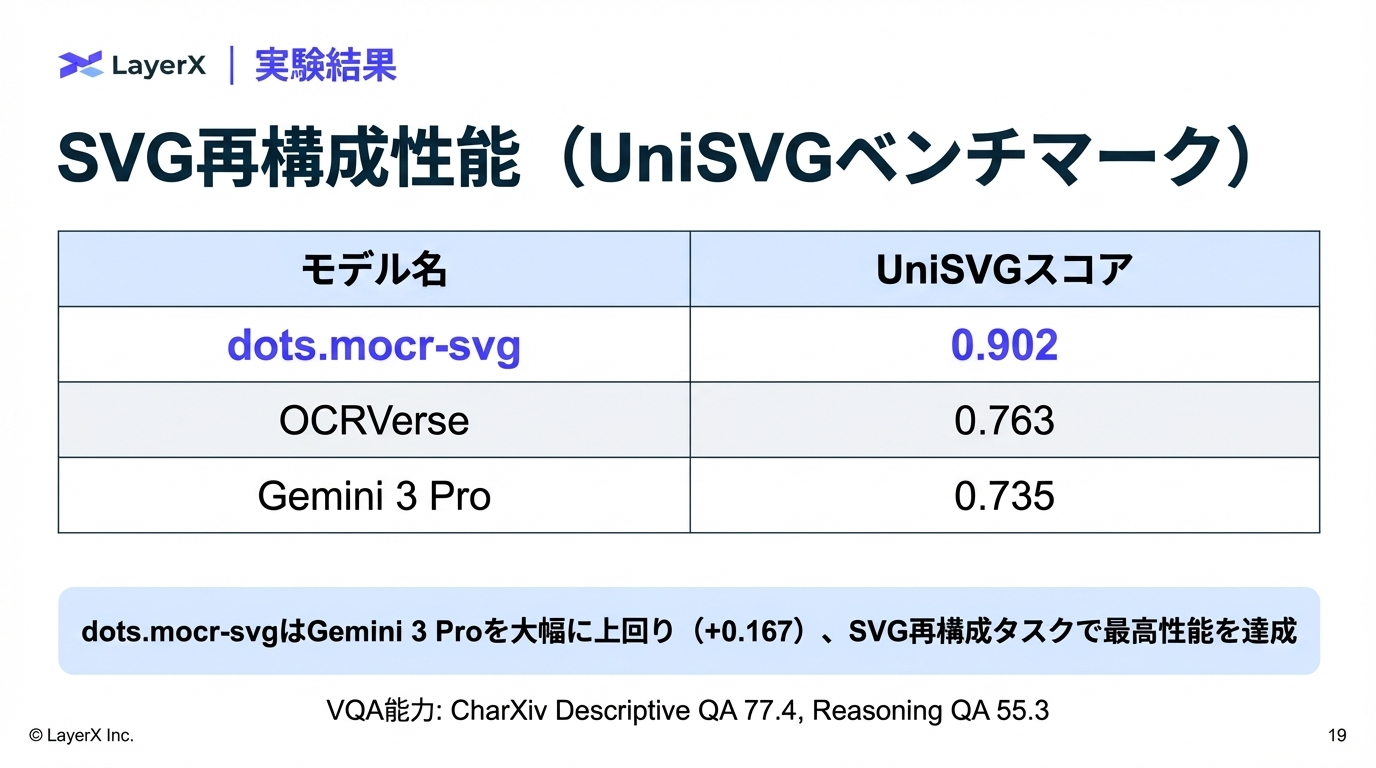
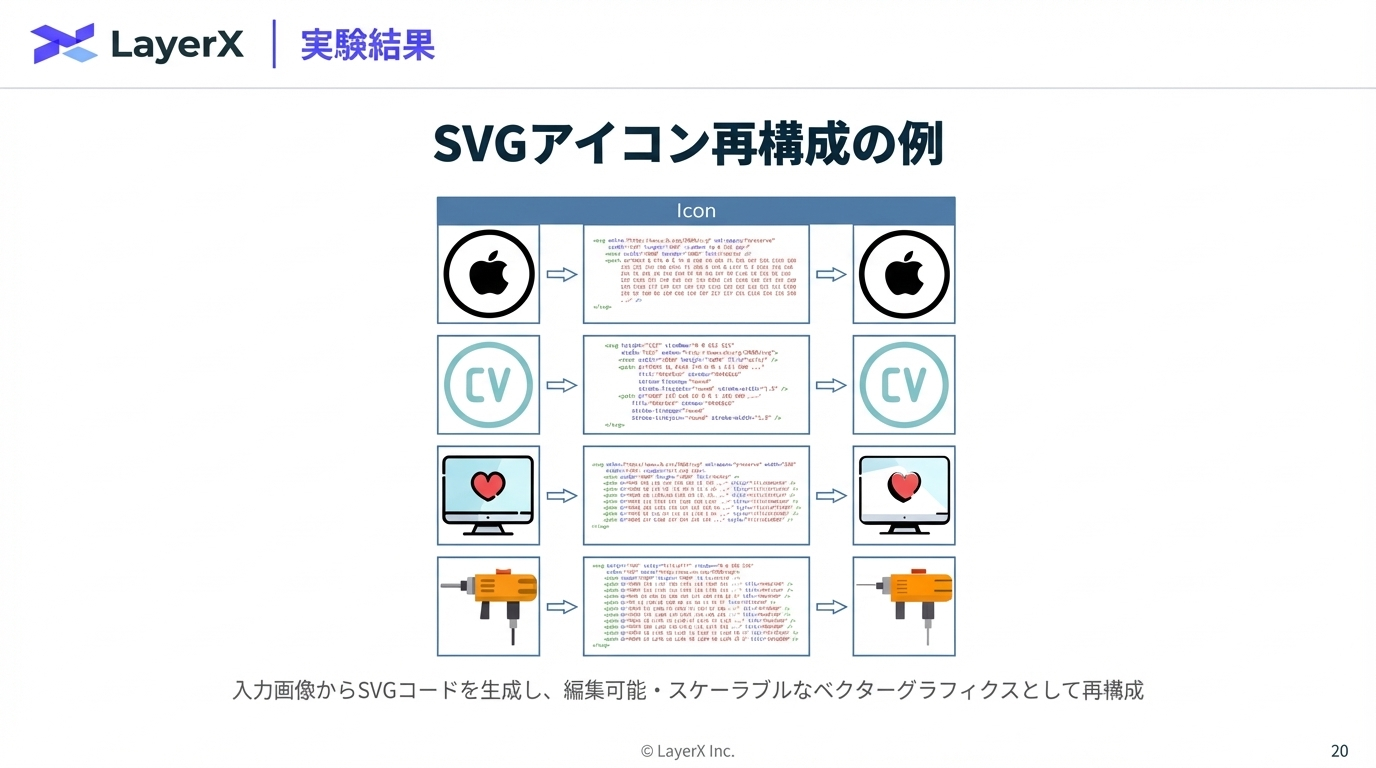





@Yuya Matsumura
[slide] Synthetic Data Powering Pretraining
LLMの事前学習における合成データについての講義資料。NVIDIA社の Eric W. Tramel 氏によるBerkely大における2026年2月の講義(こんなの大学の講義でやるのかすごい。)
The Data Wall and the Scaling Imperative
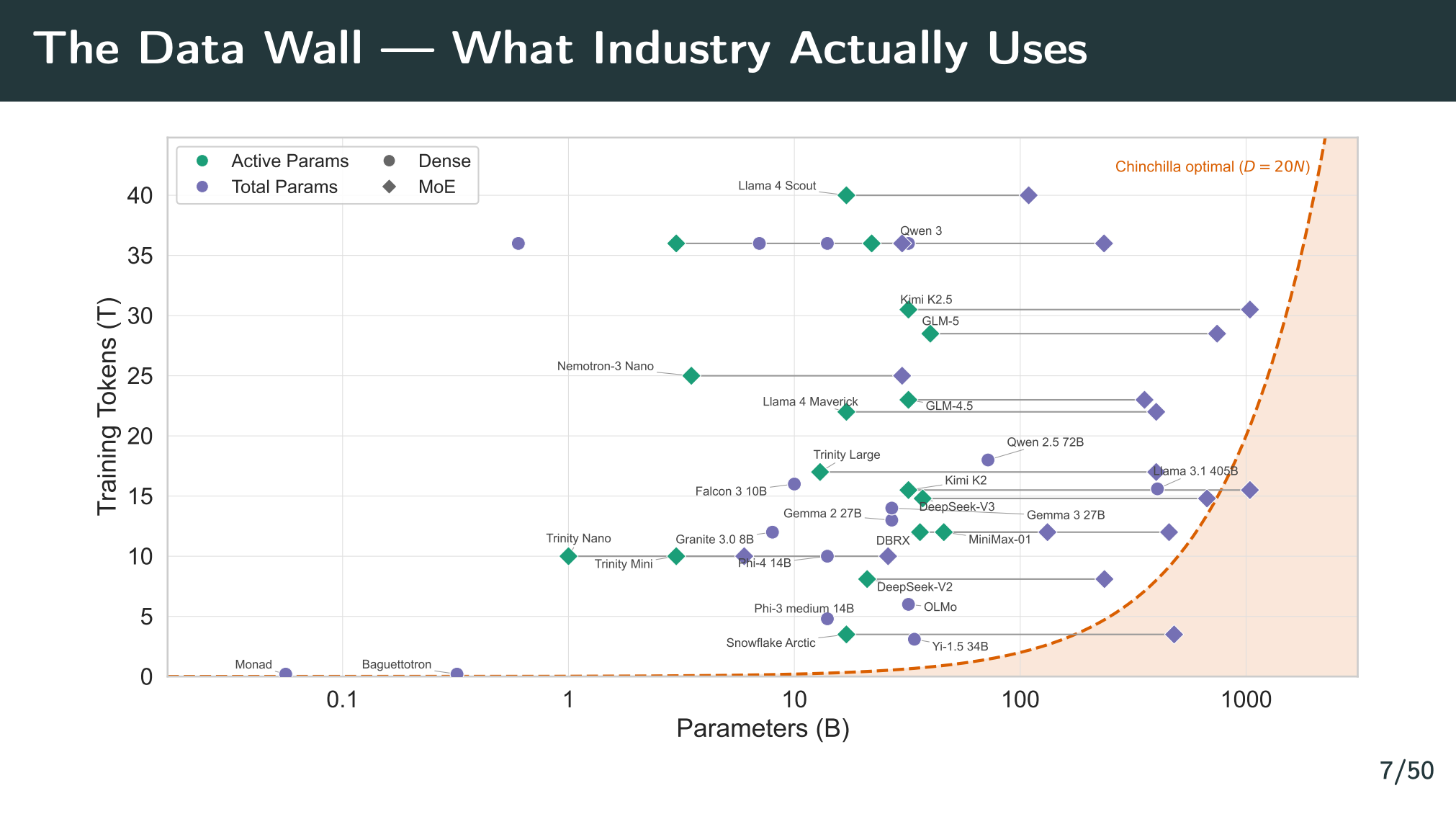
AIを賢くするには事前学習が最も必要。事後学習で性能は向上するが、能力の上限は事前学習の時点で決定されていると言える。でも、インターネットに存在する(良質な)データ量には上限があり、枯渇しつつある(Data wall)。
特に、昨今主流となりつつあるMoEというモデル構造はより多くのデータを必要としている。スケーリング則によると、Denseモデルでパラメタ数の20倍ほどと言われるが、MeEであれば40倍程度とも。
なので、AI自身にデータを作らせる合成データで頑張ろうぜ!
“But Won’t the Models Collapse?”
一方で、AIが作ったデータでAIを訓練すると、多様性が失われてモデルが劣化する「モデル崩壊(Model Collapse)」が起きるのではないかという懸念がある。
しかし、以下のような方法でなんとかなることが見えてきている。
- 現実のデータと合成データを混ぜる
- 教科書のようなデータをゼロから作らせるのではなく、既存のテキストを言い換える(Rephrasing)
Model-Amplified Data — What Works and Why
初期の合成データは、AIに教科書を一から書かせるような手法(Phiシリーズ等)であったが、これは無限の知識を網羅できないためスケールしなかった。 現在最も成功しているのは、既存のWeb上の知識を言い換えるアプローチである。元の事実を保ったまま文章の構成や表現を変えることで、学習効率が5〜10倍に跳ね上がることが報告されている。

この言い換え作業は、巨大で高価なAIを使う必要はなく、3B(30億パラメータ)程度の小さくて安価なAIでも十分な品質のデータを作れるため、非常にコストパフォーマンスが高い。画像データのシンプルなデータオーグメンテーションに考えは近い。
ただし、同じような形式ばかりを作るのではなく、多様な形式で学習させることが重要です
Seeding Capabilities — Synthetic Code and Reasoning
一般的な文章の言い換えだけでなく、特に重要とされている合成データが大きく2つ
- プログラムコード: Pythonで書かれたコードをC++に変換させるなどして言語間の構造を学習させる。コードは実際に実行して正しいか検証できるという強みがある。
- 推論(Reasoning)プロセス: 科学や数学の問題に対して、思考プロセス(Chain of Thought)を含んだデータを事前学習の段階で組み込むことで、後からモデルを微調整する際(ポストトレーニング)に、さらに能力が伸びやすくなる。
The Future — From Passive Collection to Active Curriculum Design
これまでのAI開発は「Webから大量のデータを受動的にかき集める」手法であったが限界を迎えている。
現在は、「フィルタリングされたWebデータ」+「多様性を持ったリフレージング」+「適当なデータの組み合わせ」という戦略を取るべき。
未来は、「推論過程を含む事前学習」+「マルチモーダルな合成データ」+「エージェントの行動履歴」という組み合わせにより、AIの学習カリキュラムを人間が能動的に設計する時代へと移行していく。

@Shun Ito
[paper] LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
- LLMの推論高速化のためKVキャッシュが使われるがメモリ消費が課題
- 既存手法: KV cache eviction
- 将来の生成に重要なトークンだけを残し、他はキャッシュから削除する
- 重要度を予測するためのアプローチ
- ヒューリスティック
- SnapKV: 入力プロンプト末尾トークンのattentionを使い重要度予測
- Draftベース
- LAQ: Small LMで未来の応答を生成し、そのトークンを使って重要度予測
- 課題
- ヒューリスティック: 高速だが扱う情報が局所的で性能劣化が大きい
- Draftベース: 性能は高いが生成ステップが増えてTTFTが遅くなる
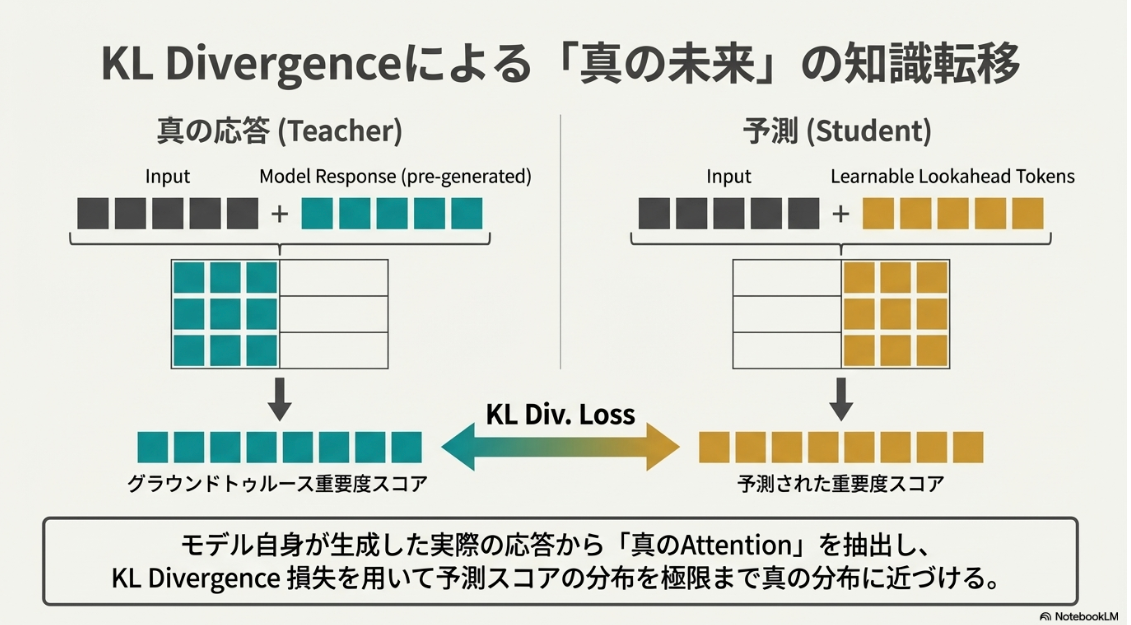
- 提案: LookaheadKV
- 将来のトークンの傾向を予測して優先度を推測する、というアイデア
- 入力トークンの最後に Lookahead Tokens を追加
- 学習時
- 「実際に生成されたトークンによる過去トークンの重要度」と「Lookahead Tokensによる過去トークンの重要度」とが近くなるように学習
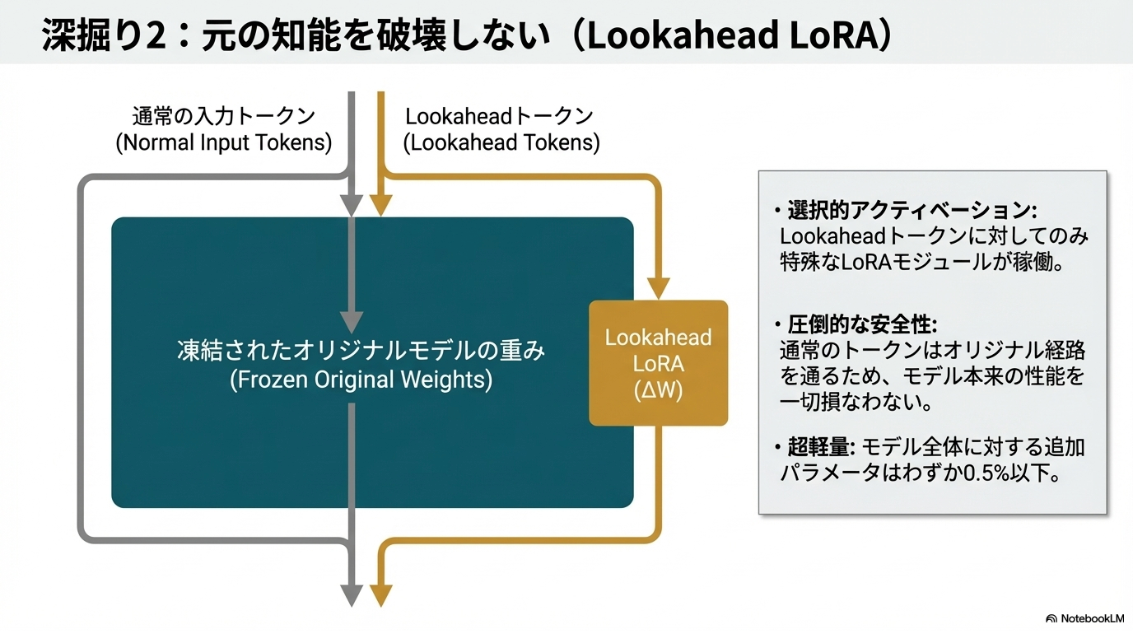
- LoRAアダプタを付与し、Lookahead Tokensに関わる部分で利用する
- 推論時
- 通常の推論はそのまま学習済みモデル(without LoRA)で行う
- with LoRAで Lookahead Tokensを生成し、KV cacheされたトークンとのattentionスコアを計算 → 重要度判定
- 未来のトークンをLookahead Tokensで近似するイメージ
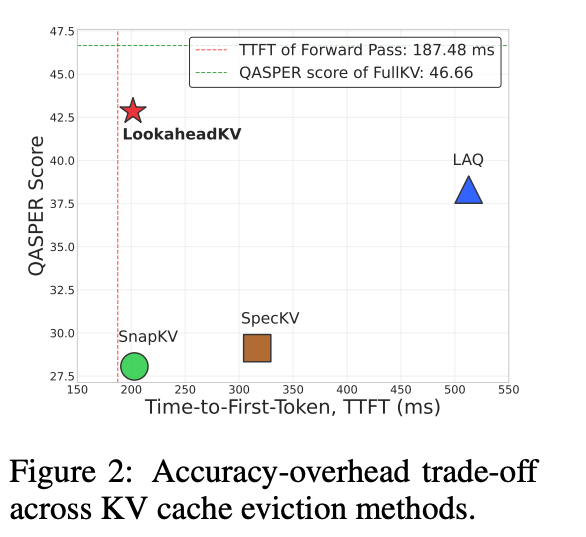
- 結果
- 論文QAタスクで、ヒューリスティック程度の速度・Draftベース程度の性能
@Takumi Iida (frkake)
[paper] Flash-KMeans: Fast and Memory-Efficient Exact K-Means
GPUを使った高速なKMeansできたよ
実装:‣
pipでインスコして、シュッと使える
概要
これまでのGPU上でKmeansがうまく行かなかった理由
- メモリ帯域
- アトミックな書き込み競合
Flash-Kmeansでは、2つのアプローチで解決
- FlashAssign:距離計算とOnline Argminの組み合わせ
- Sort-Inverse Update:Atomic Scatterをセグメント単位のreductionに変換
標準ライブラリ(cuML, FAISS)に対して33〜200倍以上高速になった。
背景
K-Meansの使われ方の変化
- これまで:オフライン データセットの前処理や整理
- 現在:オンラインの高頻度呼び出し
- LLMのsparse attention:トークンをクラスタリングして重要な組み合わせのみAttentionを計算(Roy et al., 2020; Zhu et al., 2025)
- KV cache compression:LLMのメモリ消費を削減するため、キャッシュをクラスタリングして圧縮(Liu et al., 2025)
- ビデオ生成モデル:Diffusion Transformerでトークン配置を最適化(Xi et al., 2025)
- Embedding quantization:大規模検索システムでベクトルを量子化(Khattab and Zaharia, 2020)
→1回当たりのレイテンシが求められるようになった
K-MeansのGPU実装のボトルネック
- Assignment Stage
- 距離計算:全ポイントと全重心の距離行列を計算し、VRAMへ書き込み
- Argmin:最近傍を探す
- Update Stage
- 重心を更新するときに、複数のスレッドが同時に同じクラスタを更新しようとする →アトミック競合発生 →スレッドがシリアライズ化 →高速化できない
Flash-KMeans
Flash-KMeansではFlashAssignとSoft-Inverse Updateで解決。さらにシステムレベルの最適化を行っている。
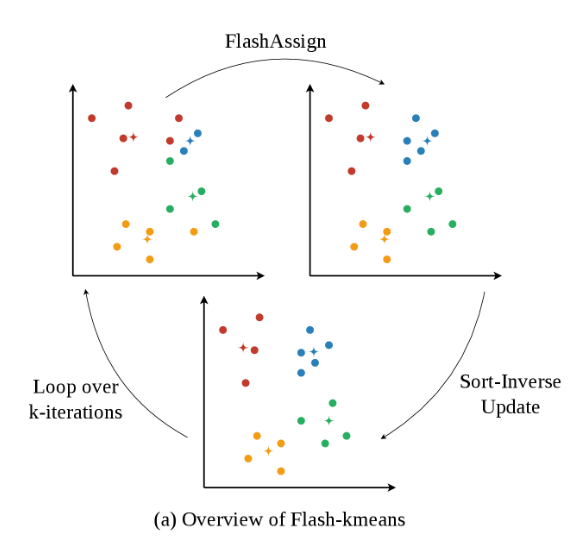
FlashAssign
距離行列を作ることをやめて、逐次最小値を更新するアプローチ
(全部計算するのではなく、計算しながら最小値を探す)
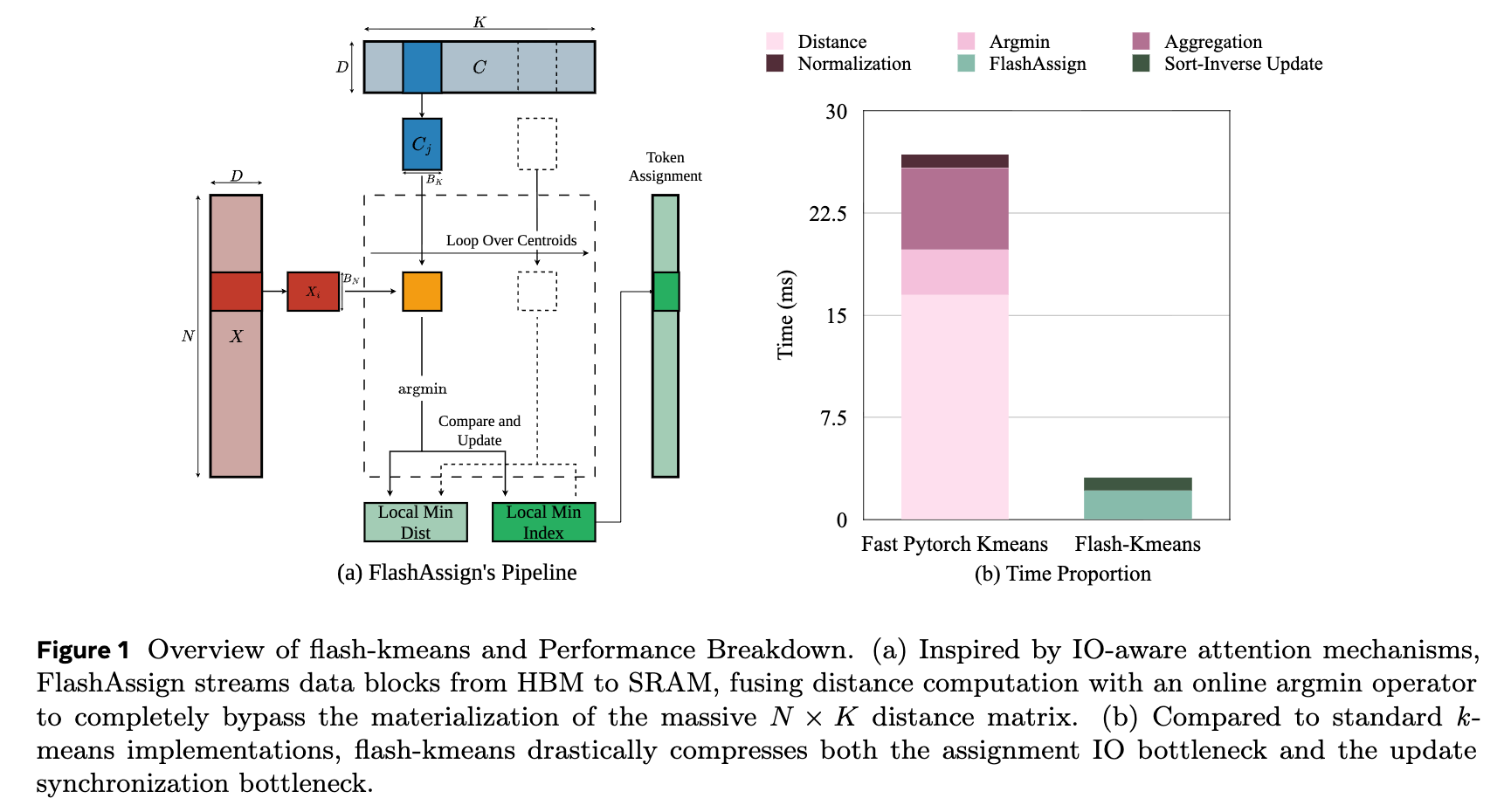
おまけにタイル化して並列化を実現している(ブロック単位で並列化)
具体例
Soft-Inverse Update
重心を更新するときの競合を解消
事前にソートしておくことで、同じクラスタが連続する → 重心計算が安定する
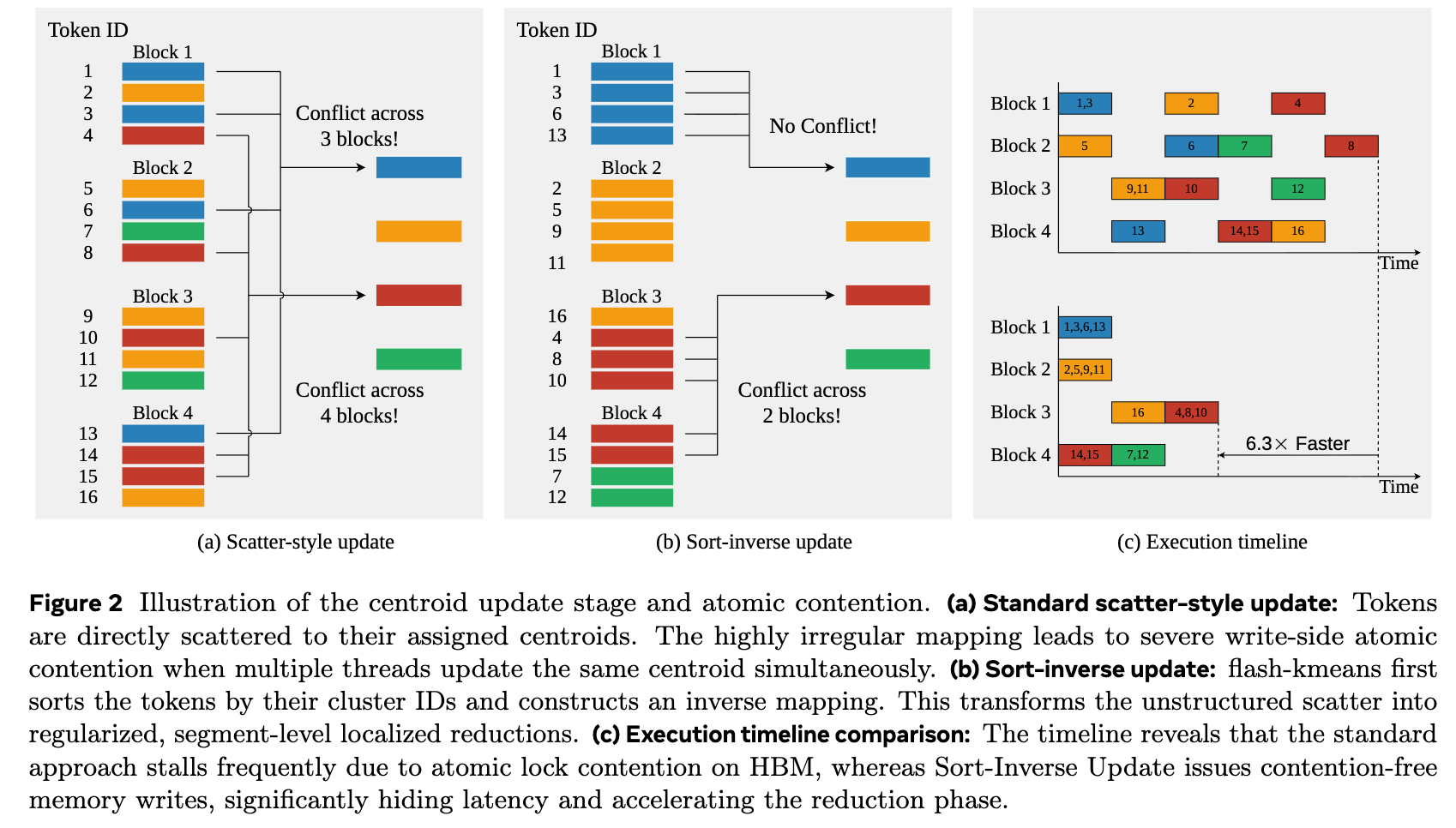
他にもシステムレベルの最適化を行っている(割愛)
- Chunked System Overlap データをチャンクに分割して、CUDA Streamを使って転送
- Cache-Aware Compile Heuristic 動的なshapeだと最適な構成(タイルサイズやスレッドブロックなど)が異なるので、ハードウェア特性から最適な構成を直接決める ([fr]事前に決めちゃうという理解)
結果
全体的な速度比較
Flash-KMeans速い
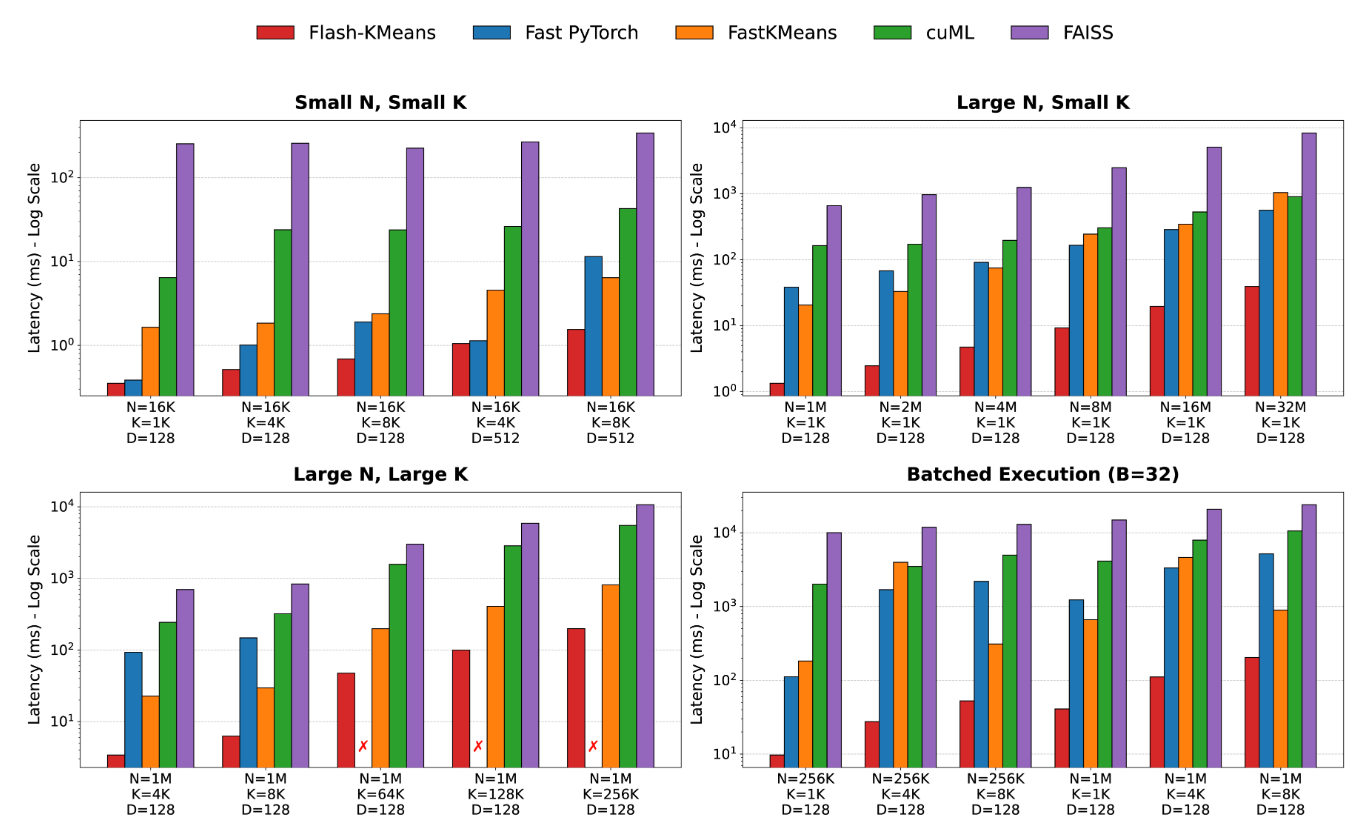
標準実装とのコンポーネント同士の比較
速い
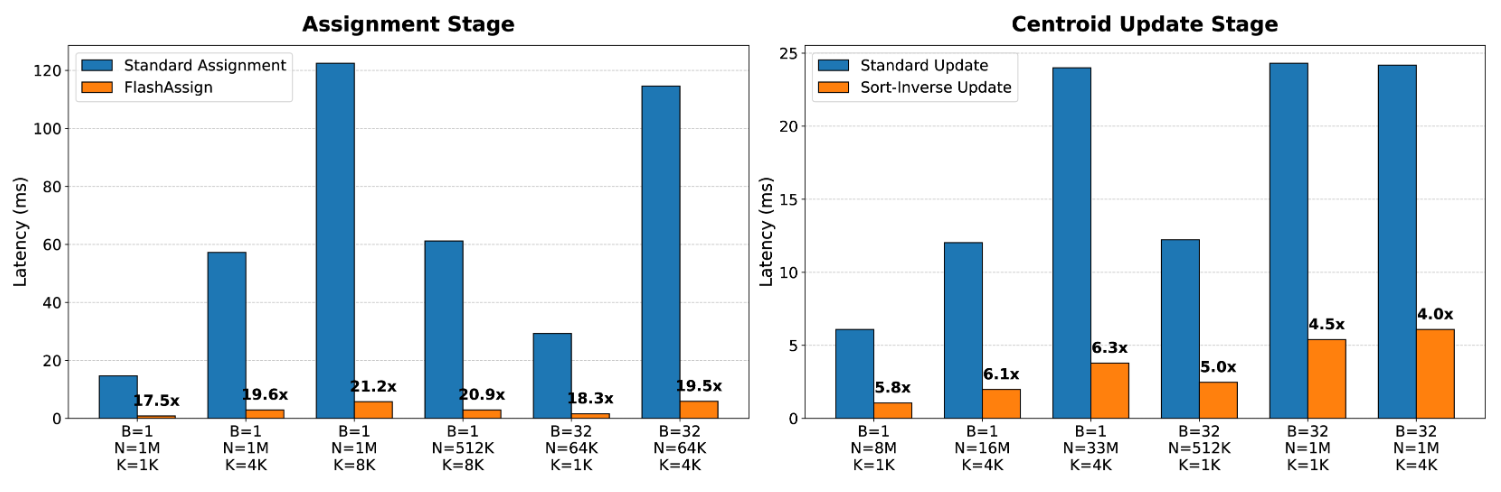
@Hiromu Nakamura (pon)
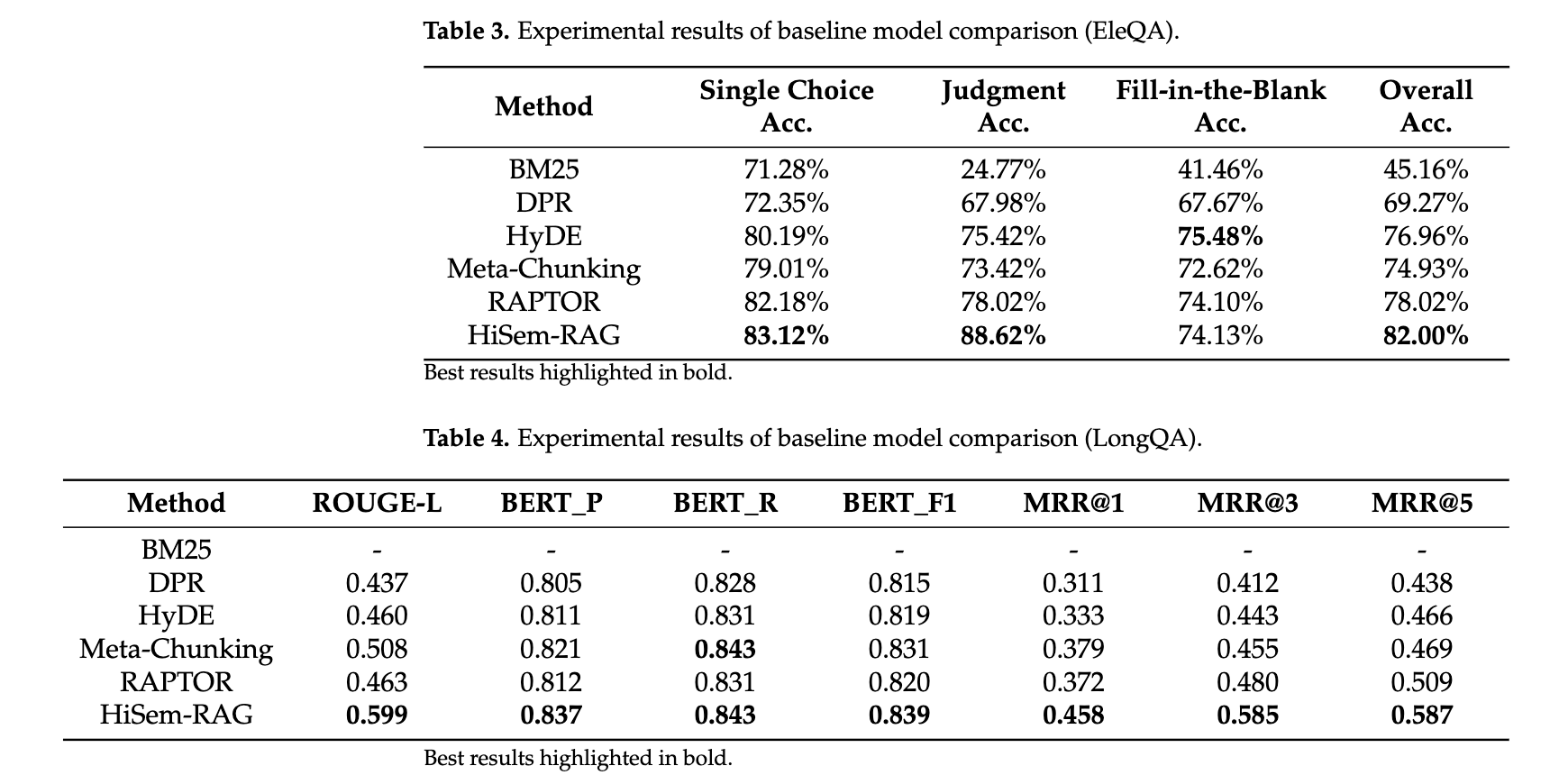
[paper] HiSem-RAG: A Hierarchical Semantic-Driven Retrieval-Augmented Generation Method
[pon] 複数のlong文書RAGなうなので色々調べてる。
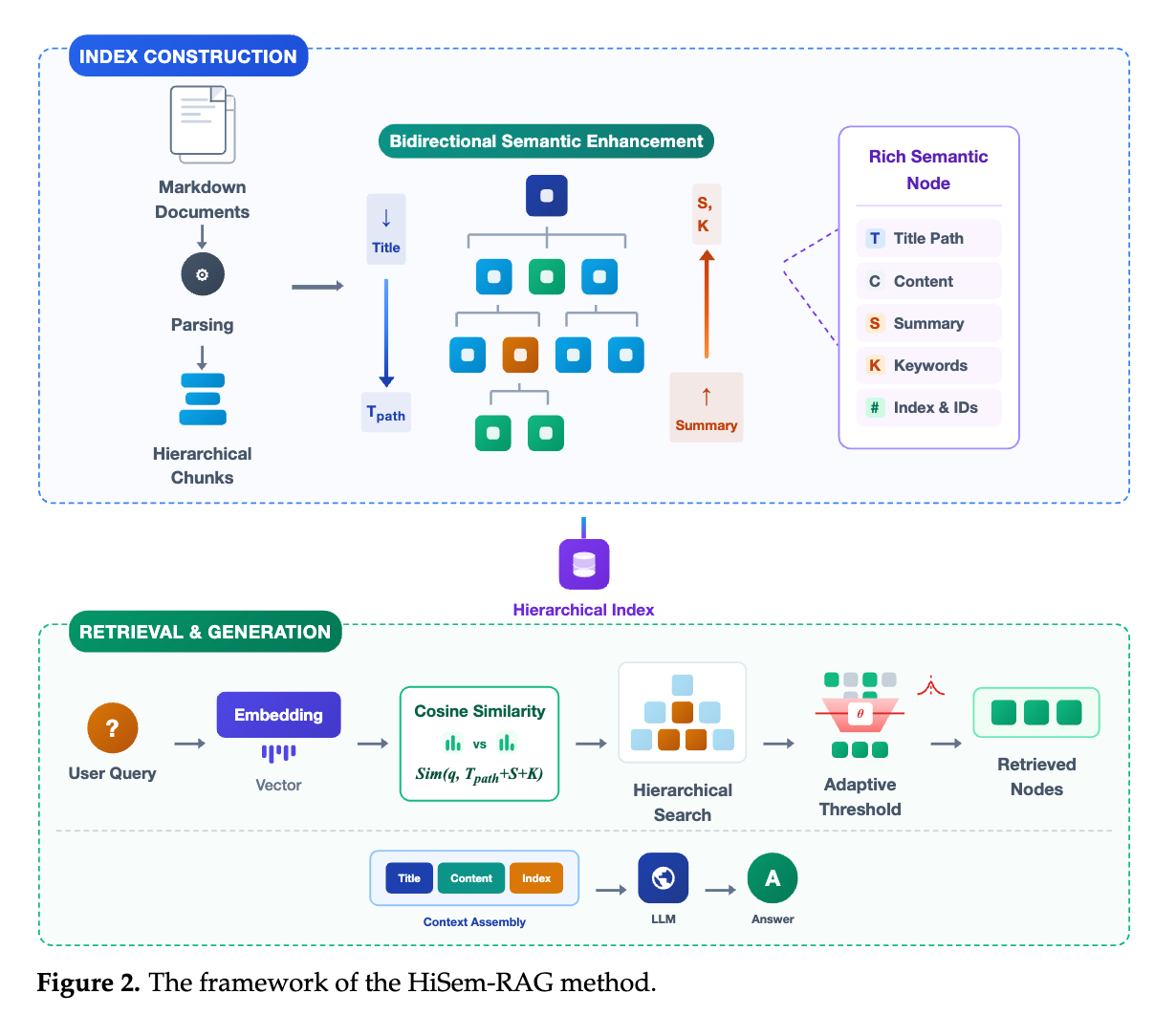
HiSem-RAGは、文書の自然な階層構造と意味的な関連性を活用する新しいアプローチを提案しています。その結果、既存の手法よりも高い精度と計算効率を達成し、特に長文の質問応答において優れた性能を発揮することを示しました。
主要な提案部分(HiSem-RAGの3つの主要モジュール)
HiSem-RAGは、以下の3つの主要なモジュールで構成されています。
- 階層的意味インデックス(Hierarchical Semantic Indexing)
- 解決する課題: 従来のRAG手法では、文書を一定の長さのブロックに機械的に分割するため、章やセクション、段落といった自然な階層構造が失われ、意味的な連続性が途切れてしまう問題がありました。これにより、特定の情報が文書のどこに位置するか、またその情報がどのような文脈にあるのかが不明確になり、検索の精度が低下することがありました。
- HiSem-RAGのアプローチ: このモジュールでは、文書をその自然な階層構造(例:章、セクション、サブセクション、段落)に基づいて解析し、木構造のインデックスを構築します。これにより、文書内の各意味単位(ノード)が、その親ノードや子ノードとの関係性を保持したまま表現されます。具体的には、
- 文書のタイトルや見出しを認識し、それらを基準に階層的なノードを作成します。
- 各ノードは、その内容の他に、親ノードの識別子、ルートから現在のノードまでの「タイトルパス」、そして後述の強化された意味情報(要約やキーワード)を持ちます。
- もしノードの内容が長すぎる場合は、意味的な境界(文や段落の区切り)を尊重しながら、再帰的に分割されます。これにより、情報の断片化を防ぎつつ、モデルが扱える適切な粒度で情報を保持します。
- このアプローチにより、特定の情報が文書全体の構造の中でどこに位置し、どのような役割を持つのかが明確になり、文脈に沿った正確な検索が可能になります。
- 双方向セマンティック強化(Bidirectional Semantic Enhancement)
- 解決する課題: 階層的なインデックスを構築しても、各ノードのセマンティックな表現が不十分だと、適切な検索ができません。特に、あるセクションの小見出しが別のセクションの小見出しと同一名称である場合など、文脈によって意味が異なる「構造的な曖昧さ」が発生することがあります。また、詳細な情報が下位のノードに分散している場合、上位のノードからその全体像を把握しにくいという問題もありました。
- HiSem-RAGのアプローチ: このモジュールは、各ノードの意味的な表現力を高めるために、情報フローを「上から下へ」と「下から上へ」の双方向で強化します。
- トップダウン(上から下へ): 各ノードの表現に、ルートからそのノードまでの完全な「タイトルパス」を付加します(例:「メイン変圧器システム」>「プロセス標準」)。これにより、たとえ小見出しが同一名称であっても、その親となる上位階層の文脈情報が付与されるため、意味的な曖昧さを解消し、正確な文脈特定が可能になります。ユーザーのクエリが特定の文脈を指している場合、このパス情報が非常に強力な手がかりとなります。
- ボトムアップ(下から上へ): 下位ノード(子ノード)の主要な知識点や要約情報を抽出し、それを上位ノード(親ノード)に集約させます。例えば、詳細な仕様が記述された複数の子ノードの内容を要約し、その要約を親ノードに持たせることで、親ノードが下位の情報の「セマンティックなアンカー」として機能するようにします。これにより、上位のノードは、下位の詳細な内容を把握しやすくなり、検索時に抽象度を調整しながら関連情報を効率的に特定できるようになります。
- この双方向の強化により、各ノードがよりリッチなセマンティック情報を持つようになり、検索の精度と文脈理解能力が大幅に向上します。
- 分布認識型適応的閾値検索(Distribution-Aware Adaptive Threshold Retrieval)
- 解決する課題: 従来のRAGシステムは、クエリに対する類似度が最も高い上位K個の文書(チャンク)を固定で取得する「トップK」戦略をよく採用していました。しかし、この方法は非効率的です。関連性の高い情報が多数存在する場合、Kが小さすぎると重要な情報を見落とす可能性があります。逆に、関連性の低い情報しかない場合でも固定でK個取得するため、Kが大きすぎるとノイズや無関係な情報を取り込み、計算コストが増大し、LLMの応答品質を低下させる原因となります。
- HiSem-RAGのアプローチ: このモジュールは、固定のトップK戦略に代わり、クエリと文書(ノード)間の「類似度スコアの分布」に基づいて、検索する文書の数を動的に調整します。
- 距離はこれ
- 動的な閾値設定: 各階層レベルにおいて、クエリと各ノードのセマンティックな類似度を計算します。そして、これらの類似度スコアの分布(最大値、平均値、ばらつきなど)を分析し、最適な「閾値」を算出します。この閾値以上の類似度を持つノードのみが、次の検索対象として選択されます。
- 文脈への適応: 例えば、クエリに非常に強く関連するノードが多数存在し、それらの類似度スコアが互いに近い場合は、閾値を適切に下げて、関連性の高い「クラスター全体」をまとめて取得します(例:図1の23個の標準項目を一括で取得)。逆に、関連するノードがほとんどなく、類似度スコアが低いノードばかりの場合は、閾値を高く設定し、ノイズとなる低関連性ノードの取得を避けます。
- 効率と精度の両立: この適応的なアプローチにより、検索範囲が必要に応じて広がり、重要な情報が欠落するのを防ぎます。同時に、不要な情報の取得を抑制することで、LLMへの入力トークン数を削減し、計算コストの削減と生成時のノイズ低減に貢献します。

探索
- 探索の開始:
- ユーザーのクエリが与えられると、まず最上位(ルート)レベルのノード(例:章)との類似性を計算します。
- 階層的な絞り込み:
- 「分布認識型適応閾値」に基づいて、類似性が高いと判断されたノード(章やセクションなど)が選択されます。再帰的な掘り下げ: その選択されたノードの子ノード(例:その章の中のセクション、そのセクションの中の段落)に対して、さらに類似性計算と閾値判定を行い、関連性の高いノードを次々と絞り込んでいきます
- 葉ノードの収集:
- このプロセスを繰り返し、最終的にコンテンツを持つ最小単位である「葉ノード(例:具体的な段落やチャンク)」に到達します。これらの葉ノードが、クエリに対する回答の生成に必要なコンテキストの主要部分となります。
- コンテキストの構築:
- 選択された葉ノードの「オリジナルコンテンツ」に加えて、そのノードが持つ「多段階のタイトルパス」や「インデックス」などの構造情報も合わせて、Large Language Model(LLM)への入力コンテキストとして組み立てられます。
結果
[pon]双方向にまとめ上げるEnhancesな埋め込みかー。面白いけどindex構築が重厚すぎるよ。
@ShibuiYusuke
[Blog/Paper] Systematic debugging for AI agents: Introducing the AgentRx framework
発行元: Microsoft Research
著者: Shraddha Barke, Arnav Goyal, Alind Khare, Avaljot Singh, Suman Nath, Chetan Bansal
GitHub: AgentRX
1. エグゼクティブサマリー
AgentRxは、Microsoft Researchが開発した、AIエージェントの実行トラジェクトリから障害を自動診断するドメイン非依存のフレームワーク。
「Agent Diagnosis(エージェント診断)」の略であり、医療の「処方箋(Rx)」になぞらえている。失敗したエージェント実行における「最初の回復不能な障害ステップ(Critical Failure Step)」を特定し、その原因を体系的に分類する。
AgentRxの主要な成果として、障害箇所の特定精度で +23.6%、原因分類精度で +22.9% の改善を達成。
フレームワークと115件の手動アノテーション付きベンチマークがオープンソース(MITライセンス)で公開。
2. 背景と動機
2.1 AIエージェントのデバッグが困難な理由
現代のAIエージェントは、クラウドインシデント管理、Webブラウジング、複雑なAPIワークフローの実行など、高リスクな環境で自律的に動作している。しかし、そのデバッグには3つの本質的な困難がある。
- ロングホライズン(Long-horizon): 数十ステップに及ぶ長大な実行トレースの中で、障害箇所が埋もれてしまう。Magentic-Oneではトラジェクトリあたり平均約16,484トークン、最大130ステップに達する。
- 確率的(Probabilistic): 同じ入力でも異なる出力が生じるため、再現が困難である。
- マルチエージェント(Multi-agent): 障害がエージェント間で伝播し、真の原因が隠蔽される。
2.2 先行研究の限界
従来のベンチマーク(AgentBench、WebArena、GAIA等)はタスクの最終的な成功・失敗のみを報告し、障害箇所のアノテーションを含まない。また、Who&When(W&W)は障害帰属を試みるが、「最初の回復不能な障害」ではなく「最初の障害」をラベリングするため、エージェントが回復した障害も誤って特定してしまう問題がある。AgentRxはこの限界を克服し、「最初の回復不能なクリティカル障害」を正確に特定する。
3. AgentRxフレームワークの詳細
3.1 パイプライン概要
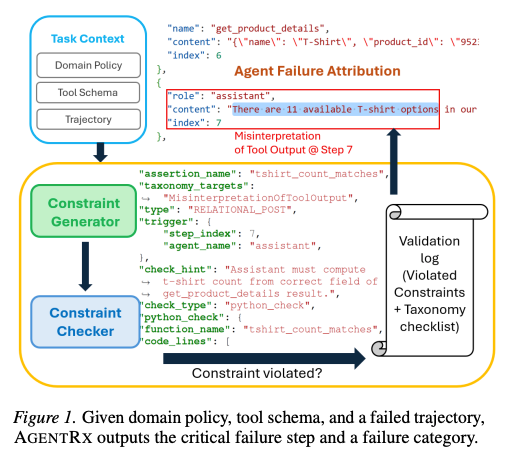
AgentRxはエージェント実行を「検証が必要なシステムトレース」として扱い、6段階のパイプラインで処理する。
| # | ステージ | 説明と出力 |
|---|---|---|
| 1 | IR正規化 | 異なるドメインのログを共通中間表現(Trajectory IR)に変換。各ステップにはエージェント名、ツール名、ステップインデックス、ツール出力または会話内容が含まれる。→ |
| 2 | Static制約生成 | ツールスキーマとドメインポリシーからグローバル制約(不変条件)を自動生成。トラジェクトリに依存しない普遍的ルール。→ |
| 3 | Dynamic制約生成 | 各ステップのコンテキスト(トラジェクトリの接頭辞 T≤k)に基づく動的制約を生成。過去のツール出力に基づく制約等。→ |
| 4 | Check(検証) | 各ステップでガード条件が成立する制約を評価。プログラマティックチェック(スキーマ検証等)とセマンティックチェック(LLMによる自然言語評価)を実行。→ |
| 5 | Judge(判定) | LLMベースのジャッジが、検証ログと障害タクソノミーチェックリストを用いてクリティカル障害ステップと原因カテゴリーを特定。→ |
| 6 | Report(報告) | 障害頻度の可視化プロットを生成。→ |
3.2 入力の定義
AgentRxは以下の3つを入力として受け取る。
- ツールセット T: 利用可能なツール/エージェントとその入出力スキーマ
- ドメインポリシー Π(任意): ドメイン固有の自然言語ルール
- 失敗トラジェクトリ T = ⟨s₁, …, sₙ⟩: エージェントの実行トレース全体
3.3 制約の合成と評価の機構
グローバル制約 C^G はツールスキーマ T とドメインポリシー Π から一度だけ生成され、グローバルストア G に格納される。例えば「APIは有効なJSONレスポンスを返す必要がある」「ユーザー確認なしにデータを削除してはならない」などのルールである。
動的制約 C^D_k は各ステップ k で、タスク指示 I と観測済み接頭辞 T≤k から生成される。例えば「前のステップでツールが返したTシャツの数と、エージェントが報告する数が一致するか」といった具体的な検証である。
ステップ k で利用可能な制約は、両者の和集合 Ck := C^G ∪ C^D_k として定義される。
3.4 ガード付き制約と評価メカニズム
各制約 C は以下の2つの要素で構成される。
- ガード条件 G_C(T≤k, sk): 制約が適用されるかを判定する条件。例:「このステップでツール t が呼び出された」「特定のエージェントが呼び出された」などの構造的条件。ガード条件が0ならSKIP。
- アサーション Φ_C(T≤k, sk): SAT(充足)またはVIOL(違反)を返す検証。判定と証拠のペア (v, e) を返す。
検証は2種類がある。プログラマティックチェックは構造化フィールドに対する述語(スキーマ妥当性、等値性、メンバーシップなど)で、セマンティックチェックはLLMベースの自然言語評価である。
3.5 検証ログとジャッジ
各ステップ k で違反が検出されると、ステップインデックス付きの検証ログ Vに記録される。このログは監査可能で、各違反が証拠に直接リンクされている。
LLMベースのジャッジは、この検証ログとタクソノミーチェックリスト K を使用して、クリティカル障害ステップと原因カテゴリーを特定する。ジャッジは違反を診断証拠として活用するが、トラジェクトリのコンテキストが示す場合はオーバーライドも可能である。
タクソノミーチェックリスト K は、各障害カテゴリーに対して、そのカテゴリーの定義を運用化する小規模なyes/no質問と簡潔な判定基準を指定する。
3.6 制約スキーマの構造
制約は軽量なJSONスキーマで標準化され、以下のフィールドを持つ。
- : 一意のスネークケース名
- : 関連する障害カテゴリーのリスト
- : SCHEMA / PROTOCOL / RELATIONAL_POST / PROVENANCE / TEMPORAL / CAPABILITY / ANY
- : ガード条件(step_index, substep_index, role_name, content_regex, tool_name)
- : 決定的手順の説明(2〜8文)
- : または
- : 実行可能なPythonコード(関数名、引数、コード行)
- : LLMベースのルーブリック評価(システムプロンプト、ユーザープロンプト、ルーブリック、評価アルゴリズム、出力フォーマット)
3.7 具体例:Tシャツカウント制約
論文で示される代表的な例として、アシスタントエージェントが を呼び出して「11件の利用可能なTシャツオプション」と報告した場面がある。AgentRxは という関係制約を合成し、ツールレスポンスから実際のカウントを再計算してアシスタントの解釈と一致するかを検証する。この例では として実行可能なPythonコードが生成され、ツール出力のvariantsフィールドから のエントリ数を数え、アシスタントの報告数と比較する。
3.8 セマンティックチェックの例
もう一つの代表例として、「書き込みアクション前のユーザー確認」を検証するセマンティックチェックがある。この制約は 、 等の書き込みツール呼び出し前に、アシスタントが意図するアクションとターゲットIDを説明し、ユーザーが明示的に確認したかを検証する。LLMジャッジにルーブリック(3基準)が渡され、各基準に対して CLEAR_PASS / CLEAR_FAIL / UNCLEAR の評価が行われ、UNCLEAR は破棄される。
4. AgentRxベンチマーク
4.1 3ドメインの構成
115件の失敗トラジェクトリが以下の3ドメインから収集され、手動でアノテーションされている。
| ドメイン | トラジェクトリ数 | 種類 | 説明 |
|---|---|---|---|
| τ-bench | 29 | 単一エージェント | 小売・サービスタスクの構造化APIワークフロー。LLMシミュレートユーザーと単一エージェント。メディアン36ステップ(範囲: 20〜62)、平均4,889トークン/トラジェクトリ |
| Flash | 42 | マルチエージェント | 実運用環境でのインシデント管理・トラブルシューティング。専門エージェントチームがトラブルシューティングガイドを実行。メディアン3ステップ(範囲: 2〜6、平均8サブステップ/ステップ)、平均6,415トークン |
| Magentic-One | 44 | マルチエージェント | オープンエンドのWeb/ファイルタスク。5つの専門エージェント(WebSurfer, FileSurfer, Coder等)を持つ汎用マルチエージェントシステム。メディアン33ステップ(範囲: 5〜130)、平均16,484トークン |
4.2 グラウンデッドセオリーによるアノテーションプロセス
アノテーションは、仮説駆動ではなくデータ駆動のグラウンデッドセオリー(GT)コーディングプロセスに従う。3名のアノテーターが独立に作業し、2フェーズで実施された。
フェーズ1(包括的障害マーキング): エージェントが復旧した障害も含め、全ての障害ステップをマーク。各障害についてステップインデックス、オープンコード(短い具体的説明)、理由を記録。
フェーズ2(クリティカル障害特定): 最終的な失敗から逆算し、エージェントが回復できなかった最も早い障害を特定。
コーディングプロセス全体を通じて、新しいコードは既存のコードと比較され、一致すれば再利用、そうでなければ新規コードを作成。理論的飽和(新しいトラジェクトリが新しい障害現象を導入しなくなった時点)に達した段階でカテゴリー定義を凍結し、クローズドコーディングで残りのトラジェクトリをアノテーションした。
アノテーションコスト: 平均所要時間はτ-benchが20分/トラジェクトリ、Flashが22分、Magentic-Oneが24分。115トラジェクトリ全体で約42.7時間の人的労力を要した。このコストの高さがAgentRxの自動化の動機である。
4.3 W&Wとの比較
W&Wのアノテーションは「最初の障害」をラベリングするが、AgentRxは「最初の回復不能な障害」を特定する。論文で示された具体例では、W&Wがステップ3のWebSurferのアクセス障害をラベリングしたが、実際にはオーケストレーターがFileSurferに切り替えて回復しており、真のクリティカル障害はステップ33のFileSurferによるハルシネーション(存在しないファイルパスの参照)であった。
4.4 ベンチマークフォーマット
各エントリはトラジェクトリに対応し、以下を含む。
- 識別子(trajectory_id)
- 実行中に検出された障害イベントのリスト(step_number, step_reason, failure_category, category_reason, failed_agent)
- クリティカル障害(root_cause: failure_id + reason_for_root_cause)
- 障害サマリー(failure_summary)
5. 9カテゴリー障害タクソノミー
グラウンデッドセオリーに基づき、理論的飽和に達するまで反復的に精緻化された9カテゴリーの障害タクソノミーが導出された。
| # | カテゴリー | 説明 |
|---|---|---|
| 1 | Plan Adherence Failure | 必要なステップのスキップや不要なアクションの追加など、計画・ポリシーからの逸脱。過少実行と過剰実行の両方を含む。 |
| 2 | Invention of New Information | 利用可能な入力・コンテキスト・ツール出力に基づかない情報の捏造・省略・改変。ハルシネーションを含む。 |
| 3 | Invalid Invocation | 不正なツール呼び出し。引数の不足・型エラー・スキーマ違反など。 |
| 4 | Misinterpretation of Tool Output | ツール出力の誤解釈。計算エラーや部分的な出力のみの考慮を含む。 |
| 5 | Intent–Plan Misalignment | ユーザーの目標や制約を誤解し、誤った計画を立案。 |
| 6 | Under-specified User Intent | 必要な情報が不足しており、タスクを進められない。 |
| 7 | Intent Not Supported | 利用可能なツールでは実行できないアクション。 |
| 8 | Guardrails Triggered | 安全ポリシーや外部アクセス制限による実行のブロック。CAPTCHA、403エラー等。 |
| 9 | System Failure | 接続問題やエンドポイント障害などのインフラエラー。 |
実験時にはこれに加え 10. Inconclusive(証拠不十分で分類不能)が使用される。
5.1 ドメイン別障害分布
各ドメインでのクリティカル障害の分布(失敗トラジェクトリに占める割合)は以下の通り。
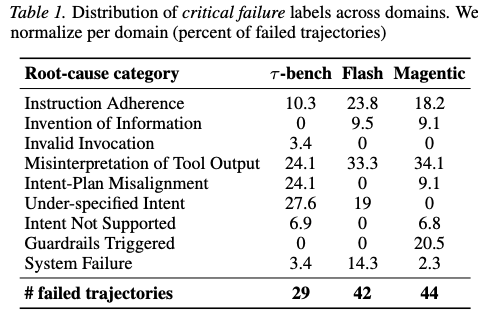
注目すべき点: 全ドメインで「Misinterpretation of Tool Output」が最も多い障害原因である。Magentic-Oneは1トラジェクトリあたり平均6.7件の障害を含み、68%のトラジェクトリが2件以上の障害を含んでいる。全体では、Magentic-Oneで295件、Flashで52件、τ-benchで39件の障害が検出された。
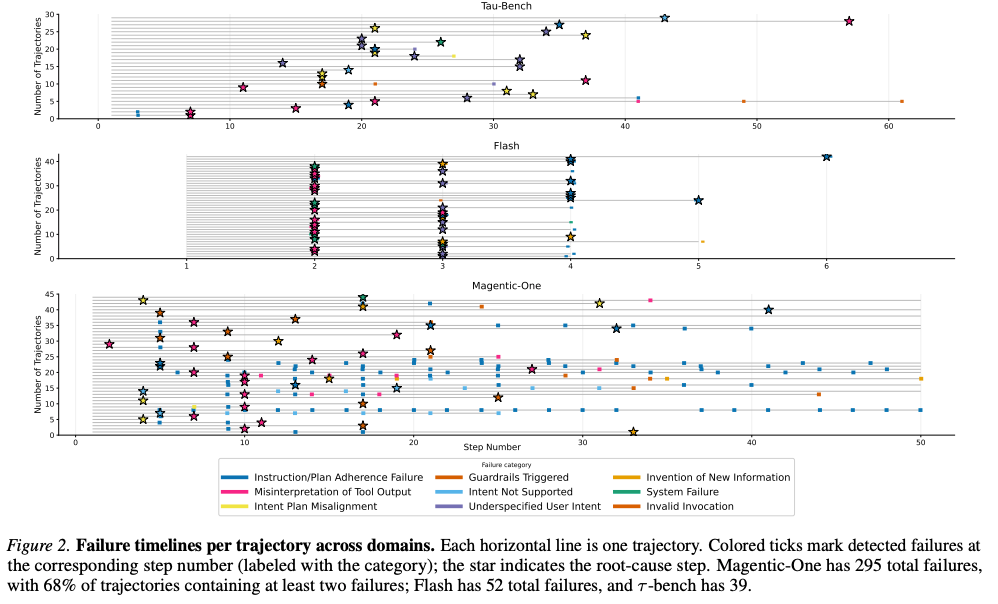
6. 実験結果
6.1 評価指標
以下の2軸で評価が行われた。
ステップ特定精度:
- Critical Step-index Accuracy: 予測ステップと正解ステップが完全一致する割合
- Accuracy@±r: 予測が正解の±rステップ以内に収まる割合(r ∈ {1, 3, 5})
- Average Step Distance: 予測と正解の平均距離(低いほど良い)
原因分類精度:
- Critical Failure Category Accuracy: クリティカル障害のカテゴリーが一致する割合
- Any-failure Category Accuracy: トラジェクトリ内のいずれかの障害カテゴリーと一致する割合
- Earliest / Terminal Category Accuracy: 最初/最後の障害カテゴリーと一致する割合
全ての実験は n=3 回実行され、平均±標準偏差で報告される。デフォルトモデルはGPT-5。
6.2 Who&Whenとの比較
| 手法 | τ-bench Agent (%) | τ-bench Step (%) | Magentic Agent (%) | Magentic Step (%) |
|---|---|---|---|---|
| Who&When* (最良) | 62 | 17.2 | 6.2 | 56.3 |
| AgentRx Baseline | 75.9 | 32.2 | 81.2 | 56.3 |
AgentRxの最もシンプルなベースラインでさえ、W&Wの最良バリアントを上回る。この改善は、包括的な障害タクソノミーに基づき、人間のアノテーターと同じ障害帰属手順をプロンプトに組み込んだベースラインの強さに起因する。W&Wのステップバイステップバリアントはトラジェクトリあたり16倍のLLM呼び出しを必要とし、all-at-onceバリアントではMagneticでわずか12.5%のステップ精度しか達成していない。
6.3 AgentRx最良構成の性能
| ドメイン | 指標 | Baseline | AgentRx Best | 改善幅 |
|---|---|---|---|---|
| τ-bench | Step Accuracy | 32.2 ± 3.2 | 54.0 ± 1.6 | +21.8pp |
| Category Accuracy | 25.3 ± 1.6 | 40.2 ± 1.6 | +14.9pp | |
| Avg Step Distance | 5.7 ± 0.8 | 2.4 ± 0.5 | -3.3 | |
| Flash | Step Accuracy | 80.9 ± 2.3 | 83.3 ± 2.3 | +2.4pp |
| Category Accuracy | 53.9 ± 3.6 | 60.3 ± 1.3 | +6.4pp | |
| Magentic* | Step Accuracy | 42.0 ± 1.8 | 46.9 ± 3.5 | +4.9pp |
| Category Accuracy | 39.5 ± 3.5 | 44.4 ± 3.0 | +4.9pp |
Magentic*はMagneticの27トラジェクトリ(長さ50ステップ以下)のフィルタリング済みサブセット。
6.4 許容範囲付き精度
| ドメイン / 手法 | Step Acc. | @±1 | @±3 | @±5 | Avg Dist. | Critical Cat. | Any Cat. |
|---|---|---|---|---|---|---|---|
| τ-bench Baseline | 32.2 | 36.8 | 50.6 | 66.7 | 5.7 | 25.3 | 35.6 |
| τ-bench AgentRx | 54.0 | 59.8 | 72.4 | 83.9 | 2.4 | 40.2 | 41.4 |
| Flash Baseline | 80.9 | 94.4 | 100 | 100 | 0.2 | 53.9 | 62.7 |
| Flash AgentRx | 83.3 | 98.4 | 100 | 100 | 0.2 | 60.3 | 65.8 |
| Magentic Baseline | 31.8 | 40.9 | 50.0 | 53.3 | 22.1 | 36.3 | 58.3 |
| Magentic* AgentRx | 46.9 | 61.7 | 72.8 | 79.0 | 4.8 | 44.4 | 67.9 |
6.5 アブレーション分析
違反証拠 vs チェックリストの効果
| 入力信号 | τ-bench Step (%) | τ-bench Cat (%) | 説明 |
|---|---|---|---|
| Baseline | 32.2 | 25.3 | 何も追加しない |
| Violations only | 47.1 | 37.9 | 違反証拠のみ |
| Checklist only | 32.2 | 25.3 | チェックリストのみ(改善なし) |
| Checklist + Violations | 48.3 | 39.1 | 両方の組み合わせ |
τ-benchでは違反証拠単独で大きな改善。Flashでは両方の信号が有効。Magenticではチェックリスト単独が最も強力で、セマンティック構造がノイズの多い違反証拠を上回る場合がある。ほとんどの設定で、チェックリスト+違反の組み合わせが単独の信号を上回る。
Global vs Dynamic制約(τ-bench)
| 手法 | Step Accuracy (%) | Category Accuracy (%) |
|---|---|---|
| Baseline | 32.2 ± 3.2 | 25.3 ± 1.6 |
| Global-Only | 41.4 ± 2.8 | 28.7 ± 1.6 |
| Dynamic-Only | 43.7 ± 1.6 | 36.8 ± 1.6 |
| AgentRx(両方) | 48.3 ± 0 | 39.1 ± 1.6 |
Dynamic-Onlyが単体で最も強力(特にカテゴリー精度)だが、両方の組み合わせが最良性能を示す。
One-shot vs Step-by-step制約生成
- 短いトラジェクトリ(τ-bench: 平均4,889トークン): One-shotが優位。最良で54.0% step / 40.2% cat。
- 長いトラジェクトリ(Magentic: 平均16,484トークン): Step-by-stepが優位。コンテキスト希釈の問題が原因。Magentic*ではstep 46.9% / cat 44.4%。
- Flash: 混合パターン。Step-by-stepがカテゴリー精度を改善。
ジャッジプロトコル
All-at-Once: ステップとカテゴリーを1回のLLM呼び出しで同時予測。AgentRxのデフォルト設定。
Step-then-Category: まずステップを選択し、そのステップに条件付けてカテゴリーを2回目の呼び出しで予測。
τ-benchではStep-then-Cat.+Vio.が最良(54.0 step / 40.2 cat)だが、FlashやMagenticの長いトラジェクトリではAll-at-Onceが安定。Step-then-Categoryは単一ステップにコミットした後にタクソノミーのセマンティクスを考慮するため、ノイズの多いステップ予測がカスケードエラーを引き起こす可能性がある。
NLチェックの有無(τ-bench, Step-by-step)
| 手法 | Step Accuracy (%) | Category Accuracy (%) |
|---|---|---|
| Without NL Check | 36.8 ± 1.6 | 32.2 ± 3.2 |
| With NL Check | 41.4 ± 2.8 | 35.6 ± 1.6 |
セマンティックチェック(NLチェック)の追加により両指標が改善。
Few-shot例の効果(τ-bench, One-shot)
| 手法 | Step Accuracy (%) | Category Accuracy (%) |
|---|---|---|
| Examples only | 33.3 ± 1.6 | 31.0 ± 2.8 |
| Examples + Violations | 49.4 ± 1.6 | 46.0 ± 1.6 |
合成few-shot例と違反証拠の組み合わせが最も高いカテゴリー精度(46.0%)を達成。
7. 感想
- 「最初の回復不能な障害」の重要性
- 多様なシステムを繋ぐAIエージェントにおけるログのIR
@Akira Manda(zunda)
[paper]UP TO 36X SPEEDUP: MASK-BASED PARALLEL INFERENCE PARADIGM FOR KEY INFORMATION EXTRACTION IN MLLMS
1. 背景と課題
請求書やレシートなどの Visually-rich Documents (VrDs) から必要な情報を抽出する Key Information Extraction (KIE) において、近年 MLLMs が高い性能を示しています。
しかし、既存の LLMs / MLLMs はトークンを順番に生成する Autoregressive Inference(自己回帰型推論) に依存しているため、以下のような課題がありました。
- 推論速度のボトルネック: 順番にトークンを生成するため、抽出するフィールド(例:価格、日付など)が多くなるほど遅延が深刻化する。
- 非効率性: KIEタスクにおいて、各フィールドの答えは「画像内の特定の領域」に依存しており、直前に生成されたテキストトークンへの依存度は実は低い(並列化が可能である)。
2. 解決すべき課題:自己回帰型推論の限界
従来のLLMやMLLMは、直前のトークン群に基づいて次のトークンを1つずつ予測する。数式で表すと以下のようになる。
しかし、領収書や請求書などの視覚的に豊かな文書 (Visually-rich Documents: VrDs) から「日付」「金額」「商品名」などを抽出するKIEタスクにおいて、それぞれの項目は意味的に独立しています。それにもかかわらず順番にトークンを生成しなければならないことは、計算効率の面で大きなボトルネックとなっていました。
3. 提案手法:PIP (Parallel Inference Paradigm)
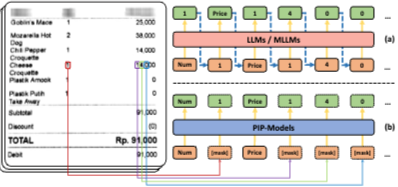
著者たちは、抽出したいターゲット値の部分を トークンに置き換えたプロンプト(例: )を入力として与える手法を提案しました。これにより、モデルはマスクされた位置の集合 M に対して、同時に予測を行うことが可能になります。
マスクされた位置の集合を とし、マスクされていないトークンを とします。
KIEは本質的に画像内の特定の視覚的領域を「検索(Retrieval)」するタスクに近いため、各 トークンが画像内の異なる適切な領域(Bounding Boxなど)に独立してアテンションを向けることができ、トークン同士が干渉せずに並列デコードが可能になります。
4. PIPを実現するための2段階学習プロセス
既存の自己回帰型MLLMをPIPアーキテクチャに適応させるため、専用の2段階の学習パイプラインを構築している。
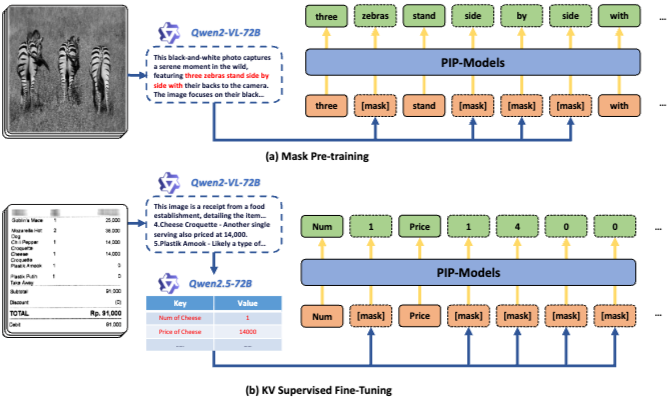
- Mask Pre-training (マスク事前学習):
- 目的: モデルに非順次的なテキスト生成能力と、文書全体のグローバルなレイアウト理解を獲得させる。
- 手法: 約1,300万の画像-キャプションペアを使用。テキスト内のトークンをランダムにマスクし、画像と可視トークンから復元させる。
- アーキテクチャ変更: 従来の単方向(因果的)アテンションから、全トークンが前後の文脈を参照できる双方向アテンション(Bidirectional Attention)に変更している。
- KV Supervised Fine-Tuning (KV 教師あり微調整):
- 目的: 獲得した並列生成能力をKIEタスクへ適応させ、情報の構造化精度を高めつつ、幻覚(Hallucination)を抑制する。
- 手法: 48クラスに分類された高品質なKV抽出データセットを構築。画像内に該当するキーが存在しない場合は明示的に unknown と出力するように学習させている。
5. 主な実験結果
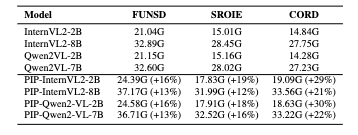
SROIE、CORD、FUNSD などの主要ベンチマークで、従来モデルとベースモデル(InternVL2、Qwen2-VL)を比較検証しました。
5.1 抽出精度と推論速度の両立
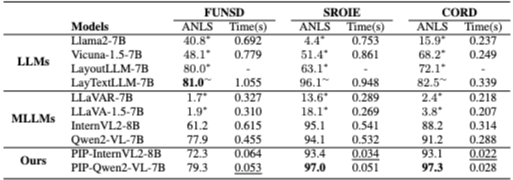
| Models | SROIE (ANLS) | CORD (ANLS) | WildReceipt (F1) | Average Time(s) / Speedup |
|---|---|---|---|---|
| Qwen2-VL-7B (Base) | 94.1 | 91.2 | 54.9 | 0.218 ~ 0.532s |
| PIP-Qwen2-VL-7B (Ours) | 97.0 | 97.3 | 71.6 | 0.006 ~ 0.053s (8.6× ~ 36.3×) |
| InternVL2-8B (Base) | 95.1 | 88.2 | 53.8 | 0.314 ~ 0.541s |
| PIP-InternVL2-8B (Ours) | 93.4 | 93.1 | 69.0 | 0.010 ~ 0.034s (14.3× ~ 34.7×) |
抽出対象のキー項目が多いデータセット(WildReceiptなど)において並列化の恩恵が最大化され、最大36.8倍の推論高速化が確認された。
5.2 トレードオフの分析(GPUメモリ消費量)
入力プロンプトに多数の [mask] トークンを配置するため入力シーケンス長が増加するが、GPUメモリの消費量はベースモデルと比較して最大で約30%(+12%〜+30%)の増加に留まっている。推論速度が5〜36倍に向上していることを考慮すると、システム全体のスループットは飛躍的に向上しており、実用上のトレードオフとして極めて優秀である。
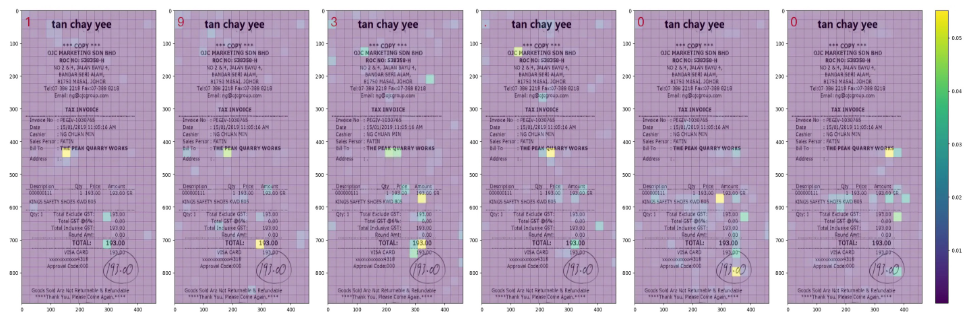
5.3 メカニズムの証明(アテンションの可視化)
並列生成時に各 [mask] トークンが干渉せずに正確な値を出力できる理由を、アテンションマップの可視化により証明している。
SROIEデータセットにおいて「193.00」という数値を生成する際、各出力トークン(1, 9, 3, ., 0, 0)は、画像内の対応する文字領域(空間的局所性)へ個別に直接アテンションを向けていることが確認された。これにより、KIEタスクが条件付き独立(conditionally independent)であり、並列デコードが有効に機能するメカニズムが視覚的に裏付けられている。
@Shuhei Nakano(nanay)
[blog] Optimizing Recommendation Systems with JDK’s Vector API
- タイトル: Optimizing Recommendation Systems with JDK's Vector API
- 著者 / 組織: Harshad Sane / Netflix
- 公開日: 2026年3月
- URL: https://netflixtechblog.com/optimizing-recommendation-systems-with-jdks-vector-api-30d2830401ec
1. どんな記事?
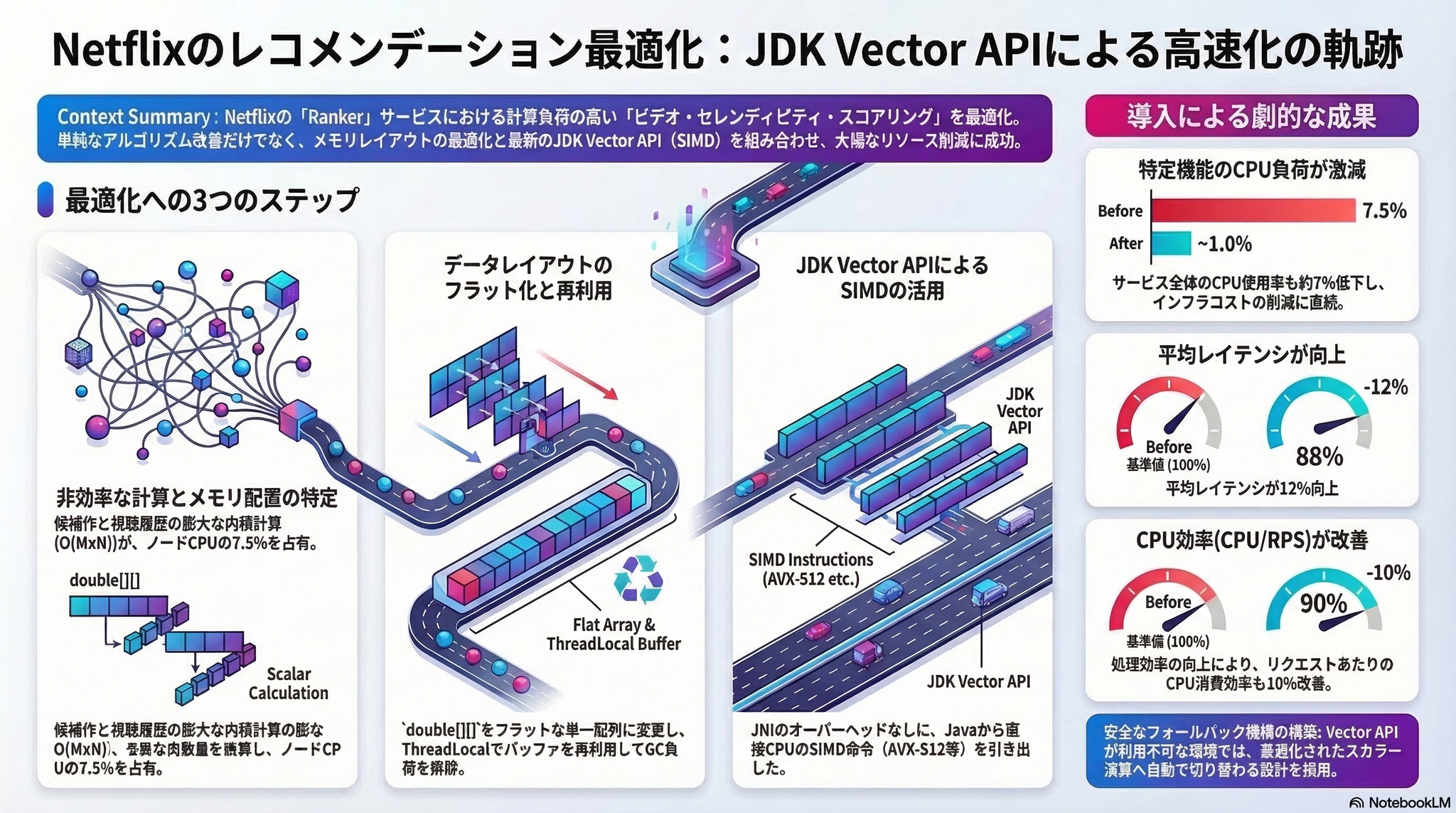
Netflixのレコメンデーション基盤であるRankerサービスにおいて、「セレンディピティスコアリング(Serendipity Scoring)」—ユーザーの視聴履歴と候補タイトルの「新規性」を測る処理—がノードあたりCPUの約7.5%を消費していた問題に取り組んだ記事。個別のドット積計算からバッチ行列演算への変換、メモリレイアウト最適化、そして最終的にJDKのベクトルAPI(Vector API)によるSIMD化を段階的に適用し、CPU消費を約1%まで削減した。
2. 何が課題だったのか?
- 候補動画ごとにユーザーの視聴履歴全件とコサイン類似度を逐次計算する O(M×N) の処理が高コスト
- メモリアクセスが散在し、キャッシュ局所性(Cache Locality)が低い
- 全リクエストの2%に過ぎないバッチリクエストが、処理量ベースでは全体の約50%を占めており、最適化効果の大きいターゲットだった
- BLAS(Basic Linear Algebra Subprograms)ライブラリはマイクロベンチマークでは有望だったが、JNI遷移オーバーヘッドや行列レイアウトの不一致(行優先 vs 列優先)で実運用パイプラインでは性能が出なかった
3. アーキテクチャ・技術的アプローチ
4段階の最適化プロセス:
- バッチ化・行列演算への変換: 個別ドット積 → 行列積 に変換し、M×N個の類似度を一括計算
- メモリレイアウト最適化: → フラットな (行優先)に変換し、連続メモリアクセスを実現。 パターンでバッファを再利用しGC圧力を排除
- BLAS調査(不採用): netlib-java BLASを検証するも、JNIオーバーヘッド・列優先変換コスト・追加アロケーションにより断念
- JDK Vector API によるSIMD化: でハードウェア最適なレーン幅(AVX2: 4レーン、AVX-512: 8レーン)を自動選択し、FMA(Fused Multiply-Add)演算で行列積を高速化
フォールバック設計: パターンにより、起動時にVector APIの利用可否を判定。利用不可時はループ展開済みのスカラー実装にフォールバック。
4. 設計上のこだわり・工夫
- Pure Java で完結: JNIやネイティブ依存なし。コードの可読性・保守性を維持しつつSIMD性能を獲得
- 段階的アプローチ: いきなりSIMD化せず、まずアルゴリズム形状(行列積化)→データレイアウト→計算カーネルの順に基盤を整備
- ThreadLocal バッファ再利用: スレッド安全性を保ちつつアロケーションゼロを実現。バッファは grow-only で shrink しない設計
- マイクロベンチマーク vs 本番の乖離を重視: BLASはベンチマークでは有望でもフルパイプラインでは逆効果だった教訓から、統合テストでの検証を徹底
- 後方互換性: 単一動画リクエスト(全体の98%)は既存パスを維持し、バッチパスを追加する形で安全にロールアウト
5. 現時点の制約と今後の展望
- JDK Vector APIはインキュベーション段階: フラグが必要で、APIの安定性は今後のJDKリリースに依存(JEP 489: 第9次インキュベーター)
- GPU活用は未着手: HNの議論ではCUDAによる100倍高速化の事例も言及されており、GPUオフロードは将来の選択肢
- データフェッチがボトルネック: 計算カーネル最適化後は、埋め込みベクトルのメモリへのロード自体が律速になる可能性
6. Take Home Message
- 「ライブラリ選定」より「データレイアウト」が先: メモリの連続性・キャッシュ局所性という基盤を整えなければ、どんな高速ライブラリも性能を発揮できない
- マイクロベンチマークを鵜呑みにしない: 部分最適が全体最適とは限らない。フルパイプラインでの統合評価が不可欠
- JDK Vector APIはPure Javaで実用レベルのSIMD性能を提供: JNI不要でネイティブライブラリ同等の性能が得られる現実的な選択肢になりつつある
- 2%のリクエストが50%の計算量を占める: トラフィックパターンの分析が最適化対象の正しい優先順位付けに直結する
7. 関連リソース
- JEP 489: Vector API (Ninth Incubator) — JDK Vector APIの仕様と現在のステータス
- netlib-java — 記事中で検証されたJava向けBLASライブラリ
- RecSysOps: Best Practices for Operating a Large-Scale Recommender System (Netflix) — Netflix推薦システムの運用プラクティス
本番パフォーマンス結果
| 指標 | 改善幅 |
|---|---|
| CPU利用率 | ~7% 削減/ノード |
| 平均レイテンシ | ~12% 改善 |
| CPU/RPS(正規化) | ~10% 改善 |
| 関数レベルCPU | 7.5% → 約1% |
@Kyohei Uto(kuto)
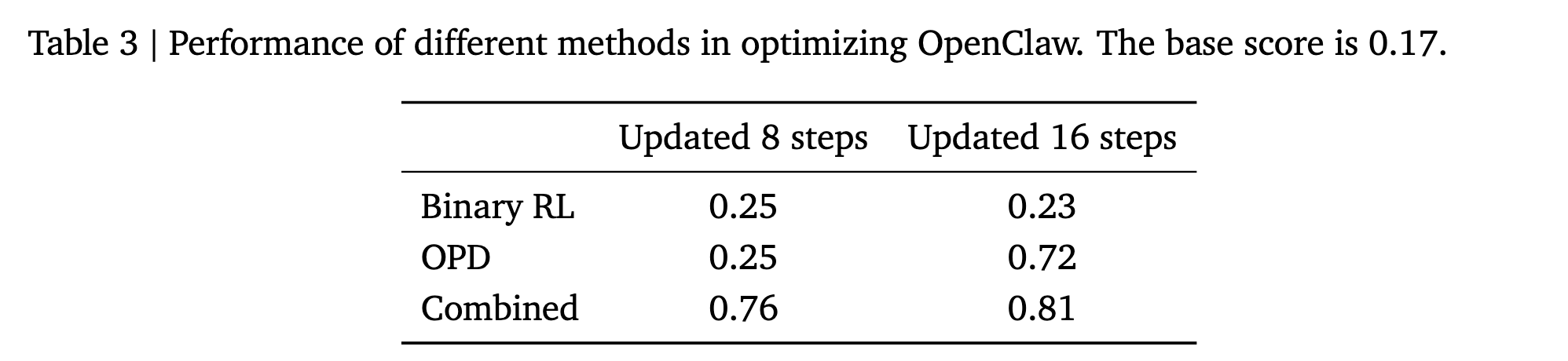
[paper]OpenClaw-RL: Train Any Agent Simply by Talking
概要
- ユーザとのインタラクションをもとに逐次非同期でオンライン学習する「OpenCraw-RL」の提案
- 論文中ではパーソナライズAIと汎用AIの2つに言及があるがここでは前者に絞って紹介する
- 実験的なプロジェクトであるため細かな手法や性能よりも、「使えば使うほど賢くなる」を実現するための継続的学習プロセスの一例としてみると面白い
背景
AIエージェントの課題
- ユーザや環境とのインタラクションから得られるフィードバックをモデル改善に自動活用していない(skill更新やプロンプト更新は一定あるがモデルパラメータ自体の更新はない)
アイデア・手法
パーソナライズエージェント
- インタラクションで得られる会話シグナルの報酬化と会話セッションをもとに非同期RLでモデル更新する点が特徴
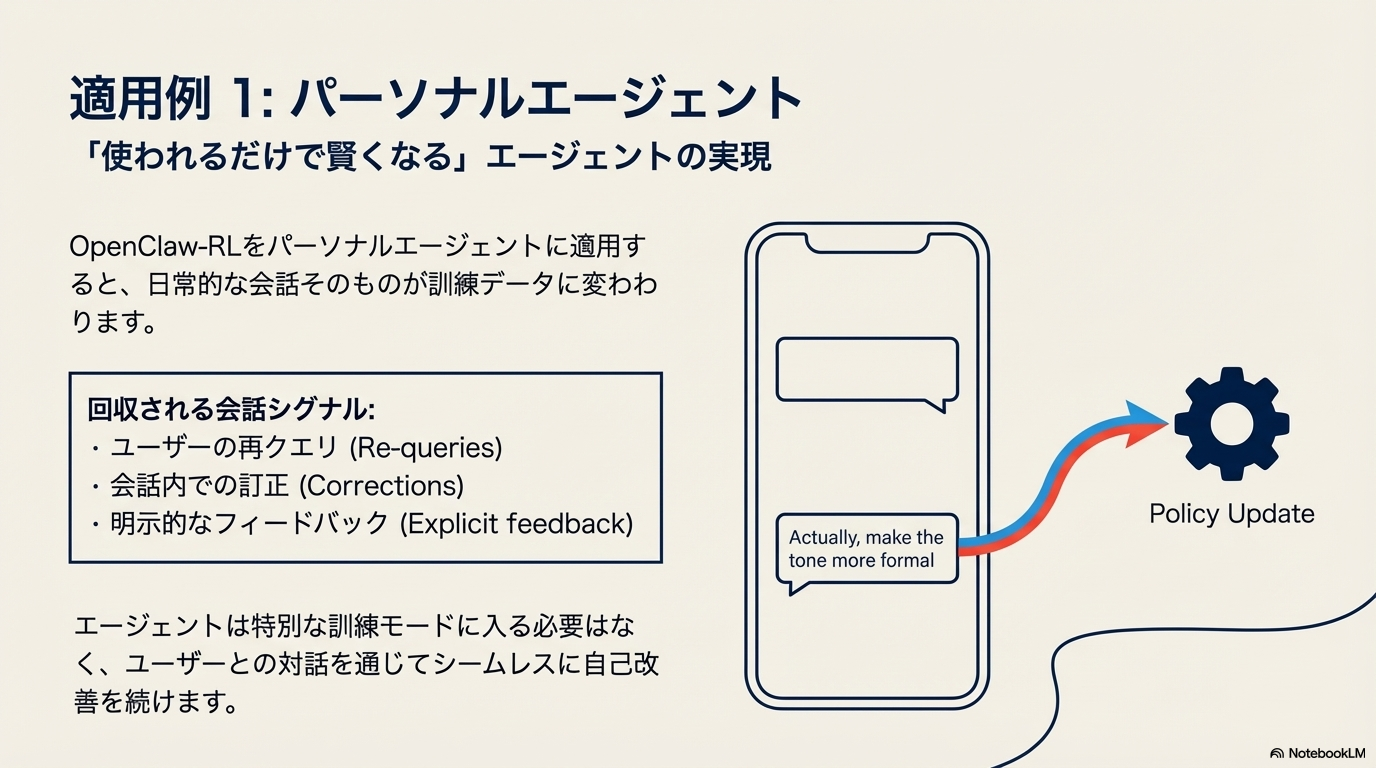
報酬設計
以下2つの加重平均を報酬として利用
- バイナリー報酬
- 次ステップで得られるユーザ応答と環境フィードバックからLLMで報酬生成(+1,-1,0)
- アウトカム報酬ではなく毎ステップのプロセス報酬
- オンポリシー自己蒸留
- 次ステップで得られるユーザ応答と環境フィードバックをコンテキストに加えた教師モデルで生徒モデルを自己蒸留
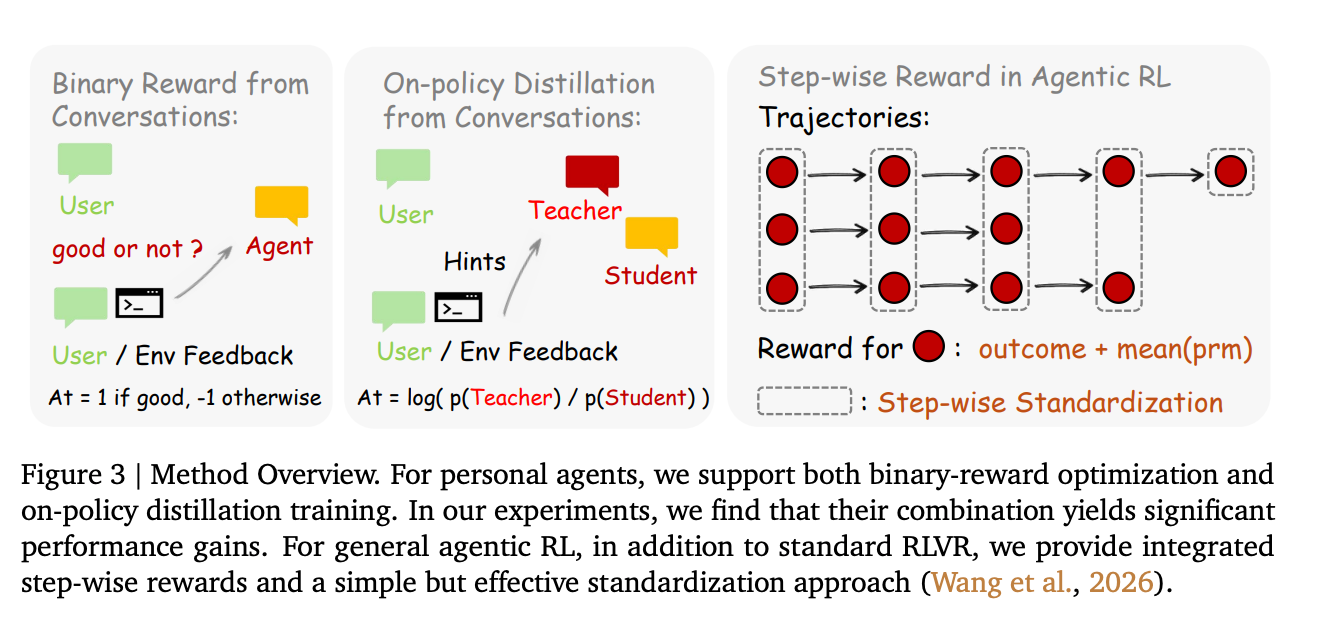
非同期強化学習
- ユーザの会話セッションが終わるとそのセッションでの会話データと上記報酬をもとに非同期RLしてエージェントの方策を逐次更新
- GLM-5でも利用される非同期RLフレームワークのslimeを利用(‣)
評価
実際のユーザインタラクションではなくLLMでユーザを模擬したシミュレーションで評価
報酬を片方のみと両方併用で比較しオンポリシー自己蒸留による報酬が改善に有効
議論
本論文で使われていた手法を実運用する場合の課題として
- LLMによるプロセス報酬の計算コスト重い
- アウトカム報酬を得られると良いが、実際のチャットのみだと明確なアウトカムは得られにくい
- ユーザからの明示的フィードバックを取る手はある
- GRPOは利用不可
- GRPOは同じタスクに対して複数rolloutが必要だがユーザとの実会話セッションを利用して学習するため1 rolloutしかない
- 本手法では報酬をそのままadvantageとして利用してるがこれだと学習不安定になりうる
- 逐次学習後の評価が必要
- 非同期学習した後にすぐエージェントの方策を更新すると性能悪化のリスクがある。性能評価した上で方策反映するかを判定する仕組みが必要そう
@Hiroaki Kudo (hmj)
Hoge
メインTOPIC
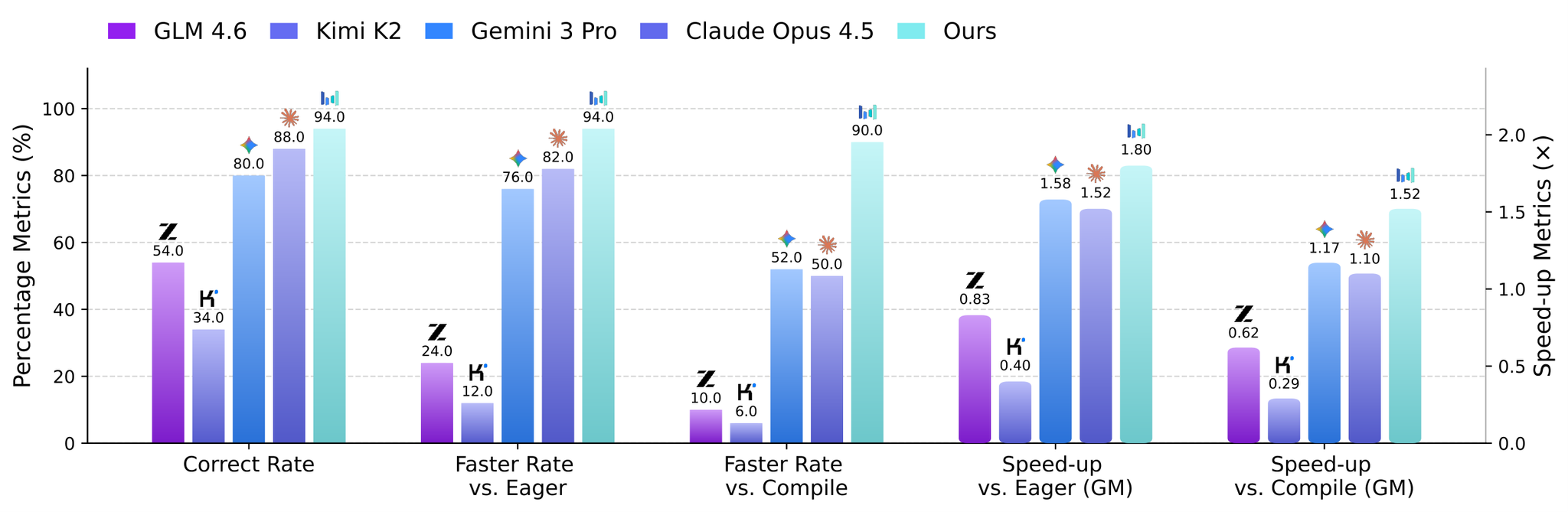
CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
概要
- CUDA kernel最適化を単発のコード生成ではなく、CUDA開発ワークフローそのものをエージェントに学習させる問題として定式化する研究
- 主眼は Agent Harnessの設計部分
- 3本柱は scalable data synthesis / skill-augmented environment / stable long-horizon RL である
- KernelBenchで Overall Pass Rate 98.8%、Faster Rate vs. torch.compile 96.8%、Geomean Speed-up 2.11x vs. torch.compile を報告する
背景と動機
GPU最適化はLLMには難しい課題
- CUDA最適化は深層学習の実効性能を左右する重要課題
- Hopper世代ではTensor Cores / TF32・FP16・FP8 / NVLink が実効性能の中心であり、単にCUDA kernelを書けるだけでは足りない
- メモリ階層(global memory → shared memory → register)の使い分け、coalesced access、occupancy制御が主要論点である
- LLMは一般的なコーディングで強いが、これらのhardware-awareな最適化は依然として難しい
torch.compileをベースラインとする
- torch.compile(TorchInductor + Triton) という十分に早いcompilerをbaseとして設定している
- はPythonコードをトレースし、operator fusion・memory planning・Triton kernel生成を自動で行う
- Tritonは OpenAI が公開したPython-likeなGPU言語・コンパイラで、CUDAより高生産性で高効率なkernelを書けることを狙ったもの
- を一貫して超えることに、CUDA Agentはフォーカスを当てている
KernelBench?
- PyTorchプログラムから正しくて速いGPU kernelを生成できるかを測る代表的ベンチマーク
- Level 1: 単一kernel演算
- Level 2: simple fusion(複数演算の融合)
- Level 3: end-to-endモデル最適化
既存手法の課題
- Training-free refinementはベースモデルのCUDA能力に性能が縛られる
- Training-basedは高品質データ不足と訓練スケール不足で伸びにくい
- ベンチマークはexploitの余地がある: Sakana AIは AI CUDA Engineerの初期評価にベンチマーク抜け穴があり、過大なspeedupを報告していたことを認め、後にrobust-kbenchを提示した —
- 今回の設計では、reward hacking防止ハーネスによりこれらのHackを防いでいる
RLの対象?
- Agent Loopでの出力をもとに、Seed 1.6の重みを更新していく
- LLMの重み(actor/critic) をPPO系で更新する
- Agentの生成物は「CUDA kernel」単体ではなく、CUDA extension一式
- — CUDAカーネル本体
- — PyTorchバインディング
- — 差し替え用最適化モデル
- PyTorch 最適化課題を含む agent 環境上で、LLM が出した reasoning・tool call・コード編集の軌跡に対して、最終成果物の correctness / speedup 報酬を返し、その軌跡で actor / critic を更新していく
手法
3本柱で構成されている
Data Synthesis(訓練問題の合成)
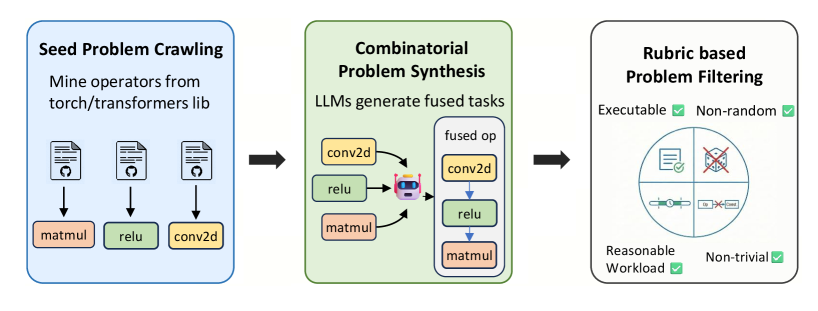
- PyTorch計算を高速化を目的とする訓練問題を大量生成する
- 3段階パイプライン:
- と からseed operatorを収集する
- LLMが最大5個の operatorを順次合成し、fused taskを生成する
- execution-based filterで残すべきサンプルを選別する
- 演算子(トレーニングサンプル)の形式:
- 各サンプルは PyTorchで実装されたPythonクラス として表現される
- 具体的には のサブクラスで、
- (パラメータ初期化)
- (計算グラフ定義)
- さらに 自己完結な実行可能タスク にするために、補助関数を2つ持つ
- :演算子クラスのインスタンス化に必要な入力を構築
- : 実行時の入力(テンソルなど)を生成
- これにより「クラス定義 + 入力生成」が1セットになり、エージェント環境でそのまま 実行・検証・プロファイル できる単位になる(論文のFig.6が代表例)[1]
を備える
- フィルタ条件(5つ):
- eager / compile の両方で動作する
- 非確率的である(deterministic)
- 出力がdegenerateでない
- eager実行時間が1–100msに収まる
- KernelBenchとのAST類似度が閾値以下(contamination対策)
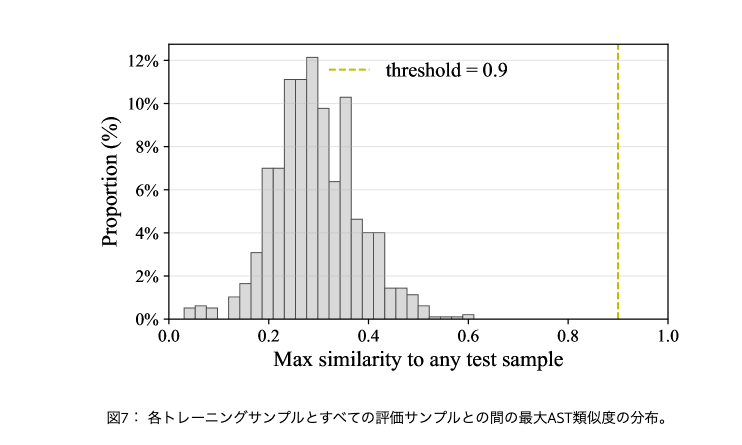
- データ汚染(contamination)チェック: AST類似度によるデコンタミネーション
- 目的は、合成した訓練データが評価ベンチマーク(KernelBench)と 構造的に重複 して、見かけの性能が過大評価されることを防ぐこと
- 手順は以下
- 各プログラムから クラスを抽出
- 商用のASTベース類似度ツール(論文では )で、訓練サンプルと評価サンプルの ペアワイズ構造類似度 を計算
- いずれかの評価プログラムとの 最大類似度が0.9を超える訓練サンプルを削除
- フィルタ後は、最大AST類似度の分布上、閾値を超えるサンプルが残っていないことを確認している(論文のFig.7)[2]
- 最終データセット構成(Table 3):
- torch演算子の逐次合成(k-op)を中心に、少数のTransformer由来モジュールを含む
- 単発(×1)と深い合成(×3〜×5)で 難易度の幅 を確保しつつ、Transformerの高レベルモジュールも少量混ぜている構成
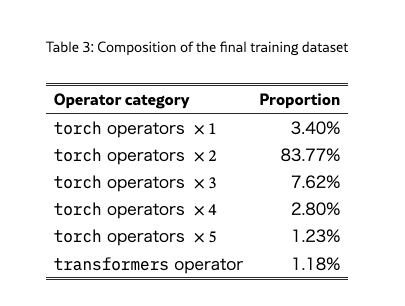
- 公開データセット
Agent Loop(SKILL.md+Harness)
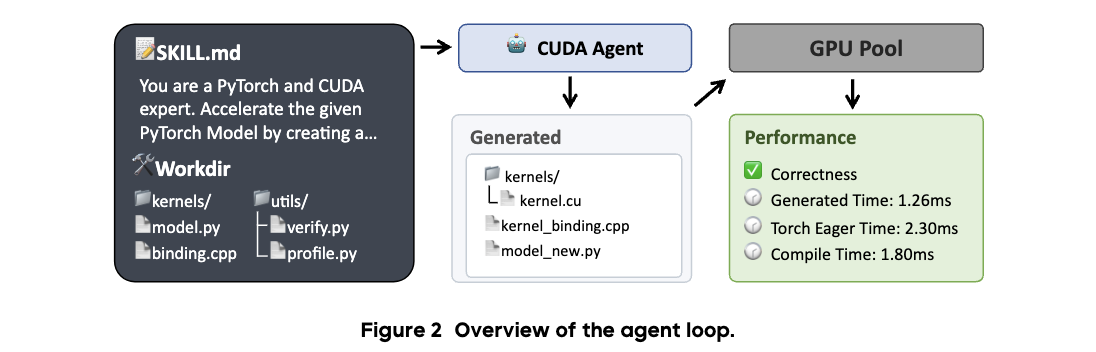
OpenHands + ReAct + Agent Skills でAgenticループを回す
- OpenHands(旧OpenDevin)はソフトウェアエージェントの実装基盤
- CUDA最適化にモダンなAgent 向け技術セットを使っている
- Agentに与えられているツールはCodingAgentと同様
SKILL.md
CUDA-Agent/agent_workdir
1. ディレクトリ構造
エージェントが変更できる範囲(アクセス権限の分離)
| ファイル/ディレクトリ | エージェントの権限 | 役割 |
|---|---|---|
| 作成・変更可 | CUDAカーネル本体 | |
| 作成・変更可 | PyTorchテンソルバインディング | |
| 変更可 | 最適化済みモデル定義 | |
| 読み取りのみ | ベースラインモデル(参照用) | |
| 変更禁止 | 評価インフラ(改竄防止) | |
| 変更禁止 | PyBindモジュール定義 | |
| 変更禁止 | カーネル登録機構 |
2. エージェント環境(Agent Workspace)
2-1. ベースラインモデル ()
上記のように、エージェントには「最適化すべきPyTorchモデル」が として提供される。
この例は AXPBY演算()だが、実際のタスクではより複雑な演算が対象となる。
2-2. 最適化済みモデル ()
エージェントは の クラスを、同一のインタフェースを維持しながら最適化する。
2-3. カーネルバインディングシステム
カーネルの自動登録は マクロで行われる:
はすべてのカーネルを自動的に収集して モジュールに公開する。
エージェントは新しいカーネルファイルを追加するだけで、モジュールに自動登録される。
2-4. CUDAカーネル実装例 ()
3. Workflow Constraints(SKILL.md)
はエージェントへの システムプロンプト兼制約仕様書 として機能する。
373行にわたる指示書で、エージェントの行動規範を定義している。
3-1. CRITICAL RESTRICTIONS(絶対禁止事項)
3-2. ALLOWED OPERATIONS(許可操作)
3-3. WORKSPACE STRUCTURE(ファイル配置規則)
エージェントが作成するカーネルは必ずペアで作成する:
3-4. 最適化優先順位(SKILL.md Section 3)
| Priority | 手法 | 期待効果 |
|---|---|---|
| P1 アルゴリズム | カーネルフュージョン、Shared Memoryタイリング、メモリコアレッシング | >50% 高速化 |
| P2 ハードウェア活用 | ベクタライズドロード(float2/float4)、Warpプリミティブ(__shfl_sync)、占有率チューニング | 20-50% 高速化 |
| P3 ファインチューニング | 命令レベル並列性、混合精度(FP16/TF32)、プリフェッチ・ダブルバッファリング | <20% 高速化 |
3-5. 成功基準(SKILL.md Section 7)
- 正確性: 全検証テスト合格必須(例外なし)
- 最低性能: より 5%以上高速 (≤ 0.95× torch.compile時間)
- 目標性能: できる限り高速(20%以上高速 = ≤ 0.80× が理想)
- 後処理: 中間ファイル(, , )を全削除
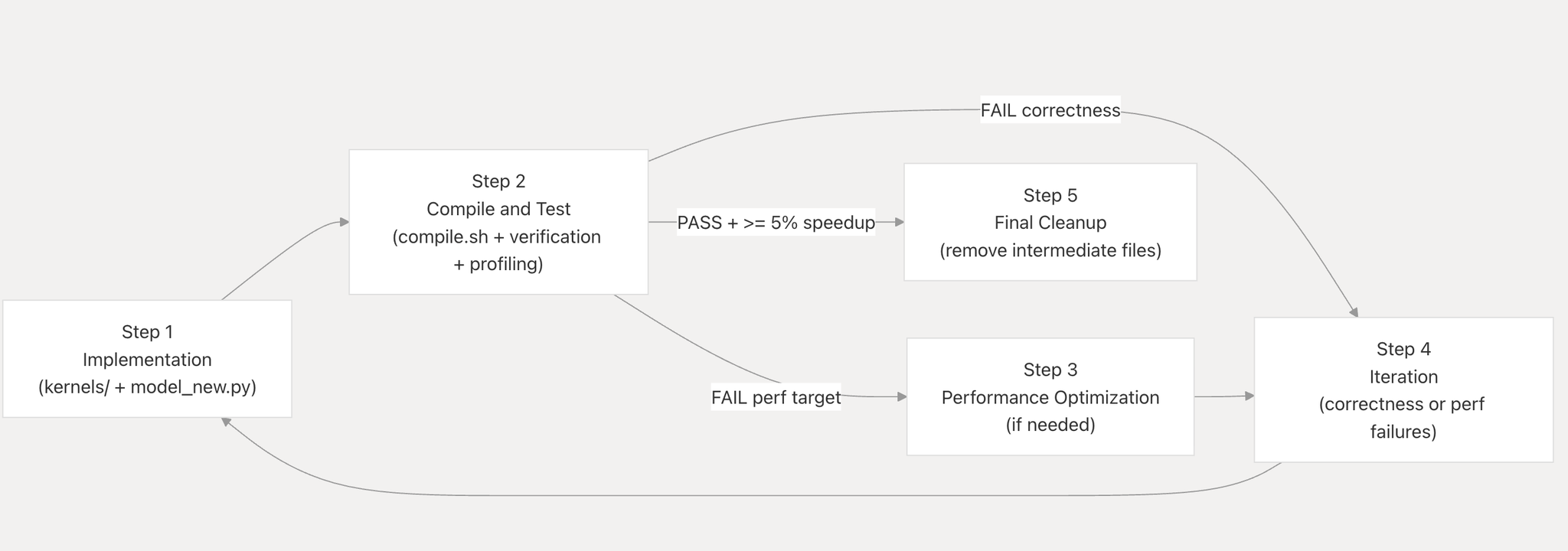
4. Iterative Agent Loop(反復エージェントループ)
4-1. 5ステップサイクル
4-2. フィードバックループの詳細
正確性フィードバック(utils/verification.py)
重要: コンテキストマネージャが の全メソッドをエラーを投げるラッパーに一時置換する。これにより「エージェントが禁止された torch 演算を使っていないか」を実行時に強制検証する。
パフォーマンスフィードバック(utils/profiling.py)
5. ビルドシステム詳細
コンパイルシステム(utils/compile.py)
実行コマンド:
6. トレーニングデータセット(CUDA-Agent-Ops-6K)
| 項目 | 詳細 |
|---|---|
| 件数 | 6,000 サンプル |
| 構築方法 | PyTorch/Transformersから参照演算子を収集 → LLMで複合化(フュージョン化) |
| フィルタリング | 実行可能性と非自明性のルールベースフィルタリング |
| 目的 | エージェントのRL学習に使用 |
- 絶対禁止: C++内の 演算 / 内のtorch演算 / cuBLAS・cuDNN以外のサードパーティライブラリ / 変更
- 許可操作: 生CUDAカーネル / GEMM→cuBLAS / Conv→cuDNN / によるメモリ確保
- 最適化優先順位: P1 アルゴリズム(fusion, tiling, coalescing: >50%高速化)→ P2 ハードウェア活用(float4, warp primitives: 20-50%)→ P3 微調整(ILP, 混合精度: <20%)
Harness(compile / verification / profiling)
- compile: で , 付き動的ビルド、 でHopper向け
- verification: 5入力で + で 全メソッドを実行時に禁止
- profiling: torch baseline / torch.compile / CUDA extensionの3-way比較(warmup 5回、計測10回)
探索空間の制約(reward hacking対策)
- fallbackや採点改ざんを防ぐため、編集領域を と に絞る
- / / の改変を禁止し、行動空間を安定化
Stable RLの設計
そのままRLをすると17ターンで崩壊する
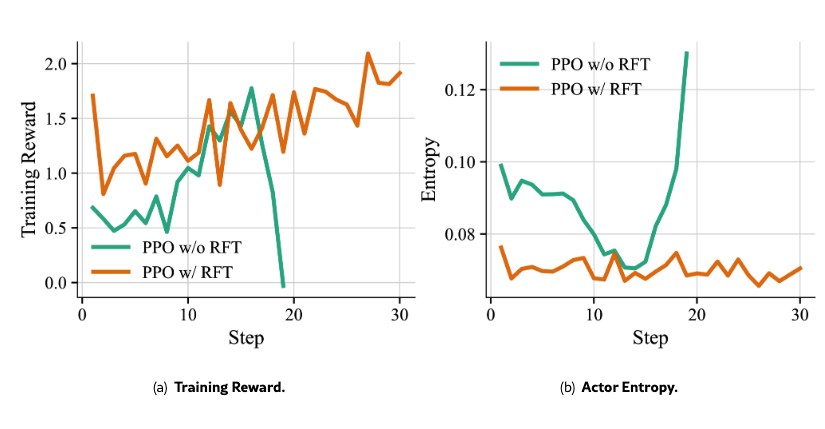
- 最初のRL試行は 17 stepでcollapse
- 原因: CUDA分布がbase model(Seed 1.7)の事前学習分布から遠く、低確率tokenとtraining/inference precisionのズレが importance ratioを暴れさせるから
- CUDAコーディングデータは事前学習データの0.01%未満
対策(3段階 warm-start + PPO)
- そこで
- base model 1つでsingle-turn PPO
- Agent Warm-up
- actor をRFTで作る
- criticをvalue pretrainingで作る
- warm upしたactorとcriticで Agentic RLを回す
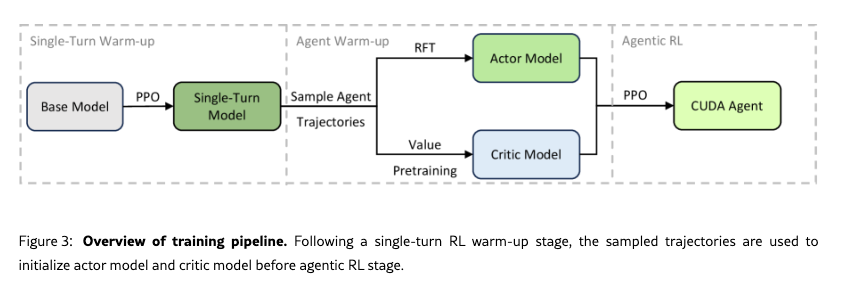
describe
- Single-turn PPO warm-up
- warm-up 後のモデルで agent trajectories を収集(compile / verify / profile を含む multi-turn)
- その軌跡で actor を RFT(rejection fine-tuning)
- 同じ軌跡で critic を value pretraining
- その後に full multi-turn PPO(本番)
2) なぜ必要か
PPO の更新は、古い方策 (pi_{theta_{text{old}}}) と新しい方策 (pi_theta) の比である
(importance ratio)に強く依存
CUDA のような「低確率 token が多い領域」では、(pi_theta(a_tmid s_t)) 自体が極小になりやすく、さらに数値精度差で確率が揺れると (rho_t) が 極端に大きく/小さくなり、
- advantage が正のときに更新が暴走
- advantage が負のときに萎縮
のような不安定挙動が起きうる。
3) Step 0: Single-turn PPO warm-up
- execution feedback なしで final kernel + bindings を一発予測するタスクで PPO
- 目的: base model の CUDA 生成能力をまず底上げし、次段の trajectory 収集の質を確保
- actor/critic をまだ分けずに warm-up
4) Step 1: Actor 初期化 = RFT
Rejection sampling(良い軌跡だけ残す)
- Outcome filtering: 正報酬((R>0))の trajectory のみ保持
- Pattern filtering: 冗長な multi-turn loop や tool-call schema 違反の hallucination を除去[1]
式(2): RFT(= 良い軌跡の teacher forcing)
- (tau): 1 本の multi-turn 軌跡
- (mathcal{D}'): rejection sampling 後の「良い」軌跡集合
- (s_t): 状態(これまでの履歴・観測)
- (a_t): 行動(token / tool call / edit など)
良い軌跡で実際に取った行動 (a_t) の対数尤度を最大化する。
5) Step 2: Critic 初期化 = Value pretraining
論文では報酬を最終 token にのみ付与する。
- (r_t=0 (t<T-1))
- (r_{T-1}=r)[1]
このとき途中状態に教師が無いので、GAE を用いて「途中状態の価値」を作る。
TD 誤差
GAE advantage
価値ターゲット
- 直感: 最終 outcome reward を TD 誤差列として途中へ“にじませ”、状態ごとの価値教師を作る
- 論文のハイパーパラメータ: (gamma=1), (lambda=0.95)[1]
式(4): Value pretraining(MSE)
critic が「この状態はどれくらい将来の報酬につながりそうか」を安定して当てられるようにする。これにより本番 PPO の (hat{A}_t) 推定ノイズが減り、更新が安定する。
6) Step 3: Full Multi-Turn PPO
actor/critic を warm-start した状態で multi-turn PPO を回す。
- RFT: actor の初期分布を CUDA / agentic 行動へ寄せて (rho_t) の暴れを抑える
- VP: critic を先に学習して (hat{A}_t) を安定化
- その上で PPO の clipping が本来の役目(過大更新の抑制)を果たしやすくなる
まとめ
- 問題: 低確率 token 領域で (rho_t) と (hat{A}_t) が不安定になり、PPO の更新が壊れる
- 対策: RFT で (pi_theta) を寄せ、VP で (V_phi) を当てられるようにしてから本番に入る
- 効果: long-horizon(multi-turn)でも PPO を 200 step まで安定化
実験結果(KernelBench)
Main Results: Table 1
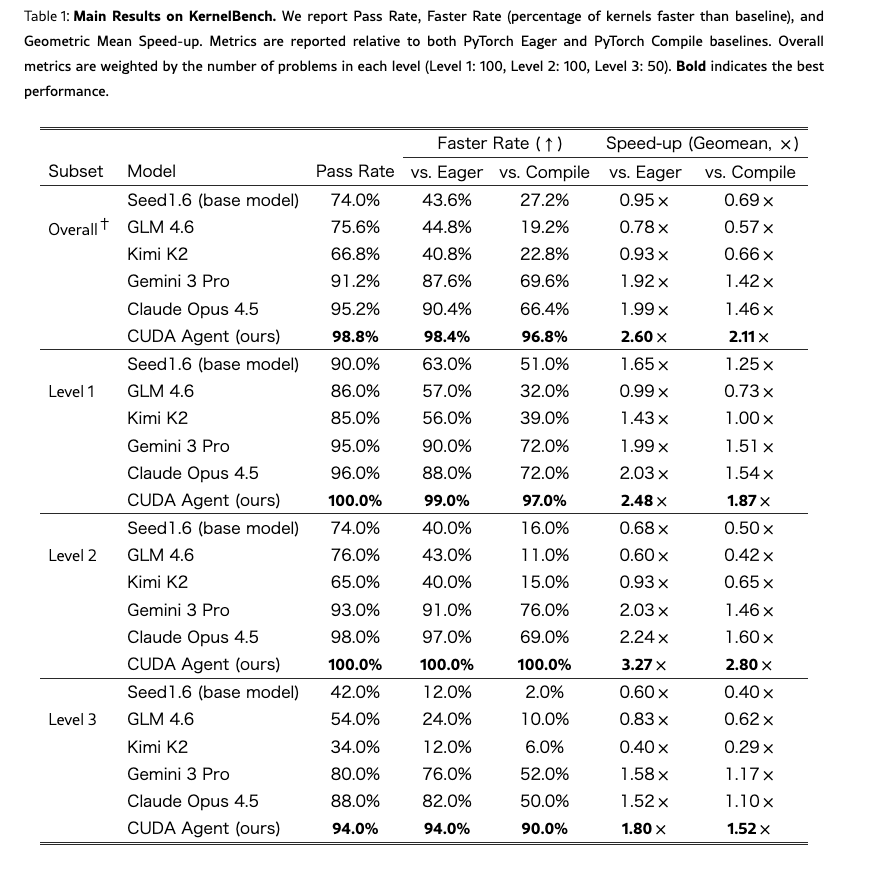
- 指標は Pass Rate / Faster Rate / Speed-up(Geomean) である
- Faster Rate: baselineよりも速かった割合
- Speed Up: baseline に対する実行時間比の幾何平均
- Eager ・Compileそれぞれと比較
- 今回の場合 vs Eagerは素の PyTorch, vs Compileは torch.compileを指す
- 比較対象: Claude Opus 4.5, Gemini 3 Pro, Seed-Coder(SFTのみ)等
We found that models in the ChatGPT-5 series (5, 5.1, and 5.2) were not amenable to evaluation on this task, as they consistently declined to respond to CUDA-related prompts.
- 全体: Pass Rate 98.8% / Faster vs. Compile 96.8% / Speed-up vs. Compile 2.11x
- Level 1: Pass Rate 100% / Faster vs. Compile 95.6% / Speed-up 1.98x
- Level 2: Pass Rate 100% / Faster vs. Compile 100% / Speed-up 2.80x ← 最も強い
- Level 3: Pass Rate 94.7% / Faster vs. Compile 94.7% / Speed-up 1.68x
Kernel Benchのレベル
- Level 1: 単一kernel演算
- Level 2: simple fusion(複数演算の融合)
- Level 3: end-to-endモデル最適化
Table 2:各手法ごとの性能
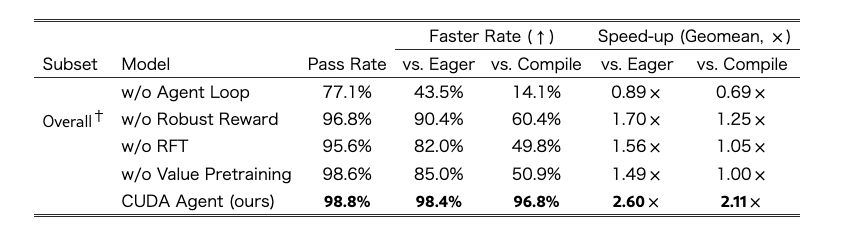
- w/o Agent Loop: Compile比Faster Rateが 14.1% まで落ちる → single-turn生成だけではまるで足りない
- w/o Robust Reward: passは高いがfaster-than-compileが 60.4% まで下がる → 報酬設計がoptimization qualityに効いている
- w/o RFT: faster-than-compileが ≈50% まで落ちる → actor初期化が本質
- w/o Value Pretraining: faster-than-compileが ≈50% まで落ちる → critic初期化も本質
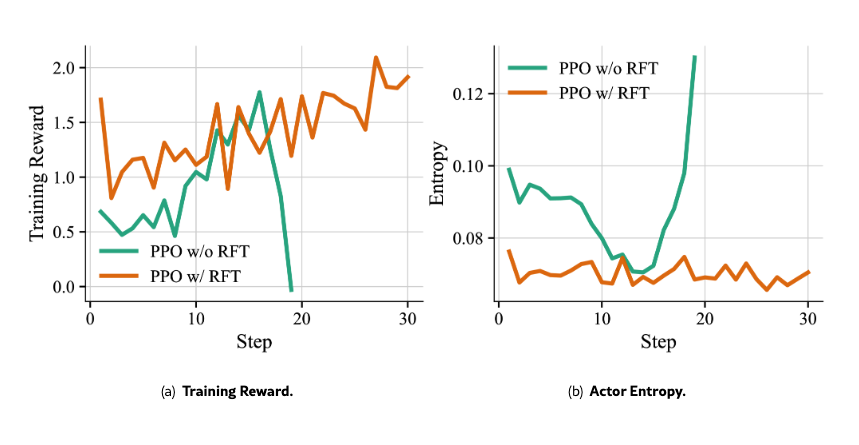
Training Dynamics: Figure 4 & 5
- Figure 4: RFTを外すとtraining rewardが崩壊し、同時にactor entropyが急上昇する → 探索の制御が崩れている
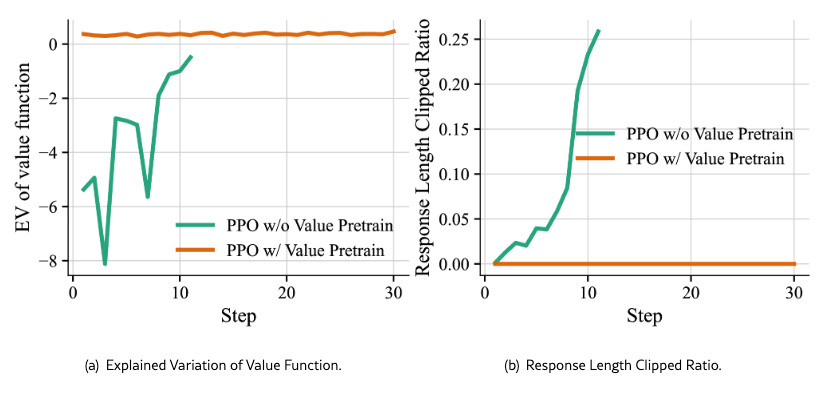
- Figure 5: Value pretrainingを外すとcriticの推定が不安定になる
Case Study
Karnel Benchの3つの難易度ごとの性能評価をしている
CUDA Agentはlow-level tuningだけでなく、代数変形 / library selection / kernel fusion をまたいで最適化する:
- Level 1(diag行列簡約): diag行列を作らずrow-wise scalingへ簡約し、不要なメモリ確保と計算を除去する
- Level 2(matmul + divide + sum + scale): weight列和とdot productに代数変形し、さらに load + shared-memory reductionで高速化する。intermediate materializationの回避とdata layout再設計が効いている
- Level 3(ResNet BasicBlock): BatchNorm foldingでパラメータを事前計算し、cuDNNのfused conv+bias+activation APIを活用し、residual add + ReLUのcustom kernel fusionを組み合わせる。TF32有効化でTensor Coresを活用する — cuDNN docs
Level2に強い理由?
- fusion taskはintermediate materialization回避やdata layout再設計が効きやすい
- static compilerのルールベースよりlearned search/policyの優位が出やすい領域であ
考察と限界
強み
- データ合成・環境・報酬・RL安定化を統合し、hardware-aware optimization policyを獲得させたシステム設計
- この論文は、CUDAの低レイヤ最適化よりも、harness engineeringをtraining loopに持ち込んだのが本質
- 「how to train an optimizer agent」の論文として位置づけるのが最も適切である
限界
- 比較対象は主にtorch.compileであり、TVM等のより強いcompiler frameworkとの比較は未実施 — TVM
- cross-GPU generalization(Hopper以外)は未検証である
- 大規模GPU poolとprocess-level isolationに依存し、再現コストが高い
- KernelBench外のgeneralizationはまだ十分示されていない — 「強いが、まだ "solved" ではない」が妥当な表現
- 公開物の表記に軽い揺れがある: paper/project page1はClaude Opus 4.5と書くが、GitHub READMEにはOpus-4.6と記載 → paper表記(4.5)に合わせるのが無難
感想
- CUDA の低レイヤ最適化よりも、むしろ harness engineering を training loop に持ち込んだのがこの論文の本質
- C数式最適化、ライブラリ選定のような複雑なタスクを要求される問題をAgenticなアプローチである程度の成果出せるようになっている。エンジニアリングでもほとんどの制約はモデルではなくAgentに提供する環境にあると改めて捉えた
参考資料
- ‣
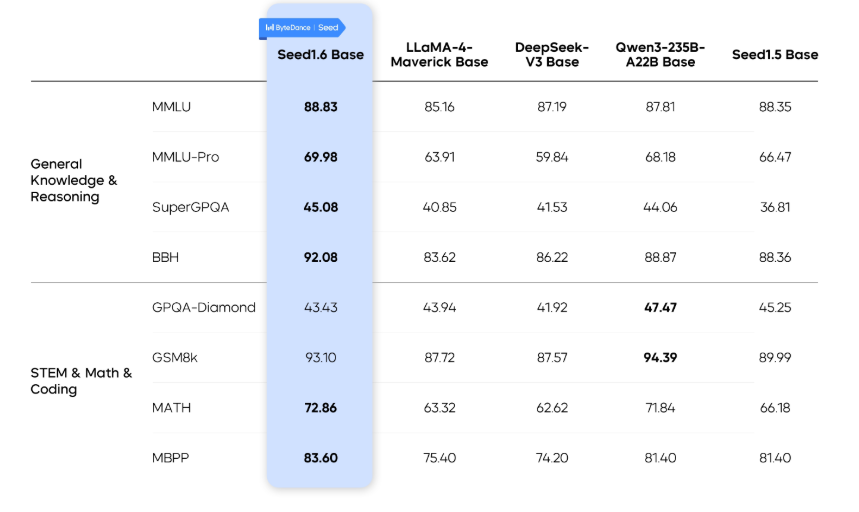
Seed1.6について
ByteDanceの汎用モデル
Seed1.6 is the latest general-purpose model series unveiled by the ByteDance Seed team. It incorporates multimodal capabilities, supporting adaptive deep thinking, multimodal understanding, GUI-based interaction, and deep reasoning with a 256K context window. Seed1.6 is now available through the open API of Volcano Engine. You can try it out via the links provided at the end of this article.