
2026-03-24 機械学習勉強会
今週のTOPIC[paper]Why AI systems don't learn and what to do about it: Lessons on autonomous learning from cognitive science[paper] Unlocking the Power of Multi-Agent LLM for Reasoning: From Lazy Agents to Deliberation[paper] SPD-RAG: Sub-Agent Per Document Retrieval-Augmented Generation[blog] Product management on the AI exponential[Paper]Attention ResidualsOnline Experiential Learning for Language Models概要先行研究と研究背景既存手法の限界関連研究主要な貢献手法の詳細フレームワーク概要ステージ1:経験的知識抽出(Knowledge Extraction)ステージ2:知識統合(Knowledge Consolidation)On-Policy学習の重要性実験結果実験設定モデル:評価指標:経験的知識 vs 生の軌跡主要な発見:On-Policy vs Off-Policy(Table 2)壊滅的忘却の防止コード実装の詳細その他の重要なポイント制限事項今後の研究課題実用的な示唆まとめ
今週のTOPIC
@Yuya Matsumura
[paper]Why AI systems don't learn and what to do about it: Lessons on autonomous learning from cognitive science
- 従来のMLモデルの限界
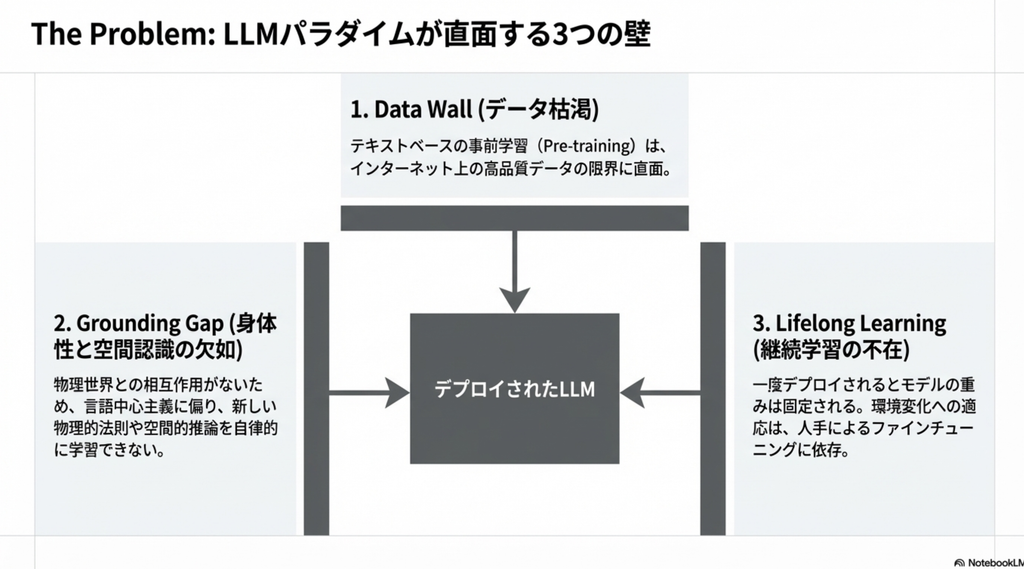
- 完全に「自律化」して学習できるAIをつくろうぜ
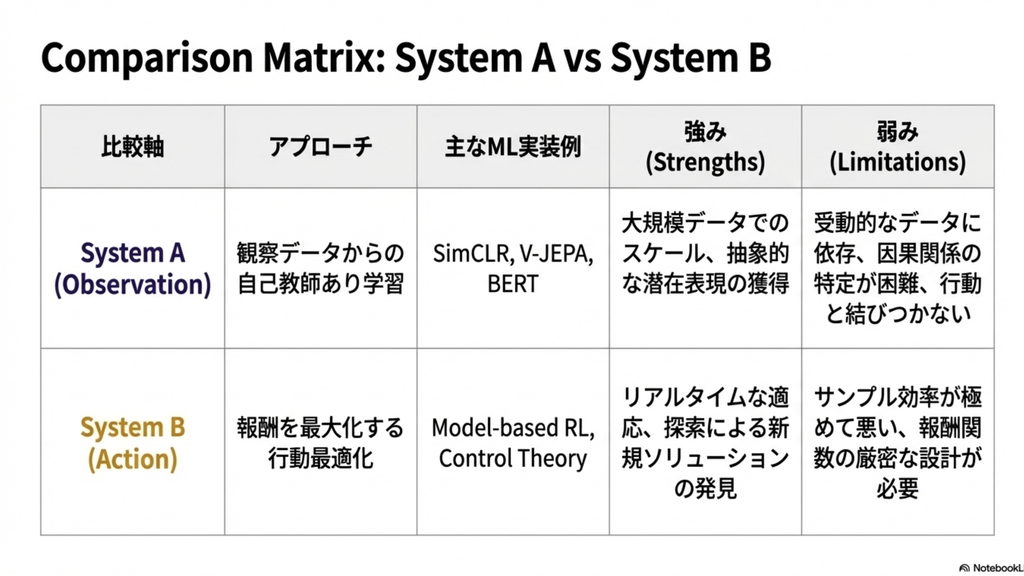
- 観察からの学習(System A)と行動からの学習(SystemB)の両方が必要。両方をうまく組み合わせたい!
- 現在は人間が事前に設計した形でしか学習できない!
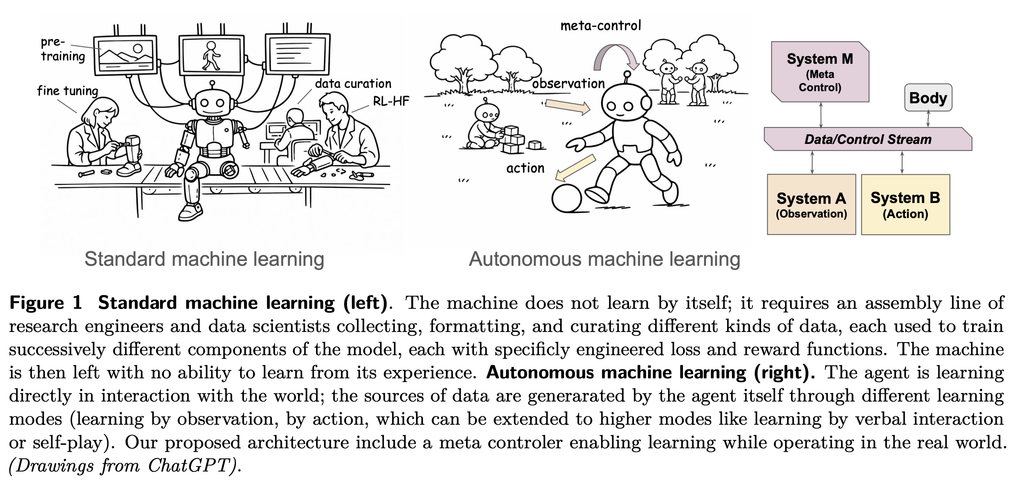
- 観察からの学習(System A)と行動からの学習(SystemB)の比較

- 両方が組み合わさることでより学習が進む
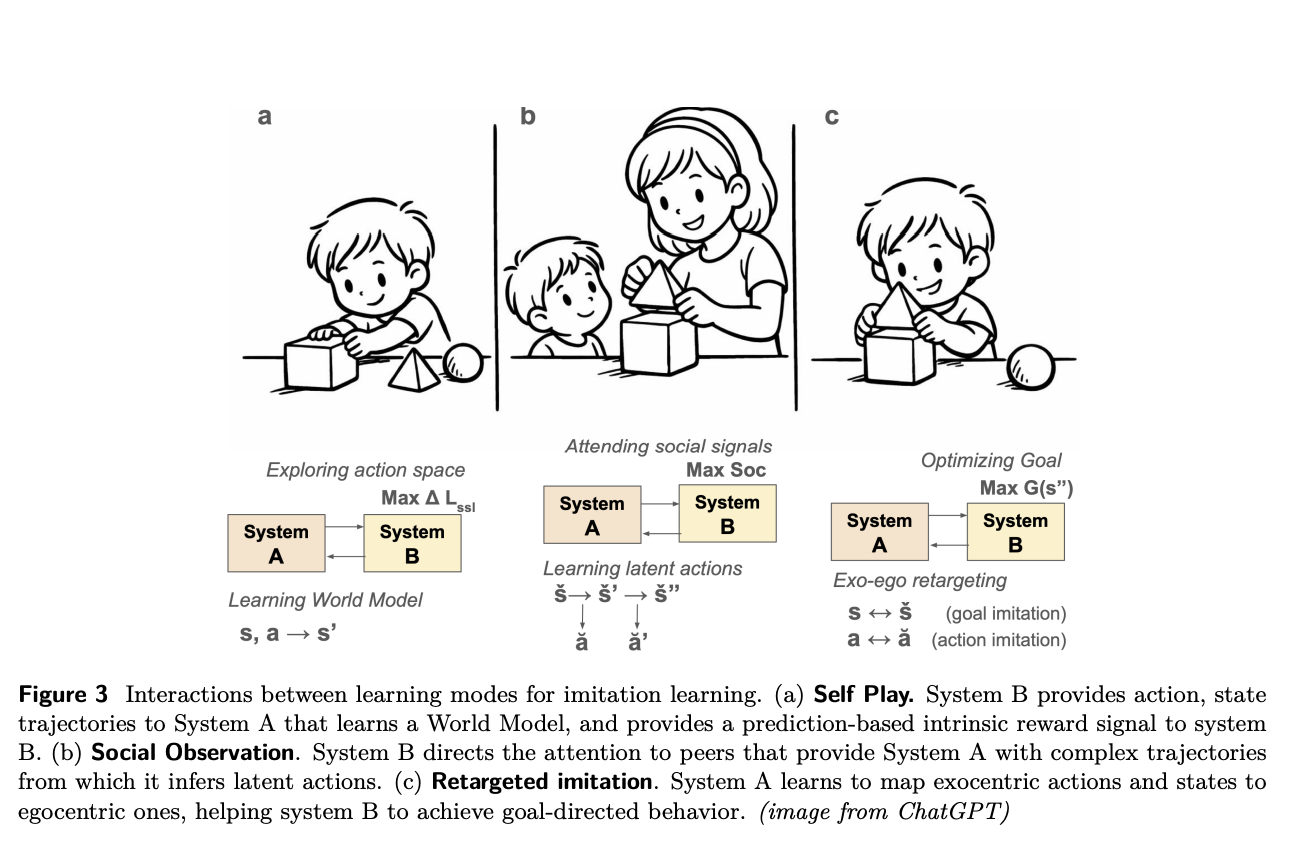
- SystemA, B の学習モードを切り替えるためのオーケスとレーターである System M の導入。
- 人間の脳(前頭前野)のように機能し、いつ探索し、いつ計画し、いつ行動するかを動的に決定する。
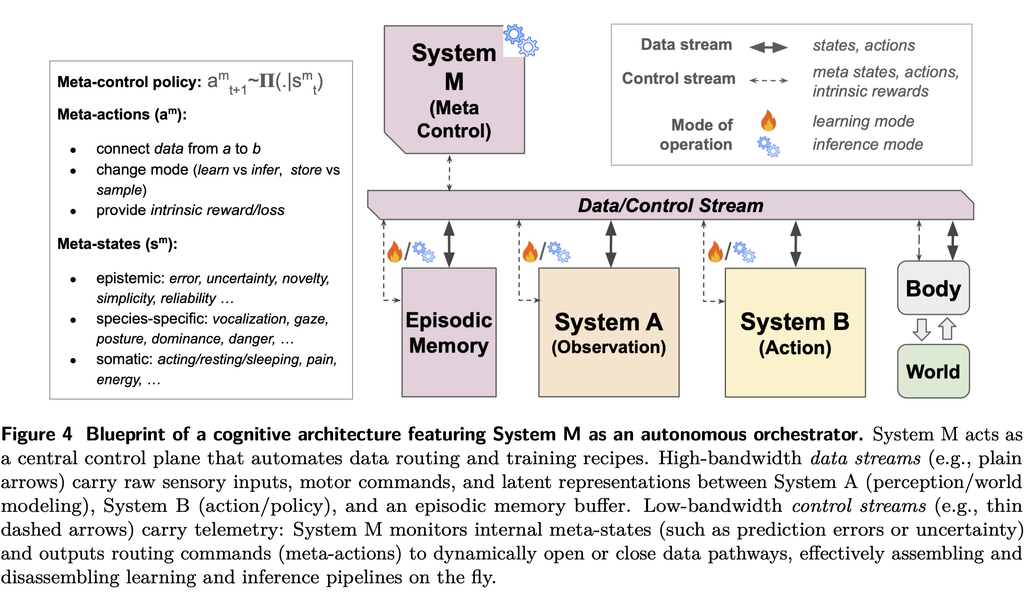
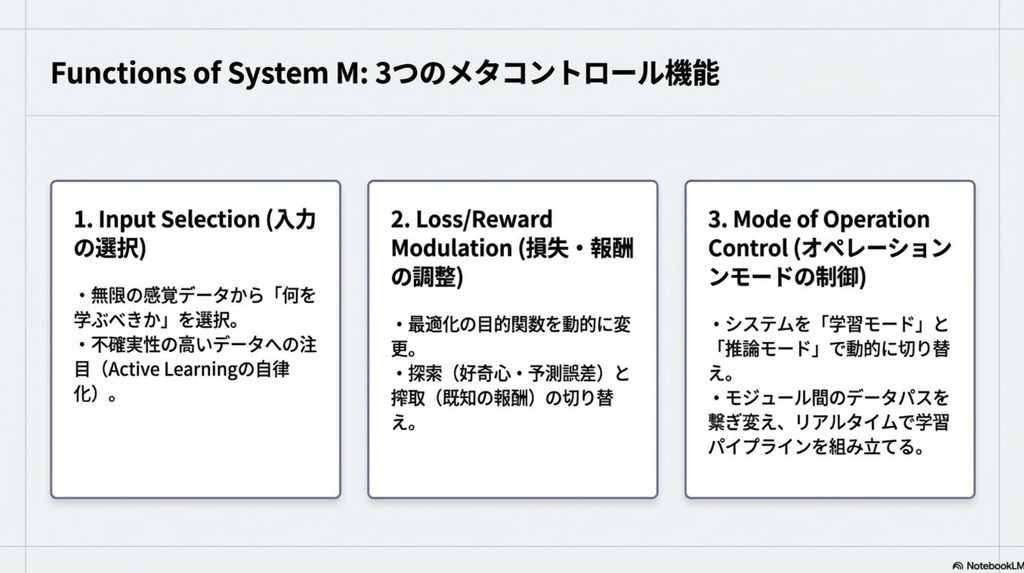
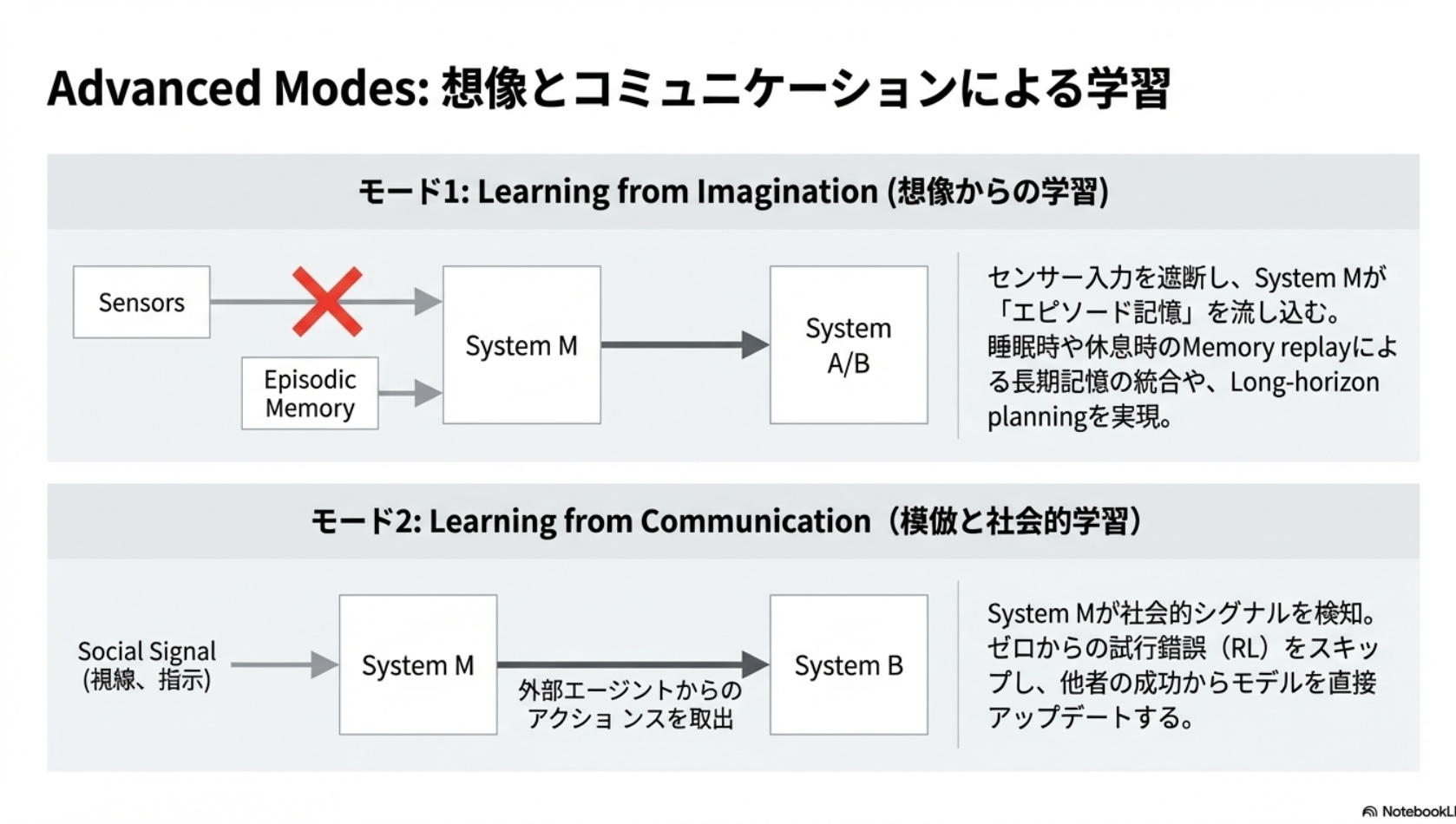
- 人間の学習を模倣した工夫
- すべてのシステムが依存し合う中で、初期の学習をどうするのか問題
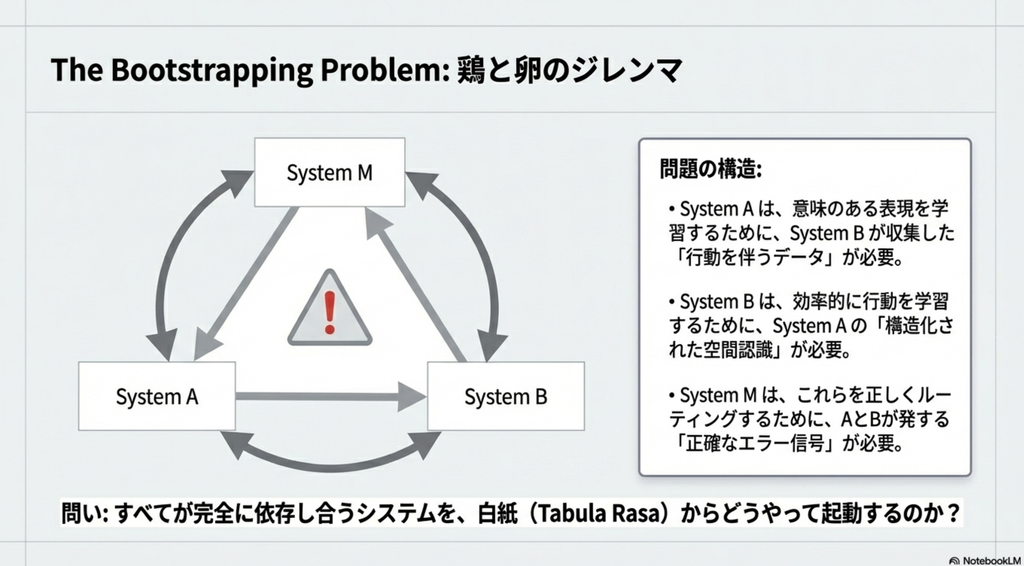
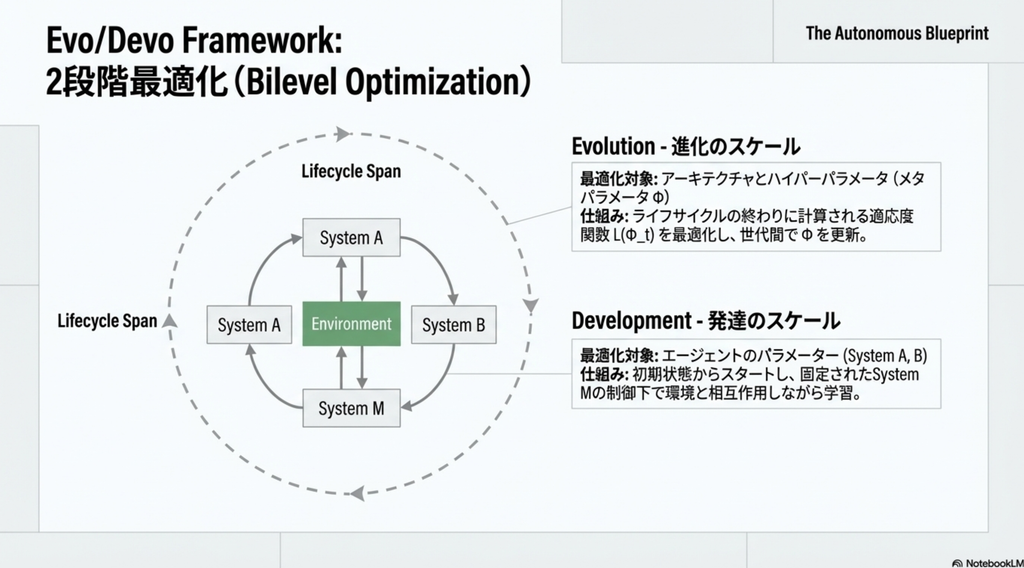
- 生物の進化に着想を得た、二段階の最適化戦略(Evo/Devo)で解決を試みる。生物は生まれた瞬間から遺伝子レベルで刻み込まれているものがある。
- 進化スケール(外側ループ / Evo): 膨大なシミュレーション上の生涯サイクルを経て、System M のメタ・ポリシーと、A と B の初期構造(パラメータ Φ)を最適化。
- 発達スケール(内側ループ / Devo): 個体の生涯を通じて、System M の制御下で A と B のパラメータを更新。ここでは System M は「固定された教師」として機能します。
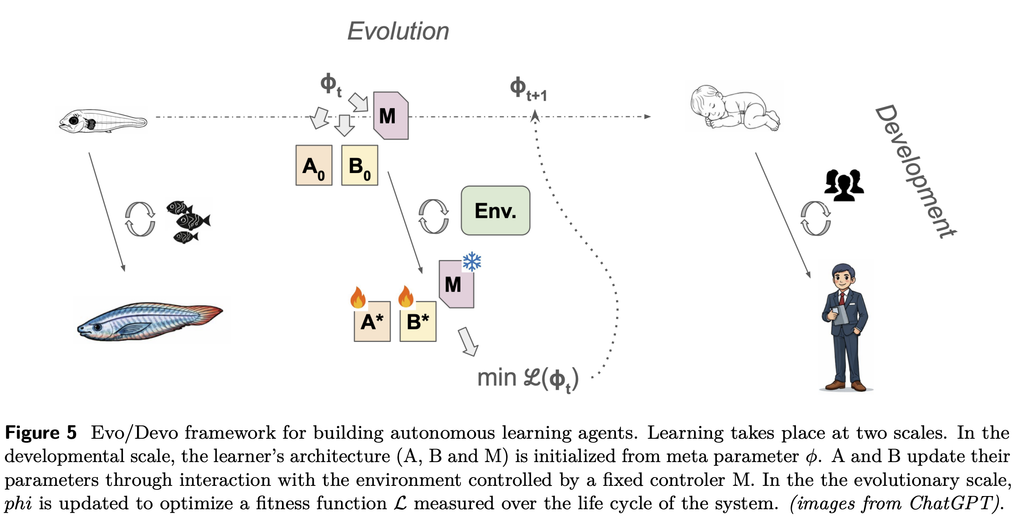
- 課題諸々。ベンチマーク確かに。

@Shun Ito
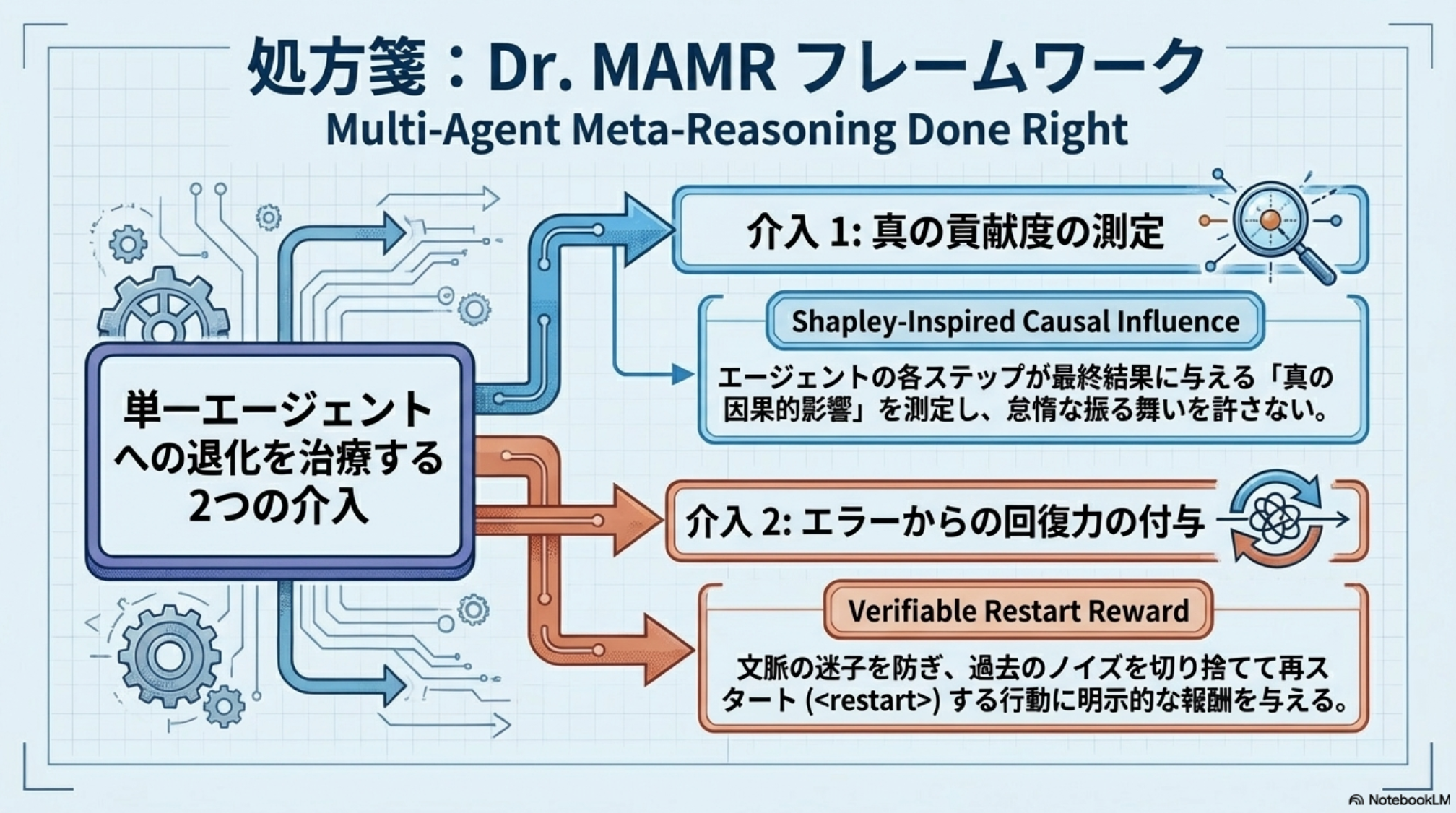
[paper] Unlocking the Power of Multi-Agent LLM for Reasoning: From Lazy Agents to Deliberation
- マルチエージェントによる課題解決でLazy Agentが発生してしまう問題
- マルチエージェント: Meta Agentが課題を分割し、Reasoning Agentが回答する。そのやり取りを通して課題を解決する。
- Meta, Reasoningは同じモデルの別プロンプト
- 単一のreasoningよりも探索的な推論に優れている。
- Lazy Agent: 短いステップで解決しようとして、片方のAgentが過剰に推論してしまい、もう一方のAgentが働かなくなる
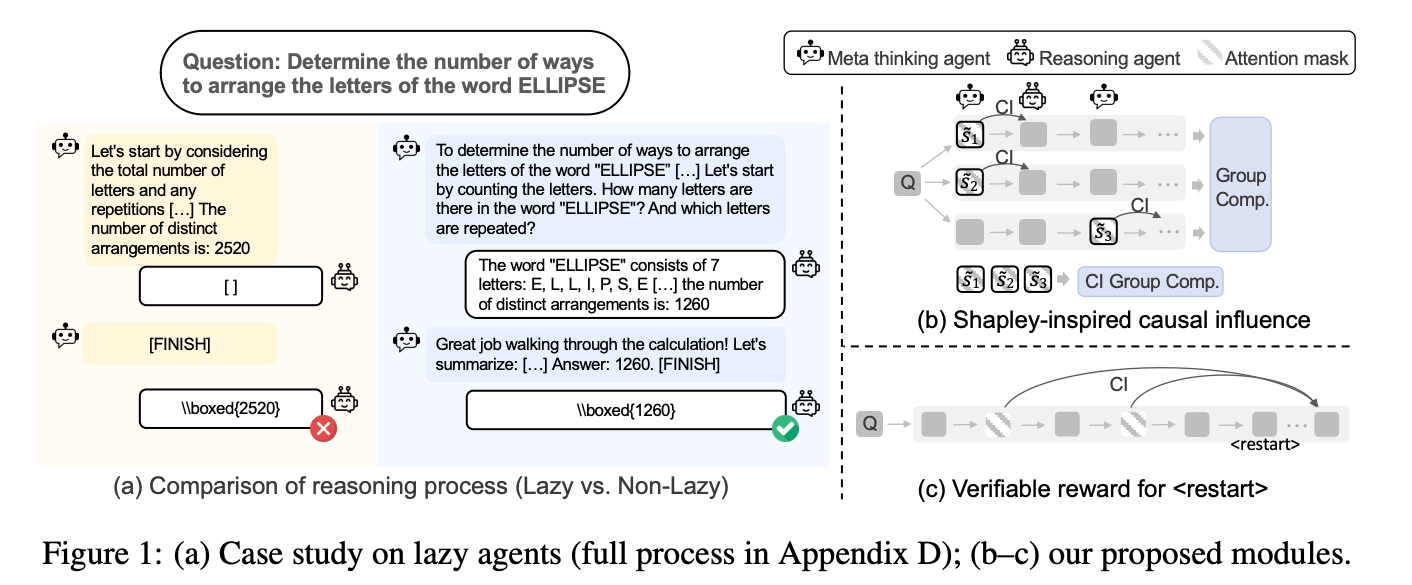
- 原因: 学習時に軌跡の長さで正規化している
- 同じ報酬でも軌跡が短い方が高く評価される。過剰に長い軌跡を抑える効果はあるが、冒頭のような問題も発生する
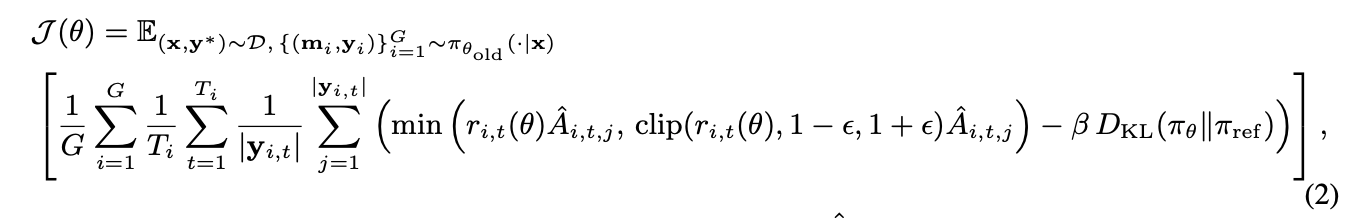
- 提案: 正規化を外して、Advantageの計算方法を変更する
- 軌跡の長さで直接制約をかけるのではなく、効果的なステップを高く評価する方針で学習させる
- C: Causal Influence
- そのstepを削除(マスク)したときに、状態分布がどれだけ変化するか。変化するものほど後続の出力に影響を与えていると考える。
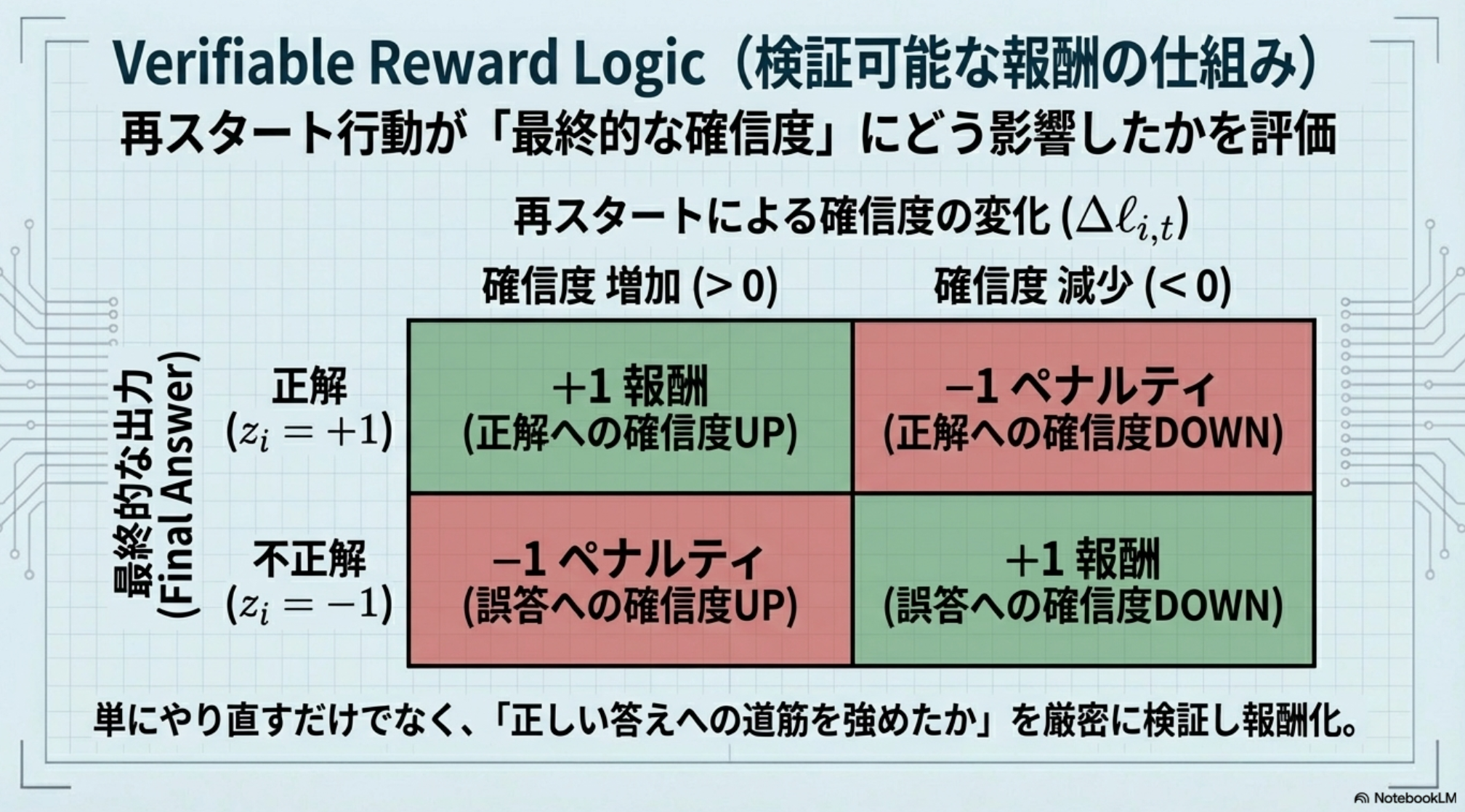
- R: Restart Reward
- 過去の軌跡に間違いが含まれていると、その後の出力も間違ったものになる。
- restartが発生したステップについて、その時点より過去のステップをマスクした場合に最終回答の正解の確信度が高くなる or 間違いの確信度が低くなるものを評価する
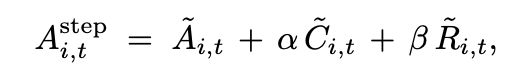
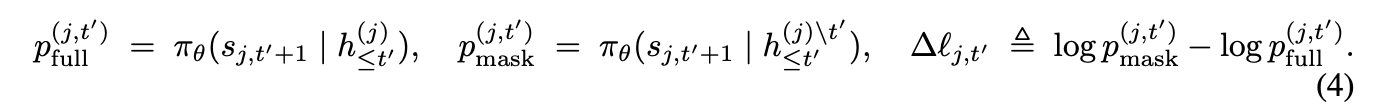
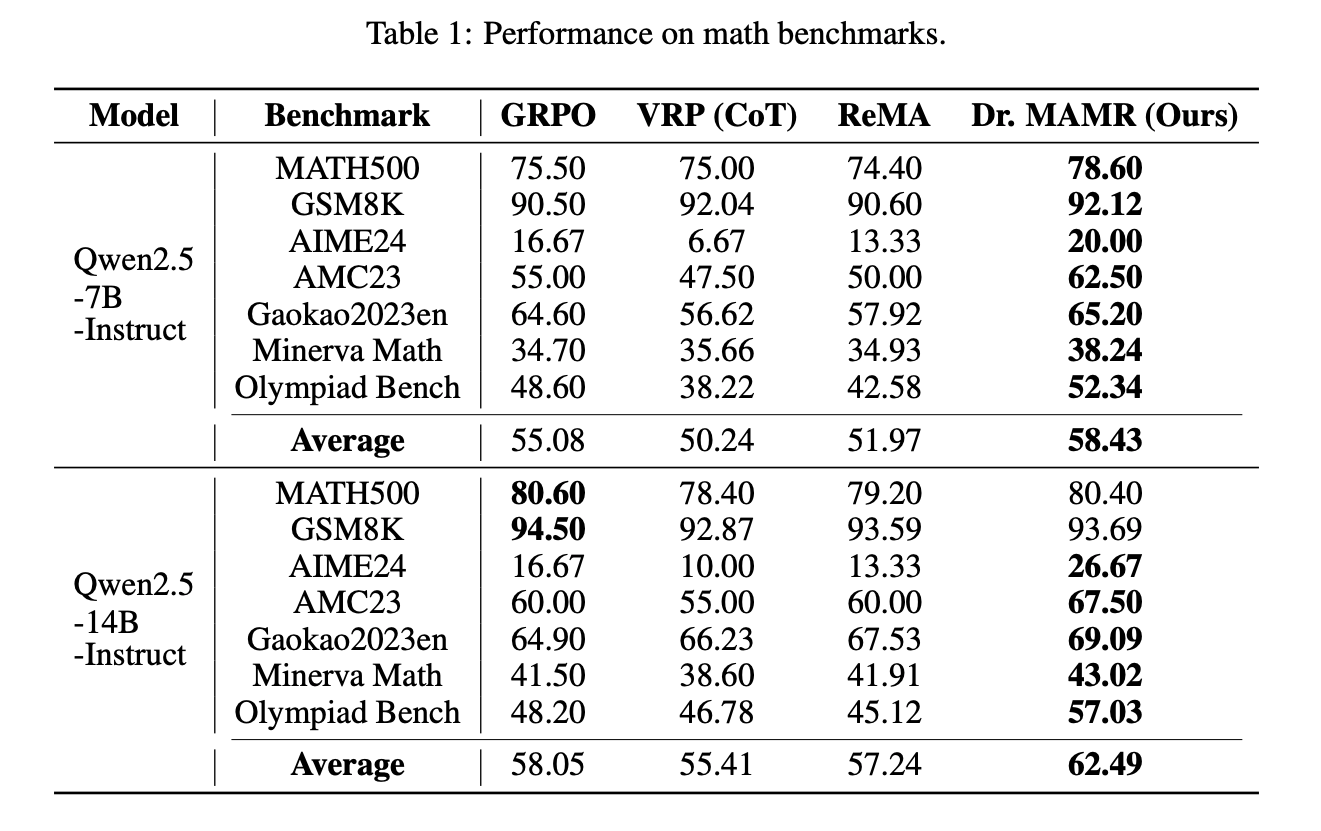
- 結果
- 数学ベンチマークでの性能向上
- 学習時に、Meta, Reasoning両モデルでCausal Influenceが維持されている
@Hiromu Nakamura (pon)
[paper] SPD-RAG: Sub-Agent Per Document Retrieval-Augmented Generation
[pon] LLM×MapReduceの組み合わせに最近注目しているので読んだ。
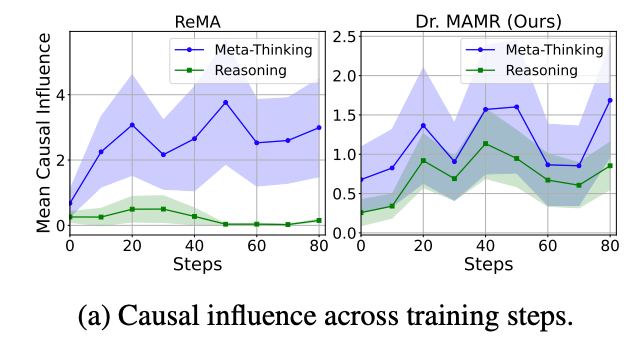
本研究は、ドキュメント軸に沿って問題を分解する階層型マルチエージェントフレームワークであるSPD-RAGを提案します。各ドキュメントは専用の「document-level agent」によって処理され、そのコンテンツのみに基づいてFocused Retrievalを実行。
Loongベンチマークの「Leave No Document Behind」(どのドキュメントも取りこぼさない)という思想に強く影響を受けており、多数のドキュメントに散らばる複雑な情報を網羅的に収集することを目的としています。
手法
SPD-RAGのシステムは、クエリを以下の3つの主要なレイヤーを通じて処理します。
- 調整レイヤー (Coordination Layer):
- コーディネーターエージェントがユーザーのクエリを分解し、すべてのサブエージェントが共有する具体的な抽出タスクのセットと、最終的な回答の構成方法を指示する「合成指示」を生成します。
- 並列検索レイヤー (Parallel Retrieval Layer):
- 各ドキュメントに専用のサブエージェントを割り当てます。これらのサブエージェントは、割り当てられたドキュメント内でのみ独立したRAG(Retrieval-Augmented Generation)ループを実行し、調整レイヤーからの指示に従って関連する情報を抽出し、知見を生成します。このプロセスは完全に並行して実行されます。
- 合成レイヤー (Synthesis Layer):
- 各サブエージェントから得られた知見と合成指示を受け取ります。ターゲットコンテキストサイズに収まるまで、Findingsを類似度に基づいてソートされたプロセスで再帰的に集約・統合します。
[pon]全てのドキュメントに対してSubAgentを割り当てるというパワー
実験
- 実験設定データセット:
- Loongベンチマーク (Wang et al., 2024a) を使用
- 拡張されたマルチドキュメントQAベンチマークで、特に「Leave No Document Behind(どのドキュメントも取りこぼさない)」という原則に基づいています。
- これは、最終的な回答にはすべての提供されたドキュメントからの証拠を合成する必要があることを意味します。
- 対象: 英語のセクションと、コンテキスト長が200K〜250KトークンのSet 4の部分に焦点を当てました。インスタンス数: 合計102インスタンス(学術論文40、金融レポート62)で評価。タスクタイプ: 4つのタスクタイプ(Spotlight Locating、Comparison、Clustering、Chain of Reasoning)が含まれています。
- ドキュメント数とコンテキスト長:
- 1インスタンスあたり平均11ドキュメント、コンテキスト長は10Kから250Kトークン以上にも及びます。
- ベースラインシステム:
- 全てGemini 2.5 Proを基盤としています。
- Baseline (Full Context): 各インスタンスの全ドキュメントを連結し、Gemini 2.5 Proのコンテキストウィンドウに直接提供する方式です。これは「理想的な上限」として機能します。
- Normal RAG: 標準的なベクトル検索(top-K個のチャンクを検索)を行い、その後、検索されたチャンクに基づいてLLMが推論を行う方式です。
- Agentic RAG: LangGraph/LangChainを用いて実装された、単一エージェントのReActスタイルのRAGシステムです。全コーパスに対して複数回の反復的な検索呼び出しを行うことができますが、ドキュメントごとの専門化はありません。
- 評価指標:
- Loongベンチマークのプロトコルに準拠しています
- Avg Score: GPT-5が評価者として、予測された回答がゴールドアンサーをどれだけ正確にカバーしているかを0〜100点で評価します
- Perfect Rate (PR%): スコアが100点であったクエリの割合。
- Avg Token Usage: クエリあたりの平均トークン使用量(入力+出力)。
- Avg Cost (USD): クエリあたりの平均APIコスト。
- Avg Latency (s): クエリあたりの平均処理時間(壁時計時間)。
- 実装詳細:LLM:
- コーディネーター、マージングレイヤー、合成レイヤーには Gemini 2.5 Pro を使用。
- ドキュメントサブエージェントには、コスト効率を考慮して Gemini 2.5 Flash を使用しました。
- GPT-5は評価のみに用いられます。
- 検索・再ランク付け: Cohere embed-v4.0で埋め込みを行い、Qdrantで類似度検索(top-K=15チャンク)後、Cohere rerank-v4.0-fastで再ランク付け(top-N=5チャンク)を行います。ドキュメントチャンク分割: LangChainのRecursiveCharacterTextSplitterを使用し、チャンクサイズ1000トークン、オーバーラップ250トークンで分割しました。
結果
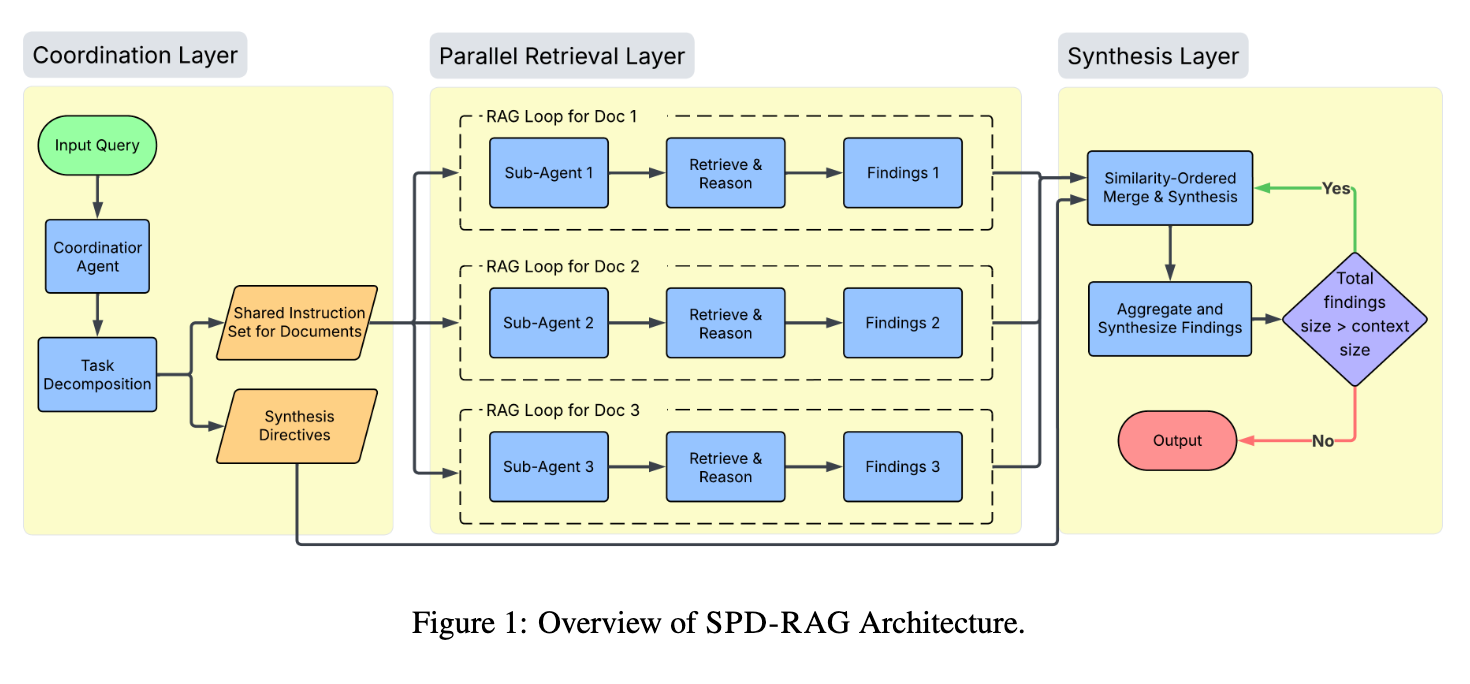
- 高い回答品質:
- SPD-RAGは Avg Score 58.1 を達成し、Normal RAG (33.0) や Agentic RAG (32.8) を大幅に上回りました。
- これは、標準的なRAGベースラインと比較して約25ポイントの絶対的な改善(約76%の相対的ゲイン)に相当します。Perfect Rate (PR%) も、Agentic RAGの約2倍(18.6% vs. 8.8%)となり、必要な事実をより網羅的に捉えていることを示します。
- コスト効率:
- フルコンテキストベースライン (68.0) が最も高い品質を達成する一方で、SPD-RAGはその品質の85.4%に達しながら、APIコストはわずか37.9%**に抑えられました。
- タスクタイプ・ドメインによる違い:
- Clustering (+40.5ポイント vs. Normal RAG) や Chain of Reasoning (+26.2ポイント vs. Agentic RAG) といった、複数のドキュメントから証拠を集約・推論する必要があるタスクで最も大きな改善が見られました。学術論文のような「密で分散した証拠」を持つドキュメントでは、Normal RAGやAgentic RAGが0%のPRを記録する壊滅的な失敗を示すのに対し、SPD-RAGは大幅に品質を回復させました。
- レイテンシー:
- SPD-RAGはベースラインと比較して、やや高いレイテンシー(54.8秒 vs. 40.6〜45.6秒)を伴いますが、これは並列処理を含む多層的なエージェントアーキテクチャに起因します。これらの結果は、ドキュメント軸に沿った階層的な分解と、ドキュメントごとの専門化されたエージェント処理が、複雑なマルチドキュメントQAにおいて、従来のRAGや単一エージェントの反復検索よりもはるかに効果的であることを明確に示しています。
[pon]ドキュメント全てでsub-agentぶん回すまでいかずとも、Recall-firstで荒く取ってきたドキュメント全てに軽量なモデルを回すとかなら良いのかもしれない。検索設計から推論設計への重心移動
@ShibuiYusuke
[blog] Product management on the AI exponential
記事の概要
Anthropic社のClaude Code プロダクト責任者であるCat Wu氏が、AIモデルが指数関数的に進化する時代において、プロダクトマネジメント(PM)の仕事がどう変わるべきかを、自身の経験と具体例をもとに論じた記事。
1. モデル進化の体感:Excalidrawのエピソード
Cat Wu氏は2024年10月のClaude Sonnet 3.5(new)以降、新しいモデルが出るたびに「Excalidrawにテーブルツールを追加する」タスクをClaude Codeで試す習慣を持っていた。
- Sonnet 3.5(初期) — 毎回失敗
- Opus 4(2025年6月) — 時折成功
- Opus 4.6(2026年) — ワンショットで確実に成功、ライブデモで披露可能に
このエピソードは、モデルの能力が短期間で劇的に向上しているという事実を象徴している。
2. 問題提起:従来のPM手法の前提が崩壊
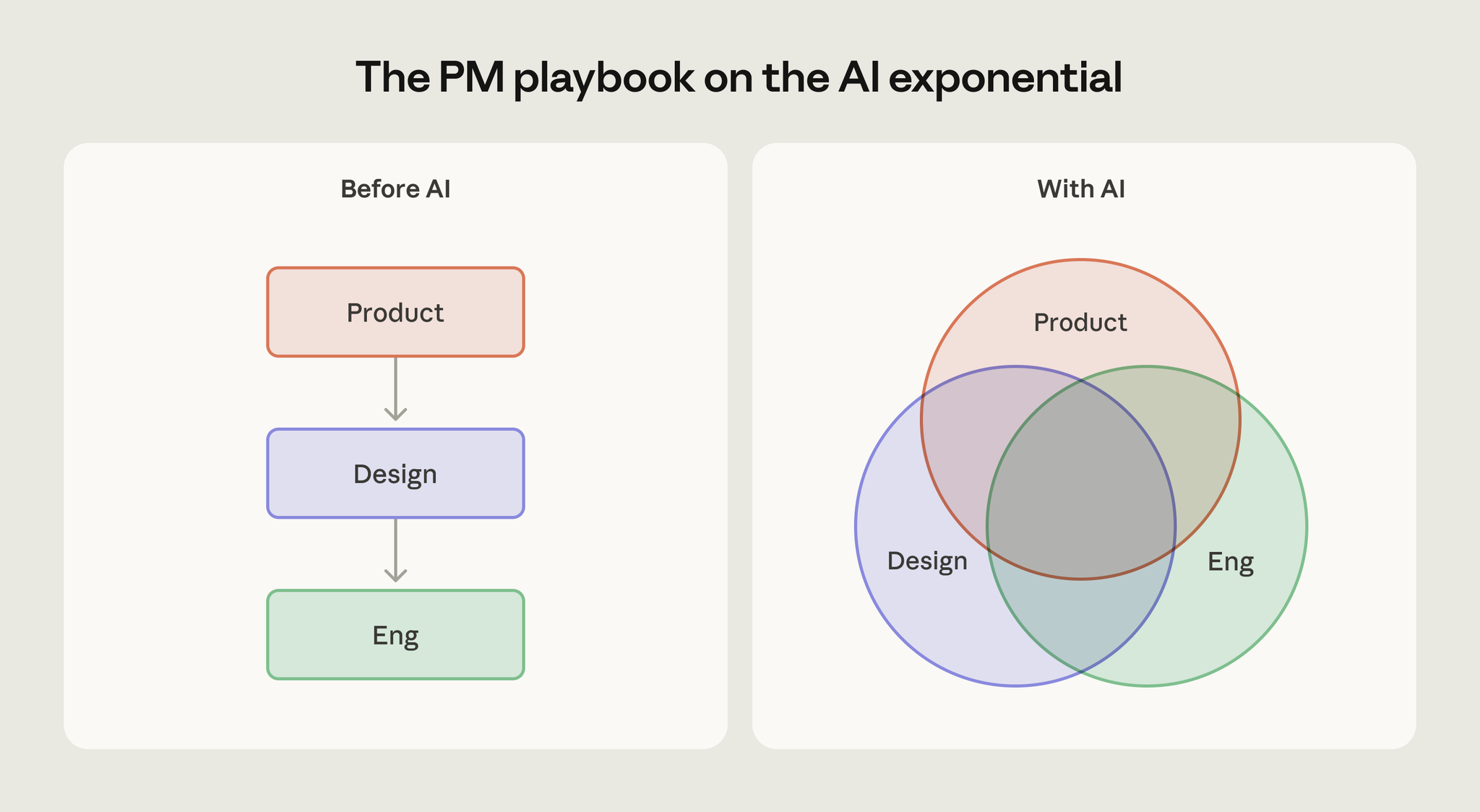
変化する前提
従来のPMの手法は「プロジェクト開始時に技術的に可能なことは、終了時にもほぼ同じ」という前提の上に成り立っていた。この前提があるからこそ、PMは数ヶ月先のロードマップを引き、PRDを書き、スコープを確定し、エンジニアに引き渡すという直線的なプロセスが機能していた。
新しい現実
指数関数的に進化するモデルがその前提を壊す。Cat Wu氏はこれを「足元の地面が自分の下で隆起しているようなもの」と表現している。設計時の制約がプロジェクトの途中で消えてしまう可能性が常にある。
求められる新しいリズム
素早い実験(rapid experimentation)、一貫した出荷(consistent shipping)、うまくいったものへの集中投資(doubling down on what works)。
3. Cat Wu氏のワークフロー:3つのツールの使い分け
| ツール | 役割 | 用途 |
|---|---|---|
| Claude.ai | 思考パートナー | 戦略の壁打ち、トリッキーな状況への対処法、クイックな質問 |
| Claude Code | コーディングエージェント | プロトタイプ、評価(eval)、スクリプトの構築(出力がコードの場合) |
| Cowork | ナレッジワークツール | メール処理、TODO管理、スライド作成、Slack検索、出張手配 |
これは「考える場」「作る場」「実務をこなす場」の三層構造と言える。
4. AIの指数関数的進化に乗るための4つのシフト
① 短いスプリントで計画する(Plan in short sprints)
従来のPM思考では、探索はロードマップが固まる前に行うものだった。それに代わり、チーム全員(エンジニア・PM・デザイナー)が「サイドクエスト」を行うことを推奨。サイドクエストとは、公式ロードマップの外で自主的に行う短期実験のこと。
成果例: Claude Code on Desktop、AskUserQuestionツール、todoリストなど、Anthropicの人気機能の多くがサイドクエストから生まれた。
② ドキュメントよりデモと評価を重視する(Demos and evals over docs)
チームはドキュメントファースト思考からプロトタイプファースト思考に移行。従来のスタンドアップの代わりに、新しいアイデアのデモを共有する。午後いっぱいでプロトタイプが作れるため、間違った賭けのコストは安い。
実践アドバイス: 仕様書を書いたらClaude Codeに送ってビルドできるか試す。粗削りなプロトタイプでも会話の質が一変する。
③ 新モデルが出たら既存機能を再検討する(Revisit features with new models)
機能を出荷した後、より優れたモデルが出るとその機能が劇的に改善される可能性がある。モデルリリースのたびに既に構築したものを見直す。
具体例: Claude Code with Chromeは、ユーザーがClaude CodeでWebアプリを作り手動でClaude in Chromeに切り替えてテストしていた行動を観察して生まれた。
注意点: プロトタイピング時は常にまず能力を最大化すべき。トークンコストの削減を早期にしすぎるのはよくある間違い。
④ シンプルなことをやる(Do the simple thing)
Anthropic全体の指針として「うまくいくシンプルなことをやる(do the simple thing that works)」がある。モデルの制限を巧みに回避する実装をしても、次のモデルが出ればその回避策は不要な複雑性になるため。
具体例: todoリストの初期実装ではモデルが項目を確実にチェックしなかったため、数メッセージごとにシステムリマインダーを入れるハックを加えた。しかし次のモデルでネイティブに対応し、リマインダーを完全削除できた。Opus 4.6ではシステムプロンプトを20%削減。
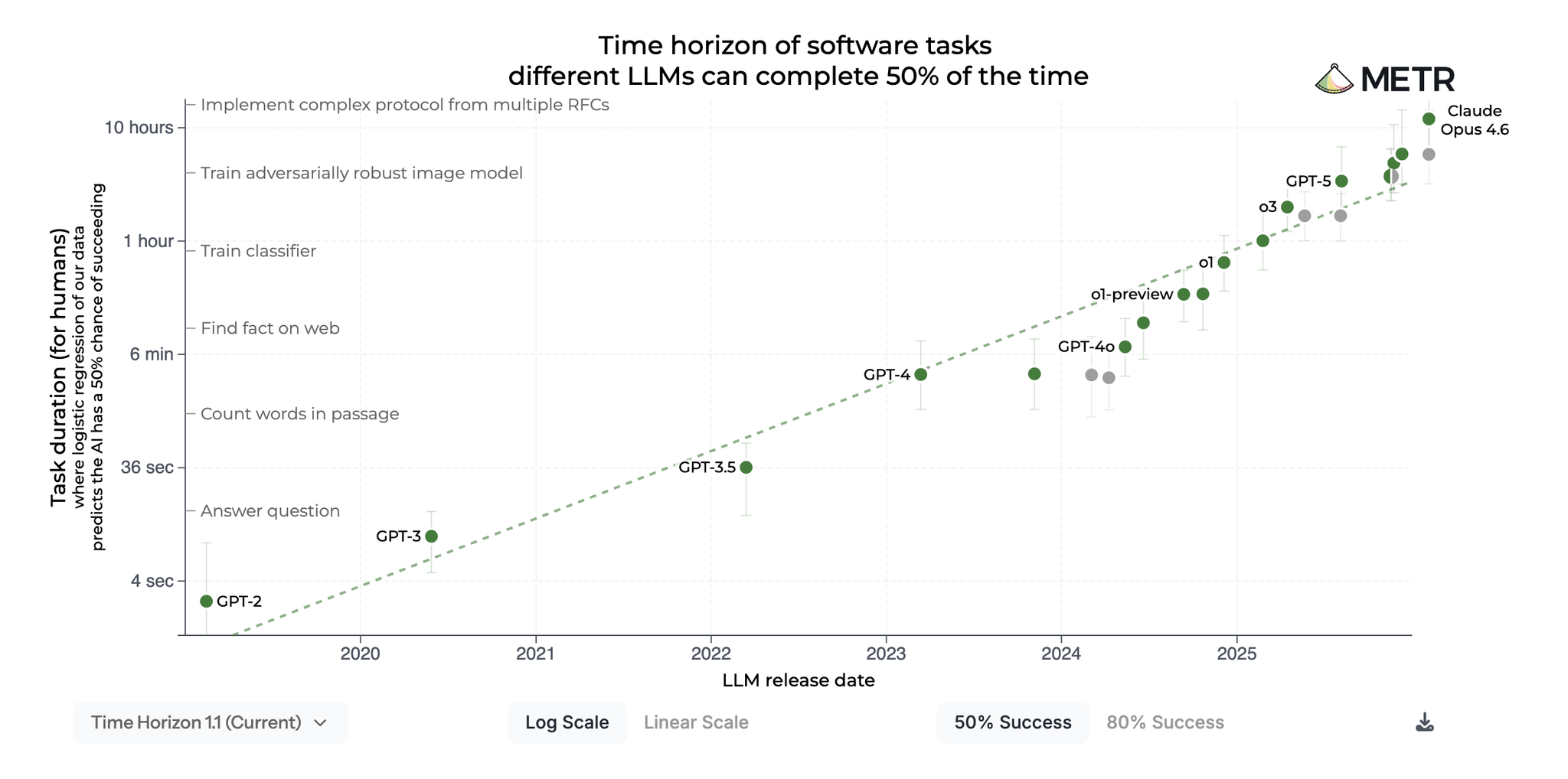
5. モデル進化の定量的インパクト
METRの調査データによる裏付け:
| 時期 | モデル | 完了可能なタスクの人間所要時間 |
|---|---|---|
| Claude Code構築開始時 | Sonnet 3.5(new) | 約21分 |
| 2026年 | Opus 4.6 | 約12時間(50%の確率) |
→ 16ヶ月で約41倍の能力向上
6. 主張
主張
「指数関数的に進化するAIモデルは、従来のプロダクトマネジメントの根本前提を破壊する。PMは"計画して実行する人"から"変化の中で方向を示す人"へと変わらなければならない」
なぜこれが最も重要か
この前提の崩壊は、単にロードマップの引き方が変わるという表面的な話ではなく、PM職の存在意義そのものに関わる。
従来のPMの価値は「不確実性を減らすこと」にあった。市場調査、技術的実現可能性の見極め、優先順位づけ、チームへの明確な指示。しかし16ヶ月で41倍の能力向上が起きる世界では、その「見極め」自体が数ヶ月で陳腐化する。
PMの価値は「正しい計画を立てる力」から「変化に適応し続ける仕組みを設計する力」へと移行している。
解法の核心:シンプルに作り、繰り返し見直す
4つのシフトの中でも特に本質的な2点:
- 新モデルが出たら既存機能を再検討する — 従来のPMにはなかった発想。AI製品では基盤技術が勝手に進化するため、「何もしないこと」がむしろ機会損失になる。
- シンプルに作る — 複雑な回避策を積み重ねていると、新モデルの恩恵を受けるために大量のコードを剥がす作業が必要になる。シンプルな実装は、次のモデルの進化を「そのまま受け取れる器」になる。
PMの新しい役割の定義
Cat Wu氏による再定義:
- 急速なモデル進化が生み出す曖昧さの中に明確さをつくる
- チームに「もっと大きく考えろ」と促す
- 出荷までの障害を取り除く
- 本当に譲れないものを少数だけ特定し、残りは手放す
これは「コントロールを手放す勇気」の話であり、完璧主義からの脱却の話。Cat Wu氏自身が「完璧主義者として、これが最も難しい変化だった」と認めている。
感想
- 「もっと大きく考えろ」は重要。
- コーディングエージェントで誰でも新しいアイデアを1日でPoCレベルで実現できるようになったので、「素早い実験(rapid experimentation)、一貫した出荷(consistent shipping)、うまくいったものへの集中投資(doubling down on what works)」を実践する開発体制を実現したい。
- B2CであればPRマーケティングを頑張ればユーザにすぐ試される→反応を見るリズムを作りやすいが、B2Bだと新しい機能をユーザがすぐ使うわけではない(業務に組み込まれない)ので、B2Bプロダクトで同様のスピード感を出すエンジニアエンジニアプラクティスは別途必要。
@Hirofumi Tateyama(hirotea)
[Paper]Attention Residuals
サマリー
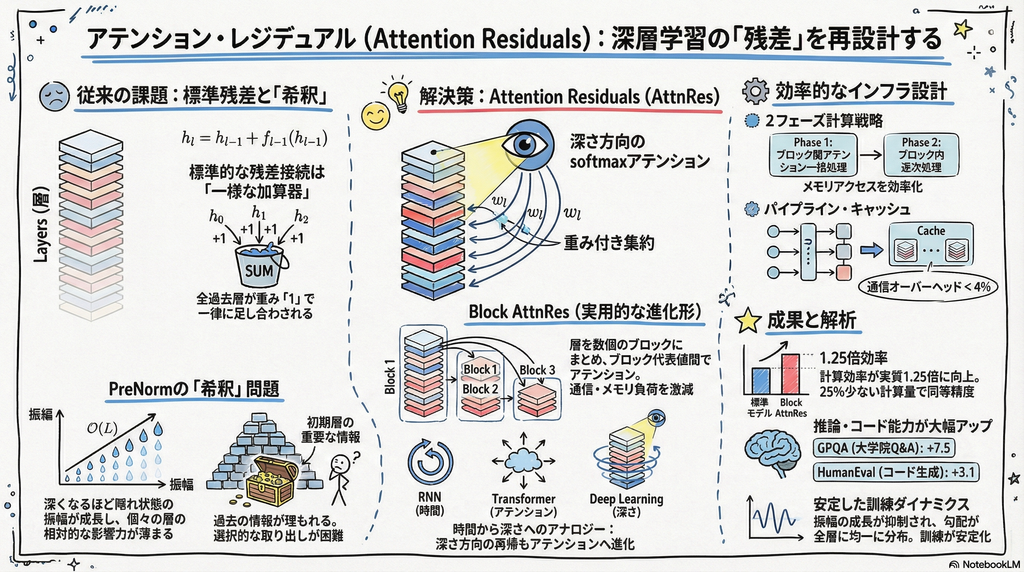
Transformer の residual connection を「ただ足すだけの固定加算」ではなく「深さ方向の attention」として再設計し、深い層で起きる表現の希釈や隠れ状態の増大を抑えつつ、実用的なコストで性能改善を示した研究
Transformer の residual connection は、ただの勾配の抜け道ではなく、深さ方向の情報集約機構でもある。
しかし標準的な PreNorm residual は、各層の出力を固定重みで足し続けるため、深くなるほど
- 過去表現が希釈される
- 隠れ状態の大きさが増えやすい
- 深い層ほど自分の寄与を強く出そうとして不均衡が生じる
という問題を持つ。Attention Residuals(AttnRes)は、これを深さ方向 softmax attentionに置き換え、各層が「どの過去表現を再利用するか」を選べるようにし、同じ演算量で1.25倍の性能向上を実現した。さらに Block AttnRes により、大規模 LLM でも現実的なコストで使えるようにしている。
何が新しいのか
1. residual を「深さ方向 attention」として再設計
標準 residual は、埋め込みと各層出力を一様に足し合わせる設計になっている。
AttnRes はここを、各層が過去層出力へ softmax attention する形に置き換える。これにより、各層は必要な過去表現だけを選択的に取得できる。論文の主張は、これが PreNorm 下の希釈と hidden-state growth を自然に抑える、というもの。
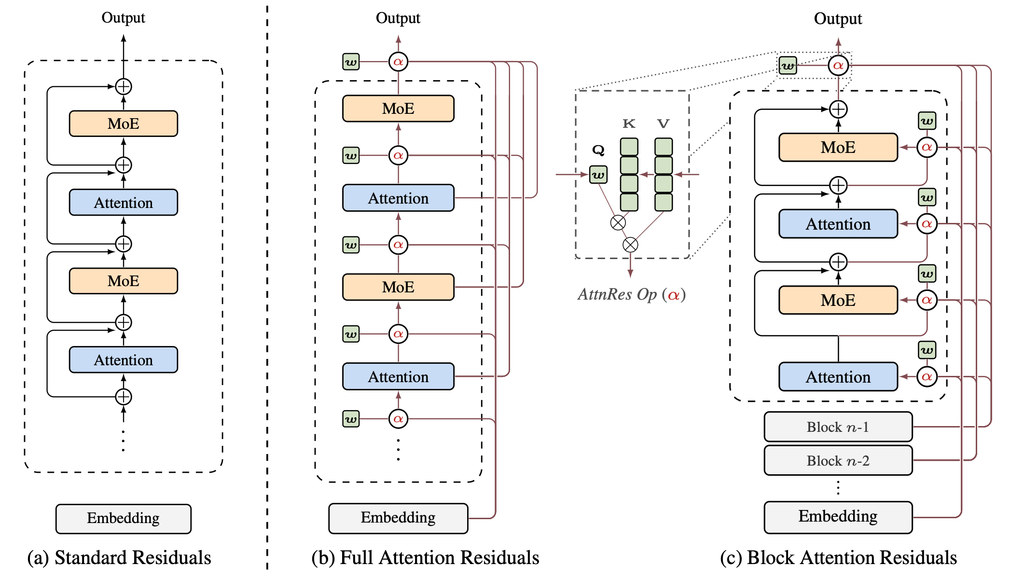
describe
残差接続を“ただ足すだけの固定加算”から、“過去層を選んで混ぜる depth-wise attention”へ置き換える流れ
左の標準 residual では、embedding と全過去層出力が等重みで足されるだけです。
中央の Full AttnRes では、各層が過去の各層出力に softmax attention し、必要な表現だけを重み付きで集約します。
右の Block AttnRes では、その full version をそのまま使うと重いので、層をブロックにまとめ、ブロック代表だけに attention することでメモリ・通信を抑えている
隠れ層の計算を
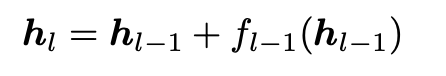
から
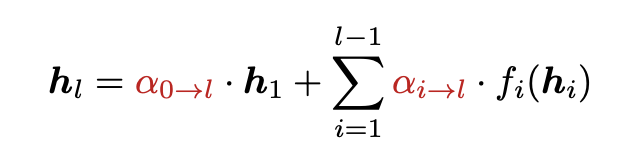
に差し替え、重みをつけていく
αはlがsoftmaxで層ごとに重みを計算している
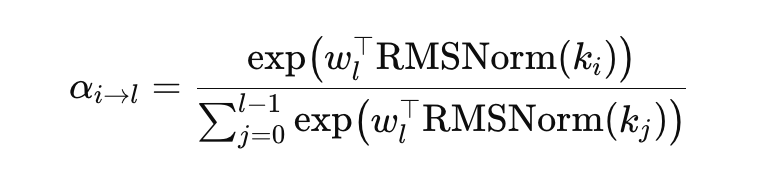
RMSNormを入れているのはベクトルがでかいだけの層にsoftmaxが偏らないようにするため
2. Full AttnRes をそのまま使わず、Block AttnRes に落として実用化
全過去層に毎回 attention すると、大規模学習ではメモリ・通信コストが重くなる。
そこで層をブロックにまとめ、ブロック代表だけを跨いで attention する Block AttnRes を導入している。これにより、Full AttnRes の利点を大きく残しつつ、drop-in replacement に近い形へ寄せている。
3. 1.25x の compute advantage を示している
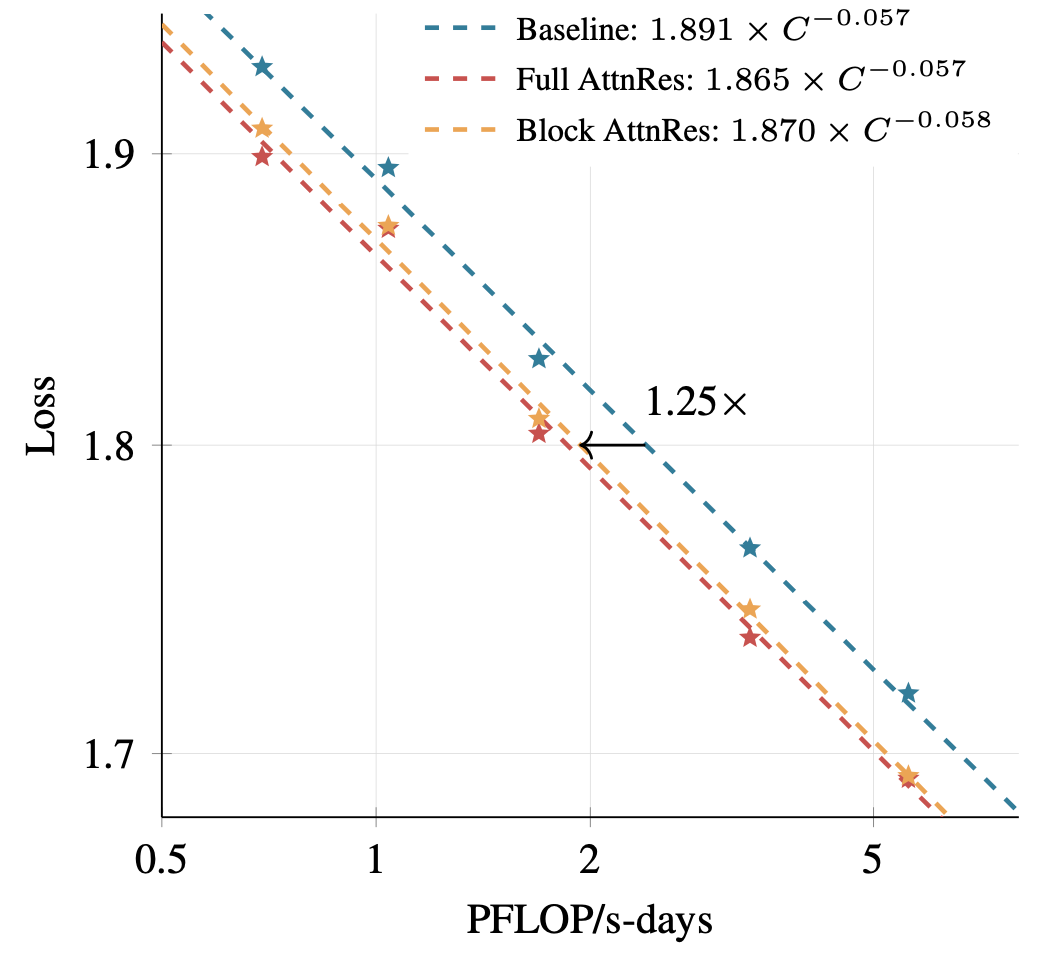
著者らは cache-based pipeline communication と two-phase computation を組み合わせ、推論レイテンシの増加を 2% 未満に抑えつつ、1.25x の compute advantageを示している。大規模訓練・推論の infra を踏まえた設計
学習過程における内部状態の変化も確認している。
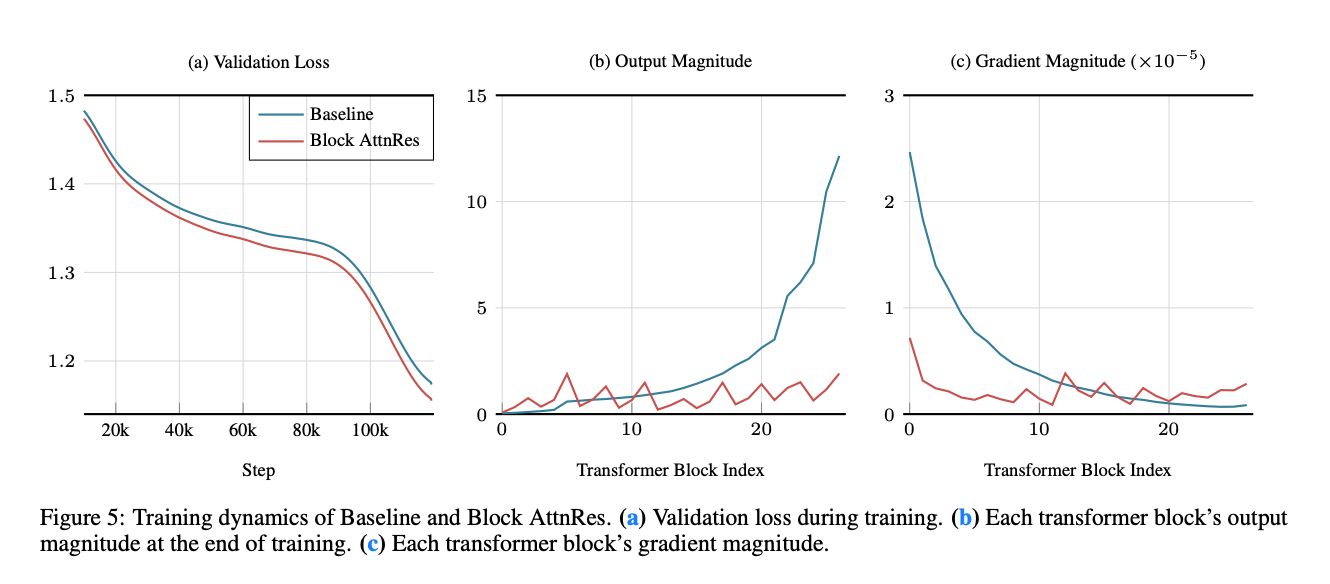
lossが下がりやすく、隠れ状態の大きさが暴れにくく、勾配も浅い層に偏りにくい。
bではBaseline は深い層ほど出力がどんどん大きくなっているが、AttnResはbloclごとに集約し直している。浅い層に偏る勾配もsoftmax weightによって均一にできている。
4. Kimi Linear 系の 48B / 3B MoE に入れて、下流性能改善まで確認
AttnRes は Kimi Linear architecture(48B total / 3B activated) に統合され、1.4T tokens で事前学習されている。論文では、training dynamics の改善に加え、評価した全 downstream tasks で一貫して改善したと報告している。
関連
- MoonShotAIはロングコンテキスト計算最適化のためのBlock attenction機構MoBAをすでに公開済み。AttentionResidualと組みわせてロングコンテキストでの推論高速化+Attention最適化をやろうとしている?
背景と問題設定
残差接続は本当に最適なのか?
ResNet 以来、残差接続は深いネットワーク学習の標準部品になり、Transformer でもほぼ所与の前提として使われている。
ただし LLM の文脈では、PreNorm residual は「安定して学習できる」代わりに、全過去層を固定比率で蓄積するという設計を引きずっている。AttnRes 論文の視点は、ここを「深さ方向の情報ルーティング問題」として見直した点にある。
論文の問題提起
標準 residual では、深くなるほど過去表現が混ざり続けるため、
- どの層の情報が効いているかが曖昧になる
- 深い層ほど出力振幅を大きくしがち
- 勾配も深さ方向で偏りやすい
という現象が起きる。
AttnRes は「系列方向では RNN 的加算から attention に進化したのに、深さ方向はまだ固定和のままだった」という構図でこの問題を説明している。
手法の核心
Standard Residual
各層の出力を単純に足す。
Full Attention Residuals
各層が、過去の layer outputs に対して深さ方向 attentionを行い、必要な表現だけを集約する。
ここで query 自体は軽量な学習ベクトルで、keys/values は各層の出力から作るので、入力依存の重み付けになる。
Block Attention Residuals
Full だと高コストなので、層を複数 block に圧縮し、block-level representation にだけ attentionする。
これにより、Full の効果をかなり残しつつ、メモリ・通信を抑えた現実的な設計になっている。
どの図を見ると理解しやすいか
Figure 1: 全体像
最初に見るべき図。
(a) Standard Residual
(b) Full AttnRes
(c) Block AttnRes
の違いが一目で分かる。**「固定加算 → 選択的集約 → ブロック圧縮で実用化」**という流れを説明するのに最適。
Figure 4: Scaling Laws
AttnRes が様々な compute budget で baseline を上回り、Block AttnRes が 1.25x 多い compute を使った baseline に匹敵することを示す図。
この論文の「地味だが強い」主張はここにある。スケールを変えても改善が消えない。
Figure 5: Training Dynamics
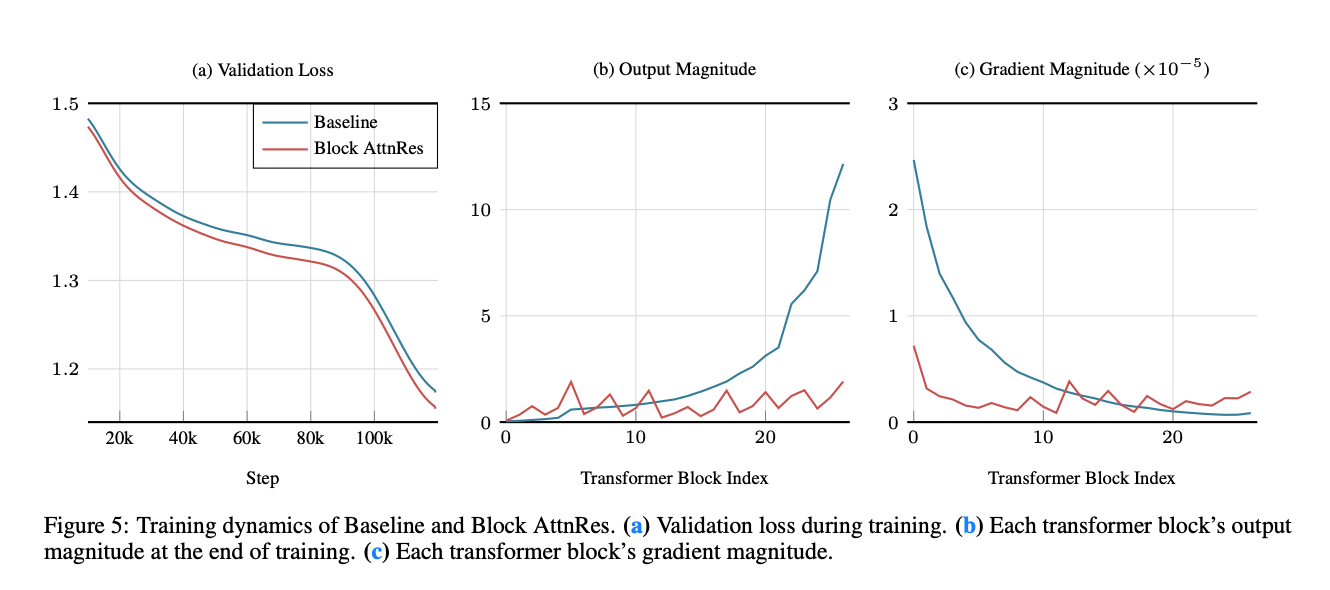
論文で最も説得力がある図の一つ。
AttnRes は
- hidden-state magnitude の増加を抑える
- gradient magnitude を深さ方向でより均一にする
ことが可視化されている。
つまり単に性能が上がるだけでなく、なぜ効いたかまで踏み込んでいる。
Figure 8: Depth-wise Attention Pattern
どの層がどの過去層を参照しているかを見る図。
直前層中心だが、必要に応じて遠い層や embedding にも重みが飛ぶ。
つまり AttnRes は residual を壊すのではなく、“基本は局所、必要時だけ長距離再利用”を学習している。([arXiv][3])
主な結果
1. スケーリング則で一貫した改善
様々なモデルサイズで、AttnRes は baseline を一貫して上回る。
特に Block AttnRes は、1.25x 多い compute の baseline と同等の lossを達成しており、論文のコアメッセージの一つになっている。
2. 実用オーバーヘッドが小さい
Block AttnRes は practical drop-in replacement を狙った設計で、推論レイテンシのオーバーヘッドは 2% 未満とされている。
研究として面白いだけでなく、導入検討の余地がある程度には軽い。
3. Kimi Linear 48B / 3B で downstream が全指標改善
Kimi Linear 系 MoE に組み込み、1.4T tokens で事前学習した結果、評価した全 downstream tasks で改善を示した。
Moonshot 側が Kimi Linear と MoBA も並行して公開していることからも、これは単発の toy architecture ではなく、同社の長文脈・効率化研究の流れの中にあると見ると理解しやすい。
この研究の面白い点
面白い点1: residual を再発明している
attention の新変種ではなく、Transformer の最も当たり前すぎて疑われてこなかった部品を見直している。
これはかなり本質的で、sequence axis の設計ばかり議論されがちな近年の流れに対して、depth axis を最適化対象に戻したとも言える。
面白い点2: “理論だけでなく infra まで降りている”
Full AttnRes を「きれいな理論」で終わらせず、Block 化と pipeline / inference の最適化までやっている。
この論文は、アーキテクチャ論文であると同時に、大規模 LLM 実装論文でもある。
面白い点3: Moonshot の研究ラインと繋がっている
Kimi Linear は hybrid linear attention、MoBA は long-context 向け block attention、そして AttnRes は depth-wise attention。
つまり Moonshot は sequence・context・depth の三方向で、attention / memory / routing を再設計しているように見える。
気になる点 / 議論の余地
1. まだ “完全に一般解として確立” とは言いにくい
現時点の公開物は論文と README が中心で、完全な再現コードや広範な第三者検証が揃っているわけではない。
したがって、「強い結果」ではあるが、どのファミリの LLM にも広く効くと断言する段階ではない。
2. 改善は堅実だが、破壊的というより累積的
1.25x compute advantage や downstream の一貫改善は十分価値がある一方で、性能差は「全部を塗り替える」というより着実に押し下げる型の改善。
したがって本質的価値は、単発 SOTA というより、残差設計の新しい自由度を示したことにある。
3. Full の最良性能と Block の実用性の間にはまだギャップがある
Block 化は practical だが、情報圧縮でもある。
つまり「最も強い設計」と「最も使いやすい設計」はまだ一致していない。ここは今後の kernel / hardware / architecture co-design の余地。
Take Home Message
- residual connectionは“ただ足すだけ”で本当に良いのか?を正面から問い直した論文
- AttnRes は、各層が過去表現を選択的に取得できるようにし、PreNorm の希釈と hidden-state growth を抑える
- Block AttnRes により、大規模 LLM でも実用的な drop-in replacementとして成立する可能性を示した
- 1.25x compute advantage、<2% inference overhead、Kimi Linear 48B/3B での downstream 改善まで含め、研究アイデアを実装レベルまで落とし込んでいるのが強い
Online Experiential Learning for Language Models
| タイトル | Online Experiential Learning for Language Models |
|---|---|
| 著者 | Tianzhu Ye, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang ,Furu Wei |
| 所属 | Microsoft Research |
| リンク | https://arxiv.org/abs/2603.16856 |
| 関連ページ | https://github.com/microsoft/LMOps/tree/main/oel |
概要
本論文は、言語モデルがデプロイ後の実際の使用経験から継続的に自己改善するフレームワーク Online Experiential Learning(OEL)を提案する。OELは、ユーザーとの対話から得られる経験的知識を抽出し、それをモデルパラメータに蒸留する2ステージの反復プロセスで構成される。人間のアノテーションや報酬モデル、スカラー報酬を必要とせず、テキストゲーム環境(Frozen Lake、Sokoban)での実験で反復ごとに一貫した性能向上と応答長の約 削減を達成した。
先行研究と研究背景
既存手法の限界
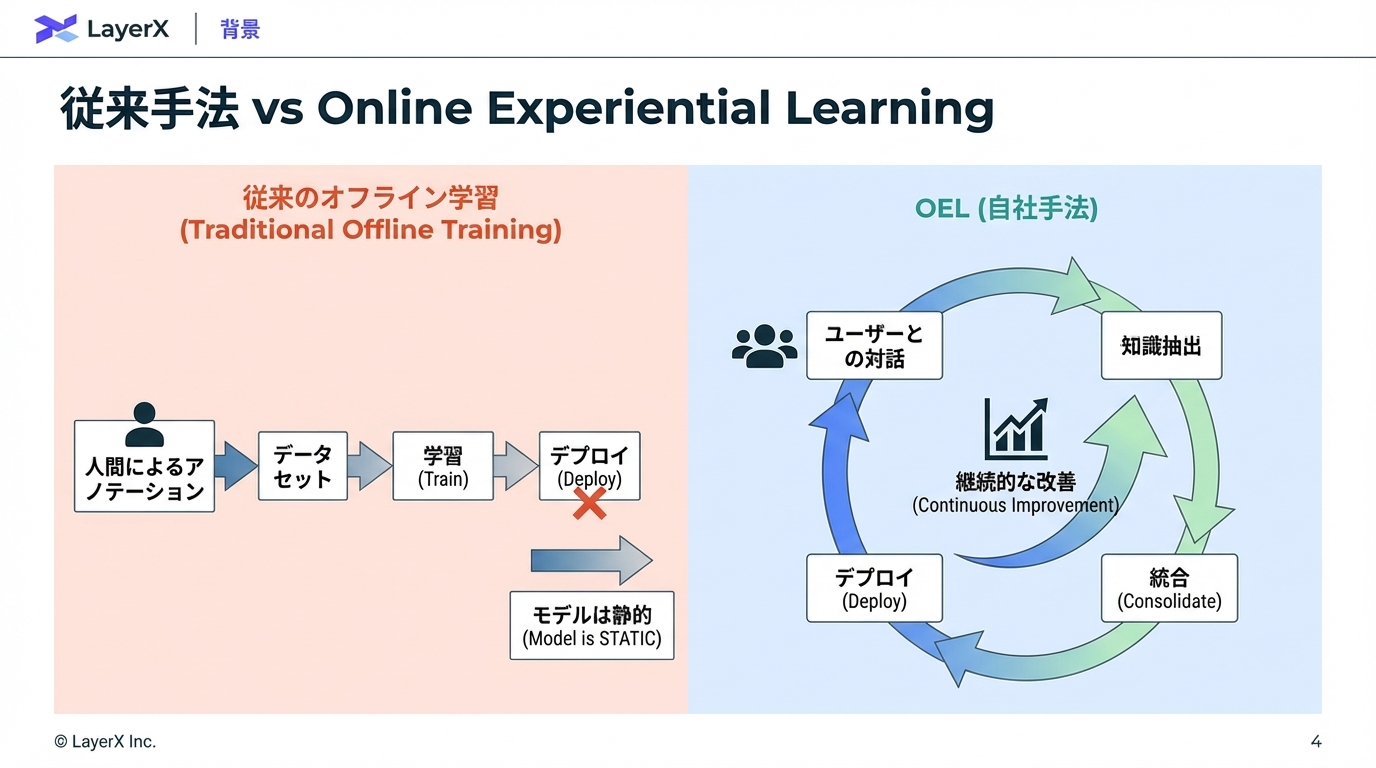
現在の大規模言語モデル(LLM)の開発パラダイムでは、モデルはデプロイ後に改善を止める。しかし、実際のデプロイ環境では多様かつ絶えず変化するタスクに直面し続ける。
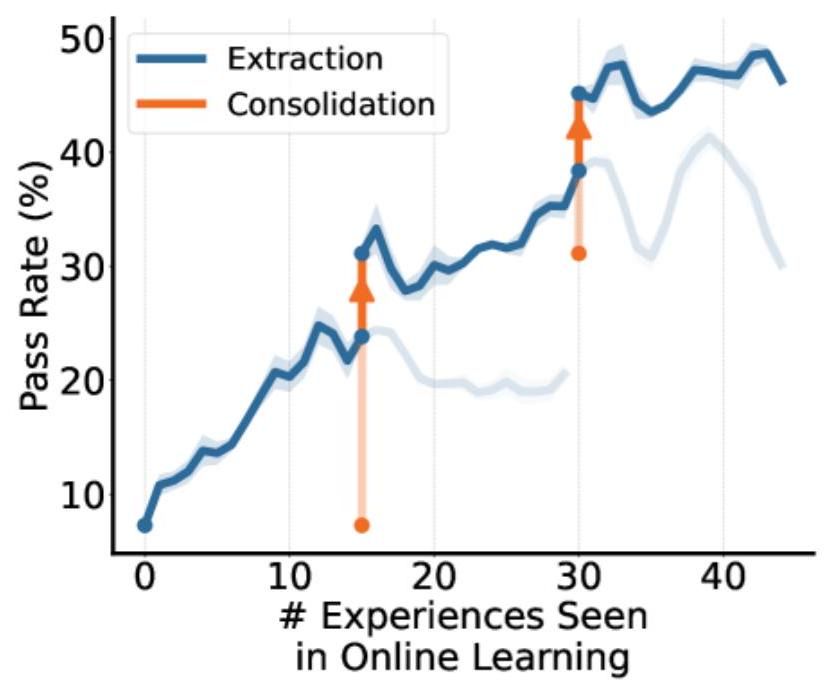
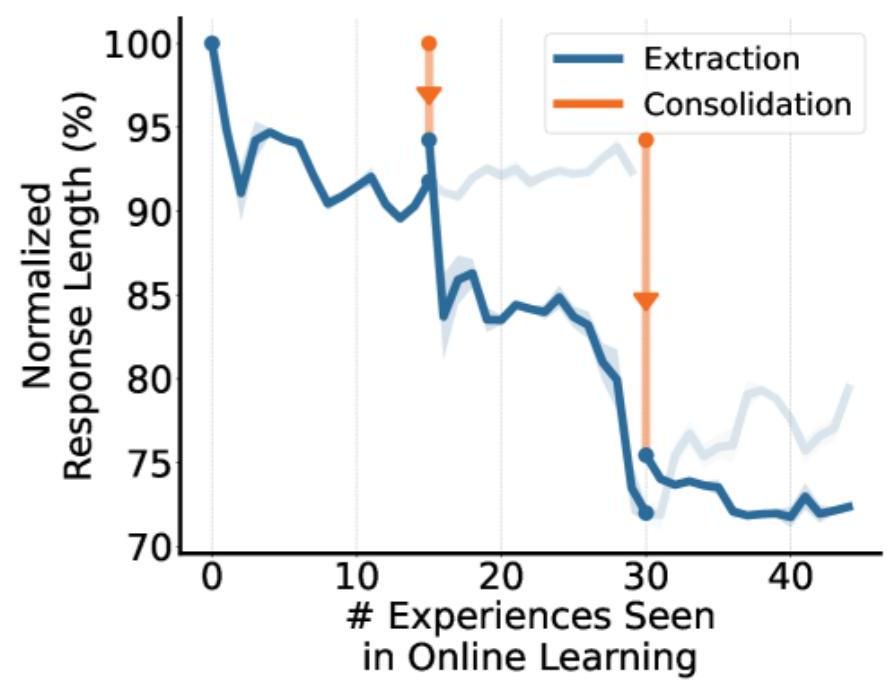
図2:オフライントレーニング(従来手法)とOnline Experiential Learning(OEL)のパラダイム比較。従来は人間 によるアノテーションと固定データセットでの学習が必要だったのに対し、OELはデプロイ後のユーザーインタラクションから継続的に学習する。
関連研究
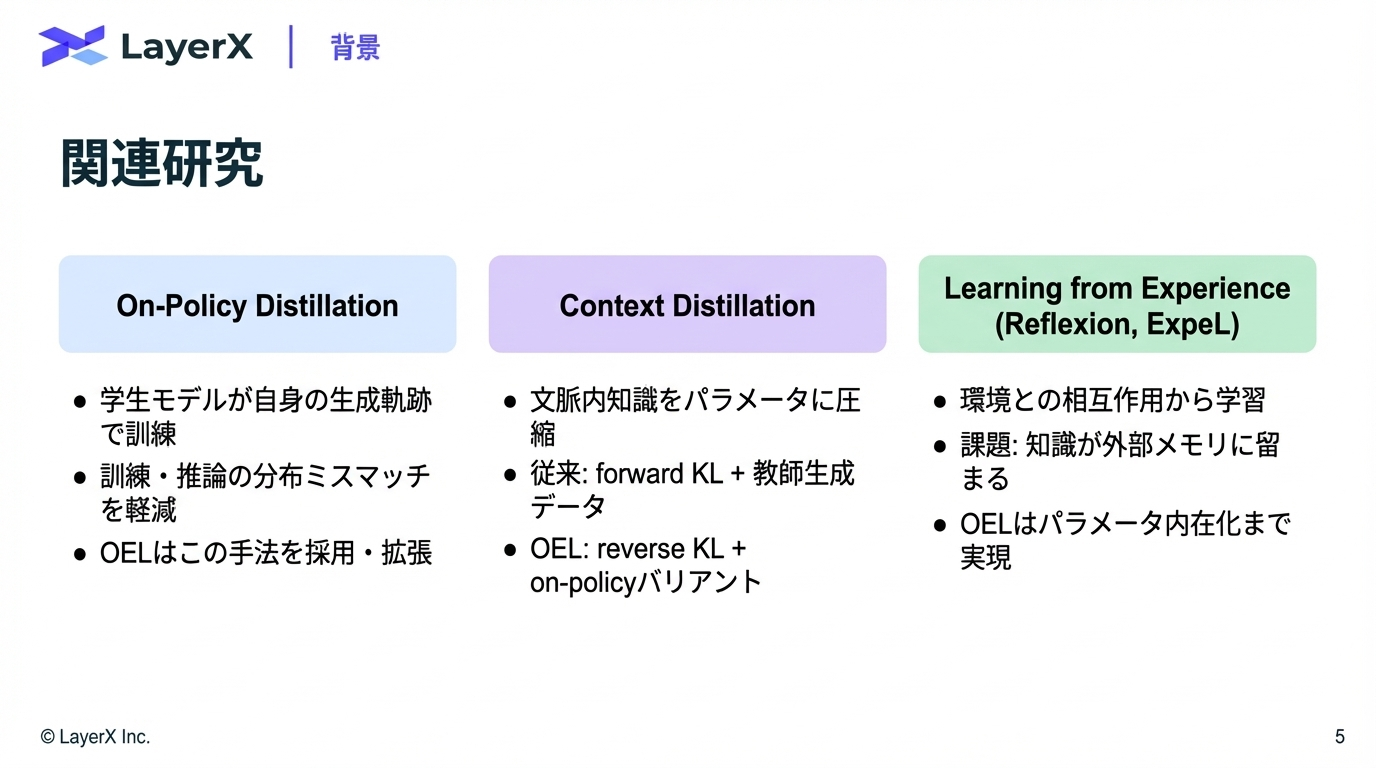
On-Policy Distillation:学生モデルが教師モデルの生成データではなく、自身が生成した軌跡で訓練する手法。訓練 と推論の分布ミスマッチを軽減する。
Context Distillation:文脈内知識をモデルパラメータに圧縮する手法。従来手法はforward KL divergenceを用いた教師生成データを使用するが、OELはon-policyバリアントとreverse KL divergenceを採用する。
Learning from Experience:エージェントが人間によるキュレーションデータではなく、環境との相互作用から学習する手法。ReflexionやExpeL等の外部メモリシステムを使った先行研究が存在するが、これらは知識をモデルパラメータに内在化しない。
主要な貢献
- デプロイ後継続学習フレームワーク:人間のアノテーション、報酬モデル、スカラー報酬を必要とせず、テキスト環境フィードバックのみでモデルを継続改善するOELフレームワークを提案
- 経験的知識抽出:生の軌跡データをそのまま使用するのではなく、再利用可能な経験的知識として構造化•蒸留するメカニズムの設計
- On-Policy Context Distillation:モデル自身が生成した軌跡から知識を蒸留することで、分布ミスマッチと壊滅的忘却(Catastrophic Forgetting)を同時に解決
- 反復的改善サイクルの実証:改善されたモデルがより高品質な軌跡を収集し、それが更なる改善につながる「好循環」の検証
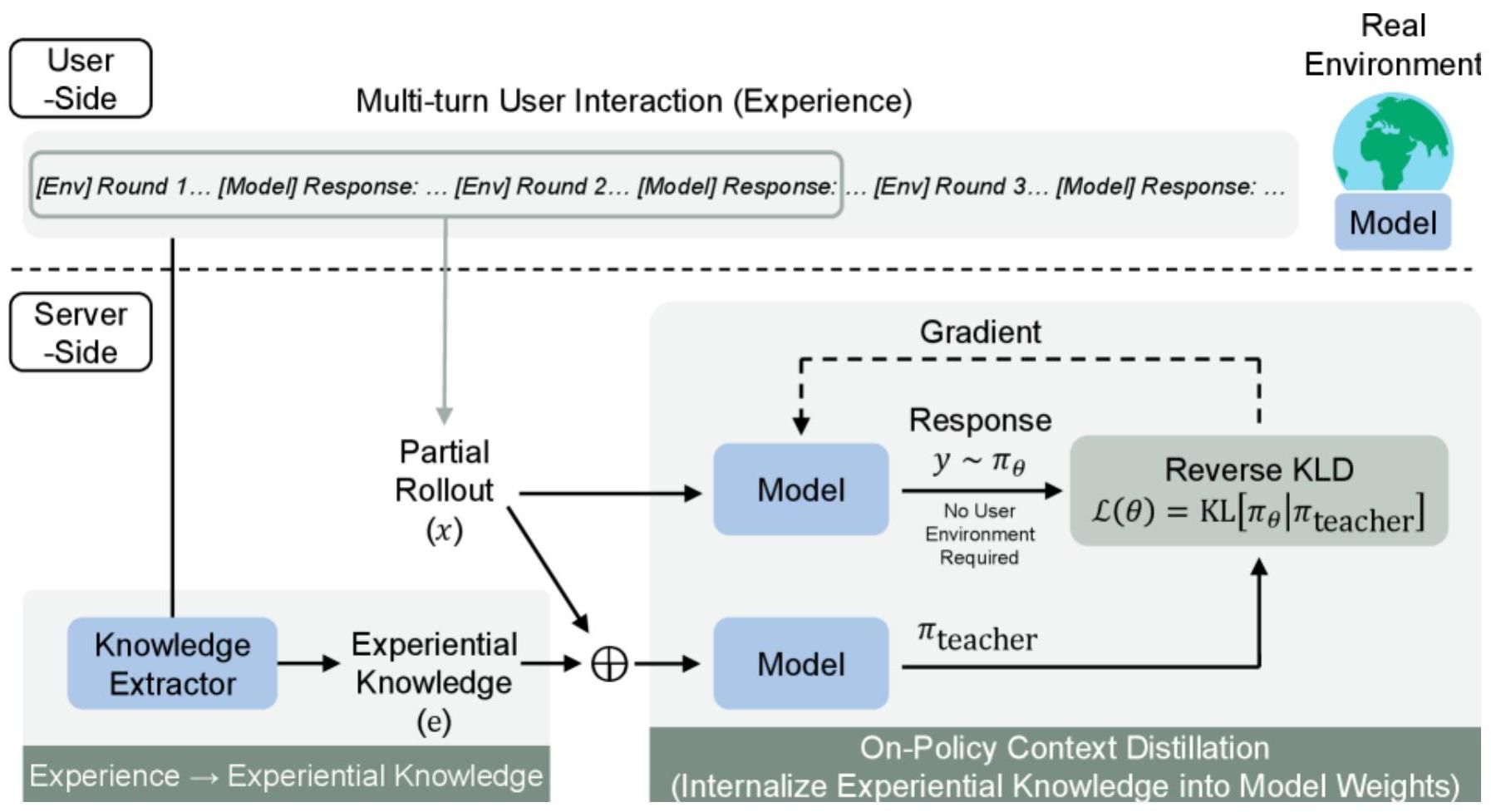
手法の詳細
フレームワーク概要
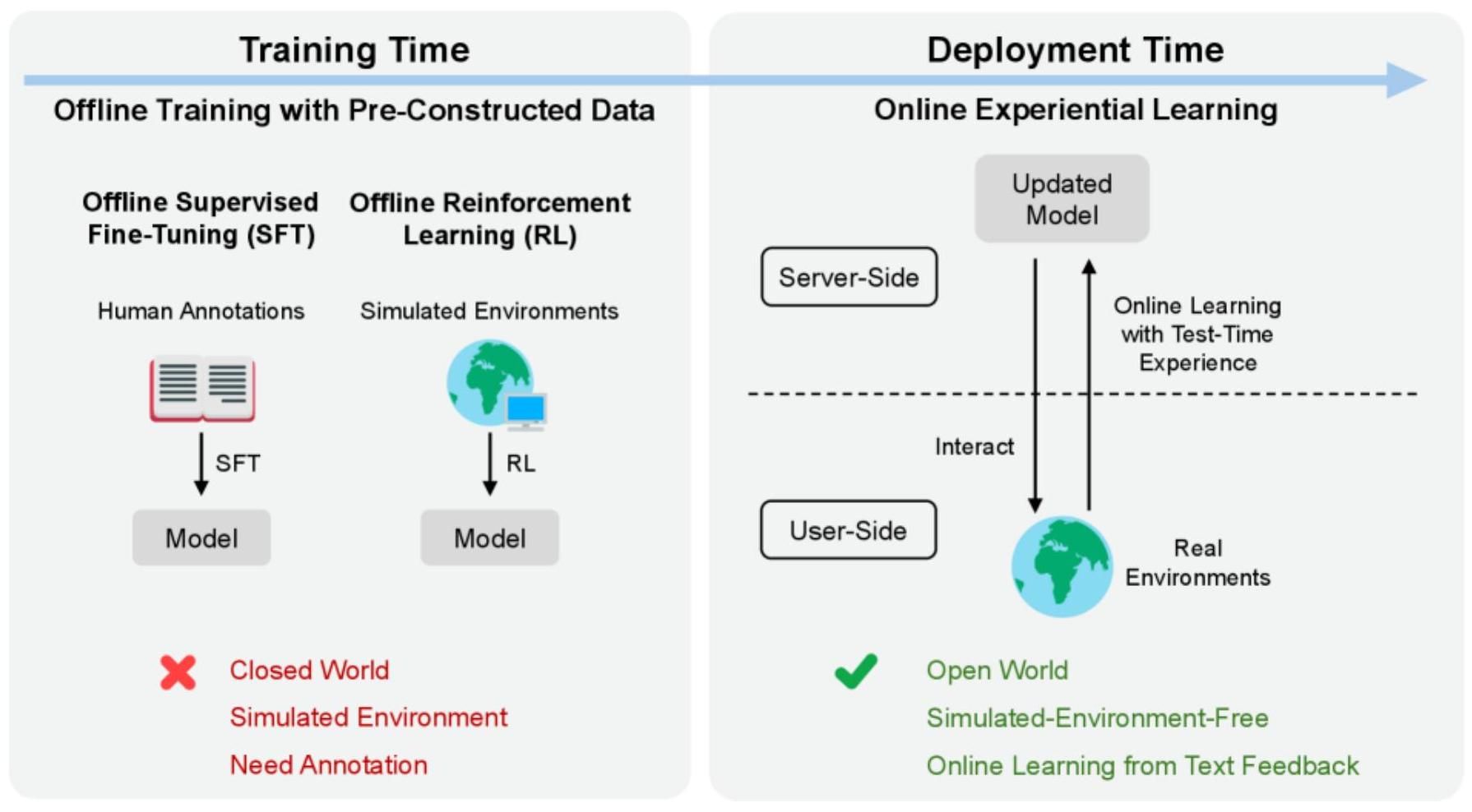
図3:OELフレームワークの全体構成。ユーザーサイド(デプロイモデルとの対話)とサーバーサイド(知識抽出•統合)の2つのコンポーネントからなる。
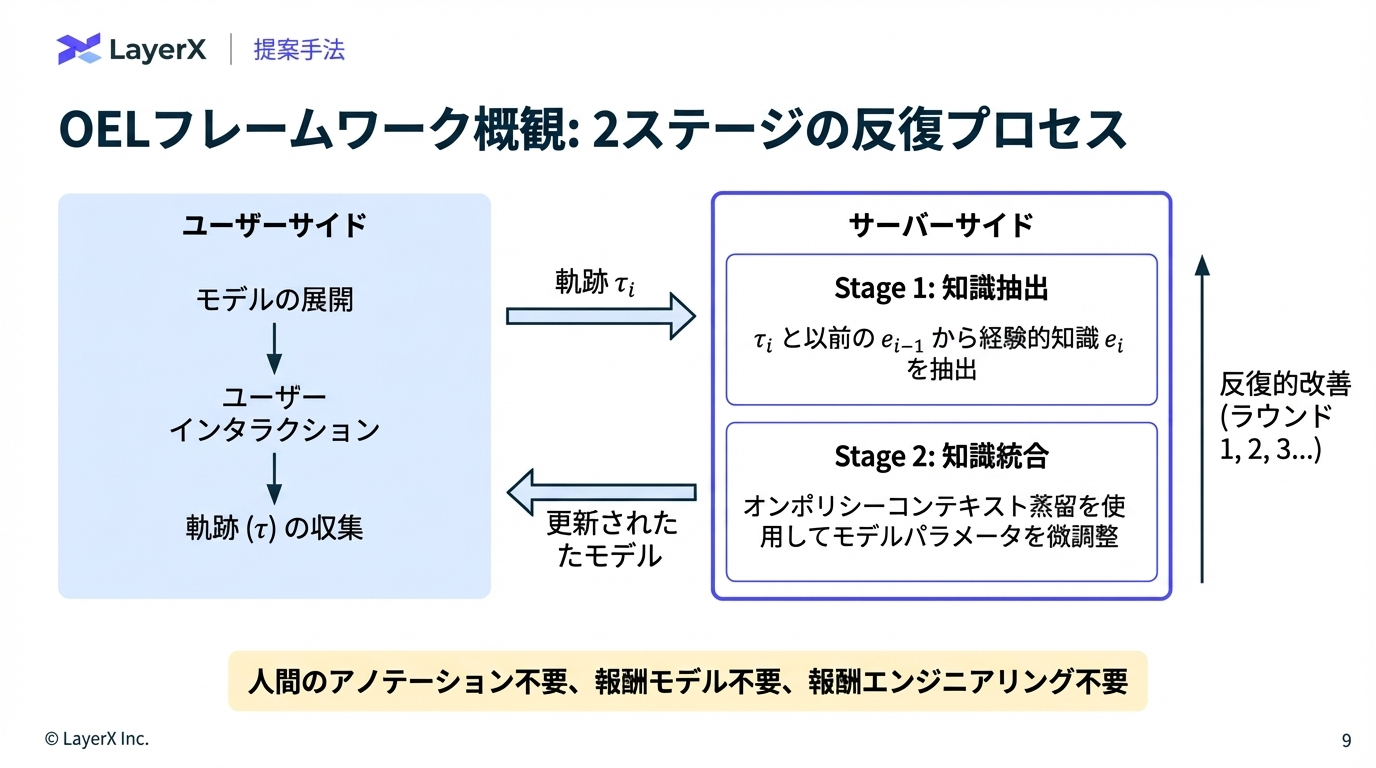
ステージ1:経験的知識抽出(Knowledge Extraction)
デプロイされたモデルが収集した対話軌跡 から、転用可能な経験的知識を抽出する。以前に蓄積された知識 を踏まえて新たな知識を再帰的に抽出する。
: 知識抽出モデル (学習モデルと一緒)
この設計により:
- Ground-truthラベル不要:軌跡自体からのみ知識を抽出
- 累積的改善:前回の知識 を踏まえた知識の積み上げ
- 構造化形式:生の軌跡よりも効率的に情報を圧縮
抽出パラメータ(実験設定)
構造化して知識を抽出するのと構造化せずに知識を抽出する二つのパターンを試す。
thinkingモデルを知識抽出に用いるが、知識に<thinking>の部分は使用しない。
- 構造化フォーマット: 軌跡、 トークン
プロンプト(和訳)
- 非構造化フォーマット: 、 トークン
プロンプト(和訳)
- 異なるランダムシードで評価
- この場合はフルの軌跡を毎回使って、知識抽出
ステージ2:知識統合(Knowledge Consolidation)
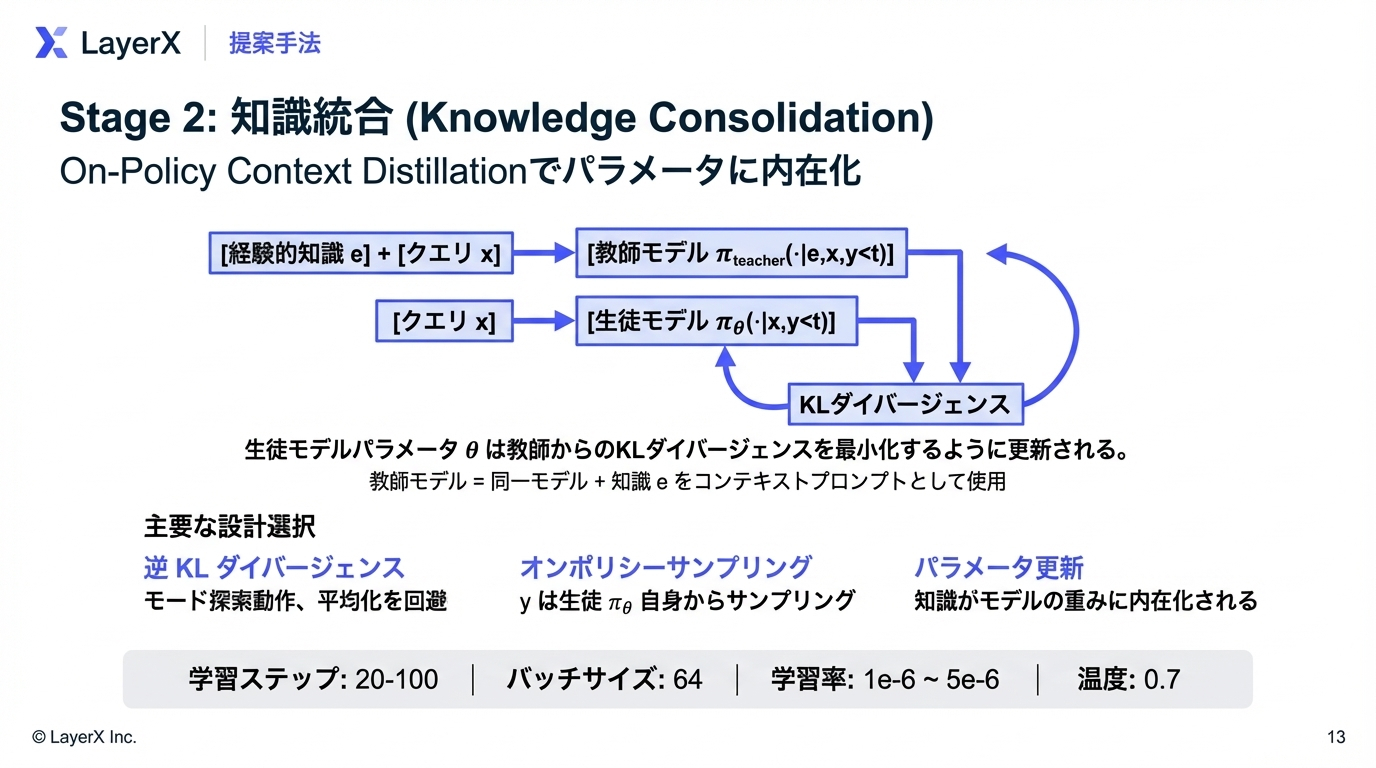
抽出された経験的知識 を、on-policy context distillationによりモデルパラメータに統合する。学生モデルが知識条件付き教師の出力に一致するよう訓練する
ここで:
- :学生モデル(パラメータ更新対象)
- : 同一モデルに経験的知識 を文脈として与えた教師
- reverse KL divergence(mode seeking挙動)を採用
mode seekingとは
通常のKLは だが、reverse KLはその逆
こうすることで、教師のMode(確率が高い部分)に寄るように学習される。
学習方法
- まず軌跡を収集して、そこからpartial rolloutを作成する
- この部分的な軌跡を用いて次のアクションを予測するというタスクで知識統合を行う
- 生徒モデルの生成する確率分布がそれぞれの時点で教師モデルではどういう確率分布になっているか?から学習を行う
続合パラメータ(実験設定)
- 学習ステップ数:20~100
- バッチサイズ: 64 サンプル/ステップ
- 学習率: ~
- 温度パラメータ: 0.7
On-Policy学習の重要性
On-policy:学生モデル自身が生成した軌跡を知識源として使用
Off-policy:別のモデル(より大きなモデル等)が生成した軌跡を使用
On-policyアプローチにより:
- 分布ミスマッチの解消:訓練データと推論時の分布が一致
- 壊滅的忘却の防止:分布外タスクの性能低下を抑制
実験結果
実験設定
環境:TextArenaのテキストベースゲーム
- Frozen Lake( グリッド):ルール説明なし、テキストフィードバックのみ
- Sokoban( グリッド):ルール説明なし、テキストフィードバックのみ

モデル:
- Qwen3-1.7B(思考モデル)
- Qwen3-4B(思考モデル)
- Qwen3-8B(思考モデル)
- Qwen3-4B-Instruct-2507(非思考モデル)
評価指標:
- Pass Rate:128マップのテストセット、10シードで平均
- IF-Eval:分布外タスクの性能(壊滅的忘却の評価)
オンライン学習の性能向上
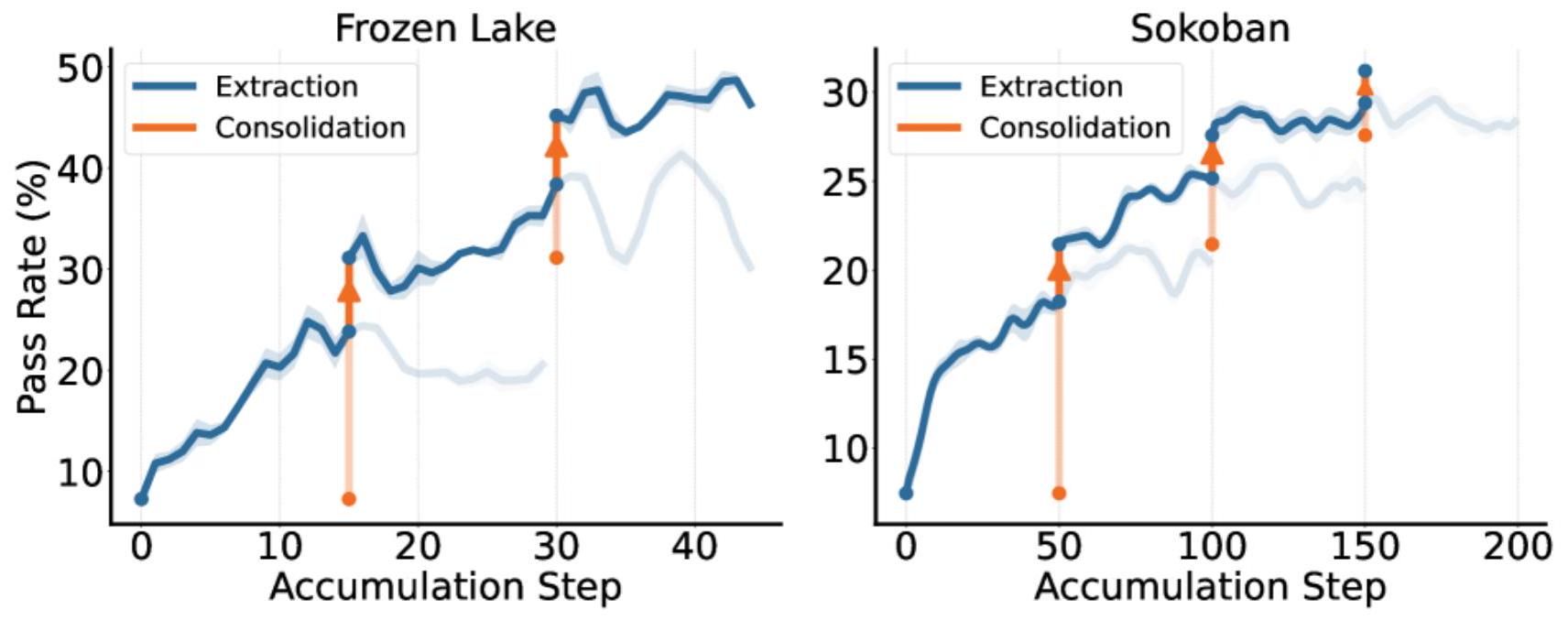
図4:OELの各反復(ラウンド)における性能改善の推移。全モデルサイズで一貫した改善が見られる。
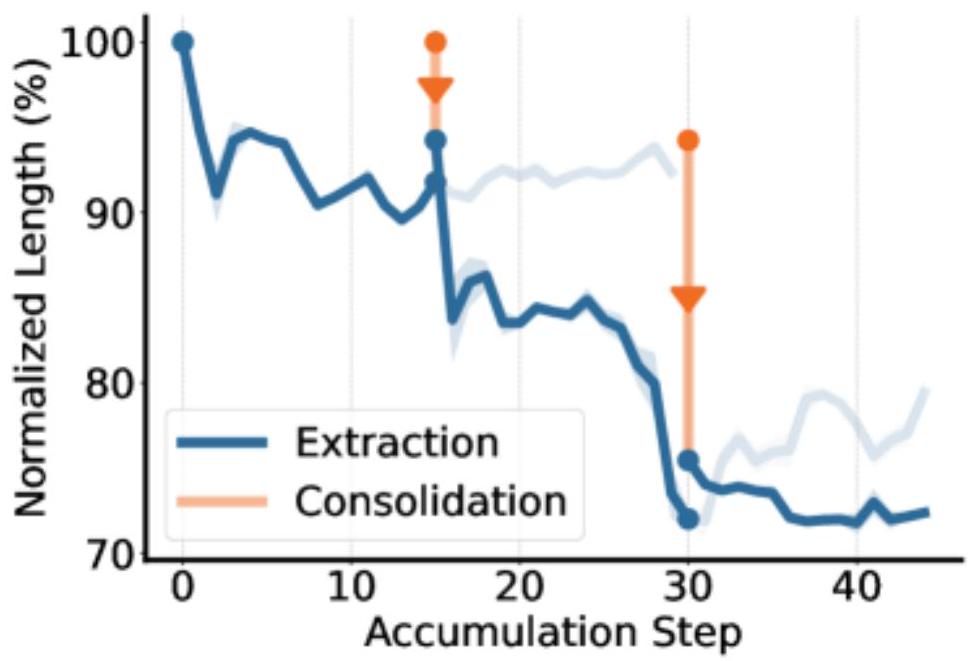
図5:正規化された応答長の推移。ラウンド 3 では初期の約まで短縮され、より効率的な推論が実現される。
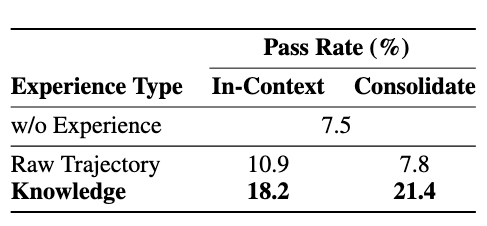
経験的知識 vs 生の軌跡
Qwen3-4B-instruct-2507のSokobanでの実験(Pass Rate):
主要な発見:
- 構造化した経験的知識は、生の軌跡よりも大幅に高い性能(In-Context: 、統合後: )
- 生の軌跡を直接統合すると、ベースラインより悪化( )
On-Policy vs Off-Policy(Table 2)
Qwen3-1.7B(自己生成 vs クロスモデル知識):Fronzen Lakeでの比較
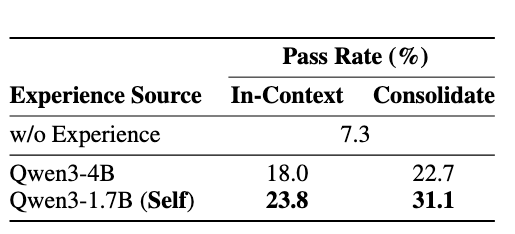
- 自己生成(on-policy)知識が、より大きなモデルからの知識よりも高性能
- 統合後に31.1%まで向上(初期ベースライン7.5%から約4倍)
壊滅的忘却の防止
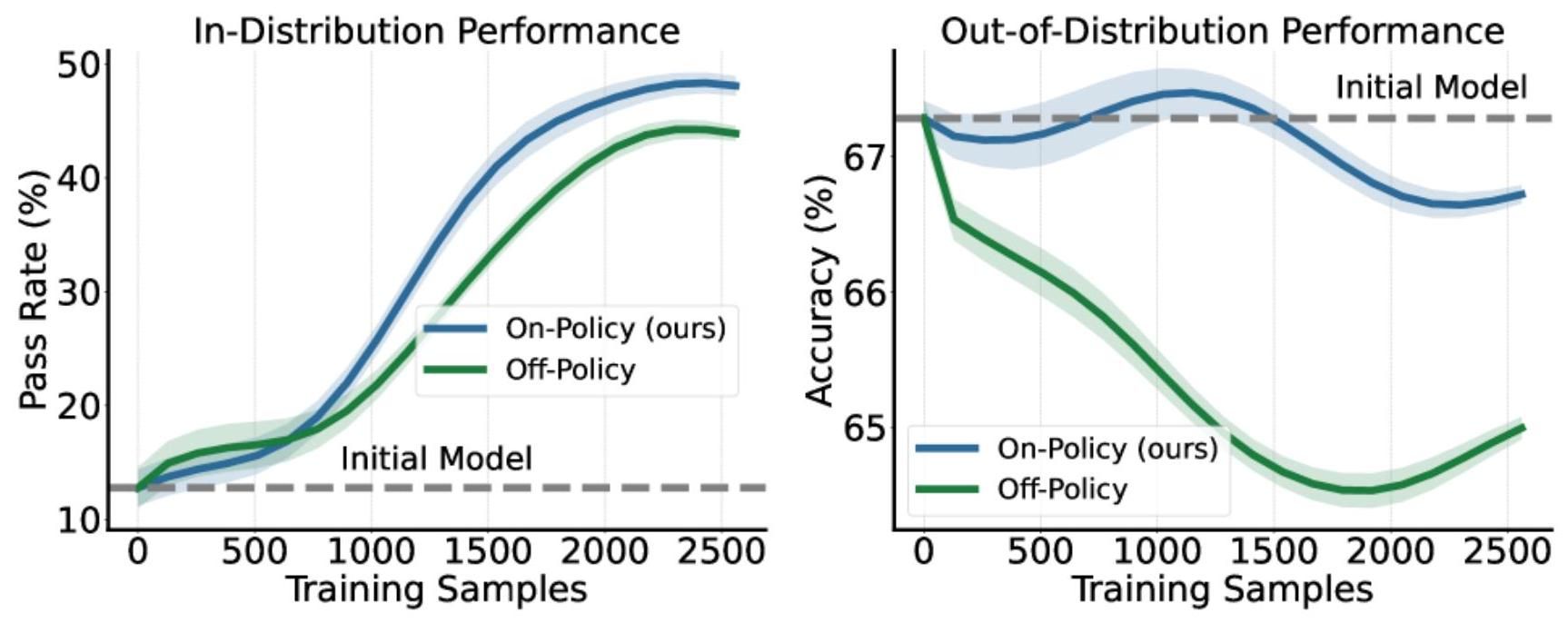
図6:On-policy(OEL)とOff-policy context distillationの比較。Off-policyでは分布外タスク(IF-Eval)の性能が大幅に低下するが、OELのon-policyアプローチではIF-Eval精度が維持される。
モデルサイズのスケーラビリティ
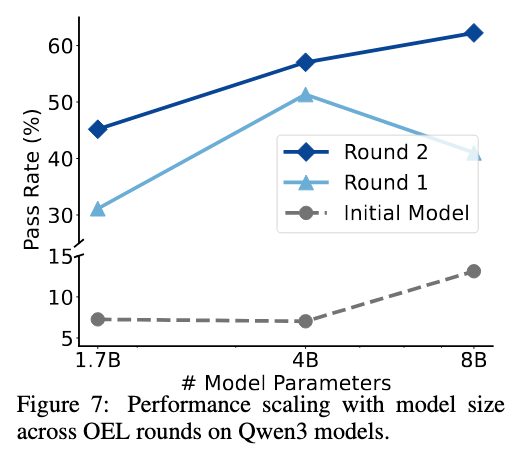
図7:1.7B~8Bパラメータの複数モデルサイズで一貫した性能向上が確認される。
コード実装の詳細
リポジトリ構造
GitHubリポジトリ:microsoft/LMOps/oel
実装はVeRL(Versatile Reinforcement Learning)フレームワークをベースとしており、以下の構造を持つ:
インストール手順
A100/H100/H200の場合:
B200の場合:
実行フロー( 3 ラウンドの反復例)
環境変数の設定:
ラウンド1:
ラウンド2以降:前ラウンドのチェックポイントを--modelとして指定して同じフローを繰り返す。
コアアルゴリズムの実装(Reverse KL Distillation)
メインの訓練ロジックはVeRLのPPOトレーナーを修正したもので、以下のようにreverse KL divergenceを計算す る:
On-policyサンプリングの重要性:学生モデル自身から をサンプリングし、同じ で教師(同モデルに経験的知識 を付与したもの)を評価することで、分布の整合性を保つ。
その他の重要なポイント
制限事項
1.テキストベース環境に限定:現時点ではテキストゲームのみで検証されており、より複雑な実世界タスクへの適用は未検証
2.知識転移の方向性:大きいモデルの経験的知識が小さいモデルに転移しにくい(on-policy一致性が重要)
3.計算コスト:反復的な抽出•統合サイクルは、デプロイ後にも継続的な計算リソースを必要とする
4.冪等性の限界:抽出段階で得られる知識の品質は、モデルの初期能力に依存する
今後の研究課題
- より複雑•多様なタスクへの拡張
- [shima] 今回のタスクの場合、従来のRLで簡単に解けそうなくらいのレベル
- 知識蒸留の効率化(少ないステップでの収束)
- 複数ドメインにまたがる経験的知識の統合
- より大規模モデル(70B+)でのスケーラビリティ検証
実用的な示唆
OELは従来のRLHF(人間フィードバックによる強化学習)パイプラインとは異なり、以下の点でデプロイ実践に有利:
- 人間アノテーター不要:テキスト環境フィードバックのみで学習
- 報酬エンジニアリング不要:スカラー報酬設計の複雑さを回避
- 環境シミュレーター不要:実際のデプロイ軌跡を直接活用
- プライバシー配慮:ユーザー軌跡を生のまま保存せず、知識として圧縮•抽象化
まとめ
OELは「デプロイ後にも学習し続ける言語モデル」という新しいパラダイムを実現する。経験的知識の抽出とon- policy context distillationという2つの仕組みを組み合わせることで、従来の強化学習手法が抱えていた「報酬設計 の難しさ」「壊滅的忘却」「分布ミスマッチ」という 3 つの主要課題を同時に解決している。Qwen3モデルシリーズ での実験で一貫した有効性が示されており、より広範なタスクへの応用が期待される。