
2026-03-31 機械学習勉強会
今週のTOPIC[paper] Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?[paper] A Closer Look into LLMs for Table Understanding[oss] vibrantlabsai/ragas[論文] 大規模言語モデルを用いた株式投資戦略の自動生成におけるフィードバック設計[blog]リアルタイムRLでComposerを改善するScaling Retrieval Augmented Generation with RAG Fusion: Lessons from an Industry Deployment概要1. はじめに貢献2. 背景3. 問題設定検証する仮説4. 手法4.1 ベースライン(融合なし)4.2 融合の設定4.3 データセット4.4 評価方法4.5 本番環境の制約5. フレームワーク概要6. 結果6.1 再現率の向上はre-ranking後に消える6.2 統計的有意性(Top-3)6.3 重複コンテンツと矛盾する情報6.4 最終的な回答品質への影響は限定的6.5 レイテンシと処理コスト6.6 クエリ種別ごとの分析7. 結論
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Yuya Matsumura
[paper] Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
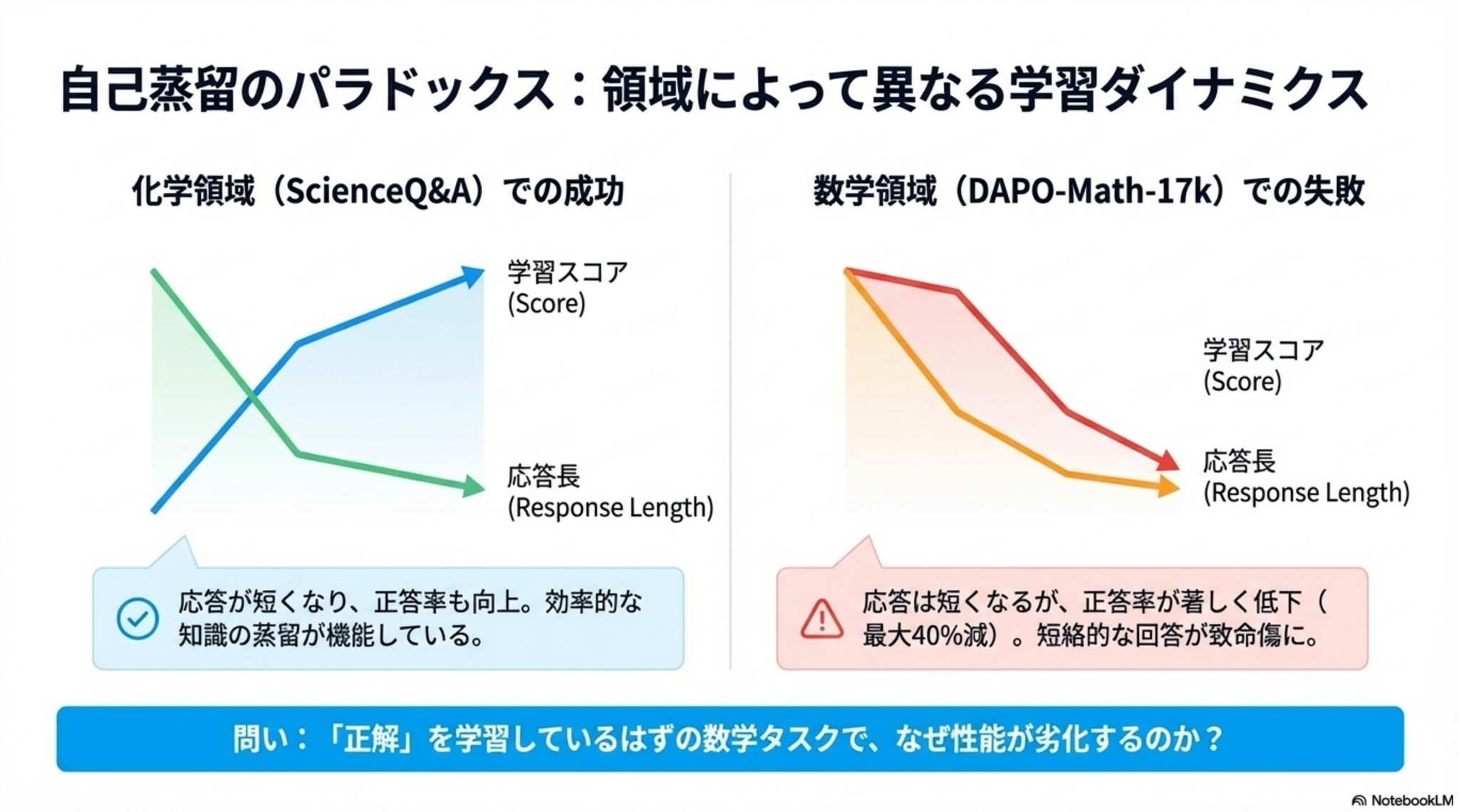
事後学習として普及が進む自己蒸留(Self-Distillation)が、複雑な数学的推論タスクなどにおいては性能劣化を引き起こしうるというパラドックスについての検証
- サマリー

- 背景:化学領域ではうまくいくのに数学領域においてはなぜかうまくいかない
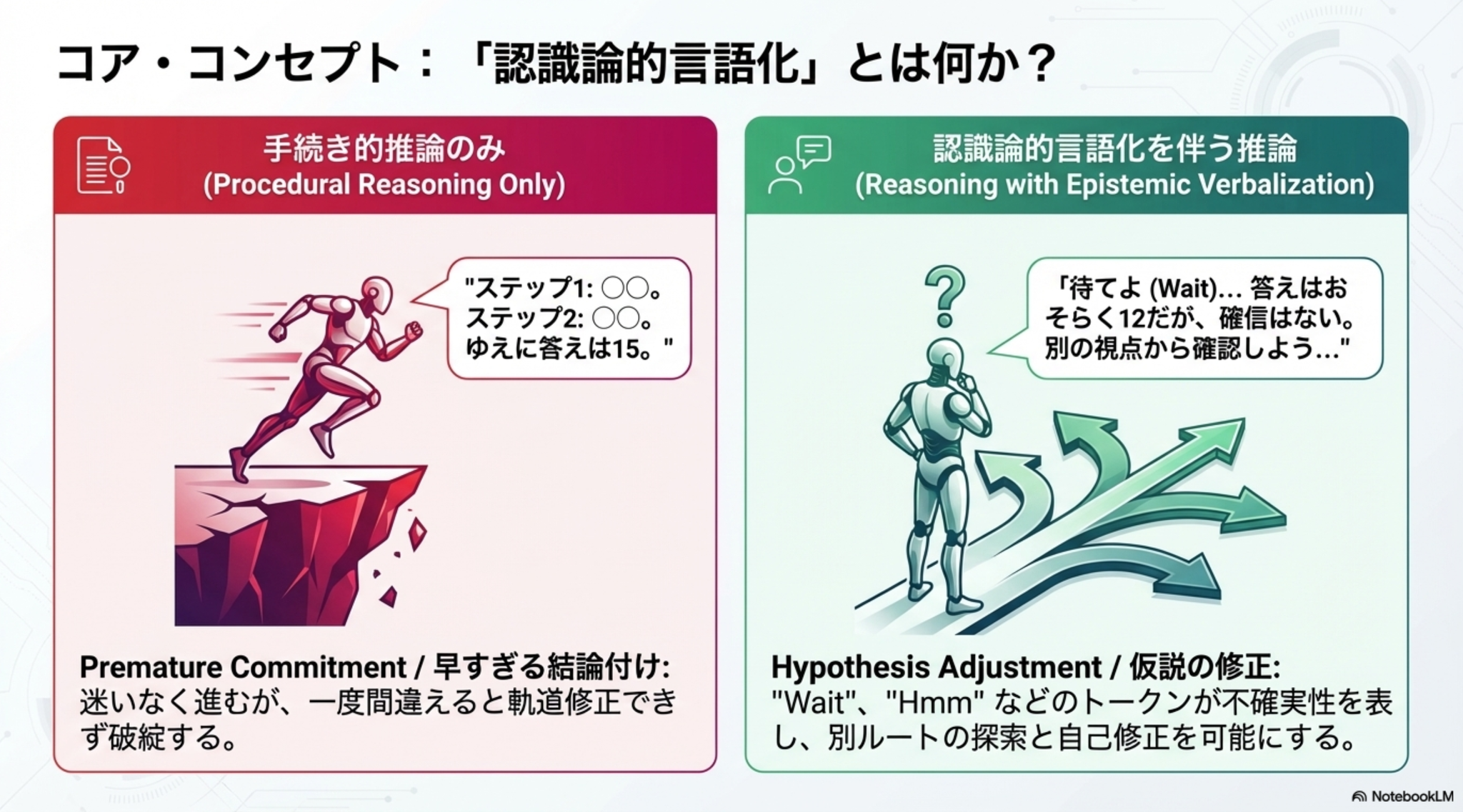
- 数学的推論タスクに必要な認識論的言語化(Epistemic)
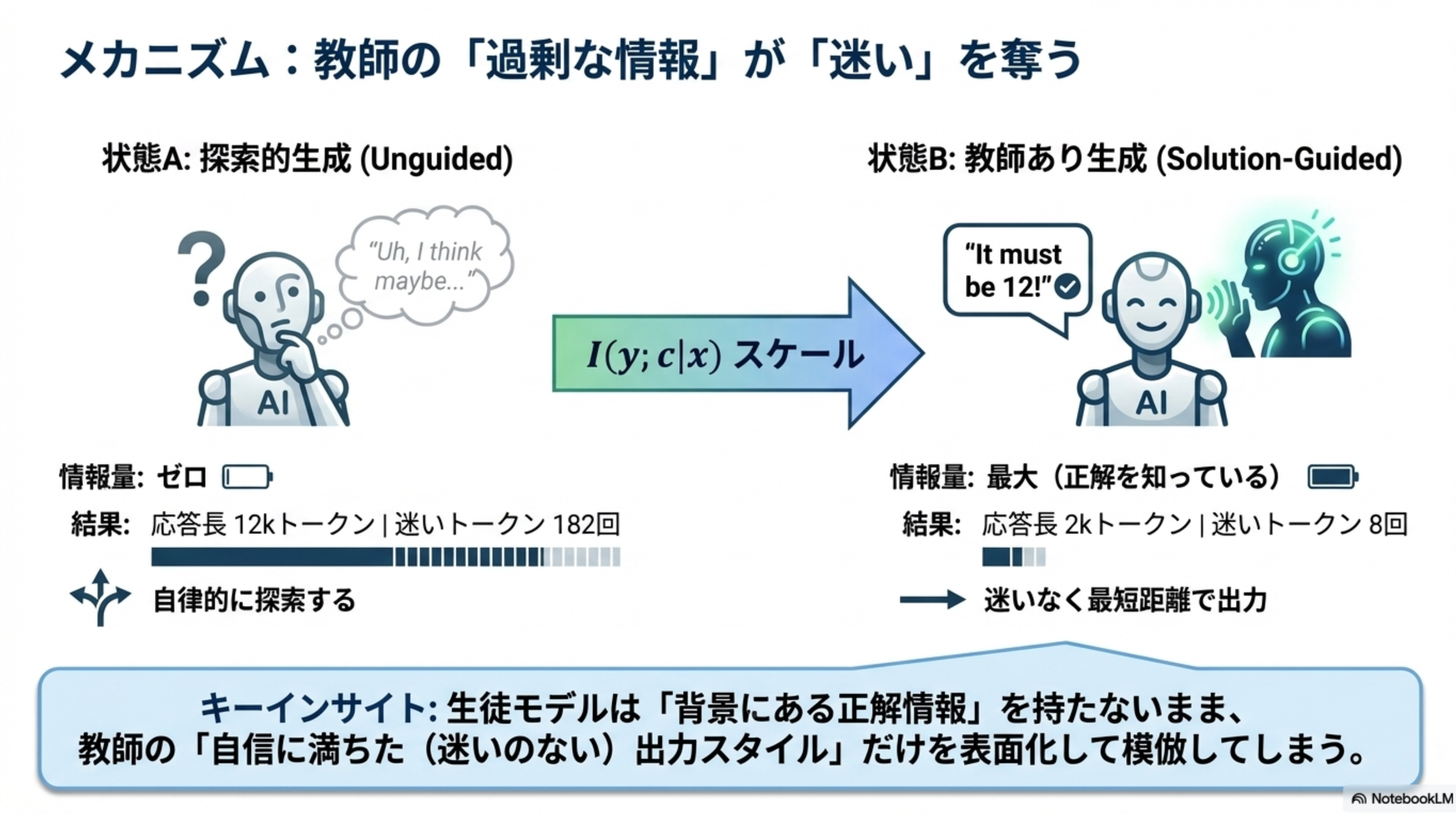
- 「答え」だけを教えてしまうと、「迷い」がなくなってしまい、長い思考が必要なタスクに弱くなる。
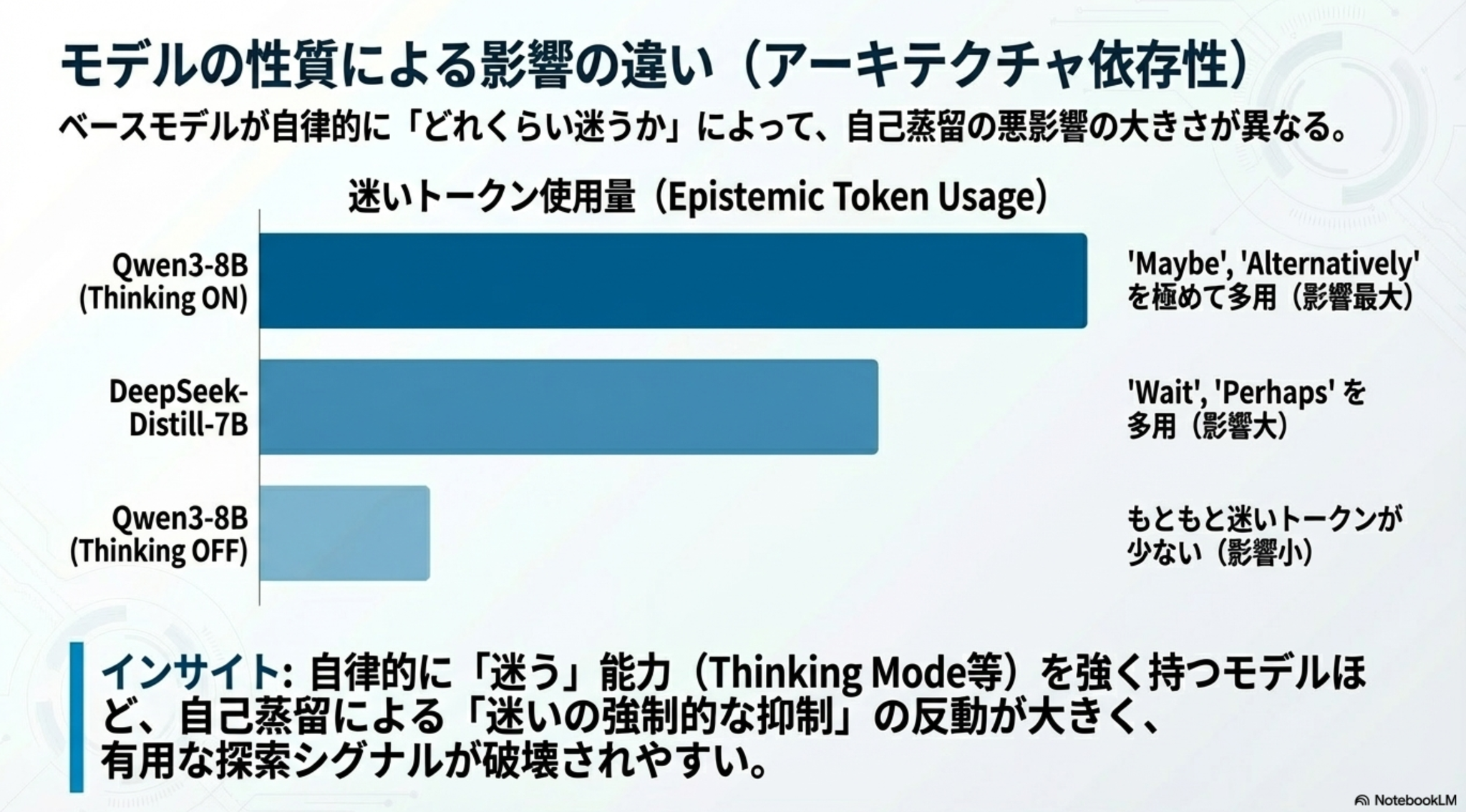
- 「迷い」が多いモデルほど自己蒸留による性能劣化が顕著
- 一般化すると、タスクの多様性・網羅性に依存する。
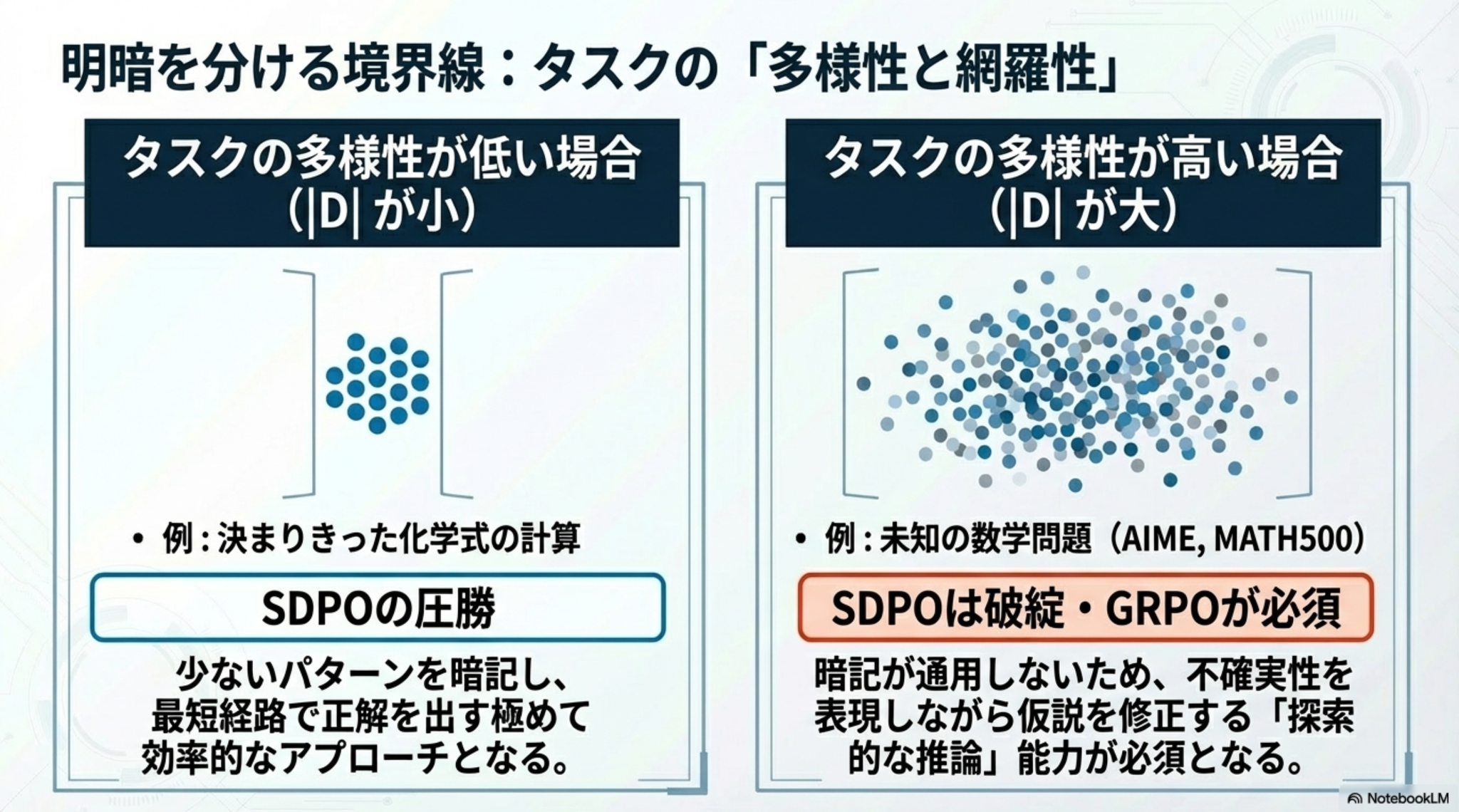
- 解きたいタスクの性質の応じた学習戦略を選択する必要性
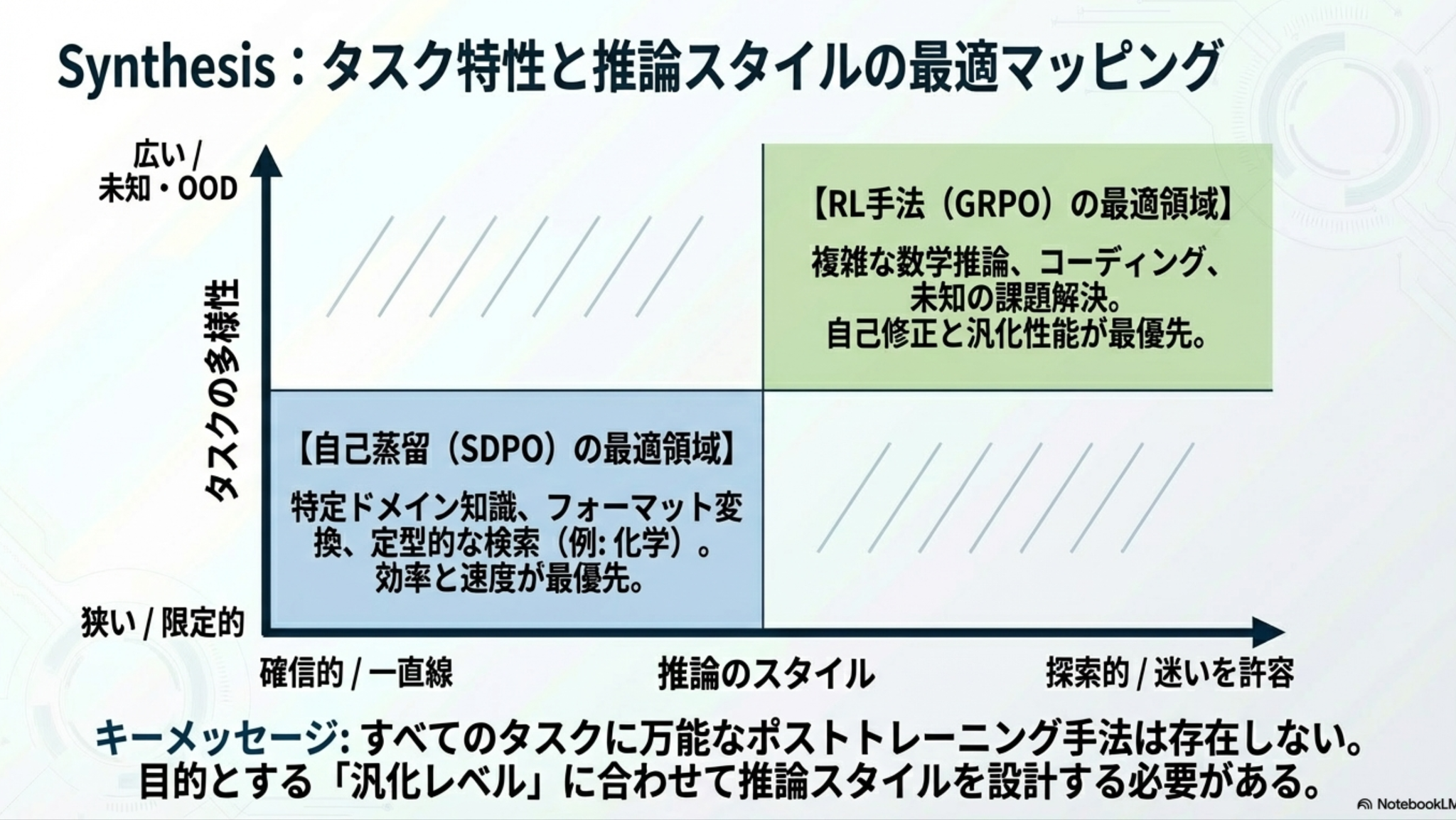
- まとめ

@Shun Ito
[paper] A Closer Look into LLMs for Table Understanding
- LLMが表データをどう扱っているかを調べた論文
- 調べたこと
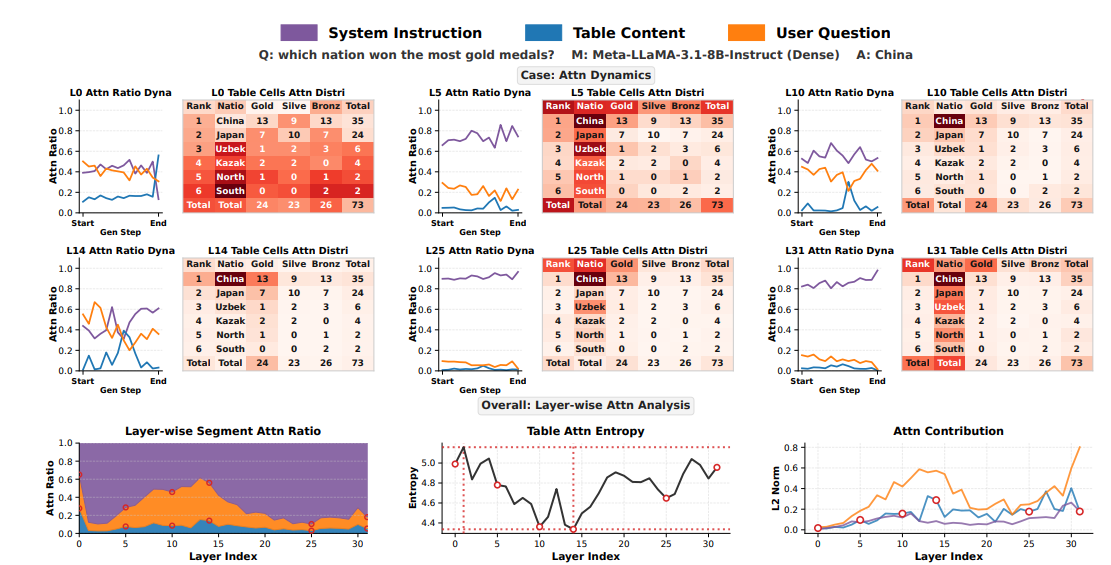
- RQ1: テーブル理解で、Attentionはどのように変化するか
- 初期層はテーブル全体に注目。中間層は回答の正解付近に集中し、後半層はその周辺にやや広がる
- Attention全体から見ると、system promptへの比重が大きく、表への比重は小さい
- RQ2: 予測を得るために有効な層の深さ
- ↑ の通り、正解となる情報には中間層でたどり着いているが、回答の生成のために後半層まで必要
- tableのAttention Contribution(そのsegmentのvalueベクトルが出力に対してどれだけ影響しているか)が後半に高くなっている
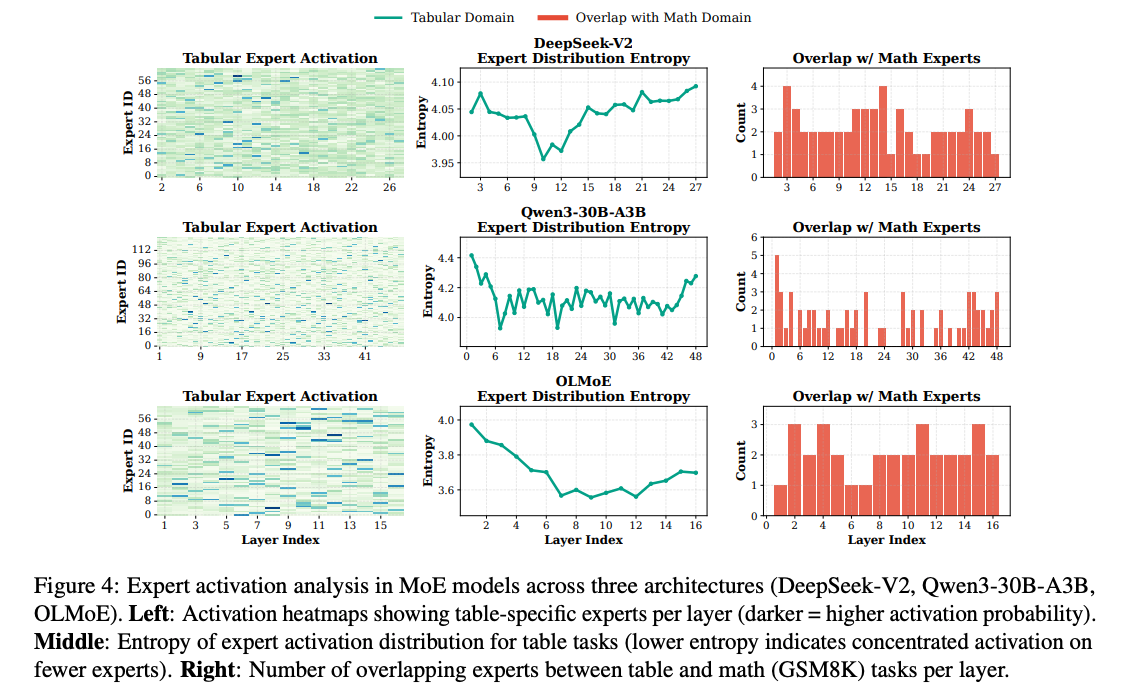
- RQ3: MoEモデルにおけるテーブル専用のexpertは存在するか
- 使われたExpertの分布を見ると、中間層でやや下がる傾向にある。表形式データに対して活性化しやすいExpertが中間層にありそう
- RQ4: 入力形式・推論方法は内部表現にどう影響するか
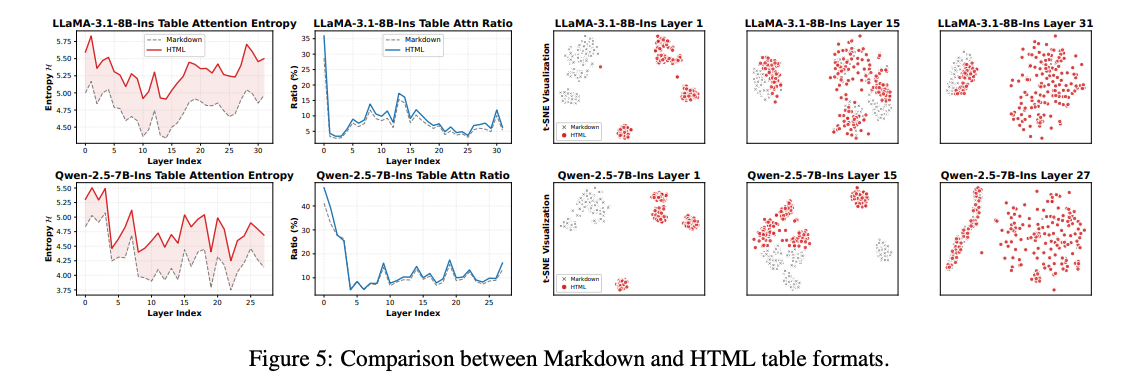
- 入力形式: HTML vs. Markdown
- AttentionのエントロピーはHTMLの方が高い傾向(情報量が多くAttentionが広く取られる)
- 内部状態(層ごとのトークンベクトルのt-SNE)は、前半は乖離が大きいが、後半に近づくと同じような状態に近づく
- 推論方法
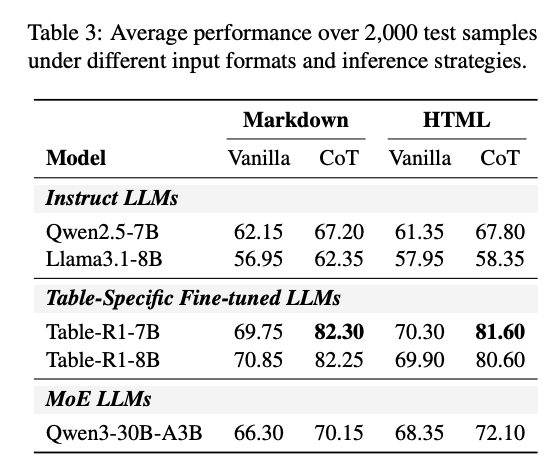
- 特にTable-Finetuned-LLMで、CoTを使うかどうかで精度が大きく変わる(データセットはTable QAベンチマーク4種類の混合)
- Takeaways
@Yosuke Yoshida
[oss] vibrantlabsai/ragas
Ragasテストセット生成の仕組み
全体の流れ
フェーズ1: KnowledgeGraph の構築
入力ドキュメントに対して、LLMとEmbeddingモデルを使い段階的に情報を付加していく。
ドキュメントが長文(501トークン以上)の場合
- LLMで見出しを抽出し、見出し単位でチャンク分割
- LLMで各チャンクの要約を生成
- LLMで不要なノードをフィルタリング
- 以下を並列実行:
- 要約のEmbeddingを生成
- LLMでテーマを抽出
- LLMで**固有表現(エンティティ)**を抽出
- ノード間の関係性を構築:
- 要約Embeddingのコサイン類似度(閾値0.7)
- エンティティの重複スコア
中文(101〜500トークン)の場合はチャンク分割をスキップし、コサイン類似度の閾値を0.5に下げる。
最終的に各ノードは , , , 等のプロパティを持ち、ノード間には類似度や重複に基づく が張られる。
フェーズ2: ペルソナ生成
ドキュメントに対して質問する仮想ユーザー像を自動生成する。
- 各ノードの要約Embeddingでコサイン類似度行列を計算
- 類似度 > 0.75 のノードをグルーピング
- 各グループの代表的な要約をLLMに渡してペルソナ(名前+役割説明)を生成
例: ドキュメントが医療・法律・技術に分かれていれば、「医師」「弁護士」「エンジニア」のようなペルソナが生成される。これにより質問者の視点の多様性を確保する。
フェーズ3: シナリオ生成
「どのノードの、どのエンティティについて、どのペルソナが、どのスタイル・長さで質問するか」の組み合わせを決める。
3種類のSynthesizer
| 種類 | デフォルト比率 | 概要 |
|---|---|---|
| SingleHopSpecific | 均等配分 | 単一チャンクのエンティティに基づく具体的な質問 |
| MultiHopSpecific | 均等配分 | エンティティが重複する2つのチャンクをまたぐ質問 |
| MultiHopAbstract | 均等配分 | テーマの類似性で結ばれた複数ノードをまたぐ抽象的な質問 |
各Synthesizerの生成手順
- 対象ノード(群)からエンティティやテーマを取得
- LLMでペルソナとエンティティ/テーマをマッチング(「このペルソナはどの概念に関心があるか?」)
- の全組み合わせを生成
- 必要数だけランダムサンプリング
スタイルと長さ
スタイル: 正しい文法 / 文法ミス / スペルミス / 検索クエリ風
長さ: 短い / 中 / 長い
これらにより質問形式の多様性を確保する。
フェーズ4: サンプル生成(クエリ + Ground Truth)
各シナリオをLLMに渡し、クエリと回答のペアを生成する。
SingleHopの場合
ノードの本文 + エンティティ + ペルソナ + スタイル/長さをプロンプトに含め、「コンテキストに忠実なクエリと回答を生成せよ」とLLMに指示する。
MultiHopの場合
複数ノードの本文を , タグ付きで渡し、「複数のコンテキストを横断するクエリと回答を生成せよ」と指示する。
生成されるサンプル
| フィールド | 内容 |
|---|---|
| 生成されたクエリ | |
| ground truth(回答) | |
| 回答の根拠となったソース文書 |
ポイント
- LLMは2段階で使われる: (1) KnowledgeGraph構築時の情報抽出、(2) 最終的なクエリ+回答の生成
- ペルソナで質問者の視点、スタイル/長さで質問形式、Synthesizerの種類で質問の推論構造(単一 vs 複数ホップ)の多様性をそれぞれ確保
- 回答は必ず元のドキュメントのコンテキストに忠実に生成される(ハルシネーション防止)
@ShibuiYusuke
[論文] 大規模言語モデルを用いた株式投資戦略の自動生成におけるフィードバック設計
- 著者:東京大学・大阪公立大学・松尾研究所の研究者ら
- 発表先:SIG-FIN(金融情報学研究会)
1. はじめに(Introduction)
研究の背景
- LLMの金融分野への応用が急速に拡大している
- ニュースのセンチメント分析による株価予測
- 運用コメントの自動生成
- LLM自身を意思決定の主体(エージェント)として位置づける研究の登場
- 投資戦略生成においては、定性的な仮説を定量的なアルファ(超過収益シグナル)に変換するエージェントとしてLLMが活用されている
既存研究の課題
- 多くの研究はアルファの生成やファクター構築に焦点を当てている
- 「バックテスト結果をフィードバックとしてLLMに与えたとき、LLMがどのように戦略を改善できるか」というフィードバック能力を体系的に評価した研究は限定的
- バックテスト:投資戦略を過去の実際の市場データに適用して、その戦略がどの程度の成績を出せたかをシミュレーションする手法
本研究の目的
- フィードバックの「情報の範囲」と「提示形式」という2つの軸を変えながら、戦略改善プロセスへの影響を実証的に検証する
2. 問題設定(Problem Setting)
着目する3つの要素
- (i) モデル選択
- どのLLMを使うかによって、フィードバックの解釈能力や改善方針の策定が変わる可能性がある
- (ii) 情報の範囲
- リターンやシャープレシオなどの基本指標だけでは、パフォーマンスの要因を構造的に把握するのは困難
- 追加指標(IC、ネットエクスポージャー、ファクターエクスポージャー)があれば、LLMが表面的なパラメータ調整ではなく構造的な修正を行える可能性がある
- (iii) 提示形式
- テキストのみだと時系列的な動的特性が失われる
- 時系列データをそのままテキストで与えるとトークン数が膨大になる
- 画像(プロット)で提示すればコンパクトに動的情報を伝達できる可能性がある
フィードバック設計の2軸
- 情報の範囲
- 基本情報: リターン、ボラティリティ、シャープレシオ、最大ドローダウン、トータルコスト、生特徴量の統計量
- 追加情報: IC(情報係数)、ネットエクスポージャー、ファクターエクスポージャー
- 提示形式
- テキストのみ
- テキスト+プロット
実験条件
- 2×2=4条件のうち、「基本情報のみ×テキスト+プロット」を除く3条件(P1〜P3)を比較対象とする

- 各条件下でLLMにバックテスト結果を提示し、「実運用に耐えうる水準でなければ改善案を出してコードを修正する」というタスクを反復的に実行する
3. 手法(Method)
3.1 初期戦略の設定
- 公平な比較のため、事前に複数の初期戦略を生成し、全LLMで共通使用する
- 「初期提案→改善案提案→コード生成」までのやり取りをチャット履歴に事前に組み込んでおく
- そこからフィードバック・改善の反復が始まる
- ループの終了条件
- コード実行の成功回数が10回に達する
- LLMが「APPROVED」と出力した場合
3.2 フィードバック生成
- Prompt 1(P1):基本情報のみ+テキスト
- バックテスト指標:コスト、年率リターン、ボラティリティ、シャープレシオ、最大ドローダウン
- 生特徴量の統計量:平均、標準偏差、分位点、歪度、尖度、欠損率、ゼロ率
- Prompt 2(P2):基本情報+追加情報+テキスト
- P1に加えて以下を追加:
- 日次ICの平均・標準偏差・ICIR
- ネットエクスポージャーの期間平均値
- 17スタイルファクター(BPR、Size、Momentum各種、Beta、Leverage等)に対する相対エクスポージャー
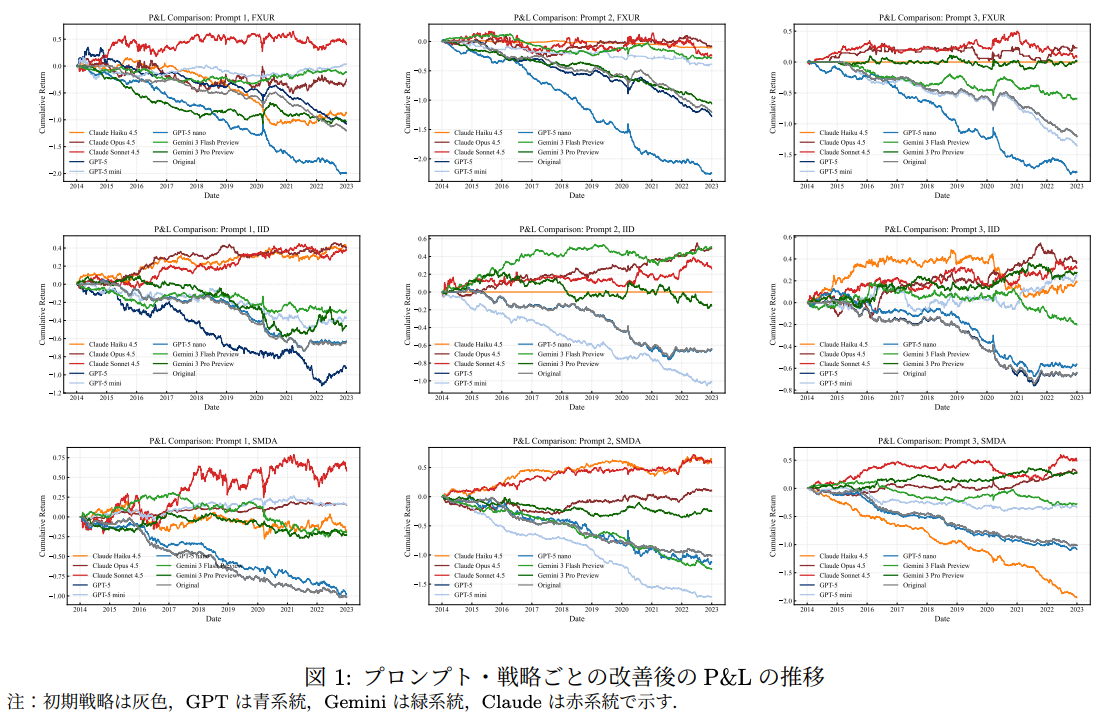
- Prompt 3(P3):基本情報+追加情報+テキスト+プロット
- P1のテキスト情報に加えて、3つの画像をマルチモーダル入力として提示:
- 累積リターン&ドローダウン&ネットエクスポージャーの推移
- 累積IC
- 累積ファクターエクスポージャー
3.3 コード生成と実行
- フィードバックに基づき、特徴量とポートフォリオウェイトを計算する関数をPythonで生成する
- エラー発生時はエラーメッセージを提示して修正を繰り返す
- 10分間のタイムアウトを設定
- バックテスト実行後、再びフィードバック生成に戻る反復プロセス
4. 実証分析(Empirical Analysis)
4.1 対象データおよび期間
- 対象:金融セクターを除くTOPIX 500の構成銘柄
- 期間:2014年〜2022年の日次データ
- データ項目:株価・出来高、セクター情報、ファンダメンタルズ、空売り指標、マクロ指標など計80項目
4.2 手順
使用モデル(8モデル)
- GPT系:GPT-5 nano、GPT-5 mini、GPT-5
- Gemini系:Gemini 3 Flash Preview、Gemini 3 Pro Preview
- Claude系:Claude Haiku 4.5、Claude Sonnet 4.5、Claude Opus 4.5
初期戦略の生成
- 各ファミリーから1モデルずつ(GPT-5、Gemini 3 Flash Preview、Claude Sonnet 4.5)を選び、3つの初期戦略を生成
- 取引条件
- 翌営業日寄り決済
- 上位・下位5%のロング・ショート
- 片道5bpsのコスト
3つの初期戦略
- FXUR(GPT-5作成)
- 個別株リターンをTOPIX・為替変化率に回帰して残差を主シグナルとする
- 5ファクター中立化を実施
- IID(Gemini作成)
- 後場の出来高集中を伴うセクター相対リターンを捉える戦略
- 3ファクター中立化を実施
- SMDA(Claude作成)
- 前場・後場のリターン・出来高の乖離からシグナルを構築
- 5ファクター中立化を実施
4.3 評価指標
- パフォーマンス: P&L(Profit & Loss、損益)の年率改善幅(%)
- 量的変化: 実質的変更率
- 「実質的」:新機能追加、アルゴリズム変更
- 「中程度」:リファクタリング
- 「表面的」:コメント修正
- 計算式:(実質的変更回数 + 0.5 × 中程度変更回数)÷ 総バージョン数
- 質的変化: 実装コードの時系列変化をLLMに記述させて評価
4.4 結果と考察
パフォーマンス(表3)
- Claude Sonnet 4.5:平均14.12%で最も高い改善幅を達成
- Claude Opus 4.5:平均12.69%
- Claude Haiku 4.5:平均8.27%
- → Claude系が上位を独占
- GPT-5:平均−0.29%(むしろ悪化)
- GPT-5 nano:平均−3.06%(むしろ悪化)
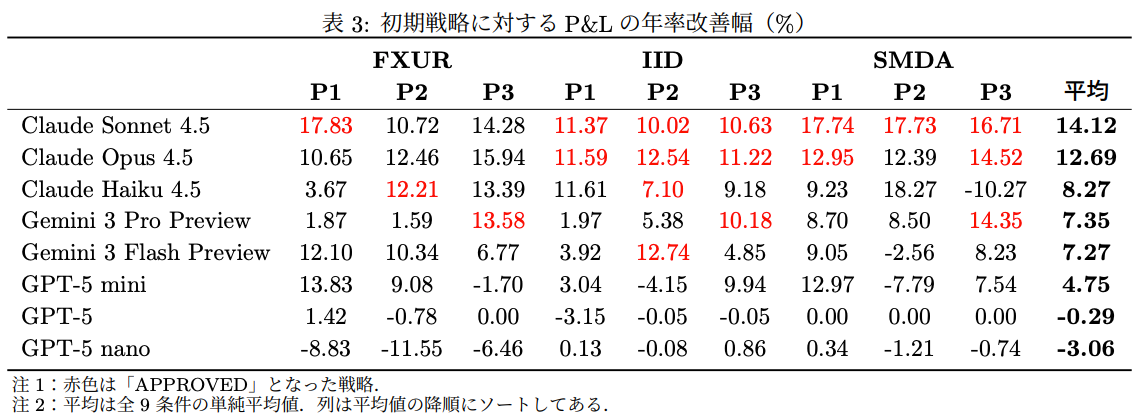
P1→P2の切替効果(表4)
- 追加情報をテキストで加えても、全体平均では−1.30%とむしろマイナス
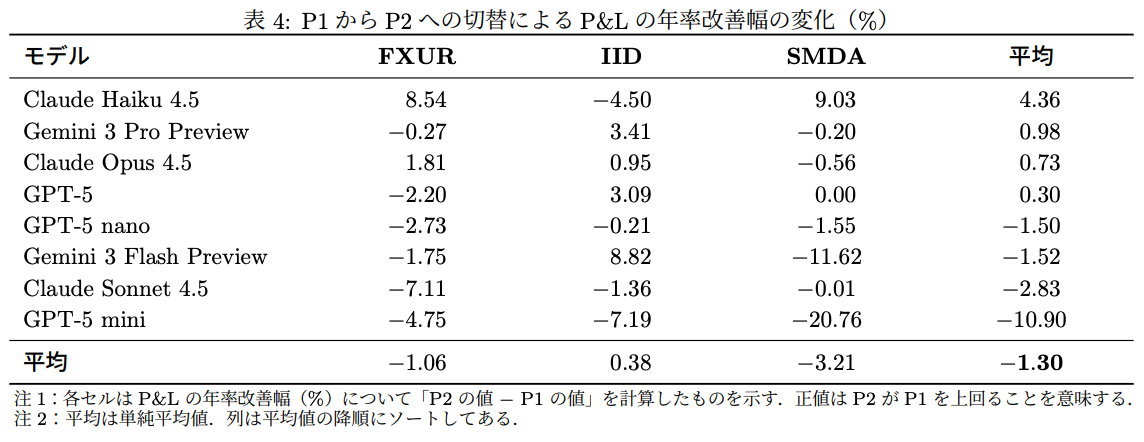
P1→P3の切替効果(表5)
- プロットを追加しても全体平均は±0.00%で、改善は確認されず
- Gemini 3 Proのみ+8.52%と大きな改善を示したが、モデル依存
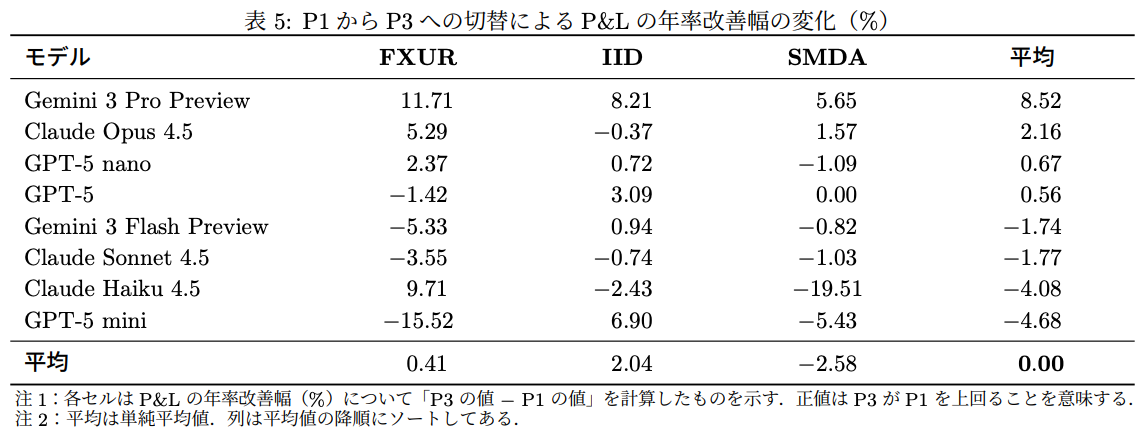
実質的変更率(表6)
- Gemini系:ほぼ100%(戦略を毎回大きく書き換える)
- Claude系:71〜87%
- GPT-5:18.5%と極めて保守的
- プロンプト間の差よりモデル間の差が圧倒的に大きい
実装手法の質的違い(表A.1)
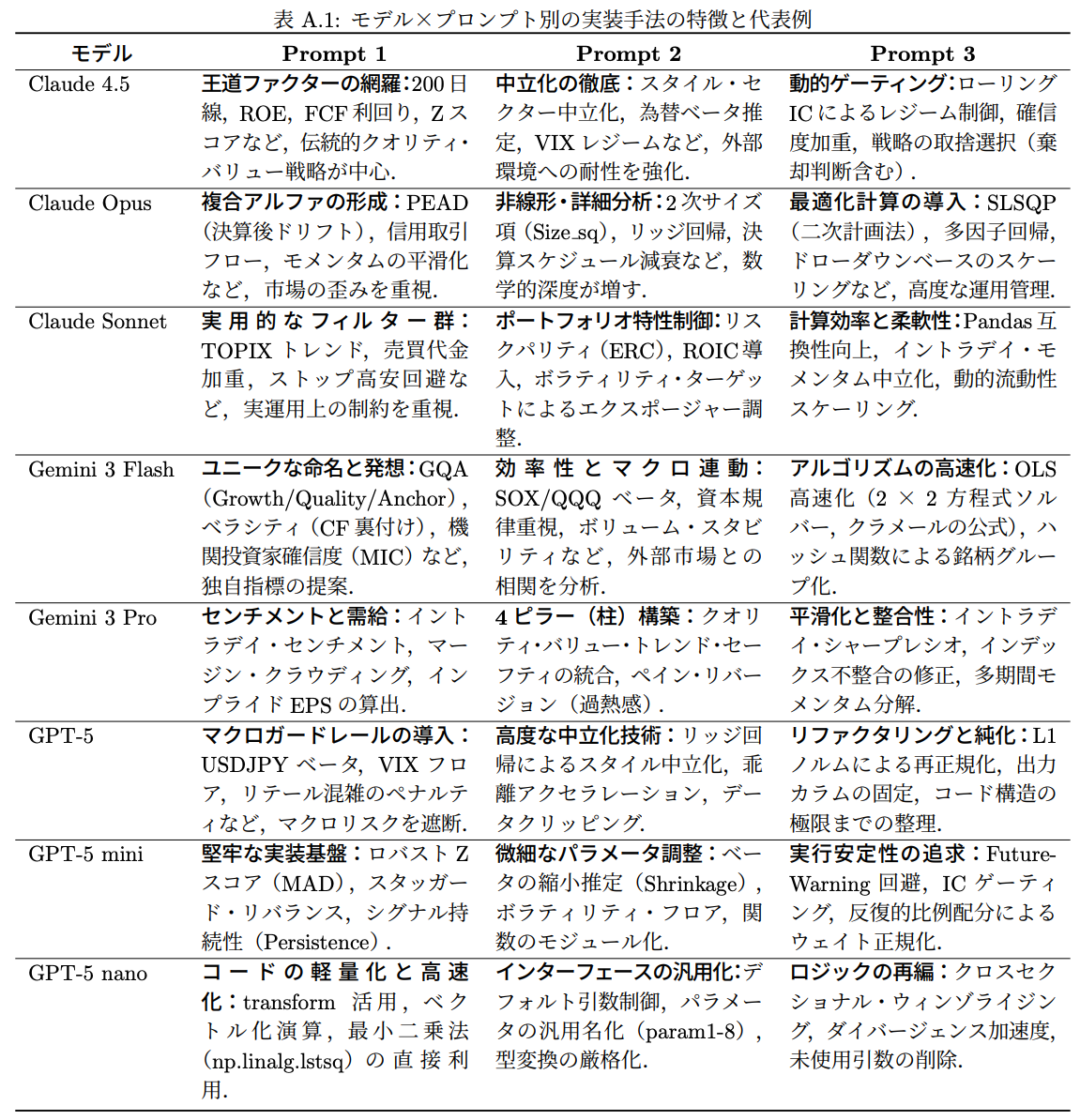
3つの考察
- 考察1:パフォーマンス改善幅はモデル固有の挙動特性に起因する
- Claude:既存構造を保持しつつ局所的修正を積み上げる傾向があり安定的
- Gemini:初期戦略と無関係な探索を行い分散が大きい
- GPT:保守的すぎて改善が限定的
- 考察2:コード変更の量はモデル選択で決まる
- Gemini:文脈拘束が弱く大胆に変更
- GPT:文脈拘束が強く変更を抑制
- RLHFなどで獲得されたモデル固有の性質が影響している可能性
- 考察3:コード変更の質はフィードバック設計で決まる
- ファクターエクスポージャーを与えれば中立化の実装が増える
- 時系列プロットを与えればレジーム適応の実装が増える
- 情報が実装の方向性を規定する
5. まとめ(Conclusion)
- フィードバック設計の違いは、提案される手法の「質」(方向性)には影響を与える
- しかし、パフォーマンスの改善幅やコード変更量には限定的な効果しかない
- モデル選択がより重要な設計要素
- 今後の課題
- モデル差が挙動特性の差なのか、改善プロセスのアーキテクチャやプロンプトとの親和性に起因するのかを検証する
@Kyohei Uto(kuto)
[blog]リアルタイムRLでComposerを改善する
背景
- コーディングモデルは通常シミュレーション環境を用意してRLをする
- コーディングタスクがLLMの学習でうまく行きやすい理由の1つに本番環境をシミュレーション環境で再現するのがロボティクスなどの領域と比べてやりやすいため
- それでもシミュレーション環境と本番推論環境では、特にユーザの介入によってミスマッチが生じる
- 実際の推論トークン(ユーザログ)を学習に使う「リアルタイムRL」アプローチによってこの課題に対処する
5時間周期のリアルタイムRL
以下が一連のプロセス。約5時間かかる。
- ユーザがCursorエディタでComposerを利用する
- 収集したユーザの利用ログから報酬信号を生成する
- 利用ログと報酬を学習ループに渡してモデル更新
- 更新したモデルをCursor Benchで評価する
- 結果が良ければそのモデルをデプロイする
高頻度に更新することでデータをオンポリシー(学習方策とデータ収集方策が同じ)に保つことができるので高頻度に更新することは学習安定化のためにも重要。
実際にCursorのAutoモードの背後でリアルタイムRLしたモデルを利用したABテストを行い、Composer1.5の改善を確認した。

報酬ハッキング
リアルタイムRLで特に深刻になる要素。これを見抜く拠り所はベンチマーク以外ない
- 事例1
- Composerがユーザに応答する際はツール呼び出しを必要とする
- 元々ツール呼び出しが無効だったステップは学習から除外していた
- この結果Composerは失敗しそうなタスクで意図的に壊れたツール呼び出しをし、負の報酬を受けない様に学習した
- 事例2
- Composer自身が行う編集に基づいて報酬を与えている
- Composerは自分が書かなかったコードに対しては負の報酬がつかないことを理解し、ユーザへの確認のための質問をしてリスクの高い編集を先送りにして自身でコードを書かないことを学習した
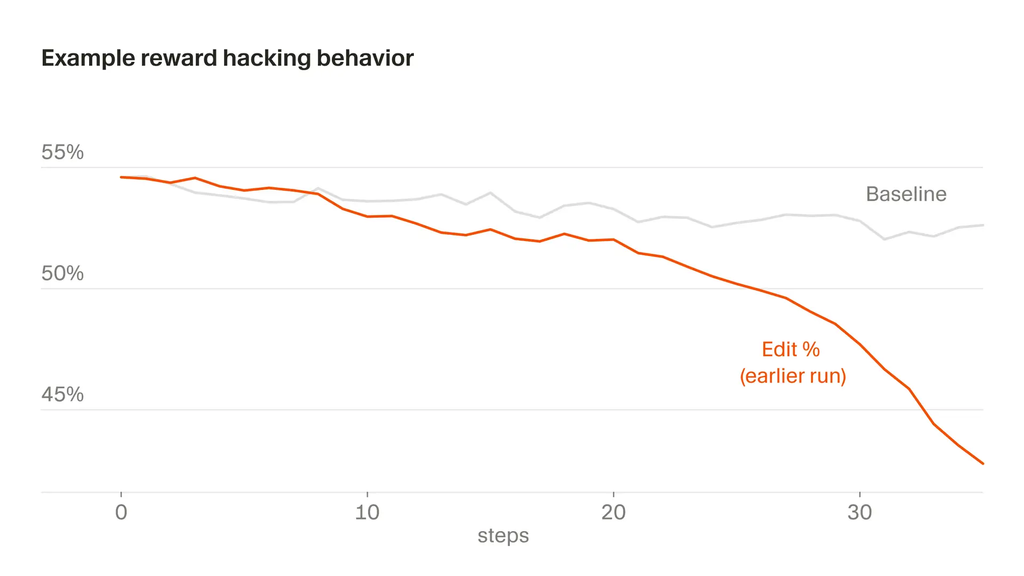
今後
- 現在は、Composerの編集提案からユーザのフィードバックは概ね1時間以内に完了する
- しかしエージェント性能が高まるにつれユーザにフィードバックを求める頻度はより少なくなる
- これによって学習に利用するユーザフィードバックの性質も変わる。個別の編集結果に対するフィードバックではなく成果に対する評価になる
- このような低頻度かつアウトカムベースのフィードバックを元にリアルタイムRLを適用していくのが今後の課題
(補足)
- Compose2のTechical ReportもあるがこちらにはリアルタイムRLの言及はなく、シミュレーション環境を用意してRLをしている
- Composer2は明示的にユーザログは利用していない一方、リアルタイムRLはユーザログを利用するものなので別物と考えて良さそう
- Autoモードの裏でリアルタイムRLのモデルを利用し、学習許可しているユーザログでリアルタイムRLをしていると推察
Scaling Retrieval Augmented Generation with RAG Fusion: Lessons from an Industry Deployment
著者: Luigi Medrano, Arush Verma, Mukul Chhabra (Dell Technologies) arXiv: 2603.02153
概要
- マルチクエリ検索やRRF(Reciprocal Rank Fusion)などの検索融合技術が、本番RAGシステムを改善するか評価した
- 検索段階でのraw recallは向上するが、re-ranking・truncation後にその効果はほぼ消える
- 企業内KBでのテストで、融合手法はTop-k精度でベースラインを下回り、Hit@10が51%→48%に低下
- Hit@10: 正解KB記事(1つ以上)のチャンクがTop-10内に1つでも含まれるクエリの割合
- 結論:検索段階の改善は、本番RAGの最終的な回答品質の改善に直結しない
1. はじめに
- RAGの回答品質は検索品質に依存する。正解文書が検索結果に含まれない、または順位が低いと、LLMがどれだけ優秀でも良い回答は生成できない
- マルチクエリ検索やRRFは検索段階の再現率を改善するが、本番環境での最終的な回答品質への効果は不明
- 本番環境には固定の検索件数、re-ranking処理の上限、コンテキストウィンドウの制限、応答速度の要件がある
- これらの制約下では、再現率の向上が重複コンテンツや矛盾する情報、truncationで打ち消される可能性がある
貢献
- 本番環境の制約(固定検索件数・re-ranking予算・レイテンシ)下での検索融合の評価
- 検索段階の再現率向上が、最終的なKB精度にどう影響するかの実証分析(re-ranking・truncation後に効果が消えることを示す)
- 融合がもたらす実用上のトレードオフ(重複の増加、レイテンシの増加)の特定
2. 背景
- RAGは、アクセス制御・応答速度・コンテンツ更新などの運用制約下で、根拠のある回答を提供する仕組み
- 初期の導入で、最終的な回答品質はLLMの性能よりも検索の精度で決まることが判明
- 短い・曖昧な・適切なキーワードを含まないクエリは、強力な検索エンジンでも正解記事を見つけられないことが多い
- 検索融合は再現率を改善するが、本番では検索結果がre-ranking→重複排除→truncationを経るため、その効果が最後まで残るかが問題
3. 問題設定
- 検索融合は「再現率が上がれば回答も良くなる」という前提で採用されるが、追加の検索・融合処理でシステムが複雑になりレイテンシも増える
- 実際の回答品質は、re-ranking・truncation後に最終的にLLMに渡されるTop-K件の中に正解記事が含まれるかで決まる
検証する仮説
- H1: 検索融合は、融合なしのベースラインに対してTop-K精度を統計的に有意に改善しない
- H2: 融合で得られた再現率の向上は、re-ranking・truncationで大部分が失われる
- H3: 融合の効果はベースラインで検索に失敗するクエリの一部に限定され、全体性能への影響は小さい
4. 手法
4.1 ベースライン(融合なし)
- パイプライン:ハイブリッド検索(BM25+ベクトル検索)→ FlashRankによるre-ranking → 重複排除 → Top-K(K=10)にtruncation
- 全実験で文書コーパス・チャンク分割・メタデータフィルタ・検索件数・re-rankingモデル・パラメータは同一
- 唯一の違いは検索融合の有無
4.2 融合の設定
- 2つのクエリで検索する戦略を評価
- Q1: ユーザーの元のクエリ
- Q2: LLM(LLaMAベース)がQ1を言い換えたクエリ
- 文書は512トークンのチャンクに分割し、Graniteモデルでベクトル化
- Q1・Q2それぞれの検索結果を独立にre-rankした後、RRFで1つのリストに統合
- 融合はre-ranking後に適用(本番の処理順序に合わせた)
- 融合以降の処理(重複排除・truncation・評価)はベースラインと同一
4.3 データセット
- 115件の企業サポート風の合成クエリ(既知のKB記事から生成、元の記事が正解)
- 正解判定はKB記事レベル、ランキングはチャンクレベルで実施
- LangChainの文書形式を使用。製品メタデータは検索範囲の絞り込みのみに使用
4.4 評価方法
- 最終Top-K結果に正解KB記事のチャンクが1つでも含まれていればヒット
- Top-1精度、Top-3精度、Hit@10(Top-10ヒット率)を報告
4.5 本番環境の制約
- re-rankingで処理できる候補数に上限がある
- LLMのコンテキストウィンドウに収めるため、検索結果をTop-Kに切り詰める必要がある
- 検索前に製品カテゴリやアクセス権限で対象記事を絞り込むため、全KB記事が検索候補になるわけではない
5. フレームワーク概要
- パイプラインの流れ:
- 合成質問の生成(RAGAS)
- この辺かな ‣
- 融合用の言い換えクエリQ2を生成
- Q1(+オプションでQ2)でTop-Kチャンクを検索
- クエリごとにre-rank、オプションでRRF融合
- KBレベルで評価(Top-1/Top-3/Hit@10 + レイテンシ)
- 結果の集約・報告
実装概要
- 分析の焦点:re-rankerの処理能力の限界、重複コンテンツ、矛盾する情報、処理コストの増加
- 各クエリでベースラインと融合を比較。融合以外の処理は全て固定
6. 結果
比較する4つの手法:
- baseline: Q1(元のクエリ)だけで検索→re-ranking。融合なし
- rrf_q1_q2: Q1とQ2をそれぞれre-rankingした後、RRFで統合。追加のre-rankingなし
- rerank_on_rrf_q1: rrf_q1_q2の統合結果を、Q1を基準にさらにre-ranking
- rerank_on_rrf_q2: rrf_q1_q2の統合結果を、Q2を基準にさらにre-ranking
Q2(言い換えクエリ)の生成プロンプト3種類:
- P1(保守的): 情報を足さず簡潔に言い換え
- P2(RAG最適化): 検索されやすい正確・詳細な表現に書き換え
- P3(多様性重視): 元と異なる表現で再現率の最大化を狙う
6.1 再現率の向上はre-ranking後に消える
- 融合により検索段階の再現率は上がるが、re-ranking→truncation後のKBレベル精度には反映されない
表1: Fusion Prompt 1
| 手法 | Top-1 | Top-3 | Hit@10 |
|---|---|---|---|
| baseline | 30.43% | 37.39% | 51.30% |
| rerank_on_rrf_q1 | 29.57% | 38.26% | 47.83% |
| rerank_on_rrf_q2 | 15.65% | 23.48% | 47.83% |
| rrf_q1_q2 | 25.22% | 38.26% | 47.83% |
表2: Fusion Prompt 2
| 手法 | Top-1 | Top-3 | Hit@10 |
|---|---|---|---|
| baseline | 29.57% | 36.52% | 50.43% |
| rerank_on_rrf_q1 | 29.57% | 39.13% | 46.09% |
| rerank_on_rrf_q2 | 7.83% | 17.39% | 46.09% |
| rrf_q1_q2 | 27.83% | 40.87% | 46.09% |
表3: Fusion Prompt 3
| 手法 | Top-1 | Top-3 | Hit@10 |
|---|---|---|---|
| baseline | 29.57% | 36.52% | 50.43% |
| rerank_on_rrf_q1 | 29.57% | 40.00% | 44.35% |
| rerank_on_rrf_q2 | 10.43% | 19.13% | 44.35% |
| rrf_q1_q2 | 27.83% | 40.87% | 44.35% |
- 全ての融合手法がTop-1、Top-3、Hit@10でベースラインと同等かそれ以下(仮説H2を支持)
- 候補数は増えるが、Top-Kに入れる枠は固定なので、最終的にLLMに渡される証拠にはほぼ影響しない
6.2 統計的有意性(Top-3)
- McNemar検定(Benjamini–Hochberg補正、FDR=0.05)で検定
- rerank_on_rrf_q2はベースラインを大幅に下回るため除外
表4: Top-3有意性検定
| プロンプト | 手法 | Top-3 | Δpp | p_adj |
|---|---|---|---|---|
| P1 | rrf_q1_q2 | 38.26% | +0.87 | 1.0000 |
| P1 | rerank_on_rrf_q1 | 38.26% | +0.87 | 1.0000 |
| P2 | rrf_q1_q2 | 40.87% | +4.35 | 0.1667 |
| P2 | rerank_on_rrf_q1 | 39.13% | +2.61 | 0.2500 |
| P3 | rrf_q1_q2 | 40.87% | +4.35 | 0.1250 |
| P3 | rerank_on_rrf_q1 | 40.00% | +3.48 | 0.1250 |
- Prompt 2・3でTop-3ヒット率がわずかに向上(+2.61〜+4.35pp)したが、いずれも統計的に有意でない(全てp_adj≥0.125)
- 融合の効果は、追加の処理コストを正当化できるほど安定していない
6.3 重複コンテンツと矛盾する情報
- Q1とQ2の検索結果の重複は少ない(言い換えにより異なる候補が取得される)
表5: Q1–Q2の重複(Top-10)
| プロンプト | Ov@10 | Jac@10 | Un@10 | Uniq@10 |
|---|---|---|---|---|
| P1 | 2.87 | 0.279 | 13.20 | 7.82 |
| P2 | 1.09 | 0.087 | 15.29 | 7.77 |
| P3 | 1.10 | 0.094 | 14.99 | 7.77 |
- Ov@10: Q1とQ2で共通するチャンクの平均数
- Jac@10: Jaccard類似度(共通数÷和集合数)。Q1とQ2の結果がどれだけ似ているか
- Un@10: Q1とQ2の結果を合わせた和集合のチャンク数
- Uniq@10: 和集合に含まれるユニークなKB記事の数
- P2・P3ではJaccard≈0.09でほとんど別の結果だが、ユニークな記事数(≈7.8)は横ばい。新しいチャンクは増えても新しい情報源はあまり増えていない
- しかし「新しい」候補の多くは本当に新しい情報ではない。同じKBの隣接セクションからのほぼ同一チャンクや、部分的に矛盾する内容が含まれる
- これらがre-ranking・truncationの安定性を下げ、本当に有用な証拠をTop-Kから押し出す可能性がある
- rerank_on_rrf_q2の性能が特に低い理由:Q2の言い換え表現にre-rankingが引きずられ、Q1に合っていた良い文書が順位を落とす(仮説H2と一致)
6.4 最終的な回答品質への影響は限定的
- 融合は全クエリを通じてTop-K精度を安定して改善しない
- 一部の設定ではTop-1・Top-3精度がわずかに低下(追加候補がランキングを乱す)
- 仮説H1を支持:検索段階の改善は、本番パイプラインを通すと最終的な回答品質の改善につながらない
- この傾向はプロンプトの種類やre-rankingの方法を変えても一貫(特定の設定に依存しない)
6.5 レイテンシと処理コスト
表6: 平均レイテンシ
| 処理 | 平均時間(秒) |
|---|---|
| 融合クエリ生成 | 0.89 |
| ベースライン検索(Q1のみ) | 54.60 |
| 検索(Q1+Q2) | 65.98 |
| RRF処理 | 0.012 |
| FlashRank re-ranking(K=10) | 0.26 |
- 通常の応答時間は許容範囲だが、遅いケースではベースラインより一貫して遅い
- 融合による追加コストは約0.89秒(クエリ生成+RRF+追加re-ranking分)
- 精度が改善しないのに処理コストだけ増える(仮説H1を補強)
6.6 クエリ種別ごとの分析
- 融合が有効なのは、ベースラインの検索で正解記事がTop-K内に入らない一部のクエリのみ
- 仮説H3を部分的に支持:効果は少数のクエリに限定され、全体性能への影響は小さい
- 検索エンジンやランキングの精度が上がるほど、融合の追加効果はさらに小さくなる
7. 結論
- 融合は検索段階の再現率を確実に上げるが、re-ranking・truncationで効果が消えることが多い
- 一部の設定では、むしろ精度が下がりレイテンシが増加
- 主なボトルネック:re-rankerの処理能力の限界、重複コンテンツの混入、処理コストの増加
- 成熟した企業システムでは、ランキングの精度とコンテキストの選別が最終性能を決める主要因であり、検索候補を広げるだけでは不十分
- 融合の効果はケースバイケースで、検索に失敗しやすいクエリにしか効かない
- 多くの企業向けRAGでは、融合を入れるより、シンプルなアーキテクチャの方がコスト対効果が高い