
2026-04-07 機械学習勉強会
今週のTOPIC[paper] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning[paper] Recursive Language Models Meet Uncertainty: The Surprising
Effectiveness of Self-Reflective Program Search for Long ContextHow Uber Built an Agentic [blog]System to Automate Design Specs in MinutesComposer 2 Technical ReportメインTOPICSKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization概要背景手法: SKILL0実験まとめ
今週のTOPIC
@Naoto Shimakoshi
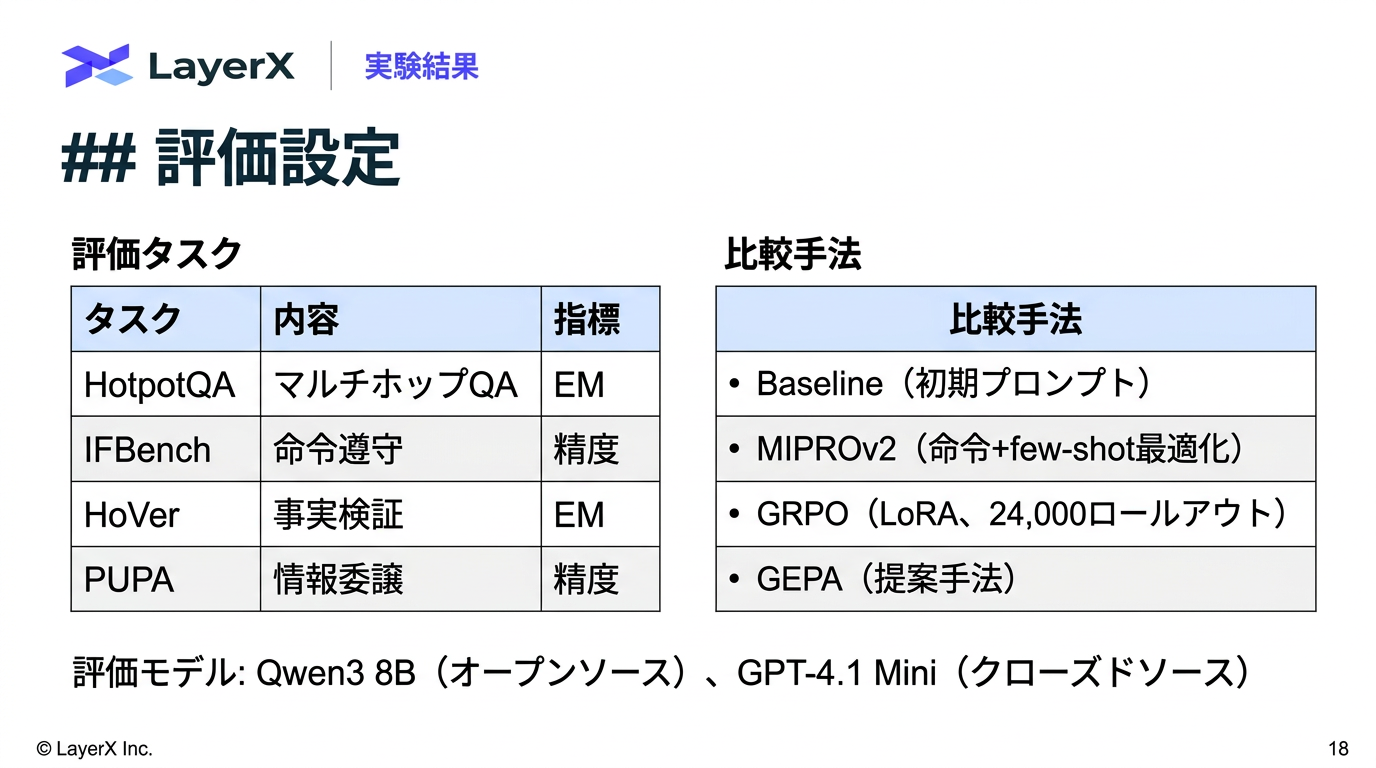
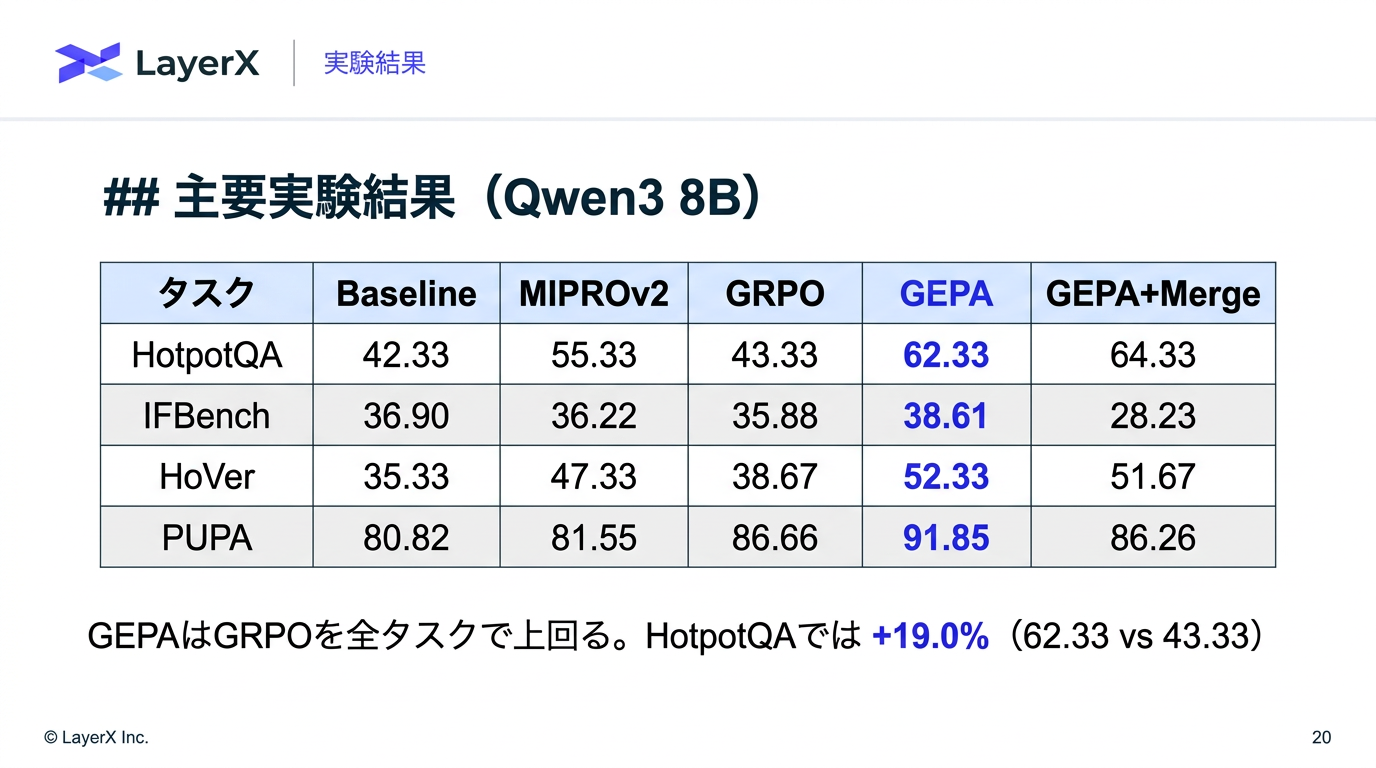
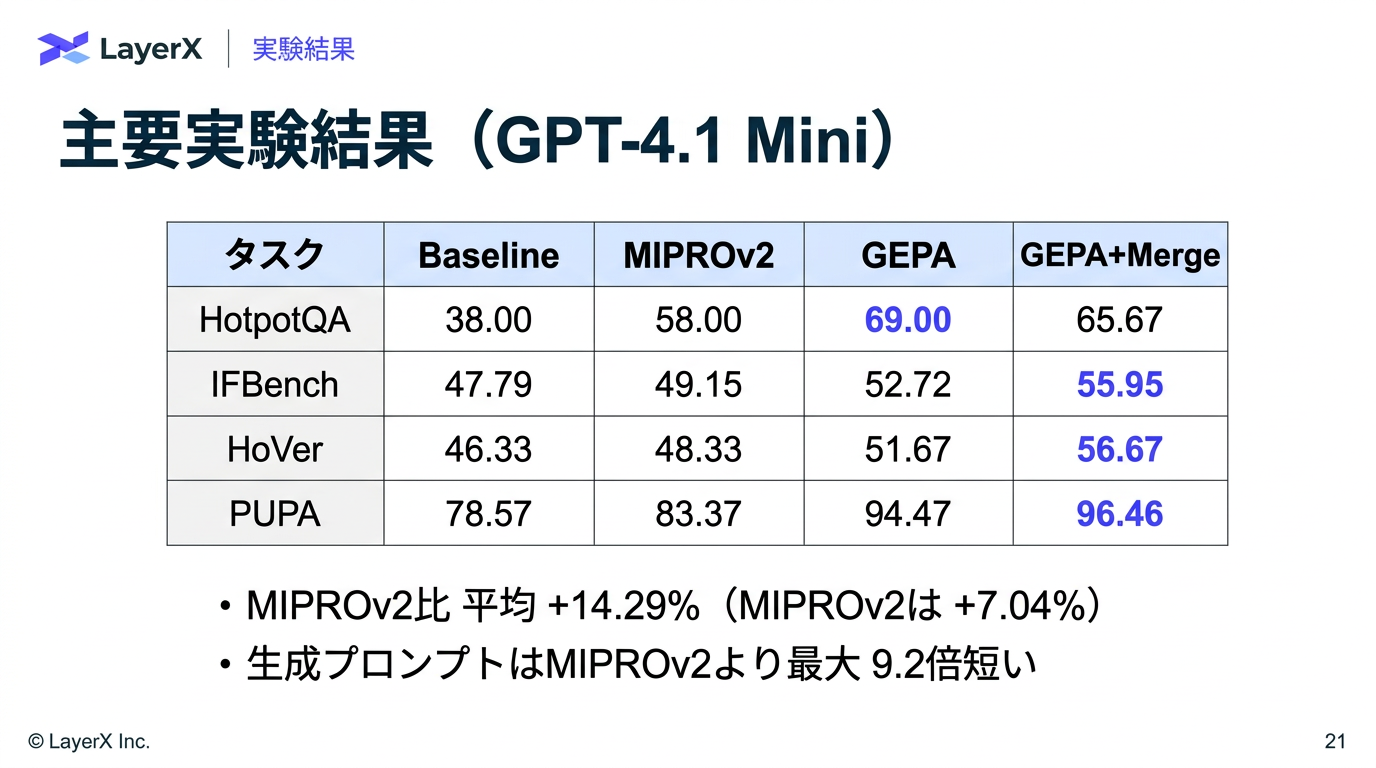
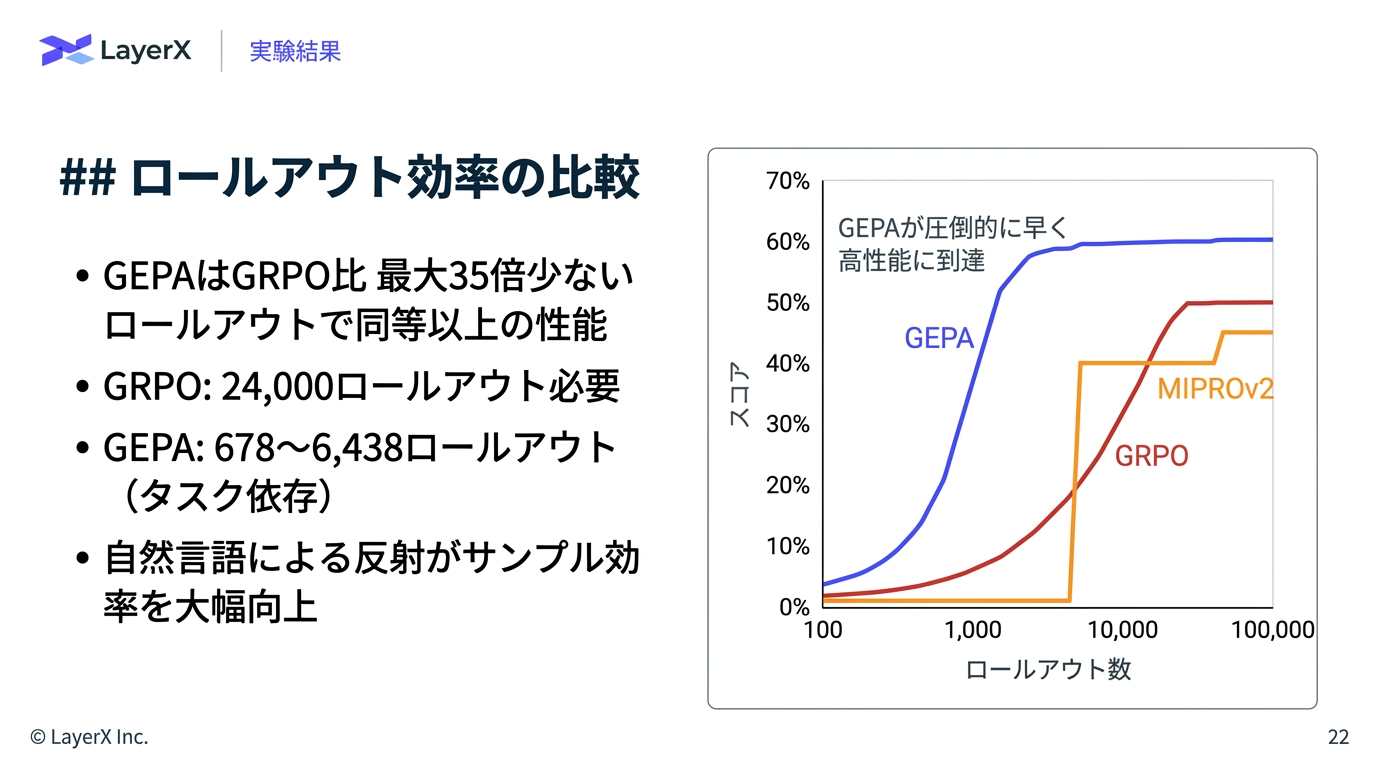
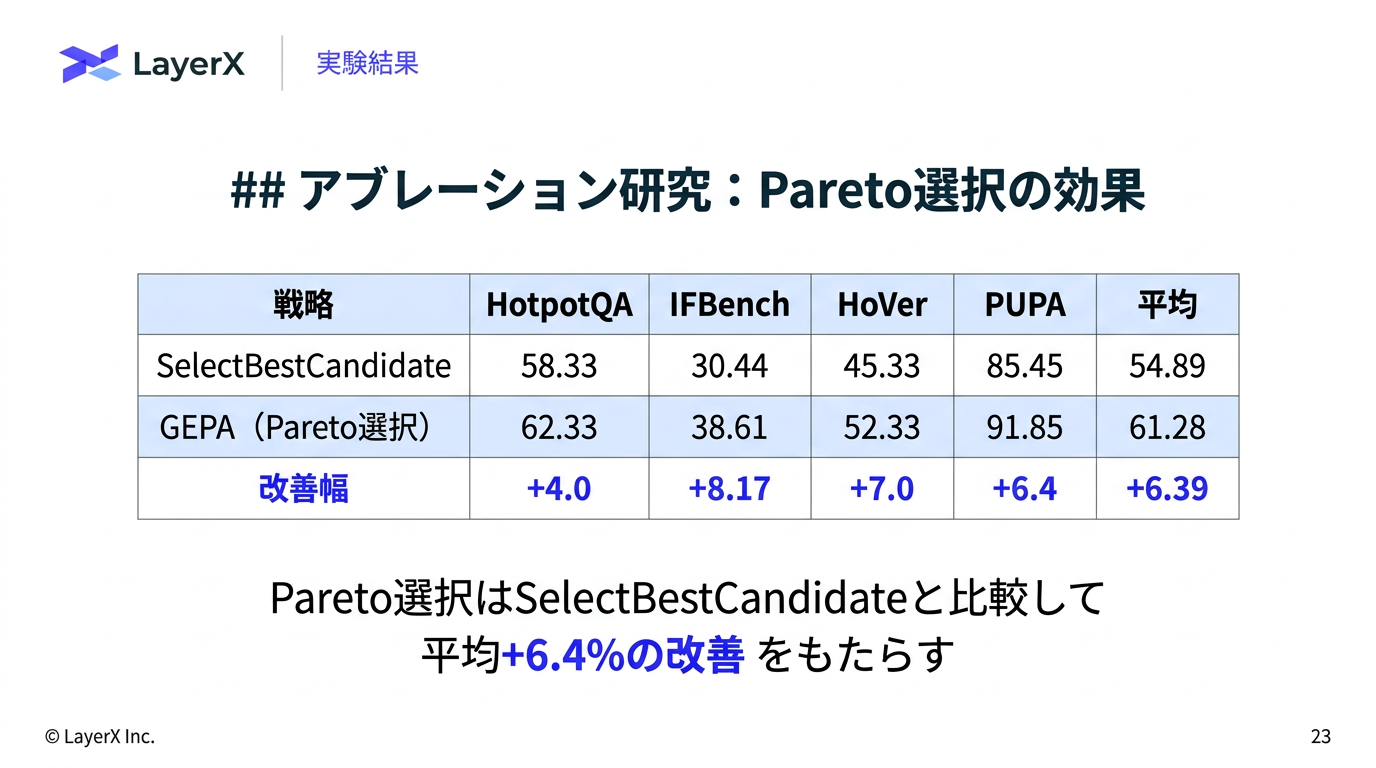
[paper] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
- ICLR 2026 Oral

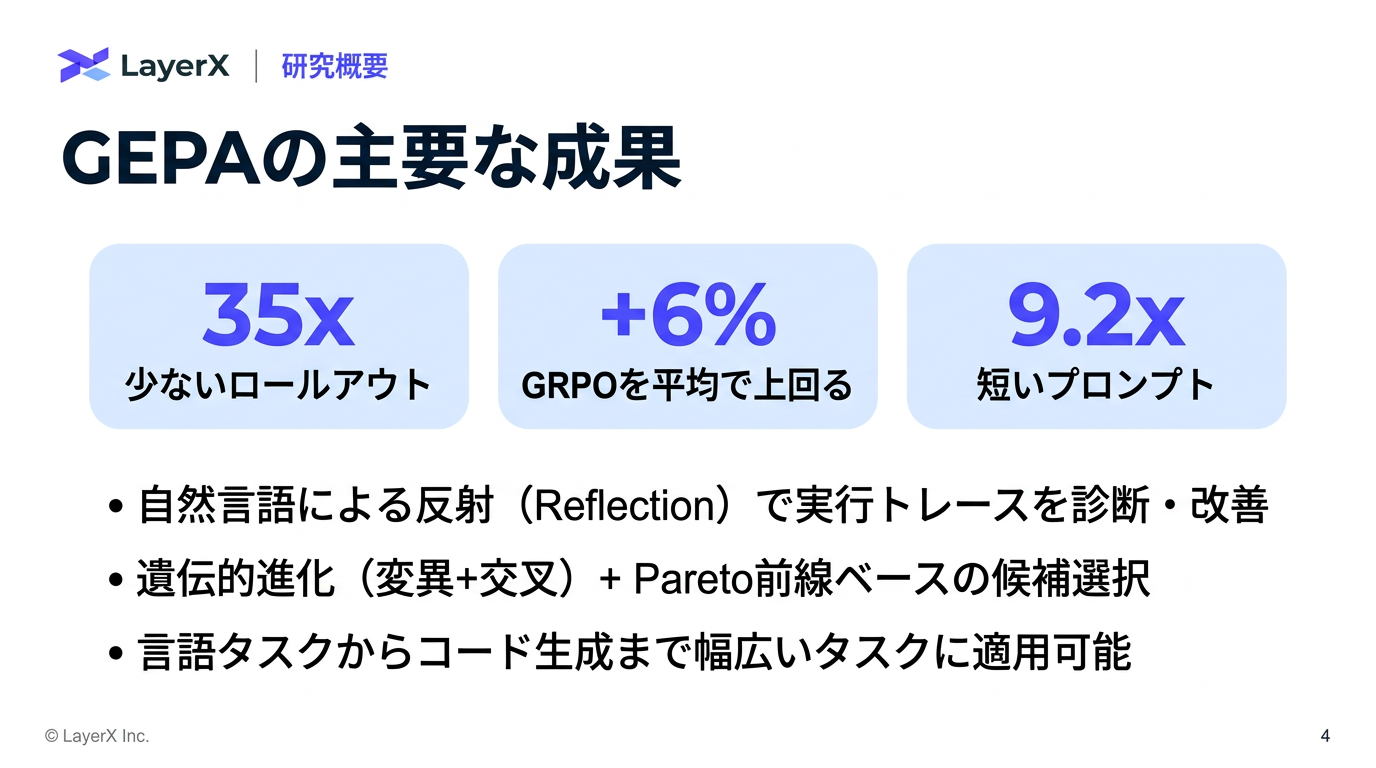
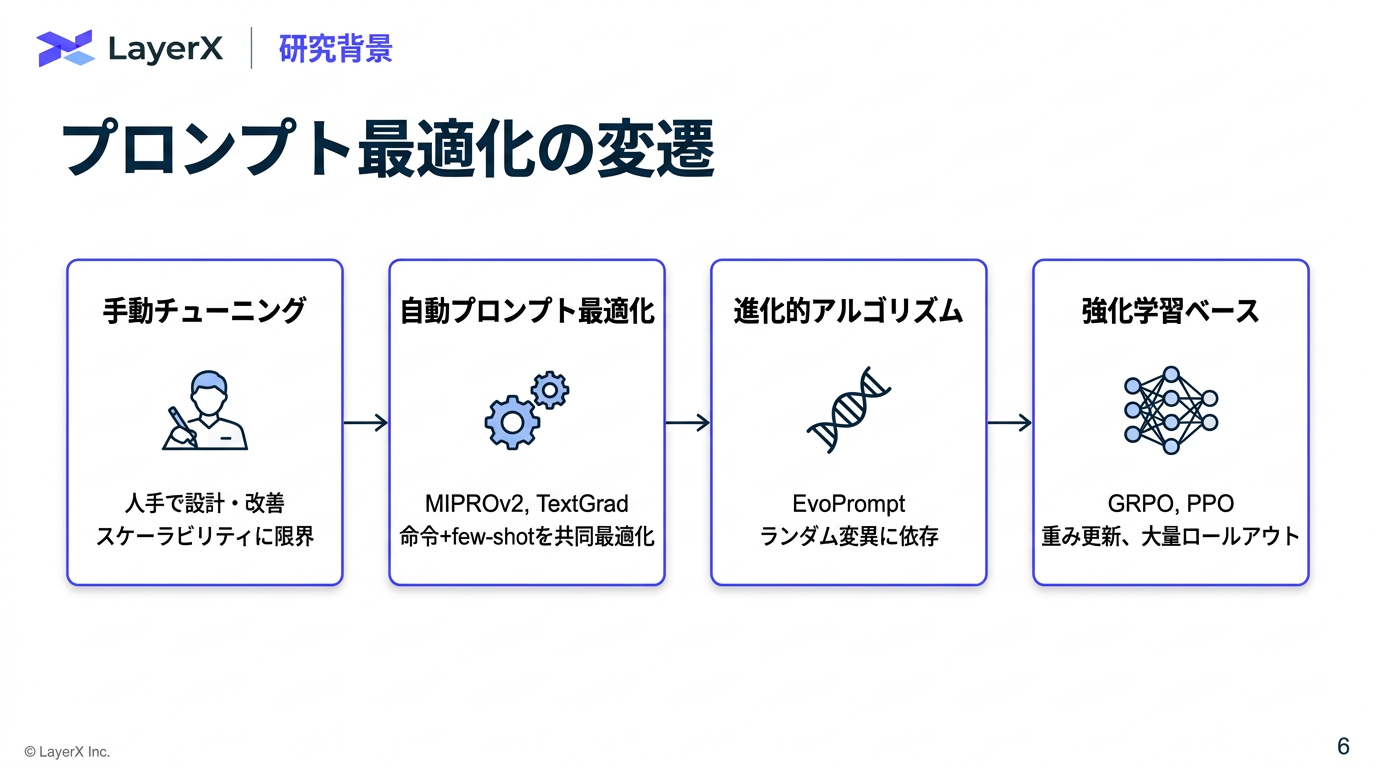

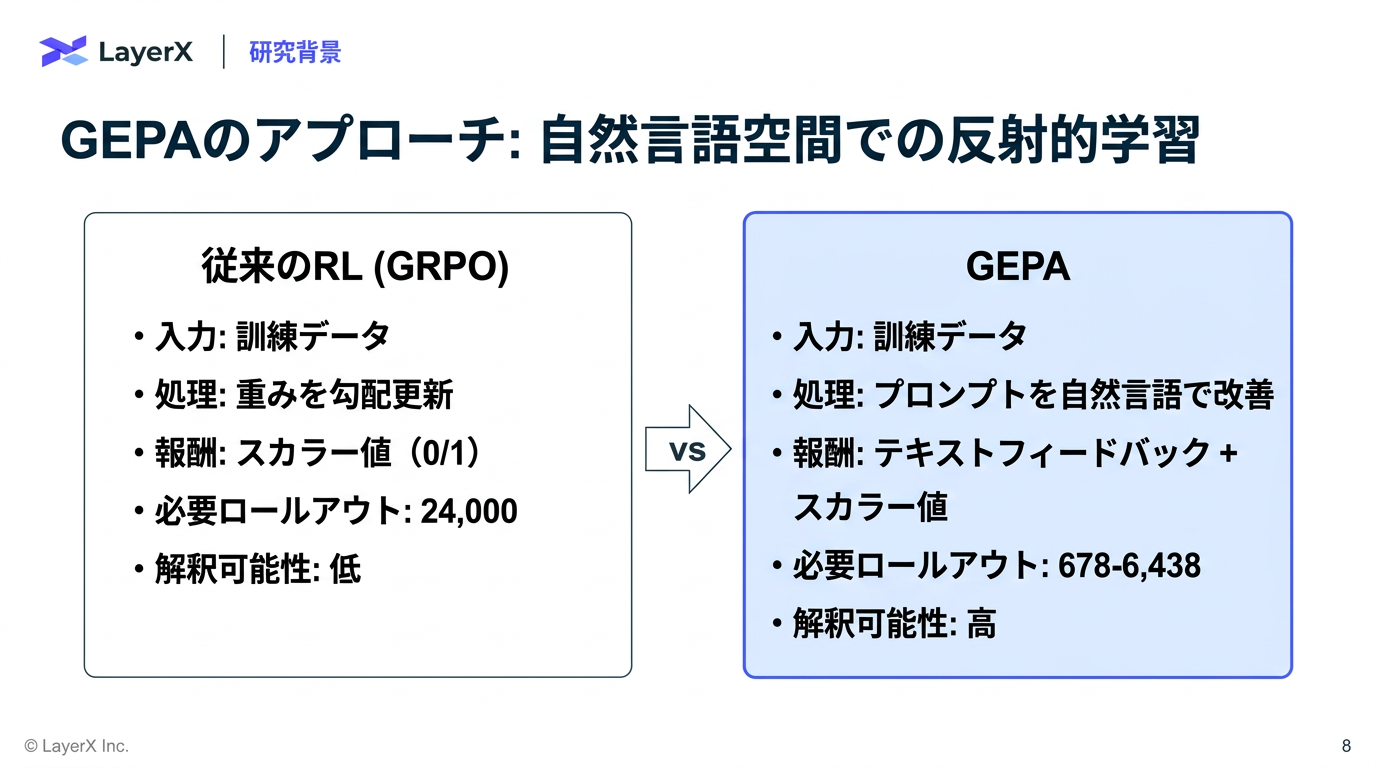
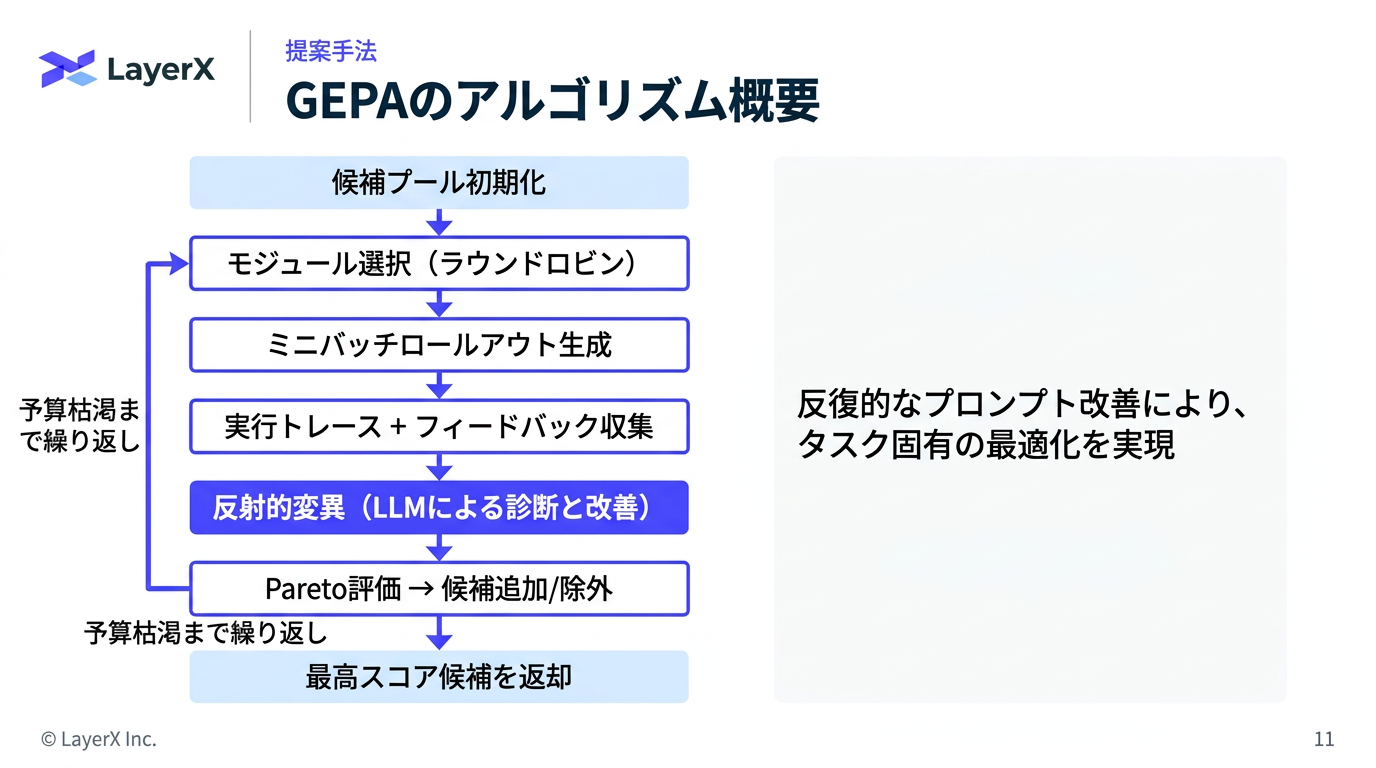
- 全体の流れ
- 各タスク(訓練インスタンス)ごとに各候補の最高スコアを記録する
- 少なくとも1つのタスクで最高スコアを達成した候補だけを残す
- 他の全候補に全タスクで負けている候補(被支配候補)は除外する
- 残った候補から、「勝利タスク数」に比例した確率でサンプリングして次の変異対象を選ぶ
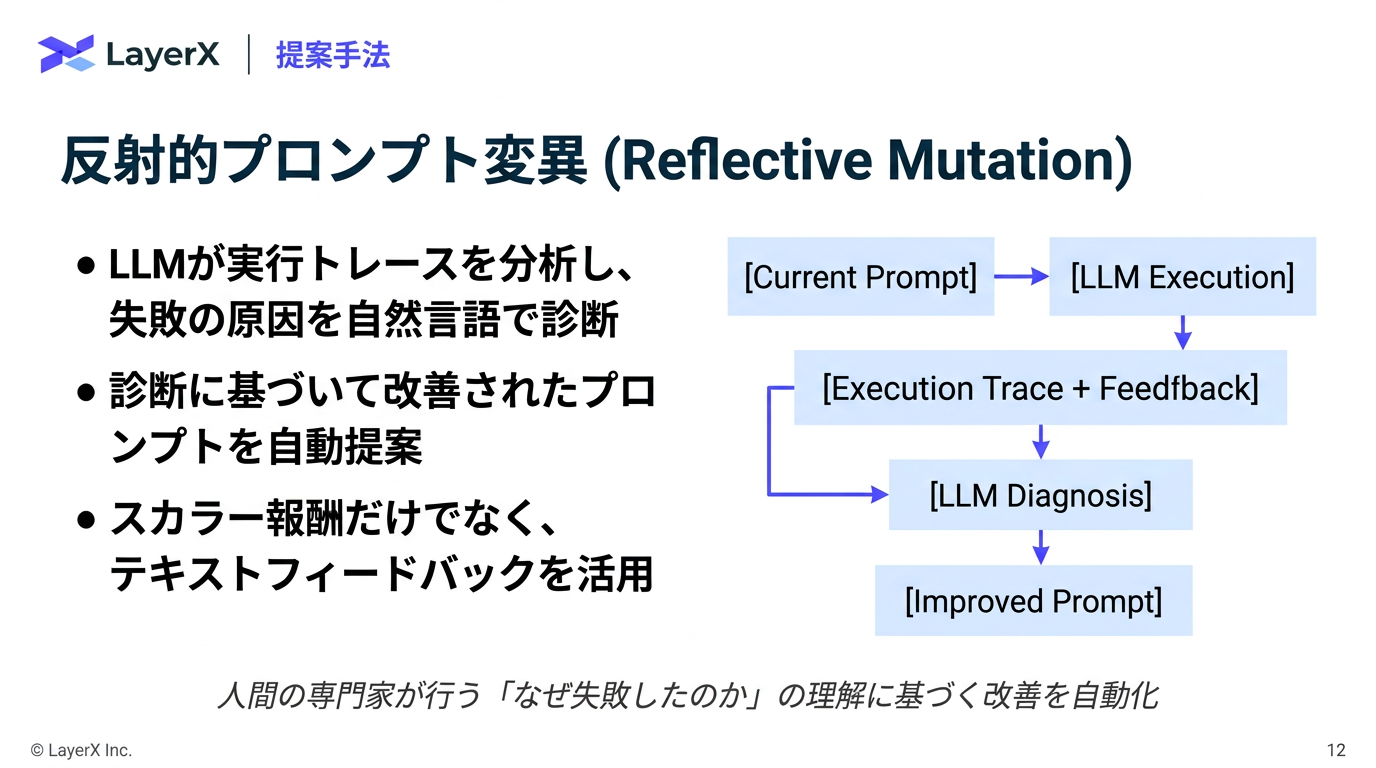
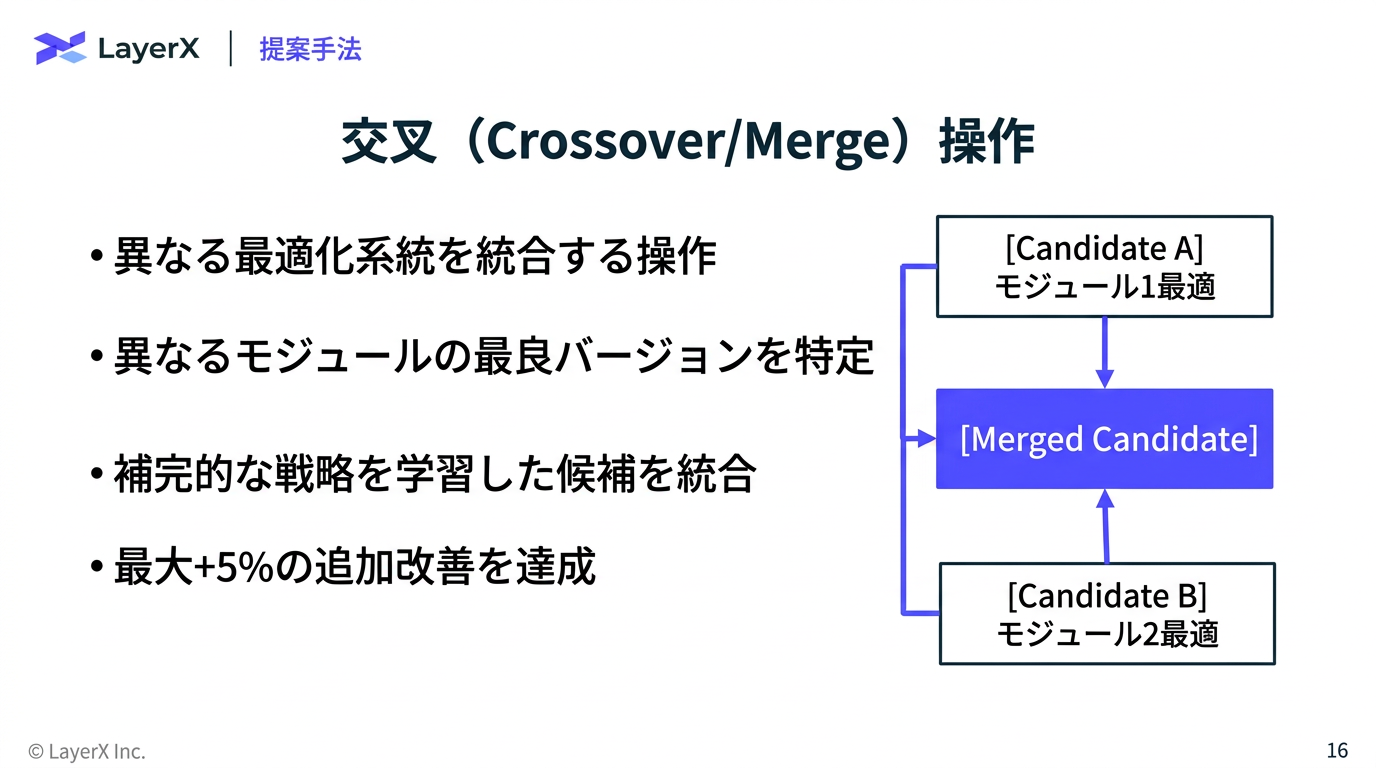
- 反射的変異 (Reflective Mutaion) or 交叉 / マージ (CrossOver / Merge)のどちらで候補を生成するかを選択
- 検証データがタスクに相当する
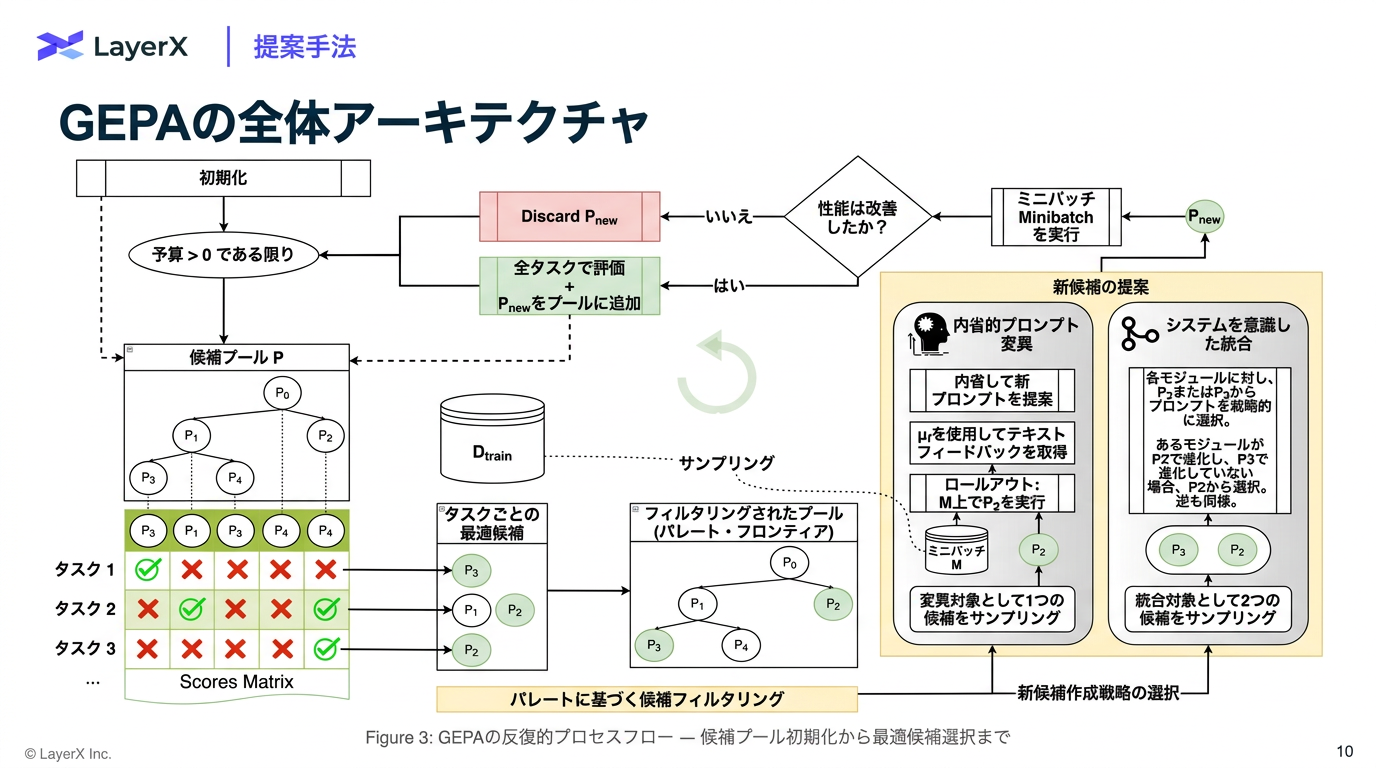
- ラウンドロビン:順番に一つずつサンプルする手法のこと

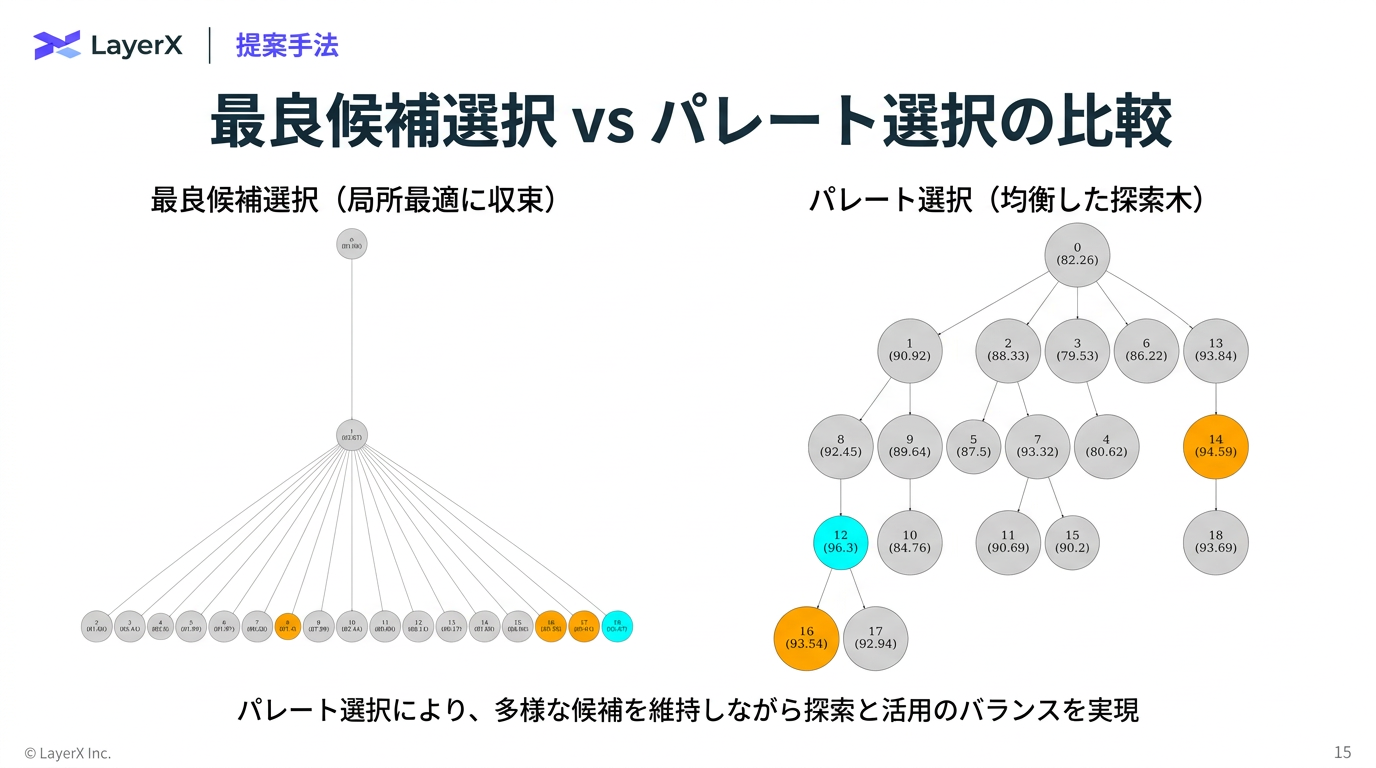
- 多目的最適化の概念で、「どの目的においても他より全面的に劣る」ことがない候補の集合をパレート前線(Pareto front)と呼ぶ。



@Hiromu Nakamura (pon)
[paper] Recursive Language Models Meet Uncertainty: The Surprising
Effectiveness of Self-Reflective Program Search for Long Context
1. 現状の課題:長文コンテキスト処理の限界
大規模言語モデル(LLM)のコンテキストウィンドウは拡大を続けているが、依然として以下の課題が残っている。
- 情報の埋没と注意の散漫: ウィンドウ内であっても、特定の情報の抽出や、離れた位置にある情報の統合に失敗する。
- 推論の劣化: コンテキストが長くなるにつれて、モデルは重要な詳細を見失い、無関係な内容に惑わされる傾向がある。
- 推論コストと効率: 数百万トークンを直接処理することは、計算資源と精度の両面で非効率である。
既存の解決策であるRLMは、コンテキストを外部変数としてプログラミング環境(REPL)に外部化し、クエリやスライス操作を行うプログラムを生成することで対応している。しかし、生成される複数のプログラム候補から、どれが最も信頼できるかを評価する原理的なメカニズムが欠如していた。
2. SRLMフレームワークの概要
SRLMは、プログラミングベースのコンテキスト対話に、**「不確実性を意識した自己省察(Uncertainty-aware Self-reflection)」**を導入する。
動作メカニズム
- プログラム生成: モデルは与えられたクエリに対し、コンテキストを操作・抽出する複数の候補プログラム(軌道)を独立して生成する。
- 自己省察による評価: 各プログラムが生成される過程で、モデル自身の内部的な不確実性を測定する。
- 軌道選択: 測定された不確実性スコアに基づき、最も信頼性の高いプログラムを選択し、最終的な回答を出力する。
このアプローチの最大の特徴は、外部の検証器や報酬モデル、ラベル付きデータを一切必要とせず、モデル自身の生成プロセスから得られるシグナルのみで完結している点にある。
3. 不確実性をガイドする3つの主要シグナル
SRLMは、相補的な3つの指標を組み合わせてプログラムの質を評価する。
| シグナル名 | カテゴリ | 概要・役割 |
|---|---|---|
| 自己整合性 (Self-Consistency) | サンプリングベース | 複数のサンプリング結果における回答の頻度を確認する。最も多数派の回答(Plurality Answer)に一致するプログラムを候補として残す。 |
| 言語化された自信 (Verbalized Confidence) | セマンティック(意味的) | 各推論ステップで、モデル自身に「自信スコア(0-100)」を出力させる。ステップごとの対数確率的な確信度を累積し、意味的な不確実性を測定する。 |
| 推論トレース長 (Reasoning Trace Length) | 行動ベース | 生成されたトークンの総数。モデルは不確実な場合に冗長で迷いのある出力を生成する傾向(エピステミックな努力の増大)があるため、これを不確実性の代替指標とする。 |
統合スコアの算出: 一貫性のある候補セットの中で、 の計算を行い、不確実性が最も低い(自信が高く、かつ簡潔で迷いのない)プログラムを最適解(p∗)として選択する。
4. 主要な実験結果と知見
Qwen3-Coder-480BおよびGPT-5をバックボーンとして、多様なベンチマークで評価が行われた。
4.1 パフォーマンスの向上
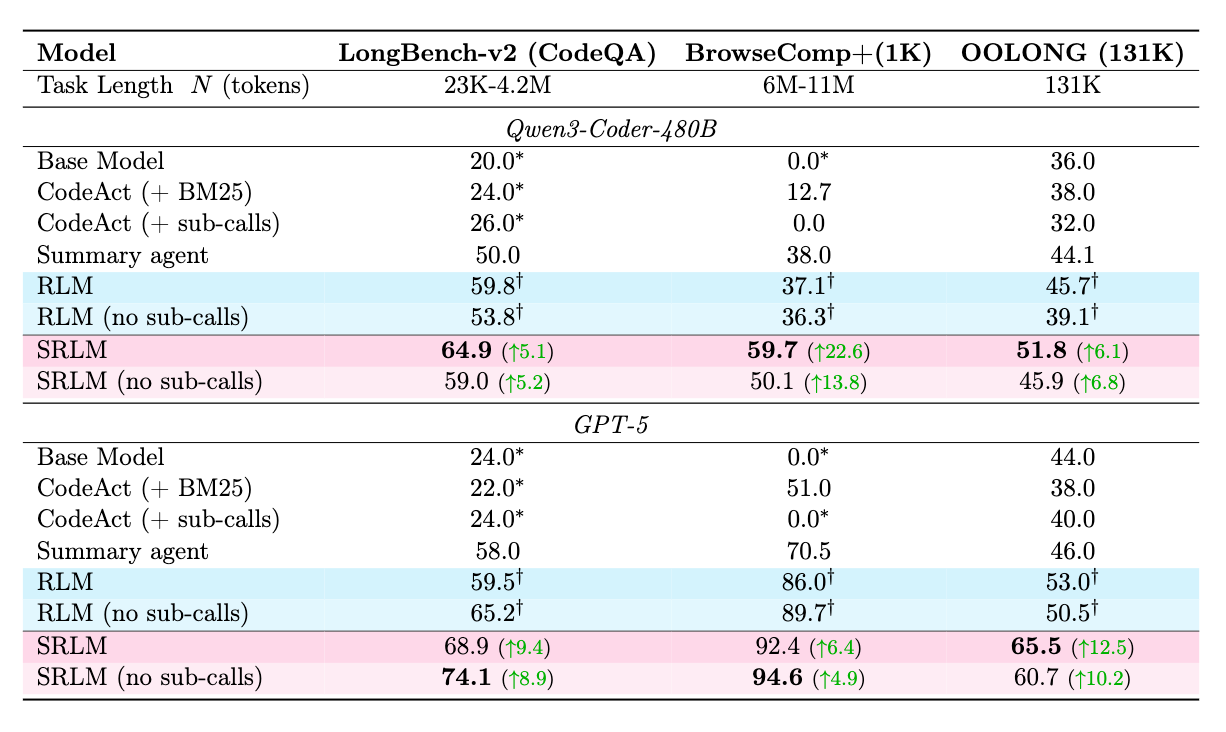
SRLMは、既存のベースラインおよびRLMを一貫して凌駕している。
- BrowseComp+ (1K documents): RLMに対して最大22.6%の改善。
- OOLONG (131K tokens): RLMに対して最大12.5%の改善。
- LongBench-v2 (CodeQA): RLMに対して最大9.4%の改善。
再帰(Recursion)の役割の再定義
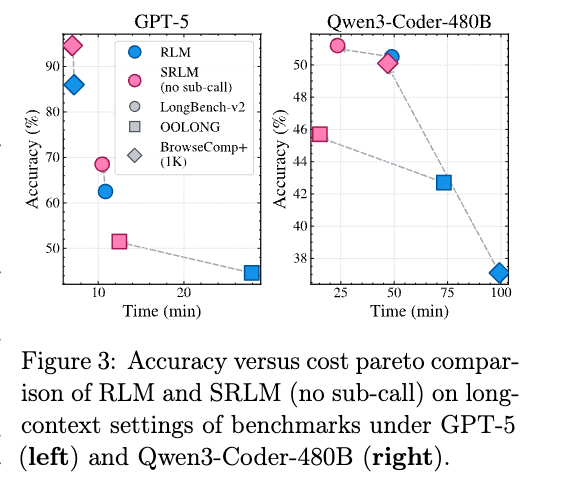
本研究における最も驚くべき発見の一つは、**「再帰そのものは性能向上の主要因ではない」**ということである。
- 知見: 再帰メカニズム(自己クエリの呼び出し)を無効化したSRLMであっても、再帰を使用するRLMと同等以上の性能を発揮する。
- 結論: 長文処理における真のボトルネックは、問題をいかに細かく分解するかではなく、**「生成された複数の推論ステップや探索プログラムの中から、いかに不確実性の低いものを選択するか」**にある。
- コスト効率: 全てのプログラム軌道を並列実行できるため、SRLMはRLMと同等の時間的コストで、より高い精度を達成可能である。
4.2 コンテキスト長に対する堅牢性
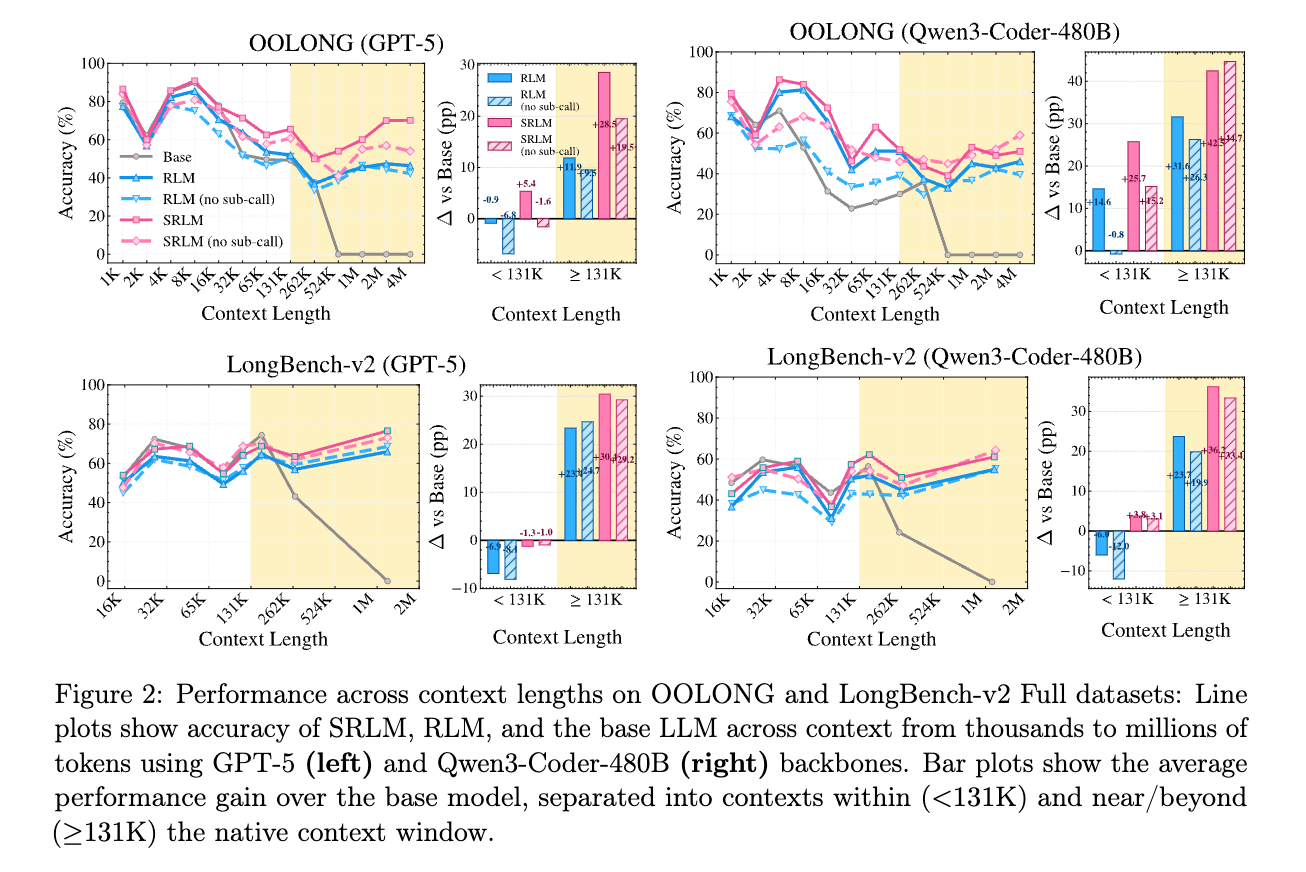
- 短文コンテキスト: RLMはコンテキストウィンドウ内(<131K)であっても、再帰的な分解によってベースモデルより性能が低下する場合がある。一方、SRLMは短文から長文まで安定してベースモデルを上回る。
- 超長文コンテキスト: 1M〜4Mトークンを超える範囲において、SRLMの優位性はさらに顕著になる。
6. タスクのセマンティクスと堅牢性
タスクの性質によって、モデルの有効性が異なることが判明した。
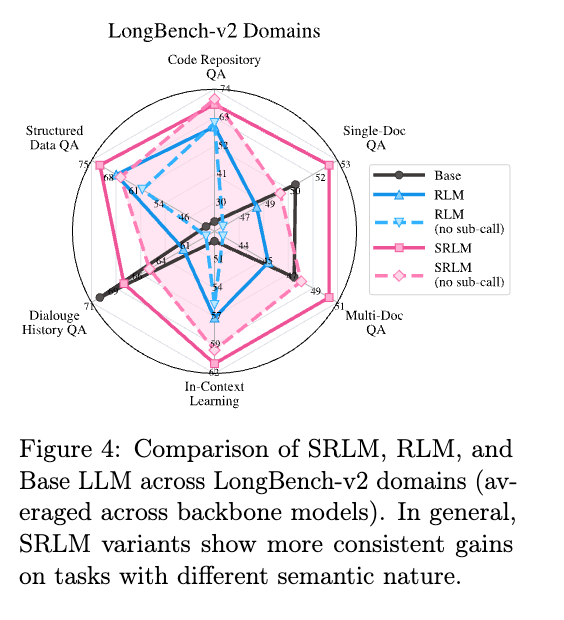
- 検索指向タスク (Search-oriented):
- Code QAや構造化データの抽出など。
- RLMのヒューリスティックなプログラム探索が比較的機能しやすい。
- 意味集約型タスク (Semantically intensive):
- 対話履歴の理解、ドキュメントQA、長文のインコンテキスト学習など。
- 単なる情報の検索ではなく、文脈全体の深い理解が必要。
- SRLMの優位性: 自己省察によるセマンティックな信号が推論を適切に誘導するため、RLMが失敗するような意味的に複雑なタスクで極めて高い効果を発揮する。
@Shuhei Nakano(nanay)
How Uber Built an Agentic [blog]System to Automate Design Specs in Minutes
- タイトル: How Uber Built an Agentic System to Automate Design Specs in Minutes
- 著者 / 組織: Ian Guisard / Uber Design Systems Team
- 公開日: 2026年3月11日
1. どんな記事?
Uberのデザインシステムチームが、AIエージェントを活用してコンポーネントの仕様書(Design Spec)を自動生成するシステム uSpec を構築した事例。Cursor IDE + Claude + Figma Console MCP(Model Context Protocol)という構成で、Figmaのデザインデータを直接読み取り、完成した仕様ページをFigma上に出力する。従来は数週間かかっていた仕様書作成を数分で完了できるようにした。
2. 何が課題だったのか?
- Uberの Base デザインシステム は7つの実装スタック(UIKit, SwiftUI, Android XML, Android Compose, Web React, Go, SDUI)にまたがる数百のコンポーネントを持ち、それぞれに正確・完全・最新の仕様書が必要
- 1つのコンポーネント仕様に含む情報が多岐にわたる:Anatomy(要素構成)、API、バリアント(Variant)、カラートークンマッピング、寸法・スペーシング、アクセシビリティ属性(VoiceOver / TalkBack / ARIA)
- 手動作成は 数週間単位 の工数がかかり、コンポーネント更新に伴う仕様のドリフト(陳腐化)が常態化
- アクセシビリティ標準の手動クロスリファレンスも大きな負担
3. アーキテクチャ・技術的アプローチ
2ステップのワークフロー:
- デザイナーがFigmaコンポーネントのリンクと関連コンテキストをCursor上で共有
- AIエージェントがFigma Console MCP経由でFigmaファイルを読み取り、構造データを抽出し、完成した仕様ページをFigma上に直接レンダリング
6つの専門エージェントスキル:
| スキル | 役割 |
|---|---|
| Anatomy | 要素の識別と属性テーブル生成 |
| API | プロパティのドキュメント化(デフォルト値含む) |
| Properties | バリアントとトグルのプレビュー付き整理 |
| Color annotation | 要素・状態ごとのデザイントークンマッピング |
| Structure | バリアント間の寸法・スペーシング情報 |
| Screen reader | マルチプラットフォームのアクセシビリティ仕様 |
技術スタック: Cursor IDE + Claude(LLM)+ Figma Console MCP(オープンソース)
4. 設計上のこだわり・工夫
- Single Source of Truth: Figmaのデザインファイルから直接トークン名、バリアント軸、変数モード、コンポーネントプロパティを読み取ることで、仕様と実データの乖離を構造的に排除。仕様書を「更新する」のではなく「生成する」アプローチへの転換
- MCP(Model Context Protocol)の活用: オープンソースのFigma Console MCPを介してLLMとFigmaを接続。既存のツールチェーンにAIを自然に統合するアプローチ
- スキルの専門化: 1つのモノリシックなエージェントではなく6つの専門スキルに分割。各仕様項目の品質と一貫性を確保しつつ、個別のスキルを独立して改善可能に
5. 現時点の制約と今後の展望
- この課題は 業界全体の構造的問題 であり、他社のデザインシステムリーダーからも同様の自動化ニーズが寄せられている
- 数百のコンポーネントへのスケーリングが進行中
- MCP接続の拡張やスキルの追加による対応範囲の拡大が今後の方向性と推察される
- Figma以外のデザインツールへの対応可能性は未言及
6. Take Home Message
- ドキュメント作成はAIエージェント自動化の理想的なユースケース: 構造化されたインプット(Figmaデータ)から構造化されたアウトプット(仕様書)への変換は、LLMエージェントが最も得意とするタスクパターン
- MCPはLLMと専門ツールの接続に有効: Figma Console MCPのようなオープンプロトコルを活用することで、個別のAPI統合を構築せずに既存ツールチェーンにAIを組み込める
- 「更新」ではなく「生成」への発想転換: 仕様書を人が書いてメンテナンスするのではなく、ソースデータから都度生成するアプローチ。デザイン仕様に限らず、APIドキュメントやテスト仕様などにも応用可能
- 数週間→数分という桁違いの効率化: 自動化の対象を「構造化されたデータから構造化された成果物を生成する」タスクに正しく選定すれば、劇的な生産性向上が実現できる
感想
- LLM活用において「構造化」しておくことに意味がある
- figmaが話しに出てたので
@Kyohei Uto(kuto)
Composer 2 Technical Report
概要
- Cursorエディタで利用可能なComposer2のテクニカルレポート
- KiMi K2.5をベースモデルとしてSFT、RLをするというのが基本構成
- コスパの良さが強みとして強調されている
- リアルタイムRLとは別物
面白かったトピックを抜粋して紹介
補助報酬
- 行動とコミュニケーションに関するさまざまな補助的報酬を適用
- コーディングスタイル
- コミュニケーションの質
- Cursor固有のペナルティ(例:To-Doリストを作成したが未完了のまま放置する行為など)
- 訓練期間中のモデル行動を監視し、必要に応じて追加の行動報酬を導入する
[事例]モデルがコメント内に長大な思考過程を記述し始めたり、最終的に端末ツールのみを使用するように収束したりする現象が確認された。これに対して下記のような長さペナルティを負の報酬として適用する
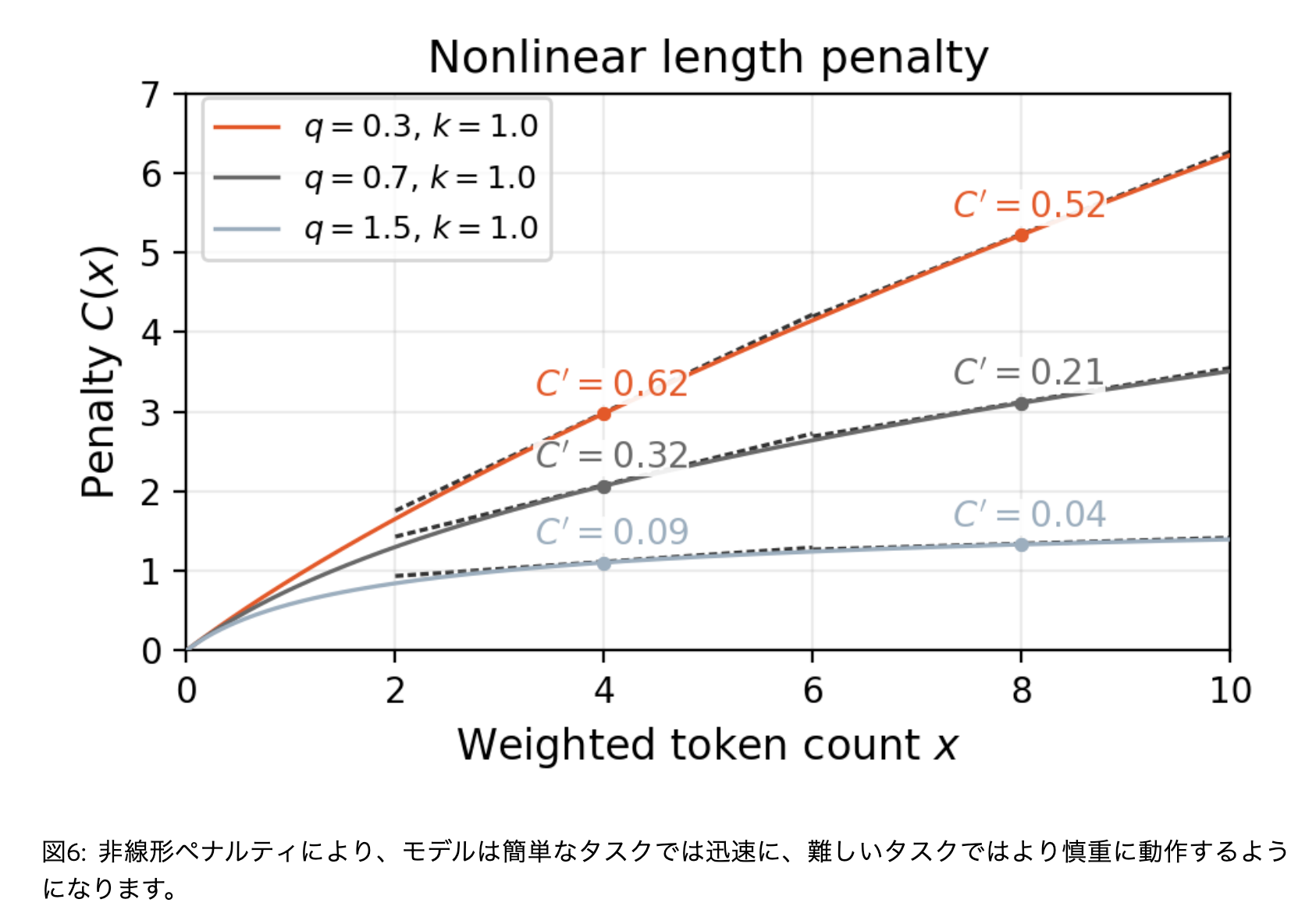
[kuto]報酬は最初にカチッと決めておくイメージだったけど、継続的な学習かつ複雑なエージェントタスクの場合は学習状況に応じて挙動が変わってくるので柔軟に変更できるようにしておくほうが良いのかもしれない
[kuto] 生成コメント長みたいな指標をモニタリングしてるのかな?学習時のメトリクスは細かくみてそうな雰囲気を感じる
RLのシミュレーション環境 Anyrun
- CursorのCloud Agentsの基盤としても利用されるAnyrunという社内のコード実行環境プラットフォームを利用
- ファイルシステムレベルおよびメモリレベルの両方で、完全なコーディング環境のフォークおよびスナップショット機能をサポート
- RLの実行中に、軌道途中のロールアウトチェックポイント作成や、事後分析のためのロールアウト後状態のキャプチャなどの機能を実現できる
- 本番環境とシミュレーション環境の整合性を保つために、本番環境と同一のbackendを共有して利用
[kuto]Cursorの環境で学習しているので、(当たり前ではあるが)他のクローズドモデルと比べてよりCursor上での性能が出やすいモデルにFTされる。シミュレーション環境でやりやすいものもあるのでリアルタイムRLと使い分け
デルタ圧縮による重み同期
- 学習・推論サーバでモデル重みをキャッシュし新しい重みとの差分のみでモデル重みを送受信するデルタ圧縮を採用
- RLによるパラメータ更新サイズは小さいらしく、フルパラメータFTでも1Tパラメータモデルの差分圧縮後の転送量は数GB程度に抑えられる
評価(CursorBench/ルーブリック)
学習プロセスの中でモデル性能の評価を下記の2つで実施している
CursorBench評価
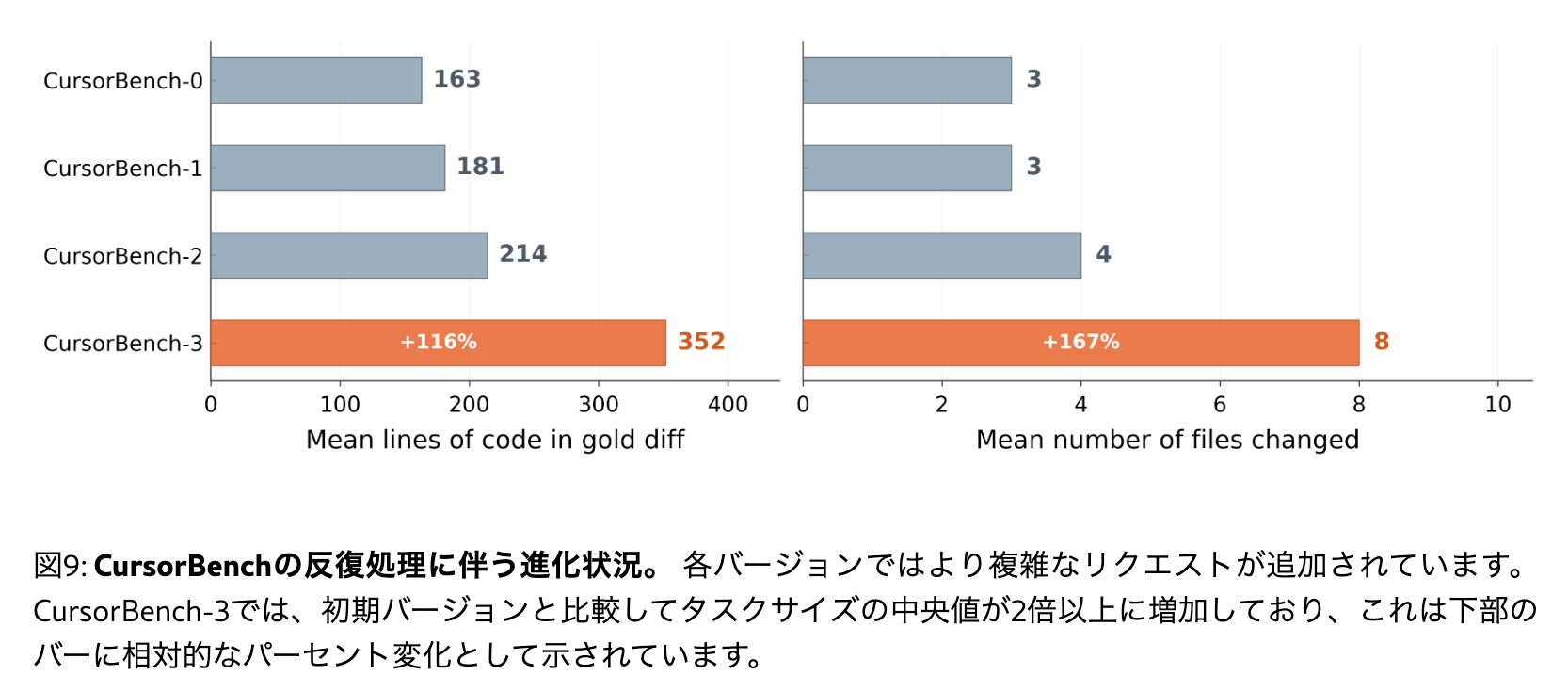
- Cursorエンジニアリングチームの実際のコーディングセッションから抽出したタスクで構成される内部評価スイート
- エージェント性能向上やユーザの作業フローの変化に合わせて定期的に評価セットを更新し、ユーザが実際にCursorをどのように使用するかに沿った評価を維持する
- 下の図のようにバージョンアップデートのたびに複雑性が増えている
ルーブリック評価
実際の開発現場ではもっと細かい振る舞いが重要となるためCursorBenchでは見れない点をこちらで評価する
- 下記5つの特化型評価を実施する
| カテゴリ | 概要 |
| 意図理解 | 曖昧なプロンプトに対するモデルの対応能力を評価する |
| 指示追従 | システムプロンプト・ユーザープロンプト・ルール・スキルへの従順性を測定する |
| 積極的な編集 | コード編集を回避すべき質問に対するモデルの応答能力を検証する |
| コード品質 | コードとコメントの品質を評価する |
| 中断処理 | ロールアウト中の中断やユーザーフィードバックへの対応能力を定量化する |
- 上記カテゴリ内でのルーブリック(評価基準)の作成方法
- 重要な振る舞いの次元を特定(上記5つの観点など)
- その振る舞いを引き出すデータを選定(特定のタイプのタスク/プロンプト)
- 採点基準(rubric)を作成(何をもって良しとするか明確に定義)
メインTOPIC
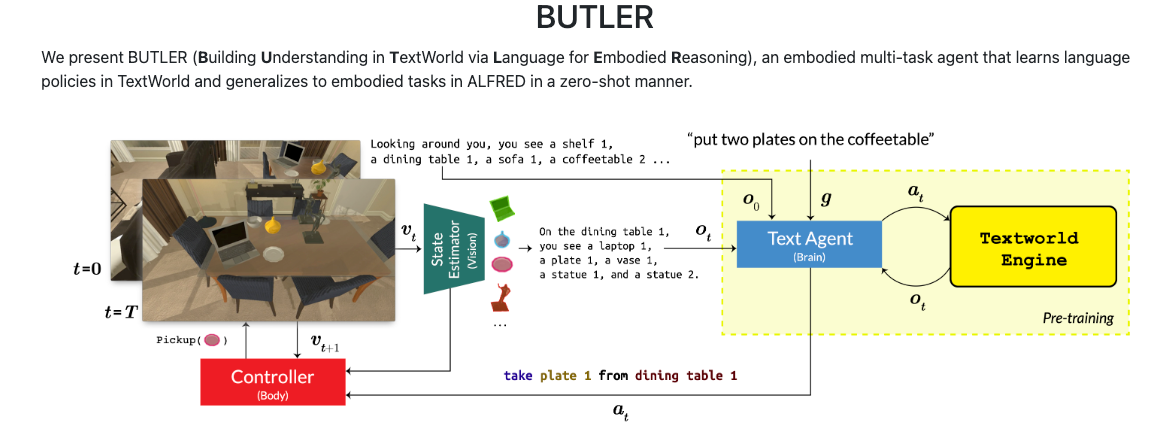
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu and Zhiyuan Yao and Jinyang Wu and Chengcheng Han and Qi Gu and Xunliang Cai and Weiming Lu and Jun Xiao and Yueting Zhuang and Yongliang Shen
arXiv 2026
 GitHub
GitHub概要
- LLMエージェントが推論時に外部スキルを毎回検索して使うのではなく、訓練中にスキルを学習し、最終的にはスキルなしで自律実行できるようにする SKILL0 を提案
- 中心アイデアは "Skills at training, zero at inference" であり、スキルを推論時の補助情報ではなく、モデル重みに内在化すべき知識として扱う。
- 提案法は、訓練中だけスキルを文脈として与える In-Context Reinforcement Learning と、学習進行に応じて有用なスキルだけを残しつつ最終的にゼロにする Dynamic Curriculum から構成される。
- 実験では、ALFWorld と Search-QA の両ベンチマークで強い RL ベースラインを上回りつつ、推論時の平均コンテキストコストを 0.5k token 未満に抑えた。
背景
- 既存の agent skill 利用は、推論時に SkillBank から関連スキルを検索し、プロンプトに注入するのが主流
- この方式には3つの限界がある。
- 検索ノイズで無関係なスキルが混ざり、コンテキスト品質が下がる。
- スキル文面と対話履歴を毎回コンテキストへ積むため、マルチターンで token cost が多くなる
- モデルはスキルを「読んで従っている」だけであり、知識そのものを内部化していない。
- 人間が最初は手順を見て行動し、後から自動化できるようになるのと同様に、LLM agent もスキルを最終的に内在化した方が良い?

手法: SKILL0
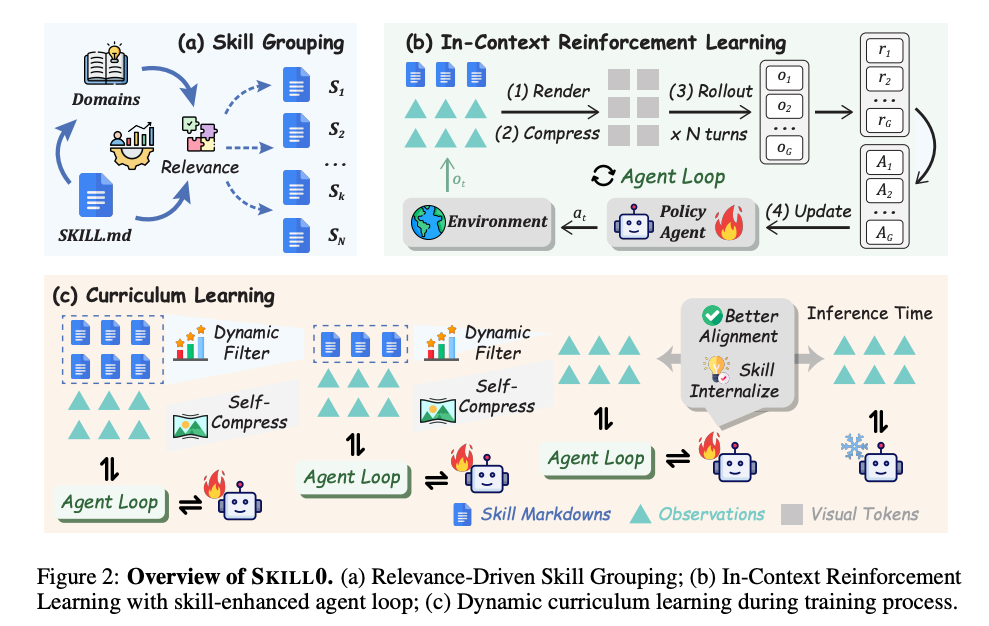
- 全体の流れ
- SkillBank 構築
- スキル付きで訓練
- 学習進行に応じてスキルを削減
- 推論時はスキルなし
- 従来法が「毎回スキルを検索して読む」のに対し、提案法は「訓練中にだけスキルを見せ、最終的に重みへ移す」
- Skill Grouping: スキルを評価可能な単位に構造化
- スキルを対応するタスクの種類(例:検索系、探索系など)ごとにグループ分け
- SkillBank = {S₁,…,S_N} として構造化される
- 各スキルグループ Sk に対して、対応するValidation Sub-Taskを事前に割り当てる
- Validation Sub-Taskは「そのスキルが有効なタスク集合」になるよう設計
- タスクの評価を通して、対応するskillの学習度合いを評価する
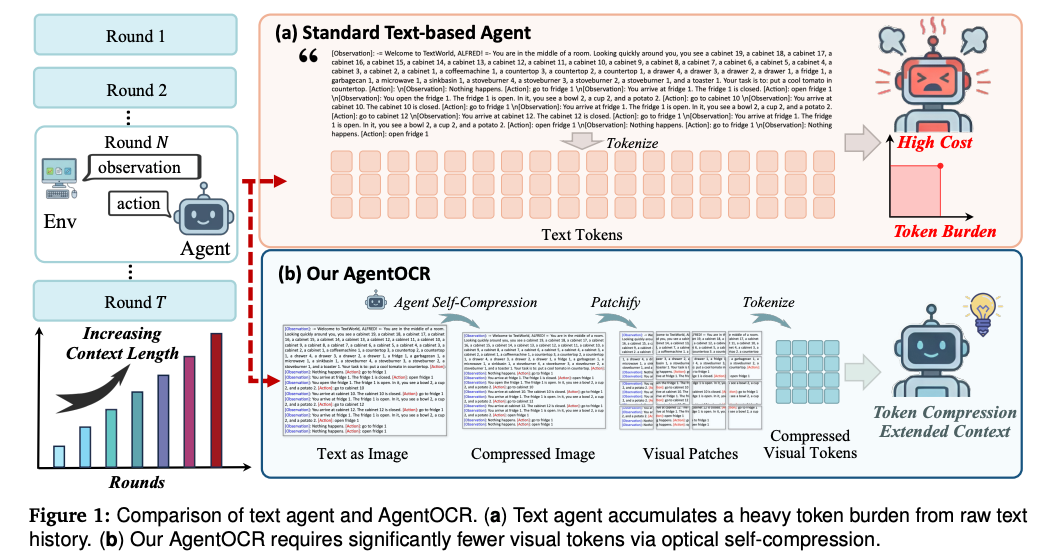
- In-Context Reinforcement Learning: スキルを使いながら圧縮・内部化するRL
- スキル・historyのトークン列から直接推論するのではなく、スキル・historyを画像化し、Vision Encoderで画像トークンに変換したものから行動 + 圧縮率を出力する
- a: アクション、c: 圧縮率
- 画像化: RGB画像へのレンダリング
- フォント:monospace
- 行間:1.2
- フォントサイズ:
- ALFWorld:10pt
- Search-QA:12pt
- 最大幅:
- ALFWorld:392px
- Search-QA:560px
- 色
- ALFWorld
- 通常テキスト:黒
- 観測(observation):青
- 行動(action):赤
- Search-QA
- query:青
- retrieval結果:赤
- 既存手法: AgentOCR
- tokenコスト削減 + ノイズ耐性向上が狙い
- 報酬は、タスク成功報酬 + 圧縮報酬の合成
- スキルを使って正解しつつも、情報量を削減する方向に学習が進む
- 気持ち
- スキルを「参照知識」として使いながら、徐々に内部表現へ蒸留するRL
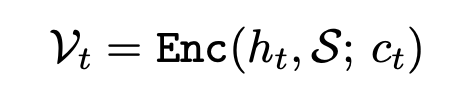
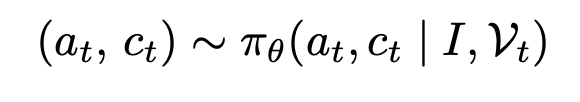
画像化設定
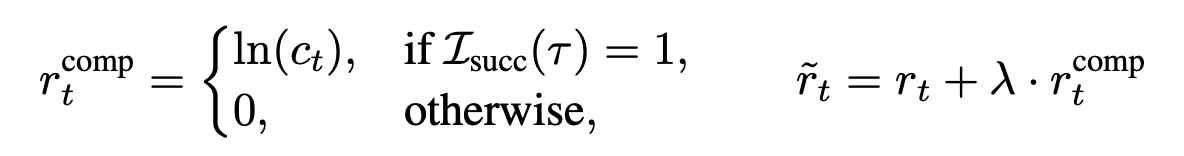
- Curriculum Learning: 有用性に応じてスキルを段階的に削除
- ある時点で、Validation Sub-Taskそれぞれについて、スキルのあり・なしでの精度差分を評価
- 差分が >0 & 差分の大きい(= スキルを渡さないと解けていない)ものから top M を選んで、次の学習時に使用する
- top M はステップに応じて段階的に少なくする

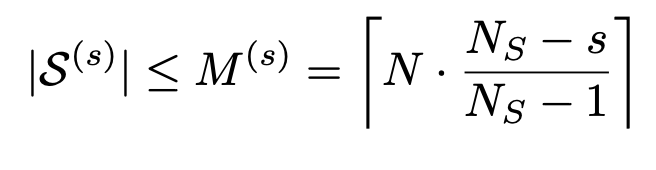
実験
実験設定
- ベンチマークは と の2種類
- ALFWorld: 家庭内作業を模したテキスト環境で、探索、取得、洗浄、加熱、冷却などの multi-step 行動計画を必要とする。
- Search-QA: 検索エンジンを使いながら答えを導く QA タスクであり、単一ホップだけでなく multi-hop reasoning も含む。
- backbone は Qwen2.5-VL 3B / 7B を使用する。
- 比較対象は zero-shot、few-shot、GRPO、AgentOCR、EvolveR、SkillRL などである。
- SkillBank は SkillRL のスキル群から初期化されている。
- 評価指標は主に success rate と、1 step あたり平均コンテキスト token cost である。
結果
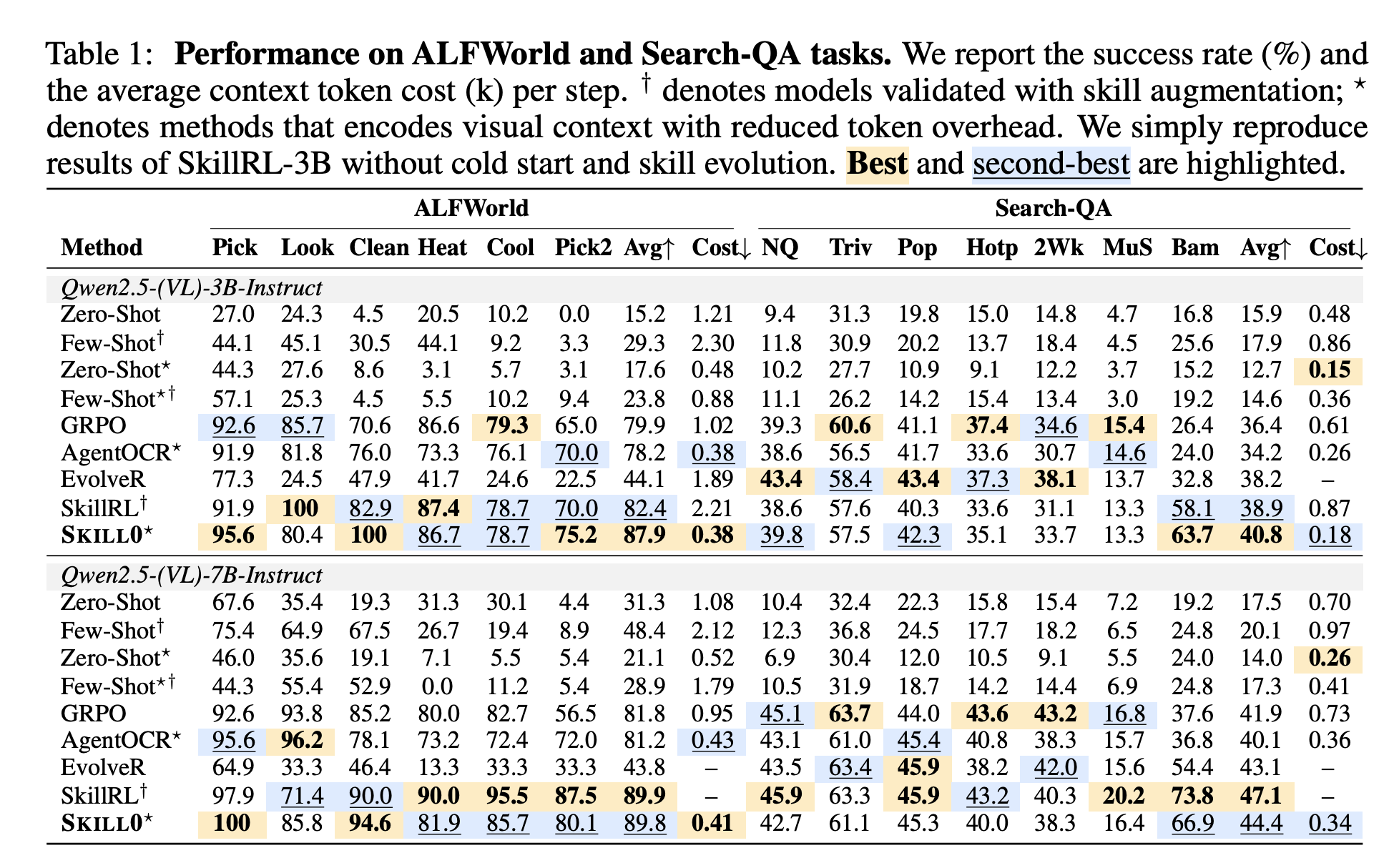
- 3B モデルでは、ALFWorld で平均 87.9、Search-QA で平均 40.8 を達成した。
- 3B では AgentOCR に対して、ALFWorld で +9.7、Search-QA で +6.6 の改善
- 7B モデルでは、ALFWorld で平均 89.8、Search-QA で平均 44.4 を達成した。
- 推論時に skill を使っていないにもかかわらず、SkillRL のような skill-augmented 法と同等以上の性能
- token cost は非常に低く、3B で ALFWorld 0.38k、Search-QA 0.18k token / step 程度に抑えられている。
学習ダイナミクス
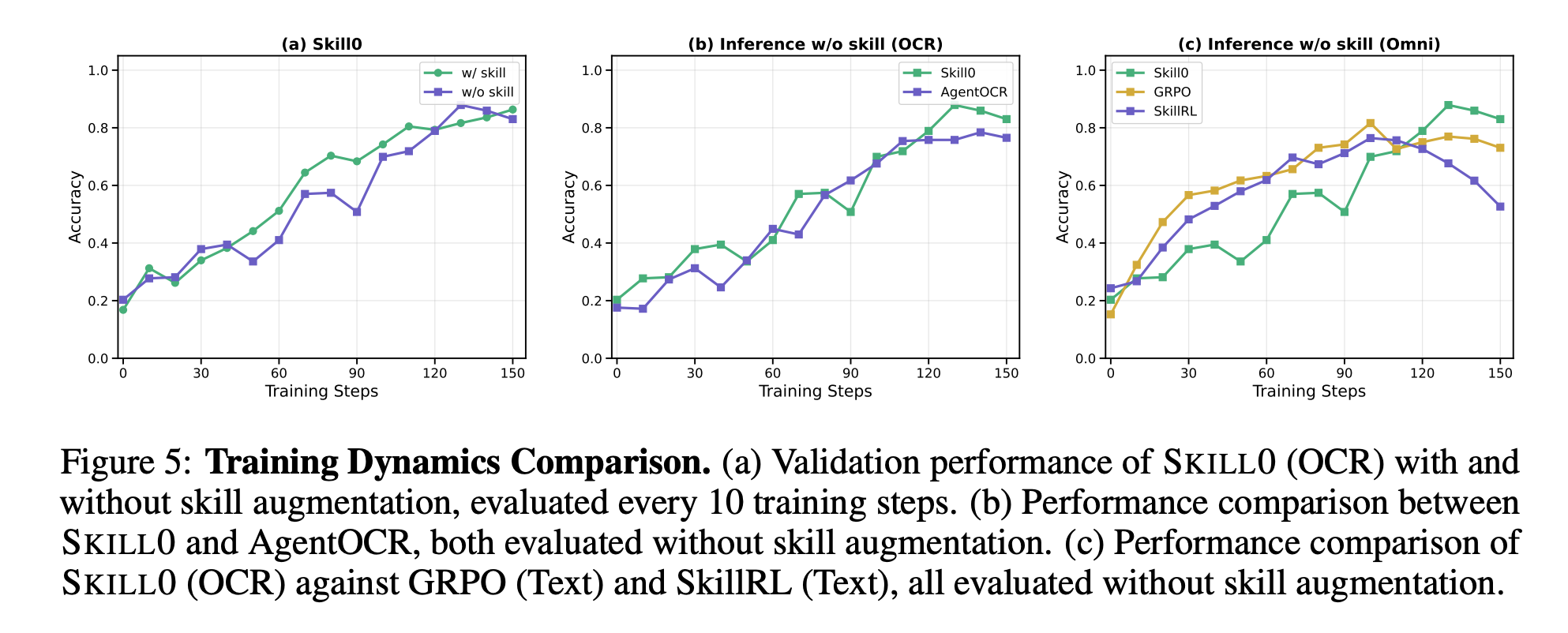
- 訓練初期は、skill あり評価の方が skill なし評価よりも早く性能が伸びる。
- これは skill が探索と初期学習の足場として機能していることを示している。
- 一方で、訓練後半になると skill なし評価が徐々に追いつき、最終的には高性能に到達する。
- skill が context から parameter に移った、すなわち internalization が起きた証拠として解釈
- GRPO や SkillRL は比較的早く頭打ちになる一方で、SKILL0 は後半まで性能改善が続く傾向
アブレーション
- skill budget を固定で多く保つ設定は、訓練中は高く見えても、推論時に skill を外した瞬間に大きく性能低下する。逆に、最初から少なすぎる skill budget は、初期探索を妨げ、学習を不安定にする。
- 論文の段階的 skill budget は、その中間で最も良いバランス
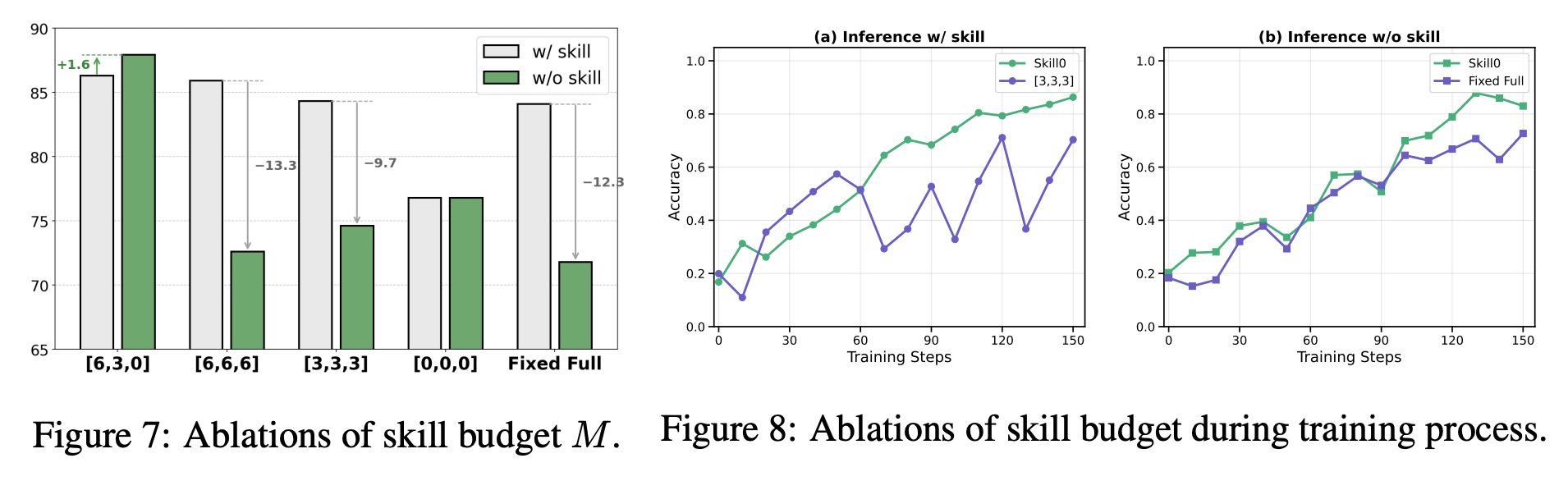
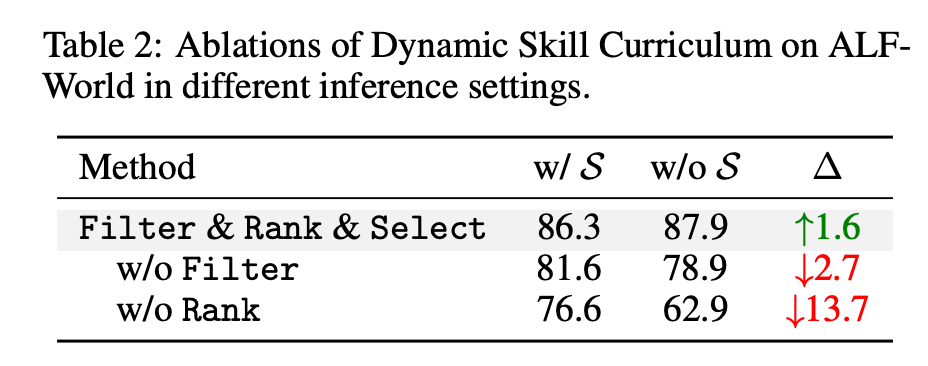
- w/o Filter では、役立つかどうかを見ずに予算内の skill を全部入れるため、著者は context noise が増えて性能が下がると説明している。
- w/o Rank では、残すべき skill の優先順位付けが崩れ、さらに大きな性能崩壊が起きる。
まとめ
- SKILL0 は、外部スキルを推論時に使い続けるのではなく、訓練中に学んで最後は不要にするという新しい agent 学習パラダイムを提案
- 内部化することでskillが混ざり合って悪くなるパターンはないか、なども見たかった