
2026-04-15 機械学習勉強会
今週のTOPIC[paper] Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks[paper] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis[White paper] Why OpenDataspaces: 設計思想とアーキテクチャパラダイムメインTOPICInterleaved Head Attention1. サマリー2. マルチヘッド・アテンション(MHA)の構造的ボトルネック2.1 ヘッドの孤立とクロスヘッド通信の欠如2.2 合成的推論における非効率性の実例3. Interleaved Head Attention (IHA) のアーキテクチャ的革新3.1 擬似ヘッド(Pseudo-heads)とQKVミキシング3.2 インターリーブ処理とRoPE互換性3.3 パラメータ効率の極大化4. 理論的証明:多段推論の代用タスクによる検証4.1 多項式グラフフィルタ(k ステップの証拠集約)4.2 CPM-3(Count Permutation Match-3)5. 実証的評価とパフォーマンス分析5.1 長文コンテキスト:RULERベンチマーク5.2 数学的推論(SFT後評価)5.3 性能向上の考察6. 結論と今後の展望6.1 本研究の総括6.2 制約と対策:スライディングウィンドウ・スケジュール6.3 今後の展望
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Shun Ito
[paper] Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
- 背景
- 長く動作するエージェントタスクの中で、特に推論時に並列に生成された複数の軌跡の統合に注目する
- agentic search, deep research, …
- 複数の結果をどのように統合するかが課題
- ヒューリスティックなもの: 多数決・Best-of-N
- LLMベース: 複数の軌跡を入力として、最終回答を再生成する
- それぞれの軌跡の中で、最終回答に必要な部分は一部分
- 必要な情報が分散しており、全ての軌跡をそのまま入力するとコンテキストが増える
- 提案: Agentic Aggregation
- いくつかのツールを用意し、Agenticに軌跡を統合し、最終回答を生成する
- : 指定した軌跡の最終回答を取得
- : trajectory内をキーワード検索
- : 指定範囲の完全なstep(thinking + tool + observation)を取得
- : 最終回答を出力
- 具体的な手順(Coarse-to-Fine)
- global survey
- get_solutionで軌跡ごとの最終回答を集め、概観を把握
- 候補の絞り込み
- surveyの結果(多数派な回答がある or それぞれがバラバラ or …)を元に、AggAgentがどの軌跡を深ぼるかを決める
- 軽量探索
- search_trajectoryを使い、固有名詞や引用文から答えの根拠となる情報を集める
- 精査
- get_segmentで、searchで見つけた箇所を精読、ツール出力の正しさを検証 & 推論ミスがあれば特定
- cross-trajectory reasoning・意思決定
- 集められた正しそうな情報を元に、それらをどのように組み合わせるか推論・決定する
- 最終出力
- finishで最終回答を生成

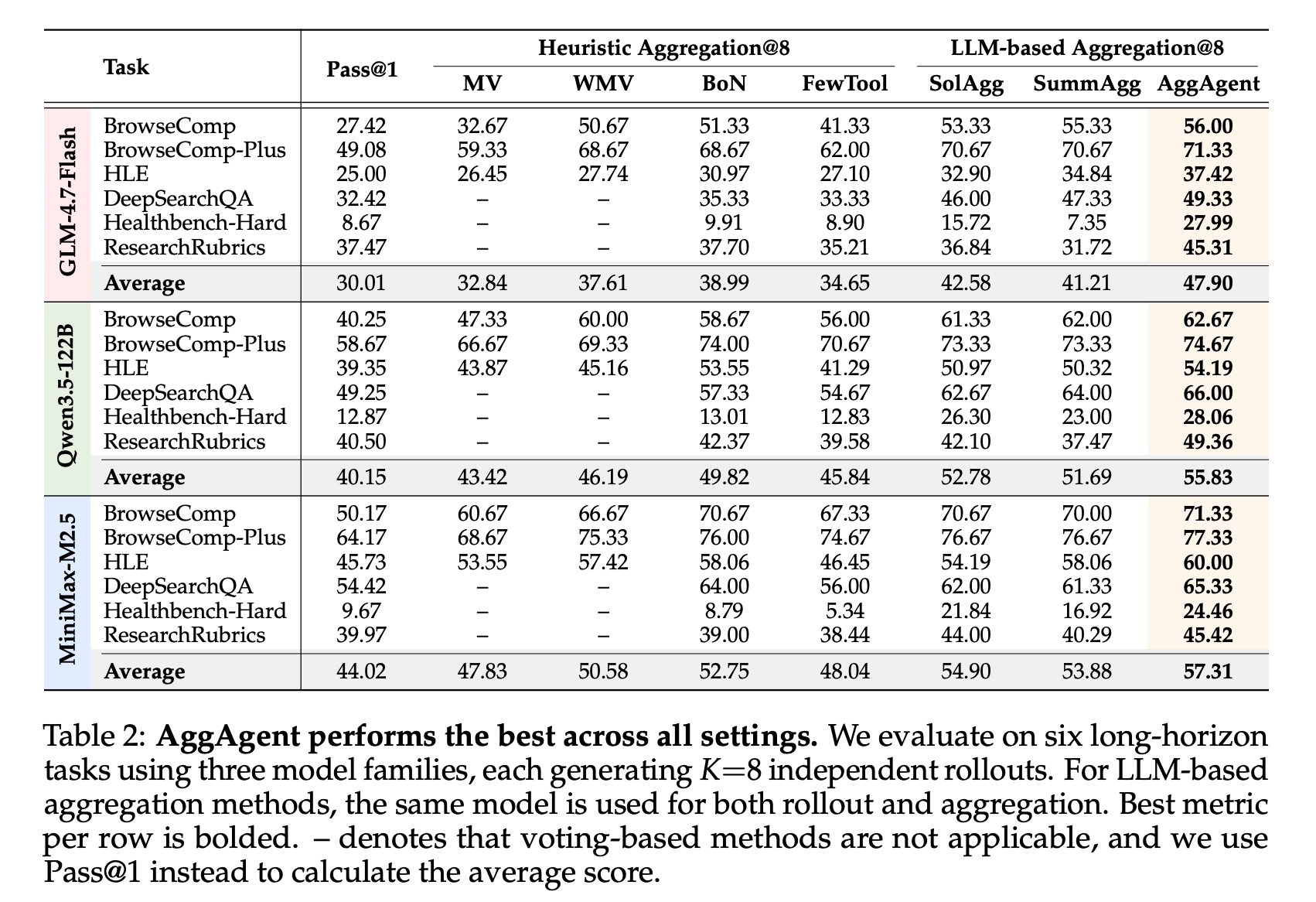
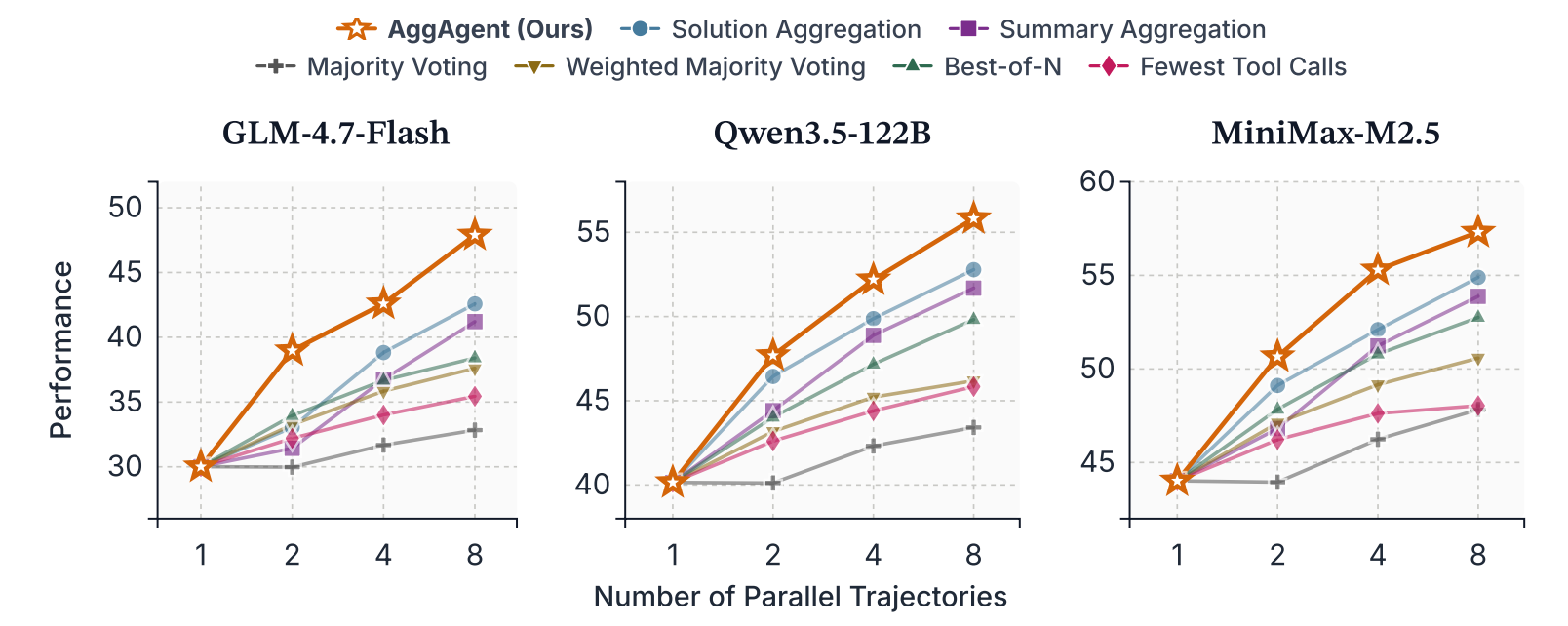
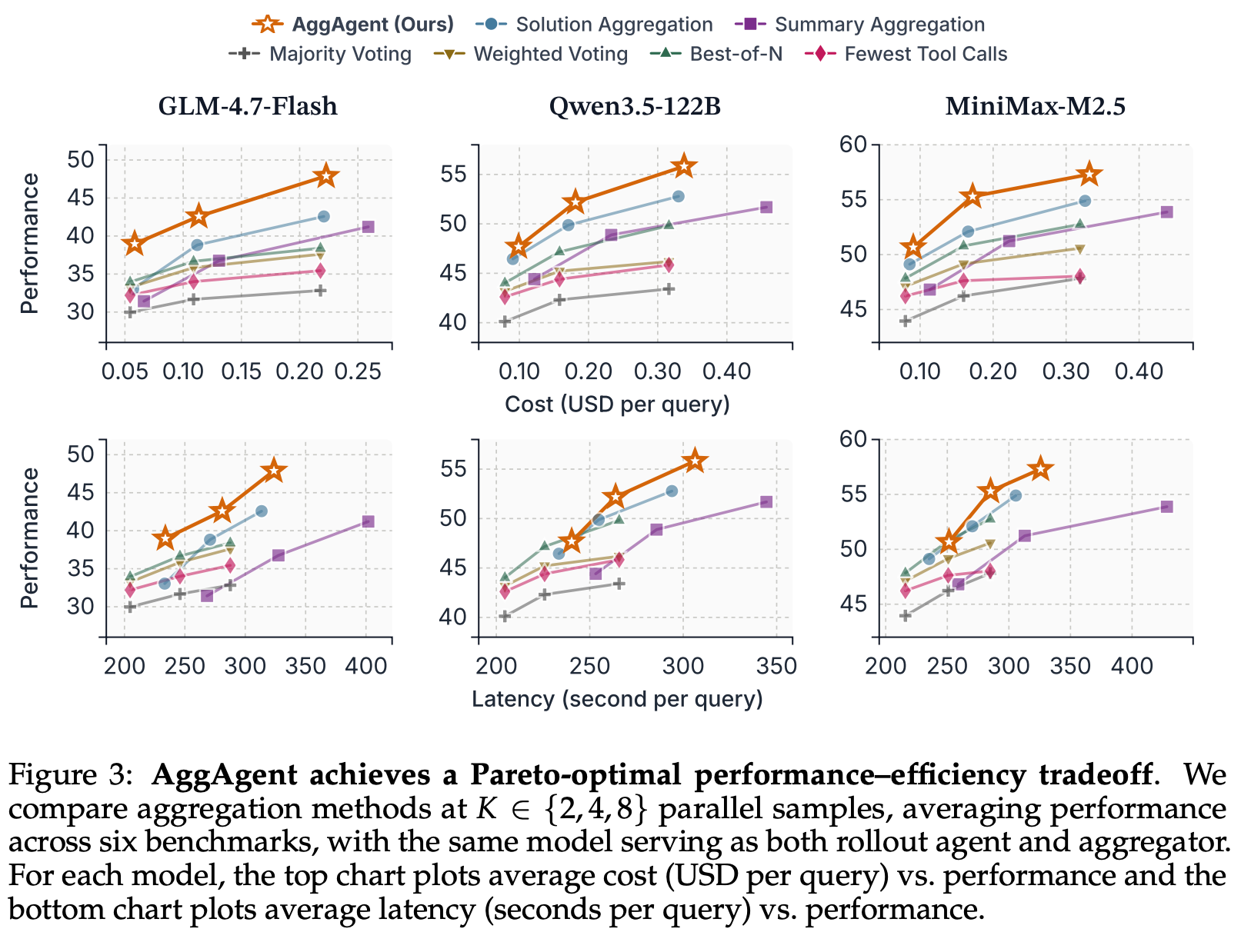
- 実験結果
- 6つのロングタスク・3つのモデル(30B、122B、229B)で検証
- 提案の統合手法が一貫して良い結果
- コスパも良い
@Hiromu Nakamura (pon)
[paper] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis
長期間にわたるDeepReseaarchの軌跡をスケーラブル、低コスト、再現可能、かつ分析に有用な形で合成するための、完全にオープンなパイプラインを提案
研究の背景と課題
- DeepResearchのトレーニングには、複雑な現実世界のブラウジング行動を反映した高品質な長期間軌跡が不可欠。
- 既存のデータ収集パイプラインは、主にプロプライエタリなWeb API(例:Google Search)に依存しており、大規模な軌跡合成が高価で、不安定であり、再現性が低いという課題があった。
- ライブWeb環境では、関連する証拠がいつ表面化し、開かれ、見逃されたかを正確に分析することが困難。
提案手法
OPENRESEARCHERは、これらの課題を解決するために2つの主要なアイデアを中心に構築されています。
コーパス構築と軌跡生成の分離:
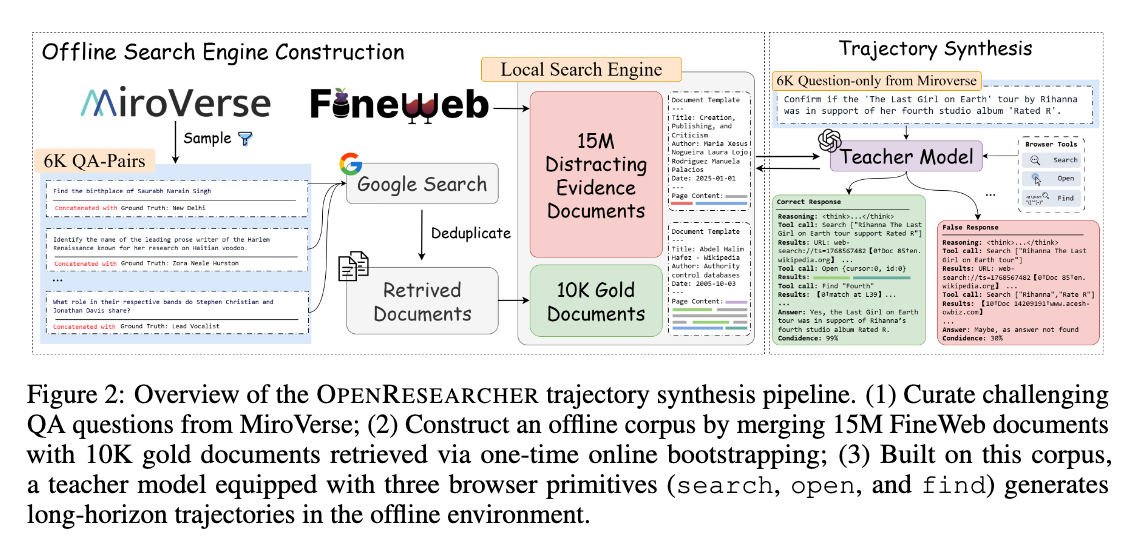
- QA質問収集: まず、MiroVerse-v0.1から、浅い検索では解決できない長期間の多段階推論を要する質問を厳選します。本手法では、約6Kの質問-回答ペアをランダムにサンプリングし、回答を簡潔で検証可能な形式に正規化します。
- オフライン検索エンジンの構築: 軌跡の再現性を確保するために、関連する証拠が常に検索可能である必要があります。このため、質問と参照回答を連結した検索クエリを用いてSerper API経由でWebコンテンツを検索し、クリーニングと重複排除を経て10Kのゴールドドキュメントを抽出します。
- コーパスの統合: このゴールドドキュメントを、リアルワールドのWebカバレッジと検索の複雑さを近似するために収集された1500万件のFineWebドキュメントとマージして、オフラインコーパスを構築します。FineWebドキュメントはディストラクタ(妨害情報)として機能し、ゴールドドキュメントは回答をサポートする証拠を提供します。
- コーパスのインデックス化: 効率的な大規模な密な検索のために、各ドキュメントはQwen3-Embedding-8Bを用いて埋め込まれ、FAISSでインデックス化されます。これにより、エージェントが自然言語クエリを発行すると、リトリーバーがランク付けされたドキュメントを返すことでWeb検索APIをシミュレートします。
明示的なブラウザプリミティブによるブラウジングのモデル化:
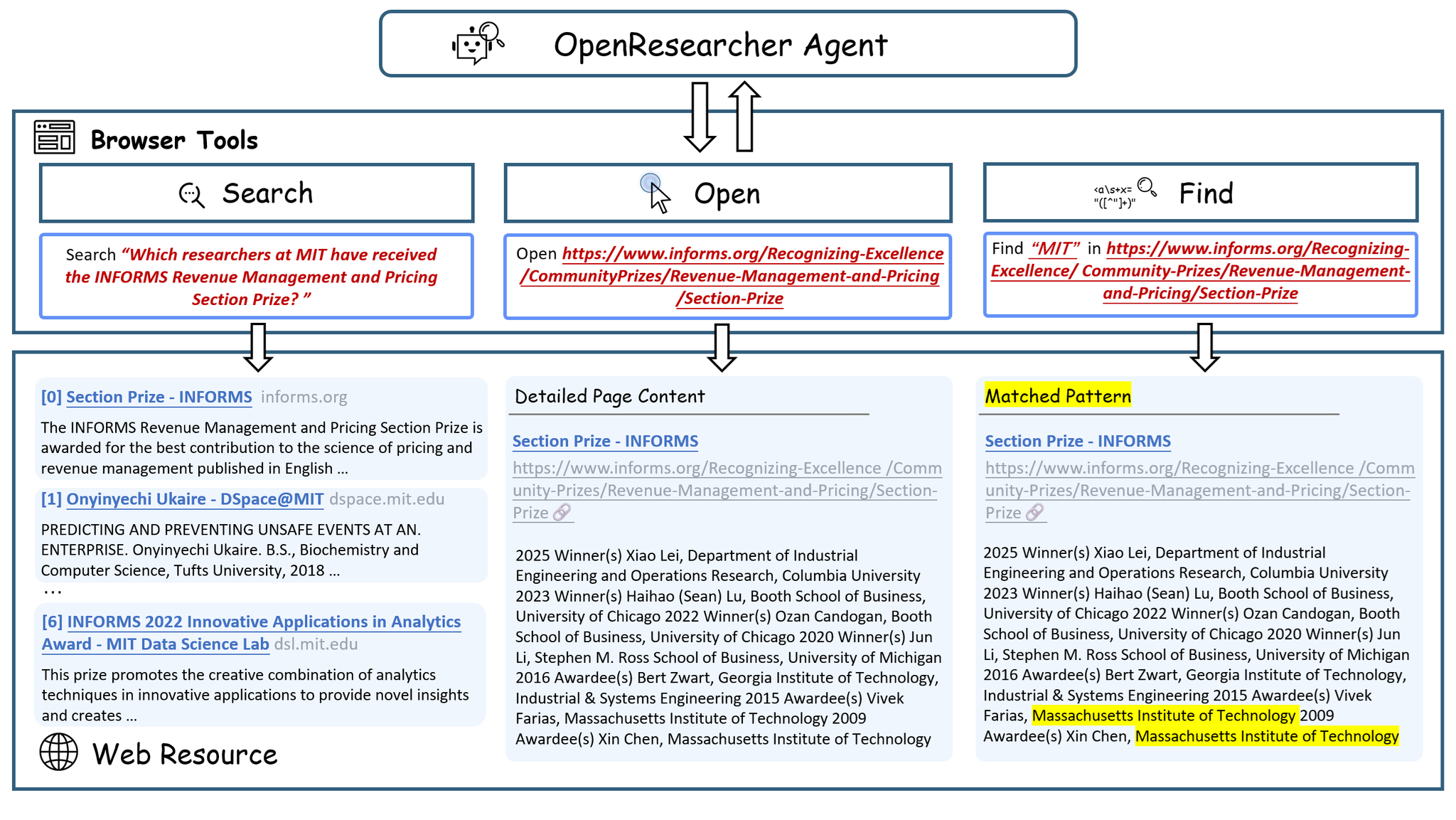
人間がWebリサーチを行う際の行動を反映するために、以下の3つの最小限のブラウザプリミティブをエージェントに公開します。これらはそれぞれ対応するツールとして実装されます。
- search: 与えられたクエリに対して、上位K件の結果(タイトル、URL、スニペットを含む)を返します。広範な情報検索を可能にし、候補ソースを特定します。
- open: URLからドキュメントの全文を取得します。これは、検索スニペットを超えてWebページを詳細に検査する人間の行動を模倣します。
- find: 現在開いているドキュメント内で指定された文字列の正確な一致を特定します。これは、固有名詞の検索、事実検証、中間仮説の具体的なテキスト証拠への接地にとって不可欠です。
これらのツールは、エージェントの焦点をコーパス全体からドキュメントへ、そして最終的に証拠へと段階的に絞り込み、多尺度での情報発見を可能にします。
軌跡生成プロセス:
オフラインコーパスとブラウザツールが整った上で、教師モデル(GPT-OSS-120B)をプロンプトし、以下の制約のもとで軌跡を合成します。
- 提供されたツール(search, open, find)のみを使用する。
- 各ツールコール前にステップバイステップで推論する。
- 最終回答に確信が持てるまでのみ終了する。
- 教師モデルは生成中に参照回答にアクセスできず、多段階の検索と推論を通じて回答を導き出す必要があります。
- 合成された軌跡は、最大コンテキスト長超過、不正なツールコール、または対話予算内での結論に至らない軌跡に対して軽量なフィルタリングが施されます。これにより、97K以上の軌跡(100以上のツールコールを要する長期間のケースも多数含む)が生成されます。
実験
- 合成された軌跡の有効性を検証するため、NVIDIA-Nemotron-3-Nano-30B-A3B-Base-BF16をベースモデルとして教師ありファインチューニング。
- 訓練データは、正解の最終回答を導き出した軌跡のみを保持するリジェクションサンプリングによりキュレーションされ、約55Kの軌跡が使用されます。
- 訓練はMegatron-LM分散訓練フレームワークを用いて8台のNVIDIA H100 GPUで約8時間行われます。長期間の軌跡に対応するため、シーケンスは最大256Kトークンにプリパックされ、完全な推論チェーンが保持されます。
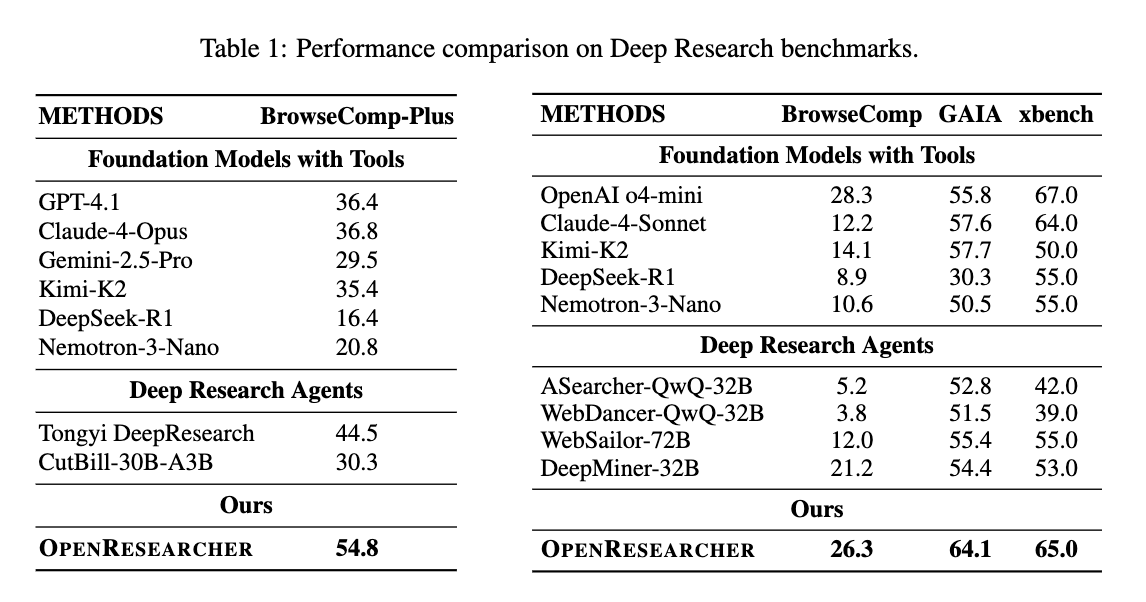
- BrowseComp-Plus
- OPENRESEARCHER-30B-A3Bは54.8%の精度を達成し、GPT-4.1 (36.4%)やClaude-4-Opus (36.8%)などの強力なプロプライエタリベースラインを大幅に上回りました。これは、ベースモデル(Nemotron-3-Nano-30B-A3B)に対する+34.0ポイントの絶対的改善を示しています。
- BrowseComp, GAIA, xbench-DeepSearch
- ライブWeb検索APIに依存するこれらのベンチマークでも、それぞれ26.3%、64.1%、65.0%の精度を達成し、主要なフロンティアモデルと競争力を維持しつつ、既存のオープンソース深層研究システムを大幅に上回りました。これは、オフライン環境で合成された高品質な軌跡が、動的な実世界検索環境にも効果的に汎化することを示唆しています。
@ShibuiYusuke
[White paper] Why OpenDataspaces: 設計思想とアーキテクチャパラダイム
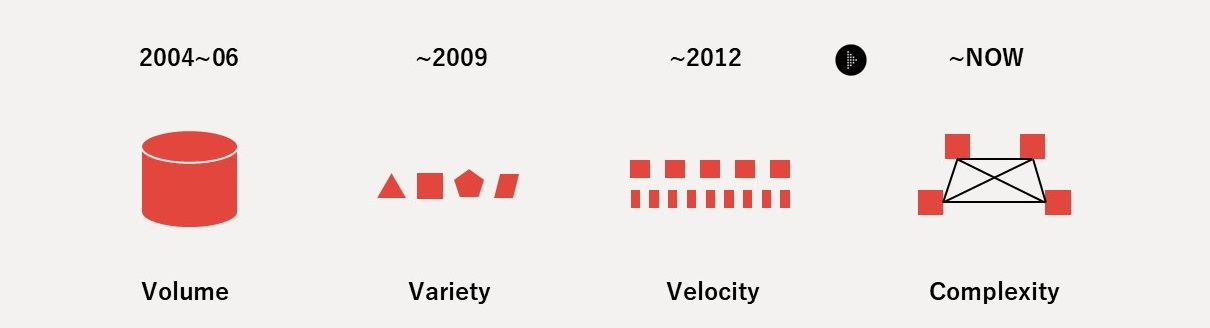
1. データの価値は「意味(コンテクスト)」にある
データそのものではなく、データに付与されるドメイン固有の文脈(コンテクスト)こそが価値の源泉。世界に約16ZBのダークデータが眠っていても、意味が付与されなければ活用できない。
「組織のシステム改修の多くは、データが変わったのではなく、データの意味が変わったことに起因している」
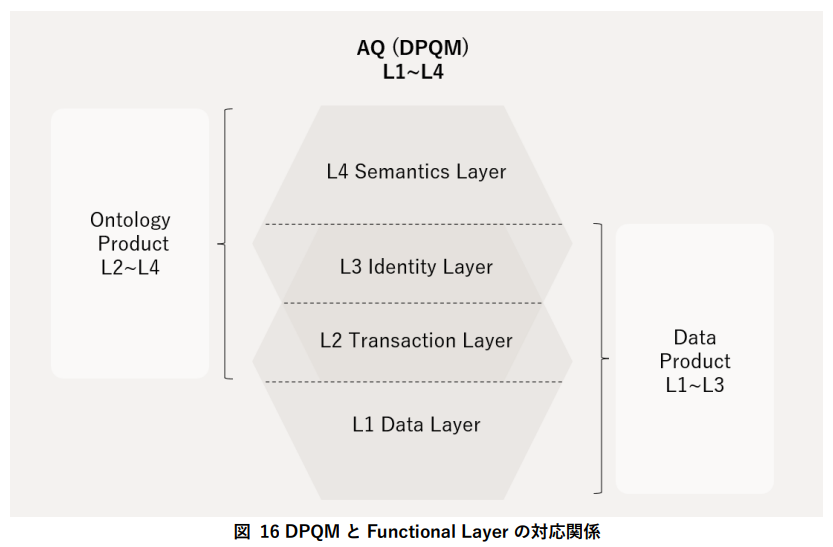
意味をデータ構造から分離して独立に管理→Data ProductとOntology Productを一対とするDouble Product Quanta Model。
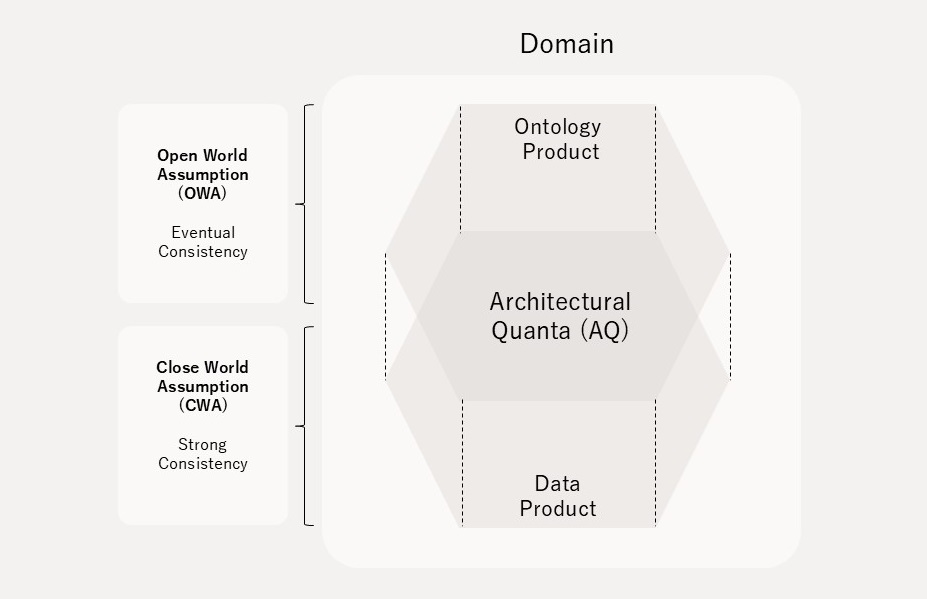
2. 開放性と厳格性は両立できる
従来の中央集権型は厳格だが閉鎖的、分散型は開放的だが品質保証が困難、というトレードオフ。OWA(開世界仮説)で多様性を包摂しつつ、CWA(閉世界仮説)で必要な箇所だけ厳格にする二層構造によってこの矛盾を解消。
Ontology Queryでは不完全な結果も排除せず、Data Queryで厳格な検証を行う。
「発見の段階では開放的に、利用の段階では厳格に」
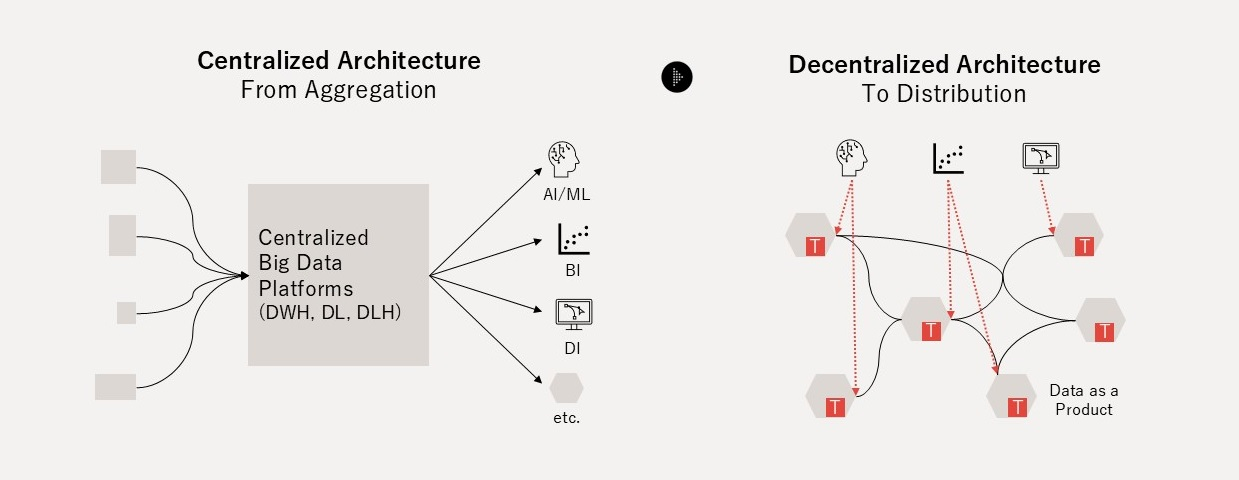
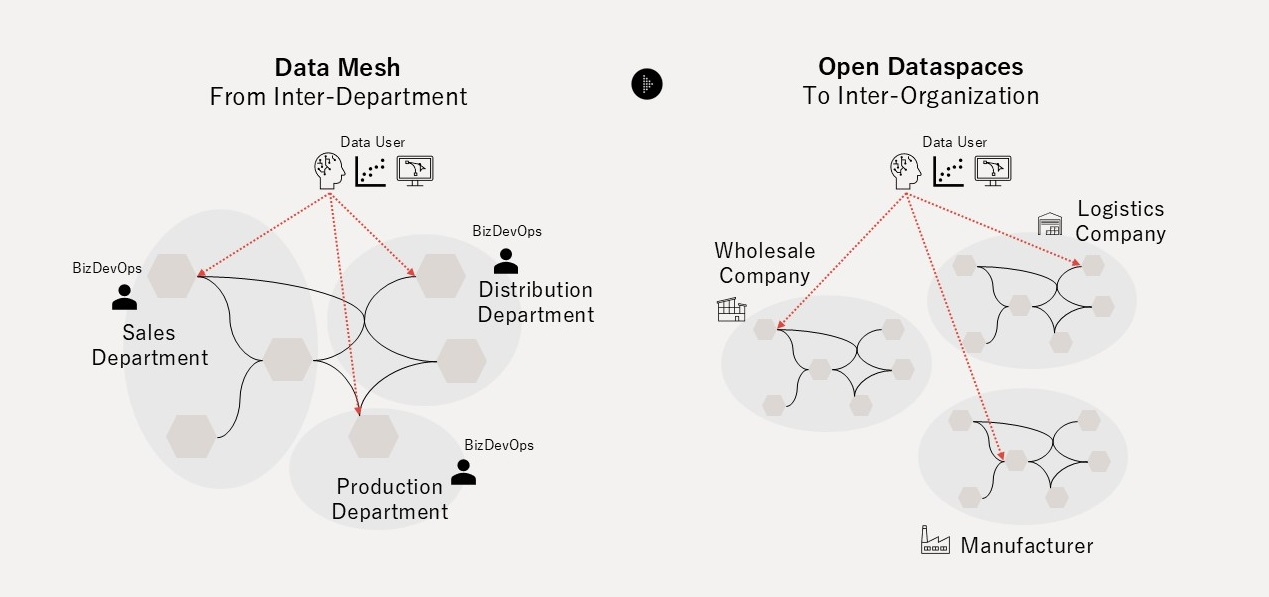
Open Dataspaces の3本の柱
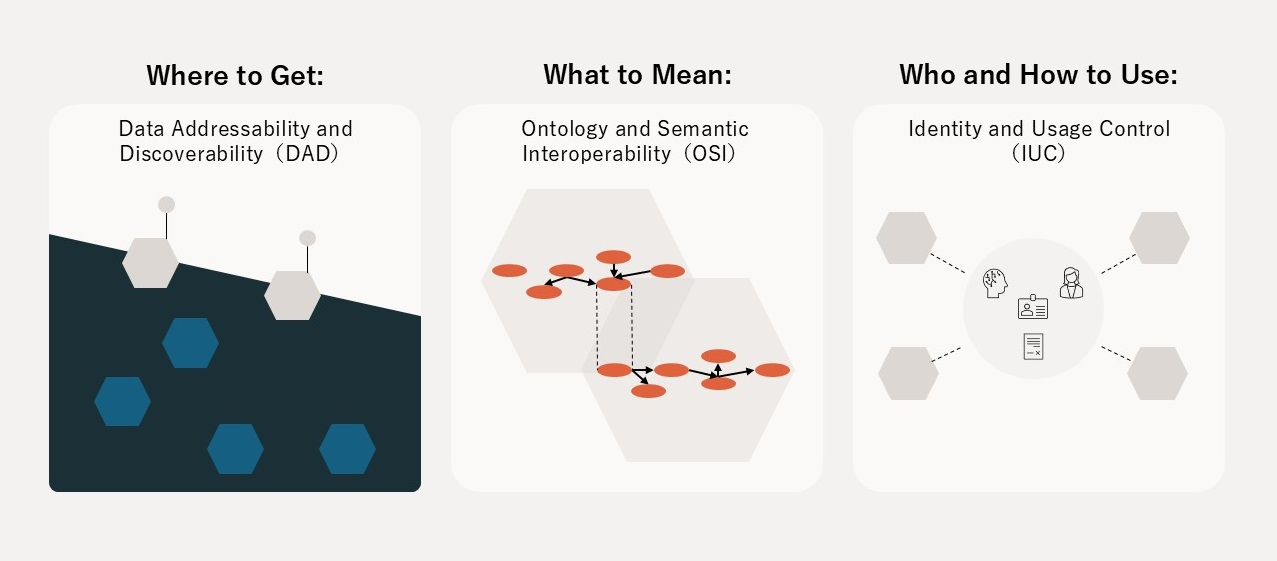
柱1:OSI(Ontology and Semantic Interoperability)
解決する問い: What to mean — それは何を意味するのか?
データモデル(事実の記録)と情報モデル(意味の管理)を分離し、「意味が変わってもデータ構造は壊れない」設計を実現する。
要点:
- DPQM(Double-Product Quanta Model):Data Productが事実を、Ontology Productが意味をそれぞれ独立に管理する。
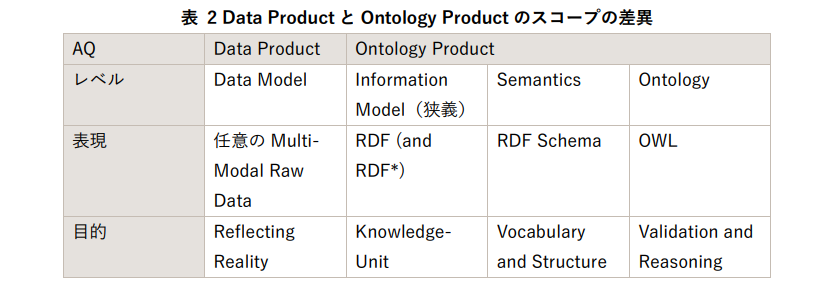
- ドメイン間の用語の食い違い(Semantic Gap)は、OWLによる論理的制約で「バグ」ではなく「論理エラー」として検出可能にする。
- Ontology同士のギャップ(Ontological Gap)は、LLMが仮説を生成しOWL推論器が検証するDynamic Ontologyで運用中に漸進的に縮小する。
- AIに与えるコンテクストはグラフで表現されるべき(Graph is Context)。テキスト注入による「推測」から、構造化された知識による「推論」へ転換する。
- 技術基盤はRDF(Resource Description Framework)/RDFS(RDF Schema)/OWL。Ontologyは完成品ではなく、運用の中で育てるリビングドキュメント。
柱2:DAD(Data Addressability & Discoverability)
解決する問い: Where to get — それはどこにあるのか?
分散したデータの「存在」を証明し、「同一性」を識別し、「発見」を可能にするインフラを提供する。
要点:
- 各ドメインはOntology Endpoint(意味の接点)とData Endpoint(データの接点)の2つを外部に公開する。
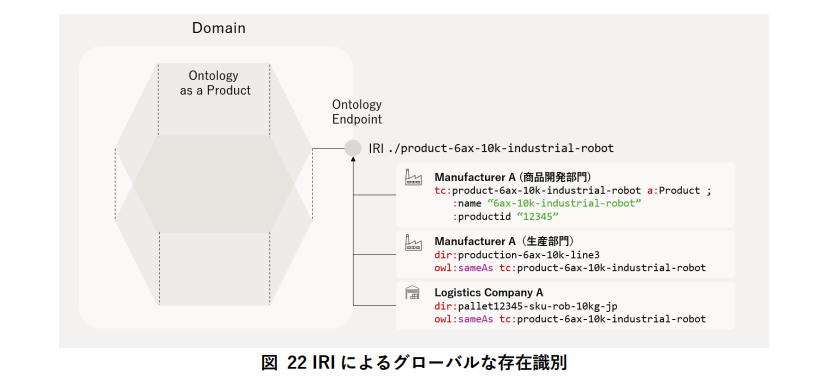
- 組織間で識別子が異なる問題は、IRI(International Resource Identifier)を採用し、内部識別子を温存したまま後付けで同一性を合意する。統一識別子の強制はしない。
- データ取得は二段階クエリで行う。第一段階のOntology QueryはOWAでBest Effort Resultを返し、第二段階のData Queryで必要に応じてCWA的な厳格性を適用する。
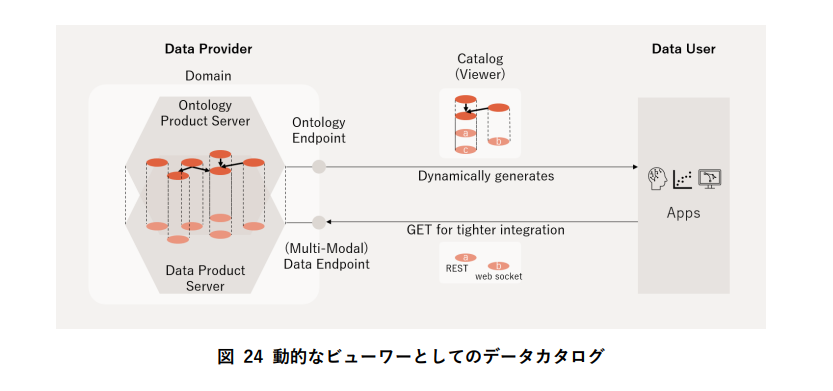
- データカタログは静的リポジトリではなく、クエリごとに動的生成されるビューワー。Web検索エンジン型のクローリング+インデキシングによる分散カタログで効率化する。
柱3:IUC(Identity and Usage Control)
解決する問い: Who and How to use — 誰が、どう使えるのか?
信頼を暗黙の前提ではなく設計対象として扱い(Trust by Design)、アクセス制御と利用制御の両方を分散環境で実現する。
要点:
- アイデンティティを「実在性の検証」「認証」「認可」の3要素に分解する。「認証できた=信頼してよい」とは同一視しない。
- 信頼の根拠(法人登録、契約、NDA等)を明示的に扱うが、単一の信頼基盤は強制しない。国・法域ごとの制度差を吸収する設計(制度的ロックインの回避)。
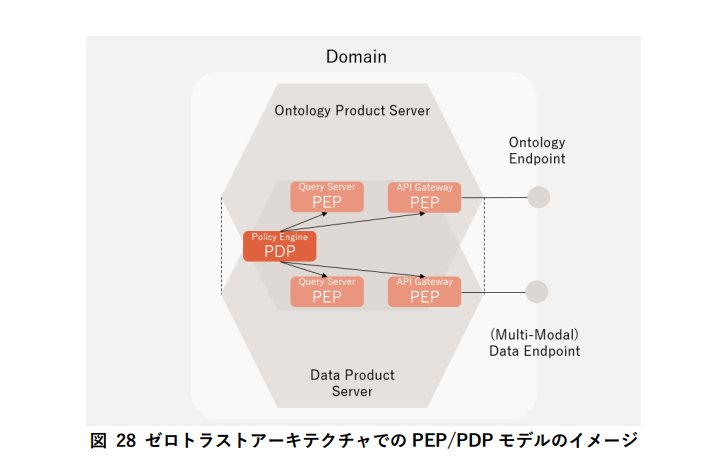
- アクセス制御はゼロトラスト前提のPEP/PDPモデルを採用。ReBAC(関係性ベースのアクセス制御)とOntologyのグラフを組み合わせたGraph-to-Graph Controlにより、主体と資源の関係を「推測」ではなく「推論」で判断する。人間にもAgentic AIにも同じ仕組みで適用可能。
- 利用制御は、データ提供者と利用者の権利義務・価格決定権の非対称性を補正するために導入。技術的手段(秘密計算、差分プライバシー、Machine Unlearning等)を制限せず、インターフェースのみ提供して多様な方式を許容する。
3本の柱の関係
3つの柱は独立して機能するのではなく、相互に連動して初めてOpen Dataspacesの全体機能が成立する。
| 柱 | なければどうなるか |
|---|---|
| OSI がない | データは見つかるが、意味が分からない |
| DAD がない | 意味は定義されているが、データにたどり着けない |
| IUC がない | データは見つかり意味も分かるが、誰がどう使えるか制御できない |
メインTOPIC
Interleaved Head Attention
Sai Surya Duvvuri, Chanakya Ekbote, Rachit Bansal, Rishabh Tiwari, Devvrit Khatri, David Brandfonbrener, Paul Liang, Inderjit Dhillon, Manzil Zahee
Meta社の論文。従来の Multi-Head Attention の制約を緩和することで多段推論に強くなる Interleaved Head Attention の提案。
1. サマリー
従来の Multi-Head Attention(MHA) の制約を緩和することで多段推論に強くなる Interleaved Head Attention(IHA) の提案。従来のMHAは、各ヘッドが独立して動作するため、複雑な合成的推論(複数の推論を掛け合わせる必要のある推論)において表現力がヘッド数に対して線形にしか向上しないという構造的ボトルネックを抱えていました。
IHAは、クロスヘッド・ミキシングによりこの制約を解消し、以下の実証的成果を達成した。
- 推論能力の飛躍的向上: 2.4Bパラメータモデルを用いた実験において、数学的推論(GSM8K)で+5.8%、高度な数学問題(MATH-500)で+2.8%の精度向上(Maj@16)を達成。
- 長文コンテキストにおける圧倒的優位性: RULERベンチマークのMulti-Key Retrievalにおいて、4kで+27%、8kで+32%、そして16kでは+112%という劇的な精度改善を記録。
- 理論的な計算効率: 多段推論の代理タスク(CPM-3)において、MHAの計算コスト に対し、IHAはで同等の表現力を実現。
- 戦略的互換性: 既存のFlashAttentionやRoPE(Rotary Positional Embedding)と完全な互換性を維持しつつ、追加パラメータを最小限()に抑制。
IHAは、計算予算を維持したままモデルの「論理的深さ」を拡張する、次世代LLMアーキテクチャの標準コンポーネントとなり得る技術であると主張されている。
2. マルチヘッド・アテンション(MHA)の構造的ボトルネック
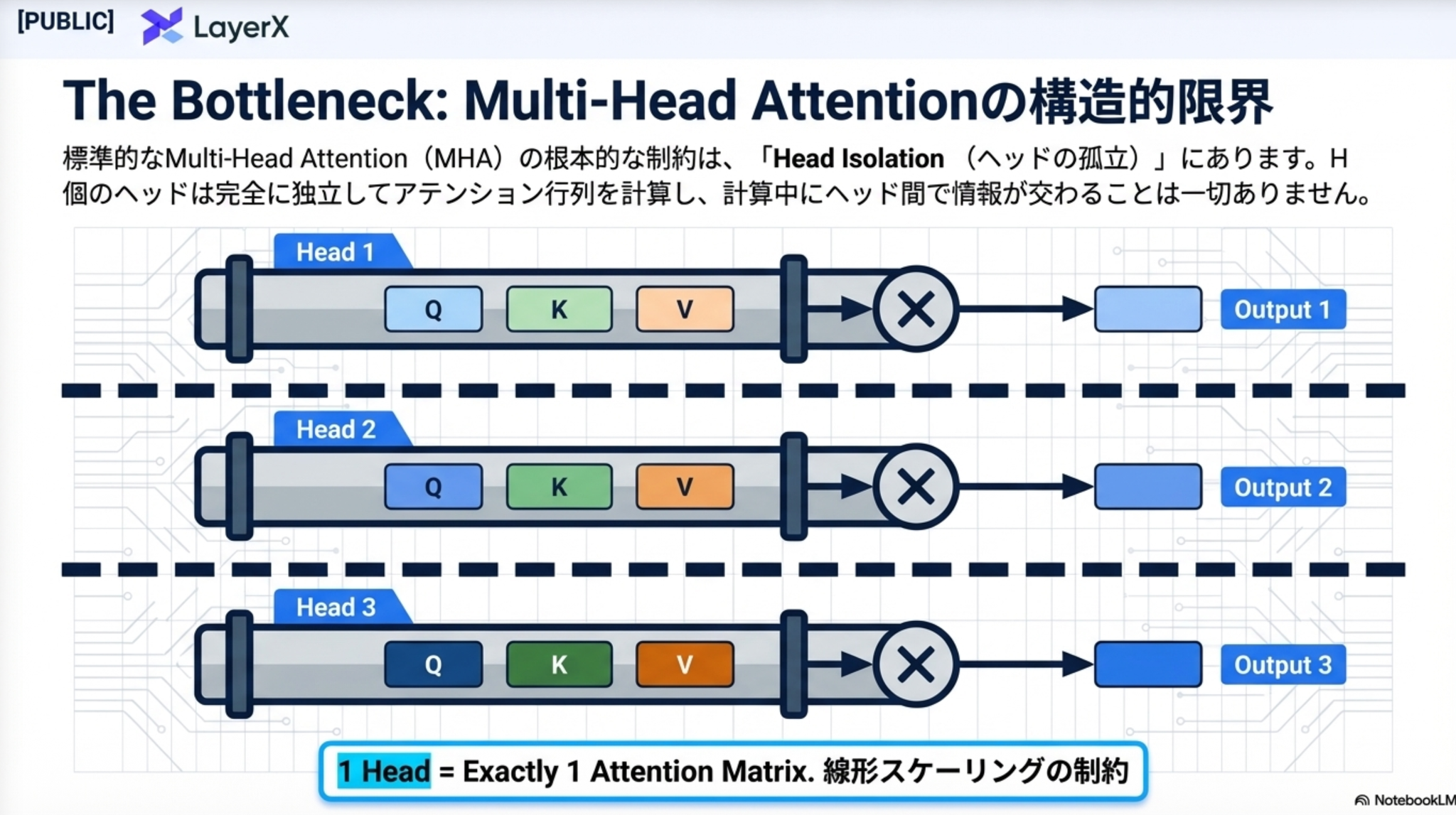
現在のトランスフォーマーモデルの中核をなすMHAは、効率的な並列計算を可能にしますが、多段階の推論結果を集約を必要とするタスクにおいては「ヘッドの孤立」と「線形スケーリング」という構造的欠陥が顕在化する。
2.1 ヘッドの孤立とクロスヘッド通信の欠如
MHAでは、各ヘッドが個別にクエリ(Q)、キー(K)、バリュー(V)を計算し、アテンション行列を生成する。各ヘッドは独立したサブスペースで動作するため、計算過程で他のヘッドからの情報が統合されることがない。この孤立は、複数のトークン間関係を組み合わせて一つの結論を導き出す「合成的推論」を難しくする。
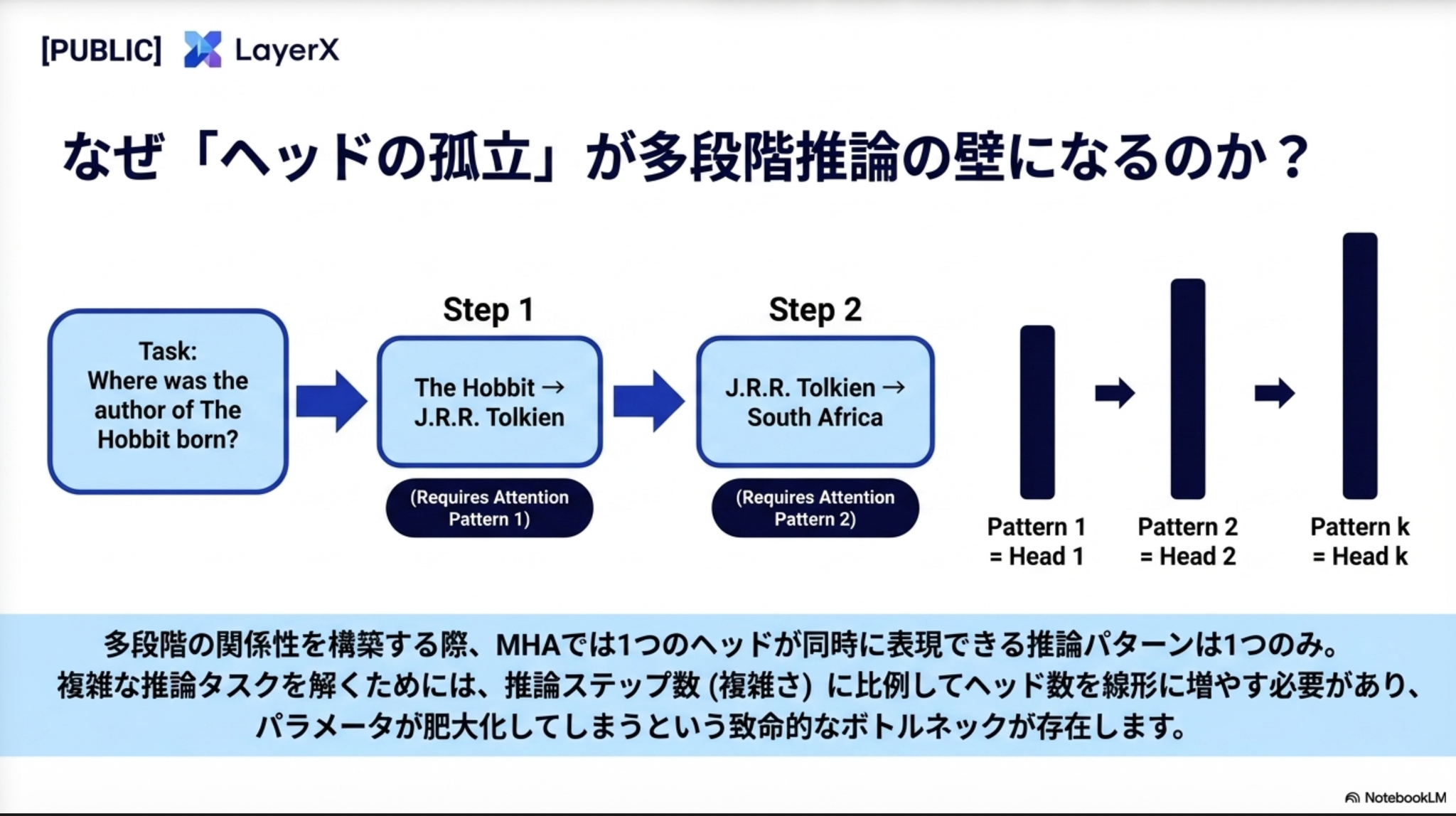
2.2 合成的推論における非効率性の実例
たとえば「『ホビットの冒険』の著者はどこで生まれたか?」という問いに答えるには、「ホビット → トールキン」という事実と、「トールキン → 南アフリカ生まれ」という事実を組み合わせて連鎖させる必要がある。
ひとつのヘッドが同時に表現できる推論パターンが1つのみであれば、複数の推論を組み合わせるためにはそれだけのヘッド数や層数が必要である。
3. Interleaved Head Attention (IHA) のアーキテクチャ的革新
IHAは、標準的なアテンション演算の枠組みを維持しつつ、アテンション計算「前」の段階で情報を混合することで、二次的な表現力を獲得する。
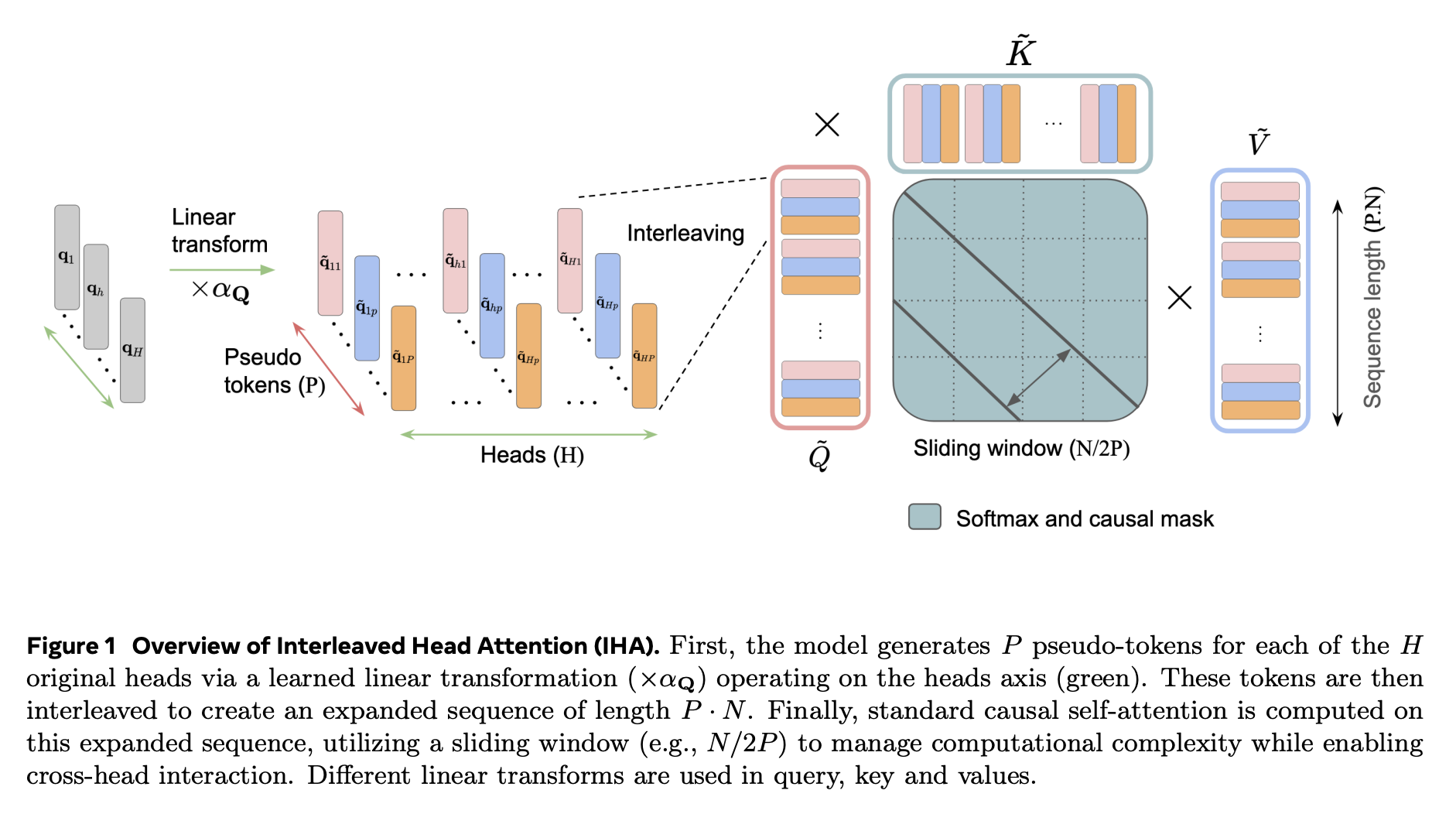
3.1 擬似ヘッド(Pseudo-heads)とQKVミキシング
IHAの核心は、学習可能な線形結合によって生成される「擬似ヘッド(Pseudo-heads)」にある。従来のTalking Heads等がアテンションのロジットや重みを混合するのに対し、IHAはアテンション演算子に入力される前の Q, K, V そのものを混合する。具体的には、元の H 個のヘッドから、ヘッドあたり P 個(通常 P=H)の擬似ヘッドを生成する。このクロスヘッド・ミキシングにより、単一のヘッドが 個のアテンションパターンを誘発可能となる。
3.2 インターリーブ処理とRoPE互換性
生成された擬似ヘッドはシーケンス次元に「インターリーブ(交互配置)」され、仮想的なシーケンス長を に拡張する。この設計の戦略的メリットは、RoPE(Rotary Positional Embedding)との整合性にある。各擬似ヘッドトークンに固有の仮想的な位置インデックスを割り当てることで、個別のRoPEフェーズ(位相)を維持でき、特殊なカーネルを要さずFlashAttention等の標準演算子をそのまま利用可能である。
3.3 パラメータ効率の極大化
IHAが導入するオーバーヘッドは、モデル次元 に対して極めて小さいヘッド数 H と擬似ヘッド数 P に依存する パラメータに限定される。これは、最小限のパラメータコストで「線形」から「二次的」な表現力への飛躍を実現することを意味する。
4. 理論的証明:多段推論の代用タスクによる検証
IHAの優位性は、多段推論の特性を抽象化した2つの理論的タスクにおいて数学的に証明されている。
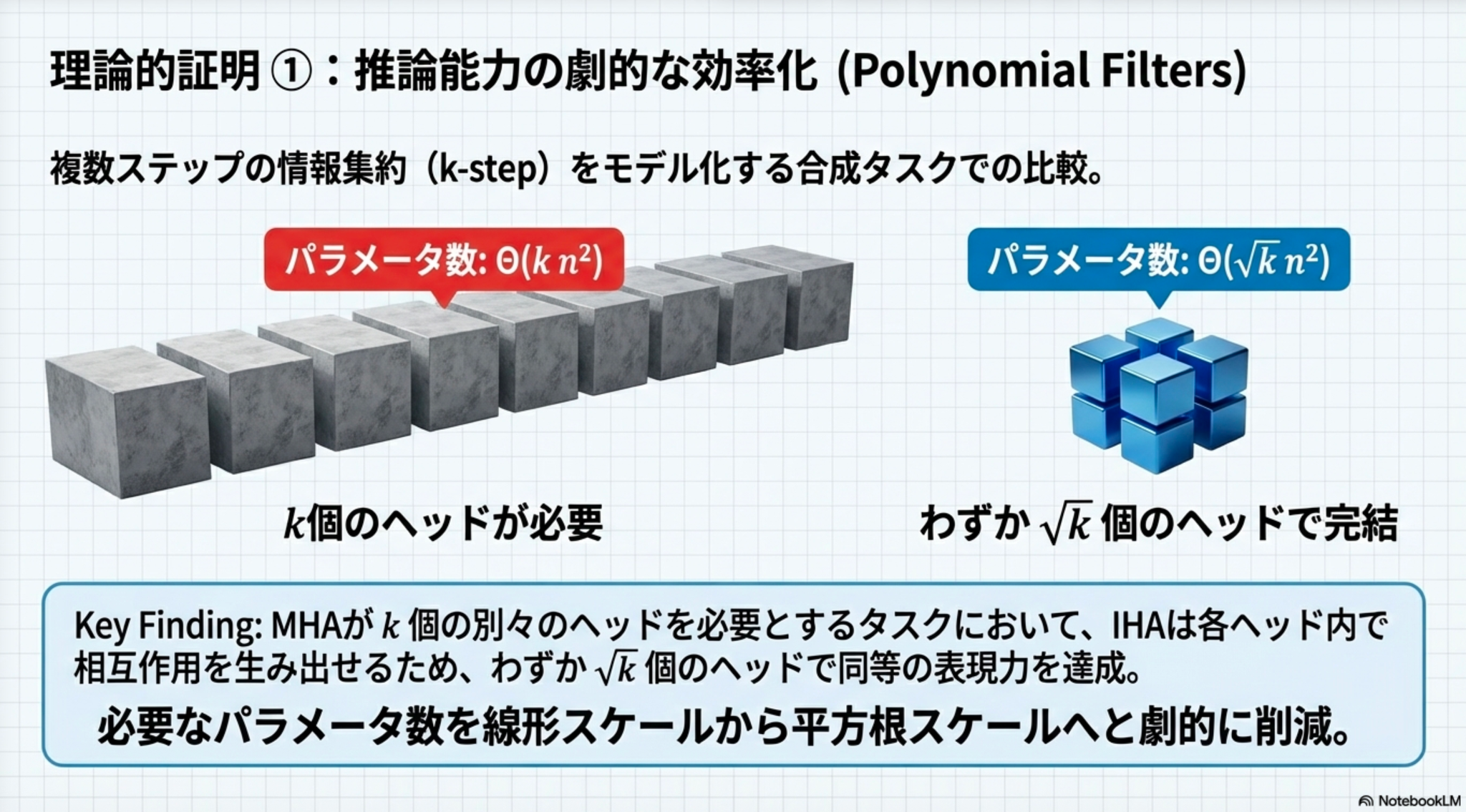
4.1 多項式グラフフィルタ(k ステップの証拠集約)
グラフ上の情報を k ステップ先まで集約するタスクにおいて、MHAとIHAのパラメータ効率を比較した結果、以下の差が証明された。
- MHA: k ステップの依存関係を表現するためにパラメータを要求。
- IHA: わずか パラメータで同等の表現力を達成。 この への効率化は、IHAが H 個のクエリ行列と H 個のキー行列のペアワイズな相互作用(パターン)を利用して、関係性を因数分解(Factorization)できることに起因する。
4.2 CPM-3(Count Permutation Match-3)
順序に敏感な合成とカウントを行う CPM-3 タスクでは、必要なヘッド数と計算コストにおいて優位性が示された。
- ヘッド数: MHAが 個のヘッドを必要とするのに対し、IHAは 個で対応可能。
- 計算コスト: MHAの ) に対し、IHAは ) に改善。
これらの理論的結果は、現実世界の複雑なコードデバッグや長大なコンテキストを伴う法的文書分析において、IHAが劇的なパラメータ効率と計算リソースの節約をもたらすことを示唆する。理論的な裏付けは、実際の大規模言語モデルのトレーニングにおいて驚異的な成果として結実している。

5. 実証的評価とパフォーマンス分析
2.4Bパラメータモデルを用いた「FLOP-Matched(計算予算一定)」の条件下での実験は、IHAが単なる理論上の提案ではなく、実践的なブレークスルーであることを証明した。
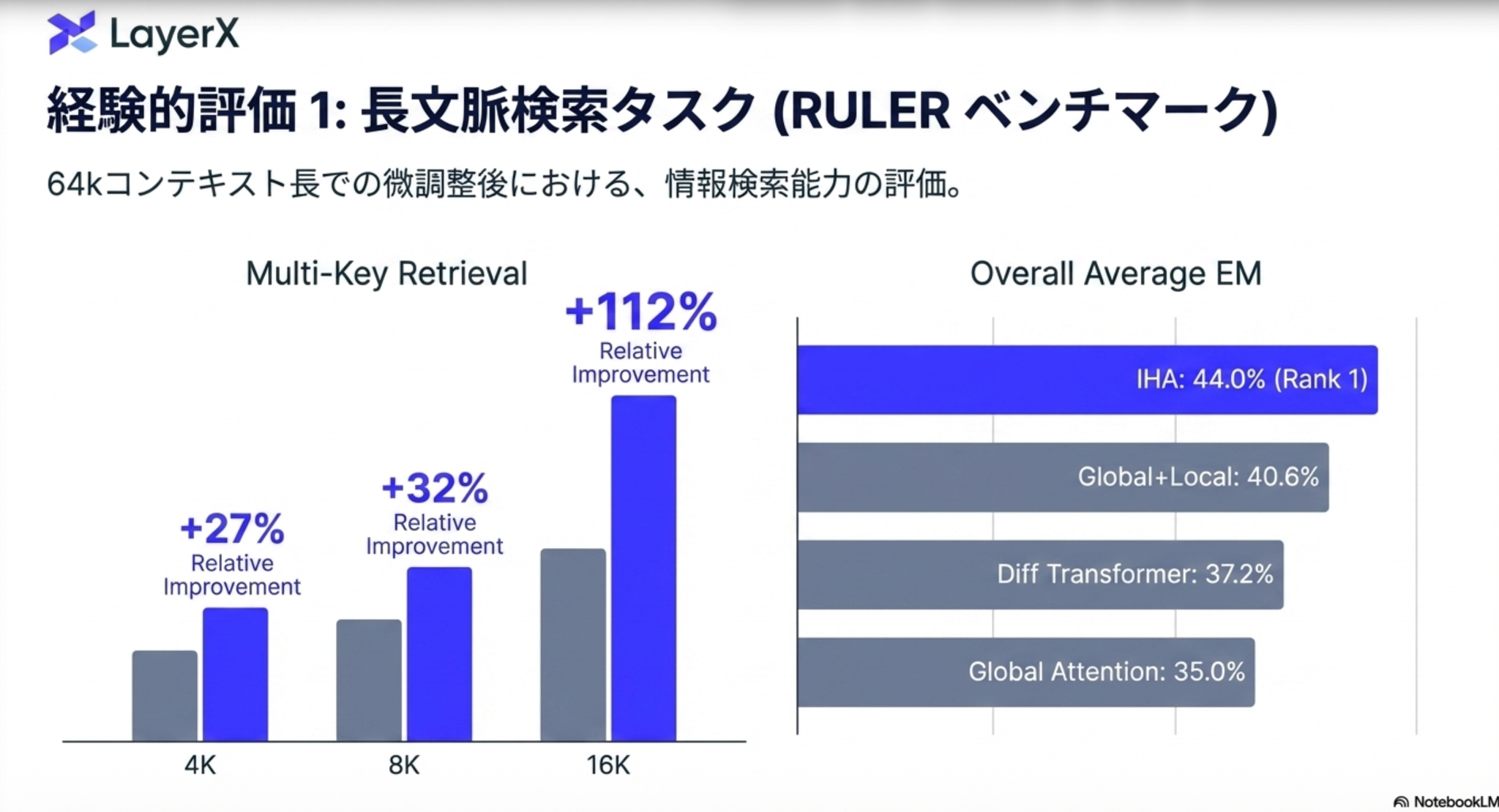
5.1 長文コンテキスト:RULERベンチマーク
複数の情報の断片を正確に抽出する「Multi-Key Retrieval」において、IHAはコンテキスト長が伸びるほどベースラインとの差を広げる結果となった。
- 4k: +27% の精度向上
- 8k: +32% の精度向上
- 16k: +112% という爆発的な改善を達成 16kコンテキストでのこの飛躍は、IHAが長文内に分散した情報の依存関係を正確に保持・追跡する能力において、既存のトランスフォーマーを圧倒していることを示す。
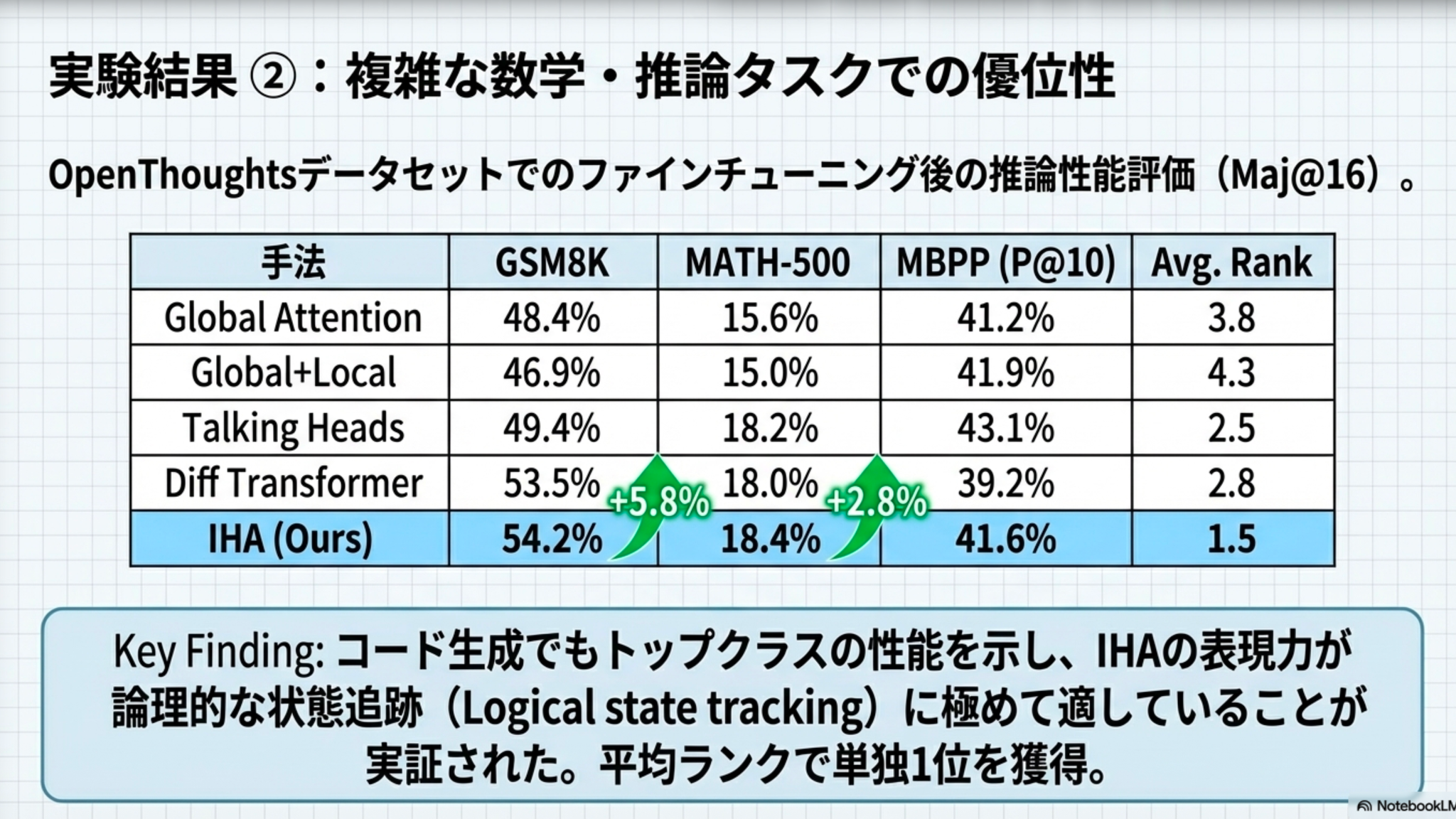
5.2 数学的推論(SFT後評価)
OpenThoughtsデータセットでfine-tuninし、Majority Vote (Maj@16) で評価した結果、論理的状態の追跡能力の向上が確認された。
- GSM8K: +5.8%
- MATH-500: +2.8%
- 総合評価: すべてのベンチマークを通じて平均ランク 1.4〜1.5 を記録し、Diff TransformerやTalking Heads等の競合手法を一貫して上回る汎用性を示した。
5.3 性能向上の考察
IHAが特に「数学的推論」において優れた性能を示す理由は、最小限の計算オーバーヘッドで、推論の各ステップにおける「証拠の鎖」を単一のレイヤー内で柔軟に組み合わせられるその表現力にある。
6. 結論と今後の展望
インターリーブ・ヘッド・アテンション(IHA)は、MHAの線形制約を打破し、多段推論を効率化したLLMアーキテクチャの進化である。
6.1 本研究の総括
IHAは「線形パラメータコストで二次的な表現力」を提供する最も論理的なMHAの後継技術です。実験データが示す通り、特に推論能力と長文コンテキストの正確な処理において、これまでのトランスフォーマーの限界を大きく拡張しました。
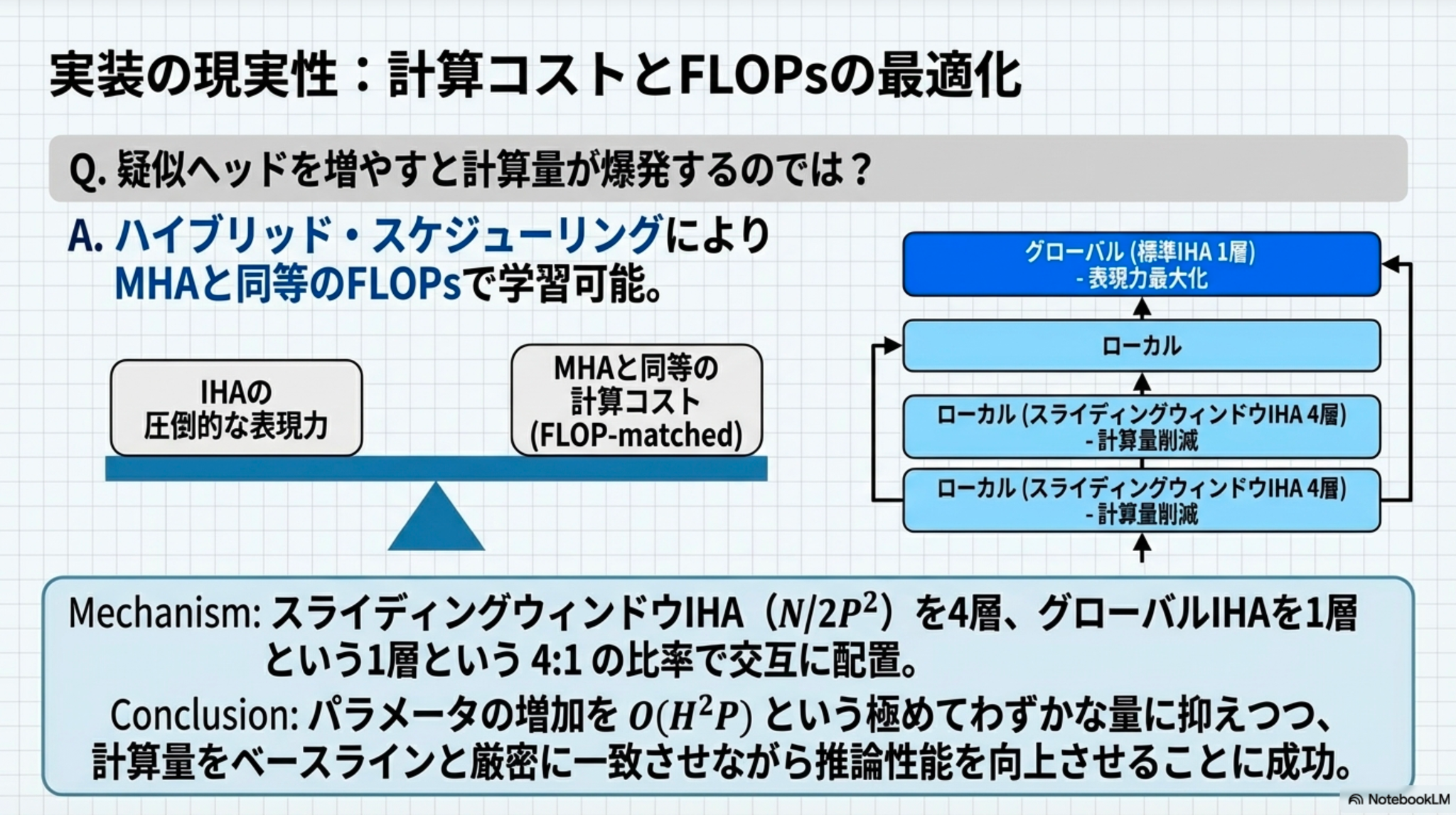
6.2 制約と対策:スライディングウィンドウ・スケジュール
グローバルなIHA計算においては、仮想シーケンスの拡張に伴いアテンションコストが増大する課題があります。しかし、本研究では という具体的なウィンドウサイズを用いたスライディングウィンドウ・スケジュールを導入することで、計算コストを増大させることなく(FLOP-matched)性能向上を実現できることを実証しました。
6.3 今後の展望
IHAは今後、以下の技術ロードマップにおいて中核的な役割を果たすと考えられます。
- 適応的擬似ヘッド割り当て: タスクの難易度に応じた動的な計算リソースの配分。
- マルチモーダルへの応用: 視覚情報等の複雑なクロスドメイン関係の抽出。
IHAは、推論効率とスケーリングのジレンマを解決する「次なる標準コンポーネント」として、AIリサーチの新たな地平を切り拓くものです。