
2026-04-21 機械学習勉強会
今週のTOPIC[paper] Attention to Mamba: A Recipe for Cross-Architecture Distillation[blog] LLM-as-a-Verifier: A General-Purpose Verification FrameworkAdaParse: Adaptive Parallel PDF Parsing[blog] Evaluating Netflix Show Synopses with LLM-as-a-Judge[paper]SkillClaw: Let Skills Evolve Collectively with Agentic Evolver[paper] InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented AgentsメインTOPICMemory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents🎯 論文概要(要点サマリー)3つの中心的リサーチクエスチョン(RQ)4つの発見(Core Findings)第1章 イントロダクション1.1 背景:学習データのスケーリング飽和と自己進化パラダイム1.2 既存手法の限界:単一ドメインへの閉じ込め1.3 先行研究のギャップ1.4 本研究の貢献第2章 関連研究2.1 コーディングエージェント(a)関数レベル(初期)(b)リポジトリレベル(c)ドメイン特化2.2 メモリベース自己進化エージェント2.3 転移学習第3章 Memory Transfer Learning (MTL)3.1 手法:2段階のメモリ活用プロセス3.1.1 メモリ生成(Memory Generation)推論履歴の収集4つのメモリ形式(抽象度の階段)3.1.2 メモリ検索(Memory Retrieval)メモリプールの構築検索戦略3.2 実験詳細3.2.1 データセット(6ベンチマーク)3.2.2 モデル・基盤ツール第4章 実験結果と分析4.1 MTLの全体性能4.1.1 メイン結果(Table 1)4.1.2 自己進化手法との比較(Table 2)4.2 MTLのメカニズム4.2.1 なぜMTLはエージェントを助けるのか?(Figure 3)4.2.2 ケーススタディ:Zero-shot vs MTL4.3 メモリ抽象度の影響4.3.1 4形式の抽象度4.3.2 抽象度と転移効果の相関4.3.3 抽象度の効果を切り分ける実験(Table 4)4.3.4 ケーススタディ:Trajectory vs Insight(Table 5)4.4 更なる分析とアブレーション4.4.1 MTLにおける負の転移(Negative Transfer)4.4.2 ケーススタディ:負のメモリ転移4.4.3 メモリプールサイズの影響(Figure 6)4.4.4 モデル間メモリ転移(Cross-Model)4.4.5 検索手法の分析第5章 結論3つの設計原則今後の展望Impact Statement🔑 本論文の学術的・実務的インパクト学術的意義実務的意義感想
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Yuya Matsumura
[paper] Attention to Mamba: A Recipe for Cross-Architecture Distillation
Abhinav Moudgil, Ningyuan Huang, Eeshan Gunesh Dhekane, Pau Rodríguez, Luca Zappella, Federico Danieli
背景・概要
Transformer の self-attention による計算量・使用メモリの大きさの課題(系列長に対して二乗の増え方)に対して、より効率の良いSSMベースのMamba(系列長に対して線形な増え方)が注目を浴びている。
参考までに関連アーキテクチャの比較📝
| モデル | 基本の考え方 | 長所 | 弱点 | ひとことで言うと |
|---|---|---|---|---|
| RNN | 1トークンずつ読み、前の隠れ状態を次に渡していく。古典的な「動的メモリ」の発想。 | 構造が単純。逐次データを自然に扱える。 | 長期依存で勾配消失・爆発が起きやすい。長い文脈を保つのが苦手。 | 毎回ほぼ同じやり方で記憶更新する |
| LSTM | RNN にゲートを入れて、書く・残す・出すを制御する。長期依存を学びやすくした。 | RNN より長い依存関係に強い。昔の系列モデルの主力。 | それでも逐次処理が基本で、並列化や超長文では不利。 | ゲート付きRNN |
| Transformer | 各トークンが他のトークンを attention で直接参照する。再帰も畳み込みも使わない。 | 遠い位置同士の関係を直接見やすい。並列化しやすい。 | self-attention の計算・メモリは系列長に対して二乗で重くなりやすい。 | 毎回全文検索して考える |
| Mamba | SSM を土台に、入力に応じて「何を保持し何を忘れるか」を選択的に変える。attention なし。 | 系列長に対して線形スケールし、長系列や高速推論に強い。元論文では Transformer より高スループットも報告。 | 生の全トークンへ毎回自由アクセスするわけではないので、Transformer 的な直接比較とは性格が違う。Mamba 自身も従来の弱点を「content-based reasoning の不足」と位置づけて改良している。 | 賢く圧縮しながら覚える |
効率の良いMambaベースのモデルを作っていきたいが、既存の事前学習済みモデルはTransoformerベースのものがほとんどである。この資産をMambaベースモデルの学習に活かしたいが、ナイーブにTransformerベースのモデルを教師、Mambaベースのモデルを生徒として蒸留を行っても、構造が根本的に異なることからうまくいかない。そこでこれまではAttentionとSSMを両方持つハイブリッドなモデルへの蒸留で妥協してきた。
この論文は、純粋なSSMに基づきMambaベースモデルを生徒として、Transformerベースモデルを教師とした蒸留をうまくいかせるための工夫を提案している。
提案手法
2-stage で蒸留を実現
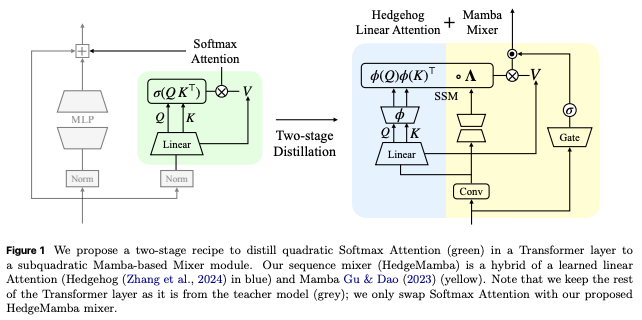
第1段階:Softmax Attentionから「線形Attention」への蒸留
最初のステップでは、計算コストの元凶であるTransformerの「Softmax Attention」を、動作の軽い「線形Attention(Linear Attention)」に変換する。
- 仕組み(Hedgehog手法): Softmax関数の複雑な非線形計算を、「カーネルトリック(Mercerの定理)」を用いて、小さなニューラルネットワーク(MLP)による「特徴量マップ」として近似します。
- 学習の工夫: 教師モデル(Transformer)のパラメータはそのままコピーして凍結し、新しく追加した近似用の特徴量マップ(MLP)のパラメータだけを学習させます。生徒モデルの出力が教師モデルの出力と一致するように、cosine similarity を使って学習。
- トークンの割り当て: 全体の学習予算(100億トークン)のうち、10%(10億トークン)をこの段階に費やす。
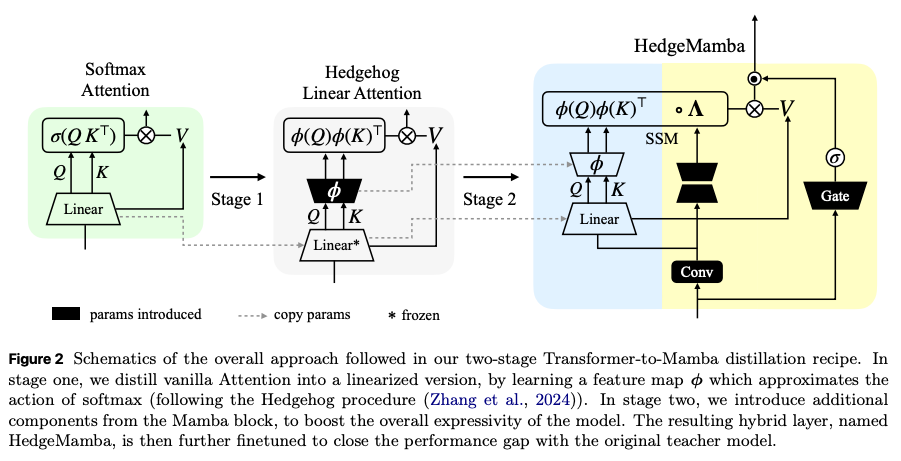
第2段階:線形Attentionから「Mamba(HedgeMamba)」への蒸留
次のステップでは、第1段階で作った線形AttentionをMambaのパラメータとして「初期化(読み込み)」し、モデル全体の性能を引き上げる。
- パラメータの直接マッピング: 線形Attentionで使われる「Query、Key、Value」の要素は、Mambaの内部計算(SSM)で使われるパラメータ「C、B、X」と数学的に同じ役割を果たします。この性質を利用し、第1段階で学習した値をそっくりそのままMambaに引き継がせます。
- 賢い初期化(Identity Initialization): Mambaには、線形Attentionには存在しない畳み込み(Conv)層やゲート(Gate)分岐といった独自のパーツが存在する。学習開始直後は、これらのパーツが第1段階の学習結果を壊さないよう、入力されたデータをそのまま出力する恒等写像の形で初期値を設定する。また、元のSoftmaxの挙動に近づけるための正規化の処理も追加します。
- 学習の工夫(ファインチューニング): 凍結していたMamba独自のパーツ(畳み込みやゲート)のロックを解除し、モデル全体を標準的なクロスエントロピー誤差を用いて微調整(ファインチューニング)します。
- トークンの割り当て: 学習予算の残り90%(90億トークン)をこの段階にたっぷりと使い、モデルの表現力を極限まで高める。
実験と結果
10億(1B)パラメータ規模のモデルを用いた100億(10B)トークン規模の実験を実施
教師モデルであるPythia-1B(Perplexity 13.86)に対し、本手法によるDistilled Mambaは14.11を記録した。
その他の実験についてもぼちぼちかな。
Ablation Study
Mamba の各コンポーネントを削った際のパフォーマンス比較。Gateの貢献が大きい。(PPLが14.58なのは、トークン割り当てを5:5にした際の実験だから)
2-stage におけるトークンの配分は重要。現在の1:9が一番よかった。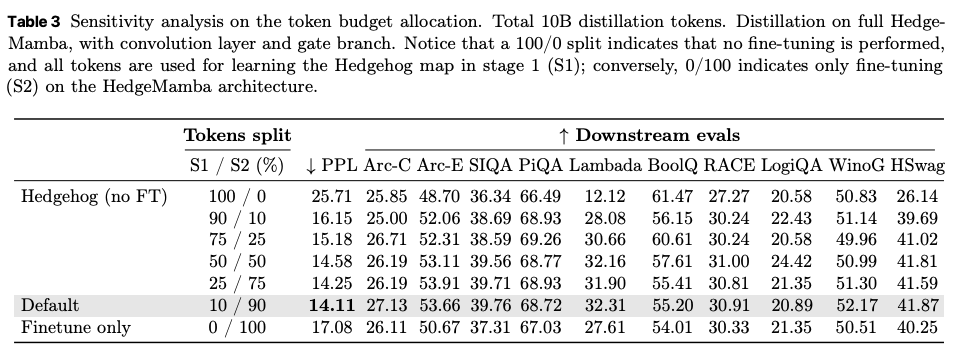
データ量に対するスケーリング則が効いている。10Bでもまだサチっていなさそう。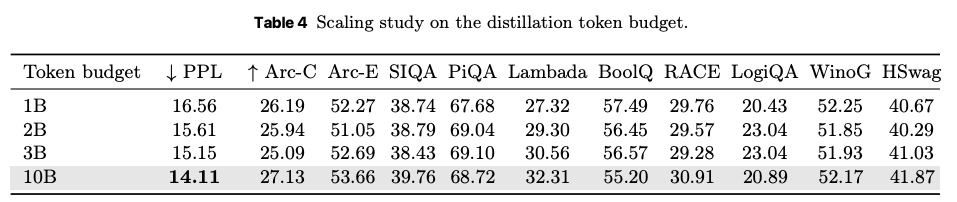
@Hiromu Nakamura (pon)
[blog] LLM-as-a-Verifier: A General-Purpose Verification Framework
[pon]かなりシンプルかつ汎用的で参考になる。
LLM-as-a-Verifierは、スコアリングの粒度、反復検証、および評価基準の分解をスケールアップすることにより、きめ細やかなフィードバックを提供する汎用検証フレームワーク。
課題
従来のLLM-as-a-Judgeの問題点:
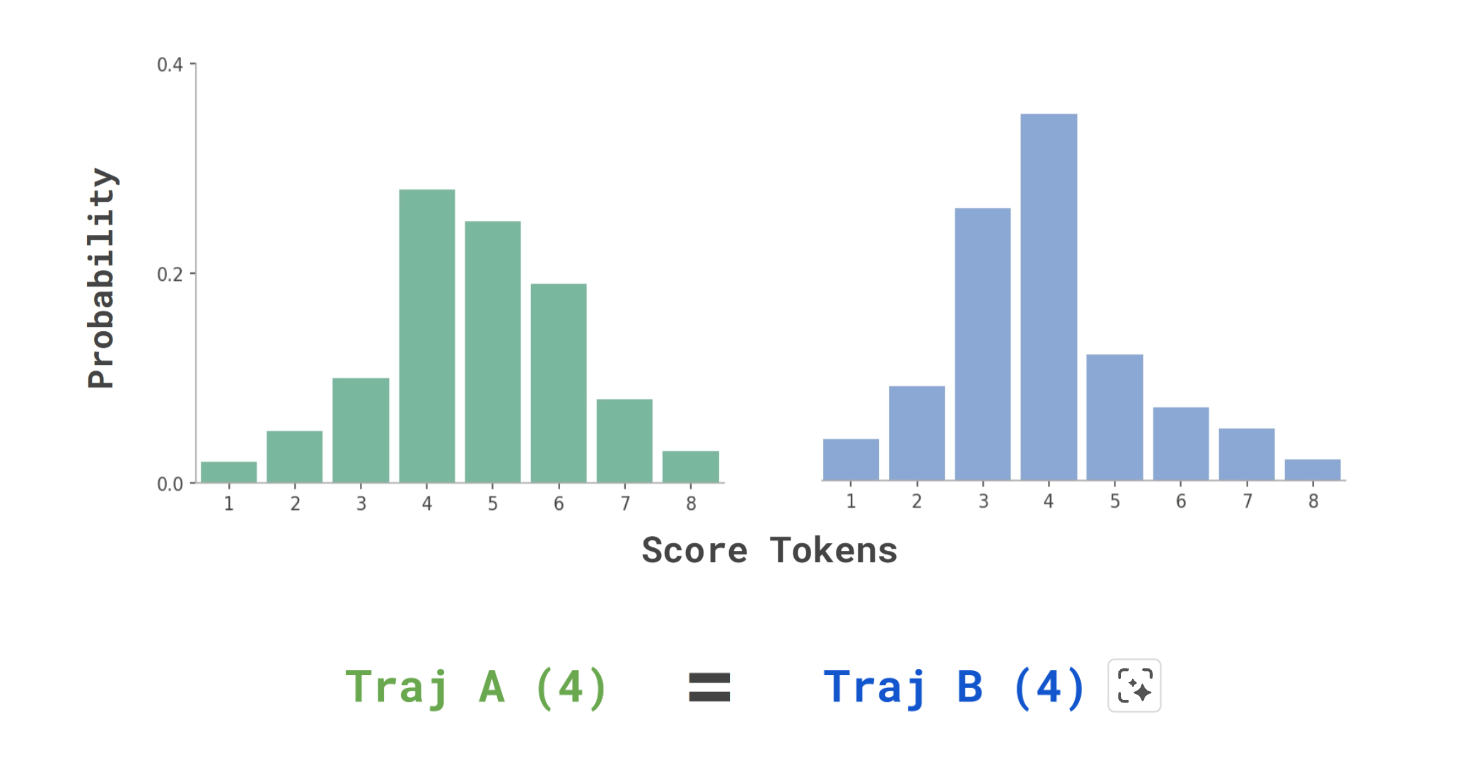
- 標準的なLLM-as-a-Judgeは、モデルに1つのスコアトークン(例:1〜8の整数)を出力させ、最も確率の高いトークンを最終的な離散スコアとして利用する。
- しかし、このアプローチは粗い粒度のスコアリングに陥りがちであり、複雑なエージェントの軌跡を比較する際に、両方の軌跡に同じスコア(例:両方4点)を割り当ててしまい、優劣を識別できない「引き分け」が多発する。
- Terminal-Benchでは、この粗いスコアリングが27%もの引き分けを引き起こしていた。
手法
本手法は、評価の精度を向上させるために以下の3つの主要な要素をスケールさせます。
LLM-as-a-Verifierは、以下の3つの要素をスケールアップすることで、ファイングレイン(きめ細かい)なフィードバックを提供する汎用的な検証フレームワークである。
- 繰り返し検証(Repeated Verifications)の回数:
- 単一の検証にとどまらず、複数回検証を繰り返すことで、ノイズやバイアスを平均化する。
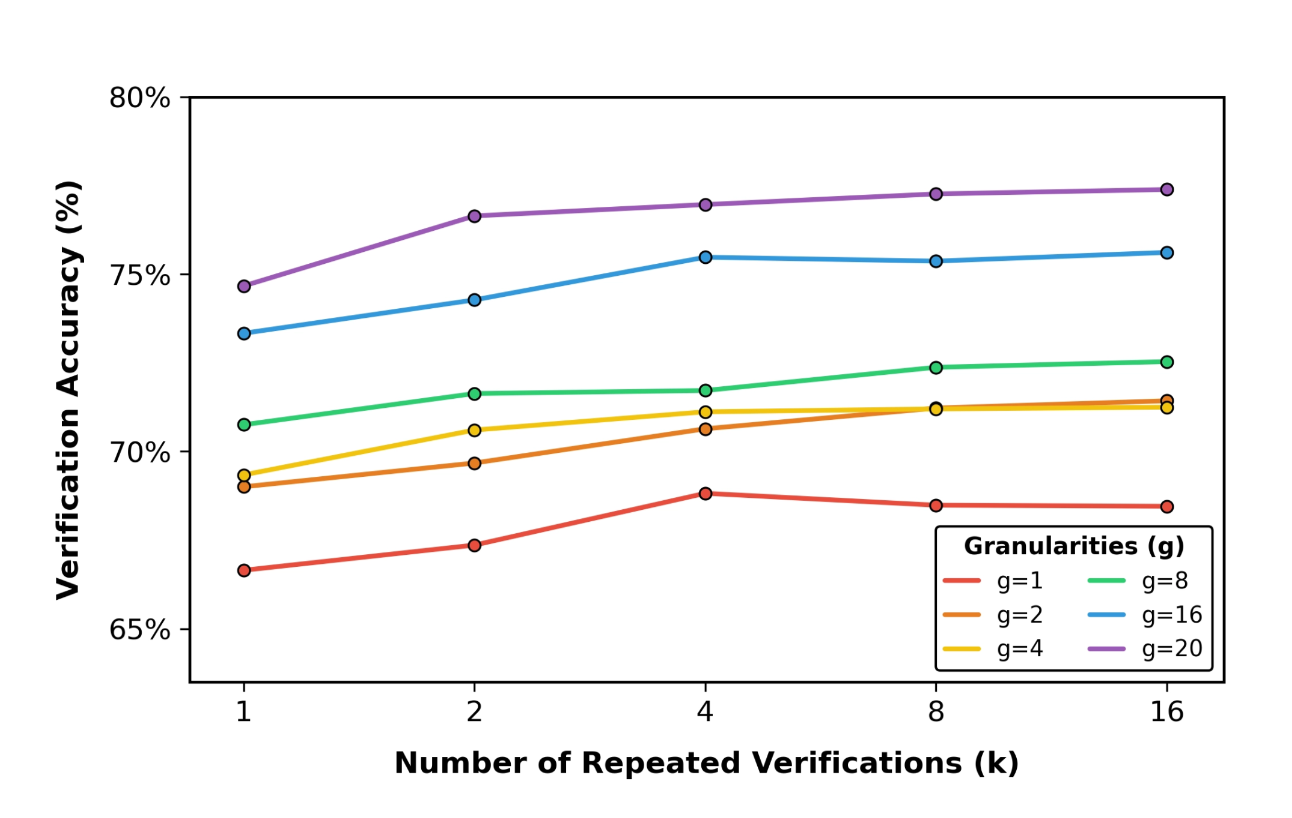
- スコアトークンの粒度(Granularity of Score Tokens):
- 従来の単一の離散スコアではなく、より多くのスコアトークン(例:1〜20など、評価尺度を細分化したもの)を用いることで、定量化誤差を減らし、基となる連続的な報酬をよりよく近似する。
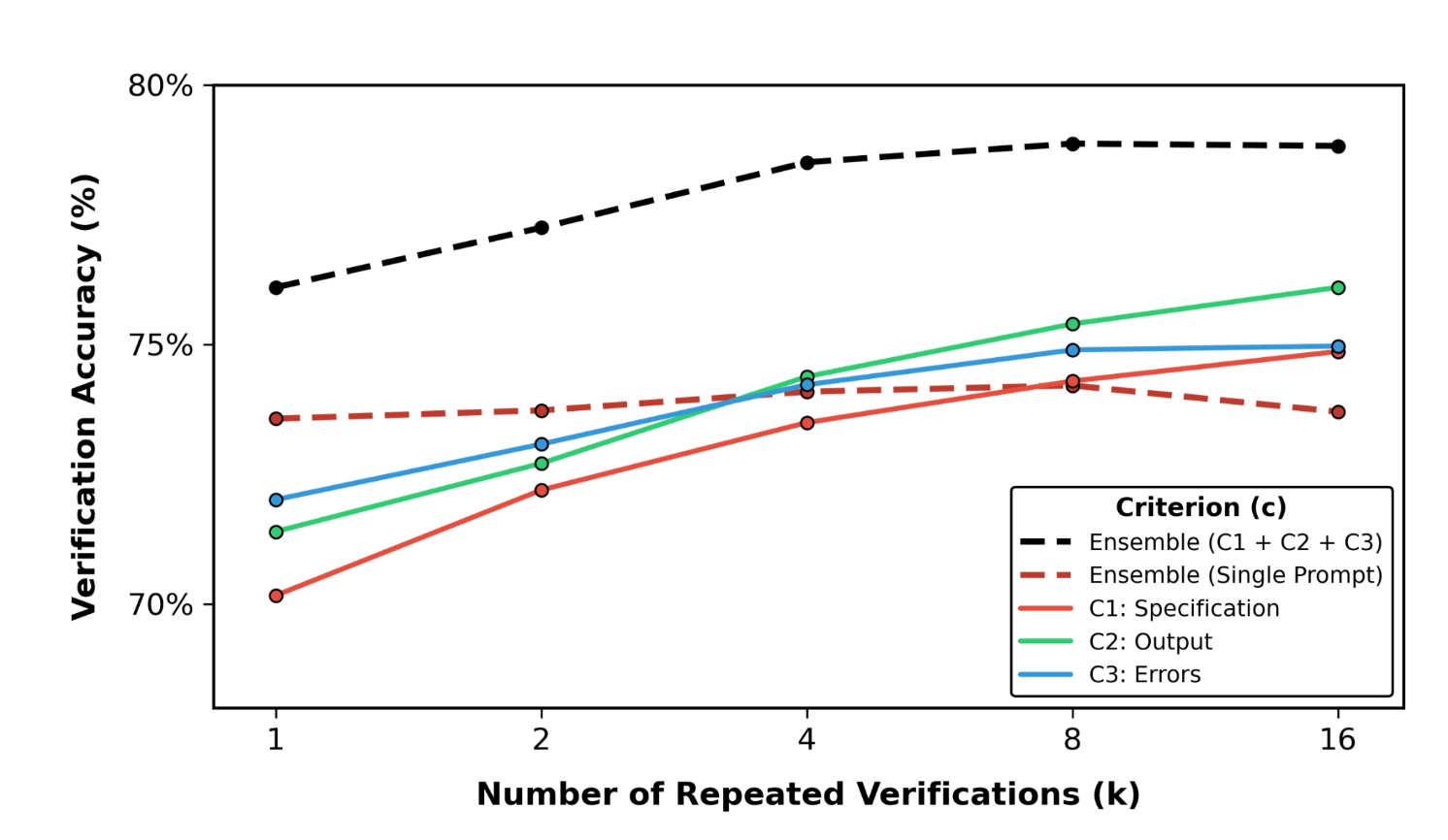
- 評価基準の分解(Decomposition of Evaluation Criteria):
- 軌跡全体の品質を直接推定するのではなく、タスク要件(Specification)、出力形式(Output)、エラーの有無(Errors)など、より単純で具体的な要因に分解して検証する。
スコアリングの仕組み:
- 例示されているプロンプト構造では、専門家としてのロールプレイングを設定し、Evaluation Criteria、Task、Trajectory A、Trajectory Bを含めたうえで、最終的なスコアを<score_A> INTEGER_1_TO_8 </score_A>や<score_B> INTEGER_1_TO_8 </score_B>といったトークン形式で出力させる。
- 従来の単一の離散スコアに還元するのではなく、スコアトークンに対するモデルの条件付き分布(logprobs)を利用して、軌跡の報酬を近似することが示唆されている。
- 例えば、1-8のスケールであれば「A, B, C, D, E, F, G, H」のような文字がスコアに対応し、それぞれの文字トークンが出力される確率を利用
- Round-robin tournamentで勝者を採択
評価
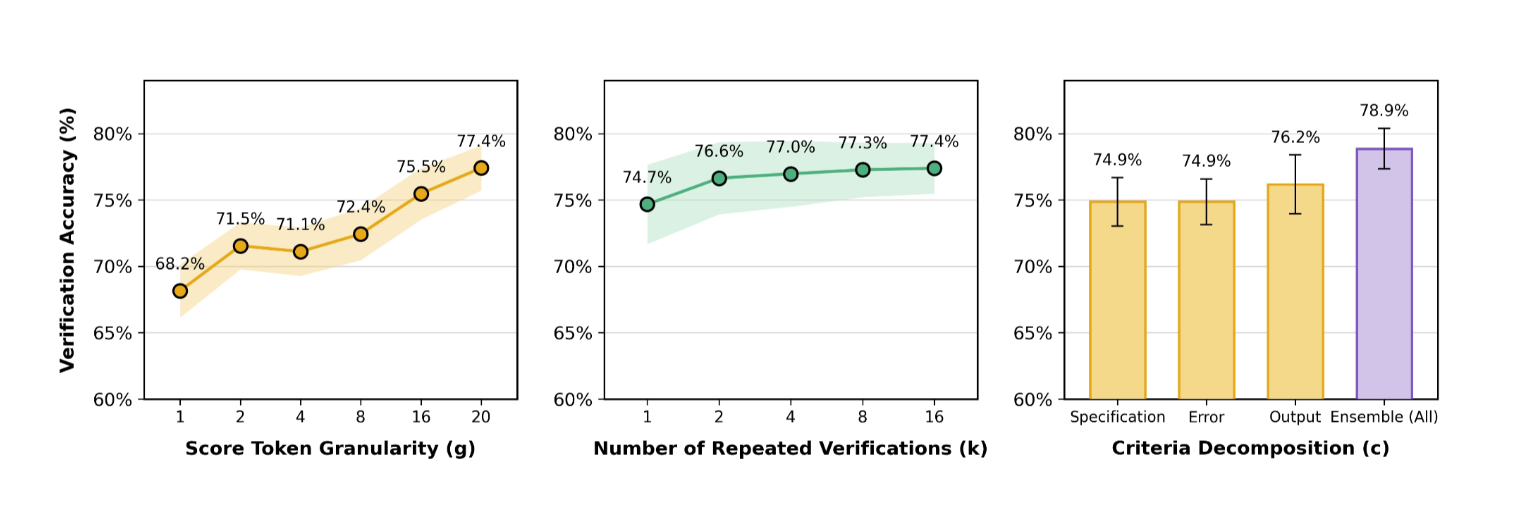
評価において、LLM-as-a-VerifierはLLM-as-a-Judgeを一貫して上回り、Terminal-Benchにおいて77.4%の検証精度を達成し、全ての反復検証予算においてタイを完全に排除しました。
Verification Accuracy

Tie Rate


- さらに、テスト時スケーリングと検証を通じて、下流の成功率を81.8%から86.4%(SOTA)に向上させました。Terminal-Bench 2.0で86.4%、SWEBench Verifiedで77.8%のSOTA性能を達成し、Claude Opus 4.6、GPT 5.4、Gemini Modelsなどのフロンティアモデルを凌駕しています。
スコアの粒度を「1 → 20」にスケールアップする[4]ことで、検証精度が着実に向上することを示しています。
全体的な品質を直接評価するのではなく、よりシンプルで補完的な3つの要素に評価基準を分解しています。これにより、LLMがより具体的な側面について判断を下すため、判断の精度が向上。
@Akira Manda(zunda)
AdaParse: Adaptive Parallel PDF Parsing
1. 背景と課題
科学文献の膨大な知識を活用するため、Large Language Models (LLMs) を科学分野に特化させる試みが進んでいます。しかし、学習データの大部分は Portable Document Format (PDF) で配布されており、これを利用するには正確な PDF Parsing が不可欠です。PDFはレイアウトベースの構造であり、機械による読み取りを前提としていないため、以下のような深刻な課題がありました。
- 軽量パーサーの精度不足: PyMuPDF のような Text Extraction ツールは非常に高速ですが、数式や複雑なレイアウトを持つPDFではエラー(不自然な空白の挿入、文字化けなど)が頻発し、LLMの学習データの品質を著しく低下させます。
- 高品質パーサーの計算ボトルネック: Nougat に代表される Vision Transformers (ViTs) や Optical Character Recognition (OCR) を用いたモデルは高精度ですが、推論コストが極めて高く(4基の A100 GPU を用いても 1〜2 PDF/秒)、数億件の文書を処理するのには非現実的です。
2. 解決すべき課題:一律なPDFパースアプローチの限界
PDF文書の品質や複雑さは多種多様であり、一律のアプローチを適用することは非効率です。
この精度と計算コストのトレードオフは、nnnn 個の文書データセットに対して mmmm 個のパーサーから最適なものを割り当てる最適化問題として定式化できます。各文書 d_idid_idi に対してパーサー \phi_{j_i}ϕji\phi_{j_i}ϕji を割り当てる場合、以下の目的関数を最大化しつつ、計算リソースの制約を満たす必要があります。
ここで、 は精度指標、 は Groundtruth Text、は計算コストの予算上限、 はデフォルトパーサーによる最初のページの抽出結果を指します。
3. 提案手法と新規性:AdaParse (Adaptive Parsing Strategy)
著者たちは、上記の課題を解決するために、データ駆動型の適応型解析戦略である AdaParse を提案しました。本論文の主な貢献と新規性は以下の3点に集約されます。
- 高速な初期抽出を「特徴量」とするメタ戦略:
メタデータだけでは文書の複雑さを測れないため、AdaParse はまず計算コストの極めて低い PyMuPDF でテキストを初期抽出します。抽出されたテキストのアーティファクト(文字化けやレイアウト崩れの痕跡)を予測アルゴリズムの入力として利用し、後続の高品質パーサーが必要かを判断します。
- Direct Preference Optimization (DPO) による人間の評価とのアライメント: BLEUなどのスコアは人間の知覚とは完全に一致しないため、ドメインエキスパートから収集した選好データ(Preference data)に基づき、LLM に DPO を適用しました。
- HPCに最適化された超並列システム: CPUで動作する軽量パーサーと GPU を占有する Nougat などのワークロードを効率的に分離するため、並列スクリプトライブラリ Parsl を拡張し、Leadership-class HPC システム上で大規模なコーパス処理を可能にしました。
4. AdaParse の2つのバリエーションと階層的分類
AdaParse は、コストと精度のバランスを取るため、2つの実装バリエーションを持ちます。
- AdaParse (FT): CLS I と CLS II のみを実行し、改善が見込まれる場合は即座に Nougat をトリガーする軽量版。LLM推論をスキップし、あらかじめ定義された fastText (FT) の単語埋め込みを使用します。
- AdaParse (LLM): CLS I を経て、バッチ処理で LLM (SciBERT) を呼び出し、各テキストに最適なパーサーを予測する(CLS III)高精度版。
AdaParse (LLM) の CLS III を担う SciBERT に対しては、DPO によるポストトレーニングが行われます。以下の DPO 損失関数(論文中の表記に準拠)を最小化することで、パーサー選択が人間の判断基準と整合するように最適化されています。
5. 主な実験結果
1000件の未学習の科学 PDF セットを用いて評価が行われました。
5.1 抽出精度と推論速度 (Throughput) の両立
AdaParse は、高品質パーサー (Nougat) の適用を「最大 5% の文書」に制限する厳しい制約下(%)であっても、単一の最先端パーサーを超える精度を達成しました。ParserCoverage (%)BLEU (%)ROUGE (%)CAR (%)Win Rate (%)Accepted Tokens (%)Nougat (Base)93.048.166.565.827.969.8PyMuPDF (Base)91.351.967.367.024.476.7AdaParse (Ours)91.552.167.667.125.576.9
結果として、AdaParse は最先端のパーサーと比較して Throughput を約17倍に向上 させつつ、BLEU スコアを 0.2% 上回るという理想的なトレードオフを実現しました。また、Nougat でさえ失敗する深刻なエラー(ページ全体の欠落など)を、最適なパーサーの切り替えによって回避しています。
5.2 劣化画像や破損テキスト層に対する堅牢性
画像レイヤーに人工的な劣化を加えた実験、およびテキストレイヤーの15%を破壊した実験でも、AdaParse は堅牢性を示しました。テキスト抽出を中心としつつ、必要な場面で適切に Nougat 等に委譲することで高い精度を維持しています。
5.3 人間の評価指標とのアライメント(DPOの効果)
数学や医学など多様な背景を持つ23名の科学者による選好データ収集の結果、BLEU スコアと人間の選好(Win Rate)の相関は であり、分散の47%しか説明できないことが判明しました。
SciBERT に DPO を組み込んだ結果(AdaParse LLM)、ベースモデルと比較して Win Rate や各精度指標が明確に向上し、科学的妥当性の高い出力を安定して得られることが実証されました。
@Shuhei Nakano(nanay)
[blog] Evaluating Netflix Show Synopses with LLM-as-a-Judge
- タイトル: Evaluating Netflix Show Synopses with LLM-as-a-Judge
- 著者 / 組織: Cameron R. Wolfe, Ph.D. / Netflix Technology Blog
- 公開日: 2026年4月
1. どんな記事?
Netflixが番組のあらすじ(Synopsis)の品質を自動評価するために構築したLLM-as-a-Judgeシステムについて解説した記事。4つの品質基準(精度・事実性・トーン・明瞭さ)に沿ってLLMが二値スコアリングを行い、クリエイティブライターとの一致率85%以上を達成した。数百タイトルのあらすじ品質を番組公開の数週間〜数か月前にプロアクティブに検出・修正できる仕組みを実現している。
2. 何が課題だったのか?
- スケールの問題: Netflixには数百のタイトルが存在し、それぞれのあらすじの品質を人手で評価し続けることはスケールしない
- 品質のばらつき: あらすじの品質が低いと、視聴開始率(Take Fraction)の低下や早期離脱率(Abandonment Rate)の上昇に直結し、ストリーミング指標に影響を与える
- 評価の主観性: クリエイティブライター間でも評価にばらつきがあり、一貫した品質基準の適用が困難
- 事前検知の必要性: 品質問題を番組公開後ではなく、公開の数週間〜数か月前に発見・修正したいというビジネスニーズ
3. アーキテクチャ・技術的アプローチ
評価基準(4次元)
| 基準 | 内容 |
|---|---|
| Precision(精度) | あらすじが番組内容を正確に表現しているか |
| Factuality(事実性) | プロット、出演者、ロケーション、メタデータが事実と一致しているか |
| Tone(トーン) | 番組のジャンルや雰囲気に合った表現がされているか |
| Clarity(明瞭さ) | 文章が明確で読みやすいか |
評価パイプラインの構成
各基準ごとに最適な評価手法を使い分けている:
| 基準 | 手法 |
|---|---|
| Precision | 標準的な推論ベースLLMジャッジ(Standard reasoning-based LLM judge) |
| Clarity / Tone | 段階的根拠(Tiered Rationale)+ 5回コンセンサススコアリング(Consensus Scoring) |
| Factuality | Agents-as-a-Judge: 4つのエージェント(プロット・出演者・ロケーション・メタデータ)がそれぞれ独立評価 + 段階的根拠 + コンセンサス |
ゴールデンセット
- クリエイティブライターが約600件のあらすじに対し、基準ごとの二値スコアと説明を付与
- Model-in-the-loop コンセンサス方式: 複数ライターがスコアリング → LLMが最終ラベルに集約 → 大きな不一致があるケースはライターが手動レビュー
- 約300件の開発セットで自動プロンプト最適化(Automatic Prompt Optimization; APO)を実施
行動指標による検証
- Take Fraction: あらすじを見たメンバーが視聴を開始する割合
- Abandonment Rate: 視聴開始後すぐに離脱する割合
- LLMジャッジの品質スコアが高いほど、Take Fractionが上昇し、Abandonment Rateが低下する相関を確認
4. 設計上のこだわり・工夫
- 基準ごとに専用ジャッジを分離: 単一プロンプトで全基準を評価するとLLMに過負荷がかかり性能が低下するため、基準ごとに専用ジャッジを設計
- 段階的根拠(Tiered Rationale)の導入: ジャッジの推論長を3段階に定義。中程度の根拠が短い根拠を顕著に上回る一方、長い根拠の追加利得は限定的 → コストと精度のバランスを最適化
- コンセンサススコアリング: LLMから複数回の出力をサンプリングしスコアを集約。特に長い根拠を用いる場合にスコアの分散安定化に有効
- Factualityのエージェント分割: 事実性を4つのファセット(プロット・出演者・ロケーション・メタデータ)に分解し、各エージェントが専用コンテキストで評価。最終スコアは全エージェントの最小値(1つでも不合格なら全体不合格)→ 精度が72.5% → 83.95%に向上
- 推論モデル(Reasoning Model)の不採用: 推論モデルは推論コストが大幅に増加する割に性能向上が限定的であるため、本番システムでは採用を見送り
- APO(自動プロンプト最適化)の活用: LLMはプロンプトの微妙な表現に敏感であるため、開発セットを用いたプロンプトの自動最適化を実施
5. 現時点の制約と今後の展望
- 推論コストとのトレードオフ: 推論モデル(Reasoning Model)は精度を若干改善するが、推論コストの大幅増加に見合わないため不採用。コスト効率の良い推論モデルの登場が今後の改善余地
- LLMの本質的な限界: 推論能力の不確実性、プロンプトへの過敏性、冗長な出力の傾向といったLLM固有の課題が残存
- 評価基準の拡張可能性: 現在は4基準だが、より細粒度の品質次元やローカライゼーション品質への拡張が考えられる
- ストリーミング指標との相関の深化: Precision と Clarity が特に予測力が高いことが判明しており、重み付けスコアの最適化による更なるビジネスインパクトの向上が期待される
6. Take Home Message
- LLM-as-a-Judgeは「万能な単一プロンプト」ではなく、基準ごとの専用設計が鍵: 評価対象の特性に合わせてジャッジ手法(標準推論、段階的根拠、エージェント分割)を使い分けることで、人間の専門家と同等以上の精度(83〜92%)を達成できる
- エージェント分割による事実性評価は汎用性が高い: 複雑な評価基準をファセットに分解し、専用エージェントで個別評価する手法は、あらすじ以外のコンテンツ品質評価にも応用可能(72.5% → 83.95%の精度向上)
- 自動評価をビジネス指標で検証する姿勢が重要: LLMジャッジの精度だけでなく、Take FractionやAbandonment Rateといった実際のユーザー行動指標との相関を検証し、評価システムのビジネスインパクトを実証している
- コスト意識を持った技術選定: 推論モデルの不採用判断に見られるように、「精度が上がるか」だけでなく「コストに見合うか」を本番システム設計の重要な判断軸にしている
@Kyohei Uto(kuto)
[paper]SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
概要
- LLMエージェントはデプロイ後にスキルが静的なままとなり、同様の失敗パターンがユーザー間で繰り返し再発見されるという問題に対処する
- SkillClawは通常のインタラクション軌跡を集合的なスキル改善シグナルとして扱い、Agentic Evolverが自律的にスキルを更新・共有するクローズドループを実現する
| 手法 | 課題 |
|---|---|
| メモリベース(軌跡をそのまま保存) | 特定インスタンスに紐付き、汎化が難しい |
| スキルベース(軌跡からスキルを作成) | スキルライブラリを静的なリソースとして扱っており、使用を通じて進化しない |
| SkillClaw | 複数ユーザーのエビデンスを集約してスキル自体を動的に更新 |
提案手法
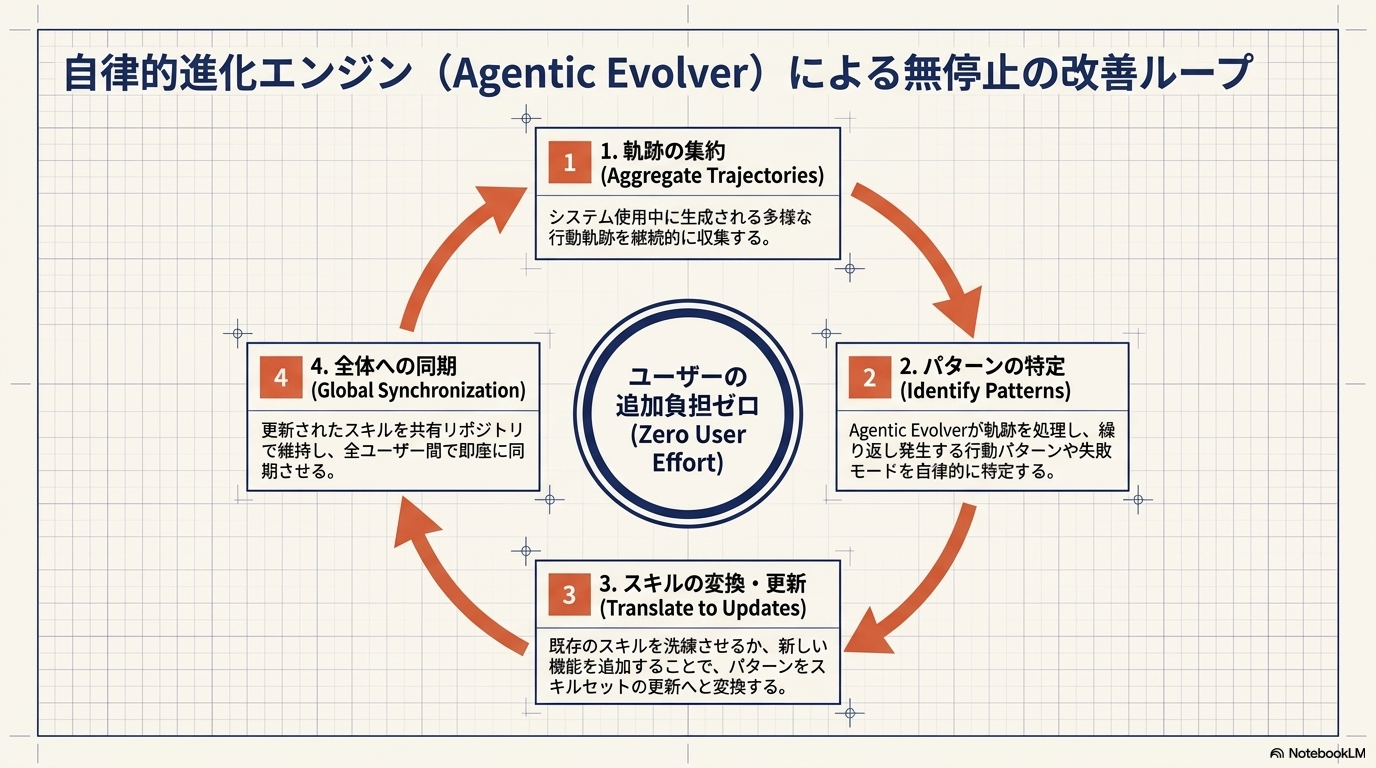
以下の流れ
1. セッション軌跡の収集と構造化
- 各ユーザのエージェントは日常的なタスク実行中にセッション軌跡 τ を生成する
- この軌跡は単なる会話ログではなく、全traceを保持する
- 後段のAgentic Evolverによる分析では_summary →_trajectory → aggregate の順で見る
| フィールド名 | 型・値 | 内容 |
|---|---|---|
| 文字列 | セッションの一意識別子 | |
| 文字列 | そのセッションが試みたベンチマークタスクの識別子 | |
| 整数 | 元セッションのインタラクション往復数 | |
| オブジェクト(省略可) | ロールアウト統計。(ORM平均スコア)、 / (成功・失敗ロールアウト数)、( / / の3値)を含む | |
| 文字列リスト | エージェントが読み込んだまたは注入されたスキル名の一覧 | |
| 浮動小数(0.0〜1.0) | 全ターンにわたる平均PRMスコア。値が高いほど良い | |
| 真偽値 | セッション中にツール呼び出しの失敗が発生したかどうか | |
| 構造化データ | ステップごとのトレース。各ステップに使用スキル・ツール呼び出しと引数・結果(成功/エラー)・エージェント応答スニペット・PRM/ORMスコアを含む。各フィールドは約400文字で打ち切り | |
| 文字列 | LLMが生成する8〜15文の分析サマリー。目標・軌跡・スキル有効性・転換点・ツール使用パターン・最終結果を網羅 |
2. セッション軌跡のグルーピング
- 収集したセッションを「どのスキルを参照したか」という軸でグループ化する
- スキルsを参照した全セッション
- : どのスキルも参照しなかったセッション
- この操作の本質は、スキル自体をコントロール変数にした自然な対照実験を生み出すこと
- あるスキルを使ったセッションが複数のユーザー・タスク・環境にまたがって集まると、ユーザーもタスクも異なるのに結果が分かれた場合、その差はスキルの中にあると特定できる
- 単一ユーザのデータだけでは「これは汎用的な改善か、その場かぎりの修正か」を区別できないが、複数ユーザーの集積があって初めて安定した判断が可能になる
3. Agentic Evolverによる分析とスキル改善
LLMエージェントとして実装されたEvolverが、グルーピングされたセッション軌跡を分析してスキルを更新する。Evolverは3つのアクションから選択する
| アクション | 内容 | 条件 |
|---|---|---|
| Refine | 既存スキルを修正・強化 | 失敗パターンが明確に特定できる場合 |
| Create | 新スキルを作成 | や に再利用可能な新しい手続きが見つかった場合 |
| Skip | 変更なし | エビデンスが不十分、または成功しているとき |
Evolverは成功セッションと失敗セッションを必ず両方参照することにより、スキルのrefineやcreateによって、一つの問題を修正しながら別の機能を壊してしまうリスクを防ぐ
- 成功セッションは「変えてはいけない部分の不変条件」
- 失敗セッションは「修正すべきターゲット」
スキル改善のポイント
- 失敗原因を分類する
- スキルの問題(誤った・欠落した・誤解を招く指示)はスキルを修正する
- エージェントの問題(スキルを読まなかった・コンテキスト溢れ・不要な再起動)はスキルの改善は行わない
- 環境の問題(API不安定性・ネットワーク断絶)は繰り返し発生する場合のみ短い注記を加える程度にとどめる
- 重要なアンチパターン
- スキルにすでに正しい情報(APIポート9110など)が明記されていたにもかかわらず、エージェントがそれを使わずに失敗した場合、これはスキルの問題ではなくエージェントの問題
- 正しい情報を削除して「ソースコードを読め」という指示に置き換えてはいけない
- スキルの存在意義は「エージェントが自力で発見しなくてもいい環境固有の知識を圧縮すること」であるため、これを崩す変更は根本的に誤り
実験結果
ベンチマーク: WildClawBench
- 60タスク・6カテゴリで構成されるリアルワールドエージェントベンチマーク
- フルLinuxコンテナ上での実行環境、テキスト・コード・画像・動画のマルチモーダル入力
- 1タスクあたり3〜27の評価指標
- 1タスクあたり15〜50ステップ
設定
- バックボーンモデルはQwen3-Max
- 8名の並行ユーザーを模した6日間のシミュレーションで評価
- 夜間に更新が走りdailyでskillを更新
結果
- 各カテゴリとも数値が下がる日はなく単調改善
- skillの更新時に過去のセッションを使ってold skillとnew skillそれぞれで動かしアウトカムが改善した場合のみ更新するようにしている
- [kuto]シミュレーションデータだからできているがHITLが絡むとこういう評価難しそう
ケーススタディ
Slackメッセージ分析

元のエージェントは全メッセージを取得してトライアンドエラーでツールエラーを対処。進化したスキルはプレビューでフィルタリング→選択的取得→ツール設定エラー修正(APIポート)という構造化パイプラインを導入
Figure 3: ICCV 2025オーラル論文分析

元のエージェントは大学名のヒューリスティックマッチングに依存し誤カウント。進化したスキルは公式PDF初ページに基づく厳密な第一所属定義とOpenAccessレコードとの整合を導入
感想
- skillの自動更新をまるっとAgentによる分析に任せてやってしまおうという感じの論文で、今のAIエージェントならこれでも割といい感じに改善できそうだなという印象は持った。
- 今回の実験ではセッション数がそこまで多くないが、セッション数が多い場合にどの軌跡を使うかの判断がこの方法だと限界ありそう。軌跡の検索が必要
- skill更新結果の評価がやはり重要な印象。逆にここがしっかりできていればこういう自動更新系もプロダクトに入れられるかも
- hermesはskill自動更新やってそう
- ‣
@Ryuhei Kawabata
[paper] InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents
複数の情報源をまたいで正しい答えを探すうえで、既存の LLM agent は web 検索への依存が強く、そのため高精度な domain-specific 情報を安定して扱いにくいという課題がある。
既存 benchmark には web 検索中心のものや API 呼び出し中心のものがあるものの、複数ツールをまたいで情報を集め、それらを最後に統合して答えを出す力までは十分に測れていない。
本研究はこのギャップに対して、web と専用ツールを組み合わせる情報探索能力を測る InfoMosaic-Bench と、その問題を自動生成する InfoMosaic-Flow を提案する。
提案の要点は「複数情報源を本当に必要とする問題」を意図的に作ることであり、実験では web 検索だけでは性能が頭打ちになり、専用ツールを足してもそれだけでは簡単には改善しないことを示した。
Original Abstract
Information seeking is a fundamental requirement for humans. However, existing LLM agents rely heavily on open-web search, which exposes two fundamental weaknesses: online content is noisy and unreliable, and many real-world tasks require precise, domain-specific knowledge unavailable from the web. The emergence of the Model Context Protocol (MCP) now allows agents to interface with thousands of specialized tools, seemingly resolving this limitation. Yet it remains unclear whether agents can effectively leverage such tools—and more importantly, whether they can integrate them with general-purpose search to solve complex tasks. Therefore, we introduce InfoMosaic-Bench, the first benchmark dedicated to multi-source information seeking in tool-augmented agents. Covering six representative domains (medicine, finance, maps, video, web, and multi-domain integration), InfoMosaic-Bench requires agents to combine general-purpose search with domain-specific tools. Tasks are synthesized with InfoMosaic-Flow, a scalable pipeline that grounds task conditions in verified tool outputs, enforces cross-source dependencies, and filters out shortcut cases solvable by trivial lookup. This design guarantees both reliability and non-triviality. Experiments with 14 state-of-the-art LLM agents reveal three findings: (i) web information alone is insufficient, with GPT-5 achieving only 38.2% accuracy and 67.5% pass rate; (ii) domain tools provide selective but inconsistent benefits, improving some domains while degrading others; and (iii) 22.4% of failures arise from incorrect tool usage or selection, highlighting that current LLMs still struggle with even basic tool handling.
1. 基本情報
| 項目 (Field) | 内容 (Content) |
|---|---|
| 論文タイトル / Paper Title | InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents |
| 著者 / Authors | Yaxin Du, Yuanshuo Zhang, Xiyuan Yang, Yifan Zhou, Cheng Wang, Gongyi Zou, Xianghe Pang, WenHao Wang, Menglan Chen, Shuo Tang, Siheng Chen |
| 掲載誌・会議 / Venue | ICLR 2026 Poster |
| 発表年 / Year | 2026 |
| DOI / URL | OpenReview: https://openreview.net/forum?id=AhQFDBBIRZ / arXiv DOI: 10.48550/arXiv.2510.02271 |
2. 目的・背景
この論文の問題意識はかなり明快であり、今の LLM agent は web 検索で多くのことができる一方、医療、金融、地図、動画のように正確で構造化された専用データが必要な場面では急に不安定になる。
著者は既存 benchmark の弱さを 3 点に整理しており、1 つ目は web 検索に寄りすぎて domain tool を扱わないこと、2 つ目は API 呼び出しの正しさだけを見て最終的な情報統合を見ないこと、3 つ目は複数情報源をまたぐ長めの探索を十分に評価していないことである。
そのため著者が作りたいのは、単なる検索問題ではなく、web だけでは解けず複数の専用ツールをまたぐ必要がある問題を集めた benchmark であり、そこにこの研究の目的がある。
3. 手法と実装
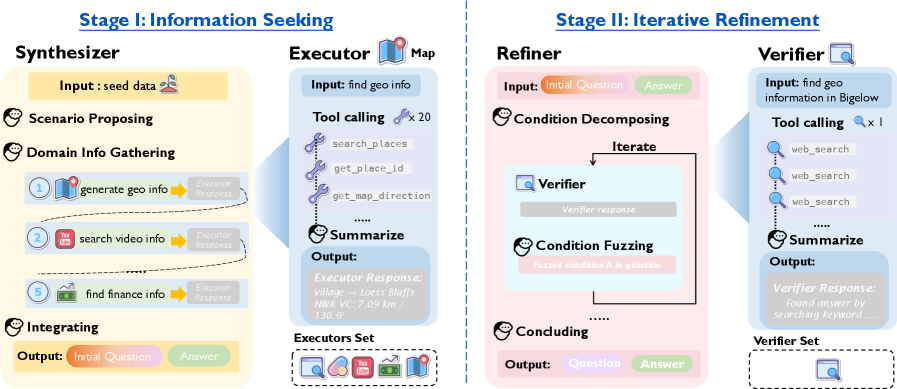
提案の中心は 2 つあり、1 つ目が benchmark 本体の InfoMosaic-Bench、2 つ目がそのデータ生成パイプラインである InfoMosaic-Flow である。
InfoMosaic-Bench は 621 問からなり、医療・生物、金融、地図、動画、web、multi-domain の 6 区分を含んでおり、77 個のツールが 7 個の MCP server にまたがっている。
各問題には最終回答だけでなく、中間条件ごとの正解ラベルとツール呼び出しの痕跡も付いているため、最終性能だけでなく途中の失敗も分析しやすい。
InfoMosaic-Flow は 2 段構成で動き、Stage 1 では organizer-worker 型の構成を取りながら、organizer が問題条件や探索計画を組み立て、domain ごとの worker が実際にツールを叩いて証拠を集める。
さらに Stage 2 では web search ベースの verifier を使い、「実は単純な web 検索だけで解けてしまう問題」を削りつつ、条件の言い換えや制約の組み換えを行って、本当に多情報源統合が必要な問題へ寄せていく。
品質管理もかなり意識されており、最低ツール呼び出し数の閾値で簡単すぎる問題を落とし、答えが証拠から導けるかを確認しつつ、条件文が不自然でないかも自動で検査したうえで、最後に人手で修正や除外を行っている。
4. 評価と結果
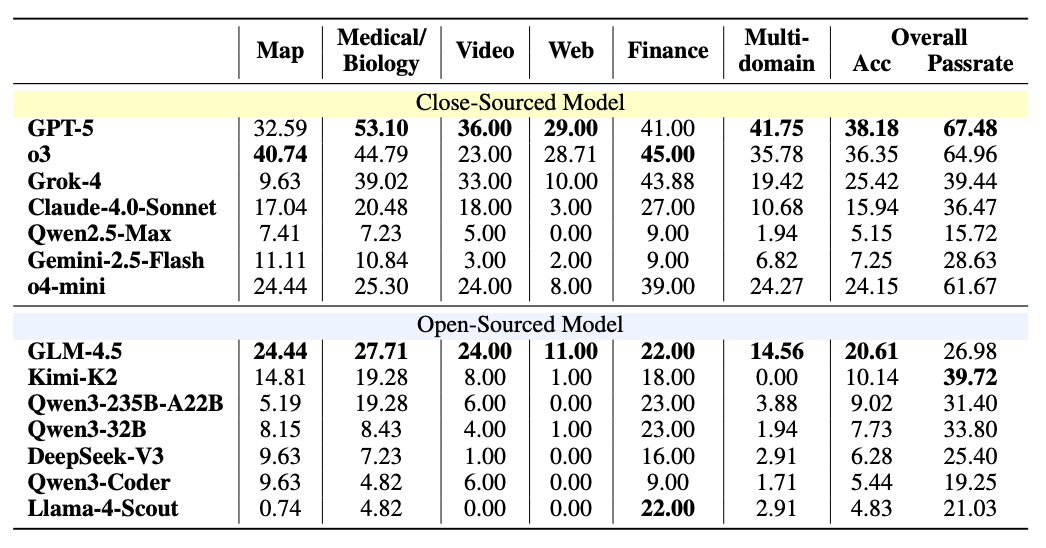
評価指標は Accuracy と Pass Rate の 2 つであり、Accuracy は問題全体を最後まで正しく解けたかを見る厳しめの指標で、Pass Rate は中間条件や小問レベルでどこまで達成できたかを見る補助的な指標である。
判定は完全一致だけに頼らず、意味的に正しい答えも拾えるよう LLM judge を併用しており、そのため実利用に近い見方をしつつ細かい分析もできるようにしている。
web search のみで 14 モデルを比較すると、最高でも GPT-5 が Accuracy 38.18%、Pass Rate 67.48% にとどまっており、一般的な web 検索能力が高くても、それだけでは複数情報源の統合問題を十分に解けないことが分かる。
著者はここから、domain-specific な情報探索では「検索できること」より「必要な情報源を見極めて組み合わせられること」が重要であり、既存 benchmark ではその難しさが十分に表に出ていなかったと解釈している。
さらに、domain tool を足せば単純に良くなるわけでもなく、GPT-5 では地図が +7.41、動画が +10.00 改善した一方で、医療・生物は -9.73、金融は -9.00、multi-domain は -1.94 となっており、全体平均では 38.18% から 38.61% へとほぼ横ばいだった。
GLM-4.5 でも似た傾向が見られているため、ツールが存在すること自体より、それを正しく選び、適切な順序で使えるかが本質的な難所だと読める。
失敗分析を見ると、domain tool 利用時の失敗の 22.4% は tool usage または tool selection の誤りに由来しており、性能はツール呼び出し回数とともに最初は伸びるものの、おおむね 8 回前後で頭打ちになる。
この結果からは、呼び出し回数を増やせば解けるわけではなく、どのツールをいつ使うかという探索戦略そのものが現在の agent の弱点だと分かる。


備考 / Comments
この論文の確かな貢献は、「web search が強い agent」と「domain-specific tool を扱える agent」の差を、同じ benchmark 上で比較しやすくした点にあり、単なる API 呼び出しの正しさではなく、複数情報源をまたいだ最終的な情報探索の成功まで評価しているため、今の tool-augmented agent の弱点がかなり見えやすい。
特に、「専用ツールを増やせば性能が上がる」とは限らず、むしろ選択と統合が新しい難所になるという結果は、今後の agent 設計や評価系を考えるうえで有用である。
一方で、評価に LLM judge を使っているため実用的ではあるものの、判定系のバイアスが完全に消えるわけではなく、人間ベースラインも AI なし・30 分制限という条件での比較である以上、agent と完全に同条件の比較ではない点には注意が必要である。
メインTOPIC
Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
Kangsan Kim, Minki Kang, Taeil Kim (KAIST), Yanlai Yang, Mengye Ren (NYU), Sung Ju Hwang (KAIST / DeepAuto.ai)
🎯 論文概要(要点サマリー)
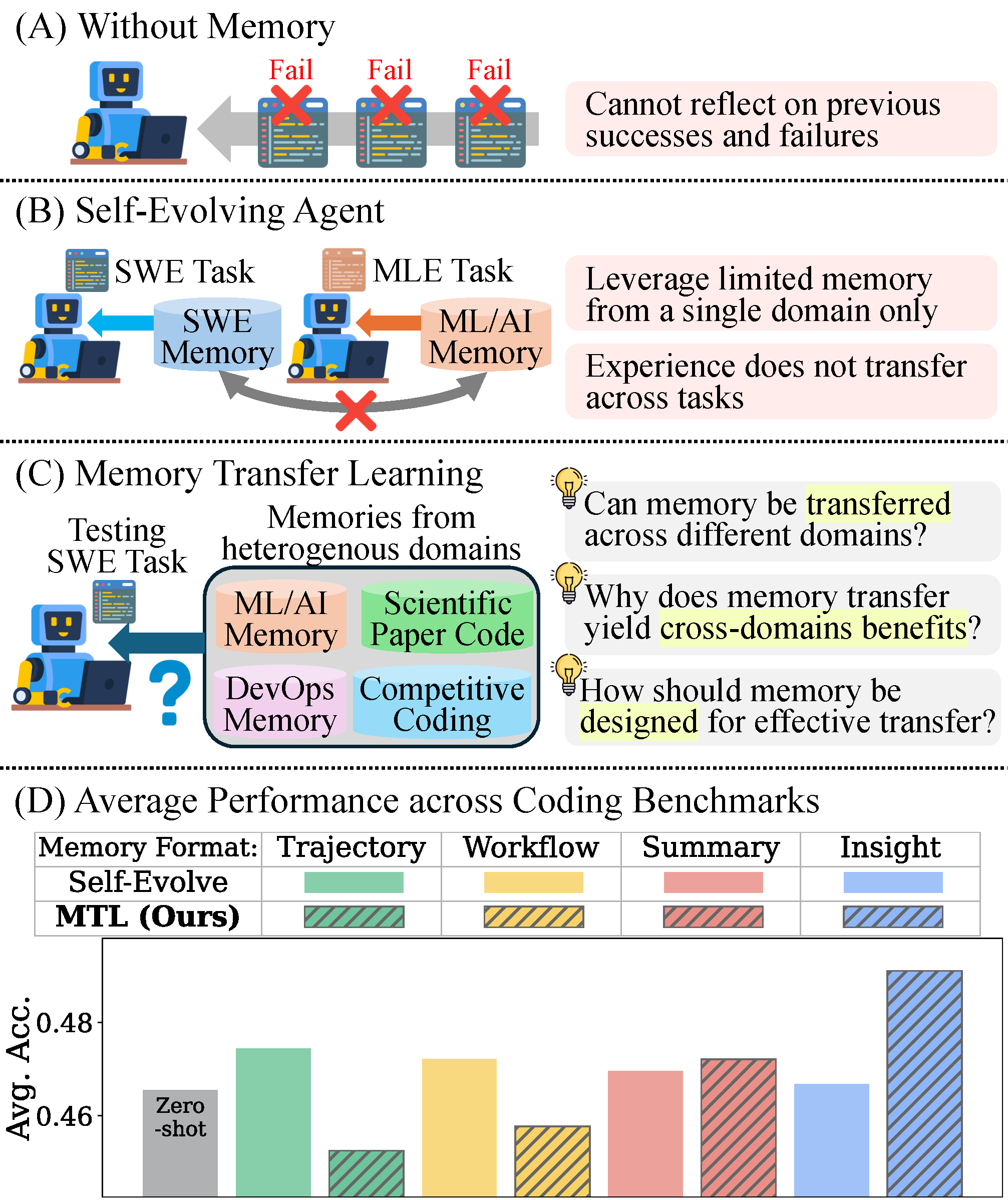
本論文は、コーディングエージェントにおける Memory Transfer Learning(MTL) の実証研究である。従来の自己進化型エージェント(self-evolving agent)は、同一ドメイン・同一ベンチマーク内に閉じたメモリ利用にとどまっていたが、本論文は「異なるドメインで得られたメモリを横断的に再利用できるか」という問いに正面から答える。
3つの中心的リサーチクエスチョン(RQ)
- RQ1: 異種ドメインのメモリはコーディングエージェントの性能を向上させるか?
- RQ2: なぜ転移されたメモリが異なるドメインを跨いで効果を発揮するのか?
- RQ3: 転移効果を左右する最も重要な因子は何か?
4つの発見(Core Findings)
- MTLは有効: 6ベンチマーク平均で +3.7% の性能向上。自己進化手法よりも少ないメモリ数で高効率。
- 転移されているのはメタ知識: コード片そのものではなく、「検証手順」「環境制約への対処」「段階的編集の規律」といった手続き的・戦略的な知恵が転移している。
- 抽象度が転移性を決める: Insight(高抽象)> Summary > Workflow > Trajectory(低抽象)。低抽象メモリは負の転移(negative transfer)を引き起こす。
- スケーリングと汎化: メモリプールのサイズ・ドメイン数の増加で性能向上、モデル間でも転移可能。
第1章 イントロダクション
1.1 背景:学習データのスケーリング飽和と自己進化パラダイム
近年、言語モデルにおける学習データ量のスケーリングによる性能向上が頭打ちになりつつある。この状況下で、自己進化(self-evolution)──すなわち、過去の推論結果を活用して追加の教師なしで将来の性能を高める枠組み──が、エージェントの能力を前進させる有望なパラダイムとして浮上している。
自己進化エージェントにおいてメモリは中心的な役割を果たす。メモリは、過去の推論から再利用可能なワークフローや転移可能な洞察を抽出し、後続のタスクに適用することを可能にする。コーディングエージェントの文脈では、メモリは以下のいずれかの形で具体化される:
- コード片(code snippets)
- 経験的知識(プランニング痕跡、デバッグ痕跡)
- 一般的なプログラミング原則
メモリを活用することで、エージェントは類似タスクにおける成功解のパターンを参照して推論オーバーヘッドを削減でき、また長期的コード編集における不要な失敗行動を累積した手続き的・戦略的ガイダンス(小刻み修正のヒューリスティクスや検証ルーチンなど)によって回避できる。
1.2 既存手法の限界:単一ドメインへの閉じ込め
既存の「メモリ拡張型コーディングエージェント」は有望な成果を示しているが、メモリの生成と検索を同一ドメイン(しばしば同一ベンチマーク内)に限定している根本的制約を抱える。
しかし現実のコーディングエージェントは、次のような広範なプログラミング問題を扱わねばならない:
- リポジトリレベルのソフトウェアエンジニアリング(SWE-Bench)
- 機械学習モデル開発(MLGym-Bench)
- 科学論文の再現コード(ReplicationBench)
- 関数レベルの競技プログラミング(LiveCodeBench)
これらは表面的には別物に見えるが、共通の基盤インフラを共有している:
- ランタイム環境(Linux shell 等)
- プログラミング言語
- ファイル横断依存スタック
この共通基盤を考慮すれば、異種ドメインから導出されたはるかに豊かなメモリプールを活用でき、同一ドメインから抽出されたものよりむしろ効果的な転移可能知識を提供できる。
1.3 先行研究のギャップ
AgentKB (Tang et al., 2025) などが、複数タスクにまたがる大規模統一メモリプールの構築を既に探求しており、「一般的推論経験がソフトウェアエンジニアリングを支援できる」初歩的証拠を示している。しかし:
- 転移のメカニズムの深い分析が欠けている
- どの形式の知識が転移可能か不明
- 転移志向のメモリをどう設計すべきかが未解明
- コーディング特有の共有原則に焦点を当てていない
1.4 本研究の貢献
本論文は、コーディングエージェントにおけるMTLを体系的に調査し、以下の貢献を成す
- 4種類のメモリ形式(Trajectory / Workflow / Summary / Insight)で性能を評価
- 6つのコーディングベンチマークで体系的な比較実験
- ゼロショット vs MTL の対比で平均3.7%の性能向上を実証
- 抽象度と転移効果の正の相関を定量的に示す
- 負の転移の原因分析、スケーリング則、モデル間転移の可能性を報告
第2章 関連研究
2.1 コーディングエージェント
LLMのコード生成能力の向上を背景に、bashシェルなどのプログラミング環境と対話するLLMベースのコーディングエージェントが活発に研究されている。発展の系譜は以下の通り:
(a)関数レベル(初期)
- AlphaCodium (Ridnik et al., 2024): フローエンジニアリングを導入。推論・生成・ランキング・デバッグを反復。
- LDB (Zhong et al., 2024): ランタイム実行情報を活用した新しいデバッグフレームワーク。
(b)リポジトリレベル
- CodeAgent (Zhang et al., 2024)
- RepoAgent (Luo et al., 2024)
- RLCoder (Wang et al., 2024b)
これらはSWE-BenchやTerminal-Bench2など、リポジトリ全体に及ぶ修正タスクを対象とする。
(c)ドメイン特化
- Paper2Code (Seo et al., 2025): ML論文の再現コード生成
- BixbBench (Mitchener et al., 2025): 計算生物学タスク
2.2 メモリベース自己進化エージェント
自己進化エージェントは、過去の経験を(成功パターンの再利用・失敗行動の回避として)活用する。代表的研究:
| 手法 | 貢献 |
|---|---|
| AWM (Wang et al., 2024c) | Webエージェントで共通ワークフローを収集 |
| ReasoningBank (Ouyang et al., 2025) | テスト時スケーリングで軌跡から有用な洞察を抽出 |
| Dynamic Cheatsheet (Suzgun et al., 2025) | 再利用可能戦略と洞察を符号化する進化的メモリ |
| ReMe (Cao et al., 2025) | 生成〜検索〜精緻化まで包括的なフレームワーク |
| MemEvolve (Zhang et al., 2025) | メタ進化によるシステムレベル進化 |
これらの決定的な限界: 同一ベンチマーク・同一タスクドメイン内でのみ評価しており、他ドメインから生成されたメモリの潜在的価値を見落としている。
2.3 転移学習
伝統的な転移学習はモデル更新(パラメトリック適応)に依存してきた(Howard & Ruder 2018; Houlsby et al. 2019 など)。LLMの強い汎化能力の出現により、最近は非パラメトリックな知識転移が注目されている。
- In-context learning (Dong et al., 2024 ほか): 文脈内に与えられた知識をLLMが再利用
- AgentKB (Tang et al., 2025): 複数タスクにまたがる統一メモリプール管理フレームワーク
第3章 Memory Transfer Learning (MTL)
3.1 手法:2段階のメモリ活用プロセス
MTLはシンプルな2段階構造を持つ:
3.1.1 メモリ生成(Memory Generation)
推論履歴の収集
メモリ生成の前段として、全ベンチマーク上でエージェント推論を実行し、得られた軌跡(trajectory)を収集する。完全な推論履歴 H は次の形で表される:
- t: タスク
- r_i: 推論文(reasoning)
- a_i: 行動(action, bashコマンドやコード)
- o_i: 観測(observation, 実行結果)
さらに、LLMベースのjudgeを用いて各試行の成否を判定し、成功/失敗ごとに異なるメモリ生成プロンプトを使用する。
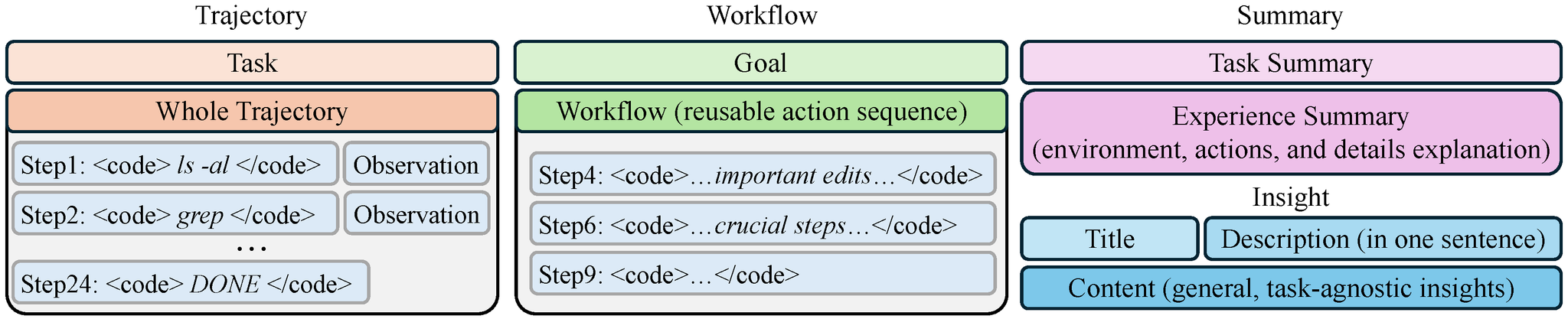
4つのメモリ形式(抽象度の階段)
本論文の核心的設計。抽象度の低いもの→高いものの順に整理される:
| 形式 | 抽象度 | 構造 | 特徴 |
|---|---|---|---|
| Trajectory (T) | 最低 | 全コマンドと観測をそのまま保存。失敗手順も含む。類似コマンドの期待結果を暗黙的に推定可能 | |
| Workflow (W) | 低 | 軌跡からLLMが目標 g と重要行動列のみを抽出。Trajectoryより大幅に短く、無関係情報による注意散漫のリスクが小 | |
| Summary (S) | 中 | タスク要約 と経験要約 の1段落。環境・行動・結果・成否理由の分析を含む | |
| Insight (I) | 最高 | ReasoningBankの設計に従う。タイトル・1文の説明・内容の3部構成。特定ファイルや詳細を明示的に禁止し、一般化可能な洞察のみを生成 |
- Insightでは「将来の類似タスクに汎化可能な洞察を書け」とLLMに明示的に指示
- 成功軌跡と失敗軌跡で異なるプロンプトを使用


3.1.2 メモリ検索(Memory Retrieval)
メモリプールの構築
評価ベンチマーク に対して、評価対象以外の全ベンチマークからメモリを集約し、異種ドメインメモリプールを構築する:
- τ : メモリ形式(memory type)
- Bi : 評価対象のベンチマーク(target / evaluation benchmark)
- Mτ(k) : 個別のメモリアイテム
- t(k) : そのメモリの生成元タスク
- Ni : メモリプールの総数
各メモリはテキスト埋め込みモデルで特徴抽出され、埋め込みと共にインデックス化される。
検索戦略
推論時、現在のタスクに対応する埋め込みと、メモリ埋め込みのコサイン類似度を計算。Top-N サンプリングで最も類似度の高い3件(N=3)を取得してシステムプロンプトの冒頭に注入する。
クエリの作り方にも工夫がある:
- Trajectoryメモリへのクエリ:タスク情報同士の埋め込み類似度(両方にTask情報があるため)
- その他(Workflow/Summary/Insight): タスク情報を持たないため、モデルに「4–5文の解法プランを書かせ」、それをクエリとする
3.2 実験詳細
3.2.1 データセット(6ベンチマーク)
| カテゴリ | ベンチマーク | 内容 |
|---|---|---|
| 競技・関数レベル | Aider Polyglot (Gauthier, 2024) | 競技プログラミング |
| 競技・関数レベル | LiveCodeBenchv6 (Jain et al., 2024) | 汚染フリー評価 |
| リポジトリレベル | SWE-Bench Verified (Jimenez et al., 2024) | GitHub実問題の解決 |
| リポジトリレベル | TerminalBench2 (Merrill et al., 2026) | CLI環境下のハードタスク |
| ドメイン特化 | ReplicationBench (Ye et al., 2025) | 天体物理論文のコード再現 |
| ドメイン特化 | MLGym-Bench (Nathani et al., 2025) | ML研究タスク |
- 100件を超えるベンチマークはランダム100件サンプリング
- 評価指標はPass@3
3.2.2 モデル・基盤ツール
- LLM: (メモリ生成・エージェント本体・judge すべて)
- エージェント基盤: (Yang et al., 2024)
- 評価プラットフォーム: (Team, 2026)
- 埋め込み: OpenAI
- 検索件数: N=3
- 追加モデル: DeepSeek V3.2、Qwen3-Coder-480B-A35B-Instruct で汎化性検証
第4章 実験結果と分析
4.1 MTLの全体性能
4.1.1 メイン結果(Table 1)
GPT-5-mini でのPass@3(主要結果)
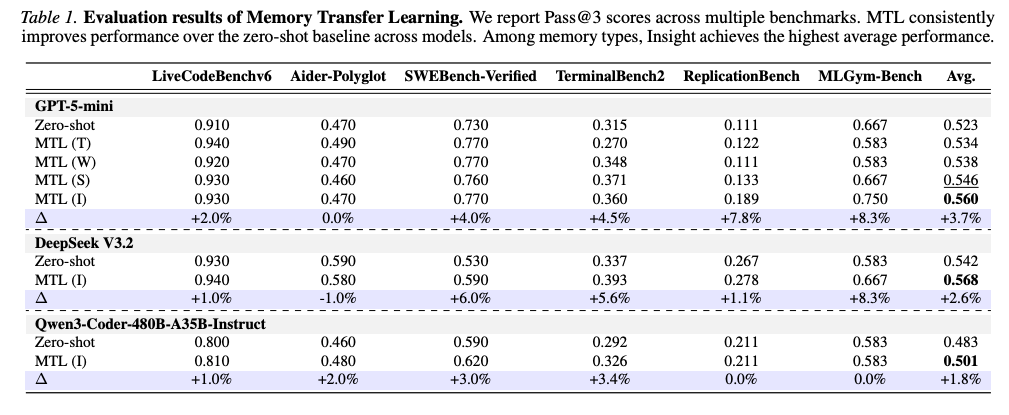
- Insight が常に最高(4形式のうち)
- 4つのベンチマークで4%以上(最大8.3%)の改善
- ReplicationBench・MLGym-Benchのような難しいドメイン特化タスクほど効果が大きい
他モデルでの再現性:
- DeepSeek V3.2: +2.6% 平均改善
- Qwen3-Coder-480B: +1.8% 平均改善
→ オープンソースモデルにも有効、広い適用性を示す。
4.1.2 自己進化手法との比較(Table 2)
3ベンチマーク(LCB / SWEB / RepliB)での比較:
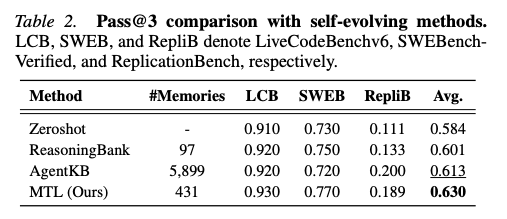
- ReasoningBankはin-domainのみで小規模プールしか使えず最低ゲイン
- AgentKBは5.8k件もの多量のout-of-domainメモリを使うが、一般推論タスク由来のため効果が制限される
- MTL はわずか431件で最高性能 → 効率・効果ともに優位
💡 Core Finding 1: MTLはコーディングエージェント性能を大幅に向上させ、自己進化手法を効率・効果の両面で上回る。
4.2 MTLのメカニズム
4.2.1 なぜMTLはエージェントを助けるのか?(Figure 3)
ゼロショットで失敗したが MTL(Insight) で成功したインスタンスを収集し、GPT-5 でカテゴリ分類した結果:
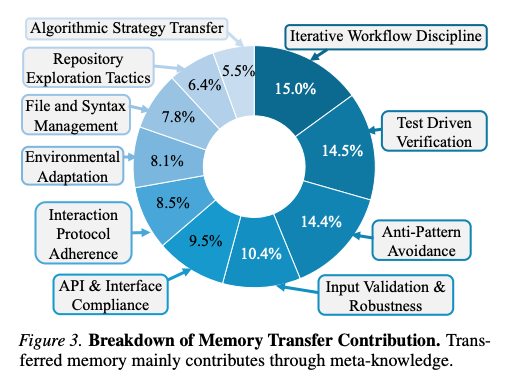
- 転移の利益の大部分は「メタ知識」から来ている
- 「どう行動するか」「実行・検証環境とどう安全にやり取りするか」の手続き的ガイダンス
- リスク制御された編集:最小パッチ戦略、公式テスト不在時の自己生成検証、ツールチェーン障害の予期
- 対照的に、具体的なアルゴリズム転移はわずか5.5%に留まる
4.2.2 ケーススタディ:Zero-shot vs MTL
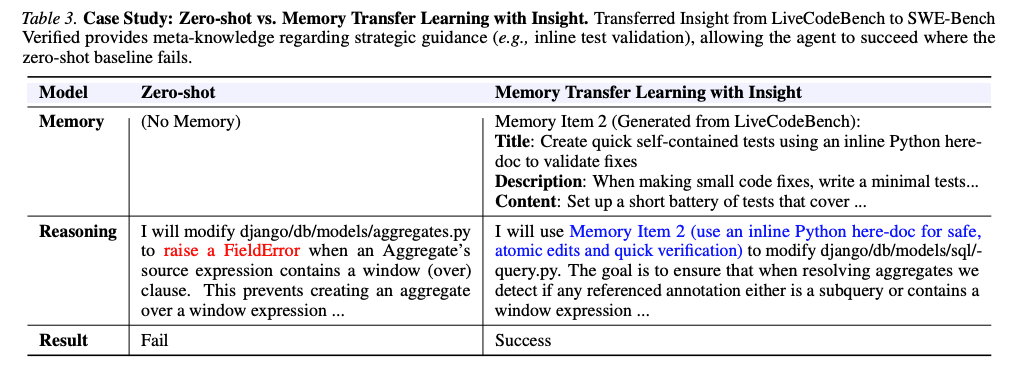
題材: SWEBench-Verified の1インスタンス(Django の集約関数における window 式の処理)
Zero-shot:
を修正し、Aggregateのソース式にwindow句があれば FieldError を発生させる → 失敗
MTL(Insight)(LiveCodeBench から転移された Memory Item 2 を使用):
- メモリ内容: "インライン Python here-doc を使って自己完結テストを作成し、修正を検証する"
- エージェントの推論: メモリのガイドを内部化し、 で解決時に subquery や window 式を検出するように修正し、インライン here-doc で検証 → 成功
異なるベンチマーク間(LiveCodeBench → SWE-Bench)でも、「how-to の知恵」は横断的に有効であることを示す。
💡 Core Finding 2: 転移可能な知識はドメインを跨いで存在し、その主要形態は手続き的・行動的ガイダンスとしてのメタメモリであり、ドメイン固有知識ではない。
4.3 メモリ抽象度の影響
4.3.1 4形式の抽象度
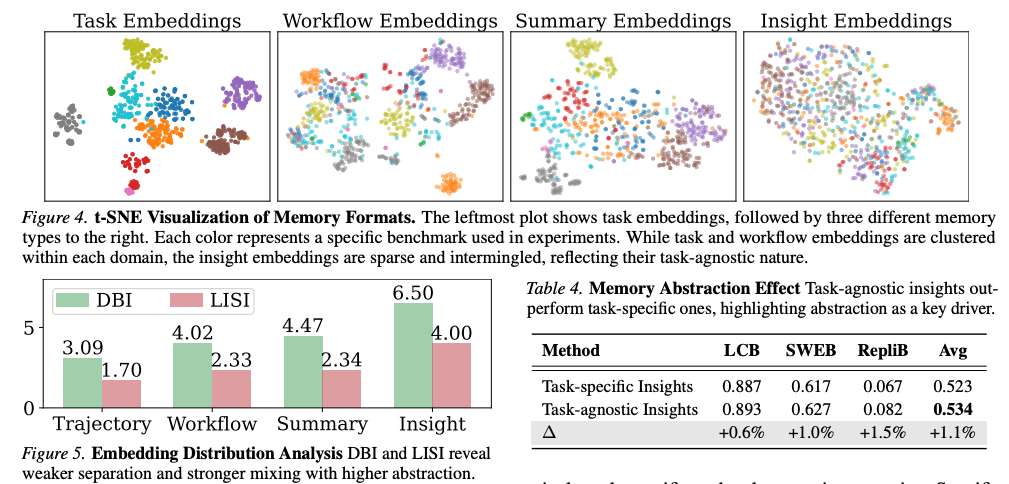
- t-SNE可視化(Figure 4)の解釈:
- Task埋め込み: ベンチマーク別に明確なクラスタを形成
- Workflow埋め込み: 依然としてドメイン別にクラスタ化
- Summary埋め込み: やや分散
- Insight埋め込み: ベンチマーク間で疎に混在 → タスク非依存の性質
- DBI(Davies–Bouldin Index): 値が大きいほどクラスタ分離が弱い
- LISI(Local Inverse Simpson's Index): 値が大きいほど局所的な混在が強い
両指標とも Trajectory → Insight で単調増加 → 抽象度が上がるほどタスク依存性が消え、汎化性が高まることを定量的に確認。
4.3.2 抽象度と転移効果の相関
Insight > Summary > Workflow > Trajectory の順で性能が高い。かつすべてのMTL変種がゼロショットを上回る。転移メモリは汎用的なメタ知識を提供する一方、実装固有の詳細は agent を混乱させるため、より抽象的で汎化された表現ほど転移効果が高い。
4.3.3 抽象度の効果を切り分ける実験(Table 4)
メモリ形式は Insight に固定し、タスク特異性のみを変える制御実験:
- 各 Insight メモリから、LLM に「元のタスクを推測させる」
- 推測タスクと真のタスクの類似度を測る
- 上位30%(高類似度 = タスク特異的)と下位30%(低類似度 = タスク非依存)に分割
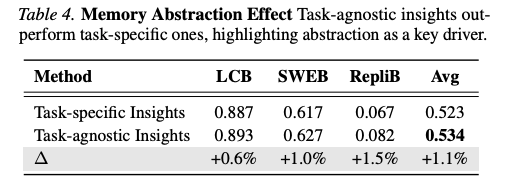
→ 同じメモリ形式内でも、タスク非依存のものが一貫して優位。形式自体ではなく抽象度という性質が本質的な駆動因子であることを立証。
4.3.4 ケーススタディ:Trajectory vs Insight(Table 5)

題材: MLGym-Bench の MetaMaze ナビゲーションタスク
Trajectory転移(失敗):
- 転移元: Housing Price Prediction(全く別の ML タスク)
- エージェントの挙動: メモリ内の「 を引数に持つ OneHotEncoder 使用」パターンを盲目的に模倣
- 結果: sklearn の API 変更により → 失敗
Insight転移(成功):
- 転移元メモリ: "評価要件を検査し、train+val を結合し、頑健な前処理を行い、ライブラリAPI変更に適応せよ"
- エージェントの挙動: 高レベルの行動原則を抽象的ガイドラインとして受け取り、新タスクに合わせて自分で実装詳細を導出
- 結果: 成功
洞察:
- Trajectory は脆い実装の「アンカー(錨)」として機能し、異なるタスク環境(言語・ファイル構造・実行パイプライン)で衝突を招く
- Insight は抽象的な手続き原則を提供し、エージェントの適応プロセスを制約せずに導く
💡 Core Finding 3: より抽象的・一般化されたメモリ表現ほど、脆い実装への固定化を避けることでより高い転移効果を発揮する。
4.4 更なる分析とアブレーション
4.4.1 MTLにおける負の転移(Negative Transfer)
Table 1 では一部ベンチマークで性能低下が見られる(例:GPT-5-mini の Trajectory on TerminalBench2 で -4.5%)。ゼロショット成功 → MTL失敗のインスタンスを分析し、3種類の失敗モードを特定:
- Domain-mismatched anchoring(ドメイン不整合アンカリング)
- 構造的には無関係だが表面的に類似したメモリが誤誘導のアンカーとなる
- 誤った仮定を導入し、エージェントの推論を核心的論理・制約から逸らす
- False validation confidence(偽の検証)
- 検証関連メモリが偽の確信を生む
- 形式的基準ではなく表面的チェックに頼った自己確認ループを招き、仕様を見落とし silent failure に至る
- Misapplied best-practice transfer(ベストプラクティスの誤適用)
- 成功パターンが無差別に転移され、タスク固有の意味論を上書きする
- 過剰な手続き化(over-engineering)や、新タスク要件に反する既存ワークフローへの硬直的順守
原因は主に:
- 間違ったメモリ検索
- 検索したメモリの新タスクへの適応失敗
→ 対策方向: 意味的類似ではなく真に有用なメモリを取り出す高度な検索、メモリ書き換えモジュール(Cao et al. 2025)などのより良い適応機構。
4.4.2 ケーススタディ:負のメモリ転移

失敗モード①:技術パターンの誤適用
- タスク: C++ 実装()
- 転移メモリ: R言語のファイル書き込みパターン()
- エージェント挙動: heredoc パターンを盲目的に C++ に適用し、既存のネームスペース・構造を確認せずにファイルを上書き
- 結果: 失敗
失敗モード②:意味的歪曲
- タスク: MetaMaze ナビゲーションで 5 つのチェックポイント生成
- 転移メモリ: 「実験前にデータセットと事前学習チェックポイントを検証せよ」
- エージェント挙動: これを「品質よりも素早い完遂を正当化する」口実として歪曲し、短い smoke test で済ませてしまう
- 結果: 失敗
💡 Finding 4: 負の転移は主に、ドメイン不整合の誤誘導アンカー、偽の検証シグナル、手続き的再利用の誤適用から生じる。
4.4.3 メモリプールサイズの影響(Figure 6)
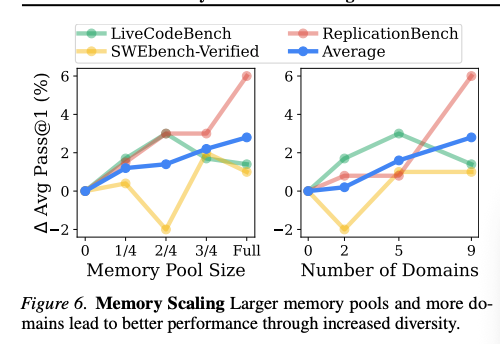
2つのスケーリング実験:
(a)メモリプールサイズのスケーリング
プールから 0 , 1/4 , 2/4 , 3/4 , Full の比率でランダムサンプリング:
- 平均性能はプールサイズに比例して単調増加
- 理由: 大きいプールほど、対象タスクに関連するメモリを取り出せる確率が上がる
(b)ソースドメイン数のスケーリング
0 , 2 , 5 , 9 ドメインと拡張:
- 9ドメイン使用で最高性能
- ドメインの多様性が増すほど、転移可能な知識の多様性が増し、有用なメタ知識を取り出せる確率が上がる
💡 Finding 5: MTLの効果はメモリプールのサイズとドメイン数にスケールする。
4.4.4 モデル間メモリ転移(Cross-Model)
仮説: もし MTL の利益が主にメタ知識から来るなら、異なるモデルが生成したメモリも有効なはず(メタ知識はモデル非依存で、テスト環境や一般的コーディングガイドラインに関わるため)。
結果(Pass@1平均):
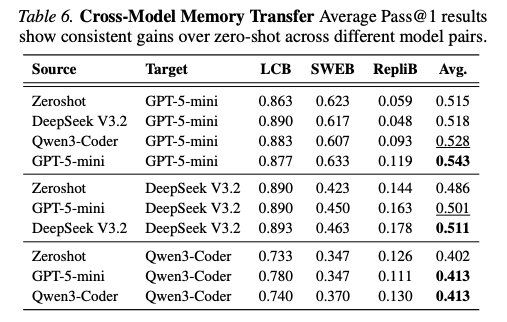
観察:
- すべてのクロスモデル転移がゼロショットを上回る
- 強モデル(GPT-5-mini)→弱モデル、弱→強の両方向で有効
- ただし、自己生成メモリが最高性能(モデル固有バイアスの存在を示唆)
💡 Finding 6: メモリは異なるモデル間でも転移可能だが、自己生成メモリが最良の性能を出す。
4.4.5 検索手法の分析
負の転移が検索・適応の不備から生じるため、より洗練された検索手法が効くかを調査:
- LLM Reranking: 埋め込みで20件候補を取得 → LLMが最有用3件を選択
- Adaptive Rewriting: 取得したメモリを対象タスクに合わせて書き換え
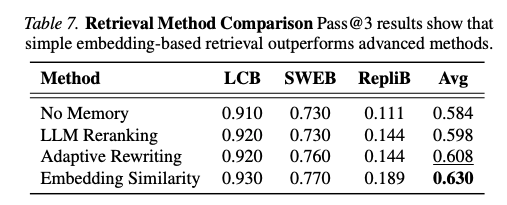
シンプルな埋め込み類似度検索が最強。
- 理由: 動的・多段階のエージェント環境では必要な知識を事前に予測することが困難
- 静的設定向けの検索手法は異種ドメイン転移に汎化しない
- 今後の研究方向: ドメインルーティング(Yeo et al. 2025a)、ステップごとのメモリ検索(Cao et al. 2025)
💡 Finding 7: クロスドメインメモリ検索は本質的に挑戦的で、静的な検索手法は異種エージェント環境で汎化しない。
第5章 結論
コーディングエージェントにおけるMemory Transfer Learningの包括的実証研究。
従来の「メモリ利用は同一ドメインに限定すべき」という暗黙の仮定に挑戦し、6つの多様なベンチマークにわたる広範な評価により、異種ドメイン統一メモリプールがエージェント性能を3.7%向上させることを実証した。
3つの設計原則
- メタ知識こそが転移価値の主源(タスク固有ワークフローではない)
- 抽象度が転移性を決める: 高抽象(Insight)は汎化し、低抽象(Trajectory)は脆い実装固定化により負の転移を招く
- 転移効果はメモリプールのサイズと多様性にスケール: 有用なメタ知識を取り出す確率が上がる
今後の展望
本研究は、単一ドメイン設定を超えるメモリ利用の実証的基盤を打ち立て、自己進化型コーディングエージェントの頑健なメモリ使用戦略のさらなる研究を喚起することを目指す。
Impact Statement
- ポジティブ: エージェントシステムの汎化性・データ効率の向上、ドメイン特化ファインチューニングの必要性削減、多用途なソフトウェアエンジニアリングエージェント開発の参入障壁低下
- 懸念: 負の転移により、実装パターンの誤適用やドメイン固有の安全制約の見落としのリスク → 頑健な検索戦略の配慮が不可欠
🔑 本論文の学術的・実務的インパクト
学術的意義
- メモリ利用の設計空間の拡大: 単一ドメインという暗黙の前提を打破
- 抽象度という新しい分析軸の導入と定量化(DBI/LISI、タスク非依存度など)
- メタ知識が転移の本体という洞察は、今後の自己進化エージェント設計に示唆を与える
実務的意義
- コーディングエージェント運用者は、異種タスクの経験ログを積極的に集約
- メモリ設計は Trajectory のような具体例より Insight のような抽象原則を優先
- モデル非依存性により、ベンダーを越えたメモリ共有・再利用が可能
感想
- MTLがコーディングエージェントだかでなく、業務的なAIエージェントでも効果を発揮するなら価値が上がりそう。
- 例:ある企業Aで経理AIエージェントXが稼働しており、そこで貯めたメモリのInsightを営業AIエージェントYに転移して効果を発揮する。
- これができるなら、経理AIエージェントXと営業AIエージェントY双方のメモリを互いに転移してメモリをブラッシュアップできそう。
- Trajectory〜Insightのメモリ数の比較が気になる
- 抽象化するということは異なる事象から共通項が見出されるということで、TrajectoryよりもInsightのほうが件数が少なる気がする。
- 十分に汎用性の高いInsightはメモリよりもハーネスとしてプロジェクト共通にしてしまうエンジニアリングもありえそう。