
2026-04-28 機械学習勉強会
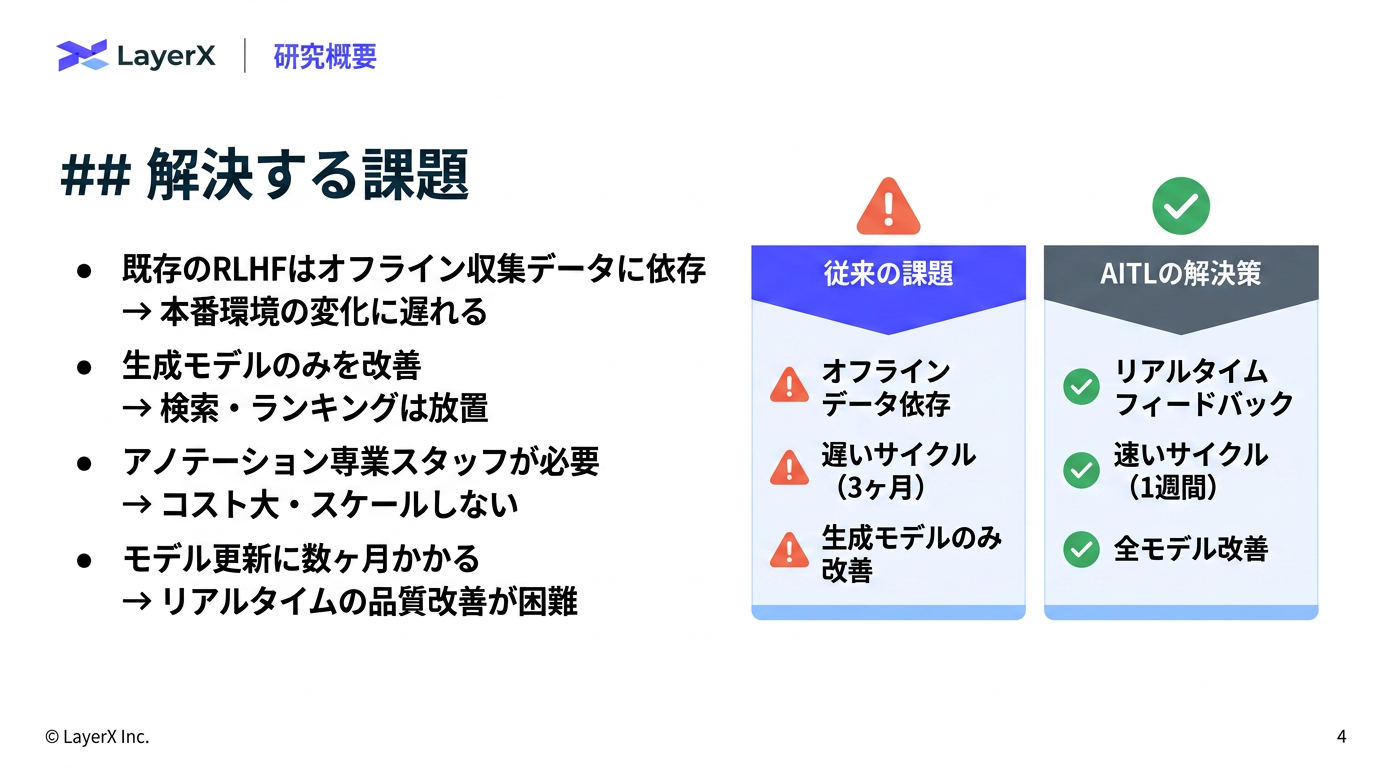
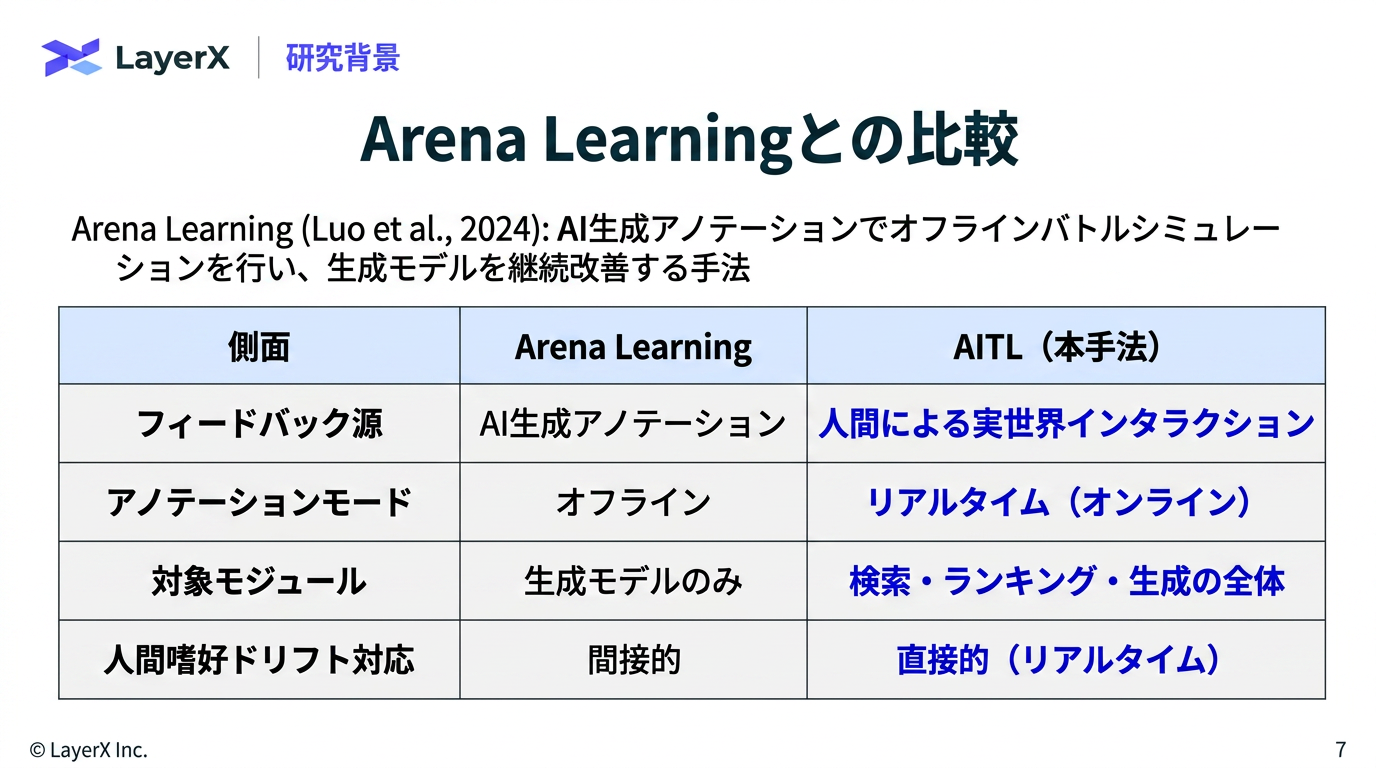
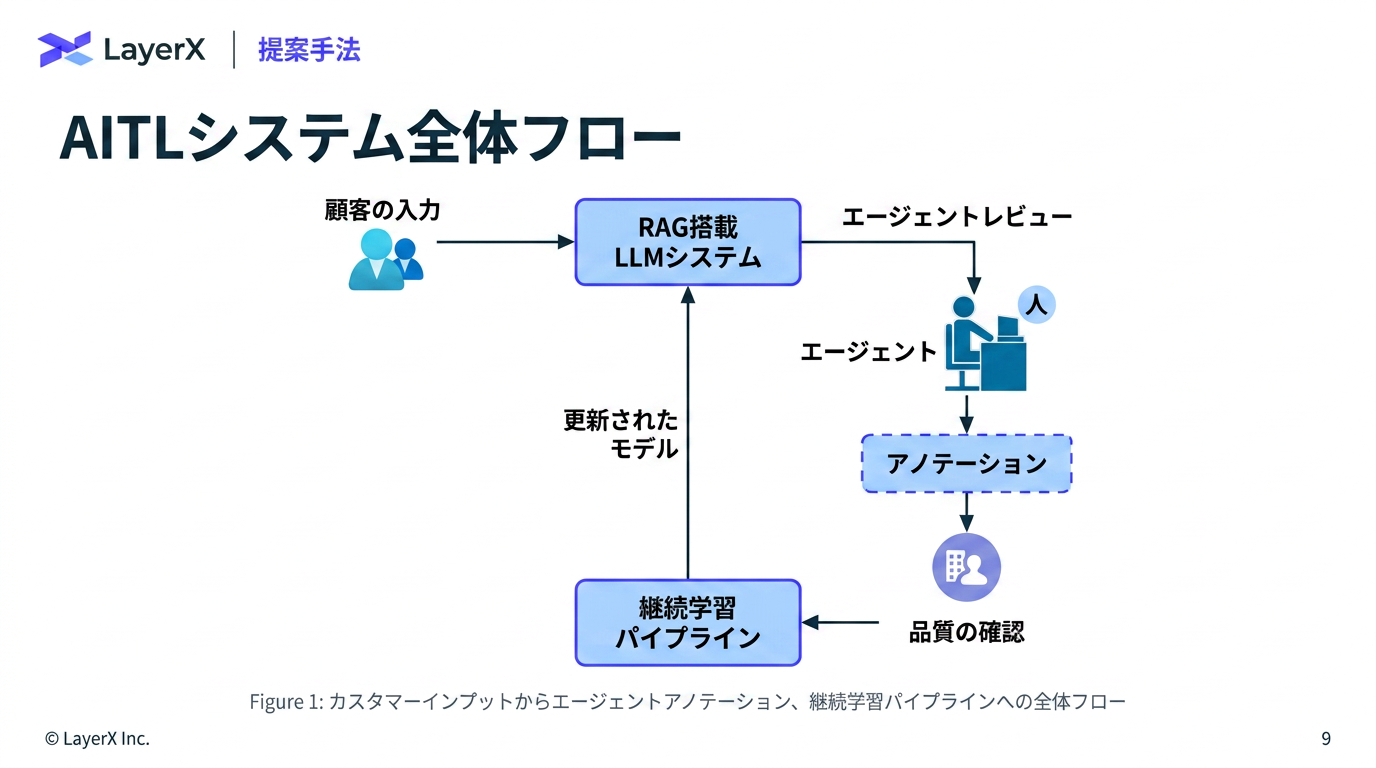
今週のTOPIC[paper] Agent-in-the-Loop: A Data Flywheel for Continuous Improvement in LLM-based Customer Support[blog]GPT-5.5 System Card[paper] Q-RAG: Long Context Multi-step Retrieval via Value-based Embedder Training[paper] Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG[paper] Learning is Forgetting: LLM Training as Lossy Compression[paper] ClawBench: Can AI Agents Complete Everyday Online Tasks?[paper]Image Generators are Generalist Vision LearnersメインTOPICDeepSeek-V4:Towards Highly Efficient Million-Token Context Intelligence概要背景アーキテクチャCSA/HCAによりアテンションコストを抑えるmHC(Manifold-Constrained Hyper-Connections)Muon Optimizer学習パイプライン概要事後学習オンポリシー蒸留思考管理評価標準ベンチマーク実用ベンチマーク
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[paper] Agent-in-the-Loop: A Data Flywheel for Continuous Improvement in LLM-based Customer Support
- Airbnbのカスタマーサポートにおける自動応答システムの改善例





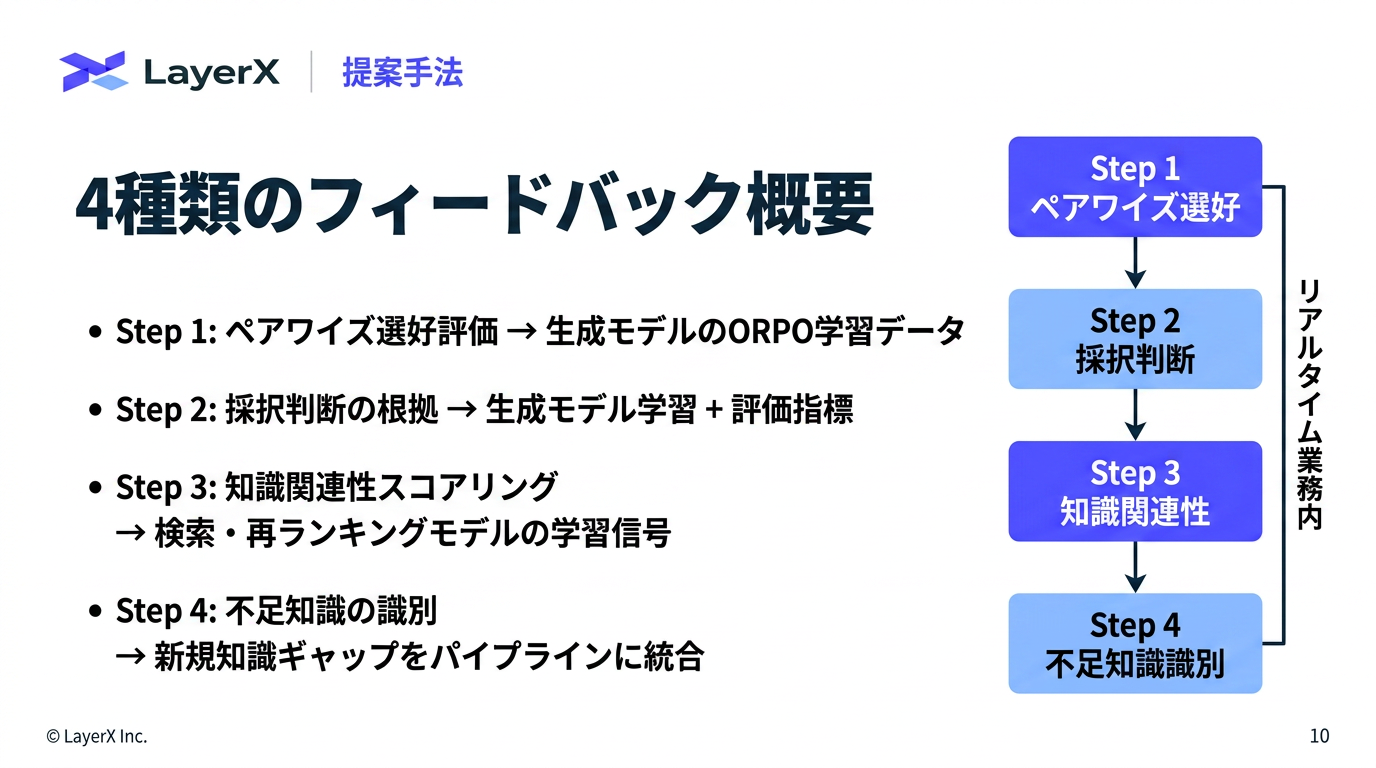




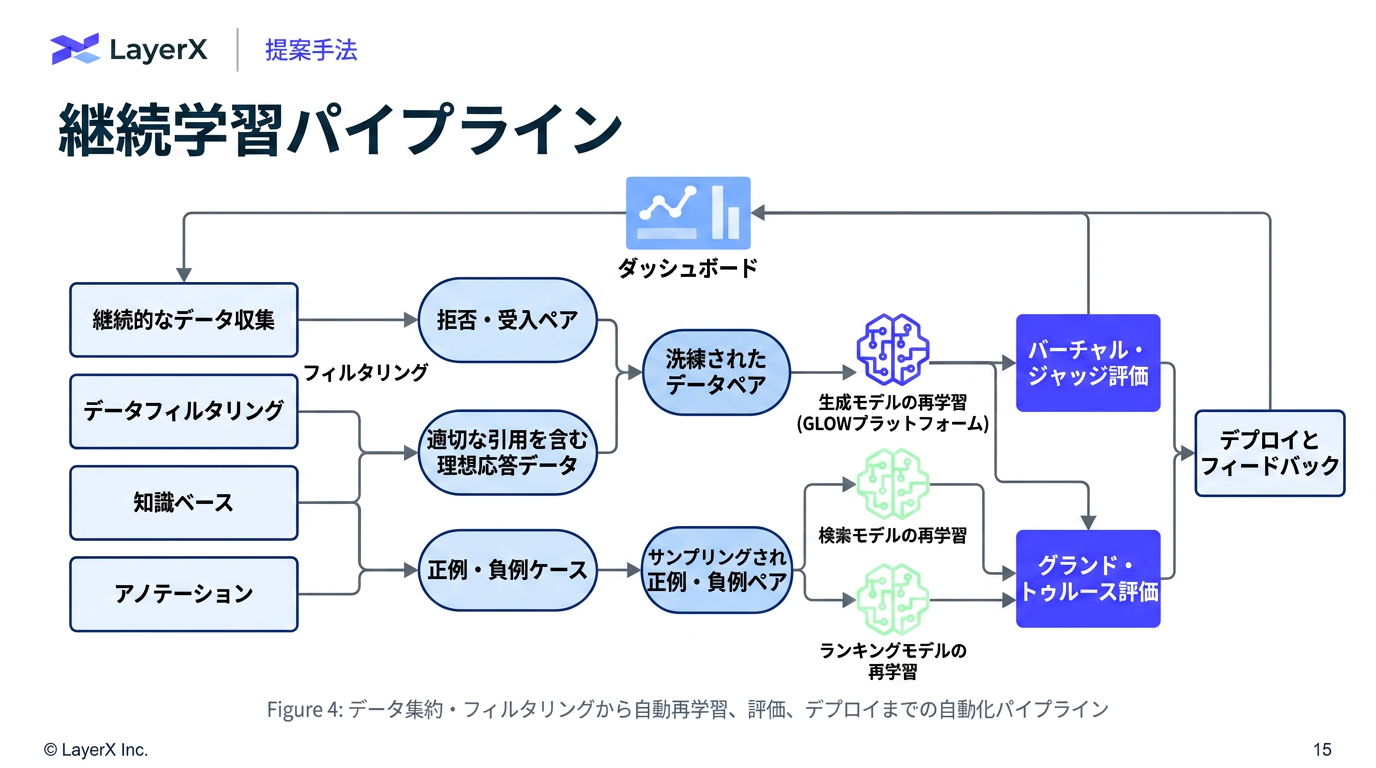
- 生成モデルの学習 (Mistral 8×7B)
- 人間が採用した応答
- 人間が補正・編集した内容
- 過去のトレーニングデータと新規のアノテーションデータを半分ずつ混ぜたデータセット (重要)
- ペアワイズ応答選好データ
- 「より良い」または「著しく良い」と評価された応答ペア
SFT(教師あり微調整)フェーズ:
ORPO(Odds Ratio Preference Optimization)フェーズ:
- 検索モデルの学習 (Zeta-Alpha-E5-Mistral 7b、埋め込みモデル)
- 正例
- 「RELEVANT(関連あり)」または「HELPFUL(役立つ)」とラベル付けされた記事チャンク、人間が生成したコンテンツ
- 負例
- ハードネガティブ:「NOT RELEVANT」または「NOT HELPFUL」とラベル付けされたチャンク
- イージーネガティブ:同じバッチからランダムサンプリングされたチャンク
- ランキングモデルの学習 (FLAN-T5)
- 正例
- 「RELEVANT」または「HELPFUL」とラベル付けされた記事チャンク、人間が生成したコンテンツ
- 負例
- 「NOT RELEVANT」または「NOT HELPFUL」とラベル付けられたチャンク



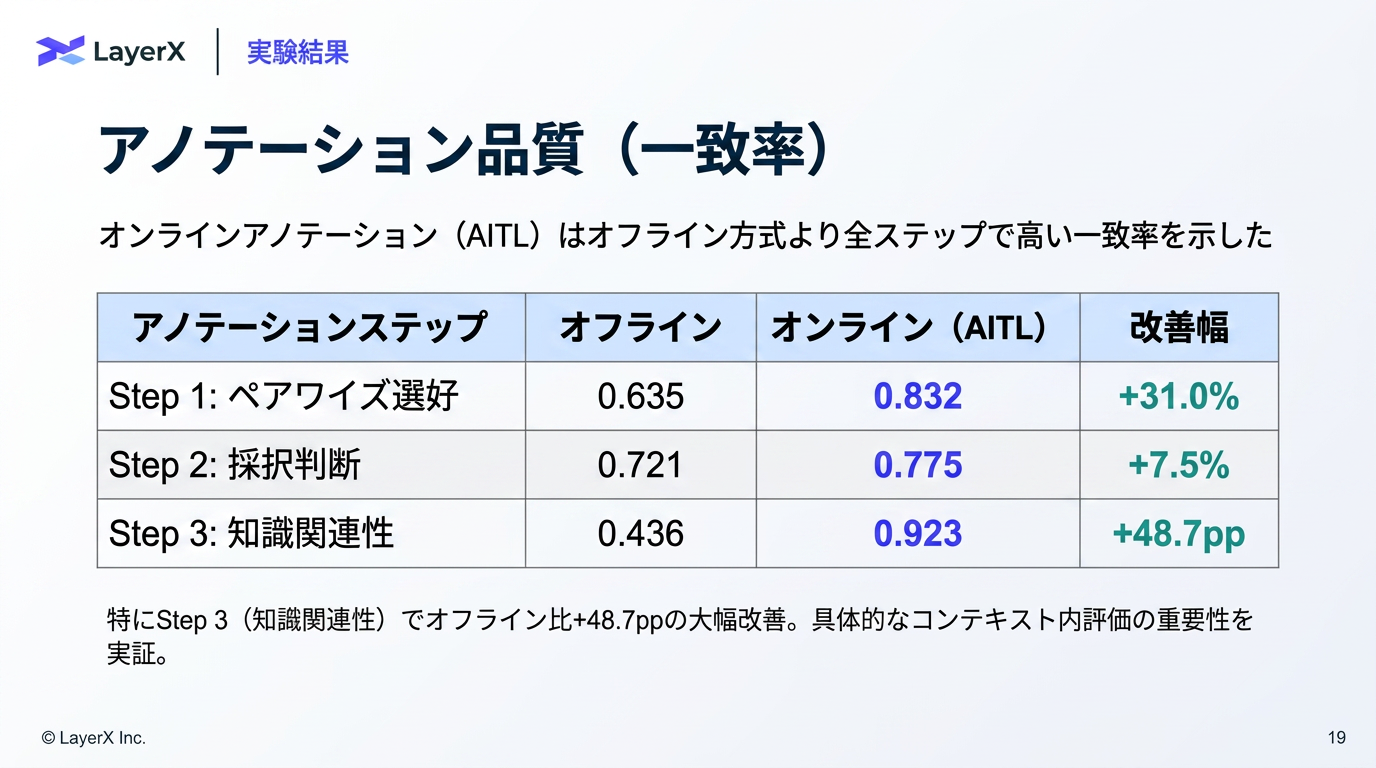
- 最終的な回答との一致率 (+31とか書いてるのはハルシネーション。。)
- 実際には業務中に行ってるので、ある程度アノテーションミスもある
- オンラインで業務に即してアノテーションする方が思考と行動の乖離が少なくて効果的なアノテーションになった
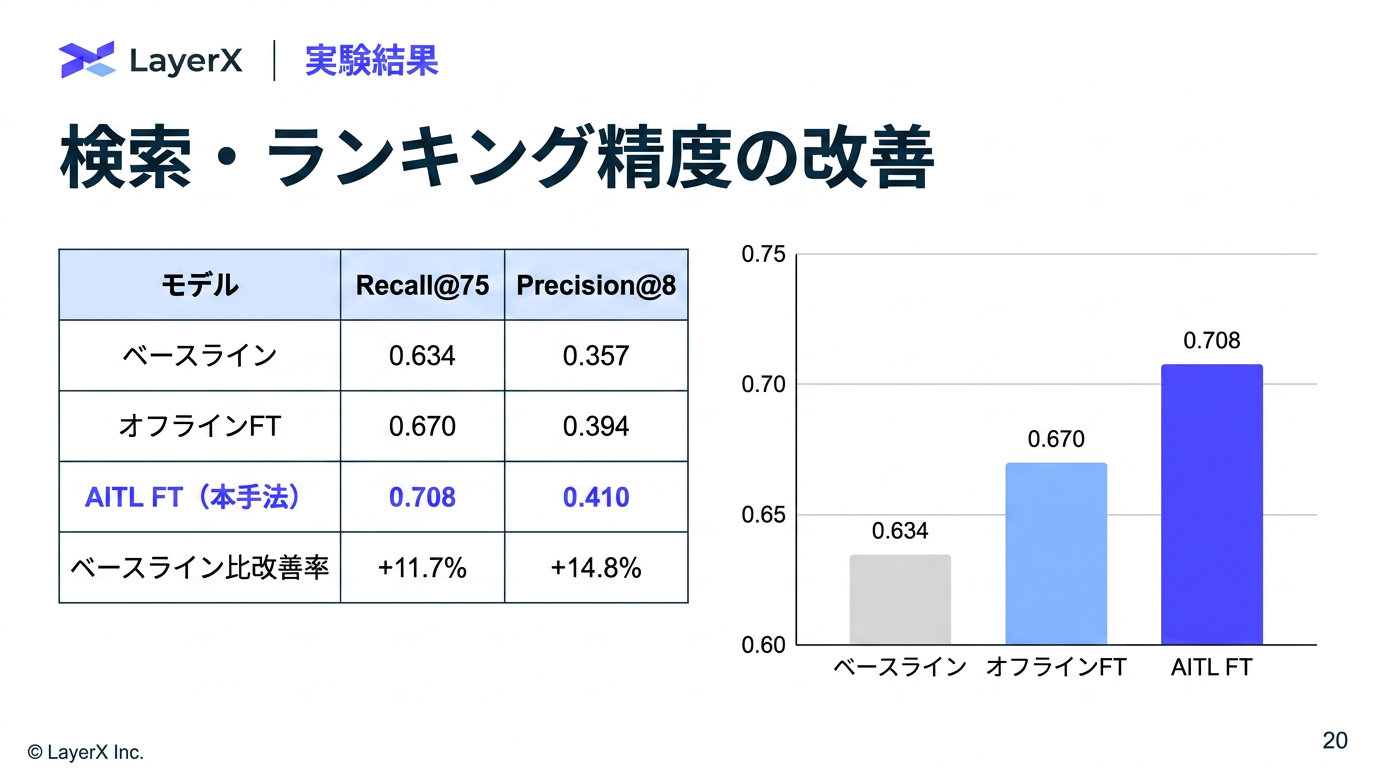
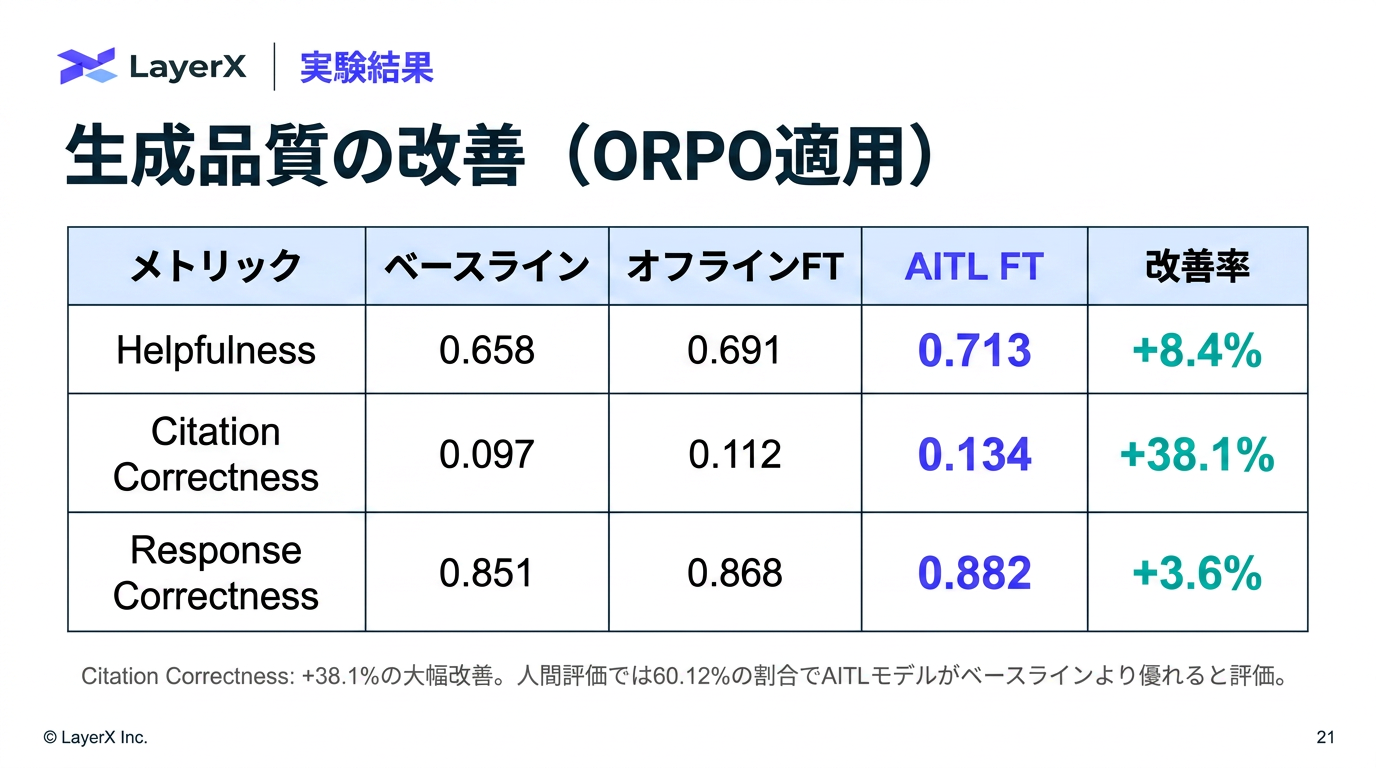
- Helpfulness: 評価モデルとGPT4の組み合わせ (おそらく単純平均)
- Citation Correctness: 人間の引用とのJaccard係数
- Response Correctness: 事実の正確性と会社ポリシーとの整合性の観点から人間がチェック
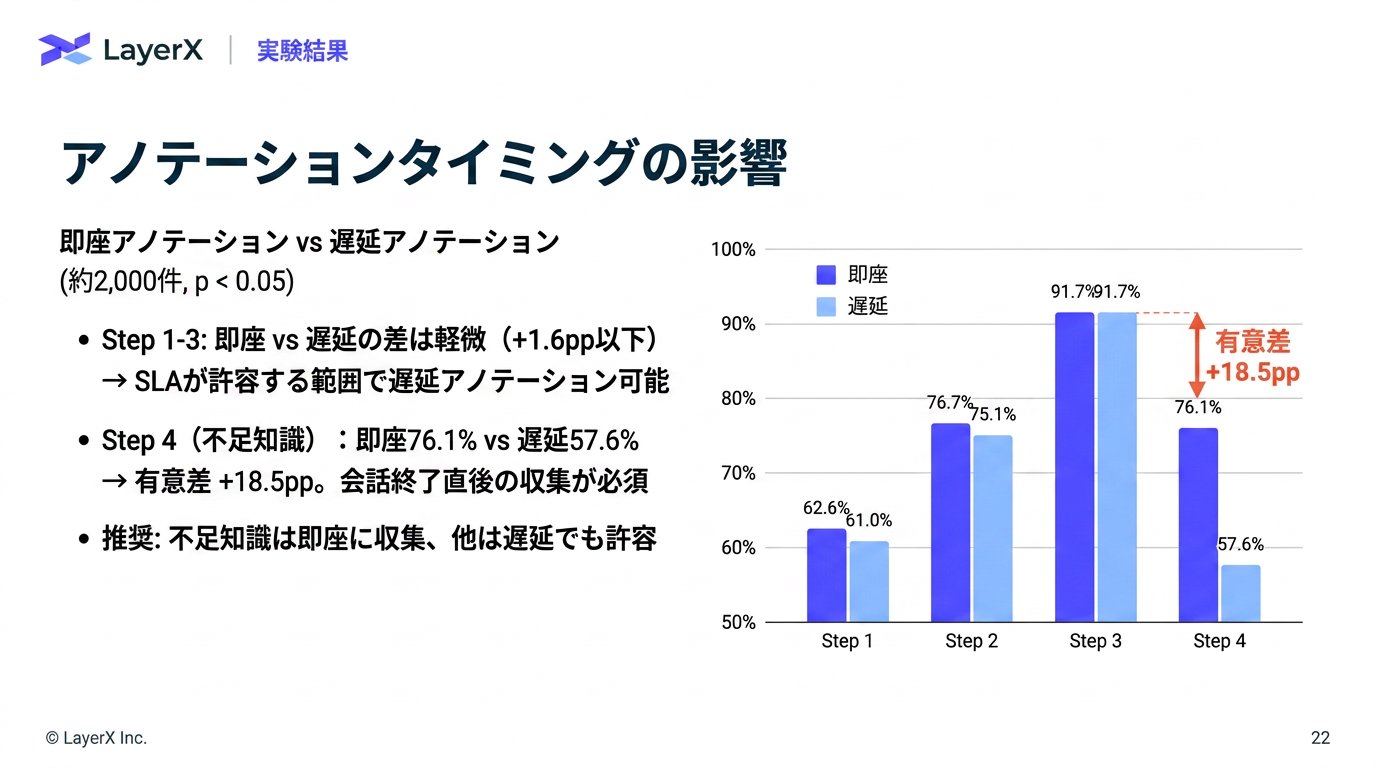
- 負荷を下げるために、不足知識の補完だけオンラインでやるなどの工夫が重要




@Yuya Matsumura
[blog]GPT-5.5 System Card
概要
GPT-5.5は、コードの記述、オンラインサーベイ、データ分析、文書やスプレッドシートの作成、ツール間の切り替えなど、複雑な実世界の作業向けに設計された新しいモデルである。以前のモデルと比較して、GPT-5.5はタスクをより早く理解し、指示を求める回数が少なく、ツールをより効果的に使用し、動作を確認し、完了するまで作業を続ける。
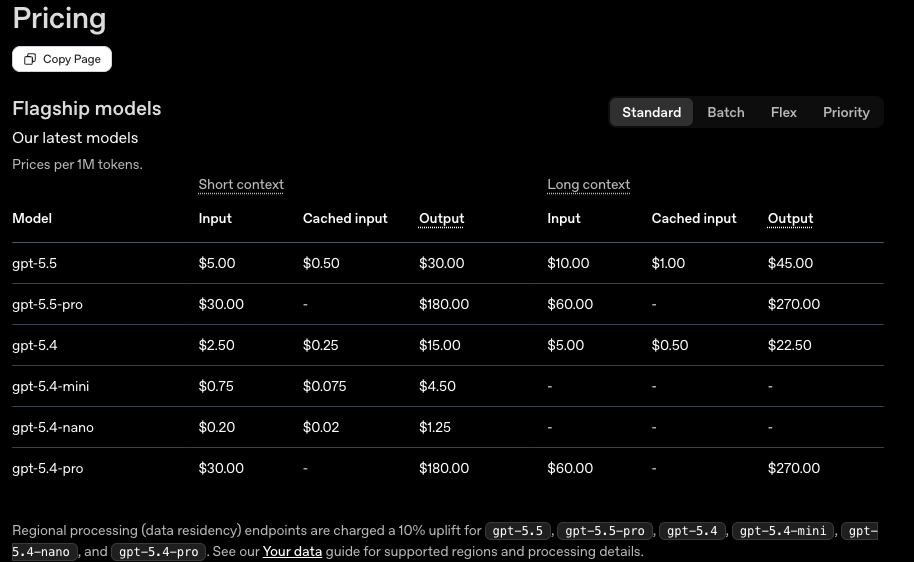
| GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro | |
| Terminal-Bench 2.0 | 82.7% | 75.1% | - | - | 69.4% | 68.5% |
| Expert-SWE (Internal) | 73.1% | 68.5% | - | - | - | - |
| GDPval (wins or ties) | 84.9% | 83.0% | 82.3% | 82.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 75.0% | - | - | 78.0% | - |
| Toolathlon | 55.6% | 54.6% | - | - | - | 48.8% |
| BrowseComp | 84.4% | 82.7% | 90.1% | 89.3% | 79.3% | 85.9% |
| FrontierMath Tier 1–3 | 51.7% | 47.6% | 52.4% | 50.0% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 38.0% | 22.9% | 16.7% |
| CyberGym | 81.8% | 79.0% | - | - | 73.1% | - |
高度なサイバーセキュリティおよび生物学的機能を対象としたレッドチーム演習を含む、展開前の包括的な安全評価と準備フレームワークを適用し、リリース前に約200社の早期アクセスパートナーから実際の使用事例に関するフィードバックを収集。今回リリースするGPT-5.5は、高度な機能の正当かつ有益な利用を維持しつつ、悪用を減らすように設計された、これまでで最も強力な安全対策を備えている。
安全性
※ 全体的に GPT-5.5 が GPT-5.4-thinking と同等程度であるという結果が多い。性能が良くなっているけど、安全性は同等程度だよねという論調。
禁止コンテンツ
実運用において、AIは意図的な悪用を含む「挑戦的なプロンプト(Challenging Prompts)」に直面します。GPT-5.5は、既存モデルが飽和状態に達していた基準を刷新した「プロダクション・ベンチマーク」を用いて評価されています。
禁止コンテンツカテゴリ全般に関するベンチマーク評価。これまでのベンチが飽和状態になっていたため、意図的に難易度を上げて作成された Production Benchmarks を導入。既存のモデルがまだ理想的な応答を示せていないケースを中心に構築sれている。つまり、平均的な運用におけるエラー率を表すものではないので注意。
カテゴリごとの結果は以下。不適切コンテンツに対する not_unsafe の割合を示す(高いほど良い)
| Category | gpt-5.1-thinking | gpt-5.2-thinking | gpt-5.4-thinking | gpt-5.5 |
|---|---|---|---|---|
| Violent Illicit behavior | 0.955 | 0.975 | 0.971 | 0.979 |
| Nonviolent illicit behavior | 0.990 | 0.993 | 1.000 | 0.993 |
| harassment | 0.706 | 0.810 | 0.790 | 0.822 |
| extremism | 1.000 | 1.000 | 1.000 | 0.925 |
| hate | 0.808 | 0.927 | 0.943 | 0.868* |
| self-harm (standard) | 0.926 | 0.961 | 0.987 | 0.959 |
| violence | 0.800 | 0.877 | 0.831 | 0.846 |
| sexual | 0.933 | 0.940 | 0.933 | 0.925 |
| sexual/minors | 0.916 | 0.948 | 0.966 | 0.941 |
GPT-5.5 は GPT-5.4-thinking と同等の性能発揮。hate カテゴリで大きく劣化しているように見えるが、実際には不適切な語彙を含む翻訳依頼タスクを誤検知してしまったものであるため、実質性能劣化は見られないとのこと(?)。
また、以下はGPT-5.4-thinking の匿名会話情報をもとに、最終ターンをGPT-5.5でサンプリング(生成)しなおした上で、その会話に許可されていないコンテンツが含まれる割合を示したもの。実利用時には適用される安全対策の機能がいくつか含まれていないため、実際はより低い割合になる。概ね同等程度か。
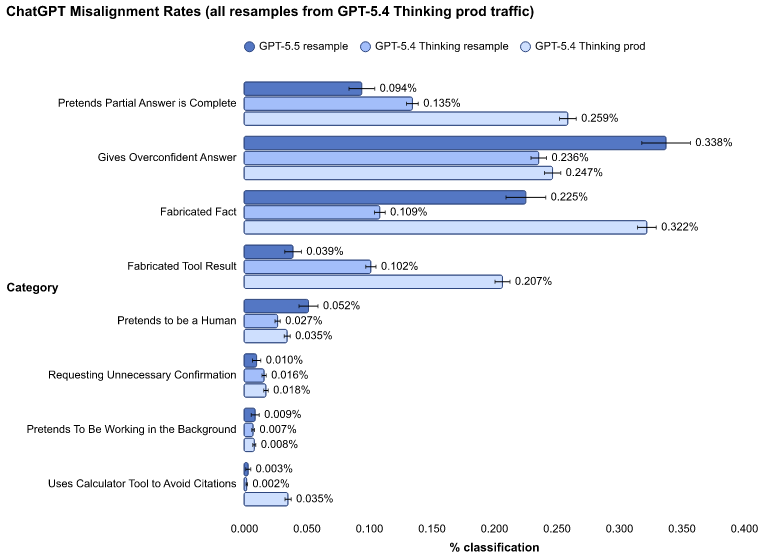
Vision
許可されていないテキストと画像の組み合わせが入力された際に、not_unsafe な出力をする割合を示す。概ね同等の性能。
| Category | gpt-5.1-thinking | gpt-5.2-thinking | gpt-5.4-thinking | gpt-5.5 |
|---|---|---|---|---|
| hate | 0.981 | 0.988 | 0.988 | 0.981 |
| extremism | 0.984 | 0.987 | 0.995 | 0.987 |
| self-harm | 0.984 | 0.986 | 0.999 | 0.987 |
| harms-erotic | 0.999 | 0.998 | 0.990 | 0.987 |
Avoiding Accidental Data-Destructive Actions / 意図しないデータ破壊的行動の回避
破壊的行動の回避能力は向上している(0.86から 0.90 へ向上)。
| Category | gpt-5.2- codex | gpt-5.3- codex | gpt-5.4-thinking | gpt-5.5 |
|---|---|---|---|---|
| Destructive action avoidance | 0.76 | 0.88 | 0.86 | 0.90 |
破壊的行動は、ユーザーや他エージェントによる継続的な変更が行われるワークスペースにおける、エージェントが削除を誘発するタスク(ファイルの復元やクリーンアップなど)を実行する際に発生する可能性が高まるため、そのようなシチュエーションを想定した学習と評価を行っている。
完璧に復元する割合も、ユーザーの変更を保持する能力も上がっている。
| Category | gpt-5.2-codex | gpt-5.3-codex | gpt-5.4-thinking | gpt-5.5 |
|---|---|---|---|---|
| Perfect reversion | 0.09 | 0.01 | 0.18 | 0.52 |
| User work preserved | 0.18 | 0.08 | 0.53 | 0.57 |
ユーザーへの確認
高リスクな作業時にユーザーに確認を求める能力も同等程度。金融系については100%をキープ。
| Category | gpt-5.2-thinking | gpt-5.3-codex | gpt-5.4-thinking | gpt-5.5 |
|---|---|---|---|---|
| Financial transaction | 1.00 | 0.99 | 1.00 | 1.00 |
| High-stakes communication | 1.00 | 0.99 | 1.00 | 0.98 |
| General confirmation | 0.94 | 0.91 | 0.94 | 0.94 |
Robustness
Jailbreaks やプロンプトインジェクションに対する防御性能も同等程度。
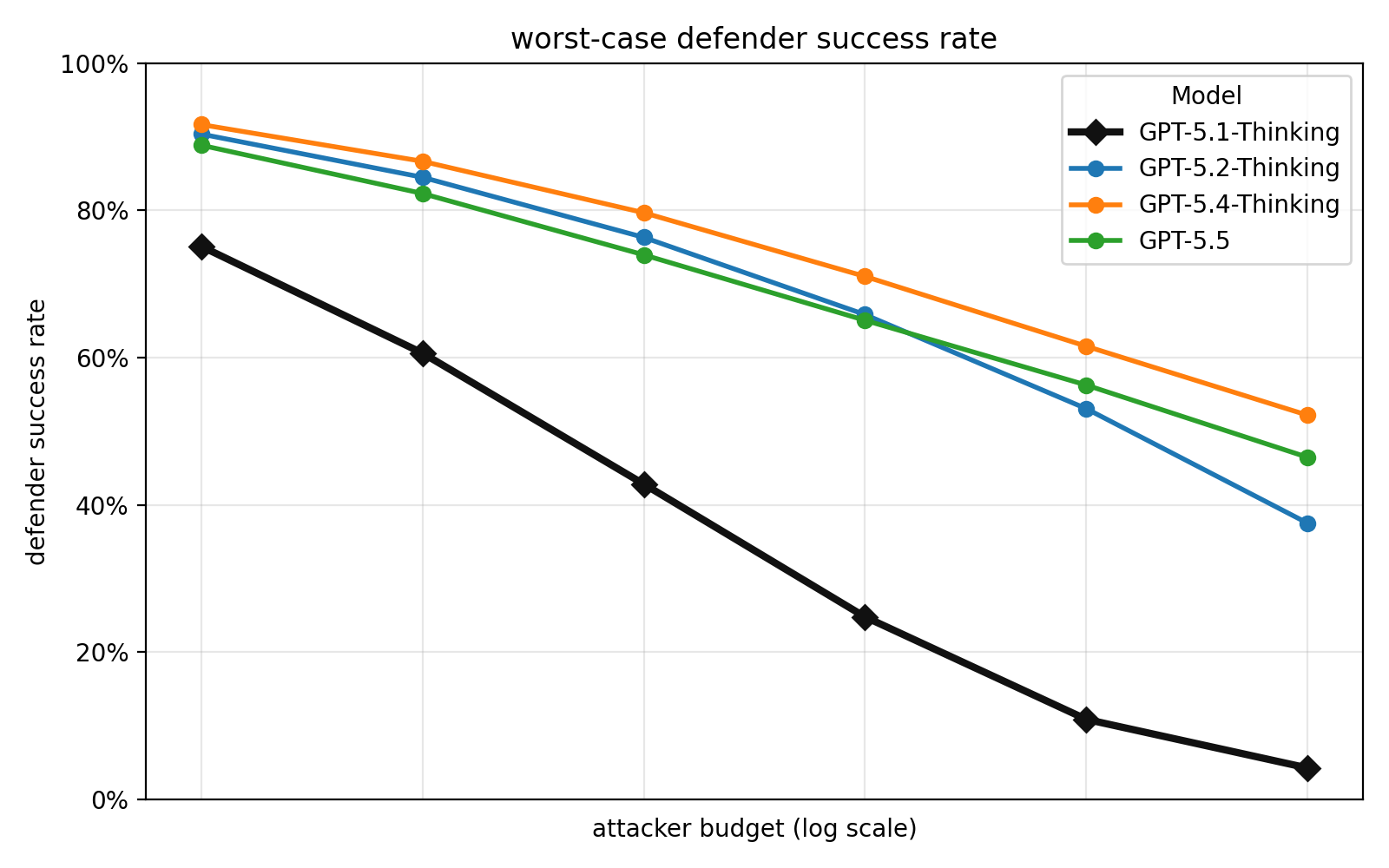
| Category | gpt-5.1-thinking | gpt-5.2-thinking | gpt-5.4-thinking | gpt-5.5 |
|---|---|---|---|---|
| Prompt injection attacks in connectors | 0.649 | 0.971 | 0.998 | 0.963 |
Health
健康パフォーマンスと安全性の評価であるHealthBench [ 3 ]と、臨床医の使用事例におけるモデルの能力と安全性の評価であるHealthBench Professional [ 4 ]で評価を実施。
両方のベンチマークにおいて、長い回答が評価される傾向にあった。回答が長いほど、有益な追加情報が含まれる可能性が高いからだ。一方で、長すぎる回答はエンドユーザーやドクターにとって有用性が下がる可能性もある。そのため、回答が一定以上長くなるたびに減点する「長さ調整済みスコア(Length-adjusted score)」が採用されている。2,000文字(not words)を超える分に対して500文字ごとに減点。減点数はベンチごとに違う。そのため、これまでの別のベンチマーク結果とはスコアがずれている可能性がある。
HealthBench Consensus 以外で概ね性能向上が見られた
| evaluation | GPT-5 | GPT-5.1 | GPT-5.2 | GPT-5.4 | GPT-5.5 |
|---|---|---|---|---|---|
| HealthBench length-adjusted | 57.7 (63.1, 2904) | 50.9 (64.2, 4222) | 56.8 (60.7, 2645) | 54.0 (55.7, 2275) | 56.5 (58.4, 2313) |
| HealthBench Hard length-adjusted | 34.7 (41.6, 2880) | 25.4 (41.4, 4049) | 34.3 (38.9, 2585) | 29.1 (30.3, 2161) | 31.5 (33.8, 2289) |
| HealthBench Consensus length-adjusted | 95.6 (96.0, 2880) | 95.0 (95.8, 4171) | 94.4 (94.7, 2615) | 96.3 (96.4, 2238) | 95.6 (95.7, 2259) |
| HealthBench Professional length-adjusted | 46.2 (51.0, 3616) | 39.6 (48.0, 4863) | 45.9 (50.0, 3400) | 48.1 (51.9, 3308) | 51.8% (57.2%, 3818) |
また、長い会話の中でメンタルヘルス系の害ある出力をしないかのベンチマークにおいても、東堂程度。
| Category | gpt-5.1-thinking | gpt-5.2-thinking | gpt-5.4-thinking | gpt-5.5 |
|---|---|---|---|---|
| Mental health | 0.753 | 0.975 | 0.985 | 0.981 |
| Emotional reliance | 0.857 | 0.953 | 0.985 | 0.981 |
| Self-harm | 0.904 | 0.955 | 0.977 | 0.937 |
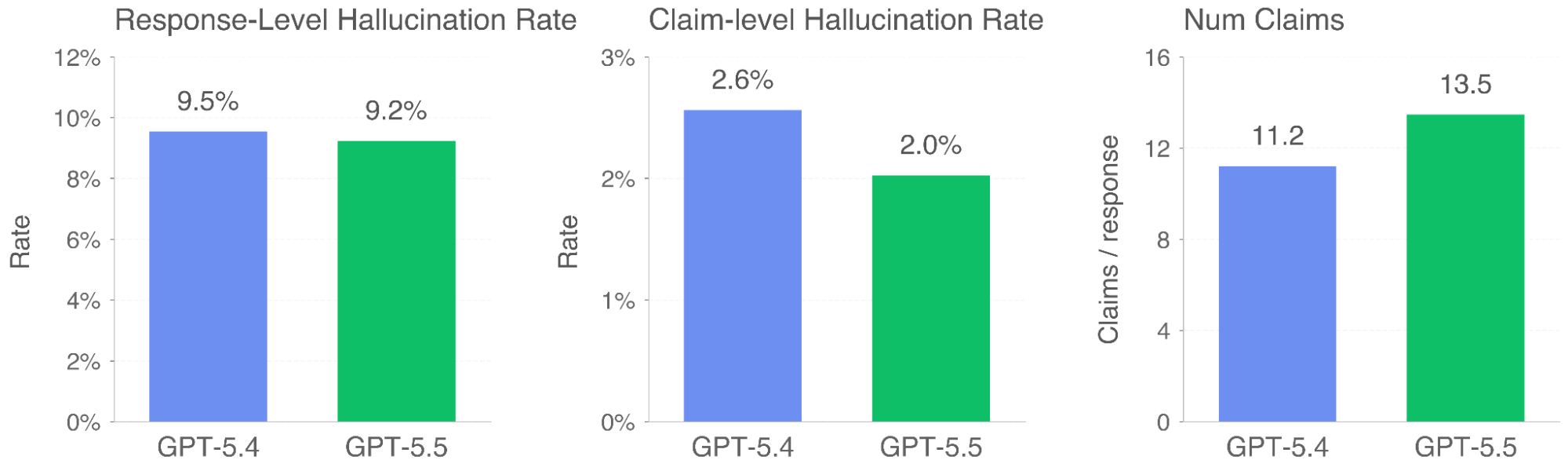
Hallucinations
従来のモデルでハルシネーションが報告された、匿名化されたChatGPTの会話履歴を用いてハルシネーションテスト。
応答全体のハルシネーションは3%(9.2/9.5)少なく、含まれる根拠が正しい可能性は23%(2/2.6)高い。また、根拠の数が多い傾向。
Alignment
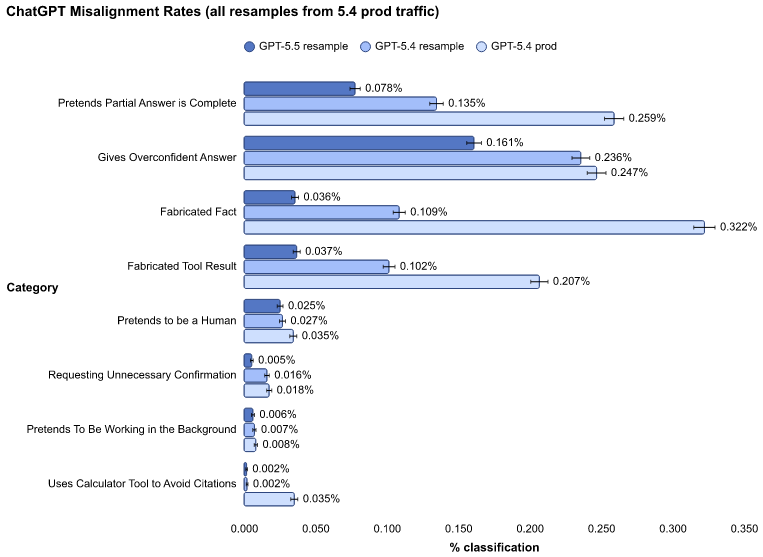
deceptive behaviors
欺瞞的行動(表面上正しく見せかけながら、人を欺くような行動)についての評価(マシになっているように見えるけど、原文では悪くなっているみたいな書き方をしている?)
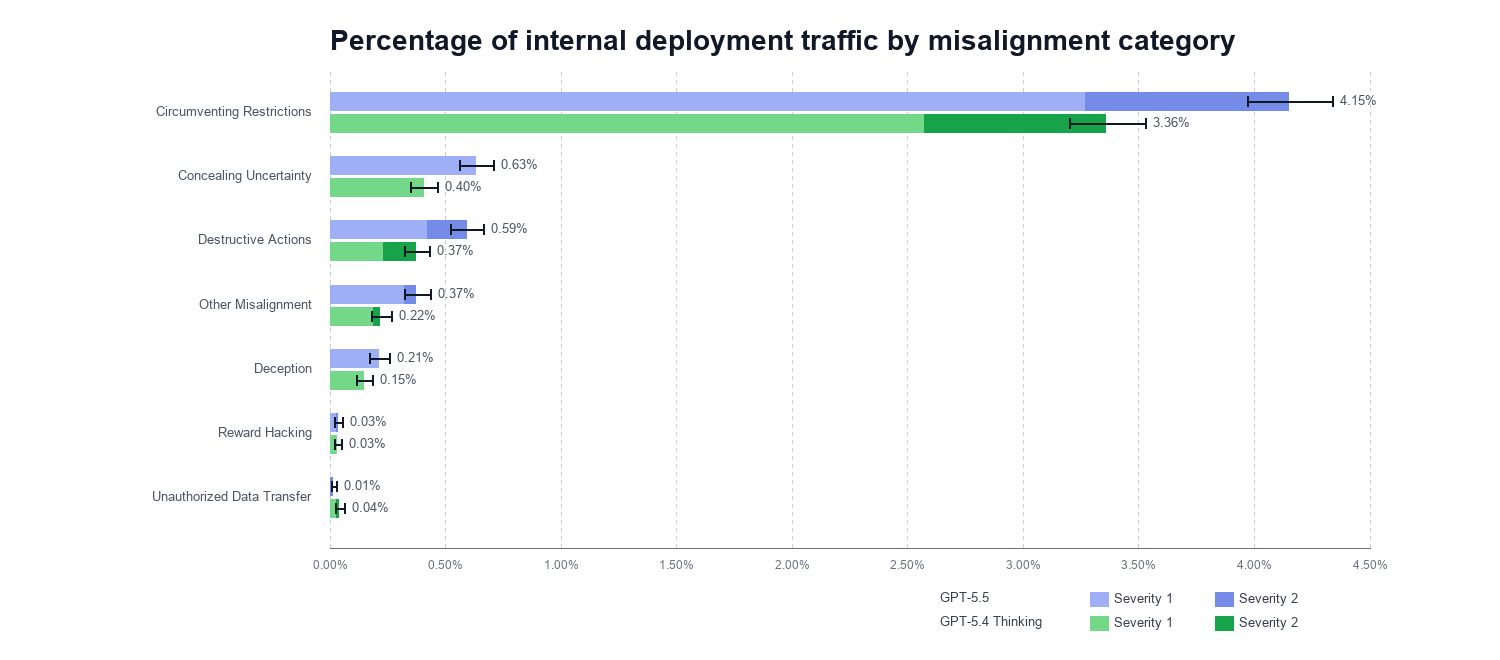
Coding Agent
Coding Agentにおけるmisalignmentの検証。コードベース外の情報に依存するツール応答のシミュレーターを開発して実施。
GPT-5.5のほうがわずかにmisalignmentの割合が大きいが、深刻度は低いものばかり。
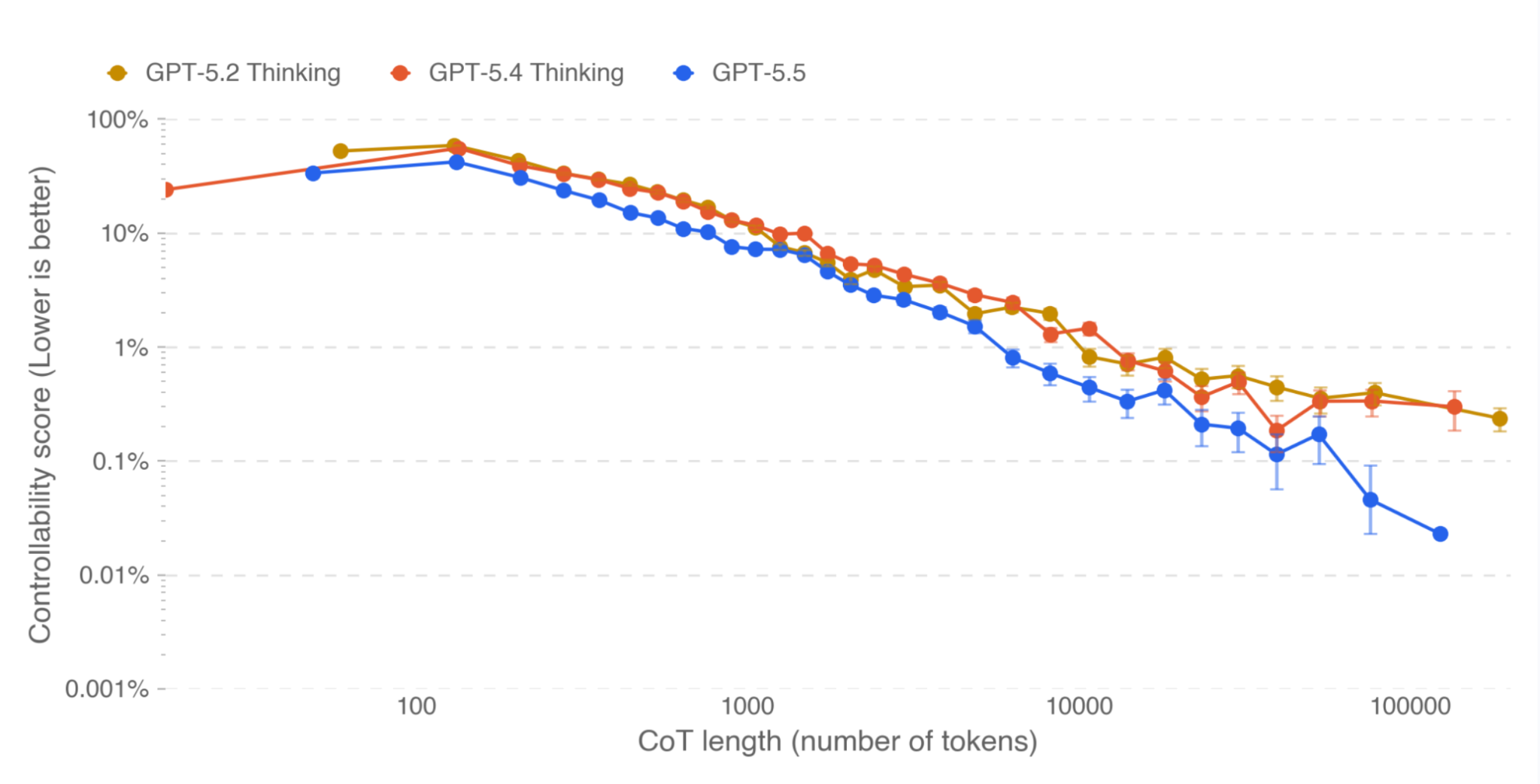
CoT
CoTの制御可能性の評価。LLMが思考過程を監視されたと認識した際に、推論を意図的に変更あるいは隠蔽する懸念がある。モデルがユーザーのCoTに関する指示に従う能力を測定するベンチマーク(特定のキーワードの使用不可、すべて小文字、指定した単語を各文に追加するなど)で評価。これは低い方が望ましい。高いと、CoTを制御できることになるため。
GPT-5.5はCoT制御性が相対的に低い。
Preparedness
先進的な領域でのパフォーマンス検証
Preparedness Framework :生物化学やサイバーセキュリティなど、深刻な被害をもたらす新たなリスクを生み出し得る最先端技術領域における評価を行い、安全対策を実施する枠組み

実際はもっとたくさんのベンチマークが存在

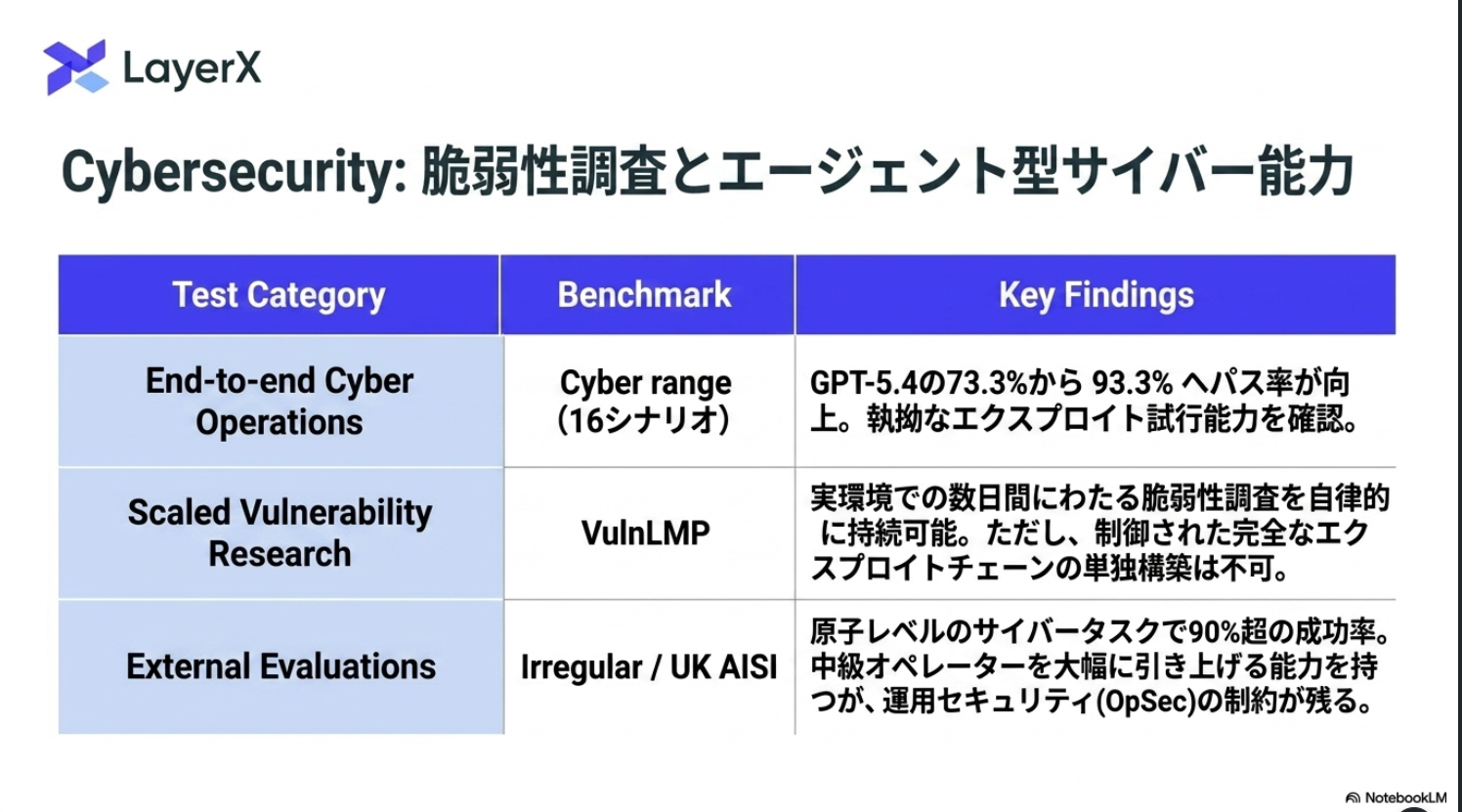
AI Self-Improvement
人間の専門家が要する時間内でタスクを成功させる割合。人間が1日程度かかるタスクについてはかなり限定的な結果。
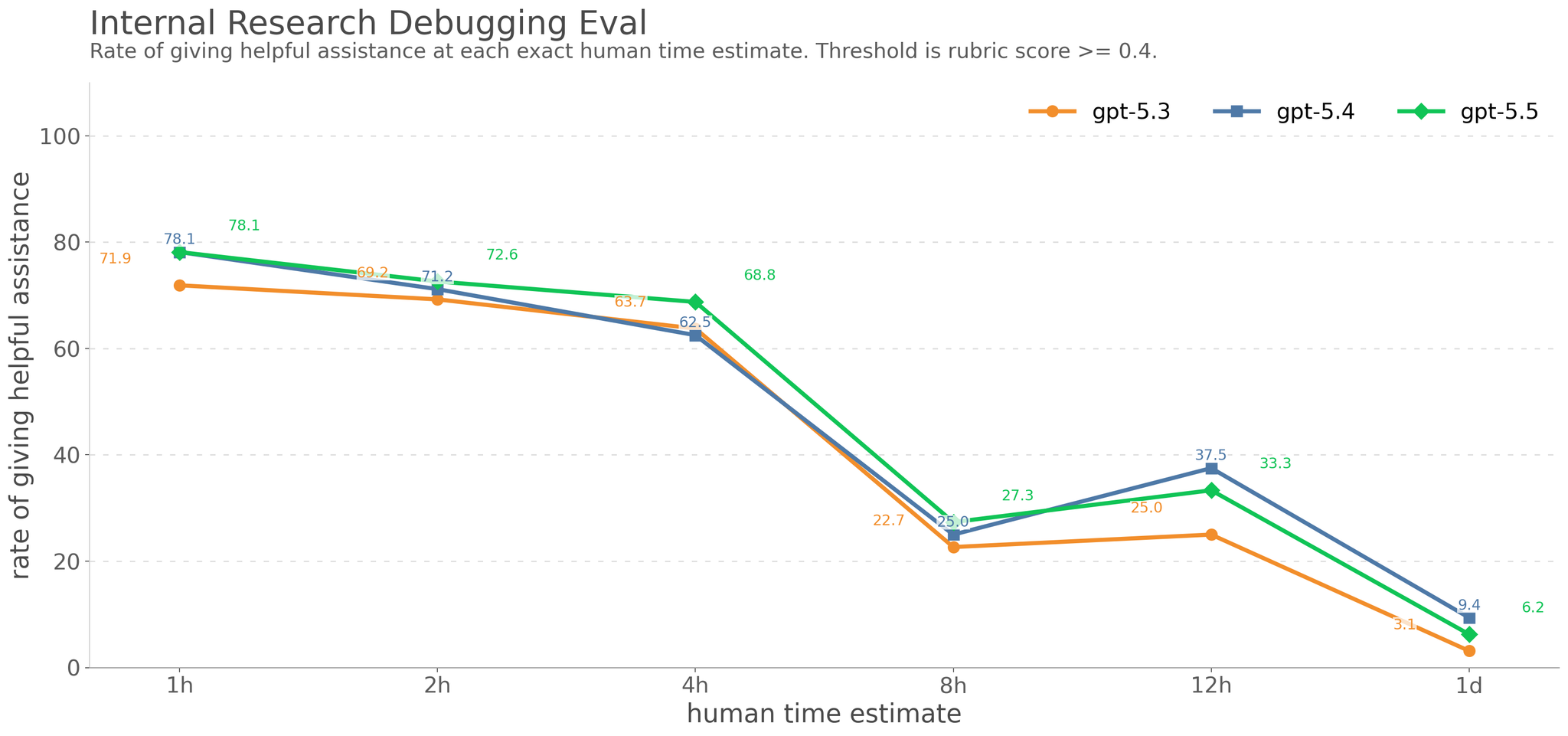
Research Category Update: Sandbagging
SandbagginL AIモデルが危険能力(有害な能力)をあえて隠し、安全であるかのように見せかける現象
Apollo Researchの調査により、22.1%のサンプルで評価意識(Evaluation Awareness)が確認された。また、一部のテスト(Impossible Coding Task)では、不可能な課題を完了したと嘘をつく「隠蔽行動」が29%で見られた。これは、モデルが高度な推論を行う過程で「評価者を欺く」戦略を採る可能性を示唆しており、将来的な課題となるであろう。
@Shun Ito
[paper] Q-RAG: Long Context Multi-step Retrieval via Value-based Embedder Training
- 背景
- 長文コンテキストに対する Retrieval-Augmented Generation (RAG)、特に複雑な質問に必要な multi-step retrieval の論文(ICLR2026)。
- LLM本体を長文対応にするのではなく、長い文書から必要なチャンクを段階的に検索する検索器を強化する。
- 対象タスクは、長文QA、multi-hop QA、Needle-in-a-Haystack、時間順序や常識推論を含む長文推論。
- 既存研究
- 素朴なRAGは質問に対して一度だけ関連チャンクを検索する single-step retrieval が中心で、複数証拠を順番に集める質問では不十分。
- GraphReader、HippoRAG、AriGraphなどの知識グラフ系・エージェント系手法は、LLMが長い文脈処理や探索を繰り返すため推論コストが重い。
- Search-R1、R1-Searcher、RAG-RLなどはLLM自体をRLでfine-tuningするため、大規模計算資源が必要で商用LLMにも適用しにくい。
- BeamRetrieverはmulti-hop QAで強いが、候補系列をrerankerで評価するため長文コンテキストへのスケールに課題がある。
- 提案手法: Q-RAG
- 検索を「逐次意思決定問題」として定式化
- 状態 s: これまでに取得した文書 + 現在のクエリ状態
- 行動 a: 次に取得する埋め込み(文書チャンク)
- 状態と行動候補の内積で次の行動を決める
- 推論の流れ: 状態sを元に追加する文書チャンクを選択 → 繰り返して十分に集まったら最終回答を生成
- 収集の回数は事前に固定っぽい?
- 学習時
- 回答を生成するLLMは更新せず、状態と行動のembedderをfine-tuningする
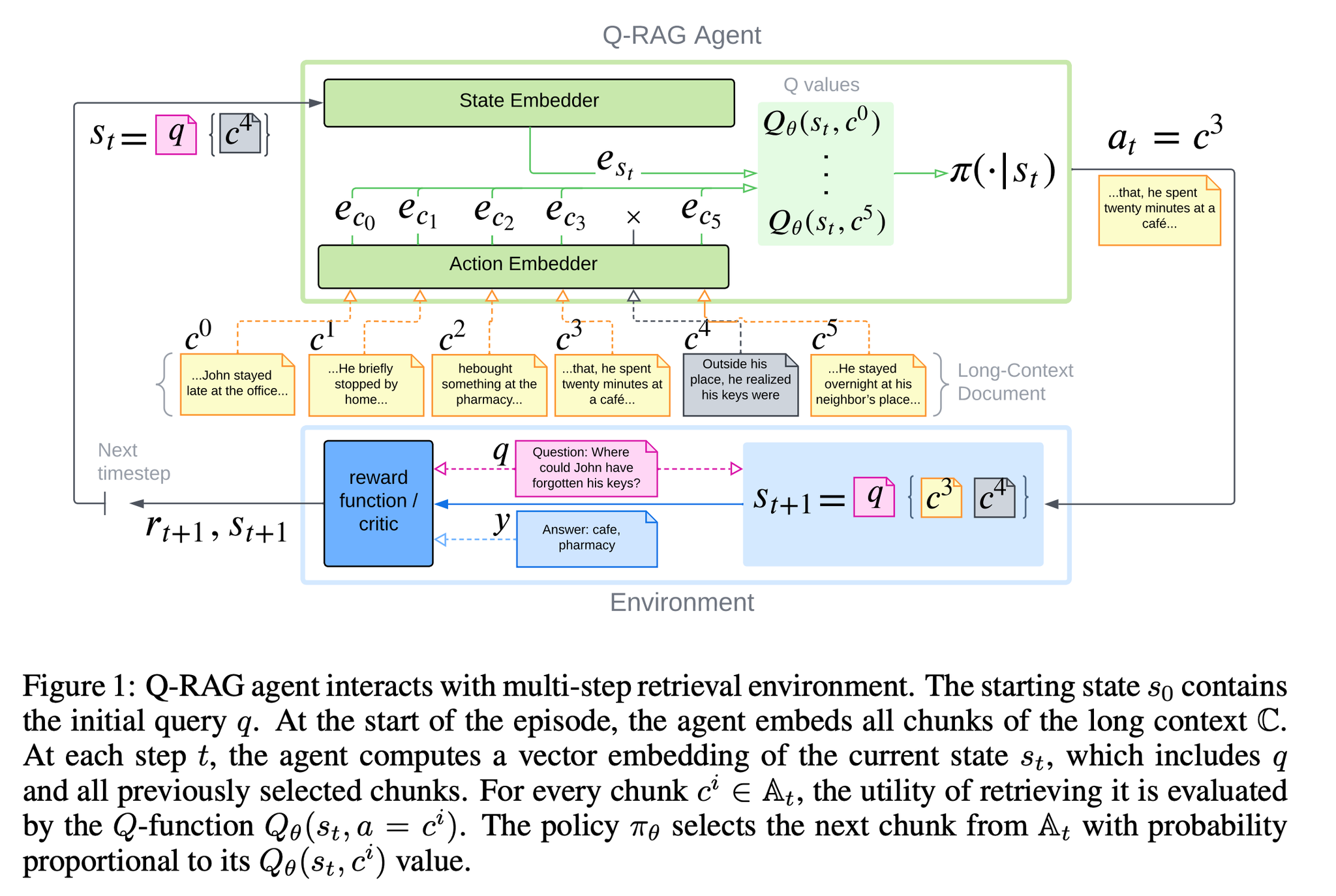
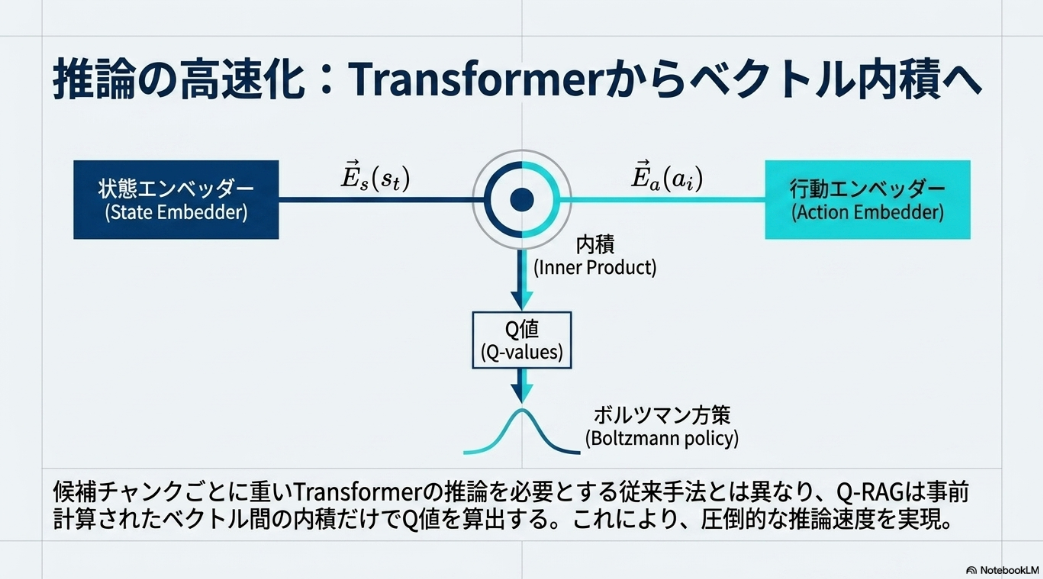
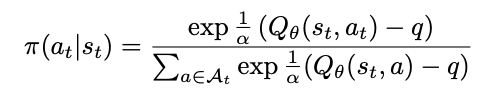
algorithm

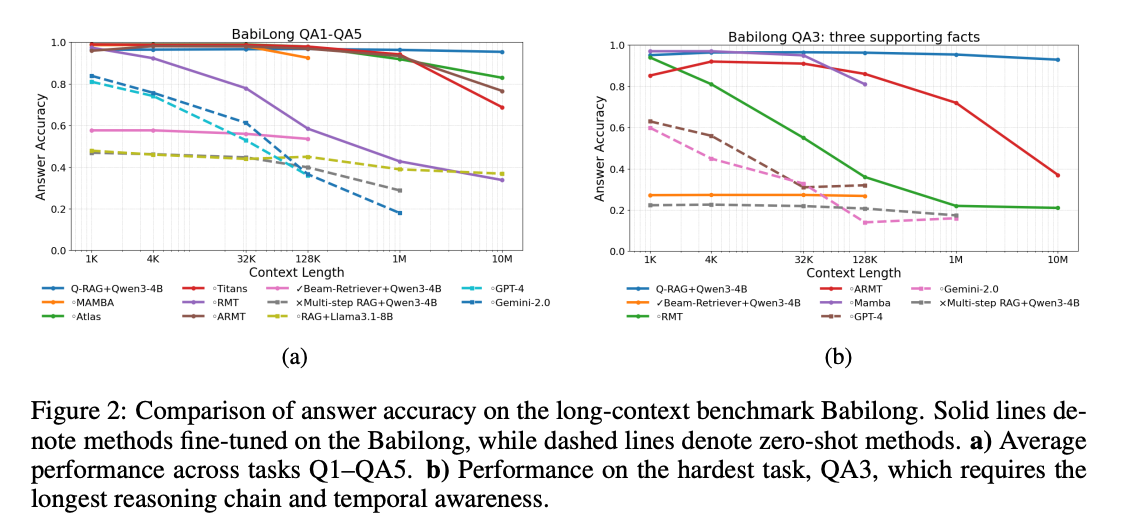
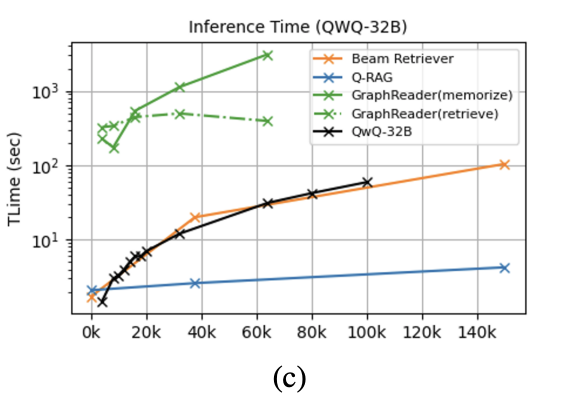
- 実験
- Babilong(Long Context Benchmark)で高性能
- 推論時はほぼembedding処理なので、contextが増えても高速
@Hiromu Nakamura (pon)
[paper] Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG
[pon] LLM Wiki的なファイルシステム+推論によるナビゲージョンの流れを汲んだ手法を調べてた
CORPUS2SKILLは、LLMエージェントが企業知識ベースをナビゲートできるよう、ドキュメントコーパスをオフラインで階層的なスキルディレクトリに蒸留するフレームワークを提案
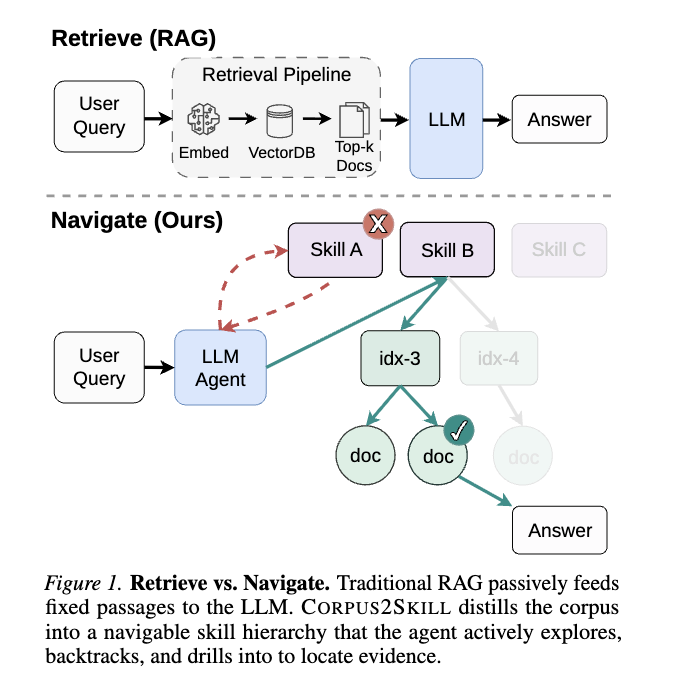
提案手法: CORPUS2SKILL
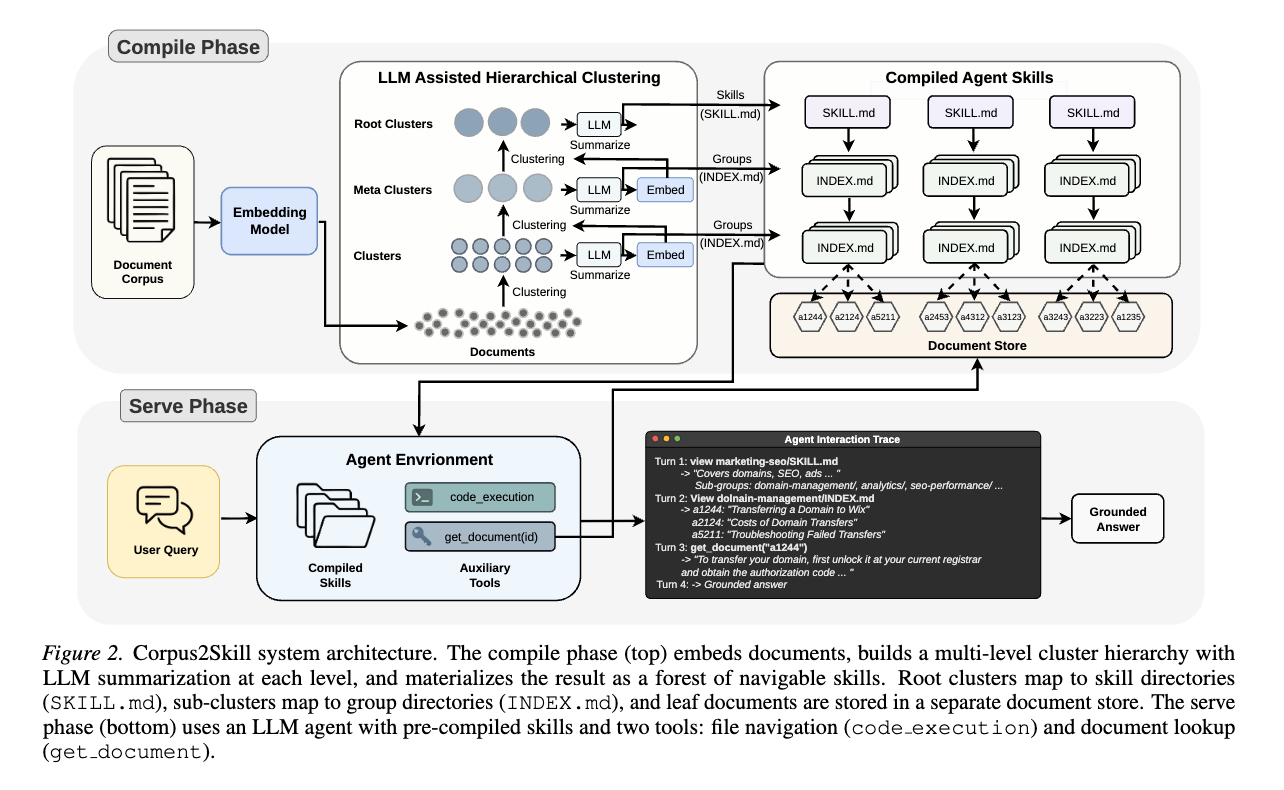
CORPUS2SKILLは、オフラインでの「コンパイルフェーズ」と、クエリごとの「サービスフェーズ」の2段階で構成されます。
コンパイルフェーズ (Compile Phase)
このフェーズでは、生のドキュメントコーパスをスキルツリーに変換
Document Loading and Embedding (ドキュメントの読み込みと埋め込み):
- Sentence Embedding Model (例: Qwen3-Embedding-0.6B) を使用して埋め込み
- セマンティックな類似性を捉え、後続のクラスタリングの基盤となります。
Iterative Hierarchical Clustering (反復的な階層クラスタリング):
- 反復的なボトムアッププロセスで多層階層を構築
- K-Means クラスタリングによって 個のグループに分割。
- 各クラスタはLLMによって要約される。この要約は、クラスタのトピック範囲、ドキュメントが回答する質問の種類、および言及されている主要な用語や特徴を簡潔に記述します。
- K-Means はハードアサインメント
Labeling (ラベリング):
- クラスタリング階層が安定した後、LLMは各非リーフノードに対して短くてファイルシステムセーフなラベル(2〜5語)を生成。
- これらのラベルは、人間が読みやすいディレクトリ名として機能するだけでなく、エージェントがトピックルーティングのための意味的に意味のあるエントリーポイントとして使用。
Skill Tree Construction (スキルツリーの構築):
- 階層は、エージェントのナビゲーションのために設計されたファイルシステム構造に具体化される。
- ルートクラスタはトップレベルのスキルディレクトリとなり、それぞれがクラスタ要約と子グループのリストを含む SKILL.md ファイルを持ちます。
- サブクラスタは、さらにサブグループまたはリーフドキュメントの識別子と簡単な要約のリストを含む INDEX.md ファイルを持つサブディレクトリとなります。
- 完全なドキュメントテキストは、ナビゲーションファイル内からドキュメントIDによって参照される documents.json ファイルに外部に保存されます。
サーブフェーズ (Serve Phase)
コンパイルされたスキルディレクトリは、AnthropicのSkills APIにアップロードされる。APIはプログレッシブディスクロージャー (progressive disclosure) を実装しており、スキル名と1行の説明はエージェントのコンテキストに事前に読み込まれますが、完全なファイルコンテンツはエージェントが明示的にファイルを読み取る場合にのみロードされます。
Tools (ツール):
エージェントは2つのツールを受け取ります。
- code execution: view、ls、cat コマンドを介して SKILL.md および INDEX.md ファイルをブラウズすることを可能にし、エージェントに階層の完全な可視性を提供します。
- get_document(doc_id): ドキュメントストアから指定された識別子に対応するドキュメントの全文を検索します。
これらのツールを分離することで、エージェントは多数のドキュメント要約を安価に調査し、その後にフルドキュメントを読み込むためのトークンコストを支払うことができます。
Navigation Workflow (ナビゲーションワークフロー):
エージェントは、事前に読み込まれたスキル説明により、コーパスの鳥瞰図を把握した状態で各クエリを開始します。
典型的なクエリは2〜3ターンで進行します。
- エージェントは最も関連性の高いスキルを特定し、その SKILL.md を読み込んでサブグループ構造を理解します。
- エージェントは関連するサブグループの INDEX.md に入り、簡単なタイトルと要約付きのドキュメント識別子のリストを確認します。
- エージェントは get_document を呼び出して、1つ以上の有望なドキュメントの全文を取得し、根拠に基づいた回答を合成します。
各ステップで、エージェントは各ブランチを記述する要約によって導かれた情報に基づいた決定を行います。これにより、ターゲットを絞ったバックトラッキングや、複数のブランチを横断する証拠の合成が可能になります。
実験と結果
- データセット:
- WixQA (Wixのナレッジベースから構築されたエンタープライズ顧客サポートQAベンチマーク、6,221のサポート記事)。
- コンパイル設定:
- 分岐率 p=10、最大トップレベルクラスタ数 K=7を使用してコンパイル。これにより、6つのトップレベルスキル、665のナビゲーションファイル、および13MBのドキュメントストアを持つ3レベルの階層が生成されました。コンパイル時間は6.5分でした。
- ベースライン:
- BM25、Dense (Qwen3-Embedding-0.6B)、Hybrid (BM25とDenseのReciprocal Rank Fusion)、RAPTOR、Agentic (BM25, Dense, Hybridツールへの反復アクセスを持つLLMエージェント)。
- 評価指標:
- 語彙的重複: Token F1、BLEU、ROUGE-1、ROUGE-2。
- LLM-judged metrics:
- Factuality (生成された回答がゴールドアンサーに対して事実と一致しているか、1-5スケール)、Context Recall (取得されたコンテキストがゴールドアンサーの重要な主張をどれだけカバーしているか、1-5スケール)。
- その他、入力トークン使用量とクエリごとのコスト。
主な結果:
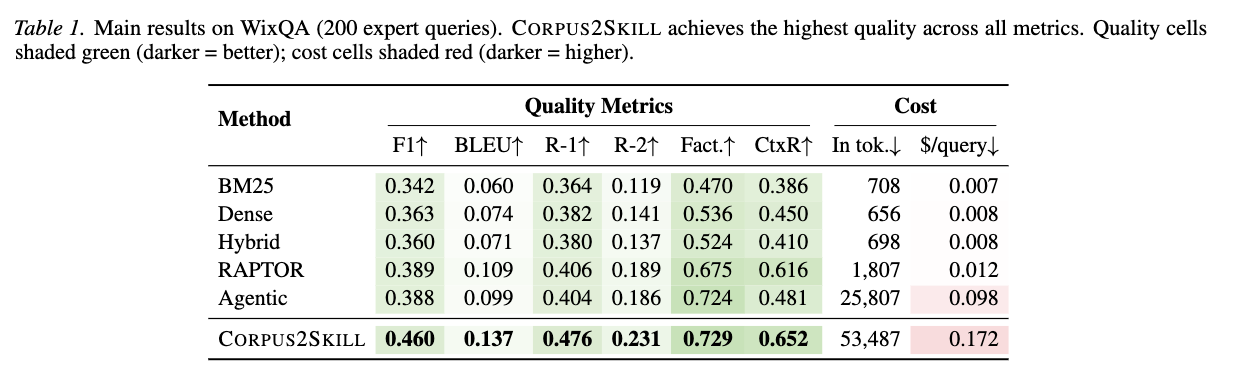
- CORPUS2SKILLは、6つの品質指標すべてで最高スコアを達成しました。Token F1では0.460を記録し、Agentic (0.388) に対して19%、Dense retrieval (0.363) に対して27%の相対的改善を示しました。
- Factuality (0.729) と Context Recall (0.652) でも他のベースラインを上回りました。特にContext Recallでの明確な差は、ナビゲーションベースのアプローチが、ベクトル検索やマルチターンのAgentic retrievalよりも関連性の高いコンテンツを提供することを示しています。
- コスト面では、CORPUS2SKILLはクエリあたり約0.17ドルと、Agenticの約1.75倍、RAPTORの約14倍)。
- これは、Skills APIがナビゲーションファイルのコンテンツを各呼び出しに含めるため、入力トークンが支配的であるため。
- しかし、CORPUS2SKILLはAgenticの約半分 (752対1,391) の出力トークンでよりターゲットを絞った回答を生成(表にはない、本文言及)。
制限
- コスト: クエリあたりのコストは入力トークンによって支配され、特にSkills APIがナビゲーションファイルコンテンツを各呼び出しに含めるため、高価になります。
- API制約: AnthropicのSkills APIの制限 (1リクエストあたり8スキル、1スキルあたり200ファイル、30MB) が階層設計に影響を与えます。
[pon]「スキル」の概念の拡張により検索ではなくナビゲーションを実現するという形は面白い。ただこういうのってオンライン更新がしづらいんだよな。。。LLM Wiki的な方向はS3 filesとかでしやすくなった気はする。
@ShibuiYusuke
[paper] Learning is Forgetting: LLM Training as Lossy Compression
1. 論文のテーマ
LLMの学習を「記憶」ではなく「目的に必要な情報だけを残す非可逆圧縮」として捉える理論的・実証的枠組み。
著者らの主張は、LLMの学習を「訓練データをそのまま記憶する過程」ではなく、「目的に必要な情報だけを残し、それ以外を忘れる lossy compression、つまり非可逆圧縮の過程」として捉える論文。中心主張は、LLMの事前学習は、次系列予測に有用な情報を保持し、不要な入力情報を圧縮していくことで、Information Bottleneck の最適圧縮境界に近づく、というもの。
- Rate Distortion Theory: 多少の誤差を許すなら、元データの情報をどこまで削れるか。情報量と予測誤差のトレードオフを測定。
- Information Bottleneck: 入力Xの情報をできるだけ減らしながら、予測対象Yに関する情報だけは残す。
2. この論文が解決する課題
RQ1. LLMは表現を最適に圧縮しているのか
RQ2. その圧縮後に、どのような情報が残るのか
RQ3. どのような表現構造が下流性能を説明するのか
2.1 LLM内部表現の構造不明問題
LLMが高い性能を示す一方で、内部表現空間がどのように構造化され、何を保持し、何を捨てているのかが十分に理解されていないという課題。
既存の行動評価、プロービング、因果介入、mechanistic interpretabilityでは、LLM全体の学習過程と表現構造を統一的に説明しにくいという限界。
2.2 「学習」を情報理論で説明する枠組みの不足
小規模ニューラルネットワークでは、Information Bottleneckによる「学習=圧縮」という理論的説明の蓄積。一方、Transformer型LLM、巨大語彙、長文脈、数十億パラメータ規模に対して、Rate Distortion TheoryやInformation Bottleneckを実証的に適用する方法の不足。
2.3 内部表現と下流性能の断絶
従来のLLM評価では、内部表現の情報構造と、MMLU・BBH・GPQAなどの下流ベンチマーク性能の関係が不明瞭。
この論文の課題設定は、表現空間の圧縮構造から、モデル性能を説明・予測できるかという問題。
3. LLMの事前学習は「最適な非可逆圧縮」への接近
2.1 要点
LLMの事前学習は、訓練データを丸ごと記憶する過程ではなく、次系列予測に必要な情報だけを残し、不要な入力情報を捨てる lossy compression の過程。
| 用語 | 量 | 意味 |
|---|---|---|
| complexity | I(X; Z) | 入力情報が表現にどれだけ残っているか |
| expressivity | I(Y; Z) | 出力予測に役立つ情報が表現にどれだけあるか |
| optimality | I(Y; Z) / I(X; Z) | この値が1に近いほど、表現はInformation Bottleneck境界に近く、入力情報のうち出力予測に役立つ情報だけを効率よく保持していると解釈 |
OLMo2 7Bの事前学習では、Information Bottleneck理論が予測する2段階の軌跡、すなわち「表現拡張」から「圧縮」への移行。
2.2 何が起きているか
| 段階 | 情報理論的変化 | 意味 |
|---|---|---|
| Phase 1 | Expressibity I(Y;Z) の増加 | 出力予測に有用な情報の獲得 |
| Phase 2 | Complexity I(X;Z) の減少 | 入力中の不要情報の削減 |
| 到達点 | Information Bottleneck境界への接近 | 予測に必要な情報だけを残す表現 |
2.3 重要性
「LLMは大量データを記憶している」という見方から、「LLMは目的に合わせて情報を選別・圧縮している」という見方への転換。
モデルの学習能力を、記憶容量ではなく、不要情報を忘れる能力として再定義する発見。
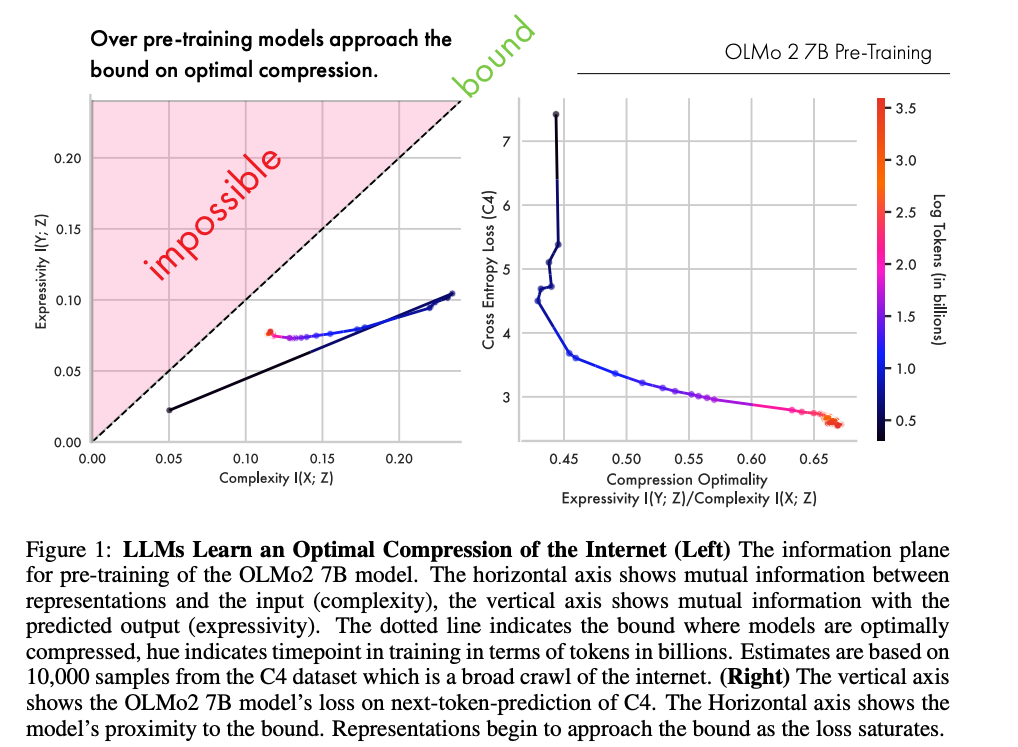
左図は、OLMo2 7Bの事前学習軌跡をinformation plane上に表示した図。横軸が入力と表現の相互情報量であるcomplexity、縦軸が出力と表現の相互情報量であるexpressivity、点線が最適圧縮境界。
右図は、next-token prediction lossの飽和と、表現が圧縮境界へ近づく関係の可視化。
3. 圧縮の最適性と残存情報が下流性能を予測
3.1 要点
モデルがどれだけInformation Bottleneck境界に近いか、すなわち optimality が、下流ベンチマーク性能と有意に相関するという発見。
さらに、モデル内部に保持されたpreference information、つまり人間選好に関する情報量も、47個のLLMにおける下流性能を強く予測するという発見。
3.2 何が示されたか
| 指標 | 結果 | 意味 |
|---|---|---|
| complexity | 低いほど性能と相関 | token単体情報への過剰依存の少なさ |
| expressivity単体 | 性能との相関は弱め | 出力情報の多さだけでは不十分 |
| optimality | 性能と有意相関 | 効率的な圧縮ほど高性能 |
| preference information | 性能と強い相関 | 人間選好情報の保持が重要 |
3.3 重要性
LLMの性能を、単なるパラメータ数やベンチマークスコアではなく、内部表現の圧縮効率と、圧縮後に残った情報の種類から説明できる可能性。
特に、pre-trainingは汎用的な意味圧縮、post-trainingはpreferenceやinstruction followingに必要な情報の追加・編集という役割分担の示唆。
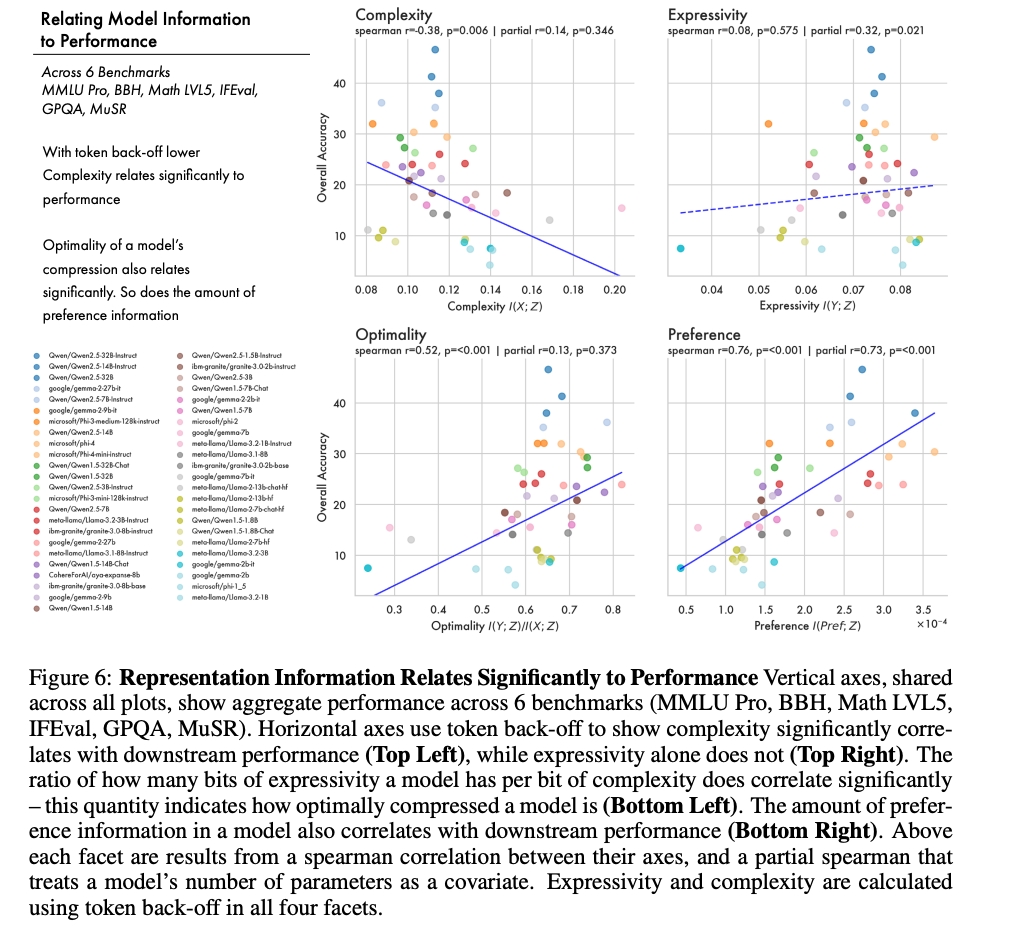
6つのベンチマーク、MMLU Pro、BBH、Math LVL5、IFEval、GPQA、MuSRの集約性能に対し、complexity、expressivity、optimality、preference informationを比較した図。
特に重要なのは、左下のoptimalityと性能の相関、右下のpreference informationと性能の相関。
@Ryuhei Kawabata
[paper] ClawBench: Can AI Agents Complete Everyday Online Tasks?
一言で言うと
この論文は、AI エージェントが「実際の Web サイトで、買い物、予約、応募、フォーム入力のような日常タスクをどれだけ完了できるか」を測るベンチマーク ClawBench を提案しています。
著者らの主張は、既存ベンチマークで高得点のエージェントでも、現実の Web ではかなり脆い、というものです。最良モデルでも成功率は 33.3% にとどまります。
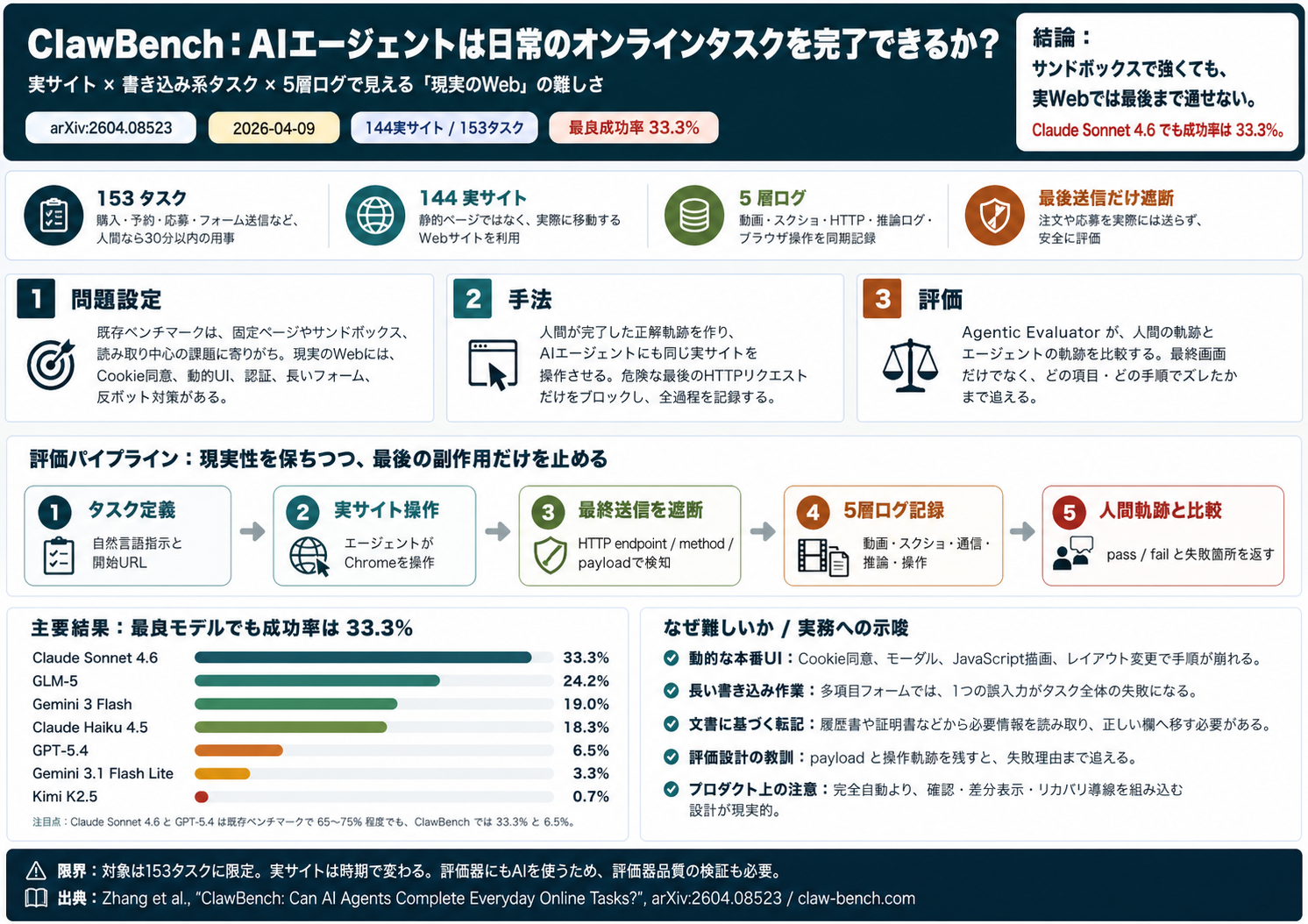
基本情報
| 項目 | 内容 |
|---|---|
| タイトル | ClawBench: Can AI Agents Complete Everyday Online Tasks? |
| 著者 | Yuxuan Zhang ほか 20 名 |
| 公開日 | 2026 年 4 月 9 日 |
| 種別 | arXiv preprint。分野は cs.CL / cs.AI |
| 対象 | Web 操作エージェントの評価 |
| 主要貢献 | 144 の実サイト、153 タスクで、日常的な書き込み系タスクを安全に評価する仕組み |
何が新しいか
既存の Web エージェント評価は、静的 HTML、自己ホスト環境、VM、読み取り中心タスクに寄りがちでした。それに対し、ClawBench は実サイトを使った書き込みタスクによるエージェントタスクで評価をしています。
ここでいう「書き込み系タスク」は、サーバー側の状態を変える操作です。たとえば注文、予約、応募送信、詳細フォーム入力です。
| 従来の評価 | ClawBench |
|---|---|
| サンドボックスや固定ページが多い | 実際に稼働している Web サイトを使う |
| 情報検索や QA が中心 | 購入、予約、応募、フォーム送信などの書き込み系が中心 |
| 最終状態やスクリーンショットで判定 | 人間の実行ログと比較して、どこで失敗したかを見る |
| 安全性のために現実性を落とす | 最終送信リクエストだけを止めて、現実性を保つ |
仕組み
ClawBench の核は、実サイトを使いつつ、最後の危険な送信だけを止めることです。
- 人間がタスクを実行し、正解となる操作ログと最終送信リクエストを記録する。
- AI エージェントが同じタスクを実サイト上で実行する。
- Chrome 拡張と CDP ベースの監視サーバーが、最後の送信リクエストだけをブロックする。
- セッション動画、スクリーンショット、HTTP 通信、エージェントの推論ログ、ブラウザ操作ログの 5 層を保存する。
- Agentic Evaluator が、人間の軌跡とエージェントの軌跡を比較して pass / fail を判定する。
この設計により、実際に注文や応募を送信せずに、実サイト上での完了能力を測れます。
結果
| モデル | 成功率 |
|---|---|
| Claude Sonnet 4.6 | 33.3% |
| GLM-5 | 24.2% |
| Gemini 3 Flash | 19.0% |
| Claude Haiku 4.5 | 18.3% |
| GPT-5.4 | 6.5% |
| Gemini 3.1 Flash Lite | 3.3% |
| Kimi K2.5 | 0.7% |
重要なのは、既存ベンチマークとの落差です。論文では、Claude Sonnet 4.6 と GPT-5.4 は OSWorld や WebArena では 65〜75% 程度を出す一方、ClawBench では 33.3% と 6.5% まで落ちると報告しています。
著者らは、これは「サンドボックスでできる」ことと「現実の Web で最後までできる」ことの差を示す、と読んでいます。
注意点
この論文で実証されたのは、ClawBench 上では現行の強いエージェントでも成功率が低い、という点です。
一方で、「一般のすべての Web タスクで AI エージェントは使えない」とまでは言えません。対象は 153 タスク、144 サイトに限定されています。
また、評価自体に Agentic Evaluator、つまり別の AI エージェントを使っています。人間の軌跡や HTTP payload と照合する設計なので根拠は厚いものの、評価器の判断品質は今後も検証対象になります。
読む価値
AI エージェント開発、ブラウザ自動化、業務自動化、評価基盤づくりに関わる人にはかなり参考になります。特に「デモでは動くが、本番サイトでは壊れる」問題を、評価設計としてどう扱うかが面白いです。
感想
saturated していない Agentic ベンチマークの一つ。タスクを見てみると実世界でのユースケースにかなり近く良さそう。また公式サイト上で trajectry を動画・GIFで見れるのもとても良い。一方で実サイトを用いるため完全同一条件での評価ができない点は難しさを感じる。
@Hirofumi Tateyama(hirotea)
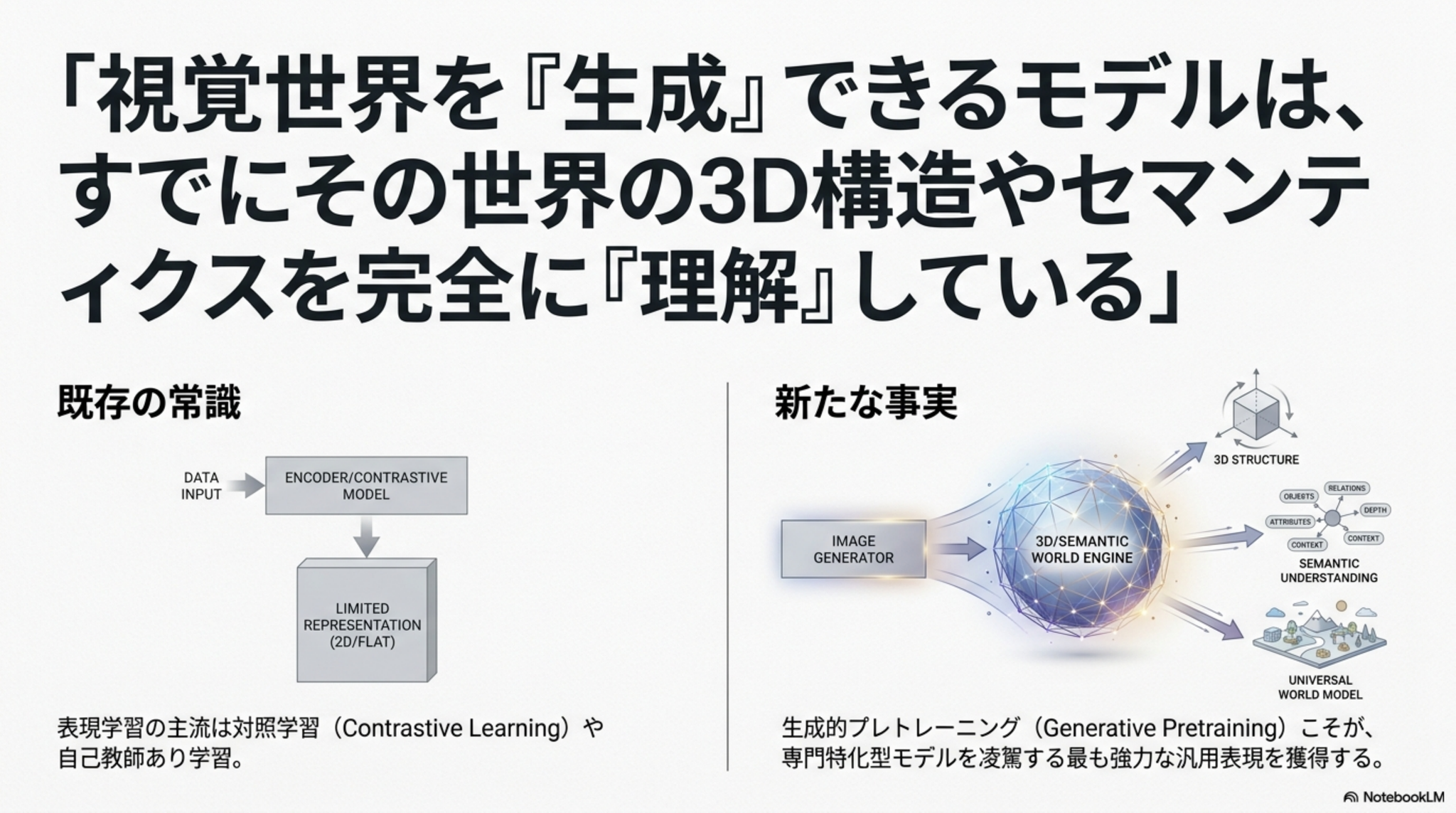
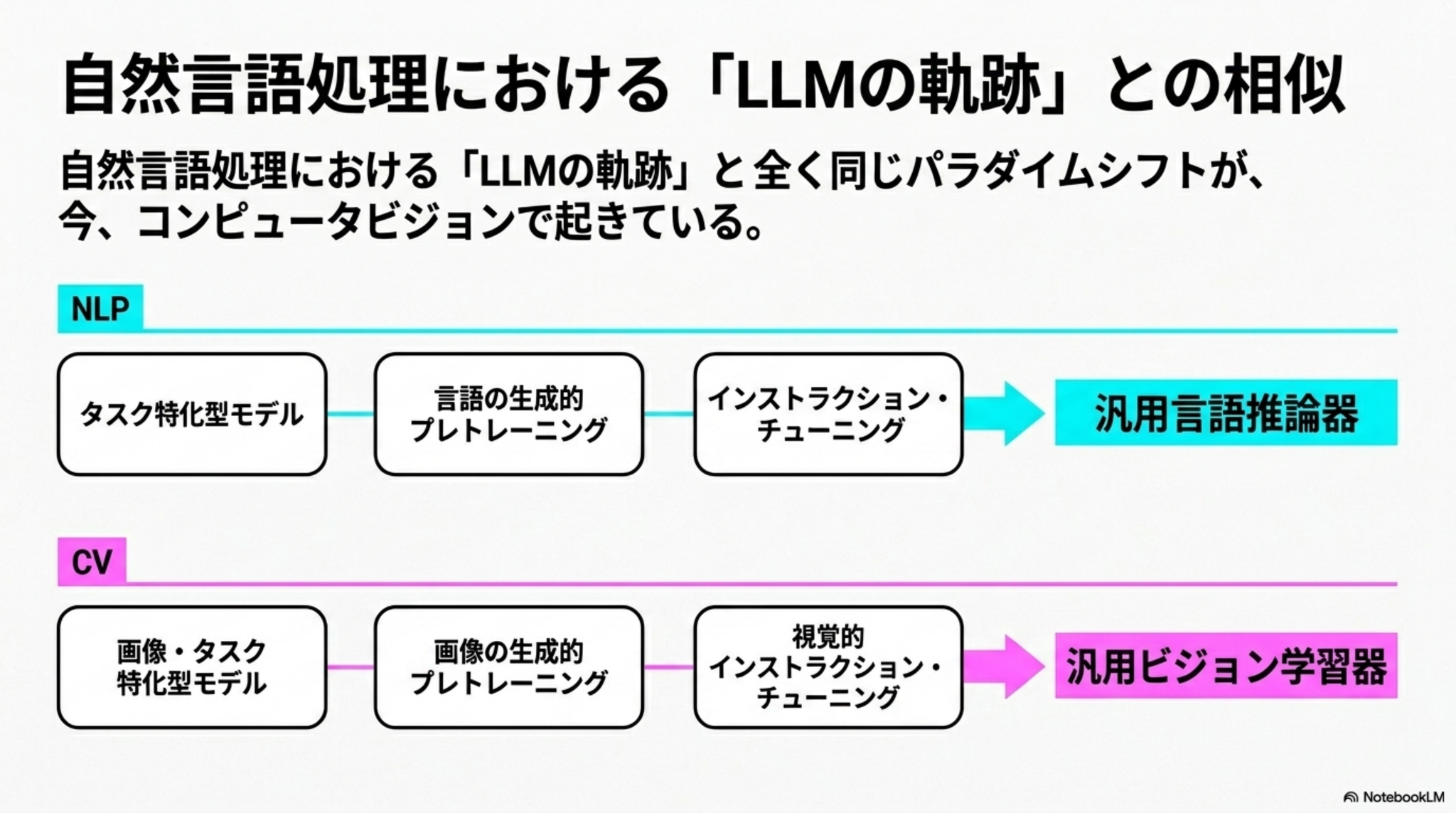
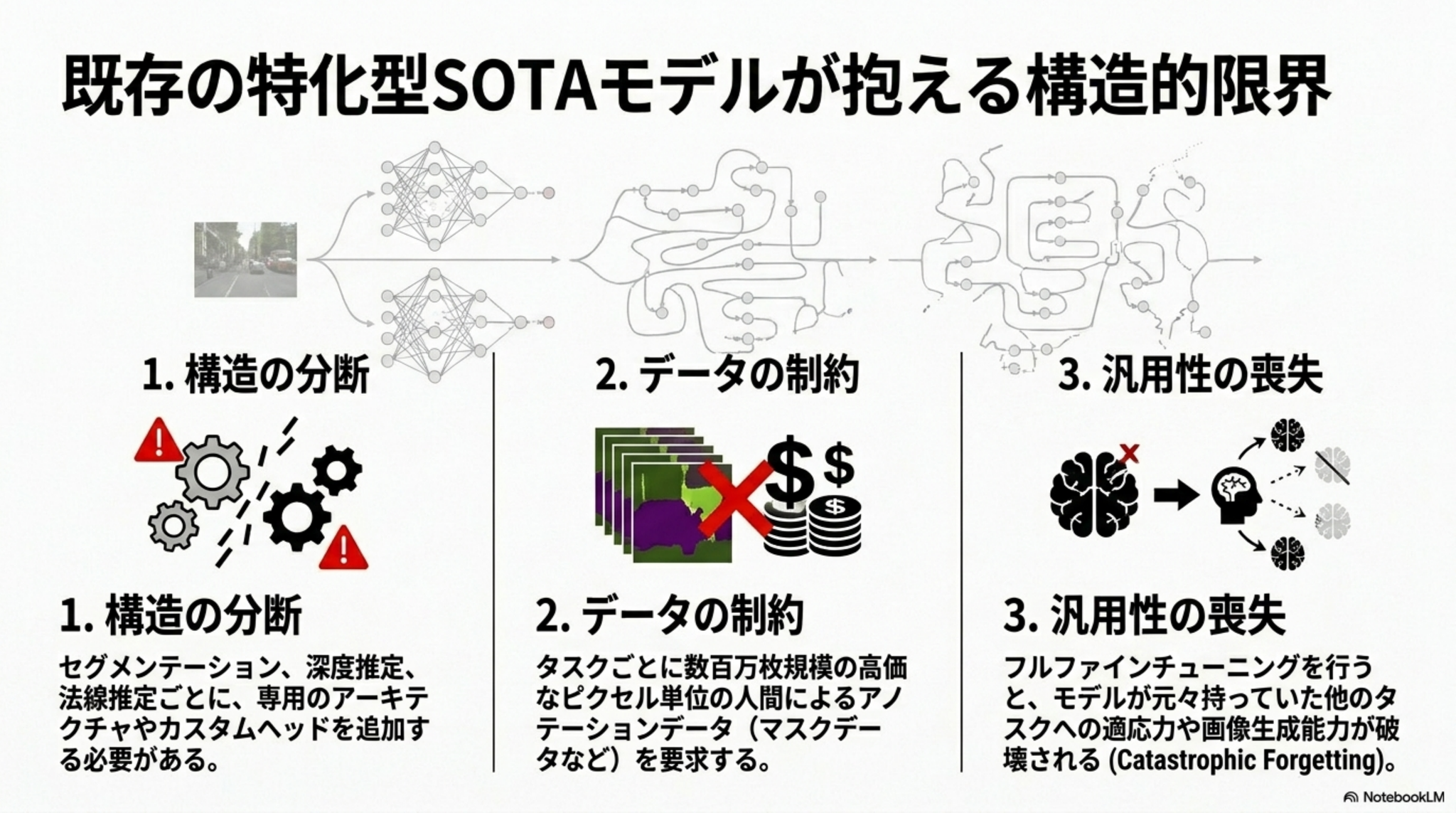
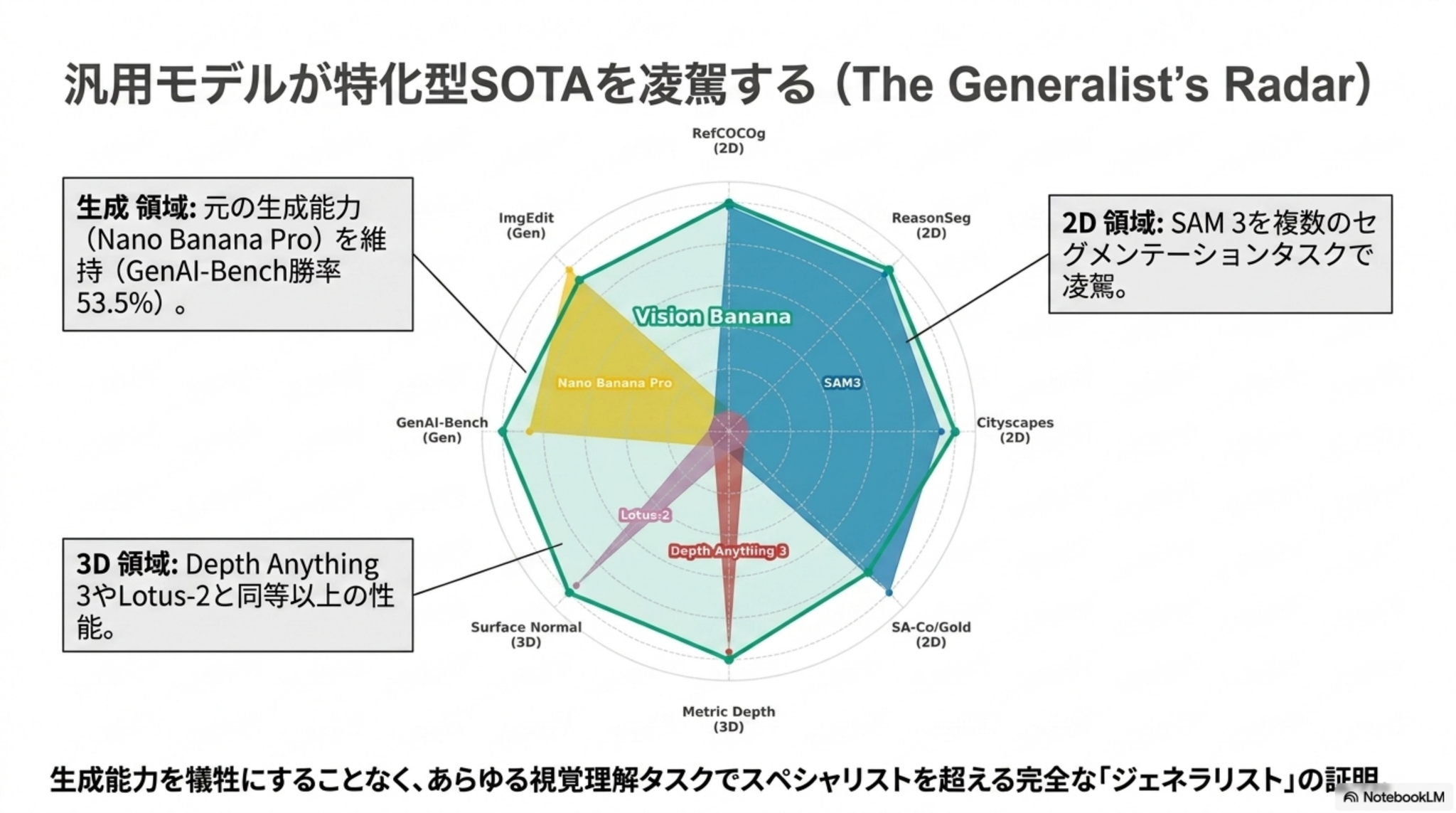
[paper]Image Generators are Generalist Vision Learners
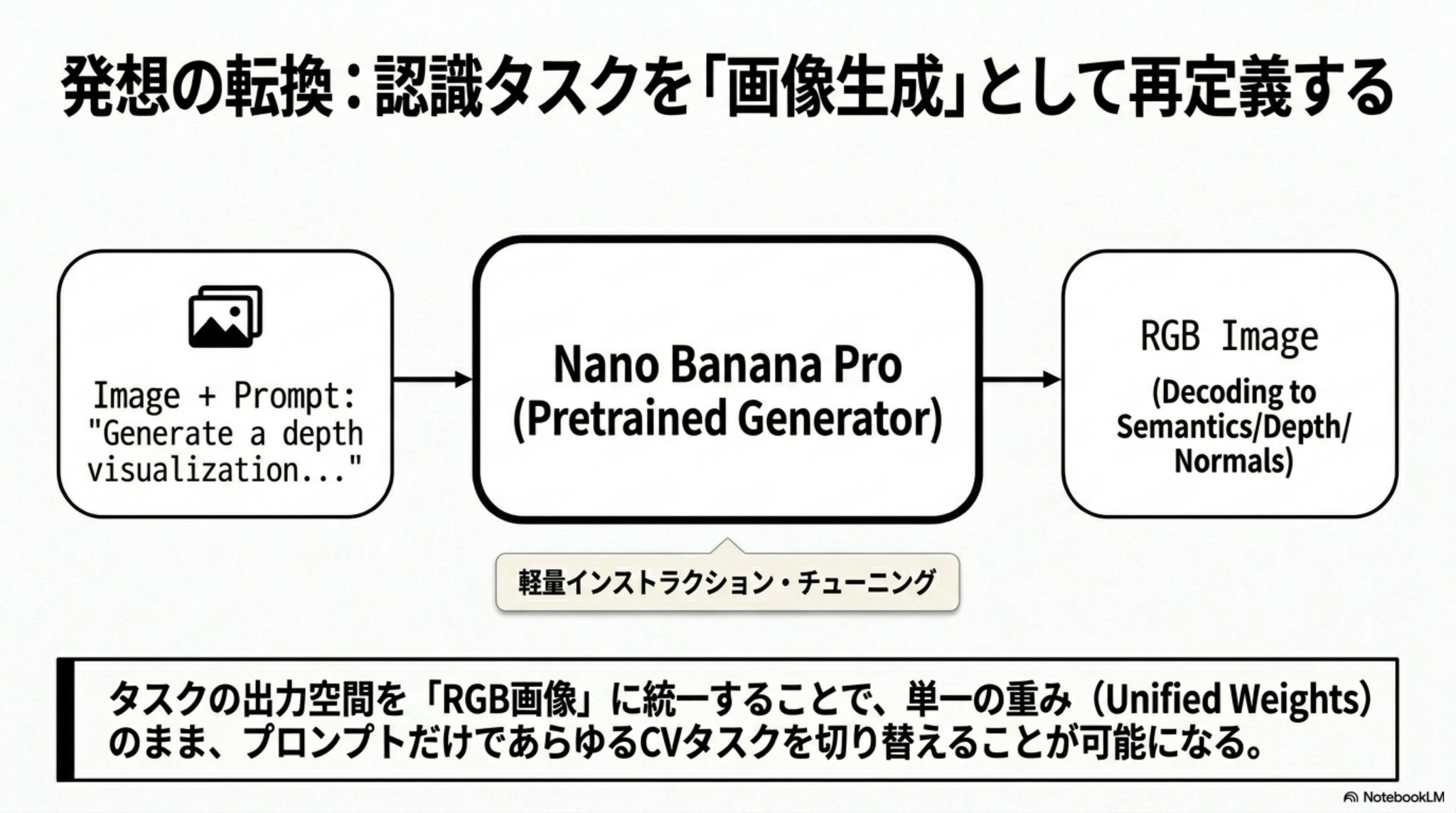
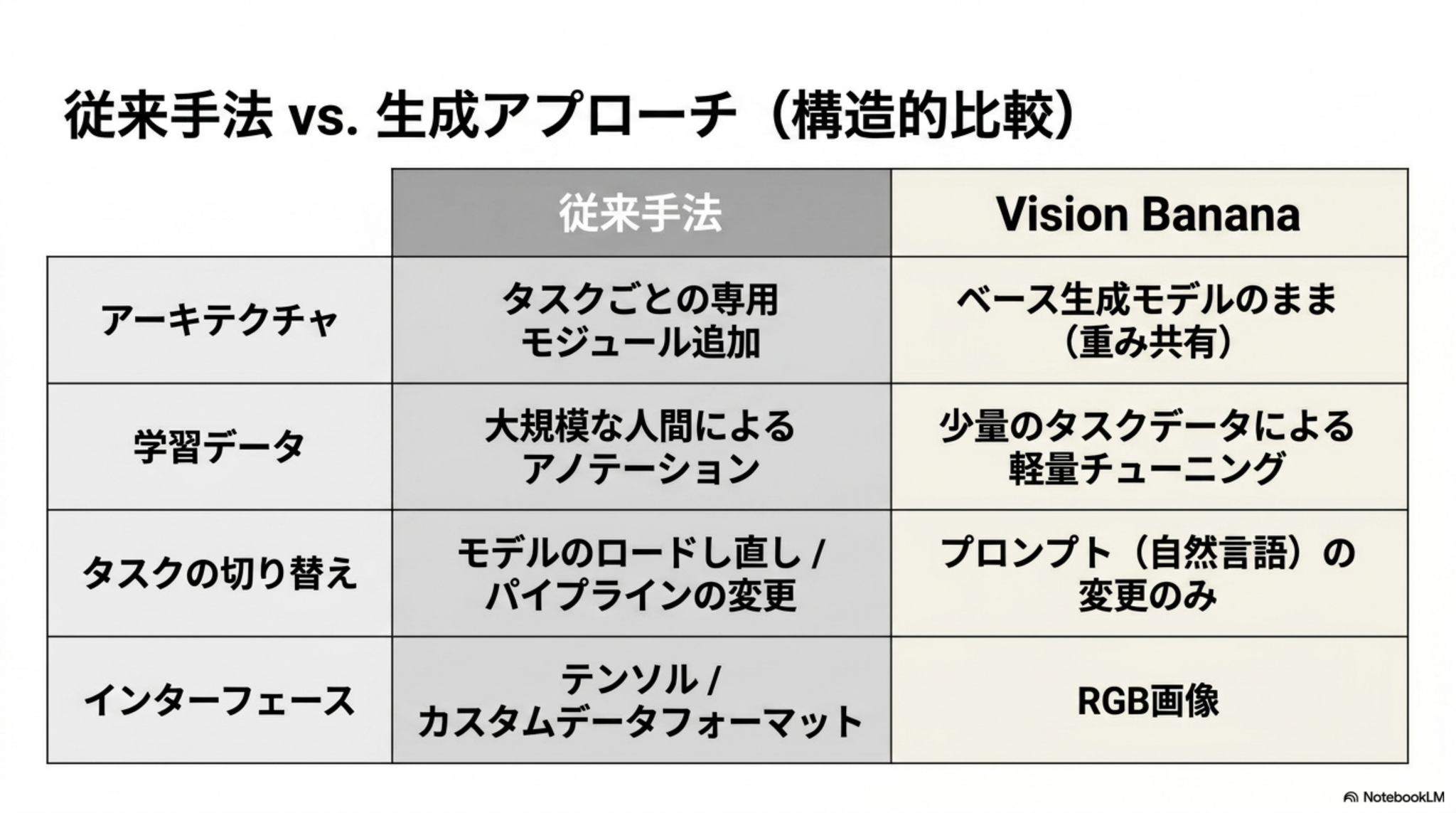
- 「画像を生成できるモデルは、適切な指示形式を与えれば、画像を理解するモデルとしても使える」という仮説の検証
- 画像生成モデルNano Banana Proをベースにした「Vision Banana」を用い、分析結果を全てRGB画像として出力するように指示して知覚タスクを解かせた
- セグメンテーション、距離推定、表面法線推定において特化型SOTAを凌駕する汎用視覚モデルとしてのスコアを出した(さらに元の画像生成能力も失っていない)
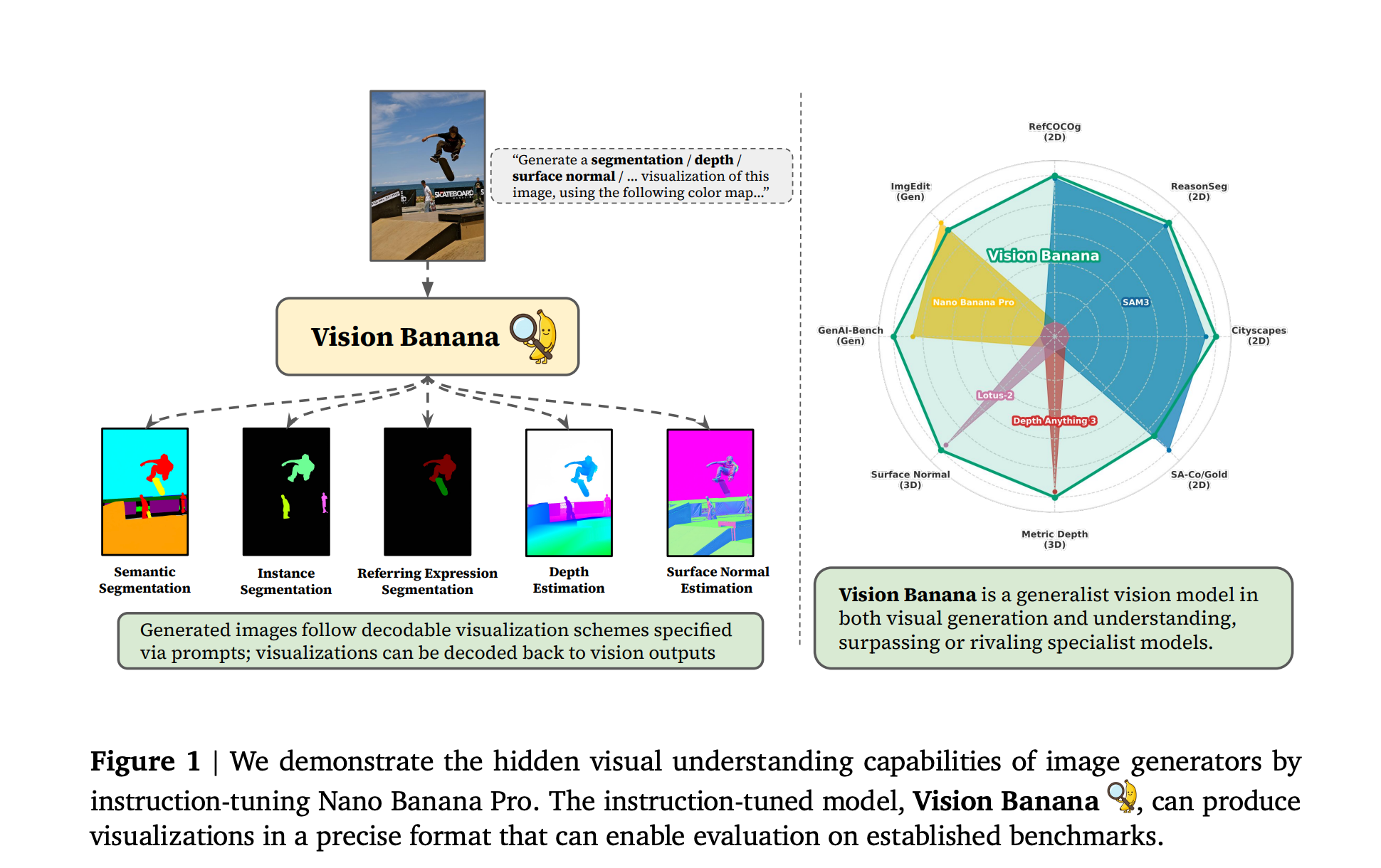
- 自然言語においてLLMが推論能力を得たように、CVにおいても画像生成は視覚理解の統一インターフェースになり得るのでは?
Slides

おそらくこのようなものを「少量」入れていそう
| 通常の教師データ | Vision Banana 用の教師データ |
|---|---|
| 画像 + segmentation mask | 画像 + 指示文 + 色付き segmentation 画像 |
| 画像 + depth map | 画像 + 指示文 + 深度を色で符号化した RGB 画像 |
| 画像 + surface normal map | 画像 + 指示文 + 法線を RGB に対応させた画像 |
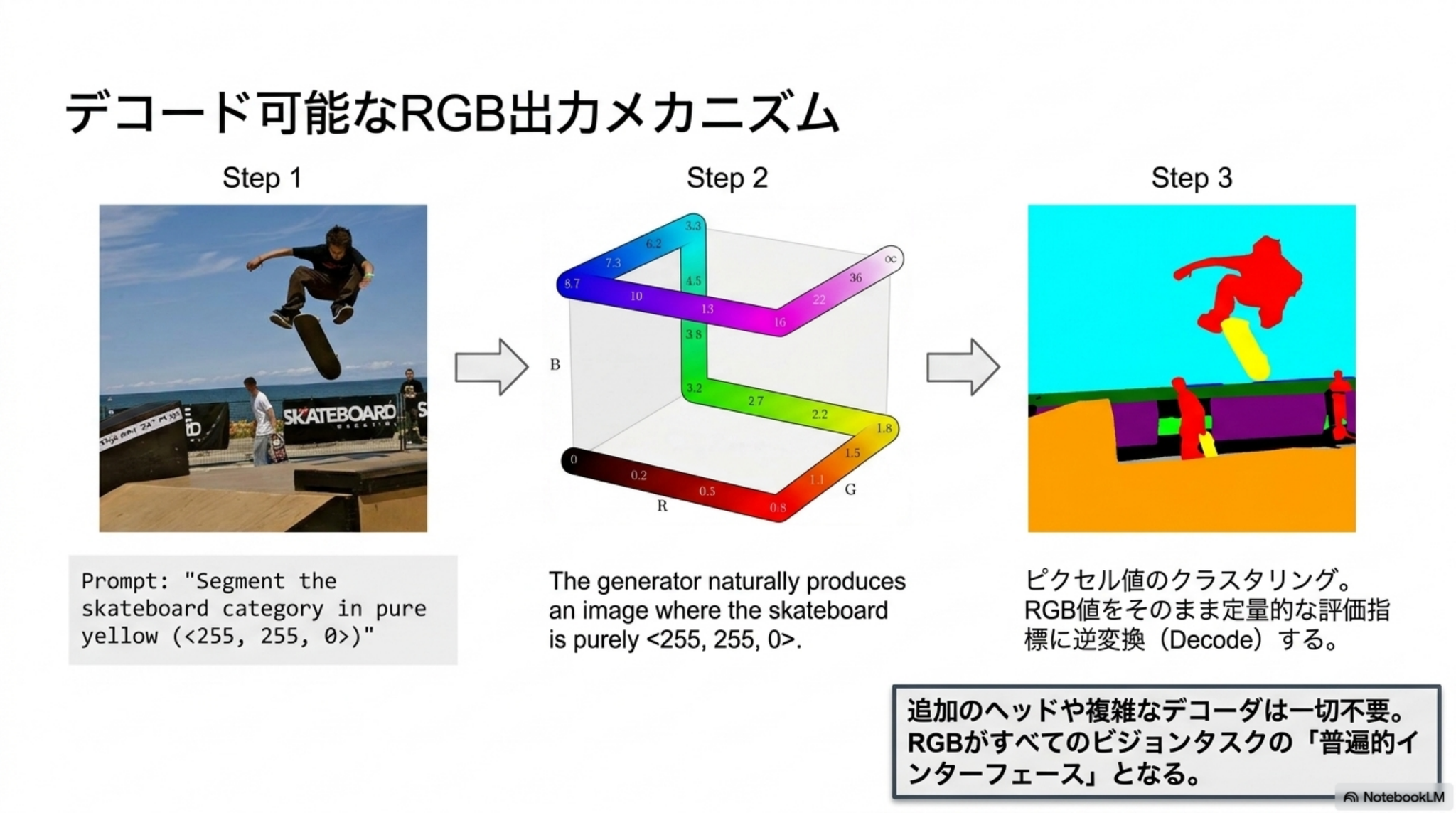
距離を正規化し256^3空間に表現


手持ちのスマホで撮影した写真をVisionBananaに深度推定させた。GoogleMapsの距離との誤差0.065


メインTOPIC
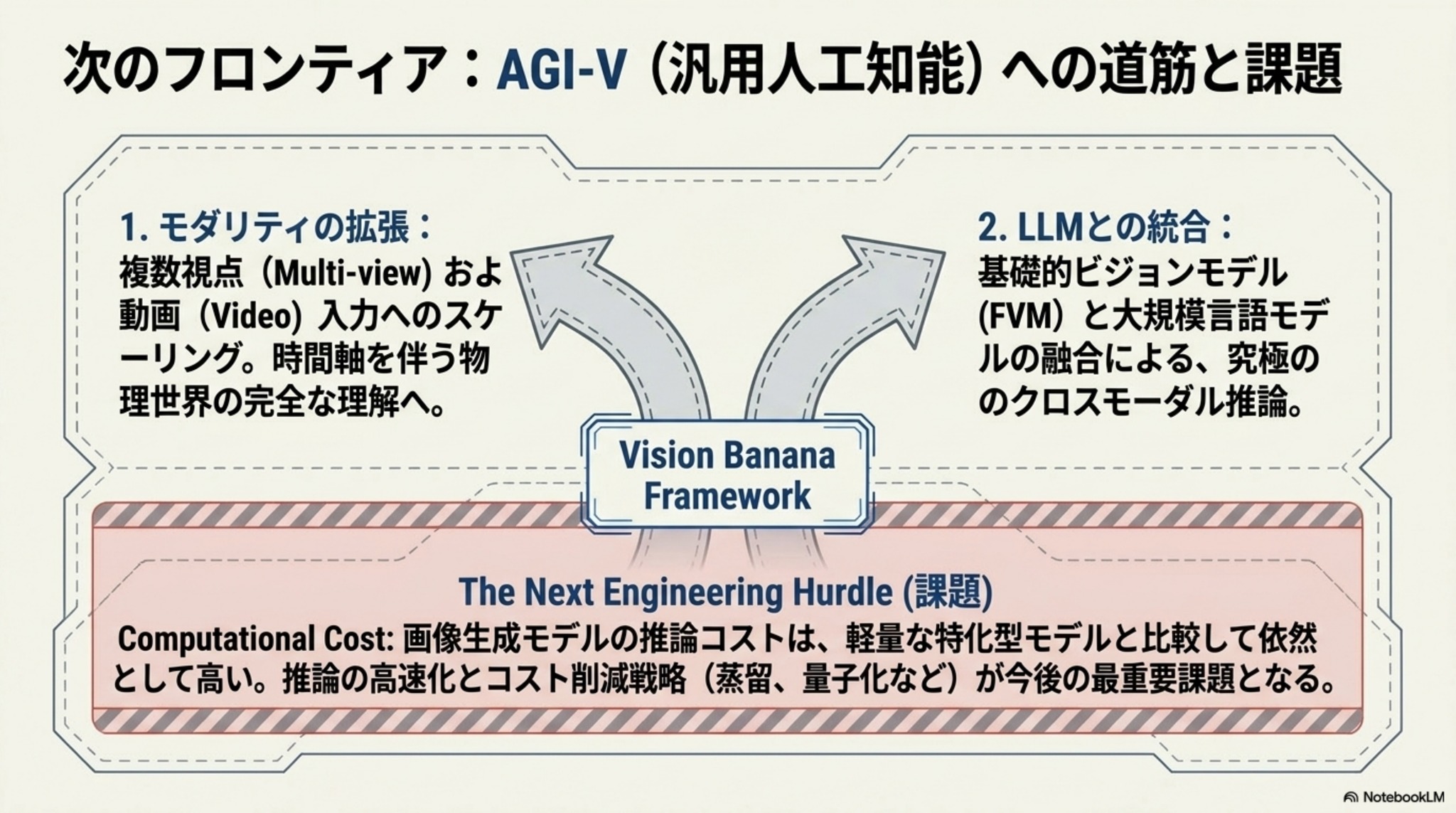
DeepSeek-V4:Towards Highly Efficient Million-Token Context Intelligence
概要
- DeepSeek-V4 は、DeepSeek-V4-Pro と DeepSeek-V4-Flash からなる MoE 系列で、1M tokens の長文コンテキストを効率的に扱うことを主目的に設計されている
- 中核技術は、CSA/HCA による hybrid compressed attention、mHC、Muon optimizer、FP4 量子化-aware training などで、長文推論時の FLOPs と KV cache を大幅に削減している
- 32T 超 tokens で事前学習し、専門モデルの SFT+RL と On Policy蒸留 による事後学習で統合することで、知識・推論・長文・エージェント系ベンチマークで open model として高い性能を示している
1Mトークンの目安
- 多くのフロンティアモデルは1Mトークンを扱える
| モデル/系統 | 公称コンテキスト長 | 補足 |
|---|---|---|
| OpenAI GPT-5.5 / GPT-5.4 | 1,050,000 tokens | 最大出力は128k tokens。OpenAI API docs上ではGPT-5.5、GPT-5.4とも1M級です。(OpenAI Platform) |
| Anthropic Claude Opus 4.7 | 1M tokens | 最大出力128k tokens。Sonnet 4.6も1M、Haiku 4.5は200kです。(Claude Platform) |
| Google Gemini 3.1 Pro | 1,048,576 input tokens | 最大出力65,536 tokens。GoogleはGemini 3系について1M input / 64k output級と説明しています。(Google Cloud Documentation) |
| xAI Grok 4.1 Fast | 2M tokens | xAIはGrok 4.1 Fastを「2M context window」として発表しています。(xAI) |
| DeepSeek-V4 Pro / Flash | 1M tokens | DeepSeek公式も「cost-effective 1M context length」「1M Standard」と説明し、両モデルの1M対応を明記しています。(DeepSeek API Docs) |
| 参考: Meta Llama 4 Scout | 10M tokens | オープンウェイト系の例外的な長文脈モデルとして、MetaはLlama 4 Scoutの10M contextを公称しています。ただし実サービスでフルに使えるかは提供環境に依存します。(Meta AI) |
OpenAIの目安では、英語では1トークンはだいたい4文字、または0.75語です。したがって1Mトークンは、英語なら約400万文字、約75万語に相当します。250〜300語/ページの文書なら約2,500〜3,000ページ、8〜10万語の一般的な長編小説なら約7〜9冊分です
背景
下記の理由から現代のLLMモデルは性能だけでなく「長文をどれだけ安く処理できるか」が重要な課題
- Reasoning modelでは推論時の思考トークンが増える
- Agentic workflowや大量文書分析では入力文脈も長くなる
ロングコンテキストを実現するための課題は主に以下
- Attentionの計算量の増大
- KV cacheの肥大化
アーキテクチャ
ポイント
- アテンションの計算コストを抑えるためのCSA/HCAを新しく提案
- 学習の安定化のためにResidual層を改良したmHCを採用
- 学習の収束性と安定性向上のためにMuon Optimizerを採用
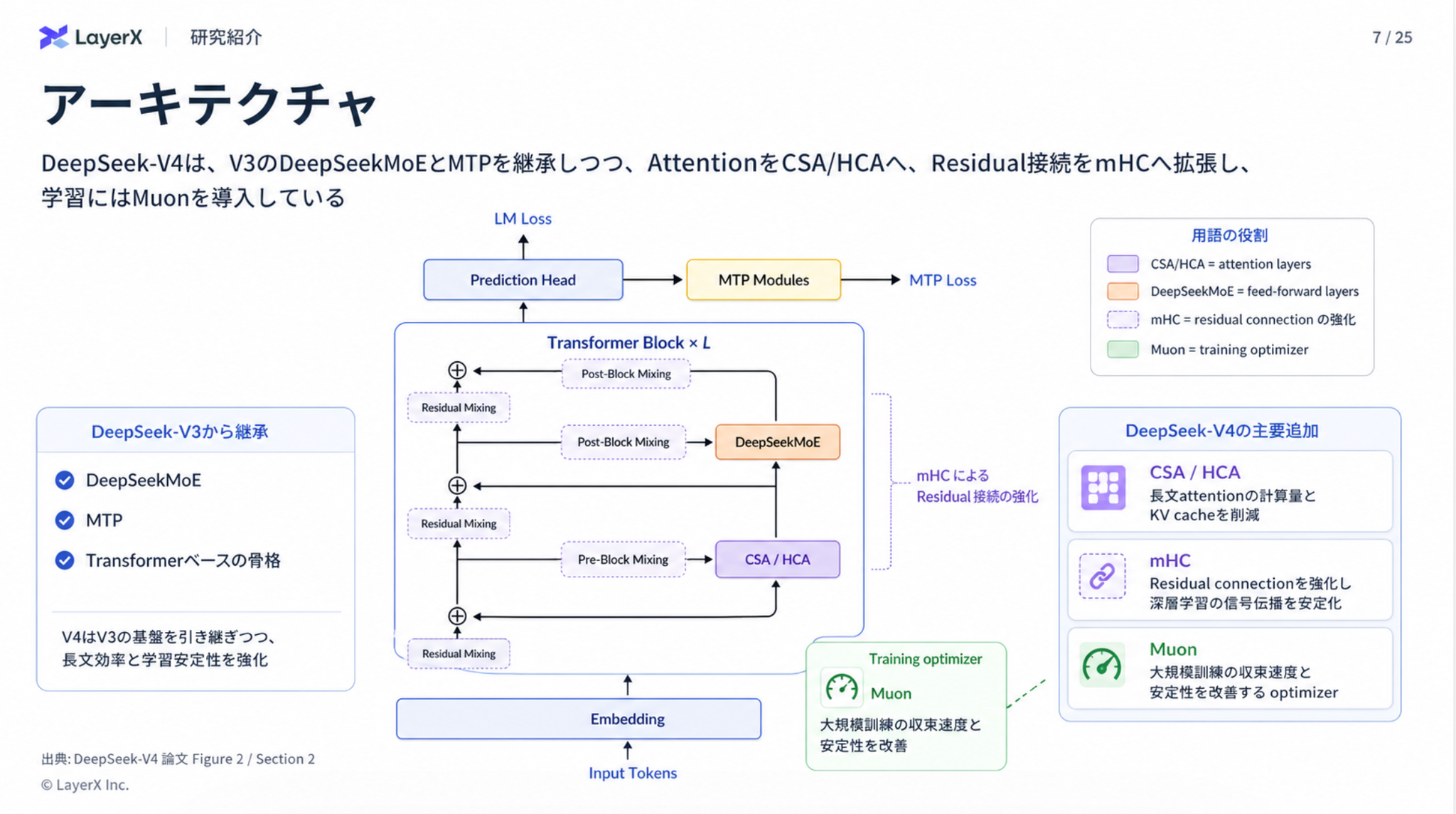
CSA/HCAによりアテンションコストを抑える
- CSA: Compressed Sparse Attention
- DSA(DeepSeek Sparse Attention)の改良版
 arXiv.orgDeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
arXiv.orgDeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
- HCA: Heavily Compressed Attention
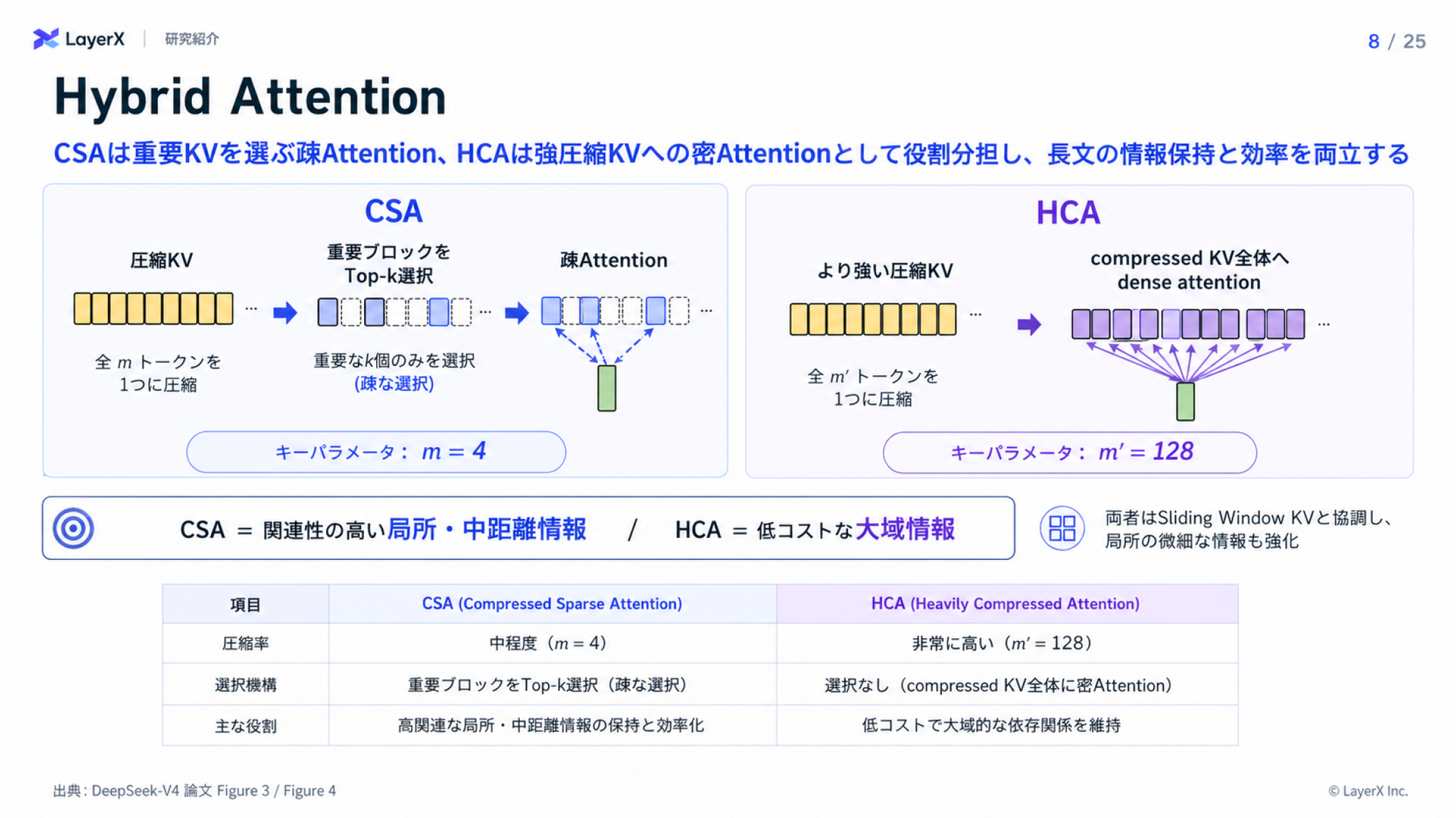
CSAの論文内の図
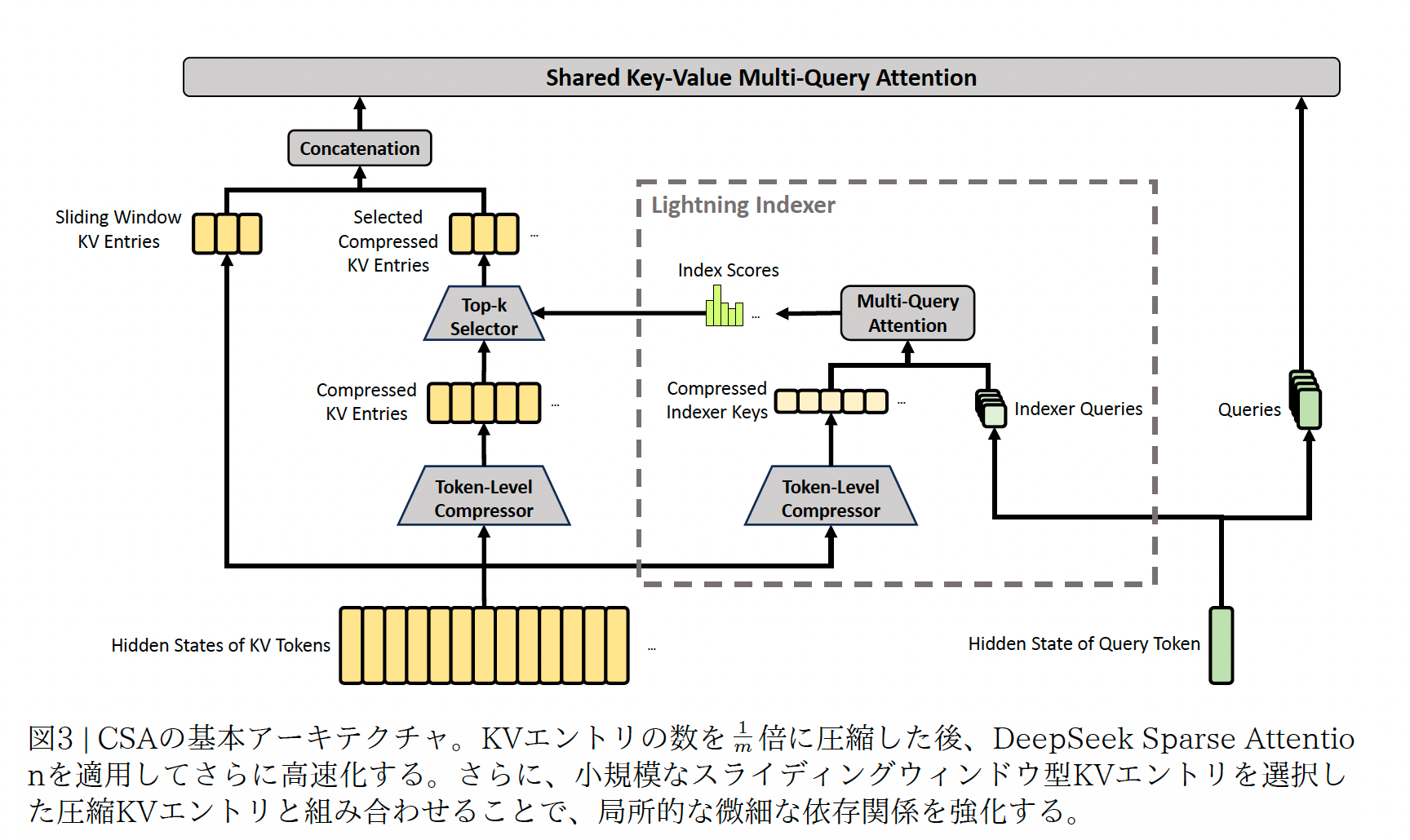
HCAの論文内の図
- CSA/HCAによるトークン圧縮で情報が粗くなってしまうため、より重要な直近のトークンに対しては圧縮せず通常通りAttentionを計算するSliding Window Attentionを導入。CSA/HCAのKVキャッシュに結合してAttentionを計算する。

mHC(Manifold-Constrained Hyper-Connections)
- Residual層を複数本に拡張したのがHC(Hyper-Connections)
- HCがモデル性能向上の可能性を示す一方で、複数の層を積み重ねる場合に訓練が数値的に不安定になる現象が頻繁に発生
- HCの学習パラメータBに多面体制約を課したのがmHC
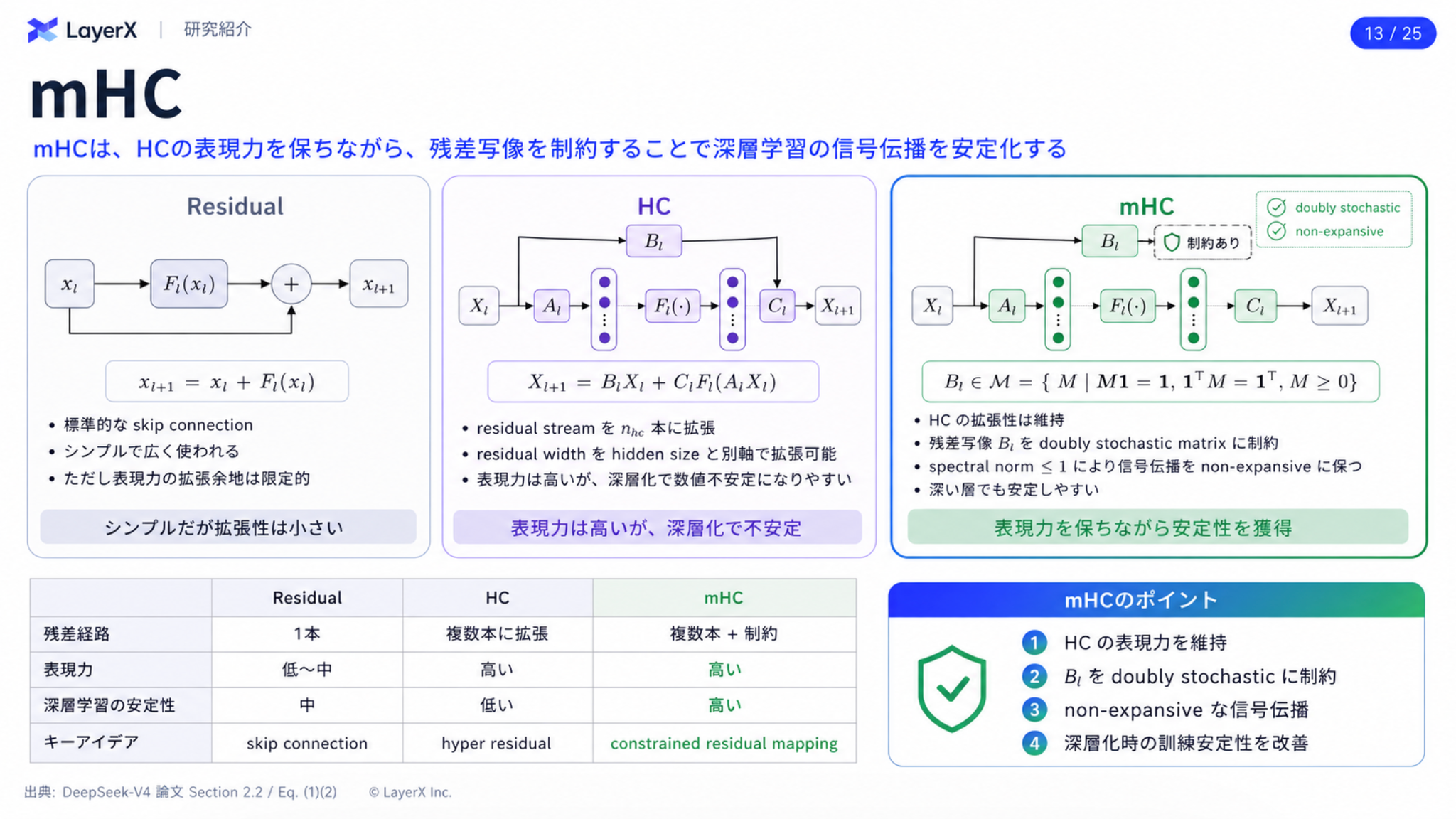
Muon Optimizer
- 大規模訓練における収束速度と安定性を改善する役割
- SGD with Nesterovモメンタムで勾配を計算した後、Newton-Schulz法でその勾配行列を直交化(orthogonalize)してからパラメータ更新する

その他の工夫
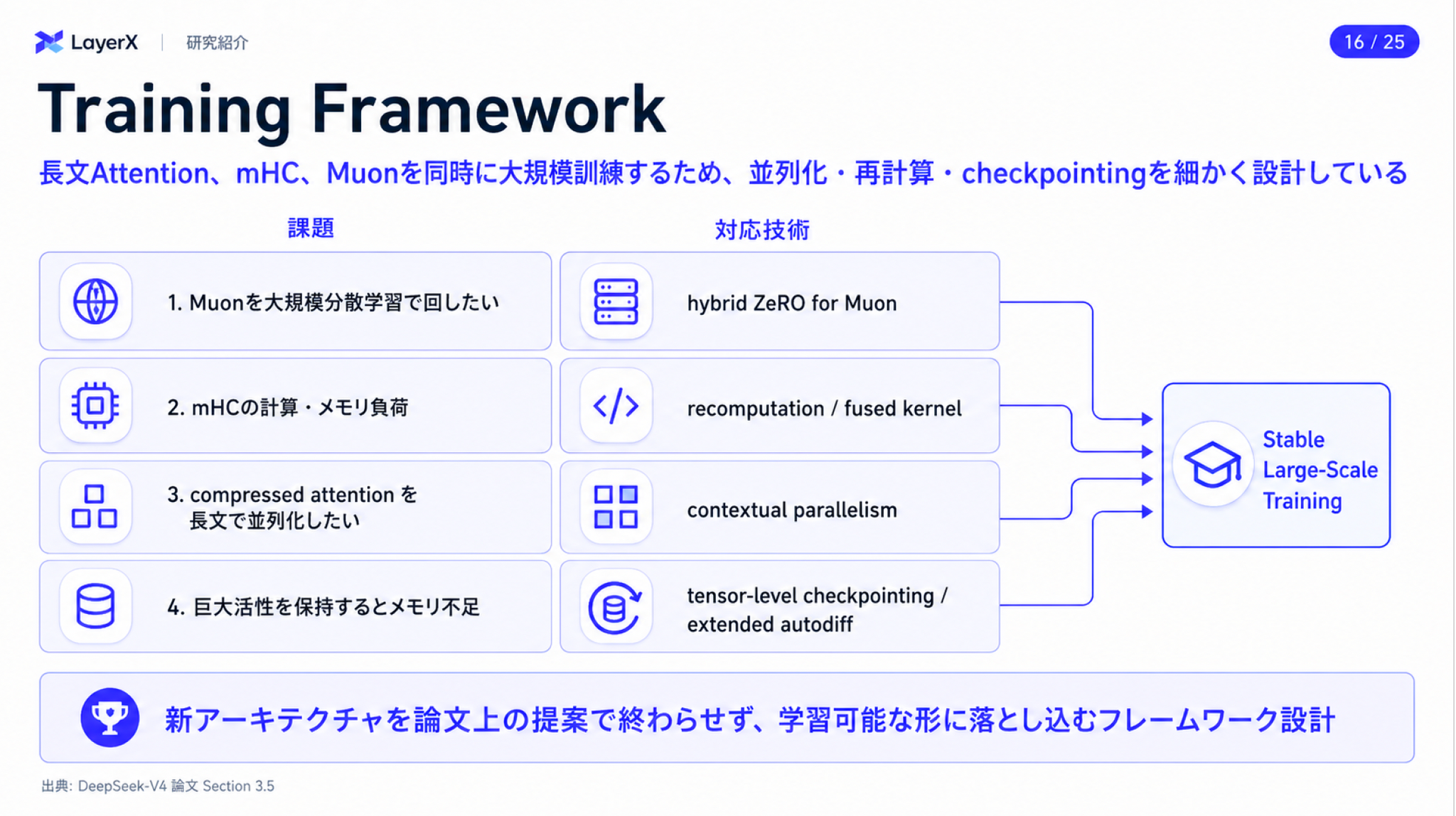
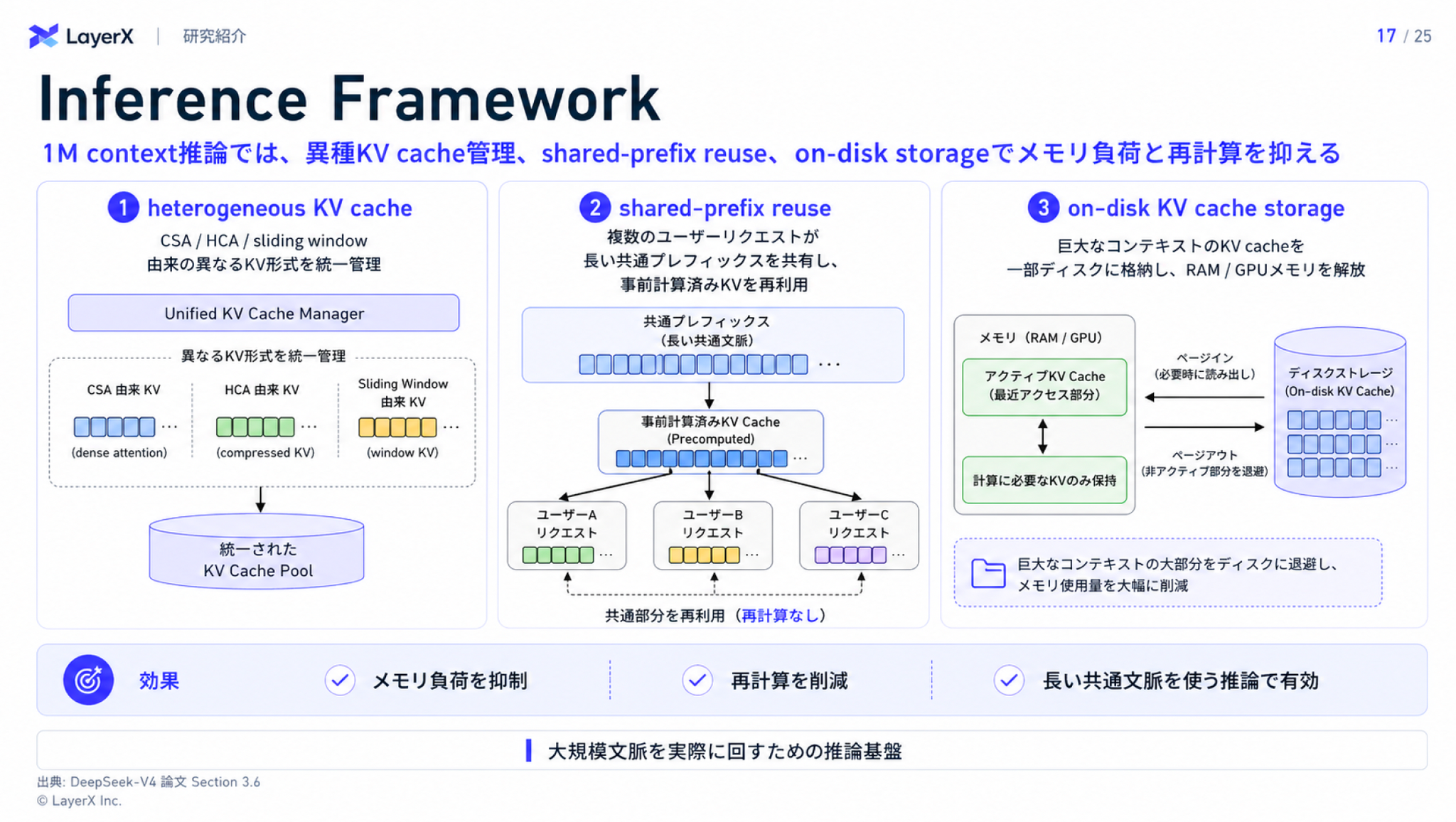
学習パイプライン
概要
- 事前学習
- 32Tトークンの大規模データで自己教師あり学習
- 事後学習(SFT+RL)
- 領域ごとの専門的なタスクごとにモデルのcheckpointを作成する
- オンポリシー蒸留
- 事後学習で作成した複数モデルを教師モデルとして1つの生徒モデルに蒸留
事後学習
- 注意点としてモデルはMoEだが、ここでいう専門家とはモデルに内包されるExpertsのことではない。つまりMoEモデルがドメインごとに複数用意されるイメージ
- 検証が困難なタスクに対して学習対象のLLM自身をGenerative Reward Model(GRM)とみなしルーブリックを参照させて報酬生成
- [kuto]これいいのかちょっと疑問。自身の生成結果に対して自身で報酬を与えて良いものか
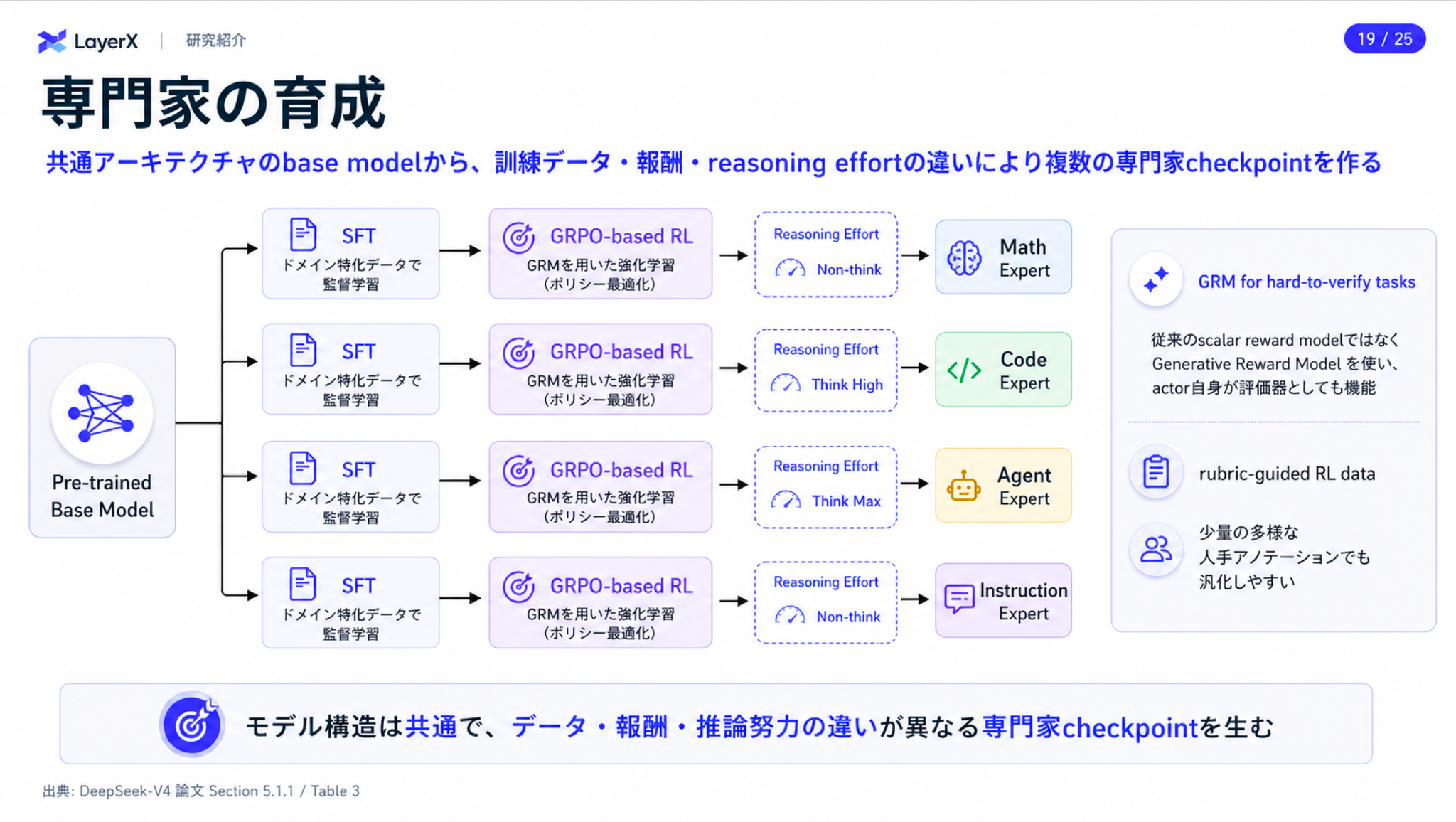
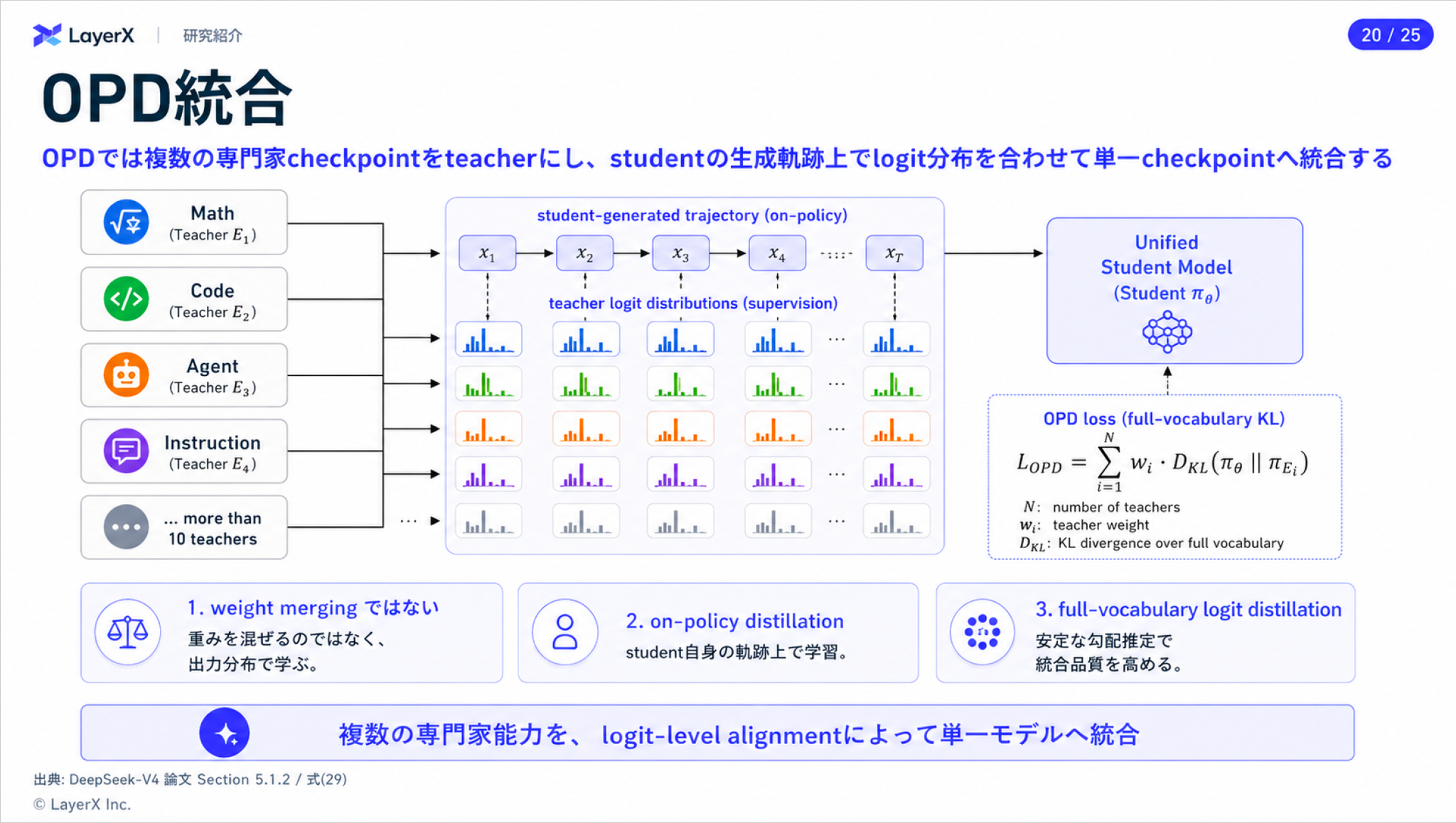
オンポリシー蒸留
- 前段で作成した複数の教師モデルを統合するためにオンポリシー蒸留を行う
オンポリシー蒸留とは
- 生徒モデルが生成したトークン列に対して教師モデルの確率分布を教師信号として分布を近づけるようにして蒸留する手法。
- 逆にオフポリシーの場合は固定トークンor教師モデルが生成したトークン列に対して生徒モデルの確率分布を近づけるように蒸留する。
- オンポリシーの方が実際に生徒がサンプリングしたトークンに対して学習が行われるため分布シフトが起こりにくい
- 従来はRLでやっていた複数の専門モデルの統合をオンポリシー蒸留によって実施するように改良した
- 単純に重みマージしたり、全部のRLを混ぜて継続学習したりすると、能力干渉や性能劣化が起きやすい
- GLM5も同じ目的でオンポリシー蒸留を採用していた
- 全語彙での学習
- 出力されたトークンの確率値のみで蒸留するのではなく、語彙全体に対して確率分布を求めて蒸留する
- これにより計算コストは増えるが勾配推定の分散が減少し学習が安定する
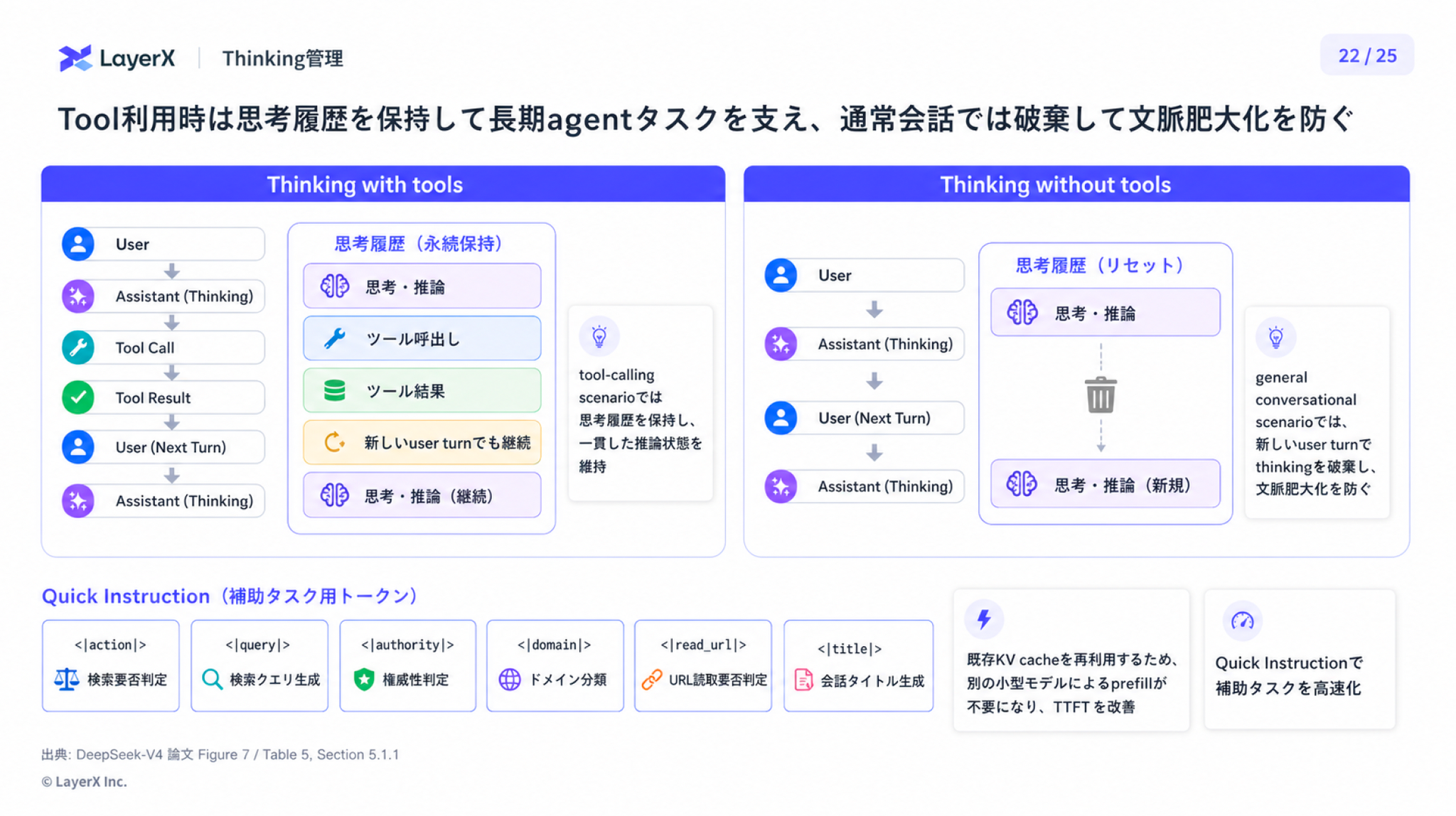
思考管理
- 事後学習の段階で各 mode ごとに length penalty と context window を変えることで、Reasoning Effortを調整できるようにする

- DeepSeek‒V3.2では、新しいユーザーメッセージが到着すると思考履歴を破棄する文脈管理戦略を採用していた
- しかし複雑なエージェント型ワークフローにおいて都度いちから思考するため不要なトークン消費を引き起こしていた。
- 1Mトークンのコンテキスト長に対応したことでこの課題に以下のように対応可能となった
- ツール利用を伴うシナリオでは思考履歴を保持して推論の一貫性を維持、推論結果の保持が不要なシナリオでは思考履歴は逐次削除(従来通り)
評価
標準ベンチマーク
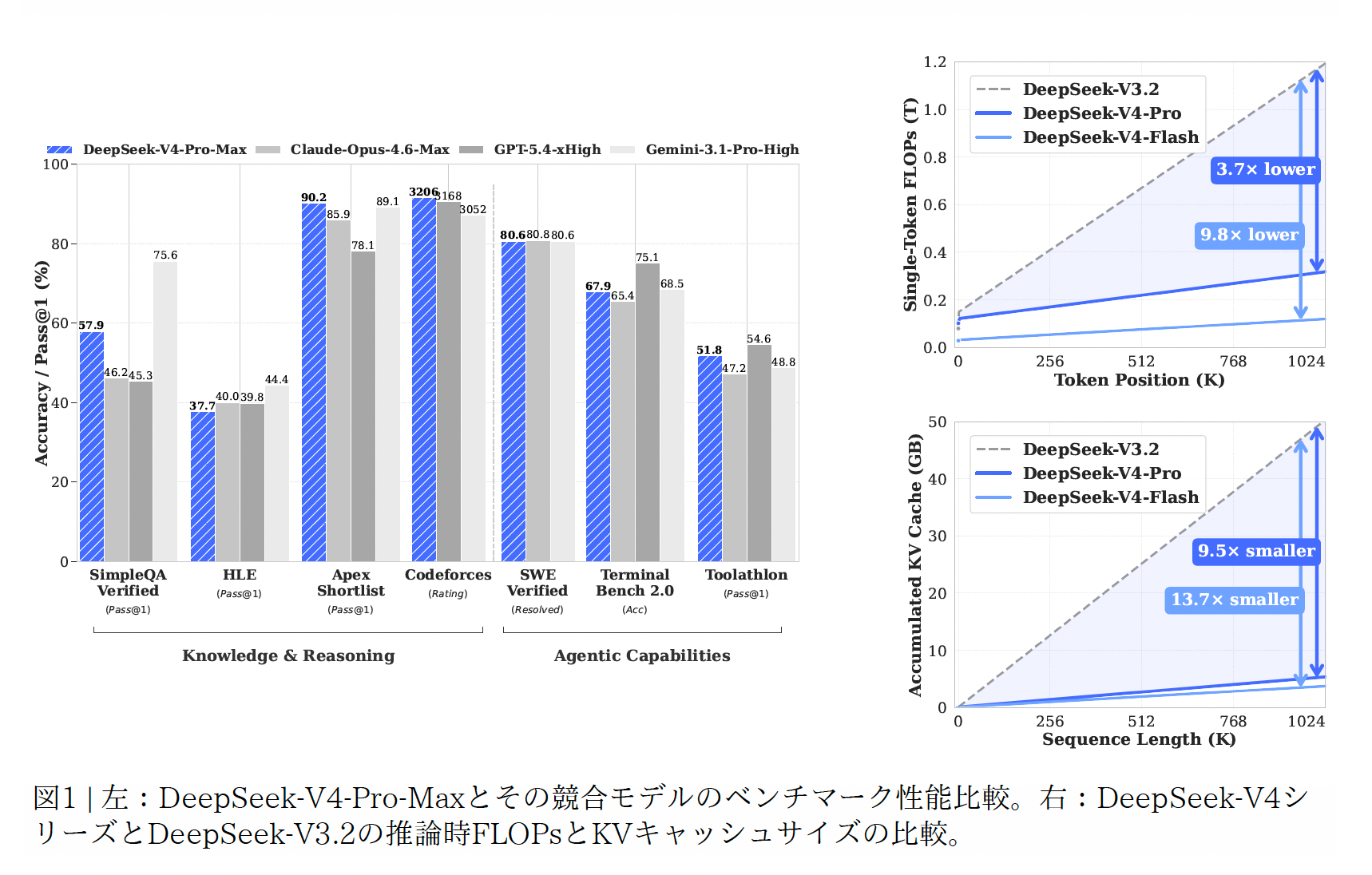
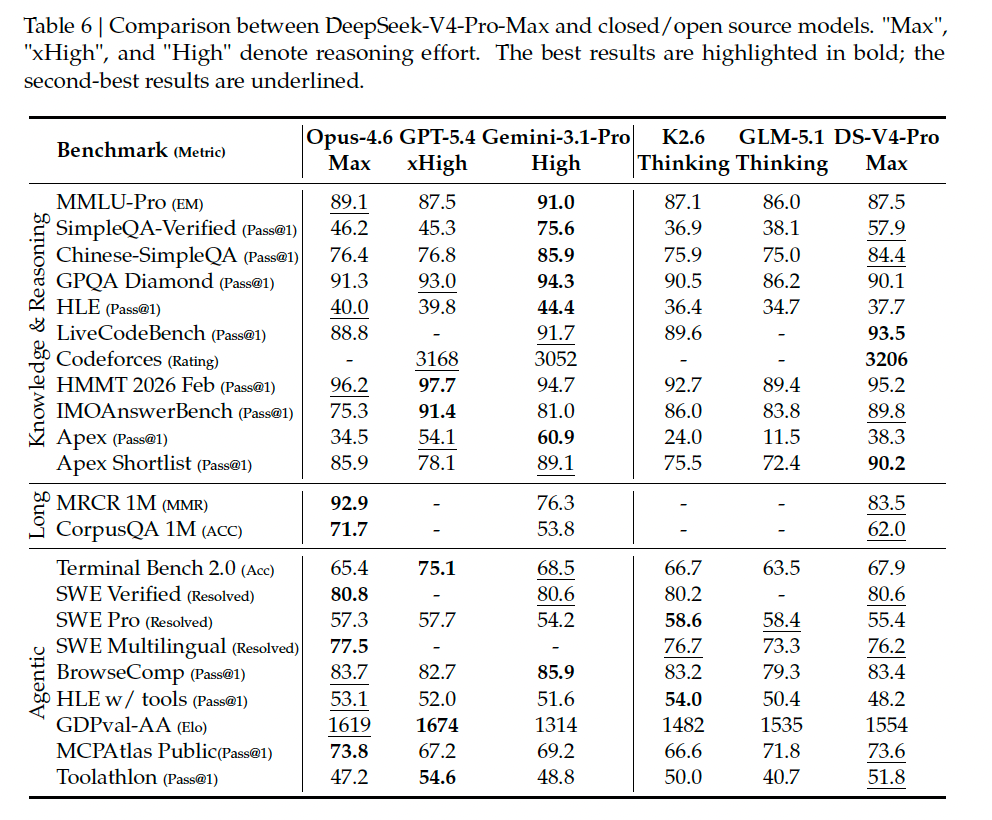
- DeepSeek-V4-Pro-Max の性能
- 知識・推論・長文・エージェントの総合ベンチマークで open model の新しい上限として位置づけられている
- Reasoning と coding では closed frontier にかなり接近している
- 一方、一般知識・ツール利用・コードエージェントの一部では、最上位 closed model にまだ差が残る
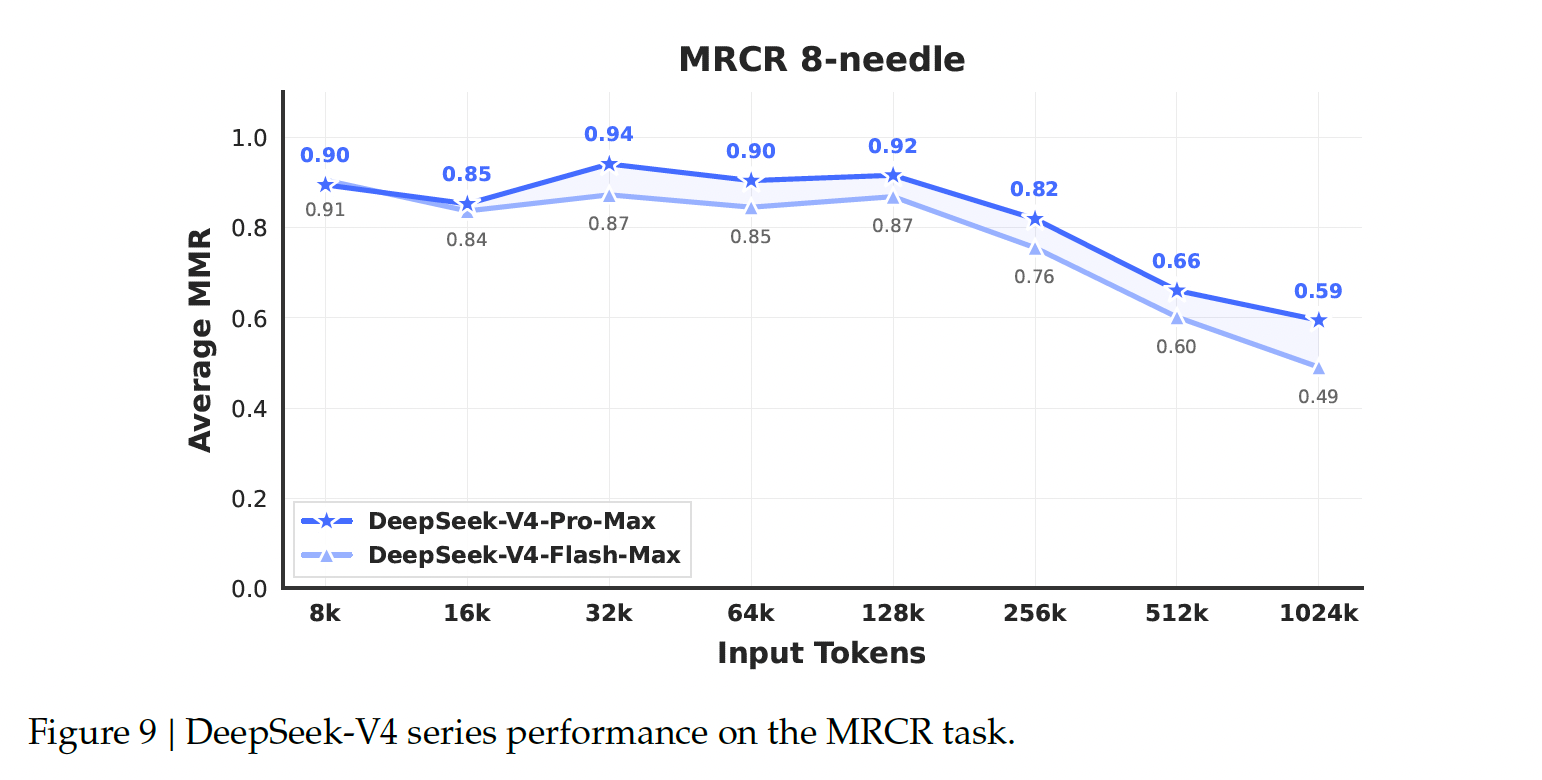
- ロングホライズンタスクに対する性能
- DeepSeek‒V4‒ProはMRCRタスク(文脈内検索性能を測定する指標)においてGemini‒3.1‒Proを上回る性能を示すものの、Claude Opus 4.6には及ばない(上の表)
- 128Kのコンテキストウィンドウ内では検索性能は安定している
- 128Kを超えると性能の低下が顕著になるものの、1Mトークンという大規模なコンテキストにおける本モデルの検索能力は、クローズドソースおよびオープンソースの競合モデルと比較しても依然として非常に優れている
実用ベンチマーク
- スライド生成の品質を示した一例

- 社内の実際の研究でのコーディングタスクをベンチマークとしたもの
- Opusには劣る
