
2026-05-07 機械学習勉強会
今週のTOPIC[paper] Qwen-Scope: Turning Sparse Features into Development Tools for Large Language Models[paper] Modular Memory is the Key to Continual Learning Agents[paper] Speculative Actions: A Lossless Framework for Faster Agentic Systems[paper] From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company[paper]Meta-Harness: End-to-End Optimization of Model Harnesses[paper] ReasoningBank: Scaling Agent Self-Evolving with Reasoning MemoryメインTOPICTurboQuant: Online Vector Quantization with Near-optimal Distortion RateIntroduction課題Problem DefinitionPreliminariesShannon Lower Bound (SLB) on Distortion (復習)QJL: 1-bit inner product quantizationTurboQuant: High Performance Quantization1. MSE Optimal TurboQuantアルゴリズム量子化と逆量子化(Algorithm 1)性能保証(Theorem 1)Inner-product Optimal TurboQuantアルゴリズム性能保証(Theorem 2):Lower Bounds ExperimentsEmpirical ValidationNeedle-In-A-HaystackEnd-to-end Generation on LongBenchNear Neighbour Search Experiments
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[paper] Qwen-Scope: Turning Sparse Features into Development Tools for Large Language Models

- LLMの各層をSAE(Sparse Auto Encoder)で置き換えるという手法自体は真新しくないが、応用の仕方が多数記載されており、実用性も証明。ユースケースだけ今回は紹介。

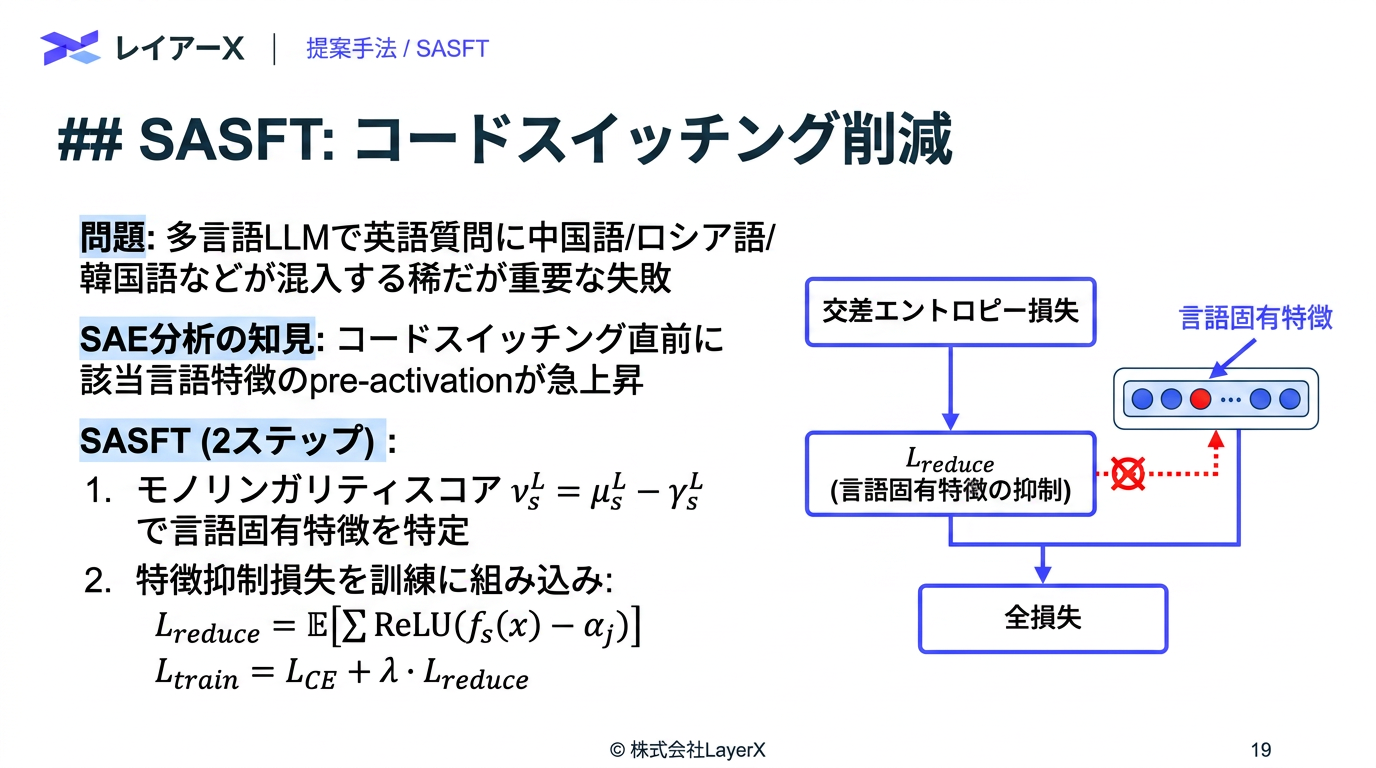
- L1正則化で学習させるのではなく、TopKの値飲み残し、それ以外を0とする方法で、MoEを含む全層を学習
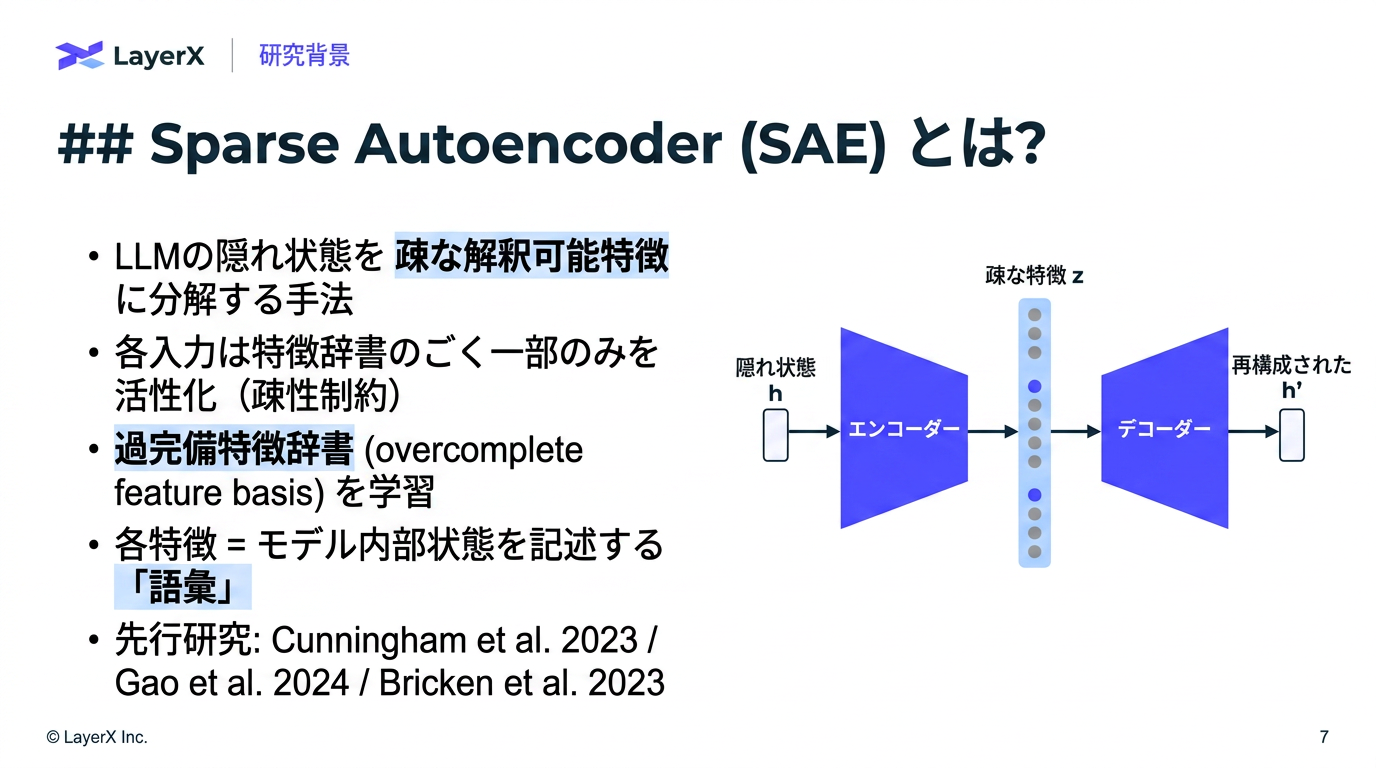
- 元の隠れ層のサイズの16倍 or 64倍のサイズで学習させてカバレッジを高めている
- 一度も活性しないデッド特徴が発生しないような補助ロス、L2ノルムが大きい特徴を除外などして工夫
- 応用例
- 推論時ステアリング
- Denseなものよりも副作用が小さい
- 評価分析
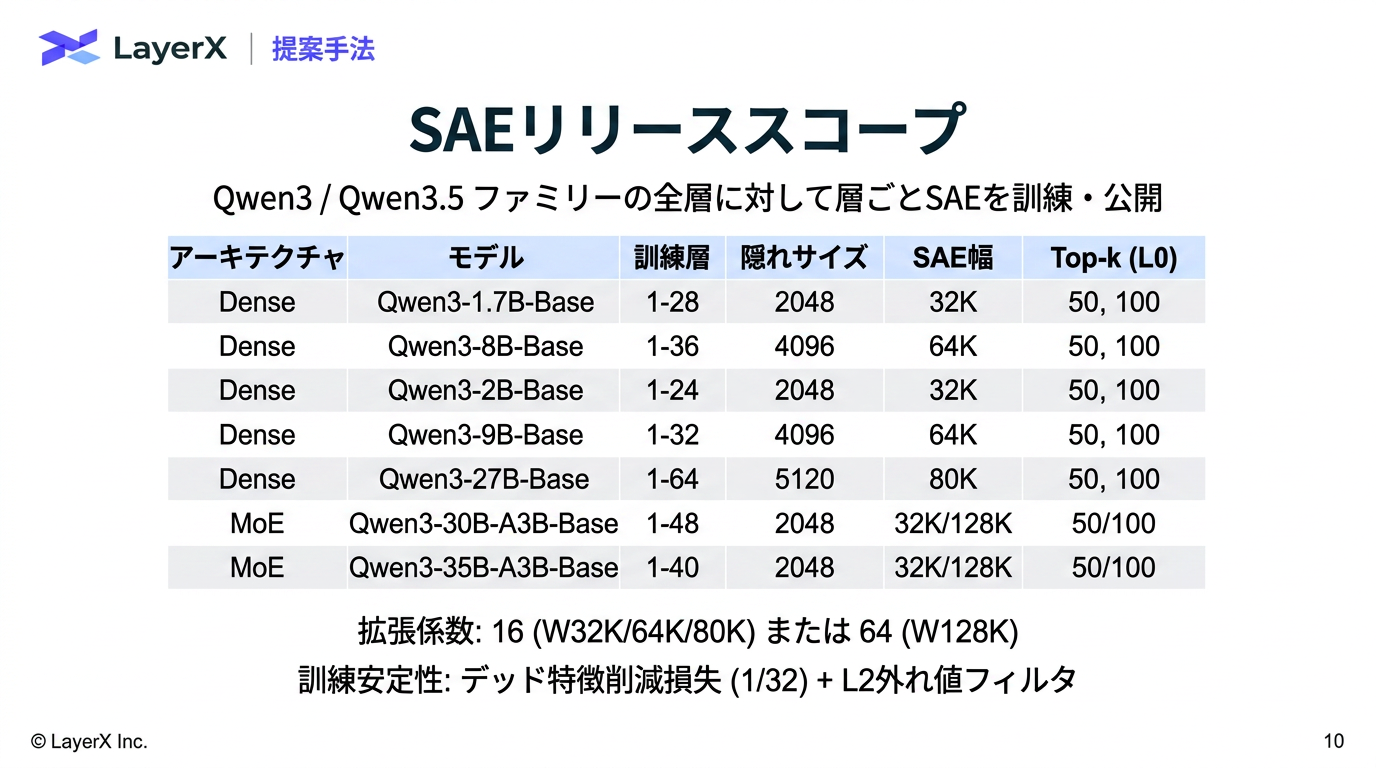
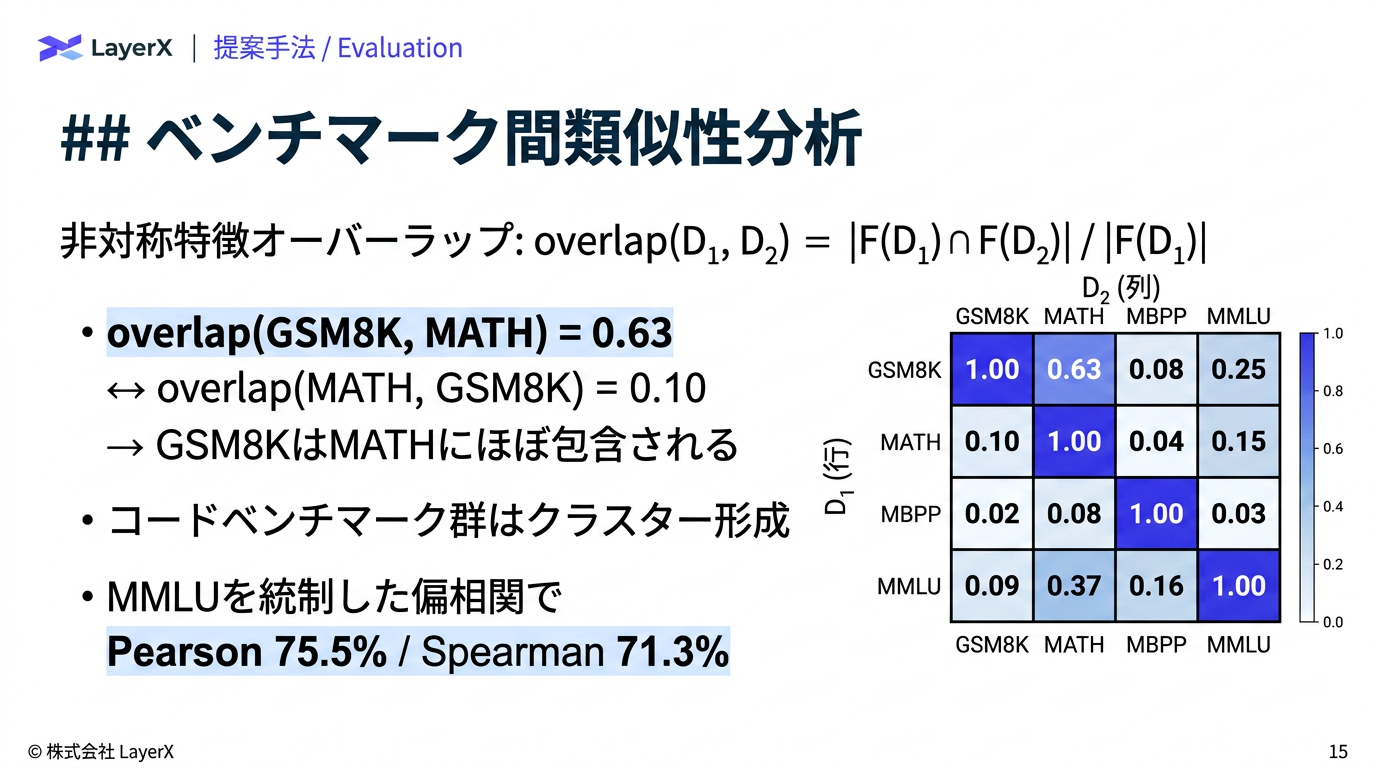
- ベンチマーク内の冗長性とベンチマーク間の類似性があるのに、現状だとMモデルxNサンプルの評価が必要
- 活性化しているSAEのindexからそのベンチマークのfootprintを抽出
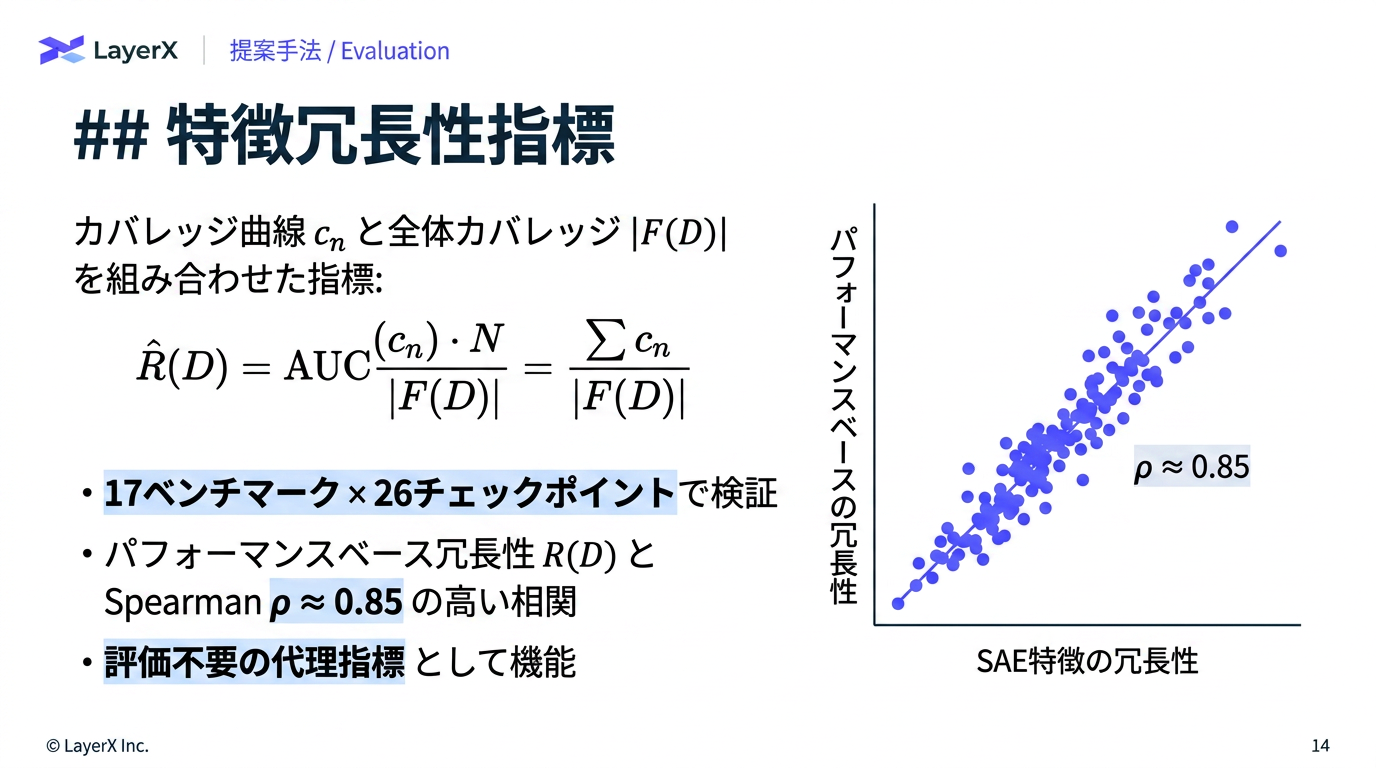
- ベンチマーク内の冗長性の削減
- サンプルを増やした時のカバレッジの増え方とサブセットでのモデルランキングを比較。→ カバレッジが大きくなりやすいモデルが強い → カバレッジだけでモデルの強さを測定可能
- ベンチマーク間の類似性の分析
- データ合成
- SAEのカバレッジ指標からデータを合成する
- ポストトレーニング
- 言語特徴の pre-activation が code-switch の前兆になることを利用して、損失を追加
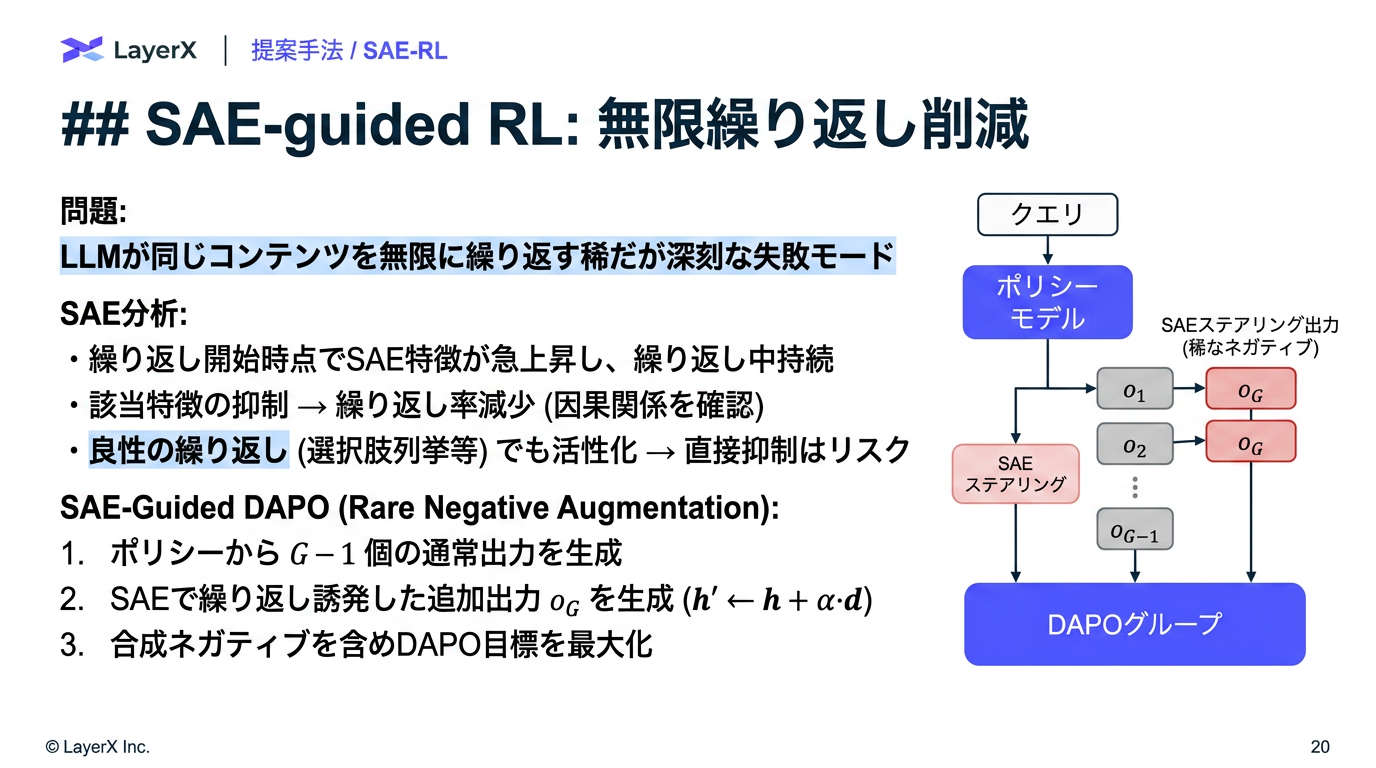
- 通常の RL rollout では「無限繰り返し」が稀にしか発生しない。推論時ステアリングをnegative sample作成に用いる。
- SASFT のように「抑制」すると、正常な repetition (質問の確認、選択肢列挙) まで阻害されてしまう (らしい)



@Yuya Matsumura
[paper] Modular Memory is the Key to Continual Learning Agents
ICML2026採択:https://icml.cc/virtual/2026/poster/67101
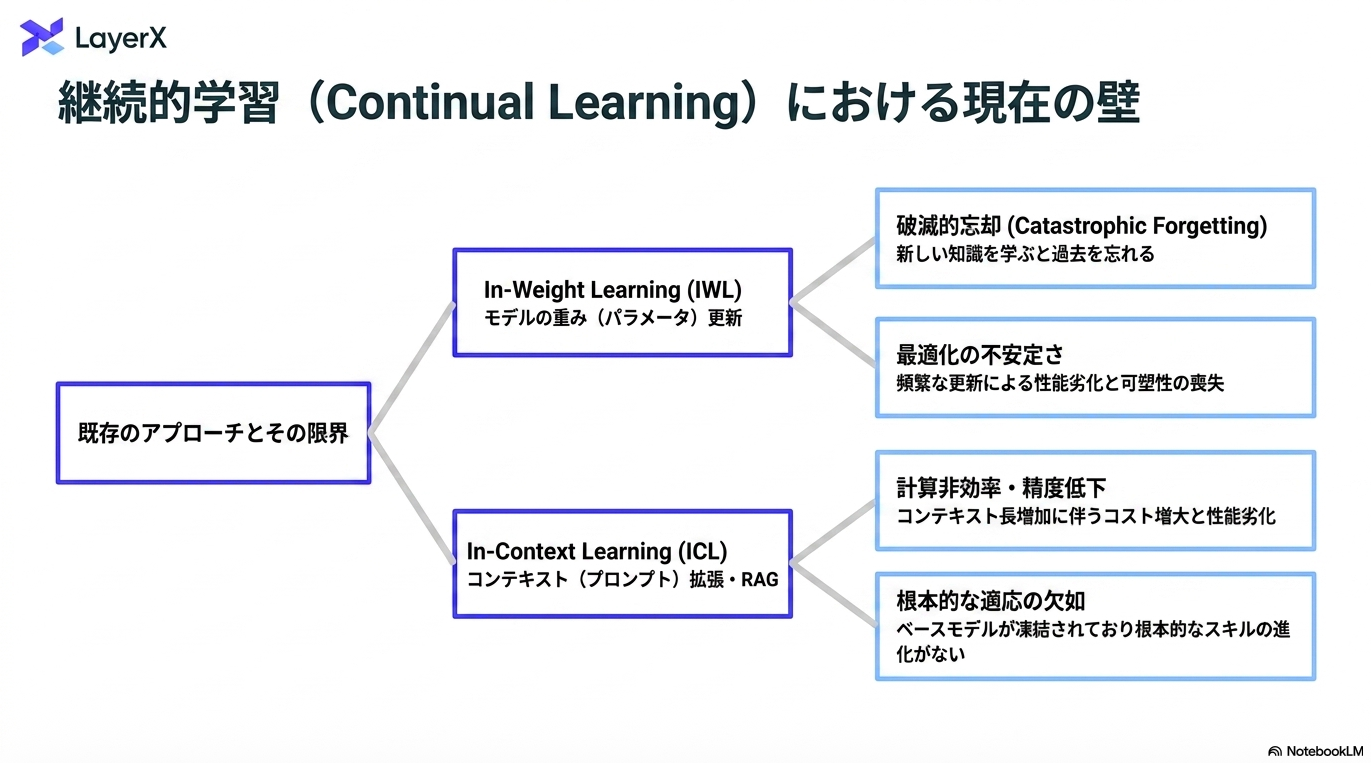
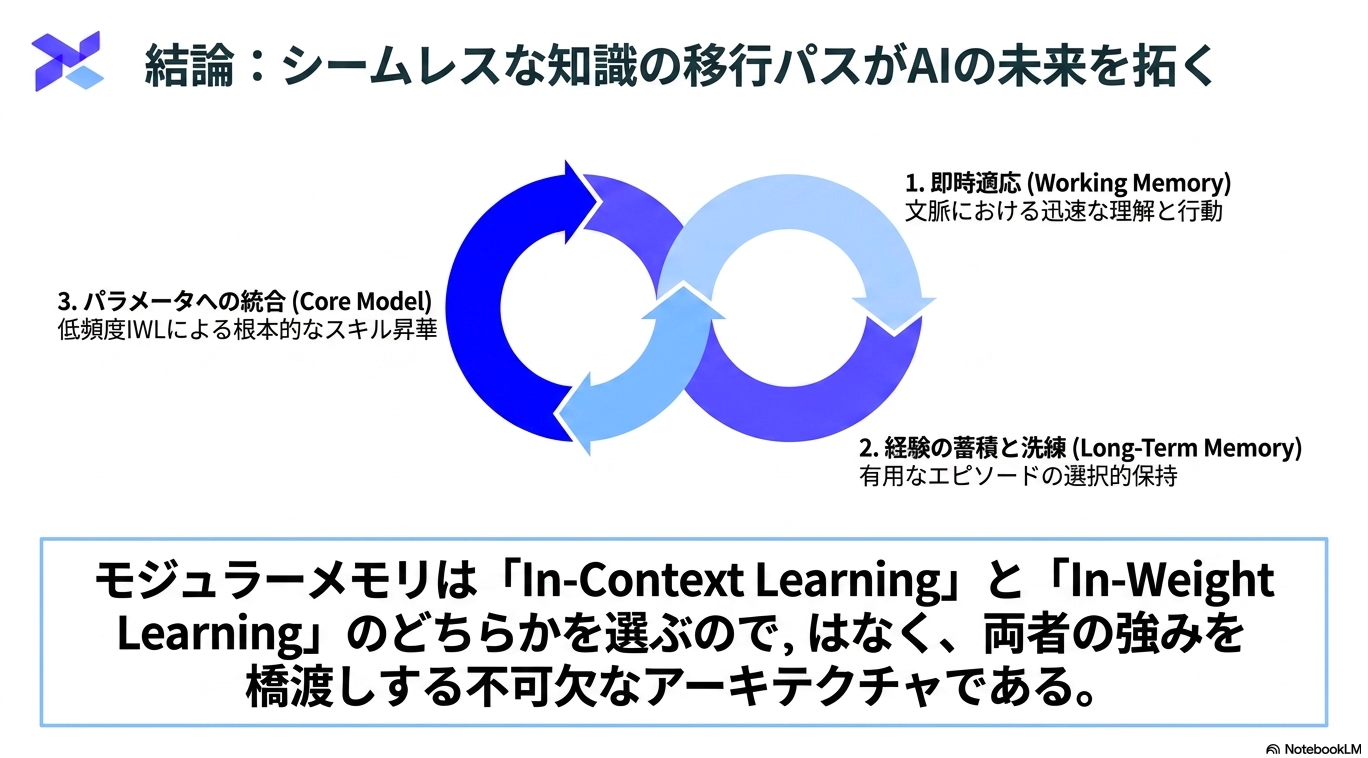
みんな大好きな継続学習の限界の話。新しい手法の提案ではなく、フレームワーク・今後の方向性を見通しよくまとめてくれている。
それぞれの強みをいい感じに融合させて解決しようぜ
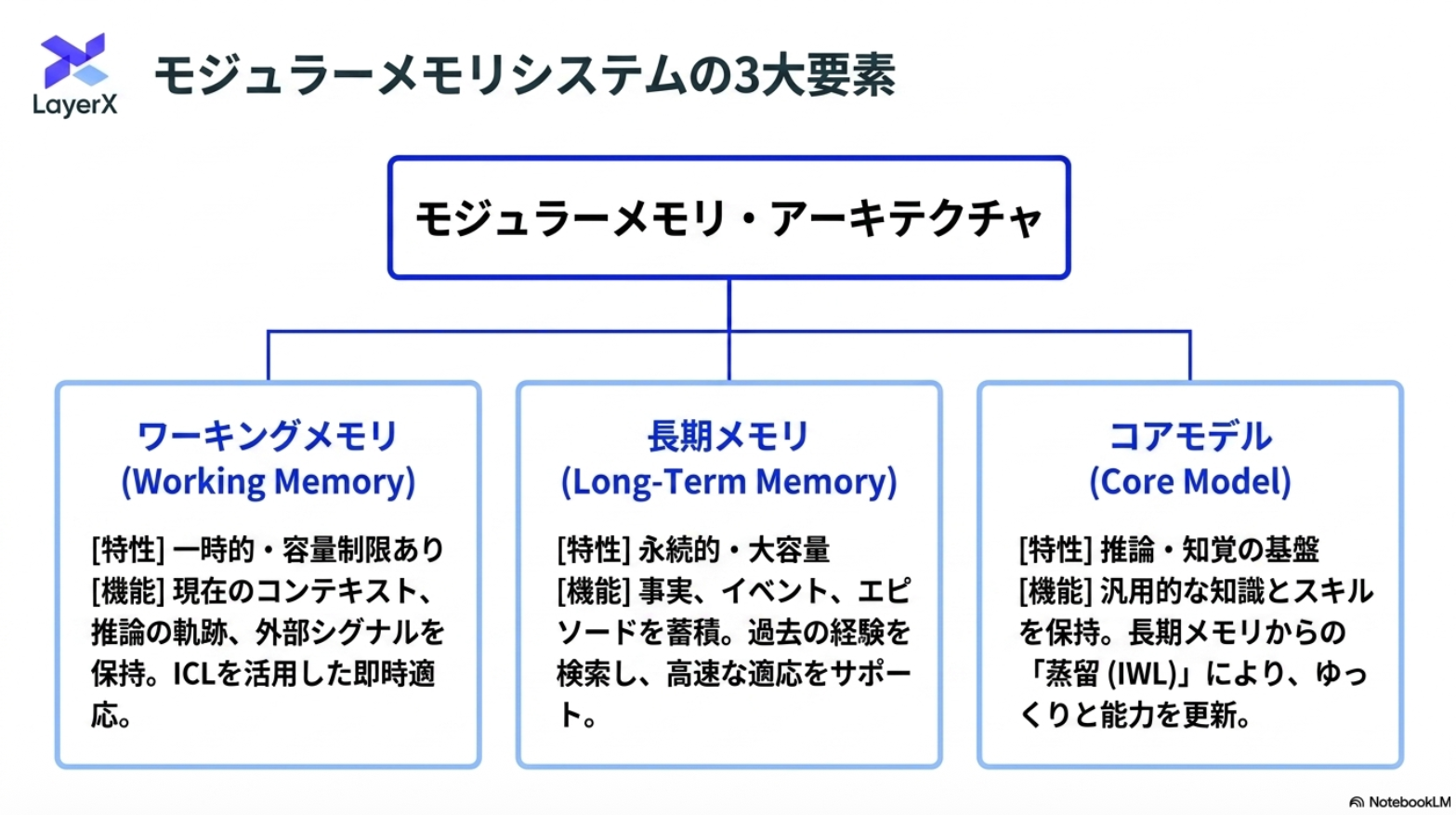
大きく2つの動作
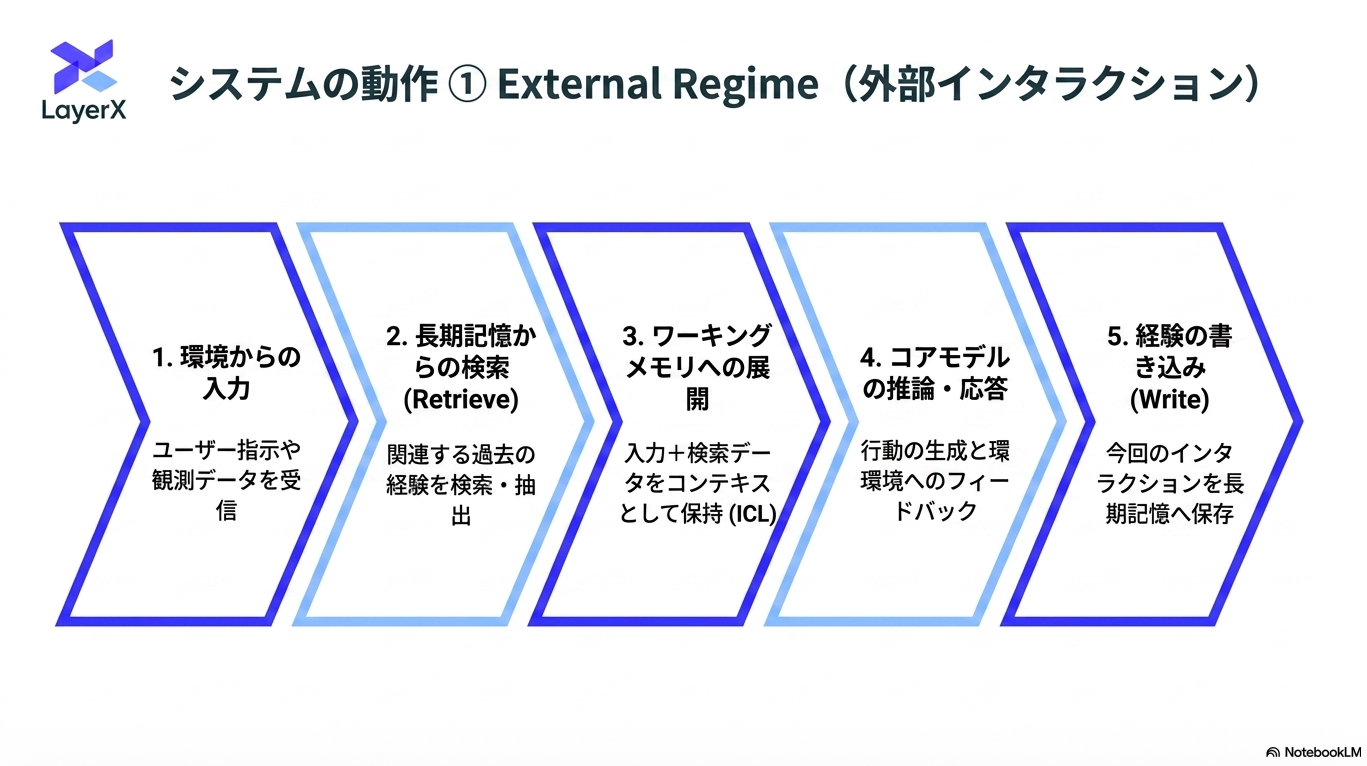
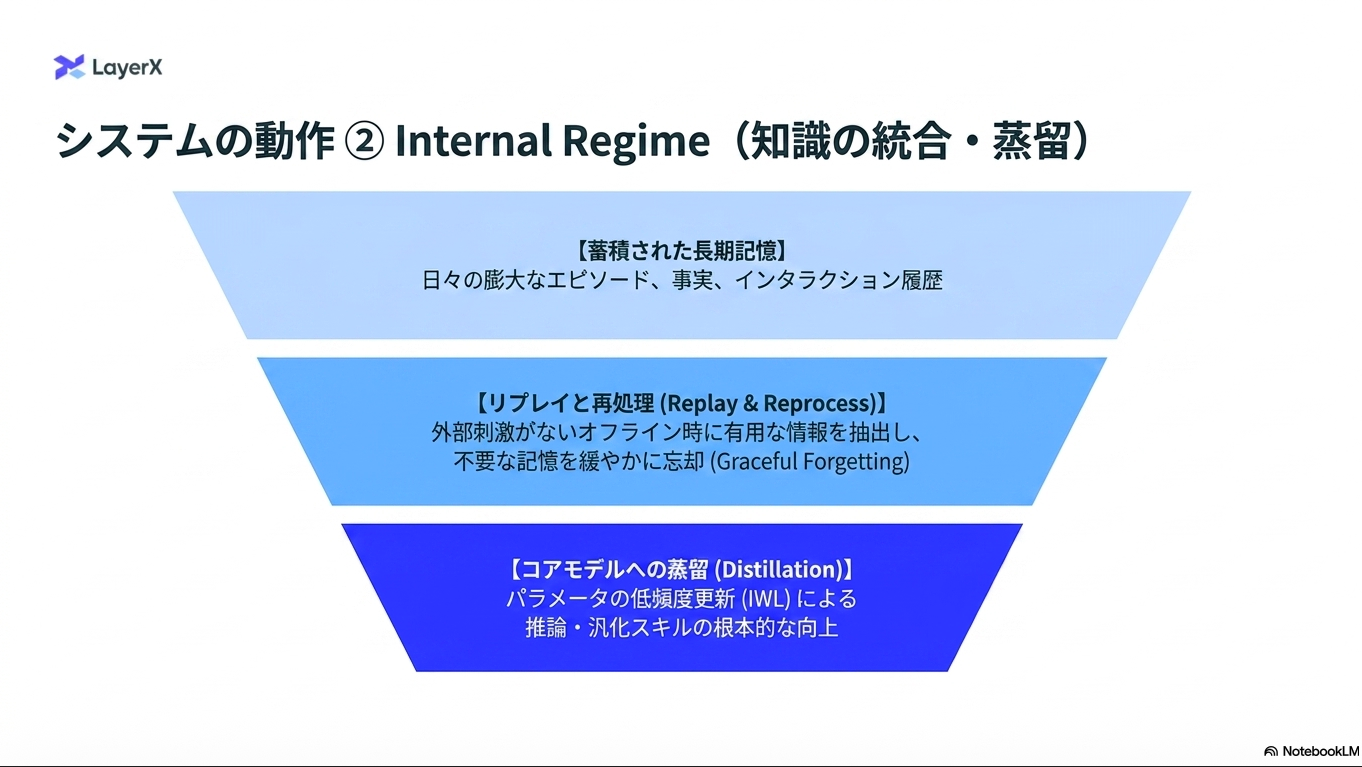
“学習”サイクルが異なる
あらゆる知識をモデルに入れ込むわけではないという設計が重要。その分、長期記憶をワーキングメモリに持ってきたり、ワーキングメモリからモデルに入れ込む情報の選択をする部分などはより発展が必要

「メモリ」の分類
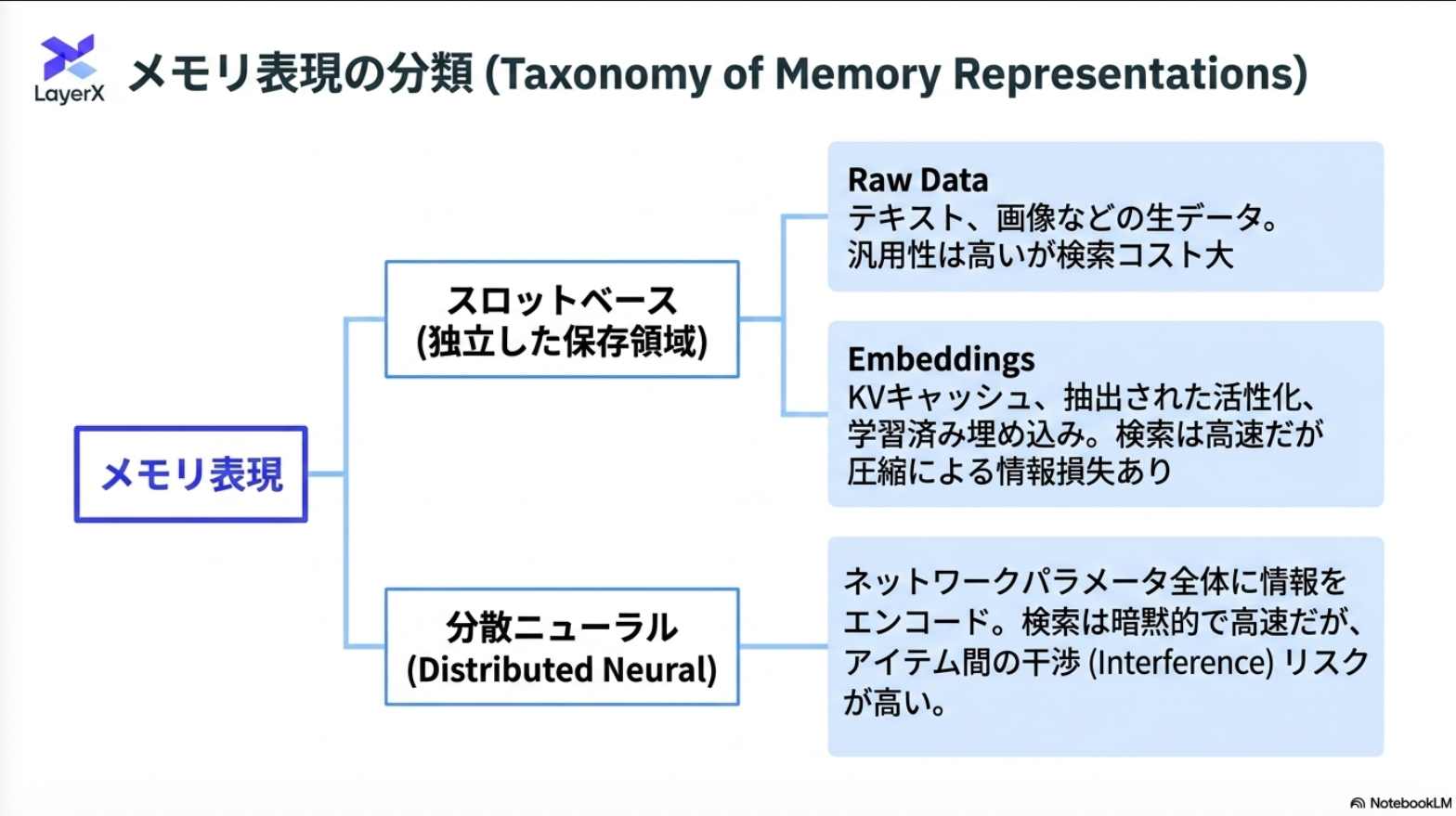
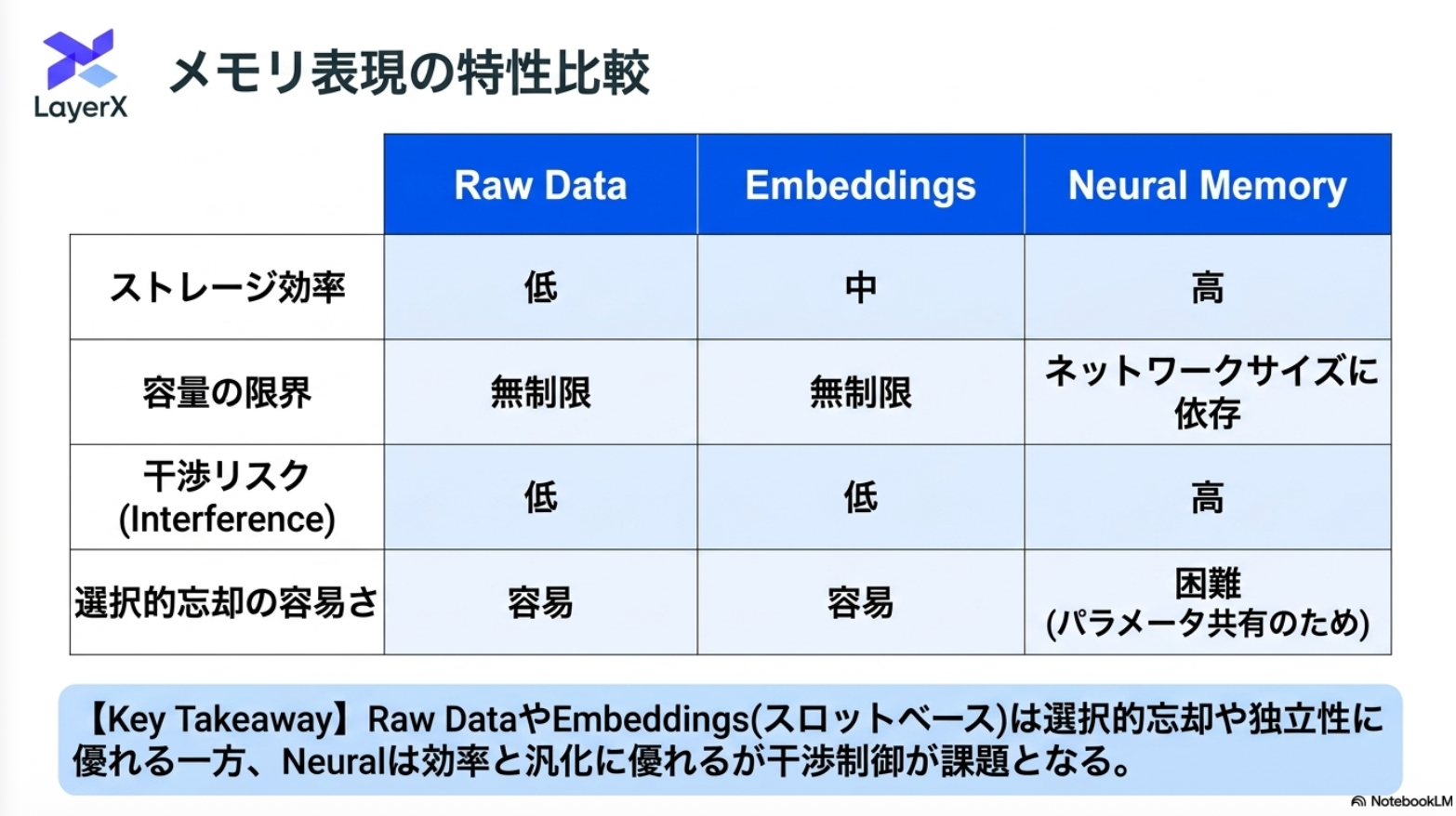
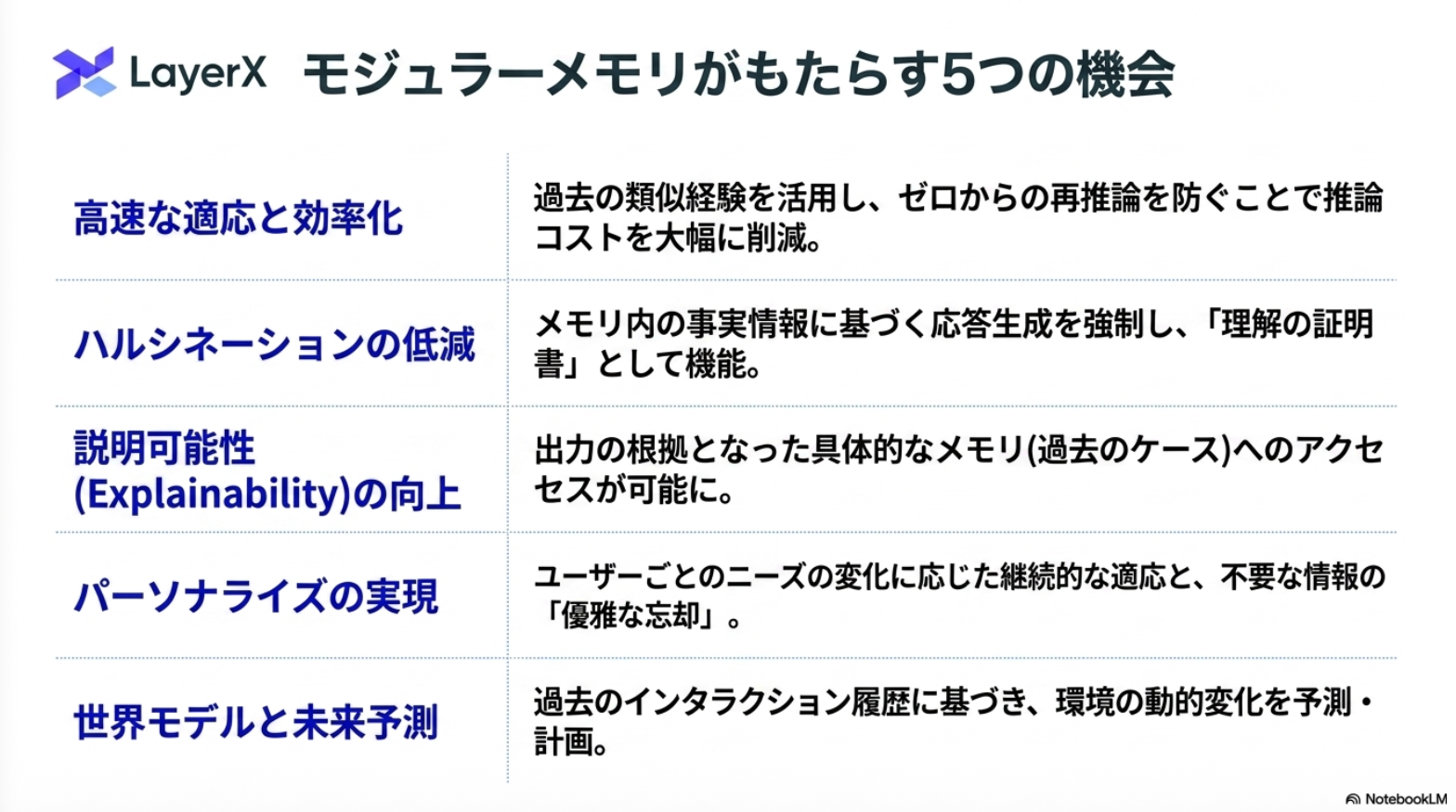
@Shun Ito
[paper] Speculative Actions: A Lossless Framework for Faster Agentic Systems
- 背景
- LLM agent / agentic system の実行高速化に関する論文。
- 対象は、ブラウザ操作、外部API、MCP server、ツール呼び出し、人間応答など、環境との逐次インタラクションを伴うagent。
- agentの各stepがAPI callとして逐次実行されるため、モデル精度が高くてもend-to-end latencyが実用上のボトルネックになる。
- 論文では、OS taskが10-20分、deep researchが5-30分、data pipelineが30-45分、Kaggle chess gameが約1時間かかる例を挙げ、訓練・評価・本番運用の反復コストが大きいと指摘。
- 関連手法: Speculative decoding
- LLMのtoken生成を小モデルの提案と大モデルの検証で高速化
- token列に対する手法のため、agentのAPI callや環境stepには直接適用できない
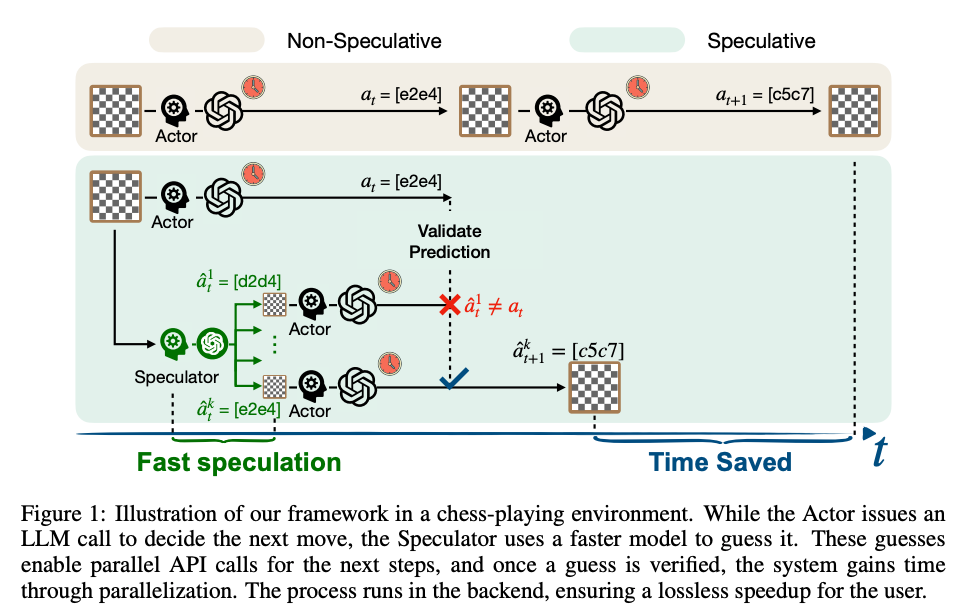
- 提案手法: Speculative Actions
- SpeculatorがActorの行動を予測し、事前に次のTool Callを流しておく
- Actorの結果が返ってきた時点で、Speculatorの予測が一致していれば、その先の計算やAPI結果をcache hitとしてcommitし、一致しなければ破棄して通常実行に戻る。
- 例
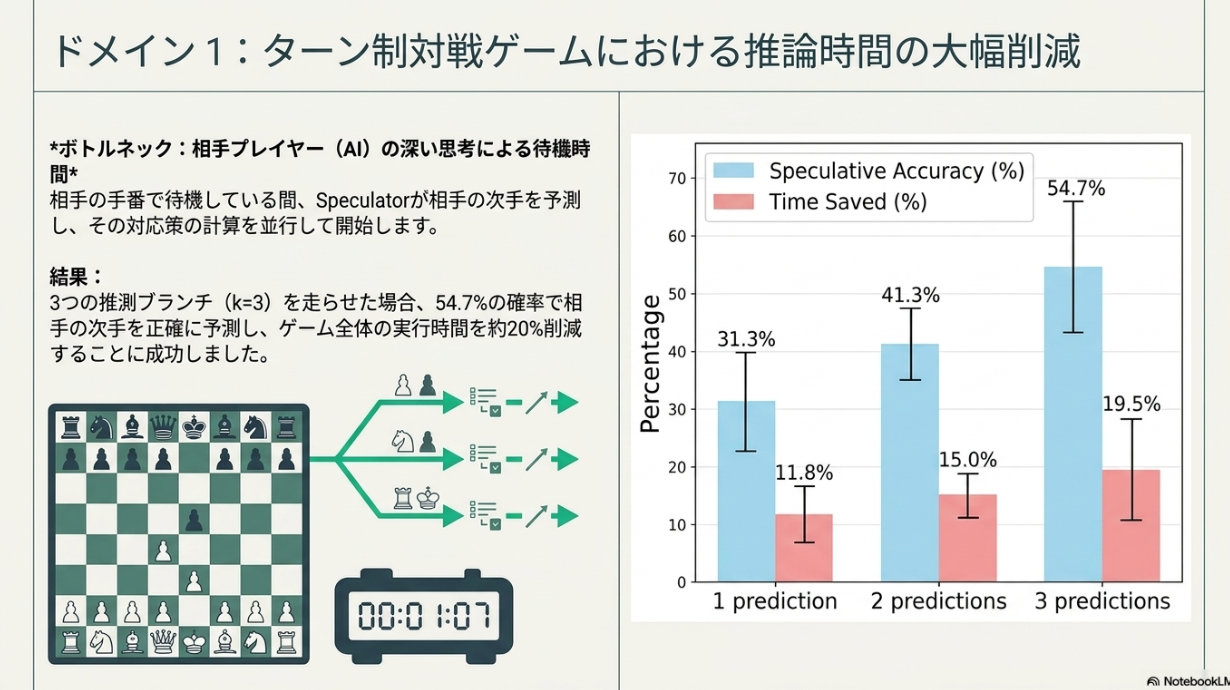
- チェス: Actorがある手を決めるためにTool Callしている間に、Speculatorがありそうな手をk個予測し、それぞれ次のTool Callを投げておく
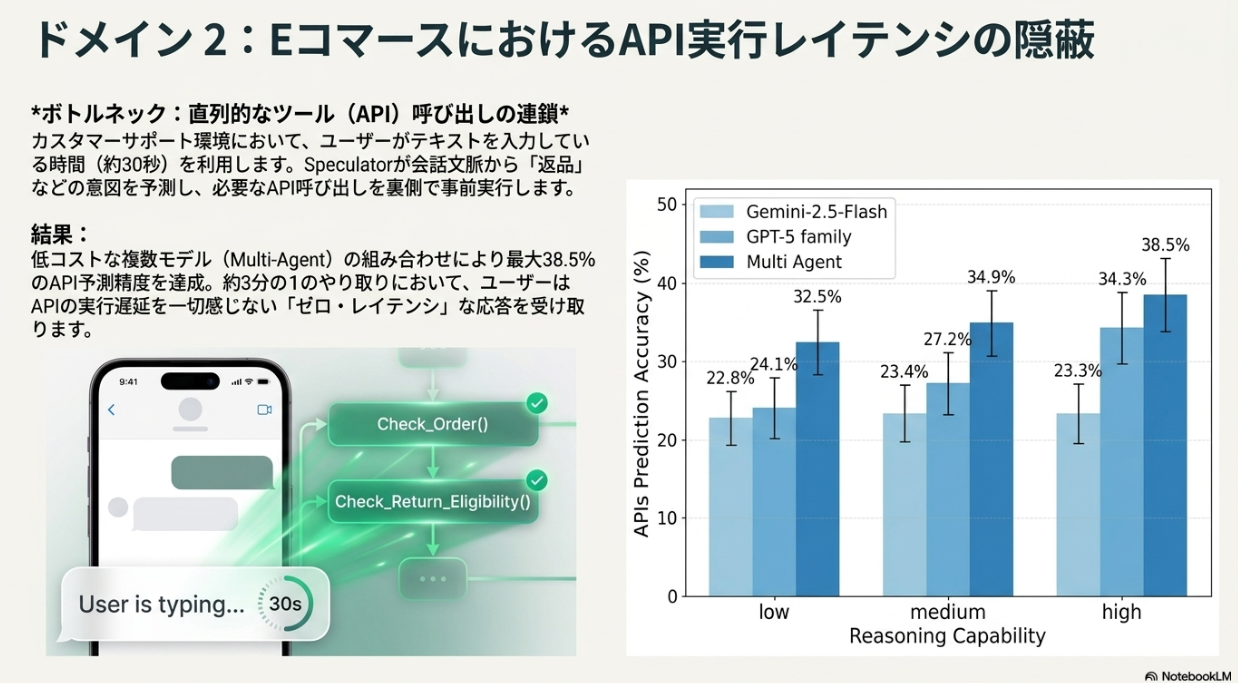
- E-Commerce: 次にユーザーから聞かれそうな質問(例えば返品など)をSpeculatorが予測し、返品処理に必要な注文情報取得や返品可能性確認を先に実行しておく
- あくまで推論部分はActorの出力で進むので、性能の損失はない
- kを増やすとヒット率は上がるが推論コストは上がるトレードオフ

- 実験
@ShibuiYusuke
[paper] From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company
Project Homepage: https://one-man-company.com
Repository: https://1mancompany.github.io/OneManCompany
Digital Talent Market: https://one-man-company.com/market
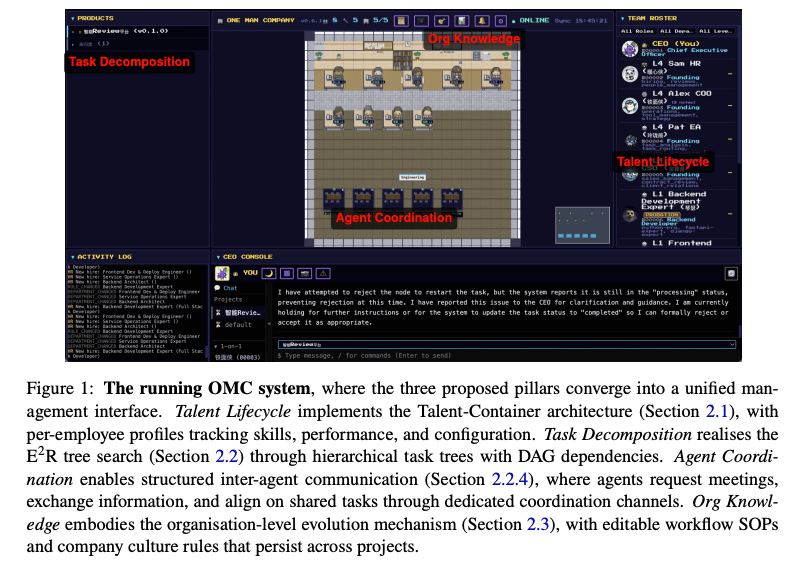
全体の要約
- 論文の主張:マルチエージェントシステムを「AI組織」として設計する提案
- 個々のエージェントのSkill拡張ではなく、複数の異種エージェントを採用・配置・実行・評価・改善する組織レイヤーの必要性
- エージェントを「ツール」ではなく、役割・能力・作業原則を持つ Talent / Employee として管理する設計
- 人間企業の採用、配属、レビュー、SOP、評価制度、退職管理をAIエージェントに適用する構想
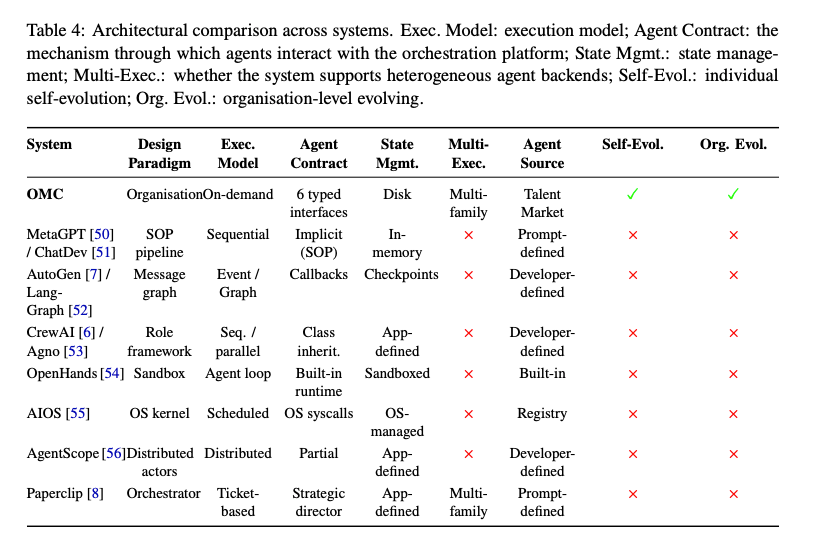
- 提案フレームワーク:OneManCompany(OMC)
- Claude Code、LangGraph、スクリプト実行系など、異なるランタイムのエージェントを同一組織で扱う基盤
- 固定チーム・固定ワークフローではなく、タスクに応じた動的採用、再分解、再実行、改善を行う仕組み
- 静的なマルチエージェントパイプラインから、自己組織化・自己改善するAI組織への転換
解決したい課題
- Skill中心設計の限界
- Skillは単一エージェントの能力強化には有効
- 複数エージェントの役割分担、協調、評価、改善には不十分
- 複雑なプロジェクトに必要な多様な専門性と長期協調への対応不足
- 既存マルチエージェントシステムの固定性
- チーム構成やワークフローが事前固定されやすい問題
- 未知のプロジェクトや実行途中の要件変更への脆弱性
- 自由交渉型の協調における収束保証、完了保証、デッドロック回避保証の不足
- 異種エージェント統合の困難性
- Claude Code、LangGraph、script-based executorなどの実行基盤の非互換性
- 新しいランタイム追加時に、スケジューリングやライフサイクル管理への大きな変更が必要になる問題
- 自己改善の弱さ
- 既存手法における改善の多くがセッション内に限定される問題
- プロジェクト横断の経験蓄積、組織SOP化、HR評価制度の不足
提案手法の概要
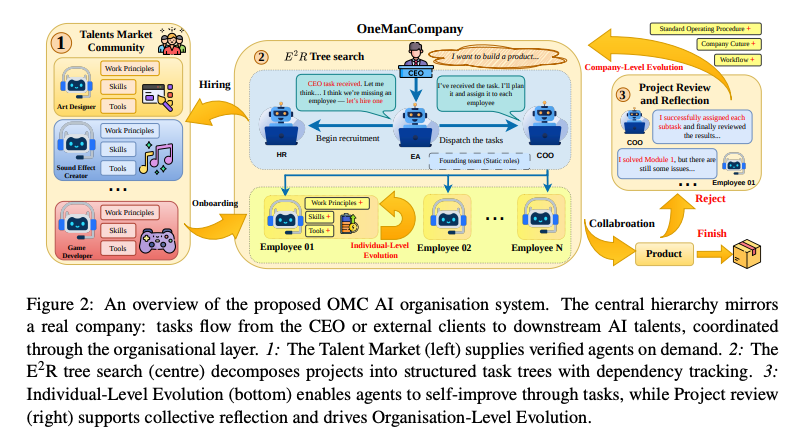
- Employee = Talent + Container
- Talent:役割、プロンプト、スキル、ツール、作業原則を含むポータブルなエージェント人格
- Container:Talentを動かす実行環境
- Employee:TalentをContainer上で実行する管理対象のAI従業員
- Talent–Container Architecture
- 「誰として働くか」と「どこで動くか」の分離
- 同じTalentを異なるランタイムで実行できる設計
- 異なるエージェント基盤を同じ組織で扱うための抽象化
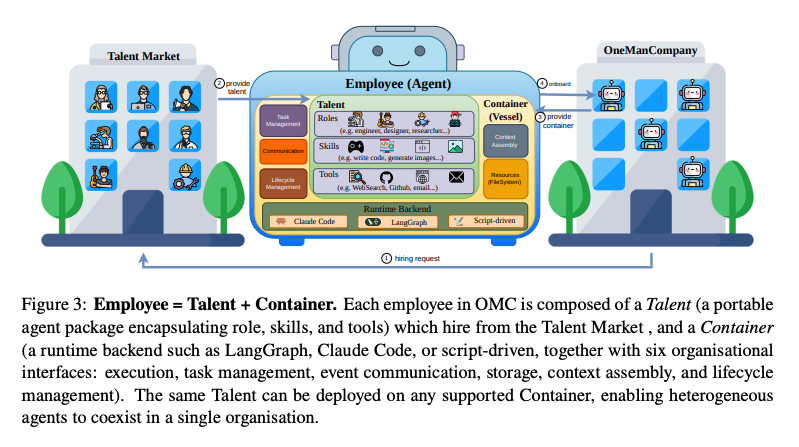
- 6つの組織インターフェース・ハーネス
- Execution:タスク実行と結果返却
- Task:タスクキューと相互排他管理
- Event:組織内イベント通信
- Storage:永続メモリ管理
- Context:実行コンテキスト構築
- Lifecycle:検証、ガードレール、自己改善
- Digital Talent Market
- 検証済みTalentを採用できる人材市場
- 不足能力が発生した際のHRによる候補検索、ランキング、CEO承認、採用
- コミュニティ投稿Talent、AIによるSkill組み立て、社内高性能Employeeの再パッケージ
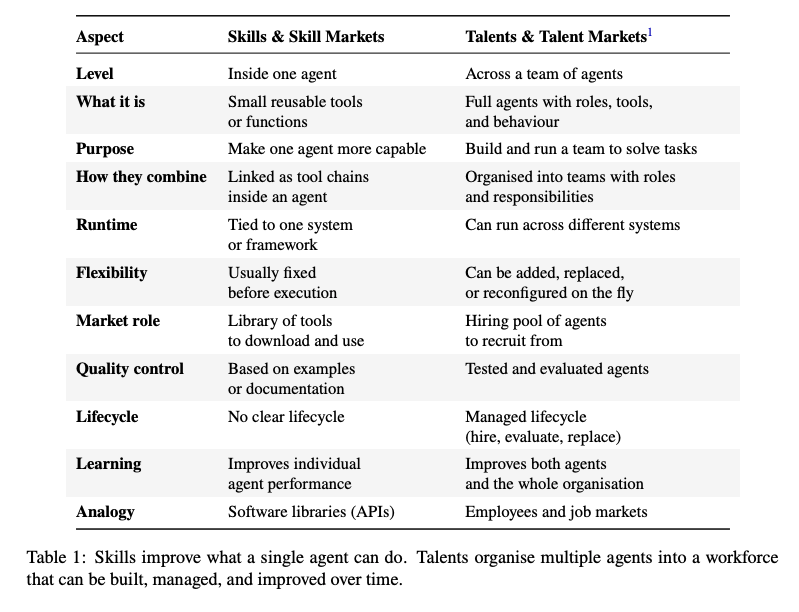
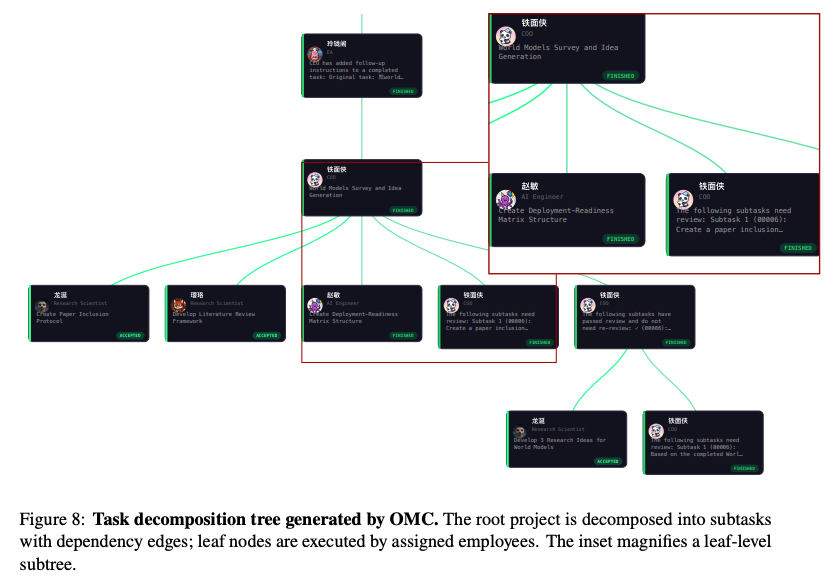
- E2R Tree Search
- Explore:タスク分解、担当者割当、必要に応じた採用
- Execute:Employeeによる成果物生成
- Review:成果物のaccept / reject、必要に応じた再分解
- 計画・実行・レビュー・再計画を閉ループ化する探索的プロジェクト実行
- DAG + FSMによる実行管理
- タスク分解は木、依存関係はDAGとして管理
- 親タスク完了には全子タスクの解決が必要というAND-tree意味論
- に明示的レビューを要求する品質ゲート
- タイムアウト、レビュー回数上限、コスト上限による無限ループ防止
- Self-Evolution
- 個人レベル:CEO 1on1、タスク後レビュー、作業原則更新
- 組織レベル:プロジェクト振り返り、SOP更新、次回プロジェクトへの反映
- HRレベル:定期評価、PIP、改善しないEmployeeのオフボーディング
提案手法の成果
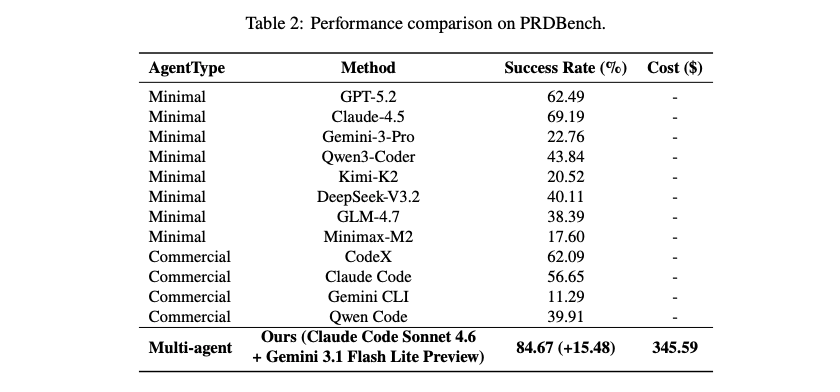
- PRDBenchでの高い成功率
- プロジェクトレベルのソフトウェア開発ベンチマークPRDBenchで評価
- OMCの成功率 84.67%
- 既存最良手法を 15.48ポイント 上回る結果
- 50タスク合計コスト $345.59
- 1タスクあたり約 $6.91
- 主な性能向上要因
- 実行中の中間結果に応じてタスク分解を調整する動的タスクツリー
- 未検証成果物の下流伝播を防ぐレビューゲート
- Talent Marketを通じた専門エージェントのオンデマンド採用
- 異なるAgent familyを同一プロジェクトで使えるTalent–Container分離
- ケーススタディでの実証
- GitHub AI Agentトレンド記事の調査・執筆・メール送信
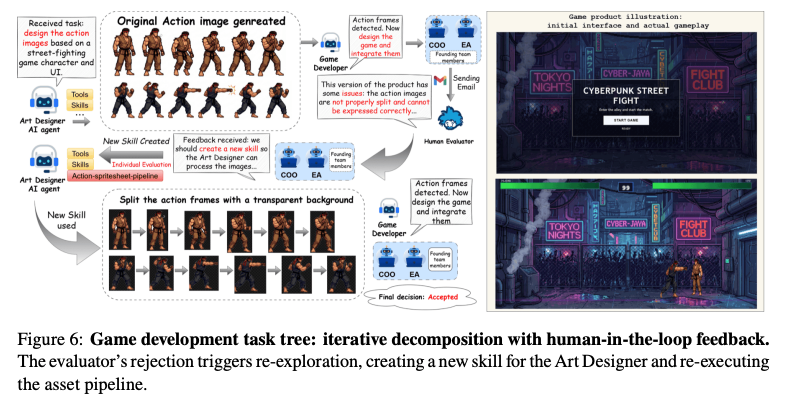
- ストリートファイト風Webゲーム開発と評価者フィードバックによる再実行
- 脚本、画像、音声、動画を統合したオーディオブック制作
- world models for embodied AI and roboticsに関する自動研究サーベイ

- 論文上の意義
- Skill中心からTalent中心への抽象化拡張
- 固定チームから動的採用可能なAI組織への拡張
- 単発実行からレビュー付き反復実行への拡張
- セッション内改善から、個人・組織・HRライフサイクルを含む継続的改善への拡張
感想
- 組織AIエージェントを実際に作ってみた研究
- 多様な要素を一つの論文で実践しているため、どの要素が効いたのか、Ablation Studyがほしい
- Skill marketからTalent marketへの移行、という発想は良さそう。人間のJob marketも単純労働よりも知的・専門労働のほうが価値が高いので、AIエージェントも同様のはず
- もし組織AIエージェントが本当に広まるなら、そのためのツールやプラクティスが必要になるので、ビジネスチャンスかも
@Kyohei Uto(kuto)
[paper]Meta-Harness: End-to-End Optimization of Model Harnesses
概要
- LLM本体の重みは固定したまま、その周囲の「ハーネス」を自動最適化する手法
- ここでいうハーネスとは、LLMに何を記憶させ、何を検索し、どの情報をプロンプトとして渡し、ツール実行や状態更新をどう制御するかを決めるコード全体を指す
- つまり、「LLMアプリケーションを動かすハーネス」を、さらに外側の「ハーネス探索システム」で改善するという構成
詳細
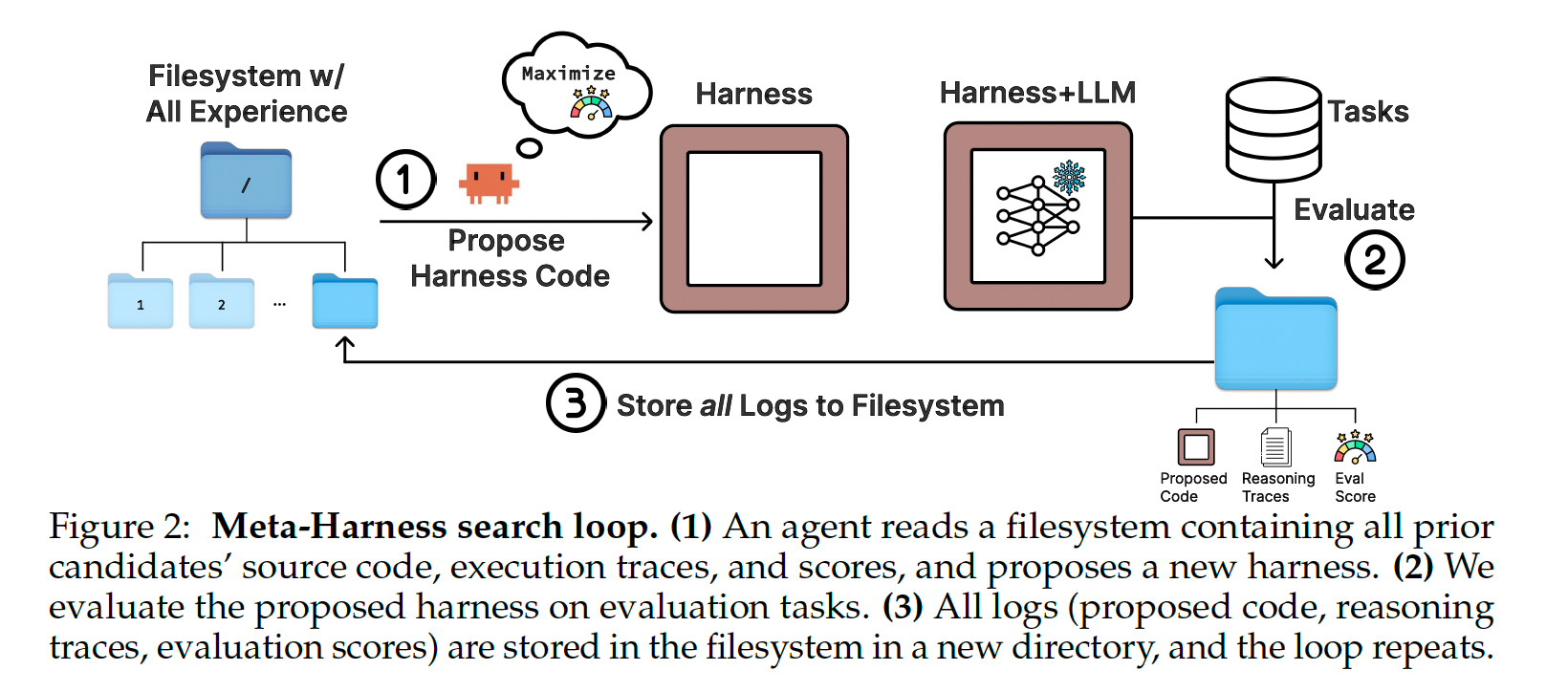
次のループを回す
- coding agent が過去候補を調べ、失敗原因を推測し、新しいハーネスコードを提案する
- 新規のハーネス候補を評価データセットで評価する
- そのコード、スコア、プロンプト、ツール呼び出し、モデル出力、状態更新などの実行トレースをログに保存する
- 最終的にパレートフロント、たとえば精度とコンテキストコストのトレードオフ上で良い候補を返す
特に生の実行トレースを残しコーディングエージェントから参照可能とする設計が重要。これにより、エージェントは「どの候補が何点だったか」だけでなく、「なぜ失敗したか」「どのコード変更が悪影響を与えたか」「似た失敗が過去にあったか」を調べられる。
目的関数は以下
- モデルMとハーネスHで構成されるエージェントに入力xを渡した時の軌跡 において期待報酬rを最大化するようにハーネスを探索する
- ただし数理的な最適化をするわけではなくあくまでエージェントの過去履歴検索とコード生成によってハーネス空間を探索する(ブラックボックス最適化)
先行研究との違い
- 従来のテキスト最適化手法は、過去候補のスコア、短いフィードバック、LLMによる要約、直近候補だけの情報など、かなり圧縮された履歴を使うものが多い。Meta-Harness は、過去のコード、スコア、実行ログ、失敗例、推論トレースをそのまま蓄積し、必要な部分だけをエージェントが選択的に読む。
- 論文では、既存手法が扱うフィードバック量は1評価あたり概ね 100〜30,000 トークン規模なのに対し、Meta-Harness では1評価から最大 10,000,000 トークン規模の診断情報が生じうると整理している。これを単一プロンプトに詰めるのではなく、ファイルシステムとして外部化する点が主張の中心
| 系統 | 代表例 | 何を最適化するか | フィードバック | Meta-Harness との違い |
|---|---|---|---|---|
| 静的ベースライン | zero-shot, few-shot | プロンプト内の例示 | なし | 探索しない。固定されたプロンプト構成だけ |
| 手設計ハーネス | ACE, MCE | コンテキスト管理・メモリ・スキル | 人間が設計 | ハーネス構造は人手。Meta-Harness はその設計自体を自動探索 |
| テキスト最適化 | OPRO, TextGrad, GEPA, Feedback Descent, TTT-Discover | 主にプロンプトやテキスト artifact | スコア、短い批評、要約、限定された履歴 | フィードバックが圧縮されやすい。Meta-Harness は生の実行ログ全体にアクセス |
| プログラム探索 | AlphaEvolve, OpenEvolve | コード、関数、アルゴリズム | プログラムDB、スカラー評価、選択ルール | コード探索ではあるが、親選択・突然変異などの構造が強い。Meta-Harness は coding agent に診断と編集判断を大きく委譲 |
評価
テキスト分類タスク
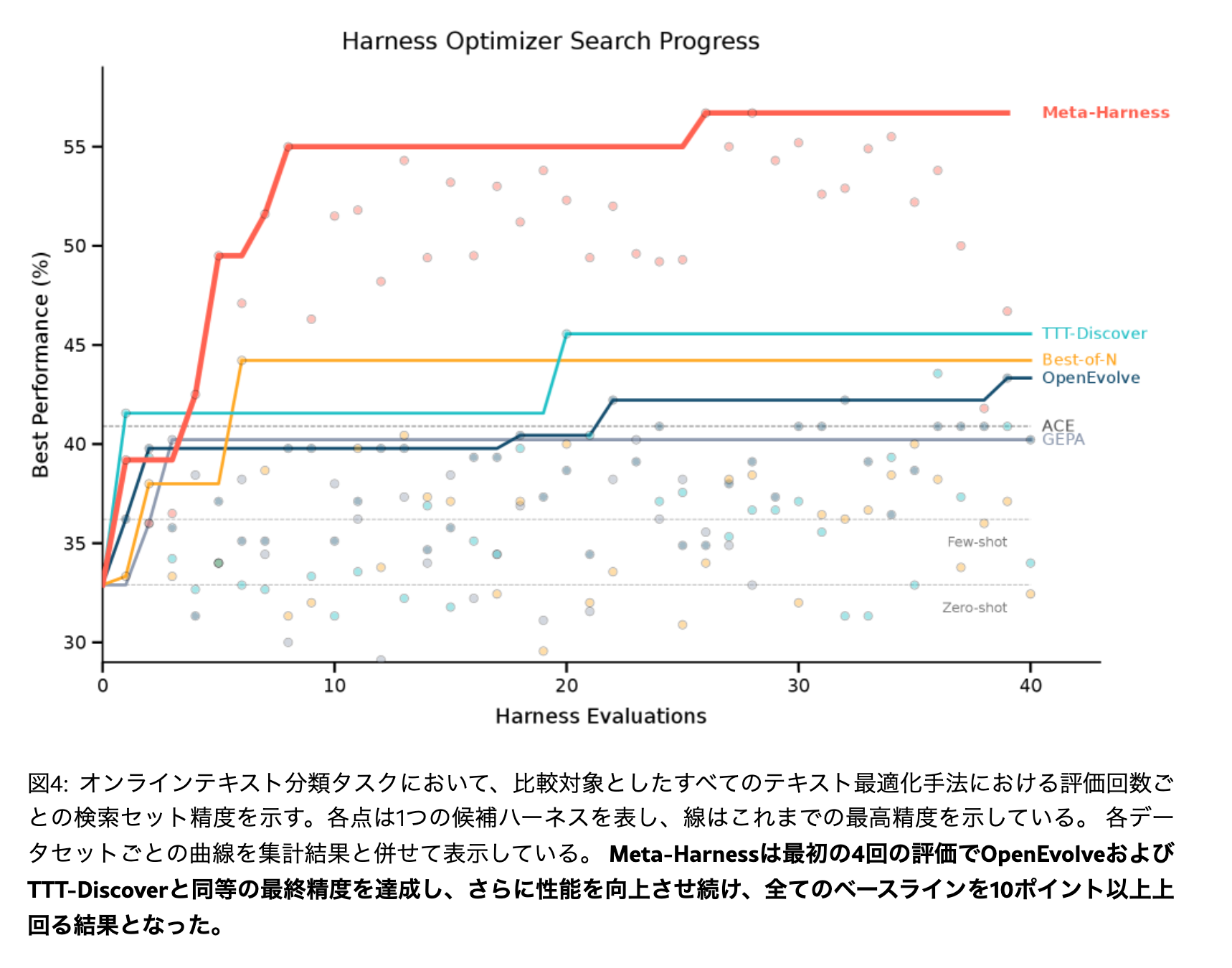
アブレーション
提案器に与える情報を「スコアのみ」「スコア+要約」「フルの実行トレース」に分けて比較している。生の実行トレースが本質的に重要で、要約では十分に代替できないという主張
実際のハーネス改良例
テキスト分類タスクにおいてmeta-harnessがうまく機能した事例を2つ紹介
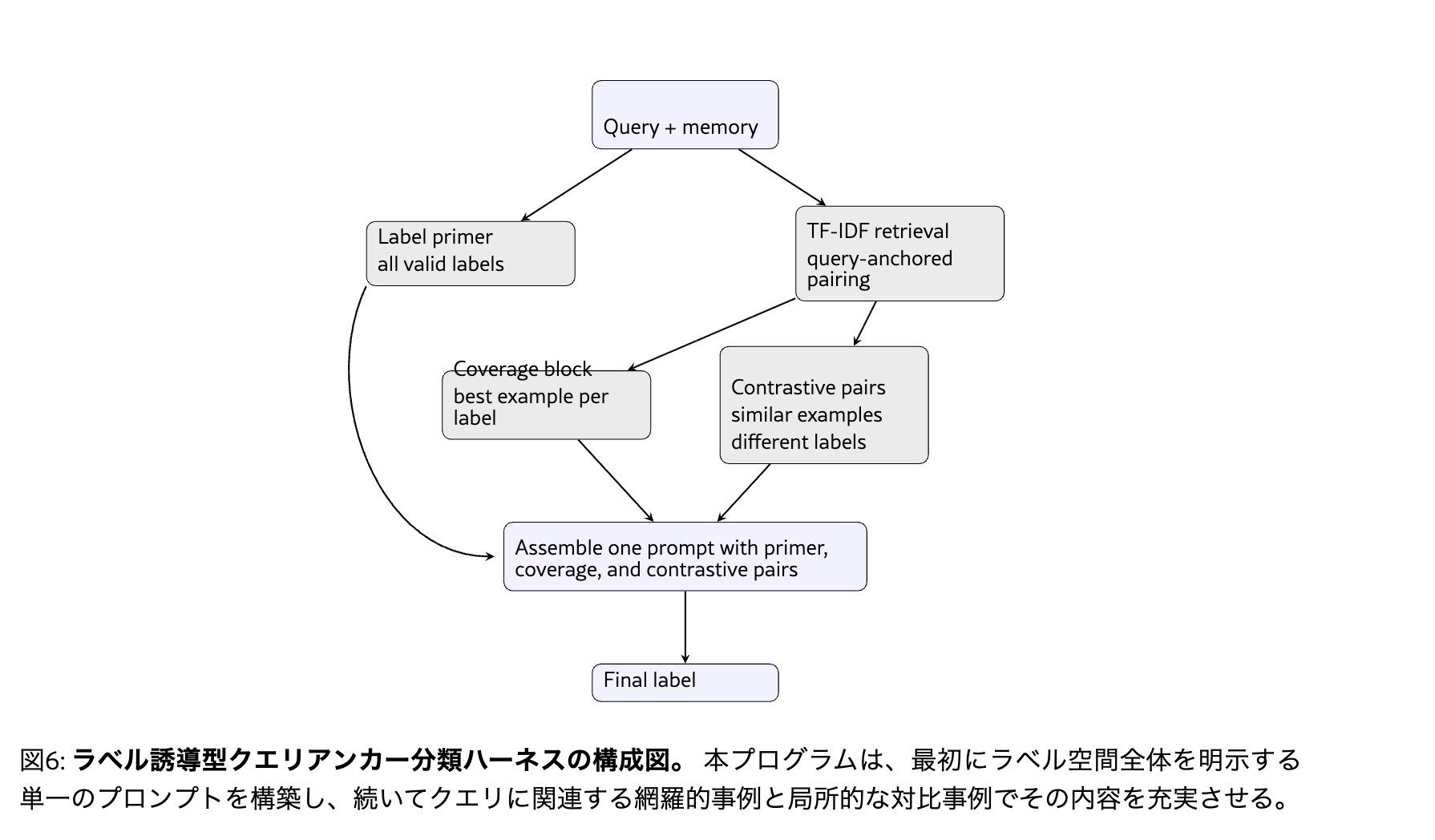
[kuto]割と良さげな検索戦略を探索によって獲得している
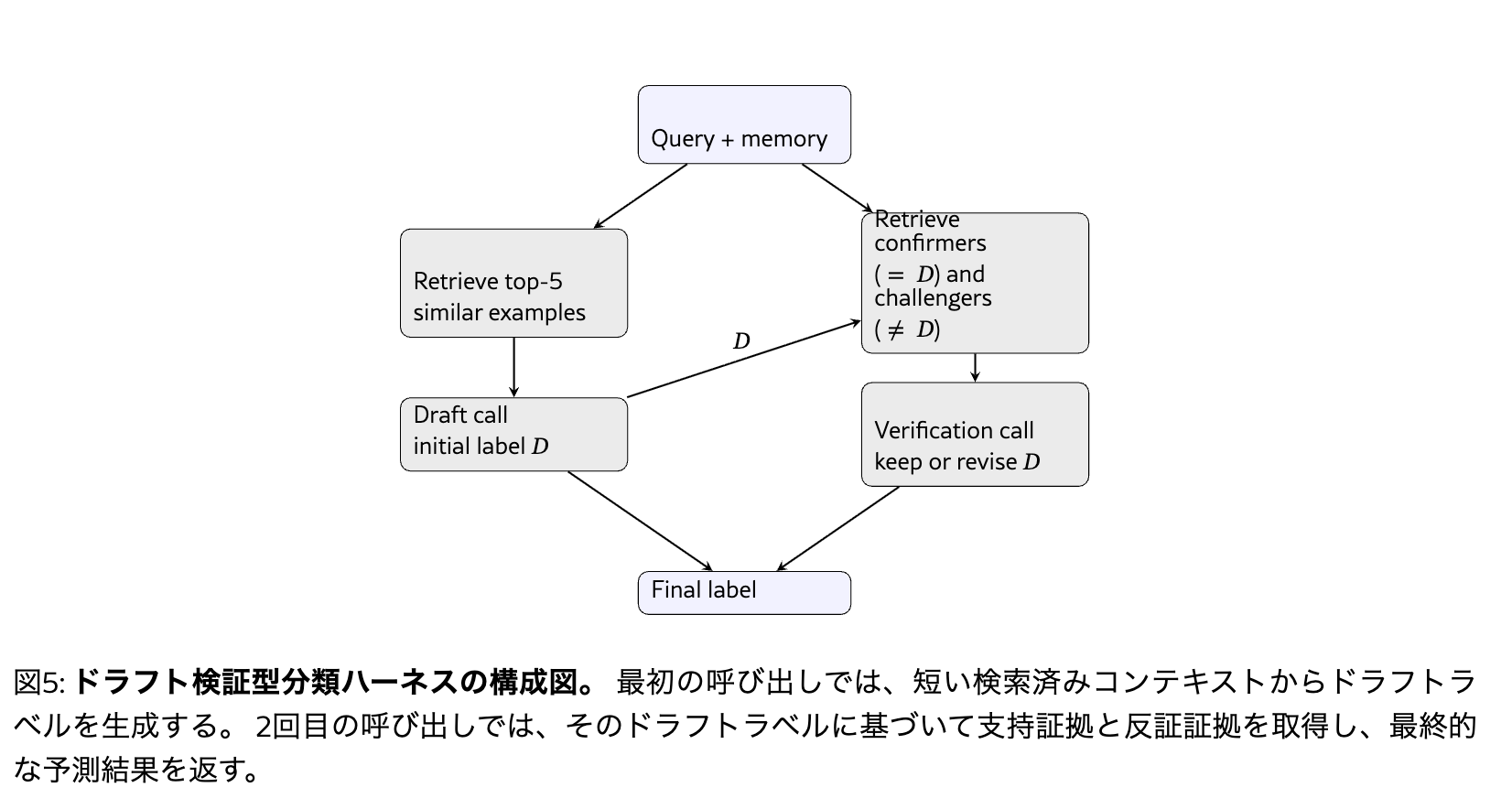
- ドラフト検証型
- 類似例top5を検索して分類ラベルを暫定的に予測
- 予測した分類ラベルをもとにそのラベルが正しいと思われる例と正しくないと思われる例を検索
- a,bの検索結果をプロンプトに入れて予測
- ラベル先行型
- 有効な出力ラベルの一覧を提示
- 各ラベルごとにクエリに最も関連性の高い事例をTF-IDFで検索し紐付ける
- クエリに関連性の高い事例をTF-IDFでk件検索
- b,cの結果をプロンプトに入れて予測
感想
- エージェントによしなに探索させて改善するアプローチ。エージェント性能が上がったことで最近こういう系が増えてきてる印象。
- もちろん完全に何も設計しなくてよいわけではなく、ログ設計、検索しやすいディレクトリ構造、軽量な validation、良い skill text などが重要
- 本番で使うというよりcoding agentを使った事前の精度改善タスクにおいてこういう形+HITLで実験自動化できると良さそう
@Ryuhei Kawabata
[paper] ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
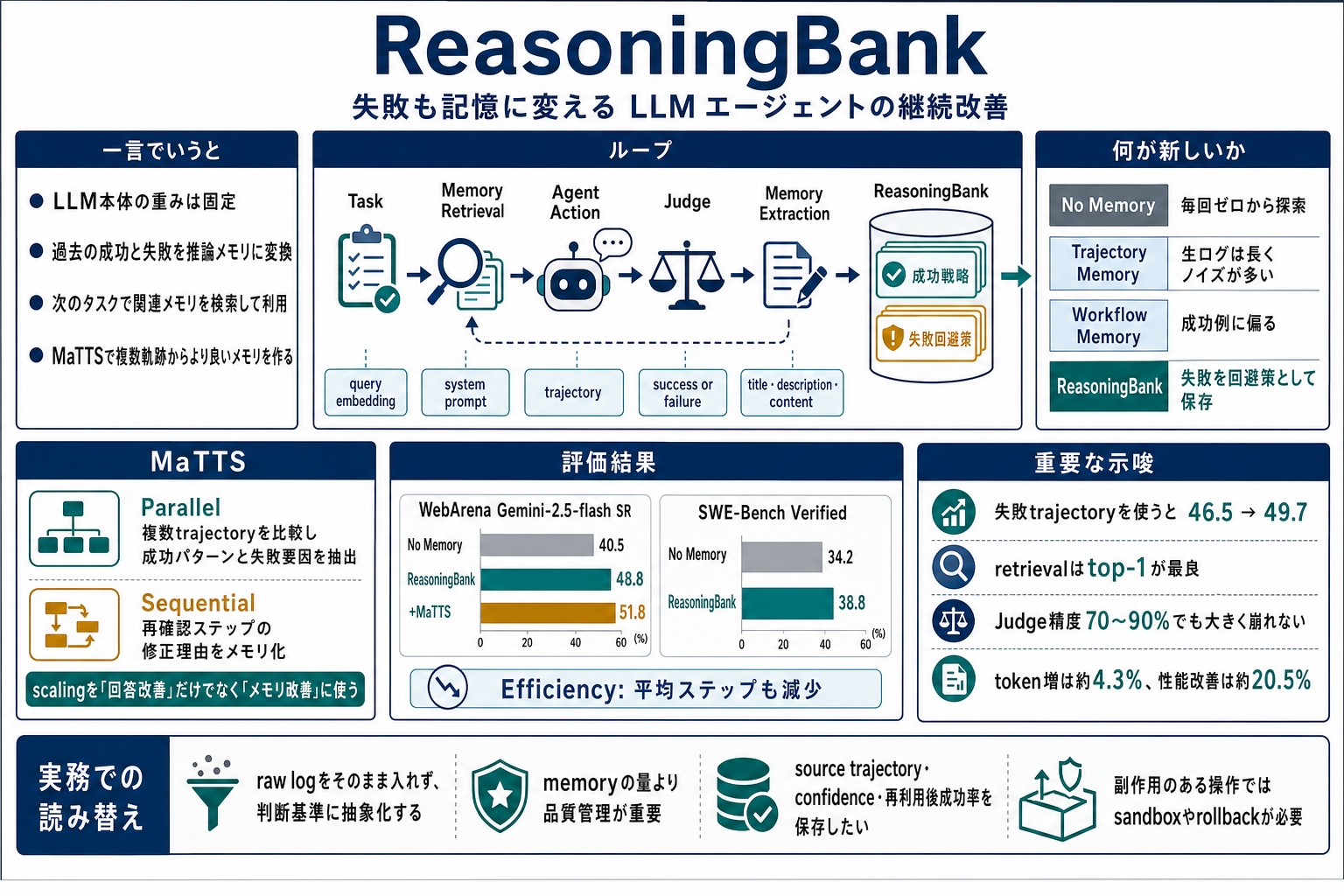
- LLM 本体の重みは固定したまま、外部メモリを更新してエージェントを改善する手法。
- ここでいうメモリは、生の実行ログではなく、過去の成功と失敗から抽出した「再利用可能な推論戦略」を指す。
- 提案手法 ReasoningBank は、各タスクの trajectory を成功または失敗に分類し、成功理由や失敗回避策を , , からなる memory item として保存する。
- 新しいタスクでは、現在の query に近い過去 experience を embedding 検索し、関連 memory item を system instruction に入れてエージェントの行動を誘導する。
- さらに MaTTS は、同じタスクに対して複数 trajectory や再確認ステップを生成し、その差分からより良い memory item を作る test-time scaling 手法。
つまり、「LLM エージェントの過去経験」を、次のタスクで使える「行動上の注意・探索戦略・失敗回避策」に変換し続ける構成。
論文情報
| 項目 | 内容 |
|---|---|
| タイトル | ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory |
| 著者 | Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, Tomas Pfister |
| 種別 | arXiv preprint |
| arXiv | |
| 公開版 | 2026-03-16 |
| 所属 | University of Illinois Urbana-Champaign, Google Cloud AI Research, Yale University, Google Cloud AI |
| コード | https://github.com/google-research/reasoning-bank |
背景
LLM エージェントは、Web 操作やコード修正のような多段タスクを解く。
しかし多くのエージェントは、各タスクを独立に処理する。過去に「Recent Orders だけを見ると最初の購入日を誤る」と分かっても、その知見が次のタスクに残らない。
既存のメモリ手法には主に 2 系統ある。
| 系統 | 何を保存するか | 問題 |
|---|---|---|
| trajectory memory | 過去の思考・観測・行動ログ | 長くてノイズが多く、次のタスクに転用しづらい |
| workflow memory | 成功軌跡から抽出した手順 | 成功例に偏り、失敗から学びにくい |
ReasoningBank は、これらの中間を狙う。生ログをそのまま使うのではなく、成功と失敗から抽象化した推論戦略を保存する。
手法
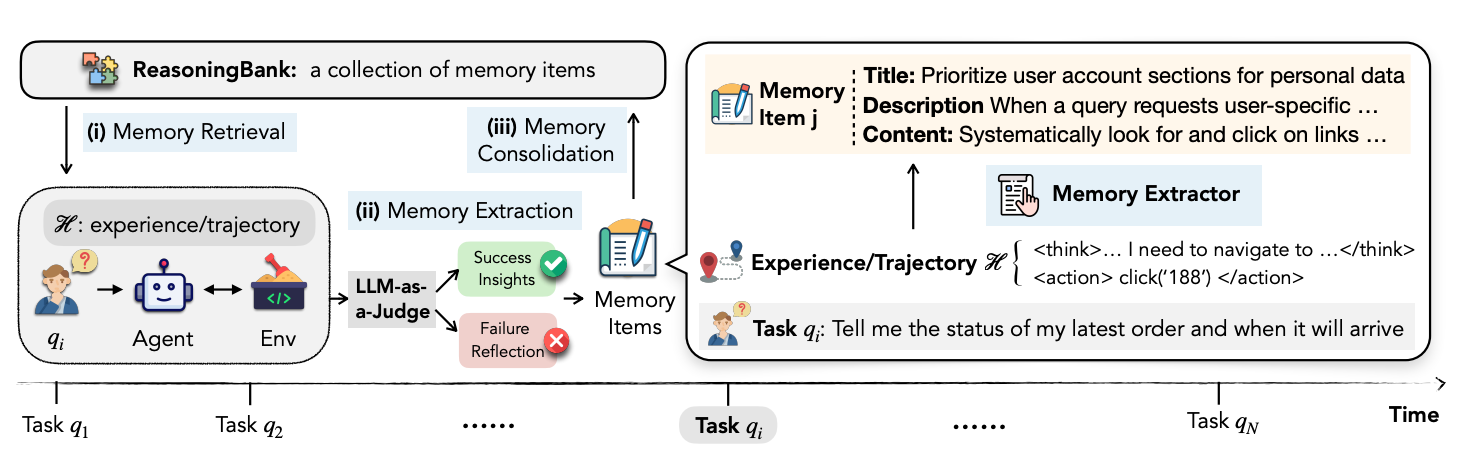
ReasoningBank は次のループを回す。
- 新しい task query が来る。
- query embedding で、過去の memory pool から関連 experience を検索する。
- 取得した memory item を system instruction に入れる。
- エージェントが ReAct 形式で環境を操作する。
- タスク終了後、LLM-as-a-Judge が trajectory を success または failure に分類する。
- success なら成功理由を、failure なら失敗理由と回避策を memory item に変換する。
- 新しい memory item を ReasoningBank に追記する。
memory item は次の schema を持つ。
| フィールド | 内容 |
|---|---|
| 戦略や推論パターンの短い名前 | |
| 1 文の説明 | |
| 具体的な判断基準、手順、注意点 |
例として、注文履歴を探すタスクでは「Recent Orders だけでなく full order history や Next Page を確認する」という memory が作られる。この memory は、購入履歴、レビュー履歴、検索履歴のような類似タスクにも転用できる。
実装詳細
論文の実装はかなり単純。
| 処理 | 実装 |
|---|---|
| memory extraction | agent と同じ backbone LLM を使う。temperature は 1.0。各 trajectory から最大 3 件抽出 |
| success/failure 判定 | LLM-as-a-Judge。agent と同じ backbone LLM を使う。temperature は 0.0 |
| retrieval | で query を埋め込み、cosine similarity で検索 |
| retrieval 数 | デフォルトは top-1 experience |
| prompt 注入 | title と content を system instruction に追加 |
| storage | task query、trajectory、memory items を JSON に保存。embedding は別 JSON に保存 |
| consolidation | append-only。merge、dedupe、forgetting はしない |
重要なのは、retrieval や consolidation をあえて複雑にしていない点。性能差を「メモリ構造」ではなく「保存する内容」に寄せて検証している。
MaTTS
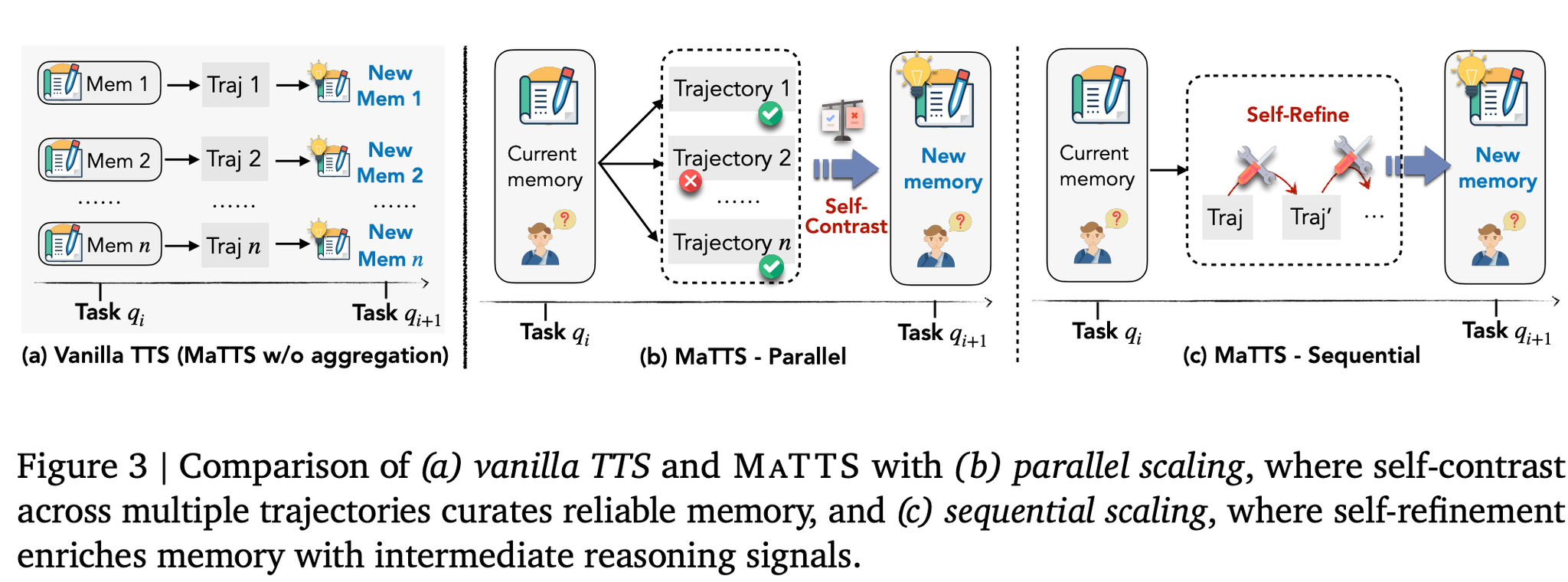
MaTTS は Memory-aware Test-Time Scaling の略。
通常の test-time scaling は、推論時に複数候補を出して良いものを選ぶ。MaTTS はそれに加えて、複数候補から「次に使える memory」を作る。
| variant | 何を増やすか | memory への使い方 |
|---|---|---|
| parallel scaling | 同じ query に対する複数 trajectory | 成功 trajectory と失敗 trajectory を比較し、成功パターンと失敗要因を抽出 |
| sequential scaling | 1 つの trajectory に対する再確認ステップ | self-refinement の修正理由や途中メモを memory signal として使う |
ここで重要なのは、単に rollout を増やすことではない。同じ問題に対する複数の成功・失敗を比較することで、より一般化しやすい memory item を作る点が主張の中心。
定式化
対象は test-time learning。
タスク列 , , ..., が順番に到着する。エージェントは未来のタスクを見られず、テスト時の ground truth feedback も使えない。
エージェントは、backbone LLM、memory module、action space に条件づけられた policy として扱われる。Web browsing では action space はクリック、入力、スクロールなど。SWE では bash command。
ざっくり言うと、ReasoningBank は次の状態を目指す。
LLM 本体を更新するのではなく、外部 memory を更新して policy の振る舞いを変える。
先行研究との違い
| 系統 | 代表例 | 保存するもの | ReasoningBank との違い |
|---|---|---|---|
| メモリなし | No Memory | なし | 毎回ゼロから探索する |
| trajectory memory | Synapse | 過去 trajectory | 生ログに近く、長くてノイズが多い |
| workflow memory | AWM | 成功軌跡から抽出した workflow | 成功例中心で、失敗を使いにくい |
| ReasoningBank | 提案手法 | 成功と失敗から抽出した reasoning memory | 失敗を「次に避けるべき戦略」として使う |
論文の差分は、失敗をノイズとして捨てない点。
失敗 trajectory には、「検索 query が曖昧だった」「ページネーションを最後まで見なかった」「表示中のデータが task requirements と一致するか確認しなかった」といった情報が含まれる。ReasoningBank はこれを失敗回避策として保存する。
評価
評価対象は 3 つ。
| ベンチマーク | 内容 |
|---|---|
| WebArena | Shopping、Admin、Gitlab、Reddit、Multi の Web 操作。684 task |
| Mind2Web | Cross-Task、Cross-Website、Cross-Domain の Web 操作。1,341 task |
| SWE-Bench-Verified | repository-level issue resolution。500 task |
backbone は Gemini-2.5-flash、Gemini-2.5-pro、Claude-3.7-sonnet が中心。追加で Gemma-3-12B-Instruct も評価している。
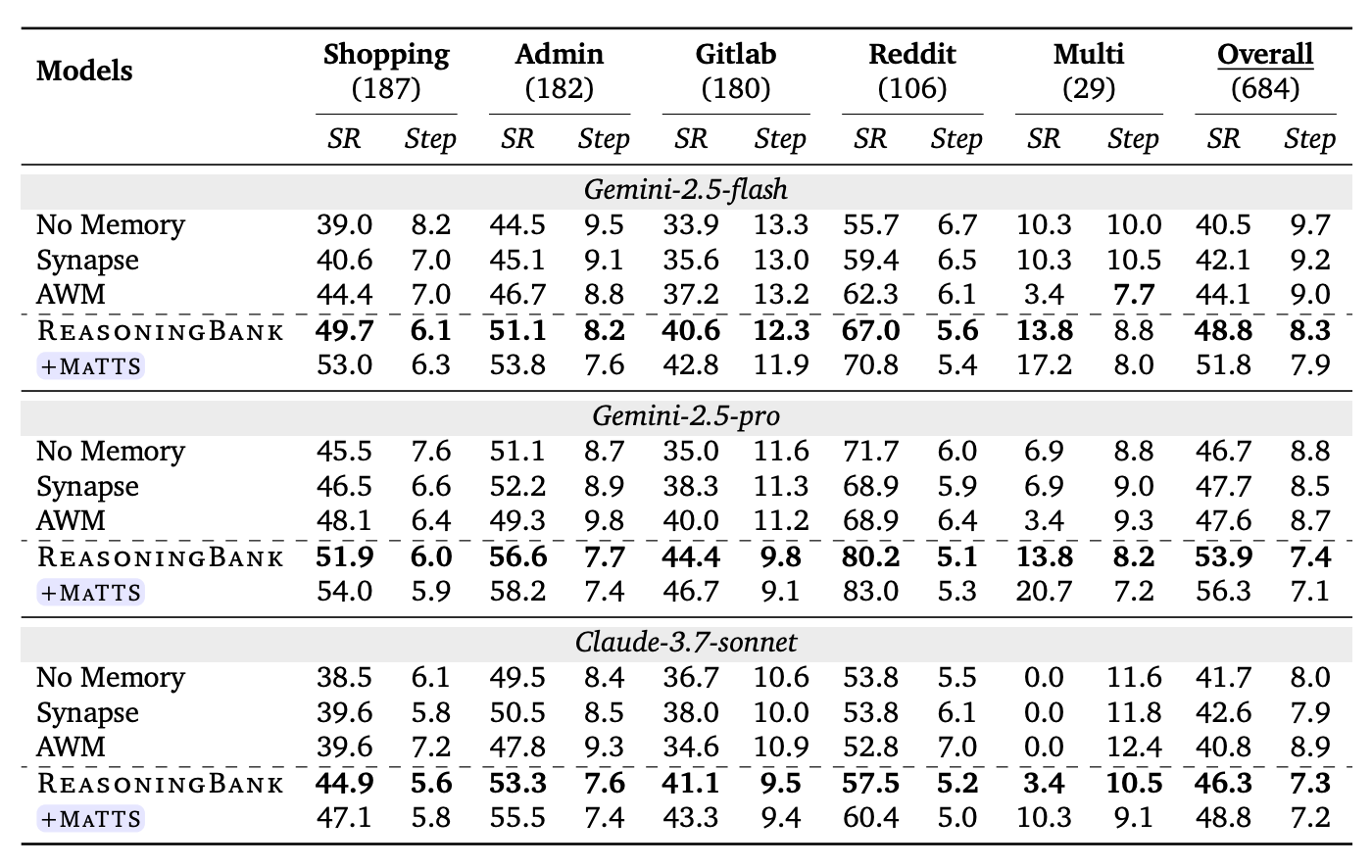
WebArena
WebArena では、ReasoningBank がすべての backbone で No Memory を上回る。
| Backbone | No Memory SR | ReasoningBank SR | +MaTTS SR | No Memory Step | ReasoningBank Step | +MaTTS Step |
|---|---|---|---|---|---|---|
| Gemini-2.5-flash | 40.5 | 48.8 | 51.8 | 9.7 | 8.3 | 7.9 |
| Gemini-2.5-pro | 46.7 | 53.9 | 56.3 | 8.8 | 7.4 | 7.1 |
| Claude-3.7-sonnet | 41.7 | 46.3 | 48.8 | 8.0 | 7.3 | 7.2 |
Gemini-2.5-flash では、No Memory から ReasoningBank で +8.3 point、MaTTS まで入れると +11.3 point。
また step 数も減っている。単に成功率が上がるだけでなく、無駄な探索も減っている。
SWE-Bench-Verified
| Backbone | Method | Resolve Rate | Average Steps |
|---|---|---|---|
| Gemini-2.5-flash | No Memory | 34.2 | 30.3 |
| Gemini-2.5-flash | Synapse | 35.4 | 30.7 |
| Gemini-2.5-flash | ReasoningBank | 38.8 | 27.5 |
| Gemini-2.5-pro | No Memory | 54.0 | 21.1 |
| Gemini-2.5-pro | Synapse | 53.4 | 21.0 |
| Gemini-2.5-pro | ReasoningBank | 57.4 | 19.8 |
コード修正でも改善している。
ここでは AWM は比較から外されている。mini-SWE-Agent の action space は任意の bash command なので、固定 workflow を抽出しにくいため。
この点は実務的にも重要。Web UI 操作のように action schema がある程度固定される領域では workflow が効きやすい。一方、coding agent のように action が開いている領域では、workflow より reasoning hint の方が使いやすい。
Mind2Web
Mind2Web でも ReasoningBank は Cross-Task、Cross-Website、Cross-Domain の各設定で改善している。
task-level success rate は全体に低い。これは、全ステップが正しい場合だけ task 成功と判定する厳しい指標だから。
| Backbone | Setting | No Memory SR | ReasoningBank SR |
|---|---|---|---|
| Gemini-2.5-flash | Cross-Task | 3.3 | 4.8 |
| Gemini-2.5-flash | Cross-Website | 1.7 | 2.3 |
| Gemini-2.5-flash | Cross-Domain | 1.0 | 1.6 |
| Gemini-2.5-pro | Cross-Task | 3.5 | 5.1 |
| Gemini-2.5-pro | Cross-Website | 3.4 | 3.8 |
| Gemini-2.5-pro | Cross-Domain | 1.4 | 1.7 |
Cross-Domain でも改善しているため、特定サイト専用の手順ではなく、ある程度抽象化された strategy が効いていると読める。
アブレーション
失敗 trajectory が効く

WebArena-Shopping で、成功例だけを使う場合と、成功・失敗の両方を使う場合を比較している。
| Method | Success only | With failures |
|---|---|---|
| Synapse | 40.6 | 41.7 |
| AWM | 44.4 | 42.2 |
| ReasoningBank | 46.5 | 49.7 |
ReasoningBank は失敗を入れると上がる。AWM は下がる。
ここから、失敗ログはそのまま入れるとノイズになりやすいが、失敗理由を推論戦略として抽出すれば有益、という主張につながる。
retrieval は多ければよいわけではない
| retrieved experiences | Success Rate |
|---|---|
| 0 | 39.0 |
| 1 | 49.7 |
| 2 | 46.0 |
| 3 | 45.5 |
| 4 | 44.4 |
top-1 が最良。多く入れるとむしろ下がる。
RAG 的に「関連情報を多めに入れる」発想は、agent memory では危ない。矛盾する memory や弱い memory が action selection を乱す。
LLM-as-a-Judge は完全でなくても動く
LLM-as-a-Judge の実測 accuracy は WebArena-Shopping で 72.7%。
著者らは judge accuracy を 100%、90%、80%、70%、60%、50% にシミュレートしている。70〜90% の範囲では性能が大きく崩れないと報告している。
ただし、誤った judge が誤った memory を作るリスクは残る。本番では task-specific verifier、複数 judge、人間レビューを足したい。
MaTTS の評価
WebArena-Shopping、Gemini-2.5-flash での結果。
| 設定 | k=1 | k=5 |
|---|---|---|
| MaTTS parallel | 49.7 | 55.1 |
| MaTTS sequential | 49.7 | 54.5 |
scaling factor を増やすと上がる。
また、vanilla TTS より MaTTS の方が良い。k=5 では、parallel で MaTTS が 55.1、vanilla TTS が 52.4。sequential でも MaTTS が 54.5、vanilla TTS が 51.9。
単に trajectory を増やすだけでなく、複数 trajectory を比較して memory を作ることが効いている。
コスト
1 task あたりの token 消費。
| Method | Action generation | Judge | Memory extraction | Total |
|---|---|---|---|---|
| No Memory | 50,847.4 | - | - | 50,847.4 |
| Synapse | 55,920.5 | 2,594.2 | - | 58,514.7 |
| AWM | 53,819.6 | 2,479.1 | 3,074.1 | 59,372.8 |
| ReasoningBank | 49,306.1 | 2,186.3 | 1,562.1 | 53,054.5 |
ReasoningBank は No Memory より total token が約 4.3% 増える。一方、WebArena-Shopping の success rate は 20.5% 改善したと整理されている。
興味深いのは、ReasoningBank の action generation token が No Memory より少ない点。memory によって無駄な探索が減り、judge と extraction の追加コストを一部相殺している。
実際の改善例
論文では、WebArena-Shopping の例が分かりやすい。
最初の購入日を調べるタスク
No Memory は Recent Orders だけを見て、最近の購入日を最初の購入日として答える。
ReasoningBank は、過去の memory を使って full order history や Next Page を確認し、正しい最初の購入日を答える。
商品購入タスク
No Memory はカテゴリや filter の場所を探して 29 steps かかる。
ReasoningBank は、過去のカテゴリ探索 memory を使って、Shoes、Men、Price filter へ進み、10 steps で完了する。
Bluetooth headphones の検索失敗
失敗 trajectory では、検索 query が曖昧で、無関係な商品が多く出る。さらにページ送りを繰り返して step limit を消費する。
ReasoningBank はこの失敗から、検索 query を具体化する、表示件数を増やす、filter を使う、といった memory を作る。
限界
- memory content の設計に焦点を当てており、episodic memory、hierarchical memory、working memory などの高度な memory architecture とは深く比較していない。
- retrieval は embedding top-k、consolidation は append-only でかなり単純。本番では dedupe、merge、forgetting、confidence 管理が必要。
- LLM-as-a-Judge に依存する。judge が誤ると、誤った memory item が蓄積される。
- parallel scaling は、同じ環境で複数 rollout できることが前提。購入、削除、外部 API 呼び出しのような副作用を持つタスクでは sandbox や rollback が必要。
- benchmark 評価が中心で、長期運用、権限管理、ユーザー別 memory 分離、privacy filter は主題ではない。
感想
- LLM 本体を更新せず、外部 memory を育てて agent behavior を変える方向の研究。
- 最近増えている「エージェント自身に過去ログを読ませ、次の探索や実装を改善させる」系の流れに近い。
- 一番のポイントは、失敗ログをそのまま保存するのではなく、失敗回避策に変換して保存するところ。
- 実用化では、memory の量より品質管理が重要。特に、誤った memory が入ったときにどう検出し、どう消すかが課題になりそう。
メインTOPIC
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
[pon] いい加減ちゃんと読まないといけないなと思って読んだ。メモリ株にも影響を与えたヤバいVQ。
量子化のおさらい
スカラー量子化 (Scalar Quantization, SQ)
各次元を独立に量子化する最もシンプルな手法。
例えば128次元のfloat32ベクトル を int8 (-128〜127) にマップする場合、各成分について
を適用するだけ。1次元あたり 4バイト → 1バイト で 4倍圧縮。実装が簡単で高速ですが、次元間の相関は全く利用しない。
ベクトル量子化 (Vector Quantization, VQ)
ベクトル全体を コードブック の最近傍コードワードに置き換える方法。コードブックは k-means で学習。
128次元ベクトルを K=256 のコードブックで量子化すると、ベクトル本体は 1バイト で済む。ただしコードブック自体 (256×128×4 = 128KB) は別途保持する必要がある。
積量子化
PQは「ベクトルの分割」と「部分的な量子化」を組み合わせた手法。
- ベクトル分割 (Splitting):
- 高次元ベクトルを \(M\) 個の小さな部分ベクトル(サブベクトル)に分割
- 部分空間の学習 (Training):
- 各部分空間において、k-means法を用いて代表ベクトル(コードブック)を作成
- 量子化 (Quantization):
- 各部分ベクトルを、最も近い代表ベクトルのID(インデックス)に置き換え
ここまでをまとめると次の問題があることがわかる
- データ依存: k-meansでコードブックを作るので、データセットごとに学習が必要
- コードブックが複数: 部分空間ごとに別のコードブックが必要
理想は「データに依存せず、座標ごとに独立にスカラー量子化できる」こと
本論文は、Vector Quantization(VQ)におけるMean-Squared Error(MSE)と内積歪みの最小化を目的とした、データに依存しないオンラインアルゴリズム「TurboQuant」を提案(1つはMSE最小化用に最適化され、もう1つは内積誤差最小化用に最適化)。既存の手法の限界を克服し、ほぼ最適な歪み率を達成することを目指す。
Introduction
- Vector Quantization(VQ)は浮動小数点座標値を低ビット幅の整数に変換する量子化を通じて高次元ベクトルを圧縮し、同時にMSEや内積誤差などの指標で定量化される歪みを最小限に抑えること
- 次に活用される
- AIモデルのトレーニング、デプロイ
- ベクトルデータベースにおける検索/検索システム
課題
- LLMのKVキャッシュ量子化や近傍探索(NN search)において、高速な内積計算とメモリ効率が求められます。既存のVQアルゴリズムは、
- アクセラレータとの互換性がない
- 計算が遅い
- ビット幅に対して最適な歪み境界を達成できない
といった問題点がある。
本研究は、これらの課題を解決するTurboQuantを提案。TurboQuantの核心は二段階のプロセスにあります。
- MSEに関して最適な歪み率を持つベクトル量子化器
- 次に残差に1ビット量子化器(Quantized Johnson-Lindenstrauss; QJL)を適用することで、不偏かつ低歪みの内積量子化器を実現
MSEに最適化された量子化器が内積推定においてバイアスを導入することを実証し、二段階ソリューションがこのギャップを効果的に埋めることを示す。
Problem Definition
目標は、 次元ベクトルを ビットのバイナリ文字列に変換する量子化写像 を設計すること
もし をある に対して設定する場合、この量子化器はビット幅 を持ち、の各実数値座標をエンコードするために使用される平均ビット数を表す。
決定的に重要なのは、逆写像 が必要であり、これは量子化された表現から元のベクトルを近似的に再構築する逆量子化を実行することである。
もちろん、この変換は本質的に損失を伴う。なぜなら、 は全単射ではないからである。したがって目的はこの歪みを最小化することであり、特に平均二乗誤差(MSE)と内積歪みに焦点を当てている(論文ではこの二つを歪みDとしている)。
(MSE)
(内積誤差)
さらに、内積量子化器に対しては、内積推定量の不偏性を要求する。これは多くのアプリケーションにとって望ましい特性である。
より正確には、以下を要求する:
(不偏内積)
特に、 個の実数値ベクトル を与えられていると仮定するとき、以下のプリミティブを設計する
- Quant: データセットを効率的に量子化し、 を計算する。
- DeQuant: 量子化されたデータセットが与えられた場合、任意の に対して を計算することにより、元のベクトルを効率的に再構築できる。
Preliminaries
Shannon Lower Bound (SLB) on Distortion (復習)
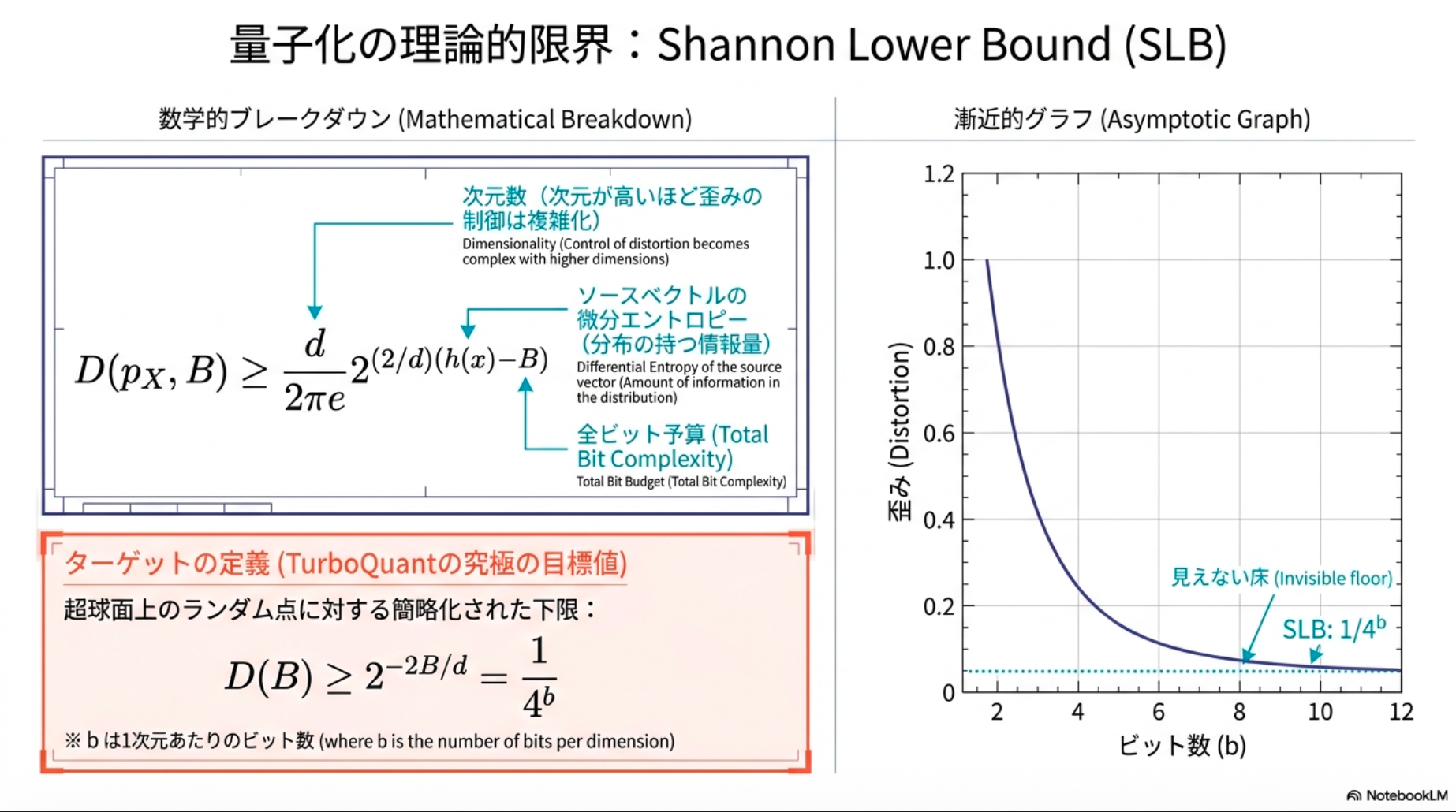
Shannonの歪みレート理論に基づき、任意のロス圧縮スキームで達成可能な最適な歪み率に対する普遍的な下限を示す。特に、MSE歪み尺度と高次元ソースに特化したSLBを使用する。
任意の確率分布 を持つランダムベクトル に対して、合計ビット複雑度 におけるMSE歪み は次で下限づけられる)。
単位超球面上に一様分布するランダムベクトル の場合(今回の手法では)、 とおくと
QJL: 1-bit inner product quantization
QJL(Quantized Johnson-Lindenstrauss)は、LLMにおける「KVキャッシュの量子化(圧縮)」をゼロオーバーヘッドで行うことを目的として開発された手法。効率的かつデータ非依存(Data-oblivious)な1ビット量子化アプローチとして提案
- たった1ビットでバイアスのない内積推定ができる→KVキャッシュを極限まで圧縮しつつ、推論時に必要となる内積計算の精度を保つ
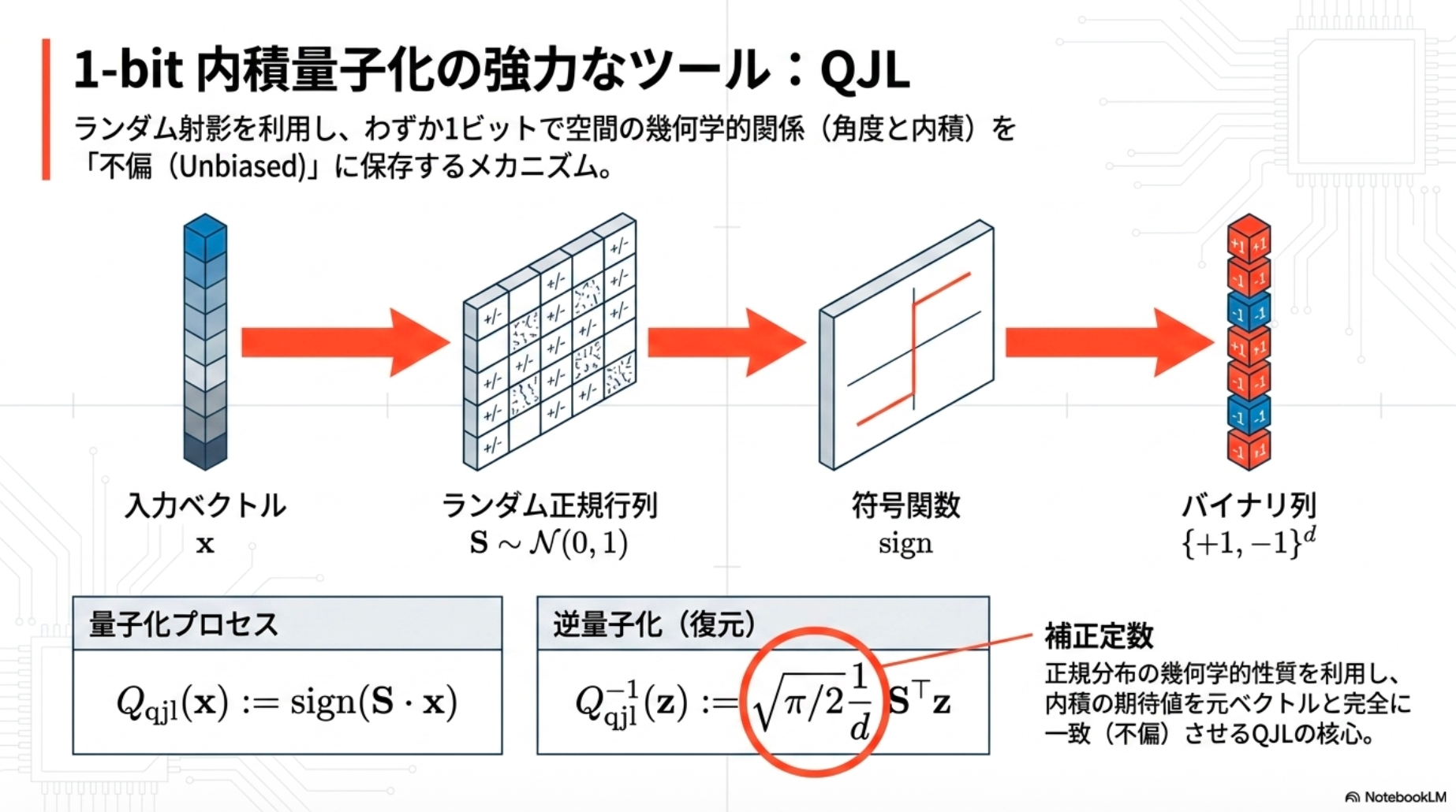
Definition 1: 入力ベクトル に対し
( は i.i.d. ガウス分布エントリを持つランダム行列)として定義される1ビット内積量子化器。
逆マップは
詳細
1. 「1/d」はどこから来た?(平均化のため)
QJLでは、量子化の際に標準正規分布 N(0,1) に従うランダムな d×d 行列 S を掛け合わせます。 逆量子化して内積を計算しようとする際、この d 個の行ベクトルで射影されたそれぞれの結果(d 個の独立したサンプル)を足し合わせることになります。 これらは確率的なばらつきを持っているため、真の内積を推定するために d 個のサンプルの「平均(期待値)」をとる必要があり、そのために d で割っています(1/d を掛けています)。
2. 「π/2」はどこから来た?(バイアス補正のため)
QJLの量子化では、ランダム行列を掛けた後のベクトルの「符号(sign関数)」だけを抽出して1ビットに圧縮します。しかし、ガウス分布(正規分布)に従う数値の符号だけを取り出して内積の期待値を計算すると、元の内積に対してどうしても数学的なズレ(バイアス)が生じてしまいます。 このQJLの推定量において、元の内積 と完全に一致する「不偏推定量(Unbiased estimator)」にするためには、符号化によって生じたズレを逆算してキャンセルするための補正値としてを掛ける必要があるのです。
Lemma 4: QJLは不偏性
と、分散境界
を満たす。
TurboQuant: High Performance Quantization
TurboQuantは、以下の2つの主要なアルゴリズムで構成されている。
1. MSE Optimal TurboQuant
このアルゴリズムは、量子化前のベクトルと復元ベクトルの MSE(平均二乗誤差) を最小化するように設計されている。
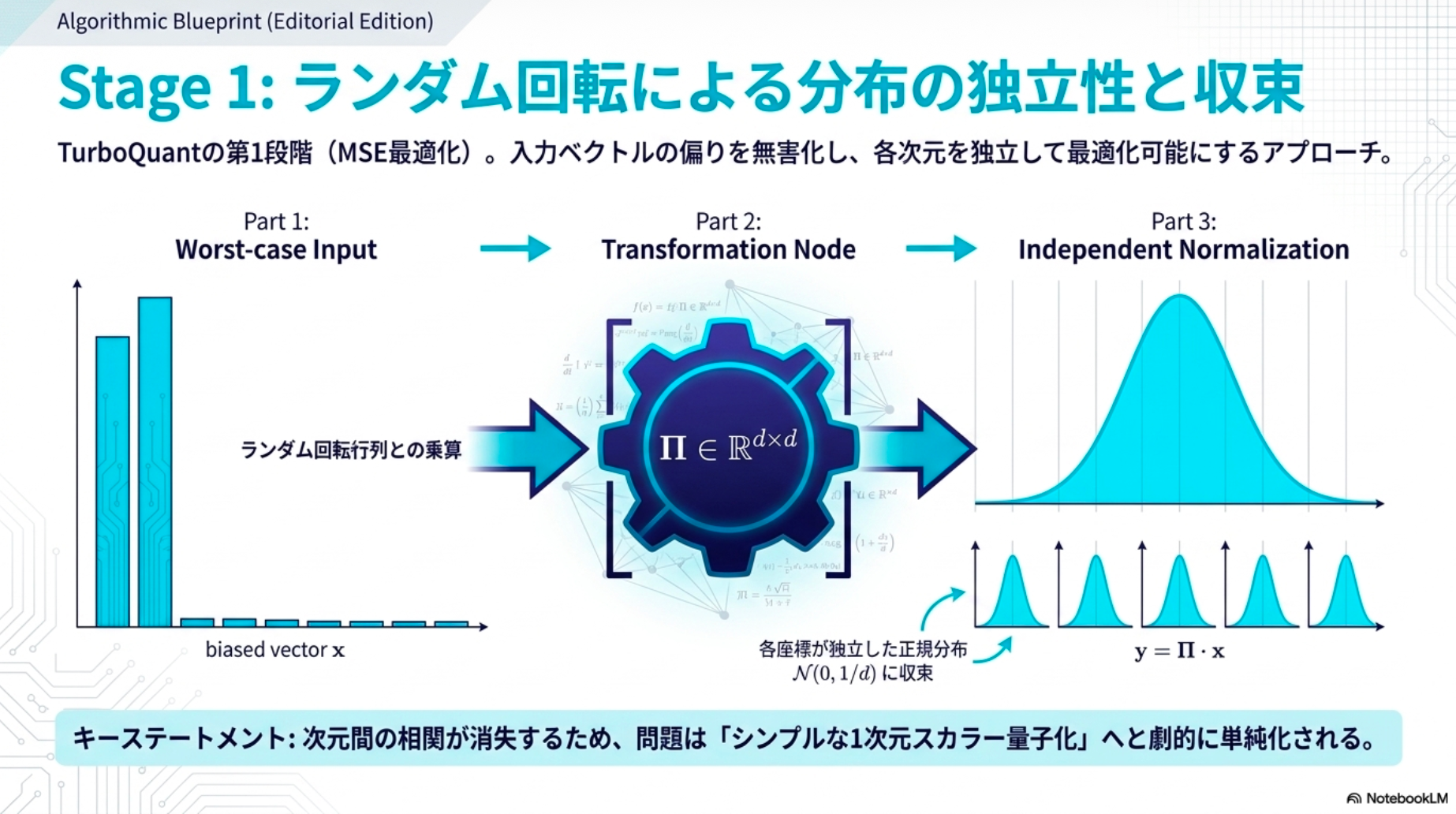
- ランダム回転
- 入力 に対して、ランダム回転行列 を用いて を計算する。
- これにより は(近似的に)単位超球面上で一様な振る舞いになる
- → どんな入力データが来ても(最悪の入力ケースであっても)、各次元の値を扱いやすい特定の確率分布に強制的に変換し、次元ごとに独立して最適な量子化を行えるようにする
- 座標分布の近似(Beta → Gaussian)
- の各座標は Beta 分布に従う。
- 高次元では正規分布 に近づく
- → 座標間の相関が小さくなるため、各座標を独立に最適スカラー量子化できる。
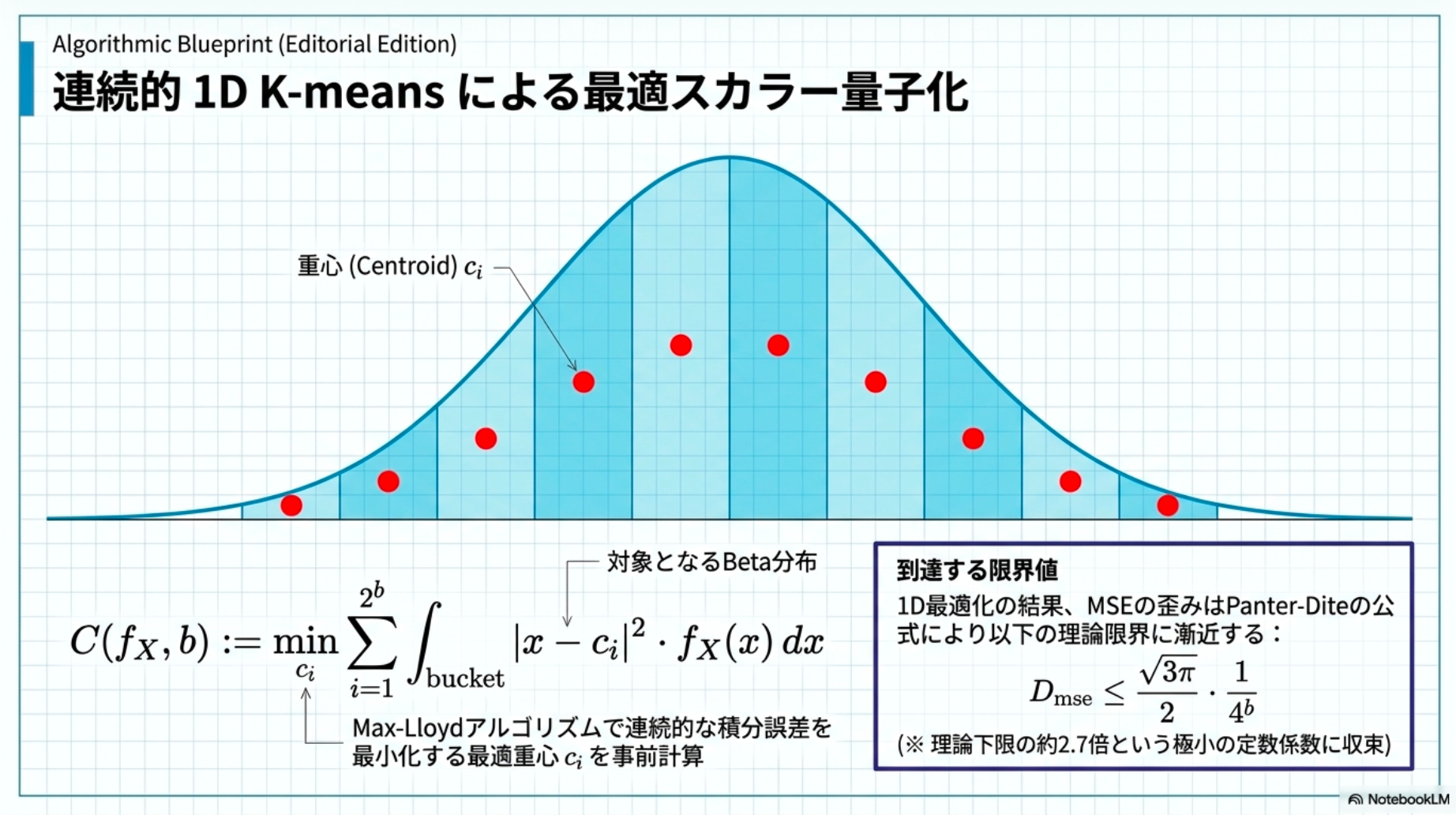
- Lloyd-Max による最適スカラー量子化(事前計算)
- 区間 を 個のバケットに分割し、セントロイド を最適化する。
- 最小化するコスト:
正規分布なので、「数式で定義された既知の確率分布」に対して、平均二乗誤差(MSE)を最小化する1次元の連続的なk-means問題の最適解(ボロノイ図に基づく分割)を求めるためのアルゴリズム:Lloyd-Maxアルゴリズムが使える。
詳細
- ここで は Beta 分布の密度関数。実用的なビット幅についてコードブックを事前に計算して保存する。
[pon] あらゆるデータに対してコードブックが一度だけ事前計算されるという点がオンライン特化で最高に嬉しい
アルゴリズム

量子化と逆量子化(Algorithm 1)
- Quant(MSE)
- 各座標 を最近傍のセントロイド に割り当て、そのインデックス を保存する。
- DeQuant(MSE)
- により復元する。
- として元の基底に戻す。
性能保証(Theorem 1)
- 任意の と に対して、MSE 歪みは次を満たす(導入が追いきれなかったすまん。。。Panter-Dite high-resolution formulaと言うのを使ってるらしい):
- 小さいビット幅(例:)では、おおよそ 。
- 直感としては、 となるため、歪みは分散に対応する:
Inner-product Optimal TurboQuant
MSE最適化された量子化器は、内積推定においてバイアスを持つことを本論文は示しています(例: の場合、倍率バイアスは)。このバイアスに対処するため、二段階アプローチが提案されています。
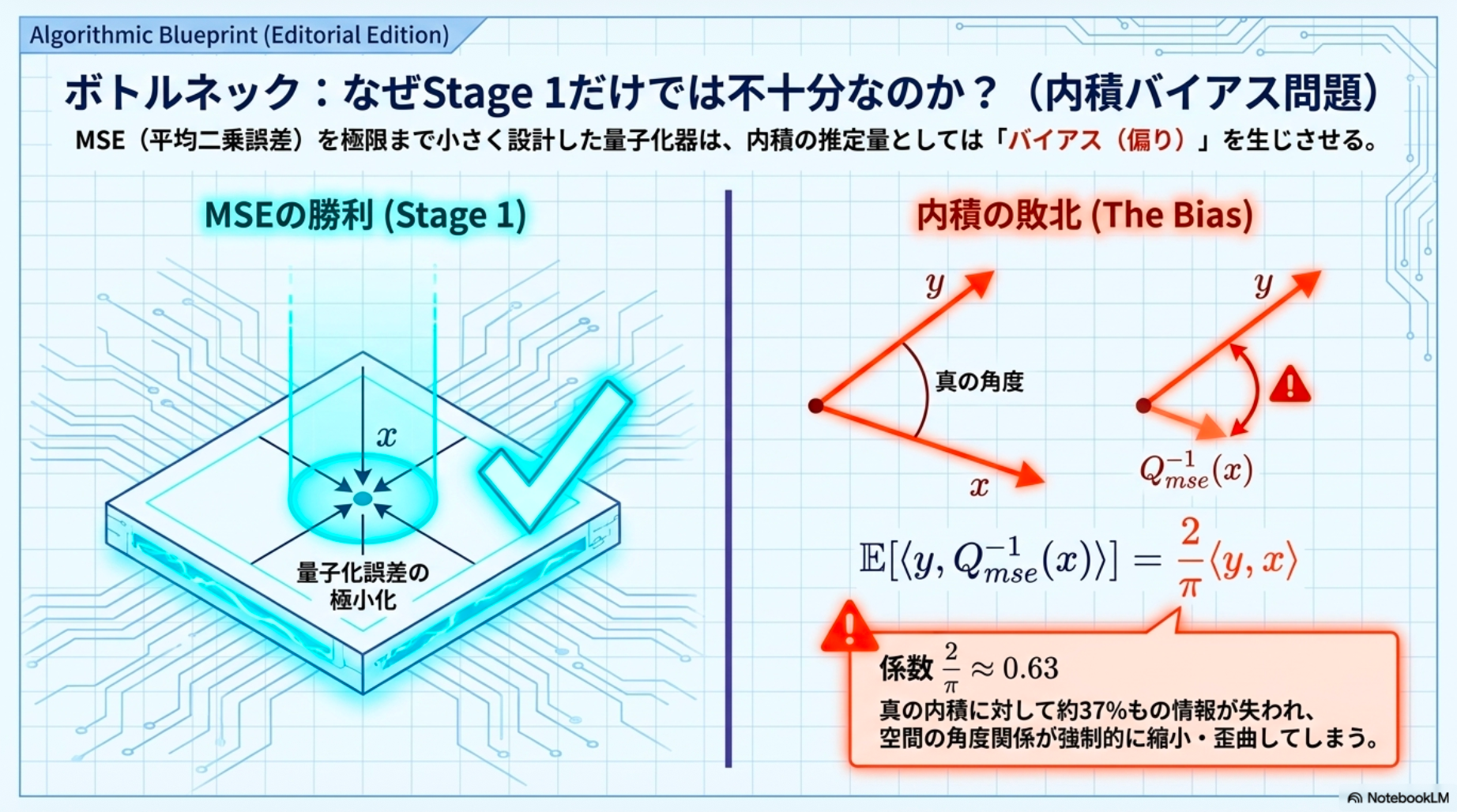
[pon] はセントロイド計算の際に重心(期待値)として出てくる 。その分のズレ。
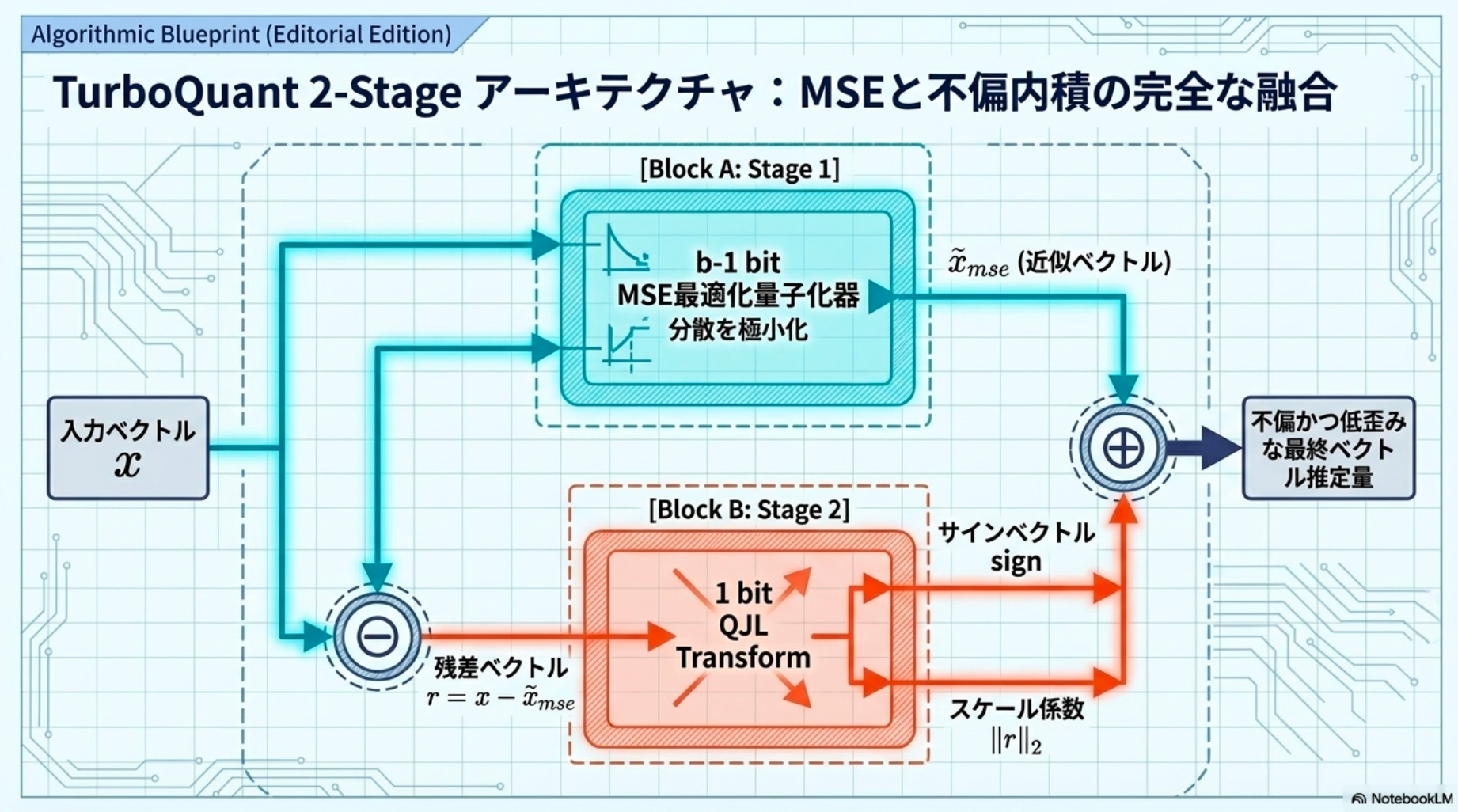
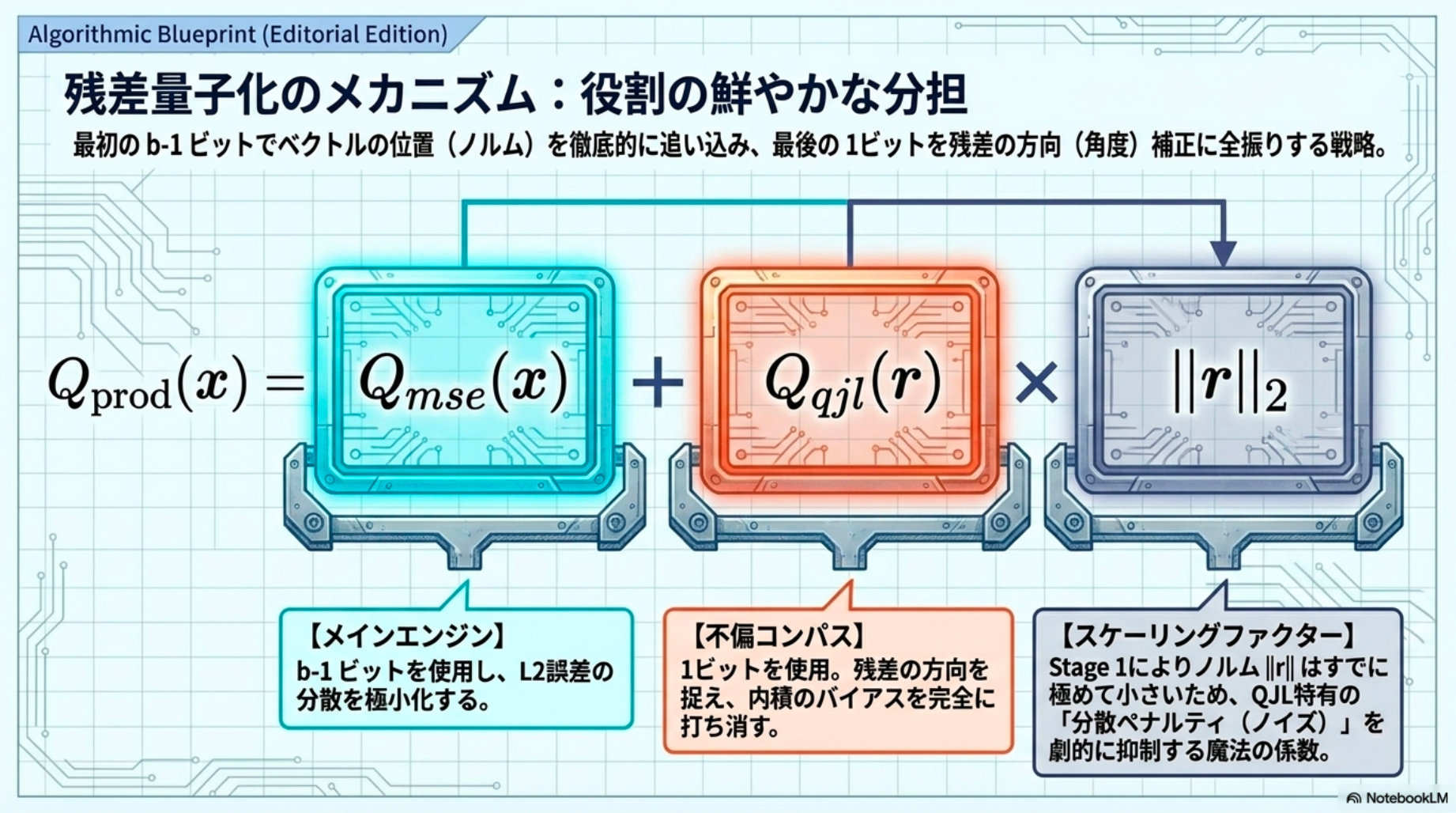
手法:
- 第一段階(MSE量子化): 目標ビット幅 より1ビット少ない ビットで を適用し、 を に量子化します。これにより、残差ベクトルの ノルムが最小化されます。
- 第二段階(QJLによる残差量子化): 残差ベクトル に対して QJL(Quantized Johnson-Lindenstrauss)を適用し、符号ビット列を生成します。(Preliminariesを参照)
また、残差の ノルムも保存します。
- 逆量子化: 内積計算時には、MSE量子化の復元 と、QJLで再構築した残差 を足し合わせます。(Preliminariesを参照)
アルゴリズム

性能保証(Theorem 2):
- 任意のビット幅 と 、任意の に対し、以下が成り立ちます。
期待内積(不偏性):
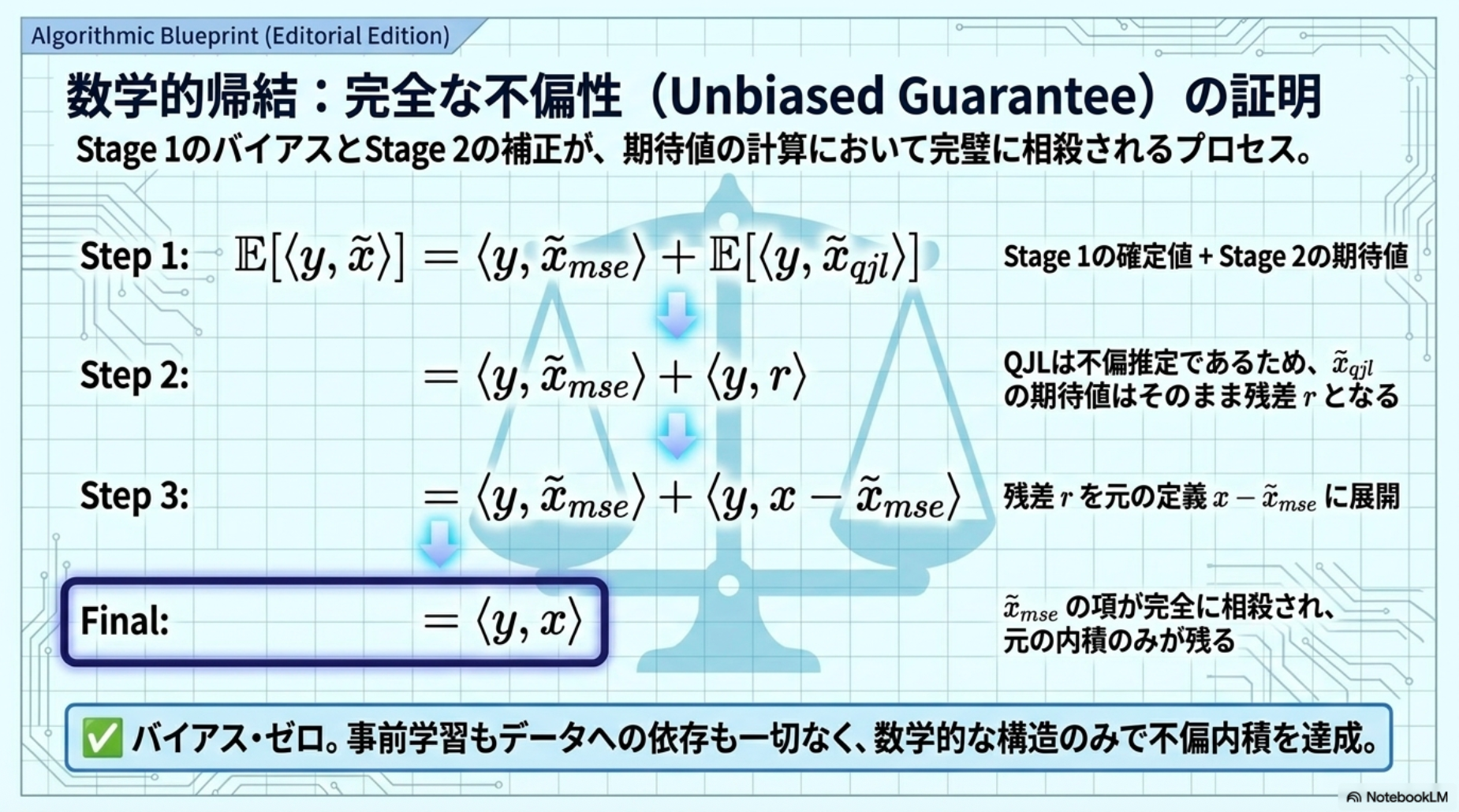
内積歪み:
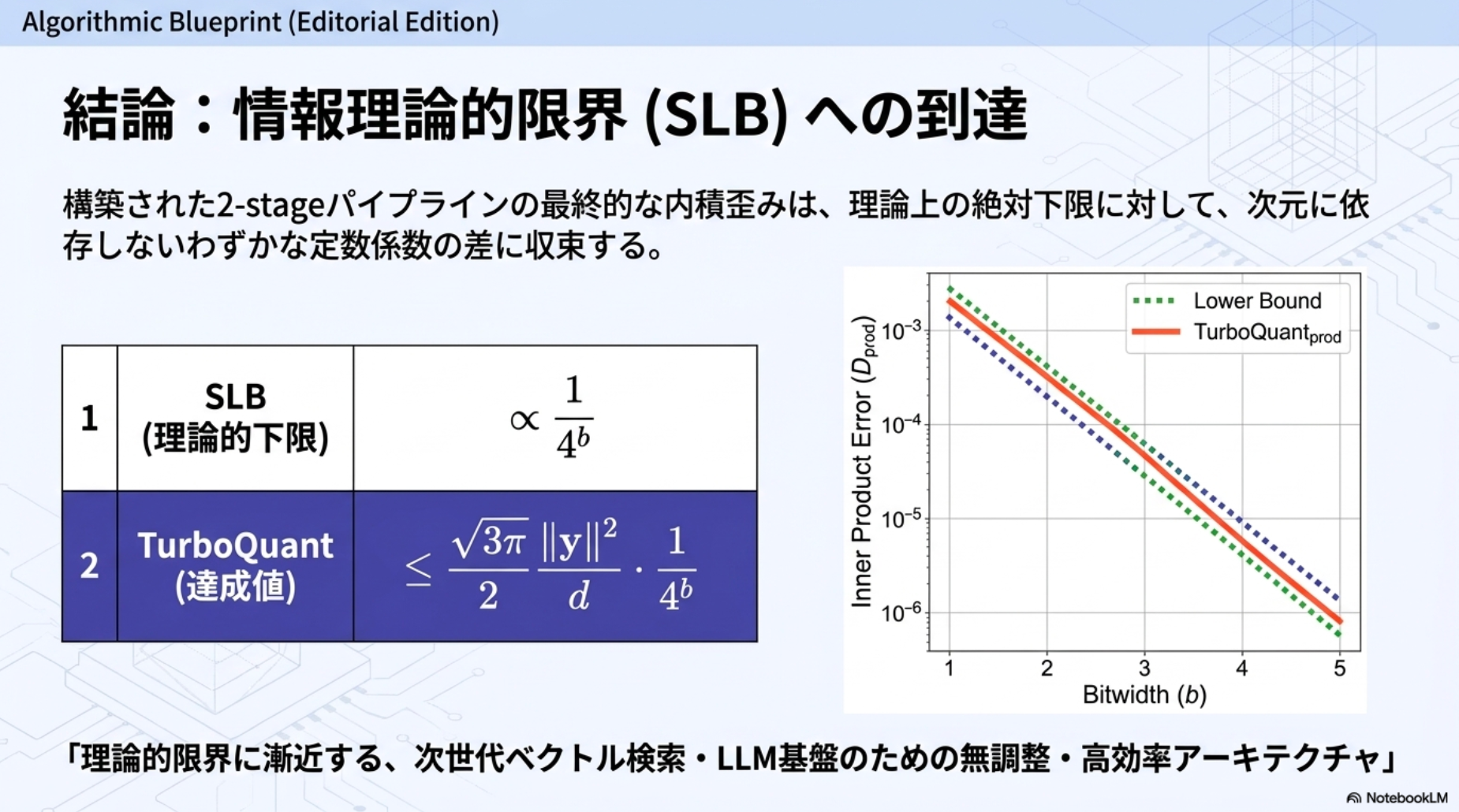
[pon] (QJLが持つ内積推定の分散の限界値() に由来)」と「前段で計算したMSEの限界値(Panter-Diteの公式に由来)」がそのまま掛け合わされて合体したもの)
小さいビット幅()では、それぞれ約 。
Lower Bounds
[pon] 導出を全部追いきれんかった。。。
Theorem 3では、Yaoのミニマックス原理とShannonの下限定理を組み合わせることで、任意の量子化アルゴリズムが達成可能な歪み率に対する情報理論的な下限を導出している。
Theorem 3: 任意のランダム化量子化アルゴリズム に対し、worst-case の入力 が存在して、以下が成り立つ。
(MSE の下限)
また、ある に対し、
(内積歪みの下限)
Experiments
Empirical Validation
OpenAI3 embeddings を使用して1536次元空間にエンコードされたDBpedia Entitiesデータセットを用いて実験を行う。実験を実行するために、データセットから100,000個のデータポイントをランダムにサンプリングし、これをトレーニングセットとして指定する。これは我々の主要なデータセットとして機能する。さらに、1,000個のユニークなエントリを抽出し、これをクエリセットとして指定し、クエリポイントとして使用する。
とという2つの量子化手法を評価する。
- TurboQuantmse手法は、量子化されたベクトルと元のベクトル間の平均二乗誤差(MSE)の推定に最適化されるように設計されている。
- 対照的に、TurboQuantprodは、量子化されたベクトルと元のベクトル間の内積の推定において不偏である。
図1と図2は、が内積推定において常に不偏であるのに対し、はビット幅の増加とともにバイアスが減少することを示しています。
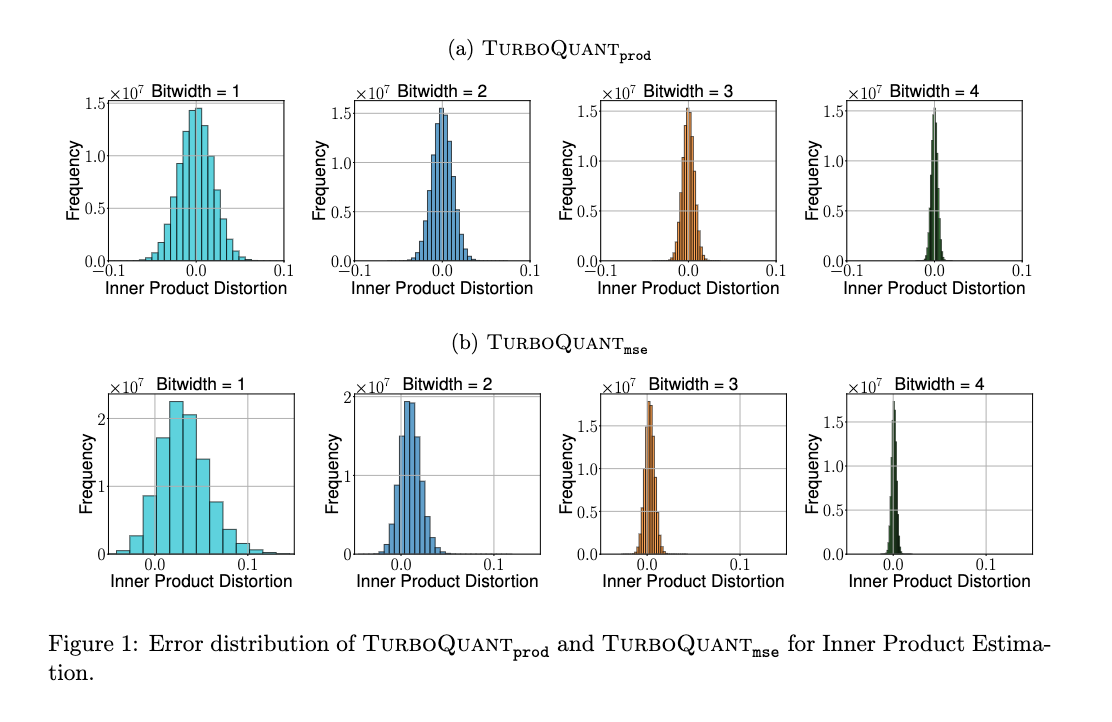
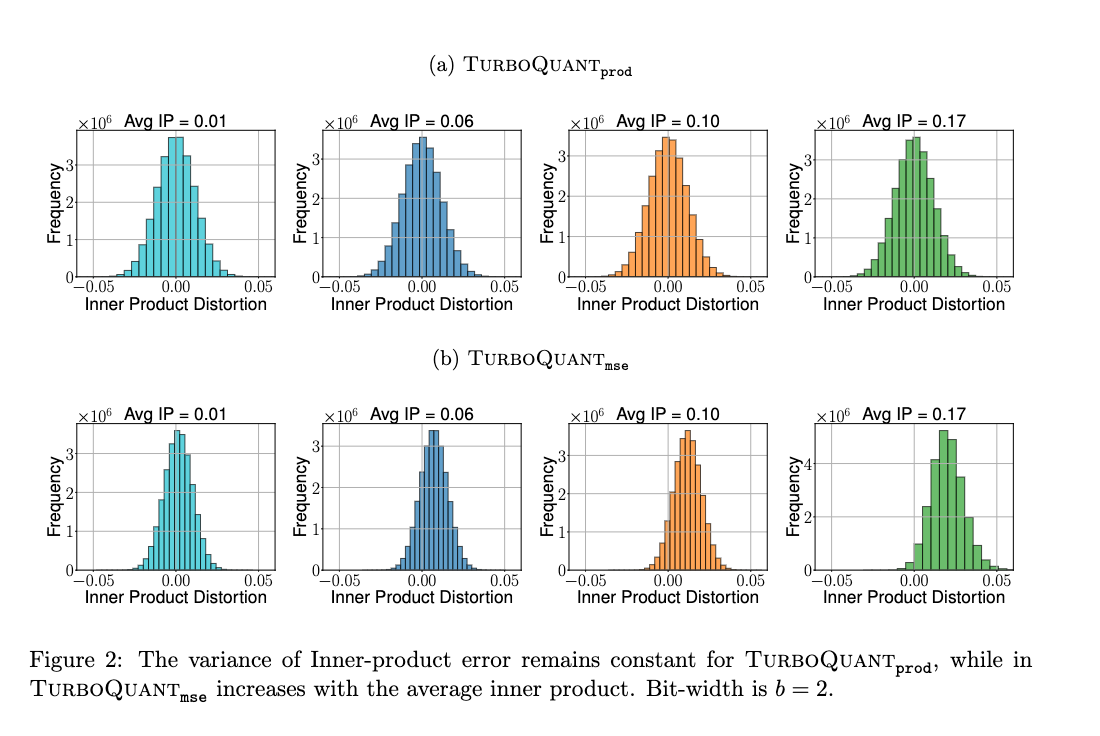
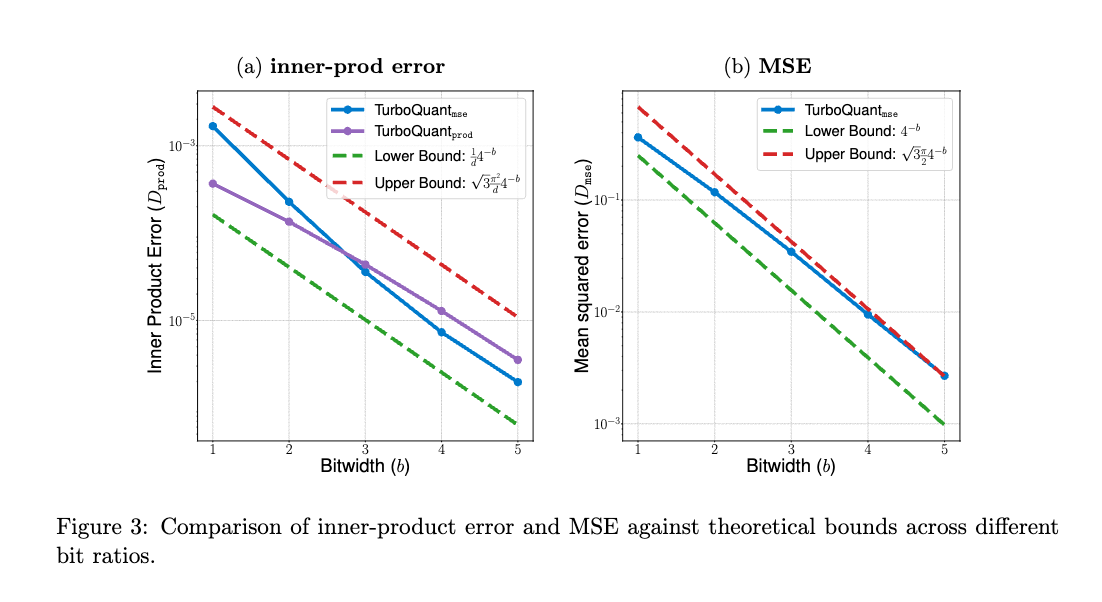
図3は、提案手法の歪み値が理論的な上下限に非常に近いことを確認しています。
Needle-In-A-Haystack
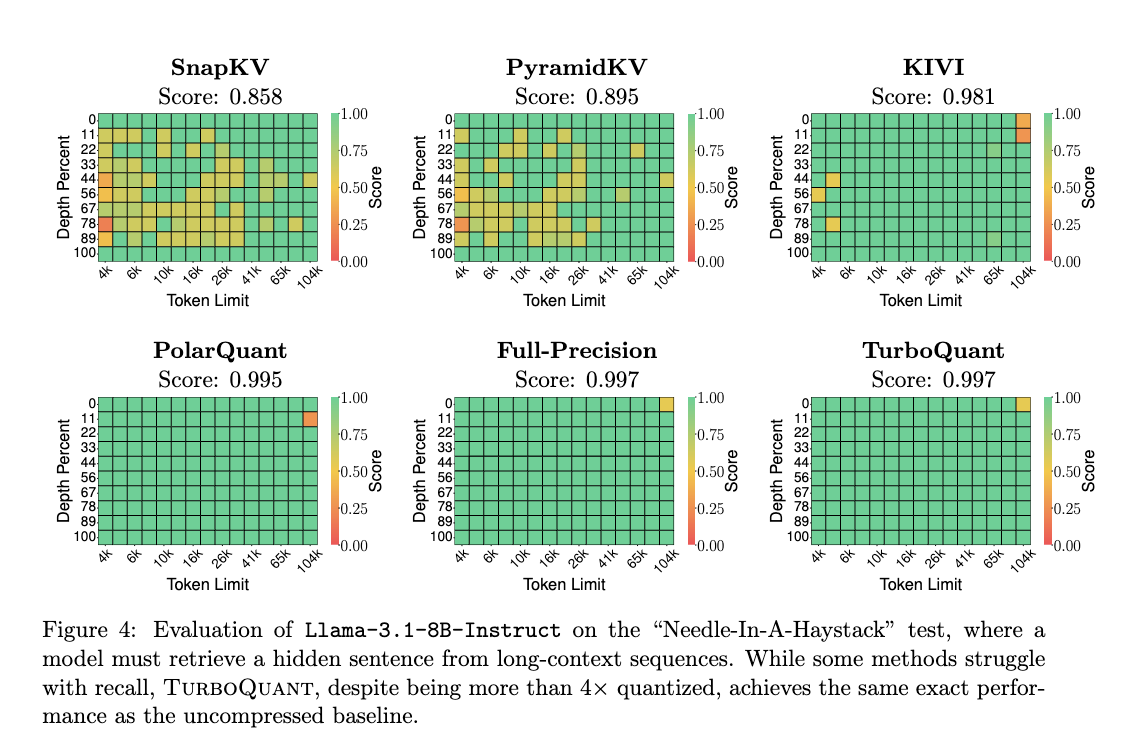
Llama-3.1-8B-Instructモデルを用いて、長文コンテキストからの情報検索能力を評価しました。図4に示すように、TurboQuantは4倍以上の圧縮率にもかかわらず、Full-Precisionモデルと全く同じ性能を達成し、既存の量子化手法やトークンレベル圧縮手法を上回る頑健性を示しました。
End-to-end Generation on LongBench
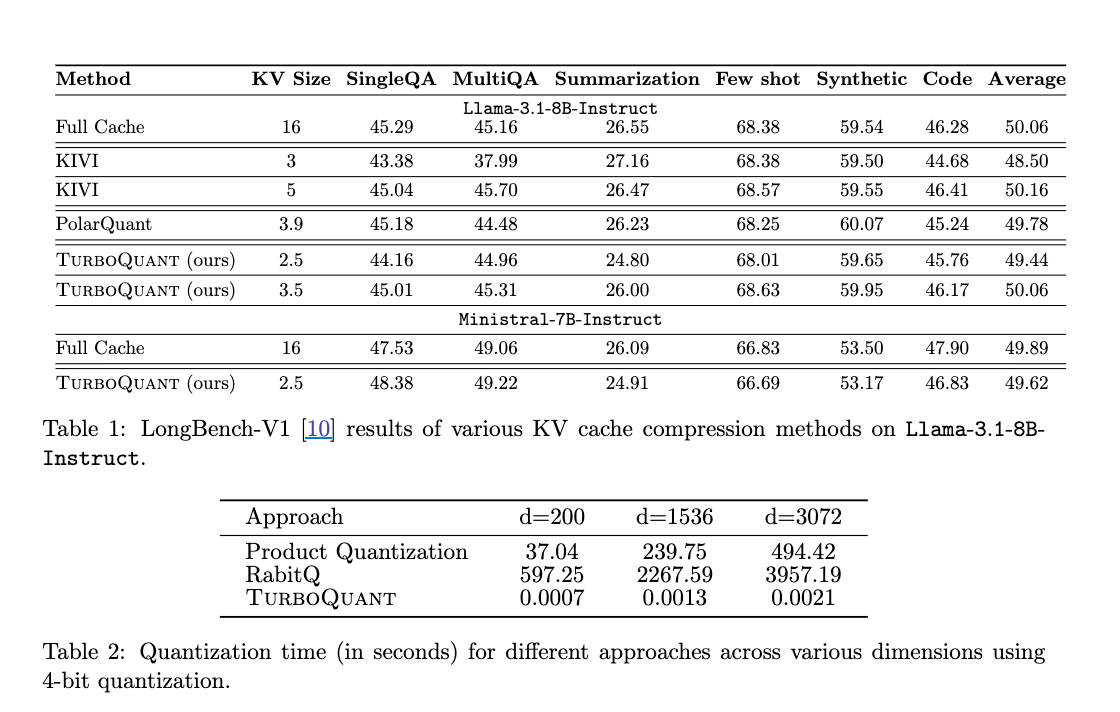
LongBench-Eデータセットを用いて、Llama-3.1-8B-InstructとMinistral-7B-InstructモデルのKVキャッシュ圧縮アルゴリズムを評価しました。表1の通り、TurboQuantは2.5ビットおよび3.5ビットの量子化設定で、他の手法よりも高い平均スコアを達成し、未量子化モデルに匹敵する性能を維持しながら、量子化ベクトルを少なくとも4.5倍圧縮できることを示しました。特に、アウトライアチャネルと非アウトライアチャネルに異なるビット精度を割り当てる戦略を採用しています。
Near Neighbour Search Experiments
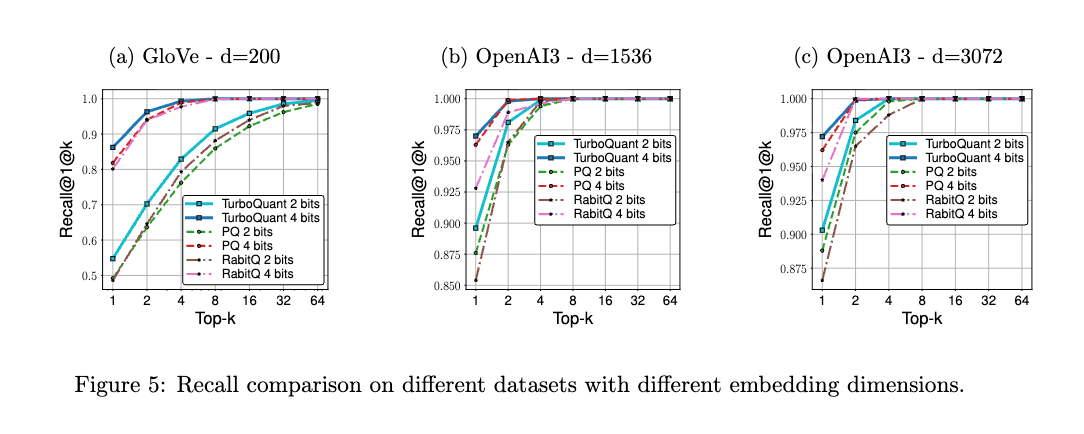
DBpedia Entitiesデータセット(OpenAI3 embeddings)とGloVe embeddingsデータセットを用いて、近傍探索タスクにおけるTurboQuantの性能を評価。図5に示すように、TurboQuantは、既存のProduct Quantization(PQ)やRabitQを、特にRecall@1@kにおいて一貫して上回る。表2は、PQやRabitQに比べてTurboQuantの量子化時間が実質的にゼロ(数ミリ秒)であることを示しており、これはデータに依存しない性質によるもの。