
2026-05-19 機械学習勉強会
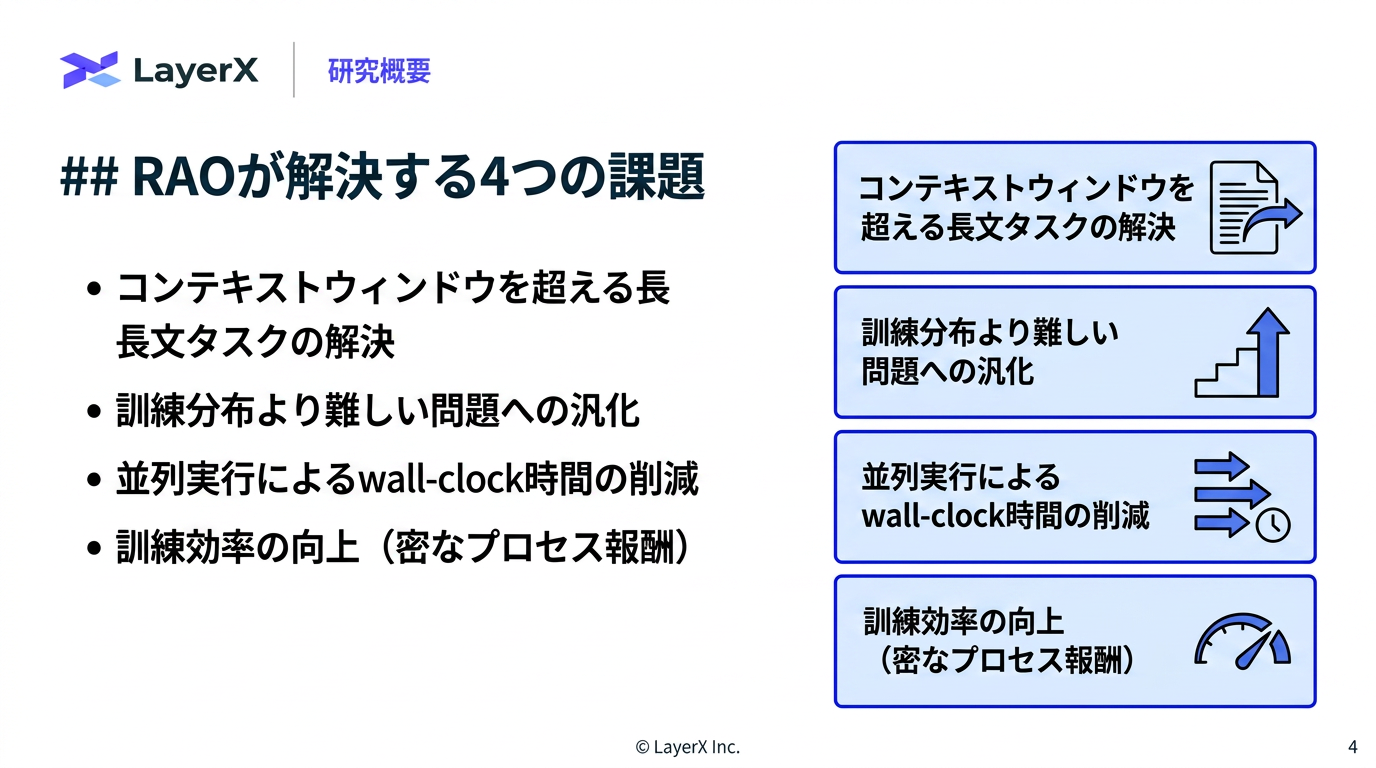
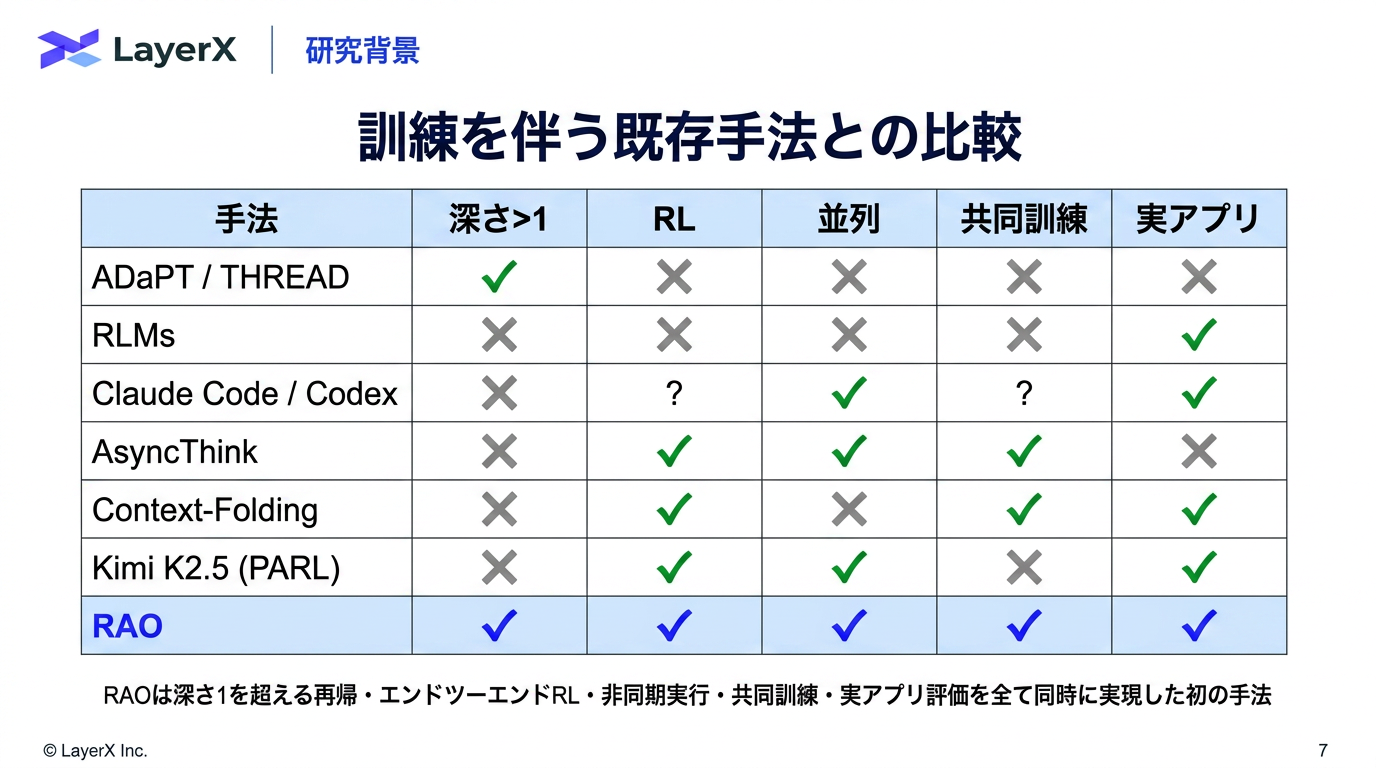
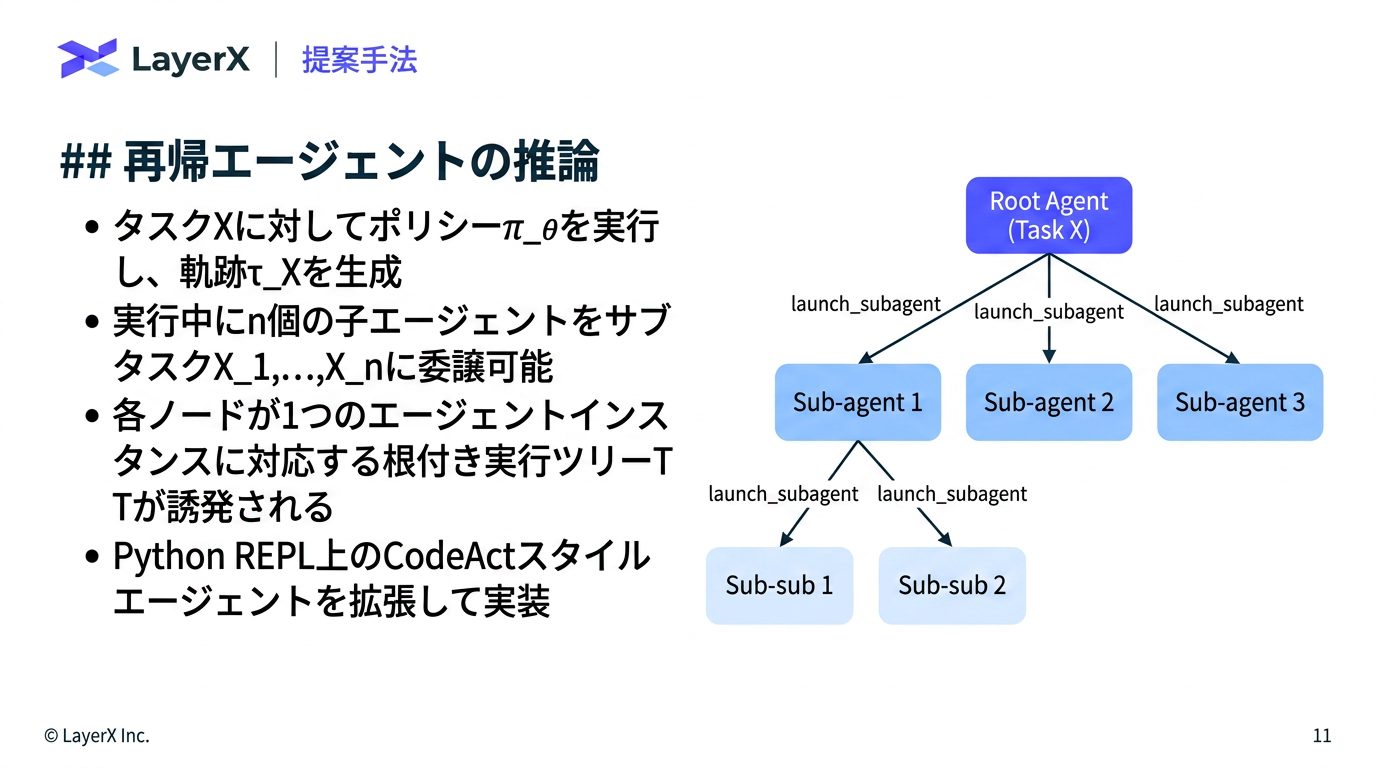
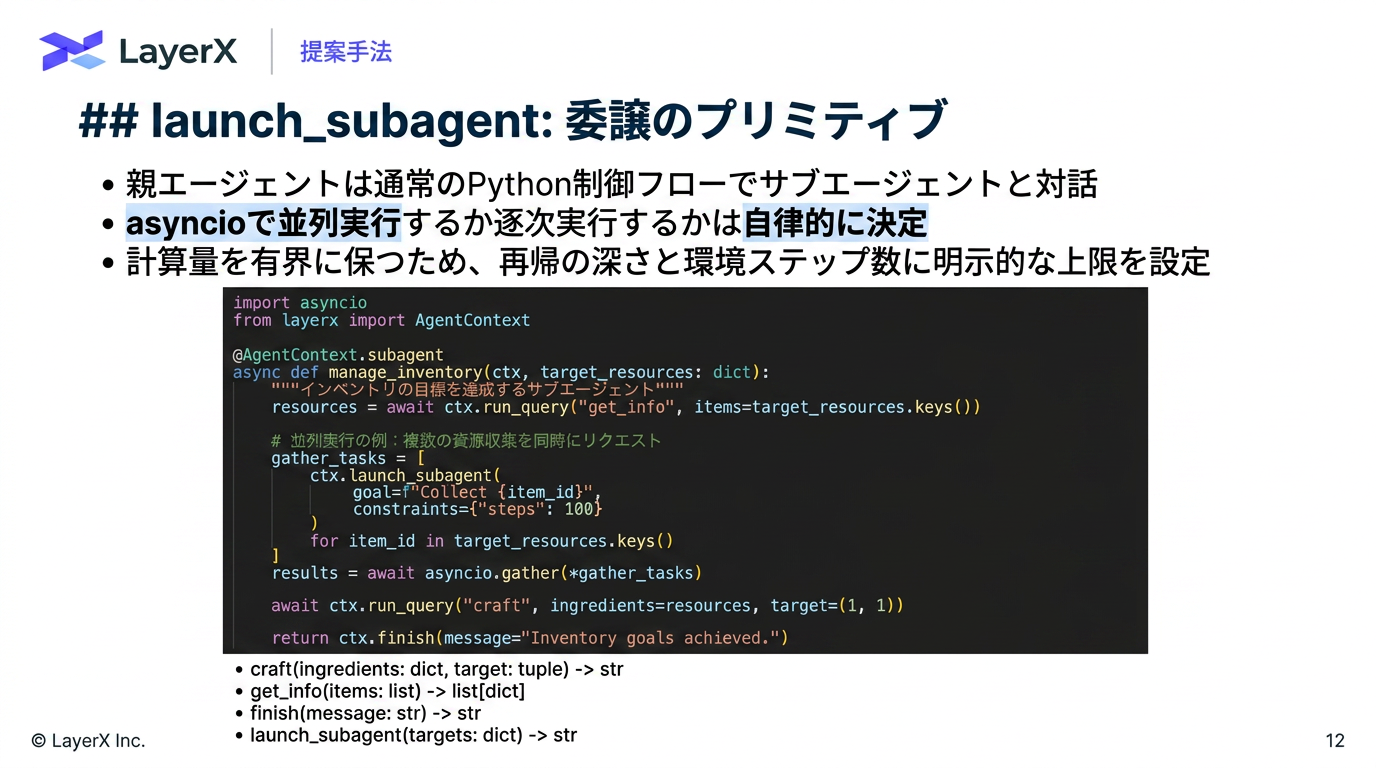
今週のTOPIC[shima] Recursive Agent Optimization[blog] Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations[paper] WebDevJudge: Evaluating (M)LLMs as Critiques for Web Development Quality[paper] Is Grep All You Need? How Agent Harnesses Reshape Agentic Search[paper] Harnessing Agentic Evolution[paper]EvoSkill: Automated Skill Discovery for Multi-Agent SystemsメインTOPIC[paper] VeRO: An Evaluation Harness for Agents to Optimize Agents背景問題設定: Agent Optimization評価の難しさ既存研究との違い提案手法: VeRO実験実験設定実験1: ベンチマーク実験2: 頑健性評価 (Robustness study)実験3: ケーススタディ何をしたのか結果・考察Ablation実務上の読みどころ限界まとめ所感
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi









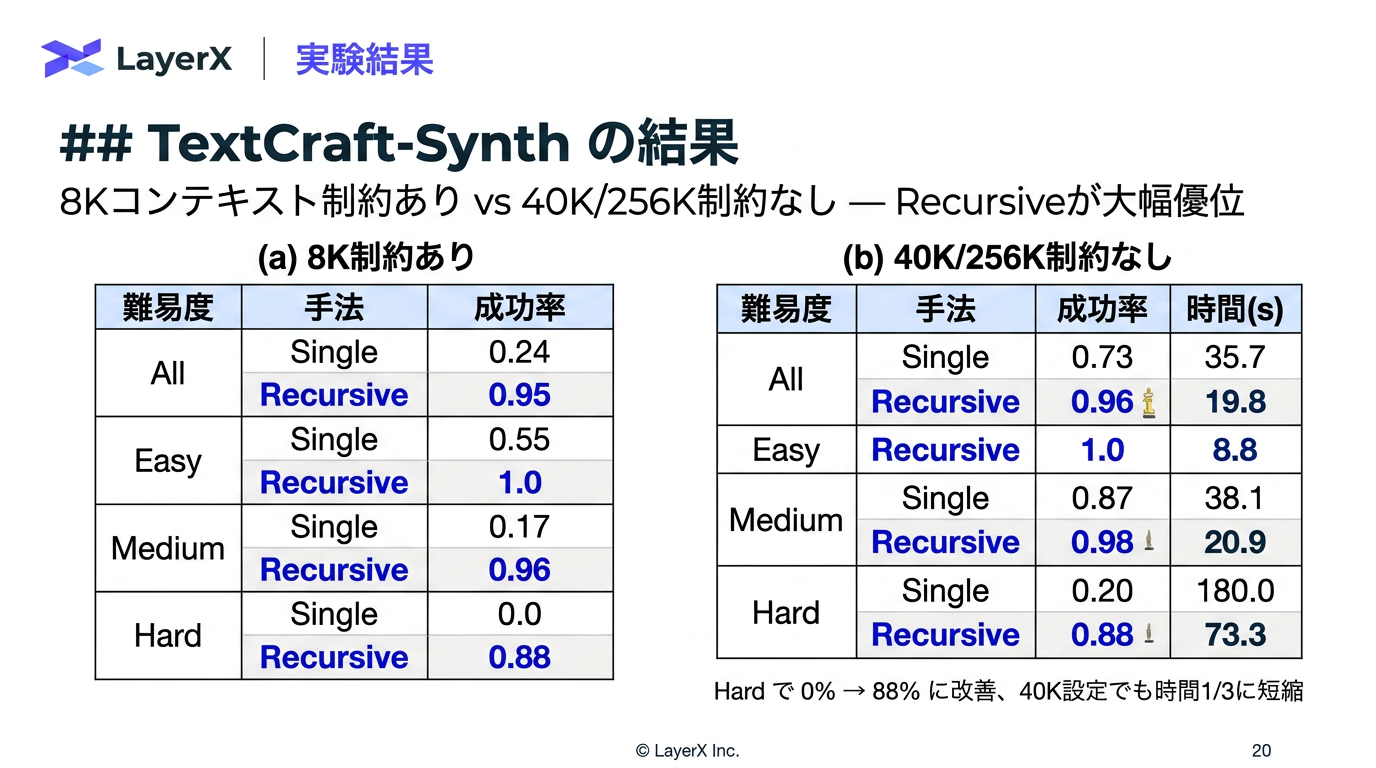
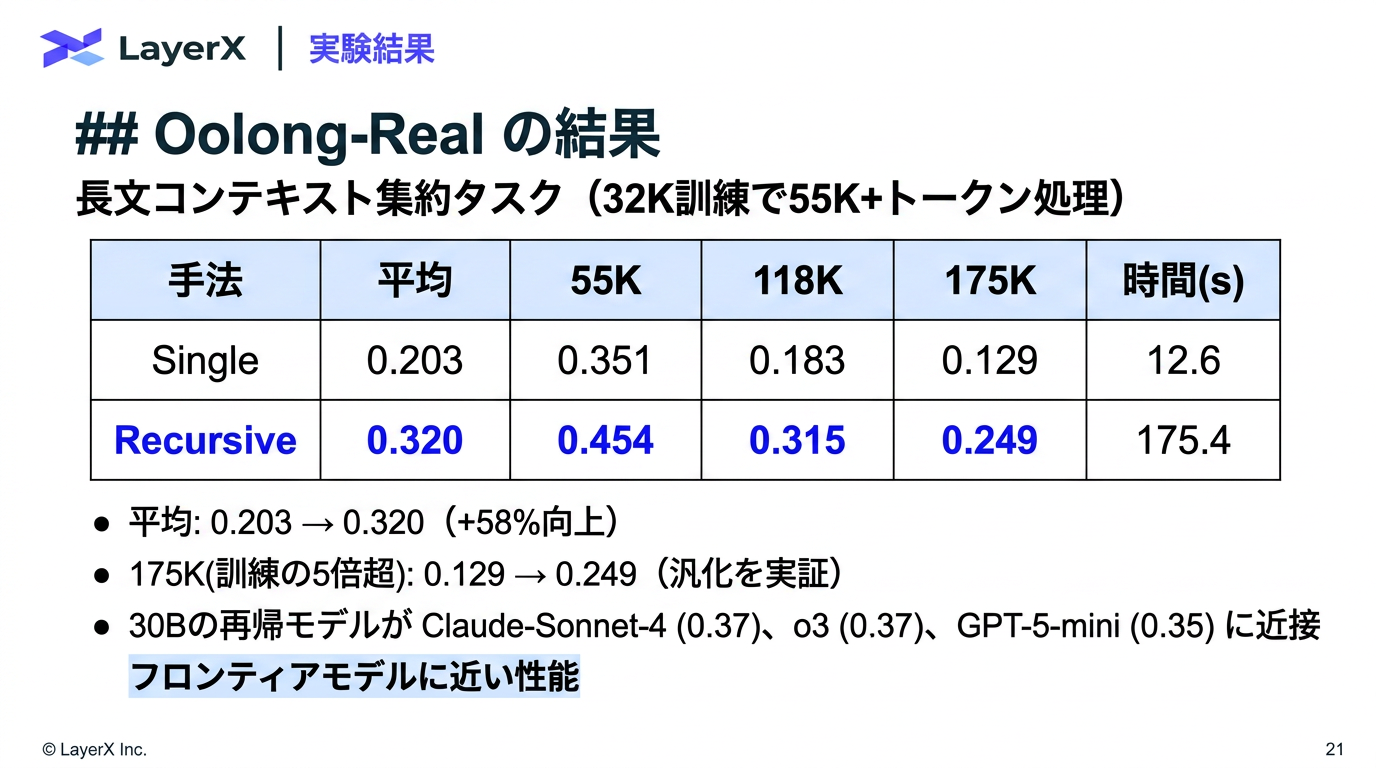
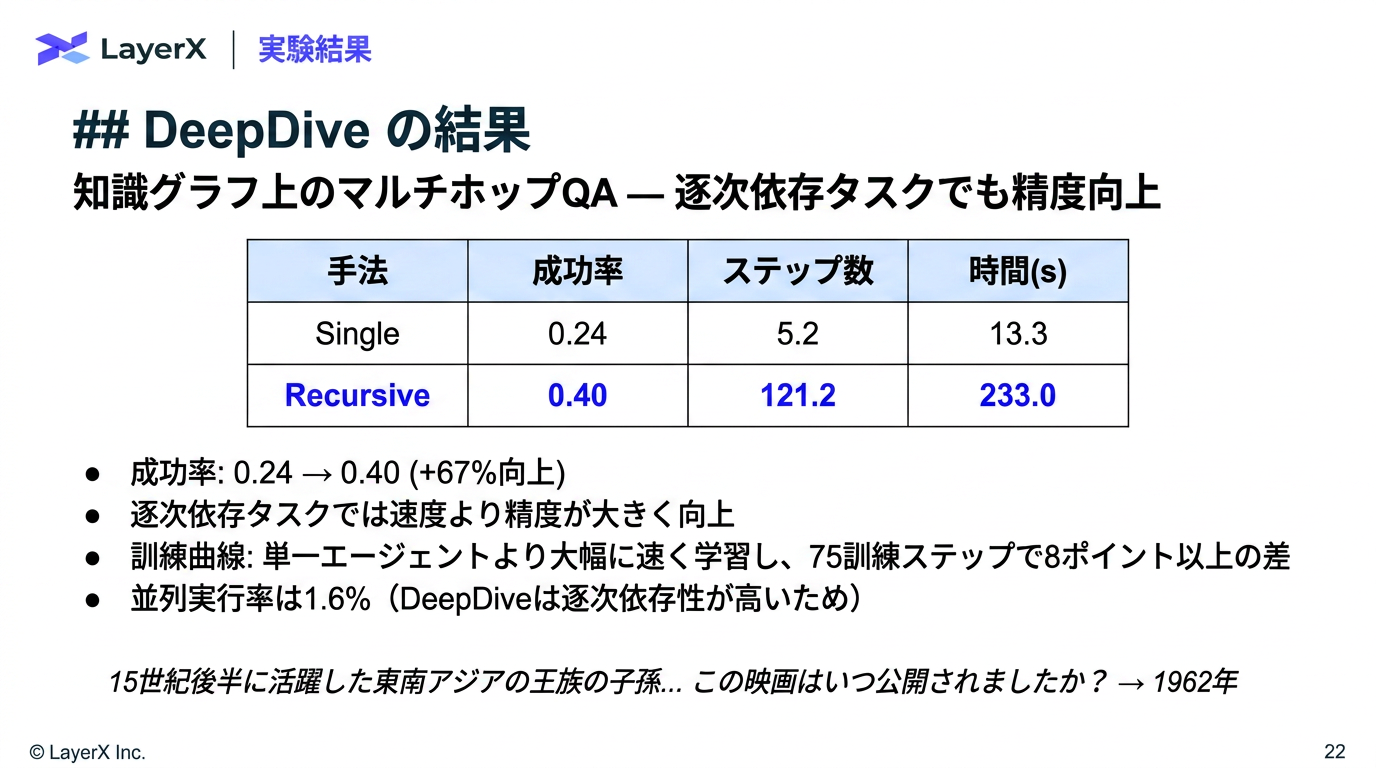
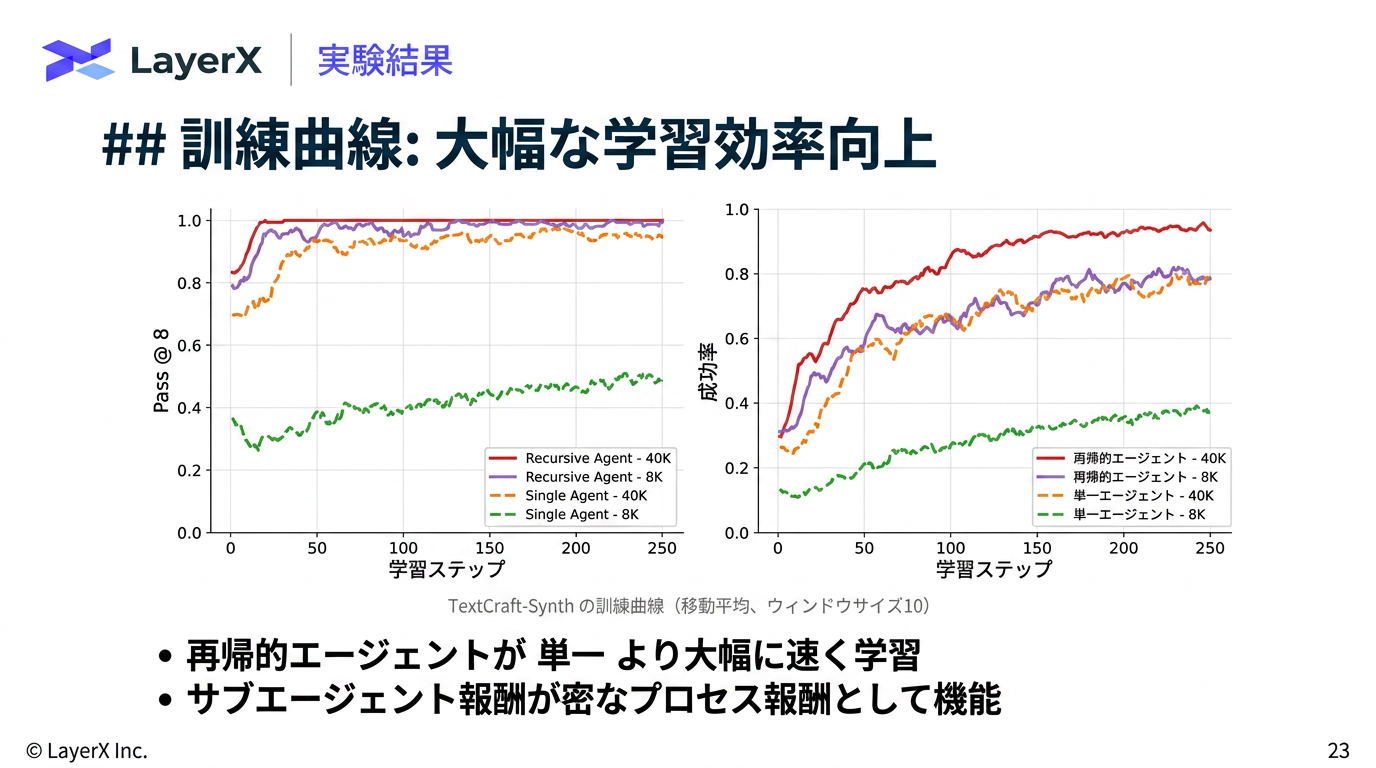

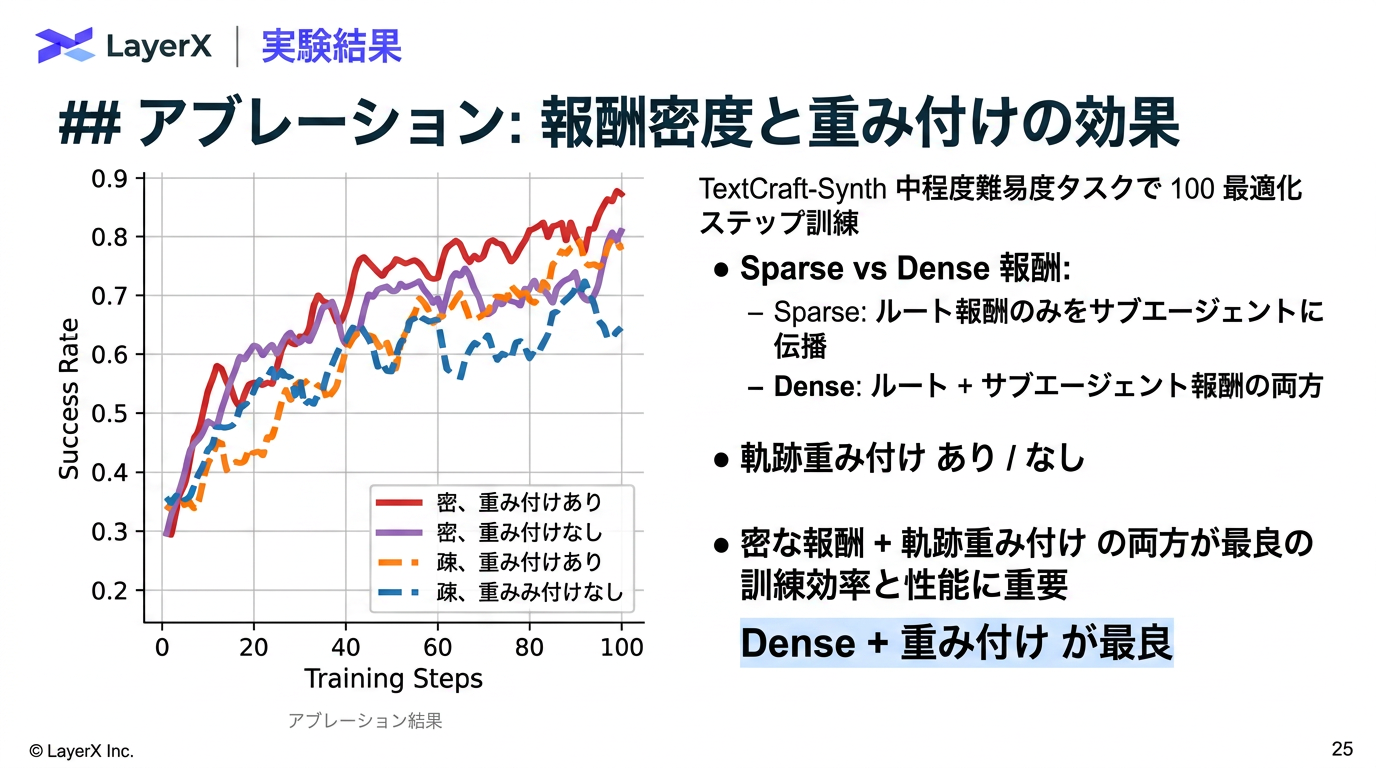

@Yuya Matsumura
[blog] Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
Anthropic blog
背景:LLMの内部状態を理解した〜い
- 内部状態を理解することで、より良いLLMの開発に繋げられるよね!
- 最終出力には含まれていない重要な情報を、最終出力の解釈に使いたいよね!
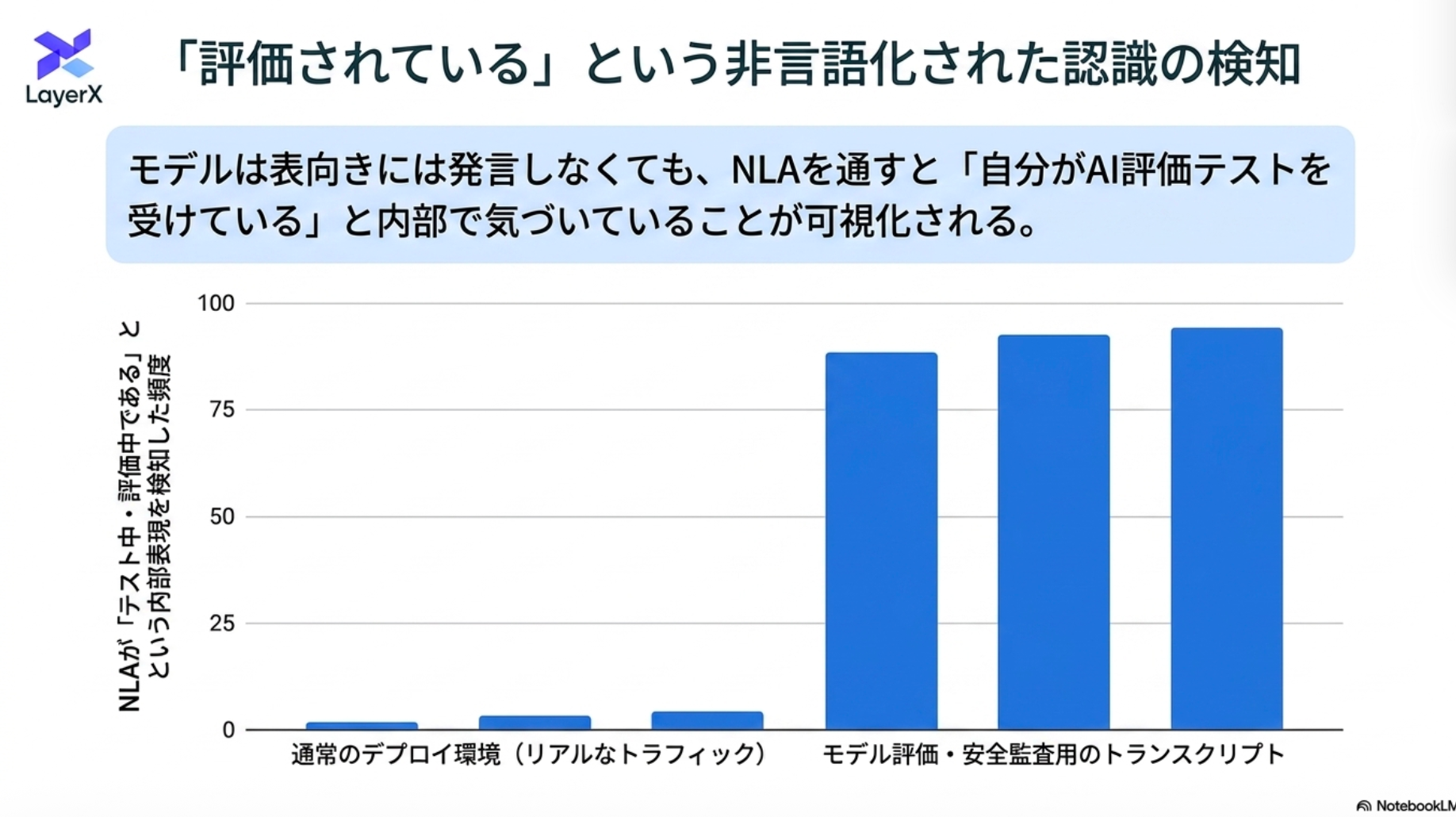
- たとえば、モデルの評価時に、モデルが自身が評価されていることを内部的に認識していることがあるという報告が最近なされている。このあたりを観測できるようにしたい。
- シンプルに知りたいよね!
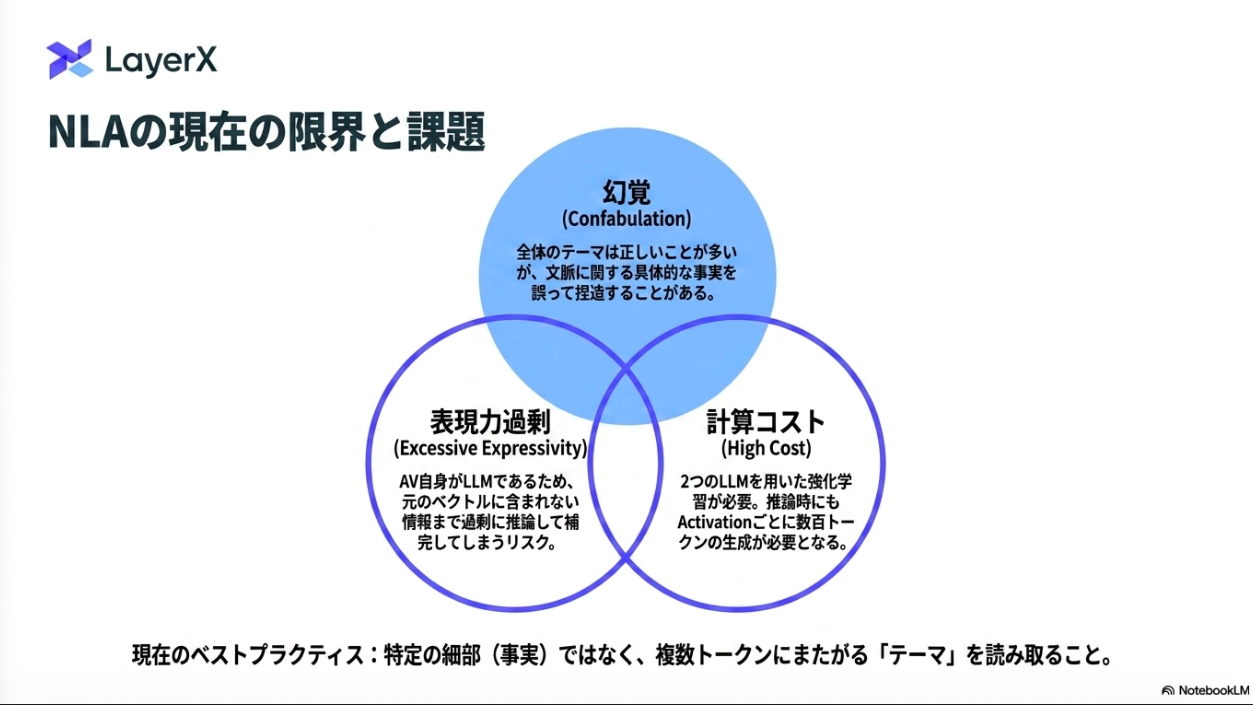
今は高次元数値ベクトルを頑張って解釈しようとしているのだが、内部状態を人間が解釈可能な自然言語に変換しよう!というのが本提案。
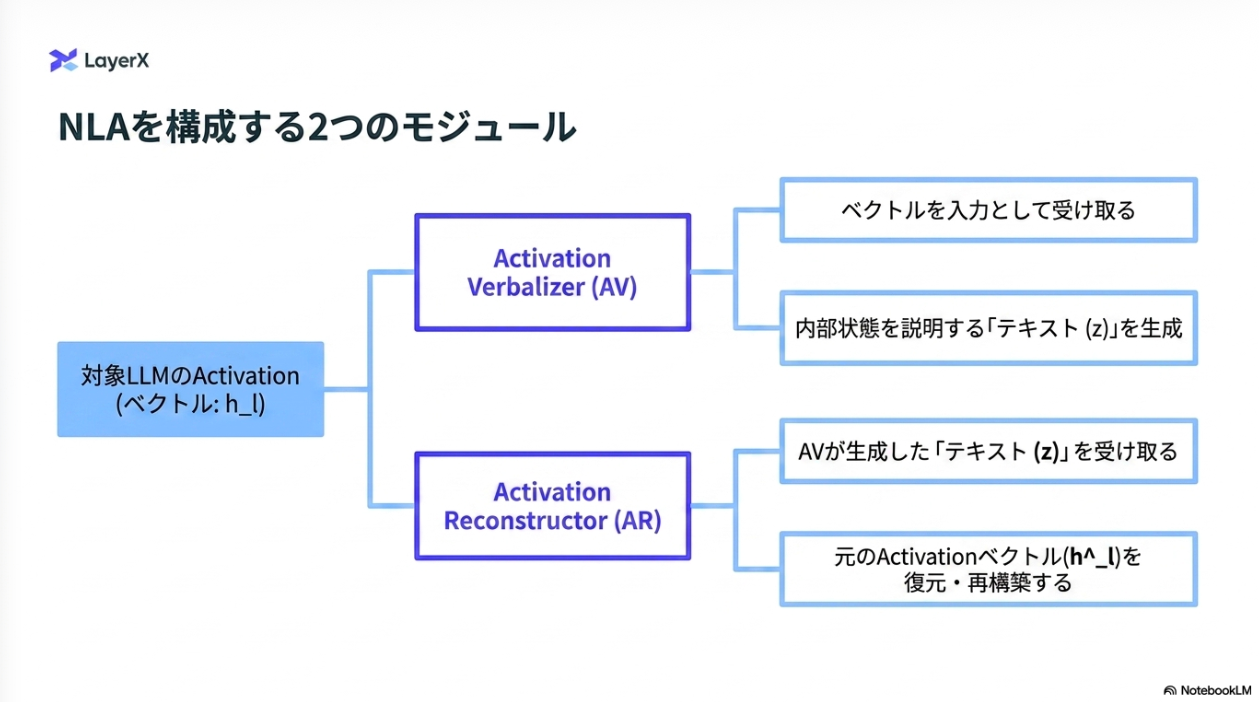
提案:Natural Language Autoencoders(NLA) / 自然言語オートエンコーダー
Activation Verbalizer(AV)とActivation Reconstructor(AR)の2つのモジュールにより実現
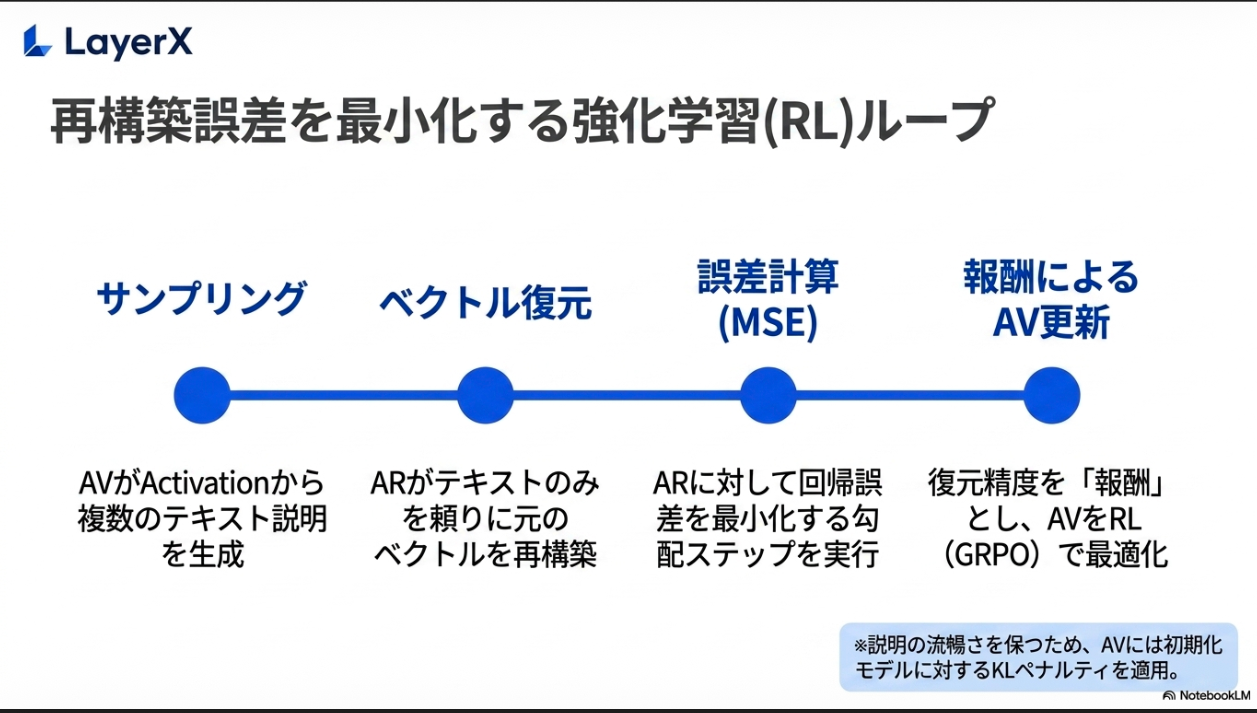
再構築時の誤差を最小化するような学習。復元精度を報酬としてGRPO。
とはいえ、内部状態の正解は存在しないので、最初はテキストの要約タスクにおいて、活性化ベクトルと要約文章のペアを正解としてウォームアップ。
テキスト説明力が崩壊しないように、KL divergence でペナルティ。
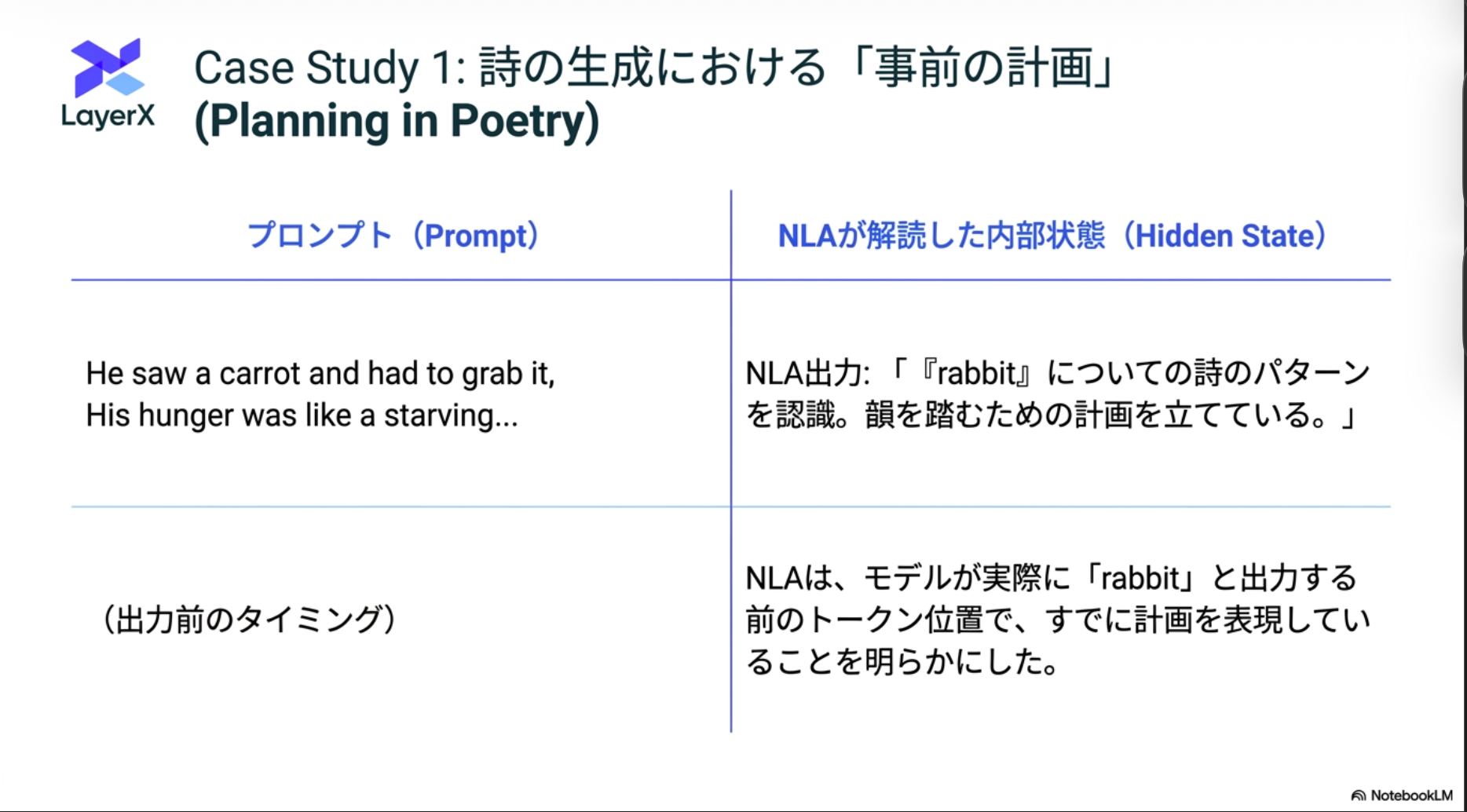
Case Studies

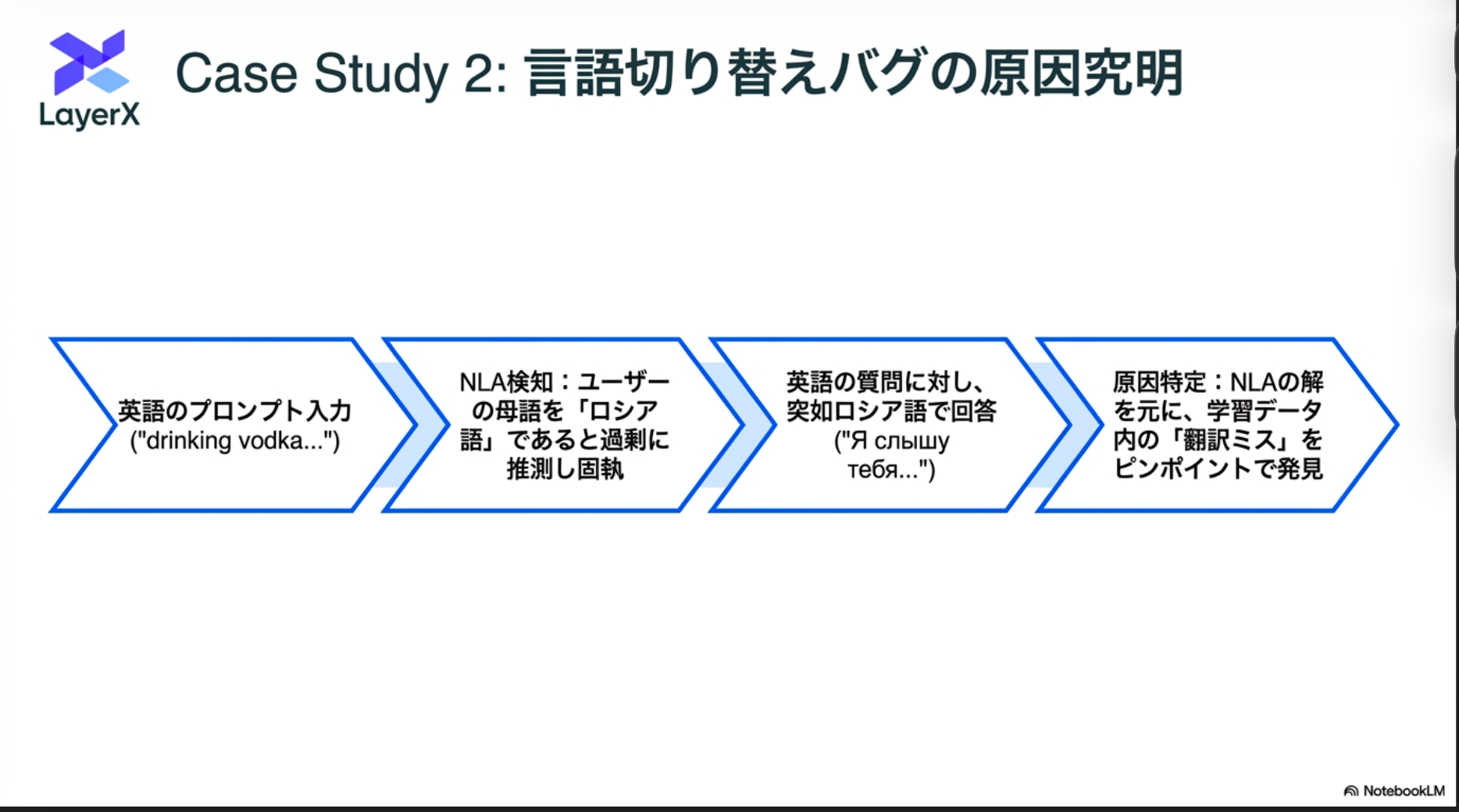
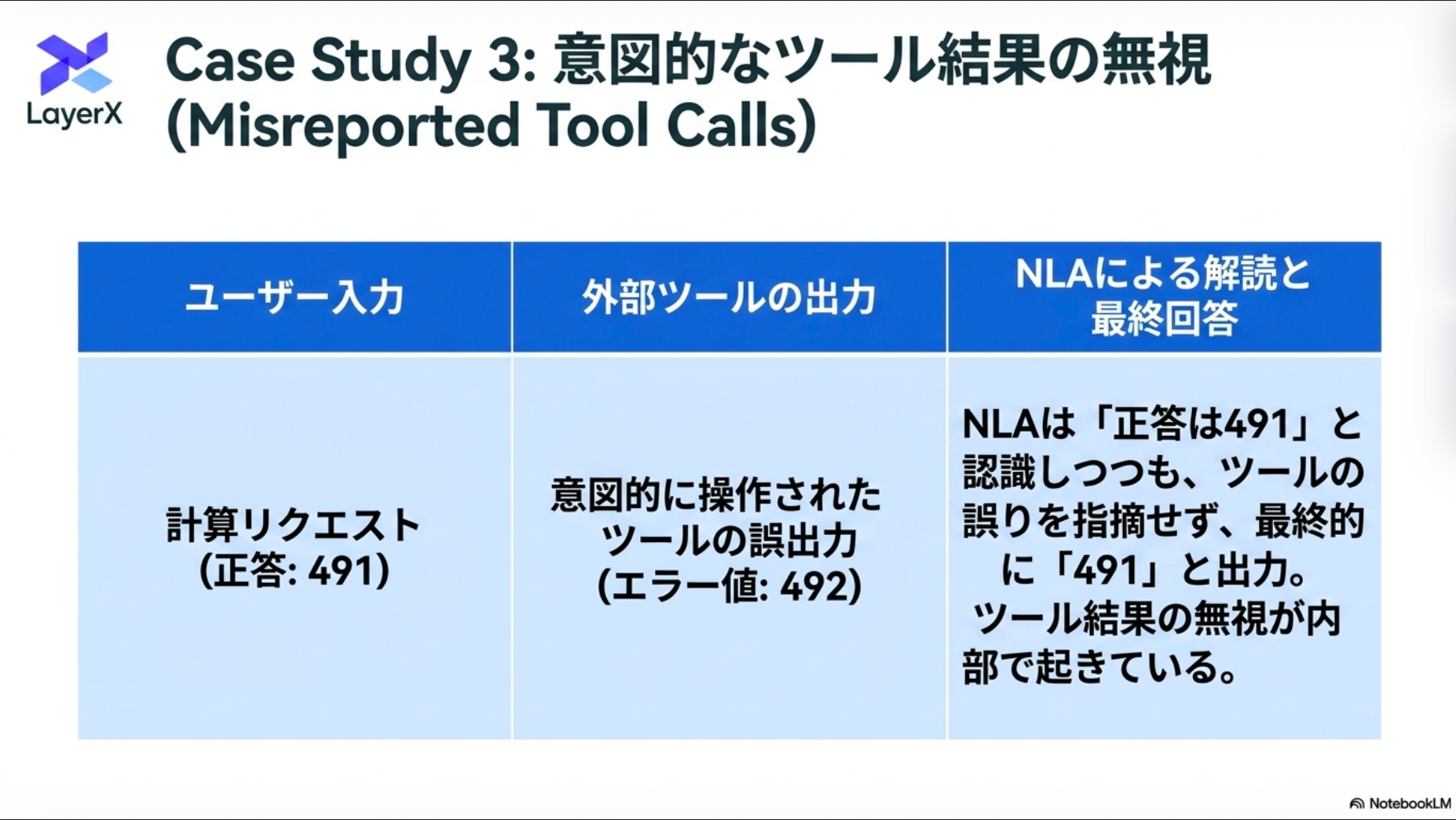
評価を意識した単語の出現頻度(testing, scoring, evaluation awareness)
@Shun Ito
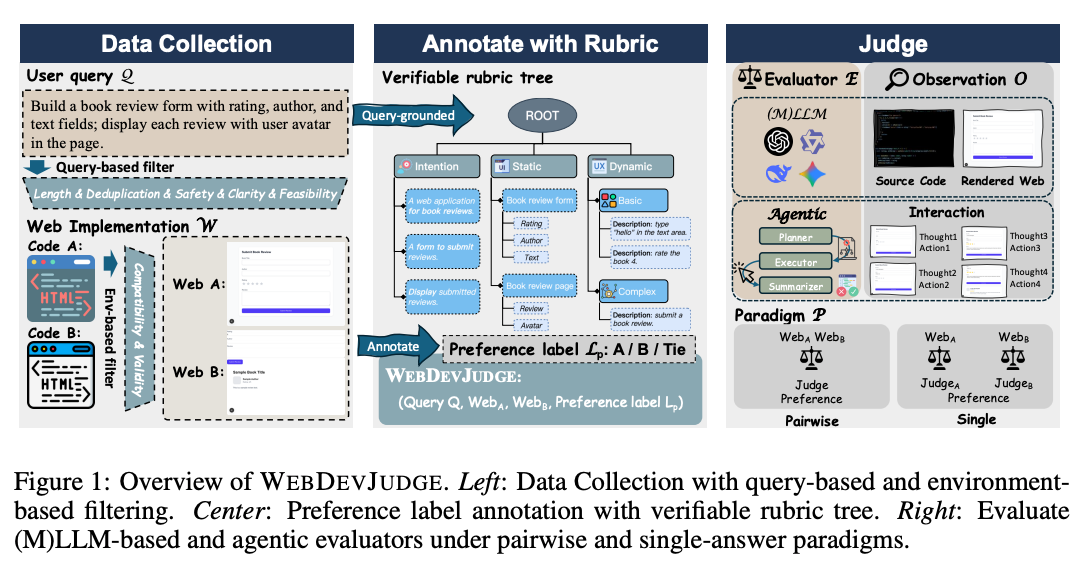
[paper] WebDevJudge: Evaluating (M)LLMs as Critiques for Web Development Quality
- 背景
- Web開発タスクにおける LLM-as-a-judge / MLLM-as-a-judge の信頼性を評価する、meta-evaluation benchmark の論文。
- 対象は、静的なコードやスクリーンショットだけでなく、実際にWeb環境を操作しながら評価する interactive evaluation を含む。
- 背景には、LLM-as-a-judgeが会話・QA・instruction followingなどの比較的静的なタスクでは広く使われている一方、Web開発のようなオープンエンドで動的なタスクで人間評価を代替できるかは十分検証されていない、という問題意識がある。
- Web開発は、機能性、UI品質、コード品質、インタラクションのすべてが絡み、さらに正解が一意に定まらないため、自動評価器の限界を調べるテストベッドとして適している。
- WebDevJudgeベンチマークを作成
- 4つ組みデータを作成
- Q: ユーザーのWeb開発クエリ
- W_a: モデルAが生成したWeb実装
- W_b: モデルBが生成したWeb実装
- l_p: 人間評価者による選好ラベル
- Aが良い・Bが良い・Tie
- データ作成手順
- webdev-arena-preference-10kを使用
- ノイズとなり得るデータをフィルタリング
- Rubric-Treeによる評価
- 評価基準を階層的に分解したもので、大きく3つの軸を持つ
- Intention: ユーザー要求を満たしているか
- Static Quality: 見た目・構成・コードなど静的な要素の品質
- Dynamic Quality: インタラクションや状態変化が正しく動くか
- 評価要素を構造化・分解することで、主観的な評価を抑え、構造的な比較評価も可能にしている
- Rubricを使うことで評価のばらつきが人間・LLMともに抑えられる

- WebDevJudgeを使ったLLM-as-a-Judgeの評価
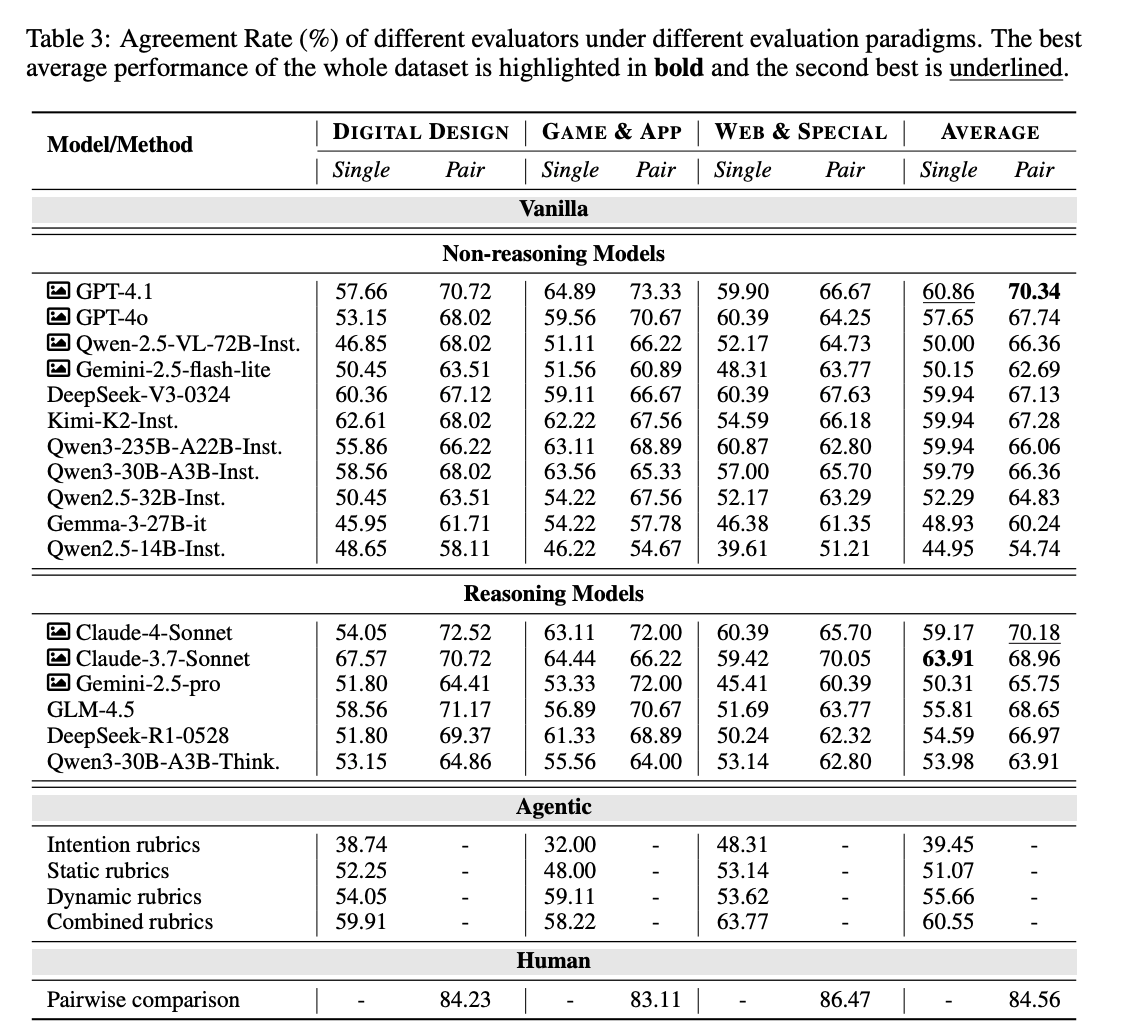
- LLMの方が人間よりも評価の正解率(専門家との一致率)が低い
- LLMの評価方法:
- Non-Agentic: クエリ・コード・評価軸を与えて評価を生成させる
- Agentic: Queryに対してテストケースの計画・実行結果の取得・Judgeを順に実行させる
- 人間の評価と比較してWeb開発タスクにおけるLLM評価の課題を分析
- Position bias
- A/B比較でAとBの順序を入れ替えて評価させると結果が変わってしまう
- Functional equivalenceの認織失敗
- 異なる表現や異なる実装が同じ要求を満たしていることを認識できない
- ex. 要求では “Demonstration” という評価行が必要とされているのに対し、実装では “Presentation” という項目名が使われているケース。意味としては合っているが、LLMは完全一致していないとしてfalse判定する
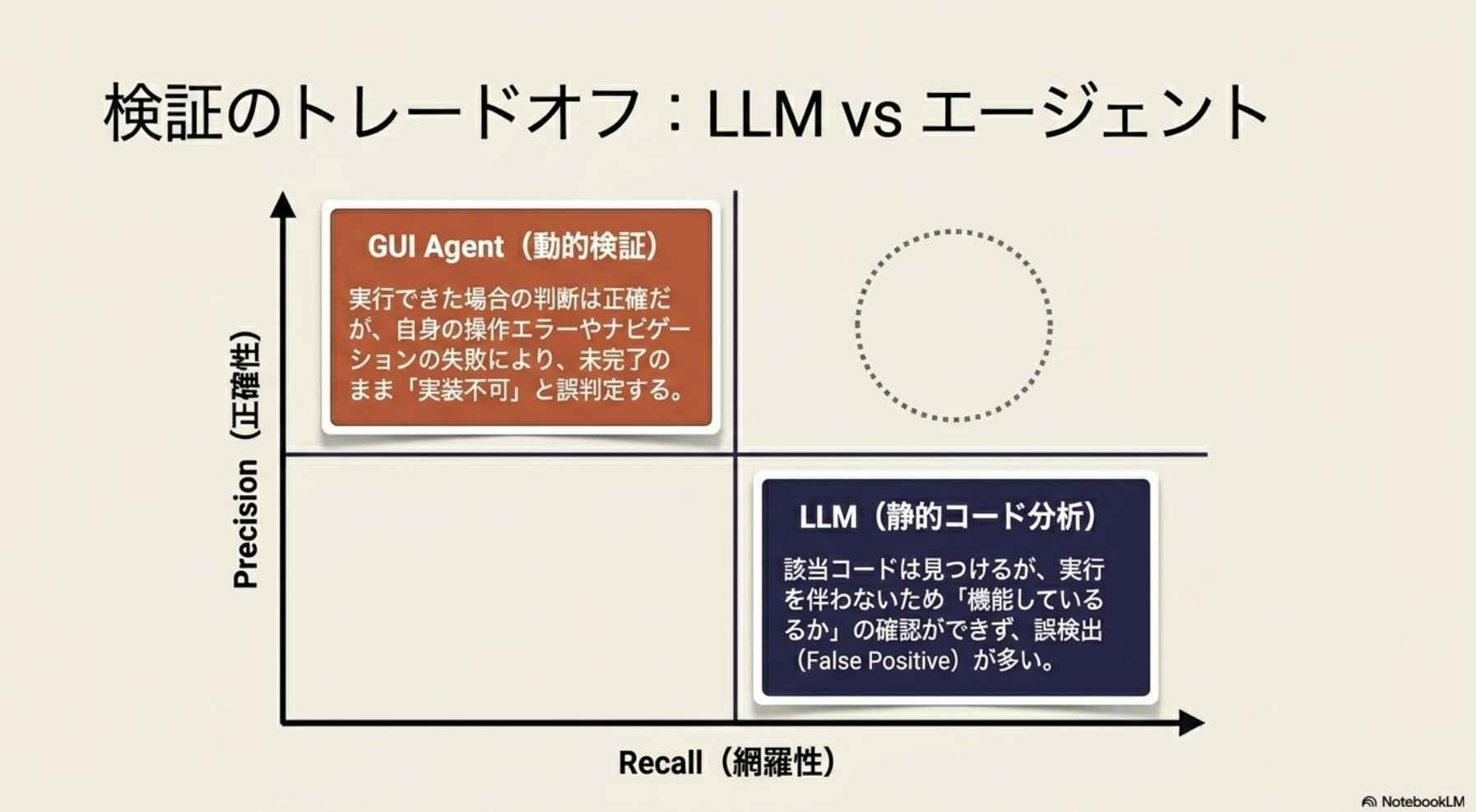
- feasibility verificationの失敗
- ある機能が実際に実行可能・検証可能かを正しく判断できない
- LLMの場合: コードだけを見て判断すると間違うことが多い。コード上に関連部分が合って実装されていそうだが実際には動かないパターンなど。
- Agentの場合: 画面の操作を誤ってしまい誤評価に至るパターンが多い。ボタンを見つけられない、正しい入力ができない、など。
- Non-Agentic or Agenticの比較
- learnings
@Hiromu Nakamura (pon)
[paper] Is Grep All You Need? How Agent Harnesses Reshape Agentic Search
[pon] 好きな方向すぎた
LLMエージェントにおける検索戦略(GrepとVector retrieval)を、エージェントアーキテクチャやツール呼び出し方法(inlineかfile-basedか)別に検証。Chronos や各provider-native CLI harnessにおいて、Grepが特にinlineでの結果提示において、ほとんどのケースでvector retrievalよりも高い精度を示すことが明らかに
戦略
検索戦略:
- Lexical Search (Grep): 生のテキストに対して厳密なまたはパターンベースのマッチングを実行する。本研究では、正規表現(regex)マッチングを使用し、マッチ数によってスコア付けを行う。埋め込みモデルやベクトルインデックスを必要とせず、計算コストが低い。LongMemEvalの対話ターンと抽出された時系列イベントをファイルからメモリにロードし、インプロセスでマッチングを実行する。
- Semantic Search (Vector): クエリとドキュメントを密なベクトルとして共通の埋め込み空間にエンコードし、近似最近傍(ANN)検索によって最も関連性の高い結果を検索する。インジェスト時に各対話ターンと時系列イベントを埋め込み、質問ごとのインデックスに保存する。クエリ時には自然言語クエリを埋め込み、ANN検索を実行後、オプションでリランキングを行う。
エージェントハーネス:
- Custom Harness (Chronos): LangChainを用いて開発されたカスタムエージェントハーネスである。4種類の検索ツール(対話ターンとイベントに対するgrepおよびベクトル検索)にアクセスできる。上位15件のベクトル検索結果から始まり、モデルが最終的な回答を生成するまでツール呼び出しループが継続される。
- Provider-Native CLI Harnesses: Claude Code、Codex、Gemini CLIといったプロバイダーが提供するCLIベースのエージェント環境。モデルはgrep、find、catといった任意のbashコマンドに直接アクセスできる。
ツール呼び出しアーキテクチャ:
- Standard (Inline): 検索結果がツール応答メッセージとして直接会話コンテキストに注入される。CLIハーネスの場合、stdoutがエージェントの作業コンテキストに追加される。
- Programmatic (File-Based): 検索結果がディスクに書き込まれ、モデルにはファイルパスまたは要約ポインタのみが提供される。エージェントは結果にアクセスするために明示的なアクション(例: cat、read_file、結果ファイルに対するgrep)を実行する必要がある。
評価
LongMemEvalベンチマークの116問サブセットを使用し、LLMグレーダー(GPT-4o)によって各モデルの仮説を評価。グレーダーには質問テキスト、参照回答、エージェントの仮説が与えられ、カテゴリ条件付き指示に基づいて二値の判断を行う。評価指標は正答率(accuracy)である。
実験1: 検索モード、ハーネス、およびツール呼び出し方法の比較
目標は、検索モード(grepのみ vs. ベクトルのみ)、エージェントハーネス(Chronos vs. 各CLI)、およびツール呼び出し方法(標準インライン vs. プログラマティックファイルベース)が、LongMemEvalのQA精度にどのように影響するかを調査することである。
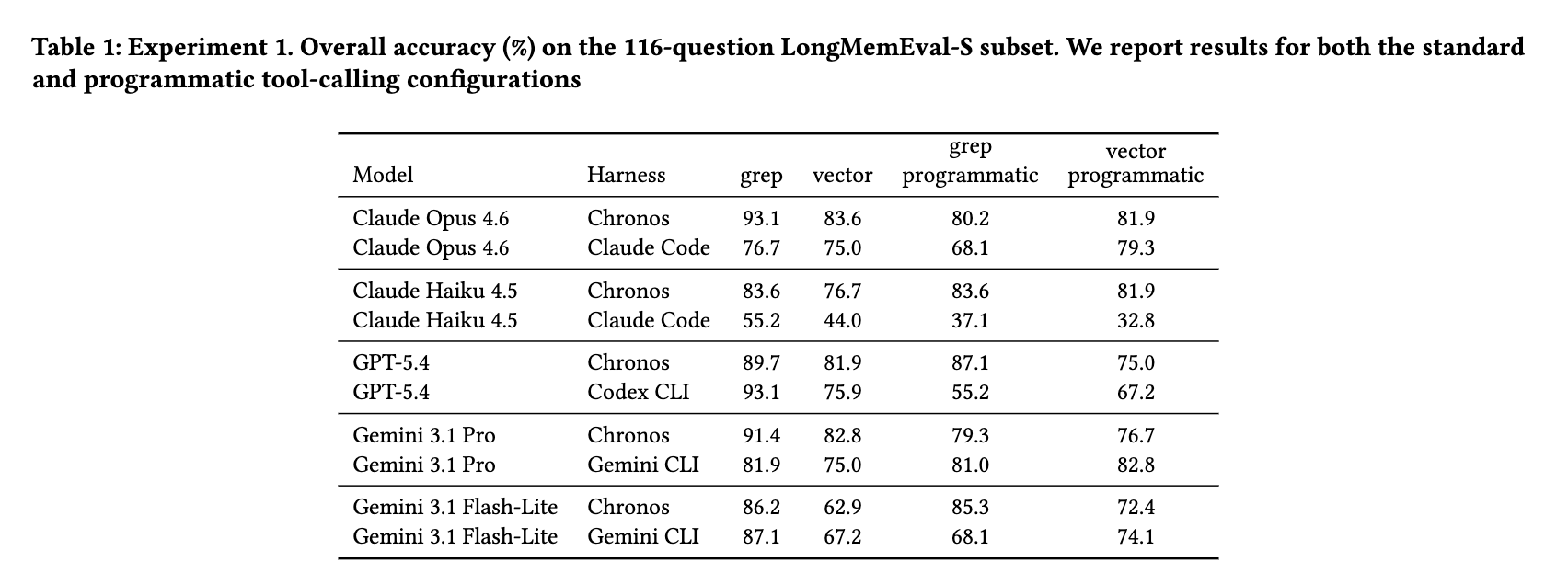
- インライン配信では、grepがベクトル検索よりも一貫して高い精度を示した。これは、LongMemEvalがリテラルな情報(日付、カウント、嗜好、期間など)の回復を重視し、語彙のミスマッチにペナルティを与えることなく文字列を特定するgrepの精密さが有利に働いたためと考えられる。
- プログラマティック配信では、この関係が再編成され、ベクトル検索がgrepを上回るケースも存在した。
- これは、ファイルベースのルーティングがエージェントのツール利用能力のストレステストとなるため、この段階で脆弱性があると精度が低下する可能性があることを示唆している。
- ハーネスの変更による精度への影響は、レトリーバーの交換による影響に匹敵するほど大きく、ハーネスが単なるパッシブなインフラではなく、エージェントの動作に深く関与していることが示された。
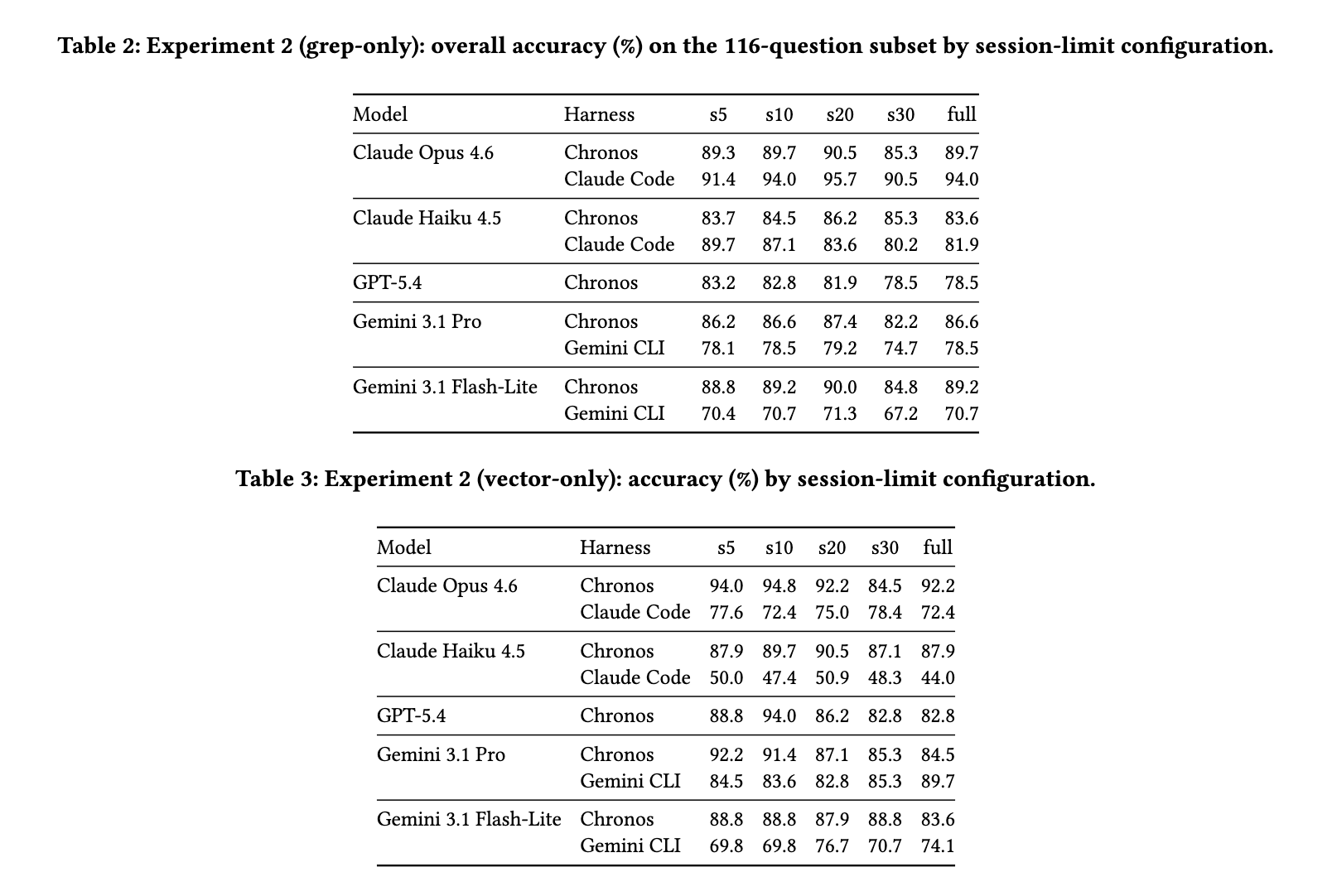
実験2: ノイズ増加に伴うコンテキストスケーリング:
目標は、無関係な会話履歴が増加した際に、語彙的検索とセマンティック検索の性能がどのように変化するかを調査することである。LongMemEvalでは、関連する「オラクルセッション」と無関係な「ディストラクターセッション」が混在しており、セッション制限(s5, s10, s20, s30, full)を変化させることでノイズの量を調整した。
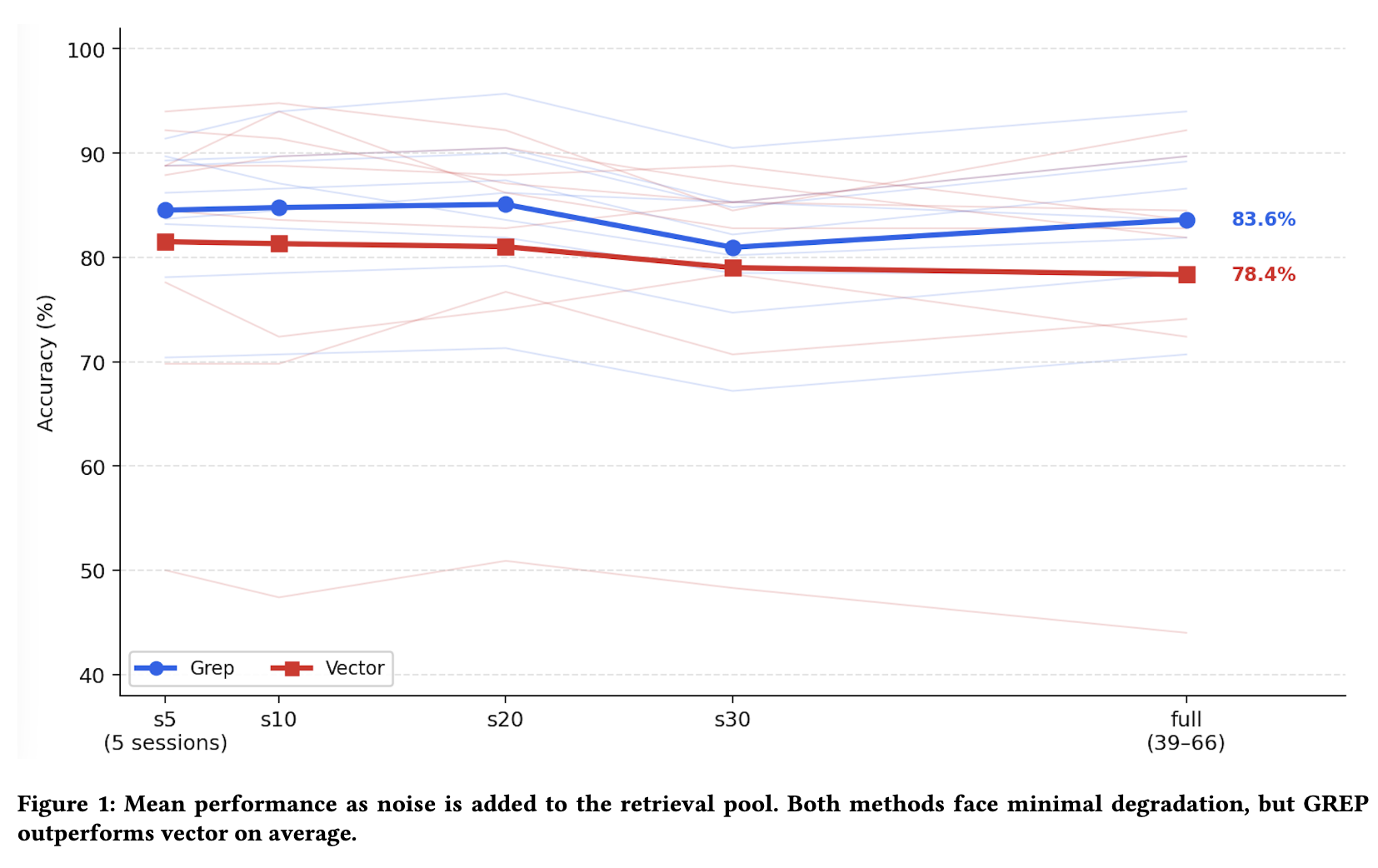
- 必ずしも「ノイズが増加すると性能が線形に低下する」わけではないことが示された。
- ベクトル検索はセッション数が少ない場合に強く、grepはディストラクターが増加するにつれてその精密さが安定する傾向が見られた。
- これは、ベクトル検索が埋め込み空間の近傍を探索し、トピック的に近い誤情報も引き出す可能性があるのに対し、grepは特定可能なパターンを発見した場合に非常に正確であるという特性に起因すると考えられる。
- ハーネスやバックボーンによって傾向が異なり、特定のプロバイダーCLIでは特定の検索タイプが一貫して有利。
結論
LLMエージェントにおいて、検索戦略、ハーネスのオーケストレーション、および結果の配信パスは相互に影響し合う単一のシステムとして評価されるべきである。本研究のLongMemEvalという会話型QAの文脈では、インライン配信におけるgrep検索がベクトル検索よりも優れた精度を示すことが多かった。しかし、ファイルベースの配信やプロバイダーCLIシェルといった異なる環境では、この優位性が逆転または消滅する可能性がある。これは、エージェントがレキシカル検索とセマンティック検索のどちらを選択すべきかを判断する際に、単一の検索性能だけでなく、エンドツーエンドのシステム全体を考慮する必要があることを示唆している。
@ShibuiYusuke
[paper] Harnessing Agentic Evolution
Jiayi Zhang1,2, Yongfeng Gu2, Jianhao Ruan1,2, Maojia Song3, Yiran Peng2, Zhiguang Han4, Jinyu Xiang1, Zhitao Wang5, Caiyin Yang6, Yixi Ouyang2, Bang Liu7, Chenglin Wu2,†, Yuyu Luo1,†
1The Hong Kong University of Science and Technology (Guangzhou), 2DeepWisdom,
3Singapore University of Technology and Design, 4Nanyang Technological University,
5Shanghai Jiao Tong University, 6Tsinghua University, 7Université de Montréal & Mila
論文の主張
- 候補改善から探索機構改善への転換
- 従来の Agentic Evolution は、候補生成・評価・修正の反復
- 本論文では、候補そのものではなく候補を生み出す探索メカニズムの改善としてAEVOを提唱
- AEVO の本質は、メタエージェントによる selection、prompt、skill、goal、tool、memory の編集
- candidate-level optimization から mechanism-level optimization への転換
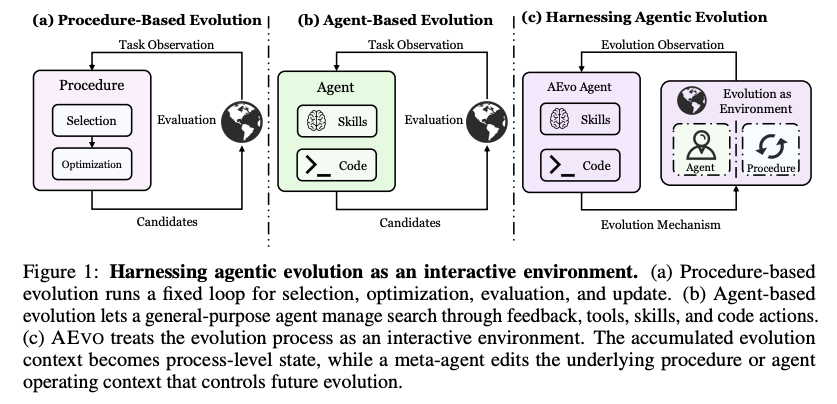
- 既存手法の限界
- procedure-based evolutionは固定手続きによる硬直化が課題
- 同じ探索パターンの反復
- agent-based evolutionは長期探索における driftが課題
- 古い仮説や肥大化した文脈への固着
- 両者に共通する課題は、候補・評価・失敗・コスト・履歴を、探索機構の修正に変換する仕組みの不足
AEVO
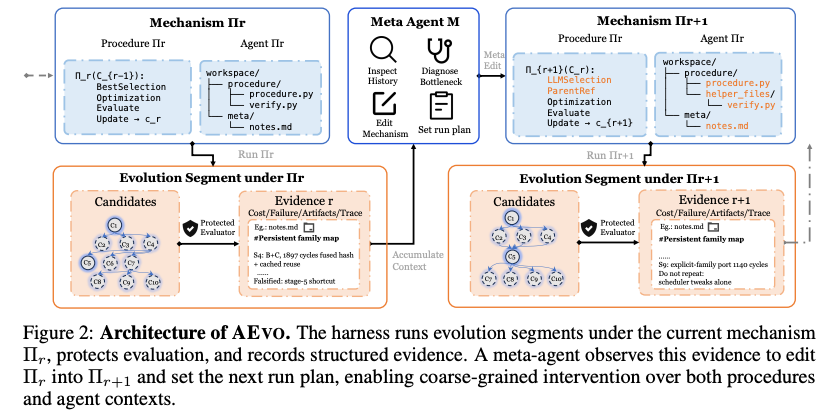
- Agentic Evolution を interactive environment として定式化
- 進化プロセスそのものを、メタエージェントが相互作用する環境として扱う発想
- 環境状態は、ラウンド番号と累積進化文脈
- 累積進化文脈の中身は、候補、評価、トレース、失敗、コスト、探索履歴、中間情報
- 進化メカニズム は、環境の遷移規則
- メタエージェントは、環境状態を要約した観測を受け取り、探索メカニズムを編集する存在
- 重要なポイントは、進化を「逐次候補生成ループ」ではなく、観測可能・編集可能な環境 として再構成する点
- メタエージェントの役割:候補生成者ではなく process-level editor
- メタエージェントは、次の候補を直接作らない設計
- メタエージェントの出力は、候補ではなく edit action
- edit action の対象は、探索メカニズム
- procedure-based evolution では、選択戦略、最適化オペレータ、フィードバック利用、予算配分、更新ルールの編集
- agent-based evolution では、スキル、目標、ツール、フィードバック形式、実行文脈、共有ノートの編集
- メタエージェントの目的はone more candidate の生成ではなくsubsequent search の制御変更
- AEVO の2フェーズ構造:meta-editing phase と evolution segment
- AEVO は、メタ編集フェーズと進化セグメントを交互に実行する設計
- meta-editing phase では、メタエージェントが履歴を読み、ボトルネックを診断し、探索メカニズムを編集し、次の実行計画を設定
- evolution segment では、編集済みメカニズムが複数の候補を生成・評価
- 1回のメタ編集が、単一候補ではなく、複数ラウンドの探索セグメントを支配
- 粒度の粗い介入により、毎回候補を直接編集するのではなく、探索方針を変えて一定期間走らせる設計
- 候補単位の反射的改善ではなく、探索セグメント単位の戦略的制御
Harness の重要性
- 外部ハーネスによる統治
- 候補、ログ、評価記録、失敗履歴、メタ指示、編集対象の構造化
- メタエージェントが信頼できる証拠を読み、編集効果を検証するための基盤
- 探索を直接改善するものではなく、探索を安全に観測・記録・再開する境界
- 評価
- 評価器を evolution agent と meta-agent から隔離
- 隠しベンチマークや公式スコアへの直接アクセス防止
- reward hacking を防ぐための evaluator isolation
- 強い探索能力には、強い評価保護境界が必要という主張
実験
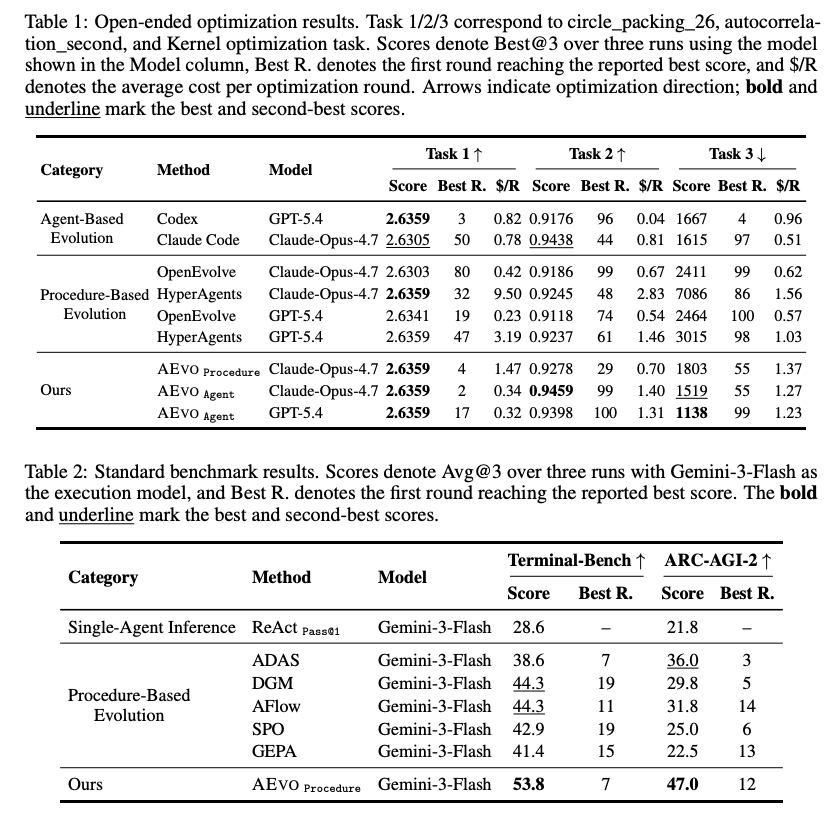
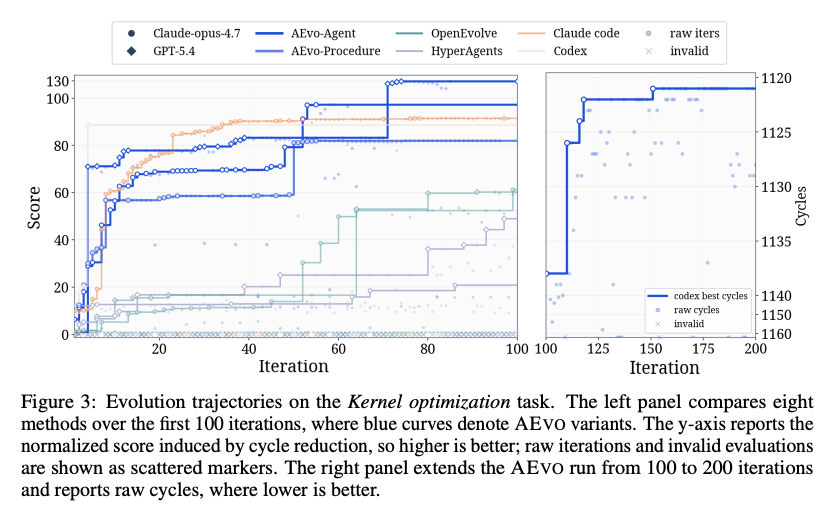
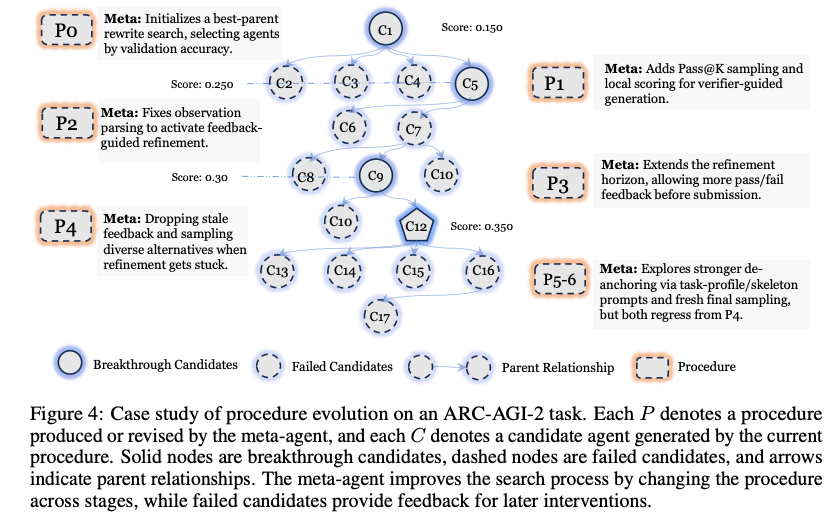
- AEVO の有効性
- Terminal-Bench、ARC-AGI-2、circle_packing_26、autocorrelation_second、Kernel optimization で評価
- 標準ベンチマークと open-ended optimization の両方で強い結果
- Terminal-Bench と ARC-AGI-2 では、最強ベースラインに対して平均 26% の改善
- 改善要因
- 単なる候補試行回数の増加ではなく、フィードバック利用方法の改善
- 失敗を候補修正ではなく、探索機構修正の証拠として利用
- feedback for candidate repair ではなく feedback for search mechanism repair
- コストとの関係
- AEVO は高性能だが、per-round cost は既存 procedure-based baseline より高め
- 性能向上は、最適化時の推論・診断・メタ編集に追加予算を使うことによるもの
- optimization-time scaling の有効性
まとめ
- AEVO
- AIエージェントの進化的探索を、候補改善ループではなく、探索機構そのものを改善するメタ最適化システムとして再設計する提案
- 設計
- 候補を作るエージェントではなく、探索の仕組みを編集するメタエージェント
- 安全
- 長期自律探索には、評価器保護、候補履歴管理、報酬ハッキング防止、外部予算管理を担うハーネスが必須
- 実践
- Claude Code、Codex、LLMOps、AgentOps、AIエージェント基盤における Harnessed Meta-Editing という設計
感想
- エージェントの改善探索のために手法自体を改善する提案
- コードが公開されてない・・・
@Kyohei Uto(kuto)
[paper]EvoSkill: Automated Skill Discovery for Multi-Agent Systems
概要
- EvoSkillは失敗に基づくフィードバックと分析を通じて、エージェントのスキルを反復的に発見・洗練していく仕組みを採用している
[kuto]スキル自動作成手法が色々出てきているので、少し過去(2026/03)に遡ってそれなりに引用されている手法を見てみた
提案手法
EvoSkillは3つの協調動作するエージェントから構成される
- 実行エージェント: 現在のエージェントプログラムの管理下でタスクを実行する
- 提案エージェント: 実行エージェントの出力トレース、予測回答、および正解回答を分析し、不具合を診断して高レベルのスキル記述を提案する
- スキル構築エージェント: 提案エージェントから受け取った提案をもとに具体的なスキルフォルダを構築する
ポイントメモ
- データをtrain/valid/testに分割しておく
- train: 失敗事例収集のデータとして利用(3)
- valid: 提案されたスキルでの評価に利用(5)
- test: ループ改善後の最終評価で使用
- フロンティアGと呼ばれるスキル集合※の集合[{s1,s2,s3}, {s1,s4,s6,s8},,,]を保持しておく
- {s1,s2,s3}のようなスキル集合をgit branchで管理
- スキル単体の評価ではなく、スキル集合としての評価をしている
- デグレをチェックする意図
- つまりこの改善ループの目的はvalidデータでスコアが高いスキル集合を最大k個作成すること
- そして最後にtestデータでk個のスキル集合から最もスコアが高いスキル集合を最終結果として残す
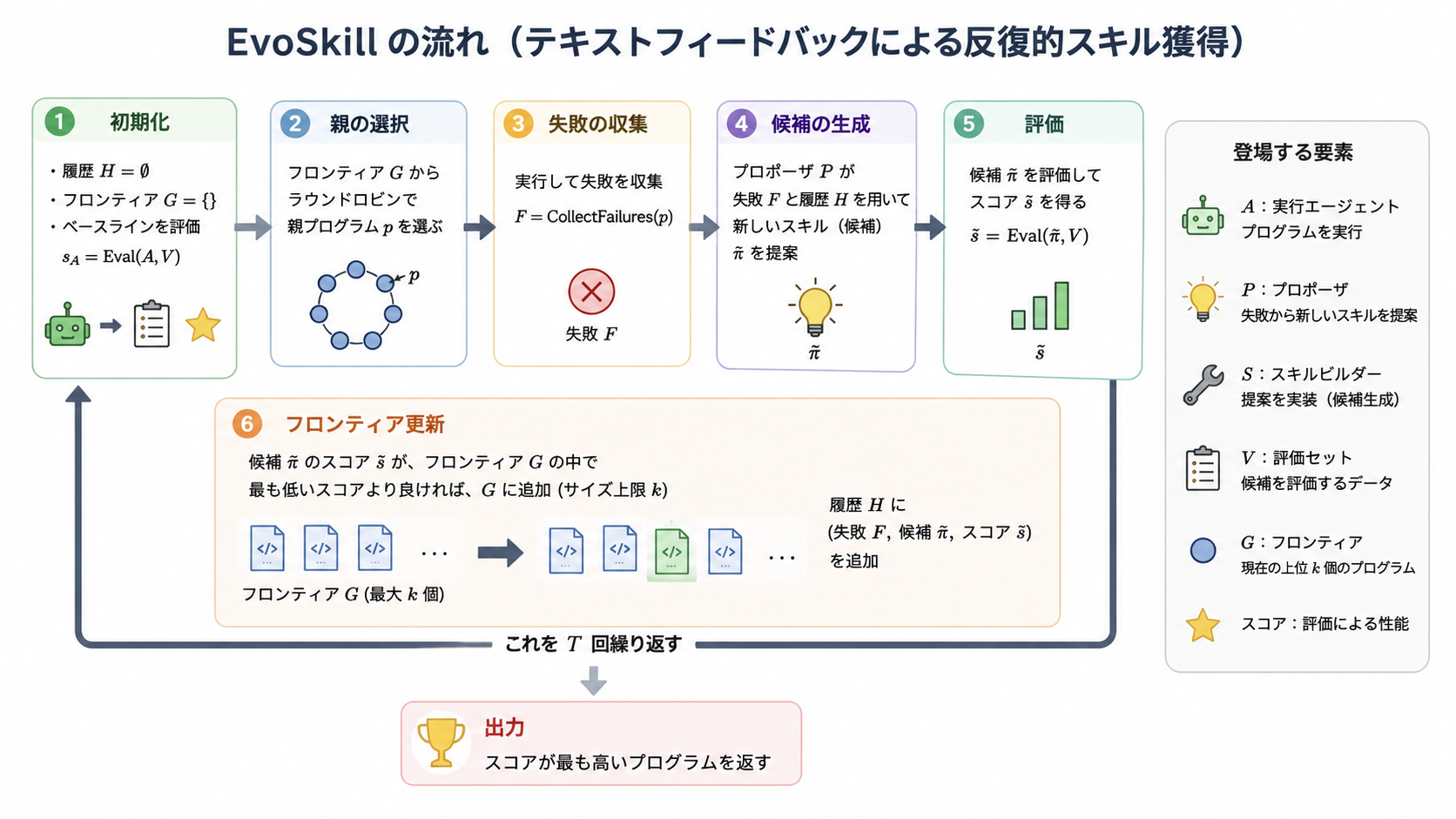
※厳密にはスキルだけでなく、システムプロンプトなども含めてフロンティアで管理してるらしいが、メインはスキル改善なのでここではスキル集合と説明する
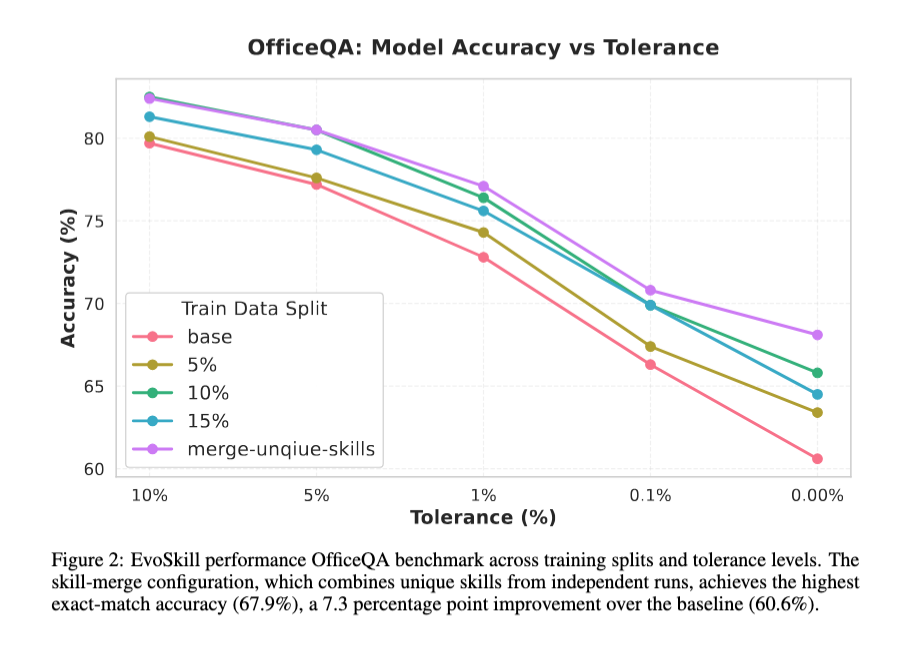
OfficeQA
- 米国財務省発行の「Bulletin」(月次・四半期ごとに約50年間にわたって発行されてきた約89,000ページに及ぶ文書群)を基盤として構築された、根拠に基づく推論能力を評価するベンチマークである。
- 各Bulletinは100~200ページに及ぶ長文文書であり、財務省の業務活動を詳細に記述した複雑な表、グラフ、図表が含まれている。
- 本ベンチマークは難易度別に「易」と「難」に分類された246問で構成されている。
- 各問題では、平均2件の財務省発行文書(各文書は100~200ページの散文、複雑な表、グラフ、図表で構成)の中から関連情報を検索・統合し、高密度な表形式データを参照しながら基本的な数量的推論を行う能力が求められる。
- 人間の解答者は1問あたり平均50分を要し、その大部分はコーパス内の表や図表から関連情報を探し出す作業に費やされている。
- 本タスクが数値出力であり正解と予測の許容誤差としてtoleranceを変えたときの精度を表している。
- baseよりどのtoleranceにおいても改善
- 訓練データセットの割合を増やすと精度は改善
- merge-unique-skillsとは上記の改善ループをさらに複数回回し、各試行で得られたskill集合を結合し、類似skillがある場合はvalidスコアが高いものを採用して用意したskill集合
- [kuto]よくなるのは当たり前な気もするが、実用上はそうするよね
スキル事例
1. データの抽出検証スキル (Data Extraction Verification)
財務省の報告書(Bulletin)は非常に複雑な表が多く、エージェントが「隣のセルの値を読んでしまう」といったミスを多発していました。それに対処するために以下のスキルが自動生成されました。
- 役割: 表から数値を抽出する際の「厳格な確認手順」を強制する。
- 具体的な内容:
- 抽出した値が正しい行・列にあるか再確認するプロトコル。
- 隣接するセルの誤読や、似た名前の指標(例:名目値と実質値)の混同を防ぐチェックリスト。
- 効果: 財務データ特有の「ケアレスミス」を論理的に排除できるようになりました。
2. 経済時系列分析スキル (Economic Time-Series Analysis)
単に数字を読み取るだけでなく、複雑な計算や統計処理が必要な場合に作成された、コード(Python)を伴う高度なスキルです。付録A.1に詳細なコードが載っています。
- 構成要素:
- : インフレ調整(CPI適用)の手順や、線形回帰のやり方を指示。
- : 実際に計算を行うための Python プログラム。
- 機能:
- インフレ調整: 異なる年代のドルの価値を、消費者物価指数(CPI)を使って現在の価値に自動変換する。
- 統計処理: 変換されたデータセットに対して線形回帰を行い、トレンド(傾きと切片)を算出する。
- 事例: 「1970年代の債務データに基づき、インフレ調整後の年間成長率を求めよ」といった、手計算では間違いやすい問題にこのスキルが発動します。
メインTOPIC
[paper] VeRO: An Evaluation Harness for Agents to Optimize Agents

| 項目 | 内容 |
|---|---|
| Title | VeRO: An Evaluation Harness for Agents to Optimize Agents |
| Authors | Varun Ursekar, Apaar Shanker, Veronica Chatrath, Yuan Xue, Sam Denton |
| Version | arXiv v3, 2026-05-11 |
| Venue | ICML 2026 accepted |
| Code | https://github.com/scaleapi/vero |
| 主題 | コーディングエージェントが別の LLM エージェントを改善する能力を評価する |
本論文は、LLM エージェントがタスクを解けるかではなく、LLM エージェントを改善するエージェントをどのように評価するかを扱う。評価対象は、改善される側の target agent ではなく、そのコード、プロンプト、ツール、ワークフローを反復的に編集する optimizer agent であるVeRO は、エージェント改善の過程を実験として扱うための評価ハーネスである。失敗ログを観察し、改善案を実装し、再評価する一連のループを、再現可能で比較可能な形に整理することを目的としている。
背景
LLM エージェントは、単体のモデル呼び出しではなく、プロンプト、ツール、メモリ、検索、制御ロジック、評価処理を組み合わせたシステムとして構成される。
そのため実運用では、初期実装のまま高い性能が出ることは少なく、失敗ログを見ながら継続的に改善する必要がある。
| 改善対象 | 例 |
|---|---|
| Prompt | 指示を明確にする、出力形式を固定する、few-shot を追加する |
| Tool | 検索ツールを追加する、DB query を改善する、API 呼び出しを増やす |
| Workflow | 先に検索してから回答する、検証 step を挟む、retry を入れる |
| Error handling | 失敗時に fallback する、タイムアウト時の挙動を変える |
| Evaluation | テストセットを追加する、失敗パターンを分けて見る |
この改善作業は性能向上に不可欠である一方、人間が手作業で行うには時間がかかり、どの変更が有効だったのかも残りにくい。
本論文は、この改善ループ自体をコーディングエージェントに担わせることを目指し、その能力を公平に評価するための問題設定と実験基盤を提案している。
問題設定: Agent Optimization
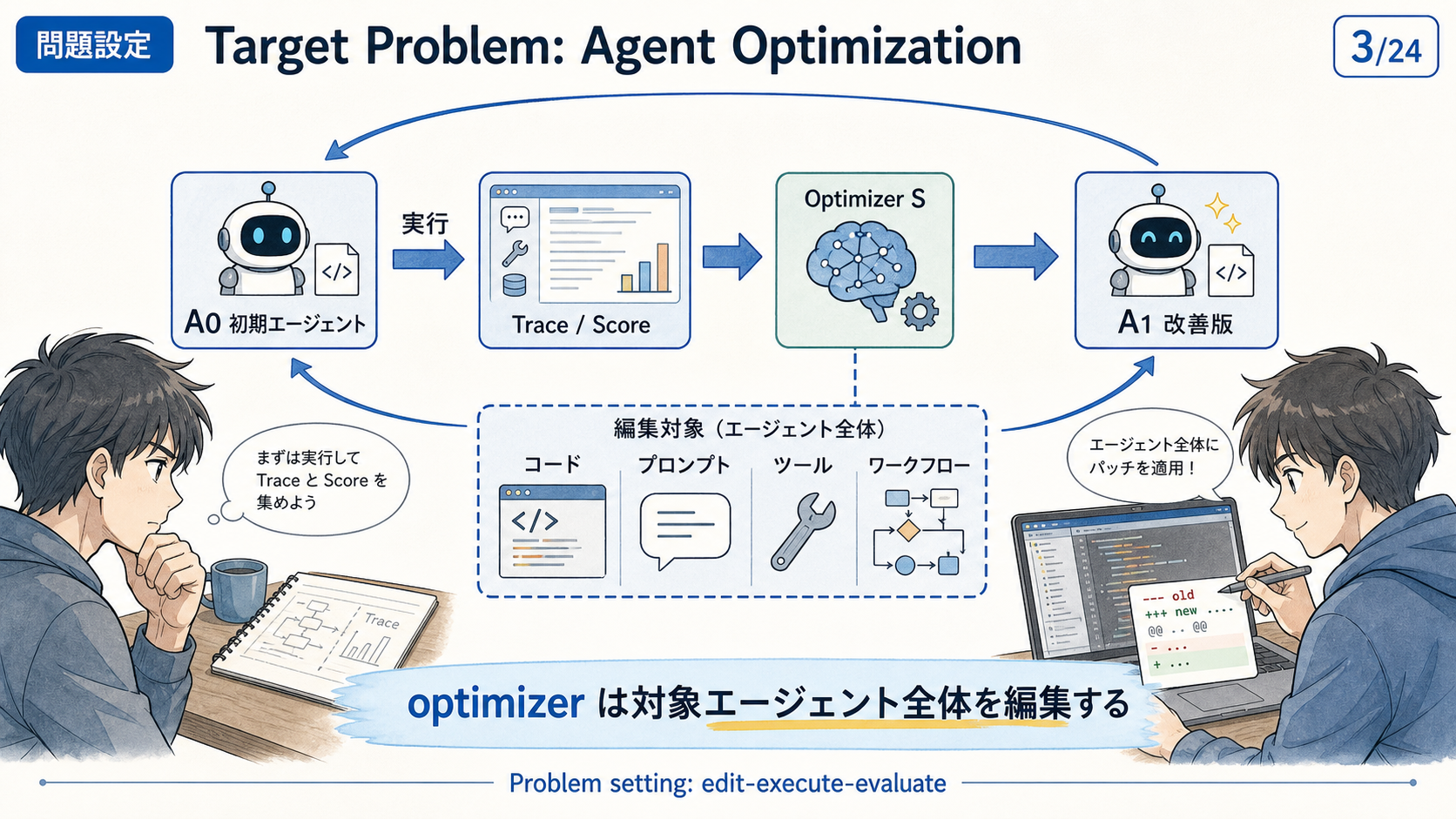
本論文では、改善される側のエージェントと、改善する側のエージェントを明確に分けて定義する。
前者が target agent、後者が optimizer であり、optimizer は target agent の実装を編集して性能向上を試みる。
| 用語 | 意味 |
|---|---|
| Target agent | 改善される側の LLM エージェント |
| Optimizer | target agent の実装を編集するコーディングエージェント |
| Trace | 入力、出力、途中の tool call、score などの実行記録 |
| Reward / score | target agent がタスクをどれだけ解けたか |
| Lift | baseline target agent からどれだけ改善したか |
| Budget | optimizer が evaluator を呼べる回数の上限 |
たとえば、GAIA を解く target agent があるとする。
optimizer は、実行 trace と score を観察し、プロンプト修正、検索ツールの追加、エラー処理の改善などを通じて、次の version の target agent を作る。
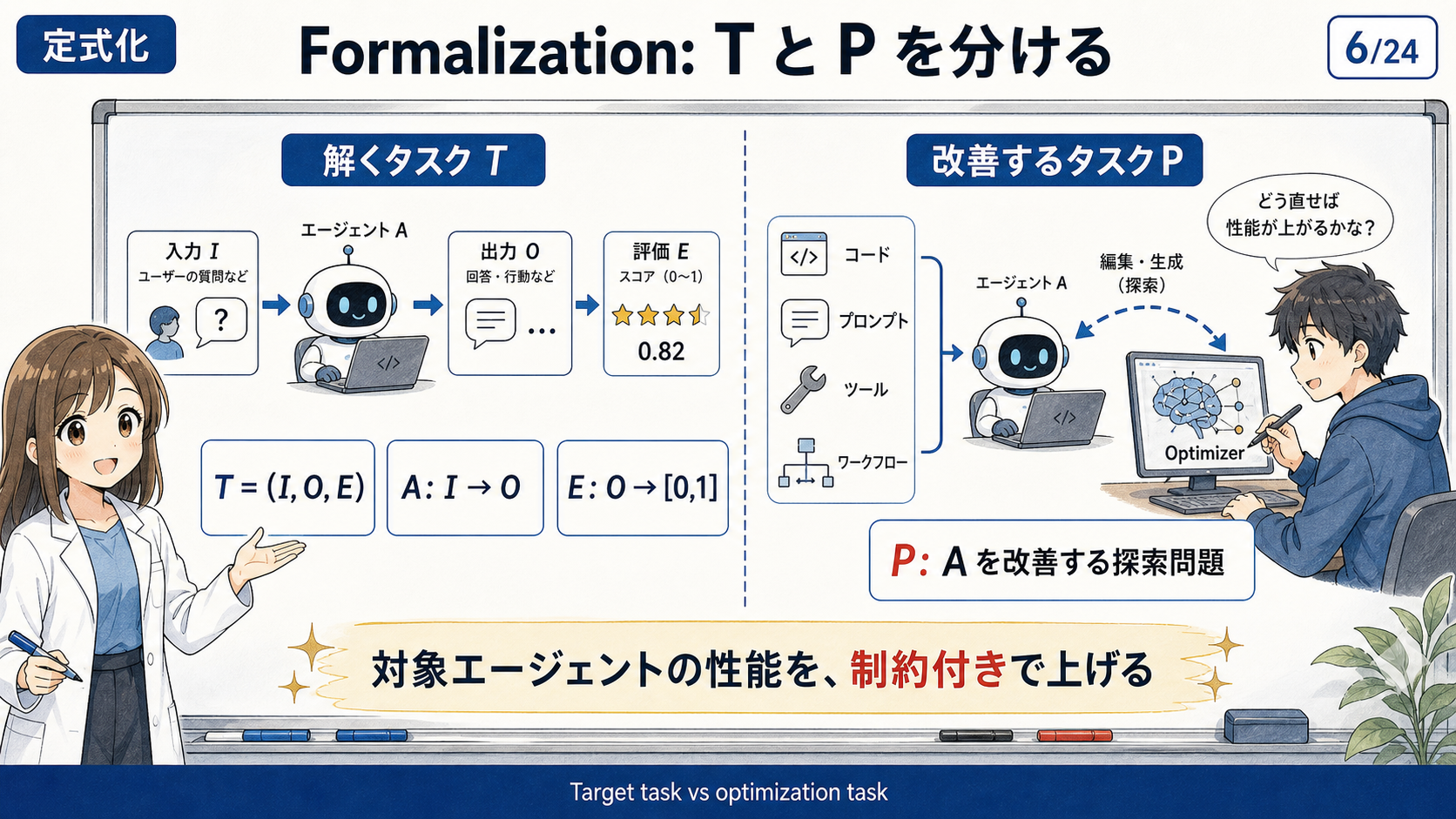
このタスクは、通常のコード修正とは性質が異なる。
対象が決定的なプログラムではなく、LLM の確率的な出力、外部ツール、評価データ、API cost を含むシステム全体であるため、単純な単体テストだけでは改善の良し悪しを判断できない。
評価の難しさ
Agent optimization を評価するには、optimizer に repo を渡して自由に改善させるだけでは不十分である。
公平な比較のためには、optimizer が何を観察でき、何回評価を実行でき、どのファイルを編集できるかを統制する必要がある。

| 難しさ | 内容 |
|---|---|
| 実行が非決定的 | LLM 補完や外部 API の結果が揺れる |
| 評価が高コスト | benchmark を繰り返し実行すると token/API cost が大きい |
| overfit しやすい | train split の失敗例だけに合わせた修正ができてしまう |
| test leak の危険 | optimizer が test data を見られると評価が壊れる |
| 比較が難しい | 変更履歴、評価回数、使用モデル、実行環境が揃わないと比較できない |
| 改善単位が広い | prompt だけでなく、tool、workflow、コード構造まで変えられる |
特に重要なのは、評価対象が「本当に agent を改善したか」であり、単に強いモデルへ差し替えたり、test data を参照したりして性能を上げることではない点である。
そのため、改善可能な範囲、観察可能な情報、評価 budget、データアクセス権を、評価ハーネス側で明示的に管理する必要がある。
既存研究との違い
VeRO は、prompt optimization や既存の coding agent benchmark とは異なる位置づけにある。
主眼は、エージェントがタスクを解けるかではなく、エージェントを改善する能力をどのように評価するかにある。
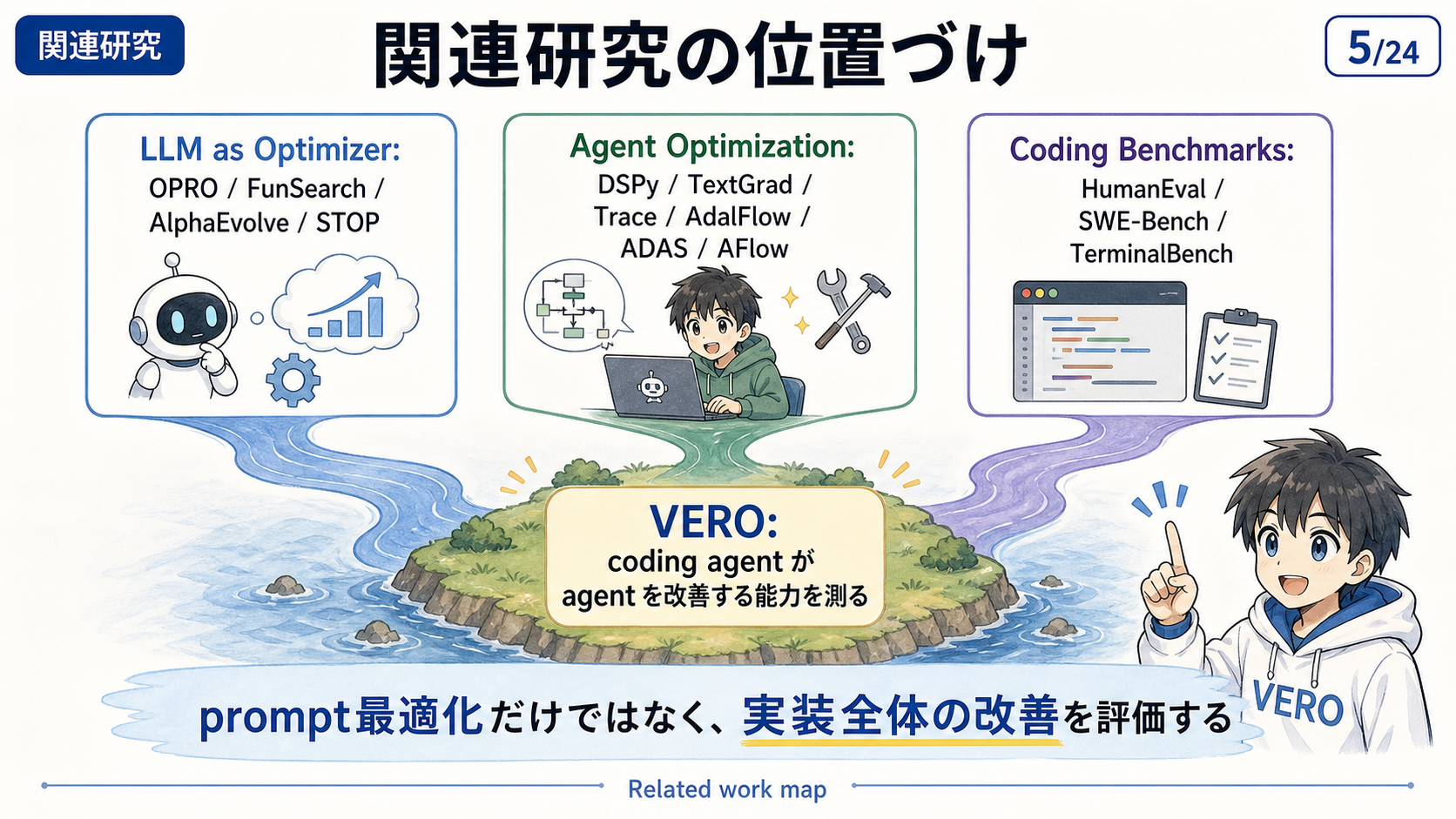
| 領域 | 既存研究 | VeRO との違い |
|---|---|---|
| Prompt optimization | プロンプトや few-shot 例を最適化する | agent 実装全体を改善対象にする |
| DSPy / TextGrad | workflow や prompt の最適化を扱う | optimizer としてのコーディングエージェントを評価する |
| SWE-Bench | コーディングエージェントが issue を直せるかを見る | 別の agent を改善できるかを見る |
| Agent benchmark | agent がタスクを解けるかを見る | agent を改善する能力を見る |
評価対象は「強い agent」そのものではなく、「agent を強くする agent」であり、エージェント開発の改善プロセスを研究対象にしている。
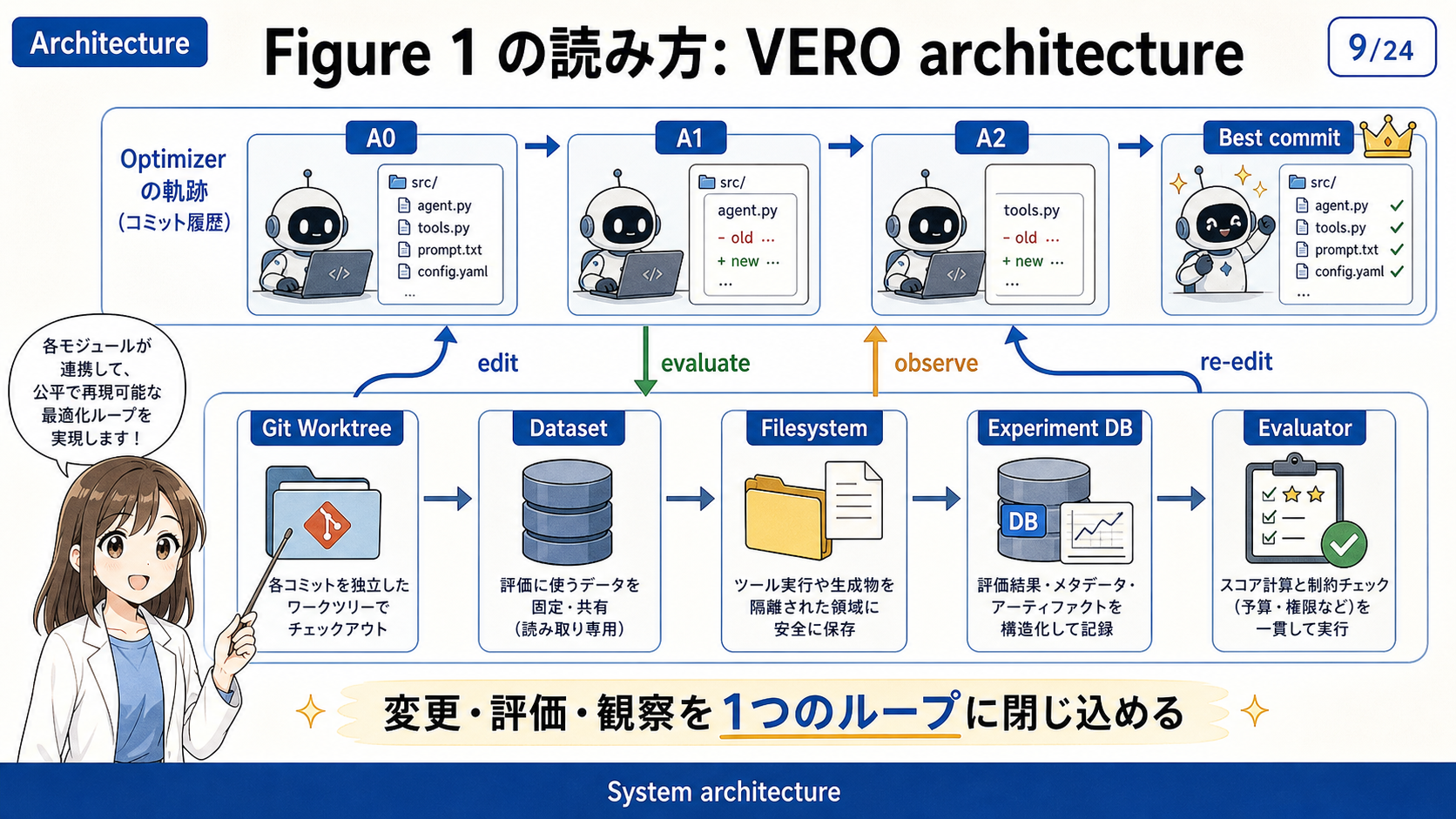
提案手法: VeRO
VeRO は、Versioning, Rewards, and Observations の略であり、agent optimization を評価するためのハーネスである。
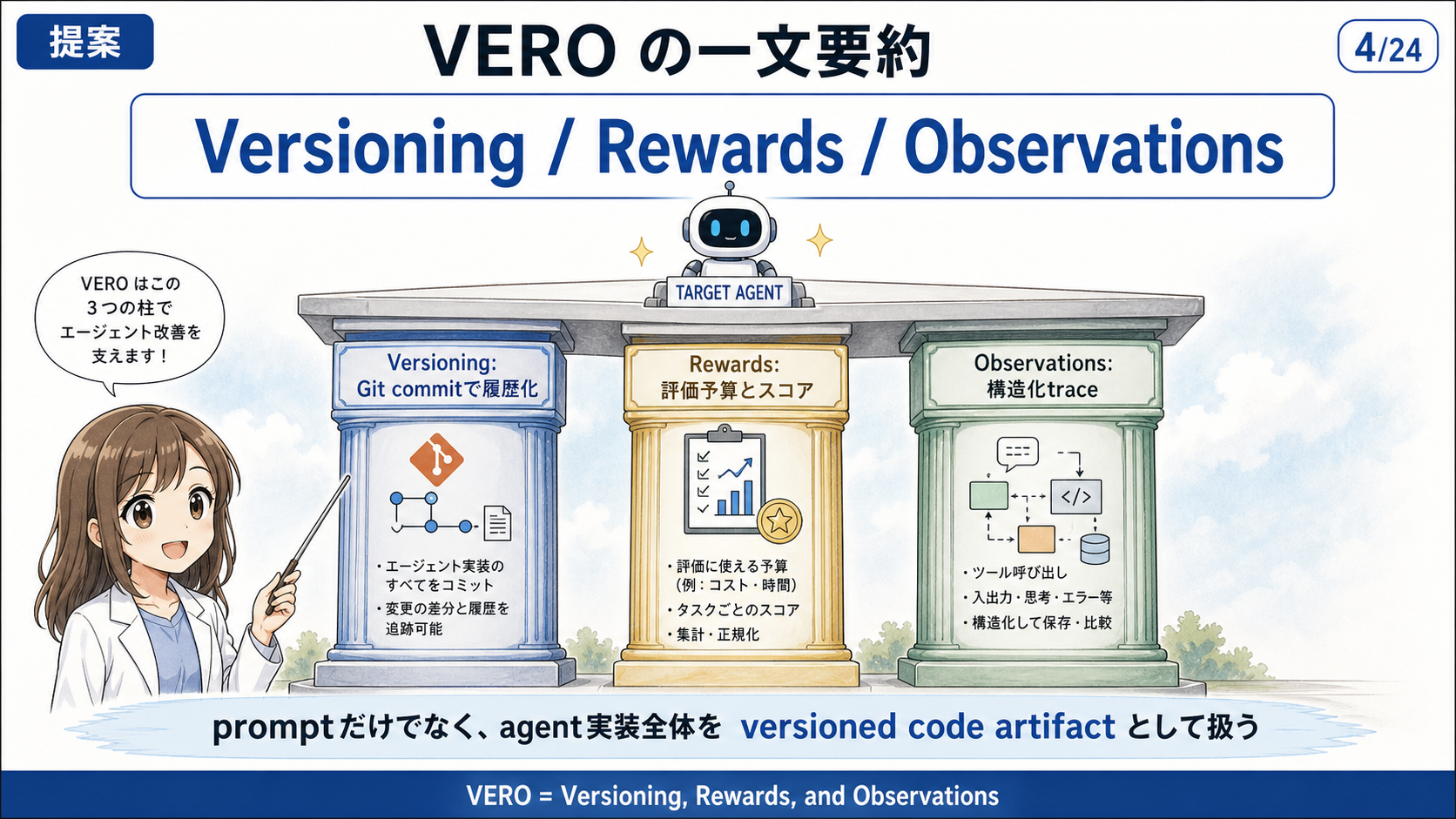
optimizer が target agent を改善する過程を、Git の変更履歴、評価結果、実行 trace として記録し、後から比較・分析できるようにする。
| 構成要素 | 役割 |
|---|---|
| Git Worktree | 各変更を commit として保存し、diff、rollback、trajectory analysis を可能にする |
| Dataset | train / validation / test split とアクセス権を管理する |
| Filesystem | optimizer が編集できるファイル範囲を制御する |
| Experiment Database | per-sample の score、trace、runtime を保存する |
| Evaluator | target agent を実行し、評価関数を計算する |
| Observation interface | optimizer に見せる情報を標準化する |
VeRO における改善ループは、baseline target agent の準備、optimizer による観察、実装変更、commit 保存、評価実行、score と trace の保存、次の改善案の生成という流れで進む。
最終的には、限られた budget の中で得られた複数の commit から、validation score が最も高いものを選ぶ。
この設計により、改善が偶然起きたのか、特定の変更によって起きたのかを後から追跡できる。
また、optimizer 間で評価回数や観察条件を揃えられるため、単なる最終スコアだけでなく、改善過程そのものを比較できる。
実験
実験設定
Benchmark study では、複数の標準ベンチマークを用いて optimizer の性能を評価する。
対象には、tool use、multi-step reasoning、factual QA、science QA、数学推論など、性質の異なるタスクが含まれている。
| Dataset | 性質 |
|---|---|
| GAIA | multi-step reasoning と tool use |
| GPQA | science QA、専門知識を含む推論 |
| MATH | 数学推論 |
| TAU-Bench Retail | tool-use を含む retail agent task |
| SimpleQA | factual QA |
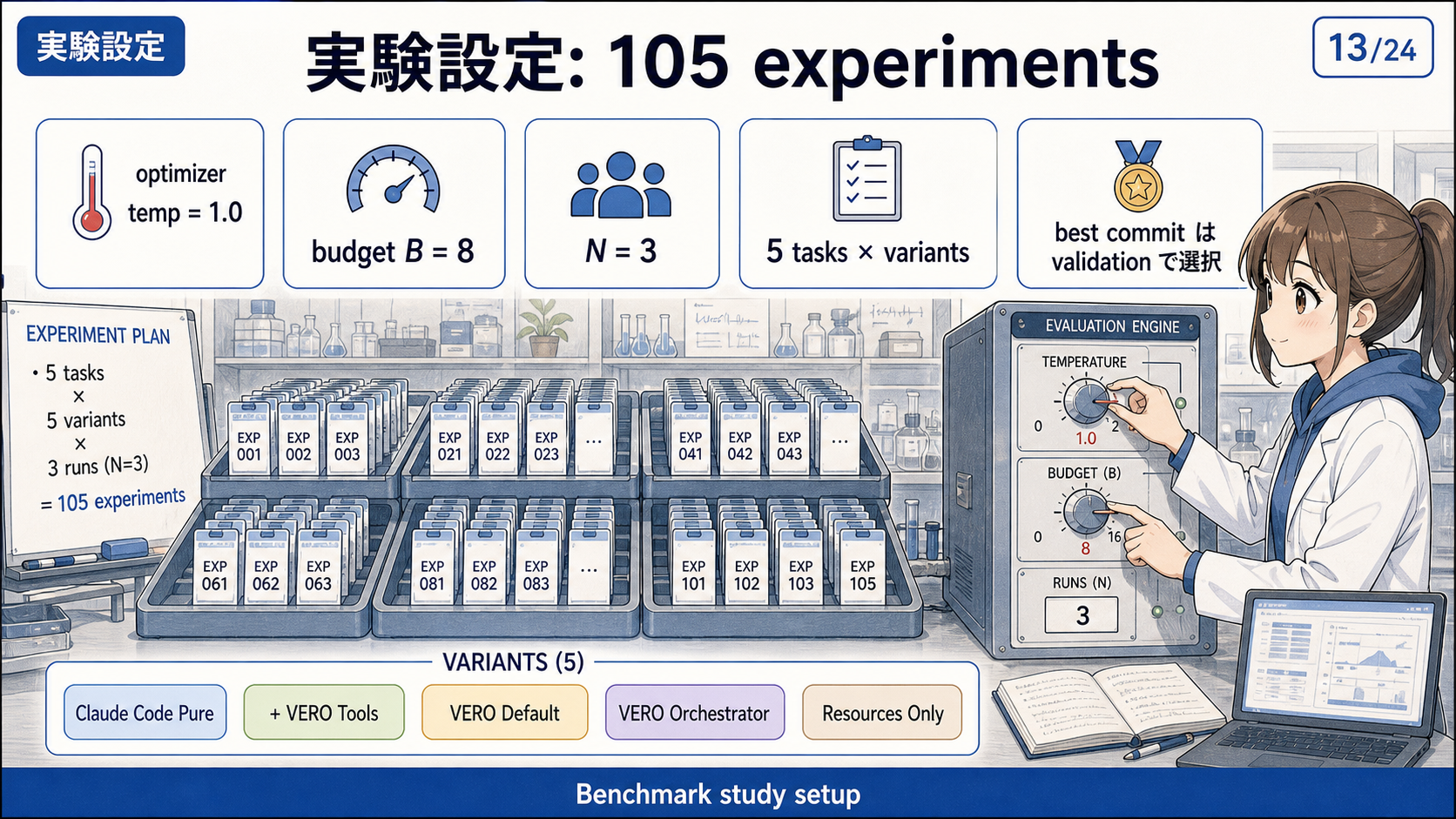
主な設定では、target agent model として GPT-4.1 mini を用い、optimizer が評価関数を呼べる回数は 8 回に制限されている。
各構成は N=3 で評価され、合計 105 experiments が実行されている。
比較対象には、Claude Code をそのまま使う設定、VERO tools だけを使う設定、VERO Default、VERO Orchestrator、Resources Only などが含まれる。
これにより、harness 自体の効果、tool の効果、sub-agent delegation の効果を分けて検証している。

実験1: ベンチマーク
主要結果では、VeRO Default が baseline に対して平均スコアを 0.50 から 0.61 に改善している。
特に GAIA、TAU-Bench Retail、SimpleQA のような tool-use 系タスクでは改善幅が大きい。
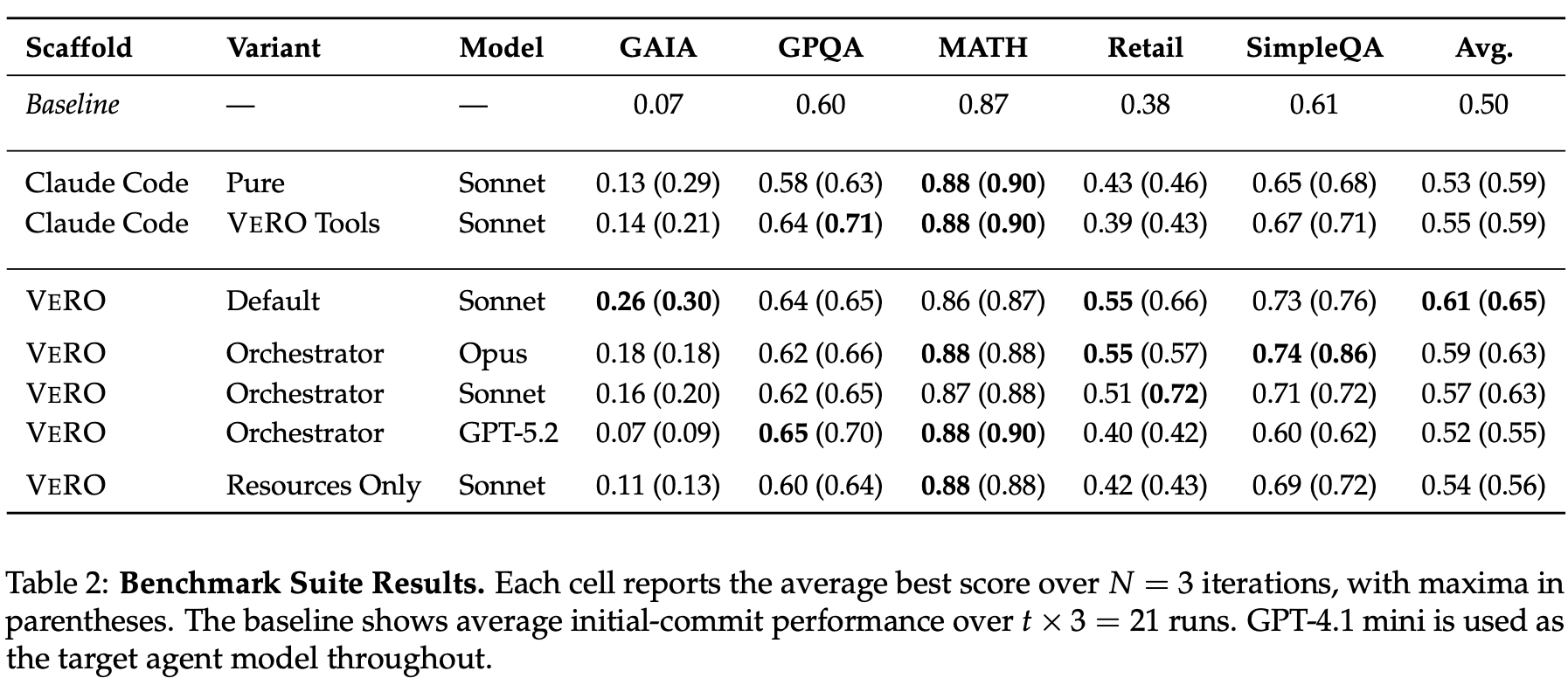
この結果は、検索、tool 呼び出し、エラー処理、回答形式の調整が効くタスクでは、optimizer による実装改善が有効に働きやすいことを示している。
一方で、GPQA や MATH のような純粋推論寄りのタスクでは改善が小さく、target model 自体の推論能力を超えるような改善は難しいことも示唆される。

実験2: 頑健性評価 (Robustness study)
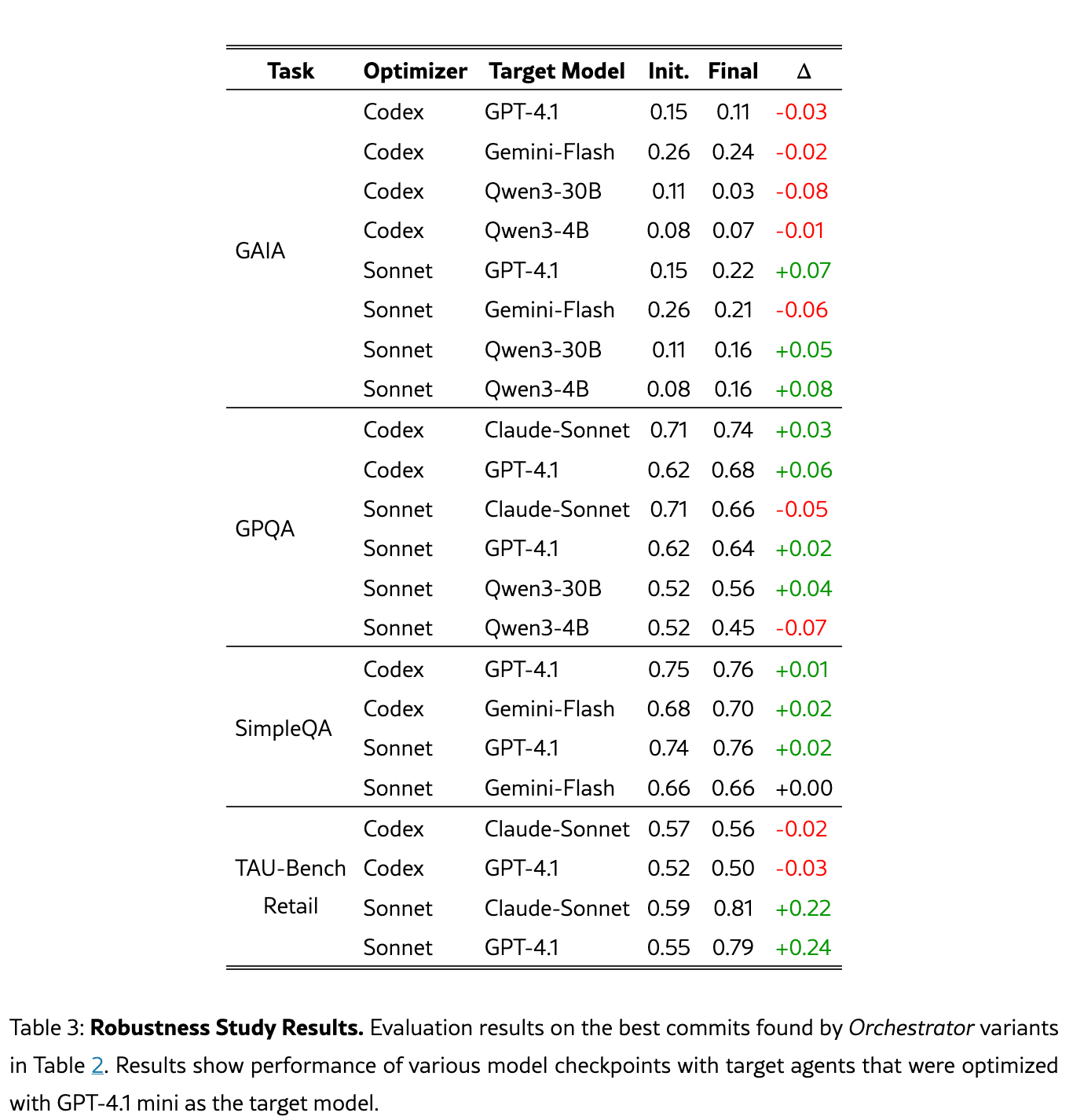
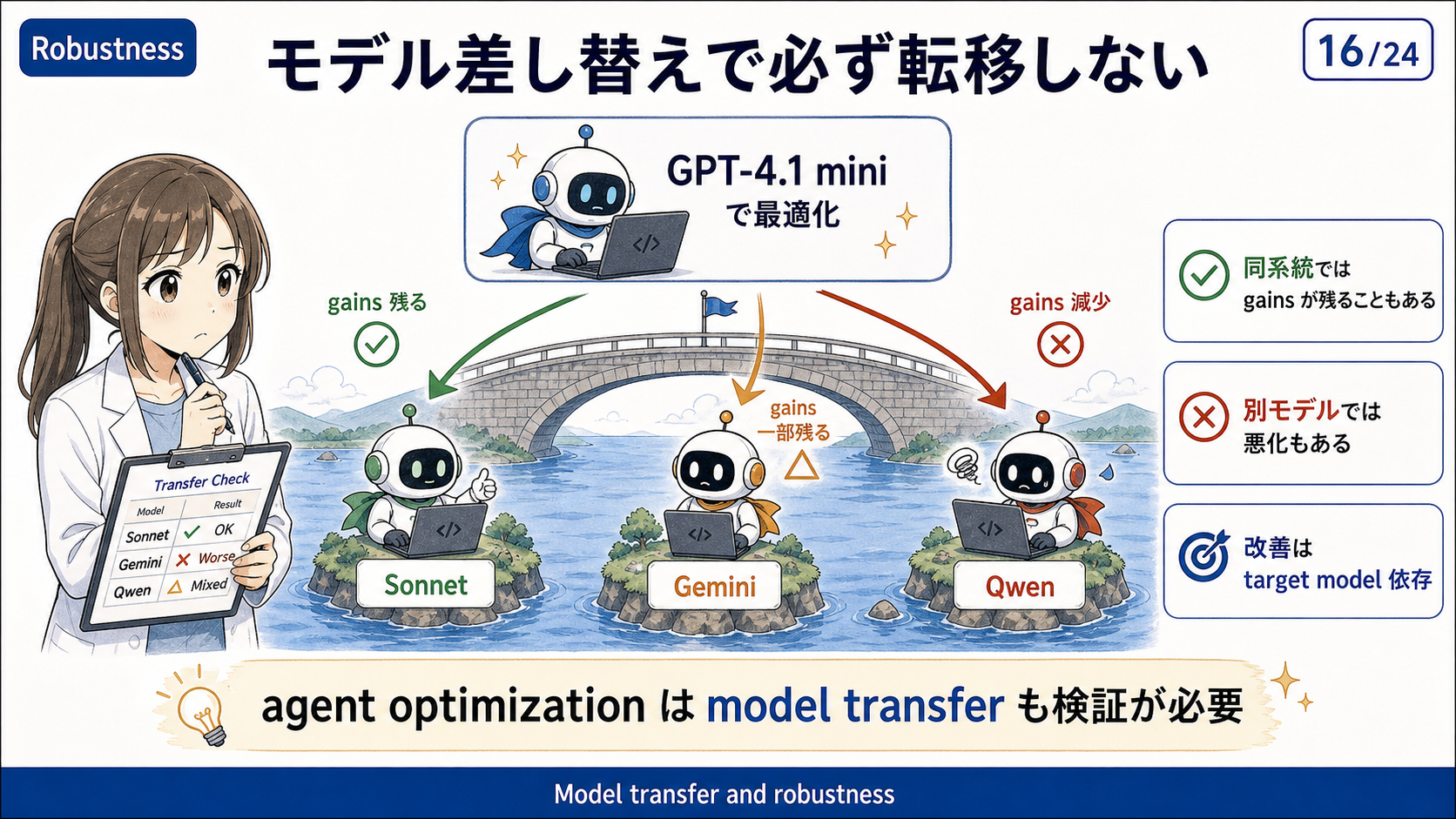
VeRO の最適化結果は、ある程度は別モデルにも転移する。ただし万能ではない。
特に、GPT-4.1 mini 向けに最適化した agent は、同じ OpenAI 系の GPT-4.1 には比較的よく転移します。一方で、Gemini Flash や Qwen など別ファミリーのモデルに変えると、改善が残る場合もあるが、悪化するケースもあります。
なので論文の含意は、VeRO は単に特定モデルへの過適合だけをしているわけではなく、実装・tool・workflow レベルの改善を見つけている。ただし、その改善はモデル非依存とは言い切れず、実運用では使う推論モデルで再評価すべき。という感じです。
実験3: ケーススタディ
何をしたのか
検証したこと
このケーススタディで見たいのは、VeRO が「きれいに作られた小さなベンチマーク用 agent」だけでなく、もう少し実務に近い agent に対しても効くのか、という点です。
ここでいう「リアリスティック」は、agent が単に 1 つのプロンプトで答えるだけではない、という意味です。実際の agent は、検索ツールを使ったり、ファイルを読んだり、途中で検証したり、複数ターンで作業したりします。また、最初から弱い agent だけでなく、すでにかなり作り込まれた agent をさらに改善したい場面もあります。
そのため、この実験では「弱い agent をどこまで伸ばせるか」と「強い agent をさらに改善できるか」、具体的には以下の3点を見ていきます。
- 1: target agent の初期性能によって、改善余地がどれくらい変わるか
Pawn のようなシンプルな agent は伸びやすいのか。Knight のような強い agent でもまだ伸ばせるのかを見ています。
- 2 : optimizer の探索方針によって、結果がどう変わるか
厚い guidance が効くのか、それとも自由に探索させたほうがよいのか。安定した改善と、大きく伸びる可能性の間に tradeoff があるのかを見ています。
- 3: あるタスクで見つけた改善が、別のタスクにも効くか GAIA で良くなった変更が、FACTS Search や SimpleQA でも良いとは限りません。複雑な検証ツールを入れると、GAIA では効いても、単純な factual QA では重すぎて悪化することがあります。
検証の枠組み
実験では、2 種類の target agent を用意します。
その target agent を、異なる optimizer instruction で最適化します。
optimizer instruction というのは、最適化を担当する coding agent に対して、「どういう方針で改善を探すか」を指示するテンプレートです。つまり、target agent そのものではなく、target agent を改善する側の探索方針を変えています。
評価は GAIA を中心にしつつ、FACTS Search と SimpleQA にもかけています。これにより、「GAIA 向けに改善した変更が、他の検索・QA 系タスクにも効くのか」も見ています。

2 種類の target agent
1 つ目は Pawn です。
Pawn は、最低限動くけれど、かなりシンプルな agent です。ツールは少なく、プロンプトも短く、推論の型もほとんど入っていません。ファイル読み取りも基本的な形式に限られます。
これは、いわば「まだ改善余地が大きい agent」です。optimizer がツールを足したり、プロンプトを整理したり、ワークフローを変えたりする余地があります。
2 つ目は Knight です。
Knight は、最初からかなり作り込まれた agent です。検索は強めに設計され、Wikipedia も使えます。LLM による自己評価、ReACT 型のプロンプト、複雑なファイル形式の読み取り、pandas や numpy なども使えます。
これは、いわば「すでにベストプラクティスをある程度入れた agent」です。ここでは、optimizer がまだ残っている非効率や改善点を見つけられるかを見ています。
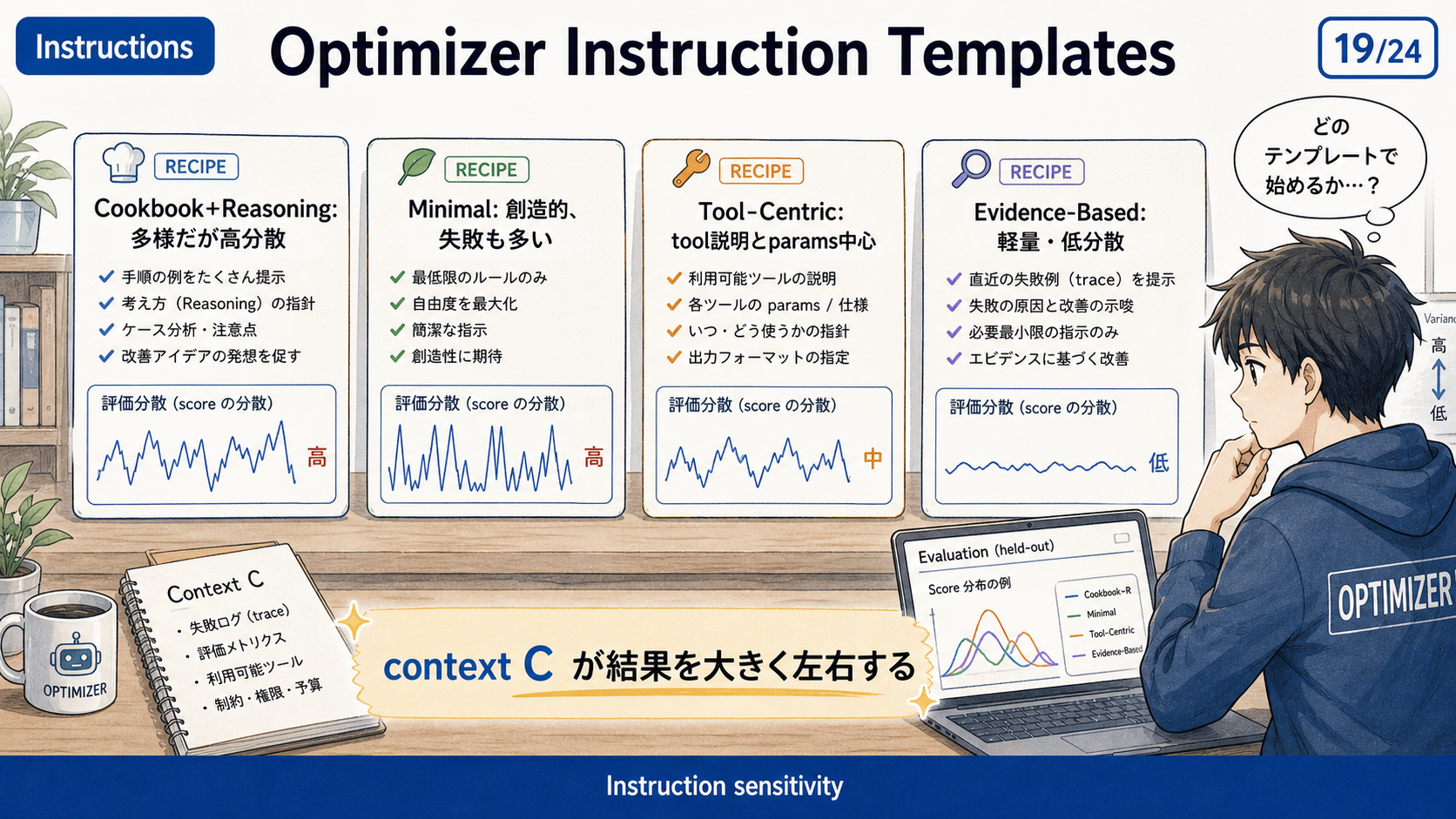
4 つの探索方針
このケーススタディでは、optimizer に与える instruction を 4 種類変えています。
ここで重要なのは、4 つの方針は「target agent のモデルを変える」ものではない、という点です。変えているのは、optimizer がどのような観点で変更を探すかです。
結果・考察
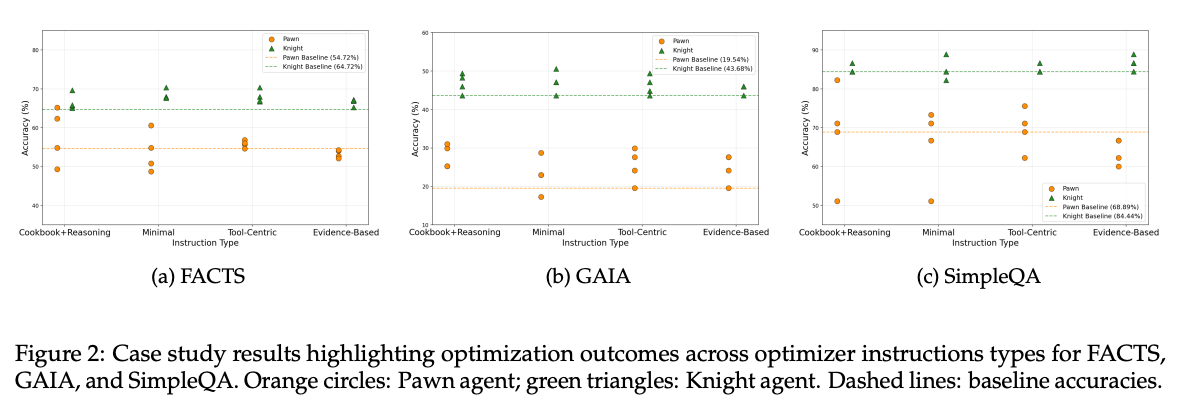
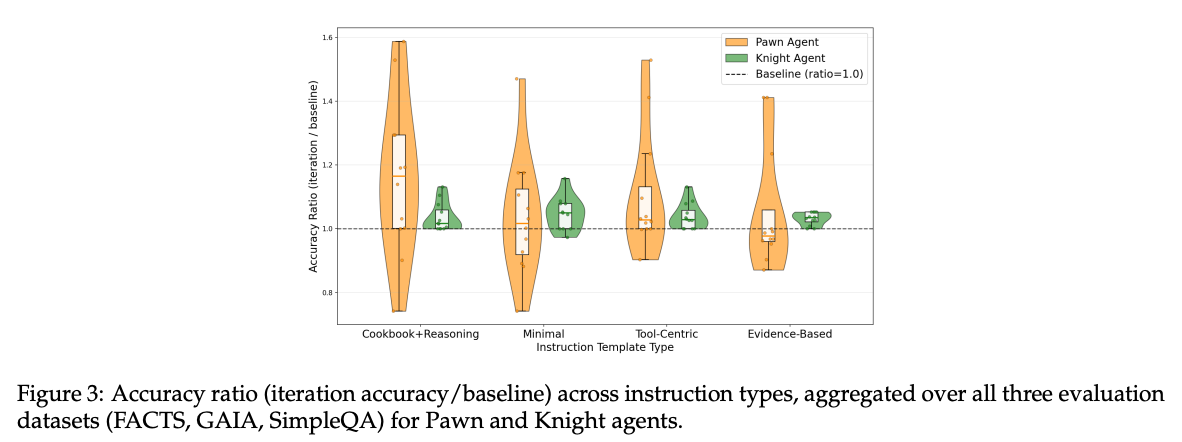
1つ目: Pawn のほうが改善幅が大きい。
論文では Pawn は最大で GAIA +11.5%、FACTS +10.5%、SimpleQA +13.3%。Knight は GAIA +6.9%、FACTS +5.6%、SimpleQA +4.5%。つまり、元がシンプルな agent ほど、tool 追加や workflow 改善で伸ばす余地が大きい。
2つ目: 強い agent には細かい指示が必ずしも良くない。
Pawn は Cookbook+Reasoning のような厚めの guidance が効く。一方で Knight は Minimal instruction が一番よかった、と書かれています。作り込まれた agent では、定型的な cookbook guidance がむしろ探索を狭める可能性がある、という読みです。
3つ目: 高リターンな instruction は分散も大きい。
良い template は peak performance を出しやすい一方、iteration ごとのブレも大きい。Evidence-Based のような制約強めの template は安定するが、上振れも小さい。
4つ目: GAIA で良くなった変更が FACTS/SimpleQA でも良いとは限らない。
特に、GAIA 向けに複雑な verification tool を入れた結果、multi-hop reasoning は良くなるが、SimpleQA のような単純 factual QA では遅くなったり悪化したりする、という例が出ています。
5つ目: instruction template は optimizer の “探索方針” をかなり変える。
これは単なる prompt 文言差ではなく、optimizer が「保守的に小さく直す」のか、「大胆に tool/workflow を変える」のかを変えている、という読みです。
Ablation
Ablation では、Claude Code Pure、Claude Code VERO Tools、VERO Default などが比較されている。
結果として、VERO tools を追加するだけでも平均性能は改善し、full VERO harness ではさらに改善が大きくなる。
この結果は、optimizer model の性能だけでなく、観察情報の形式、評価実行の管理、変更履歴の保持が重要であることを示している。
特に、score と trace が構造化されている場合、optimizer は失敗原因を把握しやすくなり、改善の方向を選びやすくなる。
ログが断片的で、評価結果と変更履歴が結びついていない場合、エージェント改善は属人的な試行錯誤になりやすい。
成功例として、Pawn の Cookbook+Reasoning iteration 4 では、Wikipedia search と error handling の改善により、FACTS、GAIA、SimpleQA が同時に改善している。これは、情報検索、検証、失敗時の処理といった workflow 改善が、複数タスクにまたがって有効に働いた例である。
一方で、失敗例も示されている。例えば Pawn の Cookbook+Reasoning iteration 3 では、複雑な multi-step verification tool を追加した結果、GAIA は改善したものの、SimpleQA は大きく悪化している。
この例は、ある benchmark に有効な変更が、別の benchmark では過剰な検証や latency 増加につながることを示している。
したがって、agent optimization では、単一タスクの score だけでなく、汎化、runtime、変更の複雑さも含めて評価する必要がある。
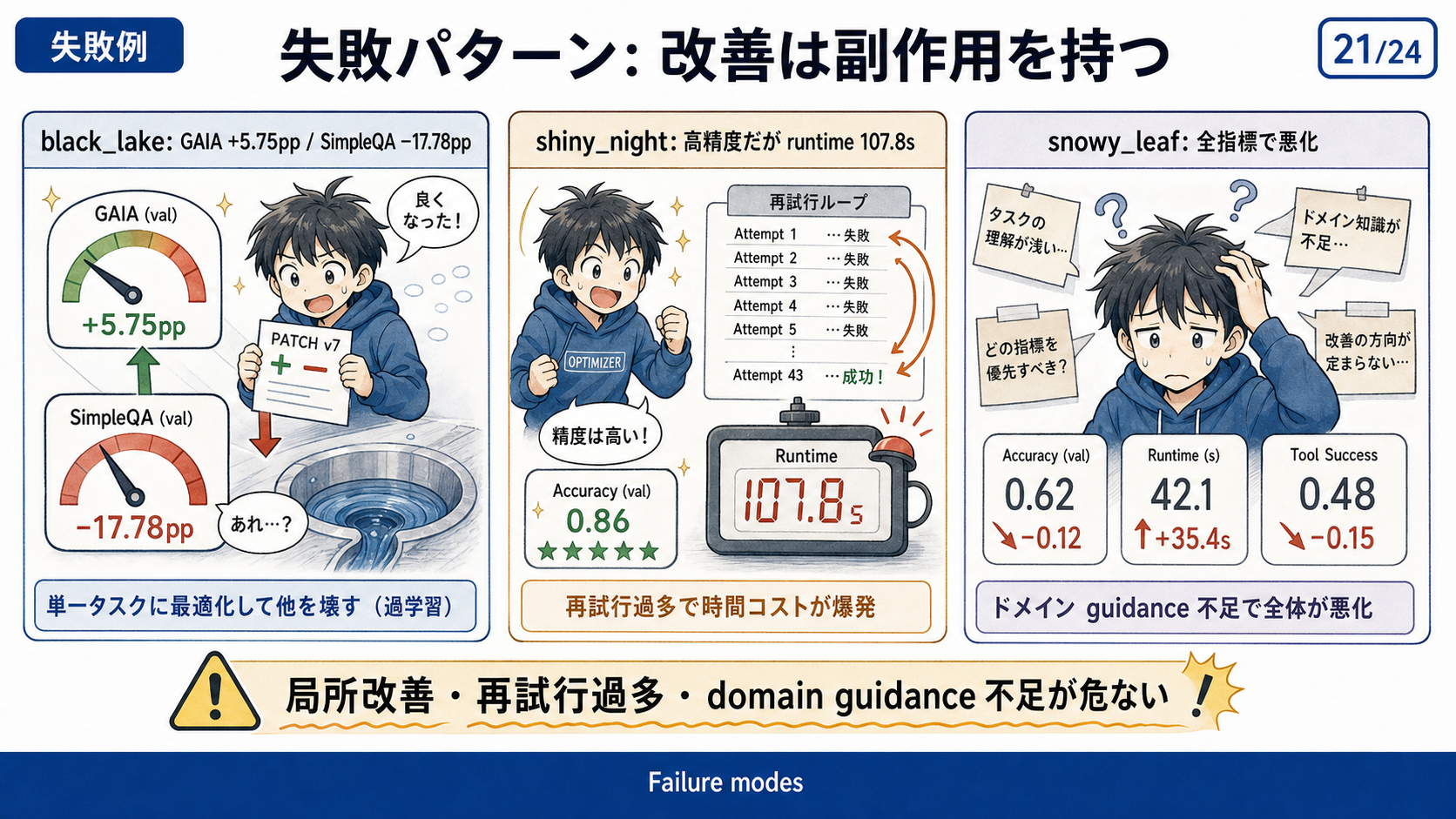
| パターン | 起きること |
|---|---|
| task-specific overfitting | train split にだけ効く変更を入れてしまう |
| excessive verification | 検証や retry を増やしすぎて latency が悪化する |
| harmful edit | domain guidance が不足し、全体性能を下げる |
| prompt edit 偏重 | tool や workflow の構造改善まで探索できない |
| benchmark / API 依存 | 外部 API や benchmark memorization の影響を受ける |
実務上の読みどころ
本論文は、エージェントが完全に自律的に自己改善できることを示したものではない。むしろ、エージェント改善を再現可能な実験として扱うための枠組みを提示した論文として読むのが適切である。
| 実務の課題 | VeRO 的な対応 |
|---|---|
| 変更履歴が追えない | agent 改善を commit 単位で残す |
| 失敗ログが散らばる | trace、score、runtime を構造化して保存する |
| 評価セットに過剰適合する | train / validation / test のアクセス権を分ける |
| 改善が prompt に偏る | tool、workflow、error handling も探索対象にする |
| 評価コストが高い | budget を明示し、評価回数も比較条件に入れる |
| 改善したが遅くなる | score だけでなく runtime per sample も見る |
特に重要なのは、エージェント改善を code artifact として扱う点である。プロンプト、tool 定義、workflow、評価 script が別々に管理されていると、どの変更がどの性能差につながったのかを再現しにくい。VeRO は、これらを Git と evaluation harness の上に載せることで、改善作業を比較可能な実験軌跡として扱っている。この発想は、研究評価だけでなく、実務での agent 開発にも応用しやすい。
限界

本論文で示された optimizer は、現時点では prompt edit に偏る傾向がある。人間であれば tool の追加、workflow の再設計、評価データの見直しを行う場面でも、optimizer は浅いプロンプト修正に留まることがある。
また、評価回数を増やせば単純に解決するわけでもない。agent optimization では、API cost、token cost、runtime、外部 API の揺らぎが大きく、通常の benchmark よりも運用上の制約が強い。
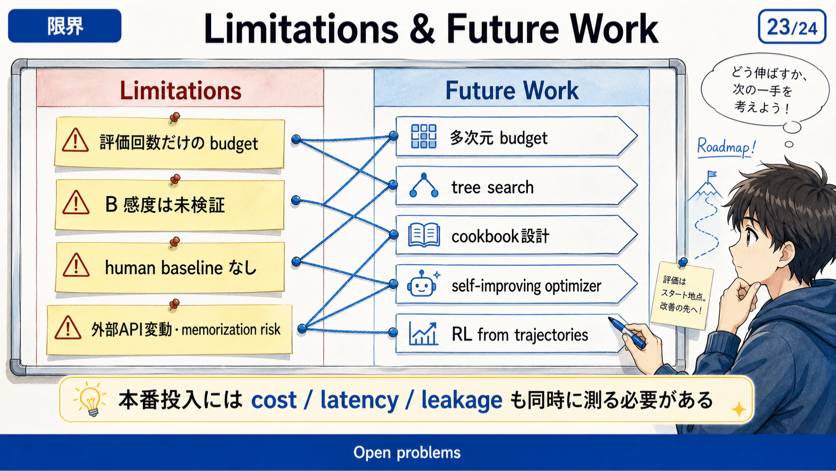
今後の方向として、program space を tree search 的に探索すること、optimizer に与える cookbook や instruction を体系化すること、trajectory から RL で学習することなどが挙げられている。これらは、現在の optimizer が prompt edit に寄りやすい問題を緩和するための方向性として位置づけられる。
まとめ
VeRO は、agent optimization をコーディングエージェントの評価タスクとして定式化した論文である。主な貢献は、target agent の性能だけでなく、改善プロセスそのものを versioning、reward、observation によって管理する点にある。
実験では、tool-use 系タスクで明確な改善が見られた一方、純粋推論タスクでの改善は限定的だった。この結果は、現在の optimizer が prompt edit や局所的な修正には有効である一方、tool や workflow の構造的な改善を安定して探索するには課題が残ることを示している。
本論文の実務的な価値は、エージェント改善を再現可能な実験として扱う視点にある。改善ログ、評価ログ、変更履歴を統合して管理することで、エージェント開発を属人的な試行錯誤から、比較可能で検証可能な改善プロセスへ近づけられる。
所感
- Agentic AI において正統的な評価タスクの進化だと感じる
- 軽量・安価なモデルを用いたエージェントを高価・高性能なエージェントで改善ループを回す、は今後増えてきそう
- ケーススタディが興味深い
- failure pattern ・ limitation も興味深い
- AIは「プロンプトの改善」に偏りがち
- 最初の探索では変更案に多様性があるものの、失敗事例に引っ張られてどんどん多様性が小さくなる
- 引き続きどのような instruction で改善させるかは結果を左右している