
2026-05-26 機械学習勉強会
今週のTOPIC[paper] SkillOpt: Executive Strategy for Self-Evolving Agent Skills[paper] KV Packet: Recomputation-Free Context-Independent KV Caching for LLMs[paper] PEEK: Context Map as an Orientation Cache for Long-Context LLM Agents[paper] GLiNER: Generalist Model for Named Entity Recognition using Bidirectional TransformerメインTOPICDoc2Query++: Topic-Coverage based Document Expansion and its Application to Dense Retrieval via Dual-Index Fusion概要背景手法コアアイデアStage 1: 文レベルトピックモデリング(BERTopic)Stage 2: ハイブリッドキーワード抽出Stage 3: トピック被覆型クエリ生成Stage 4: 疎検索と密検索への適用実験実験設定全手法の検索性能比較Dual-Index Fusion の効果各コンポーネントの寄与分析クエリ数のスケーリングとトピック被覆の関係クエリ「数」vs「被覆」(Figure 3, FiQA 疎)生成クエリ数と性能の関係(Figure 3, FiQA-2018 疎検索)トピック被覆率と検索性能の相関(Figure 2)キーワード抽出戦略の比較: KeyBERT vs Topic vs LLM 融合限界と今後
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[paper] SkillOpt: Executive Strategy for Self-Evolving Agent Skills
- Microsoft Researchの論文

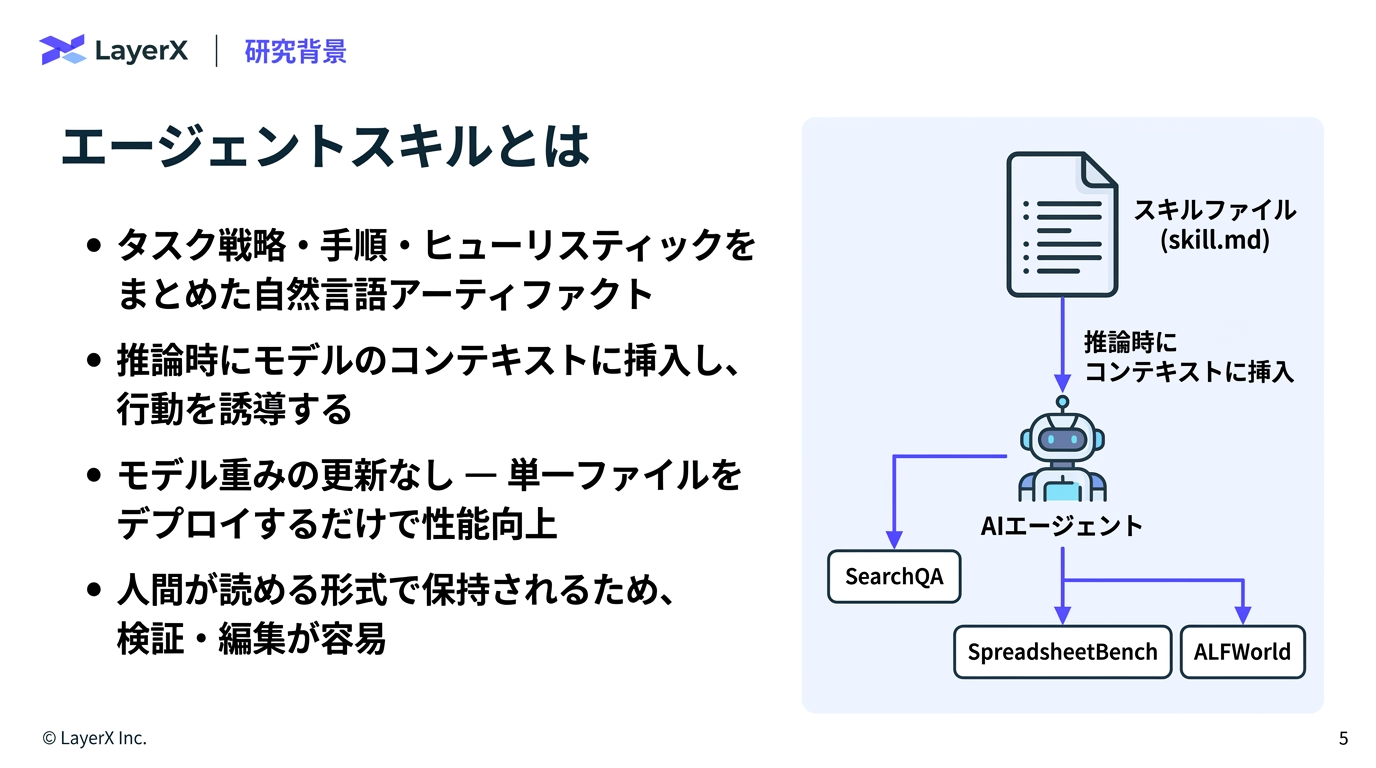



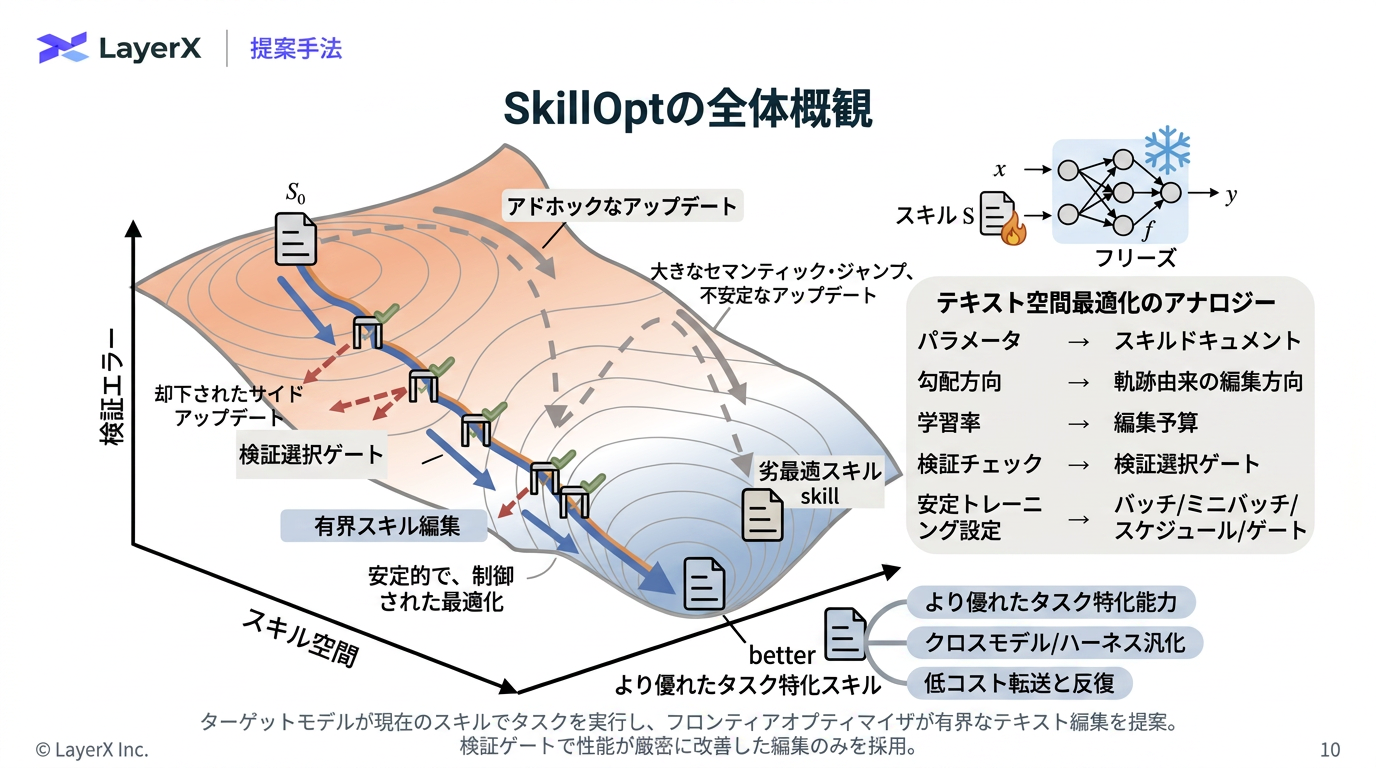
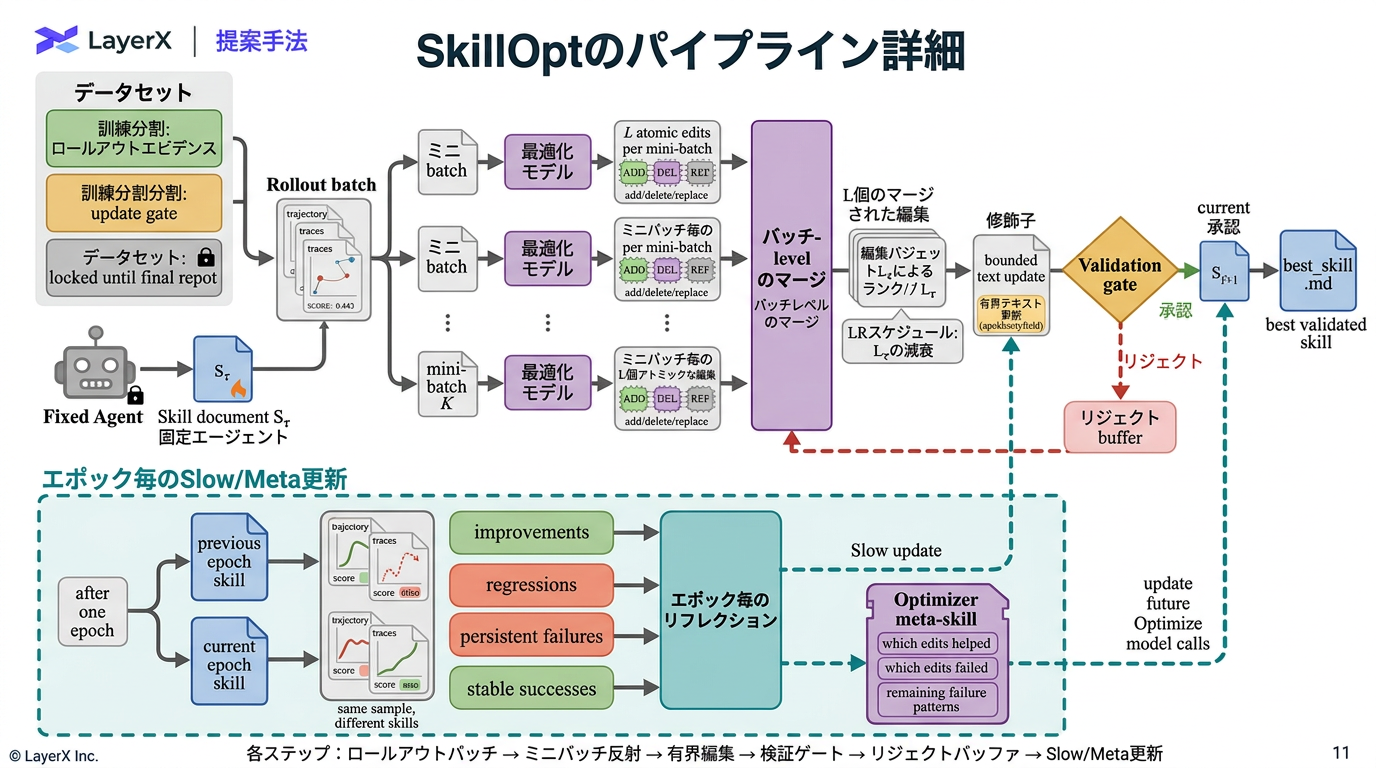

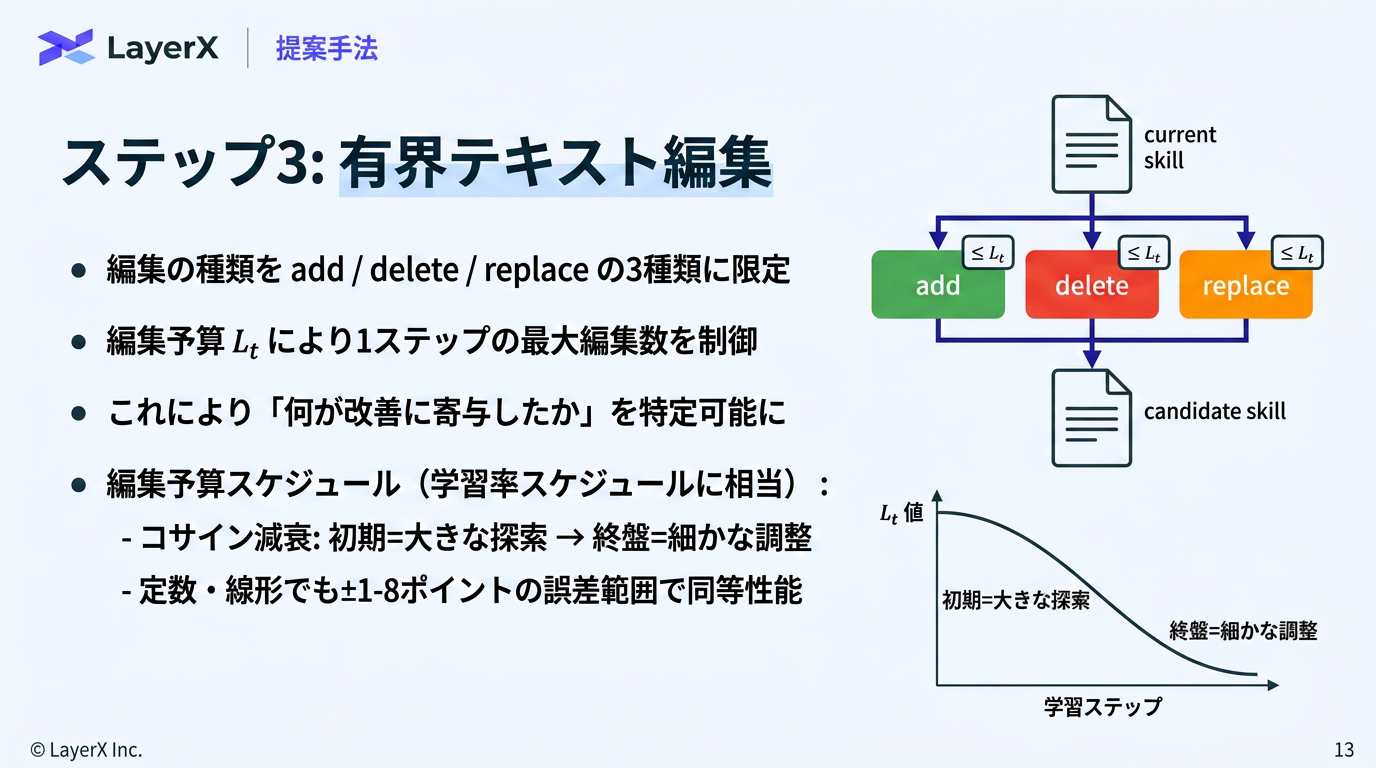
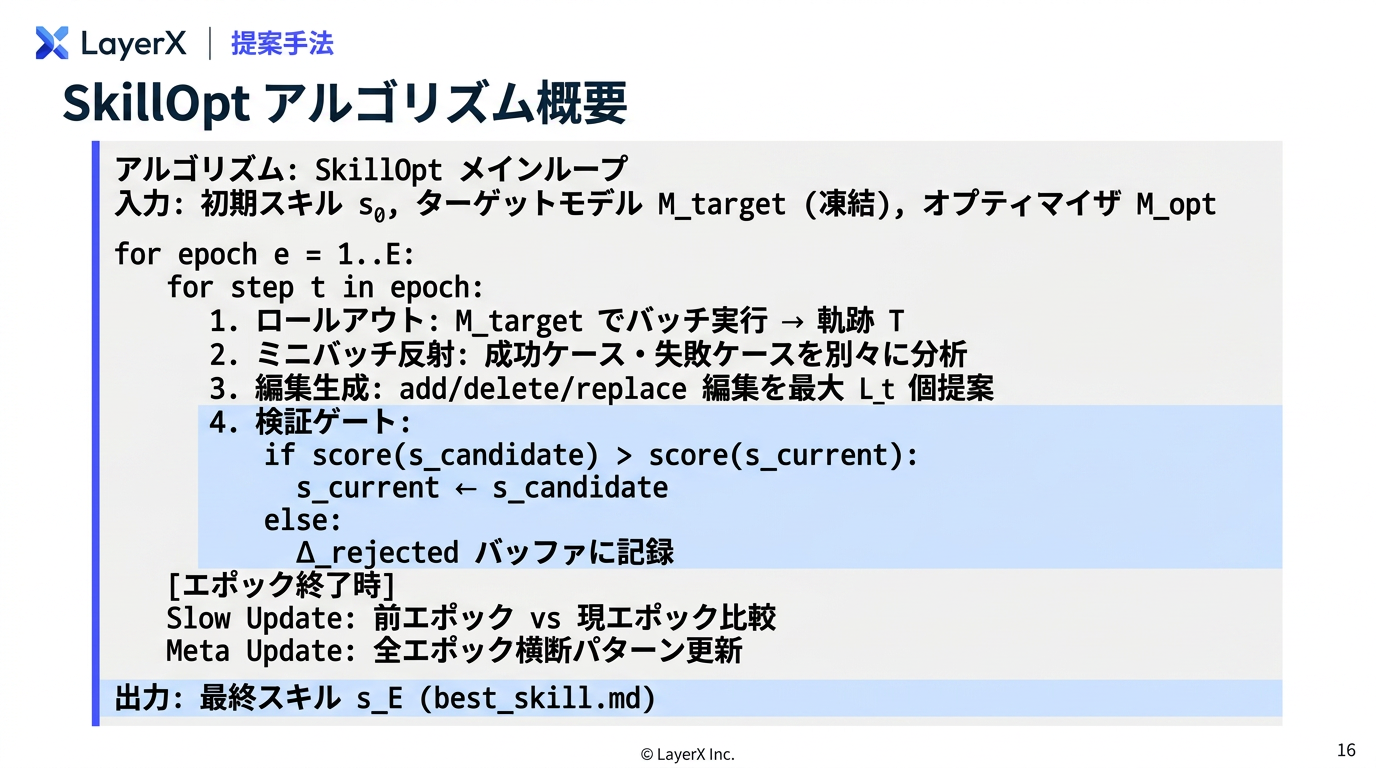
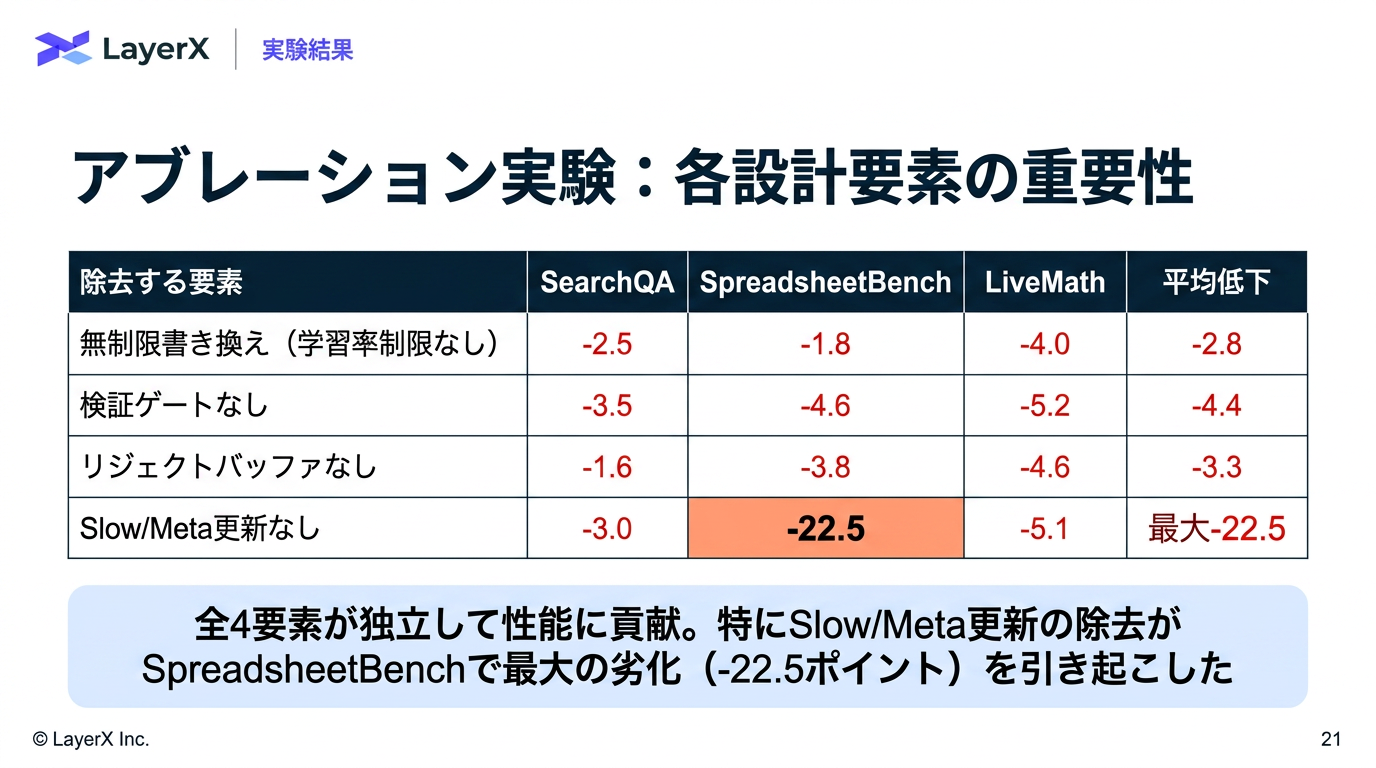
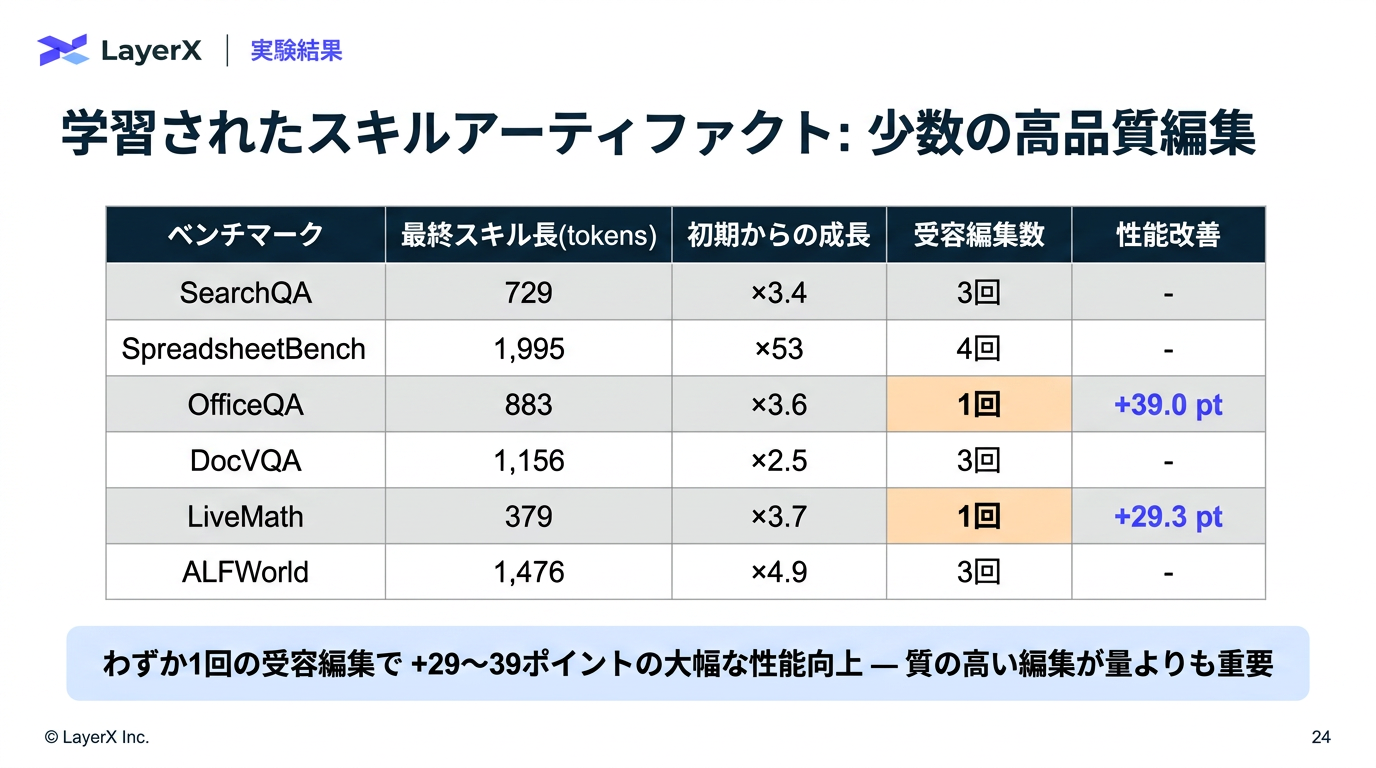
- 件数の制御だけで、テキスト量などは制御していない
- ただ後段のValidationを設けることによって1回での大量編集は、大きくスコアを落とすはずなので、大きな編集は起きない(はず)
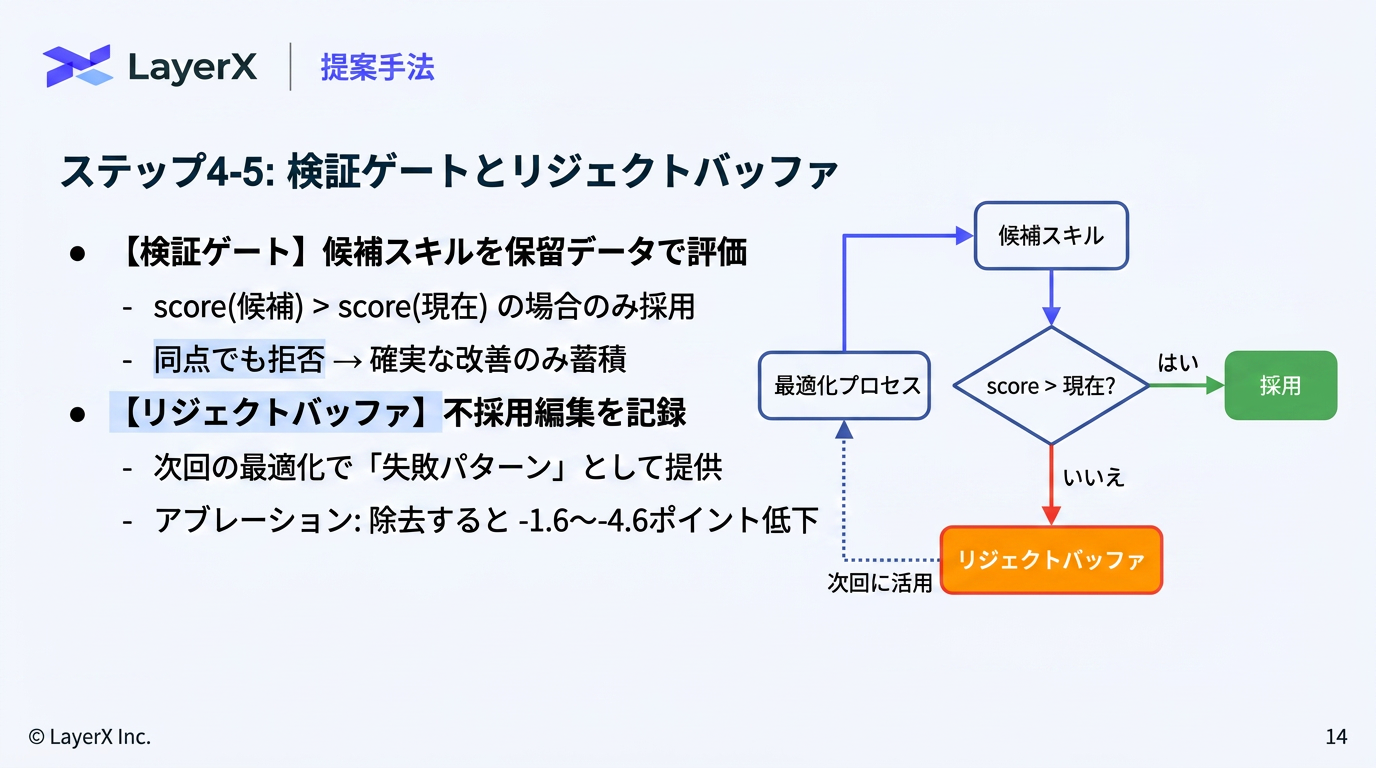
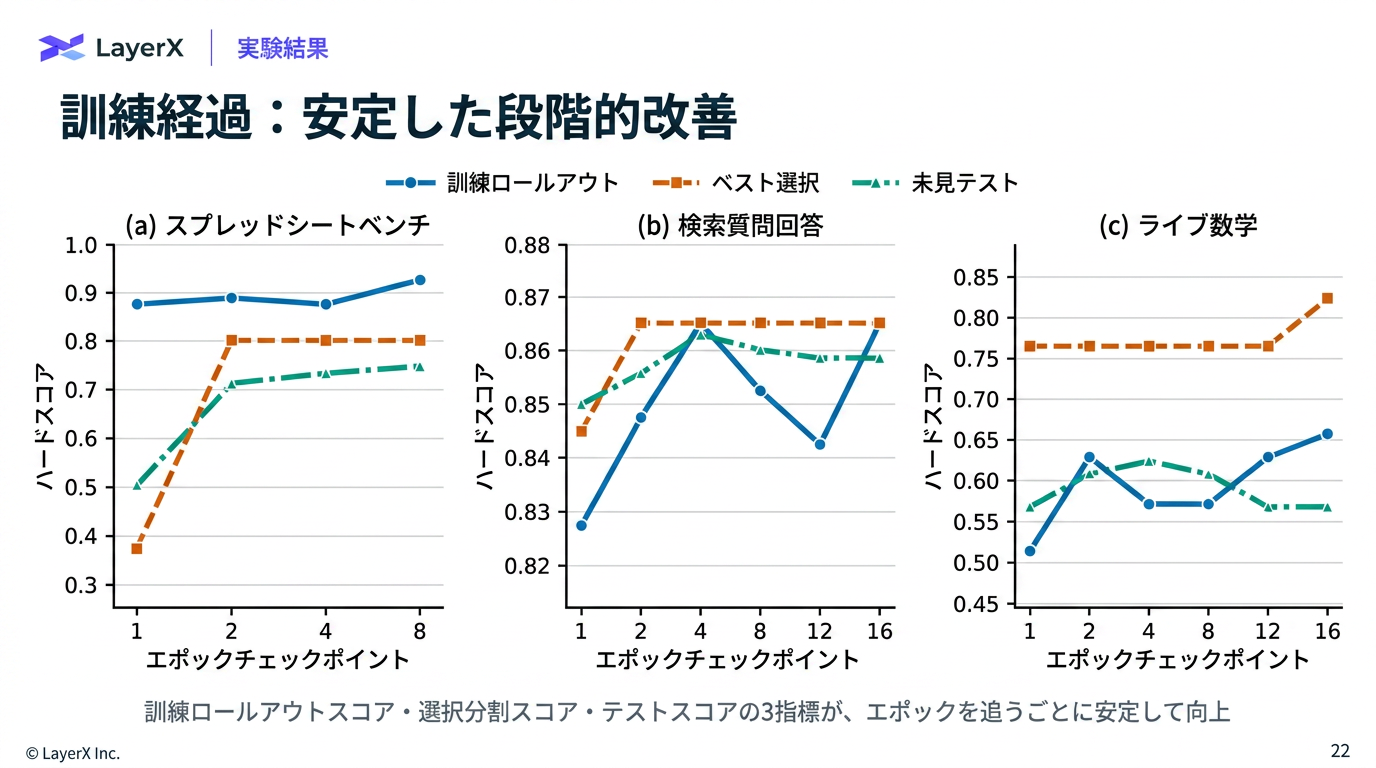
- Epoch単位での更新
- Slow Update → SKILLに追加
- Meta Update → Optimizerのメモリに追加
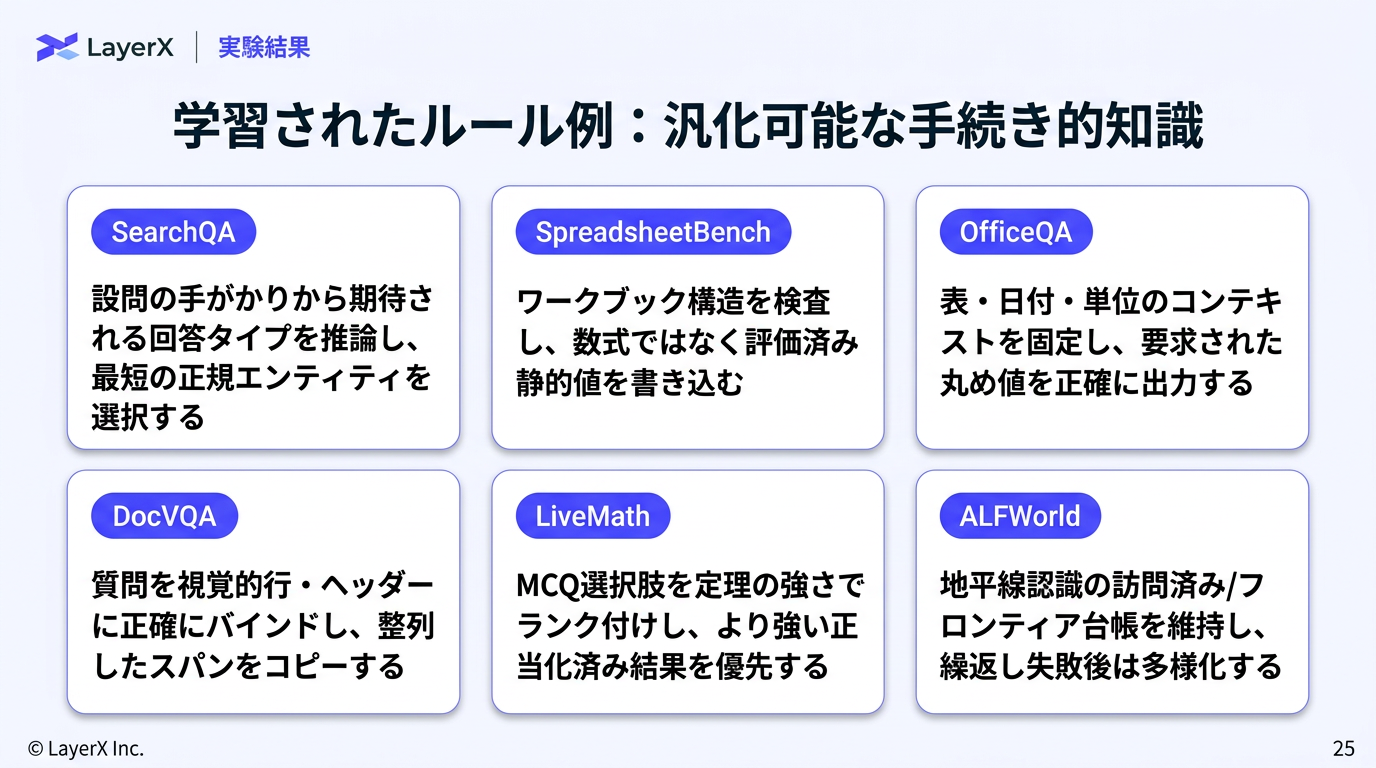
- 聞いた編集、拒否された編集、持続的な失敗をようやくする



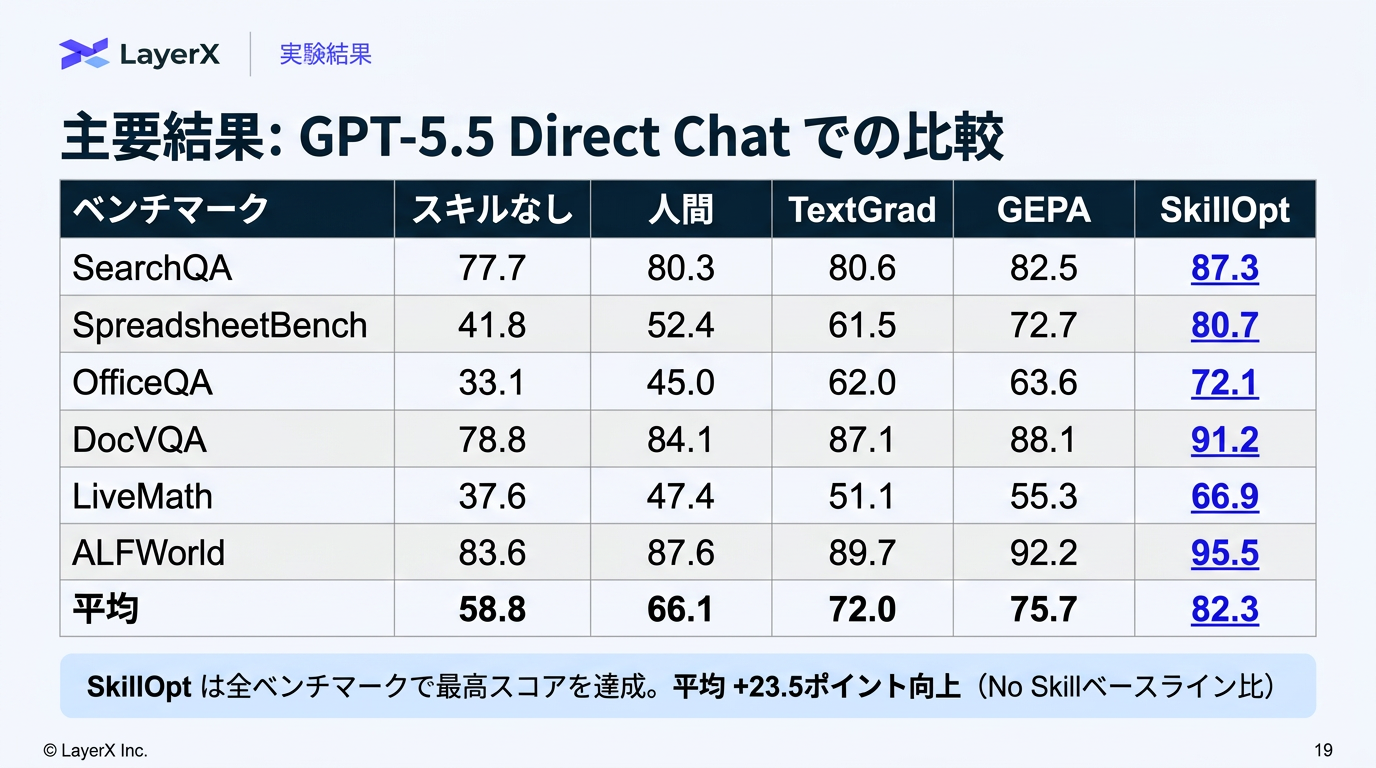
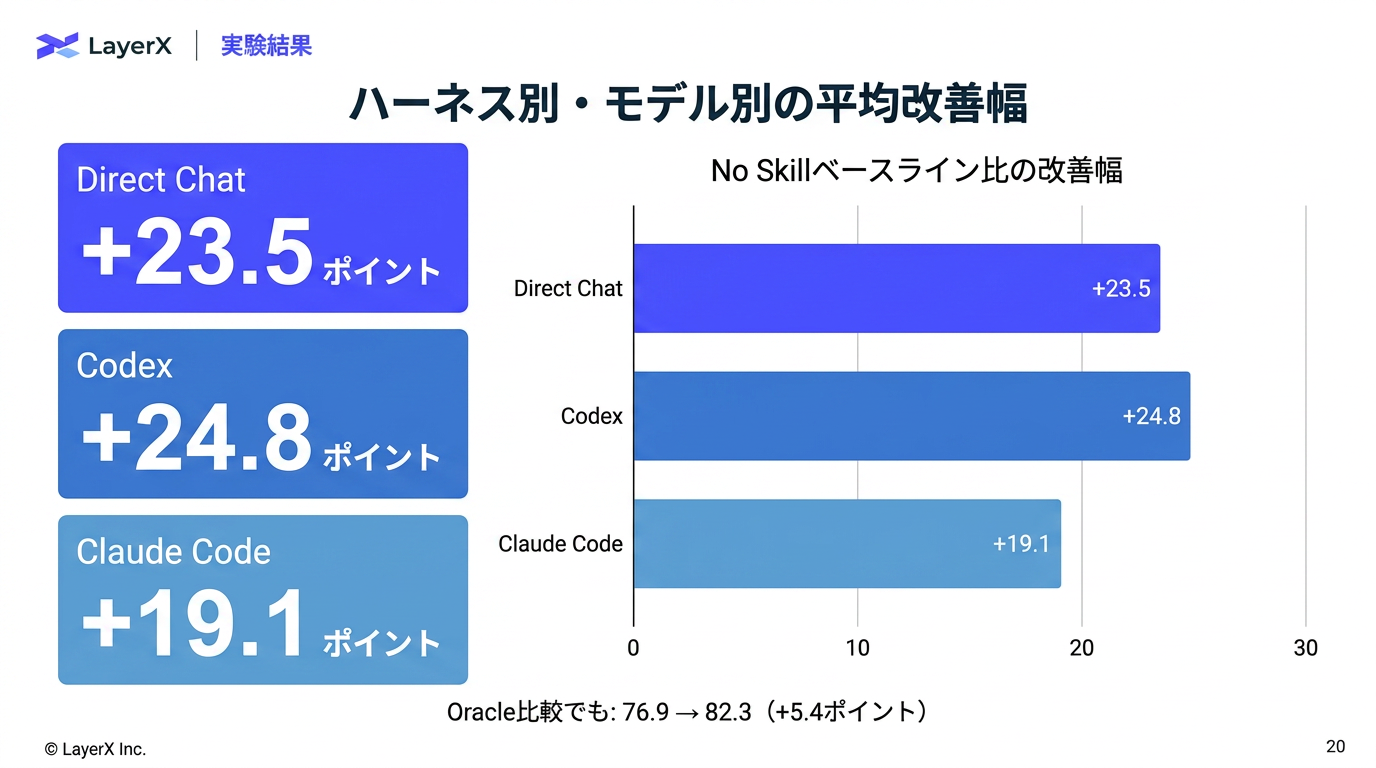




@Shun Ito
[paper] KV Packet: Recomputation-Free Context-Independent KV Caching for LLMs
- 背景
- LLM(大規模言語モデル)の推論効率化、特に RAG(Retrieval-Augmented Generation)パイプラインにおける KV Cache 再利用
- 複数の外部文書を参照するマルチドキュメント QA や長文脈推論など、同一ドキュメントを異なるプロンプトで繰り返し参照するユースケース
- 既存の課題
- DocumentごとにKV Cacheしている場合、コンテキスト内で使われる文書やその順番が変わると、KVの再計算が必要になる
- もしそのままconcat(RoPEシフトだけ適用)すると、contextが実態と即したものにならず、精度影響がでてしまう
- A → B → C の時の B のKVを D → A → B → C でそのまま使うと、Bの手前にある情報が変わっているので整合しない
- これを防ぐためには、D → A → B → C の状態でKVを再計算する。この場合は速度がボトルネック
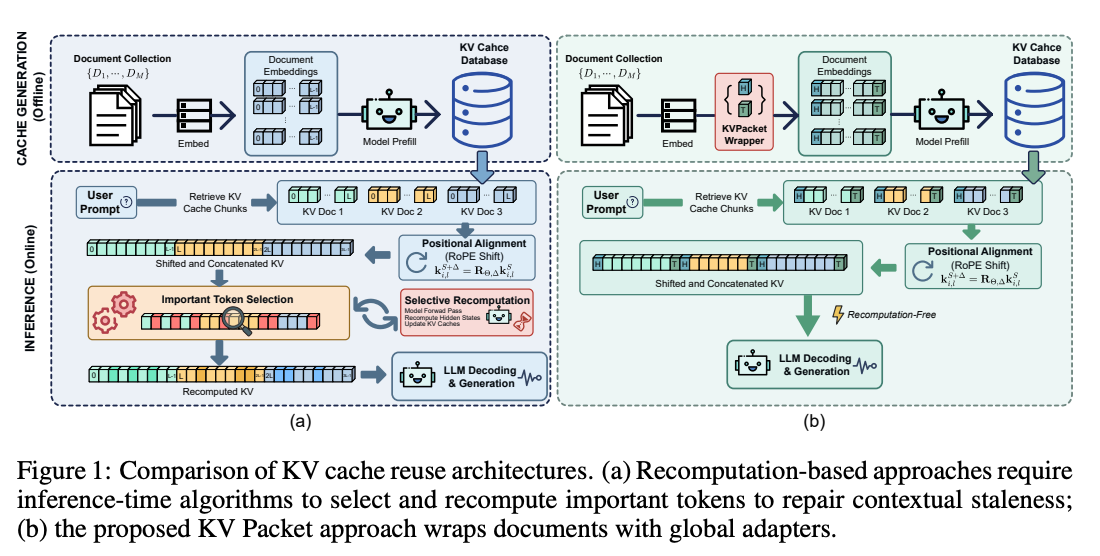
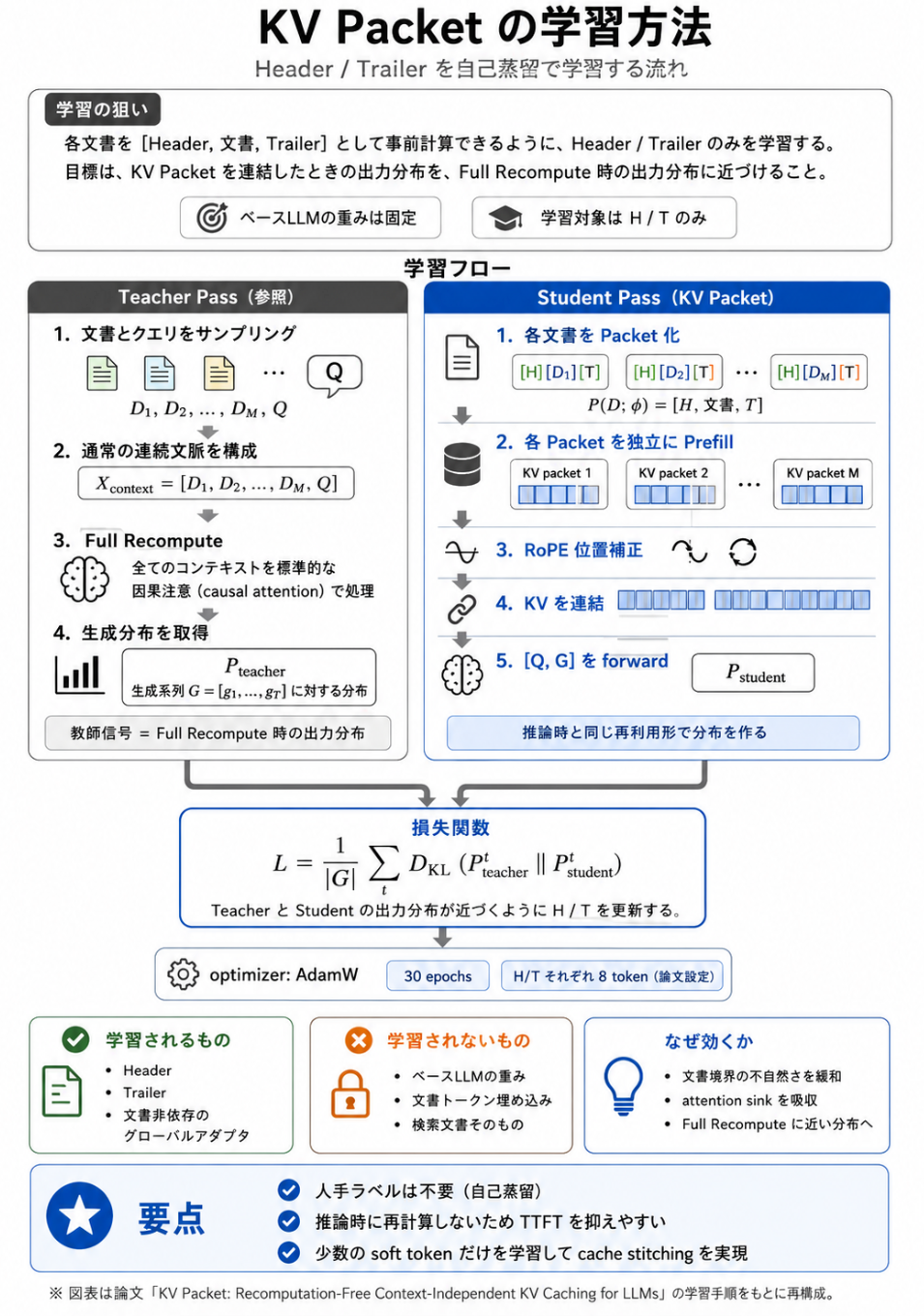
- 提案手法
- 各文書の前後にsoft token (Header, Trailer) を付与した上でKV Cacheする
- Packet = (Header, Document, Trailer)
- soft tokenは、そのまま連結しても再計算時の出力分布に近づくように学習される
- 推論時に文書本体を再計算しなくても、実用上十分な精度を保ちやすくする
- 学習方法
- ベースLLMを教師にした自己蒸留
- Teacher: 通常通り文書を連結した時の出力分布
- Student: Packet を連結した時の出力分布
- KL divergenceでsoft tokenだけを学習する
- 実験
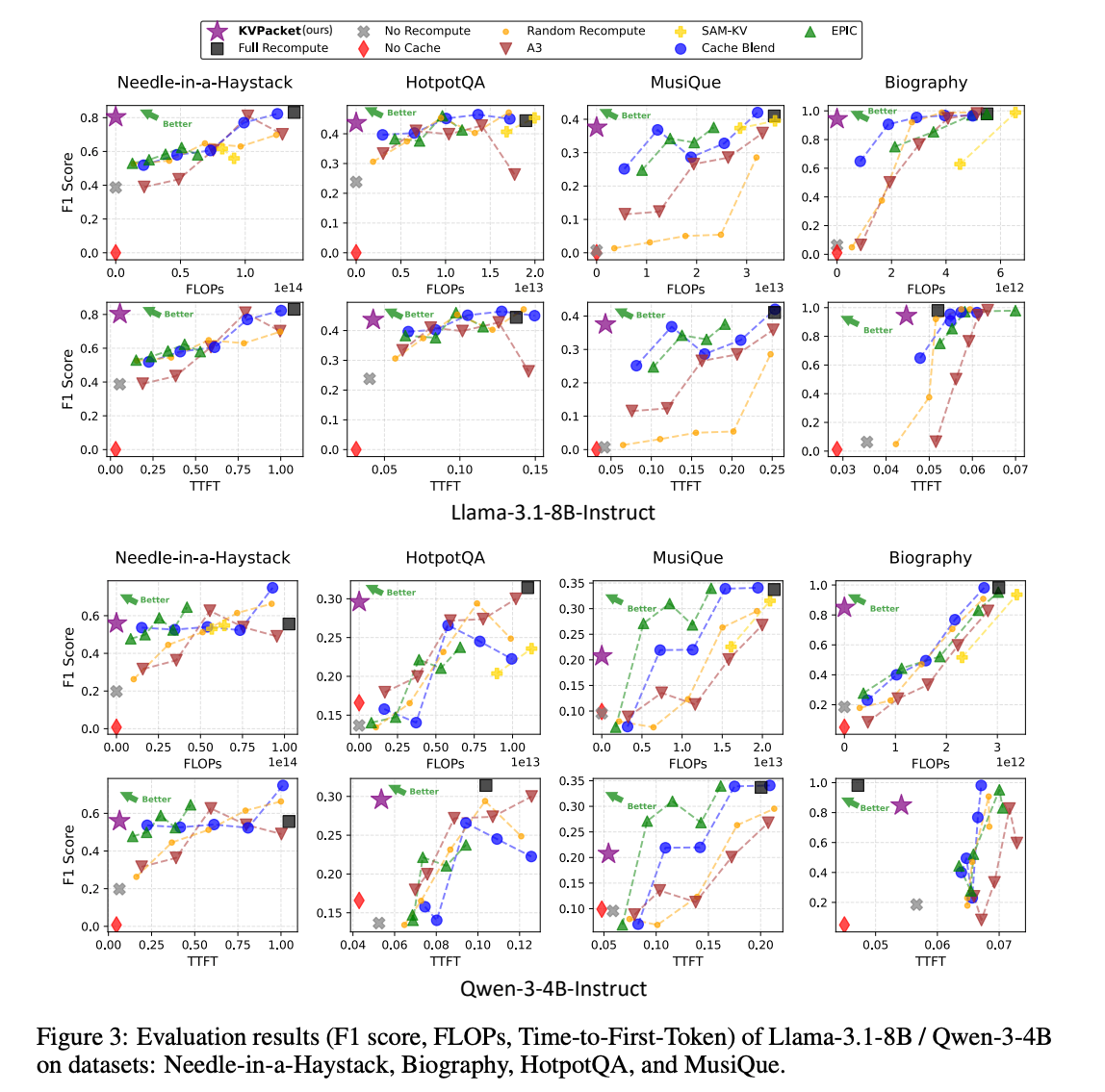
- 精度はFull Recomputationと同等かやや悪いくらい、速度は圧倒的に速い
@Hiromu Nakamura (pon)
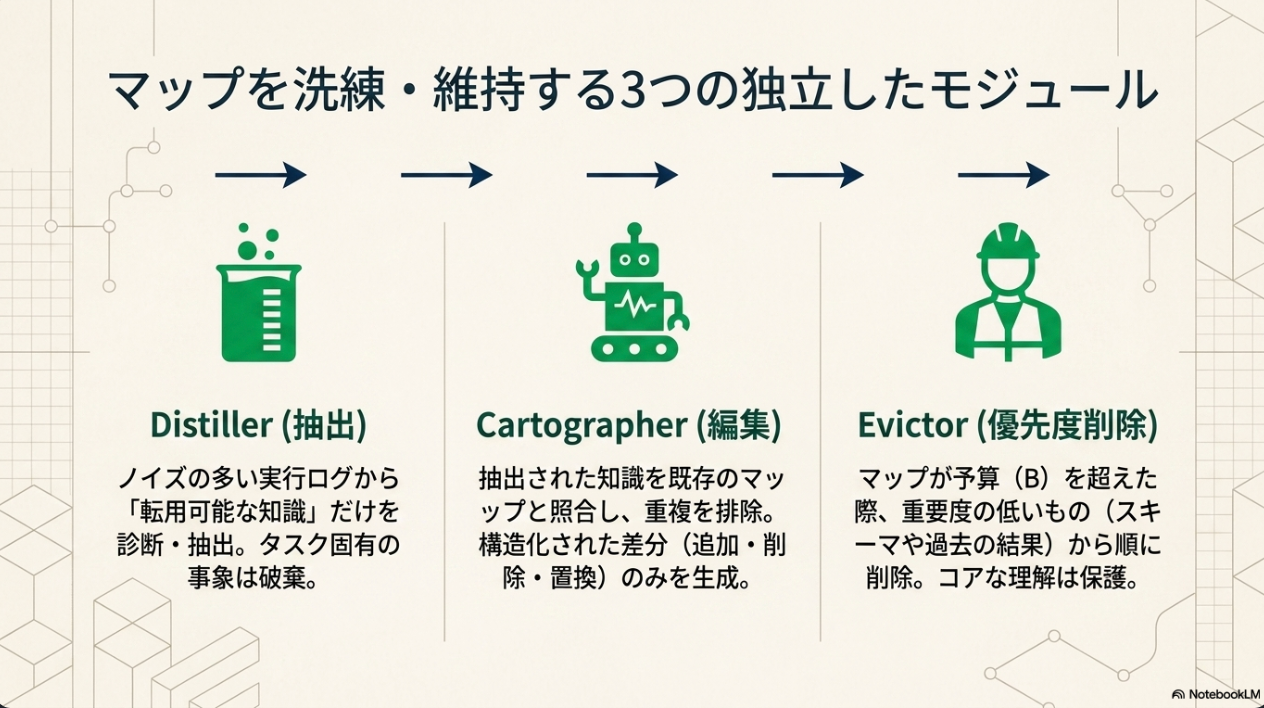
[paper] PEEK: Context Map as an Orientation Cache for Long-Context LLM Agents
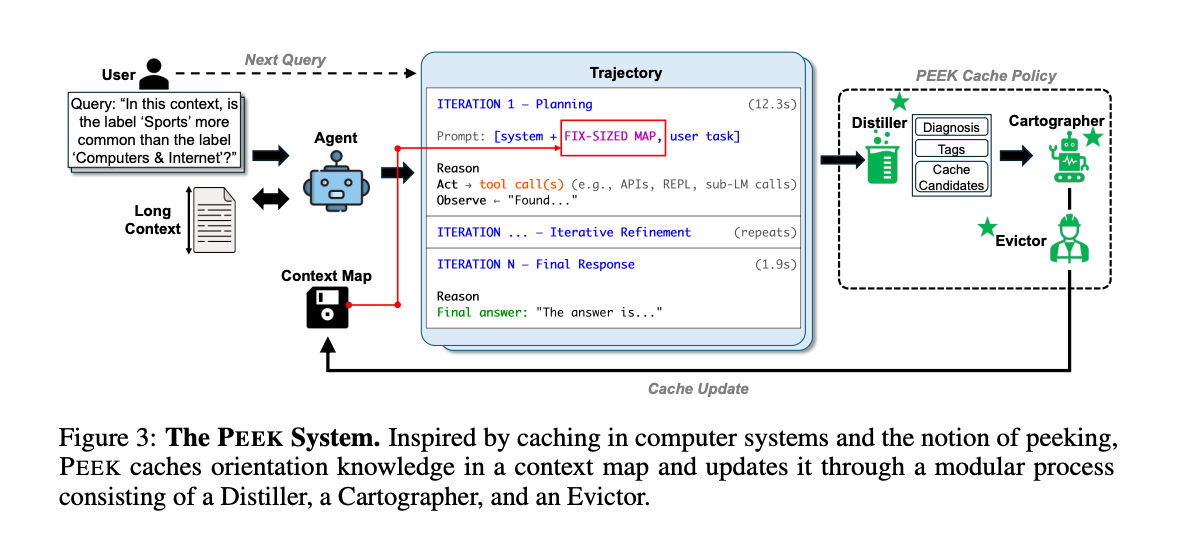
PEEKは、LLMエージェントが繰り返し利用する大規模な外部コンテキストに関する再利用可能なオリエンテーション知識を、エージェントのプロンプト内の「コンテキストマップ」としてキャッシュおよび維持するシステム。RLM(Recursive Language Models)上に構築される。
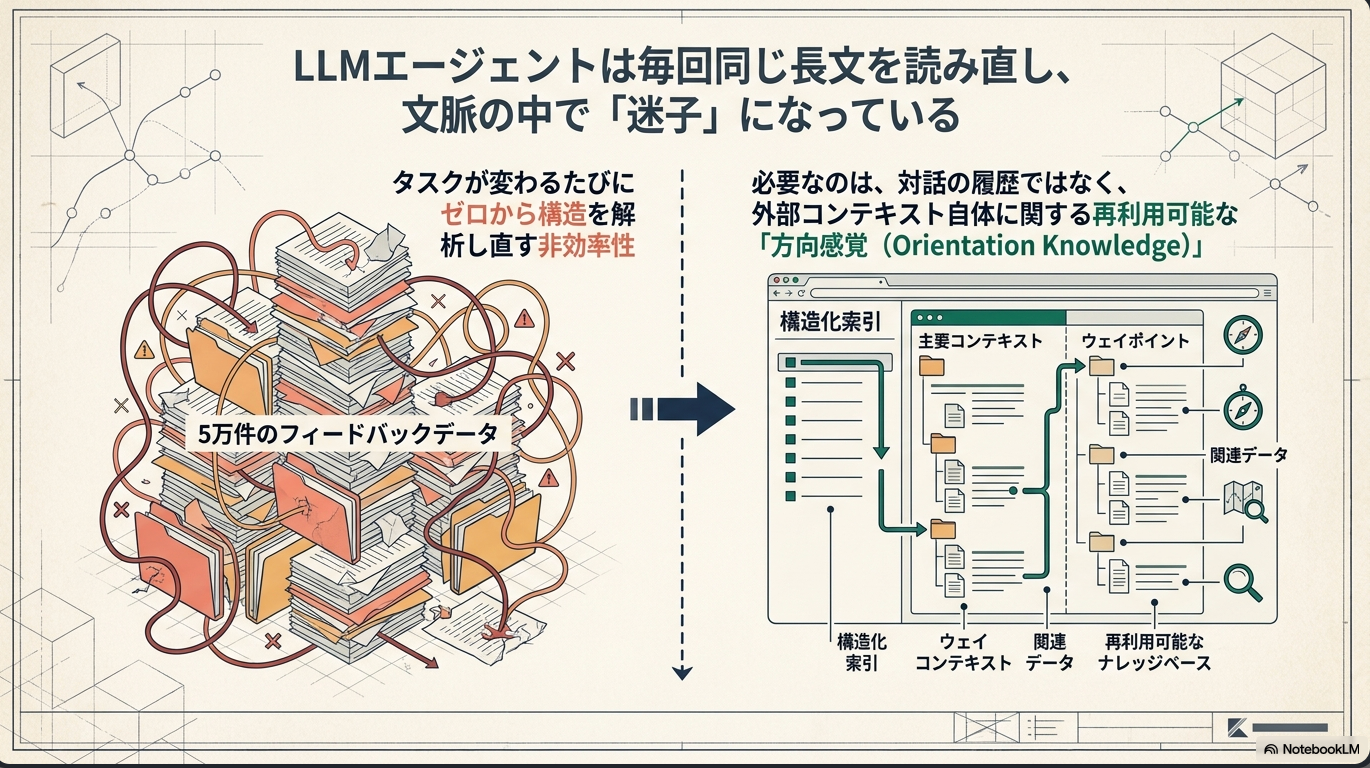
[pon]RLMはrecursiveに長文を探索するやつ。ただそれだと毎回同じ長文に対して探し回って迷子になる。PEEKは簡単にいうとRLMのキャッシュとして機能するコンテキスト
PEEK
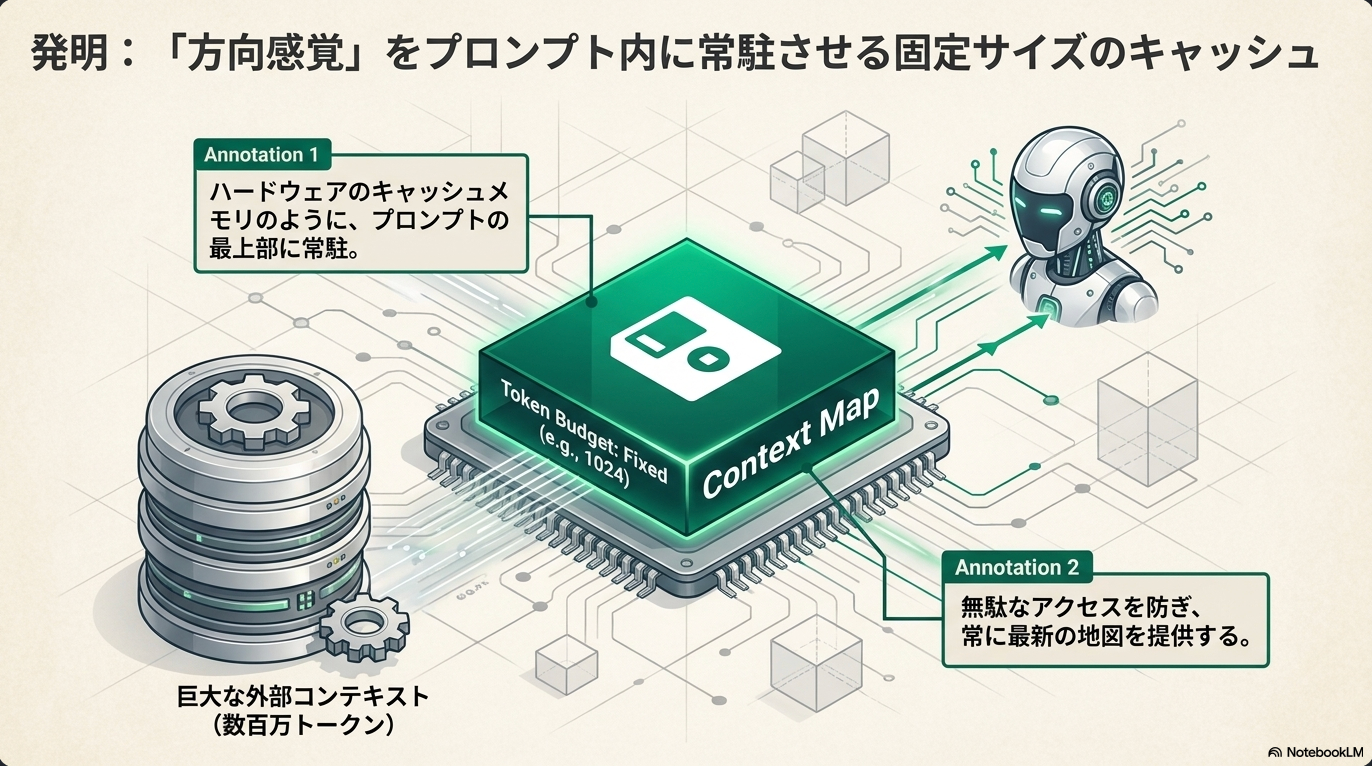
実験では一個につき512〜2048トークンのキャッシュサイズ
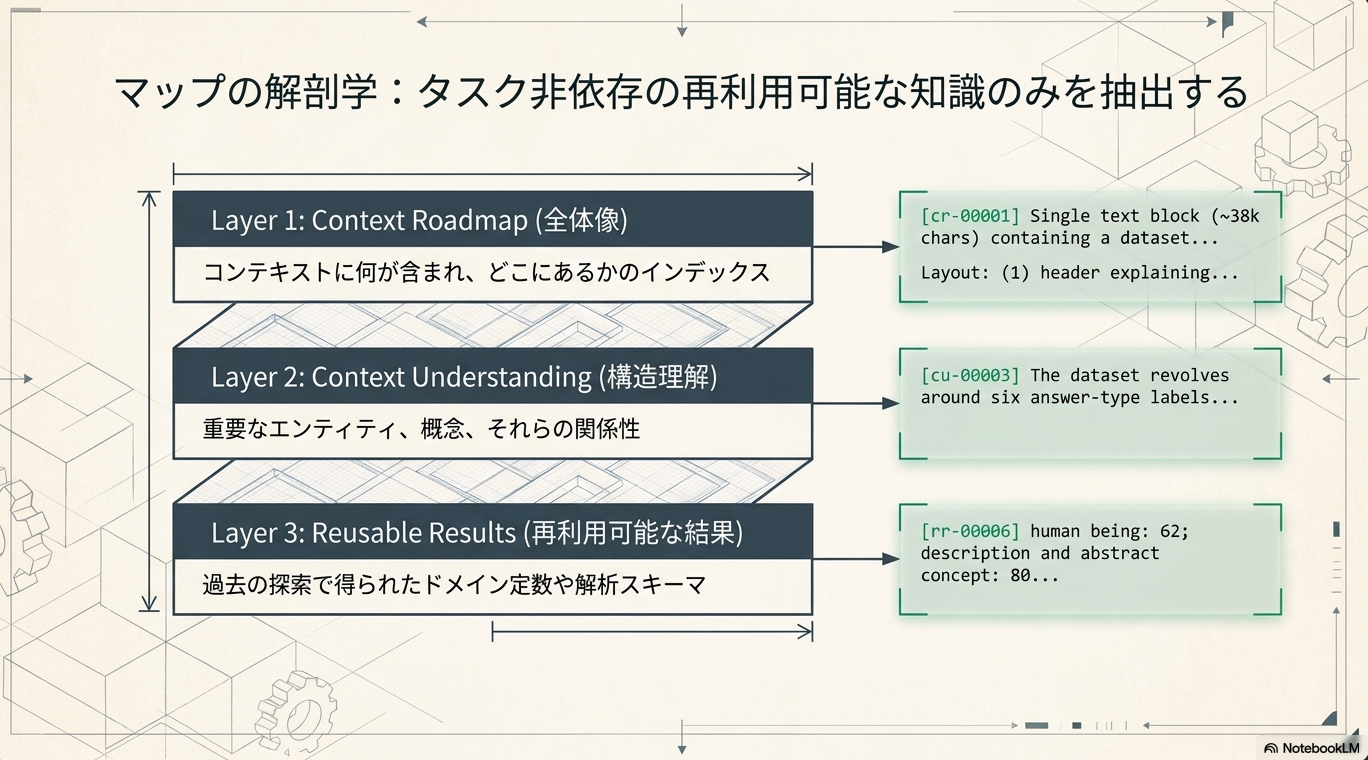
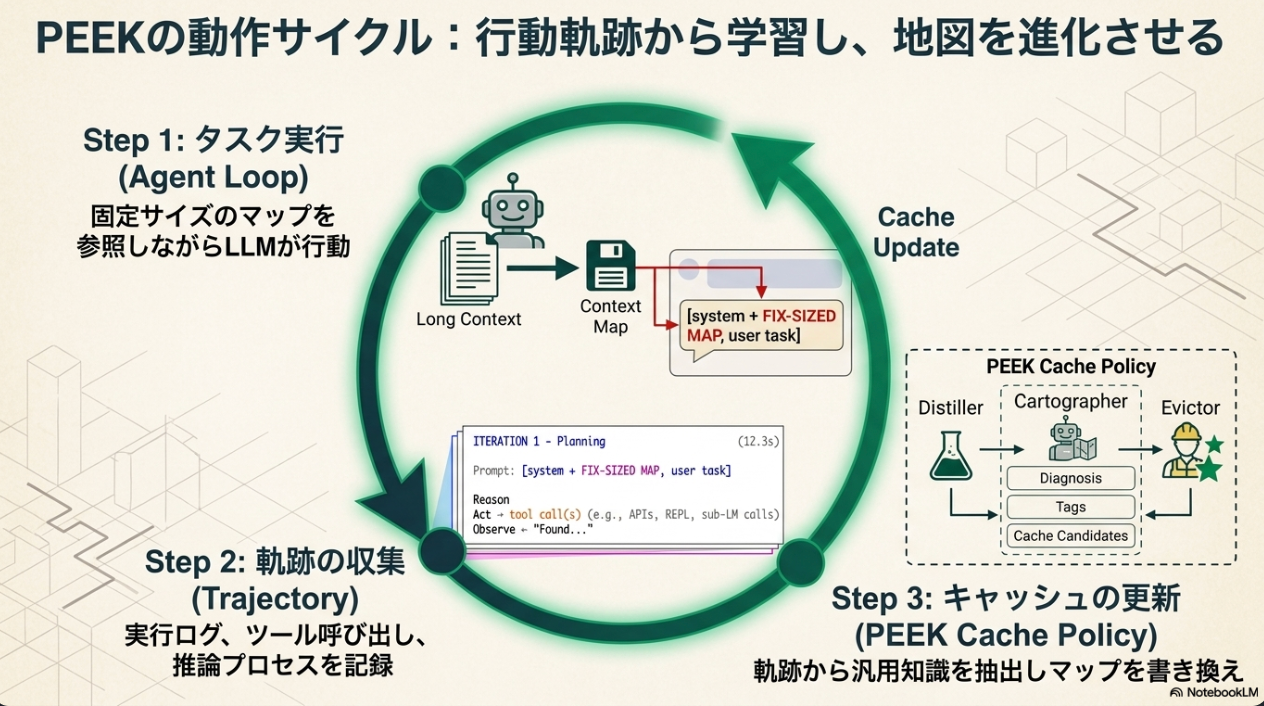
実験
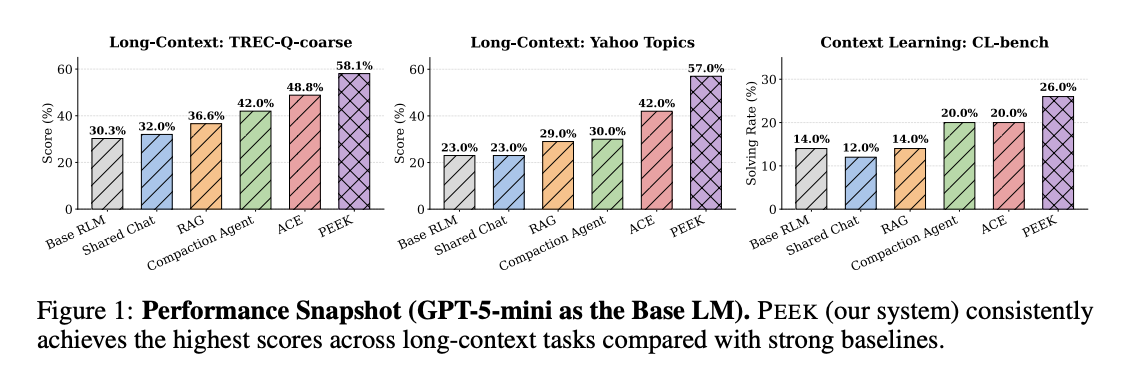
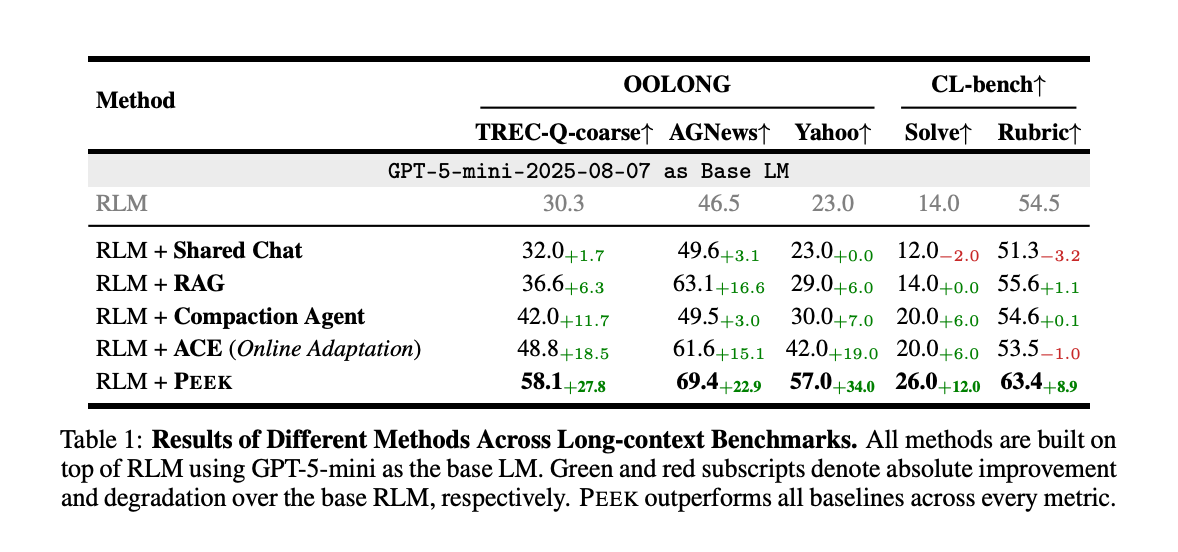
- 品質の向上: OOLONGで6.3〜34.0%、CL-benchでSolving Rate 6.0〜14.0% / Rubric Accuracy 7.8〜12.1%の改善を達成した。特に最先端のプロンプト学習フレームワークであるACEと比較して、OOLONGで10.7%、CL-benchでSolving Rate 6.0% / Rubric Accuracy 9.9%の性能向上を示した。
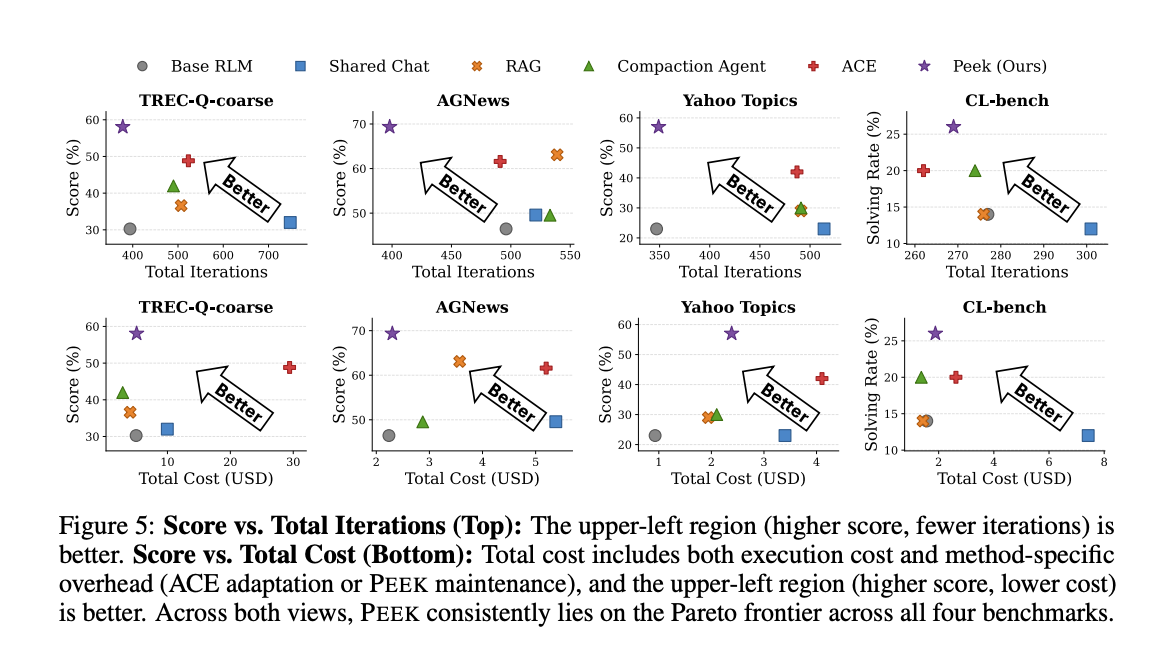
- イテレーション数の削減: PEEKは、すべてのベンチマークで品質-イテレーションのパレート最適フロンティア上に位置し、ACEより93〜145イテレーション少ない使用で、大幅に優れた品質を提供した。
- コスト-品質のトレードオフ: PEEKは、すべてのベンチマークでコスト-品質のパレート最適フロンティア上に位置し、ACEより1.7〜5.8倍低いコストで、より高い品質を実現した。
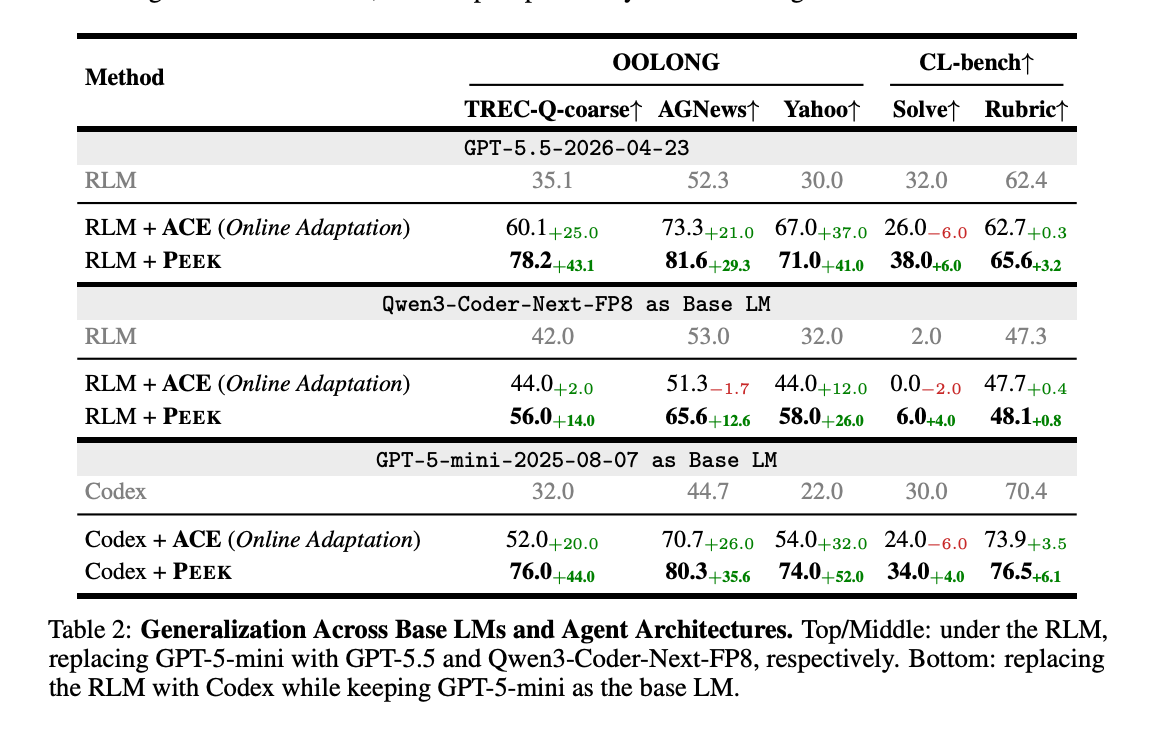
- 汎化性能: GPT-5.5、Qwen3-Coder-Next-FP8といった異なるLMや、OpenAI Codexといった異なるエージェントアーキテクチャに対しても、一貫した性能向上が確認され、PEEKの汎用性を示唆している。
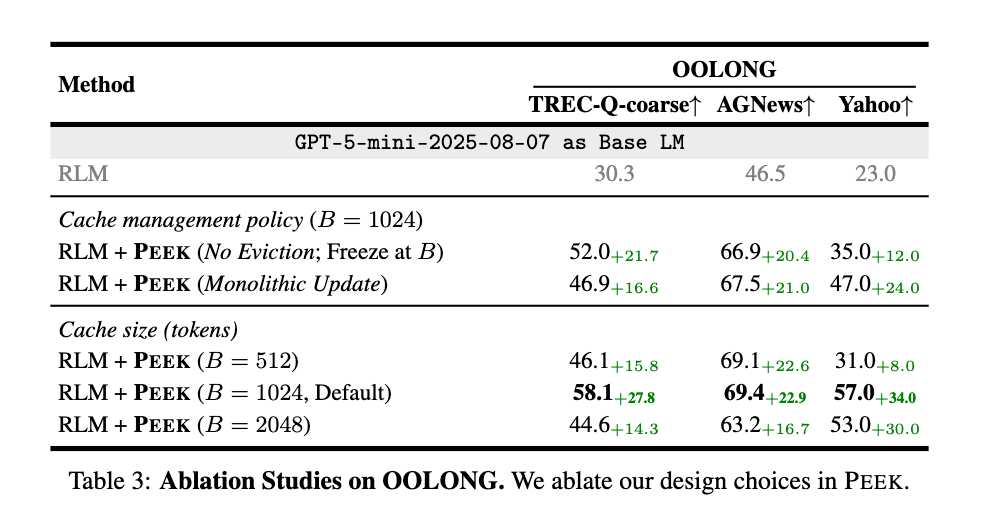
- DistillerとCartographerを分離し、優先度に基づくEvictorを含むPEEKのフルポリシーが、最も効果的なキャッシュ管理戦略であることが示されている。
- どのキャッシュサイズでも、ベースRLMに比べて大幅な改善が見られました。512トークン: 平均+15.5%1024トークン: 平均+27.8% (OOLONG TREC-Q-coarseで最も良い結果)2048トークン: 平均+20.3%この結果は、コンテキストマップの存在そのものが、その正確なサイズよりも重要であることを示唆しています
@Ryuhei Kawabata
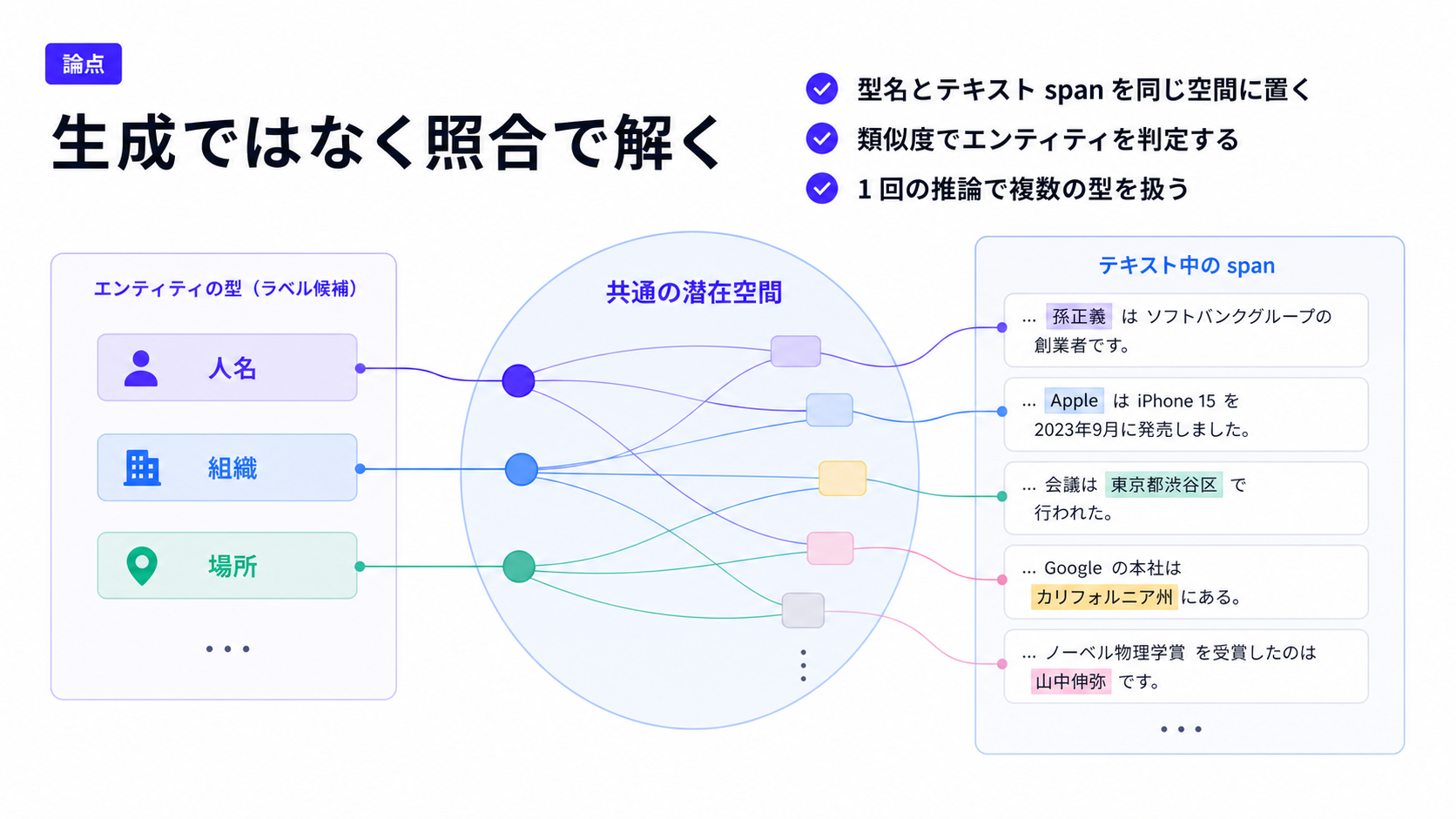
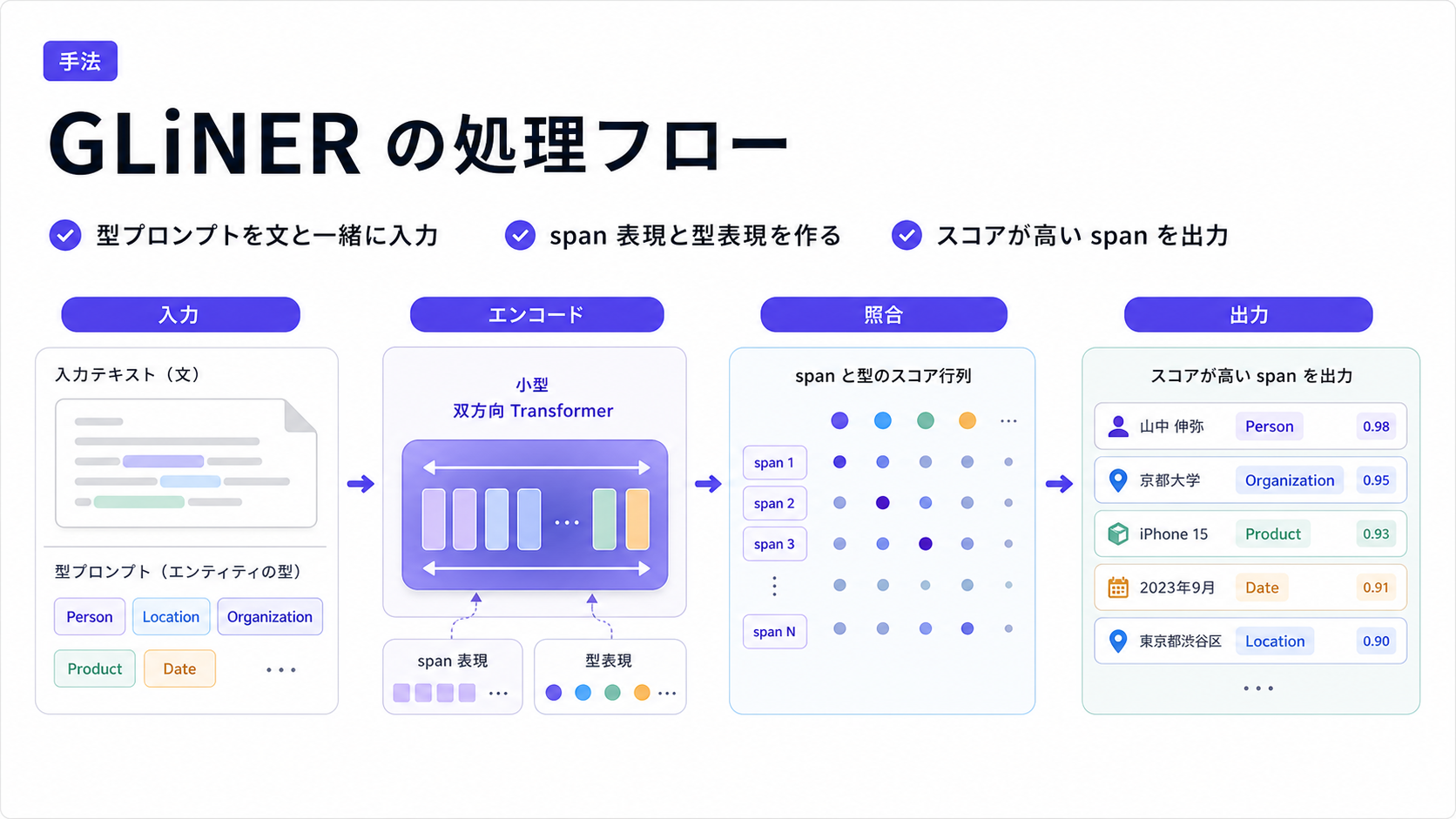
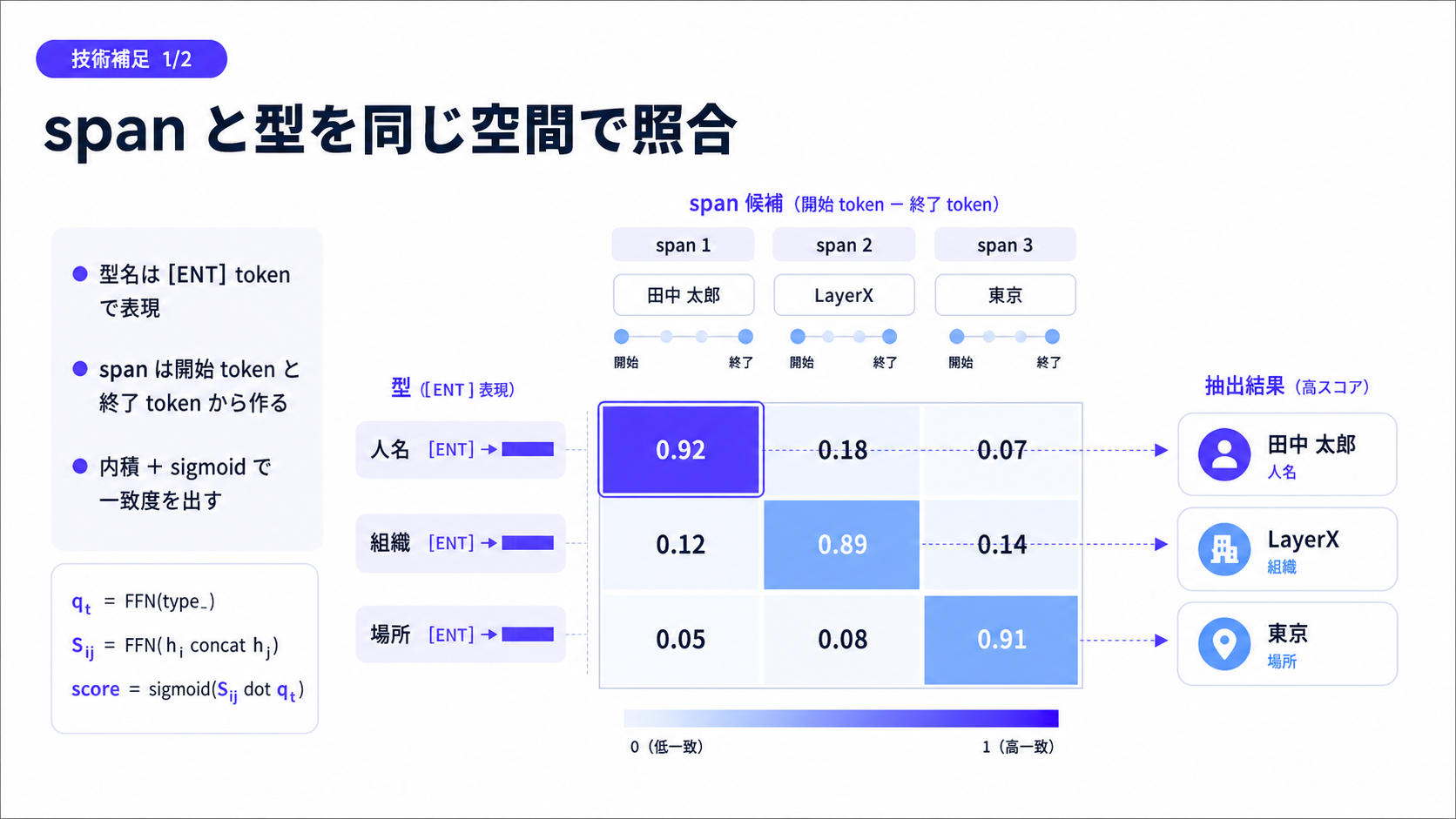
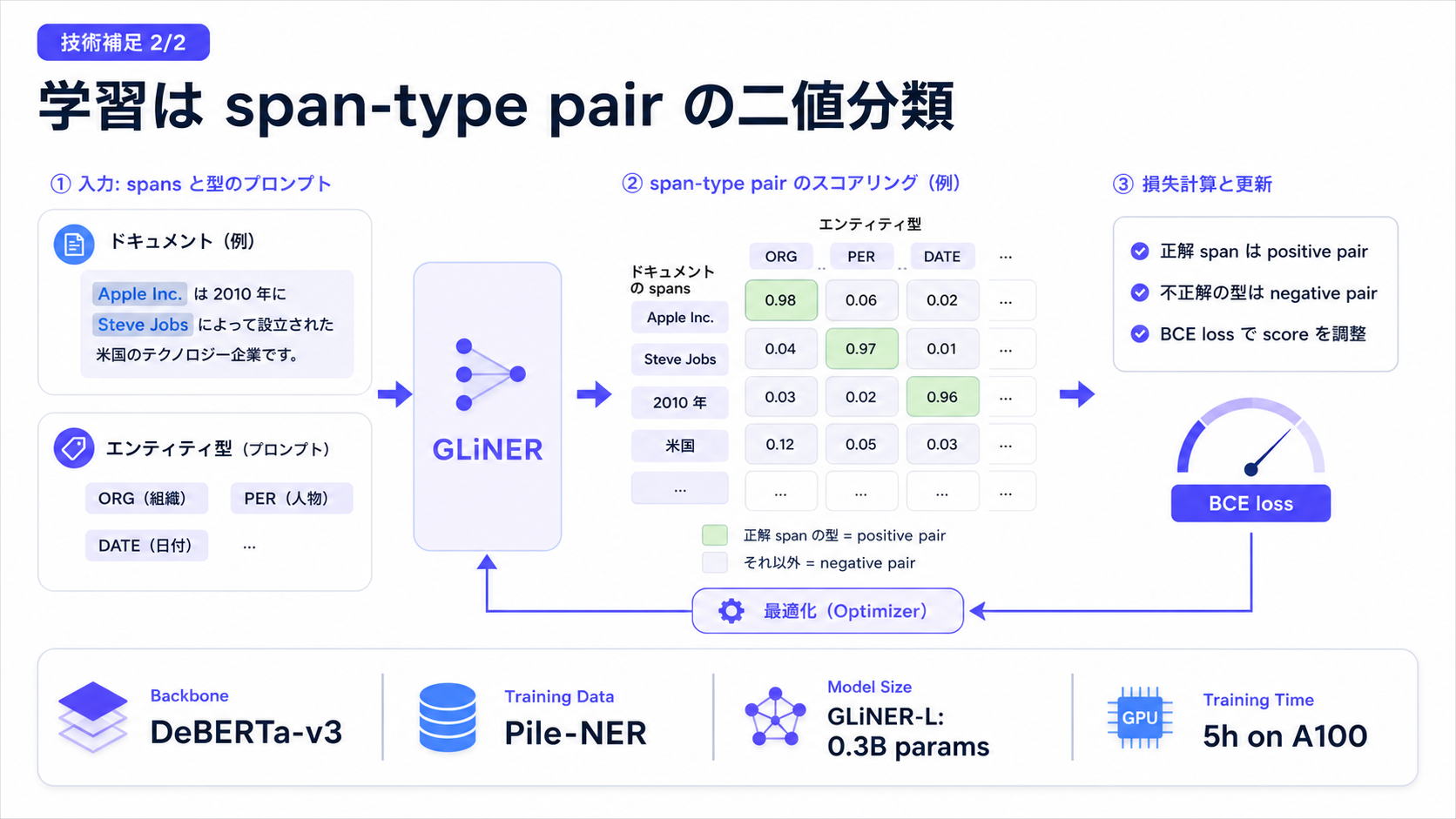
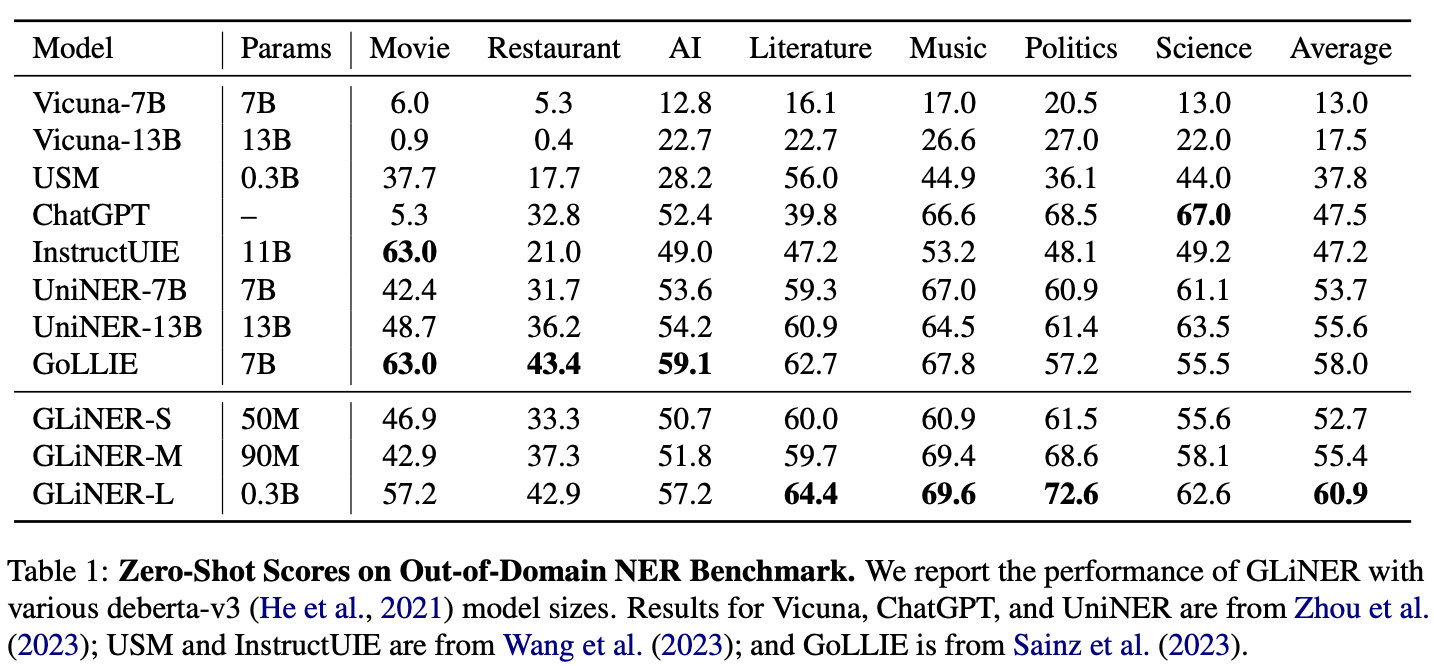
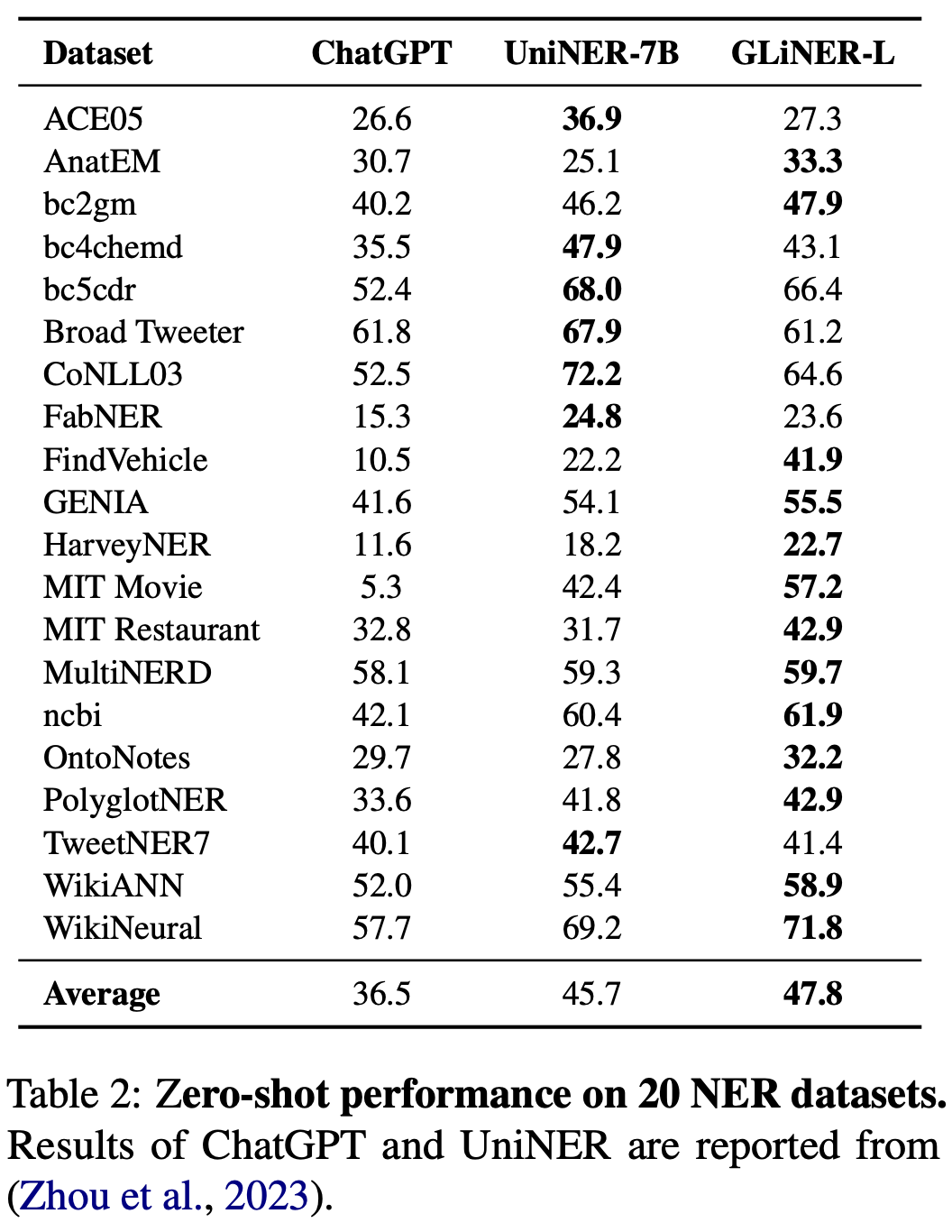
[paper] GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer
[monoke]
- OpenNER, ラベルフリーな NER 抽出 Encoder 型モデル
- 2024年で少し古いものの, その後 GLiNER2 (EMNLP2025) と続いており, 手段として知っておくのは良さそう
| 項目 | 内容 |
|---|---|
| 論文タイトル | GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer |
| 著者 | Urchade Zaratiana, Nadi Tomeh, Pierre Holat, Thierry Charnois |
| 掲載元 | NAACL 2024 (Volume 1: Long Papers) |
| 出版年・月 | 2024年6月 |
| リンク | ACL Anthology / DOI |
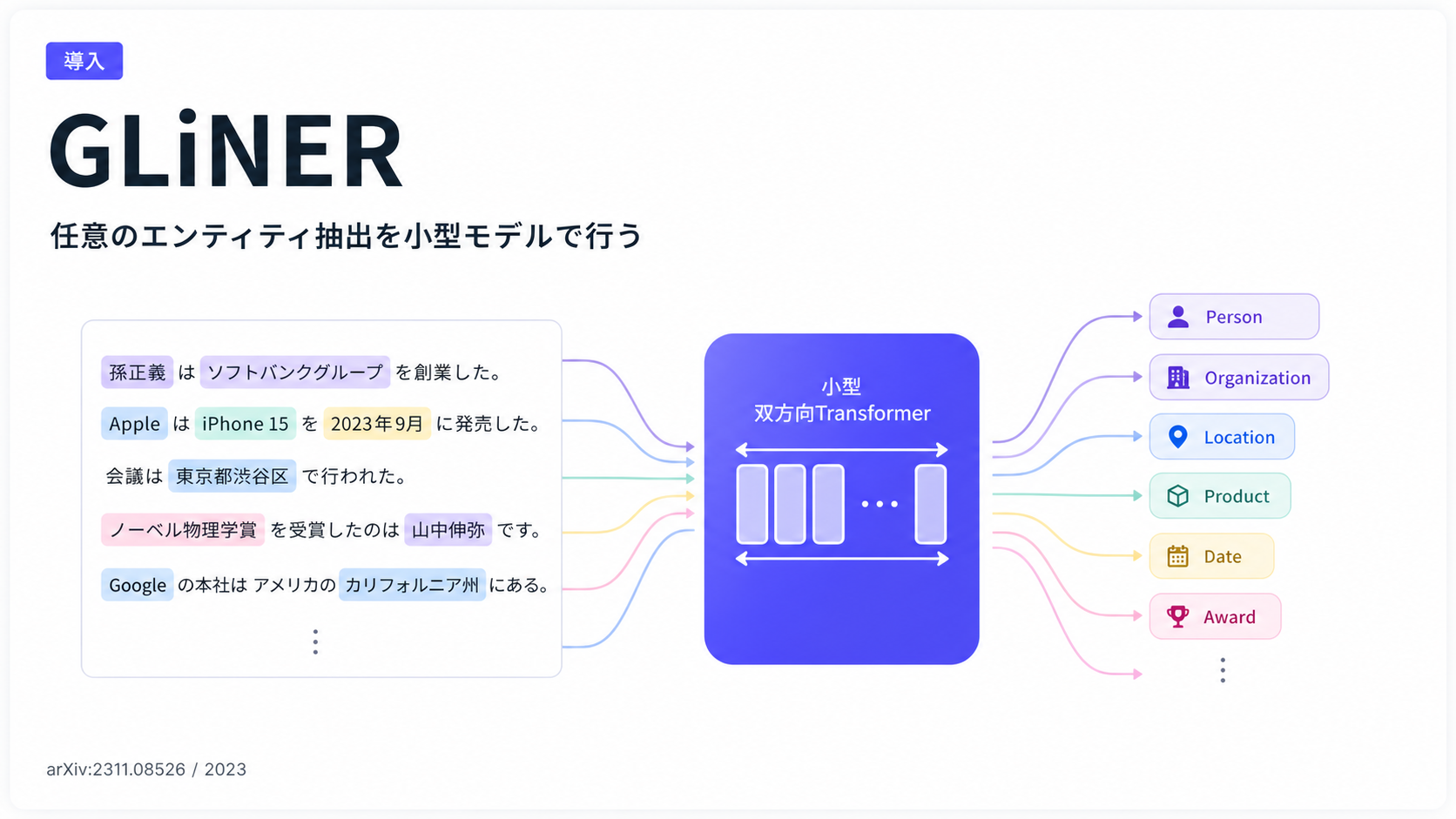
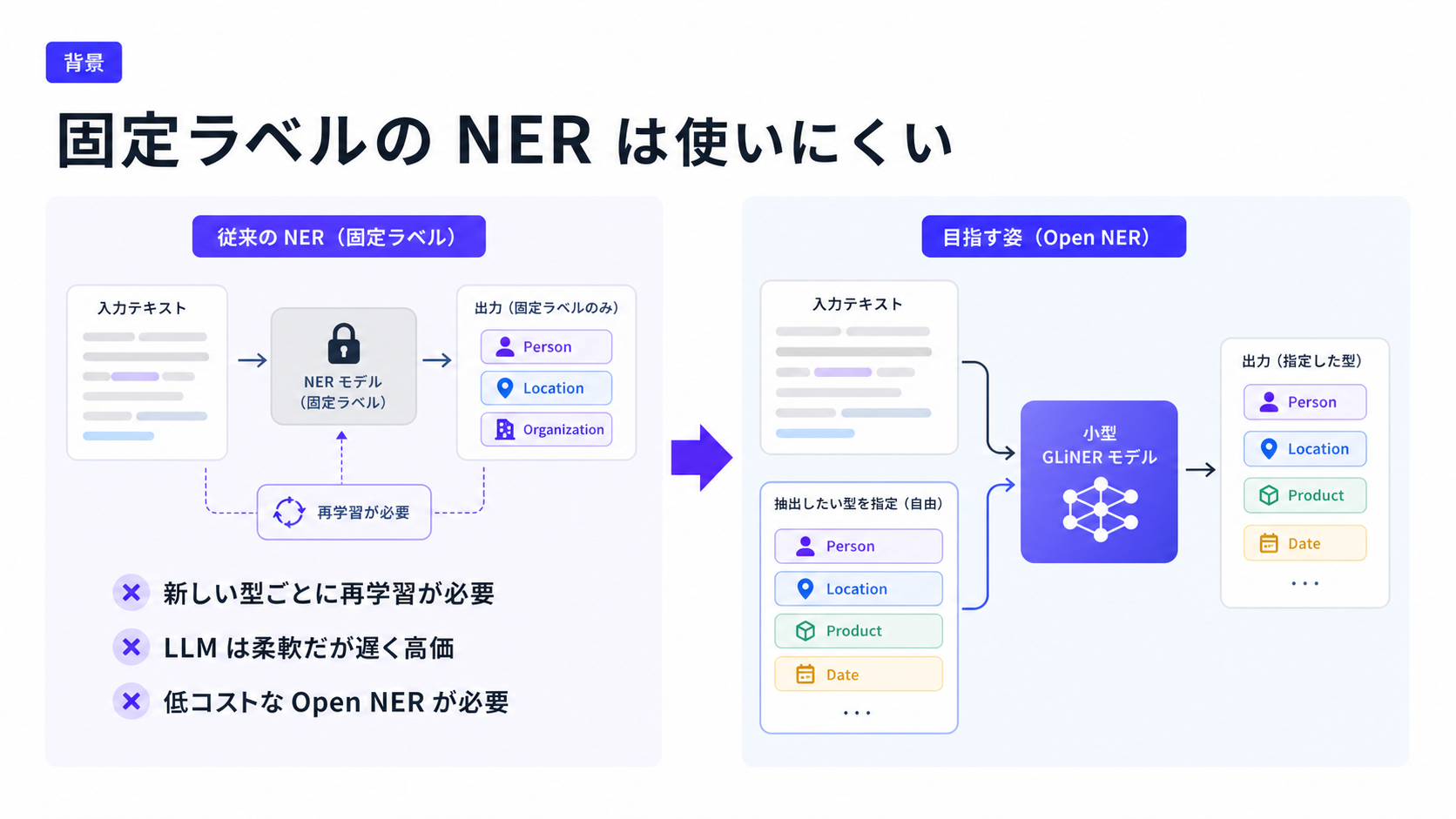



メインTOPIC
Doc2Query++: Topic-Coverage based Document Expansion and its Application to Dense Retrieval via Dual-Index Fusion
arXiv: 2510.09557 著者: Tzu-Lin Kuo, Wei-Ning Chiu, Wei-Yun Ma, Pu-Jen Cheng(National Taiwan University / Academia Sinica)
概要
Doc2Query 系の 文書展開(document expansion) は語彙ミスマッチを潰すための定番だが、生成クエリが冗長・幻覚・偏りがあり、特に 密検索(dense retrieval)では文書埋め込みにノイズを混ぜて性能を落とす という長年の問題があった。本論文は (1) BERTopic による教師なしトピックモデリングと KeyBERT を組み合わせたハイブリッドキーワード抽出、(2) LLM への構造化プロンプトによる トピック全網羅型のクエリ生成、(3) テキスト index と生成クエリ index を分けて max-pool で融合する Dual-Index Fusion の3点で再設計。BEIR 5 データセット × 疎/密の全 10 設定で既存 Doc2Query/Few-shot LLM をすべて上回り、疎で +1〜5%、密で +2〜11% の改善。
背景
検索の根本問題は 語彙ミスマッチ(クエリ語と文書語が一致しない)。これに対する2系統:
- Query expansion: クエリ側を膨らます。再 index 不要だが文脈情報を活かしにくい
- Document expansion: 文書側に擬似クエリを書き足してから index 化。Doc2Query [Nogueira+ 2019] / DocTTTTTquery がデファクト
Doc2Query 系は T5 などで「この文書から想定されるクエリ」を seq2seq 生成し、文書末尾に連結する。BM25 ではこれが効くが、以下の限界がある:
- 制御がない: 生成は幻覚・冗長・低多様性。同じ表面語ばかり繰り返してトピックを漏らす
- OOD に弱い: MS MARCO で学習した生成モデルが BEIR のドメインに転移しない
- 密検索を逆に劣化させる: 生成クエリを文書に連結すると、強い dense encoder の埋め込みに 意味的ノイズが混入 する。Weller+ (2023) が指摘済み
- タクソノミー依存の派生: CCQGen [Kang+ 2025] は事前定義タクソノミーで網羅を担保するが、ドメイン汎用性を失う
手法
コアアイデア
文書 から トピック集合 を教師なしで抽出 → トピック由来+文書由来の キーワードプール を LLM で絞り込み → そのキーワードとトピックを LLM プロンプトに渡して 複数クエリ を生成 → 疎検索ではクエリを文書に追記、密検索ではクエリを別 index に置いてスコア融合する。
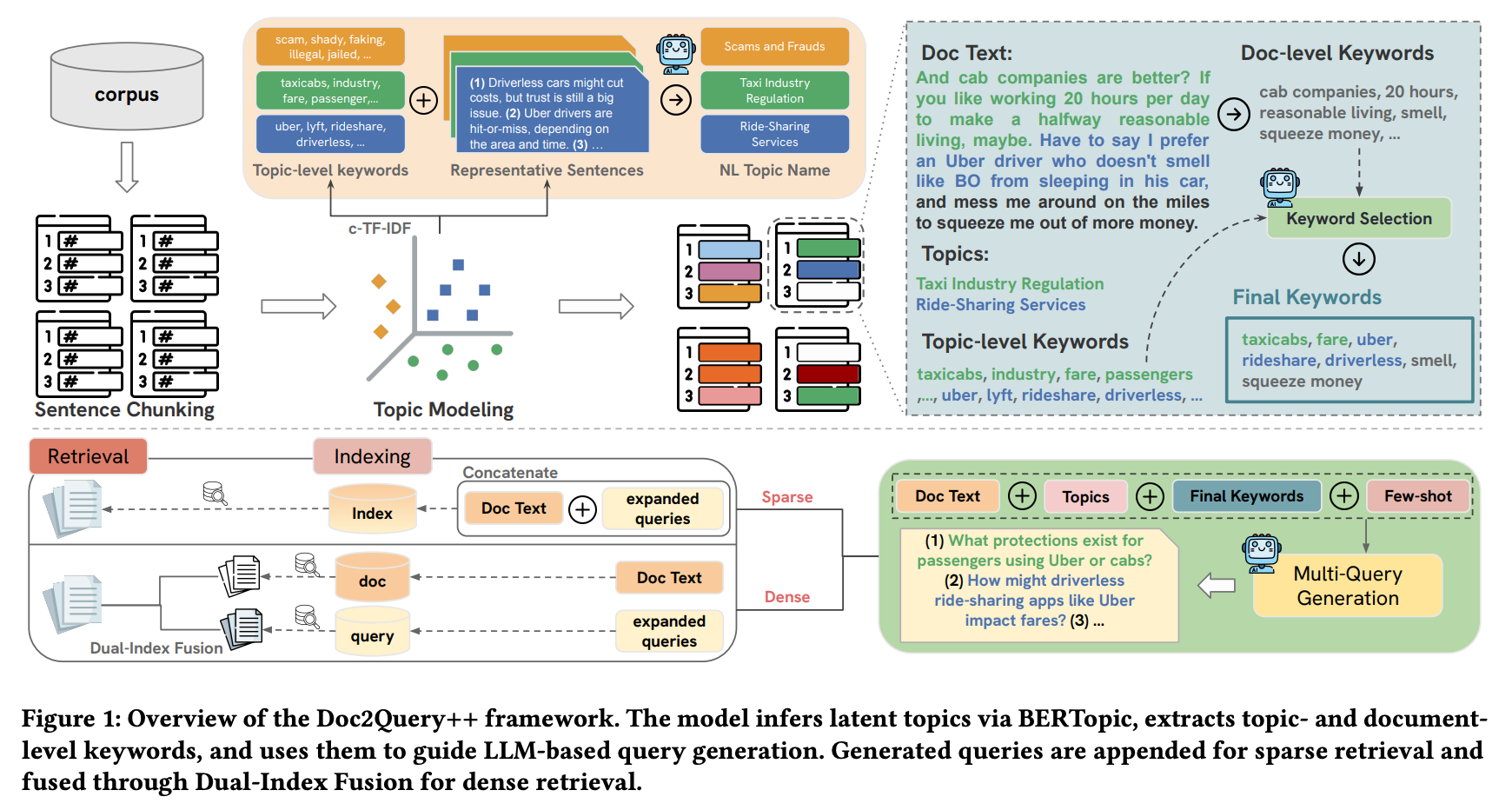
Stage 1: 文レベルトピックモデリング(BERTopic)
文書 を文 に分割。各文を SBERT で埋め込み し、コーパス全体で HDBSCAN クラスタリングして 個のトピック中心 を得る。各文は最近傍トピックに割り当てる:
文書のトピック集合は
つまり「文書 d がカバーしているトピック群」が明示的に手に入る。
なお、HDBSCAN で得たクラスタには自然言語のトピック名が付いていないため、LLM でトピック名を精製するステップがある。
📝 トピック名精製プロンプト(Appendix A.1)
日本語訳:
Stage 2: ハイブリッドキーワード抽出
2つの異なるソースからキーワードを抽出し、LLM で絞り込む:
- トピック由来 : BERTopic の c-TF-IDF から各トピック上位 10 語
- 文書由来 : KeyBERT で文書から上位 20 n-gram(MMR, で冗長除去)
候補プール から、LLM が文書本文を参照して最終 10 語 を選ぶ。
📝 キーワード選定プロンプト(Appendix A.2)
日本語訳:
📖 用語: c-TF-IDF は BERTopic 流の「クラスタを擬似文書として TF-IDF を計算」する手法で、トピック特徴語を出すのに使う。KeyBERT は SBERT 埋め込みでの cos 類似に MMR を組み合わせた抽出。両者は性質が異なる(テーマの広がり重視 vs 文書への忠実さ重視)ので相補的に使うのがポイント。📖 用語補足: MMR(Maximal Marginal Relevance): キーワード抽出時に「似たようなキーワードばかり選ぶ」問題を防ぐアルゴリズム。スコアは で計算され、「文書に関連するが、既に選んだものとはなるべく異なるキーワード」を優先的に選ぶ。 は関連度重視しつつ 3 割の重みで多様性も確保する設定。
Stage 3: トピック被覆型クエリ生成
LLM に文書本文 ・トピック集合 ・キーワード を渡し、few-shot プロンプトで クエリを生成。1回の LLM 呼び出しで クエリずつ生成し、計 10 回呼んで 30 クエリに到達させる。一度に 30 クエリを生成させると特定トピックに偏りやすいため、小刻みに生成して未カバーのトピックへ意識を向けさせる狙い。プロンプト設計上、各トピックを少なくとも1つはクエリでカバーする ように指示。temperature 0.8。
📝 クエリ生成プロンプト(Appendix A.3)
日本語訳:
Stage 4: 疎検索と密検索への適用
疎検索(BM25): 単純に文書に追記して再 index。
密検索: Dual-Index Fusion 文書のテキストとクエリを 分離した 2 つの index に置く:
- テキスト index : 文書埋め込み
- クエリ index : 生成クエリ埋め込み
検索時、クエリ に対し:
ポイントは max-pool: 生成クエリのうち最も入力クエリに似た 1 つだけがスコアに寄与する。これにより外れクエリが平均で薄まらず、かつテキスト埋め込み には生成クエリの汚染が一切入らない。
実験
実験設定
| 項目 | 内容 |
|---|---|
| データセット | BEIR から NFCorpus / SCIDOCS / FiQA-2018 / ArguAna / SciFact(下記補足参照) |
| ベースライン | BM25, Doc2Query (T5-base), Doc2Query−− (ELECTRA filter), Zero-shot LLM, Few-shot LLM (Promptagator 風) |
| 密検索エンコーダ | Contriever (msmarco) |
| LLM | LLaMA-3.1-8B-Instruct, temperature 0.8 |
| 生成クエリ数 | 全手法 30 クエリ/文書で揃える |
| 評価指標 | MAP, nDCG@10, Recall@100 |
| Dual-Index | , テキスト index top-300 と クエリ index top-1000 を融合 |
📖 データセット補足(BEIR): BEIR は異なるドメイン・タスクの検索ベンチマーク集で、OOD(out-of-domain)汎化性能を測るのに使われる。本論文で使われた5つ:
データセット ドメイン タスク クエリ数 文書数 NFCorpus 生物医学・栄養学 NutritionFacts.org の自然言語クエリ → PubMed 論文抄録 323 3,633 SCIDOCS 科学文献 論文抄録をクエリとした引用予測を検索タスクに変換 1,000 25,657 FiQA-2018 金融 投資家の質問 → ニュース・レポートの文章 648 57,638 ArguAna 議論・討論 議論文に対する反論の検索 1,406 8,674 SciFact 科学的事実検証 科学的主張 → 根拠となる論文抄録の検索 300 5,183
📖 ベースライン手法の比較:
Doc2Query Doc2Query−− Zero-Shot LLM Few-Shot LLM Doc2Query++ モデル T5-base (220M) T5-base + ELECTRA フィルタ LLaMA-3.1-8B LLaMA-3.1-8B LLaMA-3.1-8B 学習 MS MARCO で教師あり FT 同左 + フィルタも教師あり FT instruction tuning 済みをそのまま 同左 同左 プロンプト例示 なし(学習済み分布から生成) 同左 なし 6組の (文書,クエリ) ペア 6組の (文書,クエリ) ペア トピック指定 なし なし なし なし BERTopic で抽出 キーワード指定 なし なし なし なし c-TF-IDF + KeyBERT ノイズ制御 なし(全クエリ追記) ELECTRA で低品質クエリを除外 なし なし トピック被覆で生成品質自体を向上 密検索での適用 文書に連結(Append) 同左 同左 同左 Dual-Index Fusion(別index) OOD 汎化 弱い(MS MARCO 特化) 同左 中程度(汎用知識あるがガイドなし) 中程度 強い(教師なしトピック + LLM) 生成クエリ数 30 30(生成後フィルタで減る) 30 30 30(3クエリ×10回)
全手法の検索性能比較
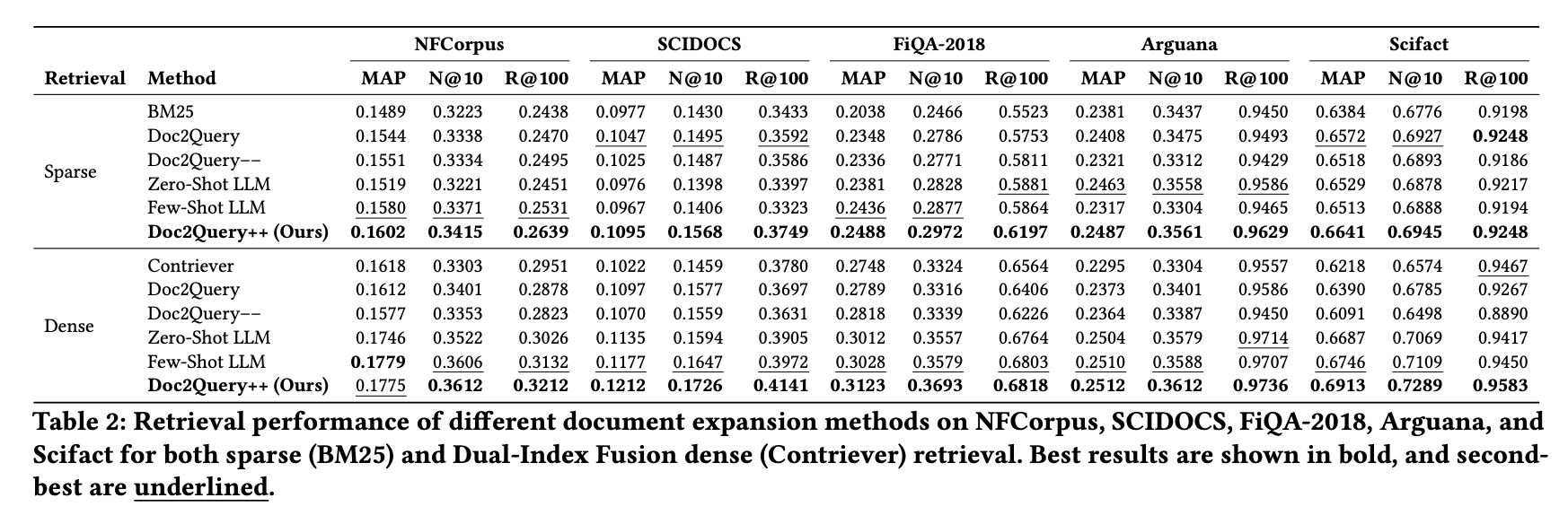
- 展開なしベースライン(疎=BM25, 密=Contriever)からの nDCG@10 改善幅は疎で +1〜5%、密で +2〜11%。
- Doc2Query−− は必ずしも Doc2Query より良くない: ELECTRA フィルタでノイズを除去するはずの Doc2Query−− が、ArguAna(疎)や SciFact(密)では素の Doc2Query より悪化している。フィルタが有用なクエリまで落としているケースがある。
- Zero-Shot / Few-Shot LLM は疎検索で不安定: NFCorpus・SCIDOCS の疎検索では Zero-Shot LLM が BM25 以下になる場面もある(NFCorpus nDCG: 0.3221 vs BM25 0.3223)。LLM のクエリ生成は質が高くても、トピック網羅がないとドメイン固有の語彙にヒットしない。
- 密検索での改善幅が疎より大きい: 特に SciFact(nDCG: 0.6574→0.7289, +10.9%)や SCIDOCS(nDCG: 0.1459→0.1726, +18.3%)で顕著。Dual-Index Fusion がノイズ回避と信号強化を同時に達成していることの証左。
- Recall@100 の改善が目立つ: SCIDOCS 密で 0.3780→0.4141(+9.6%)、FiQA 疎で 0.5523→0.6197(+12.2%)。トピック被覆によって「これまで上位 100 に入れなかった関連文書」を拾えるようになっている。
- NFCorpus 密の MAP で唯一 Few-Shot LLM に僅差で負ける(0.1775 vs 0.1779)が、nDCG@10 と Recall@100 では Doc2Query++ が上回っており、総合では優位。
Dual-Index Fusion の効果
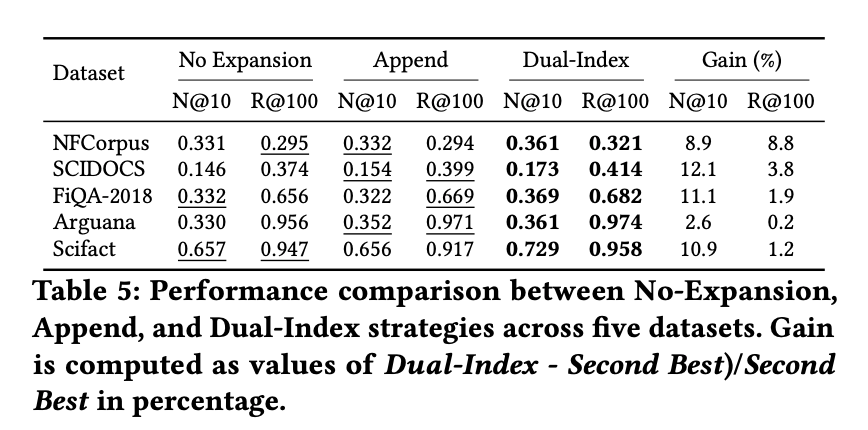
- FiQA では 連結方式(Append)が無展開より逆に悪化 している。これが「dense retrieval に生成クエリを混ぜると壊れる」現象の直接証拠。Dual-Index にすると一気に逆転して大幅改善。
- Dual-Index は全セルで展開なしを上回る: Append が悪化するケースでも Dual-Index は一貫して改善しており、ノイズ混入を構造的に回避できていることがわかる。
- nDCG@10 の改善幅が Recall@100 より大きい: nDCG は +2.6〜12.1% に対し Recall は +0.2〜8.8%。max-pool で「最も関連する1クエリ」だけを採用する設計が、上位ランキングの精度向上に特に効いている。
- (融合重み)の影響: 論文の分析(Section 4.2.5)によると、精度(nDCG@10)は でピーク、Recall は が大きいほど改善する傾向。ただし (クエリ index のみ)では性能が低下し、元テキストの埋め込みが依然として不可欠であることを示している。
各コンポーネントの寄与分析
Doc2Query++ の 3 つの構成要素(Few-shot 例示 / キーワード指定 / トピック指定)を段階的に追加し、それぞれの寄与を分離する。
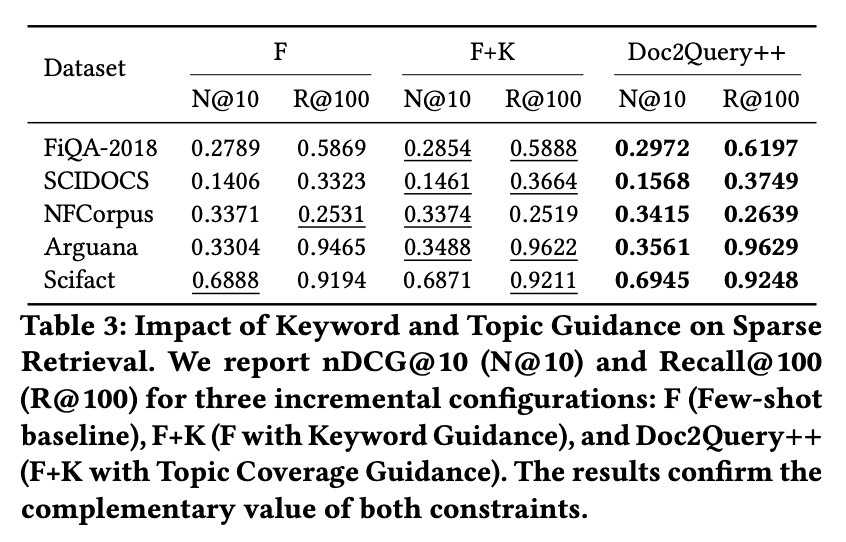
- F → F+K(キーワード追加)の効果: SCIDOCS(nDCG +3.9%, Recall +10.3%)や ArguAna(nDCG +5.6%)で大きく効く。KeyBERT + c-TF-IDF のハイブリッドキーワードが、LLM の生成を文書に忠実な方向に誘導している。一方 NFCorpus では nDCG がほぼ横ばい(+0.1%)、Recall はむしろ微減(−0.5%)で、ドメインによってはキーワードだけでは不十分。
- F+K → F+K+Topic(トピック追加)の効果: 全データセットで一貫して改善。特に FiQA(nDCG +4.1%, Recall +5.2%)と SCIDOCS(nDCG +7.3%)で顕著。キーワードが「何の語を使うか」を制御するのに対し、トピックは「どの話題をカバーするか」を制御しており、相補的に機能している。
- 改善は単調増加: F → F+K → F+K+Topic の順で、ほぼ全セルで単調に改善している。各コンポーネントが独立に正の寄与を持ち、互いに打ち消し合っていないことを示す。
- Recall@100 の改善幅が nDCG@10 より大きい傾向: SCIDOCS(Recall +12.8% vs nDCG +11.5%)、FiQA(Recall +5.6% vs nDCG +6.6%)。トピック被覆を上げると「これまで取りこぼしていた関連文書」が上位 100 に入るようになる効果が大きい。
クエリ数のスケーリングとトピック被覆の関係
クエリ「数」vs「被覆」(Figure 3, FiQA 疎)
生成クエリ数と性能の関係(Figure 3, FiQA-2018 疎検索)
Doc2Query(T5)のクエリ数を 10〜200 まで変化させた場合と、Doc2Query++ の 30 クエリを比較
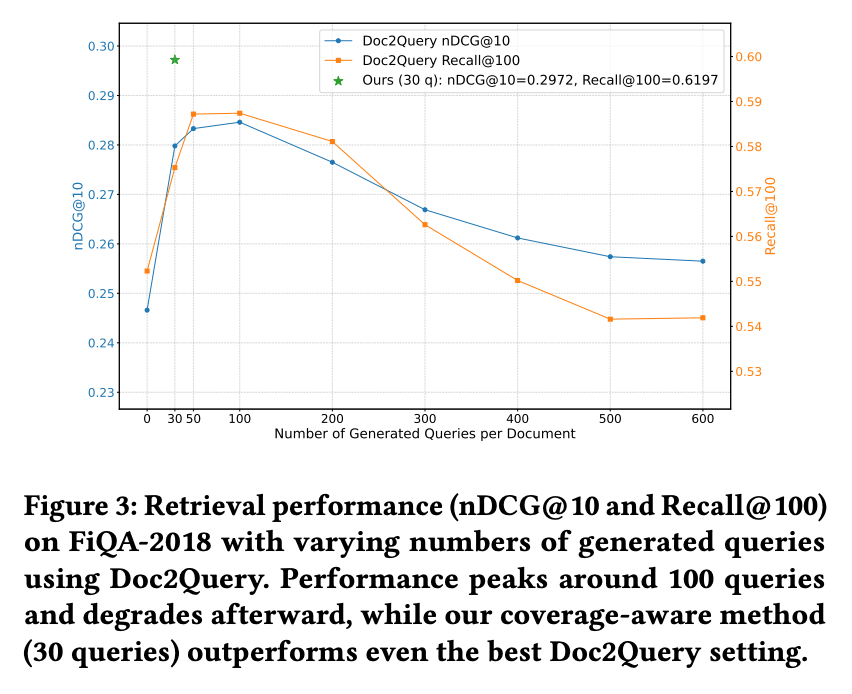
- Doc2Query は 100 クエリでピーク に達し、それ以上増やすと冗長・ノイズが増えて性能が低下する(飽和点)
- Doc2Query++ は わずか 30 クエリで Doc2Query の 100 クエリのピークを上回る(nDCG +2.4%, Recall +3.6%)
- つまり「量で殴る」アプローチには限界があり、トピック網羅による構造化の方が情報効率が圧倒的に高い
トピック被覆率と検索性能の相関(Figure 2)
著者は topic recall(生成クエリが文書のトピックをどれだけカバーしたか)と検索性能改善の Pearson 相関を分析:
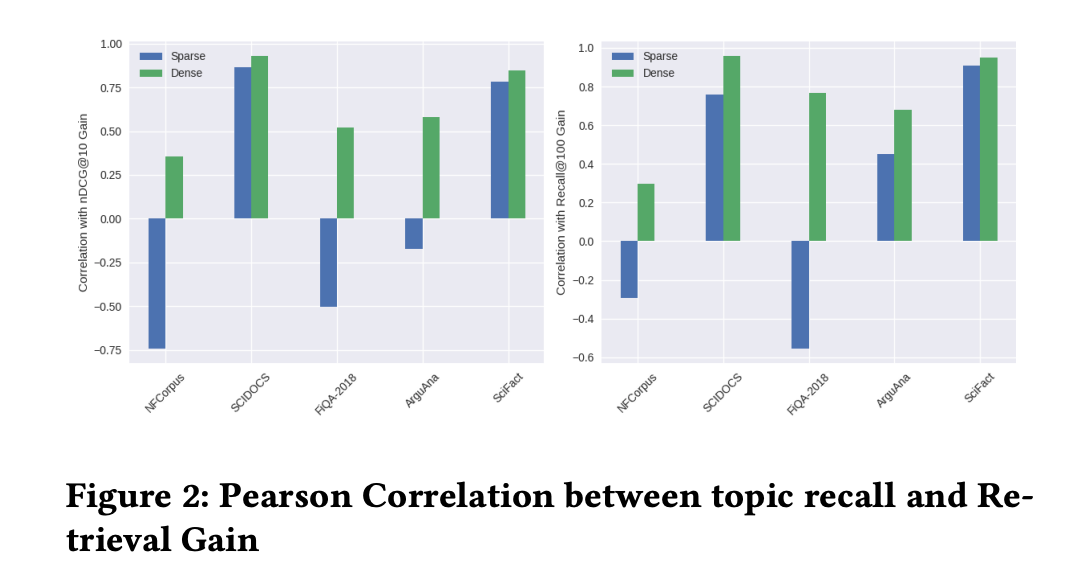
| 検索方式 | topic recall と nDCG@10 改善の相関 | 解釈 |
|---|---|---|
| 密検索 | r > 0.6(強い正相関) | トピック被覆を上げるほど性能が上がる |
| 疎検索 | 相関が弱い〜負 | 被覆を上げても BM25 では必ずしも効かない |
📖 なぜ疎と密で相関が逆転するのか
- 密検索: Contriever はトークン埋め込みの平均で文書を表現する。多様なトピックの語彙が加わると平均ベクトルが意味的に豊かになり、多様な検索クエリにヒットしやすくなる → 被覆 ↑ = 性能 ↑
- 疎検索(BM25): 単語の完全一致でスコアリングする。新語彙を追加しても検索クエリと一致しなければスコアに寄与せず、文書が長くなることで BM25 の文書長正規化により既存の一致語のスコアが薄まる → 被覆 ↑ でも性能 ↑ とは限らない
キーワード抽出戦略の比較: KeyBERT vs Topic vs LLM 融合
キーワードの抽出元を変えたときの影響を比較する。3 つの戦略:
- KeyBERT: 文書から KeyBERT(SBERT 埋め込み + MMR)で抽出したキーワードのみ使用
- Topic: BERTopic の c-TF-IDF から抽出したトピックキーワードのみ使用
- LLM 融合(Doc2Query++ 方式): 両方の候補プールから LLM が文書を参照して最終選定
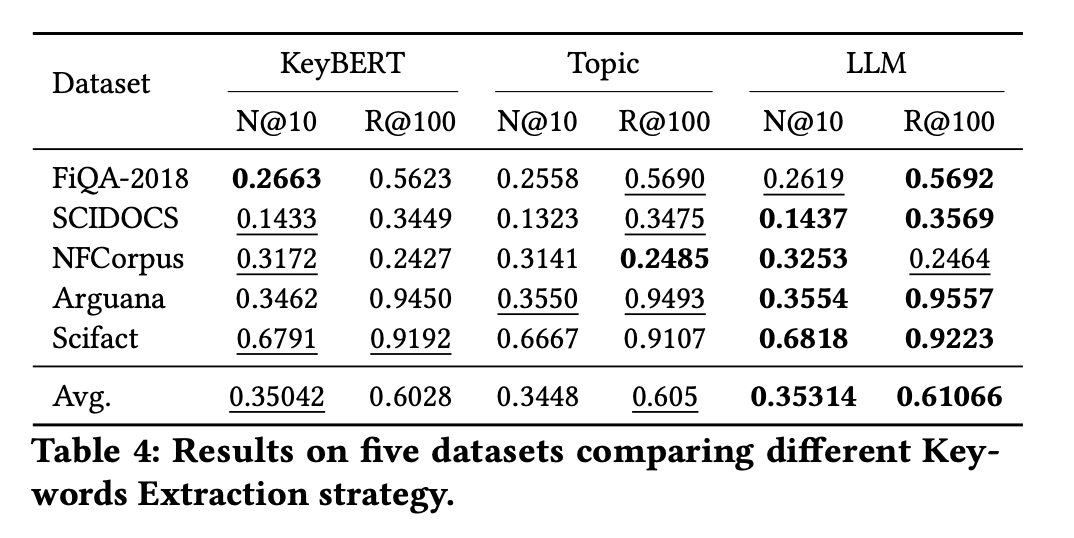
- KeyBERT は nDCG@10(精度)優位: 5 データセット中 4 つで Topic より高い nDCG。KeyBERT は文書本文から直接キーワードを抽出するため、文書に忠実な語が選ばれ、既存の検索信号を強化する方向に働く。
- Topic は Recall@100(網羅性)優位: 5 データセット中 3 つで KeyBERT より高い Recall。c-TF-IDF はクラスタ(トピック)の特徴語を抽出するため、文書本文に直接出現しない関連語も拾える → 検索の取りこぼしが減る。
- LLM 融合が両者のいいとこ取り: 平均 nDCG・平均 Recallともに単独手法を上回る。LLM が文書本文を参照しながら候補プールから選定することで、精度寄与の KeyBERT 語と網羅性寄与の Topic 語をバランスよく混ぜている。
- KeyBERT と Topic の性質の違いが相補性の源泉: 「文書に書いてある語」(KeyBERT)と「そのトピック全体で重要な語」(Topic)は観点が異なる。例えば金融文書で KeyBERT が "index fund" を拾い、Topic が "dollar cost averaging" を拾うといった補完関係が生じる。
限界と今後
- トピック数 の自動決定 が HDBSCAN 任せ → ハイパラ最適化の余地
- の固定(Dual-Index Fusion でテキスト index と クエリ index のスコア配分を決める重み)→ データセット適応的選定は未実装
- 計算コスト: 3-stage pipeline は重い。蒸留や軽量化が未検討
- 多言語 / マルチモーダルへの拡張 は今後の課題
- 疎検索(BM25)ではトピック被覆を上げて新語彙を追加しても、検索クエリと完全一致しなければスコアに寄与せず、文書が長くなることで既存の一致語のスコアも薄まるため、被覆を上げるほど性能が下がるケースがある。疎検索向けのノイズ制御(フィルタリング等)は未検討
- few-shot 例示の 手動キュレーション がデータセットごとに必要(スケーラビリティの壁)
行ったりとかみたいなことを