2026-06-02 機械学習勉強会
今週のTOPIC[paper] Progressive Searching for Retrieval in RAG[paper]Vector Policy Optimization: Training for Diversity Improves Test-Time Search[paper] DiffusionBlocks: Block-wise Neural Network Training via Diffusion InterpretationメインTOPICToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration概要背景問題設定提案手法: ToolOrchestraReward DesignToolScale実験設定結果分析
今週のTOPIC
@Hiromu Nakamura (pon)
[paper] Progressive Searching for Retrieval in RAG
[pon]どシンプルな手法ですぐ使えるかも
RAGシステムにおける高次元ベクター検索の効率性と精度を両立させるため、本研究は、低次元での検索から始め、徐々に次元を上げて候補を絞り込む「Progressive Retrieval」アルゴリズムを提案。
Progressive Retrieval
提案するProgressive Retrievalは、マルチステージの検索プロセスを通じて候補文書を段階的に絞り込む手法である。この方法は、低次元での検索から開始し、徐々に高次元へと移行することで、計算コストを削減しつつ高い検索精度を維持する。
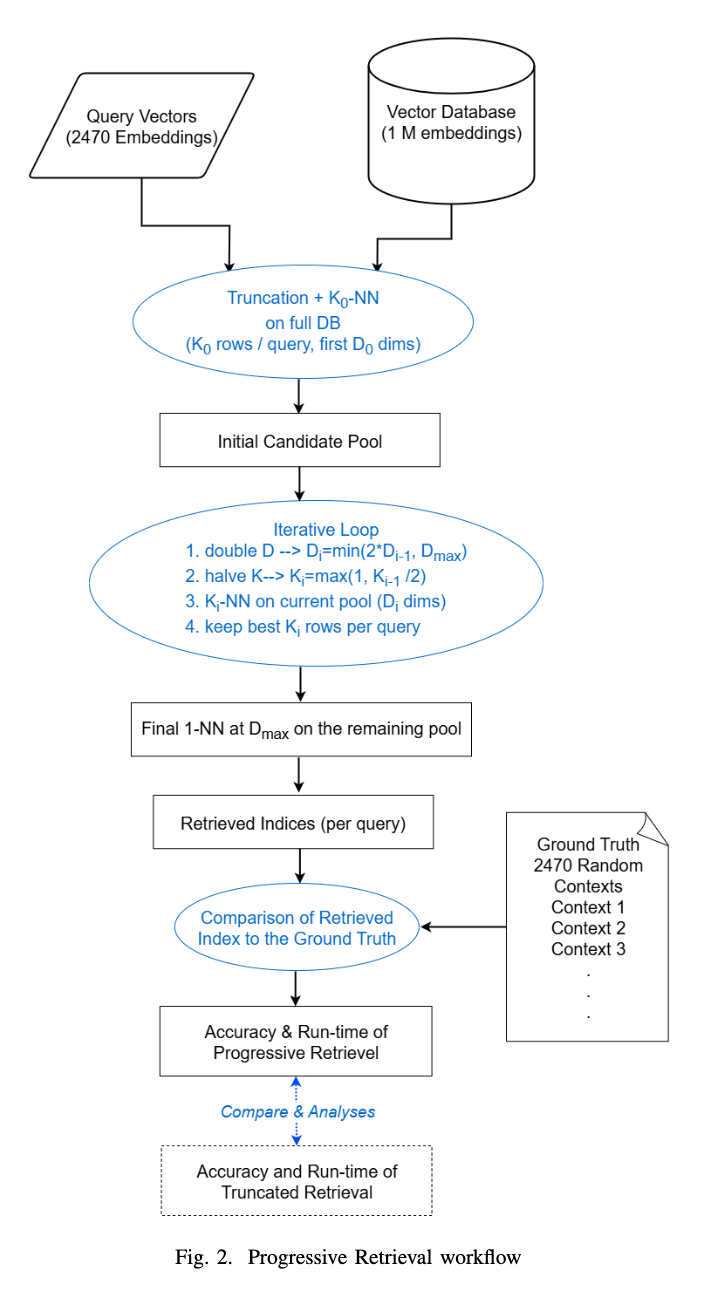
初期段階 (Initial Search):
- starting_dimensionとinitial_Kというパラメータが設定される。
- starting_dimension(例:64、128など)は、最初の検索に使用される低次元のベクトル空間の次元数である。
- initial_K(例:4、8、16など)は、この初期検索で各クエリに対して取得される最も近い近傍の数である。
- 検索は、全データセット(本研究では100万文書)に対してstarting_dimensionで実行され、initial_K個の近傍が抽出される。これらの近傍は候補プールに集められ、重複は除去される。この初期ステップが、全体の検索時間と精度に最も大きな影響を与える。
段階的絞り込み (Iterative Refinement):
- 初期検索の後、ループに入る。各イテレーションで、現在の次元数を倍増させる。 新しく設定された次元がmax_dimension(目標とする最終的な次元数)未満であるかを確認する。
- もし新次元がmax_dimension未満であれば、前段階で取得されたK値(近傍数)を半分にする(ただし最小値は1)。
- この更新されたK値と新しい次元数を用いて、先のステップで絞り込まれた候補プールに対してのみ検索を実行する。候補プールはイテレーションごとに大幅に小さくなるため、高次元での計算コストが劇的に削減される。
- このプロセスは、倍増された次元がmax_dimension以上になるまで繰り返される。
最終段階 (Final Search):
- 倍増された次元がmax_dimensionに達するか、超えた時点でループは終了する。
- 最終候補プールに対して、max_dimensionで1-NN(Nearest Neighbor)検索を実行し、最終的なトップ1文書を特定する。
このマルチステージアプローチにより、検索の大部分を低次元かつ限定されたデータセットで実行することが可能となり、従来の単一ステージ検索(Truncated Retrieval)と比較して大幅な実行時間の短縮を実現する。特に、高次元での検索が全体的なコストを支配する場合において、Progressive Retrievalはその優位性を発揮する。
評価
メトリクス
- Top-1精度: 各クエリに対し最も近いネイバーを見つけるために、Scikit-learnのNearest Neighbors関数が使用され、検索されたインデックスが元のドキュメントと比較され、正解データに対する精度が算出されます。
- 中央値検索時間(実行時間): ネットワーク起因の潜在的な遅延による外れ値を避けるため、各実験は10回実施され、その実行時間の中央値が記録されます。
データセット
- コーパス: 100万件の英文コーパスとして、dbpedia-openai-1M-1536-angularデータセットが使用されました。
- グラウンドトゥルース(正解データ): 100万件のドキュメントからランダムに2,500の文が選択されました。問題のある文(主題や内容を含まないもの)を除外した後、最終的に2,470組のクリーニングされたグラウンドトゥルースが収集されました。
- クエリの生成: 各グラウンドトゥルースドキュメントは、OpenAI ChatGPT-4o APIに入力され、対応する質問が生成されました。これにより、2,470組のクエリとコンテキストのペアが用意されました。
具体的な実験設定
- gte-Qwen2-7B-instructの場合:
- starting dimensionは64, 128, 256, 512, 1024, 2048、initial Kは4, 8, 16, 32, 64, 128, 256, 512, 1024、max dimensionは128, 256, 512, 1024, 2048, 3584など、様々な組み合わせがテストされました。
- text-embedding-3-largeの場合:
- starting dimensionは128からmax dimension 3072まで、initial Kは16, 32, 64, 128の範囲でテストされました。
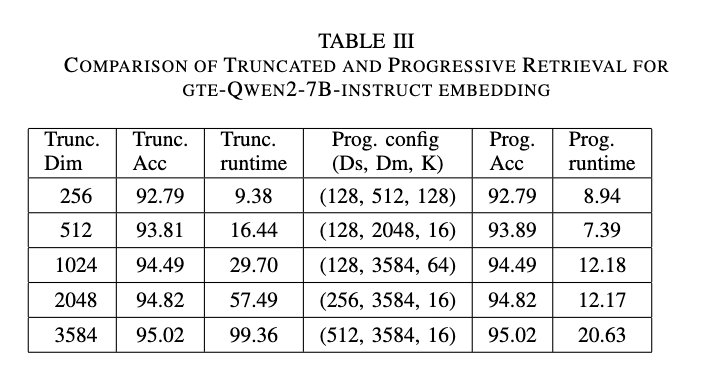
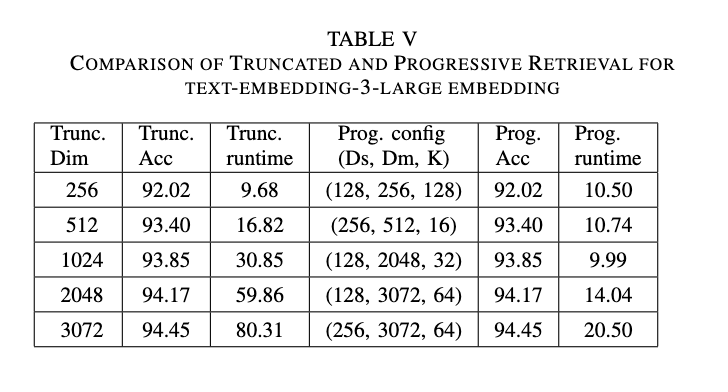
- Truncated RetrievalとProgressive Retrievalの比較結果を示しています。Progressive Retrievalは、同等または近い精度を維持しつつ、Truncated Retrievalよりも大幅に高速(約2倍から5倍)
[pon] 実際にloopで次元をあげていく手法を実験したのは面白い。ClickHouseのQBitと相性が良さそう(検索時に次元選択ができる検索データ構造)
@Kyohei Uto(kuto)
[paper]Vector Policy Optimization: Training for Diversity Improves Test-Time Search
概要
- Vector Policy Optimization (VPO) は、推論時の探索の効果を最大化するために、LLMの学習段階で回答の多様性を明示的に最適化する新しいRLアルゴリズムを提案
- 従来のRLが単一のスカラー報酬値を最大化しようとして出力が画一化してしまう問題を、報酬をベクトルとして捉え、多目的最適化問題におけるパレートフロートをカバーするように学習することで解決する
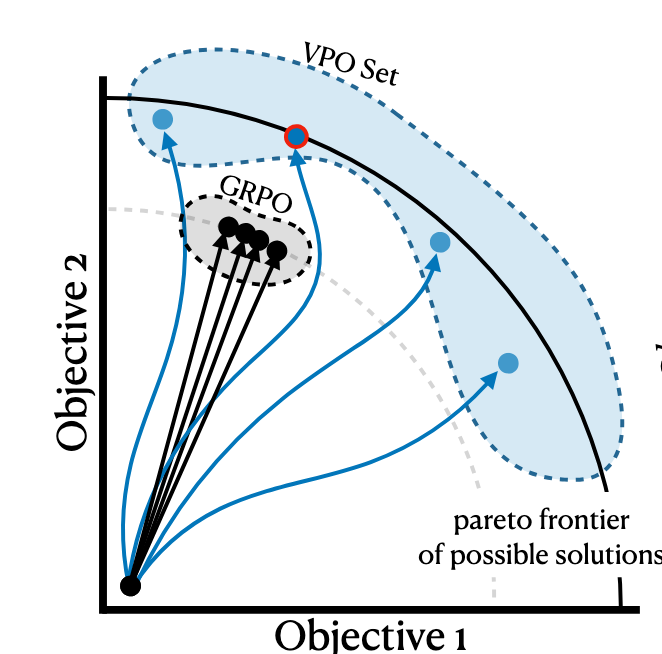
詳細
VPOは以下の2つの主要なコンポーネントを組み合わせることで、多様でありながら有能な回答を生成するようにモデルを訓練する
1. Multi-Answer Chains
- 通常は複数回rolloutをすることで、サンプリングによる回答の多様性を得ることができる
- 本手法は1回のrolloutで複数の回答案 m個を連続して生成させる。各回答は直前の回答を参照できるため、モデルは「まだ試していない戦略」を文脈から判断し、多様なアプローチを試みることが可能
- 多様性はサンプリングノイズの副産物ではなく明示的な文脈内メカニズムとして機能するようになる
ただし適切な学習信号が与えられない場合、モデルは依然としてほぼ同一の回答を生成するように収束してしまうため、これだけでは推論時の生成結果の多様性を得ることは難しい。
2. Stochastic Scalarization
- 多目的報酬関数を設計しその重みwを固定ではなくディリクレ分布からランダムサンプリングとする
- ランダムな重みwを持つ報酬関数のもと期待報酬の最大化を目指す
- これによりモデルは「ある重み付けではAが最高」「別の重み付けではBが最高」というように、多目的関数のパレートフロント上の多様なトレードオフをカバーする回答を生成するようになる
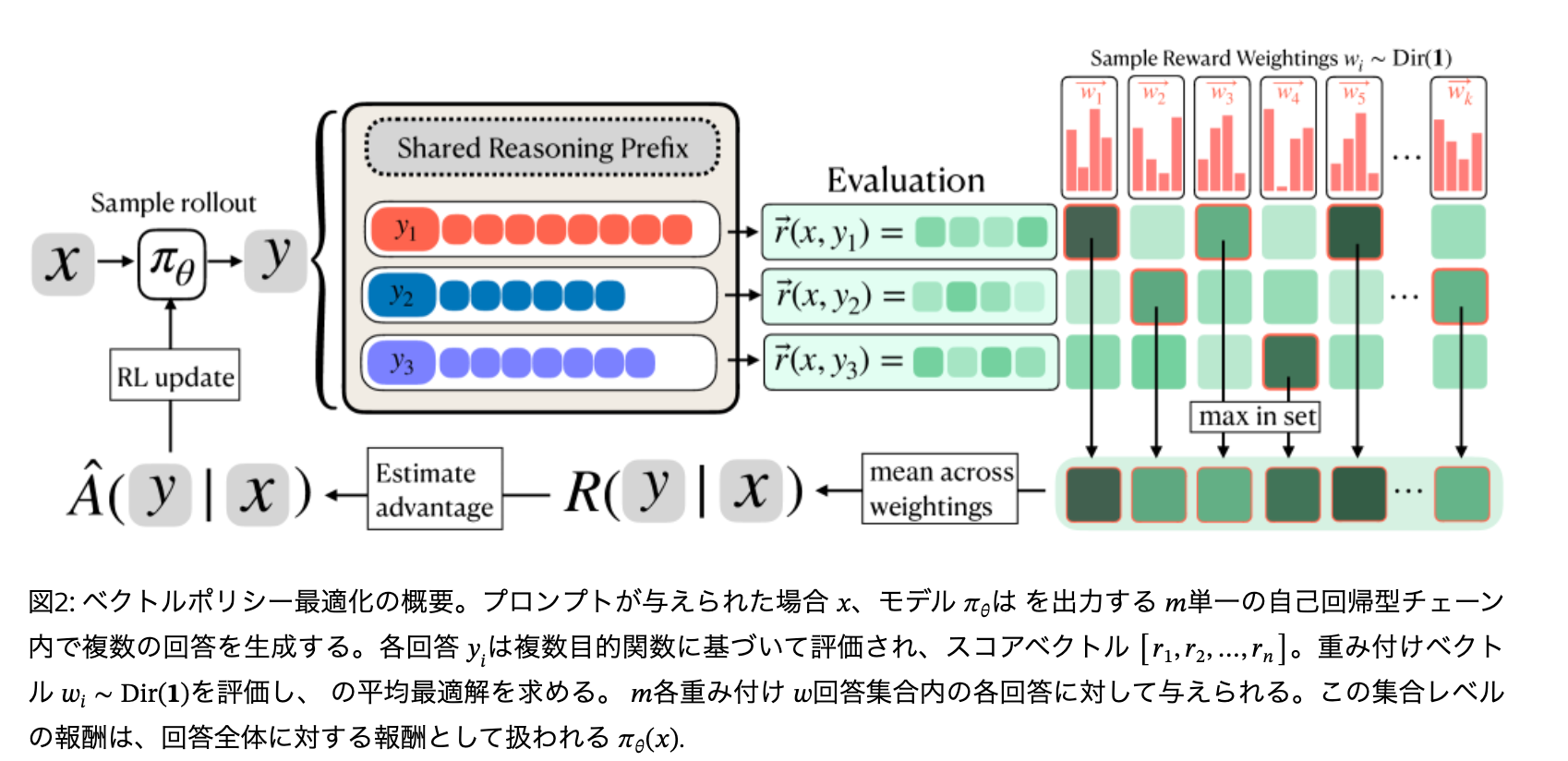
VPOは報酬計算のみを規定する手法であるため任意の方策勾配法手法と組み合わせることができる。以下の実験ではGRPOをベースとして検証している。
実験
迷路ナビゲーション、多段階質問回答(MuSiQue)、論理推論(EUREQA)、ツール利用(ToolRL)、競技プログラミング(LiveCodeBench)の5つのドメインで評価を実施。
VPOはテスト時探索の効果を向上させる
- テスト時の回答のサンプル回数(探索数)を増やすとBest@k性能が向上する
- Best@kはk回推論を実施した時の一番良い精度での比較に用いる評価指標
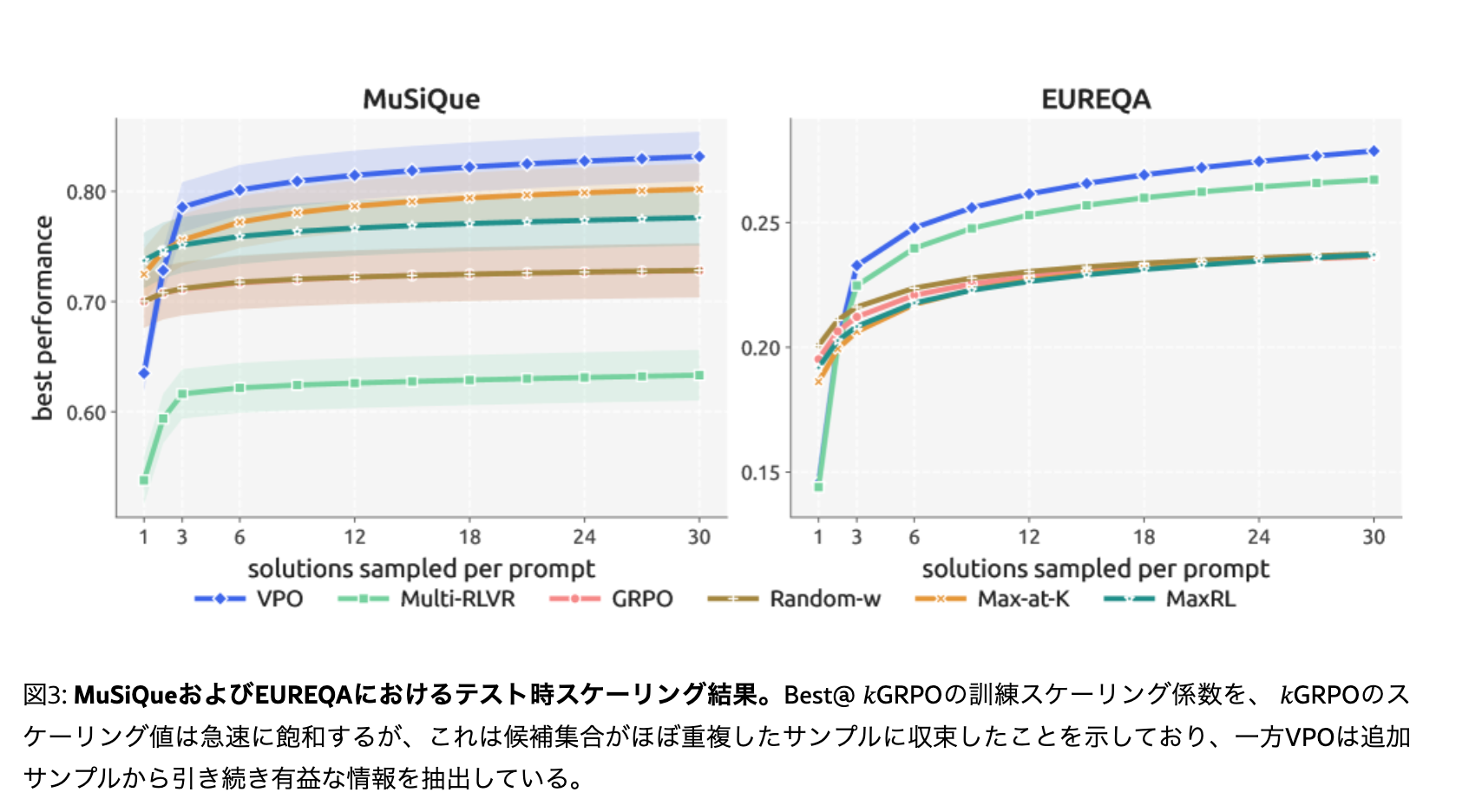
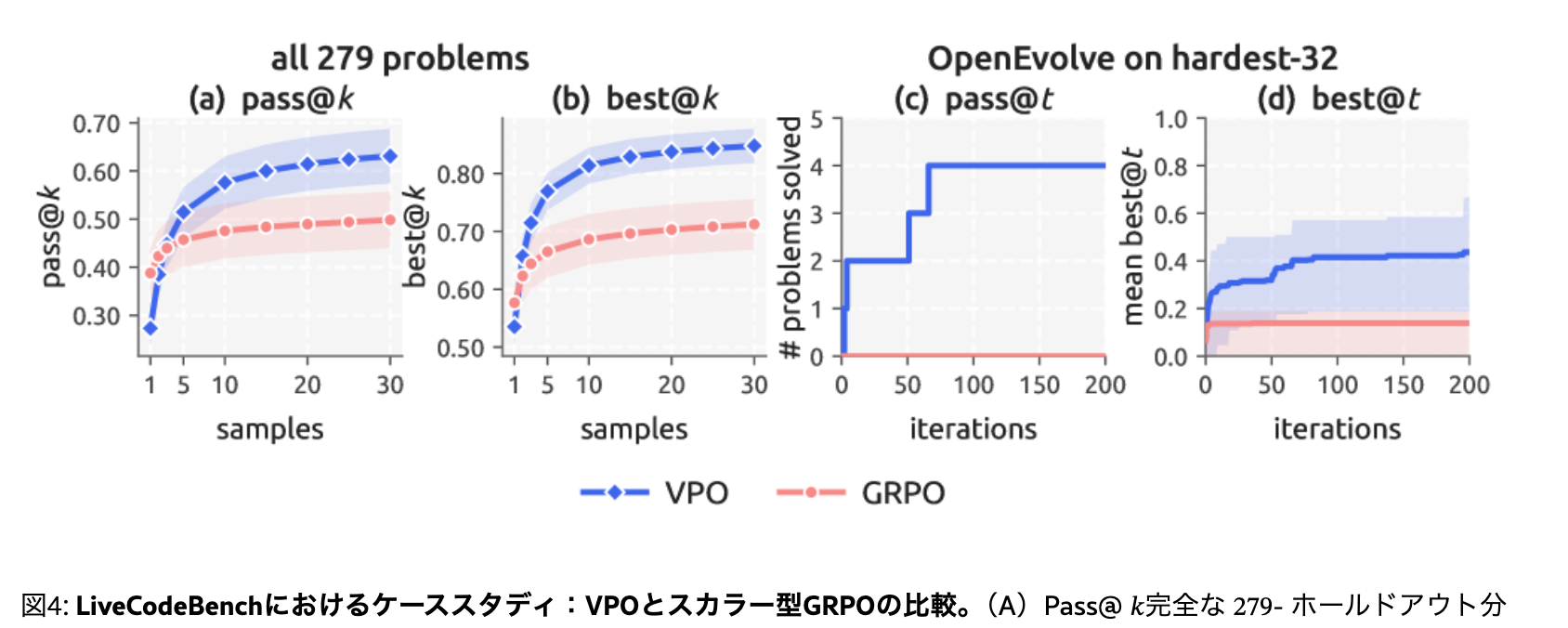
VPOによる探索活性化は難易度の高い問題でより効果を発揮する
LiveCodeBenchの高難易度タスクで評価すると
- k=1(探索0)の場合はGRPOに劣るが、kを増やすとVPOの方が性能が向上する(左図)
- 進化的な探索手法(OpenEvolve)と組み合わせた際、GRPOモデルでは解けない難問をVPOモデルは解くことに成功した。(右図)
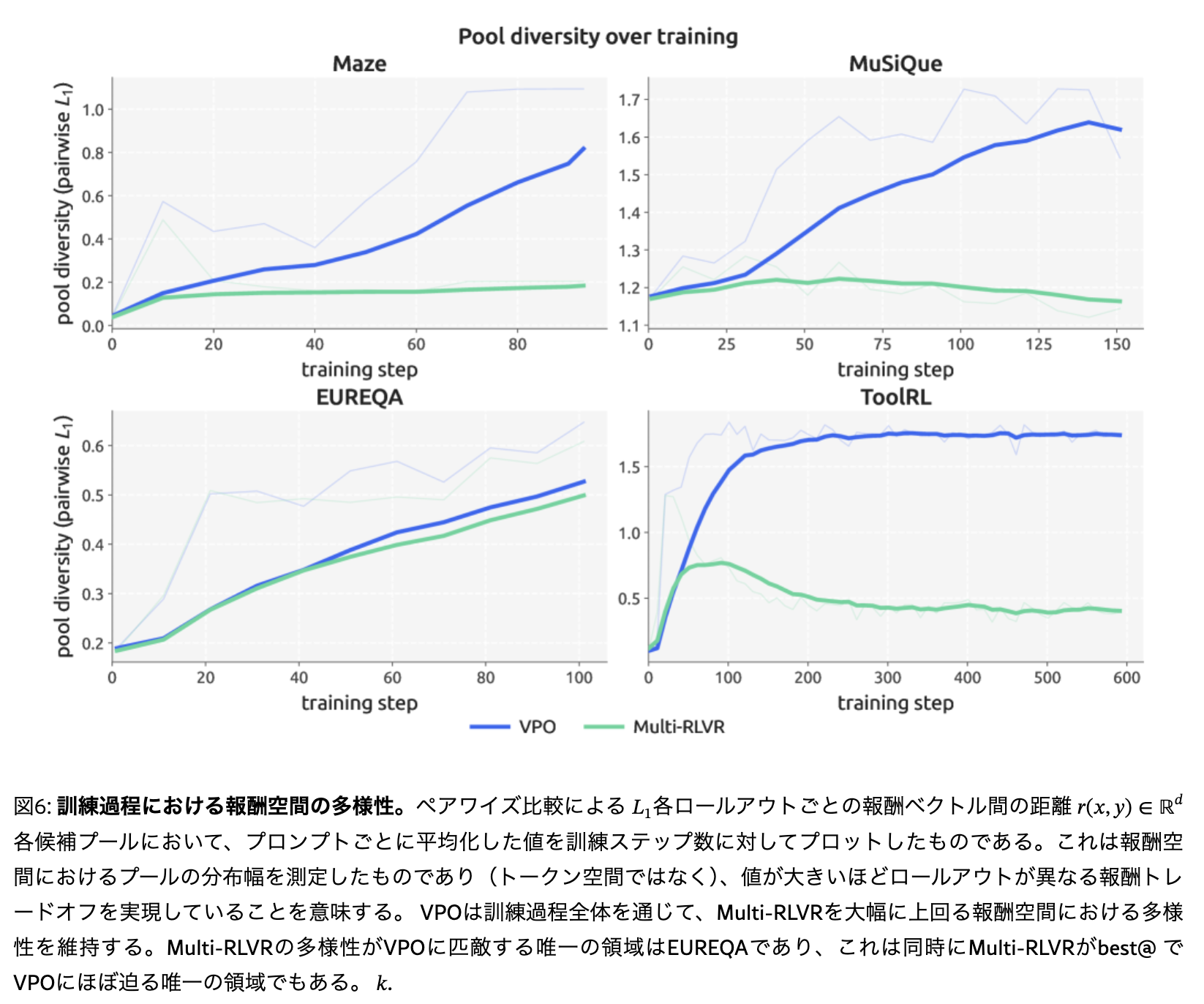
学習が推論多様性向上に寄与している
- 学習ステップが増えるにつれてモデルが生成する回答が報酬空間内で分散していることを示している
- つまり文脈内探索だけでなくランダム報酬による学習が多様性を増やすために重要
感想
- シンプルで発想も面白い
- 回答の多様性を出すために文脈内探索(1度に複数回回答)は簡単に試せるしアリ
@Ryuhei Kawabata
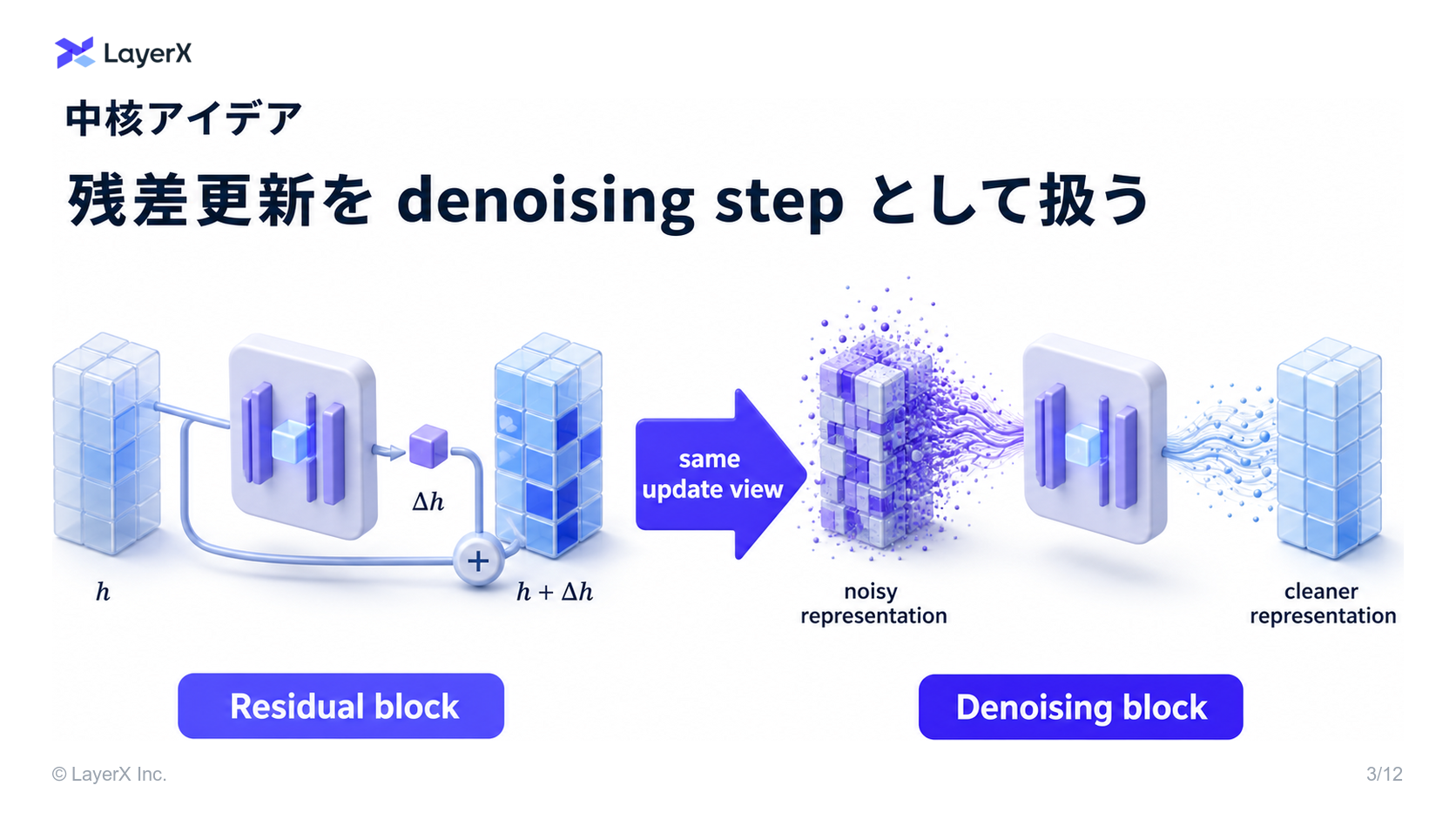
[paper] DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
- 基本情報
- 著者グループ: sakana AI
- ICLR 2026 accepted
- Elon Musk も興味を持つ DiffusionBlocks
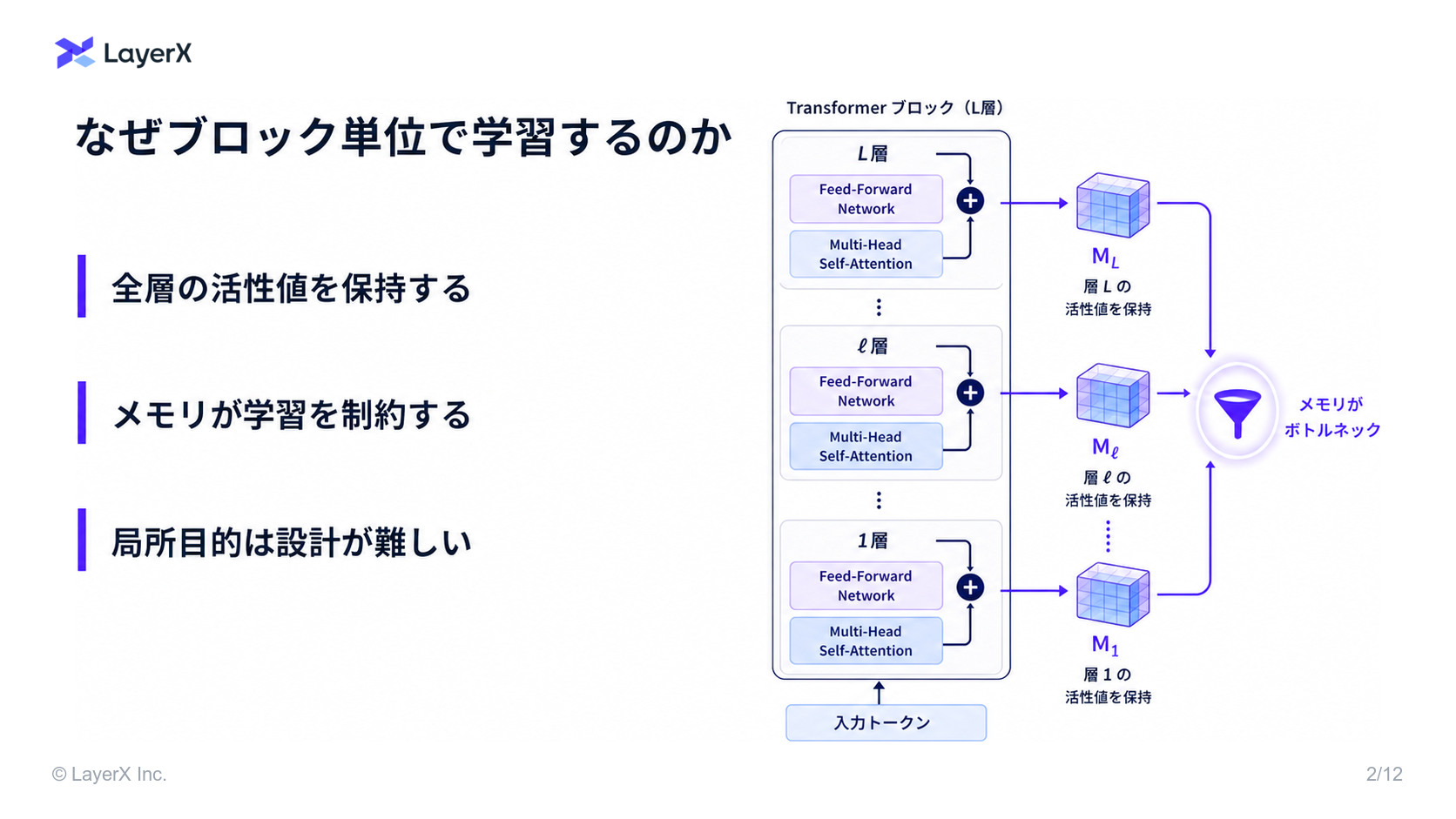
- ニューラルネットワークの訓練にはメモリの制限がある
- 訓練できるモデルのサイズはメモリに制限される
- 訓練・推論時にメモリに載せなければならない
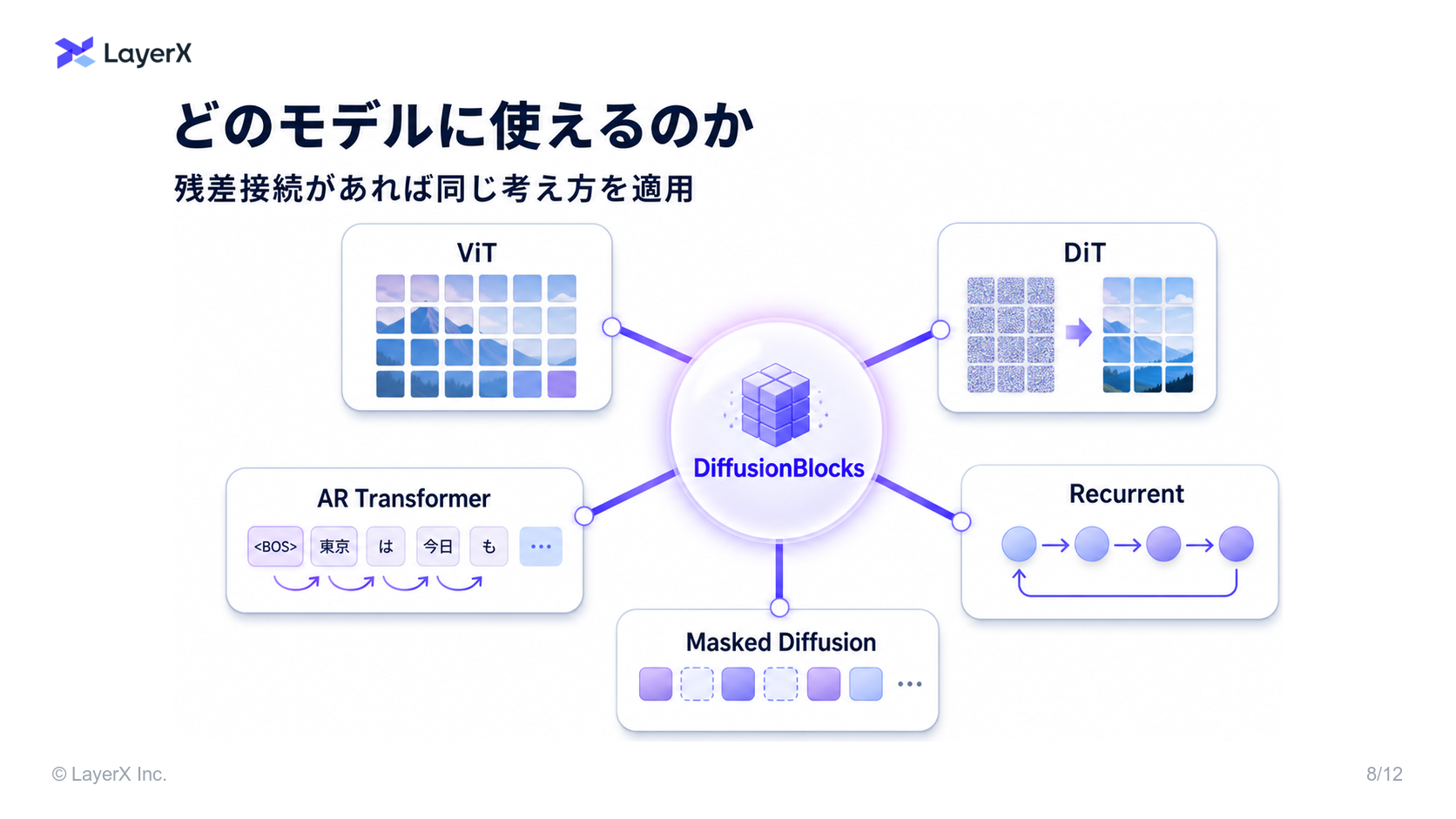
- という訳でモデルを分割してトレーニングしたいものの…
- 既存のアプローチでは
- ブロックごとのobjectiveについてad-hocに設計されており
- タスク設計に制限があり、Transformerなどで使えない
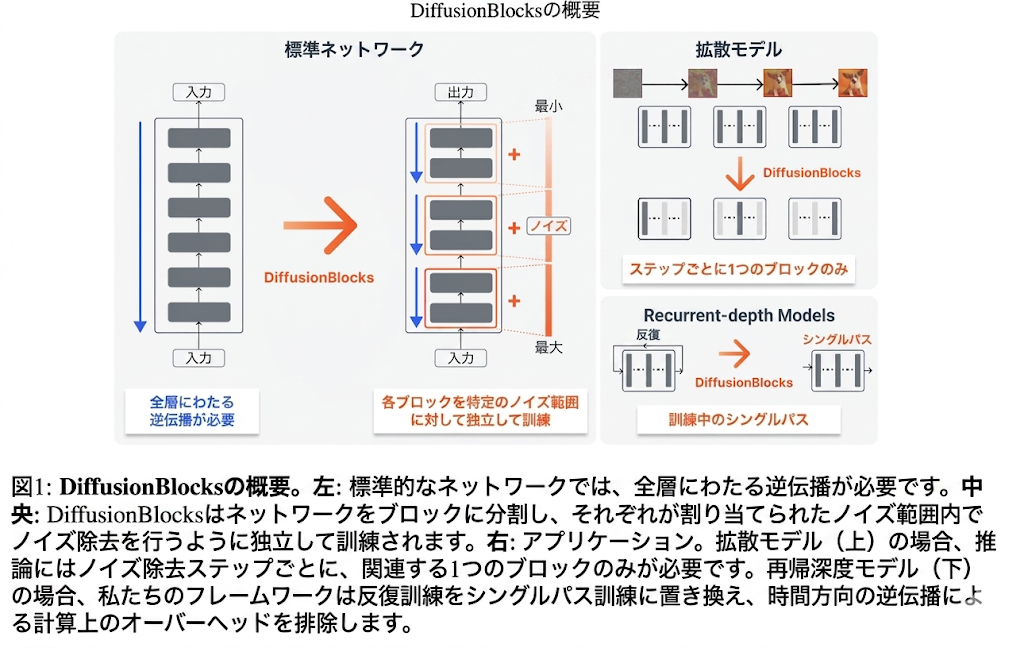
- Diffusion models:
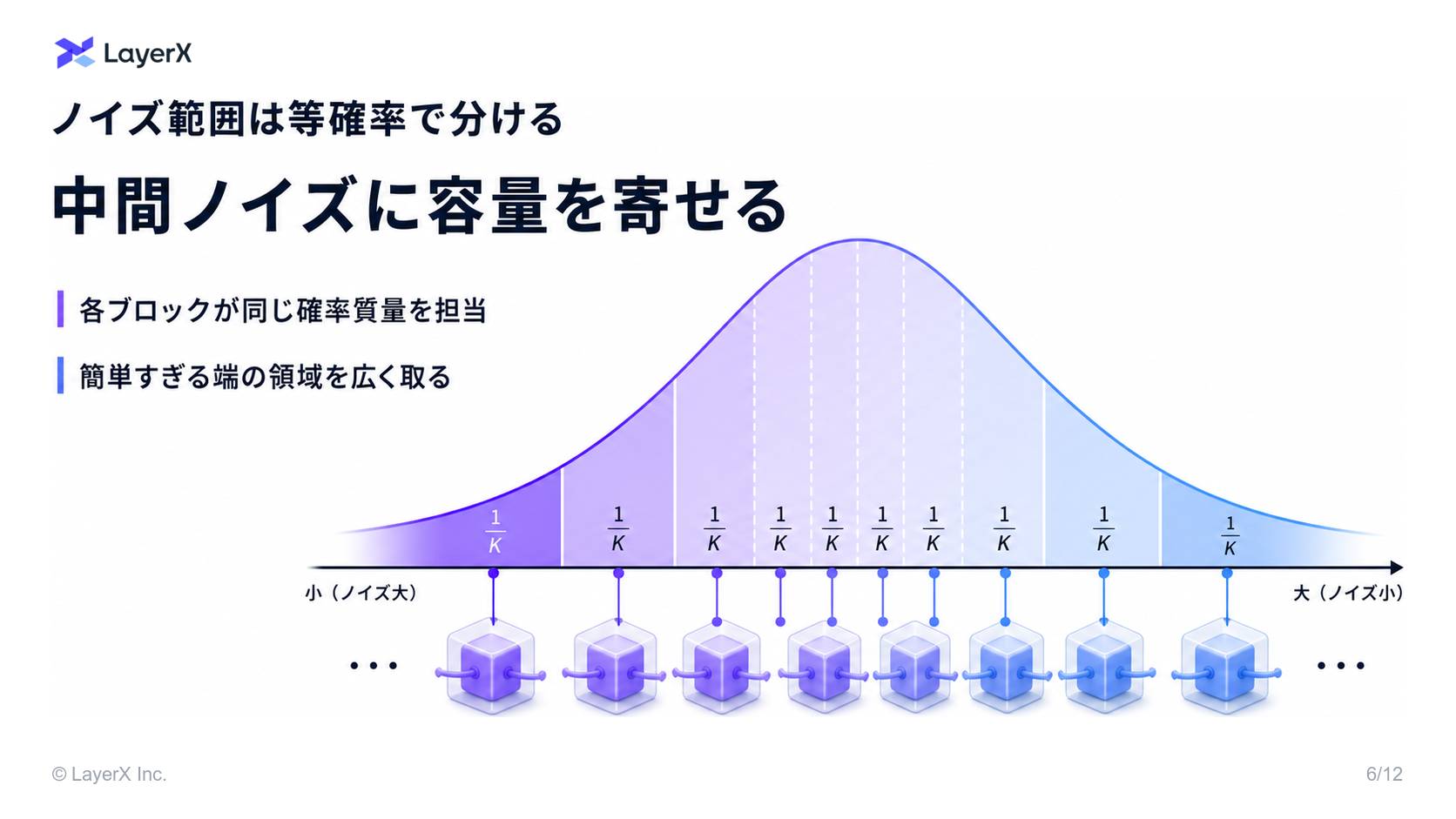
- スコアベース拡散モデルは、データを徐々にノイズ化していく連続時間プロセスを通してデータ分布をモデル化し、各ノイズレベルにおけるスコア関数を推定することで、de-noiseさせる方法を学習する
- 各ノイズレベルにおけるde-noiseのステップを完全に独立して最適化することができる
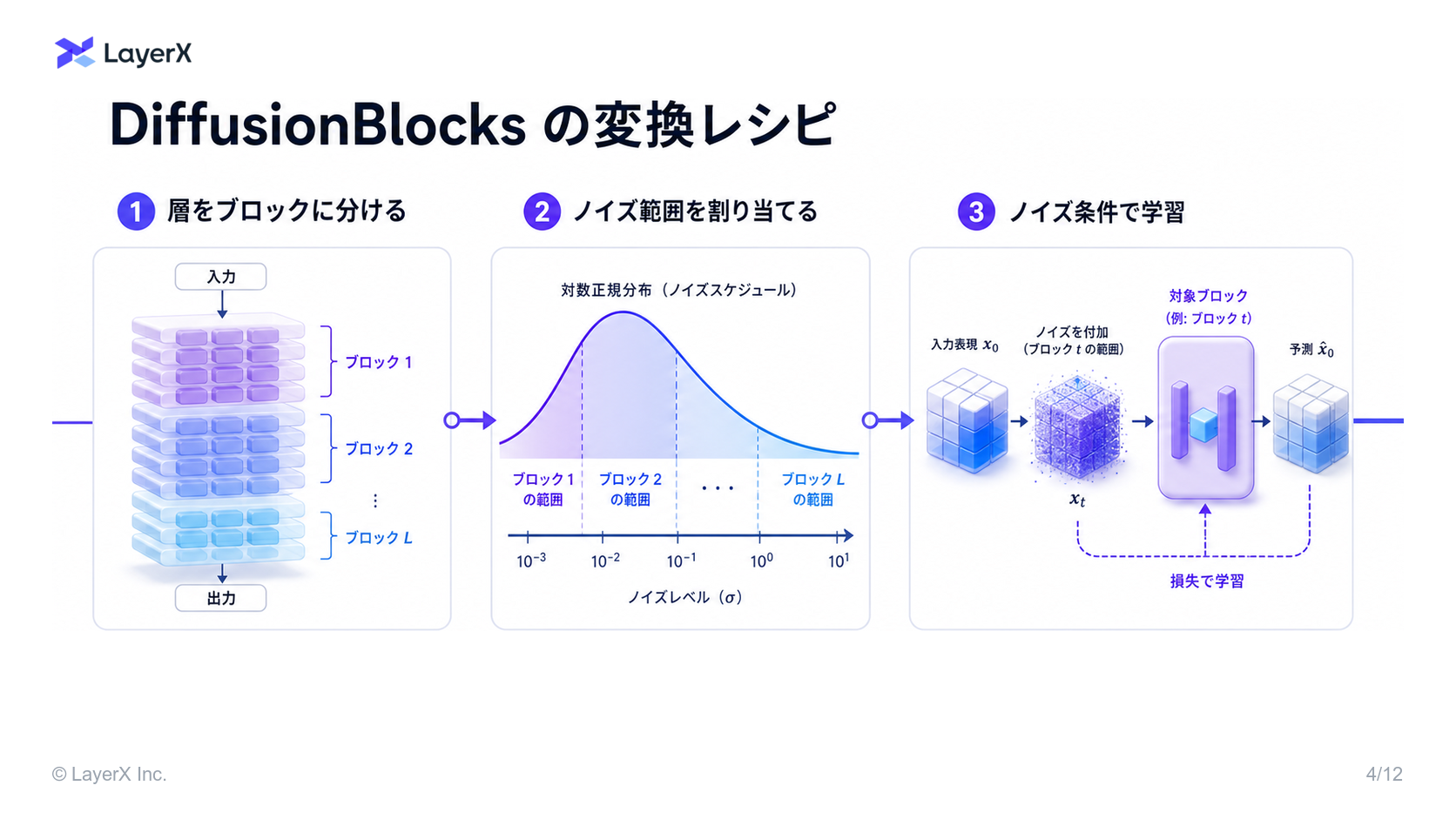
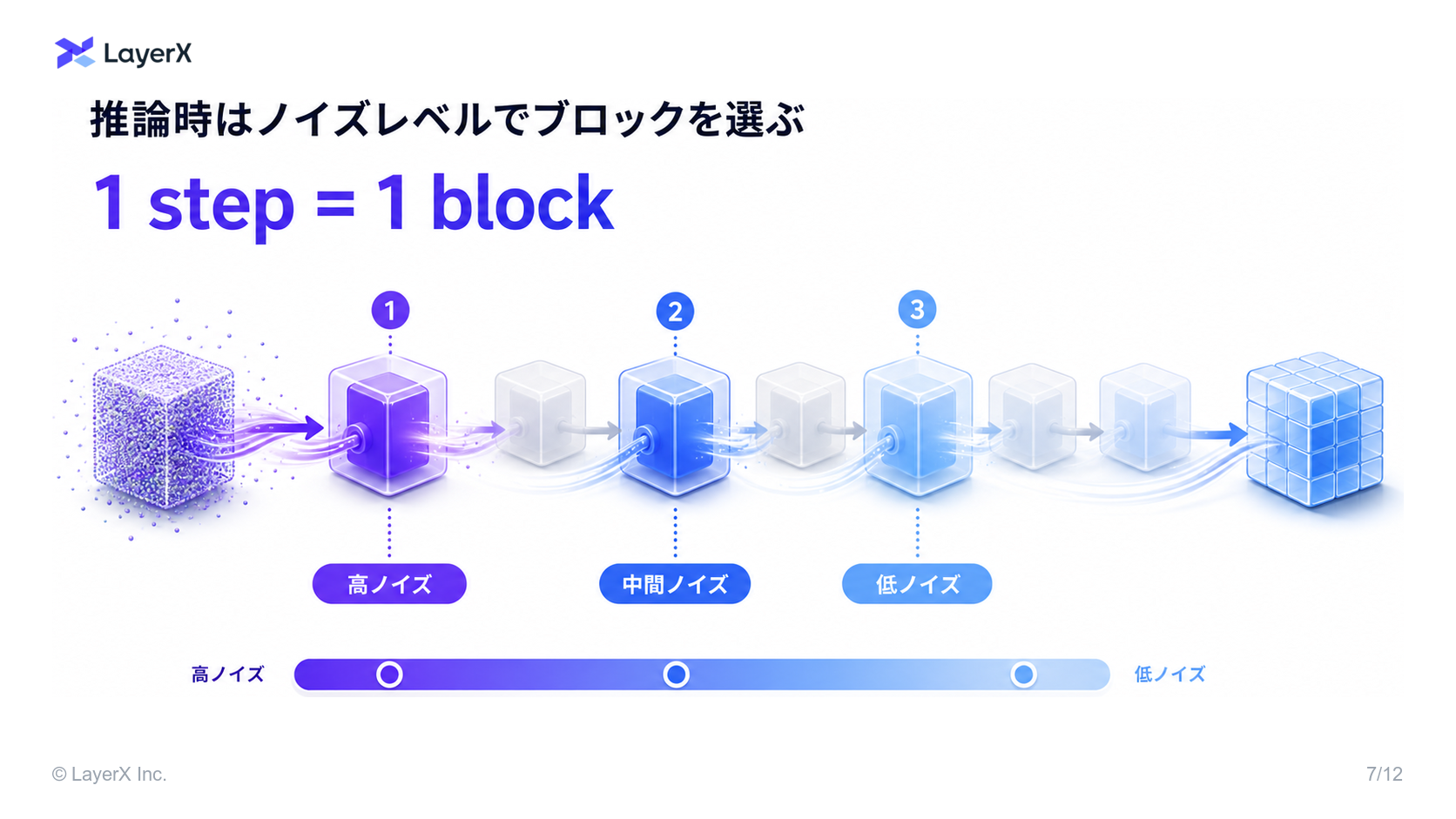
- これを元に, Neural Network を複数ブロックに分けて、それぞれのブロックに特定のノイズレベルの範囲を担当されることができる!
- Our approach:
- Transformer における Layer の更新を連続時間拡散過程の離散化ステップとして解釈する手法を提案
- Residual ネットワークと微分方程式の間に確立された関連性に基づき、Residual結合が自然と拡散モデルにおける確率フロー常微分方程式のオイラー離散化に対応することに着目
- residual network と 微分方程式の間に確立された関連性とは?
- 「ResNetの層を重ねていく性質は、微分方程式を近似的に解くプロセス(離散化)と同じである」という発見です。
- これにより、Transformer block それぞれが特定のノイズレベルを処理する複数ブロックへと分割できる
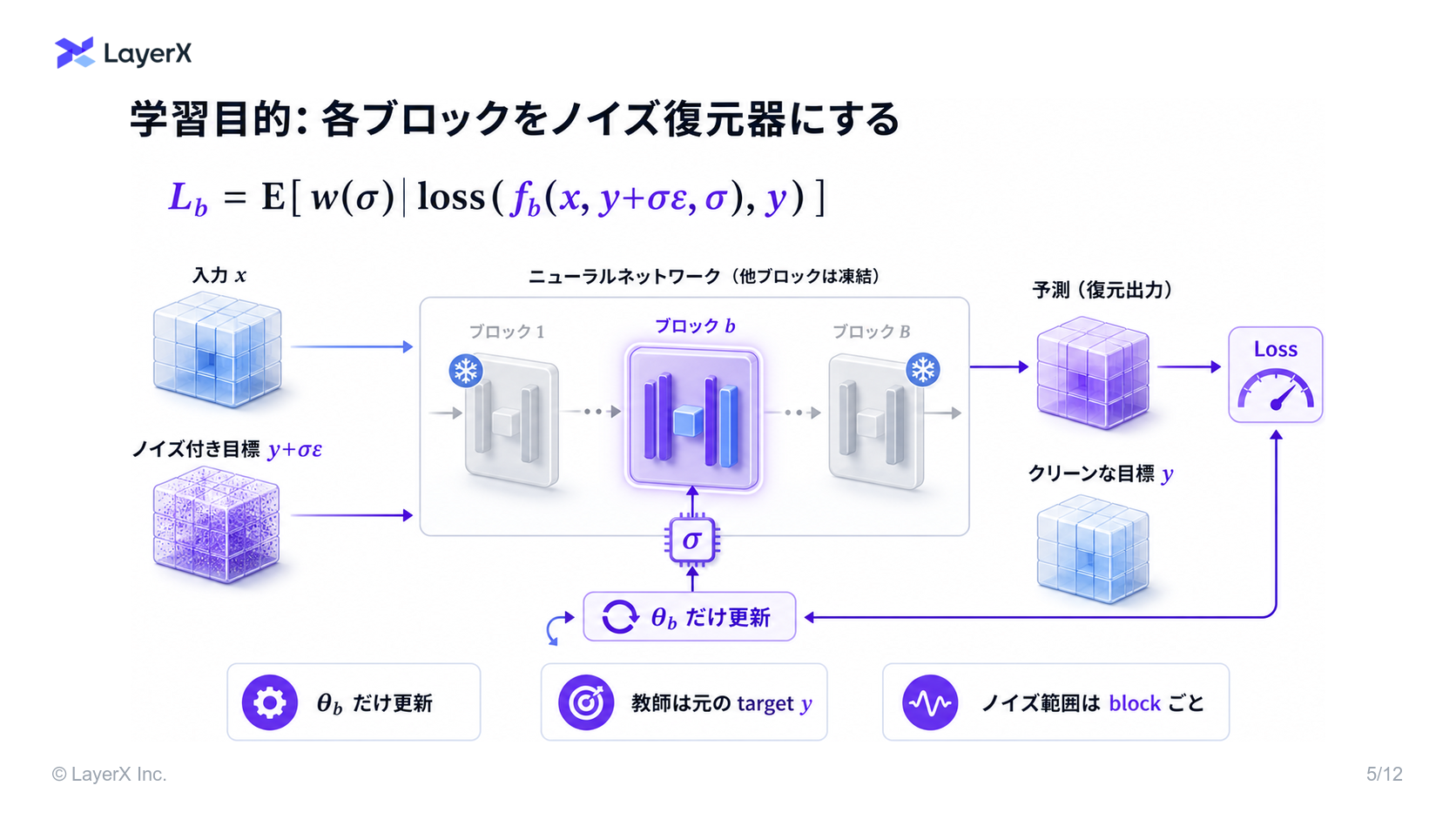
- これらのブロックは完全に独立して学習させることができ、一度に1つのブロックのgradientしか必要としない

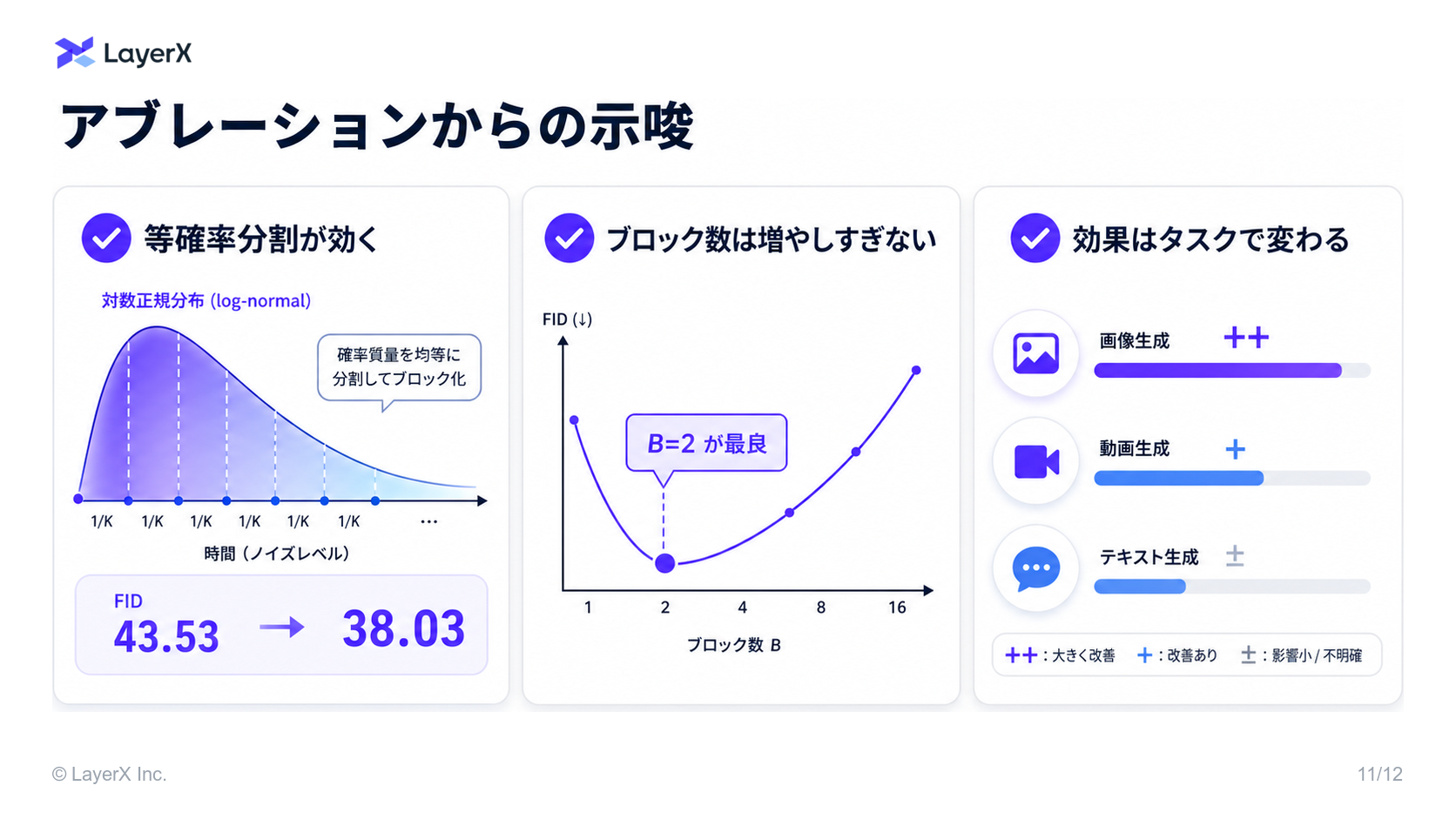
- 感想
- 小型LLMでもtuningすれば flagship モデルと戦えるという論文が増えてきた
- 一方で finetuning のコストは課題として大きく、特にメモリに関する制限は大きい
- 本論文のように大きなモデルを分けて訓練できるパラダイムが来れば,
- 低コストでfinetuneの試行錯誤を回せるようになるのでは..?
- 分散・非同期学習がさらに効率化される
- 一部タスクで性能向上している
- 著者らはカリキュラム学習のような効果が得られたのではと考察している
- 計算効率の改善だけでなく、性能向上の可能性も見えているのは興味深い
メインTOPIC
ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration
Authors: Hongjin Su, Shizhe Diao, Ximing Lu, Mingjie Liu, Jiacheng Xu, Xin Dong, Yonggan Fu, Peter Belcak, Hanrong Ye, Hongxu Yin, Yi Dong, Evelina Bakhturina, Tao Yu, Yejin Choi, Jan Kautz, Pavlo Molchanov
NVIDIA / University of Hong Kong, 2025-11-26
ICML2026
概要
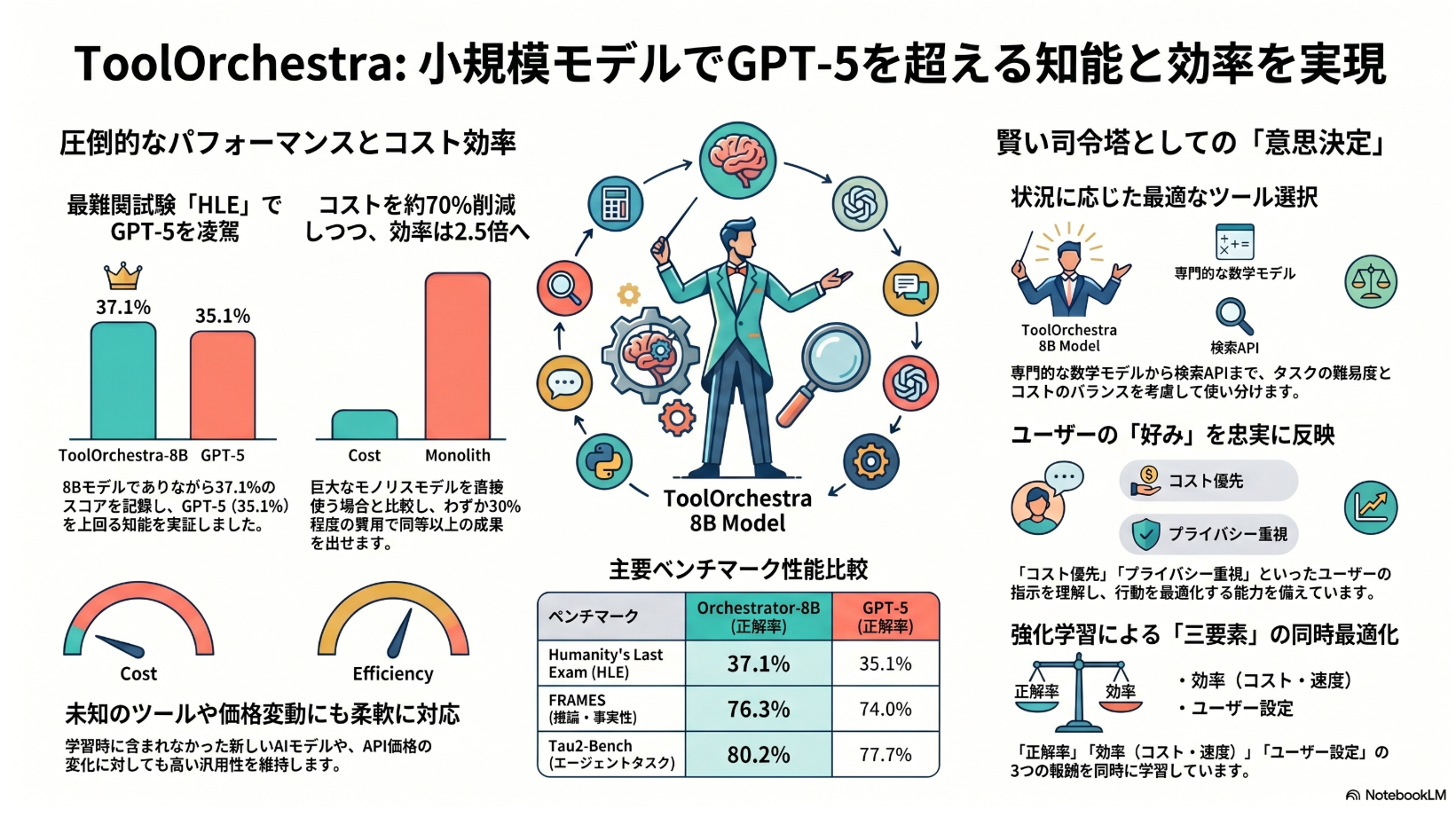
- 小さい orchestrator model が、複数の LLM / tool を使い分けることで、単体の強い model より高性能・低コストに難問を解ける、という論文。
- 提案手法は 。8B の を RL で訓練し、multi-turn reasoning の中で tool / specialized LLM / generalist LLM を選ばせる。
- reward は correctness だけではなく、cost / latency / user preference も含む。
- HLE, FRAMES, で評価し、Orchestrator-8B が GPT-5 などの強い baseline より良い性能・コスト trade-off を示すと主張している。
- 方向性としては「大きい model に全部やらせる」ではなく、「小さい model が適切な expert/tool を呼び分ける」compound AI system。
背景
- 既存の tool-use agent は、単一の強い model に web search / code interpreter / calculator などを持たせる形が多い。
- ただし現実の問題解決では、人間も domain expert や specialized software を呼び分ける。
- math に強い model
- code に強い model
- web search
- local search
- domain-specific API
- generalist frontier model
- この論文の問題意識は、tool の種類が増えると「どの tool を、どの順番で、どのコストで使うか」が本質的に難しくなること。
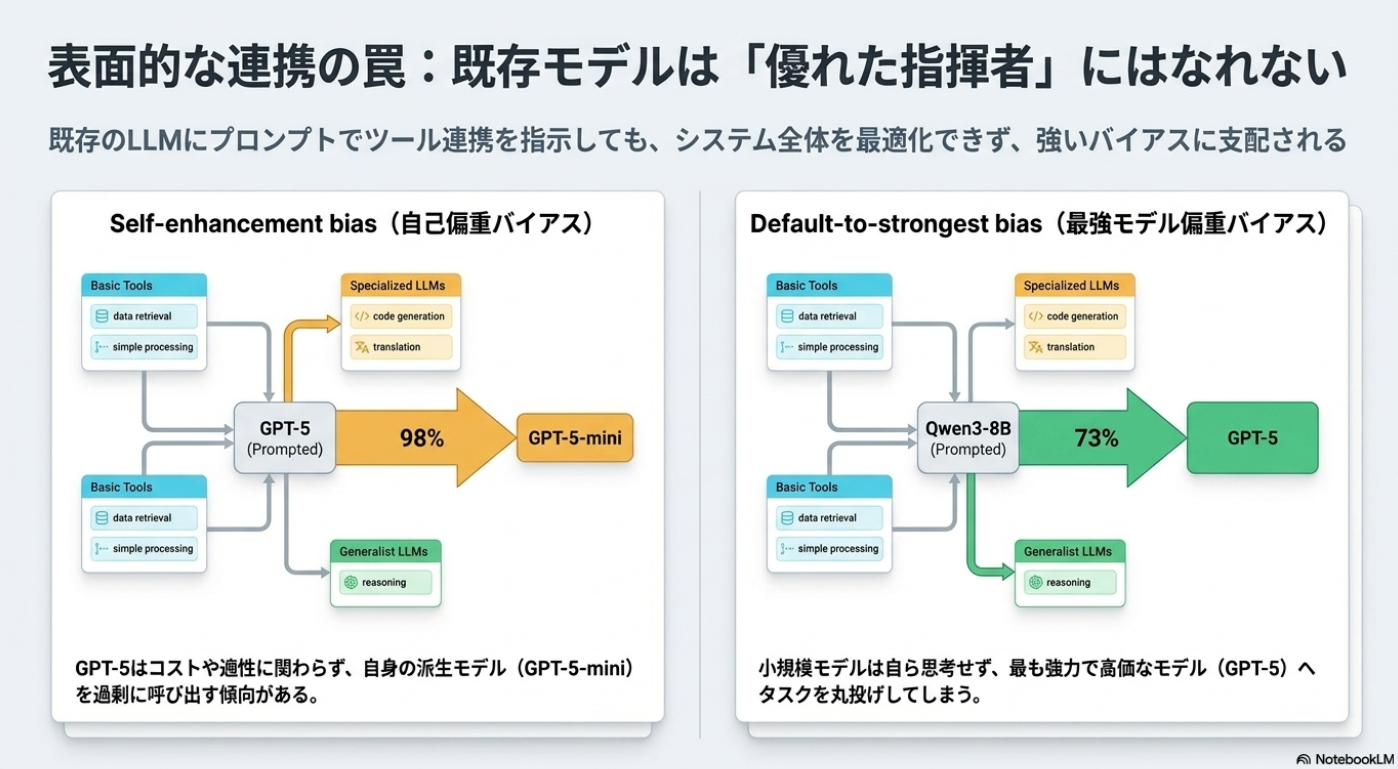
- Prompting だけで orchestrator を作ると bias が出る。
- GPT-5 orchestrator は GPT-5-mini に寄りがち。
- Qwen3-8B orchestrator は GPT-5 に頼りがち。
- cost や user preference を明示しても、最適な tool selection にはなりにくい。
問題設定
- multi-turn tool-use task を MDP (Markov Decision Process) として定式化している。
- 各 step で Orchestrator は interaction history を見て action を選ぶ。
- action は tool call, model call, final answer など。
- tool response は observation として次の turn に入る。
- 目的は単純な accuracy 最大化ではない。
- final answer の correctness を上げる。
- tool / model 呼び出しの monetary cost を下げる。
- wall-clock latency を下げる。
- user が指定した preference に沿う。
- 最大50 turn までの rollout で、reasoning -> tool call -> observation を繰り返す。
提案手法: ToolOrchestra
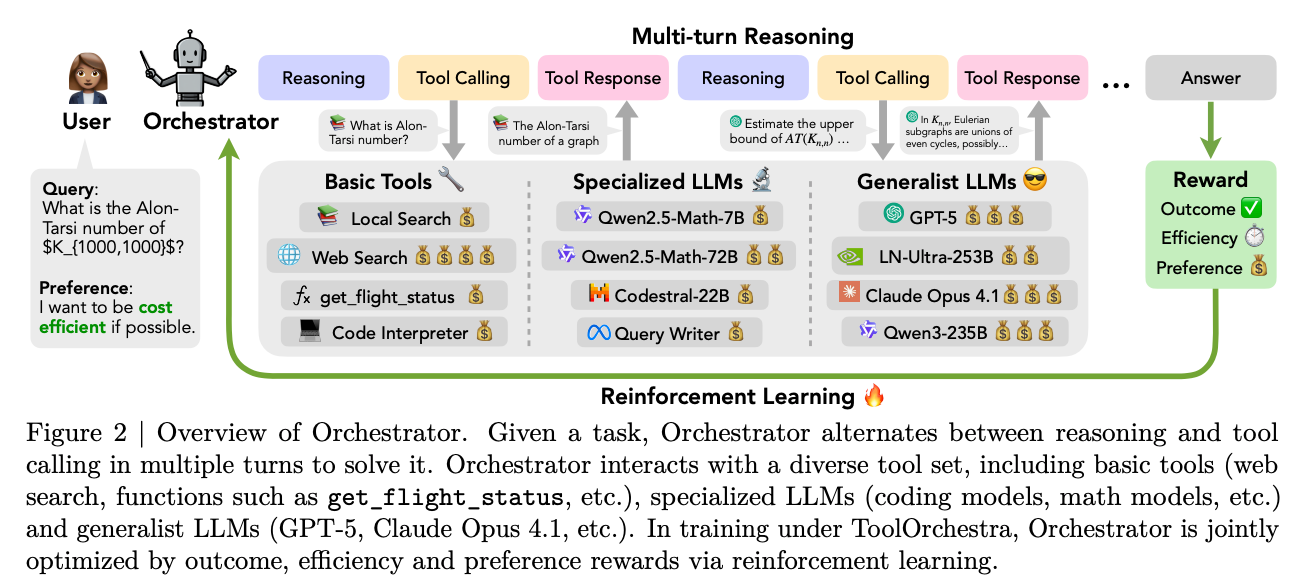
ToolOrchestra のポイントは、強い LLM に「必要なら tool を使って」と prompt するのではなく、tool / model の選択そのものを小さい model の policy として RL で学習すること。
- 中心は、Qwen3-8B backbone の を end-to-end RL training すること。
- 入力: user instruction、preference instruction、これまでの tool call / observation history。
- 出力: reasoning、tool call、または final answer。
- rollout は最大50 turn。各 turn で reasoning -> action -> observation を繰り返す。
- tool は unified JSON interface で与える。
- : tool 名。
- : 何が得意で、どんなときに呼ぶべきか。
- typed parameter schema: 引数名、型、説明。
- LLM も通常の tool と同列に扱う。
- Basic tools: web search、local search、code interpreter、domain function。
- Specialized LLMs: code writer、math model、query writer。
- Generalist LLMs: GPT-5、GPT-5-mini、Llama-3.3-70B、Qwen3-32B など。
- LLM tool の description は手書きではなく、trajectory から生成する。
- 10個の training task を sample。
- その LLM に task を解かせ、trajectory と成否を集める。
- 別 LLM に「この model は何が得意/不得意か」を description として要約させる。
- unseen tools に対しても同じ procedure で description を作り、Orchestrator がそれを読んで使い分けられるかを見る。
- training 時は tool configuration を意図的に揺らす。
- 各 training instance で使える tool subset を random sample。
- price configuration も変える。
- 固定 tool set / 固定価格への overfit を避け、「この環境では何を呼ぶのが得か」を学ばせる。
- 直感的には、Orchestrator は「問題を全部自分で解く model」ではなく、sub-problem を切り出して適切な expert/tool に投げる policy。
- 高い model を毎回呼ぶと cost が悪い。
- 安い model / search / code で足りる場面を見極めると、accuracy と efficiency の trade-off が良くなる。
Reward Design
- reward は「正解したか」だけではなく、solved trajectory の中でどれだけ効率・preference に合っていたかを見る設計。
- Outcome reward:
- task が解けたかどうかの binary reward。
- 答えの比較には GPT-5 judge を使う。
- Efficiency reward:
- proprietary / open model をまとめて扱うため、input/output token usage を third-party API pricing 相当の monetary cost に変換する。
- Preference reward:
- user が「安く済ませたい」「local search を使いたい」「特定 tool を避けたい」などを指定できる。
- trajectory ごとに、各 tool の呼び出し回数、outcome、cost、latency を並べた vector を作る。
- batch 内で normalize した と preference vector の内積を reward にする。
- ただし final reward は task が solve された trajectory にだけ与える。失敗 trajectory は cost が安くても reward 0。
- preference instruction と preference vector も synthetic に作る。
- tool set と価格/latency metadata から LLM が を生成。
- 別 LLM で instruction と vector の整合性を検証。
- training / evaluation 用に split し、user instruction に preference instruction を連結する。
- RL algorithm は GRPO。
- 同一 task から複数 trajectory を rollout し、group 内で reward を normalize して advantage を作る。
- clipped surrogate objective で policy update する。
- training 安定化のため、reward variance が低い batch、format 不整合、invalid output は filter する。
ToolScale
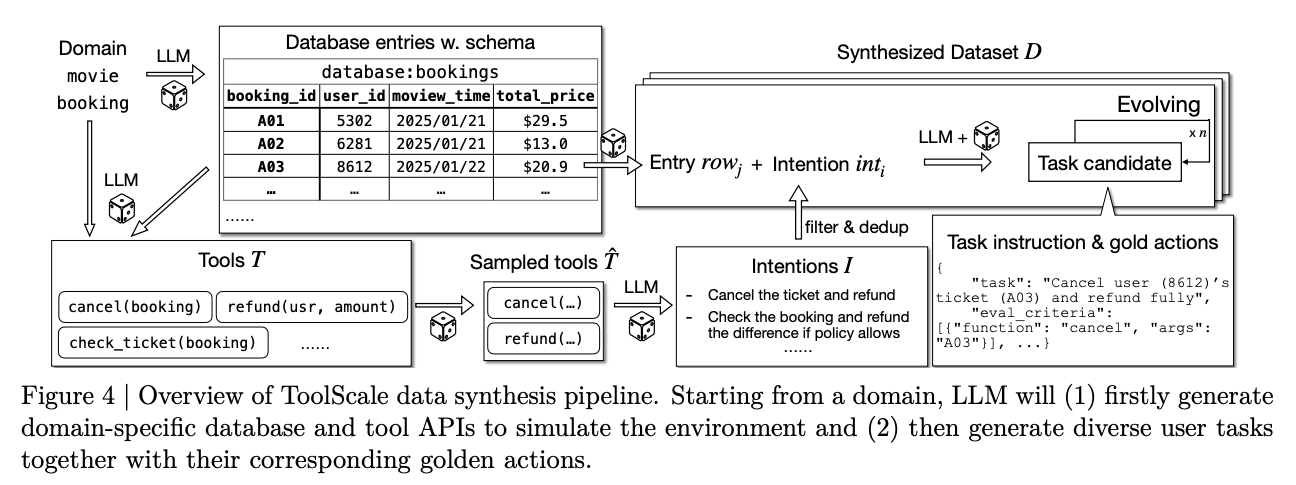
- end-to-end RL には、検証可能な multi-turn tool-call task が必要だが、既存データは少ない。
- そこで という synthetic dataset を作っている。
- 生成の流れ:
- domain を決める。
- LLM で database schema / entries / tool API を生成する。
- domain-specific intent から user task を作る。
- golden function calls と、途中で伝えるべき情報を付ける。
- 追加LLMで task を複雑化する。
- filter 条件:
- golden function calls の実行が error になるものを除外。
- LLM が pass@8 でも解けないものを除外。
- action なしで解けるものを除外。
- task success は execution correctness, process fidelity, operation completeness で見る。
- execution correctness: 実行後の database state が golden function calls 実行後の結果と一致するか。
- process fidelity: 途中で user に伝えるべき情報を trajectory 内で伝えているか。
- operation completeness: golden trajectory が操作した database entry を漏れなく操作しているか。
- 10 domain で作成している。
- Finance, Sport, E-commerce, Medicine, Entertainment, Railway, Restaurant, Education, Travel, Weather。
- 各 domain は 14-25 tools、423-920 DB entries、247-622 tasks。
- つまり単純な API call dataset ではなく、状態を持つ domain environment + tool API + user task をまとめて synthetic に作る。
実験設定
- Backbone:
- Qwen3-8B を Orchestrator の backbone として使用。
- Training:
- GeneralThought-430K + ToolScale。
- GeneralThought-430K: 汎用 reasoning 用の大規模データセット
- learning rate 1e-6。
- max input length 24k, max generation length 8k。
- training batch size 16, rollout batch size 8。
- 16 NVIDIA H100 GPUs。
- Evaluation benchmarks:
- HLE: 専門家レベルの高難度の多分野QA。
- text-only subset を使う。既存報告値の full set とは条件が違う点に注意。
- FRAMES: RAG / factual reasoning の multi-hop benchmark。
- 824問。2-15本の Wikipedia article をまたぐ multi-hop reasoning。
- : conversation 上の tool/function calling benchmark。
- telecom, retail, airline の3 domain。
- Evaluation tools:
- Basic tools: Tavily web search, Python sandbox, Faiss local search, domain functions。
- Specialized LLMs: GPT-5 / GPT-5-mini as code writer, Qwen2.5-Coder-32B, Qwen2.5-Math-72B/7B。
- Generalist LLMs: GPT-5, GPT-5-mini, Llama-3.3-70B, Qwen3-32B。
- Baseline は3段階で見る。
- No tool: model 単体。
- Basic tools: search / code interpreter / domain function などの通常 tool だけ。
- Basic tools + Specialized LLMs + Generalist LLMs: LLM-as-tool まで含めた expanded tool set。
- evaluation では temperature 0。Orchestrator は最大50 turn で task を解く。
- cost / latency は proprietary model は公式価格、open model は TogetherAI pricing 相当で比較。
結果
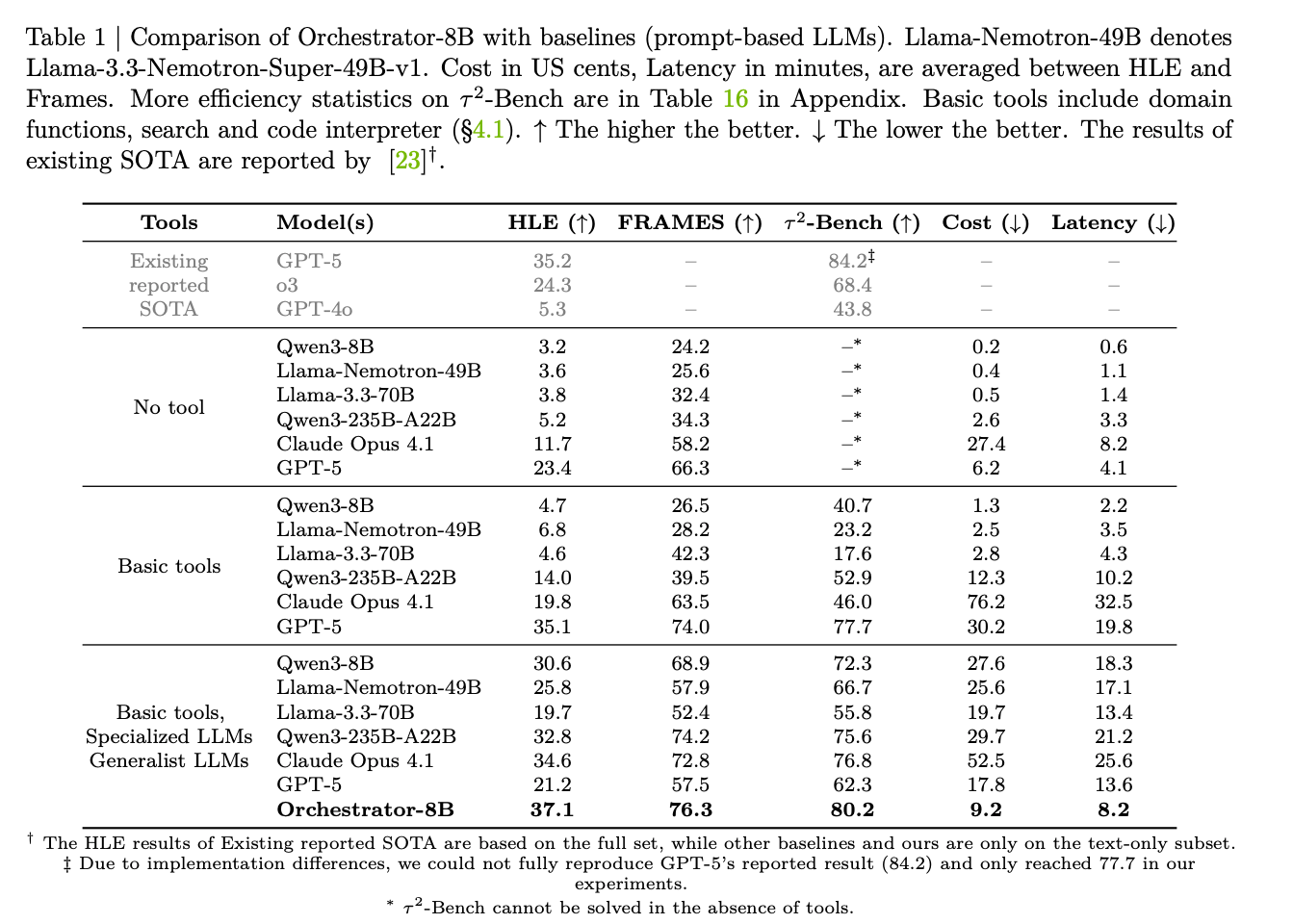
- HLE では Orchestrator-8B が 37.1 で、GPT-5 + Basic tools の 35.1 を上回る。
- FRAMES では 76.3、 では 80.2。
- cost / latency も強い。
- 論文中では HLE で GPT-5 より 2.5x efficient。
- FRAMES / では GPT-5 の約30%の cost で上回る、としている。
- no-tool / basic-tool / expanded-tool の比較から見えること:
- No tool では frontier model でも HLE / FRAMES がかなり低い。HLE で GPT-5 23.4、Claude Opus 4.1 11.7、Qwen3-235B 5.2。
- Basic tools を足すと GPT-5 は HLE 35.1 / FRAMES 74.0 まで伸びるが、cost 30.2 / latency 19.8。
- expanded tool set は多くの model で効く。Qwen3-235B は HLE 14.0 -> 32.8、FRAMES 39.5 -> 74.2。
- ただし tool を増やすだけでは安定しない。GPT-5 は expanded tool set で HLE 21.2 / FRAMES 57.5 / 62.3 まで落ちる。
- GPT-5 に tools/models を全部渡すと逆に性能が落ちている。
- 論文の分析では、GPT-5-mini など特定 tool への偏りが出る。
- tool を増やせば勝手に良くなるわけではなく、orchestration policy の学習が必要という主張につながっている。
- の efficiency も同じ傾向。
- GPT-5 + Basic tools: 77.7、cost 31.3、latency 20.2。
- Orchestrator-8B: 80.2、cost 10.3、latency 8.6。
- function calling benchmark でも「毎 turn 強い model に任せる」より、必要な call を選ぶ方がよいという結果。
分析
- Tool use analysis:
- Orchestrator-8B は GPT-5 だけに寄らず、search / code interpreter / smaller model / stronger model を比較的バランスよく使う。
- ORchestrator以外はGPT-5系を選びがち。

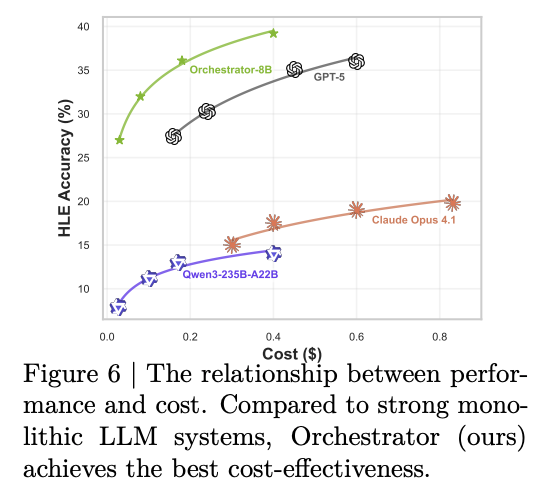
- Cost analysis:
- 最大 turn 数を 10, 20, 50, 100 と増やしても、Orchestrator は同じ budget で GPT-5, Claude Opus 4.1, Qwen3-235B より高い HLE accuracy を維持。
- これは単に呼び出し回数が少ないというより、限られた budget でどの tool call に使うかの policy が効いている、という主張。
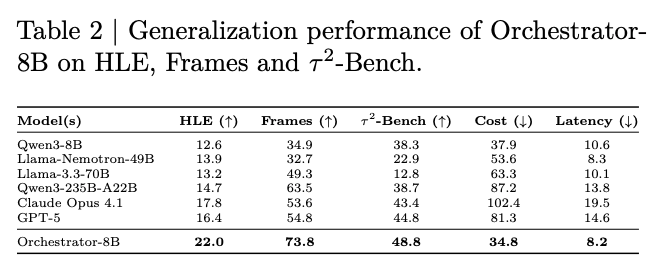
- Unseen tools への generalization:
- training で見ていない Claude Opus 4.1, o3-mini, GPT-4o, Codestral, DeepSeek-Math などを tool として与えても、Orchestrator-8B が最良。
- HLE 22.0 / FRAMES 73.8 / 48.8 で、cost 34.8 / latency 8.2。
- model description だけから新しい tool の使いどころを推定できている、という解釈。
- Price generalization:
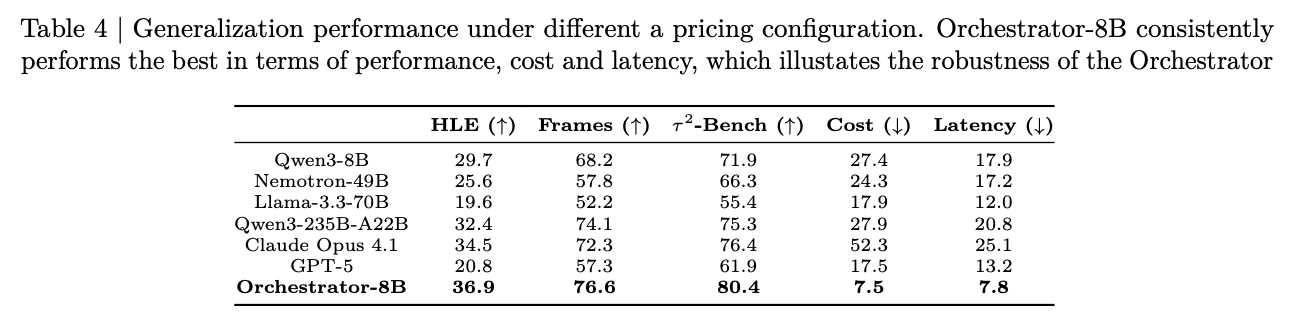
- training で見ていない DeepInfra pricing configuration でも Orchestrator-8B が最良。
- HLE 36.9 / FRAMES 76.6 / 80.4、cost 7.5 / latency 7.8。
- 価格が変わっても policy が崩れにくいことを示す追加実験。
- User preference:
- preference-aware reward は、正解かつ metric vector と preference vector との内積値で計算。
- preference-aware reward で見ても Orchestrator-8B が最も高い。これは通常の accuracy ではなく、preference vector との整合を含む指標。
- HLE 46.7 / FRAMES 68.4 / 79.5。
- 強い monolithic model でも preference に沿った tool selection は難しく、GPT-5 は HLE 34.6 / FRAMES 62.3 / 70.3。