2026-06-17 機械学習勉強会
今週のTOPIC[paper] GrepSeek: Training Search Agents for Direct Corpus Interaction[paper] V1: Unifying Generation and Self-Verification for Parallel Reasoners[paper] LLM-Emu: Native Runtime Emulation of LLM Inference via Profile-Driven Sampling[paper]Trust Region On-Policy Distillation[paper] Jailbreak Foundry: From Papers to Runnable Attacks for Reproducible BenchmarkingメインTOPICAgents' Last Examサマリー1. Introduction2. Benchmark Design and Dataset Construction3つの設計原則カバーするドメインタスク構築パイプラインpublic / private 戦略3 Evaluation Pipeline4 Experiment5. Sample
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
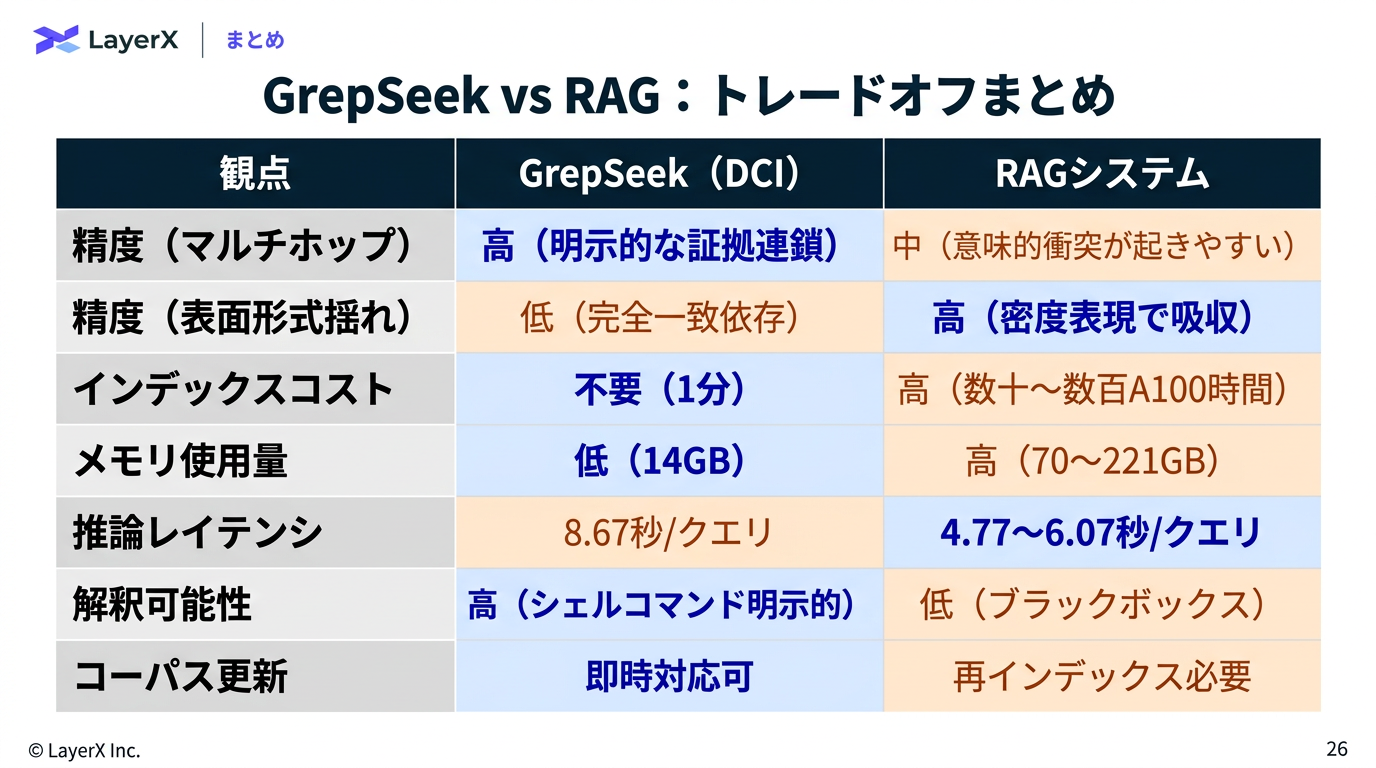
[paper] GrepSeek: Training Search Agents for Direct Corpus Interaction










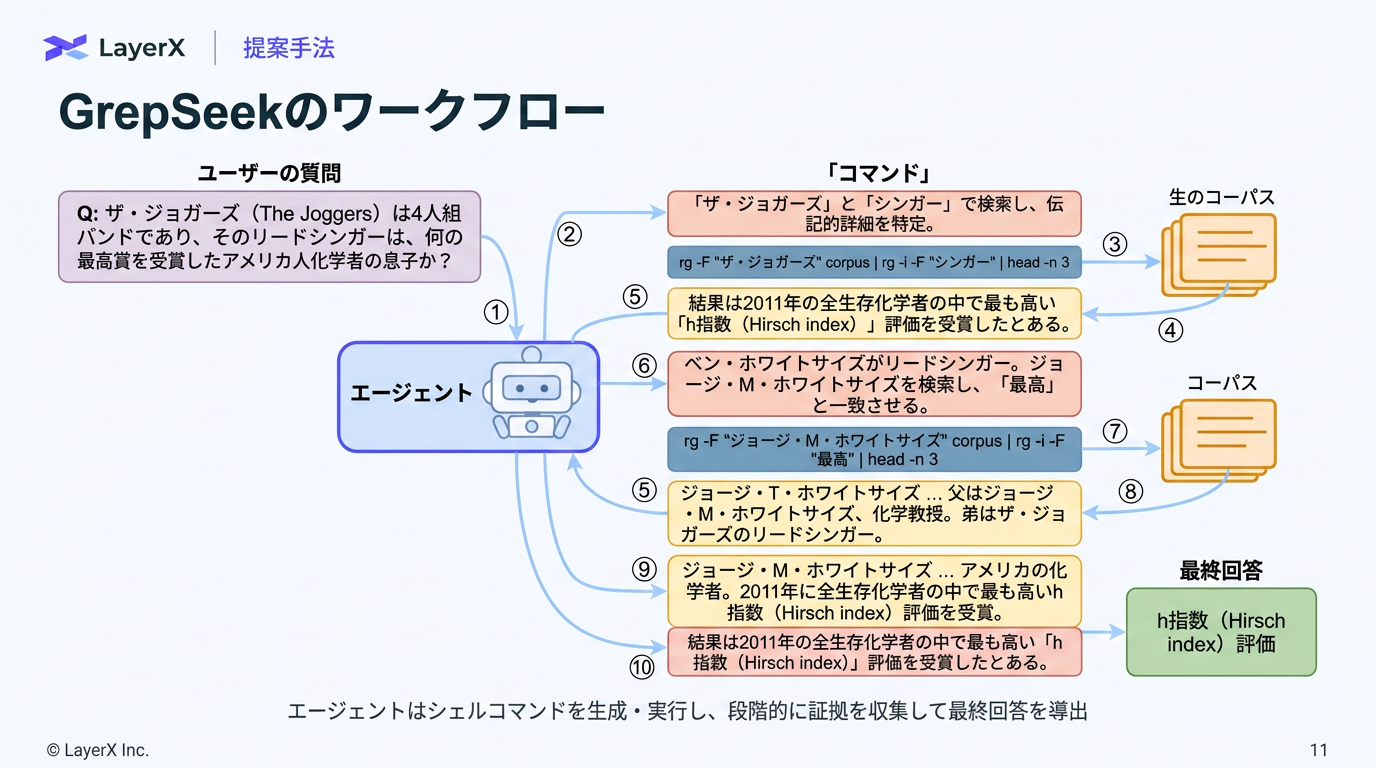
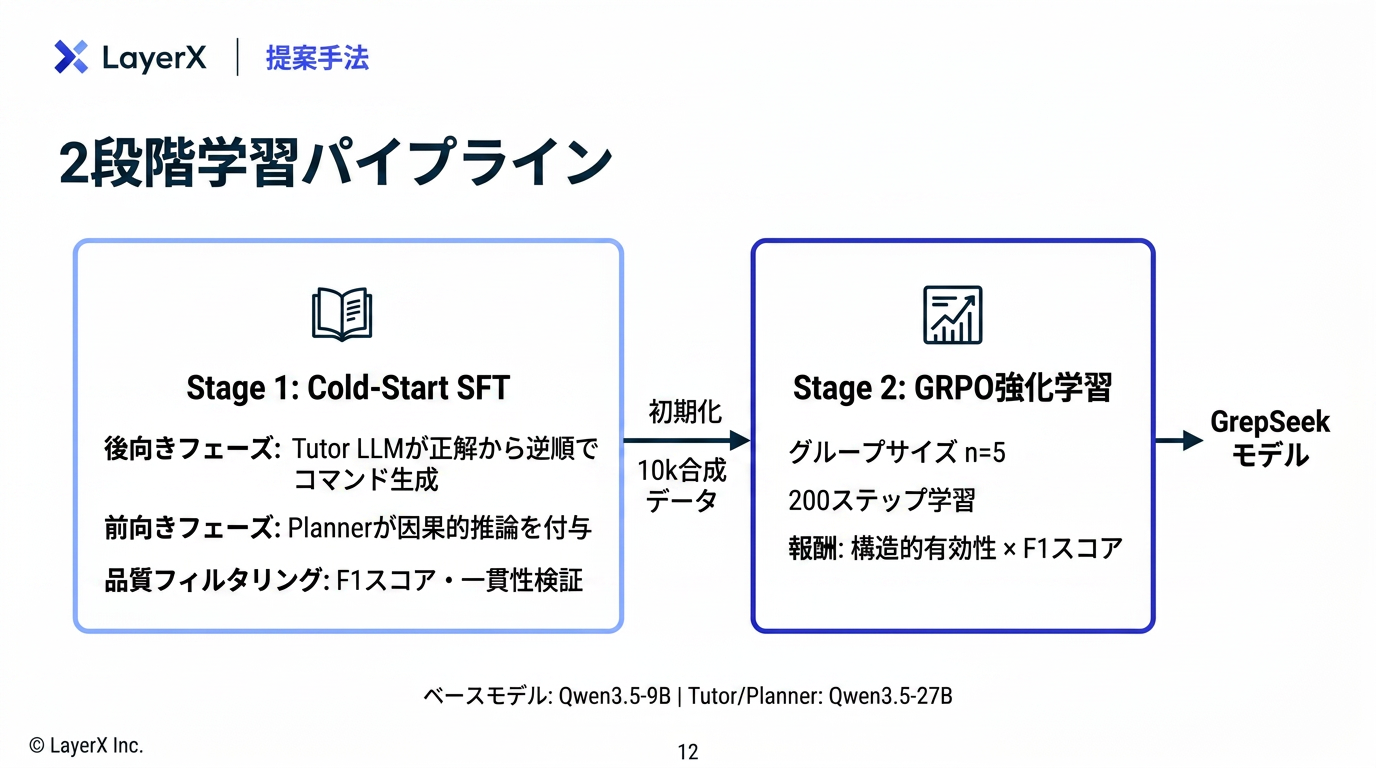



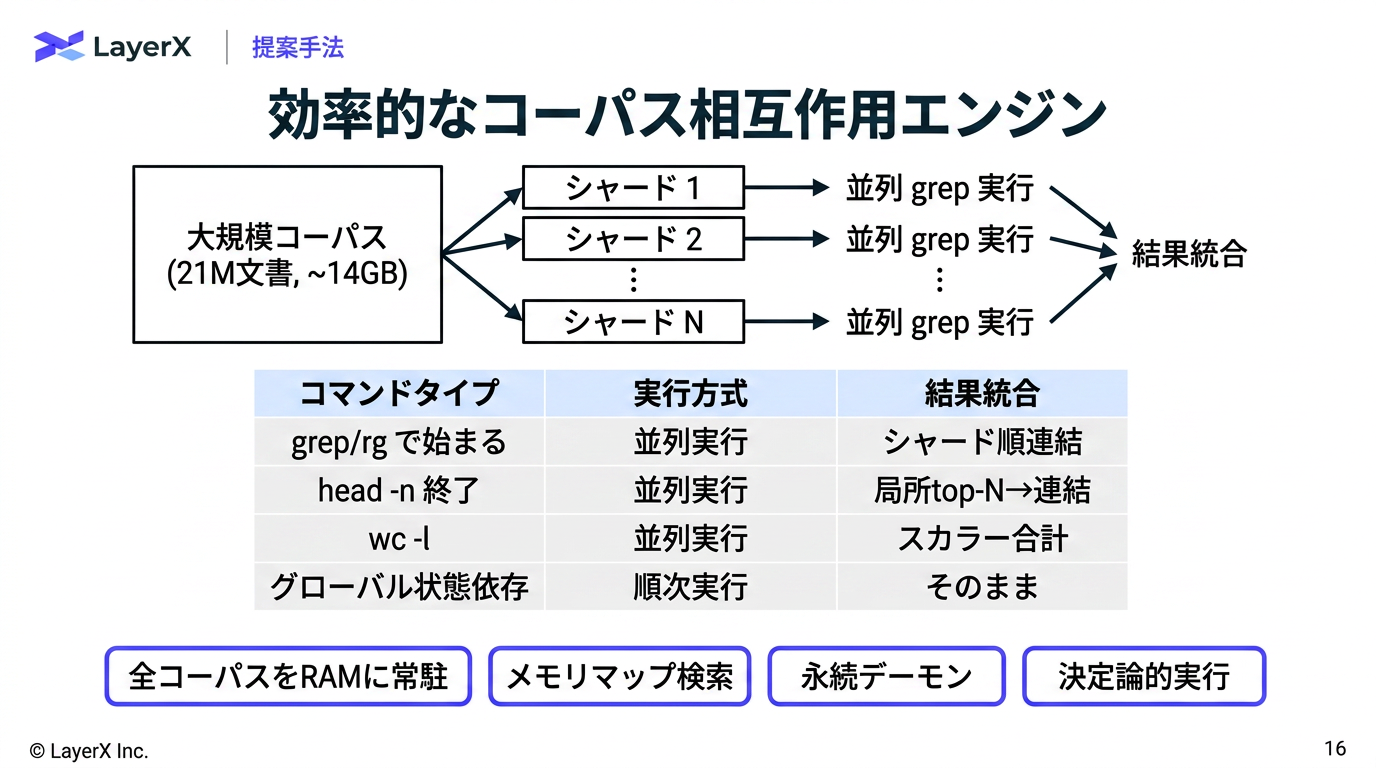

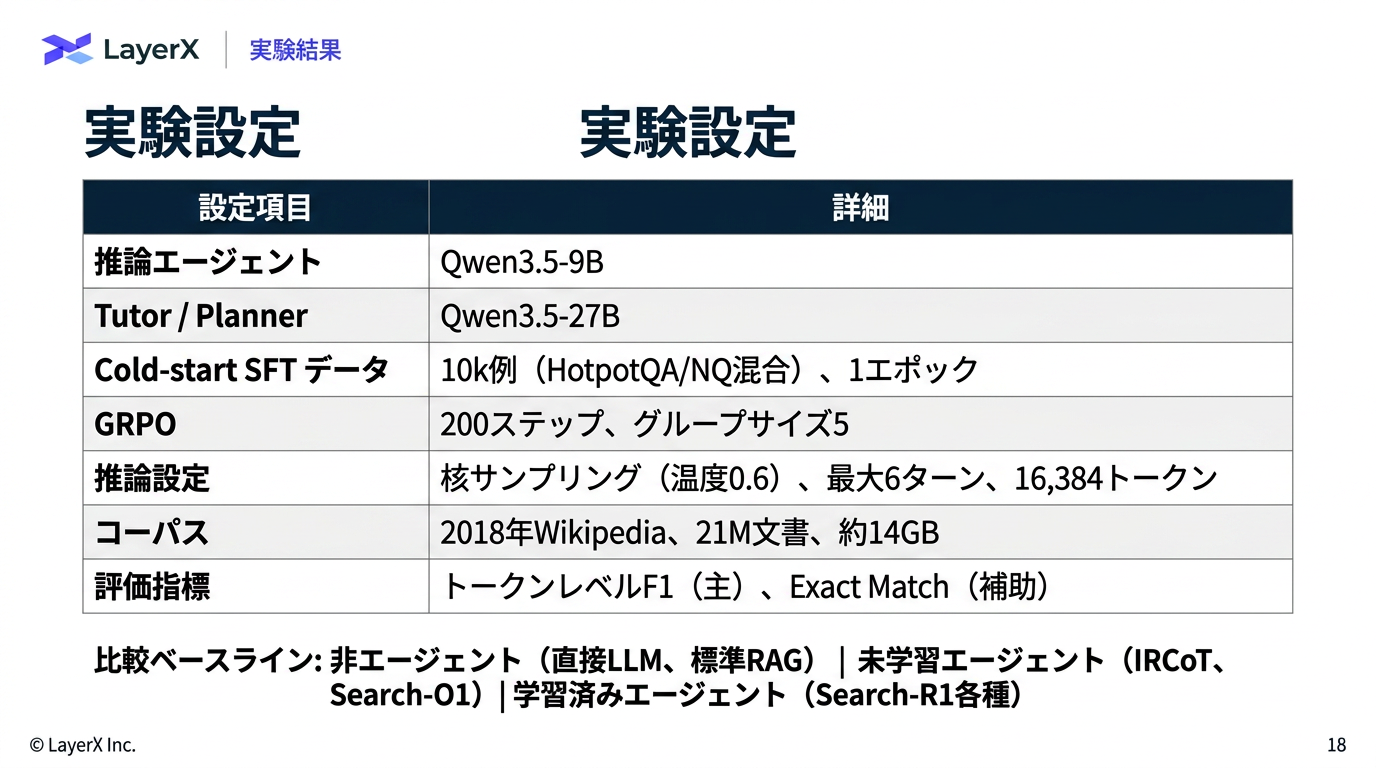
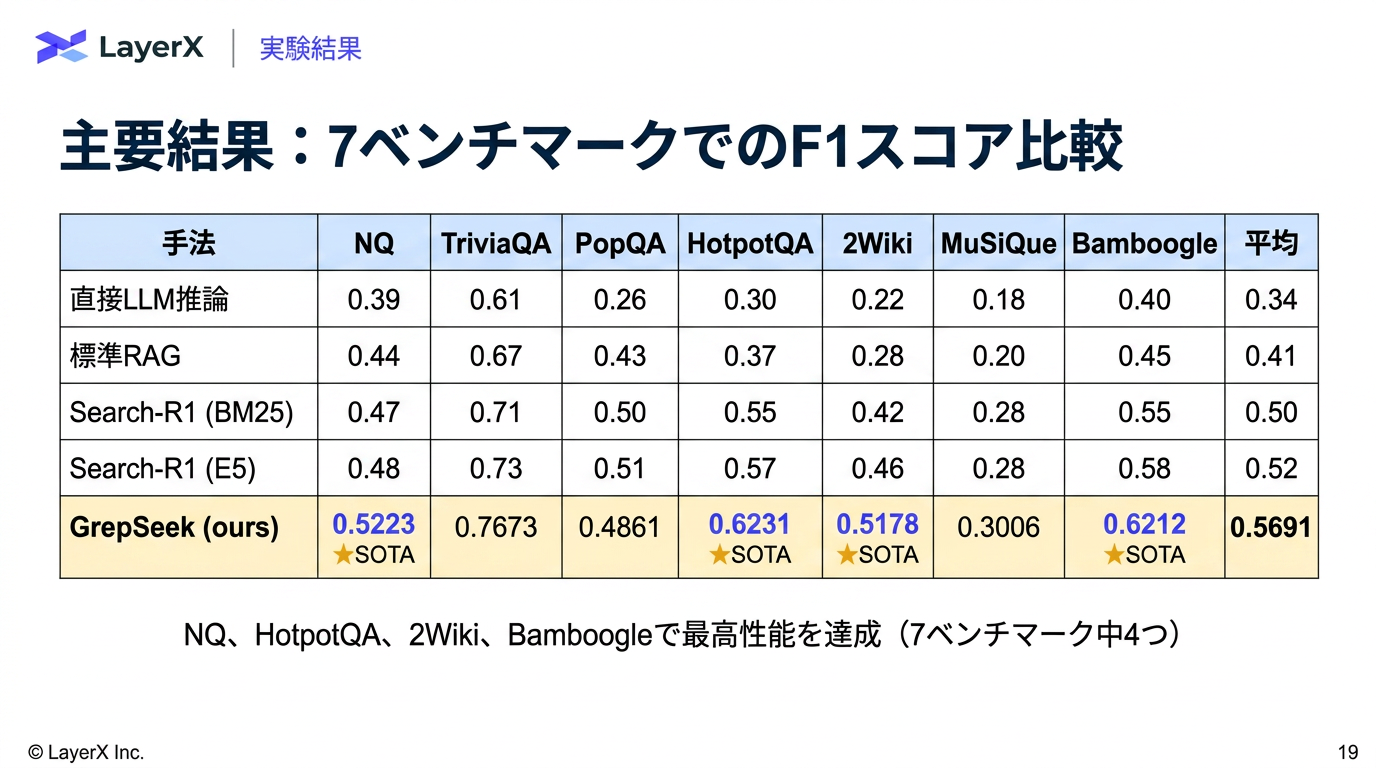
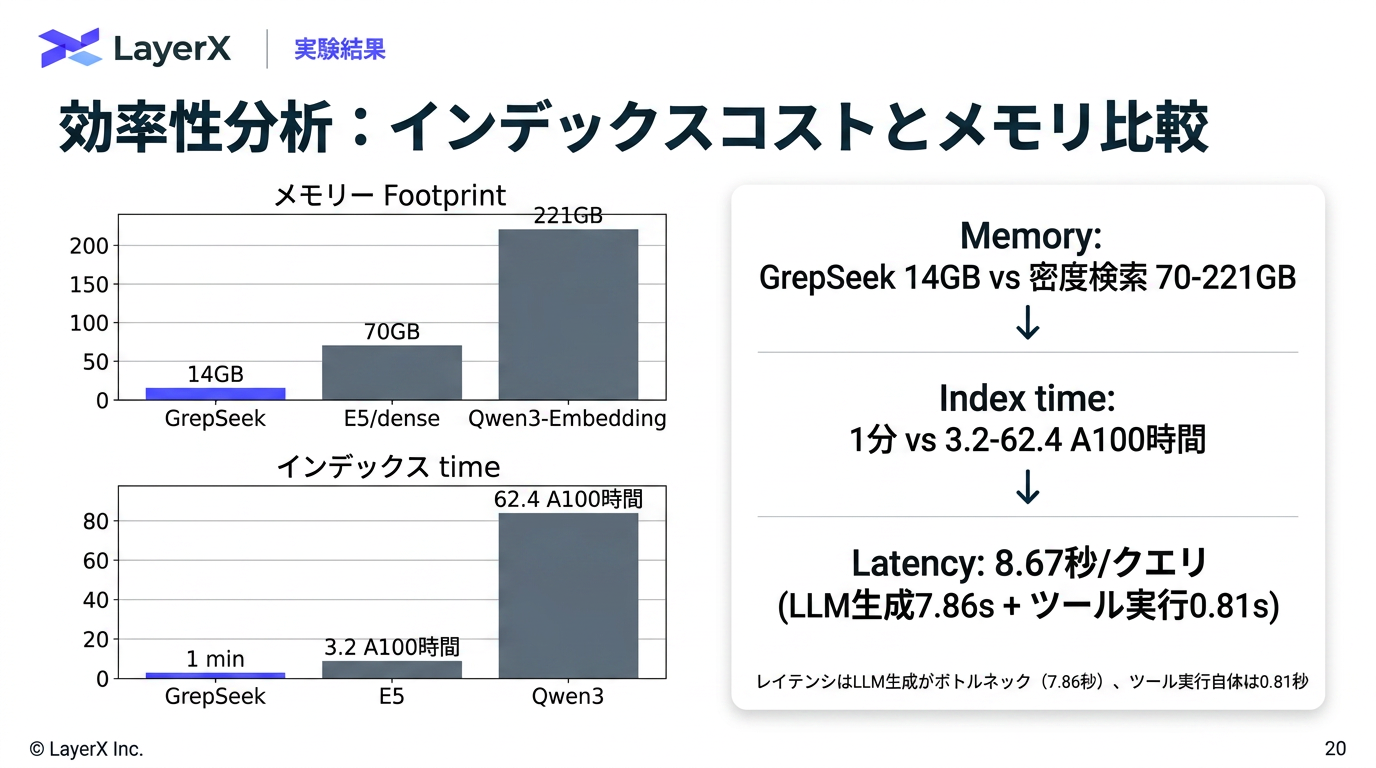
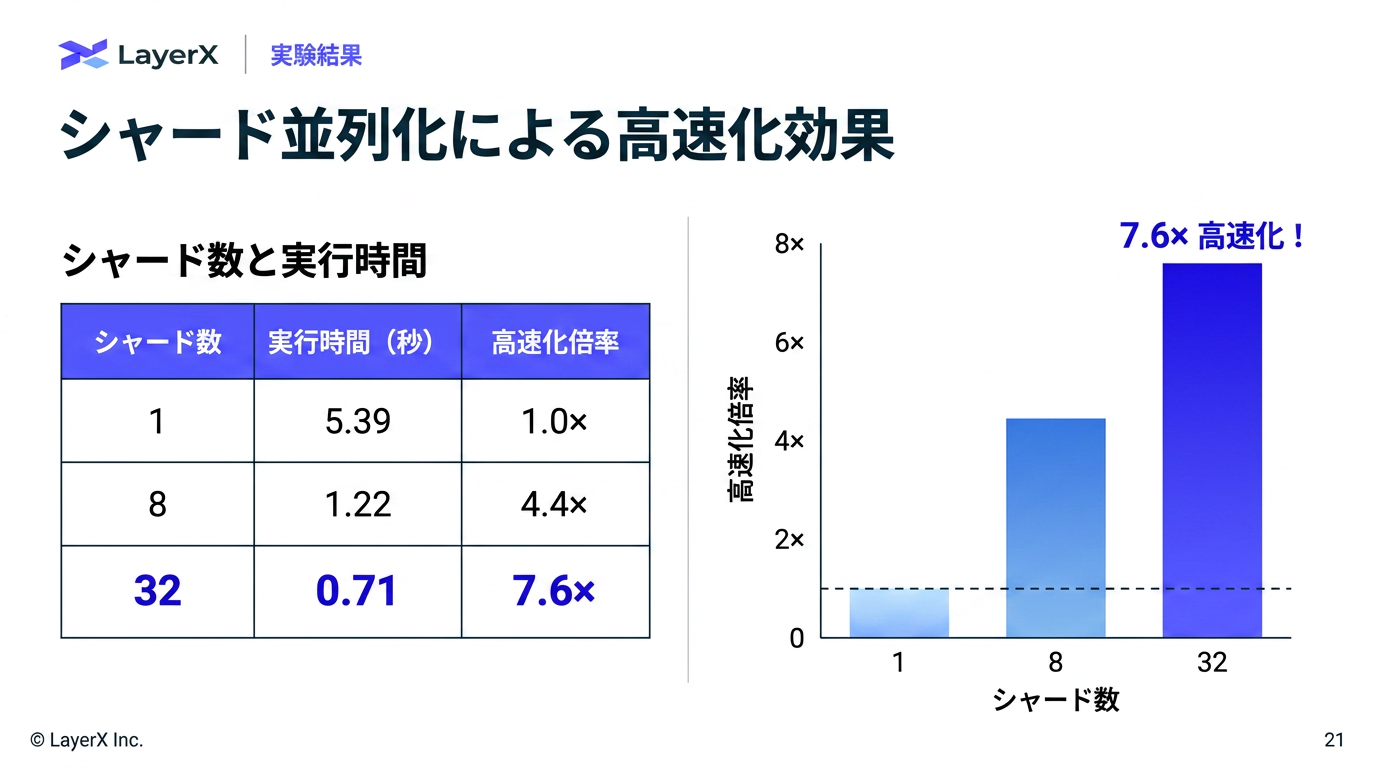
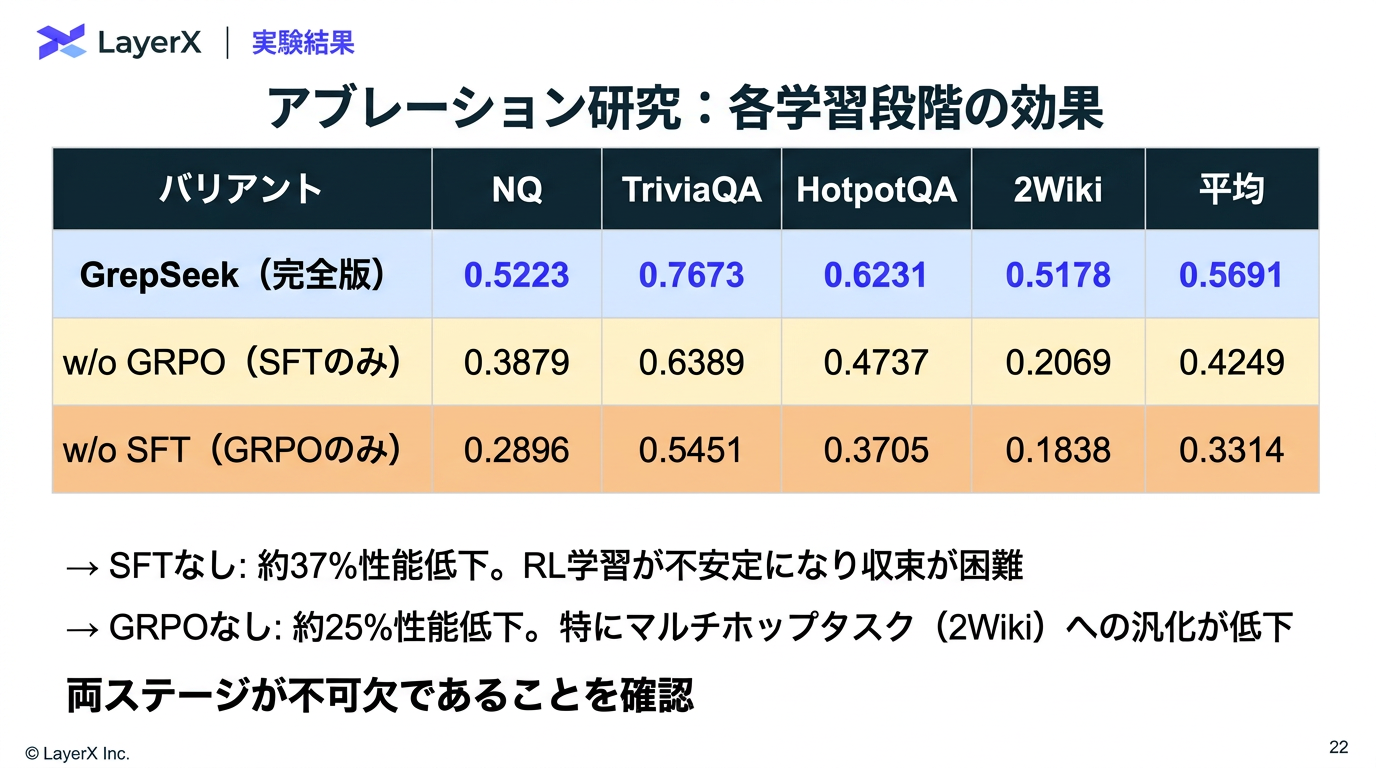



@Shun Ito
[paper] V1: Unifying Generation and Self-Verification for Parallel Reasoners
概要
- parallel reasoning / best-of-N では、複数候補を生成しても「正しい候補を選べる verifier」が弱いと性能が伸びない。
- この論文は、候補を単独で採点する pointwise verification より、候補同士を比較する pairwise self-verification が強いと主張。
- 提案は、inference-time selector の V1-Infer と、generator 兼 verifier を同時に鍛える V1-PairRL。
課題
- majority voting は数学の exact answer には使いやすいが、code / patch / open-ended reasoning では多数派が正しいとは限らない。
- pointwise scoring は、候補ごとに絶対スコアを付けるので calibration が難しい。
- それっぽくて間違った解に高得点を付ける。
- 多数の候補に 10/10 を付けてしまう score saturation が起きる。
- self-aggregation 系は候補をまとめて新しい解を作るが、correct outlier を捨てる diversity collapse が起きうる。
self-aggregation は複数候補を統合して新しい候補を作るため、少数派だが正しい候補が多数派の誤った候補に上書きされることがある。結果として候補集合が似た誤答に収束し、Pass@N が下がる。これを diversity collapse と呼んでいる。
提案手法

- N個の候補を全ペア比較するのではなく、限られた budget で pairwise 比較する。
- まず全候補が最低限比較されるよう Topology Coverage。
- 1度も比較されない候補を作らないようにする。
- 比較ペアそれぞれに、LLMが 1 ~ 10 の score を付与する。
- 候補ごとに、比較されたアイテムとの score の差を考慮した勝率 score を計算
- 次に、現在の score が近い候補同士を比べる Swiss Refinement。
- pairwise rating の差を confidence として、margin-weighted win rate で候補を ranking する。
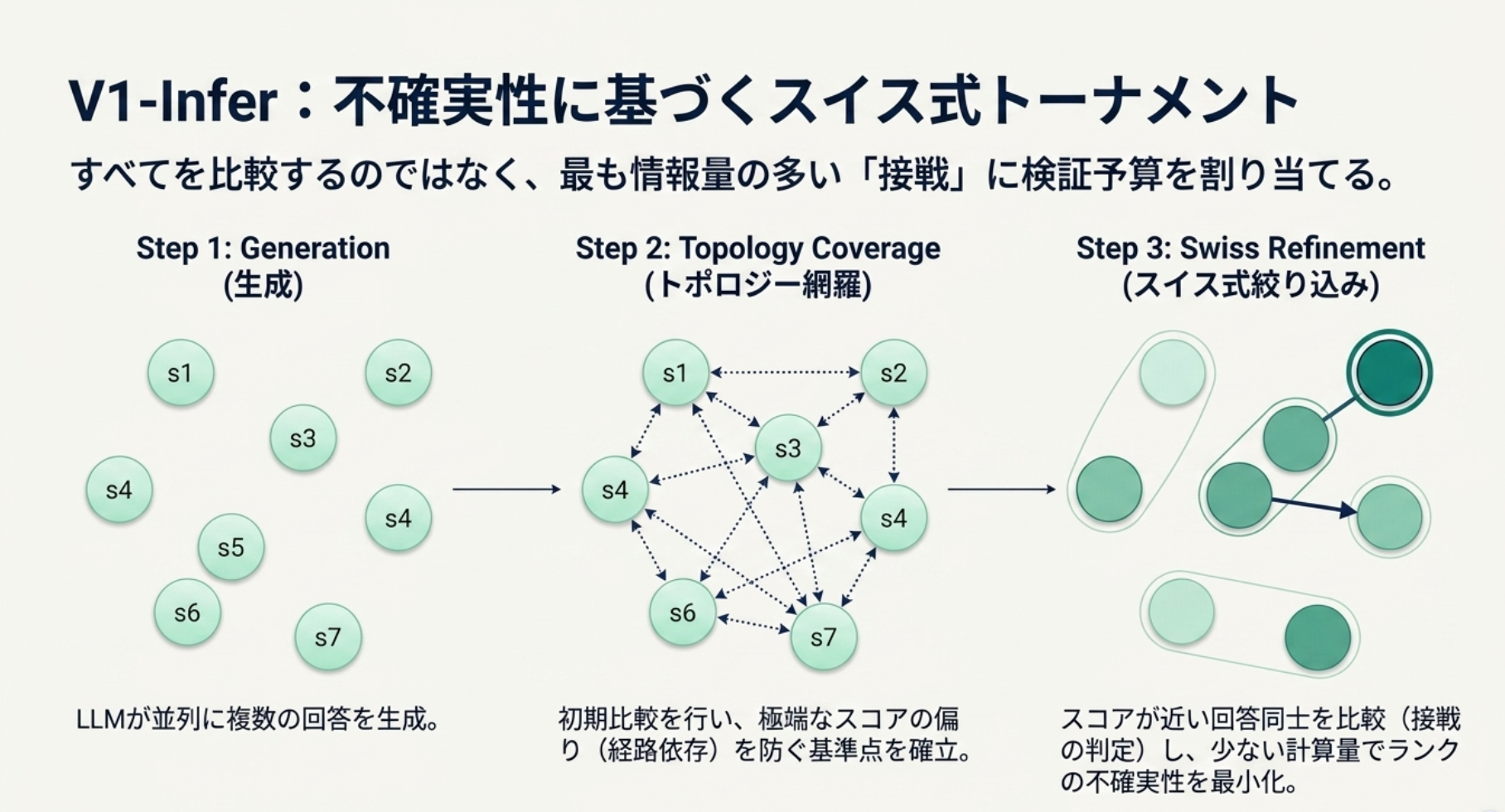
margin-weighted win rate は、pairwise の勝敗を rating 差で重み付けした暫定 score。10 vs 2 の勝ちは強い証拠、6 vs 5 の勝ちは弱い証拠として扱う。
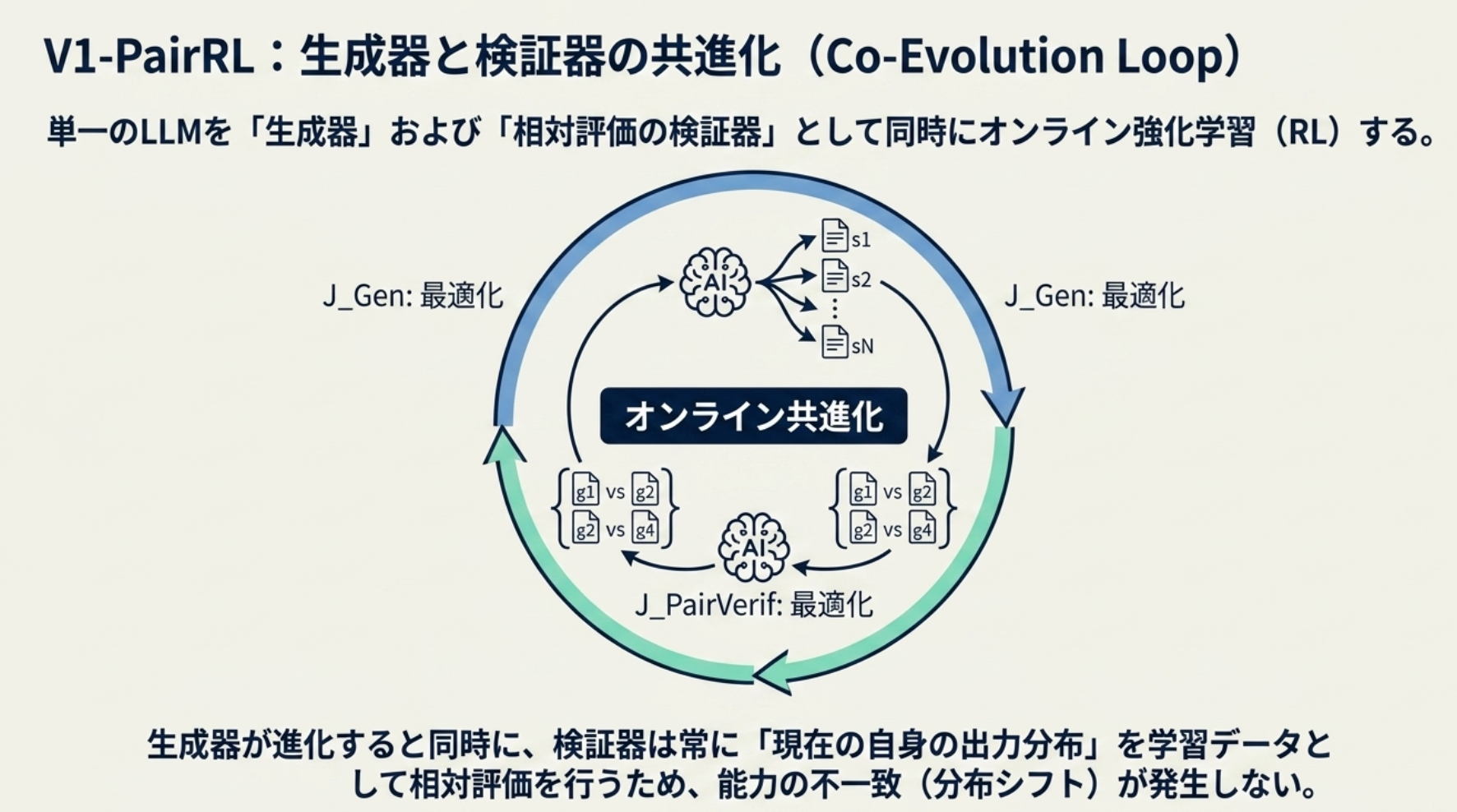
- inference 後段の verifier を後付けするだけでなく、1つの model を solution generator 兼 pairwise verifier として RL training。
- verifier は固定データではなく、その時点の generator が出した候補ペアで学習する。
- 報酬は生成側・検証側それぞれの報酬の和
- 生成側: 生成したコードが ground-truth test cases を全部通れば 1、それ以外は0
- 検証側: 生成された候補をpairwise比較 → 10段階で score 付け → 0 ~ 1 に正規化し、その候補が正しいかどうかのラベルと比較
- ground-truth test cases を全部通るものが 0.8 以上の score or 通らないものが 0.2 以下の score → rewardあり
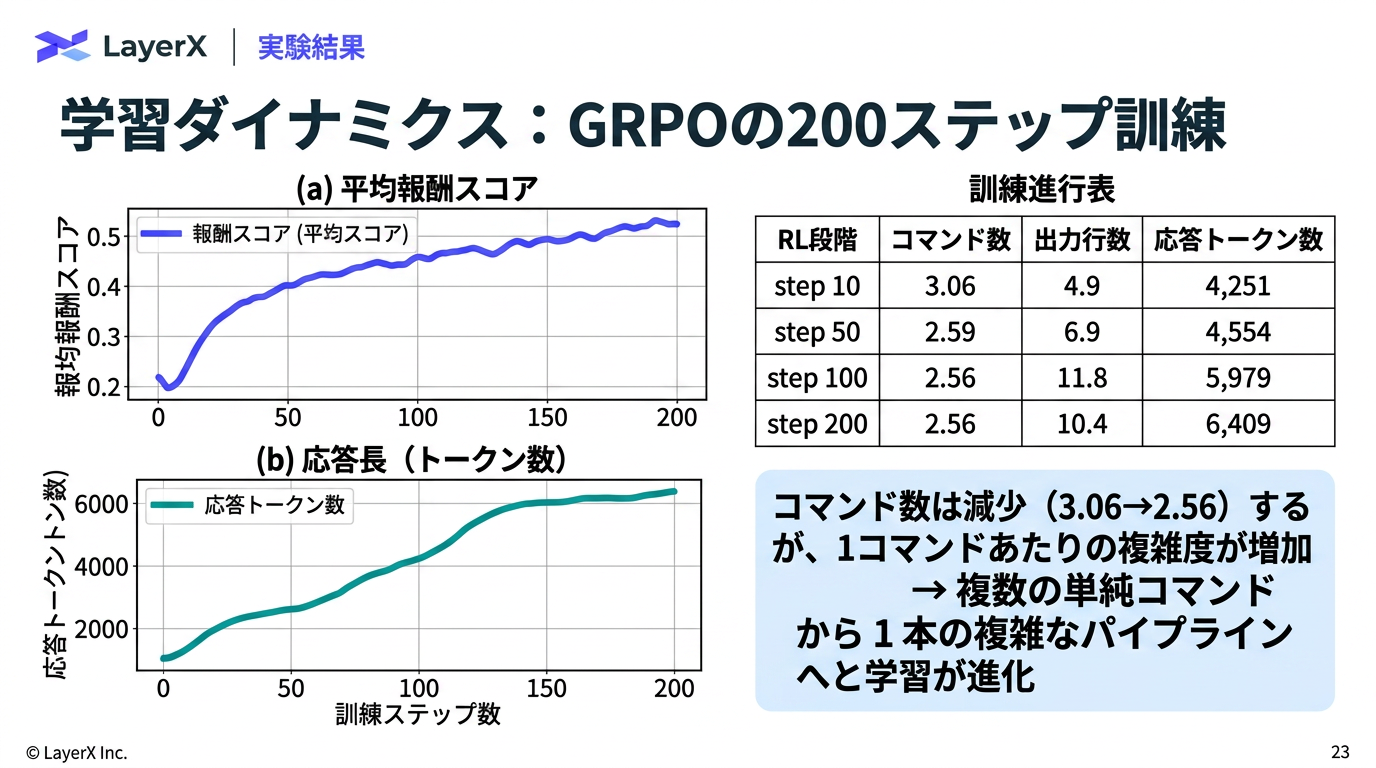
結果
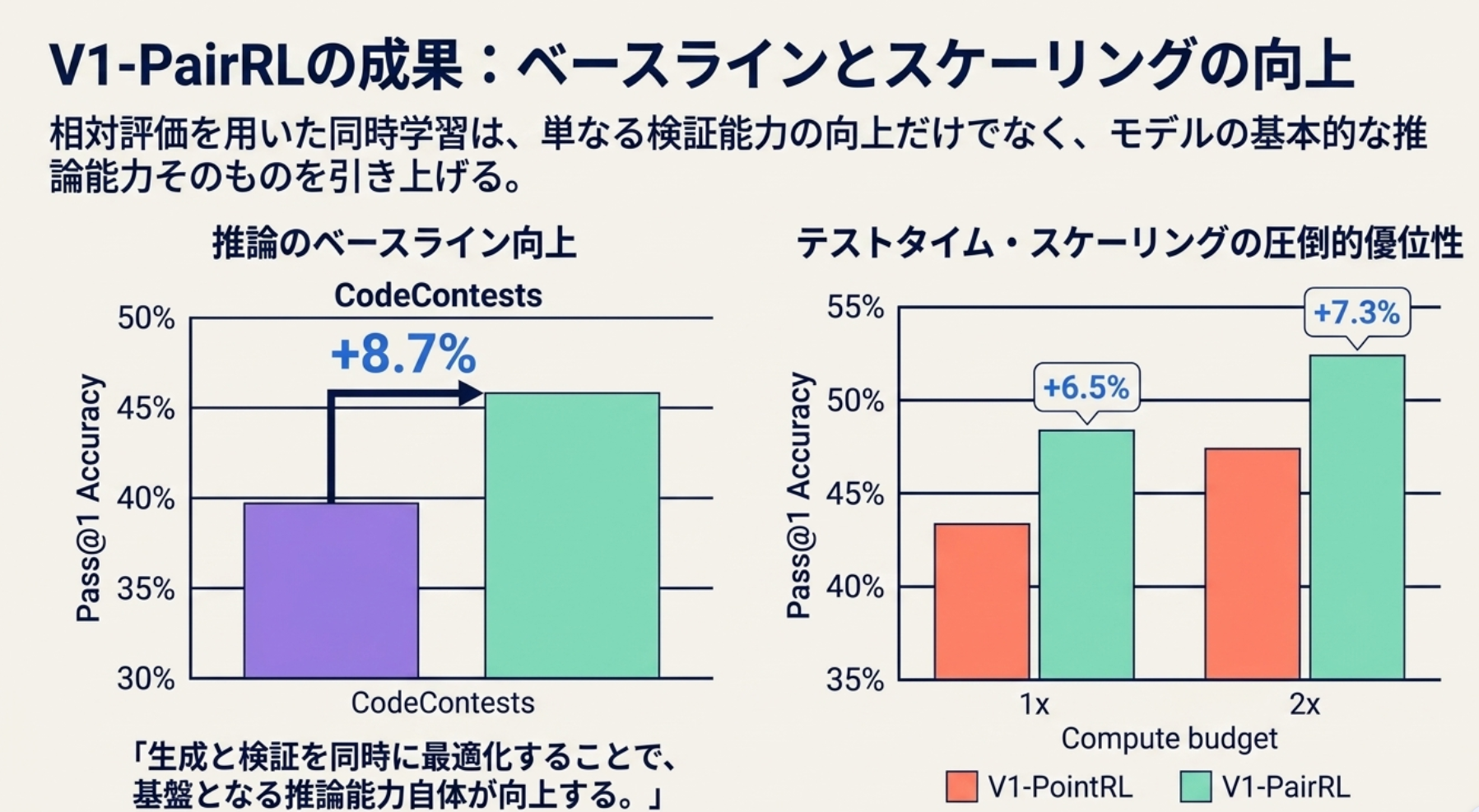
- 同じ budget で比較して、提案手法が一貫して高い Accuracy (Pass@1)
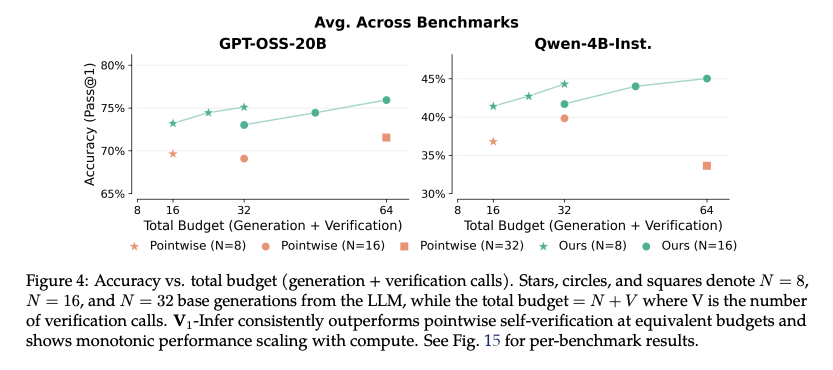
- RLにより推論精度も上がり、reranking性能も上がる
@Hiromu Nakamura (pon)
[paper] LLM-Emu: Native Runtime Emulation of LLM Inference via Profile-Driven Sampling
[pon] LLM呼び出しを含むworkflowの負荷試験したくて出会った。
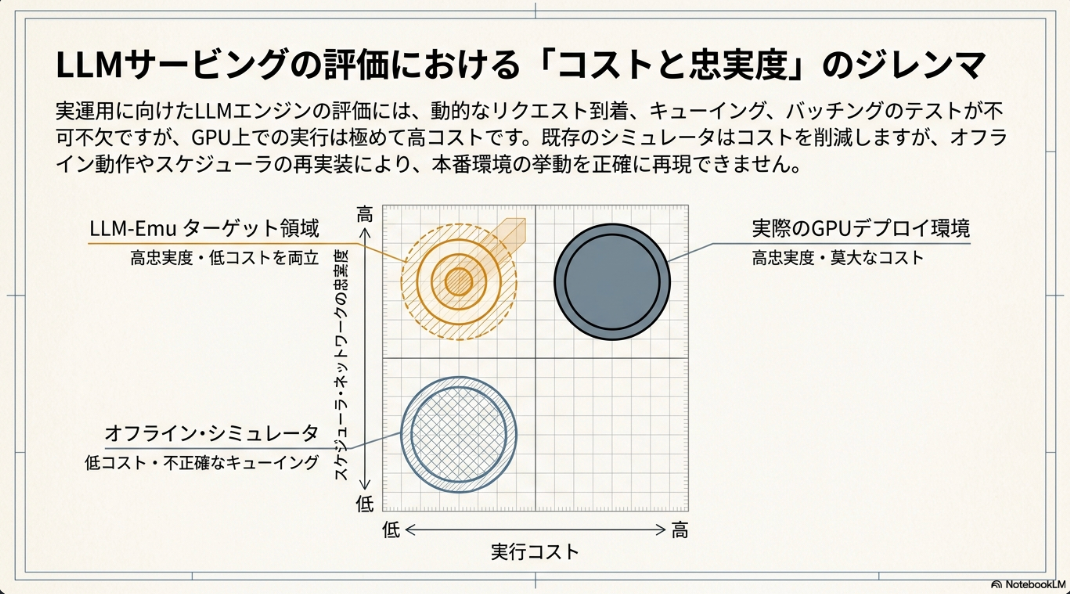
本論文は、LLM推論のGPU利用における高コストな課題に対処するため、既存のシミュレータが抱えるギャップを埋める、リアルタイムでオンラインなLLMサービングエミュレータ「LLM-Emu」を提案している。
背景
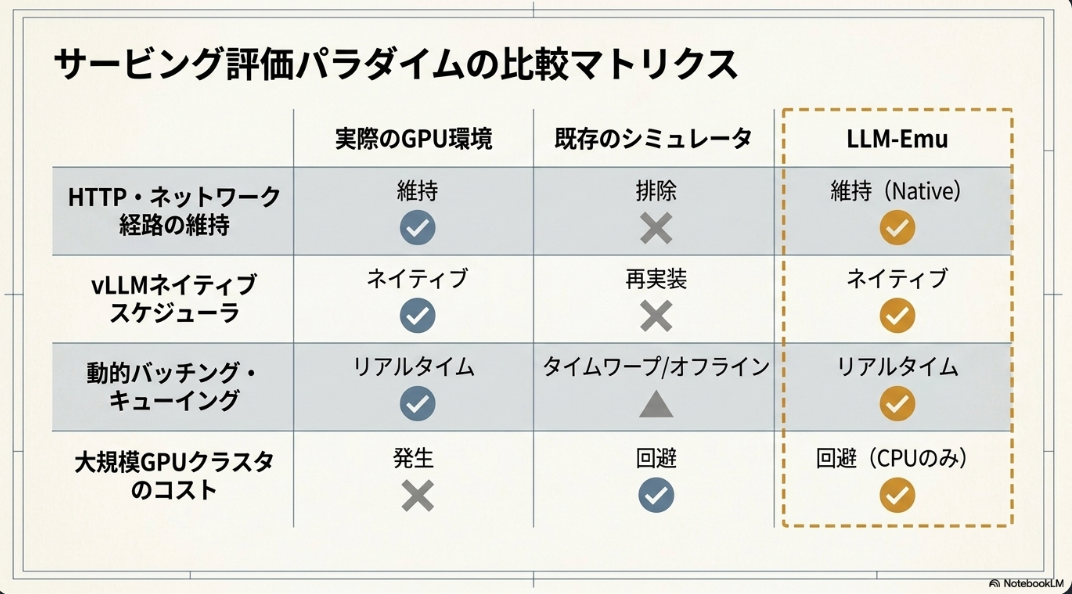
既存のLLMサービングシミュレータやエミュレータは、主に以下の点で制約がある。
- 多くはライブHTTPトラフィック、動的なリクエスト到着、キューイング動作、デプロイされたサービングスタックにおけるランタイムオーバーヘッドを直接評価できない。
- サービングエンジンのスケジューラを再実装していることが多く、vLLMなどのエンジンが進化するにつれて、その並行実装をマニュアルで同期させる必要が生じ、メンテナンスコストが増大する。
- オペレータレベルのレイテンシモデルや学習済み予測器に依存しており、正確なキャリブレーションが必要で、ワークロード、ハードウェア、エンジンバージョン間で汎化が難しい。
LLM-Emu
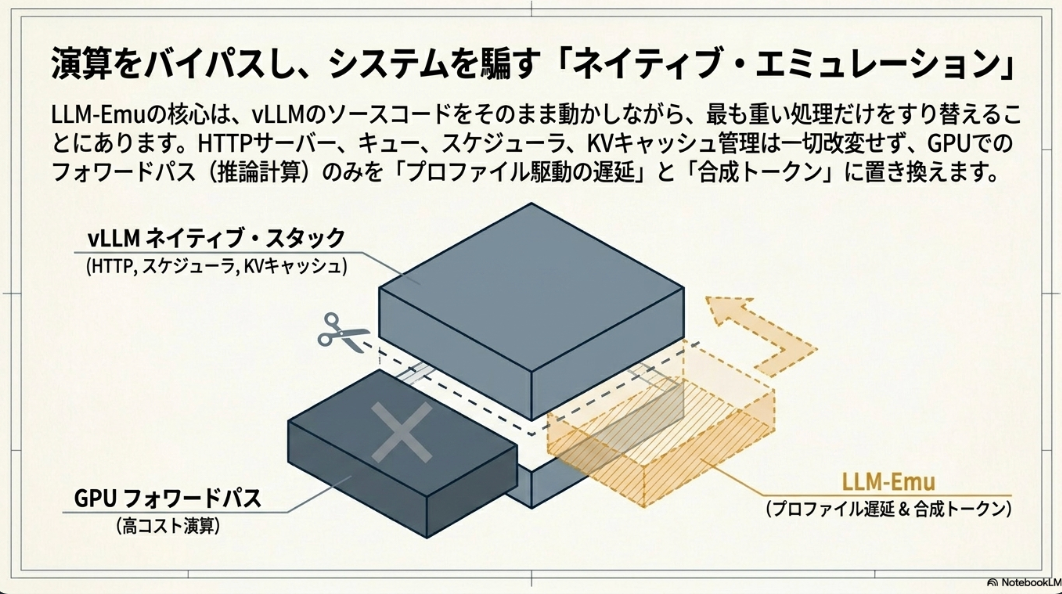
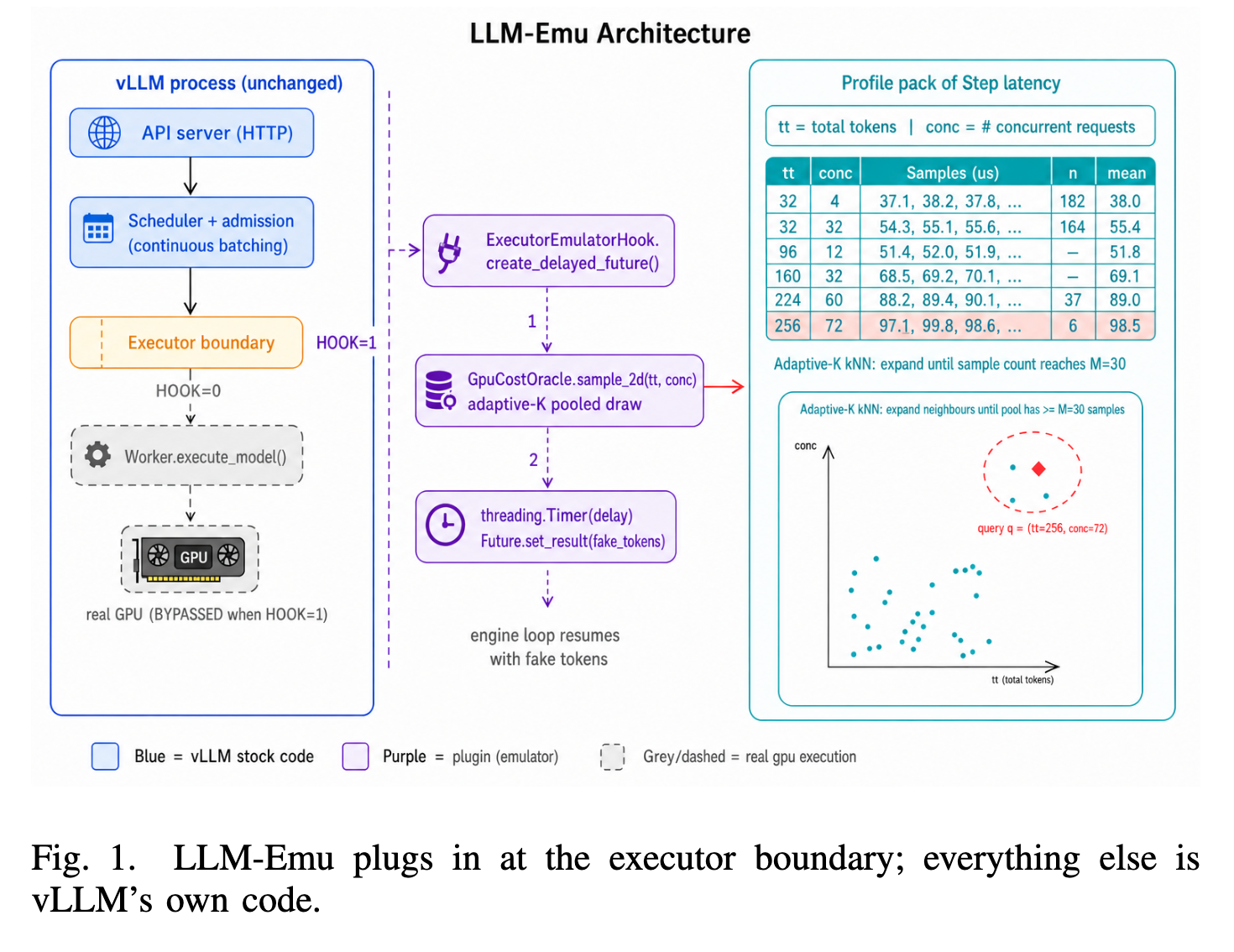
LLM-Emuはこれらのギャップに対処するため、vLLMプロセス内で動作する、プロファイル駆動型のオンラインエミュレータとして設計されている。その核となる設計思想は、vLLMのHTTPスタック、アドミッションパス、スケジューラ、KVキャッシュ管理、出力処理といった生産環境のコンポーネントをそのまま維持しつつ、GPUフォワード実行のみを置き換える点にある。
具体的には、GPUフォワードパスを、オフラインで収集されたプロファイルからサンプリングされたレイテンシと合成出力トークンに置き換える。これにより、並列スケジューラの実装、オペレータごとのレイテンシモデリング、CUDAインターセプトといった複雑さを回避し、既存のvLLMサーバーCLIやHTTPクライアントを修正せずに利用できる。
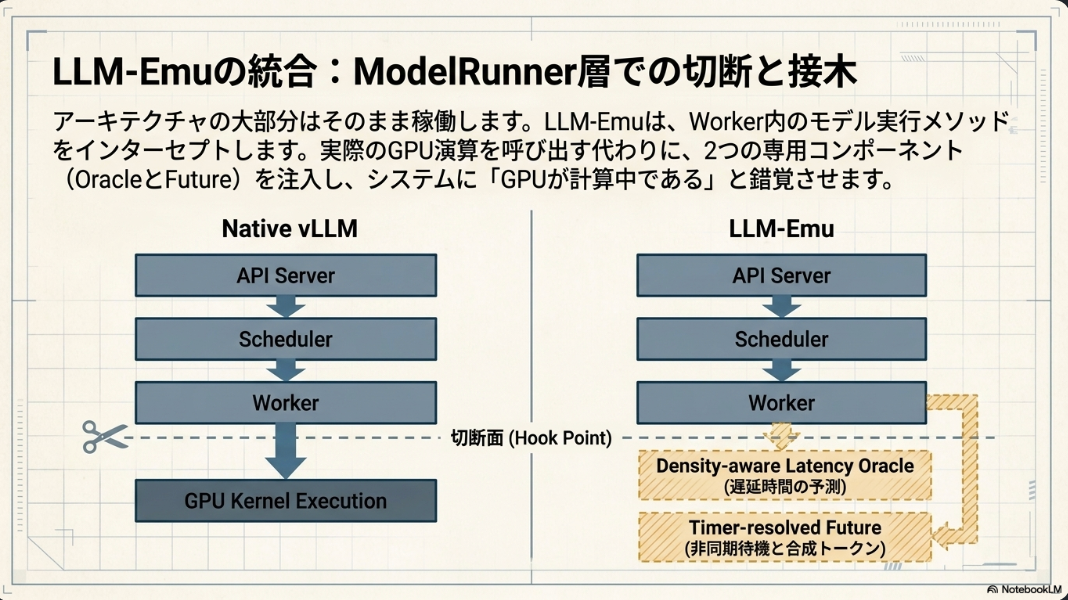
LLM-Emuのコアとなる技術要素は以下の通り。
Density-aware latency oracle
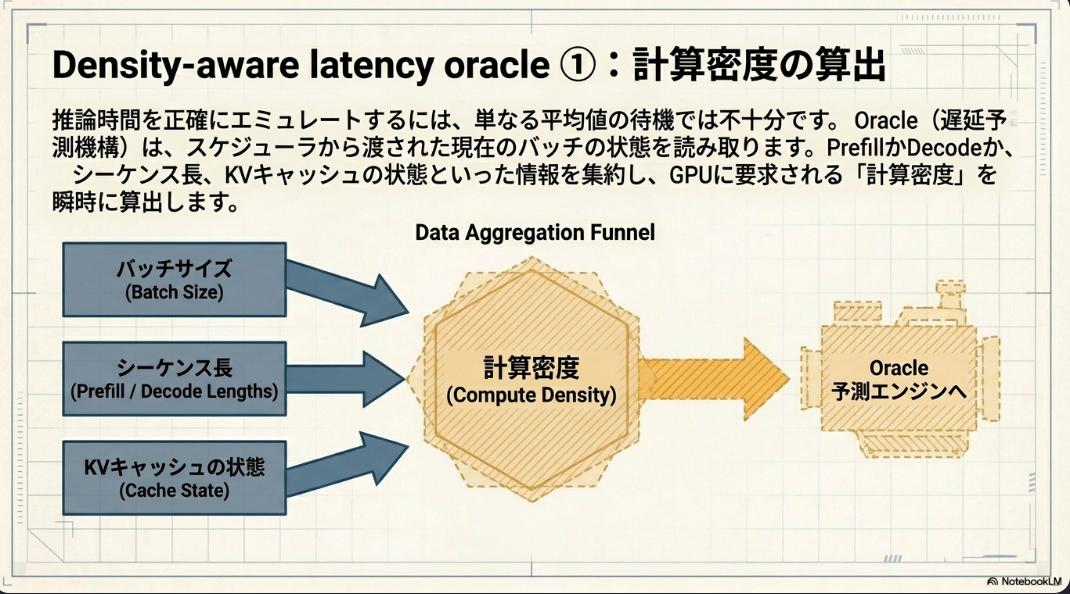
- 遅延を予測するために必要とするのは、現在のバッチの特性。具体的には、以下の2つの次元でインデックス付けされたデータを使用。
- (total tokens): そのステップで処理される総トークン数。
- (concurrency): 現在実行中のリクエストの数(並行度)。
- 二つの指標がKVキャッシュのサイズ、アクセスパターン、メモリ使用量、そしてそれらがGPUの実行時間に与える複合的な影響を「結果として生じるGPU実行時間」の形で間接的に取り込んでいる
- total tokens は処理されるデータ量(計算量)を、concurrency はバッチの「形状」(並列度、シーケンス数)をそれぞれ捉えており、これら2つが、連続バッチ処理におけるGPUの効率性とパフォーマンスを決定する主要な要因として機能。
- デコードのみのステップと、プリフィルまたは混合ステップでは遅延の挙動が異なるため、これらを分けてプロファイルを収集している。
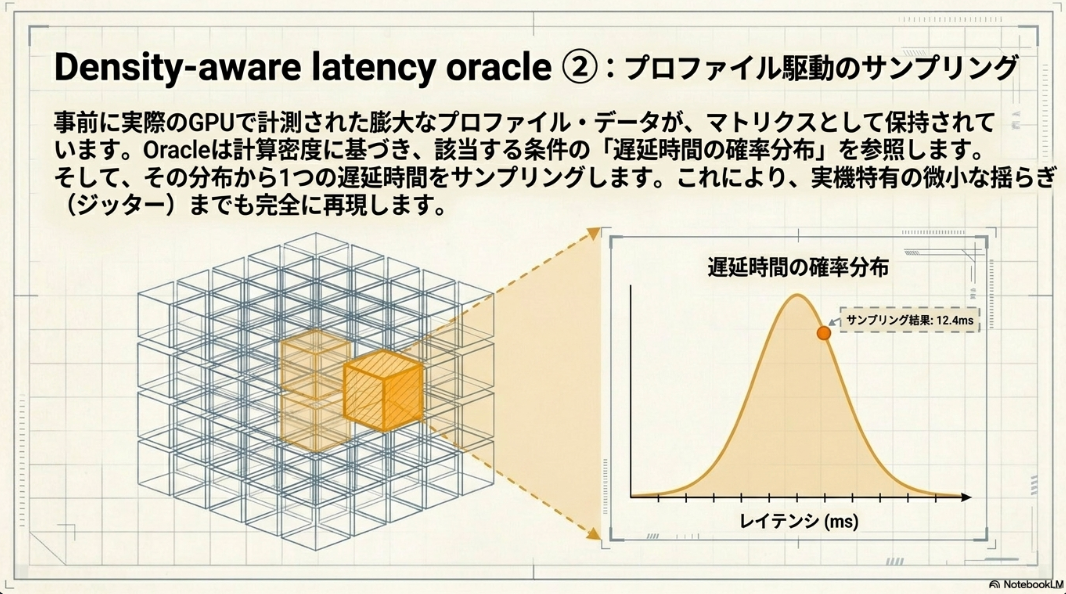
- オラクルは、事前に収集された「プロファイルパック」というJSON形式のデータに収められる。このプロファイルは、 と をキーとする2次元のバケット構造をしています。重要な点は、各バケットが観測された生のリソース (raw list of observed latencies) のリストを保持していること。
- 平均値や標準偏差のような事前集計された要約ではなく、個々の遅延サンプルを保持することで、リアルな分散をエミュレーションに反映させることができる。
Density-aware neighbor pooling

- クエリされた のバケットに十分なサンプルがない場合(疎な領域の場合)、オラクルは「適応的な最近傍拡張」を用いて、周辺のデータを考慮する
アルゴリズムのステップ:
タイマー解決型Future (Timer-resolved Future):
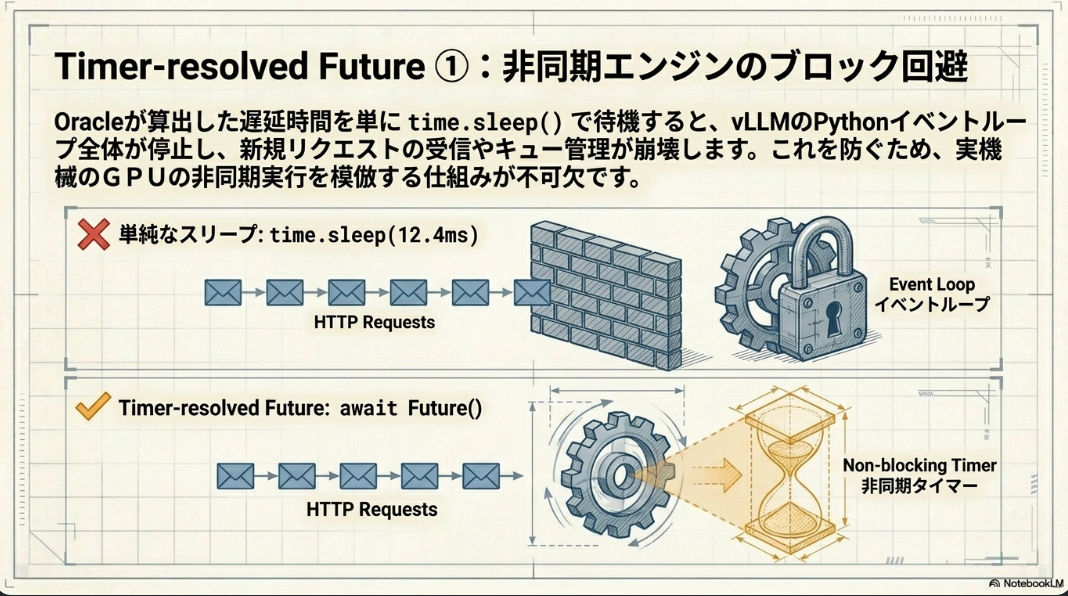
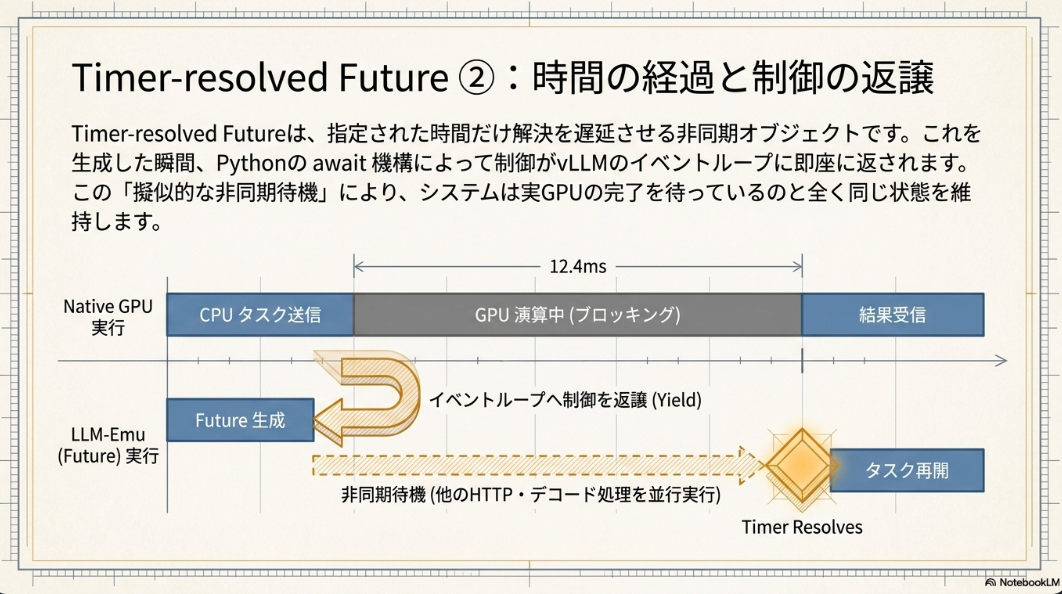
- 予測された遅延後に合成出力トークンを返すasyncio.Futureをスケジューリングすることで、非同期スケジューラとワーカーのオーバーラップを維持し、vLLMの非同期実行モデルと整合する。
評価
評価においては、LLM-Emuを実際のvLLM実行と比較している。
評価環境
- RTX 8000(FlashInferバックエンド)
- A40(FlashAttention 2バックエンド)
の2種類のGPUを使用し、Qwen3-8B、Qwen3-14B、Qwen3-4B、Llama-3.1-8Bといった4種類のモデル、Poissonおよびバースト性のShareGPTワークロードが用いられた。
評価指標
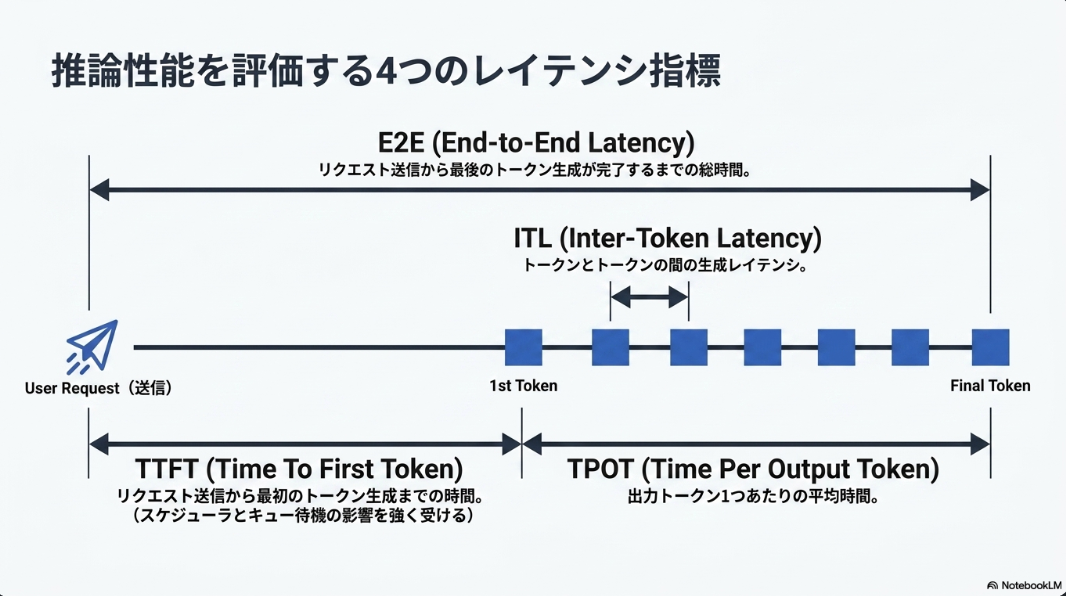
実験結果
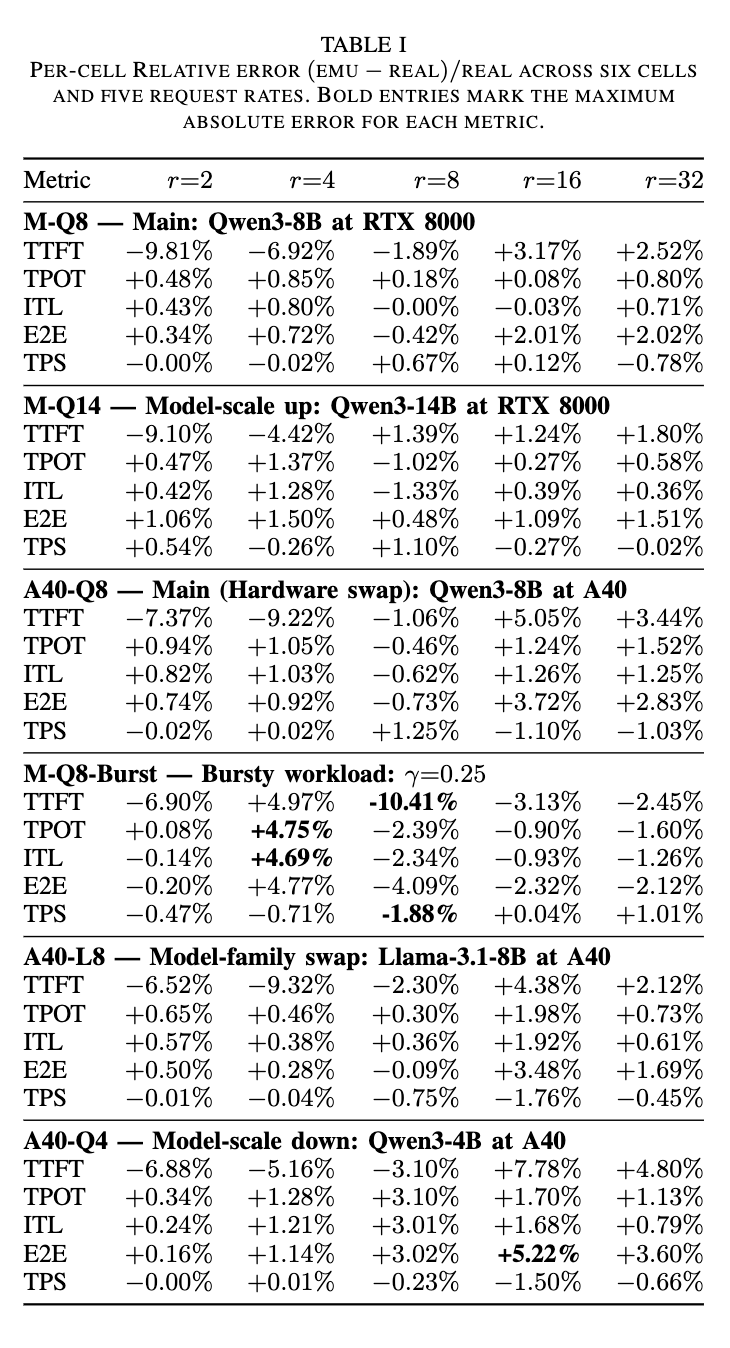
- LLM-Emuが定常状態のサービングメトリクスにおいて、実際のvLLMの振る舞いを密接に追跡していることを示している。
- TPOTとITLは絶対誤差4.8%以内、E2Eレイテンシは5.3%以内、出力スループットは1.9%以内に収まっている。TTFTは最大絶対誤差10.41%と、他のメトリクスと比較して不安定であるが、これはTTFTがアドミッションのタイミング、キューの状態、CUDAグラフキャプチャやキャッシュウォームアップなどの起動効果に非常に敏感であるためと説明されている。
[pon]
- 276Kのサンプルかー。新規サービス開発中は苦しいか。一応OSSで出てるので、vllmサービング含む負荷試験とかならもしかしたら使えるかもしれない。
- サンプルからバケット作って、そこから遅延を選ぶというのはプロバイダ提供モデルでもワンチャン模倣はできるか?
@Kyohei Uto(kuto)
[paper]Trust Region On-Policy Distillation
背景
- LLMの小型化において蒸留は有効な手法の1つ
- off-policy蒸留
- 教師モデルが生成した回答を生徒モデルに模倣させる
- 実際の生徒モデルの推論と乖離があると学習が不安定となる
- on-policy蒸留
- 生徒モデルが生成した回答を元に教師信号を当てて学習するためoff-policyより分布ズレを緩和できる
- 教師の確率分布が0に近い場合勾配が不安定になる
- 難しいタスクの場合生徒モデルの回答品質が低く有益な教師信号を受けることができない
- on-policy蒸留のこれらの課題を解決するためのTrOPDという手法を提案
詳細
信頼領域の判定
生徒モデルを 、教師モデルを とする
生徒が生成したトークン に対して、教師と生徒の確率比を次のように定義する
この比率から、教師信号が信頼できる確率を定義する
- M_t = 1 → trust region
- M_t = 0 → outlier region
生徒モデルの出力トークンに対する教師モデルの確率が非常に小さいとr_tは小さくなりM_tも0が発生する確率が高くなる(outlierになりやすい)
判定結果別の処理
- トークン単位でTrustとOutlierに判定後、各領域のトークンごとに異なる蒸留手法を適用(後述)
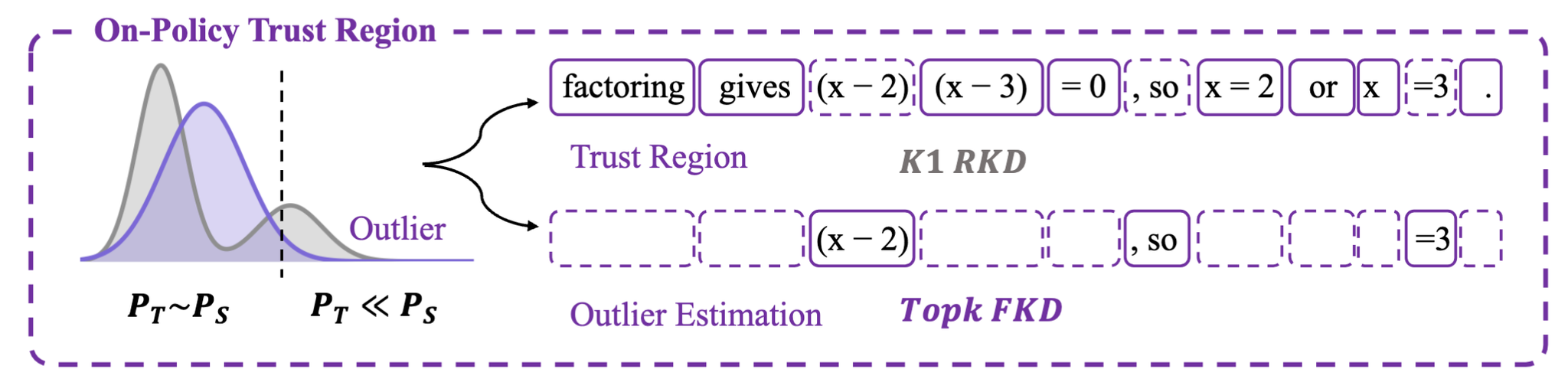
模倣学習による生徒モデルの品質改善(Off-Policy Guidance)
- 最初の数トークンを教師モデルの生成結果を利用して模倣学習する(off-policy蒸留)
- その後のトークンに関しては上述のルールに従いtrustとoutlierごとの蒸留手法を適用
- 学習序盤は教師モデルが生成するトークン数lを大きくとり、学習が進むにつれて徐々に小さくしていく(Cosine Annealingでスケジューリング)
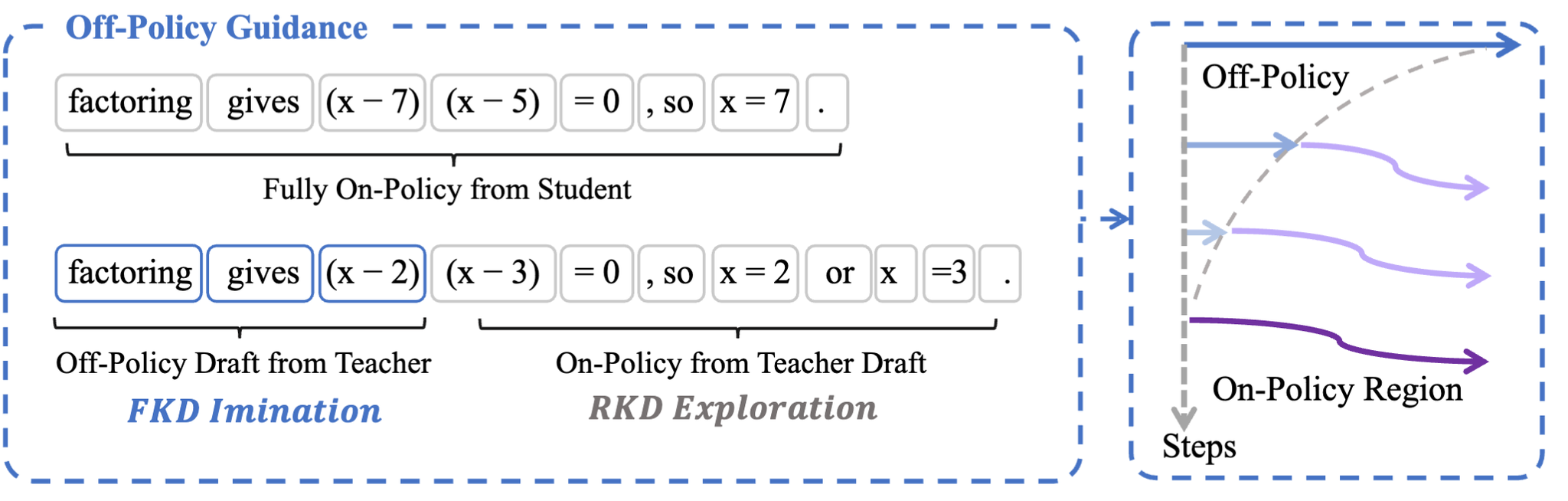
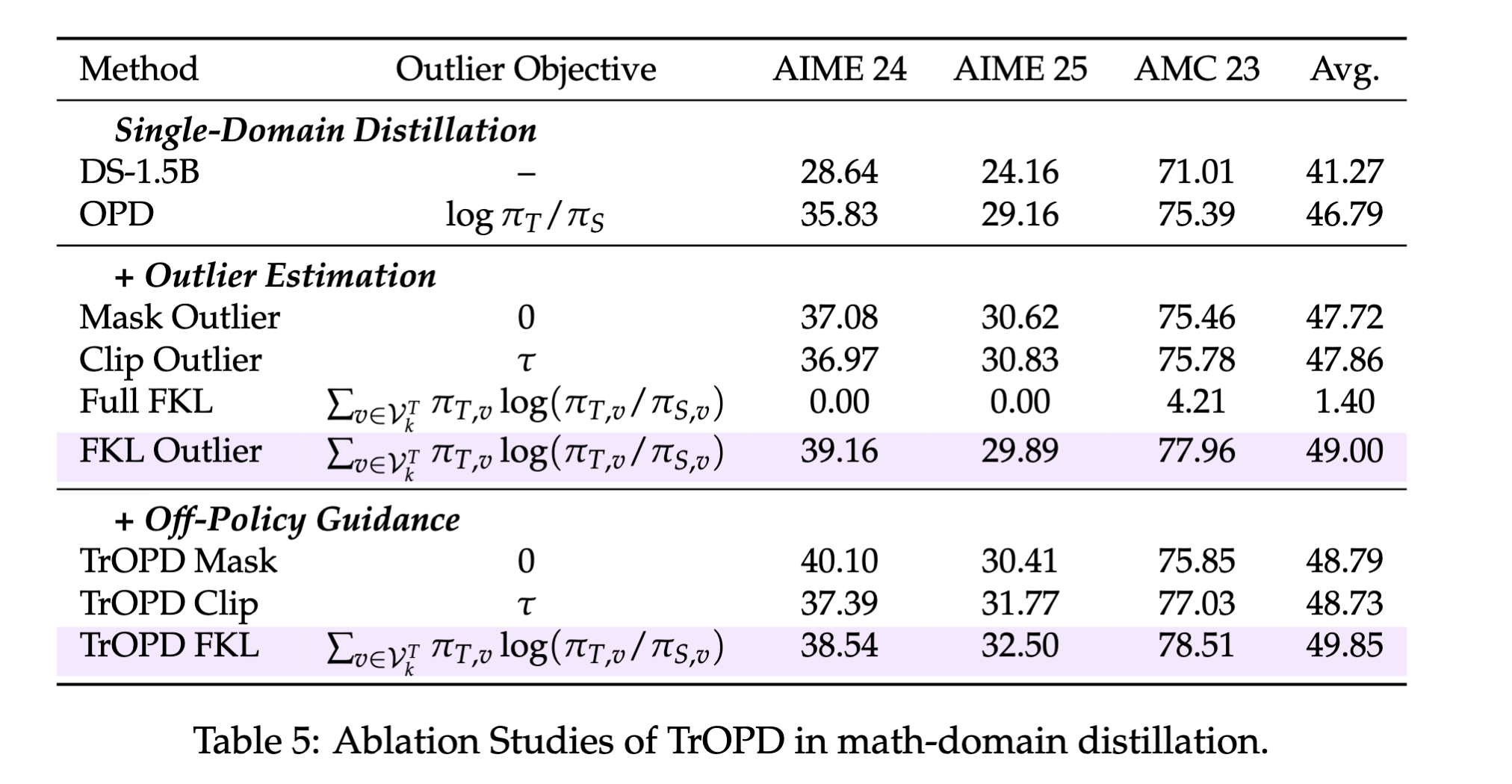
具体的な蒸留手法の違い
Forward KLとReverse KL
3パターンある
- Trust領域でのon-policy蒸留
- 通常通りon-policy蒸留(Reverse KL)
- Outlier領域でのon-policy蒸留
- 教師モデルのtop-k(k=64)のトークンを対象にon-policy蒸留(Forward KL)
- top-kとすることでより多くの情報を使って学習可能
- reverse KLだと比率が0に近づき学習が不安定となるためforward KLを採用する
- (outlierの判定は生徒出力で決めるが、outlierの修正方向は教師top-kで決める)
- 教師モデルによるoff-policy蒸留
- 最初の数トークンを対象に教師モデルの出力をもとに生徒モデルを模倣学習する(Forward KL)
- という設定なのでweightは小さい
schedulerによる模倣学習対象のトークン長の推移

実験
- Qwen3-SFT-1.7Bを生徒モデル、Qwen3-Nemotron-4Bを教師モデルはとして蒸留
- 通常のOPDや既存のOPD改良手法と比較して全てのベンチマークでtop1の性能を達成
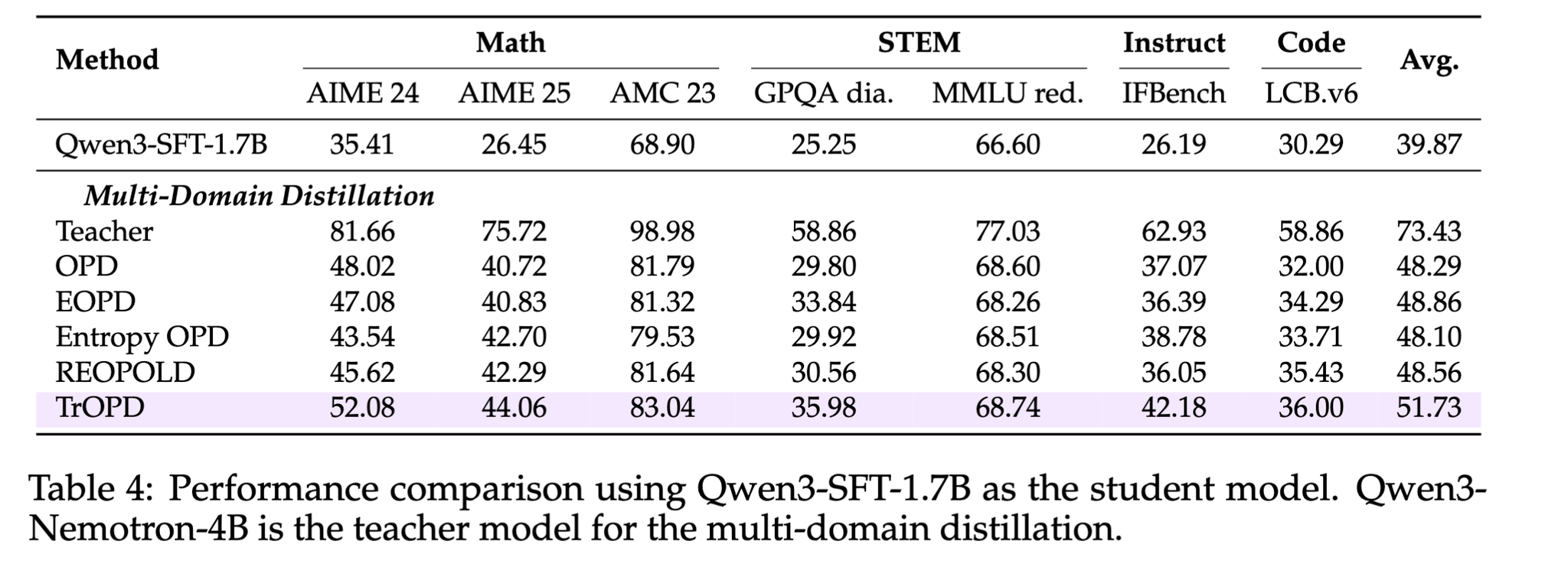
アブレーション
- 外れ値領域に対してForward KLによるオンポリシー蒸留とOff-policy Guidance(冒頭数トークンの模倣学習)を行うことで通常のオンポリシー蒸留からスコアが伸びることを確認
- Full FKLとは外れ値領域だけでなく全てのトークンを対象にForward KLをやる手法。これはスコアを著しく低下させる
感想
- 蒸留の曖昧なところ(on/off policy, reverse/forward KL)の整理ができた
@monokemonoke
[paper] Jailbreak Foundry: From Papers to Runnable Attacks for Reproducible Benchmarking
[monoke]
- Eval is MOAT。その観点で参考になりそう。
- ICML2026 の Spotlight 選出なので内容に信頼がおけそう。
- 新しい評価データセットを提案したのではなく、「同じ評価ハーネスで継続的に比較できるようにしている」ところが良さそう。
この論文は「新しい jailbreak 攻撃」ではなく、jailbreak 論文をすばやく実行可能な攻撃モジュールに変換し、同じ評価ハーネスで継続的に比較できるようにするシステム論文です。提案システム 、略称 は、論文理解、実装、監査、評価を多エージェントで回し、30 攻撃を再現して平均 ASR 差 まで元論文の結果に近づけた、というのが主張の中心です。
論文情報
| 項目 | 内容 |
|---|---|
| タイトル | Jailbreak Foundry: From Papers to Runnable Attacks for Reproducible Benchmarking |
| 著者 | Zhicheng Fang, Jingjie Zheng, Chenxu Fu, Wei Xu |
| 会議 | ICML2026 Spotlight (top 2.2%) |
| 初稿 / v3 | 2026-02-27 / 2026-03-05 |
| 対象領域 | LLM safety, jailbreak evaluation, paper-to-code agents, reproducible benchmarking |
問題設定
| 段階 | 言っていること | 噛み砕くと |
|---|---|---|
| 1. 背景 | LLM は安全対策されているが jailbreak で破られる | 危険な出力を防ぐ仕組みはあるが、プロンプトの工夫で回避されることがある |
| 2. 必要性 | 安全性を測るには jailbreak benchmark が必要 | モデル A と B のどちらが堅いかを見るには、同じ攻撃セットで試す必要がある |
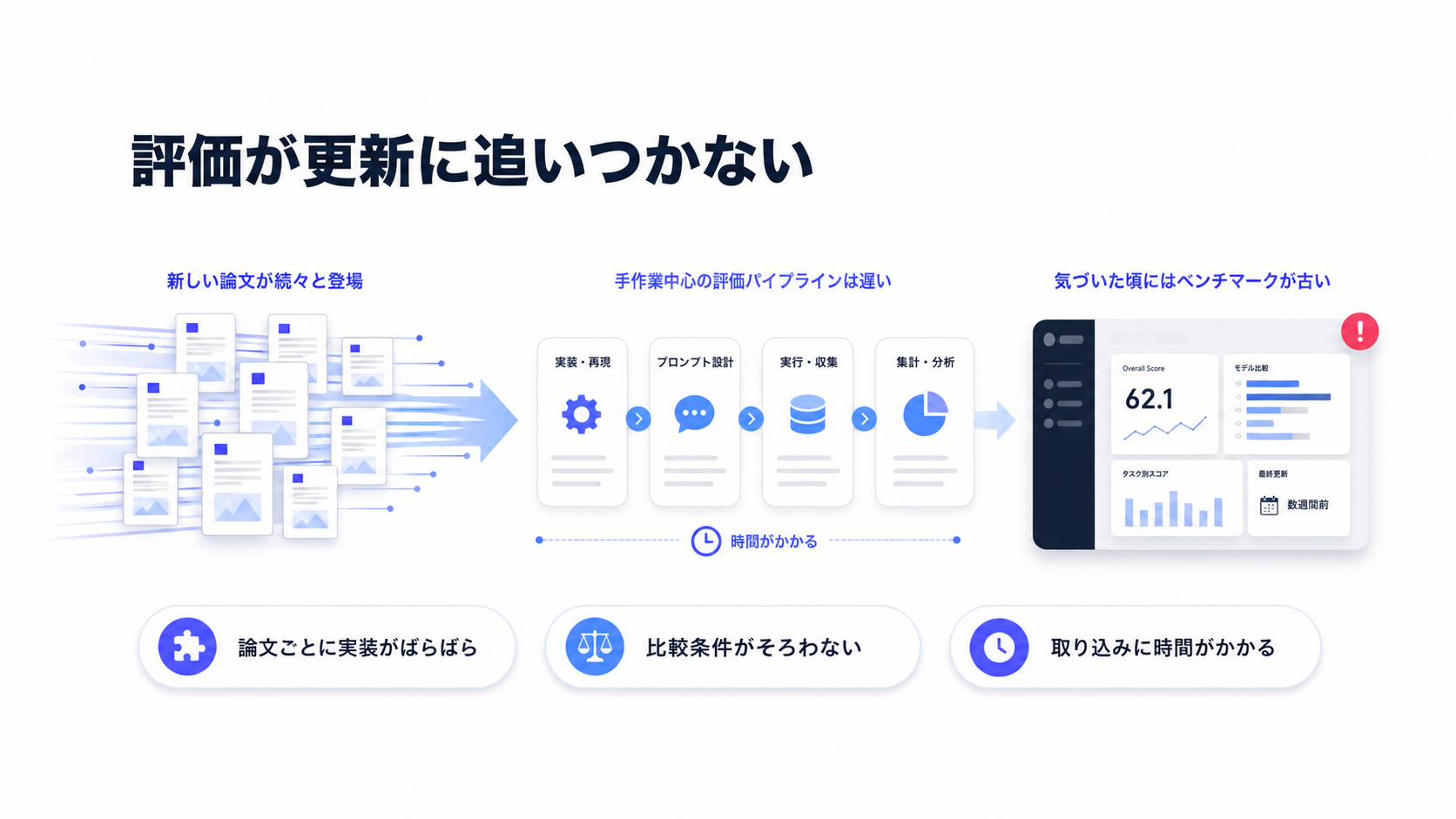
| 3. 問題 | 攻撃論文が次々出るので benchmark が古くなる | 新しい攻撃が出ても、評価セットに入るまで時間がかかる |
| 4. 原因 | 論文ごとに実装・設定・評価条件がバラバラ | 人間が論文を読み、公式 repo を読み、既存評価基盤に合わせ直す必要がある |
| 5. ギャップ | 既存フレームワークは「すでに実装済みの攻撃」を回すのは得意だが、「新しい論文を取り込む」のは苦手 | 評価基盤はあるが、論文から実行可能コードにする部分が詰まっている |
| 6. 提案 | Jailbreak Foundry で、論文から runnable attack を作る | 論文を読ませ、攻撃の仕様を抽出し、コード化し、監査し、同じ評価基盤で回す |
| 7. 検証 | 30 個の攻撃で元論文の ASR に近い結果を再現 | 「この工場で作った攻撃コードは、元論文の挙動にかなり近い」と示す |
用語を一度ほどく
| 用語 | 意味 |
|---|---|
| jailbreak | LLM の安全制約を回避して、本来拒否すべき出力を引き出す攻撃 |
| ASR | Attack Success Rate。攻撃が成功した割合 |
| victim model | 攻撃対象の LLM。例: GPT 系、Claude 系、LLaMA 系など |
| runnable attack | 論文に書かれたアイデアではなく、実際に評価基盤上で実行できる攻撃コード |
| paper-matched evaluation | 元論文と同じ条件にできるだけ寄せて再現する評価 |
| Jailbreak Foundry | 論文から runnable attack を作り、評価まで回すシステム |
一番大事な読み替え
普通に読むと「jailbreak 攻撃を自動生成するヤバい話?」に見えると思います。
でもイントロの著者側の建て付けは少し違っていて、
「安全性評価のためには、既知の攻撃を正しく・速く・同じ土俵で再現できないと困る」
という話です。
なので、この論文は ML の新モデル論文というより、LLM safety evaluation のための infrastructure / benchmark automation 論文として読むと通ります。
中核アイデア
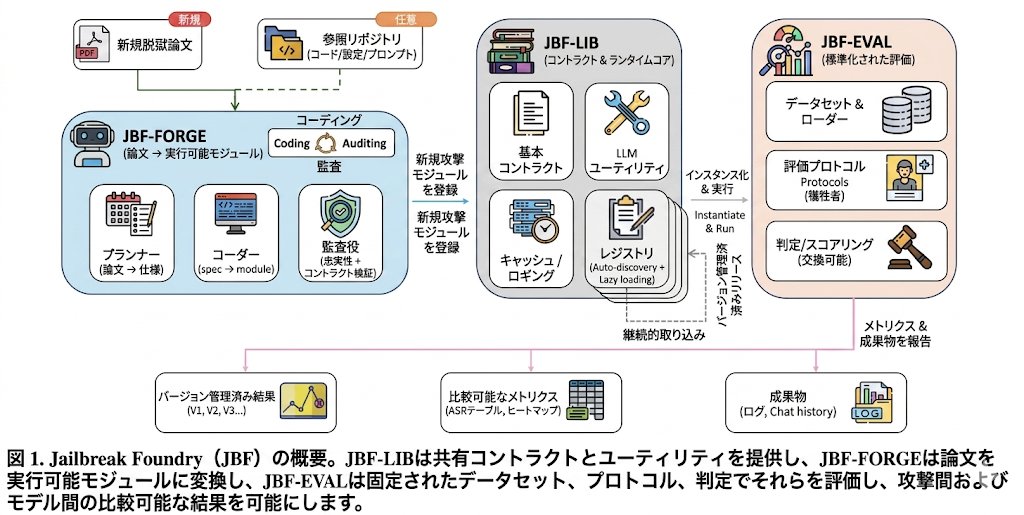
JBF は「攻撃手法の固有部分」と「共通の評価・実行基盤」を分離する。jailbreak 攻撃は多くの場合、共通の LLM 呼び出し、試行管理、judge、ログ、dataset loader の上に、攻撃固有の prompt transformation / search / wrapper が乗っている。そこで共通部分を に寄せ、論文から攻撃固有モジュールだけを生成し、 で同じ条件で評価する。
システム構成
| 構成要素 | 役割 |
|---|---|
| 攻撃・防御の base contract、typed parameters、registry、LLM adapter、cache/logging、cost tracking、thread-safe context を提供 | |
| 論文と必要なら公式 repo を入力に、Planner / Coder / Auditor で runnable module を生成 | |
| dataset loader、victim model 実行、judge/scoring、CLI、resume、batch sweep、result matrix を標準化 |
JBF-FORGE の流れ
- 論文 PDF を markdown に正規化する。
- 論文中の公式 repo URL があれば取得し、曖昧な実装詳細の参照に使う。
- が攻撃アルゴリズム、制御フロー、テンプレート、パラメータ、デフォルト値を structured spec に落とす。
- が spec と contract に合わせて攻撃モジュールを実装する。
- がコードを静的に監査し、spec / contract / reference repo に対する fidelity を line-level で確認する。
- audit に落ちたら修正を繰り返す。最大反復数 の bounded loop。
- paper-matched setting で ASR を測り、元論文との差 を出す。
- のような大きな下振れでは enhanced refinement pass を使う。
Agent の役割
| Agent | 入力 | 出力 | 重要な制約 |
|---|---|---|---|
| Planner | 論文 、contract 、任意の repo | structured plan | 攻撃手順、parameter、template、control flow を明示 |
| Coder | , , | module | 評価ロジックを攻撃本体に混ぜすぎない。typed parameters を expose |
| Auditor | , , , | accept flag , revision report | static analysis のみ。100% fidelity 以外は accept しない |
監査基準
Auditor は の優先順位で見る。最優先は Planner の structured spec、次に framework contract、最後に公式 repo。公式 repo は論文が曖昧なときの gold reference として使うが、spec や contract にない要件を勝手に発明しない。100% fidelity の条件は、全アルゴリズム手順、制御フロー、prompt/template、パラメータ、数式、search/retry/attempt control、I/O contract がそろっていて、挙動を変える未記載の追加がないこと。
評価設定
30 jailbreak attacks を対象にする。うち 22 は公式実装あり、8 は論文テキストのみ。評価対象は AdvBench または JailbreakBench を報告している論文に限定し、比較しやすい場合は AdvBench を優先する。paper-matched reproduction では、元論文の dataset、victim model、攻撃 parameter、protocol、judge/rubric を可能な限り合わせる。標準化評価では AdvBench、固定 GPT-4o judge、10 victim models を使う。
主要な再現結果
平均 で、元論文の ASR とかなり近い。範囲は から 。30 攻撃中、 が 16、 が 14。大きな下振れ は SCP と ISA の 2 件。生成時間は平均 28.2 分、中央値 25.0 分、82% が 60 分以内。
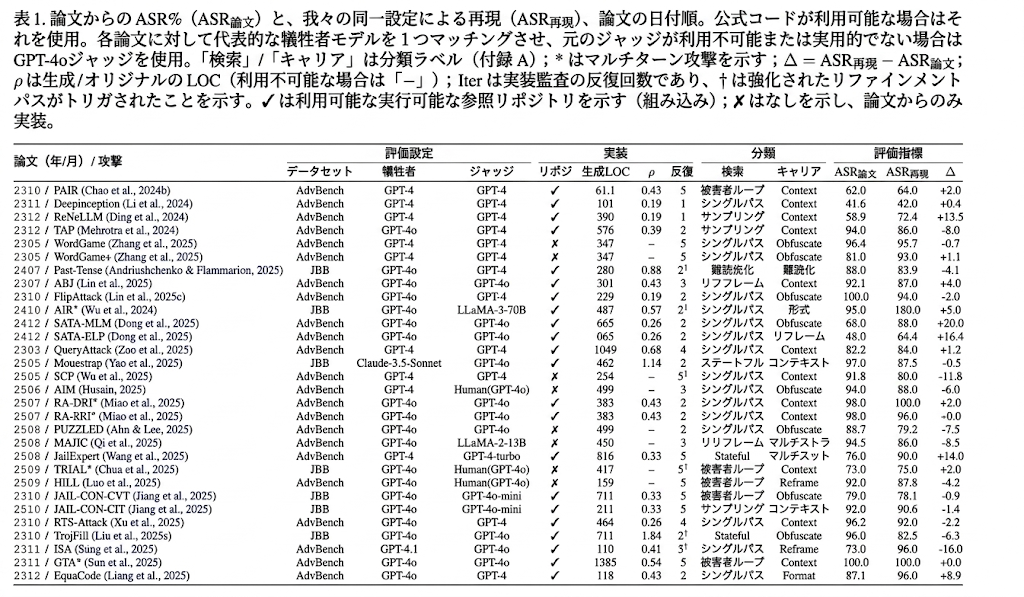
with-repo vs no-repo
公式 repo を使う効果は大きい。5 攻撃の代表比較で、paper-only では平均 ASR 、paper+repo では 、差分 。特に scaffold-heavy な GTA 、SATA-MLM で効く。論文テキストから中核機構は復元できても、role background、出力 contract、retry、serialization などの低レベル詳細が ASR を大きく左右する、という読み。
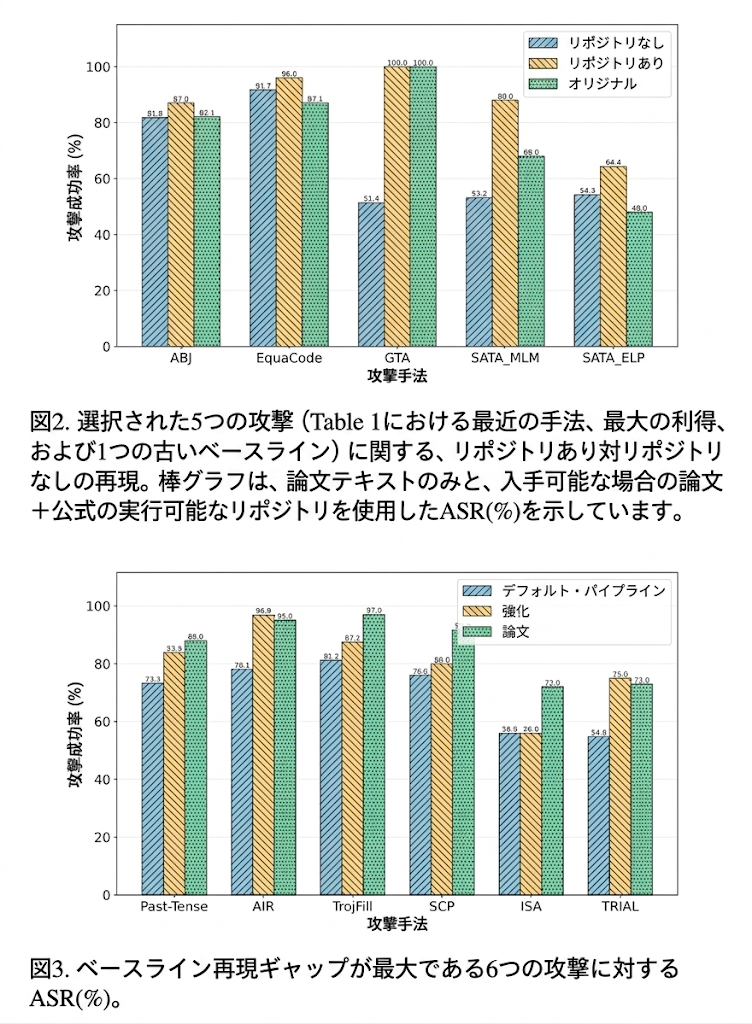
enhanced refinement の意味
大きく下振れした hard subset では、enhanced refinement により 6 件中 5 件で gap が縮む。平均 gap は から に改善。これは、失敗の多くが「論文からは復元不能」ではなく「実装上の細かい不一致」によることを示す。一方 ISA は改善せず、system/message formatting、max tokens、二段階 rewrite の prompt serialization、provider-specific behavior など、pass の範囲外の差が残った可能性がある。
JBF-LIB の効率
公式 repo がある 22 攻撃、19 unique codebases で、元実装 が JBF 統合後 になり、compression ratio は 。つまり約 42% のサイズに圧縮される。さらに JBF-LIB core を共有基盤として見ると、統合コード全体の が共有コード、攻撃固有コードは 。これは「新規攻撃追加時の保守対象が小さい」ことを示す。
攻撃 taxonomy
論文は攻撃を と の 2 軸で分類する。 は候補 prompt をどう作るか、 は有害意図をどう包むか。
| 軸 | 分類 |
|---|---|
| Search | Single-pass, Sampling, Stateful, Victim-loop |
| Carrier | Reframe, Context, Formal, Obfuscate, Multi-strat |
Single-pass は一回で prompt を構築する。Sampling は複数候補をランダムに生成して選ぶ。Stateful は victim feedback なしで履歴やテンプレートを更新する。Victim-loop は victim model や judge の反応を見ながら反復最適化する。Carrier 側では、言語的言い換え、roleplay/narrative、code/query/spec などの formal wrapper、encoding/masking などの obfuscation、複数戦略の組み合わせを区別する。
標準化評価の発見
JBF-EVAL は 30 攻撃 × 10 victim models の heatmap を作る。10 モデルは Claude-3.7-sonnet、Claude-3.5-sonnet、GPT-4、GPT-4o、GPT-3.5-Turbo、LLaMA3-8B-Instruct、LLaMA2-7B-Chat、Qwen3-14B、GPT-5.1、GPT-OSS-120B。標準化条件では、20/30 攻撃が 10 モデル中 6 モデル以上で ASR 、15/30 が 7 モデル以上で 、13/30 が 6 モデル以上で を達成する。
モデル別の観察
GPT-5.1 は平均 ASR だが、攻撃ごとの範囲は から と広い。つまり平均では比較的強く見えても、特定 mechanism には大きな穴がある。GPT-OSS-120B は平均 ASR 、15/30 攻撃で と最も堅いが、Mousetrap 、RTS では大きく崩れる。GPT-3.5-Turbo、GPT-4o、Qwen3-14B は平均 ASR がそれぞれ , , と高く、多様な carrier/search に対して一貫して脆い。
攻撃機構別の観察
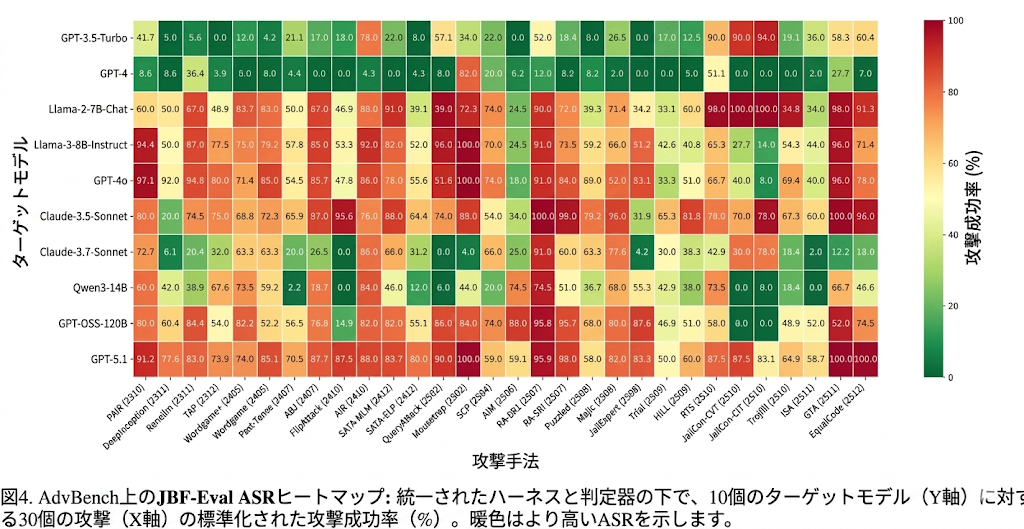
全 victim-attack pair 平均では、Search 軸では Victim-loop が最強 、Stateful が最弱 。ただし victim ごとに逆転する。GPT-5.1 では Sampling が Victim-loop を上回るが、GPT-4 では Victim-loop が Sampling を上回る。Carrier 軸では Formal wrapper が平均 で最も高く、Context 、Reframe が続く。ただし GPT-OSS-120B は Formal にほぼ強く、GPT-5.1 は Formal に弱い。
この論文の実務的な含意
単一モデル・単一攻撃・単一 judge の評価では安全性を見誤る。平均 ASR が低いモデルにも特定形式への blind spot があり、逆に強い攻撃でもモデル間 transfer は限定的。実務の red-teaming / safety eval では、攻撃 family と carrier family を分け、複数 victim、固定 judge、versioned artifacts で継続評価する必要がある。
限界
JBF の品質は、Planner の spec 抽出、Coder の実装、Auditor の静的監査、公式 repo の有無に依存する。Auditor は実行せず静的解析のみなので、runtime behavior の完全保証ではない。paper-matched evaluation でも、API provider、system prompt、message serialization、token limit、judge prompt の微差で ASR が動く。さらに、jailbreak 実装の自動化は防御研究に有用な一方で、既知攻撃の実行コストを下げる dual-use risk がある。
読みどころ
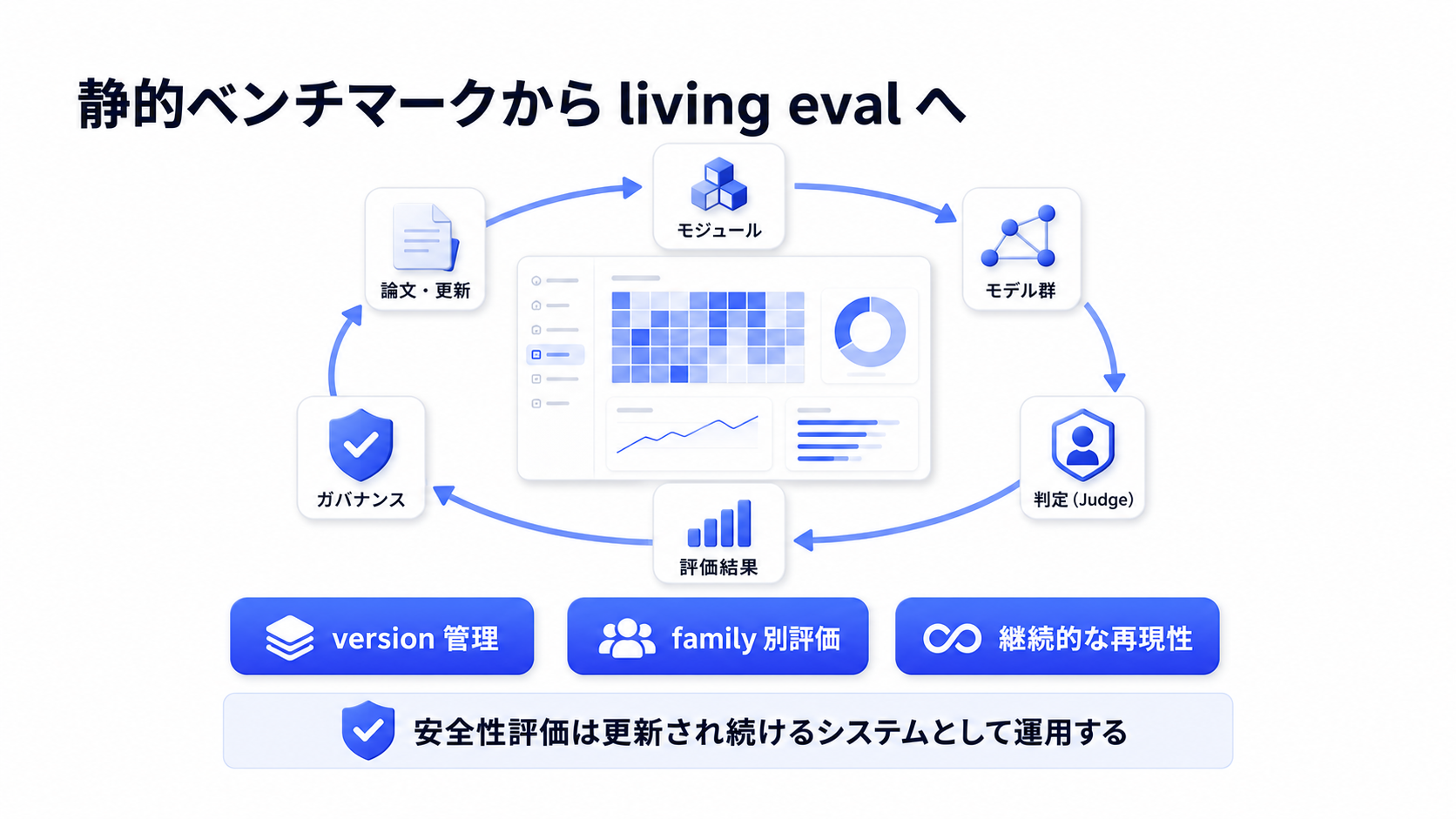
この論文で一番重要なのは、 そのものよりも、「公式 repo の細部が ASR に +19.8 pp 影響する」「prompt/control-flow/serialization の小さな差が再現性を壊す」「モデルの堅牢性は攻撃 family ごとに大きく違う」という点です。LLM safety eval を運用するなら、ベンチマークを静的な表ではなく、攻撃・防御・モデル・judge・dataset を version 管理する living system として扱うべき、という論文です。
メインTOPIC
Agents' Last Exam
ベンチマークについて思いを馳せているとことにちょうどいいのが来たので読んでみました & 紹介します。本論文で提案するベンチマークで性能が出た時が、LLMの性能が産業界に大きなインパクトを与えるタイミングになるであろうというもの。経済効果における真の先行指標を目指している。
サマリー
AIは囲碁や数学、競技プログラミングといった抽象的なドメインで人間を凌駕してきましたが、実際の経済を支える中核産業における寄与は依然として限定的であり、最先端モデルのベンチマーク更新速度と、GDPへの実質的インパクトが乖離している。この”実用性の問題(Utility Problem)” に関する問題提起とベンチマークの提案。
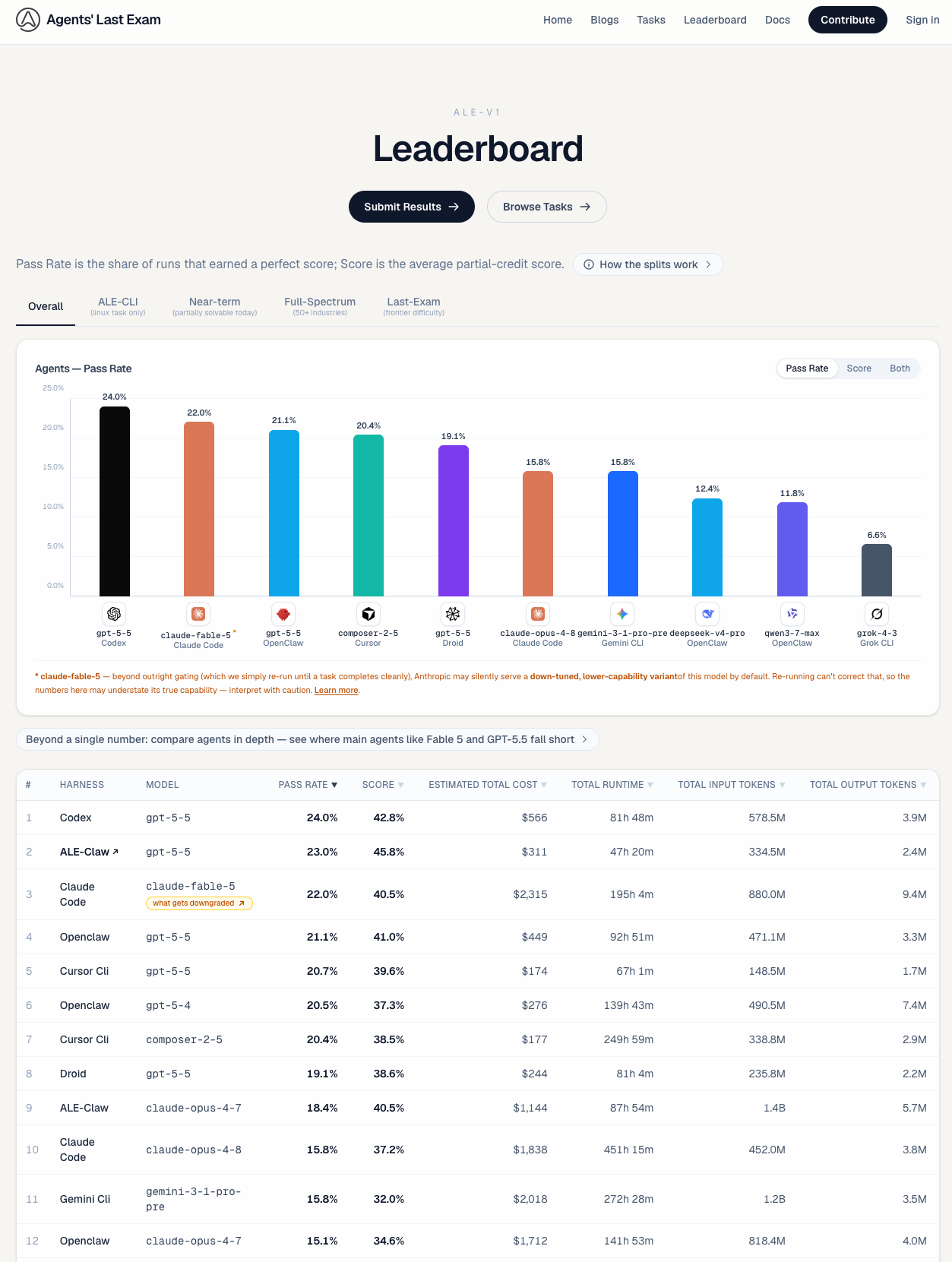
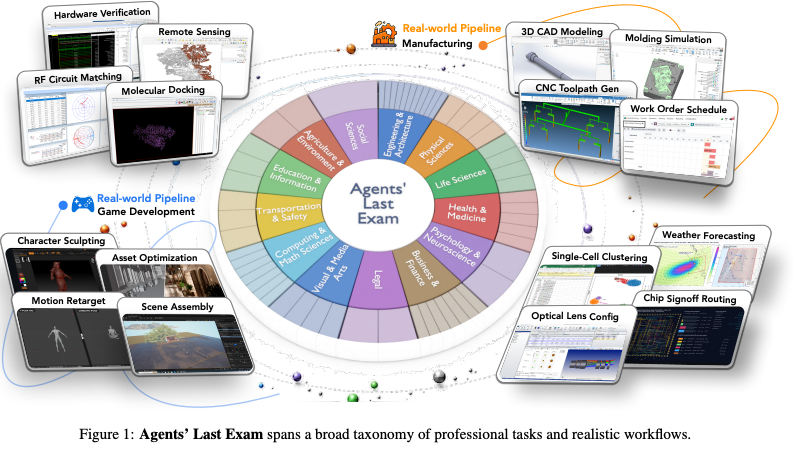
Agents’ Last Exam (ALE) は、カリフォルニア大学バークレー校(UC Berkeley)を筆頭に、HubSpot、nTop、ハーバード大学、スタンフォード大学などの一流実務家および研究者で構成される諮問委員会、そして250名以上の専門家ネットワークが共同開発した、次世代のAI評価指標である。13の産業クラスターと55のサブドメインを網羅し、1,490のタスクインスタンスを通じて、数時間から数週間に及ぶ”プロフェッショナルな実務ワークフロー”の完遂能力を測定する。
現状、GPT-5.5やClaude Opus 4.7といった最高峰のモデルであっても、極めて困難な「Last Exam」層における合格率は0%という結果に。これは、現行AIが産業導入レベルに達するには、依然として決定的な技術的・戦略的隔たりがあることを示していると考えられる。
1. Introduction
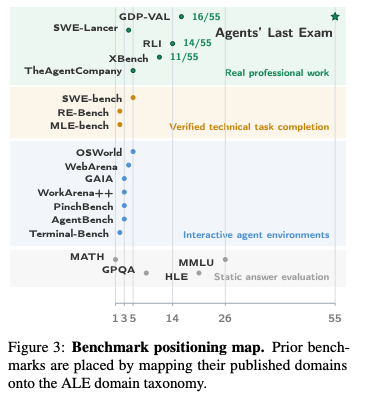
歴史的に、ImageNetがコンピュータビジョンのエンジニアリング目標を定義し、特定ドメインの進歩を加速させたように、ベンチマークは研究開発の焦点を決定づける。一方で、これまで金融、法律、電気工学、製造といった経済の中核をなすセクターには、実務の複雑性を捉える評価系が存在していないと考えられる。
既存ベンチマークとの比較:時間軸と真正性の欠如
| 評価指標 | 評価対象 | 時間軸(Horizon) | 検証方法 |
|---|---|---|---|
| MMLU / GPQA | 知識・静的QA | 秒単位 | 自動一致(多肢選択) |
| SWE-bench | コード生成 | 分〜数時間 | ユニットテスト |
| OSWorld | GUI操作(単発) | 分単位 | 状態チェック(State check) |
| ALE (提案) | エンドツーエンド実務 | 数時間〜数週間 | 決定論的検証 / 専門家ルーブリック |
実務ドメインの評価指標が不在だった理由は、タスク収集のコスト、高度な専門知識の必要性、そして不均質な成果物に対する検証の困難さにあると考える。既存指標は「短時間の単発アクション」に偏重しており、経済的価値の源泉である「長期のワークフロー」を無視していました。ALEは、この空白を埋めるべく設計された。

2. Benchmark Design and Dataset Construction
3つの設計原則
- 代表性(Representativeness)
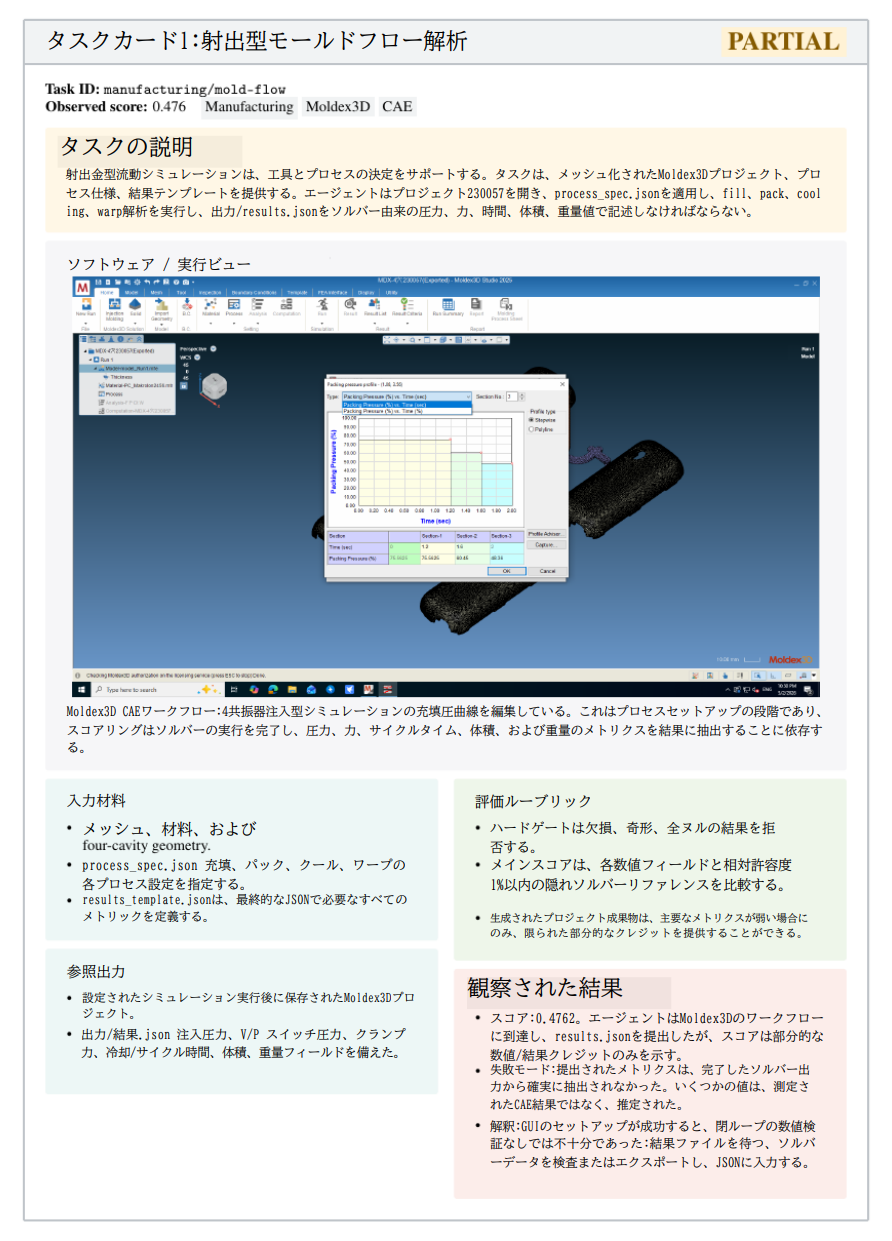
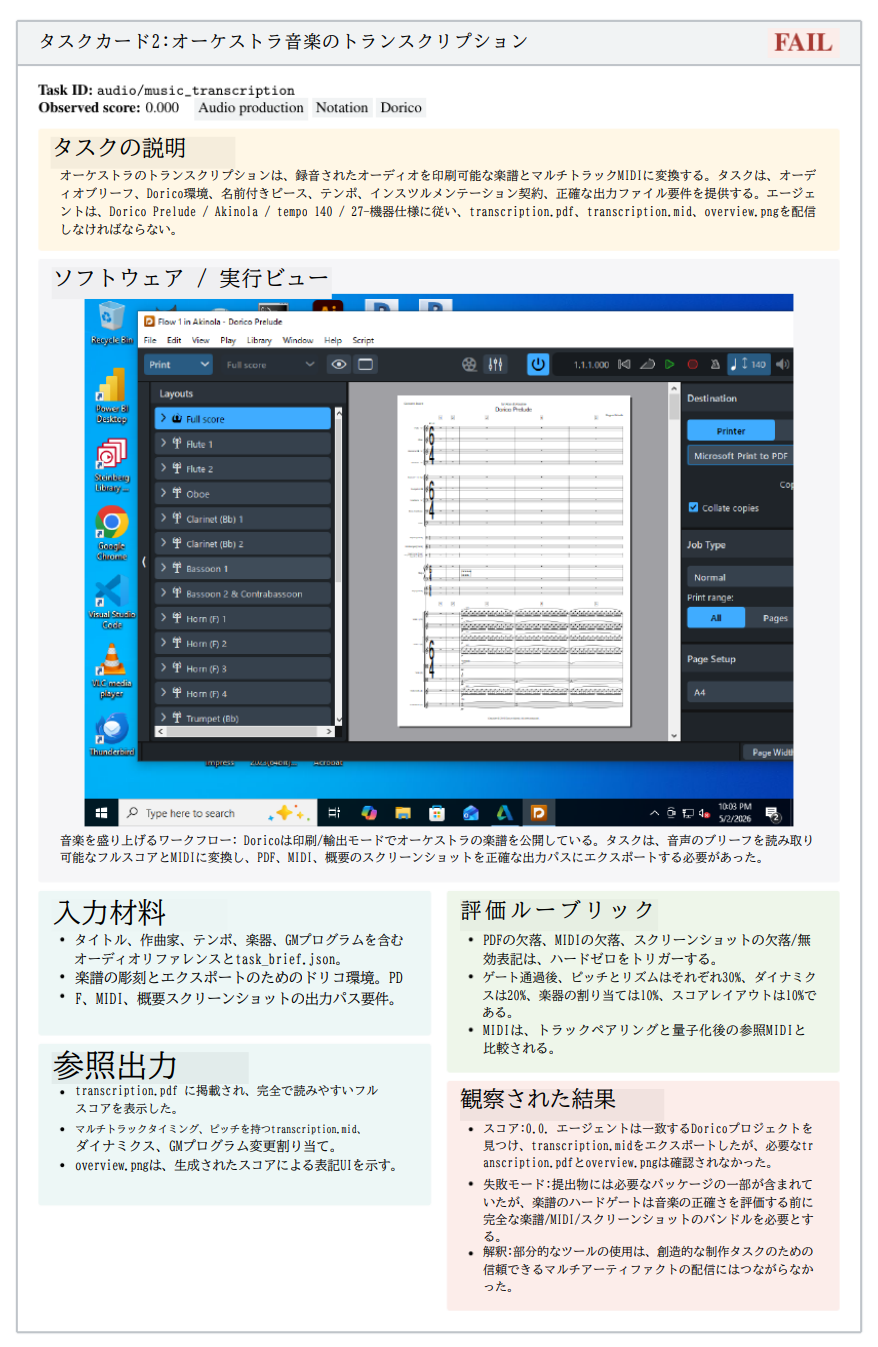
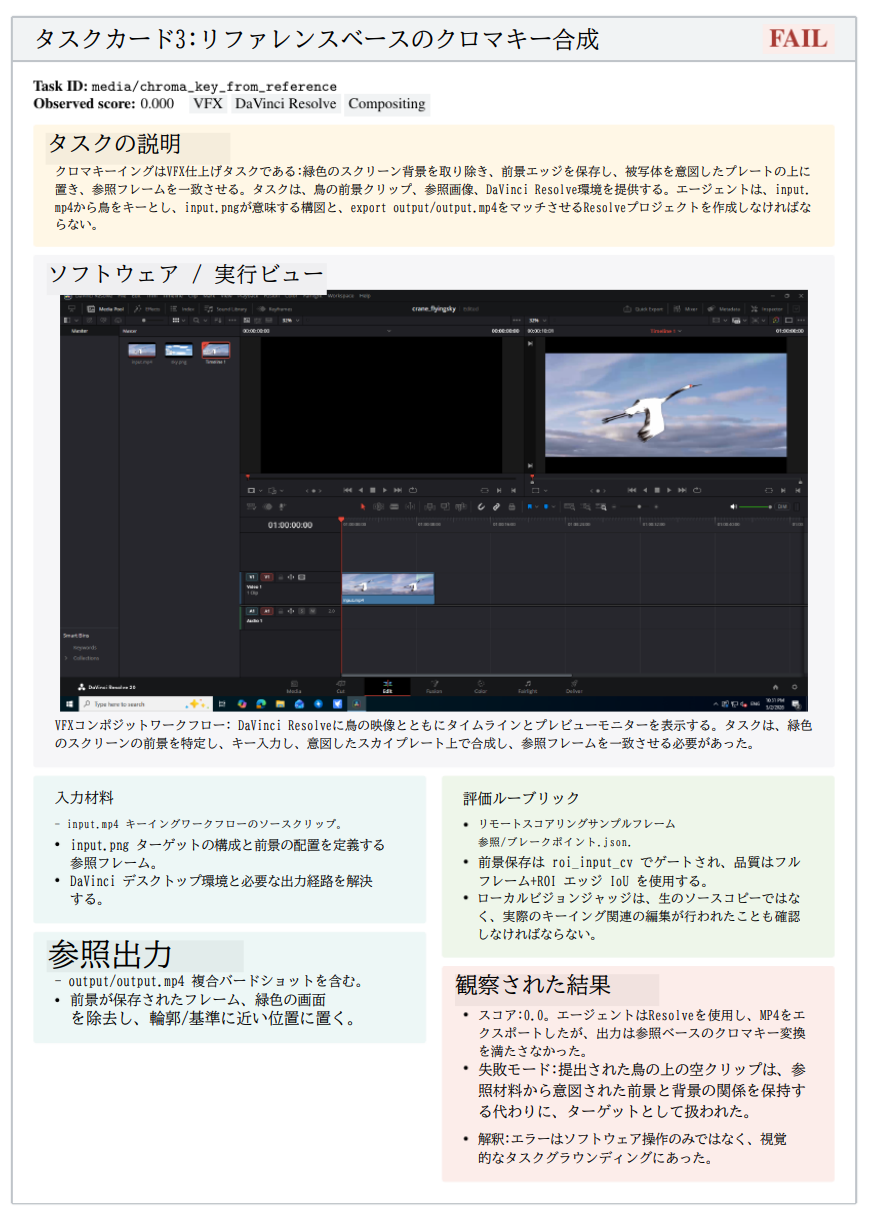
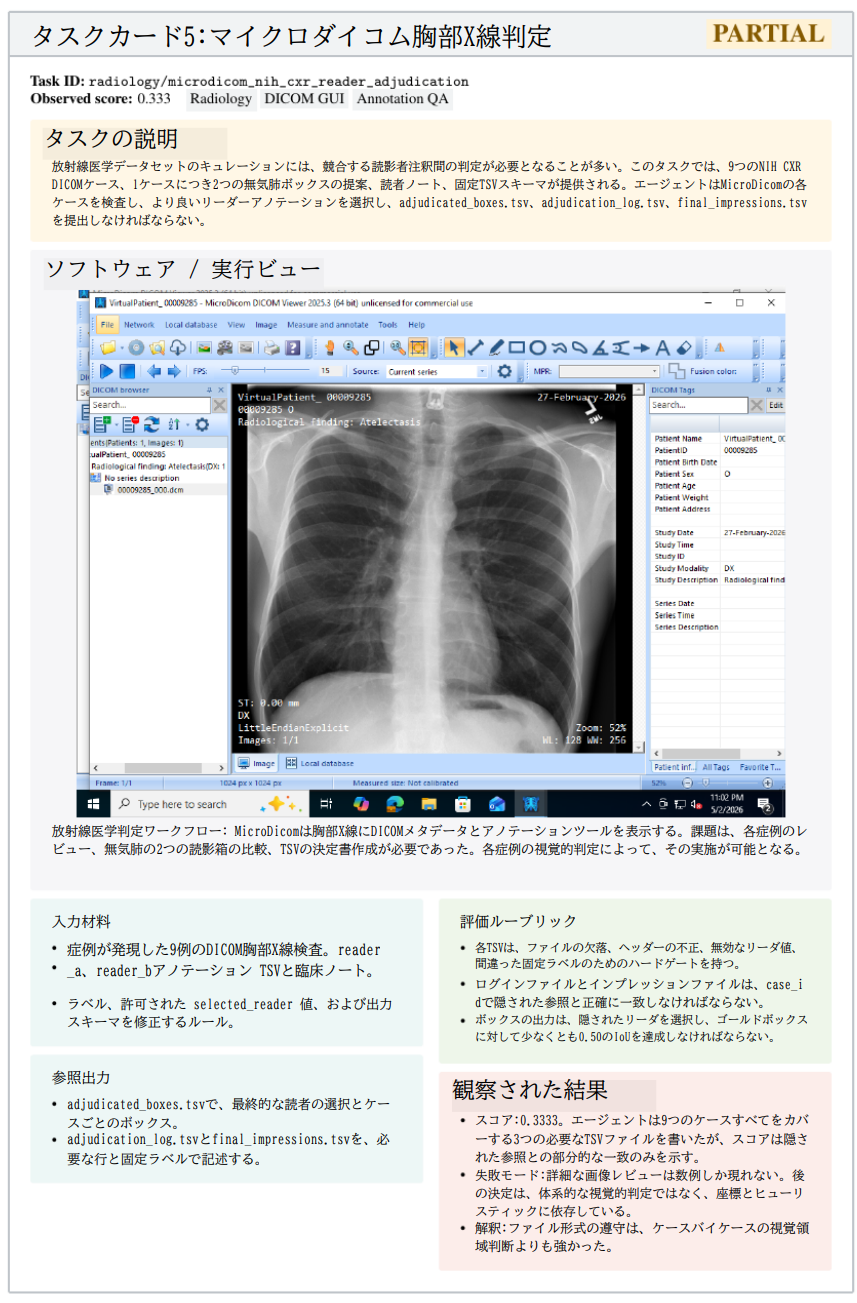
専門家が実際に使用するツールを前提とします。例えば、建築・エンジニアリング実務において、単なるAutoCADではなく、SolidWorksやRhinoを使用して2D図面を3Dモデル化するような実務慣行を忠実に反映しています。
- 複雑性(Complexity)
単発のアクションを排除します。「DaVinci Resolveで色調整をする」といった単一操作ではなく、「トラッキング、マスキング、色合わせを統合して、走っているチーターを別の背景動画に合成する」といった複合的ワークフローを評価します。
- 検証可能性(Verifiability)
「RPGを作れ」といった曖昧な指示ではなく、「RPGMaker XPを使用して特定のゲーム(mota.exe)を再現せよ」と指示することで、内部変数やマップ構造、イベント状態を自動比較可能にします。
カバーするドメイン
13の産業クラスターと55のサブドメインを網羅し、1,490のタスクインスタンスが存在

既存のベンチマークと比較した際のドメインカバレッジの差は明らか
タスク構築パイプライン
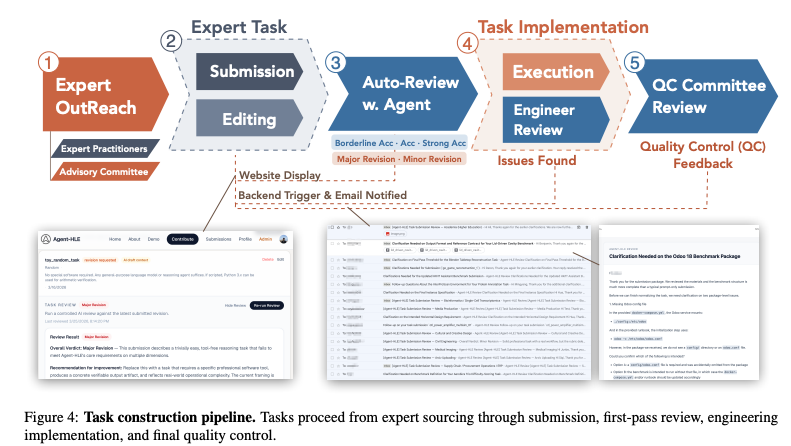
- 専門家による選定
- 実務で数日〜数週間を要した過去のプロジェクトを提出。
- 第1次審査
- 会議形式で、真正性と複雑性を評価し改訂を指示。
- エンジニア実装
- コンテナ化された実行環境と検証ロジック(main.py)をコード化。
- QC(品質管理)委員会
- 専門家委員会による最終査読。リファレンスの正確性と難易度を担保。
- 最終承認
- SOC 2018 / O*NETに基づいた13の産業クラスターへの組み込み。
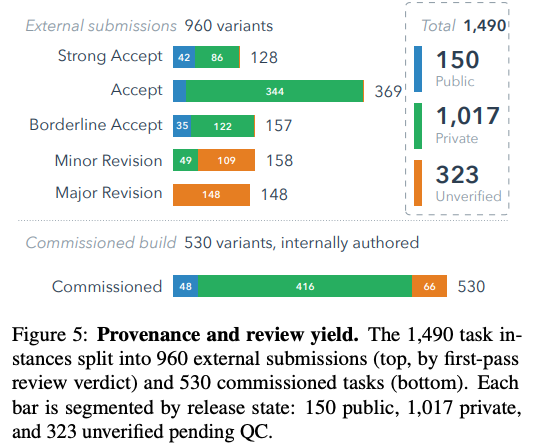
public / private 戦略
一部のみをPublicとしてリリースし、ある程度の期間ごとにprivateのものを順次公開していく方針。
3 Evaluation Pipeline
評価は (タスク宣言)、(VMの決定論的初期化)、(成果物スコアリング)の3フェーズで進行。
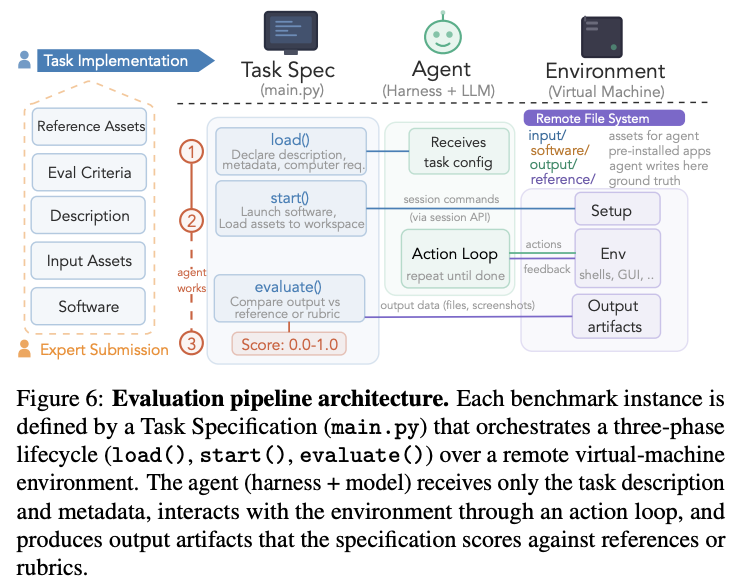
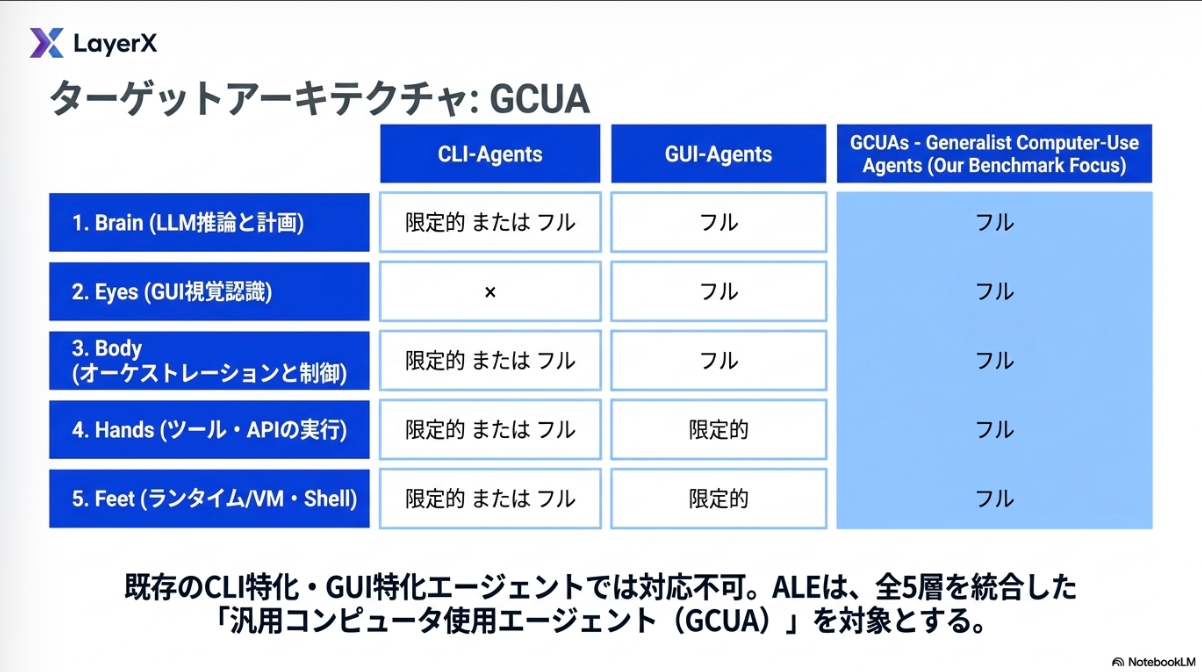
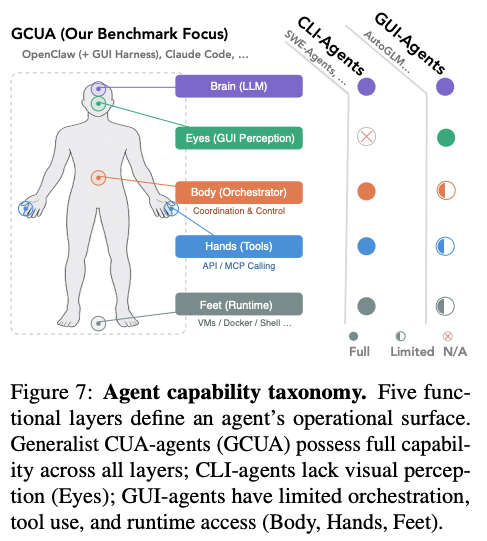
ALEは、特定のアプリに依存せず、人間と同様にOSを縦横無尽に操るGeneralist Computer-Use Agent (GCUA) を評価対象とする。
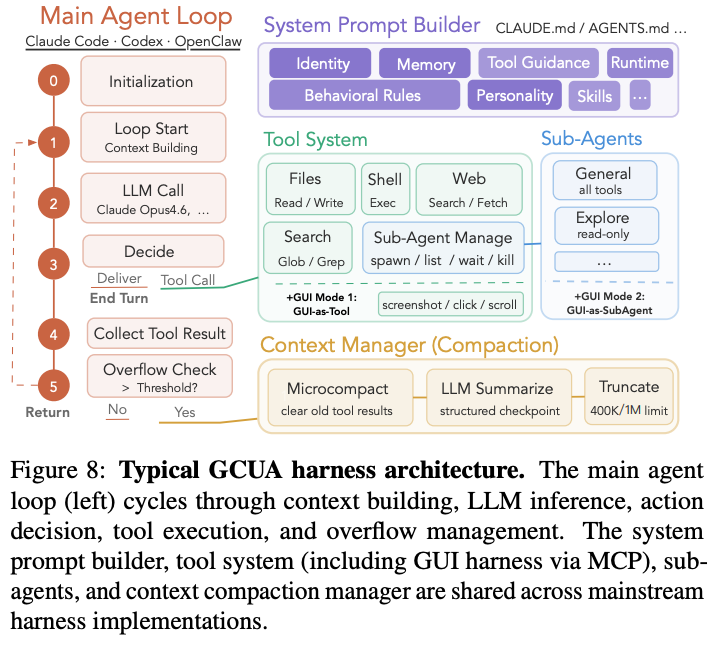
要するにハーネスをうまいこと設計するのが重要で、Claude Code や Codex、 OpenClawなどを利用するよ。
評価にできるだけLLM-as-a-Judge は使わない!原則として決定的に評価する。視覚的な評価が避けられない場合のみ利用。
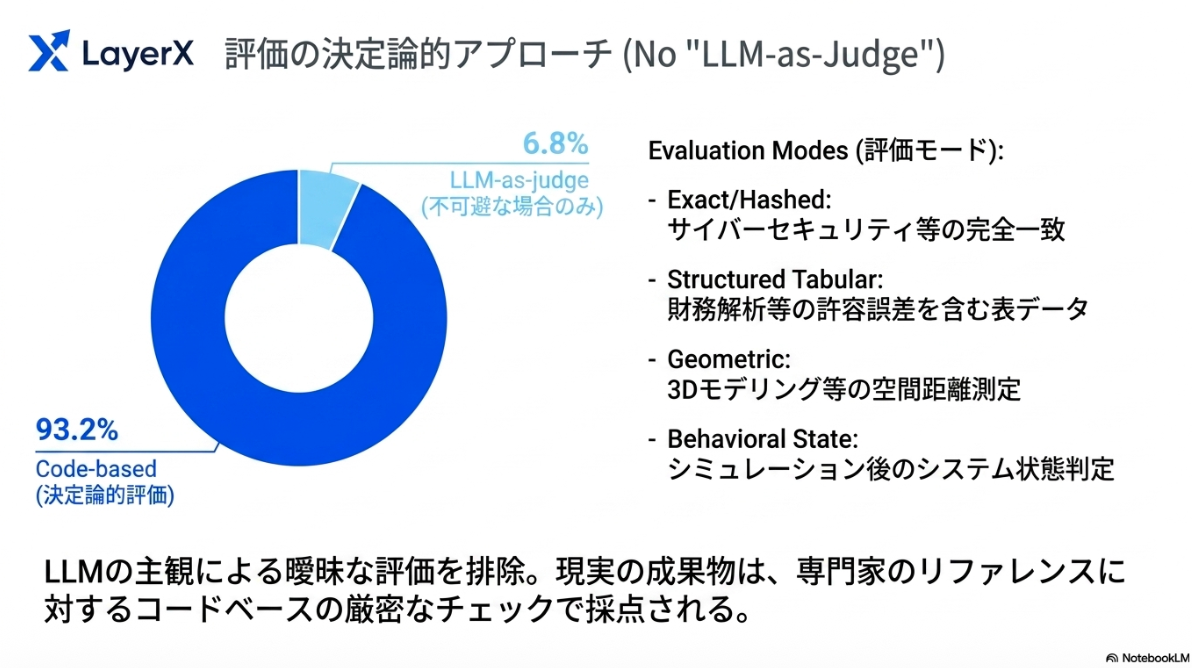
4 Experiment
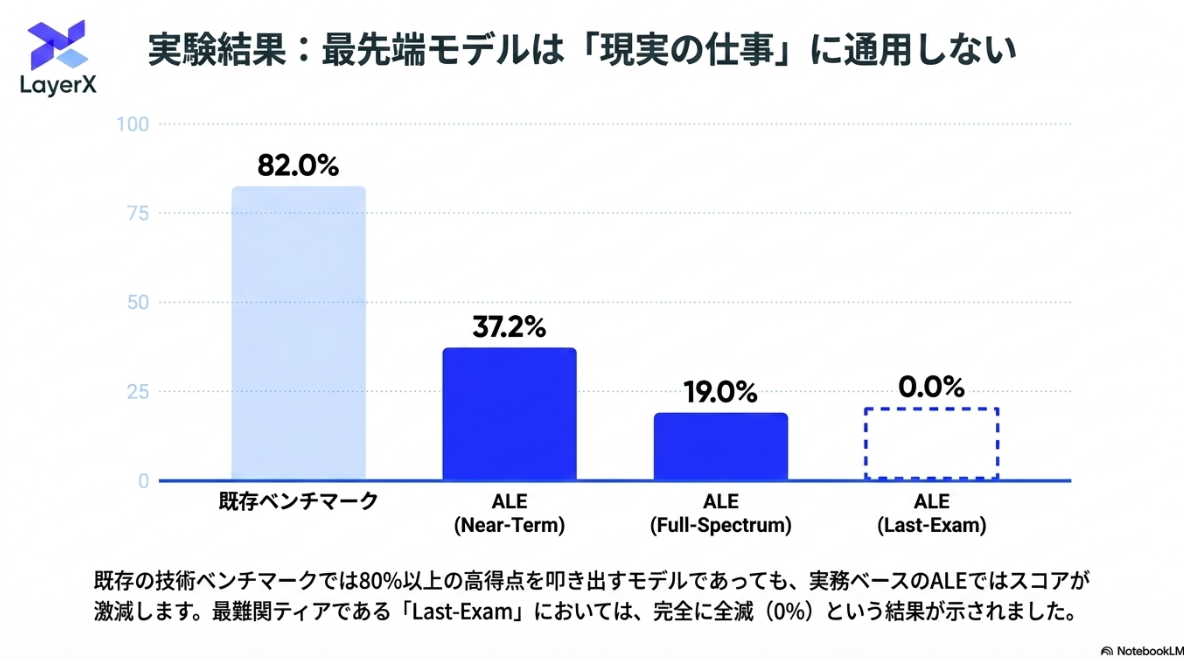
すべてのタスクでの評価はコストや時間観点で現実的でないので、難易度別に3つに区切ってサンプリングしたデータセットを提供。基本的に実務者はこちらでベンチを取ればよい。

Last-Exam は現在のフラグシップメントモデルでも壊滅。既存のベンチマークとのギャップも改めて明らかに。
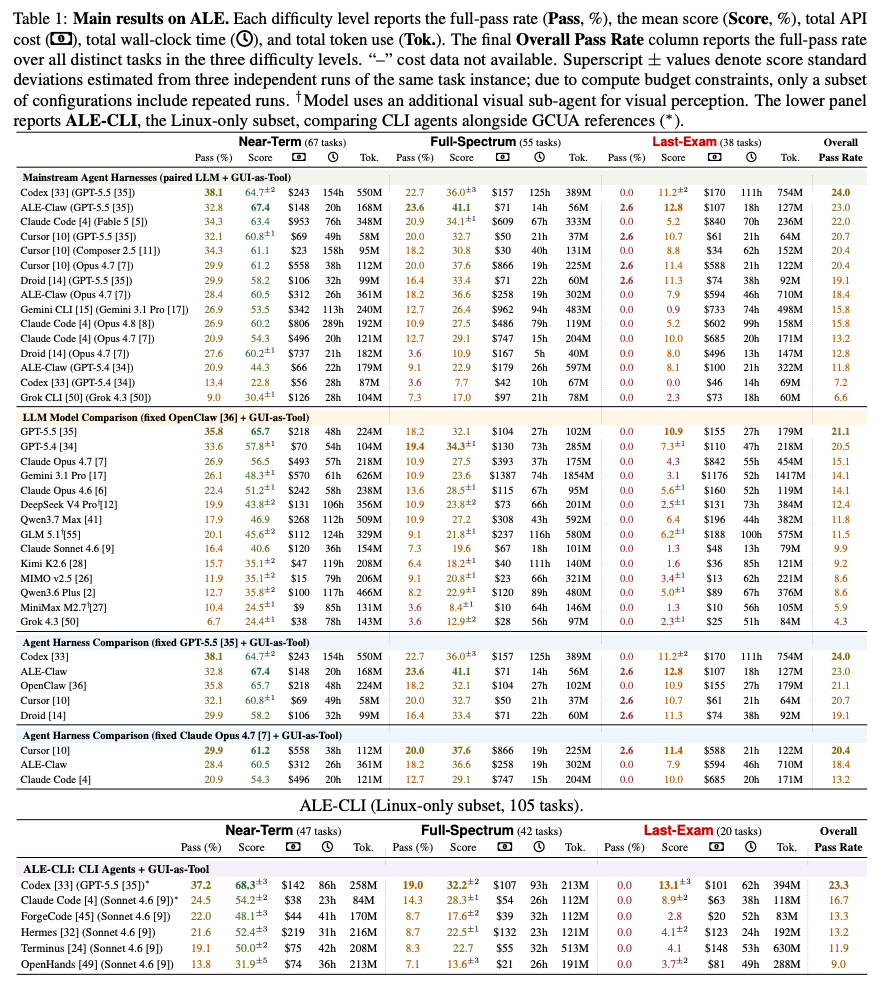
結果の表(細かい)
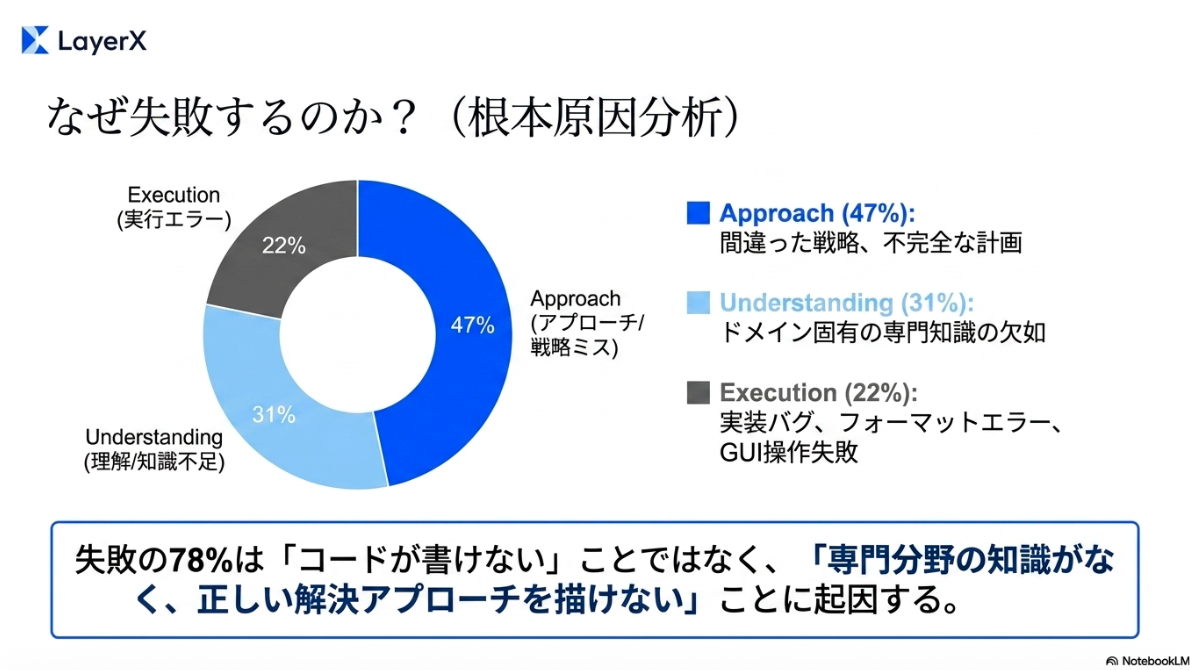
失敗分析。専門分野の知識の欠如によるものが大きいように見える。「モデル(Brain)の選択は、エージェントの仕組み(Harness)の選択よりも性能に約3倍の影響を与える」
投資対効果の観点からは、エンジニアリングによるハネースの改良よりも、強力な基盤モデルの選定とドメイン知識の注入が優先されるべきであるとのこと。
詳細
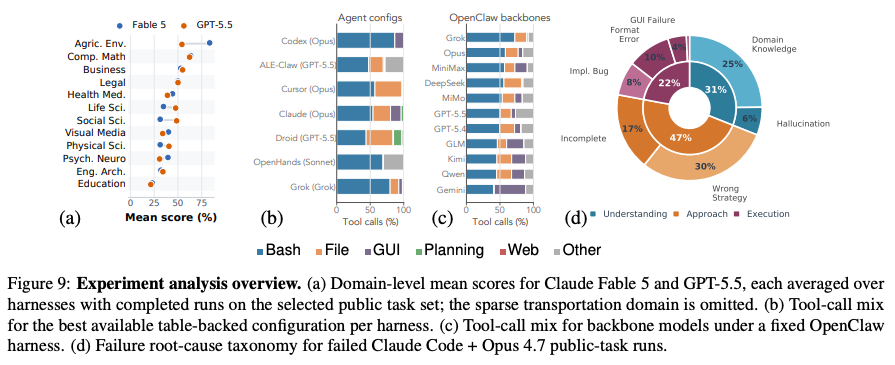
5. Sample