2026-06-23 機械学習勉強会
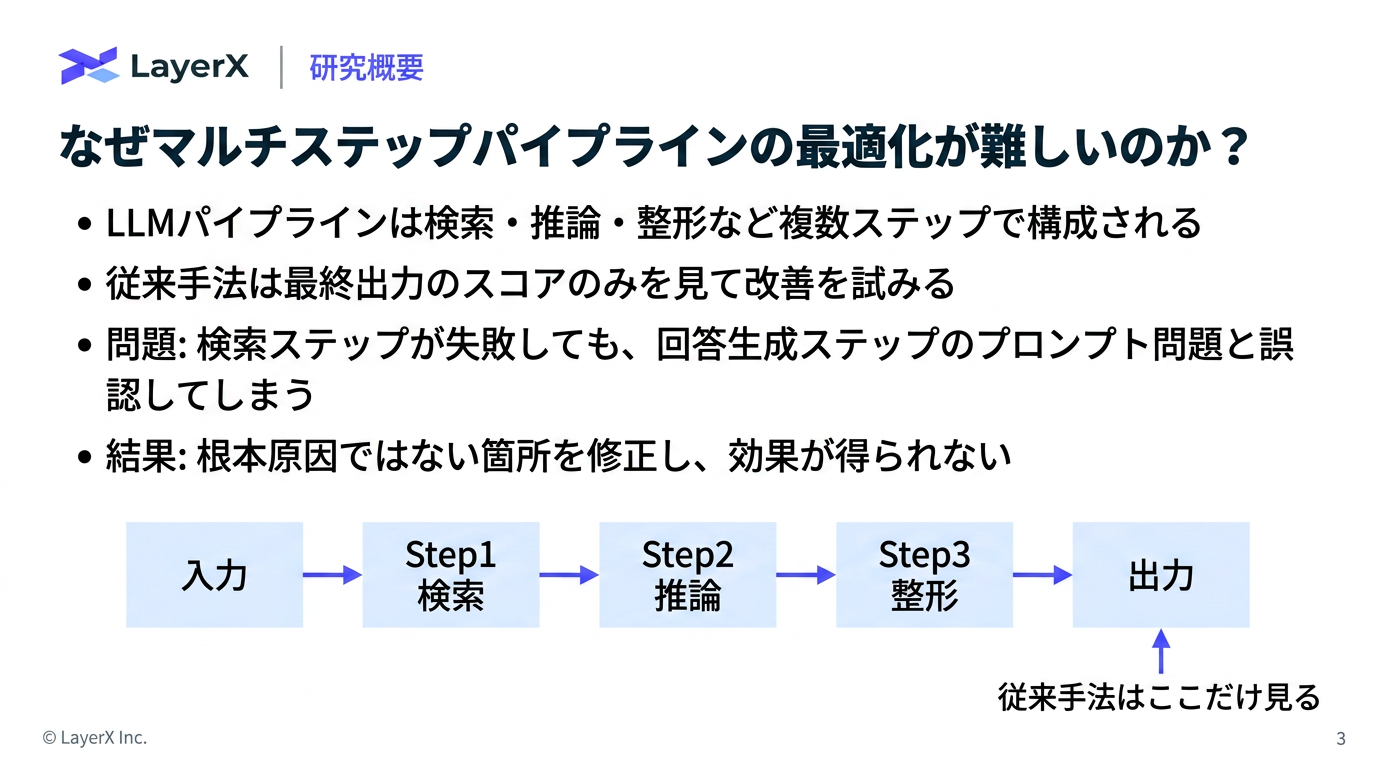
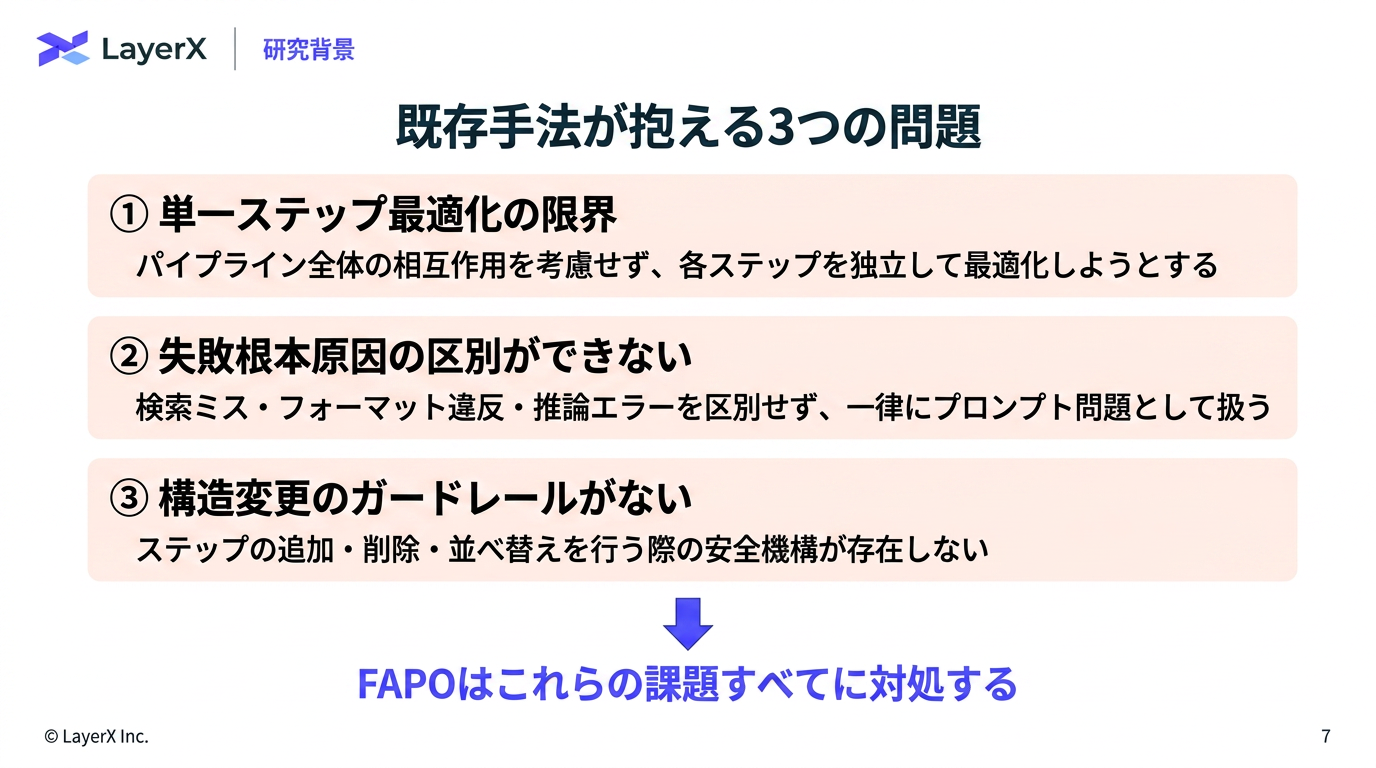
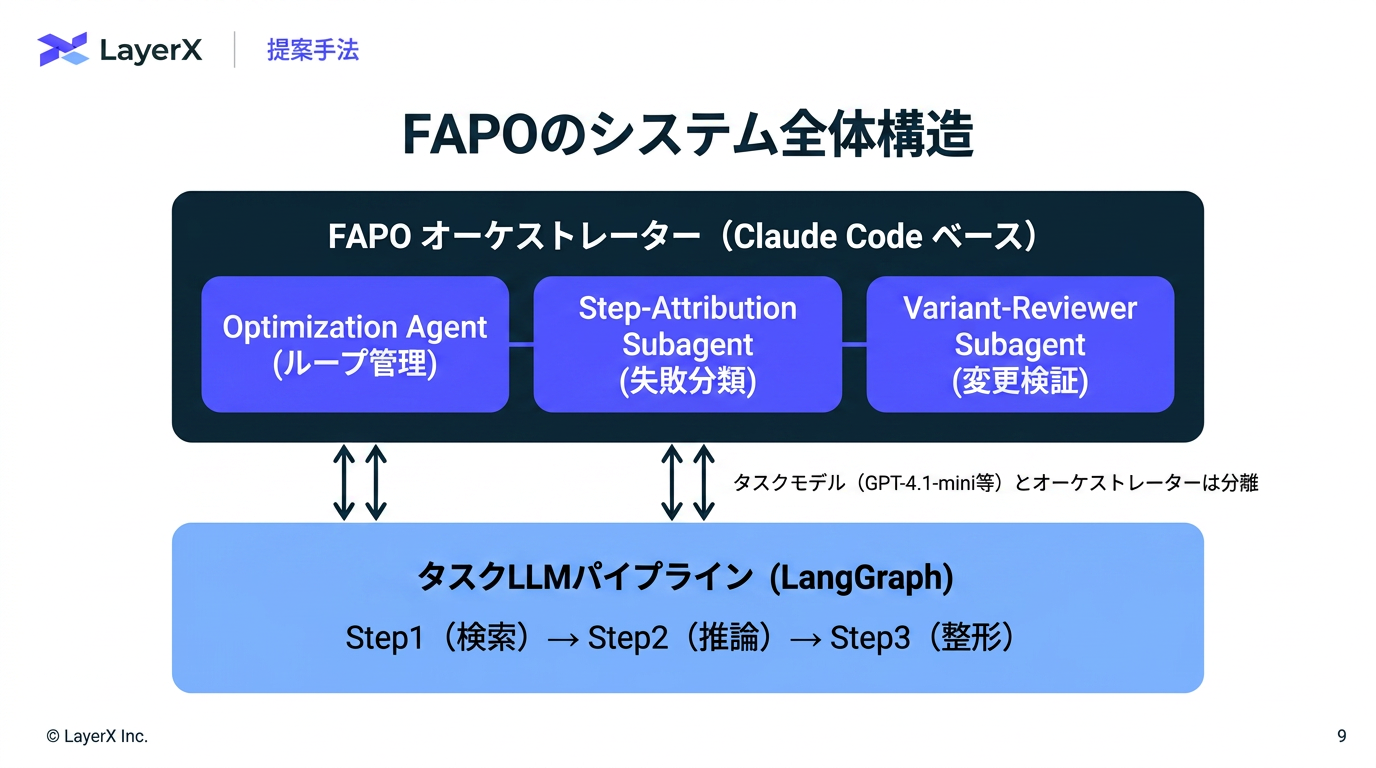
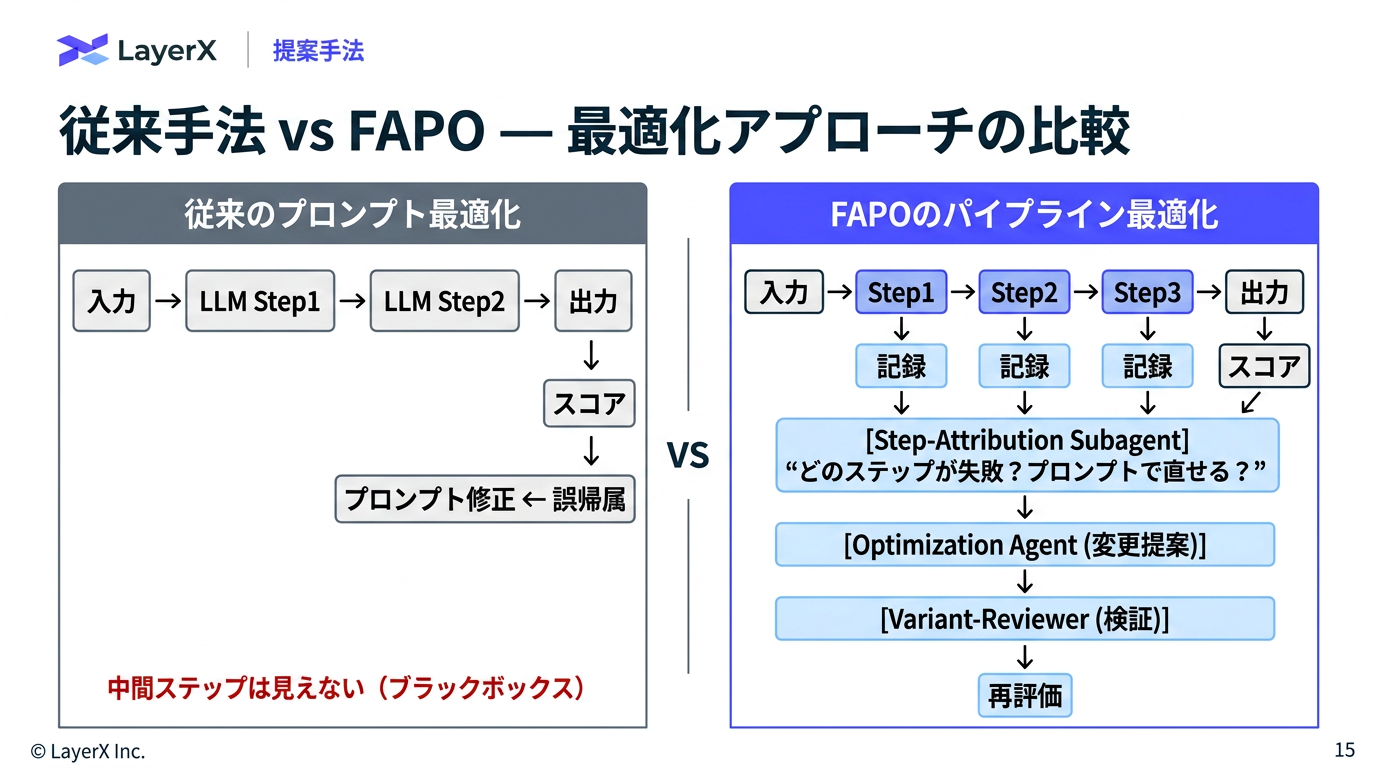
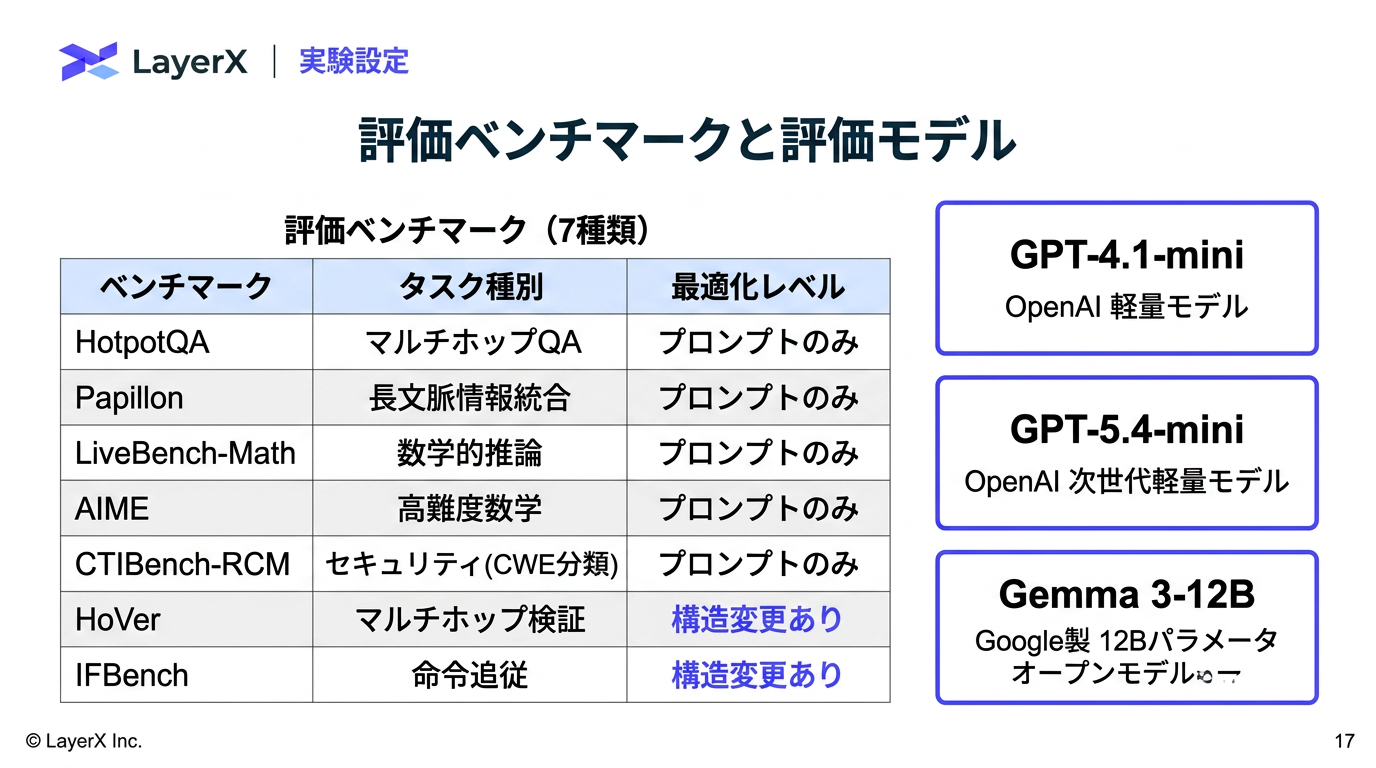
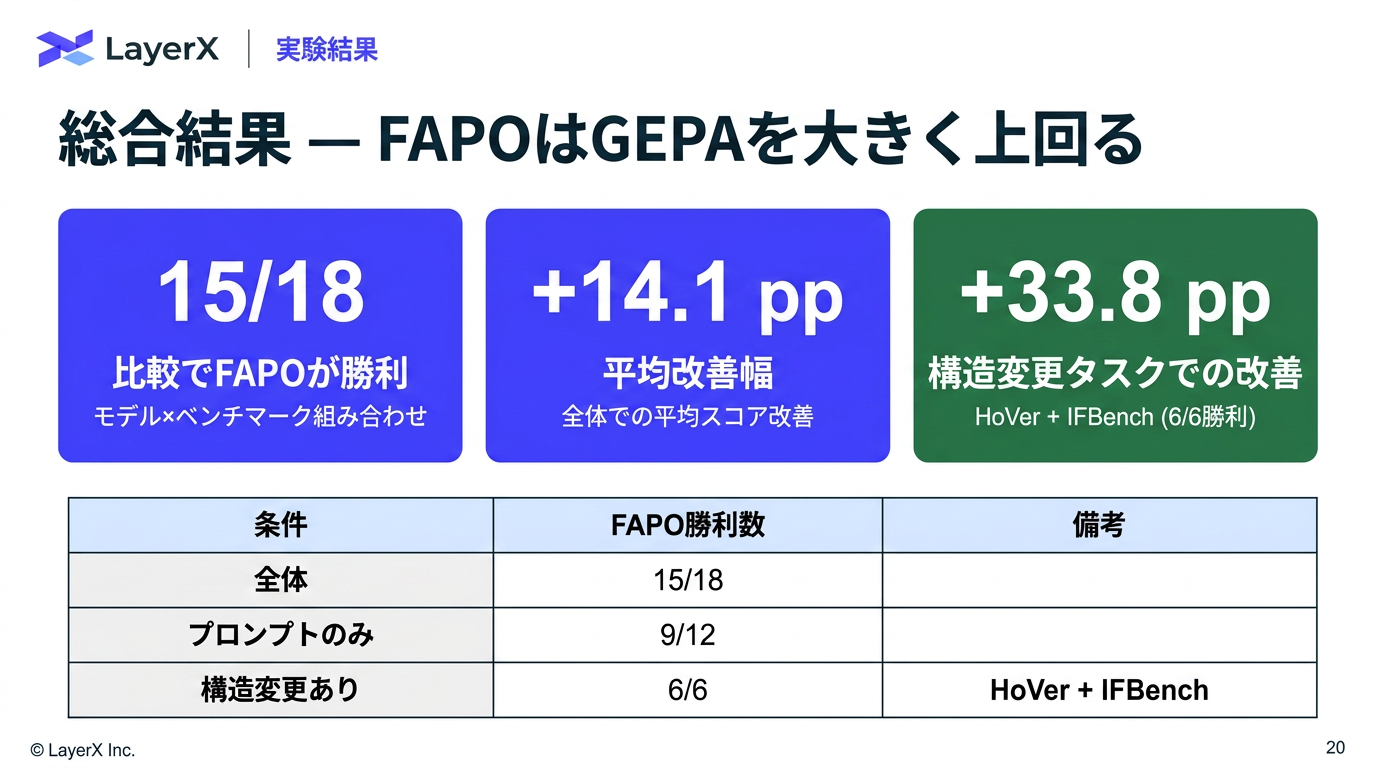
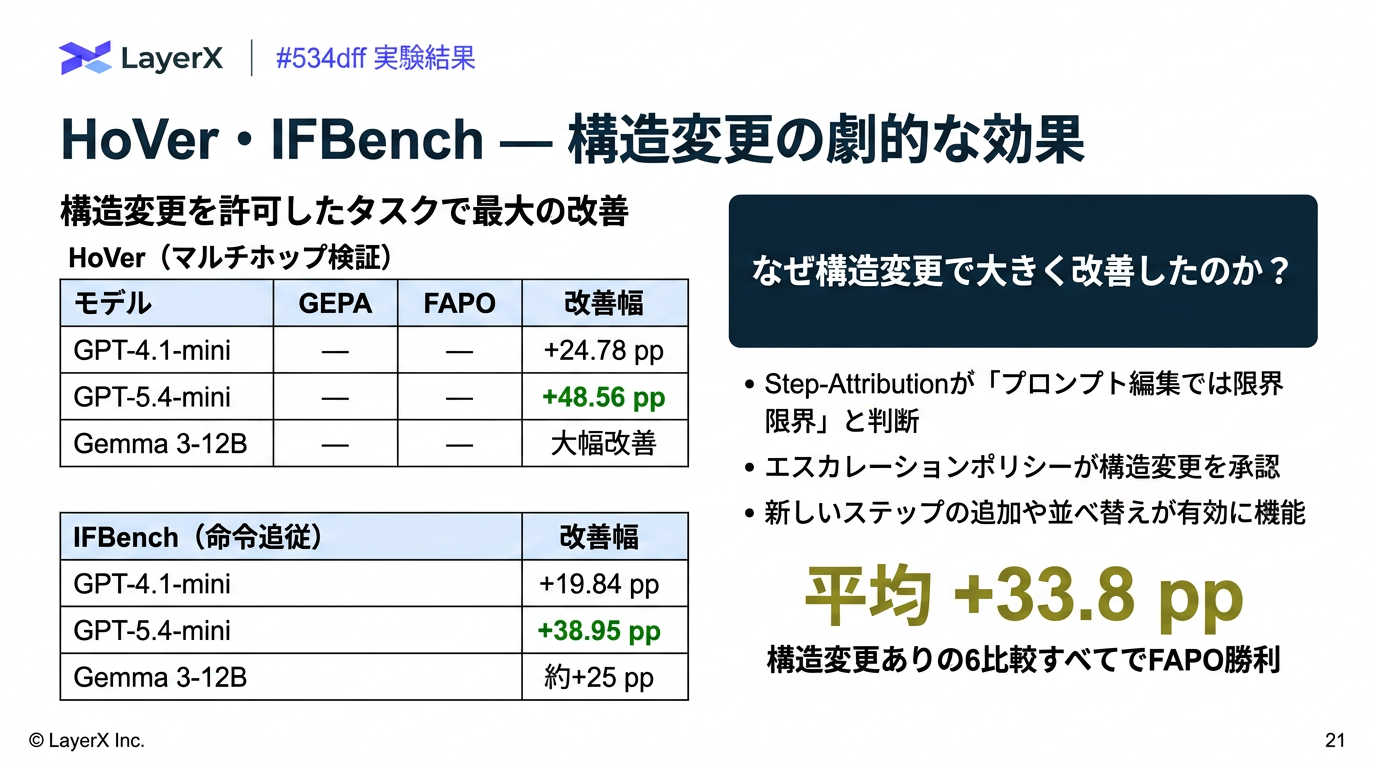
今週のTOPIC[paper] FAPO: Fully Automated Prompt Optimization of Multi-Step LLM Pipelines[paper]General-purpose large language models outperform specialized clinical AI tools on medical benchmarks
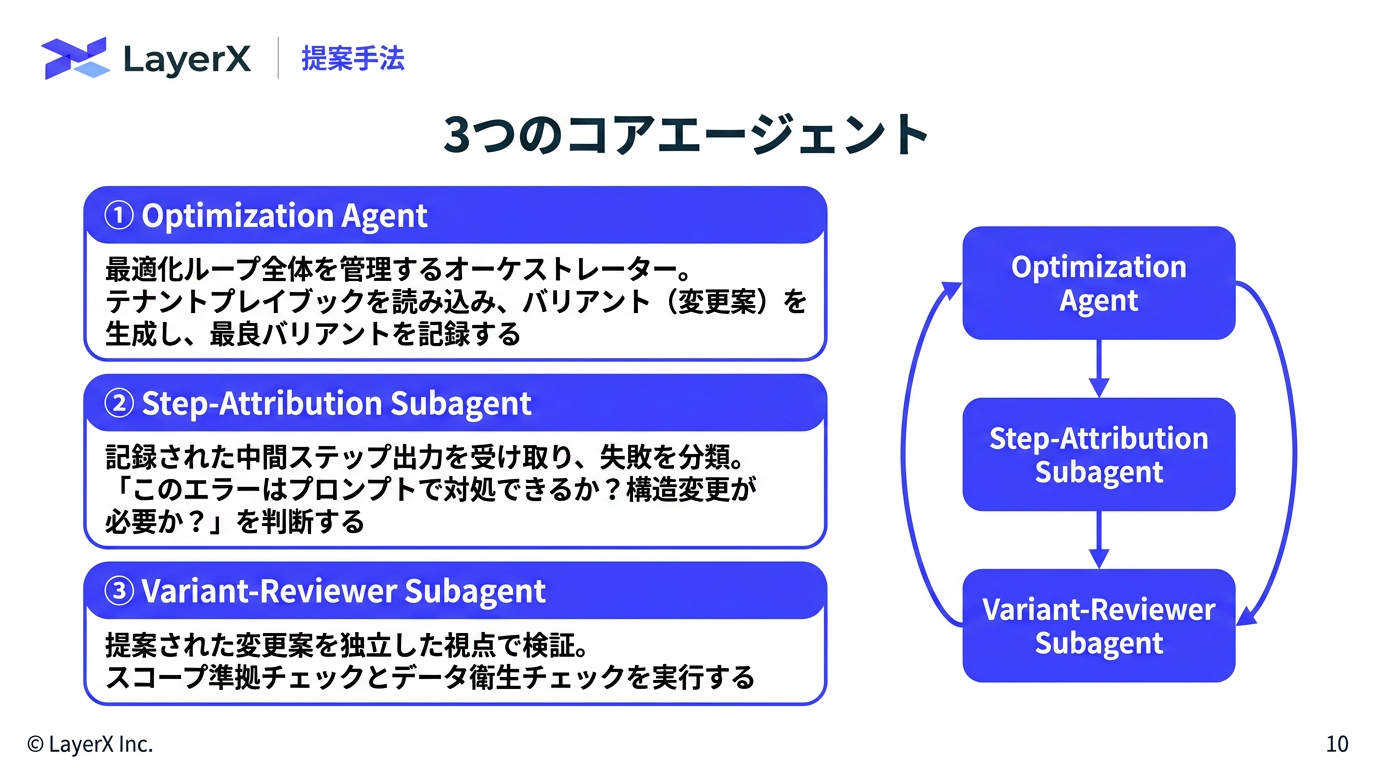
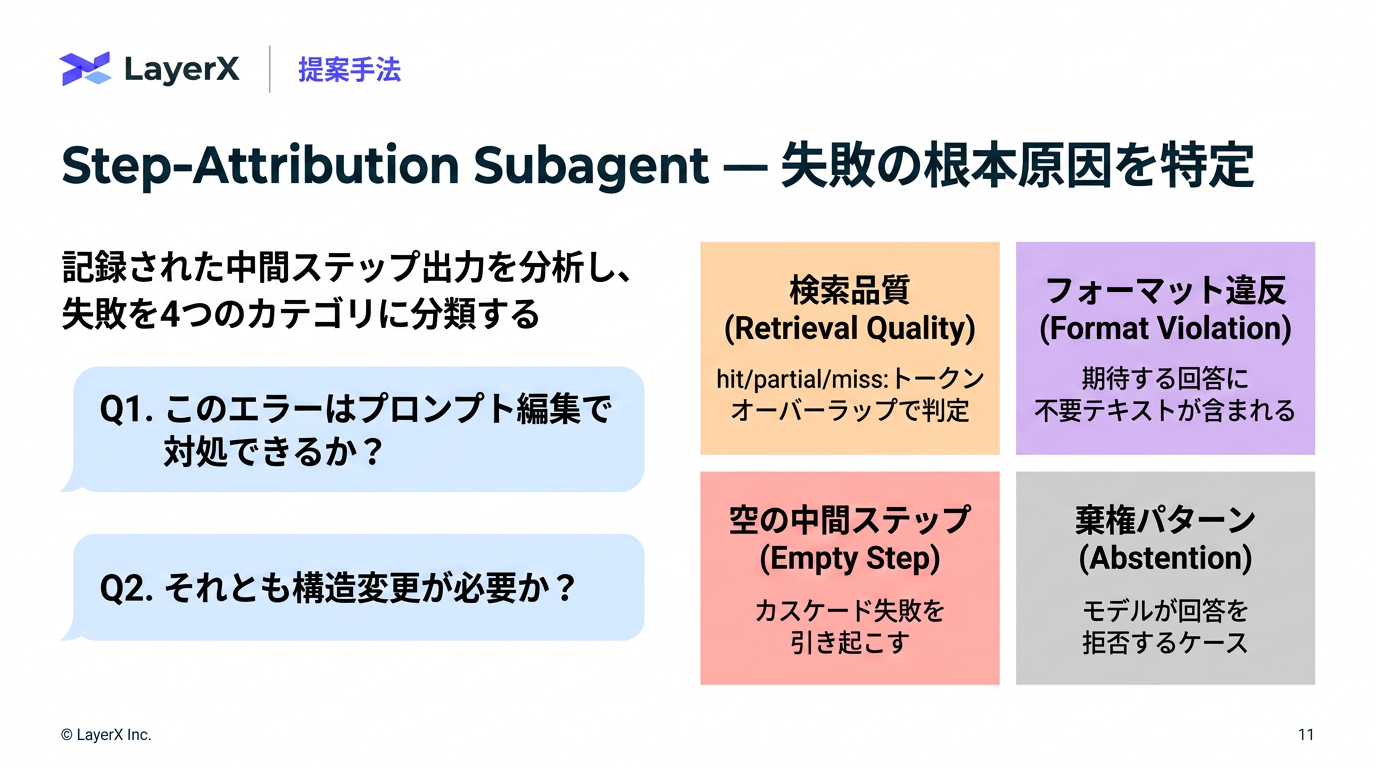
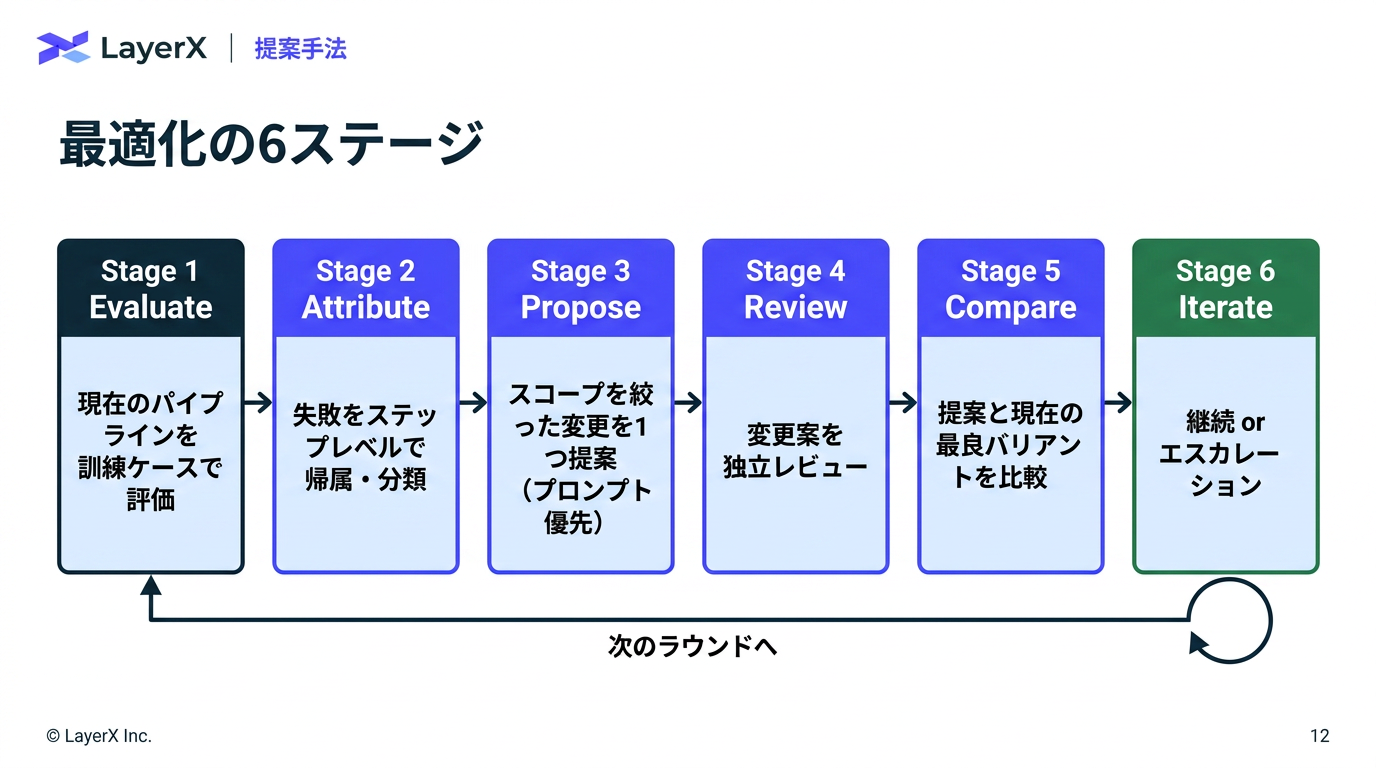
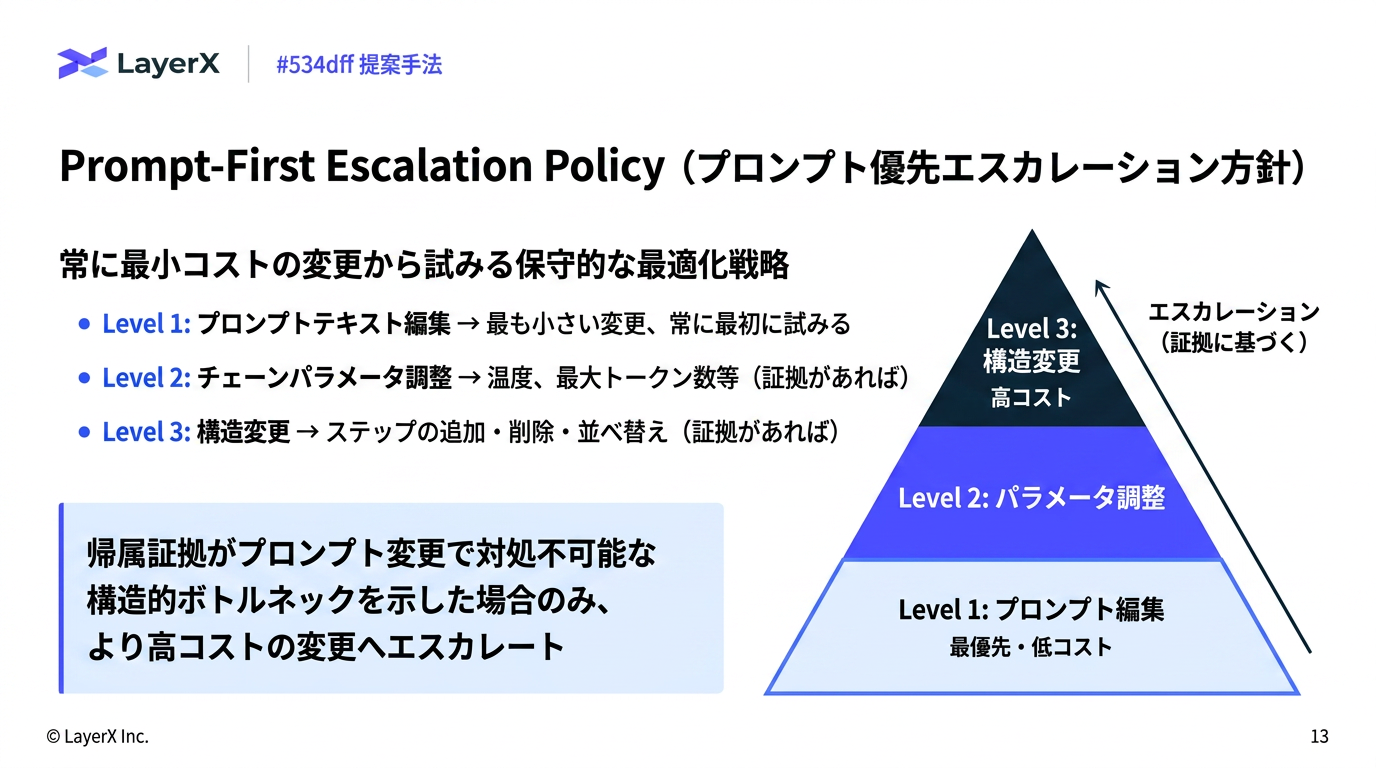
[paper] L3: Large Lookup LayersメインTOPICSakana Fugu Technical Report概要背景既存手法との違いモデルFugu (Router)学習1. シングルターンタスクでの教師あり学習2. マルチターンタスクでの進化戦略Fugu-Ultra (multi agent workflow生成)アクセス制御学習評価結果タスク別のモデル利用頻度の分布AutoResearch性能利用事例
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi














@Yuya Matsumura
[paper]General-purpose large language models outperform specialized clinical AI tools on medical benchmarks
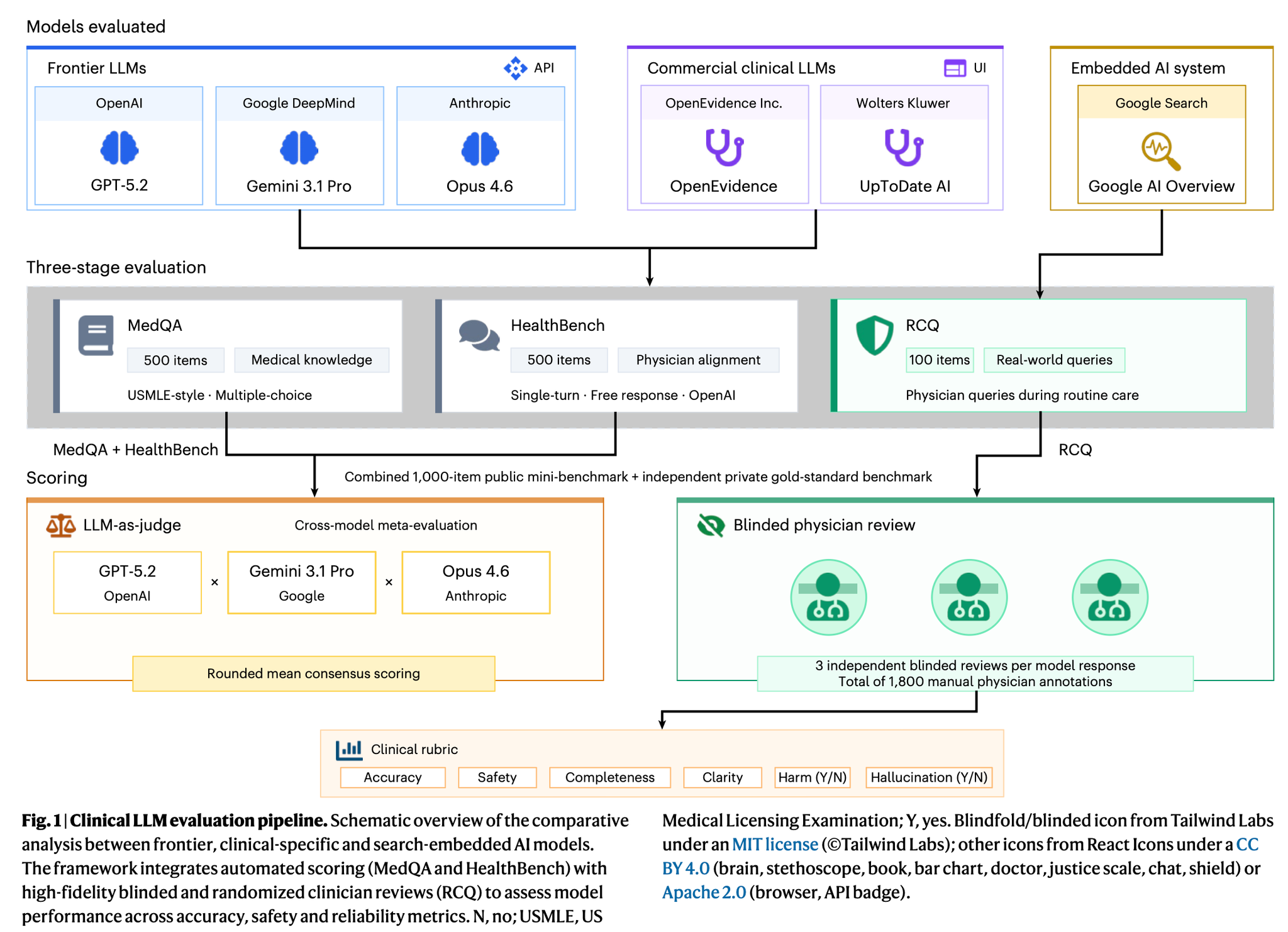
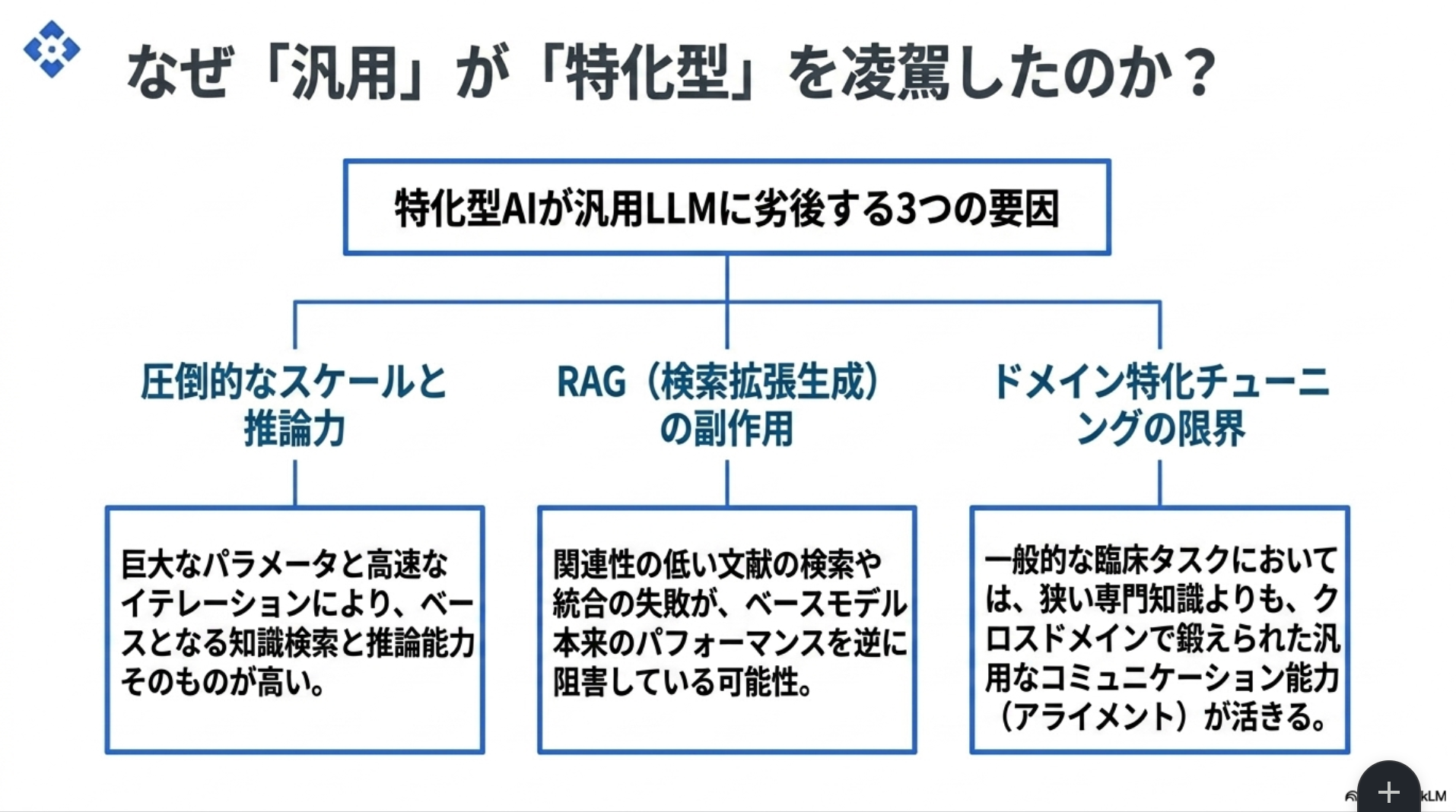
Nature Medicine誌に掲載された論文。医療領域のタスクについて、汎用モデルが医療特化AIツールを上回る結果を残したというベンチマークについての報告。一方で、比較対象とされたOpenEvidence(医師などの医療専門家向けのAI医療検索・臨床意思決定支援ツール) が論文内容に対して猛烈に批判(詳細はポストスレ参照)。ベンチマーク難しい。。。
評価は3パターン
- MedQA (医学知識)
- 米国医師免許試験(USMLE)形式の500問を用い、基礎的な医学的事実の理解と論理的推論力を定量化
- HealthBench (医師との整合性)
- 500項目のベンチマークにより、自由回答に対する医師の判断基準との一致度を、複数のLLMを評価者とする LLM-as-judge で測定
- RCQ (実際の臨床クエリ)
- ライブ臨床環境から抽出された100件の非特定化クエリを使用し、12名の米国医師によるランダム化ブラインド・レビュー(計1,800件のアノテーション)を実施
- 正確性・網羅性・安全性・明確さの4軸で[1-4]のスコアリング
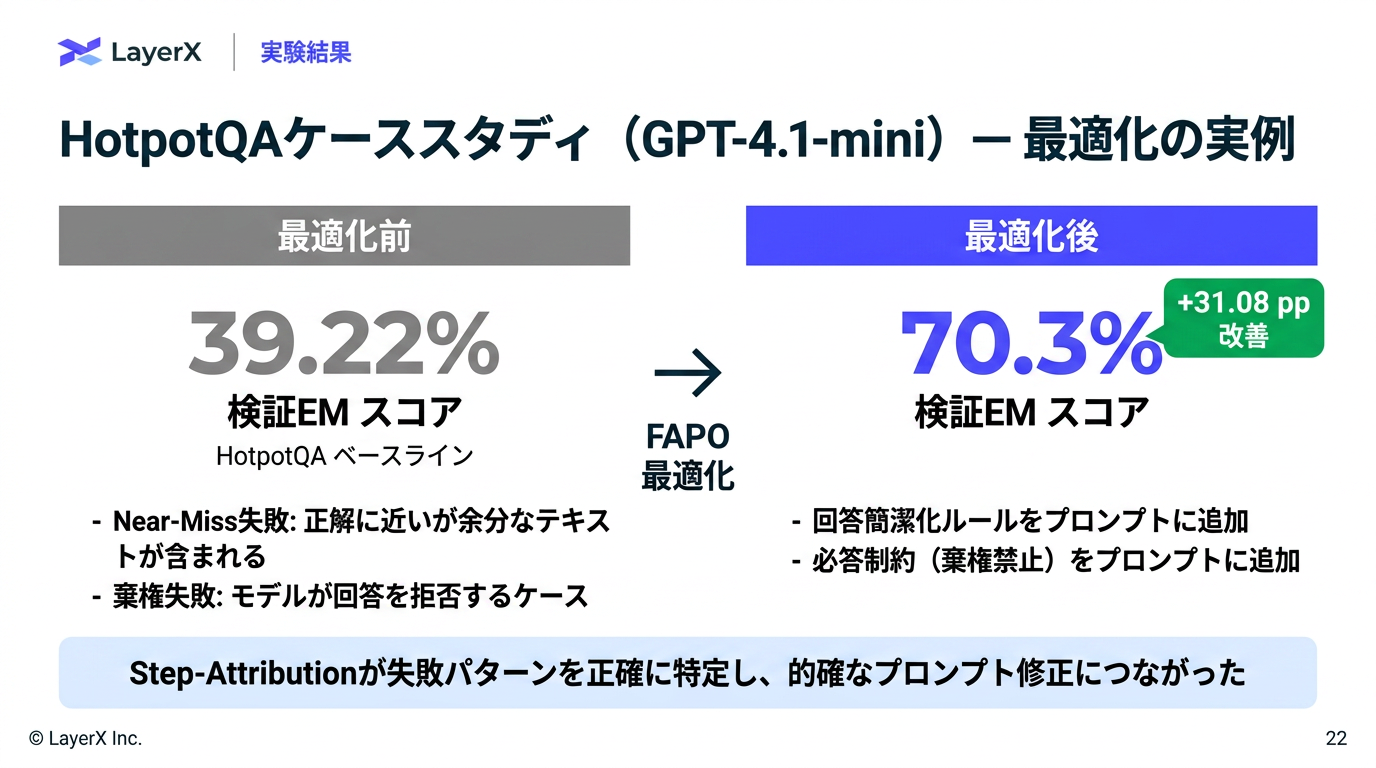
汎用LLMが勝利したよという結果
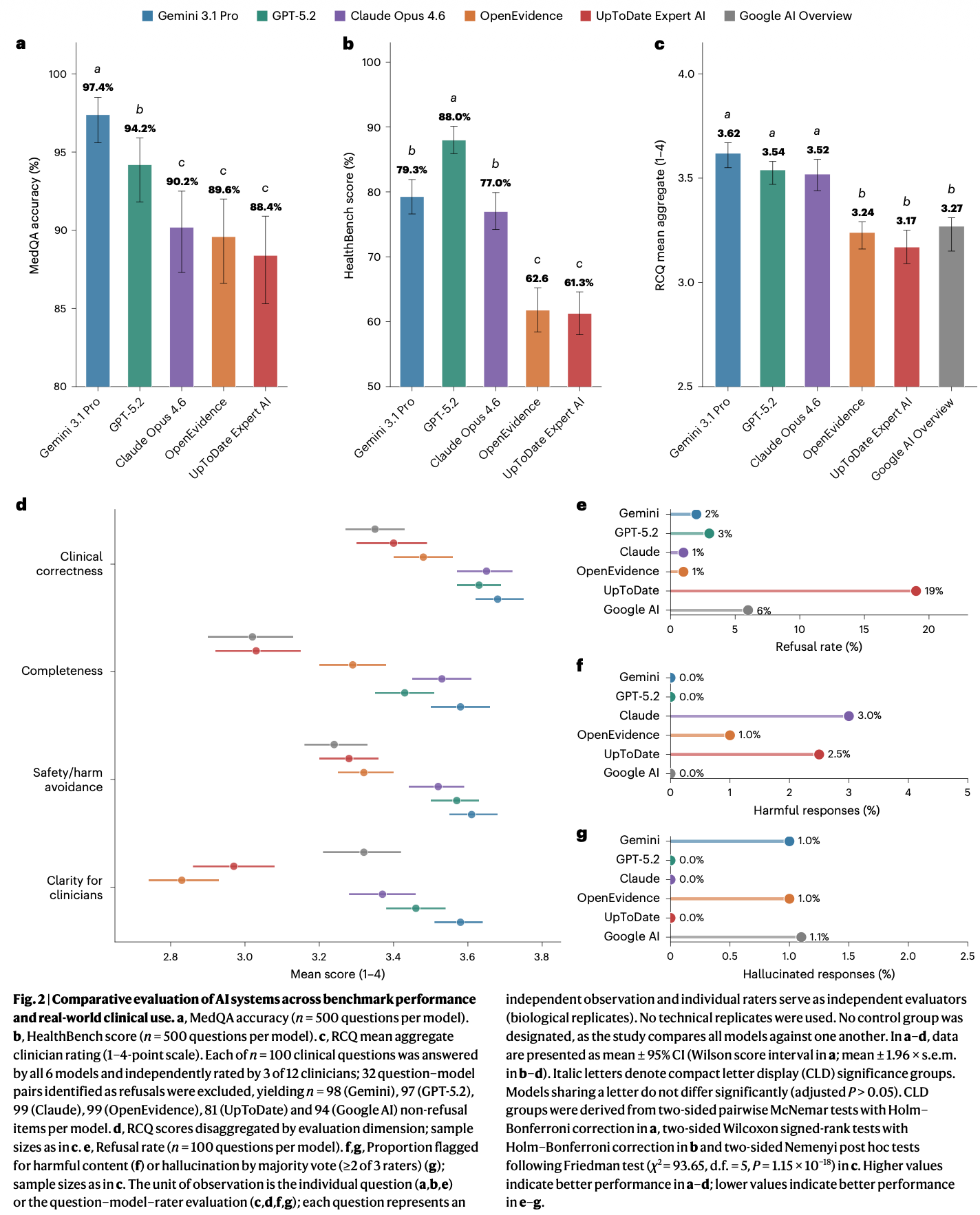
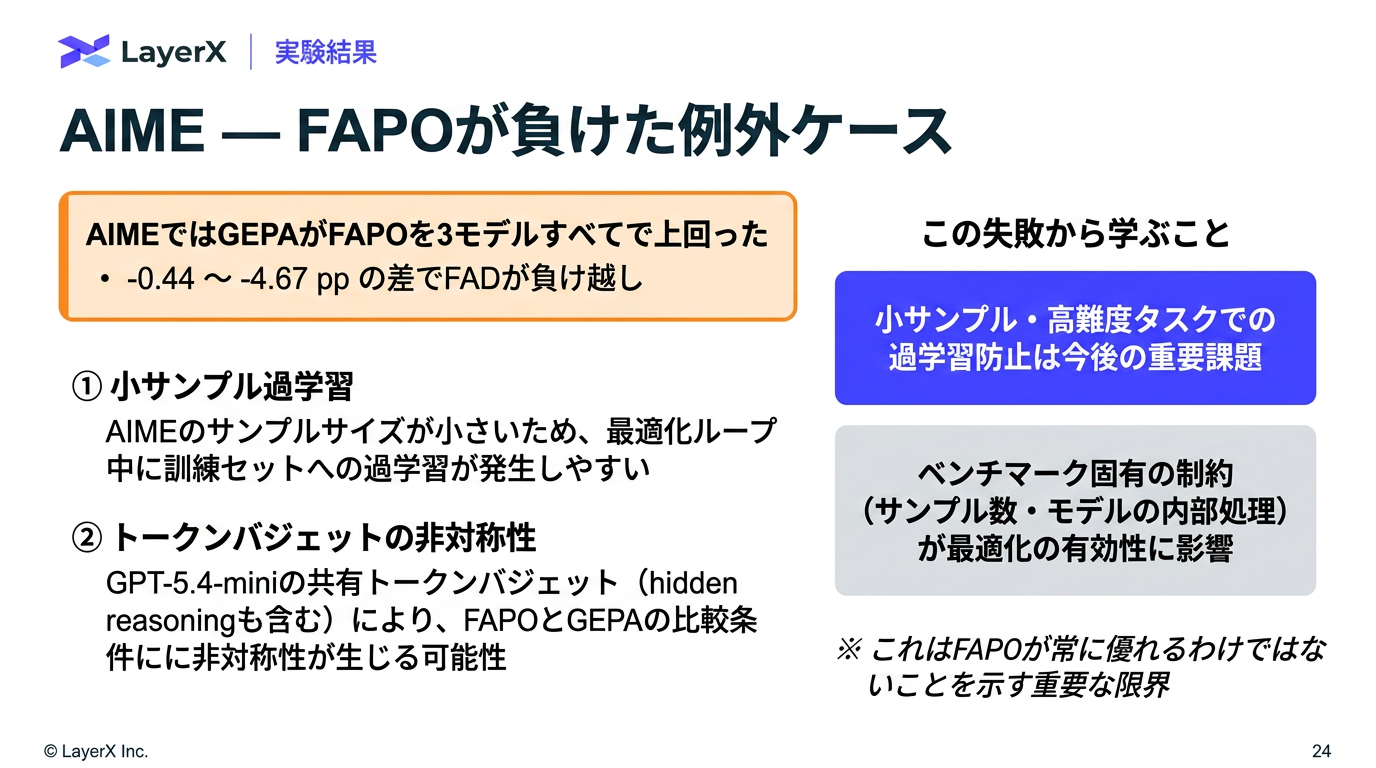
[yu] 1, 2 は過学習してそうだが(それでも勝てるならいい気も)、3は信憑性ある気もする。が、主観が入る過ぎるという指摘も頷ける。
考察
RAGの副作用とかはありそう。下手なことするよりもLLMに任せてしまう方がいい世界はあると思う。ドメイン特化finetuneも、人間が選択した知識だけで学習する限界はある気もする。
@Shun Ito
[paper] L3: Large Lookup Layers
- 背景
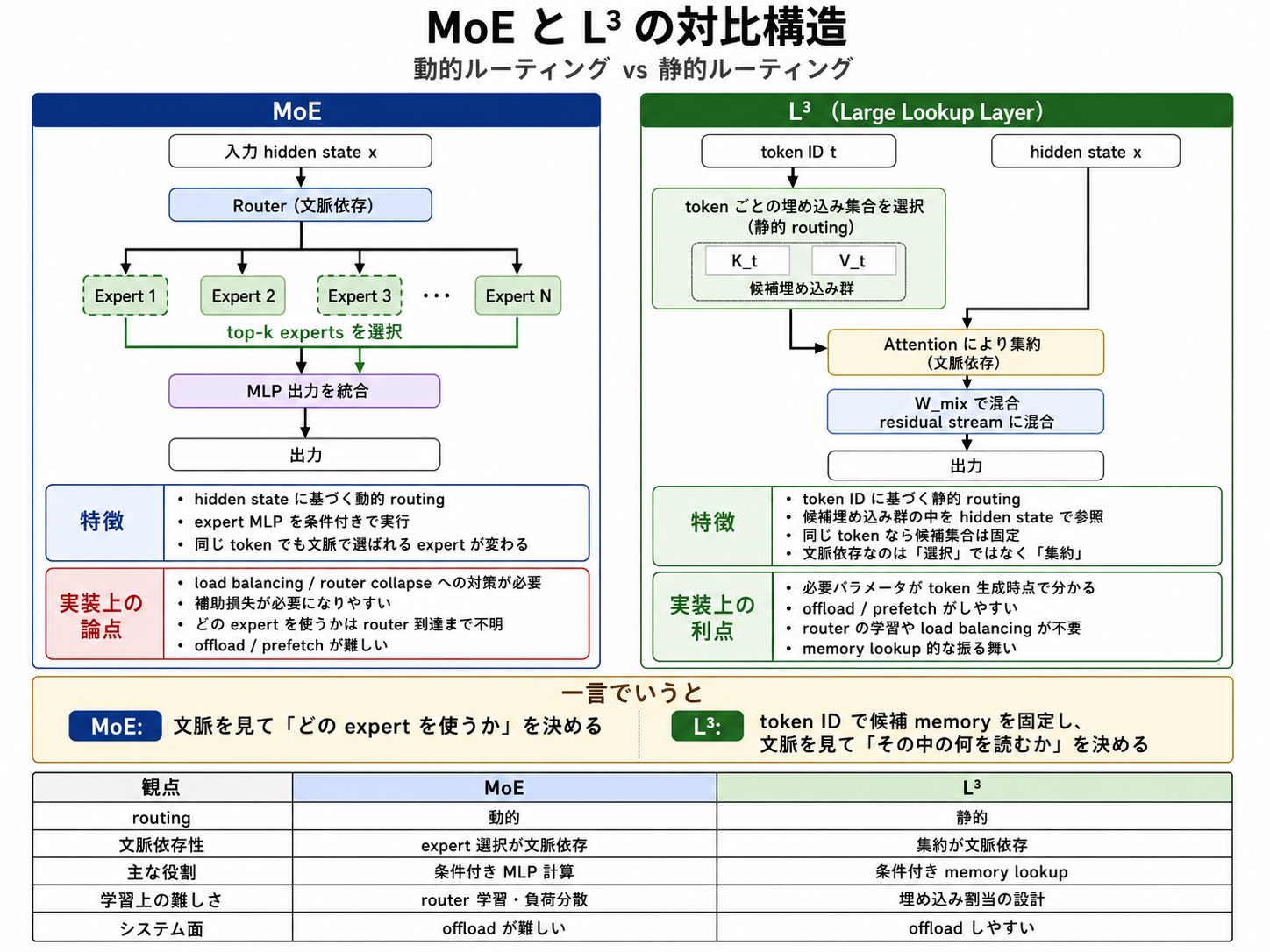
- 最近の sparse LLM で主流なのは MoE。各 token を hidden state に基づいて expert に割り当てる。
- MoE は total parameters を増やせる一方、router collapse、load balancing loss、router z-loss、expert sharding などのシステム負荷がある。
- tokenizer embedding table は token ID で1行だけ lookup するので非常に扱いやすいが、文脈情報を使えない。
- L3 の問いは、「embedding table の lookup しやすさ」と「MoE 的な文脈依存の集約」を両立できるか。
- 提案手法
- MoEはMLPをMoEに置き換えるが、L3はdecoder layerの間に差し込む
- [Attn → MLP] → L³ → [Attn → MLP] → [Attn → MLP] → L³ → …
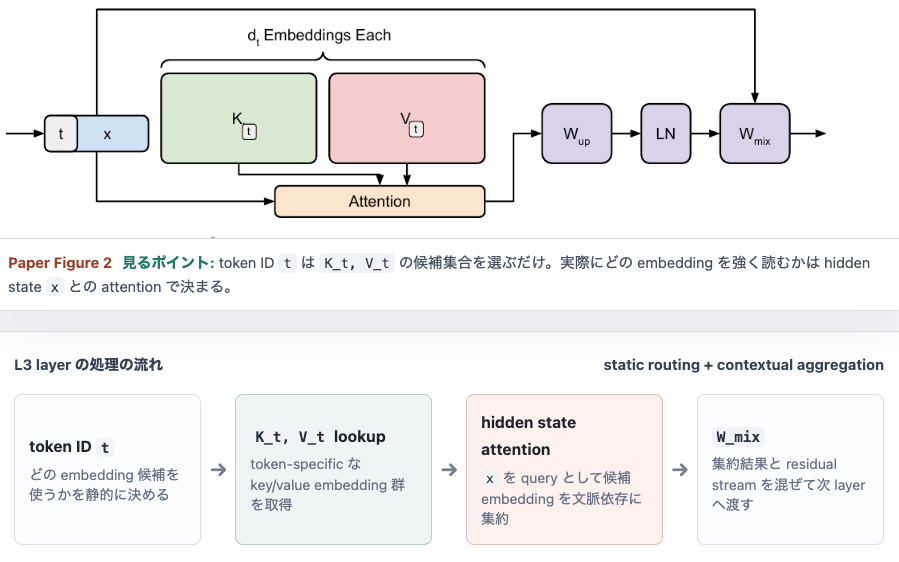
- L3の処理の流れ
- [Is, this, a, pen, ?] → token [t1, t2, t3, t4, t5]
- 初期hidden state [x1^0, x2^0, x3^0, x4^0, x5^0]
- decoder layer (attention + MLP) でhidden stateが更新
- L3層
- tokenごとにn種類のK, V embeddingが用意されている
- K_pen = [k1, k2, ..., k128]
- V_pen = [v1, v2, ..., v128]
- 現在のhidden state x_pen と K_pen から重みを計算
- α = Softmax(K_pen x_pen) = [0.01, 0.03, 0.20, ..., 0.00]
- 重み と V_pen から m_pen embedding
- m_pen = V_pen^T α
- m_pen → 線型変換 → x_penとconcat → 線型変換 → 次のhidden state
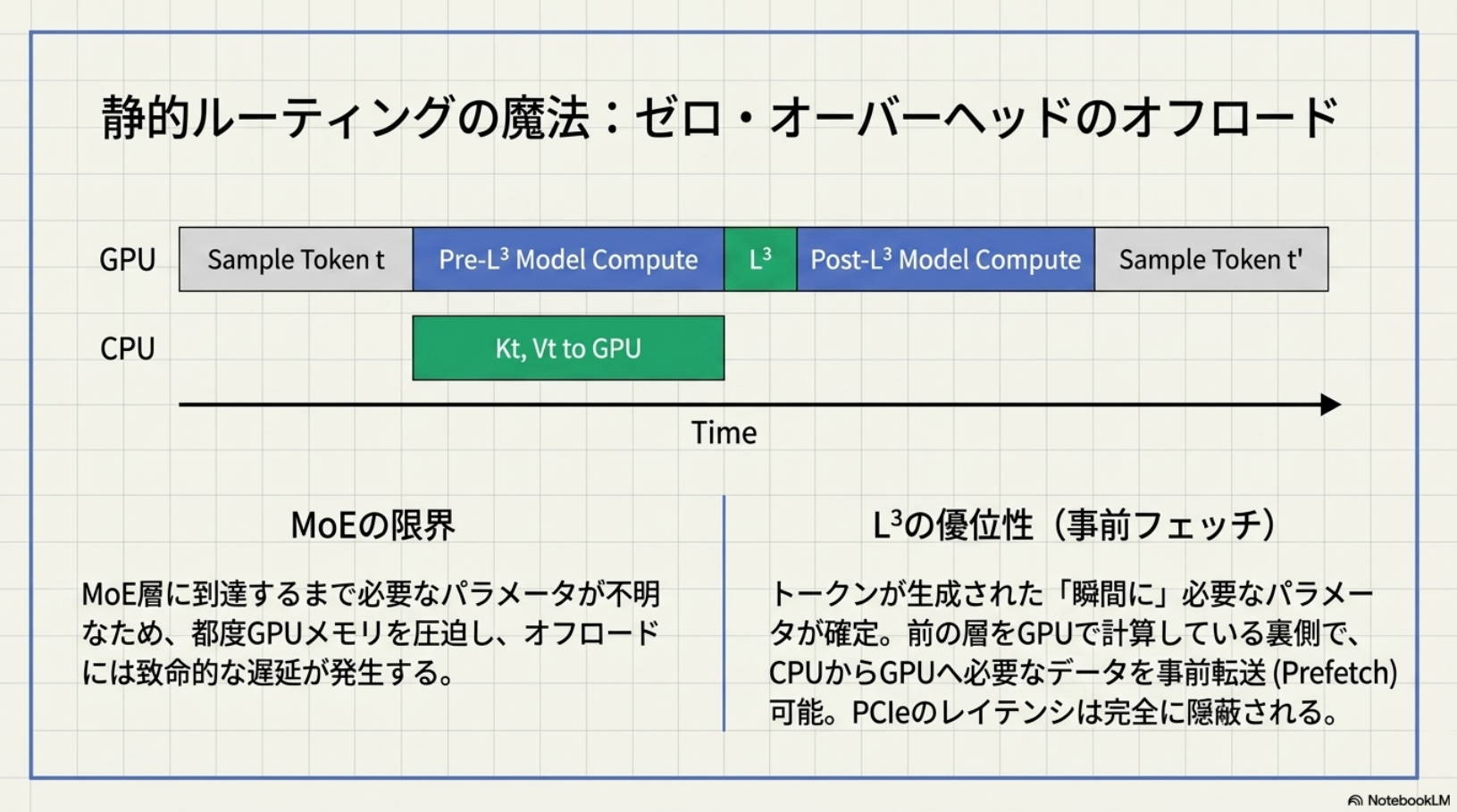
- MoEだとhidden stateをrouterに入力し各expertとのscoreを計算してから初めてactiveになる経路が確定する。L3 parameter は token が生成された瞬間に分かるので、CPU offload / prefetch / batch sorting がやりやすい。
- 実験
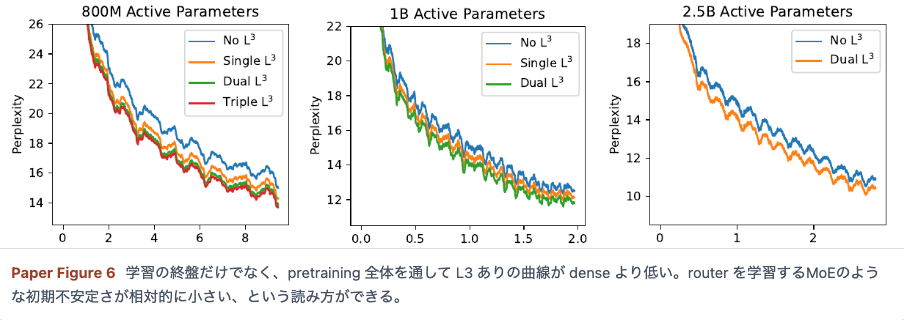
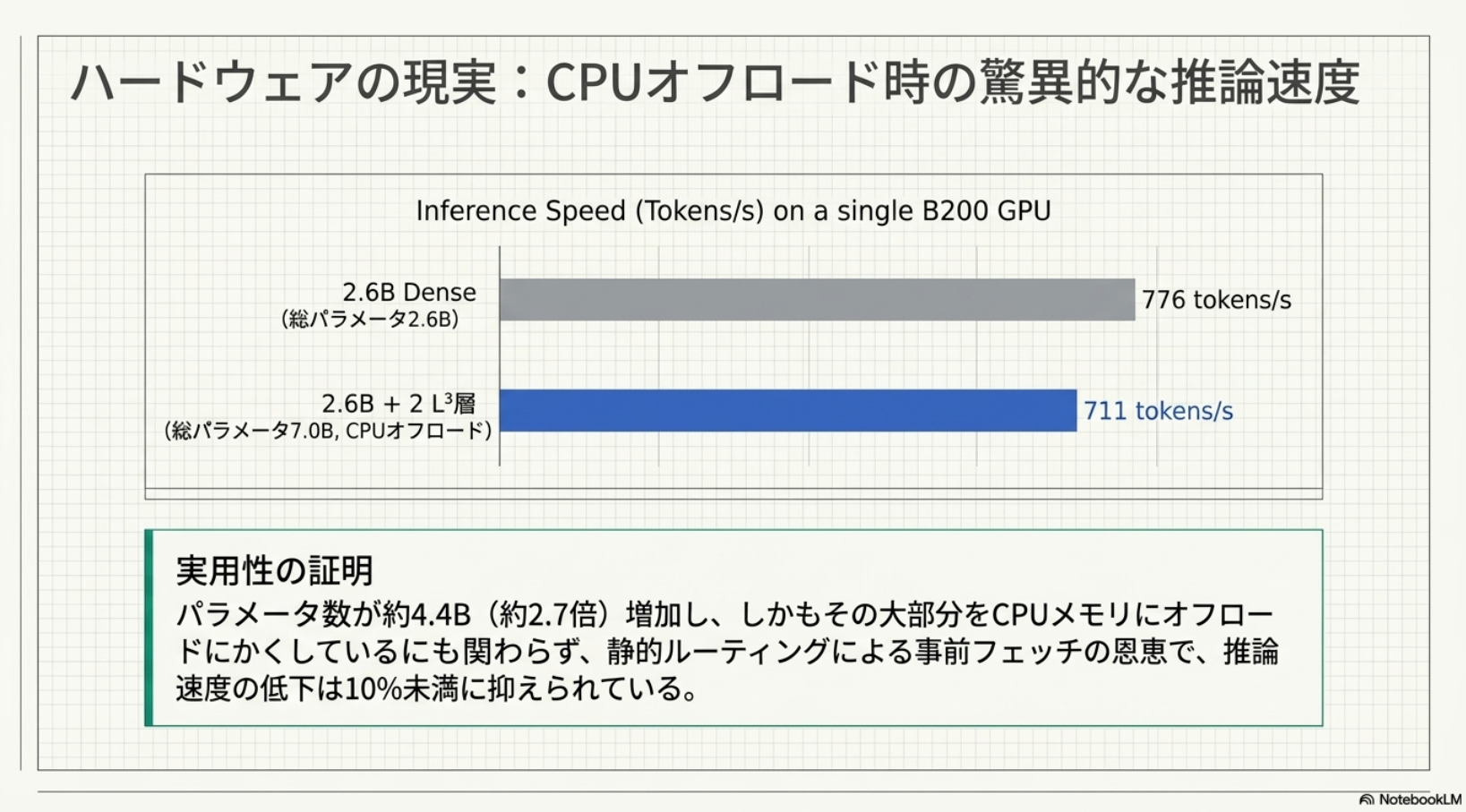
メインTOPIC
Sakana Fugu Technical Report
概要
- Sakana Fuguは、複数のフロンティアLLMを「1つのモデルのように」使えるようにする学習済みオーケストレータモデル
- ユーザーからの質問に対して、Fugu自身が問題の性質を判断し、どのLLMエージェントを使うか、どう役割分担させるか、どう結果を統合するかを動的に決める
- 前提として最近注目を集めているコストを抑えるためのオーケストレーションではなく、性能を上げるためのオーケストレーションに主眼を置いている
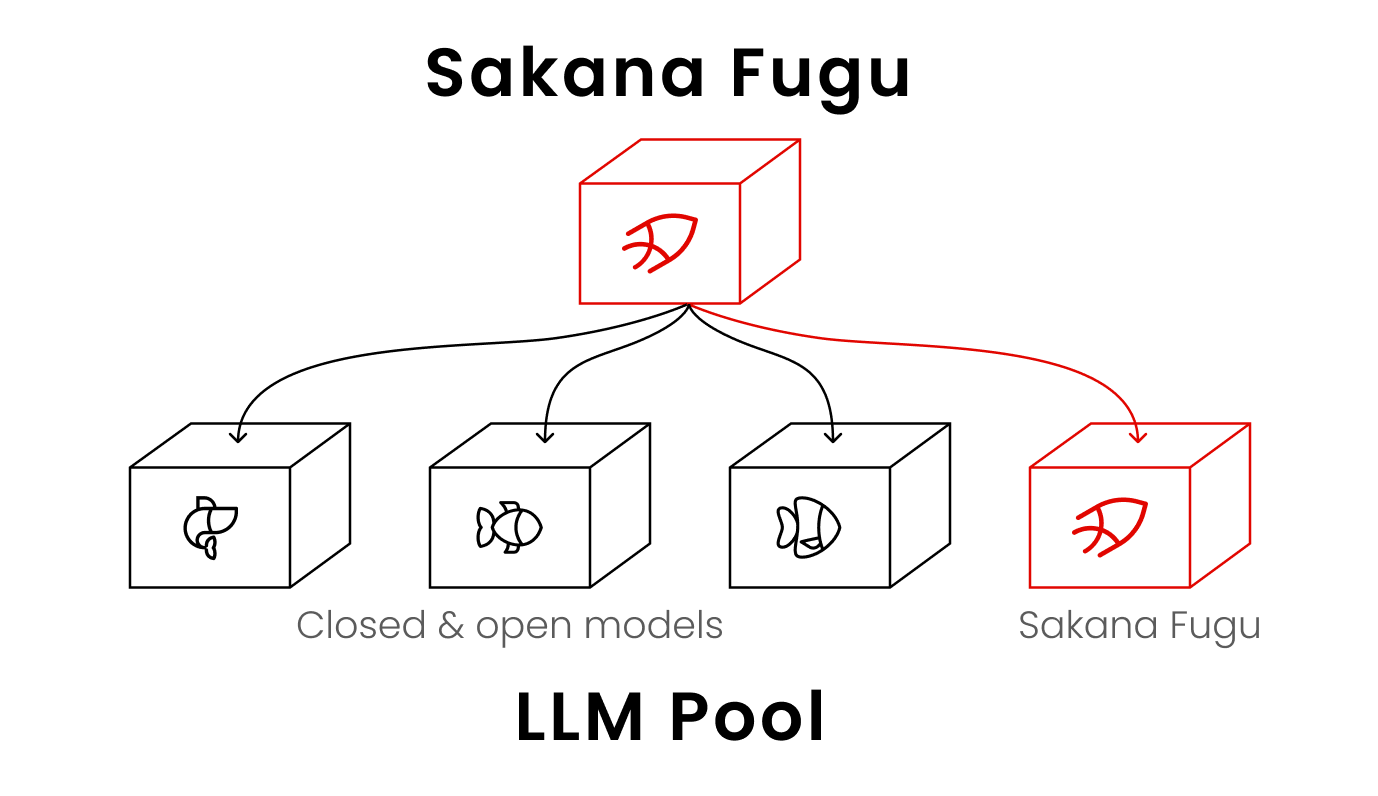
背景
- 近年のLLMが単純に「全モデルが同じ方向に強くなる」のではなく、モデルごとに得意領域が分かれている
- 同時に、LLMの実用性能はモデル本体だけでなく、ツール利用、環境フィードバック、メモリ、自己反省、コード実行などを含む agentic scaffoldに大きく依存する
- そこでFuguは、「より大きな単一モデルを作る」以外のスケーリング軸として、複数モデルの専門性を状況に応じて組み合わせる collective intelligence を提案
既存手法との違い

モデル
2つのオーケストレーターモデルがあり性能だけでなく役割が異なる
- Fugu
- 速度重視
- 1つのagentを選ぶrouter型
- Fugu-Ultra
- 性能重視
- multi agentのworkflowを生成するconductor型
Fugu (Router)
- FuguはLLMに分類ヘッドを付与してどのagentにroutingすべきかを推論する
- backbone の hidden state を取り出し、その上に lightweight selection head を付ける
- この head はmodel数を L とすると、L 個の logits を出す
- 各 logit は「この入力をどの worker に投げるべきか」のスコア
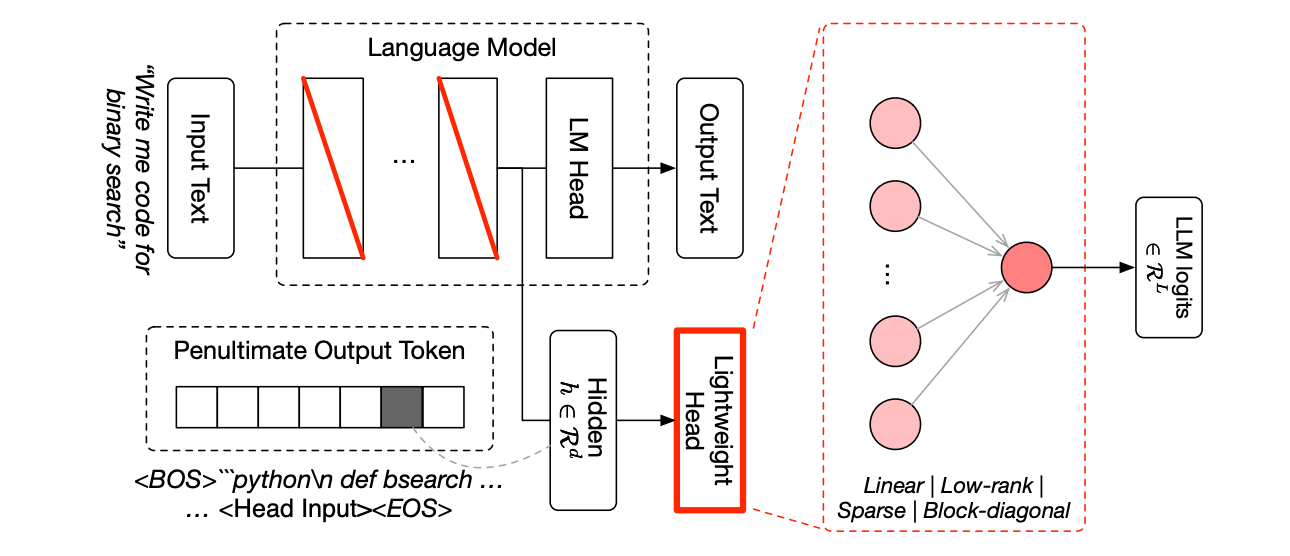
以下の工夫によりレイテンシを下げている
- Trinityという既存手法と違い、役割の割り当てはせずモデルの選定のみを実施
- 生成テキストではなくlogitsを使う
[kuto]対象モデルを追加する場合は学習し直す必要あり。モデルの数や種類は変えたくなりそう
学習
Fuguは以下の2段階で実施
- シングルターンタスクでの教師あり学習
- マルチターンタスクでの進化戦略
1. シングルターンタスクでの教師あり学習
- コーディング、数学、言語理解などの単発タスクを用意。各問題は全て検証可能な正解あり
- どう正解ラベルを作成するか?
- 各問題iに対して全てのモデル候補jをn回ずつ推論させ平均報酬を計算する
- モデル毎の平均報酬をsoftmaxに通してターゲット分布とし、Fuguのpolicy分布(モデル毎のlogits)とのKLダイバージェンスの最小化として解く
- hard labelではなくsoft labelとして扱う意図
2. マルチターンタスクでの進化戦略
- Claude Code、Codex、OpenCode のような環境から multi-turn trajectories を集める
- 各ターン毎にFuguでroutingを行い、最終的なタスクの成功可否でbinary報酬(0,1)を得る
- sep-CMA-ESという進化戦略でパラメータ更新
- ランダムな摂動を加えたパラメータ候補をk個用意してタスクを実行し結果の良かった上位候補を重みつき平均してパラメータを更新する
Fugu-Ultra (multi agent workflow生成)
- Fugu-Ultra の目的は問題を解くための agentic workflow を設計すること
- 以下がFugu-Ultraの役割
- サブタスク作成
- サブタスクへのエージェントの割り当て
- 過去ステップのコンテキストへのアクセス制御
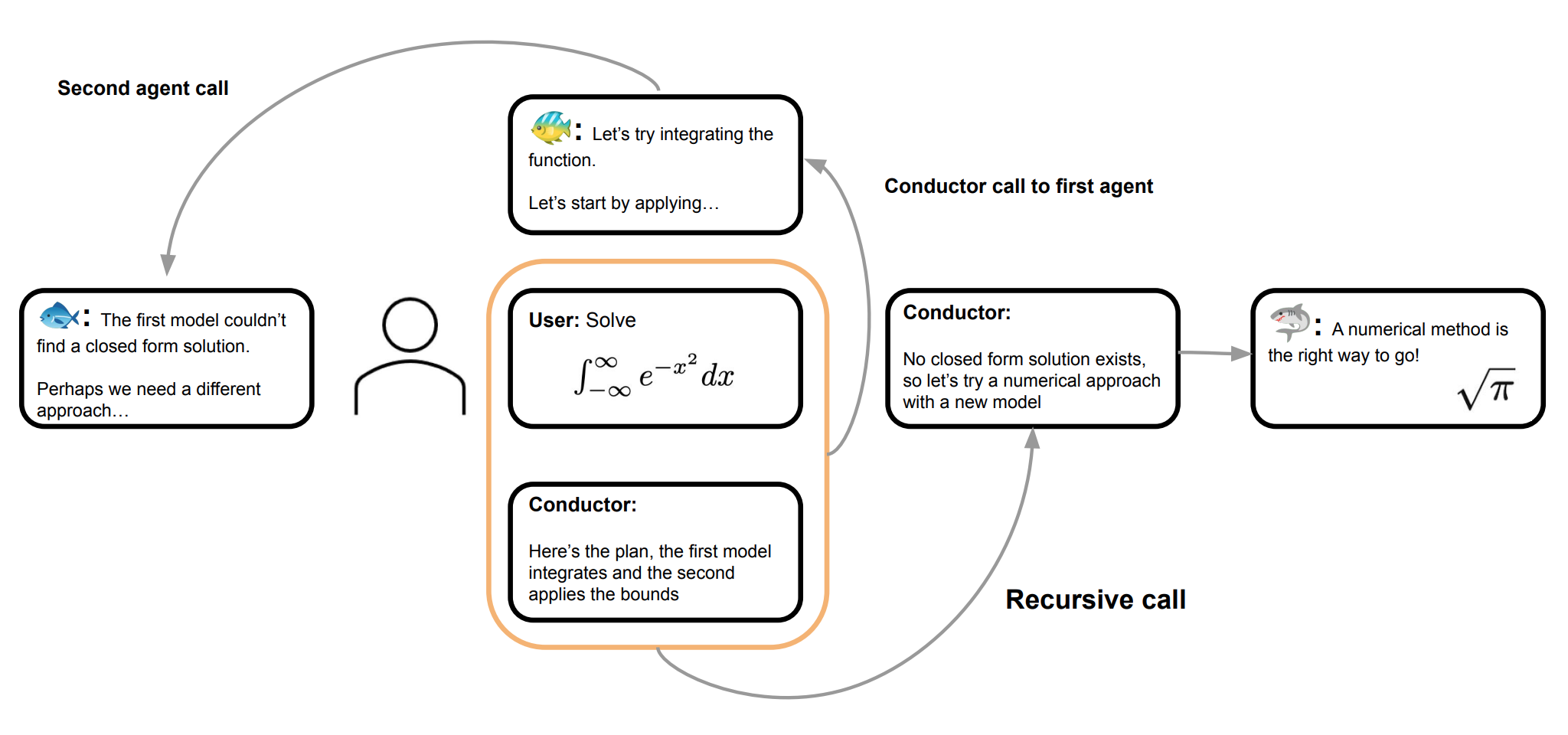
conductorの図。Fugu-Ultraとは違うところもある
アクセス制御
- オーケストレータであるFugu-Ultraは全体の状態を観測する
- エージェントには必要な範囲だけコンテキストを与える。この制御をFuguがやる
- ex)
- step1: Agent1 access_list=[]
- step2: Agent2 access_list=[]
- step3: Agent3 access_list=[step1, step2]
- 最初にツールを使ったエージェントの軌跡に後続エージェントが引きずられ、全員が似た作業をしてしまうorchestration collapseを回避する狙い
学習
- 最大5ステップのAgentic workflowを設計するように訓練する
- 学習はGRPOでRL
- fuguがタスク作成、エージェント割り当て、アクセス制御を失敗したら報酬0
- workflowの最終結果が正解であれば1
- workflowの最終結果が不正解なら0.5
[kuto]推論コストを抑制するような報酬はなさそう? 5ステップ制約で担保している
評価結果
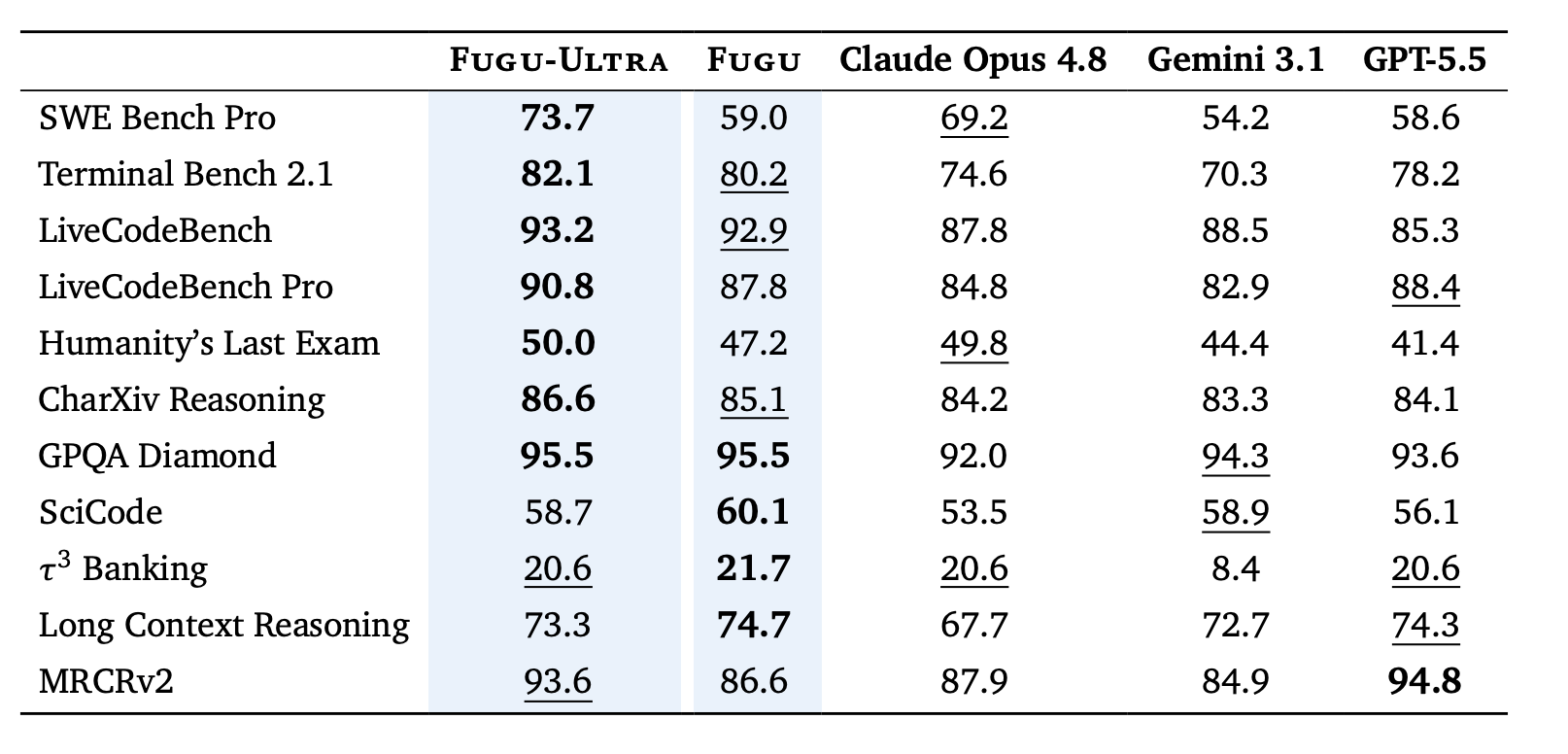
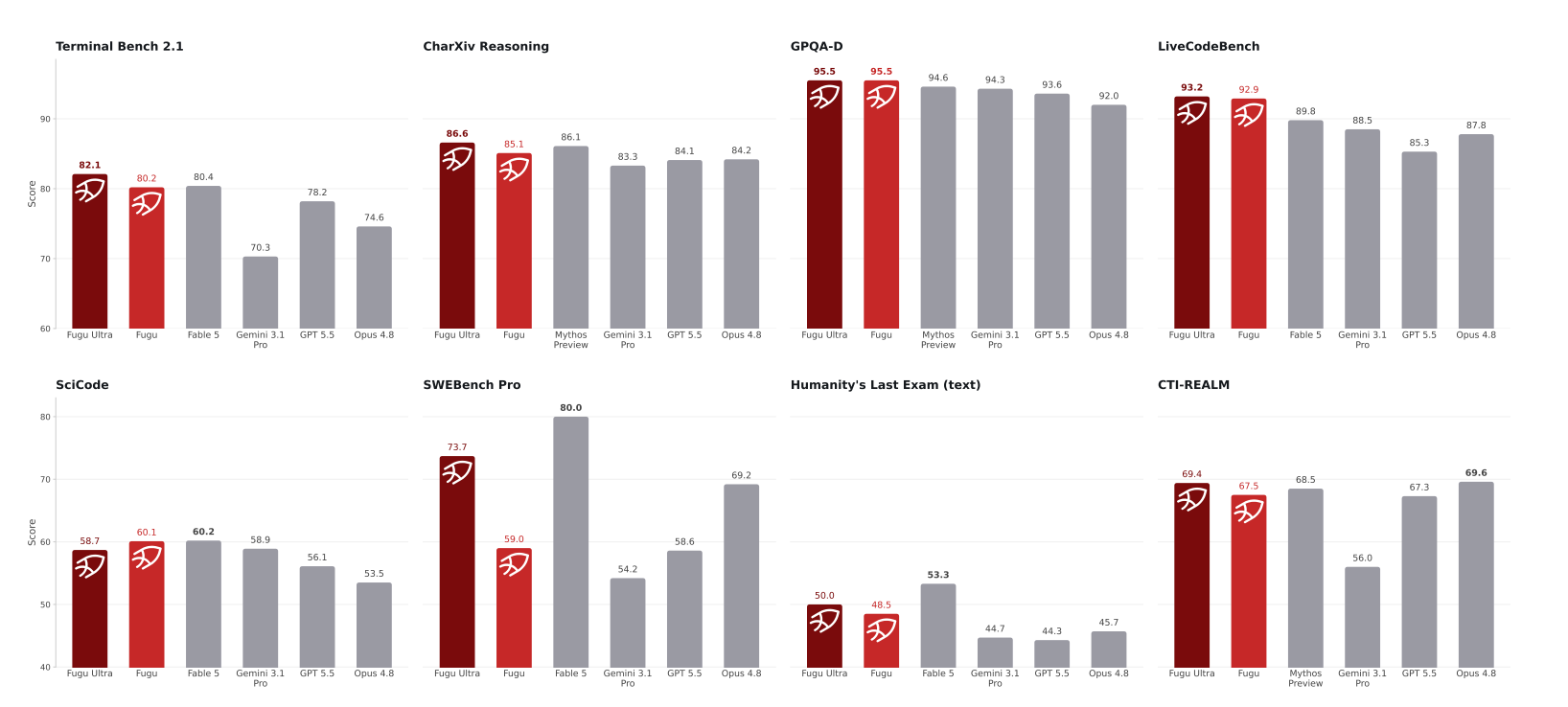
[kuto] 実験部分では推論時間や推論コストに関する結果は無し。routingによって推論コストを抑える効果は現状なさそう?
タスク別のモデル利用頻度の分布
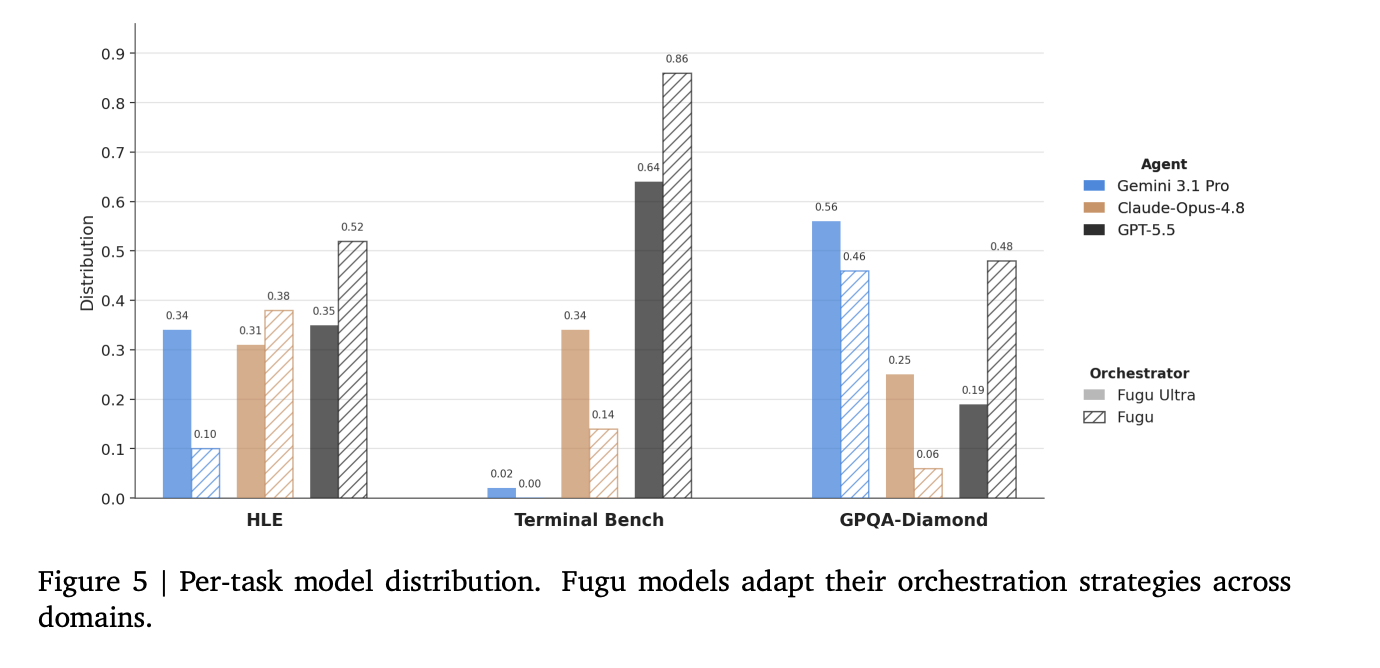
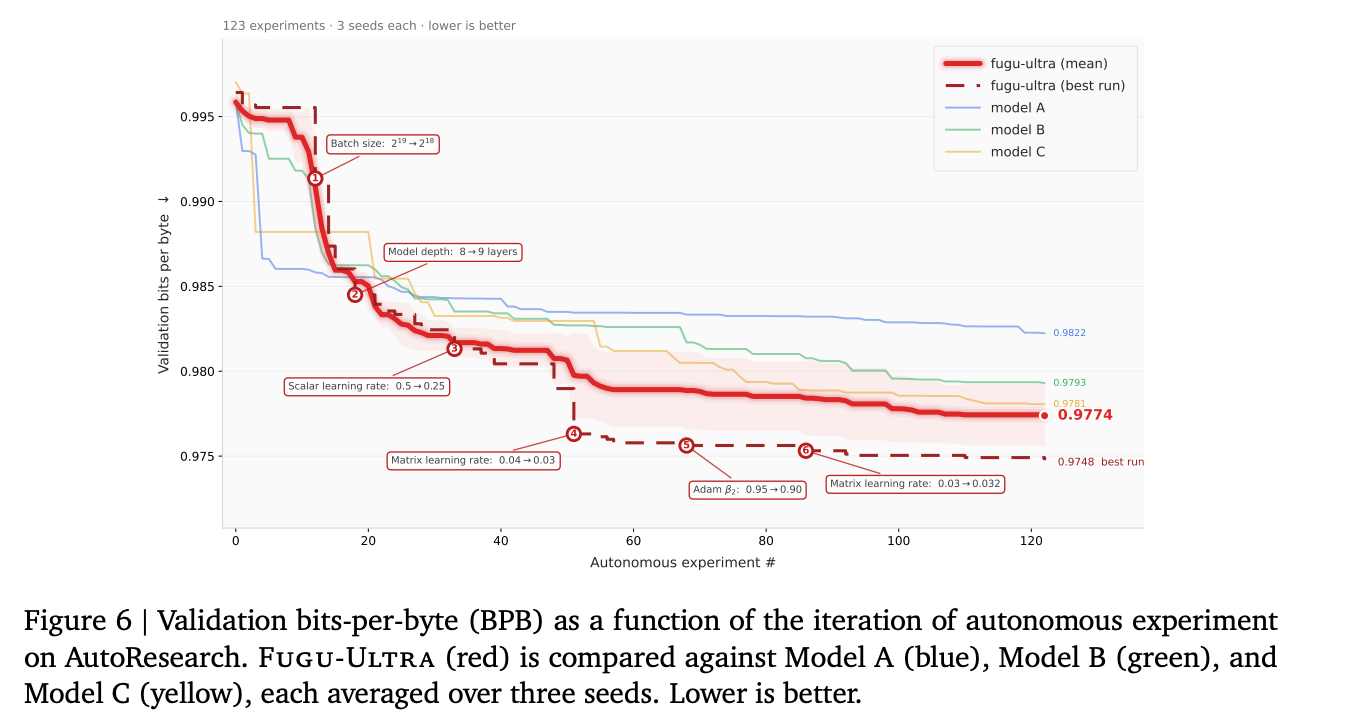
AutoResearch性能
AutoResearchを題材とし、実験数の増加に伴うスコアの減少の推移を比較
- Gemini 3.1 Pro(high), Opus 4.8(max), GPT 5.5(xhigh)の3つのフロンティアモデルと比較
- 個別モデルではなく挙動の違いに注目できるよう、ベースラインを Model A 、 Model B 、 Model C として匿名化
- [kuto]あまり意図は分かっていない
- 123ステップのautoresearchを3回実施し、一番結果が良かったものが赤点線、3回の平均値が赤実戦。
- [kuto]これは有利な見せ方になってそう