
2026-06-30 機械学習勉強会
今週のTOPIC[paper] PTCG-Bench: Can LLM Agents Master Pokémon Trading Card Game?Hoge[paper] JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree DraftingHogeHoge[paper]Towards Robust Real-World Spreadsheet Understanding with Multi-Agent Multi-Format Reasoning[paper] How Far Can LLM Agents Reason with Tables? Benchmarking Multi-Turn Agentic Table Question Answering in the WildメインTOPICDSpark: Confidence-Scheduled Speculative Decoding with
Semi-Autoregressive Generation1 背景ドラフタの2系統自己回帰ドラフタ(AR)並列ドラフタ(Parallel)2 解くべき2つのボトルネック3 DSpark 全体アーキテクチャ4 半自己回帰生成(Semi-Autoregressive Generation)並列ステージ(Parallel stage)逐次ステージ(Sequential stage)Markov ヘッド(標準)RNN ヘッド5 信頼度スケジュール検証(Confidence-Scheduled Verification)5.1 信頼度ヘッド(Confidence Head)5.2 ハードウェア対応プレフィックススケジューラ6ドラフトモデルの学習目的関数① Cross-entropy loss \mathcal{L}_\text{ce}② 分布マッチング損失 \mathcal{L}_\text{tv}③ 信頼度損失 \mathcal{L}_\text{conf}(ソフト受理ラベル c^*_k に合わせる)7 オフライン実験結果Table 1:主な結果(受理長 τ/高いほど良い、太字=最良)8 分析:受理長の源泉と賢い検証8.1 なぜ並列ドラフタが自己回帰に勝てるのか(位置ごとの受理率)8.2 「ほんの少しだけ前を見る」が大きく効く8.3 賢く検証する:信頼度ヘッドの役割(しきい値を振ってみる)9 本番デプロイ(DeepSeek-V4)(時間あれば)10 制約とまとめ制約(Limitations)まとめ
今週のTOPIC
※ [paper] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi



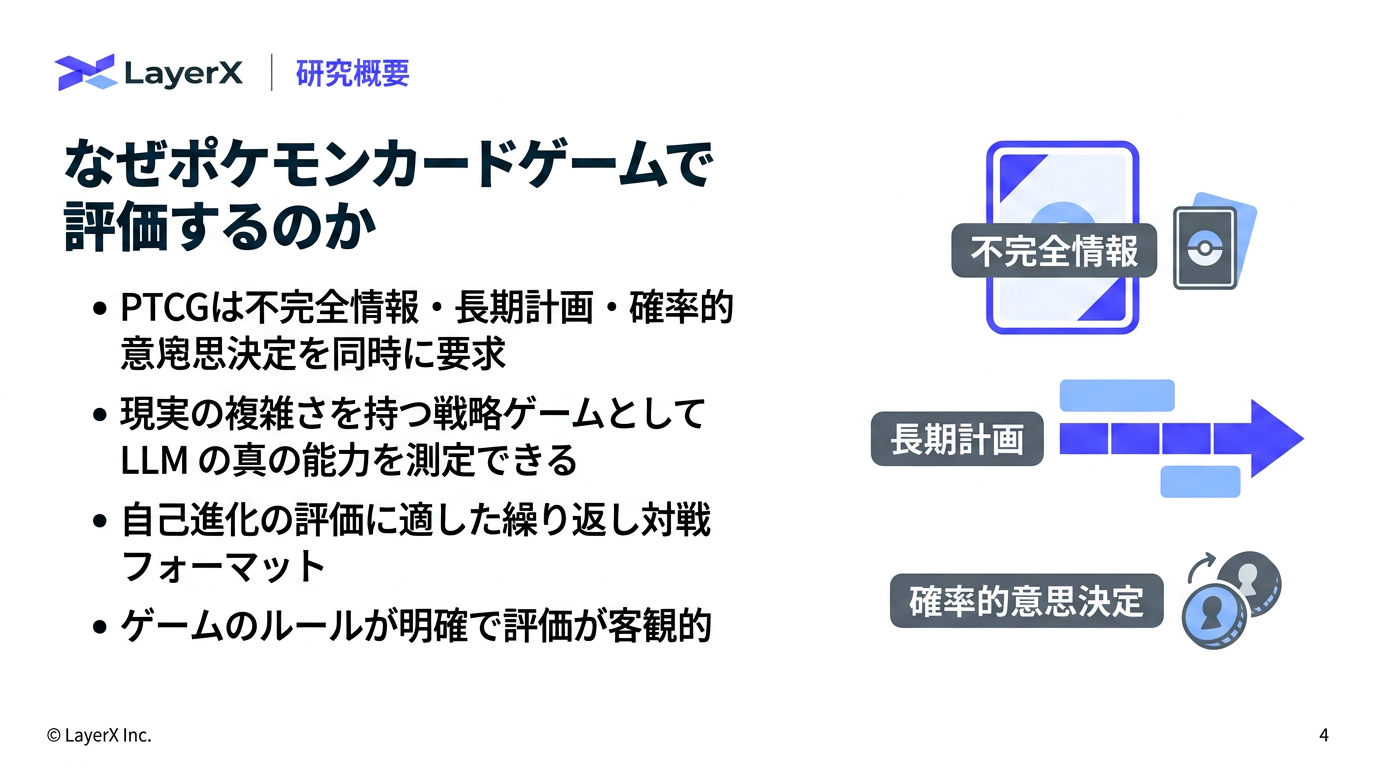


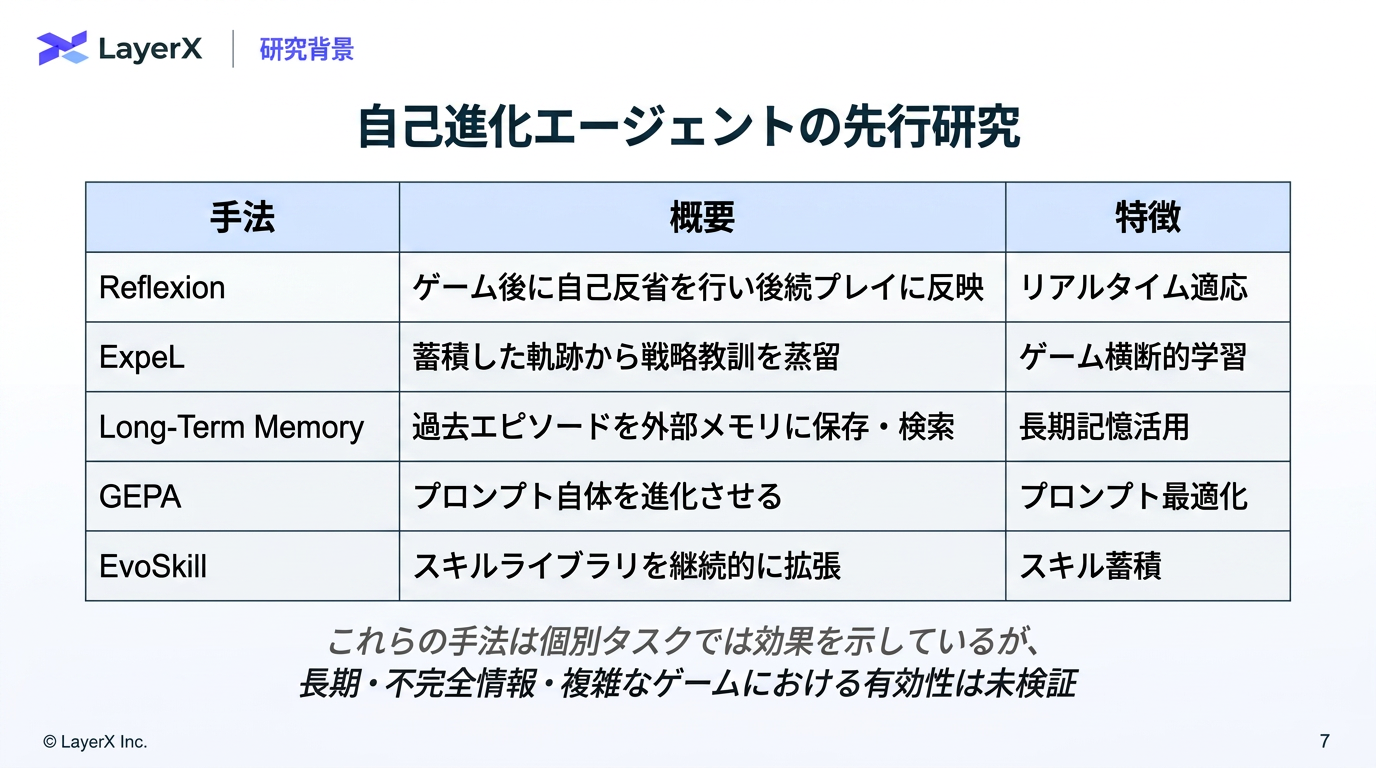


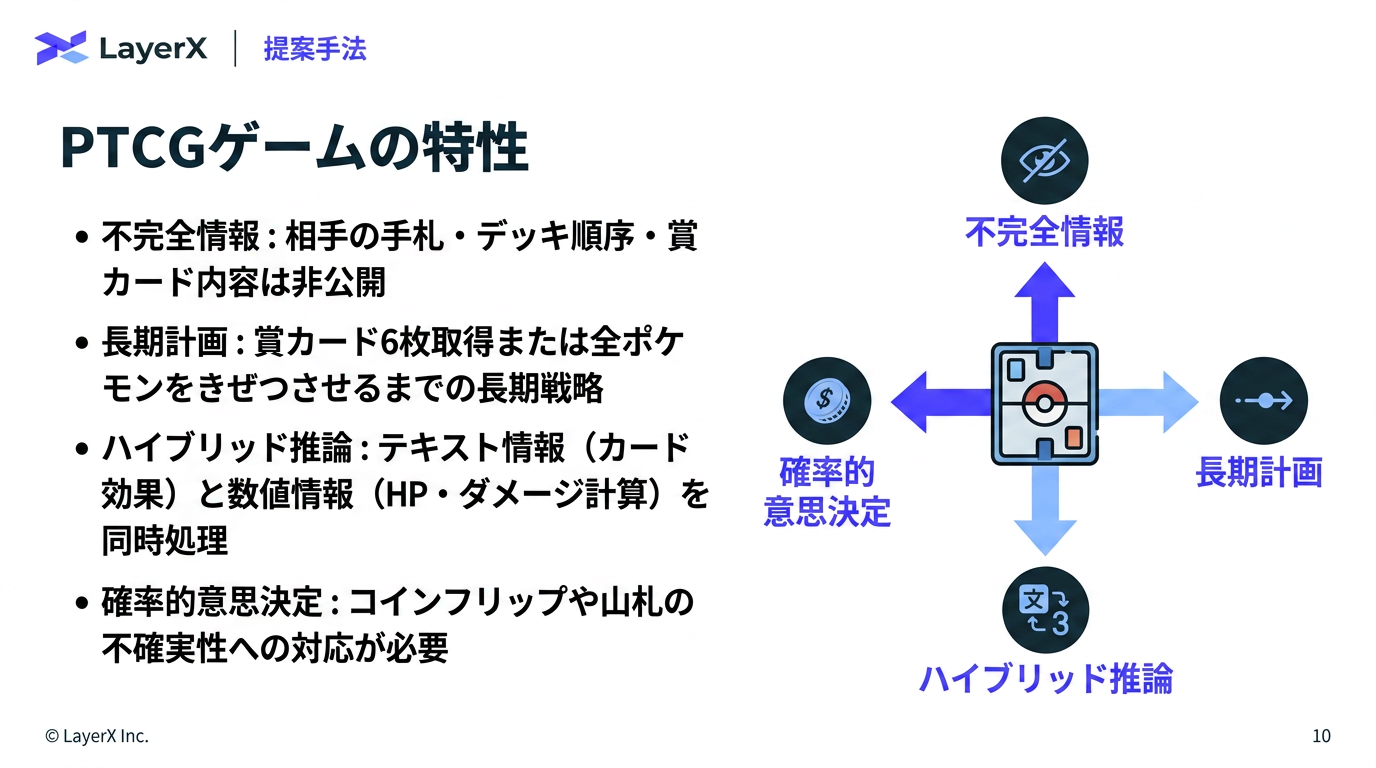
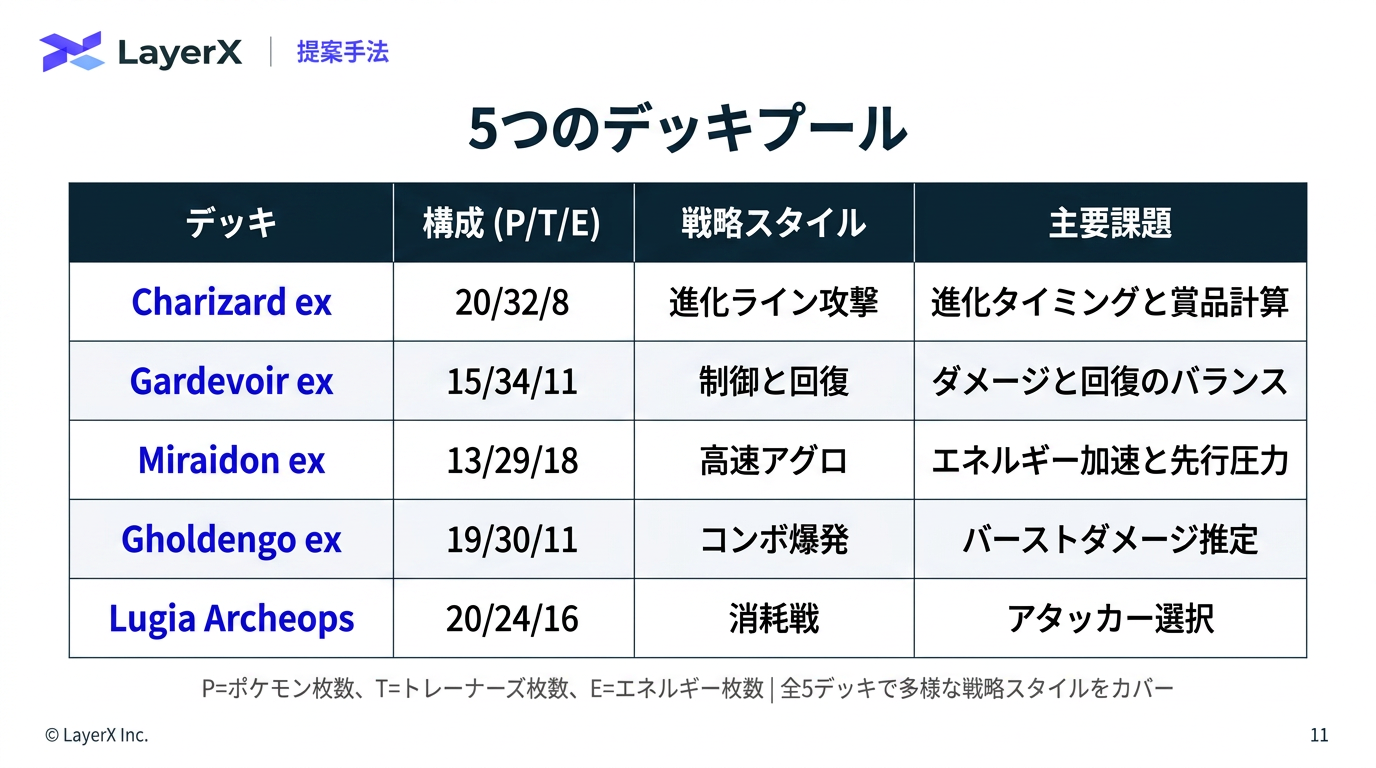
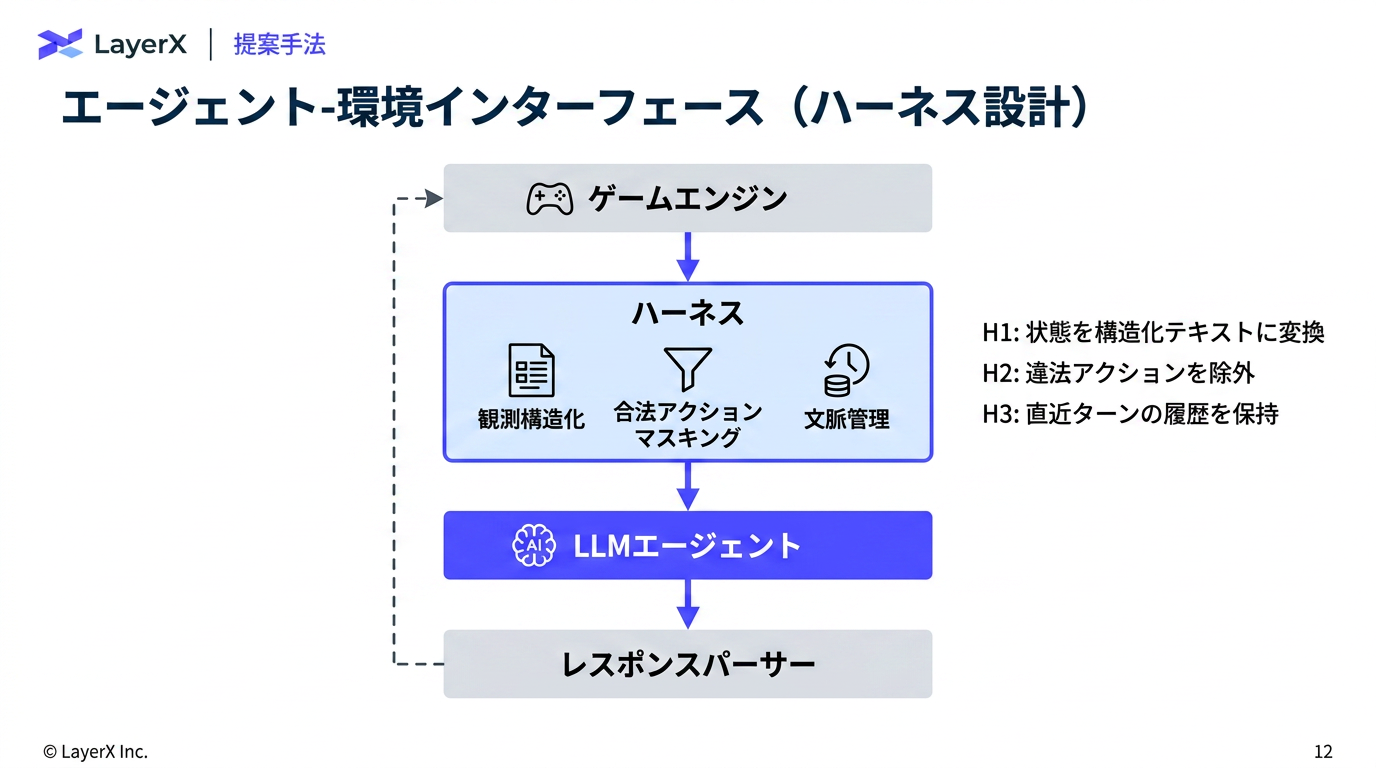



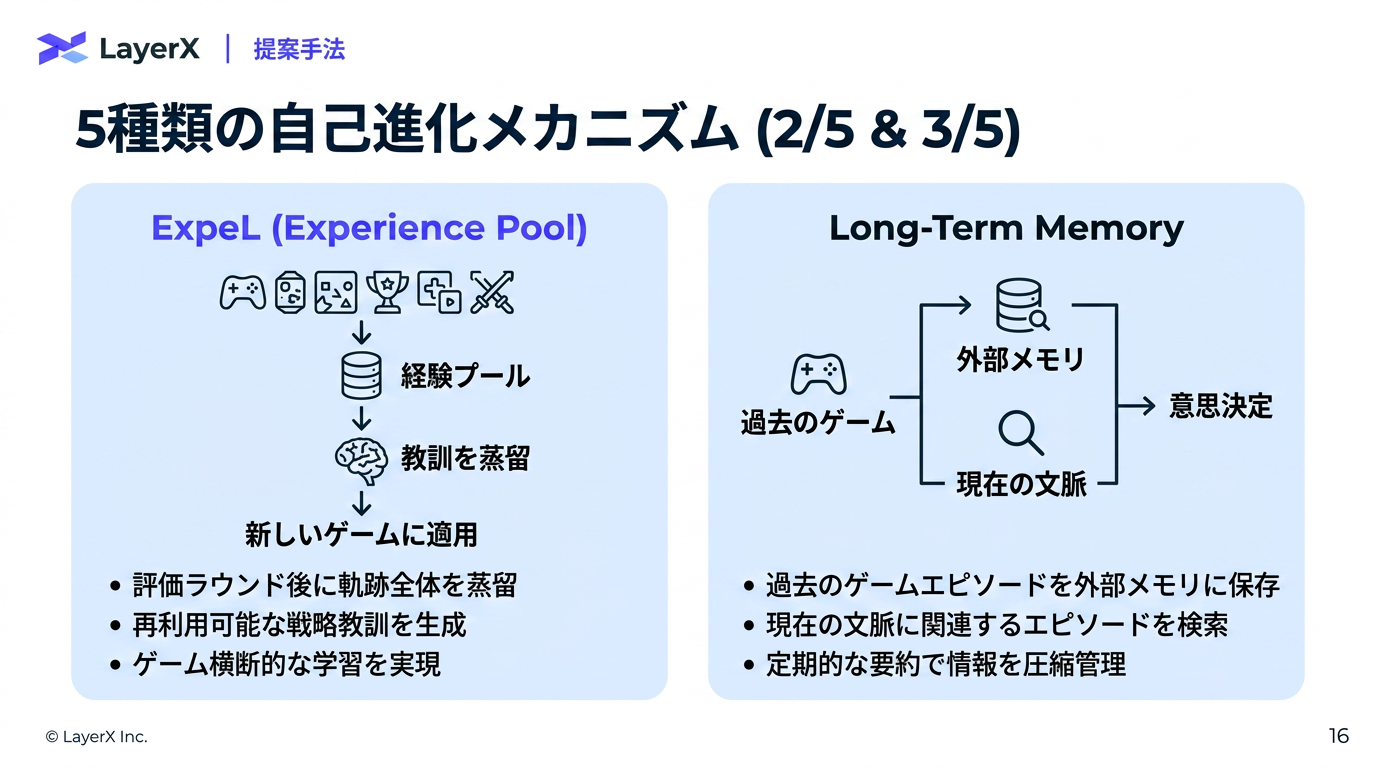
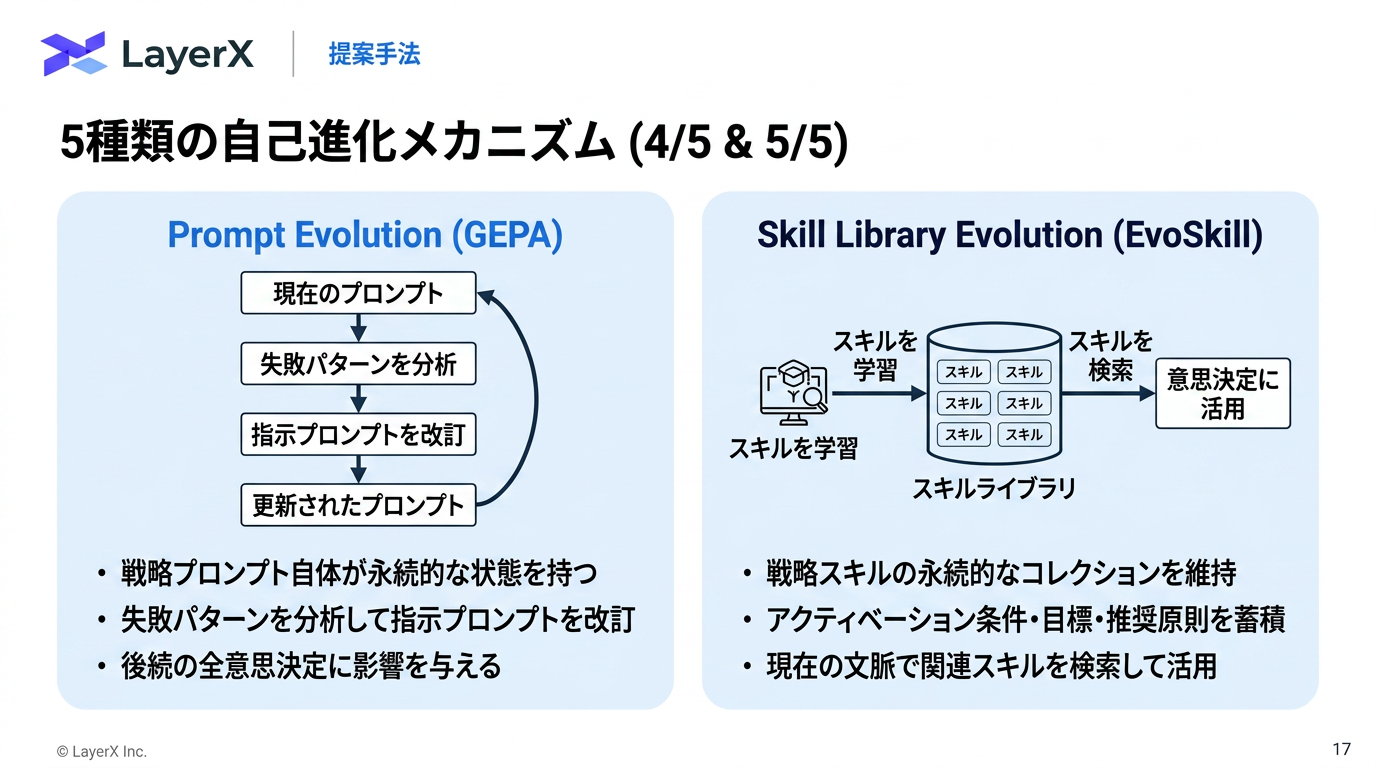

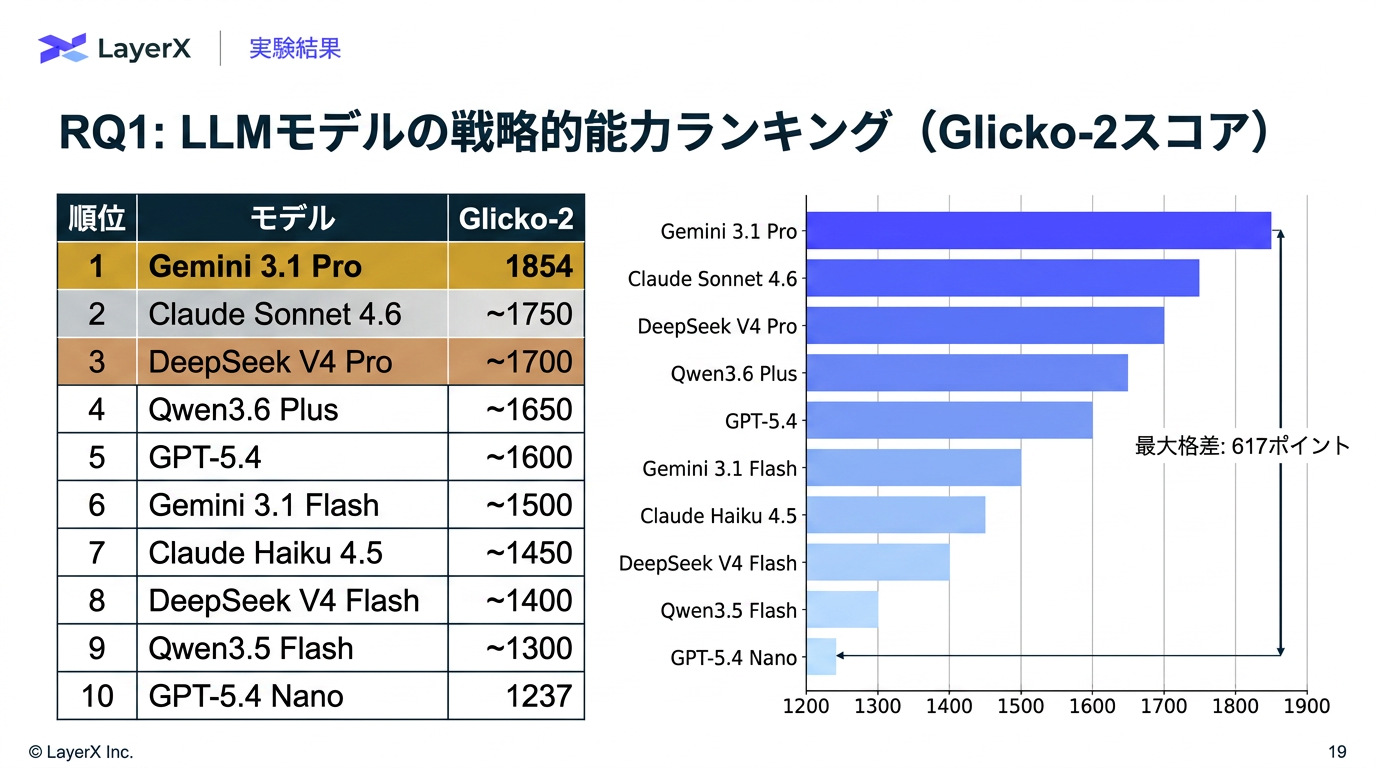
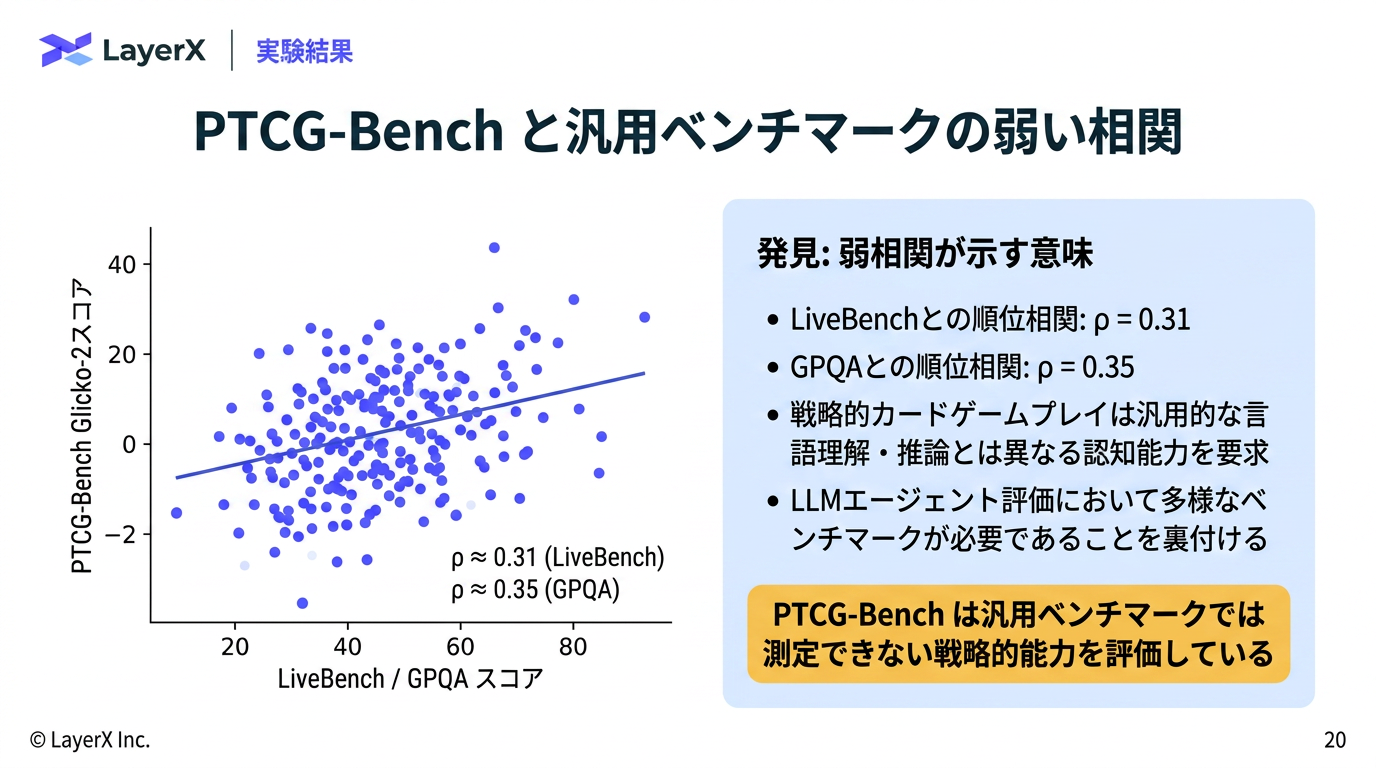
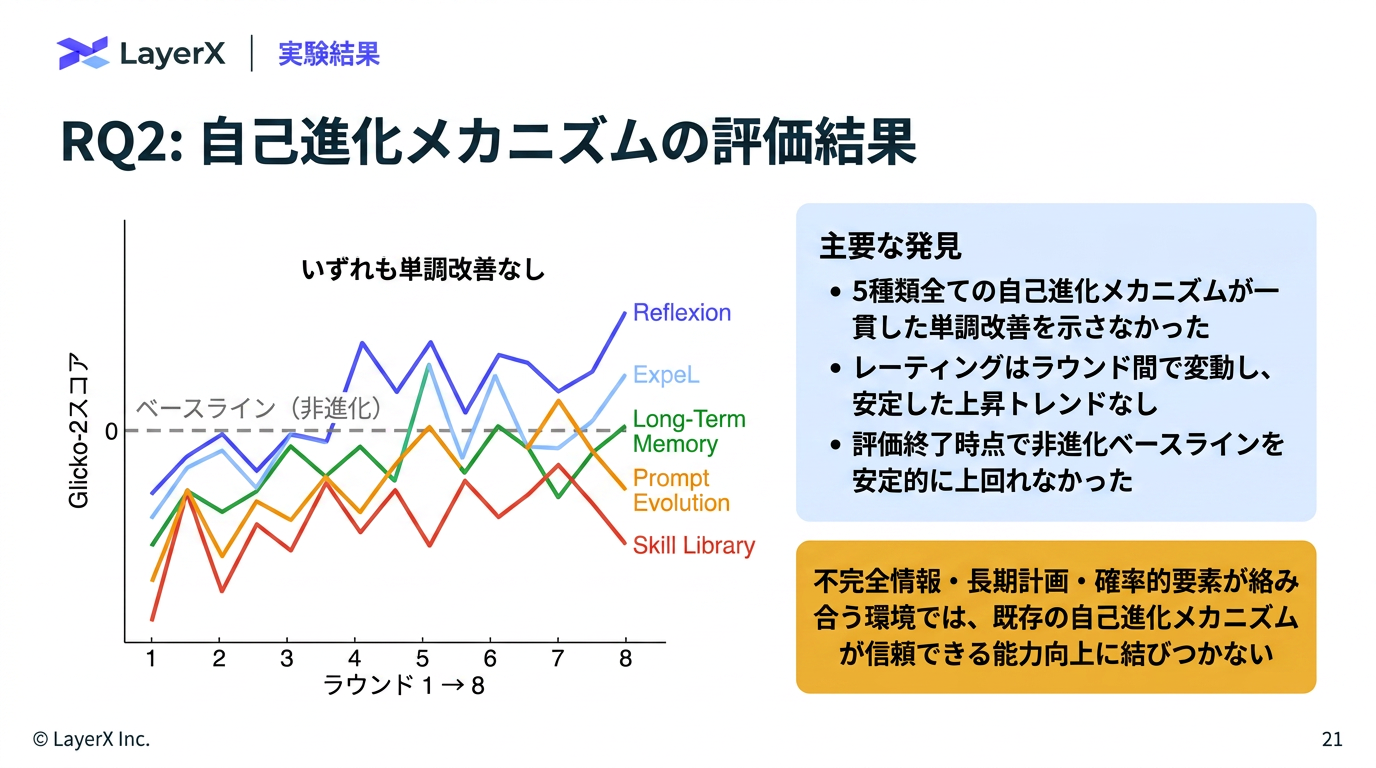
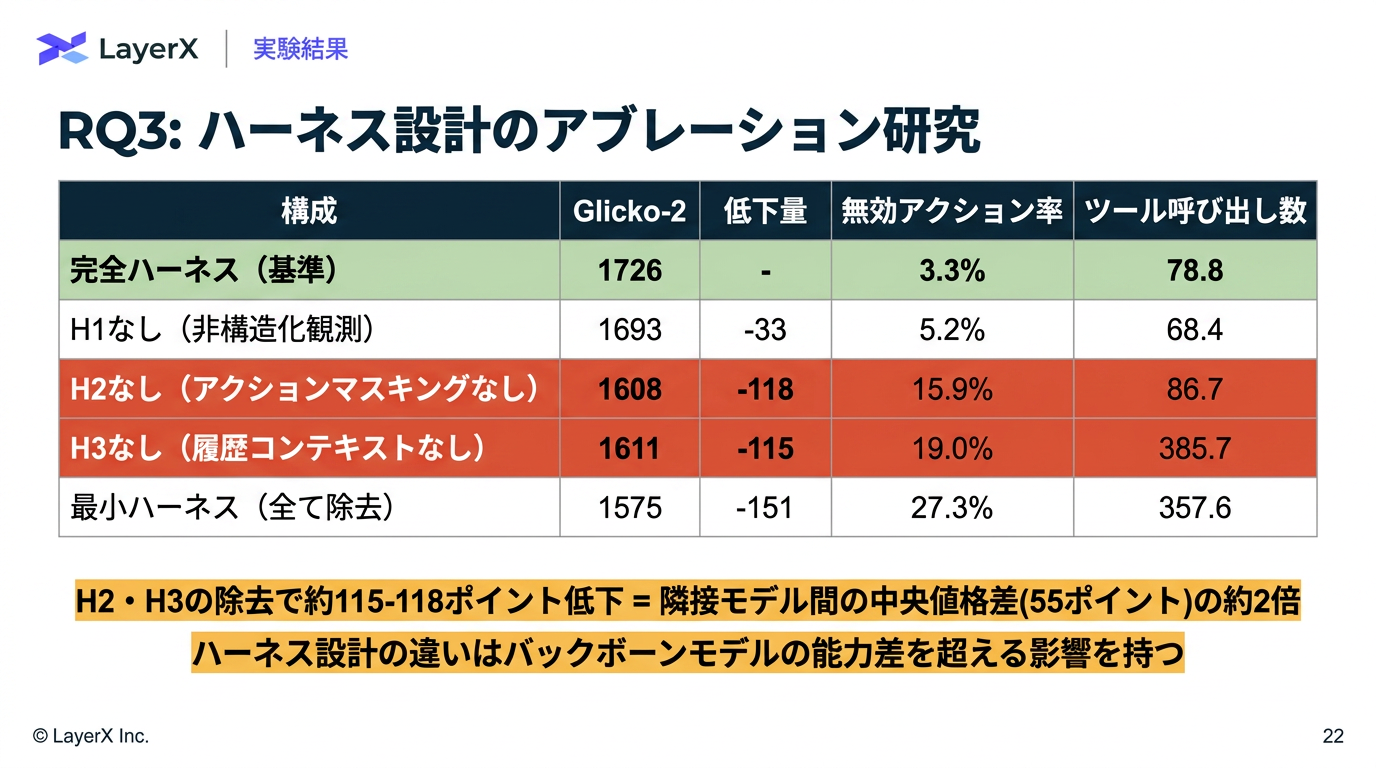
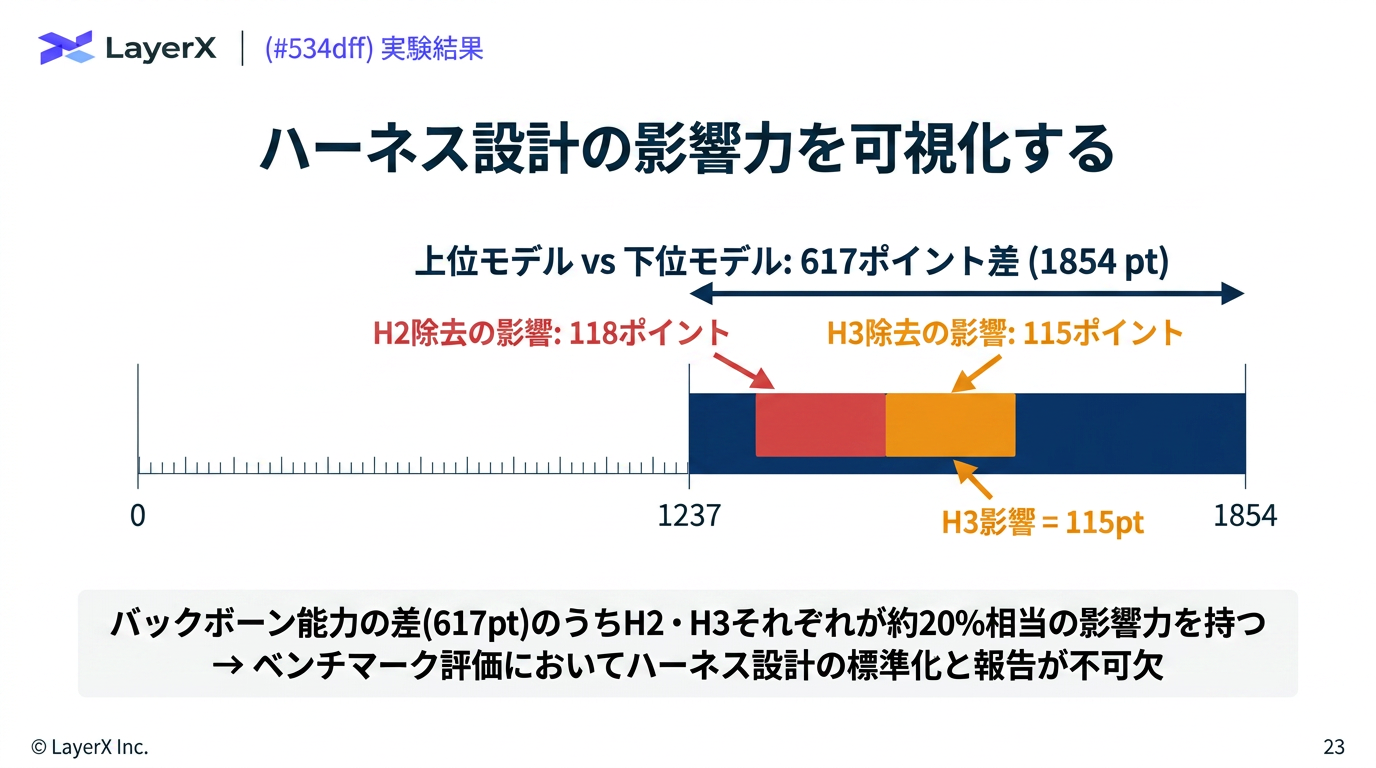



@Yuya Matsumura
Hoge
@Shun Ito
[paper] JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
- Speculative Decodingをスケールさせたい話
- 典型的な1本の候補列を伸ばすパターンは、途中で外れると後続候補が無駄になりやすい。
- 既存手法: EAGLE
- tree-based な speculative decoding
- tree にすると複数 branch を同時に検証でき、生成の品質向上が見込める
- イメージ
- 深い tree を作るほど draft 側の生成コストがボトルネック
- draft modelがtarget LLMのhidden stateを予測して推論
- target LLMが処理したtokenのhidden stateを使い、次のhidden stateを予測して次のtokenを生成
- draft model LLMが直接推論するよりも高性能らしい
- 既存手法: DFlash
- 複数の位置・候補を並列して生成
- 入力
- 出力: slotに対応するロジット
- branch ごとの条件付き整合性が弱くなりやすい
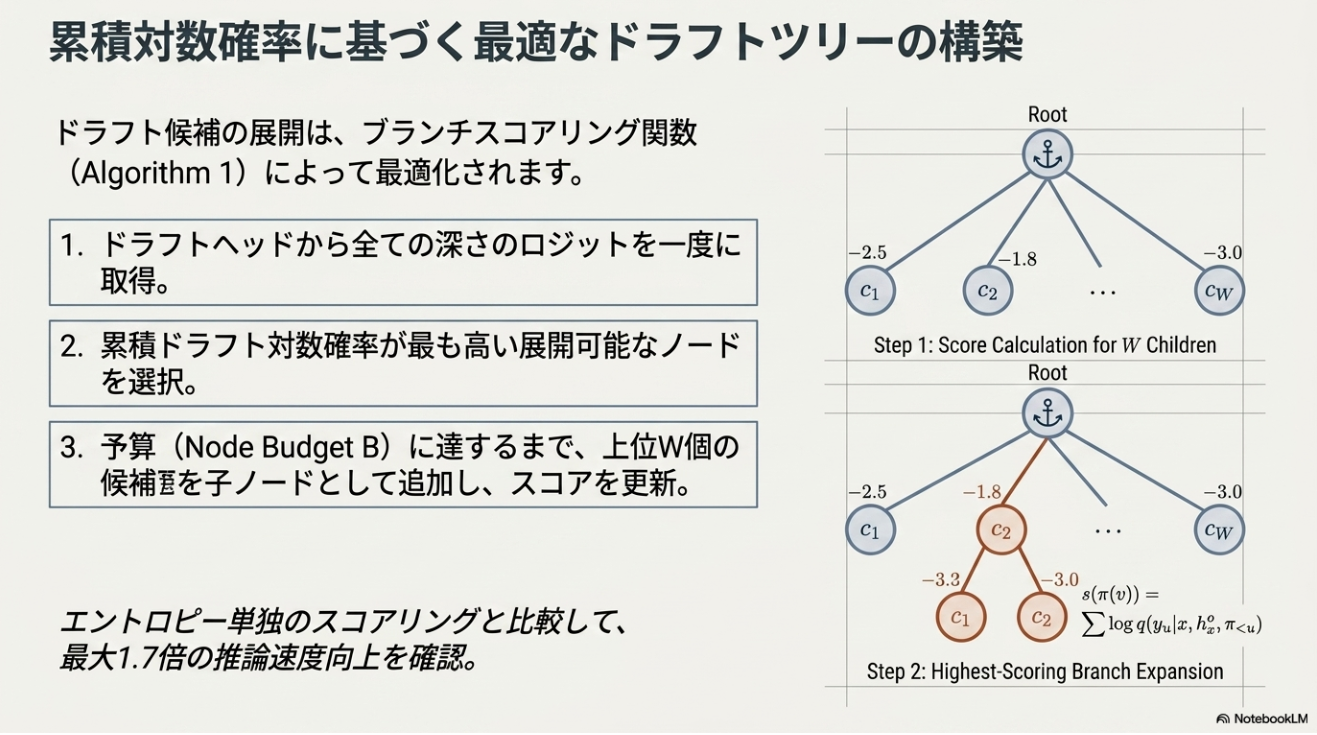
- 提案手法: JetSpec
- branch文脈を守りながら、tree nodeを並列生成する
- tree nodeを1回のdraft-head forwardで並列に予測する
- tree-causal mask: 別branchの先祖を見ないように、tree構造を考慮したattention maskを利用する
- logitsからcandidate treeを作る
- budgetに達するまで上位候補を子ノードとして追加
- (追記)メイントピックのDSparkとの違い

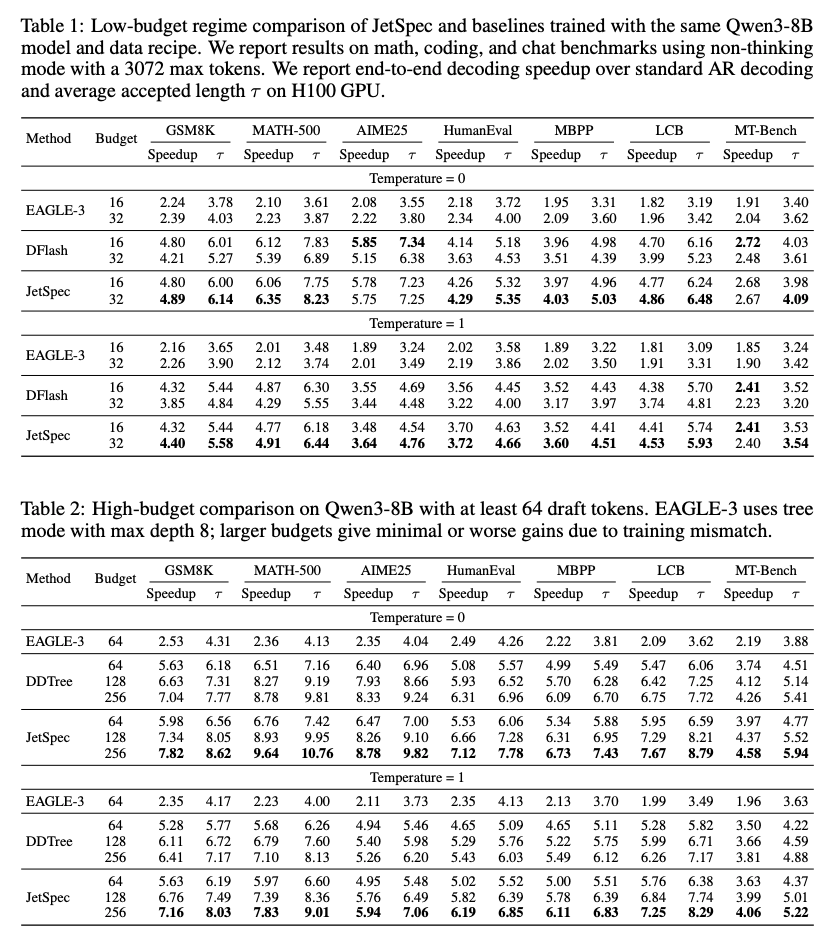
- 実験
- budgetの大小によらず生成スピードと採択率を向上
@Yosuke Yoshida
Hoge
@Hiromu Nakamura (pon)
Hoge
@Kyohei Uto(kuto)
[paper]Towards Robust Real-World Spreadsheet Understanding with Multi-Agent Multi-Format Reasoning
概要
実世界の複雑なスプレッドシートをLLMで理解するための手法 SpreadsheetAgent を提案
背景
- 実世界のスプレッドシートは単純な表ではなく複数表、結合セル、階層見出し、注記、色、罫線、チャート、非標準レイアウトを含む
- 監査、経営レポート、科学データ管理、行政資料などでは、セル値だけでなく「どこが見出しか」「どこが明細か」「どこが集計欄か」が重要
- 課題
- 平文テキスト化すると、レイアウトや視覚的意味が失われる
- 全体を一括でLLMに入れると、コンテキスト長・誤読・構造理解不足が問題になる
提案手法
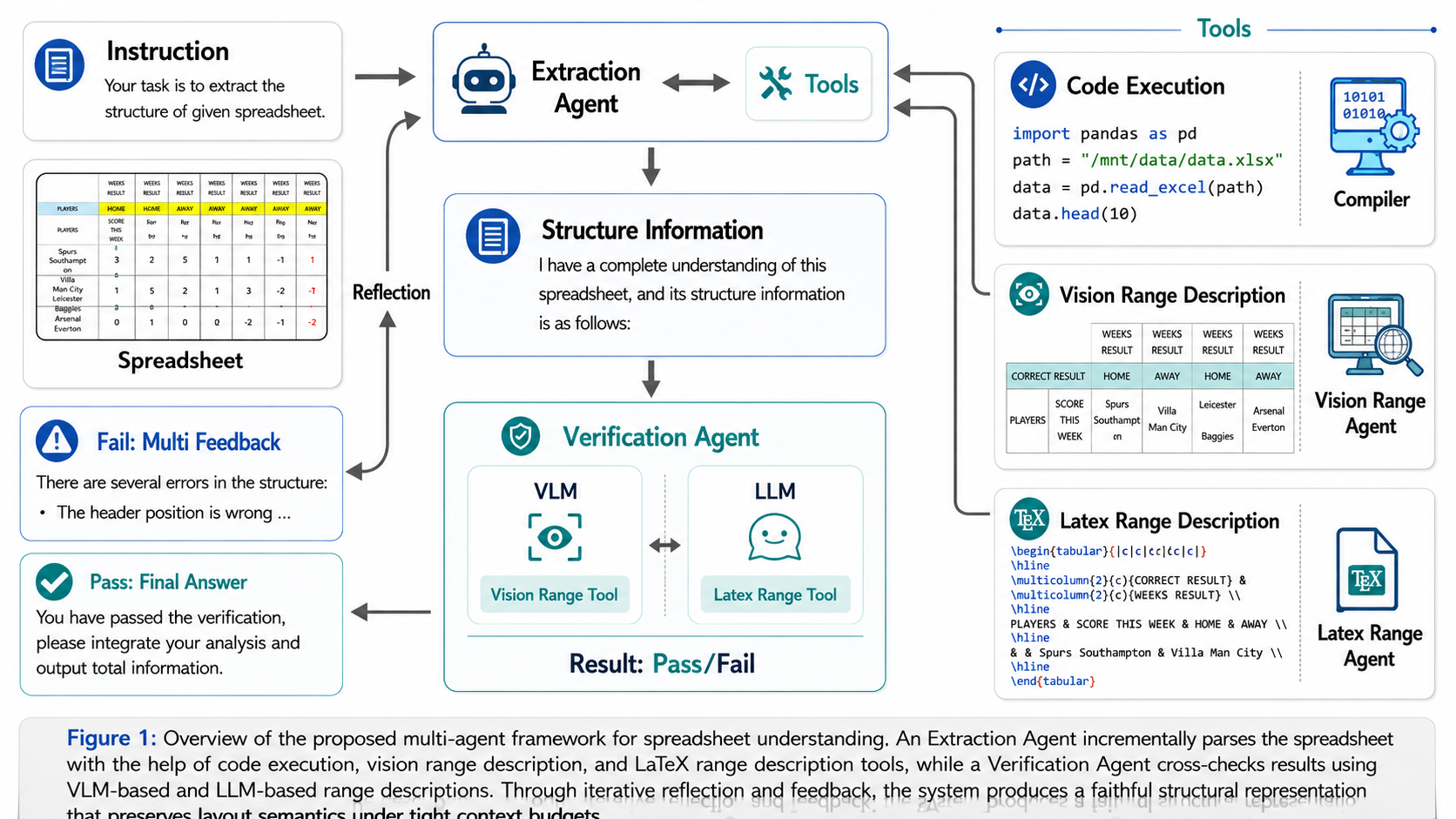
構造抽出パート
構造抽出エージェントで下記3つのツールを使用してスプレッドシートの構造を抽出
- コード実行: セル値取得、計算、範囲確認に使う
- シート画像: 色、罫線、視覚的配置、チャート要素の確認に使う
 GitHubSpreadsheetAgent/src/core/excel2image.py at master · renhouxing/SpreadsheetAgent
GitHubSpreadsheetAgent/src/core/excel2image.py at master · renhouxing/SpreadsheetAgent- 画像をマルチモーダルのGLM-4.5Vに渡しテキスト化
- Latex: 結合セル、階層見出しなど複雑なセル構造をLatex化して構造化
yamlによる中間表現
スプシ構造の読み込み結果をyaml形式に変換して持つ
例

- YAMLには以下のような情報を構造化して入れる
- テーブル名などのメタデータ
- テーブルのセル範囲やヘッダー構造
- セルの階層構造
- なぜyaml?
- 人間が読みやすく、ネスト構造を損なわず、プログラムでパースしやすい
- 自由記述よりも曖昧さが減り、後段のreasonerが安定して使える
検証パート
- yamlで構造化されたスプシ情報を元スプシに問い合わせて検証
- 問題があれば差分を抽出エージェントへ戻す
解答パート
得られた情報をもとにベンチマークのタスクを解く
実験
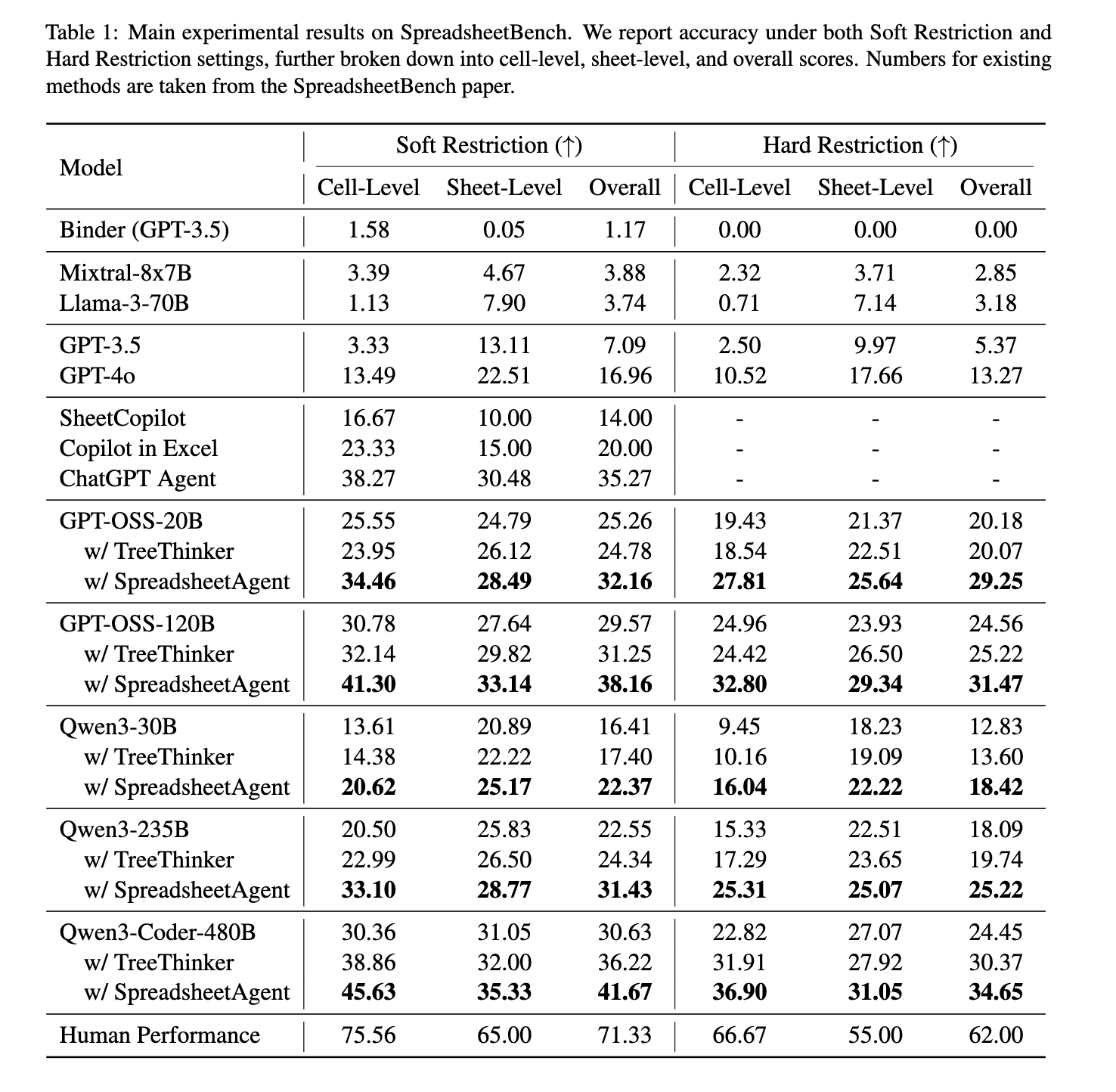
- SpreadsheetBenchで評価
- 全てのモデルにおいて提案手法によってスコアが改善
- 人間性能 71.33 / 62.00 にはまだ大きく届かない
アブレーション
- 以下を外すと性能低下
- 検証ループ
- yaml構造化表現
- ツール
- yamlをjsonに変えても悪化
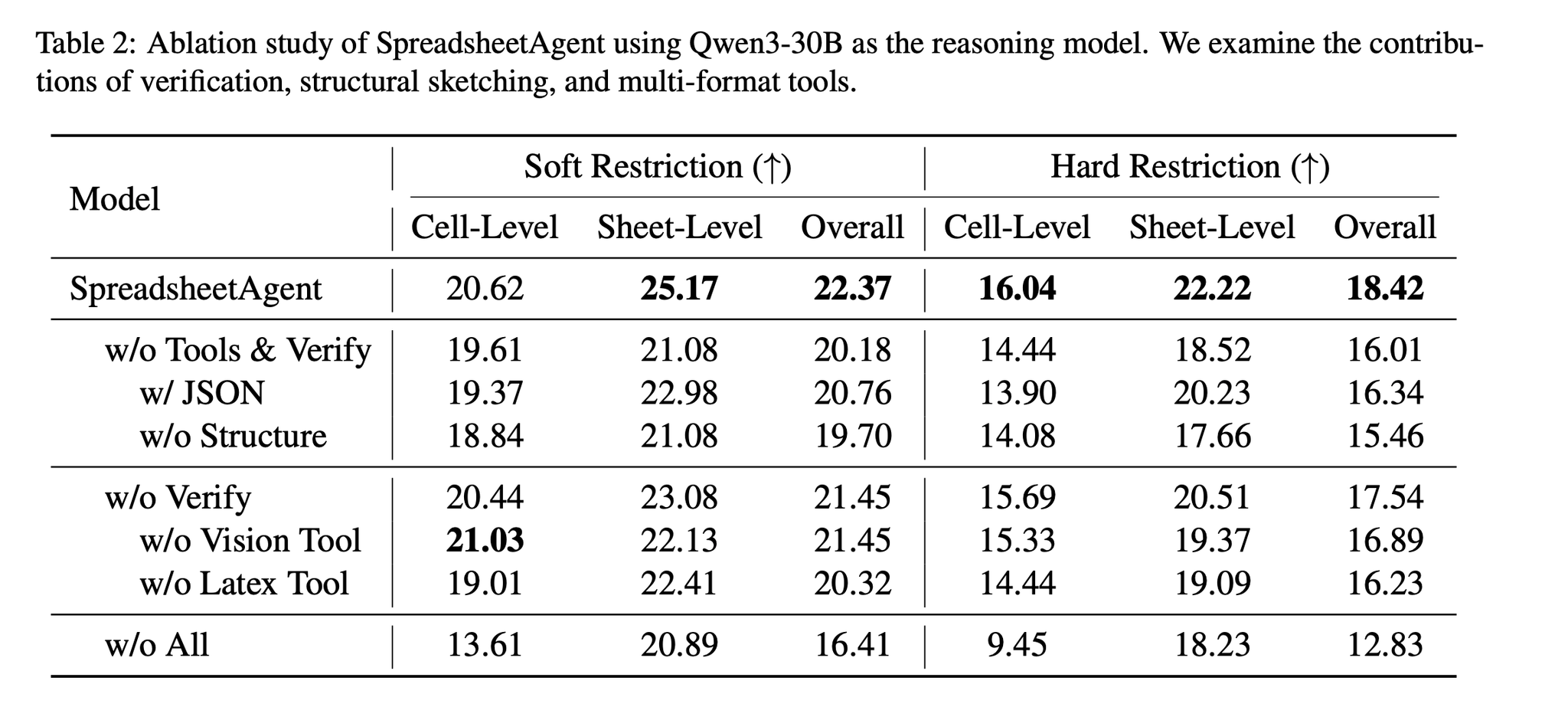
構造抽出モデル(Extractor)とその結果を使ったタスク実行推論モデル(Reasoner)の使い分け
- Extractorの精度が最終スコアに影響する
- Extractorが弱い場合は、Extractor無しとスコアはあまり変わらない
今後の課題
- 強力なマルチモーダル基盤モデルへの依存が大きい
- 平均 97.49 秒 / シート、19.54 agent calls、最大21GB程度のコストがあり、軽量ではない
- 数式情報や参照セル情報
@Ryuhei Kawabata
[paper] How Far Can LLM Agents Reason with Tables? Benchmarking Multi-Turn Agentic Table Question Answering in the Wild
論文の一言: TableQA を「1問1答」ではなく、複数表・複数ターン・tool call を含む agent 評価に作り替えたベンチマーク論文です。
要点
- 提案: と
- データ: 1,310 multi-turn dialogues、2,275 industrial tables
- 評価軸: 情報カバレッジ、タスク通過率、表選択の recall/precision、tool 成功率
- 結果: 最強モデルでも Information Coverage は 53.4%、Avg@3 は 5% 程度
- 示唆: tool call が成功しても、表理解・コード生成・長期文脈維持はまだ弱い
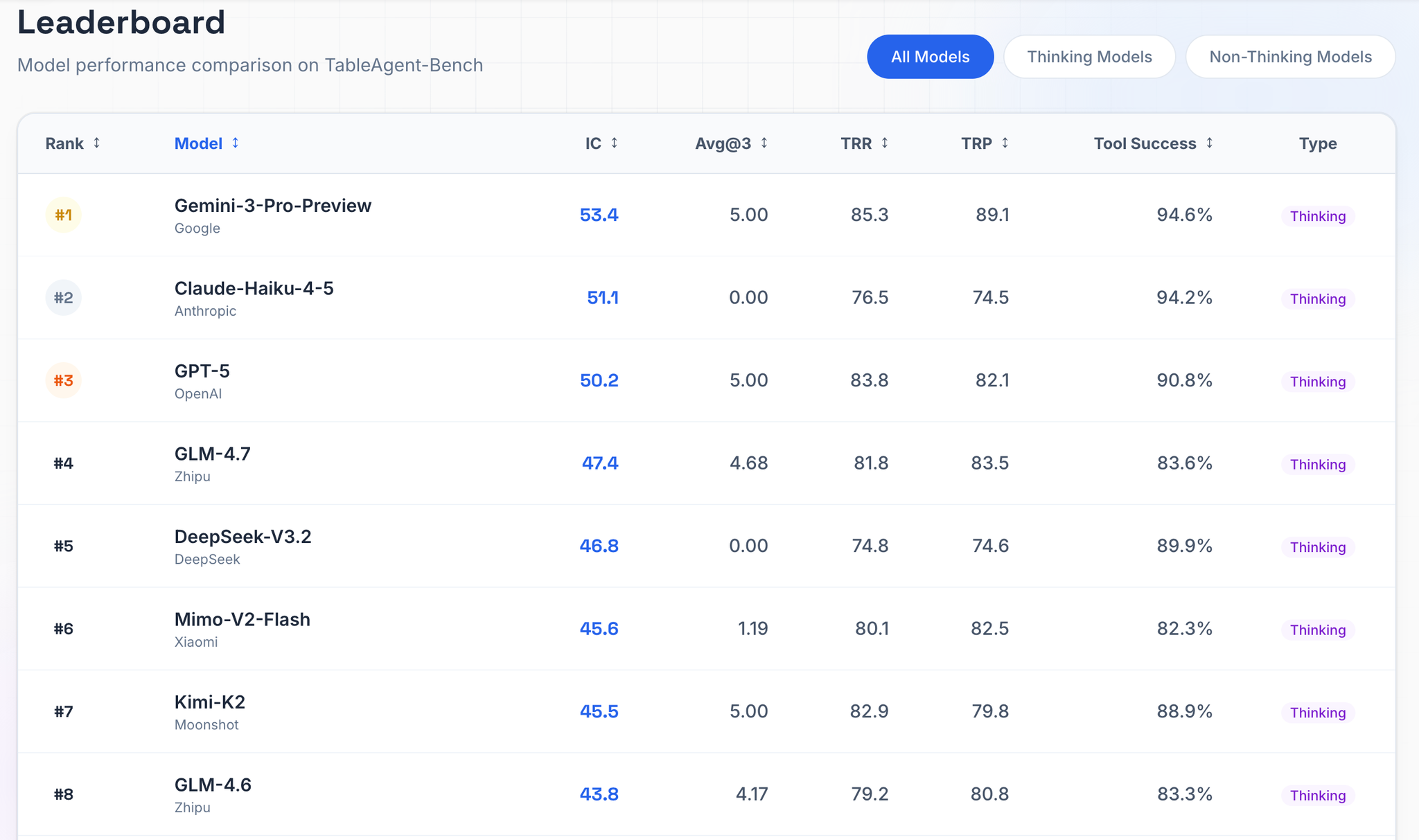
- IC: information coverage
- Avg@3: タスク*3回実行したときの成功率
- TRR: Table Retrieve Recall
- TRP: Table Retrieve Precision
効いた理由 / 読みどころ
従来の TableQA benchmark は「質問に答えたか」中心。この論文は、途中でどの表を見つけたか、どの tool を呼んだか、複数ターンで誤りが蓄積しないかまで見る。つまり、agent の最終回答だけでなく trajectory の失敗箇所を診断できるのが価値。
感想
- 実際の使われ方に近いと性能はまだまだ
- 評価設計の参考になりそう、
メインTOPIC
DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation
大盛り上がりなので読んだ
1 背景
投機的デコーディング(Speculative Decoding)は、軽量なドラフトモデル が複数の候補トークン (=1回のドラフトで引くトークン数。以降ブロック長と呼ぶ)を提案し、本体のターゲットモデル が1回の前向き計算で一括検証する手法。
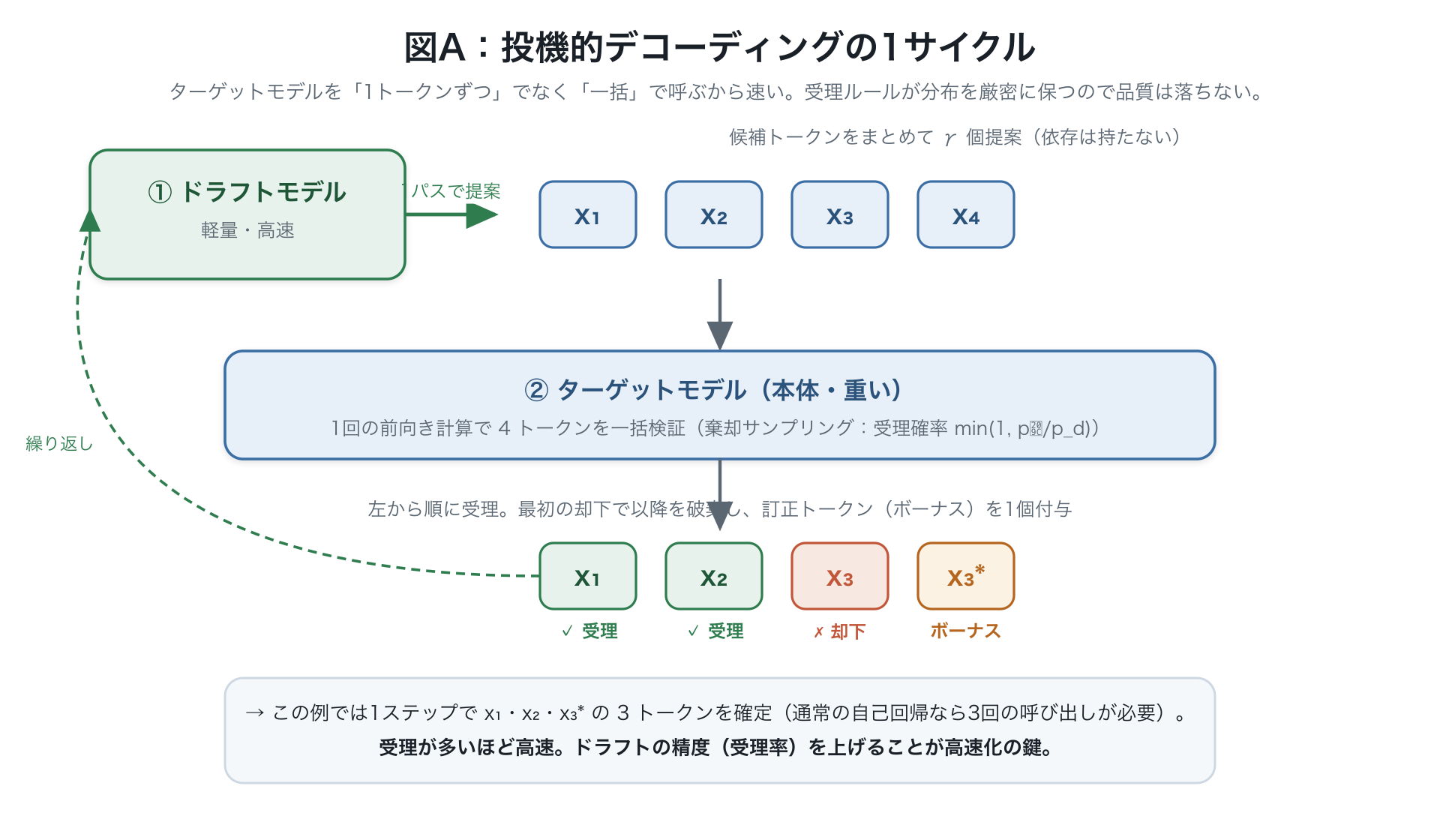
* 各位置 で受理確率により左から順に検証し、最初に却下された位置以降を破棄、末尾に1つボーナストークンを付ける。棄却サンプリングによりターゲット分布を厳密に保つため、品質を落とさずに高速化できるのが本質。1トークンあたり平均遅延は次でモデル化できる。
- ここで はドラフトを1ブロック引くのにかかる時間、 はターゲットが1回検証するのにかかる時間、そして (タウ)は1サイクル(ドラフト+検証)で平均いくつのトークンが受理できたか=「受理長」を表す。
- 1サイクルで トークンぶん前に進めるので、1トークンあたりの平均遅延は上式になる( が大きいほど、同じ計算で多く進めて速い)。
- 高速化=この を下げること。レバーは3つ: を下げる(速く引く) τ を上げる(上手く引く=受理長を伸ばす) を減らす(賢く検証)。DSpark はこの3つすべてに効く設計になっている。
ドラフタの2系統
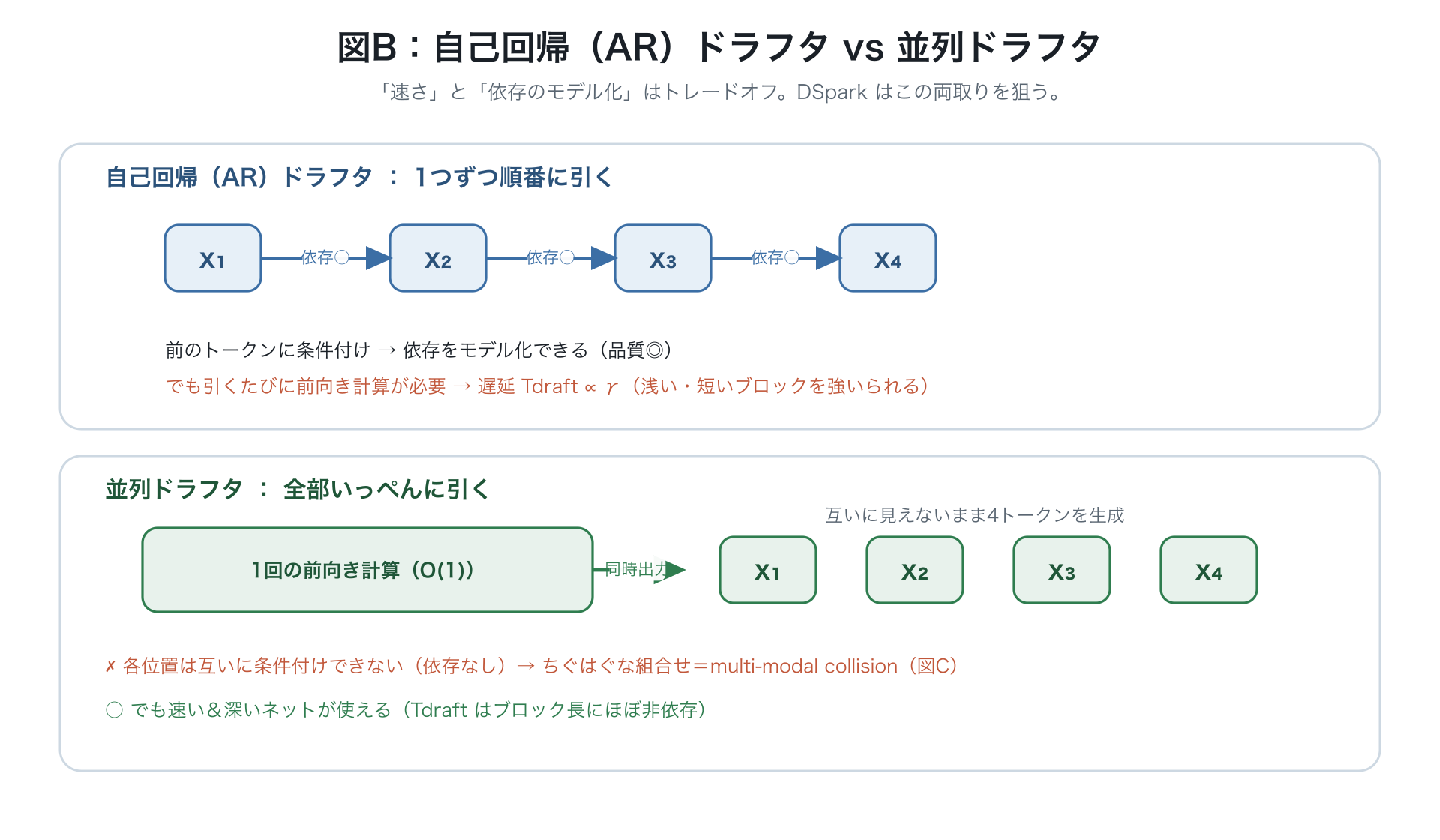
自己回帰ドラフタ(AR)
1単語ずつ、直前に書いた結果を見ながら書くのでつじつまは合いやすい。ただし1単語ごとに計算が要るので、先読みを長くする( を増やす)ほど比例して遅くなる()。→ 先読みは短く、ドラフトモデルのネットも浅くせざるを得ない(例:Eagle3)。候補を枝分かれさせて検証する手もあるが、検証する量が増えてスループットが落ちる。
- 代表例: Eagle3
並列ドラフタ(Parallel)
個ぜんぶを1回の計算でまとめて書くので、先読みを長くしても下書きの時間がほぼ変わらない。長い先読み(例 )も可能。代表が DFlash(現状最強の並列ドラフタ。詳細は下記)。ただし各単語を別々に決めるので、単語どうしのつながりを作れない。
- 代表例: DFlash
2 解くべき2つのボトルネック
長くまとめて下書きする良さを活かしきるには、下書きの質と仕組みの効率という2つの壁を越える必要がある。
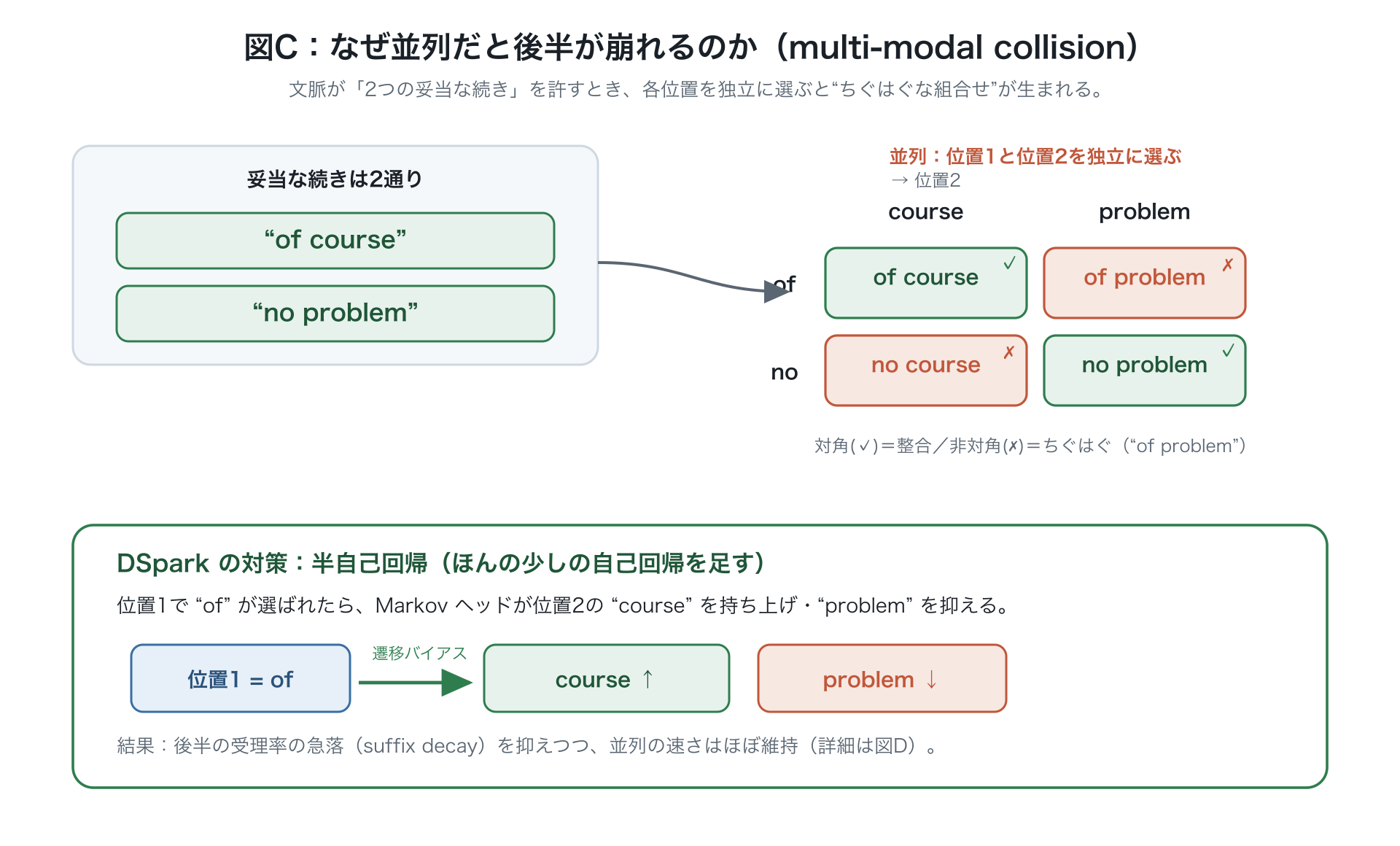
- ① 単語どうしのつながりが作れない → 後半ほど受理率が急落(suffix decay)。 並列ドラフタは各単語を「ありうる続きを全部ならした平均」で選んでしまうため、"of course" と "no problem" のように複数の自然な続きがあると、それらが混ざって "of problem" のようなちぐはぐな組合せ(multi-modal collision=続きの取り違え)が出る。結果、下書きの後ろほど受理率が落ち、下書きと検証の計算が無駄になる。
- ② 最適な検証長が一定でない。 長い下書きを区別なく全部検証すると、混んでいるときにスループットが落ちる。ちょうどいい検証長は2つの事情で変わる: ・内容しだい:コード生成のようなカッチリした作業は受理率が高く、自由な対話は低い。 ・混み具合しだい:すいているときは追加検証してもほぼタダだが、混んでいるときは「却下されそうな単語の検証」が、本来ほかの人に回せたはずの処理枠を奪ってしまう。
DSpark はこの2つを、半自己回帰生成(①への対策)と信頼度スケジュール検証(②への対策)という、補い合う2つの仕掛けで同時に解決する。
3 DSpark 全体アーキテクチャ
下図が DSpark の全体像と1サイクルの流れ。入力 ABC に対し、
- ① ターゲットモデルが次の単語 D を書く(これが下書きの出発点=アンカー/確定済みの1単語)。
- ② D をもとに、重い並列バックボーン+軽い逐次ヘッドが下書き EFGH と、各単語の信頼度スコア – を出す。
- ③ スケジューラがスコアを見て、頭の EFG を残し、自信のない H を捨てる。ターゲットモデルが EFG をまとめて検証し、E・F は受理、G は却下、ターゲットモデルが正しい単語 G\* を出してこのラウンド完了。
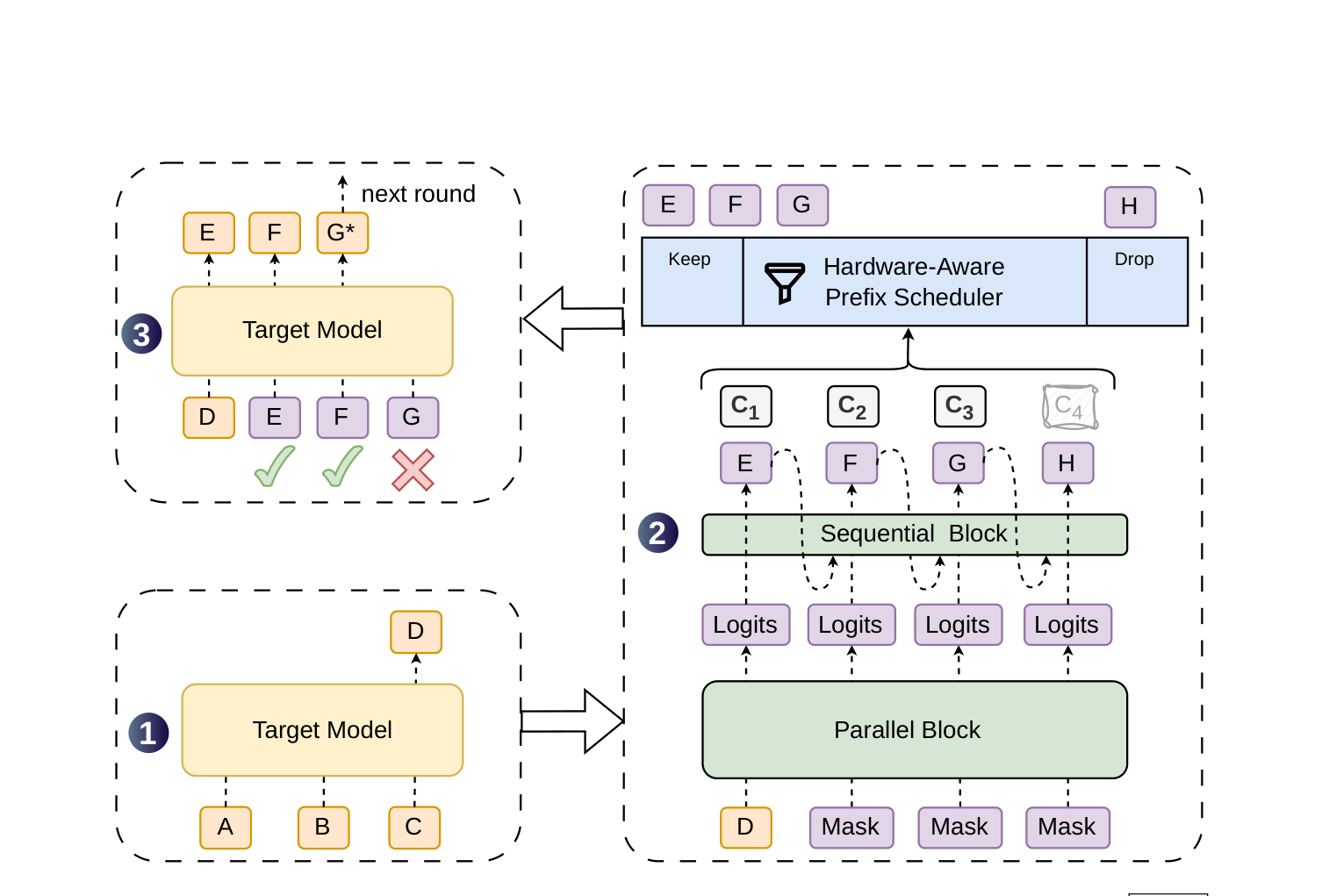
Figure 1:DSpark の全体像と1サイクル。 ①ターゲットモデルが出発点 D を書く → ②並列バックボーン+逐次ヘッドが下書き EFGH と信頼度 – を出す → スケジューラが EFG を残し H を捨てる → ③ターゲットモデルがまとめて検証(E,F受理/G却下→G\*で訂正)。「上手く下書きする(draft better)」と「賢く検証する(verify smarter)」を両立する。
4 半自己回帰生成(Semi-Autoregressive Generation)
狙いは「並列ドラフタがもつ、序盤の単語の高い受理率」と「自己回帰がもつ、後半のつじつまの良さ」の良いとこ取り。下書き作りを2段に分ける。
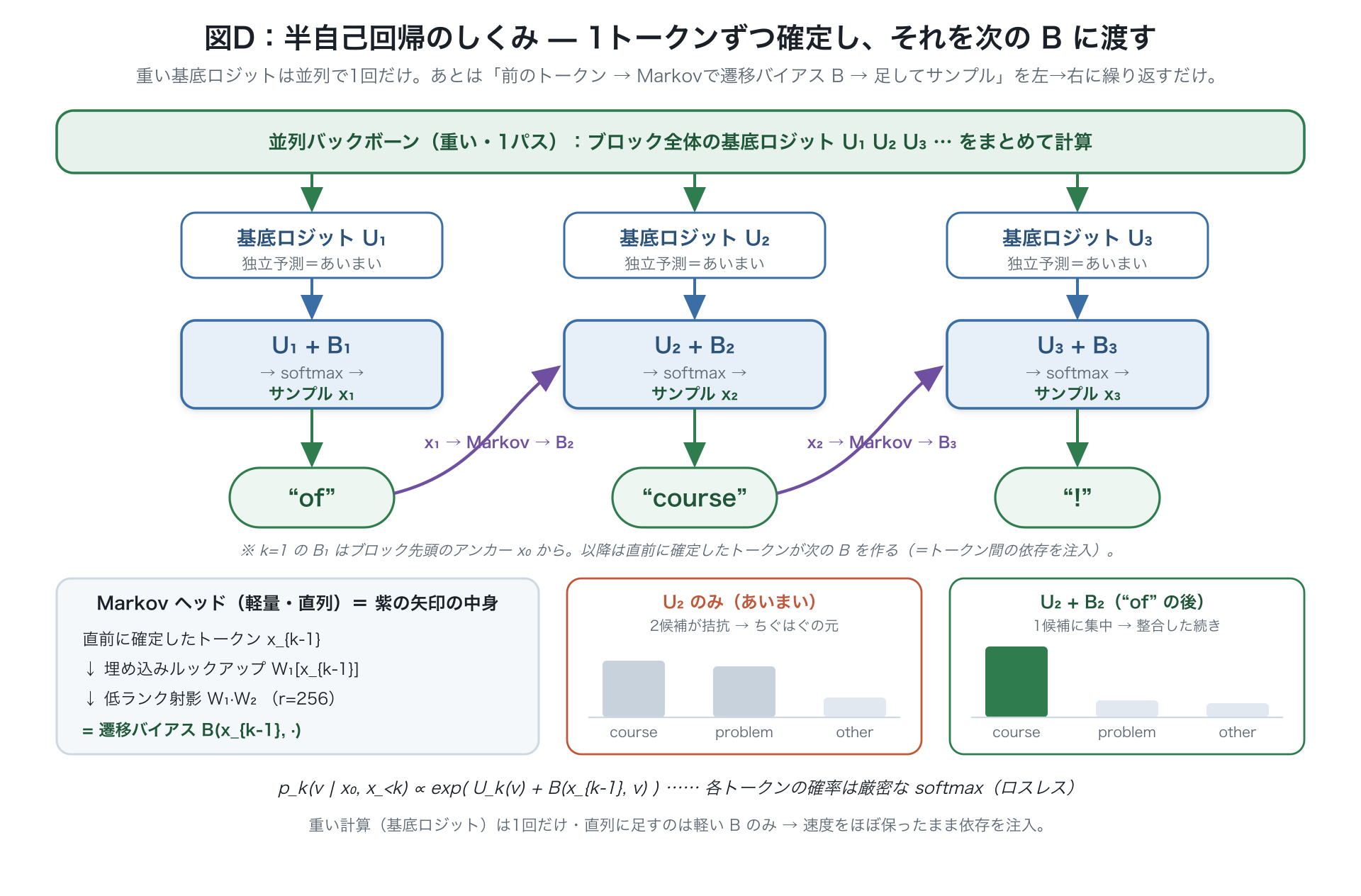
重い並列バックボーンが1回で全位置の基底ロジット を出す(バラバラ予測なので候補が拮抗=あいまい)。あとは左→右に1単語ずつ、直前に決まった単語 から Markov ヘッドが を作り、 で選ぶ。選んだ単語が次の位置の補正を作る(紫の矢印=つながりの注入。先頭の は出発点の単語 から)。下のバーは、基底ロジットだけ()だと2候補が拮抗するのに対し、"of" の後に補正 を足すと "course" に山が寄る様子。重い計算は1回だけ、順番にやるのは軽い足し算だけなので、速さをほぼ保ったままつながりを足せる。
並列ステージ(Parallel stage)
重い並列バックボーン(実装は DFlash)が先読み全体を1回で処理し、各位置の内部状態 と基底ロジット を出す。
- ここで DSpark は DFlash に小さな改造を1つ加える(DFlash が元から持つ仕組みではない)。元の DFlash は「アンカー(=出発点の単語 )+ 個のマスク」を入力に与え、マスクの位置だけを予測する。
- DSpark は代わりにアンカー自身を最初の予測位置として扱い、「アンカー+ 個のマスク」の計 入力で 個ぶん予測する。入力トークンが1つ減るぶん下書きの計算を少し減らせて、品質はほぼ同等のまま、という変更。
逐次ステージ(Sequential stage)
基底ロジットに、「直前までに何を書いたか」で変わる補正 (遷移バイアス)を足し、各位置が同じ下書き内ですでに決まった単語に合わせて選ばれるようにする。難しい全体最適の方式ではなく、前から順に確率を掛け合わせていく素直なやり方で、流れに沿った下書きを作る:
- 上の式は、下書き全体 ができる確率を各位置の確率の掛け算に分解したもの( は出発点の単語)。各位置 の確率 は「出発点 と、そこまでに選んだ単語 」を条件に決まる=前を見ながら左から1単語ずつ作るという意味。
- 下の式はその の中身で、基底ロジット に補正 を足してから softmax で確率に変換しているだけ(分母は語彙 全体で足し合わせて合計1に正規化)。要するに「下地のスコア+文脈の補正 → 確率」。
この第2段は1単語ずつ順番にやる作業なので、計算は軽く(=逐次ヘッドの時間は並列バックボーンよりずっと小さい)抑える必要がある。大事な利点は、補正を「ちょっとした足し算」にとどめることで各単語の確率がきちんとした形のまま計算でき、品質を一切落とさない性質(ロスレス)を壊さないこと。逐次ヘッドの作り方は2種類:
Markov ヘッド(標準)
- 補正を直前の1単語だけから決める、いちばんシンプルな形 。本来は語彙×語彙の巨大な表になるが、小さな2枚の表のかけ算 (既定で中間サイズ )で軽く近似する。例:1個目で "of" を選ぶと、2個目で "course" を後押しし "problem" を抑えて、続きの取り違えをやわらげる。
RNN ヘッド
- Markov は「直前の1単語」しか覚えていない。RNN ヘッドは内部のメモ に下書き内のこれまでの流れ全部をためていく。直前のメモ・直前の単語・今の内部状態をまとめて、1回だけ更新をかける:
- 表現力はRNNヘッドだが、作りが複雑で本番に乗せにくく、後で見るように効果はわずか。
結論:「ほんの少しだけ前を見る」やり方が大きく効く。標準は Markov ヘッド(RNN は長い先読みでわずかに上回るだけ)。
5 信頼度スケジュール検証(Confidence-Scheduled Verification)
長い下書きを作れても、全部検証するのは無駄が多い。特に自由な対話では、末尾の単語ほど却下されやすい。そこで「各単語が通る確率=信頼度を予想する信頼度ヘッド」と「混み具合を見て検証長を決めるスケジューラ」を組み合わせ、検証する価値がプラスの単語にだけターゲットモデルの計算を割り当てる。
5.1 信頼度ヘッド(Confidence Head)
各ドラフト位置 にスカラー を出力。これは「先行する全トークンが受理された条件下で、位置 のトークンが検証を生き残る条件付き確率」をモデル化する。軽量な線形射影+シグモイド:
この信頼度ヘッドを学習させるときの正解ラベルは、計算で求まる「1単語だけ見たときの受理率」。これはドラフトモデルの確率 とターゲットモデルの確率 の食い違いの大きさ(全変動距離)から決まる:
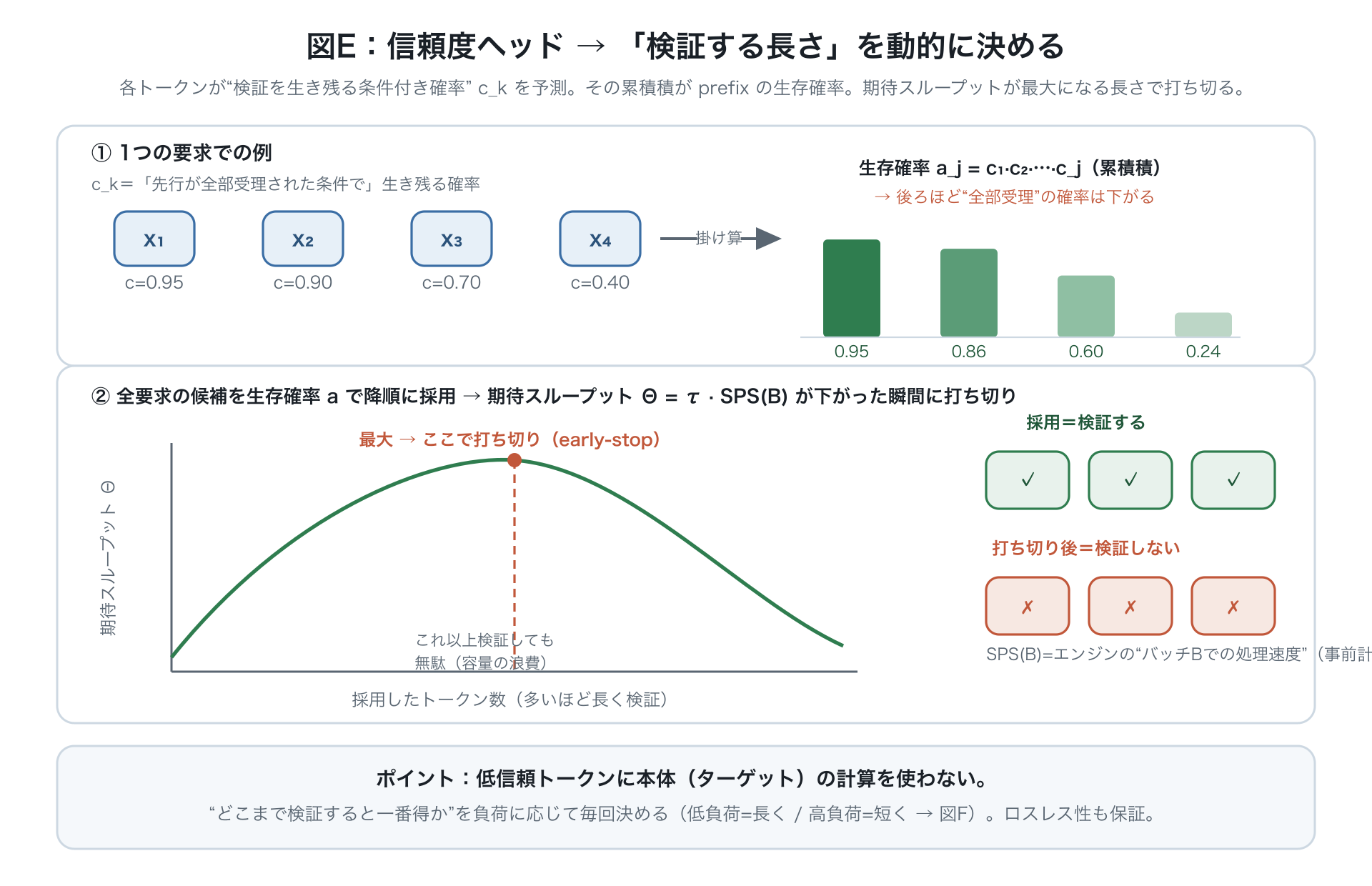
信頼度 と、それが検証長の決定にどう使われるか。
- 各位置の「手前が全部受理された前提で通る確率」 を前から掛け合わせると、「頭からそこまで全部通る確率」(後ろほど下がる)。次節のスケジューラはこの を使い、全リクエストの候補を高い順に採っていきながら、期待されるスループット を計算して、下がった瞬間に打ち切る。
- 要するに信頼度が「あと1単語検証して得かどうか」の判断材料を与え、自信のない単語にターゲットモデルの計算を使わせない。
5.2 ハードウェア対応プレフィックススケジューラ
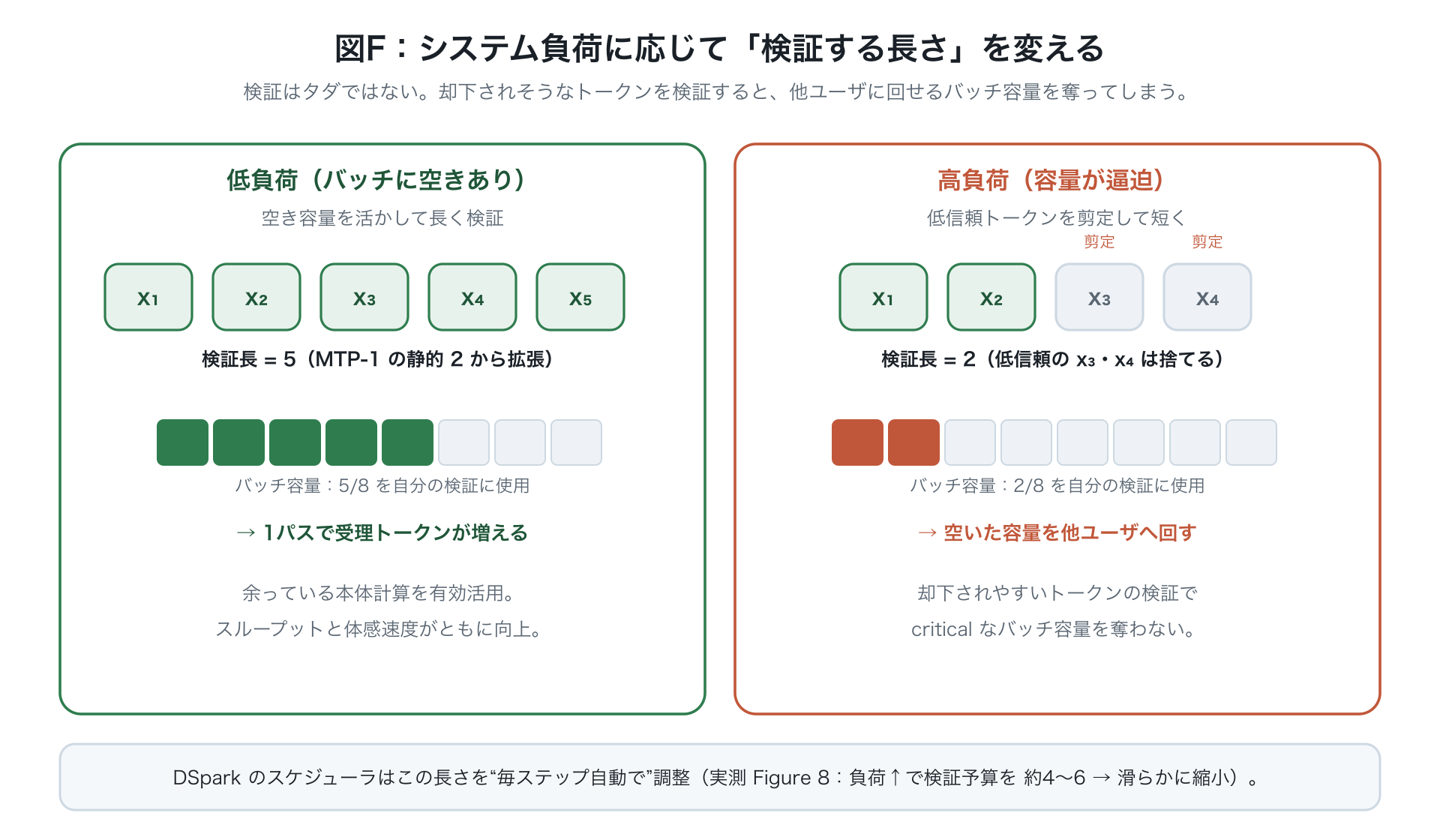
従来は信頼度に固定のしきい値を当てて検証長を決めるが、混み合う本番では「あと1単語検証する価値」が今の混み具合で大きく変わるので、固定では最適にならない。DSpark は検証長の決定を全体のスループットを最大にする問題として組み立てる。
- リクエスト の位置 まで全部通る確率は、確率を掛け合わせた 。
- 1回の検証で送る量(バッチサイズ)は (=各リクエストの検証長)、期待される受理単語数は 。
- さらに、起動時に一度だけ計測したのときの1秒あたり処理ステップ数)という早見表を持ち、全体のスループットがいちばん大きくなるように、各リクエストの検証長をその場で選ぶ。
- 貪欲解が最適になる鍵:
- は に対し単調非増加なので、検証長を に延ばす限界利得はちょうど 。よって全 を生存確率の降順にソートして貪欲に採用すれば、ブロック内のプレフィックス依存を自然に尊重しつつ最適配分が得られる。
- ロスレス性の保証:
- 投機的デコーディングは「未来の候補に依存して採用判断してはいけない(non-anticipating property)」。
- 遡及的大域探索(全体を最後まで計算してから一番良い長さを選ぶ方法)の場合、ステップ kのトークンを検証バッチに入れるかどうかを判断する際、「ここで打ち切った場合のスループット」と、「もう一つ先(k+1)まで検証バッチに入れた場合のスループット」を比較することになり、漏洩が起こり、トークン生成の確率が歪む。
- そこでスループットが下がった瞬間に貪欲探索を打ち切る early-stopping により、判断をその時点までのプレフィックスのみに依存させ、ターゲット分布の厳密な復元を保証する。
6ドラフトモデルの学習目的関数
何を学習するのか: DSpark で学習するのはドラフトモデルだけで、本番のターゲットモデルはそのまま固定。
学習時、各ターゲット系列から複数のアンカー位置をランダムに選び、 単語ぶんの下書きまとまりを作る。ドラフトモデルのうち入力・出力まわりの部品は固定し、実際に学習するのは並列バックボーン・逐次ヘッド・信頼度ヘッドの3つだけ。3つの誤差はすべて、前の位置ほど重く見る重み をかけて足す。
① Cross-entropy loss
② 分布マッチング損失
ドラフトモデルとターゲットモデルの確率の食い違いは、そのまま受理率の裏返し(受理率 )。だからこれを小さくすると、受理率が直接上がる。
③ 信頼度損失 (ソフト受理ラベル に合わせる)
7 オフライン実験結果
- 条件: ターゲットモデルは Qwen3-{4B,8B,14B} と Gemma4-12B。
- 比べるドラフトモデルは DFlash(並列ドラフタの最強)と Eagle3。
- すべてのドラフトモデルを同じ仕組み・同じデータ(Open-PerfectBlend 130万件)で学習し直し、先読み長は 7 にそろえ、層数は Eagle3=1、DSpark/DFlash=5。物差しは1ラウンドあたりの受理長 (高いほど良い)。この評価ではスケジューラはオフにして、純粋に下書きの質だけを比べる。
Table 1:主な結果(受理長 τ/高いほど良い、太字=最良)
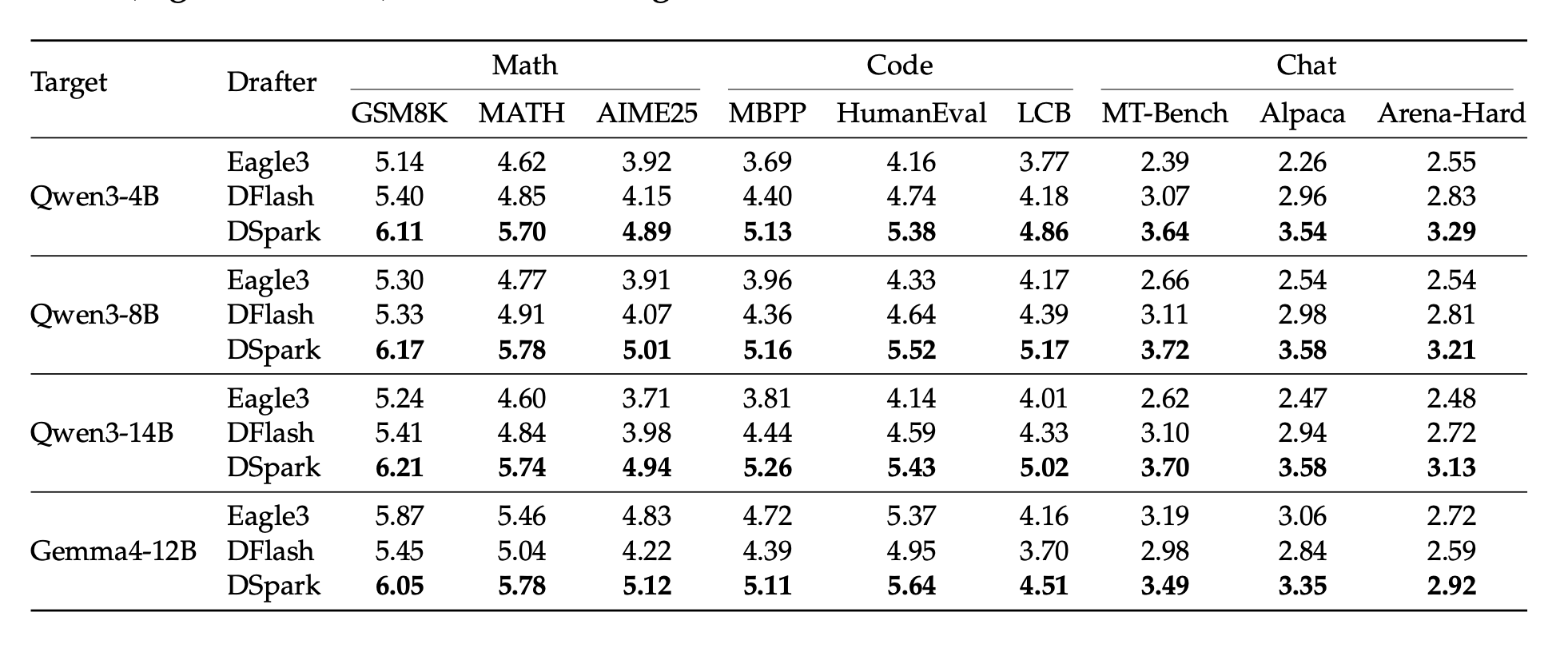
- DSpark は全ターゲットモデル・全ジャンルで、自己回帰ドラフタ(Eagle3)と並列ドラフタ(DFlash)の両方を安定して上回る。
- 平均の受理長で Eagle3 比 Qwen3-4B/8B/14B が +30.9%/+26.7%/+30.0%、DFlash 比 +16.3%/+18.4%/+18.3%。Gemma4-12B でも改善し、モデルの種類をまたいで効く。
- ジャンルによる差がはっきりしていて、カッチリした作業(math/code)の方が自由な対話(chat)より受理長が高い。この「当てやすさのばらつき」こそ、次に出てくる信頼度スケジュール検証が必要になる理由。
8 分析:受理長の源泉と賢い検証
8.1 なぜ並列ドラフタが自己回帰に勝てるのか(位置ごとの受理率)
Table 1 で意外なのは「並列ドラフタ(DFlash)や半AR(DSpark)が、完全な自己回帰(Eagle3)より長く受理することが多い」点。これを位置ごとの受理率に分けて見る(位置 の評価は「1〜 が全部受理された事例」だけを対象にし、前の失敗の巻き添えを取り除いて、その位置そのものの予測の良さを見る)。
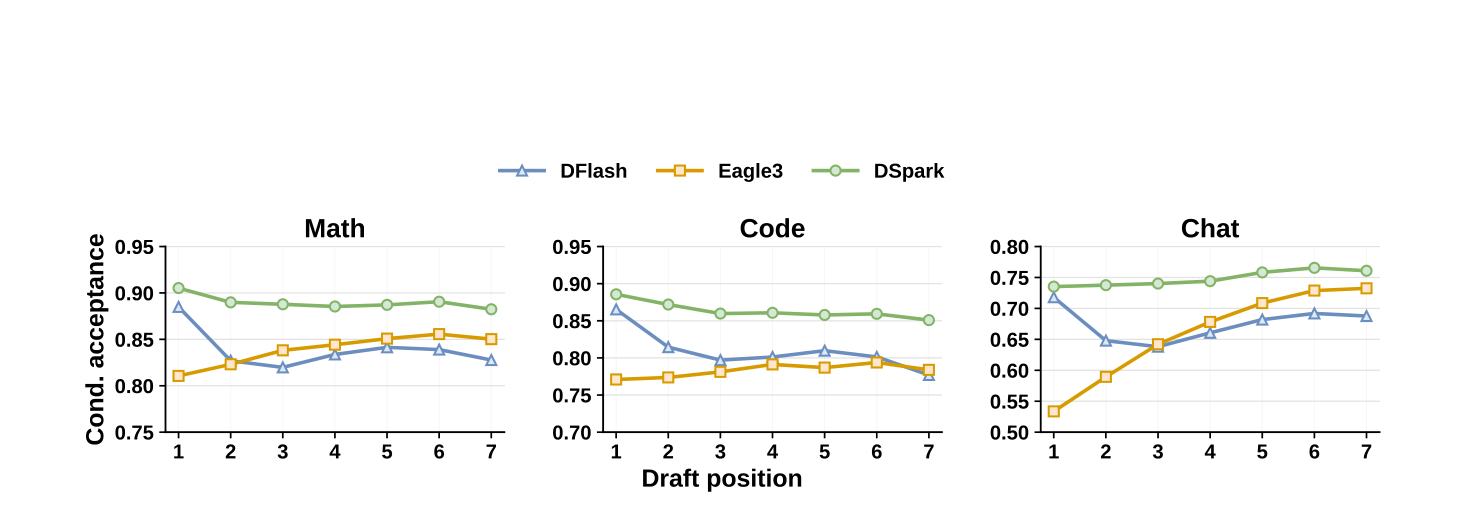
位置ごとの受理率(Qwen3-4B)。 自己回帰(Eagle3)は後ろでも安定〜上昇するのに対し、並列ドラフタ(DFlash)は後ろで受理率が落ちる(suffix decay)。DSpark は並列ドラフタの高い序盤の受理率(Math で約0.93スタート)を引き継ぎつつ、軽い逐次ヘッドで後ろの落ち込みを抑え、最後まで高く安定させる。
8.2 「ほんの少しだけ前を見る」が大きく効く
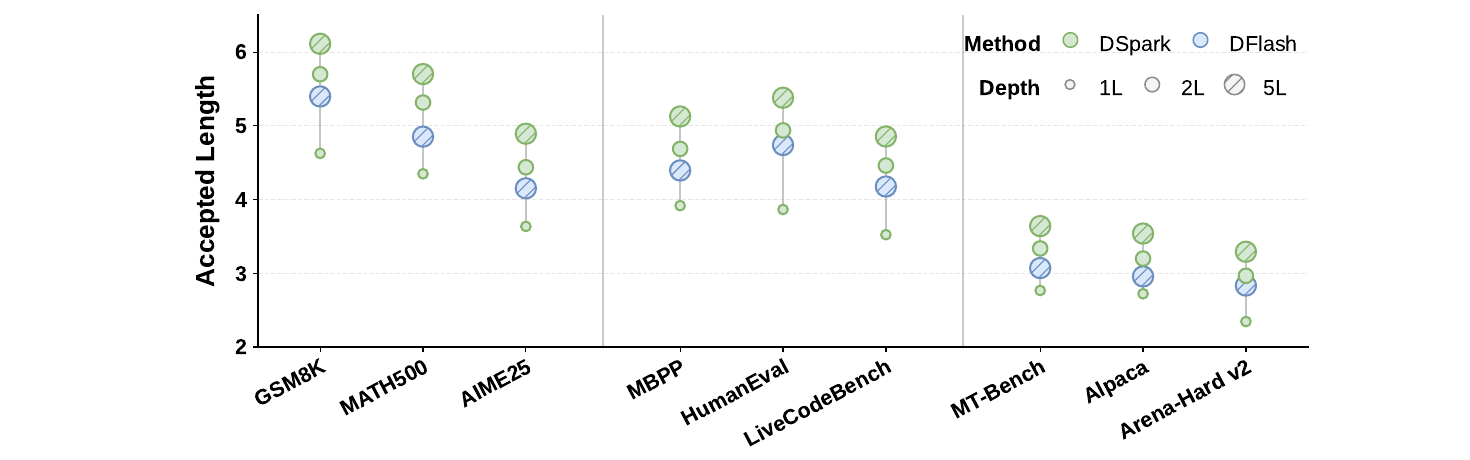
Figure 3:ドラフトモデルの深さの効果(先読み長は固定)。
- DSpark は層を増やすほど受理長が伸び、1→2層の伸びが最大。
- 注目は2層の DSpark が5層の DFlash を全ジャンルで上回ること。
- 軽い逐次ヘッドを足す方が、並列層を深く積むより精度もパラメータ効率も良い。
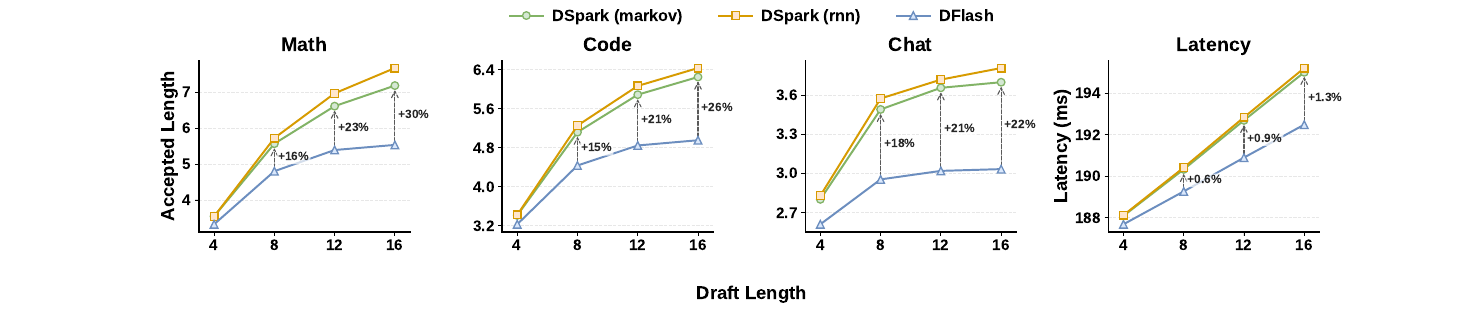
Figure 4:先読み長の効果と、増える遅れ。
- 左3枚:DSpark はどの先読み長でも DFlash を上回り、 が増えるほど差が開く( で math/code/chat +16/+15/+18% → で +30/+26/+22%)。
- 並列ドラフタだけだと後半が急落して長い先読みでうまみが減るが、DSpark はそれをやわらげる。RNN ヘッドは Markov に対し、長い先読みでわずかに上回るだけ。
- 右1枚:逐次ヘッドで増える遅れはごくわずか(先読み4→16で1ラウンド全体の遅れに +0.2〜1.3% だけ、受理長は最大+30%)。
8.3 賢く検証する:信頼度ヘッドの役割(しきい値を振ってみる)
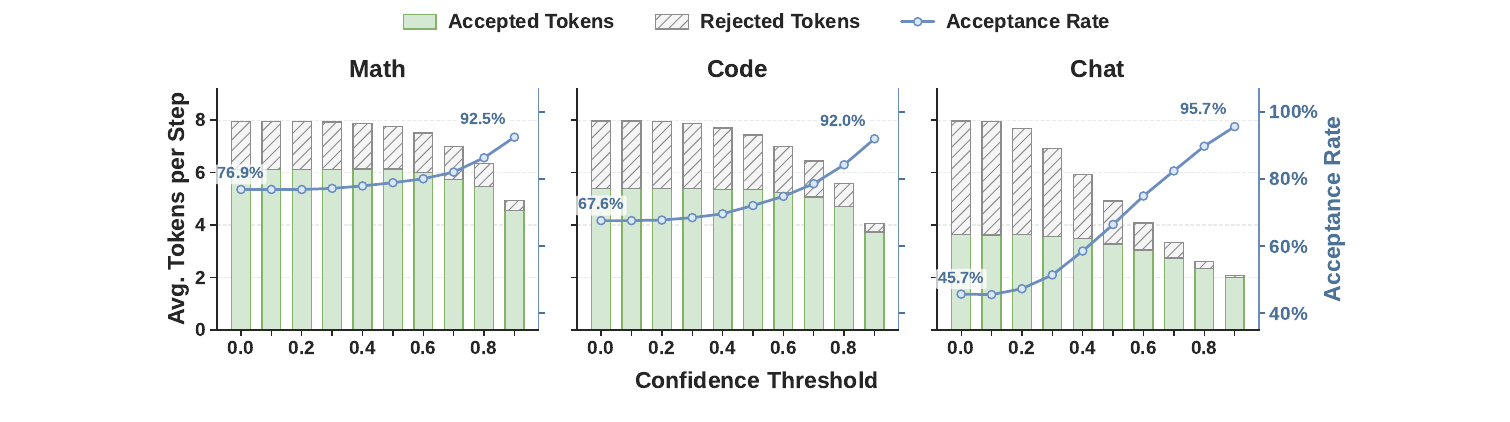
Figure 5:信頼度のしきい値を振る(Qwen3-4B)。
- しきい値0=従来の「固定長で全部検証」。しきい値を上げると、最後には却下される単語(斜線バー)を信頼度ヘッドが先に除くので、受理率が着実に上がる。
- 効果は受理率の低い Chat で最大(受理率 45.7%→95.7%)。カッチリした作業はもともと穏やか(Math 76.9%→92.5%、Code 67.6%→92.0%)で下書きを多く残す。
固定しきい値は様子を見るには便利だが、混み具合を無視するので、刻々と変わる本番では二番手。だからこそ、ハードウェア対応スケジューラが必要になる。
9 本番デプロイ(DeepSeek-V4)(時間あれば)
DSpark のドラフトモデルは **DeepSeek-V4-Flash / V4-Pro(preview)**と一緒に動かす。並列バックボーンは MoE 3層(mHC 付き)+スライディングウィンドウ注意(128)、最大の先読み 、逐次ヘッドは Markov ヘッド。信頼度ヘッドはドラフトモデルとまとめて学習する。
9.1 大規模な学習の仕組み(HAI-LLM)
§6 が「何を目指して学習するか(誤差の測り方)」を決めたのに対し、本節はそれを DeepSeek-V4 という巨大さで実際に学習しきるための工夫。本番モデル向けの話なのでデプロイの節に入れる。ポイントは2つ:
- 隠れ状態通信: 全語彙ロジット()の転送は帯域ボトルネック。代わりに LM ヘッド直前の隠れ状態だけを通信し、LM ヘッド射影はサンプル位置のみドラフト側ワーカでローカル実行 → 通信量を に削減。
- アンカー境界シーケンスパッキング: ドラフト計算をターゲットの文脈長から切り離すため、固定数のアンカーをサンプルし、孤立した予測ブロックを密なバッチにパック。2Dマスクではなくトークン単位の attention index で複数独立系列の厳密な因果マスクを維持し、パディングのオーバヘッドを回避。
9.2 実機でのスケジューラ適応
- 非同期化: 次ステップのバッチサイズを現ステップ完了前に知る必要があるため、同期スケジューリングは GPU パイプラインをストールさせる。そこで2ステップ前の信頼度ヘッド出力で次の検証容量を近似。現ステップの候補は最新の累積信頼度で厳密にソートし、2ステップ前の予測は動的な切り詰め長(バッチ容量上限 )の決定にのみ使う=動的 top- 選択。順位保存的で、最も自信のあるトークンが常に優先される。
- 「2ステップ前」というのは、「現在のステップの検証の長さ(バッチの容量上限)を決めるために、時間差で2ステップ前に計算しておいた予測データを使う」という意味で。
- このような仕組みになっている理由は、GPUの計算を止めない(パイプラインを止めない)ためです。DSparkが稼働するような大規模システム(Zero-Overhead Schedulingを採用したシステム)では、現在のステップの処理が完了する前に、次のステップのバッチサイズをあらかじめ確定させておく必要があるから。
- もし、現在のトークンが出揃ってからその場で即座に長さを計算しようとすると、計算結果が出るまでGPUが待機してしまい、処理が一時停止してしまう。この「計算待ち」を防ぐために、DSparkでは以下のように処理を工夫しています。
- **検証の長さ(どこで打ち切るか)の決定**: 待ち時間をなくすため、2ステップ前の予測スコアを使って、現在のステップのバッチ容量を近似して決定します。
- **どのトークンを検証するか(優先順位)の決定**: トークンの順位付け自体は、常に最新のスコアを使って正確に行われ、優先度の高いものから順にバッチに割り当てられます。
つまり、計算回数を減らしているのではなく、**「長さの計算に使うデータを少し前のものにズラすことで、GPUの待ち時間を完全に無くしている」**というのが「2ステップ前」の本当の役割です。
- 非平滑 SPS 対策: 階段状の SPS 崖で局所最適に陥らないよう early-stopping break を外し、無制約な大域探索に。通常これは未来トークン漏洩でロスレス性を破るが、評価対象が2ステップ前の履歴予測のみのため採用判断は現トークン の実現から隔離され、非同期設計が因果バリアとして働き厳密なターゲット分布を保ったままハードウェア崖を越える。
9.3 高スループット・低遅延推論
本番は要求あたりのレイテンシ(QoS)と総スループット(同時ユーザ数)の両立が課題。だが KV キャッシュ容量や利用可能トラフィック(RL のロングテール負荷など)により実効バッチサイズが GPU 飽和閾値を恒常的に下回る運用域では、トレードオフが単純化し、per-GPU 総スループット最大化と tok/s/user 最大化が競合せず相関する。
可変長クエリを1バッチで効率処理するため、論理的なシーケンス追跡と物理実行を分離し、全トークンを独立要素としてフラット化、依存関係はスパースAttensionの marker tensor で伝える。DeepSeek-V4 では index-attention と compress カーネルの修正のみで可変長ルーティングを実現。
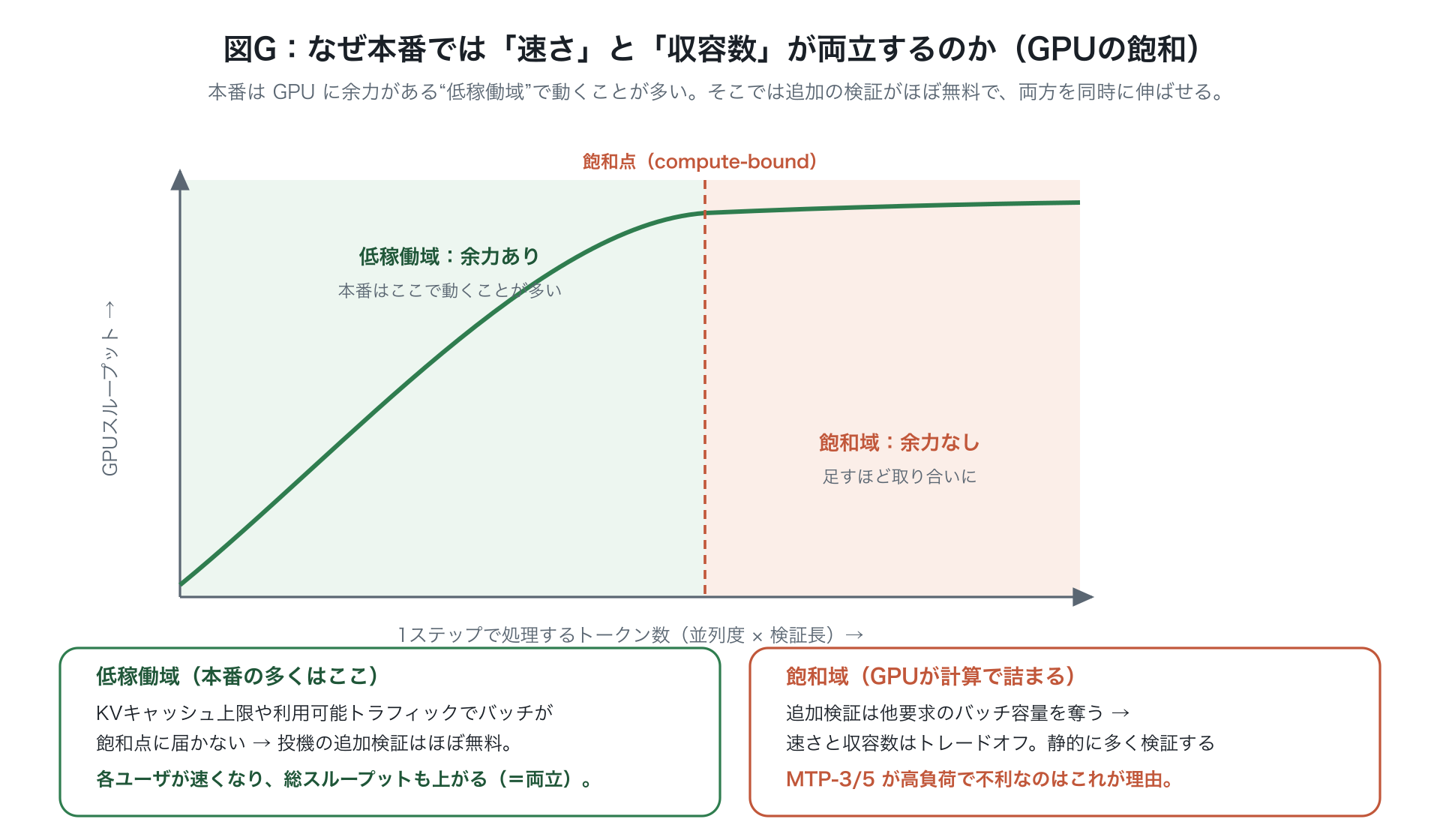
図解なぜ本番では「速さ」と「収容数」が両立するのか。 普通はユーザを速くするほど収容数(スループット)が下がる板挟み。でも GPU が限界に達していないすいている状況では、追加で検証してもほぼタダなので、各ユーザを速くしつつ全体のスループットも上げられる(ぶつからない)。本番はメモリ上限やリクエスト量の都合で、このすいている状況に留まりやすい。混んでくると逆に枠の取り合いになり、いつも多く検証する MTP-3/5 が不利になる。
9.4 ライブトラフィックでの性能
比較は DSpark-5()vs MTP-1(旧本番設定)。MTP-1 が1単語のままだったのは、いつも多く引く方式(MTP-3/5)が混雑時に余計な検証でスループットを必ず落とすため。つまり DSpark との比較は「刻々と変わる本番で、長い下書きの良さを安全に引き出せるか」を直接示す。
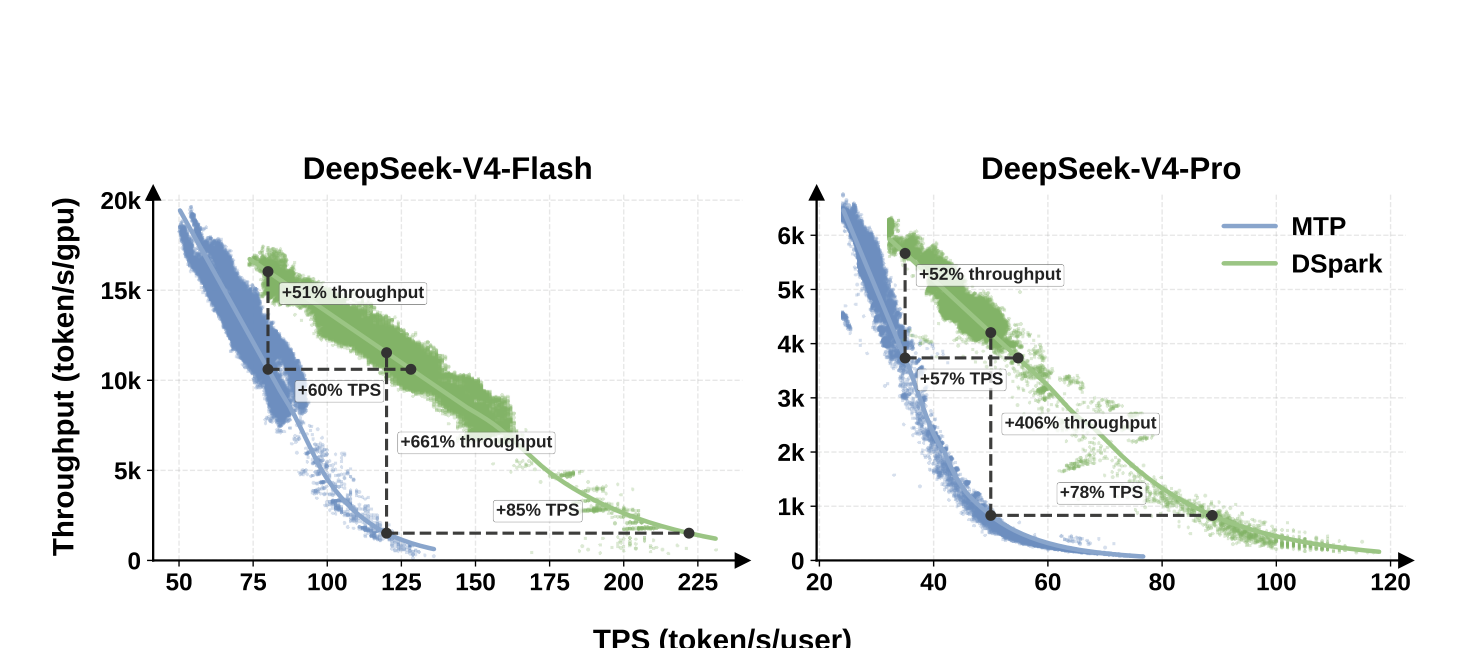
Figure 7:スループット vs ユーザ1人あたりの速さ(実トラフィック)。
- 点は実際のログ、実線がその傾向線。V4-Flash:1人あたり80 tok/sを保証する条件でスループット +51%、より厳しい120 tok/sでは MTP-1 が限界に達して小さくしか回せず、DSpark は見かけ +661%(=速さの限界を押し広げた証拠と解釈)。
- 実用的にそろえた水準では 1人あたりの速さを 60〜85% アップ。V4-Pro:35 tok/sで +52%、50 tok/sで見かけ +406%、そろえた水準で 57〜78% アップ。全体として「速さ」と「収容数」の両立ラインを外へ押し広げる。
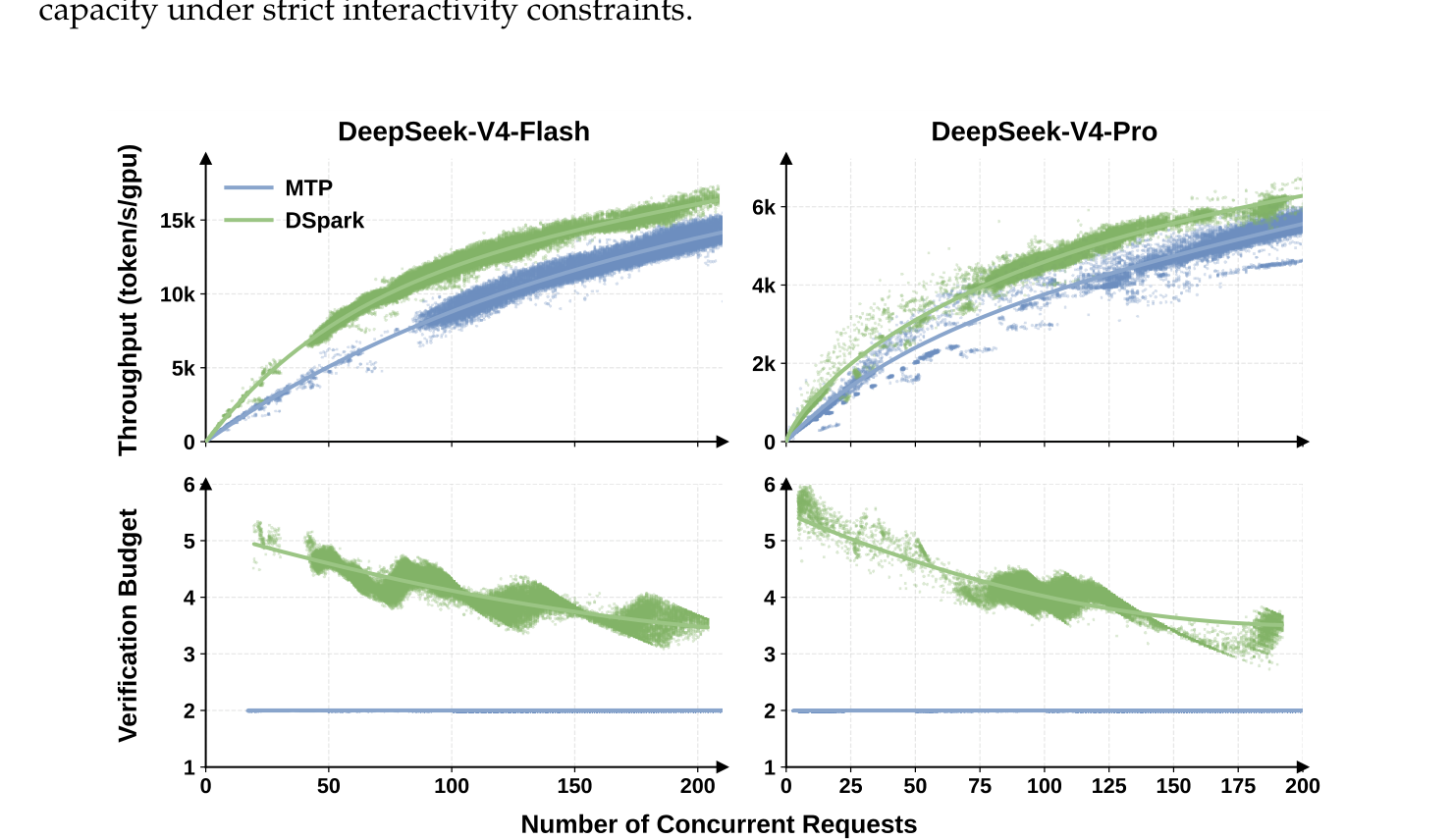
Figure 8:混み具合に応じたスループットと検証量。
- 上段:同時リクエスト数に対する全体のスループット。
- 下段:1リクエストあたりの平均検証量。
- そこそこの混み具合(V4-Flash で <200、V4-Pro で <150 リクエスト)ではスケジューラが空き枠を活かし、MTP-1 の固定2単語から1リクエストあたり約4〜6単語へ検証量を増やす → 1回で受理される単語が増えて、両立ラインの押し広げに直結。
- 混んできて枠が埋まると、検証量をなめらかに減らし、自信のない単語が大事な枠を食う前に切り落とす。すいているときは余った計算を最大限使い、混んでいるときは枠を守る——この混み具合への自動対応が本番を安定させる。
10 制約とまとめ
制約(Limitations)
スケジューラは検証の無駄を最小にするが、並列バックボーンで最初の 単語ぶんの下書きを作る分の固定コストは残る。そもそも受理率の低い難しいリクエストでは、この先払いの下書き計算が取り返せない。今後は難しさに応じて下書きを途中で打ち切る工夫で、まとめて全部作るのを省く改良が考えられる。
まとめ
- アルゴリズム: 重い並列バックボーン+軽い逐次ヘッドの半自己回帰生成で、並列ドラフタの弱点(後半の受理率の急落=suffix decay)をやわらげる。
- 仕組み: 検証長の決定を全体のスループットを最大にする問題として組み立て、各単語の生存確率と今の混み具合に応じて、ターゲットモデルの計算をその場で配分するハードウェア対応スケジューラ。
- 成果: オフラインで最強の各ベースラインを多ジャンルで大きく上回り、DeepSeek-V4 本番でも混雑時の収容数を保ちつつユーザ1人あたりを安定して高速化、LLM 提供の両立ラインを外へ押し広げた。
- 公開: DSpark の学習済みモデル(V4-Flash/Pro preview 向け)と、Eagle3・DFlash・DSpark を含む学習リポジトリ DeepSpec をオープンソース化。
- ‣
vllmでももうすぐ使えるようになりそう
[Spec Decode] DSpark
Updated Jun 30, 2026