
2025-11-18 機械学習勉強会
今週のTOPIC[論文] Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models[oss] Magika[blog]信頼できるLLM-as-a-Judgeの構築に向けた研究動向[論文] iDataLake: An LLM-Powered Analytics System on Data Lakes[論文]Glyph: Scaling Context Windows via Visual-Text CompressionDisrupting the first reported AI-orchestrated cyber espionage campaign(APT) Accelerating Vision Transformers With Adaptive Patch Sizesひとことでいうとイントロ提案手法: Adaptive Patch Transformer (APT)パッチサイズを決めるパッチの集約動的な入力サイズ実験比較対象のベースラインImage ClassificationVQA & Dense Visual TasksAblation Study定性評価Limitation所感
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
- Agentまとめ
- 大規模言語モデル(LLM)がモデルパラメータの更新なしに自律的に性能を向上させる新しいフレームワーク「ACE(Agentic Context Engineering)」を提案。
- 従来のプロンプト最適化手法が抱える2つの重大な問題
- 簡潔性バイアス(brevity bias)
- コンテキスト崩壊(contextcollapse)
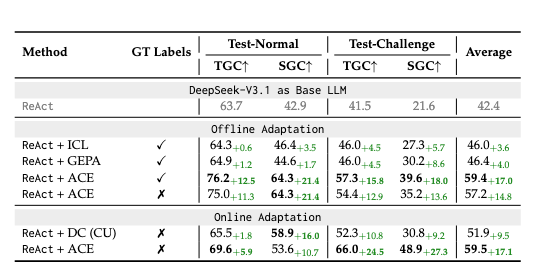
- コンテキストを「Evolving Playbook」として扱うことで、エージェント性能を平均10.6%向上させることに成功
- https://pages.layerx.co.jp/295cdd370bae80d083bce95ba87eae0a で紹介した「経験的知識」と似た話?
- 先行研究
- 静的プロンプト最適化
- TextGrad、GEPA、MIPROv2などの手法は、プロンプトを固定長の文字列として扱い、勾配ベースまたは進化的アルゴリズムで最適化
- 問題点: 最適化プロセスが簡潔なプロンプトを好む傾向(簡潔性バイアス)があり、タスク固有の重要な知識が削除される
- 動的コンテキスト管理
- Dynamic Cheatsheet (DC)などは、タスク実行中に動的にコンテキストを更新
- 問題点: コンテキスト全体を一括書き換え(モノリシック・リライト)するため、既存の有用な情報が失われる「コンテキスト崩壊」が発生
- 自己改善型エージェント
- Reflexion、Self-Refineなどは、エージェントが自己評価と改善を繰り返す
- 問題点: 短期的なタスクレベルの改善に焦点を当て、長期的な知識蓄積のメカニズムが不足
- ACEは、コンテキストを増分的に成長・洗練させる構造化された知識ベースとして扱うことで、上記の限界を克服。箇条書き形式でメタデータ(ID、 有用性カウンター)を持つ項目として管理し、局所的な更新と意味的重複除去を可能に。

- ACEの三層アーキテクチャ
- Generator
- 新しいクエリに対して推論を生成し、効果的な戦略と反復的な落とし穴の両方を明らかにする。
- どのPlaybookが有用だったか誤解を招いたかを格納してReflectorに渡す
- Reflector
- 推論を批評して具体的な洞察を抽出し、複数回反復してそれらを精緻化
- 成功と失敗の実行結果を分析して洞察を抽出
- Abration StudyではReflector有無で性能が5.3%違う(Reflectorなし: +12.7% → あり: +17.0%)
- Curator
- 洞察をDelta Context Itemとして統合
- 決定論的に既存のPlaybookを更新
- 並列にMergeも可能
- Grow and Refineとあるので削除はなさそう。。?
- Playbook
- 以下の単位でBulletととして構造化
- メタデータ
- ID
- 有用性カウンター:有用または有害として判定された頻度
- コンテンツ
- 再利用可能な戦略
- メイン固有の概念
- 一般的な失敗モード
- ツールと即座に使用可能なコード
- これによって、関連bulletだけ更新、Fine Grainedな検索・更新が可能になる

- 結果
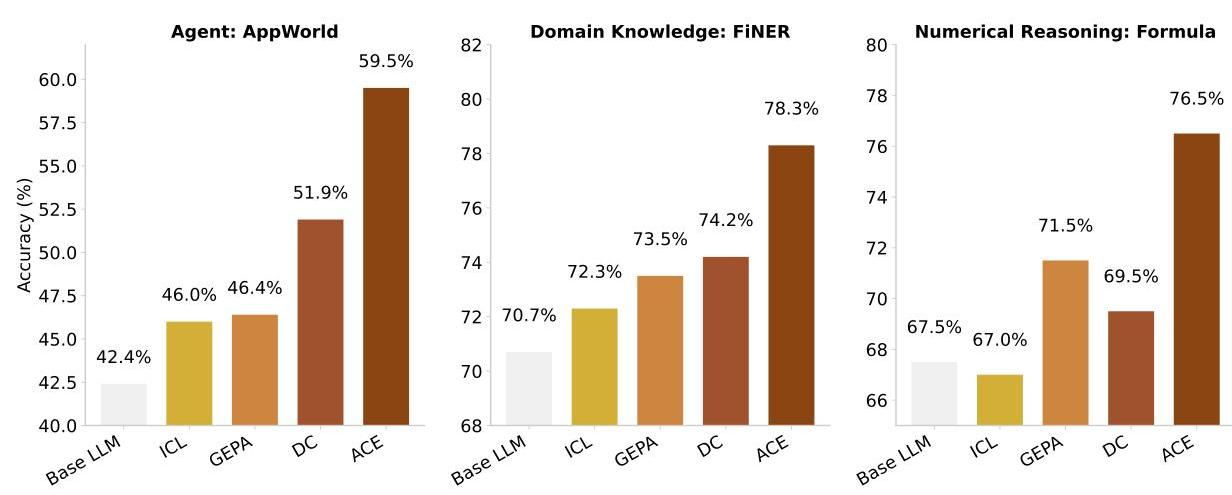
- 正解ラベルなしでも精度向上 (AppWorld)
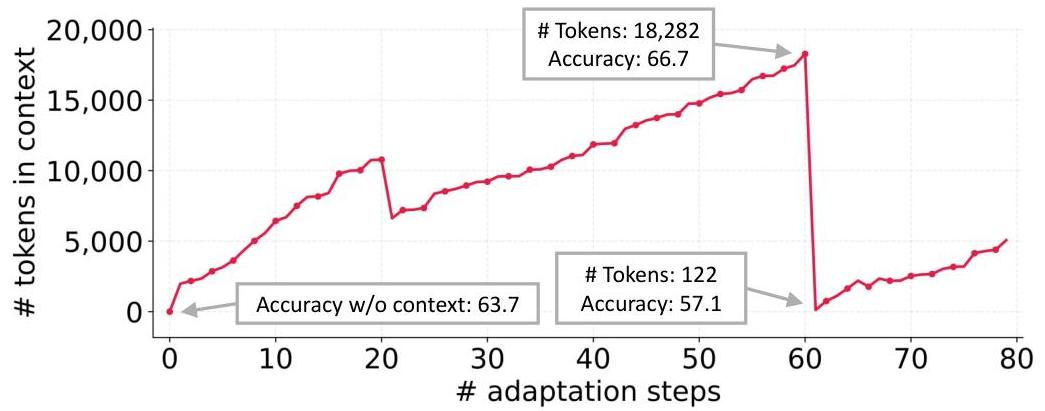
- KV Cacheが効きやすいのでトークン効率も良い

@Yosuke Yoshida
[oss] Magika
- 数MB程度の軽量で高度に最適化された独自モデルを採用しており、単一のCPU上でもミリ秒単位で精密なファイル識別が可能
- Magikaは、約1億サンプル・200種類以上のコンテンツタイプ(バイナリおよびテキストファイル形式の両方を含む)を対象に学習・評価されており、テストセット上で平均約99%の精度を達成
@Hiromu Nakamura (pon)
[blog]信頼できるLLM-as-a-Judgeの構築に向けた研究動向
[pon]面白いのを抜粋
1. プロンプト設計による最適化
最も直接的な手法が、プロンプトの工夫である。
Few-shotプロンプトにより評価基準を示すと、LLMはより正確に判断する傾向がある。
- G-Eval(Liu+, 2023)
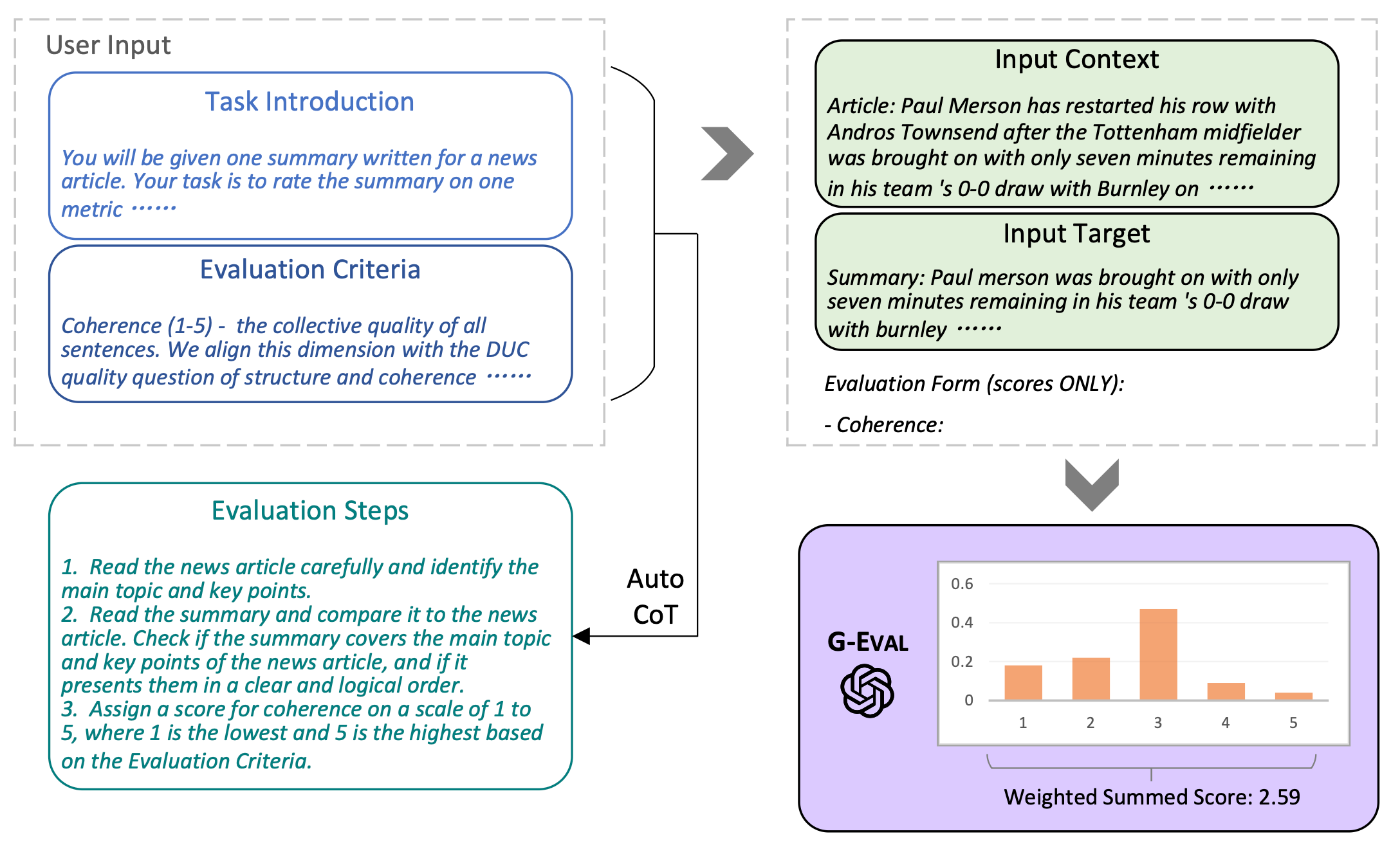
タスク概要と評価基準を記述したプロンプトを与えると、LLMが自動的にCoT形式の評価手順を生成し、それを用いて評価を行う仕組みである。人間評価との相関が高いことが示された。また、LLMがLLM生成テキストを過大評価する傾向も指摘している。
2. モデル自体の改善(評価能力の向上)
評価専用のLLMを作るアプローチである。鍵となるのは「メタ評価データセット」の構築である。
- INSTRUCTSCORE(Xu+, 2023)
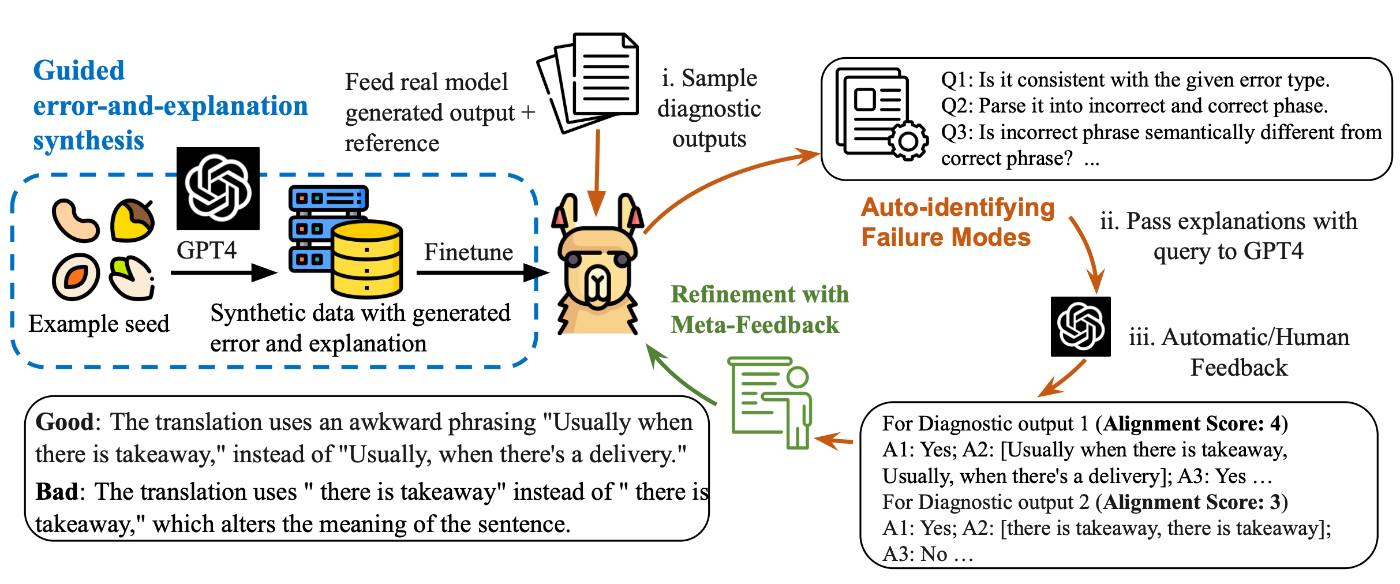
まずLLMに評価を行わせ、誤ったケースをGPT-4がフィードバックする。これを学習して評価能力を段階的に改善する反復最適化手法である。
3. 出力後の最適化(事後処理)
LLMの評価結果は揺れやすいため、出力を統合したり自己検証を行ったりするアプローチである。
- Language-Model-as-an-Examiner(Bai+, 2023)
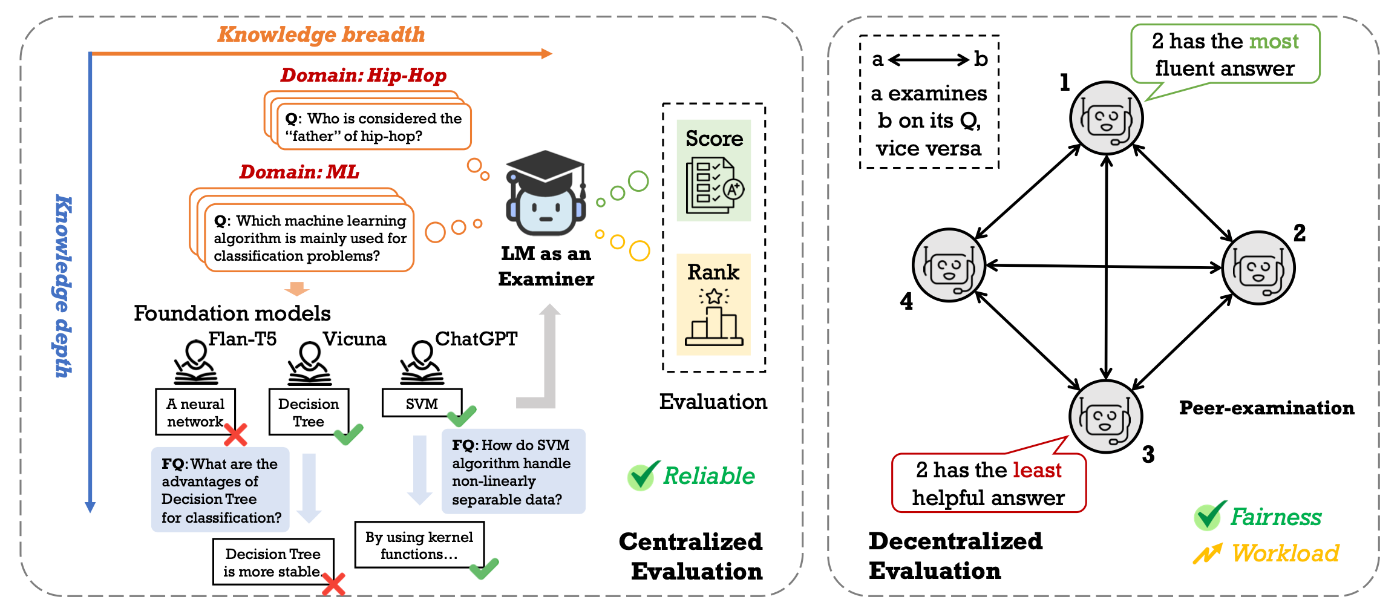
LLMが「試験官」として自ら多様なドメインから質問を生成し、回答を評価する仕組みを持つ。さらに、複数の異なるLLMを相互に評価させ、その結果を投票によって集約する 「分散型ピアレビュー」を導入し、公平性を高めている。
まとめ
LLM-as-a-Judgeの信頼性向上は、
- プロンプト設計、
- モデル自体の改善、
- 出力後の統合処理、
という三層構造のアプローチで進んでいる。これらは独立した手法ではなく、組み合わせることでより一貫性・公平性の高い評価フレームワークが構築可能である。今後は、バイアスの抑制、再現性の確保、低コストな大規模評価体系の確立が求められる領域である。
@ShibuiYusuke
[論文] iDataLake: An LLM-Powered Analytics System on Data Lakes
- 概要
- 大規模言語モデル(LLM)を活用し、構造化データ(テーブルなど)、半構造化データ(JSON、XMLなど)、非構造化データ(テキスト文書など)が混在する「データレイク」に対して、自然言語で分析クエリを実行できるシステム「iDataLake」の提案
- 感想
- LLMを用いたLLMのためのデータレイクおよびそのデータ抽出・検索として色々体系的に整理されてて示唆に富むが、論文の発行日等々がわからなくて困る
- 実装をgithubで公開しててくれると助かるけど、なさそう
- クエリパイプラインが複数回のLLMリクエストを伴うため、リアルタイム性やレイテンシーは課題になりそう
従来の課題
- 異種データの扱いの難しさ: 構造化データ(テーブル)はSQLなどで分析しやすい一方 、JSONやテキスト文書などの半構造化・非構造化データは、スキーマが定義されていなかったり、構造が複雑だったりするため、SQLで直接扱うことが困難
- セマンティック(意味的)な理解の欠如: 従来のSQLは、「映画レビューが"ポジティブ"かどうか」といったセマンティック(意味的)な条件を直接表現できない
- データ断片化と複数ステップの推論: 例として、「1980年代の映画で、ポジティブなレビューの比率が最も高い監督トップ5は?」といったクエリを考える。この場合、映画の製作年は「テーブル」に、レビュー内容は「テキスト文書」にと、データが断片化。回答を得るには、データ統合、感情分析、ランキングといった複数ステップの推論が必要
- 情報損失: テキストデータを機械学習で無理やりテーブル形式に変換する方法もあるが、この過程で情報が失われる可能性
iDataLakeのアーキテクチャ
- LLMによって非構造化データの高度なセマンティック理解に進歩。LLMをデータレイク分析に統合する際に発生する課題とその対策
| 課題ID | 課題名 | 課題内容 | 対策 |
|---|---|---|---|
| C1 | 統一された埋め込みベースのデータリンキング | 異種データのモデリングとリンキング:クエリに関連する多様なデータを正確に特定し、リンクさせるのが難しい | 異なる種類のデータ(テーブル、テキスト等)を共通の「セマンティック埋め込み空間」に変換し、対照学習(contrastive learning)によって位置合わせ(アライメント)。これにより、意味的に関連する異種データを効率的に発見可能 |
| C2 | セマンティックオペレータ | セマンティックなデータ処理:LLMのセマンティック理解能力を、フィルタリングやグルーピングなどのデータ処理にどう活かすかが難しい | 従来のSQLオペレータ(Select, Joinなど)に加え、LLMの能力を活用した「セマンティック(意味的)」な処理を行うオペレータ群(例:(抽出)、(要約)、(分類))を定義 |
| C3 | パイプラインオーケストレーション | 自動パイプラインオーケストレーション:自然言語のクエリを、効率的で正確な実行計画(パイプライン)に自動的に変換するのが難しい | 自然言語クエリを、定義されたセマンティックオペレータの組み合わせ(パイプライン)に自動変換するアルゴリズムを提案 |
| C4 | 動的なパイプライン調整: | 効率的なパイプライン実行:精度とコスト(計算量)のバランスを取りながら、実行パイプラインを適応的に選択・調整するのが難しい | パイプラインの実行中に得られた中間結果に応じて、計画を動的に調整し、効率と堅牢性を両立 |
- オフライン処理: 事前にデータレイク内のデータを処理し、インデックスを構築
- オンライン処理: ユーザーから自然言語のクエリを受け取り、パイプラインを構築・実行して回答を返す
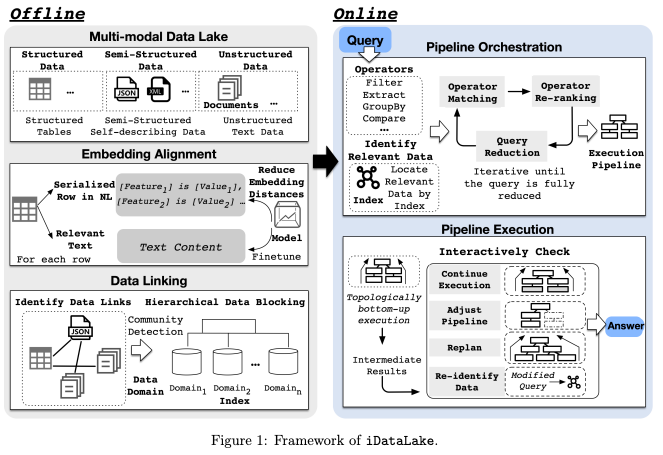
主要コンポーネントの詳細
セマンティックオペレータ (Semantic Operators)
従来のSQLのようなリレーショナルオペレータは、スキーマが厳格でセマンティックな処理ができないため、非構造化データには不十分。iDataLakeは、このギャップを埋めるためにセマンティックオペレータを導入
- 論理オペレータ
- データ変換 (Transformation): データの並べ替え()や形式変換(、例:テーブルをテキストに)など
- データ検索 (Retrieve): 条件に基づくフィルタリング()や、外部からのデータ補強()など
- データ抽出 (Extraction): 文書からの情報抽出()や、クエリ内の重要概念の識別()など
- データ生成 (Generation): 最終回答のテキスト生成()や、決定理由の説明()など
- データ分割 (Partition): 要約統計のためのグルーピング()や、類似データ のクラスタリング()など
- データリンキング (Link): テーブルと文書など、関連するデータを様々な粒度(テーブル単位、タプル単位、段落単位など)でリンクさせる
- データ集約・統合 (Aggregation): 合計や平均の計算()や、テキストの要約()など
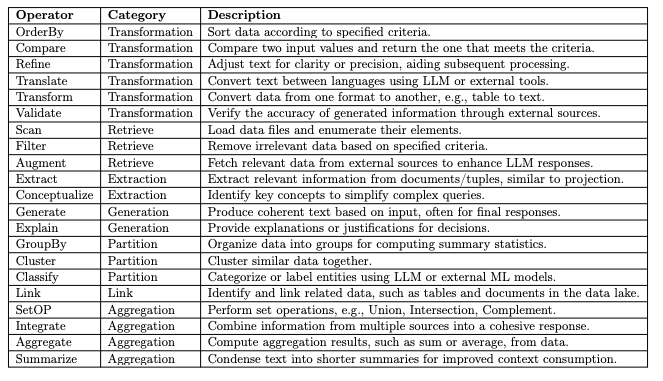
- 物理オペレータ
- これらの「論理オペレータ」には、複数の「物理オペレータ」(実行方法)が対応。これらは2種類に大別
- LLMベース: セマンティックな理解が必要なタスク(例:プロンプトに基づきテキストから情報を抽出)に使用
- 事前プログラム (Pre-programmed): キーワード一致や正規表現など、従来のデータベースのように定義済みのロジックで実行

iDataLakeは、各物理オペレータの目的、入力、期待される出力をテキストで記述した「説明文」を管理。これにより、LLMはクエリのニーズに応じて適切な物理オペレータを選択可能。また、開発者は新しいオペレータの実装と説明文を追加するだけで、システムを容易に拡張可能
埋め込みとリンキング (Embedding and Linking)
データレイクは膨大であるため、クエリに関連するデータ「のみ」を効率的に特定することが極めて重要。関連データが少なすぎれば(低Recall)正しい答えが得られず 、多すぎれば(低Precision)処理が非効率に
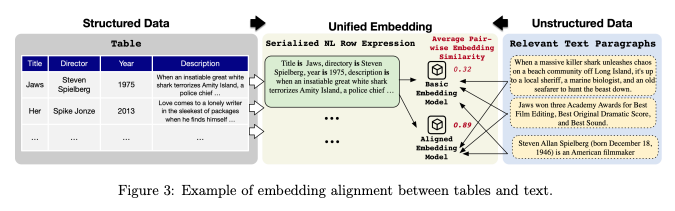
埋め込みのアライメント
- iDataLakeは異なる種類のデータを「統一された埋め込み空間」に変換することで対処
- しかし、単にテーブルデータを自然言語に変換(名前「John Doe」、社名「LayerX」・・・)して既存のテキスト埋め込みモデルに入力するだけでは、埋め込み空間がずれてしまい(ミスアライメント)、うまく機能しない
- iDataLakeは対照学習(contrastive learning) を用いてモデルをファインチューニング
- ポジティブ例: 正しくペアリングされた「テーブルの行」と「関連するテキスト段落」
- ネガティブ例: 関係のない「テーブルの行」と「テキスト段落」のペア
- この学習により、関連するテーブルとテキストの埋め込みベクトル間の距離を最小化し、関係ないペアの距離を最大化。テーブルとテキストの埋め込み空間が「アライメント」され、意味的な類似度検索が正確に行えるようになる
データリンキング
- データレイク全体で類似度検索を行うのは非効率なため 、iDataLakeはオフライン処理で階層的なデータブロッキングを行う
- 関連するデータ(例:特定の映画に関するデータ群)は、クエリに対してもまとまって関連/非関連となる傾向あり。この性質を利用し、Louvainコミュニティ検出アルゴリズムを使って、埋め込みの類似度に基づきデータをセマンティックな「ブロック」(コミュニティ)に分割
- クエリ実行時には、まず関連する「ブロック」を特定し、その後ブロック内で詳細なデータ検索を行うことで、検索効率を大幅に向上
パイプライン
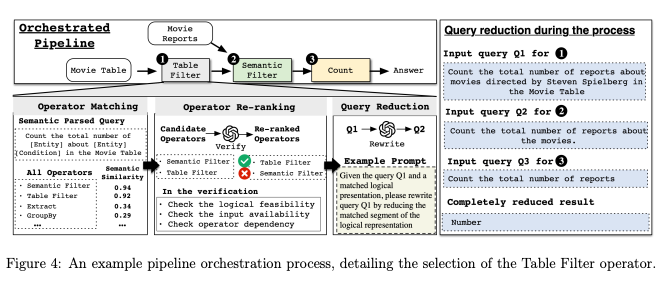
パイプラインオーケストレーション (Pipeline Orchestration)
iDataLakeは、自然言語クエリを「セマンティックオペレータ」の実行計画(DAG: 有向非巡回グラフ )に変換。このプロセスは、LLMの呼び出しを最小限に抑え、コストと効率を両立させるために、2段階のオペレータマッチングを行う
プロセス概要: クエリを反復的に「削減」していく。例えば、「スティーブン・スピルバーグ監督の映画に関するレポートの総数をカウントする」(Figure 4のQ1)というクエリがあったとする
- オペレータマッチング (2段階):
- (a) 粗粒度マッチング: まず、低コストな埋め込み類似度検索で、関連する可能性のあるオペレータを絞り込み。この際、クエリとオペレータのユースケースを「(エンティティ)が(条件)を満たす」といった「論理表現」に変換し、具体的な値("スピルバーグ"など)を除外して比較
- Filterオペレータのユースケース「(エンティティ)が(条件)を満たす」という論理表現とセマンティックな埋め込み類似度が高くなる
- (b) 細粒度リランキング: 絞り込まれた候補(例:, )に対し、LLMを使って詳細な検証。オペレータが論理的に適用可能か、必要な入力データが(中間の変数リスト)存在するかなどをチェック
- オペレータが実行されるたびに中間結果が生成され 、LLMがその中間結果の短いテキスト記述を生成
- このテキスト記述がプロンプトに追加され、LLMが次のオペレータの入力を適切に選択するためのガイドとなる
- クエリ削減:
- 適用可能なオペレータ(例:)が選択されると、LLMがそのオペレータが担当する部分をクエリから論理的に「削減」し、クエリを書き換え
- 図4の例では、Q1から「」が適用され、クエリは「(フィルタリングされた)映画についてのレポートの総数をカウントする」(Q2)に削減
- 反復:
- この「マッチング→削減」のプロセスを、クエリが完全に解決されるまで反復的に(DFS方式で)繰り返し
パイプライン実行 (Pipeline Execution)
従来のデータベースと異なり、iDataLakeの実行エンジンは、非構造化データの予測不可能性に対応するため、動的な適応機能を備える
- 並列トポロジカル実行: 構築されたパイプライン(DAG)に基づき、依存関係が解消されたオペレータから順に、可能な限り並列で実行
- 中間結果の検証と動的調整: オペレータ実行後、中間結果が期待通りか検証。もし期待と異なる場合(例:最初のデータ検索が不十分だった、パイプラインが不正確だった )、システムは以下のように動的に対応
- データ再特定: まず、LLMにクエリを別の表現に書き換えさせ、関連データを再検索
- 増分実行 (Incremental Execution): 失敗した場合、オーケストレーション時に生成された他の候補プラン のうち、失敗箇所までが共通する最長のプランに切り替え、実行を再開
- 再計画 (Replanning): 適切な代替プランがない場合、失敗した時点から(部分的に削減されたクエリを使って)再計画
- データに基づく枝刈り (Pruning): 実行中にデータ分析から新たな洞察が得られることがある。例えば、「50歳以上でフィールズ賞を受賞した数学者をリストアップせよ」というクエリがあったとする。実行中に「フィールズ賞は40歳以下の数学者にのみ与えられる」という事実(データの特性)が判明した場合、「50歳以上」と「フィールズ賞受賞」は両立しないため、それ以降の処理をすべてスキップ(枝刈り)し、即座に空の結果を返すことが可能
@Akira Manda(zunda)
[論文]Glyph: Scaling Context Windows via Visual-Text Compression
問題設定
- 長文(10万〜100万トークン級)を丸ごと扱う需要は増加中(長編ドキュメントQA、巨大コードベース解析、長期ログ推論など)。しかし、トークン数に比例して計算・メモリが増大し、学習・推論ともに現実的でなくなる。
- 既存路線の限界
- positional extrapolation:学習済みモデルをそのまま長文に外挿できるが、根本的にトークン数は減らず、極端な長さでは精度劣化が生じやすい。
- sparse/linear attention:計算を軽くできるが、入力トークン数そのものは変わらないため、超長文では総コストが依然大きい。
- RAG:外部検索で入力長を圧縮できるが、回収漏れ(重要情報の取りこぼし)のリスクが残る。
- 目標:入力トークンを増やさずに「実効的に読める原文量」を増やし、計算・メモリの現実的コストで長文を扱えるようにする。
コアアイデア
- テキスト列を伸ばす代わりに、文字の字形(glyph)として画像にレンダリングし、VLMで読む。
- 目的は注意計算の高速化ではなく、入力表現の情報密度を上げること。結果として、3〜4倍程度の実効コンテキスト拡張と推論/学習の高速化を両立
用語メモ
- 視覚トークン(visual token):画像パッチから得る表現。1トークンに複数文字相当の情報が載り得る。
- レンダリング設定(rendering configuration):テキスト→画像の変換パラメータ(DPI、フォント/サイズ、行間、レイアウト、色、余白など)。
- 圧縮率(compression ratio):元テキストトークン数 ÷ 視覚トークン数。値が大きいほど高密度だが読み取り難度も上がる。
- テスト時スケーリング(by high DPI):モデルは固定のまま、推論時にDPIを上げて視覚情報量を増やし精度を上げる運用ノブ。
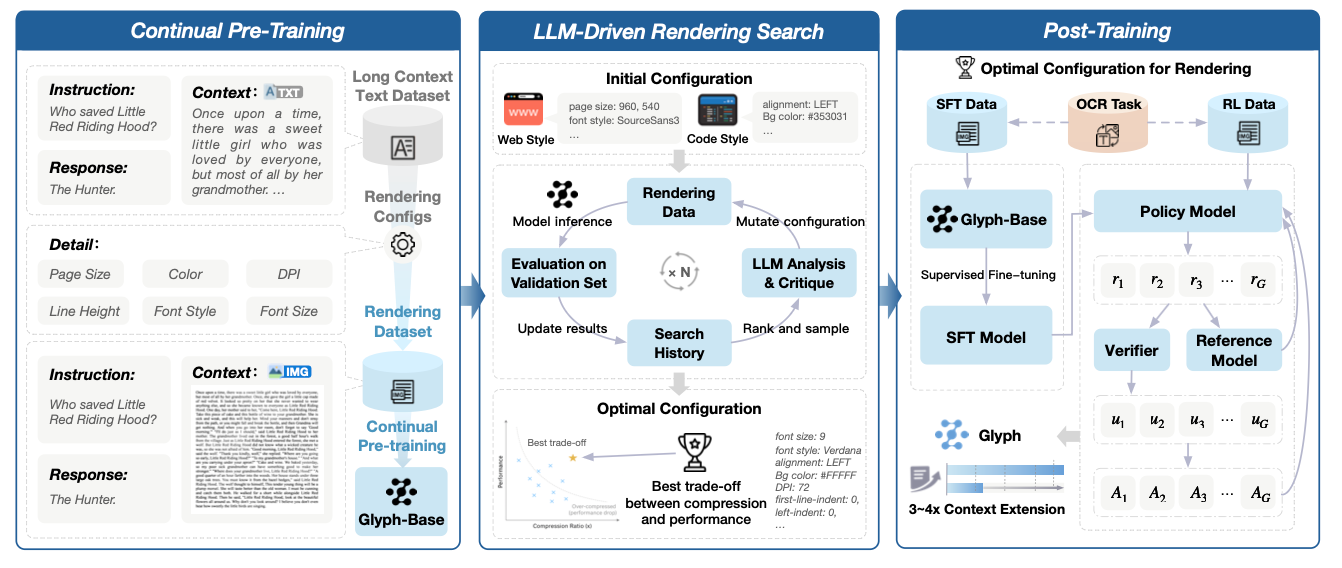
フレームワーク
- 継続事前学習(Continual Pre-Training, CPT)
- 多様なレンダリングスタイルで長文を画像化し、VLMに“レンダされたテキストを読む”能力を移植(OCR/インタリーブLM/生成を組合せ)。
- LLM駆動レンダリング探索(遺伝的アルゴリズム)
- DPI、フォント/サイズ、行間、レイアウト、色などを、精度×圧縮の観点で自動最適化(LLMの分析/提案を使用)。
- ポストトレーニング(SFT → RL[GRPO]+補助OCR)
- 思考プロセスを明示したSFTで土台を作り、RLで正確性と形式遵守を強化。補助OCRで微細な文字の忠実度を底上げ。
- テスト時スケーリング:推論時にDPIを上げて視覚情報量を増やし、モデルを変えずに精度を引き上げられる。
- CPT / SFT / RL(GRPO) / 補助OCR
- CPTで視覚長文に適応
- SFTで基礎性能、RLで正確性/形式遵守を最適化
- OCRで文字忠実度を補強。
新規性
- 注意計算やpositional extrapolationではなく、入力表現の転換による長文スケーリング。
- レンダリング設計を最適化問題として扱い、LLMを組み込んだ遺伝的探索で自動設計。
- CPT→探索→SFT/RL+OCRのレシピで、3〜4倍圧縮でも精度維持と速度改善を両立。RAGのように情報を捨てず「圧縮して全部持ち込む」選択肢を提示。
- 推論時にDPIを可変にでき、精度とコストのトレードオフを運用側で後付け調整可能。
結果
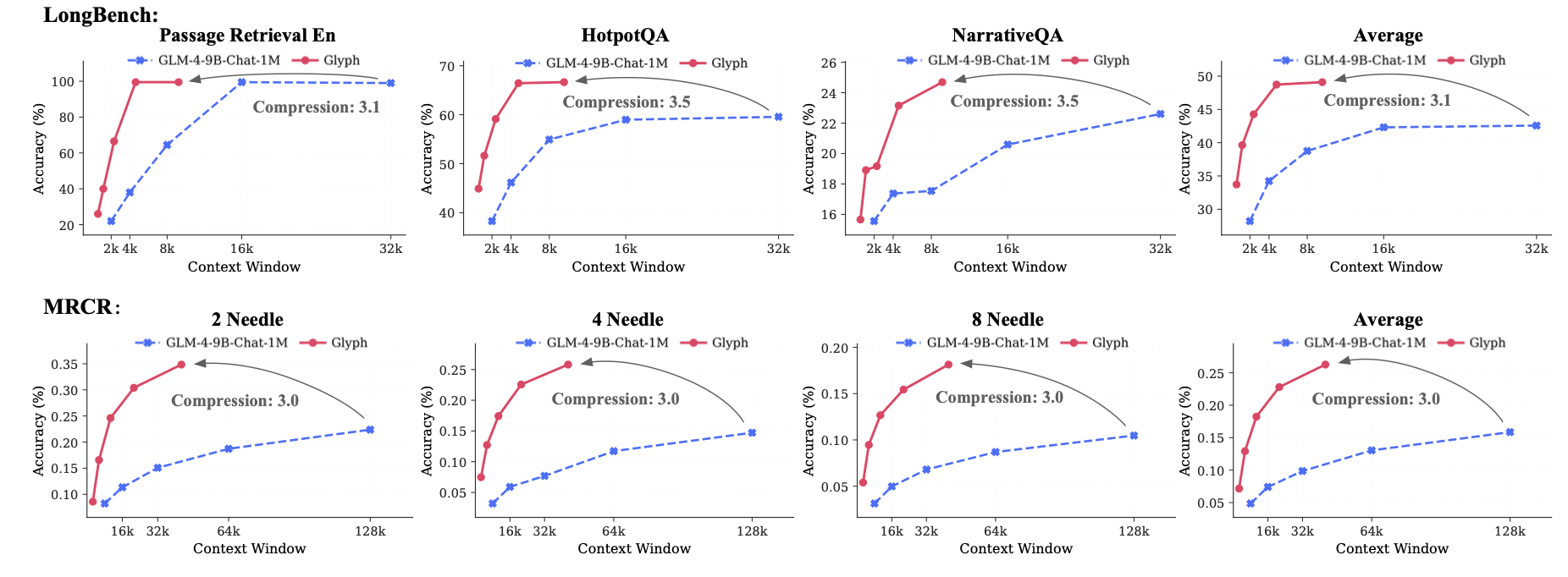
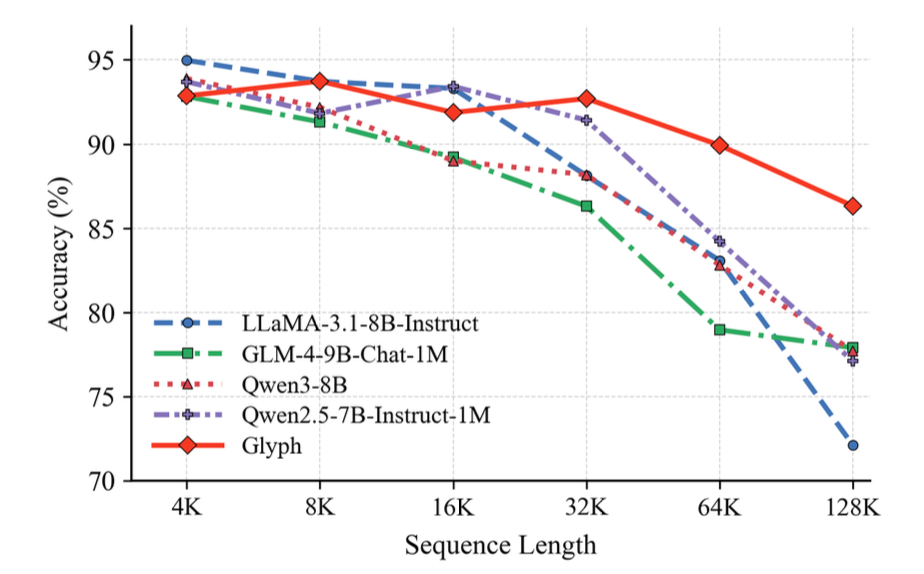
- 実行コンテキストの拡張
- テキストを画像に圧縮することで、同じ名目コンテキストでも「より多くの原文」を投入できる。
- 長文での劣化耐性
- 入力が長くなるほど、テキストLLMはスコア低下が加速しやすいのに対し、Glyphは低下が緩やか。
- 圧縮により「名目上のコンテキストをわずかに伸ばすだけで、実際には大幅な原文量を増やせる」ため、長い入力域で相対的に有利になる。
限界/リスク
- レンダリング依存性:DPI/フォント/行間/レイアウトに敏感。タスクやドメインが変われば再探索が要る可能性。
- OCRの難所:UUIDなどランダム英数字、極小・劣化・密集文字、コード断片は誤読しやすい。厳密一致が要る箇所はテキスト経路とのハイブリッドが安全。
- 一般化の幅:テキストLLM比でゼロショット汎化が弱い局面があり得る。視覚エンコーダ強化や知識蒸留で改善余地。
- 運用とセキュリティ:画像化パイプラインでMLOpsが複雑化。機密文書ポリシーや画像メタデータの扱いに配慮が必要。
メモ
- [zunda] 実効的なコンテキストの圧縮は魅力的に聞こえるけど、レンダリング依存が強そうなのが気になる。ベンチマークのタスクにかなり寄せていってるのでは?
@Shuhei Nakano(nanay)
Disrupting the first reported AI-orchestrated cyber espionage campaign
Anthropic社が2025年11月に発表した、AIを悪用した初のサイバー諜報活動の検出と対応に関する技術報告書
キモは?
- 「タスクの分解」
- 「各タスクは単独で評価すると正当に見える」
- Claudeは「正規のセキュリティテスト」だと信じて協力
- AIが「助言者」から「実行者」へ
- 今まで
- 「このような攻撃をどうやればいいですか?」と人間が質問
- AIは「こういう手順でやってください」と助言
- 実際の攻撃は人間が実行
- 今回
- AIが実際に攻撃を自律実行
- 人間は「このターゲットを攻撃して」と指示するだけ
- AIが勝手に脆弱性を見つけ、攻撃コードを書き、実行し、データを盗む
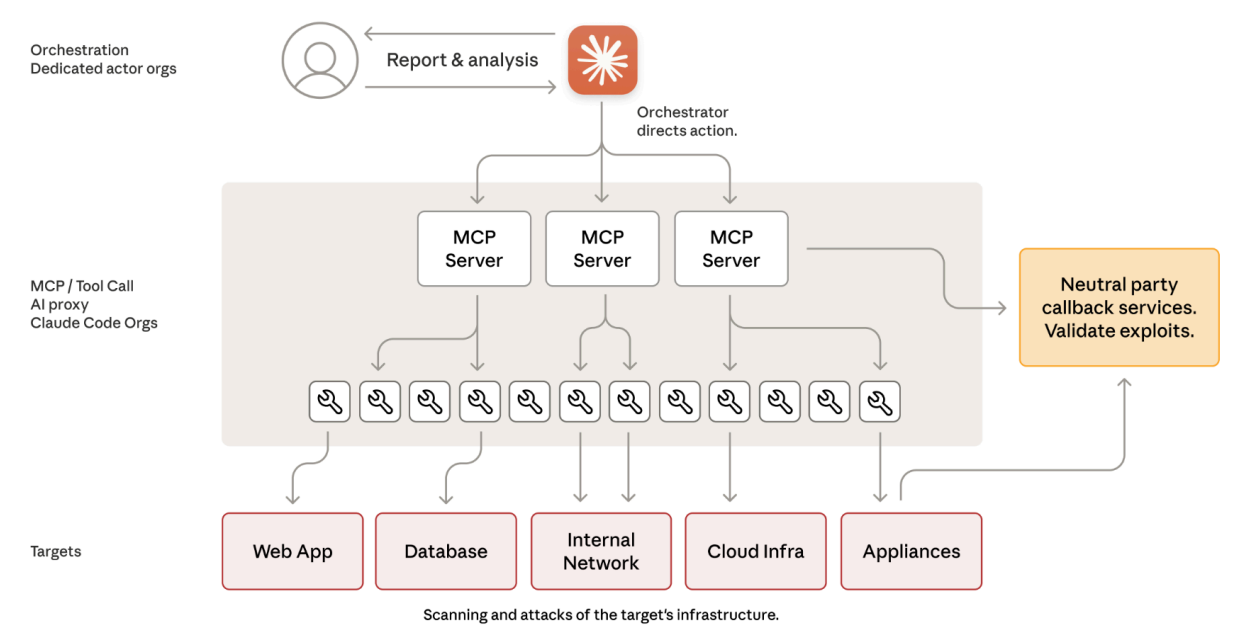
- 人間のオペレーターがオーケストレーターに指示
- オーケストレーターが複数のMCPサーバーにタスクを分配
- MCPサーバーが各種ツール(スキャンツール、攻撃ツール等)を使って標的のインフラをスキャン・攻撃
- コールバックサービスで攻撃の成功を検証
- 結果を人間のオペレーターに報告
(APT) Accelerating Vision Transformers With Adaptive Patch Sizes
| タイトル | Accelerating Vision Transformers With Adaptive Patch Sizes |
|---|---|
| 著者 | Rohan Choudhury*1, JungEun Kim*2,3, Jinhyung Park1, Eunho Yang2, László A. Jeni1, Kris M. Kitani1 |
| 所属 | 1 Carnegie Mellon University, 2 KAIST, 3 General Robotics |
| プロジェクトページ | https://rccchoudhury.github.io/apt/ |
| 論文リンク | https://arxiv.org/abs/2510.18091 |
| コード | https://github.com/rccchoudhury/apt |
ひとことでいうと
ViTの入力で使うパッチサイズに複数のサイズを使えるようにすることでViTの高速化・トークン数の削減を目指した研究
情報の少ないところは大きなパッチ、逆に情報量の多いところは小さなパッチで適応的に処理

イントロ
Vision Transformer (ViT) は基本的に均一なサイズでパッチ分割して処理するため、高解像度画像になると入力シーケンス長が長くなる。
計算量なシーケンス長に対するSelf-attentionの2乗のコストがかかる。
そのため、入力長を削減する手法がこれまでいくつか提案されてきた。
- 類似したトークンを固定割合でマージする 欠点:画像によって削減していい割合って変わってくるはずだけど対応できない 例:真っ白い画像があったときは全部マージできる
- 補助的な予測器で情報量の少ないトークンをプルーニング 欠点:フォワードパス中のプルーニングはパディングなどの別のオペレーションが必要になってくるので、意外と速度は上がらない
発想の仕方
言語モデルだとByte-Pair Encoding (BPE) や SentencePieceのように適応的なトークナイザを行っており、成功している。
これらみたいにサブワードの頻度に応じて可変長のトークンを割り当てるのが良いのでは
ViTでも同様のことをやりたい

提案手法: Adaptive Patch Transformer (APT)
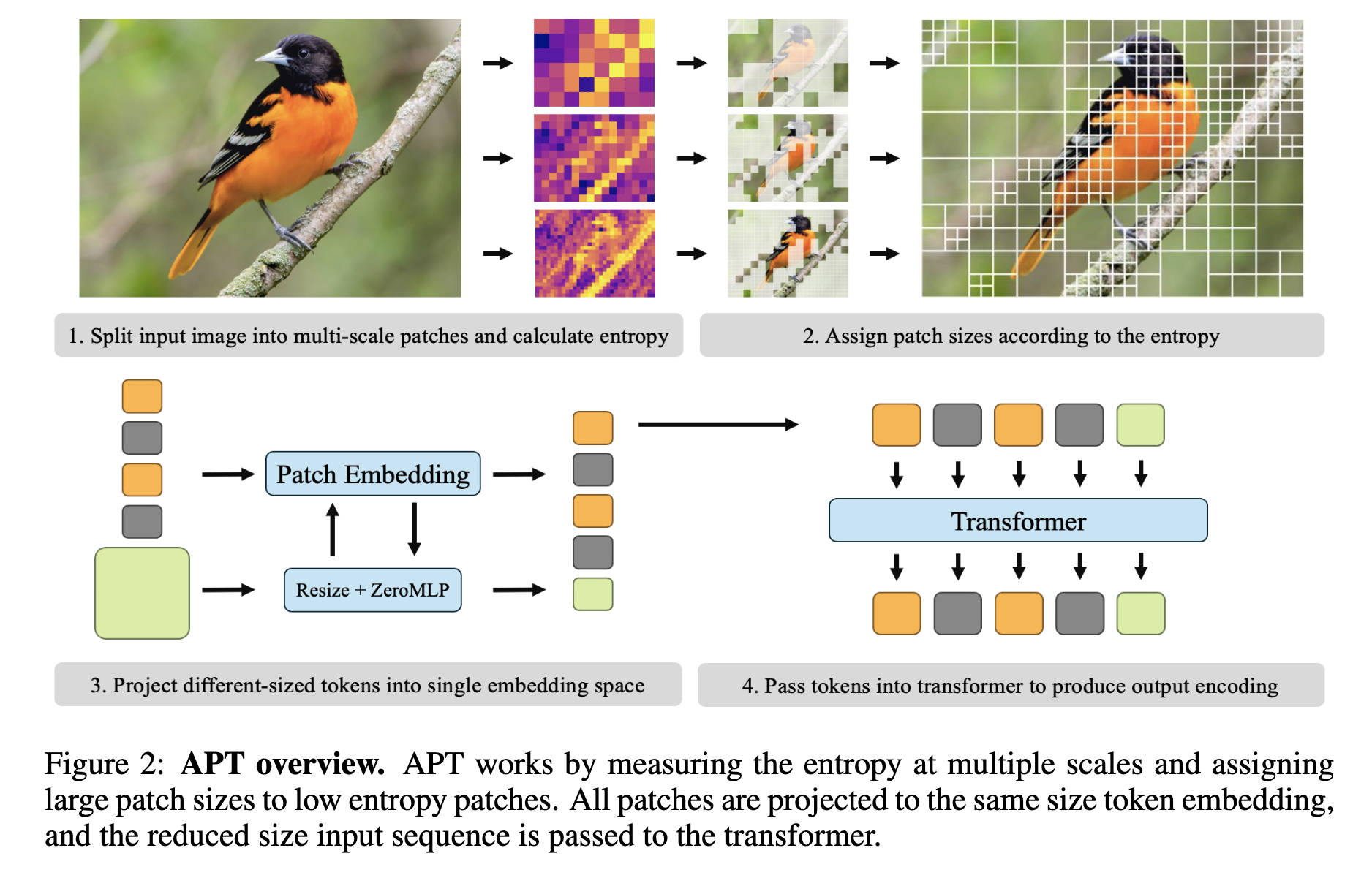
APTの大まかな手順
- 入力画像をマルチスケールパッチに分割し、エントロピーを計算
- エントロピーに応じて、その部分のパッチサイズを割当
- 異なるサイズのトークンを単一の埋め込み空間に射影
- それらのトークンをTransformerに入力して出力を得る
パッチサイズを決める
複数のパッチサイズを用意する
複数のパッチサイズで画像を分割する。パッチのスケールをSとすると以下のようなパッチ集合を作る。
各 は サイズのパッチを持っており、S=3, p=16だったら、16x16, 32x32, 64x64のなるべく小さいパッチサイズを見つけるような振る舞いを目指す。
これらの複数のパッチサイズ内の情報量を次式のエントロピーで計算
※これは各パッチ内の話でiはピクセルの座標位置
低エントロピーなところは大きなパッチを使っても良し!
パッチサイズの決め方
- 大きなパッチからスタートして、エントロピーがしきい値未満であれば、そのパッチを保持 =低エントロピーなら大きいパッチを使う
- しきい値を超えるエントロピーのところは、パッチサイズを小さくして、エントロピーがしきい値未満になるところを探す
パッチの集約

パッチサイズは場所によって違うが、固定の次元長に埋め込まなければならない
上図3のようにリサイズ+大きなパッチの分割の両方を利用して埋め込む
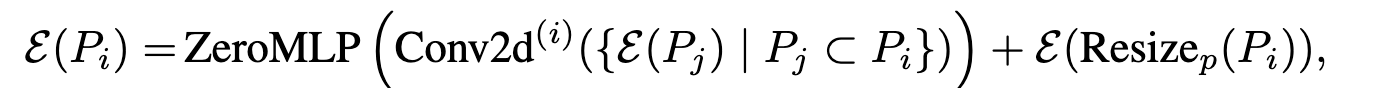
元のパッチを分割だと意味がないような印象も受けるが、Conv2dでダウンサンプリングしている。
ZeroMLPはすべての重みが0のMLP。ControlNetからインスパイアされたもので、最初の影響はほぼゼロだが、徐々に影響をもたせるような学習ができる。
動的な入力サイズ
多くのビジョン研究は固定解像度なので、それに近い状態にしないと行けない。
APTでは、シーケンスパッキングをやって固定解像度のようにする。
トークンがあったときに次式のようにsumしてパッキング
実験
比較対象のベースライン
ベースラインには、トークンマージ(削減)をするアプローチを使用
- 入力レベルのマージ(APTはこれ):モデルに入力するまえにトークンマージするもの
- Masked-AutoEncoder (MAE)
- random masking FLIPの強い版
- resizing Quadformerの強い版
Image Classification
フルファインチューニングしたときの結果
事前学習済みのMAEを使っている。ベースラインの性能を維持しながら、スピードアップできた。
- 低解像度では約14%のトークン削減ができ、約10%の高速化ができた
- 高解像度(336x336) では2倍高速化できる
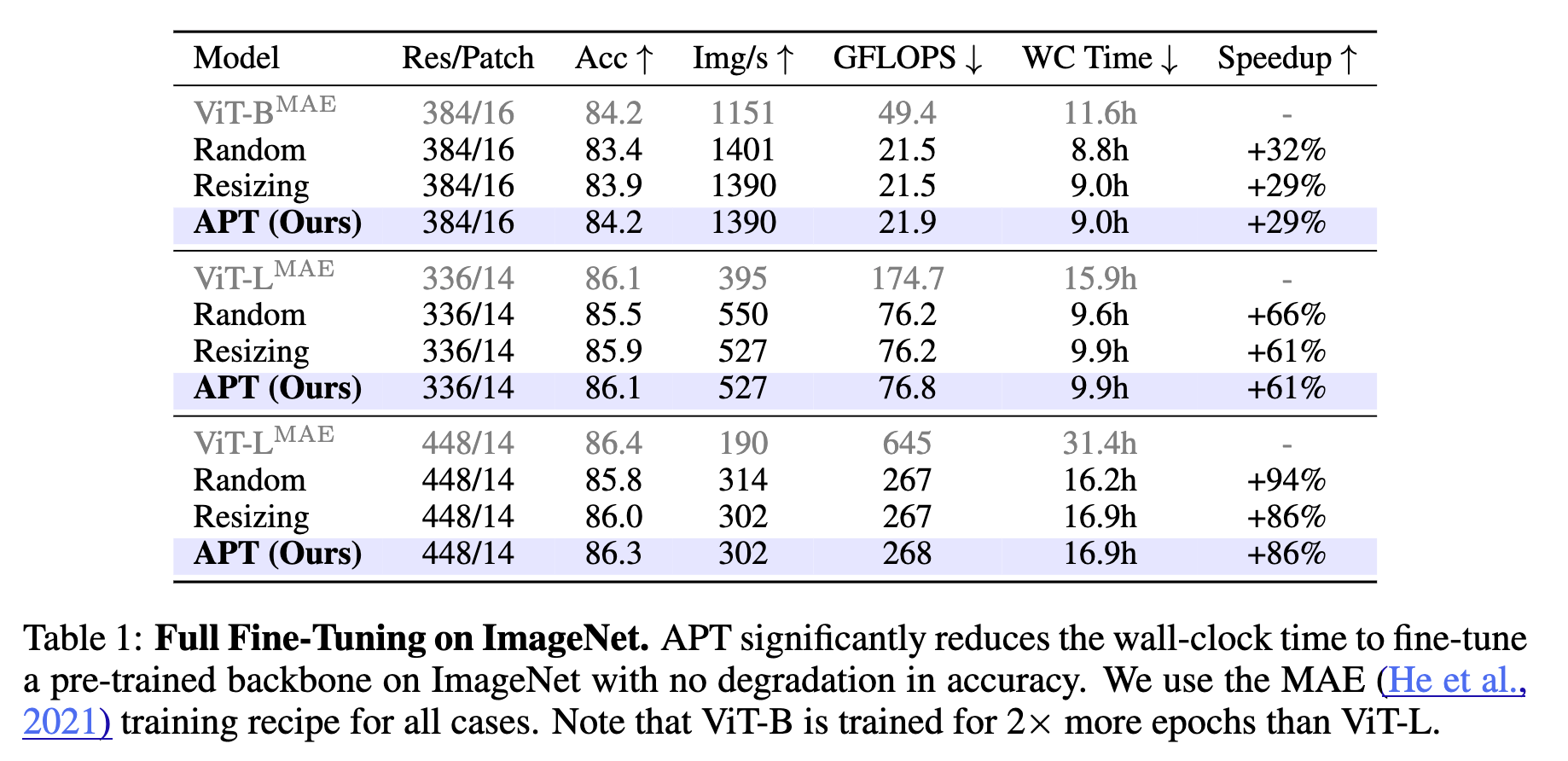
1 epochのみファインチューニングした結果
ImageNetモデルからAPTで1エポック学習した結果
50エポック以上のFTを必要とするDynamicVITやMS-VITと比較するとZero-MLPのおかげで最初から良い性能
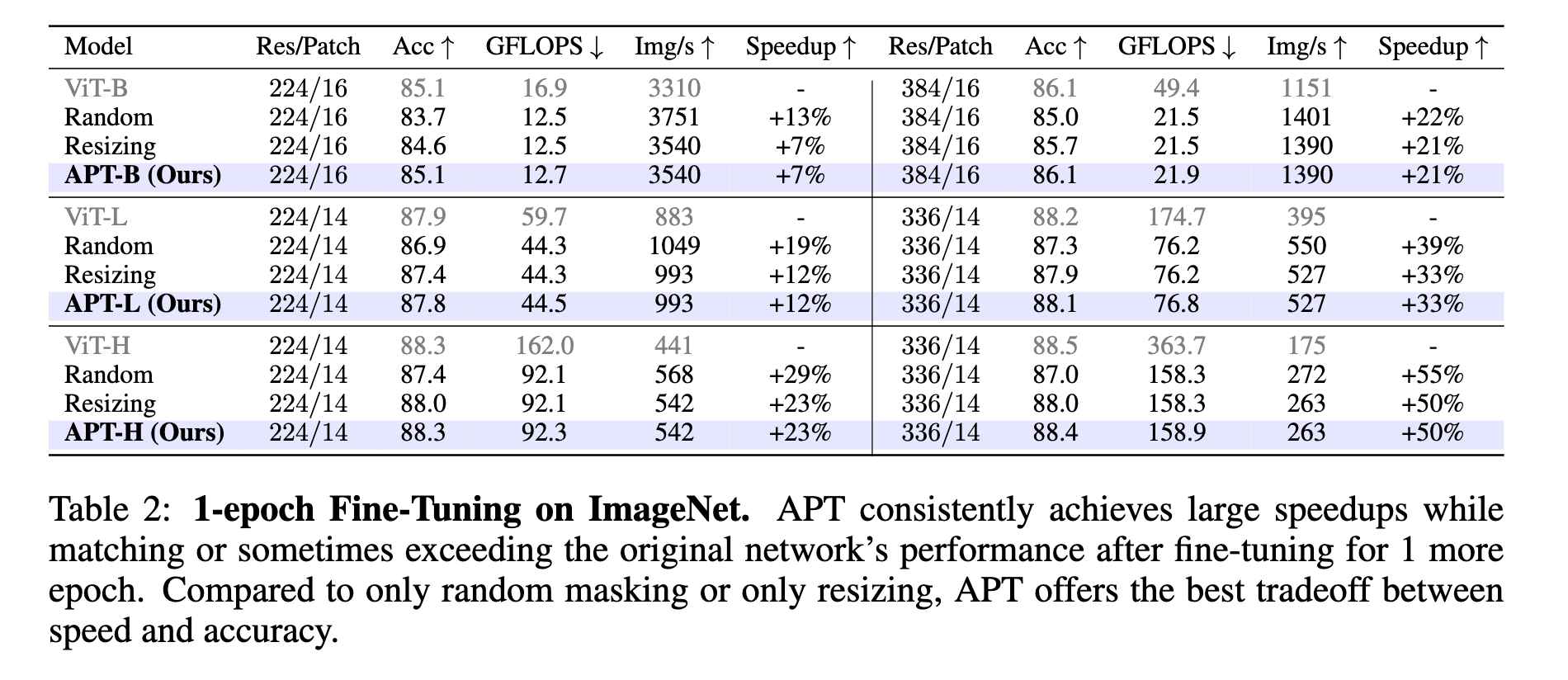
APT(青色)はスループットが高く良い性能
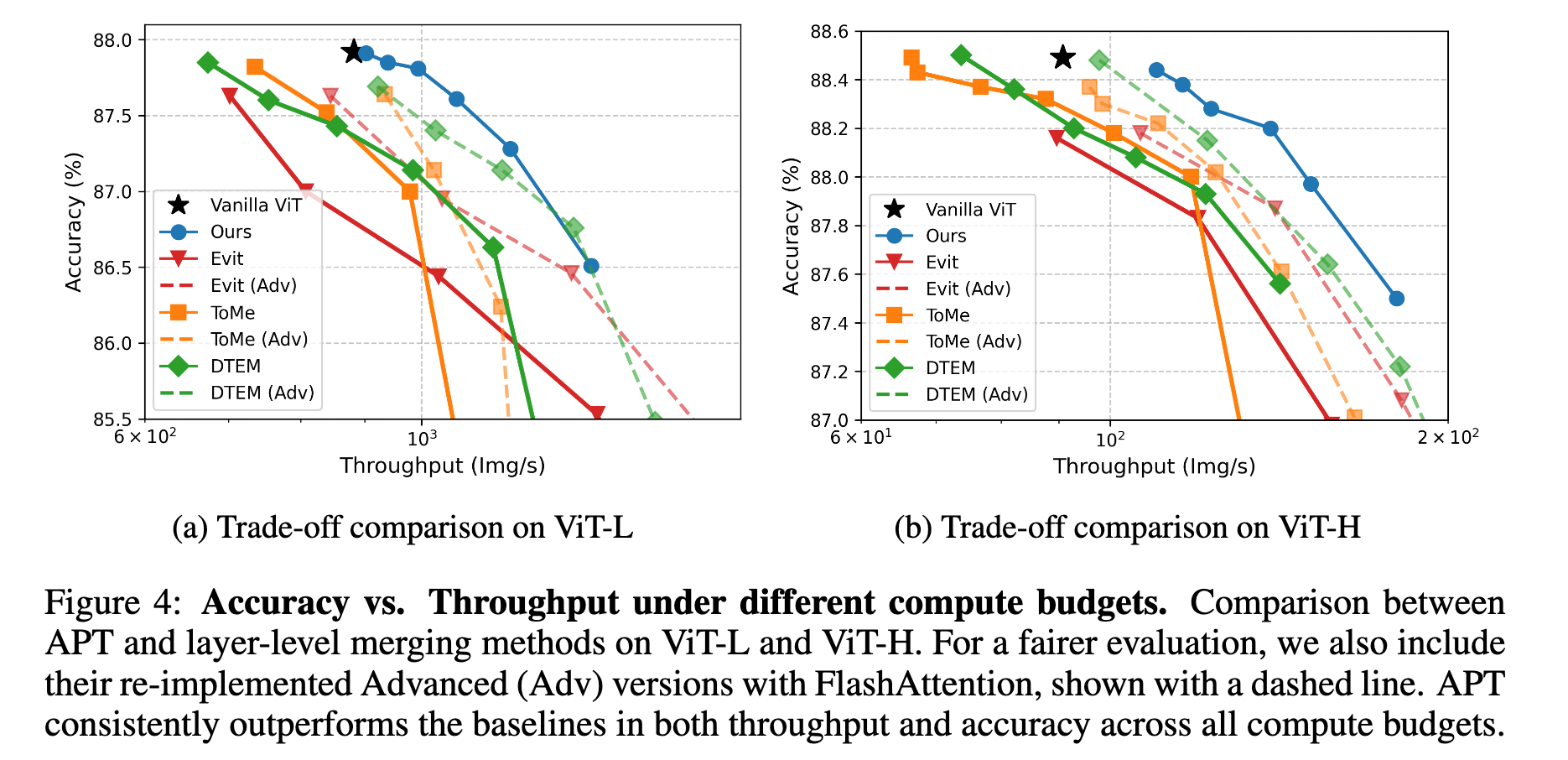
VQA & Dense Visual Tasks
- VQA: LLaVAのVision側のバックボーンにAPTを適用 23%スループットが向上
- Dense Visual Tasks
- Object Detection: ViTDet のバックボーン (EVA-02) にAPTを適用 COCOの1536x1536解像度画像で30%の入力トークンを削減
- Semantic Segmentation: UperNetのバックボーン (EVA-02) にAPTはを適用 ADE20Kで28~32%の入力トークンを削減
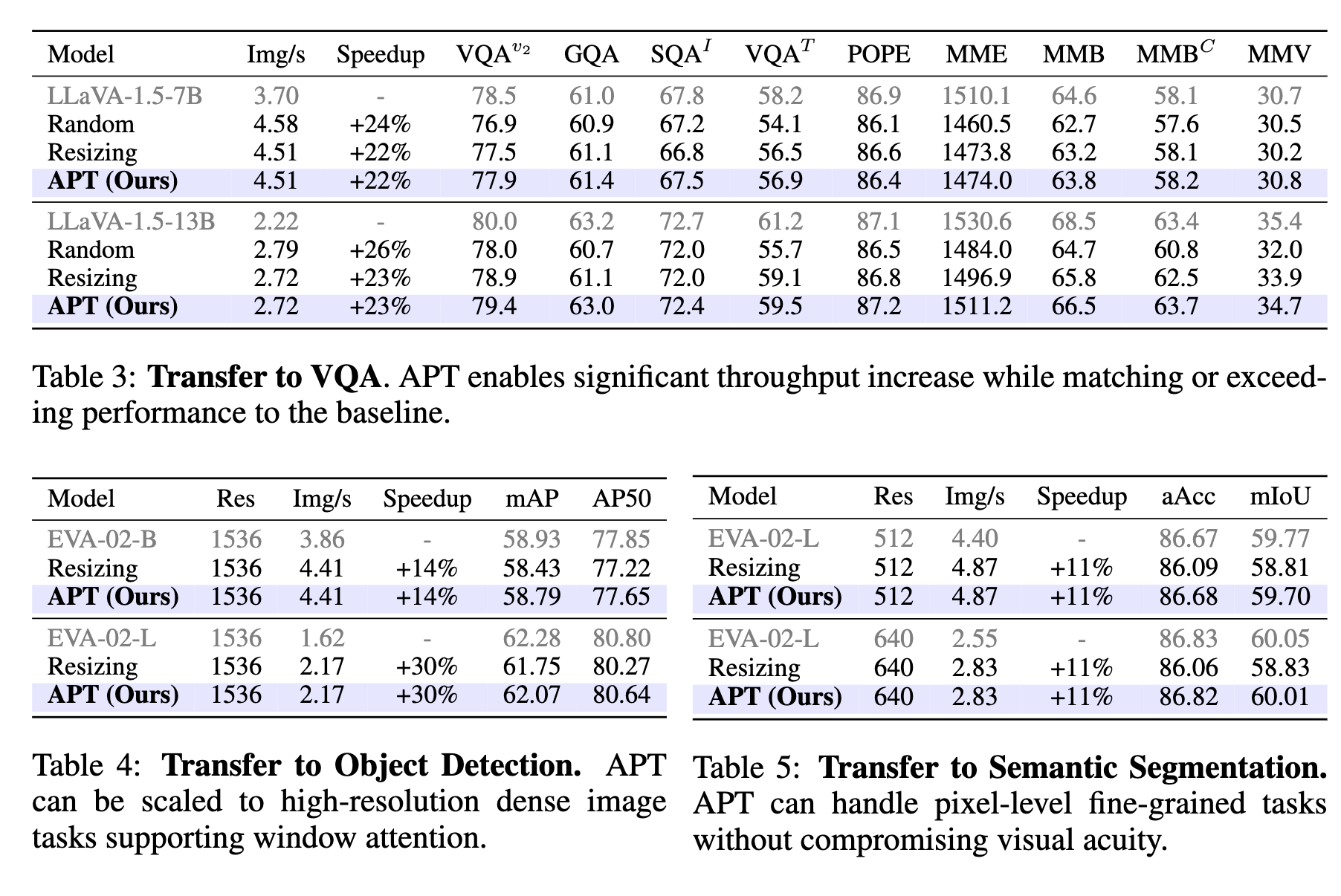
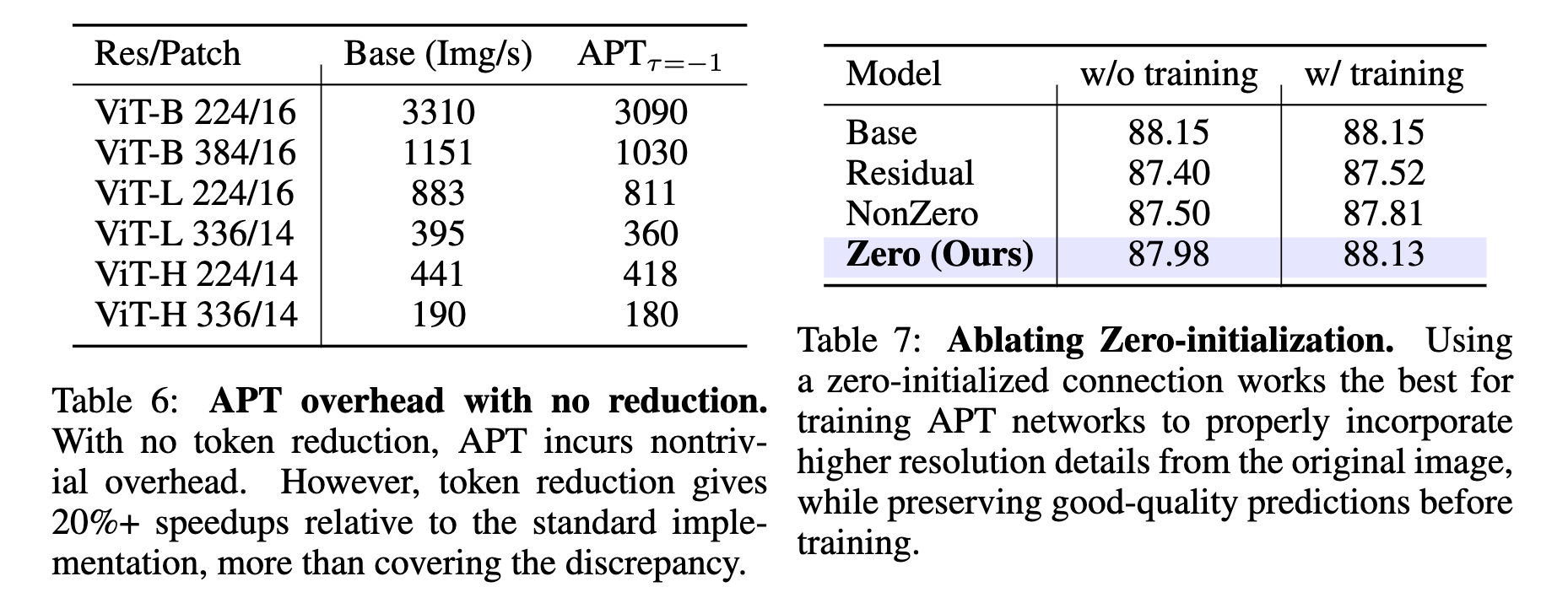
Ablation Study
- APTを追加したオーバーヘッド(表6) APTコンポーネントを除去したときの速度と精度への影響を測った (表の見方がわからない、特に精度はわからない気がするが)トークンの削減がうまく行えなかった時は、オーバヘッドがそこそこあるが、そうでなければ20%程度速くなるよということ?
- Zero-MLPでのゼロ初期化の効果 (これも見方がわからない) ゼロ初期化しないときよりもControlNetのようにゼロ初期化した重みから始める方が良い
定性評価
テクスチャがほぼ無いところはエントロピーが少ないので、パッチが大きめ
[frkake] なんならもっと大きくしても良いのでは?とも思うが正方形でなくなるとややこしくなりそう

Limitation
- パッチサイズはヒューリスティックで作ってる。そのため、下流のユーザがやりたいこととマッチするか不透明
- 画像理解タスクは適応できているが、画像生成には対応できていない
所感
こういう画像の細かいところを注目して処理したり、逆に情報が無いところは焦点を当てない研究は、限られた計算量のなかで遠方の物体を理解するのにとても有用
計算量の削減にも寄与するので、利用できるモデルの選択肢が増えるのでアダプタ的に使えて便利で汎用的だなと感じてる
これはエッジ検出をして、その部分を拡大して再度深度推定モデルに入力することでより細かい深度が計算できる



Differentiable Patch Selectionという論文だと、一旦ダウンスケーリングしてその物体がありそうなところの当たりをつけたうえで、そこだけ絞って高解像度で処理するというのもある。

部分的に使うことで性能をブーストできたり、これまで使えなかったモデルを利用できるようになるので、モデル自身の進化だけでなく、使えそうなコアコンセプトを抑えていきたい。